re:Invent 2023: AWSが語るSaaSとAI/MLの融合 - マルチテナント戦略
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - SaaS meets AI/ML & generative AI: Multi-tenant patterns & strategies (SAS306)
この動画では、SaaSとgenerative AIの融合について深く掘り下げています。Tod GoldingとJames Joryが、マルチテナント環境でのgenerative AI実装の課題や、RAG、fine-tuningなどの技術の活用方法を解説します。Amazon Bedrockを使ったテナント固有の体験提供や、IAMを活用したセキュリティ確保、さらにはLangChainなどのツールの活用まで、最新のSaaS開発のトレンドを包括的に学べる内容となっています。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
SaaSとGenerative AIの融合:re:Inventセッションの導入

このセッションにご参加いただき、ありがとうございます。re:Inventが皆様にとって有意義なものになっていることを願っています。SaaSと生成AIについて議論するために、皆様がMandalayまでお越しいただいたことに感謝申し上げます。毎年re:Inventの計画を立てる際、私たちは新興技術や新しいパターンを考慮します。今年は、生成AIが明らかにリストのトップに浮上しました。多くの顧客、パートナー、そして他の方々が、生成AIをアプリケーションにどのように統合できるかだけでなく、特にマルチテナント環境に生成AIを組み込むとはどういうことかを理解したいと熱心に考えていることを観察してきました。
私たちは、SaaSのワークフローと原則をサポートするために必要な微妙な違いやアーキテクチャの考慮事項を探求したいと考えました。特に、生成AI体験の上にテナント固有のカスタマイズや改良をどのように提供しながら、顧客に独自の体験を届けることができるかを検討することを目指しました。これが、このトークの主な動機でした。私たちは、可能性の全体像を概説し、すべてをマルチテナンシーのレンズを通して見て、それが生成AIのストーリーにどのような影響を与えるかを検討したいと思います。データの分割、分離、価格設定にどのように影響するか、そしてRetrieval Augmented Generation(RAG)やファインチューニングなどのツールを生成AI体験とどのように組み合わせることができるかについて議論します。
この考え方はまだ初期段階にあることを認識することが重要です。誰もが様々な体験を通じて生成AIのストーリーを決定しようとしており、SaaSプロバイダーも例外ではありません。今日の目標は、皆様がいくつかの可能性を理解して帰っていただくことです。1年後にこのトークを聞いたら、おそらく全く新しい選択肢の範囲があるでしょう。しかし、マルチテナンシーを生成AIのストーリーに結びつけるための思考モデルを皆様に提供できればと思います。
プレゼンターの自己紹介とセッションの概要

自己紹介をさせていただきます。私はTod Goldingで、約8年間、様々な顧客やパートナーとSaaS分野で働いてきました。今日は幸運にも、同僚のJames Joryが舞台に同席しています。James、自己紹介をお願いできますか?

「はい、ありがとうTod。私はAWSのAI/MLグループのスペシャリストソリューションアーキテクトです。また、リテールのスペシャリストでもあり、多くのパートナーとAI/MLサービスをプラットフォームに統合する作業を行ってきました。今日はここにいられて嬉しく思います。」
Jamesはgenerative AIの分野で深い専門知識を持っているので、このプレゼンテーションでは彼が私のサポート役です。彼はこの内容をまとめて皆さんに発表するのに大きな助けとなってくれました。では、技術的な側面に踏み込んでいきましょう。これは307レベルのセッションなので、IDEを開いたり大量のコードを書いたりはしませんが、アーキテクチャの詳細については確実に探っていきます。
SaaSとGenerative AIの適合性:可能性と課題

まず、generative AIとSaaSの適合性について考えてみましょう。SaaSをgenerative AI分野に適用する際に、人々が考えるべき共通の接点は何でしょうか?最も広範な可能性から始めましょう。SaaS自体には大きな勢いがあります。ビジネスを展開し運営する標準的な方法となっています。マルチテナントモデルでアプリケーションが前例のないペースで構築されています。つまり、SaaSはすでに提供モデルとして大きな勢いを持っているのです。

そこに、generative AIが導入されています。私の予想では、generative AIとSaaSは密接に結びつくでしょう。アプリケーションを提供する方法としても、SaaSアプリケーションの体験を豊かにする全く新しい方法を導入する手段としても。今日、より具体的に焦点を当てるのは、generative AI環境でターゲットを絞ったテナント体験を提供することの意味です。Large Language Models (LLMs)や基盤モデルに質問するメカニズムがありますが、特定のドメインでテナントにターゲットを絞った体験を提供したい場合、それはどういう意味を持つのでしょうか?
SaaS環境で、ユニークなSaaS環境が1つあるけれども、すべてのテナントが異なるコンテキストでそれを消費していて、全てを同じように扱いたくない場合、私たちに何ができるでしょうか?テナントごとにユニークな体験を提供したいのです。これが今日深く掘り下げるテーマであり、Jamesが話を進める中で大きな部分を占めます。これは、generative AIとマルチテナンシーを組み合わせた価値提案の重要な側面なのです。

考慮すべきもう一つの側面は、価格設定とパッケージングです。価格設定とパッケージングについて言及すると、多くの人はそれは他の人の責任、おそらくビジネスパーソンの仕事だと考えがちです。しかし、話を進めていくと分かるように、マルチテナントのgenerative AI環境をどのように実装するかは、価格設定とパッケージングに大きな影響を与えるのです。
実際、消費量の測定方法、消費量の帰属方法、そしてそれがソリューションの価格にどのように反映されるかは、他の環境と比べて generative AI では大きく異なります。そのため、検討すべき点が多く、それらをアーキテクチャにどのように組み込むかについて、多くのことを考える必要があります。

もう一つの分野は、少し推測的ですが、一般的に SaaS を見ると、常に SaaS 環境の効率性について話します。迅速に動けること、テナントがリソースをどのように消費しているか、全体的にどのような負荷をかけているかを示す素晴らしい分析や洞察を得られることについて話します。このような豊富な洞察データを持つことの重要性を、何度も強調します。SaaS のこの運用と分析の部分全体も、generative AI によって強化されるのは自然なことのように思えます。ただし、この分野での素晴らしい事例を見出すにはまだ手探り状態だと思います。今日はこの部分については実際に取り上げませんが、考慮すべき範囲の一つだと思います。

関連して、意外かもしれませんが、テナントのオンボーディングの分野で generative AI を使用している人々がいます。テナント管理のライフサイクル全体と、テナントがあなたの顧客としてどのように旅を進めるかということに、generative AI が適用されています。あるいは、それを最適化するために generative AI が適用されています。テナントがどの段階にいるかをどのように識別するか、カスタマーサクセスがいつ連絡すべきかなど、すでにこの分野で generative AI を適用している良い例があります。

そして最後に、最も関連性が高く、誰もがあらゆる分野で探し求めているのは、自分の SaaS アプリケーションに generative AI を活用して差別化できる魔法のような機能は何かということです。それは既存の機能を強化したり、環境に新しい機能をもたらしたり、あるいは新しい市場の可能性へと範囲を広げたりするものです。誰もがここに時間を費やし、そのスイートスポットがどこにあるかを見つけようとしています。ここには一つのスイートスポットではなく、多くのスイートスポットがあると思いますが、パターンやテーマが何なのかをみんなが理解しているとは思いません。まだまだ進化している分野だと思います。
Generative AI体験の構成要素:基盤モデルからSaaSアプリケーションまで


詳しく掘り下げる前にもう一つやらなければならないのは、この体験の大きな動く部分を概説することです。Generative AI には膨大な領域があります。AWS のサービスと機能は体験の多くをカバーしていますが、私たちの SaaS に関する議論の部分では、この体験の非常に特定の動く部分に焦点を当てたいと思います。そしてそれらが、私たちが本当に深く掘り下げる領域になります。明らかに、この全体験の基礎にあるのは、誰もが話題にする foundation models、LLMs です。これらが generative AI 環境の心臓部であり頭脳です。これらが、他のすべてが構築される本当に基本的なツールなのです。


そして、その上に、ステートレスな生成AIサービスがどこに位置するかが見えてきます。これは、AWSではSageMakerとBedrockが該当する部分で、これらは基盤モデルの上に乗るAPIのようなものです。これらは、その体験への入り口となります。ここで、モデルで何をしたいかを設定します。場合によっては、基盤モデル自体の根本的な体験をここで設定することもあります。その仕組みについても後ほど見ていきます。しかし、これは間違いなく、これらの体験への玄関口となります。


その上に、いくつかのオプションコンポーネントが見えてきます。実際のところ、私の入り口はステートレスな生成AIサービスだけでも構いません。SageMakerを通じて、あるいはBedrockを通じて入り、これらの基盤モデルのいくつかを利用するだけでも十分です。しかし、このマルチテナントのストーリーを見ていく中で、我々がここでどのようなツールを持っているかをお話しします。そのうちの1つがファインチューニングです。Jamesがファインチューニングで何ができるかについて詳しく説明しますが、このレベルでは、ファインチューニングによって実際にこれらの基盤モデルの動作をカスタマイズします。テナント固有のコンテキストでモデルを強化し、どの顧客にも提供できる機能を超えて、特定のテナントに特化したことができるようにします。

次のレベルでは、私が「注入されたコンテキスト」と呼ぶものがあります。これはLLMの外部にありますが、基本的に、Bedrockの外部で、この体験への入り口で何ができるか、送信するリクエストをどのように修正できるかということです。送信するリクエストを洗練させることはできるでしょうか?ここでRAGが登場します。生成AIに携わっていれば、これを見たことがあるでしょう。また、これはこの世界の外部にあるため、このレベルで状態とメモリも関係してきます。つまり、これらはどちらもこの世界の外側に位置します。ここで、体験に注入する必要のあるものを検出します。


そして、それが私たちの体験を洗練させることになります。そして当然、これらすべての上に私たちのマルチテナントSaaSアプリケーションが位置します。ここで常に問題となるのは、これらのうちどれがどのパターンを使用しているかということです。ご覧のように、私は意図的にレーンを開けたままにしています。これは、ファインチューニングだけを使用するかもしれないし、RAGだけを使用するかもしれない、あるいはRAGとファインチューニングの両方を使用するかもしれないということを強調するためです。その組み合わせ方は、環境のニーズによって異なります。しかし、これらが今日お話しする問題の動く部分です。これで、物事がどこに位置するかについて少し理解していただけたと思います。
マルチテナントSaaS環境におけるGenerative AIの実装

ここで、基礎として最もシンプルな生成AIのケースから始めたいと思います。これが最もシンプルなケースです。今日、Amazon Bedrockを利用したいだけで、アプリを書きたい場合、アプリを書いて、顧客がリクエストを出すことができます。それはBedrockを通じてより直接的に表示されるものかもしれませんし、Bedrockを利用する私のアプリケーション内のサービスを通じてかもしれません。いずれにせよ、それはプロンプトを生成し、そのプロンプトがBedrockに入力され、Bedrockが応答を返します。Bedrockはただのステートレスサービスです。リクエストを処理して応答を返すだけです。したがって、この体験の左側にいる顧客が全員同じリクエスト、あるいはほぼ同じリクエストを送信している場合、彼らも同じ応答を得ることになります。つまり、ここでは左側の顧客体験に特別なものは何もないのです。

さて、同じモデルを少し先に進めて、マルチテナントSaaS環境ではどうなるかを考えてみましょう。 左側にこれらのテナントがあり、各テナントに対して独自の体験を提供したいと考えています。テナント1が特定のドメインや特定の領域からアクセスして質問をすると、ターゲットを絞った回答を得られるようにしたいのです。テナント2が同じような質問を別のドメインから行った場合、ユニークな体験を提供したいと考えています。では、これをどのように組み込むのでしょうか?



私たちがやりたいのは、テナントのコンテキストが流れ込み、 そしてテナントのコンテキストが流れ込む一部として、Bedrockに行く前に、Bedrockとこの拡張体験の間に位置取りをすることです。Bedrockに入る前にリクエストを拡張したいのです。ここで、リクエストをどのように拡張するか、テナント固有の体験を提供するすべてのコンテキストをどのように導入するか、 という全体的な概念が出てきます。これがBedrockに流れ込むと、テナントで拡張されたプロンプトができ、 応答が返ってくると、テナント固有の応答が得られます。これが、生成AIの体験におけるマルチテナンシーの最高レベルの概要だと私は考えています。実際には、拡張の方法はソリューションごとに大きく異なります。


この点をもう少し明確にするために、具体的な例にマッピングしてみましょう。例えば、eコマースソリューションがあるとします。 人々は私のeコマースプラットフォーム上で店舗を作ります。これは1つのソリューションで、誰もが同じように利用しますが、私のeコマースプラットフォーム上で店舗を構築する顧客は、すべて同じドメインから来ているわけではありません。ゴルフドメインから来る人もいて、ドライバーやウェッジを販売し、顧客はゴルフクラブを購入することに対して非常に具体的な期待を持っています。工具を販売する人もいて、ハンマーやのこぎりなど、別の種類のものを求めています。彼らはそれに関連したユニークな体験を望んでいます。そしてもちろん、衣類もあります。


これらのドメインがありますが、すべて私の1つのプラットフォーム上で動作しています。彼らが「製品を見つけたい」 または「何かを探したい」と言ってきたとき、例えば「私は左利きのゴルファーで、スライスがひどいんです。この特定の条件に合うクラブはどれがいいでしょうか?」と言った場合、このバックエンド体験に対するリクエストに、何らかの形でそのドメインのコンテキストを注入したいのです。そうすることで、ゴルフドメインに特化した具体的な応答が得られます。 そして、工具ドメインからリクエストが来たときも、同様の体験を提供したいのです。これは、ショッパーが素晴らしい体験を得られるという点で価値があるだけでなく、生成AIから得られるものに対する期待が誰もが同じではないという事実を強調する素晴らしい方法でもあります。そして、特にSaaS環境では、その体験をカスタマイズする方法を見つけ出すのが私たちの仕事なのです。

ここで、Jamesにバトンタッチします。Jamesはこの概念を取り上げ、さらに詳細に掘り下げていきます。 この概念を取り上げ、RAG(Retrieval-Augmented Generation)を使用してもう少し深く掘り下げていきます。
RAG(Retrieval-Augmented Generation)の概要とSaaSへの適用

SaaSやマルチテナントアプリケーションにおいて、 RAGは外部ソースから取得した追加データでLLMを基礎付けることで、LLMの出力の質と予測可能性を向上させる技術です。このデータはプロンプトに提供され、LLMが課題に集中できるようにします。検索レイヤーの典型的なデータソースタイプは、k-NNプラグインを備えたOpenSearchや、人気のSaaSベースのベクトルデータベースであるPinconeなどのベクトルデータベースです。Enterprise RedisやMongoDBもベクトルベースの検索をサポートするようになりました。これはデータベースコミュニティで急速に変化している分野で、多くのプロバイダーがベクトルベースの類似性検索のサポートを追加しています。
ベクトルデータベースはRAGのユースケースに適していますが、これは自然言語クエリやセマンティッククエリを受け取り、意味的に類似または関連する文書やオブジェクトを見つけることができるからです。しかし、ベクトルデータベースを使用することは必須ではありません。DynamoDBやリレーショナルデータベースを使用して、プロンプトで使用できる事実やデータを取得する方法の例を示します。

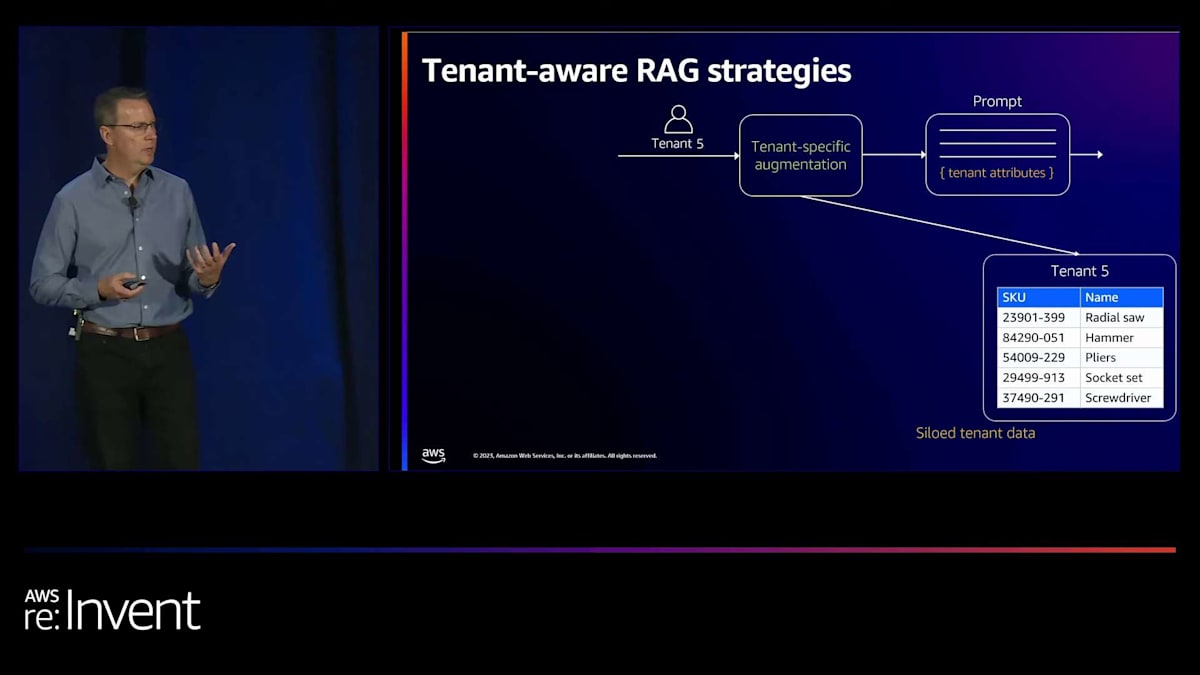
テナントが共有SaaSアプリケーションに入る場合を考えてみましょう。例としてテナント番号5を使用します。このテナント専用のテーブルから製品を取得する拡張パターンを構築しようとしています。このeコマースストアで現在プロモーションされている製品を取得し、モデルにそれらの製品をユーザーにとってより魅力的にするマーケティングコピーで包むよう依頼するというユースケースかもしれません。製品情報を取得し、このデータでプロンプトを拡張し、 そしてプロンプトを通じてLLMに何を生成してほしいかを指示します。


次に、別のテナント(番号4)が同じソリューションに入ってきたとします。同じプロセスに従い、テナント番号4の専用テーブルにリクエストを行って製品を取得し、テナント4の製品を含むプロンプトを生成し、そして応答を返します。 最後に、データが共有テーブルまたはプール構成にある3番目のテナント(番号2)があります。この場合、DynamoDBテーブルでテナント番号2のテナントIDをパーティションキーとして使用し、共有テーブルからそのテナントの製品を取得します。
これは、SaaSアプリケーションの構築に使用される多くの同じSaaSパターンが、ここでの生成AIアプリケーションのユースケースにも適用されることを示すために意図的に設定しました。これらの学びは、構築できる新しいクラスのユースケースや体験に適用できます。
RAGのデータソース選択とSaaSアプリケーションへの統合

RAG体験のためのデータソースを選ぶ際には、多くの選択肢があります。ベクトルベースの検索には、OpenSearchやPG vectorライブラリを使用したPostgresを利用できます。Amazon Kendraも別の選択肢で、S3や他のアプリケーションにある文書をインデックス化できる完全マネージド型サービスです。私たちのeコマースの例では、ユーザーの過去の購買行動に基づいておすすめ商品を抽出し、それらの商品に関するプロンプトを作成したいかもしれません。
これらの異なるソースを紹介する理由は、構築するユースケースに合わせてデータストアを選ぶ必要があるからです。ベクターデータベースだけに限定されるわけではありません。意思決定プロセスの一部は、マルチテナントSaaSアプリケーションで行う一般的なトランザクションデータソースの選択と似ています。データをパーティション化する能力や、テナント間でワークロードをどのように管理するかを考慮する必要があります。また、テナントの分離や、ノイジーネイバーのような運用上の特性も検討します。
これらはすべて、生成AIの分野でも同様に重要な考慮事項です。Retrieval Augmented Generation(RAG)や生成AIで非常に一般的なベクターデータベースについて、もう少し詳しく見てみましょう。SaaSベースのアプリケーションでこれらのベクターデータベースをどのように構築するかを検討します。

まず、テナントデータから始まります。そのデータをベクターデータストアにインデックス化します。ベクターデータストアは、ご存じない方のために説明すると、ベクター埋め込みとして表現される非構造化オブジェクトをインデックス化して保存するタイプのデータベースです。これらの目的は、類似性ベースの検索や意味ベースの検索を可能にすることです。これらのインデックスにクエリを行う際は、自然言語クエリや意味的なクエリを取り、そのクエリからも埋め込みを生成します。そして、コサイン類似度などのベクターベースのアルゴリズムを使用して、意味的に類似したオブジェクトをインデックスから検索します。他のアプローチもありますが、基本的にはそのクエリベクトルに近い、または最近傍の他のオブジェクトのベクトルを見つけるのです。

ここでは、テナントデータがデータレイクなどにステージングされています。データの埋め込みを生成する前に、おそらく何らかの準備が必要です。テキストベースのデータの場合、これは通常「チャンキング」と呼ばれ、長いテキストを小さな塊に分割します。そして、各データの塊に対して埋め込みを生成します。ここではAWS GlueやAmazon EMRなど、データ処理に適したAWSサービスを使用できます。
Amazon Bedrockを活用したKnowledge Baseの構築

データの準備が整ったら、埋め込みを生成する準備が整います。ここでは、いくつかのオプションを紹介します。Amazon SageMakerでは、例えばHugging Faceのモデルをホストして、提供された入力に基づいて埋め込みを生成することができます。また、Amazon Bedrockも埋め込みを生成できる完全マネージド型のモデルを提供しています。これらが利用可能な2つのオプションです。

埋め込みが生成されたら、それらをベクトルデータストアにインデックス化する時です。ここではAmazon OpenSearch Serviceを使用しています。2つの異なるテナント用に2つの異なるOpenSearchドメインがあるのがわかります。これは、OpenSearchを使用してサイロベースのアプローチを取る方法を示しています。インデックスには埋め込みとテキストの両方が含まれているので、ベクトルベースの検索を行うことができます。

今週たくさん耳にしたであろうAmazon Bedrockは、foundation modelsへのAPIアクセスを提供するように設計された完全マネージド型サービスです。Bedrockの高度な機能の1つに、今週GAとなったknowledge baseがあります。これは、先ほどのスライドで見た自分で行うステップの一部を自動化したり、代行したりするものです。先ほど見たのと同様のプロセスを、今度はBedrockのknowledge baseを使ってどのように行うかを説明したいと思います。


まず、テナント固有のデータから始めます。そして、Bedrockにデータをインデックス化するよう指示するため、事前にOpenSearchインデックスを作成する必要があります。 Amazon OpenSearch Serverlessはベクトルベースのデータベースをサポートしているので、インスタンスやノードを管理する必要はありません。すべてサービスに任せることができます。OpenSearch Serverlessはここでぴったりです。テナント1用のインデックスを作成し、Bedrockにそのインデックスの管理と入力を依頼します。

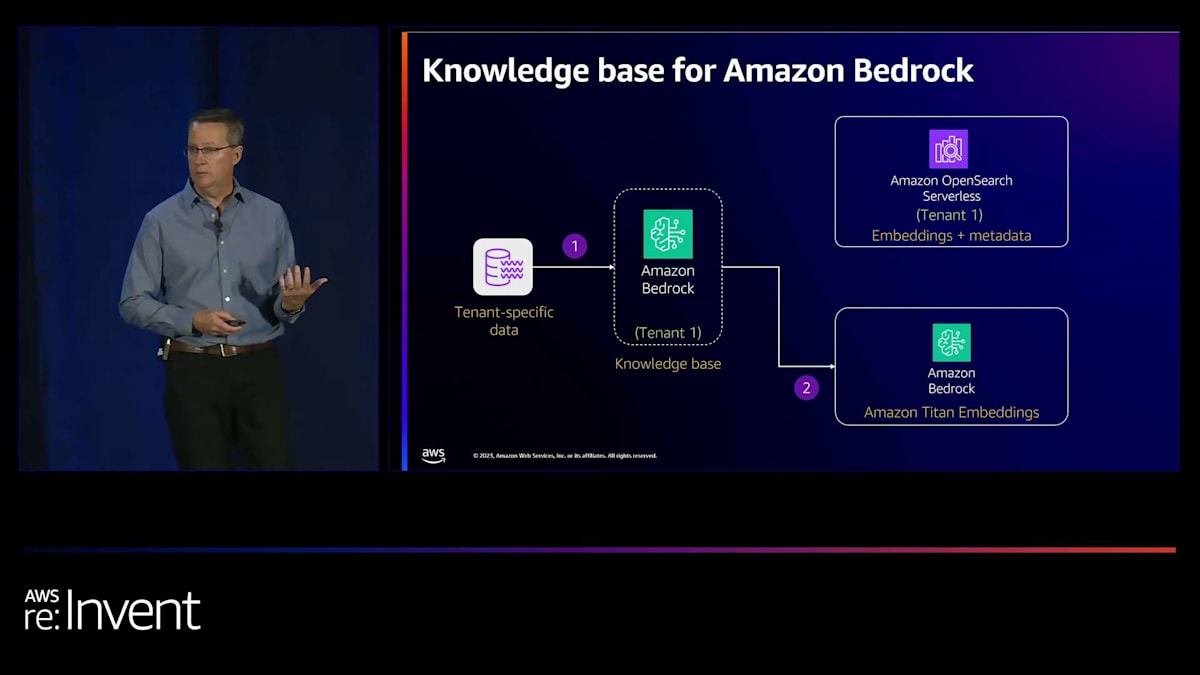
Bedrockはデータを取り込み、準備し、Amazon Titan Embeddings foundation modelを呼び出して埋め込みを生成します。 これを私たちの代わりに行うので、私たちがその呼び出しを行う必要はありません。また、knowledge base設定時に指定したOpenSearchインデックスに、埋め込みとメタデータを直接インデックス化します。knowledge baseの素晴らしい点は、自然言語クエリを提供できる推論エンドポイントまたはクエリエンドポイントを提供することです。knowledge baseは自動的にそのクエリから埋め込みを生成します。そして、この場合OpenSearchインデックスにそのクエリを送信し、結果を返します。つまり、インデックスの構築と入力だけでなく、インデックスのクエリにも役立つのです。

ここで少し話題を変えて、Bedrockの別の機能について、そしてそれをSaaSベースのアプリケーションでどのように活用できるかについてお話ししたいと思います。今週一般提供が開始されたAmazon Bedrock用のAgentsは、大規模言語モデルの推論能力を活用することができます。これらのモデルは複雑なタスクを受け取り、それを段階に分解し、そのタスクを実行するためにそれらの段階を実行することができます。例えば、保険金請求を処理するエージェントを作成したり、ユーザーをeコマースの購入体験に導いたり、旅行予約で消費者を支援したりするなどが考えられます。可能性は無限大です。これらのエージェントは、タスクを完了するために必要な情報をユーザーに促し、それを段階に分解し、必要に応じて消費者からさらに情報を要求する能力を持っています。
Amazon Bedrock Agentsの活用:複雑なタスクの自動化

また、エージェントはAWS環境内のLambda関数を呼び出して、それぞれの段階を実行することもできます。タスクを完了するためにデータが必要な場合、ナレッジベースからそのデータを検索し、それを取り込んでLLMへのプロンプトを作成し、タスクを続行することができます。例を見てみましょう。まず、アプリケーションからタスクを取り込み、そのテナントを識別するテナントコンテキストを含めます。ここではSaaSの世界を維持しています。そしてタスクはエージェントに送信されます。

エージェントを作成する際、我々は指示を与えます。この例では、ゴルフでのTodのスライス状況を助けるシナリオを使用します。指示は次のようになるかもしれません:「あなたは顧客がゴルフクラブを選択し購入するのを支援する小売アシスタントです。」エージェントにタスクが提供されると、それは実行可能なすべての手順、その役割のコンテキスト、そしてゴルフのeコマースストアフロントの小売アシスタントとして取ることができるアクションを含むプロンプトをLLMに作成します。



そのプロンプトはLLMに送信され、思考の連鎖と呼ばれる推論アクションフローを実行します。これはLLMでこれらの手順を進めるためのプロンプトエンジニアリングフローです。左利きか右利きかなど、顧客にさらに情報を求める場合もあります。エージェントは、設定したAPIコールを行うことで、この一連の手順を進めていきます。
これらのLambda関数は、ゴルフクラブセットの在庫確認、注文の発注、配送追跡番号の取得など、さまざまなタスクを実行できます。実際、これらのLambda関数の背後では何でも行うことができます。ビジネスロジックを含めることも、既存のSaaSアーキテクチャのマイクロサービスを呼び出すだけのシムにすることもできます。また、さまざまなデータソースからデータを検索することもできます。テナントコンテキストはこのプロセス全体を通じて渡され、織り込まれているため、これらのLambda関数はテナントを認識し、セッション識別情報を持つことができます。


エージェントはまた、情報を得るためにナレッジベースを参照することもできます。例えば、プレイヤーのスキルレベルに基づいてゴルフクラブをマッチングする方法に関するナレッジベースがあるかもしれません。このナレッジベースを活用し、プロセス全体をガイドするプロンプトを構築するために使用できます。ステップの最後に、結果をエージェントに返します。エージェントはタスクと結果を受け取り、最終結果を作成するためのプロンプトを作成し、それをユーザーに返します。例えば、「PINGのアイアンを注文しました。発送されましたので、木曜日までに到着する予定です」といった具合です。
Fine-tuningの導入:カスタマイズされたモデルの作成

RAGやさまざまなテクニック、プロンプトやプロンプト拡張の使用について話してきました。必ず出てくる質問は、プロンプトエンジニアリングでできることの限界に達した場合はどうするか?あるいは、ユースケースが非常に特殊または複雑で、既存のfoundation modelでは不十分な場合はどうするか?ということです。確かに、ゼロからfoundation modelを構築することもできますが、それは通常、コストがかかりすぎ、ほとんどの組織のスキルを超えています。非常に大きな取り組みとプロセスです。既存のfoundation modelを取り、ユースケースやドメインに特化した追加のトレーニングデータを提供し、そのspecialized modelを使用できたらどうでしょうか?その方法を探ってみましょう。

ユースケースやドメインに特化した追加のトレーニングデータを提供し、そのspecialized modelをアプリケーションに統合して使用できます。このプロセスはfine-tuningと呼ばれ、Amazon Bedrockはこれを完全に管理されたエクスペリエンスとして提供します。実際、コードを書く必要さえありません。


fine-tuningを考える際には、複数の次元を考慮する必要があります。テナントレベルでは、実際に各テナントごとにモデルをfine-tuningすることもできます。これには、custom modelを作成する際にBedrockに提供するテナント固有のトレーニングデータと検証データ、そしてハイパーパラメータを作成することが含まれます。ハイパーパラメータは、エポック数、バッチサイズ、学習率など、トレーニングプロセスを制御するパラメータです。これらはすべて、トレーニングプロセスで制御できるパラメータです。

カスタムモデルを作成した結果として得られるのは、ファインチューニングされたモデルです。ここでは、テナント1とテナント2のための2つの異なるモデルを示しています。これらのモデルはBedrockによって管理され、お客様のアカウントからのみアクセス可能です。これらは環境内でプライベートに保たれ、後ほどIAMを通じてどのように制御できるかについて詳しく説明します。

考慮すべきもう一つの側面は、テナント固有のファインチューニングが不要な場合はどうするかということです。 業界やドメインレベルでファインチューニングを行いたい場合はどうでしょうか?例えば、ヘルスケアや金融サービスの顧客がいて、これらのドメインでより良い体験を提供するためにファウンデーションモデルをファインチューニングするためのデータがある場合です。同じプロセスを業界レベルで適用し、それぞれのドメインのすべてのテナントで共有するファインチューニングされたモデルを作成することができます。


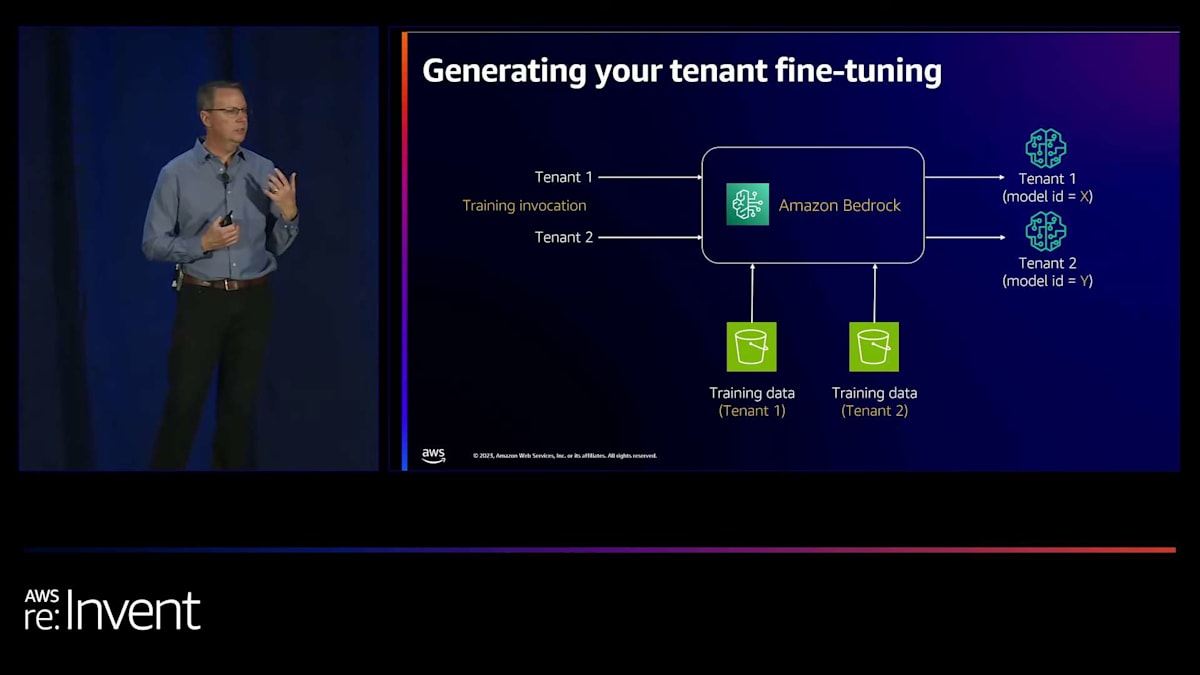
これをより手順的またはライフサイクルの観点から見ると、Bedrockから始まり、カスタムトレーニングジョブを起動します。 これは各テナントのためのモデルカスタマイズジョブです。各テナントのトレーニングデータを取り込み、結果として2つのファインチューニングされたモデルが出力されます。 Bedrockは各モデルにモデルIDを関連付け、これらをオンボーディングプロセスとリクエストフローの両方にどのように組み込むことができるかを見ていきます。
マルチテナントSaaS環境におけるGenerative AIのオンボーディングとリクエスト処理





では、RAGやファインチューニング、あるいはその両方を含むオンボーディングプロセスを考えてみましょう。 テナントがオンボーディングプロセスを開始します。 これはアプリケーション内部で管理されるか、テナントによって駆動される可能性があります。 私たちは従来のSaaSのアプローチとデザインパターンを使用し、オンボーディングサービスを持つコントロールプレーンを設けます。 このサービスはすべてのプロビジョニングタスクを実行するテナントプロビジョニングサービスと連携します。 そのサービスは、アーキテクチャの生成AIコンポーネント以外の部分のプロビジョニングを行うために外部にリーチアウトする場合もあります。
生成AIコンポーネントについては、テナントレベルのソリューションの一部である場合、ファインチューニングのフローを開始できます。また、OpenSearch vector databaseなどのベクトルデータベースの入力も開始できます。これらのプロセスは本質的に非同期です。通常、開始されてから後で完了し、最終的にテナントがこれらの特殊化されたリソースの使用を開始できる状態になります。

テナント設定を保存する必要があるため、テナント管理サービスとインターフェースを取ります。このサービスは、ファインチューニングしたモデルのモデルID、S3上のトレーニングデータの場所、そして場合によってはRAG OpenSearchインデックスの保存場所を管理します。これらの情報をテナント管理プレーンでテナントに関連付けます。


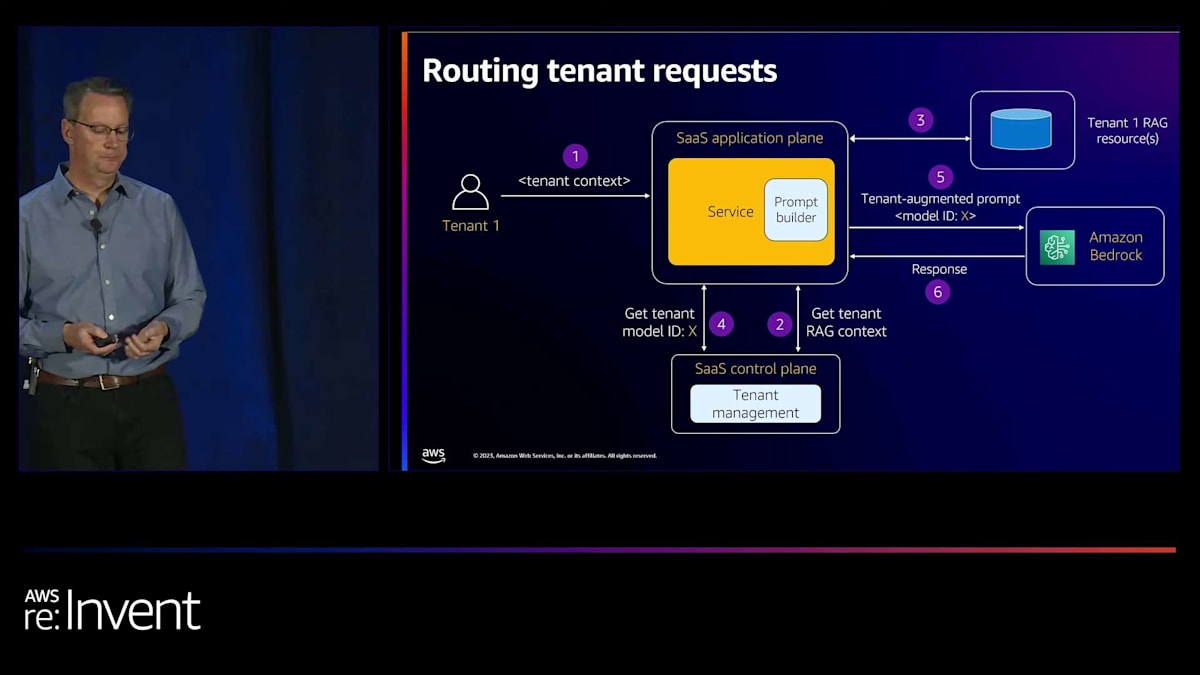
次に、アプリケーションに入ってくるリクエストのルーティング方法を考えてみましょう。まずテナント1から始めます。リクエストはテナントコンテキストと共に到着し、これを使ってユーザーをテナントに関連付けます。これらのリクエストを処理するアプリケーションプレーンサービスがあります。最初に行うのは、先ほど見たテナント管理サービスから、この特定のテナントに必要な情報を検索または解決することです。RAG情報があれば、そのRAGデータソースにアクセスできます。これは、先ほどのDynamoDBテーブルのようなデータベース呼び出しかもしれませんし、OpenSearchインデックスへのクエリかもしれません。
そこで関連文書やアイテムを取得します。モデルを呼び出すには、ファインチューニングされたモデルのモデルIDが必要です。そこで、テナント管理サービスからそれも取得します。これで、プロンプトを作成してモデルに渡す準備が整いました。そのプロンプトでモデルを呼び出し、レスポンスを受け取ってユーザーに返します。

ファインチューニングとRAGについて考えると、多くの決断を下す必要があります。ここに絶対的なルールはありません。本当に、generative AIで実現したいユーザー体験やユースケースから逆算して考える必要があります。すべてのテナントで単一のファインチューニングされたモデルを使用できるかもしれません。あるいは、1つの基盤モデルをファインチューニングし、別のユースケースには Amazon Bedrock の別の基盤モデルをそのまま使用するかもしれません。また、Bedrockのknowledge baseやagentの一部をすべてのテナントで使用するかもしれません。逆に、テナント固有のファインチューニングやテナント固有のRAGを行いたい場合もあるでしょう。ここに厳密なガイダンスはありませんが、これらを様々な方法で組み合わせることができます。

これが本当に、generative AIについて考え、これらの異なるテクノロジーを組み込む難しい部分です。ドメインレベル、テナントレベル、テナントコンテキストレベルで利用可能なデータを組み合わせることです。私たちが話してきたこれらのツールやメカニズム:ファインチューニング、RAG、Bedrock knowledge basesとagents、そしてユースケースから逆算して考えること。どのようなデータがあるのか?このユースケースでgenerative AIを使うために必要なデータはあるのか?もしなければ、そのデータをどのように入手できるのか?そのデータを準備するために何をする必要があるのか?そして、これらのツールをアーキテクチャにどのように組み込むのか?
それでは、Todに話を引き継いでもらいましょう。
Generative AI環境におけるテナント分離とセキュリティの確保
ありがとう、James。ここでJamesの指摘を改めて強調したいと思います。つまり、これらのツールは全て素晴らしく優れていますが、結局のところ、組織の誰かがこれらの情報源を把握する必要があるということです。ファインチューニングはどこから来ているのか?どのRAGの公式?どのツール?私たちとしては、XやYを行えば済むという簡単なパッケージ化された方法をお伝えできればいいのですが、残念ながらそうではありません。皆さんが自分たちにとって最適な方法を見つけ出す必要があるのです。


さて、テナントの改良や新しい構成要素の導入に加えて、SaaS環境に新しい構成要素を導入する際には、常に「あるテナントが他のテナントのリソースにアクセスできないようにするには、どうすればよいか?」という問いを自問する必要があります。これはSaaSの基本中の基本です。そして今、私たちの世界に生成AIの新しい構成要素が導入されました。 Jamesが話した要素を見てみると、ファインチューニングのエンドポイントや、利用可能なモデルがあり、これらのモデルはそれぞれ個別のテナントに関連付けられています。

また、RAGのソース、つまりベクトルデータベースやDynamoDBテーブルなど、選択した環境下にあるものがあります。これらが個別のテナント用にデプロイされていたとしても、完全に分離されているわけではありません。表面上は、あるマイクロサービスがテナント1からテナント2のリソースへの境界を越えることを防ぐものは何もありません。 そこに何かを導入する必要があります。例えば、テナント1がテナント2のRAGデータを見ることができないようにする仕組みが必要です。また、これらのエンドポイントやモデル間で、あるテナントが他のテナントのモデルを呼び出せないようにする必要もあります。これは基本的なテナント分離ですが、生成AIの世界に足を踏み入れる際に見落としがちな重要な点です。

では、それはどのように実現するのでしょうか?良いニュースは、 テナント分離に関する私たちの多くの講演や、IAMでロールを引き受ける方法についてのトークンベンディングマシンの話をご覧になった方はご存知かもしれませんが、ここでもIAMを主に使用して、これらのメカニズムの多くを保護し、あるテナントが他のテナントのリソースを見ることができないようにすることができます。この場合、ファインチューニングは非常に単純です。テナントは、SaaSソリューション内のどこかにテナントのコンテキストを含むJWTトークンを持ってやってきます。何らかのライブラリやそれに類するものが、「ここに異なる生成AIモデルへのアクセスを制限するポリシーがあります。そのテナント用のロールを引き受け、そのロールから認証情報を取得し、それを使用して呼び出したいモデルにアクセスし、呼び出します。そして、自分に属していないモデルを呼び出そうとすると、拒否されます」というプロセスを実行します。非常に単純ですが、見落とさないようにすべき重要な点です。

さて、RAGの観点から見ると、少し面白くなります。RAGは単にモデルとモデルIDを持ち、それをロックダウンする必要があるというだけではありません。

ここでは、考慮しなければならない様々な技術やリソースが存在します。OpenSearch、Pinecone、 あるいはRDSなどがこの世界に存在する可能性があります。これにより、私たちは一般的に分離を適用する基本的な方法に立ち返ることになります。


アプローチの1つは、 RAGデータのリソースがサイロ化されている場合、リソースレベルの分離を使用することです。この場合、IAMを使用してそのデータベースへのアクセスを制御します。一般的に、リソースレベルでアクセスを制限するためのIAMやその他のメカニズムが存在します。少し厄介になるのは、 アイテムレベルの分離に至る場合です。リソース内に複数のテナントのデータやアイテムが混在している場合、そのレベルで分離を適用する方法を見つける必要があります。ここで、状況によって対応が異なってくるかもしれません。


場合によっては、IAMが味方となり、望む通りのことができます。他の場合では、分離の方法について創造的にならなければなりません。ここでIAMを使用してRAGデータの分離 を見てみると、それは同じ古い公式です。私たちのソリューションは、テナントのコンテキストに基づいてロール を引き受け、これらのテーブルの1つにアクセスします。この場合、プールされたテーブル、つまりテナントデータが混在しているテーブルにアクセスしています。このモデルでは、アイテムレベルの分離の概念があります。そのため、ここでDynamoDBを選んだのは便利です。DynamoDBはアイテムレベルの分離をサポートしているからです。つまり、このテーブルではテナント2のアイテムだけを見ることができると指定できます。

これはDynamoDBでは素晴らしく機能します。もしこれがRDS MySQLだったら、別の議論になるでしょう。Postgresの場合は、行レベルのセキュリティになります。考慮すべき他のオプションもあります。そして、Jamesが話した2つのサイロ化されたテーブル、つまりゴルフとツールのビットが入っているテーブルがあります。これらはリソースレベルの分離を使用できます。ここには特別な、あるいは非常に奇抜なものはありませんが、マルチテナントSaaSについて話し、これらのリソースをこの環境に投入する 際に、「これらをどのように保護するか」と自問しないわけにはいきません。
Generative AIを活用したSaaSのティアリングと価格設定戦略
私にとってより興味深い視点、そして顧客との会話で繰り返し出てくるのは、ティアリングとは何か?ということです。Generative AIの経験において、ソリューションをティアリングするとは実際にどういう意味を持つのでしょうか?私のソリューションの裏側でどこかにGenerative AIを使用している場合、それは既存のティアリングと同じことで、Generative AIは単にツールバッグの中の新しいツールの1つに過ぎないのでしょうか?それとも、Generative AIによって、テナントが私たちの経験をどのように消費するか、私たちがその消費をどのようにコントロールするか、そしてその消費をどのように測定するかについて、考え方が変わるのでしょうか?

最も単純なレベルで見ると、これには運用的な視点と製品的な視点があります。運用レベルでは、私のSaaSソリューションのバックエンドのどこかでBedrockを消費している異なるテナントがある場合、私は単に1つのテナントが私のシステムに過度の負荷をかけていないかを心配します。これは基本的なSaaSの考慮事項です。また、彼らの消費量をサポートできたとしても、彼らが消費しているものが他のテナントの経験に影響を与えていないかも心配です。そのため、システムを稼働させ続けるためには、それをコントロールする方法が必要になります。
しかし、この議論の製品レベルでは、すべての顧客に同じエントリーポイントと価格ポイントを提供したくないかもしれません。私は自分の提供するものを異なる経験に分割したいかもしれません。そこで、基本、上級、プレミアムティアのテナントを設けて、「基本ティアのテナントの皆さん、あなたがたのSLAはXやYのようになります。そしてBedrockを消費できる程度を制限します」と言うかもしれません。これは部分的にはシステムの健全性のためであり、部分的にはノイジーネイバーの懸念のためですが、ビジネス上の決定でもあります。
私は、月額で少額しか支払っていない基本ティアのテナントが、システムを過剰に使用してBedrockの請求額の80%を消費することは望みません。一方で、プレミアムティアのテナントはそのテナントの影響を受けているかもしれませんが、消費量はさらに少ないかもしれません。そのため、システムの異なるティア間で、環境にかける負荷のレベルにアンバランスが生じてしまいます。これを行うにはこのツールが必要です。しかし、問題はこれをどのように行うか、そしてBedrockでも従来と同じやり方でいいのか、それとも考慮すべき新しい要素があるのかということです。

実は、考慮すべき新しい要素があります。基本、上級、プレミアムティアのテナントがあり、彼らがアクセスしてくる場合、それらのテナントとBedrockの消費の間に何かを置く必要があります。なぜなら、それらのリクエストを遮断し、スロットルするかどうかを検証する必要があるからです。

この例では、Amazon API Gatewayを選びました。正直なところ、この目的に最適なツールについてはまだ模索中ですが、API Gatewayは私が馴染みがあり、この問題を説明するのに使いやすいものです。


API Gatewayを使って、これらのリクエストを一つずつ処理します。従来のスロットリングと同様に、Lambda authorizerを使用します。 実際には、ここでも呼び出しの頻度を見ることができるので、単純に頻度に基づいてリクエストを制限する従来のスロットリングを使うかもしれません。しかし、今回のスロットリングには新しい要素があります。それは、 Amazon Bedrockに送信しようとしているリクエストの複雑さです。

これらの生成AIソリューションを見ると、入出力されるトークンの複雑さ、サイズ、出力の複雑さが、利用するサービスの負荷と相関しています。つまり、呼び出しの回数だけでなく、その呼び出しの複雑さも考慮する必要があるのです。そこで、 入力される呼び出しの複雑さを評価し、バックエンドへの通過を許可するかどうかを決定するauthorizerポリシーを作成する必要があります。

頻度ベースのポリシーと複雑さベースのポリシーを別々に設定したり、両者を組み合わせたりすることもできます。複雑さを測定するようになった今、ポリシーの境界をどのように決定すればよいでしょうか?基本層の複雑さと上級層の複雑さをどのように区別すればよいでしょうか?また、特定の複雑さのリクエストをSLA制限に達するまでどの程度の頻度で送信できるでしょうか?考慮すべき要素は多岐にわたりますが、重要なのは何らかの制御を実装する必要があるということです。アプリケーションでBedrockを無制限に使用できるようにしておくわけにはいきません。

階層化を考える上でもう一つの側面は、Large Language Models (LLMs)の選択です。基本層とプレミアム層のテナントがあり、それぞれ強みや専門性の異なる複数のLLMにアクセスできるとします。階層化戦略の一環として、異なる層に異なるLLMを提供することができます。例えば、基本層のテナントには一つのLLMへのアクセスを提供し、プレミアム層のテナントには別の、おそらくより高度または専門的なLLMへのアクセスを提供するといった具合です。
ここでの課題は、何がLLMをより高いティアにとって魅力的にするかを判断することです。これは主にあなたのドメインと、ソリューションにおけるLLMの具体的な使用例に大きく依存します。これは有効なモデルですが、その適用可能性はあなたのソリューションで実際に何をしているかによって異なります。
Generative AI SaaSの価格モデルと消費量測定の重要性


さて、価格設定に関しては、多くの人々が generative AI を使用する SaaS プロバイダーの価格モデルについてのガイダンスを求めています。これはまだ発展途上の分野であり、学ぶべきことが多くあります。私は、generative AI サービス自体が価格設定アプローチにおいて大きく進化すると考えています。 しかし、もし私がいくつかのオプションを提案するとすれば、一つの方法は体験のみに基づいて価格設定を行うことです。

例えば、基本ティアのテナントには全員が同じ体験を共有するモデルを提供し、プレミアムティアのテナントにはテナントごとのカスタマイズを提供するといった具合です。もう一つのオプションは、純粋に SLA とスループットに基づいて価格設定を行うことです。 このモデルでは、基本ティアのテナントを一定のレベルでスロットリングし、プレミアムティアのテナントはより多く消費できるようにします。重要なのは、誰も無制限のアクセスを得られないということです。全てのレベルでスロットリングが行われますが、プレミアムティアではより高い制限が設定されます。

最後に、generative AI サービスへのリクエストの性質が複雑さ、入力、出力の面で非常に変動的で予測不可能な環境では、推論ごとのコスト価格モデルを検討するかもしれません。これは、各タスクを実行するためにバックエンドで発生する実際のコストと密接に相関します。ただし、私はインフラコストをそのまま価格モデルに反映させることは好みません。それを少し抽象化したいと思いますが、それでもこのアプローチを取らざるを得ない場合もあるでしょう。

実際の答えは、おそらくこれらの組み合わせになるでしょう。全ての人に当てはまる一つの解決策はありません。あなたはこれらのバケットの一つだけに入るわけではなく、 これらの組み合わせが必要かもしれません。繰り返しになりますが、ここでは注意事項が重要です。来年にはこれについてもっと多くのことが言えるようになると思いますが、これは妥当な出発点だと考えています。


最後に価格モデルについて少し触れたいと思います。従来のサイロ型とプール型のモデルを考えてみると、完全なプール環境では、すべてのテナントがすべてのリソースを共有し、サイロ環境では、テナントごとに専用の環境が用意されますが、それらは一つの統合された経験として所有・運用されていました。では、生成AIの環境ではどのようになるでしょうか?ここでは、すべてのサービスを共有する完全共有環境を想定し、「全員が同じモデルを共有している」というモデルを考えてみましょう。このモデルでは、オンデマンド価格設定を採用するかもしれません。使用できる様々な価格戦略がありますが、もちろん、このプール環境がどれくらいの頻度で呼び出されるかによって決まります。ここではオンデマンド以外の選択肢もあります。

また、このモデルでは、これらのテナント特有の処理を行わないため、モデルのトレーニングコストはかかりません。基本的な考え方としては、この側面では、経験をできるだけ軽量に保ち、可能であれば生成AI側のコストを抑えようとしています。一方、サイロ側では、「ここからは豊富なモデルカスタマイズが可能になる」と言えるでしょう。実際、モデルカスタマイズを行いたい場合は、生成AIサービスの別の価格帯に入ることになります。サイロ型、プール型、その他どの方式を選択しても、モデルカスタマイズを行う場合は、生成AIサービスから追加のコストと期待が発生します。

ここでは、プロビジョンドスループットを設定して、環境からより予測可能なレスポンスを得ることができます。この経験からは、オンデマンドモードとは少し異なる課金モデルが得られます。オンデマンドモードでは、経験の予測可能性を理解するのが少し難しくなります。この問題の最後の部分は、テナントあたりのコストです。私たちが話すすべてのコンテンツでテナントあたりのコストについて言及するのは、ビジネスが単に請求の理由だけでなく、テナントごとのコストを理解する必要があるからです。彼らは内部分析のためにそれを知りたいのです。異なるテナントが環境にどのような負荷をかけているかを理解したいのです。そして、それを分析したいと考えています。ちなみに、それを価格設定の一部として使用することもできます。



そのため、私は人々に強くお勧めしています。ソリューションの一部として、これらの生成AIサービスの消費量を測定することを。ここでは、アプリケーション層があり、サービスが入ってきて、生成AIサービスにリクエストを送ろうとしています。ここで interceptして、リクエストの複雑さを評価します。それを記憶しておきます。そして、プロンプトを Amazon Bedrock に送信します。そして戻ってきたら、出力時にも評価する必要があります。出力時に評価する際には、入力時のリクエストの複雑さと出力時の複雑さがあるので、それを記録して捕捉します。

私たちの例で見てきたように、SaaS環境のコントロールプレーンで実行されるメトリクスと分析サービスが必要だと話してきました。ここですべてのデータを集約し、それをどのように使用するかを選択します。内部分析だけに使うのか、請求に使うのか、何に使うのかはあなた次第です。また、必要に応じて、入力時に評価して記録し、出力時に別々に評価することもできます。これらを完全に別々のイベントとして扱うこともできます。しかし、重要なのは、このデータが必要であり、複雑さを評価する必要があるということです。そして、これはおそらく、スロットリングの複雑さの評価と重複する部分があるでしょう。そこでは、コードの一部を共有できるかもしれません。
James、ツーリングについて話してもらうために、すぐにあなたに引き継ぎます。
Generative AI開発のためのツールとフレームワーク:LangChainとHugging Face


ありがとう、Tod。ここでツーリングのセクションを設けた理由は、オープンソースのフレームワークや様々なツールの開発に多くの労力が費やされており、これらの異なるツールを使うことで大きな生産性の向上が見込めるからです。つまり、ゼロから構築する必要がないのです。この分野では多くの活動が行われています。ここに挙げたのはほんの一部で、実際には積極的に開発されている膨大な数のプロジェクトがあります。その中でも最も初期から存在し、人気のあるフレームワークの1つがLangChainです。これはPythonとJavaScriptで書かれたオープンソースプロジェクトで、最も一般的な生成AIの開発パターンに対する抽象化、実装、ラッパーを提供しています。これまで話してきたRAGを使用したプロンプトエンジニアリングや、エージェントに関連する思考の連鎖などがその例です。
LangChainには独自のエージェント機能が組み込まれており、それを利用することができます。Chainsは、望ましい結果を得るために複数のLLMへの呼び出しを連鎖させる方法です。プロンプトエンジニアリングやプロンプトテンプレートの作成も支援します。つまり、生成AIアプリケーションをより迅速に開発できる生産性向上ツールなのです。LangChainはAmazon Bedrockを含む複数のAWSサービスの実装も提供しています。そのため、BedrockをベースにLangChainを使って生成AIアプリケーションを構築することができます。他のAWSサービスでは、Amazon KendraもRAGソースとして組み込まれています。Amazon Personalizeもまた、RAGソースとして利用可能です。さらに、チャットボット体験のためのメモリ取得にElastiCacheなどの基盤的あるいはインフラストラクチャサービスも利用できます。

LangChainは素晴らしいライブラリです。この分野では多くの活動が行われており、今後も進化し続けると予想されます。Hugging Faceは、開発者が機械学習モデルを構築、トレーニング、デプロイするのを支援するコミュニティとプラットフォームです。多くのライブラリを提供し、何千ものオープンソースライブラリと基盤モデルを提供しており、これらはSageMaker JumpStartを通じてAmazon SageMakerに取り込むことができます。これにより、SageMakerでこれらのオープンソースモデルを素早く立ち上げることができます。もちろん、それにはより多くの責任が伴います。設定、保守、運用を自分で行う必要があります。価格モデルも、先ほど話したBedrockのトークンベースの消費型とは少し異なります。

それでも、生成AIの体験をより細かく制御したい場合や、機械学習の専門知識がある場合は、SageMaker JumpStartでHugging Face を使用するのは検討に値する優れた選択肢です。今日はBedrockとその上に構築されたツールについて多く話してきました。基盤モデルにアクセスできるだけでなく、エージェントやナレッジベースを構築することもできます。今週発表されたGuardrailsは、プロンプト、入力および出力プロンプトのコンテンツモデレーションを行うための興味深い発表でした。Bedrockではこのように多くのことが進行中です。


それでは、LangChainの実際の動作を簡単に見てみましょう。これは少し作為的な例ですが、Pythonのコードがあります。ここでは、LangChainを通じてBedrockを導入しています。foundation modelに渡す推論パラメータを作成しています。クライアントを作成し、ここではAnthropic Claude Instantを使用しています。 そして、プロンプトテンプレートを使ってプロンプトを構築し、モデルを呼び出して応答を得ることができます。これが、LangChainでBedrock foundation modelとインターフェースする方法の簡単な例です。
次に、Embeddingsを使用した例を見てみましょう。LangChainのBedrockEmbeddingsというクラスを使用できます。この例ではTitan Embeddingsモデルを使用して、embeddingsを生成し、先ほど見たOpenSearchインデックスにインデックスを作成するのに使用できます。Tod、お願いします。
セッションのまとめと今後の展望


ありがとう、James。では、手短にまとめましょう。終わりに向けて、いくつかの重要なポイントを挙げたいと思います。 ご覧の通り、Fine-tuningとRAGという概念は非常に強力で、マルチテナントに大きな影響を与える可能性があります。一般的に有用ですが、テナントごとに異なる体験を提供しようとする場合に特に価値があります。そして、 システムのカスタマイズ方法と場所、RAGとFine-tuningを導入するべき適切なポイント、そしてそのデータの出所を見極めることが、この問題の大きな部分を占めています。そこから逆算して考え始めるべきでしょう。


silo、pool、isolationなど、私たちがいつも話題にするこれらの基本的なSaaSの概念は、 ここで議論している概念の一部と重なるか、少なくとも交差していることがわかるでしょう。これらの基本原則を忘れずに考慮する必要があります。noisy neighborの問題、スロットリングの概念全体が、この取り組みの重要な領域となるでしょう。スロットリングと価格設定は、 基本的に全て複雑さの影響を受けます。この複雑さの概念、つまりプロンプトの複雑さや出力の複雑さが、スロットリングや価格設定の方法に連鎖的な影響を与え、考慮すべき多くの要素に影響を及ぼします。

siloやpoolなどのデプロイメント戦略のうち、どれを選択するか、プロビジョニングにするか、オンデマンドにするかを決める必要があります。これらの組み合わせのうち、どれがワークロードに最適かを検討しなければなりません。リクエストの頻度が低いのでオンデマンドでよいのか、それともプロビジョニングが必要なのか。テナントごとのカスタマイズを全て行いたいのか。そうであれば、Bedrockのどのフレーバーが最適かを見極める必要があります。そして、先ほどのLangChainのスニペットは、マルチテナントSaaSの例ではありませんでしたが、ツールが味方になるということを思い出させてくれます。ツールを使えば多くのことが簡単になるので、ツールを積極的に活用し、最適なものを見つけることをお勧めします。

ブレイクアウトセッションはほとんど終了していると思います。残っているものはないかもしれませんが、カンファレンス後にビデオで見たい場合は、こちらにリストがあります。これらについては省略させていただきます。以上です。ご参加いただき、ありがとうございました。James、協力ありがとう。 この内容を初めて発表できて良かったです。質問がある方は、こちらで受け付けます。
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion