re:Invent 2024: AWSが語るApache Icebergで実現する大規模Data Lake
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Build large-scale transactional data lakes with open table formats (ANT336)
この動画では、Transactional Data Lakesの歴史から最新動向までを包括的に解説しています。Apache Iceberg、Apache Hudi、Delta Lakeなどのオープンテーブルフォーマットが、データレイクにデータベースのような機能を提供する仕組みを詳しく説明し、特にAWSが注力するApache Icebergの優位性について具体的に触れています。Amazon EMR 7.5でのApache Spark 3.5.3との比較で3.6倍のパフォーマンス向上を実現した事例や、新しく発表されたAmazon SageMaker Lakehouseとの連携など、AWSのサービス群との統合についても紹介しています。また、Apache XTableやDelta UniFormといった、オープンテーブルフォーマット間の相互運用性を目指す新しい取り組みについても言及しています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Transactional Data Lakesセッションの導入


皆様、re:Inventへようこそ。Transactional Data Lakesのセッションにお越しいただき、ありがとうございます。私はRadhika Raviralaと申します。Amazon EMR、AWS Glue、そしてAmazon Athenaサービスのプリンシパルプロダクトマネージャーを務めており、主にこれらのエンジンのセキュリティを担当しています。本日は、AWSのシニアソフトウェアエンジニアリングマネージャーであるGiovanni Matteo Fumarolaと一緒に登壇させていただきます。Giovanni、ありがとうございます。セッションを始める前に、簡単にお伺いしたいのですが、現在Data Lakeを運用されている方は手を挙げていただけますでしょうか? わあ、素晴らしいですね。99%の方が手を挙げられました。では、Apache IcebergをData Lakeで使用されている方はどのくらいいらっしゃいますか?かなりの数の手が挙がっていますね。このセッション後には、きっと皆様に持ち帰っていただけるものがあると思います。

本日のアジェンダについてですが、まず過去を振り返り、Transactional Data Lakesの歴史について簡単に見ていきます。Giovanniが、オープンテーブルフォーマットについて詳しく解説します。また、プロダクトの観点から、Data Lakeの構築と最適化の方法、そしてオープンテーブルフォーマットを使用してどのように機能を強化できるかについてお話しします。最後に、重要なポイントをまとめてQ&Aで締めくくりたいと思います。 歴史を振り返ってみると、Transactional Data Lakeの初期の形態は、リレーショナルデータベースシステムの形で現れました。お客様がリレーショナルデータベースシステムを使用したのは、トランザクションの基盤となるブロックだったからです。トランザクションを実行できるように設計されており、insert、update、deleteなどのプリミティブを提供していたため、大量のトランザクション処理環境に適していました。
データ管理の進化:RDBMSからData Lakeへ
しかし、欠点がないわけではありませんでした。集計データに対する大規模な複雑なクエリを実行する能力に制限があったのです。この問題に対処するため、オンプレミスのData Warehouseが台頭してきました。Data Warehouseはこれらの問題に対処し、構造化データの管理に優れていただけでなく、BIシステムを支える複雑なクエリや分析を実行するという重要な機能も提供しました。しかし、Data Warehouseの基盤はRDBMSであり、RDBMSはスケーリングが困難です。通常、すべての書き込みリクエストをサポートするプライマリノードが1つあり、すべての読み取りリクエストをサポートするプライマリと複数のレプリカがあります。


このような構成では、コストと時間の両面でスケーリングが高価になります。そこで、Hadoopがこの制限に対する解決策として登場し、弾力的なスケーリングを可能にし、さらに分散ファイルシステムを提供することで、コンピュートとストレージを独立してスケーリングできるようになりました。 Hadoopの登場により、多くのお客様がData Lake アーキテクチャを開発するようになりました。これにより、Data Warehouseですでにサポートされていたアプリケーションの管理だけでなく、ストレージとコンピュートの分離という重要な概念が可能になり、さらに従来の構造化データに加えて、半構造化データや非構造化データなど、様々な種類のデータをサポートできるようになりました。

しかし、HadoopとData Lakeにも本質的な制限がありました。考えてみると、Data LakeはACIDプロパティ(アトミック性、一貫性、分離性、永続性)を欠いているため、Data Warehouseが提供するような一貫性と整合性を提供できません。同様に、Data Lakeのデータレイアウトを見ても、高いパフォーマンスを実現できる構造になっていないという欠点があります。三つ目の制限は、Data Warehouseのようなデータガバナンスができないことです。RDBMSシステムでは権限を定義できますが、Data Lakeではそのような機能はなく、ファイルレベルでしか制御できませんでした。
クラウドコンピューティングの登場とオブジェクトストレージの柔軟性により、お客様はLakehouseのようなよりモダンなアーキテクチャを構築できるようになりました。Lakehouseは、データレイクの柔軟性とコスト効率の良さに、データウェアハウスのメリットを組み合わせることを可能にしました。この融合は非常に強力ですが、Lakehouseはデータレイクとデータウェアハウスを統合するだけのものではありません。データレイクとデータウェアハウス、そして現在利用している非リレーショナルデータベース、ビッグデータ処理、ログ分析、機械学習などの機能を、一貫性のあるソリューションとして結びつけることなのです。

Lakehouseアーキテクチャを完全にサポートするためには、従来のデータレイクにおけるいくつかの課題に対処する必要があります。第一の課題は、様々なソースから急速に到着するデータを最新の状態に保つための継続的な更新機能です。第二の課題は、毎秒到着する多数の小さなファイルを素早く圧縮する必要がある、一貫したパフォーマンスの維持です。第三の課題は、多くのデータアーキテクチャで一般的なパーティション更新に関するものです。さらに、コンプライアンス規制に従うために、必要に応じてデータを削除できる機能も求められます。

これらの課題に加えて、アーキテクチャの進化に伴い、お客様から新たな要件が提示されています。データウェアハウス上でトランザクション処理と分析処理の両方を実行できる単一のプラットフォームについて、根本的な質問が投げかけられています。データレイクがオープンソースの柔軟性、エンドツーエンドのガバナンス、そしてデータウェアハウスの核となる機能であるパフォーマンスやACIDライクな特性を備えることができるのかという疑問です。Lakehouseアーキテクチャを効果的に機能させるためには、両者の長所を兼ね備える必要があります。
Apache Icebergが提供するトランザクショナルData Lakeの機能

ここで登場するのが、トランザクショナルデータレイクです。トランザクショナルデータレイクは、トランザクションのサポートを提供し、データレイクの最適化と管理を簡素化するオープンテーブルフォーマットによって実現されています。主要なオープンテーブルフォーマットには、Apache Hudi、Apache Iceberg、Delta Lakeの3つがあります。これらのオープンテーブルフォーマットは、データレイクにデータベースのような機能を提供します。


このような機能が必要となるユースケースを見ていきましょう。まずはストリーミング取り込みのようなモダンなデータユースケースから始めます。 ストリーミング取り込みは、多くの組織で広く採用されています。このシナリオでは、無数のストリーミングソースが、Apache Kafka、Amazon MSK、Amazon Kinesis Data Streams、Kinesis Data Firehoseなどのストリーミングサービスを通じて継続的にデータを送信します。これらのストリーミングデータは、Amazon EMR、AWS Glue ETL、Amazon Managed Service for Apache Flinkなどのストリーム処理エンジンによって取り込まれ、処理されます。その後、データは保存、キュレーション、カタログ化、セキュリティ保護され、Amazon Redshift、Amazon Athena、Amazon EMR、Amazon SageMakerなどの様々なサービスを通じて利用できる状態になります。

ストリーミングインジェストのユースケースをサポートするには、小規模なストリーミング更新をすぐに適用できるよう、アトミックな変更を行う機能が必要です。また、書き込み処理が継続している間も、読み取り側がデータを参照できるようにスナップショットを提供する必要があり、これにはデータベースの特徴である読み書きの分離が求められます。さらに、データは非常に高速で到着するため、高スループットのインジェスト機能も必要不可欠です。

このような高速なデータ到着に対応するために、パフォーマンスを考慮した小さなファイルのコンパクション機能や、行レベルの挿入・更新機能が必要になります。これについては、後のスライドで詳しく見ていきましょう。

トランザクションが一般的な2つ目のユースケースは、データプライバシー規制へのコンプライアンスです。毎月のGDPR削除パイプラインや、AWS GlueやAmazon Managed Service for Apache Flinkなどのストリーミング処理サービスを通じて定期的に実行されるバッチ削除ジョブがあります。レコードを削除し、データレークを最新の状態に保ち、メタデータを更新し、利用可能な状態にする必要があります。




データプライバシー規制への準拠は、まさに「干し草の山から針を探す」ようなもので、非常に困難です。まず特定のユーザーのレコードを見つける必要がありますが、これにはデータに対する全テーブルスキャンが必要で、非常にコストがかかります。対象のファイルが見つかったら、それらのレコードをテーブルから削除する必要があります。Apache Sparkのようなビッグデータフレームワークでは、パーティション全体を上書きする必要があるため、コンプライアンス要件を満たすには、同時書き込みのサポートや行レベルのアップサート、削除機能が必要になります。

これらに加えて、Amazon Bedrockを使用する生成AIアプリケーションなど、新しいタイプのアプリケーションがデータレークに追加されています。これらの基盤モデルは常にデータレークに問い合わせを行うため、新しいアプリケーションをサポートするにはデータを常に新鮮な状態で利用可能にしておく必要があります。企業では、ログ分析、データウェアハウス、リレーショナルデータベース、生成AIアプリケーションなど、さまざまなアプリケーションをサポートするために、トランザクショナルデータレークが中心的な役割を果たすようになってきています。

それでは、お客様が実際にどのようにTransactional Data Lakeを実装しているのか、いくつかの事例を見ていきましょう。まず1つ目は、Amazon EMR上でApache Hudiを使用してストリーミングログの取り込みと効率的なデータ削除を実装したZoomの事例です。Zoomが直面していた課題は、セキュリティチームのコンプライアンス要件に従いながら、大量のアプリケーションログデータを取り込む必要があったことです。そこで、Amazon AthenaとApache Hudiを活用して、データを効率的に削除できる最適化されたスケーラブルなインフラを構築しました。この解決策を導入した結果、ストレージ使用量を90%削減し、1,000件のレコードを2分以内に削除できるようになりました。

次に、Orca Securityの事例をご紹介します。彼らはデータ保持管理機能を備え、ストリーミング取り込みを最適化したペタバイト規模のData Lakeを構築していました。統合が必要な多数のデータサイロがあり、この統合とデータ保持のユースケースを実現するため、Amazon Athena、Amazon S3、そしてApache Icebergを採用しました。比較分析の結果、Apache Icebergが彼らのユースケースにより適していることが分かり、スケーラブルで費用対効果が高く、高性能なTransactional Data Lakeの構築にApache Icebergを選択しました。その結果、パイプライン管理とクエリのコストを50%削減し、シームレスにスケールアップすることができ、このペタバイト規模のData Lake上で新しいユースケースの展開が可能になりました。
Apache Icebergの技術的詳細:構造とメカニズム

ここで、Open Table FormatがどのようにしてData Lakeの課題を解決するのか、より詳しく説明するためにGeoさんにバトンを渡したいと思います。ありがとうございます、Radikaさん。それでは視点を変えて、Open Table Formatの技術的な側面について詳しく見ていきましょう。Radikaが述べたように、効率的なOpen Table Formatには複数の要件があります。まず、レコードレベルの更新と削除をサポートし、データの整合性と一貫性を確保する機能が必要です。
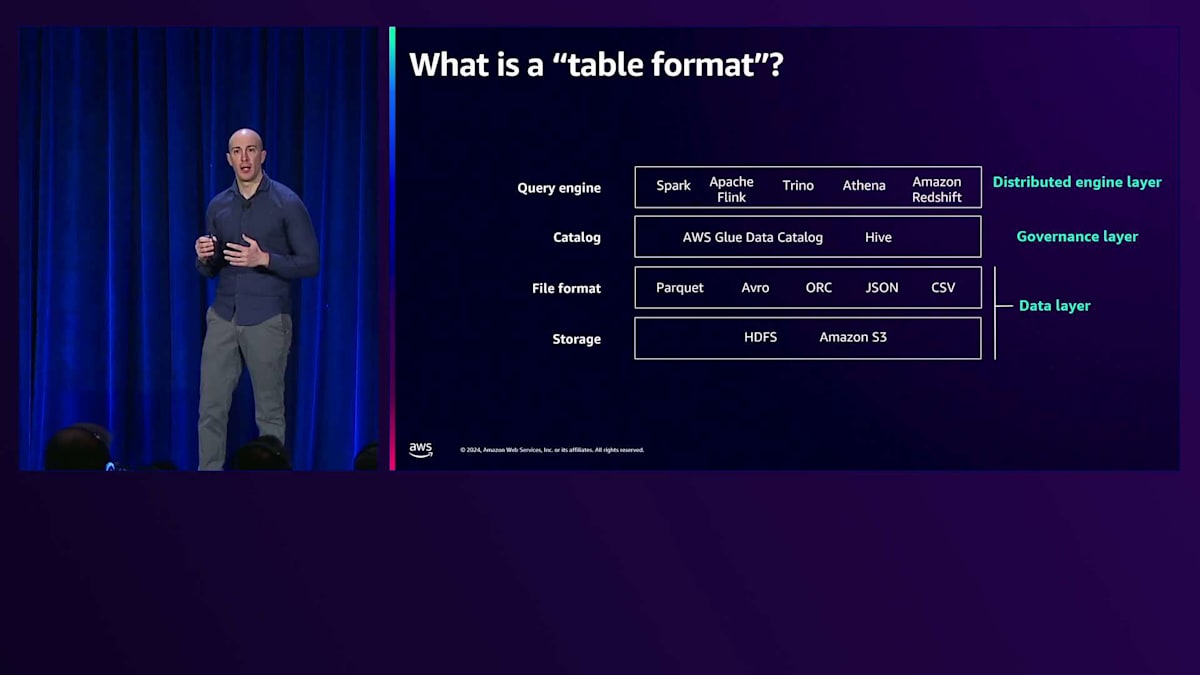
また、エンジンがきめ細かなアクセス制御を行える機能や、時間の経過とともにテーブルを進化させる機能、ファイル管理機能、そして優れたパフォーマンスも必要です。この図は分散クエリエンジンのアーキテクチャコンポーネントを表していて、私のお気に入りのスライドです。上部には、Apache Spark、Apache Flink、Trino、Amazon Athena、Amazon Redshiftなど、ジョブやクエリを実行するクエリエンジンがあります。これらのクエリエンジンは、AWS Glue Data CatalogやHive Metastoreなどのカタログに登録されたテーブル上でクエリやジョブを実行します。
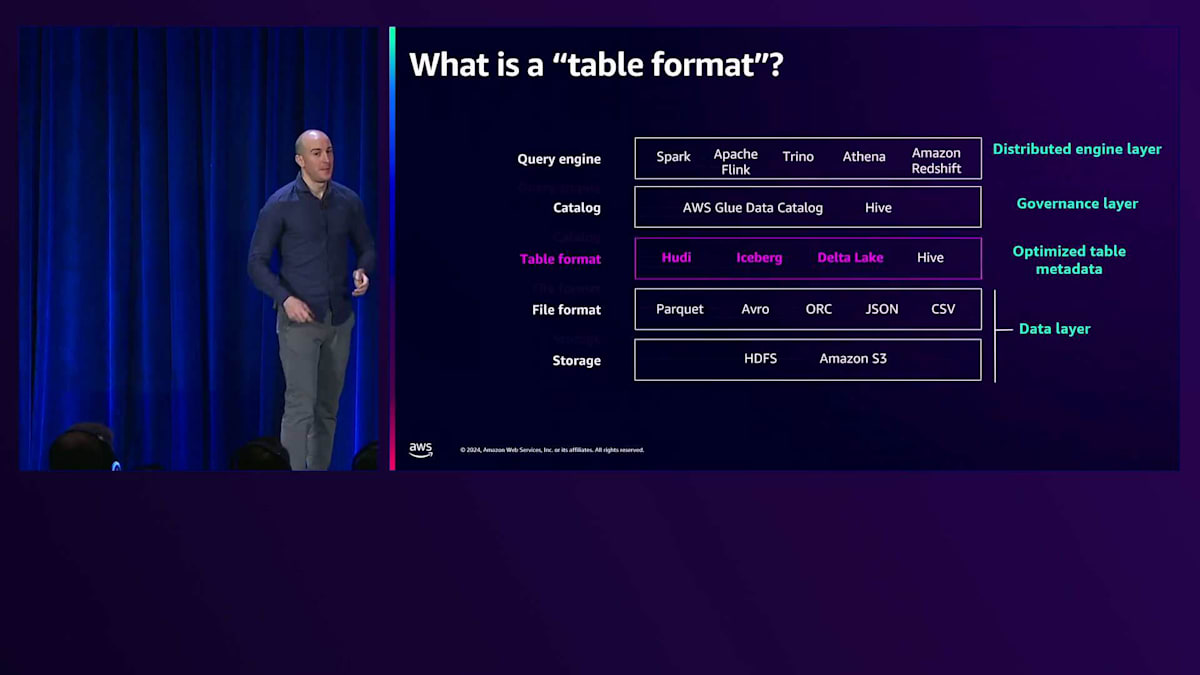

これらのテーブルは、Parquet、Avro、JSON、CSVなどのファイルフォーマットで保存されたオブジェクトの集合です。これらのオブジェクトは、HDFSやAmazon S3などのストレージレイヤーに配置されています。Open Table Formatは、カタログとファイルフォーマットの間に位置します。Hudi、Iceberg、Delta Lakeを紫色で、Hiveを白色で強調表示しています。通常、テーブルはHiveフォーマットで、フォルダ内のすべてのオブジェクトが同じテーブルまたはパーティションに属します。一方、Hudi、Iceberg、Delta Lakeはマニフェストと呼ばれる概念を提供します。Hudi、Delta Lake、Icebergの間では、チェックポイントやチェックファイルなど、異なる用語が使用されています。しかし、特定の時点のテーブルはマニフェストを指し示し、そのマニフェストがテーブルの状態を要約しています。



この例では、テーブルにはわずか4つのオブジェクトしかありません。誰かがInsert操作を実行したとします。このInsertによってストレージレイヤーに2つのオブジェクトが追加され、Open Formatは新しいManifestを指すように更新されます。 その後、UpdateやDeleteなどの別の操作が行われると、Manifestは7つのオブジェクトを追跡するようになります。そして、Open Table Formatには Compactionと呼ばれる機能があり、 これは既存のオブジェクトを新しいものと圧縮して、必要に応じて新しいオブジェクトを作成します。この例では、元の白いオブジェクトと新しいオブジェクトをManifestから削除し、2つのターコイズ色のオブジェクトを作成しています。




ただし、古いオブジェクトはストレージに保持されたままです。Manifestでは、 点線で囲まれた5つのオブジェクトのみが表示されます。Open Table Formatは、Time Travel機能のためにこれらのオブジェクトをストレージに保持します。この時点で、テーブルは5つのオブジェクトを持つ最新バージョンにありますが、Open Table Formatは過去のデータに対してクエリを実行する、いわゆるTime Travelクエリを実行する機能を提供します。この例では、 Manifestの2番目のバージョンの時点に対してクエリが実行されました。Time Travelクエリを好むお客様もいますが、 ストレージスペースとコストを節約したいと考える方もいます。Open Table Formatでは、不要なオブジェクトとManifestをストレージから完全にクリーンアップするVacuumingを通じてこれを実現します。 これが、このセッションの主要なポイントの1つです。
少し話を戻しましょう。Iceberg、Apache Hudi、Delta Lakeについて、オンラインのブログや意見で様々な議論を目にしますが、どれを選ぶのがベストなのでしょうか?このセッションで覚えていただきたい重要なポイントの1つは、AWSはこれら3つのOpen Table Formatすべてをサポートしているということです。Amazon Athenaも3つすべてをサポートし、AWS Glueも3つすべてをサポートしています。ただし、AWSはApache Icebergの機能リリースを優先しています。例えば、Apache SparkによるFine-grained Access Controlのサービスリリースは、Icebergと同時に行われました。

なぜAWSはIcebergのリリースを優先しているのでしょうか?その理由は、お客様の関心、フィードバック、Iceberg自体のパフォーマンス特性、そしてオープンソースコミュニティにあります。AWSがIcebergの主要な貢献者であり、コミュニティの活発なメンバーであることを示すこのグラフは、とても印象的です。


では、Apache Icebergについて説明しましょう。Icebergがオープンソースでデフォルトで提供している主な機能のいくつかを強調したいと思います。要件について説明した最初のスライドに戻ると、 Open Table Format、この場合はIcebergは、効率的なレコードレベルのUpdateとDeleteを提供する必要があると述べました。これには様々なユースケースがあります。 IcebergはマルチエンジンのOpen Table Formatで、Delete、Merge、Updateを実行する機能を提供します。

これは今回のプレゼンテーションで唯一の技術的なスライドですが、以前のスライドでOpen Table Formatがブロックとして示されていたものが、この2つの点線の中に要約されています。Icebergには3つのレイヤーがあり、最初の部分はメタデータファイルで、テーブルの状態を時系列で示すスナップショットを保存します。各スナップショットにはManifest Listがあり、これは複数のManifestのリストを含んでいます。そして各Manifestは、その時点で追加されたファイルまたはファイルのリストを指し示します。これから、これらのManifestがIceberg内でどのように追跡されるのかを見ていきましょう。



Icebergには、皆さんもご存知の通り、Copy-on-WriteとMerge-on-Readという2つの主要な概念があります。Copy-on-Writeのシナリオでは、 Open Table Formatがエンジンに対して、更新、削除、挿入が発生した際にデータ全体を書き直すように指示します。つまり、Icebergはクエリエンジンに必要なデータファイルをすべて書き直すように明示的に指示するのです。 もちろんトレードオフもあります。例えば、書き込み操作の際にはデータを書き直すため、書き込みのコストが高くなります。一方、読み取り側では、クエリエンジンがテーブルの変更を理解するために新しいオブジェクトをすべて確認する必要がないため、影響はありません。



一方、Merge-on-Readの場合を見てみましょう。Merge-on-Readのシナリオでは、更新、削除、マージの際に新しいオブジェクトが追加され、 このオブジェクトは通常、テーブルに何が起こったかを追跡するログファイルです。例えば、IDが5に等しい更新や、特定の住所への更新などを追跡します。この場合、書き込みは非常に高速で、 これは一般的にストリーミングのユースケースで使用されます。一方、読み取りの際には、クエリエンジンがテーブルの変更を理解するためにこれらのログファイルをすべてスキャンする必要があります。

では、Copy-on-Write操作と比較してみましょう。まずはCopy-on-Writeの場合のManifestの変化を見ていきます。これが最後の技術的なスライドになることをお約束します。まず、先ほど述べたように、新しいファイルが書き直されます。次に、新しいManifestが作成されます。これらはすべて2つの点線の中で、Apache Icebergによってバックグラウンドで処理されます。新しいManifestファイルが作成され、そのManifestファイルは、書き直されたすべてのレコードを含む新しいデータファイルを指し示します。そして、Manifestファイルを指し示す新しいManifest Listが作成されます。



最後に、メタデータファイルが作成され、今や3つのスナップショットを持つようになります。もちろん、s2が作成され、 新しいManifest Listを指し示すようになります。これがCopy-on-Writeで起こることです。Merge-on-Readの場合、 新しいデルタファイルまたはログファイルが作成され、ストレージレイヤー自体に追加されます。Icebergは両方を指し示す新しいManifestファイルを作成し、Manifest Listは古いManifest Listと新しいものの両方を指し示すようになります。そして最後に、 新しいManifest Listを指し示すメタデータファイルが作成されます。これらすべてがバックグラウンドで処理されます。
AWSによるトランザクショナルData Lakeの最適化と強化


主なポイントの1つは、IcebergがMerge-on-ReadとCopy-on-Writeの両方をサポートしているということです。では、別の要件について話を移しましょう。それは、時間の経過とともにテーブルスキーマを進化させることです。データの正規化やストリーミングのケース、コンプライアンスなど、いくつかのユースケースがあります。Icebergは、Schema EvolutionとPartition Evolutionという2つの素晴らしい機能を提供しています。まずはSchema Evolutionについて見ていきましょう。Icebergでは、副作用なしでテーブルのスキーマを変更することができます。データの操作や移動を必要とせず、データカラムの削除、名前の変更、順序の変更を独立して行うことができます。管理者がカラムやスキーマを追加・削除して更新した特定の時点以降、テーブルの状態を追跡し続けます。これらの変更を記憶し、カラムの有無に関わらず、クエリエンジンが適切なカラムを選択できるようにします。


Icebergが提供するもう1つの機能は、Partition Evolutionです。ある組織の全期間の売上データを含むテーブルがあるケースを考えてみましょう。このテーブルは月単位でパーティション分割されています。このスライドでは、2023年1月と2月のデータがあります。しかし、時間が経過するにつれ、この組織は月単位でパーティション分割されたテーブル構造がもはやスケーラブルではないことに気付きました。売上が多すぎて、このテーブルに対して実行されるジョブやクエリにはその形式が不要だったのです。この時点で、管理者はパーティションを月単位から日付単位に変更することを決定しました。


3月1日に新しいパーティションが作成され、月末までに31の新しいパーティションができあがります。これらはすべて、データの移動やテーブルの移行、クエリの再作成といった追加コストなしで実現されます。Icebergは、クエリエンジンにこの形式でクエリを実行するための適切な情報を提供します。例えば、2月11日から3月18日までの全売上データを取得するために、salesテーブルに対してSELECT *を実行する場合、



クエリを分割し、クエリエンジンに適切な情報と適切なオブジェクトを提供してそのクエリを実行します。繰り返しになりますが、Partition Evolutionは副作用がなく、単なるメタデータ操作です。次の要件はデータの整合性と一貫性で、データの追跡や変更のロールバックなど、いくつかのユースケースがあります。これはAWSがオープンソースに貢献した機能です。

先ほど述べたように、Insert、Update、Delete、Merge、Compactionなど、各トランザクションは新しいスナップショットを作成します。1月末のイベントのタイムラインを見てみましょう。月末のスナップショットであるS1があります。2月中に発生した他の2つのスナップショット、2月末に発生したS4、そしてS5があります。管理者は特定のスナップショットに「end of the month」というラベルを付けることを決定しました。そして3月に別のスナップショットが作成されます。最後に3月末に別のスナップショットが作成され、管理者はS7を「end of the month 2024」としてタグ付けすることを決定しました。
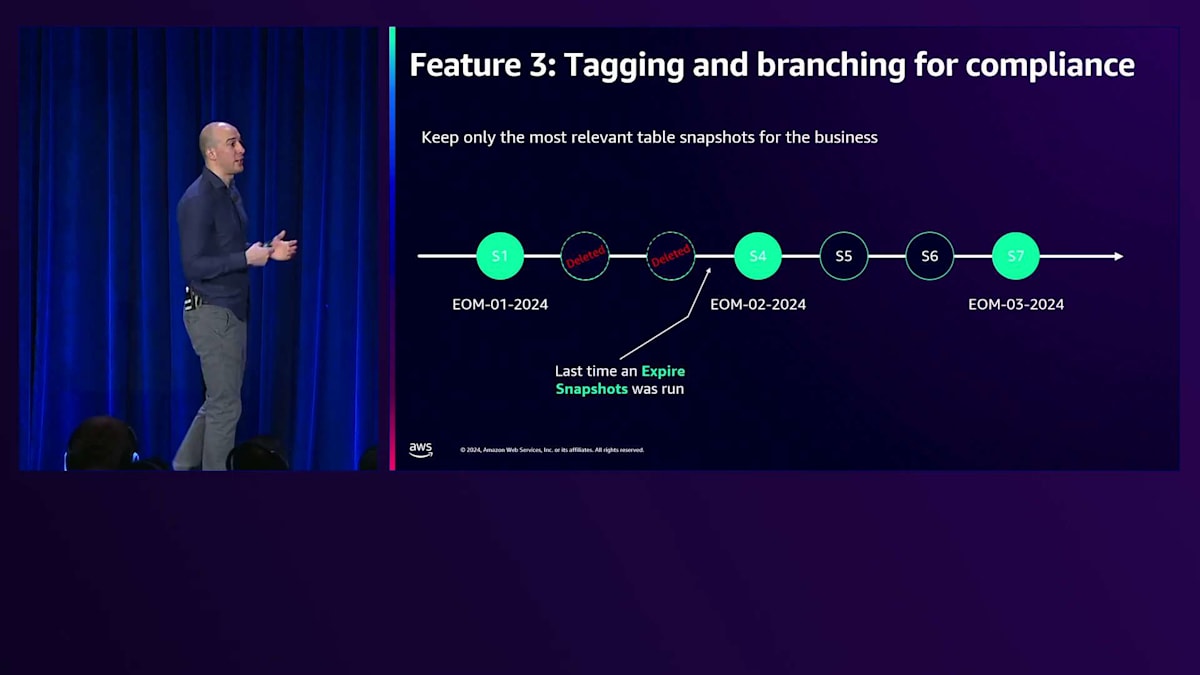



この時点で、管理者はexpire snapshotsと呼ばれる別の操作を実行します。これにより、タグが付いていない不要なスナップショットが削除されます。このようにして、タイムトラベルは引き続き可能ですが、管理者が決定したタグを指すスナップショットへのタイムトラベルに限定されます。ブランチングとタグ付けはGitの仕組みに似ており、Apache Icebergがどのようにブランチングを扱うのかを見ていきましょう。先ほどと同じケースを見てみましょう。3つのタグがあります。削除されたスナップショットは忘れて、スナップショットをS7にリセットし、そこから分岐して異なるブランチで新しいテーブルを作成することにします。これで、T1という異なるバージョンのテーブルができました。その後、T2で別の操作を行います。最後に、コンパクション処理を実行します。


このユースケースの一例として監査が挙げられます。例えば、元のテーブルを別のブランチに分岐させ、監査担当者がアクセスできない、またはアクセスすべきでない列をすべて削除し、データをコンパクトにしてから監査プロセスを実行することができます。最後の要件はパフォーマンスですが、これは実際に私の大好きなトピックの1つです。もちろん、誰もが素晴らしいパフォーマンスを望んでいます。パフォーマンスを向上させる2つの機能をご紹介します。1つ目はhidden partitionです。




このケースシナリオを見てみましょう。テーブルにはいくつかの列があり、例えばlevels、event time、そしてevent dateがこのテーブルのパーティションとなっています。event timeでフィルタリングするこのクエリを実行しようとすると、Hiveはクエリエンジンにすべてのデータをスキャンするように指示します。これを解決するために、event dateが2018-12-01と等しいという新しいフィルターを追加します。この場合、クエリは部分的なスキャンのみを実行します。event dateとevent timeには相関関係があり、Hiveでは2つの異なる列が必要ですが、Apache Icebergではhidden partitionの概念により、event dateは不要になります。event timeがあれば、event timeの日付関数によってパーティショニングが行われ、先ほどのクエリを実行すると自動的に部分スキャンの恩恵を受けることができます。これは実際に私がIcebergで最も気に入っている機能です。

私たちはこの機能の3つのバージョンを提供してきました。ご存知の通り、Hiveはテーブルをツリー形式で保存し、年、月、日付オブジェクトなどでパーティション化していました。しかし、すべてのオブジェクトが同じprefixのtable dataを持っています。同じprefixを共有しているため、すべてのリクエストが同じノードに集中し、error 503のスロットリングが発生してパフォーマンスが低下していました。

Icebergはrandomized prefixという概念を導入しました。これは一例ですが、Icebergは各パーティションの前にprefixを追加します。これにより、クエリエンジンはAmazon S3へのリクエストを分散させ、より良いパフォーマンスを実現します。最近、この機能をIcebergのオープンソースに追加しました。EMR 7.4では、この機能の3番目のバージョンを追加し、社内のお客様であるAmazon Adsがブログを公開し、error 503の大幅な削減と22%のパフォーマンス向上を実証しています。
AWS analyticsサービスとの相互運用性:SageMaker Lakehouseを中心に

Icebergがオープンソースでこれらすべての機能を持っていることを確認したところで、Radikaがトランザクショナルデータレイクの最適化について説明します。ありがとう、Geoさん。私とGは共にプロダクトを代表しており、このセクションでは、オープンテーブルフォーマットを使ってデータレイクを最適化・強化するための機能をどのように構築しているかを、プロダクトの視点からご説明したいと思います。まずはパフォーマンスについてです。 AWSでの経験の中で、現在のパフォーマンスに満足していて、これ以上何も必要ないというお客様の声を聞いたことは一度もありません。
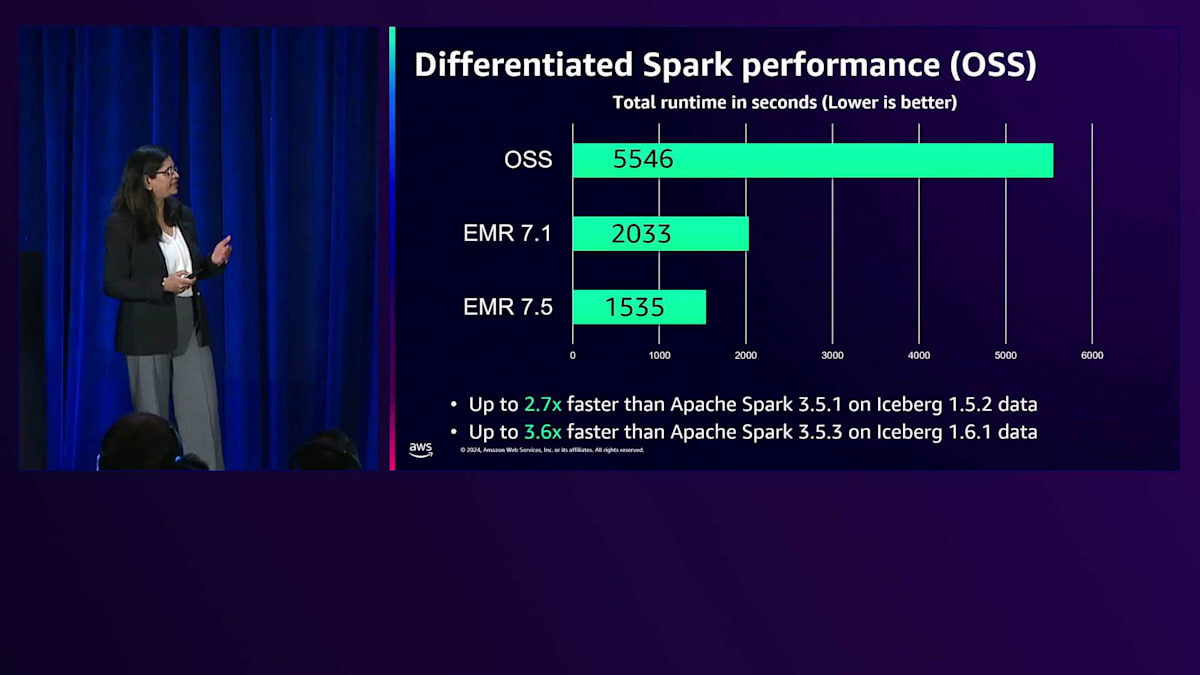
パフォーマンスの改善は私たちが毎年掲げる目標であり、今年もSparkのパフォーマンス向上を目標に掲げています。さらに今回は、ベンチマークテストにオープンテーブルフォーマットも含めることにしました。年初にEMR 7.1をリリースした時点では、Iceberg 1.5.2ベースのデータセットに対してApache Spark 3.5.1と比較して約2.7倍高速でした。最新のEMR 7.5リリースでは、最新のApache Spark 3.5.3とIceberg 1.6.1データセットを使用した場合と比較して、パフォーマンスを3.6倍まで向上させています。これは、Sparkアプリケーションとオープンテーブルフォーマットのパフォーマンスを確保し、アプリケーションの実行を高速化してコスト最適化も実現するための、プロダクト視点での継続的な改善です。

これらのパフォーマンス数値を達成するため、Geoのチームは、シャッフル削減、冗長スキャンの排除、最適化されたデータ構造、最適化されたコード生成、アダプティブジョイン選択、アダプティブBloomフィルターなど、数多くの機能に取り組んできました。私たちは毎年パフォーマンスを向上させるためのさまざまな機能に継続的に取り組んでおり、これらのパフォーマンス改善はデフォルトで有効になっているため、これらの利点を得るために追加の設定は必要ありません。すべてのランタイムで100%の互換性を維持しています。

つまり、どのランタイムを使用してもこれらのメリットを得ることができるということです。これには、すべてのAmazon EMRデプロイメントだけでなく、Sparkを実行するAWS Glueエンジンも含まれます。


このプレゼンテーションの前半で説明したように、ガバナンスはデータレイクにとって大きな課題であり、オープンテーブルフォーマットではより細かいレベルでの権限設定が必要となるため、さらに課題が複雑になります。データレイクが最初に導入された時は、ファイルレベルでしか権限を定義できませんでした。 また、データ量の爆発的な増加、ペルソナの多様化、そして実装したいアプリケーション数の加速により、多くの企業にとってデータアクセスも重要な課題となっています。
その結果、アナリティクスエンジンには2種類の細かい権限設定が可能になっています。1つ目は、オープンテーブルフォーマットにおける粗粒度の権限設定で、S3 Access Grantsという機能を通じて利用できます。この機能は昨年リリースされ、S3プレフィックスに対する詳細なアクセス制御を大規模に実施し、それをエンジンを通じて適用することができます。Apache HudiとDelta Lakeでは、S3向けコネクタであるEMRFSを通じてこれをサポートし、Apache Icebergでは、Iceberg関連クライアントを使用する際のS3 File IOを通じてサポートしています。IAM Identity Centerで信頼されたアイデンティティ伝播を使用する場合など、外部の企業IDディレクトリからアイデンティティに直接権限を付与でき、さらにエンドツーエンドの監査も可能です。

細かい権限設定とは、テーブル、行、列、セルレベルで定義できる権限のことを指します。このアーキテクチャでは、ストリーム処理サービスやバッチ処理サービスを通じてデータの取り込みが可能です。Amazon S3に生データを配置し、AWS Lake Formationを使用して細かいアクセス制御を適用することで、これらのストリーム処理エンジンとバッチ処理エンジンが、Sparkジョブで作業する際のHiveテーブルやApache Icebergテーブルに対してそれらのポリシーを適用します。これは今年の夏にAmazon EMR Serverlessでリリースした新機能で、昨日リリースされたばかりのAWS Glueでも提供を開始しています。

もう1つの注目すべき機能は、AWS Glue Data Catalogを通じてマルチ方言ビューを定義できる機能です。AWS Glue Data Catalog Viewsと呼ばれるこの機能により、ビューを1回定義するだけで、Amazon Redshift、Amazon Athena、そして近々Amazon EMRやAWS Glueなど、複数のアナリティクスエンジンで使用できるようになります。これらのビューの考え方は、1回定義すれば好みのエンジンから照会できるというものです。AWS Lake Formationで定義された詳細なアクセス制御を使用して、ベーステーブルとビューの両方を通じてデータを保護することができ、これらのビューはアカウント間で共有したり、リージョン間でリンクしたりすることも可能です。

AWS Glue Data Catalog自体も、Change Data Captureをサポートするためのマルチカタログ対応など、今年は多くの機能の実装に取り組んできました。現在のAWS Glue Data Catalogを考えると、カタログとAWSアカウントは1対1で対応しており、階層構造はとてもフラットです。

今月から、マルチカタログのサポートを追加し、1つのアカウント内で複数のカタログを持つことができるようになり、外部ソースからフェデレーションしているカタログも含めることができるようになりました。AWS Glue Data Catalogは、Apache Icebergテーブルの自動コンパクション機能も実装し、スナップショットの保持を可能にすることで、ストレージコストの削減に役立ちます。また、メタデータとデータのフェデレーション機能により、Amazon Athenaを使用して外部ソースへのフェデレーションとその機能の実装が可能になり、AWS Glue Data Catalogのテーブルの統計情報も常に更新して、より優れたパフォーマンスを提供しています。
トランザクショナルData Lakeの未来と、AWSを選ぶ理由


それでは、AWS analyticsとの相互運用性に関する新しいトピックに入っていきましょう。データレイクでオープンテーブルフォーマットをサポートすることは素晴らしいことですが、他のAWSサービスがこれらのオープンテーブルフォーマットをどのようにサポートし、どのように連携するのか気になるところですよね。昨日のKeynoteで発表された Amazon SageMaker Lakehouse についてお話しできることを大変嬉しく思います。Amazon SageMaker Lakehouseのコンセプトは、データの保存場所や方法に関係なく、単一のデータコピーで分析やAIの取り組みに必要なあらゆるソースのデータを統合することです。お好みの分析エンジンを使用し、きめ細かなアクセス制御権限を定義し、 取り込み、フェデレーション、共有のためのゼロETLを実現できます。

Amazon SageMaker Lakehouseでは、JupyterノートブックやAWSでサポートされている分析エンジン、あるいはAmazon Bedrock APIなど、Apache Icebergと互換性のある好みのツールを使ってデータにアクセスすることができます。さらに、ツール全体で反映される、データに対する統合された細かなアクセス制御という利点も得られます。詳しく見ていくと、 Amazon SageMaker Lakehouseは、Amazon Redshiftのマネージドストレージと、Amazon S3ですでに利用可能なストレージの利点を組み合わせて、RMSテーブル、Amazon Redshiftテーブル、そしてS3のデータに対する統合されたデータアクセスを複数のツールを通じて提供します。

また、ParquetやApache Icebergなどのオープンファイルフォーマットもサポートしているため、オープンソースツールも利用できます。Apache Iceberg APIを使用したサードパーティアクセスも可能で、Apache API互換のツールであれば、Amazon SageMaker Lakehouseのデータにアクセスできます。さらに、AWS Glue Data CatalogとAWS Lake Formationを使用した細かなアクセス制御権限により、セキュアに統合されています。既存のデータアーキテクチャを変更する必要はありません。プレビュー中のAmazon SageMaker United Studioから直接使い始めることができ、 現在のLakehouseアーキテクチャを活用することができます。

これは、Amazon SageMaker Lakehouseを支えるコンポーネントの概要です。多様なワークロードに対応する柔軟なストレージ、すべてのデータを管理する統合テクニカルカタログ、データを安全に共有するための統合権限管理システム、そして分析サービスやサードパーティアプリケーションからこのデータにアクセスするためのApache Iceberg APIのサポートが含まれています。データレイクを強化するためのもう一つのサポートとして、 Amazon Data FirehoseからApache Icebergテーブルへの書き込み機能を追加しました。ストリーミングサービスを使用している場合、Apache IcebergのサポートはAmazon Data Firehoseを通じて提供されます。これにより、宛先のS3バケットに直接新しいテーブルやカラムを作成する機能、スキーマ進化のサポート、PIIデータのフィルタリングが可能になります。また、VPC内のデータベースへの接続も可能で、MySQLとPostgreSQLをサポートしています。

すでにGAとなっている包括的なサービスセットがあり、現在プレビュー中の他のデータベースも今後GAとなる予定です。これらすべてにより、Apache Icebergフォーマットでトランザクショナルデータレイクに書き込む機能が提供されます。

Apache XTableやDelta UniFormという言葉を耳にされた方は、これらが何なのか気になっているかもしれません。これらは、オープンソースコミュニティで始まった新しいプロジェクトで、オープンテーブルフォーマット間の相互運用性を提供することを目的としています。Apache XTableは、Apache IcebergとDelta Lakeのメタデータを読み取る機能を提供します。これは、Apache Hudiを商用化した企業が立ち上げ、オープンソース化したプロジェクトで、この3つのオープンテーブルフォーマット間の相互運用を可能にする取り組みを進めています。一方、Delta UniFormはDelta Lakeコミュニティから始まったプロジェクトで、Delta Lake テーブルからApache HudiとApache Icebergのメタデータを読み取る機能を提供することを目指しています。これらは新しく登場したプロジェクトですが、すでに一部のお客様がこの相互運用性を活用したアーキテクチャの検討を始めています。私たちもこの分野の探求を進め、今後この2つのトピックについて新しい情報を皆様と共有できることを楽しみにしています。

まとめますと、オープンテーブルフォーマットは、データレイクにデータベースのような機能を実装し、データの鮮度を保ち、行レベルの更新を可能にするために不可欠なトランザクション更新機能を提供します。また、データレイクアーキテクチャでは、スキーマやパーティションが継続的に進化するため、スキーマ進化とパーティション進化もサポートしています。私たちは、必要なスピードを実現するためにCompactionなどを通じて継続的にこれらのフォーマットを最適化し、さらにオープンテーブルフォーマットが提供するTime Travel機能によって特定時点のクエリも可能にしています。

なぜトランザクショナルデータレイクにAWSを選ぶべきなのでしょうか?先ほど説明したように、AWSのアナリティクスサービスのエコシステム内で、このオープンテーブルフォーマットをサポートする包括的なサービス群が用意されています。AWS管理型でもオープンソースでも、柔軟に選択できます。Amazon SageMaker Lakehouseの例で示したように、幅広いパートナーエコシステムのサポートも備えています。また、私たちは継続的に最適化を行い、スピードを向上させているため、コスト効率も優れています。ストリーミングアーキテクチャをトランザクショナルデータレイクに組み込むことで、ビジネスのリアルタイムな洞察をより速く得ることができます。さらに、データとメタデータに対するきめ細かなアクセス制御を実現するためのセキュリティ強化にも常に取り組んでおり、Amazon SageMaker LakehouseやAmazon SageMaker Studioを通じてデータの統合も実現しています。これらすべての機能を1か所で利用でき、しかもベンダーロックインの心配もありません。
AWSは、トランザクショナルデータレイクを実装するのに最適な環境を提供しています。皆様のトランザクショナルデータレイクでの経験をぜひお聞かせください。今後も引き続きこのトピックについて皆様と協力させていただけることを楽しみにしています。本セッションにご参加いただき、ありがとうございました。ご質問がございましたら、この場で、あるいは会場の外でもお答えいたしますので、お気軽にお声がけください。素晴らしいカンファレンスをお楽しみください。ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion