re:Invent 2023: AWSによるSageMaker JumpStartを活用した生成AIモデル開発と運用
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - Accelerate FM development with Amazon SageMaker JumpStart (AIM328)
この動画では、AWS re:Inventでのgenerative AIセッションの内容を紹介しています。SageMaker JumpStartを使った最新のオープンソースモデルの活用方法や、Hugging Faceとの連携による革新的な取り組みについて解説しています。また、大規模言語モデルの選択からfine-tuning、本番環境へのデプロイまでの一連のプロセスを、具体的なコード例を交えながら詳しく説明しています。SageMaker endpointのセキュリティ機能やスケーリングについても触れており、実践的な知識が得られる内容となっています。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
AWS re:Inventセッションの概要と参加者の生成AI導入状況



よし、始めましょう。皆さん、ようこそ。AWS re:Inventの月曜の夕方、ご参加いただきありがとうございます。夕食の直前ですが、とてもエキサイティングな内容になりますよ。まず自己紹介させていただきます。私はKarl Albertsenで、SageMaker ModelsとPartnershipsチームを率いています。そして、すぐにステージに登場するJeff Boudierは、Hugging Faceのプロダクトとグロースチームを率いています。また、Marc KarpはSageMakerチームのシニアマシンラーニングアーキテクトです。先ほど申し上げたように、今日は本当にワクワクする1時間を用意しています。generative AIの採用を始める際に直面する、エキサイティングな側面と課題について話し合います。AWSでこれらのプロセスを簡素化するために行ってきたこと、特にSageMaker JumpStartについてお話しします。そして、Jeffが、Hugging Faceで行われているオープンソースモデルを皆さんに提供し、簡単に実装できるようにするための革新的な取り組みについて説明します。最後に、Marcが登場し、これらのモデルを実際にどのようにカスタマイズし、大規模展開のために最適化できるかを詳しく説明します。

それでは、まず皆さんのgenerative AIの導入状況を把握するために、簡単なアンケートを取りたいと思います。3つの質問をしますので、手を挙げて教えてください。まず1つ目の質問です。large language modelsやgenerative AIモデル全般を使い始めた方は手を挙げてください。素晴らしい、会場の大半の方ですね。次に、さらに一歩進んで、モデルの比較、カスタマイズ、fine-tuning、あるいはパラメータの最適化を始めた方はいらっしゃいますか?素晴らしいですね。最後に、モデルを限界まで活用し、特定のビジネスユースケースのためにproduction endpointsに実装した方はいらっしゃいますか?なるほど、皆さんの経験や導入段階が非常に多様であることがわかりました。これは本当に興味深いですね。会場には大きな期待感がありますが、様々な段階を経験された方々は、その経験や苦労話を共有できると思います。そこには多くの課題があるのです。
生成AIモデル採用における主要な課題
それでは、いくつかの課題について触れてみましょう。まず、large language modelsやgenerative AIの分野は急速に拡大し、進化しています。ここ半年ほどで、新しいモデル、大規模モデル、中規模モデル、小規模モデルが大量に登場しました。飛ぶことができる動物や、セーターに変えられるものを持つ動物など、思いつく限りのモデルが作られています。また、量子化されたバリエーション、特定のアプリケーション向けに最適化されたモデル、さらにはドメイン固有のモデルや言語固有のモデルも見られます。これは、選択肢となるモデルの範囲が広大であり、今後も急速に拡大し続けることを示しています。

2つ目はセキュリティとコンプライアンスです。実験室の環境でモデルを扱うのは一つのことですが、本番環境での使用やビジネスユースケースへの適用を考え始めると、規制遵守が極めて重要になります。GDPR、PCI、HIPAA、FedRAMPなどの略語がありますが、さらに重要なのは、データ、プロンプト、推論の制御を維持し、それらがどこに行くかを把握することです。これは多くの顧客が直面している重要な課題です。3つ目は、先ほど述べたように、多くのモデルが存在しますが、これらのモデルをどのように比較し、モデルがもたらす精度、パフォーマンス、コストの最適なバランスをどのように見つけるか、そして時間とともに変化する中で、新しいモデルとどのように比較し、fine-tuningなどを通じてどのように改善していくかということです。

最後に、プルーフオブコンセプトから本番環境での大規模展開を考える際、コストの問題が浮上します。求める精度、あるいはそれに近い精度を、ビジネスニーズに合うスケーラブルなコストで実現できるでしょうか?これらは、この会場の多くの方々が現在直面している、あるいは今後直面する課題であり、まさにAWSで私たちが考えていることです。どのようにしてこれらを簡素化し、皆さんから取り除くことができるでしょうか?そのために、いくつかのサービスがあります。特に2つのサービスについて、今週たくさん耳にすることになるでしょう。1つはAmazon Bedrock、もう1つはAmazon SageMakerです。これらのサービスについて詳しくは説明しませんが、Bedrockを考えるべき時、SageMakerを考えるべき時について、いくつかのポイントをお伝えしたいと思います。
AWSのサービスとSageMaker JumpStartの紹介
Bedrockは、生成AIを始めるための最も簡単な場所になるよう設計されています。生成AIモデルの上にアプリケーションを構築することに焦点を当てているなら、間違いなくBedrockがあなたのために設計されたサービスです。モデル自体に踏み込んで、fine-tuningに焦点を当てたり、オープンソースモデルや独自モデルの限界を押し広げたり、あるいはゼロからトレーニングすることに焦点を当てたりすることを考えているなら、そこがSageMakerが真価を発揮する領域です。
この違いを説明するために、画面に2つのアイコンを表示しています。多くの顧客は、モデル構築におけるSageMakerのパフォーマンスを望みつつも、簡単な開始点も求めています。そこで、SageMaker JumpStartをHugging Faceと連携させ、生成AIモデルをあなたのニーズに合わせて提供できるよう設計しました。しかし、必要に応じていつでも深く掘り下げることができ、ゼロからのトレーニングまで可能です。多くの大規模モデルプロバイダーがSageMaker上でモデルをゼロからトレーニングしています。必要であれば、そのすべてのパワーと柔軟性があなたの指先で利用可能です。

JumpStartの現状についてのスクリーンショットをお見せしますが、同時に機械学習で見られるパラダイムシフトについても説明し、なぜ我々がここに投資し続けているのか、そしてなぜこれが生成AIの未来だと考えているのかについての我々の考えを説明します。1年前でも、もしこの舞台に立っていたら、ほとんどの顧客がデータから始めると話していたでしょう。彼らは基本的にデータから始めて、モデルに向かって構築、トレーニング、デプロイを行います。大規模言語モデルについて興味深いのは、このパラダイムが今や変化したことです。モデルから始めることができるようになりました。誰かが一般的な目的や特定のドメイン向けにトレーニングしたモデルを、あなたのアプリケーションで使用できるという転移学習の約束が、今や可能になっています。
これで80%から90%の目標に到達できるかもしれません。そして、fine-tuningやその他のテクニックを通じて90%から100%に到達するための作業はまだ必要です。しかし、すぐに使えるモデルで0%から80%まで到達できるという考えは全く新しく、非常にエキサイティングです。多くの顧客がこれらの目的でSageMakerを使用したいと考えていましたが、多くの場合、彼らのニーズに十分適合する、あるいはほぼ適合するモデルから始めたいと考えていました。そこでJumpStartが登場しました。

現在JumpStartで提供しているものは何でしょうか?これらの多くのモデル、そしてこれはすべてを読んでもらうためのものではありません。ただ、今日この分野で最も関連性の高い多くのモデルがJumpStartで利用可能であることを示しています。例えば、Llama 2ファミリーのモデル、7、13、70億パラメータの両方、ベースモデルとチャットモデルの両方が、推論用およびfine-tuning用スクリプトとともに今日利用可能です。FalconやMistralからのモデル、さらにAI21やCohereなどの主要な独自モデルプロバイダーのモデルもすべて利用可能です。我々は最も関連性が高いと思われるモデルを皆さんに提供し、それらをSageMaker内で直接利用できるようにしようとしています。これらは、皆さんがご存知のSageMakerのエンタープライズ対応の機能やツールとともに使用でき、その多くが今週中に展開される予定です。
これで、Jeffが話す内容に移ります。オープンソースモデルの数は、このページに載っているものをはるかに超えています。そこで私たちは、Hugging Faceとのパートナーシップを深めることに本当にワクワクしています。Hugging Faceでモデルを見つけてSageMakerにデプロイするにしても、すでにSageMakerのお客様で、SageMakerから始めたいと思っているにしても、Hugging Faceの最高のものがすべて、非常にシンプルに、すぐに利用できるのです。
AWSとHugging Faceの協力関係:オープンモデルの活用

データ保護とセキュリティに関してこの点を取り上げたいと思います。なぜなら、これは常にSageMakerを深く使用しているお客様から受ける重要な質問だからです。このスライドには、覚えておいていただきたい2つの要素があります。まず、私たちは、お客様のデータはお客様の管理下にあるということに非常に注力しています。オープンソースモデルの世界では、実際にそれをお客様のアカウント内のエンドポイントにデプロイすることになります。モデルの重みを完全に可視化し、プロンプトや推論などを完全に可視化・制御できます。AI21、Cohere、Stability AIの独自モデルなど、独自のモデルプロバイダーのモデルを使用する場合も同様です。これらのモデルは実際にお客様のアカウント内に置かれるので、お客様が提供するプロンプトや推論がお客様のアカウントを離れてモデルプロバイダー自身に行くことはありません。これは、企業環境で運用している多くのお客様にとって重要なポイントです。
SageMakerとJumpStartでは、さらに一歩進んでいます。これらのモデルをお客様のVPCにデプロイできるだけでなく、ネットワーク分離がある場合でもデプロイできます。私たちはこれらをAWSインフラストラクチャに取り込み、ワンクリックで簡単にデプロイできるようにパッケージ化しています。ここでは、JumpStartをどこで見つけられるか、どのように始められるかを簡単に説明し、その後、JeffとMarcが詳細を説明します。

SageMaker JumpStartは現在、SageMaker Studio内にあります。 ここには、探索できるグラフィカルユーザーインターフェースがあります。モダリティ別にモデルを簡単に閲覧できます。特定のモデルを探している場合は検索することもでき、今週リリースされる多くのクールな機能があります。
火曜日と水曜日にリリースされるこれらの新機能は、様々な属性でフィルタリングする方法、UXの重要な改善などについて、さらに深く掘り下げていきます。私たちは、これをどんどん使いやすくしていくことにワクワクしています。
SageMaker JumpStartを使用したモデルのデプロイと展開

目的のモデルを見つけたら、モデル詳細ページに進みます。そこにはモデルの機能を理解するために必要なすべての情報があります。説明、サイズ、用途、そして重要なのはライセンスとライセンスタイプです。非常に寛容なApache 2.0から、より制限的なライセンスまで様々なものがあり、ビジネスに適した選択ができるようになっています。このページでは直接アクションを取ることができます。推論のためにモデルを実行したい場合や、概念実証、さらには本番環境に持っていきたい場合は、ワンクリックで実行できます。モデルをファインチューニングしたい場合は、Amazon S3上のファインチューニングデータを指定するだけで始められます。プログラムで使用したい場合は、APIコードスニペットをワークフローに直接コピー&ペーストできます。
デプロイメントについては、デフォルトのデプロイメントがありますが、特定のエンドポイント設定を選択する機会も提供しています。例えば、コスト最適化された実装や、レイテンシー最適化された実装、スループット最適化された実装を探している場合、それらのデフォルトを提供します。もちろん、ハイパーパラメータを完全にコントロールすることもできます。Amazon SageMaker JumpStartの重要な要素の1つは、できる限りオープンボックスまたはクリアボックスサービスを提供しようとしていることです。簡単に始められるようにしていますが、使用しているコードを完全に可視化できます。オープンソースモデルの場合は、重みそのものも見ることができます。そこから、カスタマイズして完全に自分のものにすることができます。


ファインチューニングに関しては、提供している主要なモデルの多くにファインチューニングスクリプトが用意されており、SageMaker Studioから直接アクセスできます。トレインボタンを使えば、S3バケット内のデータを指定するだけで簡単に始められます。これをプログラムで使用したい場合も、APIコードスニペットとサンプルノートブックがあり、トレーニングスクリプトとトレーニングデータを使用する方法が示されています。最後に、Marcが後ほど説明しますが、スケールアップする準備ができたとき、またはプログラムでモデルをテストする準備ができたときには、SageMaker SDKを通じてすべてが指先で利用可能です。
ここで少し時間を取って、Jeffに移る前に、実際の世界で顧客が異なるオープンソースモデルやクローズドモデルを使い始め、実験する様子について少しお話ししたいと思います。これは数ヶ月前、大手企業のお客様と仕事をしていたときのことです。彼らは、生成AIと大規模言語モデルを顧客体験のユースケースに導入することにとても興奮していました。これについて興味深い点が2つあります。1つは、これを内部ユースケースと呼べるもので、チャットボットや大規模言語モデルを直接顧客に公開するわけではありませんでした。そのため、信頼性と安全性のレイヤーはそれほど重要ではありませんでした。また、彼らが試みていたのは、入ってくる多くの通話をどのように分析できるかを検討することでした。
生成AIモデルの選択とカスタマイズのアプローチ
カスタマーサービスエージェントに電話をかけると、数分間の会話が行われ、そのトランスクリプトは500語から1,000語程度になることを想像してみてください。多くのカスタマーサービス施設では、要約しようとする際に、同じような基本的な質問を何度も繰り返すことがあります。例えば、「通話の内容を2文で教えてください」「根本原因は何でしたか?」「エージェントはどのような行動を取りましたか?」などです。そこで、私たちはこれをガイド付きQ&Aユースケースと呼びました。同じ質問が何度も繰り返されるからです。最終的に、私が一緒に仕事をしていたこの顧客は、それを使って分析を行いたいと考えていました。
その話をしたのは、彼らが非常に強力なクローズドモデルを使ってこの要約を行ったからです。想像通り、それは完璧に機能しました。彼らは結果に感動し、素晴らしいと言いました。しかし、計算を始めると問題が見えてきました。彼らは「このプルーフオブコンセプトでは機能するが、実際のユースケースでは毎日、あるいは毎週10万件ほどの会話を要約する必要がある」と言いました。そこで、本番環境にどう持っていくか、ビジネスケースを成立させるのに苦労しました。もっと安く、効率的に実行する方法はないだろうか、と。
そこで私たちは彼らと協力し始め、「より小さなモデルを検討しましたか?オープンソースモデルを見てみましたか?十分に良いモデルがあれば、実際にデプロイできるかもしれません」といった提案をし始めました。当時彼らが選んだモデルは非常にシンプルなもので、今から3〜6ヶ月経った今では古めかしく感じるかもしれませんが、彼らのユースケースには十分でした。そして本当に印象的だったのは、スケールでのワークロードのコストが95〜97%も下がったことです。
彼らは目を見開いて、とても興奮しました。なぜなら、これはおもちゃのプロジェクトと実際の世界で本番環境に投入できるものとの違いだったからです。彼らがその後そのワークロードをオープンソースモデルで本番環境に投入したことを、私は本当に嬉しく思います。そこには、いくつかの興味深いテーマがあると思います。オープンソースモデルとエコシステムは健在であり、顧客が本番環境に移行する際に重要だと思います。精度、コスト、スループットを最適化しようとする場合、適切なモデルのバランスを取る必要性は、2024年を通じて多くの顧客、そしておそらくあなた方自身にとっても重要なテーマになるでしょう。

SageMaker SDKを用いたモデルのデプロイとfine-tuning
それでは、ステージをJeffに譲りましょう。彼がHugging Faceで行われている素晴らしいイノベーションと、私たちがSageMakerで行っていることについて話してくれるでしょう。
Karl、ありがとうございます。皆さん、こんにちは。オープンモデルとオープンソースライブラリを使って、Hugging Faceで独自のAIを構築する方法についてお話しできることをとてもうれしく思います。また、AWSとのコラボレーション、パートナーシップについてもお話しします。これにより、SageMakerとJumpStartを使用して、安全で、スケーラブルで、コスト効率の良い方法でこれらの作業を行うことができます。でも、まず最初の質問は、Hugging Faceとは何でしょうか?Hugging Faceをご存知の方はどれくらいいらっしゃいますか?ありがとうございます。

Hugging Faceは、実に様々な人々によって日々利用されています。論文をHugging Faceに公開する研究者かもしれません。Hugging Face hubで事前学習済みモデルを見つけて評価するデータサイエンティストかもしれません。使いやすいAPIを使いたいと思い、最適なモデルを見つけるためにHugging Faceを訪れる開発者かもしれません。エンドポイントをスケールしようとしているマシンラーニングエンジニアかもしれません。データサイエンスについて学んでいる学生さんかもしれません。これらの人々の経験は全く異なり、これらの視点をスライドにまとめるのは難しいので、代わりに30秒の動画を用意しました。これらすべてを高速なペースの小さなストーリーにまとめています。皆さんにお見せしますが、とても速いので注意して見てください。そのあと、テストしますよ。

モデルの定量的・定性的評価方法


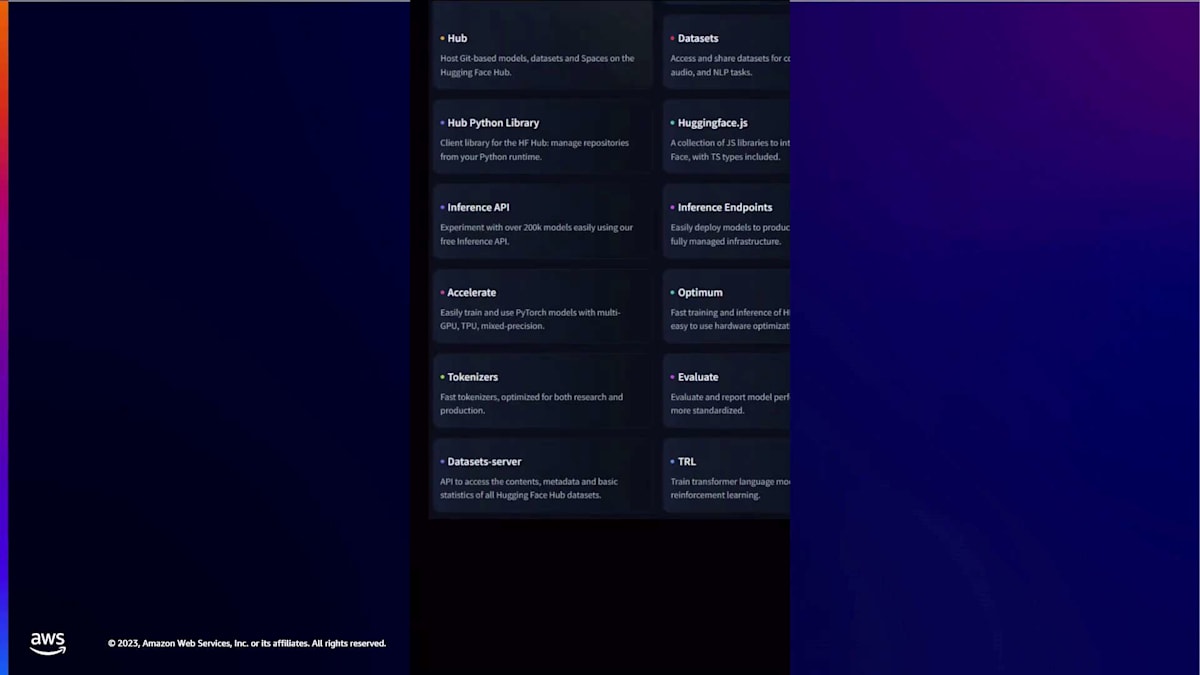
Hugging Faceとは実際何なのでしょうか?それは、優れたマシンラーニングを民主化するAI開発者向けの主要なオープンプラットフォームです。でも、それは実際どういう意味なのでしょうか?3つの柱があります:モデル、データセット、そしてスペースです。モデルは実際にAIを行うものです。私たちは何十万ものモデルをホストしています。GoogleやMicrosoft、Metaなどの大手企業のモデルや、Stanfordのような研究機関、EleutherAIのようなオープンソースコミュニティのモデルも含まれます。次にデータセットがあります。これはモデルのトレーニングに使用されるオープンにアクセス可能なデータです。そして最後に、スペースがあります。これによってモデルを簡単にデモンストレーションやショーケースすることができます。最近の例としてはDelusion Diffusionがあります。これらの柱はすべて、Transformers、Diffusers、Accelerateなどのオープンソースライブラリと組み合わされ、最新のAIモデルの構築、共有、使用を容易にしています。これらはすべて無料ですが、より多くの計算リソースや独自のモデルのデプロイに助けが必要な場合は、それも提供しています。

簡単でしょう?理解できましたか?最も重要なポイントをダブルクリックしてみましょう。おそらく最初のポイントは私たちのミッションです。私たちのミッションは、良質な機械学習を民主化することです。そして民主化には複数の層があります。 私たちは、できるだけ多くの人々にAIをアクセス可能にしたいと考えています。できるだけ多くの人々にAIを理解しやすくしたいと思っています。できるだけ多くの人々にAIを使いやすくしたいと考えています。そして、AIをコスト効率の良いものにしたいと考えています。これらの層のすべてが、AWSやSageMakerのチームとの協力や共同作業に適用されています。
私たちは良質な機械学習を民主化したいと考えていますが、それは私たちにとって何を意味するのでしょうか?それは、オープンソースから構築された機械学習、コミュニティ主導の機械学習、そして倫理を最優先に構築された機械学習を意味します。これが私たちのミッションです。そして、現在の状況はどうでしょうか?今日、私たちは100万以上のAIリポジトリをホストしています。これは100万のモデルやデータアセット、アプリケーションのことで、私たちはこれをspacesと呼んでいます。そして、これはあらゆる種類の機械学習タスクを行うモデルです。例えば、transformerモデルを使用して翻訳などの自然言語処理タスクを行うかもしれません。
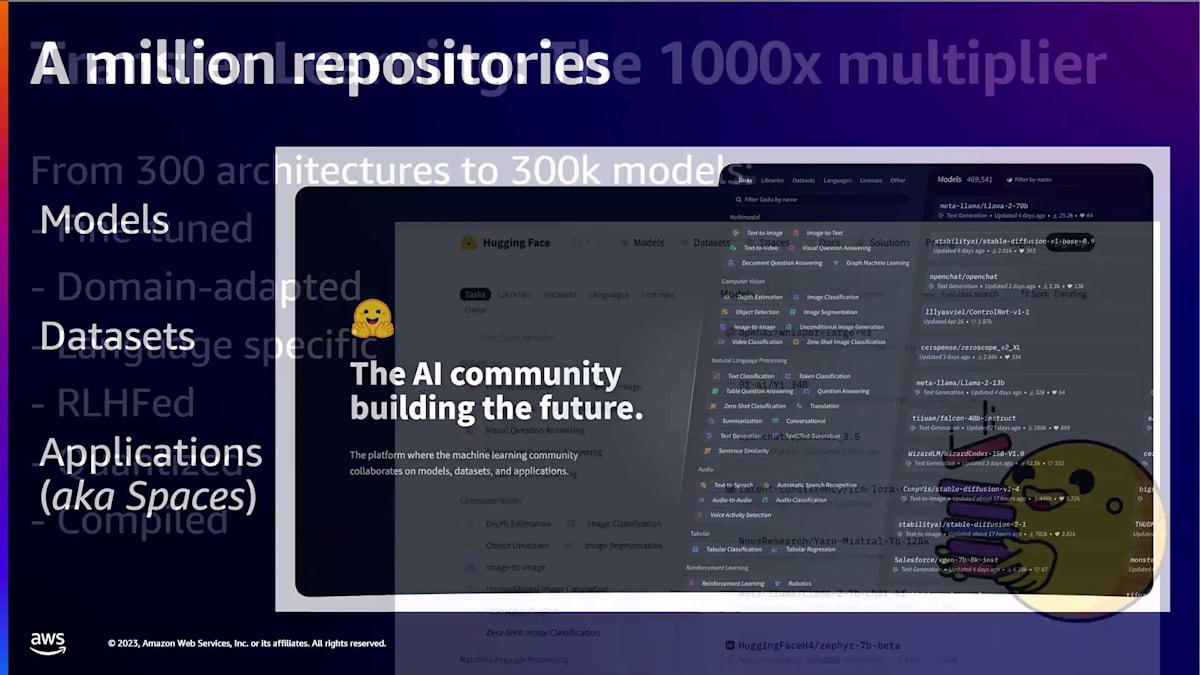
他の例としては、要約、テキスト生成、分類などがあります。あるいは、音声やオーディオモデルを実行して、私の発言をテキストに書き起こしたり、会話の中で話者を認識したりするかもしれません。また、diffusersライブラリを使用して画像を生成するコンピュータビジョンモデルもあるかもしれません。今日では、機械学習のすべてのモダリティを網羅しており、Hugging Faceのオープンソースライブラリだけでなく、30以上の異なるオープンソースライブラリからのモデルも含まれています。
SageMaker endpointの概要と構造

しかし、どのようにしてここまで来たのでしょうか?Karlは転移学習について言及しました。 過去5年間の機械学習の指数関数的成長において、最大のゲームチェンジングな革新は何かと聞かれれば、私にとってそれは転移学習です。転移学習とは、膨大な費用をかけて作成された巨大なモデルを活用する能力のことです。これらのモデルは、大量の計算能力と巨大なデータセットを長期間にわたって使用して作成されたものです。そして、これらの事前学習済みモデルを使用して、比較的少量のデータで非常に効率的に適応させることができます。
そして、これが、Transformersライブラリのようなライブラリ内のモデルのコード実装であるアーキテクチャの数百から、数十万のモデルチェックポイント、つまりモデルの重みへと発展していく過程です。今日、Hugging Face hubでは、コミュニティによって提供されたこれらのモデルの重みとリポジトリをすべて見つけることができます。これにより、あなたが目指すタスク、作業する言語、データのドメインに関わらず、適切なモデルを見つけることができます。そして、これが、コミュニティがこれらの既製の事前学習済み、微調整済み、コンパイル済み、量子化済みモデルを共有しアクセスするための中心的な場所の必要性を生み出し、100万のリポジトリに至った経緯です。

これらのモデルは、驚異的な使用量に繋がっています。 現在、Hugging Face hubでは毎日1000万以上のモデルダウンロードが行われています。これらの統計情報もオープンソースで、Hugging Faceのスペースで見ることができます。興味深いのは、トップ10のアーキテクチャを見ると、実に様々なモダリティとライブラリをカバーしていることです。音声転写用のWhisper、テキスト分類用のモデル、Llamaのようなテキスト生成用のモデル、そしてコンピュータビジョン用のモデルがあります。

現在、Hugging Faceは、AIビルダーのための主要なオープンプラットフォームであり、 また機械学習の一部である大規模言語モデルと生成AIのホームとなっています。LLMに焦点を当てると、これはこのセッションのテーマですが、私が皆さんに覚えておいてほしいのはOpen LLM Leaderboardです。これは、Hugging Face hubでホストされているオープンLLMの世界を探索するための、無料でアクセス可能なリソースです。現在、Open LLM Leaderboardでは、約5,000のオープンな大規模言語モデルが継続的に評価されています。モデルサイズ、事前学習済みか微調整済みかチャットモデルか、特定のアーキテクチャやライセンスを探しているかなど、あなたに最適なモデルを簡単に見つけることができます。このツールを使えば、非常に簡単にフィルタリングできます。

さて、企業がこれらの素晴らしい基盤モデルを構築し、 Hugging Face hubを通じてコミュニティに提供してきた方法についてお話ししましたが、私たちはそこで止まりません。私たちも独自の基盤モデルを作成したり、貢献したりしています。これには、SageMaker上の管理クラスターを使用し、すぐにお聞きいただく非常にクールな機能を活用しています。SageMaker上の管理クラスターを使用して作成できた素晴らしいモデルの例として、例えばStarCoderがあります。StarCoderはbig codeイニシアチブから生まれたもので、リリース時にすべての独自モデルを凌駕した、コード生成のための最先端のオープンモデルです。
SageMaker endpointのアプリケーション統合方法
StarCoderが特別だったのは、完全にオープンなデータセットから構築されたことです。このデータセットは、同意を得た透明性のあるデータから作られました。もう一つの素晴らしい例がIdeficsです。Ideficsは最大のオープンマルチモーダルモデルで、テキストだけでなく画像も入力として受け取り、FlamingoyGPT-4のようにテキストを生成します。最新の例はZephyrです。Zephyrは70億パラメータのモデルで、Mistral 7 billionの微調整版です。新しい微調整ポリシーにより、同じ重量カテゴリーで最も役立つアシスタントモデルとなっています。

私たちは今、AWSとの協力関係が3年目に入ろうとしています。私が話してきた素晴らしいことのすべては、AWSとSageMakerとの協力で構築した体験を通じて、今すぐに利用できるものです。3年間の協力と努力の成果を、すぐに使える体験として享受できるのです。この協力を通じての私たちの目標は、最高のオープンモデルを簡単に、安全に、そしてコスト効率よく活用できるようにすることです。私たちはツールを提供することで簡単にし、SageMakerプラットフォームに組み込まれたすべてのセキュリティ、Karlが先ほど話したすべてのことから恩恵を受けることで安全にしています。そして、スポットインスタンス、ハードウェアアクセラレータ、Trainium、Inferentiaなど、SageMakerに組み込まれたすべてのコスト最適化テクニックを使用できるため、コスト効率も高くなっています。
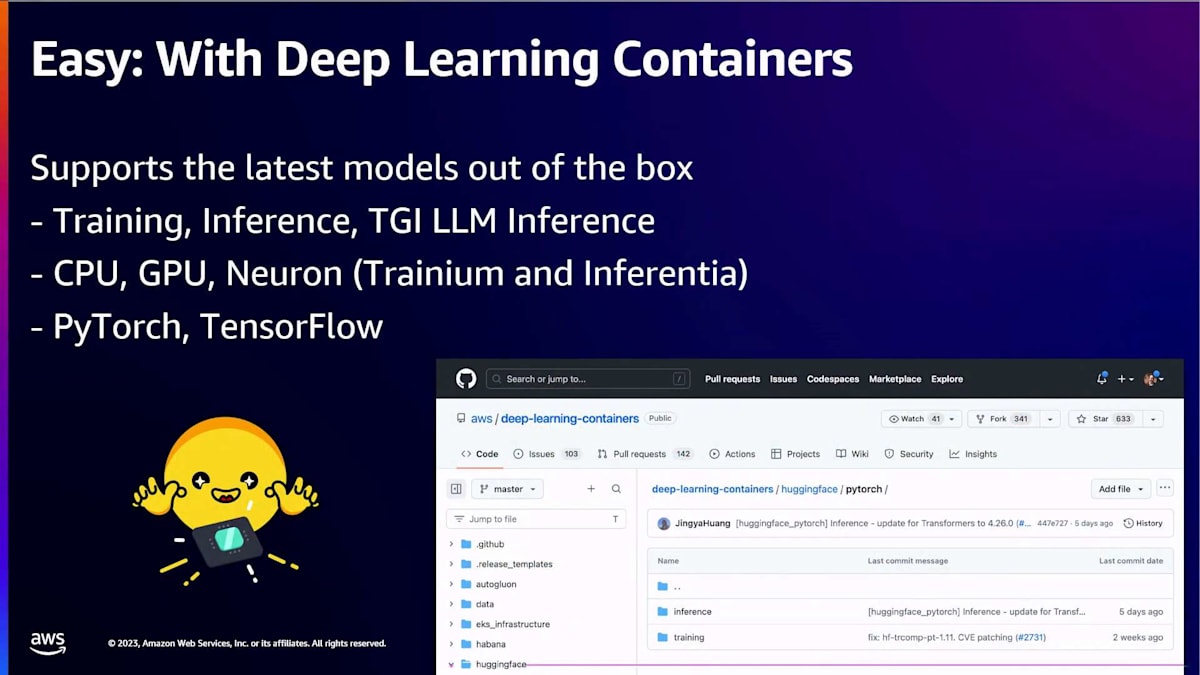
では、簡単なところから始めましょう。これらの素晴らしいオープンモデルを、どのようにして直接自分の環境で活用できるでしょうか?そのための最も重要なツールは、SageMakerチームと協力して構築・維持している深層学習コンテナです。MetaがLlama 2をHugging Faceでリリースすると、数日以内にSageMakerで使用できるようになります。Mistral AIがMistralモデルをリリースすると、数日以内にSageMakerで使用できます。これらの深層学習コンテナは、どのタイプのモデルやハードウェアを対象としていても、すぐに使える体験を提供するために作られています。現在、モデルのトレーニング用、推論用、そして特に大規模言語モデルの推論用の深層学習コンテナを提供しています。CPU、GPU、そして今ではTrainiumとInferentiaのneuronアーキテクチャを対象とした深層学習コンテナも提供しています。もちろん、PyTorchやTensorFlowなど、お好みの機械学習フレームワーク用に最適化された深層学習コンテナも提供しています。
SageMaker endpointのAuto-scaling機能

これらのモデルを大規模に展開するのを非常にコスト効率よく行えるようにしています。大規模言語モデルのユースケースに焦点を当てた主要なツールの1つが、Text Generation Inference(TGI)です。TGIは、ハードウェアアクセラレータ上で可能な限り高いスループット、つまり1秒間に生成できるテキスト量を最大化するために構築されたオープンソースのアクセス可能なライブラリです。本日、neuronアーキテクチャをサポートするTGIの対応を発表できることを大変嬉しく思います。先ほど、同僚のPhilip Schmidtが、Inferentia 2を使用してLlama 2を展開し、これらの最適化のすべてを活用する方法について素晴らしいデモを行いました。もう1つ興奮することは、オープンソースのアクセス可能なライブラリであるTGIが、新しい使用許諾ライセンスの下で制限なくSageMakerを通じて使用できるようになったことです。

最後に、これらすべてをまとめるために、Karlが説明したワークフロー全体を非常に簡単に進められるようにするにはどうすればよいでしょうか?モデルの発見からモデルの大規模展開まで、どのように進めることができるでしょうか?その最良の例が、Hugging Face hubで直接利用できる、すぐに使用可能なコードスニペットです。前のスライドで紹介したHugging Faceモデルのモデルページに行き、deployをクリックすると、「Deploy on SageMaker」オプションが見つかります。それをクリックすると、JumpStartを使用して、SageMaker SDKを活用した、すぐに使えるコードスニペットが提供されます。これを使えば、モデルを超簡単に展開できます。モデルの展開は、SageMaker JumpStartで実行できることの1つに過ぎません。JumpStartで実行できる素晴らしいことすべてについて説明するために、Marcに引き継ぎたいと思います。ありがとうございました。

ありがとう、Jeff。

さて、これでAWSの生成AIオファリングにおけるSageMaker JumpStartの位置づけがわかりました。また、UIを通じてこれらのモデルを発見し展開する方法も見てきました。そして、Hugging Faceがこれらのモデルへのアクセスを加速する重要な要因であることも分かりました。
SageMaker endpointのセキュリティ機能とJumpStartの始め方

しかし、これらのモデルを分析、評価、テスト、そして場合によっては再トレーニングするには何が必要でしょうか?SageMakerでそれがどのように行われるか見てみましょう。
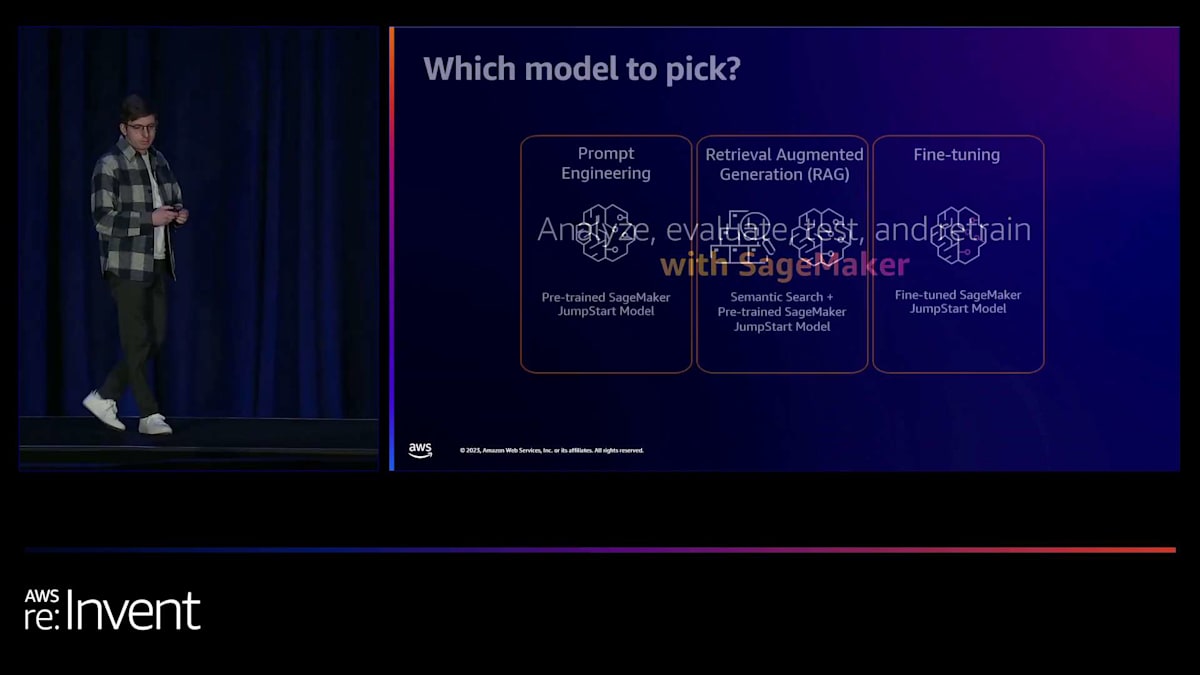
多くの方がご存知かもしれませんが、現在さまざまなモデルが存在しており、お客様からよく寄せられる質問は「どのモデルを選べばいいのか」というものです。私たちがお勧めするのは、まずユースケースから逆算して考えることですが、ある程度次のような方法に従うことをお勧めします。まず最初は prompt engineering です。現在利用可能な様々な pre-trained モデルを見てみましょう。テキスト生成の場合は、特定のテキスト生成モデルを見てください。コード生成モデルの場合は、pre-trained のコード生成モデルを見て、プロンプトを操作するだけでどこまでできるかを確認してください。
例えば、テキスト生成のユースケースを考えていて、Llama 2 ファミリーのモデルに注目したとします。まずは小さなバリエーションから始めて、どこまでできるか、何が達成できるかを確認してみましょう。例えば、コールセンターの通話記録を要約する必要があるユースケースがあり、モデルがそのユースケースを解決できるかどうかを確認したい場合、zero-shot の例をモデルに与えても機能しないかもしれません。モデルが特定のデータを期待する正しい形式や構造で要約する方法を理解できない可能性があります。そこで、要約の方法についていくつかの例をモデルに提供することを検討できます。これを few-shot learning と呼びます。いくつかの例を与えて、ユースケースを達成できるかどうかを確認してみましょう。
次は Retrieval Augmented Generation (RAG) です。注意すべき点は、これらのモデルが持つ知識は時間的に固定されており、訓練されたデータのみに限られているということです。では、外部の知識ベースを組み込みたいユースケースがある場合はどうでしょうか?例えば、内部のポリシーや手順について質問し、回答を得たい場合です。pre-trained モデルはそのままでは、当然ながら内部の知識ベースで訓練されていません。そこで RAG を実装できます。概念的には、内部の知識ベースや外部の知識を取り、そのデータをクエリし、クエリに関連する情報を取得し、その知識とソースを pre-trained モデルに渡して最終的な回答を導き出すというものです。RAG は chatbot や Q&A などのユースケースに適しています。
しかし、prompt engineering と RAG だけではユースケースを解決できない場合はどうすればよいでしょうか?そのような場合は、モデルをある程度カスタマイズする必要があります。モデルのカスタマイズには別の利点もあります。それは、より小さなモデルを使用する機会を得られる可能性があることです。

特定のタスクに fine-tune された小さなモデルでも十分な場合があり、実際に小さなモデルを本番環境でホストする方が費用対効果が高いことがわかっています。7 billion パラメータのモデルをホストするには、70 billion パラメータのモデルをホストするよりも少ない GPU メモリで済みます。
さて、テストしたい複数のモデルを決定したとしましょう。これまで説明してきたヒューリスティックに従ってモデルをテストしたいと考えています。SageMaker SDKを使用する場合、どのように進めればよいでしょうか? SDKを通じて事前学習済みモデルをデプロイするのは、UIを使用する場合と同様に簡単で、わずか数行のコードで済みます。具体的には、SageMaker SDKで必要なのは、JumpStartモデルを作成し、特定のモデルIDを渡すことだけです。今回の場合、事前学習済みのFalcon 7Bモデルをテストしたいので、JumpStartモデルオブジェクトを作成したら、単にdotデプロイを実行し、そのモデルに送信したいペイロードまたはプロンプトを渡して予測を行うことができます。
このコードの出力は、SageMaker endpointとして知られるもので、モデルとやり取りすることができます。SageMaker endpointの詳細については、次のスライドで見ていきましょう。さて、事前学習済みモデルをデプロイしましたが、RAGシステムの実装も行いたいかもしれません。先ほど議論したようなチャットボットQ&Aを作成したいかもしれません。そのためにはどうすればよいでしょうか? 実は、SageMaker endpointはLangChainと統合されています。LangChainは、生成AIアプリケーションをデプロイするためのフレームワークです。ここでは、LangChain SDK内でSageMaker endpointオブジェクトを作成し、特定のendpoint名を渡す必要があります。これは、先ほどのコードスニペットでデプロイしたendpoint名になります。

そして、fine-tuningについてです。このモデルをカスタマイズする必要がある場合や、より小さなモデルを試してみて、特定のタスクに対してfine-tuningを行いたい場合はどうでしょうか? SageMaker SDKを使用したfine-tuningも、数行のコードで済みます。ここでも、モデルIDを渡します。今回はFalcon 7Bモデルです。JumpStartが公開している、調整可能なハイパーパラメータを渡し、特定のインスタンスタイプを指定します。そして、S3に保存されているトレーニングデータとバリデーションデータを渡して、シンプルなdot fit関数でジョブを開始します。
さて、モデルをデプロイし、RAGソリューションに組み込み、さらにいくつかのモデルにfine-tuningを施しました。これらのモデルをどのように分析し評価すればよいでしょうか? これには定量的アプローチと定性的アプローチの2つの方法があります。定量的には、毒性、精度、意味的頑健性などのモデルの特定の指標を見ることができます。オープンソースのベンチマークがいくつか存在し、そこで特定のモデルの毒性に関する具体的な指標を確認したり、オープンソースのアルゴリズムを実行して計算したりすることができます。
SageMakerでは、この作業を容易にするための取り組みを進めており、近日中にその成果をお見せできる予定です。しかし、今日のところは、事前学習済みモデルとfine-tuningを行ったモデルを比較したいとしましょう。デフォルトでは、fine-tuningジョブを開始すると、SageMaker JumpStartモデルはトレーニング中にlossやperplexityなどのデフォルトの指標をCloudWatchに出力します。画面に表示されているperplexityは、モデルがシーケンス内の次の単語をどれだけ正確に予測できるかを測る指標で、値が小さいほど良いとされています。ここでは、事前学習済みモデルのPPLが8.147であったのに対し、fine-tuning後には1.437まで下がったことがわかります。
これが定量的な側面です。定性的には、実際にモデルを使って、その性能を確認することができます。例として、ここでは事前学習済みモデルに「10-K SEC filingの項目7は何についてですか?」と質問しています。この質問の文脈では、モデルがAmazonの10-K SEC filing(事業運営と状況を含む報告書)に関して回答することを期待しています。
事前学習済みモデルの回答を見ると、あまり良い結果が得られませんでしたが、fine-tuning後には正確な回答が得られました。これは、知識がモデル自体に組み込まれたためです。このように定量的・定性的に見ることで、fine-tuning済みモデルと事前学習済みモデル、さらには異なる事前学習済みモデル同士を比較することができます。
さて、本番環境に移行できる特定のモデルを作成したとしましょう。このモデルに対して実際に推論を行い、アプリケーションと統合し、ユーザーが利用できるようにし、リクエストに応じてスケールさせるには何が必要でしょうか?また、本番アプリケーションでは重要なセキュリティ上の考慮事項もあります。
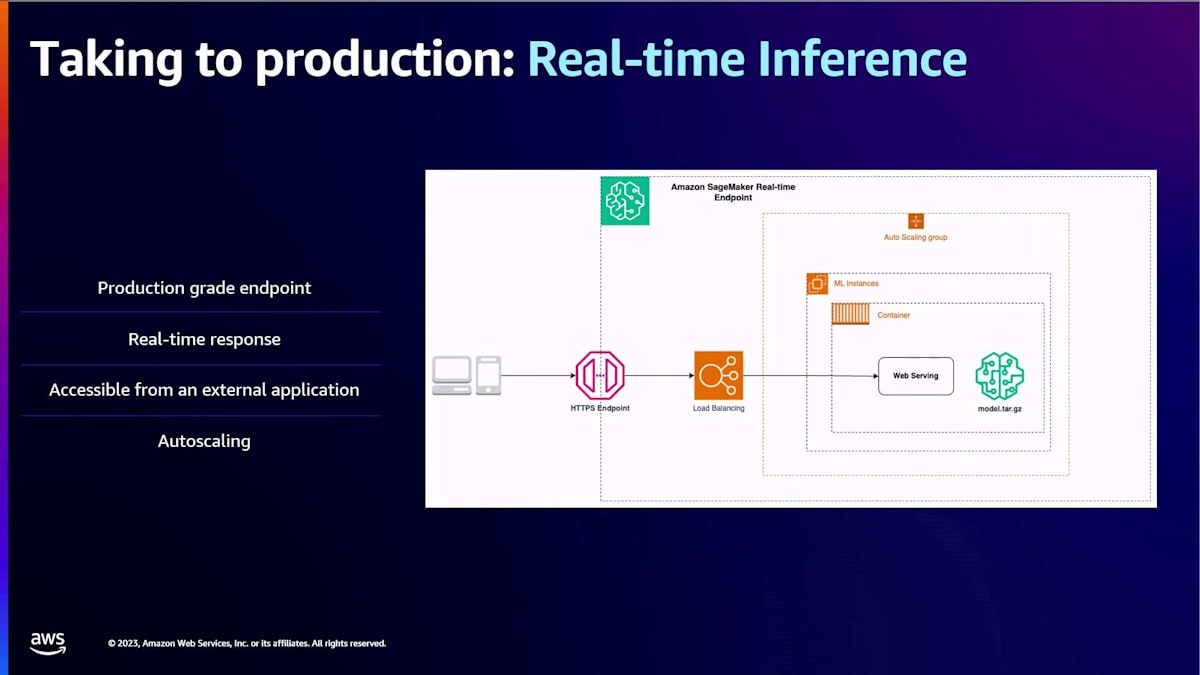
Amazon SageMakerでのリアルタイム推論に関して、まず重要なのはSageMaker endpointの概念です。SageMaker endpointは、モデルをホストしてリアルタイムで対話できる、管理された本番グレードのエンドポイントです。リアルタイムでレスポンスを得ることができ、HTTPSエンドポイントを通じて外部アプリケーションからアクセス可能で、application auto-scalingとも統合されているため、ニーズに応じてスケールアップ・ダウンができます。
SageMaker endpointの内部構造を見てみると、これらはすべて管理されていますが、例えばリクエストをインスタンスに負荷分散するマネージドロードバランサーが含まれています。また、特定のコンテナも実行されます。多くの場合、お客様は独自のコンテナを使用したり、Jeffが言及した事前構築済みのdeep learning containerを使用したりします。そして、モデルの重み自体も含まれます。SageMakerはフレームワークに依存しないプラットフォームなので、現在のお客様は好きなように柔軟に使用することができます。
しかし、JumpStartとは何でしょうか?JumpStartは、本質的にモデルのホスティングに関連するすべてのものを包含しています。例えば、コンテナ、ホスティングスクリプト、実際にモデルをホストするモデルサーバー、さらには一部のインスタンスタイプなどです。お客様から、特定のモデルをどのインスタンスタイプでホストすべきかわからないという声をいただいています。量子化の違いや、GPUのサイズの違いなどがあるからです。SageMaker JumpStartはこれらすべてを包含しているので、ユーザーはそれについて心配する必要がありません。
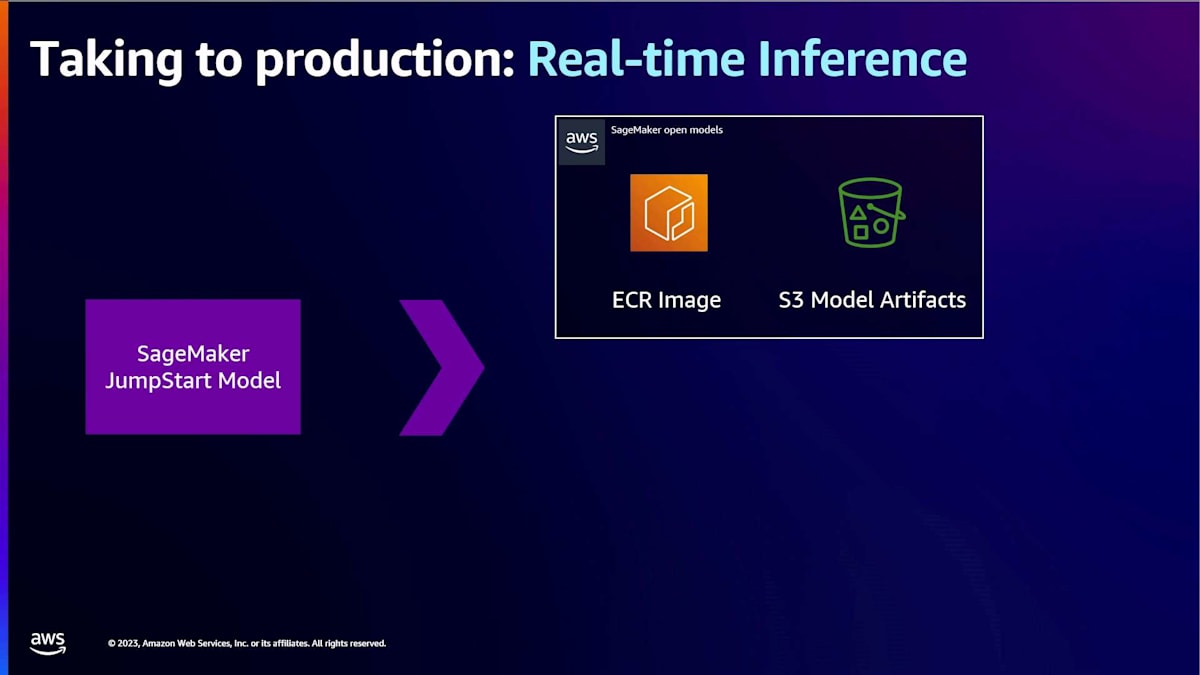
その小さな紫色のボックスをダブルクリックすると、 SageMakerのオープンモデル用のJumpStartモデルが表示されます。これは、先ほど話題に上がったECRイメージで構成されています。これは、モデルサーバーを含むイメージです。Hugging Faceモデルの場合、おそらくtext generation inferenceコンテナになるでしょう。そして、S3モデルアーティファクトがあります。これは、モデルをホストするためのロジックを含む推論スクリプトと、モデルの重みそのものかもしれません。これは、FalconやLlamaなどのオープンモデルの場合です。
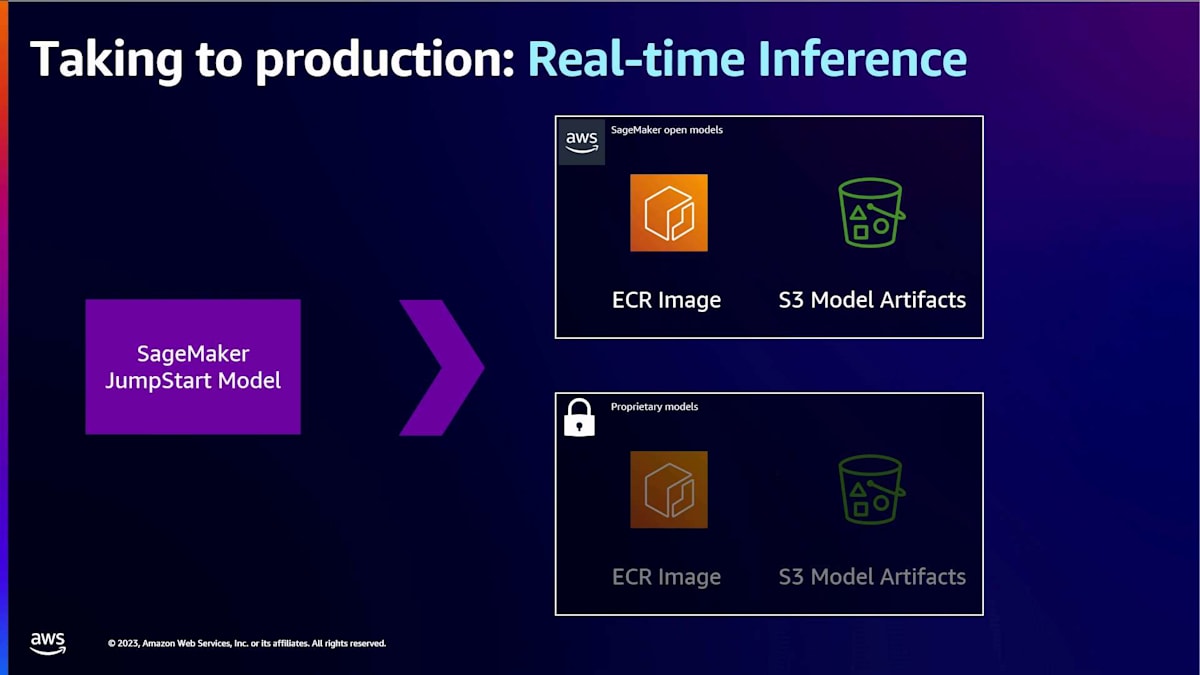
SageMaker上の独自モデルも、これらの主要な構成要素で作られています。 ECRイメージとモデルの重みは当然ですが、エンドユーザーである皆さんは、実際の基礎となる重みやイメージを見ることはできません。モデルプロバイダーが、これらの本番環境ready、すぐに使用可能な状態で提供しているのです。

さて、SageMakerのリアルタイムエンドポイントにモデルをデプロイして推論を得る方法を見てきましたが、実際にそれをアプリケーションと統合するにはどうすればよいでしょうか?SageMakerエンドポイントは、いくつかの方法で統合することができます。まず一つ目は、Amazon API Gatewayです。何らかの理由で認可や認証を制御したい場合、SageMakerエンドポイントをAPI Gatewayと統合することができます。これは、AWS Lambda関数を使用するか、直接統合するかのいずれかの方法で行えます。
Lambda関数を使用する場合、例えば前処理を行い、最終的にエンドポイントに推論を行わせることができます。それが必要ない場合は、API Gatewayも直接統合を提供しています。もう一つの方法は、Boto3や高レベルのSageMaker SDKを介してSageMakerエンドポイントと対話することです。これは、特に認可や認証を制御する必要がない場合に適しています。最後に、特定のSDKを使用したくない場合や、直接POSTリクエストを行いたい場合も、それが可能です。例えば、推論ペイロードを含むPOSTリクエストを単に行いたい場合、エンドポイントに直接それを行うことができます。唯一の考慮事項は、リクエストにSIGV4ヘッダーで署名する必要があることです。

トラフィックのニーズに応じてスケールアップやダウンを行うことは、本番環境に移行する際の重要な考慮事項の一つです。SageMaker endpointはapplication auto-scalingと統合されています。Auto-scalingは、これらのインスタンスを可用性を高めるために、Availability Zone全体に自動的に分散させます。これは完全に管理されたサービスです。トラフィックを中断することなく、必要に応じてインスタンス数を動的に調整できます。スケールインとスケールアウトのオプションは、お客様独自のトラフィックパターンに適応可能です。私たちは、任意の時点でendpointに到達する呼び出し回数のような事前定義されたカスタムメトリクスと、お客様独自のカスタムメトリクスの両方をサポートしています。例えば、アプリケーション内にキューがある場合、そのキュー内のリクエスト数に基づいてendpointをスケールすることができます。
Auto-scalingの設定も非常に簡単です。SDKを使用することもできますが、コンソール内にも機能があります。最小および最大インスタンス数と特定のターゲットメトリクスを設定するだけです。この例では、SageMaker invocations per instanceを使用しています。特定のターゲット値を設定すれば、auto-scalingが設定されます。また、スケールインのクールダウンやスケールアウトのクールダウンなど、必要に応じてオプションパラメータを設定することもできます。

最後にセキュリティについて説明しましょう。Karlはセキュリティに関する組み込み機能のいくつかについて言及しましたが、SageMakerはデフォルトで、インフラストラクチャとネットワーク分離の両面で予防的な制御機能を備えています。SageMaker endpointをVPC内にデプロイすることで、モデルコンテナへのアクセスを制御できます。SageMaker endpointはAWS PrivateLinkと統合されているため、リクエストが自社のVPCを離れることなくendpointに推論を行うことができます。また、endpointにVPC configを提供する機能もあり、特定のサブネットとセキュリティグループを設定できます。コンテナ自体がネットワーク呼び出しを行う必要がある場合、それらの呼び出しはすべてお客様のVPC内で行われます。
ネットワーク分離は、もう一つの重要なセキュリティ機能です。オープンモデルの場合、これはトグル可能なスイッチで、ネットワーク分離を設定できます。これは基本的に、コンテナがネットワーク呼び出しを一切できないようにロックダウンすることを意味します。例えば、モデルにプロンプトを送信する際に、そのプロンプトをモデルプロバイダーに送信したくない場合、そのコンテナを完全に分離してロックダウンできます。オープンモデルの場合、これはトグル可能です。デフォルトでは、SageMakerはプロンプト情報を一切共有しませんが、推論スクリプトを好みにカスタマイズすることができます。一方、プロプライエタリモデルの場合、デフォルトでネットワーク分離されており、トグル可能なオプションではありません。AI21やCohereのようなプロプライエタリモデルを実行するコンテナは完全にネットワーク分離されています。これらのコンテナからネットワークリクエストを行うことはできません。

SageMaker JumpStartを始めたい場合は、JumpStartのドキュメントをぜひご覧ください。これらの人気のあるモデルを使い始めるための素晴らしいサンプルリポジトリがあります。また、最新のJumpStartの提供内容については、SageMaker JumpStartの製品詳細ページをチェックしてみてください。

私、Jeff、そしてKarlからのお礼を申し上げます。re:Inventの初日を楽しんでいただけたことを願っています。モバイルアプリでセッションのアンケートにご協力いただけますようお願いいたします。ありがとうございました。
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion