re:Invent 2024: AWSチームがDynamoDBの設計思想と実装を解説
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - An insider’s look into architecture choices for Amazon DynamoDB (DAT419)
この動画では、Amazon DynamoDBのProduct Management DirectorのJoseph IdziorekとSenior Principal EngineerのAmrith Kumarが、DynamoDBの設計思想と実装の詳細について解説しています。DynamoDBが1秒あたり50万件を超えるリクエストを処理する大規模システムとして機能する仕組みや、予測可能な低レイテンシーを実現するための設計原則、高可用性を確保するための具体的な手法が紹介されています。特に、Warm Throughputの実装方法や、Global Tablesでの同期レプリケーション、On-demandの50%の価格引き下げなど、最新のアップデートについても言及されています。DynamoDBが採用する分散システムアーキテクチャの特徴や、マルチテナント環境での運用方法など、システム設計の核心に迫る内容となっています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
DynamoDBの設計思想と本セッションの概要

私はJoseph Idziorekです。AWSのすべての非リレーショナルデータベース、特にAmazon DynamoDBのProduct Management Directorを務めています。本日は、DynamoDBのSenior Principal EngineerであるAmrith Kumarが一緒に登壇します。Amrithは、フィードバックを通じて私の毎日をより良いものにしてくれる一人です。彼から学び、笑いを共有し、フィードバックをもらっています。今日、彼と一緒に登壇できることを嬉しく思います。
私たちは、今日お話しする内容にとてもワクワクしています。DynamoDBにおいて、これまでに、そして現在も行っている設計上の選択について、お客様にサービスを提供するための方法を詳しく見ていきます。DynamoDBの使い方や考え方をより深く理解していただけるよう、また私たちが直面してきた課題から学んでいただけるよう、なぜそうしているのか、どのようにしているのかについて、より詳しく説明していきたいと思います。
DynamoDBの誕生背景と進化の歴史


画面に表示されているお客様企業を見て、技術的な観点から共通点を考えると、これらの企業はすべて、同じ処理を繰り返し実行する高スループットのアプリケーションを持っているということです。 ショッピングカートにアイテムを入れる、タクシーの位置情報を取得する、セッションを開始する、クレジットの状態を確認する、ゲームプレイヤーの状態を取得するなど。これらは複雑なクエリではありません - 同じことを何度も繰り返し実行したいのです。そして、これらの企業はすべてその目的でDynamoDBを使用しています。


今日は、あらゆる規模でのスケーラビリティ、高可用性、そしてスケールにおける一貫したパフォーマンスを実現するための設計上の選択について、特にばらつきをいかに減らすかという観点からお話ししていきます。 この説明を通じて覚えておいていただきたい考え方の一つは、DynamoDBは本質的に最適化の結果だということです。DynamoDBの開発に着手した時、私たちは単にリレーショナルデータベースを少し改良しようとは考えませんでした。スケーラビリティ、一貫したパフォーマンス、高可用性の面で、大幅に優れたものを作ろうと考えたのです。


では、私たちが誰のために開発しているのか、何を目指して開発を進めているのか、そして設計上の選択を行う際に常に念頭に置いているのは誰なのかを見ていきましょう。 すべては約20年前のちょうど今頃から始まりました。休暇シーズンのショッピング中にAmazon.comのウェブサイトにアクセスしたら、何時間もダウンしていた - そんな状況を想像してみてください。それが20年前に実際に起きたのです。オンラインリテーラーにとって、決して良いことではありませんでした。

Amazonでは、このような大規模な障害が発生した際、Correction of Error(COE)と呼ばれる文書を作成します。COEは技術的な観点から何が問題だったのかを詳しく分析します。5つのなぜ(Five Whys)を用いて原因を追究し、改善策を検討します。COEから得られた興味深い発見の1つは、20年前に私たちがリレーショナルデータベースを使用していた方法において、アクセスパターンの70%が単一テーブルの単一キーへのアクセスだったということです。20%は単一テーブル内の複数キーへのアクセスでした。つまり、データベースに対する操作の90%がリレーショナルの機能とは全く関係のないものだったのです。

SwamiやWernerを含む何人かの方々(今週の講演でお見かけしたかもしれません)が、このようなワークロードにリレーショナルデータベースを使用する必要性について疑問を投げかけました。同じことを繰り返し行っているだけなのに、なぜクエリプロセッサーやヒューリスティクス、統計情報、クエリプランナーが必要なのか、と。彼らは実際にシステムを数年間運用した経験を踏まえてDynamoの論文を執筆しました。この論文は、AmazonにおけるNoSQLデータベースへの最初の取り組みでした。良いシステムでしたが、自己管理が必要で、Amazonの社内チームしか利用できないという欠点がありました。
その後も私たちはDynamoを使い続けましたが、ここで明確にしておきたいのは、DynamoとDynamoDBは全く別の独立したシステムだということです。確かに両者とも非リレーショナルな分散データベースですが、まったく異なるものです。私たちは設計を続け、外部のお客様とも対話を始めました。彼らはMySQLの上でシャーディングアーキテクチャを実装し、主キーによる検索という同様のアクセスパターンを使用していました。特にクラウドやよりスケーラブルなアプリケーションが増加する中で、これらのシャード化されたアプリケーションの保守に多大な労力を費やしていました。
DynamoDBの基本アーキテクチャと設計原則


2012年、私たちはDynamoDBをローンチしました。今年1月で約13年が経過しましたが、この間に多くのことを学び、今後の方向性についても継続的に検討を重ねています。 新機能に関するブログ投稿やお客様向けの情報など、目に見える形でのイノベーションを行う一方で、スケール、高可用性、信頼性を追求するために、舞台裏でも数多くの取り組みを行っています。
本日は、通常お話しする内容とは異なる、一貫したパフォーマンスとそれを実現する設計上の選択について、いくつかの取り組みをご紹介させていただきます。


長年にわたり、私たちはDynamoDBを利用するお客様から様々な声を聞いてきました。 DynamoDBは現在100万以上のお客様にご利用いただいており、サービス開始当初から現在に至るまでの成長を考えると、本当に身の引き締まる思いです。 DynamoDBに興味を持っていただくお客様は、主に2つのグループに分かれます。1つ目は、既存のデータベースの限界に達したお客様や、サービス開始時から大規模なスケーラビリティが必要なアプリケーションを構築されているお客様です。「1億人規模の顧客基盤を見込んでいる」「200テラバイトを超える数百のテーブル」「1時間あたり10億リクエスト以上を処理する数百のテーブル」「1秒あたり50万リクエスト以上を処理する数百のテーブル」といった規模感です。

2つ目のグループは、将来的にそこまでの規模になる可能性はあるものの、現時点ではDynamoDBの運用負荷の低さに魅力を感じているお客様です。インフラのプロビジョニング、バージョン管理、ハードウェアの管理が不要で、キャパシティについてもほとんど気にする必要がありません。 このような大規模なユースケースを考え、そのスケールのアプリケーションからバックワードで考えていく際には、それらの機能を実現するためにどのようなアーキテクチャを構築する必要があるかを検討しなければなりません。


DynamoDBは分散ハッシュテーブルとして考えることができます。このメンタルモデルは、一貫したパフォーマンスを維持しながら、ほぼ無制限のスケールを提供する方法を理解する助けとなります。そのためには、DynamoDBを最適化として捉え、これらの目標を達成するために必要なトレードオフを行う必要があります。これらのトレードオフの一部は、APIの観点から提供する機能の範囲という形で現れます。 単一システムからデータを取り出したり、共有プロセッサー、共有メモリ、共有ディスクを持つ場合、分散システムではデータモデリングが極めて重要になります。
これが分散システムでデータモデリングが重要な理由です - これはDynamoDBに限った話ではなく、データを複数のマシンに分散させるシステム全般に当てはまります。データモデルとデータの配置について慎重に考える必要があります。これが、re:InventでDynamoDBのデータモデリングセッションが数多く開催される理由です。Alex DeBrieは素晴らしい話者で、彼の講演や著書が非常に価値があるのは、分散システムではデータへのアクセス方法とそのデータの分散方法を考慮する必要があるからです。
パーティショニングとスケーラビリティの実現方法


DynamoDBがこれを実現するために、私たちはデータをパーティション化します。このパーティションを表す小さな緑のアイコンを使用しますが、これは読み取り、書き込み、ストレージを備えた計算単位として考えることができます。テーブルのアイテムを1つまたは複数のパーティションに配置します。 非常にシンプルに言えば、Partition Keyを持つテーブルがあり、それが内部のハッシュ関数を通過して、サーバー内でそのパーティションがどこに位置するかが決定されます。



シンプルなシナリオでデータベースのスケーリング方法を考えてみましょう。0から9までのキー範囲を持つ1つのパーティションを持つテーブルを考えてみます。実際にはもっと複雑ですが、説明のために、そのテーブルへのトラフィックや需要が増加すると、最終的にそのパーティションを分割します。キー空間を半分に分け、一方のパーティションに半分、もう一方に残りの半分を配置します。さらにトラフィックが増加すると、これも同様に分割します。特定のキーへのトラフィックが続く場合、データベース内のアイテムを個別のパーティションに分割またはスケールアウトして、単一のPrimary Keyを個別のパーティション上に配置することができます。



このアーキテクチャは特定のアクセスパターンを可能にします。分散ハッシュテーブルとして、Primary Keyによる検索は非常に高速で、ビッグO記法で表すとO(1)となり、このデータモデルにとって非常に効率的なアクセスパターンです。DynamoDBにはRange Keyという概念もあり、注文日付や単調増加する数値などの場合に、Partition Key内でRange Scanを実行することができます。もちろん、これらの機能を使ってTable Scanも実行できます。Partition KeyやPrimary Keyによる検索を考えると、これらのパターンは見覚えがあるはずです。

これらのパターンが馴染み深いのは、Partition KeyやPrimary Keyによる検索がユースケースの70%を占めているからです。そして残りの20%についてはRange Scanで対応できるよう取り組んでいます。これはまさに私たちが取り組んでいることであり、Amazon.comの社内ユースケースを満たすために選んだアーキテクチャそのものです。これが Amazon以外の方々にも非常に有用であることが分かってきました。

DynamoDBの全体的なアーキテクチャを見ると、考慮すべきあらゆる側面が水平方向にスケールできなければなりません。サービス内の単一のコンポーネントが、他のレイヤーのボトルネックになることは許されません。Transaction Manager、Request Router、Load Balancerなど、あらゆる面について深く考慮しており、システムのすべての要素が最初から無限に近いスケーラビリティを備えている必要があります。

パーティショニングの話が出たので、Storage Nodeについて説明しましょう。特定のStorage Node内では、Serverlessの魔法とは、実は裏側で多くのサーバーが動いているということです。私たちがその複雑な作業を抽象化することで、ユーザーの皆さんは気にする必要がないようにしています。確かに多くのサーバーが存在していますが、それだけのことです。論理的に考えると、DynamoDBは多数のStorage Nodeで構成されており、多くのパーティションを持つテーブルがあり、それらは特定のStorage Node上に存在すると考えられます。これは単一テナントシステムの場合の話です。


DynamoDBの重要な特徴の一つは、マルチテナントシステムであるということです。これにより、私たちは効率的にキャパシティを管理し、シングルテナントシステムでは開発者が単独で実現するのが難しい機能を、スケールを持って提供することができます。データの分散を見てみると、Storage Node 上には、あなたのテーブル用の1つのパーティションがありますが、同じStorage Node上には他にもたくさんのパーティションが存在する可能性があります。DynamoDBは、これらがあたかも専用リソースであるかのような仕組みを提供しており、私たちはこれらのサーバーのリソースガバナンスに関して、分離性能とパフォーマンス保証を実現するために多くの作業を行っています。

これは新しい機能の一つです。テーブルをサポートするすべてのパーティションを見渡すと、それぞれの異なるパーティションのスループットの合計が、そのテーブルが実際に処理できる能力を示しています。これは数週間前にリリースした、Warm Throughputと呼ばれるコンセプトです。これは実際にテーブルが処理できる能力を示すもので、バックグラウンドでトラフィックをサポートできるパーティションの実力を表しています。

説明のために、そしてなぜこれが重要だと考えているかというと、マルチテナントアーキテクチャ、スケールアウトアーキテクチャ、そして私たちがこれを実現する方法が、お客様や開発者の皆様にとってなぜ重要なのかを、このグラフで説明させていただきます。On-Demandテーブルを例に取ると、上部のオレンジ色の線がWarm Throughputを示しています。これがテーブルの処理能力です。DynamoDBへのトラフィックを継続的に送信すると、私たちはワークロードに対応するためにパーティションを分割してリソースを追加し続けます。トラフィックが減少しても、そのWarm Throughputは維持されます。トラフィックがしばらくゼロになっても、Warm Throughputは維持されます。特にOn-Demandの場合、実際のリクエスト分だけを支払うにもかかわらず、専用リソースを持っているかのような体験を得ることができます。
高可用性システムの設計と実装


では、私の良き友人のAmrithに引き継ぎたいと思います。このトークが楽しいのは、私の仕事の中で最も好きな部分の一つが、お客様である皆様と協力して、皆様が解決しようとしている問題を理解し、それをどのように支援できるかを考えることだからです。皆様の中で、アプリケーションのメンテナンスによるダウンタイムを顧客が喜んで受け入れてくれると思われる方はいらっしゃいますか?

メンテナンスとダウンタイムを顧客が喜んで受け入れると思われる方は手を挙げてください。よく見えませんが、誰も手を挙げていないようですね。私たちは、絶対にダウンタイムのないシステムを構築する必要があると考えています。お客様がそれを望んでおり、そのためには、同じことができるデータベースが必要です。私はAmazon DynamoDBに4年間携わってきましたが、この期間中に計画的なメンテナンスによる停止は一度もありませんでした。DynamoDBを使用されている方に伺いたいのですが、「DynamoDBのアップグレードがあるのでダウンタイムが発生します」というメールを受け取ったことは何回ありましたか?私たちはこれを実現するためにDynamoDBの構築に多くの時間を費やしてきましたし、それを実現できていることを本当に嬉しく思っています。


もちろん、Murphy's Lawは存在します。データベースにメンテナンスが必要だということは、アプリケーションの可用性が失われるということです。とてもシンプルな話です。私は35年ほどデータベースに携わってきましたが、ダウンタイムを好む人は誰一人としていません。高可用性システムを設計するのは困難です。可用性は後付けではできないのです。このような講演をする理由は、高可用性システムを構築する際に学んだことをお伝えしたいからです。皆さんも同じようなことを実現したいと考えているはずだからです。システムを設計する際に、私たち一人一人が間違いを犯すことは間違いありません。ですから、私たちと同じ間違いは繰り返さないでください。新しい間違いを犯して、それを私たちに、そして皆に共有してください。そうすれば皆で学ぶことができます。

この後の講演は、いくつかのルールと例を用いて構成されています。Joeが話したように、DynamoDBは1秒あたり50万件を超えるリクエストを処理する何百ものお客様に対応する規模で運用されています。これはAmazon社内の利用分は含まれていない数字です。そして、ここがLas Vegasなので、とても適切な例えですが:公平なコインを50回投げた場合、表が出る回数は何回でしょうか?期待値は、全体の回数に確率を掛けたものです。もしエンジニアが「このコードを作って、テストしました。10億回に1回しか失敗しません」と言ってきたら、そのコードを受け入れますか?私たちの場合、10億回に1回の失敗は、1日に何度も失敗が発生することを意味します。失敗が起きないようにシステムを設計する必要があります。なぜなら、大規模な環境では、失敗する可能性のあるものは必ず失敗するからです。

これは統計的な側面です。現実には、最も不都合なタイミング、つまりページャーで呼び出されたくないときに限って障害は発生します。だからこそ、失敗しないようにシステムを設計する必要があります。例を挙げましょう。ここにいる皆さんはおそらくDynamoDB Global Tablesについて聞いたことがあるでしょう。これは4つのリージョンにテーブルがある Global Tablesの図です。どのリージョンに書き込んでも - これはActive-Activeです。そして昨日、Active-Active同期Global Tablesを発表しました。あるリージョンで書き込むと、他のリージョンに同期的に更新されます。では、これをどのように実現するのでしょうか?上の図では、Replicator 1というシングルトンがあります。US-EAST-1での書き込みはReplicatorを通してAP-EAST-1に伝わります。US-EAST-2での書き込みは、同じReplicatorを通して他の3つに伝わります。もう一つのアーキテクチャでは、一方向の各リージョンの組み合わせごとにReplicatorがあります。これが2つの選択肢です。最初の方を考えると、明らかにこちらの方が安価です。1台のホストで動作する1つのReplicatorです。こちらは各方向に3つのReplicatorがあります。US-EAST-2で書き込みを行うと、異なるReplicatorが使用されます。
4つのリージョンで、12個のReplicatorと1個のReplicator、どちらがより可用性の高いシステムだと思いますか?2番目の方法で私たちはGlobal Tablesのレプリケーションを構築しました。送信元と送信先の各ペアの組み合わせに対して、1つのReplicatorを用意しています。US-EAST-1とUS-EAST-2間のネットワークリンクに遅延が発生した場合、そのレプリケーションを行うReplicatorが他のリージョンへのレプリケーションも停止させたいでしょうか?いいえ、問題のあるリンクに障害の影響を限定したいはずです。最初の方法だと、他のリージョンにも影響が及ぶ可能性があります。

高いスケーラビリティを持つシステムを構築したい場合、高可用性を考慮して設計する必要があります。何が失敗する可能性があるのか、失敗した場合どうなるのかを考え始めてください。なぜなら、必ず失敗するからです。複数のReplicatorを持つことで、最小限の被害に抑えることができます。これが私たちの考え方の基本です。新しいエンジニアがチームに加わったとき、このような考え方を教え始めます。もう一つ例を挙げましょう。30年以上データベースに携わってきて、Amazonに来て、私が長年存在すると考えていたものに名前が付いていることを知りました。システムを構築する際は、可能な限り定常的な負荷で運用されるように設計してください。これは、システムが全ての状況で定常的な負荷で動作している場合、何か予期せぬことが起きても、そのまま動き続けるからです。

キャッシュを備えたシステムについて考えてみましょう。クライアントがあり、クライアントにバンドルされたキャッシュがあり、そしてデータベースがあります。キャッシュは非常に優れものです。キャッシュが温まっていて、クライアントからのリクエストの99%でキャッシュにヒットする場合、データベースへのトラフィックはわずか1%で済みます。これがキャッシュのメリットです - 高速なレスポンスとデータベースの負荷軽減です。ここでクイズです。同じクライアント、同じキャッシュ、同じデータベースがあります。クライアントから毎秒20億リクエストのトラフィックが発生していて、キャッシュヒット率は99.99%です。このデータベースをどのように設計しますか?ヒントを1つ言うと、「上記のいずれでもない」という選択肢ではありません。それ以上のヒントは控えさせていただきます。
予測可能なレイテンシーを実現するための戦略

では、下から見ていきましょう。Dが正解だと思う方は?手を挙げてください。Cはどうでしょう?会場に手は見えませんね。Bは?Bに数人手が挙がりましたね。Aは?そうですね、皆さんは正解をご存知でした。システムは常に一定の負荷に対応できるように設計すべきです。キャッシュが故障したことを想定してください。分散システムで毎秒20億リクエストを処理している場合、時にはキャッシュが故障することもあるからです。99.99%のキャッシュヒット率にしか対応できないようにシステムを設計したとします。キャッシュをホストしているサーバーでソフトウェアデプロイメントを行い、キャッシュの1%が使えなくなったとしましょう。すると、データベースがダウンしてしまいます - これは高可用性システムとは言えません。

高可用性システムを構築するにはコストがかかりますが、長期的には見合う投資となります。一昨日、Amazon DynamoDBの内部コンポーネントであるMDSについて講演しましたが、私たちはこのような考え方で設計しています - いつかキャッシュが冷えることを想定して、すべてのキャッシュが冷えている状態を前提に設計します。そうすれば、その時が来たときに感謝することになります。システムが稼働し続けることで、お客様にも感謝されるでしょう。高可用性のための設計とは、これらのことを事前に考え、その対価を支払うことです。それだけの価値があるからです。もう1つ似たような例を挙げましょう。DynamoDBにはRequest Routerがあります - リクエストはまずRequest Routerに届き、そこからデータが格納されているStorage Nodeに送られます。
皆さんと同様、私たちもAWSのサービスを利用しています。新しいハードウェアが登場すると、より効率的なので使用したいと考えます。私たちの規模で運用していると、コスト削減にもなり、地球にも良いことです。新しいハードウェアをテストしたところ、このRequest Routerは約9,000 RPSまでは良好なレイテンシー基準を満たすことができました。Request Routerにそれ以上のRPSをかけると、使用率が上がってレイテンシーが悪化します。これが超えてはいけない赤線で、9,000 RPSが限界となります。

通常運用では、何が故障する可能性があるかを考慮する必要があります。DynamoDBはリージョナルサービスで、単一のAZの故障に対応できるように設計したいと考えています。ソフトウェアデプロイメントやネットワークの問題でAZ全体が使用できなくなっても、DynamoDBは問題なく動作し続ける必要があります。私たちがホストを指定する方法は、可用性ゾーン全体が停止した場合、通常の環境にあるRequest Routerのフリートに全負荷がかかることを想定しています。9,000が限界であれば、ホストあたり6,000以上の負荷をかけることはできません。単一のAZがいつでも停止する可能性があることを想定して、Request Routerのフリートに継続的にホストを追加しています。

このアプローチの利点は、Request Routerへのソフトウェアの継続的なデプロイ方法に表れています。世界のどこかで、常に何百もの Request Routerが最新バージョンのソフトウェアを受け取っています。それらは停止し、キャッシュが冷え、再起動し、そして稼働し続けます。これこそが高可用性を実現するエンジニアリングの方法なのです。 2番目のルールは、複雑なシステムを構築する際、複雑な一枚岩として作るのではなく、シンプルなパーツから組み立てるということです。シンプルなパーツには、シンプルな障害モードがあります。同じパーツを多くの場所で使用することで、そのパーツの問題を1か所で修正できます。一方、複雑な一枚岩システムには、非常に特殊な障害モードが存在してしまいます。
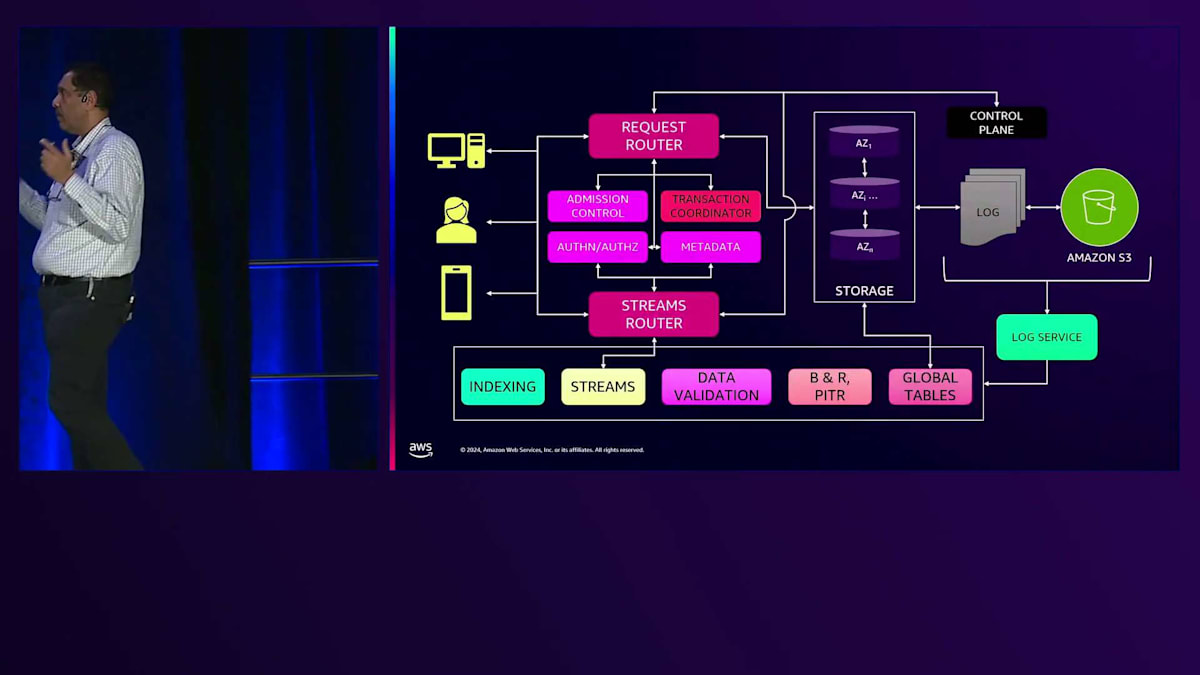
こちらは DynamoDBアーキテクチャのシンプルなブロック図です。私たちは文字通り、これらの各要素をマイクロサービスとして構築し、さらにそれぞれのマイクロサービス内にはサブサービスが存在します。これにより多くの利点が得られます。Amazonには「2枚のピザチーム」という考え方があります。これは2枚のピザで食事ができる規模のチームのことです。Conwayの法則によると、組織構造とアーキテクチャ図は時間とともに似通ってくるとされています。小規模なマイクロサービスとして構築することで、各コンポーネントは独自の役割を果たします。Request Routerチームは APIコールを通じて契約を公開し、Streamsチームも同様に行い、これらの各コンポーネントは契約を提供し、独立した障害ドメインを形成します。

具体例を挙げましょう。Storage Nodeと Request Routerがあり、Storage Node上にデータを保存します。すべてのアイテムを3つのコピーで保存します。Request Routerはほぼステートレスで、常にデプロイを行っています。1つのAZずつデプロイする限り、他の2つのAZが常に稼働しているため、完全に安全です。継続的な運用を維持するために、このような方法でデプロイする必要があります。
Request Routerへのデプロイは安心して行えます。実際、1つのAvailability Zone全体を停止しても、気付かないほどです。このような点を考慮して高可用性を実現することで、長期的にはダウンタイムゼロの、より安定したシステムを手に入れることができます。

何十万台ものホストのStorage Nodeに直接コードをデプロイすることはできません。私たちは、エンジニアがSandboxで開発とテストを行う通常のソフトウェアエンジニアリングプロセスに多くの時間を費やしています。 Sandboxでの作業が完了してコミットすると、より大規模なクラスターのテストのための小規模な DynamoDB環境である One Box環境に移行します。Alpha、Gamma、Zeta - 私たちは Zetaクラスターで非本番ワークロードや重要度の低いワークロードを実行しています。
問題が発生した時点で - レイテンシーの低下や、メモリ使用率の上昇、あるいはFile Descriptorの数が時間とともに増加していることに気付いた場合は、すぐにロールバックしてください。エンジニアリング組織にとって良い習慣となるのは、問題が発生した時点でロールバックするという方針を確立することです。その理由は、大規模な運用では、失敗する可能性があるものは必ず失敗するからです。いつか本番環境で障害が発生するでしょう。その時に初めてロールバックの方法を考えるのでは、良い結果は得られません。うまくいかない場合はロールバックすることを常に想定しておく - これが最初の対応であるべきです。
一貫したパフォーマンスを維持するための設計原則


システムをスケールを考慮して設計し、十分なMicroservicesと分離を実現していれば、デプロイとロールバックが行われたコンポーネントの影響は顧客には気付かれないはずです。3番目のポイントとして、継続的デプロイメントを行う場合、これらのデプロイメントを互換性のある方法で行うことが非常に重要です。クライアントとサーバーの間でバージョンに強い依存関係がある状態でコードをデプロイしても意味がありません。私たちは意識的に、SDKは非常にThin Clientを提供するという決定を下しました。SDKを使用せず、Native APIを直接使用している顧客もいます - SDKでできることはすべてNative APIでも実現できます。
このClientがThin Clientである理由は、スケールを考えた時に、このClientが何万台ものホストにデプロイされることを考慮する必要があるからです。何十万台ものホストにデプロイする顧客もいます。すべてのClientを同時にアップデートする必要があると言えば、それは大変なことになります。新機能が必要な場合は新しいSDKにアップデートしてください。新機能が不要な場合は、SDKをアップデートする必要はありません。セキュリティ修正などの理由から、定期的にSDKをアップデートすることは良い習慣ですが、すべてのClientを同時にアップグレードする必要がないようにシステムを設計してください。

今年11月、2週間前に、Warm Throughputという機能をリリースしました。これにより、顧客はTableやIndexが実行できる1秒あたりの読み取りや書き込みの数を指定できるようになりました。この開発には約6ヶ月を費やしました。システム全体をデプロイし、現在では数百の顧客がこれを使用しています。この機能を使用しない顧客にとっては完全に透過的でした - Warm Throughputを必要としない顧客には影響がありませんでした。必要な顧客はSDKをアップデートするだけで良く、私たちはその設計に多くの時間を費やしました。

Clientがあり、SDKがあり、ClientとServerの間にはデータ交換のためのデータモデルがあります。これは後方互換性のあるデータモデルです。すべての機能実装はこちら側にあります。機能がデプロイされる数週間前から、Amazon DynamoDBのすべてのTableとIndexについて、Warm Throughputを算出する作業を開始しました。Tableのwarm throughputを判断するジョブを構築し、メタデータの投入を開始しました。これは数ヶ月前に行われました。34のリージョンにわたって何十万、何百万ものTableがあり、そのすべてにメタデータを投入しました。現在では、このメタデータを継続的に最新の状態に保つパイプラインが稼働しています。

次に私たちが行ったのは、新しいAPIを理解するコードをRequest Routerにデプロイすることでしたが、無効化した状態でデプロイしました。もし誰かがこの新機能が近々リリースされることを察知して、Warm Throughputを使ってDescribeTableを呼び出したり、UpdateTableを呼び出したりしても、Request Routerは「申し訳ありませんが、理解できません」と応答するようになっています。私たちは1つのAZずつデプロイを行いました。コードは無効化されているので問題なく、誰も使用できない状態です。数十万のRequest Routerに新しいコードが配置されました。その後、内部アカウントで有効化してテストを開始しました。私たちのテーブルのWarm Throughputをチェックし、CloudFormationが適切に使用できることを確認しました。なぜなら、それがDynamoDBで最初に使用されるものだからです。
そのアカウントで有効化して問題がないことを確認した後、アナウンスを行い、スイッチを切り替えました。コードが有効化され、数十万のRequest Routerが新しいリクエストを受け付けられるようになりました。コードは既に配置されていました。プレスリリースを行い、SDKをプッシュアウトし、数時間以内に最初の顧客が使い始めました。これによるダウンタイムは完全にゼロでした。使用したい顧客は使用でき、使用したくない顧客はSDKをアップデートしませんでした。SDKはコンソールにもプッシュされました。コンソールもSDKのユーザーの1つです。スイッチを切り替えて有効化した瞬間、コンソールを更新するとWarm Throughputが表示されるようになりました。

並行デプロイについて話しましたが、安全にデプロイすることが重要です。先ほど、データには3つのコピーがあり、各AZに1つずつあると説明しました。大規模な環境では、失敗する可能性のあるものは必ず失敗します。現在、水曜日の午後5時10分の世界中の状況では、約100のStorage Nodeがソフトウェアデプロイ中であるか、障害が発生しているか、何らかの問題を抱えています。そこには多数のパーティションがあります。それらのパーティションは他の2つのAZにそれぞれ1つずつ、合計2つのコピーしか持っていません。このStorage Nodeにソフトウェアをデプロイするのは安全でしょうか?いいえ、そうすると1つのコピーしか残らなくなってしまいます。
ソフトウェアデプロイを進める際、そのStorage Node上の各レプリカをチェックします。他のAZに行き、冗長性があるかどうかを確認します。冗長性がある場合はデプロイを行い、ない場合は行いません。デプロイできなかったStorage Nodeのリストを作成し、後でクリーンアップを行います。これらすべては自動化されています。過去13年間で学んだことの1つは、手作業で行うべきではないことがあるということです。このソフトウェアデプロイのプロセス全体が自動化されています。自動化して継続的に実行できるようにすれば、システムにとってより良いのです。


可用性の部分について話してきましたが、顧客がDynamoDBを選ぶ理由は、常に利用可能であることに加えて、どんな規模でも予測可能なレイテンシーと予測可能なパフォーマンスを提供することです。これを可能にするために行ったいくつかのことについてお話ししましょう。大規模なアプリケーションは同じことを繰り返し行います。皆さんのアプリケーションについて考えてみてください。大規模に運用する際、ショッピングカートが突然何か別のこと、例えば検索をしたくなったりするでしょうか?いいえ、ショッピングカートはショッピングカートの操作を行うだけです。

これらの反復的な操作に関する重要な考慮事項として、人間はレイテンシー(遅延)自体は許容できますが、パフォーマンスの一貫性がないことは耐えられないということがあります。人々は一貫性を求めるのです。ボストンからのフライトを例に考えてみましょう。6時間のフライトについて誰も文句を言いませんが、5分の遅延が発生すると大惨事のように反応します。レイテンシーは許容しても、一貫性は求めるものなのです。皆さんのお客様も同じだと思います。

お客様はウェブサイトで何度も検索を行います。検索に3秒かかることもあれば、2秒で済むこともあります。常に同じ時間がかかるのであれば、それは許容されます。しかし、ある時は3秒で、次は10秒かかるようなことがあれば、非常に不快に感じるでしょう。お客様は予測可能なレイテンシーを持つアプリケーションを求めており、Amazonのお客様も同様です。そのため、データベースも予測可能なレイテンシーを提供する必要があります。私たちは予測可能なレイテンシーを提供するために多大な時間を費やしています。 これは、より良いカスタマーエクスペリエンスを生み出すだけでなく、システムのエンジニアリングをより容易にします。

私たちは予測可能性を構築するために多くの時間を費やしており、その方法の一部を共有したいと思います。なぜなら、皆さんの役に立つかもしれないからです。予測可能性と一貫性を2つの軸として考えると、これらは直交しています - どのようなスケールでも予測可能であることが常に求められます。DynamoDBの使用を始めたばかりのお客様とお話しすることがあります。リレーショナルデータベースからの移行を検討している彼らにとって、これは新しいものです。彼らは実用的なスケール、例えば毎秒100万リクエストでベンチマークを行いたいと考えます。そのレベルでテストして満足し、その後、毎秒500万リクエストの本番環境に移行しても、レイテンシーが全く同じままであることに喜びを感じています。


どのようなスケールでも予測可能なレイテンシーを維持することは、私たちが非常に重視していることです。高可用性のためにエンジニアリングを行う必要があるのと同様に、 アプリケーションでもこれを考慮する必要があります。私たちのコードには、文字通りカウントを行う箇所があります。Flameグラフを使用し、コードの経過時間を調べ、コードの各部分でどれだけの時間が費やされているかを正確に把握します。私たちは変動要因の排除に多大な時間を費やしています。 コードが異なるシナリオで大きく異なる処理を行う場合、予測可能なレイテンシーは得られません。そのため、常に同じことを行い、ほぼ同じ時間がかかるようにしています。

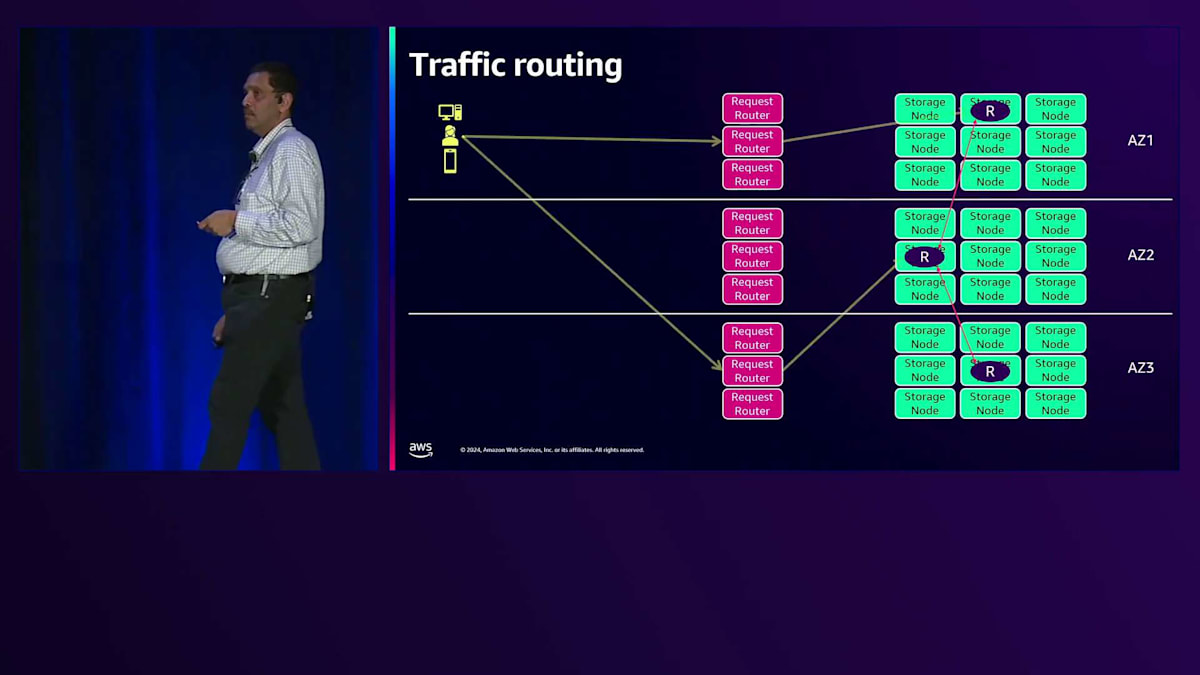
例を挙げましょう。DynamoDBには複数のAvailability Zone(AZ)にホストがあります。クライアントアプリケーションがAZ1にあると仮定します。そのリージョンのDynamoDBのリージョナルエンドポイントを解決します。AZ3のRequest Routerで接続が終了し、一貫性のある読み取りリクエストを行うとします。この特定のケースでは、書き込みリクエストを行っており、リーダーはAZ2にあるとします。この書き込みを完了するために、AZ1のクライアントはAZ3と通信し、AZ2のリーダーと通信し、データが他のAZの1つに確実に到達することを保証する必要があります。AZ間の境界を何度も越えすぎて数えきれないほどです。リーダーが別のAZにある可能性もあり、その場合、AZ間の境界を越える回数が全く異なり、予測可能なレイテンシーは得られません。

私たちは昨年、これら2つの機能の構築に多くの時間を費やしました。クライアントの所在地を確認し、可能な限り同じAZ内のRequest Routerに接続するようにしました。リクエストを行う際、Eventually Consistentな読み取りであれば、可能な限り同じAZ内でリクエストを処理するようにしています。これにより、AZを跨ぐ通信がゼロとなり、リクエストに対して予測可能なレイテンシーを提供できます。私たちも同様に、不必要なAZ間の通信を避けるようにしています。


さて、必要がない限りAZの境界を越えないようにすると申し上げましたが、それが不可能な場合もあります。例えば、書き込みを試みる際にLeaderが別のAZにいる場合や、Strongly Consistentな読み取りを別のAZで行う場合は、AZ間の通信が必要になります。 可能な限り、同じことを繰り返し行うようにします。これには技術的な検討が必要で、開発者にもこのような考え方を持ってもらう必要があります。私たちが話しているアプリケーションは、同じ処理を何度も繰り返し実行します。

「このテーブルからこの3つのフィールドを選択する」というようなSQLを書くのは簡単です。リレーショナルデータベースでこれを行うと、まず英語を読み、英語を理解し、その英語で何をすべきかを理解しようとし、統計情報を確認して最適化を試みます。同じことを繰り返し行っているわけですが、私たちは同じことを繰り返し行うようにしましょうと言いました。そこで注目すべき言葉は何でしょうか?統計 - 統計自体が変動性を意味します。 予測可能なレイテンシーを実現したい場合、計画はこうです:1つのステップを実行して終了。これがDeclarativeモデルとImperativeモデルの違いです。私たちは理由があってこのモデルを選択しました。

もう1つの例として、Amazon DynamoDBでのトランザクションの実装方法があります。 リレーショナルデータベースでは、beginで始まり、いくつかのステートメントを実行するといった形でトランザクションを行えます。読み取りと書き込みを混在させることができる独立したステートメントです。DynamoDBでは、トランザクション全体がAPI呼び出しの中に含まれています。トランザクションの途中でハングしているように見える問題をデバッグしていて、誰かがトランザクションを開始してコーヒーを飲みに行ってしまったという状況に遭遇したことはありませんか?DynamoDBではそれが起こり得ません。なぜなら、すべてがそこにあるからです - 同じことを繰り返し行いますが、同じ時間で行います。

これらのルールの最後は、可能な限り分割統治を行い、並列処理を活用するということです。私たちは 200テラバイト以上の数百のテーブルを持っています。100テラバイトのテーブルを単一のパーティションとして保存したと仮定して、それを復旧する必要がある場合を考えてみましょう。障害の分離という観点から見ると、それは本当に恐ろしいことになります。しかし、10ギガバイトの小さな断片に分割すれば、テーブルが200テラバイトであろうと何であろうと、これらすべてを並列で処理できます。復旧時間は同じで、10ギガバイトを復旧する時間になります。これらのことはアプリケーションを設計する際に考慮する必要があります。なぜなら、後からこれらの機能を追加することはできないからです。


多くのお客様が予測可能な低レイテンシーを求めています。タイムアウトを調整することでこれを実現しようとするお客様がいますが、これは危険な方法です。その理由を説明しましょう。社内での調査で分かったことですが、クライアントが分散サービスにリクエストを送る場合、個々の独立したサーバーのレスポンスタイムは正規分布のような特性を示します。予測可能な低レイテンシーを実現したい場合は、リクエストをヘッジします。つまり、同時に2台のサーバーにリクエストを送信するのです。1つのリクエストがレイテンシー曲線の悪い方に当たったとしても、統計的に見てもう1つは低い方に位置するはずです。最初に返ってきたレスポンスを使用して先に進めばよいのです。

キャッシュを使用したクライアントサーバーの例で説明しましょう。分散データベースを使用して、99%のキャッシュヒット率で1秒あたり20億リクエスト(RPS)を処理したいとします。このデータベースのサイジングをどうすればよいでしょうか?20億RPSを処理するために、私たちが採用している方法、そして実際に社内で行っている方法では、そのデータベースは40億RPSを処理できるようにします。
なぜなら、ヘッジングを行うだけでなく、先ほど説明した第一のポイントである一定の負荷で運用する必要があるからです。Amazon DynamoDBが1秒あたり数億のリクエストを処理している一方で、私たちの社内のMedsデータベースはその2倍のリクエストを予測可能な低レイテンシーで処理しています。Medsは数十マイクロ秒で処理を完了します。高可用性と低レイテンシーを実現するためには、エンジニアにこのような考え方を教育する必要があり、実際に私たちはそのように実践しています。


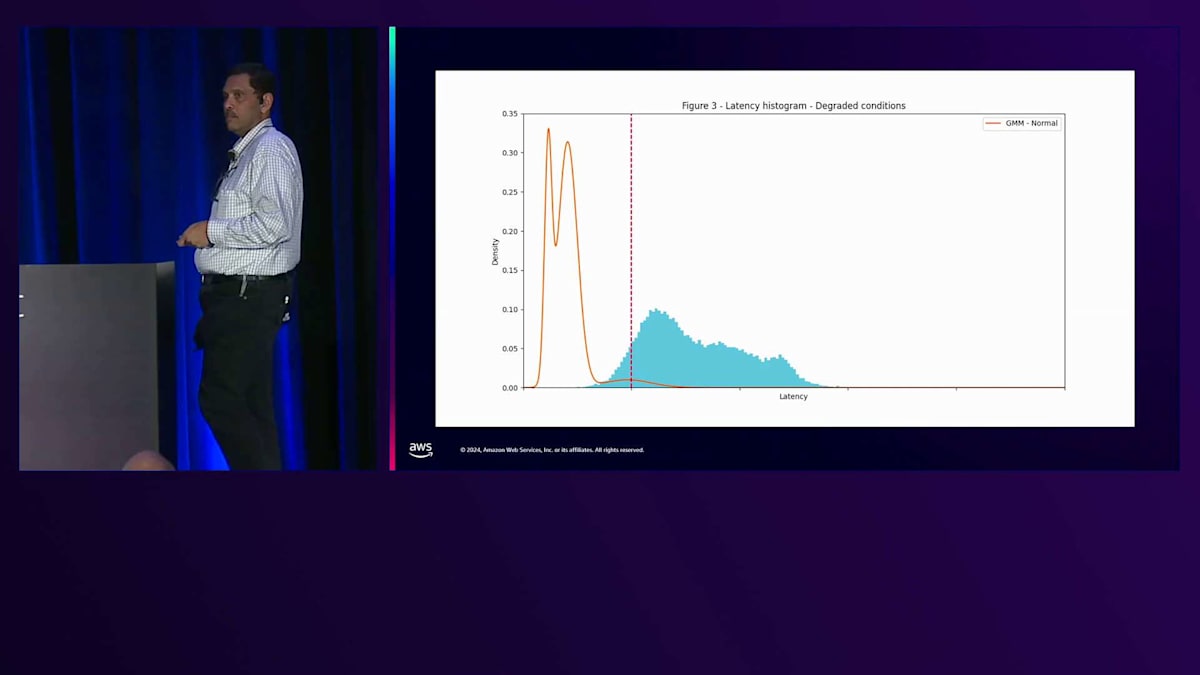

タイムアウトの調整が危険だと申し上げましたが、その理由をお話しします。これは実際のお客様との事例から得たデータによるシミュレーションです。このお客様はアプリケーションのテストを行い、Amazonから低いレイテンシーを使用するようアドバイスを受けました。彼らはこの赤線で示されているレイテンシーを選択しました。システムは問題なく長期間動作していました。私たちがこのシミュレーションを行い、レイテンシーのヒストグラムを作成し、このガウスモデルを計算しました。これが2つの曲線です。これは三峰性分布です。ごくわずかな時間でタイムアウトが発生していました。ある日、ネットワークで何かが起こりました。これが彼らのアプリケーションが経験したレイテンシーです。これは何を意味するのでしょうか?彼らのアプリケーションは大規模な障害状態に陥りました。タイムアウトを変更することは、レイテンシーやレスポンスタイムを改善しようとする危険な方法なのです。ヘッジングの方がはるかに安全です。

これらが私たちの学んだことです。人間はレイテンシーを許容しますが、一貫性については絶対に要求します。失敗する可能性のあるものは必ず失敗するので、それに備えましょう。シンプルな部品を何度も使用して、シンプルなシステムを構築します。後方互換性を考慮して構築し、継続的なデプロイメントができるように構築し、並列処理の利点を活用できるように構築します。


結局のところ、私たちが目指すのは退屈なシステムを構築することです。 DynamoDBを使ってシステムを構築する際に、「DynamoDBにデータを置いてから、毎日Pagerが鳴り響いてワクワクドキドキの日々を過ごしています」というオプション1を選びたい方は何人いらっしゃいますか?おそらく誰もいないでしょう。私たちが望むのはこちらです:これは実際の顧客の声です:「DynamoDBにデータを置いたら、とても退屈になりました」。夜も眠れなくなるようなアプリケーションではなく、安心して眠れるものを作りましょう。その時間を投資する価値は十分にあります。
DynamoDBの最新機能と価格改定

では、Joeにマイクを戻したいと思います。ありがとう、Joe。私がなぜここにいるのか、皆さんにもおわかりいただけたと思います。ここで簡単に振り返ってみましょう。DynamoDBのさまざまな側面について話してきました。私たちが使用している原則や、お客様のために何ができるのか、そして次にどのような機能を構築すべきかについて、どのようにバランスを取っているのかについて、より深く理解していただけたと思います。

今年行ったいくつかの取り組みについてご紹介したいと思います。ご存知ない方もいらっしゃるかもしれませんが、約3週間前にOn-demandの価格を50%引き下げたことは、私たちにとって大きな出来事でした。私たちのエンジニアチームが普段から行っていることの一つに、システムの継続的な最適化があります。そして、その成果をお客様に還元できる段階に達しました。頻繁には行いませんが、今回はDynamoDB On-demandをデフォルトオプションとして推奨できるようになり、とても嬉しく思っています。お客様の手間が大幅に減り、Warm Throughputでの使用がより簡単になりました。また、その性能についてより透明性が高まり、テーブルのスケーリングを増やすためのAPIも用意されています。

この価格改定を実現できて本当に嬉しく思います。Global Tablesについても同様で、プレミアム料金を引き下げました。以前はDynamoDBでリージョン間の書き込みを行う際にプレミアム料金が発生していましたが、現在はリージョン内の書き込みもレプリケーションされる書き込みも同じコストになり、プレミアム料金はなくなりました。セキュリティ面でも大きな進展がありました。Resource-based Policiesの導入により特定のテーブルへのアクセス制御が容易になり、PrivateLinkのサポート、そしてAttribute-based Access Controlも一般提供を開始し、AWS全体とのインテグレーションを強化しました。Mattが昨日発表したように、Global TablesにStrong Multi-region Consistencyも追加しました。
これまでのGlobal Tablesは非同期レプリケーションでしたが、現在は同期レプリケーションを実現し、Strong Consistencyを使用するアプリケーションでRecovery Point Objectiveをゼロにすることができ、AWS リージョン間でStrong Consistent Readsを実行することが可能になりました。

今年は、Warm Throughputと価格引き下げに加えて、On-Demandテーブルに対して最大スループットを指定できる機能を導入しました。これは開発テスト環境で特に有用です。テストワークロードが予期せず暴走してコストが急上昇したというチケットをよく受け取りますが、On-Demandテーブルのスループットに上限を設定できることは、状況に応じて非常に役立つコスト削減策となります。また、DynamoDBは現在、Amazon OpenSearch Service、Amazon Redshift、そして最近立ち上げたばかりのAmazon S3との Zero-ETL連携など、様々な改善を実現しています。

私たちが特に嬉しく思うのは、お客様がDynamoDB上での開発経験を共有してくださることです。今年は、Duolingo、JPMorgan Chase、Hermès、Robloxなど、様々な業界のお客様がDynamoDB上で構築したアプリケーションについてのセッションを行っています。これらはすべてYouTubeで公開される予定ですので、ぜひご覧いただくことをお勧めします。私たちはお客様から多くを学ばせていただいています。
セッションのまとめと追加リソースの紹介


DynamoDBサービスチームによる講演をもっとお聴きになりたい方は、日付が記載されているものはこれからのセッションですので、まだ参加可能かもしれません。YouTubeと表示されているものはインターネットでご覧いただけます。本日のDynamoDBに関する建築的な概念についての講演に関連して、こちらに補足資料をご用意しています。DynamoDBチームが過去に行った講演やホワイトペーパーで、DynamoDBの様々な側面について解説しているものです。

最後に、本日1時間お時間を割いてご参加いただき、心より感謝申し上げます。素晴らしいre:Inventをお過ごしください。ご質問のある方は、私とAmrithがあちらの隅におりますので、お気軽にお声がけください。ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion