re:Invent 2023: AmazonのAgents for Bedrockで生成AIアプリ開発を簡素化
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - Simplify generative AI app development with Agents for Amazon Bedrock (AIM353)
この動画では、Amazon BedrockのシニアマネージャーであるHarshal Pimpalkhuteが、Agents for Amazon Bedrockの魅力を紹介します。Foundation modelの能力を拡張し、APIの操作や情報検索を自動化するAgentsの仕組みや、Athene HoldingsでのETLプロセス改善事例が語られます。さらに、エージェントを使ってエージェントを作成するデモなど、最新のAI技術の可能性を垣間見ることができます。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
Amazon Bedrockとagentsの概要:セッション導入

みなさん、こんにちは。このセッションへようこそ。本日はご参加いただき、ありがとうございます。私はAmazon Bedrockのシニアマネージャー・プロダクトのHarshal Pimpalkhuteです。今日はAmazon Bedrockとagentsについてお話しします。Mandalay Bayまでお越しいただき、渋滞を乗り越えてご参加くださり、本当にありがとうございます。
本日は、AWSのプリンシパルマシンラーニングアーキテクトのMark Royも同席しています。そして、ゲストスピーカーとしてAthene HoldingsのCTOであるShawn Swanerにもお越しいただきました。Shawnさん、このセッションに参加していただき、ありがとうございます。
本題に入る前に、Bedrockの概要を簡単にご紹介したいと思います。この数日間で多くの発表がありました。generative AI全般、そしてBedrockにとって、これは非常にエキサイティングな時期です。Bedrockでは、generative AIアプリケーションの構築とスケーリングを非常に簡単にすることを目指しています。その目標を達成するために、私が呼ぶ3つのレイヤーそれぞれに機能を提供しています。
モデルの選択肢については、いくつかのモデルをローンチし、評価機能を提供しました。次に、fine-tuning、continued pre-training、retrieval augmented generationによる新しいカスタマイズ機能と、ランク機能を簡素化するAPIを提供しました。今日の議論の焦点は、モデルの選択、カスタマイズ、統合という3つのレイヤーにわたる統合になります。

今回はagentsに焦点を当てます。ご存知かもしれませんが、agentsは基盤モデルを拡張して実際に何かを行うのに役立ちます。agentsについて、そのユースケース、そしてAtheneが自社の環境でどのようにagentsを使用したかについてお話しします。大まかな議題としては、簡単な紹介の後、Markがagentsの調整と構造について話します。そして、デモを行い、ShawnにAtheneの環境でのagentsの使用方法について話してもらいます。

これから数分間で、盛りだくさんの内容をお話しします。ただし、Q&Aの時間も確保したいと思います。もし全ての質問に答えられない場合でも、セッション後にMarkと私がこの場に残って、皆さまの質問にお答えしますので、ご安心ください。
Agents for Amazon Bedrockの目的と機能
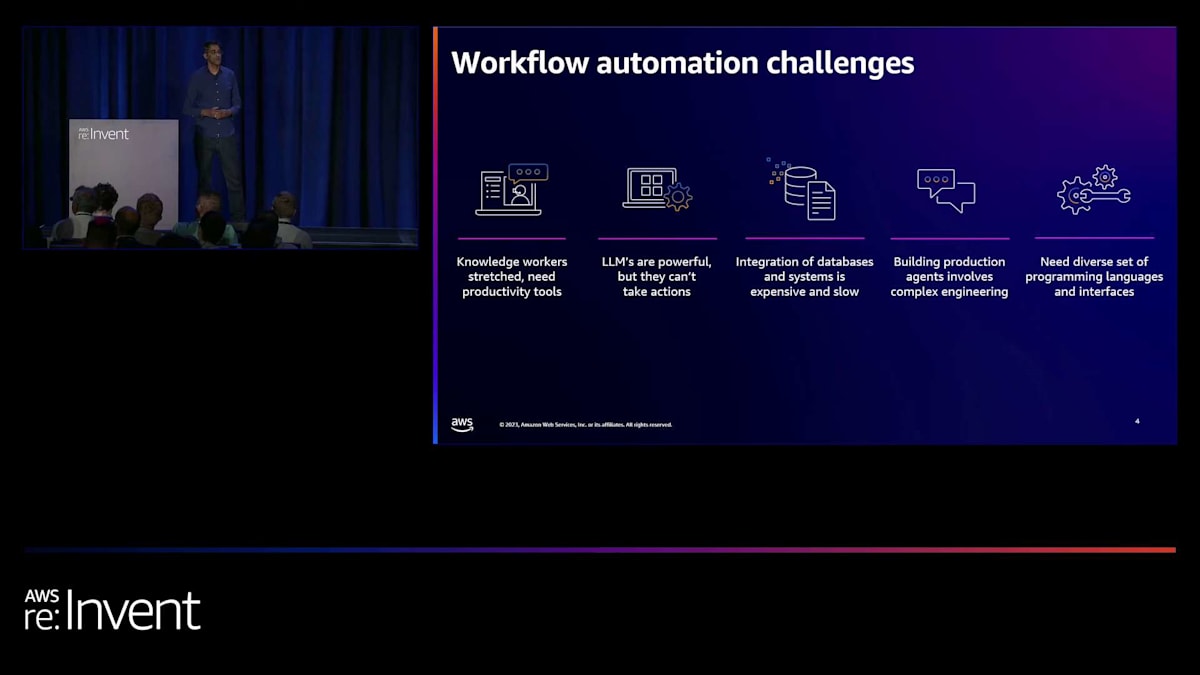
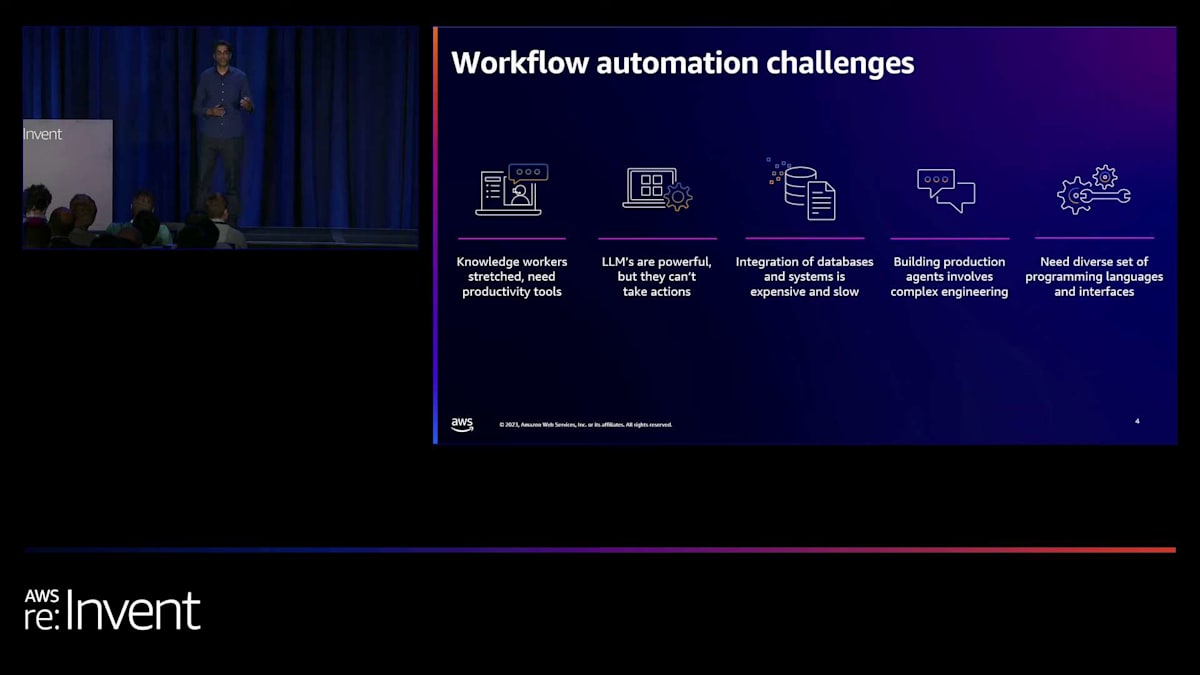
それでは、本題に入りましょう。Foundation modelはユーザーとのインタラクションに優れています。私たちは皆、その会話能力をよく知っています。さらに、これをカスタマイズして、企業のデータソースを参照し、ユーザーの質問に答えることもできます。 しかし、agentの出番はここからです。Foundation modelの能力を拡張し、実際にタスクを実行させることができるのです。これには、APIの操作、情報の検索、そしてユーザーが要求したタスクを完了するための機能拡張が含まれます。
現在、これを実現しようとする際の自動化の課題には、プロンプトを作成し、オーケストレーションができるようにプロンプトエンジニアリングを行うためのコードを大量に書く必要があります。さらに、Lambda関数を通じてAPIを呼び出すために、企業のシステムと統合する必要があります。そして、agentがインタラクションの一部としてユーザーの質問に答えられるよう、情報ソースを接続する必要もあります。

私たちはこれらの問題に取り組み、Agents for Amazon Bedrockを作成しました。目標はシンプルでした:開発者から自然言語の指示を受け取り、裏側で思考連鎖プロンプティングを適用し、オーケストレーション用に最適化されたカスタムプロンプトを作成することです。そしてこれらすべてを安全かつプライベートに行い、企業向けのシステムを提供することです。
これから数枚のスライドで説明したいことがいくつかあります。私たちの目標は、このオーケストレーションを行う際に、制御、可視性、そしてセキュリティを提供することでした。agentを一般提供可能にしたことに加えて、今週初めに、Markが説明するプロンプトエディターと呼ばれるものと、各ステップを確認できる思考連鎖トレースも提供しました。これが制御と可視性の部分で、セキュリティはLambda関数への安全な呼び出しを通じて実現しています。

Amazon Bedrock の Agents は、タスクを複数のステップに分解し、それらのステップを自動化された方法で実行するのに役立ちます。 簡単に触れましたが、要約すると、複数ステップの orchestration を作成します。これは、generative AI アプリケーションの構築とデプロイを簡素化するもので、まさに Amazon Bedrock の基本理念であり目標です。そして、この orchestration のために Bedrock 上に完全マネージド型のインフラストラクチャを提供します。

これから agent の基本について話しますが、次のセクションを担当する Mark を紹介したいと思います。Mark、お願いします。
Agents for Amazon Bedrockの基本的な理解

ありがとう、Harshal。マイクチェックですが、音量は大丈夫そうですね。皆さん、お越しいただきありがとうございます。カンファレンス4日目ですが、4日目の終わりにまだ元気な方はいらっしゃいますか?
はい、一人いますね。よし、始めましょう。これから数分間、Agents for Amazon Bedrock の基本的な理解について説明します。orchestration や、agent が利用できる action group についてお話しします。また、agent の使用用途についても少し時間を割いて説明します。興味深い機能ですが、世界の飢餓問題を解決しようとしているわけではありません。では、何が得意なのでしょうか?それについても話し合いましょう。


では、始めましょう。Agent を使うと、利用可能な action のセットと knowledge base のセットをまとめることができますが、指示を与えることもできます。 つまり、agent を作成し、指示を与え、いくつかの API や knowledge base を利用可能にすると、Amazon Bedrock を内部で使用してリクエストに応答します。次のスライドでは、指示、action、knowledge base の使い方について簡単な例をいくつか紹介します。


ここで簡単な例を紹介します。指示だけを使って、約2分でagentを作成できます。ここでは、ジョークを作るだけの指示を与えています。例えば、「AIが学校に行った理由は?学習率を向上させるためです。」うーん、これはあまり受けませんでしたね。



さて、ここではLLMと連携するagentを使っているだけです。あまり役に立ちませんが、本当の力を発揮するのは、例えば会議アシスタントを作る時です。ここでは、agentが得意とすることについての指示があります。そして、いくつかのアクションを提供します。ここでは、会議に関するアクションがあります。利用可能な会議のリスト、それらの会議からのアクションアイテムの取得、利用可能なユーティリティのセットなどです。メールの送信、チームメンバーのリストの取得などもあります。


このagentに「この会議のアクションアイテムを取得して」と言えば、会議の内容を文字起こしし、LLMを使って要約してくれます。そして「チームに送信して」と言えば、それを実行します。HR(人事)ポリシーアシスタントはどうでしょうか?ここでは、action groupsだけでなく、knowledge basesも使用できることを示しています。
HRポリシーアシスタント:action groupsとknowledge basesの活用例



Adamのキーノートで、Amazon Bedrock knowledge basesが一般提供されることが発表されました。knowledge baseは、完全に管理された形でvector storesとembeddingsモデルを活用する機能です。つまり、ポリシーが記載された文書を指定するだけで、完全に管理されたknowledge baseを持つことができます。これらをagentに組み込むことができます。そうすれば、例えば休暇ポリシーについて知る必要がある場合、「パートタイムに切り替えたら休暇は取れるの?」とagentに尋ねることができます。agentは利用可能なknowledge baseを見つけ、検索を実行し、回答を返すことができます。


action groupsやknowledge basesを使用する必要はなく、それらを組み合わせることもできます。ここでは、HRポリシーアシスタントの別バージョンを紹介します。このバージョンは、そのような情報を検索できるだけでなく、休暇の承認も得られます。ここでは簡単なaction groupがあり、1つのアクションが利用可能で、既存のAPIをバックグラウンドでラップしています。


さて、「年間の休暇はどのくらいありますか?」と尋ねることができます。これはナレッジベースに対する検索を使って判断できます。そして、これは私にとって重要なのですが、12月8日から15日まで休暇を取りたいのですが、許可が下りるかどうか見てみましょう。この場合、実際に既存のAPIを呼び出して休暇を承認することができます。つまり、agentができることを定義し、データベースやすでに存在するAPIをラップするアクションをまとめ、ナレッジベースを組み込む柔軟性があるのです。そして、agentは与えられたリクエストを実行するためのプランを見つけ出す能力があります。
エージェント構築の簡便性とセキュリティ


Harshalが先ほど言及しましたが、私たちのすべてのサービスにおいて、セキュリティは非常に重要です。Agentも非常にセキュアです。IAMロールがあり、個々のアクションやagent、ナレッジベースへのアクセスを拒否したり許可したりできます。そして基本的に、Amazon BedrockはバックグラウンドでLLMを呼び出す方法であり、これも完全にセキュアです。さて、agentを作成するのはどれくらい難しいのかと思われるかもしれません。agentにやってほしい作業のほとんどは、すでにあなたが知っていることです。企業は何十年もの間、マイクロサービスを構築してきました。既存の運用データストアやデータレイクがあり、すべてがそこにあります。

私たちがしているのは、その基盤の上に構築し、それをラップして、agentがそれらを横断的に調整できるようにすることです。ここでは、HR方針のドキュメント、8年前にJavaで構築されたと仮定する休暇マイクロサービス、そして休職データベースがあり、これらは全く統合されていません。agentを構築することができ、そのナレッジベースは完全に管理され、それらの方針ドキュメントを消費します。そして、time off agentを使用すると、そのような質問の答えを見つけられる場所だと知っているので、自動的にそれを検索します。
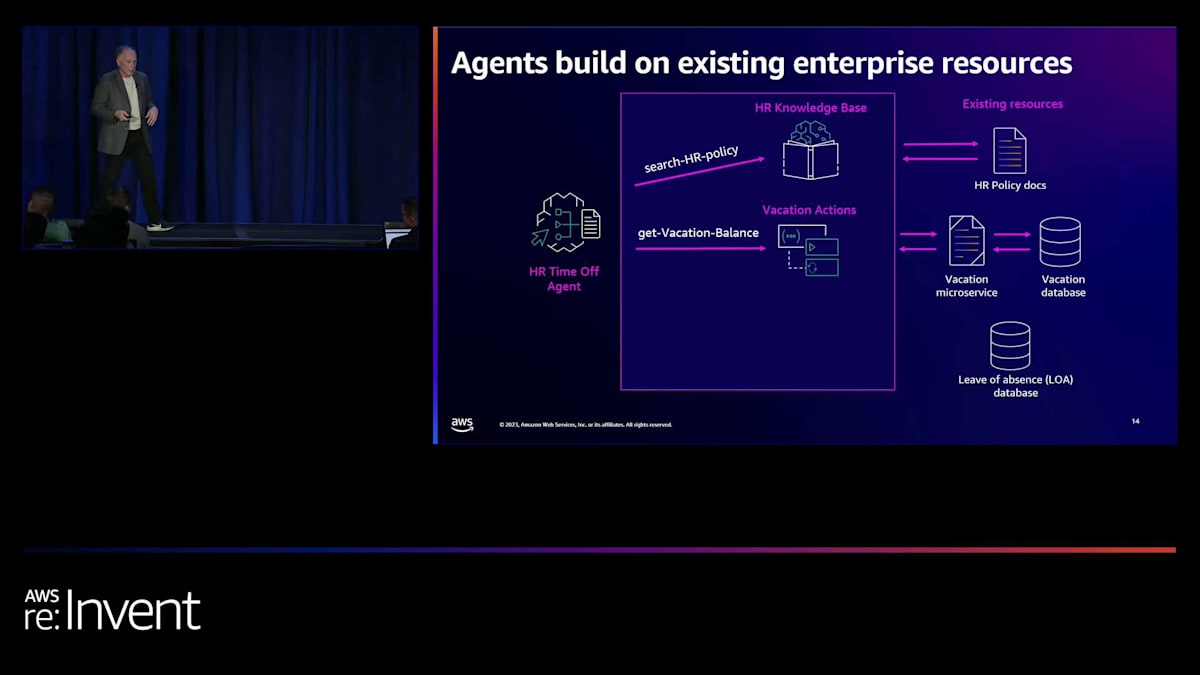

「利用可能な休暇はどのくらいありますか?」と尋ねる場合、それをアクショングループに入れ、会話に関連する時期を説明すると、既存のサービスを使用できるようになります。同様に、サービスが利用できなくても、データベースがあれば、データベースへの単純な検索やこの場合のトランザクションを構築するだけです。つまり、企業リソースを基に、それらをより効果的かつ動的に調整できるように構築しているのです。

さて、どのようなものを構築できるでしょうか?これらはほんの一例で、皆さんがたくさんのアイデアを思いつき、何を構築しているか教えてくれることを期待しています。多くのテクニカルサポート機能がここでの良い候補となります。例えば、私のラップトップはかなり定期的に故障します。そして時々、サポートを受けるのに少し長く待たされることがあります。そこで、私を助けようとしているサポート担当者に何らかの支援を提供し、ラップトップサポートアシスタントを持つのはどうでしょうか?ラップトップの扱い方について説明している既存のWikiを取り、一般的な問題に関するトラブルシューティングガイドを取り、その上にナレッジベースを置くことができます。


ここでいくつかのアクショングループを作成してみましょう。例えば、サポート履歴を引き出すものなどです。これらはどこかに記録されているはずです。ノートパソコンの交換申請を行う方法もあるかもしれません。簡単でしょう?このようなことをすべてエージェントに説明すると、次のような質問ができるようになります。「新しいノートパソコンを注文したけど、どこにあるの?」既存の追跡システムに基づいて、自動的に検索することができます。チケットのトリアージを別の例として挙げてみましょう。サポートポリシーがあり、特定の問題を解決するための人材がいて、スキルプロファイルがあります。チケットのルーティングや分類を支援するアクションを設けることができます。場合によっては、これらを組み合わせて使用することもあるでしょう。ここで重要なポイントが出てきます。エージェントは特定のパスをハードコーディングするものではありません。今日でも、任意の言語で書くことができ、あらゆる種類のカスタムハードコーディングされたアプリケーションを書くことができます。エージェントが得意とするのは、リクエストを受け取り、使用可能なものを確認し、動的に計画を立て、その計画を実行することです。
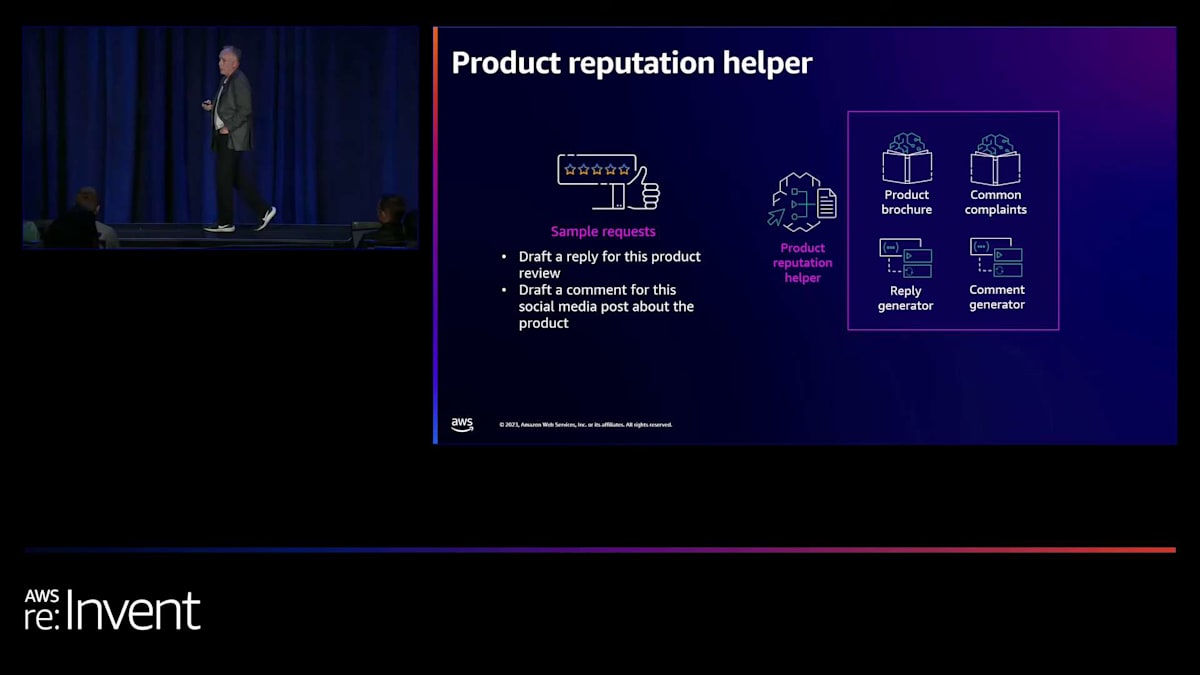
製品評判ヘルパーはどうでしょうか?管理している製品やいくつかの製品があるとします。人々はレビューを書きます。時には良いものもあれば、そうでないものもあります。ソーシャルメディアへの投稿もあるかもしれません。そしてそれらにより迅速に対応したいと考えています。ここでイベント駆動型のものを用意し、エージェントをトリガーして、自動的にそれを取り上げ、LLMやその他の履歴、そして対応すべき方法や対応してはいけない方法に関するポリシーを使用して、自動的に下書きを作成することができます。そしてその下書きを人間に渡し、「はい、これに返信を投稿しましょう」と決定してもらいます。これにより、悪いレビューが3日間放置されるのを見るのではなく、より迅速に対応を行うことができるようになります。


トラクターのメンテナンス、ここにいる人の中でトラクターのメンテナンスをしている人はいますか?冗談ですが、どんなメンテナンス状況でも想像できるでしょう。車の修理マニュアル、グローブボックスに入っている500ページもある大きな車のマニュアルを知っていますよね?そのマニュアルを簡単にナレッジベースに入れて、簡単な質問をすることができます。しかし、それは単なる質問応答ではなく、行動を起こすことです。ここでは修理計算機があります。X、Y、Zを行うのにいくらかかるのかをすぐに知りたいですよね?それをアクショングループの背後に置いて、簡単な計算を行うことができます。LLMを使用していますが、LLMはこれらのことを知りません。そこで、その空白を埋め、LLMの上に本当に実用的なものを提供しているのです。
Athene Holdingsにおけるエージェントの活用事例

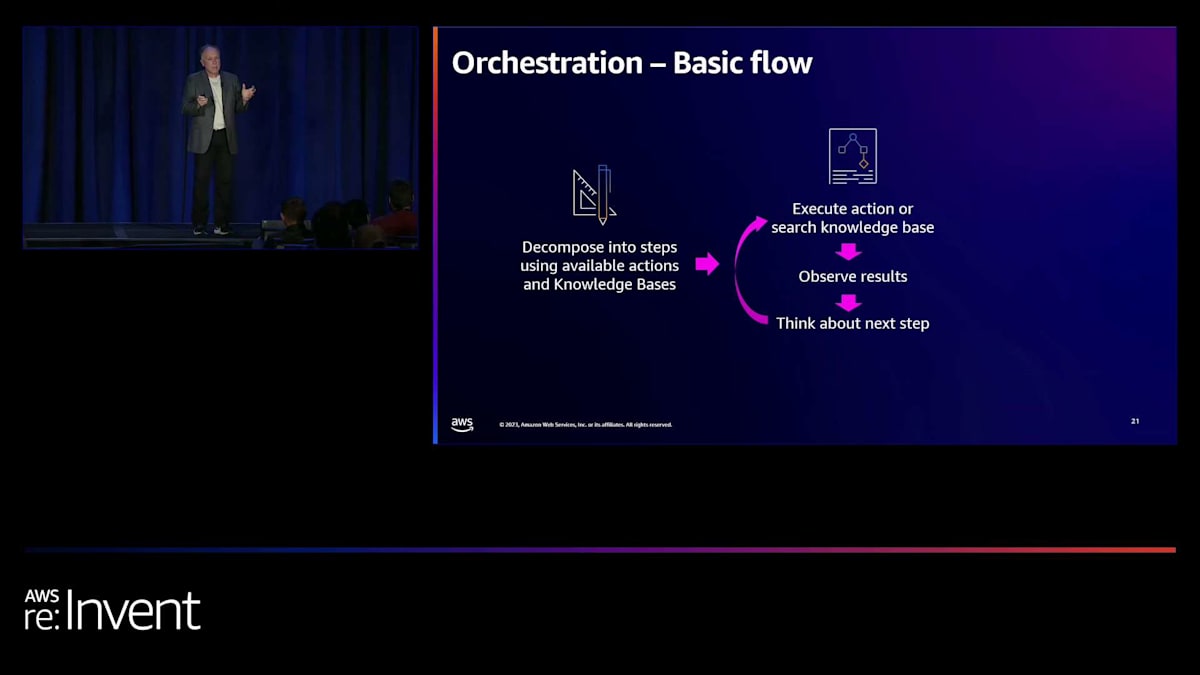
さて、オーケストレーションについて簡単に掘り下げてみましょう。基本的な概念はすでに触れましたが、もう少し深く掘り下げてみたいと思います。これはレベル300のトークですよね、Harshalさん?では、もう少し深く掘り下げてみましょう。まず、高いレベルで言えば、リクエストを与えると、Agents for Bedrockはリクエストを受け取り、利用可能なアクションとナレッジベースのセットを確認し、計画を立てます。これは、SQLエンジンを構築する場合に似ています。誰かがSQLクエリを与え、計画を立てるようなものです。そして実行します。以前にそのような経験がある人もいるでしょう。これがエージェントの行っていることです。計画ができたら、それを実行します。何が起こったかを確認し、少し方向転換したり、軌道修正したりするかもしれません。


そして、次のステップについて考え、良い答えが得られるまで続けていきます。毎回評価を行い、「ユーザーが求めているのはこれで、ここまで進めてきた。これで完了だな」と判断します。そして、その時点で回答を返します。あるいは、「なるほど、良いリクエストだけど、それに対応できるアクションやナレッジベースが本当にないな」と判断して、「申し訳ありませんが、回答できません」と返すこともあります。さらに詳しく見ていくと、誰かがタスクを Bedrock agent に送信すると、Harshal が言及したような、自分でやろうとすると必要になる重労働が行われます。ここで、chain of thought プロンプティングを構築しようとした人はいますか?少し手が挙がりましたね。では、私が何を言っているか分かると思います。

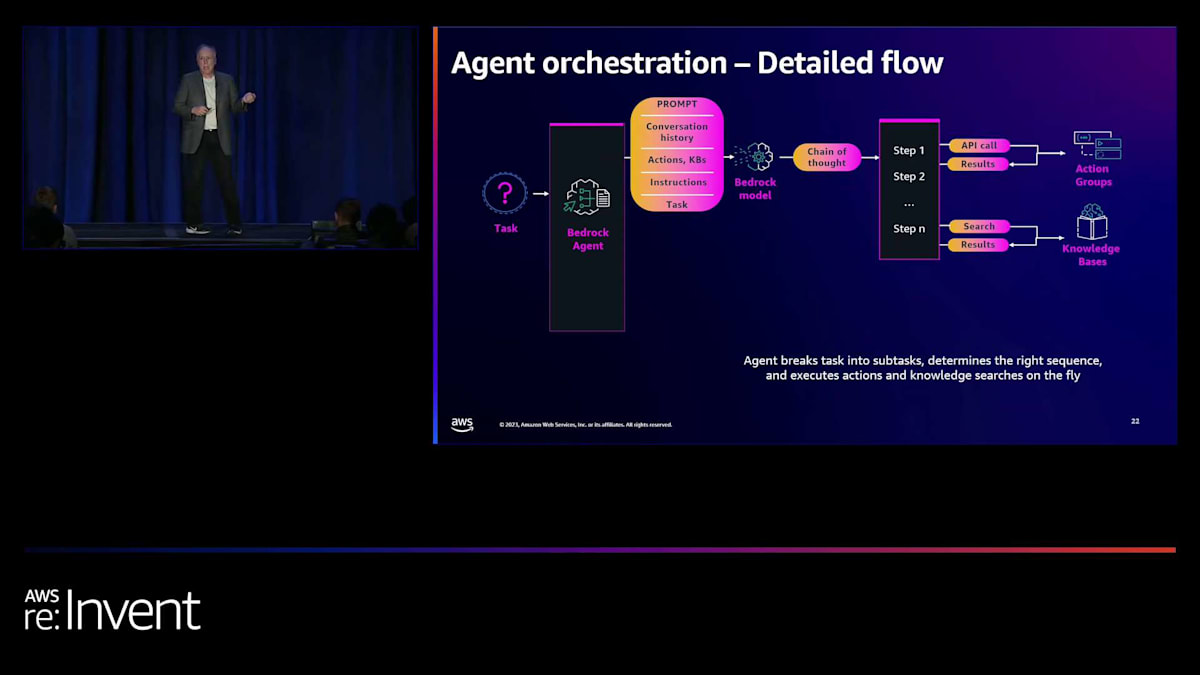
プロンプトエンジニアリングは非常に複雑で、正しく行うのは難しいものです。ここでは、エージェントが自動的に、会話の履歴、アクションの説明、ナレッジベースの説明、提供された指示を考慮に入れたプロンプトを組み立て、そこにタスクも含めています。そして、chain of thought アルゴリズムを使って、ステップの実行を開始します。そのステップには、API 呼び出し、アクショングループの使用、あるいはナレッジベースでの検索が含まれる可能性があります。
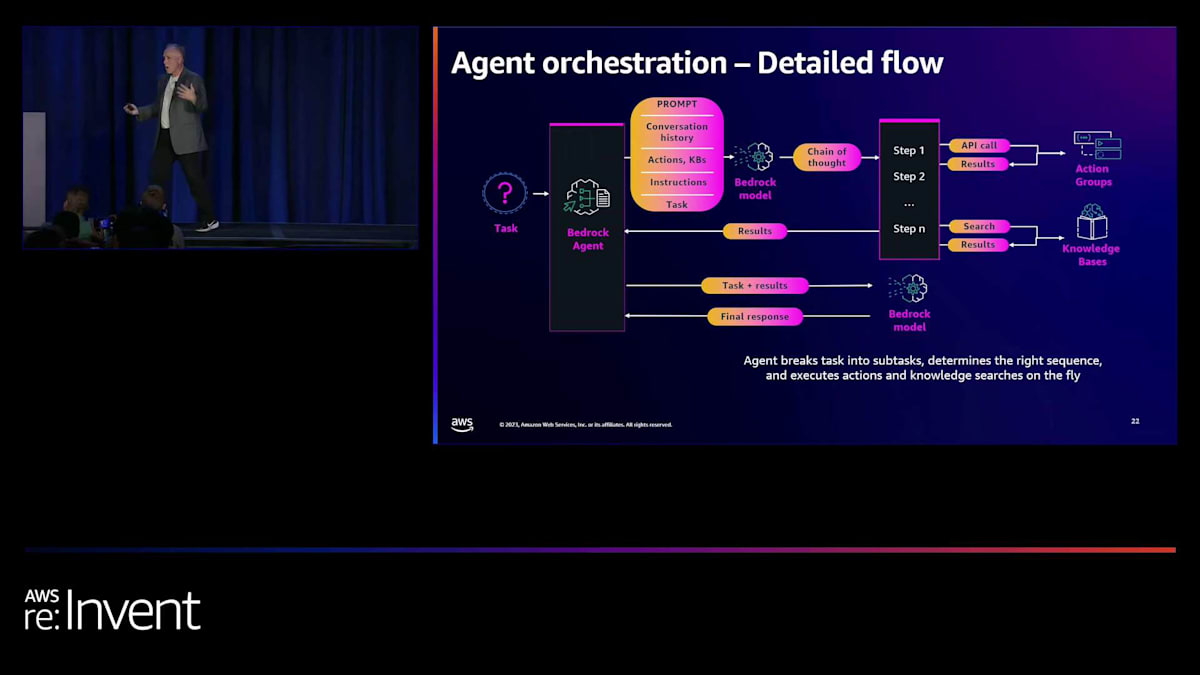
エージェントは、必要だと判断した順序で、これらのステップを組み合わせて使用し、結果を返します。エージェントはその結果を受け取り、それらは少し生のデータです。データベースから返ってきたリストかもしれませんし、検索から返ってきた大きなテキストの塊かもしれません。そして、Bedrock モデルを使用して、消費可能な形に変換します。



では、一つの例を挙げて、デモでも強調しますが、保険金請求エージェントを見てみましょう。ここでの質問は、「書類が不足している保険契約者にリマインダーを送信し、必要な書類の要件を含めてください」というものです。エージェントは考えて、この質問に答えるために4つのことを行うという計画を立てます。そして開始します。まず、未処理の請求を取得します。リクエストからデータを取得し、そのデータが何かを把握する必要があるかもしれません。場合によってはユーザーに確認を求めることもあります。そしてそれを渡し、答えを得ます。次に、その結果を見て、次に何をすべきかを判断します。次のステップに進むわけです。また、繰り返し処理を行うこともできます。例えば、リストが返ってきた場合、そのリストに対して繰り返し処理を行うことができます。



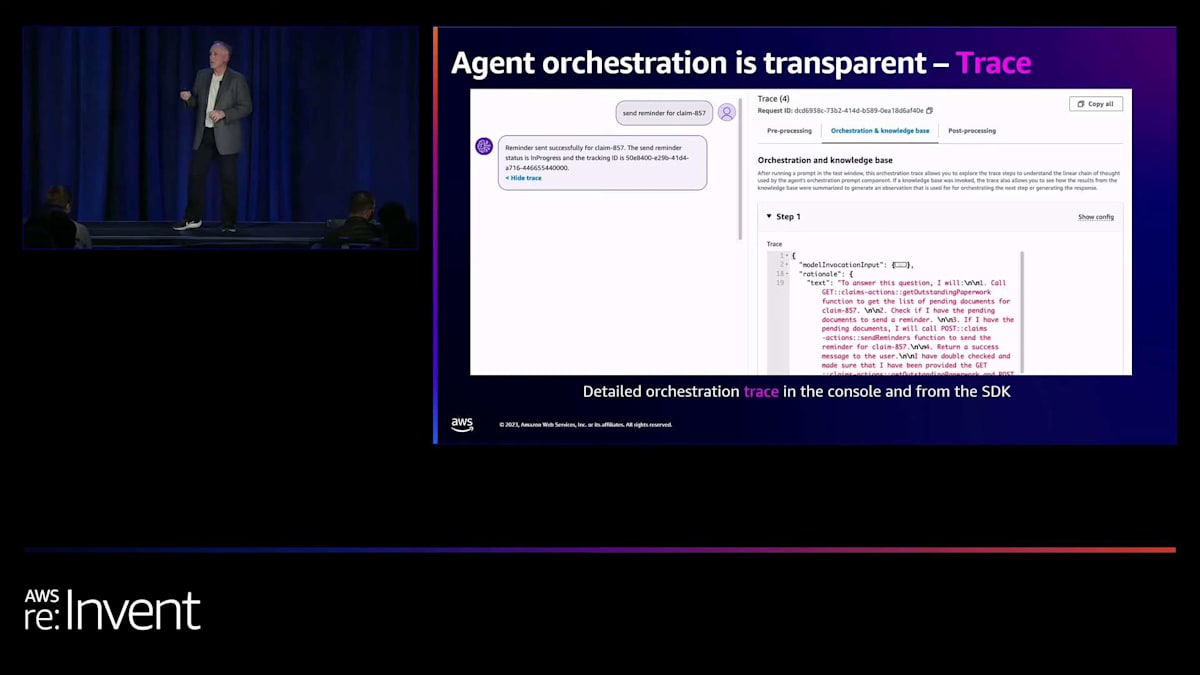
ここでは、「これらの不足書類に関連する保険証券IDを取得する」としています。次に、「顧客が実際に必要とする情報をもう少し含めた適切なメールを作成するために、ナレッジベースを参照する必要がある」と判断します。そして「リマインダーを送信する」と言い、これらすべてのアクションを実行して答えを返します。デモでもこの部分をご覧いただきますが、ここで少し先取りしてお話しします。Harshal が reasoning trace について言及しましたが、ここにいる方々の中で、エージェントが何をしているか知らずに、ミッションクリティカルなリクエストをエージェントに処理させることに抵抗がない人はどれくらいいますか?後ろの方に一人いるようですね。そうはしたくないですよね?
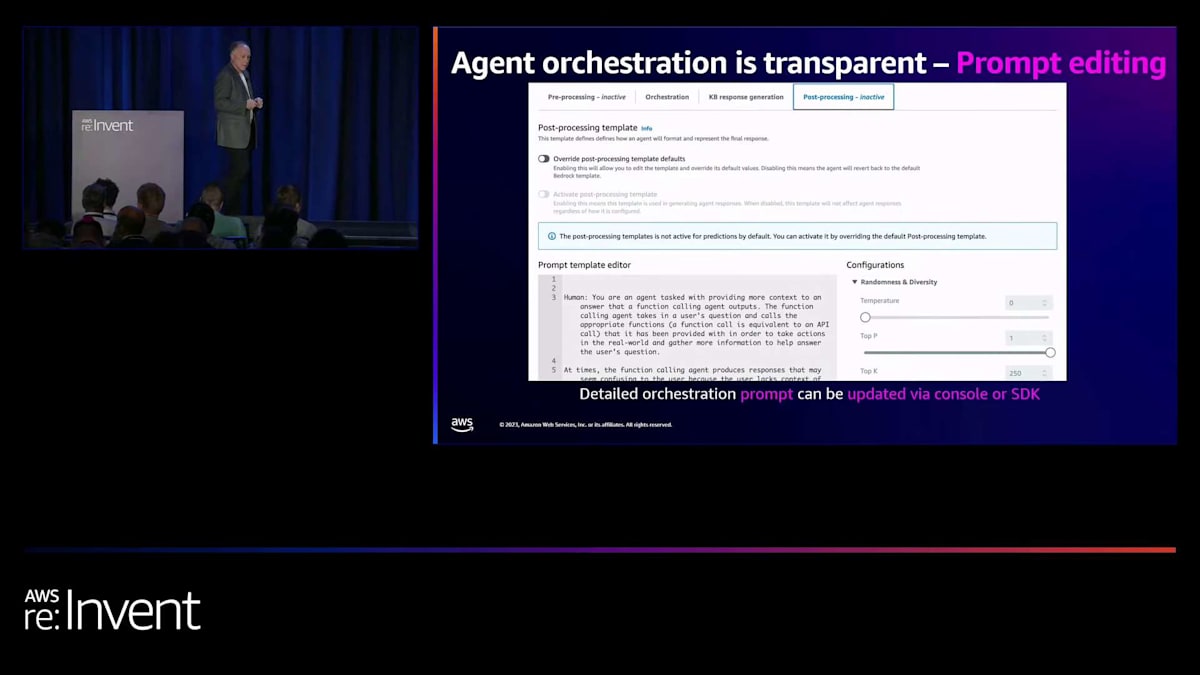
Amazon Bedrock用のAgentsが提供するのは、非常によく整理された使いやすいトレースです。これはテストコンソールの画面で、リクエストを実行し、「トレースを表示」と言えば、何が起こっているかを正確に見ることができます。APIからも同様に取得でき、これについてのデモをお見せします。 最後の要素はプロンプト編集です。Agentsがすでにサポートしている基本的なフローに適合しない、高度なロジックが必要なユースケースもあるかもしれません。しかし、ブラックボックスではないので、行き詰まることはありません。実際に基礎となるプロンプトを見て、それを変更することができるのです。これは上級者向けのユースケースで、400レベルのセッションに近いものですが、このような機能があることをお知らせしておきます。この部分は飛ばしますね。
データマッピングエージェントの効果と時間節約


さて、あと数分お時間をいただいて、それからShawnに引き継いで、実際の顧客がAgentsをどのように使用しているかをお見せします。ここでAction groupsの概念を定着させるために、3つの部分があることをお話しします。1つ目は、Action group全体の説明です。次はAPIスキーマです。APIスキーマは、8つのメソッドがあり、これらがそのリストだということを示します。各メソッドについて、説明を加え、どのようなパラメータを取るか、何を返すかを正確に記述します。これが重要な理由は、例えば新人開発者を雇って「このAPIを使ってこういうことをしてください」と言った場合、APIのドキュメントが不十分だったり貧弱だったりすると、どんな結果になるでしょうか? そのため、このAPIスキーマが非常に重要なのです。利用可能なアクションについて詳細な説明があるわけです。

そして、それに対応するのが実装です。例えば、メールを送信するアクションがあれば、どんな入力を受け取り、何を返すかを説明し、それを実装します。シンプルなLambda関数で、Lambdaは9つの異なる実装言語をサポートしています。Pythonが非常に人気ですが、JavaScriptもあります。さらにJavaやC#も使えます。Agentsの呼び出しや実装には、多くの柔軟性があります。通常、Lambda関数でAgentsを実装するのは数行のコードで済みます。



Lambda関数は通常、既存のものを呼び出すだけなので、数行のコードで済みます。これがアクションを構築する典型的な方法です。例えば、先ほど言及したユーティリティAction groupの場合、このAction groupは一般的によく使用されるアクションのセットを提供するという説明を書きます。そしてスキーマでは、アクション1とアクション2があると指定します。これをJSONやYAMLで書くか、あるいは生成することもできます。後ほどその方法をお見せします。そして、説明したアクションを実装するLambda関数を書きます。これもかなり簡単で、デモでお見せします。



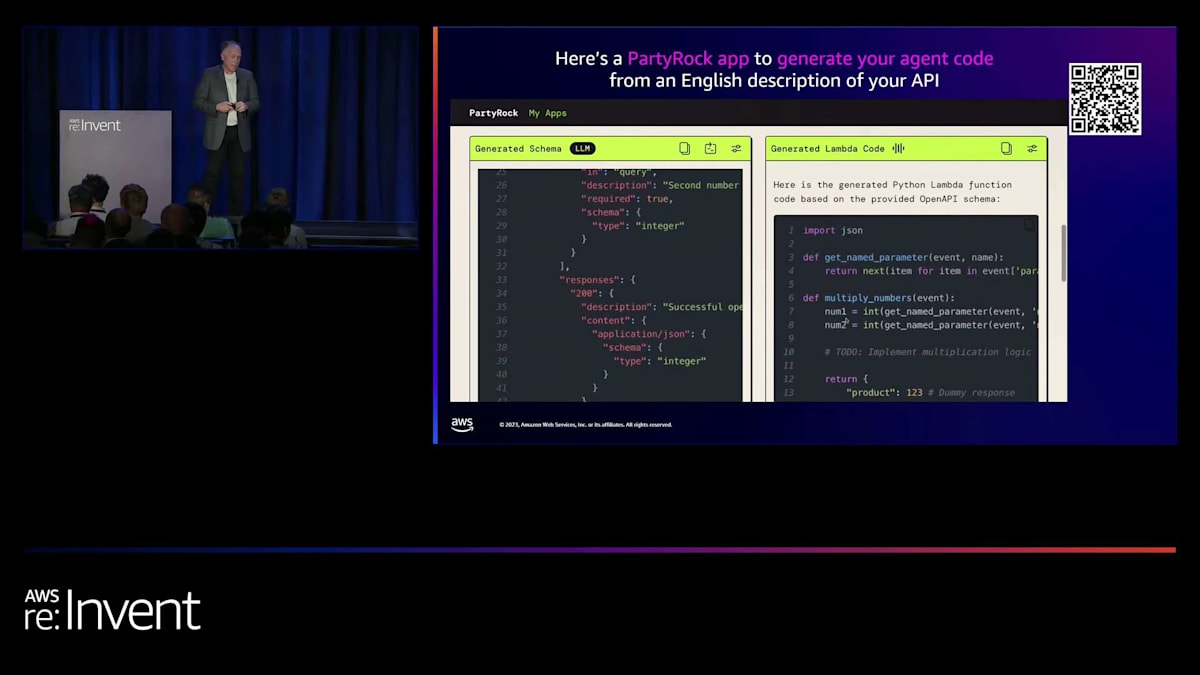

これを聞くと、定義を書くのに余計な手間がかかるように思えるかもしれません。実際にはそれほど難しくありませんが、Lambda関数を書くことについて疑問に思うかもしれません。そこで、この目的のためにPartyRockアプリケーションを作成しました。これは皆さんも試すことができます。APIを説明し、必要なメソッドを指定できます。例えば、2つの数字を掛け算するメソッドを要求し、JSONフォーマットでスキーマを求めました。数秒以内に、完璧にフォーマットされたOpenAPIスキーマが生成されます。これは標準的な定義で、アプリケーションが自動的に生成できます。ただし、オンラインにはコピー&ペーストして編集できる多くの例もあります。このアプリケーションはLambda関数も生成します。


さて、Atheneについて議論する前に、もう少しスライドを進めましょう。 エージェントについて初めて聞くと、主にコンソールで使用し、チャットボットのようにリクエストを出すものだと思われがちです。確かに、新しいエージェントを構築してプロトタイプを作る際はそうですが、実際にはこれらのエージェントを本番環境にデプロイすることができます。単に別個に実行する単純なコードではありません。エージェントを構築し、それをアプリケーションから使用するのです。


では、そのプロセスはどのようなものでしょうか?エージェントの構築とテストには、コンソールやSDKを使用してエージェントの下書きを作成します。アクションの追加や削除、Lambda関数の修正、徹底的なテストを繰り返し行います。 デプロイする準備ができたら、新しいエイリアスを作成します。バージョン管理機能が組み込まれています。そして、そのエージェントを使用したい人は、ウェブサイト、アプリケーション、スクリプトなど、どこからでも、アプリケーションを構築してエイリアスを通じてエージェントを呼び出すだけです。
エージェントを活用した業務効率化の将来展望


エージェントを呼び出すリクエストを送信し、レスポンスを受け取ります。イベント駆動型にすることも可能です。私たちは、プロトタイプを作成するだけでなく、本番環境にデプロイできる実際のエージェントを開発するためのツールを提供しています。左側にエージェントを呼び出すための簡単なコードがあります。 テキスト、エージェントID、エイリアスIDを渡します。会話を維持するためのセッションを持つことができ、推論トレースを取得するためにトレースを有効にすることもできます。ストリームとして返されます。最終的な回答だけが欲しい場合は、それを受け取ります。あるいは、レスポンストレースを処理したい場合は、それも取得できます。
次の部分は詳細情報なので省略します。必要であれば写真を撮るか、オンラインでエージェントのドキュメントを参照してください。他のAWSサービスと同様に、エージェントを作成するための完全なAPIセットがあります。では、Shawnに引き継ぎ、その後デモに戻ります。


ありがとうございます、Mark。今日、re:Inventで皆さんとお会いできて光栄です。お忙しい中、エージェントについて探求する時間を取っていただき、ありがとうございます。Markが言ったように、私はShawn Swanerで、Atheneの最高技術責任者です。 私たちは、アイオワ州ウェストデモインを拠点とする、定額年金と指数連動型年金の主要プロバイダーです。小売事業に加えて、再保険事業も行っています。この再保険事業の一環として、他の保険会社からブロックを引き受ける際、処理のために大量のデータファイルが送られてきます。保険会社として、このビジネスを適切にシステムで処理するためには、 保険数理作業、処理作業、データサイエンス作業が必要です。このレガシーコードのマイニングプロセスは時間がかかります。

長年にわたり、ブロックごとに、私たちはデータセットを取り込み、そのデータをロードするコードを書いてきました。その結果、同じことを行うための多くの異なる方法が蓄積されてきました。最近、このコードを近代化するプロジェクトを開始しました。最初のステップは、コードを見て、データを調べ、データをマッピングすることです。この作業では、特定のデータ要素が顧客ファイルから入力され、コード内で一連の変換を経て、私たちのシステム内のデータ値にマッピングされます。
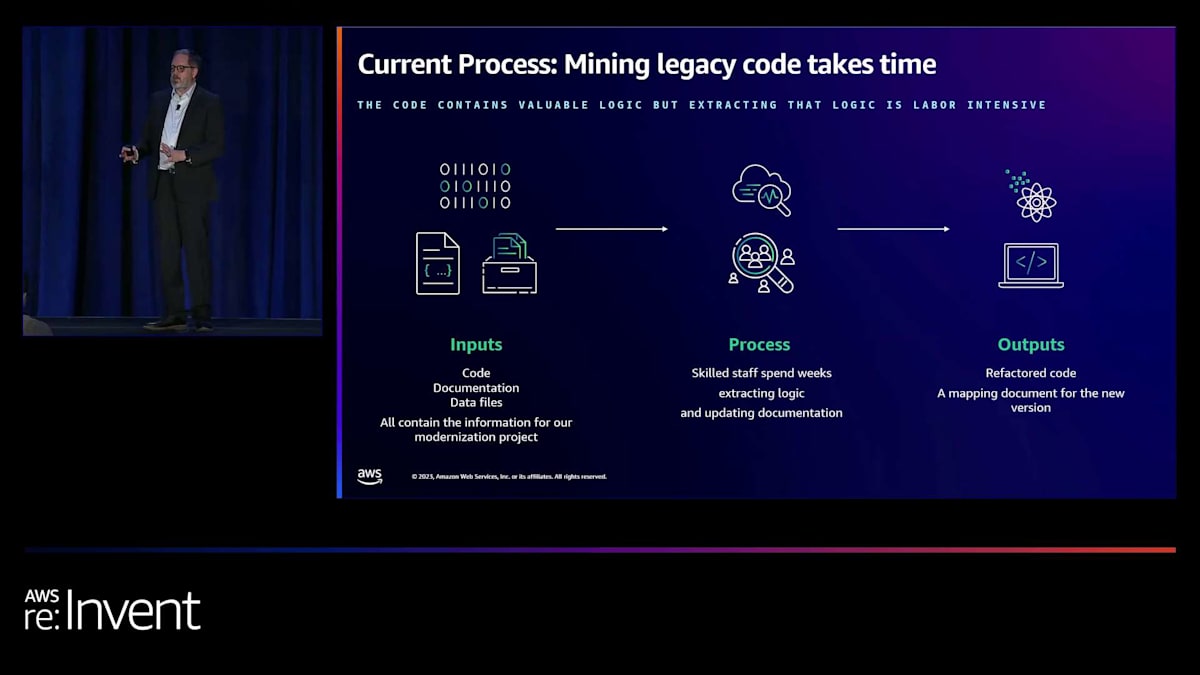
このデータの仕組みを理解するために、高度なトレーニングを受けたアナリストのチームが何時間もかけてコードとデータを精査し、マッピング文書、システム文書、設計文書を作成します。その後、これらを開発者に渡して、リファクタリングされたコードを書いてもらいます。開発者はこのデータマッピングと文書を受け取り、 このプロジェクトの一環として、現在の標準的なアプローチを使用して、クライアントから送られてくるデータを私たちのシステムで必要な形に変換します。これは手作業のプロセスです。


私たちの再保険ビジネスでは、すべての顧客が独自のファイル形式を持っています。私たちは顧客にサービスを提供する立場なので、顧客は彼らに適した形式でファイルを送ってきます。すべてを1つの大きなファイルで送ってくる顧客もいれば、数十の異なるファイルを含むzipファイルで送ってくる顧客もいます。CSVの場合もあれば、XMLの場合もあります。 これらのファイルには共通の一貫性がなく、非常に大きいです。アナリストがファイルを開くだけでも、これらのCSVの中には100列以上あり、行数も多すぎて、レビューや処理のためにラップトップで開くのが困難なものもあります。
再保険業務におけるデータ処理の課題とエージェントの活用

私たちが持っているコードは、どんなレガシーコードと同様に、複数のPythonモジュールと複数のリポジトリに分散しています。データファイルを処理して出力を生成するまでのコードの流れを追跡するのは難しく、これは典型的なETLの問題です。このプロジェクトでブロックごとに近代化を進めていくには、膨大な時間がかかります。


皆さんの多くと同様に、私たちも2023年の大半を、生成AIがビジネス上の問題をどのように解決できるかに非常に興味を持って過ごしました。特に、AWSのパートナーと話し合う中で、Amazon Bedrockで現在利用可能な機能について議論しました。AWSと協力して、私たちは一連のエージェントを構築しました。 これが私たちが取った最初のステップで、Markが説明していたものと似ています。データファイルとコードをAmazon S3バケットに入れました。そして、エージェントを定義し、単純にそのエージェントの仕事はマッピング文書を生成することだと伝えました。マッピング文書の例を後ほどお見せします。

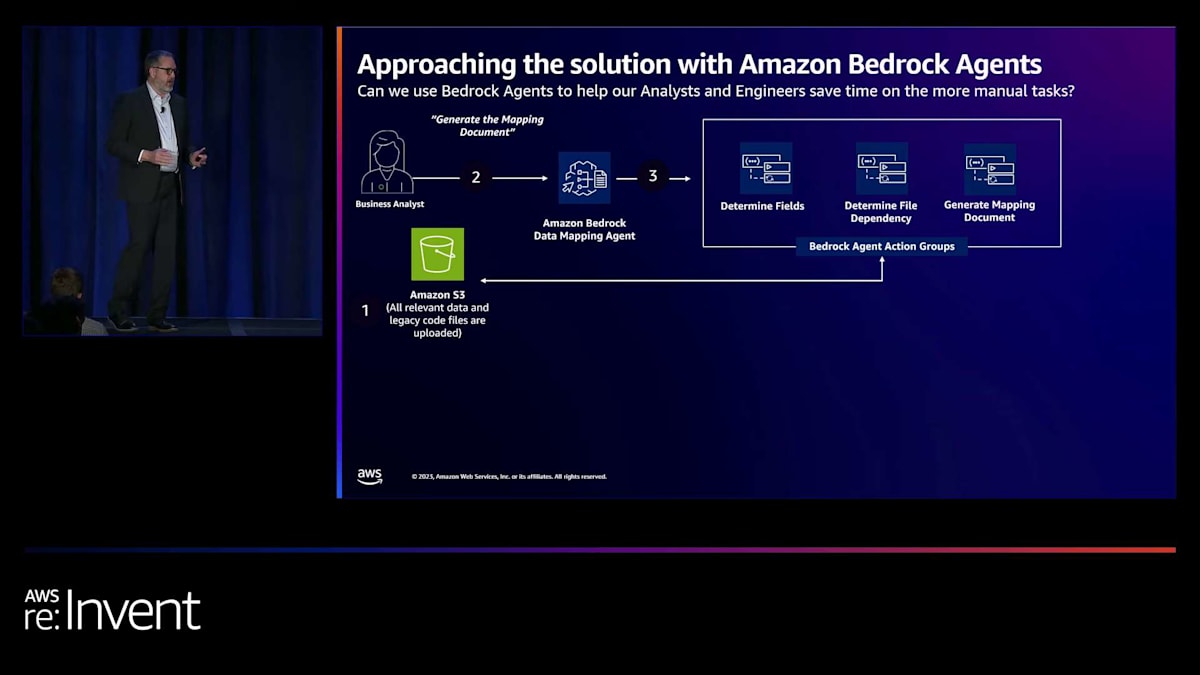
私たちは、いくつかのことを行うアクショングループを設定しました。まず、エージェントにデータファイルを読み込ませ、 データのマップを作成させました。これらのデータファイルには、何百もの異なる要素が含まれています。データ要素の一部は顧客から送られてきますが、他の要素は1つ以上のデータフィールドの計算結果として、私たちの処理コードによって決定されます。次に、特定のデータ要素がどのようにデータファイルを流れていくかを把握する必要がありました。一部はそのままファイルに含まれていますが、他の要素は異なるPythonモジュールが一連のインポートを通じて連携し、計算を実行してその値を決定します。
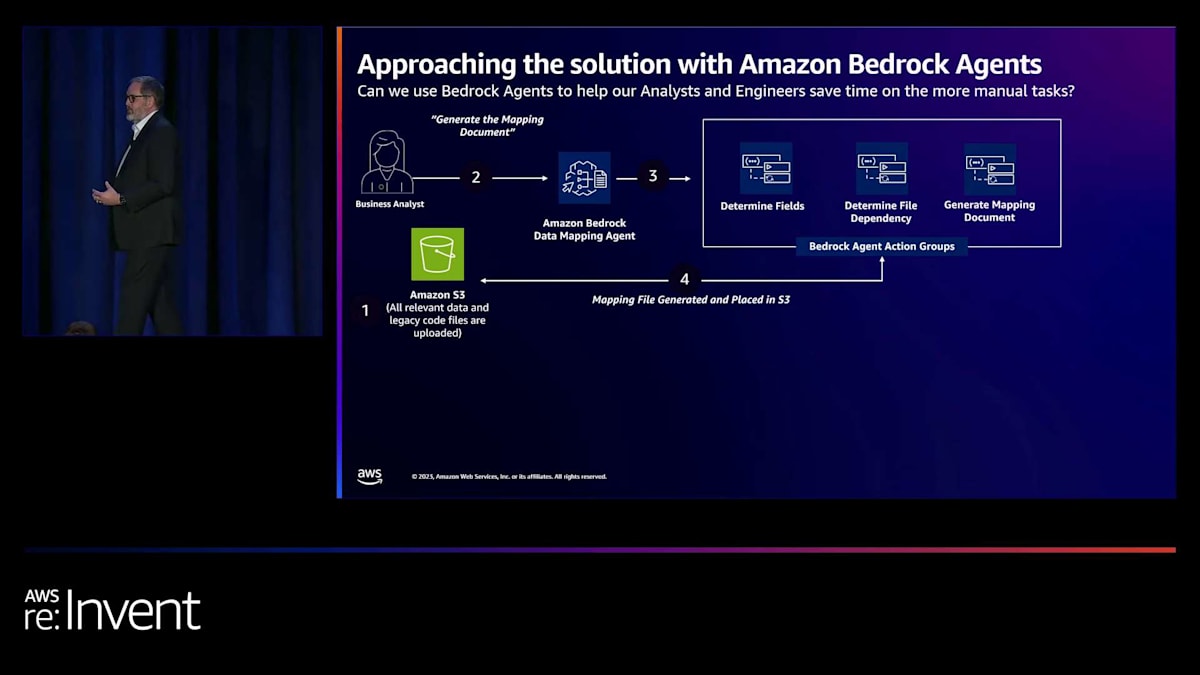
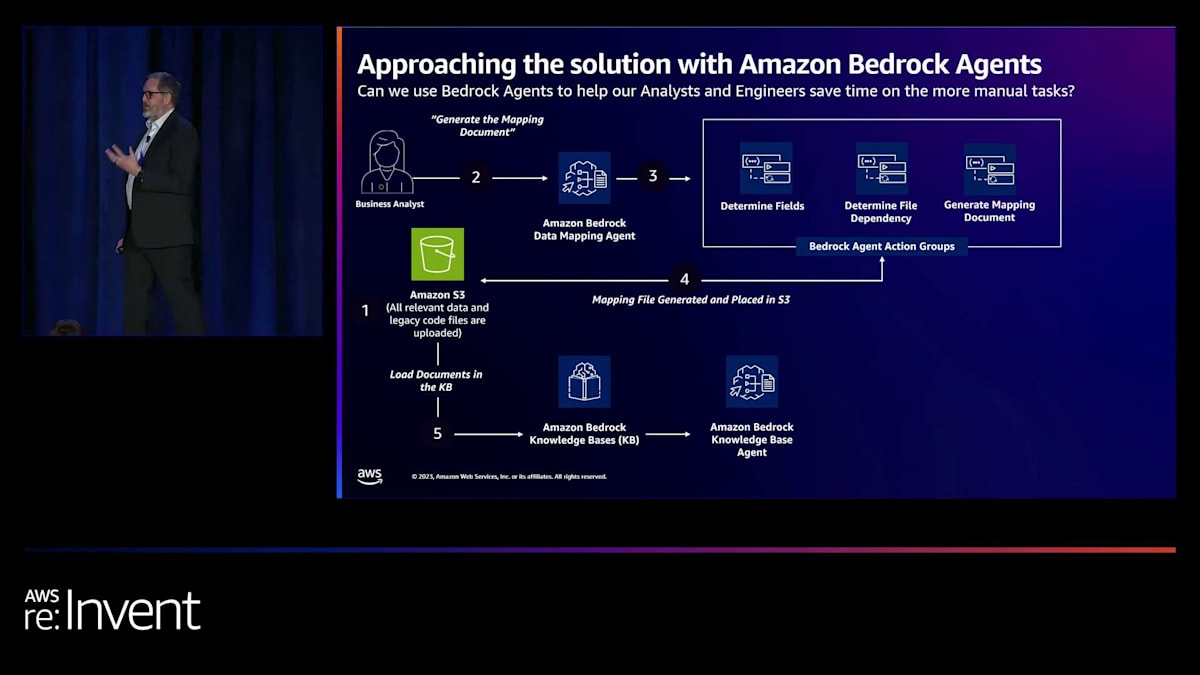
これらを把握できたら、データマッピングドキュメントを作成します。これは、ブロックのすべてのデータ要素をリストアップし、データの取得方法と処理方法を理解するのに役立つシンプルなMarkdownドキュメントです。 そして、そのドキュメントをS3バケットに戻します。ここからが本当に興味深くなります。なぜなら、2つ目のエージェント、つまりナレッジベースエージェントを作成したからです。 このエージェントは、データマッピング、元のソースコード、元のデータを取り込み、 スタッフが一連の質問をできるようにするプロンプトを提供します。
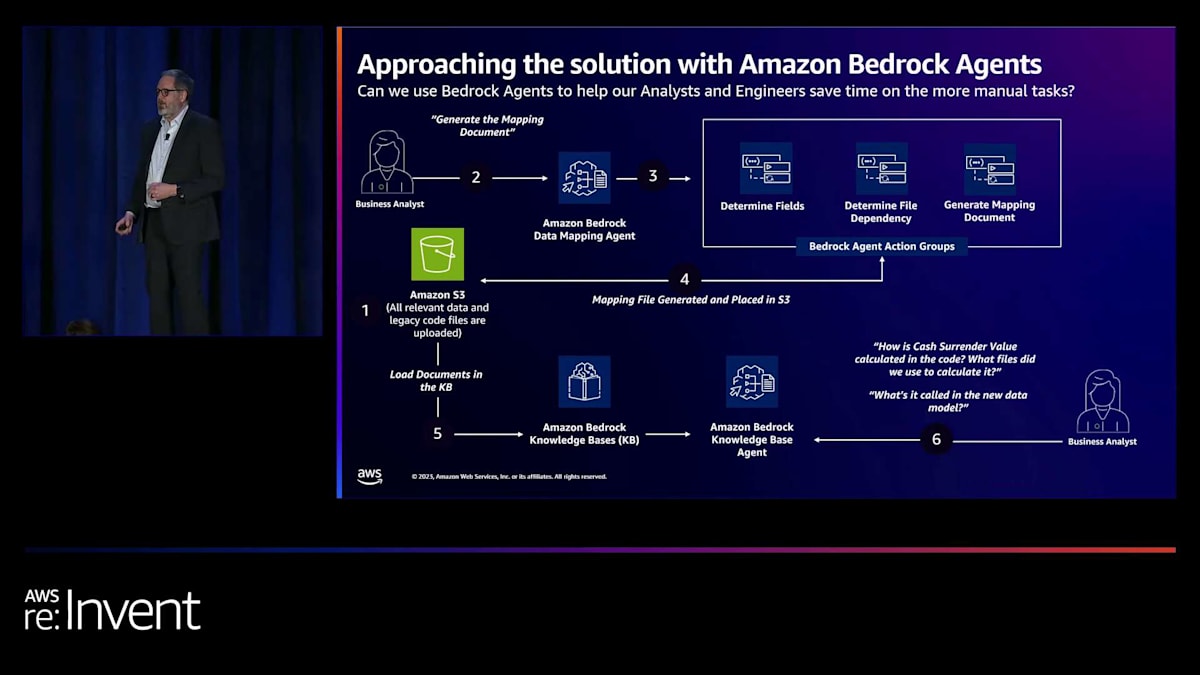
もし私たちのチームのアナリストだったら、エージェントが今あなたを導いた地点まで到達するのに、手動で多くの時間をかけて、メモを取り、スプレッドシートを作成し、図を描き、これらをまとめ上げる必要があったでしょう。今では、アナリストはログインしてエージェントにアクセスし、質問をして、「この値はどこから来ているの?」「この計算はどのように決定されるの?」「ソースコードのどこでそれを見つけられるの?」と尋ねることができます。
このアプローチは、いくつかの点で私たちの助けになります。一つは、多くの時間を節約できることです。二つ目は、Markの言っていたことに同意するのですが、エージェントに最終的なシステム仕様書を書かせることはしないということです。それは私たちのチームの高度なスキルを持つ人間の仕事です。しかし、このエージェントが行うのは、データ要素や計算を説明する下書き文言を提供することです。エージェントはアナリストの理解を検証するのに役立ち、質問をしてデータとコードの理解を確認できます。これらすべてが合わさって時間の節約につながります。
エージェント活用の成果と今後の展開
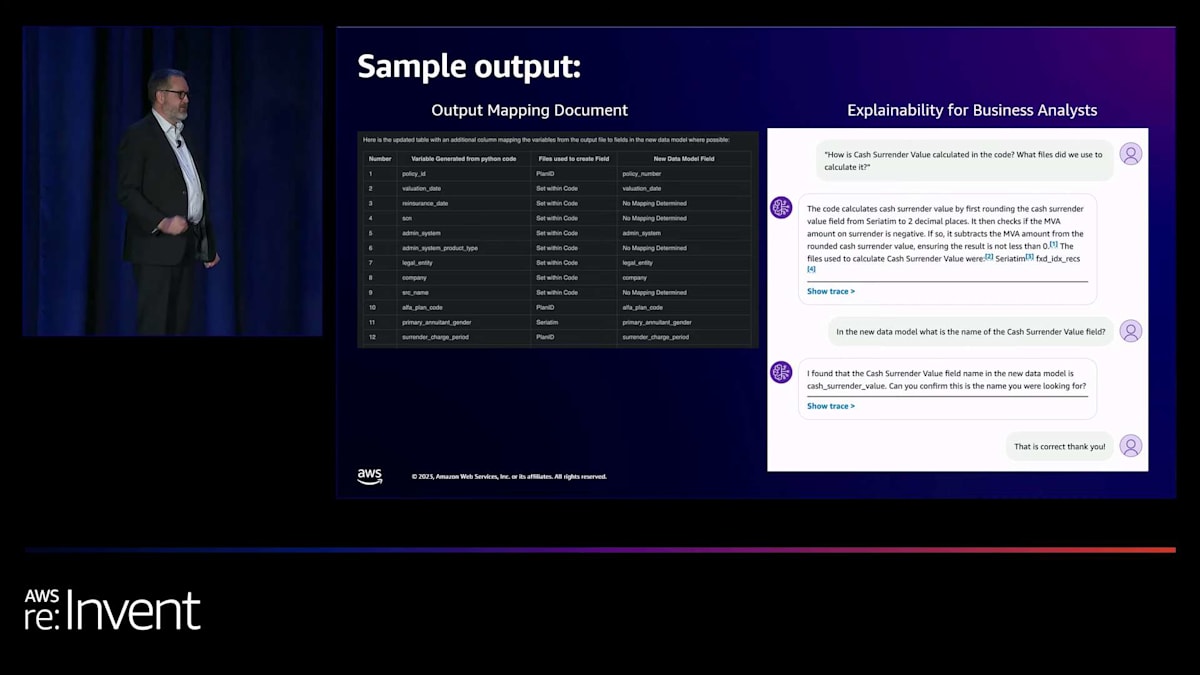
さらに、その文書を開発者に渡す際、エージェントへのアクセスも提供できます。これにより時間が節約され、コーダーがアナリストに質問する代わりに、まずはエージェントに質問を始めることができます。こんな感じです。 12行というのはそれほど多くないように見えるかもしれませんが、これはエージェントが生成した何百行ものデータの一部です。このエージェントで得られるのは、このマッピング、これらのデータ列で、通常なら作成に多くの時間がかかるものです。これは、人間が作成するドキュメントの基となり、他のエージェントのナレッジベースにも力を与える文書化の参照を提供します。
右側では、エージェントのプロンプトと、チャットインターフェースで質問できる機能の例が見られます。これは、ナレッジベースをRAG(Retrieval-Augmented Generation)スタイルで使用しています。このプロンプトは... この例では Claude 2 を使用していますが、そのバケットにあるすべての情報を含むナレッジベースとも統合されています。その情報を取り込み、チャットレスポンスを生成し、ナレッジベースに問い合わせて回答を提供します。

では、この作業から何が得られたのでしょうか? まず第一に、エージェントは大規模なデータファイルの処理に非常に効果的でした。アナリストにとっては、ファイルを開くこと自体が難しい場合もありましたが、エージェントはこれらの大規模ファイル(列数が多く、行数も多い)を処理し、分析を行うことができました。また、エージェントは Python のソースコードファイルから計算ロジックを逆エンジニアリングするのが得意です。さらに、前のスライドで示したデータマッピング文書は、私たちに多くの時間を節約させてくれる非常に価値のある成果物です。

Q&A 機能を備えたエージェントは、私たちにとって長期的で永続的な資産となるでしょう。再保険の性質上、このビジネスブロックは何年もの間、私たちの帳簿に残る可能性があり、開発者やスタッフの一部よりも長く存在するかもしれません。しかし、この文書化とエージェントがあれば、アクティブな生きた文書ソースとして機能し続けます。

プロジェクト計画では、アナリストがこのデータマッピングと分析を2週間かけて行う予定でした。コードとデータを S3 バケットにロードしてエージェントを実行した時点から、データマッピングファイルを数分で作成することができました。これにより、アナリストにより興味深く価値のある仕事をしてもらうことができます。他人の古いコードを読み解いてビジネスロジックを理解するのは楽しい作業ではありません。その代わりに、アナリストはより価値の高い仕事に取り組むことができます。この ETL プロセスが完了した後も、まだまだやるべきことがたくさんあります。私たちのデータモデルへのマッピングや、そのデータが保険数理システムで使用するのに適しているかどうかを判断するなど、スタッフはこれらの成果に集中できるようになります。

しかし、これで終わりではありません。さらに良くなると思います。これは比較的短期間で作成した POC ですが、 印象的な結果が得られました。次に行うのは、これらのエージェントを拡張して、より多くのデータブロックに対応させることです。これらのデータブロックの中には、異なるデータ形式、構造、そしてデータのロードと処理方法に関する異なる期待があるでしょう。これらのデータブロックを処理する私たちのコードの一部は、より難しくなる可能性があります。そこで、エージェントを進化させ、適応させて、このような作業をさらに多く行えるようにしていきます。
第二に、これは皆さんにとって重要なポイントですが、私たちは常にプロンプトの微調整のプロセスにあるということです。これは、AIに関する全てのエージェントとの作業を通じて学んだ重要な点です。プロンプトエンジニアリングとプロンプトチューニングは一度で終わる活動ではありません。Markがこの後のデモで示す画面を見ていくと、エージェントに何を達成すべきかを自然言語で説明する機会があることがわかります。これを継続的に評価し、調整することが重要です。今週、BedrockがClaude 2.1をサポートするようになったと聞きました。2.0から2.1への移行でさえ、プロンプトの再調整とすべてが正しく機能しているかの再評価を引き起こすはずです。
次に私が本当にワクワクしているのは、このプロジェクトの目標が単なる分析ではなく、実際にコードをリファクタリングすることです。エージェントを使って、例えば、このデータ要素を顧客のソースファイルから変換を経て私たちの標準データモデルにマッピングし、それを何かに使用したり、標準データモデルに入れたりする必要があるとします。エージェントは、いくらかのトレーニング、サンプルコード、そしてガイダンスがあれば、その作業や変換を行うための提案コードを提示できると強く信じています。
ここが本当にエキサイティングになるところです。なぜなら、プロジェクトのすべての要素において、エージェントが単調で反復的な作業、より退屈な作業を引き受けるからです。これにより、高度なスキルを持つスタッフがより意味のある、付加価値の高い仕事に集中できるようになります。私はその段階に到達することを本当に楽しみにしています。それでは、デモのためにMarkに戻します。ありがとうございました。
保険金請求エージェントのデモンストレーション
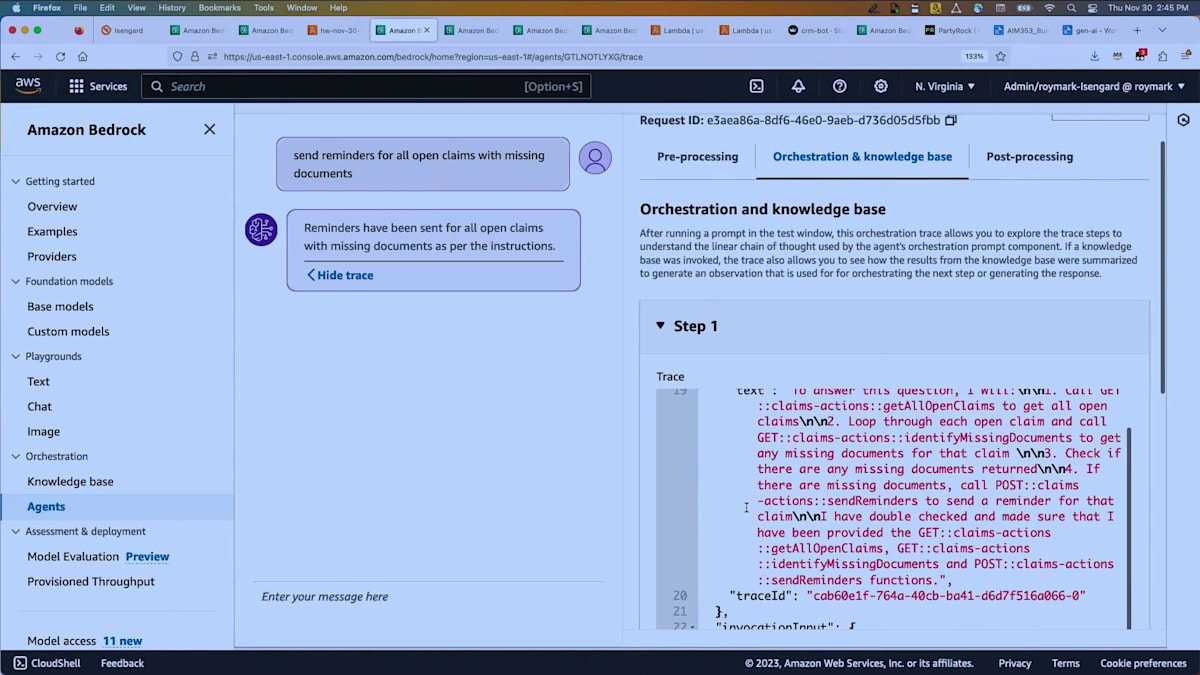
ありがとうございます。それでは、いくつかの簡単なデモをお見せしたいと思います。もう1、2時間あれば、agentの世界ツアーをお見せできるのですが。最初のデモは、先ほどのスライドでお見せした保険金請求のagentに関するものです。ここでは、一見単純に見えますが実際にはそれほど単純ではない要求をしています。「書類が不足している未処理の請求すべてに対してリマインダーを送信する」というものです。これはすでに実行済みで、「show trace」ボタンを押しました。こちらに推論のトレースが表示されています。
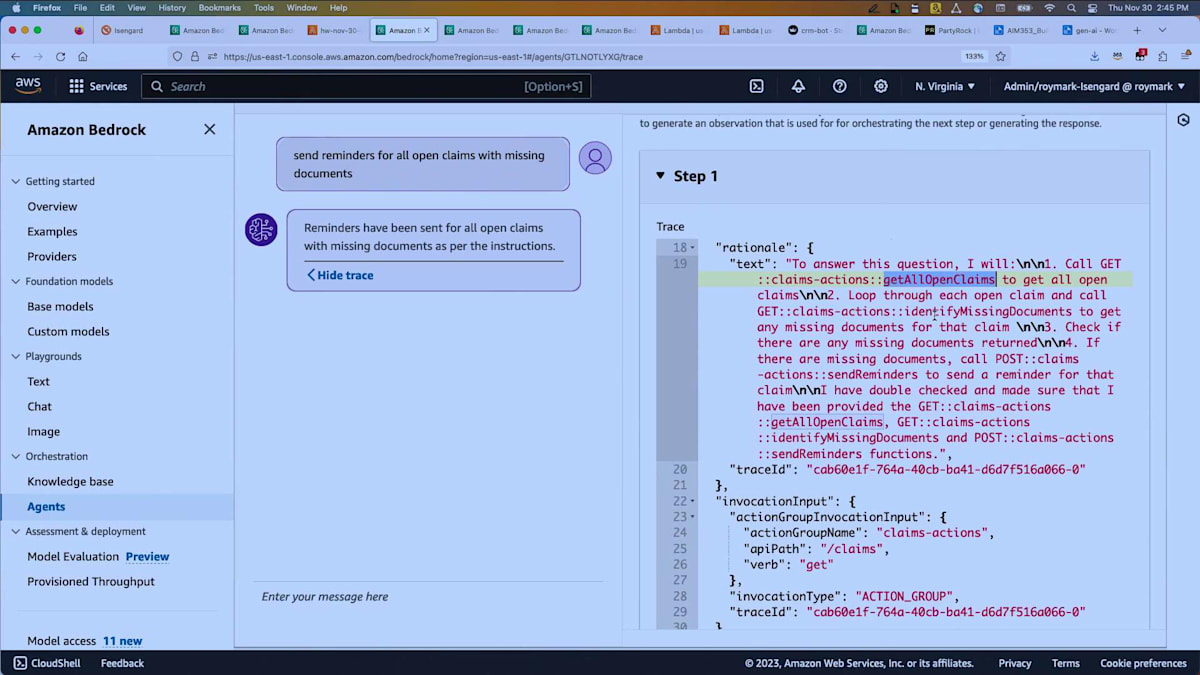
複数のステップがありますが、ステップ1を展開して詳しく見てみましょう。 ここでは、「この質問に答えるには、get all open claimsを呼び出す必要がある」と言っています。 そして、それらの未処理の請求それぞれに対してループを行い、不足している書類を特定します。これは請求リストから返ってきた情報には含まれていなかったからです。不足している書類がある場合、send remindersを呼び出して顧客にメールを生成します。そのメールには請求ID、不足している書類、必要な対応、場合によっては対応するためのURLなどが含まれます。
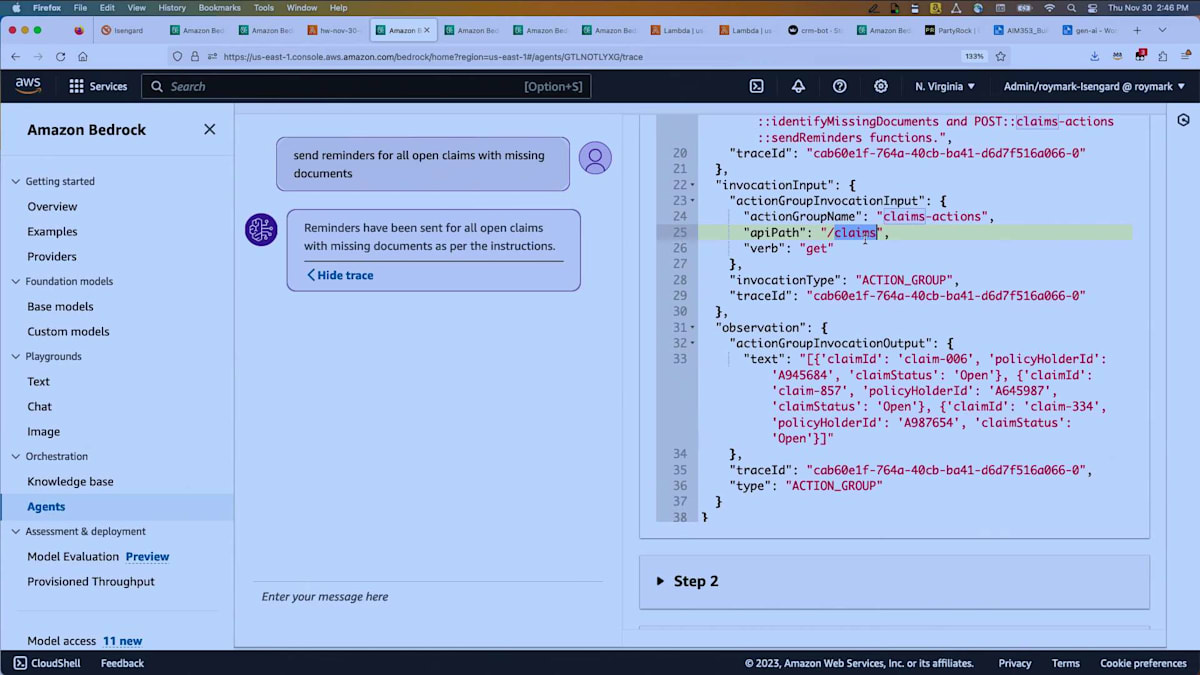
これが最初の計画です。そして、その計画の最初の部分を実行します。つまり、請求を調べるということです。 これはAPI schemaで定義されたAPIの1つで、こちらが返ってきた出力です。ここでは完全なトレースが表示されています。計画は何か?どのアクションが見つかったか?どの知識ベースが見つかったか?そして実際に実行され、何を渡して何が返ってきたかが表示されています。また、Lambda CloudWatch logsも利用可能です。そこで、受け取った入力ペイロードや実行内容、Lambda自体で行いたいログ記録などを確認できます。これが続いていきます。

ステップ2、ステップ3と進みますが、ステップ3で何をしているか見てみましょう。 ステップ3では、send remindersを呼び出し、claim IDを渡しています。この場合、claim 006で、事故の画像が不足していることがわかりました。ここで知識ベースを連携させることもできます。検索を行い、「事故の画像が不足している」とはどういう意味か調べます。例えば、フロントガラス、車の側面、車の後部などの写真を顧客に要求するといったことです。これらの情報をメールに含めることもできます。これがagentを使用した簡単な例です。



もう少し詳しく見てみましょう。 コンソールでは、実際のagentを表示しており、action groupの詳細を見ています。先ほど3つの部分があると言いましたよね?action group descriptionがありました。 前のページにあったと思います。ここでは詳細を編集しており、API schemaを確認できます。 これはOpenAPI standardと呼ばれるもので、調べてみるとよいでしょう。インターフェースを記述する標準的な方法です。この説明は重要です。なぜなら、これによってagentがこれらのアクションの用途を理解できるからです。

これが私の最初のAPIで、クレームのリストを取得し、何が返ってくるかを示しています。 返ってくるのは、クレーム、保険契約者などの詳細を含むオブジェクトの配列です。入力と出力を詳細に記述することで、エージェントにこれらのアクションをどのように調整するかを理解させる知能を与えています。どのような計画を立て、どのような手順を踏むべきかを判断できるのです。
もう一つの例をお見せしましょう。最近、製薬会社のお客様と話をしていたのですが、私たちのシステムで認知度調査を扱えるかどうか尋ねられました。これらの調査は、市場での薬の性能を評価するもので、顧客の意見、効果、副作用、費用対効果、投与の容易さなどの側面をカバーしています。彼らは四半期ごとにこれらの調査を行っており、エージェントがこのデータから意味のあるトレンドを識別できるかどうか知りたがっていました。
製薬会社向け認知度調査エージェントとCRMエージェントの実例

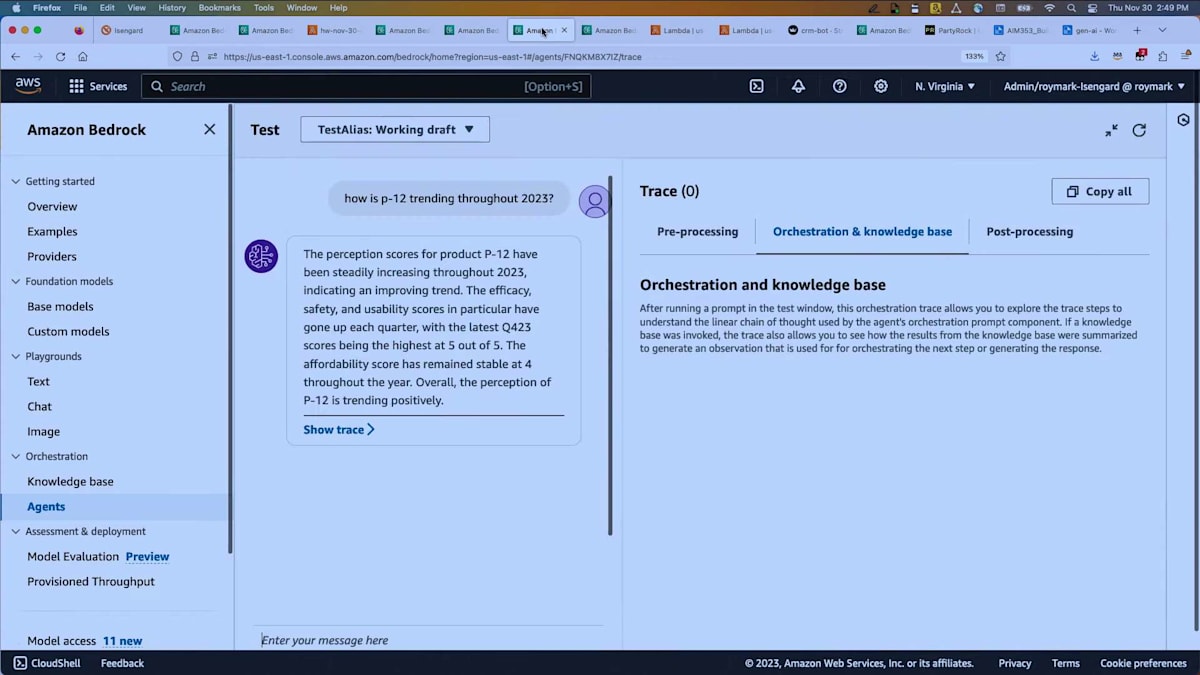
私はすぐに例を作成し、「この製品は2023年を通してどのようなトレンドを示していますか?」と尋ねました。利用可能なアクションは、四半期調査を参照する1つだけでした。エージェントは、2023年とはQ1、Q2、Q3、Q4の4回の異なる呼び出しを意味すると解釈しなければなりませんでした。 トレースを見ると、各四半期についてgetPerceptionByQuarterを呼び出し、その後分析を行うことを決定したことがわかります。
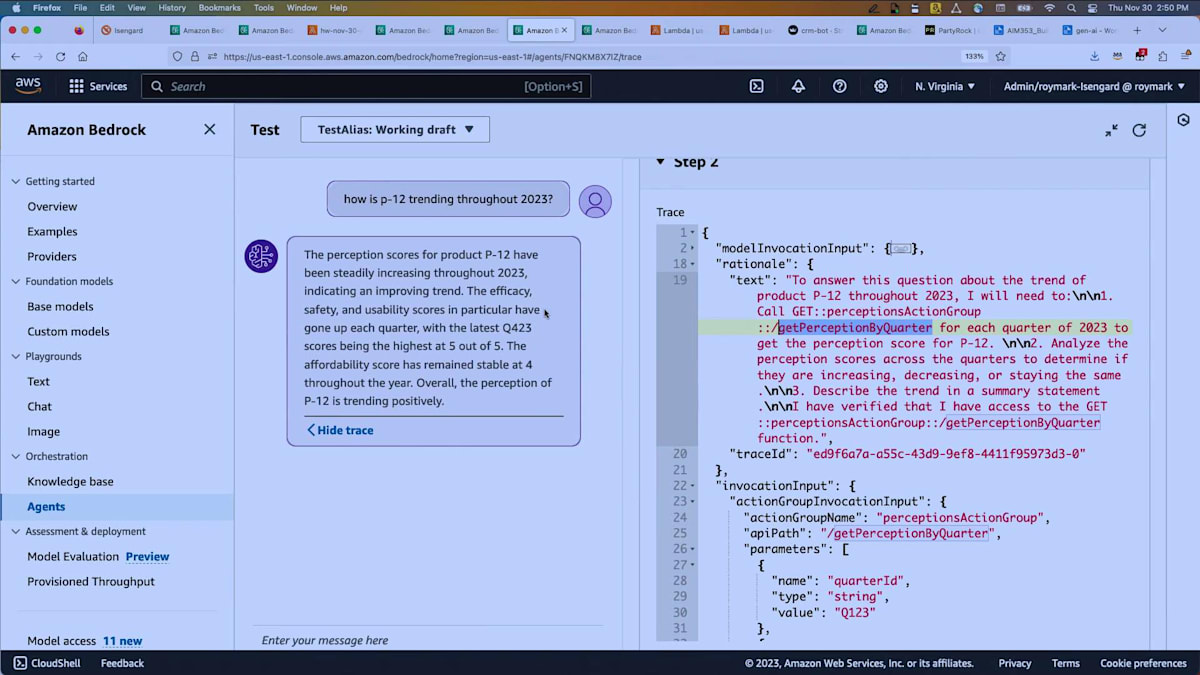
返ってきた回答は、スコアが年間を通じて着実に上昇していたことを示していました。使いやすさのスコアなどが各四半期で上昇し、手頃さは年間を通じて4で安定していました。これは単純な一連のステップではなく、エージェントが反復して同じアクションに対して複数の呼び出しを行う方法を見出せることを示しています。

私が気に入っているもう一つの例をお見せしましょう。 顧客関係管理システムを考えてみてください。あなたがアカウントマネージャーや営業チームの一員の営業担当者で、来週顧客と会う予定だとします。しかし、あなたは十数人の異なる顧客と仕事をしていて、すべての出来事を把握しきれません。そこで、エージェントに顧客との会議を提案してもらい、会議のトピック、議題、そして顧客の好みに基づいた推奨時間を提供してもらいます。
エージェントが行うのは、直近5回のやり取りを調べることです。各やり取りには日付と一連のメモがあります。エージェントはそれらのメモを分析し、状況を理解します。例えば、顧客の予算が削減されたこと、サービスの信頼性に不満があること、新しいサービスを検討したいと考えていることなどです。この情報に基づいて、エージェントは自動的にアイデアとアジェンダを提案します。

これがアプリケーションに実装された場合、どのように機能するかをお見せするために、Amazon Bedrockを使って簡易的なアプリを作成しました。というのも、私にはユーザーインターフェースのコードを書く知識がないからです。ここでは、エージェントに問い合わせています。なお、エージェントをデプロイし、新しいバージョンを作成し、エイリアスを取得し、アプリケーションからinvoke agent APIを使用しています。これが、アプリケーションでエージェントを使用する典型的な方法です。

ライブデモなので、処理に少し時間がかかっています。そしてここに結果が出ました。一方にトレースを表示し、もう一方に実際の応答を表示しています。エージェントはlistRecentInteractionsを呼び出し、この顧客が好む会議時間を決定するために設定を参照しました。結果を見てみましょう。ここに特定の日付に行われた一連の会議と、それらのやり取りの中で取られたメモがあります。
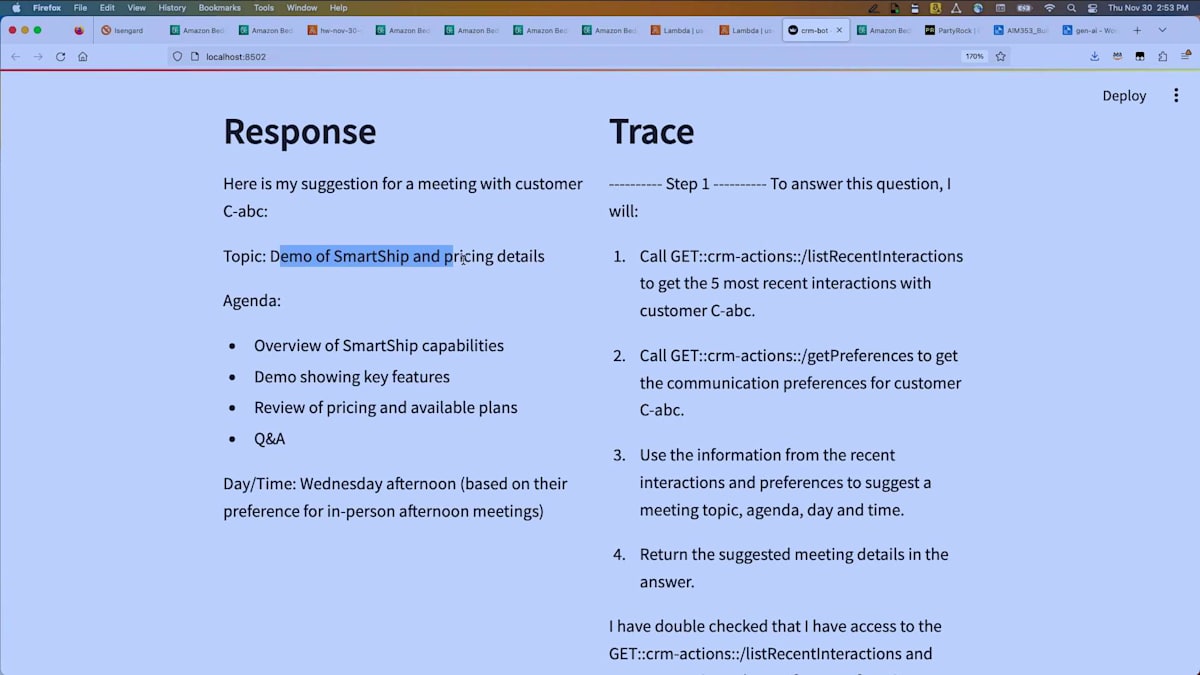
これらはCRMシステムから直接取得したもので、エージェントの一部としてLLMの力を使って、これから行う会議の内容を提案しています。デモの実施、価格の詳細説明、そしてアジェンダを提供しています。顧客は水曜日の午後に会議を好むようなので、そのように設定されています。
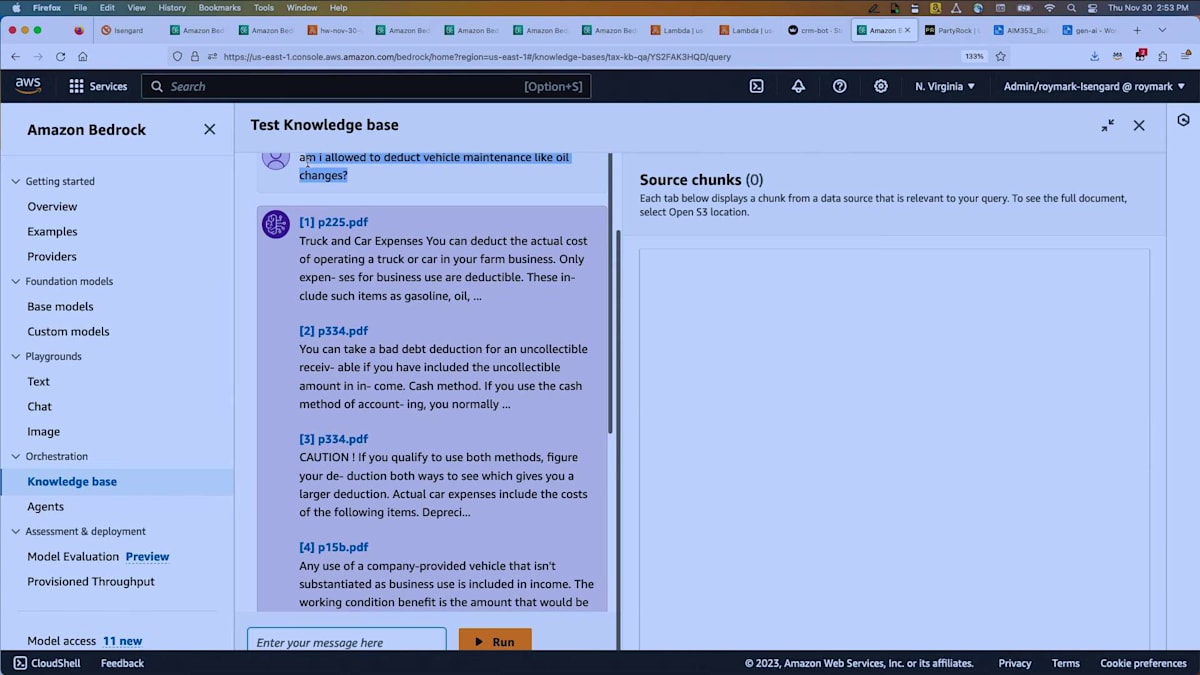
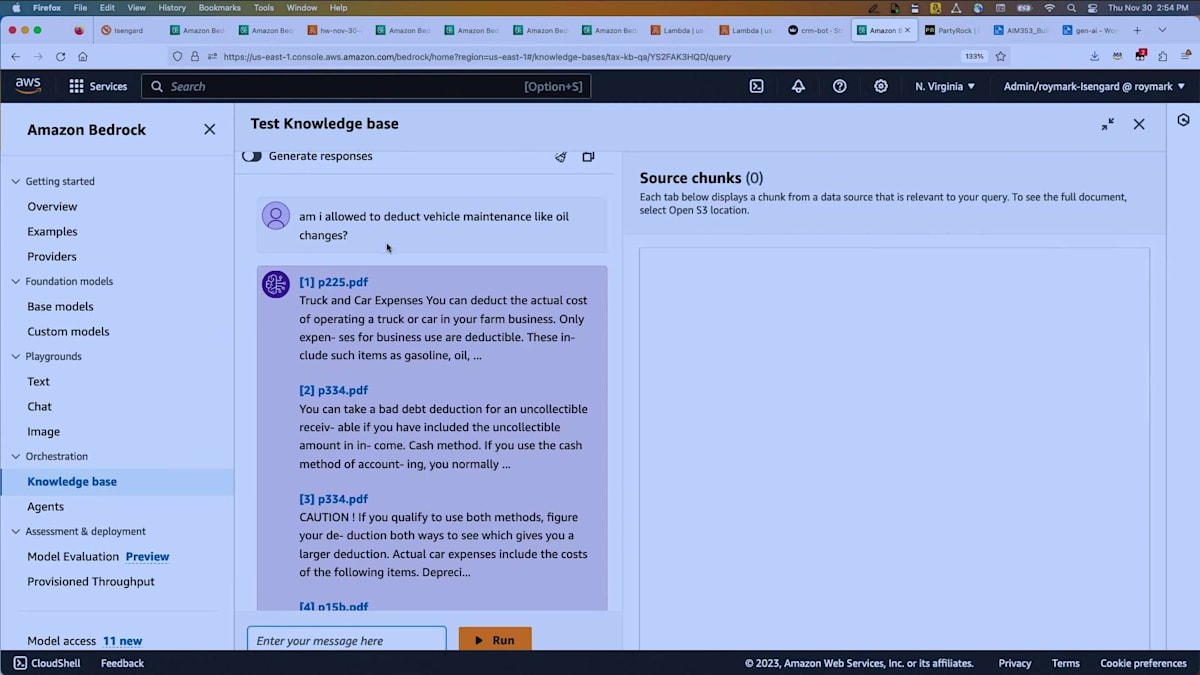
さて、最後に簡単にお見せするのは、ナレッジベースについてです。約50のIRS(米国内国歳入庁)の出版物をダウンロードして、簡単なナレッジベースを作成しました。それぞれに5〜10ページ、多いものでは50ページほどの税務方針に関するPDF情報が含まれています。私は税金の処理が嫌いなので、この質問を投げかけてみました。ご覧の通り、応答が非常に速いですね。すべてのデモが苦痛というわけではありません。ここでは、「車両のメンテナンス、例えばオイル交換は控除対象になりますか?」と尋ねました。APIとナレッジベースを使用して関連する情報のチャンクを取得し、回答を生成しました。


また、レスポンスを生成するオプションをオンにすることもできます。モデルを選択できるのですが、ここではClaude Instantを使用しています。同じ質問を実行してみましょう。ナレッジベースから関連する5つの情報を検索するだけでなく、回答を作成してくれます。答えと、元の文書に戻るための引用が提供されます。これがBedrockの一部であるナレッジベースで、エージェントやアクショングループにも組み込むことができます。
エージェントによるエージェント作成とセッション終了
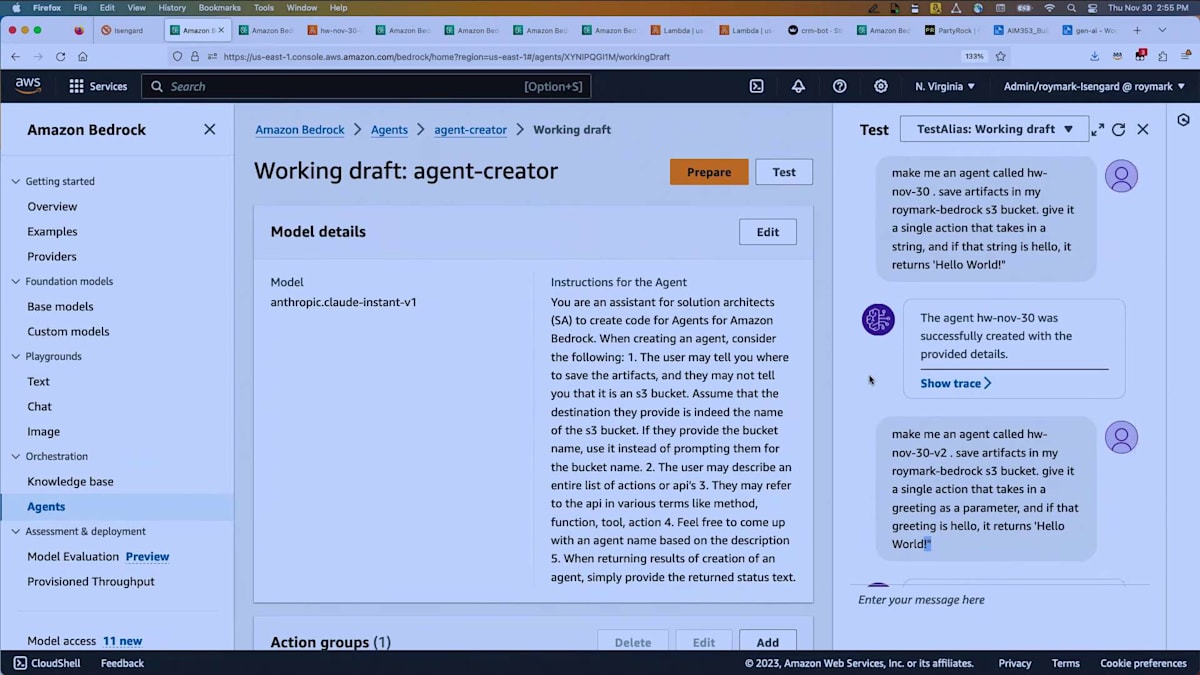
最後のパートとして、Q&Aの時間を少し取る前に、もう一つお見せしたいものがあります。エージェントを使ってエージェントを作ることができるのです。私たちは自分でエージェントを書くのに飽きていたので、エージェントにエージェントを書かせたいと思いました。ここでは、挨拶をパラメータとして受け取り、挨拶が「hello」の場合に「hello world」を返すエージェントを作成するよう指示しました。約1分でそれを作成してくれました。エージェントが出来上がり、私は1行のコードも書いていません。


コンソールに戻ってみると、私のために作成されたこのエージェントが見つかりました。「hello」と入力すると、どうでしょう?以前に2回動作したのが分かります。「Hello world」、はい。これが私のために作成されたLambdaで、APIを呼び出してLambda関数に関連付けられたエージェントを作成し、Lambda関数をデプロイしたりしています。さて、これで良さそうですね。
では、ここで切り替えましょう。HarshalとShawn、ステージに上がってもらえますか?時間切れですが、ありがとうございました。質問は外で受け付けます。ありがとうございました。
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion