re:Invent 2023: AWSのEKSでKubernetes運用を加速 - 管理・スケーリング・最新機能


はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - Accelerate your Kubernetes journey with Amazon EKS (CON206)
この動画では、Amazon EKSを使ってKubernetesの運用を加速させる方法を学べます。コントロールプレーンの管理やクラスターのスケーリング、アップグレードなど、本番環境での主な懸念事項に対するEKSの解決策を紹介します。また、Karpenterやcluster autoscaler、API Priority and Fairnessなど、EKSの最新機能やベストプラクティスについても詳しく解説。さらに、新しいEKSデジタルラーニングバッジの獲得方法も紹介されています。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
Amazon EKSによるKubernetesの旅:セッション概要と登壇者紹介

こんにちは。CON 206「Amazon EKSでKubernetesの旅を加速させる」へようこそ。このセッションでは、コントロールプレーンの管理、クラスターのスケーリング、アップグレードなど、本番環境でKubernetesワークロードを実行する際のお客様の主な懸念事項についてお話しします。また、Amazon EKSがこれらの懸念にどのように対処し、本番グレードのKubernetesを提供するために構築されたかについても学びます。さらに、お客様との協業から得られたEKSのベストプラクティスについても洞察を提供します。最後に、世界で最初に新しいアチーブメントを解除する機会を得られる、エキサイティングな発表で締めくくります。
私はLiz Dukeで、AWSのContainers担当Principal Specialist SAです。ステージには、KubernetesチームのSenior Software EngineerであるPrateek Gogiaも加わります。まず、Kubernetesがコンテナオーケストレーションに与えた影響について話したいと思います。その影響は非常に大きいものです。Kubernetesはオープンソースであり、Cloud Native Computing Foundation (CNCF)の卒業プロジェクトです。
Kubernetesの影響とEKSの役割
CNCFのプロジェクトをすべて見たことがあるでしょうか。少しこんな感じです。そうですね、言葉にできませんよね。これは数年前のスライドで、最近では1枚のスライドにすべてのサービスを収めることができません。これだけの選択肢があると、どこから始めればいいのか分からなくなることがあります。EKSは、これらの選択肢の多くを簡素化します。もちろん、これらのプロジェクトを含めることもできますし、必要に応じて一部だけを使うこともできます。EKSはアップストリームのKubernetes準拠なので、ロギング、コンテナネットワークインターフェース、イングレスなどのプリビルトオプションが付属しています。また、EKSはセキュリティとスケーラビリティについて実戦で検証されたサポート対象のKubernetesバージョンを提供します。





さて、お客様の声を聞いていると、 コンテナに移行する理由について、いくつかの共通のテーマが聞こえてきます。技術革新のペースに追いつくために素早く動きたいという要望があり、マイクロサービスは 個々のチームが特定の機能に取り組めるようにすることでそれを可能にします。しかし、素早く動きたいと思っても、 セキュリティが不十分では困ります。そのため、セキュリティは最重要事項です。ただし、多くの機能を持つセキュアなソリューションでも、スケールせず、パフォーマンスが出ないのでは意味がありません。 お客様は他に行ってしまうでしょう。今日の経済状況では、 必要なときに必要なものにだけお金を払うことがこれまで以上に重要です。別の地理的地域でお客様にサービスを提供するために拡張する必要がある場合、予算を超過せずに迅速にそのソリューションを作成できることが求められます。

今まで以上に、組織はレガシーシステムのモダナイゼーションを検討しており、その多くがAWS上でKubernetesを使用して行おうとしています。これは同時に、特にKubernetesのリリースサイクルと企業組織に伴う追加のガバナンスとの調整に関して、独自の課題をもたらします。もちろん、Kubernetesの俊敏性とイノベーションのペースは望ましいものです。では、EKSはどのようにしてそのスピードをプロセスに合わせ、アップグレードの影響を把握しやすくし、アップグレード体験を改善してリスクを軽減するのに役立つのでしょうか?
EKSクラスターの構成要素とコントロールプレーンの管理
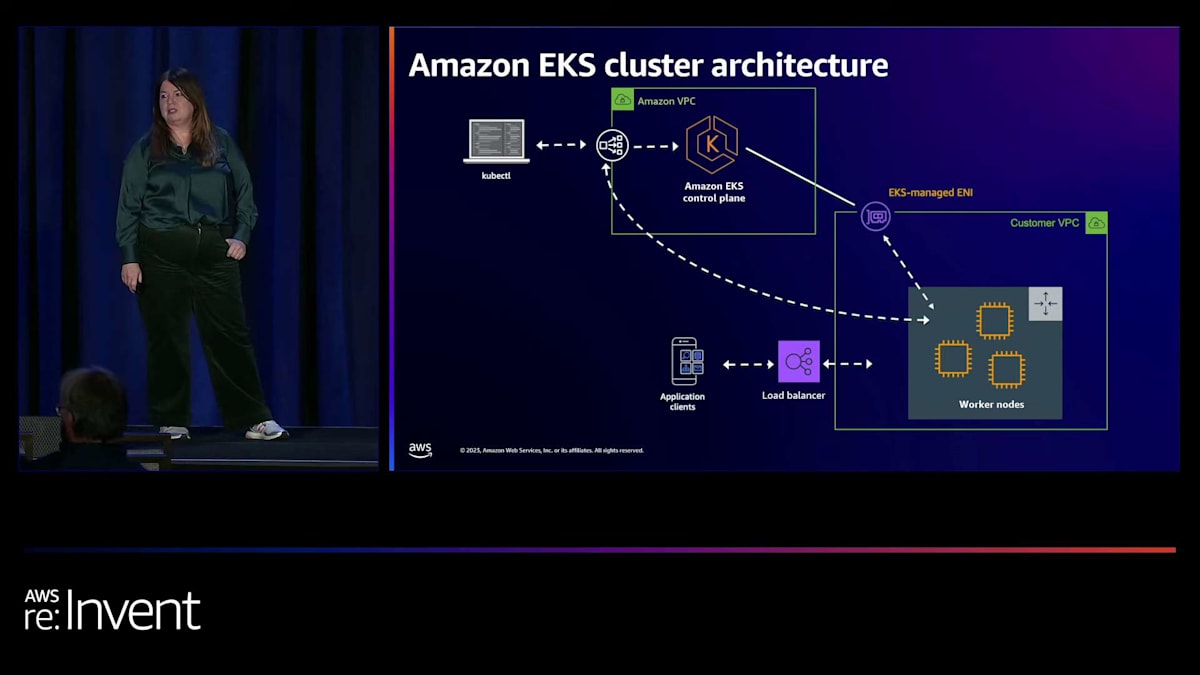
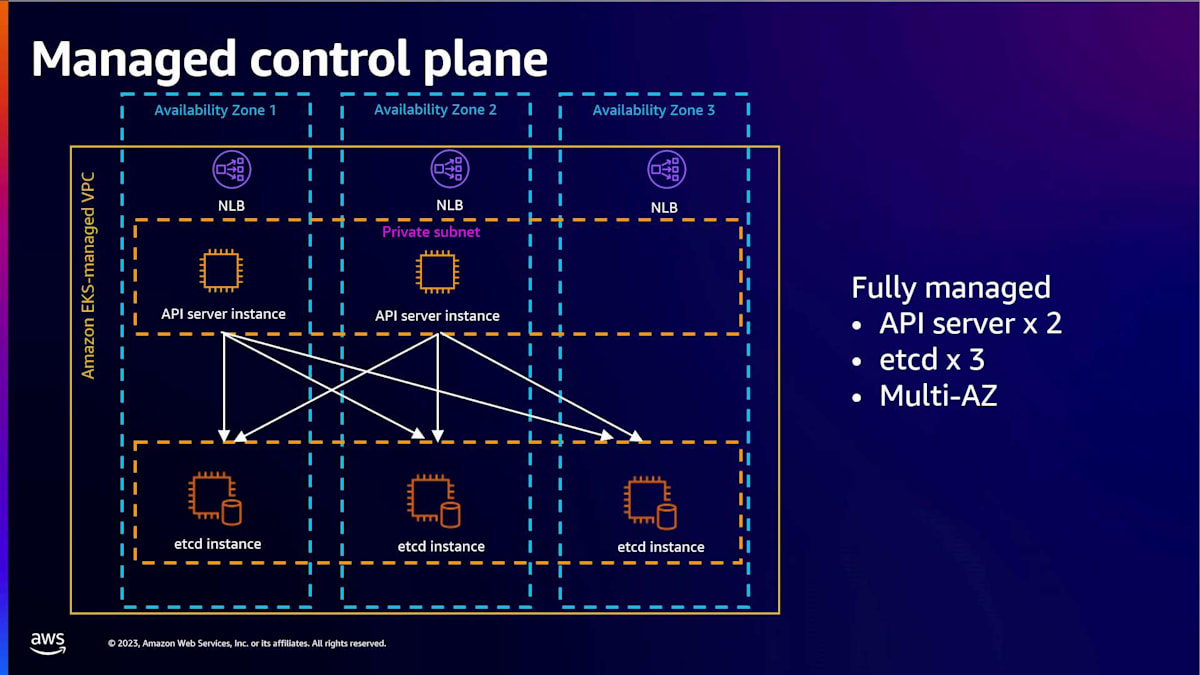
EKSクラスターの構成要素を見てみましょう。EKSクラスターはKubernetesクラスターであり、Kubernetesに精通している方もそうでない方もいらっしゃるでしょう。Kubernetesクラスターは、ポッドと呼ばれる単位でコンテナを実行する方法で、主に2つの領域から成り立っています。クラスターの運用に使用されるコントロールプレーンと、ポッド内のアプリケーション自体を実行するためのデータプレーンです。EKSは、顧客が最も問題を抱えていると指摘したコントロールプレーンの管理から始まりました。特にアップグレードが課題でしたが、スケーリングも同様でした。Amazon EKSは、完全に管理された耐障害性のあるコントロールプレーンを提供することで、これらの課題に対処しています。
私たちは、AWSが管理するアカウント内の複数のアベイラビリティーゾーンにわたって、APIサーバーの2つのコピーとKubernetesの状態ストアであるetcdの3つのコピーを実行しています。EKSコントロールプレーンは、単一のアベイラビリティーゾーンのイベントに耐えられるように設計されており、さらにEKSクラスターにはAWSのサポートも付いています。

コントロールプレーンのアップグレードに関しては、Kubernetesの年3回のリリースに追従することが重要です。EKSでは、これらのアップグレードはコンソール、API、CLI、または私たちが推奨するコマンドラインツールであるeksctlを通じて、たった1つのアクションで行えます。私たちは現在、Kubernetesの4つのバージョンをサポートしています。 Kubernetesクラスターを運用する際、クラスターを簡単にスケールできることが重要です。ポッドとノードをスケールすると、EKSが裏側でコントロールプレーンのスケーリングを自動的に行います。私たちは、ワーカーノードの数やetcdデータベースのサイズなど、さまざまなメトリクスを使用して、そのスケーリングをより応答性の高いものに調整しました。コントロールプレーンをスケールアップした後は、利用率がスケーリングのしきい値を下回り、数日間そのままの状態が続かない限り、スケールダウンはしません。



EKSコントロールプレーンにはセキュリティが組み込まれています。公開前の共通脆弱性識別子(CVE)を含むセキュリティパッチを適用し、 etcdデータベースを暗号化し、コントロールプレーンへのアクセスを保護しています。先ほど述べたように、EKSは常に 4つのKubernetesバージョンをサポートしており、アップグレードまでに最大14ヶ月の猶予があります。ただし、できればもっと頻繁にアップグレードしていただきたいと考えています。 アルファ機能フラグは、ほとんどの場合、本番環境での使用に十分な安定性がないと判断しているため、許可していません。
EKSのセキュリティとクラスターアクセス管理

クラスター自体へのユーザーアクセスに関して、Kubernetesにはユーザーディレクトリが付属していません。Kubernetesはポッドのオーケストレーションという中核的なタスクに集中し、ユーザーディレクトリはユーザーが提供することを想定しています。私たちには、ユーザー管理を扱うIAM(Identity and Access Management)というサービスがあり、これは非常にうまくスケールします。私たちはIAMを、Kubernetesオブジェクトの1つであるconfig map(YAMLの設定ファイル)を使用して、クラスターのユーザー認証サービスとして統合しました。しかし、顧客からのフィードバックに基づき、 このプロセスを改善するためにIAMクラスターアクセス管理を導入しています。
クラスターアクセス管理を使用すると、1セットのAPIを使用してユーザー認証と認可の両方を制御できるようになり、扱いにくいYAML設定ファイルが不要になります。Amazon Elastic MapReduceなど、EKSと統合された他のAWSサービスも、クラスターアクセス管理コントロールを使用して、クラスター管理者が複数の前提条件となる設定手順を実行することなく、EKSクラスター上でアプリケーションを実行するために必要な権限を取得できます。



先ほど述べたように、Kubernetesは年に3回新バージョンをリリースし、EKSは常に4つのバージョンをサポートしています。Kubernetesを使用するには、このリリースサイクルに合わせる必要があり、この分野でより多くのサポートを求めるお客様が増えています。サービスチームが注力してきた分野の1つは、コントロールプレーンのアップグレード時間の短縮です。以前は、アップグレードの開始から完了まで最大40分かかることがありました。現在では、10分以内に完了するはずです。お客様は、1回のアクションで簡素化されたアップグレード体験を高く評価しています。

1回のアクションで、コントロールプレーンのアップグレードだけでなく、データプレーンとアドオンのアップグレードも可能になりました。お客様はまた、自信を持ってアップグレードする能力についてもより多くのサポートを必要としています。同じEKSクラスター上で複数のチームが稼働している場合、彼らが呼び出しているすべてのAPIを把握していない可能性があり、Kubernetesのバージョン間では、新しいAPIが導入され、古いAPIが非推奨になることがあります。これを支援するため、ロードマップには、次のバージョンへのアップグレードに対するクラスターの準備状況レポートを生成する機能が含まれています。これらの機能とともに、メタデータAPIも提供されるので、これらのアクションをプログラムで実行できるようになります。
EKSの延長サポートとデータプレーンオプション

Kubernetesのサポートライフサイクルは、Kubernetesプロジェクトから提供されており、EKSもそのライフサイクルに従っています。この講演の冒頭で、各Kubernetesバージョンを14ヶ月間サポートすると述べましたが、Kubernetesのリリースサイクルに追いつくのが難しいことは承知しています。これは特に、新しいバージョンのKubernetesに対してアプリケーションをテストするサードパーティに依存しているお客様や、財務報告目的や休暇期間のために長期の変更凍結期間を設けているお客様にとって当てはまります。今では、ビジネス要件に集中し、都合の良いタイミングでアップグレードできます。なぜなら、今年の初めにAmazon EKSの延長サポートをプレビューで発表したからです。


これにより、14ヶ月のアップグレード期間が26ヶ月に延長されます。最も良いのは、バージョン1.23以上を使用している限り、このサービスに登録するための特別な操作は必要ないことです。使用しているバージョンが通常のライフサイクルサポート期間を過ぎても、引き続きサポートされます。 これまでコントロールプレーンについて多く話してきましたが、データプレーンについてはどうでしょうか? EKSのデータプレーンには様々なオプションがありますが、ここでもお客様からアップグレードとスケーリングに関するサポートの要望がありました。
データプレーンについて、さまざまなオプションを見ていきましょう。元々のオプションは、現在でも利用可能な自己管理型EC2インスタンスです。これらの自己管理型インスタンスでは、インスタンスのライフサイクルを完全に制御する責任があります。プロビジョニングを行い、アカウント内に存在し、ノードのアップグレードやインスタンスのライフサイクル管理を確実に行う必要があります。その際、セキュリティリリースがある場合には、基盤となるAMIもアップグレードする必要があることに注意が必要です。
EKS managed node groupsは別のオプションで、私たちがその責任の一部を引き受けます。ノードのプロビジョニング、スケーリング、アップグレードプロセス中の処理をサポートします。そして、新顔のKarpenterがあります。これはEKSクラスターと連携して、ワークロードに適したノードをプロビジョニングするオープンソースの自動スケーラーです。最後のオプションはAWS Fargateです。Fargateでは、必要なCPUとメモリの量を指定するだけで、それに基づいて課金されます。これにより、ポッドレベルまでの細かい課金が可能になります。
EKSのネットワーキングとモニタリング

managed node groupsについてもう少し詳しく見てみましょう。EKSのmanaged node groupsには、EC2インスタンスを起動時に設定するAuto Scaling groupsが付属しています。 managed node groupsは、ノードの調整とドレイニングを管理し、アップグレードプロセス中に容量が減少しないようにAuto Scaling groupsのノード数をスケーリングすることで、ワーカーノードのアップグレードを簡素化します。以前はノードごとに行われていましたが、ノードグループに多数のノードを持つお客様がいたため、これではうまくいきませんでした。そこで、ノードを並行してアップグレードできるように拡張しました。現在では、同時にアップグレードするノードの割合や特定の数を選択できます。

そして、managed node group用の新しいAmazon Machine Image (AMI)が利用可能になると、通知を受け取ることができます。
では、なぜKarpenterをKubernetesのインテリジェントコンピューティングと呼んでいるのでしょうか?アプリケーションのコピーをより多くのポッドで実行したい場合、より多くのインスタンスが必要になります。通常、Kubernetesではcluster autoscalerと統合することでこれを実現します。cluster autoscalerはEC2 Auto Scaling groupと通信し、「より多くのインスタンスが必要だ」と伝えます。これらのノードがクラスターに参加し、pending状態だったポッドがノードにスケジュールされます。しかし、Auto Scaling groupsとEKSクラスターの間には常に断絶がありました。なぜなら、Auto Scaling groupはクラスターのことを知らないし、気にもしていないからです。ただ、より多くのインスタンスが必要だと言われただけなのです。
Auto Scaling グループは、どのノードがグループに含まれるかについてより制限的であると見なされており、Auto Scaling グループの多様化もお客様にとって課題となっています。そこで、EKS サービスチームは Karpenter を作成しました。これは EC2 フリート API に直接インターフェースし、ポッド仕様に基づいて最適なノードを選択します。例えば、アプリケーションが CPU ではなく GPU で実行する必要があり、それをポッド仕様に記述した場合、Karpenter は適したノードを見つけ出します。Karpenter はまた、ポッドをノードにどのようにパッキングできるかを確認し、ビンパッキングを代行します。
Karpenter は、アプリケーションの需要が減少してノードとポッドがスケールインする場合、ポッドをより小さなノードに統合します。現在、多くのお客様が本番環境で Karpenter を実行しており、優れたパフォーマンスだけでなく、素晴らしい最適化によってクラスター全体で印象的なコスト削減を実現しています。

コンピューティングを全く管理したくない場合は、EKS Fargate というサーバーレスオプションを使用できます。Fargate では、基盤となるノードのパッチ適用、更新、スケーリングを私たちが管理し、これらの基盤ノードを他のポッド(他の顧客のものであれ、同じアカウント内のものであれ)と共有しません。スライドに示されているように考慮すべき点はありますが、Fargate を使用すれば、インフラストラクチャの管理ではなく、ビジネスアプリケーションに時間を費やすことに真に集中できます。
EKSクラスターの運用と最適化

デフォルトで Amazon EKS VPC CNI コンテナネットワークインターフェイスを実装しています。 EKS クラスターを構築すると、VPC CNI が作成される各ポッドに新しい VPC IP アドレスを要求します。Kubernetes では、デフォルトですべてのポッドが他のすべてのポッドと通信できるため、ポッド間のトラフィックを制限するには、Kubernetes ネイティブな方法としてネットワークポリシーを実装します。以前は、お客様は EKS クラスターでネットワークポリシーを実装するために、追加のサードパーティ CNI を導入する必要がありました。これは管理と更新の両面で余計な作業を必要としました。

VPC CNI に組み込まれたネットワークポリシーのサポートは、ロードマップで最も要望の多かった機能の1つであり、今年初めにその機能をリリースしました。この機能の実装には eBPF を使用しており、IP テーブルなどの従来の方法と比べて多くの利点があります。これらの利点には、より効率的なパケットフィルタリングなどがあり、パフォーマンスの向上につながる可能性があります。 ネットワークポリシーを使用することで、ポッド間の細かなネットワーク制限を実装し、ポッドレベルで最小権限を実装できます。これにより、EKS の多層防御戦略が強化されます。
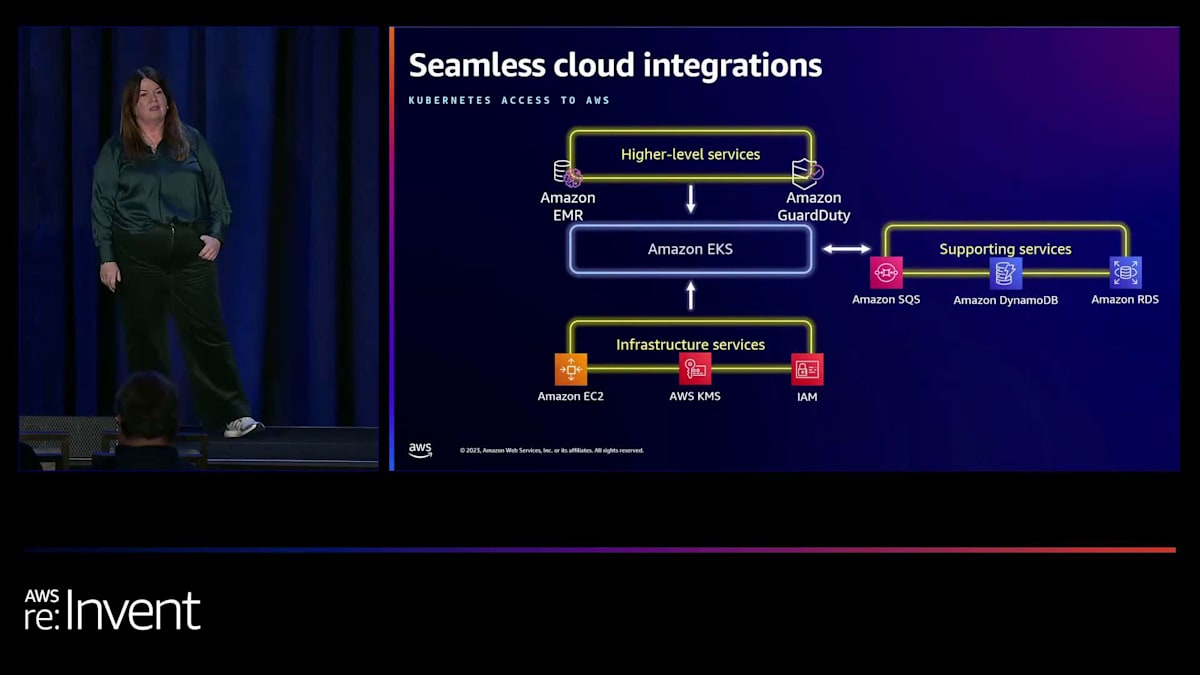
さて、Kubernetesクラスターが単独で存在することはほとんどありません。それらは通常、ワークロード環境の一部として機能しています。例えば、アプリケーションがAmazon SQSのようなメッセージキューを必要とする場合や、Amazon DynamoDBやAmazon RDSなどの1つ以上のデータベースと連携する場合がほとんどでしょう。そのため、他のAWSサービスとの連携におけるセキュリティについても考慮する必要があります。すでにユーザーアクセスにIAMを使用し、ネットワークトラフィックを制限するためにネットワークポリシーを使用することについて触れましたが、他のAWSサービスへのアクセスを制限するためにIAMロールを使用することはどうでしょうか?EKSを使用すれば、それも可能です。
パスワードなどの機密情報についてはどうでしょうか?Kubernetesは、他のコンテナオーケストレーターと同様に、secretsと呼ばれるオブジェクトに機密情報を保存します。これらはetcdに保存されます。Kubernetesのデフォルトでは、これらは単にbase64エンコードされているだけですが、Amazon EKSでは、secretsが保存される場所を保護するetcdの暗号化がデフォルトで提供されるだけでなく、AWS KMSエンベロープ暗号化を使用して、secretsが使用される場所も保護することができます。

EKS上でAmazon EMR on EKSを使用して分析ワークロードを実行したい場合もあるでしょう。単一のEKSクラスターを使用して、複数のApache Sparkバージョンと構成を実行し、自動プロビジョニング、スケーリング、より高速なランタイムを実現することができます。EKSと直接統合されているもう一つの高レベルサービスがAmazon GuardDutyです。Amazon GuardDutyは、AWSアカウントとワークロードを継続的に監視し保護するための、より正確で簡単な方法を提供するマネージド型脅威検出サービスです。


AWS CloudTrailを使用してEKS APIアクションを監視し、Kubernetesの監査ログにアクセスすることは以前から可能でした。今では、GuardDutyコンソールでわずか数ステップで、組織全体のすべてのAmazon EKSクラスターを継続的に監視できるようになりました。さらに、個々のコンテナランタイムアクティビティの可視性を高める新しいGuardDutyセキュリティエージェントを使用して、EKSワークロードを保護することができます。 Amazon GuardDuty EKSランタイム保護を使用すると、実装に必要な作業はほとんどなく、セキュリティの層を追加することができます。
アドミッションコントローラーWebhookとAPI Priority and Fairness
わずか2つのステップで有効にすることができます。最初のステップでは、アカウントでEKSのGuardDutyランタイムモニタリングを有効にし、2番目のステップでは、クラスター全体にエージェントをデプロイします。これで、GuardDutyは異常や不審な動作を監視し始めます。例えば、ポッドが既知のコマンド&コントロールサーバーのIPにコンタクトを試みてボットネットの一部になろうとしていたり、IAM認証情報にアクセスするためにホストのメタデータを参照しようとしていたりする可能性があります。これらの発見に基づいて、適切な判断を下すことができるのです。


皆さんは少なくとも1つの運用チームを持っているでしょう。もしかしたらそれ以上かもしれません。そこで、集中管理された運用チームがKubernetesクラスターについて把握しやすくするために、Amazon EKSにはすべてのKubernetesクラスターを表示できるコンソールがあります。これには他のEKSクラスター、AWSで稼働している他のKubernetesクラスター、オンプレミス、さらには他のクラウド上のクラスターも含まれます。これはEKS Connectorを使用して実現しています。

ワークロードを適切なパフォーマンスレベルで運用し、適切な可用性を確保することと、それらのワークロードを実行するコストのバランスを取ることの間には、常に緊張関係がありました。これはKubernetesで行う場合、より課題が大きくなる可能性があります。なぜなら、同じ基盤クラスター上で複数のチームが稼働している可能性があるからです。それらのチームに正確にコストを割り当てる必要があります。あるいは、顧客向けのマルチテナントクラスターを運用していて、顧客が使用しているリソースに対して適切な金額を請求する必要があるかもしれません。

つまり、チャージバックやショーバックを行っており、おそらくレポート作成、予算予測、コスト最適化も行いたいでしょう。FinOps Foundationが行った調査によると、組織の66%未満しか詳細なKubernetesコストモニタリングを行っておらず、調査対象の組織のわずか22%しかKubernetesのコストを5%以内の精度で正確に予測できないことがわかりました。
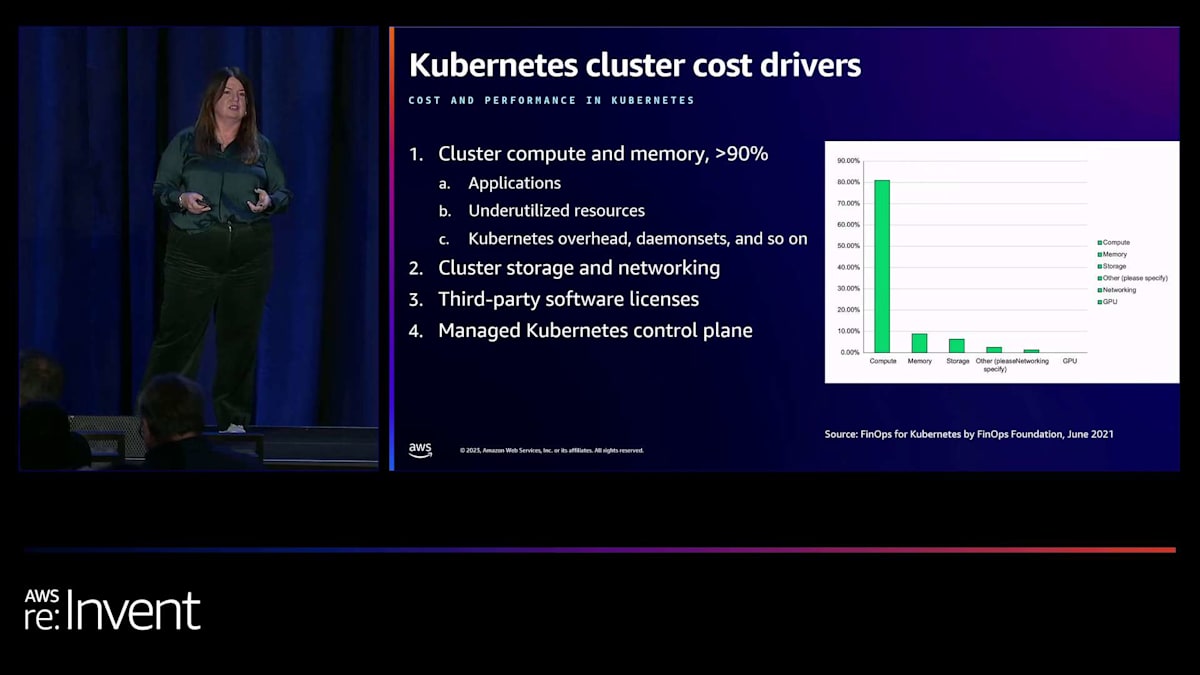
では、これらのコストを左右する要因は何でしょうか?彼らの調査で分かったこと、そして私たちが目にしているのは、Kubernetesクラスターのコストの大部分が、EKSでも他のKubernetesクラスターと同様に、コンピューティングとメモリから来ているということです。全体のコストの90%以上を占めています。例えば、クラスター上でサードパーティアプリケーションを実行している場合、そのライセンス料金などの他のコストもあるかもしれません。ステートフルなワークロードがある場合はストレージのコストがかかるかもしれませんし、アベイラビリティーゾーン間でデータを送信している場合はデータ転送コストがかかるかもしれません。実際、マネージドコントロールプレーンのコストは、これらの他のコストと比較するとほとんど無視できるほどです。これらのコストが、必要なCPUとメモリの量を誤って指定されたアプリケーションから来ている場合、私たちが目にするのは、多くの未使用リソースです。
皆さんもご存じだと思いますが、誰かにこのアプリケーションを実行するのに必要なCPUとメモリの量を尋ねると、最初の見積もりはほとんどの場合、当て推量です。これは、アプリケーションのパフォーマンスに基づいて継続的に測定し、調整している限りは問題ありません。そうでなければ、スケジューラーは単にそのポッドに指定された量を見て、クラスター内で利用可能なリソース量を探します。オートスケーラーを使用していて、そのリソースが存在しない場合、ポッドをホストするためにさらにリソースがスピンアップされます。したがって、ポッドにかかるコストを把握しておく必要があります。

コストの最適化を検討する際、ポッド内のアプリケーションのパフォーマンスを測定するだけでなく、それらがどれだけのコストを発生させているかを把握する必要があります。これはポッドレベルでもよく見られる namespace レベルでも同様です。多くの顧客が Kubecost を使用しています。 当初、Kubecost には2つのバージョンがありました。機能が限定されているものの、コミュニティからのサポートを受けられる無料のオープンソース版と、Kubecost から直接サポートを受けられ、より豊富な機能セットを持つ enterprise ライセンス費用が必要な enterprise 版です。Amazon EKS では、3つ目のオプションとして EKS 最適化 Kubecost バンドルが提供されています。私たちは Kubecost と提携し、オープンソース版よりも多くの機能を持つ Kubecost バージョンを提供しています。この Kubecost バージョンでは AWS から直接サポートを受けられますが、料金は発生しません。ライセンス料は私たちが負担します。

この Kubecost バージョンは、helm チャートを使用するか、マネージドアドオンとして、またはマーケットプレイスからアドオンとしてデプロイすることで、Amazon EKS クラスターにデプロイできます。また、この最適化された Kubecost バンドルを使用することで、クラスター全体で発生しているコストの統合ビューを得ることもできるようになりました。 つまり、新しいクラウドネイティブアプリケーションを構築するために AWS が提供する幅広いサービスを活用する場合でも、Amazon EKS クラスター上でサードパーティのソフトウェアアプリケーションを使用したい場合でも、AWS がサポートします。AWS Marketplace と Amazon EKS は提携して、顧客により良い体験を提供しています。プロバイダーのソフトウェアソリューションをアドオンとしてデプロイできます。利用可能なオプションには、Upbound の Crossplane、Confluent の Apache Kafka、Dynatrace の Dynatrace などがあります。

クラウドで Kubernetes を実行したい場合には素晴らしいですが、データレジデンシー要件のために特定の国で必要な場合はどうでしょうか?あるいは、オンプレミスのインフラに多額の投資をしていて、廃棄する前に使用したい場合はどうでしょうか?私たちの目標は、顧客が望む形で、必要な場所で Kubernetes を提供することです。これには、クラウド、オンプレミス、そしてその中間のあらゆる場所が含まれます。このように、Amazon EKS が本番環境グレードの Kubernetes を提供し、常にサービスを改善して顧客をより良くサポートすることに注力している理由がおわかりいただけたと思います。それでは、Prateek に引き継ぎ、Amazon EKS を迅速に立ち上げて実行するための一般的な問題点とベストプラクティスについて説明してもらいます。
EKSクラスターのトラブルシューティングとベストプラクティス

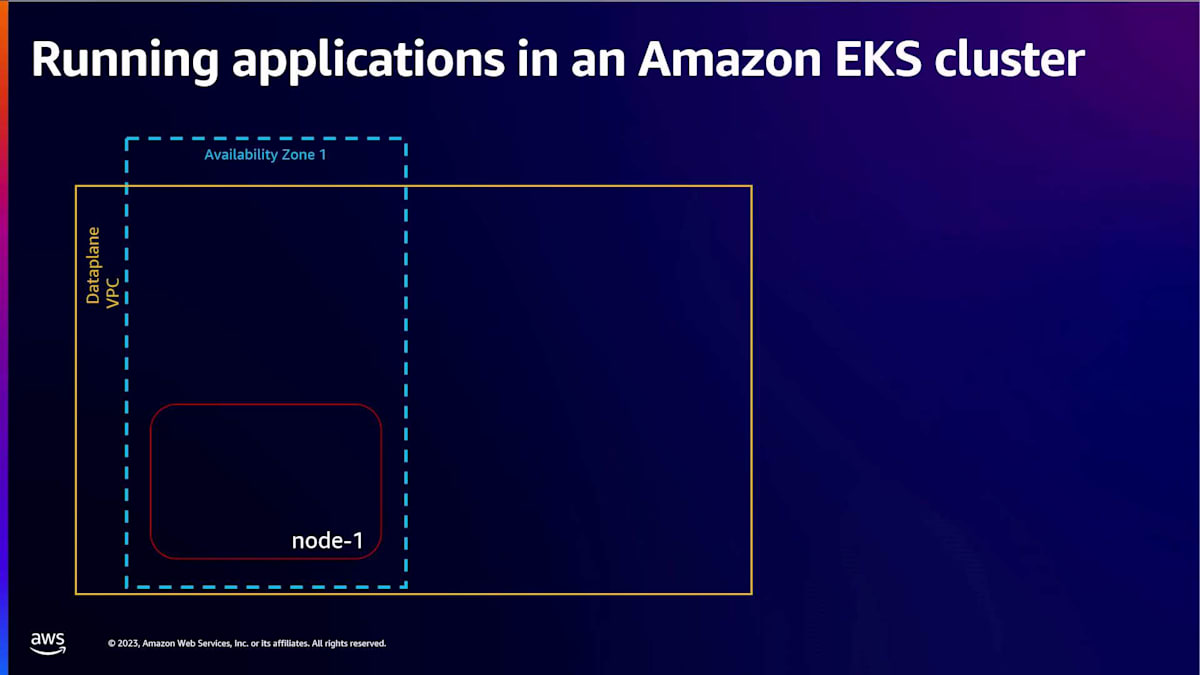
ありがとう、Liz。皆さん、こんにちは。Amazon EKS のアーキテクチャと AWS で Kubernetes を実行するオプションについて探ってきましたが、ここでは Amazon EKS が推奨するいくつかのベストプラクティスをご紹介したいと思います。これらは、世界中で 数十万の Kubernetes クラスターを管理し、顧客がこれらのクラスター上で重要な本番ワークロードを実行するのを支援してきた経験に基づいています。それでは見ていきましょう。まずシナリオから始めましょう。コーヒーショップのデジタル注文の受付を開始することになり、これらのコーヒー注文を受け付けるアプリケーションをデプロイする必要があります。 そのために、Amazon EKS クラスターを作成し、このクラスターにノードを追加しました。そして、アプリケーションをデプロイし、それが availability zone 1 のこのノード 1 上で実行されています。この重要なビジネスアプリケーションを実行しているポッドが availability zone 1 にデプロイされ、現在顧客にサービスを提供していることを考えると、何らかの理由でノード 1 の再起動やアップグレードが必要になった場合、ダウンタイムが発生する可能性があります。これはビジネスにとって受け入れられません。注文の損失につながる可能性があるからです。
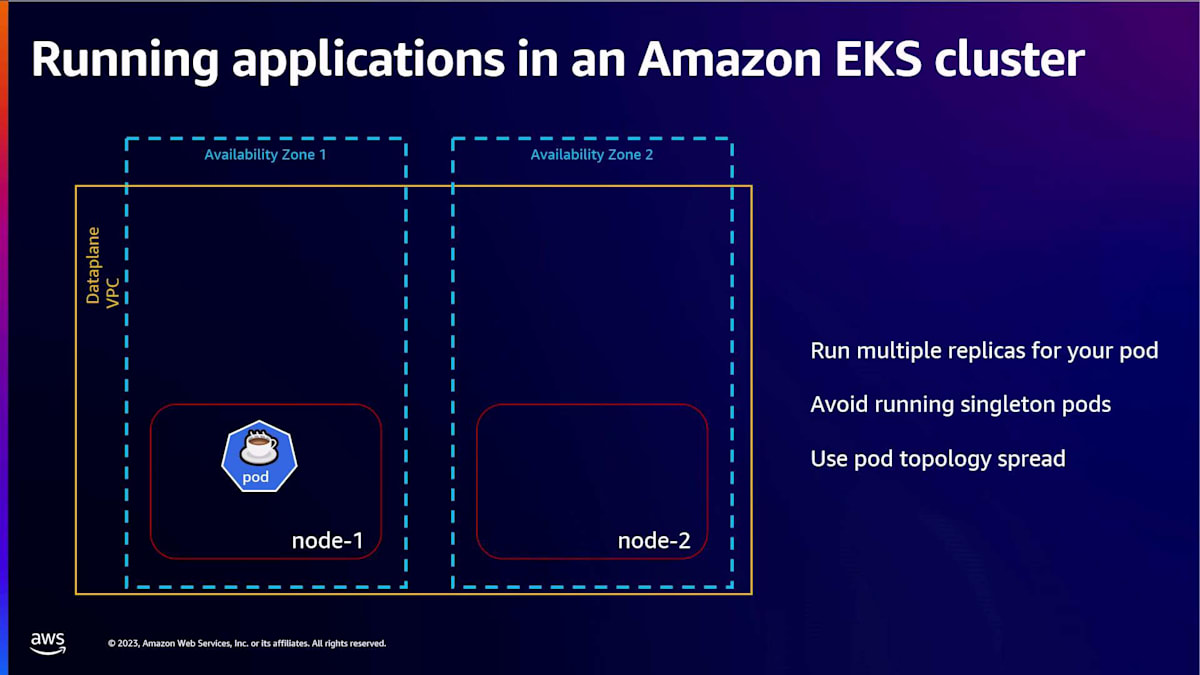
これを軽減するために、ポッドの複数のレプリカを実行し、シングルトンポッドの実行を避け、topology spread を使用してこれらのレプリカを異なる availability zone の異なるノードにわたって実行することをお勧めします。
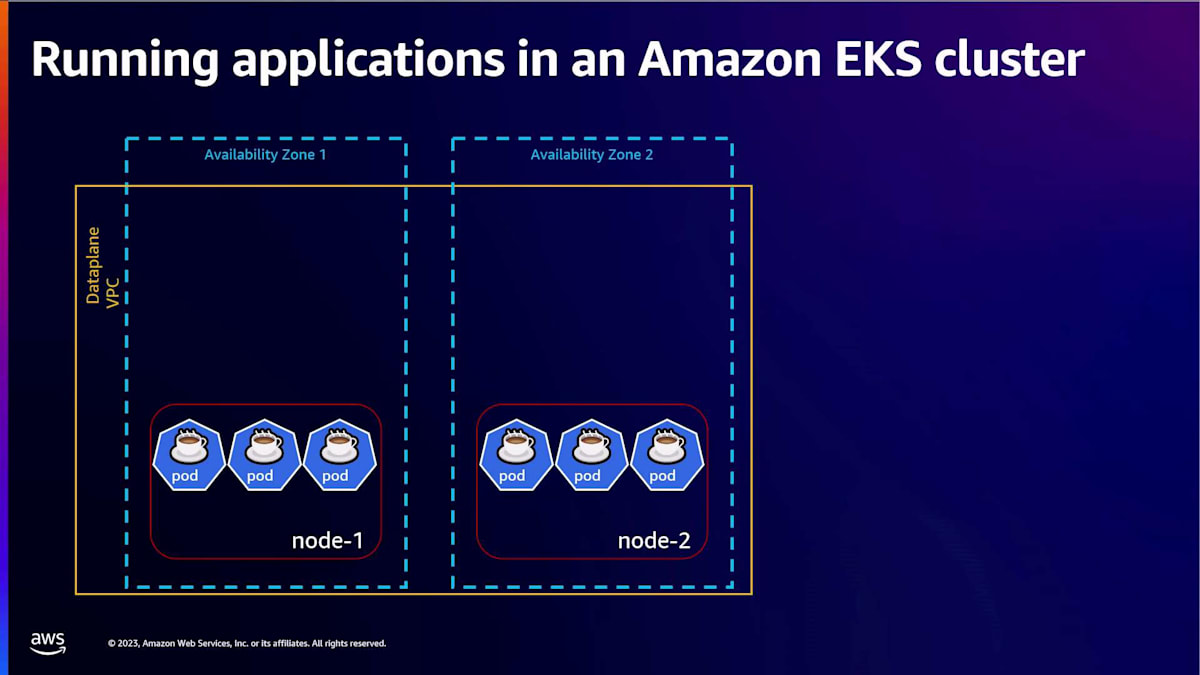

さて、安定したアプリケーションが稼働し、顧客にサービスを提供して注文を受けられるようになったところで、これらのデジタル注文の需要が増加し、大量のリクエストを処理する必要が出てくるかもしれません。 アプリケーションのスケーリングを改善するには、Horizontal Pod AutoscalerやVertical Pod Autoscalerの使用を検討してみましょう。 これらを使用することで、大量の注文が入ってくる際に現在の需要に対応するために必要なポッドの数を管理し、夜間など人々がコーヒーを注文しなくなった時にはスケールダウンすることができます。

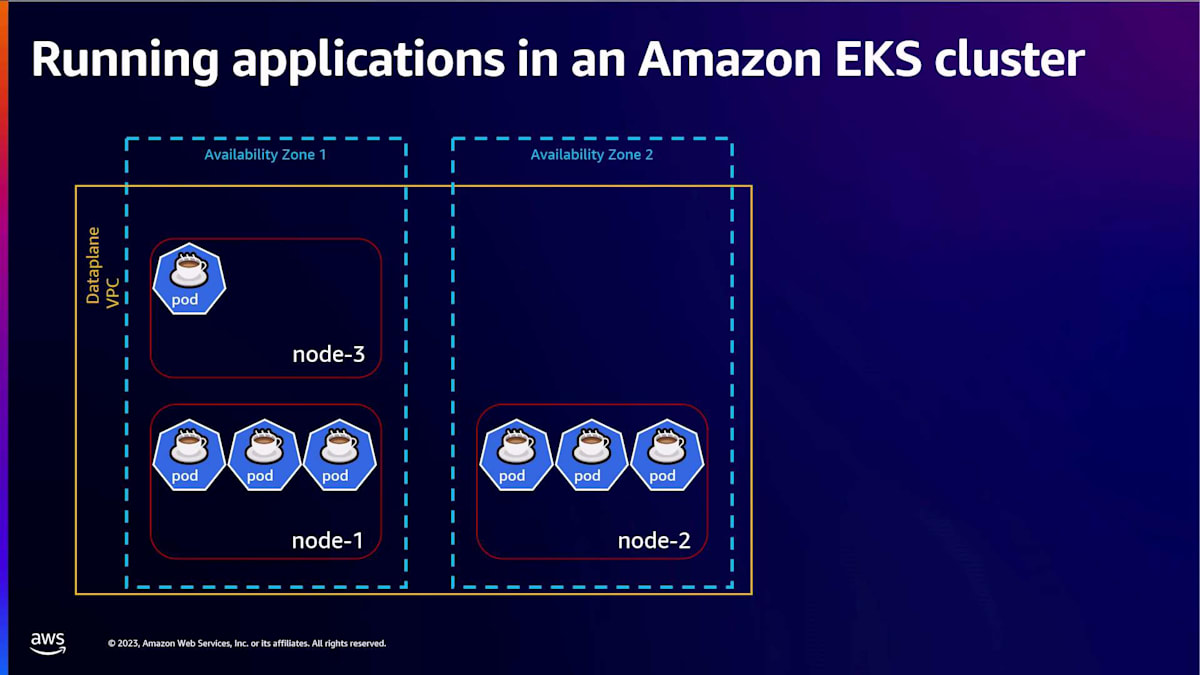
ポッドが自動的にスケーリングされるにつれて、 これらのポッドが実行できるノードが利用可能であることを確認し、需要が減少した際にはこれらのノードをスケールダウンする必要もあります。 これは、顧客に気付かれることなくシームレスかつ迅速に行われることが望ましいでしょう。このようなシナリオでは、ノードを管理するためにKarpenterやcluster autoscalerなどのノードオートスケーラーを設定して実行することをお勧めします。以前のスライドで見たように、EKSチームは、このようなシナリオでインフラコストを削減し、効率的なリソース利用を実現するためにKarpenterを開発しました。

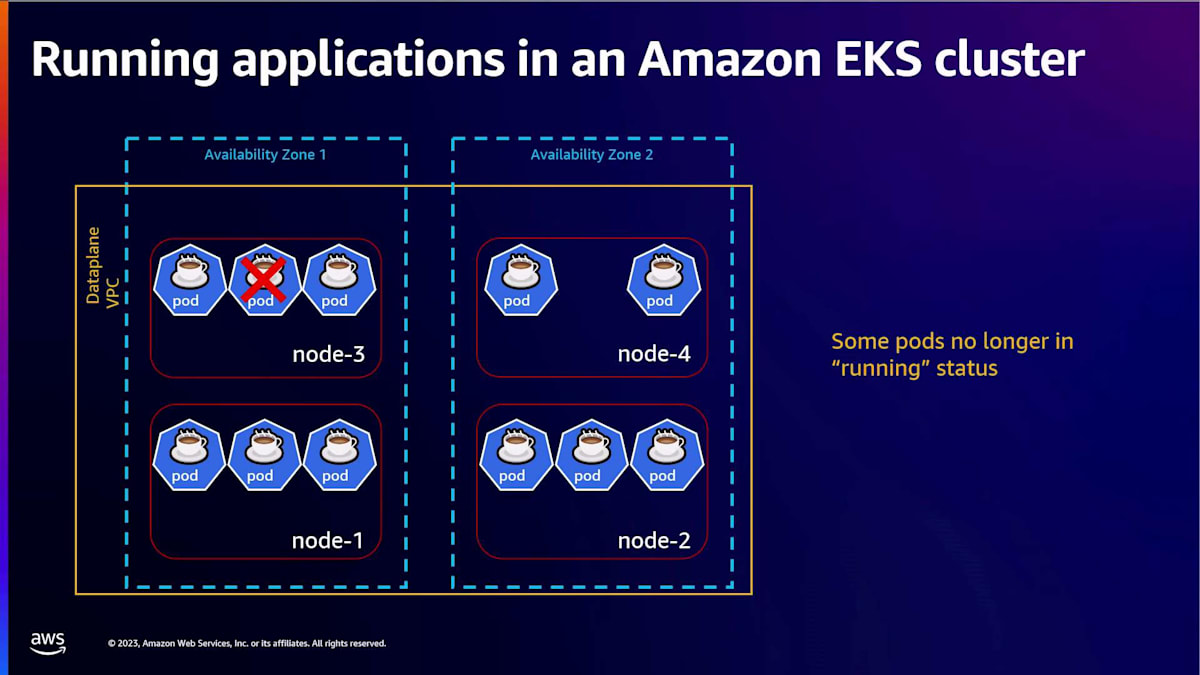
ここまでは順調です。 アプリケーションが自動的にスケールインとスケールアウトを行い、不要な時には数十万ドルものインフラと運用コストを節約し、顧客に最高のサービスを提供できています。しかし、突然、一部のポッドが動作しなくなったり、顧客のリクエストに応答しなくなったりする事態が発生します。 まずは、EKSユーザーとして、このような状況を診断するためにどのようなツールが利用可能で、それらをどのように使用できるかを見てみましょう。


まず始めに、クラスター内で発生しているエラーや、クラスターのパフォーマンスを監視したいと思うでしょう。コントロールプレーンを確認して、 コントロールプレーンで実行されているAPIサーバーがリクエストをどのように処理しているかを確認します。次に、 実行中のすべてのノードを監視し、何か問題が発生していないか、あるいはストレージやネットワークなどの重要なコンポーネントに、クラスター内でこのような問題を引き起こす可能性のあるネットワーク関連の問題がないかを確認したいと思うでしょう。



これらのコンポーネントからのメトリクスとログを収集し、分析を開始します。しかし、どのように進めればよいでしょうか? これらのメトリクスとログを調べるために、どのツールを使用すればよいでしょうか?利用可能なツールを見てみましょう。 クラスターの洞察を簡単に収集して可視化できるように、EKSは コントロールプレーンとデータプレーンからのすべてのログとメトリクスをお客様のCloudWatchアカウントに提供しています。
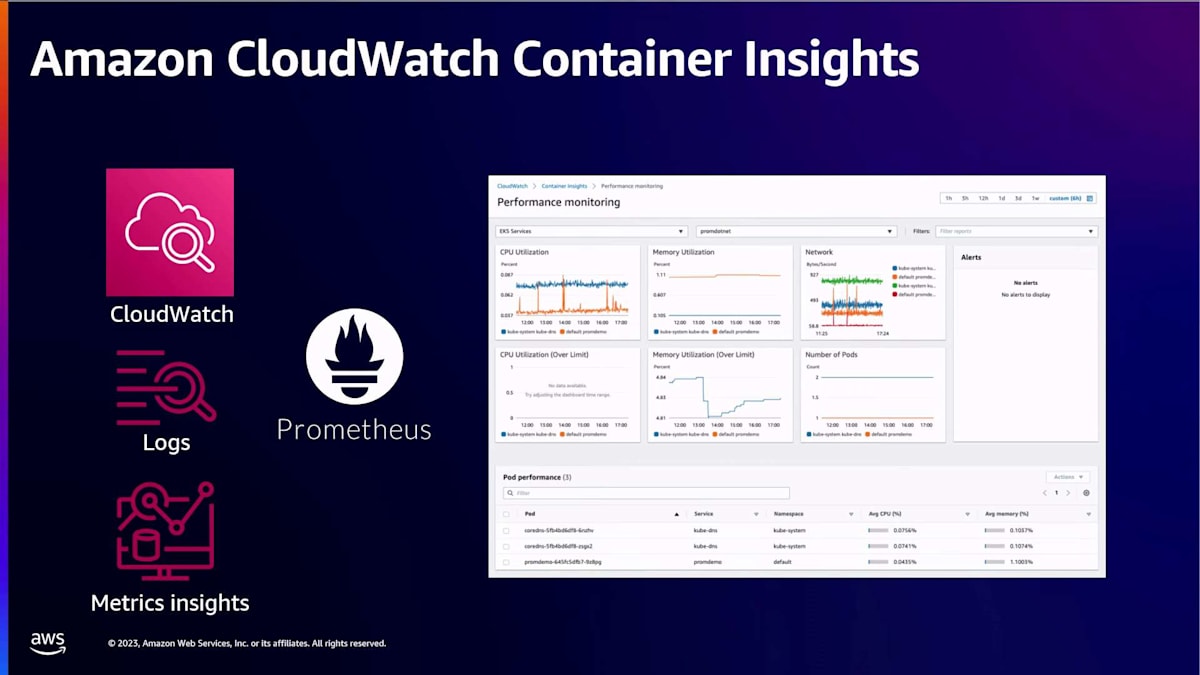
ユーザーは CloudWatch Insights クエリを実行して、Kubernetes コントロールプレーンを分析し、コントロールプレーンがリクエストをどのように処理しているかを確認できます。同様に、ノードのリソース使用率、パーツのネットワークパフォーマンス、ノードのステータスなど、ワークロードに関連するメトリクスを取得するためのインサイトを実行することもできます。CloudWatch では、メトリクスの事前構築されたダッシュボードも利用でき、すべてのメトリクスを一元的に確認できます。また、数日前に発表されたばかりのエージェントレス機能を通じて、これらのメトリクスをすべて Amazon Managed Prometheus に公開することもできます。
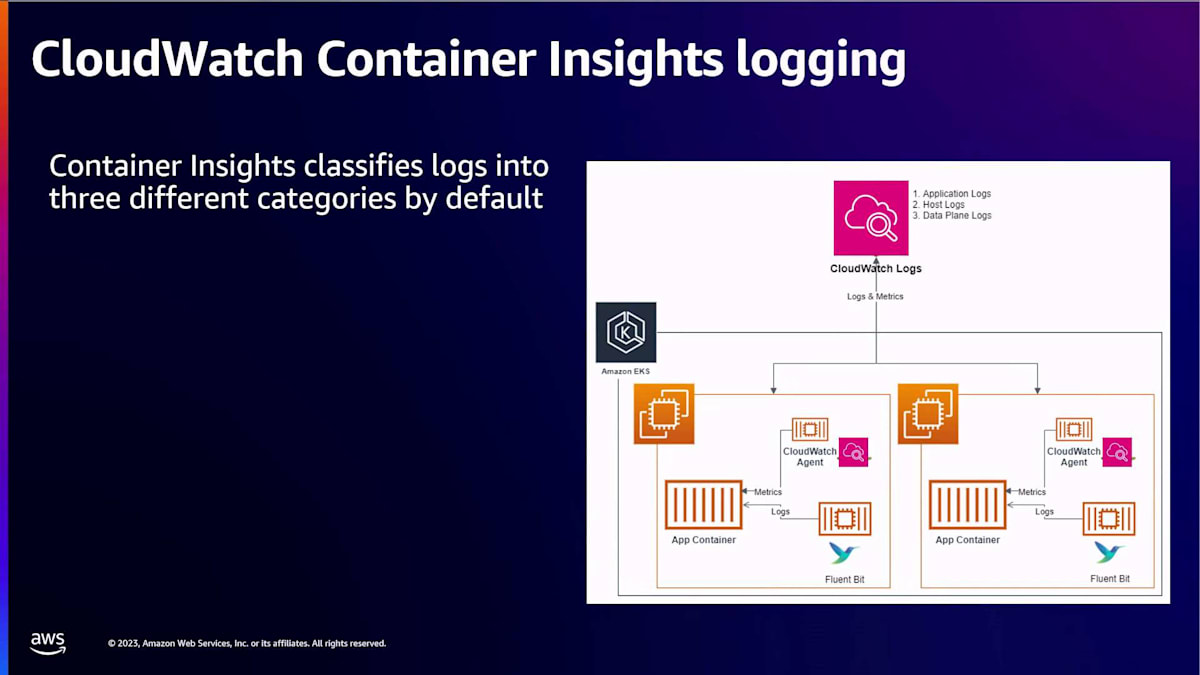


次はロギングです。クラスターを設定して、すべてのコントロールプレーンとデータプレーンのログを CloudWatch アカウントに公開できます。データプレーンについては、Fluent Bit のような DaemonSet をインストールする必要があります。すべてのログが CloudWatch に公開されると、Container Insights はこれらのログをデフォルトで3つのカテゴリに分類します。まずはアプリケーションログです。これらは直接アプリケーションのロググループにストリーミングされます。次にホストログです。これらは var log messages のようなもので、ノードごとのホストログに記録されます。最後のカテゴリはデータプレーンログです。これらは kube-proxy、AWS node、またはすべてのワーカーノードで実行されているコンテナランタイムなどのコンポーネント用です。

クラスターのメトリクスモニタリングとロギングが確立され、収集しているこれらのツールとデータを活用して、最初に話題に上がったクラスターでポッドが実行されない理由を絞り込んでみましょう。

まずは、コントロールプレーンで何が起きているかを確認することから始めましょう。API サーバーのメトリクスと API サーバーの監査ログをチェックできます。メトリクスから始めると、API サーバーが健全で利用可能かどうかを確認できます。API サーバーからの遅延はなく、API サーバーに送信されるリクエストにエラーがないことがわかります。つまり、API サーバーのメトリクスに関しては、すべて良好な状態です。


引き続き、監査ログを見てみましょう。これは API サーバーの動作に関する深い洞察を得るのに役立ちます。例えば、特定のユーザーエージェントから送信されたリクエストに対してエラーが返されているか、kube-controller-manager で実行されているコアコントローラーから送信されたリクエストにエラーがあるか、kube-scheduler からこれらのポッドをスケジューリングする際にエラーが発生しているかなどです。これらは、Container Insights を使用してメトリクスとログに基づいて答えを見つけられる例の一部です。EKS チームは、ログ集約の下にある AWS Observability Guide でサンプルの Container Insights クエリも公開しています。




ポッドが準備完了状態にならない理由を探る過程で、次はKubernetesノードのデータプレーンメトリクスとログを分析してみましょう。ここでもCloudWatch Container Insightsが役立ちます。これを使えば、すべてのKubernetesノードが正常かどうか、ノードがCPUやメモリ圧迫などのリソース制限に直面していないかといった疑問に答えることができます。データプレーンのログを見ると、すべてのポッド用のコンテナイメージがノードで利用可能か、secretsやconfig mapsなどの依存オブジェクトが利用可能か、そしてノードがIPアドレスの枯渇に直面していないかを確認できます。今回のケースでは、まさにそれが起きているようです。ノードで使用可能なIPアドレスが不足しており、そのためにポッドが準備完了状態にならないのです。

この情報が他の場所でも確認できるか見てみましょう。ここで、クラスターネットワーキングの世界に入ります。クラスター内でポッドが作成・終了されると、IPアドレスが割り当てられたり解放されたりします。クラスターネットワーキングから得られるメトリクスを見る前に、クラスターネットワーキングに馴染みのない方のために、その概要を理解しておきましょう。クラスターネットワーク(より一般的にはCNIプラグインとも呼ばれます)は、Kubernetesクラスター内のポッドネットワーキングを設定するために使用できます。


EKSには、このネットワーキングが最初から設定されています。これはAmazon VPC CNIプラグインで、AWS IP address managementを使用してIPアドレスを割り当てます。つまり、ネイティブVPCネットワーキングが利用できるのです。これは、シンプルで安全なネットワーキングが組み込まれていることを意味し、VPC flow logsなどのツールを使用してトラフィックを監視できます。EKSチームは、この情報を収集するためのCNIメトリクスヘルパーツールを提供しています。これはクラスターレベルでメトリクスを集約し、すべてのメトリクスをCloudWatchに公開します。

このツールが公開するメトリクスは多岐にわたりますが、VPCやクラスター内で利用可能または割り当て済みのENI(Elastic Network Interface)の数や、VPC内で利用可能または使用中のIPアドレスの数など、重要な情報を得るのに役立つサンプルメトリクスがあります。これにより、問題が発生する前にアラームを設定して対処することができ、ユーザーは二次CIDRの追加やクラスターへのIPv6アドレスタイプの使用など、事前に対策を講じることができます。
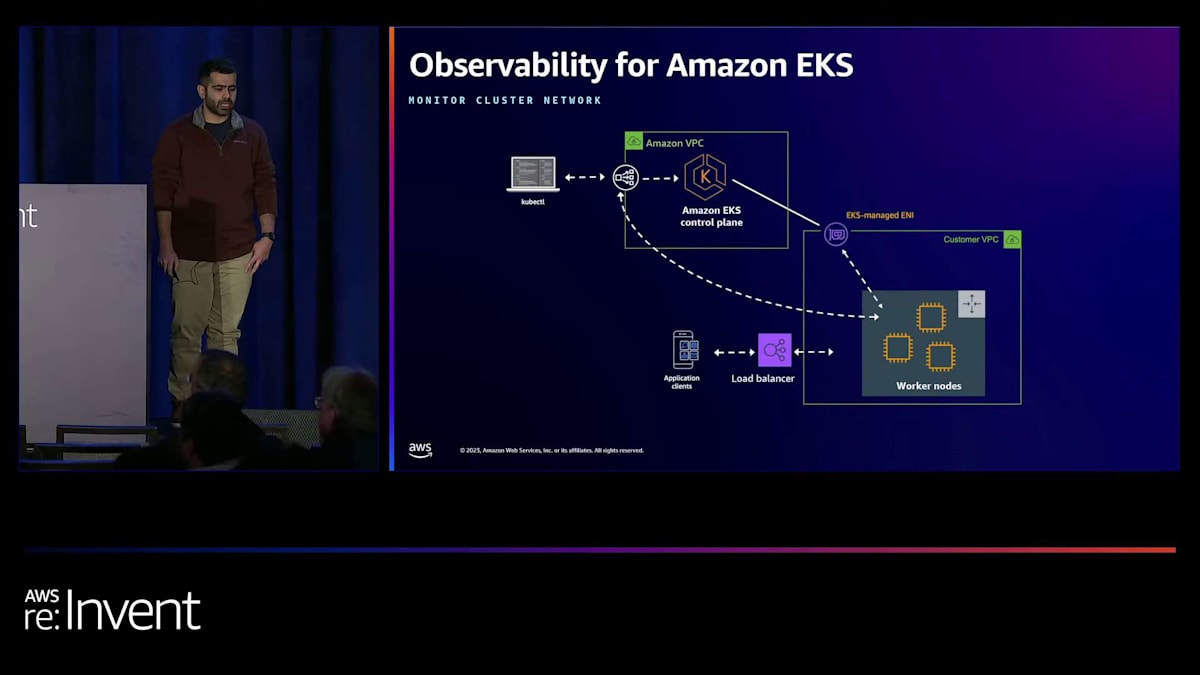
クラスターに使用されるサブネットのENIとIPの使用状況をモニタリングすることが非常に重要になる理由を見てみましょう。先ほどのEKSアーキテクチャのスライドで見たように、顧客VPCとコントロールプレーン間の通信もEKS管理のENIを通じて確立されます。アカウントがENI作成やIP枯渇に関するこれらの制限に達し、新しいENIが作成できなかったり、使用可能なIPがなくなったりすると、クラスターのスケーリングやセキュリティ関連のパッチ適用といったアップグレードがブロックされてしまいます。

その結果、クラスターは劣化状態としてマークされます。これらのクラスターで多数の重要なアプリケーションを実行し始めると、必要に応じてクラスターのコントロールプレーンをスケールアップしてアップグレードすることが極めて重要になります。クラスターの別のシナリオを見てみましょう。 クラスターの使用量が増えるにつれて、より多くの開発者やオペレーターがこれらのクラスターにアプリケーションをデプロイするようになり、彼らが正しくポッドにラベルを付けていることを確認する必要があります。そのために、クラスターにアドミッションコントローラーWebhookを追加することを検討します。
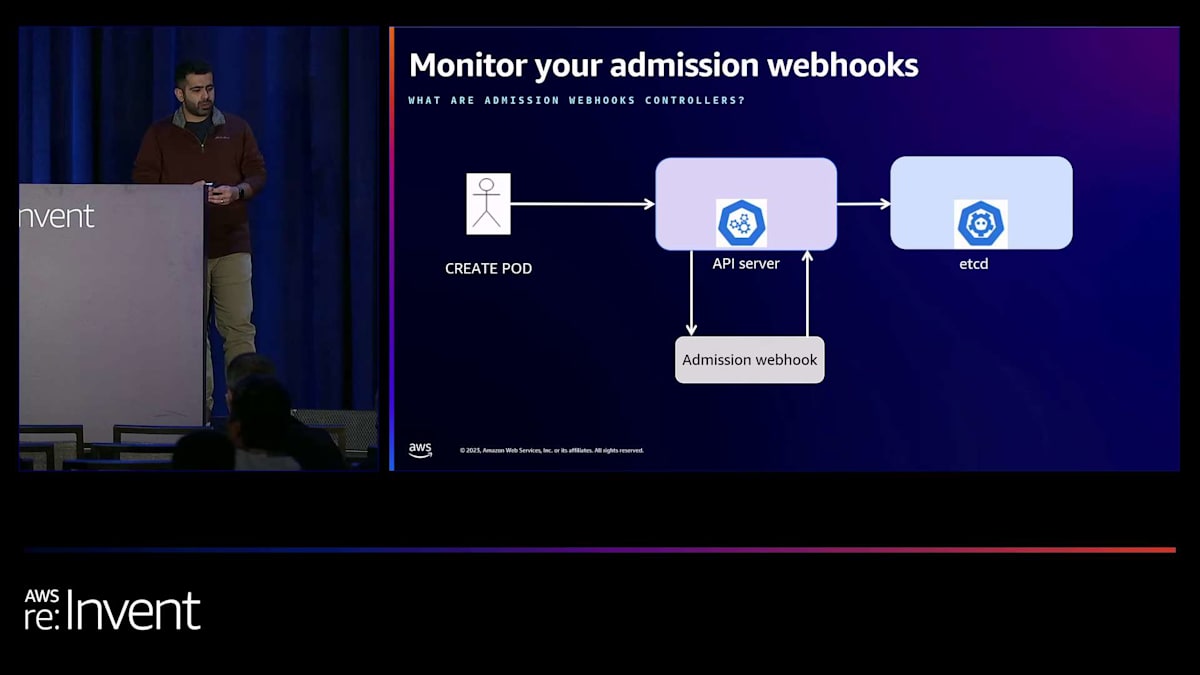
要件を踏まえて、これがどのように機能するか高レベルで見てみましょう。 APIサーバーとやり取りするユーザーがいます。これはエンドユーザーかCI/CDかもしれません。彼らはポッドを作成するリクエストを送信します。ポッド作成のリクエストが送信されると、APIサーバーはそれをアドミッションWebhookコントローラーに転送します。コントローラーは、ポッドの仕様に必要なラベルが含まれているかを確認します。すべてが正しければ、APIサーバーに応答を返し、ポッドオブジェクトがetcdに作成されます。すでに様々な用途でWebhookをクラスターで実行しているかもしれません。

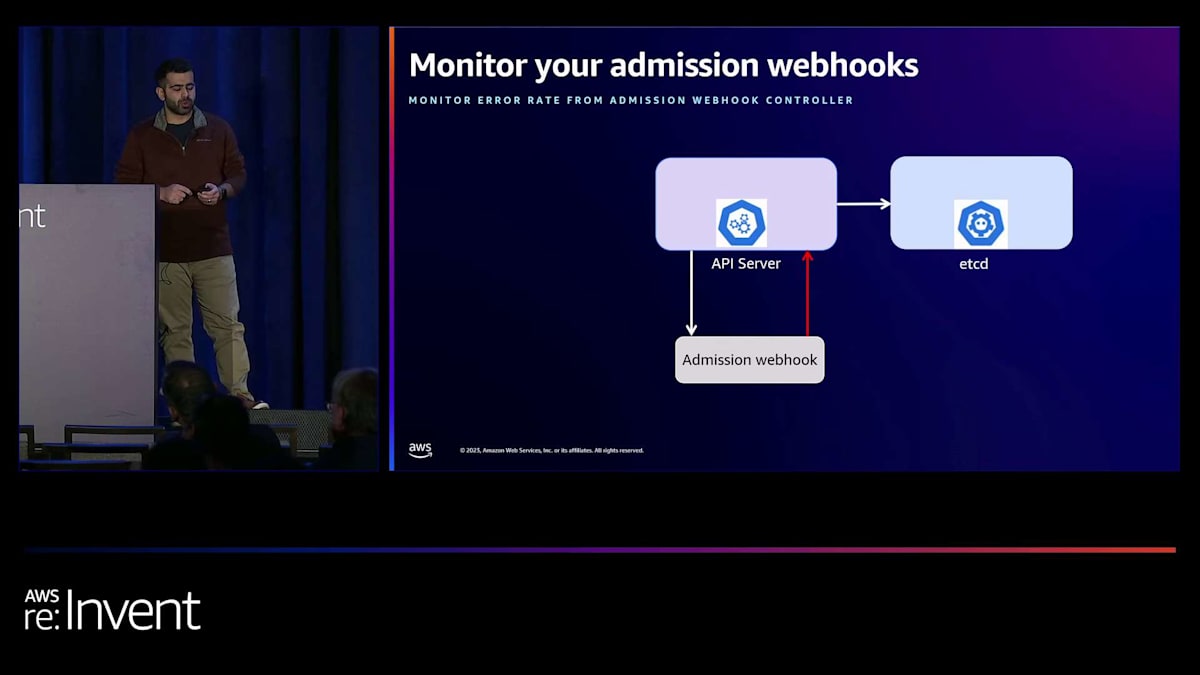

これらのWebhookがAPIサーバーのリクエストに影響を与えていないことをどのように確認できるか見てみましょう。EKS Kubernetesコントロールプレーンは、 APIサーバーがアドミッションWebhookコントローラーに到達できない場合に監視するのに役立つAPIサーバーのメトリクスを提供します。同様に、 アドミッションWebhookコントローラーがAPIサーバーから送信されたリクエストに対してエラーで応答している場合も監視する必要があります。可能なシナリオでは、 30秒未満のfail-openポリシーでアドミッションWebhookを設定し、リクエストがAPIサーバーによって完全に拒否されるのを防ぐべきです。Kubernetesのドキュメントには、実際にプロダクション環境でアドミッションWebhookを実行するためのベストプラクティスがさらに記載されています。追加の考慮事項については、それらのドキュメントを確認することをお勧めします。
API Priority and Fairnessの詳細とEKS運用のベストプラクティス


もはや小さなコーヒーショップではなく、 毎時数百件の注文を受け、他の商品も提供するようになったため、クラスターの規模が拡大しました。その結果、APIサーバーに大量のリクエストが送信され、時々コントロールプレーンとのやり取りで429 のようなエラーが表示されることがあります。APIサーバーでこれらのエラーの最も一般的な原因と対処方法を見る前に、まずAPIサーバーがこれらのリクエストをどのように処理するかを理解しましょう。

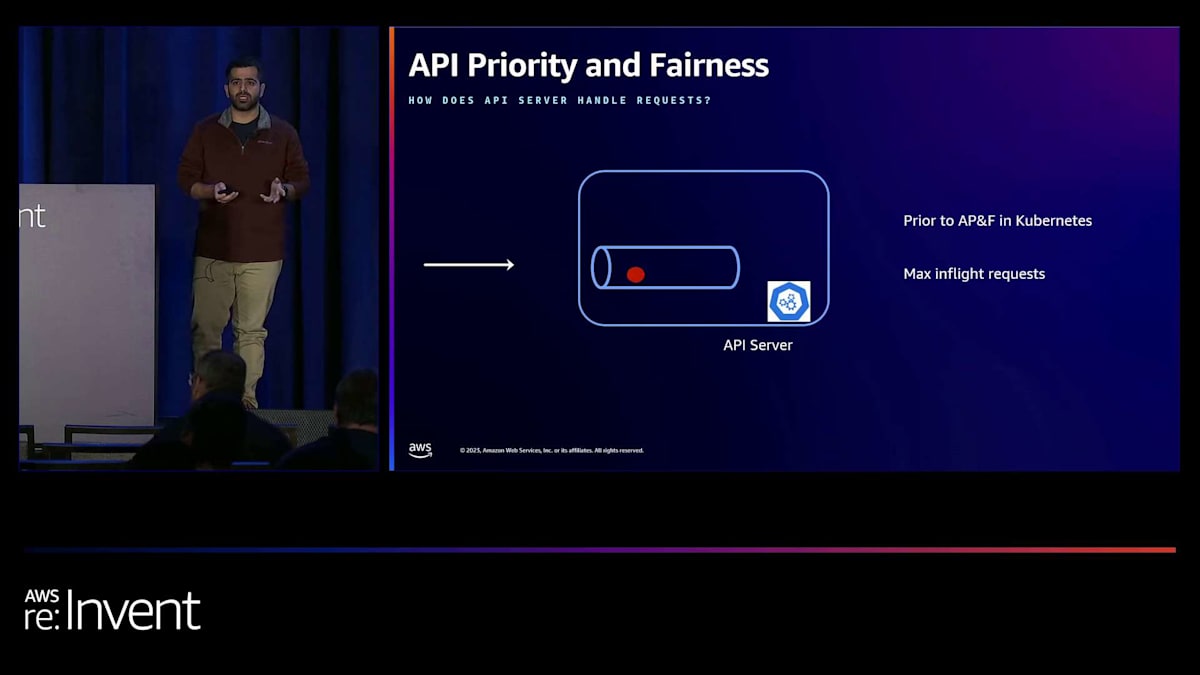
Kubernetes 1.20で追加された新機能であるAPI Priority and Fairnessの導入以前は、ヘルスチェックリクエスト、kubectlからの呼び出し、リストリクエストなど、あらゆる種類の呼び出しがAPIサーバーレベルで同等に扱われていました。APIサーバーは、処理中の変更リクエストと非変更リクエストの数を制御するためのフラグをいくつか提供し、残りの呼び出しは429ステータスコードで拒否されていました。これは、クラスター内の何十万ものオブジェクトをリストするような、ここで赤で表されている重い呼び出し が大量に行われた場合、APIサーバーがこれらの時間のかかるリクエストを処理している間に他のヘルスチェックリクエストが拒否される可能性があるため、コントロールプレーンの安定性に影響を与える可能性があったことを意味します。


では、API Priority and Fairness (APF) はこのケースでどのように役立つのでしょうか?APFは、priority level configurationsとflow schemasという2つのリソースを導入します。priority level configurationsはリクエストの優先度レベルを定義し、flow schemasは各リクエストを分類して優先度レベルに紐付けます。簡単に言えば、これらは別々のキューに追加されるリクエストと考えることができます。これにより、 ヘルスチェックやクラスターの安定性に関わる他の重要な呼び出しは、独自のキューに入れられ、クラスター内で他の遅いまたは大規模なリクエストが行われている場合でも影響を受けなくなります。

しかし、アプリケーションのcreate podコールのような重要な呼び出しをAPFで設定し、同じバケットを使用しているlistコールもある場合、すべてが同じバケットに入ってしまうため、create podコールに影響を与える可能性があります。したがって、重要な操作が重要度の低いリクエストやリソースを多く消費するリクエストの影響を受けないよう、優先度レベルとflow schemasを慎重に設定することが重要です。

この時点で、API Priority and Fairness (APF)のコントロールプレーンメトリクスをモニタリングすることが非常に重要になります。これにより、接続制限に達しているかキューが満杯になっているかを早期に診断することができます。また、コントロールプレーンに対する大量の高コストなlistコールを減らすことも推奨されます。EKS scalabilityチームに感謝したいと思います。彼らはEKS Best Practices Guideに素晴らしいドキュメントを公開しています。このガイドには、APFに関するベストプラクティス、モニタリングすべきメトリクス、そしてAPFに関するより詳細な背景情報が記載されています。



ここで、Amazon EKSクラスターを運用する際の学びとベストプラクティスをいくつかまとめたいと思います。 まず、ポッドをデプロイメントの一部として実行し、トポロジースプレッドを使用します。 次に、ポッドとノードのオートスケーラーを設定し、コントロールプレーンとデータプレーンのメトリクスとログをモニタリングします。CNIメトリクスのモニタリングにはcni-metrics-helperを使用するか、デプロイしている他の重要なコンポーネントを使用します。admission controller webhooksのモニタリングを確実に行ってください。重要なリクエストのためのAPI flowsを設定し、APFメトリクスをモニタリングします。
これらは、運用の大部分を容易にするための最も推奨されるベストプラクティスの一部にすぎません。EKSチームは、セキュリティ、スケーラビリティ、信頼性、ネットワーキングなどのトピックをカバーする包括的なベストプラクティスガイドを公開しています。まだご覧になっていない方は、このリソースをチェックすることを強くお勧めします。では、最後のアナウンスのためにLizにバトンタッチします。
EKSデジタルラーニングバッジの発表とセッション終了

Prateek、ありがとうございます。私たちの講演も終わりに近づいてきました。先ほど申し上げたように、新しいアチーブメントを獲得する機会があります。これまで、EKSに特化したデジタル認定はありませんでしたが、初めてのEKSデジタルラーニングバッジとそのラーニングパスを発表できることを嬉しく思います。実際、つい先日ローンチされたばかりです。

Amazon EKSの基本概念や始め方について学びたい方々のために、私たちは準備を整えています。アセスメントを受けて、デジタルバッジを獲得することができます。このバッジは、履歴書や雇用主、あるいはソーシャルメディアで共有できます。これにより、Amazon EKSに関する知識をテストし、自分の知識をアピールすることができます。本日の講演にご参加いただき、ありがとうございました。長い1日の終わりにもかかわらず、皆様の時間と注目をいただき、感謝しております。
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion