re:Invent 2024: AWSによるGenerative AIのセキュリティアプローチ


はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - The AWS approach to secure generative AI (SEC323)
この動画では、AWSにおけるGenerative AIのセキュリティアプローチについて、包括的な解説が行われています。AWS Nitro SystemやNitro Enclavesといった基盤技術から、Amazon BedrockやAmazon Q Businessなどの上位サービスまで、各レイヤーでのセキュリティ確保の方法が詳しく説明されています。特に、Generative AIアプリケーションにおけるデータプライバシーの保護、アクセス制御、暗号化の仕組みについて具体的な実装方法が示されており、AWS Identity CenterやBedrock Guardrailsを活用した包括的なセキュリティ制御の方法が紹介されています。また、Foundation Modelへのアクセスを制御し、企業の機密データを安全に活用するための実践的なアプローチも解説されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
AWS Generative AIセキュリティアプローチの概要

皆様、こんにちは。AWS における Generative AI のセキュリティアプローチについて学びに来られた方々、おめでとうございます。正しい場所にいらっしゃいました。今日の午後のお時間を私たちと共に過ごしていただき、ありがとうございます。午後には皆さんが砂漠に出かけて Replay を楽しまれることと思います。私は Jason Garman と申します。AWS の Principal Security Solutions Architect として約2年半勤務しており、本日は Generative AI とそのセキュリティに対する私たちの考え方、そして Generative AI アプリケーションのセキュリティ確保についてお話しできることを楽しみにしています。

本日は3つのトピックについてお話しします。まず、AWS における Responsible AI とセキュアな AI へのアプローチについて理解を深めていきます。私たちが使用しているフレームワークや、Generative AI におけるセキュリティの分類方法についてお話しします。次に、AWS の Generative AI サービスを支えるテクノロジースタックに移り、そのスタックの各レイヤーで、AWS 上の Generative AI アプリケーションのセキュリティをどのように確保しているかを見ていきます。最後に、注目すべきいくつかの AWS セキュリティサービスと、それらを Generative AI アプリケーションにベストプラクティスとして統合する方法についてご紹介します。

Generative AI がどのようにイノベーションを促進するかについては、多くを語りません。このカンファレンスでも、多くの方々からすでにお話があったことと思います。私たちが今日お話しするのは、この新しい技術の採用に伴う新たなリスクと課題にどのように対処できるかということです。
Responsible AIとセキュリティの分類

情報は山のようにありますが、まずは AWS が Responsible AI を定義する際に使用している8つの次元についてお話ししたいと思います。正直に申し上げますと、これは非常に広範な内容です。私は日頃から多くのお客様と、Generative AI ワークフローのセキュリティ確保について話し合っています。お客様は最初、これは圧倒的だとおっしゃいます。AI アプリケーションのレスポンスにおいて、すべての人々に対して公平であることを確保するといった社会レベルのリスクから、新しい AI サービスを使用する際にお客様のデータを確実に安全かつプライベートに保つための保証まで、すべてをカバーしているからです。

理解すべきことが本当に多いのです。そこで、お客様とお話しする際には、Responsible AI のこれら8つの次元を2つの大きなカテゴリーに分解することにしています。これを私は「Responsible AI の分解」と呼んでいます。安全性から始めると、私が通常お客様にお話しする方法は、有害なシステム出力を防ぎ、正確で適切なレスポンスを促し、公平性やバイアスに関する目標に沿うようにこれらのシステムをどのように設計するかということです。皆様の会社にはそれぞれブランドボイスがあり、AI システムがそれを反映することを確実にしたいと考えています。そして安全性とそれに関連するすべてのカテゴリーについて考えるとき、これらのリスクはサービスの適用を通じて管理することができます。後ほどこのトークでお話ししますが、Amazon Bedrock Guardrails のようなサービスを通じてのみ管理可能なのです。

これらのリスクについて考える際に重要なのは、適切にリスクレベルを評価し、現行のシステムを通じてそれらに対処することです。現在のシステムは通常、確率論的なものとなっています。そのため、AIセーフティに関して受容可能なリスクレベルを考慮する必要があります。セキュリティの観点では、システムの設計において、機密情報や秘密情報が権限のないユーザーに漏洩することを防ぐための幅広い制約を考える必要があります。セキュリティに関して良いニュースは、私たちは既にセキュアなシステムの構築について豊富な経験を持っているということです。重要なのは、それらのセキュリティシステムをGenerative AIアプリケーションのワークフローにどう組み込むかを理解することです。ここでのベストプラクティスは、従来のセキュリティ制御を使用して、決定論的で監査可能、かつ説明可能な制御によって、Foundation Modelに入力される前にデータをフィルタリングすることです。本日は特にセキュリティに焦点を当て、AWSでGenerative AIサービスを使用する際にどのようにセキュアなシステムを構築できるか、そしてより重要なこととして、AWSのどの機能を使えばそのようなセキュアな成果を得られるかについて説明していきます。


AWSでお客様の理解を深めるために使用している、もう一つの有用な考え方のフレームワークが、 Generative AI Security Scoping Matrixと呼ばれるものです。ちょっとお聞きしたいのですが - この中で既にご存知の方はどれくらいいらっしゃいますか?これについては既にいくつかのブログ記事を公開していますが、比較的新しい概念です。 お客様とGenerative AI実装におけるセキュリティ要件について話し合う際、まず最初に尋ねるのは、どのようなユースケースで、そのGenerative AIアプリケーションやサービスとどのように連携するのかということです。私たちはこれらを5つの異なるスコープに分類しています。Amazon PartyRockやChatGPTのような、一般に公開されている既製のGenerative AIアプリケーションを使用する場合、それらはスコープ1に分類され、プライバシーとガバナンスに関する特定の制約があります。

スコープ2は企業向けアプリケーションです - 後ほどこのプレゼンテーションでAmazon Q Businessを使用してセキュアなパイプラインを構築する方法について見ていきます。スコープ3に移ると、購入者というよりも開発者の視点で、Amazon Bedrockなどのサービスを使用し、それを安全に採用する方法を理解することに焦点を当てています。これら5つのスコープすべてにおいて、ガバナンスとコンプライアンス、法務とプライバシー、リスク管理、制御、そしてレジリエンスという次元があります。これらが、皆さんが問いかけるべき質問と、セキュアな開発プロセスをどのように推進するかを導く要素となります。
AWS Nitro Systemによる堅牢なインフラストラクチャセキュリティ


このマトリックスのスコープ3、4、5を見ると、これはセキュリティの各次元の概要を示しています。本日は、AWSでGenerative AIサービスを採用する際に、これらの目標にどのように対処するかについて詳しく説明していきます。他のすべてと同様に、私たちはこれらの機能をテクノロジースタック全体にわたって構築しており、その最下層にはすべての基盤となるインフラストラクチャ層があります。

この点についてもう少し詳しくお話しするために、私の友人であるJD Beanをお招きしたいと思います。彼がAWSのインフラストラクチャ層について詳しく説明してくれます。ありがとうございます、Jason。私はJD Beanです。 AWS Compute Services OrganizationのPrincipal Security Architectです。私は主にAWS Nitro Systemなどの基盤となるコンピューティングサービスや、NitroTPMやAWS Nitro Enclavesなどを含む機密計算技術に関する業務に携わっています。先ほどJasonが興味深い指摘をしていましたが、確かにGenerative AIは私たちIT専門家、特にセキュリティ専門家にとって新たな課題とリスクをもたらします。しかし、一歩下がって考えてみると、コンピューティングシステムやデジタルシステムのセキュリティを確保するために従来から重要とされてきたツール、テクニック、アプローチ、スキルの多くは、Generative AIの分野でも依然として有効であることを覚えておく価値があります。それでは、この基盤層についてお話ししていきましょう。

GPUやコンピューティング、そしてネットワーキングなどの側面について説明し、これらのテクノロジーがどのように基本的なセキュリティを提供し、お客様が独自のGenerative AIシステムを構築する際に、トレーニング、推論、その他のアプリケーションにどのように活用できるかについてお話しします。

高いレベルで考えると、お客様が独自のワークロードを構築できる、真に安全なGenerative AIインフラストラクチャを提供するということは、3つの属性を通して考えています。1つ目は、AIデータをインフラストラクチャオペレーター(基盤となる物理ハードウェアの運用者)から完全に分離することです。2つ目は、お客様が自身のオペレーターと、システムが処理する機密性の高いAIデータとの間に分離を導入できる能力です。3つ目は、機密データがインフラストラクチャコンポーネント間を行き来する際に、常に保護された方法で行われるよう、インフラストラクチャ通信を保護することの重要性です。

インフラストラクチャレベルでこれらのテクノロジーに対処する方法の鍵となるのが、Confidential Computingという概念です。この用語は業界で耳にしたことがあるかもしれませんが、人によって異なる意味を持つことがあります。お客様との会話を通じて、私たちは明確な区分けを特定しました。お客様が私たちと話す際のConfidential Computingには、実際に2つの次元があります。1つ目は、クラウドオペレーターまたはインフラストラクチャオペレーターを、お客様のEC2インスタンスの内容から分離することに関するものです。これが最初の次元であり、図の緑の線で示されているように、これら2つのセキュリティドメイン間の分離を表しています。

2つ目の次元は、実際にはお客様のEC2インスタンス内で実行されるコンポーネント間の分離と隔離に関するものです。これは様々な理由で重要となり、後ほど詳しく説明します。この2つ目の次元は、お客様のデータとコード、あるいは管理者のような対話型オペレーターと、分離された方法で処理される必要がある特に機密性の高いコードやデータとの間の分離に関するものです。

AWSがこれらのテクノロジーや側面にどのように対応しているかについて、2つの主要なテクノロジーがあります: AWSのEC2仮想コンピューティングサービスを提供するための基盤技術であるAWS Nitro Systemと、AWS Nitro Enclavesです。Nitro Systemは、インフラストラクチャ運用者からの保護という第一の側面に対応するAWSの主要テクノロジーです。AWS Nitro Enclavesは、お客様の環境内で追加の分離を提供することで、第二の側面に対応できる強力なツールです。

Nitro Systemをご存じない方のために、その概要と背景についてお話しさせていただきます。左側に示されているのは、Nitro System以前のものです。これは完全にソフトウェアで仮想化されたEC2インスタンスを非常に簡略化して表現したものです。このような形で最後にお客様にリリースしたのは2012年頃でした。これはXenハイパーバイザーを使用し、小さなピンク色の四角で示されているお客様のEC2インスタンスに対して、DOM zeroと呼ばれる特権を持つオペレーティングシステムを通じて、ネットワークインターフェースやブロックストレージデバイスのエミュレーションなどのサービスを提供していました。AWSは約10年かけて、仮想化の在り方を根本的に変革することに取り組みました。その journey の到達点が、画面右側に示されているNitro Systemです。私たちは、お客様のEC2インスタンスと同じハードウェア上で実行する必要があったAWSのソフトウェアや機能の大部分を取り除き、VPCサービス、EBSストレージ、ローカルに接続されたインスタントストレージ、そしてEC2サービスを構成する他のすべての管理、セキュリティ監視、オーケストレーションを提供するために設計された特殊目的のハードウェアデバイスに移行しました。

システムメインボード上に残されたのは、お客様のインスタンスと、Nitro Hypervisorと呼ばれる小さな専用ファームウェアハイパーバイザーだけでした。Nitro Systemには3つの主要なコンポーネントがあります。その中心となるのがNitro Cardsです。これらは専用のシリコン、専用メモリを持つ独立したコンピューティングデバイスで、私たちの仮想化システムの大部分をハードウェアアクセラレーションで提供することを可能にします。すべてのNVMeストレージ、ブロックストレージ、ネットワーク、モニタリングはこれらのNitro Cards上で動作します。
Nitro Security Chipは、システムメインボード内部または上部に配置される小さなコンポーネントです。Nitro Cardsはセキュアブートとアテステーションのプロセスに従って起動し、Nitro Security Chipを通じて、そのハードウェアルートオブトラストをシステムメインボードに拡張します。これにより、世界中のどの施設にある各サーバーで何が実行されているかを正確に把握できる、非常に強力なハードウェアルートオブトラストを実現しています。最後にNitro Hypervisorですが、これは非常に軽量なハイパーバイザーで、メモリとCPUリソースを分割して仮想マシンに割り当て、その後は邪魔にならないよう控えめに動作することで、お客様が仮想化システム上でベアメタルに近いパフォーマンスを得られるようにしています。

Nitro SystemはAWSの基盤となるものです。今週の基調講演やセッションをお聞きになった方はお分かりかと思いますが、Nitro SystemはAWSのあらゆる場所に存在しています。Nitro Systemは、GravitonプロセッサーやTrainium、Inferentiaを担当するAWS内の部門であるAnnapurnaとの関係が、Nitro開発の初期段階で始まったところでもあります。私たちは、自社のハードウェアに投資することで得られるセキュリティ、パフォーマンス、効率性の価値に情熱を持って取り組んでおり、それによってお客様がアーキテクチャを構築するための非常に強固なセキュリティ基盤を実現することができています。
Amazon Bedrockを中心としたGenerative AIツーリングレイヤーのセキュリティ
2018年初頭以降にリリースされたすべてのEC2インスタンスは、Nitroシステムによって動作しています。このシステムは、セキュアブートプロセスによるハードウェアベースの強力な信頼の起点に従っています。Nitroシステムの重要なコンポーネントすべてを、お客様のワークロードにほとんど、あるいは一般的には全く影響を与えることなく更新できるように設計されています。これは、お客様に影響を与えることなく、このインフラストラクチャのメンテナンス、パッチ適用、セキュリティ強化が可能であることを意味します。また、生成AIの分野においても、ストレージ、ネットワーキング、メモリの透過的な回線速度での暗号化を提供することができます。
この優れた例が、Elastic Fabric Adapterです。これは、Nitroカードの1つによってEC2インスタンスに公開できるネットワークデバイスで、非常に高いスループットと低レイテンシーを実現しながら、クラスターやノード間のすべての通信に対して回線速度での透過的な暗号化を提供します。これにより、トレーニングやその他の高性能コンピューティングのユースケースにおいて、データの機密性とセキュリティを維持しながら、非常に高速にデータを交換することが可能になります。しかも、この保護を受けるために追加の暗号化レイヤーを追加する必要がないよう、すべて透過的に行われます。

おそらくNitroシステムの最も重要なセキュリティ特性の1つは、システムを動かすシリコンとソフトウェアを一から設計することで、私たちが掲げた大胆な目標を達成できたことです。その目標とは、世界中のクラウドスケール、ハイパースケールで動作する仮想化システムを構築し、かつAWSのオペレーターが顧客のEC2インスタンスの内容にアクセスする機能や仕組みを一切持たないようにすることでした。これは、すべてのAWSオペレーターやシステムから完全に隔離されています。SSHや汎用的なアクセス、シェルは一切ありません。システムによって、またはまれにヒューマンオペレーターによって実行されるすべてのNitro操作は、セキュアで認証された、最小権限の承認された監査可能な管理APIを通じて実行され、これらのAPIはいずれも設計上、顧客のEC2インスタンスの内容へのアクセスを提供することはできません。Nitroシステムは、顧客の生成AIアプリケーションに不可欠なこれらの高速化されたインスタンスタイプすべてを動作させています。

これには、Inferentia、Trainium、Trainium 2といったAWS自身が設計した一部のアクセラレーターや、NVIDIAやIntelのGadiアクセラレーターなど、他のパートナーが提供するGPUも含まれます。

私たちは、このシステムのセキュリティ設計について詳細な説明を記したホワイトペーパーを公開しています。これは第三者機関であるNCC Groupによって検証され、さらに全顧客に適用されるサービス利用規約に、Nitroシステムにはオペレーターアクセスが存在しないことを明確かつ明瞭に記載しています。

真に安全な生成系AIインフラストラクチャアプリケーションにとって重要な基本機能として、Nitro Systemには理解しておくべき機能がいくつかあります。その一つがNitroTPMで、これはEC2インスタンスで利用可能な標準準拠のTPM 2.0デバイスです。これによりEC2インスタンスは、自身の状態を収集して証明し、暗号データを保存・生成し、さらにリモートシステムに対して暗号レベルで自身のアイデンティティを証明することができます。また、Nitro Enclavesを使用すると、EC2インスタンス境界内に追加の分離された計算環境を確立でき、さらにAWSのキー管理システムであるKMSとのファーストクラス統合を実現する証明機能も提供します。


例えば、NitroTPMを使用すると、インスタンスのコンテンツ、コード、状態を測定し、リモートシステムに対して証明を提供することができます。これにより、そのインスタンスが意図した特定のコードを特定の構成で実行していることを検証できます。 ここで、Nitro Enclavesの用途や存在意義、そして生成系AIとの関連性についてお話ししましょう。
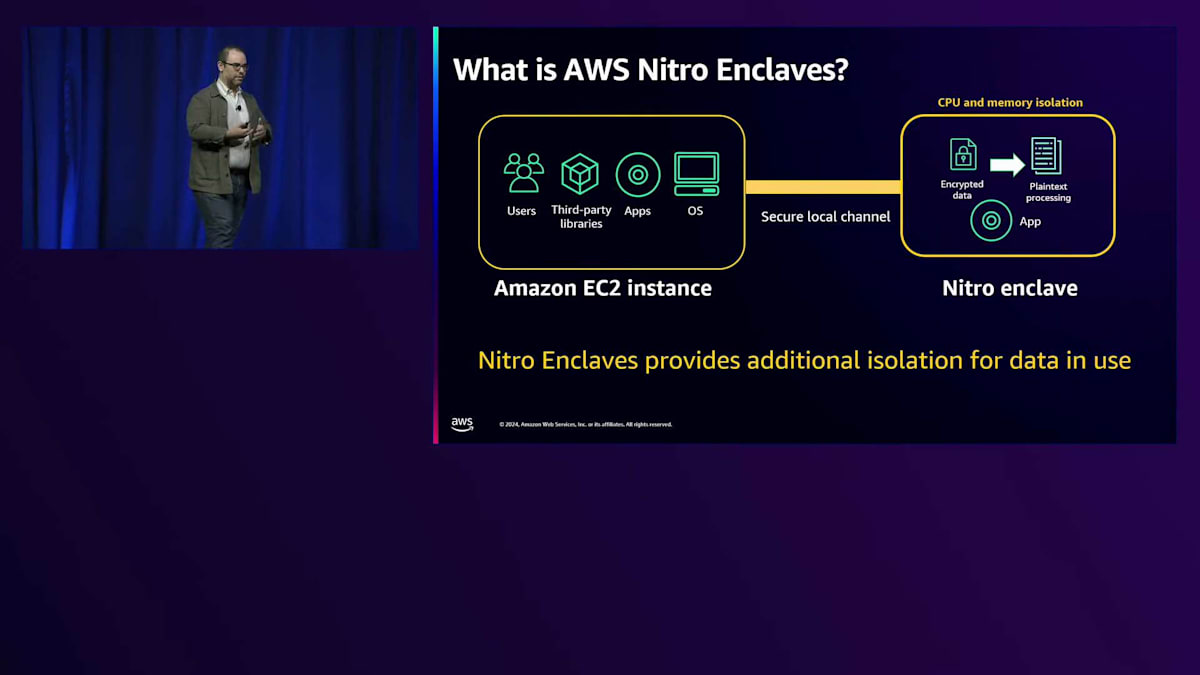
先ほど申し上げたように、Nitro Enclavesでは、EC2インスタンスの外部境界が非常に強固に保護されており、AWSのオペレーターが一切アクセスできない仕組みになっています。しかし、EC2インスタンス内に非常に機密性の高いデータがある場合、そのデータにアクセスできる可能性のある、インスタンス内の他の要素についても考慮する必要があります。対話型ユーザー、サードパーティライブラリ、アプリケーション、豊富なオペレーティングスタックなどが存在する可能性があります。 Nitro Enclavesを使用すると、これら2つのドメインを分離することができます。汎用ソフトウェアのための大きなドメインと、最も機密性の高いデータにアクセスして処理する必要がある特定のコードのための、より狭いスペースを分けることができるのです。

Nitro Enclavesは、デフォルトでこの追加の分離とセキュリティを提供します。 デフォルトではストレージを持たず、リモートアクセス機能もなく、直接のIPベースのネットワーク接続も提供しません。外部との唯一の実質的な通信経路は、それを作成したEC2インスタンスへの安全なローカルチャネルのみです。これは基本的に仮想シリアルケーブルのようなものと考えることができます。また、プロセッサに依存せず、大小様々なサイズに対応できる柔軟性があり、先ほど述べた暗号による証明機能も備えています。

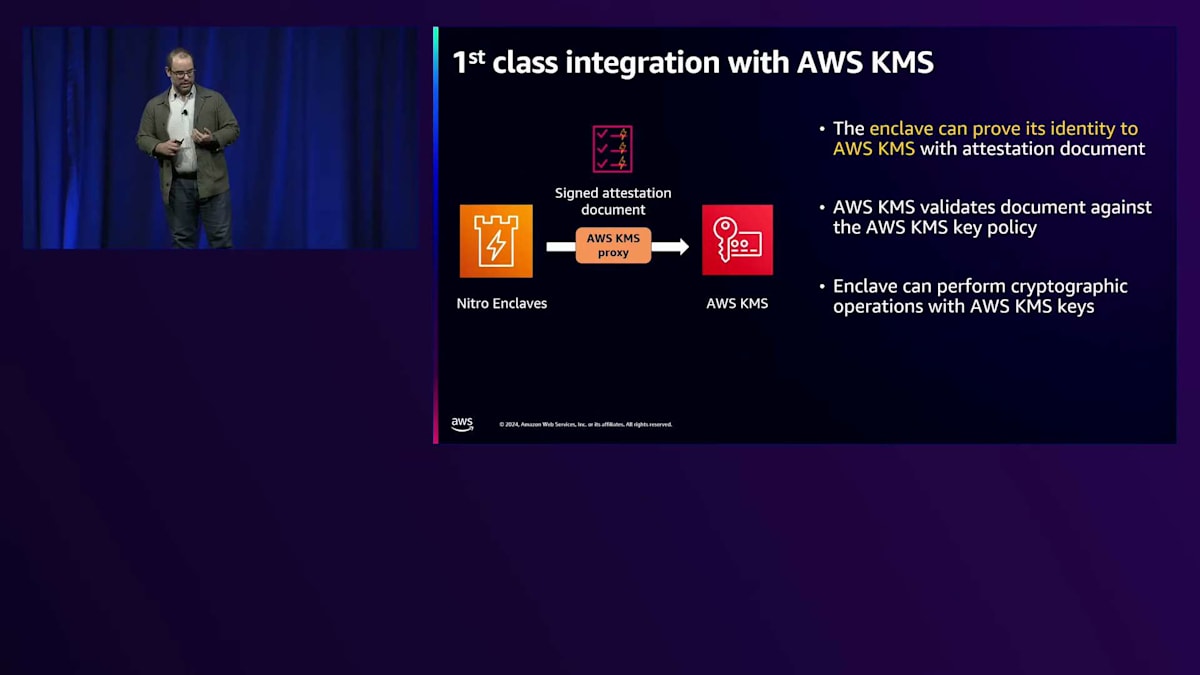
これは、Enclaveが第三者のサービスやAWS KMSに対して直接、 自身が何であるかを証明できることを意味します。具体的には、特定のEnclaveファイルであること、特定のIAMロールが割り当てられた親インスタンスに接続されていること、そしてノンスなどのユーザー設定可能なデータを含むことを証明できます。これは、顧客が非常に興味深い方法でシステムを構築できる低レベルのプリミティブです。 例えば、KMSとのファーストクラス統合により、特に機密性の高いデータの復号化を、特定の高度に信頼され制約された Enclaveアプリケーションからのリクエストでのみ実行できるようにすることが可能です。
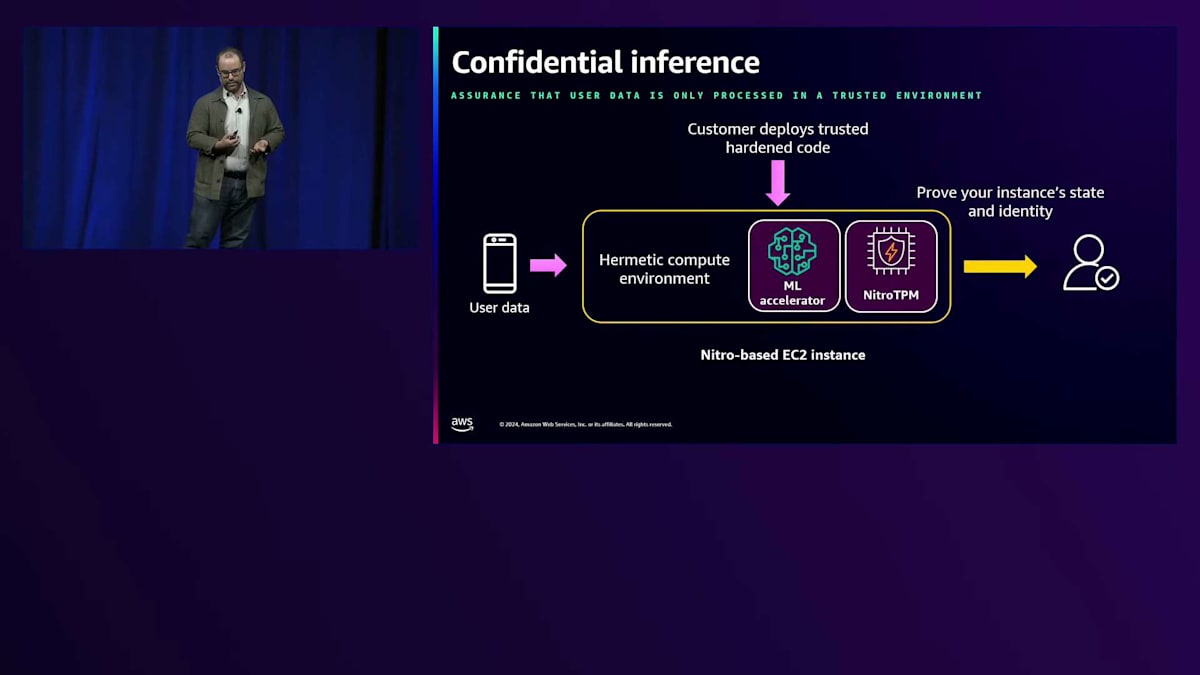
インフラストラクチャレベルにおける、真に深く排他的な機密推論がどのようなものになり得るかについて、少しお話ししたいと思います。お客様は、信頼できる堅牢な制約環境を構築することができ、そこにHermeticなコンピュート環境 - つまりリモートアクセスのない密閉環境 - をロードすることができます。そこで行われるデータ処理は、レビューされ、監査され、信頼できるものとなっています。これらのインスタンスはMLアクセラレーターやNitroTPMにアクセスでき、設計された通りの堅牢で機密性の高い制約環境であることを証明することができます。これにより、このコードが何を行うのか、また情報を推論のために提供する際にどのような保証が得られるのかについて、特定の前提を立てることができます。
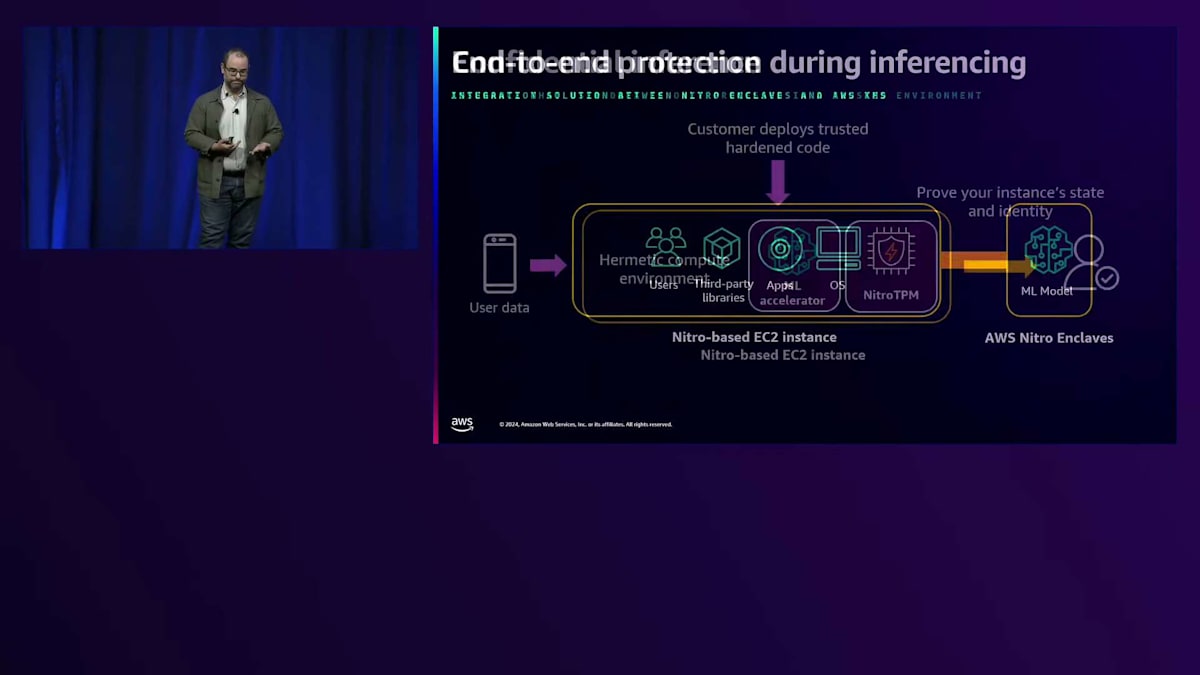
例えば、AWS Nitro Enclavesの場合、高度に機密性の高いMLモデルを暗号化された形でNitro Enclaveにロードし、AWS Key Management Service(KMS)のエンドツーエンドの暗号化機能を使用してそのモデルを復号化し、Nitro Enclaveで利用可能なCPUとメモリリソースを使用して推論を行うことができます。また、MLモデルの推論やトレーニング以外にも、Generative AIにとって重要な処理を行うことができます。例えば、プロンプトやCompletionの前処理や後処理を行うことができます。

先日のCISO Chrisの講演でも触れられていたように、MLモデルのテストなどのユースケースにも活用できます。Nitro Enclave内から始まる暗号化されたチャネルを使用して推論を開始することで、モデルのテストに使用されるプロンプト自体の機密性を維持することができます。 近々発表される予定のものとして、Nitro Systemのエンドツーエンドの保護をMLアクセラレーターにまで拡張することがあります。これにより、お客様は自身が所有・管理する鍵を使用して機密性の高いAIデータを暗号化し、選択した場所にデータを保存し、その暗号化されたデータを分離された信頼できる機密コンピューティング環境に安全に転送して、最も機密性の高いデータの推論を行うことができます。これは、今後登場するNVIDIA GB200 NVL72ベースのプラットフォームやTrainium2でサポートされる予定です。

これらは、AWSがお客様に提供する基本的な機能と、お客様が独自のアプリケーションを構築するためにAWSが実現する高度な機能や特徴の一部です。しかし、先ほど述べたように、私たちのスタックは、お客様のニーズに合わせて異なるタイプのアプリケーションや機能、サービスを選択できる豊富なオファリングとなっています。 ここで、スタックの次のレイヤーであるGenerative AIツーリングレイヤーについて、もう少しJasonにお話しいただきたいと思います。質問は後ほど受け付けます。
企業データとGenerative AIの安全な統合手法


JDさん、ありがとうございました。JDが言及したように、スタックを1レイヤー上に移動して、 ビルダー向けのツーリングレイヤーサービスと呼ばれるものを見ていきましょう。このレイヤーには、私たちが全員よく知っている大きなサービスが1つあり、今年のre:Inventでも多くを学んだと思いますが、それがAmazon Bedrockです。 Amazon Bedrockは、独自のインフラストラクチャを管理することなく、Foundation Modelにスケーラブルにアクセスできる私たちのプレミアサービスです。シンプルなAPIを使用するだけで、インフラストラクチャを作成したり維持したりすることなく、Generative AIアプリケーションの開発を加速することができます。ファーストパーティおよびサードパーティの様々なソースからFoundation Modelを選択でき、データのセキュリティ、プライバシー、安全性を念頭に置いて構築されています。

まず最初に申し上げたいのは、モデルの選択肢についてです。今週、私たちはAmazon Novaブランドの下で、いくつかの新しいモデルを発表しました。動画やテキストなどを扱うマルチモーダルモデルに加えて、AnthropicやMetaなどのモデルもご用意しています。お客様からは、このモデルの選択肢が最も重要な機能の一つだとご評価いただいています。これにより、お客様は実験を行い、特定のユースケースに最適なモデルを選択することができます。これは、セキュリティや安全性の観点からも重要な意味を持っています。

Bedrockのデータセキュリティとプライバシー機能について見ていきましょう。 このスライドの最初の項目にあるように、お客様のデータが基盤モデルのトレーニングに使用されることは一切ありません。さらに、お客様のデータが第三者やAWS自身と共有されることもありません。他のすべてのサービスと同様に、Bedrockでもデータのプライバシーを守ることを非常に重視しています。データの転送時および保管時については、保管時の暗号化にKMSを使用し、転送時にはTLS 1.2を最低基準として暗号化を行っています。
ネットワークの転送について話す際には、AWS PrivateLinkとVPCエンドポイントを使用して、パブリックAPIではなくプライベートエンドポイントでAmazon Bedrockに接続する方法を見ていきます。これらの機能が実際にどのように実装されているのか、詳しく見ていきましょう。ただ説明するだけでなく、共有責任モデルにおけるAmazonの責任範囲で、お客様のデータを安全に保つためにどのようなアーキテクチャを採用しているのかをお見せしたいと思います。



Amazon Bedrockとの間のデータフローを見てみましょう。 これは、下部にある企業のオンプレミスネットワークと、左側にあるAmazon VPC内のリソースからBedrockサービスにアクセスする場合のネットワーク構成を示す概念図です。中央にAmazon BedrockサービスのAPIエンドポイントが表示されています。 ほとんどのお客様は、パブリックAPIエンドポイントを使用し、インターネットから直接、オンプレミスネットワークから、またはVPC内のNATゲートウェイを経由してこのエンドポイントにアクセスします。先ほど触れたように、 VPCエンドポイントを使用することもできます。これにより、AWS PrivateLinkをサポートする当社のサービスとVPCの間でプライベートなポイントツーポイント通信が可能になります。AWS Direct Connectなどのサービスを通じて、この機能を企業ネットワークにまで拡張することができます。

しかし、これはお客様とエンドポイント間の通信をセキュアにする方法を示しているだけです。では、その裏側では何が起きているのでしょうか? 裏側には、オーケストレーション層があります。先ほど説明したように、様々なモデルの選択肢があるため、選択されたモデルに応じて、リクエストをどのコンピュートスタックに送信するかを決定する必要があります。ベースモデルのS3バケットから、特定のモデル用のコンピュートインスタンスにモデルをロードする一方向の矢印があることにお気付きでしょう。先ほど述べたように、ファーストパーティでもサードパーティでも、お客様のデータをモデルのトレーニングに使用することは一切ありません。Amazon Bedrockでは、お客様のデータを当社のモデルのトレーニングに使用することは決してありません。
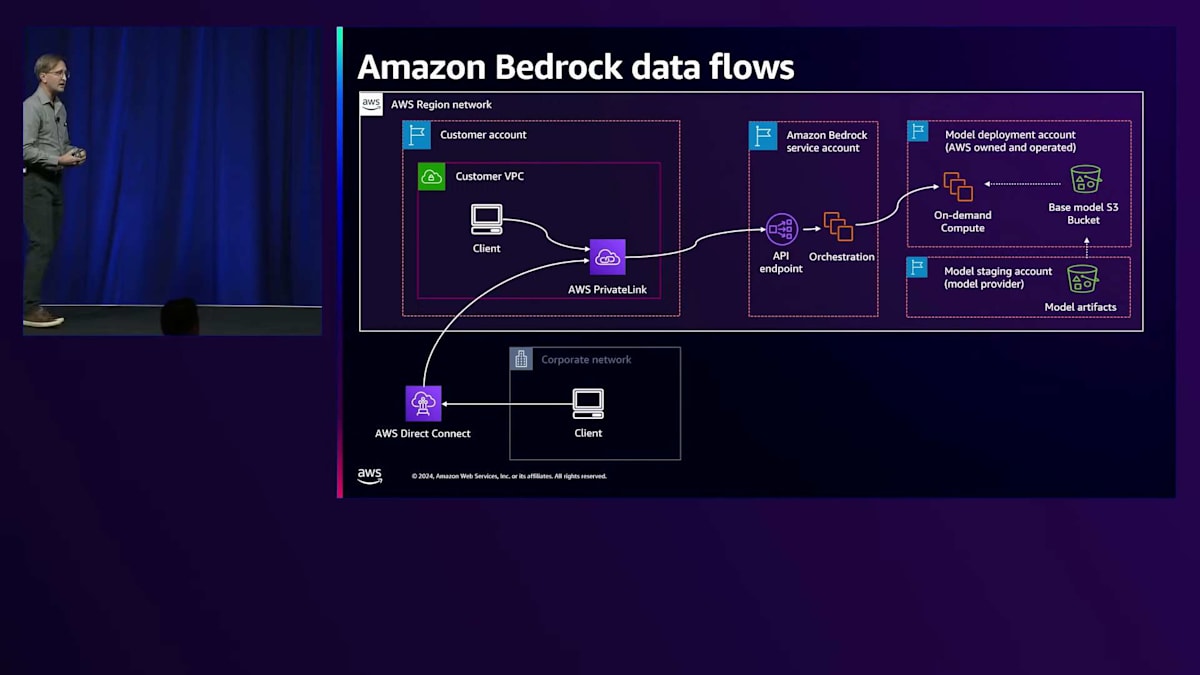
また、私たちはサードパーティのモデルも使用しています。MetaのモデルであるLlamaを選択することも、Anthropic Claudeモデルを選択することもできます。最小権限と関心の分離という私たちのベストプラクティスに従い、これらのモデルプロバイダーには専用のAWSアカウントを提供し、そこでモデルのアーティファクトをAmazon S3にアップロードしています。これらを本番環境にプロモートしてお客様に公開する準備が整ったと判断した時点で、そのデータはモデルデプロイメントアカウントにコピーされます。重要なポイントとして、お客様のデータが、これらのモデルのトレーニングや変更に使用されることは一切ありません。推論は関数のようなもので、データを入力して出力を得るだけであり、その過程でモデルが変更されることはありません。

これらすべての機能を包括的に支えているのが、AWSの基盤となるセキュリティサービスです。APIコールを監査するAWS CloudTrailや、プロンプトやコンプリーションのログ取得に使用できるAmazon CloudWatchなどがあります。ログ取得は任意で、オプトインする必要があり、データは独自のAWS KMSキーで暗号化することができます。お客様は、プロンプトとコンプリーションのログ取得を選択した場合、そのデータが自身のアカウント内で独自のキーを使用して安全に保管されることを確信できます。また、モデルへのアクセスを制御するIdentity and Access Managementや、生成AIサービスのAPI利用パターンにおける異常な活動を検出するAmazon GuardDutyなどのツールも用意されています。これらの基盤となるセキュリティサービスはすべて、Amazon Bedrockサービスのフローのあらゆる部分に統合されています。

先ほどガバナンスと監査可能性について触れましたが、モニタリングとログ機能に関して、前述の通り、AWS CloudTrailを通じてAPIアクティビティを監視することができます。
AWS CloudTrailを通じてAPIアクティビティを監視し、Amazon CloudWatchを使用して使用状況メトリクスを追跡することができ、さらにコンプライアンス基準への対応もサポートしています。これらは、様々なコンプライアンス基準を満たすのに役立つ製品に組み込まれた機能です。ここには基本的な機能が備わっており、責任共有モデルの両面的な側面がありますが、私たちはそのサポートを提供できます。


生成AIのセキュリティについて、一つ重要なことをお伝えしたいと思います。これまで、基盤モデルのセキュリティ確保や暗号化、ネットワーク制御についての多くの話や情報を共有してきました。しかし、ここで念頭に置いておくべき重要なポイントは、これが氷山の一角に過ぎないということです。その氷山の底にあるのが、お客様のデータです。生成AIは、お客様自身の機密性の高い企業データにアクセスできなければ、実際にはあまり役に立ちません。このことを考えると、データのプライバシーとセキュリティを維持しながら、どのようにデータへのアクセスを管理するかということを念頭に置く必要があります。
Amazon Q Businessによる安全なEnterprise-readyソリューション

お客様が Generative AI ベースのシステムで機密データにアクセスする際に見られる主要なパターンが3つあります。1つ目は Retrieval Augmented Generation です。これは、特定のクエリに関連する情報を既存の知識ベースから検索する方法です。これらの関連情報は Generative AI モデルのプロンプトに追加され、モデルはユーザーのプロンプトと内部データソースから得られた関連情報の両方を使用して回答を生成します。この方法では Foundation Model を変更する必要はありません。
AI Agents の場合、Vector データベースの検索を行う代わりに、AI Agent が外部 API を呼び出してデータをリクエストすることができます。また、AI Agents を通じてアクションを実行することも可能です。例えば、ユーザーのクエリに応じて、LLM がユーザーに代わって API を呼び出してアクションを実行するといったことができます。最後に Model Customization があります。これは既存の Foundation Model に新しいデータを追加して、まったく新しいモデルの重みを持つモデルを生成する方法です。Foundation Model のプライベートコピーを作成し、最終的なモデルを暗号化して、推論実行時のアクセス制御を行うことで、セキュリティを確保することができます。

Generative AI アプリケーションを既存の企業データセットと統合する際のセキュリティ上の懸念に対処する方法をいくつかご紹介したいと思います。まず、従来のセキュリティ制御をこのフレームワークにどのように実装するかについてお話ししましょう。最初のポイントは、ユーザーがシステムにクエリを入力してから応答が返されるまでの Generative AI アプリケーションのライフサイクル全体を通じて、ゼロトラストと包括的な認可を採用することです。つまり、プロセス全体を通じてアイデンティティを追跡し、パイプラインの各段階で決定論的で監査可能なセキュリティ制御と認可制御を実行するということです。アイデンティティから始まり、最小権限の原則を適用し、AWS Identity Center を使用して、きめ細かなアクセス制御を追加できます。AWS Verified Access や Amazon Verified Permissions などの既存のサービスを利用できます。システム全体へのアクセスを提供するために、Verified Access のようなゼロトラスト機能を使用できるので、VPN を使用する必要はありません。アクセス制御をどのように実装し、どこに配置するのでしょうか。

具体例を見てみましょう。これは Generative AI アプリケーションの簡略化された図です。左側にユーザーがいて、右側に LLM によって生成される最終的な応答があり、下部に機密データセットと API があります。
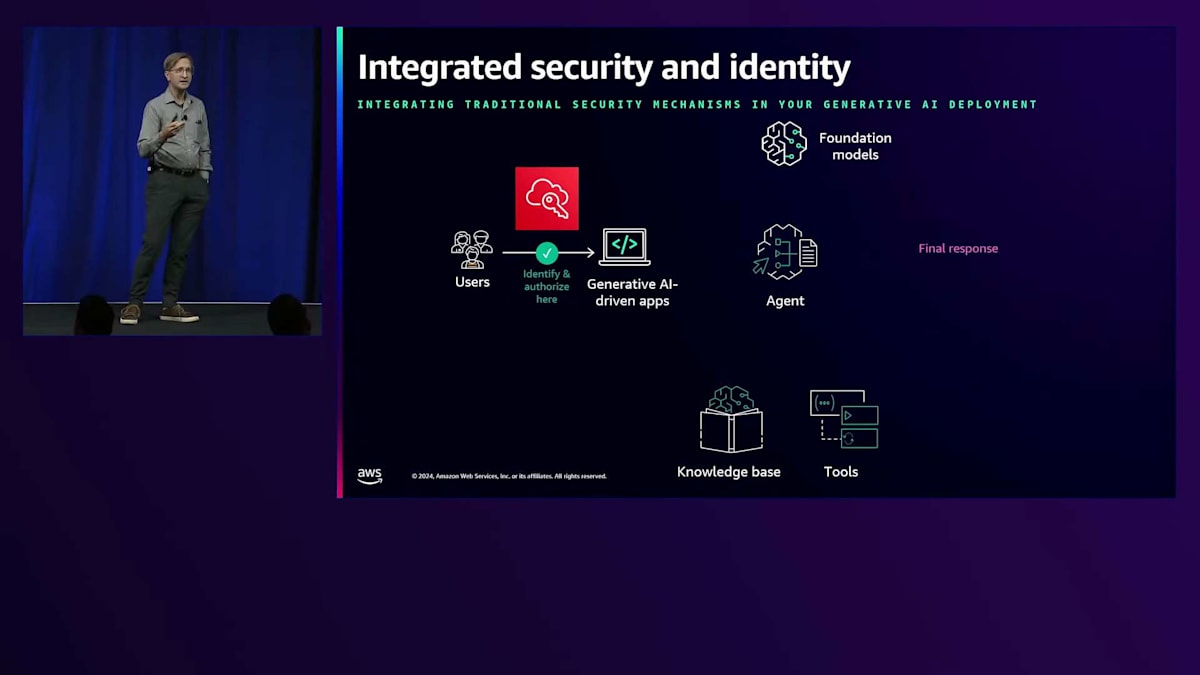
まず、ユーザーが Generative AI 駆動のアプリケーションにログインします。AWS IAM Identity Center を使用して、ユーザーを識別し、認証し、アプリケーション全体へのアクセスを認可します。しかし、それだけでは十分ではありません。次のステップとして、そのデータがこのエージェント、つまりオーケストレーションエンジンに入る際(この時点では LLM ではありません)、Amazon Bedrock Knowledge Bases や Bedrock Agents を使用するか、独自に構築することができます。このエージェントは、データへのアクセスや API 呼び出しを試みる際に、そのアイデンティティ情報を使用して認可の判断を行います。
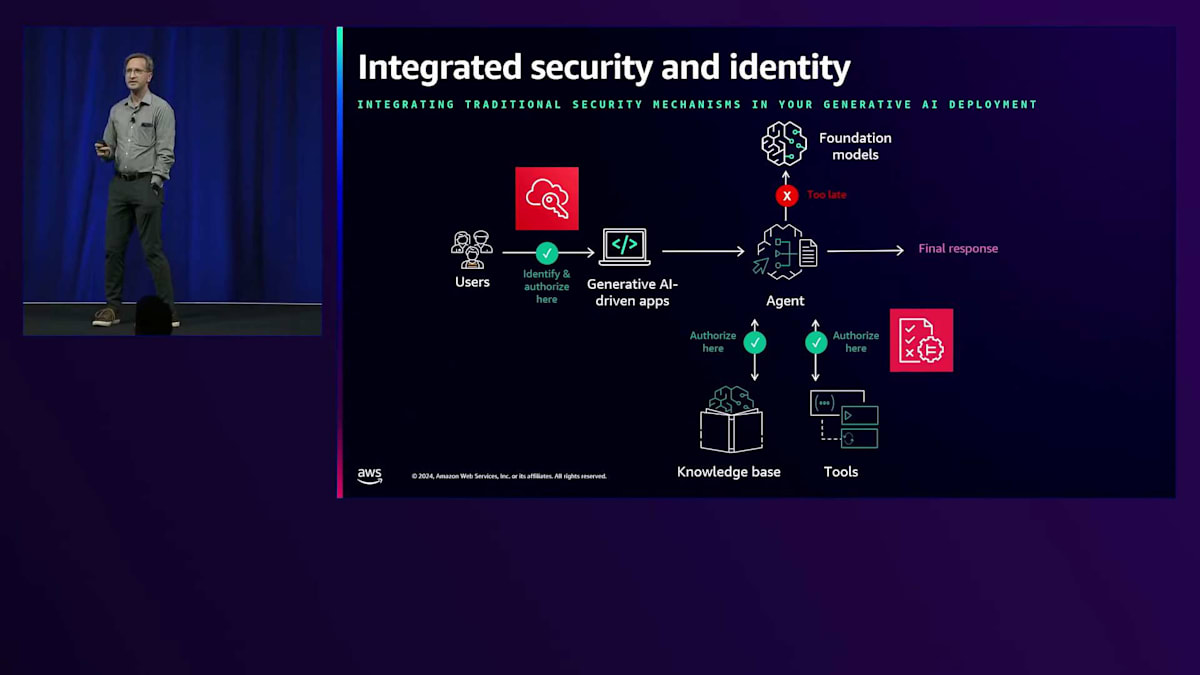
データがAgentを出てFoundation Modelに入る時点では、エンドユーザーがアクセスできるデータとアクションのみがFoundation Modelに送られることになります。なぜなら、LLMに入ってしまうと認可を実行するのは遅すぎるからです。ここで最も重要なのは、Foundation Model LLMがデータ、データへのアクセス、APIへのアクセスに関するセキュリティ上の判断を行う権限を制限することです。これらの判断は、監査や理解が可能な従来の決定論的なセキュリティコントロールに委ねることで、リスク計算がより容易になります。

セキュリティの実務者として、すべてを多層的なアプローチで考える必要があり、Amazon Bedrock Guardrailsについての議論は欠かせません。Bedrock Guardrailsについて考えるとき、それはAI安全性に役立つものです。LLMが有害なコンテンツを生成する懸念がある場合や、ユーザーが不適切な質問をする可能性がある場合、Bedrock Guardrailsが私の頼りになるサービスです。Bedrock GuardrailsはFoundation Modelに関係なく、プロンプトとモデルのレスポンスを評価できます。Foundation Modelを全く使用せずにBedrock Guardrailsを使用することも可能で、APIを通じて呼び出し、入力や出力をGuardrailsのルールに照らして評価できます。

有害なコンテンツ、Jailbreak、プロンプトインジェクション攻撃のフィルタリングしきい値を設定したり、禁止トピックを定義したり、個人を特定できる情報を削除またはマスクしたりできます。最近追加された新機能として、Groundednessを検出し、レスポンスがユーザーの入力クエリに関連しているかどうかを確認することで、Hallucinationをフィルタリングする機能があります。これはユーザー入力とFoundation Modelの出力の両方で行われます。中央に表示されている6つの異なる機能がBedrock Guardrailsによって提供されています。これはオンデマンドで実行することもできますし、Bedrockへの推論呼び出しのインラインで実行することもできます。



スタックを上に移動すると、最後の層である最上位層はEnterprise-readyソリューションです。AWS内で安全なGenerative AIアプリケーションを構築する方法について説明してきましたが、既存のデータコーパスを既に構築されたGenerative AIアプリケーションに安全に公開したい場合はどうすればよいでしょうか?その方法の1つがAmazon Q Businessを通じて実現できます。Amazon Q Businessは、ビジネス上の質問に対して、安全かつプライベートに、迅速で正確、そして関連性の高い回答を提供する事前構築されたシステムです。
Q Businessを既存のデータサイロに接続すると、提供されたデータに基づいてユーザーの質問に回答することができます。40以上の一般的なEnterpriseアプリケーションやドキュメントリポジトリに接続できます。

このトークは、セキュリティと安全性のメカニズムについての説明なしには完結しません。有害な応答やリクエストを理解してフィルタリングするためのGuardrailsを設定でき、応答を企業のコンテンツのみに制限することができます。これにより、関連性とハルシネーションの問題に対処する能力が得られます。先ほどBedockで触れたように、AWS PrivateLinkを使用することで、VPCからVPCエンドポイントを介してQ Businessに安全にアクセスできます。最も重要なのは、AWS Identity Centerと統合されているということです。私は、生成AIアプリケーションを安全に使用する上で最も重要な要素の1つは、アプリケーションの中心にIdentityを置くことだと考えています。Q Businessはまさにそれを実現しています。

データプライバシーとガバナンスの観点から、Q Businessでは、お客様が常にデータを管理できます。Q Businessを使用する際、お客様のデータは、AWSによる機械学習モデルのトレーニング、ファインチューニング、改善には一切使用されません。お客様のデータは転送中も保管時も暗号化され、AWS Key Management Serviceのキー、お客様管理キーを使用してデータのプライバシーとセキュリティを確保できます。

生成AIアプリケーションを検討する際に常に懸念されるのは、応答の関連性とアプリケーションが提供する応答の正確性を理解することです。Q Businessには素晴らしい機能があります - 右側のテキストを読むと、ユーザーのクエリに対する応答の下部に「sources」というボックスがあることに気づくでしょう。Q Businessがユーザーのクエリに答える際、応答自体の中の上部に表示される上付き文字と、「sources」というボックスの両方を提供します。これを展開すると、この回答の基となったすべての元ソースへのリンクが表示されます。これにより、ユーザーは生成されたデータを読むだけでなく、元のソースに戻って検証することもできます。これは大幅な時間の節約になり、得られた回答への信頼性も大きく向上します。
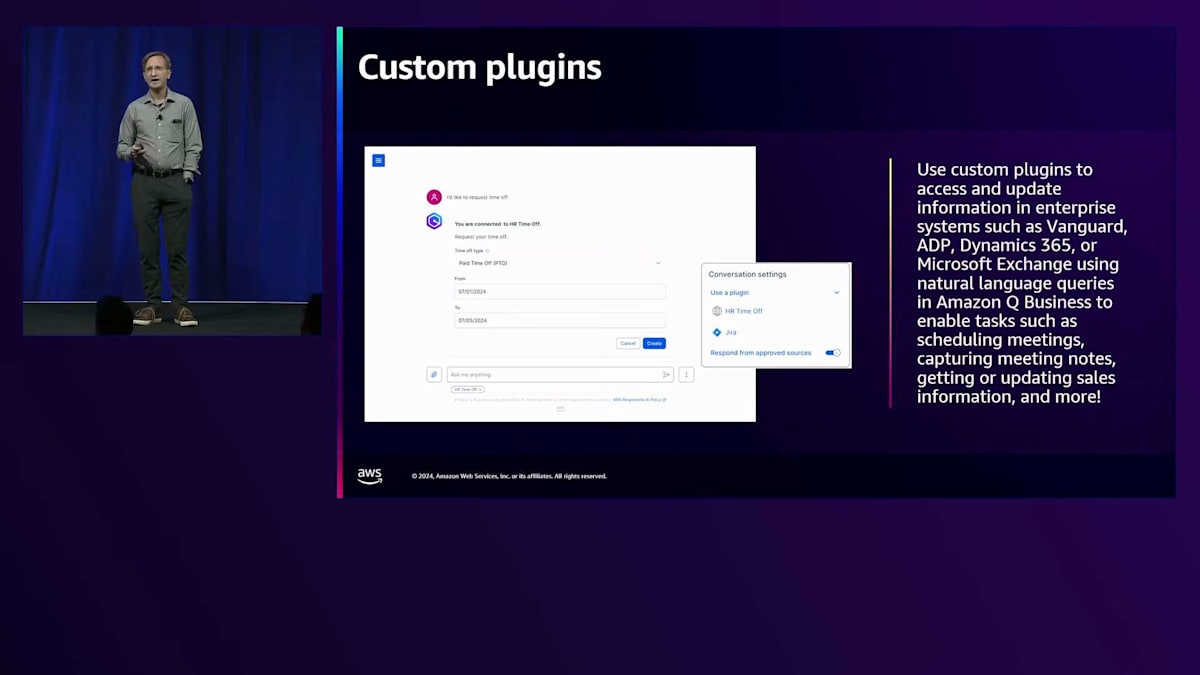
セキュリティの観点からQ Businessが優れている最後の点は、カスタムプラグインです。40個の事前構築されたプラグインでカバーされていない企業のデータソースがある場合や、ユーザーがデータに関する質問だけでなくAPIを介してアクションを実行できるようにしたい場合、Q Businessのカスタムプラグインが役立ちます。Q Businessのカスタムプラグインを使用すると、OIDC認証を利用して、任意のOpen API仕様のAPIに接続できます。Open API仕様を提供すると、そのユーザーに対してOIDC認証を実行します。これにより、ユーザーはQ Businessのアプリケーションインターフェース内で、適切なIdentityを使用して外部APIの呼び出し、アクションの実行、データのクエリをすべて行うことができ、ユーザーが承認されたデータとアクションにのみアクセスできるようになります。Q Businessの素晴らしい点は、これらすべてを統合してくれるので、実際にプログラミングを行う必要がないことです。
Generative AIセキュリティの総括と今後の展望

それでは、これらすべてをまとめるために、JDにバトンを渡したいと思います。ありがとうございました、Jason。今日のセッションの終わりに近づいてきましたので、いくつかの重要なポイントをお伝えしたいと思います。

信頼性の高いセキュアなシステムの最も強力な特性として、まず挙げられるのはディフェンス・イン・デプスです。 Generative AIアプリケーションは破壊的な力を持つ新技術であり、私たちの機密情報へのアクセスを通じて輝きを放っています。これらのシステムを保護する上で、アプリケーションセキュリティのあらゆる要素や属性をカバーする、層状の厳密なアプローチを考えることが最も重要です。



データ保護、アプリケーション保護、インフラストラクチャ保護、脅威検知、インシデント対応をカバーする必要があります。 Identity and Access Management、ネットワークとエッジの保護、ポリシー、手順、啓発活動に取り組む必要があります。 業界として長年かけて確立してきたベストプラクティスに従い、Generative AIがもたらす新しい課題や技術に適応させていく必要があります。

AWSの機能やサービスはGenerative AI技術から始まったわけではないということを覚えておくことが重要です。 AWSは、Generative AIサービスに加えて、セキュリティ、アイデンティティ、コンプライアンスサービス、基盤となるインフラストラクチャ、運用の可観測性とロギングサービスの充実したスイートを提供しています。AIスタックのどのレベルで運用しているかに関わらず - AWSインフラストラクチャプリミティブ上で独自のGenerative AIアプリケーションを構築する場合でも、Amazon BedrockやSageMakerツールのパワーを活用する場合でも、Amazon Q Businessのような上位のAWS Generative AIアプリケーションサービスレベルで運用する場合でも - これらすべてのサービスは、より広範なAWSエコシステム内で運用できることのメリットを享受し、Infrastructure as Code、ユビキタスなロギング、モニタリング、その他AWSの基本的なセキュリティ技術の恩恵を受けることができます。

本日は、私たちのSecure Generative AIアプローチに関するいくつかのリソースをご紹介して締めくくりたいと思います。 今年初めに、Generative AIインフラストラクチャへの私たちのセキュアなアプローチの詳細について説明したAWSブログを公開しました。また、先ほどJasonが話したGenerative AIアプリケーションにおけるデータ認可に関する具体的なトピックをカバーしたブログ記事もあります。本日は誠にありがとうございました。皆様が貴重なお時間を私たちと共に過ごしてくださったことを大変光栄に思います。アンケートへのご記入をお忘れなく。もちろん、私たち二人はこの後も会場に残っておりますので、どなたからのご質問やディスカッションも大歓迎です。ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion