re:Invent 2023: AWSによるSaaS DevOpsの自動化 - マルチテナント環境の実装例


はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - SaaS DevOps deep dive: Automating multi-tenant deployments (SAS406)
この動画では、AWSのPrincipal Solutions ArchitectであるAnubhav SharmaとAlex Pulverが、SaaSとDevOpsの自動化について深掘りします。コンテナ化されたAmazon EKS環境とサーバーレス環境での具体的な実装例を通じて、SaaSワークフローの自動化のベストプラクティスを学べます。テナントのオンボーディングからデプロイメントパイプライン、段階的デプロイメントまで、SaaSプロバイダーが直面する実践的な課題とその解決策を詳しく解説しています。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
SaaSとDevOpsの自動化:セッション概要

みなさん、こんにちは。本日のセッションにご参加いただき、ありがとうございます。今回は、SaaSとDevOpsについて、特にSoftware as a Service(SaaS)モデルにおける自動化のベストプラクティスに焦点を当てて話し合います。私はAWSのPrincipal Solutions ArchitectのAnubhav Sharmaです。同じくPrincipal Solutions ArchitectのAlex Pulverも同席しています。私たちは両方ともAWS SaaS Factoryチームの一員で、AWSのお客様がAWS上でSaaSソリューションを構築、設計、アーキテクトするお手伝いをしています。


今日のトークは3つのセクションに分かれています。まず、今日取り上げる問題について説明します。SaaSワークフローの自動化について、特に興味深く、チャレンジングな点を説明します。 次に、Alexがコンテナ化されたAmazon EKS環境でこのユースケースを解決する方法をデモンストレーションします。最後に、私が戻ってきて、同じ問題についてサーバーレスアプローチを使って解決する方法を説明します。私たちの目標は具体的な例を提供することで、最後にGitHubリポジトリのリンクを共有しますので、後で実際に試すことができます。これは300から400レベルのセッションですので、EKSやサーバーレスの基礎は扱わず、SaaSベースのワークフローにおける高度なユースケースの解決に焦点を当てます。
SaaS自動化ワークフローの基本と課題


まずは、基本的なSaaS自動化ワークフローがどのようなものか見てみましょう。多くの人がSaaSアプリケーションを考えるとき、顧客がサービスにアクセスする中央集中型のホスト環境を想像します。本質的に、私たちは顧客にサービスを販売しているのです。通常、顧客が同時にアクセスする共有環境やリソースを考えます。 一般的に、このようなSaaS環境を作成するには、デプロイメントパイプラインやインフラストラクチャ・アズ・コードを使用します。


しかし、SaaSアプリケーションは、オンボードされた顧客がいなければ意味がありません。SaaSプロバイダーは通常、テナントオンボーディングサービスと呼ばれるものを構築します。このサービスの役割は、テナント設定、ユーザー、メータリングおよび課金プロファイルを作成することで、顧客をSaaSアプリケーションにオンボードすることです。SaaSアプリケーションにテナントまたは顧客をオンボードしたら、 テナントユーザーがアプリケーションにアクセスし始めます。同時に、デプロイメントパイプラインが環境を常に更新していることを確認する必要があります。

SaaSプロバイダーとして、SaaSアプリケーションのアーキテクチャが最新のデプロイメントとリリースで常に更新されていることを確認する必要があります。理想的には、これは顧客の視点から完全に透明性を持って行われるべきです。SaaSプロバイダーの顧客は、裏で行われているリリースを意識すべきではありません。場合によっては、SaaSプロバイダーはテナントオフボーディングサービスも構築します。これは本質的にオンボーディングの逆で、システムからすべての設定、ユーザー、プロファイルを削除します。
私たちは、多くのSaaSプロバイダーがこのように自動化されたワークフローを実現できることを期待しています。なぜなら、リソースをテナント間で共有できれば、コスト効率と運用の卓越性を達成できるからです。更新する必要があるのは1つのリソース、1つの環境だけです。しかし、過去数年間、多くの顧客と協力してきた中で、私たちが気づいたのは、これが思ったほど簡単ではないということです。
SaaSプロバイダーが直面するリソース管理の複雑性


実際、SaaSプロバイダーがテナントごとやティアごとにリソースを作成しているのをよく目にします。なぜそうするのか不思議に思うかもしれません。 いくつか理由があります。時には、SaaSプロバイダーがオンプレミスのソフトウェアデプロイメントモデルを持っていて、SaaSベースの環境への移行を試みているケースがあります。ソフトウェア自体がマルチテナンシーをサポートしておらず、それに対する組み込みのサポートがない場合もあります。ビジネス側がSaaSへの迅速な移行を推進しているため、技術者としては、裏でSaaSアプリケーションの再設計を続けながら、サイロ化されたリソースを作成する以外に選択肢がない場合もあります。あるいは、特定のティアのテナントに対して特定のSLAを保証するためかもしれません。

これがまさに私たちがここで示していることです。すべてのベーシックティアのテナントがアクセスしようとするプールされた環境があるベーシックティアがあり、一方で特定のプレミアムティアのテナントには専用のリソースやサイロ化されたリソースがあります。多くの場合、アーキテクチャは特定のSLAを保証するためにサイロ化されたリソースを作成する以外に選択肢がないように設計されています。
この時点で、テナントやティアごとに異なる設定があるかもしれません。この例を具体的に見ると、ベーシックティアのテナントにはポッド数が2つ、メモリが256という設定があります。しかし、プレミアムティアのテナントには、より高可用性や低レイテンシーの要件など、より良いインフラがあるかもしれません。特定のティアのテナントに対するSLAをサポートするために、専用リソースを作成しなければならないケースをよく見かけます。繰り返しになりますが、これはビジネス上の要因と、SaaSベースの戦略でどのように市場に出ていくかに関係しています。
コンプライアンスも別の要因です。アプリケーションが複数の顧客をサポートできるように設計されているかどうかに関わらず、現地の法律や規制をサポートするために、ヨーロッパ、アメリカ、カナダの地域にデプロイメントを持たなければならないケースをよく見てきました。もちろん、もう1つの要因として、ブラストラディウスがあります。何百何千ものテナントや顧客がいて、何か問題が起きた時のブラストラディウスを限定したい場合があります。そのため、SaaSデプロイメントの一部を作成することになるかもしれません。

このような状況では、複数のリソースを持つことでコスト削減を妥協することになり、より多くの費用がかかってしまいます。また、更新するリソースが複数あるため、運用効率も低下します。新機能をリリースするたびに、すべてのSaaSデプロイメントにわたってリリースする必要があるのです。
階層型デプロイメントモデルと自動化ワークフローの実装

これを踏まえて、より現実的な自動化ワークフローを見てみましょう。ここでは、特定のテナントをプールする基本ティアがある階層型デプロイメントの例を考えてみます。SaaSアプリケーションの初期設定の一環として、まずこの基本ティアを作成することを考えるかもしれません。常に基本ティアのテナントがいくつか存在することは分かっていますよね。

さて、特定のテナントがあなたのSaaSアプリケーションにオンボーディングしようとする場合、オンボーディングサービスには、このテナントが基本ティアのテナントであることを認識し、基本ティアのプール環境やプールリソースにオンボーディングする責任があります。その過程で、いくつかの設定を作成し、テナントユーザーを作成し、計測や課金プロファイルを追加するなどの作業を行います。

では、サイロ化されたテナントやプレミアムティアのテナント用に専用リソースをプロビジョニングする場合はどうでしょうか?この場合、オンボーディング機能に「テナントプロビジョニング」と呼ばれる別の機能を追加する必要があります。このプロビジョニングの役割は、基本的にそれらのサイロ化されたテナントリソースを作成することです。この時点で、サイロリソースの設定内容についても検討する必要があるかもしれません。

ここで重要なのは、デプロイメントパイプラインが、これらすべてのリソースを同期させる追加の責任を負うということです。SaaS環境では、顧客にサービスを提供しているのだということを忘れないでください。そのため、すべてのテナントデプロイメントとテナントリソースが単一のコードベースから生成されていることを確認する必要があります。これが典型的なSaaSプロバイダーのあり方です。すべてが単一の一貫したコードベースから生成され、最終的にはすべてのテナントとティアが単一のリリースに含まれることになります。

さて、これが今日私たちが達成しようとしている目標です。これから例を見ていく中で取り上げる問題は次のようなものです:どうすれば、シームレスなプロビジョニング体験を実現できるでしょうか?どうすれば、デプロイメントパイプラインがこれらの環境を常に同期させられるようにできるでしょうか?もちろん、テナントのオフボーディングにも新たな責任が加わります。特定のテナントリソースを削除しなければならない場合があるからです。
では、具体的な例を見ていきましょう。Alexに登場してもらって、コンテナの例でこの問題をどのように実装するかについて話してもらいます。
コンテナ環境でのSaaSデプロイメントモデルと自動化ツール
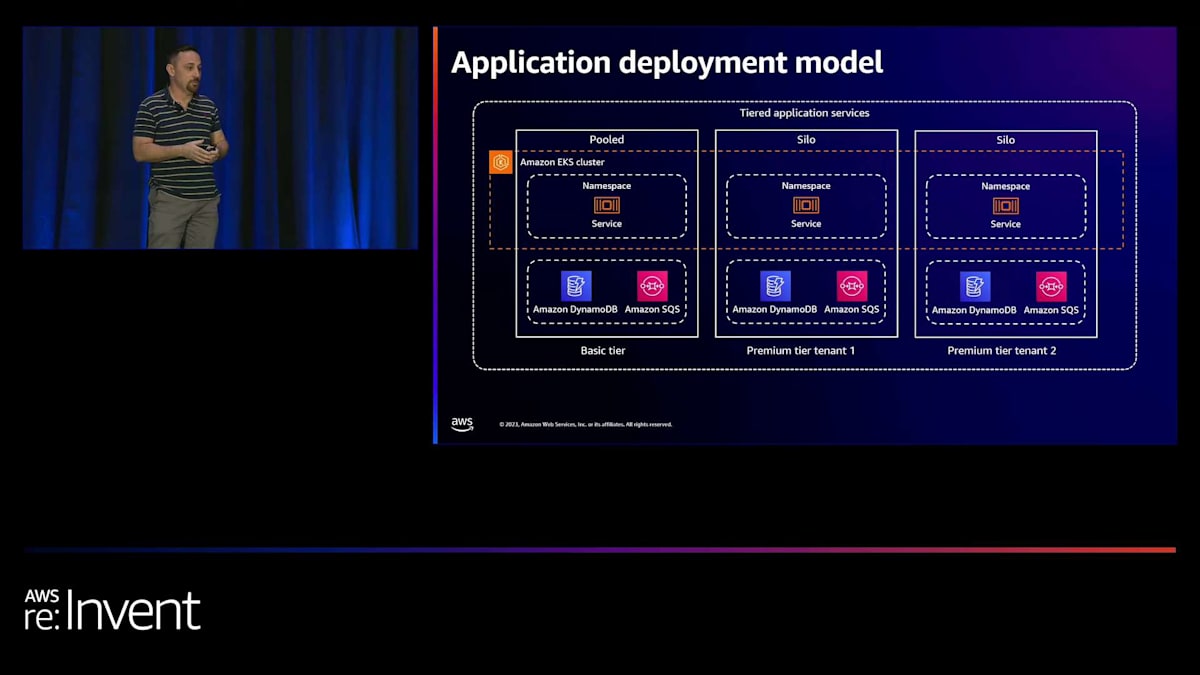
はい、こんにちは。テナントのオンボーディングとデプロイメントパイプラインの具体的な実装の詳細に入る前に、まずアプリケーションのデプロイメントモデルを見てみましょう。この場合、Anubhavが先ほど言及した2つのティア、つまりベーシックティアとプレミアムティアがあります。ベーシックティアの顧客には、共有リソースを使用します。これをプールデプロイメントモデルと呼んでいます。この場合、Amazon EKSクラスター上で動作するKubernetesの名前空間を共有し、Amazon DynamoDBとAmazon SQSのリソースも共有します。
プレミアムティアのテナントには、Kubernetesの専用名前空間を使用します。これは、この特定のユースケースでの任意の決定であり、もちろん、各ユースケースで要件は異なる可能性があります。また、専用のAmazon DynamoDBとAmazon SQSリソースも作成します。これが私たちのアプリケーションデプロイメントのレイアウトであり、これがプロビジョニングと更新が必要なものです。

ここで使用する自動化ツールについても触れておきたいと思います。まず、2つの特定の要素が必要です。Anubhavが言及したように、ティア構成を定義する必要があります。これは、ビジネス要件、つまり価格設定とパッケージングモデルを技術仕様に変換する方法です。例えば、ベーシックティアでは、一定量のメモリとCPU、そして一定数のインスタンスまたはコンテナを使用します。プレミアムティアのテナントでは、より多くのメモリを使用してレイテンシーを低くするなどの対応が可能です。
これが私たちの階層設定テンプレートです。テナントをオンボーディングする際、これらの設定の具体的なインスタンスを作成します。これがここでいうテナント設定です。複数のテナント設定が存在することになります。この講演では、インフラストラクチャの自動化とプロビジョニングツールである Terraform と、Kubernetes でアプリケーションを管理できる Helm を使用してこれを実現する方法をお見せします。Helm chart と Helm release を使用しますが、Helm chart は Kubernetes クラスター内のアプリケーションのデプロイメントモデルを記述するものです。

次に、テナントのプロビジョニングとデプロイメントパイプラインを実装する必要があります。ここでは、オープンソースのワークフロー・オーケストレーションツールである Argo workflows と、継続的デリバリーとプログレッシブデリバリーのワークフローを定義できる Flux を使用します。これらは私たちの例ですが、もちろん Terraform の代わりに AWS CDK を使用するなど、他のツールを使うこともできます。
Terraformを活用したティア設定とテナント設定の実装

まず、階層設定がどのようなものかを、Terraform の実装から見ていきましょう。 これらのスクリーンショットは、後ほどご紹介する builder session からのものです。スライドを見て、後で自分で試すことができます。これはリポジトリ構造で、Terraform テンプレートがあります。階層ごとにファイルがあることがわかります。プレミアム階層である silo リソース用のファイルと、ベーシック階層である pool リソース用のファイルがあります。

silo リソースファイルの中身を覗いてみると、これが Terraform モジュールであることがわかります。このモジュールはアプリケーションのように機能し、tenant apps という別のモジュールの非常に具体的なバージョン、1.0.0.1 を参照しています。tenant apps モジュールは、基本的にすべての ingress デプロイメントやその他の Kubernetes リソース、さらには Amazon DynamoDB テーブルや Amazon SQS などのリソースを定義します。また、deploy consumer や producer などのパラメータも提供しています。このモジュールに渡すこれらのパラメータは、ビジネス設定に影響を与えます。silo カスタマーやプレミアム階層のカスタマーに対しては、常に producer と consumer コンポーネント用の専用リソースをデプロイします。しかし、ベーシック階層のカスタマーに対しては、これらの専用リソースをデプロイしないかもしれません。まさにここで、この設定を調整して適応させることができるのです。次に、Kubernetes リソースをカバーする Helm を見てみましょう。


各階層用の Helm release テンプレートがあります。silo のものを見てみましょう。 ここでも、tenant ID はプレースホルダーです。下部に、具体的な仕様を持つ2つの設定値があります:deploy apps と deploy ingress です。この場合、ingress のデプロイはルーティングを担当します。私たちのシナリオでは、テナントごとのサブドメインを使用する場合、ベーシック階層のカスタマーをデプロイするかプレミアム階層のカスタマーをデプロイするかに関わらず、常に ingress をデプロイしてサブドメインを提供する必要があります。しかし、ベーシック階層のテナントの場合、リソースを共有するため、毎回アプリをデプロイしないかもしれません。silo デプロイメントモデルでは、テナントごとにアプリケーションをデプロイします。ここで具体的なパラメータを定義しますが、tenant ID の設定はテンプレート化します。ビジネスモデルが変更された場合、その変更を技術仕様に落とし込むための判断を行う必要があります。


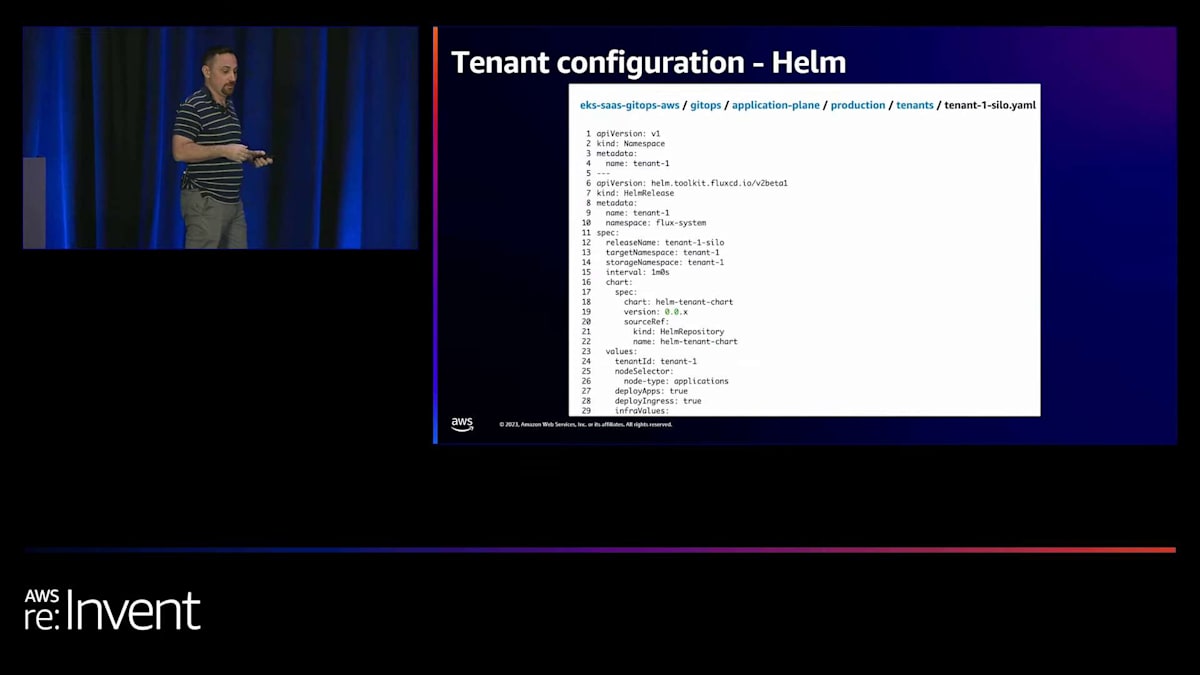
それでは、テナント設定について見ていきましょう。これは基本的にティア設定のインスタンスです。Terraformでは、テナントのオンボーディング後に毎回ファイルを作成する別のフォルダがあります。サイロデプロイメントモデルを使用するテナント1を見てみましょう。以前見たのと同じファイルですが、今回は具体的なテナントIDがあります。後ほど、このバージョンをHelmで段階的デプロイメントに使用し、この反転制御の維持にどう役立つかを見ていきます。Helmについては、サイロ型かプール型かに関わらず、オンボーディングする各テナントに対してHelmリリースファイルがあります。重要なのは、Helmリリースファイル内に記述される値です。Helmリリースは、クラスター内のKubernetesリソースのデプロイメントレイアウトを記述するHelmチャートのインスタンスです。


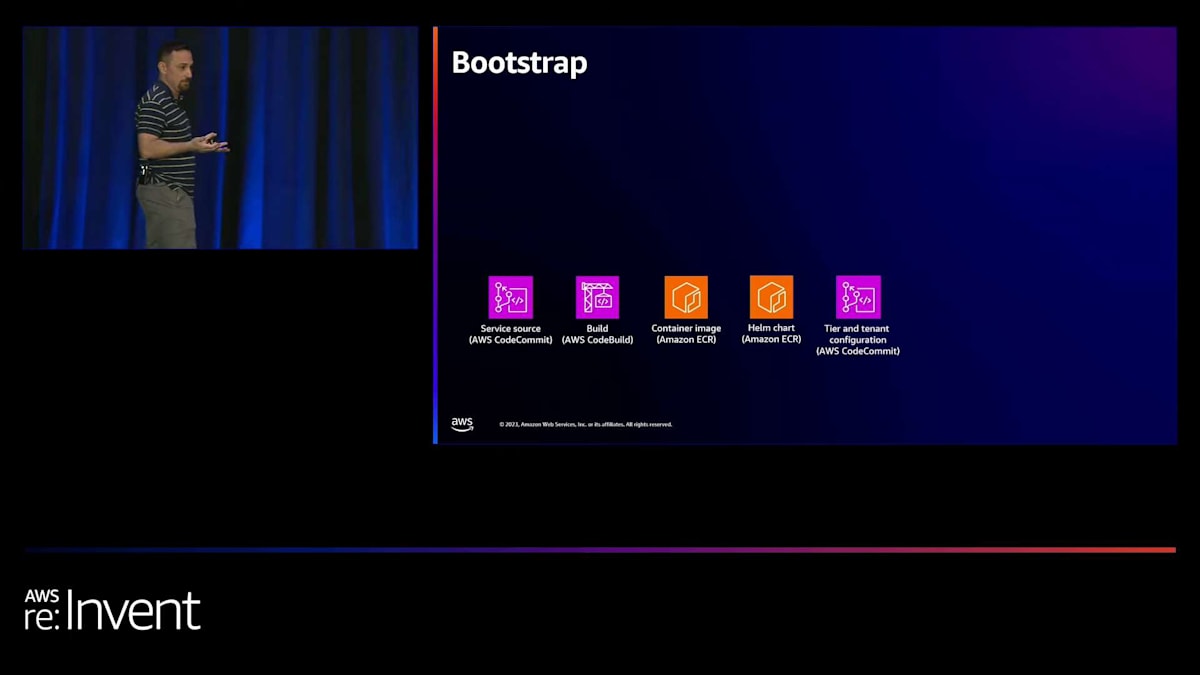
では、これらの設定をどのように使用するかを説明しましょう。前述の通り、テナントをオンボーディングする前にシステムをブートストラップする必要があります。例えば、Atlasアカウントの作成など、特定のリソースを作成する必要があります。他の追加リソースも見てみましょう。まず、サービスのソースコードを管理するためのソースコードリポジトリが必要です。次に、このソースコードをコンテナイメージに変換するビルドプロセスが必要です。そのコンテナイメージを保存するリポジトリも必要です。この場合、Amazon ECR(Amazon Elastic Container Registry)を使用しています。Kubernetesアプリケーションの管理にHelmを使用しているので、Helmチャートバージョンも作成し、後で使用するためにリポジトリにプッシュします。最後に、ティアとテナントの設定、つまり設定部分を管理する方法が必要です。これはコンテナイメージを参照するHelmチャートへの参照をすべて保存するためです。
SaaSシステムのブートストラップとリソースプロビジョニング




Kubernetesクラスターも必要です。この場合、Amazon EKSを事前にプロビジョニングする必要があります。これは別のアプリケーションや中央チームによって管理される可能性があります。つまり、ここには複数レベルのテナンシーがありますが、そのクラスター内でテナントをオンボーディングする前に、クラスターを準備しておく必要があります。FluxとArgo CDを使用しているので、専用のnamespaceにFluxコントローラーをインストールする必要があります。Argo workflowsコントローラーもインストールする必要があります。最後に、基本ティアのリソースを事前にプロビジョニングすることにしました。これは、基本ティアの顧客がサインアップしたときに即座に対応できるようにするためです。プレミアムティアの顧客の場合、営業チームとやり取りしながら取引を締結する過程でリソースをプロビジョニングする別の営業プロセスがあるかもしれません。しかし、基本ティア(無料トライアルなど)の場合は即時対応を望むため、この場合は事前プロビジョニングを選択しました。ただし、これはあくまでビジネス上の判断です。

では、これらのリソースの上でテナントのオンボーディングをどのように行うか見てみましょう。すでにKubernetesリソースが準備されており、このインフラストラクチャを使用してテナントのオンボーディングを開始する準備が整っています。
ティア設定とテンプレート化された設定を含むconfigリポジトリがあり、Fluxコントローラーをインストールしました。ここでFluxコントローラーが行うのは、テナント設定の変更を監視することです。新しいテナントを追加したい場合、Fluxにそれを知らせたいのです。
Argo workflowsを用いたテナントオンボーディングの自動化
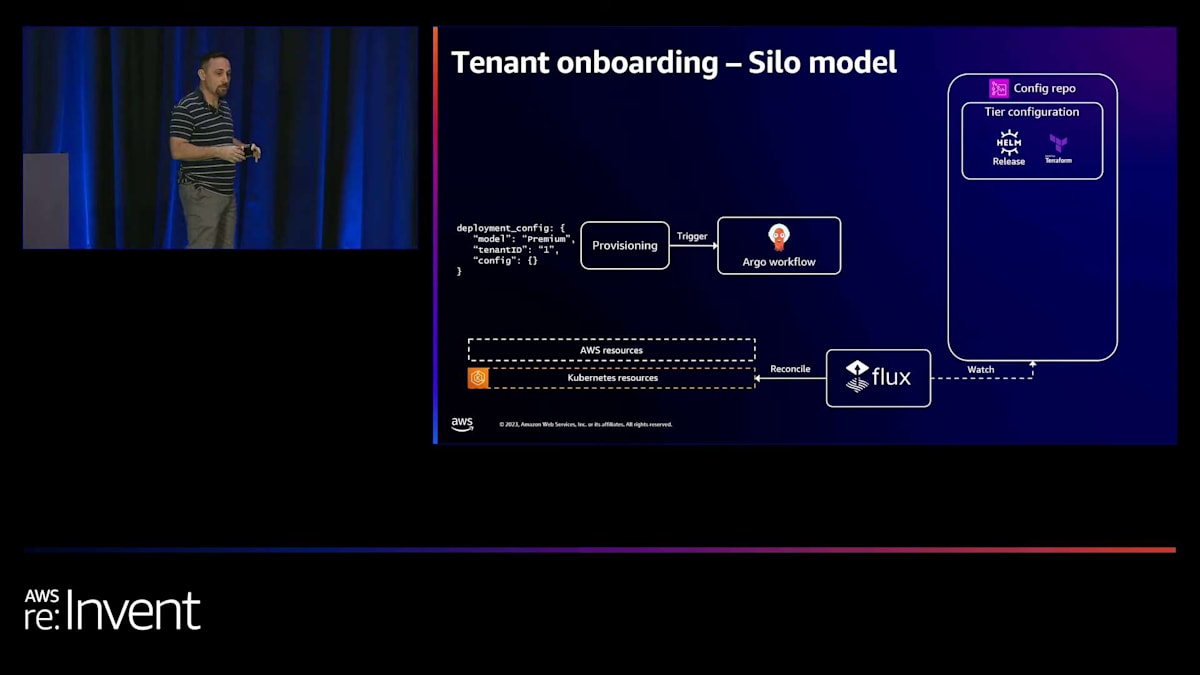
外部のテナント管理システムが、新しいテナントがサインアップしたことをアプリケーションに通知するケースを想定してみましょう。この例では、テナントIDが1のプレミアムティアのテナントがあります。通常、テナントには何らかのユニークなIDがありますが、これは単なる例です。ここにはプロビジョニングコンポーネントがあり、このイベントを受け取ってArgo workflowの実行をトリガーし、テナントのプロビジョニングを調整します。Argo workflowsが一般的に行うのは、ティア設定を扱うことです。先ほどお見せしたテンプレートファイルを使用し、TerraformとHelmの両方のプレースホルダーを実際の値に置き換えます。


まず、AWSリソースをデプロイします。通常、これらはKubernetesクラスターで実行されるランタイムコードの前提条件となるからです。例えば、データベースやキューなどがそうです。次に、ワークフローは具体的なテナント設定をconfigリポジトリにドライブバックします。TerraformとHelmのリソースはFluxによって監視されています。Fluxは新しいテナントがあることを認識し、基本的に新しい名前空間とサービスデプロイメントを作成することでKubernetesリソースを調整します。


さて、別のテナント、例えばテナントIDが2の別のプレミアムティアテナントのリソースをプロビジョニングしたい場合、基本的に同じプロセスになります。再びワークフローが実行され、ワークフローはティア設定のテンプレート化された設定を取得し、テナントID値で置き換えてAWSリソースをデプロイします。その後、Helmリリース設定をconfigリポジトリにコミットし戻します。これによってFluxがトリガーされ、Kubernetesリソースが調整されることになります。
Fluxを活用した継続的デプロイメントと段階的ロールアウト

それでは、Argo workflowの詳細を見ていきましょう。Argo workflowは、ワークフローテンプレートを実装するためにカスタムリソース定義(CRD)を使用します。通常、これによって一連のステップ、つまり実現したい機能を実装する一連のテンプレートを定義することができます。各ステップは通常、任意のコードを実行できるコンテナ内で実行されます。この場合、クローンレポフェーズでは、まずそのconfigリポジトリをコンテナにクローンします。その後、TerraformファイルとHelmファイルの置換を行い、最初にterraform init、plan、applyを実行します。ちなみに、この時点で失敗があれば、ワークフローを停止してエラーを出すなどの対応ができます。すべてが順調なら、Terraformファイルの変更をconfigリポジトリにコミットし直します。この場合、現在は追跡にのみ使用しているため、何もトリガーされません。
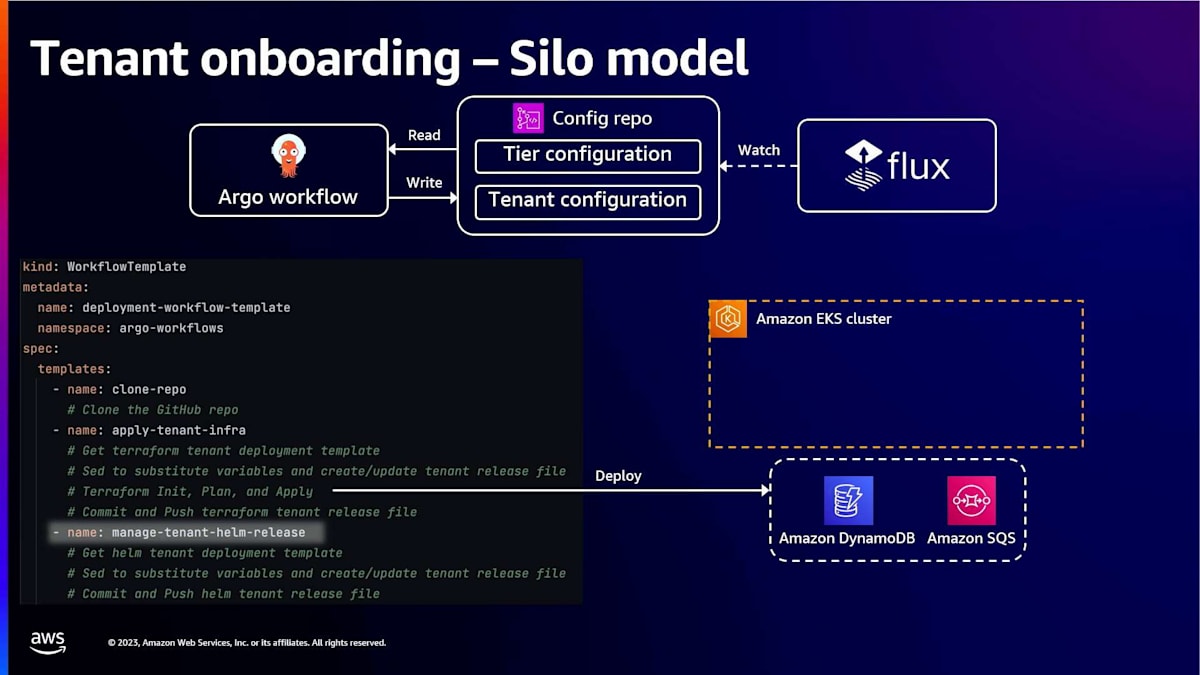
次に、Helmリリースファイルに同じ変更を加えます。ここでも、テナントIDを具体的な値に置き換え、さらにテナントのティア(ベーシックまたはプレミアム)に基づいて具体的なテンプレートを使用します。変更をコミットしてリポジトリにプッシュすると、今度はFluxがKubernetesリソースを調整し、このテナント用の新しいnamespaceを作成(プレミアムテナントなので)し、サービスをデプロイします。これで、Argo workflowの実行の詳細が少し明確になったのではないでしょうか。

さて、テナントのオンボーディング、つまり新しいプレミアムテナントをどのようにオンボードするかについて話してきました。ですが、ここからはAnubhavが言及したもう一つの部分、デプロイメントパイプラインを見ていきましょう。これらのリソースを効果的に継続的に更新する方法です。すでに2つのテナントがプロビジョニングされており、もちろんベーシックティアもありますが、スペースの都合上ここでは表示していません。また、ブートストラップのステップでお見せしたAmazon ECRリポジトリも追加しました。そこに私たちのHelmチャートを公開しています。
サーバーレス環境でのSaaSアプリケーション構築

継続的デプロイメントやデプロイメントパイプラインのために、新しいサービスバージョンをプッシュする際にFluxがHelmチャートの変更も監視する必要があります。ここではインフラストラクチャの更新については触れません。Anubhavがサーバーレスの例で説明しますが、他のツールやTerraformでも同様のアプローチです。では、パイプラインを見てみましょう。FluxをECRリポジトリの監視用に設定する必要があります。開発者として、サービスのソースコードに新しい変更をプッシュする場合、このソースコードをビルドし、コンテナイメージをAmazon ECRリポジトリにプッシュする必要があります(ここでは図示されていません)。また、Helmチャートの新バージョンを作成する必要もあります。例えば、1.0から1.1へのバージョンアップです。
Fluxをマイナーバージョンの変更を監視するように設定しました。薄い青色で強調表示されている1.Xのパターンが見えますね。このパターンに一致するHelmチャートバージョンをプッシュすると、Fluxは自動的にそのセマンティックバージョンに一致するすべてのリソースを調整します。基本的に、これらの変更をランダムな順序で適用します。ただし、Basic tierテナントとPremium tierテナントがあり、多数のテナントがある可能性があるため、通常はこのロールアウトをある程度制御したいものです。まず少数のテナントでこれらの変更をテストし、メトリクスを監視し、システムが変更に対してうまく動作するかどうかを確認するための時間を設け、大規模な障害が発生する前にロールバックすることもあるでしょう。


Amazonでは、これを通常「段階的デプロイメント」と呼びます。本質的に、変更を段階的にデプロイできます。例えば、最初にBasic tierにデプロイし、次にPremium tierにデプロイしますが、すべてのPremium tierテナントではなく、その一部だけにデプロイするといった具合です。この例でどのようにこれを実現できるかをお見せしたいと思います。この場合、Helmリリースやテナント設定のバージョンセレクタにワイルドカードを使用しません。代わりに、具体的なバージョン1.0を指定します。新しいバージョンのコンテナイメージを作成してAmazon ECRリポジトリにプッシュし、バージョン1.1になったとしても、この場合、Fluxは何もしません。バージョンが一致しないため、単に無視します。
ここで、Flux notification controllerを使用するワークフローを実装できます。まずテナント1に変更をプッシュし、テナント1のHelmリリース設定をバージョン1.1に変更し、その後、調整の成功または失敗を待ち受けます。Flux notification controllerは、調整が成功した場合にイベントを送信し、失敗した場合にアラームを発生させます。これは非同期のフローなので、ここで待機ループを実装する必要があります。すべてが成功したというイベントを受け取ったら、テナント2の設定のバージョンも昇格させることができます。Terraformでも同様のことができます。アプリケーションに使用するTerraformモデルの具体的なバージョンがあったことを覚えていますか?各ステップでインフラストラクチャリソースについても同様の進行ができます。
以上が、コンテナのテナントオンボーディングとデプロイメントパイプラインの構築方法の例でした。次に、Anubhavがサーバーレスの例を完成させます。ありがとうございました。
AWS SAMとAWS Step Functionsを用いたサーバーレスSaaS自動化
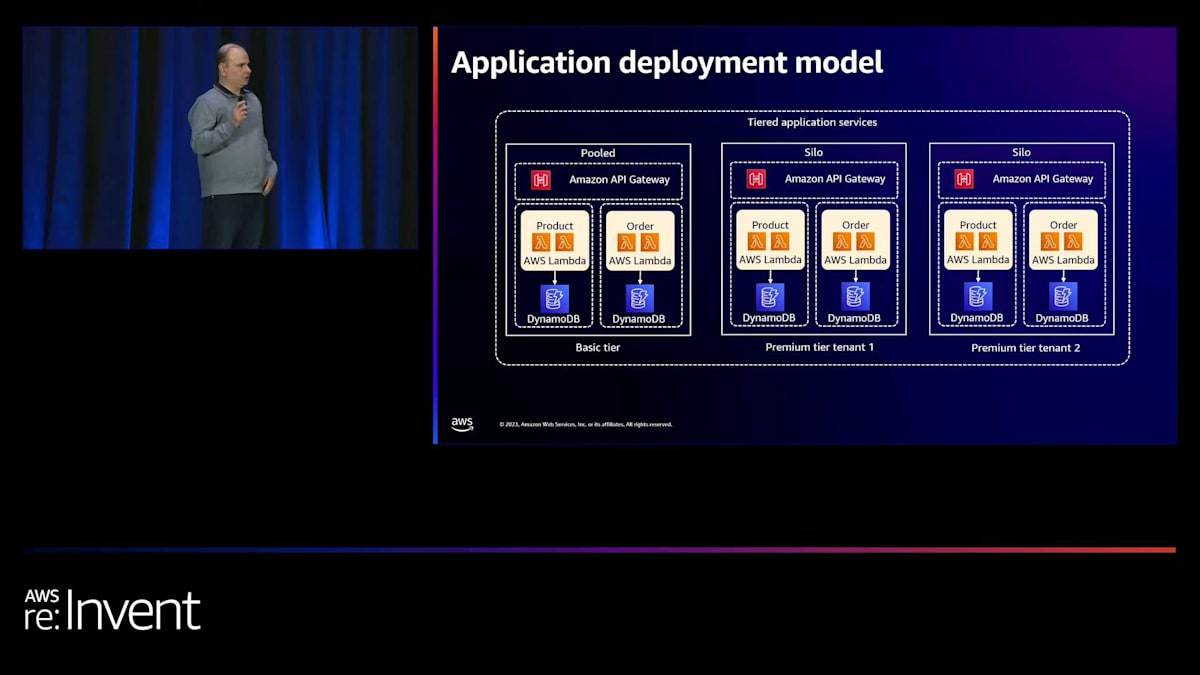
ありがとう、Alex。では、同じ問題設定をサーバーレス環境でどのように解決するか見ていきましょう。アプリケーションのデプロイメントモデルについては、先ほどのコンテナの例で示したものを再度参照します。この問題設定の一部として、Basic tierのテナントが単一のリソースセットを共有するプール型環境と、Premium tierのテナントのためのサイロ型環境があります。それでは、このプロビジョニングとデプロイメントの問題をサーバーレスサービスを使ってどのように解決するか見ていきましょう。

ところで、SaaSアプリケーション全体のアーキテクチャもサーバーレスであることを言い忘れていました。ご覧の通り、APIにはAmazon API Gateway、コンピューティングにはAWS Lambda関数、データストアにはAmazon DynamoDBを使用しています。ただし、この単一のSaaSアプリケーションが異なるテナントとティアにまたがってデプロイされているのです。ツールに関しては、今回の場合、インフラストラクチャ・アズ・コードの構築にAWS Serverless Application Model(AWS SAM)を使用します。Alexも言ったように、CDKやTerraformなど、好みのものを選んでいただいて構いません。ただし、今回の例ではサーバーレスアプリケーションのインフラ定義に特化したSAMを使用しています。
デプロイメントに関しては、コアデプロイメントパイプラインを構築するためのマネージドサービスであるAWS CodePipelineを活用します。さらに興味深いのは、デプロイメントワークフロー全体をAWS Step Functionsを使ってオーケストレーションすることです。このStep Functionの動作と定義をお見せしますし、複数のテナントとティアにまたがってデプロイメントをどのように段階的に行うかもご紹介します。
設定に関しては、テナントとティアの設定をすべて保持するためのキーバリューデータストアとしてAmazon DynamoDBを活用しています。プロビジョニングサービスは、基本的にAmazon API Gatewayの背後にある単純なAWS Lambda関数です。

これらのサービスをすべて連携させて、どのように機能するか見ていきましょう。先ほど問題設定を説明した際に触れたように、私たちの目標は、すべてのテナントが単一のコードベースと単一のリリースを共有することです。つまり、すべてのテナントのインフラストラクチャを構築するためのテンプレートが必要になります。このテンプレートYAMLがまさにそれを実現するもので、すべてのテナントとティアを構築するための単一のテンプレートです。このテンプレートをパラメータ化することで、異なるティアに対して異なる設定をサポートすることができます。

ご覧のように、provisioned concurrencyというパラメータがあります。これは、特定のプレミアム層のテナントに対して、より高いprovisioned concurrencyを提供し、低いレイテンシーを保証できることを意味します。Lambda関数にprovisioned concurrency機能を使用すると、基本的に特定のLambda関数のインスタンスを事前にウォームアップし、コールドスタートを回避します。これがテンプレート化してこのパラメータを使用する考え方で、同じコードベースを使用しながら、異なるテナントに対してインフラストラクチャを異なる方法で構成できるようにしています。

では、ブートストラッピングがどのように機能するかを見てみましょう。 ブートストラッピングに関して最初に行うことは、共有サービスとデプロイメントパイプラインを作成することです。プロビジョニングやオンボーディングサービス、デプロイメントパイプライン自体を含むすべてのサービスは、SaaSアプリケーションプランの構築を開始する前に作成する必要があります。この場合、bootstrap.yamlを使用します。これは、AWS SAMを使用して構築されたインフラストラクチャアズコードであり、これらの共有サービスをすべて構築するために使用されます。

次のステップは、Amazon EKSで行ったのと同様に、基本層のプール環境をブートストラップすることです。ここでは、deployment configurationと呼ぶDynamoDBテーブルを活用しています。このdeployment configurationが、すべてのプロビジョニングとデプロイメントを一箇所にまとめる役割を果たしていることをお見せします。

次に行ったのは、Lambda triggerを使用してAWS CodePipelineをプロビジョニングまたは開始することです。アイデアとしては、このDynamoDBテーブルにエントリを作成するとすぐに、DynamoDB streamsが有効になり、それによってCodePipelineが開始されるというものです。

このCodePipelineはいくつかのことを行っています。まず、template.yamlを含むソースコードリポジトリをクローンします。次に、SAM buildとSAM packageを使用してデプロイメントアーティファクトを生成します。これは基本的に、すべてのLambda関数のコードを含むZIPファイルであり、S3バケットに配置されます。その後、デプロイメントステップを開始します。ご覧のように、そのアイコンは実際にはステップ関数を表しています。AWS Step Functionsワークフローを、CodePipelineの一部として統合しています。
AWS Step Functionsによる段階的デプロイメントの実装

この Step Functions ワークフローは、デプロイメント構成を監視しています。ワークフローの一部として、最初のステップでは、デプロイメント構成 DynamoDB テーブルを確認し、新しく作成すべきスタックがあるかどうかを確認します。この場合、ブートストラップを行っているため、ベーシックティアのテナント用の stack-basic があります。また、ティア構成 DynamoDB テーブルも確認します。このテーブルには、ティアごと、テナントごとのすべての設定が含まれています。このDynamoDB テーブルには、必要に応じて列を追加し続けることができます。
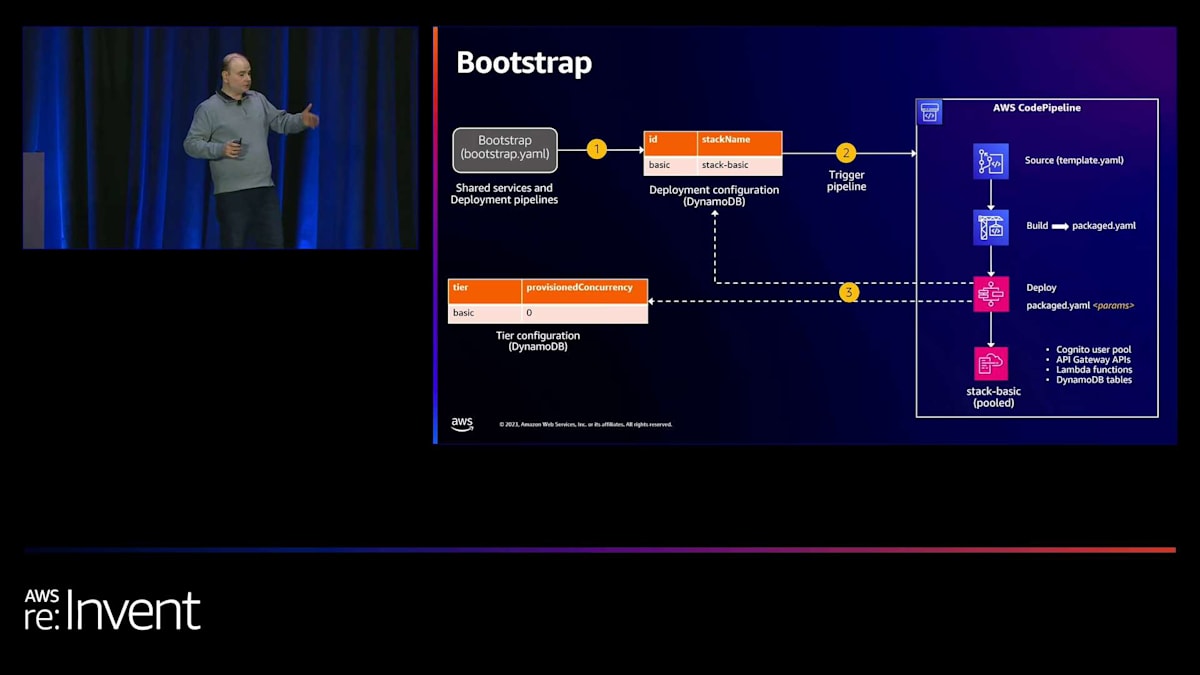
これらの構成は、前のステップで構築された packaged.yaml のパラメータとして使用されます。出力は、ベーシックティアスタックであり、この場合、Amazon Cognito ユーザープール、API Gateway API、Lambda 関数、DynamoDB テーブルが含まれます。この時点で、ベーシックティアスタックが稼働している状態になります。

さて、ベーシックティアスタックに顧客をオンボーディングしようとする場合、このスタックはすでに稼働しています。そのため、この時点で必要なのは、おそらく設定を追加するだけです。
私たちの場合、ベーシックティアのテナントをオンボーディングするたびに、共有ユーザープール内にユーザープールグループを作成し、テナント管理者ユーザーを作成します。管理者ユーザーには「あなたのアカウントが作成されました。SaaS アプリケーションにアクセスを開始できます」というメールが送られ、テナント管理者ユーザーは新たにユーザーを追加し、自己オンボーディングを行うことができるようになります。


では、サイロモデルについてはどうでしょうか? サイロテナントとそのオンボーディングのオーケストレーションはどのように行うのでしょうか?ご記憶かもしれませんが、サイロ顧客には専用のリソースを作成します。そこで、同じデプロイメント構成 DynamoDB テーブルを再び利用します。 プロビジョニングサービスが行うことは、オンボーディングサービスがプロビジョニングプロセスを開始するためにプロビジョニングサービスを呼び出していたことを思い出してください。テナント名やテナント ID など、選択したものに応じて、同じ DynamoDB テーブルにエントリを作成します。



これにより、同じパイプラインが再び起動し、同じステップを再度オーケストレーションし始めます。再びビルドを行い、リポジトリをクローンし、ビルドを実行し、Step Functions ワークフローを使用してデプロイメントを開始します。そして再び、このデプロイメント設定テーブルを参照し、今回は新しいテナント1のスタック、テナント1を作成する必要があることがわかります。では、package.yaml を使ってそのスタックを作成しましょう。今回はプレミアムティアの設定を使用します。
テナント1がプレミアムティアのテナントであることがわかっているので、このスタックを構築するために package.yaml に渡すプレミアムティアの設定を使用する必要があります。これはプレミアムティアのテナントに特化したものです。そして再び、出力として専用の User Pool が得られ、プレミアムティア用の API が得られ、Lambda 関数や DynamoDB テーブルもすべてプレミアムティアのテナント用に作成されます。


では、デプロイメントパイプラインはどうでしょうか?ここでも、すべてのテナントに対して一貫した方法で変更をデプロイすることが重要です。プロビジョニングとデプロイメントの唯一の違いは、トリガーポイントが変わることです。なぜなら、今度はソースコードをソースコードリポジトリにコミットするからです。この AWS CodePipeline が行うのは、コードの変更を監視し、変更があればコードパイプラインをトリガーすることです。ソースコードリポジトリに変更を加えると(Lambda 関数の変更など)、すぐに同じ SAM build と SAM package を使用してビルドし、デプロイメントアーティファクトを生成します。


しかし今度は、Step Functions ワークフローがすべての環境を一貫して更新する責任を負います。環境の数は関係ありません。5つでも10つでも50つでも構いません。そして重要なのは、再びそのデプロイメント設定に戻り、更新が必要なスタックの数を確認することです。これをフックとして使用し、すべてを結びつけ、そのデプロイメント設定とティア設定を使用して、すべてのテナントとティア設定スタックを更新します。

Alex が高レベルで触れた一つの点があります。それは段階的デプロイメントの概念です。多くの場合、SaaS プロバイダーが行っているのは、まず特定のベーシックティアのテナントに機能をデプロイし、その結果を見てから特定のプレミアムティアのテナントにその機能をロールアウトするということです。ここでの wave number カラムは、基本的にその機能を実装するために利用されており、アイデアは変更を波状にデプロイすることです。つまり、wave number 1 が最初にデプロイされ、次に wave number 2、というように続きます。ユースケースに応じて、x 個の波があるかもしれません。

これが段階的デプロイメントの概要です。ここで見ていただけるのは、デプロイメントパイプラインがソースビルドを行い、まず第1波としてベーシックティアのテナントにデプロイしている様子です。ここで重要なのは、一定期間このデプロイメントをモニタリングすることです。これにはいくつかの方法があります。例えば、エラーログやCloudWatchログを確認して、ベーシックティアで一定時間エラーが発生していないことを確認できます。
あるいは、手動のワークフローや承認プロセスを構築して、ビジネスチームがベーシックティアのテナントからフィードバックを得ることもできます。問題ないと判断されれば、プレミアムティアのテナントに変更を適用することができます。

では、AWS Step Functionsワークフローの詳細と、このプロセス全体がどのように調整されているかを見ていきましょう。 AWS Step Functionsをご存じない方のために説明しますと、これはワークフローを調整するためのサービスです。Step Functions内では、さまざまなタスクやステートを定義できます。今回の場合、最初のタスクはLambda関数です。このLambda関数は、先ほど定義したデプロイメントとティアの設定を参照します。このLambda関数の出力は、スタックの配列になります。

この配列は、先ほど説明したデプロイメント設定を使用して構築されます。この配列の要素(スタック名、テンプレートURL、パラメータ、ウェーブ番号)に注目すると、これらのパラメータが先ほど構築したデプロイメントとティアの設定から来ていることがわかります。スタック名はデプロイメント設定テーブルの一部として定義されました。テンプレートURLはCodeBuildステップによって提供され、S3内のベースビルドアーティファクトの場所を示しています。パラメータは、テナントが属するティアに応じてティア設定から取得されます。そして、先ほど言及したように、ウェーブ番号はデプロイメント設定の一部です。

Lambda関数内でこの配列を構築したら、次のステップは並行してウェーブをデプロイすることです。Step Functionsでは、Map stateを使用してすべてのタスクを並行して実行します。ここでのアイデアは、まずウェーブ番号1の変更をデプロイすることです。Map state内には、スタック配列をフィルタリングしてウェーブ番号1の要素のみを処理するロジックがあります。つまり、ワークフローの最初の反復では、第1波をデプロイしているのです。
Step Functionsワークフローの詳細と実装例
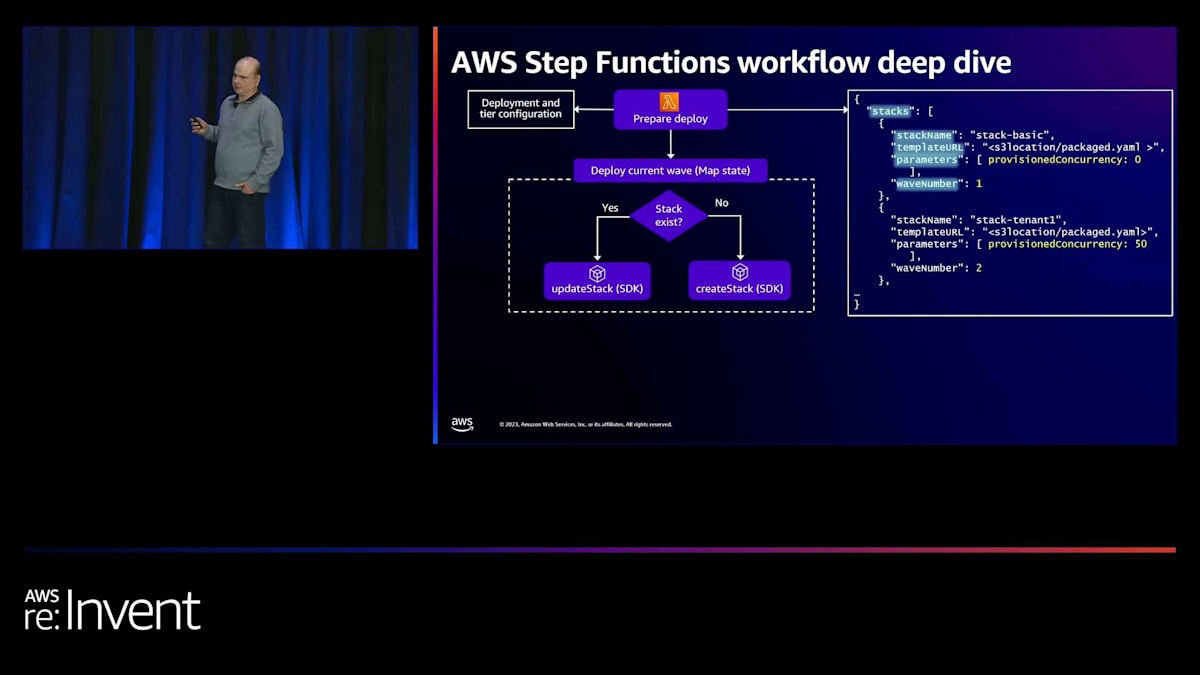

このMap stateでは、Step Functionsが提供するSDKサポートを使用して、他のAWSサービスを呼び出しています。具体的には、CloudFormation SDKを使用してスタックが存在するかどうかを確認しています。このアプローチにより、プロビジョニングとアップデートの両方に同じステートマシンを使用できます。スタックが存在する場合は更新されます。これは開発者がコードに変更を加えた場合のシナリオです。 スタックが存在しない場合は作成されます。これが私たちの例におけるプロビジョニングのユースケースです。

ウェーブをデプロイした後、次のウェーブがデプロイされるのを待つ必要があります。ここで承認プロセスを構築します。Step Functionsはこの状態で最大1年間待機できますが、通常はそこまで必要ありません。基本的な考え方としては、ベーシックティアのテナントに変更をデプロイしたら、メッセージを送信します。今回の場合、メッセージの送受信を管理するサービスであるAmazon SQSを使用しています。これらのメッセージをサブスクライブし、CloudWatchのログを監視するシステムを構築できます。
また、お好みの監視ツールを使用することもできます。これにより、ログにエラーがないことを確認し、ビジネスチームが環境を監視して、問題がなく、ビジネス要件と一致していることを確認できます。このデューデリジェンスを完了したら、Step Functionにコールバックを送信します。Step Functionにコールバックする方法のコードをお見せしますが、基本的な考え方は次のウェーブに移行することです。今回のユースケースではプレミアムティアのテナントがそれに当たります。

次に、このループをインクリメントします。この段階では、Lambda関数を使用してインクリメントとイテレーションを行っています。Step Functionでは、ご覧のように複数のパターンを使用しています。Lambda関数の呼び出し、SDK APIの呼び出し、Map stateを通じたループなどを使用して、このユースケース固有の全体的なワークフローを実現しています。次のウェーブ番号を2に設定すると、次のウェーブのテナントのデプロイが開始されます。これが、私たちのユースケースにおけるテナント間の段階的デプロイ(実質的には複数の環境と考えられます)を構築する方法です。

このStep Function workflowの定義と内部構造について見てみましょう。左側には、Step Function workflowからLambda関数を呼び出すタスクの使用例が示されています。この場合、単に呼び出したいLambda関数を指定するだけです。Step Function workflowがLambda関数を呼び出し、必要な処理を行った後、ステートマシンの次のステップに渡すことができる出力を生成します。右側は、Step Function workflow内でSDK統合を使用する例を示しています。この例では、AWS SDK for CloudFormationを使用して、ワークフロー内に新しいスタックを作成しています。同様に、スタックの更新にも使用できます。

これは、先ほど言及した段階的デプロイメントとwaitタスクの実装方法です。Step Functionでは、「wait for task token」というキーワードを使用すると、Step Functionはコールバックを待つ必要があることを認識します。この場合、「send message.wait for task token」があり、Step Functionが生成するタスクトークンをメッセージ本文に渡しています。誰かがそのStep Functionをサブスクライブすると、メッセージを受け取り、ベーシックティアのデプロイメントを承認し監視する必要があることがわかります。これらのパラメータはすべてStep Functionsワークフローの一部として送信できます。そのデューデリジェンスが完了したら、ここに示す簡単なCLIコマンドまたはSDKコマンドを使用してコールバックを行い、同じタスクトークンを使用してタスク成功を送信できます。これにより、Step Functionは次のステップに進みます。この例では、次の波のテナント、つまりプレミアムティアに進みます。

SaaS自動化の主要な学びと追加リソース
私たちは2つの具体的な例を見て、コンテナ化された環境とサーバーレス環境でSaaSワークフローを自動化する方法を探ってきました。今日の主な学びは何でしょうか?まず、自動化はSaaSのアジリティの鍵です。テナントごと、ティアごとのリソースを持つことは、SaaS環境のアジリティを損なうことを意味しません。異なるティアとテナントを持つSaaSアプリケーションのデプロイメントモデルを構築する場合でも、頻繁なリリースに依存するSaaSソリューションの成長をサポートし、アジリティを維持するためのデプロイメントパイプラインと自動化を構築できるはずです。アプリケーションのティアリングモデルがプロビジョニングとデプロイメントの設計をどのように導くかを見てきました。サイロデプロイメント、サイロ顧客向けの専用リソース、基本ティアプールを持つことが、プロビジョニングとデプロイメントの設計にどのように影響するかを見ました。あなたのユースケースでは、少し異なるティアリングメカニズムがあるかもしれません。
アイデアは、ティアリングモデルに基づいてワークフローを設計できるということです。常にすべてのティアで単一のソフトウェアバージョンを維持してください。今日持ち帰りたい重要なポイントが1つあるとすれば、それはすべてのティアで単一のソフトウェアバージョンを維持することです。段階的なデプロイメントを実装し、リリースを徐々にテナントにロールアウトする方法を見てきました。しかし、これは特定のテナントを10バージョン遅れさせることを意味しません。これは私たちが推奨しないアンチパターンです。
通常、SaaSベースのモデルでは、ティア間の移動にはさらなる自動化が必要です。今日議論しなかったことの1つは、テナントをティア間で移動するなど、より多くの自動化ユースケースがあるかもしれないということです。また、オフボーディングサービスについても話しませんでした。これらの変数はすべて、SaaS環境でより多くの自動化ワークフローを構築する必要がある場合に役割を果たす可能性があります。

ここに、私たちが議論したリポジトリへのリンクがあります。左端の「SaaS GitOps Workshop」は、基本的にAlexが私たちと共有したAmazon EKS環境の例です。そして右端は「Serverless SaaS Reference Solution」で、Step Functionsの実装を含むサーバーレスの例です。他にも興味深いリンクをいくつか共有しています:Serverless SaaS WorkshopとAmazon EKS SaaS Reference Solutionです。SaaSソリューションを構築している場合は、これらのリポジトリをチェックしてください。SaaSワークフローの自動化方法や、今日カバーしなかったテナント分離、セキュリティ、その他の側面に関する一般的なガイダンスを提供してくれるでしょう。


私たちのチームは、さらに多くのSaaSセッションを実施しています。実際、BWP301は今日議論したことと非常に関連しています。これはAmazon.comのBuy with Primeチームの例で、彼らがどのように運用フットプリントを構築し、分離テストを実装したかなどについてです。残りのセッションは、AWSでSaaSソリューションを構築している場合に関連があるかもしれません。また、さらに多くの講演やワークショップがあります。SaaS 403 は木曜日に実施するワークショップです。テナントを意識したダッシュボードの構築方法、SaaSアプリケーションでの可観測性の実装方法、ティアリングメカニズムの構築と特定のテナントアクションの制限方法、一般化されたソリューションテストなどの様々な詳細をカバーしています。これらのセッションを見つける最も簡単な方法は、セッションカタログでSaaSでフィルタリングすることです。

ありがとうございました。本日のプレゼンテーションは以上です。もし追加の質問がある方がいらっしゃいましたら、あと数分ここに残っております。本日はご参加いただき、ありがとうございました。
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion