re:Invent 2024: AWSがECSとFargateでGenerative AIを実装する方法
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Supercharge your AI and ML workloads on Amazon ECS (SVS331)
この動画では、Amazon ECSとAWS Fargateを活用したGenerative AIアプリケーションの構築方法について解説しています。特に、Stable Diffusionを用いた画像生成システムの実装例を中心に、信頼性・パフォーマンス・スケーラビリティの3つの観点から具体的な設計手法を紹介しています。Amazon EFSを活用したモデルファイルの高速ロード、Warm Poolsによるインスタンスの事前初期化、Application Auto ScalingとCapacity Providerを組み合わせた効率的なスケーリングなど、実践的な最適化手法が示されています。また、AWS X-RayやNVIDIA DCGMを用いた監視の実装や、Spotインスタンスによるコスト最適化についても言及されており、本番環境での運用に必要な要素を包括的にカバーしています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Amazon ECSとGenerative AIの概要

こんばんは。re:Inventの火曜日へようこそ。私はSteve Kendrexで、Amazon ECSとAWS Fargateのプロダクトシニアマネージャーを務めています。本日は、Amazon ECSでのMachine Learningを検討する際の重要なポイントについて説明するAbhishek Nautiyalと、これからお話しする内容を実践的に活用する方法のデモを行うFrank Fanが登壇します。まず手を挙げていただきたいのですが、現在Amazon ECSをお使いの方、または導入を検討している方はどのくらいいらっしゃいますか?ライトが明るくてよく見えないのですが、ほぼ全員の方が手を挙げていただいているようですね。それは素晴らしいですね。

本日のお話の概要を簡単にご説明させていただきます。このre:Inventでは、AWSでGenerative AIを活用する方法について、様々な観点から多くのセッションが行われています。皆さんの多くがすでにAmazon ECSをお使いとのことですが、おそらく既存のプラットフォームを活用してAIを導入し、お客様により良い体験を提供する方法を検討されているのではないでしょうか。あるいは、Amazon ECSで手軽に始められる方法を探っているかもしれません。もしくは、より高度なものを構築したい、あるいはできるだけ迅速、シンプル、そしてスケーラブルなGenerative AIプラットフォームの構築方法を検討するよう依頼されているのかもしれません。このセッションでは、なぜAmazon ECSを選択するのか、その方法と、考慮すべきアーキテクチャの要点についてお話しし、最後にAmazon ECS上でStable Diffusionを使用したGenerative AI推論アプリケーションの実践的なデモをご覧いただきます。
AI/MLアプリケーション構築の課題とアーキテクチャ

DevOpsエンジニアやアーキテクトの立場で、組織のリーダーからAI/MLやGenerative AIの力を活用して、エンドユーザーに革新的なソリューションを提供するためのシステム構築を任されたとしましょう。Generative AIの世界は日々進化し、新しいモデルが次々と登場し、新しい計算能力やアクセラレーターが発表される中で、AI/MLアプリケーションの構築には大きく異なる課題があると考えるかもしれません。しかし、それは部分的にしか正しくありません。なぜなら、従来型のアプリケーションでも、スケーラブルなソリューションをエンドユーザーに提供するための基本的な課題は同じだからです。
これらの課題について詳しく見ていきましょう。AI/MLワークロードの実現は、皆さんの組織ですでに解決してきた課題と大きく異なるわけではありません。まず柔軟性について考えてみましょう。Generative AIを使用する際には、モデルの選択、カスタマイズの方法、利用したいMLツールキットやライブラリの種類について柔軟性が必要です。また、モデルとアプリケーションは、結果の一貫性と正確性の面で信頼性が高く、顧客の要求に応えられる高可用性を備えている必要があります。チャットボットのような即時の対話が必要なアプリケーションでも、キューベースの非同期モードでも、お客様が求める体験を提供するために適切なパフォーマンスが必要です。特に、計算インフラストラクチャーや必要なアクセラレーターの選択において、パフォーマンスの選択肢をコントロールできることが重要です。同時に、スケーラビリティも重要です。エンドユーザーからの需要の増加に応じてアプリケーションと基盤モデルを提供する基盤層をスケールアップし、需要が減少したりユーザーがログオフしたりした際にはスケールダウンできる必要があります。これはコスト最適化されたソリューションの運用と密接に関連しています。
同時に、アプリケーションの適切なモニタリング、トラブルシューティング、デバッグに必要なツールや機能にアクセスできることも重要です。これらすべての課題の基盤となるのは、エンドユーザーに適切な体験を提供するために、セキュアでコンプライアンスに準拠した方法でソリューションを構築する必要性です。
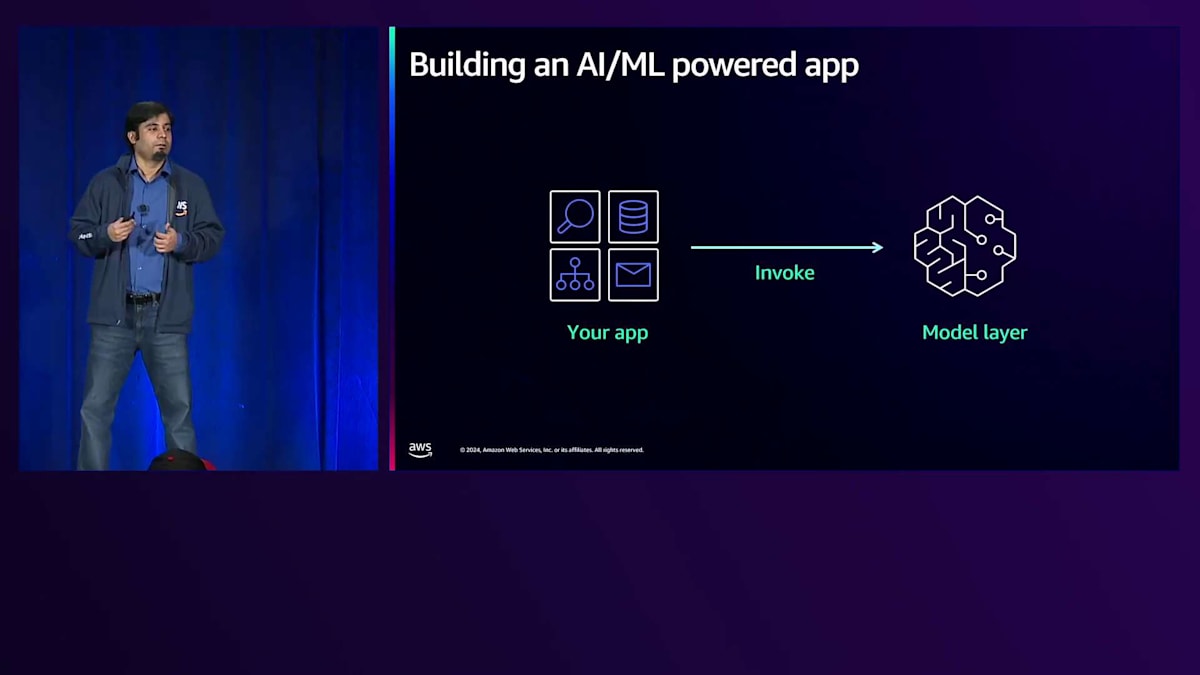

このような種類のアプリケーションを構築する際に検討していただきたいメンタルモデルは、アプリケーションを2つの異なるレイヤーとして考えることです。1つは、お客様がリクエストを送信するWebベースのアプリケーションなどのカスタマーフェイシングなアプリケーション、もう1つはカスタマーフェイシングなアプリケーションから切り離されたモデルレイヤーまたはモデルエンドポイントです。このメンタルモデルの主なメリットは、マイクロサービスアーキテクチャに似た利点が得られることです。モデルサーバーとエンドアプリケーションを切り離すことで、異なるチームが使用する技術の選択を分離できます。両方のレイヤーについて、使用したい技術に応じて適切なスキルセットを持つ異なるチームを育成することができます。
同様に、カスタマーフェイシングなアプリケーションと基盤となるモデルレイヤーを独立してスケールさせることができます。Webベースのアプリケーションの例では、ユーザーセッション数やお客様からのリクエスト数に基づいてアプリケーションをスケールさせたい場合があります。一方、これらのカスタマーリクエストをサポートするモデルエンドポイントは、キューに送信されたタスクのバックログなど、お客様のリクエストを処理するレートに基づいてスケールする必要があるかもしれません。この分離により、チームと組織はこれらのアプリケーションを独立して展開・構築できるようになり、より俊敏性が高まり、最終的にはお客様により早く結果を提供することができます。
Amazon ECSを活用したGenerative AIソリューションの実装
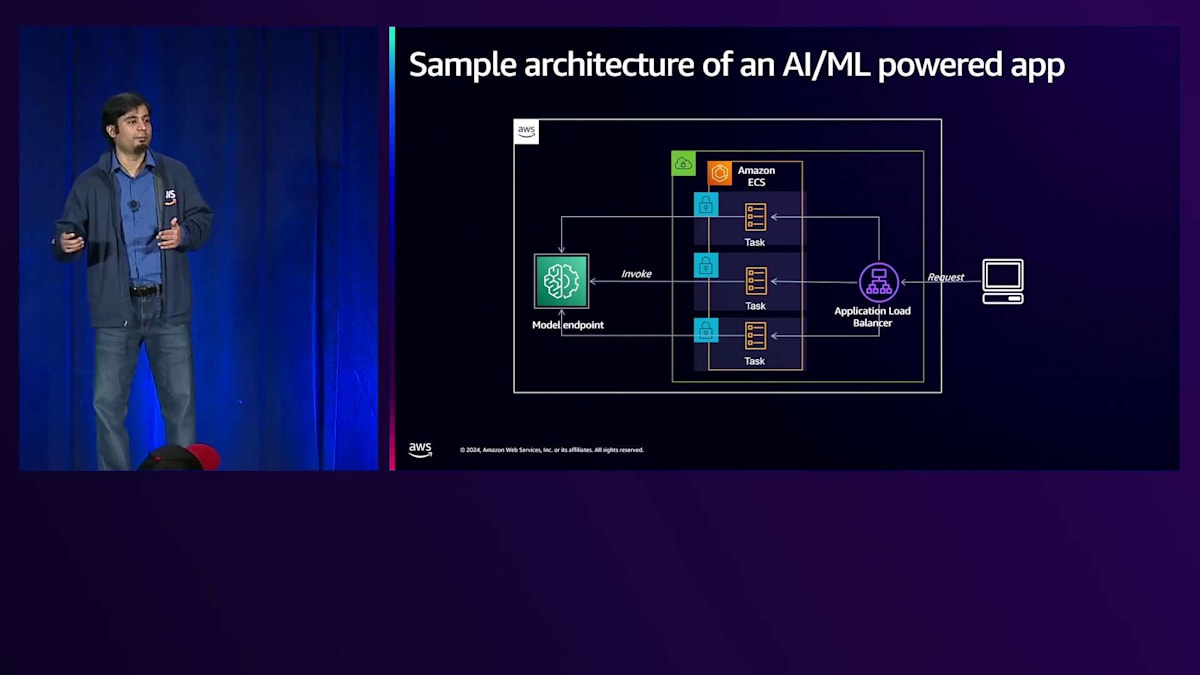
具体的な内容に入る前に、このようなAI/MLを活用したアプリケーションのサンプルハイレベルアーキテクチャをお見せしたいと思います。このアーキテクチャでは、お客様がロードバランサーを介してWebアプリケーションからリクエストを送信します。カスタマーフェイシングなアプリケーションはAmazon ECSサービスとして展開され、お客様のリクエストに基づいてスケールする一連のタスクが実行されています。もう一方にはモデルエンドポイントがあり、ここで分離のメリットが明確に見えます。モデルエンドポイントは必ずしもECSアプリケーションである必要はなく、お好みの技術やサービスでホストできます。このような方法でアーキテクチャを設計することの主なメリットは、今日ここにいらっしゃる皆様の多くがすでにECSを使用されており、おそらく同様のアーキテクチャでECSを使用して従来のアプリケーションを構築されているため、そのアーキテクチャを拡張してECSを使用するか使用しないかに関わらず、モデルを利用できるようになることです。

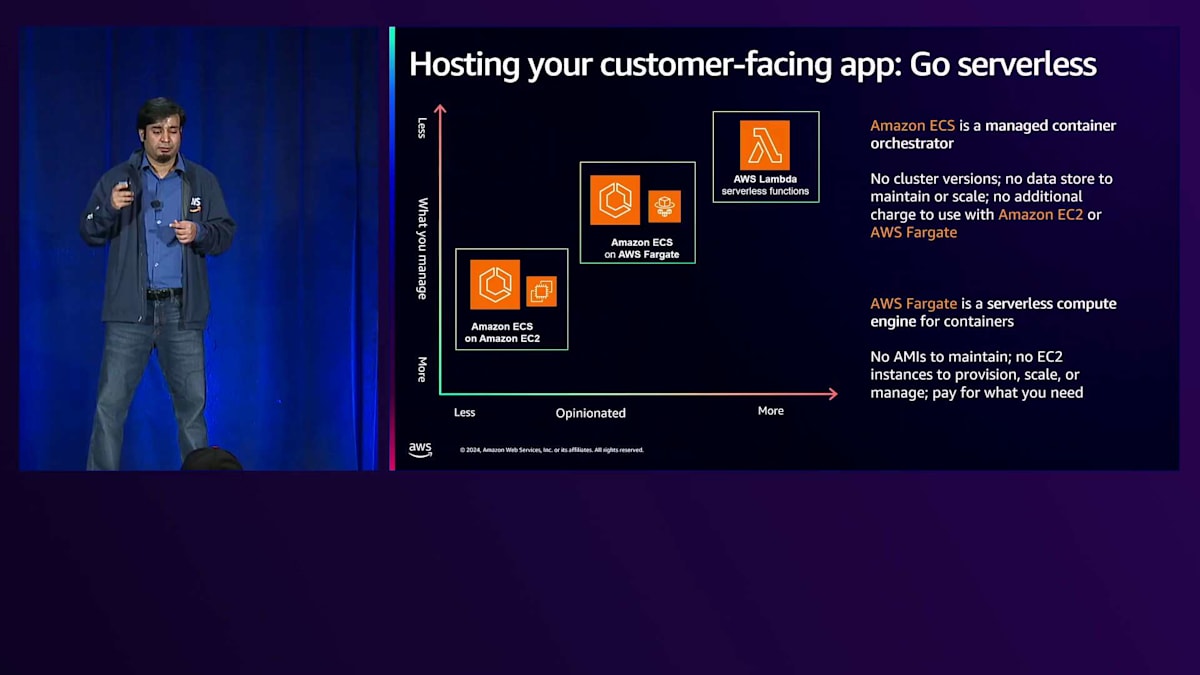
カスタマーフェイシングなアプリケーションのホスティングに関して、私たちはServerlessテクノロジーの採用を強くお勧めします。なぜなら、開発チームがアイデアから完成までより迅速に進み、お客様により早く結果を提供できるようになるからです。基盤となるサーバーのパッチ適用や、セキュリティとコンプライアンスの要件を満たしているかどうかなど、インフラストラクチャの選択について考える必要がありません。Serverlessパターンは、私たちが本当に考えている運用モデルを実現します。これは、これらの差別化されていないタスクをすべてAWSに任せることができ、コアビジネスロジックに集中してお客様により良い結果を提供することができるからです。Serverlessコンピューティングのオプションについて説明します。
このチャートでは、Serverlessコンピューティングの全体像を示しています。2つの軸は、ソリューションがどの程度オピニオネイテッドであるかと、どの程度のコントロールが可能かを表しています。右上にはAWS Lambdaがあり、これは非常にオピニオネイテッドなServerlessソリューションで、Lambdaのプログラミングモデルを使用する必要があります。実行時間やストレージ制限などの制約がありますが、特にイベント駆動型のサービスアプリケーションを構築する際に、非常に迅速に開始できます。
ここで、Amazon ECSがこのスペクトラムの中でどのように位置づけられるのかについてお話ししたいと思います。Amazon ECSはフルマネージド型のコンテナオーケストレーションサービスです。ECSはサーバーレスのコントロールプレーンと考えることができます。なぜなら、ECSではクラスターのバージョンアップデートについて考える必要がないからです。新しいタイプのファームウェアのインストールも、ECSがすべてバックグラウンドで処理してくれます。そして、ECSが構築する新機能はすべて、アップグレードについて考えることなく無料で利用できます。このECSのサービスコントロールプレーン内では、AWS Fargateというサーバーレスのデータプレーンを使用するオプションがあり、これによってフルサーバーレスの体験とサーバーレスアーキテクチャのすべての利点を得ることができます。もし、特にAIや生成AIアプリケーションのように、パフォーマンスベンチマークで使用した特定のアクセラレーターの方が適している場合など、基盤となるインフラストラクチャをより詳細に制御したい場合は、Amazon ECSをEC2コンピュートと組み合わせて使用することで、それらのコンピュート機能にアクセスすることができます。

カスタマーフェイシングアプリケーションのオプションを見てきましたが、ここでモデルレイヤーやモデルエンドポイント自体をホストするためのオプションを概観してみましょう。これも同様にスペクトラムとなっており、使いやすさと制御・設定可能性の観点から考えることができます。使いやすさの極端な端にあるのがAmazon Bedrockで、これは完全マネージド型のサーバーレスAPIサービスとして、素早く開始でき、幅広い基盤モデルへのアクセス、微調整などが可能です。中間に位置するのがAmazon SageMakerで、MLモデルの実行、構築、デプロイ、トレーニングのための環境を提供する目的特化型サービスです。より多くの制御とカスタマイズが可能な極端な端には、Amazon ECSによる自己ホスティングがあり、これは基本的に汎用的なコンテナベースのソリューションで、生成AIアプリケーション自体が既存のアプリケーションの拡張として扱われます。
パフォーマンス最適化とスケーラビリティの実現

では、他のオプションと比較して、なぜAmazon ECS上でモデルをホストすることを検討すべきなのかを見ていきましょう。もし組織がすでにAmazon ECS上でモデルやサービスの実行とデプロイメントの経験を持っている場合、モデルもECSにデプロイすることで、一貫したツールを使用できるというメリットがあり、既存のプラットフォームをAIアプリケーションにシームレスに拡張することができます。それに加えて、モデル、インフラストラクチャ、インストールしたいライブラリの選択に関して、完全な制御と設定可能性、そして柔軟性も得られます。ECSが持つフルマネージド機能セットと他のAWSサービスとの深い統合を活用でき、これによって可観測性、セキュリティ、アプリケーションの自動スケーリングに関するニーズを満たすことができます。さらに、AWS Fargateと組み合わせることで、すぐに使えるサーバーレスコンピュートを手に入れることができます。

それでは、コンピュートオプションから始めましょう。ECSでは、AWS上のすべてのコンピュートオプションにアクセスすることができます。
すでにAWS Fargateのサービスモードとそのメリットについて説明しました。生成AIワークロードについては、CPUベースのサービング利用を検討することをお勧めします。すべてのモデルがアクセラレーターを必要とするわけではないからです。小規模なモデルの中には、CPUを使用して提供できる可能性があるものもありますが、これはパフォーマンスとレイテンシーに関する要件次第です。
中央には、Amazon EC2インスタンス上で動作するAmazon ECSがあります。ECSはAuto Scaling groupsと深く統合されており、アプリケーションの需要に基づいてアプリケーションとコンピューティングインフラをシームレスにスケールすることができます。現在AWSで利用可能なすべての高速コンピューティングオプションにアクセスでき、GPUをサポートする最新のインスタンスもECS上で利用できます。さらにスペクトラムの最端にはAmazon ECS Anywhereがあり、AIベースのワークロードをハイブリッドな方式でエッジで実行することができます。データのレジデンシーやプライバシーに厳しい要件を持つお客様が、オンプレミスでインференスを実行するためにデータを収集しながら、モデルはクラウドで実行するというハイブリッドな方式で運用しているパターンも見られます。
コスト最適化については、EC2の購入オプションや割引オプション、特にSpotインスタンスやSavings Plansにアクセスでき、これらはFargateとEC2の両方のコンピューティングオプションで利用可能です。また、FargateとEC2の両方のコンピューティングオプションでより優れた価格性能を提供するAWS Gravitonベースのインスタンスにもアクセスできます。

顧客向けアプリケーションとモデル層の両方のスケーラビリティニーズに関して、ECSはAWS Application Auto Scalingとの深い統合により、サービスの自動スケーリング機能を提供します。お好みの指標で使用できる幅広いスケーリングポリシーにアクセスできます。ECSはCPU使用率やロードバランサーのリクエスト数など、事前定義された指標を提供します。また、ECSではキューのバックログの深さなどのカスタム指標も、これらのスケーリングポリシーで使用できます。
スケーリングオプションについては、設定可能な範囲が非常に広くなっています。ステップスケーリングでは、タスク数を増減させる際の細かいステップサイズについて、スケーリングポリシーの動作を正確に定義できます。ターゲットトラッキングは完全に自動化されたモードで、アプリケーションやECSサービスに求める目標値だけを考えればよいようになっています。例えば、すべてのタスクの平均CPU使用率を75%に保ちたい場合、ターゲットトラッキングポリシーでその目標を設定すれば、ECSとAuto Scalingが負荷パターンに基づいてアプリケーションのスケーリングを処理します。
また、アプリケーションのスケールアウトやスケールダウンのステップを手動で定義できるスケジュールスケーリングも利用可能です。例えば、毎朝9時にトラフィックが急増し、毎日午後5時に減少することが分かっている場合、これらの正確なスケーリングステップを設定することでスケジュールスケーリングアクションを定義できます。予測スケーリングは、約2週間前にリリースした新しいスケーリングポリシーです。これは私たちが構築した、プロアクティブな機械学習ベースのアルゴリズムで、過去の需要パターンを自動的に分析します。午前9時のトラフィック急増や月曜日の顧客ログインなど、繰り返しや周期的なパターンを検出すると、予測Auto Scalingはこれらの需要パターンを予測し、事前にアプリケーションをプロアクティブにスケールすることができます。
Predictive Scalingの主なメリットは、需要パターンに対応するためにアプリケーションを過剰にプロビジョニングする必要がないことです。ここで重要な推奨事項として、Target TrackingとPredictive Scalingを組み合わせて使用することをお勧めします。Predictive Scalingは、Target Trackingやその他のスケーリングポリシーを補完するものとして開発されました。アプリケーションを事前にスケールするためのセーフティネットを提供しますが、それ自体ではスケールダウンは行いません。PredictiveとTarget Trackingを併用することで、予測的な履歴やサイクルパターンに基づくスケーリングと、リアルタイムのトラフィックサージへの対応の両方が可能になります。

基盤となるコンピュートインフラストラクチャについて簡単に見ていきましょう。サーバーレスの大きな利点は、基盤となるコンピュートインフラストラクチャについて考える必要がないことです。ただし、Generative AIアプリケーションを特定のアクセラレーターで実行したい場合は、T2インスタンスの使用を検討することになるでしょう。アプリケーションのスケーリングニーズに合わせて基盤となるインフラストラクチャとT2インスタンスをスケールするために、Amazon ECSはCapacity Providerというソリューションを提供しています。これは実行中のインスタンス数を自動的にスケールアップまたはスケールダウンします。この例では、サービスに対してスケールされた3つのタスクに対するリクエストがあり、必要なインスタンス数に応じて、ECS Capacity Providerが起動するインスタンス数やスケールアウト・スケールインを決定します。Capacity Providerを使用すると、SpotキャパシティとOn-Demandキャパシティを利用できるため、ワークロードが中断に対して耐性がある場合は、混合して使用したりSpotキャパシティを利用したりすることができます。また、特にGenerative AIベースのアプリケーションでは、Auto Scaling GroupのWarm Poolsの使用をお勧めします。これは、大規模なGPUベースのインスタンスのコストを考慮した場合に必要となる可能性のあるT2インスタンスの起動時間を短縮するため、インスタンスを事前に初期化するためです。

ストレージオプションについては、Amazon ECSで複数の選択肢があります。アプリケーションのコンテナイメージと一緒にモデルをバンドルすることも可能です。これは従来のアプリケーションではうまく機能するかもしれませんが、AI/MLベースのアプリケーションではこのアプローチは推奨されません。モデルサイズ自体が数ギガバイトから数百ギガバイトになる可能性があり、コンテナイメージやアプリケーションイメージとバンドルするとアプリケーションの読み込み時間が遅くなってしまうためです。また、Amazon S3を使用してモデルをホストし、実行時にECSアプリケーションやコンテナにプルすることもできます。さらに、フルマネージドな弾力的ファイルシステムであるAmazon Elastic File Systemにアクセスすることもできます。後ほど、EFSを使用して構築したアプリケーションのデモをご覧いただきますが、これが推奨オプションとなります。
モニタリングとObservabilityの重要性

最後に、アプリケーションの監視については、Amazon ECSはAmazon CloudWatchとネイティブに統合されており、特にCloudWatch Container Insightsは、アプリケーションの監視とトラブルシューティングを可能にする様々なメトリクスを提供します。実は今週初めに、Enhanced CloudWatch Container Insightsをリリースしたばかりで、これによりタスクとコンテナレベルでより詳細なインサイトやメトリクスが提供されます。Generative AIとMLアプリケーションについて話題にしているので、一点お伝えしておきたいのは、現在ECSではGPUの予約状況に関するメトリクスは提供していますが、GPUの使用率やGPU温度のメトリクスはすぐには利用できません。デモでもご覧いただきますが、NVIDIA Data Center GPU Managerのようなパッケージをインストールして使用することができます。これらのメトリクスは現在開発中で、より詳細で具体的なメトリクスもロードマップに含まれており、リリースされ次第ECSで無料で利用できるようになります。
ECSはまた、FireLensとネイティブに統合されており、Amazon CloudWatchを使用したくない場合や、別のAWSサービスを使用したい場合に、ログやメトリクスをパートナーソリューションにルーティングすることができます。AWS X-Rayは、ECSアプリケーションと一緒にインストールできるデーモンで、特にAI/MLワークロードで何か問題が発生した場合のトラブルシューティングやデバッグのために、エンドツーエンドのユーザーリクエストをトレースしたい場合に推奨されます。

Amazon ECSを使用して、すでに多くのお客様がGenerative AIで成果を上げています。 WOMBOとScenarioは、Gen AI推論ワークロードを構築し、特にAWS FargateとECS、あるいはEC2とFargateを使用することで、市場投入までの時間を短縮できたと評価しています。Keplerは、Amazon ECS Anywhereを活用してハイブリッドおよびクラウドベースのワークロードを実現し、機械学習アプリケーションのクラウドへの移行を加速させました。また昨日Andyが話したように、Amazonは最近、世界最大のeコマースプラットフォームでより個人に合わせたショッピング体験を提供する機械学習ツールRufusを、AWS TrainiumとAWS Inferentiaを搭載したEC2インスタンスをECSを通じて使用して構築しました。


このように、お客様は現在、大きな成果を上げています。これからのデモを通じて、お客様がECSを使用してどのように大規模な展開を実現し、そのシンプルさを活用できるかをご紹介します。 先進的なデジタル企業からの依頼を受けたとイメージしてください。彼らはデジタルランドスケープを変革したいと考えており、 画像生成のためのリアルタイム推論アプリケーションの設計を依頼されました。ここで注目すべき3つのポイントがあります。1つ目は信頼性です。 フロントエンドとバックエンドで推論を行うため、計画的・非計画的な停止に関係なく、システム全体が常時稼働している必要があります。2つ目はパフォーマンスです。エンドユーザーは画像生成に長時間待たされたくないため、レイテンシーとスループットに細心の注意を払う必要があります。そして最後に、スケーラビリティです。エンドユーザーのトラフィックには大きな不確実性があるため、急激な負荷の変動にどう対応し、静かな時間帯にはスケールインしてコストを削減するかが課題となります。
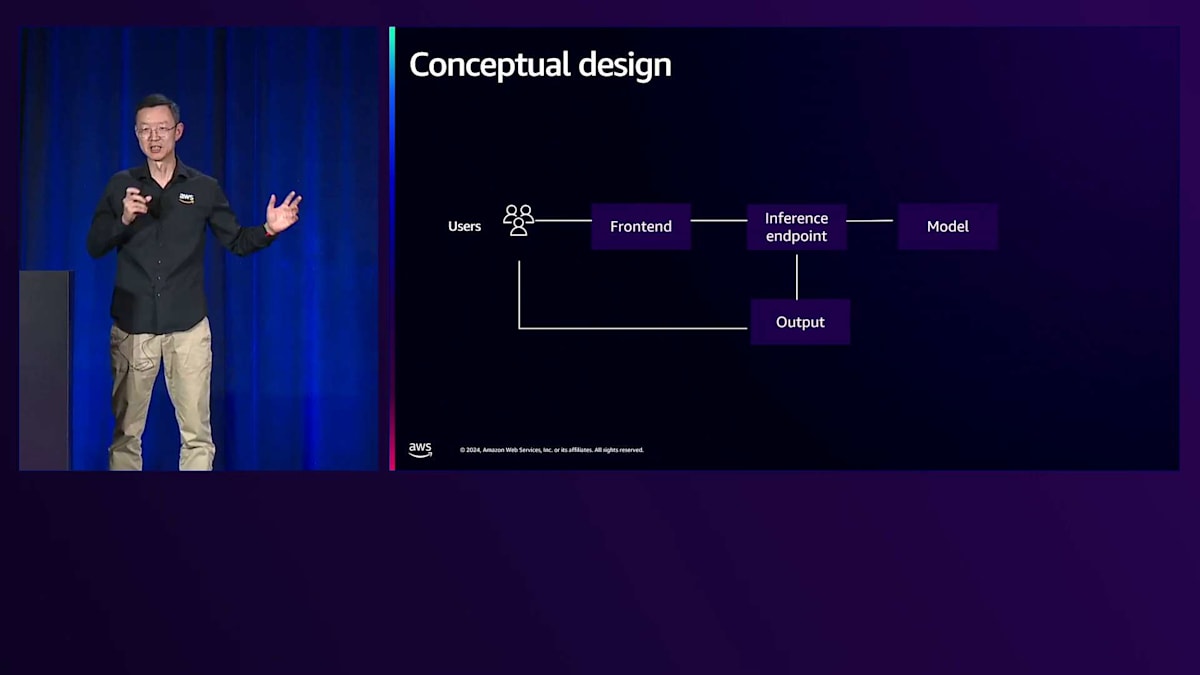

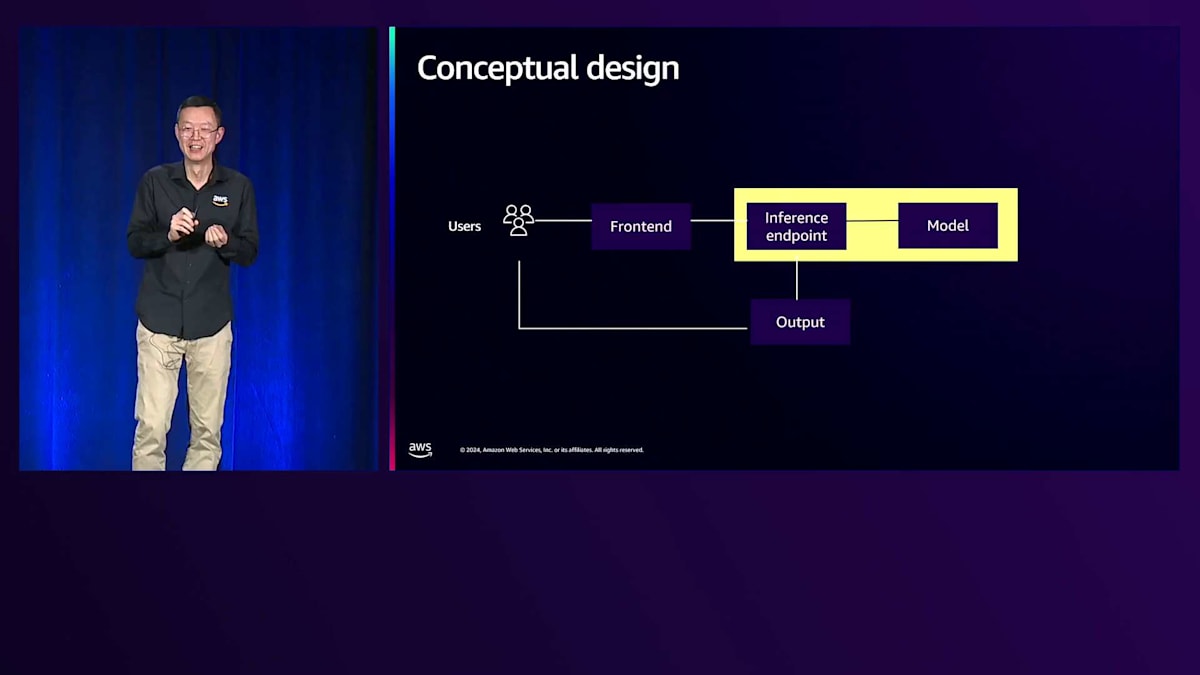
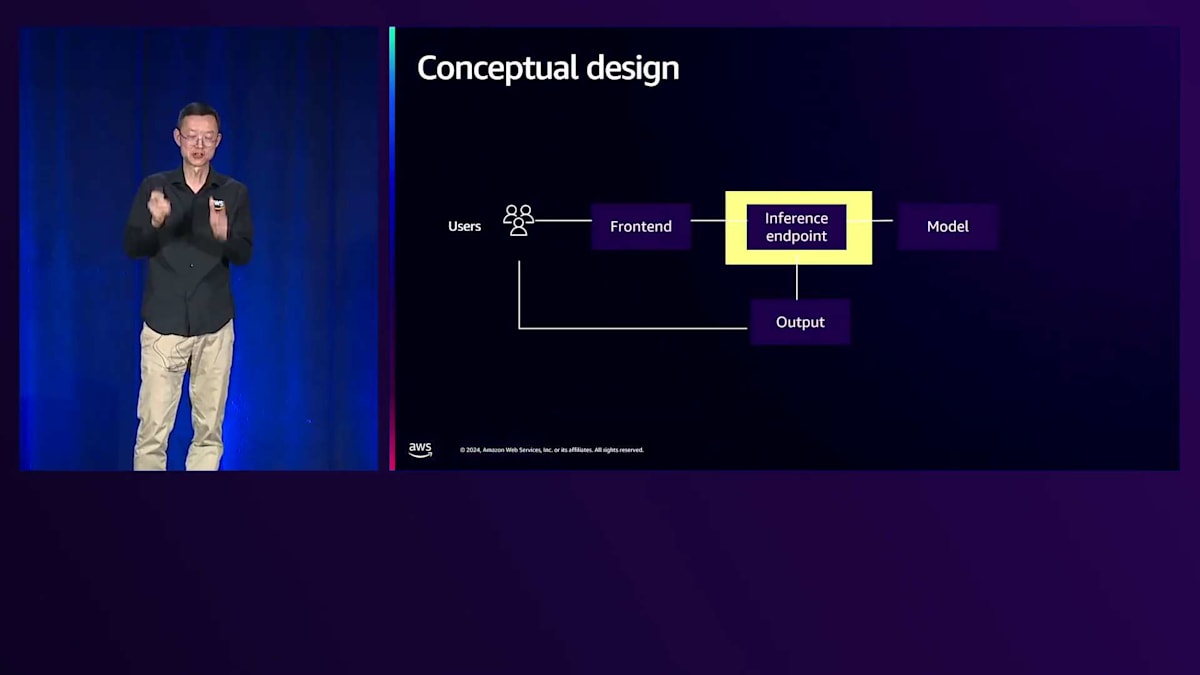
ここで、概念的なアーキテクチャを見てみましょう。シンプルに見えます - エンドユーザーがフロントエンドにリクエストを送信し、フロントエンドは推論エンドポイントと呼ばれるランタイムと連携してモデルファイルを読み込み、画像を生成してアウトプットを返します。生成された画像はユーザーが閲覧できるようになります。信頼性の観点で最も重要なコンポーネントは何でしょうか?実は全てのコンポーネントが重要で、それらの間の接続も同様です。全体的な視点でアーキテクチャを考える際、まずは同期モードから見ていきましょう。
同期モードでは、エンドユーザーが推論エンドポイントと直接通信します - 素早く失敗を検出でき、シンプルです。しかし、推論エンドポイントについてさらに詳しく考えてみましょう。シンプルではありますが、いくつかの考慮点があります - 急激な負荷増加時にバックエンドが追いつかない場合はどうでしょうか?パフォーマンスの制限が発生する可能性があります。また、推論エンドポイントが停止した場合、エンドユーザーは即座にエラーメッセージを目にすることになります。

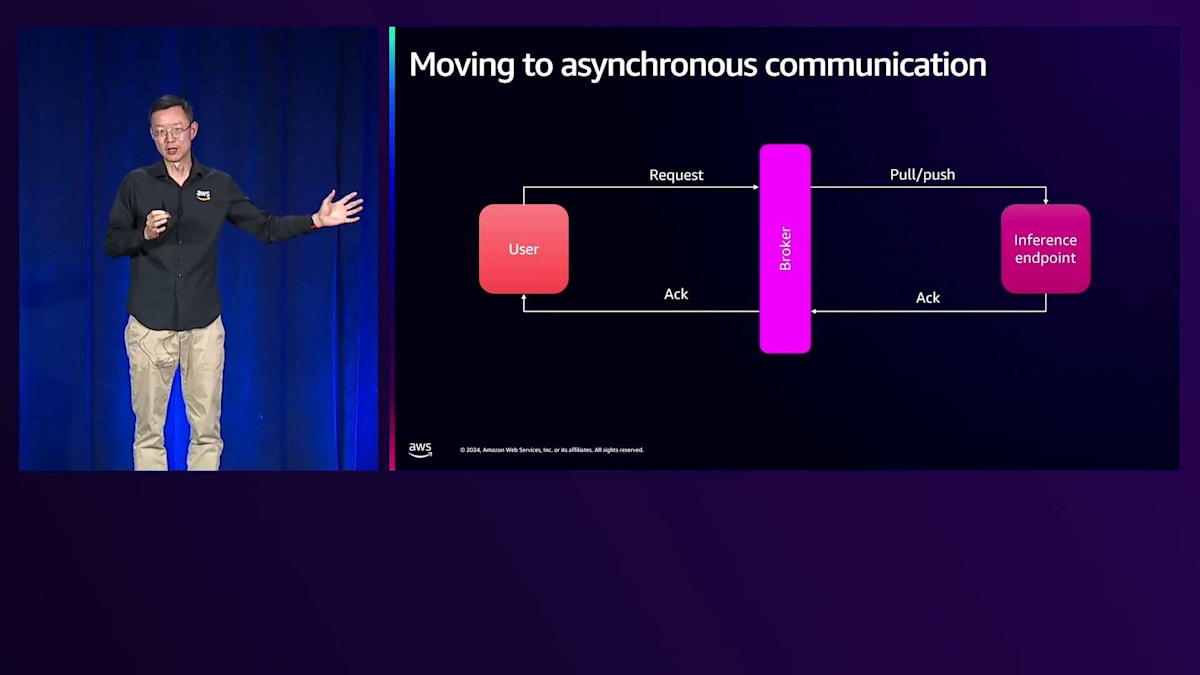
これを非同期方式で実装することができます。これが現在私たちが採用している方法です。 中間にブローカーを配置することで、これらを分離できます。ブローカーがリクエストを受け取ったことを確認し、その後バックエンドがリクエストを取得します。このアプローチの利点は、スケーラビリティと柔軟性が向上し、最も重要な点として、より高い信頼性を実現できることです。
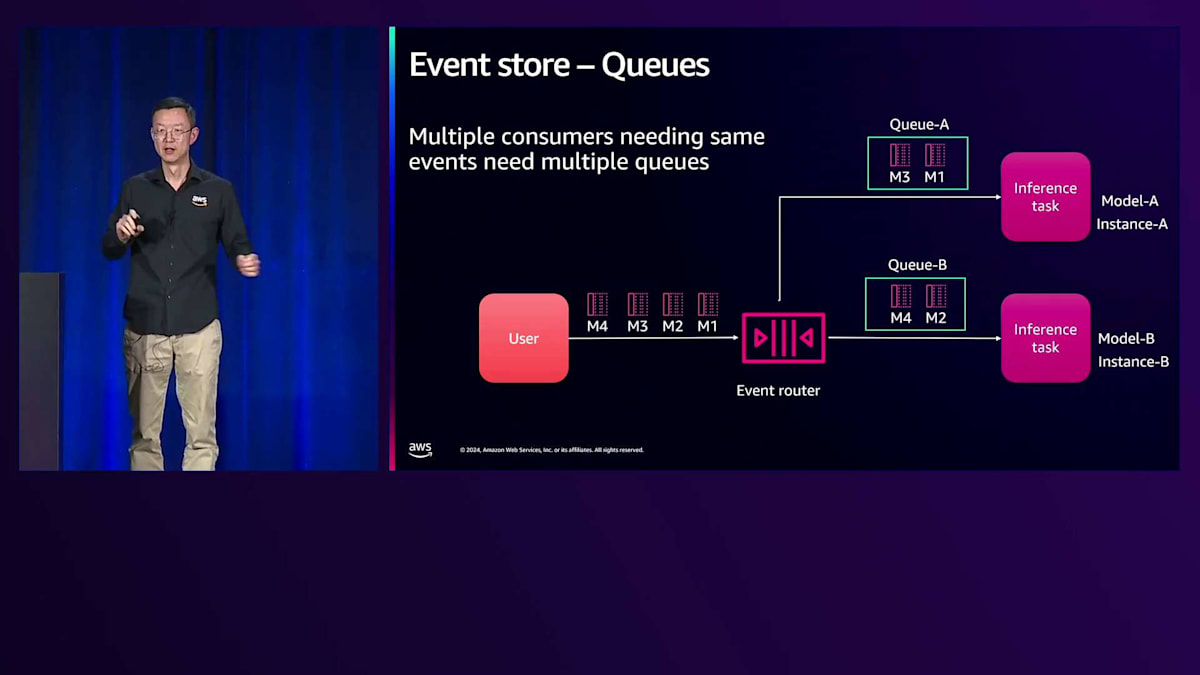
これは$1の実装例で、複数のメッセージを送信するフロントエンドと、属性に基づいて異なるキューにルーティングするイベントルーターを備えています。信頼性を高めるため、2つのキューが並行して動作しており、1つが停止しても他方が機能し続け、並列実行で効率も向上します。右側には、異なるインスタンスタイプに関連付けられたInferenceエンドポイントがあります。プレミアムユーザーには最速で最高のインスタンスタイプを提供し、無料ユーザーにはよりコスト効率の良いものを使用できます。また、今日のオープンソースコミュニティには、Stable Diffusionと連携するための様々なランタイムが存在するため、異なるランタイムを関連付けることも可能です。Foundation Modelを使用するものもあれば、特定のスタイルを生成するために拡張モデルと組み合わせるものもあります。
Stable Diffusionを用いたデモンストレーション
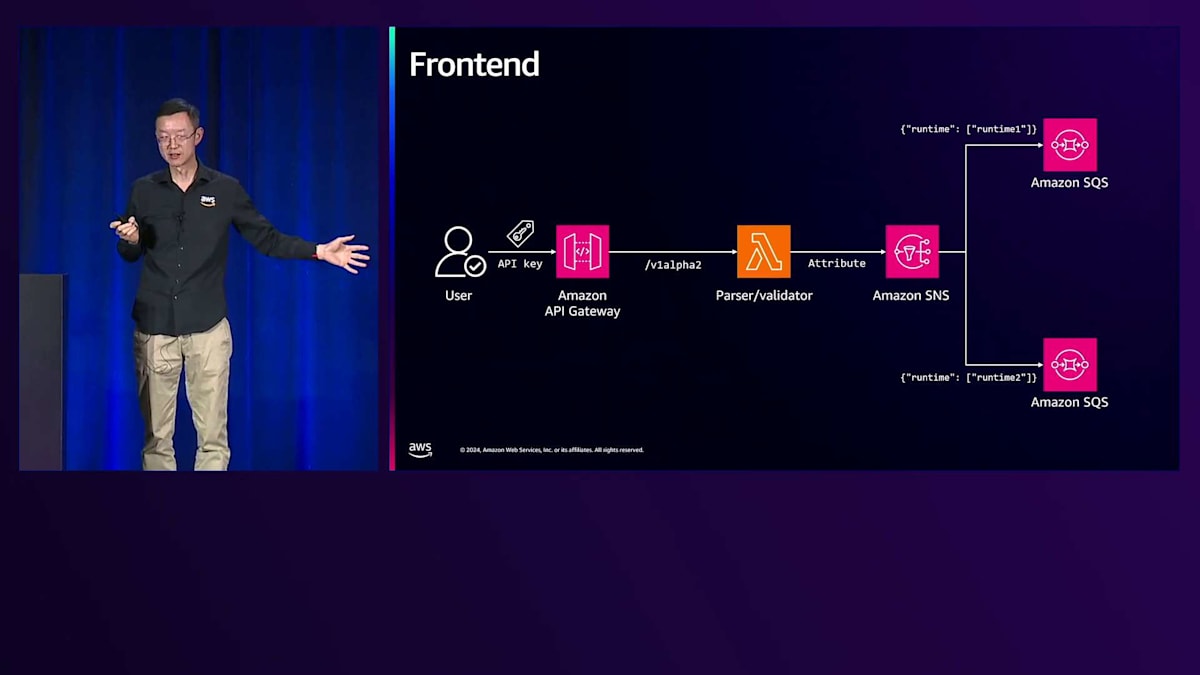
では、このソリューションをAWSテクノロジーを使用してどのように実装するのか見ていきましょう。左側では、ユーザーは認証と認可のためにAPI Keysを使用してAmazon API Gatewayを利用します。Lambda関数がリクエストを検証し、検証が完了するとAmazon SNS(Simple Notification Service)に渡されます。SNSは属性に基づいて異なるキューにルーティングします。ここでは、単純な画像生成や、ComfyUIを使用してより高度な画像生成ワークフローを実現するなど、異なるランタイムをInferenceエンドポイントに使用できます。
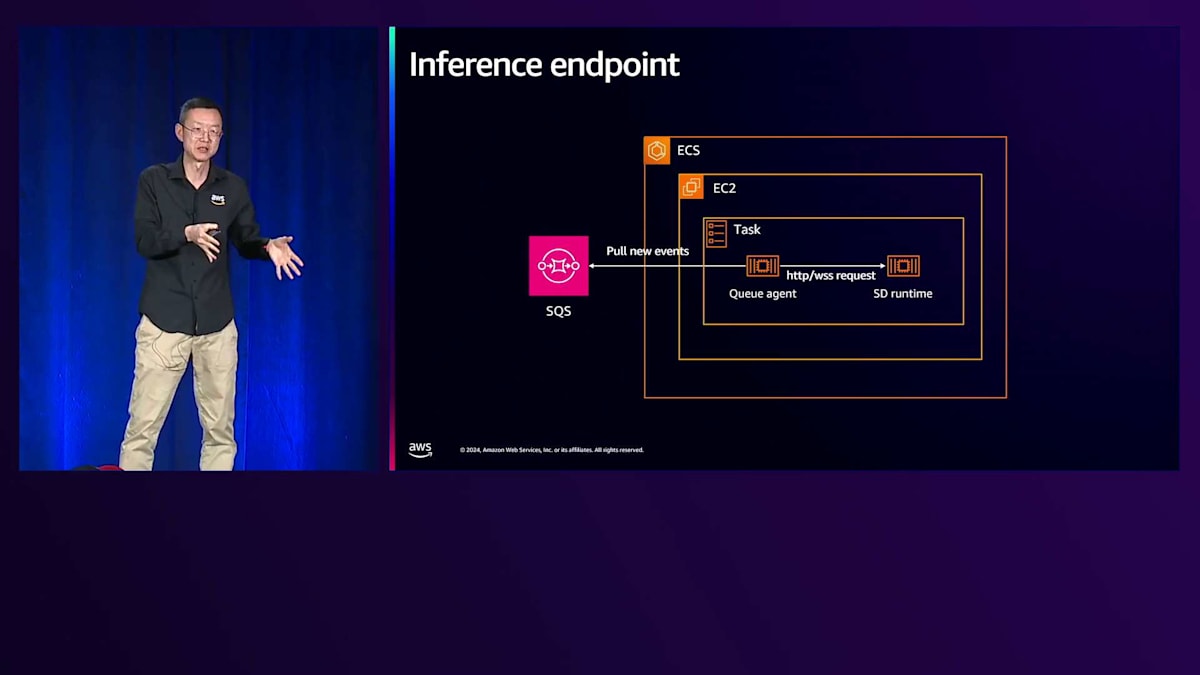
エンドポイントコンポーネントを見てみましょう。左側にはすでにAmazon SQSにメッセージが格納されています。右側には2つの重要なコンポーネントがあります。1つ目はInferenceエンドポイント用のSDランタイムです。ただし、多くのオープンソースランタイムはキューをネイティブにサポートしていないため、私たちはエージェントを作成しました。このエージェントは、メッセージをランタイムが認識できる形に変換し、これらのコンポーネントが連携して動作するようミドルウェアとして機能します。
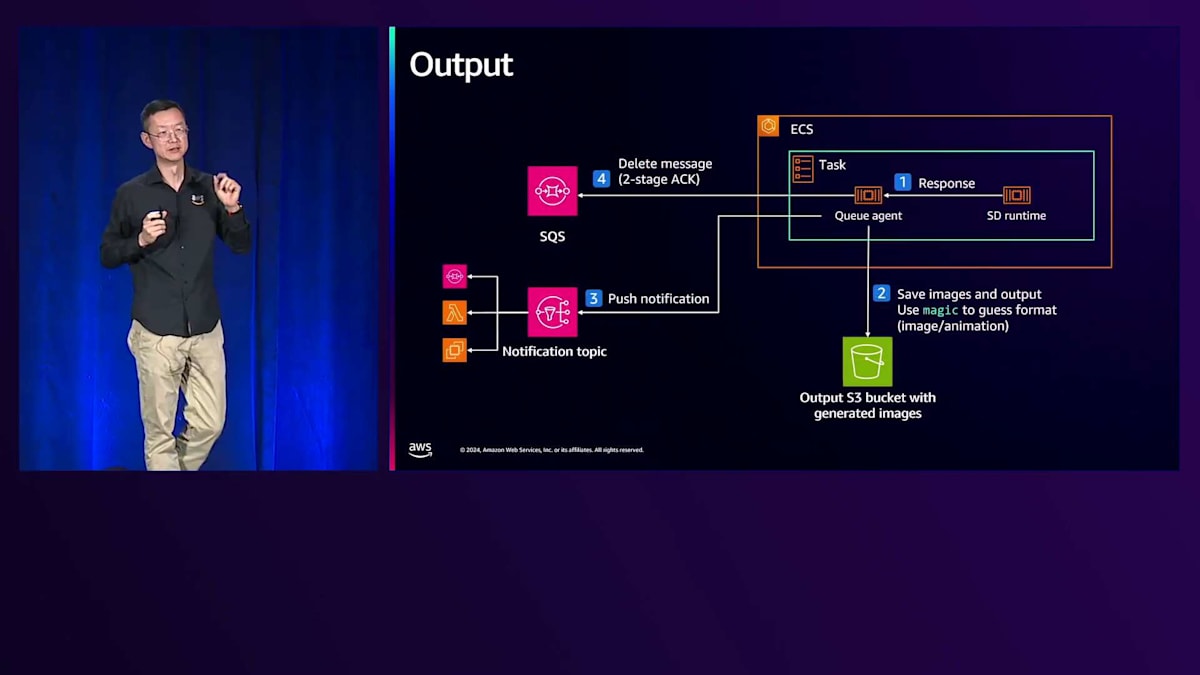
完全なワークフローを見ていきましょう。ステップ1では、メッセージをキューにドロップし、エージェントがメッセージを取得してSDランタイムに渡し、モデルファイルを読み込んで画像を生成します。信頼性について議論したので、障害シナリオについて疑問に思われるかもしれません。Inferenceエンドポイントが失敗した場合、SQSキュー内のそのメッセージはこの段階では削除されず、単に非表示になります。失敗した場合、新しいタスクがそのメッセージを再試行します。ステップ2では画像生成を完了してバケットに保存し、ステップ3ではエンドユーザーにタスクが完了したことを通知し、画像の場所を提供して「タスクが完了し、閲覧可能な画像があります」と伝えます。

ステップ4では、すべてが正常に完了したため、メッセージを削除できます。ご覧のように、このアーキテクチャは、バックエンドの計画的または予期せぬ障害に関係なく、最大限の信頼性を確保します。

次の課題であるパフォーマンスについて見ていきましょう。パフォーマンスについて、どこから始めるべきだと思いますか?エンドユーザーにとってのレイテンシーをどのように最小化できるでしょうか?モデルパスについて考えているかもしれませんね。その通りです。エンドポイントには2つの重要なコンポーネントがあります。エンドポイントを素早く立ち上げることはできるでしょうか?そして最も重要なのは、モデルファイルを素早くロードして、それらを連携させることができるかということです。
どのようなチップでホストするべきかを考える必要があります。これはエンドポイントのインスタンスタイプに影響を与えます。選択肢として幅広いチップをご用意しています。CPUは非常にコスト効率が良く、汎用的で、カスタマイズの必要性も低いのが特徴です。シリアル実行に非常に適しています。小規模なモデルを使用し、レイテンシーの要件がそれほど厳しくない場合、CPUが最もコスト効率の良い選択肢となるかもしれません。それでは不十分な場合、GPUの方が適しています。モデルが大規模で非常に低いレイテンシーが必要な場合、GPUは並列実行に非常に優れているためです。推論エンドポイントにGPUが必要とされる理由はここにあります。
スペクトルのもう一方の端を見ると、AWS InferentiaのようなASIC(特定用途向け集積回路)は推論ワークロード専用に設計されています。目的特化型であるため、高性能でコスト効率も非常に良好です。これらのテクノロジーを採用する際の考慮事項として、モデルの互換性を確認する必要があります。これらはAWS Neuron SDKに依存して特定の操作を公開するため、お使いのモデルがサポートされていることを確認する必要があります。どれを選ぶべきでしょうか?これはどちらか一方という話ではなく、ユースケースによって異なります。柔軟性や専門性の要件に応じて、これらの異なるインスタンスタイプを組み合わせて使用することができます。

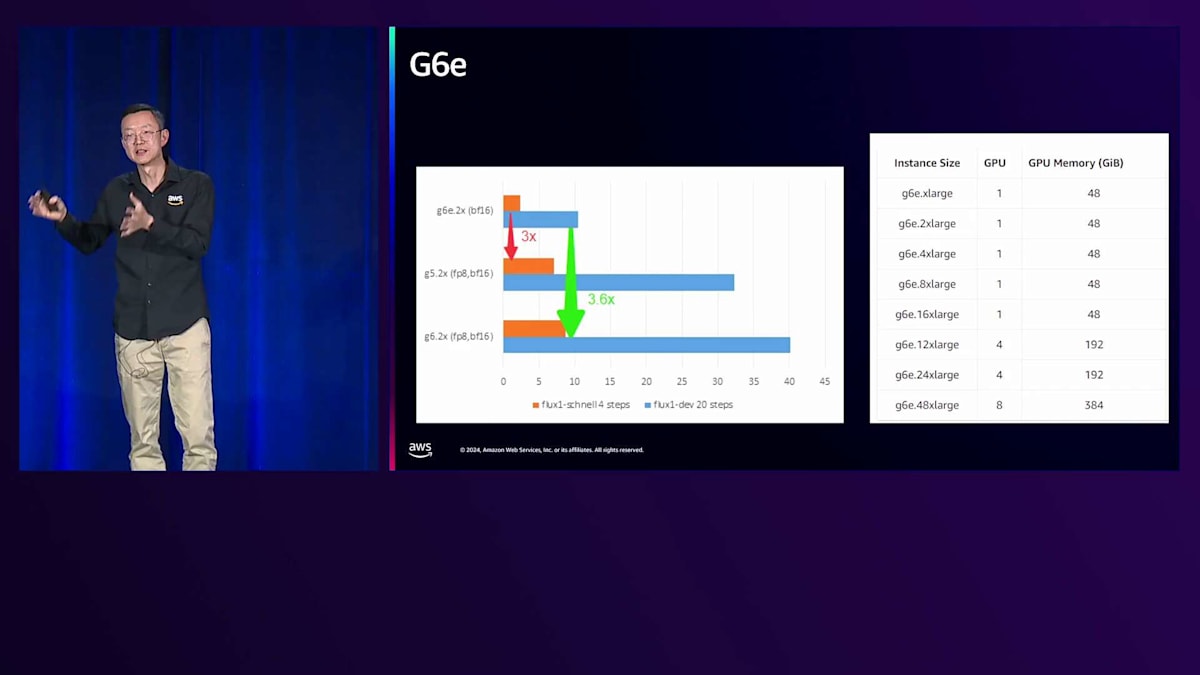
コストの観点から、GPUを選択する場合を考えてみましょう。GPUを使用する場合、GPUのタイプとファミリーを決める必要があります。中央に表示されているA10はNVIDIAのGPUカードファミリーで、G5はそのハードウェアを使用しているインスタンスです。パフォーマンスをどのように判断し、どれを選択すればよいでしょうか?多くの選択肢がありますが、考慮すべき重要な要素として、GPUファミリー、GPUメモリサイズ、およびバンドワイドスがあります。この場合、G6eが際立っています。なぜなら、右側の仕様を見ると、最大8個のGPUを搭載可能で、各GPUは少なくとも48GBのGPUメモリを備えているからです。多くのインスタンスはシングルカードで、リアルタイム推論ワークロードに最適です。左側のグラフでは、G5やG4などの前世代と比較して、少なくとも3倍のパフォーマンスを発揮することが示されています。

エンドポイントをジョブ受信可能な状態にするにはどうすればよいでしょうか?主に3つのステップがあります。1つ目は、バックエンドインスタンスをどれだけ早くロードしてAmazon ECSに配置できるかということです。2つ目は、コンテナイメージをどれだけ早くロードできるかです。これらは大きなサイズになります。3つ目は、モデルをどこに配置するかということです。
それでは、パフォーマンスを最大化するにはどうすればよいのかという問題に移りましょう。ホスト、コンテナイメージのロード、モデルファイルのストレージという3つの重要な課題について見ていきます。ホストに関しては、ジョブを待機するためにインスタンスを過剰にプロビジョニングする代わりに、Warm Poolsを使用することにしました。Warm Poolsは、すぐに使用できる事前初期化されたインスタンスを提供し、過剰なプロビジョニングを避けることでコストを削減できます。2番目の課題は、かなり大きくなる可能性のあるコンテナイメージに関するものです。推論エンドポイントのようなコンテナイメージには、複数のPyTorch依存関係やCUDAドライバーが必要で、最大14ギガバイトに達し、ロードに6分かかる可能性があります。

コンテナイメージについて、1つの選択肢はホストに保存することですが、これには課題があります。コンテナイメージを変更するたびにAmazon EC2フリートの更新を実行する必要があり、大規模な環境では簡単ではありません。そこで、革新的なアプローチを検討しています。左側を見ると、AWSが設計した専用のLinux OSであるBottlerocket OSがあります。Bottlerocket OSには2つのボリュームがあります:独自の更新サイクルを持つオペレーティングシステムとセキュリティパッチ用のOSボリュームと、データボリュームです。このデータボリュームに推論エンドポイントイメージをロードできます。EC2インスタンスの実行環境がすでにECSにある状態で、このEBSボリュームのスナップショットを作成し、Bottlerocketを使用して既存のECSインスタンスにマッピングできます。単純にアタッチして、これらのファイルをメモリにロードするだけです。このプロセスはEBSのパフォーマンスに大きく依存するため、1000メガバイトまで最大化します。メモリにロードされたら、Lambdaファンクションをスケジュールしてキャパシティを削減できます。
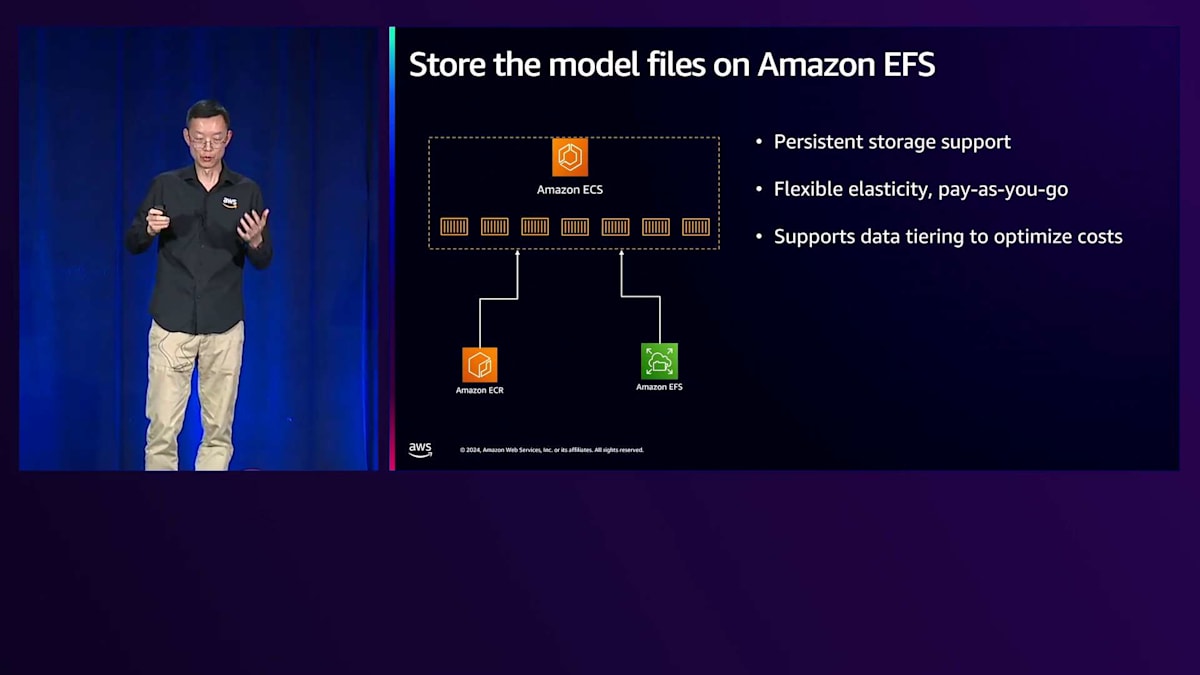

モデルファイルについては、より良いレイテンシー、スループット、エラスティシティを提供するAmazon EFSを活用できます。これらの最適化を実装することで、ファイルのロード時間を大幅に削減できます。一部のコンテナイメージファイルをEFSにオフロードすることも選択できます。結果として、イメージサイズを20ギガバイトから1ギガバイト未満に削減し、1分以内にロードできるようになりました。モデルのロード時間も30秒から10秒に短縮されました。
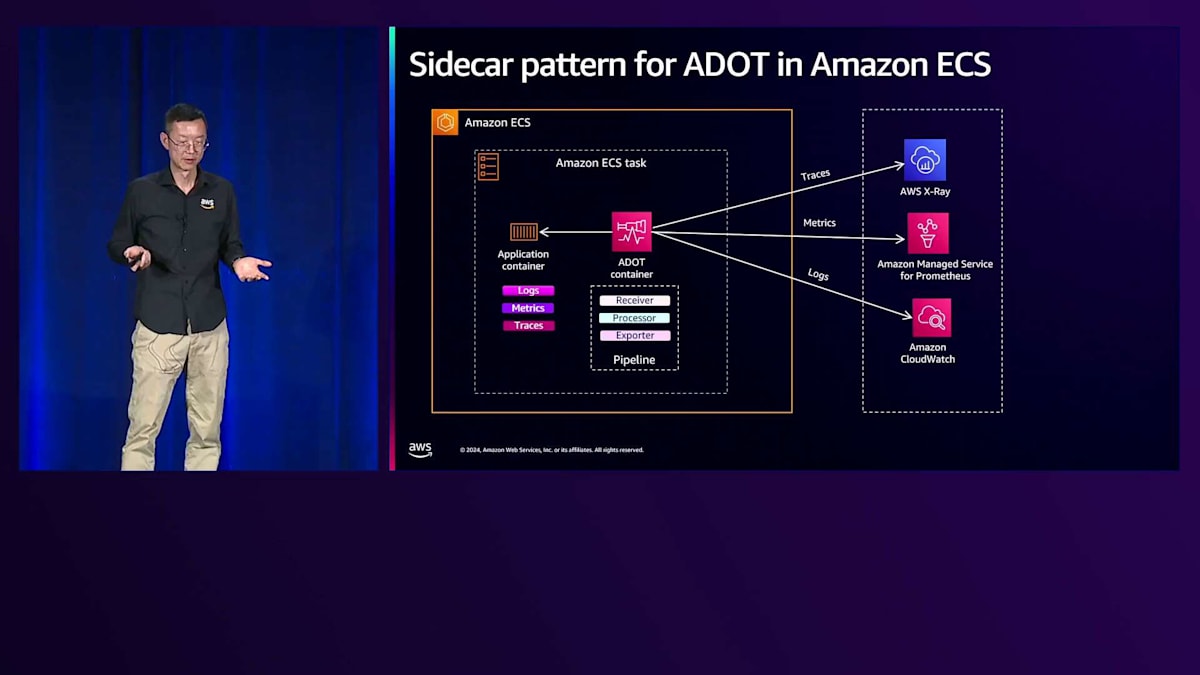
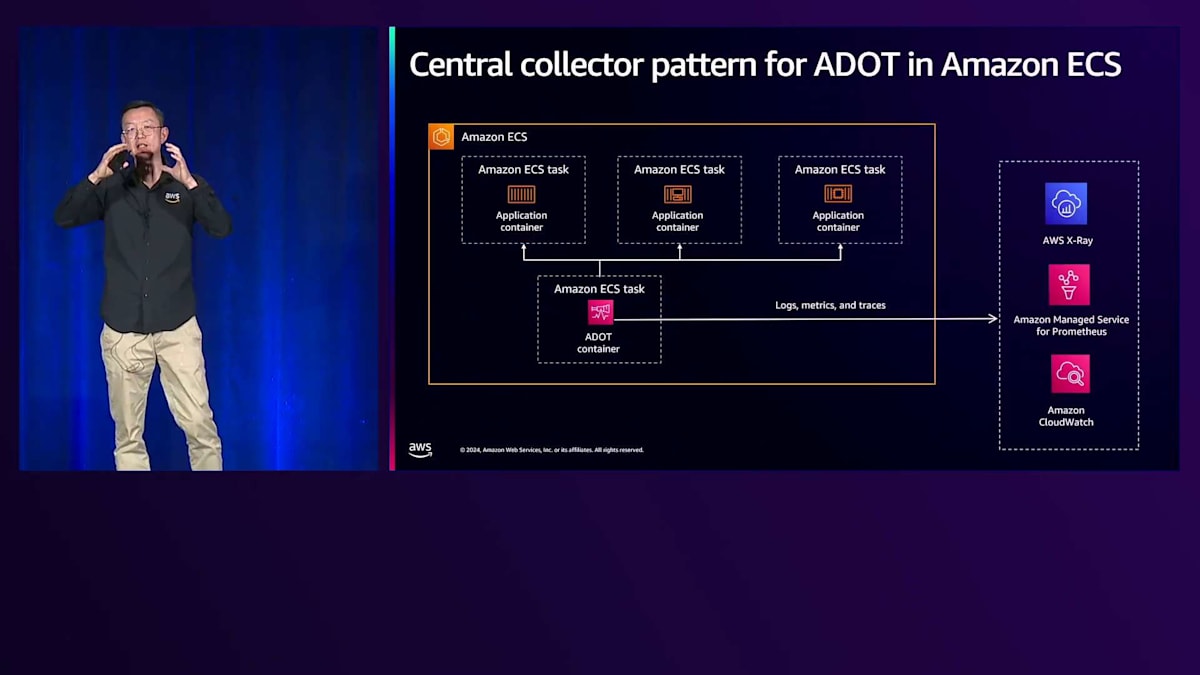
リソースの使用状況を理解し、環境がレイテンシー要件を満たしているかどうかを確認する必要があるため、パフォーマンスモニタリングは重要です。サイドカーパターンと集中型パターンという2つのパターンがあります。サイドカーパターンでは、Amazon Distro for OpenTelemetry(ADOT)をコンテナとして実行し、タスク内の他のコンテナからメトリクス、ログ、トレースを収集してバックエンドにプッシュします。より一般的な集中型パターンでは、専用のタスクで実行されるADOTを使用して、他のタスクから情報を取得し、バックエンドにプッシュします。
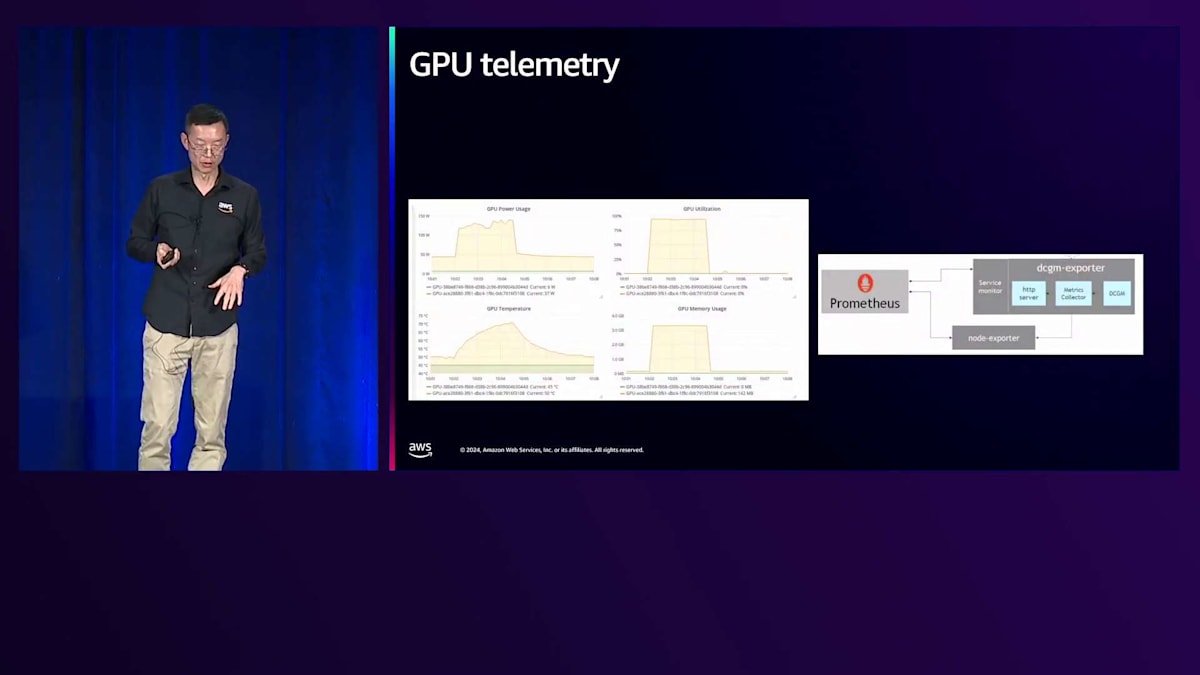
GPUモニタリングに移ると、GPUの使用状況を監視するためのNVIDIAのツールであるDCGMを活用しています。これで次の課題であるスケーラビリティに進みましょう。
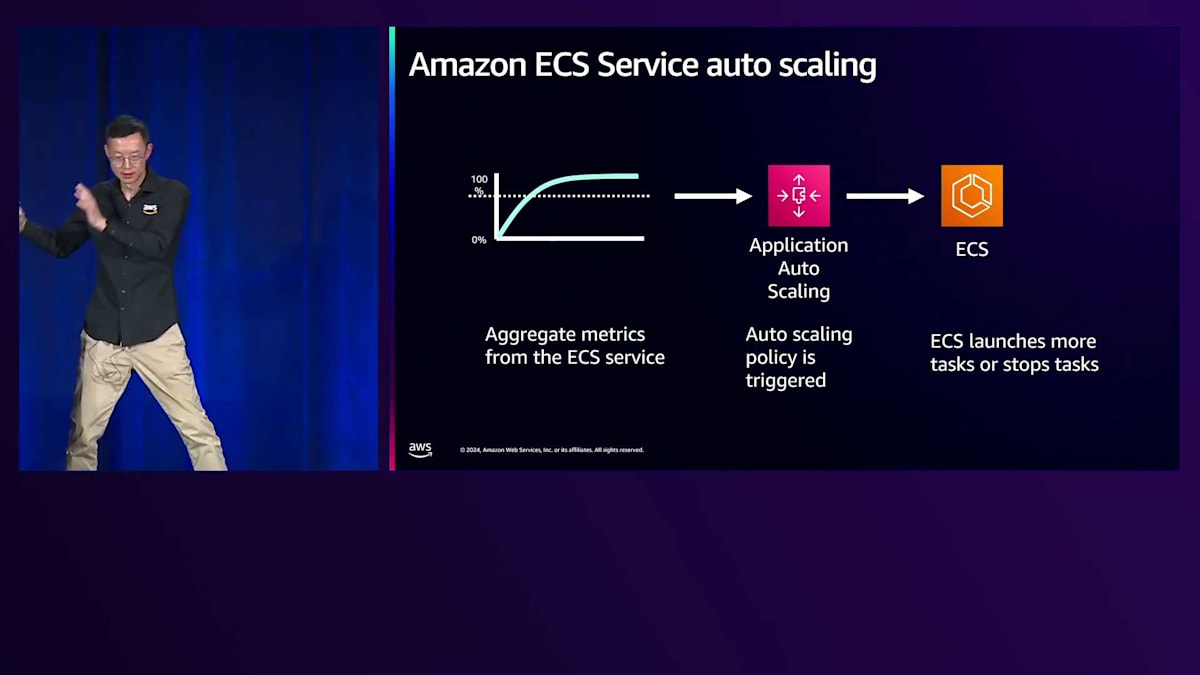

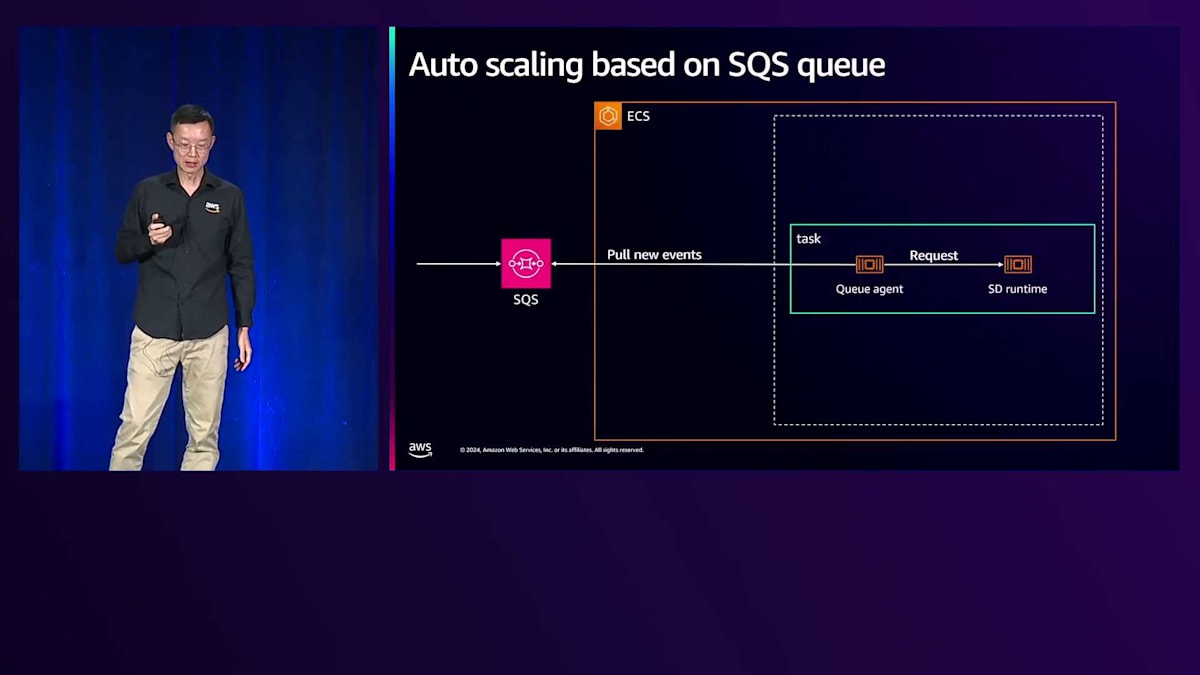
推論エンドポイントに焦点を当てると、豊富なメトリクスが自動スケーリングアプリケーションに渡されます。 Amazon ECSは、Auto Scalingポリシーに基づいてタスクの停止や開始を行います。 同期型アーキテクチャを使用しているため、キューにはすでにジョブやメッセージが存在します。メトリクスとしては、そのキュー内の保留中メッセージ数を単純に使用します。

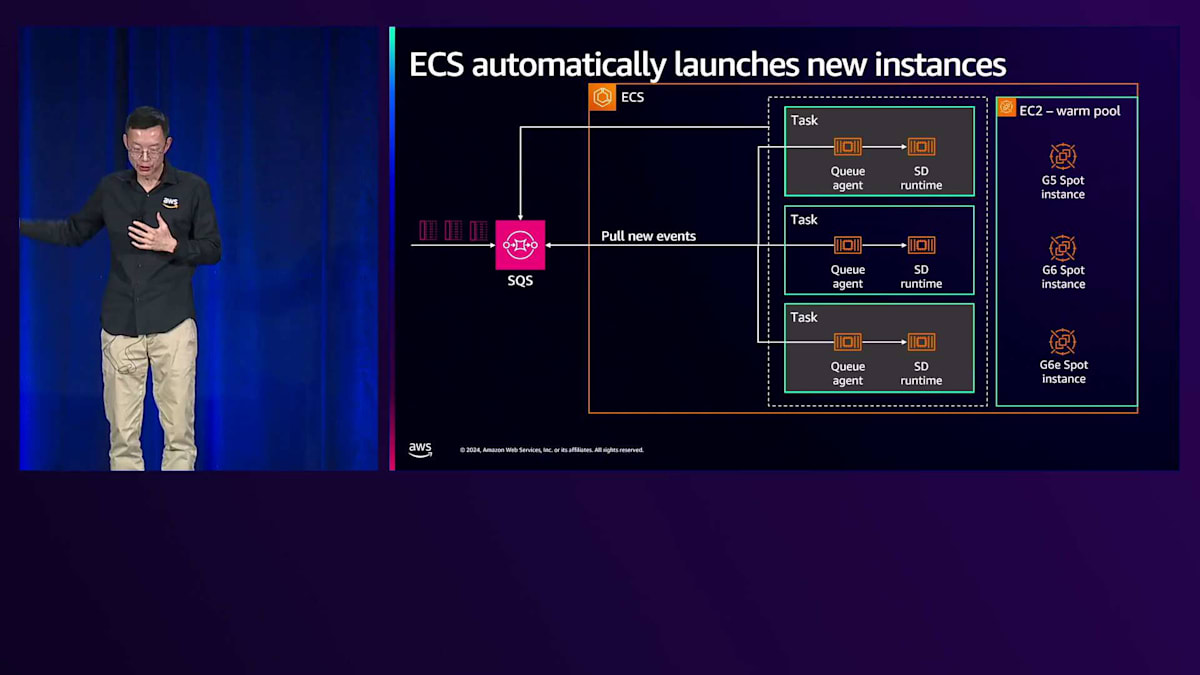
実際の動作をお見せしましょう。1つのタスクが動作している場合は問題ありませんが、より多くのジョブが入ってくると、 保留中のジョブを処理するためにより多くのタスクが必要になります。そのニーズを満たすためにバックエンドインスタンスが必要です。 1つのプールがあるため、いくつかのインスタンスを事前に初期化できます。また、Spotインスタンスも使用できます。というのも、1つのSpotインスタンスが利用できなくなってもメッセージを失うことはないため、信頼性が高いのです。グレーの領域で、これら2つの保留中タスクがアクティブになっているのがわかります。


このアーキテクチャに何か問題点が見えますか? これらのジョブの処理時間が示されていないのです。例えば、右側の図を見てみましょう。3つのタスクが アクティブに実行されていて、キューに12の保留中ジョブがあるとします。これはタスクあたり4つの保留中ジョブということになります。しかし、負荷テスト中に、タスクあたり10ジョブに達すると性能低下が発生することがわかりました。そこで、カスタムメトリクスのしきい値として10を使用しています。保留中のジョブをアクティブなタスク数で割ることでタスクあたりのバックログを計算し、より正確なスケーリングを実現しています。
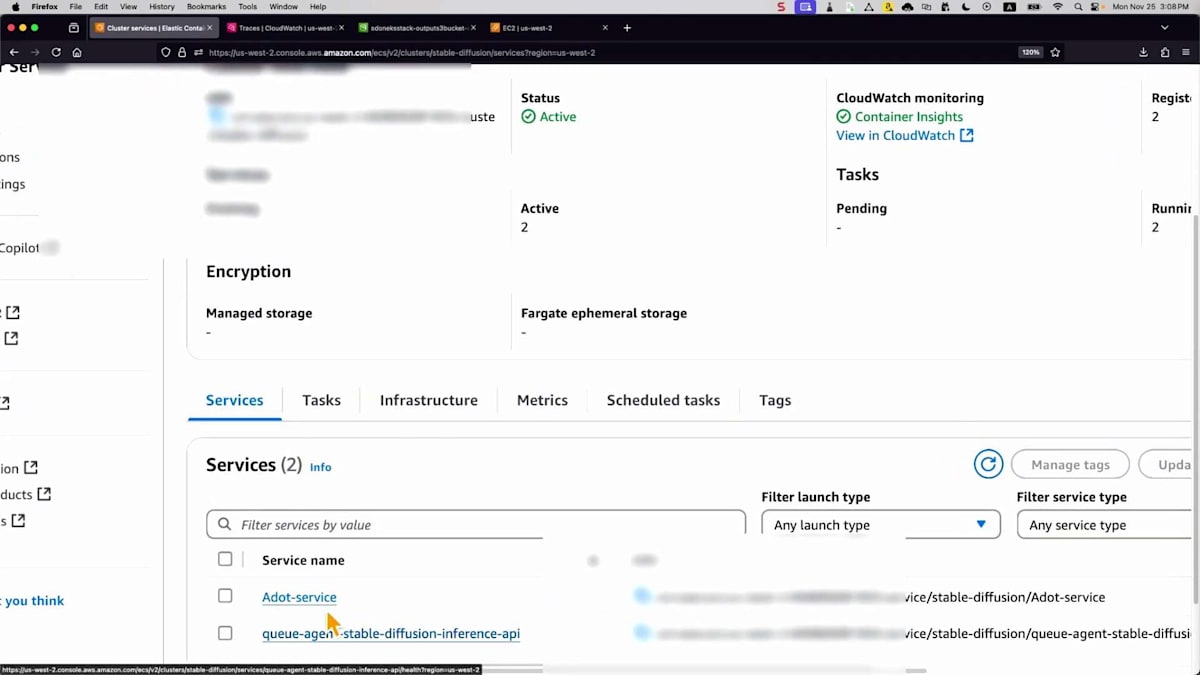
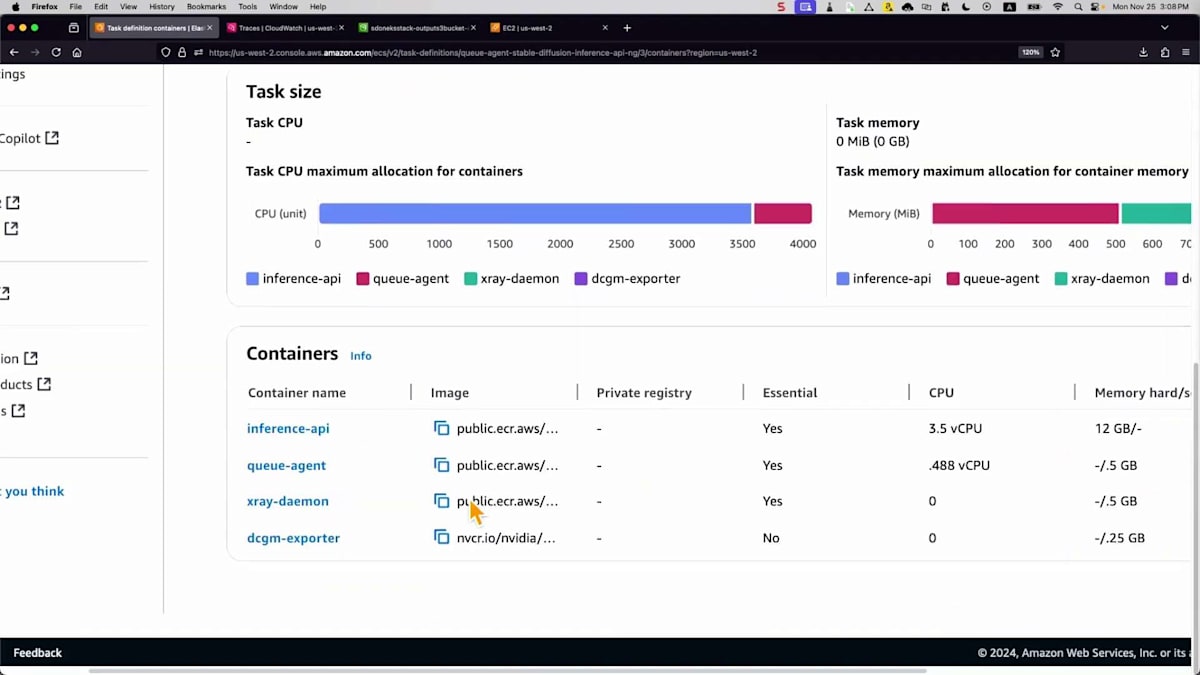
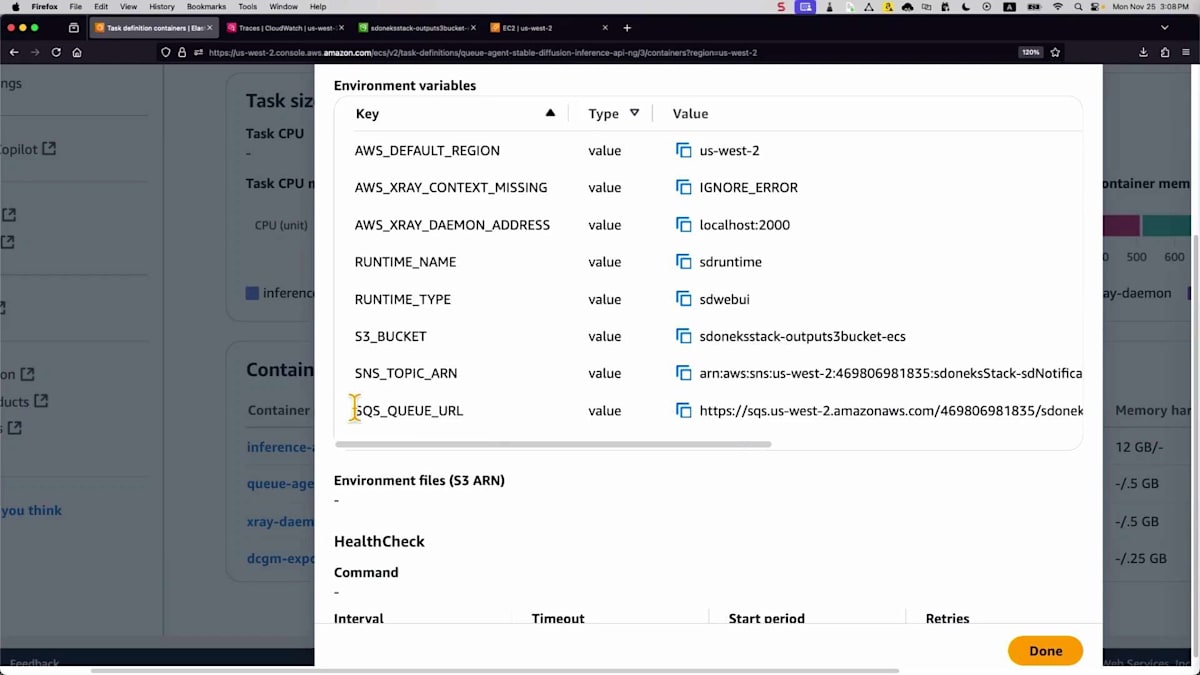
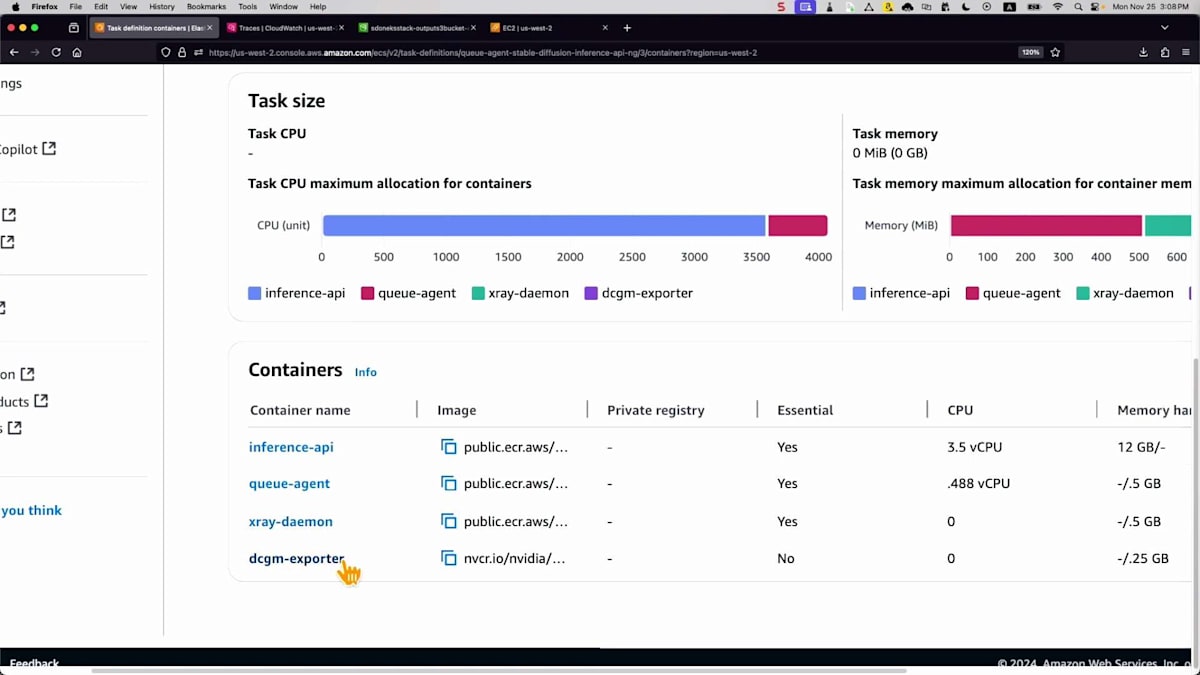
これまで説明したテクノロジーをすべてデモンストレーションしてみましょう。この環境では、2つのサービスが確認できます。 GPUメトリクスを公開するサービスと、推論エンドポイント用のキューサービスがあります。タスク設定を見ると、 4つの主要なコンテナがあります:推論API、キューエージェント、 キューからメッセージを取得してS3バケットに画像を保存する必要があるもの、トレース情報を取得するX-Ray、 そしてGPUメトリクスを公開するDCGMです。これらのGPUリソースは両方のコンテナで共有する必要があります。
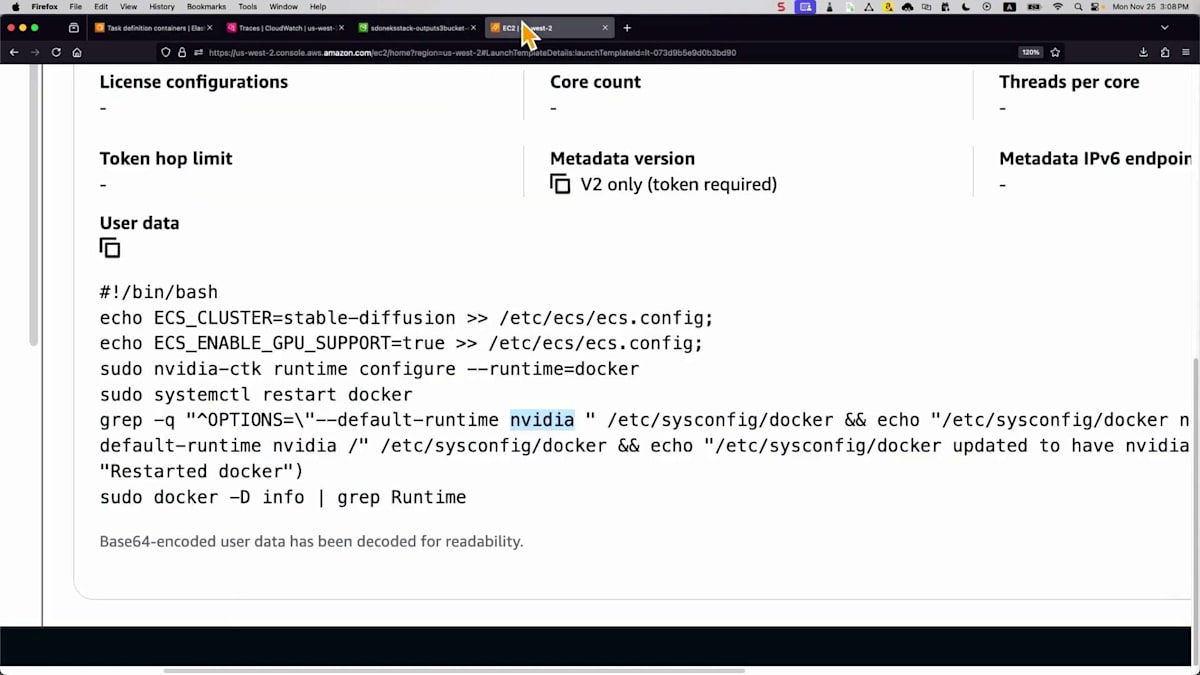
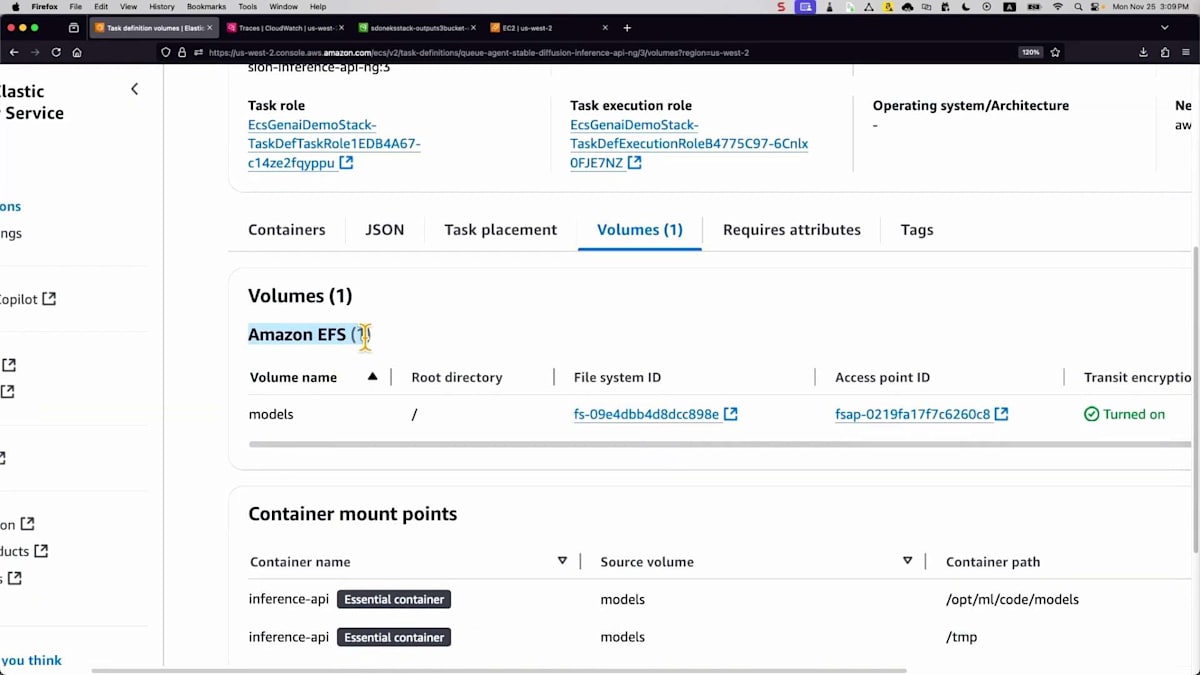
起動テンプレートでGPUサポートを有効にし、ランタイムをDockerからNVIDIAに変更して、コンテナがタスク内のGPUリソースを共有できるようにする必要があります。モデルファイルを高速にロードするために、 Amazon EFSボリュームを作成します。ボリュームにファイルを単純にロードし、コンテナの観点からは、それらのファイルにアクセスするためのマウントポイントを作成するだけです。新しいモデルがある場合は、ボリュームにダンプするだけで、 コンテナが自動的に利用できるようになります。
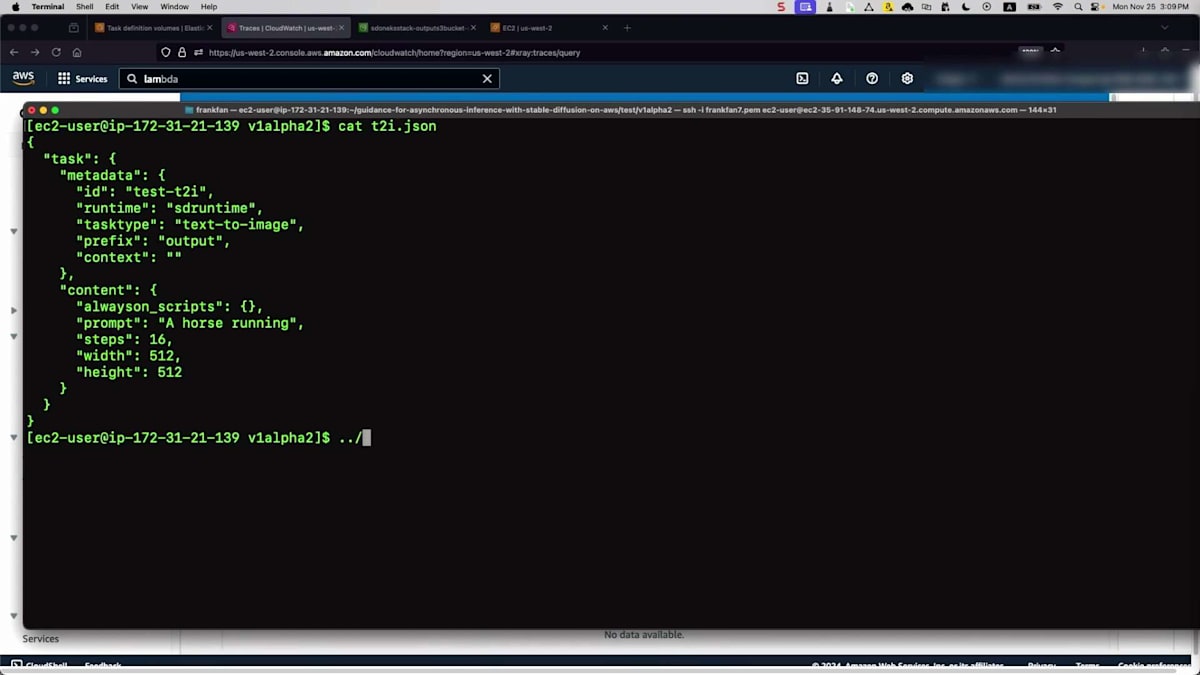
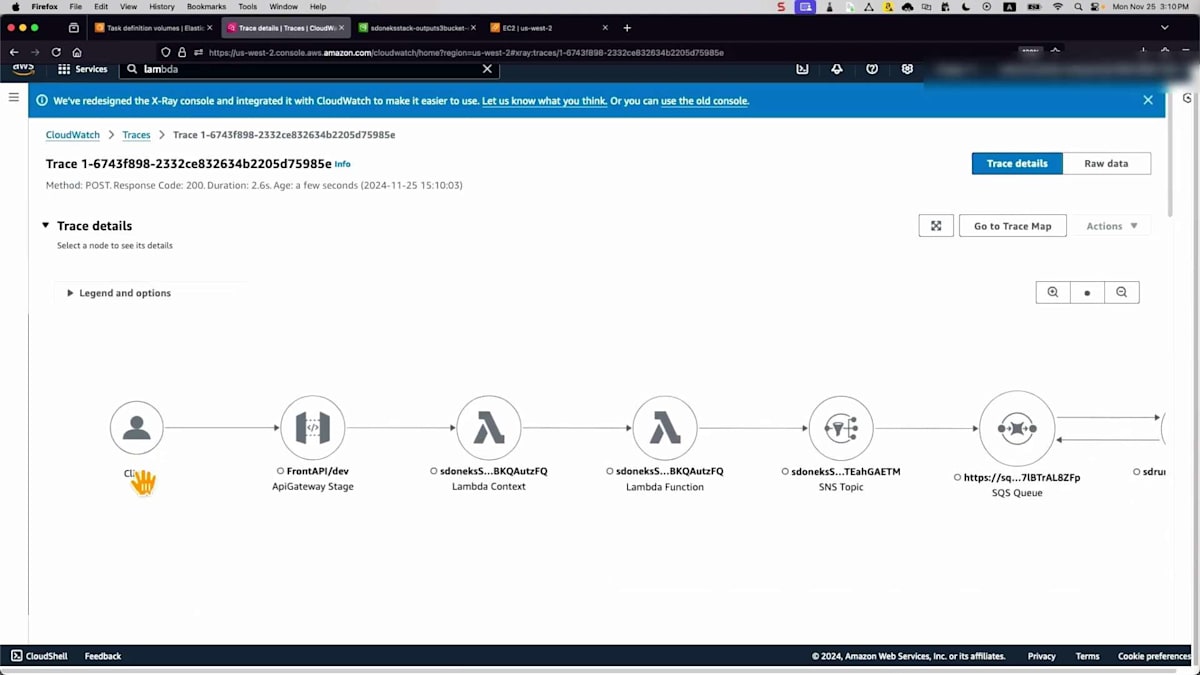
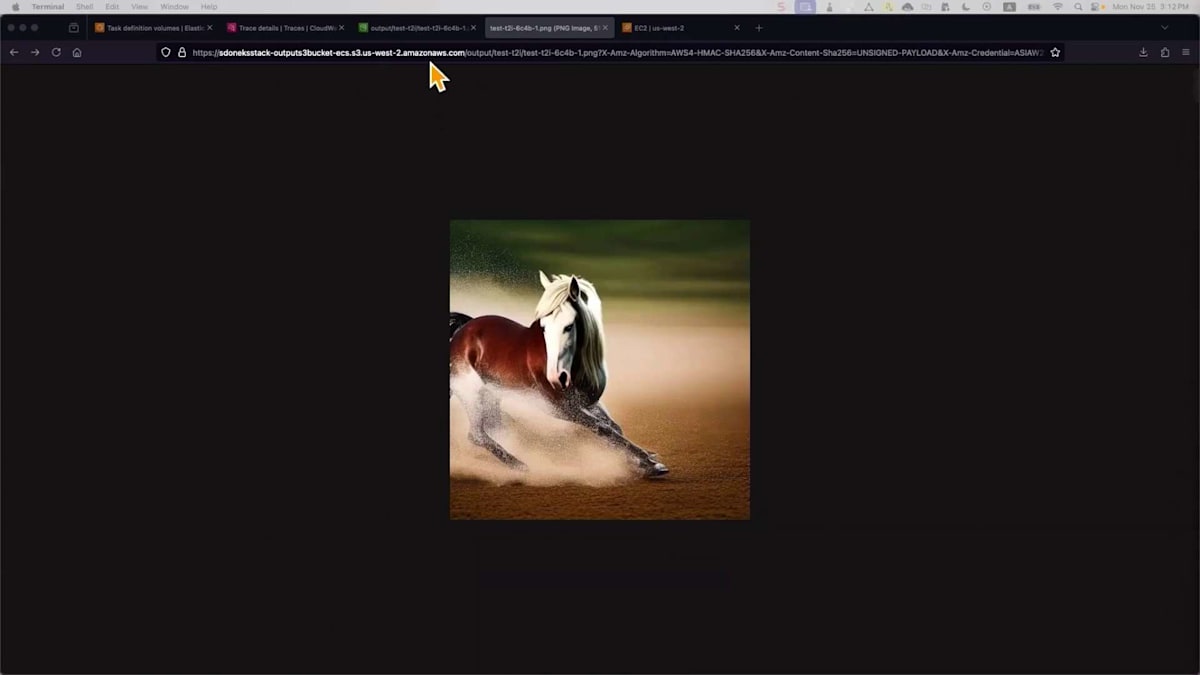
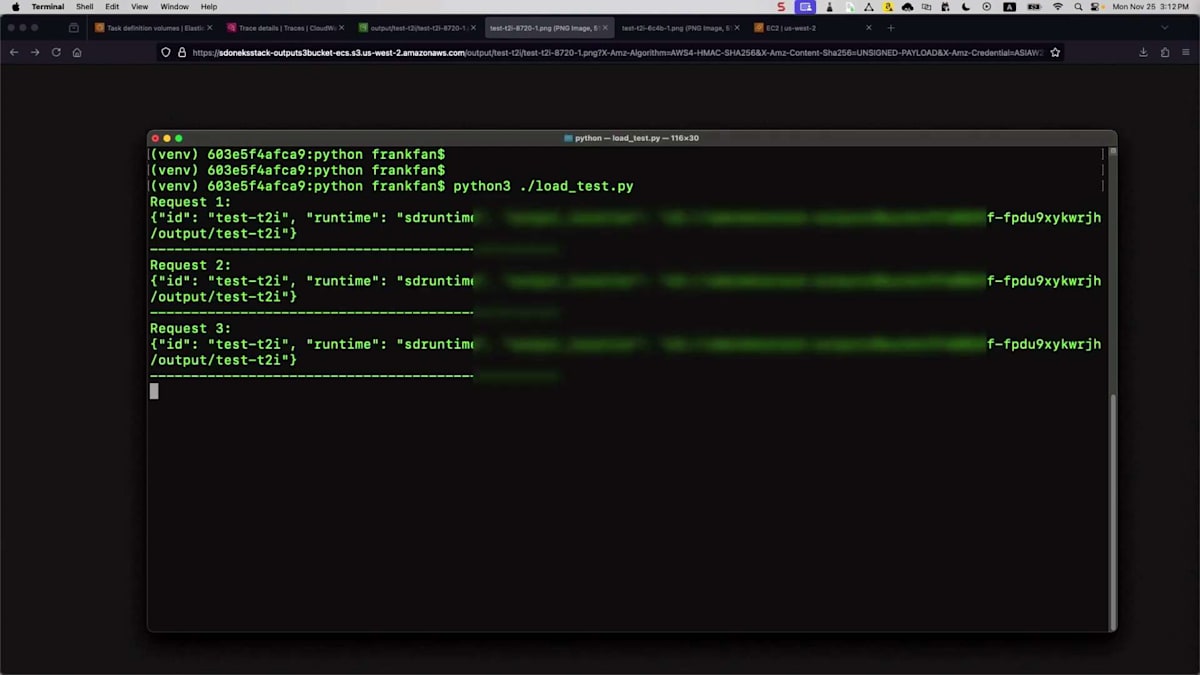
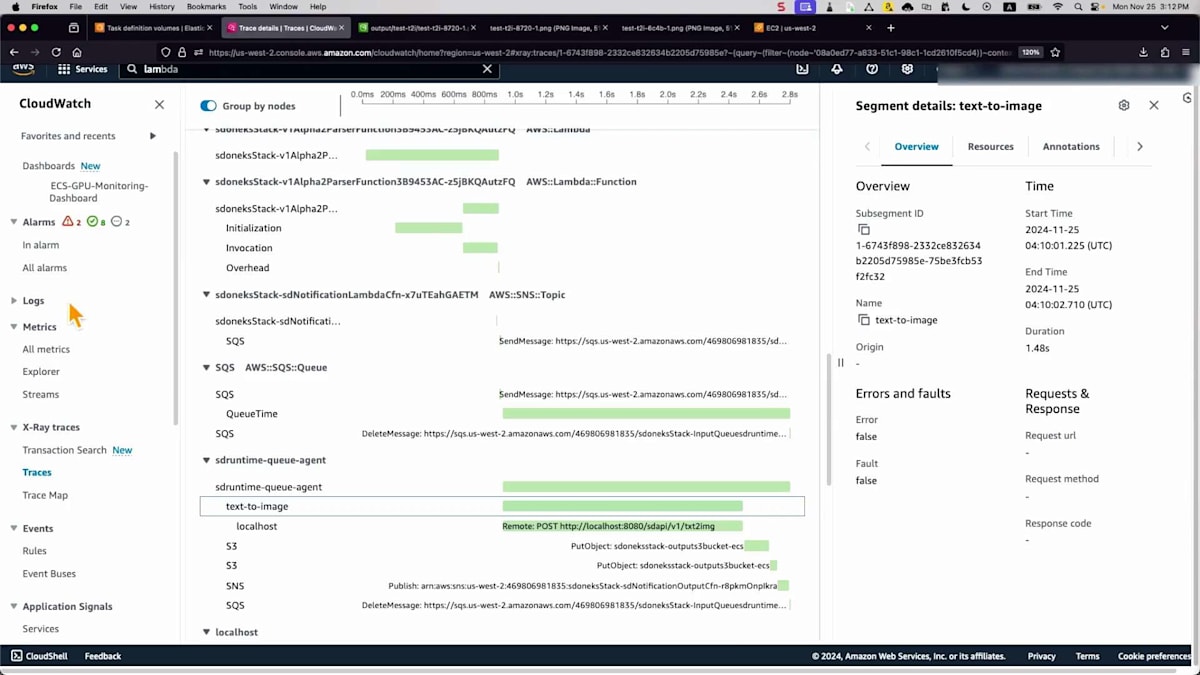
それでは、テストをシミュレーションしてみましょう。これはAWS X-Rayのインターフェースで、すでにプロンプトを定義するためのシンプルなJSONファイルを用意しています - たった1行で「走る馬」というものです。Amazon API Gatewayを通じて処理用のエンドポイントにメッセージを送信するスクリプトがあります。更新すると、左側からトレースが取得されているのが分かります。API Gatewayを通過し、Lambda関数がメッセージを検証し、その後Amazon SNSが属性に基づいてメッセージを受け取り、Amazon SQSに転送します。キューエージェントがジョブを取得し、推論エンドポイントで処理して、この時間内にS3バケットに保存しました。所要時間が確認できます。
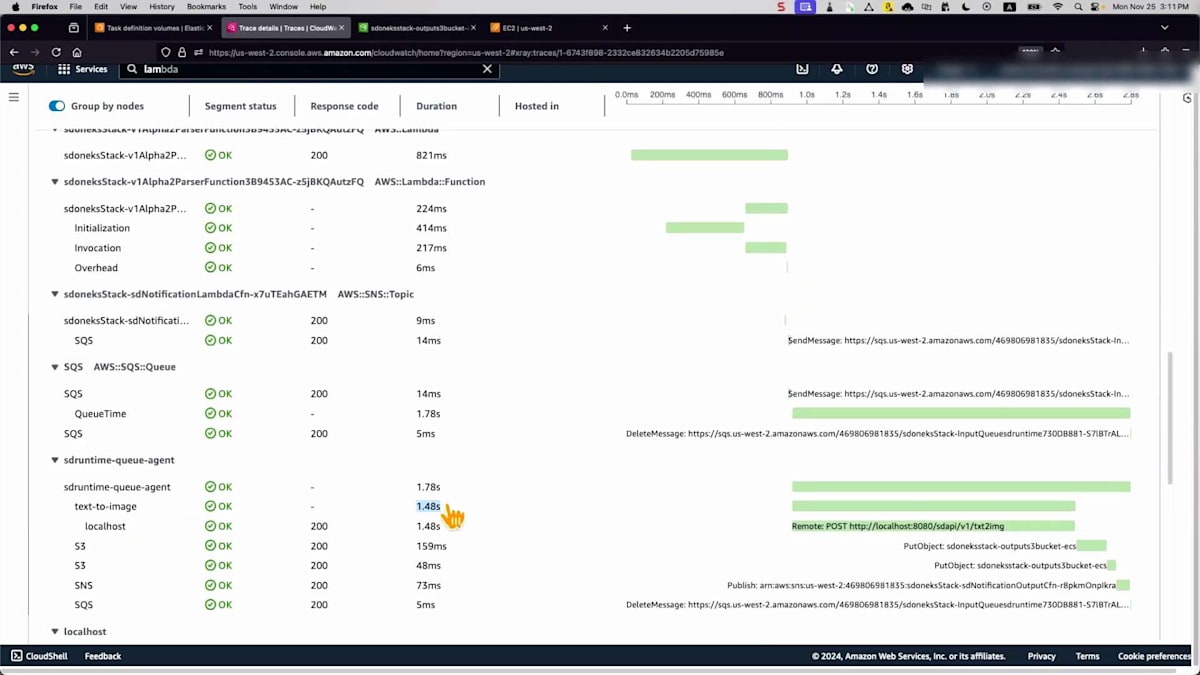
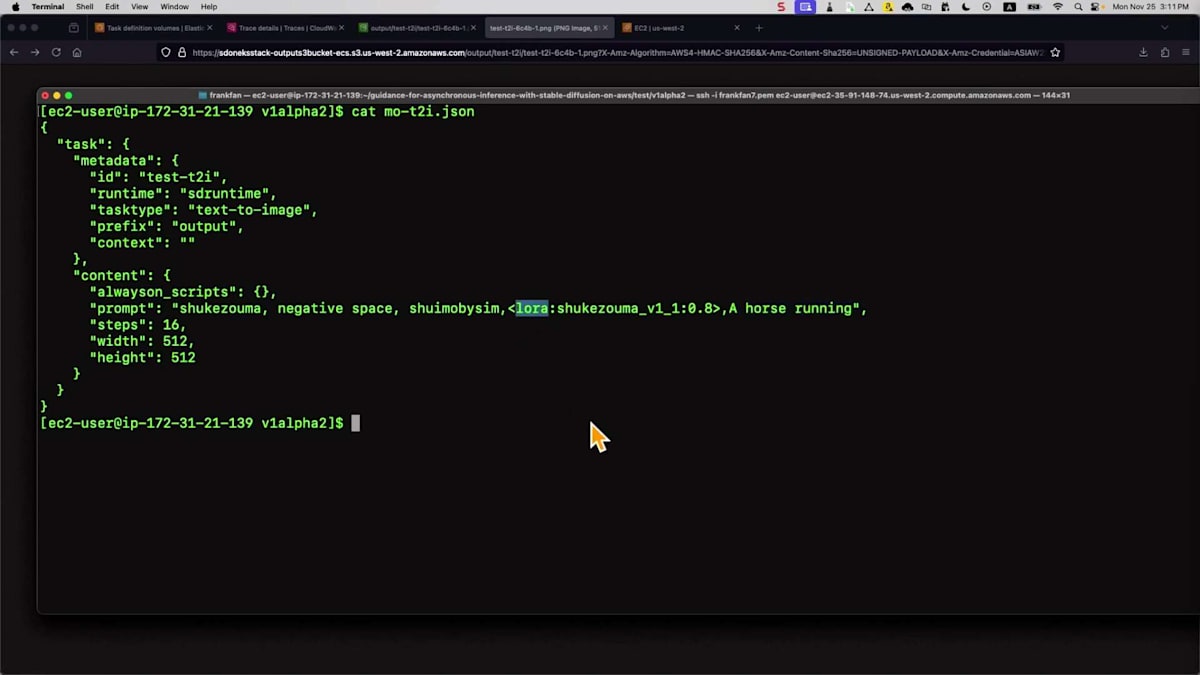
画像をS3バケットに保存するまでの全プロセスは、およそ1.41秒かかっています。これは非常に強力です。S3バケットの出力を確認してみましょう。画像を見ると単純に見えますが、異なるユースケースに向けて独自のスタイルで何かを作成したい場合もあるでしょう。ここでは同じシンプルなプロンプトで異なるモデルを選択しましたが、Loraという別の拡張モデルを使用しています。これは基盤モデルであるStable Diffusionと連携して動作します。モデルはすでに特定の画像スタイルで事前学習されているため、他の設定は変更していません。
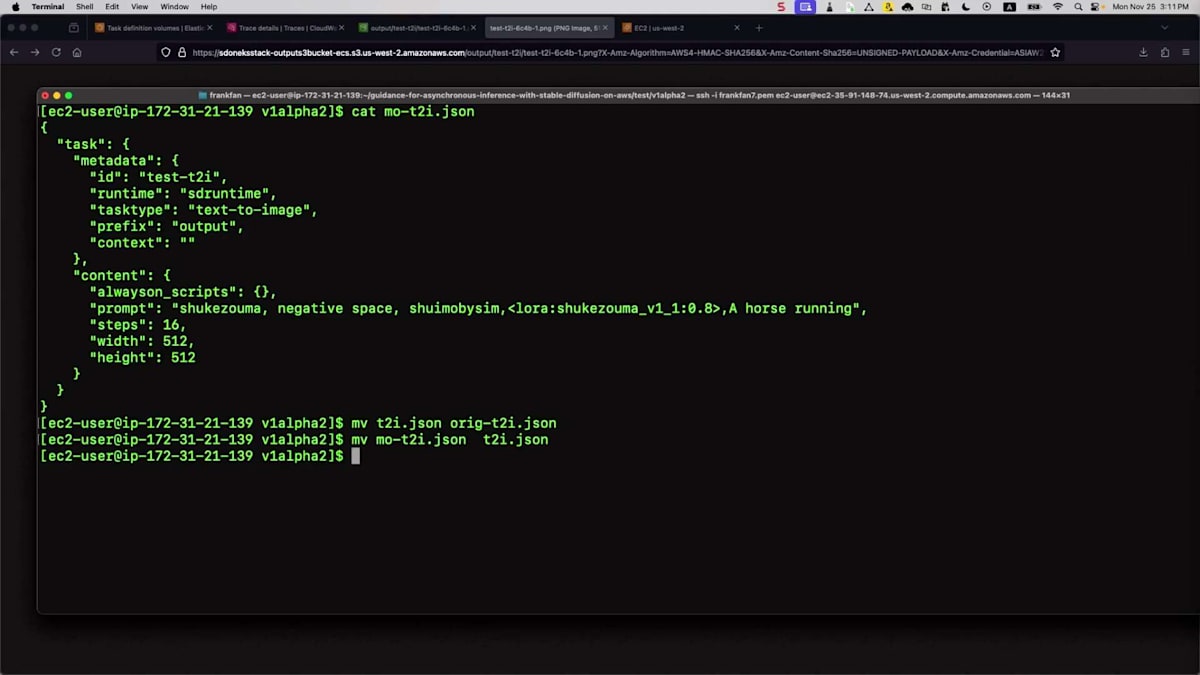
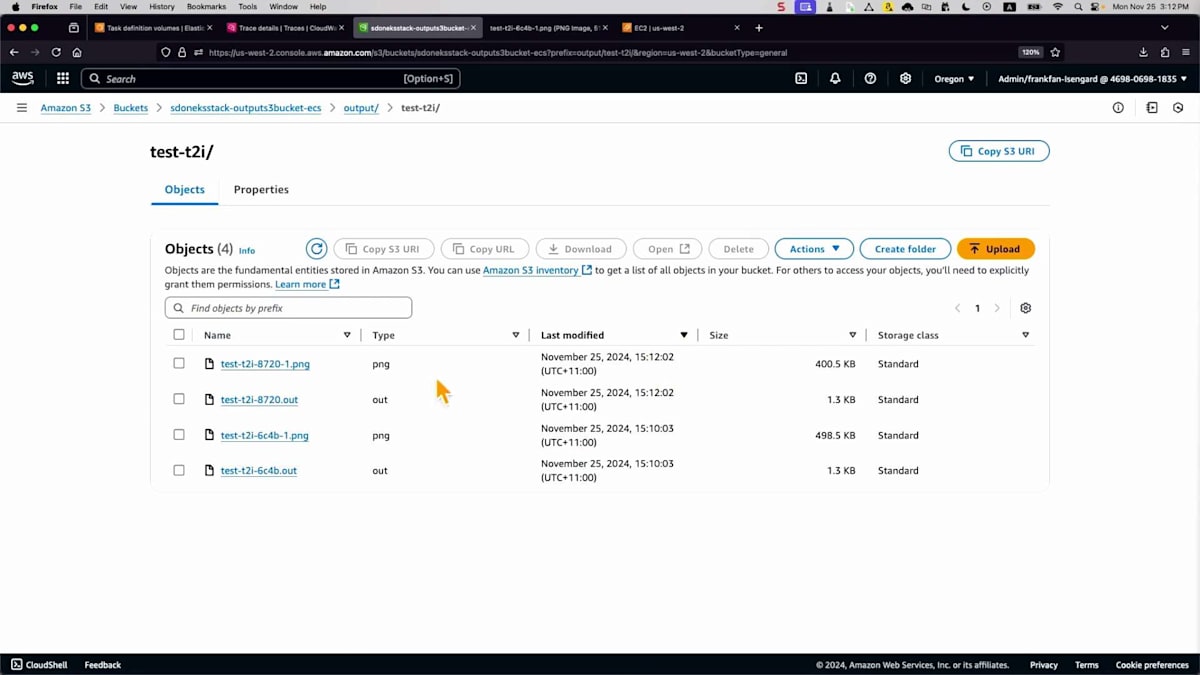
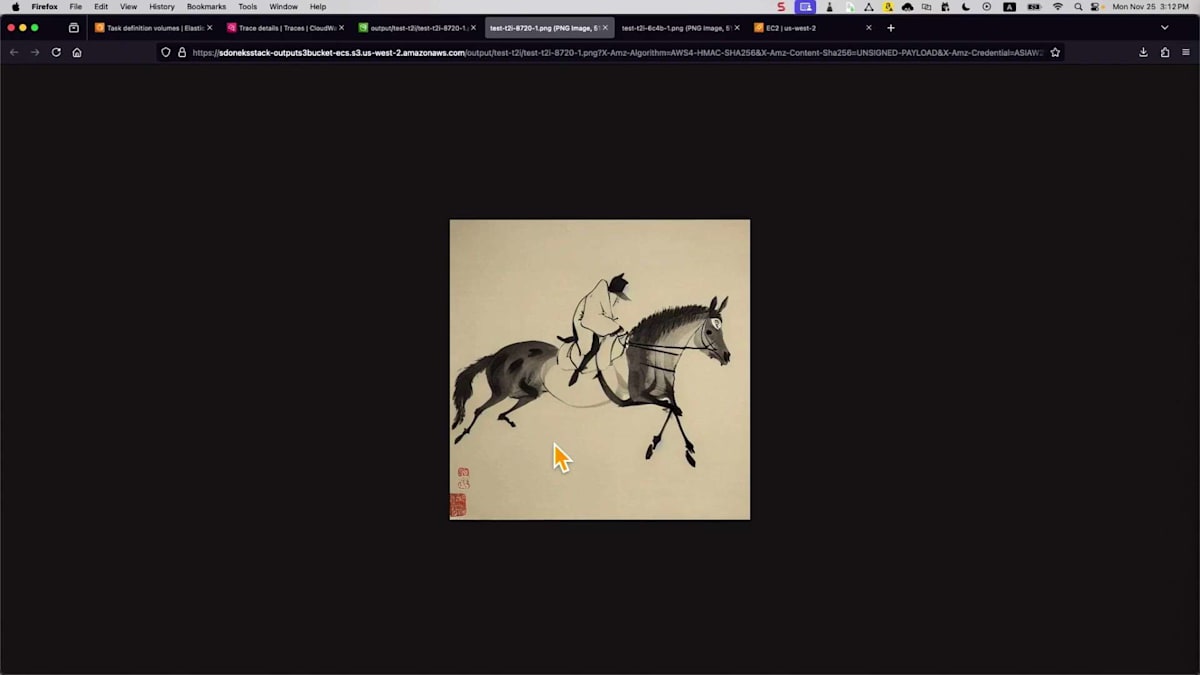
結果がどのようになるか見てみましょう。これを反映させるために、ファイル名を変更してリネームする必要があります。そして、スクリプトを実行するだけです。API Gatewayに送信されて処理されるのは同じプロセスで、あとはS3バケットを確認するだけです。それでは開いて、正しいものであることを確認しましょう。最新のものが今生成したばかりのものです。これは全く異なるスタイルです - 異なるモデルを使用したため、中国画風になっています。異なるモデルを使用することで、様々なスタイルを生成し、ユースケースに対応することができます。
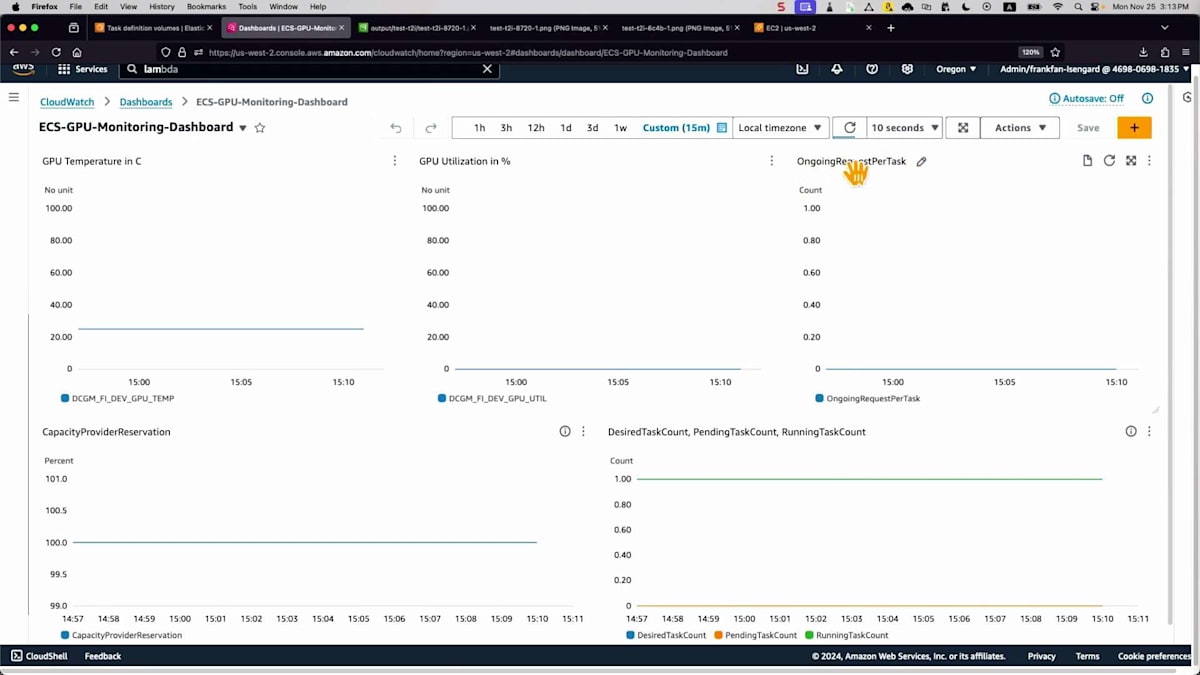
ここまでは単一の画像生成について説明しましたが、本番環境ではどうでしょうか?多くのリクエストが入ってきた場合、迅速にスケールアウトし、スケールインできることを確認する必要があります。そこで、リクエストを継続的に送信してシステムの反応を確認するロードテストを実行します。ダッシュボードを見てみましょう。スケーリングに使用するメトリクスについて言及しましたが、ここにタスクあたりのバックログがあります。まだバックログはありませんが、しばらく待ってみましょう。これは保留中のジョブを実行中のタスク数で割った独自のメトリクスで、現在の環境の負荷状況を測定し、判断を下すために使用します。
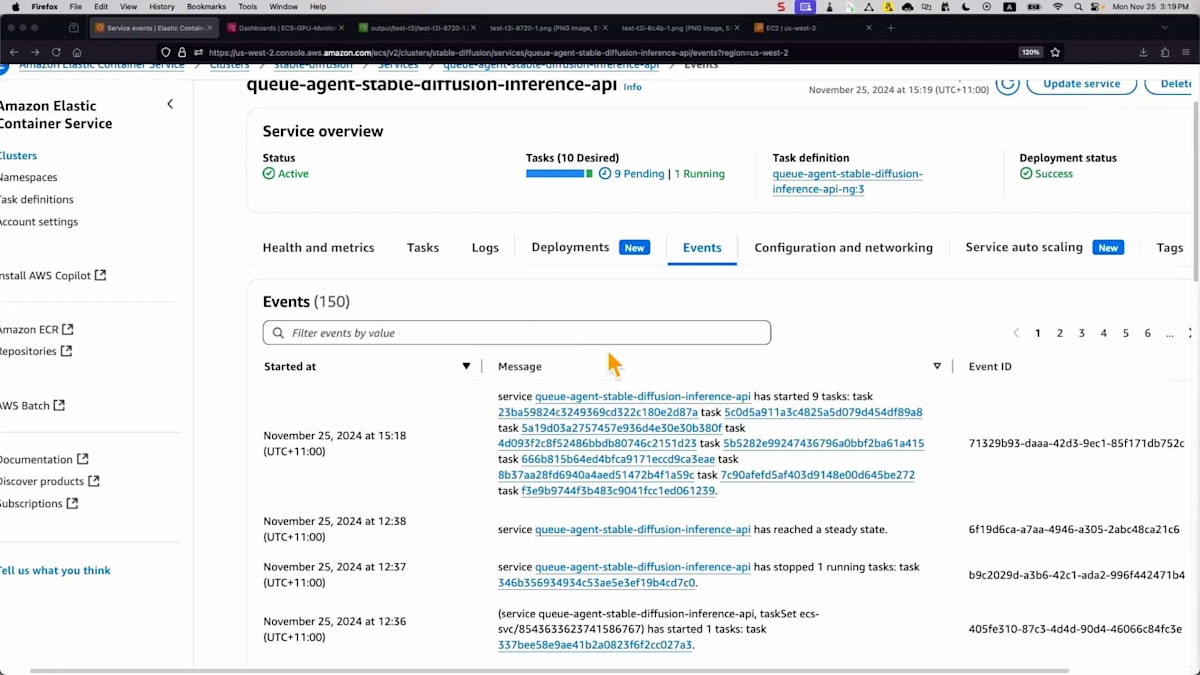
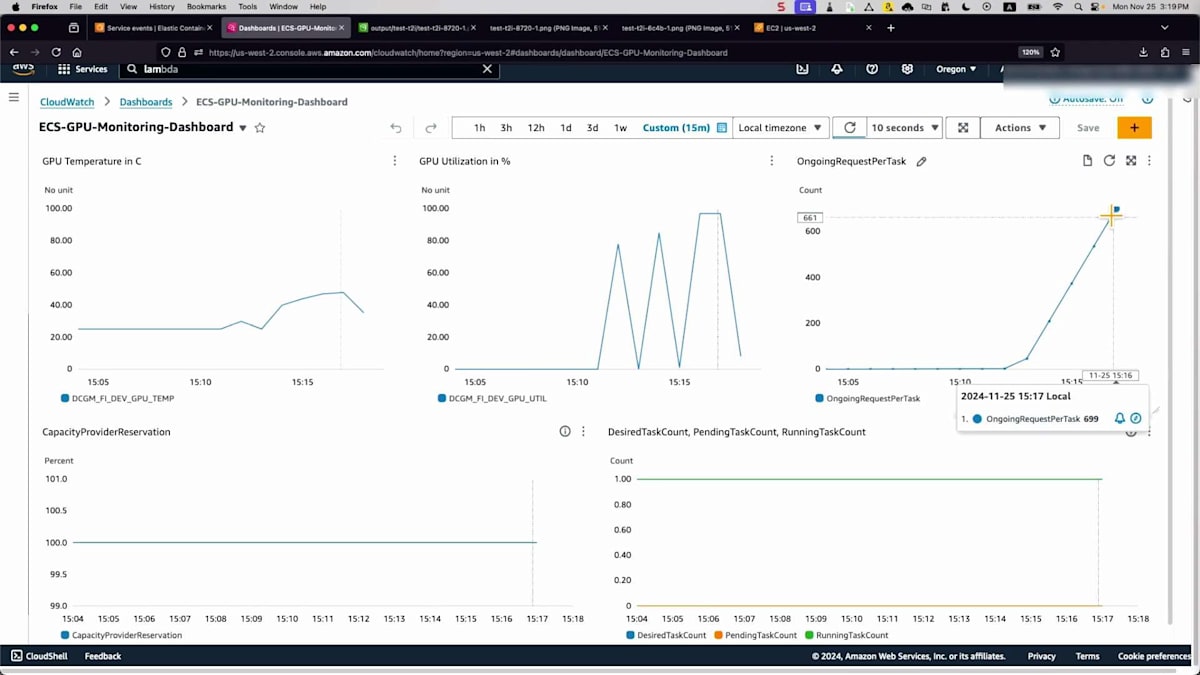
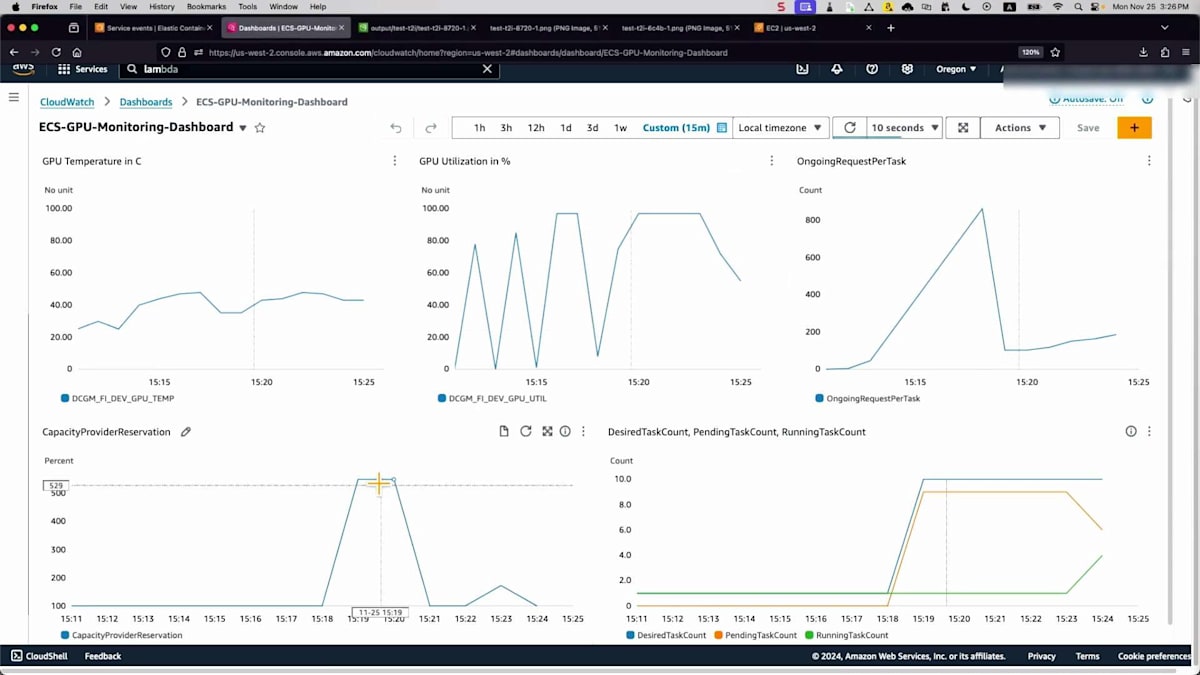
そしてイベントを見ると、多くのタスクがトリガーされていますが、バックエンドのEC2インスタンスの準備を待っているため、保留状態になっています。これはApplication Auto Scalingと連携して処理されます。より多くのタスクがトリガーされたため、これらのメトリクスが500や600まで上昇しているのが分かります。目標のタスク数を確認する必要があります。10タスクまでスケールしようとしていて、これには時間がかかります。この動画記録を早送りしました。キャパシティプロバイダーがバックエンドのEC2インスタンスをスケールするためのシグナルを受信したのが分かります。インスタンスの準備が整うと、タスクの増加とCPU使用率が安定化しているのが確認できます。
まとめと今後の展望
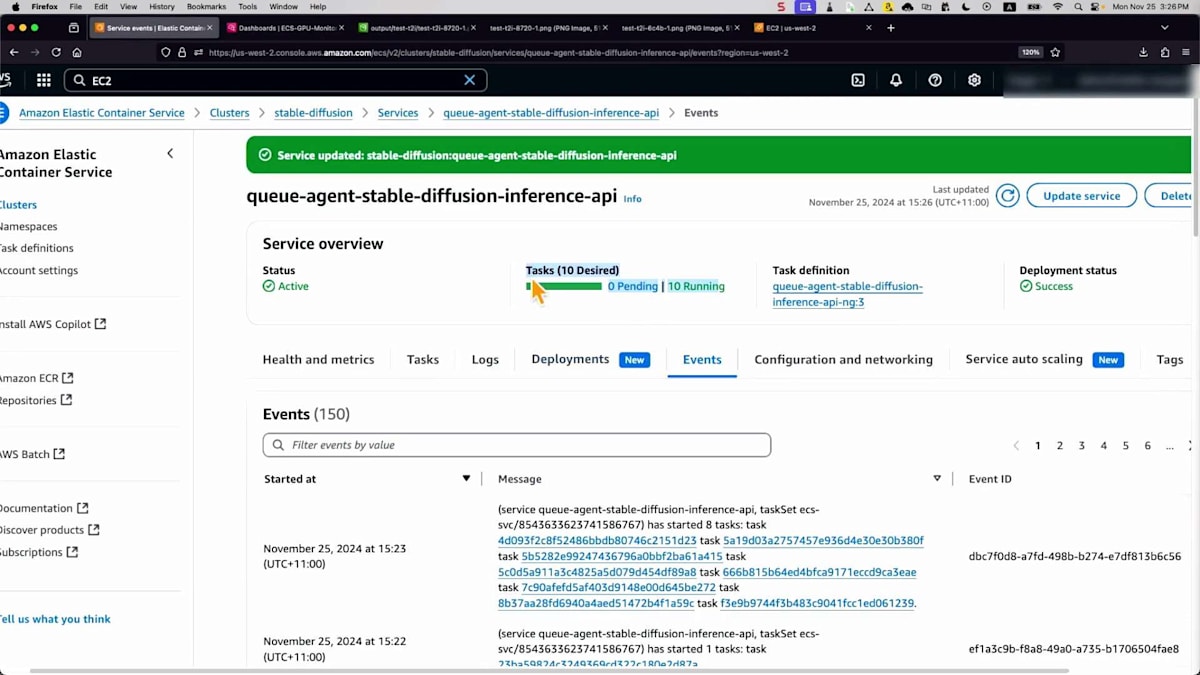

これはスケーリングの仕組みを示すものですが、EC2コンソールに戻ってみると、すべてが期待通りに動作しています。このテストが完了すると、コスト削減のために縮小されます。このセッションで扱った内容について、簡単なまとめで締めくくりましょう。最初の柔軟性について特に注目していただきたいと思います。画像生成におけるStable Diffusionのエコシステムは非常に大きいため、これは重要なポイントです。Stable Diffusionや新しく登場するモデルなど、さまざまな種類のFoundation Modelを活用できます。さらに、先ほどお見せしたように、特定のスタイルを実現するためのLoraや、画像のスタイルを変更できるControlNetなどの拡張モデルを活用する必要があるユースケースもあります。そのため、さまざまなユースケースに対応できる柔軟性を持つことが重要です。
信頼性も非常に重要です。エンドツーエンドで環境が常に稼働していることを確認する必要があり、私たちはAmazon ECSと、API Gateway、Lambda、SNS、SQSなどの他のサービステクノロジーを活用しています。これらのサービスにはすべて、環境に組み込まれたスケーラビリティと信頼性があり、アプリケーション全体に信頼性の高いパフォーマンスを提供します。AWS、Azure、GCPの最新かつ最速のGPUインスタンスなどを、さまざまなユースケースで活用できます。Amazon EC2を使用することで、Amazon EFSなどのストレージサービスと組み合わせてモデルファイルを素早くロードする柔軟性があります。スケーラビリティは、意味のある指標を使用してECS内部の機能を活用し、Application Auto Scalingやキャパシティプロバイダーと連携してバックエンド環境を迅速にスケールすることで実現されます。また、Warm Poolsを使用してプリウォーミングを実装することもできます。
Observabilityは非常に重要です。システムが期待通りに動作しているかどうかを示すだけでなく、GPUの使用率や割り当てを監視し、環境全体を微調整することができるからです。スケールアウト環境を運用する際のコスト管理も重要です。スケールアウトとスケールインを行ってコストを最適化できます。Spotインスタンスのことも忘れないでください。信頼性の高い環境では、Spotインスタンスが利用できなくなっても、メッセージが失われることはありません。処理の完了に若干時間がかかるものの、再試行されて処理が継続されます。



これらすべてのメリットがありますが、このトピックに関連するセッションにもぜひ注目してください。スマートフォンを取り出してこのコードをスキャンしてください。すでに公開されているスライドやブログ記事をすぐにダウンロードでき、AI/MLワークロードの環境最適化に関するすべての詳細が記載されています。最後に、ご参加いただいたみなさまと共同発表者の方々に感謝申し上げます。一つお願いがあります。アンケートにぜひご回答ください。より良いソリューションを作り、より多くの人々に恩恵をもたらすために、皆様からのフィードバックは非常に重要です。ご協力いただければ大変ありがたく思います。ご清聴ありがとうございました。それでは、素晴らしい一日をお過ごしください。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion