re:Invent 2024: ZooxのRobotaxi自動運転を支えるMLインフラ構築


はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - ML infrastructure at Zoox that powers autonomous driving of robotaxis (AMZ201)
この動画では、自動運転Robotaxiを開発するZooxのML Infrastructure構築について詳しく解説しています。Perception、Prediction、Planner、Collision Avoidanceなど、自動運転に必要な機械学習モデルの開発から、それらを支えるデータインフラ、トレーニングインフラ、サービングインフラの具体的な構成まで、包括的に説明されています。特に、数万台のGPUを活用する大規模なシミュレーション環境や、Amazon S3 Intelligent-Tiering、Amazon FSx for Lustre、ML Capacity Blocksなど、AWSの各種サービスを活用してインフラを最適化している実践的な取り組みが紹介されています。また、自動運転企業特有の厳格な推論レイテンシー要件への対応など、独自の技術的課題への取り組みも詳しく解説されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Zooxの自動運転技術とML Infrastructureの概要

まず、皆様が正しいセッションにいらっしゃることを確認させていただきます。こちらは、Robotaxiの自動運転を支えるZooxのML Infrastructureについてのセッションです。はじめに、re:Inventにご参加いただいた皆様、おめでとうございます。本日の感謝祭も素晴らしいものだったことと思います。私はAvinash Kolluriと申します。AWSのSenior Solutions Architectとして、AWSのお客様であるAmazonとその子会社をサポートしております。本日は、Prasanna Padmanabhanと一緒に登壇させていただきます。では、Prasannaから自己紹介と、本日のトピックについてお話しさせていただきます。

ありがとう、Ash。皆様、おはようございます。このように活気に満ちたコミュニティの成長を目の当たりにできるre:Inventに参加できることを、大変嬉しく思います。Avinashの紹介にもありました通り、私はPrasannaと申します。ZooxでML Infrastructure部門を率いており、私のチームはZooxにおけるRobotaxiの自動運転を支えるインフラを構築しています。 本セッションを通じて、Zooxの概要や現在の取り組み、そして私たちが対応している機械学習のユースケースについて理解を深めていただけると思います。これらの機械学習ユースケースをカバーするML Infrastructureの概要についても説明させていただきます。さらに、自動運転企業におけるML Infrastructure構築の特徴的な側面についてもお話しします。そして最後に、AWSがZooxのイノベーションをどのように加速させているのか、Avinashから詳しくご説明させていただきます。
Zooxのビジョンと自動運転車の開発


Zooxをご存じない方のために説明させていただきますと、Zooxは2014年に設立され、個人の移動手段をより安全で、よりクリーンで、より快適なものにすることを目指しています。そして最も重要なのは、私たちがドライバーではなく、乗客のために特別に設計された完全自動運転の電気自動車Robotaxiを開発しているということです。 私たちのビジョンは、個人の移動手段を根本から再発明することです。Zooxは単なる改良された自動車ではなく、全く新しい形態の移動手段なのです。皆様の中には、私たちのRobotaxiを実際にご覧になる機会に恵まれた方もいらっしゃるかもしれません。ご興味がおありでしたら、木曜日の夜のリプレイパーティーで展示を予定していますので、ぜひお越しください。
運転をする必要がなければ、交通渋滞を気にすることもなく、はるかにストレスが少なくなることは想像に難くありません。私たちの広々とした車内で、好きなことをして時間を過ごせるというのは、多くの方々の共感を得られるのではないでしょうか。アメリカで発生する事故の94%以上が人為的ミスによるものだということをご存知でしょうか?私たちの目標は、この技術によってそうしたエラーを減らし、何千もの命を救うことです。また、共有型の電気自動車Robotaxiを通じて、San FranciscoやVegasをはじめとする世界中の都市部での環境汚染や交通渋滞の軽減も目指しています。

このミッションとビジョンは野心的すぎると思われるかもしれません。その通りです。非常に野心的です。しかし、なぜ私たちがこれに取り組んでいるのか、その理由をお話しさせていただきます。 世界では年間140万人もの方々が交通事故で亡くなっています。ここにいらっしゃる多くの方々も、私と同じように複数の車を所有されていると思いますが、それらの車は96%の時間は使用されずに止まっています。今この瞬間も、私の車は自宅に、皆様の車の多くは職場の駐車場に止まっているはずです。このカジノの駐車場に車を停めてこの講演に来られた方も、どれくらいいらっしゃるでしょうか。そして私がまだ触れていないのは、大気汚染の問題や、世界中で移動や運転に費やされている膨大な時間についてです。

それでは、なぜこれが必要なのかが明確になったところで、この問題を解決するには根本的な変革が必要です。かつて馬車で人々をAポイントからBポイントへ運んでいた時代から、現在の自動車へと素晴らしい変革を遂げました。しかし、私たちは未来に向けて同様の変革が必要だと考えています。それは特にライダー(乗客)のためにデザインされたものです。これから、Zooxについての短い動画をお見せしますが、なぜ未来はドライバーではなくライダーのためのものなのか、より理解していただけると思います。Zooxは完全自律型のRobotaxiで、ハンドルも運転席も、運転手の後ろの窮屈な後部座席もありません。実際、運転手そのものが存在しないのです。私たちはカリフォルニアでZooxをゼロから構築し、すべての座席とセンサーの配置を設計し、アプリからエアバッグまであらゆる細部にこだわり、AIを訓練して、雨の日も晴れの日も、都市交通で起こりうるあらゆる危険を予測できるようにしました。
これらすべては、ライダーの皆さんのために行ったことです。自分の好きな音楽を大音量で楽しんだり、静かにプレゼンテーションの仕上げをしたり、遅刻しそうな時にメイクをしたり、時間に余裕がある時には仮眠をとったりできる空間を作りたかったのです。足を伸ばして空を眺めることもできます。皆さんはきっと、これはいったいどんな車なんだろうと考えるでしょう。でも、ひとつお伝えしたいことがあります - これは車ではありません。これはZooxなのです。
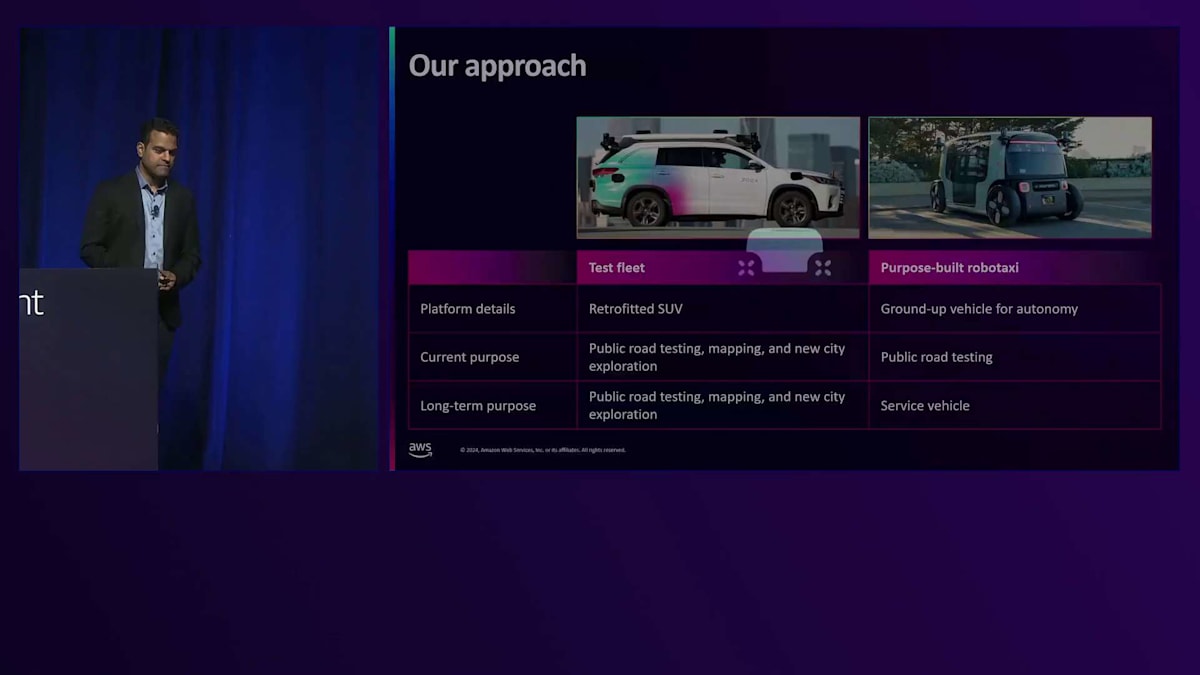
では、現在私たちはどのようなアプローチでこの課題に取り組んでいるのでしょうか?私たちには2種類の車両があります。1つはテストフリートで、改造したSUVを使用して公道テスト、Robotaxiの運行エリアとなるジオフェンスのマッピング、そして新しい都市の探索を行っています。ご存知の方もいるかもしれませんが、私たちは次のRobotaxi展開都市としてAustinとMiamiを積極的に検討しています。一方、私たちの目的に特化して作られたRobotaxiは、自律走行のためにゼロから設計されています。現在は公道テストに使用していますが、近い将来、このRobotaxiを配車サービスとして利用できるようになる予定です。
ZooxにおけるMachine Learningの活用事例


ここまでで、Zooxで私たちが何をしているのか、なぜそれを行っているのかについて、ある程度ご理解いただけたと思います。では次に、Zooxで取り組んでいるMachine Learningのユースケースについてお話ししましょう。最も明白なのは自律走行で、これについてはすでにお話ししました。まずPerceptionから始めましょう。Perceptionは、Robotaxiの目と耳のようなものだと考えてください。これらのモデルは、私たちのRobotaxiと一緒に道路上にいる他の存在を認識するのに役立ちます。歩行者はいますか?他の車はいますか?動物はいますか?信号や交通標識をどのように検知するのでしょうか?
これらすべてを、カメラ、サーマルカメラ、Lidar、レーダー、さらにマイクなど、様々なタイプのセンサーを組み合わせて検知しています。私たちのPerceptionモデルは、ジェスチャーを含む数百もの動的オブジェクトをリアルタイムで追跡し分類することができます。歩行者が待つように、あるいは進むように合図している場合、そういったことも検知できなければなりません。また、歩行者やライダーが携帯電話を使用しているときの気が散っている状態なども検知できます。さらに、工事現場や緊急車両なども検知することができます。


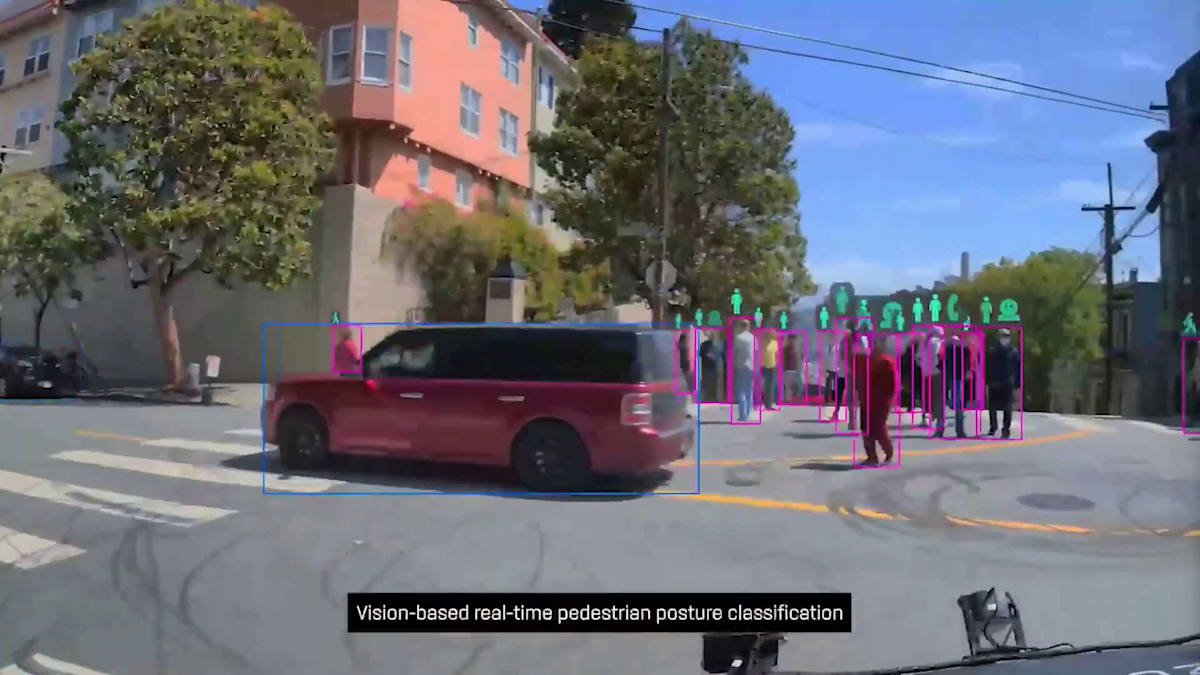
私たちのPerceptionスタックが実世界をどのように認識しているか、短い動画でお見せしたいと思います。ご覧のように、私たちは歩行者を検知することができます。それも車両の前方だけでなく、非常に広い角度で - 左端の歩行者、右端の歩行者、そしてまもなく、歩行者が私たちに対して、まず自分が通り過ぎてからRobotaxiを発進させるようジェスチャーをしているのが見えるはずです。ここはカジノの前で、お客様の乗降場所となっています。そしてご覧の通り、多くの歩行者が様々なレーンを不規則に横切っています。歩行者だけではありません - すぐにタクシーがレーンを無視して走行しているのも見えるはずです。

これはSan Franciscoの様子です。ここでも多くの歩行者がいて、おそらく観光客も大勢います。スマートフォンに気を取られている人もいれば、San Franciscoのこの素晴らしい場所の写真やビデオを撮影している人もいます。これがPerceptionです。まとめますと、Perceptionモデルは私たちのRobotaxiと一緒に道路上にいる他のアクターを特定する手助けをしています。それに基づいて、Predictionスタックは、それらの道路上のアクターが今後数秒間で何をするかを判断する責任を負っています。近くの歩行者は左に曲がるのか、右に曲がるのか?隣や前方の車両はどの方向に進むのか?私たちのPredictionモデルは、複数の未来のバージョンを考慮し、道路上の各アクターが最終的にどのような行動を取るかを判断する責任があります。

つまり、Perceptionは道路上の誰がいるかを特定する役割を担い、Predictionは彼らが今後数秒間で何をするかを判断する役割を担っています。そして次はPlannerです。この出力に基づいて、Plannerは私たちのRobotaxiが何をすべきかを判断する責任があります。直進すべきか?左に行くべきか?そしてポイントAからポイントBまで、安全で快適な方法でミッションを遂行するにはどうすればよいか?Plannerは車線変更、加速、制動を行うべきかを判断し、Robotaxiの低レベル制御と通信します。目標はポイントAからポイントBまでのミッションを完了することで、その名の通り、私たちが取るべきルートを計画します。

次はCollision Avoidanceです。これは端的に言えば、エンド・ツー・エンドのシステムと考えてください。つまり、Perception、Prediction、Planningを行いますが、すべては安全性を確保し、さらなる冗長性を追加するための冗長な方法として機能します。
Collision Avoidanceの主な目的は、衝突を予測し、さらに重要なことは、この冗長性によってメインのAIスタックでまだ捕捉されていない衝突を回避することです。エンド・ツー・エンドシステムであることから、Perceptionスタックと同様の機能を実行します。例えば、道路上の障害物を検知し、Occupancy Grid(どの車両がどのレーンにいて、近い将来どのレーンにいるか)を判断します。それに基づいて、潜在的な衝突を予測し、衝突回避のための新しいルートを生成します。つまり、Collision Avoidanceの全体的な考え方は、最初から衝突を予測し、回避することを確実にする冗長システムなのです。

Zooxでは、Machine Learningは自動運転だけでなく、さまざまな用途で活用されています。例えば、Generative AIも私たちがMLを活用している分野の1つです。シミュレーションのためのシナリオ生成やScenario Diffusionに活用しています。Robotaxisに実装する前に、シミュレーションを通してAIスタックの検証を行いますが、そのシナリオ作成にMachine Learningモデルを活用しています。以前は、AIスタックを検証するためのシナリオを人手で作成していましたが、それではスケールしません。そこで、新しいDiffusionベースのモデルアーキテクチャを活用して、Machine Learningでシナリオを生成しています。ChatGPTのPrompt Engineeringと同様に、必要なシナリオを指定すると、Machine Learningモデルがそれらのシナリオを作成してくれます。
他にも多くの活用事例があります。例えば、さまざまなタスクを実行するためのFoundation Modelsを構築しています。これらのモデルは、AIスタックの検証が比較的難しい興味深いシナリオを特定するのに役立ちます。そして、それらのシナリオを共通のバンクや基準として、コードベースを更新するたびにAIスタックの検証に使用しています。また、データマイニングにも役立ちます。例えば、Robotaxisが生成したさまざまな映像の中から、歩行者が多く、さらに警察官もいるような、ストリップ道路での保護のない左折といった特定のシーンを見つけたい場合などです。これらのツールはFoundation Modelsによって生成され、シーン理解を通じて何が起きているかを理解するのに役立っています。
ZooxのML Infrastructure:データ、トレーニング、サービング


その他の活用事例としては、トリアージがあります。これは、バグがどこにあるのか、どのコンポーネントが特定のバグを引き起こしているのかを突き止めるシンプルなプロセスです。これらのプロセスもFoundation Modelsで自動化しようとしています。近い将来、これらのFoundation Modelsを活用してチケットの複製も可能になるでしょう。このように、ZooxではMachine Learningが多くの場面で活用されています。 ここで話題を変えて、これらすべてのML活用事例を支えるML Infrastructureについて説明します。 ML Infrastructureチームの目標は、Machine Learningモデルの開発からデプロイまでにかかる時間を短縮することです。これが私たちの成功基準です。所要時間が短ければ短いほど、ML Infrastructureが優れているということになり、MLの実践者がより良い予測を行える新しく優れたモデルを開発できるようになります。
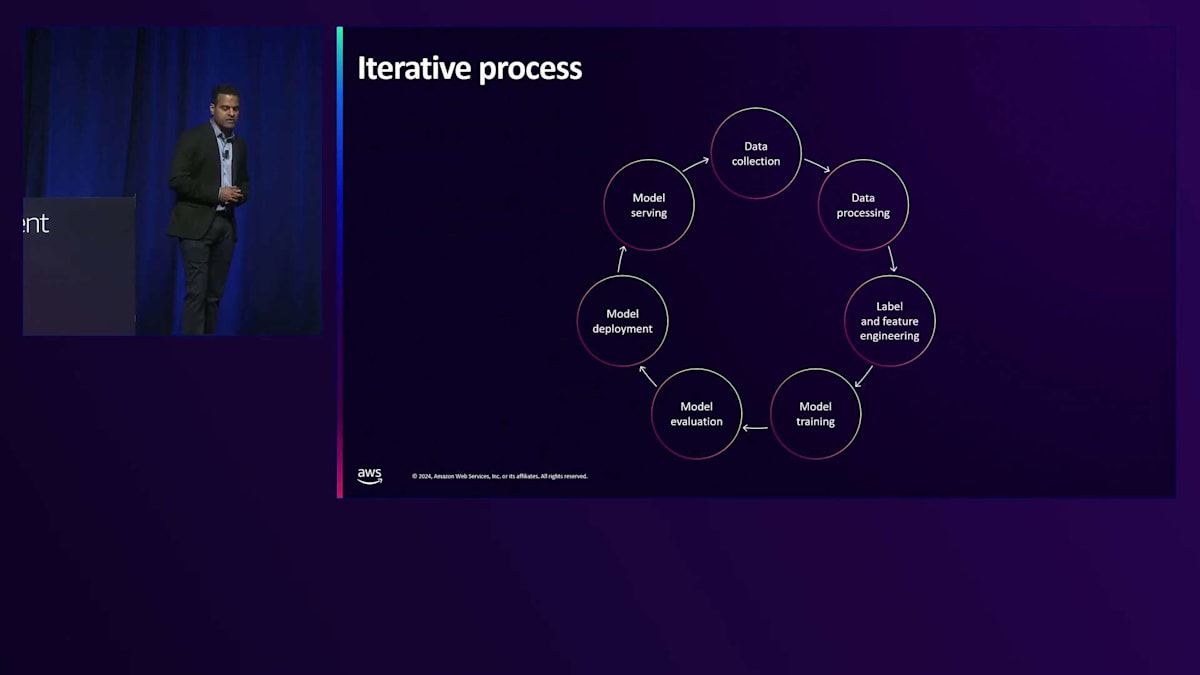
ML Infrastructureについてさらに詳しく説明する前に、多くの方がすでにご存じかもしれませんが、このMLライフサイクルについて説明します。通常、Machine Learningモデルを構築するためのデータ収集から始まり、その後、データの処理、クリーニング、異なるデータソースの結合、重複の削除などを行います。これが私の言うデータ処理のステップです。これはMachine Learningモデルが正しく機能するために非常に重要で、良いデータがなければモデルは多くのことができません。次のステップはラベル付けとFeature Engineeringです。ご存じの方もいるかもしれませんが、非常にシンプルなモデルアーキテクチャでも、適切なデータを使用すれば、はるかに優れた予測を実現できます。必要なデータがすべて揃ってトレーニングデータセットを作成できたとしましょう。その後、通常はPyTorchやTensorFlowなど、好みのトレーニングフレームワークを使用してMachine Learningモデルをトレーニングします。モデルのトレーニングが完了したら、そのモデルが本番環境のものよりも優れた予測を行えるか、または新しいモデルの場合は予測が良好かどうかを検証する必要があります。
モデルが評価され、効果的であることが分かったら、デプロイを行います。モデルのデプロイはソフトウェアのリリースデプロイと似ています。5%、10%、50%というようにフェーズを分けてロールアウトする必要があります。トラフィックを最初にテストするために、Canaryテストやred-blue-greenテストなど、どのような用語を使用するにせよ、適切なテストを行いたいものです。その後、リアルタイム予測やバッチ推論予測など、より良い予測を行うためにモデルを提供します。モデル提供インフラストラクチャの出力は、多くの場合データ収集段階に渡され、毎日モデルを少しずつ改善していく継続的なサイクルを形成します。


このML Infrastructureチームの目標は、このサイクル全体をできるだけ効率的に完了できるようにすることです。強力なML Infrastructureを構築するためには、まず優れたデータインフラを整備し、その上で優れたトレーニングインフラと優れたサービングインフラを構築する必要があります。 そして最後に、これらのコンポーネントすべてを結びつける基盤要素として、コンピューティングとストレージのインフラが必要になります。これから数分間、 Zooxで構築したこれらのインフラについて、それぞれ詳しくご説明していきます。


まずはデータインフラからお話ししましょう。何度も申し上げていますが、機械学習モデルは、与えられたデータの質に大きく左右されます。 では、なぜそれがそれほど重要なのでしょうか?この分野には多くの課題があります。 私たちのRobotaxiは道路上で起きていることを記録し、大量のデータをデータレイクに記録しています。時には、Zooxは自動運転を行う会社というよりも、ログを取る会社になっているのではないかと思うほど、膨大な量のデータを記録しています。適切なデータ管理ツールを構築しないと、ストレージに多額の費用がかかってしまいます。適切な保持ポリシーを確保し、将来必要のないデータを削除する必要があります。この点で、Amazon S3 Intelligent-Tieringは私たちの大きな助けとなっています。
同時に、データ転送コストやジョブの遅延を避けるため、保存するデータをコンピューティングにより近い場所に配置するようにしています。2番目の課題はデータの発見可能性です。大量のデータがある中で、まさに干し草の山から針を探すような作業になります。適切なデータ発見ツールを構築することで、MLの実践者ができるだけ早く適切なデータセットを見つけられるようにしています。3番目の課題はデータの可用性です。これは、Robotaxiからデータを取り込んでから、分析や機械学習といった下流のユースケースで使用できるようになるまでの時間のことです。最後に、データガバナンスが重要です。私たちはライドヘイリングサービスから個人情報を、Robotaxiからカメラデータを収集しているため、適切な人が適切なアクセス権を持ち、データアクセスの監査証跡を維持する必要があります。

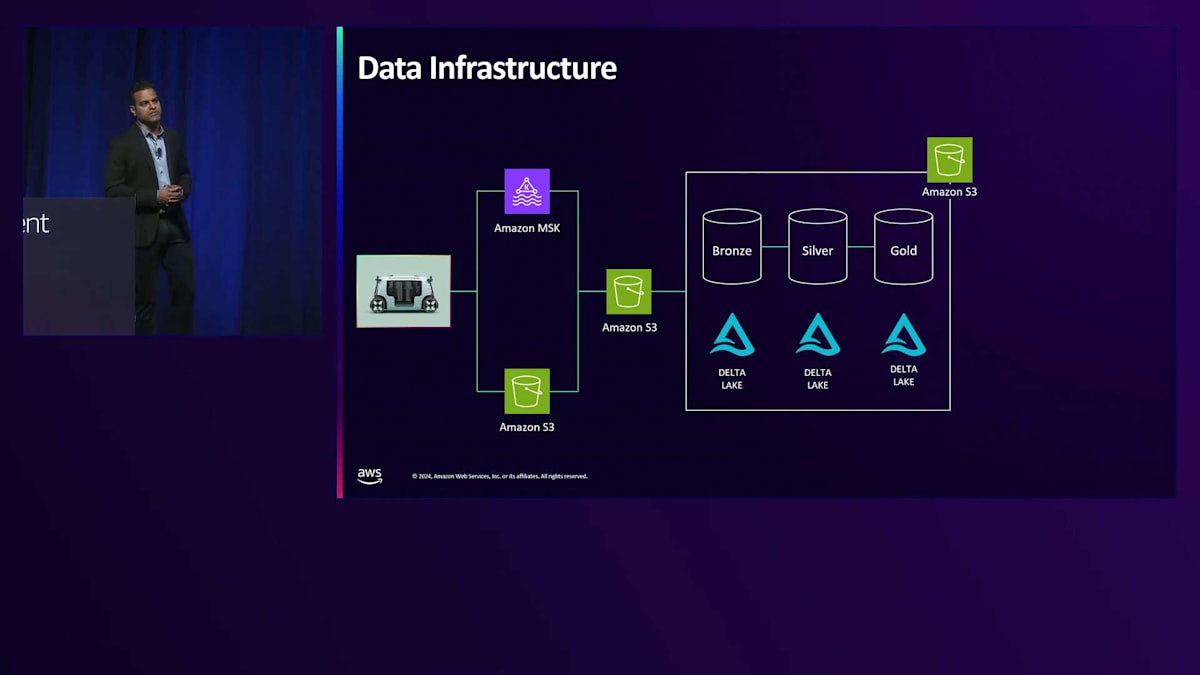
Zooxのデータインフラがどのように構築されているか、その概要をご説明しましょう。まず、すべての車両データと乗客データを提供するRobotaxiから始まります。乗客データは通常Kafkaに送られ、そこからさまざまなリアルタイム分析のユースケースに使用できます。すべての車両データはAmazon S3に保存され、これがデータレイクとして機能し、これらのデータはすべて着信用のS3テーブルに統合されます。 Zooxではメダリオンアーキテクチャを採用しており、Bronze、Silver、Goldテーブルのインフラを活用しています。S3上でDelta LakeをParquetストレージフォーマットと共に使用しています。Bronzeテーブルは、すべての生のセンサーデータと車両データを含むものと考えてください。それを基に、Silverジョブでは、クリーニングや異なるデータソースとの結合など、さまざまな変換を行います。最後に、要約されたすべてのデータがGoldテーブルに書き込まれます。この構造が重要なのは、私たちが保存するデータ量を考えると、Goldテーブルの保持ポリシーをBronzeテーブルとは異なるものにできるからです。
結局のところ、Goldテーブルは機械学習の目的やデータ分析の目的で使用されるものです。そのため、Goldテーブルのデータはより長期間保持し、Bronzeテーブルのデータはより短期間で削除することができます。
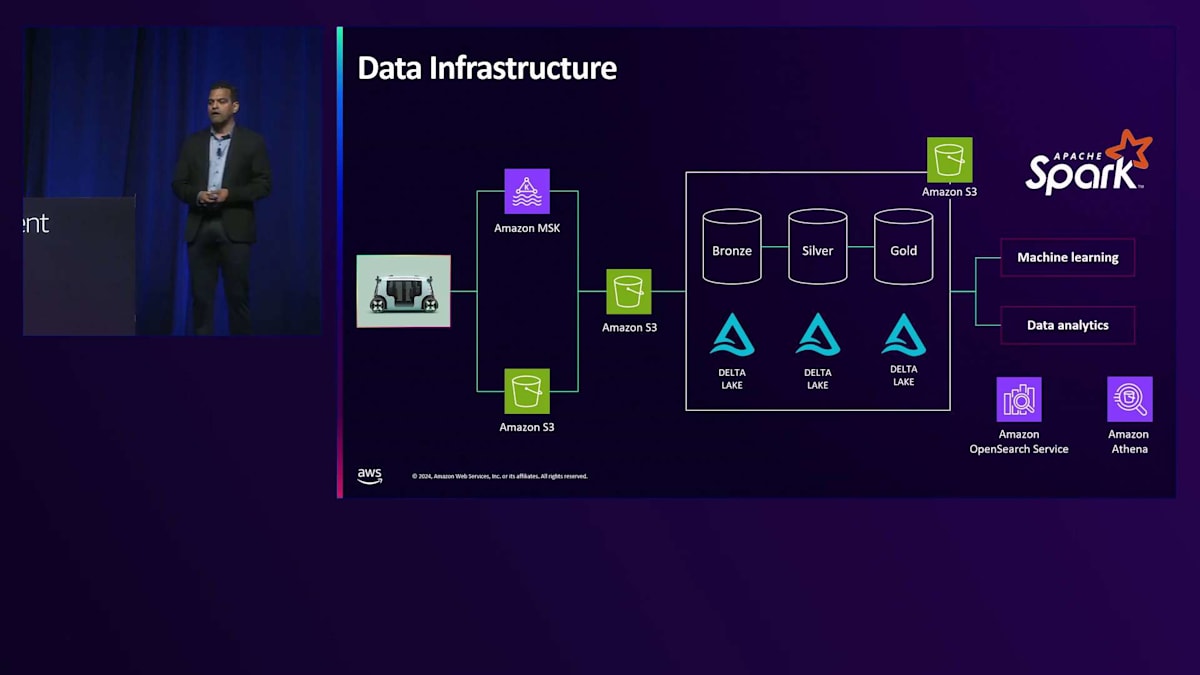
私たちのツール環境では、Machine Learningのユースケースにおけるトレーニングデータセットの作成に、Apache Sparkを広範に活用しています。データ分析のアドホックなユースケースにはAmazon Athenaを使用し、また、エンベディングの保存にはAmazon OpenSearch Serviceを利用しています。シーン理解やOpenSearch Serviceを使用した最近傍探索などのデータマイニングユースケースには、データマイニングツールを活用しています。これがZooxにおけるデータインフラの構成です。このインフラにより、MLの実務者は効率的にトレーニングデータセットを作成したり、様々な分析を行ったりすることができます。

データが金鉱のように価値があるのと同様に、堅牢なトレーニングインフラを持つことは非常に重要です。なぜなら、これによって迅速な実験や新しいモデルアーキテクチャの開発が可能になるからです。Deep Learningの進歩により、より良い予測を行うために多くのモデルが複雑化してきています。そのため、これらの大規模なモデルアーキテクチャを実現できるトレーニングインフラを持つことが極めて重要なのです。

ここで、Zooxのトレーニングインフラの主要な特徴をいくつか共有させていただきます。まず、すべてがOSSフレームワークの上に構築されています。多くのモデルはPyTorch、特にPyTorch Lightningで学習されています。最近の強化学習モデルの一部はJAXを活用し始めており、また、分散マルチノードGPUトレーニングを誰でも簡単に行えるようにしたオープンソースのRayも活用しています。私たちのトレーニングデータセットは非常に大規模なため、モデルの学習時間を短縮し、GPUの利用効率を向上させるための最適化されたデータローダーが必要です。データパラレルは業界では当たり前の技術となっており、私たちもそれを上手く活用しています。
高スループットのトレーニングユースケースには、Mosaic Data ShardsやAmazon FSxなどの技術を使用しており、マルチノード間の通信を高速化するEFA(Elastic Fabric Adapter)などのネットワークインターフェースも活用し始めています。また、Zooxで学習されたすべてのモデルを追跡するモデルリポジトリも持っており、誰がこのモデルを学習させているのか、どのくらいの頻度で学習されているのか、どのデータセットを使用しているのか、モデルの学習にかかるコストはどのくらいかなど、広範なメタデータを保持しています。さらに、学習時間、エラー時間、データ読み込み時間、エラー率などの運用メトリクスも管理しています。最初に測定することなしには改善できないため、エコシステムにとって優れたモデルメトリクスを持つことは重要です。
最後に、実験の追跡にも多くの投資を行ってきました。ML実務者が過去に実行したすべての実験を追跡し、後で再現したり、他のML実務者と共有して彼らの作業を再利用できるようにすることは非常に重要です。これが、ML実務者がモデルを学習させるのを支援しているトレーニングインフラの全容です。

モデルのトレーニングが完了したら、次のステップはそれらの機械学習モデルをサービングすることです。ここでの目標は、車両上で効率的にモデルを稼働させることです。同時に、先ほど申し上げたように、多くのユースケースは車両外での使用を想定しており、高スループットのバッチ推論が必要とされています。

サービングに関して、自動運転のRobotaxiを手がける企業として、車両上で実行されるモデルの推論の最適化は極めて重要です。そこで私たちは、NVIDIA TensorRTのエコシステムを活用して、車両上での推論を大幅に高速化しています。すべてのモデルをPythonから中間ステップとしてONNXに変換し、その後TensorRTに変換しています。ただし、自動運転に必要なモデル以外にも多くのモデルが存在します。ここで私たちのクラウドサービング基盤が重要な役割を果たしており、その多くはバッチ推論のユースケースです。これらの高スループットのユースケースでも確実に機能するようにする必要があります。ここでもRay、特にRay Serveを活用し、Amazon EKS上にクラウドサービング基盤を構築しています。Ray ServeとEKSにより、様々なタイプのCPUやGPUアーキテクチャを使用することが可能になります。コスト効率を考慮して、できる限りCPUを活用するようにしていますが、モデルサービングにおいてもGPUでの実行が必要なモデルが存在します。AIスタックを検証する際には、Robotaxiで実際にGPUを使用して実行した場合と、クラウドインフラで実行した場合の結果に一貫性があることを確認する必要があります。
同時に、Ray Serveは自動スケーリング機能を提供しており、需要が高まった時にGPUを追加し、需要が低下した時に返却することができます。また、モデルの初期化コストを何度も発生させないように、同じまたは類似の入力タイプを持つ複数のモデルをレプリカセットにロードするモデルマルチプレキシングもサポートしています。



データインフラ、トレーニングインフラ、サービングインフラについて述べたように、堅固な基盤となるコンピューティングとストレージのインフラが必要です。ここでの主要なユースケースは、データセットの構築、大規模なモデルトレーニング、そしてクラウドでのバッチ推論です。 クラウドインフラ技術については、私たちが利用するすべてのCPUとGPUの基盤となるコアバックボーンとしてAmazon EC2とAmazon EKSを使用しています。 ストレージインフラについては、クラウドでの主要なソリューションとしてAmazon S3とAmazon FSxを活用しています。


これらのリソースを確保したら、それらを管理するリソーススケジューラーが必要です。ここで私たちが使用しているのが、オープンソース製品のSLURM(Simple Linux Utility for Resource Management)です。このツールはワークフローをスケジューリングし、これらのコンピューティングおよびストレージインフラを活用します。 最後に、ワークフローオーケストレーターとしてApache Airflowを使用しています。私たちのML実践者たちは、Airflowを使用してDAG(Directed Acyclic Graphs)を作成し、それを用いてSLURMを通じてコンピューティングリソースにワークフローをスケジューリングしています。

ML実践者がAirflowを通してワークフローを実行する際の、エンドツーエンドのコンピューティングおよびストレージインフラがどのように構成されているか見ていきましょう。まず最初に、多くのマイクロサービスのエントリーポイントとなるロードバランサーにアクセスします。このマイクロサービスは、誰がワークフローを作成したのか、実行にどのくらい時間がかかったのか、ワークロードのエラー率はどうかといったメタデータを収集します。これらのワークフローについて、広範な会計処理とモニタリングを行っています。ワークフローの進捗状況を確認できる仕組みと、リクエストの取りこぼしを防ぐための冗長性を確保する内部キューを用意しています。
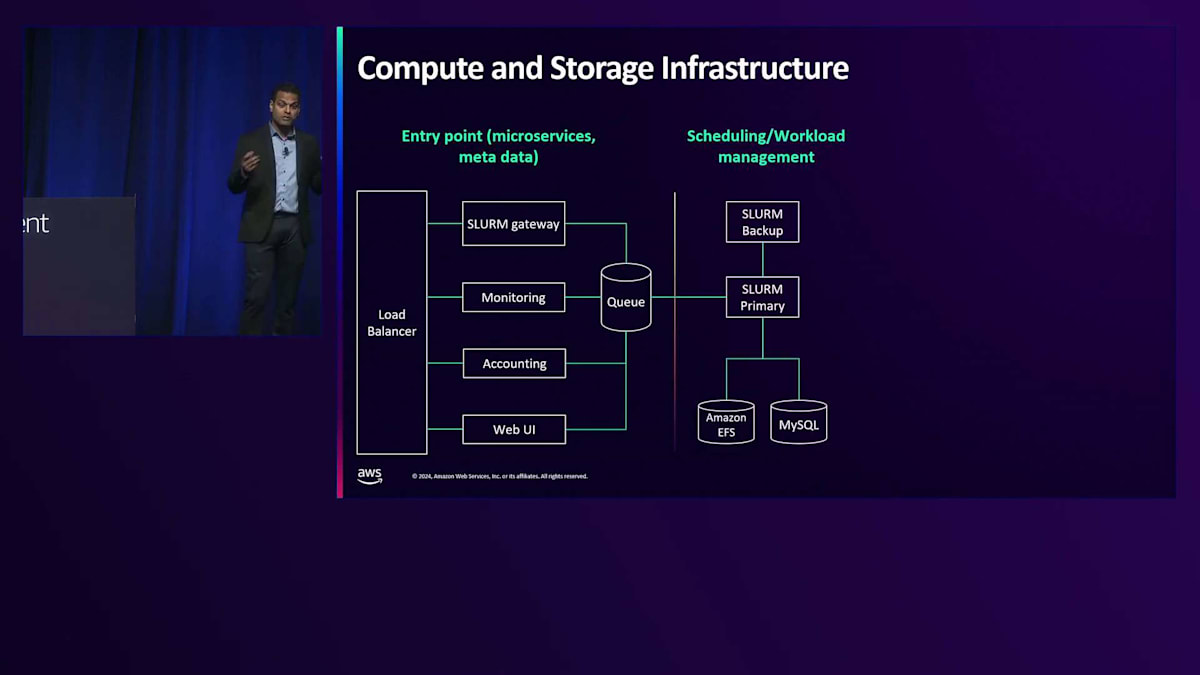
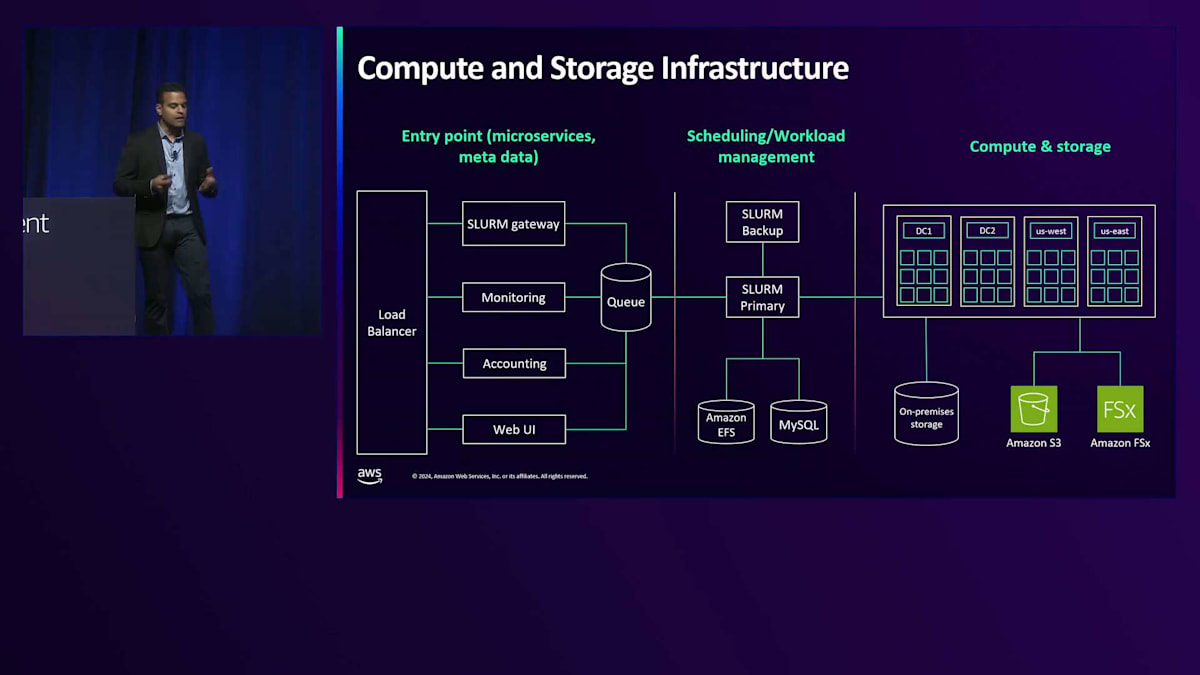
SLURMにも独自の冗長性があり、SLURM PrimaryとホットSLURMバックアップがあります。Primaryがダウンした場合、即座に切り替えることができます。内部的には、SLURMはAmazon EFSとMySQLを使用して、状態や各種メタデータを保存しています。 コンピューティングとストレージインスタンスについては、以前は自社でデータセンターを構築し、オンプレミスのストレージを持っていました。近年は、AWSをより多く活用するようになってきています。Zooxでのイノベーション促進、コスト効率、信頼性、自社構築した場合の実行リスクなど、様々な観点から長期的なコンピューティングとストレージ戦略を検討してきた結果、クラウドサービスインフラとしてAWSを使用することが明確な選択肢となりました。
自動運転車企業特有のML基盤構築の課題


ここで話題を変えて、自動運転車企業におけるML基盤構築の特殊な側面についてお話ししたいと思います。 まず最初に思い浮かぶのがシミュレーションです。私たちは、モデルをRobotaxisにデプロイする前にAIスタックを検証するため、シミュレーションに多大な投資を行ってきました。これが従来のML企業と自動運転車企業との大きな違いです。シミュレーションを作成する際は、自律走行技術をエッジケースでも検証できるよう、あえて一般的ではない、より難しい運転状況に焦点を当てています。実世界の見た目や動きを再現する最先端のシミュレーションソフトウェアを構築しました。シミュレーション環境でAIスタックを検証できれば、実世界でも同じように動作するはずだ、というのが目標です。
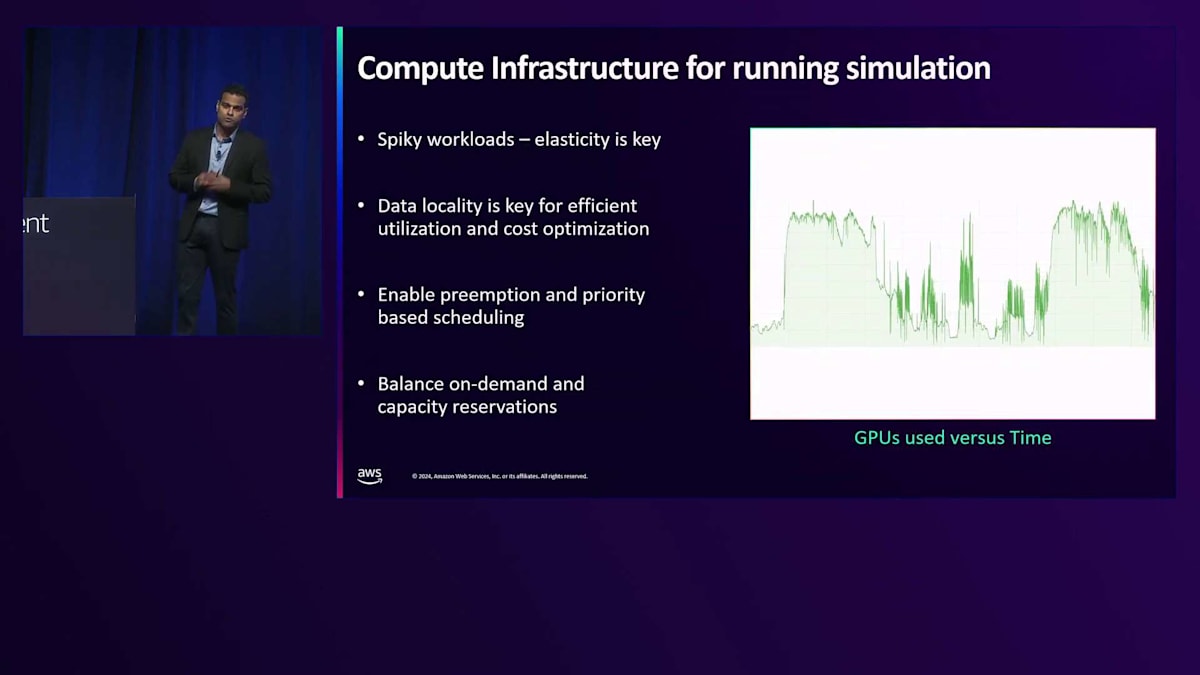
このような広範なシミュレーションには、相当な計算リソースが必要となります。 自動運転車企業の大きな特徴の一つは、大量のGPUリソースが必要で、ワークロードが著しくスパイク的だということです。このグラフは数週間にわたるGPU使用状況を示しており、シミュレーションのために数万台のGPUを活用していることがわかります。ご想像の通り、これらのGPUは安価ではなく、AWSでも簡単には入手できないため、コスト効率と利用率に十分な注意を払う必要があります。
GPU使用を最適化するために、いくつかの戦略を実装する必要があります。データのローカリティについては既に説明しましたが、ワークフロー研究スケジューラーには優先度ベースのスケジューリングを実装する必要があります。これにより、重要なワークフローがGPUに優先的にアクセスできるようになります。また、プリエンプションを有効にすることで、高価なGPUを使用している低優先度のジョブよりも、高優先度のジョブを優先させることができます。Spotインスタンス(より費用対効果が高い)、オンデマンドインスタンス、予約容量など、様々な手段を通じてGPUの調達バランスを取り、可用性を確保することが重要です。

自律走行車両の企業として、私たちは厳格な推論レイテンシーを維持しなければなりません。優れた自律走行体験を提供するために、Perception、Prediction、Planner、そしてCollision Avoidanceのモデルは1秒間に複数回実行される必要があります。そのため、モデルが大きくなりすぎないようにする必要があります。というのも、モデルが大きすぎると推論の遅延を引き起こすからです。大規模なトレーニングデータを使用してモデルを学習させているため、車両上でのモデル推論を高速化することに投資する必要があります。私たちは、Floating Point FP32からFP16やINT8への量子化などの手法を活用し、精度を大きく損なうことなくメモリ要件を削減し、より高速な推論を実現しています。また、モデルから重要度の低いレイヤーを取り除くPruning手法も採用しています。
モデルの推論レイテンシーを改善すると、MLの実務者は通常、より大規模なデータセットでトレーニングを行い、モデルを拡張しようとします。これはまさに望ましい反応です。MLインフラストラクチャチームの究極の目標は、先ほど説明した反復ループにおいて、アイデアから製品のデプロイメントまでの時間を最小限に抑えることです。ここまでで、Zooxが何をしているのか、私たちの動機、MLのユースケース、MLインフラの構成、そして従来のML企業と比較してAV企業におけるMLインフラ構築の特徴について説明してきました。
AWSを活用したZooxのCompute、Storage、Analytics戦略

これで、AV企業を支えるためのCompute、Storage、Analyticsの要件について理解できました。先ほど述べたように、Prediction、Perception、Planner、推論レイテンシーに関する多くのユースケースがあります。これらすべてにおいてComputeは重要で、MLワークロードをスケールさせるためにGPUが必要です。今日、業界の誰もがより多くのGPUを必要としており、AWSでは、ベストプラクティスのガイダンスを提供し、GPUの効率的な利用を確保することを誇りにしています。


この目的のために、いくつかのオプションを推奨しています。1つ目は、EC2インスタンス内のOn-Demandキャパシティと同様の、On-Demand Capacity Reservationsです。 これを使用すると、可用性に応じてP4やP5インスタンス向けのGPU予約を確保できます。次に、Spot Instancesがあります。 これは、ワークロードが断続的な停止を許容できる場合や、機械学習プロセスが実行中の中断を受け入れられる場合に有用です。

ただし、これらは可用性に左右されます。 これらの異なるオプションについて理解したところで、最適なオプションは何でしょうか?通常、最適なのはML Capacity Blocksです。これは昨年リリースされた新しいサービスの1つで、キャパシティを予約することができます。ZooxはGPUの活用と管理に、このML Capacity Blocksを大いに活用しています。

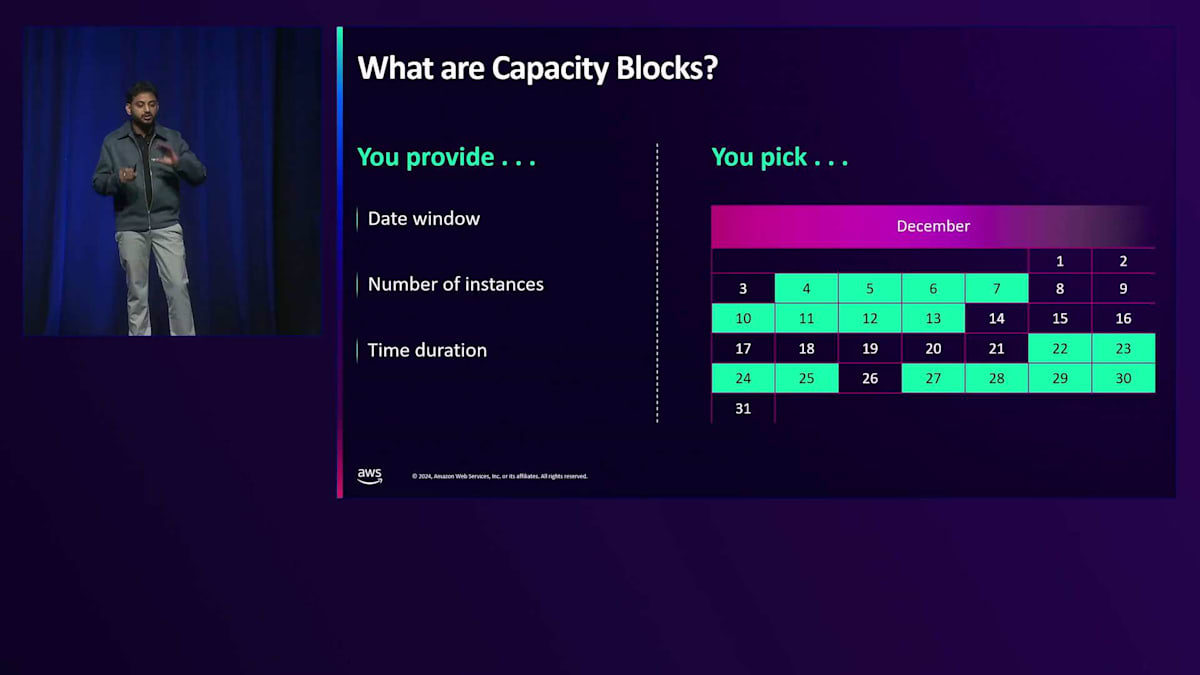
Capacity Blocksの主な要件は、日付、時間、インスタンス数の指定です。AWSではカレンダーが用意されており、希望の日付と利用可能な時間を選択することができます。 これはホテルの予約と同じような仕組みで、特定の日付を指定すると利用可能な部屋が表示され、実現可能なものを予約できるというものです。このように、確実に確保できるキャパシティが保証されています。




Zooxの機械学習ワークロードにおける重要なユースケースの1つとして、長期的なキャパシティのコミットメントが不要になったため、より広範な実験を実施できるようになったことが挙げられます。 これらの実験の進捗状況をすぐに確認することができました。 さらに、シミュレーション実行とマイルストーンの中で、正確なタイムラインに沿ってローンチできるよう、モデルトレーニングの実験を微調整することができました。 ZooxのPrediction and Behavior MLを担当するKai Wangからは、Capacity Blocksを使用することで、GPUスケジュールの制約を超えて多くの実験を実行し、MLモデルの実行用にP4インスタンスを確実に調達できたというフィードバックを得ています。


次に、ストレージについて見ていきましょう。先ほど述べたように、車両やライダーのデータなど、膨大なデータが収集されています。ストレージは、すべての機械学習ワークロードの分析、処理、微調整において重要な役割を果たします。Amazon S3 Intelligent-Tieringは、Zooxがデータレイク内で採用したオプションの1つです。 すべての車両とライダーから膨大なデータが送られてくる中で、予測できないパターンが多数存在します。センサーデータや分析を扱う際に、これらの予測できないパターンを管理するには、コストを抑えられるソリューションが必要です。
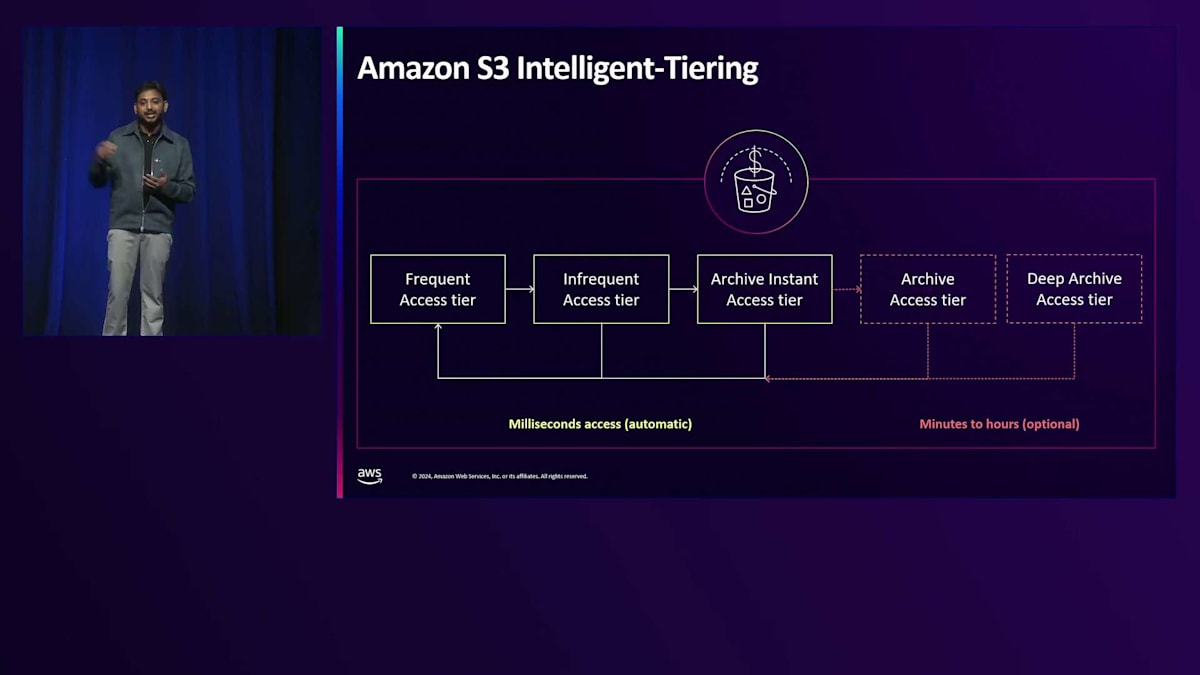

Amazon S3 Intelligent-Tieringは、パフォーマンスを損なうことなく、自動的にパターンとデータ使用状況を検出します。データを分析し、アクセスパターンを理解して、様々な階層間でデータを移動させます。データは頻繁アクセス階層から低頻度アクセス階層へ、そして異なるアーカイブプロセスへと進んでいきます。このように、Amazon S3はインテリジェントに運用を管理するため、コスト最適化を維持しながらデータを効果的に管理する心配をする必要がありません。 Robot Data PlatformのAlbert Chengからは、Amazon S3が彼らのデータレイクと分析の基盤として機能しているというフィードバックを得ています。

もう1つのストレージソリューションとして、Amazon FSx for Lustreについてお話ししたいと思います。先ほど述べたように、推論のレイテンシー、コンピュート、モデルトレーニングは最小限のレイテンシーで行う必要があります。Amazon FSx for Lustreは、何百万IOPSもの性能を持つ高度にスケーラブルなファイルシステムで、コンピュートのすぐ隣に配置することができます。このような配置により、コンピュートとストレージが隣接することになり、トレーニング時のレイテンシーが大幅に削減されます。Amazon FSx for Lustreは高度にスケーラブルでストレージに最適化されており、HDDとSSDの両方のオプションが用意されているため、最適化とコストの観点から最適なものを選択することができます。
先ほど申し上げたように、Amazon S3内には大量のデータが生成されるため、S3のデータを直接GPUに取り込むためのリンケージシステムが必要です。Amazon FSxが提供する機能の1つに、S3 Linked File Systemと呼ばれるものがあり、S3内のすべてのデータがFSxと直接リンクされ、GPU上でファイルシステムとして存在します。データに加えた編集や変更は、自動的に同期されます。


こちらが簡単な概要です。Amazon FSx for Lustreは、コンピュートとS3の間に位置し、S3のすべてのデータをファイルシステムとしてコンピュートに提供します。 ZooxのエンジニアリングマネージャーであるTom Larsonから、高性能コンピューティングワークロードをどのように実現しているかについてフィードバックをいただきました。Amazon FSx for LustreはPOSIXシステムを作成し、S3のデータを直接GPUに活用するための中間オペレーティングシステムとして機能しています。


次は、ストレージの話題からアナリティクスの分野に移ります。これまで見てきたように、S3バケットには大量のデータが保存されており、このデータから洞察を得る必要があります。Zooxはログやメトリクスを収集しており、可視化して洞察を得る必要のある膨大なデータが存在します。 Amazon OpenSearch Serviceは、このような洞察を得るのに役立ちます。これは、OpenSearchを実行し、スケールで管理できる機能の1つです。ログ分析機能を備え、Serverlessモードで提供されています。大量の入力データを活用し、検索やログの洞察を生成したい、あるいはEmbeddingを実行してVector Storageとして使用したいチームには、Amazon OpenSearch Serviceをお勧めします。

Zooxの場合、先ほど述べたように、ログデータが入力され、テキストを読み取って洞察を生成するためのログ分析が必要です。これは、ZooxがAmazon OpenSearch Serviceを活用している主要なユースケースの1つです。MLモデルと広範なトレーニングにより、Semantic Embeddingやk-Nearest Neighbor検索を必要とする多くのベクトルが生成されます。これらが、ZooxがOpenSearchを活用し、スケールでサポートしている2つの主要なユースケースです。

ここで紹介したリソースについては、多くの情報が入手可能であることは承知しています。先ほど申し上げたように、このセッションでは、すぐに効果的に利用できる最適なリソースを厳選しました。その中には、ML Capacity BlocksとCapacity Blocksのウォークスルーが含まれています。Zooxについてさらに学び、自動運転のユースケースやリリースについて理解したい場合は、その情報も入手可能です。皆様、ありがとうございました。素晴らしいre:Inventをお過ごしください。また、木曜日のリプレイパーティーでは、Zoox Robotaxiが展示されますので、ぜひご覧ください。ご参加いただき、ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion