re:Invent 2023: Amazon Bedrockで基盤モデルをカスタマイズ - NYSEの事例とデモ
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - Customize FMs for generative AI applications with Amazon Bedrock (AIM247)
この動画では、Amazon Bedrockを使用したGenerative AIアプリケーション向けのカスタマイズされた基盤モデルについて学べます。NYSEのAnand Pradhanが、取引ルールチャットボットの構築事例を紹介します。また、Chris FreglyによるLlama 2のファインチューニングと継続的な事前学習のデモンストレーションも見られます。Amazon Bedrockを活用した最新のAI技術と実践的な応用例が凝縮された150分です。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
Amazon Bedrockを用いたGenerative AIアプリケーションの基盤モデルカスタマイズ:イントロダクション

みなさん、こんにちは。本日は、Amazon Bedrockを使用したGenerative AIアプリケーション向けのカスタマイズされた基盤モデルに関するプレゼンテーションにご参加いただき、ありがとうございます。私はAmazon Bedrockチームのプリンシパル・テクニカル・プロダクトマネージャーのKishor Aherです。一緒に登壇するのは、NYSEのシニアディレクターのAnand Pradhanと、AWSのGenerative AI担当プリンシパル・ソリューションアーキテクトのChris Freglyです。

本日のアジェンダを見ていきましょう。まず、基盤モデルのカスタマイズについて紹介し、なぜカスタマイズが必要なのかを説明します。次に、ファインチューニングと継続的な事前学習について触れます。その後、Amazon Bedrockのカスタムモデルについてお話しします。NYSEでのAmazon Bedrockモデルのカスタマイズについて探り、最後にChrisがAmazon Bedrockを使用したファインチューニングと継続的な事前学習のデモンストレーションを行います。
基盤モデルのカスタマイズが必要な理由

では、なぜカスタマイズが必要なのでしょうか?ご存知の通り、基盤モデルは大量の一般的な公開データを使用して構築されています。アプリケーションを構築しようとすると、一般的な結果を生成できますが、多くの場合、特定のユースケースに合わせて、自社のデータを使用した結果が欲しいものです。カスタマイズにより、特定のビジネスニーズに適応させることができます。例えば、医療業界では、基盤モデルが医療用語を理解し、正確な回答を生成することが重要です。あるいは、金融業界のように、異なる用語や専門用語がある特定のドメインに適応させる必要があるかもしれません。基盤モデルにそのドメイン固有の言語を理解させたいのです。
カスタマーサービスでは、応答をフレンドリーにし、顧客の質問に非常に特化したものにしたいかもしれません。最後に、応答のコンテキスト認識を向上させたい場合、カスタマイズが役立ちます。顧客がGenerative AIチャットボットと対話し、特定のトピックについて質問している場合、アプリケーションがその特定のコンテキストで応答を生成することが望ましいでしょう。

カスタマイズが必要な理由がわかったところで、基盤モデルをカスタマイズするための一般的なアプローチを見ていきましょう。これらのアプローチを、複雑さ、品質、コスト、時間の要件に基づいて検討します。
基盤モデルカスタマイズの一般的アプローチ

まず最初に、最も簡単な方法であるプロンプトエンジニアリングについてお話しします。これは、ゼロショットまたはフューショットの例を使用し、それらを基盤モデルに送信して応答を生成する方法です。プロンプトの構築とテストが非常に簡単で、プロンプトを送信して応答を得るだけなので、コスト効率も良いです。プロンプトエンジニアリングは、これらのアプローチの中で最も複雑さが低いものです。

次のアプローチは、Retrieval Augmented Generation(RAG)です。この技術は、外部ソースからデータを取り込むのに役立ちます。大量のデータを取り、embeddings を作成し、vector database に保存します。そして、この情報が必要になったときに、データを検索し、関連情報を取得して、プロンプトに挿入します。これにより、ドキュメントから提供されたコンテキストに基づいて、非常に具体的な結果が生成されます。embeddings の作成が必要で、複数のシステムが関与するため、プロンプトエンジニアリングよりも少しコストがかかり、複雑さも増します。

次はカスタマイズです。モデルの外部に存在する繰り返しデータがあり、数週間または数ヶ月ごとにこのデータをモデル内に取り込みたい場合、カスタマイズが必要になります。後ほど、さまざまなカスタマイズ技術についてより詳しく見ていきます。

最後に、モデルをゼロから訓練する方法があります。このアプローチには、インフラストラクチャ、データサイエンティスト、そしてモデルを訓練するための大量のデータが必要です。これは最も複雑で、最高の品質を提供しますが、コスト効率が悪く、多くの時間を要します。
Amazon Bedrock custom modelsの概要

さて、プロンプトエンジニアリングが最もシンプルなアプローチで、ゼロからの訓練が最も複雑であることがわかりました。ここで、中間の2つのオプション、つまりカスタマイズと拡張(augmentation)に焦点を当ててみましょう。


まず、タスクから始めましょう - あなたは何を達成しようとしていますか? もしあなたのタスクが外部データや最新の情報を必要とする場合、リアルタイムの情報が必要かどうか自問する必要があります。APIやデータベースからのリアルタイム情報が不要で、単に文書からの情報が必要な場合は、他の選択肢を検討できます。



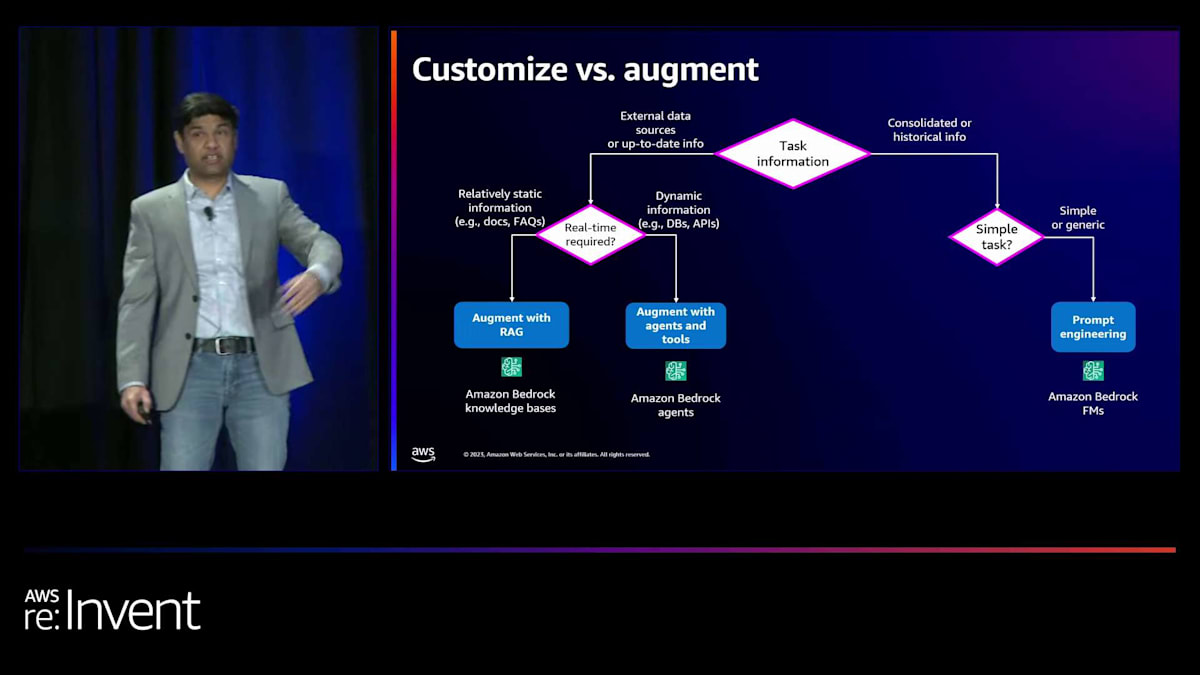
その場合、RAGによる拡張を使用します。 そのために、Amazon Bedrock knowledge basesを使用できます。リアルタイムの情報が必要な場合、つまりデータベースやAPIをクエリする場合、 エージェントとツールによる拡張を使用します。これには、Amazon Bedrock agentsを使用できます。 タスクが統合された情報や過去の情報を必要とする場合、それが単純なタスクかどうかを問う必要があります。タスクが非常に単純で一般的な場合、 先ほど議論したように、プロンプトエンジニアリングと任意のモデルを使用して結果を得ることができます。最後に、タスクが複雑で特定の動作を必要とする場合、カスタマイズを使用します。これはAmazon Bedrock custom modelsでサポートされています。

カスタマイズには2種類あります:ファインチューニングと継続的事前学習です。ファインチューニングでは、スタイルなどのタスク固有のパフォーマンスを達成しようとします。例えば、特定のフォーマットで文書を要約したい場合、例を与えてモデルをファインチューニングします。継続的事前学習は、モデルに特定の用語や専門用語、または大量のドメイン固有データを学習させたい場合に使用します。 ラベル付けされていないデータを持ち込み、継続的事前学習を使用してモデルを訓練できます。両方を組み合わせることも可能です。まず、組織に特化した大量のデータでモデルを訓練し、その後、同じモデルを特定のタスク用にファインチューニングすることができます。
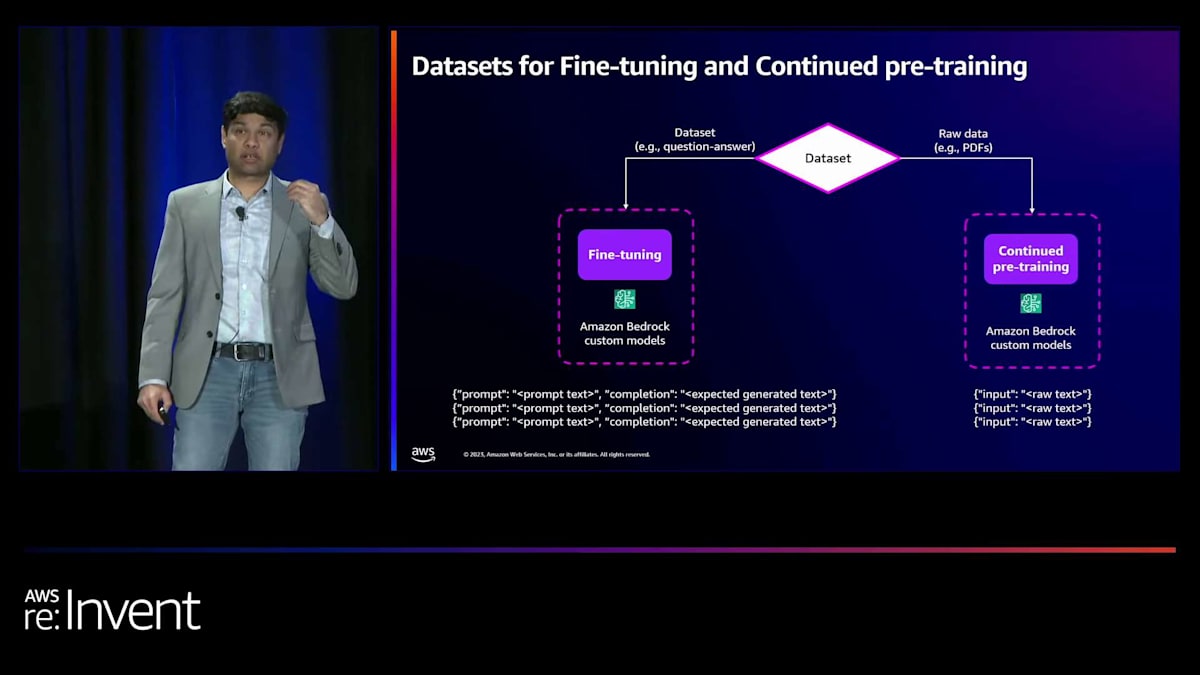
ファインチューニングと継続的事前学習のデータセット要件は何でしょうか?ファインチューニングの場合、 プロンプトと完了が必要です。特定の入力に対して、どのような出力が生成されるべきかをモデルに示す必要があります。モデルはそれを一般化し、学習します。継続的事前学習の場合は、生データだけが必要です。すべての文書やその他のライブラリを含む生データを持ち込み、継続的事前学習を使用してモデルを訓練できます。
NYSEにおける継続的イノベーションとGenerative AIの実装

Amazon Bedrock custom modelsをご紹介しましょう。同じAPIまたはコンソールを使用して、ラベル付きデータ またはラベルなしデータを提供することで、foundation modelsの精度を最大化できます。プロビジョンドスループットを使用してデプロイし、APIまたはプレイグラウンドを通じてカスタマイズされたモデルを使用できます。ファインチューニングにはファーストパーティとサードパーティのモデルをサポートし、継続的事前学習には現在ファーストパーティモデルをサポートしています。


カスタマイズジョブのコンポーネントを見てみましょう。これらのコンポーネントは、Amazon Bedrockのファインチューニングと継続的事前学習の両方で同じです。入力は何でしょうか?まず、カスタマイズしたいベースモデルを選択します。次にハイパーパラメータを提供します。ハイパーパラメータはモデルプロバイダーによって異なり、デフォルトのハイパーパラメータやハイパーパラメータ最適化のオプションを提供する場合もあります。Amazon Bedrockでは両方をサポートしています。そして入力データがあります。ファインチューニングと継続的事前学習のフォーマットをご覧いただきました。JSONL形式でその入力データを提供するだけです。


次は出力です。S3バケットとそのS3バケット内のフォルダを指定する必要があります。そこに、トレーニングと検証のロスなどのメトリクスを生成し、それらのメトリクスやその他のログをログファイルとしてそのフォルダに保存します。また、ジョブ完了時にモデルの名前として使用される出力モデル名を提供する必要があります。ストレージについては、生成されたカスタムモデルはAmazon Bedrock内で安全に保存され、Amazon Bedrock内でプロビジョンドスループットを使用してデプロイできます。
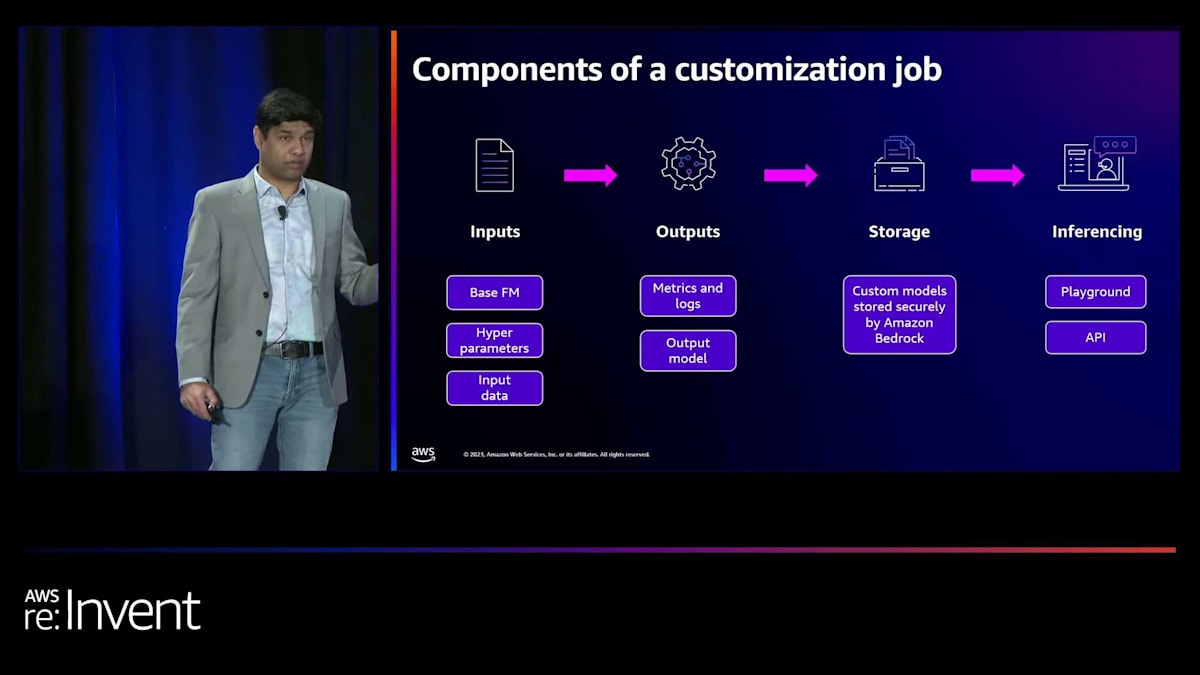
最後に、推論については、プロビジョンドスループットを使用してデプロイすると、他のベースモデルと同様にInvoke model APIを使用するか、Playgroundを使用してモデルを利用できます。
そして最後にセキュリティとプライバシーについて見てみましょう。モデルの改善に使用されるデータは、ファーストパーティもサードパーティも含め、どのモデルプロバイダーとも共有されません。顧客データはAmazonリージョン内に留まり、セキュリティとIAMロールとの統合のためにPrivateLinkとVPC設定の両方をサポートしています。API監視はCloudTrailとCloudWatchを通じて利用可能です。カスタムモデルは、サービスキーを使用して暗号化されるか、モデルの暗号化に独自のカスタマー管理キーを提供することができます。ここで、NYSEにおける継続的イノベーションと生成AIの実装について話すために、Anandをステージにお招きしたいと思います。ありがとうございました。
NYSEの技術革新:クラウドコンピューティングへの移行

皆さん、こんにちは。re:Inventの終盤に予定されているイベントにこれほど多くの方々にお集まりいただき、大変嬉しく思います。私はNew York Stock Exchangeのテクノロジー部門のシニアディレクターであり、テクノロジーリーダーシップチームの一員であるAnand Pradhanです。約20年前に技術の世界に足を踏み入れ、2007年からNew York Stock Exchangeに勤めています。医療画像処理のC++エンジニアとしてキャリアをスタートし、その後New York Stock Exchangeでマシンエンジン開発に携わりました。その後、低遅延・高スループットの市場データ統合システム、規制技術、そして最終的に機械学習の分野に移りました。私のような技術愛好家にとって、re:Inventは非常に魅力的です。新興テクノロジー企業だけでなく、確立された企業からも多くの素晴らしい技術アイデアが共有されます。これは私たちの考えを共有し、お互いから学ぶ絶好の機会です。そこで、私たちの学びの一部を共有し、Bedrockのカスタマイズについてお話ししたいと思います。

皆さんの中で、New York Stock Exchangeについて聞いたことがある人はどれくらいいますか?むしろ、聞いたことがない人はいるのかと聞いた方がいいかもしれませんね。でも、New York Stock Exchangeについて話す前に、まず私たちの親会社であるIntercontinental Exchange、略してICEについてお話しします。ICEは、人々と機会をつなぐ統合データ・テクノロジー企業です。私たちは、取引所、清算機関、データサービス、モーゲージテクノロジーを運営するグローバルな金融組織です。データとテクノロジー、イノベーションと専門知識、そして究極的には人と機会をつなぐサービスを提供しています。私たちは企業が資金を調達し、世界を変える手助けをしています。

ICEの傘下にあるNew York Stock Exchangeは、世界最大の証券取引所です。5つの株式取引所と2つのオプション取引所を運営しています。最近、New York Stock Exchangeは231歳の誕生日を祝いました。路上での対面取引の時代から完全自動化された電子取引まで、私たちは長い道のりを歩んできました。現在、株式プラットフォームでは11,000以上の株式とETFを、そしてオプションプラットフォームでは160万以上のオプションシリーズを取引しています。全システムを合わせると、9時30分から16時までの間に処理した記録的な取引数は、1日で5,000億のメッセージに達します。これは「兆」のTですよ。そしてこの数字は日々増え続けています。
これらのことは、常に革新的であり、時代の先を行こうとする努力なしには実現できません。この200年の間、私たちは多くのストレージ革新を行ってきました。注文の遅延を減らすための空気圧送管の使用から、株式取引データを送信する最初のティッカーテープの導入、さらには商業用エアコンを備えた最初のビルの建設まで。最近の革新について話すために、私たちが運用しているコア取引プラットフォームに触れてみましょう。私たちは巨大なデータセンターと非常に洗練されたグローバルネットワークを運用して、データを送信しています。

ご存知の通り、世界中でコンピューティング能力は日々向上しています。また、新しい取引手法の進化に伴い、データの複雑さと量も日々増大しています。私たちは資本市場の中心にいるため、必然的にこれらのデータセットはすべて私たちの取引所に集まってきます。

これに対応するため、私たちは常に改善方法を考え、次世代のコンピューターや取引システムに備える必要があります。少し具体的に言うと、私たちの単一の市場データフィードは、9時30分から16時までの間に150億以上のトランザクションを20マイクロ秒未満の遅延で毎日処理しています。この数字は、過去1年半で約2.5倍に増加しました。私たちは低遅延で動作するすべての取引プラットフォームの最適化に多くの時間を費やしています。
取引プラットフォームの最適化を完了し、レイテンシーを低減し続けた後、私たちが直面した次の大きな課題は、規制当局が市場を監視できるよう、取引所で行われるすべての取引を監視する方法でした。トレーダーがルールを守っているかを確認するため、彼らはすべての取引を見る必要があります。将来を見据えたプラットフォームを考えていた時、CTOと私はブレインストーミングを行い、クラウドコンピューティングを使用してAWSに移行するアイデアを思いつきました。
これは美しいハイブリッドアーキテクチャです。発生するすべてのマイクロバーストを吸収するために、オンプレミスで10台未満のサーバーを稼働させています。そして、AWSへの小さなパイプがあります。リアルタイムですべてのデータを収集し、夜間に150〜200台のサーバーを起動してすべてのデータセットを処理します。これについては前回のre:Inventで詳しく説明しましたが、興味がある方はそのセッションがYouTubeで視聴できます。このアプリケーションでは40以上の異なるAWSサービスを使用しています。これは、私がNYSEとICEのためにAWS Cloudへの移行をリードした最初のアプリケーションでした。

組織として、私たちは多くのことを学びました。そして、その結果、その後クラウドで多くの新しいイニシアチブに着手しました。これはまた、エンタープライズデータウェアハウスが稼働するSnowflakeへの移行への道を開きました。また、AWSのS3を通じて提供される履歴取引や気配値製品などの市場データ製品もあります。私たちはCloudEdgeという第三者ツールを使用していますが、オンプレミスのインフラストラクチャと同じ規制とコンプライアンスのセットを使用しています。クラウドを機能的な実行可能性、パフォーマンス、市場投入までの時間、コストなど、多くの側面から評価しています。そのため、クラウドで多くの新しいイニシアチブが生まれています。私は、クラウドが必要な場所で最適に使用されていると感じています。
NYSE LaunchPadとGenerative AIの活用

次のレベルに進むと、クラウドでの運用が可能になったので、最近、NYSE LaunchPadというプログラムを立ち上げました。これは、常に進化する市場環境の次の章です。私たちは企業が資本を調達し、世界を変えるのを支援しているため、多くの新興テクノロジー企業と関わり始めました。このプログラムの目的は、これらの企業に価値あるフィードバックを提供することです。このプログラムでは、複雑な問題を解決してきたICE全体の幅広い技術的専門知識を活用します。製品を評価し、テストを行い、企業は実用的な洞察を得ることができます。最後に、NYSEの独自の可視性プラットフォームを使用して、彼らのイノベーションを幅広いグローバルな聴衆と共有します。

そして次は、Generative AIです。GenAIの前、規制監視プラットフォームのAWSクラウドへの移行を完了し、日々の運用上の課題が解決された後、Siddharthとブレインストーミングをしていた時、私は機械学習への投資を提案しました。当時、LLMは話題の中心ではありませんでした。機械学習の専門家であるSureshが私たちのチームに加わり、機械学習を中心にチームを構築し始めました。全体的なアイデアは、MLモデルを使用して時系列データのパターンを見つけることでした。
GenAIが流行の最先端になった頃には、私たちは準備ができていました。チームも、パイプラインも整っていました。私たちは積極的にGenAIに時間を投資し、多くの革新的なプロジェクトを進めています。高度に規制された取引所であるため、パイプラインのあらゆる側面を理解しようと努めています。GenAIを使用したプラットフォームの運用に何が必要かを理解しています。

先ほど述べたように、私たちはGenerative AIを使って多くのことを行っています。 Amazon Bedrockを使用して構築したユースケースの1つをご紹介しましょう。
Amazon Bedrockを用いた取引ルールチャットボットの開発

弁護士の息子として育った私は、pro bono、de novo、signet、ayeなどの法律用語に囲まれて育ちました。これらの法律用語を理解することは、秘密のコードを解読するようなものです。2007年にNYSEに入社した当時、法律文書を読むだけでは取引ルールを理解できませんでした。説明を簡単にしてくれる、理解しやすい形で教えてくれるチームメンバーを探していました。個人の仕事量や気分によって、様々な回答を得ていました。その時、私は本当の意味でのsubject matter expertsの重要性を理解しました。
Generative AIで何ができるかブレインストーミングをしていた時、このユースケースが浮かびました。NYSEに限らず、米国のすべての取引所の法律文書や取引ルール文書を取り上げ、インテリジェントな取引ルールチャットボットを作ってみてはどうかと考えました。約2万ページの文書を使ってこのチャットボットを作成しました。目的は、ルールから要件、テストケースへのトレーサビリティを向上させ、質問に対して簡単な説明を得ること、取引ルールのコンプライアンス要件のリスクを軽減すること、そしてドメイン専門知識に頼らず純粋に技術的な才能に頼ることで、テクニカルタレントの活用を最適化することでした。
先ほど述べたように、私たちは常に先を行くよう努めています。そのため、ルールが変更されても最新の状態を保つことができます。これはまた、ICEで持っている他のユースケースの参照フレームワークにもなります。ここに示した例を見ると、このチャットボットにcube ordersについて説明を求めています。理解しやすい説明が得られますが、このチャットボットの主な特徴は文脈を理解する能力です。フォローアップの質問として、「他の取引所にcube orderに相当するものはありますか?」と尋ねると、同じ名前ではないものの、同じ基準を持つ他の取引所の注文タイプを明確に示してくれます。モデルは文書を読み込んで、その注文の動作を理解し、その洞察を私たちに提供することができるのです。これを持ち、簡単に構築できることは非常に魅力的だと思います。

さて、アーキテクチャについて話しましょう。Bedrockについて説明する前に、このパイプラインの構築を始めた時、Bedrockはまだ準備ができていなかったことをお伝えしておきます。私たちは多くの時間を費やして手作業で作業を行っていました。VMを使って手動で微調整を行うことから始まり、Amazon SageMakerでさまざまなことを試したり、異なる種類のベクトルデータベースなどを試したりしました。しかし、AWSチームと協力している時、Kishorが「これらすべてのことをBedrockでできるから、試してみてはどうか」と言ってくれました。数日のうちに、チャットアプリが動作し、埋め込みが実行されるこのソリューションを構築することができました。私たちのドキュメントはAmazon S3にあり、埋め込みの保存にはベクトルデータベースを使用しています。
質問とコンテキストはFoundation Modelに送られ、そこからレスポンスを得ます。ここでRedisについて触れたいと思います。彼らはこの問題を解決する上で素晴らしいパートナーでした。これは、私たちが彼らと密接に協力する唯一のユースケースではないでしょう。彼らは素晴らしいベクトルデータベースソリューションを提供しています。カスタマイズについて少し話すと、私たちはAnthropicのClaude、微調整ありとなしのAmazon Titan、Llama 2、Jurassic-2など、さまざまな種類のモデルを試しました。RAGを使った微調整、その上にプロンプティングを追加する、ClaudeのようなFoundation Modelをそのまま使用してみるなど、あらゆる種類の組み合わせを試しました。これらすべてのことをAmazon Bedrockで非常に簡単に行うことができました。

これは私にとってゲームチェンジャーでした。チームメンバーとよく話をしますが、数日のうちにここで組み立てることができたものは本当に驚くべきものです。
ICEで現在積極的に取り組んでいる他のイニシアチブには、新しいセンチメント分析と相関分析があります。非構造化データを取得するニュースフィードがあり、それを要約する生成AIモデルの1つに送り、その後、株価が上がるか、下がるか、横ばいかを予測する別のモデルにデータを送ります。また、ネットワークトラフィックの異常検出、データ品質チェック、債券価格設定のための電子メール解析、複雑なOTC構造の変換、不正検出、住宅ローンのライフサイクル分析なども構築しています。

最後に、私たちが立ち上げたプログラム、NYSE LaunchPadについて改めて強調したいと思います。 これは今日の起業家を支援するためのプログラムです。皆さんが活用できる豊富な技術的専門知識があります。これは、製品やアプリケーションが評価され、実用的な洞察を得ることができる安全なクラウドベースのプラットフォームです。そして最後になりましたが、NYSEの独自の可視性プラットフォームがあります。以上で終わります。セッション後、他に質問があればお答えしますので、よろしくお願いします。
Llama 2のファインチューニングデモ:要約タスクの改善


コードを見たい人はいますか?みなさん、そうですね。ありがとうございます。それが私の仕事です。 デモの準備ができています。 ちなみに、このコードはすべてこのGitHubリポジトリで公開されています。今日は2つのデモをお見せします。時間の都合上、ノートブックはすでに実行済みですが、これらは皆さんの環境でも実行できる本物のノートブックです。
1つ目はLlama 2のファインチューニングです。チャット対話、より正確には要約タスクを使用します。会話データを使ってファインチューニングを行います。Amazon Bedrockを使ってLlama 2を利用します。 これは130億パラメータのモデルですが、700億パラメータのモデルも使用できます。2つ目のデモは継続的な事前学習で、大量の本や文書のPDFを入力し、モデルがどのように変化するかを見ていきます。
両方のケースで、セットアップ方法、ファインチューニングや継続的な事前学習(カスタマイズとも呼ばれます)の前のベースモデルのテスト、カスタマイズ用のデータセットの準備、Amazon S3へのアップロード、カスタマイズの実行、そしてそのカスタムモデルをAPIでアクセスできるエンドポイントとしてプロビジョニングする方法をお見せします。その後、カスタマイズされたモデルをテストし、コスト削減のため、使用していないときはこれらのエンドポイントを削除することをお勧めします。

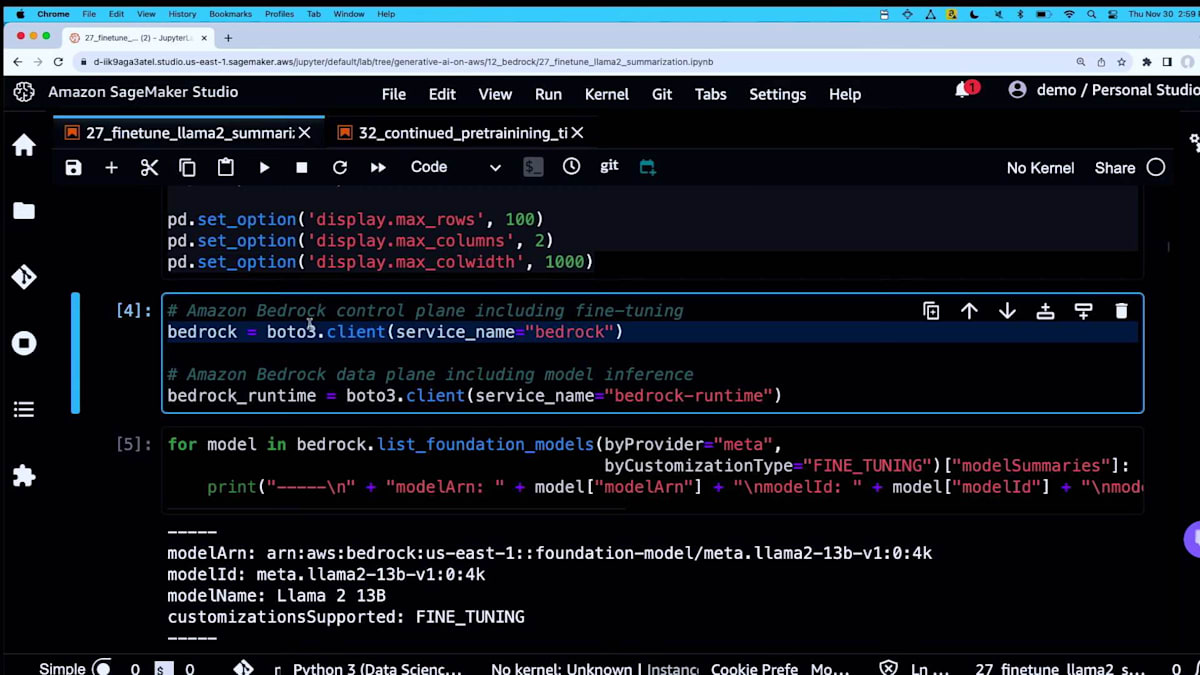
こちらはPIPインストールで、おなじみのものです。これは公開データセットを取得するHugging Face datasetsライブラリです。ここでPandasの設定をして、importを行います。これはAmazon Bedrockのコントロールプレーン用です。 これがカスタマイズジョブを起動する方法です。Pythonの変数に格納するだけです。ランタイムは推論側のためのものです。つまり、分割されているわけです。私はこれをコントロールプレーンとデータプレーンと考えています。
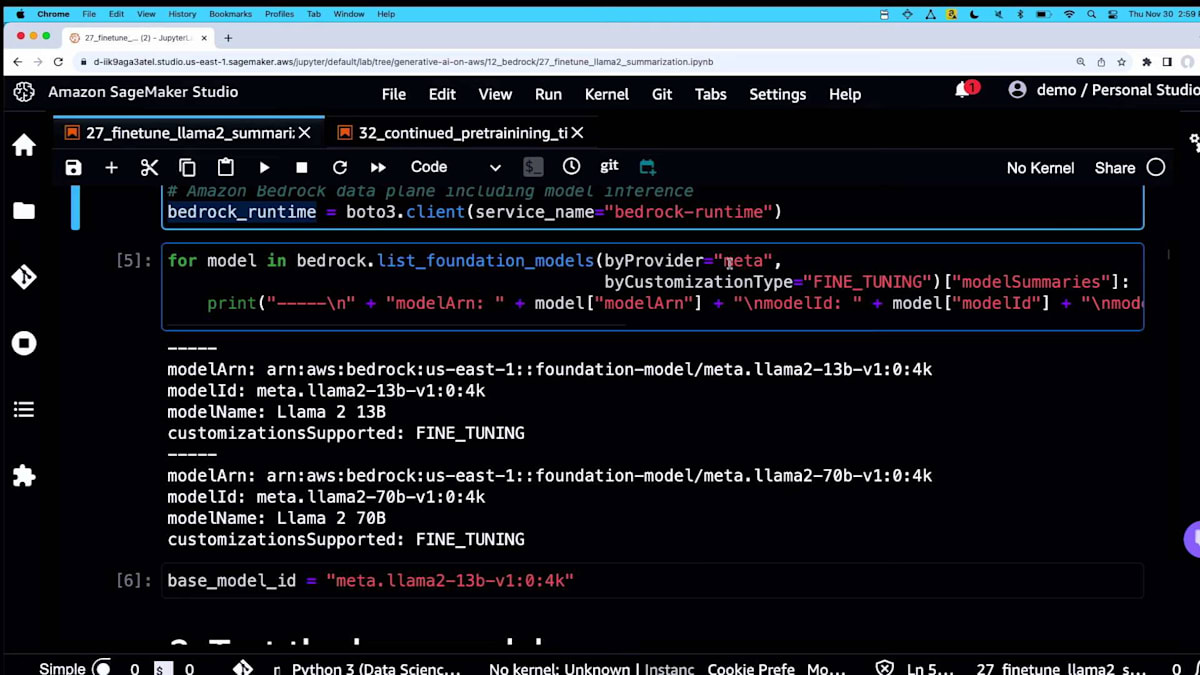
ここで実際にMetaのモデルを検索して表示できます。Amazonのモデルをここに入れることもできます。 Cohereを入れて、ファインチューニングをサポートしているものを表示することもできます。そうするとこのリストが表示されます。時間とコストの都合上、今回は130億パラメータのモデルを使用していますが、これでもかなり良い結果が得られます。そのため、このモデルを使用します。そのIDを取得して、ここの変数に入れるだけです。

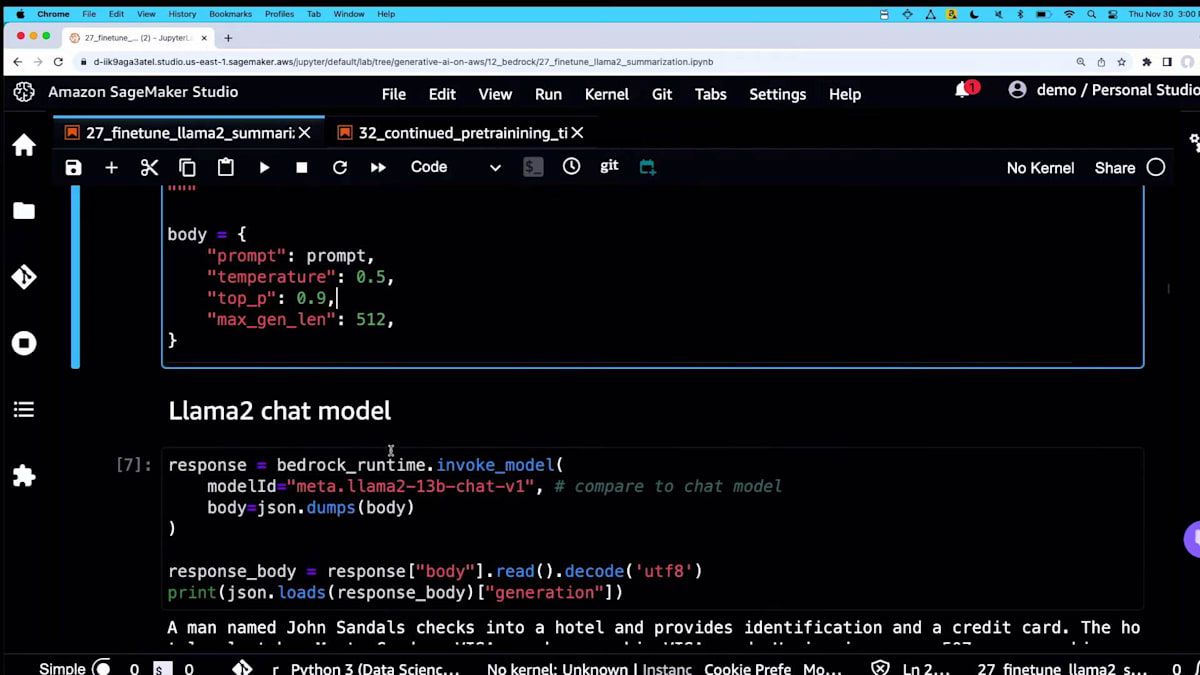
では、サンプルの会話を見てみましょう。 ここでのポイントは、モデルに以下の会話の最もシンプルで興味深い部分だけを要約するよう依頼していることです。これは、カスタマイズなしの Amazon Bedrock を通じた Llama 2 です。ここにいくつかの推論パラメータがあります。探索の余地を与えるために、temperature を中程度に設定しています。 そして、これが呼び出し方です。
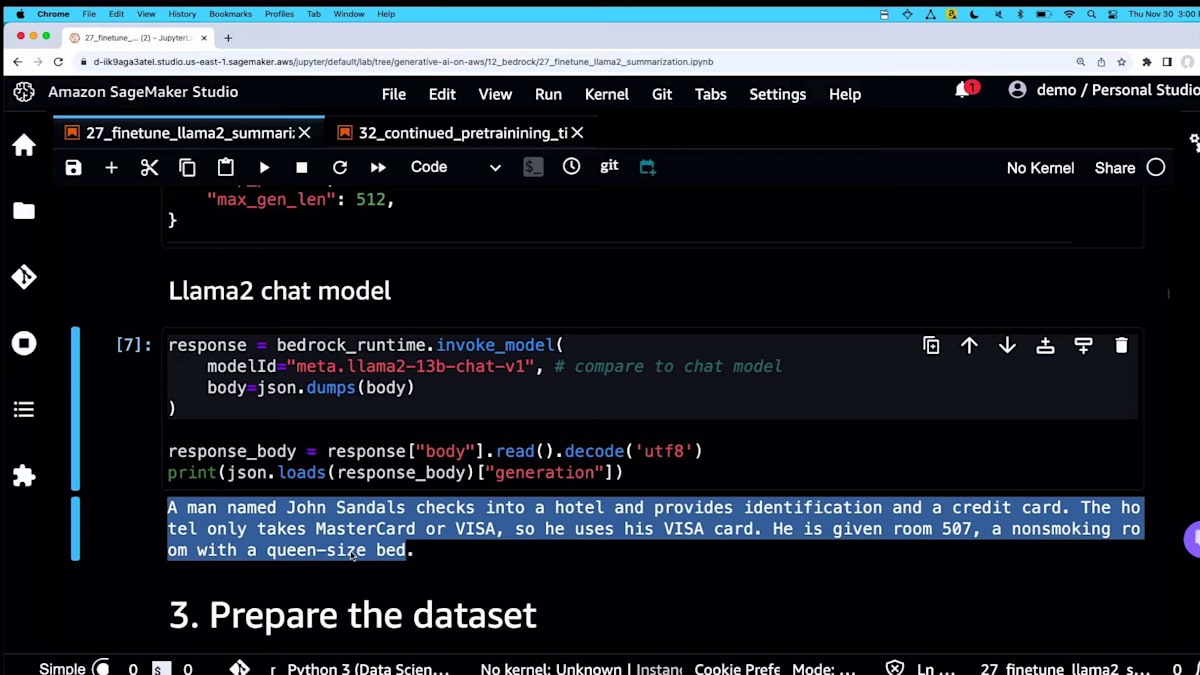
この会話の主要な要素は、ある人がホテルにチェックインしているということです。カウンターの人が特定のクレジットカードを求めています。American Express は使えず、Visa と MasterCard のみ対応しているそうです。きっと私たちの中にも経験した人がいるでしょう。その人は禁煙ルームにチェックインし、すべて問題ありません。

これは、カスタマイズなしの Llama 2 13B で、起こっていることのほぼすべてを説明しています。悪くはありませんが、私は最もシンプルで代表的な部分、最も興味深い部分だけが欲しいのです。そこで、応答を縮小し、最も重要な部分にのみ焦点を当てるようにチューニングしていきます。
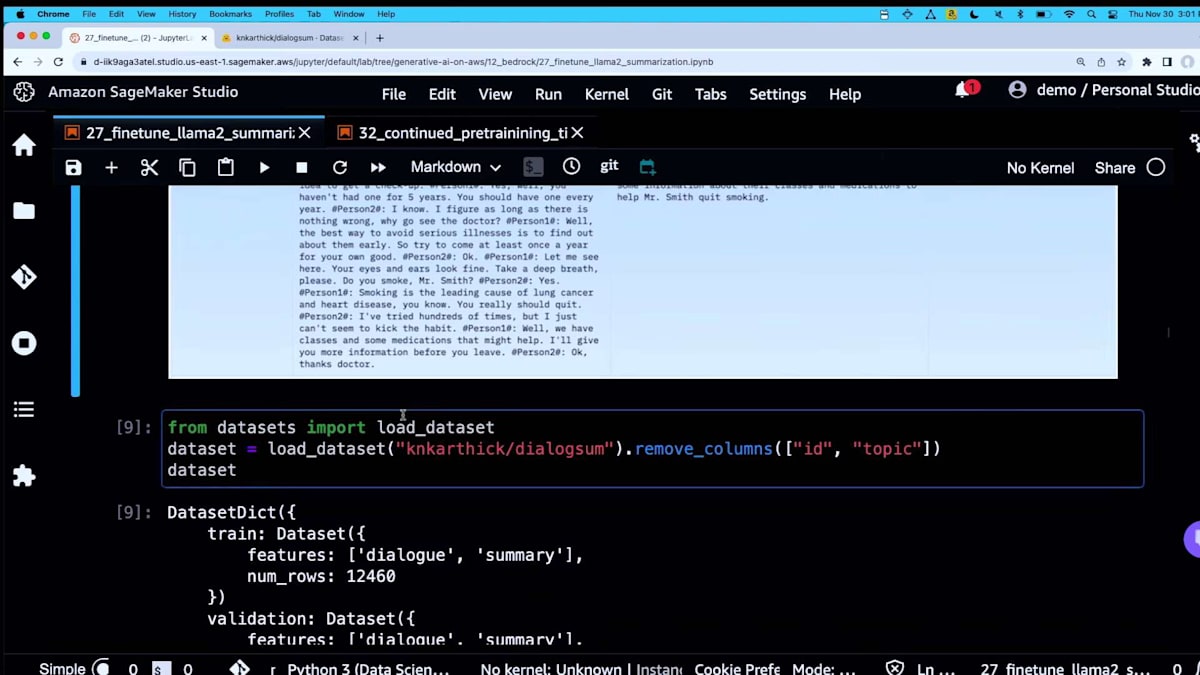

DialogSum というデータセットを使用します。Hugging Face ライブラリを使って Hugging Face から取得します。実際のデータセットにアクセスできるディープリンクがすべてのノートブックに含まれています。これがサンプルで、戻ってくる最初の行です。これは人と医者の間の会話です。 これは公開データセットなので、誰でも入手できます。ID と topic 列を取り除きます。必要なのは、dialogue と呼ばれる実際の会話と、その要約だけです。これを fine-tuning に使用します。


ここで、この関数を使って 各 dialogue と summary を、instruction プロンプトに使用するものにラップします。これが instruction fine-tuning の方法です。このテキストを JSON lines に変換します。SageMaker Bedrock は JSON line 形式を好む傾向があるので、ここではそれを使用します。テーブルで表示すると、このような感じになります。

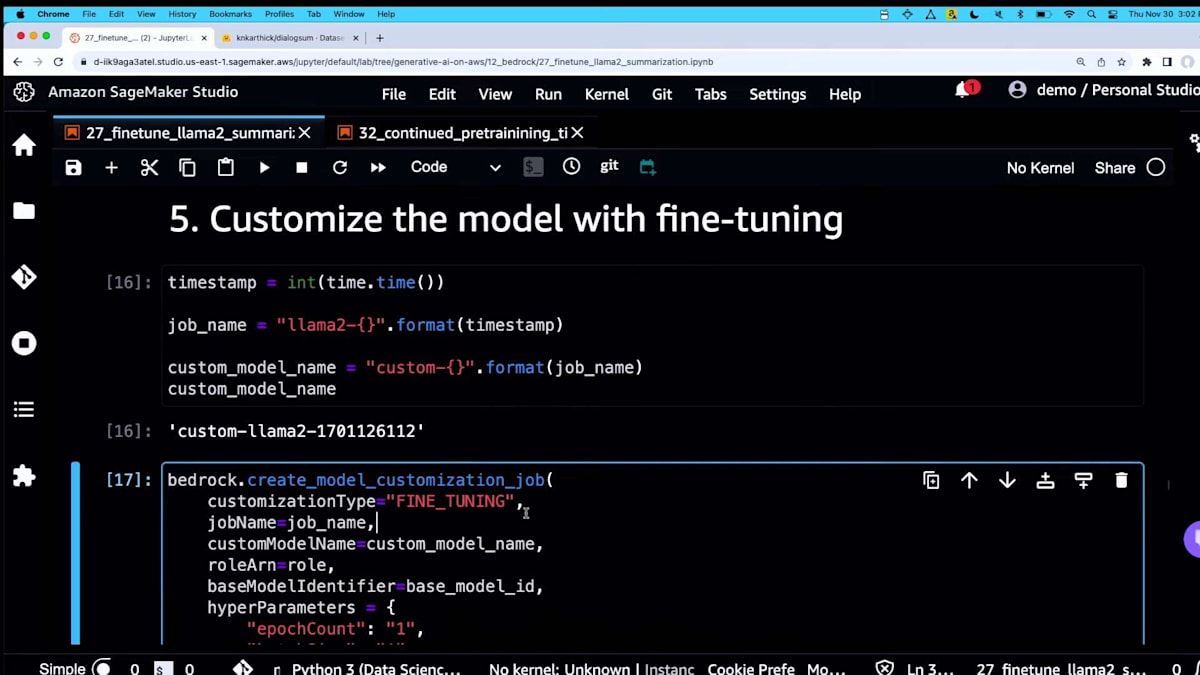
私は1000行だけを取り込みましたが、かなり良い結果が得られたようです。コストを抑えるためには、小規模から始めて必要に応じて追加するのが最適です。 こちらがKishorが言及していたS3バケットです。これは入力用で、ローカルからS3の場所にアップロードする必要があります。出力の場所もあります。ほとんどの部分は定型文で、他の人の例からコピー&ペーストしただけです。

名前を付けるか、タイムスタンプや1970年からの経過秒数を使う古典的な方法を使います。create model customizationを呼び出します。カスタマイゼーションタイプを指定しますが、このパラメータに注目してください。次のデモでcontinued pre-trainingに切り替える際に使用します。ハイパーパラメータを指定することもできます。Kishorが言ったように、学術論文や他の人の作業を参考にして、どこから始めるかを決めます。モデルプロバイダーが指定したデフォルト値から始め、類似のドメインの研究に基づいて調整していくことができます。



これがコンソールでのモデルの様子です。 木曜日なので、今ではすべてがリリースされていると思います。 これが実際のトレーニングジョブ名で、ここをクリックできます。ここがソースモデルで、Llama 2 13Bでした。そしてこれらがハイパーパラメータ、 入力場所、出力データです。
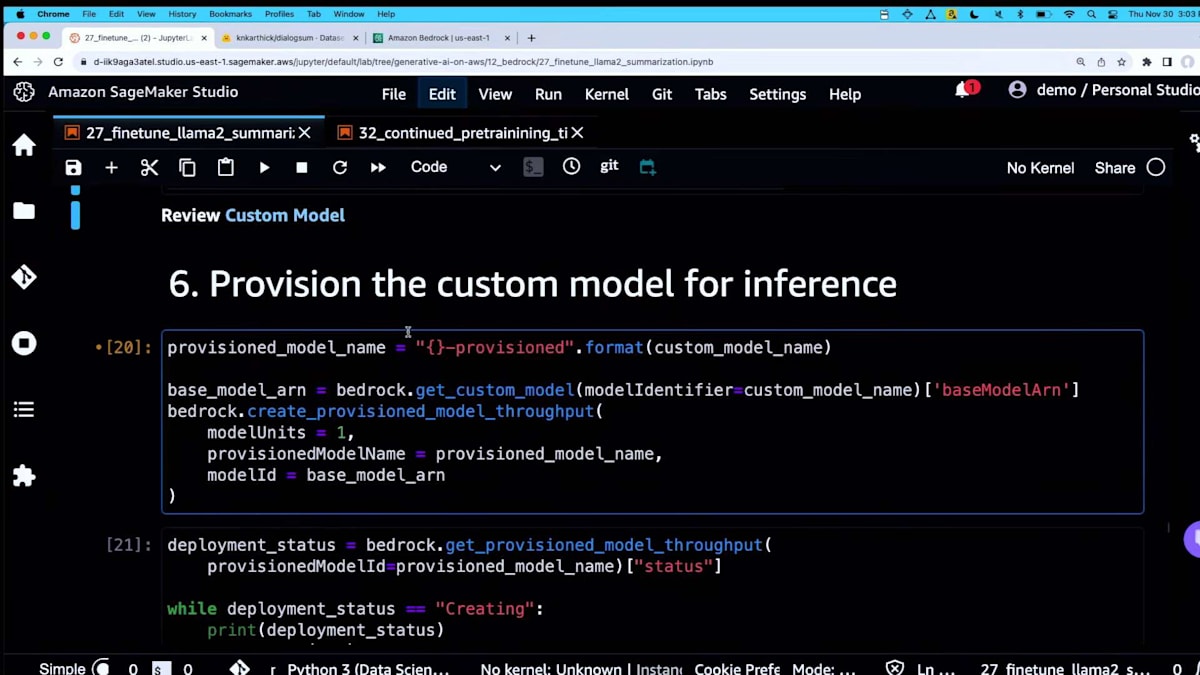

モデルのトレーニングが完了したので、 はい、ここに来る前にオフラインで行いました。次は、そのカスタムモデルをBedrock APIの背後にプロビジョニングします。これ以降、APIを呼び出す際には、どこかの変数に入れておいたカスタムモデル名を指定します。


これがプロビジョンスループットと呼ばれるものです。 ここでモデルユニットを購入できます。モデルユニットが何かを確認し、そのレベルまで掘り下げる必要があります。このエンドポイントがプロビジョニングされたら、必要に応じてスケールアップできます。タグ付けする方法もあります。そして、これがエンドポイントが提供しているモデルです。

Llama 2モデルを使用する場合、Llama 2に適切な入力フォーマットを知っておく必要があります。これらのモデルには、いくつかのトリックや慣例があります。繰り返しになりますが、モデルカードを見つけて、何を入力する必要があるかを把握してください。こちらが同じ例です。これがベースです。

ここでは同様の出力を示しています。これがベースです。Llama 2 13B chatを使用しています。これは基本的にLlama 2のチャットバリアントです。先ほど言ったように、かなりおしゃべりです。次に、ファインチューニングされたバージョンを使ってみましょう。ここでは、エンドポイントをプロビジョニングした後に得られたプロビジョニング済みモデルARNを渡し、簡潔でクリーンな出力を得ています。これは、スタイルや実際の出力を変更しようとしている例です。これはファインチューニングの良い使用例です。
Titan Expressの継続的事前学習デモ:新書籍データの導入
KishorさんやAnandさんが言ったように、RAGから始めることを明確にしておくべきですね。RAGについては今回カバーしませんでした。皆さんはGenerative AIに興味がある方々なので、おそらくすでにたくさんのRAGの講演を見ていると思います。多くの例があります。これは実際にモデルの応答スタイルを変更したい場合の第2段階といえるでしょう。そして、エンドポイントを削除します。

次は、continued pre-trainingに話を移しましょう。これは面白いものです。continued pre-trainingは、非構造化データを渡すだけで済みます。PDFを与えるだけで、いわゆるpre-trainを続けることができます。これらの基盤モデルは、Meta、Cohere、Anthropic、AI21によってpre-trainされています。新しい用語を導入し、重みの分布や確率を変更して、あなたの文書セットを学習させたい場合があります。

最も難しかったのは、Titanがまだ見ていないものを見つけることでした。特に、私たちが得ているほとんどのデータが公開データセットからのものだからです。同じ構造に従います:セットアップ、continued pre-training前のベースモデルのテスト、データのアップロード、そしてプロビジョニングです。実際にはLangChainを使用します。皆さんの中にはすでに馴染みのある方もいるかもしれません。これは今では生成AIアプリケーションを調整するための標準的なライブラリだと思います。彼らはまた、PDFをテキストに変換し、それをテキストに分割するための優れたライブラリも持っています。そして、それが実際にJSON linesとしてcontinued pre-trainingに供給されることになります。


さらにPandasの魔法を使って、ジョブを呼び出すためのコントロールプレーンと、モデル推論を行うためのデータプレーンを準備します。ここではTitan Expressを使用します。Titan Liteもありますが。 先ほど言ったように、データを見つけるのは難しかったのですが、ちょうどこの本が出版されました。Titanはまだこれを見ていないはずです。なぜなら、まだリリースされていないからです。来週から出荷が始まると思います。これは300ページの本で、私と同僚たちが執筆しました。


実際にこれをJSON lines形式に変換します。ああ、そうですね、少し戻って説明すると、 カスタマイズされていない基本のTitan Express モデルに、この本について説明してもらいます。もちろん、モデルはこのデータを見たことがないので、実際には知っているふりをし始めます。ここでいくつかの幻覚(ハルシネーション)が見られます。これはTitanが親切に、「Generative AI on AWS」というタイトルの本について何か言おうとしているところです。

私は著者の一人なので、これが本当の内容ではないことを知っています。実際、Amazon Bedrockについての言及さえ見当たりません。Amazon SageMakerについての言及は見られますが。Amazon RekognitionやAmazon Transcribeなどの他のサービスについても触れています。カスタマイズなしでは、このような結果になります。ここで、私自身のドキュメント、つまりこの本を導入し、変換しようと思います。

こちらが実際のPDFです。RAGコードで使用しているLangChainライブラリの一部を使用します。これを再利用して、このドキュメントをチャンクに分割します。大まぐさに言えば、チャンクのサイズとオーバーラップを調整して、1ページあたり約1行のアイテムになるようにしました。偶然そうなっただけですが、うまく機能しているようです。これは単なるボイラープレートコードで、JSON lines形式に変換します。Kishorのスライドを覚えていれば、継続的な事前学習では入力だけを渡す必要があります。ここには完了や出力はありません。なぜなら、ファインチューニングではなく、生のデータを与えているだけだからです。

約305ページあり、データをアップロードします。非常に簡単です。
では、ここで継続的な事前学習を行うジョブを開始します。これはファインチューニングのプロセスではなく、少し異なるハイパーパラメータを使用します。継続的な事前学習では、通常エポック数を増やし、学習率を少し下げることが重要です。実は、適切なバランスを見つけるために、Amazonの科学者たちと協力する必要がありました。チームにAmazonの科学者がいるのは常に良いことですね。

Titan Expressに基づいてトレーニングされたこのモデルを見てみましょう。続けると、ここにプロビジョニングのプロセスがあります。 Amazon Bedrockのコントロールプレーンを呼び出して、プロビジョニングされたモデルのスループットを作成します。これは基本的に、このカスタマイズされたモデル用の特定のエンドポイントを作成することです。これで呼び出すことができます。


どのような結果が得られるか見てみましょう。 これがプロビジョニングされたスループットと呼ばれるものです。ここでは、ファインチューニングされたモデルと同じように、モデルユニットを選択します。これらはすべて同じになります。ここでも同じ入力があります。「本について説明してください」と言います。 そして、どのような結果が返ってくるか見てみましょう。

申し訳ありません。先ほどと同じ間違いをしてしまいました。それは以前と同じでした。これが実際のカスタム事前学習モデルです。そのモデルのプロビジョニングされたエンドポイントの一意のIDであるARNを渡します。ここでAmazon Bedrockに関する情報が表示されています。私たちが本を分解した方法は、データの準備からライフサイクル全体にわたり、データから始まり、生成モデルの最適化、そして評価に至るまでです。 これは私たちが実際に書いたものにずっと近いですね。
デモンストレーションの結論

私たちが行ったのは、基本的にトークンの確率をシフトさせることです。次のトークンを予測しようとするとき、モデルに与えた追加情報に基づいて予測を始めるように、それらの確率をシフトさせました。ここにすべてのコードがあります。 これでデモは終わりです。質問はオフラインで受け付けることになっていますよね?そうですね。
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion