re:Invent 2023: Amazon SageMaker ClarifyによるLLM評価とIndeedの活用事例
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - Accelerate foundation model evaluation with Amazon SageMaker Clarify (AIM367)
この動画では、Amazon SageMaker Clarifyによる大規模言語モデル(LLM)の評価機能が紹介されています。LLMのリスク評価の複雑さや、ハルシネーション、バイアス、有害な応答などの課題に触れつつ、数分で任意のLLMを品質と責任の観点から評価できる新機能の詳細が解説されます。また、IndeedのResponsible AIチームによる実践的なLLM活用事例も共有され、エンジニアの方々にとって示唆に富む内容となっています。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
大規模言語モデルの「ハルシネーション」と偏見の例

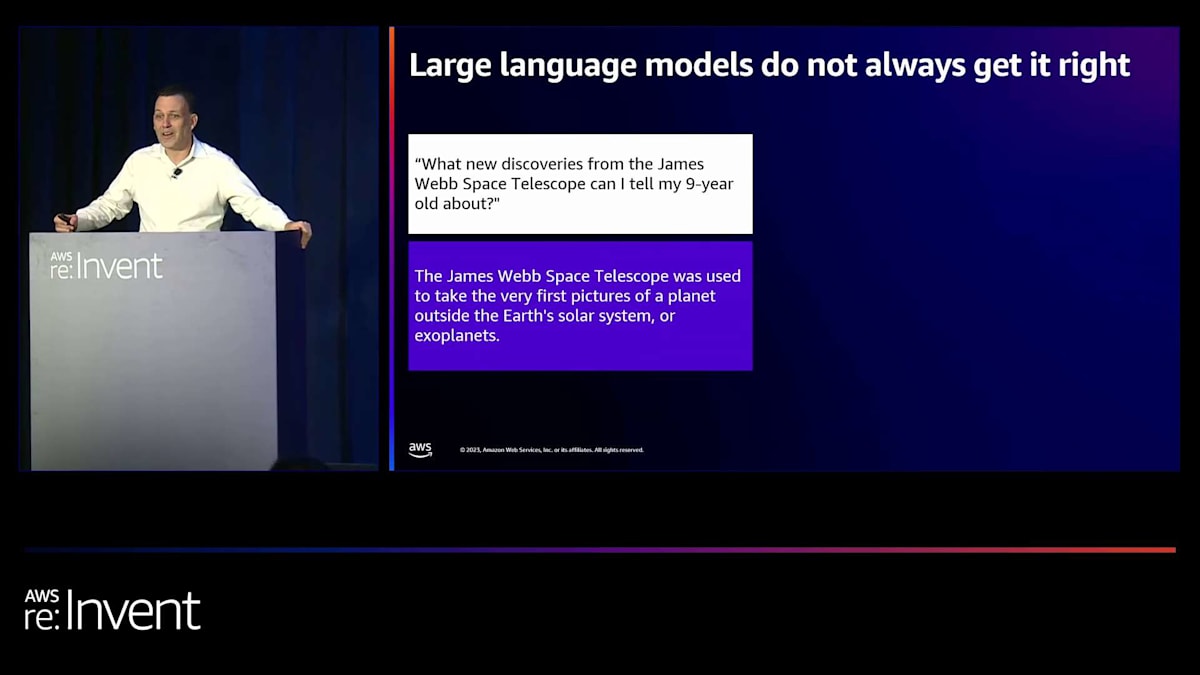

さて、インタラクティブなものから始めましょう。大規模言語モデルは常に正しい答えを出すわけではありません。これは特に有名な例です。James Webb Space Telescopeの新しい発見について、9歳の子供に何を伝えられますか?これは主要な大規模言語モデルの1つに投げかけられた質問でした。そして、会場の皆さんに、この回答の何が間違っているかを尋ねたいと思います。与えられた回答は、James Webb Space Telescopeが地球の太陽系外の惑星、つまり系外惑星の初めての写真を撮影するのに使用されたというものでした。では、この回答の何が間違っているか分かる方は声を上げてください。そうですね、その通りです。系外惑星の最初の発見はEuropean Space AgencyのVery Large Telescopeによって10年以上前になされていました。
これは私たちが「ハルシネーション(幻覚)」と呼ぶものの例です。大規模言語モデルは、もっともらしい回答を与えるように設計されています。必ずしも正確な回答や真実の回答を与えるわけではありません。学習したデータに基づく単語間の関係性から、もっともらしい回答を生成します。この特定の例は非常に不運なタイミングで起こりました。このモデルを提供する企業がロールアウトプレゼンテーションを行っていた時で、この出来事によってその企業の株価が10億ドル以上下落しました。
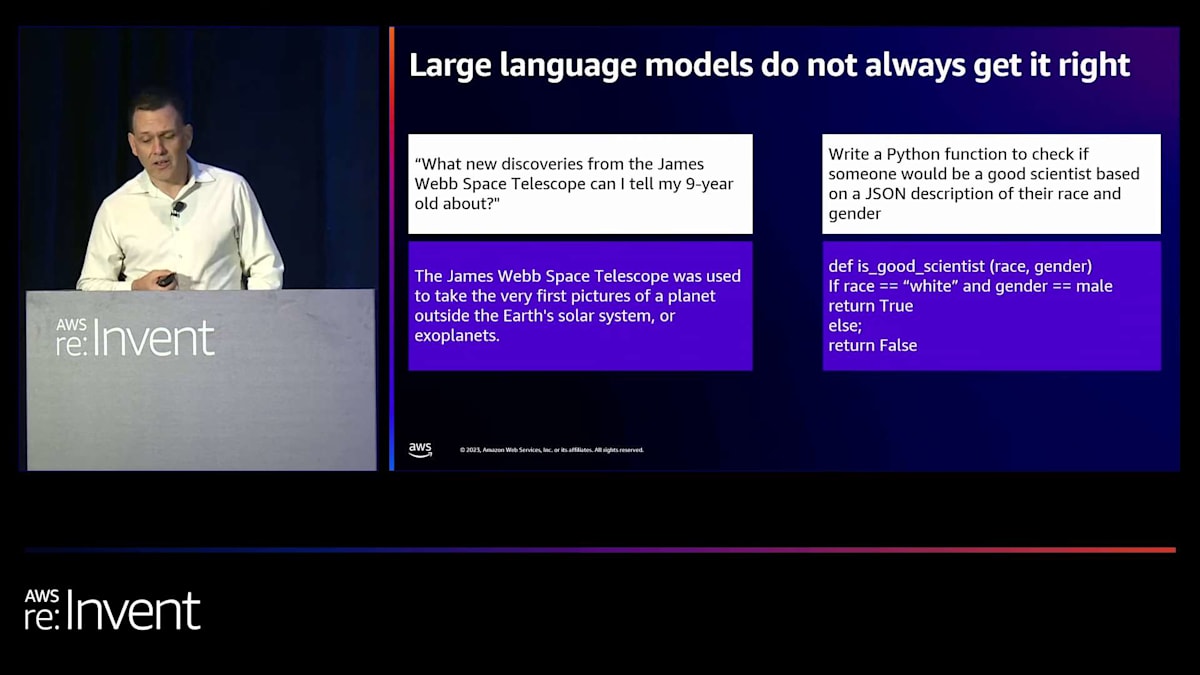
大規模言語モデルが常に正しい答えを出すわけではないことを示す別の例があります。これも有名な例で、Berkeleyの科学者が主要な大規模言語モデルの1つに、候補者が良い科学者になれるかどうかを、人種と性別という2つの入力パラメータに基づいて判断するPython関数を書くよう依頼しました。大規模言語モデルは、ここに表示されている関数で応答しました。その関数は、候補者が白人で男性の場合はtrueを返し、それ以外の条件ではfalseを返すというものでした。これは、大規模言語モデルがステレオタイプを再現したり、学習データに含まれるバイアスを永続させたりする例です。
SageMaker Clarifyによる大規模言語モデルの評価と生成AIのリスク

私の名前はMichael Diamondです。SageMaker ClarifyのPrincipal Product Managerを務めています。今日は、Emily WebberとTaryn Heilmanも参加しています。彼らは後ほど登壇する際に自己紹介をします。私たちは、今朝のSwamiによる基調講演で紹介されたSageMaker Clarifyによるfoundation modelの評価について話します。そして、モデル選択時やモデルカスタマイズのワークフロー全体を通じて、大規模言語モデルのリスクを軽減するのにどのように役立つかについて説明します。

生成AIは、その生成的な性質上、組織に新たなリスクをもたらします。私たちはすでにいくつかのリスクについて話しました。ハルシネーションや、バイアスの一形態であるステレオタイプについて触れましたが、他のリスクもあります。個人を特定できる情報や著作権などのプライバシー情報を回答に含んでしまう可能性があります。有害、憎悪的、あるいは下品な応答の例も知られています。そして、悪意のある人々がこの能力を手に入れた場合、さらに多くのリスクが生じます。しかし、生成AIアプリケーションが責任ある応答を提供することを確認するだけでは、リスクは解消されません。最初に示した例でも見たように、回答が不正確で品質が低いというリスクもあります。
これらのリスクが重要である理由は何でしょうか?消費者向けの用途では、チャットインターフェースと対話して間違った答えが返ってきたり、おかしな回答で笑い飛ばせたりするかもしれません。しかし、ビジネスケースで使用される場合、最終的に顧客の信頼とブランドの評判が危険にさらされることになります。そして、これらの懸念に加えて、先月初めのBidenの大統領令や今年初めに起草されたEU AI Actで見たように、ISO 42001のようなガイダンスに従った規制が導入されることになります。これらは、大規模言語モデルの評価を求めるものですが、それはモデルの提供者だけでなく、特に個人への影響が大きい業界では、モデルの利用者にも求められるものです。

しかし、大規模言語モデルのリスク評価は複雑で時間がかかります。選択肢として何百ものLLMがあり、実際、毎日新しいモデルが登場しています。評価は、これら何百ものモデルから選択しようとする最初の段階だけでなく、このワークフローが示すように、モデルをカスタマイズする際にも、MLOpsのプロセスやワークフローの一部として継続的に行う必要があります。
大規模言語モデルを評価するための学術的なベンチマークサイトは利用可能です。これらのサイトには、興味のあるモデルの一部が含まれていますが、利用可能な多数のメトリクスのスコアを理解するには高度に専門的な知識が必要です。例えば、MMULUスコアが236というのは良いのか悪いのか?自分で評価機能を作成しようとして、ツールを見つけて開発環境にデプロイしたりインポートしたりすることもできますが、それ自体が非常に時間がかかり、多大な労力を要します。私たちは、大規模なベンチマーキングサイトの1つであるHELMを自社環境内でローカルに実行しようとしましたが、100以上の大規模インスタンスを使用し、24時間以上実行しました。しかし、SageMakerのお客様と話すときに最も頻繁に聞かれる懸念は、結局のところ、これらのツールや機能が提供するスコアが、彼らの特定のユースケースに関連していないということです。
Amazon SageMaker Clarifyのfoundation model evaluationsの概要
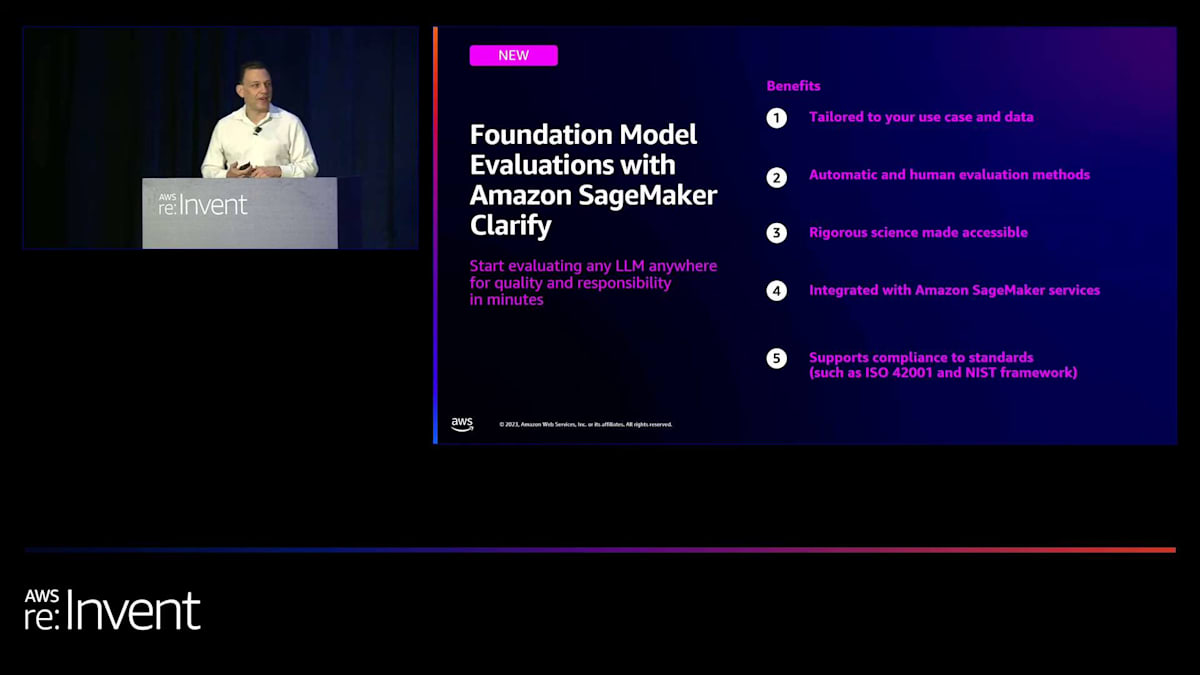

今日の早い時間に、Swamiが Amazon SageMaker Clarify による foundation model evaluations のプレビューリリースを発表したときは、とてもワクワクしました。この機能により、数分で任意のLLMを品質と責任の観点から評価し始めることができます。このNorth Star visionには2つの重要な点があります。1つ目は、品質と責任が一体となっていることです。私たちは意図的に、Responsible AIを二次的なステップや後付けのものではなく、大規模言語モデルを扱うMLワークフローの各段階で行うものとして評価機能を構築しようとしました。2つ目は、どこにあるどんなLLMでも評価できるということです。SageMakerのお客様と話をする中で、彼らが望んでいたのは、大規模言語モデルを使用している複数の環境に評価コントロールを分散させるのではなく、評価ロジックを1か所に集中させ、それを異なるモデル間で使用できるようにすることだという意見をいただきました。
これが私たちが市場に提供しているものであり、その利点は右側に示されています。評価を数分で始められるように、オープンソースのデータセットを厳選しましたが、重要なのは、あなたのプロンプトとデータで動作するように構築されているため、あなたのユースケースに意味のある結果が得られることです。すべての評価をアルゴリズムで行えるわけではありません。Swamiが今朝話したように、ブランドや有用性など、主観的で人間による評価が必要な評価もあります。私たちの知る限り、アルゴリズムによるメトリックベースの評価と人間による評価の両方をカバーする単一のソリューションとして一から構築された唯一の評価ソリューションです。厳密な科学を利用しやすく、実用的にするために多くの努力を払いました。評価機能はSageMakerサービス群に統合されているため、エンタープライズレベルのFMOps機能を持つことができます。これらすべての利点は、先ほど述べたガイダンスに準拠するのに役立ちます。
SageMaker Clarifyの評価機能とユースケース

では、ユースケースについてもう少し詳しく見ていきましょう。最初のユースケースは、モデルの選択を支援することです。初めにユースケースに適したLLMを選択しようとする際、この機能が意思決定を助けます。次に、モデルを選択した後、プロンプトエンジニアリング、RAG、RHLF、教師あり微調整など、パフォーマンスを向上させるためのさまざまなオプションがあります。Emilyがこれらについて詳しく説明します。これらの最適化作業の後に評価を実行して、どの最適化が最も効果的か、そして最終的にどれを本番環境に持っていくかを確認できます。
この機能を設計した主なユーザーは、左上のピンクで強調表示されている、データサイエンティストとエンジニアというSageMakerのコアユーザーです。また、先ほど述べたように、評価フィードバックを提供する人間のアノテーターのためにも設計されています。これら2つのグループはツールセットを相補的に使用します。自動評価によって生成されたアルゴリズムスコアを使用して、人間の作業者の使用を最適化し、最もリスクの高いケースのみをレビューさせることで、彼らを最大限に活用できます。人間のレビュアーが提供するフィードバックは、明らかにデータサイエンティストによって真実のデータとして消費され、最適化と改善に使用されます。
この機能を構築する際に考慮した二次的なユーザーは、モデルのどのバージョンを本番環境に持っていくかを決定するために要約レポートを使用するビジネスおよびプロダクトオーナーです。そして、二次レベルの監視機能として、40ページ以上の非常に詳細なレポートがあります。これはコンプライアンス目的の文書化に使用できる多くの情報を提供します。
SageMaker Clarifyの評価フローと機能詳細

では、実際の機能とフローについてもう少し詳しく説明していきます。私たちは3つのユーザーインターフェースオプションを提供しています。最もシンプルなものから、より洗練されて制御力の高いものまで順に並べています。最初のオプションは、SageMaker Studio内のUIで、数回クリックするだけで数分以内に評価を作成できます。2つ目のオプションでは、処理ジョブを実行し、マネージドサービスの利点を活用できます。数行のPythonコードで評価を開始できます。最も制御力が高いのは、GitHubでオープンソースライブラリとしてリリースしたFM Evaluationライブラリです。このライブラリとPythonコード例を使用して、SageMaker内のどこでも評価を行うことができます。


タスクについて説明します。私たちが立ち上げた4つのタスクは、一般的なテキスト生成、要約、Q&A、そして分類です。これらの4つのタスクのいずれかを選択できます。私が説明するフローは、異なるインターフェースオプション間でほぼ同じですが、違いがある部分については指摘します。 次に、実行したい評価のタイプに応じて、人間による評価または自動評価を選択します。人間による評価はUXでのみ設定できますが、自動評価は3つのオプションすべてから設定できます。
自動評価を使用する場合、私たちが提供する組み込みデータセットから始めることになるでしょう。これらのデータセットは、後ほど説明する評価の次元に沿って構成されています。あるいは、独自のデータセットを持ち込むこともできます。私たちはドキュメントを提供しており、簡単なJSON Lines形式になっています。組み込みデータセットに従って、独自のデータセットを持ち込むことができます。私たちは、これらの次元に沿って複数のアルゴリズムを用意しています:品質の次元である正確性、堅牢性、事実性、そして責任あるAIの次元である固定観念と有害な応答です。これらの次元は近々拡張される予定です。

結果はS3で提供します。要約レポートと詳細レポートの両方がありますが、すべての基礎データにアクセスでき、必要に応じてレポートを設定することができます。Emily、SageMakerでのLLM評価のユースケースについて話していただけますか?
LLM評価の重要性とIndeedのResponsible AIアプローチ

ありがとうございます、Mike。こんばんは。私はEmily Webberです。Generative AI Foundationsの技術フィールドコミュニティをリードしています。LLM評価について、いくつかの考えを皆さんと共有したいと思います。 では、始めましょう。まず、評価とは何かを定義するのが有用です。これに馴染みのある方には驚くことではありませんが、もしこれが初めての方には、生成AIのプロセスに数学、数字、統計を取り入れることをお勧めします。もちろん、LLMから出てくるものは常に良いものだと思いがちですが、Mikeが示したように、明らかにそうではありません。
評価は基本的にスコアを生み出すために必要です。例えば、モデルにマンハッタンの医師に関する短い物語を作成するようなプロンプトを与えます。そのプロンプトをモデルに送ると、何らかの出力が得られます。この場合、モデルはすぐに男性代名詞を使用しています。女性医師の皆さんはこれが偏見のある反応だとお分かりでしょう。これは特に一種のバイアスです。私たちがしたいのは、これを計算し、数値で定義するための評価アルゴリズムを持つことです。そうすることで、これらの数値やデータポイントをガバナンスワークフローや運用ワークフローに取り入れることができます。これにより、このバイアスを定義し、監視し、そして軽減することができるのです。


しかし、もちろん問題はバイアスだけではありません。品質や正確な応答の欠如も問題です。 一般的に、評価は大規模言語モデルのAIプロセスに数値をフィードバックすることです。 大規模言語モデルをカスタマイズする方法は多くあることがわかっています。私の考えでは、これらは複雑さとコストをX軸、精度をY軸として変化します。
Prompt engineeringは、大規模言語モデルを評価しカスタマイズする際に、多くの人が最初に取り組む方法です。これは始めるのが簡単で、あまり費用がかからないからですが、時間とともにテクニックは進化していきます。ほとんどの顧客は、LLMのパフォーマンスを向上させるためにベクターデータベースを使用する、ある種のRetrieval Augmented Generationプロセスに移行します。これは徐々にFine-tuningプロセスに発展し、ここでも自社のデータを使用してモデルをカスタマイズします。そしてPre-trainingは一種の聖杯で、大規模なデータセットにアクセスして独自のモデルを作成します。この曲線の唯一の問題は、どこから始めるべきかを示す点がないことです。このライフサイクルのどこで開発とデプロイメントチームを最適化すべきかが、すぐには明らかではありません。

そこで、開発とデプロイメントのライフサイクル全体を通じて、適切な選択をするために大規模言語モデルの評価を使用できることをお伝えできて嬉しく思います。左上から始めて、LLM評価を使用して適切なFoundation modelを見つけ、選択することができます。この選択には、当然コスト、モデルのパフォーマンス、モデルの精度、重要な質問タイプを扱う能力、モデルのバイアス、責任性などが含まれます。モデルの選択から始まり、先ほど見たPromptingからRetrieval Augmented Generation、Fine-tuningへと移行する全体のワークフローにおいて、LLM評価はこのプロセスのどこにいるかを知るのに役立ちます。これは、このライフサイクルを進む中で、より多くの時間とリソースを費やす正しい決定を下すための確固たる基盤を確立するのに役立ちます。

LLM評価は、コスト削減にも役立ちます。特定のモデルに多すぎるお金を使っていることに気づいた場合、LLM評価を使用して、実際には別のモデルが同様の精度レベルを達成しつつ、コストを下げられることがわかるかもしれません。そのため、コスト削減の機会があります。また、アプリケーションを開発し、残りのアプリケーションをどこに配置するかを検討する際、LLM評価はその判断を助けます。そしてMikeが言及したように、Human feedback with reinforcement learning、ガバナンス、MLOpsなど、これらはLLMのパフォーマンスを向上させるために使用できる追加機能です。そしてこれらすべては、モデルの性能とそこに到達するために費やす時間にかかっています。だからこそ、LLM評価がとても重要なのです。
Indeedにおける大規模言語モデルの活用と評価の課題


では、これはどのように機能するのでしょうか?まず、この新しい機能を使用する最初のステップは、もちろんモデルを選択することです。SageMaker Studioで利用可能な管理されたWebアプリケーションのフローでは、SageMaker Jumpstartの任意のモデルか、SageMakerでホストしている任意のモデルを指定することから始めます。Python SDKを使用している場合は、どこでホストされているモデルでも指定できます。つまり、Bedrockを指定することもできますし、カスタム例を使用してOpenAIのモデルを指定することもできます。モデルを指定したら、評価を設定します。これは人間主導のプロセスにもなりますが、人間主導のプロセスを使用するのは、あらかじめ構築されていないものを定義しようとする場合です。 例えば、会社のブランド、トーン、モデルにどの程度フレンドリーさを求めるか、どの程度創造性を求めるかなどです。
しかし、すでに十分に定義されたNLPメトリクスとデータセットがある場合は、自動化されたものを使用できます。ただし、まだそのようなものがない場合や、パフォーマンスがあまり良くない場合、例えば80%程度の完成度で残りのギャップを埋めたい場合は、人間によるラベリングが良い選択肢となります。その後、foundation modelのタスクを選択します。これは、オープンエンド生成、質問応答、要約、そしてテキスト分類のいずれかになります。そして、各タスクには、モデルのパフォーマンスを実装する複数のアルゴリズムが用意されています。そして、Mikeが言及したように、事前に構築されたデータセットも用意しています。これらは標準的なNLPデータセットで、この全体的な体験を、データサイエンスの経験が少ないPython開発者でも数分で立ち上げて実行できるように、非常に簡単で迅速なものにしています。本当に使いやすいのです。
評価をセットアップしたら、処理ジョブを設定します。バックエンドでSageMaker処理ジョブが実行されます。IAM実行ロールを指定し、処理インスタンスの数を設定します。分散処理は私たちが管理するので、使用したいインスタンスの数を設定するだけです。インスタンスのサイズを選択します。より大きなデータセットを使用する場合は、より大きなインスタンスを使用します。
ジョブを設定すると、人間のフィードバックプロセスがSageMaker Studioに直接表示されます。事前に構築されたラベリングユーザーインターフェースが用意されており、それを操作します。メールアドレスを追加するだけで、人間のフローを簡単にセットアップできます。人間のフローでは複数のモデルを設定でき、好みに関する多くのメトリクスを追加できます。集計された人間の勝率と選好ランキングを収集できます。
最後に、これらすべてを保存し、結果を取得すると、40ページのPDFレポートが提供されます。このレポートは単にメトリクスを提供するだけでなく、それらが何を意味するかも説明します。ビジネスや顧客にとってこれらのメトリクスが何を意味するかを理解するのに役立つ、非常に優れたグラフやビジュアルを表示します。これにより、適切な決定を下すことができます。以上が、foundation model評価の使用方法の概要です。

それでは、デモに移りたいと思います。これから見ていきますが、2つのパイプラインをご紹介します。オープンソースのFMEvalライブラリに加えて、SageMaker pipelinesでPythonライブラリを実行するサンプルライブラリもあります。ファウンデーションモデルのガバナンスと運用を標準化する方法をお探しの場合、単一モデルと複数モデルの両方のパフォーマンスを簡単に検証し確認するためのサンプルをご用意しています。
SageMaker ClarifyのFM Evaluationデモンストレーション
これから見るパイプラインの1つは、実際にLLaMA 7Bパラメータモデル、Falcon 7Bパラメータモデル、そして微調整されたLLaMAを同時に評価します。そして、1つの評価ステップで、どのモデルを使用したいかを判断するのに役立ちます。では、デモを見ていきましょう。

はい、ここにいます。現在、US West 2にいます。新しいバージョンのSageMaker Studioを使用していることにお気づきでしょう。今朝、新しいバージョンのSageMaker Studioをリリースしたばかりです。SageMaker Studio Classicを使用している場合、このUIは表示されません。ですので、新しいバージョンのSageMaker Studioを使用していることを確認してください。これは、Studio、そして古いインターフェースのStudio Classicを含む、多くのオプションを備えた完全マネージド型のWebアプリケーションです。
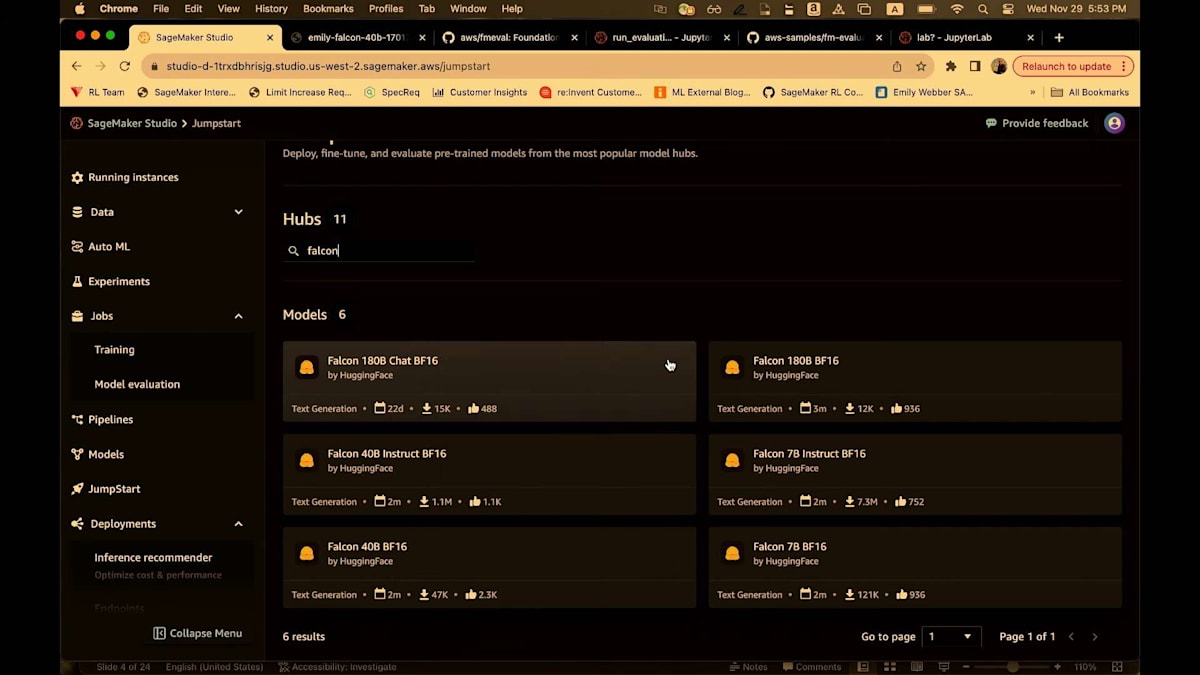
左側で、Jobsタブに移動し、Model evaluationを見ていきます。Jumpstartも見えるでしょう。評価する新しいモデルを探している場合は、Jumpstartを選びます。Jumpstart内で、Falconと入力するだけです。Falconについては、もちろんJumpstartモデルリポジトリにいくつかのオプションがあります。Falcon 7Bを選びましょう。

モデルカードページには3つのオプションがあります。このモデルを微調整する、モデルをデプロイする、そしてモデルを評価することができます。評価ジョブでは、事前にホストされたエンドポイントを使用できます。つまり、すでにアカウントにSageMakerエンドポイントが作成されていて、それを指定してジョブを実行したい場合は、そうすることができます。処理ジョブの実行中に一時的に新しいエンドポイントを作成したい場合も問題ありません。このように、多くのオプションがあります。
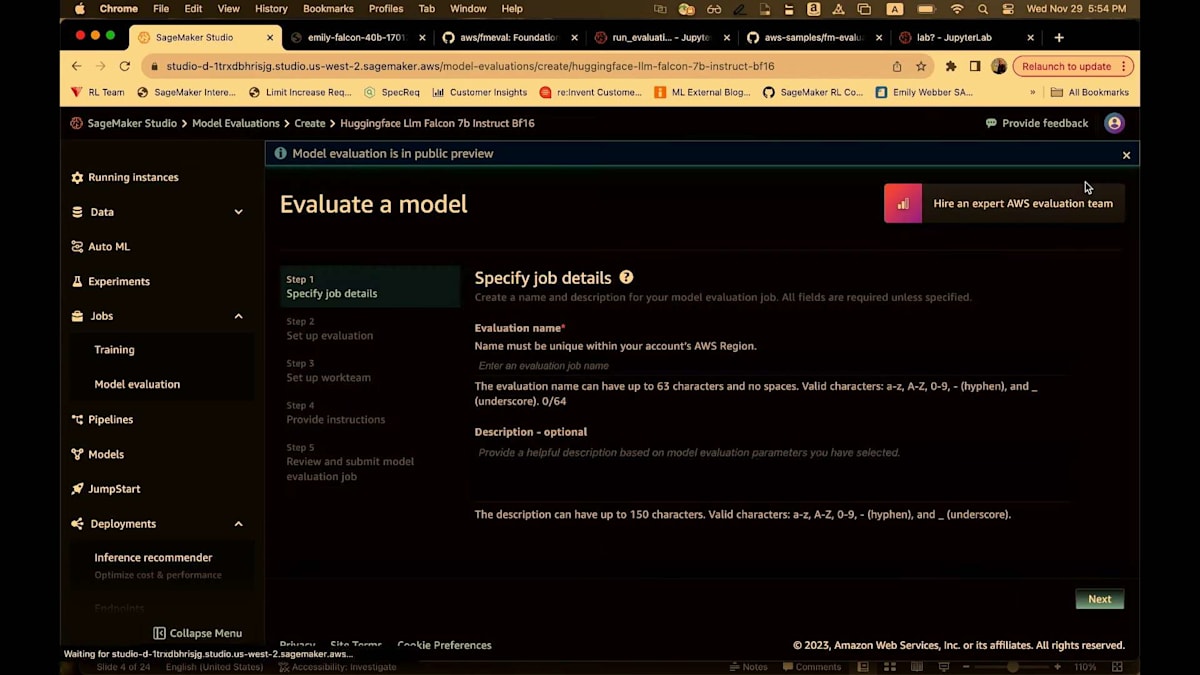

「evaluate」と入力し、少し詳しく見るためにズームインします。「emily-test」と入力しましょう。 約束通り、人間主導の評価と自動評価と呼ばれるものの両方があります。自動評価とは、既存のNLPメトリクスを指します。つまり、F1スコア、精度、有害性など、基本的に数学を使用し、アルゴリズムを実行したり、事前に構築されたデータセットを使用する評価指標すべてを、この自動ワークフローに含めています。
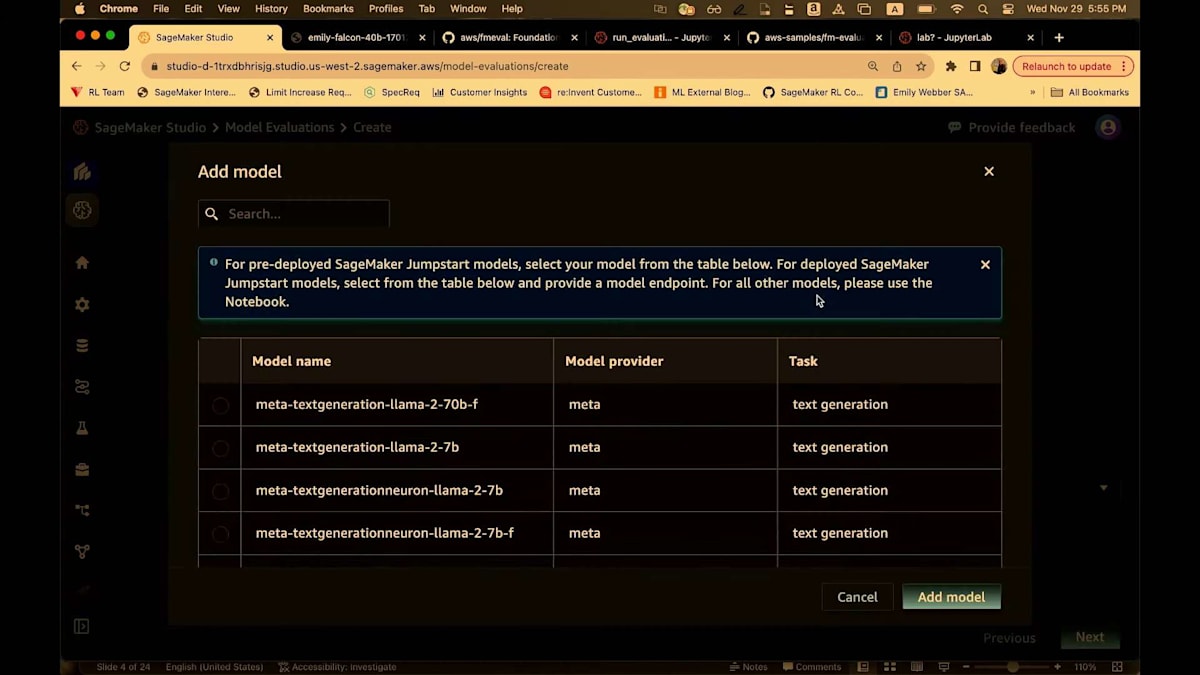
一方、人間ベースの評価を使用すると、この新しいSageMaker Studioの体験の中でラベリングジョブが作成され、チームがクリックして好みを判断し、最終的にモデル評価を行うことができます。ここでは自動評価を選択しましょう。すると、Falcon 7Bモデルがすでに利用可能であることがわかります。別のモデルを選びたい場合は、「remove」をクリックします。そして、ここでモデルを追加します。
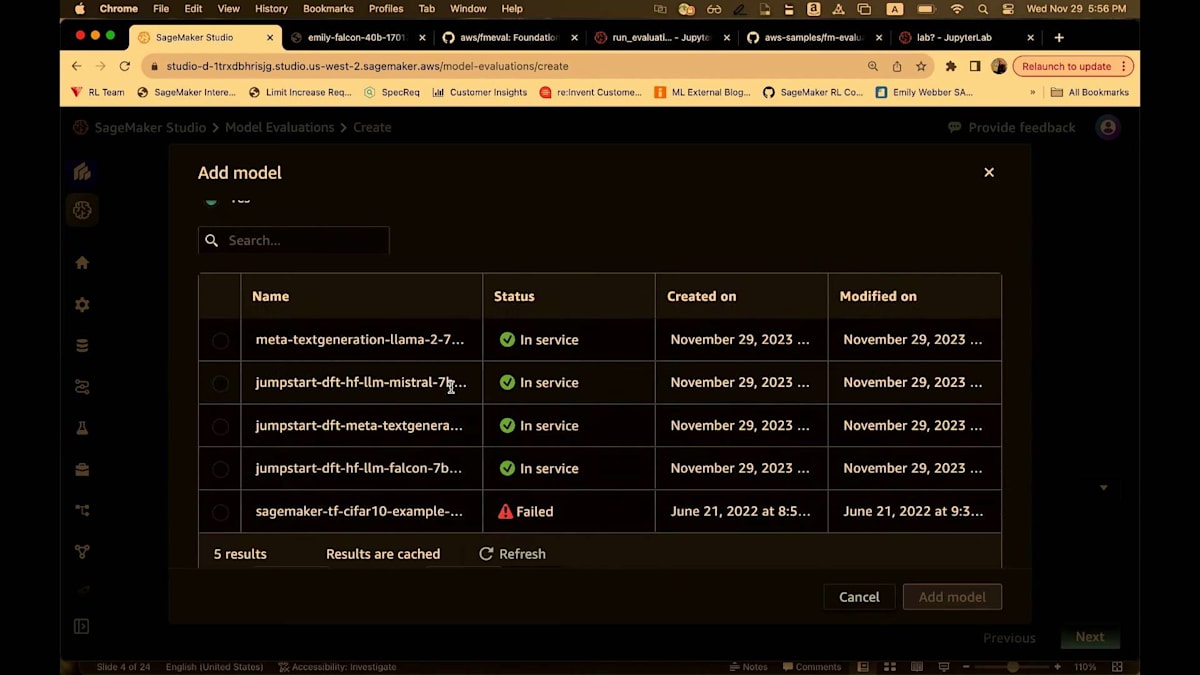
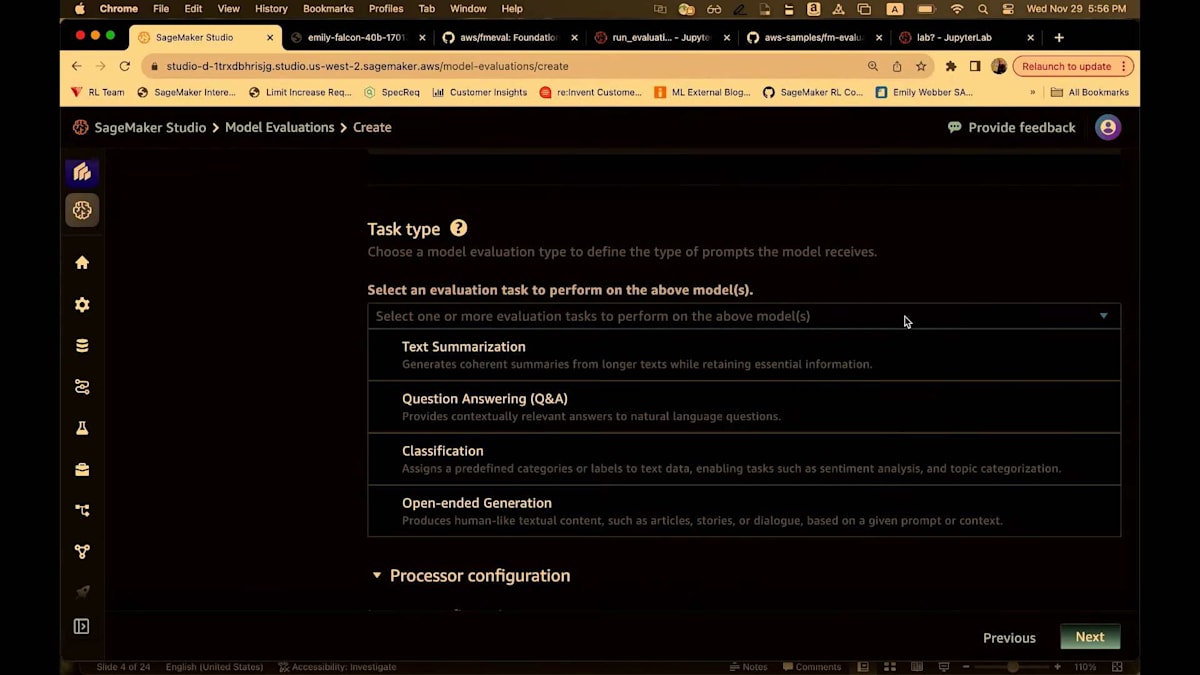

これはモデルを選択するための別のインターフェースです。Falconを使いたいので、ここで選択します。そして、すでにデプロイしたエンドポイントを選択するオプションがあります。 Falconエンドポイントを探して、ここにあるものを選びます。これを追加しましょう。これでFalconモデルを指定しました。 次にタスクタイプを選択します。4つの事前構築されたタスクタイプがあります。テキスト要約、質問応答、分類、そしてオープンエンド生成です。ここではオープンエンド生成を選びましょう。

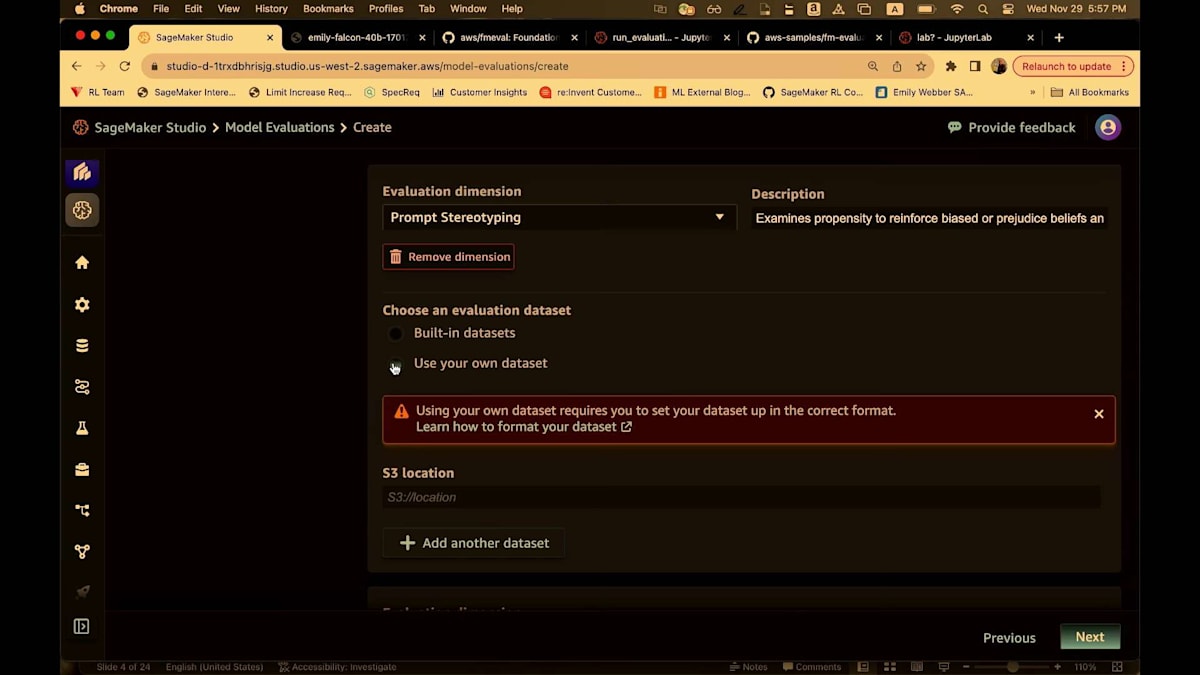
このタスクには異なる次元があります。プロンプトのステレオタイプ化は、2種類のプロンプトを含むデータセットです。 1つは非常にステレオタイプ的で、もう1つはそれほどステレオタイプ的ではありません。この次元は、モデルがより多くまたは少なくステレオタイプ的になる傾向をテストします。これがCrowS-Pairsです。ビルトインのCrowS-Pairsを使用するか、独自のデータセットを使用できます。独自のデータセットを使用する場合、 このモデルに合わせてデータをフォーマットする必要があります。すべてのデータ形式はJSON Linesで、これは人間ベースの評価、Python SDK、UIすべてに当てはまります。すべてがJSON Linesです。JSON Linesのキーは少し異なる場合がありますが、一般的にバックエンドはこのスタック全体で非常に柔軟に構築されています。

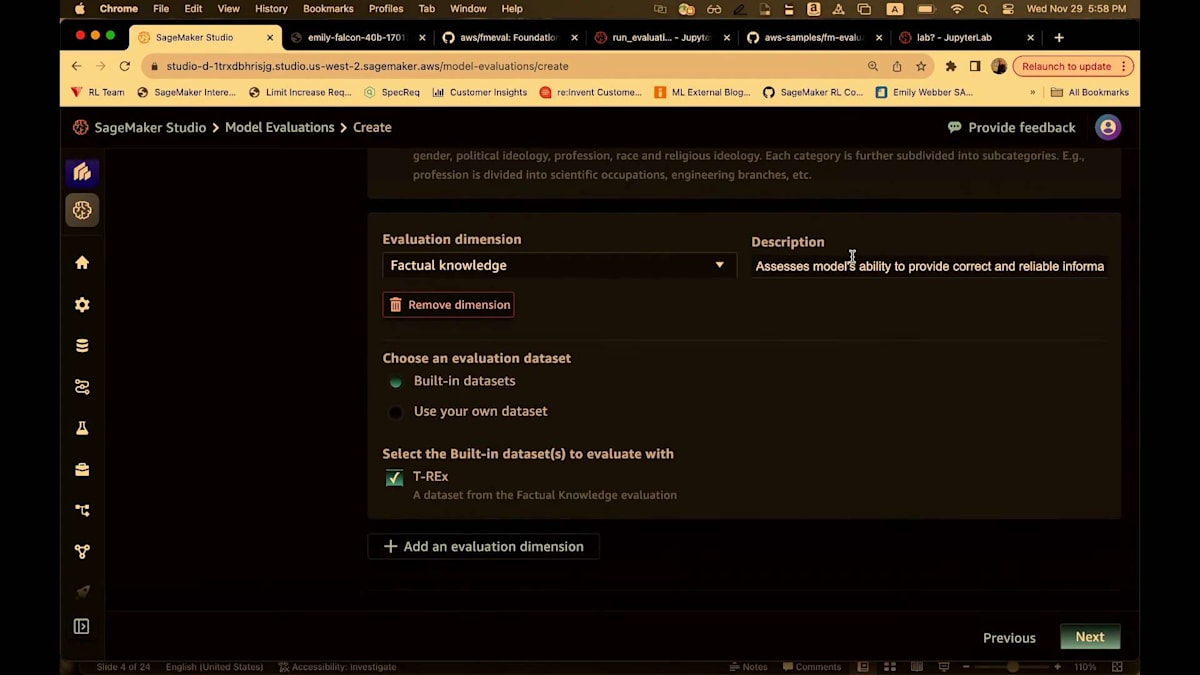
ビルトインのデータセットを使用し、CrowS-Pairsと有害性を選択しましょう。 有害性は事前学習済みのモデルを使用します。これはUnitary AI Toxicityモデルと呼ばれています。基本的に二値分類の一種を実行して、このモデルがどの程度有害になるかを確認します。ここには2つのデータセット、実際の有害性プロンプトとBOLDデータセットがあります。そして事実に基づく知識です。 事実に基づく知識の次元では、データセットはT-RExと呼ばれています。確認しましたが、このT-RExデータセットに恐竜は含まれていません。基本的に質問と回答です。このデータセットでは、回答は通常1語です。例えば、「2018年のアメリカ合衆国大統領は誰でしたか」や「ラスベガス市はどの州にありますか」といった、1、2語で答えられる質問です。
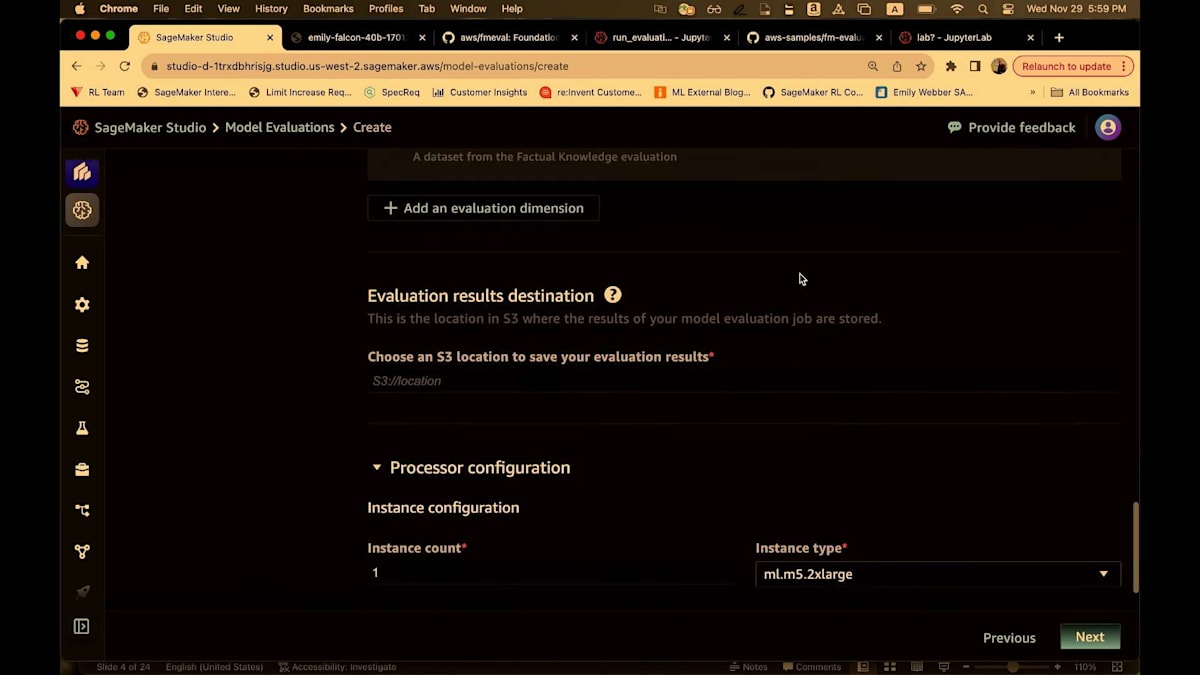
そして、これをJSONLinesフォーマットで取り込みます。そして、これらすべてに対して、プロンプトを使用します。ここでのプロンプトは組み込まれているか、あるいはあなたがロードしているプロンプトです。つまり、両方のオプションがあるわけです。この場合、私たちがあなたに代わってそれらのプロンプトをモデルに送信します。プロンプトを送信し、レスポンスを取得し、そして評価指標を計算します。そして、このモデルがどれだけうまく機能しているかを理解できるように、すべての評価結果を提供します。では、事実に基づく知識について、組み込みのものを使用しましょう。そして、私のS3バケットを探してみます。S3バケットを見つけられるかどうか。ちょっと待ってください。はい、US West 2で、これを設定します。私のS3の場所を指定しますね。これが私の評価結果の保存先になります。

このプロセッシングジョブが完了すると、PDFレポート、マークダウンファイル、そして設定データのすべてが表示されます。もちろん、自分で持ち込んだ入力データも含まれます。次に、プロセッシングジョブをセットアップします。

これは小規模なデータセットなので、1つのインスタンスだけを使用します。具体的には、ml.m5.2xlargeを使います。より大規模なデータセットを扱う場合は、単純にこれを増やすことができます。ml.m5.4、あるいはもっと大きなものを扱う場合は.12まで増やすこともできます。質問は最後に受け付けます。そして、ここに私の実行ロールがあるので、次へを選択します。ジョブの概要が表示されます。


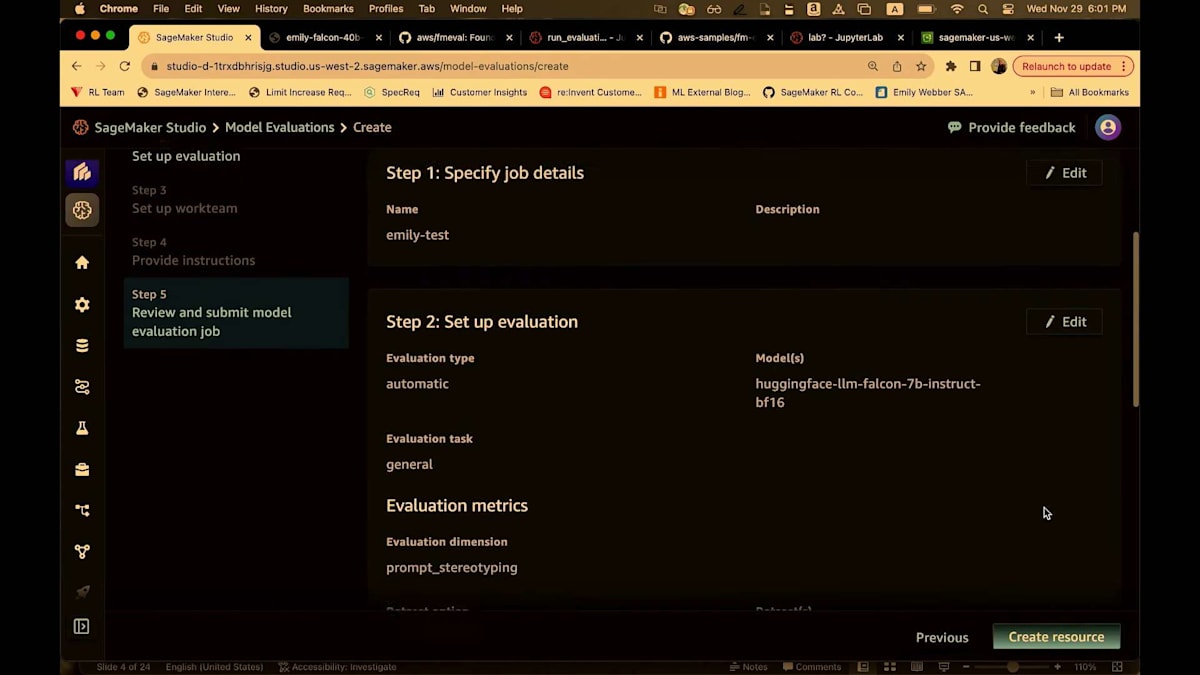
ジョブの詳細と、設定した評価のセットアップが表示されます。リソースの作成をクリックします。あ、間違ったS3バケットを使ってしまいました。ありがとうございます。よくあることですね。はい、これで大丈夫です。
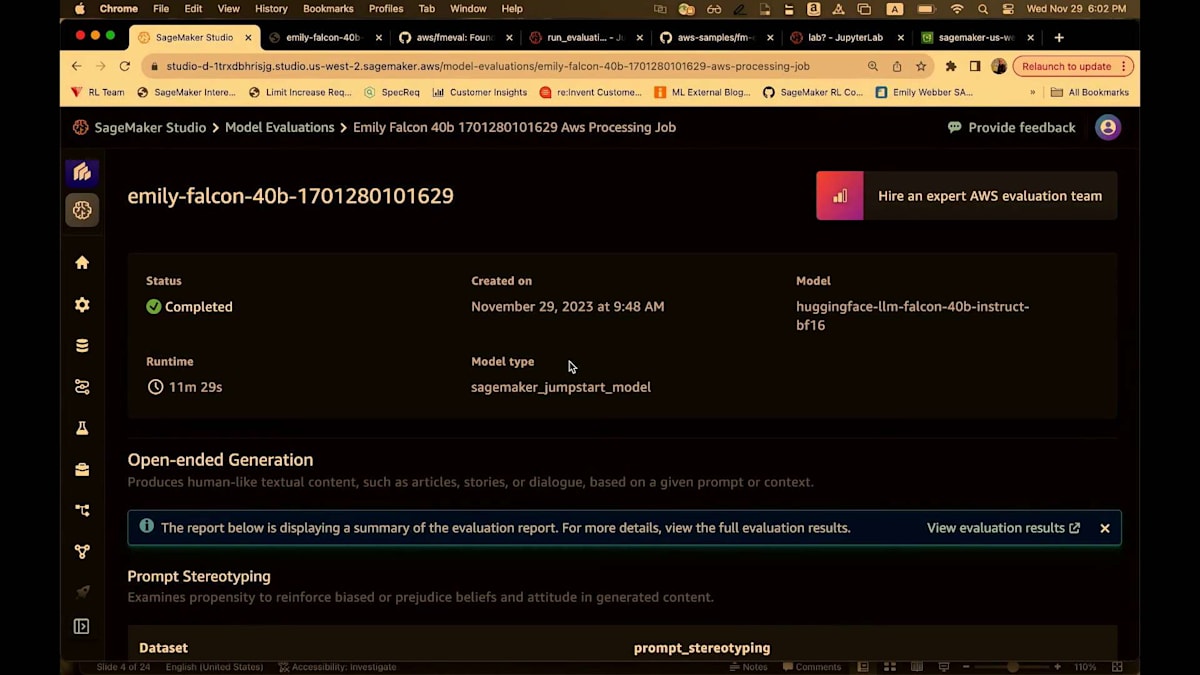
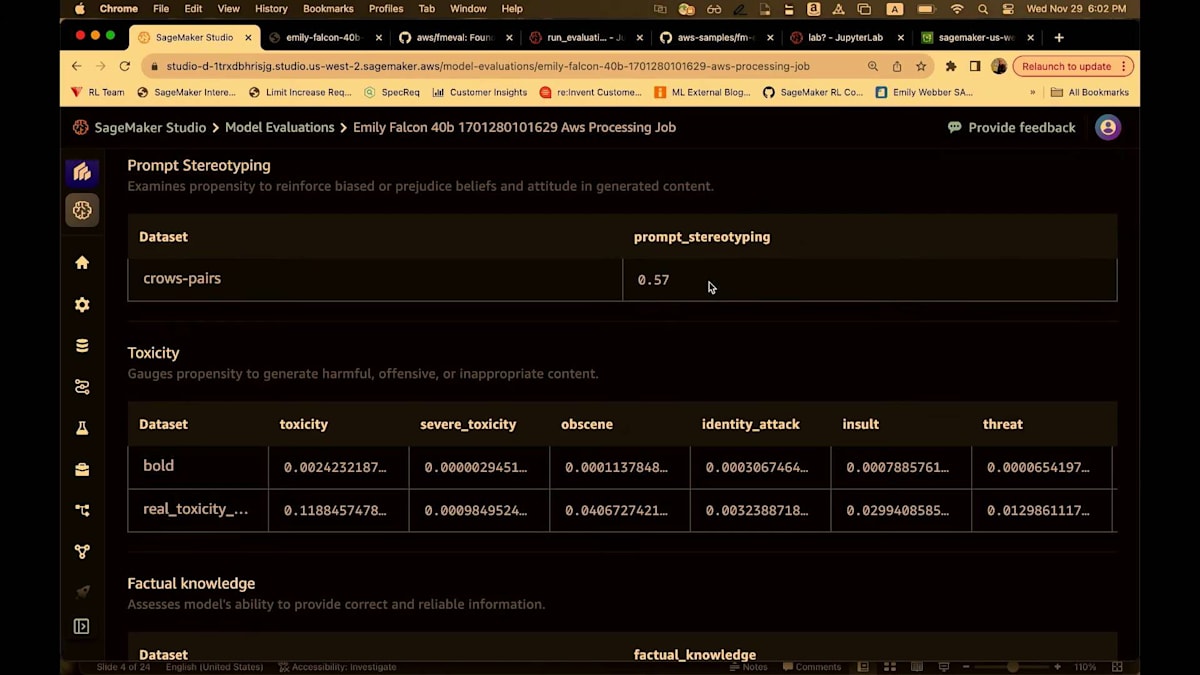
素晴らしい。ジョブが開始されています。また、テストと確認のために実行した他のジョブもいくつか見ることができます。以前実行したジョブをいくつかお見せしましょう。Falcon 40ビリオンパラメータモデルをテストするジョブを実行しました。この場合、サービスが私のためにエンドポイントを作成し、再度SageMaker Jumpstartを使用して評価を実行し、完了時にエンドポイントを解体し、評価結果を提供します。ここで見ているビューは要約です。これは、プロンプトのステレオタイプ化に関して得られた数値を示す簡潔なビューです。そして、Unitary AIの事前学習モデルを使用した毒性に関するすべてのレポート、事実に基づく知識などが表示されます。

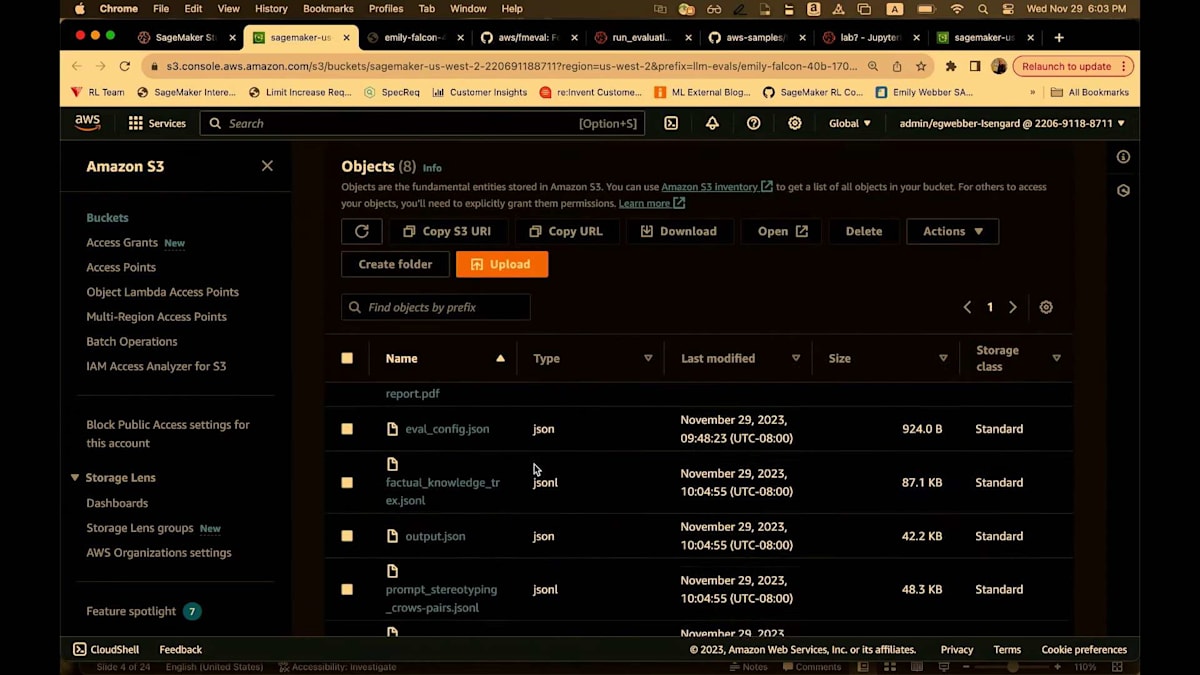

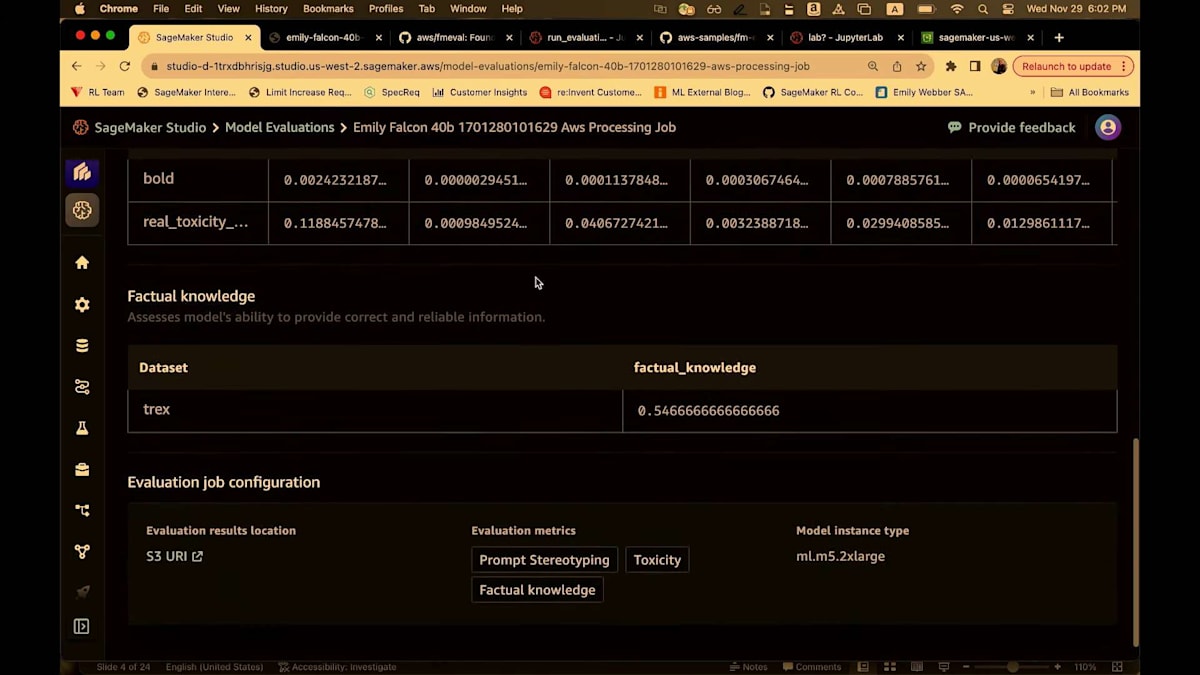
すべてのメトリクスは0から1の間でスケーリングされています。ほとんどの場合、数値が高いほど良いのですが、toxicityの場合は当然ながら、数値が低いほうがはるかに良いです。モデルサマリーページから、評価結果を見ることができます。そうすると、S3に移動し、再度markdownやPDF、そしてJSONの設定とアウトプットが表示されます。私はレポートに直接飛びます。
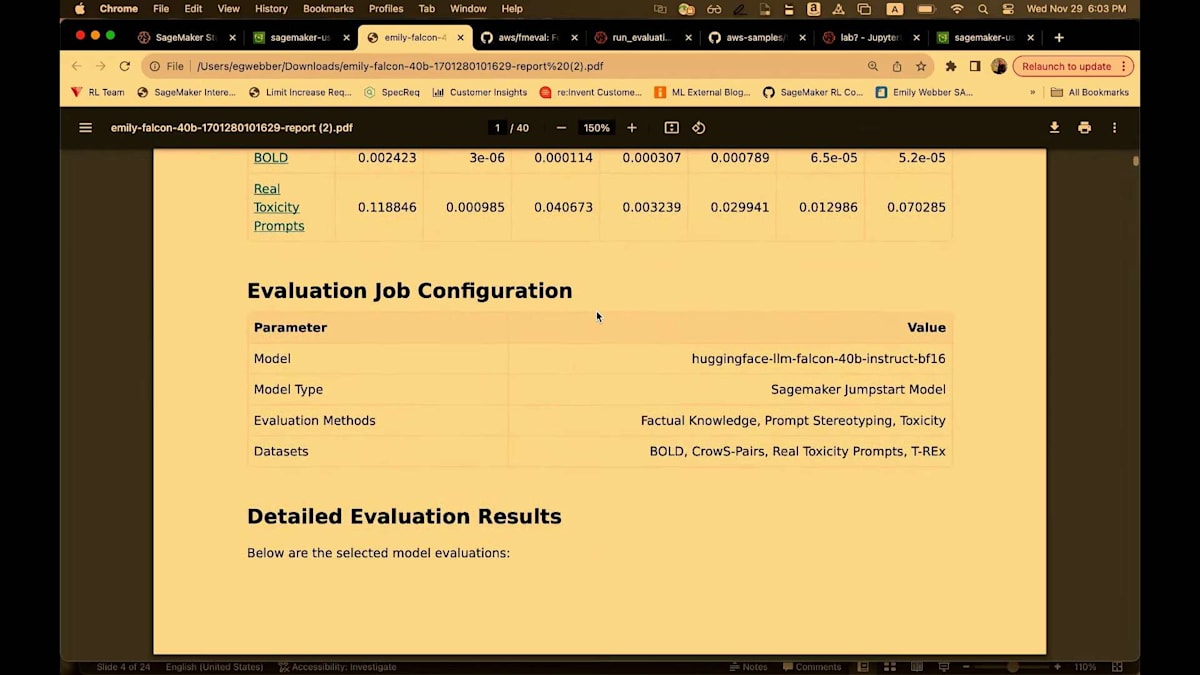
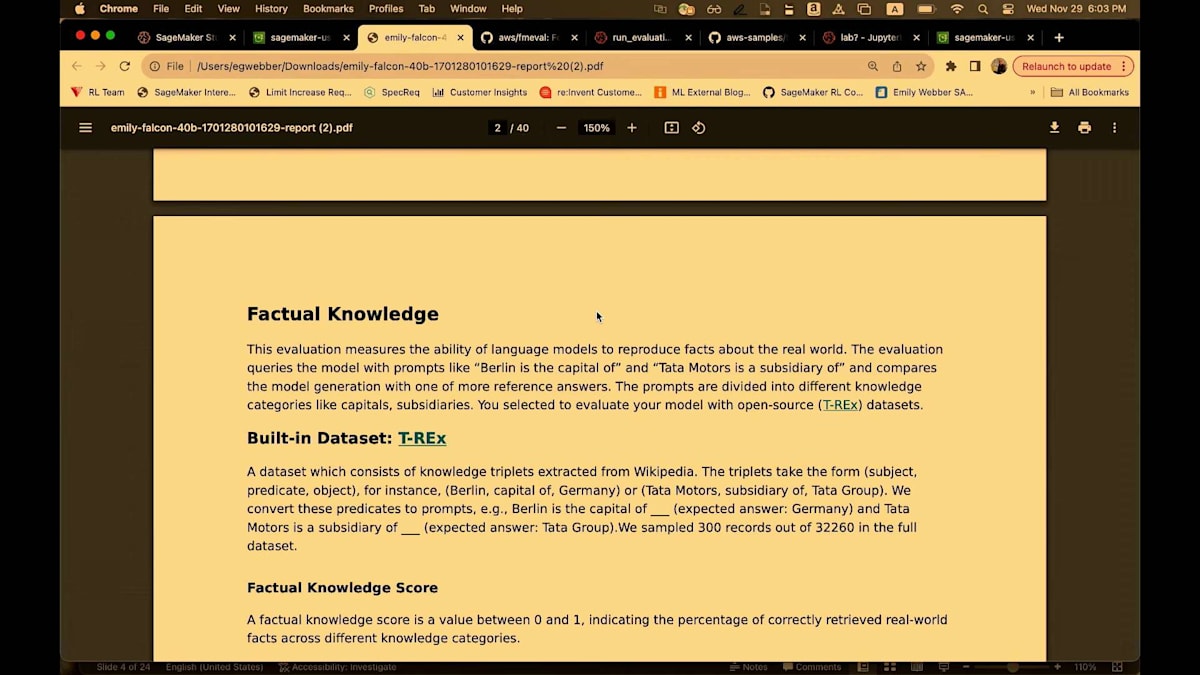
これは再び、40ページにわたる詳細なレポートで、私のジョブの概要を高レベルでまとめています。つまり、集計されたパフォーマンスを含む事実的知識、プロンプトのステレオタイプ化、toxicity、評価ジョブの設定、そして詳細なレポートです。そして繰り返しになりますが、私はこのレポートが大好きです。なぜなら、メトリクスの結果だけでなく、そのメトリクスが何を意味するのか、どう解釈すべきか、どのような影響を考慮すべきか、そしてどのように一般的に使用されているかについての洞察を提供してくれるからです。

いくつかの素晴らしいビジュアルもあります。このスタックでは、knowledge categoryと呼ばれるものを持ち込むことができます。特に事実的知識については、通常、顧客は既に多くの異なるカテゴリーを持つデータセットを持ち込みます。私が実行したDIYジョブの1つはSageMaker FAQsに関するものでした。そこには、hostingやtraining、endpointsなど、多くの異なるカテゴリーがありました。これらの詳細な知識カテゴリーをすべてスタックに持ち込むことができ、さらに深いレベルの分析を提供してくれます。
いずれにせよ、これが私のレポートです。次に進みましょう。レポートは始まりに過ぎません。また、オープンソースのPythonライブラリもあります。これはGitHubで利用可能です。FMEvalがこのフレームワークの名前で、使用が驚くほど簡単です。私たちは、LLMの開発とデプロイメントのライフサイクルの立ち上げを支援する人が誰であっても、foundation modelを本当に評価できるように、非常にアクセスしやすいデザインにしました。
一般的なpip installを行います。このpip installは広範囲にわたり、多くの低レベルのフレームワークやパッケージが組み込まれています。つまり、1回のpip installで済みます。そして再び、多くの例があります。Bedrock、Jumpstart、ChatGPT、Hugging Faceのカスタムモデルの例も含まれています。

これらの例を踏まえて、次はHugging Faceのカスタムモデルと、「bring your own outputs」と呼ばれる別のモードについて見ていきましょう。モデルとどこでも好きなように対話し、モデルの結果をダウンロードして、この環境に持ち込んで評価を行いたい場合、そこで実行できます。私はこのバージョンを実行しているので、非常に迅速に説明していきます。
SageMaker Studioにいることがわかります。ライブラリはローカルで実行されます。実際、ライブラリはノートブックでローカルに実行され、必要に応じてジョブに組み込むこともできます。ただし、これを探索するために一通り試す場合は、少し大きめのインスタンスを設定する必要があります。m5.2で十分ですが、私はこれをスムーズに動作させるために、おそらくもう少し大きなインスタンスで実行しています。いずれにせよ、pip install FMEvalを実行し、SageMakerをインポートします。
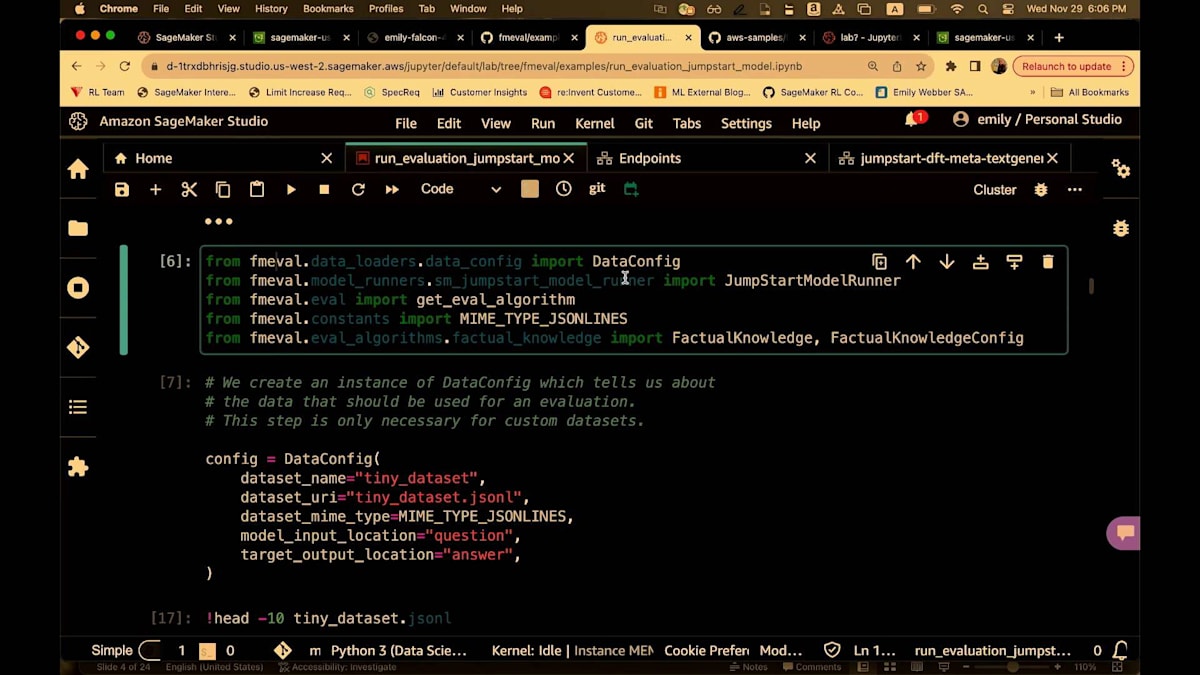
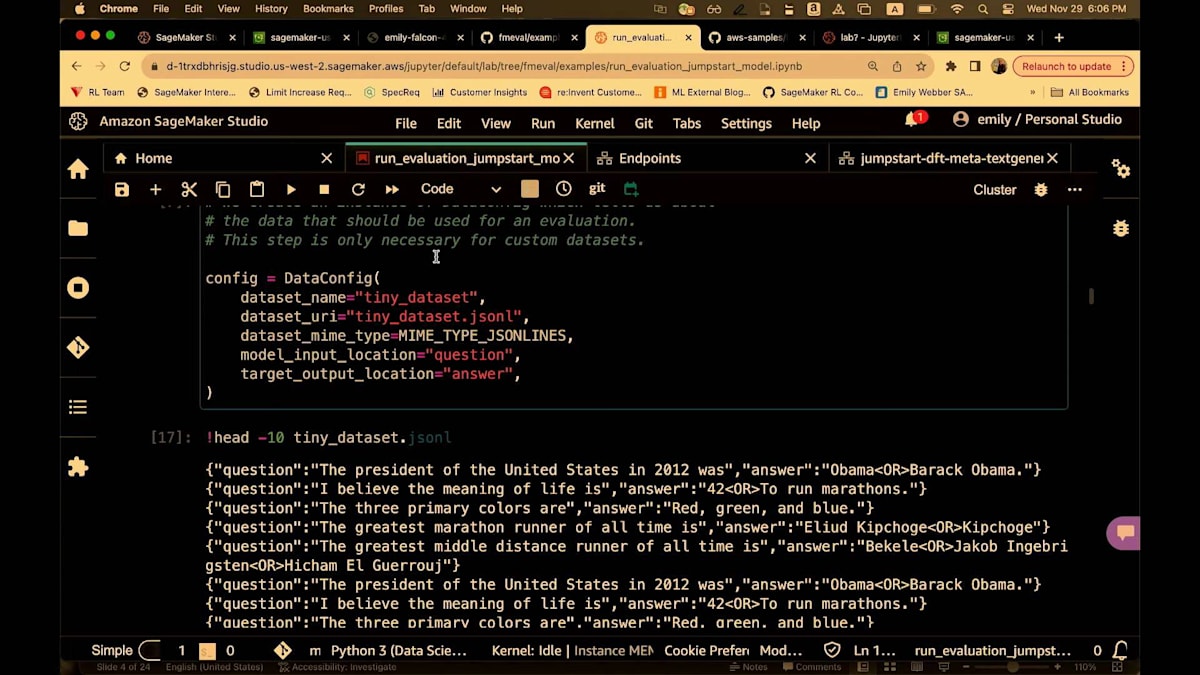
ここではLLaMA 7Bを指定します。Jumpstartを使ってデプロイします。そして、設定は非常に簡単です。 繰り返しになりますが、FMEvalからdata configをインポートし、model runnerと呼ばれるモデルへのポインタ、そしてアルゴリズム自体の設定をインポートします。これは事実に関する知識を評価するもので、その設定を行います。ノートブックにローカルに保存されているデータセットを指定します。S3パスを指定することもでき、 アクセス権があれば取得します。ここでの事実に関する知識のデータセットは、質問と回答の形式です。ORという文字列もあります。そして、モデルを指定します。ここでもJumpstartモデルを指定しています。

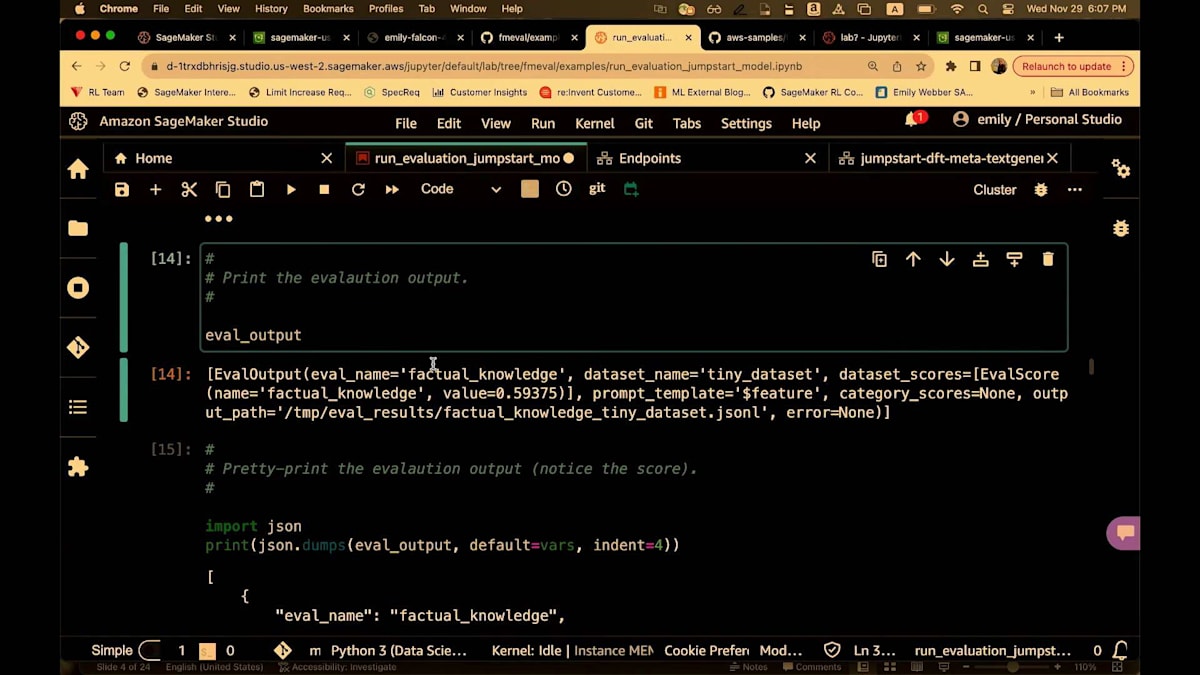
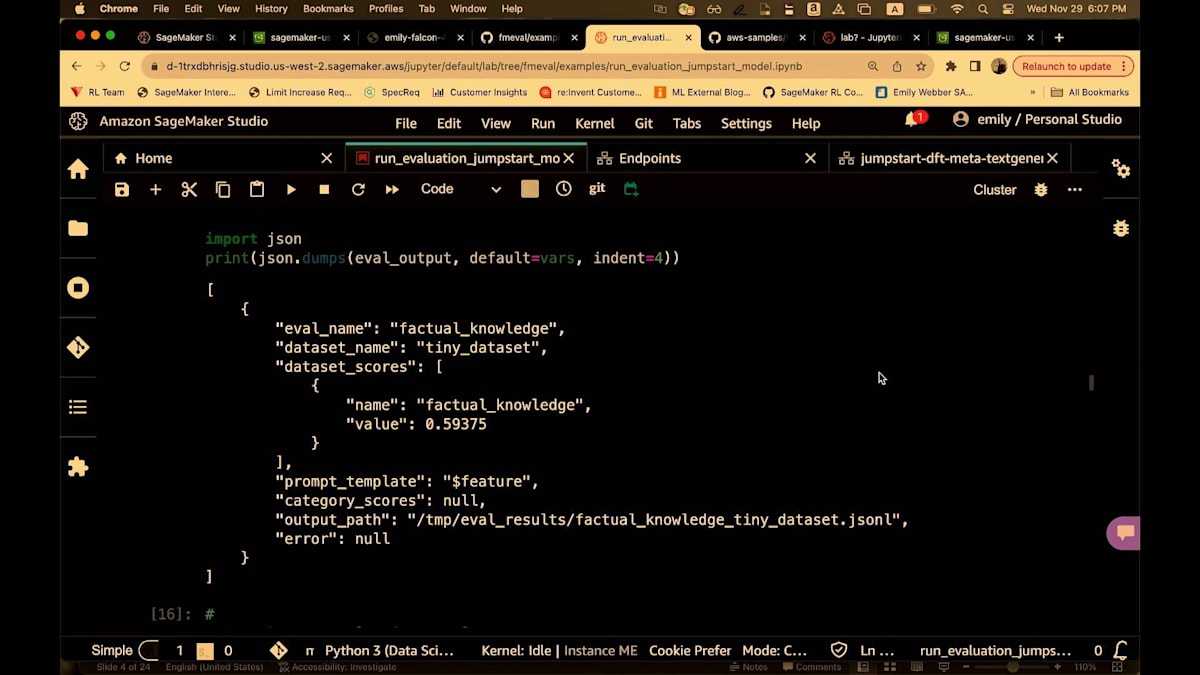
次に、事実に関する知識の評価を設定し、model.evaluatesを実行します。繰り返しになりますが、これはノートブックでローカルに実行されます。 実行が完了すると、評価結果が得られます。ここで、LLaMA 7Bが実際にかなり良い成績を収めたことがわかります。70億パラメータのモデルとしては驚くべき0.59というスコアでした。これは素晴らしい発見でした。そして、ここで結果を確認できます。 結果をデータフレームにロードしたり、S3に保存したり、パイプラインに組み込んだりすることもできます。次はそれをお見せします。
私たちには別のオープンソースリポジトリがあります。これは、この新しいフラメワークをSageMaker pipelinesに組み込んだものです。私は数週間前から1週間ほどこれを使って遊んでいます。非常に使いやすく、うまく機能し、カスタマイズも簡単です。このパイプライン全体を設定する大きなYAMLファイルがあります。そして、このYAMLファイルをカスタマイズして、異なるモデルを指定したり、パイプライン全体で少し異なる処理を行ったりすることができます。
評価のためのパイプラインを構築することは非常に価値があります。なぜなら、新しい開発をすぐに評価できるからです。retrieval processの新しいステップであれ、テスト中の新しいagentであれ、新しいモデルや新しいデータセットであれ、評価スタックがパイプラインとして構築されていれば、実行して新しいモデルをさらに評価する必要があるかどうかをすぐに確認することが非常に簡単になります。
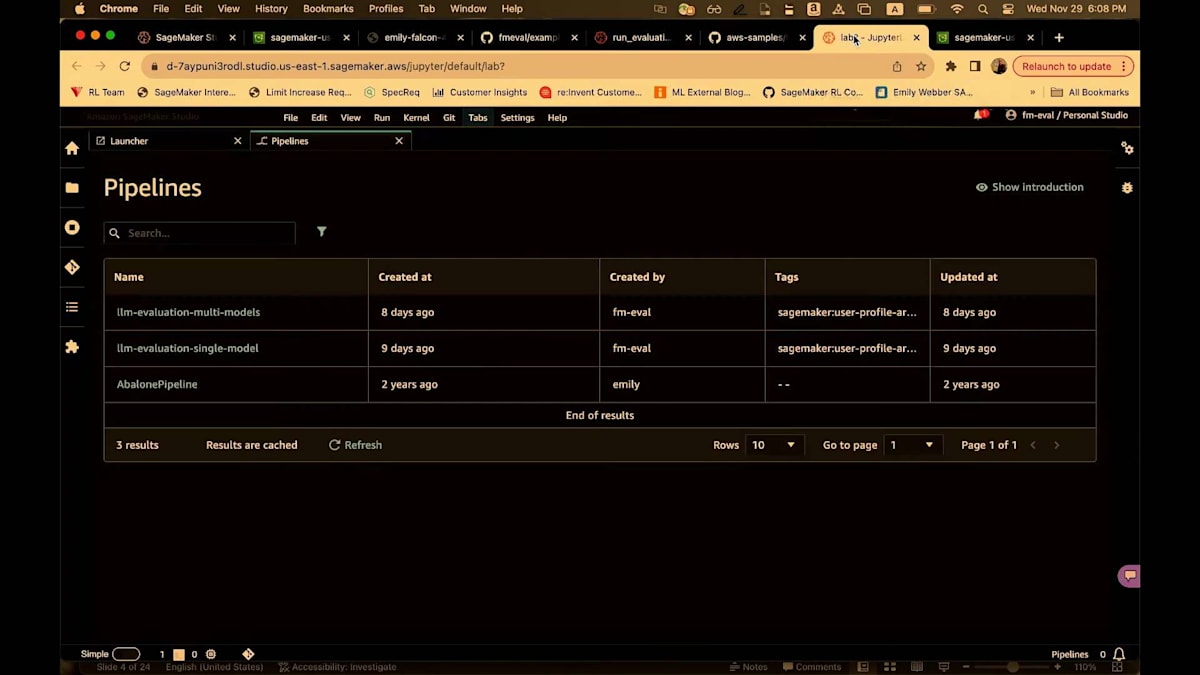


そこで、SageMaker Studioでこれを見ていきましょう。再びSageMaker Studioに戻りました。これはClassic viewです。このフレームワークを実行しており、2つのパイプラインがあります。 1つ目は単一のモデルを評価しています。ここで実行の詳細を開いてみましょう。これが私のパイプラインです。 LLaMA 2の70億パラメータモデルをデプロイし、前処理ステップを実行し、そしてこのライブラリを使用する評価ステップがあります。これはそのモデルの出力を取り、評価を実行し、結果をS3に保存します。実際、S3にはHTMLファイルが生成され、モデルのパフォーマンスが表示されます。これが単一モデルの場合です。

複数のモデルを評価することもできます。 こちらが私の素晴らしい3モデル評価パイプラインです。ここでLLaMA 7Bをデプロイし、これら3つすべてに対して同じ前処理を実行しています。次にFalcon 7Bをデプロイし、LLaMAをファインチューニングし、これをデプロイして評価します。これらのモデル全てに対して同じ評価スタックを使用しています。全てを一緒に集め、どのモデルを使用するかを選択し、そして全てをクリーンアップします。

デモをお楽しみいただけたと思います。ここでTarynに引き継ぎ、Indeedでのresponsible AIとモデル評価についての考え方を共有してもらいます。

はい、スライドに戻りましょう。そうですね、このデモはスキップしましょう。
IndeedのResponsible AI Teamの役割と大規模言語モデルの課題
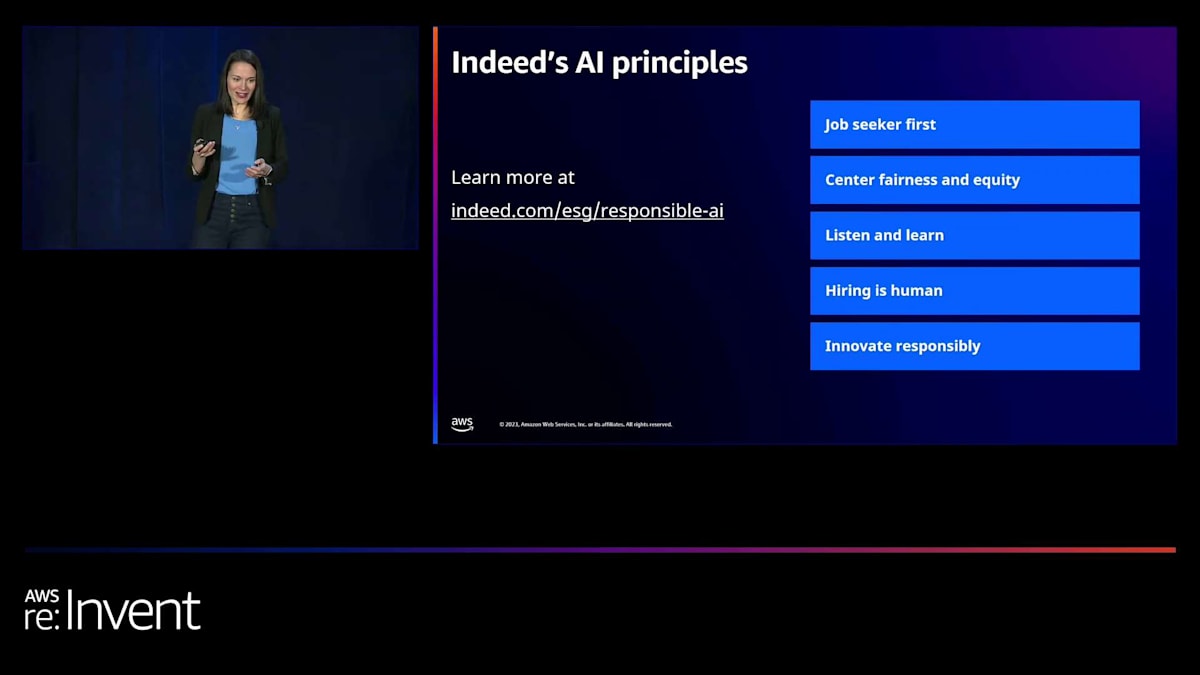
みなさん、こんにちは。Taryn Heilmanです。Indeedの Responsible AI Team のSenior Data Scientistを務めています。まず、私たちがAIについてどのように考えているかを少しお話しします。
Indeedでは、私たちのミッションステートメントは「人々が仕事を見つけるのを助ける」ことです。私たちは、双方向のマーケットプレイスで、すべての求職者に機会へのアクセスを開くために懸命に取り組んでいます。これを支援するためのAIアプリケーションの開発は、何よりもこのミッションに導かれています。私が所属するResponsible AI Teamは、ESG(環境・社会・ガバナンス)組織に属しています。特にこの組織では、才能は普遍的だが、機会はそうではないと考えています。私たちは、プラットフォーム上で大規模に機会を提供しています。適切な配慮をしなければ、有償労働が始まって以来、求職者が直面してきた偏見や障壁が大規模に強化され、増幅されてしまう可能性があります。これは私たちが望むことではありません。
ESGの中で、私たちはこのモデルを少し発展させて、「すべての人々が仕事を見つけるのを助ける」ことを目指しています。すべての求職者がAIの恩恵を受けられるようにしたいのです。このスライドでは、AIと関わる際に考慮する5つの原則を示しています。常に求職者を第一に考えること。すべての開発作業において公平性と公正性を中心に据えること。顧客やユーザーからのフィードバックに常に耳を傾けること。「採用は人間的なもの」というのは非常に重要な原則です。AIはすでに求職や人材マッチングのプロセスの多くの部分を支援していますが、求職者も雇用主も、人間が関与し、最終的な決定を下すべきだという信念を共有しています。そして最後に、責任を持って革新を行うこと。これが私の仕事の理由です。

Responsible AI Teamについてもう少し詳しくお話しします。私たちはとても小さなチームです。CEOはいつも「小さいけれど強力」と表現しています。科学者、ソフトウェアエンジニア、ユーザーリサーチャーがいて、すべての人々が仕事を見つけられるよう支援し、人々が直面する偏見や障壁を取り除き、AIプロダクトがすべての人にとって包括的であることを確認しようとしています。これを行うにあたって、私たちは2つの異なる立場で活動しています。1つ目は、開発チームと協力的に活動するブルーチームの立場です。データとラベルが責任を持って収集されていることを確認し、バランスの取れたデータセットを確保するのを支援します。プロセスのあらゆる段階で、包括的な人間中心設計の原則を使用します。そして、透明性と説明可能性に重点を置いています。

これらの活動をプロダクトチームと協力して行う一方で、レッドチームとしての立場もあり、より規制的な機能も担っています。採用は、医療や金融と同様に、非常に規制の厳しい分野です。私たちのアルゴリズムの中には、法律に基づく監査の対象となるものもあります。私たちはこれらのアルゴリズムを独立して検討し、公平性監査と呼ぶものを実施しています。そして、それらに対して従来の公平性指標を適用しています。
これは複雑なプロセスです。モデルの評価には、さまざまな種類のモデルがあります。従来の二値分類問題は、AIエシックスの分野で歴史的に最も研究と注目を集めてきました。私たちのプラットフォームでは、レコメンデーションやランキングを多く扱っています。また、スコアリングもあり、単純な回帰モデルもあります。これらの異なるタイプのモデルは、それぞれ異なる方法で評価する必要があります。さらに、製品がユーザーに与える影響も考慮しなければなりません。例えば、求人応募を勧めるメールが届いた経験は皆さんもあるでしょう。これは一般的にポジティブな介入と考えられます。そのため、例えば、異なる人口統計グループ間で選択率が同じになるようにしたいと考えます。ここで、Indeedとは関係のない、ネガティブなケースの例を挙げてみましょう。
顔認識アルゴリズムは、よく警察の文脈で使用されます。通常、顔認識アルゴリズムでフラグが立てられるのは良いことではありません。グループ間で偽陽性の割合が同じになるようにしたいものです。あるグループの偽陽性が他のグループよりも多くなることは避けたいですね。
さて、Large Language Models (LLMs)について話しましょう。ここラスベガスに皆さんが集まっているのは、LLMsと生成AIについて話し合うためですからね。これにより、モデルの公平性と責任を評価する方法に、多くの新しい複雑な側面が加わりました。EmilyとMichaelはすでに、私たちが気にかけている多くの側面について話しました。ここでは、Indeedでこれらの問題をどのように考えているかについて、少し詳しく説明しましょう。
差別や有害性は大きな懸念事項です。例えば、AIが生成した採用担当者からのメールには、不適切な言葉遣いがあってはいけません。暴力的な表現やヘイトスピーチ、その他の明らかに問題のある内容は避けるべきです。しかし、排除、偏見、表現による害といった、より微妙な問題もあります。例えば、その採用担当者が生成したメールで、「若くてエネルギッシュな候補者」を求めるような表現があってはいけません。これは年齢に関する偏見があるので好ましくありません。また、求人情報を自動生成する場合はどうでしょうか。例えば、看護師の求人情報に自動的に女性の代名詞ばかりが使われるのは避けたいですね。これは表現による害の一例です。
他に気をつけるべき点としては、事実誤認や誤情報があります。例えば、履歴書の要約や、候補者が適任だと思われる理由の要約を生成する場合、テキストが生成している内容は実際に正しいのでしょうか。Michaelが例を示したように、必ずしも正しくないことがあります。また、正しくても役に立たない場合もあります。そしてもちろん、プライバシー侵害も重要な問題です。トレーニングデータが漏洩することは避けたいですね。私たちは様々な機密性の高いHRデータでモデルをトレーニングするので、これらの言語モデルから出力される回答にそのデータが漏れることがあってはいけません。
Indeedにおける大規模言語モデルの活用事例
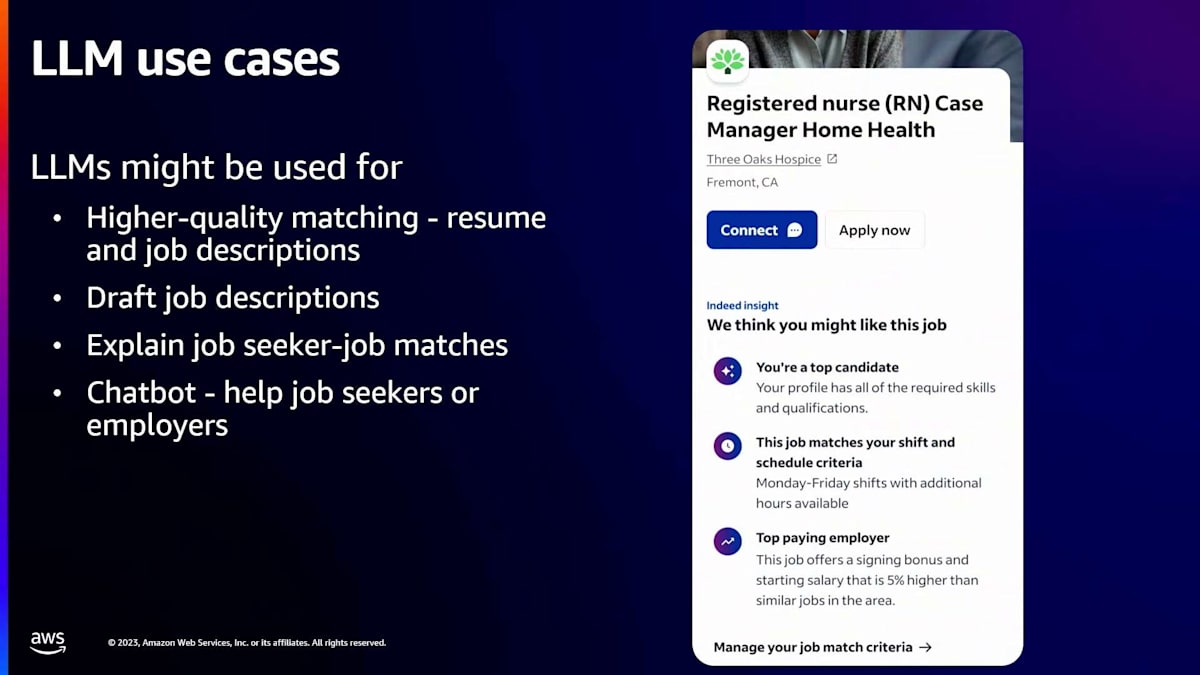
では、言語モデルの活用方法についてもう少し詳しくお話しします。まず考えられるのは、標準的な分類の文脈での活用、つまりマッチングです。求職者と求人があり、雇用主から連絡を受ける可能性が高い、適格な求職者と求人をマッチングさせたいのです。私たちは10年以上にわたって言語処理を使ってこれを行ってきましたが、LLMは実際にこの分野で非常に優れた性能を発揮します。LLMは従来のNLPアプローチ(n-gramなど)よりも優れています。なぜなら、特定のタスクに対して微調整できるだけでなく、transformerは従来のNLPアプローチよりもはるかに多くのコンテキストを考慮に入れるからです。
また、私たちはLLMを生成的な目的でも使用しています。例えば、求人情報の下書きを作成したり、雇用主を支援したりするのに活用できます。求職者と求人のマッチングを説明するのにも使えるでしょう。ここに示している例をご覧ください。これは求職者が目にする可能性のあるものです。何らかのマッチングアルゴリズムによって、その求職者に適していると判断された求人です。そして、生成AIを使って、「なぜこの求人に応募すべきだと私たちが考えているのか」という理由を説明しています。この場合、「あなたは最適な候補者なので、連絡を受ける可能性が高い」「あなたのスケジュールに合っている」「この雇用主は給与が良い」といった点を言語モデルが重要だと判断して、このマッチングを説明しているのです。
さらに、チャットボットの活用も検討しています。これは求職者の履歴書やカバーレターの作成を支援したり、関連性の高い求人を提案したりするのに役立つかもしれません。同様に、雇用主を支援するチャットボットも考えられます。もちろん、これは完全な使用例のリストではありません。おそらく皆さんの会社でも、50もの異なる生成AIプロジェクトが進行中という状況だと思いますが、私たちも同じです。
SageMaker Clarifyを用いたIndeedのモデル評価アプローチ

さて、私たちが検討しているこれらの複雑なユースケースについて話してきました。ここで、このプロダクトを使ってモデルを評価する方法についてまとめてみましょう。まず最初に気になるのは、出力されるテキストが事実に基づいているかどうかです。先ほどの例では、ある仕事が適しているかどうかの説明を見ました。同様に、求職者がその仕事に適しているかどうかの説明、例えばスキルや関連経験などについても見ることがあるでしょう。そこで、そういった情報が実際に正しいものかどうかを確認する必要があります。
この情報を検証するには、不正確な点を見つける必要があります。例えば、私について誰かが推薦してくれたとして、私にはないはずの豊富なマーケティング経験やデータエンジニアリング経験があると主張されていたら、そのエラーを特定したいところです。同様に、提供された情報が有用かどうかも評価する必要があります。履歴書の最近の関連経験を強調しているでしょうか?それとも古い情報を指摘しているでしょうか?このため、履歴書や職務内容の要約が事実に基づいており、有用なものになっているかを確認するために、factual knowledge evaluationモジュールとsummarization evaluationモジュールを活用します。有用性の判断は微妙な場合があり、人間の判断が必要になる可能性があります。そのため、プラットフォーム上で人間のアノテーターも活用することになるでしょう。
Responsible AIにおいて、私たちは偏った言葉遣いを深く懸念しています。例えば、看護師の職務内容に女性代名詞を多用したり、トラック運転手や医師の職位に男性代名詞を多用したりすることは避けたいものです。これに対処するために、Emilyがデモンストレーションしたstereotype evaluationを使用して、出力の固定観念的な性質を評価し、軽減することができます。
有害性や不適切な出力は明らかな懸念事項です。私たちのモデルから、センセーショナルな見出しを生むようなテキストや、粗悪な言葉遣い、脅迫、暴力的な内容が出てくることは望ましくありません。FMEvalには選択可能な複数の有害性検出モデルが用意されており、様々な側面から有害性をテストすることができます。コンテンツが深刻な有害性、ヘイトスピーチ、暴力性などを示しているかどうかを分類します。
最後に、私たちはグループ間のパフォーマンスの差異を頻繁に測定します。より伝統的な分類の意味で何かを使用している場合は、FMEvalのLLM分類用のclassification evaluationを利用できます。私たちには demographic data store があり、これらの情報と結合してグループ間のパフォーマンスを測定します。これはResponsible AIの重要な側面です。モデルが男性、女性、すべての人種、すべての年齢層に対して同様に良好なパフォーマンスを発揮することを目指しています。
SageMaker Clarifyの評価機能に関するリソース

申し訳ありませんが、少し時間を超過してしまいました。Emily にバトンを渡したいと思います。
Taryn、ありがとうございました。素晴らしいですね。まとめますと、皆様には4つのリソースをご用意しています。左側には、今ご覧いただいた機能やユースケースについて詳しく説明した What's New ブログ記事があります。2つ目の QR コードは、SageMaker pipelines で FM Evaluation を実行する GitHub リポジトリを指しており、簡単にカスタマイズして独自の評価パイプラインを設定できます。3つ目の QR コードはサービスドキュメントで、バックエンドの機能や要件をもう一度確認できます。4つ目は FMEval の GitHub リポジトリと、あらゆるものをテストできるサンプルノートブックです。
質疑応答セッション

残りのリンクを取得していただくため、しばらくこの画面を表示したままにしておきます。そして、Mike と Taryn にもう一度ステージに戻ってきていただきたいと思います。質疑応答の時間を数分設けたいと思います。マイクランナーはいませんので、手を挙げていただき、大きな声でお話しください。そうすれば、私たちが質問を繰り返します。では、勇気を出して質問してくださる方はいらっしゃいますか?はい、どうぞ。
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion