re:Invent 2023: AWSとCiscoが語るSageMakerでの基盤モデル活用と最適化
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - Deploy FMs on Amazon SageMaker for price performance (AIM330)
この動画では、Amazon SageMakerを使って基盤モデルをデプロイし、生成AIアプリケーションの価格性能比を最適化する方法を学べます。Large Model Inference (LMI)コンテナの活用や、複数モデルの同一インスタンスへのデプロイなど、コスト削減のテクニックが紹介されます。さらに、CiscoのTravis Mehlingerさんが、WebExでのSageMaker活用事例を共有。開発者の生産性向上やグローバル展開の容易さなど、実践的な知見が得られる内容です。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
Amazon SageMakerを活用した生成AIアプリケーションの最適化

こんばんは。Amazon SageMakerで基盤モデルをデプロイし、生成AIアプリケーションに最適な価格性能比を実現する方法についてのセッションへようこそ。私はVenkatesh Krishnanで、Amazon SageMakerのプロダクトマネジメントを率いています。本日は同僚のRama Thammanも同席しています。彼は、お客様がSageMakerに基盤モデルをデプロイし、最低コストで最高のパフォーマンスを得られるようパフォーマンスチューニングを支援する、スペシャリストソリューションアーキテクトのチームを率いています。また、Cisco SystemsのTravis Mehlingerさんをお迎えできることを大変嬉しく思います。彼は、SageMakerを活用して基盤モデルの価値実現までの時間を短縮した成功事例についてお話しいただきます。

それでは始めましょう。2023年は生成AIが世界を席巻した年だと、皆さんも同意されることでしょう。Gartnerのハイプサイクルに従えば、現在、生成AIは誇大な期待のピークにあります。これは、お客様が自社のビジネスを成長させるために生成AIを活用できるあらゆる方法を想像していることを意味します。しかし、この期待をどのように現実に変えることができるでしょうか?素晴らしいスタートを切りましたが、目的地にどのように早く到達できるでしょうか?企業はどのようにして生成AI製品の価値実現までの時間を短縮できるのでしょうか?
生成AIモデルの実験から本番デプロイメントまでの道のり
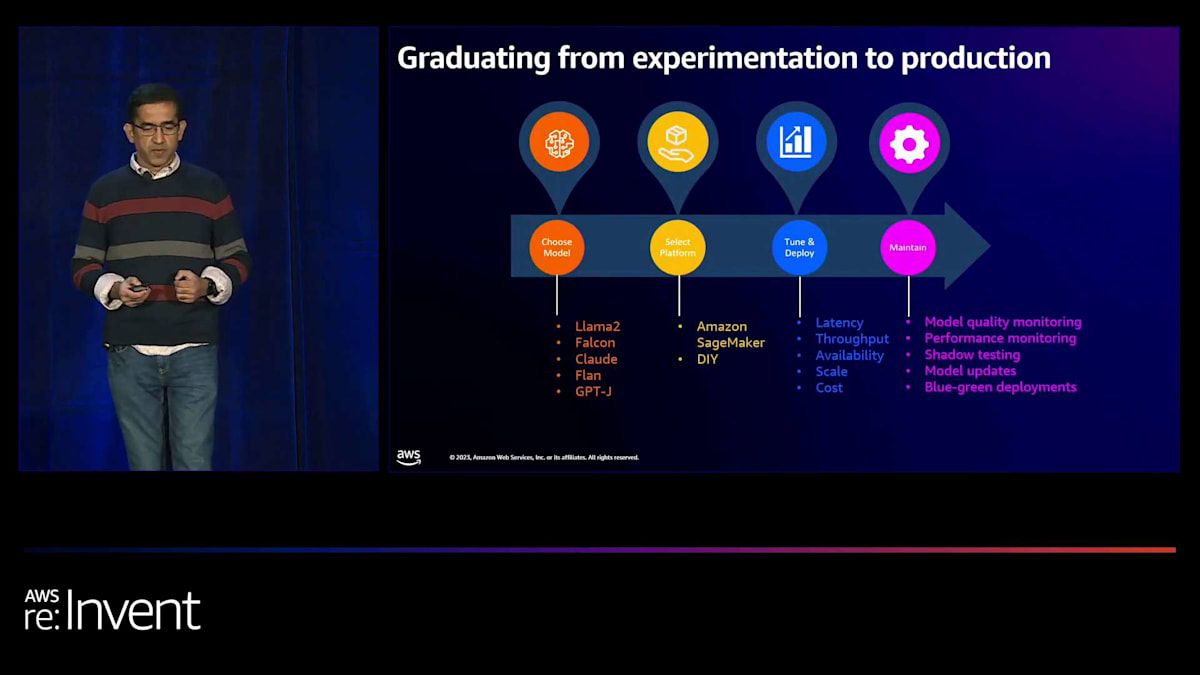
これらの質問に答えるために、実験から本番規模のデプロイメントまでの道のりを詳しく見て、どのように高速レーンに切り替えられるかを見てみましょう。まず、異なる基盤モデルを実験して、どれがあなたのユースケースに適しているかを確認します。ユーザーの質問に答えたり、テキストを要約したり、詩を書いたりするのに役立つ言語モデルがあります。また、テキストを画像や音声に変換するのに役立つモデルもあり、視覚や音声ベースの生成AIシステムを構築できます。モデルを試して選択したら、そのモデルをあなたのデータでカスタマイズまたは微調整したいと思うかもしれません。
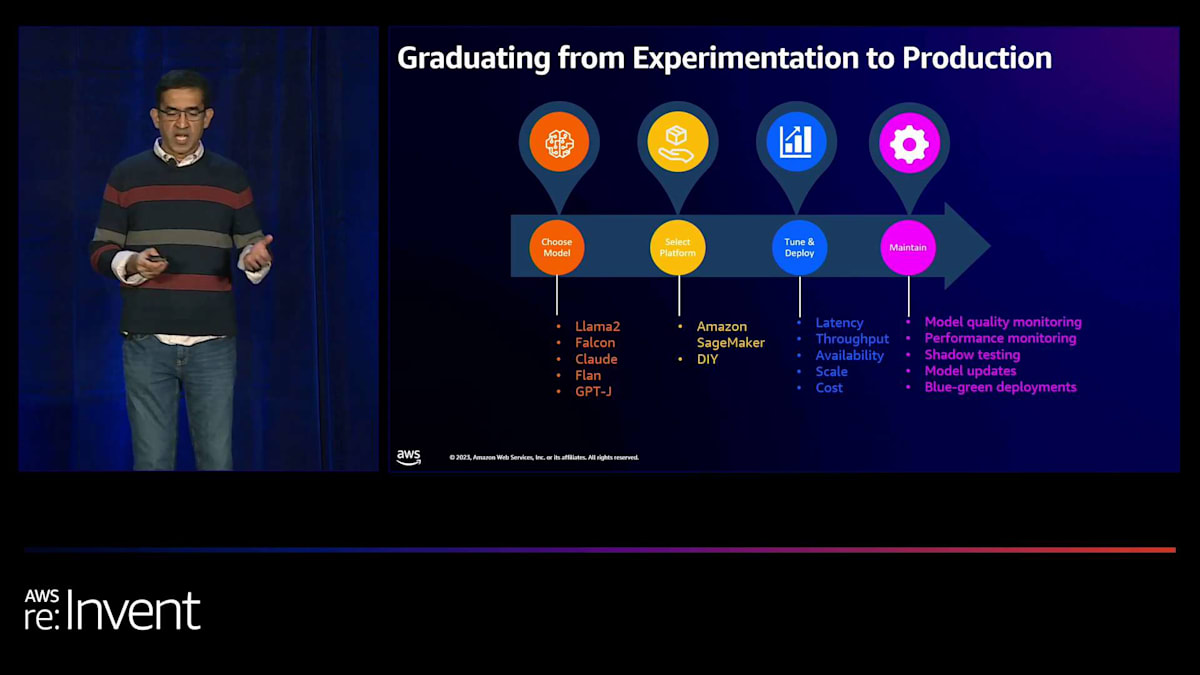
その後、次の一連のステップは、モデルを本番環境にデプロイし、アプリケーションや製品に大規模に統合することです。まず、SageMakerのような適切なモデルデプロイメントプラットフォームを選択します。次に、パフォーマンス目標を達成するためにデプロイメントをチューニングする必要があります。これらの目標には、レイテンシー、スループット、スケールが含まれる可能性があります。もちろん、コストも最小限に抑えたいでしょう。開発環境でレイテンシー、スループット、コスト目標を達成するためのパフォーマンスチューニングが完了したら、テスト環境や本番環境にモデルをデプロイするためのCICDパイプラインをセットアップしたいと思うでしょう。
最後に、モデルをデプロイしたら、本番環境でそれらを維持したいと思います。つまり、モデルの品質をモニタリングし、引き続き良好なパフォーマンスを発揮していることを確認したいと思います。そして定期的に新しいバージョンでモデルを更新したいと思います。この更新が行われる際、本番デプロイメントに影響を与えずに行いたいと考えます。
生成AIアプリケーションにおける複雑性、パフォーマンス、コストのトリレンマ

この旅を進むにあたり、generative AIアプリケーションを展開する際に最高のパフォーマンスを最低コストで達成するために、3つの要因のバランスを適切に取る必要があります。これらの3つの要因とは、複雑性、パフォーマンス、そしてコストです。複雑性は、モデルのサイズ、あるいは複数のモデルのアンサンブルを展開する場合、または一連のモデルを一緒に展開したい場合に現れます。コストは重要な考慮事項であり、モデルのホスティングコストだけでなく、運用上のオーバーヘッドも最小限に抑えたいところです。そして、パフォーマンスがあります。インタラクティブなアプリケーションを構築している場合、推論の遅延を数ミリ秒まで最小化したいでしょう。アプリケーションが何百万人ものエンドユーザーにサービスを提供している場合、推論の高いスループットを達成したいと考えるでしょう。
これらの3つの要因、つまりコスト、パフォーマンス、複雑性は、しばしばトリレンマを引き起こします。これは、これらの要因のうち2つを自由に選択できますが、3つ目の要因の最適化が難しくなることを意味します。例えば、非常に大規模なモデルを展開し、非常に厳しい遅延とスループットの要件がある場合を考えてみましょう。これらのモデルを非常に強力な加速計算インスタンス、つまりGPUベースのインスタンスに展開する必要があり、コストが非常に高くなってしまいます。

これらの課題について、foundation modelからの推論コストから詳しく見ていきましょう。foundation modelから推論を得る上で最も困難な計算ステップは、実行しなければならない大規模なベクトル行列および行列行列の乗算です。これらの計算を効果的に実装するために、foundation modelは推論にGPUなどのアクセラレータを必要とします。GPUは高価です。例えば、m1.P4d.24xlargeインスタンスは1時間あたり約38ドルかかり、より強力なm1.P4de.24xlargeインスタンスは1時間あたり47ドルかかります。Llama 2をP4インスタンスで大規模に展開すると、月に50,000ドル以上のコストがかかる可能性があります。
これらのコストは急速に積み重なっていきます。概算で計算してみると、Llama 2モデルをP4dインスタンスに展開すると、確かにそのような高額な月間経費になることがわかります。これは、foundation modelの大規模展開に必要な多額の財政投資を浮き彫りにしています。
本番環境での基盤モデル統合におけるパフォーマンス要件と課題

次に、本番環境でアプリケーションに基盤モデルを統合する際のパフォーマンス要件について見ていきましょう。チャットボットなどの対話型アプリケーションでは、モデルは数秒以内、可能であればミリ秒単位で応答を開始する必要があります。モデルからの完全な応答に数秒かかる場合でも、モデルからトークンのストリーミングを開始し、ユーザーに表示してエンゲージメントを維持したいものです。また、推論の生成にかかる時間はプロンプトによってかなり異なります。そのため、モデルに送信するトラフィックを複数のモデルコピーに分散させる必要があります。
モデルを本番環境にデプロイした後は、定期的に更新したいものです。その際、アプリケーションを停止させたくありません。24時間365日利用可能であることが求められます。これを実現するには、新しいモデルを含む全く新しいデプロイメントスタックを立ち上げ、古いモデルから新しいモデルにトラフィックを切り替える必要があります。そのためには、これらの更新時に2倍のインスタンス数が必要になります。GPUの供給が不足している状況では、これはかなり困難な課題となります。また、モデルを本番環境にデプロイした後は、インスタンスを常時監視し、GPUに障害が発生した場合は迅速に交換する必要があります。これは、アプリケーションのダウンタイムを最小限に抑えるために重要です。

Amazon SageMakerが提供する多様な推論オプションとその利点
これらの課題に効果的に対処するには、推論用のモデルをホストするための非常に堅牢なプラットフォームが必要です。特にこれらの大規模言語モデルをホストするためのプラットフォームを自前で構築・管理しようとすると、イノベーションのペースを妨げかねない多大な労力が必要になります。そのため、Amazon SageMakerのようなマネージドデプロイメントサービスを利用すべきなのです。


SageMakerは、あらゆるユースケースに対応する最も幅広い推論オプションを提供します。SageMakerを使用すると、モデルをエンドポイントの背後にデプロイし、そのエンドポイントをRESTful APIコールでペイロードと共に呼び出し、その呼び出しに対する推論を応答として取得できます。超低レイテンシーの予測にはSageMakerのリアルタイム推論を使用したり、大規模データセットのオフライン推論にはバッチ変換を使用したりできます。推論に大きな画像ファイルやビデオを使用して予測を実行する必要がある場合や、推論の実行に長時間かかる可能性がある場合、SageMakerの非同期推論オプションを使用できます。
SageMakerを使用すると、単一のモデルまたは複数のモデル(最大数千のモデル)を単一のエンドポイントの背後にデプロイできます。また、前処理と後処理のステップを推論ステップと一緒にSageMaker上でシリアル推論パイプラインとして共同デプロイすることもできます。インフラストラクチャレイヤーでは、CPUやGPU、AWS Inferentia、AWS Gravitonベースのインスタンスにモデルをデプロイするか、完全にサーバーレスを選択することができます。つまり、SageMakerを使用すれば、ユースケースに適したモデルホスティングオプションを得られるだけでなく、最低コストで最高のパフォーマンスを実現できるのです。

SageMakerによる基盤モデルのデプロイコスト削減手法
次に、SageMakerが基盤モデルのデプロイコストを削減するのにどのように役立つかを見てみましょう。SageMakerの3つの主要な機能について詳しく説明します。まず、同じインスタンス上に複数のモデルをデプロイでき、これらのモデルはインスタンス上で利用可能なハードウェアリソースを共有できるため、コストを削減できます。次に、AWS InferentiaやAWS Trainiumベースのインスタンス上にSageMakerでモデルをデプロイできます。これらのインスタンスは、同等世代のGPUベースのインスタンスと比較して最大40%優れた価格性能比を提供します。SageMakerのもう一つのコスト削減機能は、動的オートスケーリングです。トラフィックに基づいてエンドポイントの背後にあるインスタンスを動的にスケーリングするオートスケーリングポリシーを設定できます。これにより、必要な時にのみインスタンスを追加し、トラフィックが少ない時にはスケールダウンしてコストを削減できます。これらの機能についてさらに詳しく見ていきましょう。
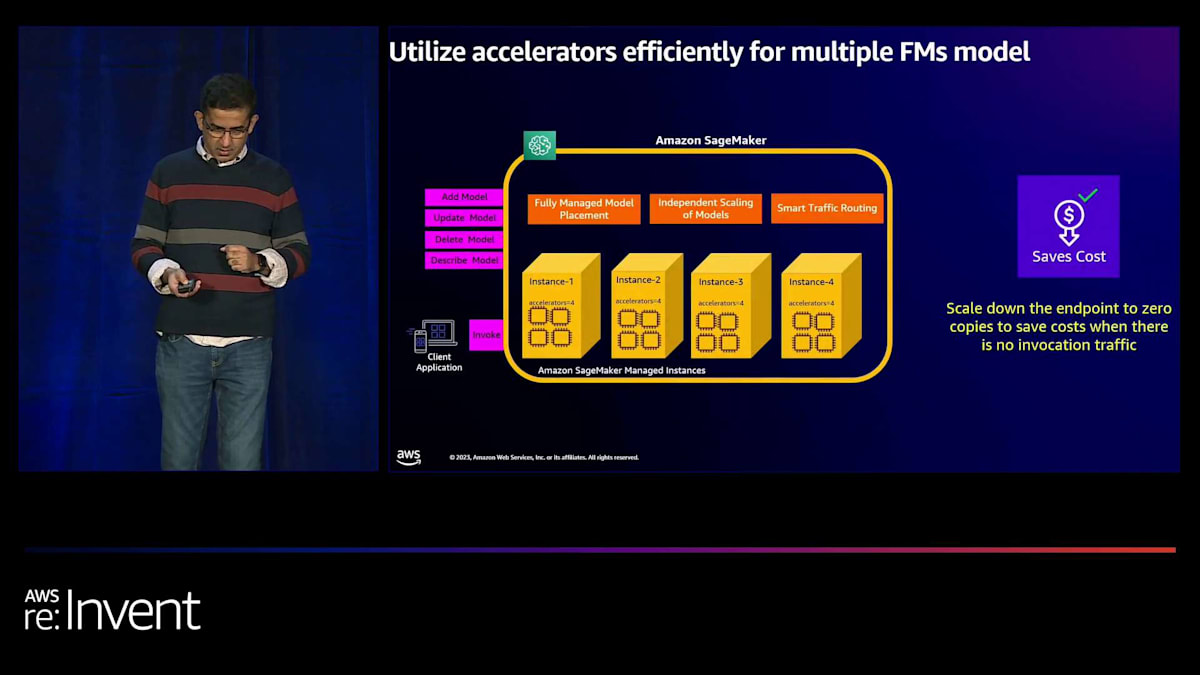
Amazon SageMakerを使用すると、単一のインスタンス上に複数のモデルをデプロイして、モデル間でインスタンスのリソースを共有し、モデルごとにコンピューティングとメモリリソースを割り当てることができます。例えば、1つのインスタンスに8つの異なるモデルをデプロイすると、モデルあたりのコストは8分の1で済みます。各モデルに対して、固定数のアクセラレータやメモリを割り当てることができます。また、既存のエンドポイントにモデルを追加し、各モデルへのトラフィックに応じて個別にスケールアップやスケールダウンを行うこともできます。

SageMaker は、設定された自動スケーリングポリシーに基づいて、モデルのコピーを自動的に追加したり削除したりします。SageMaker がこれらの処理を行う際、新しいインスタンスを追加する前に、利用可能なすべてのアクセラレーターを使用して効率的にモデルをビンパッキングします。同様に、スケールダウン時には、利用可能なインスタンスにできるだけ多くのモデルを詰め込むように効率的にデフラグメンテーションを行います。 SageMaker には、エンドポイントへのトラフィックを非常に効率的にルーティングするスマートルーティングアルゴリズムも含まれています。大規模な環境では、このスマートルーティングアルゴリズムがモデルのどのコピーがトラフィックを処理しているかを追跡し、それに応じて新しいリクエストをルーティングします。これにより、エンドツーエンドのレイテンシーを20%以上削減できます。

AWS Inferentia ベースのインスタンスにモデルをデプロイすることで、さらにコストを削減できます。 先ほど述べたように、これらのインスタンスは、同等世代のGPUベースのインスタンスと比較して、最大40%のコストパフォーマンスの向上を提供します。SageMaker では、この利点は同じインスタンスに複数のモデルをデプロイする機能と組み合わさります。つまり、SageMaker では Inferentia ベースのインスタンスに複数のモデルをデプロイし、両方の利点を得ることができるようになりました。Inferentia ベースのインスタンスにモデルをデプロイするには、Neuron SDK を使用してモデルをコンパイルする必要があります。SageMaker で Inferentia ベースのインスタンスへのモデルのデプロイを非常に簡単にするために、SageMaker はエンドポイントのセットアップ時に自動的にモデルをコンパイルします。
SageMakerのLarge Model Inference (LMI)コンテナがもたらす最適化

次に、SageMaker が Generative AI アプリケーションでインタラクティブなユーザーエクスペリエンスを作成する方法について説明しましょう。例えば、お客様のお気に入りの目的地への3日間の旅行プランを立てるのを支援するチャットボットを構築しているとします。チャットボットが全体のプランを生成するまでウェブページを空白のままにしておくと、数分かかる可能性があり、お客様は興味を失ってしまうかもしれません。そこで SageMaker は、モデルがレスポンスを生成する際に、トークンが生成されるたびにモデルからレスポンスをストリーミングで返す機能を提供します。



多くの場合、基盤モデルは非常に大きいため、 単一のアクセラレーターやインスタンス上の単一のGPUに収まりきらないことがあります。その結果、非常に大きなモデルを単一のアクセラレーターにデプロイできない可能性があります。 たとえアクセラレーターにかろうじて収まるモデルであっても、大規模な環境で低い推論レイテンシーを達成するのは困難でしょう。 そのため、モデルを並列シャードに分割し、インスタンス上の複数のアクセラレーターにわたって推論を実装する必要があります。レイテンシーを改善するために、モデルの重みと活性化関数を浮動小数点演算のままにするのではなく、int16 や int8 の量子化に変換することもあります。

推論を高速化するもう一つの技術は、モデルがデプロイされる特定のインスタンス用にモデルをコンパイルすることです。しかし、これらの最適化技術を実装するには、多大な時間と専門的なスキルセットが必要であり、そのような人材を見つけるのは困難です。そこで SageMaker は、最先端の最適化技術のすべての利点を単一のコンテナにパッケージ化しました。それが Large Model Inference (LMI) コンテナです。このコンテナには、最高のコストパフォーマンスを達成するためにモデルを自動的に最適化およびデプロイするのに役立つライブラリやツールが詰め込まれています。
LMIコンテナに搭載された最新機能をいくつかご紹介します。LMIコンテナには、DeepSpeedなどのライブラリが含まれており、分散推論のためにモデルを自動的に並列化します。最新のLMIコンテナには、NVIDIAのTensorRT LLMライブラリも含まれており、GPU間通信を高速化してレイテンシーを改善する追加の改良が施されています。TensorRT LLMを使用したモデルのコンパイルを容易にするため、コンテナにはコンパイルプロセスを簡素化する低コードインターフェースが含まれています。必要なのは、モデルIDといくつかのオプションのモデルパラメータを指定するだけで、TensorRT最適化モデルを構築するために必要な重要な作業はすべてLMIコンテナによって管理されます。LMIコンテナは連続バッチ処理もサポートしています。

この推論リクエストの連続バッチ処理によりスループットが向上します。さらに、GPTQ、AWQ、SmoothQuantなどの最新の量子化技術を活用できます。これらはすべてLMIコンテナですぐに利用可能です。SageMaker上のLMIコンテナを使用することで、お客様は大規模言語モデルを最適化し、クラス最高の価格性能比を実現できます。
SageMakerを活用した本番環境でのモデル更新とメンテナンス

例えば、SageMaker上のLMIコンテナを使用してLlama 2 70億パラメータモデルをデプロイする場合、以前のバージョンのコンテナと比較して、推論レイテンシーが最大33%低下し、スループットが60%向上します。では、デプロイ後のメンテナンスについて話しましょう。 モデルを本番環境にデプロイした後、新しいバージョンや、さらに微調整されたバージョンで定期的に更新したい場合があるでしょう。SageMakerを使用すれば、本番トラフィックに影響を与えることなく、また更新中に2倍のインスタンス数を必要とせずに、安全に本番環境のモデルを更新できます。
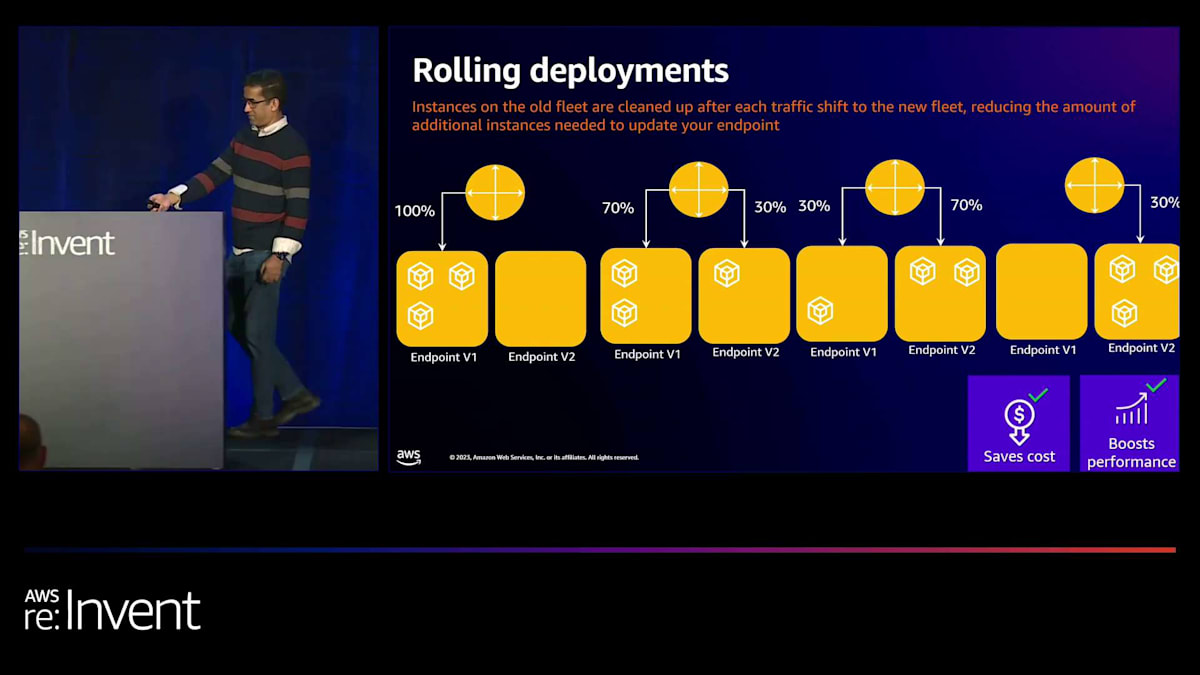
SageMakerのローリングデプロイメント機能を使用すると、トラフィックを古いモデルから新しいモデルへ、1インスタンスずつシフトさせることができ、新しいモデルにトラフィックがシフトするにつれて古いフリートをクリーンアップします。これにより、モデル更新に必要な追加インスタンス数を最小限に抑えることができます。SageMaker上で本番レベルの基盤モデルのデプロイを実現し、数時間で生成AIアプリケーションを本番環境にロールアウトすることがいかに簡単かを示すために、ここで同僚のRamaを紹介します。Ramaが実際のSageMakerの動作をお見せします。
CiscoのWebExチームによるSageMaker活用事例:通話要約ユースケース
Venkyが指摘した利点をご紹介いただき、ありがとうございます。 また、SageMaker上で大規模言語モデルをデプロイすることがいかに簡単かをデモでお見せします。挙手でお聞きしますが、ここにいる方々の中で、SageMakerやEC2インスタンスで大規模言語モデルをデプロイした経験がある方はどれくらいいらっしゃいますか?かなりの数の方がいらっしゃいますね。では、より迅速な実験から始めましょう。SageMakerを活用しているお客様は、機械学習の概念やアイデアを本番環境に移行するのにかかる時間を短縮できると言っています。これは、お客様が迅速に行動できるような包括的なツールとモデルのセットを提供しているからです。
例えば、要約のユースケースがあるとしましょう。Llamaモデル、FLAN-T5モデル、Falconモデルなどを使って、すぐにユースケースをテストできるはずです。多くの方がLLMのデプロイを経験されていると思いますが、それには多くの作業が伴います。どのコンテナを使うべきか、モデルをシャーディングする必要があるか、どのライブラリを使うべきかなどを考えなければなりません。今日、私たちはこれらすべてを簡素化する開発者向け機能をリリースしました。SageMakerのためのモデルのパッケージング方法、使用するコンテナ、最適化戦略などを心配する必要のないデモをお見せします。

より迅速な実験のためには、これらの大規模言語モデルを手元に置くことが重要です。私たちにはSageMaker JumpStartというモデルハブがあり、そこにはすべての人気のあるオープンソースおよびクローズドソースのモデルがあります。数回クリックするだけで、これらのモデルをSageMakerにデプロイでき、一部のモデルではファインチューニングも可能です。Venkyが話したような異なる推論オプションを持つことは、コストを下げるために非常に重要です。ある顧客は、顧客ごとに1つのモデルを持つ、数万のモデルを持つパーソナライゼーションのユースケースを持っていました。そのような場合、10,000のエンドポイントをデプロイするのはコスト的に禁止的です。そこで、マルチモデルエンドポイントが必要になります。より少ないエンドポイントで背後に複数のモデルを持ち、SageMakerがモデルのロードの魔法を処理します。
ユースケースに応じて、マルチモデルエンドポイントやリアルタイムエンドポイントなどのオプションが必要で、これによりコストを下げることができます。また、これらのLLMの多くはアクセラレータを必要とするため、NVIDIAインスタンス、AmazonのInferentiaやTrainiumへのアクセスが全体的なコストを下げるために重要です。多くのLLMがアクセラレータを使用するため、これらのアクセラレータを効率的に使用することが重要です。Venkyが示したように、NVIDIA P4dは1時間あたり約38ドルかかります。では、これをどのように効率的に使用するのでしょうか?モデルをGPUにピン留めする必要があります。例えば、Llamaモデルが4つのGPUを使用する場合、4つのGPUにモデルをピン留めし、残りのGPUは他のモデルに使用できるようにする必要があります。SageMakerがこの重労働を代わりに行います。
あなたがすべきことは、そのモデルに何個のアクセラレータを接続したいかを指定するだけで、私たちが裏側で処理します。
私たちは、これらのライブラリと最適化をすべて含むLarge Model Inference (LMI)コンテナについて話しました。これらを簡単に推論に使用できます。モデルのレイテンシーは、コンテナ内で時間が費やされる主要な部分です。そのコンテナを非常に鋭く効率的にすることが非常に重要です。これにより、より高いスループットと低いレイテンシーを実現できます。また、スマートなトラフィックルーティングも行っています。モデルコピーが十分なトラフィックを受け取っていない場合、そのインスタンスにリクエストを送ることを知っています。このような知能がすべてSageMakerに組み込まれています。「ラウンドロビンを使うべきか、それとも他の方法を使うべきか」などを心配する必要はありません。最適化されたルーティングを私たちが代わりに処理します。


最後に、コンプライアンスはしばしば見過ごされがちです。 FedRAMP、HIPAA、SOCなどのコンプライアンスプログラムに準拠する必要がある場合、これを管理するには多くのリソースが必要で、差別化されない重労働を行わなければなりません。SageMakerは、これらのコンプライアンスを最初から備えており、そのメリットを活用してコストを削減できます。これらがいくつかのメリットです。
次に、コストについて少しお話ししましょう。SageMakerを使用する場合と、KubernetesやAmazon EKSなどで独自のプラットフォームを構築する場合のコストを比較したいと思います。SageMakerでは、コンピューティングインスタンス、ストレージ、ネットワークを含む少しのインフラコストがあることがわかります。独自のプラットフォームを管理している場合、インフラコストと運用コストがかかります。これは、インフラの維持管理に人員が必要な部分です。パッチ管理、インスタンスに問題が発生した場合の交換方法など、システムの新機能の構築や維持管理のために人員が必要です。つまり、多くの重労働を行う必要があるのです。さらに、セキュリティとコンプライアンスのための様々な機能が必要です。コストがすぐに積み重なっていくのがわかりますが、SageMakerを活用しているお客様は、以前のDIYシステムと比較してコストを50%削減できたと言っています。

では、デモに移りましょう。このデモでは、2つのバージョンをお見せします。1つはNotebookを通じたものです。 多くの人がNotebookを使用することを好みます。データサイエンティストやMLエンジニアであれば、コードを使用したいでしょう。そのバージョンをお見せします。また、UIを使用して大規模言語モデルをデプロイできるUIバージョンもお見せします。Notebookでのデプロイは3つのステップからなるプロセスです。まず、スキーマビルダーを作成します。ここでは基本的に、サンプルの入力プロンプトとサンプルの応答を渡します。これは、どのシリアル化を使用するかを判断するためです。ユーザーとしては、どのシリアル化を使用すべきか心配する必要はありません。さらに、モデルがデプロイされた後にエンドポイントをテストするためにも使用します。
2番目のステップは、ModelBuilderクラスを活用することです。ここでモデルを指定できます。カスタムモデルの場所を指定できます。例えば、モデルを構築した場合、これはXGBoostやscikit-learnなどを使用した表形式モデルや古典的なモデルかもしれません。LLMモデルでも構いません。カスタムモデルを使用している場合は、それをS3に置いて、ここでそのパスを参照します。また、Hugging FaceのモデルIDを渡すオプションも提供しています。Hugging Face hubを閲覧していて、テストしたいモデルを見つけた場合、そのモデルIDをコピーしてここに渡すことができます。あるいは、Amazon SageMaker JumpStartのモデルIDをここで使用することもできます。そして、スキーマビルダーのロールを渡します。buildを呼び出すと、裏側で魔法が起こり、適切なコンテナ、適切なパッケージング構造、シリアル化などを判断します。つまり、SageMakerがどのようなパッケージングを必要とするかを理解するための学習曲線が非常に小さくなります。その複雑さは今や抽象化されています。最後に、モデルをデプロイして予測を実行できます。

実際の動作をお見せしましょう。このデモでは、Amazon SageMaker examplesのサンプルの1つを活用しています。 これは皆さんがアクセスできるGitHubリポジトリです。様々な機能に対する複数の例があります。推論だけでもセクションがあり、多くの機能に対する例を見つけることができます。ここからmodel builderの例を取り上げ、Amazon SageMaker Studioで実行してみます。
これを実演するために、AWS Consoleに移動し、そこからSageMaker Studioに進みます。 Studioには私用のプロファイルが設定されているので、それを使用します。プロファイルがない場合でも、すぐに設定できます。これでSageMaker Studio Consoleに移動します。 これは最近リリースした新しいコンソールです。複数の統合開発環境(IDE)から選択できるようになっています。今回の例では、JupyterLab Notebookだけが必要なので、JupyterLabをクリックして起動します。
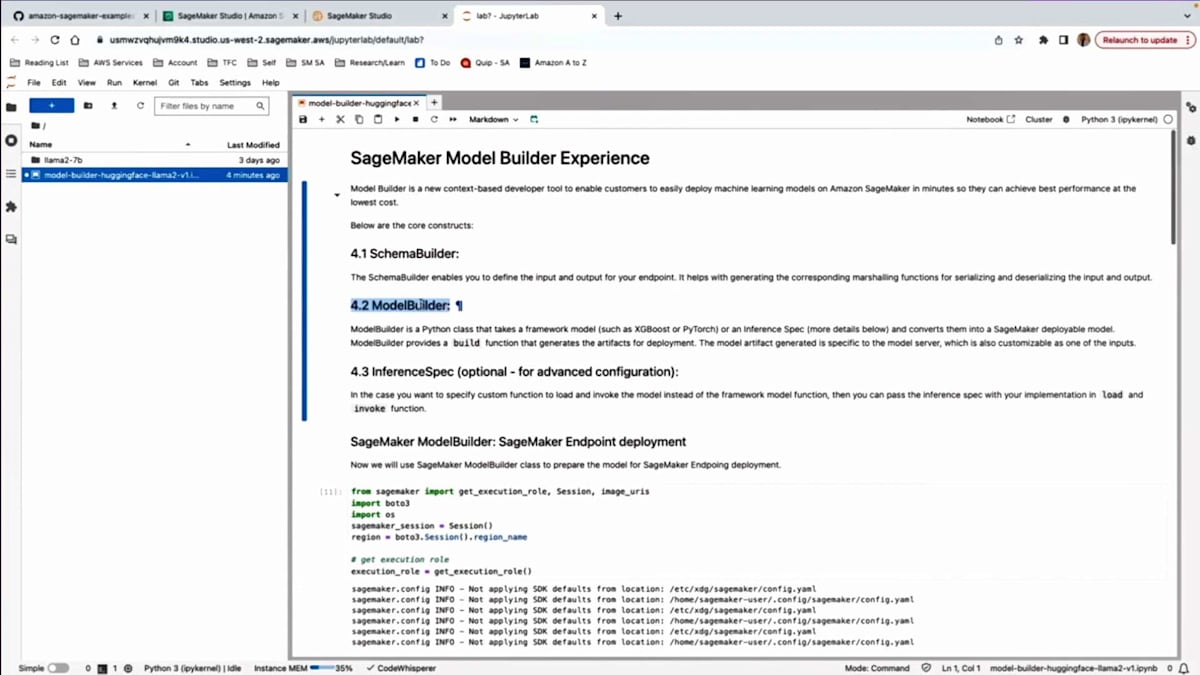
時間の都合上、すでに用意してあるNotebookを使用します。 openをクリックすると、JupyterLabのNotebookが表示されます。実行したいサンプルはすでにアップロードしてあります。お見せしたGitリポジトリ全体をクローンして、さまざまな例を試すこともできます。このデモでは、知っておくべき3つの主要な構成要素について説明します。1つ目はSchemaBuilderとその活用方法、2つ目はModelBuilderクラスとその使用方法です。 3つ目のステップでは、load関数やinvoke関数をオーバーライドしたい場合などの高度なユースケースを扱います。ModelBuilderを使ってこれらを行う方法をお見せします。

まず、基本的なインポートから始めます。SageMakerライブラリをインポートし、必要な実行ロールを取得します。これらは始める際に必要な基本的なものです。最初のステップは、サンプルプロンプトの作成です。テキスト生成のユースケース用のプロンプトがあります。大規模言語モデルにDiamondback Terrapinについてさらにテキストを生成してもらいたいと思います。これをSchemaBuilderでラップします。 これをModelBuilderに渡すことができます。サンプルに基づいてどのシリアライゼーションを使用するかを判断します。以前はユーザーが手動で提供する必要があり、ユーザー体験が良くありませんでした。私たちはこの複雑さを抽象化したいと考えています。
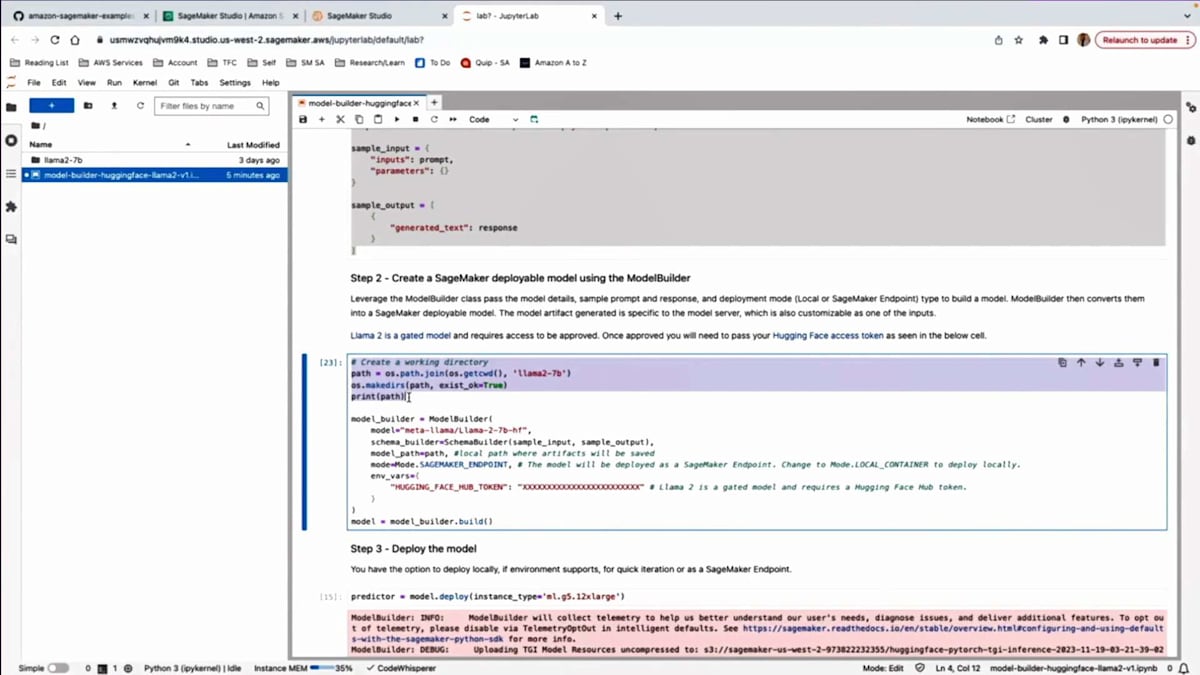
2つ目のステップは、ModelBuilderの活用です。 ここでは、ModelBuilderがすべてのアーティファクトを組み立て、パッケージ化するためのサンプル作業ディレクトリを作成しています。次に、ModelBuilderクラスを使用し、モデルIDを渡します。この場合、Hugging Face hubからLlama-2-7bモデルをデプロイしています。モデルIDを指定するだけです。ここでSchemaBuilderとサンプル作業ディレクトリも渡します。モードも指定できます。これは重要な側面です。モデルをリモートエンドポイントの別のインスタンスにデプロイするか、実験中で素早く行いたい場合は、Notebook自体にローカルでデプロイすることもできます。ただし、Notebookに必要なリソースがあり、Dockerをサポートしている必要があります。

最後に、model.buildを呼び出します。 ここで魔法が起こります。モデルに基づいて適切なコンテナを選択し、SageMakerが必要とするパッケージング構造を処理し、先ほど言及したシリアライゼーションを管理します。これらの重要な作業がすべてこの1行のコードで行われます。以前は、これらの詳細をすべて事前に知っておく必要がありましたが、今では抽象化されています。これにより、パッケージが作成され、モデルのデプロイの準備が整います。
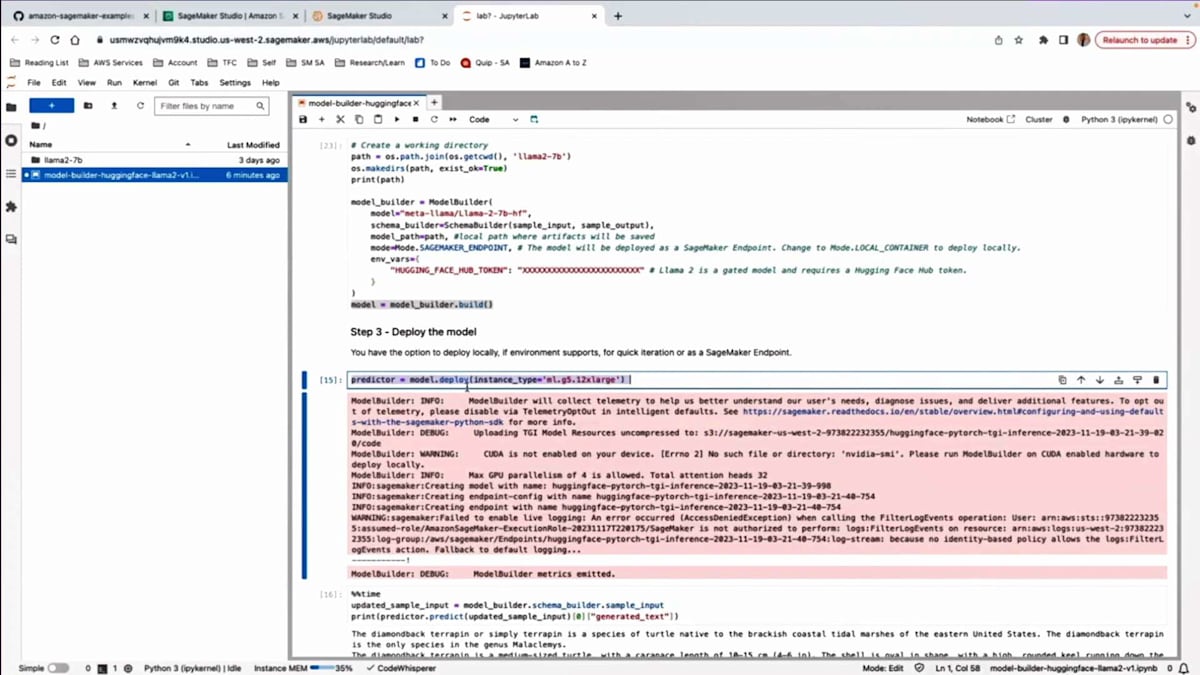
model.deployを呼び出すことでモデルをデプロイできます。必要なインスタンスタイプを指定します。そのエンドポイントの背後に配置したいインスタンス数も指定できます。数分以内にエンドポイントが立ち上がり、使用可能になります。このセルでは、SchemaBuilderで使用したのと同じプロンプトを使って予測を実行しています。ご覧のように、モデルはDiamondback Terrapinについて、その生息地が米国東部であることや種の詳細、その他の情報など、より多くの情報を提供しています。これは、大規模言語モデルに対して推論を素早く実行できることを示しています。必要に応じて、試したい異なるプロンプトで実験することができます。

そして同じ実験で、もしこれで十分でない場合は、Llama 2モデルを変更したいかもしれません。必要なのは、そこでモデルIDを変更するだけです。130億パラメータのモデルなどを使用して、素早く実行できます。大規模言語モデルで簡単に実験できることがわかります。高度な設定のユースケースでは、loadとinvoke関数をオーバーライドし、独自のコードを渡して推論仕様オブジェクトを使用し、それをmodel builderに渡すと、使用したいコードが尊重されます。

最後に、ここでエンドポイントなどをクリーンアップします。これがNotebook体験です。3つのステップで、いかに簡単にLLMをデプロイできるかがわかります。コードを扱いたくない場合や、UI体験が欲しい場合は、その方法をお見せします。では、UIでの操作方法に移りましょう。ここで、最初にいたstudioコンソールに戻ります。
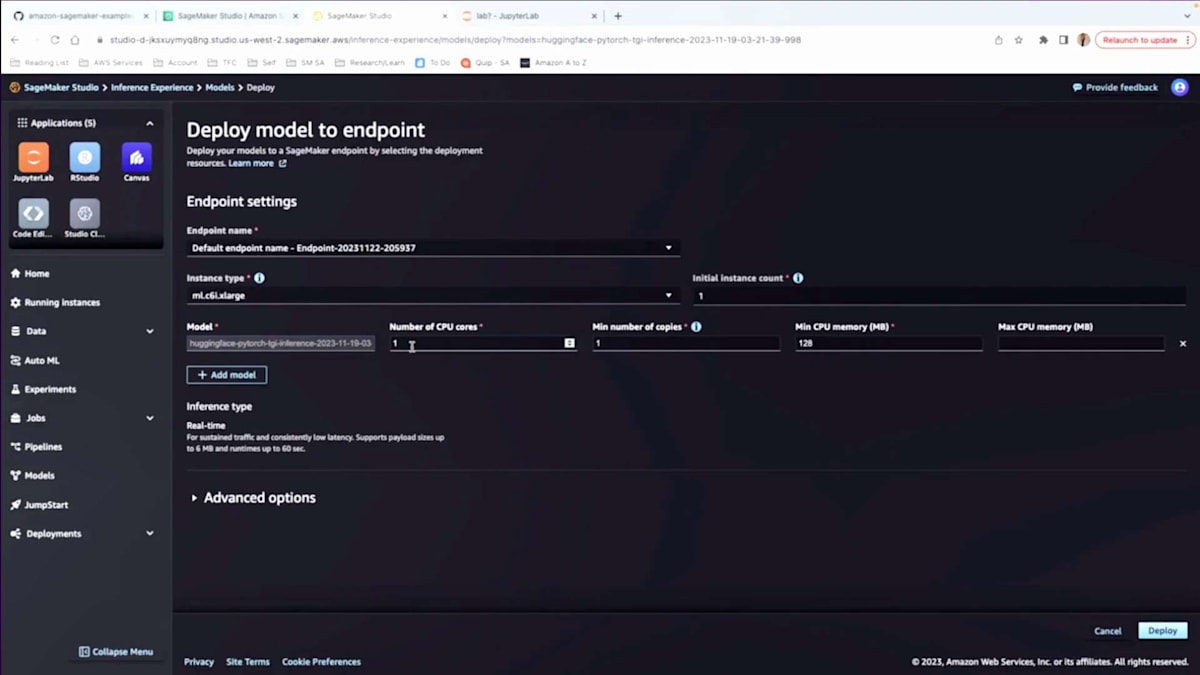
そこで「models」をクリックします。デプロイ可能なモデルを作成できます。作成時には、コードで渡したのと同様の情報を入力するよう求められます。最後にデプロイ可能なモデルを作成でき、バックグラウンドでパッケージングなどを行います。作成後、モデルをデプロイできます。私はすでにいくつか作成済みです。「Deploy」をクリックすると、バックグラウンドでモデルのベンチマークがある場合、どのインスタンスタイプを使用すべきか教えてくれます。一部の人気のあるモデルでは、「どのインスタンスを使うべきか」を心配する必要さえありません。ベンチマークがあるので、教えてくれます。CPU要件などの詳細も教えてくれます。そしてモデルをデプロイし、UI自体でテストできます。モデルをデプロイするには、NotebookオプションとUIオプションの2つがあることがわかります。
Flan T5 Foundation Modelの選択とSageMakerを活用した実装

ここで、SageMakerを活用した彼らの経験について、Travisに話してもらいましょう。「はい、ご紹介ありがとうございます。私はTravisと申します。CiscoのWebEx事業部門のCollab AIというチームで働いています。私たちのチームの責任は、WebExエコシステムの機能にAI機能をもたらすサービスを開発することです。私たちが扱っている規模感を理解していただくために、CiscoのWebExのマーケティング資料から選んだいくつかの指標をご紹介します。ご覧のように、1ヶ月あたり4000万件の月間ミーティングがあります。これらのミーティングで合計7億6000万時間のミーティング時間があり、40億件のメッセージがやり取りされています。これらのミーティングには、1対1のミーティング、大規模なチームミーティング、セミナー、ウェビナーなどがあります。メッセージには、チームが互いに協力するための大規模なスペース、1対1のスペース、単なるアナウンスメントスペースなどがあります。
確かに、その全ての情報を理解する必要はありませんが、お客様がWebExプラットフォームをどのように使用しているかについて、より良い洞察を得るために、AI、ML推論を通じてどれだけの情報を処理する必要があるかについて、ある程度の概念が得られます。これは、AIとML機能を構築するために使用しているデータソースの種類の一例に過ぎません。私たちにはコンタクトセンタープラットフォームもあります。セキュリティビジネスもあります。このような膨大な情報量を扱う際に、効果的かつコスト効率よくスケールすることがいかに重要であるかがお分かりいただけると思います。

それでは、研究と実験にSageMakerプラットフォームをどのように活用しているかについて少しお話しします。 開発者が新機能を迅速に反復し、新しいモデルを試し、評価し、比較できるようにする方法についてお話しします。また、取り組んできた特定のユースケースについても少しお話しします。これは、コンタクトセンタープラットフォームからの通話の要約です。そして、RamaとVenkyがプレゼンテーションの中で話した内容を活用して、私たちのサービスに将来加えられる改善点についてお話しします。

まず、実験と統合について話したいと思います。左側の図の重要な要素は、必ずしもStudio自体ではありません。JumpStartカタログが描かれているのがお分かりいただけると思います。JumpStartカタログは、私たちのチームがモデルを選択し、それらを迅速に展開する方法を提供してくれるという点で、非常に価値があります。チームは自分たちでテストできるだけでなく、推論リクエストを行うアクセス権を与えることで、モデルのパフォーマンスと動作を確認することができます。さらに、これらのモデルは、開発環境でモデルと統合されたアプリケーションを展開できる場所にも配置されています。これにより、コストを少し節約し、より効率的に使用することができます。また、アプリケーションでモデルを使用する際、実際に自分たちがアクセスしている時と同じように動作することを確認できます。
しかし、私たちにとってより大きな利点は、カタログの規模そのものです。利用可能なモデルの数だけでなく、JumpStartカタログが推論コンテナを選択するために必要な情報と共に、試すことができる全てのモデルを提供してくれることです。これにより、全ての決定を自分たちで行わなくても、両者を組み合わせてAIとMLモデルを展開し、サービスを開始することができます。さらに、同僚たちが先ほど話したように、Amazon SageMaker Notebooksは非常に価値があります。私たちのチームにはML実践者とMLエンジニアがおり、これは彼らが研究、テスト、開発、実験に使用するのを好む非常に馴染みのあるツールです。

この通話要約ユースケースに関する要件について少しお話しします。 その一つは、明らかにこの特定の問題に対する大規模言語モデルの適合性を評価できる必要があるということです。特定のユースケースに対して十分に正確で、十分なパフォーマンスを発揮するモデルを選択するだけでは不十分です。また、それらのモデルに適したコンピューティングリソースを選択し、ユースケースを実際に提供するためのコスト効率の良いモデルとコンピューティングリソースの組み合わせを得る必要があります。さらに、これをグローバルに展開できる必要があります。Amazonは、コスト効率の良い方法でグローバルに展開することを非常に容易にしてくれますが、実際に展開する全ての場所でローカライゼーションや規制要件を満たす必要もあります。
私たちは、ローカライゼーションや規制要件を満たすだけでなく、世界中のあらゆる地域で異なるスケーリング要件にも対応する必要があります。世界のある地域に多くの顧客が集中しているホットスポットがあるかもしれません。United Statesには多くの顧客がいますが、他の地域ではそれほど活動が活発ではありません。これらを可能な限り効率的に独立してスケールする良い方法が必要で、Amazon SageMakerを使えばそれが非常に簡単に実現できます。
先ほども申し上げたように、効果的にスケールする必要があります。ワークロードは1日や週を通じて変化します。日中は活動が活発で、夜間は落ち着き、そのような活動の波が地球上を移動します。平日の5日間は活発で、週末は落ち着きます。私たちは、自分たちで重労働をしてオペレーションのオーバーヘッドを負担するのではなく、SageMakerが提供するプラットフォームの機能を使って、いつどのようにスケールするかを決定したいと考えています。
最後に、コンテナのサービングとサービングコンテナの選択は、先ほども触れた通り、難しい問題です。ライブラリ、ツール、コンテナイメージのオペレーティングシステム、そしてこれらすべての要素を組み合わせて機能させるのは困難です。特にCUDA Librariesのバージョンは、私たちのチームに多くの苦労をもたらしました。SageMakerチームのおかげで、特定のモデルに適したコンテナを選択し、エンドポイントにデプロイすることが非常に簡単になり、多くの時間とエネルギーを節約できています。
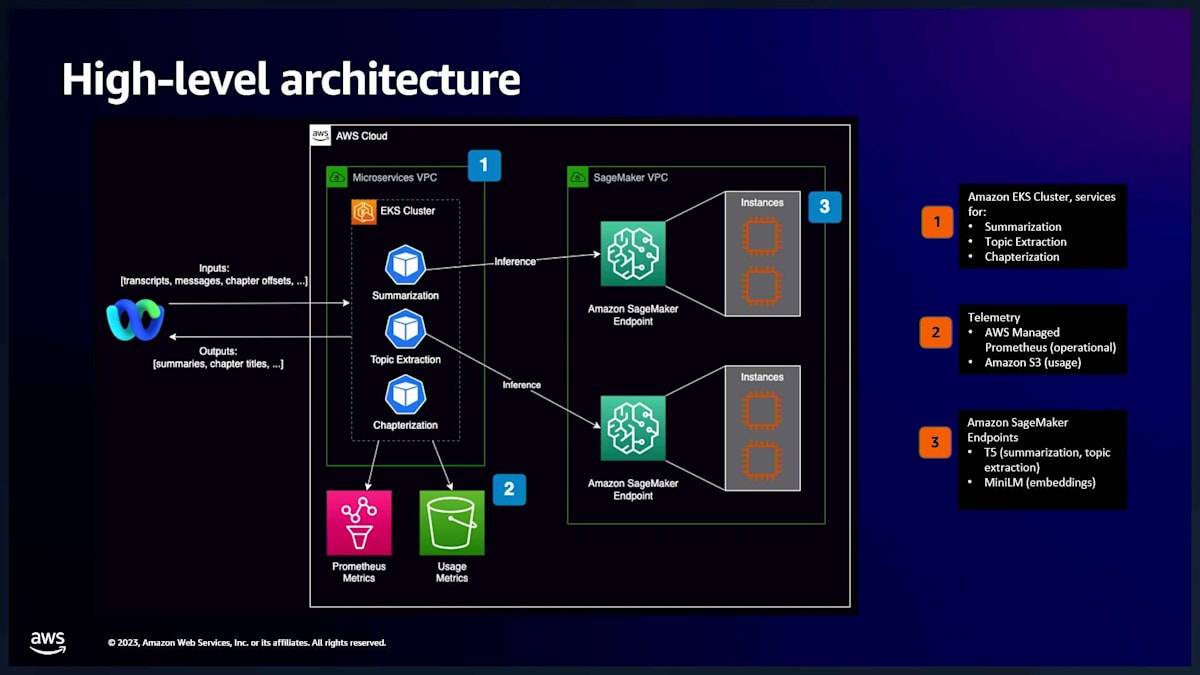

ここでは、先ほど言及したサービスのエコシステムの高レベルアーキテクチャをご覧いただけます。もちろん、これはコールサマリゼーション以外のユースケースも含んでいますが、私たちのアーキテクチャ全体がどのように組み合わさっているかを示したかったのです。左側にWebExアプリケーションがあります。サマリゼーション機能、トピック抽出機能、チャプター化機能があり、これらはAmazonエコシステムの様々なリソースや製品を統合しています。しかし、ここで重要なのは、SageMakerエンドポイントに対して推論を実行できることです。
これらのアプリケーションのいずれもが、これらのエンドポイントの1つを使用できます。ここには線で示されていませんが、特定の問題を解決するためにモデルのアンサンブルを行う場所もあります。これらのアプリケーションのいずれもが、これらのエンドポイントの1つを再利用できます。EKSボックス内のポッドの1つから2つのSageMakerモデルへの線を引き、SageMaker推論をどのように使用できるかを示す交差する線がたくさんあるかもしれません。これにより、自分たちでそのような作業を行う際に負担するオペレーションのオーバーヘッドの多くが削減されるだけでなく、非常に効果的に再利用できます。これらのAmazonサービス間の統合、特にAmazon EKSで実行されているポッドがSageMakerエンドポイントと通信できるようにすることは、非常に簡単です。

それでは、実装についてもう少し詳しくお話しします。当然ながら、通話の要約を行うために大規模言語モデルを選択しました。最終的に、Flan T5 Foundation Modelを選ぶことにしました。私たちのチームがこのモデルをファインチューニングしました。SageMakerのおかげで、このモデルのテストと検証が非常に簡単になりました。特に、異なる量子化を用いて複数の方法でデプロイできるようになったことが大きいです。これは以前は自分たちで行わなければならなかった作業でした。数分後に、SageMakerが将来的にこれをさらに容易にしてくれる改善点についてお話しします。
Flan T5 Foundation Modelを選んだ理由は、優れたパフォーマンス、高い精度、そして私たちにとって受け入れられるコストで良好なスループットを提供してくれたからです。SageMakerのエコシステムのおかげで、このソリューションの実装とデプロイが非常に簡単になりました。また、モデルの構築方法、アプリケーションへの統合方法、そして最終的に決定した内容の検証など、さまざまな組み合わせをテストすることができました。
モデル構成では、予測可能なパフォーマンスを得るためにAmazon SageMakerも活用しています。SageMakerエンドポイントを使用することで、効果的にスケールすることができます。先ほど説明したように、容量が必要な時にスケールアウトし、不要になればスケールバックすることができます。この点についても、後ほど改善できる点をお話しします。
Amazon SageMaker Auto Scalingを使用すると、モデルのパフォーマンスやアプリケーションの使用状況に関するメトリクスを簡単に確認できます。推論を提供するために必要な容量を確保し、不要になれば縮小することができます。また、Amazon SageMaker LMIコンテナを使用しています。LMIコンテナの構築は非常に難しい作業です。SageMakerチームがこの作業を行い、メンテナンスしてくれることは非常に価値があります。オペレーティングシステムだけでなく、ライブラリのアップデートも彼らが処理してくれます。新しいバージョンのサービングコンテナを取得し、異なるエンドポイントで並行して配置し、パフォーマンステストを行って比較することができます。
これらのモデルを推論サーバー上で比較し、互いの振る舞いを理解するための作業を行いましたが、コンテナイメージを構築してテストの準備をする手間をかけずに済みました。最後に、最適なコストで開発者のイテレーションを高速化できます。冒頭で開発環境での再利用について触れましたが、アプリケーションがエンドポイントを使用し、開発者も同じエンドポイントを使用できるようになっています。これにより、開発者が自分のマシンでモデルを実行する代わりに、私たちがデプロイして運用できるSageMakerエンドポイントを使用できるため、開発者の時間を大幅に節約できます。
アプリケーションを実行する際には、モデルをメモリにロードし、推論を実行し、その後シャットダウンするまでに起動時間がかかります。開発者がモデル自体を変更せずに、アプリケーションがモデルを使用する方法を変更したい場合、小さな変更であっても、推論の準備ができるようにモデルをメモリにロードするサイクル時間に縛られてしまいます。そこで、SageMaker endpointsを使用することで、開発者の労力とエネルギーを大幅に節約することができます。

SageMakerを活用したアーキテクチャとサービスの将来的な改善点
最後に、アーキテクチャとサービスに多くの改善を加えることができます。一つは、同じインスタンス上に複数のモデルをデプロイして、利用率を最大化することです。現在は単一モデルのendpointsを使用しています。過去にmulti-model endpointsを使用したこともありますが、操作したいモデルの中には適していないものもありました。また、asynchronous inferenceも試しましたが、この特定の問題に対する我々の規模では、asynchronous inferenceはあまり適していないとアドバイスされました。asynchronous inferenceは本当に大規模な用途を想定しており、我々の規模はそれに適していませんでした。
現在、複数のモデルがあり、bin packingと自動スケーリング機能、そしてshardingがあるため、特定のワークロードに必要なモデルのインスタンス数にモデルをスケールアウトできます。そのモデルのインスタンスが不要になった場合はスケールインさせることができます。何も起こっていない場合は、完全にゼロまでスケールダウンすることもできます。定期的に利用される小規模なモデルをベースラインとして用意しておき、それらのモデルを再度拡張する必要がある場合に備えて、一定の容量をウォームな状態で保持することができます。必要に応じて、SageMakerエコシステムがGPUを搭載した追加の基盤となるコンピュート容量を追加し、モデルの追加インスタンスを提供します。
現在は単一モデルのendpointsを使用しているため、常に少なくとも1つのモデルのコピーが存在します。ゼロにできれば本当に素晴らしいですね。これは近々、過去よりもはるかに簡単に実現できるようになります。この特定のユースケースでasynchronous inferenceに頼る必要もありません。最後に、Amazon SageMakerの開発者エクスペリエンスに関するこれらの改善点をすべて採用することができます。現在、チームには特定のserving libraryや特定のserving containerのモデル構築方法、パッケージング、バケットへの配置方法を非常によく理解しているスペシャリストがいます。
SageMaker ツールキットが重要な作業を代行してくれることで、私たちは単にアーティファクトを指定し、モデルを提供し、S3 バケットに配置するだけで済みます。そして、CI/CD に任せてエンドポイントのデプロイと運用を行わせることができるため、多くの時間とエネルギーを節約できます。ご清聴ありがとうございました。ここで Q&A セッションに移りたいと思います。
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion