re:Invent 2024: Amazon Q BusinessでAWSイベント企画を効率化


はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Build Amazon Q apps to scale and drive community engagement (DEV201)
この動画では、AWS Senior Developer AdvocateのViktoriaとAWS HeroのLindaが、Amazon Q Businessを活用したイベント企画の効率化について解説しています。Amazon Q BusinessにAWS User GroupやAWS Partnersのデータを取り込み、Lambda関数やWebクローラー、S3バケットを組み合わせて、イベントの会場選定やスピーカー探し、日程調整、プロモーション文の生成を自動化する方法を具体的に紹介しています。robots.txtの確認やメタデータマッピングなど技術的な注意点も詳しく説明され、最終的にはEvent Organizer AppとEvent Planning Assistantという再利用可能なアプリケーションの構築方法まで網羅的に解説されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
re:Inventでの出会いから生まれたコラボレーション

みなさん、こんにちは。最初のセッションの1つへようこそ。この先の5日間のre:Inventに向けてワクワクしていますか?素晴らしいですね。月曜の朝からこんなにたくさんの方々にお集まりいただき、本当に嬉しく思います。始める前に、隣に座っている方を見て笑顔を向けてみてください。その方が将来の友人や、あるいは共同発表者になるかもしれませんよ。
実は笑い話のようですが、私とLindaの出会いもそんな感じでした。私たちはre:Invent 2023で出会うまで、お互いのことを全く知りませんでした。イベント中、Lindaは技術コミュニティに関わり始めた経緯や、Viennaのユーザーグループリーダーになり、後にAWS Heroとして認められるまでの感動的な story を私に話してくれました。イベント後、私たちは世界の異なる国で通常の生活に戻り、LinkedInで連絡を取り合うだけでした。世界中で働いているので、何が共通点だったのかと思われるかもしれませんが、ある時、私がヨーロッパへの旅行を計画していました。
そこでLindaと私は話し合いを始め、Viennaのユーザーグループで素晴らしいイベントを企画しました。Lindaが私を講演者として招待してくれたイベントは素晴らしいものでした。AWS Partnerやユーザーグループリーダーチームの全員とAWSエコシステム全体と力を合わせることの重要性を示してくれました。Viennaの中心にある歴史的な象徴的な会場で開催されましたが、実はこの会場は私が初めてAWSのMeetupに参加した場所でもありました。AWS Partnersがスポンサーとなった技術的なディスカッションとネットワーキングイベントは本当に素晴らしいものでした。
その後、私たちはSeattleからNew York、MunichからParisまで、様々な技術イベントで顔を合わせることになりました。これらの技術イベントで私たちが目にしたのは、コミュニティを集めることで、皆が協力し、学び、互いに成長するためのユニークな機会が生まれるということでした。だからこそ私たちは今日ここにいます。技術イベントの企画、オンラインとオフラインの両方でのコミュニティ構築、そしてあなたのインパクトを拡大する方法について、私たちが学んだことを共有したいと思います。
私はViktoriaです。AWSのSenior Developer Advocateとして4年間働いており、過去3年間はコンテンツの共有も始めました。このコンテンツ作成の旅のおかげで、ゼロから60万人以上の技術愛好家のコミュニティを構築することができました。今日は、AWSで生成AIアプリを構築する方法と、コンテンツ作成を通じて学んだ知見をお話しします。私はLindaです。AWS Heroであり、Viennaのユーザーグループリーダーでもあります。また、コミュニティ内のサポート協会の会長も務めており、過去5年間にわたって700人以上が参加するMeetupやCommunity Daysを企画してきた経験を共有できることをとても楽しみにしています。
Amazon Q BusinessとAWSのAIスタック:Generative AIの活用



2024年を迎え、誰もがGenerative AIについて語っている今、皆さんがGenerative AIを活用して成果を最大化する方法についてお話ししたいと思います。 まず、AWSがAIアプリケーションを構築するために提供しているテクニカルスタックを見てみましょう。最下層には、コスト効率の良いインフラストラクチャがあります。モデルのトレーニングを行いたい場合、そこには高速なコンピューティングリソースとデータサイエンティスト向けのツールであるAmazon SageMakerがあり、モデルのトレーニングやファインチューニングに利用できます。 中間層には、Amazon Bedrockがあります。これは、AmazonとAnthropicやClaude AI、21 Labs、Llamaなどのパートナー企業が提供する様々なFoundation Modelを実験・利用できるサービスです。Amazon Bedrockを使えば、たった1回のAPI呼び出しで、異なるFoundation Modelにアクセスすることができます。 最上層には、Generative AIアプリケーションがあります。これらは技術的な知識がないユーザーでも使えるツールで、ビジネスにおける真の価値はここにあります。コーディングなしで簡単にアプリケーションを作成できるからです。

Amazon Q製品群があり、AWSのあらゆる場所でAmazon Qを見かけることができます。AWSコンソールを開けばAmazon Qがあり、IDE、コンソール、QuickSightなど、様々な場所に存在します。ただし、今日はそのQについては話しません。今日は特にAmazon Q Businessについてお話しします。この中でAmazon Q Businessを実際に試したことがある方はいらっしゃいますか?あまり多くないようですね、おそらく10%程度でしょうか。それは良いことです。今日は新しいことを学べますよ。
Amazon Qの機能について簡単に見ていきましょう。まず、QがほかのGenerative AIシステムと大きく異なる点は、自社のデータを統合できる能力です。皆さんはおそらくChatGPTやClaudeなどを試したことがあり、質問をすることはできますが、それらは一般的な知識に基づいて回答を提供するという問題があります。では、自社の独自データを取り込んで、そのデータに基づいて質問したい場合はどうでしょうか?そのためにAmazonはQを構築しました。40以上の組み込みコネクターを使用して、データソースに接続できます。わずか数回の設定クリックで、Salesforce、Google Driveに接続でき、今日はWeb Crawlerコネクター、S3コネクターなどを使用したWebスクレイピングの方法もご紹介します。

Amazon Qにデータを取り込むと、2つのものが取り込まれます。コンテンツと権限です。Q以外でデータにアクセスできないユーザーは、Q内でもそのデータにアクセスできません。データを取得する際、Qはアイデンティティプロバイダーに対して権限を照会し、その権限に基づいて、要求された情報を提供します。私たちは意思決定のために質問をすることが多いですが、そのためにプラグインと呼ばれるものを使用できます。

プラグインを使用すると、データに基づいてアクションを実行できます。例えば、イベントを計画していて、地域内の様々なスピーカーについて知りたい場合、スピーカーを特定してプラグインを使用してメールを送信することができます。Amazon Qからカスタムアクションを作成して、スピーキングセッションの招待状の送信を開始できます。SalesforceやZendeskでチケットを作成するなど、他のプラグインもあります。基礎的な部分を説明したところで、今日何を行うのか少しお見せしましょう。
イベント企画のためのAmazon Q活用事例

カリフォルニアでイベントを企画していて、イベントをそこで開催したいと想像してみてください。どの都市で開催するか決めかねているので、協力できるAWS User Groupがカリフォルニアにあるかどうか確認したいと思います。自分たちだけでイベントを企画するより、共同開催する方がずっと簡単ですからね。そこでAmazon Qに、カリフォルニアを拠点とするAWS User Groupを教えてもらいます。すると都市名と一緒にUser Groupのリストを提供してくれました。このような情報をAmazon Qに取り込む方法については、後ほどご説明します。
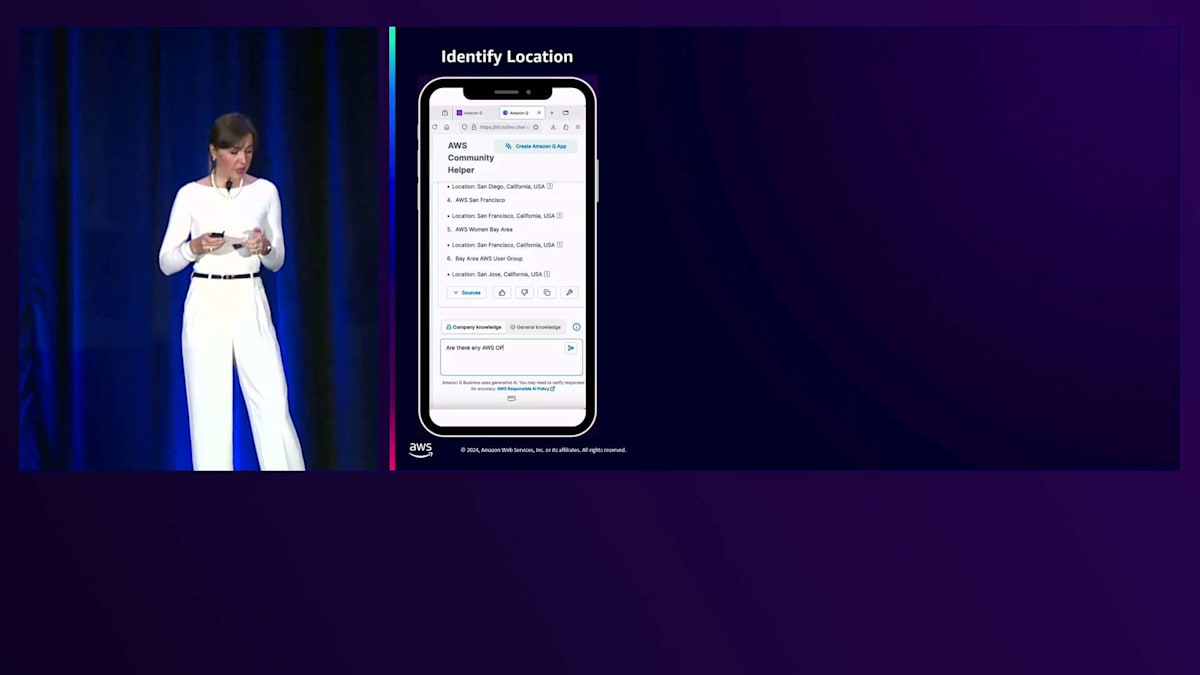
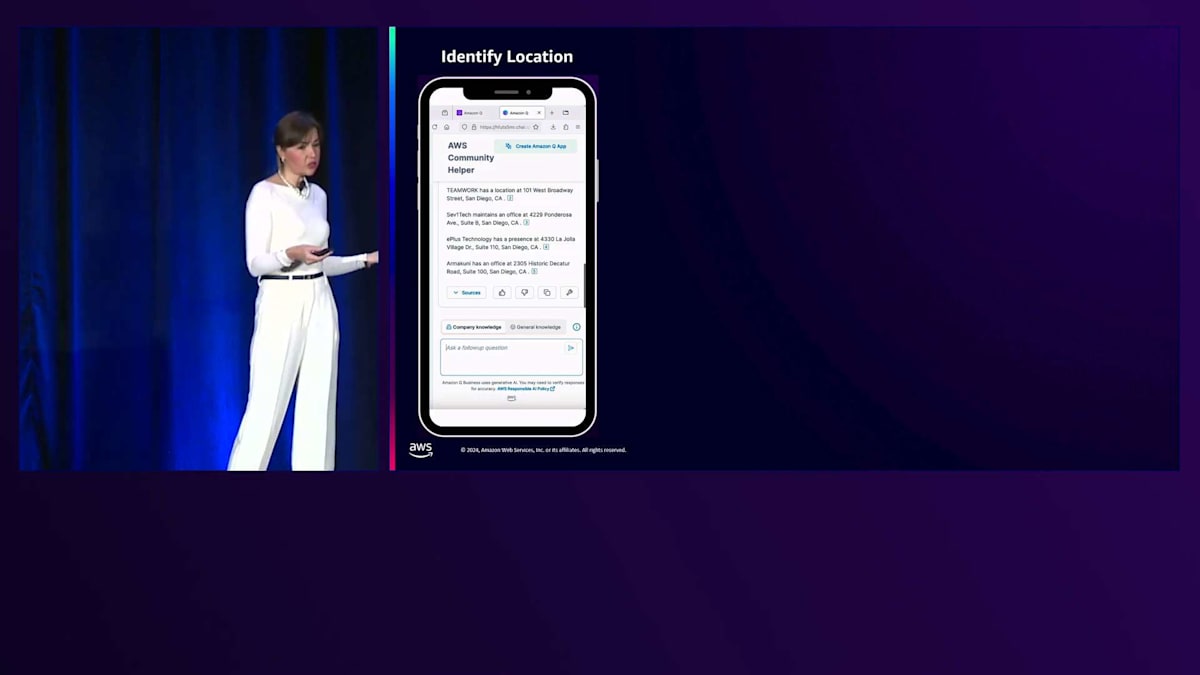

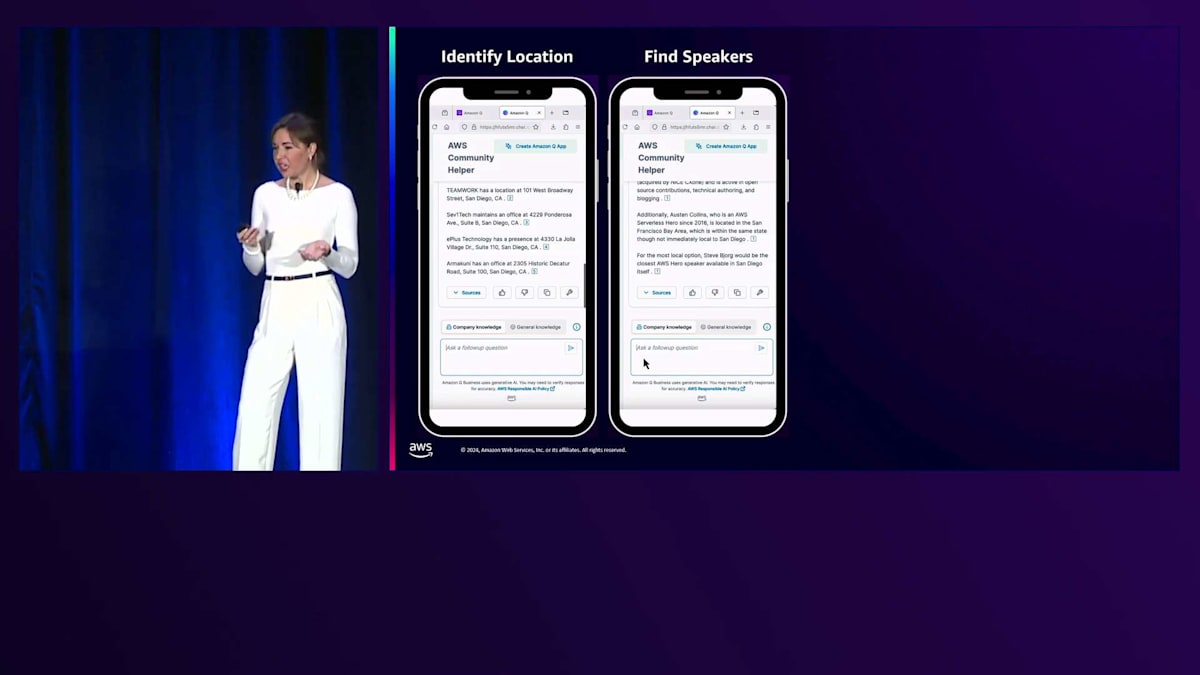
サンディエゴという都市が目に留まりました。素晴らしい都市ですよね。では、サンディエゴを拠点とするイベントのスポンサーになってくれそうなAWS Partnerがいないか見てみましょう。そこでQに、AWS Partnerの名前と所在地を教えてもらうようお願いしました。すると連絡を取れそうなAWS Partnerのリストが表示され、スポンサーシップとその場所でのイベント開催をお願いできそうです。会場は確保できましたが、この地域を拠点とするAWSのスピーカーがいないか確認してみましょう。そこで、サンディエゴを拠点とするAWS HeroやCommunity Builderがいないか尋ねてみると、情報を提供してくれました。はい、Heroが何人かいますね。実際、近くに住んでいるHeroが何人もいるようです。

良さそうですが、Serverlessがトレンドのトピックかどうか確認してみましょう。人々はServerlessについて学ぶことに興味があるのでしょうか?これを確認するために、AWS EventsのYouTubeチャンネルから視聴回数データを取得しました。このデータをCSV形式で投入して、これらの視聴回数から見て、どんなトレンドがあり、注目を集めそうなトピックは何か提案してもらいましょう。
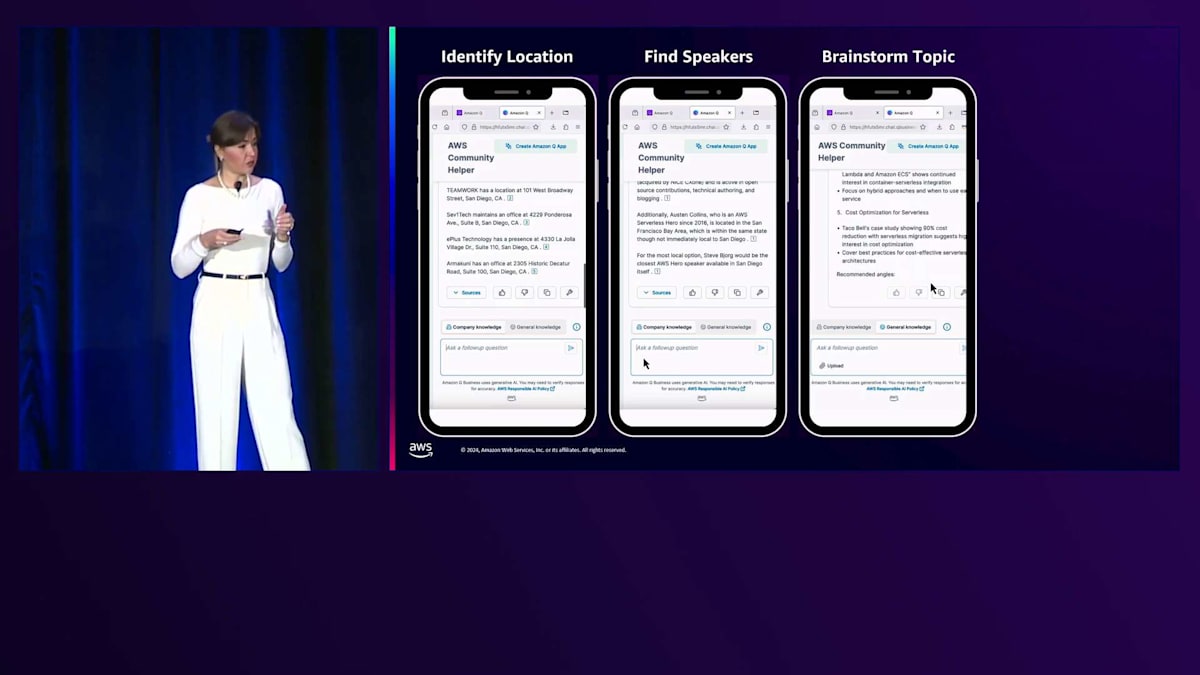
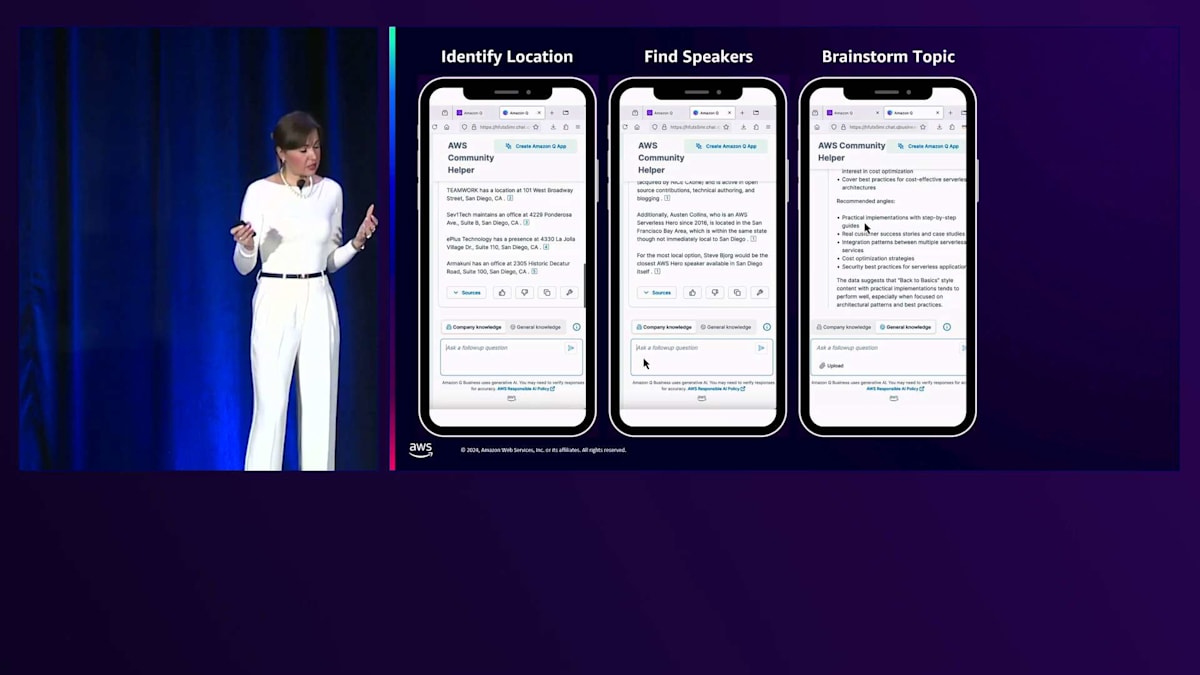
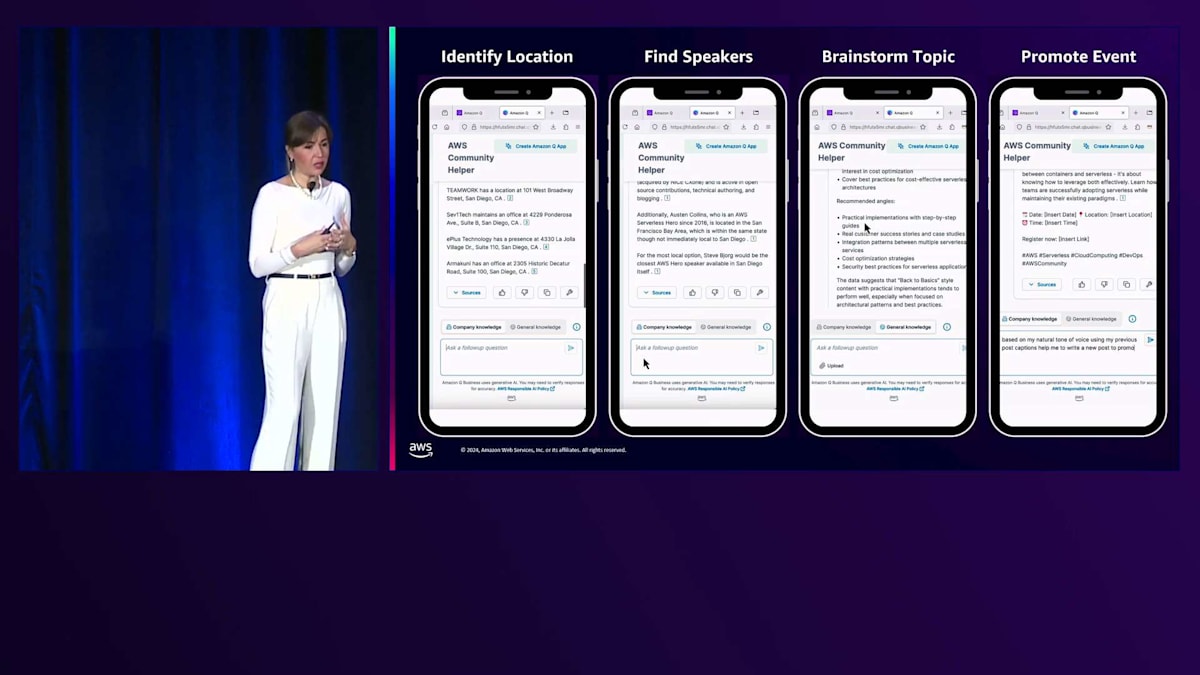
トピックを提案してくれて、ステップバイステップの実装ガイド、セキュリティに関する議論、その他いくつかの提案を含む一般的なアドバイスをくれました。これで場所もスピーカーもトピックも決まりました。最後はイベントの宣伝です。でも正直なところ、「私は発表できることを大変嬉しく思います」なんて投稿は誰も使いませんよね。そこで、私の投稿例を提供して、私の自然な話し方を使って、これまで話し合った情報に基づいてイベントを告知する投稿を作成してもらいました。すると概要を提供してくれ、私がよく使うコンテンツへのCall To Actionも含めてくれました。私が普段使うフォントも使い、箇条書きリストまで作ってくれました。このようにAmazon Qは、私のイベントについてのコミュニケーションスタイルを採用してくれたのです。
このユースケースのアイデアから実装までは、正直なところかなりの道のりでした。最初に講演を申し込んだ時は、「やれる」と言いました。しかし実際に構築を始めると、うまく機能しないことに気づきました。これから、私たちの経験と学んだことについてLindaが説明します。皆さんも構築を始めると、きっと同じような課題に直面すると思います。ご清聴ありがとうございました、Victoria。
新技術導入の課題とAmazon Qデータソースの構築

みなさんの中には、Gartnerのハイプサイクルをご存知の方もいらっしゃるのではないでしょうか。ハイプサイクルをご存知の方は手を挙げていただけますか?たくさんの手が上がっていますね。会場の半分近くの方が手を挙げていらっしゃいます。これは素晴らしいことです。というのも、新しいテクノロジーの実験を始めるとき、最初の興奮は素晴らしいものがあります。すぐに使える40以上のConnectorのような新機能を探索して、この新しいテクノロジーを使ってどんなソリューションやアプリケーションが作れるかを考えるわけです。


そして、その興奮は高まっていき、期待のピークに達します。AIがすべての問題を解決してくれる、この新しいサービスがすべての問題を解決してくれると考えるようになります。しかし、そこで気づくのは、まだやるべき宿題がたくさんあるということです。まだまだやることがたくさんあり、予期せぬ課題や実装上の障壁に直面します。でも、これは全く普通のことなんです。これは新しいテクノロジーを使って、今まで作ったことのないアプリケーションを構築する際の通常の道のりなのです。



データの準備がまだ必要で、宿題をこなさなければならず、それらをどのように構築するかという戦略を考える必要があることに気づくと、啓発のフェーズに入ります。この新しいサービスとテクノロジーで何が構築できるのかについて、明確な理解と現実的な見方が得られるようになります。そして実際に価値を見出し始め、生産性のピークに達します。そこでは、私がUser Group Leaderとしてイベントを企画する際にそうしたように、AIを使って全体的なプロセスを改善し、効率化し、多くのタスクを自動化できるようになります。

では、それらをどのように構築するかに入る前に、このイベント企画がどのようなものかを見てみましょう。こちらが私たちのUser Group Viennaのミートアップ準備ガイドです。これは、スポンサーやスピーカーの皆さんに送る準備ガイドで、いつ、何を、誰が行うのかを全員が把握できるようになっています。通常は日程と会場の選定から始めます。皆さんがまず知りたいのは、どこで、いつ集まるのかということだからです。その後、トピックを選んでスピーカーを探します。これらが決まったら、プロモーションの準備を行い、ソーシャルメディアで告知して、このイベントの開催を皆さんに知っていただきます。

では、技術的な詳細に入って、アーキテクチャと実際の構築方法を見ていきましょう。場所の特定については、まず必要なデータから始めます。場所の特定のために、私たちは2つのデータソースを使うことにしました。1つ目はAWS User Groupsの特定です。これは私たちがパートナーシップを組みたいコミュニティだからです。2つ目は、AWS Partnersに関するデータの取得です。これにより、彼らの所在地を活用し、関連するイベントやコンテンツのスポンサーになっていただけるよう依頼することができます。


私たちはAWS User Groupsから始めました。AWS User Groupsをご存じない方は、Meetupページで見つけることができます。最初は静的なコンテンツだったので簡単だと考え、Webクローラーを使ってコネクターを構築し、この情報をスクレイピングする計画を立てました。しかし、AWS User Groupsのディレクトリが必要だということに気づきました。AWSのWebページに全てリストアップされているのを確認しましたが、このWebページは動的に生成されており、現在の標準コネクターは静的コンテンツをスクレイピングできないという問題がありました。ここで幻滅期を迎え、かなり落ち込みました。

でも、どんな問題にも解決策はあるものです。調査を進めるうちに、AWSがユーザーグループのリストを取得するために使用しているAPIを見つけました。これを基に、全てのユーザーグループをスクレイピングするLambda関数を作成し、独自のカスタムWebコネクターを構築することができました。AWS Partnersを見てみると、AWSのWebサイトで同様の状況に遭遇しました。既に動的スクレイピングの方法を知っていたので、より簡単だと思いましたが、やはり課題は存在しました。AWS Partnersの各ページを確認していくと、単純にCSVファイルに保存できない非構造化データが含まれていることに気づきました。例えば、パートナーによって1つの所在地を持つ場合もあれば14の所在地を持つ場合もあり、コンピテンシープログラムを持つパートナーもいれば、追加の説明を持つパートナーもいました。
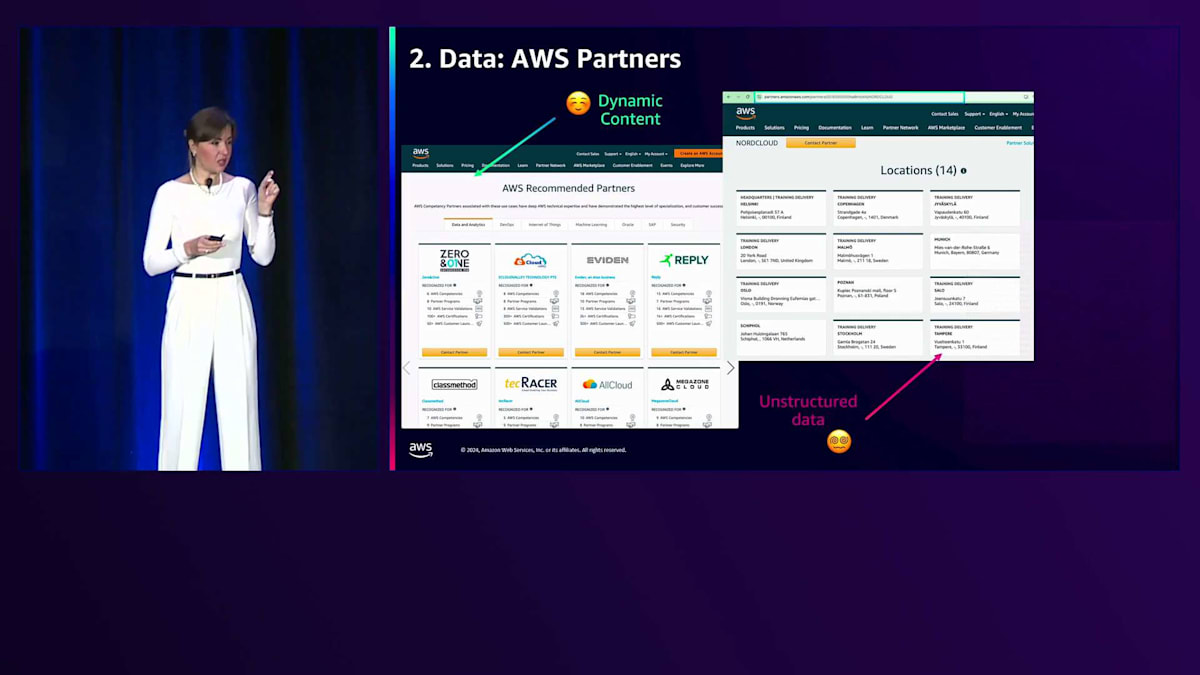


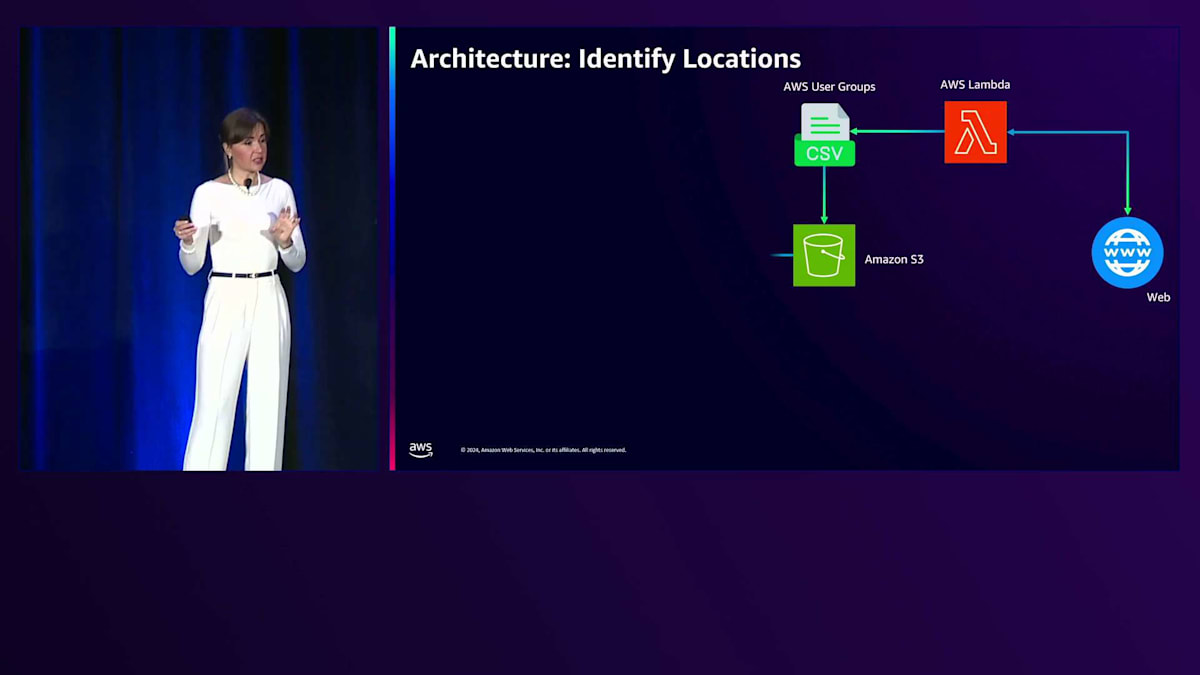

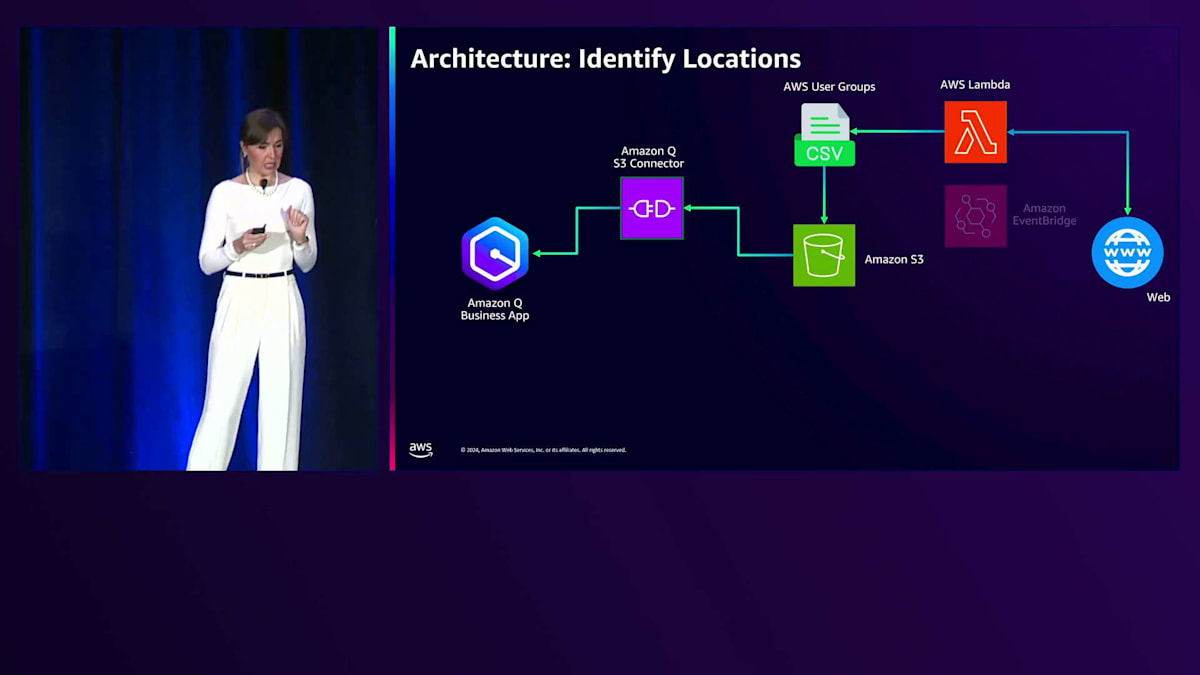
構造化データを保存する方法が必要で、そこでWebクローラーを使用することにしました。具体的には、APIコネクションからパートナーIDを取得し、リンクを構築して、Amazon Qの標準Webクローラーを使用してインデックスを作成しました。アーキテクチャ図で説明させていただきましょう。まず、AWS Lambda関数を使ってAWS User Groupsからデータをスクレイピングし、CSVファイルを作成します。このCSVファイルはAmazon S3バケットに保存され、そこからAmazon Q S3コネクターを作成します。先ほど共有したコネクターのリストを覚えていますか?私たちは標準コネクターを使用しているだけです。コネクターを作成すると、RetrieverとIndexが作成され、Retrieverはインデックス化されたデータをリアルタイムで検索するのに役立ちます。このインデックスをプロビジョニングすると、Amazon S3に追加した全てのデータがインデックス化され、質問をするとAmazon Q Businessアプリケーションに返されます。

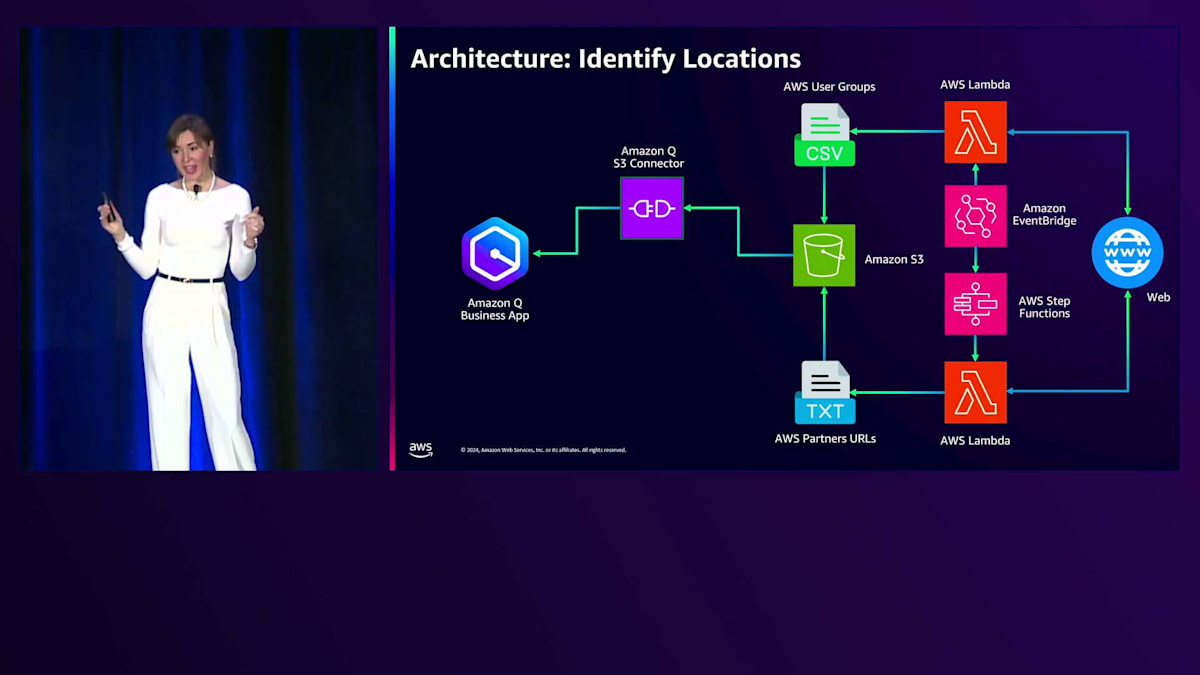

データを更新したい場合は、Amazon EventBridgeを作成して、Lambda関数を定期的に実行するようにスケジュールすることができます。AWS Partnersについても同様のアプローチを取りました。Webクローラー内で使用できる全てのURLを含むテキストファイルを提供するAWS Lambda関数を作成しました。AWSのエコシステムは8,000以上のパートナーを抱える非常に大規模なものであり、最大15分しか実行できないAWS Lambda関数がタイムアウトしてしまうことがわかりました。そこで、Step Functionを作成して、最後のチェックポイントから再開してすべての8,000パートナーをスクレイピングできるようにしました。全てのリンクが構築できたら、Amazon Q Webクローラーを使用して、8,000のパートナーデータ全てをクローリングしました。
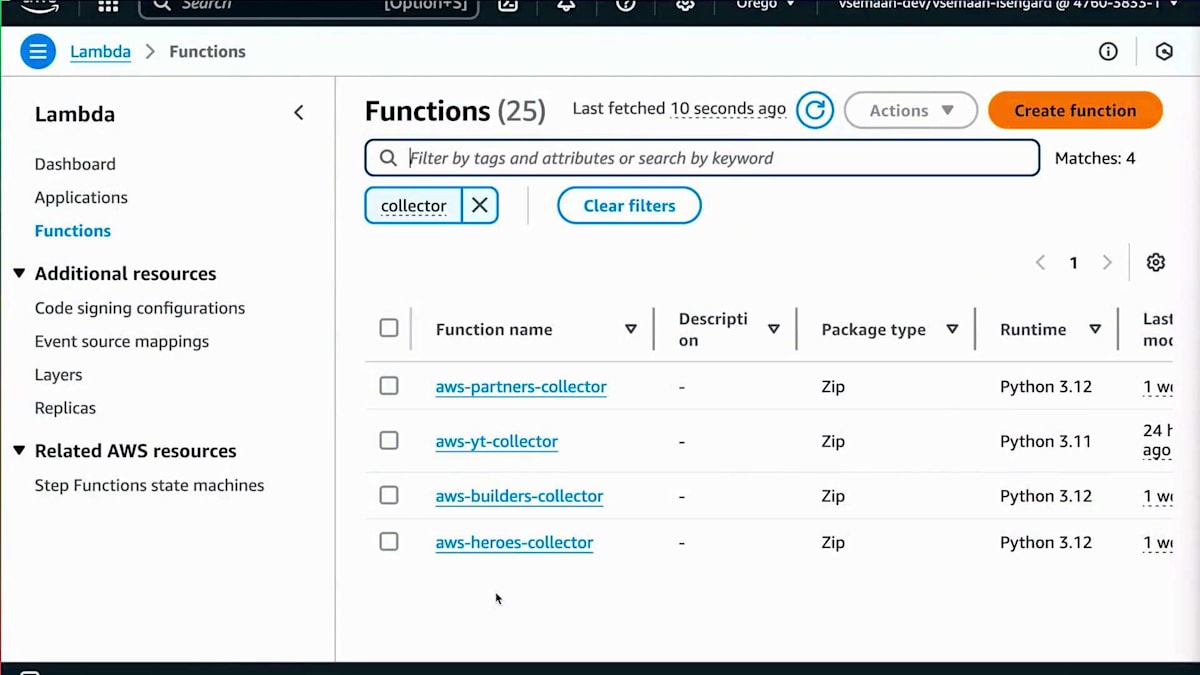
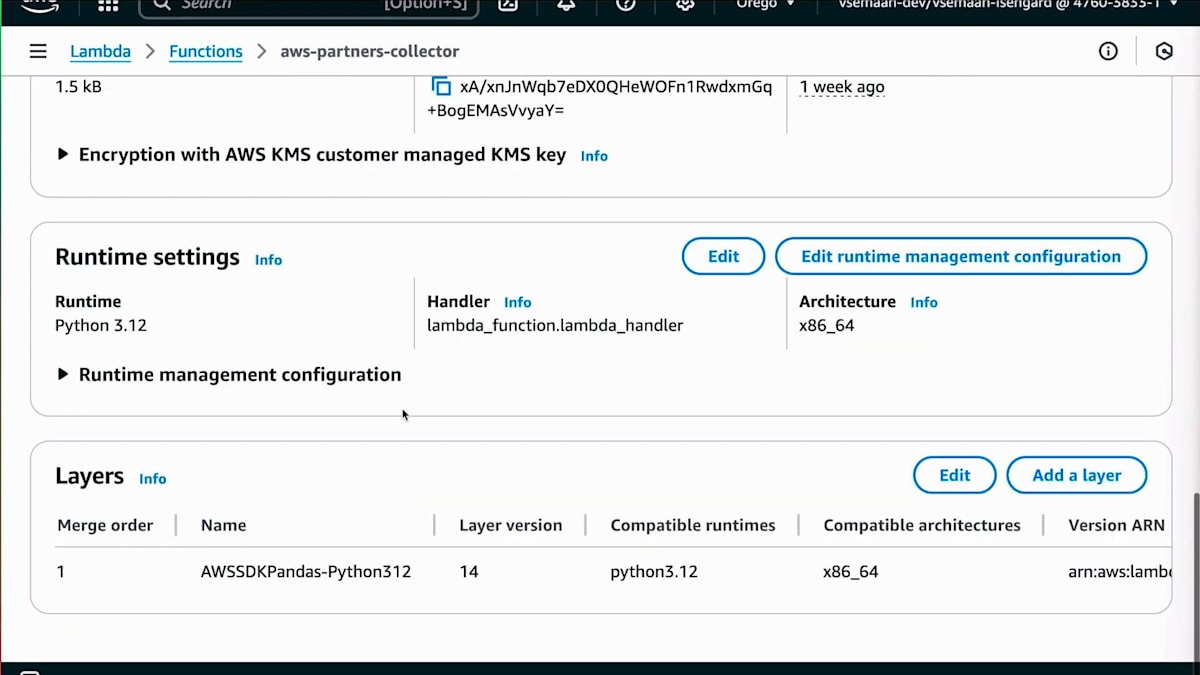
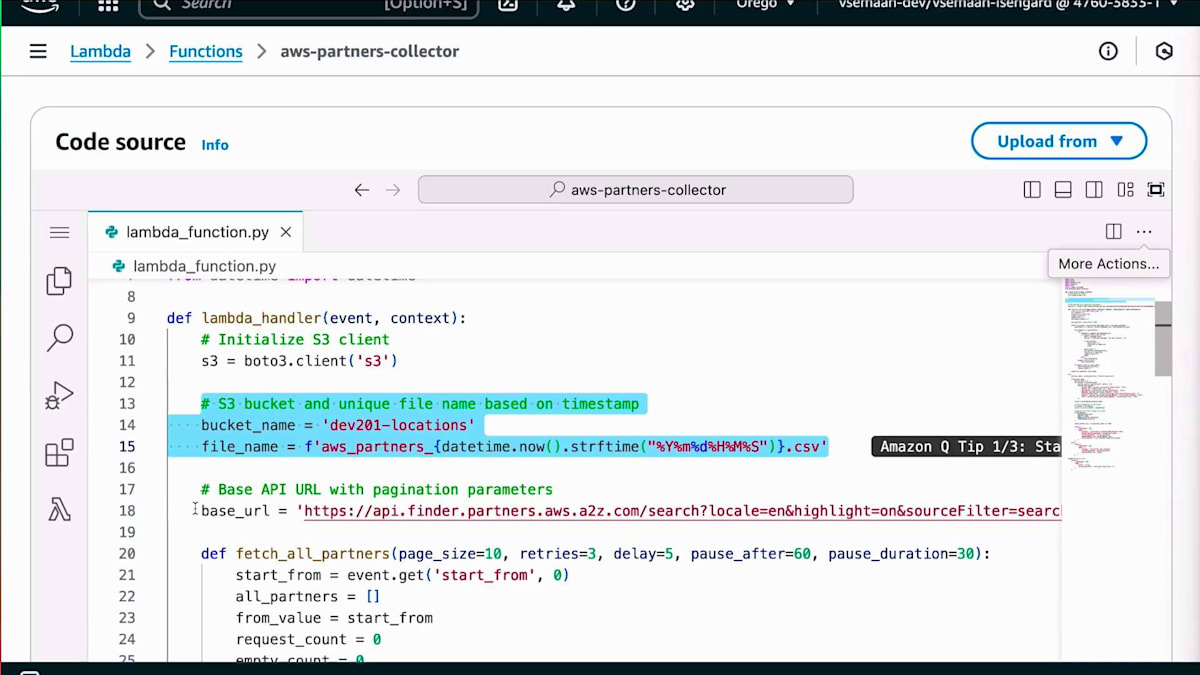

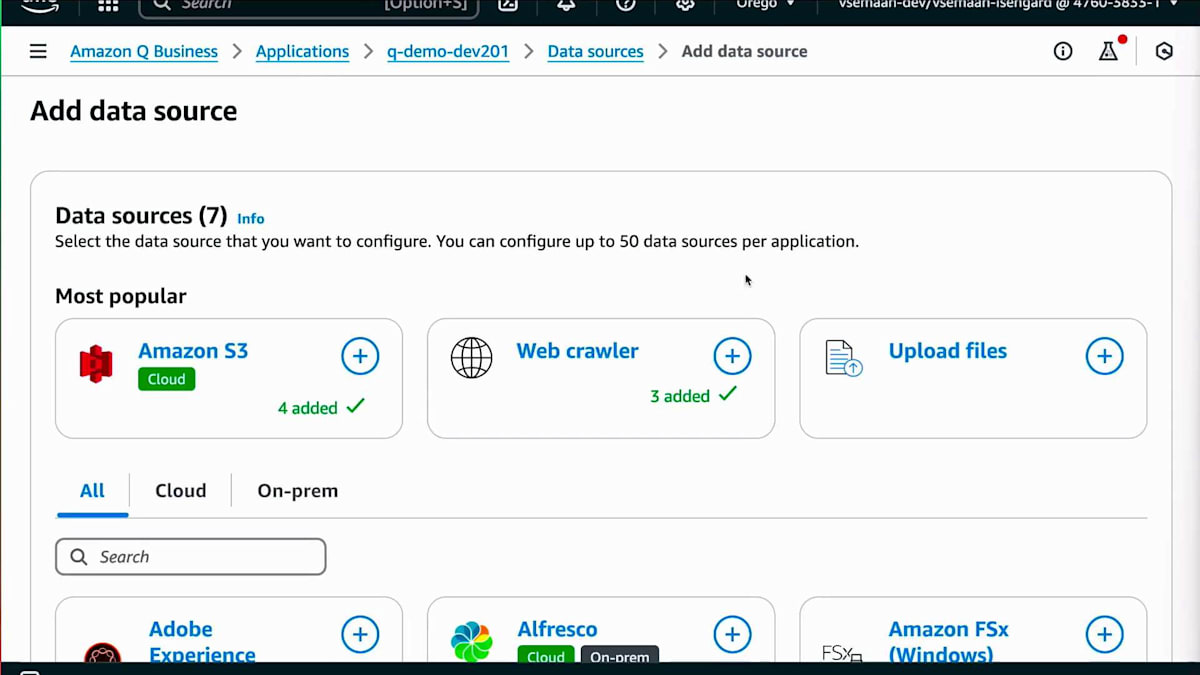
このアーキテクチャをAWSコンソールで実装する方法をお見せしましょう。まず、Webスクレイピングに使用するLambda関数の1つをお見せします。ここでは、Layerが作成されており、このLayerにはpandasに必要な依存関係が含まれています。AWSが提供する事前構築されたLayerを使用しました。次にS3バケットを用意します。S3バケットでは、スクレイピングする情報のAPIを呼び出すCSVファイルの出力先を確認できます。情報の構造化方法については、コンソールとAmazon Qに移動します。Amazon Qにはいくつかのオプションがあります。先ほど申し上げたように、今日はAmazon Q Businessについてお話ししています。Amazon Q Businessでは、データソースを選択すると、この設定に追加できる様々なデータソースのリストが表示されます。ここでWebクローラーを追加します。データソースを選択したら、適切な説明を提供する必要があります。
Amazon Q Businessを活用したイベント日程決定とプロモーション


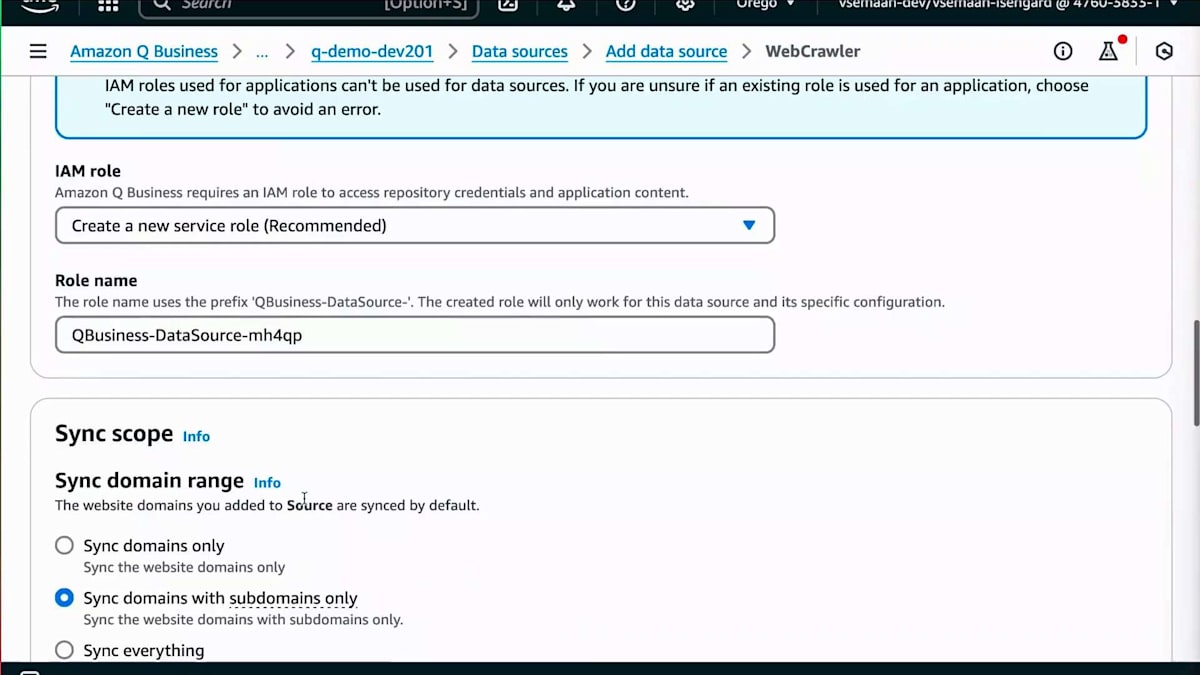
この設定には Web Crawler を追加する必要があります。適切な説明を提供することは非常に重要です。というのも、1つの Amazon Q Business アプリケーションに対して最大50個のデータソースを持つことができるからです。質問をする際、適切な説明があることで、システムが質問の意図をより正確に理解できます。これが完了したら、すべてのリンクを含むテキストファイルを追加し、ロールを作成することができます。

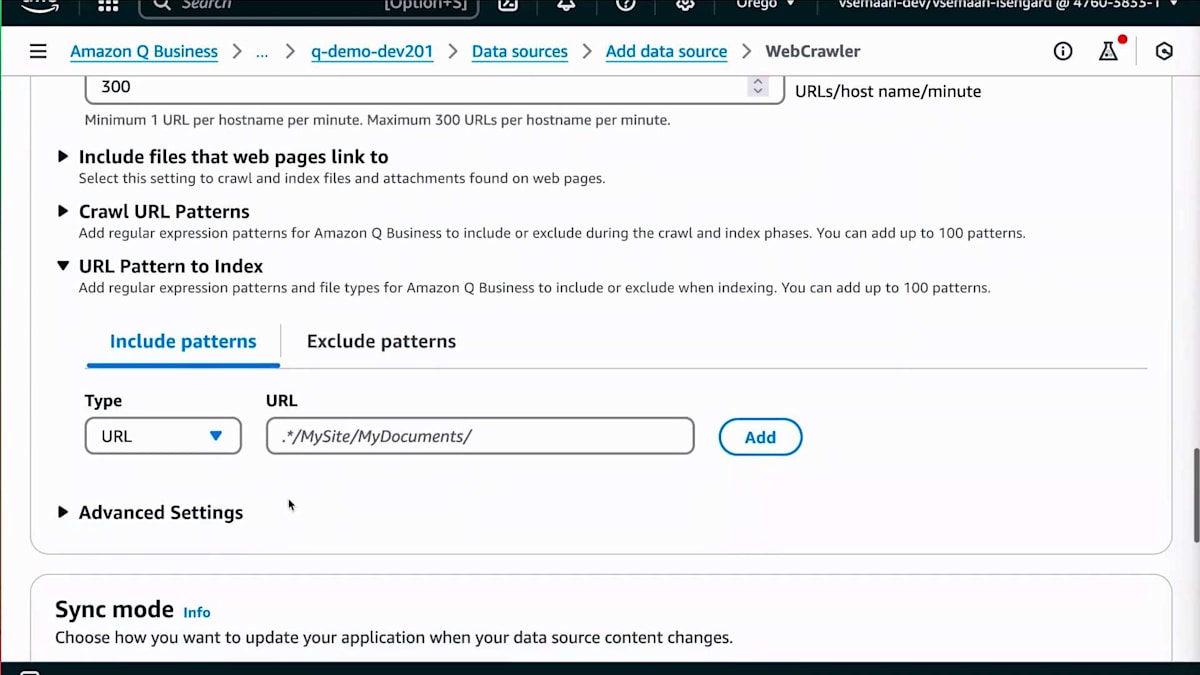
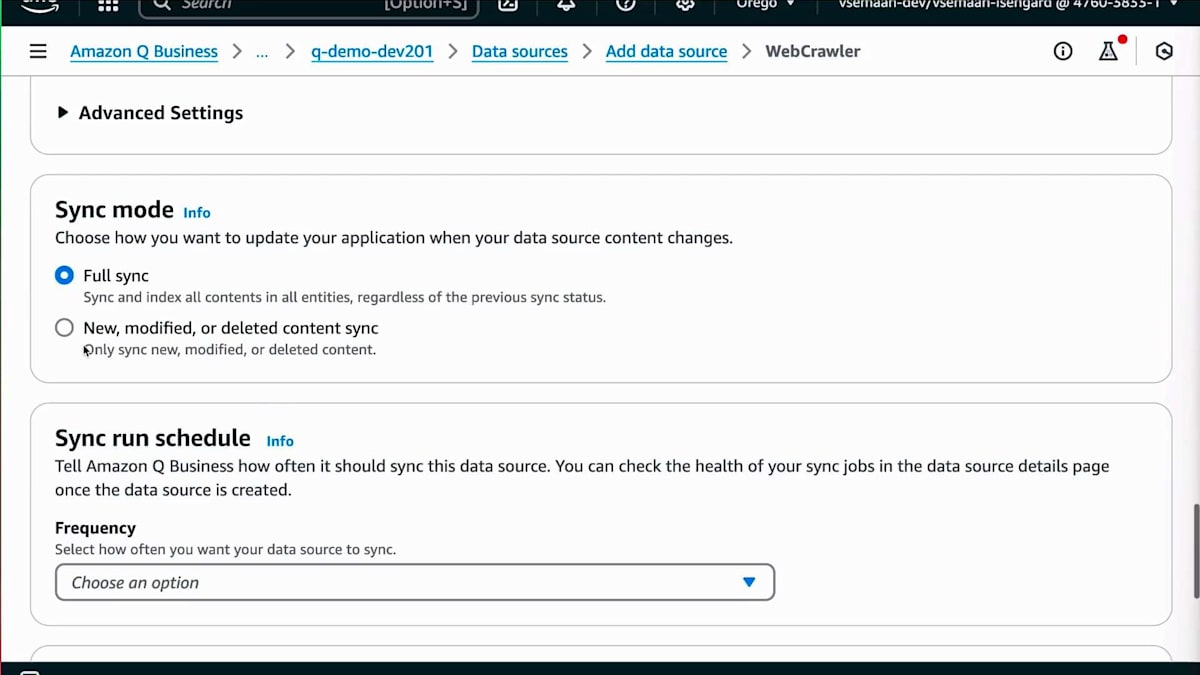
その後、具体的な同期スコープを設定できます。今回は正確なリンクを提供しているので、ドメインのみを同期することにしますが、サブドメインの同期も可能です。クロール深度を1に設定し、ファイルで提供している特定のリンクのみをクロールするように設定します。Webサイト全体をクロールしたい場合は、クロールするデータ量を最小限に抑えるため、include パターンと exclude パターンを使用することをお勧めします。関連性のないデータが含まれている可能性があるためです。
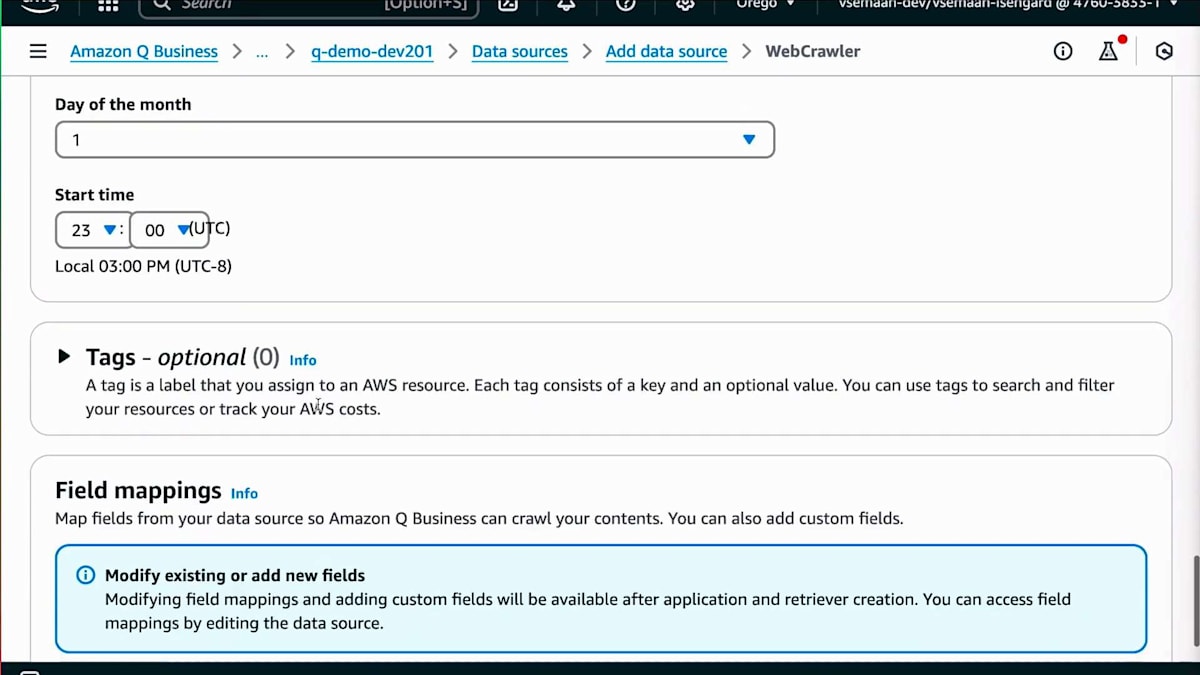


また、同期モードを設定することもできます。定期的に同期するか、完全同期を行うか、新しいデータのみを同期するかを選択できます。パートナー情報は頻繁に変更されないため、コストを抑えることにもつながる月次の同期スケジュールを選択できます。これが完了したら、データソースを作成して最初のデータ同期を実行するだけです。
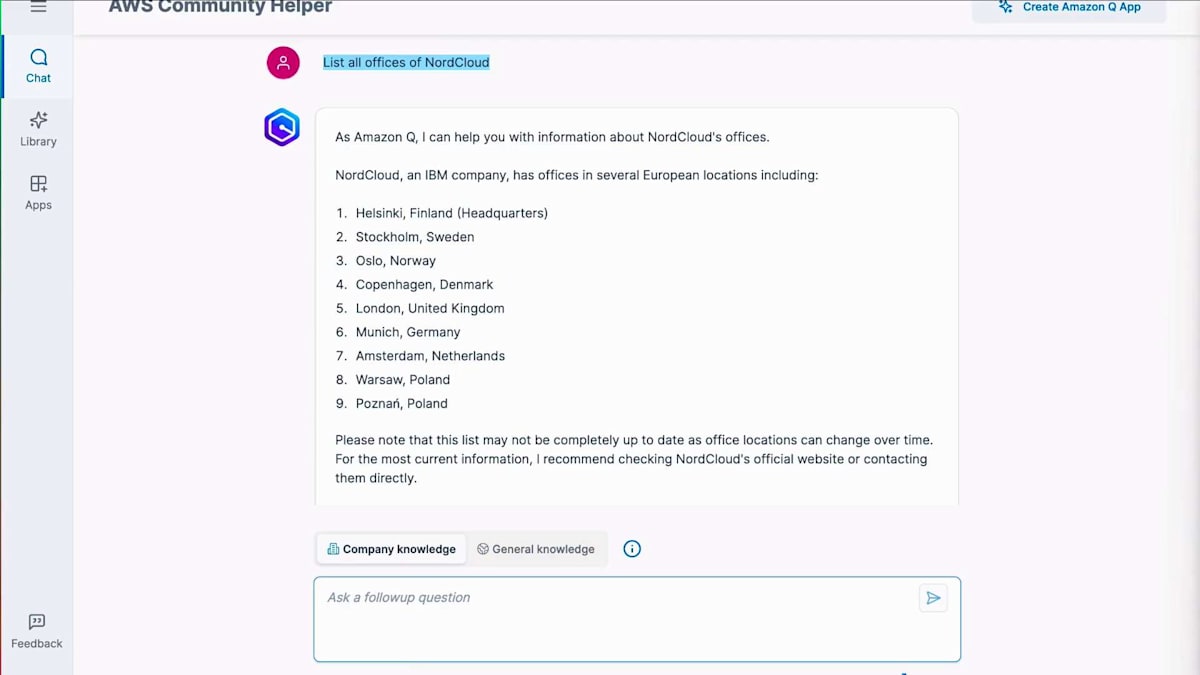

では、セットアップを検証してみましょう。Nordcloudのページを見ていますが、彼らには14の拠点があります。Amazon Qに質問する前に、一般的な知識オプションを使用してテストしてみましょう。ここでは一般的な知識を選択して、Nordcloudのすべての拠点リストを尋ねています。9つの拠点を挙げ、IBMの企業であることにも触れており、かなり良い回答でしたが、14の拠点すべてを提供してはいませんでした。では、同じ質問をコピー&ペーストして、今度は企業知識を選択してみましょう。すでにクロールしたデータに基づいて、Webサイトに記載されている14拠点すべての正確な住所を、パートナーのソースリンクとともに提供してくれました。

これで拠点データが得られたので、次はスピーカーの特定に関する章に移りましょう。VictoriaはすでにAWS Community BuildersやAWS Heroesのデータを含め、AWSのページから多くの情報をスクレイピングしていることを説明しました。しかし、User Groupのリーダーとして、スピーカーを見つけることがいかに大変かを知っているので、イベントのスピーカーをAWS Community BuildersやHeroesだけに限定したくありません。そのため、追加のコンテンツソースを活用したいと考えています。
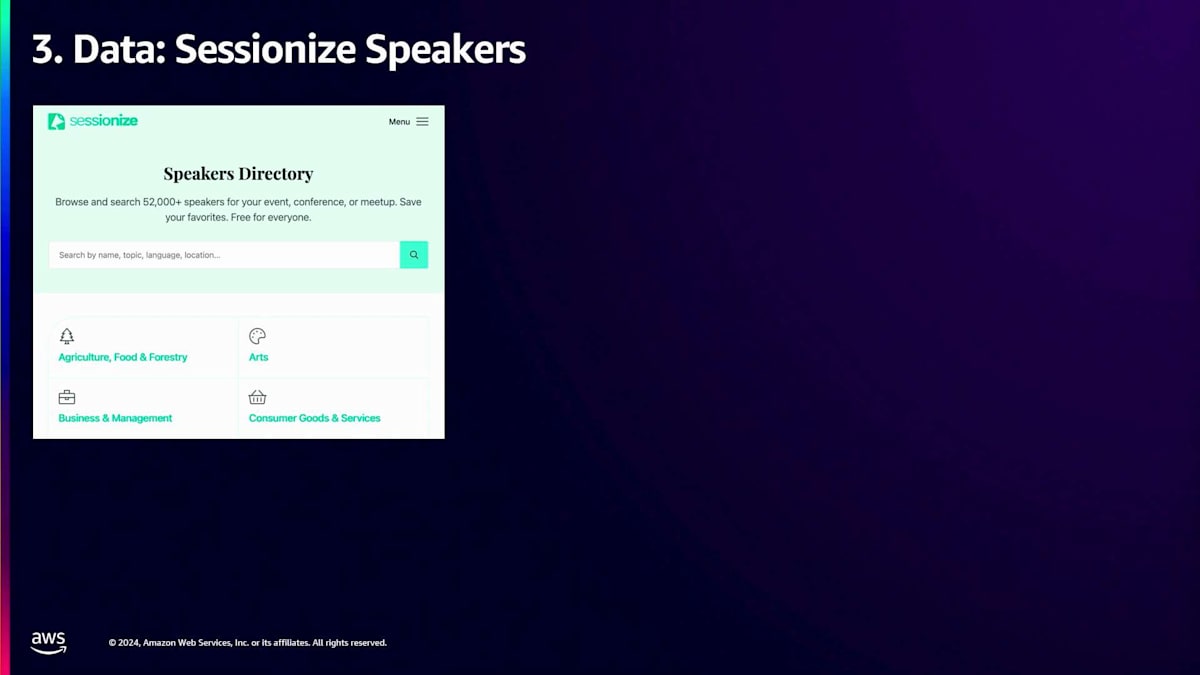
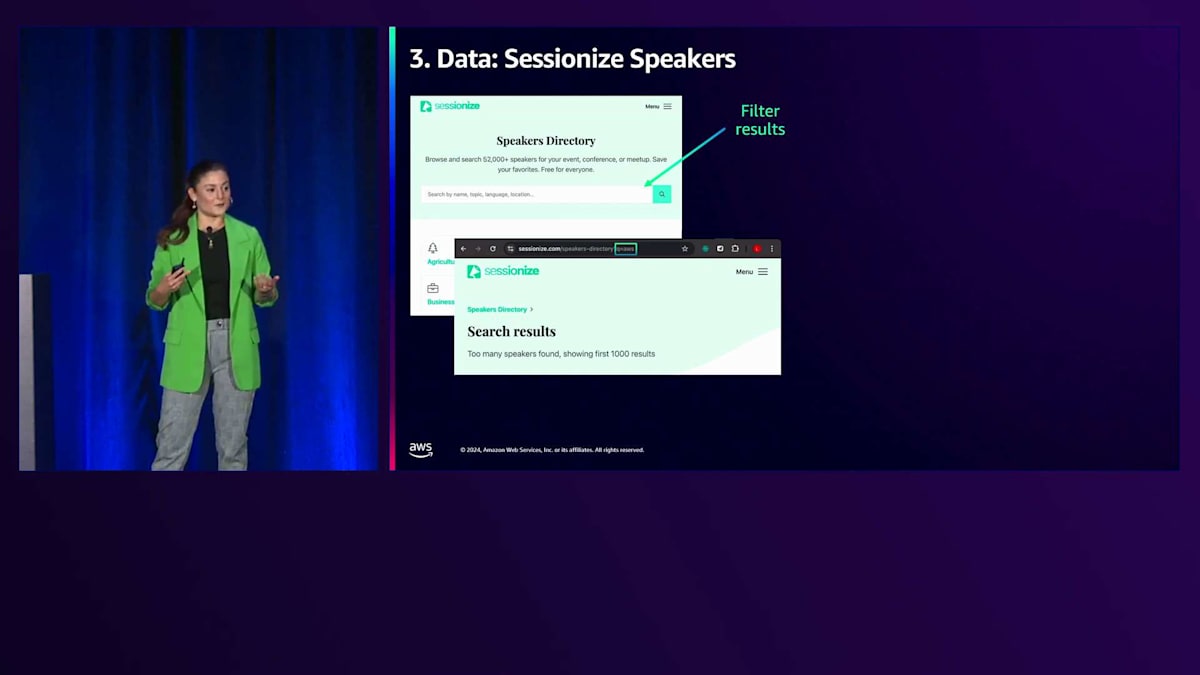

私たちは、農業やアート関連のスピーカーなど、様々なカテゴリーを含むセッションスピーカーディレクトリを見つけました。テックイベントでは農業関連のスピーカーには興味がないので、AWSトピックについて話すスピーカーに絞って検索することにしました。このAWSパラメータを用意したフィルターで検索し、スピーカープロフィールから全てのデータを抽出するためのカスタムスクレイピングソリューションを作成していきます。具体的には、スピーカーの名前、肩書き、講演トピック、そして活用できる公開済みセッションの情報を取得したいと考えています。

構造化データを扱うため、カスタムスクレイピング用のLambda関数を作成します。ただし、その前に、このデータ収集が許可されているかどうかを確認する必要があります。Amazon Q Businessはrobots.txtファイルをチェックしてスクレイピングの許可を判断するからです。Amazon Qのスクレイピング時のログを見ると、許可されていないものは全てスキップされているのが分かります。そこで、データのスクレイピングが許可されているかを手動で確認します。では、データを見ていきましょう。AWS Communityからデータを取得する方法はすでに分かっていますが、今回はスピーカーディレクトリも含めたいと思います。Viktoriaはすでに、S3バケット内のカスタムデータを使用してAmazon Q用のフリーコネクターを活用する方法をデモンストレーションしましたが、今回は追加情報を含むカスタムレイヤーを作成します。これにはデータ処理用のBeautiful Soupが必要になります。
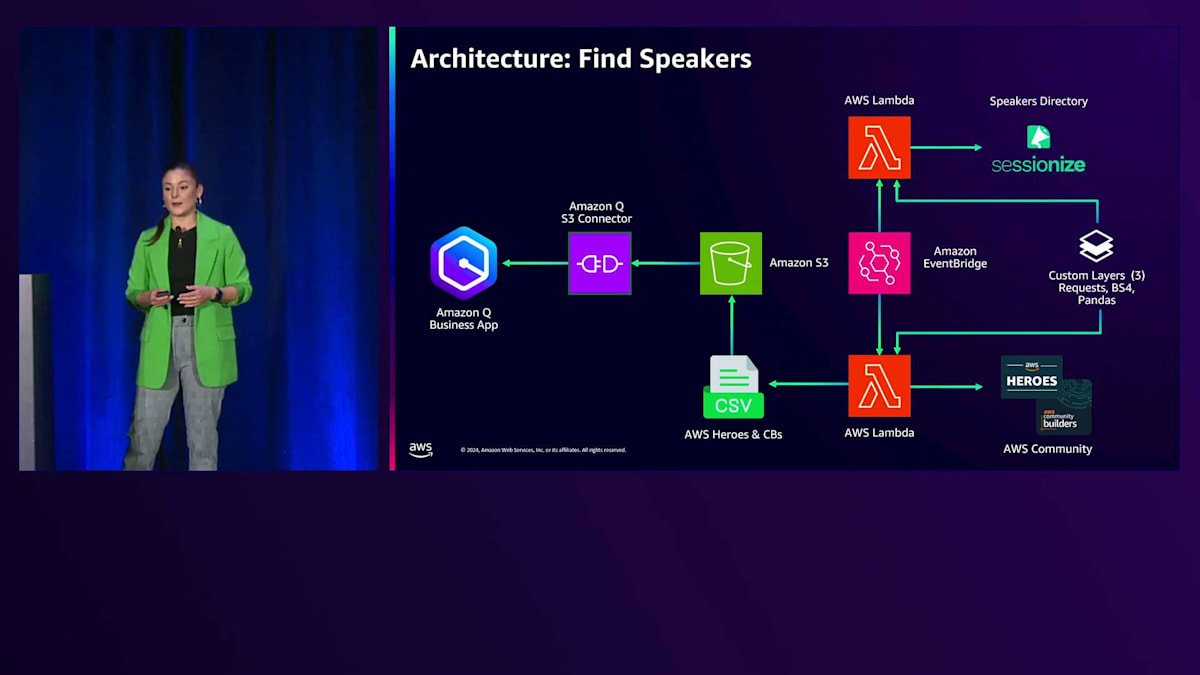
このカスタムレイヤーには、スクレイピングのための追加情報が必要です。Pythonライブラリの Beautiful Soupを活用する必要があり、また、全てのデータを同じフォーマットで保存するための構造化と準備のためにpandasも必要です。これにより、後ほどお見せするメタデータマッピングを使用することができます。
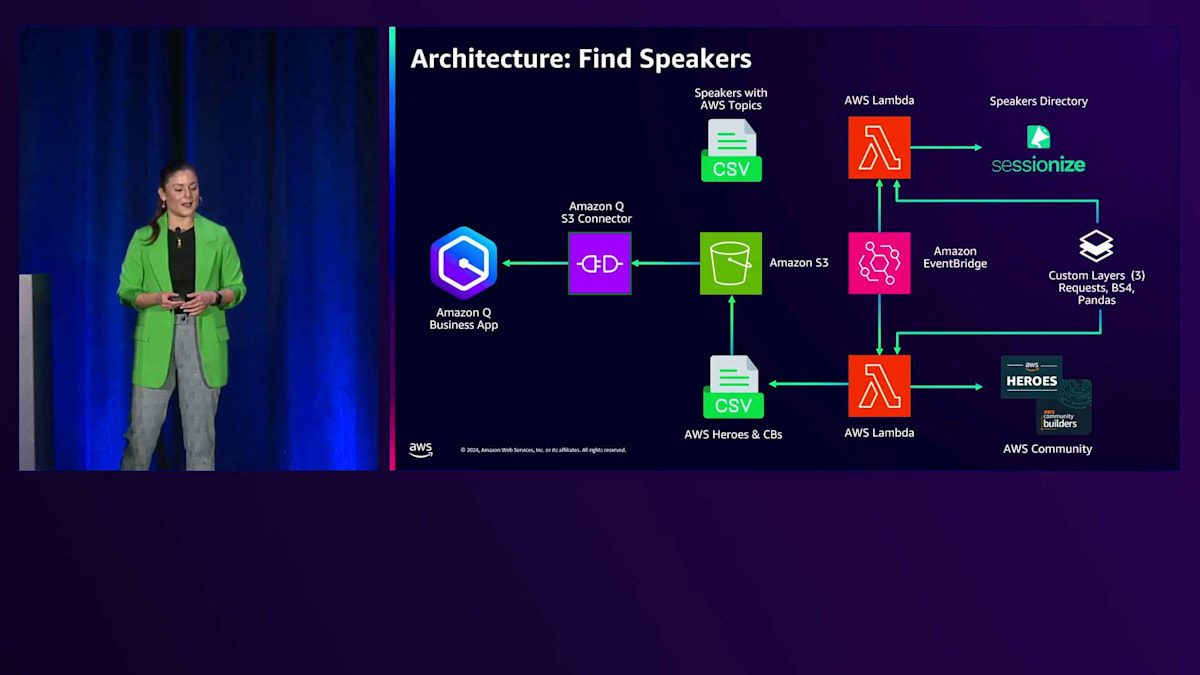

定期的にデータを更新したいので、Amazon EventBridgeによってトリガーされるAWS Lambda関数を用意しています。AWSトピックに関連するスピーカーの情報をCSVファイルに保存し、AWS HeroesとCommunity Buildersの情報を別のCSVファイルに保存します。

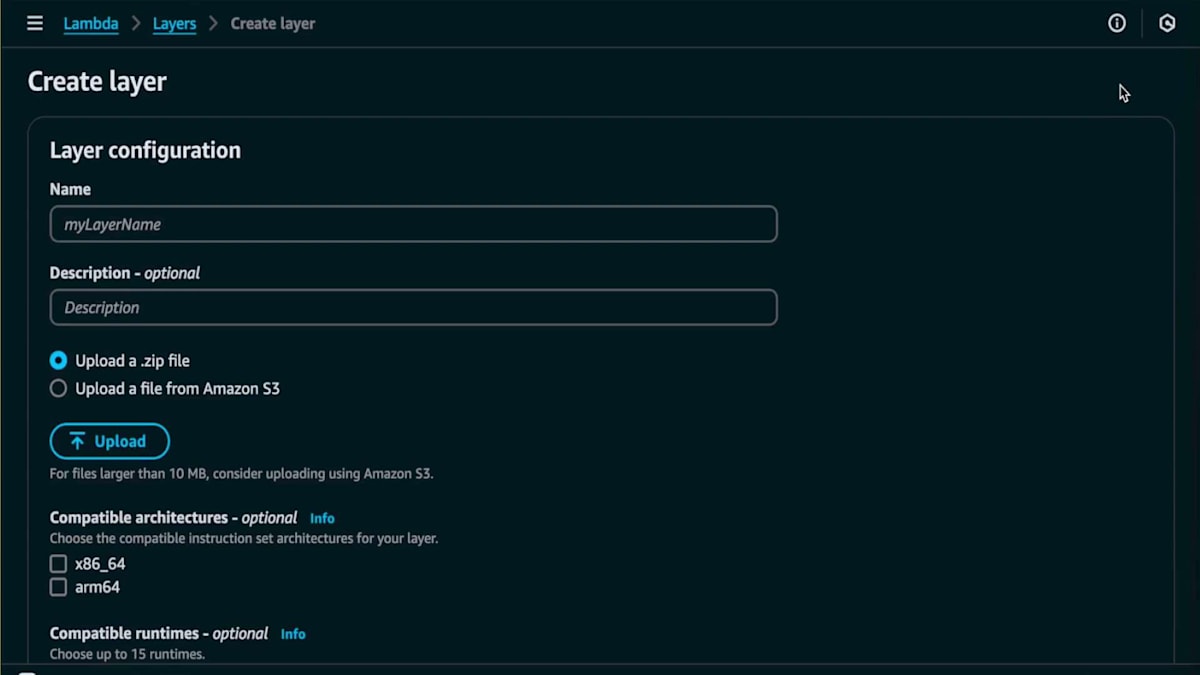
このLambda関数の作成方法を見ていきましょう。Lambdaに移動して、下部までスクロールして新しいレイヤーを追加します。レイヤーのパッケージが20メガバイト未満の場合、このレイヤーを作成してファイルをドラッグ&ドロップできます。名前を付けますが、Amazonとは異なり、ここでの説明は任意なので重要ではありません。パッケージを追加するだけです。もしサイズが大きい場合は、S3バケットに保存する必要があります。ランタイムを選択して作成をクリックします。
Lambda関数とWeb Crawlerを用いたデータ収集の実践



Lambda Layerを作成すると、AWS アカウント内のすべての Lambda 関数で使用できるようになります。さまざまなユースケースで活用でき、必要なレイヤーを選択することができます。ここでご覧のように、AWS のエコシステムにまだ存在していないパッケージが必要な場合は、カスタムレイヤーを使用します。また、必要なバージョンを選択することもできます。レイヤーを作成したら、EventBridge のトリガーを簡単に追加し、次のトピックであるデータの準備方法に進むことができます。

現在持っているデータを見てみると、Community Builders、Heroes、そしてセッションのスピーカーが同じフォーマットで存在します。しかし、使用しているサービスを振り返ってみると、これはLLM(大規模言語モデル)を使用しています。スピーカーのエントリーだけを使用して、テーブルデータから情報を取得するのは簡単ではないことがわかりました。このセッションのスピーカーとしての私の例でご覧いただけるように、異なるデータソースから得られる様々な情報があります。しかし、Amazon Qは自然言語による説明形式が最も効果的であることがわかりました。そこで、異なるデータポイントからの文字列を連結して、データをより理解しやすい自然な文章にしました。
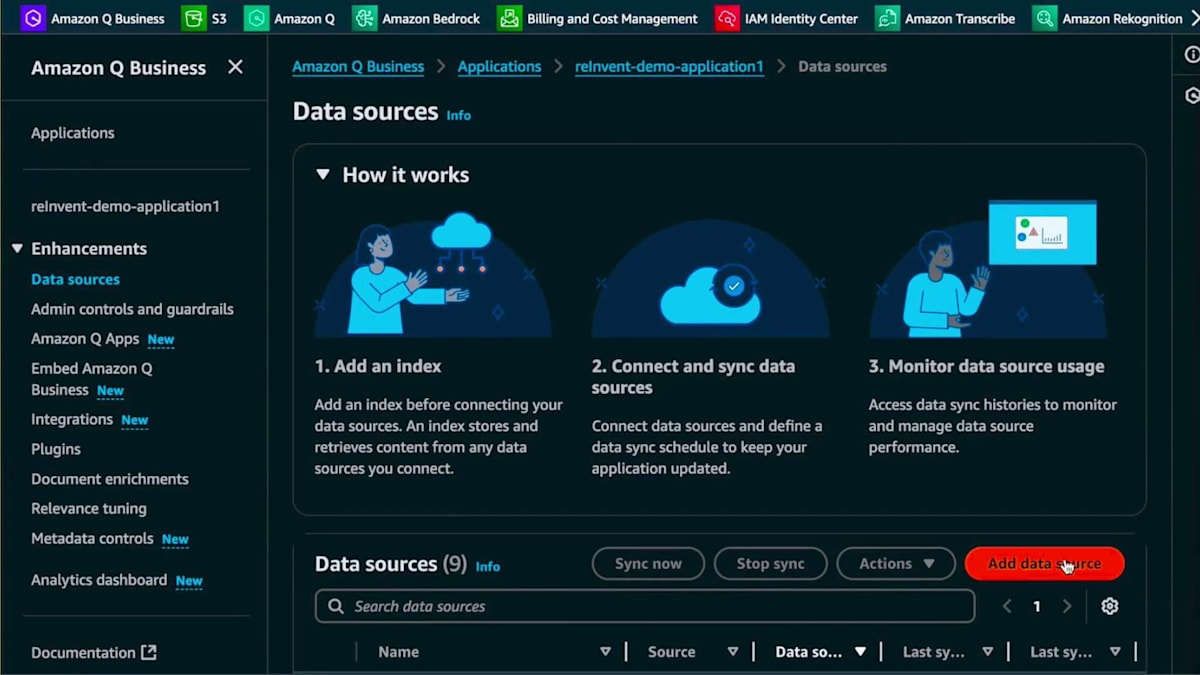
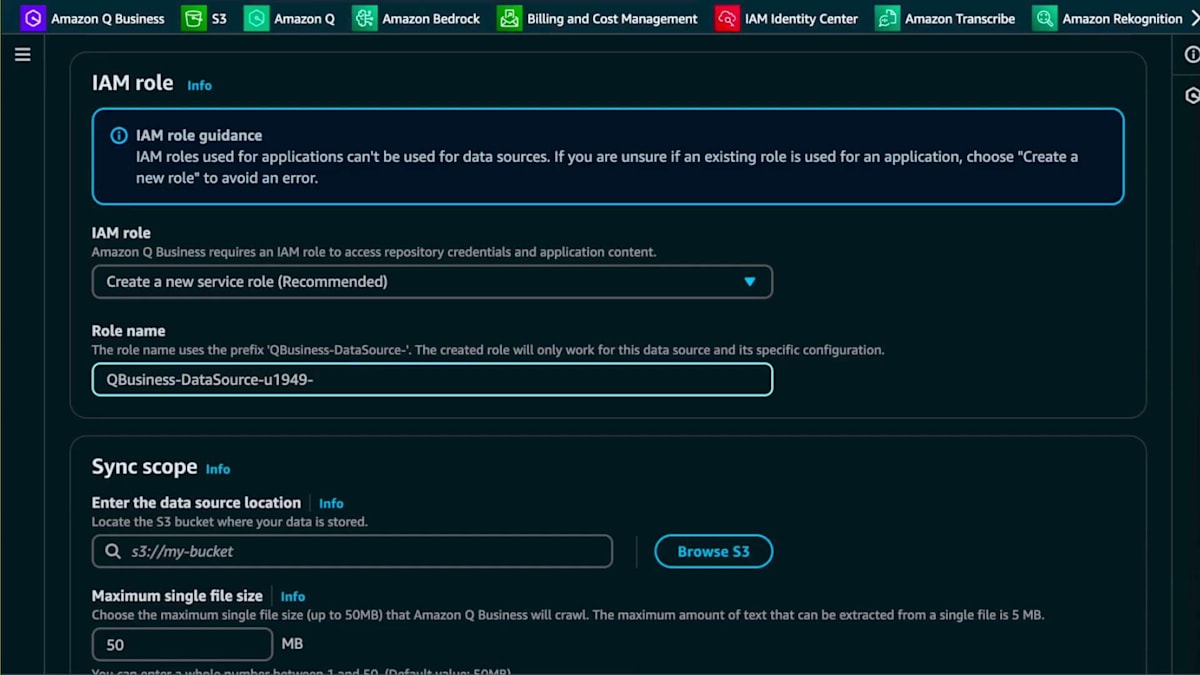
では、このデータソースを追加する方法を見てみましょう。既にご存じのAmazon Q Businessに戻り、S3 Bucketコネクターを選択します。説明を追加し、新しいロールを作成します。作成したロールを後で見つけられるように、ロールに名前を付けています。次に、同期スコープを設定します。スピーカーの所在地を把握して連絡を取れるようにするため、国と都市を見つけられるように、メタデータマッピングがあることをAmazon Qに伝えたいと思います。


このユースケースで分かったことは、CSVデータではうまく機能しなかったということです。そこで、他の要素はメタデータで対応できたので、この自然言語による説明を追加してJSONファイルを作成しました。同期モードを選択します。新規および変更されたデータのみを同期したいと思います。これはデモ用なのでオンデマンドで実行し、データソースを追加します。
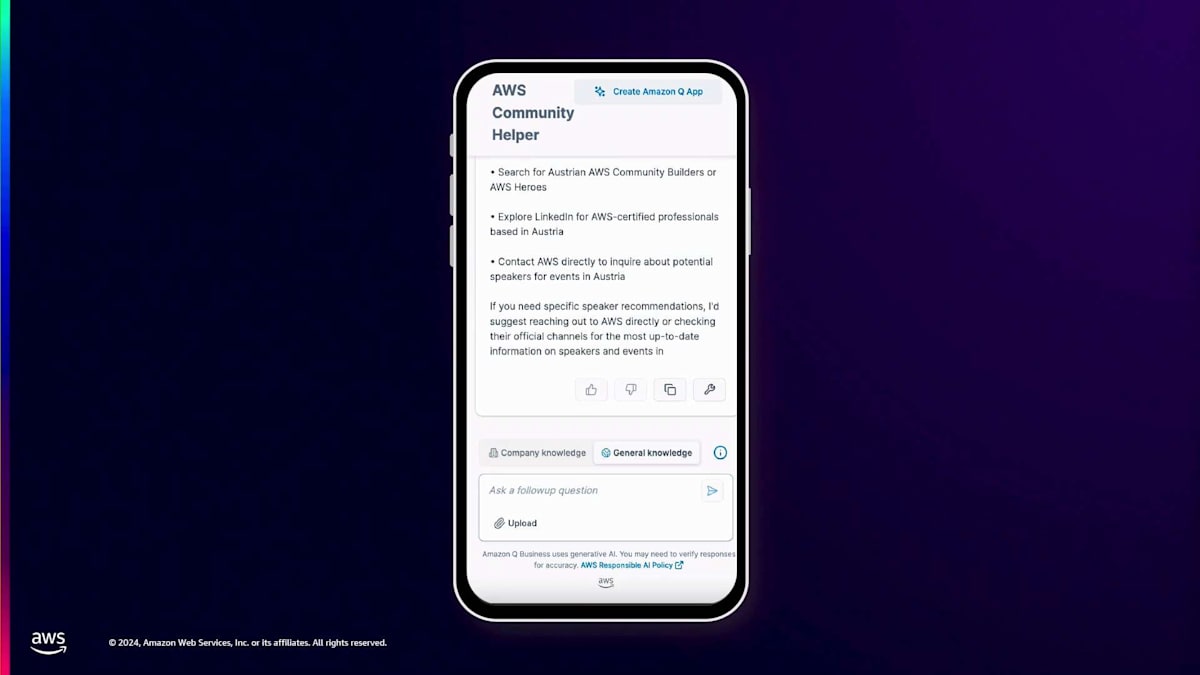
データソースを追加すると、Amazon Q のウェブエクスペリエンスでこのデータを活用できます。これがどのように機能するか見てみましょう。同じ方法で行います。まず、一般的な知識について尋ね、オーストリア地域のスピーカーについて質問します。Amazon Qがどのように答えるか見てみましょう。一般的な知識として尋ねた場合、一般的な知識のみでは、スピーカーについての情報を持っていないため、申し訳ないという回答が返ってきます。

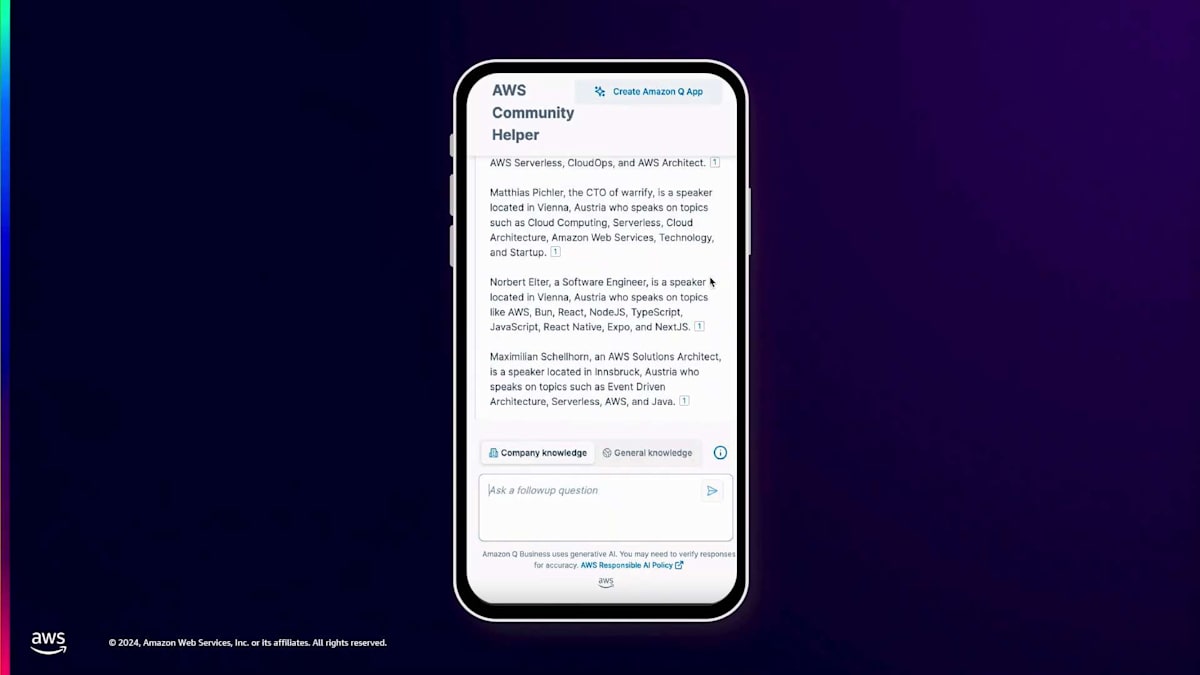

では、先ほどと同じようにコピー&ペーストで会社の情報に切り替えて、同じ質問をしてみましょう。ここで多くのスピーカーが表示されています。一方ではHeroやCommunity Builderがいますが、これらのMeetupの主催者として私にとって重要なのは、追加のスピーカーも確保したいということです。Sessionizeからもスピーカーを活用できることがわかり、私のMeetupやカンファレンスに招待できるスピーカーの範囲をさらに広げることができます。次のユースケースを見てみましょう。




次のユースケースは、日程の特定に関するものです。Meetupの日程をどのように決めるかを考えてみましょう。例えば、AWS re:Inventが開催されている時期にMeetupを実施したくありません。なぜなら、多くの人がLas Vegasに行ってしまい、そのような大きなイベント以外の場所でのMeetupには誰も参加しないでしょう。ここで、先ほどと同じように検索リクエストを活用する方法をお見せします。検索を実行し、ネットワークトラフィックを確認して、このデータを取得するために活用したいAPIリクエストを取得します。Viennaでのイベントを探してみましょう。Viennaにはイベントがありませんが、検索の仕組みを確認するだけなので問題ありません。
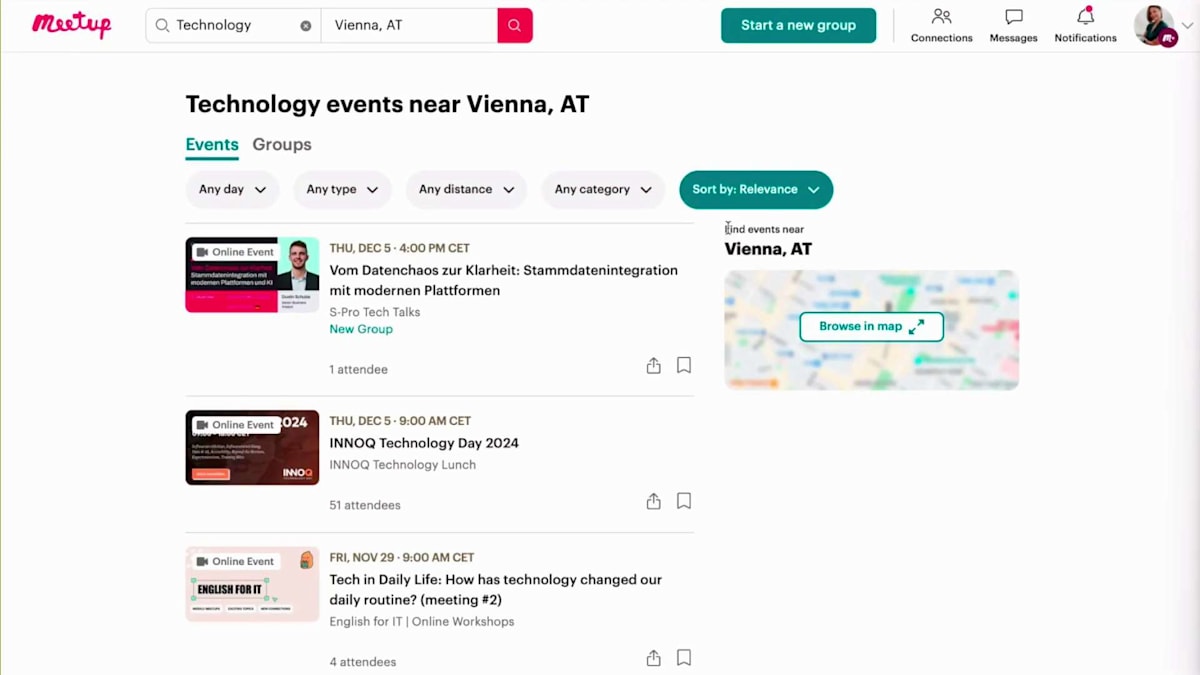
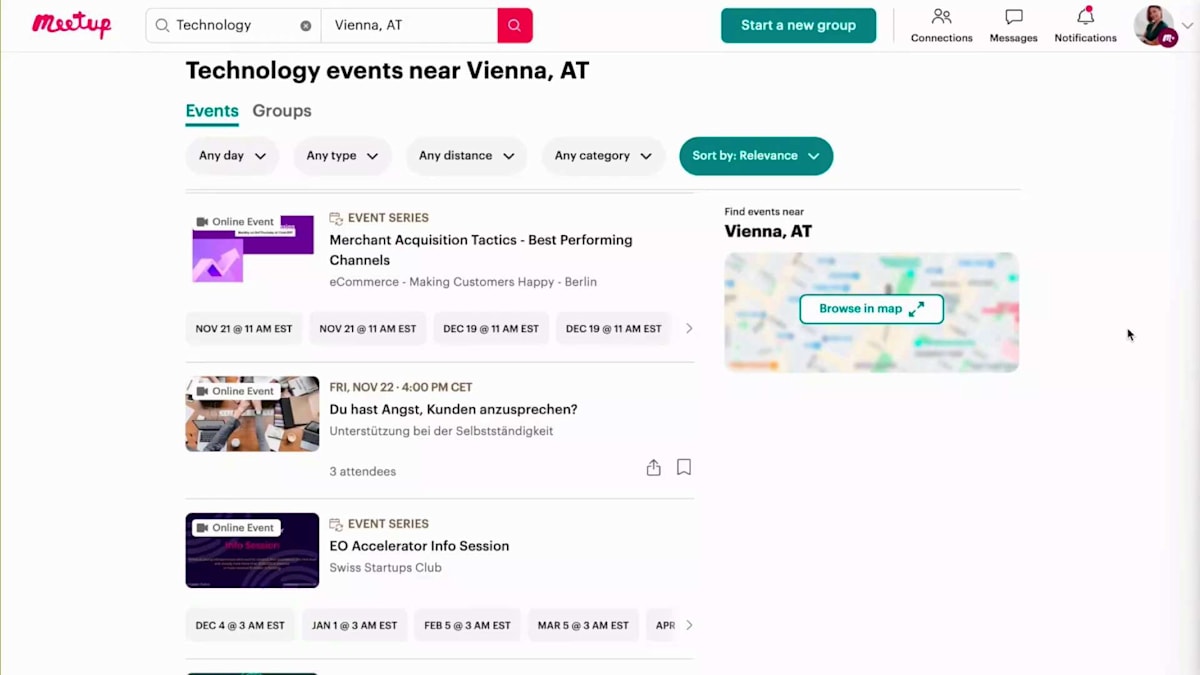

次に、ヘッダーを確認してURLを見てみましょう。このURLをコピー&ペーストすると、S3バケットに保存できるJSONデータが返ってくることがわかります。Victoriaが説明したように、このデータはブラウザで解析することもできます。そして、AWSのイベントだけに焦点を当てたくありません。Meetup.comにはAWSのMeetupだけでなく、例えばViennaには開発者コミュニティなど、他にもたくさんのMeetupがあります。クラウドやAWSについても話題にしているので、同じようなターゲット層があります。そのため、Meetup.comにある技術系イベントも全てスクレイピングしたいと考えています。
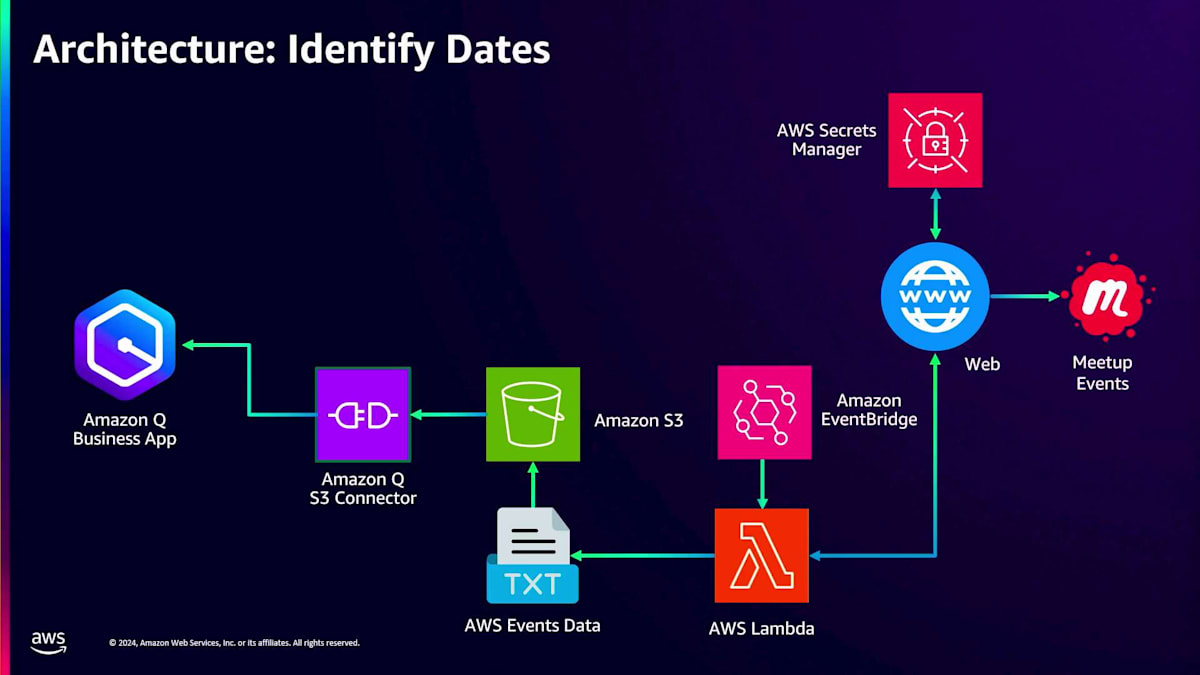

アーキテクチャを見てみましょう。Amazon S3コネクターの活用方法はすでに知っていますが、今回は少し異なります。引き続きWebクローラーを使用しますが、Meetupのイベントを見ていく中で、Meetup.comからイベントを取得するにはログインが必要だとわかりました。そこで、組み込みのAmazon Q Web Crawlerを活用するために、AWS Secrets Managerでシークレットを設定します。これがどのように機能するか見てみましょう。Amazon Q Businessに戻って、新しいデータソースを追加します。このデータソースも再度Webクローラーです。


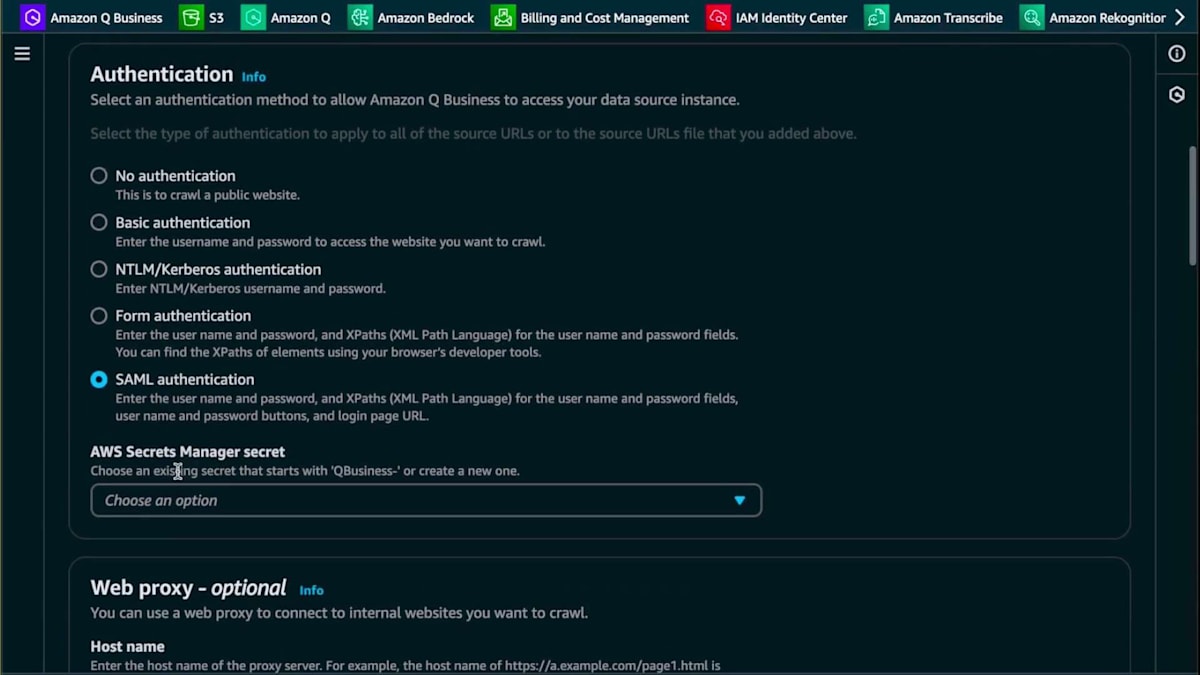
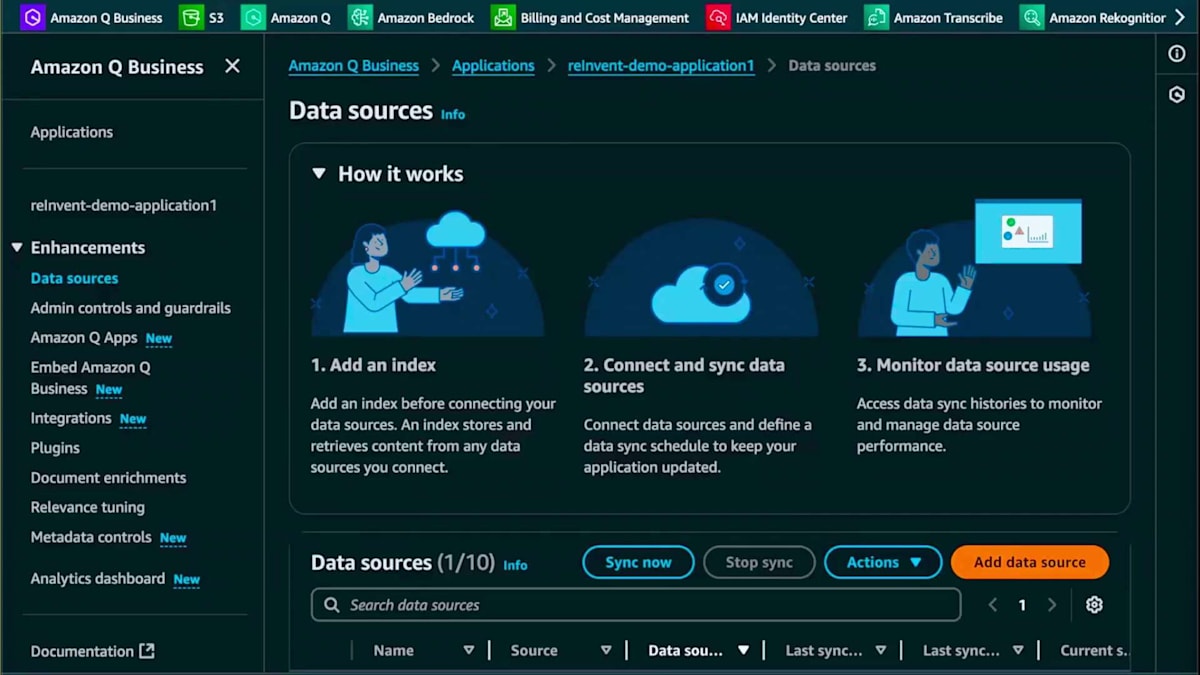
先ほどと同じ手順で進めていきます。Victoriaが言及したように、Amazon Qが実際に何をスクレイピングしているのか、そのデータソースが何に関するものなのかを理解できるように、適切な説明を付けることが重要です。このデータソースは、異なる地域のMeetupデータや類似イベントに関するものだと説明します。次に、ソースURLを選択し、ソースURLフィールドに追加します。続いて認証を追加します。どのページにどの認証方式が最適かを判断する必要がありますが、この認証とシークレットはWebクローラー内で直接作成できます。

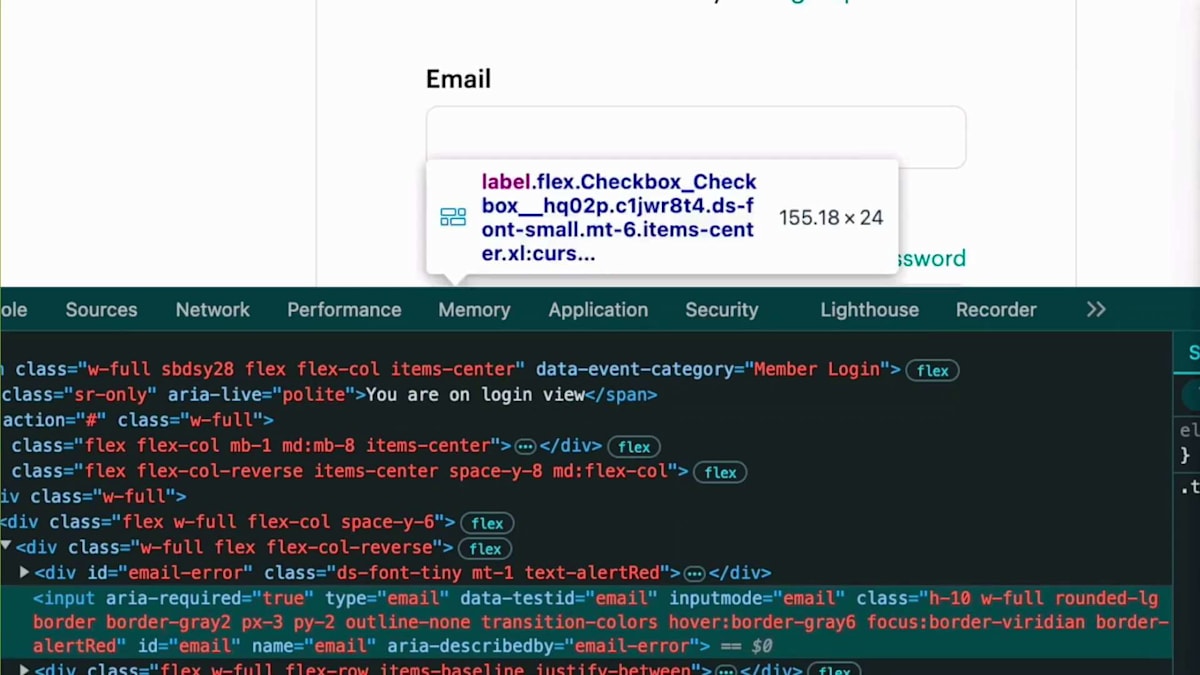

新しいSecretを作成して、Meetupページのスクレイピングにどのように追加されるか確認してみましょう。Secretに名前を付け、ログインページのURLを追加し、次にログインページのラベルとパスワードのXPathを見つける必要があります。これはブラウザのInspectを使って確認できます。Inspectに移動してラベルフィールドを確認しましょう。XPathをコピーしてWeb Crawlerに戻ります。XPathを入力し、次にパスワードフィールドも同様にXPathをコピーしてQ Business Web Crawlerに戻り、このパスワードフィールドを追加します。これはSecretではありませんが、パスワードフィールドなのでSecretのように機能します。その後、パスワードボタンのXPathを追加してこの新しいSecretを作成します。
Amazon Q Appsの構築と活用:イベント企画の効率化


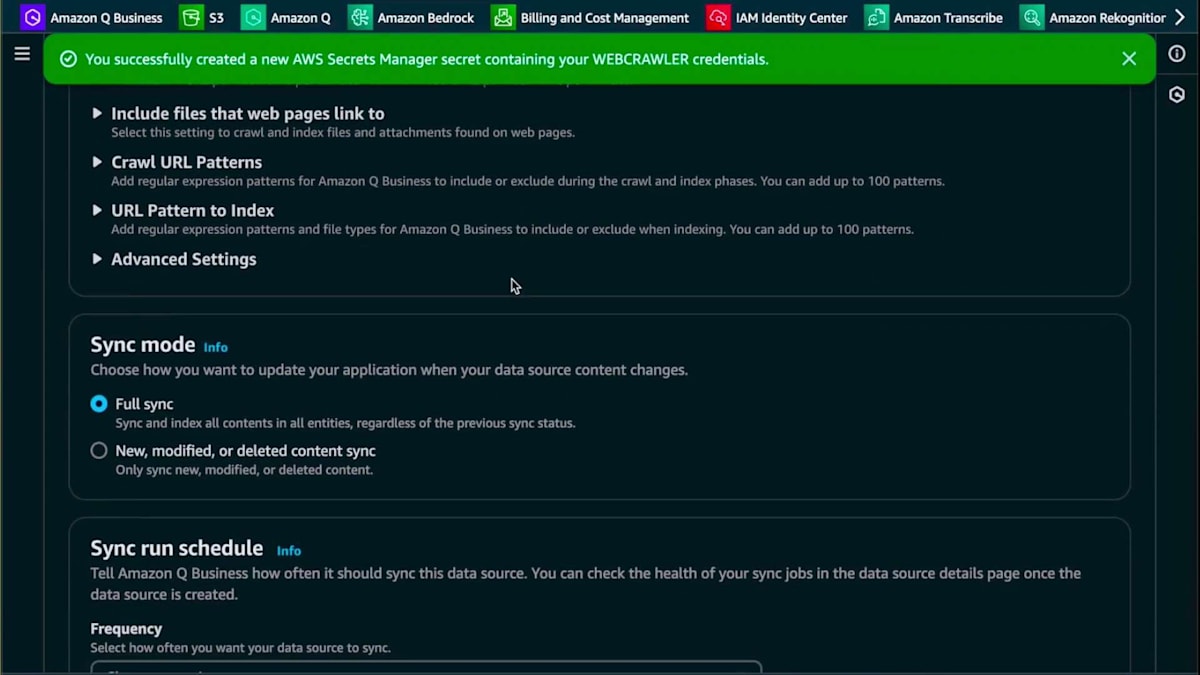
下にスクロールすると、ロールに名前を付けてロールを作成し、同期サイクルを選択するなど、既に知っている項目があります。ここでは、ドメインをサブドメインと同期させたいと思います。また、Meetupのリストだけでなく、実際のMeetupページまでスクレイピングしてそのMeetupの具体的な内容を取得したいので、クロール深度を2に設定します。コストを抑えるために新規および変更されたデータに限定し、データソースを追加します。

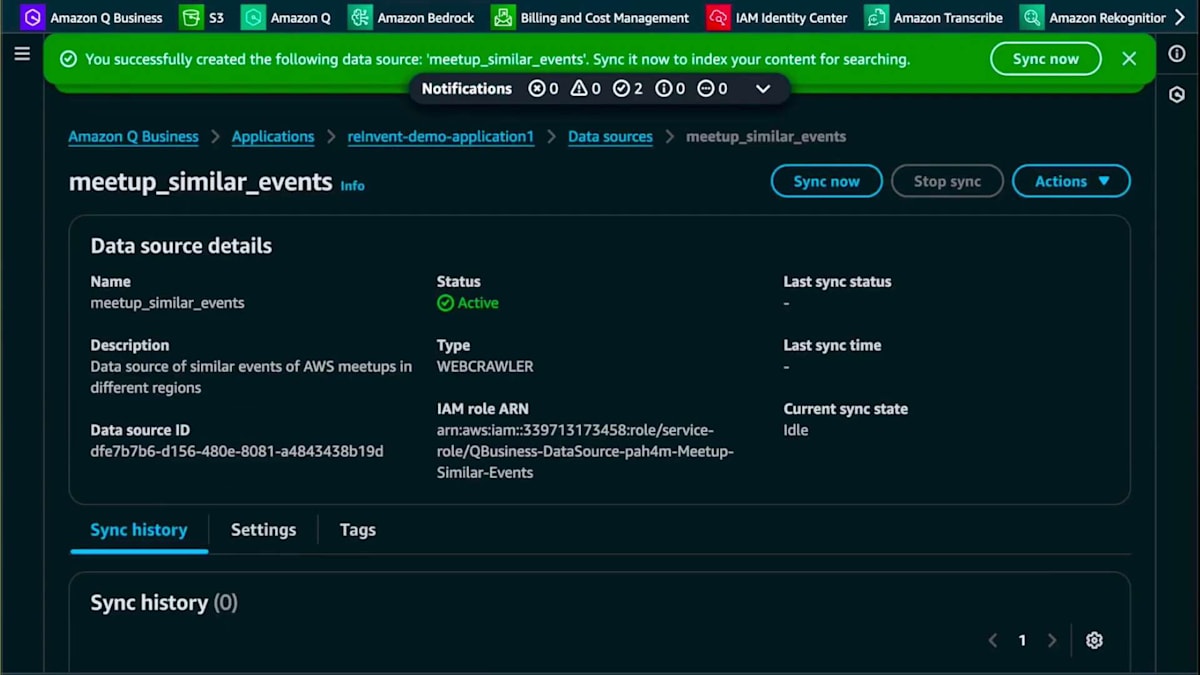
完璧です。データソースを編集したら、「Sync now」をクリックできます。Web Crawlerを使用する際は、2段階のスクレイピングメカニズムがあります。まず最初に同期とクロールが行われ、既に説明したように、そのページをスクレイピングすることが許可されているかrobots.txtをチェックします。
その後、データのインデックス作成が行われます。データソースからより多くのデータを活用する際に、このプロセスがどのように機能するか見てみましょう。
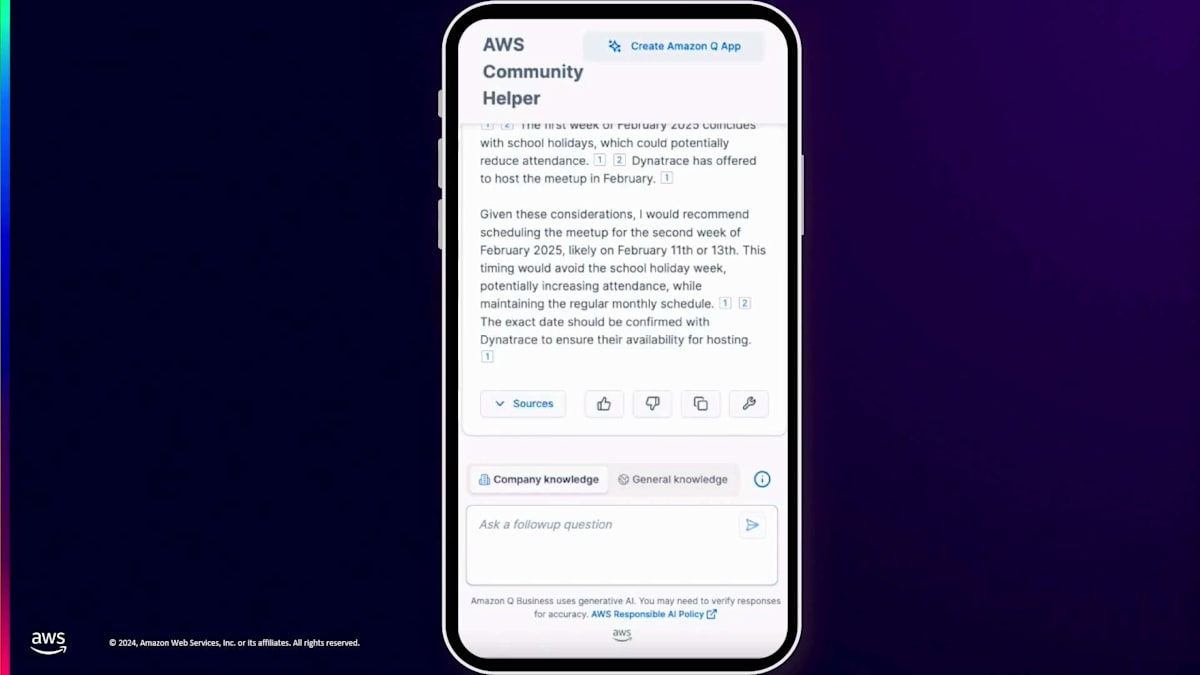
私たちのMeetupでの実際のユースケースを共有させていただきます。次回のMeetupをいつ開催できるかについて、誰かが質問をしました。これが機能するかテストするために、Slackからこれらの質問の1つをコピー&ペーストしました。Amazon Qは最初に見たプレップガイドをドキュメントとしてアップロードしたため、私たちのAWS User Groupについて広範な知識を持っていることが確認できます。ViennaのUser Groupは通常、火曜日か木曜日にMeetupを開催していることを教えてくれました。2月の休日を考慮して、2月11日か14日にMeetupをスケジュールすることを提案してくれました。これは自分たちで考える手間が省けるので素晴らしいですね。また、この地域で開催される他のイベントも考慮に入れています。

では最後のステップ、イベントのプロモーションについて見ていきましょう。 計画を立て、スピーカーを確保し、日程を決定しました。今度は、私たちの素晴らしいイベントを世界に知らせる時です。先ほど申し上げたように、単に「次のAWS Meetupの開催をお知らせできることを嬉しく思います」とだけ言うのではありません。Amazon Qに私たちの言葉を理解させ、私たちと同じように伝えられるようにしたいのです。また、Amazon Qにトレンドを理解させ、コミュニティがイベントについてどのように語り合うのかという技術的な深い知識も持たせたいと考えています。




これを実現するために、まず AWS Eventsのページに移動します。AWS re:Inventのすべてのブレイクアウトセッションは、AWS EventsのYouTubeチャンネルに投稿されます。このセッションを含め、見逃したものは後でAWS EventsのYouTubeチャンネルで見ることができます。これは公開されているWebページなのでクローリングやスクレイピングができると考え、最適だと思いました。しかし、先ほど学んだように、物事は必ずしも望み通りにはいきません。このデータは公開されているものの、YouTubeは自動クローリングを禁止していることがわかりました。先ほどrobots.txtについてお話ししたように、これは許可されていませんが、YouTubeはAPIを提供しており、私たちはまさにそのAPIを使用してすべての情報を取得しました。


次に、どうすればより多くの知識を提供し、Qがコミュニティの言葉で話せるようになるかを考えました。community.awsというウェブサイトがあり、そこではコミュニティメンバーとAWS社員がブログ記事を投稿しています。これは静的コンテンツなので素晴らしいと気づきました。幸運なことに、ウェブサイト全体が静的なので、特別な操作は必要なく、サイト全体を簡単にスクレイピングすることができました。また、私の投稿のキャプション例もいくつか提供し、私が読者とどのようにコミュニケーションを取っているかを理解させることで、投稿の作成やイベントの告知に役立てることができます。


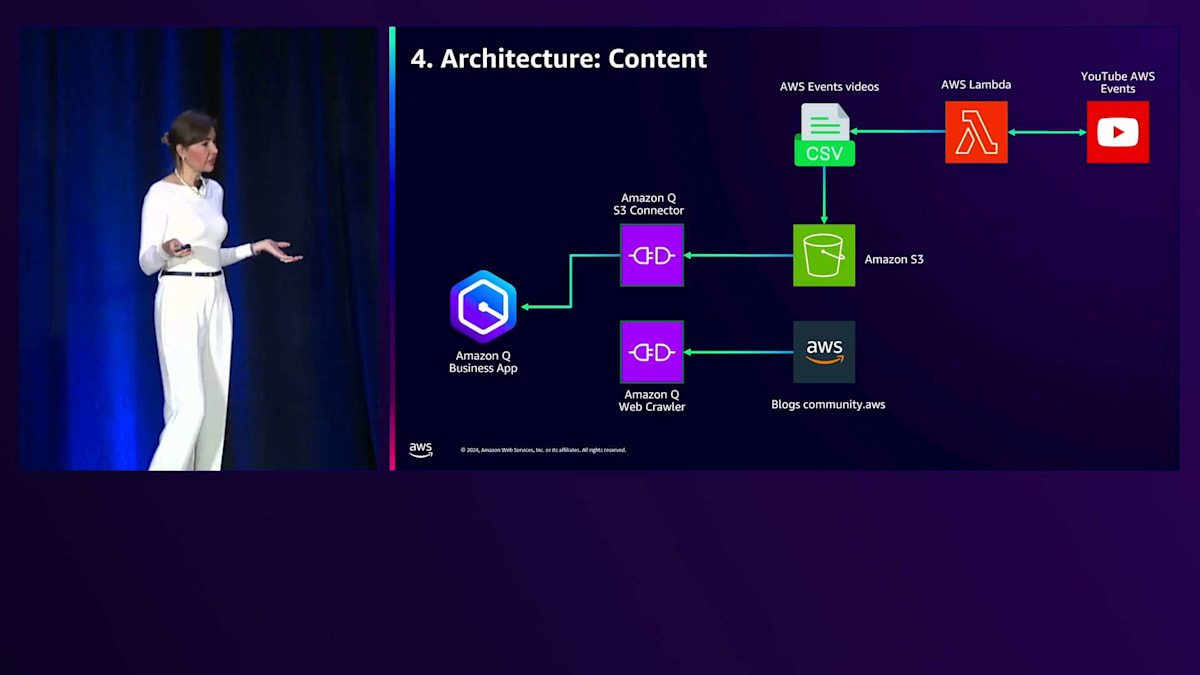
では、アーキテクチャを見てみましょう。AWS Events YouTubeからデータを取得し、CSVファイルを作成してS3に保存し、S3コネクタを作成するAWS Lambda関数があります。これでAmazon Qに取り込むことができます。コミュニティブログのウェブサイトについては、通常のWebクローラーを使用しています。
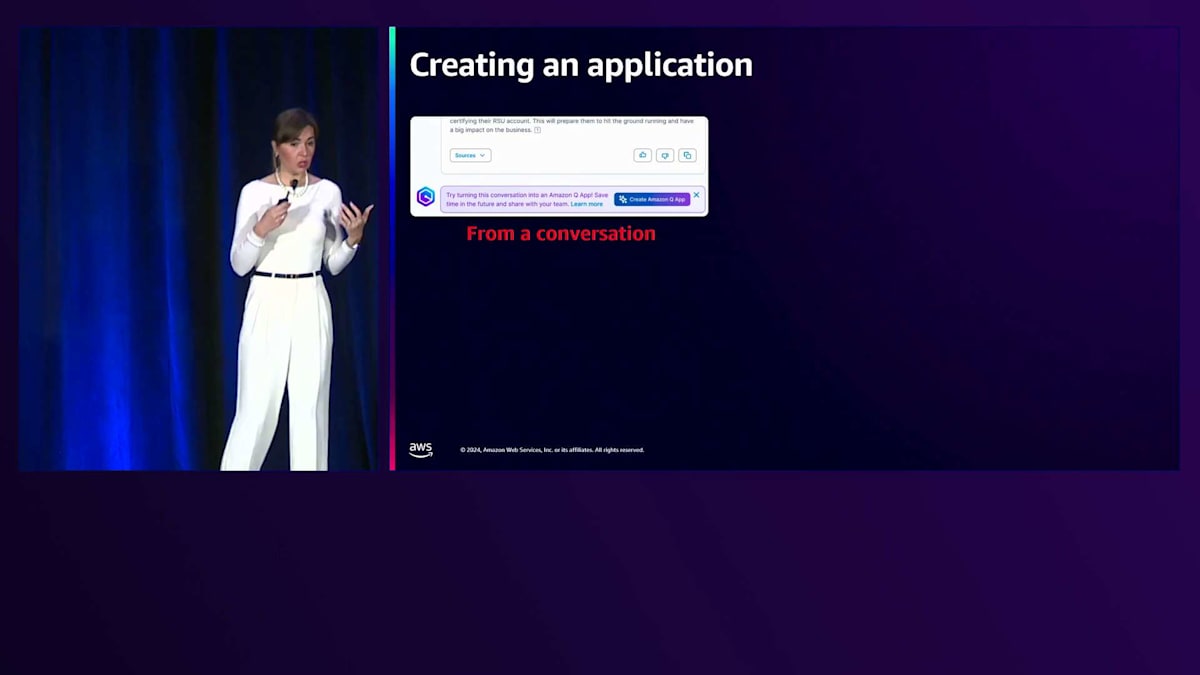

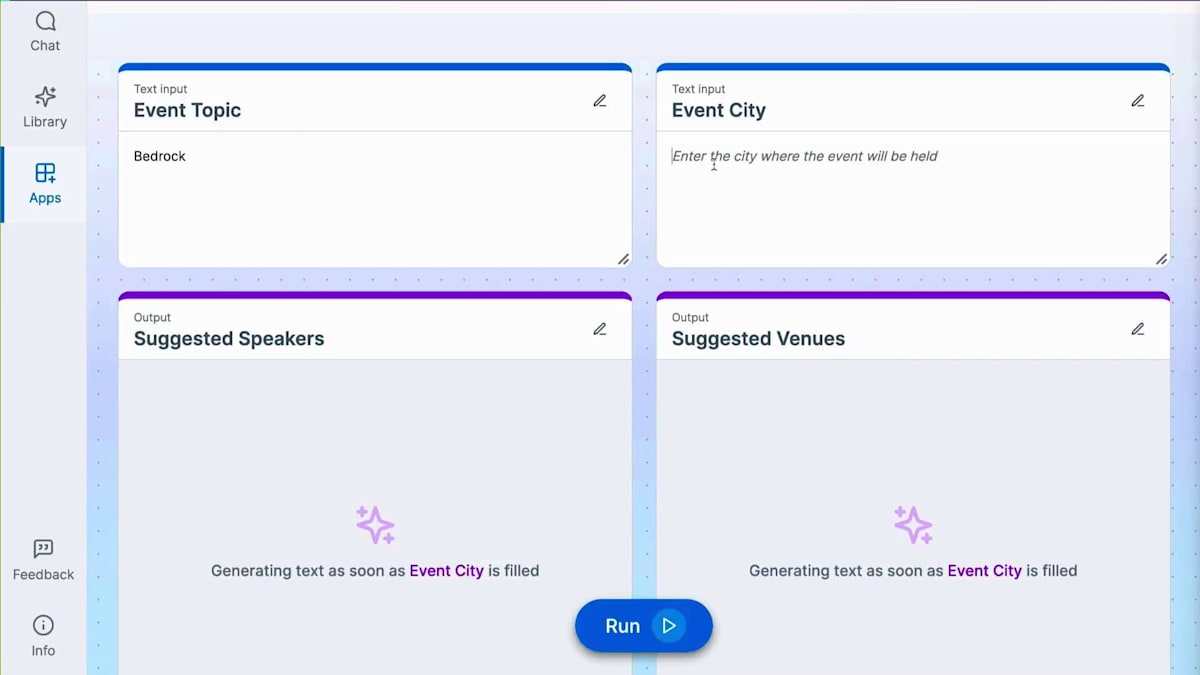
データの準備がすべて完了したので、避けたいことが1つあります。それは、同じ質問を何度も繰り返すことです。スピーカー、会場、日程を別々に尋ねるのではなく、いくつかのパラメータを入力するだけですべての情報を得られるものを作りたいと考えています。これはAmazon Q Appsを使用することで可能です。先ほどデータとのチャットの方法をお見せしましたが、このチャットからAmazon Q Appを作成することができます。あなたの質問に基づいて、再利用可能なアプリケーションを作成するか、または自分で説明してアプリケーションを作成する2つ目の方法を使用することができます。
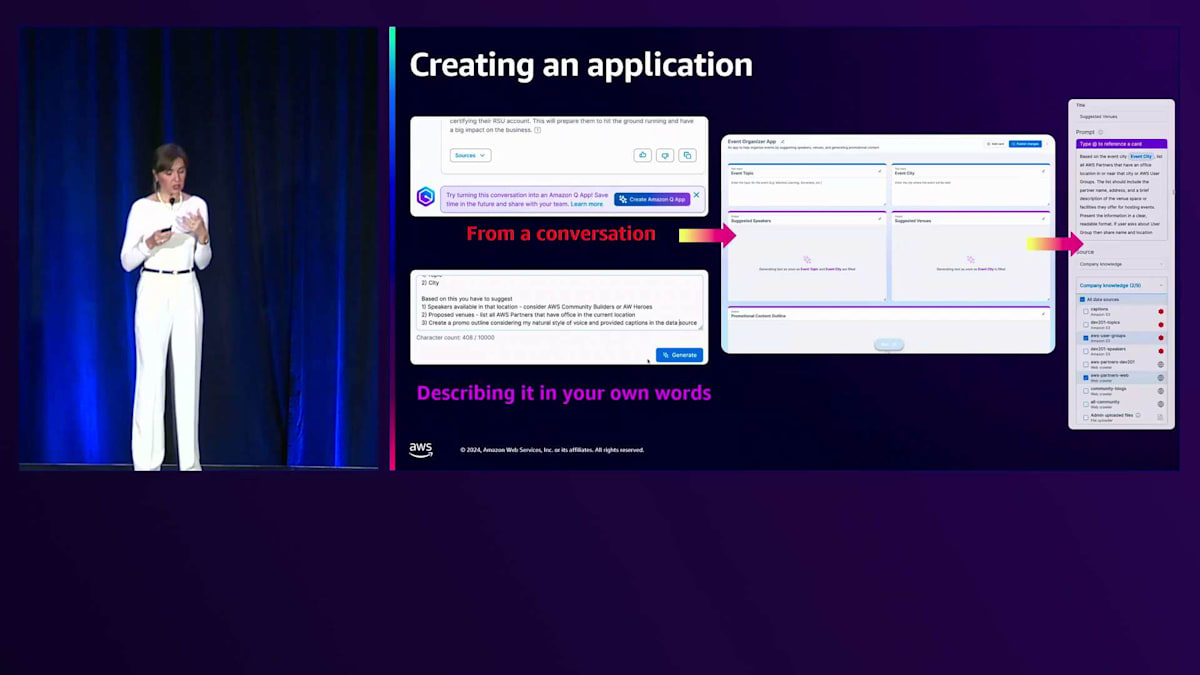
私のアプリについてご説明させていただきたいと思います。とてもシンプルなものなんです。いくつかの指示を入力するだけです。例えば、CCとトピックを入力する2つの入力ウィンドウを指定できます。都市やトピックなどの情報を入力できる入力ウィンドウを作成し、その入力に基づいて会場の提案、トピックの提案、プロモーション用コンテンツを生成する3つの出力UI要素を作成する方法をお見せしましょう。本当にシンプルで、普通の言葉で説明できるんです。そうすると、このアプリケーションを作成してくれて、実際に編集することもできます。 各ウィンドウのプロンプトを変更したり調整したりできます。データソースも調整可能です。例えば、会場のウィジェットについて、Speakerに関するデータのインデックス作成や検索にあまり興味がない場合は、AWS PartnerとAWS User Groupのデータソースだけを選択して、他のものはチェックを外すことができます。これによってアプリケーションのパフォーマンスが向上します。

各カード(基本的にはウィンドウやUIウィジェットのことです)について、プロンプトを調整し、Amazon Qが提供するデータを活用できます。会場カードにSpeakerからのデータを取得させたい場合は、単に@speakersと参照するだけで、他のすべてのデータソースに加えて、Amazon Qが生成したすべてのデータを取得できます。コンソールでの動作をお見せしましょう。 トピックと都市という2つの入力機能を持つWebアプリを構築し、これらに基づいてSpeakerの提案、会場の提案、プロモーションのアウトラインを作成するよう、Amazon Qに依頼しています。
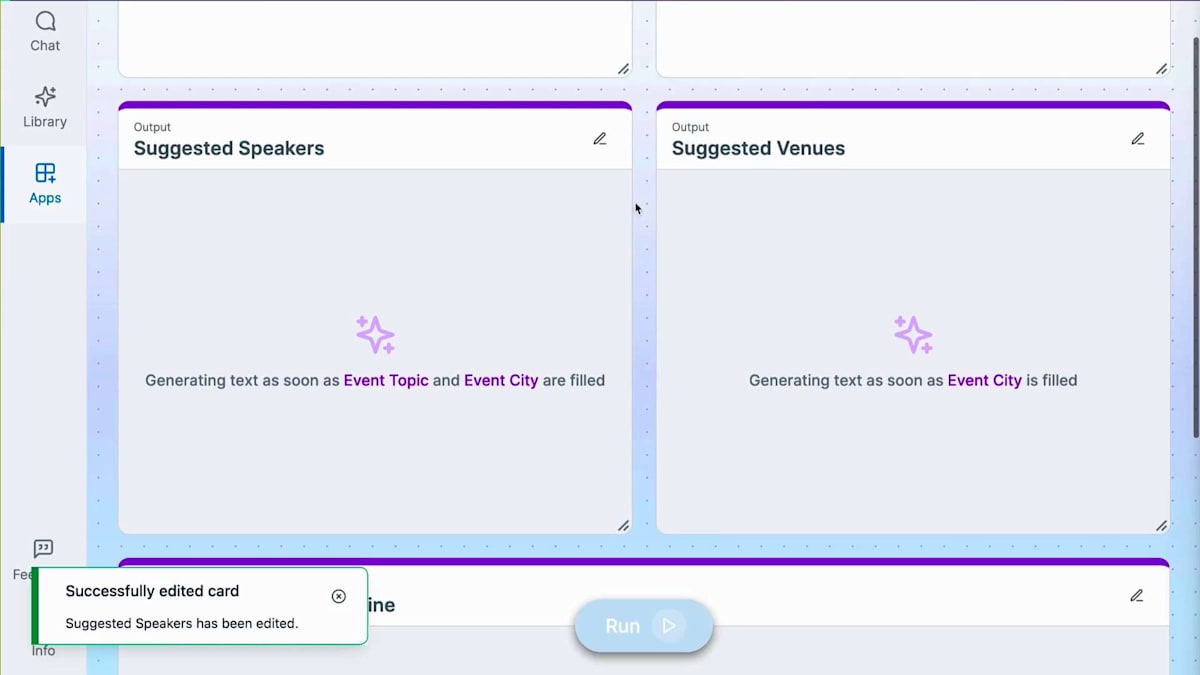

これから私が提案した内容に基づいてアプリを作成します。 私の指示に基づいて自動的に作成されたプロンプトが表示されていますが、これは自分の言葉で修正したり、企業の知識を調整したりすることができます。ウィジェットを追加することもできます。例えば、投稿と一緒に画像を表示するような視覚要素を作成したい場合は、追加のカード(新しいウィンドウ)を作成し、そこに新しいプロンプトを設定できます。
私が提供する入力とは異なり、Amazon Qが生成する出力を作成しようと思います。この場合、画像生成用であることを指定し、イベント開催都市の景色とイベントトピックに基づいて画像を生成するプロンプトを書きます。 これには企業の知識は必要ないので、言語モデルがすでに持っている一般的な知識だけを使用できます。

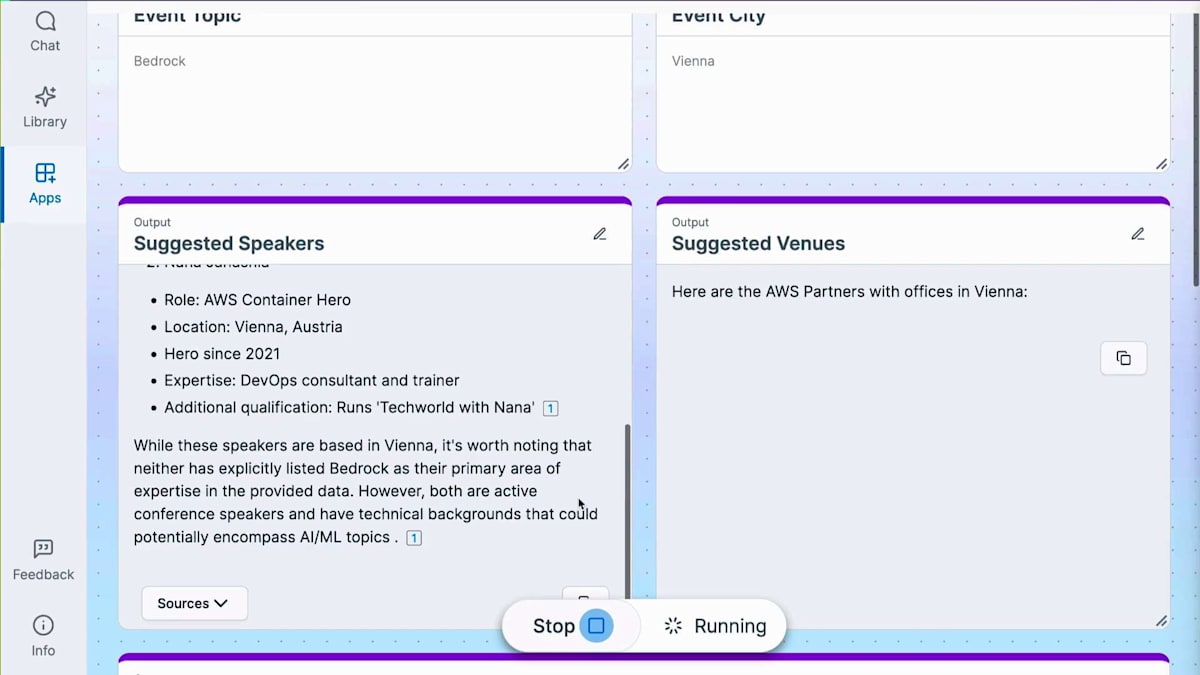


イベントトピックとしてBedrockを、開催都市としてViennaを試してみましょう。これらの質問を個別に入力して尋ねる代わりに、2つの単語を入力するだけです。 まず、推奨されるSpeakerが表示され、実際にViennaのLindaを特定してくれました。さすがAmazon Qですね。 Speakerの処理が終わると、推奨会場の検索を開始し、Viennaを拠点とするAWS Partnerを特定します。 これにより、異なるデータソースで情報を検索する時間が大幅に節約できます。都市を変更するだけで、数秒で情報を得ることができます。
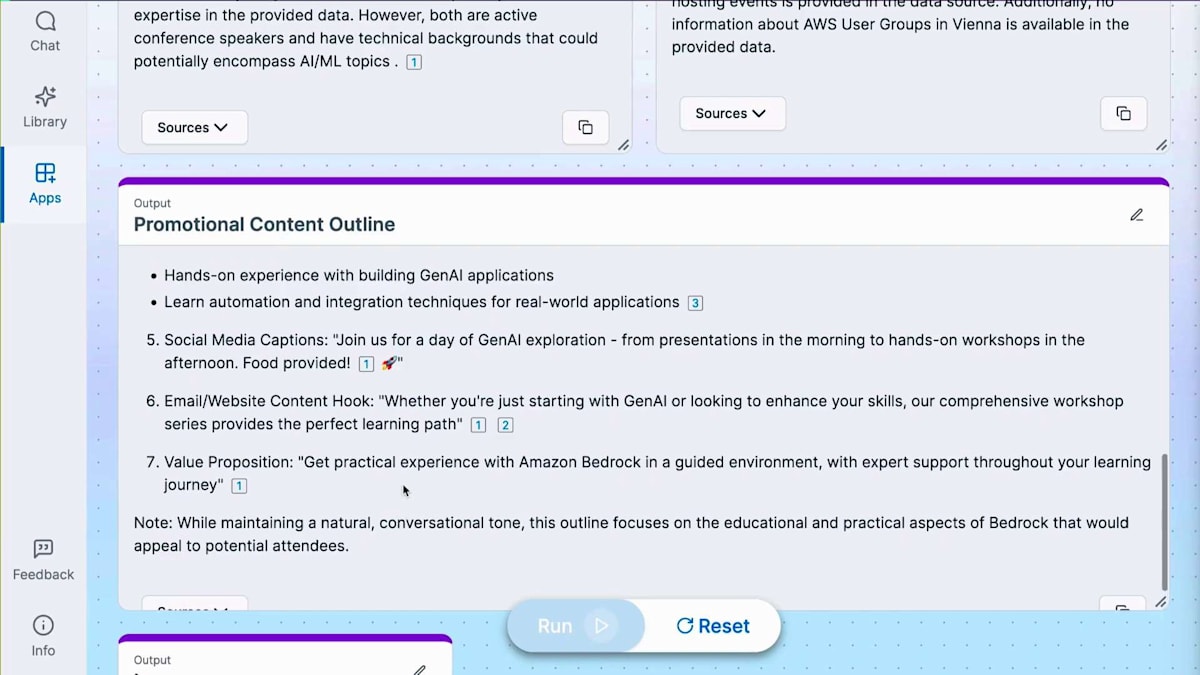
プロモーションコンテンツが完成すると、 画像生成に使用できるプロンプトを作成します。実際に、プロモーション投稿を補完するための画像を作成するために使用できる5つの異なるプロンプトが提供されました。Amazon Q Appの構築が完了したので、これを公開してチームメンバーと共有し、活用してもらうことができます。ここで、 私たちが議論した多くのユースケースを要約し、このソリューション全体の完成したアーキテクチャを共有してもらうために、Lindaにバトンタッチしたいと思います。
総括:アーキテクチャの全体像と重要ポイント

では、私たちが構築したものを見ていきましょう。非常に使いやすいドキュメントアップロード機能を活用しました。多数のCSVファイルやS3バケットストレージを使用し、Webクローラーも活用しました。AWS Partnerのテキストファイルに含まれるURLも使用し、さらにViennaのユーザーグループチーム内で使用しているGoogle Driveも活用しました。これらのデータをすべてAmazon Qに取り込みました。

すでにご存じの通り、すべての権限を管理するIdentity Providerがあり、ユーザーは様々な情報を作成することができます。Viennaでの次のAWS Meetupの適切な日程について質問することもできますし、 コミュニティについても多くの情報を把握しています。例えば、Munichでの次のAWSコミュニティの日程についても質問できます。

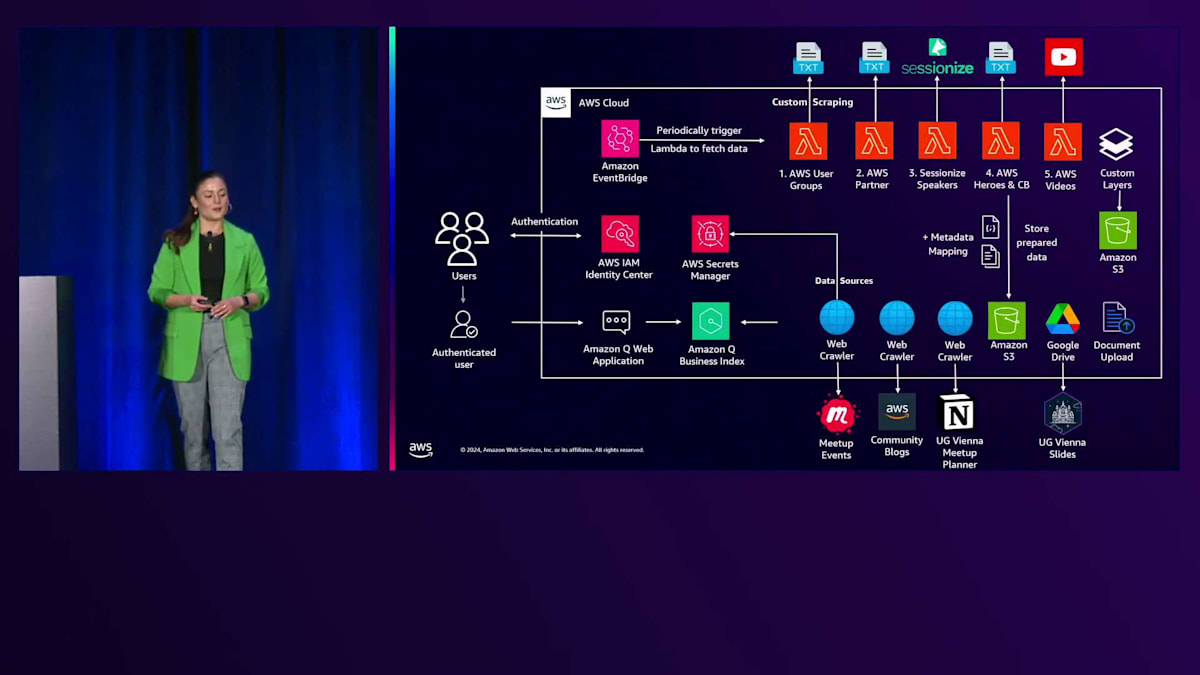
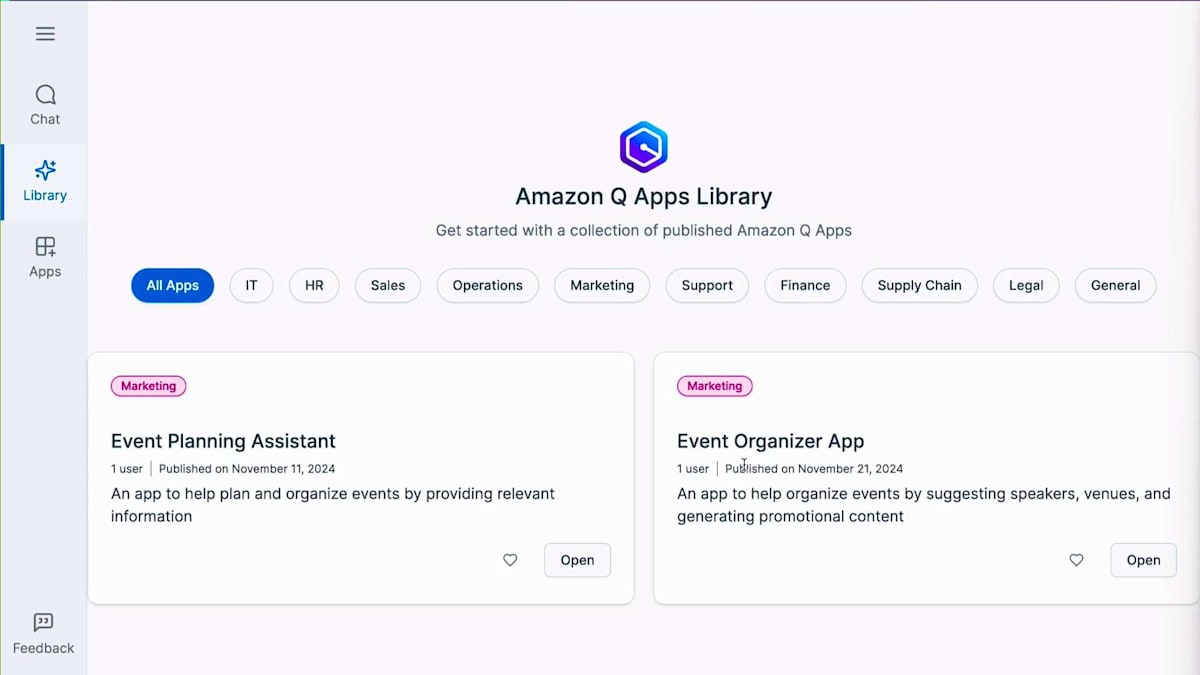
私たちは、 質問したいことをすべて組み合わせるためにそれらのアプリケーションを作成しました。Event Organizer AppとEvent Planning Assistantを用意しています。組織内でさらに多くのアプリケーションを作成して公開することも可能です。
では、アーキテクチャ全体を見てみましょう。私たちが構築したものには、Meetupイベントを使用するWebクローラーの下にある様々なデータソースが含まれています。コミュニティブログ用のWebクローラーがあり、さらにMeetupやイベントの運営方法に関する情報をより多く得るために、User Group ViennaのパブリックNotionページも活用しています。S3バケットには、ユーザーグループ、AWS Partner、セッションスピーカー、HeroやCommunity Builder、そしてAWSビデオに関する独自のスクレイピングデータがすべて保存されています。最終的に20メガを超えたため、S3バケットに保存したカスタムレイヤーもあり、スピーカーの国や都市など、必要な情報をマッピングするメタデータマッピングも用意しています。
Amazon Q Webアプリケーションを使用するためには、すべてのユーザーが認証を行う必要があります。認証後は、私たちが追加したすべてのデータソースを含むAmazon Q Business Indexを活用します。また、データを定期的に取得するためのカスタムLambda関数のトリガーとして、Amazon EventBridgeを活用していることもお分かりいただけると思います。


それでは、重要なポイントをご説明しましょう。 このGenerative AIには、非常に具体的なユースケースが必要だということが分かりました。まだ汎用的な人工知能の段階には至っていないのです。ですから、具体的なユースケースを必ず設定し、包括的なデータ戦略を立てて、どのようなデータが必要かを考える必要があります。データの更新頻度はどのくらいにすべきでしょうか?どの程度の鮮度が必要でしょうか?データを更新するたびにインデックスも更新され、当然それにはコストがかかりますので、毎日更新する必要はないかもしれません。


私たちが本当に重視しているのは、コスト効率の最適化です。期待する結果を得るために何が必要なのかを慎重に検討する必要があります。また、先ほどお見せしたように、コンプライアンスに準拠したAIの実装を確実に行う必要があります。公開されているものを何でも使えるわけではありません。このデータを使用する権利が本当にあるのか、しっかりと確認する必要があります。

最後に、スタートするためのリソースをいくつかご紹介します。このアプリケーションの構築方法に関する情報は、GitHubリポジトリでどんどん共有していく予定です。最初のQRコードをスキャンすると、私たちがどのように構築したかについての情報が得られます。これは他のユースケースのために更新していく予定です。また、Generative AIとAmazon Q Businessアプリケーションの構築方法に関するワークショップもあります。これらのQRコードを保存できるよう、ぜひ写真を撮っておいてください。ご清聴ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion