re:Invent 2024: AWSファイルストレージの新機能 - FSx、EFSの進化
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - What’s new with file storage (STG211)
この動画では、AWSのファイルストレージサービスの最新機能について、FSx Managed NASサービスを率いるPrashanth BungaleとChristian Smithが解説しています。Amazon FSx for OpenZFSの新機能として、S3 Intelligent-Tieringと同様の自動階層化機能を持つFSx Intelligent-Tieringストレージクラスの導入や、Amazon EFSの読み取りIOPSを250,000から250万IOPSへ10倍に向上させる性能改善などが紹介されています。また、EFS BackupのLogically Air-Gapped VaultやEFSのクロスアカウントレプリケーションなど、データ保護に関する新機能も発表されており、AWSのファイルストレージサービスが、データ管理、パフォーマンス、レジリエンスの3つの領域で着実な進化を遂げていることが分かります。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
AWSファイルストレージサービスの概要

ファイルストレージの新機能についてご紹介いたします。私はAWSのFSx Managed NASサービスを率いるPrashanth Bungaleです。本日は、AWSのワールドワイドストレージスペシャリストGTMチームを率いる同僚のChristian Smithと共に、Amazon EFSとAmazon FSxという2つのストレージサービスに関する、この1年間の発表内容とre:Inventウィークでの新しい発表についてお話しさせていただきます。

まずは、AWSでファイルワークロードとファイルストレージのお客様をどのようにサポートしているかを簡単に振り返ってみましょう。私たちは、ファイルストレージの利用パターンを主に3つ確認しており、それぞれに対応したソリューションを提供しています。1つ目は、クラウドでNASを必要とするユーザー共有やエンタープライズアプリケーションで、これにはFSx Managed NASサービス群で対応しています。2つ目は、HPCやAI、MLなど、コンピューティングの性能要件に対応できる高性能ストレージを必要とする計算集約型ワークロードで、これにはFSx for Lustreで対応しています。そして3つ目は、シンプルなクラウドファイル共有を必要とするクラウドネイティブアプリケーションや開発者向けで、これにはAmazon EFSで対応しています。
Amazon FSxの多様なファイルシステムとユースケース

それでは、これらの領域について1つずつ詳しく見ていきましょう。まず、ユーザー共有とクラウドでNASを必要とするエンタープライズアプリケーション向けのファイル共有については、Amazon FSxで様々なNASファイルシステムを提供しています。お客様は、オンプレミスの既存NAS環境を、同じ機能とAPIを持つクラウド上の同等のストレージに移行する際にこれらのファイルシステムを使用します。AWS上でNetApp ONTAPやWindows File Service、ZFS、Linuxファイルサービスなどの同等の環境を構築できることで、お客様はアプリケーションの再設計やユーザーの再トレーニング、ワークロードの再認証、ワークフローやプロセスの再構築を行う必要がありません。

次に、大規模な並列計算集約型ワークロードについては、Amazon FSx for Lustreを提供しています。これは、世界で最も人気のある高性能ファイルシステムであるLustreをベースに構築されており、増え続けるコンピューティングの要件に対応できる高速でシンプル、かつコスト効率の良いストレージを提供します。FSx for Lustreは、サブミリ秒の低レイテンシーを維持しながら、膨大なレベルの性能にスケールアウトすることができます。つまり、1つのファイルシステムに何十万ものコンピュートコアをマウントし、そのコンピューティング規模にストレージを提供できるということです。FSx for Lustreは、石油・ガスのシミュレーションから金融分析、さらには生成AIモデルのトレーニングやファインチューニングを含む最新のML/AIワークロードまで、様々な高性能コンピューティングのユースケースで使用されています。また、FSx for Lustreには、S3上の既存データに簡単に接続できる機能も備わっています。

3つ目の領域については、Amazon EFSを提供しています。これは、ストレージの設定や各種パラメータ、必要なストレージ容量やパフォーマンスの設定、それらの構成方法などを気にする必要のない開発者やビルダーのようなお客様向けの、とにかく簡単に使えるストレージです。ストレージもパフォーマンスも設定不要で、コンピュートインスタンスからコンテナ、サーバーレス関数まで、あらゆる最新の統合機能を提供します。さらに、自動階層化と複数の低コスト階層によって、コスト最適化されたストレージを実現しています。

これら3つの分野において、前回のre:Inventから今年のre:Inventまでの間に、20以上の機能をリリースしてきました。そして今週、さらに6つの新機能をリリースする予定です。このペースからお分かりいただけると思いますが、私たちは平均して2週間に1回のペースでイノベーションを続けています。
このイノベーションのペースは平均的なものです。これらの機能の一部をご紹介できることを楽しみにしています。本日は全ての機能についてご説明する時間はありませんが、ファイルストレージの提供についてご理解いただく上で役立つと思われるいくつかの機能について詳しくご説明させていただきます。
データスプロール管理とFSx for OpenZFSの新機能

私たちは、ファイルワークロードの分野でお客様にとって最も重要だと認識している3つの領域に継続的な投資を行っています。1つ目はデータスプロールの管理です。これは、データの規模が拡大する中で、お客様がすべてのデータを管理し、成長を管理し、コストを管理し、そして増大するデータセットの回復力を管理する必要性に関するものです。2つ目は、パフォーマンスのスケーラビリティに関するもので、アプリケーションのパフォーマンス要件が増大し続ける中で、ストレージがこれまで以上にコンピューティングに追従する必要があるということです。最後の領域は回復力に関するもので、回復力、コンプライアンス、高可用性の確保をお客様の手から離れ、自動的に組み込まれるようにすることに焦点を当てています。

まず、データスプロールの管理という最初の領域について詳しく見ていきましょう。 先ほど申し上げたように、私たちはAmazon FSxを構築し、お客様がオンプレミスで運用しているNetwork Attached Storageと同等のNAS機能を提供するさまざまなファイルサービスを提供しています。興味深いことに、特にAmazon FSx for OpenZFSに関して、お客様は以前ZFSやLinuxファイルサーバー、その他のオープンソースNASデプロイメントでオンプレミスに保存されていたデータセットだけでなく、さまざまなオープンソースや商用NASデプロイメントに以前保存されていたデータセットの保存先としてもこのサービスを選択しています。

お客様がワークロードのニーズにAmazon FSx for OpenZFSを選択する理由は、主に次の3つのカテゴリーに分類されます。 第一に、OpenZFSはスナップショット、クローニング、圧縮、レプリケーションなど、広範なNAS機能を提供しており、これらはすべてお客様のエンタープライズアプリケーションのニーズとコンプライアンスのニーズを満たすために不可欠です。お客様は、オンプレミスの代替デプロイメントで行っていたことが、OpenZFSが提供する重要なNAS機能により、Amazon FSx for OpenZFSでも実現できることを発見されています。第二に、お客様は可能な限り低いレイテンシー、高いスループット、高いIOPSという点で、非常に高いパフォーマンスを必要としています。OpenZFSは高性能を目的として設計されており、数百マイクロ秒のレイテンシー、最大20ギガバイト/秒のスループット、100万IOPSを提供します。最後の領域はライセンスコストに関するもので、OpenZFSはオープンソースであるため、商用ライセンス製品と比較して30%以上優れた価格性能比を提供します。

これまで私たちは、Amazon FSx for OpenZFSが提供するオールSSDストレージ、オールフラッシュストレージ上で、幅広い高性能アプリケーションを展開しているお客様を見てきました。OracleやPostgreSQLなどのデータベースワークロードから、Perforceを使用したゲーム開発、さらにはビデオストリーミングや特殊効果レンダリングなどのメディア・エンターテインメントまで、実に様々です。オールフラッシュストレージの恩恵を受けられる高性能アプリケーションは、非常に広範囲に及んでいます。

お客様がAmazon FSx for OpenZFSにワークロードを展開していく中で、より幅広いワークロードをこのサービスに移行したいというニーズが高まってきました。しかし、お客様から一貫して聞かれるフィードバックは、オンプレミスでHDDストレージ(オールHDDまたはHDDとSSDのハイブリッド)を使用している大規模なデータセットを移行する際に、オールSSDストレージのコストが障壁になっているということです。
より魅力的なトータルコストが必要な大規模データセットにとって、現状のコストポイントでは採算が合わないのです。データセットは様々な理由で、かつてないスピードで増大しています。お客様は、最新のGenerative AIや機械学習アプリケーションからデータ分析や可視化まで、あらゆる手法を用いて、データの新しい活用方法や処理方法を見出しています。これらの進歩により、お客様はデータをより長期間保持するようになり、コスト最適化と効率的なデータ管理の重要性がさらに高まっています。
AI/MLワークロード向けFSx for Lustreの性能強化
お客様から聞かれる3つ目のフィードバックは、多くのデータセットの成長パターンが予測不可能だということです。今日の大規模データセットは、数週間の処理後にその大部分が破棄され、一部のみが保持される場合もあれば、長期保存が必要になる場合もあります。このようにデータの増減が予測できないため、キャパシティプランニングがお客様にとって非常に困難な課題となっています。数日後、数週間後に必要となるストレージ容量を決定することができず、この不確実性や予測不可能性により、ストレージ容量の計画と準備が大きな課題となっているのです。

これらの課題を踏まえ、私たちは一歩下がって現在提供しているサービスを見直し、お客様が移行したいと考えている大規模で成長を続けるデータセットに関する課題を解決するために、どのような追加機能が必要かを検討しました。私たちはすでに、お客様が必要とする機能性に合致したNAS機能、高性能アプリケーションに必要なパフォーマンス、そしてAWSエコシステムとの統合(コンピューティングやコンテナとの統合から、可観測性やその他のAWSエコシステムサービスとの統合まで、すべてを含む)を提供していました。

同時に、お客様からいただいたフィードバックにある追加の課題に対応するには、すでにクラウドネイティブなストレージサービスで解決されている問題にも取り組む必要がありました。クラウドネイティブなストレージサービスとは、オブジェクトストレージのAmazon S3、ファイルストレージのAmazon EFS、キーバリューストアのAmazon DynamoDBなどを指します。これらのサービスに共通しているのは、ストレージを事前にプロビジョニングする必要がない完全な弾力性を持つという、AWSならではのメリットです。データの増減に応じてストレージが自動的に対応してくれるのです。また、高性能で高価なストレージだけでなく、さまざまな価格帯とパフォーマンスニーズに対応する幅広いストレージオプションを提供しています。さらに、これらのティア間で自動的にデータの階層化を行うため、お客様はデータの配置場所やアクセス頻度を気にする必要がありません。サービスが自動的に低頻度アクセスデータを検出してコールドストレージに移動し、頻繁にアクセスされるようになると再びホットストレージに戻します。

そこで私たちは、クラウドにおけるNASの在り方を一から見直すことにしました。お客様のワークロード、アプリケーション、ユーザーが慣れ親しんだNASの機能をすべて維持しながら、クラウドネイティブなストレージサービスで提供している基本的なAWSのメリットも同時に享受できる、そんな理想的な環境を実現できないかと考えました。


そして、まさにそれを実現したのが、今回のre:Inventで発表する新しいサービスです。2日前から利用可能になったAmazon FSx for OpenZFSの新しいストレージクラスの発表をさせていただきます。FSx Intelligent-Tieringストレージクラスと呼ばれるこの新機能は、使い慣れたNASの特徴とAmazon S3ストレージのような完全な弾力性とインテリジェントな階層化を組み合わせたものです。この新しいストレージクラスは完全な弾力性を備えており、 ファイルの追加や削除に応じてデータセットに合わせてストレージが自動的に拡大・縮小します。


S3 Intelligent-Tieringと同様に、このストレージクラスは頻繁にアクセスされるティアと、 低頻度アクセスティア、アーカイブティアの間で自動的にデータを移動します。NASデータセットに最適なコストとパフォーマンスを実現できるよう設計されており、より幅広いワークロードや大規模なデータセットをクラウドに移行することが可能になります。さらに、AWSの豊富なサービスを活用してデータをより効果的に活用することができます。

この新しいストレージクラスには、S3 Intelligent-Tieringと同様に、Frequent Access(頻繁アクセス)、Infrequent Access(低頻度アクセス)、Archive Instant Access(アーカイブ即時アクセス)の3つのティアがあります。コールドデータ向けに2つの低コストティアを提供していますが、データがどのティアにあっても常に即座にアクセスと取得が可能です。どのティアでも最初のバイトのレイテンシーは数十ミリ秒です。また、基盤となるストレージのレイテンシーからアプリケーションやユーザーを保護し、すべての書き込みで約1ミリ秒の最初のバイトレイテンシーを実現するために、SSDライトログを内蔵しています。このSSDライトログを使用することですべての書き込みが高速で行われ、さらにレイテンシーに敏感なワークロードやIOPS集約型のワークロードのために、頻繁にアクセスされるデータの低レイテンシー読み取りを実現するオプションのSSDリードキャッシュも提供しています。

このオプションのSSD読み取りキャッシュは、お客様のニーズに応じてカスタマイズ可能です。アプリケーションがキャッシュアクセスの恩恵を受けられない場合は、キャッシュを全く使用しないという選択もできます。一方、キャッシュが有効な場合は、選択したスループット容量に基づいてサービスが自動的に設定するデフォルト値を使用するか、アクティブな作業セットとキャッシュサイズの要件が既にわかっている場合は、カスタマイズすることもできます。
料金設定はS3 Intelligent-Tieringと同じです。これは私たちが皆様と共有できることを嬉しく思う重要なメリットです。保存データについては、データが配置されているTierに応じてギガバイト単位で月額料金が発生します。画面に表示されている価格はUS East-1リージョンのものです。S3 Intelligent-Tieringをご利用の方にはお馴染みの数字だと思います。これはS3と全く同じ料金だからです。また、データを自動的にTier間で移動する監視と自動化の機能に対して少額の料金が発生します。この場合、S3のようにオブジェクト単位ではなく、ギガバイト単位で月額の監視・自動化料金をお支払いいただきます。
データアクセスに関して、これまでFSxではSSDストレージに対して特定のIOPS数をプロビジョニングする必要がありました。しかしIntelligent-Tieringでは、事前に特定のIOPSやI/Oアクティビティを確保する必要のない、エラスティックな体験を実現しました。このストレージは、必要に応じて読み取りリクエストと書き込みリクエストを処理します。ファイルシステムがサポートする制限まで、ワークロードが必要とする数だけ実行でき、完全にエラスティックな形で読み取りリクエストと書き込みリクエストごとに料金が発生します。
Amazon EFSのパフォーマンス改善と新機能

それでは、パフォーマンスのスケーラビリティに関する新機能の発表に移りましょう。私はChristian Smithと申します。ファイルストレージのワールドワイドGo-to-Marketチームを率いています。ちょっとした余談ですが、私はファイルストレージの分野で約22年間働いてきました。そして今朝、追い打ちをかけるように、 AARPへの入会を勧めるBlack Fridayのお得な案内が届きました。AARPをご存知の方なら、私がこの仕事をどれだけ長くやってきたかお分かりいただけると思います。
AARPというのは、ある年齢に達すると加入できるもので、シニア向けの割引が受けられる組織です。まだそんな年齢ではないと思いたいのですが、パフォーマンスのスケーラビリティに関する発表について話を進めましょう。これから、私たちが取り組んでいるとてもエキサイティングな内容についてお話しします。この中で、High-Performance ComputeやMachine Learningで、大容量メモリインスタンスやGPUインスタンスを多用されている方はいらっしゃいますか?

Prashanthは既にFSx for Lustreについて説明しましたが、FSx for Lustreはスケーラブルなコンピューティングの高性能ニーズに対応する、スケールアウト型の高度な並列ファイルシステムです。私たちはこれを、数千ギガバイト/秒のスループットをサポートし、数百万IOPSを実現しながら、サブミリ秒の遅延で処理できるスケールアウトファイルシステムとして捉えています。Prashanthが説明したように、FSx for Lustreには多くの一般的なユースケースがあり、S3バケットとの連携機能により、S3バケットに保存されているデータの利用範囲を広げ、そのデータの処理をスケールアウトして高速化することができます。

FSx for Lustreは多くのユースケースをカバーしており、より多くのお客様がLustreを使用してアプリケーションをスケールアウトし、HPCアプリケーションを実行し、AWSが提供するコンピューティングリソースにアクセスするためにAWSを利用するようになっています。しかし、メタデータを集中的に使用するHPCアプリケーションのカテゴリーがあります。基本的に、メタデータ集中型ワークロードとは、データに関するデータへのアクセス方法のことです。ファイルの作成やメタデータの読み取り、つまりファイルやディレクトリに関するデータの読み取りなどが含まれます。これまで、このようなメタデータ集中型ワークロードに適したアプリケーションは一部存在し、AWSでの実行に課題を抱えていました。
これらの課題が存在した理由は、メタデータリソースやメタデータIOPSを割り当てる際、割り当てられたストレージ容量に比例していたためです。つまり、計算化学やML研究のように数百万から数十億の小さなファイルを扱うメタデータ集中型ワークロードや、ビジュアルシミュレーションや気象関連のワークロードでは、この課題に直面していました。メタデータIOPSが不足してGPUやCPUが待機状態になり実行時間が長くなるか、必要なメタデータIOPSを確保するためにストレージを過剰にプロビジョニングする必要がありました。



これは年の半ばに発表した内容ですが、非常に重要な発表なので、皆様に確実にお伝えしたいと思います。現在では、メタデータIOPSのプロビジョニングをストレージ割り当てから切り離すことが可能になり、これにより従来のバージョンと比較して最大15倍高いメタデータIOPSを実現できます。Lustreをご存じの方なら、この機能はDistributed Namespace(DNE)と呼ばれる機能をベースにしていることがわかるでしょう。これによりメタデータ操作をストレージ容量とは独立して水平方向にスケールすることができ、ファイルシステムごとに数十万のメタデータIOPSをサポートすることが可能になります。


これは単にこれだけのIOPSをサポートするということだけではありません。より高速な結果が得られ、CPUを効率的に稼働させ続けることができます。また、追加リソースのために余分な支払いが発生することもなく、ワークロードに合わせて適切なサイジングが可能になります。この変更がどのようなものかを具体的に示すと、これがFSx for Lustreの導入前後の制限値です。例えば、ファイル作成操作は現在、1秒あたり最大400,000件のファイル作成をサポートしています。これは、大きなファイルを小さなファイルに分割し、それらの小さなファイルを複数のコアに分散して計算させる場合に非常に重要です。ファイルの存在確認や変更の有無を確認するファイルstatオペレーションは、ワークロードがマルチステージの場合の同期作業によく使用されます。ファイル読み取り操作については、1秒あたり300,000件のファイルメタデータ読み取り操作が可能になり、これは7倍の改善です。これにより、高度に分散化されたコンピューティング環境での同期や調整の一環として、ファイルやフォルダのメタデータを読み取り、ファイルシステムの変更を確認する能力が向上しました。

次に、AIストレージについてですが、これはHPCとよく似ています。違いは、機械学習のトレーニングや微調整を行い、世界を席巻する次のLLMを作成するために、数千のGPUインスタンスを使用するという点です。
HPCワークロードの要件を理解する必要があります。これらのワークロードでは、データセットを繰り返し読み取るデータパターンが含まれるため、非常に低いレイテンシーが必要です。トレーニング実行中、すべてのGPUインスタンスからストレージにチェックポイントを書き込んでいきます。ここで、Amazon FSx for Lustreの共有ストレージ機能が重要になります。すべてのノードでデータを利用可能にし、GPUが必要とする速度を維持して、フルスケールで最適なパフォーマンスを実現できるのです。

GPUは高価であり、GPUのアイドル時間は直接的に実費用、トレーニング時間の長期化、反復回数の減少につながります。そのため、現在ファインチューニングを行っている組織のほとんど、というかすべてが、何らかの形でLustreを使用してGPUを最大限に活用し、結果を得るまでの時間を短縮しています。しかし、GPUは進化し続けており、これは新しい高度なコンピューティングオプションである P4dインスタンス、Trainum One、本日GAが発表されたばかりのTrainum Two、P5やC6などで見られます。これらはデータとデータスループットに対してますます厳しい要件を持っており、ストレージがボトルネックとなってトレーニング時間が延長されることは避けたいところです。


今回のre:Inventで、2つの新しいアクセラレーション機能を発表します。1つ目はElastic Fabric Adapter (EFA)のサポート、2つ目はNVIDIA GPUDirectのサポートです。これらの2つの機能により、インスタンスごとのスループットが最大12倍まで加速され、FSx for LustreはクラウドにおけるGPUインスタンス向けの最速のストレージパフォーマンスを実現し、AI/MLトレーニングジョブをより速く完了させ、ワークロードコストを削減できるようになりました。
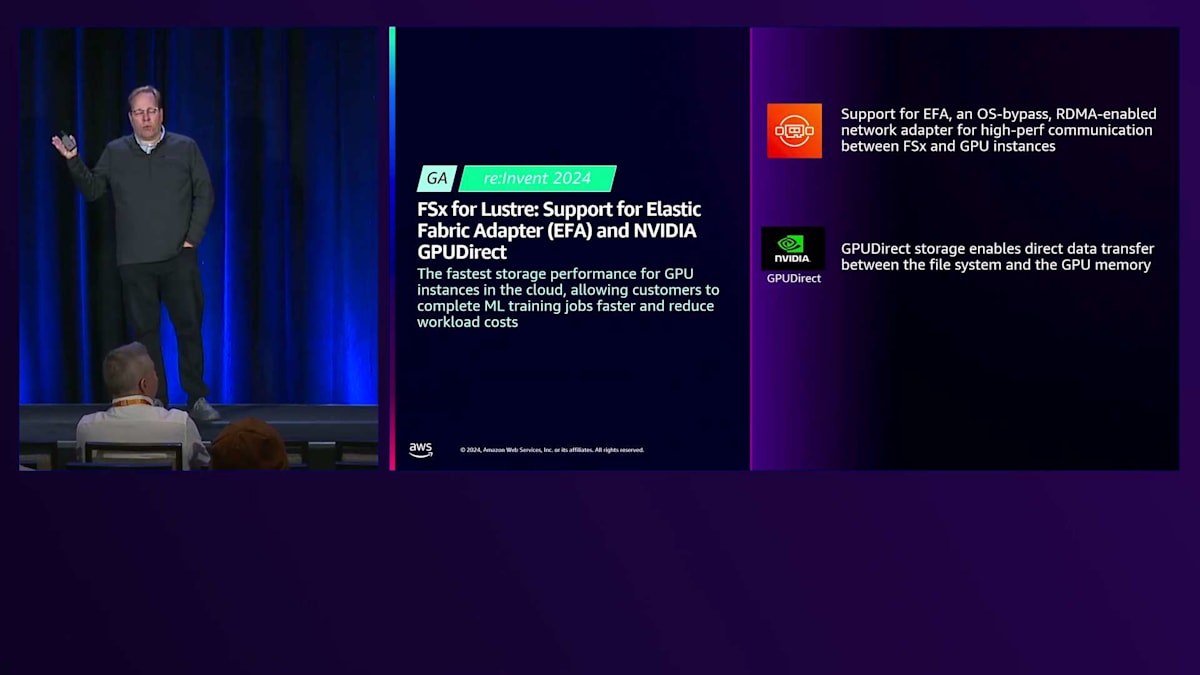
EFAについて説明しましょう。SRDプロトコルをご存知の方もいると思いますが、これは過去2年間提供してきたもので、CPUとGPUインスタンス間の軽量なインターノード通信プロトコルで、低レイテンシーで高性能な通信を可能にします。今回、FSx for LustreがSRDプロトコル(Scalable Reliable Datagramプロトコル)を使用してこのネットワークに参加することで、ネットワークカードからメインメモリへのRDMAを使用してパフォーマンスを向上させ、ホストOSバッファをバイパスしてアプリケーションにデータを供給できるようになりました。

NVIDIA GPUDirectは、データをネットワークインターフェースから直接転送し、CPUコンプレックスやメモリを完全にバイパスして、GPUに直接データを読み込むことを可能にします。これは、GPUインスタンスで多くのワークロードを実行する際に重要です。なぜなら、CPUがネットワークインターフェースからメインメモリ、そしてGPUへとデータを移動させるだけで相当な作業を行っており、これがトレーニング環境のボトルネックとなる可能性があるためです。これらの2つの機能により、NVIDIA搭載のGPUコンプレックスにおいて、100 Gbpsから1,200 Gbpsへと12倍の向上を実現しています。
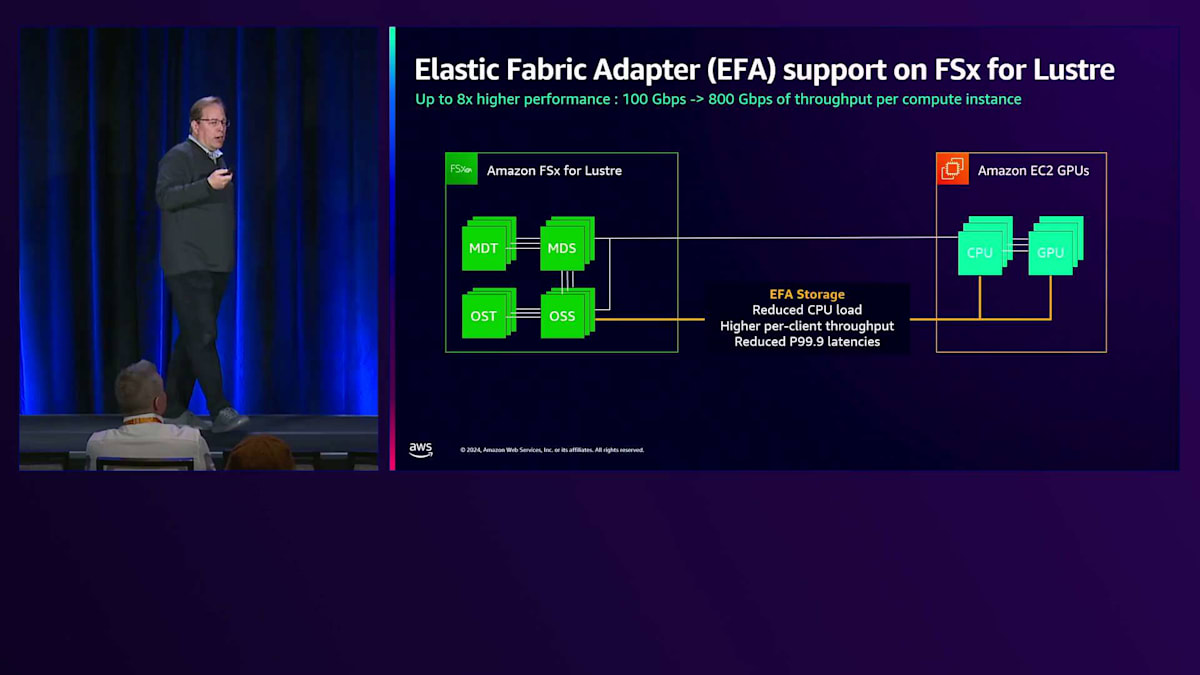

この仕組みについて説明させていただきます。まず、EFAについてですが、これは高性能なM、R、Cインスタンスを含む私たちのコンピュートインスタンスで動作し、ネットワークインターフェースからメインメモリへ直接データを転送してホストOSをバイパスできます。また、GPUインスタンスではカードからメインメモリへホストOSをバイパスして転送できます。これによりCPUのオーバーヘッドが削減され、CPUサイクルを取り戻してより多くのデータをより速く処理できるようになります。また、クライアントあたりのスループットが100 Gbpsから800 Gbpsに向上し、レイテンシーウィンドウが縮小してP99.9カテゴリーまで低下します。
EFAを基盤として構築されたGPUDirectは、ネットワークインターフェースからストレージ、ネットワークインターフェース、メインメモリ、GPUへと至るI/Oパターンをこのように変更します。


ネットワークインターフェースは、リダイレクトバッファーを使用してメインメモリとGPUに接続し、データがストレージからネットワークインターフェースを経由してGPUに直接転送され、CPUとメモリコンプレックス全体をバイパスします。これら2つの機能を組み合わせることで、インスタンスあたりのスループットが100 Gbpsから1,200 Gbpsに向上します。これは合計ではなくインスタンスあたりの数値であり、非常に画期的です。

先ほどお話ししたように、FSx for NetApp ONTAPが、オンプレミスのNetAppと互換性のあるフルマネージド版としてAWSで利用可能になり、必要に応じて展開できるようになりました。お客様が様々なNASベースのワークロードを展開する中で、高い採用率を見せています。自己管理型データベースから、チップ設計における高性能アプリケーション、エネルギー部門での油井シミュレーション、金融分野でのバックテスト、自動車産業でのCAE、オンプレミスからAWSへの直接データ保護レプリケーション、PerforceやCRM、PLMなどのエンタープライズアプリケーション、そして標準的なユーザー共有ディレクトリまで、あらゆる用途に使用されています。
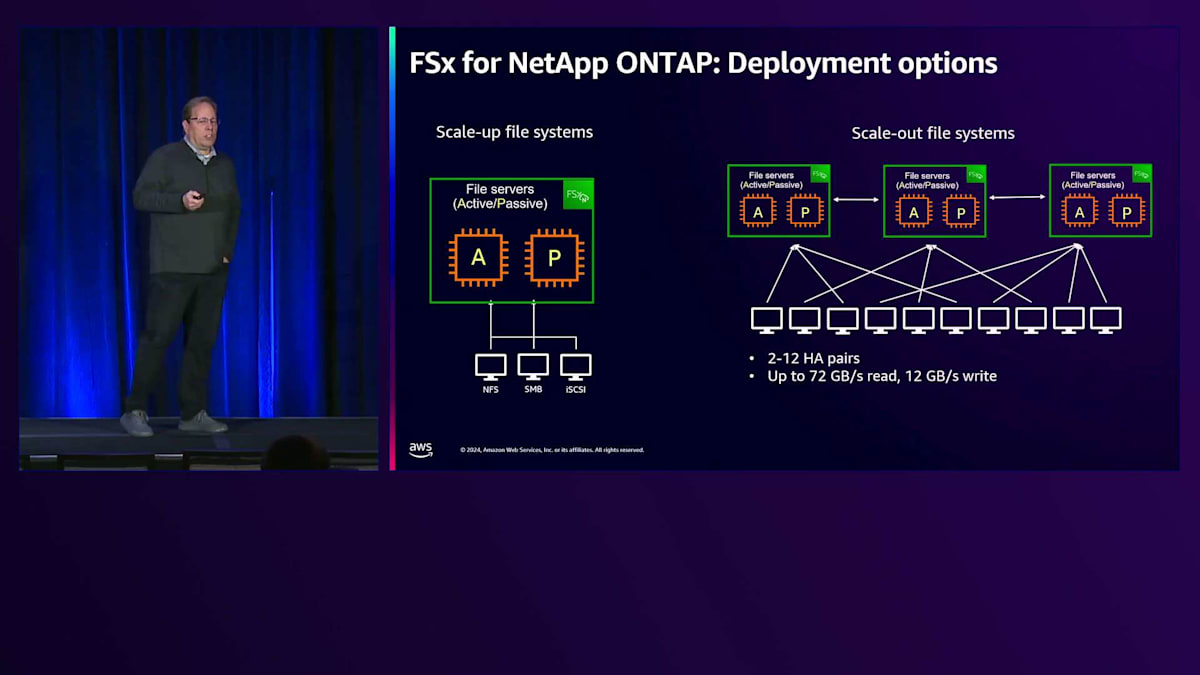
FSxには2つのモードがあります。1つ目は、単一のHAペアがプロビジョニングされるスケールアップファイルシステムで、そのHAペアに関連する性能を活用します。もう1つは、2~12個のHAペアをプロビジョニングするスケールアウトファイルシステムで、単一のファイルシステムビューでより高いスループットやパフォーマンスが必要な場合に選択します。これまでの課題は、将来のニーズを予測してあらかじめモードを決定する必要があったことです。つまり、静的な環境に縛られ、1年後には運用に影響を与える変更が必要になる可能性がありました。

今年の8月9日、私たちはFSx for NetApp ONTAPファイルシステムの第2世代をリリースしました。これにより、FSx for NetApp ONTAP環境において、大幅な柔軟性とパフォーマンスの向上が実現しました。最も重要な点は、1つのHAペアから始めて、パフォーマンスとスループットのニーズに応じて、動的かつ無停止でHAペアを追加できるようになったことです。また、ファイルシステムのパフォーマンスとネットワークインターフェースのパフォーマンスの両方を動的に管理しながら、ネットワークスループットをスケールできるようになりました。

スケールアップからスケールアウトへの移行機能に加えて、HAペアあたりのスループットとパフォーマンスも向上しました。具体的には、スループットが4GBpsから6GBpsに増加し、IOPSも160Kから200Kに向上し、ペアを追加しても安定したパフォーマンスを維持できます。さらに、ブロックベースのワークロード向けにNVMe over TCPのサポートも追加され、FSx for NetApp ONTAPはファイルシステムだけでなく、ブロックベースのシステムとしても利用できるようになりました。低レイテンシーを必要とする要求の厳しいデータベースアプリケーションでは、FlexClonesやスナップショットなどのNetAppが提供するデータ管理機能を活用しながら、ブロックベースのワークロードにNVMe over TCPを利用できます。

最後に、バックアップの復元に関する課題も解決しました。これまでは、アプリケーションを開始する前にバックアップの完了を待つ必要がありましたが、現在では、バックアップを開始すると同時にアプリケーションを起動でき、データはアクセスされた時点でロードされ、完全に復元されるまでバックグラウンドでデータのロードが継続されます。これにより、以前のバージョンと比べてRTOが17倍改善されました。

次に、Amazon EFSについてお話ししましょう。先ほど触れたように、EFSは、シンプルに動作するストレージを必要とするクラウドネイティブアプリケーションを構築するビルダー向けのソリューションです。EFSで実行されているワークロードの種類を見ると、探索的データ分析から機械学習の推論ワークロード、さまざまなSoftware-as-a-Serviceアプリケーションまで、データ集約型のビルダーワークロードが多様に存在しています。

ソフトウェアやサービスアプリケーション、そしてLine of Businessアプリケーションには、非常に高いパフォーマンスが要求されます。お客様が新しいデータ処理方法を見出し、データの成長が加速し続ける中で、パフォーマンスに関連する2つの具体的な課題についてフィードバックをいただいています。1つ目の課題は、一定レベルのプロビジョンドスループットを使用してアプリケーションのパフォーマンスをサイジングすることが、データの増加とアプリケーションのパフォーマンス要件の高まりとともに非常に困難になっているということです。これは、事前にプロビジョンドスループットを計画することが難しいためです。2つ目の課題は、ファイルシステム間でのデータの分割、データの整理とシャーディング、単一ファイルシステムがサポートできる容量の判断、そしてワークロードのニーズに基づいて複数のファイルシステムを使用して総合的なニーズに対応することに関連しています。

これらの課題を1つずつ見ていきましょう。従来のパフォーマンス計画が困難である最初の部分は、プロビジョニングの難しさに関連しています。プロビジョニングされたスループットレベルと、実際のワークロードが生み出すアクティビティがあります。最初の問題は、ワークロードのアクティビティがプロビジョニングされたスループットレベルを超えてスパイクする場合に発生します。この場合、スループット容量が不足してプロビジョニングされ、ワークロードのスロットリングが発生します。その結果、結果を得るまでの時間が長くなり、IOの待ち時間で停滞する可能性のある高価なCompute instanceの使用時間が延長されます。2つ目の問題は、アクティビティがプロビジョニングされたレベルを常に下回る場合に発生し、これはオーバープロビジョニングにより、使用されていないリソースに対して支払いが発生することを意味します。両方のシナリオにおいて、これらの問題を監視し、プロビジョニングされたスループットレベルを適切に調整することが困難であるため、管理と設定が課題となります。

パフォーマンス計画におけるもう1つの重要な問題として、お客様から報告されているのは、単一ファイルシステムのスケーラビリティとデータ編成に関する課題です。単一ファイルシステムが特定のスループットレベルしかサポートしていないのに、実際のワークロードのニーズがそのレベルを超える場合、データを複数のファイルシステムにシャーディングしてワークロードを集約して実行するか、シャーディングが不可能な場合はワークロードのニーズを満たすことができない可能性があります。

これらの課題に対応するため、私たちは継続的にパフォーマンスの改善に投資してきました。過去2年間で、Amazon EFSに数多くのパフォーマンス改善を導入してきました。約2年前に、Elastic Throughputを導入しました。これは完全に弾力的なパフォーマンスモデルで、スループット容量がニーズに応じて自動的にスケールします。事前にスループット容量をプロビジョニングする必要はなく、アプリケーションを起動するだけで自動的にすべてが機能します。これにより、パフォーマンス計画の必要性がなくなり、使用した分だけ支払えばよいため、より簡単でコスト効率的になります。

ファイルシステムごとの制限に関するスケーラビリティについては、読み取りと書き込みのスループット、そして読み取りIOPSと書き込みIOPSの両方について、時間をかけてさまざまな改善を行ってきました。読み取り指標を例にとると、約2年前の3ギガバイト/秒から最近では30ギガバイト/秒まで改善しました。IOPSについては、35,000から250,000の読み取りIOPSまで改善し、過去2年間で約10倍の向上を示しています。そしてここで終わりではありません。今週、Amazon EFSにさらなる大幅なパフォーマンス改善を導入することを発表できることを嬉しく思います。読み取りIOPSを10倍に向上させ、ファイルシステムあたり250,000から250万IOPSに改善し、書き込みIOPSを20倍に向上させ、25,000から500,000 IOPSに改善することを発表します。

また最近、読み取りスループットを30ギガバイト/秒から60ギガバイト/秒へと2倍に向上させました。先ほど触れたように、Elastic Throughputを使用することで、必要に応じてパフォーマンスを自動的にスケールし、使用した分だけお支払いいただけます。この一連の改善により、お客様は大多数のワークロードにおいて、パフォーマンスの計画や拡張性の制限を気にする必要がなくなりました。これらのパフォーマンスレベルは驚くほど高く、ほとんどのお客様のワークロードでは、パフォーマンスについて考えたり心配したりする必要すらないと確信しています。
ファイルストレージのレジリエンス強化

それでは3つ目の投資分野である「レジリエンス」について、Christianが続けて説明します。最後の分野はレジリエンスについてです。誰もがデータとアプリケーションを確実に保護したいと考えているからです。お客様が常に新しいデータ保護方法を求めているという共通のテーマがあります。そこで、レジリエンシーに関する新機能をご紹介し、さまざまな脅威や攻撃からデータを費用対効果の高い方法で保護する方法をご説明します。

高性能構成のFSx for OpenZFSには、2つの異なる構成があります。1つはストレージを備えた単一のファイルサーバーであるSingle-AZ、もう1つは2つのAZ間でデータを同期レプリケーションする主系と待機系のファイルサーバーを持つMulti-AZ-HAソリューションです。Multi-AZ-HAモードはほとんどのHAワークロードのニーズを満たしますが、2つの副作用があります:AZ間のデータレプリケーションによる高いレイテンシーと、データの2つのコピーに対して支払う必要があることによる高いストレージコストです。

お客様から、高性能ワークロードのために低レイテンシーと低ストレージコストを実現するHAバージョンの要望がありました。8月9日に、FSx for OpenZFSのSingle-AZ-HAデプロイメントモードをリリースしました。このリリースにより、ゾーン内デプロイメントで単一のストレージセットに接続された、主系と待機系のHAペアファイルサーバーが利用できるようになりました。ここではAZ間のミラーリングやデータの二重コピーは行われないため、書き込みを含めてサブミリ秒のレイテンシーを実現する、Single-AZの非HA版と同様のパフォーマンスが得られます。
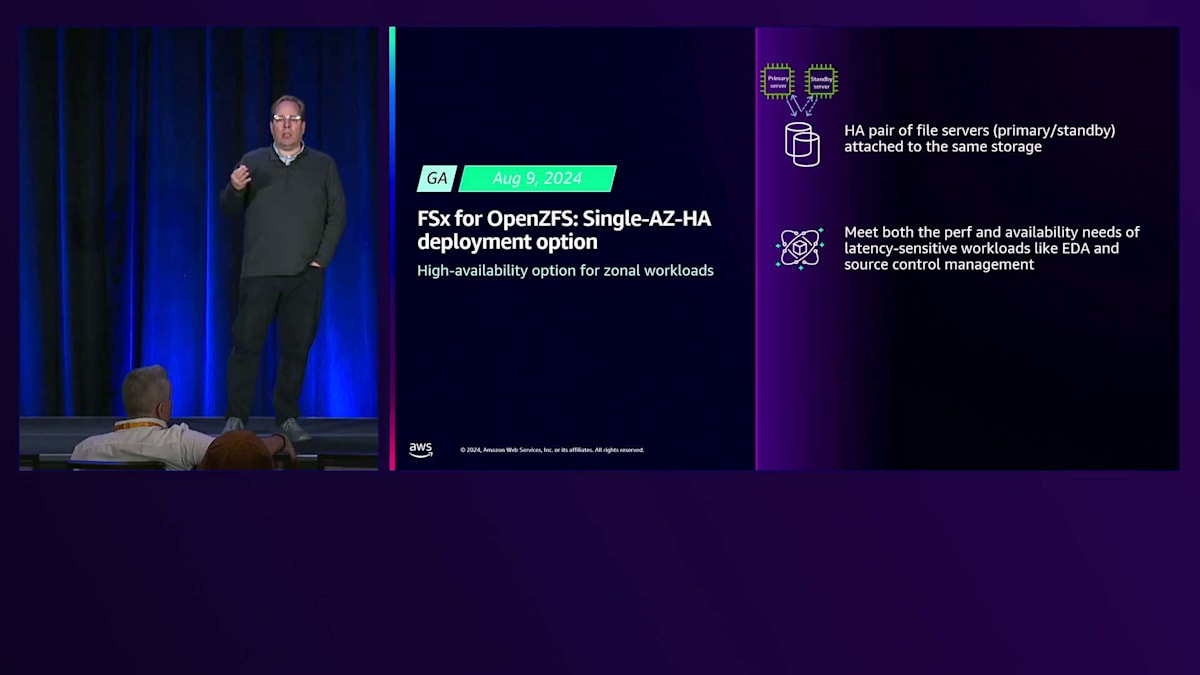

これは、高可用性と低レイテンシーを必要とするワークロードを持つお客様にとって特に重要です。例えば、何百万から何十億もの小さなファイルを扱うチップ設計やソースコード管理などが挙げられます。また、このタイプのワークロードを活用しようとするゾーン内データベースや自己管理データベースをデプロイするお客様も増えています。もう1つのユースケースはコスト削減に関するもので、派生データや再作成可能なデータ(S3のどこかに保存されている分析データなど)の場合、必ずしもMulti-AZのレジリエンシーが必要ないケースです。これは分析やMLのユースケースでよく見られます。

次の2つのアナウンスは、データの冗長性と災害復旧の強化に焦点を当てています。ビジネス継続性と災害復旧への需要が増え続けているのを実感しています。さらに、規制の厳しい分野では、悪意のあるユーザーや悪意のないユーザー、侵害されたアカウントなどの脅威から保護するための様々な方法を実証することが求められています。これは、異なる権限モデルを持つデータの分離されたコピーを、異なるリージョンや別のAWSアカウントに配置する方向に進んでいることを意味します。最初のアナウンスは8月に発表された、EFS BackupのLogically Air-Gapped Vault(LAG Vault)です。


これらはAWS Backupを通じて実行され、データのイミュータブルなバックアップコピーは完全にロックされ、有効期限が切れるまではバックアップ管理者でさえもバックアップコピーを削除できないようになっています。 これらは物理的にアカウントから分離され、AWS Backupのキーで暗号化されています。これらのバックアップVaultやLAG Vaultの利点は、アカウント構造内に存在しながらも、 異なる権限とリソースでアカウントから分離されていることです。AWS Resource Access Managerを通じて、これらのVaultを異なるアカウント間で共有することができ、復元には3つのうち2つの認証プロセスが必要です。


データを同じアカウントに復元してから目的の場所にコピーする必要はありません。クリーンルームを設定して、そのアカウントにデータを直接復元することができます。そのデータに対して追加の調査が必要な場合も、その機能を利用できます。 本日発表する2つ目は、Amazon EFSのクロスアカウントレプリケーションです。EFSは昨年リリースしたリージョン間レプリケーションをすでにサポートしていますが、この新機能により、データセキュリティと保護の追加レベルを提供するため、異なるアカウント間でのデータレプリケーションが可能になります。


この新機能は、悪意のあるユーザー、誤操作を行うユーザー、暗号化キーの紛失、侵害されたアカウントなどの権限モデルの脆弱性からの保護を目的としており、セカンダリ側の権限セットを変更することで、これらの脅威からデータを物理的に分離します。 さらに、このクロスリージョンレプリケーションをビジネス継続性戦略として活用できます。権限の分離要件を満たしながら、プライマリに何か問題が発生した場合に備えて別の場所にコピーを保持できる、一石二鳥の利点があります。これにより、必要に応じてセカンダリ側にフェイルオーバーすることも可能です。
まとめと今後の展望


3つ目の利点は、セカンダリ側を最適化できることです。同じ高性能な構成を維持する必要がない場合、より積極的なIntelligent-Tieringポリシーを設定したり、Intelligent-Tieringに自動管理を任せたりすることができます。これにより、データは徐々に最も低コストのアーカイブ層に移動し、何か問題が発生した場合でも経済的な方法でビジネスを再開できます。以上で終わりとさせていただきます。 私たちは、本日議論した主要なテーマ、つまりファイルデータの管理改善、データ活用の拡大のためのパフォーマンス向上、そして様々なビジネスニーズに対応するためのデータアプリケーションの保護に向けた、より優れたレジリエンシーオプションの提供に、引き続き投資していきます。

来年は、Proshanthと私が、これらの同じカテゴリーで多くの新しい発表をステージ上で行えることを願っています。ここにいる皆様に感謝申し上げます。 私たちは皆様に触発されています。このスライドは、私たちのFile Serverを使用してイノベーションと発明を行っているお客様のほんの一部です。私たちの取り組みは、皆様からのご意見に基づいています。皆様からのフィードバックをいただけることを嬉しく思っており、このようなスライドは、私たちのエンジニアやプロダクトチームにとって、皆様のためにより良いものを作り続ける原動力となっています。
最後に、ぜひアンケートにご回答ください。皆様からのフィードバックを心より感謝いたします。私たちの良い点と改善すべき点をお聞かせください。皆様からのフィードバックは、私たちにとって大きな意味を持ちます。ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion