re:Invent 2023: SageMaker Canvasの新LLM機能とBain & Companyの活用事例
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - New LLM capabilities in Amazon SageMaker Canvas, with Bain & Company (AIM363)
この動画では、Amazon SageMaker Canvasの新機能が紹介されています。コードを書かずにデータ準備やモデルのファインチューニングができる機能や、自然言語を使ったデータ変換など、最新のAI技術を活用した革新的な機能が解説されています。また、Bain & Companyのパートナーが実際のビジネスケースを交えて、これらの技術がどのように企業の課題解決に貢献するかを示しています。機械学習の民主化と生成AIの融合がもたらす可能性を、具体的な事例とともに学べる内容です。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
Amazon SageMaker Canvasの紹介とセッション概要

はい、ようこそ。こんにちは。ご参加いただき、ありがとうございます。re:Playからお時間を頂戴していますが、きっと興味深い内容になると約束します。そうすれば、re:Playも楽しめるはずです。皆様、re:Inventの週はいかがでしたか?私たちAWSにとっても素晴らしい1週間でした。多くの方々とお会いし、学び、そして今週発表したイノベーションについてお話しする機会がありました。今日は、そのいくつかについてお話しします。
始める前に、簡単に挙手をお願いします。generative AIについて学ぶためにre:Inventに来られた方はどのくらいいらっしゃいますか?今日のホットトピックですね。では、機械学習を使って解決できそうなビジネス上の問題をお持ちの方は?半数以上ですね、素晴らしい。そして、機械学習とgenerative AIの力を一緒に学びたい方は?皆さん、適切な場所に来られましたね。
AI M3603へようこそ。私はShyam Srinivasanと申します。AWSのAI/MLチームのプリンシパルプロダクトマネージャーです。機械学習の低コード・ノーコードソリューションを担当しており、特に今日お話しするAmazon SageMaker Canvasというサービスに注力しています。本日は、Bain & CompanyのパートナーであるPurna Doddapaneniさんにもご登壇いただけることを光栄に思います。PurnaさんとBainは素晴らしいパートナーで、Purnaさんがチームやクライアントとこれらのイノベーションに取り組んだ話を共有してくださるのを楽しみにしています。

それでは始めましょう。アジェンダを簡単に見てみましょう。機械学習とgenerative AI、そしてSageMaker Canvasを使ってコードを1行も書かずにこれらを実現する方法について話します。今週発表した新機能、特に昨日発表したSageMaker Canvasの機能について詳しく説明します。大規模言語モデルを使用したデータ準備(機械学習の基礎)とモデルのファインチューニングに焦点を当てます。その後、Purnaさんに登壇していただき、彼の経験を共有していただきます。最後に、Q&Aの時間を設けますので、皆さんからの質問をお聞きし、お答えしたいと思います。
機械学習の民主化:ビジネスユーザーとデータサイエンティストの協働


数年前、このre:Inventの舞台で、AWSの目標として、すべての開発者とデータサイエンティストに機械学習を提供することをお話ししました。それ以来、私たちは大きな進歩を遂げました。今日、私たちの目標は、すべての人に機械学習を提供することです。これはどういう意味でしょうか? 組織を見ると、大きく2つのスペクトルの人々がいるかもしれません。一方には、技術的に熟練していないかもしれないビジネスチームがいて、 機械学習のような技術を使ってビジネス上の問題を解決しようとしています。ビジネス上の問題を解決したいと手を挙げた方もいらっしゃいましたね。

スペクトルの反対側には、機械学習に精通し、その本質を理解しているデータサイエンスチームなどの技術チームがいます。しかし、彼らはビジネスのために対応しなければならないプロジェクトが山積みで制約を受けています。ご存知の方もいるかもしれませんが、これは簡単なことではありません。では、これらの両チームが、効果的なビジネス成果という共通のビジネス目標に向けて、それぞれの目標を達成するためにどのように支援できるでしょうか?


目的は、これらの各チームを個別に支援することはもちろん、より重要なのは、ビジネスの共通目標を達成するために、どのように協力し合えるかということです。そこで役立つのが Amazon SageMaker Canvas です。機械学習の実験だけでなく、本番環境への展開まで支援します。 SageMaker Canvas は、ビジネスユーザー向けのノーコードワークスペースです。ここでいうビジネスユーザーとは、先ほど述べた両極端の人々が、目標達成の手段として機械学習を実際に使用することを指します。機械学習について話すとき、後ほど詳しく説明しますが、一連のワークフローがあります。データから始まり、最終的には本番環境にデプロイしてビジネス課題に対処することを目指します。Amazon SageMaker Canvas は、特にビジネスユーザー向けに設計されています。
ビジネスユーザーと言うとき、例えばビジネスアナリストを指しています。これには、セールスアナリスト、マーケティング担当者、財務アナリストなど、大量のデータを扱い、そのデータを熟知しているものの、時にはテクノロジーを活用してデータを利用し、効果的に働かせる必要がある人々が含まれます。また、データサイエンティストのような技術者にも適しています。

機械学習のワークフローについて簡単に触れました。これが実際に意味するのは、データから始まるということです。データは機械学習の基盤であり、データなしに機械学習は成り立ちません。Canvas が支援するのは、お好みのデータソースからデータをインポートし、そのデータを探索し、目標達成のために準備することです。そして、コードを1行も書くことなくモデルの構築を始めることができます。これについては後ほど詳しくお見せします。データから予測を生成したいのですが、より重要なのは、先ほど触れた協力の部分です。これらのモデルを他のチームや同僚と簡単かつシームレスに共有し、最終的には自動化プロセスを通じて本番環境に移行したいのです。
Amazon SageMaker Canvasの適用範囲と他サービスとの連携

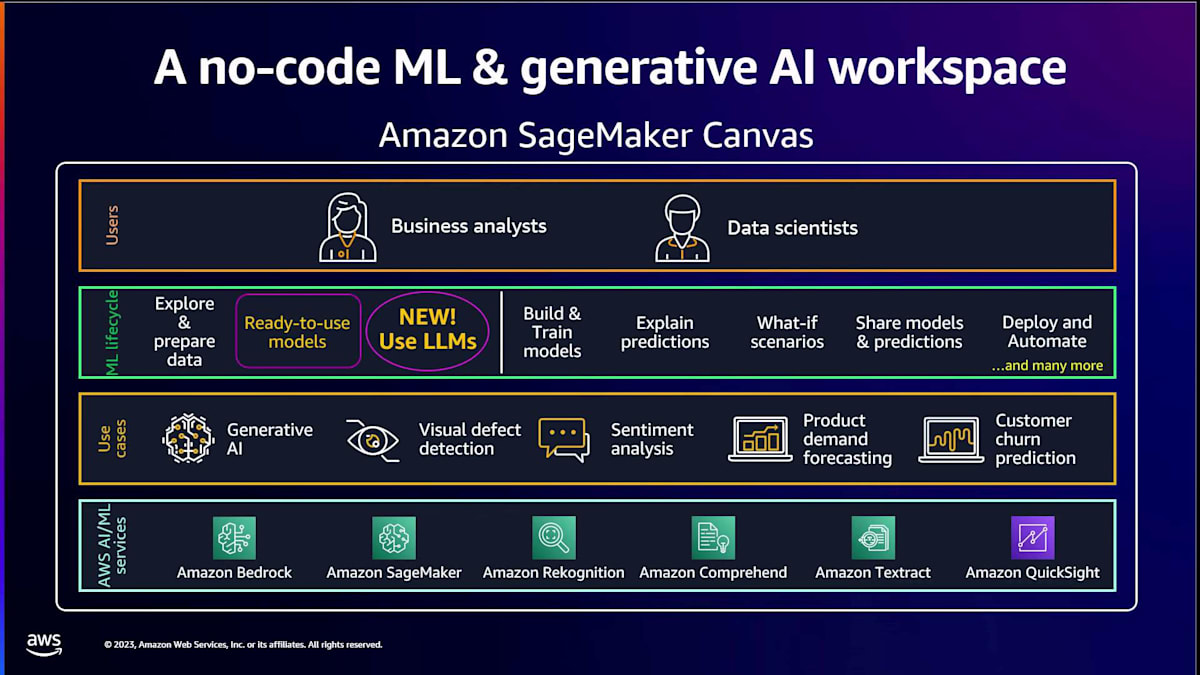
さて、ここで疑問が生じます。これらは素晴らしいですが、どのようなユースケースに対応できるのでしょうか? 答えは、ユースケースに境界はないということです。ここで紹介するのは、ほんの一部に過ぎません。ここ12ヶ月ほどでホットトピックとなった generative AI について触れました。需要予測が必要な問題や、顧客の離反を防ぐために顧客離反予測を行いたい場合について話しています。感情分析や視覚的欠陥検出なども行えます。先ほど申し上げたように、これはお客様のような方々が SageMaker Canvas を使用しているユースケースのごく一部のサンプルに過ぎません。

私たちは孤立して活動しているわけではありません。この週や以前に聞いたことがあるかもしれない多くの他のAWSサービスと協力しています。Amazon Bedrockはその一つです。また、私たちは全体的なSageMakerエコシステムの一部でもあります。多くのテキストおよびビジュアルサービス(AIサービスと呼ばれる)と連携し、Amazon QuickSightを通じてBIアナリティクスとも統合しています。ご覧のように、ユーザーに対応し、全体的なMLワークフローに対処し、多数のユースケースを提供し、他のサービスと連携しているのです。
Large Language Models(LLMs)を活用したデータ準備の革新

では、新しい点は何でしょうか? プレゼンテーションのタイトルには新しいLLM機能について言及されていました。そこで、最近大きな勢いを得ているLarge Language Modelsを使用したCanvasの新機能について話していきます。Large Language Modelsについて話す際、まず最初に取り上げるのは、これらのモデルをどのようにデータ準備を容易にするために使用できるかということです。先ほど言ったように、データの準備が良ければ良いほど、モデルの出来も良くなります。


しかし、まずはデータ準備そのものについて話しましょう。 データ準備には特定の重要な課題があります。データを準備するのは簡単なプロセスではありません。 最初の課題は、通常、少量のデータであれ大量のデータであれ、このデータを準備するために個別に微調整する必要がある多くのツールが必要だということです。これらのツールは、持っているデータの種類によって異なる可能性があります。多くの場合、これらのツールを組み合わせる必要がありますが、これもまた面倒なプロセスです。

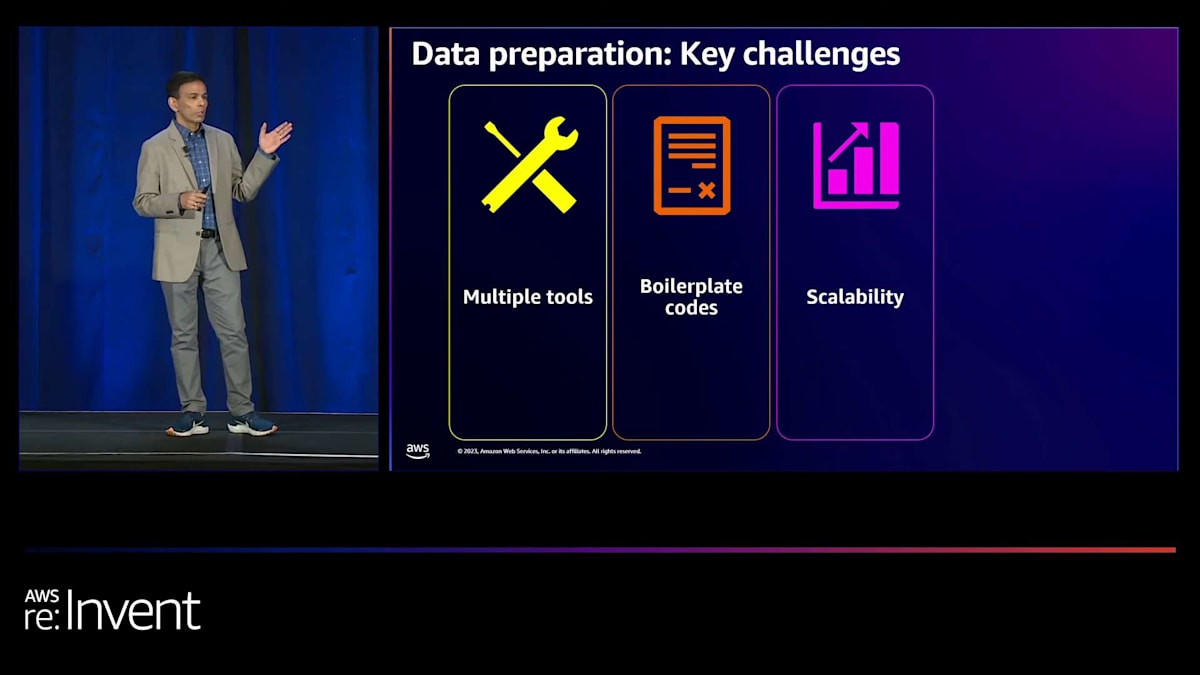
多くの場合、実際にそのデータを活用するためにボイラープレートコードを書く必要があるかもしれません。技術的に熟練している方もいらっしゃるでしょうし、ボイラープレートコードを書くのは大変な作業ではないかもしれませんが、非常に時間がかかります。退屈で、時には最初からやり直さなければならないこともあります。最終的には、データをスケールアップしたいと思うでしょう。 ギガバイトやペタバイトのデータにスケールアップしたいと思いますが、これは常に課題となります。データがどんどん増えていくからです。

そして、運用にデプロイしたい、そのデータを構築するために使用されたコードを最適化したい、そしてさらに進めたいと思うでしょう

このプロセス全体を再度行うことは、1つのチームでは不可能です。複数のチームとデータエンジニアやMLエンジニアの専門知識と経験が必要です。そして最後に重要なのは、お客様からよく聞く話ですが、MLプロジェクトの60%から80%の時間がデータ準備に費やされており、これは膨大な時間の浪費です。

しかし、Amazon SageMaker Canvasを使えば、これらの問題は過去のものとなります。SageMaker Canvasでは、包括的なデータ準備のための単一のワークスペースを提供しています。今週の月曜日に発表したばかりですが、300以上の組み込みデータ変換と視覚的分析を備えたエンドツーエンドのデータ準備が可能です。コードを書く必要はありませんが、コードを書きたい方のために、カスタム変換を作成する機能も提供しています。Canvasはこのデータのスケーリングを容易にし、データを準備した後、データを保存するか、モデル構築以降に進むかの柔軟性があるため、本番環境への移行も簡単です。


前のスライドで紹介した課題は、Canvasを使用することで、コードを書かずに、または必要に応じて最小限のコードで、単一のワークスペースで解決できます。しかし、お客様との対話で常に出てくる質問は、「もっと簡単にできないか?」「これらの機能があっても、もっと使いやすくできないか?」というものです。答えはイエスです。そして、それが今日のトピックの1つです。昨日発表したばかりの新機能、「chat for data prep」を紹介できることを嬉しく思います。これは業界初の機能で、自然言語、つまり私が今日最新かつ最高のプログラミング言語と呼ぶ英語を使って、データのクエリ、探索、可視化、さらにはデータの変換まで行うことができます。後ほど実際にお見せします。
Amazon SageMaker Canvasによるデータ準備とモデル構築のデモンストレーション
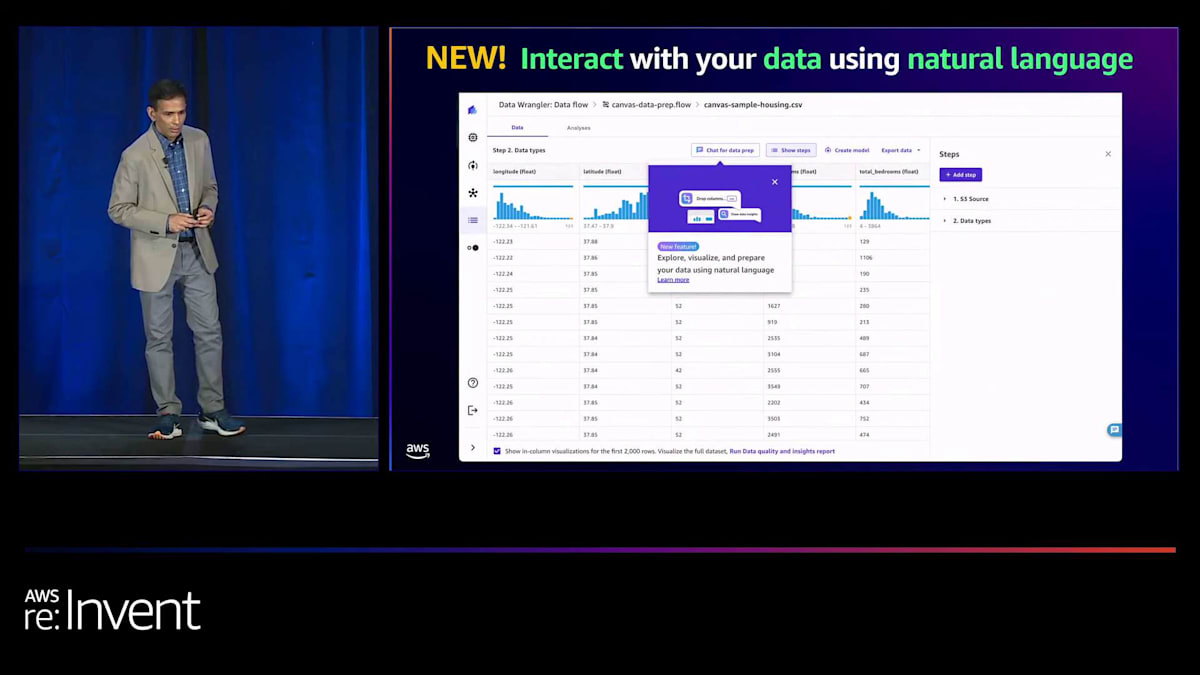
データのインポートについて、多くのソースからインポートできると言いましたが、もう少し詳しく説明しましょう。オンプレミスのデータやクラウド上のデータレイク(Amazon S3、Redshiftなど)、さらにはAWS以外の世界でも、Salesforce、Snowflake、Databricksなどのパートナーにデータがある場合でも対応しています。Canvasでは55以上のデータソースがあり、その数は増え続けています。ボタン1つでデータをインポートできます。

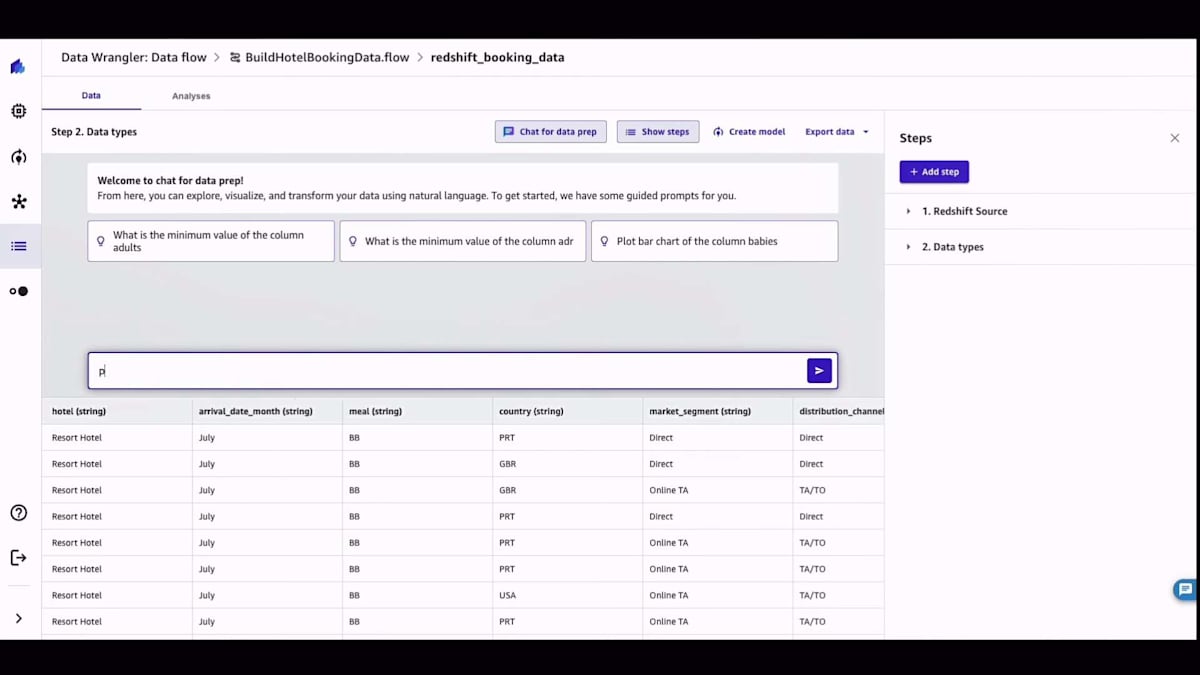
データをインポートすると、ここに示すようにデータの視覚的な表現が表示され、新機能の「chat for data prep」を使って自然言語でデータとやり取りできます。では、データを入力した後、どのように始めるのでしょうか?まず、データに関連する親しみやすいプロンプトがいくつか表示されます。例えば、ここに住宅データセットがありますが、使用できるプロンプトがいくつか提示されています。もちろん、チャットパネルで自分のプロンプトを使ってデータをクエリすることもできます。この発表では、非常にシンプルなプロンプトを選びました。もし望めば、ワンホットエンコーディングのような複雑なプロンプトや、欠損値の補完、標準偏差による値の置換など、やりたいことに応じたプロンプトを使用できます。

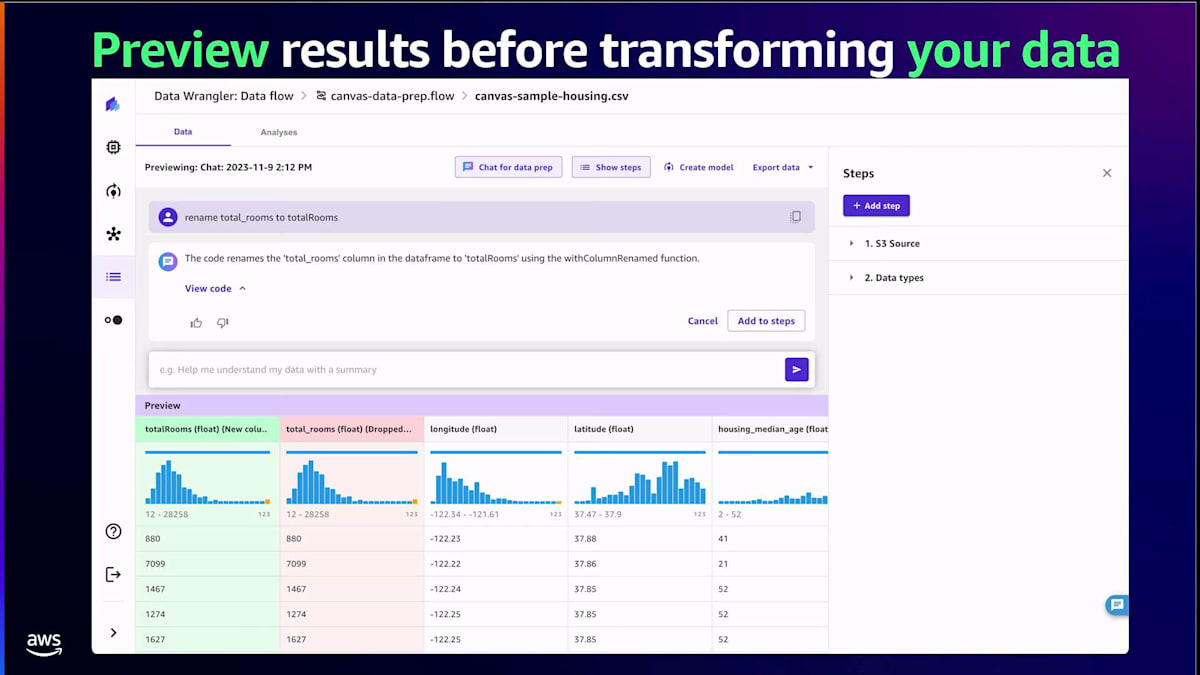
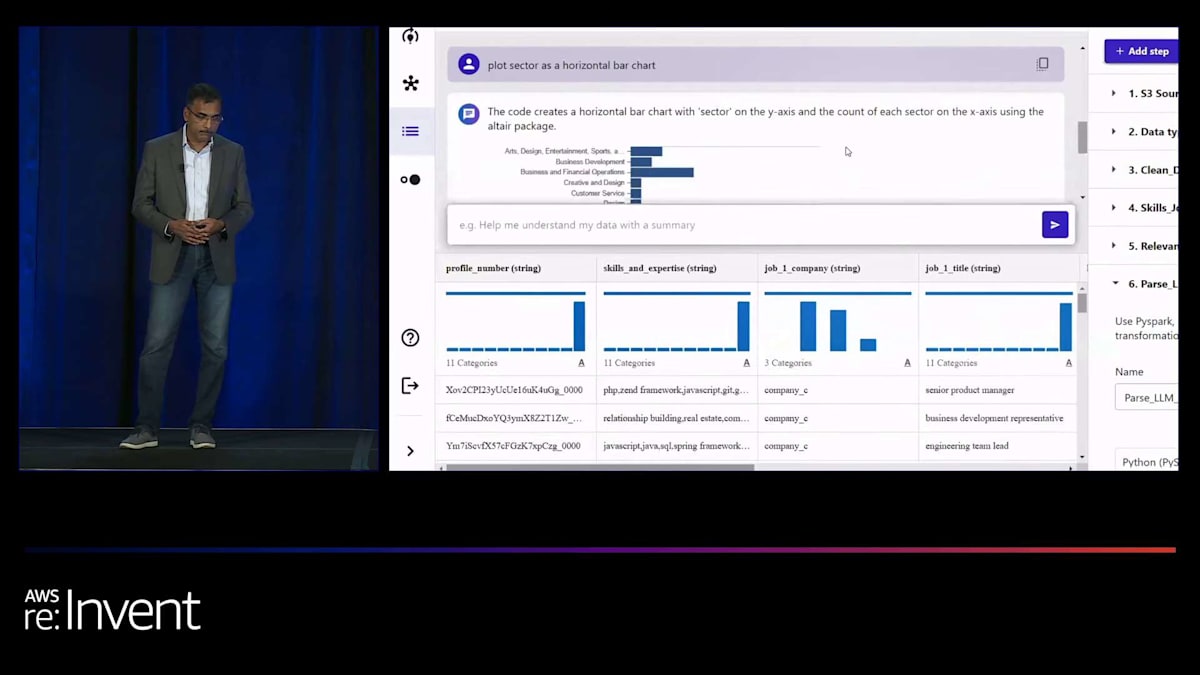
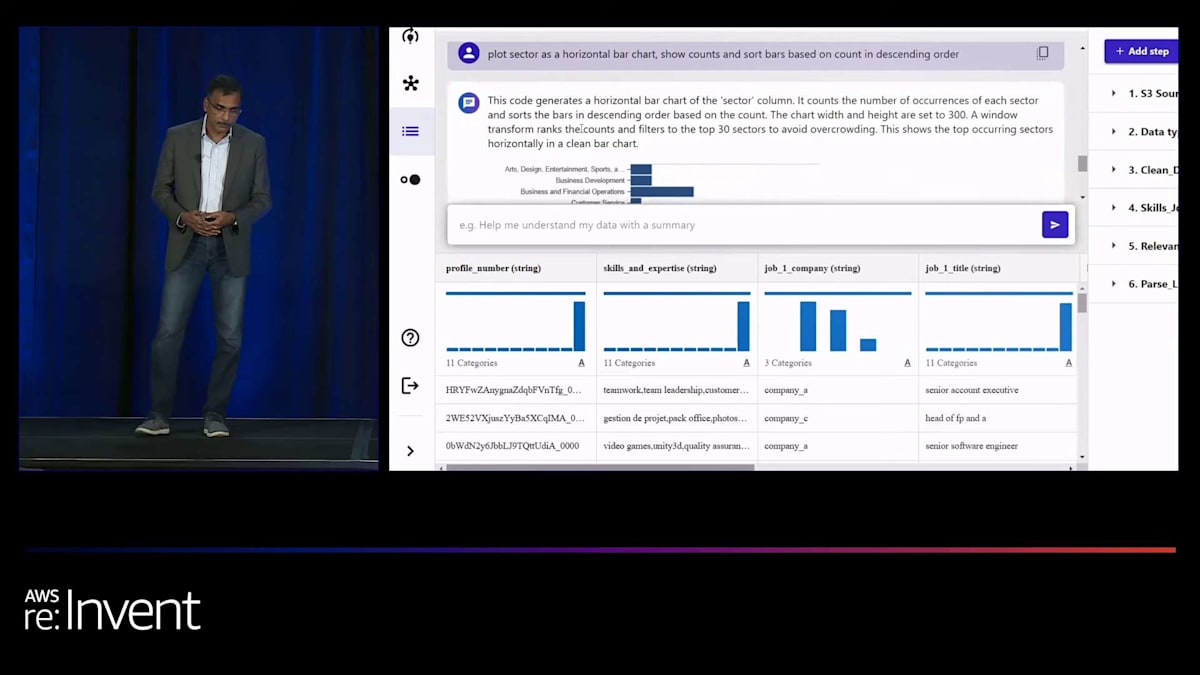
Canvasはその答えを私に提供してくれます。私自身、視覚的な人間なので、データを可視化し、データの分布を見ることが好きです。そこでCanvasに、データのいくつかの特徴の分布を実際に示してもらうことができます。すると、チャートが表示され、そのチャートを変換することもできます。例えば、画面に表示されている散布図を棒グラフやヒストグラムに変更したい場合は、「棒グラフにして」と指示するだけです。データを変換する際、Canvasは変換後のデータを簡単にプレビューできるようにしてくれます。緑色の列が新しく変換されたデータで、それを適用するか、満足できない場合はキャンセルすることができます。


しかし、私たちはそこで止まりませんでした。多くのお客様から、ブラックボックスのソリューションは望まないと言われました。変換を生成した実際のコードを見たいというのです。そこで、Canvasはノーコードのワークスペースですが、変換の基となるコードを表示する機能を提供しています。必要であれば、コードを更新することもでき、編集機能も備えています。コードと結果に満足したら、それを変換のリストに適用します。このリストは右側のレシピに表示されます。そこから、モデルの構築に進むことができます。
Bain & CompanyのPurna Doddapaneniによるプレゼンテーション:ローコード/ノーコードと生成AIの融合
個人的に、スライドだけでは実際の製品の良さを伝えきれないと思っています。そこで、製品のデモをお見せしましょう。これが実際に動作するソリューションであることを、皆さん自身の目でご確認いただけます。ホテルの予約データを例にしたデモをお見せします。ホテルの予約データを示す表があり、ホテルのキャンセルが発生するかどうかを予測しようとしています。

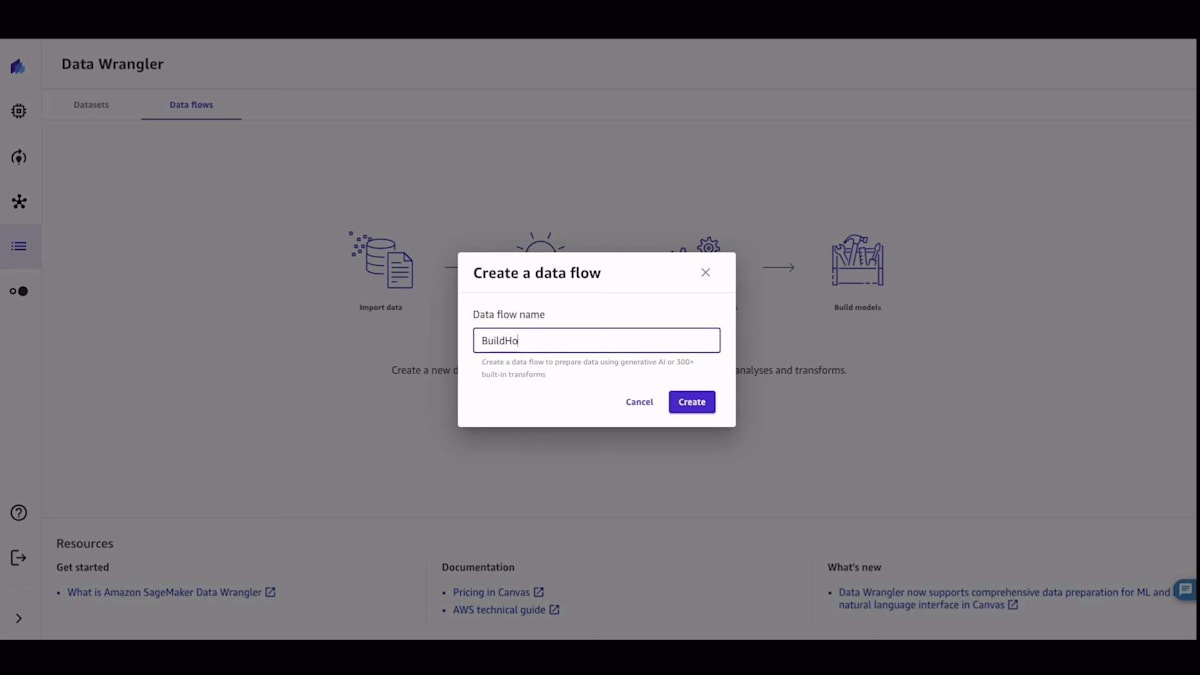

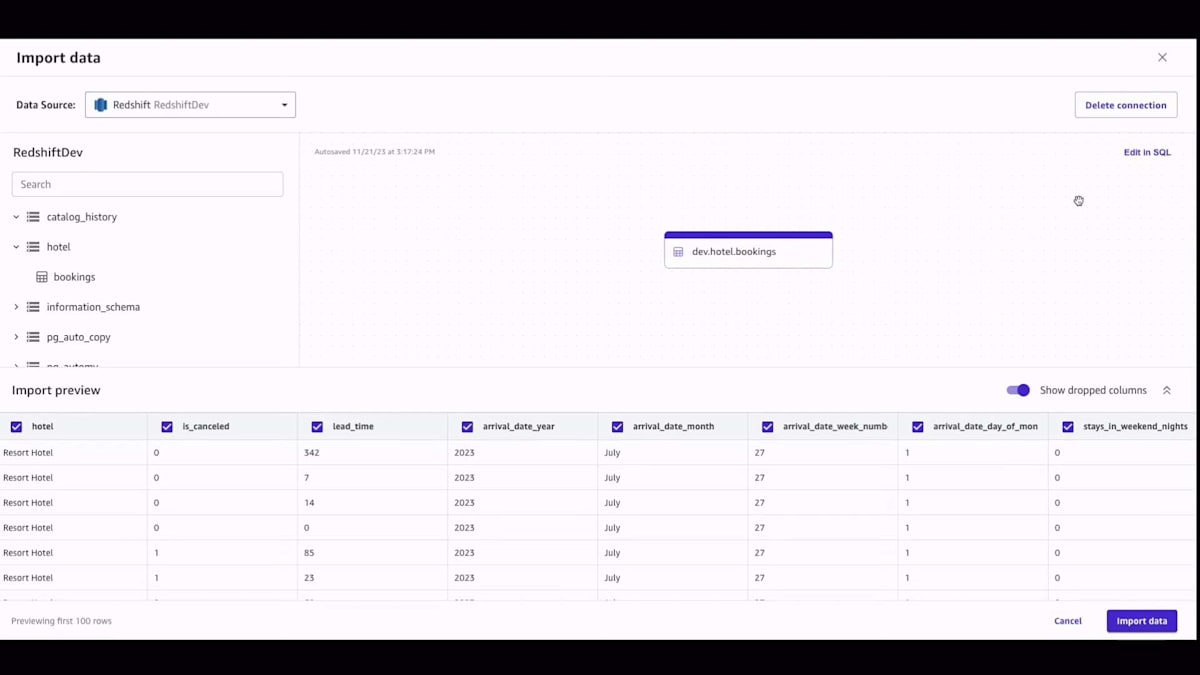
まずはCanvasのホームページから始めましょう。このデモでは、データ準備に焦点を当てます。左側で、データフローの構築を開始したいと選択します。データフローは、データの構築プロセス全体を示してくれます。先ほど言及した予約データセットがここにあります。これに名前を付けました。データをインポートしたいのですが、これがデータソースのリストです。55のデータソースが利用可能です。私のデータはAmazon Redshiftにあるので、テーブルを取り込んで可視化し、そのテーブルをCanvasにインポートできます。

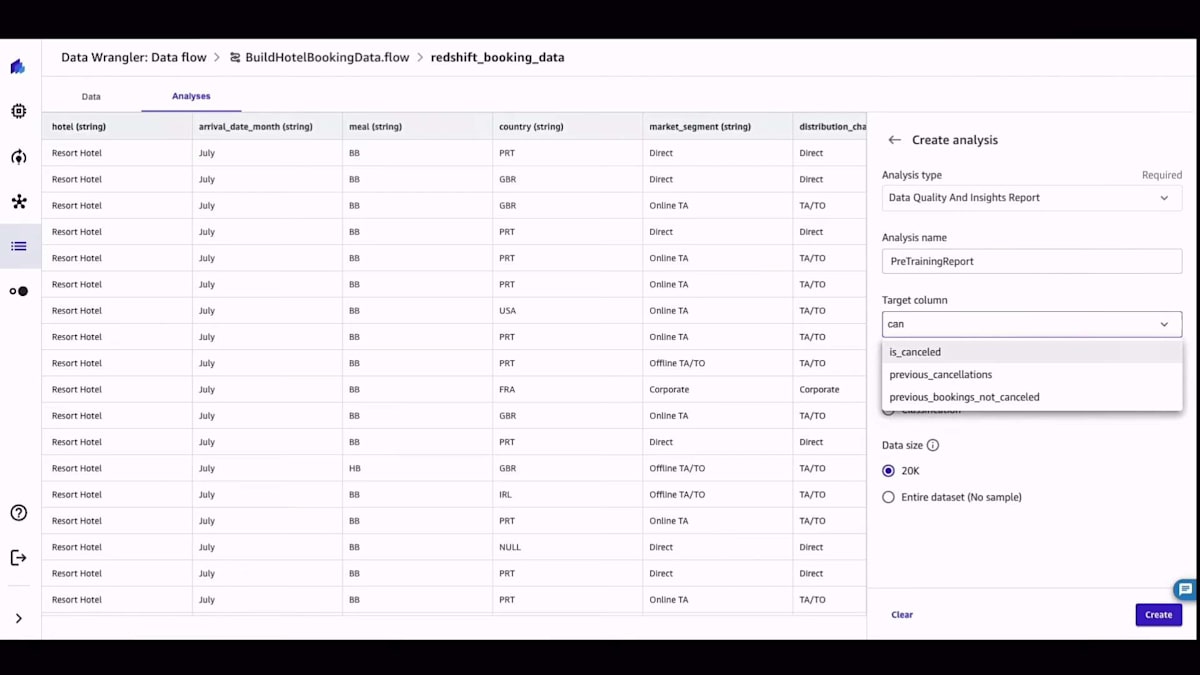
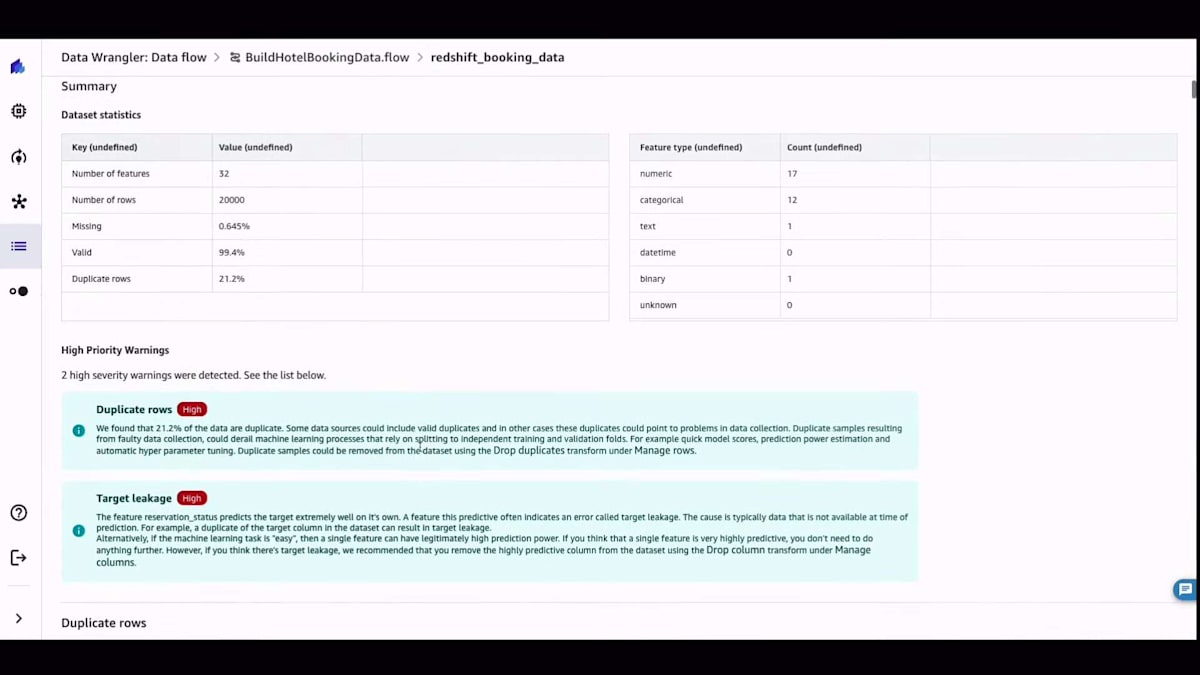
テーブルを取得したら、それを可視化できます。SQLに詳しい方なら、必要に応じてSQLクエリを実行することもできます。データをCanvasにインポートした後、通常最初にやりたいのはデータの品質を理解することです。Canvasでは、詳細なデータ品質インサイトレポートを作成でき、データが自分にとって何を意味するのか、どのように見えるのかを調べることができます。これは分類問題で、データ品質インサイトレポートが作成されると、データに多くの重複行があることがわかり、それを削除したいと思うかもしれません。

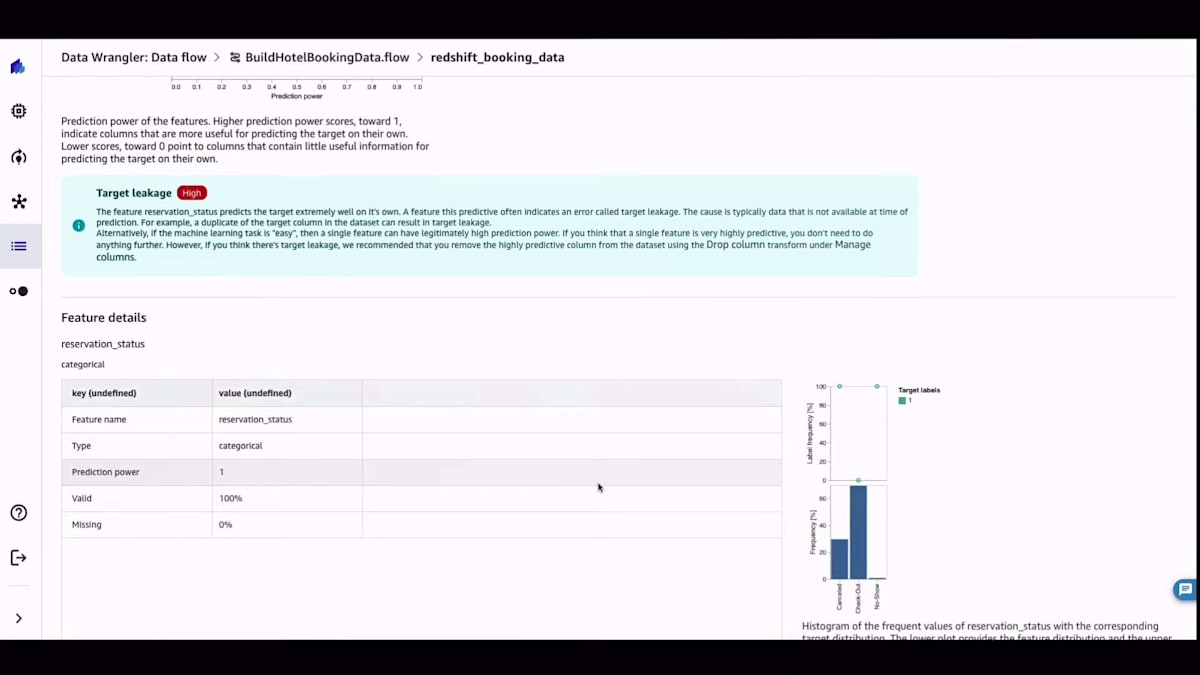

レポートでは、データ内の各特徴量についてのターゲットリーケージと特徴量の重要度を確認できます。それらの特徴量の分布も示されており、データの準備を始める前に、データの品質について包括的な洞察を得ることができます。このデータインサイトレポートを手に入れれば、データをどのように扱うべきかについて良いアイデアが得られます。そして、質問をしたりデータを可視化したりすることで、データとのインタラクションを始めることができます。

先ほど申し上げたように、私は視覚的な人間なので、データをプロットするよう依頼しました。このプロットを生成するコードを確認し、必要に応じて更新することができます。その後、データの準備に進むことができます。データインサイトレポートで多くの重複が見られたので、モデルを構築する前にクリーンなデータセットを得るために、それらの重複行を削除します。データを準備するために追加のステップを踏みたい場合もあるでしょう。Canvasはプレビューを表示し、コードを示し、それを更新することができます。そして、準備したデータからモデルを構築する準備が整います。
ご覧の通り、シンプルな自然言語の指示を使ってデータを準備しました。コードやボイラープレートを書くことなく、モデルの構築に進むことができます。このプレゼンテーションは新機能のローンチに焦点を当てているため、Canvasでの完全なモデル構築プロセスはお見せしませんが、モデルを構築すると、Canvasは2つの方法のいずれかで完全に訓練されたモデルを作成します。約15分で特徴量の重要度を含む単一のモデルを構築することができます。


モデルのリーダーボードが欲しい場合、Canvasは実際に異なるアルゴリズムと組み合わせを用いて数十から数百のモデルを構築し、その中から最適なモデルを選択することができます。ここでモデルの構築を開始し、モデルを構築させました。 これが昨日のファーストローンチで、実際に自然言語を使ってデータを準備することができるようになりました。
Chiefsightを活用したgo-to-market intelligenceプラットフォームの構築
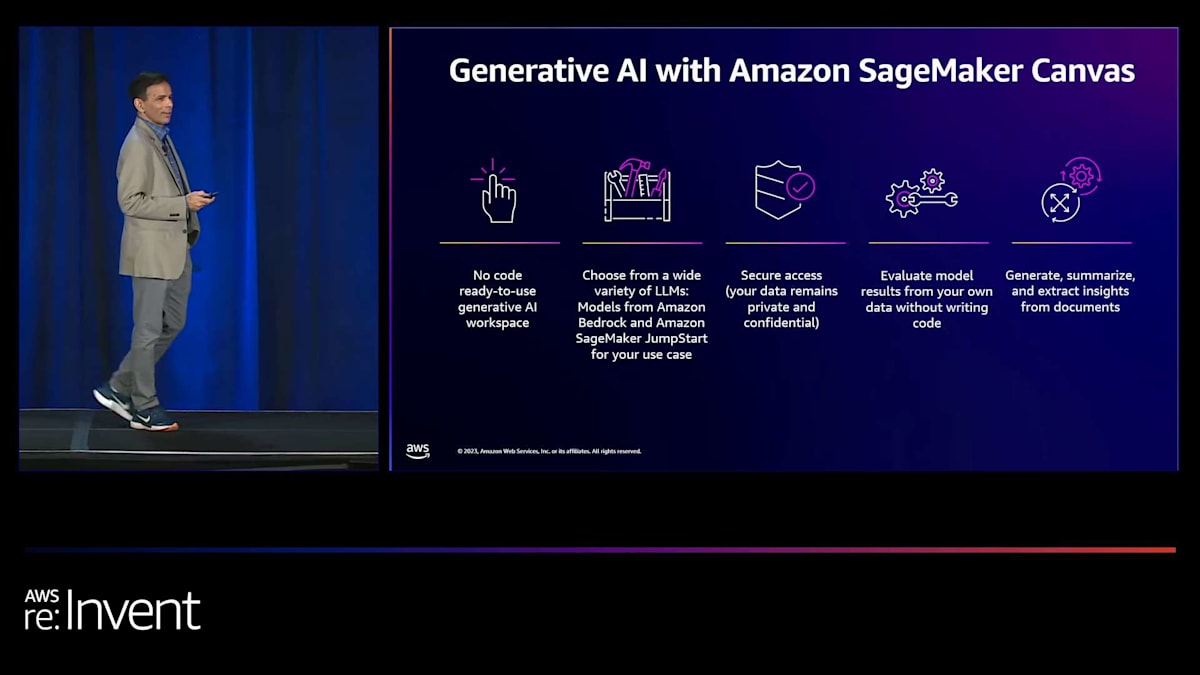
プレゼンテーションの冒頭で、生成AIと大規模言語モデルについて触れました。次はCanvasのその部分についてお話ししたいと思います。自分でモデルを構築する以外に、Canvasは完全に訓練された既製のモデルを提供し、それをユースケースに活用することができます。詳しく見ていきましょう。生成AIは頻繁に使われる用語になりました。Canvasで生成AIは有効なのでしょうか?答えはイエスです。どのように実現しているのでしょうか?第一に、多くのAWSリーダーから聞いたように、LLMと生成AIに対する我々のアプローチは、モデルの選択肢の柔軟性を提供することであり、Canvasも例外ではありません。
Canvasでは、使用するLLMを選択することができます。さらに一歩進んで、Amazon Bedrockが提供する一連のファウンデーションモデルや大規模言語モデルから選択できるだけでなく、Amazon SageMaker JumpStartというサービスのモデルハブが提供するオープンソースモデルの中からも選択することができます。つまり、Canvasでは豊富なモデルの中から選択できるため、それらのモデルにアクセスするためのAPIを呼び出すコードを書いたり、何か特別なことをする必要がありません。AWSの多くの人々から聞いたことがあるかもしれませんが、重要な側面の一つがセキュリティです。データは自分の環境内で安全に保管され、他の人がアクセスすることはできません。また、データのセキュリティ態勢は自分で定義することができます。
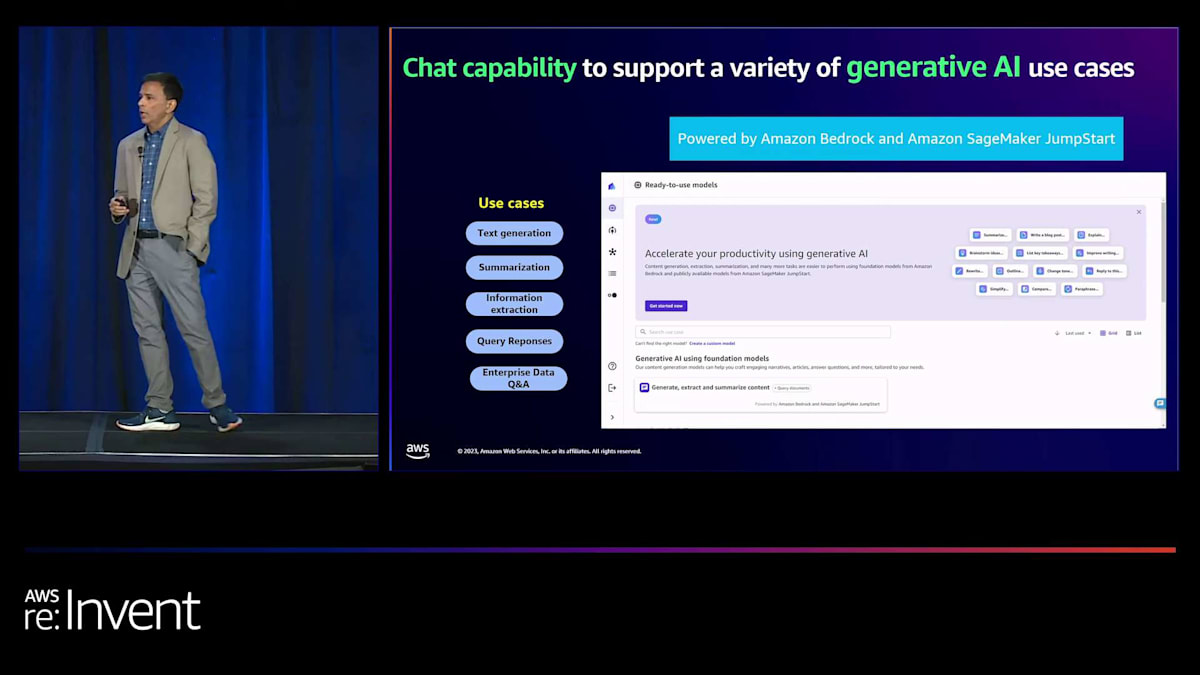
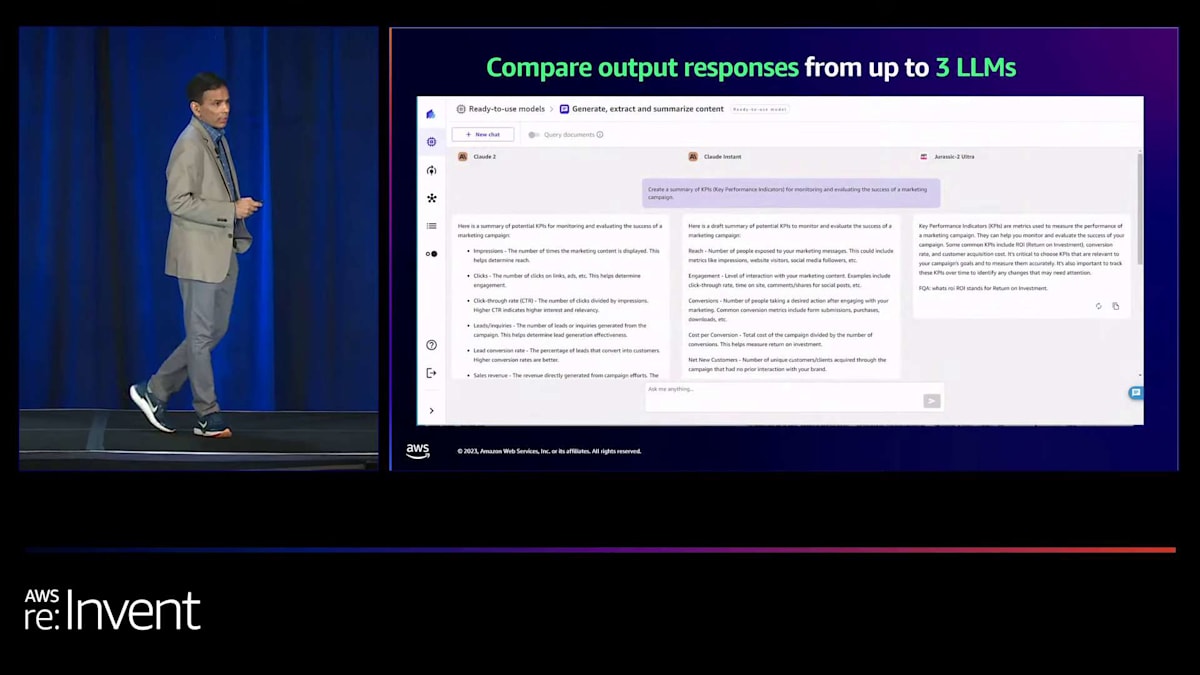
モデルの結果を評価したら、要約や洞察の生成、データの集合体から洞察を抽出するなどの作業を行うことができます。では、実際にどのように機能するか見てみましょう。まず、Canvasはチャット機能を提供しており、先ほど述言ったように、複数のモデルと様々なユースケースについてチャットすることができます。画面に表示されているように、テキスト生成、要約、クエリ応答、企業データQ&Aなどが含まれます。先ほど述べたように、Canvasの主要な機能の一つは、同時に最大3つのモデルを選択し、3つのモデルの結果を比較して好みのモデルを選ぶことができることです。これは重要な点です。なぜなら、ご存知の通り、すべてのLLMは互いに大きく異なっているからです。それぞれが独自の専門性を持ち、独自の方法で回答を提供します。そのため、同じクエリに対する応答を比較して、お気に入りのLLMを選ぶことができるのです。
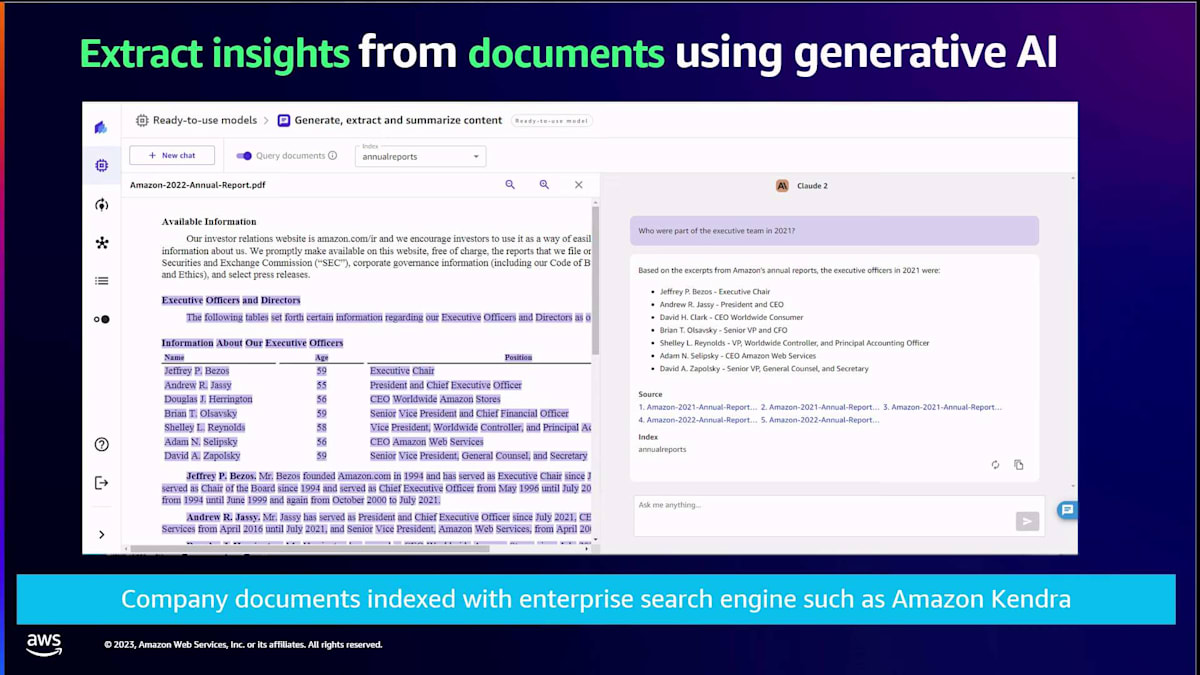

ドキュメントQ&Aについて話しましたね。Canvasが行うのは、例えばAmazon Kendraのようなベクトルデータベースにある大量のデータから洞察を抽出することです。つまり、これらのドキュメントをすべてデータベースに保存し、Canvasがそのデータベースにクエリを行って結果を提供します。しかし、それだけではありません。結果が得られた参照ポイントも示してくれます。ここでは、Amazonの年次報告書の例を挙げています。その特定の年次報告書のどのページの、どの段落の、どの行から情報が得られたかを教えてくれます。このように、柔軟性と可視性が得られるため、抽象的な回答ではなく、具体的な情報源を知ることができます。しかし、ここで疑問が残ります。通常、回答は一般的なものですが、もっと良くすることはできないでしょうか?自分のデータに基づいて、自分のユースケースや分野に特化した回答を得ることはできないでしょうか?


この質問に答えるために、昨日発表したばかりの機能をご紹介できることを大変嬉しく思います。それは、コードを1行も書かずに大規模言語モデルをファインチューニングできる機能です。これにより、業界、会社、ユースケースに合わせてモデルの出力をカスタマイズすることができます。Amazon SageMaker Canvasに新しいオプションが追加され、ファウンデーションモデルをファインチューニングできるようになりました。モデルを構築する際に、ファウンデーションモデルをファインチューニングすることができます。入力と出力のクエリを選択し、Canvasにモデルのファインチューニングを依頼します。


Canvasは、モデルのパフォーマンスに関する詳細な分析結果を返します。技術的な知識をお持ちの方で、これらの指標の一つ一つを詳しく調べたい場合は、自由に行うことができます。さらに、Canvasはノートブックなどの成果物を提供し、それらを閲覧したり、SageMaker Canvas以外でも使用できるようにダウンロードすることができます。そして最後に、ファインチューニングされたモデルの結果を、ベースモデルと比較することができます。ファインチューニングされたモデルは、あなたのネットワーク内にのみ存在します。他の人がアクセスすることはできません。それはあなたのモデルです。ベースとなるLLMのコピーがあなたの環境にあるので、その業界に関連するケースにファインチューニングされたモデルを使用することができます。


では、実際に見てみましょう。 始めると、Canvasはこのようなインターフェースを提供し、データに対してクエリを実行できます。ひとつ注意点があります。ここでの例は金融アドバイスのオプションですが、Canvasは金融アナリストではありませんので、投資には使わないでください。これはあくまで説明のための例です。ここでは、ある夫婦が快適な退職生活を送るという目標を持って、投資オプションを検討しているという設定です。これを一般的なfoundation modelに問い合わせると、ここではAmazon BedrockのTitan Expressの例を示していますが、いくつかのオプションが提示されます。しかし、これは少し一般的すぎないでしょうか?もっと良くできないでしょうか?その解決策がmodel fine-tuningです。
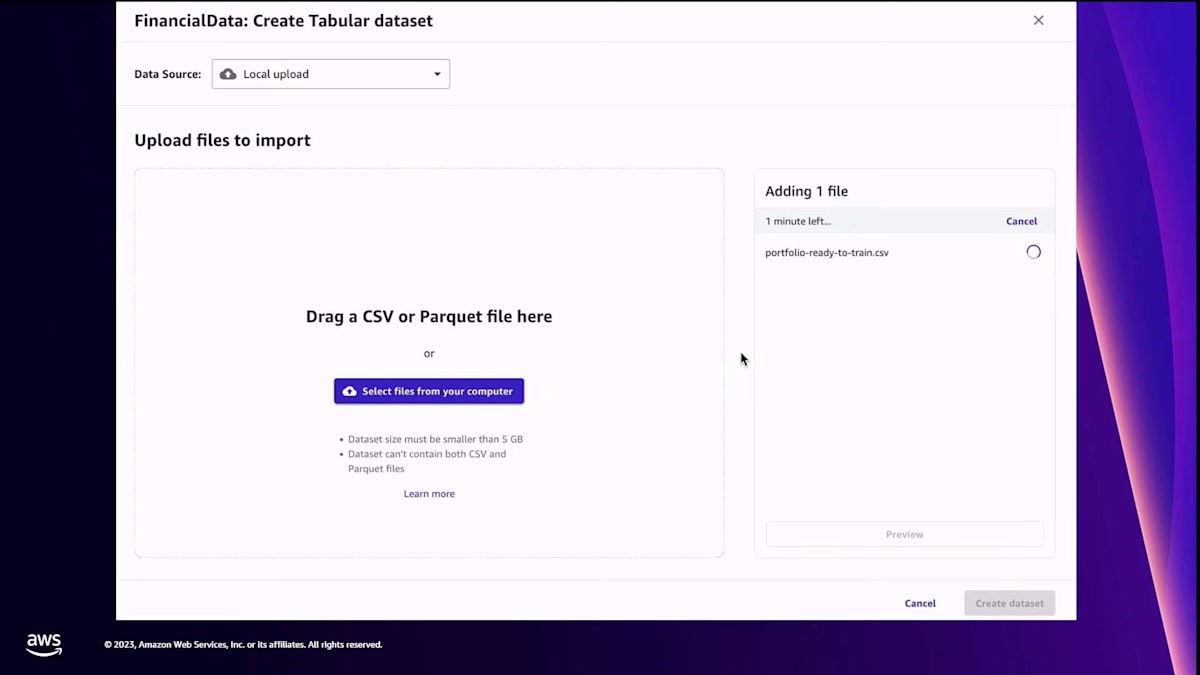

Canvasでは、先ほど説明した新しいfine-tuned modelを作成するオプションがあり、これはあなたのアカウントで利用できます。fine-tuningのプロセスを開始し、モデルに名前を付け、トレーニングデータを提供して、モデルに使用してほしい言語や求めているfine-tuningの種類を理解させます。 データソースからCanvasにデータをインポートしました。 モデルが理解できるように、入力と出力の両方のプロンプトが必要なので、それらを用意しています。そして、そのデータをCanvasに入力し、それがモデルをfine-tuneするためのトレーニングデータとなります。

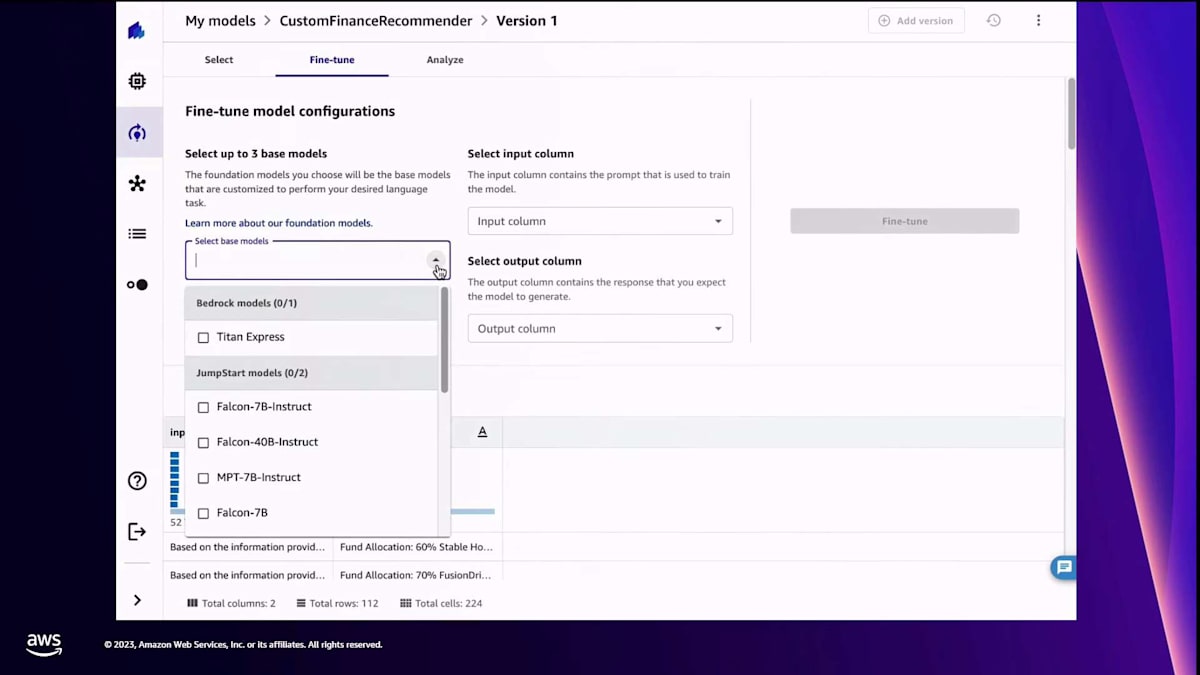
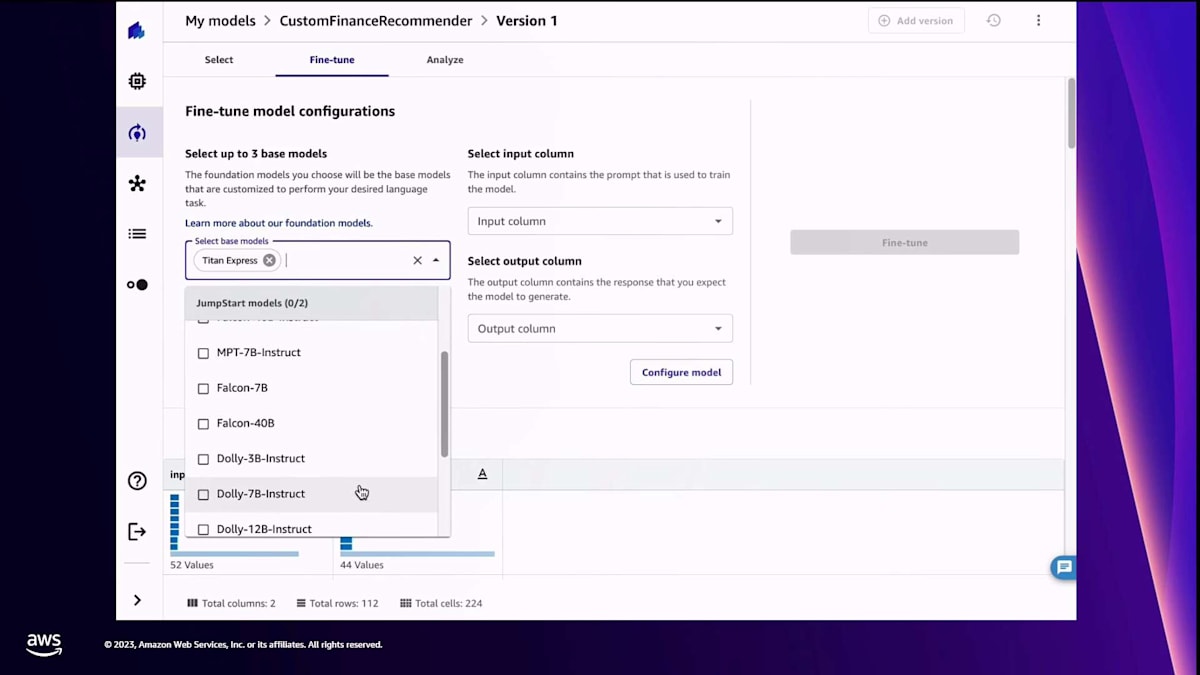
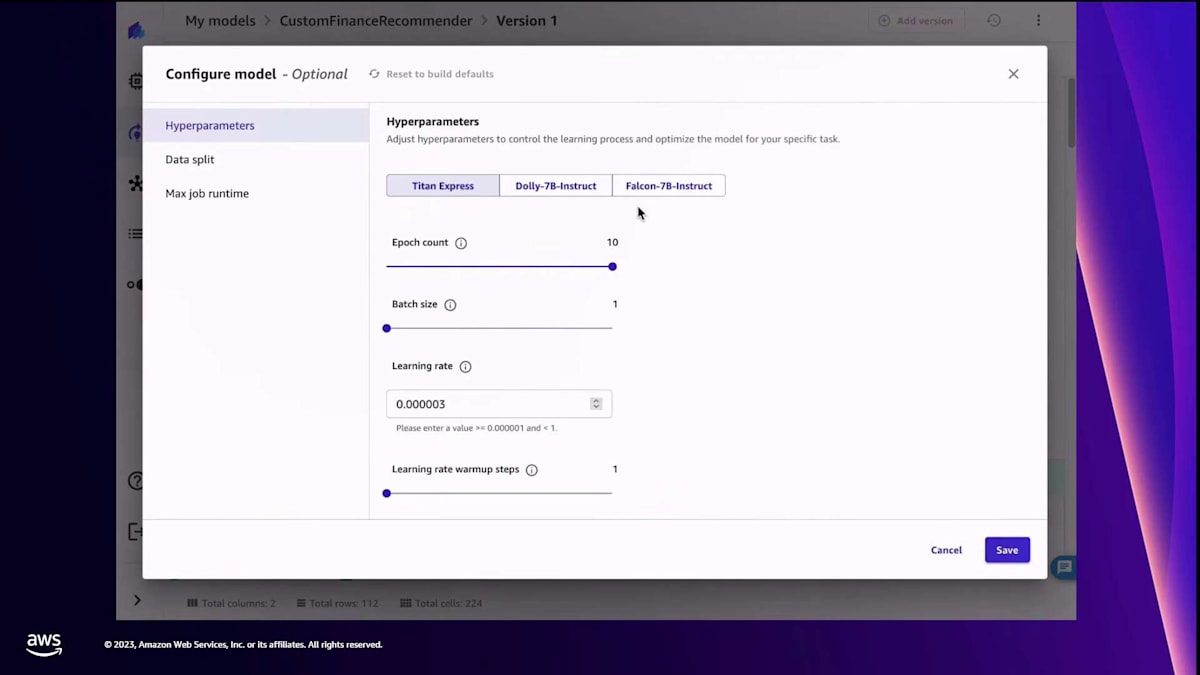
データセットを選択したら、 次にベースモデルを選びます。しかし、その前に入力と出力のプロンプトを確認して、モデルに理解してほしい形になっているか確認します。 これはモデルのfine-tuningにとって重要です。Canvasでは、同時に最大3つのモデルを選択できます。 先ほど言ったように、オープンソースのモデルやAmazon Bedrockのモデルなど、選択肢が用意されています。次に、プロンプトに基づいて入力列と出力列を定義します。 必要に応じて、ランタイムやデータ分割などの追加パラメータを設定する高度な設定もできます。今回はデフォルト設定のままで、Canvasにモデルのfine-tuningを依頼します。
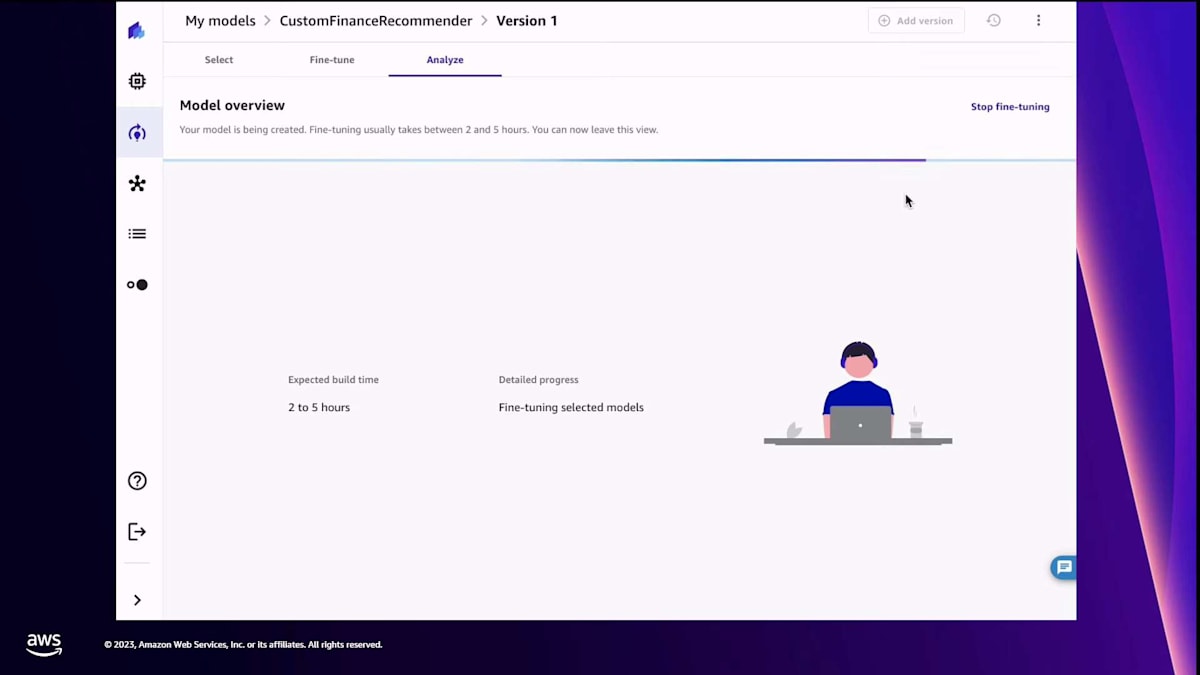

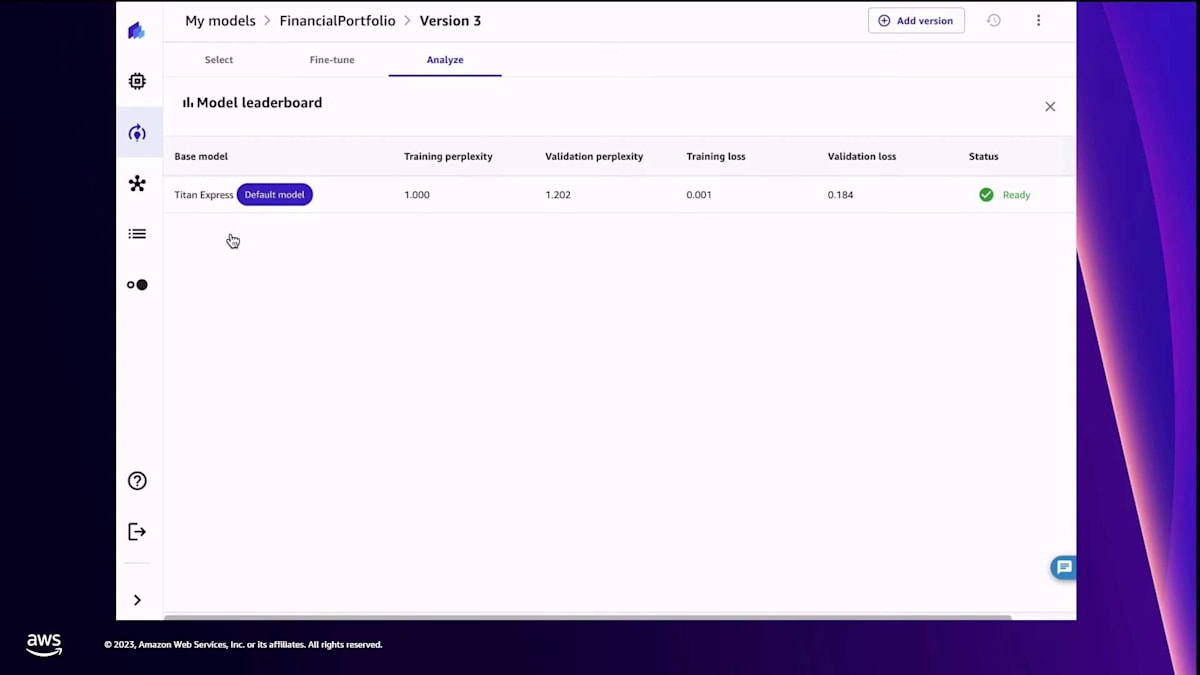

Canvasがモデルをfine-tuneします。もちろん、時間がかかります。結果が出たら、 ご覧のように、モデル内や fine-tuning用に選んだすべてのモデル間のリーダーボードで確認できる、多くの指標を含む詳細なレポートが提供されます。これらの指標を使って、どのモデルを選ぶか informed decisionを下すことができます。 最終的には、これらのモデルをテストして結果を比較したいでしょう。そこで、2つのモデル、

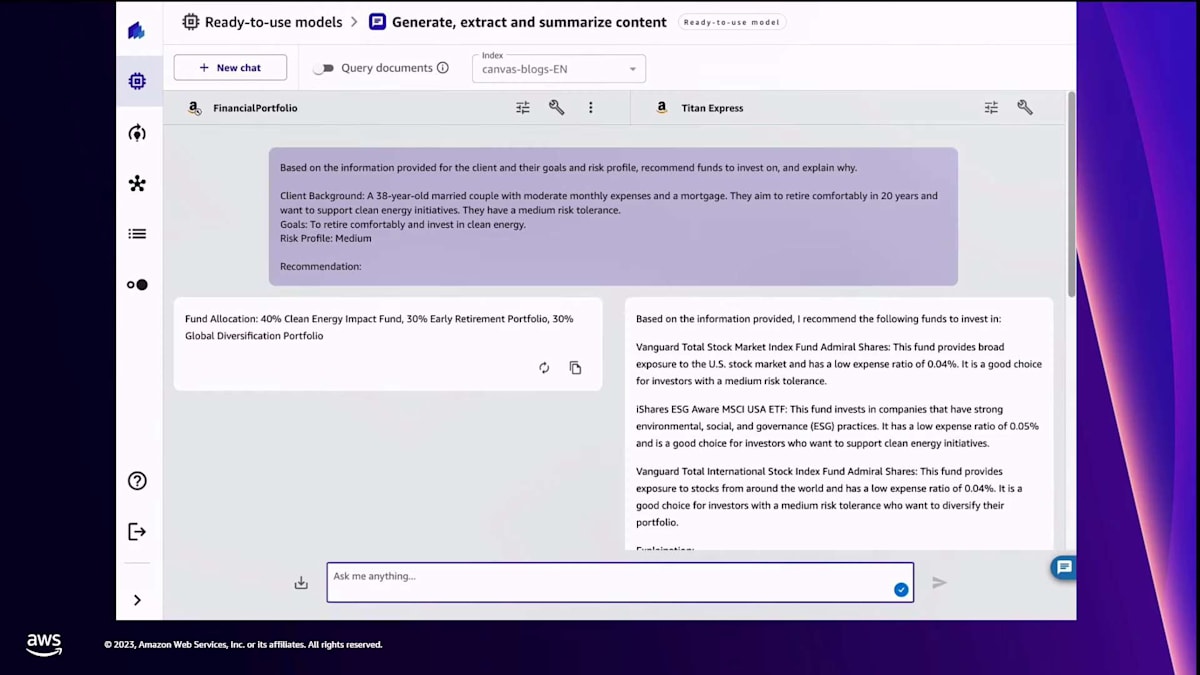
ベースモデルと私のfine-tuned modelをテストしました。私のfine-tuned modelは金融ポートフォリオモデルです。Canvasは両者を比較して 結果を提供します。ご覧のように、一般的な結果が間違っているわけではありません。ただ、一般的な結果には記載されていないファンドがあるかもしれません。私は金融アドバイスについて、より詳細な結果が欲しかったのです。繰り返しますが、これはあくまで説明のための例です。ここでお伝えしたいのは、コードを1行も書かずにモデルをfine-tuneできるということです。これまでの2つの発表、つまりデータ変換に自然言語を使用することとモデルのfine-tuningについて、コードを書かずに目標を達成できました。必要に応じて、プロセスのコードをより深く見ることもできます。

これをみなさんと共有できることを大変嬉しく思います。しかし、それ以上に重要なのは、Purnaをステージにお招きすることです。BainのPurnaが、彼とそのチームが顧客と取り組んできたことや、彼らの分野での素晴らしいイノベーションについて話をしてくれます。Purna、ようこそ。
ローコード/ノーコードとgenerative AIの市場動向と採用の課題

Shyam、ステージに招いていただきありがとうございます。また、本日、特にre:Inventの直前にもかかわらず、貴重なお時間を割いてご参加いただいたみなさまにも感謝申し上げます。 私はPurna Doddapaneniと申します。Bain & Companyのパートナーであり、当社のcorporate venture studioの最高技術責任者を務めています。世界最大級のテクノロジーカンファレンスの一つに参加できて大変光栄です。同時に、BainとAWSが今週初めに発表した、クラウドや関連技術の事業価値を最大限に活用するために顧客と協力するというパートナーシップの強化についても、とてもワクワクしています。

簡単に自己紹介させていただきます。Bain & Companyは、世界で最も野心的な変革者たちが未来を定義するのを支援するグローバルコンサルティング企業です。顧客サポートに加えて、Bain Founder's Studioを通じて社内のイノベーションも推進しています。Founder's Studioの目的は、起業家精神あふれる人材を育成しながら、革新的なB2B SaaSベンチャーを構築することです。 こちらが現在のベンチャーポートフォリオで、HRアナリティクス、マーケティングアナリティクス、go-to-market intelligence platform、ESGデータサービス、そしてサイバーセキュリティまで多岐にわたっています。驚くことではありませんが、これらのベンチャーに共通するテーマは、すべてAI駆動のプラットフォームであるということです。今週リリースされたAWS SageMaker Canvasの新機能で構築した機能セットをご紹介する際に、これらのベンチャーのいくつかについて触れたいと思います。

これから数分間、融合しつつある2つの自動化技術についてお話しします。それは、ローコード/ノーコードと生成AIです。これらの技術が一緒になることで、組織は競争の場で他社との差別化を図ることができます。ローコード・ノーコードの側では、コードを一切書かずにアプリケーションを素早く構築できるソリューションや技術があります。これらのプラットフォームの利点は、ユーザーフレンドリーなインターフェースと直感的なドラッグ&ドロップ機能です。さらに、これらの技術の多くには、ビジネスニーズに対応した事前パッケージ化されたテンプレートやワークフローが付属しています。
一方で、世界を席巻している生成AIがあります。生成AIは、ビジネスユーザーとプロの開発者の両方が、システムと自然にコミュニケーションを取り、複雑な技術ソリューションを構築することを可能にします。Shyamが示したように、生成AIのもう一つの利点は、コードスニペットを生成してコード構築プロセスを加速し、半構造化データや非構造化データを処理してコンテンツ作成を強化できることです。ローコードと生成AIを組み合わせることで、ほとんどの組織がより効率的になり、ビジネスニーズに合わせたカスタムアプリケーションを構築できるようになっています。

それでは、これを具体的に示すために簡単なデモをお見せしましょう。 Chiefsightは私たちのベンチャーの1つで、go-to-market intelligenceプラットフォームです。通常、データとデータ駆動型インサイトの力を活用してビジネスの成長を促進するのに役立ちます。Chiefsightのために構築したいと考えていたユースケースや機能の1つは、過去の売上データを分析して、現在の販売パイプラインを使用して販売の成約までの日数を予測することでした。

ご覧のように、Shyamが発表したすべての機能を紹介します。まずはデータをインポートします。 データがどこにあるかは問題ではありません。これは過去のデータが取り込まれているところで、データが表示されるのがご覧いただけるはずです。 データが揃ったら、Shyamが示したように、コードを1行も書くことなくデータに対してインサイトや分析を実行できます。システムがデータを処理し、注目すべき異常がないかを探します。ここでは、外れ値を見つけたバージョンが1つあります。


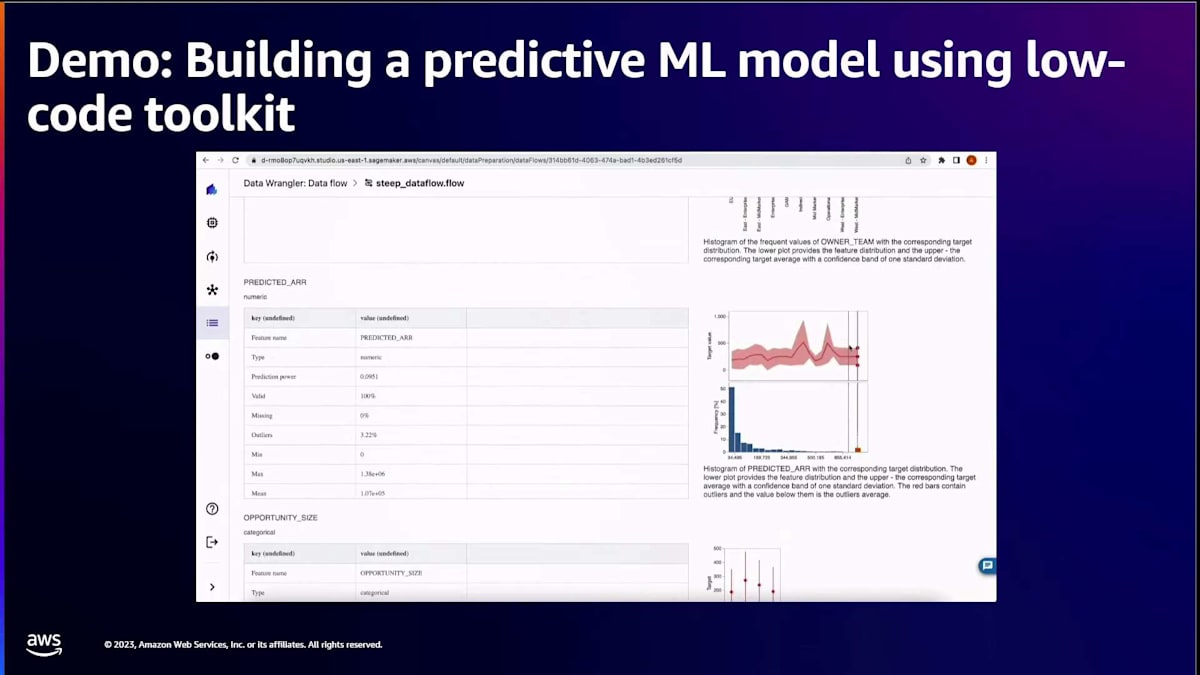
インサイトを得たら、次のステップとして、これらの例外に対処するためにデータを変換します。ご覧のように、ボタンをクリックしてドラッグ&ドロップするだけで、 変換を構築できます。この変換を構築したら、先ほど見た外れ値が処理されたかどうかを確認するために、分析を再実行してみましょう。 スクロールダウンすると、以前あった外れ値が0%になったことがわかります。 Shyamが言及したように、この素晴らしい点は、バックエンドが複数のMLモデルにわたってデータを実行し、最も高いRMSE値を持つ最適なモデルを選択することです。

その利点は、私がコードを書く代わりにシステムが大部分の重労働を行うことと、データを分析してデータの影響がどこにあるか、どの要因が影響を与えているかを把握しようとすることです。これが完了したら、予測値でデータを更新でき、各予測に応じて成約までの日数が更新されるのがわかるはずです。これらはすべてバックエンドで行われ、ビジネスケースに応じて必要なときにトリガーできるジョブを作成できます。

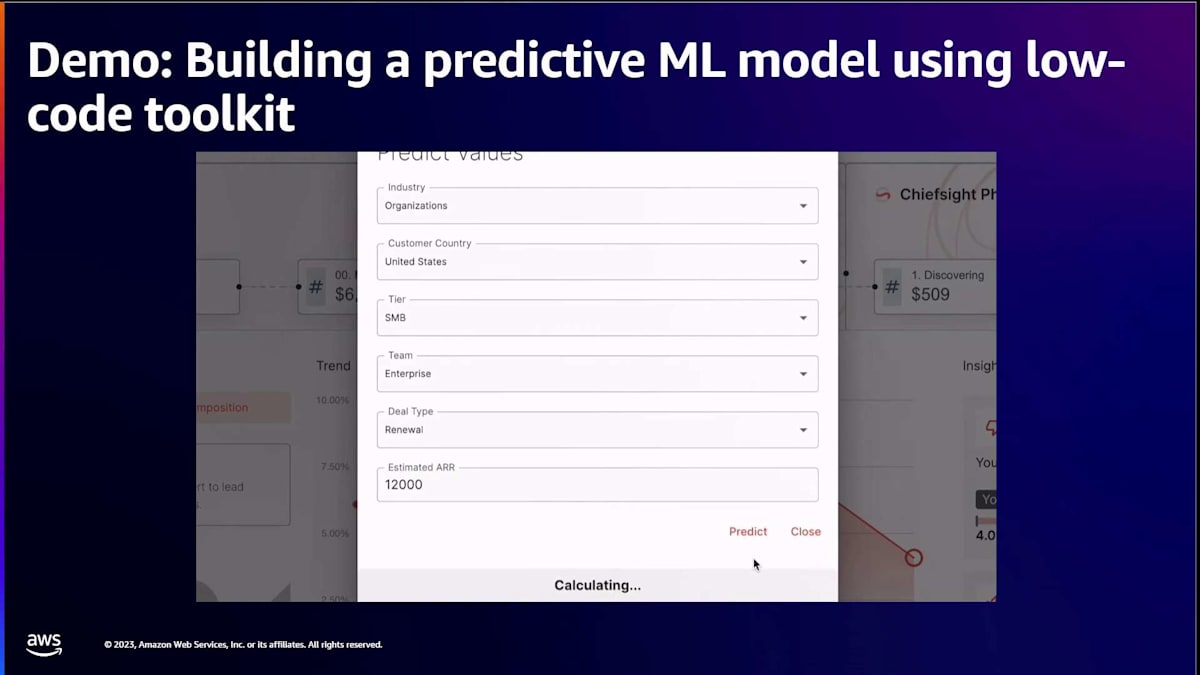
すぐにご覧いただけますが、これを本番環境にデプロイすると、ユーザーまたは顧客側で、持っている異なる要素をドラッグして選択できるようになります。 そして、成約までの日数の予測が計算されます。ご覧のように、これらすべてが開発者の作業をより速く、より簡単にし、1行のコードも書くことなく、システムが大部分の重労働を行っています。
Inside-Out Defenseによるサイバーセキュリティソリューションの構築

さて、振り返ってみると、low-codeとgenerative AIプラットフォームの融合を促進している変化は何でしょうか?スライドの左側を見ると、労働力に関する労働統計局のデータが数年間にわたって示されています。各棒グラフの緑色の部分に注目してください。これは、コンピューターサイエンティスト、コンピューターエンジニア、プログラマー、データサイエンティストなどのIT専門家の割合を示しています。全労働力と比較すると、かなり低いことがわかります。そもそも小さな割合であり、成長を見込んでもさらに小さくなっています。
これは、カスタムソリューションの構築を支援できる技術リソースの供給に問題があることを示しています。一方で、ビジネスニーズをサポートするためのユースケースや技術ソリューションを構築したいという企業の需要は衰えていません。Gartnerのデータポイントによると、このタイプのソリューションの予測市場規模は2027年に約848億ドルに達し、この期間のCAGRは約20%と予測されています。さらに、3つ目のポイントとして、ソリューションが進化するにつれて、ビジネスユーザーがこれらのソリューションを採用し、自らビジネスケースを構築したいと考えるようになっています。
Bainの調査データからわかるように、非IT系のビジネスユーザーの41%が実際にこれらのソリューションを採用しており、2026年までには、これらのユーザーの80%が正式なIT役割以外の人々になると予想されています。このデータを踏まえると、組織は技術人材の確保に苦戦しながらも、増大するビジネスニーズに対応する必要があることがわかります。そのギャップを埋めるため、ITの関与なしにソリューションを追求する権限が与えられるケースが増えています。各セクターのリーディング企業はこれを理解し、適応を進めています。


これに関連するもう一つのデータポイントは、EMEA地域のCIOを対象とした最近のGartnerの調査です。46%のCIOが、ITとビジネス部門が協力して構築し、ソリューションの提供部分を担当するco-buildについて、CXOの同僚と協力していると述べています。 これらのソリューションを求める顧客のタイプを分類すると、私たちの経験では4つの主要なアーキタイプがあります。これらは、コーディング能力を横軸に、ユースケースを縦軸にして分類されています。コーディング能力の範囲は、非技術的なバックグラウンドを持つシチズン開発者から始まります。これらは主にこれらの技術を使用する傾向のあるビジネスユーザーです。
スペクトルの反対側には、正式なトレーニングを受け、長年にわたって複雑なソリューションを構築してきたプロフェッショナルコーダーがいます。これらの各カテゴリーは、サポートするユースケースに基づいて、バックエンドの機能的ユースケースとフロントエンドの顧客向けユースケースに分かれています。
Shyamが最初に示したギアのスライドに戻りますと、一方にlow-codeユーザー、もう一方にpro-codeユーザーがいて、両者が協力してより良いソリューションをより速く構築しています。low-codeユーザーにとっては、ソリューションやイノベーションを市場に出すのがずっと早くなります。そのため、pro-codeユーザーへの依存が減り、より良い協力関係が築けます。pro-codeユーザーにとっては、面倒な作業が加速され、高品質な開発が迅速かつコスト効率よく行え、ビジネスユーザーと協力して要件をより良く理解し、ソリューションを早く市場に出せるようになります。

ここにgenerative AIによる変革をlow-codeに重ねると、コード生成からエラー削減、rapid prototyping、生産性向上まで、さらに多くのメリットが生まれます。例えば、rapid prototypingでは、先ほどのデモで見たように、開発者はデータに適合するMLモデルを迅速に構築できました。システムがほとんどのコードを生成するため、十分にテストされ、エラーが少なく、より速く、これらの機能を構築する生産性を向上させるのに役立ちます。

では、これを具体化する別のデモを見てみましょう。Inside-Out Defenseは、サイバーセキュリティ分野の我々の別のベンチャーです。彼らは、事後ではなく、脅威が発生した時点で検出し対処するという差別化されたアプローチを取っています。我々が解決したかった一つのユースケースは、脅威が発生したときに通知が溢れかえるアラート疲れです。Large Language Models (LLMs)の推論能力を使って脅威を理解し、組織のシステムセキュリティポリシーと照らし合わせ、そうでなければ見つかるノイズを特定して減らしたいと考えました。
組織におけるローコード/ノーコードとgenerative AIツールの効果的な活用戦略



これが、システムに提供している入力で、ある時点でキャプチャしたすべてのイベントのイベントログです。ポリシー、時間、イベントの種類などが見えます。システムを通すと、これが生成される出力です。ご覧の通り、平易な英語で問題点を明確に説明し、要約し、推奨事項を提供し、その理由を特定しています。
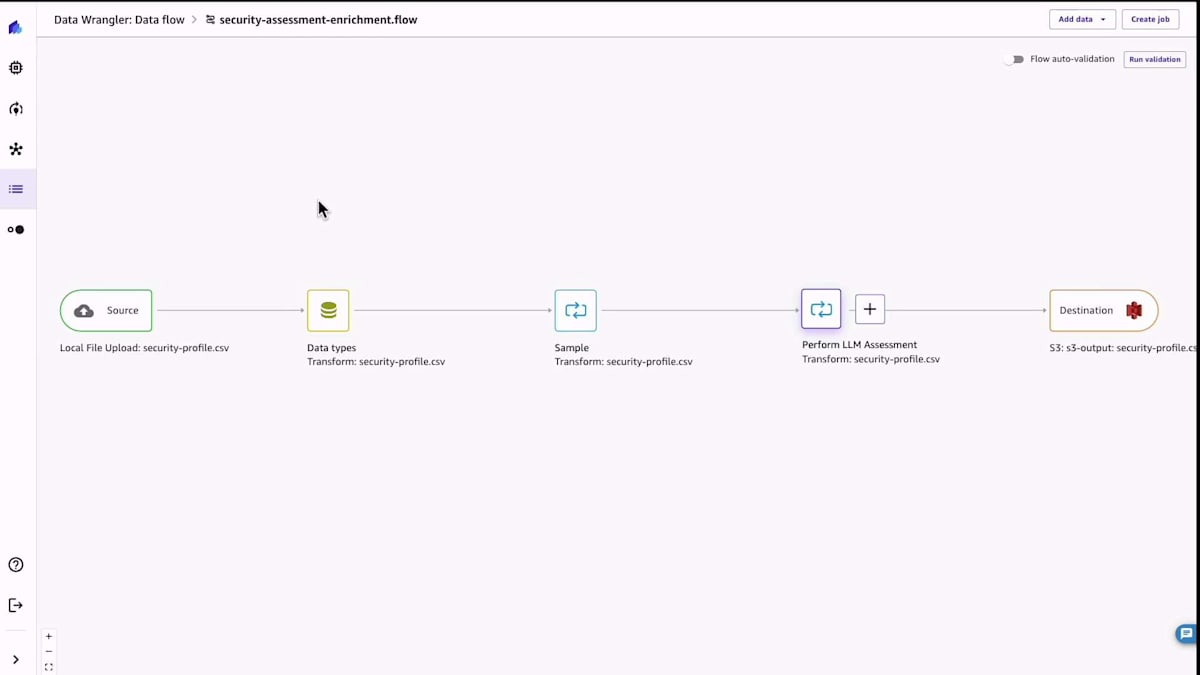
では、デモを見てみましょう。この場合、データワークフローを構築しました。前回のものと比べるとかなりシンプルなはずです。やっているのは、イベントデータを読み込むだけです。すぐにYAML形式で表示されるのが見えるでしょう。そして、組織のセキュリティポリシーと組み合わせます。これができたら、サンプルにあるようなデータフローになります。次に、LLM分析を実行して、先ほど見た出力を得ます。

ここでは、限られた量のコードスニペットが表示されていますが、一番下を見てください。私たちは単に平易な英語で、何を探すべきかを説明しているだけです。コードを一行も書かずに、システムがそれを処理し、私たちが見てきた出力を提供しているのです。

さて、私たちはこの破壊的な変化を目の当たりにし、これらのツールが採用されるのを見てきました。そして、近い将来、これらのツールの成長が続くことは明らかです。 私たちの調査によると、low-codeを採用した組織の現在の採用率は17%ですが、2年後には40%に達すると予測または目標としています。generative AIについては、私たちが話をした組織の40%以上が、新しいgenerative AIのユースケースを構築、採用、または探索しています。つまり、円グラフの左側に示されているように、ほとんどの組織がAI採用の初期段階にありますが、目標達成のためにこの技術を活用したいと考えています。

将来を見据えて、組織が競争力を維持し、これらのツールを活用するには何ができるでしょうか? 第一に、効果的な運用モデルを確立することです。これは、C-suiteから実行レベルまで一貫して行う必要があります。リーダーシップのサポートとスポンサーシップが必要ですが、同時に成功を推進できるよう適切なインセンティブを設定することも重要です。第二に、ビジネスユーザーがビジネス上の問題に対してこれらのツールが何をできるかを理解するための啓発プログラムを正式に立ち上げることです。さらに、IT組織と協力して、ビジネスユーザーがより良く協働できるようにこれらのツールを利用可能にし、適切なガバナンスを確立することが重要です。
第三に、これらのツールは流動的で動的であり、単に手近な成果を求めるのではなく、エンドツーエンドのユースケース全体に適用することで、より大きな機会を生み出すことができます。最後に、実験が不可欠です。大規模な産業用エンタープライズユースケースに拡大する前に、まずはシンプルなユースケースから始めましょう。セキュリティ、データ保護、知的財産権を確保するためのガバナンスを確立することをお勧めします。
Auraを活用したtalent intelligence platformの構築

最後にもう一つデモをお見せして、締めくくりとしてShyamにバトンタッチしたいと思います。 Auraは私たちのもう一つのベンチャーで、talent intelligence platformです。これは、workforce analyticsデータを分析し、適切なシグナルを構築することで、組織が労働力に関する適切な決定と選択を行えるよう支援します。Auraが処理する規模について言及すると、9億5000万件のプロフェッショナルレコードを処理する必要があります。これには2000万件のjob skillsetデータベースと4億件のjob postingが含まれます。必要なinsightsを生成するには、これらすべてを処理しなければなりません。従来のAIアプローチでは、この規模でスケーラブルなものを構築することは困難でした。そこで私たちにとっての利点は、LLMsを使用してデータ生成をカスタム自動化し、さらにそれに基づいてinsightsを導き出すことです。

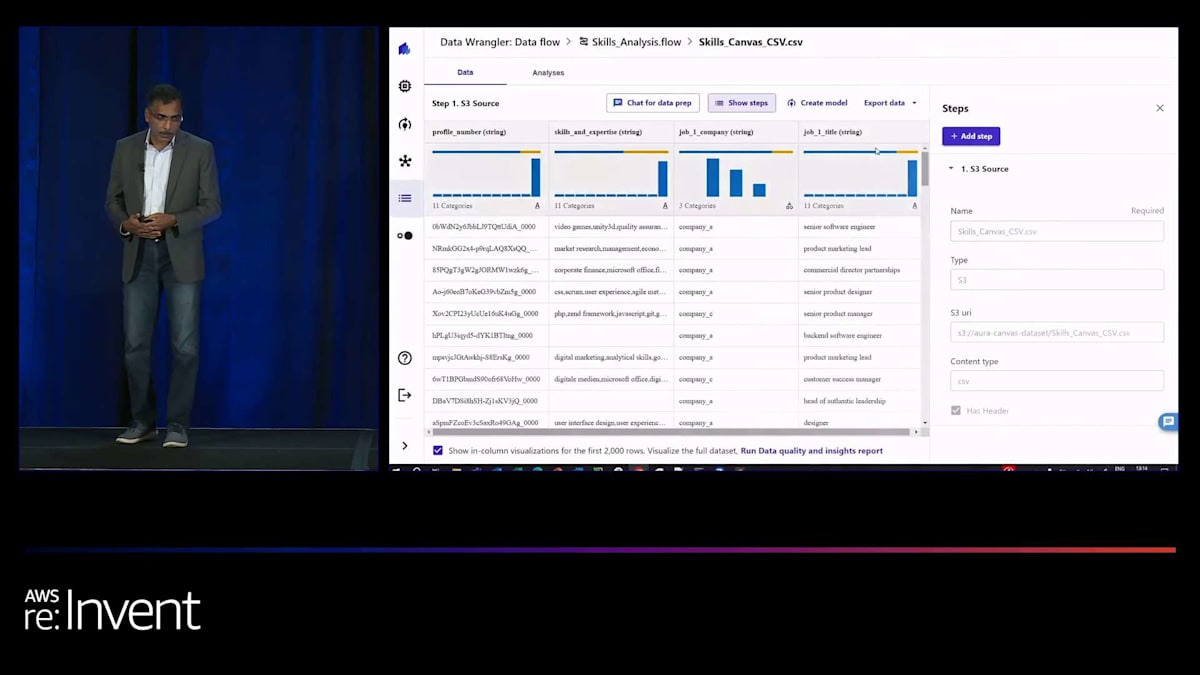
さて、再度データ wrangler から始めましょう。データのインポートを開始しますが、これは私たちが構築した複雑なデータワークフローの1つです。3つのデモの中で、ご覧のように、job data、skills、job titles をインポートしています。 そして Shyam が示したように、このプロセスでデータを可視化し、さらに変換によってデータをクリーンアップすることができます。 job title に合致しないスキルがある場合、それらをクリーンアップできます。ご覧のように、小さなコードスニペットを書くだけで、それを job skills database に結び付けることができます。
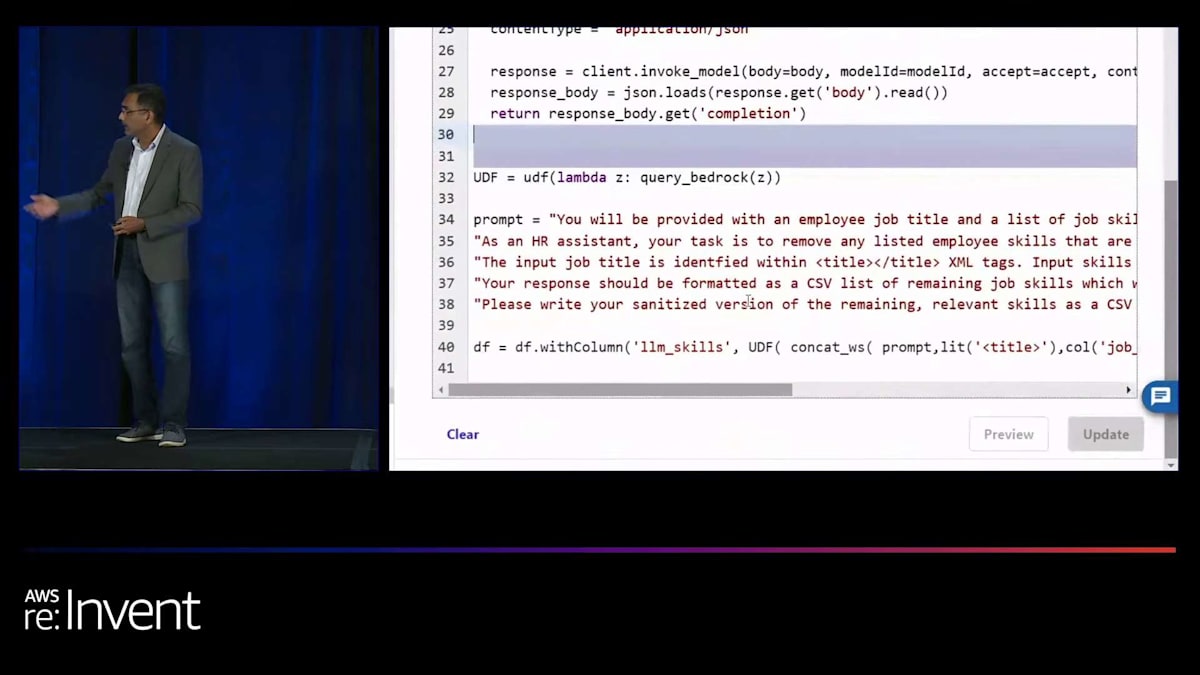


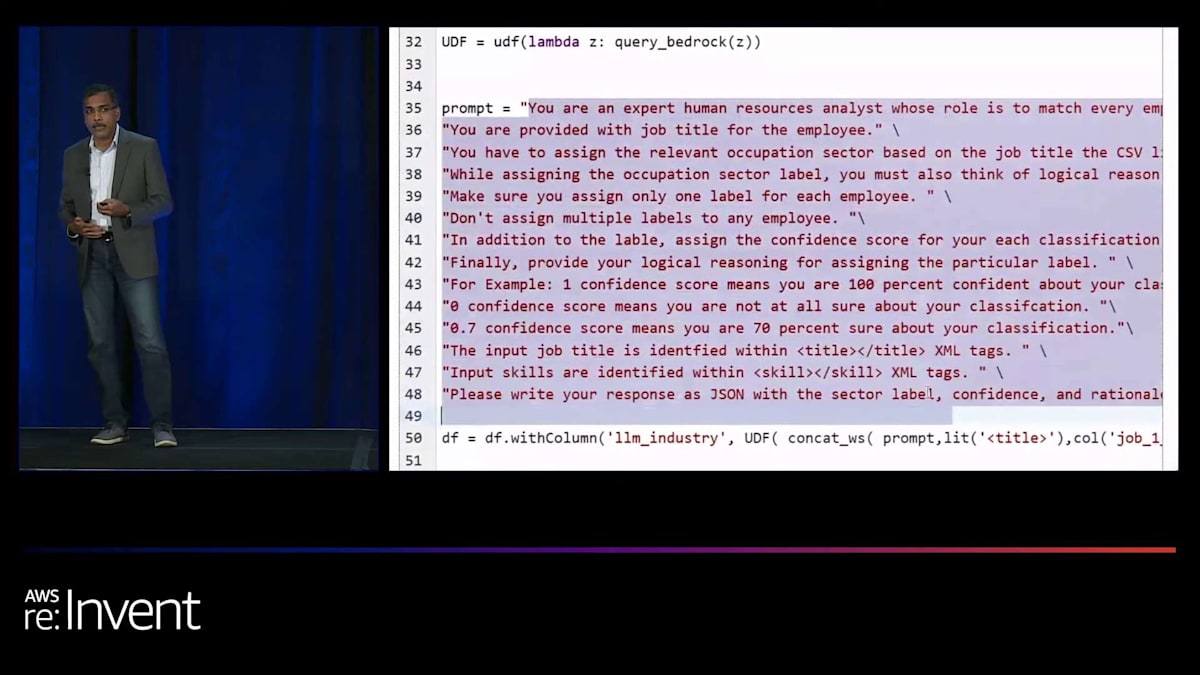
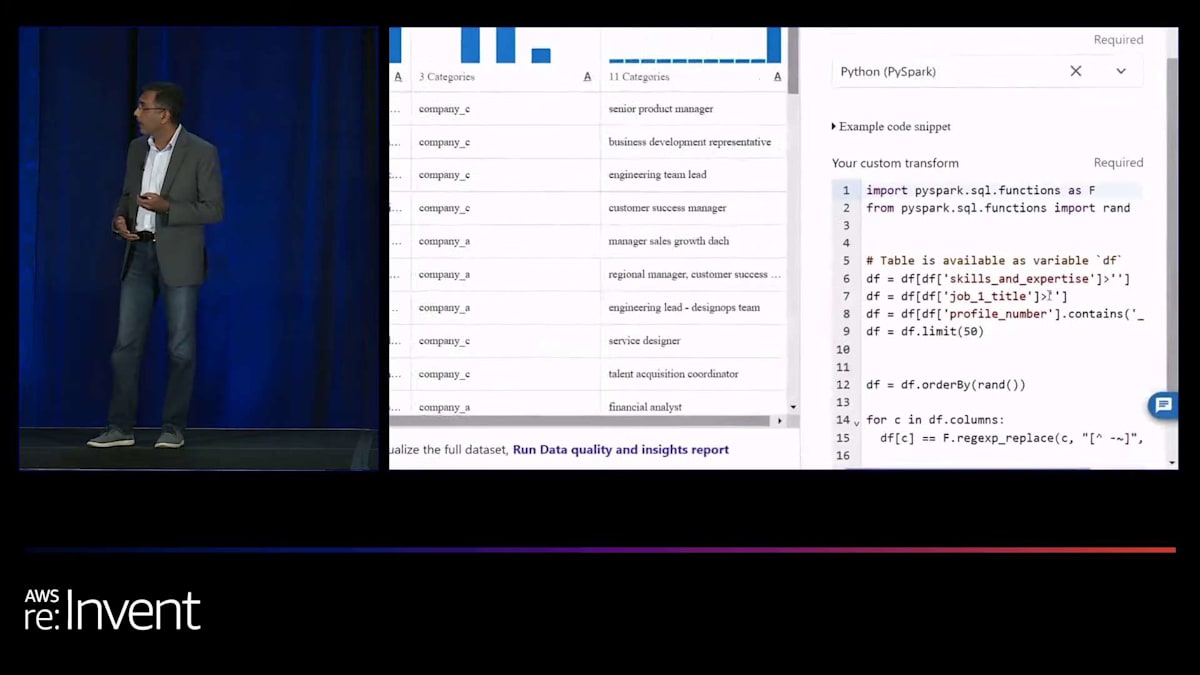
再度、下部をご覧ください。やりたいことを平易な英語で説明するだけで、システムが重要な作業を行ってくれます。 そして、データが準備できたら、LLM ができることに基づいてデータをスコアリングする必要があります。すぐにわかるように、スコアだけでなく、なぜそのようにコーディングされたのかという理由も正確に示されます。 そのため、手動でそれを行う必要はありません。そして再び、下部をご覧ください。以前は同じことを手動で行うために何百行ものコードを書く必要がありましたが、 それでも問題は解決しませんでした。しかし今では、自分の意図を説明するだけで、システムがそれを理解し、重要な作業を行ってくれます。


そして、1つのクールな機能、少なくとも今週発表された機能は、データ準備のためのチャットです。 システムを離れる必要はなく、実際にデータと対話して何をしているのかを理解したり、データの可視化を依頼したりできます。これにより、ワークフローを構築するかどうかを決定する前に、プラットフォーム上で生成されているインサイトを見ることができます。 好きな方法でプロットするよう依頼し、その上にデータをどのように表示したいかを追加できます。 そして、システムがデータについて説明してくれているのもわかります。 これらすべてが完了したら、他のすべてと同様に、製品からユーザーが使用する際に任意の方法でトリガーできる job を作成できます。
以上で、皆様の貴重なお時間をいただきありがとうございました。ここで Shyam にマイクを渡し、まとめと追加の質問を受け付けたいと思います。

以上で、皆様の貴重なお時間をいただきありがとうございました。ここで Shyam にマイクを渡し、まとめと追加の質問を受け付けたいと思います。
セッションのまとめとAmazon SageMaker Canvasの活用促進

Purna、ありがとうございます。 その素晴らしい事例を共有していただき、本当にありがとうございます。これこそが、実践的な企業の事例に落とし込むということの意味です。ご覧いただいたように、データを準備し、機械学習を企業全体に展開して民主化する方法には、3つの異なる例がありました。
すべてをまとめると、このセッションですべての例とデモでご覧いただいたAmazon SageMaker Canvasを使用することで、ビジネスチームが効果的なビジネス成果を達成するために、コードを使用せずに単一のワークスペースでワークフロー全体を実行できます。Canvasは機械学習モデルに対して2つの大きな柱を提供します。1つは、すでに訓練済みのモデルを提供する「すぐに使えるモデル」で、これには基盤モデルや大規模言語モデル、あるいは他のAIサービスで構築されたモデルが含まれます。一方で、特定のユースケースがある場合は、独自のカスタムモデルを構築することもできます。データの準備から始まり、組み込みの変換を選択するか自然言語を使用し、ボタン一つでモデルを構築、トレーニングし、洞察と予測を生成した後にデプロイします。
最後に重要な点は、コラボレーションです。孤立して仕事をすることはできません。私たちは、複数のチームが互いに協力し合う組織で働いています。Canvasを使えば、これらのモデルをシームレスに同僚や他のチームと共有できるので、ビジネスチームがデータを準備し、データサイエンスチームがそれらのモデルを本番環境にデプロイする前に検証するという、両方の世界の利点を得ることができます。
ぜひAmazon SageMaker Canvasをお試しください。ブラウザ上で動作するので、AWSマネジメントコンソールにアクセスする必要はありません。お好みのブラウザを使用して、ML全体のワークフローを実行するための単一のワークスペースを持つことができます。 今すぐ始めることができます。顧客離反予測、需要予測、製造欠陥など、8〜10以上のユースケースを含む多数のハンズオン演習が用意されており、Immersion Day labsで今すぐCanvasを始めることができます。


ぜひ試してみてください。そして何より重要なのは、 フィードバックをお寄せいただくことです。それによって、Canvasをより良いものにし、皆様のニーズに応えることができます。午後のお時間を私たちと過ごしていただき、ありがとうございます。お話しする機会を得られたことを光栄に思います。 私はShyam Srinivasanと申します。AWS AI/MLチームのPrincipal Product Managerで、Bain & CompanyのパートナーであるPurna Doddapaneniと一緒に登壇させていただきました。
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion