re:Invent 2023: AWSとAdobeが語るAmazon EKSでの生成AIモデル展開


はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - Navigating the future of AI: Deploying generative models on Amazon EKS (CON312)
この動画では、Amazon EKSを使って生成AIワークロードを実行する方法を詳しく解説します。AWSのMikeとRamaが、EKSプラットフォームの拡張方法や、最新のAWS機械学習イノベーションとの統合について説明します。さらに、AdobeのJohn Weberが、EKSを活用してAdobe Fireflyを構築・展開した実例を紹介。JARKスタックやData on EKSプロジェクトなど、MLワークロードの構築を加速させる最新のツールやアプローチも学べます。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
Generative AIとKubernetesの融合:新たな課題と機会

はい、AIの未来、生成モデル、Kubernetesです。確かに、このセッションのタイトルにはかなりのバズワードが含まれています。このセッションに参加したことをレジュメに追加すれば良く見えるでしょうか?そうするのを止めはしませんが、それが皆さんがここにいる本当の理由だとは思いません。むしろ、より従来型のワークロードにすでにKubernetesを使用している組織で働いており、機械学習ワークロードのサポート方法を探っているのではないでしょうか。おそらく、この1年の間に、「Gen AIについて何をすべきか?我々のGen AIストーリーは何か?」と経営陣から緊急会議に呼ばれたことがあるかもしれません。Gen AI FOMOと呼びたければそう呼んでもいいでしょう。最近はそういったことがたくさんあります。
そこで、組織がブレインストーミングの帽子をかぶり、Gen AIの潜在的な応用を考え出し、新たな一連の課題があなたの肩にのしかかります。あなたは、組織のアプリケーション開発環境を提供する責任を負うDevOpsエンジニア、ML opsエンジニア、ソフトウェア開発マネージャーです。そして、データサイエンティストがあなたのところにやってきます。彼らは、より高速なストレージ、より多くの計算能力、最新のライブラリ、機械学習ツールキットへのアクセスを必要としています。財務部門はGen AIのコストを心配して神経質に見守っています。経営陣は昨日の結果を求めており、あなたはセキュリティ、コンプライアンス、高い基準を維持しながら、何かを提供する必要があります。

これを実現するために、全く新しい一連のテクノロジーを一から学ぶ必要があるのでしょうか?このトークでは、私、Amazon EKSのPrincipal Product ManagerであるMikeと、AWSのSenior Containers SpecialistであるRamaが、EKSプラットフォームを拡張して機械学習ワークロードをサポートすることで、組織のGen AIワークロードの構築と展開への道のりを実際にどのように加速できるかについてお話しします。EKSがコンピューティング、ネットワーキングインフラストラクチャにおける最新のAWS機械学習イノベーションを簡単に統合し、使用できるようにする方法をお見せします。また、既存のEKS環境を迅速に変換して、 Kubernetesの専門家になる必要のないデータサイエンティストにストレスフリーで、おそらく喜ばしい体験を提供するために活用できる、Kubernetes機械学習オープンソースコミュニティの最新の開発についてお話しします。
すべてを組み合わせると、MLとGen AIワークロードのためにEKSを活用し拡張することで、Gen AIのアイデアから本番アプリケーションまでを、思っていたよりも速く進めることができます。最後に、AWSの従業員が2人ここに立って1時間話すよりも良いことは何でしょうか?それは、この旅をすでに経験した実際の顧客の話を聞くことです。今日は特別ゲストとして、AdobeのSenior Director of Developer ProductivityであるJohn Weberをお迎えしています。彼は、機械学習ワークロードをサポートするために内部EKSプラットフォームをどのように拡張し、それを使って非常に成功したAdobe Firefly製品を構築・展開したかについて共有してくれます。
機械学習におけるKubernetesの役割と課題

それでは、まずRamaに引き継ぎます。彼はKubernetesと機械学習の背景から始めます。 ありがとう、Mike。皆さん、こんにちは。Rama Ponnuswamiです。AWSのSenior Container Specialistです。EKS上のAI MLワークロードのワールドワイドなGo-to-Marketを推進し、世界中の顧客のEKSの旅をサポートしています。

では、今日のトピックに入りましょう。実は、EKSの話に入る前に、そもそもなぜKubernetesなのかという点から始めたいと思います。なぜKubernetes上で機械学習を行うのか、そして今日なぜ多くの顧客がそれを行っているのか、その理由についてお話しします。Mikeも言及したように、KubernetesでのMLは単なるバズワードの組み合わせのように見えるかもしれません。しかし、機械学習の実際のニーズを深く掘り下げていくと、Kubernetesが機械学習の世界に完璧にフィットすることがわかってきます。

そこで、このスライドでは機械学習のニーズと、Kubernetesを使った機械学習、あるいは一般的な機械学習でそれらのニーズを満たそうとする際に直面する課題をまとめてみました。機械学習の開発は、まず構築のベースとなるフレームワークを選ぶところから始まります。これらのフレームワークは、依存関係の管理という形で多くの複雑さをもたらします。機械学習ライブラリやフレームワークの依存関係をすべて含めるだけでなく、GPUドライバーやGPUが必要とするその他のものすべてを確実にロードし、コードがGPUレイヤーと通信してその機能をすべて活用できるようにする必要があります。
さて、この課題を解決したとしましょう。次の課題は、分散トレーニングや推論のニーズに対応するための大規模なコンピューティングリソースをどのように確保するかです。機械学習においては、AWSのおかげでボタン一つで大規模なコンピューティングリソースにアクセスできます。しかし、コンピューティングリソースへのアクセスは最初のステップに過ぎません。
それでも、特定のニーズに合わせて、これらの大規模なコンピューティング、ストレージ、ネットワークリソースを管理し、オーケストレーションする必要があります。機械学習の場合、ニーズは主に大規模な分散トレーニングをいかに行うかということです。短時間で大量のデータにモデルを露出させ、学習させて推論結果を得ることが求められます。推論の観点からは、需要が増えたときにスケールアップする方法を考える一方で、需要が減ったときにはリソースとコストを節約するためにスケールダウンすることも確実に行う必要があります。
分散トレーニングの観点からは、リソースの無駄を防ぐために障害を減らすことも必要です。これらの課題を解決できたとしても、機械学習モデルのロギング、モニタリング、観測可能性をどのように構築するかを決定する必要があります。組織全体の複数のチームが効率的かつセキュアにリソースを共有できるよう、大規模なアイデンティティアクセス管理をどのように行うかを考慮する必要があります。もちろん、これらすべての課題に取り組み、克服しようとする一方で、常にセキュリティとコンプライアンスの要件を満たす必要があることを忘れてはいけません。これ自体が複雑な課題です。
Kubernetesが機械学習にもたらす利点
これらの課題すべてを克服しようとすると、インフラの基本要素の管理とオーケストレーションに多くの時間を費やすことになります。それは、コアビジネス価値、つまり機械学習モデルの開発から時間を奪うことになります。これは、運用コストを増加させながら、モデルやML製品の市場投入までの時間を長引かせるという、損失の多い状況を生み出します。本当に必要なのは、インフラの基本要素をすべて抽象化しながら、望むカスタマイズを行うための十分なレバーを提供するツールです。Kubernetesはまさにそれを実現し、それがKubernetesの強みでもあります。

Kubernetesに移行する前でも、Kubernetesへの道を歩んでいるなら、機械学習ワークロードのパッケージング方法としてコンテナを使用するという本質的な選択をしていることになります。それによって、すでに最初のパズルのピース、つまり依存関係の管理を解決しています。コンテナを使えば、MLコード、ライブラリ、フレームワークの依存関係、GPUドライバー、ツールキットなどをすべてパッケージ化できる単一のユニットが得られます。これにより、一貫性を心配することなく、環境間で簡単に移動できる単一のユニットが提供されます。また、軽量な方法でこれを行えることも確認する必要があります。単一のユニットなので、複数のコンピューティングインスタンスに簡単に展開でき、必要に応じて分散トレーニングやオンデマンドの推論を行うためのスケーリングが容易になります。

Kubernetesに話を戻すと、アプリケーションをコンテナにパッケージ化した後、Kubernetesが本当に提供するのは、組み込みの自動スケーリングです。これは、HPA(Horizontal Pod Autoscaler)やクラスターオートスケーラーの形で、Kubernetesのネイティブな機能であり、現在他にもいくつかのオプションが登場しています。これにより、クラスターのプロビジョニングのニーズをすべて満たすことができます。Kubernetesは実際のコンピューティングのプロビジョニングを抽象化し、大規模に必要なスケーリングを提供します。
これを解決した次のステップは、Kubernetesによるリソース利用率の向上です。Kubernetesは、コンテナレベルで多くのオプションを提供し、アプリケーションごとにVMをスピンアップする必要なく、すでに最小限のリソースを使用しています。また、リソースクォータなどの機能も提供しており、これを使ってKubernetesのリソース利用率をさらに向上させることができます。技術的な問題は別として、大規模な管理も行う必要があります。これらのリソースを公開できる必要があり、私たち全員が直面しているGPUの不足を考えると、利用可能なリソースが完全に活用されていることを確認する必要があります。
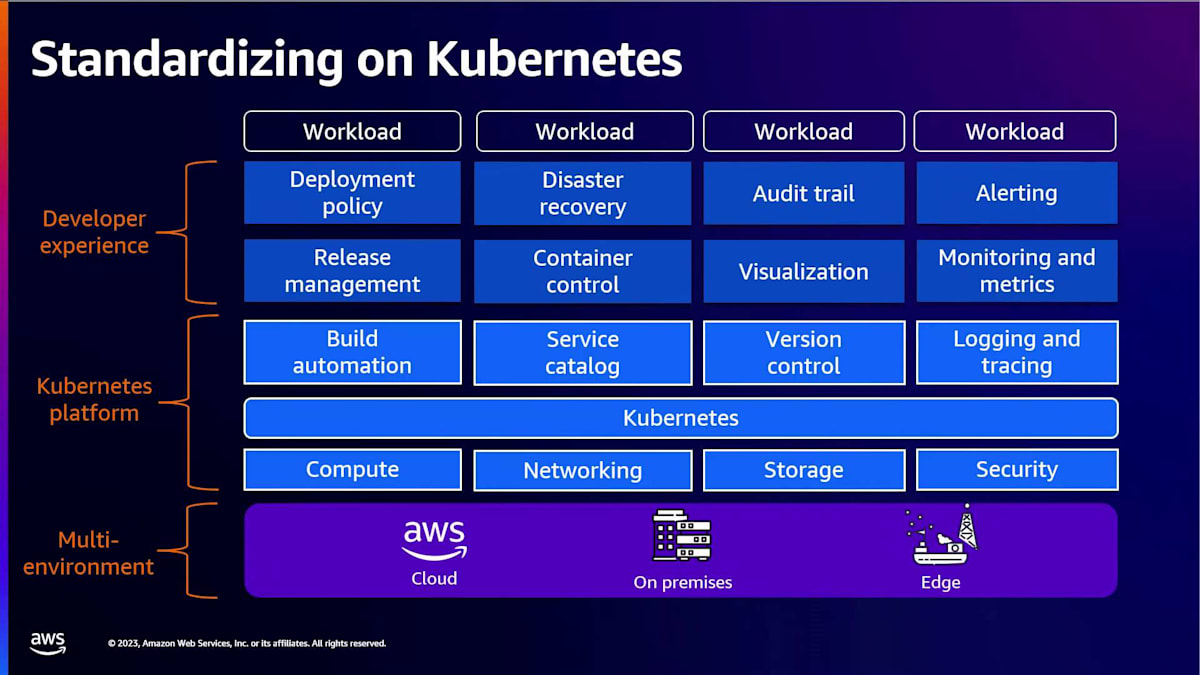
多くの場合、それは複数のチーム間でリソースを共有することに帰結します。どのように安全に行うのか?ワークロードを分離し、他の人がアクセスできないようにするにはどうすればよいのでしょうか?これもKubernetesのネームスペース構造によるネイティブな機能です。Kubernetesのもう一つの重要なポイントは、オープンソースコミュニティへの影響力です。実際、この生成AIの革命を引き起こしている基盤モデルのほとんどは、Kubernetes上に構築されています。これがKubernetesの影響力の一部です。Kubernetesには、常に大規模に貢献し革新を続ける多数の人々からなる強力なオープンソースコミュニティがあります。そして、Kubernetesを導入することで、これらのイノベーションをエンタープライズにより迅速に採用できるのです。
EKSによるGenerative AI開発の加速

では、機械学習のワークフローにおいて、Kubernetesは実際どこに適合するのでしょうか? それは、機械学習の開発者がローカルでの実験に満足し、モデルをスケールアウトして利用可能なすべてのデータにさらしたいと考えた時点です。Kubernetesを使えば、機械学習の開発者は使用したいコンテナをKubernetesに指示するだけで済みます。

そして、Kubernetesはそのコンテナの実行に必要なリソースの種類と量の情報を要求します。その後、Kubernetesがマシンをプロビジョニングし、コンテナをデプロイし、スケーリングを完全に管理します。これにより、シンプルなスケーリングとCPUやGPUなどの異なるタイプのリソースを定義する柔軟性が提供されます。 しかし最も重要なのは、Kubernetesのコントローラーが、クラスターを継続的に監視し、設定した希望の容量や状態を満たしているかを確認する固有の能力を持っていることです。つまり、障害が発生した場合、手動介入なしに自動的に対処できるため、分散トレーニングや推論プロセスのスピードアップが可能になります。
これらが、多くの顧客が機械学習ワークロードにKubernetesを採用している技術的な理由です。しかし、この採用には戦略的な理由もあります。多くの顧客が、アプリケーションを実行する方法としてKubernetesを標準化し、その上にプラットフォームを構築することを選択しています。これは主に、Kubernetesがクラウド、オンプレミス、エッジロケーションにわたってデプロイメントを標準化するための共通インターフェースを提供するためです。彼らはデプロイメントの実践を標準化するだけでなく、ロギング、モニタリング、アイデンティティ管理、セキュリティなどの基本的な機能を大規模に構築します。企業全体にセキュリティガバナンスを適用する方法を見出し、それらすべてがKubernetesの上に構築されたプラットフォームに組み込まれています。
この基盤があれば、多くの顧客はそのプラットフォームを再利用し、その上にML機能を構築する傾向があります。このアプローチには3つの明確な利点があります。まず、既に構築されたものを再利用でき、既存の企業標準やガバナンスに合わせることができます。次に、ゼロから構築する必要がないためコストが削減され、追加のプレミアムなしでオープンソース技術を使用できます。第三に、既に構築されたものを利用するため、市場投入までの時間が短縮され、機械学習製品をより迅速にローンチできます。Johnは彼のプレゼンテーションで、Adobeがこのアプローチをどのように実装したかを示唆するでしょう。
では、再びMikeに引き継ぎます。彼は生成AIについてより具体的に、そしてAmazon EKSがどのように関係するかについて話します。
Generative AIの概要と進化


では、始めましょうか。re:Inventの4日目だったら、Gen AIの概要をもう一度説明することは控えたかもしれませんが、まだ2日目なので手短に説明しましょう。Gen AIは、この1年間で物語を書いたり、ミュージックビデオを制作したり、会話を生成したり、さらにはコードを書いたりする能力で私たちの想像力を捉えてきました。しかし、Gen AIに触れる前に、一歩下がって最初から始める必要があります。AIとは単純に、これまで人間の知能を必要としていたことをコンピューターが再現する能力のことです。


次のレベルでは、機械学習があります。これはAIのサブセットで、明示的に指示されることなくタスクを再現できるようにAIを自動化することです。ここで最も一般的な例として思い浮かぶのは、お気に入りのストリーミングプラットフォームが次に見るべきコンテンツをおすすめしてくれることでしょう。そして、ディープラーニングに到達します。これはさらに機械学習のサブセットで、人間の脳にインスパイアされています。ここでの一般的なタスクには、画像認識や音声認識が含まれます。機械学習が顔を認識できるのに対し、ディープラーニングはそれがあなたの顔であることを識別できます。



そして、生成AIに到達します。Gen AIは、既存のコンテンツを取り込み、新しいオリジナルのコンテンツを生成する機械の能力です。この1年間で話題になったGen AIについて、突然現れたのではないかと思うかもしれません。なぜ今なのでしょうか?実際には、その種は何十年も前からあり、ここ数年で可能になった重要な発展がいくつかあります。まず、データの増加とそれを効率的に保存する能力です。WikipediaやRedditのようなソースが膨大な量のトレーニング入力を提供しています。次に、クラウドコンピューティングがあり、巨大なGPUインスタンスのクラスターをスピンアップする能力を提供しています。
これは、自社のデータセンターに多額の先行投資をすることなく、ジャストインタイムで行うことができます。ここ数年で、生成AIを実現するのに本当に役立ついくつかの重要な機械学習の革新がありました。ここ数年だけでの規模の感覚を掴んでいただくために、2019年には最大のBERTモデルは約3億パラメータのサイズでしたが、今日の最先端の大規模言語モデルは約5,000億パラメータです。これらの機械学習の革新に基づいてトレーニングできるモデルのサイズが1500倍以上増加しています。


一般的に、生成AIのユースケースは3つの大きなカテゴリーに分類されます。1つ目は、カスタマーエクスペリエンスの向上です。おそらく最も一般的に思い浮かぶのはチャットボットでしょう。チャットボットは必ずしも新しいものではなく、何年も前から存在していましたが、以前はルールベースで、維持が複雑で、しばしば会話らしさに欠けていました。生成AIベースのチャットボットは、はるかに迅速に開発でき、ユースケースに対してより汎用的で、しばしば人々はボットと話していることに気づかないほど会話らしく聞こえます。


次は従業員の生産性向上についてです。ほとんどの方がステータス文書を書くのを好まないと思います。例えば、Generative AIアシスタントを使用して、メールやSlackのメッセージを確認し、上司向けのステータスレポートを自動生成することができます。コード生成も多く耳にする話題の一つです。アシスタントが面白くない定型的なコードを処理してくれるので、より興味深いコードの作成に集中できます。 そして最後に、従業員の生産性向上と似ていますが少し異なる点として、ビジネスプロセスの改善、テキスト抽出、文書処理などがあります。


さて、ここでGenerative AIに関する観客参加型のチャレンジを行います。これらの画像の一つは標準的なAdobe stock photoで、もう一つはAdobe Fireflyで生成されたものです。挙手で答えてください。左側の画像が生成されたものだと思う人は?約半々ですね? 左側の画像がAdobe Fireflyを使用してその入力で生成されたもので、右側が標準的なAdobe stock photoです。まだ初期段階ですが、Johnが言うように、彼らは常にモデルの改善に取り組んでおり、時間とともに生成された画像と標準的な実際の写真との区別がますます難しくなるでしょう。


では、Amazon EKSがGenerative AIワークロードの実行にどのように役立つかについて説明しましょう。 まず、従来の機械学習モデルとGenerative AIモデルの違いについて話したいと思います。従来のモデルでは、多くの場合、手動でのラベル付けやデータ収集に数ヶ月の高額な先行投資が必要です。そして、そのデータセットを使用して、非常に特定のタスクのためにモデルをトレーニングします。Generative AIでは、基盤モデルと呼ばれるものをトレーニングします。これは大量のラベルなしデータ、つまりモデルに投入できる生データでトレーニングでき、多くのタスクで一般的に良好なパフォーマンスを発揮する基盤モデルを出力します。その後、そのモデルを特定のユースケースに合わせて微調整できますが、ラベル付きデータと比較してはるかに少ないデータ量で済みます。従来のモデルとの主な違いは、Generative AIモデルを使用する場合、新しいユースケースごとにゼロから始める必要がないということです。
EKSを活用したGenerative AIワークロードの実装



Generative AIに関連する課題は、従来のモデル以上にスケールが大きくなります。なぜなら、前述のように、これらの基盤モデルをトレーニングするために膨大な入力を使用する可能性があるからです。Kubernetesを使用する場合、そのスケールを処理するためにノードを自動プロビジョニングできるものが必要です。また、クラスター内の数百、場合によっては数千のノードを処理できるコントロールプレーンも必要です。 スケールの大きさのため、特に基盤モデルの場合、トレーニングジョブを単一のノードに収めることはできません。数千のインスタンスを実行する可能性があり、そのデータをクラスター全体に効率的に分割して分散させる方法が必要です。

そして、障害を減らしたいと考えます。数千のGPUインスタンスを扱う場合、ハードウェアの障害は避けられません。その影響を最小限に抑えたいものです。一般的に、大規模分散トレーニングのためのEKSの焦点は、 MLに使用できるすべてのAWSのコンピューティング、ストレージ、ネットワークプリミティブへのシームレスなKubernetes nativeな統合を提供することです。EKSコントロールプレーンは自動的にスケールします。多数のインスタンスを実行している場合、私たちはバックグラウンドでスケールします。r5.24xlarge インスタンスを5つ実行しているかもしれません。クラスター内に数百のノードを実行している場合でも、私たちは同じ1時間あたり10セントを請求します。これは、自前でクラスターを構築しようとするよりもはるかにコスト効果が高いでしょう。
また、NVIDIA や昨年リリースされた Amazon の Trn インスタンスなど、様々な EC2 アクセラレーテッドインスタンスとすぐに使える、アクセラレーテッド AMI も提供しています。ストレージ面では、様々な AWS ストレージサービスと統合するための Kubernetes ネイティブドライバーを構築しています。大規模なトレーニングによく使われているのが FSx for Lustre です。ネットワーキング面では、トレーニングに使用できる EC2 ネットワーキングコンポーネントと統合するプラグインを構築しています。ここで注目すべきは Elastic Fabric Adapter で、これはノード間の高帯域幅通信用に設計された特殊な EC2 ネットワークインターフェースです。EFA と EKS を使用することで、オンプレミスの HPC クラスターのパフォーマンスを、AWS のスケーラビリティと柔軟性とともに実現できます。




次に推論に移ります。構築したすべてのモデルが成功するわけではありませんが、成功したモデルは本番環境で使用し、ユーザーに予測を提供したいと思うでしょう。ここでもスケールは課題となります。ただし、これは異なるタイプの課題です。ユーザーの需要に応じてスケールアップとダウンを行う必要がある従来のワークロードのスケーリング課題に近いものです。パフォーマンスも非常に重要です。推論はユーザーの実際のパスに含まれる可能性があります。遅い予測によって良好なユーザーエクスペリエンスが損なわれることは避けたいものです。そしてコストは特に重要です。これは成功したアプリケーションの場合、長期間にわたって実行する可能性があるためです。比較的成功したモデルがあれば、微調整のためのトレーニングは時々行うだけで済むかもしれませんが、コストの最大90%は推論から生じる可能性があります。

では、EKS はここでどのように役立つのでしょうか?今年の EKS のブレイクアウトセッションで Karpenter に言及しないわけにはいきませんね。Karpenter をご存じない方のために説明すると、これは数年前にオープンソース化したプロジェクトです。高性能で柔軟な Kubernetes のノードオートスケーリングのために設計されています。従来の Kubernetes のノードオートスケーリングでは、コンピュートを事前に定義します。「ノードグループ A にはこれらのインスタンスタイプ、ノードグループ B には別のインスタンスタイプ」というように指定するかもしれません。クラスター内で何百ものノードグループを実行しているお客様もいますが、これは管理が非常に難しく、AWS のコンピューティングオファリングを十分に活用するのも困難です。
Karpenter はこのパラダイムを変えます。すべてを事前に定義する代わりに、Karpenter に制約のセットを提供します。これは具体的にも広範囲にも設定できます。そして Karpenter にワークロードの要件を見てもらいます。例えば、X 個の GPU が必要な場合、Karpenter が直接 EC2 API を呼び出して、ワークロードに適したジャストインタイムの適切なサイズのコンピュートを提供します。正直なところ、ML のユースケースを念頭に置いて Karpenter を構築したわけではありません。しかし、特に推論に関しては、従来のウェブアプリケーションに似ているため、Karpenter がこのケースにとてもよく機能することがわかりました。
AdobeのGenerative AI戦略:Fireflyの事例


さて、今後はどうなるでしょうか?満足していますか?いいえ、もちろんそうではありません。私たちは不満足な顧客を好みます。それが私たちのイノベーションを促進するからです。これからも新しい AWS インフラストラクチャ機能との統合を続けていきます。実は、このスライドは少し古くなっています。昨晩、S3 用の CSI ドライバーを発表したばかりです。S3 は今年初めに Mount Point というテクノロジーをオープンソース化しました。これを使用すると、S3 バケットを EC2 インスタンスにマウントし、ローカルファイルシステムコマンドを使用して自動的に S3 オブジェクト API コールに変換できます。CSI ドライバーを使用すると、S3 への Kubernetes ネイティブなインターフェースが得られます。カスタムアプリケーションコードを書いたり、バケットをマウントするための特別な権限を持つ必要はありません。CSI ドライバーがそれを行います。EKS と S3 を組み合わせると、EKS アドオンとして利用できます。
EKSとS3を組み合わせると、数千のインスタンスにまたがってペタバイト規模のデータを処理でき、S3のスケーラビリティと高スループットの恩恵を受けることができます。私たちはこれにとてもワクワクしています。ぜひ発表内容をチェックして、詳細を学んでいただくことをお勧めします。

私たちは、特にMLのためにKarpenterに力を入れています。これは、多くのお客様がMLワークロードにKarpenterを使用していると教えてくれたからです。ここで強調したい機能の1つは、EFAのネイティブサポートです。プルリクエストがまだマージされていなければ、間もなくマージされるでしょう。Karpenterの1、2回のリリース後には、EFAのネイティブサポートが実現するはずです。つまり、ポッドがEFAインターフェースを要求すると、Karpenterがそれを認識し、インスタンスを起動する際に必要なEFA設定インターフェースを自動的にセットアップします。

パフォーマンスと回復力は、マーケティングの観点からは最も魅力的なトピックではないかもしれませんが、私たちは常に投資を続けていく分野です。ここで注目したいのは、コンテナイメージの遅延ロードです。MLにおいて、コンテナイメージが数十ギガバイトに及ぶお客様とよく話をします。50ギガバイト、さらには数百ギガバイトのイメージも聞いたことがあります。インスタンスを起動すると、インスタンスは30秒で立ち上がりますが、イメージのダウンロードに10分待たされるのはフラストレーションがたまります。
AWSは今年初めにSeekable OCIというテクノロジーをオープンソース化しました。これは現在でもEKSで使用可能ですが、動作させるにはかなりの設定が必要です。来年のロードマップの1つは、このテクノロジーをEKSでより簡単に使えるようにすることです。これは特に、MLワークロードで迅速にスケールアップしたいが、大きなコンテナイメージがある場合に役立ちます。トレーニングジョブを開始する前に、そのすべての時間を待つ必要がなくなります。
最後のポイントですが、これが最も重要だと私は考えています。それは、MLとEKSが単純に動作するべきだということです。EKSをML作業負荷に使用する際、最高のパフォーマンスと柔軟性を得るために特別な設定をする必要はないはずです。実は、このスライドは少し古くなっています。数週間前から、EKS accelerated AMIは既にEC2 P-5インスタンスで動作する最新のNVIDIAドライバーをサポートしています。
Adobeの開発者プラットフォーム「Ethos」の進化

素晴らしいですね。では、実際に誰がGenerative AIとEKSを使用しているのでしょうか?ここでいくつかの顧客を紹介します。まず中央から始めましょう。ここには基盤モデルのトレーニングにEKSを使用している顧客がいます。これらは膨大な量のデータでトレーニングを行うため、最大規模で運用している顧客です。RamaがAnthropicについて言及しました。今朝のAdamの基調講演をご覧になった方は、彼らのCEOが登壇していたのをご覧になったでしょう。彼らはすべてのトレーニングにEKSを使用しています。ClaudeモデルのトレーニングにEKSを使用しているのです。
下の層には、EKS上に独自のGen AIプラットフォームを構築している顧客がいます。これは出発点として選択できるかもしれません。Kubernetesライクな体験でGen AI作業負荷を実行するためのより簡単なインターフェースになるでしょう。そして上の層には、消費者向け製品を構築しているEKSの顧客がいます。彼らはMLやGen AI作業負荷をサポートするためにEKSプラットフォームを拡張しています。もちろん、ここで強調したいのはAdobeですが、私から説明する必要はありませんね。代わりに、Johnに引き継いで、彼らがどのようにGen AI作業負荷をサポートするためにEKS環境を拡張したかについて話してもらいましょう。
ありがとう、Mike。今日は、AdobeがAIの力をユーザーに提供する方法についてお話しできることをとてもうれしく思います。これがAdobe Fireflyです。

Ethosを活用したアプリケーションデプロイメントの実際



Adobe Firefly では、 クリエイティブな専門家から私の10代の娘まで、誰もが想像したコンテンツを単に説明するだけで作成し、操作できるようにすることを目指しています。私たちは、Firefly を含む様々な AI 機能を全てのクラウドに統合し、これらの製品や機能を組み込むことで、ユーザーが Adobe の魔法のような体験をできるようにしています。

Adobe では、製品を市場に出すのは難しい場合があります。開発者によっては、ゼロから「Hello World」まで最大30日かかることもあります。この過程には、observability やソース管理などのツールへのアクセス権を得るためのチケット発行、新しいクラウドアカウントの作成、コーディング、統合テスト、デプロイメントなどが含まれます。一方、チケットを処理する側は、実際のニーズを誤解していることが多く、数多くの質問をします。そして、これら全てが終わった後でも、適切なモニタリングの設定、バックアップ戦略の定義、火曜日の午前2時の緊急事態に対するインシデント管理の確立など、本番環境の準備に関する懸念が残ります。

私はデベロッパープラットフォームグループの一員で、私たちのモットーはシンプルです:開発者がより良いソフトウェアをより速く書けるよう支援することです。この複雑な状況を開発者にとってシンプルにするために、私は抽象化とプラットフォームを信じています。開発者のために単純化し、しばしば過度に単純化する必要があります。また、私たちよりも優れたスケールで管理・運用できるAWSのようなクラウドプロバイダーにも感謝しています。これらの原則が交差するところに、図の下部の青いボックスで示されているAdobe Internal Developer Platformがあります。
AdobeのGenerative AI開発における課題と今後の展望

Adobeでは、2016年に構築された開発者プラットフォームの中核をEthosと呼んでいます。当初はMesosで構築されましたが、間違った技術に賭けていたことに気づいてすぐにKubernetesに移行しました。Ethosの目的は、開発者がクラウドインフラのスケール運用、CICDパイプラインの作成、セキュリティとコンプライアンスの管理、コスト効率の対応などを心配する必要がないように機能を提供することです。開発者は、これらの決定を自分に代わって入力なしで行うプラットフォームを望んでおり、Ethosはこれらの目標をすべて達成しています。

当初、私たちはEC2ノード上でKubernetesを実行していましたが、スケールでのETCDの管理、レート制限、APIサーバーの遅延などの課題に直面しました。これらの問題に対処するため、すべてのEC2ベースのクラスターをAmazon EKSに変換するプログラムを開始しました。予想通り、EKSは私たちのAWS EC2 Kubernetesセットアップよりもコスト効率が高く、はるかに信頼性が高いことがわかりました。

チームが生成AIプロジェクトなどのアイデアを持ってくると、経営陣は通常すぐに実装を望みます。Adobeにとってこの分野は重要度が高いため、開発者と会社が安心できる、最初から正しく実装できるソリューションが必要でした。また、顧客体験を理解する必要があったため、開発者は分散トレーシング、Prometheus、ログ取り込みなどのツールを使用して、顧客が期待する世界クラスの体験を提供していることを確認します。生成AIのような製品やサービスについては、選択は明確でした:Ethosの上に構築し、抽象化の力を活用して開発とデプロイメントを効率化します。

抽象化とプラットフォームの良さは分かりました。 では、例えばFireflyのようなプロジェクトはどのようにアプリケーションをデプロイするのでしょうか?Adobeでは、Argoを活用したGitOpsを採用していますが、まず通常はこのような画面でブートストラップを行います。私たちは、先ほど言及したすべての統合を容易にするAdobe Service Runtimeと呼ばれる一連のライブラリと機能を提供しています。オンボーディングセクションでは、どのクラスターにデプロイしたいか、必要な環境の数、コンテナのサイズと数など、簡単な質問をします。その後、リポジトリ内に基本的なGitHub appをインストールするプロセスを案内し、これによってすべてのhelmチャートとワークフローが作成され、動作するCI/CDワークフローが構築されます。

アプリケーションが実際にデプロイされオンボーディングされると、DNSエントリーなどを作成します。開発者が本番環境に移行するために必要なすべてのもの、つまり名前空間なども作成します。 Adobeの開発者にとって、本番環境とはこの画面のことです。この画面で、開発者はランタイムを確認できます。その画面では、Argo Syncのステータスやアプリケーションの健全性などが表示されます。また、名前空間の情報も得られます。そのため、開発者が腕まくりをしてデバッグに取り組む必要がある場合、自分の名前空間にどのようなイメージがデプロイされているかも把握できます。そして幸いなことに、この開発者はPrometheusをインストールしてメトリクスを収集し、長期保存用に送信することを決めています。1つの画面で、開発者が必要とするすべての関連情報が得られるのです。

統一された開発者プラットフォームがあれば、すべてが簡単になるのは明らかですよね?実はそうでもありません。GPUの入手はいまだに困難です。コードの出荷準備ができていても、そのコードをデプロイするためのハードウェアがない可能性があります。また、私たちが有名なのは、Kubernetes APIを乱用する傾向があり、AWSの友人たちからレート制限をかけられがちなことです。最後に、コンテナの起動時間の問題があります。残念ながら、このタイプのコンテナはかなり大きく、数秒や1分以内には起動しません。そのため、スケーリングが非常に難しくなります。
では、私たちは何をしたのでしょうか?まず、AWSのパートナーと協力して、generative AIのようなアプリケーションをデプロイするための供給準備を整えました。次に、Amazonのエキスパートに電話で相談し、Kubernetes APIの使用状況を確認してもらい、少し叱られながら、私たちが興味を持っているメトリクスをより良い方法で取得する方法を教えてもらいました。最後に、シンプルに保ちました。依存関係をローカルに保ち、アプリケーションの起動時間を最適化しました。これは驚くほど効果があります。スケーラビリティに関しては、EKSにアプリケーションをデプロイする際の利点は、コントロールプレーンについて考える必要がないことです。初日にそれを正しく設定すれば、インシデントは発生せず、美しくスケールします。

Adobeはどこに投資しており、その投資からどのようなリターンを得ているのでしょうか?私のレベルで最初に見るメトリクスは、クラスターと運用者の比率です。つまり、デプロイするインフラストラクチャを管理するのにどれだけの労力が必要かということです。EKSに移行したことで、この比率を10対1から30対1以上に改善できたことを嬉しく思います。次に、自社開発のCI/CDパイプラインを廃止し、generative AIのような新しい特殊なユースケースにはるかに柔軟に対応できるArgoを全面的に採用する予定です。最後に、開発者にとってのフリクションをさらに減らす必要があります。開発者が行く場所を減らすことで、彼らの生産性と満足度が大幅に向上し、より高い速度を達成できるでしょう。

次は何でしょうか?先月のMaxの発表をご覧になった方もいると思いますが、これらの機能を拡張していく予定です。Firefly Audio、Firefly Video、Firefly 3D Modelsなどです。Ethosサイドでは、年明け近くに予定されているEC2コントロールプレーンの廃止パーティーを本当に楽しみにしています。残念ながら、GPUは依然として不足しています。そのため、推論用にInferentia 2シリーズの検討をAmazonのパートナーと進めています。最後に、私は常に挑発的な質問をするよう心がけています。皆さんにもそうすることをお勧めします。「誰か、または何かが、私よりもこれをうまくやっているのだろうか?」と。そのため、オープンソースソリューションやマネージドソリューションを引き続き検討し、選択肢を探っていきます。最後に、こう言って締めくくらせていただきます。単一のURLの力を過小評価しないでください。

ありがとうございます。
MLワークロードのためのJARKスタックの導入


John、ありがとうございます。今日はかなり明るい展望を描いてきましたが、Kubernetesで機械学習を実行することには課題がないわけではありません。Kubernetesは機械学習を念頭に置いて設計されたものではありません。DeploymentやStatefulSetなどのKubernetesネイティブな構成要素は、アプリケーション開発者にとっては理にかなっており、簡単に採用できます。しかし、ML科学者にとっては、これらは馴染みのない概念です。私たちには、彼らが慣れ親しんだ環境で作業しながら、Kubernetesネイティブな構成要素を簡単に利用できるような新しい抽象化レイヤーが必要です。

多くの顧客が従っている一般的なパターンは、Johnが言及していたものとそれほど変わりませんが、カスタムツールを使って迅速に市場に投入できる生成AIの製品やモデルの構築から始めます。その生成AI製品の有効性が実証されると、一歩下がって、今後何年にもわたってスケールアップできる標準化されたエンドツーエンドのMLプラットフォームの構築を検討します。私たちの顧客が通常取るアプローチは、Kubernetesをその得意とするインフラストラクチャのプリミティブの管理に使用しながら、オープンソースソリューションを活用することです。ネイティブなKubernetes統合を提供するML向けソリューションが豊富に存在し、既存のKubernetesクラスターで追加コストなしにML固有の機能を、Kubernetesとの緊密な統合とともに実現できます。

先ほど述べたように、ML関連のソリューションは非常に多岐にわたっており、多くの顧客が標準的なスタックや、AWSが推奨するより標準化された方法でエンドツーエンドのML機能を実現する方法についてのガイダンスを求めていました。そこで私たちが考案したのが、JARKスタックと呼ばれるものです。これはJupyter Hub、Argo、Ray、Kubernetesの頭文字を取ったものです。これら3つのツールを組み合わせることで、エンドツーエンドのMLスタックを形成し、Amazon EKS内でMLプラットフォームを構築・拡張するために必要なML機能を提供します。

Jupyter Hubは、データサイエンティストにとってモデルの実験や開発のための馴染みやすいインターフェースを提供します。Argo workflowsは、MLタスクの管理に必要なML固有のワークフローをすべて処理します。Rayは、モデルの並列処理のオーケストレーションを担当し、モデルから推論を提供するためのエンドポイントを提供します。ご興味があれば、このスタックのブループリントをご用意しています。これはTerraformモジュールで、ダウンロードして単一のTerraform applyコマンドで完全なスタックをエンドツーエンドでデプロイできます。また、EKSクラスターにこのスタックをデプロイする方法を段階的に説明したブログも用意しています。
もしもっと詳しく知りたい方は、今日の午後5時30分にMGM GrandのCON404で行われるハンズオンワークショップにご参加ください。そこでは、EKSクラスターの作成、私たちのblueprintを使用したJARKスタック全体のデプロイ、Hugging Faceから独自のstable diffusionモデルのダウンロード、そのファインチューニング、そしてファインチューニングされたモデルからの推論の取得について、順を追って説明します。さらに学びたい方は、ぜひチェックしてみてください。
Data on EKSプロジェクトとGenerative AIの未来

昨年後半、多くのお客様が、特に本日お話しした、データ分析、データストリーミング、AI/MLなどのデータワークロードにEKSを採用したいと考えているのを目にするようになりました。そこで、Data on EKSという新しいプロジェクトを立ち上げました。これは、これらのデータワークロードに特化したblueprint、ベストプラクティス、ガイダンスを提供し、お客様がEKS上にこれらを簡単にデプロイできるようにするものです。

私たちはこれを略してDoEKSと呼んでいます。これはData on EKSの略です。simple Terraform applyで全てのスタックをデプロイできるTerraform blueprintを提供しています。
これらのスタックには、EKS上のApache Flink、EKS上のJARK、EKS上のApache Sparkなど、様々なデータ分析やデータストリーミングソリューションが含まれています。私たちのウェブサイトをチェックし、GitHubで私たちとやり取りしてみてください。これらのワークロードにKubernetesやEKSを採用することに興味がある場合は、アカウントチームに連絡してください。彼らがあなたの地域のコンテナスペシャリストを紹介してくれるでしょう。スペシャリストは、DoEKSからどのスタック、ソリューション、またはblueprintを活用できるかについて、会話を通じてガイドし、議論することができます。


連絡を取りたい場合は、私のDMはいつでも開いていますし、LinkedInでも連絡できます。DoEKS blueprintについて説明し、それらの採用方法についてのガイダンスとベストプラクティスを提供するために、いつでも皆さんとの通話に応じる用意があります。 プレゼンテーションの終わりに近づいてきましたので、いくつかの要点を手短に共有し、 EKS上で生成AIをデプロイし、それを成功裏に採用している既存のお客様からの引用をご紹介したいと思います。

これらの顧客の声のハイライトを見ると、顧客が得られた利点やメリットのほとんどは、開発の労力と時間を削減しながらコストを最適化することに関連しています。それでは、ここからポイントをまとめていきましょう。 まず、EKSは市場投入までの時間を短縮します。これは、プラットフォームに組み込まれた多くの機能を再利用できるためです。インフラストラクチャの基本要素の管理に注力するのではなく、それらを抽象化し、代わりに独自のMLモデル開発とビジネスの中核的価値のより迅速な提供に集中できるのです。


次に、既存のプラットフォームを使用することでコストを削減できます。一から再構築したり車輪の再発明をしたりするのではなく、必要なML固有の機能を実現するためにプレミアムを支払う必要のないオープンソースソリューションを多く使用しています。最も重要なのは、EKSでは私たちがコントロールプレーンを管理することです。 これにより、自己管理型のKubernetesよりもはるかに大規模にスケールすることができます。

最後になりましたが、先ほど述べたように、Data on EKSは、エンドツーエンドのMLスタック、データ分析スタック、データストリーミングスタックをより簡単にデプロイする方法を提供するために立ち上げたプロジェクトです。これらを活用して、あなたの旅路を加速させることができます。以上で、このセッションは終了です。 お時間とご注目いただき、ありがとうございました。アンケートにぜひご協力ください。皆様からのフィードバックは、私たちのコンテンツの微調整に大変役立ちます。
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion