re:Invent 2024: AWSのZero-ETLによるデータ統合とRedshiftの進化
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Innovations in AWS analytics: Zero-ETL and data integrations (ANT348)
この動画では、AWSのZero-ETLによるデータ統合について詳しく解説しています。Amazon RedshiftのシニアプロダクトマネージャーのJyoti Aggarwalが、Zero-ETLの機能や利点を説明し、Amazon Aurora、Amazon RDS、Amazon DynamoDBなど様々なソースからのデータ統合方法をデモを交えて紹介します。また、Motive TechnologiesのPaul Van Liewが実際の導入事例を共有し、Zero-ETLの導入により同期メソッドが4つから1つに削減され、レイテンシーが40-45分から15-30秒に改善、月額約1万ドルのコスト削減を実現した具体的な成果を報告しています。さらに、Amazon SageMaker LakehouseやApache Icebergとの連携による新しい可能性についても言及されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Zero-ETLとデータ統合:AWSのイノベーション

皆様、こんにちは。これまでのre:inventを楽しく、そして実りあるものとして過ごされていることを願っています。お忙しい中、このセッションにご参加いただき、ありがとうございます。私はAmazon Redshiftのシニアプロダクトマネージャーを務めるJyoti Aggarwalです。本日は、AWS Analyticsにおけるイノベーションの1つである、Zero-ETLとデータ統合についてお話しさせていただきます。本日は、私の同僚のHarshida Patelと、Motive Technologiesのお客様代表であるPaul Van Liewにもご登壇いただきます。

本題に入る前に、アジェンダを簡単に確認させていただきます。まず、Operational Analytics、つまりそれが何を意味し、なぜお客様がそれを必要とするのかについてお話しします。次に、お客様が現在このような分析をどのように行っているか、そしてどのような課題に直面しているかについて説明します。そして、AWSがZero-ETLを通じてお客様の分析をどのように支援しているか、そしてこの分野で私たちが行ってきたイノベーションについてお話しします。Harshidaが詳細なデモを行い、Zero-ETLでお客様が採用しているユースケースやパターンについても説明します。最後に、Paulが、Motiveにおけるゼロ-ETLの導入の経緯と、その成果についてお話しします。
データ駆動型ビジネスとZero-ETLの必要性

データがイノベーションを推進しています。企業がますますデータドリブンになり、それを競争優位の源として活用している状況を目の当たりにしています。データはもはやバックオフィス業務だけにとどまらず、異常検知やゲームのリーダーボード、脅威検知といった主要なビジネス変革イニシアチブの基盤となっています。さらに、生成AIや機械学習の出現により、適切なタイミングで適切なデータを取得することがより重要になっており、皆様の組織は、このデータを取得し、データパイプラインを構築するために多大な時間と労力を費やしています。しかし、従来のETLアプローチでは、これらの要件を常に満たせるわけではないということが分かってきました。



挙手していただきたいのですが、Operational Analyticsや企業データの分析が必要な方はいらっしゃいますか?遠慮なさらずに。はい、かなりの方がいらっしゃいますね。また挙手をお願いしたいのですが、データパイプラインの構築や保守が必要な方はいらっしゃいますか?申し訳ありません。皆様こそが、AWSがZero-ETLの未来に継続的に投資している理由なのです。私たちは、シンプルで信頼性が高く、データアプリケーションのパイプラインを取り除いてデータへのアクセスを提供し、皆様がデータからの洞察の創出に集中できるようにしたいと考えています。


AWSでは、データの保存と処理に関して、用途に応じて適切なツールを提供するという目的に沿ったデータ戦略を持っています。私たちは、アプリケーションのモダナイゼーションを検討している場合でも、単にマネージドアプリケーションへの移行を検討している場合でも、様々なユースケースに対応できる、最も広範で深いデータベースポートフォリオを提供しています。Amazon AuroraやAmazon RDSなどのリレーショナルデータベース、そしてAmazon DynamoDB、Amazon DocumentDB、Amazon MemoryDBなどの非リレーショナルデータベースをサポートしています。



また、大規模な分析を提供するために特別に設計されたクラウドデータウェアハウスとして、データジャーニーの中心に位置するAmazon Redshiftがあります。これは完全マネージド型のペタバイトスケールのデータウェアハウスで、クラウドデータウェアハウスとして最高の価格性能比を実現するために、すべてのデータ製品と深く連携しています。これらの目的特化型システムは、Redshiftのパワフルな環境で分析したくなるような大量のデータを生成します。そしてここで、なぜZero-ETLが必要なのかという話に戻ります。お客様からは、現在Redshiftでこれらのデータを分析するために、自作のETLソリューションを使用してスクリプトを書いたり、APIを設定したり、データの正確性チェックやその他の機能を追加してデータをウェアハウスに格納するか、あるいはこの作業を代行するサードパーティのツールを使用しているとお聞きしています。
しかし、データ統合を扱うサードパーティツールは、長期的な運用を想定して作られていないため、必ずしも効果的に機能するとは限りません。このようなツールやパイプラインの構築と保守には大きな運用オーバーヘッドが伴います。何か問題が発生した場合、複数のホップやタッチポイントがあるため、すべてを正常な状態に戻すのが困難になることがあります。データがウェアハウスに到達する頃には、古くなっていて使用に適さない状態になっていることがよくあります。

私たちは、データパイプラインを完全に放棄すべきだと言っているわけではありません。データパイプラインを構築し、既存のものを使用し続けるべき説得力のある理由は多くあります。例えば、ストリーミング分析を実行したい場合や、同じデータを複数のダウンストリームアプリケーションに送信するユースケースがある場合は、データパイプラインを引き続き使用すべきです。しかし、Amazon Redshiftでデータ分析を行うことだけが目的であれば、Zero-ETLが最適なソリューションです。


Zero-ETLは、AWSが提供する完全マネージド型のツールで、目的に特化して設計されています。統合を作成するための安全で正確、信頼性が高く、効率的でパフォーマンスの高いツールです。Amazon Console、CLI、統合APIから好みの方法を選択でき、数分で統合が作成されます。システムがすべてのDDLとDMLを処理します。また、バックグラウンドで何が起きているかをより深く理解するための、組み込みのモニタリングと可観測性も備えています。システム全体をサーバーレスにすることができ、インフラストラクチャ管理なしでデータの変動に対応します。

私たちは、データ移動の複雑さを解消し、Zero-ETLの未来に向けて進化を続けています。この数年間で、Amazon Aurora MySQLとPostgreSQL、Amazon RDS for MySQL、Amazon DynamoDBからのZero-ETL機能を追加してきました。昨日、Matt GarmanがZero-ETL for Applicationsを発表しました。これは、Salesforce、SAP、ServiceNow、ZendeskなどのSaaSアプリケーションからAmazon Redshiftと新しく発表されたAmazon SageMaker Lakehouseの両方へのフルマネージドソリューションです。このローンチにより、Amazon Redshiftは12の異なるZero-ETLソースをサポートし、すべての運用データベースとアプリケーションからの統合分析を同じRedshiftウェアハウスで実行できるようになりました。
Zero-ETL統合の仕組みと実装デモ

Zero-ETLはアプリケーション向けに、データの取り込みとレプリケーションを1つのプロセスに統合することで、データアプリケーションパイプラインを構築する必要性を排除します。完全なデータ同期、増分更新と削除の検出、ターゲットのマージ操作に関するベストプラクティスが組み込まれています。統合の保守は自動化されており、データエンジニアリングチームの運用負荷を軽減します。

Zero-ETLの事例をいくつかご紹介させていただきます。インドの大手子供用品EコマースプラットフォームであるFirstCryは、分析を実行するためにAmazon AuroraとAmazon Redshift間でZero-ETLを使用しています。Zero-ETLに移行する前のSLAは15秒でしたが、移行後はSLAが120ミリ秒まで短縮され、99%という劇的な改善を実現しました。

2つ目の事例は、様々な業界にソリューションとサービスを提供する大手分析企業のVerisk Analyticsです。彼らはAmazon DynamoDBからAmazon RedshiftへのZero-ETLを利用しています。彼らの証言によると、以前は自社開発のソリューションを使用していましたが、頻繁にタイムアウトが発生し、大きな運用上の課題となっていました。しかし、Zero-ETLに切り替えてから大幅な改善を実現しています。それでは、次のセッションのためにHarshidaをステージにお招きしたいと思います。本日はご参加いただき、ありがとうございました。これからZero-ETLの仕組みについて詳しく見ていきましょう。


Harshidaが詳細について説明してくれます。 まずはリレーショナルソース、NoSQLアプリケーションから始めて、その後、お客様がZero-ETL統合で使用しているパターンについて見ていきましょう。
Zero-ETL統合を作成するには、IAMポリシーに基づく認可が必要です。認可を得たら、AWS Console、CLI、またはAPIを使用してZero-ETL統合を作成できます。統合の作成時には、ソース、ターゲット、および設定を指定します。セットアップが完了すると、レプリケーションが開始されます。Zero-ETL統合の状態を監視するには、Amazon Redshiftコンソール、AWS CloudWatch、およびAmazon Redshiftシステムビューを使用できます。


それでは、リレーショナルデータソースから始めましょう。ソースとしては、Aurora MySQL、PostgreSQL、あるいはAmazon RDS for MySQLなどが考えられ、送信先はAmazon Redshiftとなります。パイプラインを作成すると、 ソースを指定します。この例ではAmazon Auroraを使用し、送信先としてAmazon Redshiftを設定します。パイプラインを設定した後、Zero-ETLは何を行い、どのような処理を自動的に行ってくれるのでしょうか?



まず最初に行われるのがデータのシーディングで、これはフルロードまたは初期ロードと考えることができます。 これはソースデータベースエンジンのスナップショットから実行されます。次に、Change Data Capture(変更データキャプチャ)の識別です。 ソース側でのデータの挿入、更新、削除、テーブルの追加、カラムの削除などの変更を検知します。これらの変更は拡張されたbinlogから検出され、Amazon Redshiftに複製されます。また、Amazon Redshift上でalterステートメントを使用することで、 特定のテーブルを再シードまたはフルロードすることも可能です。


お客様からよくある質問として、特定のスキーマ、 データベース、またはテーブルのみを複製したいというものがあります。Zero-ETLの設定では、データフィルターを適用して特定のパターンを含めたり除外したりすることで、複製するオブジェクトの数を制限することができます。こちらが Aurora PostgreSQLの例で、データベース、スキーマ、テーブルという階層でオブジェクトが表示されています。それに対応してRedshift側でも、データベース、スキーマ、テーブルが表示されます。ソース側で行が挿入されると、その変更がターゲット側に複製されます。ソース側でカラムが削除された場合も、同じ変更がターゲット側に反映されます。1つの統合で複数のスキーマ、データベース、テーブルを扱うことができます。Change Data Captureを実行する際には、チェックポイントを追跡することで、メンテナンス変更に対する耐性を確保しています。
Zero-ETLのユースケースとパターン



それでは、デモに進みましょう。事前に作成済みのAmazon Aurora PostgreSQLとAmazon Redshiftを使用します。このデモの手順を見ていきましょう。最初にRDSコンソールに移動します。この Aurora PostgreSQLデータベースには、departmentとnationという2つのテーブルがあります。Zero-ETL統合を設定する際、departmentのみを複製し、 nationを除外したいと思います。また、事前に作成されたAmazon Redshift ServerlessのZero-ETL namespaceもあります。





AWSコンソールを使用してパイプラインを作成していきます。Zero-ETL統合を作成しましょう。名前をAurora PostgreSQL Zero-ETL demoとして、次のステップに進みます。ここでソースを指定します。 互換性のあるソースのみが表示されます。ソースを選択した後、データフィルターを適用します。すべてのテーブルを含め、 nationテーブルを複製から除外するように設定します。次にターゲットを選択します。ターゲットとなるAmazon Redshiftは、同じアカウント内 または異なるAWSアカウントにすることができます。このデモでは同じアカウントを使用します。この設定中に、 不足している設定が識別され、「修正」をクリックすると、認可やリソースポリシーの作成、Amazon Redshiftの大文字小文字の区別の設定が行われます。




それでは確認して先に進みましょう。 タグを適用し、独自の暗号化キーを使用して暗号化設定をカスタマイズすることができます。 設定を確認した後、「次へ」をクリックしてZero-ETL統合を作成します。統合がアクティブになると、 ウィザードがAmazon Redshiftでのデータベース作成をガイドしてくれます。このデータベースは、すべてのテーブルが作成され、データがレプリケーションされる送信先として機能します。



それでは、Amazon Redshiftでデータベースを作成していきましょう。名前をZero-ETL DBとします。ソースはZero-ETL DBで、Amazon Redshift上のターゲットデータベースは任意の名前を選べますが、このデモではZero-ETL DBとしています。データベースが作成されるとすぐに、レプリケーション、シーディング、変更データキャプチャのプロセスが開始されます。コンソールでこの統合の状態を監視でき、ラグが5秒で、レプリケーションされたテーブル数が1つであることが確認できます。 また、テーブルの統計情報を確認すると、Departmentテーブルが同期されていることがわかります。



テーブルがAmazon Redshiftに作成され、データが同期されたので、Query Editor V2を使ってAmazon Redshiftにログインしてみましょう。 データベースエクスプローラーを開いてPublicスキーマをクリックすると、Departmentテーブルが利用可能になっているのが確認できます。Zero-ETLプロセスは、データ型の照合と変換を自動的に処理します。Departmentテーブルをクエリして、レプリケーションされたレコードを確認してみましょう。Zero-ETLの状態を監視するには、システムビューを使用できます。これにより、チェックポイントやその所要時間、挿入、更新、削除されたレコードの統計情報を確認できます。


次に、トランザクションのソースとしてNoSQLデータベース、具体的にはAmazon DynamoDBを使用し、送信先としてAmazon Redshiftを使用するシナリオを考えてみましょう。ソースとしてAmazon DynamoDB、ターゲットとしてAmazon Redshiftを選択すると、ウィザードはAmazon DynamoDBのポイントインタイムリカバリを有効にします。この統合ではDynamoDB Export APIを使用して、 Amazon Redshiftでの統合や増分更新を行う前に、データをAmazon S3にアンロードします。このアプローチにより、レプリケーション中にDynamoDBに影響が及ばないようになっています。



このプロセスでは、データの初期シードにDynamoDB Export APIを使用し、 その後、必要に応じて再シードのオプションを備えた変更データキャプチャを行います。この例では、パーティションキーがArtist、ソートキーがSong TitleであるMusicという名前のDynamoDBテーブルがあります。Amazon Redshiftに作成される対応するテーブルは同じ名前を維持しますが、Artistを分散キーとし、Song Titleをソートキーとして使用します。追加のDynamoDB属性はSuperデータ型を使用して列に格納されます。変更データキャプチャでは、再シードのオプションがあります。DynamoDB側のアイテムの例を見てみましょう: DynamoDBにはデータベースの概念がないため、1つの統合につき1つのDynamoDBテーブルを含めます。アイテムにはArtist、Song Title、Genre、Ratingフィールドが含まれており、これらはAmazon Redshift側でArtist、Song Titleの列と、半構造化されたJSON形式のデータを含むValue列として反映されます。

リレーショナルデータソースとNoSQLを比較する際、いくつかの重要な違いがあります。データフィルタリングのオプションでは、レプリケーションされるデータを制御するためのフィルターを適用できます。更新間隔については、リレーショナルデータベースでは0秒から5日まで、DynamoDBでは5分から5日までの範囲でレプリケーションの頻度を制御できます。この柔軟性は、常時レプリケーションが不要な場合や、1日1回のみデータをレプリケーションしたい場合に特に便利です。データがAmazon Redshiftに到着すると、Materialized Viewを含むRedshiftのすべての機能を活用できます。
テーブルの結合やデータの集計を行う際、このデータを物理的に保存するMaterialized Viewを作成できます。基となるテーブルが変更されると、Materialized Viewは増分更新され、パイプラインやELT統合の効率化に役立ちます。Zero-ETLテーブルは読み取り専用ですが、Redshiftでalter table文を実行してSort Keyを指定することで、スキャンパフォーマンスを向上させることができます。リレーショナルデータベースとNoSQLデータベースを比較する際の重要な考慮点として、レプリケーションのラグタイムがあります。リレーショナルデータベースでは数秒程度ですが、Amazon DynamoDBでは15〜30分かかります。

ここで、AWS Glueを使用してアプリケーションとSuccessアプリケーションがZero-ETLを実行できるようにする最近の発表について見てみましょう。出力先はAmazon RedshiftやAmazon SageMaker Lakehouseなど、お好みで選択でき、ストレージも自由に選べます。Amazon S3を選択した場合、テーブルはApache Icebergテーブル形式でレプリケートされ、AWS Glueにカタログ化されます。また、RedshiftのマネージドストレージをネイティブなZero-ETLとして使用することもできます。




それでは、デモを見てみましょう。 まず、AWS Glueのランディングページに移動し、Zero-ETL Integrationを選択します。Zero-ETL Integrationを作成し、 ソースとしてSalesforceを指定してから、nextをクリックします。AWS Glueでは、 Salesforceからデータを抽出するためのConnectionが必要です。Connectionを指定し、AWS GlueにIAMロールを付与した後、Salesforceから必要なエンティティの選択を開始します。まずAccountを選択します。コンソールでは、 スキーマのプレビューとデータのプレビューも表示されるので、データの内容を確認することができます。



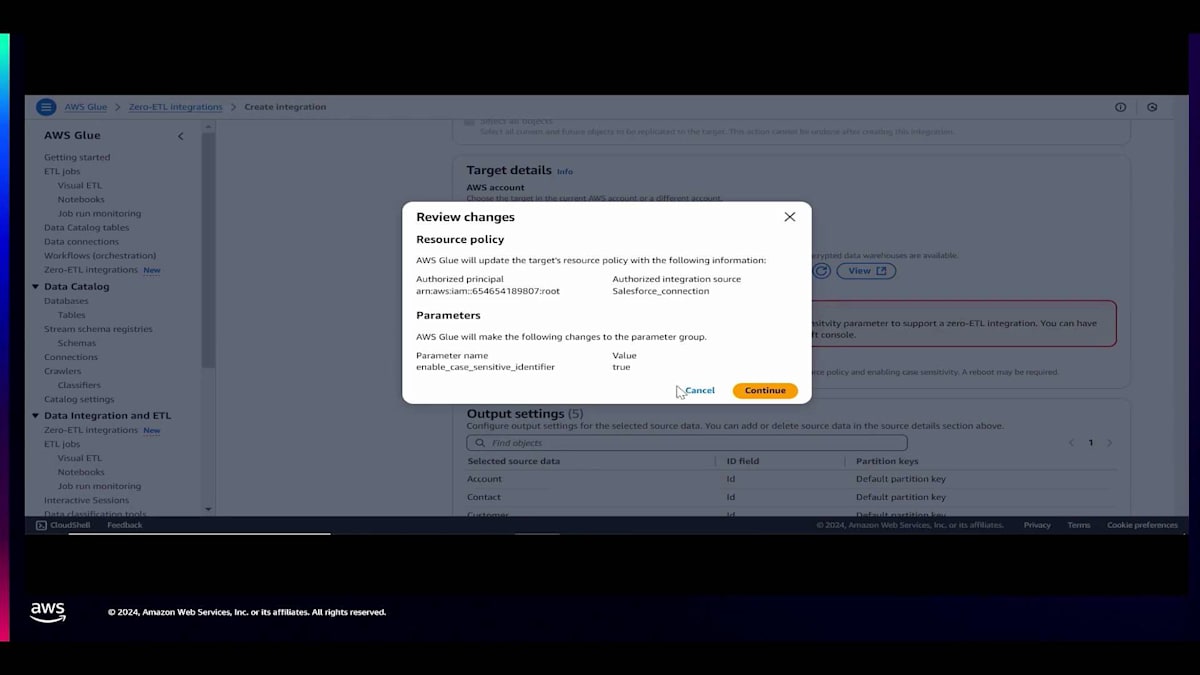

Accountを選択したら、 追加のエンティティとしてCustomer、Opportunity、Campaign、Contactを選択していきます。まずOpportunityを選択し、 続いてCampaign、そしてContactを選択します。これらを選択した後、出力先を選びます。 出力先は同じアカウントでも別のアカウントでも構いません。Amazon S3、SageMaker Lakehouse、またはAmazon Redshiftを使用できます。 システムが自動的に認可ポリシーを作成し、パラメータグループを設定します。このIntegrationに「salesforce-zeroetl-demo」という名前を付け、 nextをクリックします。設定内容を確認した後、このIntegrationを作成します。




統合が作成されると、アクティブなステータスが表示されます。ただし、Amazon Redshiftにデータベースを作成するまでレプリケーションは開始されません。 ウィザードの案内に従って、Amazon Redshift上に「salesforce」という名前のデータベースを作成していきます。 このデータのクエリを実行する前に、コンソールで統合の状態を確認します。 レプリケーションされたテーブル数は5つであることが表示されています。テーブルの統計情報を確認して、すべてのテーブルが同期され、Amazon Redshift上で利用可能になっていることを確認します。



Query Editorを通してログインし、データベースsalesforceのpublicスキーマを展開すると、このデータベースにレプリケーションされて作成された5つのテーブルが確認できるはずです。基となるデータやZero-ETLパイプラインが継続的にデータを更新・レプリケーションするため、これらのテーブルに対して分析の実行、統合の利用、またはデータの変換を開始することができます。 こちらが、レプリケーションされたテーブルからの単純なレコードの例です。 ここまでZero-ETL統合について、そしてリレーショナル、NoSQL、アプリケーションとどのように連携するかを見てきました。次は、お客様が実際にZero-ETLをどのように活用しているのか、そのパターンを見ていきましょう。
Motiveの事例:フリート管理におけるデータ活用


Amazon Redshiftを使い始めたばかりの場合や、リレーショナルな運用ソースをレプリケーションする必要がある場合は、Zero ETLを使用できます。このデータに対して変換を行う必要がある場合、つまりAmazon Redshift上に既に存在するテーブルを統合または結合したい場合は、Materialized Viewでの増分更新を使用するか、dbt、AWS Glue、Amazon EMRなど、お好みのツールを使用することができます。


例えば、注文データは既にあるものの、売上データをAmazon Redshiftにレプリケーションしたいといった具合に、データソースを追加する必要がある場合は、選択的に行うことができます。すべてのテーブルをレプリケーションする必要はないので、データフィルターを適用できます。 この例では、すべてのテーブルを含めつつ、プレフィックスが「external」の売上テーブルだけを特別に除外しています。


さらにデータソースを追加して、 Amazon DynamoDBも含めていきます。先ほど確認したように、DynamoDBの統合ラグは15分であるのに対し、リレーショナルソースの場合はゼロです。統合を実行する際は、データが同時に到着するようにする必要があります。リレーショナルソースから列やキーを参照してDynamoDBの属性と結合したい場合、パイプラインを構築するためには同時に同期される必要があります。このような場合、 Refresh Intervalを適用することで、レプリケーションを同時に実行することができます。この例では、1時間間隔を使用しています。



ここでは、アプリケーションからゼロETLを追加していきます。Salesforceのデモでは、CustomerとContactのテーブルを選択しましたが、これらには個人を特定できる情報を含む列があり、ユーザーがクエリを実行する前にマスキングや編集が必要です。これらのテーブルがAmazon Redshiftにランディングする際、Redshiftのロールベースのアクセス制御を使用して、これらのテーブルや列に動的なデータマスキングポリシーを適用できます。エンドユーザーがデータをクエリする際、そのロールに基づいてデータが編集されます。

次に、既存のETLパイプラインやソースがあり、このデータをレプリケートまたは取り込んで増分変更を適用したい場合を考えてみましょう。従来のプロセスでは、ソースからAmazon S3にデータを完全にアンロードし、Redshiftのテーブルを切り捨てて、毎晩フルロードを実行するかもしれません。あるいは、AWS Database Migration Serviceを使用して変更を取得し、EMRでデータを変換してからAmazon Redshiftに変更を適用したり、Debeziumを使用してKafkaでレプリケーション用の変更を取得したりするサーバーレスパイプラインを使用している可能性もあります。これらすべてがゼロETL統合によって簡素化できます。

データがAmazon Redshiftに格納されると、データ共有を含むすべての機能を活用できます。これにより、読み取りと書き込みの両方をスケールできます。AWS アカウント内のAmazon Redshiftデータウェアハウス間、AWSアカウント間、そしてAWSリージョン間でデータ共有を実行できます。データ共有を行う際は、セキュリティが確保され、データの重複がなく、データのライブなトランザクション整合性のあるビューを提供します。

ここまでをまとめてみましょう。リレーショナル、NoSQL、そしてアプリケーションからのゼロETL統合について確認しました。Amazon S3に到着するイベント駆動型データについては、Amazon Auto CopyやS3 Auto Copyを活用できます。例えば、特定のS3パスにある100個のファイルに対してCopyジョブを作成し、1時間以内に20個の新しいファイルを受信した場合、Auto Copyは新しく到着したファイルのみをロードし、Amazon Redshiftがチェックポイントを管理します。IoTやWebログなど、Amazon Kinesis Data Streams、Amazon Managed Streaming for Apache Kafka、あるいは独自のKafkaやConfluentセットアップを使用するイベント駆動型ソースがある場合、Amazon Streaming Ingestionがこれらすべてのソースと統合され、データはAmazon Redshiftに取り込まれます。
これらすべての機能と性能により、データサイロを解消することができます。データを統合し、統一されたビューを提供し、データ共有を使用してアナリティクスをスケールできます。異なるペルソナや異なる製品を使用するエンドユーザーにアクセスを開放できます。これが、Generative AIエクスペリエンスを構築するためのデータ基盤です。ここで、Motiveの取り組みについて、Paulにバトンタッチしたいと思います。
Motiveのデータアーキテクチャと課題

こんにちは。Motiveからまいりました。 Motiveでは、実体経済を支える事業を展開しています。私たちは幅広い製品とテクノロジーを提供していますが、その中心となるのが、AI Dashcam、全方位カメラ、そしてドライバーの行動や衝突検知を監視するセンサーです。社内で開発したAIモデルを使用し、AWSを基盤として、ドライバーの安全性とコーチングに重点を置いています。
このような大量のデータを活用して、大規模な車両管理を行っています。数万台規模の車両を保有する企業にとって必要不可欠な、安全性とコンプライアンスに関する情報を提供しています。これには位置情報の追跡やTelematics、走行ルート、そして支出管理が含まれます。私たちはクレジットカードを提供し、これらのフリート全体の支出を追跡・管理する機能を備えています。これが、本日お話しするテーマにつながります。

私は約20年間、グローバルSaaSの分野で仕事をしてきました。言葉にすると不思議な気分になりますね。プライベートでは、パラグライダーやフリーライドで少し冒険的なことにチャレンジするのが好きです。そのせいか、チームやテクノロジーの限界に挑戦することもあります。しかし実際のところ、これらすべてを実現しているのは、Motiveのプラットフォームチームとプラットフォームエンジニアリングです。インフラストラクチャーやSREのメンバーから、データベースエンジニア、セキュリティチーム、開発生産性を担当するDevOpsチーム、そして100万台以上の車両と連携するためにAWS IoT Coreを使用するIoTチームまで、すべてのメンバーが貢献しています。
私たちのアプリケーションアーキテクチャは、すべてのプロダクトサービスチーム、ライブラリと連携し、これらのイベントデータに関する車両ゲートウェイパイプラインを運用しています。MLプラットフォームチームとデータプラットフォームチームは、本日お話ししているような多くのテクノロジーを活用し、この取り組みを推進しています。

支出管理と取引処理に関して、フリート全体のデータを統合することの大きな利点の一つは、このデータを活用して不正を防止し、企業と私たち自身を保護できることです。位置情報を活用することで、カードの取引が車両やドライバーの予定位置の近くで行われているかを確認できます。また、燃料購入の申告があった場合、実際に燃料レベルが上昇したかどうかも確認できます。一見単純なことのように思えますが、これらを実現するにはデータと追跡の仕組みが必要なのです。
これを実現するために、私たちは2つの方法を採用しています:トランザクションが発生した時点でのリアルタイムブロッキングと、後ほど説明する理由でデータのタイミングに6時間以上かかる場合もあるバックグラウンド検出です。膨大なデータに対して広範なモデルトレーニングと分析を行い、戦略とテクノロジーを進化させることで、不正検出率と防止の改善を支援しています。

ソースデータに関して、私たちは主にPostgreSQLを使用しており、RDSを利用し、基本的にまだ移行していないものすべてをAuroraに移行しているところです。燃料関連のイベントやトランザクションデータはすべてPostgreSQLに格納されています。重要ではありますが、最初は11テラバイトという控えめなユースケースから始めました。現在では数百テラバイトのものもあり、1日あたり約1ギガバイトのペースで増加しています。これらのテーブルやカラムには、VARCHAR(65,000文字未満という制限があります)やタイムスタンプなど、さまざまなデータ形式があります。また、複数のDynamoDBテーブルも使用しており、この場合は主にJSONの位置情報データである場所のメタデータやその他のプロファイリングデータを格納しています。参考までに、主要な位置情報データは300テラバイトに迫っています。Zero-ETLには100テラバイトの制限があります。
現時点ではデータが大きすぎるため、おそらくOpenSearchに移行する予定です。では、私たちのケースではどのような状況なのでしょうか?

多くの組織と同様に、自然な成長に伴ってデータは広く分散しています。上部にサービス用のリレーショナルデータがあり、下部にデータプラットフォーム層があります。ご覧のように、ソースからデータを取得するための方法が複数存在します。時間の経過とともに、RedshiftでS3から基本的なローディングを行うものから、外部の大規模なデータウェアハウスにデータを取り込むためのAirflowジョブ、さらにはKafkaのSync Connectorまで、さまざまな方法を採用してきました。PostgreSQLやDynamoDBなどのソースを接続するために外部のConnectorベンダーを使用し、その後、より良い考えのもとDebeziumの展開を開始しました。すべてがコンテナ化されコード化されているとはいえ、Debeziumのセットアップにはかなりの手間がかかります。データを取得するための方法が多数あるのです。この点線に注目していただきたいのですが、高頻度・低レイテンシーのトランザクションでは、アプリ内のユースケースでは外部ウェアハウスを使用できないため、外部ウェアハウスからPostgreSQLにデータを送り返すこともあります。つまり、データを移動させた後でも、使用するためにはデータを戻さなければならないことがあるのです。これはまさにジャングルと呼べるでしょう。

ご覧の通り複雑さがあり、特にこれだけの量のデータを移動させるとコストが制御不能になります。すべてのユースケースにおいて、データ移動だけでもネットワークコストは膨大で、ベンダーやConnectorの運用などは言うまでもありません。これらのプロセスの実行間隔は、PostgreSQLテーブルの場合、30分間隔で設定されていても実際の実行に18分かかるため、約50分かかります。そしてDynamoDBテーブルの場合は現在、ほとんどのものが3時間から6時間かかっています。メンテナンスは膨大で、Connectorのチューニングやサイジングが必要です。Debeziumのセットアップには複数のチーム(データプラットフォームチームとデータベースエンジニア)が関与し、レプリケーションスロットを設定し、実際に機能することを確認するために全員が協力する必要があります。可視性についても、テーブルが失敗したかどうかだけで、実際のレイテンシーがどうなっているかは後になってわかります。これまでのところ、多くの課題が存在しているのです。
Zero-ETL導入による劇的な改善とMotiveの今後

私たちの目標は明らかにシンプル化することです。実行する必要のある同期メソッドが少なければ少ないほど、やるべきことが減り、問題が発生するリスクも下がります。ストリーミングにもっと力を入れる必要があります。エンタープライズのお客様は、6時間以上かかるのではなく、よりリアルタイムにデータとレポートを求めています。そして当然ながら、不正検出はできる限り迅速に行う必要があります。直接アプリケーションでの利用をサポートし、データを再度移動させる必要がなく、高頻度のケースでもアプリ内で使用できるようにする必要があります。コスト削減ができれば、それは常にボーナスです。ビジネスにとっても良いですし、優先順位を上げることでプロジェクトの優先順位付けやコラボレーションの促進にもつながります。

Zero-ETLが救世主となります。これについて聞いたとき、とても魅力的でした。 詳しく見ていきましょう。私たちが使用している Aurora RDS、PostgreSQL、Redshift など、すべてと緊密な統合が可能です。データが3つの異なる場所にあり、いくつかの外部にもあって、誰がどのデータにアクセスできるかを心配する必要がないため、コンプライアンスも容易になります。実際にセットアップを始めると、その簡単さが分かってきました。デモでご覧いただいたように、セットアップ手順をガイドしてくれます。
Point-in-time Recoveryが設定されていない場合に識別し、リスクがある場合に警告を出し、必要な権限を示し、実際に問題を修正することもできます。これにより、データプラットフォームチームだけでなく、データベースエンジニアにとっても、誰でも本当に簡単にセットアップできるようになりました。専門家数人に頼る必要がなくなりました。また、デモで見たIncludesとExcludesによるフィルタリング機能は、私たちにとって特に価値がありました。将来のテーブルを含められることは重要で、個々のテーブルを追加するための継続的なリクエストがなくなり、すべてを同期状態に保つための作業負荷が減り、時間を節約でき、皆が幸せになります。


もう一度ジャングルを見てみましょう。 これが私たちが対処してきた状況です。そしてZero-ETLを実装した後、この魔法のような変化で単純化されました - 多くのものが取り除かれ、それ自体が雄弁に物語っています。PostgreSQL、MySQL、DynamoDBを直接接続するだけで、データが表示されます。Amazon MSKに移行するにつれて、それを直接接続でき、S3へのロードや同期コネクタなど、他の多くのものが不要になりました。この単純化は本当に素晴らしく、図がシンプルになったことを嬉しく思います。

結果は印象的です - 4つの同期メソッドが1つになり、これは大きな進歩です。専門知識も必要ありません - データベースの専門家やコネクタチューニングの専門家は必要ありません。レイテンシーの改善も大きく、40-45分から15-30秒に短縮され、このようなパフォーマンスを達成するためのチューニングは必要ありません。DynamoDBの3時間以上かかっていた同期が今では15-20分になりました。これは私たちのデータニーズにとって大きな進歩であり、6時間の遅延を考慮する必要がなく、よりリアルタイムにレポートを作成したり、データを使用したりする可能性が開かれました。つまり、これはレイテンシーの改善だけでなく、機能面での勝利でもあるのです。
必要な労力は大幅に削減されました。プロビジョニングは、デモでご覧いただいたように非常にシンプルです。可視性も劇的に向上しました。以前は、何かが壊れたり動作しなかったりした時にしか分かりませんでしたが、今では遅延時間や行数などのメトリクスが分かり、CloudWatchのすべてのモニタリングソリューションに統合できるようになりました。すべてが簡単になり、より可視化されたことで、データの欠落を報告されるのを待つのではなく、プロアクティブにモニタリングできるようになりました。コストに関しては、シンプル化とデータ移動の削減が自然とコスト削減につながります。これらの比較的小規模なユースケースでも、コネクターやデータ転送のコストが不要になったことで、月額約1万ドルの節約になっています。Warehouseへのデータロードのための計算コストもなくなり、DynamoDBのリーダーユニットやAmazon RedshiftのCPUを消費することもありません。AWSがどのように処理しているのかは分かりませんが、私にとってはまさに魔法のようで、ビジネスにコスト削減をもたらしています。

私たちの次のステップは何でしょうか? 実際のところ、すべてをZero-ETLにすることです。コスト削減だけでなく、その機能性のために、すべてをAmazon MSKに移行しています。移行するものすべてがこの機能を獲得し、それによって私たちにとって作業量の削減とデータの高速化という新しい世界が開かれます。PostgreSQLについては、私たちの環境の大部分がPostgreSQLなのですが、Zero-ETLを使用するには最新のマイナーバージョン16である必要があります。そのため、どのみちアップグレードする必要があり、今や多くのアップグレードを行う良いインセンティブができました。
ユースケースについて話すと、私たちのメインの車両メッセージパイプラインは、毎秒200メガバイト以上を処理する30テラバイトのKafkaトピックです。これは私たちにとって非常に大きな案件になるでしょう。メッセージパーサーやS3へのダンプ、外部WarehouseのAmazon Redshiftへのダンプなど、すべてにAmazon Managed Service for Apache Flinkを先行させることで、Kafkaに入るデータを望む形式にできるようになり、Zero-ETLで出力する際に何も変更やチェックを必要としなくなります。
Zero-ETLによる魔法のような転送を実現するために、データを準備する必要があります。このPOCと実行を通じて、データのロード、コピー、転送などが不要になることで、年間約75万ドルの節約になる見込みです。これは本当に素晴らしい技術で、コスト削減と運用の容易さをもたらします。数字の面から見てもプロジェクトの最優先事項となりますが、レイテンシーの改善によるビジネスへのメリットはさらに大きいものです。
プレビューしたAmazon SageMaker Lakehouseが正式にGAになったことを知り、とてもワクワクしています。Apache Icebergによって移行が容易になるため、これは素晴らしいことです。データをAmazon Redshiftに移行して再構築するユースケースでは、まだ移行していないデータソースにアクセスする必要がある分析もあります。Icebergを通じてデータを公開することで、どちらの場所からでもクエリを実行できるため、段階的な移行が可能になります。すべてを準備して一度に大規模な切り替えを行う必要がありません。共有テーブルやZero-ETLテーブルをIcebergを通じて公開できることで、このプロセス全体がより簡単になり、私たちにとってストレスの少ないものとなります。
データの品質については、こういった話をする度に必ず質問が出ます。私たちの場合、Open Metadataを立ち上げたばかりです。Zero-ETL統合によってネイティブに行数の可視性を得られているものの、Open Metadataを立ち上げることで、データの系統関係のための実際のデータ品質チェックを開始しています。これにより、確実性を最終的に高めることができます。また、さらなるレベルアップのためにも、これを導入する必要があります。しかし、これは非常にエキサイティングな取り組みで、大幅なコスト削減につながり、私たちの作業も大幅に減らすことができます。そのため、これらすべてを実現するためのアップグレードを喜んで行っています。

チームワークが重要です。今回は少し魔法のような要素もありましたが、本当に大切なのはチームです。Motiveのチーム、特にデータプラットフォームチーム、Tianyao Zhangさん、そしてデータベースエンジニアの皆さんに大きな感謝を捧げたいと思います。また、この実現に関わった他のすべてのチーム、そして最新情報を提供し、プレビューへのアクセスを可能にし、多くのPOCでサポートしてくれたAWSチームにも感謝します。皆さんのおかげで、私たちはより簡単にこれらすべてを実現することができました。このように夢を現実のものにしてくれた皆さんに、心から感謝申し上げます。

ご清聴ありがとうございました。可能な方はぜひアンケートにご協力ください。QRコードがどこかにあるはずです。モバイルアプリのどこかにQRコードがあります。本当にありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion