re:Invent 2024: AWSが次世代Systems Managerを発表 - 運用管理の進化
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
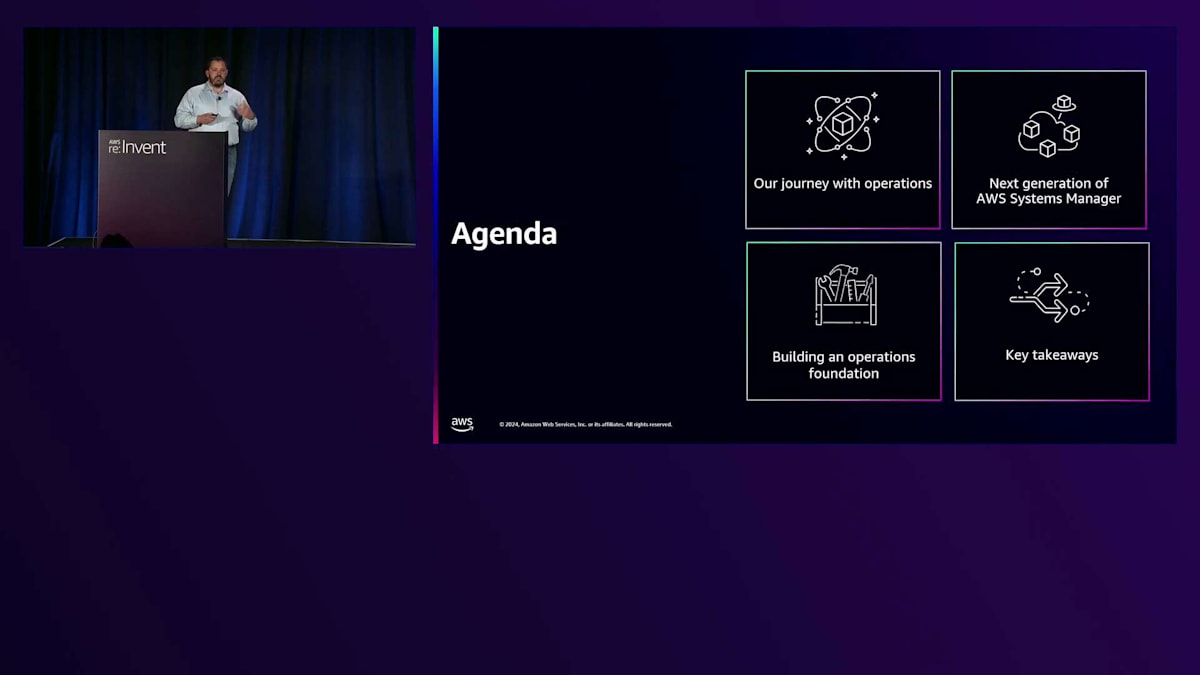
📖 AWS re:Invent 2024- Scaling IT with the next generation of AWS Systems Manager (COP380-NEW)
この動画では、AWS Systems Managerの開発背景とその進化について、AWSのSystems Managerチームディレクターであるjon Galentineが解説しています。EC2 Windowsチームの社内ツールとして始まったSystems Managerは、現在4億5000万以上のコンピュートノードの管理と月間25億以上の自動化スクリプトの実行に使用される重要なサービスへと成長しました。また、Cloud OperationsのスペシャリストソリューションアーキテクトのNereida Wooが、新しく発表されたSystems Managerの次世代バージョンをデモを交えて紹介しています。この新バージョンでは、マルチアカウント・マルチリージョンでのノード管理の一元化や、Automation Runbook Builderによる運用自動化の簡素化など、従来の課題を解決する機能が実装されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
AWS Systems Managerチームによる自己紹介

こんにちは。本日はお越しいただき、ありがとうございます。私はJon Galentineと申します。AWSのSystems Managerチームを率いています。AWSには約10年在籍しており、最初の4年間はEC2組織で過ごし、その後Identityの組織に4年ほど所属していました。現在はSystems Managerのディレクターとして1年ほど務めています。本日は同僚のNereida Wooと一緒に登壇させていただきます。Nereida、自己紹介をお願いできますか?
皆さん、こんにちは。Nereida Wooと申します。Cloud Operationsのスペシャリストソリューションアーキテクトを務めています。Cloud Operationsにおける2つの主要なユースケースを担当しています。1つは集中運用管理、つまりSystems Managerで、もう1つは昨年立ち上げたApplication Operationsです。これは、AWS上のアプリケーションへのリソース管理について考えることです。AWS入社前は金融業界で働いており、AWSが提供する軍事向け見習いプログラムを通してテック業界に転身しました。私はよく「クラウドで生まれた」と言っています。私のテクノロジーの知識は常にAWSと共にあり、現在はSystems Managerのサポートを行っています。皆様、よろしくお願いいたします。
Systems Managerの概要と新世代バージョンの紹介
ありがとう、Nereida。本題に入る前に、皆さんのSystems Managerに関する知識レベルを簡単に確認させてください。Systems Managerというタイトルのこのre:Inventセッションに参加を決めた時点で、少なくともこのサービスについて多少はご存知だと思います。会場に専門家の方がいらっしゃるか見てみましょう。クイズを出させていただきます。答えがわかる方は声を出してください。質問です:SSMのアンブレラの下には、私たちが「ビルディングブロック」と呼んでいる個別のサービスがいくつありますか?答えは22です。Systems Managerのアンブレラの下には22の異なるサービスが存在します。

簡単な挙手をお願いします。Systems Managerのビルディングブロックを2つ以上使用している方は手を挙げてください。5つ以上使用している方は、そのまま手を挙げたままでお願いします。10個以上はどうでしょうか? これは他のお客様から聞く状況とよく一致していますね。長年にわたり、私たちは強力なビルディングブロックサービスを提供してきました。 しかし、それらを組み立てて連携させて使用するための作業は、すべてお客様にお任せしていました。ワークロードが増加し、私たちが提供するビルディングブロック機能の数も増えるにつれて、それらすべてを追跡し管理することはますます複雑になってきました。今日は、この複雑さを軽減し、より使いやすくする方法をいくつかご紹介できることを楽しみにしています。
大きな変更が控えています。しかし、Systems Managerの今後について説明する前に、これまでの経緯を理解することが重要だと考えています。今日のお話は、Systems Managerを構築するきっかけとなったインスピレーションについてのオリジンストーリーから始め、さらにAWSクラウドの運用経験がこのサービスをどのように形作ってきたかについてもお話しします。次に、数週間前に発表したSystems Managerの次世代バージョンについて説明し、緩やかに結合したビルディングブロックの集まりから、ジョブベースの完全統合されたエンドツーエンドソリューションへと、どのように進化しているかをご説明します。その後、Nereidaがその新しいエクスペリエンスのデモをいくつか行い、最後に職場に持ち帰って今日から適用できる具体的なポイントをまとめて締めくくります。
Systems Managerの進化:EC2運用ツールから統合ソリューションへ

2015年にSystems Managerの構築に着手した当初、私たちの目的は、EC2のお客様がEC2インスタンスの設定やパッチ適用を行い、定期的なメンテナンスプロセスを自動化し、運用上のイベントや障害からの復旧を容易にすることでした。おもしろい話ですが、Systems Managerは元々、EC2 Windowsチームが、すべてのWindows系AMIに毎月パッチを適用するプロセスを自動化するために開発したものでした。これは当初、人の手による非常に手作業的なプロセスでした。各リージョンでAMIの数が100を超えたとき、チームは迅速かつ確実にスケールアップして月次のパッチ適用プロセスを実行するために、自動化への投資が必要だと気づきました。また、お客様も同様に、定期的なプロセスの自動化や環境の更新に関して同じようなニーズと要件を持っていることにも気づきました。そこでチームは、構築中の自動化システムを、お客様も利用できるように柔軟で堅牢なものにすることを決めました。先ほど言及した初期ツールの公開版には、EC2 Simple Systems Manager(SSM)という名前が付けられました。これは後に独立したサービスとして再配置され、AWS Systems Managerとしてリブランドされました。AWSの多くのサービスとは異なり、Systems Managerは私たち自身のニーズのためのソリューションとして始まり、後にクラウドでの運用に伴う一般的な課題に対応するためにお客様にも提供されるようになりました。

これらの課題には、拡大し続けるリソースランドスケープを管理しながらの運用の一元化、運用の速度を上げ手作業によるエラーを減らすための定期的なメンテナンスプロセスの自動化、ホストパッチ適用などのミッションクリティカルな機能を実行するためのツールの標準化、そしてホストフリートの状態を可視化するための一元化が含まれます。 そこで、EC2 Windows用のAMIメンテナンス自動化の構築に着手した際、最初に必要だったのは、プロセスの各ステップの実行を調整するためのシンプルで柔軟、そしてスケーラブルなワークフローシステムでした。

例えば、新しいWindows AMIを構築するには、まずそのAMIの現行バージョンを使用してインスタンスを起動し、スクリプトを実行してそのインスタンスにパッチを適用し、インスタンスを停止し、EBSボリュームをデタッチしてデフラグとコンパクト化を行い、そのデフラグされたボリュームから新しいAMIを作成し、内部APIを呼び出してそのAMIを登録し、最後にお客様が使用できるようにAMIを公開する必要があります。全体として、これは複雑な多段階のプロセスで、Windows系のAMIすべてに対して、毎月、すべてのリージョンで実行する必要がありました。その数は合計で数千に及びました。これを実現するために構築したワークフローオーケストレーションシステムが、後にAWS Systems Manager Automationサービスとなりました。

AMIの更新に関連するステップのほとんどは、異なるWebサービスを呼び出すことで、これは自動化が比較的容易でした。しかし、インスタンス自体のパッチを更新するプロセスは、より大きな課題となりました。そのためには、インスタンス上のソフトウェアを更新するための昇格された権限が必要で、管理スクリプトをインスタンス上で安全かつ制御された方法で実行する必要がありました。これを実現するために、AMIにあらかじめ組み込まれ、インスタンス上で実行される管理エージェントを構築しました。このエージェントはSystems Managerサービスを呼び出して、オペレーターが実行する必要のあるスクリプトを取得し、それをインスタンス自体で実行します。
次に、大規模なホストフリート全体でこれらのアップデートスクリプトの実行を調整する必要がありました。長年にわたり、多くのAWSサービスチームが、大量のホストでスクリプトを実行するという一般的な運用ニーズに対応するための社内ツールを開発してきました。当然のことながら、初期の頃は、暴走したスクリプトが一度に多くのサービスホストをダウンさせてしまうことによって、数々の障害が発生しました。2017年にUS-East-1でS3に大規模なサービス障害が発生したことを覚えている方もいるかもしれませんが、これも同様に、運用スクリプトが一度に多くのホストをダウンさせてしまったことが原因でした。
これらの失敗から学び、AWSは運用手順を改善し、このような問題を減らすためのツールを開発しました。例えば、サービスチームに対して、すべての運用スクリプトのコードレビューを実施し、ソースコントロール下に置くこと、そして本番環境のホストでそれらを実行する際には承認を得ることを義務付けました。これらのベストプラクティスを導入することで、障害の発生件数を大幅に削減し、AWSの成長に合わせて運用を安全にスケールさせ、フリート全体のリモート運用をお客様にとってより安全なものにすることができました。SSMでは、これらのベストプラクティスの多くを標準機能として備えたRun Commandというサービスを追加しました。例えば、Run Commandには、スクリプトを同時に実行できるインスタンスの最大数を定義するレート制御制限を指定する機能があり、これは特定のホスト数またはフリートの割合として設定できます。また、Run Commandでは、スクリプトがエラーコードを返す回数が設定可能な制限を超えた場合に、実行を停止するように指定することもできます。

Run Commandは、各ステップの前後でエラーを検出し、自動的にロールバックアクションを開始する条件付き実行ロジックを含む、複雑な多段階プロセスの実行にも使用できます。さらに、より複雑なソースコード管理要件に対応し、GitOpsテクニックを可能にするため、Run CommandはGitHubなどの外部ソースコードリポジトリから子スクリプトをダウンロードして実行することもできます。

このAWS Systems Managerのメンテナンス自動化ワークフローを完全に自動化できたことで、SSM AgentとRun Commandを組み合わせることで、長時間実行されるインスタンスのパッチ適用プロセスの自動化など、お客様にとって付加価値の高い機能を提供できることに気づきました。これを実現するために、このプロセスのすべてのステップを完全に自動化するPatch Managerというサービスを構築しました。これは、Run Commandを介してインスタンス上でSystems Managerドキュメントを実行し、Patch Managerサービスを呼び出して、インスタンスのパッチベースラインルールに従って必要なパッチセットを取得します。その後、ローカルパッケージマネージャーを呼び出してパッチをインストールし、このプロセスを完全に自動化します。

最後のピースは、何か問題が発生した場合にこれらのワークフローをトラブルシューティングできるようにすることでした。システム管理者は、通常SSHやリモートデスクトップを介したリモートターミナルアクセスを使用して、ホスト上の問題を調査し、修正する必要があります。SSHの設定と管理には大きなオーバーヘッドが伴います。例えば、AWSは長年にわたり、ローカルユーザーとSSHキーのプロビジョニングを制御し、SSHセッション中に実行されたすべてのコマンドが監査可能で後から確認できるように、すべてのセッションアクティビティを確実にログに記録するための複雑なシステムを構築してきました。
SSHには内向きのネットワークアクセスが必要なため、それを有効にするためにはSecurity GroupやFirewallルールを設定する必要があります。また、管理者がチームを去る場合など、不要になったSSH鍵を確実に削除する必要があります。私たちは、このような運用の複雑さを伴わずにリモートターミナルアクセスを可能にする方法を見つけたいと考えました。そこで、緊急時のシナリオに対応するため、個々のサービスホストへの双方向ストリーミングターミナルアクセスを可能にするSession Managerというサービスを追加しました。
この仕組みでは、インスタンス上で動作するSSM Agentが各セッションに対して外向きのソケット接続を作成するため、内向きのネットワークポートを開放する必要がありません。さらに、Session ManagerはIAMでアクセスを制御するため、鍵のインストールやローテーションは不要で、管理者がチームを去る際のアクセス取り消しもIAMコンソールでの簡単な操作で行えます。また、Session Managerはすべてのセッション作成をCloudTrailに記録するため、システムへの管理アクセスの監査ログが常に残ります。セッションアクティビティはS3やCloudWatchにも記録できるため、そのセッションで実行されたすべてのコマンドをS3またはCloudWatchに保存して確認することができます。


これらの機能により、Session Managerは、AWSで私たちが自社システムを管理する際に使用しているような、セキュアで監査可能なターミナルアクセスを、運用の複雑さやオーバーヘッドなしでお客様に提供します。 これらのBuilding Blockは、2016年に他のいくつかの機能とともにリリースされ、お客様がノード管理のAWSベストプラクティスを実装できるようになりました。 現在では、AWS Systems Managerは4億5000万以上のコンピュートノードの管理と、毎月25億以上の自動化スクリプトの実行に使用されており、これは私たちが長年かけて達成した本当に印象的な規模と採用率です。 これまでの道のりを振り返ると、EC2の運用を効率化するための運用ツールとして始まったものが、成長し進化してお客様のニーズに応えてきました。
現在では、AWS、ハイブリッド、マルチクラウドプロバイダーのいずれにワークロードがあっても、自動化を使用して安全に大規模な運用を行うことができます。長年にわたり、私たちはSystems Managerに機能を追加し、より多くの運用ベストプラクティスを組み込むことで改善を続けてきました。例えば、自動化されたRunbookの実行を制御するための承認ワークフローを設定できます。また、Super BowlやBlack Fridayに向けた数週間など、ビジネスクリティカルなイベント中に環境設定の変更が行われないようにするためのChange Calendarを活用することもできます。
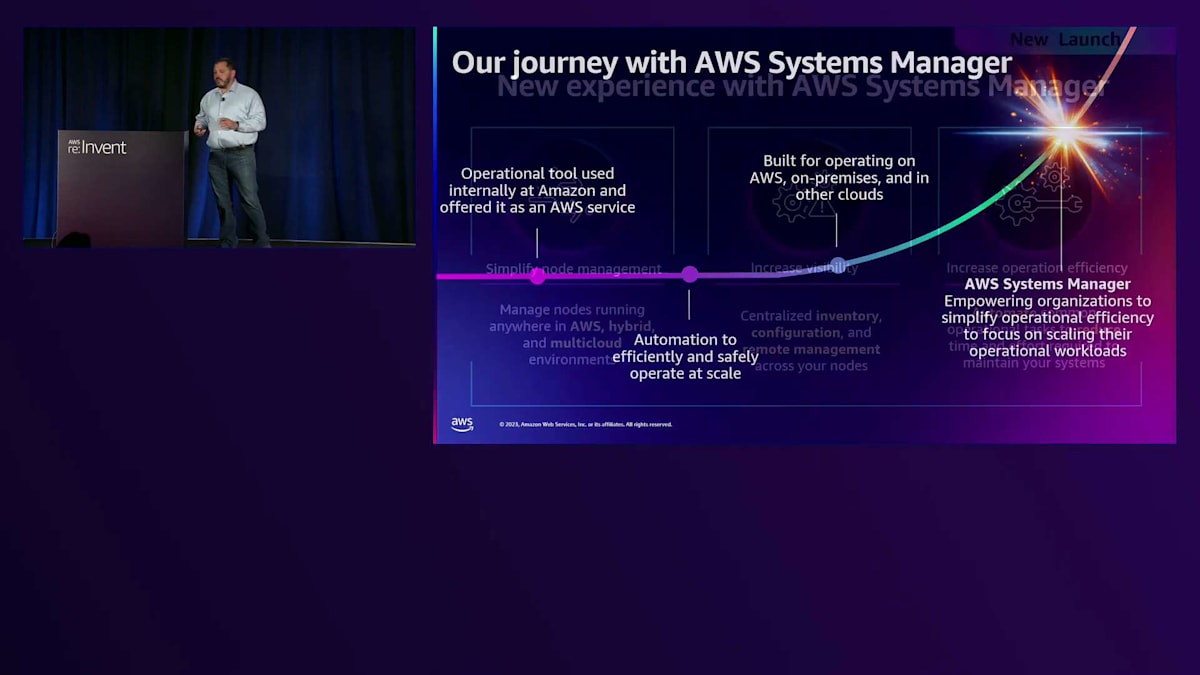

長年使用してきたBuilding Blockアプローチは多くのお客様にとって有効でしたが、これらのBuilding Blockの発見、セットアップ、運用が複雑で管理が難しいという一貫したフィードバックを受けてきました。その代わりに、お客様が求めているのは、すぐに使える事前設定された完全なエンドツーエンドのエクスペリエンスです。 このフィードバックに応えるため、数週間前にリリースしたAWS Systems Managerの次世代バージョンを発表できることを嬉しく思います。 これは、皆様がよくご存知のSSM Building Blockを基盤とした、完全に統合されたソリューションです。
この新しいエクスペリエンスでは、AWS、ハイブリッド、マルチクラウドのインスタンスを一元的に表示でき、すべてのリージョンとアカウントにまたがるノードを1か所で一括管理することができます。一目で、どのインスタンスが未管理状態なのかを特定し、数回のクリックでRunbookを実行してSSM Agentのインストールを素早く修正することができます。最新のOSセキュリティパッチがインストールされていないインスタンスを追跡して修正することができ、コンプライアンス態勢をより簡単に維持することができます。また、インスタンスをアプリケーションや、インストールされているパッケージに基づいてフィルタリングし、Low-codeのRunbookエディターを使用して、数回のクリックでインスタンス上のライブラリバージョンやパッケージを修正することができます。
運用基盤構築の課題と新エクスペリエンスの提案

私たちはこのローンチにとても興奮しています。ここで、Nereidaに新しいエクスペリエンスのデモをお見せしてもらい、その真価をご紹介したいと思います。まず、堅固な運用基盤の構築から始めましょう。誰もが最初から効率的な基盤を持っているわけではないという前提に立っています。先ほどJohnが言及したように、私たちは運用基盤の構築方法を理解するのに時間がかかりました。そして、私たちの失敗と経験を通じて、お客様が堅固な運用基盤を構築できるようサポートしています。皆さんの journey において、失敗することは問題ありません - 失敗は学びの場であり、成長の機会であり、最初は気づかなかったことに気づくきっかけとなります。
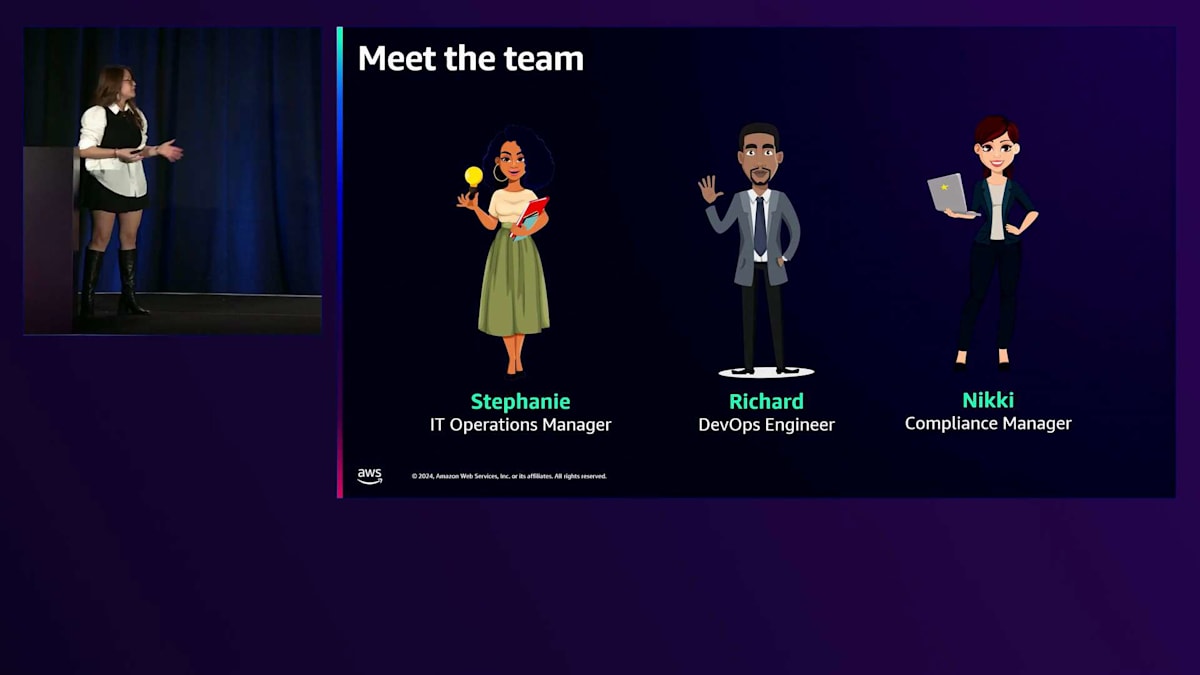
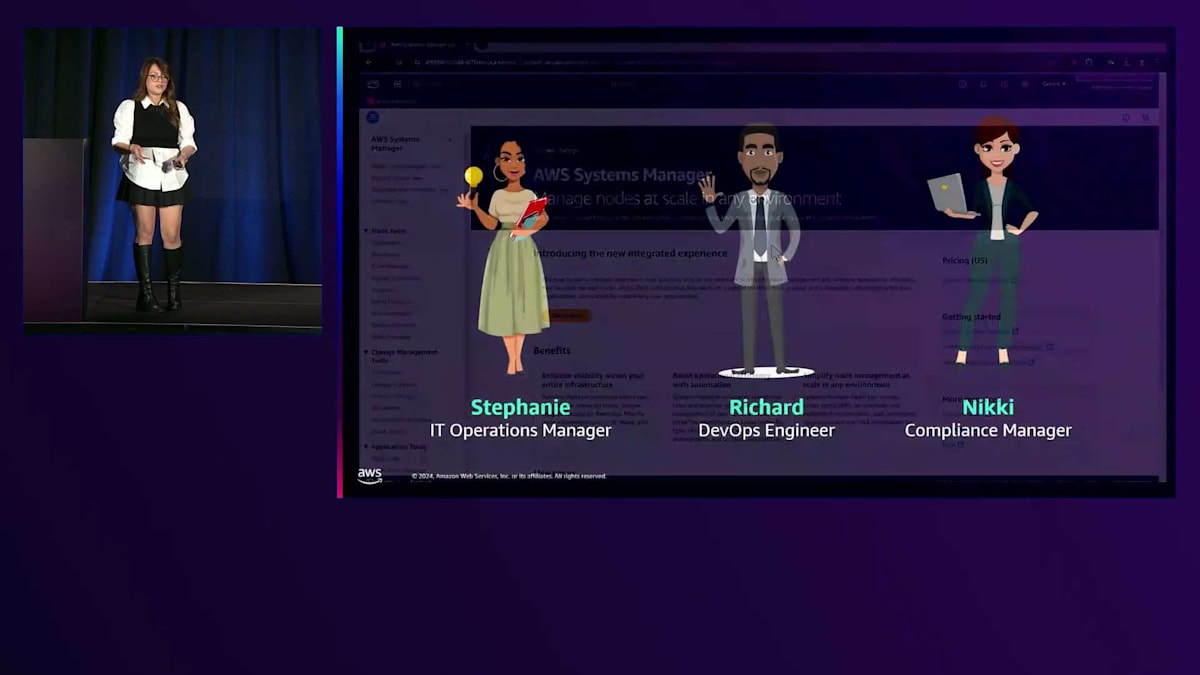
その基盤構築について話す際、まずはチームの紹介から始めましょう。ストーリーテリングが好きなのは、私たちがどこから構築を始めたのかを理解していただけるからです。今日のチームは、IT Operations Managerのステファニーです。彼女はパフォーマンス、可視性、そしてチームが適切に運用できるように効率的な実装を確実に行う責任者です。次にDevOps EngineerのRichardがいます。彼はアカウント内のさまざまなリソースのデプロイと作成を担当しています。そして、Compliance ManagerのNikkiがいます。彼女はステファニーとRichardの作業すべてを監督しています。なぜなら、デプロイしたすべてのものが社内外の規制フレームワークに準拠していることを確認したいからです。後になって予期せぬ事態が発生しないよう、プロアクティブに対応したいのです。これが今日のチームです。皆さんの場合は少し異なるかもしれませんが、運用チームがどのような構成になっているかイメージしていただけると思います。

運用基盤を構築する際の望ましい成果とは何でしょうか? やりたいことについてのアイデアはすでにあります。私たちの場合、デプロイメントの簡素化を本当に目指しています。つまり、全体的な視点を持ち、どのリソースがどのアカウントやリージョンにあるのかを理解し、それを一元化したいということです。もう一つは、組織のインフラストラクチャの維持です。リソースの事前作成からデプロイ、そしてインフラストラクチャの保守まで、それがどのように見えるでしょうか?これらすべてを行いながら、インフラストラクチャの維持に伴うさまざまな管理タスクを効率化したいと考えています。


始めるにあたって、まず環境とノードをスケールに応じて効率的に管理する方法を決定します。私たちのシナリオでは、これが現在のアーキテクチャです - 最初からこれほど大きくはありませんでした。 皆さん自身のjourneyを考えてみてください。私たちは小規模から始めました。いくつかのリソースがあり、いくつかのアカウントを数個のリージョンにデプロイし、おそらくマルチリージョンで、その後徐々にアカウント内のリソースを増やしていきました。ここでも同じことが起こりました。オンプレミスから始まり、オンプレミスで限界に達したため、クラウドに移行してAWSのスケーラビリティなどのメリットを活用することにしました。
私たちは1つのアカウントから始めて、徐々にマルチアカウント構造とマルチリージョン戦略へと移行し、アーキテクチャとインフラストラクチャの効率性とスケーラビリティを向上させてきました。現在、マルチアカウントおよびマルチリージョン戦略で運用されている方はどのくらいいらっしゃいますか?かなりの数の方がいらっしゃいますね。シングルアカウントでマルチリージョン、あるいはシングルアカウントでシングルリージョンで運用されている方は?1人見かけましたが、見なかったことにしておきましょう。というのも、ベストプラクティスとしてスケールアップする際には、レジリエンシーを構築し、それを異なるチームやワークロードに適用できるよう、マルチアカウント構造や戦略の構築を始めることが望ましいからです。
マルチアカウントであれシングルアカウントであれ、すべてを可視化できる体制を整えることが重要です。しかし、スケールアップに伴い、その可視性の確保や多様なアカウントとリソースの管理には課題が生じることも理解しています。これは在庫管理に関する疑問を引き起こします - そのアカウントには何があるのか?何をデプロイしたのか?要件を満たしているのか?また、特定のアカウントでリソースを見つけ出すプロセスや、ノードにSSH接続する必要がある場合の特定の権限についても考慮が必要です。さらに、運用タスクを実行するためのアカウントアクセス権限の有無を確認する必要があり、これによってオーバーヘッドが増加します。
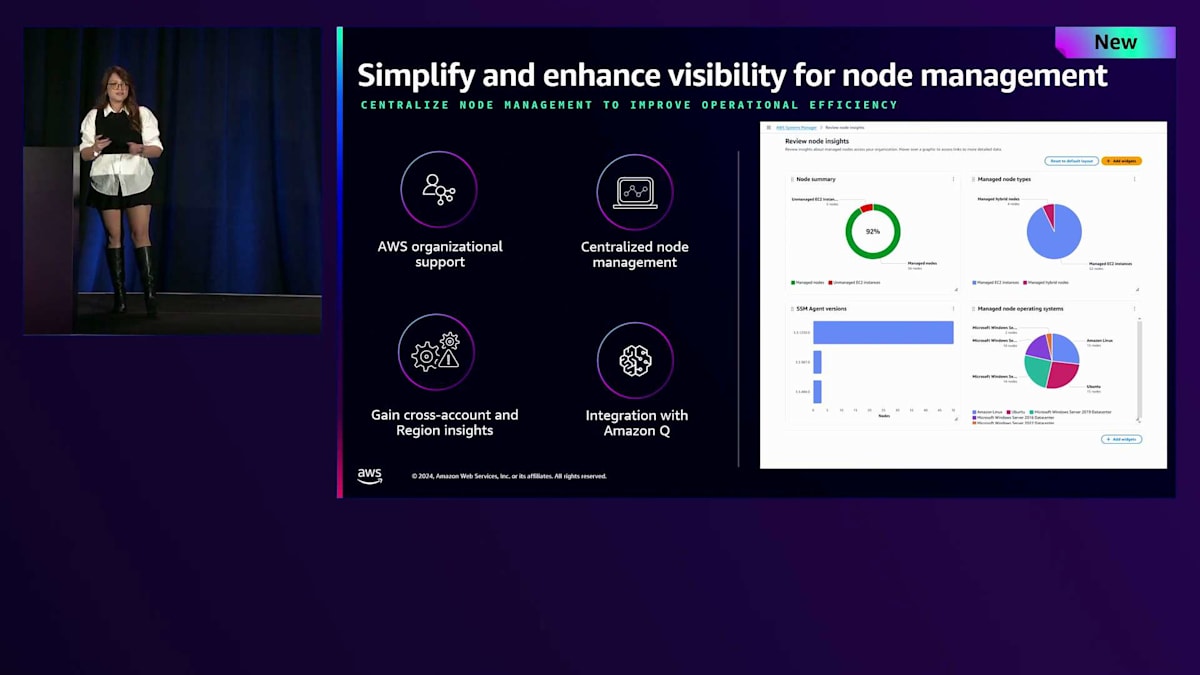
私は楽観的に考えて、これを良いオーバーヘッドだと捉えています。オーバーヘッドが増えているということは、ビジネスが大きく改善している証 - つまり、スケールアップし、新しい技術を採用し、より多くのリソースを会社に追加しているということです。 そこで、Systems Managerの新しいエクスペリエンスを通じて、これらの課題にどのように対応しているかをご紹介したいと思います。すでにご覧になった方もいらっしゃるかもしれませんが、AWS Organizationsとの新しい統合エクスペリエンスでは、委任された管理者アカウントを通じて、オンプレミス、AWS、マルチクラウドのすべてのノードを一元的に管理・統制し、アカウント内のさまざまなインベントリの集中管理と可視性を提供します。
実際の動作を詳しく見ていきましょう。ボタン一つで実行できますが、私の言葉だけでなく、実際に目で確認していただきたいと思います。 では、コンソールに移りましょう。まず、Organizationがあり、そのOrganizationに委任された管理者が登録されています。このアカウントが私の委任された管理者アカウントです。Systems Managerに移動し、委任された管理者を登録すると、Systems Managerのエクスペリエンスに進みます。
Systems Manager新エクスペリエンスによる一元管理と自動化
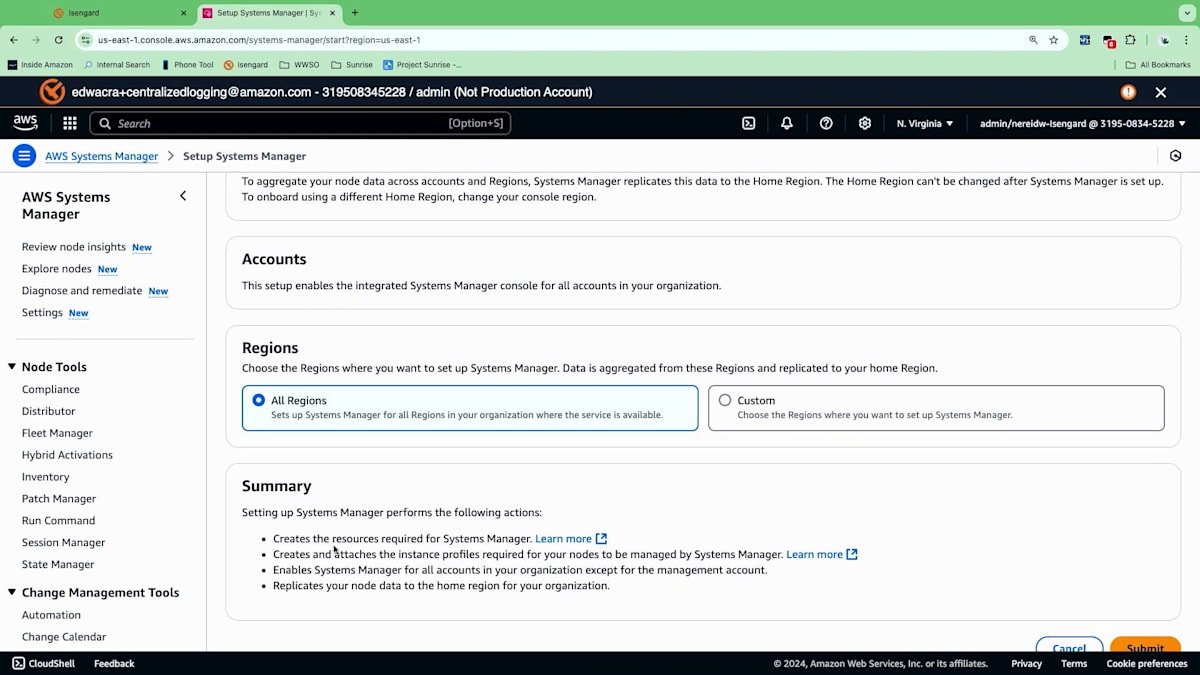
「はじめに」をクリックすると、Organizationの使い方を説明するホームページに移動します。 ここで、各リージョンや異なるアカウントにノードをデプロイするかどうかに応じて、すべてのアカウントとすべてのリージョン、またはカスタムリージョンをターゲットにすることができます。すべての異なるアカウントをターゲットにし、異なるリージョンをセットアップします。このデモでは、すべての異なるリージョンにデプロイします。
バックグラウンドで起きているのは、Systems Managerが組織内の各アカウントに対して異なるCloudFormation Stack Setをデプロイし、様々なリソースを展開していることです。これは全て自動化によって実現されています。Johnが話していたように、組織内での異なるデプロイメントをどのように自動化するかということですね。これにより、Systems Managerが必要とする標準化されたリソースが各アカウントに追加され、全てのアカウントとリージョンからインベントリを収集して一元的に把握することができます。
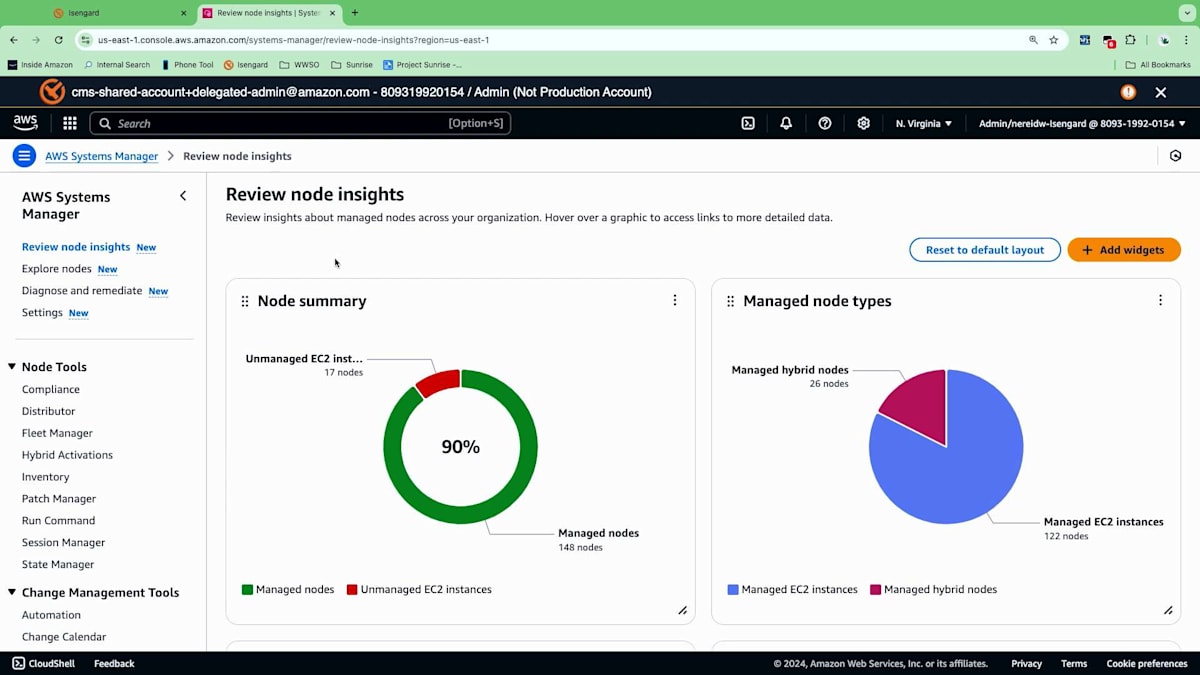
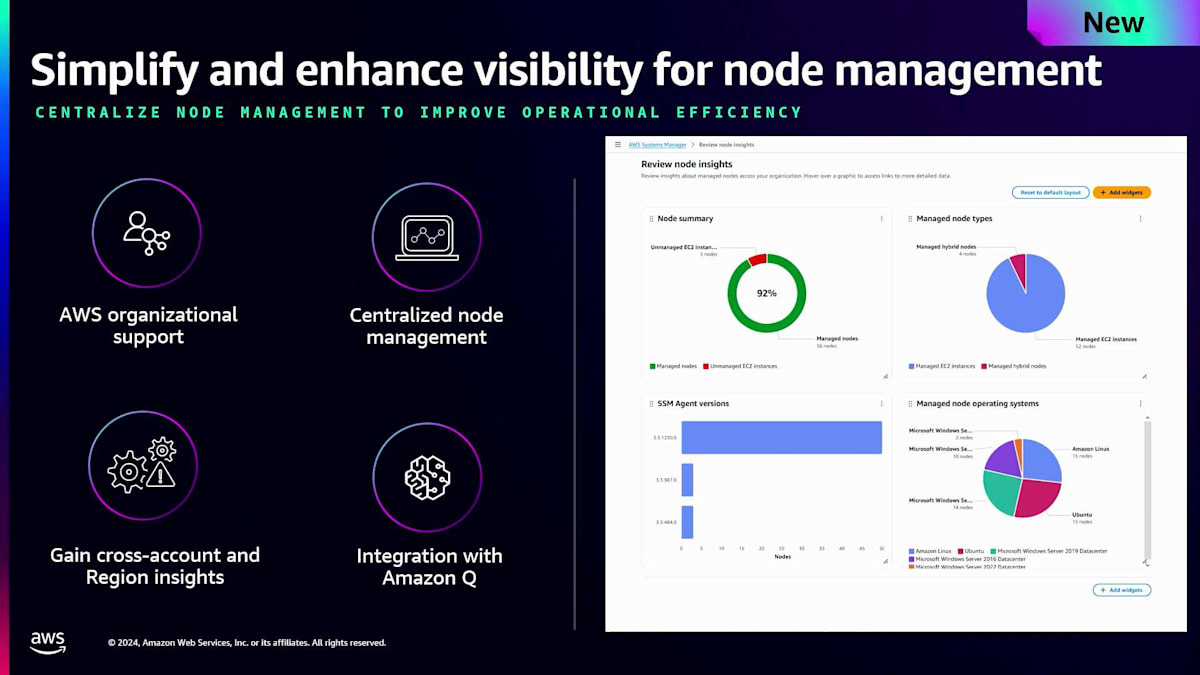
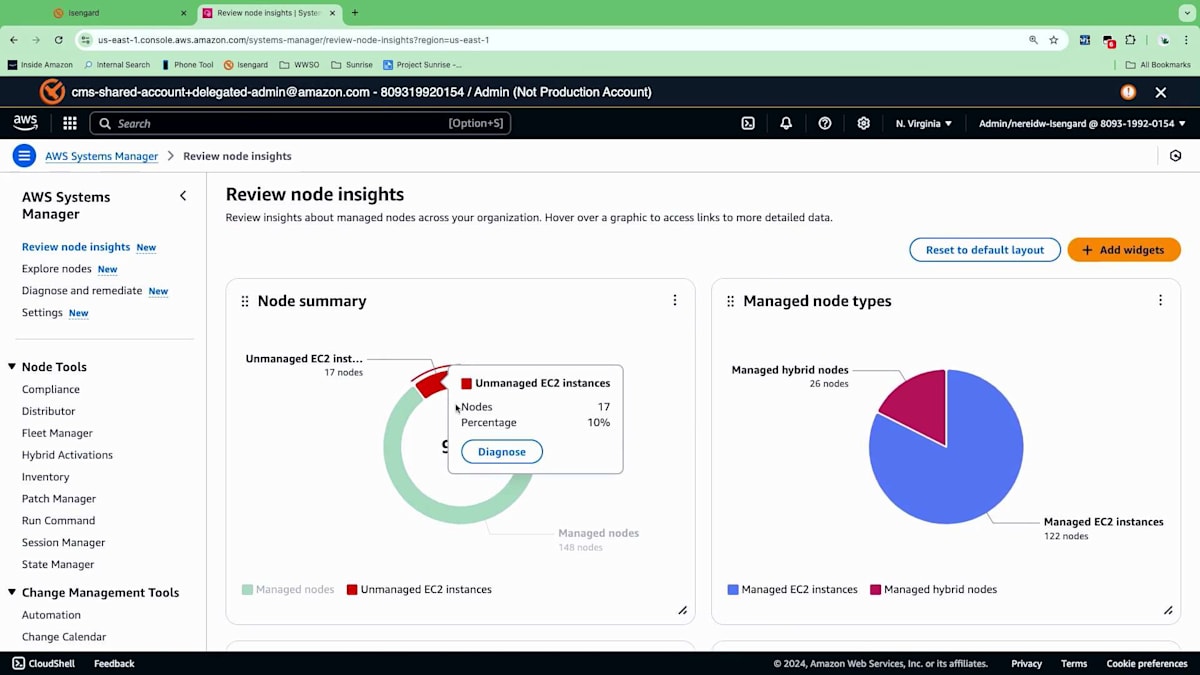
ダッシュボードの表示には時間がかかるので、すでに設定済みのアカウントを見てみましょう。 Systems Managerに移動すると、このアカウントで有効化した後、すべての情報が収集され始めています。 この新しいエクスペリエンスでは、アカウント内のすべてのインベントリを表示するダッシュボードが提供されます。先ほどのアーキテクチャを思い出してください。オンプレミスのノードとAWSのノードがありましたね。このセクションでは、検出された全てのノードの概要が表示されます。Systems Managerで管理されているノード、管理されていないノード、そしてノードの種類の内訳まで確認できます。
ハイブリッドノードはSystems Managerに登録されており、オンプレミスやマルチクラウドの環境にある可能性があります。また、AWS管理のEC2インスタンスもあります。次に、様々なSSM Agentのバージョンについて見ていきましょう。新しいサービスや機能をリリースする際、特定のバージョンのエージェントに適用されますが、セキュリティのベストプラクティスに従って、エージェントを最新の状態に保つ必要があります。これにより、ノードで実行されているエージェントのバージョンを把握し、新機能の追加や異なる機能の統合のために後でアップデートすることができます。また、管理ノードのオペレーティングシステムについてもより詳しく確認できます。この象限では、アカウント内の様々なタイプのオペレーティングシステムを確認できます。私の場合、QAやDEV環境の複数のアカウントからこの情報を、このダッシュボードに一元的に集めています。
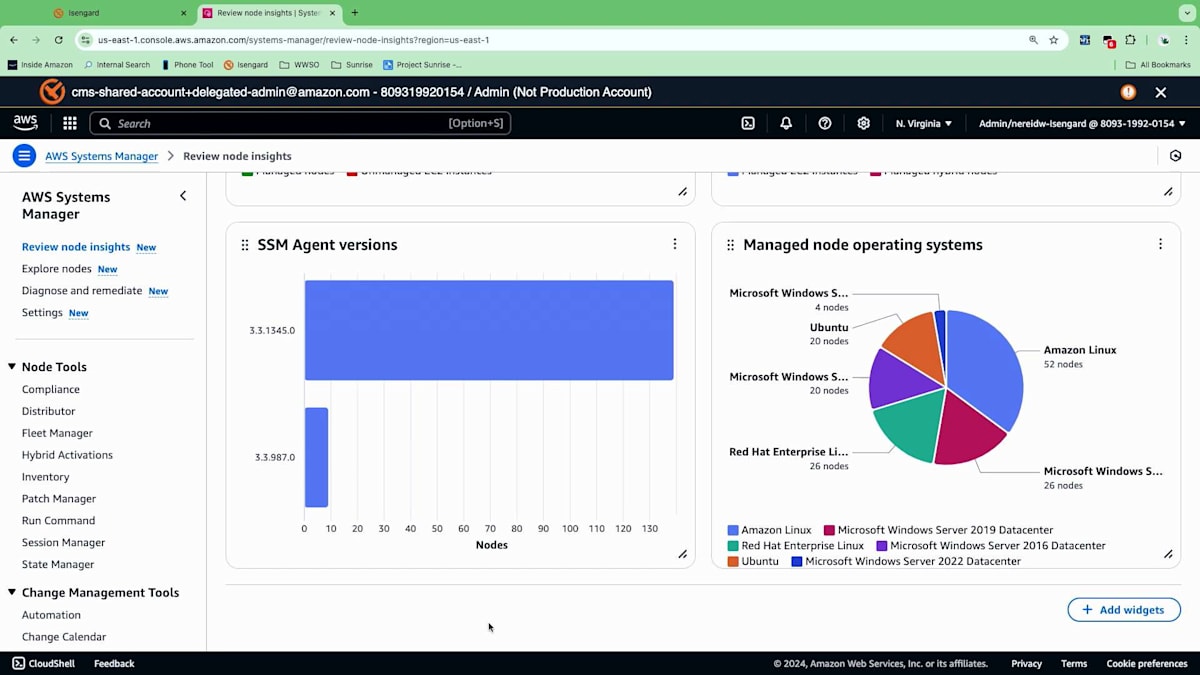

これがStephanieの課題でした - この環境を構築し始め、組織全体の包括的な視点、一元的な視点を実現することで、RichardとNikkiが自分たちの環境を理解し、運用タスクを実行できるようにすることです。 では、DevOpsエンジニアであるRichardが次に行うべきフェーズは何でしょうか? 彼の旅は、現在持っているこれらの異なる運用をどのように一元化し、自動化するかということです。

Dr. Werner Vogelsは、効果的にスケールするためには自動化が重要だと述べています。私たちの旅とJohnの例に戻って考えてみましょう。AMIを作成し、バックアップを取り、EC2に移動してアップデートし、そしてスナップショットを作成する - これは非常に面倒なプロセスで、繰り返し行われる一般的なタスクです。そこで、成長とスケールに伴い、自動化の方法を考える必要があります。結局のところ、規模の大小に関わらず、単一のクラウドか完全なクラウド環境かに関係なく、自動化が重要になります。なぜなら、組織やタスクには一貫性があるからです - 繰り返しのタスク、一般的なタスク、ダッシュボードの確認、パイプラインのブロック解除などを行う必要があります。そこで自動化を活用するのです - これがあなたにとって重要なメカニズムとなります。

先ほど触れた自動化やRun Commandのインフラストラクチャーは、すべてに関連しています。実際にどのように自動化を行い、アクションをコード化できるか考えてみましょう。
多くの作業が手動であっても、それが拡張性のある解決策とならなかった理由は、それが繰り返し発生し、長期的な要件になることが分かっていたからです。インスタンスの更新やパッチ適用は毎月必要になりますし、常にスケーリングを行うワークロードにはAMIが必要かもしれません。また、AMIが起動するたびに特定の設定が必要かもしれません。長期的に使用することが分かっているなら、自動化の仕組みについて考え始めるべきです。ただし、安全に実行することが重要です。すべてをターゲットにして何が起こるか様子を見るのではなく、異なる制御とメカニズムを追加して、安全に大規模な運用ができるようにしたいものです。

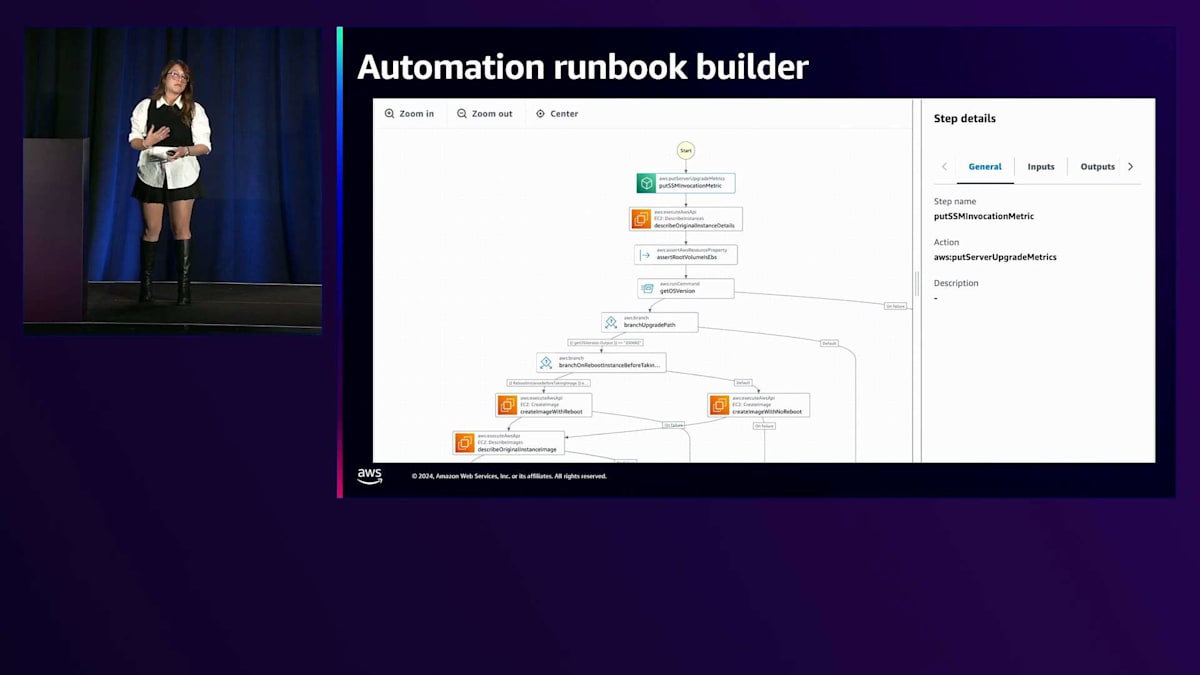
新しいエクスペリエンスとAWS Systems Manager全体において、 コンプライアンスへの対応とリスクの軽減をどのように自動化するのでしょうか?それは Automation Runbook Builderを通じて実現します。昨年、私たちはRunbookを作成する新しい方法を導入しました。以前は、必要な入力を理解し、これらを構築するのは時間のかかるプロセスでした。現在は、この新しいAutomation Runbook Builderによって、ドラッグ&ドロップで様々なRunbookを構築し、アカウント内にデプロイできるようになりました。何が不足しているか、何ができるかが分かるようになっています。
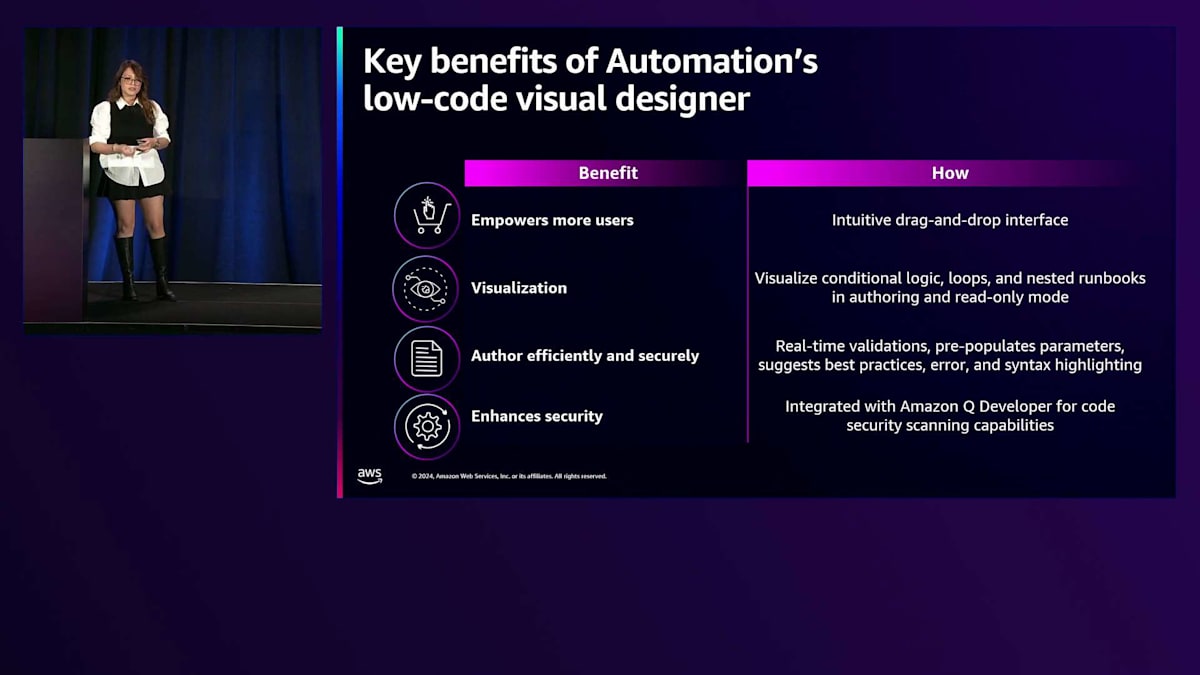

この利点の1つは、様々なRunbookの作成の複雑さを軽減できることです。また、Amazon Q Developerと統合することで、構築時のセキュリティリスクや脆弱性を理解できます。これまでRunbookを作成したことがない場合、セキュリティやコンプライアンス基準について知らないかもしれませんが、このツールにはリスクを警告し、ガイダンスを提供する仕組みが既に組み込まれています。

では、実際にダッシュボードから始めて、これまでの作業を確認し、運用のために活用する方法を見ていきましょう。Windows Server 2016のアップグレードを任されたというシナリオを例に説明します。オペレーティングシステムの新しいリリースが行われると、更新が必要になることは皆さんご存知だと思います。これは、WindowsでもLinux Red Hatでも、定期的に行う必要がある一般的なタスクです。より定期的にすべての作業を行う必要が出てきます。
では、このジャーニーの最初のステップと前提条件は何でしょうか?まず、アカウント内のさまざまなノードをどのように特定すればよいのでしょうか?その方法はいくつかあります。1つは、Amazon Q Developerを使用する方法です。これを使えば、自然な問い合わせを通じて質問し、ノード内で何が起きているかのリストと出力を得ることができます。EC2インスタンスのリストを要求したり、管理下にあるWindowsのEC2インスタンスの一覧を確認したりできます。しかし、私は管理されていないEC2インスタンスを確認したいのです。すべてのノードをターゲットにして、まだ更新が必要なものがないかを確認する手間を省きたい場合、これらのEC2インスタンスが管理されていないのか、そしてそれらがWindowsなのかを実際にどうやって確認できるのか、理解する必要があります。この点について、管理されていないWindowsノードについて説明させていただきます。
Automation Runbookを活用した効率的な運用タスクの実行
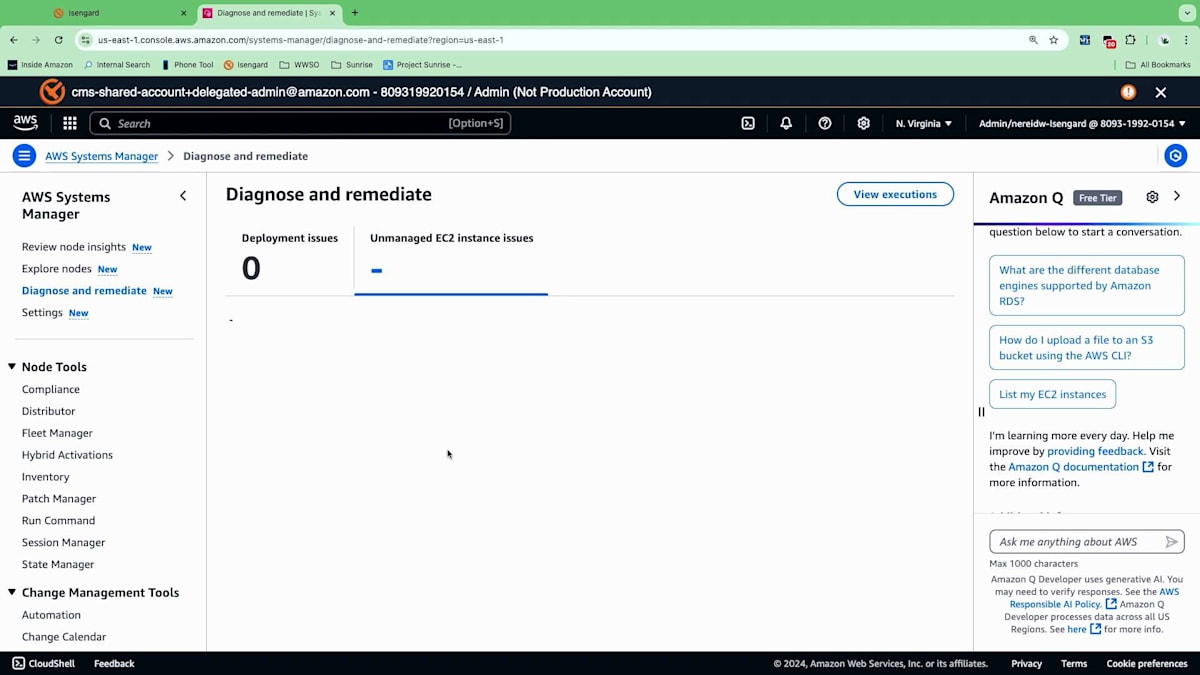
管理されていないセクションに移動すると、Diagnose and Remediateと呼ばれる機能が起動します。以前は、お客様がエージェントやノードがAWS Systems Managerに登録されていない理由を理解し、この問題を特定して解決することに苦労していました。この新しいエクスペリエンスにより、EC2インスタンスやノードがSystems Managerによって管理されていない理由を理解し、診断することができるようになりました。
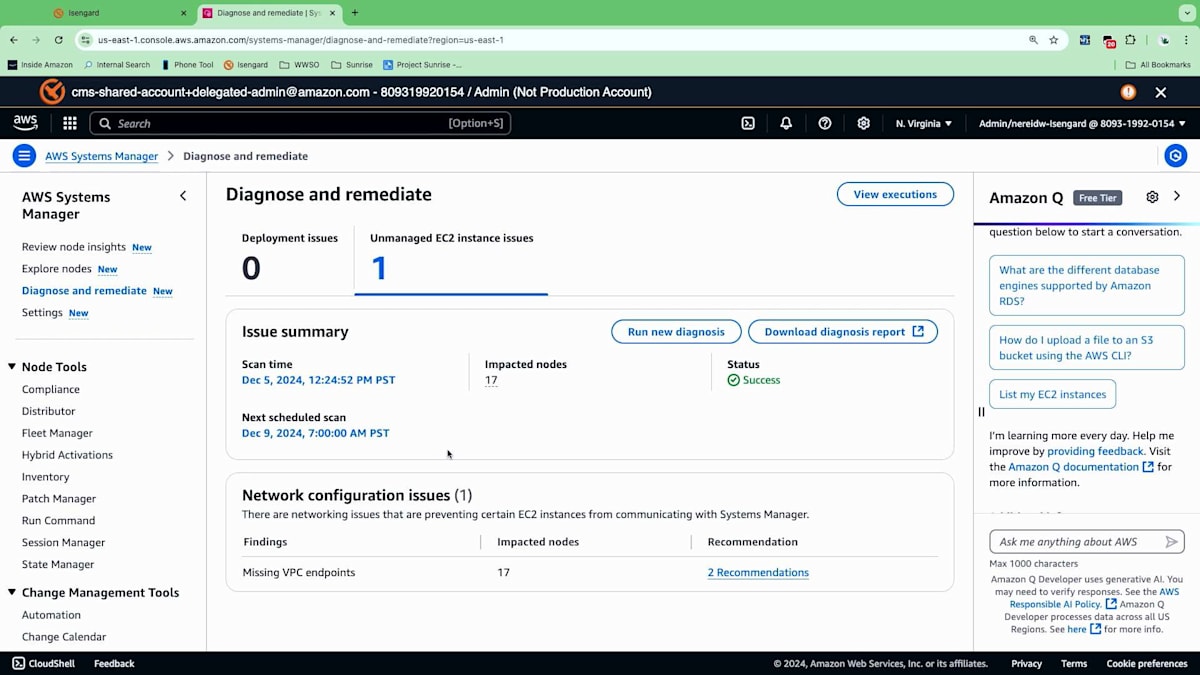
今日の早い時間に、新しい診断を実行しました。これは定期的に実行することができ、Systems Managerによる管理を妨げている問題を特定します。主にネットワーク構成とSystems Managerの前提条件に焦点を当てています。これらの前提条件には、適切な権限セットの保持、インスタンスへのSSM Agentのインストール、エージェントとSystems Manager間の適切なネットワーク接続の維持が含まれます。この診断を実行したところ、ネットワーク構成の問題が明らかになり、具体的には17のノードにVPC Endpointsが不足していることがわかりました。
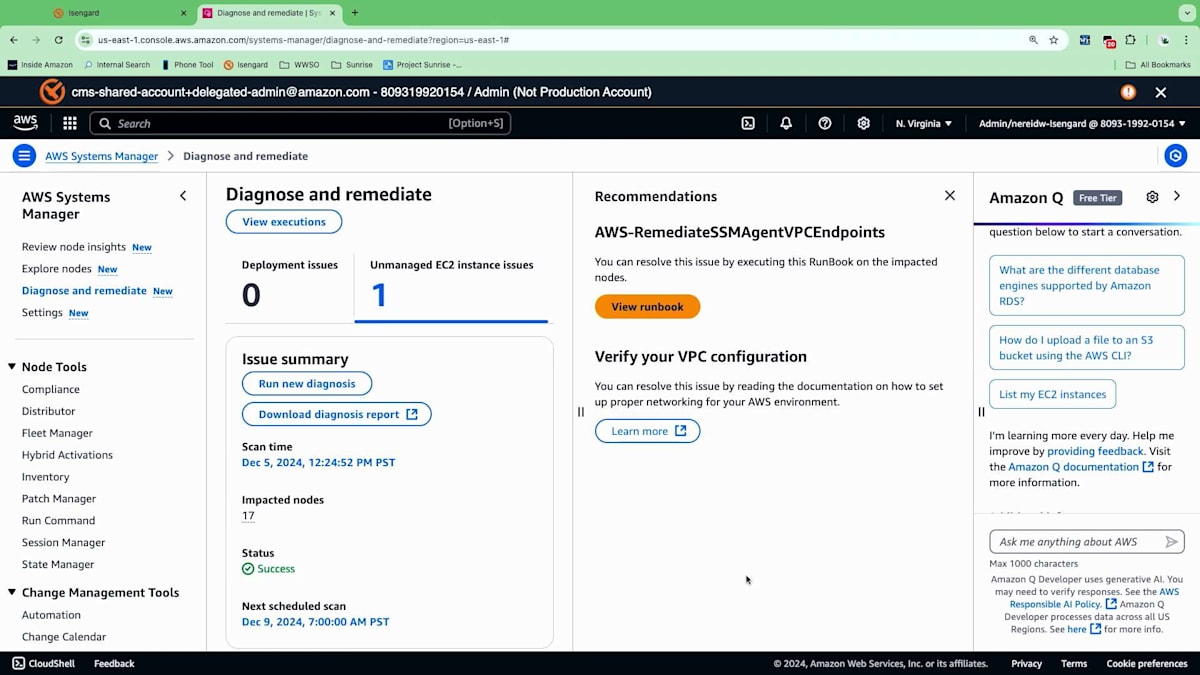
この新しいエクスペリエンスでは、Automation Runbookを通じて修復のための推奨事項を提供します。これらのAutomation Runbookは、Systems Managerがお客様に代わって実行する自動化されたタスクです。この場合、異なるノードで実行できる事前に用意された、事前に構築されたRunbookがすでに利用可能です。もちろん、手動で行うこともできます。17のノードがある場合、手動で設定すると、すべてのVPC Endpointsを設定し、管理されていない状態から管理された状態に変換するのに数時間かかる可能性があります。しかし、効率性を考えて、Runbookを使用してこれらの一般的なタスクを自動化したいと思います。
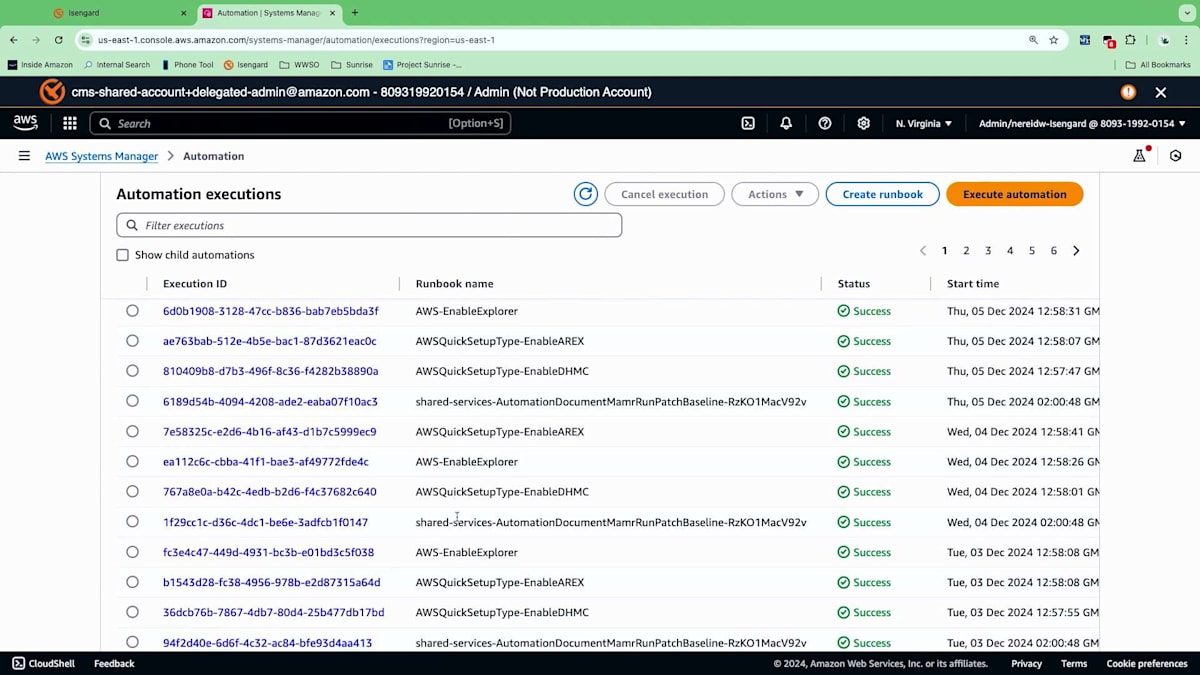
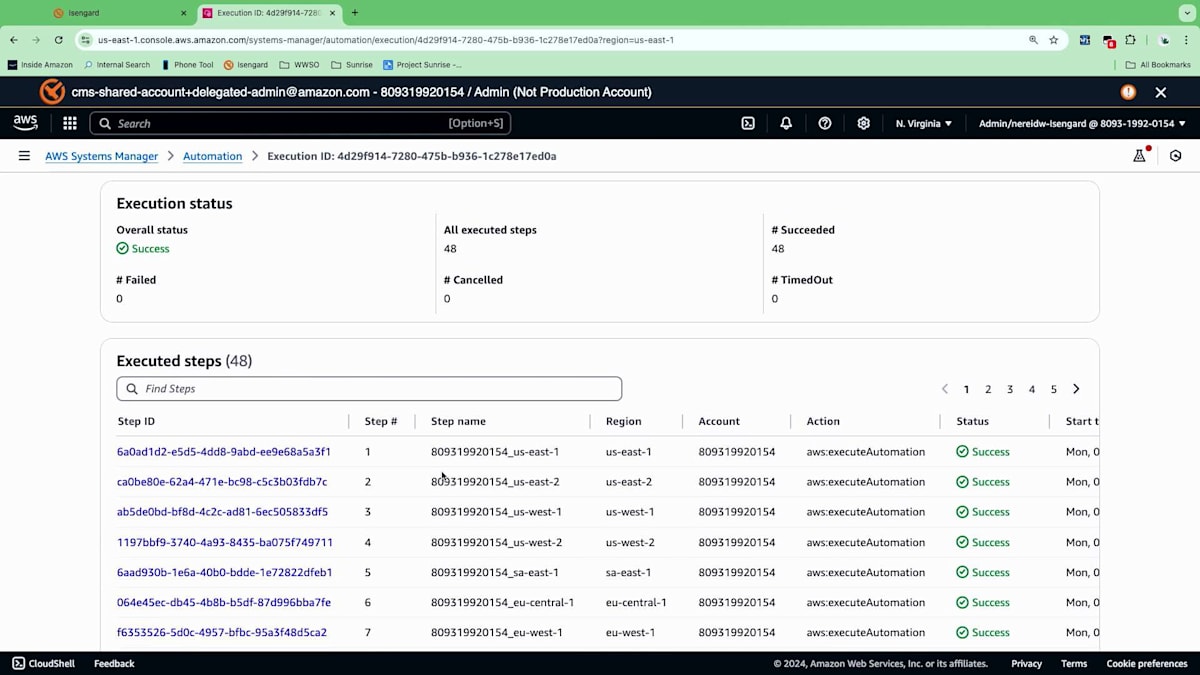
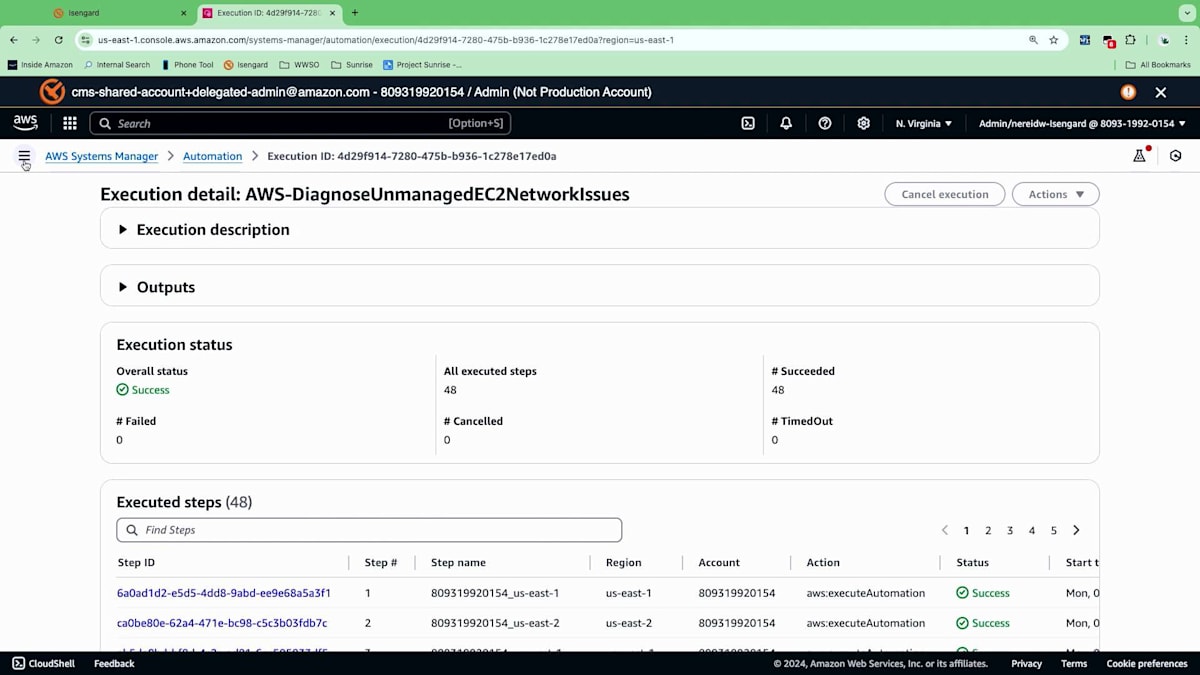
ライブデモは予測不可能な場合があるので今は実行しませんが、バックエンドでは修復のためのさまざまなスクリプトが実行されます。実行ログはすべて監視でき、このようになります。実行ログには出力が作成され、どのようなアクションが実行されたか、どのノードが影響を受けたか、具体的なステップは何だったのかを理解するのに役立ちます。ステップIDをドリルダウンすると、実行時間やプロセスに関する詳細情報を確認できます。
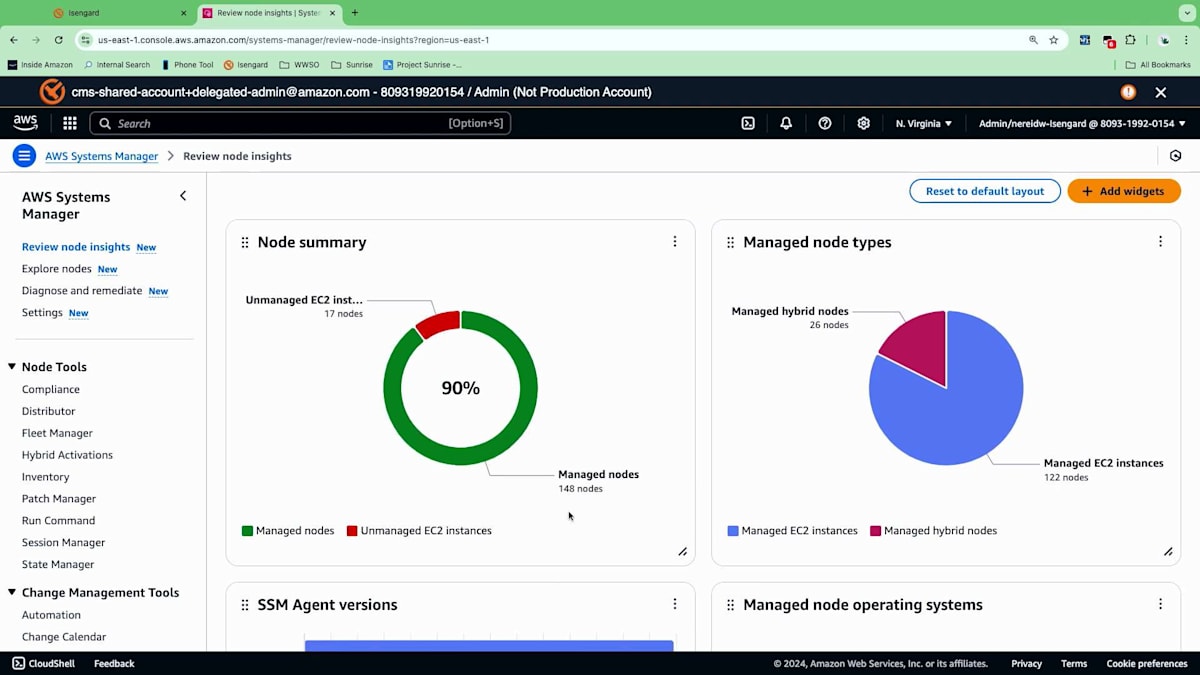
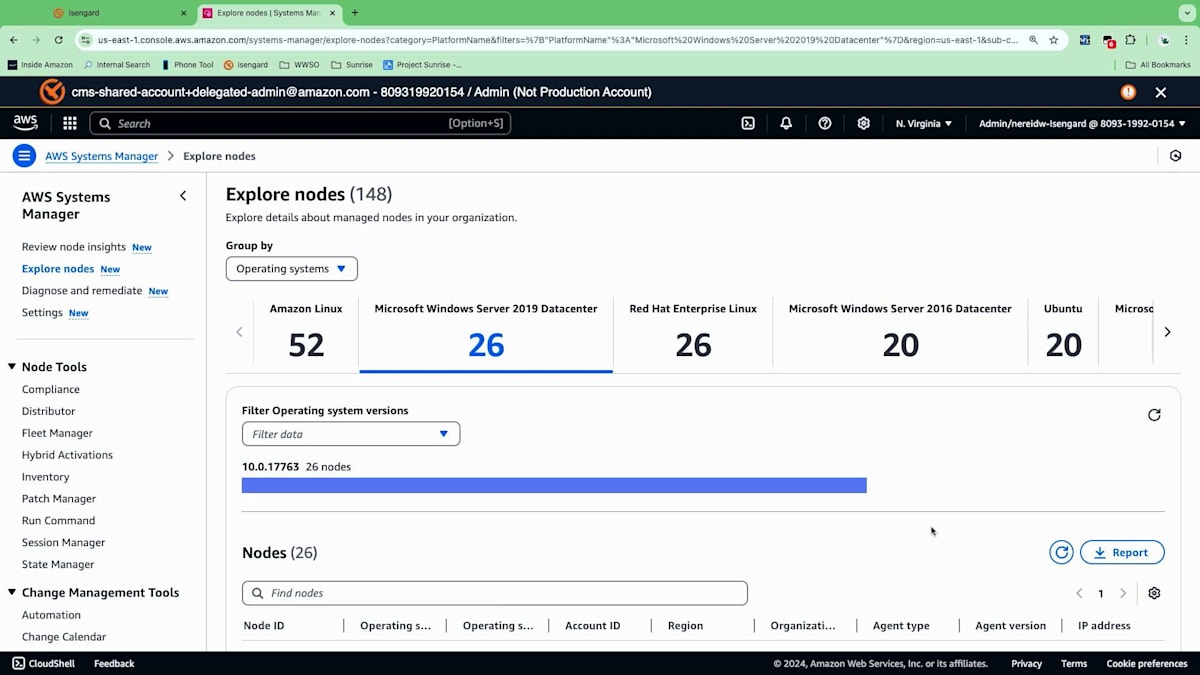
これがフェーズ1です - ノードの管理を行うことです。これらはWindowsノードではありませんが、 ここでWindows システムが何台あるのかを確認する必要があります。合計で約 148台のノードがあります。もう一つの作業は、オペレーティングシステムを確認し、ノードをクリックすることです。具体的にはMicrosoft Windows Server 2019を探しているのですが、異なるノードをクリックすると、アカウント内のすべての異なるノードが表示される別のビューに移動します。このビューでは、どのアカウントに紐づいているのか、どのデプロイメントリージョンにあるのかが表示されます。
これらすべての異なるオペレーティングシステムをアップデートまたはアップグレードするというシナリオを考えると、これらのノードを所有する様々なチームと共有するためのレポートを生成して、今後のアップデートについて知らせたいと思います。Systems Managerでは、これらの情報をJSONまたはCSV形式でダウンロードして、新しいアップデートバージョンへの移行計画についてチームに知らせることができるようになりました。必要な作業を特定したので、次のステップはアップグレードです。この場合、26台のノードをアップデートする必要がありますが、手動で行うには多すぎます。そこで、自動化をどのように活用できるか見ていきましょう。かなりの作業量になるので、Automation Runbookを活用していきます。
現在提供しているAutomation Runbookについて見ていきましょう。Automation Runbookを使用している人は何人いるか尋ねたところ、2人だけでしたね。ありがとうございます。
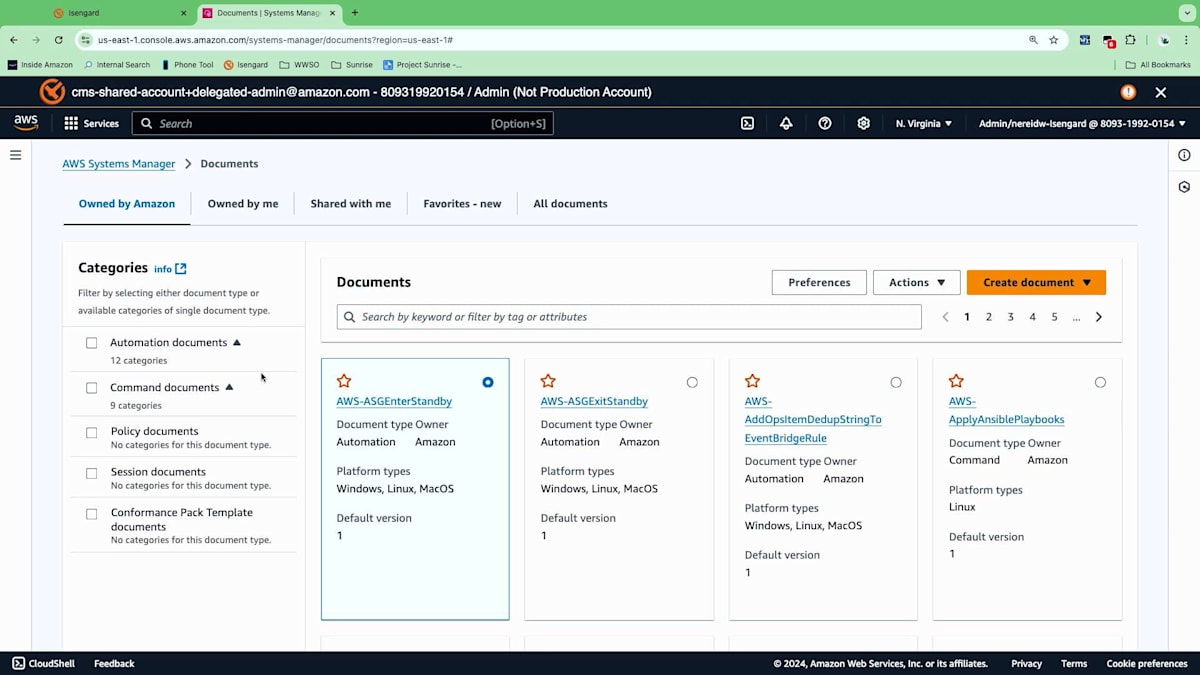
Automation Runbookは本当に役立ちます。Runbookと言いましたが、誰に聞くかによってはドキュメントと呼ばれることもあり、実際にコンソールでもドキュメントとして表示されています。この領域では、事前に構築され管理された100以上の Automation Runbookを提供しており、どのような種類の作業を自動化する必要があるか、またどのようなアイデアを自動化できるかを理解するための方法として提供しています。これは、「何を自動化すべきか」「どのように自動化できるか」という、よくお客様から受ける質問の理解に役立ちます。コンソールに入って、EBSボリュームなど自動化したいものを調べると、そのニーズに合うRunbookが見つかる可能性が高いです。必要に応じてさらにカスタマイズを加えることも、現在のAWS管理型Runbookをそのまま活用することもできます。
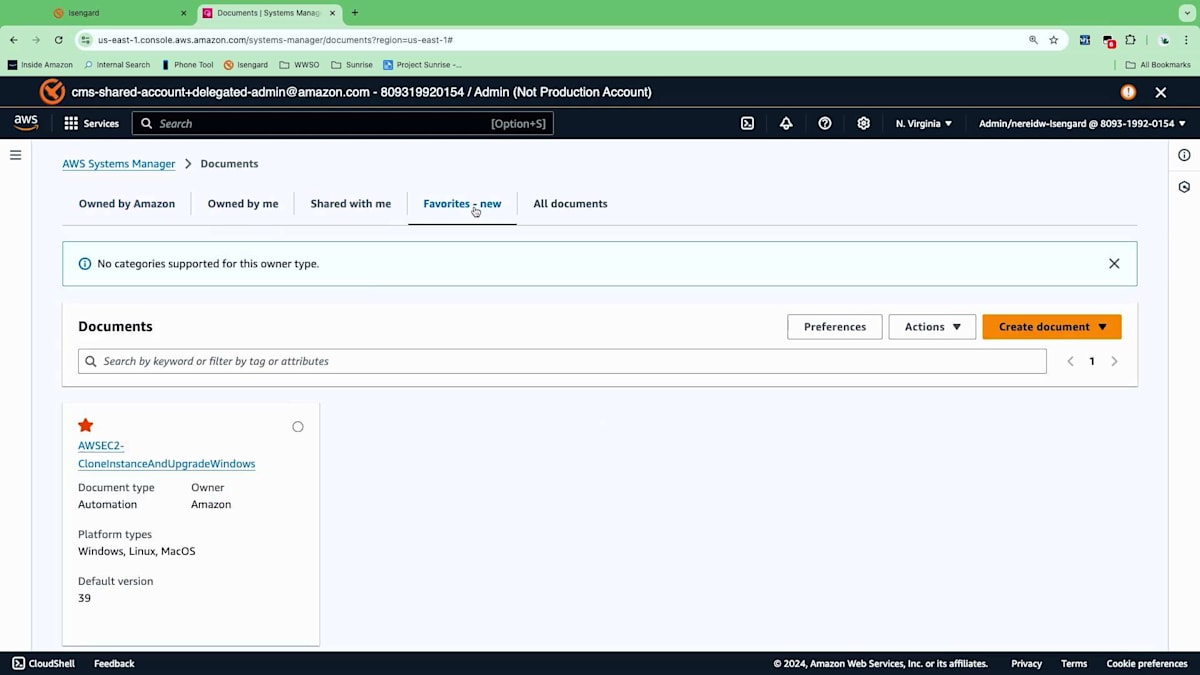
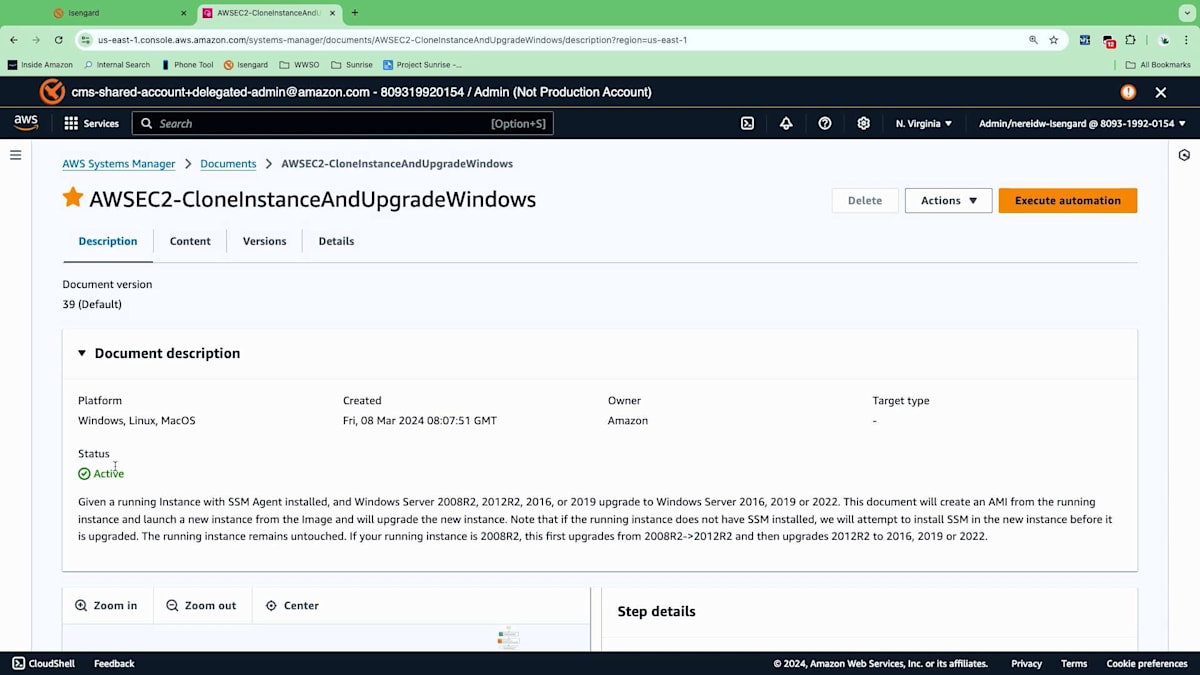
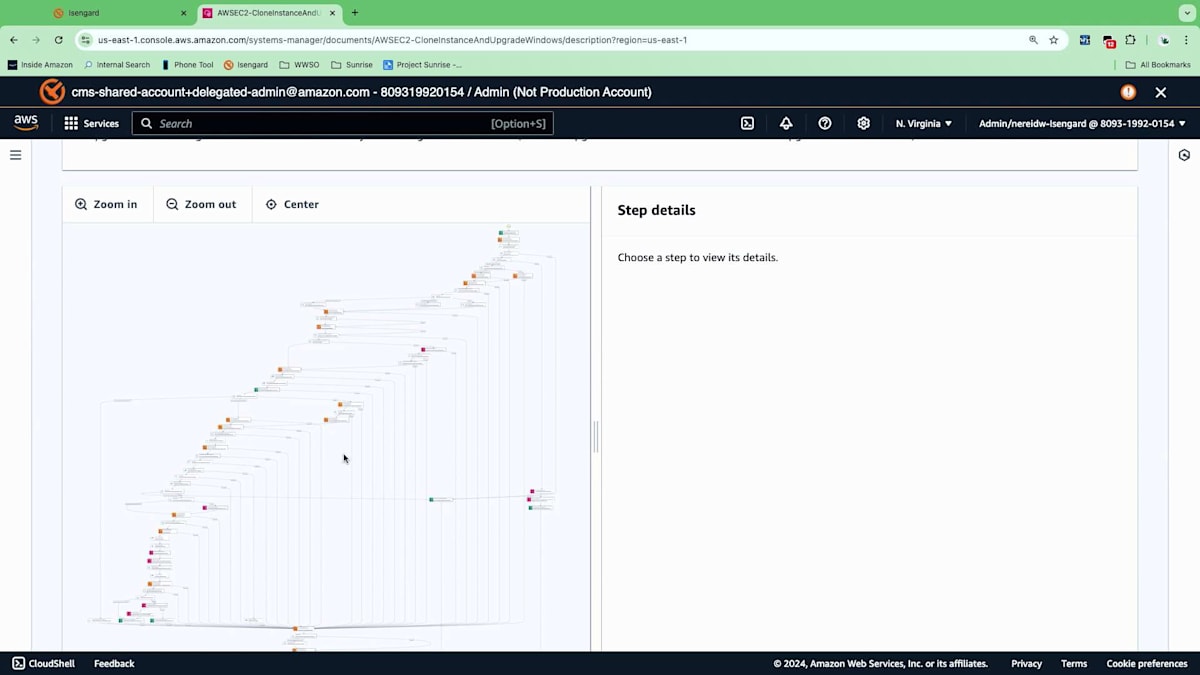
この場合、Windowsをアップグレードするための Runbookがあり、これを使用する必要があることがわかっていたのでお気に入りに登録しました。これはJohnが話していたプロセス - スナップショットの作成、EBSボリュームの作成などを実行します。これらの異なるステップがすべて安全な方法で実行されます。少し下に行くと、安全な方法で実行する必要があるすべての異なるステップの視覚的な設計が表示されます。EBSボリュームの取得やロールバック手順を含め、これらすべてを実行してくれます。これを見ただけでも少し intimidatingですよね?しかし、このRunbookを使用して私たちの代わりにこれを説明し実行できることは非常に有用です。
これらのRunbookは組織間で共有することができ、その組織に共有する必要がある特定のRunbookを持つことができます。何か起きた時には、自分のアカウントにあるこのRunbookを使用できます。これをデプロイする際、ノード内のすべての異なるステップを実行し、それらを一緒に更新して、何が起こったかの出力を提供します。また、レート制御も可能で、17以上あるインスタンスやノードすべてをターゲットにする代わりに、特定の割合のみをターゲットにすることができます。エラー率が上昇した場合、安全に実行するためにそれをRunbookに追加できます。コンプライアンスのニーズを満たさない場合は、そのAutomationを停止させることができます。
私たちの取り組みについて話を戻しますが、何か起きた時のためにバックアップも用意していました。新しいエクスペリエンスを構築する際には、アカウント内で何が起きているかを全員が理解できる一元化されたビューの構築から始めます。その取り組みを発展させスケールアップしていく中で、運用効率を高めるためのAutomation Runbookの構築と、コンプライアンス戦略の構築をより効率的に行いたいと考えています。各チームは非常に異なっており、時にはサイロ化していることもあるため、すべてを統合することが重要です。これらのRunbookを構築することで、リソースのコンプライアンスを確保し、問題を放置せずに迅速に修復することができます。

このセッションの重要なポイントをお伝えすると、Systems Managerの新しいエクスペリエンスはワンクリックでセットアップできます。これが、現在のSystems Managerで問題の診断と修復を行うために目指している効率性です。
まとめと今後の展望:Systems Manager活用のポイント

未管理ノードを修復できるようにする必要があります。これにより、最終的にOSでの運用タスクを効率的にスケールして実行できます。これらのノードを管理し、AWS Systems Managerがそれらと通信してAutomationを実行できるようにしたいと考えています。さまざまな運用タスクを自動化するには、繰り返し行っている一般的なタスクを特定することで、何を自動化すべきかを理解することから始めます。これをホワイトボーディングセッションとして始め、その後、運用タスクに活用できるAutomation Runbookの構築を開始します。
リソースとしては、「Getting Started with Centralized Operations Management」という主要なワークショップがあり、これはすべての異なるユースケースをカバーしています。Johnが話していた20以上の機能すべてについて、それらの異なる機能をどのように活用し、ソリューションを構築するかについて説明しています。また、新しいエクスペリエンスの使い方や、Systems Managerの高度なトピックと高度なユースケースについても、このワークショップでカバーしています。
私たちの新しいエクスペリエンスは、インタラクティブなストーリーライン形式になっており、ダッシュボードを通じてインサイト、説明、そしてダッシュボードの使い方を探索できます。Systems Managerの新機能について解説したブログでは、Amazon Qとの統合や、パッチ管理を主要なユースケースとしたダッシュボード自体、そしてSystems Managerと新機能がもたらすメリットについて説明しています。ありがとうございます。ここでJohnから最後の言葉をいただきたいと思います。
本日のセッションにご参加いただき、誠にありがとうございます。私たちはこの新機能のローンチに大変興奮しています。まだSystems Managerの次世代バージョンをご覧になっていない方は、ぜひチェックしていただければと思います。これは、運用を効率化し、複数のリージョンやアカウントにまたがるすべてのノードを一元的に管理するための重要な基盤となります。本日はご参加いただき、ありがとうございました。ありがとうございます。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion