re:Invent 2024: AmazonがAWS Regionsを活用し顧客体験を向上


はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - How Amazon.com uses AWS Regions to improve customer experience (ARC328)
この動画では、AmazonがAWS Regionsをどのように活用してカスタマーエクスペリエンスを向上させているかについて、Principal Solutions ArchitectのFrank StoneとPrincipal Software EngineerのLisa Gutermuthが解説しています。Prime VideoやMiddle Mileなどの具体的な事例を交えながら、複数Regionへの展開における課題と解決策、Infrastructure as Codeの重要性、データ移行の戦略などを詳しく説明しています。特に、DynamoDB Global TablesやS3 Cross-Region Replicationなどの具体的なツールの活用方法や、Region間のレイテンシー、データの整合性に関する考慮事項など、実践的な知見が豊富に共有されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
AWSリージョン活用によるカスタマーエクスペリエンス向上:イントロダクション

Amazon.comがAWS Regionsを活用してカスタマーエクスペリエンスを向上させている方法についてご紹介します。私はPrincipal Solutions ArchitectのFrank Stoneです。AmazonでAWSサービスの活用をサポートする仕事をしています。本日は、AmazonのPrincipal Software EngineerのLisa Gutermuthも参加しており、AmazonがRegionsをどのように活用しているかについてお話しいただきます。本題に入る前に、手を挙げていただきたいのですが:現在、すべてのリソースを単一のRegionに置いている方は何人いらっしゃいますか?少しいますね。2つのRegionを使用している方は?もう少し多いですね。2つ以上のRegionを使用している方は?素晴らしいですね。皆さんの中にはすでにかなり進んでいる方もいらっしゃるようで、本日お話しする内容を共有できることを楽しみにしています。

本日のアジェンダをご紹介します。まず、Amazonにおいて時間とともにRegionsに対する考え方がどのように進化してきたか、そして数年前には行っていなかった現在のRegionsの活用方法についてお話しします。次に、皆さんが追加のRegionsへの移行を加速できるよう、私たちが得た知見についてお話しします。また、時間の経過とともにRegionsの採用を加速するために使用できるメカニズムについても説明します。さらに、どのRegionに移行するかを検討する際に考慮すべき点や、私たちが経験した考慮事項についてもお話しします。そして最後に、すべての機能を自前で開発することなくRegionへの移行を支援するAWSツールボックスの中のツールについてご紹介します。それでは、Lisaにバトンタッチします。
Amazonにおけるリージョン戦略の進化と課題



私はAmazonのPrincipal EngineerのLisaです。過去3年半、AWS以外のAmazonの部門をより多くのRegionsに展開する方法に注力してきました。 ご存知の通り、AWSはRegion拡大戦略を持っています。既存のRegionのインフラを別の場所に展開することを目指していますが、データの移行について考える必要はありません。新しいRegionの利用を希望し、好みに応じて設定するのは、お客様次第なのです。

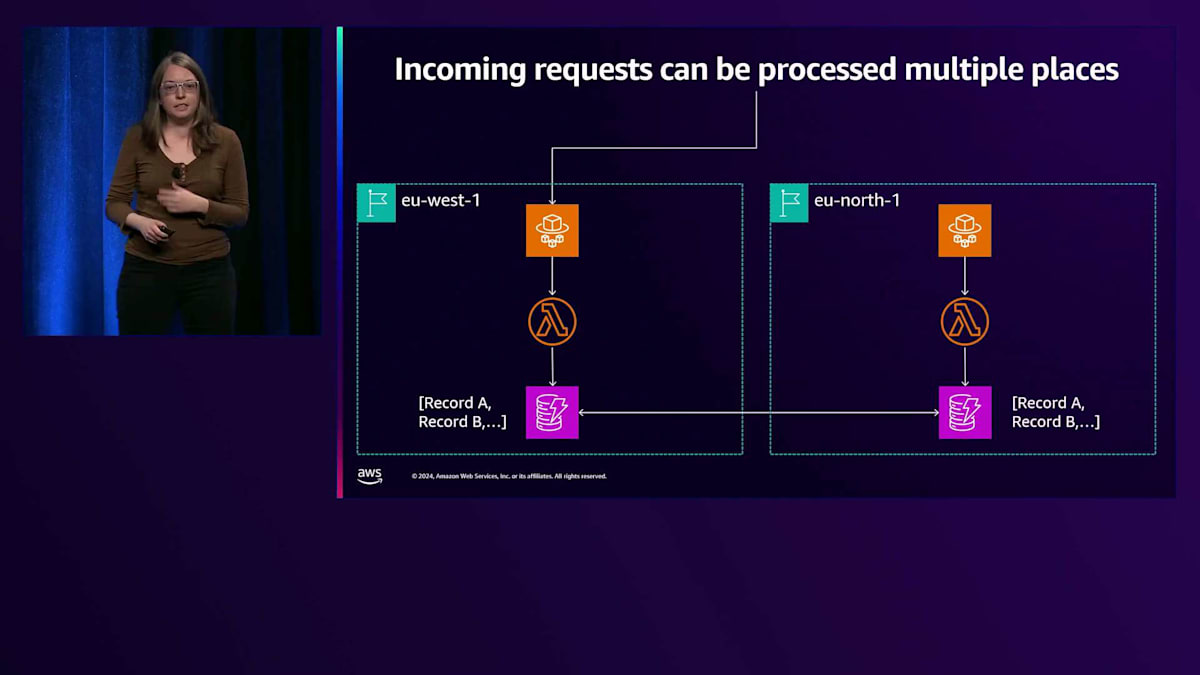

Amazonの他の部門では、Prime Videoが最初の事例の一つでした。これは優先的に取り組む必要があると判断したのです。彼らのアプローチは、インフラを構築し、可能な限りデータを同期し、実際にマルチRegion化を目指すというものでした。同じお客様の同じユースケースに対するリクエストを複数の場所で処理することを目指したのです。 これは、ライブイベントに参入する際に特に重要でした。スポーツの試合やその他のピーク時のイベントのストリーミングを始めるにあたり、フットボールのタッチダウンシーンを見ている最中に映像が途切れないよう、確実な耐障害性を確保する必要があったのです。


次に、Middle Mileと呼ばれるチームがRegionフェイルオーバーの検討を始めました。Middle Mileは貨物の移動を担当しており、具体的には荷物をお客様の近くまで運ぶ(ただし必ずしも自宅までではない)役割を担っています。 彼らが発見したのは、Amazonの大部分がAvailability Zone耐障害性を活用し、1つのAZがダウンした場合は別のAZを利用できるようにしていたのに対し、彼らはさらに一歩進んで、Regionがダウンしたり、重要なサービスで大規模な障害が発生したりした場合に、完全に別のRegionにフェイルオーバーできるようにしたいと考えたのです。できるだけ早くお客様に荷物をお届けできるよう、トラックを止めることなく動かし続けることを目指したのです。


私は、Amazonの他の部門で働いていた期間のほとんどを、Selling Partner Servicesで9年間過ごしました。私たち他の部門は、少数のRegionで満足していました。必要なAWSサービスはすべて利用可能で、可用性も十分に高く、特に心配することはありませんでした。 時々AWSで障害が発生すると、「すぐに新しいRegionに移行しなければ。これは重要だ」と言っていましたが、数週間か数ヶ月が経過すると、AWSの信頼性は十分に高いと実感していました。



同様に、Amazonにとって遅延は大きな課題でした。私たちにはLeadership Principlesがあり、その最初の原則は意図的に「カスタマーオブセッション(顧客への徹底的なこだわり)」としています。常にお客様にとって正しいことを行いたいと考えていますが、私たちは別の対処方法を見つけました。CDNをユーザーの近くに配置して遅延を低減し、新機能をリリースする際には、すべてのユーザーに対して遅延を抑制するという目標を定期的に設定していました。 実際に、より多くのRegionを継続的に検討することが意味を持つと感じたのは、昨年になってからでした。Prime VideoとMiddle Mileの成功を見て、私たちは可用性の向上、遅延の低減、そしてお客様に還元できるコスト削減を実現したいと考えました。また、新しいデータローカライゼーション規制が議論される中、ロードマップ全体を破棄することなく、迅速に対応できるようにしたいと考えています。


私たちは新しいビジネスチャンスを開拓したいと考えています。 Prime Videoの成功を目の当たりにし、新しいRegionへの展開を容易にすれば、ビジネスの可能性が広がり、まだ思いもつかない多くの新しいアイデアが生まれると考えています。


私たちは最高のカスタマーエクスペリエンスを提供したいと考えていますが、AWSと同様に、最初の目標はRegion展開です。ただし、AWSとは異なり、私たちはデータを移行する必要があります。ドイツのウェブサイトにアクセスする場合、お客様にEU West OneとEU North Oneのどちらかを選んでもらいたくありません。そうではなく、トラフィックとデータを適切な場所に配置する役割を私たちが担う必要があります。 一時的にマルチリージョン対応が必要です。これを最終目標とするのではなく、後悔するような取り返しのつかない選択をすることなく、確実に進歩を遂げながら構築していきたいと考えています。

Amazon全体として新しいRegionに進出したのは、 恐竜が地球を歩いていた時代のようなものです。私がAmazonに入社したばかりの頃でした。長い間これを行っておらず、新しいシステムのアーキテクチャとインフラストラクチャは完全に変化し進化しています。後ほど詳しく説明しますが、必ずしもすべてを引き継ぐわけではありません。この取り組みはまだ初期段階ですが、外部のお客様と話をする中で、Regionの活用方法について、私たちと同じような課題に直面している方々が多いことがわかったため、公に話し始めることにしました。
リージョン移行の学習プロセスと戦略構築




私たちはどのように学び、何をすべきか理解したのでしょうか?最初のものは本当に馬鹿げて聞こえるかもしれませんが、とにかく真剣に考えました。Amazonで長年働いている上級社員を見つけ、彼らは新しいRegionを導入する際に物事が大変なことになったり、あるいは自分たちが引き起こしてしまった問題を経験していました。これにより、いくつかの問題が明らかになりました。例えば、設定が大きな問題になることがわかりました。次に、AWSが常に新しいRegionを展開している方法を調べ、彼らの学びをどのように活用できるか検討しました。Infrastructure as Codeに関して、彼らから学べる側面がありました。



そこで私たちは、データとトラフィックの問題があることに気づきました。AWSとは異なる経験をすることになるのです。これはAWSとの会話で非常に興味深いものでした。彼らが「ああ、これは私たちのRegionプロセスと同じように動作します」と言うと、私たちは「いいえ、そうではありません。理解していただく必要がある違いがあります」と応答しました。次に、ハッカソンレベルのプロジェクトでプロトタイプを作り始め、何が問題になるかを把握しました。これにより、私たちの想定を検証し、新しい問題を発見することができました。例えば、LambdaのソースとしてSQSを使用している場合、一方だけを別のRegionに切り替えようとすると完全に失敗することがわかりました。



次に実験に移りました。まだ新しいRegionへの移行準備はできていませんでしたが、レイテンシーの影響を理解する必要がありました。コールスタックのどこかで5ミリ秒追加した場合、顧客にとって何ミリ秒の影響があるのでしょうか?新しいRegionを活用し始めると、クロスRegion通信が何回発生する可能性があるのでしょうか?ここで私たちは非常に興味深い乗数効果を発見し、それが最終的に私たちの戦略を形作ることになりました。最後に、いよいよ移行に踏み切る時が来たと判断しました。これが今年の主な取り組みでした。移行を開始してわかったのは、実際のクロスRegionレイテンシーは単純なping値よりも複雑だということです。Regionの間には異なるリンクが存在し、基本的なネットワークの上に追加したいセキュリティやネットワーキング基準によって、顧客に与える実際のレイテンシーを考慮する必要があります。
この部分で覚えておいていただきたいのは、特に多数のサービスと多様な技術を持つ大規模な技術基盤がある場合は、早めに移行を開始することです。これは、人々が実際に試してみて、何が機能しないかを発見する中で、最も多くを学んでいる部分です。このプロセスに早く着手していれば、より良かったでしょう。
リージョン移行における設定とインフラストラクチャの課題


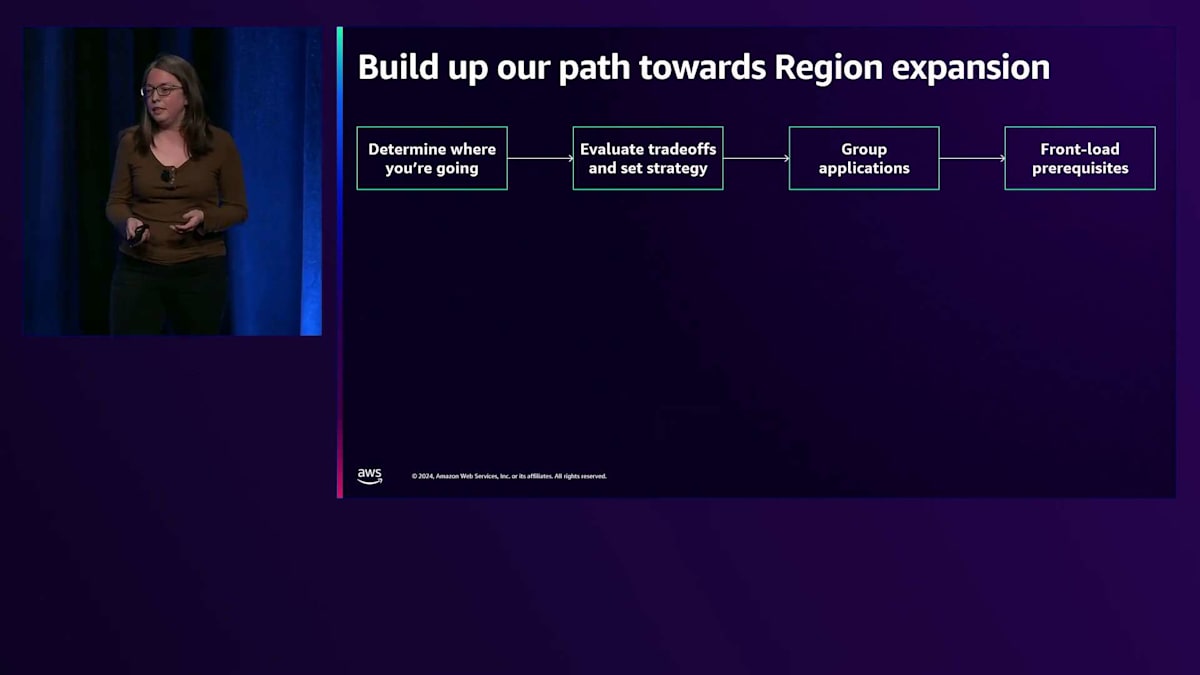
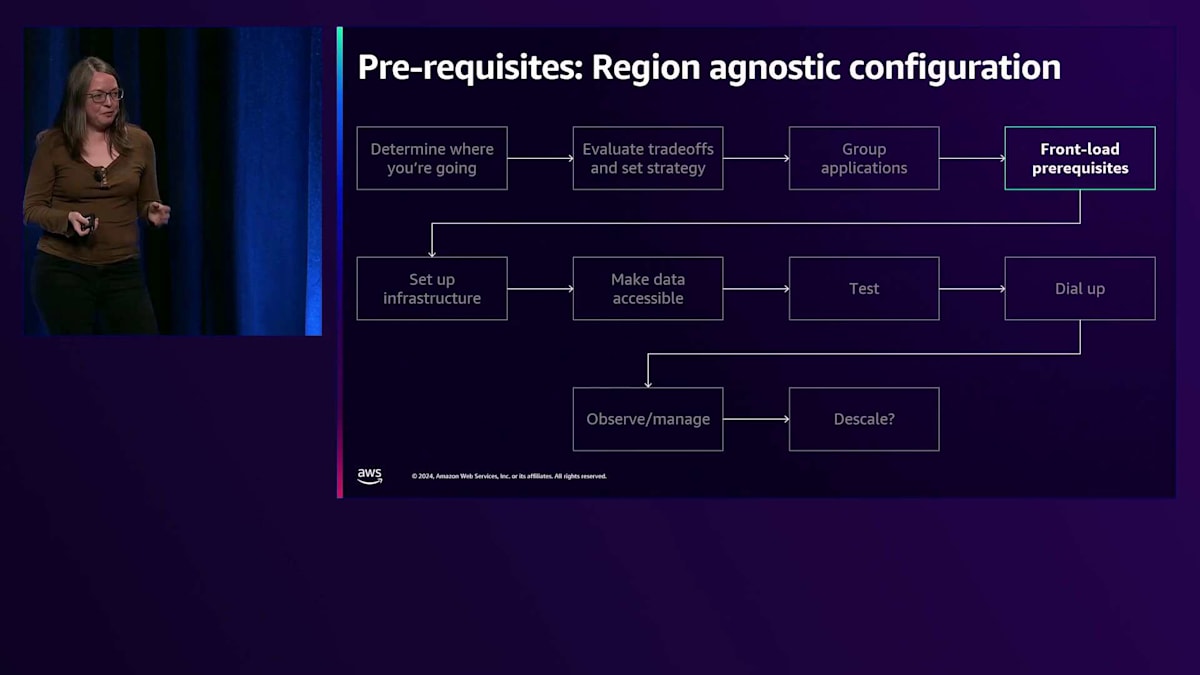
初期段階でも重要なことを学び、それらを検討することは有意義でしたが、移行に早く取り掛かることで、全体的にはより多くの利点が得られたはずです。これにより、私たちは実際の戦略に到達することができました。まず、Frankが後ほど説明しますが、AWS Regionにはそれぞれ特徴があるため、どこに移行するかを決める必要があります。次に、特にどのアプリケーションやサービスを一緒に移行するかについて、トレードオフを評価して戦略を設定する必要があります。そこから、前提条件を先に整えることが重要です。既存のサービスやアーキテクチャについて、いくつかの変更が完了するまで実際に開始できない場合があります。
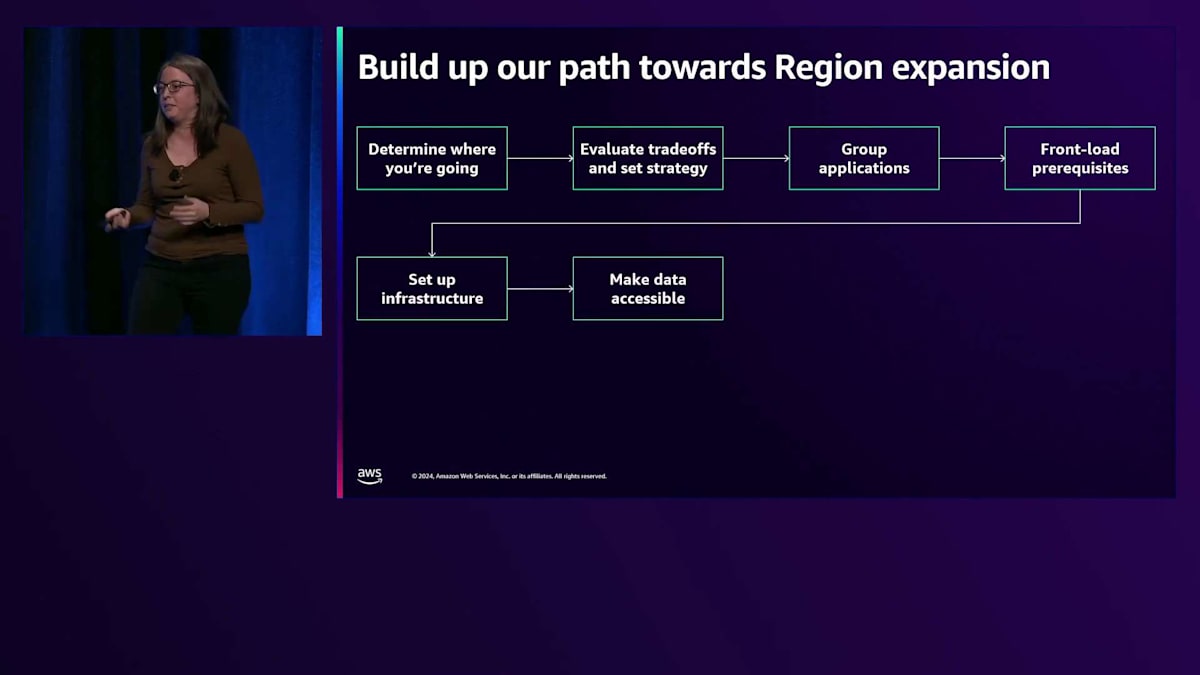


これまで説明してきた図の標準的な流れを見ていきましょう。まずインフラを構築し、データにアクセスできるようにして、それが機能することをテストし、スケールアップして、観察・管理の方法を見出し、そして最終的にRegionの戦略に応じてスケールダウンする可能性もあります。これが私たちの道のりです。新しいシステムを構築する際に、私たちの経験から何を学び、より良いスタートを切ることができるでしょうか?まずはトレードオフとアプリケーションのグループ化という概念から始めましょう。これは実際、私たちが整理するのにかなりの時間を要したもので、正直なところ、今やっと効果的にテストし始めたところです。


トレードオフを考える際には、いくつかの要因を考慮する必要があります。システムを停止できるかどうか?つまり、一時的にシャットダウンして別の場所で再起動できるものなのか?顧客にどの程度のレイテンシーまで許容できるか?コストについてはどうか?並行して保持するコストを負担できるか、そしてそれをどのくらいの期間維持できるか?どれくらい早く移行する必要があるか?これはビジネス上の「あったら良いもの」なのか、それとも期限が定められた規制に先んじて対応しなければならないものなのか?同様に、労力の面では、個々のチームレベルでビルダーがより速く動けるようにするために、中央のツール開発にどの程度の先行投資を行う意思があるか?これが実質的に私のチームの焦点です - AWSと協力して、これをより簡単にするためのツールをどのように構築するかということです。

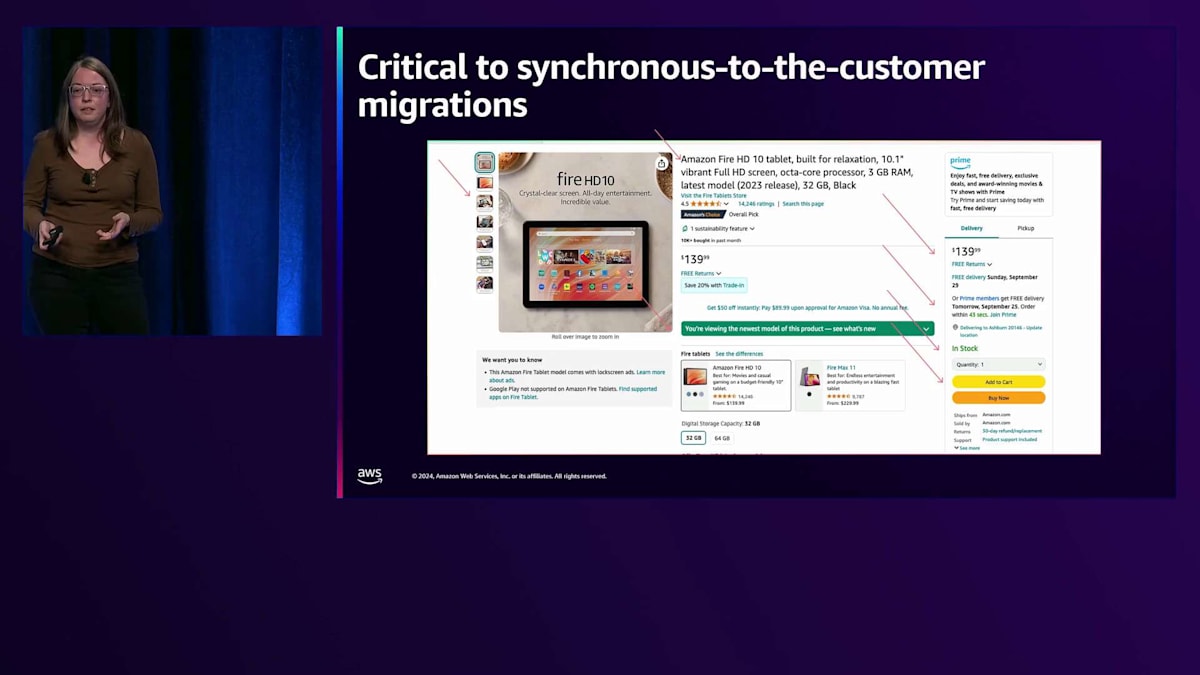
この過程で最も後悔していることは、サービスグラフを持っていなかったことです。もしサービスとデータの相互作用に関するナレッジベースをお持ちでしたら、それを絶対に手放さないでください。むしろ、それを発展させてください。これは私たちが現在最も力を入れて取り組んでいることの一つです。これは数年前の私たちのグラフのスナップショットで、サービスの一部を示していますが、その時点ではデータがグラフに含まれていませんでした。この移行を成功に導くために、これらのつながりを理解するには、長年勤務している従業員に相談して再度確認する必要がありました。これが重要な理由は、同期的な顧客エクスペリエンスの数が多いからです。詳細ページのスナップショットを見ると、それぞれの矢印が異なるサービスやAPIコールを指していますが、これは実際に存在するものの一部に過ぎません。


私たちは、全員が同時に準備が整うのを待って遅延するのではなく、いかに繰り返し調整を行いながら前進できるかを考える必要があります。重要なポイントの一つは、全員を待つことなく、より小さな部分に分割する方法を見出すことでした。例えば、私たちのシステムの中には、コンピューターの顧客ではなく人間の顧客を相手にするものがあり、レイテンシーの要件が異なります。また、国ごとの考慮も必要です。米国のマーケットプレイスは長年存在しており、おそらく他の地域よりも複雑で分岐が多いため、一度に移行する範囲を制限したい場合は、最初に移行する対象として選ばないかもしれません。
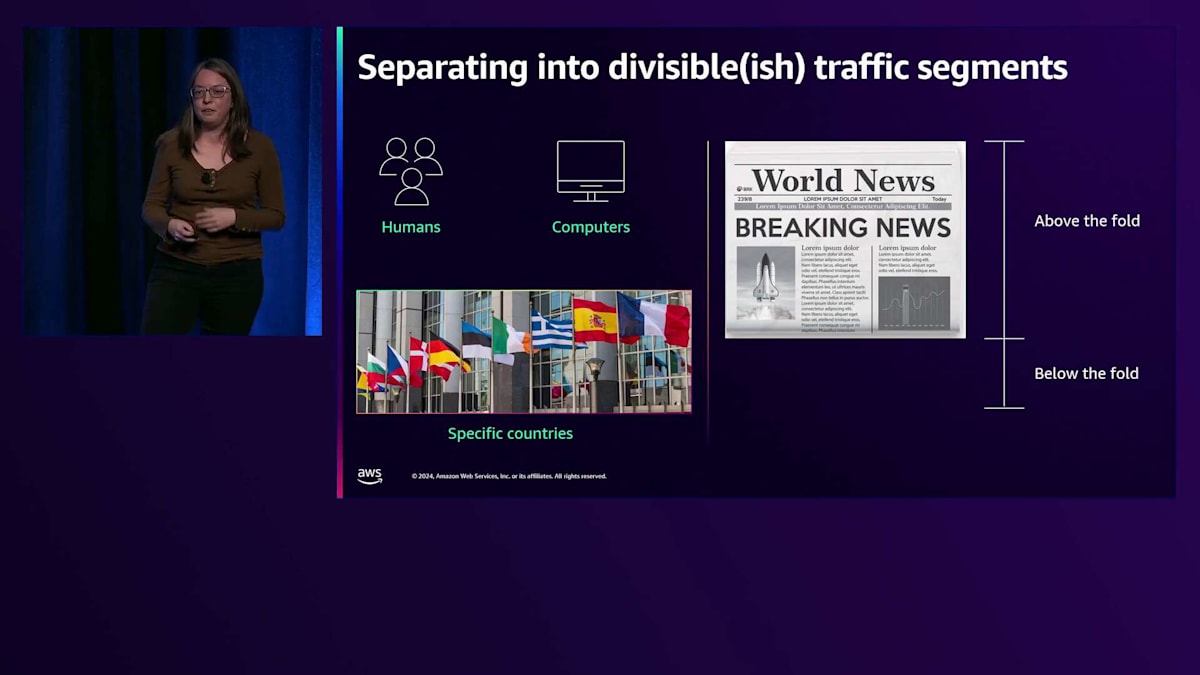


私たちにとって最も興味深かったのは、実はフォールドの上と下の違いです。ウェブサイトを読み込む際、最初に表示される部分と、スクロールして表示される部分があります。両者に対して異なるレイテンシーの期待値を設定することができ、私たちはそれを積極的に活用しています。これに関連して、以前は会社として真剣に考えていなかったのが、エクスペリエンスレベル目標です。私たちは常にService Level Objectives(SLO)について話し合っており、これは非常によく理解されており、各チームがそれに焦点を当てています。しかし、全体として見れば、いくつかのチームが目標より数ミリ秒遅れていても、他のチームが優れたパフォーマンスを発揮していれば、顧客は必要なものを得られます。私たちは、個々のサービスではなく、エクスペリエンスレベルでこれらを定義する方法を見出そうとしています。これは非常に困難な課題です。なぜなら、このようなタイムアウトファイルが多数存在するからです。これは私たちがまだ解決していない領域ですが、現在、シニアエンジニアの一人がこの問題に取り組んでいます。来年には、サービスレベルからエクスペリエンスレベルの目標への移行について発表できることを願っています。先ほど設定を問題として挙げましたが、これは私が言及した前提条件の曖昧な部分の一つです。
データの整合性とConsistencyモデルの選択


リージョンの停滞により、私たちは設定の定義方法についてやや怠慢になってしまい、それが今になって問題となっています。 これが典型的なAmazonの設定キーの始まり方です - "prod"は私たちがステージと呼ぶもので、本番環境なのか、テスト環境なのかなどを示します。 "NAAmazon"は私たちがRealmと呼ぶもので、ここでの"NA"はNorth Americaを表します。会社全体でさまざまなバリエーションが使用されていますが、ほとんどの設定キーでこのようなパターンが見られます。



そして残りの部分が実際のキーとなります。これはCanadaで特別な処理を行いたい場合の例で、このような設定をビジネス設定と呼んでいます。 そして、このような形式の設定も多く存在します。ここでの主な区別点はリージョンです。このパブリッシャーの場合、NAAmazonのすべてがus-east-2で動作することを前提としており、これが参照すべきARNとなります。 これはCanadaが常にus-east-2で動作することを前提としています。


では、新しいリージョンに拡大しようとする場合はどうでしょうか。もしus-east-1に移行したらどうなるでしょうか?最初のキーは一見良さそうに見えます - NAAmazonはそのままで問題ありません。しかし、将来マルチリージョンになったらどうでしょう?何か深刻な問題が発生した時にBrazilにフェイルオーバーしたい場合、これは機能しません。 同様に、技術的な設定もus-east-2に紐付けられているため、すでに機能しません。 そのため、基本的にすべての設定を変更する必要があります。ビジネス設定については、実際にはより自然なパラメータに移行したいと考えています。


キーはどうあるべきでしょうか? 時間とともに築き上げてきたこの曖昧なNAAmazonというバケットの代わりに、私たちはそれを完全に取り除こうとしています。 これがテスト環境なのか本番環境なのか、Canadaがどこでホストされているのかは関係なく、これがCanada用に常に使用すべき設定となります。これには若干の変更が必要ですが、現在では多くの人々が合理的に理解できるようになっています。同じパターンを技術的な設定にも適用できます。ここでは、us-east-2が実際にキーとなるパラメータです。

この変更を行うこともできますが、実際にはもう少し先に進みたいと考えています。なぜなら、ここでは規約による命名が本当に可能だからです。us-east-2のアプローチを採用した場合、新しいリージョンに進出するたびに、コピー&ペーストして修正し、タイプミスがないことを祈らなければなりません。実際には、これで永久に対応できると言えます。これこそが、私たちが各チームに推進してほしいと考えているものです - 必須のステップではありませんが、長期的なリージョンの柔軟性に向けて本当に役立つものとなります。


できるだけ左側にシフトしていきたいと考えています。まず、各チームがリージョン移行に必要なすべての変更を行えるようサポートすることから始めます。次に、新しいリージョンへの展開を難しくする可能性のある問題をPull Requestで検出し、ガイダンスを提供できるようにしていきます。2025年には、コードを書いている段階でIDEからガイダンスを提供できるようにする予定です。 すでに存在する大量のコードについては、Amazon Qの活用を検討しています。私たちは新しいリージョンへの展開方法の専門家なので、皆さんが手を触れることなくPull Requestを送信する方法を検討しています。



これにより、新しいリージョンへの展開を検討する際に再検討する必要がないように、設定を時間をかけて変更する方法についての指針が得られるはずです。インフラのセットアップにも同様の課題が多くあります。 Infrastructure as Codeは本当に重要です。なぜなら、ClickOpsベースの展開は問題が多いからです。多くのチームがClickOpsから始めていますが、必ず後悔することになります。 Amazonでは特にCDKを検討していますが、これはリソースの発見とヒューマンエラーの削減に大いに役立ちます。これまでの経験から、人員の入れ替わりやサービスの進化により、チームは特定のサービスの運用に必要なリソースを実際には把握していないことがわかっています。新しいリージョンでの展開を始めると、DynamoDBテーブルやS3バケットを忘れていたことに気付いたり、特定の接続について疑問を持ったりします。Infrastructure as Codeを使用していれば、必要なものすべての自然なインベントリが得られます。そこには接続関係があり、その役割を理解する必要があります。

コンソールやCLIで細かい作業をする必要がなくなります。この作業を始めたばかりの人々のタイプミスの数は相当なものでした。そのため、これは確実に事前に対処しておくべき課題です。最終的には、リージョンの追加がどこかのリストに追加するだけという単純な作業になることを目指していますが、そこまでにはまだ時間がかかりそうです。

既存のシステムをCDKを使用してInfrastructure as Codeに移行する方法については、AWSが提供するIaCジェネレーターを活用できます。 新しいサービスを構築する際は、Infrastructure as Codeから始めることをお勧めします。ほとんどの方にはこれを説明する必要はないでしょう - 私たちは長年これを実践してきました。ただし、歴史的な経緯のあるインフラが大量に存在しています。変更されないまま残っているサービスが多数あり、近代化する必要があるものが多くあります。
新リージョン選択時の考慮事項とネットワーク接続性

データの整合性は興味深い課題です。多くの人々がリージョン間でのデータ移行について不安を感じています。 それも当然です。Amazonでは、この問題に対する良いモデルケースがありません。数十ミリ秒の遅延がある複数のリージョン間で強整合性のあるデータを同期させることは、恐ろしい課題です。多くのユーザー体験でダウンタイムを取りたくないため、これらの多くはライブマイグレーションである必要があり、それがさらなる複雑さを加えています。

Eventual Consistencyで良いのであれば、それは簡単なモードであり、実際にPrime Videoはこの方法を選択しました。彼らはDynamoDBを多用していたため、可能な限りGlobal Tablesを設定しました。これはかなり分かりやすい方法でした。新しいRegionに展開しようとする中で、私たちが経験した予想外の出来事の多くはあまりポジティブなものではありませんでした - 「それについて考えていなかった」とか「思っていたより難しそうだ」といったものでした。しかし、Prime VideoがEventual Consistencyモデルに移行できたデータセットの数は、実際に最大の良い驚きの一つでした。

彼らはDynamoDBのSLAを確認し、新しいRegionに展開しようとしているほとんどのシステムでこれが機能すると判断しました。これは彼らにとって大きな簡素化となり、トラフィックのシフト時にチーム間の調整が大幅に減少しました。私は皆さんにもConsistencyモデルの評価をお勧めします。より簡単なモードに常に移行できるわけではないことは十分理解していますが、どれだけ物事がシンプルになるかを考えると、評価する価値は確実にあります。同様に、レイテンシーが大きな問題でなければ、Region間で呼び出しを行うのは比較的straightforwardな対処方法です。あるいは、バックエンドで全てが同期されるように新しいRegionでキャッシングを開始することもできます。


先ほど申し上げたように、Strong ConsistencyからEventual Consistencyに常に移行できるわけではありません。それは十分理解しています。しかし、Strong Consistencyのユースケースであっても、作業を簡素化するためのステップを取ることは可能です。これは実際に、私たちの広告部門が新しいRegionに展開する際に採用している方法です。彼らは相互に排他的なキースペースを持っており、効果的に一度に1つの顧客を移行しようとしています。これはトラフィックとデータの間で調整の問題が発生することを意味しますが、各顧客に関しては、1つのRegionにのみ存在すると考えることができ、データを時間をかけて同期する方法について考える必要がありません。一時的な切り替えの瞬間だけが課題となります。
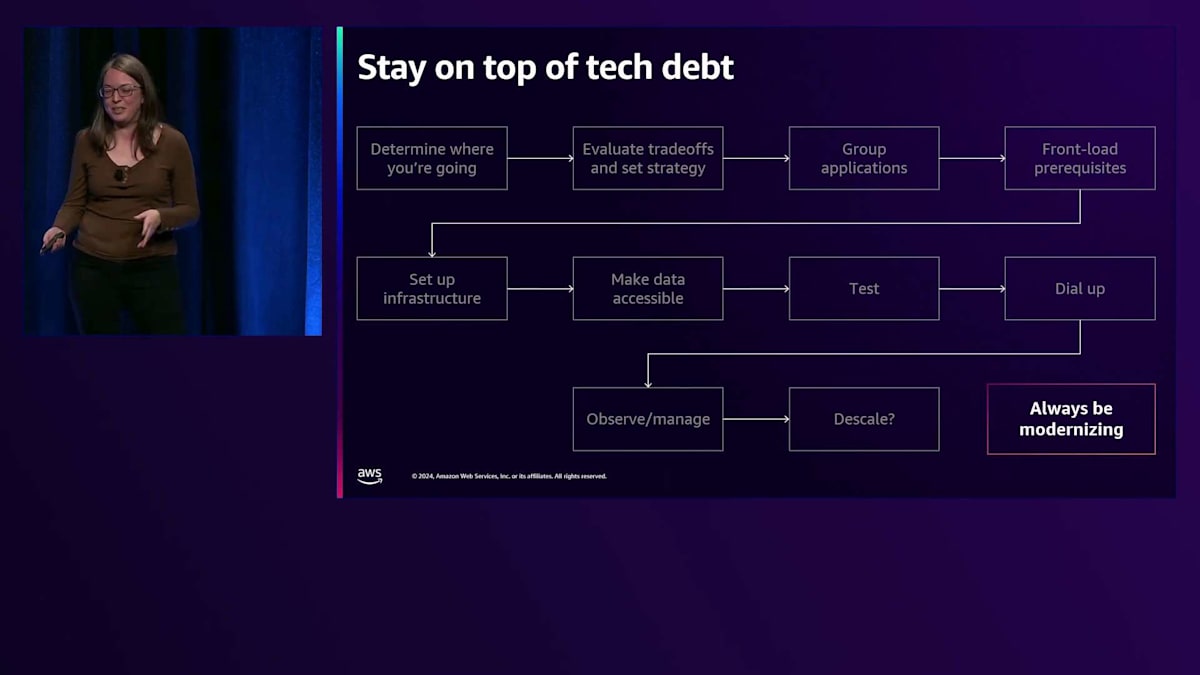

図にもう1つボックスを追加したいと思います。それは「常にモダナイズする」です - これについては何度か触れてきたので、その理由はおわかりいただけると思います。Technical Debtは、Amazonがここで物事をクリーンアップするための作業の大部分を占めています。ハードコードされた設定や前提があり、「Natural Parameters」というフレーズはここ5年ほどAmazonの中で飛び交っています。これが問題であることは分かっていて、修正のための対策も始めていましたが、新しいRegionに展開する必要が出てきて初めて、これが私たちにどれほどの影響を与えるかを実感しました。

ここで質問ですが、Amazon SimpleDBをご存知の方はどれくらいいらっしゃいますか?2、3人しか手が挙がりませんね。これは2007年にAmazonが立ち上げた、Eventually Distributedで、Eventual Consistencyを持つデータベースです。今ではConsoleで見つけることはできませんが、まだ裏で密かに存在しています。変更する十分な動機がなかったため、私たちはまだこれを使用し続けています。このように、望ましくないTechnical Diversityを生み出すものが多くあることがわかりました。問題は、今では私たちは、人々をそこから移行させるための時間を投資するか(これは私たちが現在行っている正しい対応です)、あるいは、当時優先されていなかったデータ移行の方法を新たに考案するかのどちらかを選ばなければならないということです。AWS Resourcesの手動管理は間違いなく問題です。


先ほど申し上げたように、AWSリソースの手動管理は私たちが直面している明確な課題です。新しいものについては適切に対応していますが、近代化が必要な古いインフラが多く存在します。そのため、常に最新化を進めていく必要があります。これらの問題の一部については以前から認識していましたが、解決策を見出せずにいました。しかし、各チームがこれらの潜在的な問題に気付き始めています。Amazon内の様々なチームの考え方が徐々に変化し始めているのです。


ここで私のパートを要約させていただきます。この進展には、可用性、レイテンシー、コスト、データ規制、新しいビジネスチャンスなど、複数の異なる動機づけが必要でした。全員にとってより良いものにしたいと考えていましたが、それが十分な動機づけとなるまでには時間がかかりました。包括的なフローを構築しましたが、テストや、これまで考慮する必要のなかったリンク依存関係の理解など、すべての側面については触れませんでした。Observabilityに関して言えば、Amazonではエンジニアがオンコール対応を行います。深夜3時に呼び出されてカナダのログを確認する必要がある場合、より多くのRegionに展開している現在では、以前とは全く異なる課題となります。

私たちはRegion展開を重点的に進めていますが、マルチリージョン対応の可能性も残しておきたいと考えています。先ほど述べたように、当面はマルチリージョンである必要がありますが、まだまだ多くの作業が残っています。数多くの課題が見つかっており、AWSへの要望も増えています。Frankが近づいてきましたが、私の話を聞きながら考えていたアイデアや、AWSに実装してほしい機能についての経験がありましたら、私たちも同じように望んでいる可能性が高いです。講演後にFrankに対してこれらのアイデアを共同で提示しましょう。
データ移行ツールとストラテジー:S3からデータベースまで

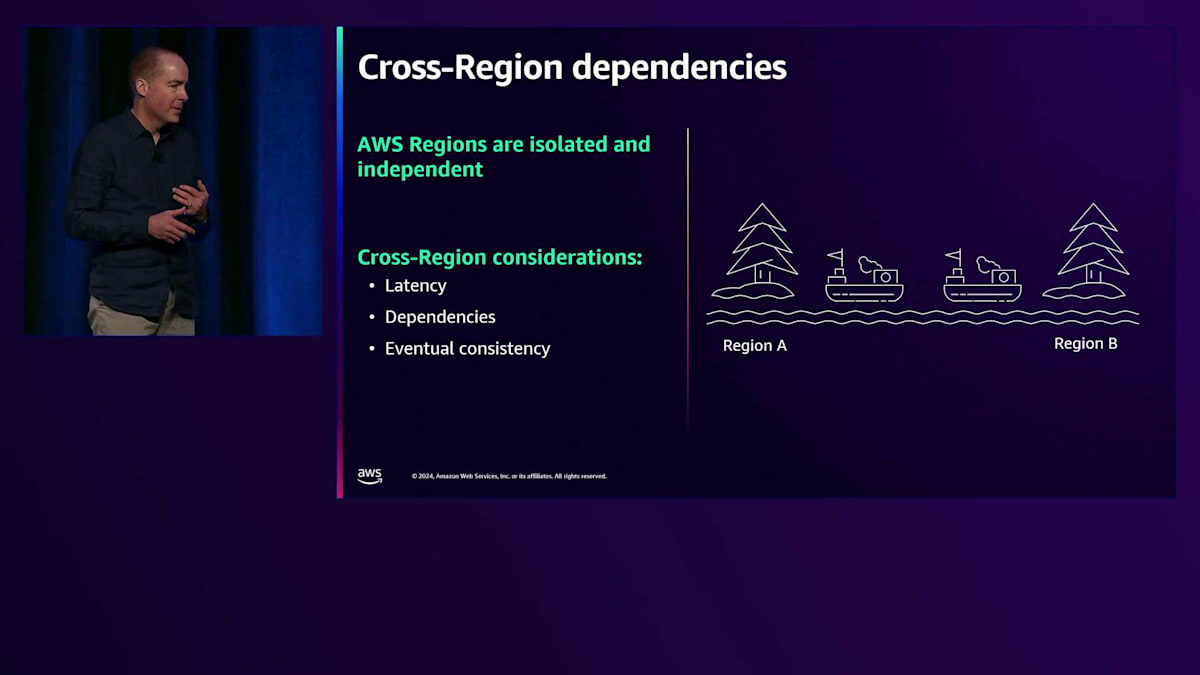
Frank:ありがとう、Lisa。新しいRegionを選択し、そこでの展開を始める際に考慮すべき点について説明したいと思います。私たちのRegionは自律的で独立するように設計されています。二つの島の間を移動するように、Region間の移動は可能ですが、全く同じというわけではありません。Lisaも触れていましたが、重要な考慮事項の一つがRegion間のレイテンシーです。Region内では、接続は非常に高速で、1ミリ秒以下です。アプリケーションがこのレベルの接続性を持っていることに慣れているでしょう。私たちのRegionは通常かなり離れており、光速という物理的な制限に直面します。パケットがRegion間を移動する際には、その距離を考慮する必要があります。
レイテンシーが数十ミリ秒であったとしても、それは単一のRegionで経験していた値よりも大きく、考慮が必要です。多くの場合、アプリケーションはその距離を1回だけではなく、顧客のために何かを完了するために3回、4回、あるいは5回traverseする必要があります。これが、依存関係の理解を重視する理由です。それによって、そのレイテンシーを気にする必要があるかどうかを判断できます。ソースRegionに依存関係を残す場合は、アプリケーションの設計と依存関係の動作に基づいて、顧客への影響を評価する必要があります。

Eventual consistencyについて、もしデータの同期が1秒程度遅れても問題ない場合は、多くの選択肢があります。しかし、Strong consistencyが必要な場合は、それらのコンポーネントを新しいRegionに一緒に移行するか、Lisaが提案したアプローチを使用してアプリケーションを変更し、これらの問題を軽減する必要があります。もう1つの重要な点は、私たちには異なるタイプのRegionがあるということです。従来のClassic Regionがありますが、2019年以降、コンソールではデフォルトでアクセスできない新しいRegionを構築してきました。これらはOpt-in Regionと呼ばれ、現在約12のRegionが存在します。

これらのOpt-in Regionは異なる動作をします。私たちは意図的にIAMの動作を変更し、Classic Regionのように全Regionに認証情報を配布するのではなく、選択したRegionにのみ配布するようにしました。これはIAMデータに対するセキュリティ基準の向上を表しており、明示的な選択が必要です。APIまたはコンソールを使用して、アカウントレベルでRegionを有効にすることができます。複数のアカウントがある場合、この作業は煩雑になる可能性があるため、AWS Organizationsを使用できます。AWS Organizationsでは、コンソールで希望するRegionを選択すると、その後追加するアカウントにもこれらの設定が適用されます。Opt-in Regionの利点は、

組織内で後から追加するRegionやアカウントに対しても、同じRegionが自動的にOpt-inされることです。これにより、時間と労力を節約し、Regionのアクセシビリティに関する混乱を防ぐことができます。Opt-in Regionを使用する際は、Security Token Service(STS)に関する重要な注意点があります。通常、Regional endpointの使用を推奨していますが、Global endpointが長年デフォルトとなっていました。Opt-in RegionとRegional endpointでは、セキュリティキーが数バイト長くなります。その時点でSTSトークンのバージョン2を選択する必要がありますが、これはOpt-in RegionとClassic Region間でシームレスに動作します。

私たちのRegionは高度な一貫性を持ち、コンソールにアクセスする際も同じ体験を提供します。ただし、主にRegionが構築された時期に関連するいくつかの違いがあります。新しいRegionでは、現行のインスタンスタイプと、新しく利用可能になるインスタンスタイプのみを実装しています。古いCPUが入手できないか入手困難なため、古いインスタンスタイプはバックフィルしていません。長期間あるRegionを使用し、古いインスタンスタイプでアプリケーションの特性を把握している場合は、新しいRegionで再度特性を把握する必要があります。新しいインスタンスは通常、より高性能で良好な結果を提供しますが、必要な作業は行わなければなりません。

ほとんどのAPIはRegion間でシームレスに移行できますが、古いAPIの中には、機能が強化された新しいバージョンのみを構築しているものもあります。現在のRegionで新しいAPIにアップグレードしていない場合は、それに応じてアプリケーションを適応させる必要があります。さらに、新しいサービスが発表された場合、32ほどあるすべてのRegionに即座にデプロイされるわけではありません。新しいRegionでは、必要とするタイミングで全てのサービスが構築されていない可能性があります。簡単な監査を行い、関心のあるRegionでサービスが利用できない場合は、AWSサービスチームに相談して、利用可能時期や代替オプションについてのガイダンスを受けることをお勧めします。



Cyber Mondayのような大規模なイベントを抱える大規模カスタマーの場合、計画が非常に重要です。Amazonでは、Cyber Mondayのスケーリングに向けて数ヶ月前から計画を立てています。新しいRegionでも同様のアプローチをお勧めします - サービスチームと協力して、最大スケーリング能力を把握しておきましょう。 では、移行に役立つツールボックスの中身と、これらのツールを使用する際の戦略について説明していきます。Regionへの移行には、いくつかのアプローチがあります。最も簡単な方法は新規構築で、他のRegionからの移行ではなく、新しいRegionでゼロからインフラを構築します。これにより、データ移行や結果整合性を気にすることなく、必要なタイミングでインフラを有効化できます。


2番目の戦略は、計画的な移行です。この場合、ある程度のダウンタイムを取ることができます。事前に計画を立て、すべてを準備し、アプリケーションとクライアントを段階的に制御された方法で切り替えることができます。最も困難な戦略ですが、多くの場合必要となるのがライブ移行です。これは、新しいRegionでスタックを構築し、データを同期させ、時間をかけて徐々にクライアントを移行していく方法で、通常はRoute 53 DNSを使用します。最終的に、すべてのクライアントを移行先Regionに移動し、移行元Regionをシャットダウンすることができます。


どの戦略を選択する場合でも、アカウント戦略を考慮する必要があります。1つのアカウントですべてを管理し、そのアカウント内で必要な数のRegionを使用することができます。これは多くの方が採用している方法です。より厳密なセキュリティガードレールと境界が必要な場合は、Regionごとに別々のアカウントを使用することもできます。ただし、開始前にアカウントを設定しておく必要があります。Lisaが説明していたInfrastructure as Codeについて強調したいのですが、まだ投資していない場合は、ぜひ検討してください。
例えばカナダなどの新しいRegionに移行する際、それが最後のRegion移行になることはないと私たちは知っています。インフラストラクチャとコードの整備に投資した効果は、何度も繰り返し享受することができます。また、障害時の再構築が必要になった場合や、既存のRegionで何か問題が発生した場合にも、その投資は大きな価値を発揮します。
最後に注意すべき点として、クォータはRegion固有であるということです。以前にRegionでインスタンス数のクォータを引き上げた場合でも、アクセス可能な他のRegionではそのクォータは引き上げられていません。クォータサービスを使用するか、サービスチームに連絡してクォータを設定する必要があります。新しいRegionでの作業を開始する前に、これを考慮に入れてください。


さて、Regionを選択したら、次に接続性とネットワークアクセスを確保する必要があります。AWS Backboneは、Region間のすべてのバックボーン接続で400ギガビット/秒以上のスループットを持つ堅牢なバックボーンで、非常に冗長性の高いインフラストラクチャとなっています。回線に障害が発生しても、複数のリンクが用意されているため、システムは継続して稼働できます。アプリケーションの接続性は、さまざまな方法で簡素化できます。ソースRegionにVPCがあり、そのVPCと送信先RegionのVPC間で分離されたIPアドレス空間を設定している場合、これらのVPCをペアリングすることで、自分のRegionのVPCに接続するのと同じように、新しいRegionのデバイスやリソースへ簡単にルーティングできます。


より複雑なインフラストラクチャを持ち、Region内に複数のVPCがある場合は、おそらくTransit Gatewayを使用してVPC間のルーティングを行っているでしょう。新しいRegionにTransit Gatewayを設定し、Region間でTransit Gatewayをピアリングすることで、同じアプローチを適用できます。これによって、信頼性の高いネットワーク接続が実現できます。1週間ほど前に発表された機能の1つが、Region間でPrivateLinkを使用できるようになったことです。この発表まで、PrivateLinkは特定のRegion内で使用できる優れたツールでしたが、Region間での接続はできませんでした。現在では、サービス用に作成したエンドポイントにRegionを越えてリモートでアクセスできるようになりました。
本日の新しい発表は、Gateway、NAT Gateway、Network Load Balancer、Gateway Load Balancerの背後にあるサービスだけでなく、VPCリソースにアクセスできる機能についてです。RDSやIP、DNSなど、基本的にすべてのリソースを共有できるようになりました。エンドポイントを使用してRegion間で接続できる機能が大幅に向上しています。発表内容を確認し、PrivateLinkを使用したVPCリソースアクセスについて詳しく読んでみてください。これは非常にエキサイティングな新機能です。

接続性が確保できたら、多くの人がデータの移行について考え始めます。私たちを含め、多くの人がデータ移行にSimple Storage Service(S3)を使用しています。データを移行する最善の方法は、実は移行しないことです。S3に保存しているデータの多くは、診断用に収集しているログファイルや、新しいRegionで新たにバックアップを取得できるため移行する必要のないバックアップファイルなどであることがわかりました。

実際に移行が必要なデータを特定したら、S3には Region間でデータを移動するための優れたツールが用意されています。それらのツールが、Cross-Region Replication(CRR)とS3 Batch Replicationです。あるRegionから別のRegionにバケットをコピーする場合は、Cross-Region Replicationをセットアップします。まず、送信先Regionに新しいバケットを作成し、Cross-Region Replicationを設定します。この時点で、新しく作成されたオブジェクトは新しいRegionにコピーされます。ただし、Cross-Region Replicationを設定する前にバケットに存在していたオブジェクトはまだ残っています。そこでBatch Replicationの出番です。これを1回設定することで、ソースRegionから送信先Regionにすべてのオブジェクトを移動できます。メトリクスで監視できる一定期間後、送信先Regionにすべてのオブジェクトが存在することを確認でき、移行の残りの作業を行っている間もCross-Region Replicationによってすべてが同期された状態を保つことができます。
プライマリの移行コピーを行う前に、このプロセスを実行しておくことをお勧めします。ファイルは同期が保たれ、最新の状態であることが保証されるため、一度実行すれば、アプリケーションやその他の要素がバックグラウンドで変更されても、データが更新されることを確信しながら移行作業を進めることができます。

考慮すべき重要な点として、S3バケット名はグローバルで一意である必要があります。つまり、移行先のRegionに作成したバケットは、ソースRegionのバケットとは異なる名前になります。そのため、そのバケットを参照するソフトウェアを、新しいバケット名を使用するように修正する必要があります。また、レプリケーション速度のデフォルト制限は1ギガビット/秒です。ほとんどのユースケースではこれで十分ですが、1ギガビット/秒以上が必要な場合は、サポートチームに連絡してクォータの調整を依頼することができます。


DynamoDBも、移行の際によく使用されるサービスの1つです。DynamoDBは高性能なNoSQLデータベースで、ほとんどのユースケースでは、DynamoDB Global Tablesを使用した移行アプローチが推奨されています。 このプロセスでは、移行先のRegionの既存のテーブルを選択し、Global Tableに変換するオプションを選び、そのテーブルをレプリケートしたいRegionを指定します。その時点で、DynamoDBは新しいRegionにテーブルを作成し、トランザクションのレプリケーションを開始し、テーブルのデータをバックフィルします。数時間後には、読み書きが可能な複数のRegionのテーブルが、わずか数回のクリックやコマンドで用意できます。

もう1つのアプローチは、テーブルのバックアップを作成してターゲットRegionに保存し、新しいRegionでテーブルを復元して進める方法です。Global Tablesの場合、レイテンシーメトリクスは通常、テーブル間のトランザクションのレプリケーションに1秒以下を示します。Global Tables間のレプリケーションは非常に高速ですが、Eventually Consistentです。支払いアプリケーションのように、ユーザーが複数のRegionにアクセスして1秒以内にデータを確認する必要があるような、Strong Consistencyが要求される場合は、アプリケーションロジックで対応する必要があります。
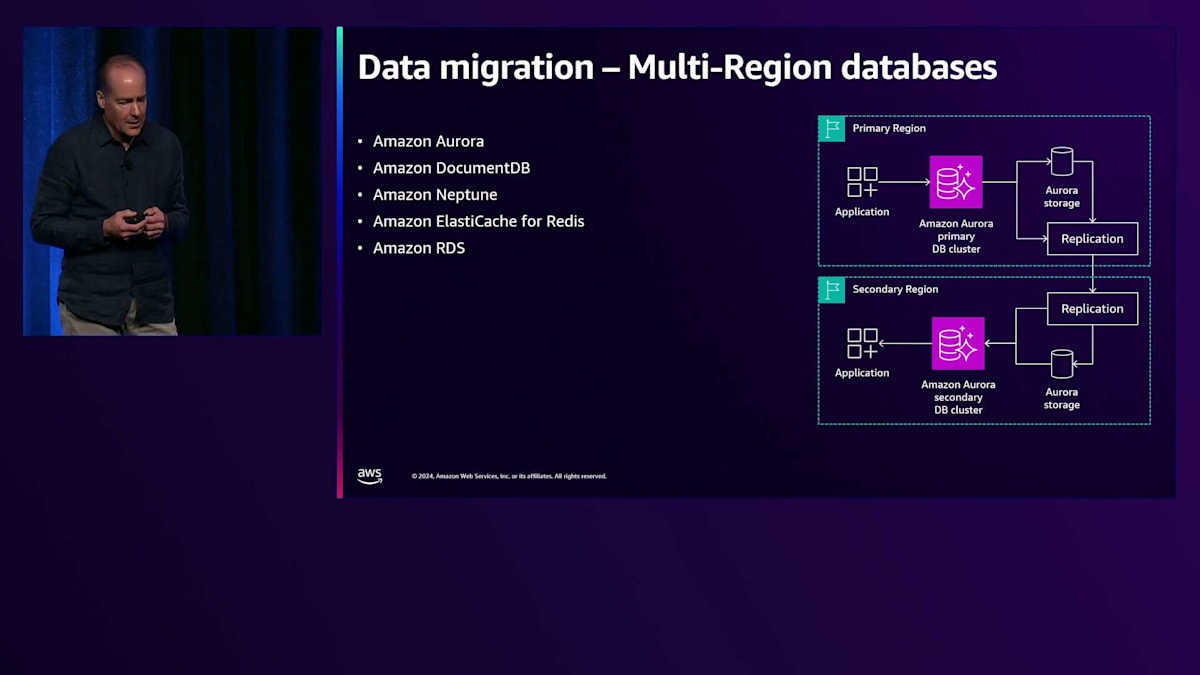


Amazon Aurora、Amazon DocumentDB、Amazon Neptune、Amazon ElastiCache for Redis、Amazon RDSなど、ほとんどのデータベースプラットフォームは、同様の移行アプローチに従います。 その戦略は、ターゲットRegionにRead Replicaを作成して同期を行い、フェイルオーバーの場合と同様に、そのRead Replicaに書き込みを移行するというものです。ただし、この場合は移行後もそのまま運用を継続します。 このアプローチはEventually Consistentで、通常、書き込みプロセスの際に短時間の停止が必要になります。


このプロセスは、クライアントとそのクライアントがアクセスするデータベースから始まります。まず、Read Replicaを作成してデータをコピーし、その後Read Replicaからの読み取りを開始します。 次に、書き込みを切り替え、準備が整ったらソースリージョンを無効にすることができます。特にAurora Global Tablesでは、バックエンドの改善により、フェイルオーバーがわずか数秒で完了するなど、レプリケーションがとてもスムーズに行えるようになっています。一部のRDSデータベースではやや時間がかかる場合もありますが、全体的なプロセスは同じように機能します。

最後に紹介したいツールは、ほとんどのストレージやデータベースプラットフォームで一貫して使用できるクロスリージョンバックアップの機能です。このアプローチでは、データストア、データのスナップショット、またはデータベース自体をバックアップし、新しいリージョンにコピーしてから、新しいリージョンでスナップショットやデータベースを復元します。復元後は、そのデータベースやデータストレージに対してクライアントからの運用を開始できます。
マルチリージョン戦略の重要ポイントと結論

さて、 ここで、Lisaとわたしがこのトークから得た重要なポイントをいくつか共有させていただきたいと思います。


Lisaが述べたように、 複数のRegionを使用することには多くのメリットがあります。レイテンシーの観点からお客様により近い場所でサービスを提供できる、フェイルオーバーのメリットがある、異なるRegion間でロードバランシングやロードシェアリングができる、またはデータプライバシーの理由で複数のRegionが必要になる場合があります。 また、このトークを通じて、計画が不可欠だということをご理解いただけたと思います。技術的負債を抱えている可能性もありますが、インフラストラクチャやコードに関して、将来的にRegionを移行する可能性を考慮に入れた準備を早めに始めれば始めるほど、より良い結果が得られます。


意図的に計画を立て、どのRegionに展開するかを検討し、 調査を行い、移行を実施する際には、AWSが提供している ツールを活用することが重要です。いくつかのツールについてはすでに触れましたが、本日や今週中にさらに新しい発表があると思いますので、アナウンスにご注目ください。 以上で、Lisaとわたしのセッションを終わらせていただきます。セッション後、入り口で質問をお受けしますので、ぜひお立ち寄りください。また、アンケートへのご記入もお忘れなく。素晴らしいイベントをお楽しみください。ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion