re:Invent 2024: NatWestがAmazon ConnectとAI/MLで顧客体験を向上


はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - NatWest: Personalizing customer experience with Amazon Connect & AI/ML (FSI316)
この動画では、英国の大手銀行NatWestが9,000人以上のエージェントを抱えるコンタクトセンターをAmazon Connectに移行した事例が紹介されています。年間2,500万件の通話を処理する大規模なコンタクトセンターで、Amazon ConnectとAI/MLを活用して顧客体験を向上させた具体的な取り組みが説明されています。Natural Language Call Steeringの実装やLexチェーニングの活用、Amazon Q in Connectを使った実験的な取り組みなど、最新のAI技術の実践的な活用事例が示されています。また、Contact Lensを活用したVulnerable Customerの特定や、データに基づくコーチングによってSentimentスコアを向上させた成果など、具体的な改善効果も詳しく解説されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
NatWestのAmazon Connect活用:セッション概要

皆様、おはようございます。コンタクトセンターで働いている方で、お客様が何のために連絡してくるのかをより深く理解するための、正確でタイムリーなデータが欲しいと思っている方はどれくらいいらっしゃいますか?また、お客様との対応方法について、タイムリーなデータと洞察を提供することで、エージェントがより良いサービスを提供できるようにしたいとお考えではないでしょうか。私はChris Ibbitsonと申します。AWSのPrincipal Solutions Architectとして、金融サービスのお客様がAWS上でビジネス課題を解決するお手伝いをしています。本日は、セッションFSI316「NatWestがAmazon ConnectとAI/MLを活用してカスタマーエクスペリエンスをパーソナライズした方法」にようこそお越しくださいました。


本日は、NatWestから二人の同僚、Jill BeattieさんとStephen Couchさんをお迎えしています。 このセッションでは、 NatWestという企業についてと、なぜAmazon Connectを採用することにしたのか、そしてその導入を支えた journey(道のり)とアーキテクチャについてお話しいただきます。また、Amazon Connectが提供する豊富なデータを、コンタクトセンターの運営だけでなく、銀行全体でどのように活用しているかについても説明します。さらに、AIを活用してお客様とエージェントの双方により良いサービスを提供する方法についても触れ、最後にAmazon Connectの今後の展開についてお話しいただきます。
NatWestの紹介とAmazon Connectへの移行プロセス
では、NatWestの紹介をしていただくために、Jillさんにバトンをお渡しします。ありがとうございます、Chrisさん。皆様、おはようございます。それではNatWestについてご紹介させていただきます。私たちはFTSE 100に上場している英国を拠点とする銀行で、リテール、コマーシャル、アフルエント事業を通じて1,900万人のお客様をサポートしています。実際、私たちは英国最大のビジネス向け銀行です。多くの組織と同様に、お客様はデジタルチャネルにうまく適応しており、毎日1,000万回のモバイルアプリへのログインがあり、お客様はそこで銀行取引を行っています。しかし、アプリで困っているお客様や、追加の確認が必要な場合、または複雑な問い合わせがある場合、そこでコンタクトセンターが重要な役割を果たしています。
NatWestには9つのコンタクトセンターがあり、年間2,500万件の電話を受け付けており、9,000人のエージェントがサポートしています。具体的な電話の例をいくつかご紹介させていただきます。口座で不正取引が発生していることを心配されているお客様や、詐欺の被害に遭ったのではないかと心配されている方、あるいは支払いについて異議を申し立てたい方などがいらっしゃいます。また、来月の住宅ローンの支払いに困っていて、どのような支援が受けられるのかを知りたいお客様もいます。あるいは、大口の支払いを行いたいビジネスのお客様で、その支払いが確実に処理されたことを確認したい場合や、モバイルアププで簡単な取引を行うのに苦労しているお客様もいらっしゃいます。

これらのコンタクトセンターを、私たちはAmazon Connectに移行しました。これまでの経緯を簡単にお話しさせていただきます。 私たちのConnect journeyは2019年に始まり、クレジットカードセンターでパイロットを実施した英国の銀行の先駆けとなりました。皆様の中にも同じような経験をされた方がいらっしゃるかもしれませんが、NatWestでは事業計画の承認を得るのに非常に時間がかかり、9つのコンタクトセンター全て、9,000人のエージェント全て、そして2,500万件の通話全てをAmazon Connectに移行するという完全な事業計画と決定が下されたのは、2022年末のことでした。
私たちは2023年1月に正式にこのプログラムを立ち上げ、その年末までに66%のエージェントをAmazon Connectに移行できたことを大変嬉しく思っています。実際、その中には最も複雑なContact Centerも含まれていました。そして2024年10月までに、すべてのContact Centerを移行し、現在9,702人のエージェントがConnectを使用しています。完全な移行には1年10ヶ月かかり、22回の移行イベントを経て実現しました。現在は、システムの廃止作業を開始しており、その後は最適化に移行する予定です。ビジネスの観点から見ると、Amazon Connectから得られている主要なメリットがいくつかあります。
Amazon Connectがもたらすビジネス上のメリットとアーキテクチャ
まず第一に、豊富なデータとそれを活用して顧客とエージェント双方の体験を向上させる方法についてです。これについては、後ほどプレゼンテーションで具体例を交えてご紹介します。開発のスピードは素晴らしいものでした。今年だけでも30以上の新しいセルフサービスの仕組みを電話システムに実装し、それらの設計、構築、デプロイを3週間程度で完了することができました。以前の従来型プラットフォームでは、約6ヶ月かかっていたものです。
従量課金モデルは、組織の考え方を大きく変え、最適化への取り組みを促進します。顧客体験を改善し、通話数やAverage Handling Timeを削減できれば、翌月にはすぐに経済的なメリットが表れるからです。これは、固定契約や複数年契約を結んでいた以前とは大きく異なり、私たちの考え方や最適化への取り組み方を本当に変えつつあります。
では、Platform LeadのSteven Couchを紎介させていただきます。彼が私たちの取り組みについて詳しくご説明します。皆様、おはようございます。これから、NatWestでのConnectのアーキテクチャについてお話しし、その後、私たちが行った移行の過程について説明します。そして、データの活用方法とそのアーキテクチャについて触れた後、最後にAIの活用、特にAmazon Q in Connectについてお話しします。

このスライドについて少しお時間をいただき、私たちが構築したシステムの概要をご説明させていただきます。スライドの左側を見ていただくと、Connectへの通話の主要な入口が2つあることがわかります。お客様の大多数は依然として従来型のPSTN電話を使用してご連絡いただいており、私たちの様々なブランドで1000以上の電話番号を使用しています。その大部分は自動セルフサービスに振り分けられ、一部は直接エージェントにつながり、特に不正対策の部門では外部への発信も行っています。
最近、私たちは新しい機能をリリースしました。それは、モバイルアププリから直接VOIPを使用して通話を受けられる機能です。Jillが先ほど述べたように、私たちのモバイルアプリには毎日1,000万件のログインがあり、お客様とのエンゲージメントにおいて重要な手段となっています。この機能により、お客様が別の電話番号をダイヤルする必要なく、モバイルアププリから直接コンタクトセンターへとシームレスな顧客体験を構築することができます。
具体例を挙げてご説明しましょう。モバイルアププリで友人や家族への送金を試みていて、支払いがうまくいかない場合、まず最初にアプリ内蔵のDigital Assistant(AIツール)を使って問題解決を試みます。それでも解決しない場合、「タップして通話」というボタンが表示され、そのボタンをクリックすることでバックエンドのConnectに直接接続されます。この通話はモバイルプラットフォームを経由して一連のLambdaを通り、Connectサービスに直接つながり、適切なキューに即座に振り分けられます。この仕組みの素晴らしい点は、例えば、モバイルアプリで顔認証による本人確認が済んでいる場合、その認証トークンを引き継ぐことができ、電話対応の際に再度認証を行う必要がないことです。
Natural Language Call SteeringとVoice Biometricsの活用
通話がどのルートで入ってきても、Connectに到達した時点からは、Connectによって通話のオーケストレーションが管理されます。私たちの優先事項は、お客様が最初から必要なサービスを認識していなかった場合でも、できるだけ早く適切なスタッフにつなぐことです。これを実現するために、Natural Language Call Steeringを使用した一連のLex botを活用し、お客様が求めているものを特定するための適切な会話を行います。私たちは1,700以上のintent(お客様からの問い合わせ内容)に対応しています。
私たちのシステムの仕組みは、お客様が話す内容から発話(utterances)を拾い、それらをintentにマッピングします。それに基づいて、Lex botが会話をどの対応フローに振り分けるかを判断します。私たちの優先事項は、その通話をIVR内で完結させることです。経験上、オペレーターに取り次ぐと時間がかかることがわかっているため、できるだけオペレーターとの会話は避けたいと考えています。運用コストの観点からも、両者にとって、必要なサービスを自動的に素早く提供し、お客様が日常生活に戻れるようにすることが望ましいのです。
必要な場合は、もちろんお客様をオペレーターにつなぐこともできます。これは通常、Jillが言及したような委任状や死亡関連の手続き - つまり重要な局面 - や、人間からの安心の言葉が必要な不正取引のケースなどの場合です。intentを特定してお客様が電話してきた後、次に必要なのは、お客様が本当に本人であることを確認することです。これは主にVoice Biometricsによるセキュリティで行いますが、まず最初に本人確認を行う必要があります。
本人確認プロセスでは、セキュリティのためVPC内で複数のLambda統合機能を使用しています。これらはバックエンドへの呼び出しを行い、新たに開発した発信者番号識別機能を利用します。お客様の発信番号を特定し、バンキングシステムにクエリを実行して、その番号に紐づけられた口座を確認し、お客様に自己紹介をしていただくことなく本人確認が可能です。これにより時間を節約でき、頻繁に電話をされない方にとって煩わしい顧客IDを覚えておく必要もなくなります。
さらに詳細な識別も可能です。例えば、Lexボットは夫婦で同じ電話番号を使用しているけれど別々の口座を持っている場合や、同じ番号に複数の口座が紐づいている場合なども判別できます。それと並行して、お客様が会話を続けている間に、サードパーティの生体認証サービスへの呼び出しも行います。お客様の音声パターンを聞き取り、その口座に登録されている音声パターンと照合して、本当に正しいお客様が話しているかを確認します。
同時に、不正音声検出と呼ばれる処理も実施しています。サードパーティプロバイダーが保存している既知の不正利用者の音声と比較して、不正利用者が通話していないかを確認します。また、なりすましの可能性を示す通話品質の不整合がないかもチェックしています。これらの対策により、お客様が本人であることを確実に確認できます。これらはすべて、ユーザー名やPINの入力なしで自動的に行われ、甥や姪に20ポンドを送金するお客様でも、新車を購入する裕福なお客様でも、同じように扱われます。
意図の特定と本人確認が完了したら、理想的にはIVR内で会話を継続しながら、よりリッチな対話を提供したいと考えています。お客様が応対を進める中で、Amazon SQSとLambdaの機能を使用して、バックエンドシステムへの呼び出しを継続的に行います。残高、口座詳細、住所など、お客様の用件に応じた情報を取得します。これらの呼び出しはすべて非同期で行われるため、レスポンスを待つことなく自然な会話の流れを維持できます。
取得したすべての情報はDynamoDBに保存します。これにより、お客様が同じ情報を再度提供する必要がなく、同じ情報を何度もクエリする必要もなくなります。セキュリティトークンもここに保存しますが、通話終了時にはすべてのデータが削除され、セキュリティトークンは完全に消去されます。これにより、Connectサービス内にデータが残ることはなく、すべての情報はバックエンドのバンキングシステムで高度なセキュリティを維持しながら管理されます。
Amazon Connectによるデータ活用とアーキテクチャの簡素化
エージェントへの転送が必要になったジャーニーでは、Connect Contact Control Panel (CCP) 上にコール情報を表示します。これにより、顧客がすでに行った操作や提供した情報の詳細を、エージェントが改めて尋ねたり再認証したりすることなく、直接エージェントに提示することができます。この表示は、標準のCCPをそのまま使用するか、既存のエージェントワークスペースにCCPを組み込んで行います。というのも、私たちのコンタクトセンターでは複数の異なるアプリケーションを使用しているからです。
Contact Center as a Service (CCaaS) は、これらのアプリケーションにネイティブに組み込まれています。エージェントの視点からは、まるで1つのアプリケーションのように感じられ、別個の電話サービスデスクトップアプリケーションを実行する必要はありません。すべてが1つのソリューションにシームレスに統合されているのです。私たちの従業員の多くはリモートまたはハイブリッド勤務で、週に2、3日は在宅で働いています。デスクトップはすべてCitrixベースなので、Citrixセッションを通じて接続します。エージェントは自身の個人デバイスまたはシンクライアントを使用して、Citrixサーバーにリモート接続してアプリケーションにアクセスします。
移行後に最初に直面した問題の1つは、通話品質の問題、あるいは少なくとも通話品質に関する認識の問題でした。最近、HDXを導入しました。これはCitrixのコンポーネントで、Connectアプリケーションの外部で音声トラフィックの処理を行うことができます。エージェントが通話している際、トラフィックはローカルデバイスで実行されている別のソフトウェアに渡され、そこで暗号化とエンコードが処理されます。その後、エージェントの自身のブロードバンド接続を通じてインターネット経由で直接Connectに送られます。これにより、私たちのサービス内のCitrixサーバーや既存の内部ネットワークを経由する必要がなくなりました。この実装により、音声トラフィックの品質は大幅に改善されました。
品質が悪いとマークされるコール(MOSスコアで4未満を品質不良とみなします)は、現在では1%未満です。これらのケースの大多数は、調査してみると、通常はConnectサービスの問題ではなく、顧客が車の中にいる場合や電波の悪い場所にいる場合など、顧客のモバイル通信状況に関連していることがわかります。また、エンドツーエンドのモニタリングのために、OPERATAという新しいツールも試験的に導入しています。このツールを使用すると、エージェントのデスクトップまでの全体的なジャーニーを通じてトラフィックを監視し、サーバーベースの指標だけでなく、エージェントの実際の体験に基づく品質スコアを得ることができます。
このアーキテクチャにおけるデータ表示は、主に2つの場所で行われています。以前はコンタクトセンターの物理的な画面でキュー情報やエージェントのステータスを表示していたウォールボードは、エージェントのデスクトップ上のWebページに変更されました。この変更により、インフラコストが削減されただけでなく、エージェントが通話を転送する際に異なるキュー情報を確認し、待ち時間を顧客に案内したり、キューコールバックサービスを提供したりすることが可能になりました。もう1つのデータ表示は、QuickSightレポートとContact Lensによる分析を通じて行われ、運用上の意思決定のためのビジネスインテリジェンスを提供し、技術チームがカスタマージャーニーの最適化機会を特定し改善するのに役立っています。

Connectへの移行による重要な技術的メリットの1つは、アーキテクチャが大幅にシンプル化されたことです。以前のアーキテクチャでは、エンドツーエンドのサービスを提供するために、複数のベストインクラスのアプリケーションを使用していました。これは非常に分散化されたアーキテクチャで、多数の統合ポイントがあり、一部のシステムでは複数の統合が必要でした。異なるシステムのアプリケーションを統合し、異なるデータ属性を突き合わせて意味のあるインサイトを生成する必要があったため、データ収集はより困難でした。結果として、サービスユーザーが直接活用できるものというよりも、主にデータと分析のサービスとなっていました。最後の課題はサポートに関するもので、複数の統合アプリケーション間での問題の原因特定が複雑でした。
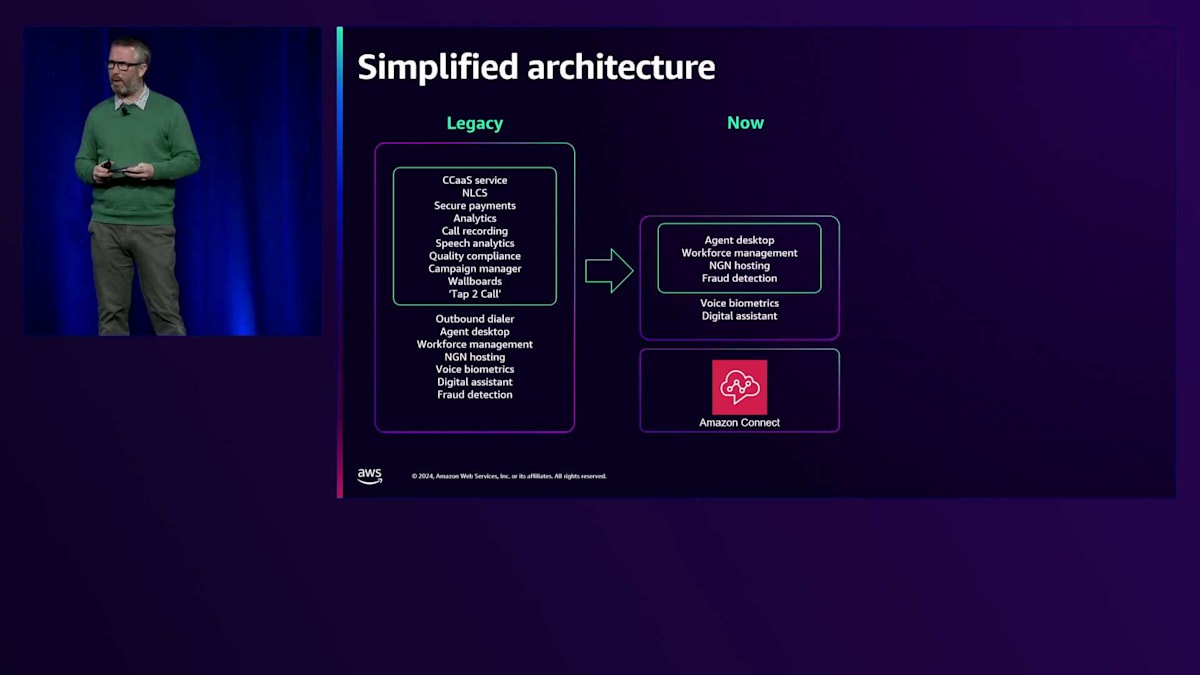
Amazon Connectへの移行により、音声分析、通話録音、Natural Language Call Steering(NLCS)などのサービス内の数多くの組み込み機能を活用して、アーキテクチャを大幅に統合することができました。
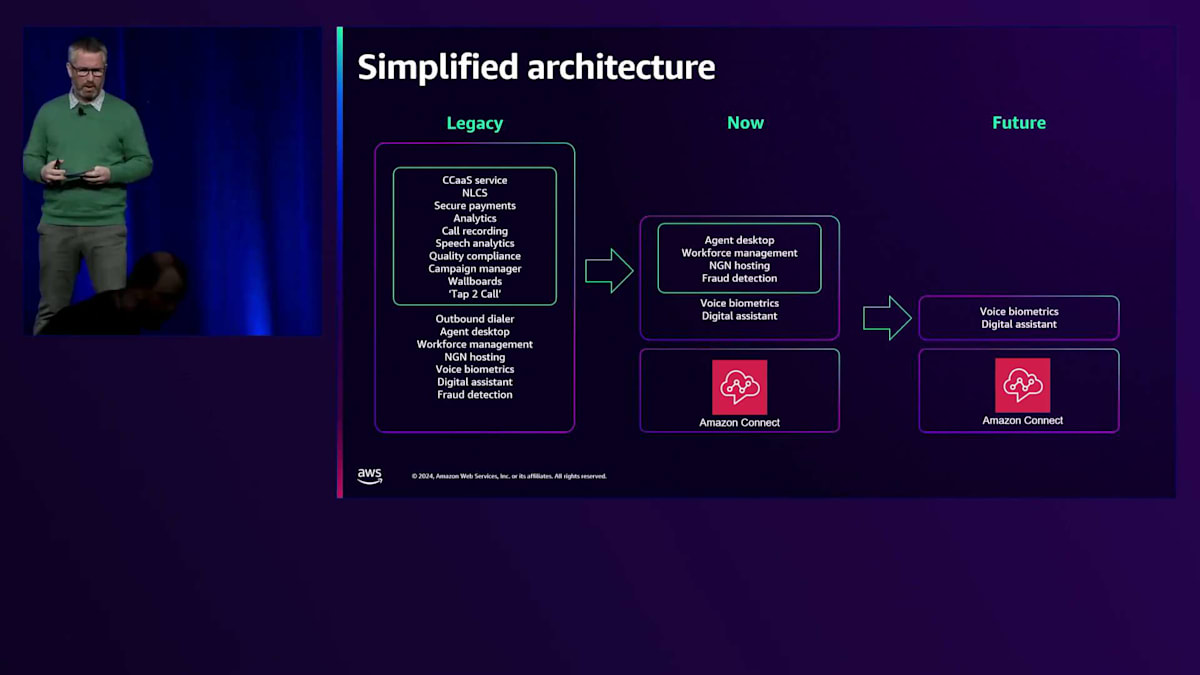
これらの機能は最初から備わっているため、別個のソフトウェアプロバイダーは必要なくなりました。実験を続けるにつれて、新機能が開発されているため、さらなる進展が期待できます。Amazonが取り組んで構築している workforce management toolingやAgent Desktopは、このシンプル化の道をさらに進めるために、将来的に実験していく予定のものです。
シンプル化自体とすでに言及したデータ以外の主なメリットは、Jillが述べたコスト削減です。左側の元のアーキテクチャでは、それらはすべて個別のサプライヤーで、個別の契約があり、その多くは長期間にわたって何十万もしくは何万ものライセンスを契約する従来型のモデルを使用していました。現在、これらのサービスの多くがAmazon Connectで提供されているため、通話量が減少し、お客様が電話チャネルからデジタルチャネルに移行することを選択した場合、実際の通話自体からの節約だけでなく、他のすべてのサービスからも節約ができます。なぜなら、それらのサービスの消費も減少するからです。
Amazon Connectへの移行戦略とデータ活用の進化

私たちにとって大きな優先事項は、安全に移行することでした。先ほど述べたように、私たちには9つのコンタクトセンターと1,900万人の顧客がおり、多くのコンタクトセンターは24時間365日体制で運営されています。このような規模の移行が課題になることは最初からわかっていました。Jillが言及した約2年の間に、サービスを構築するためにAmazon Connectに対して220回のプロダクションリリースを行いました。また、678のContact Flowと、LambdaとLex Botを合わせて500のオートメーションを実装しました。サービスを構築するには相当な開発が必要でしたが、本当の課題は切り替えをどのように行うかということでした。
図にあるように、私たちは幸運なことに、レガシーサービスの前段に2つのTelcoプロバイダーが存在していました。Telcoプロバイダーは、顧客向けに複数のNGN(非地理的番号)を提供する形で機能していました。イギリスの場合、これは顧客が電話をかける0800のフリーダイヤル番号に相当します。その後、この番号はレガシープラットフォームと通信する直通番号に変換されます。Amazon Connectも同様の仕組みで動作します。私たちは、ターゲットサービスをすべて構築し、それらの直通番号を直接ビジネス部門に提供し、本番トラフィックがまだレガシーサービスを通じて流れている間に、それらのサービスのすべてのチェックアウトを可能にしました。
移行を実施する際には、番号ごとに切り替えることができました。移行作業自体はとてもシンプルになりました。夜間に大規模なリリースやコードのプッシュを行い、多くの人々がチェックアウトを行う必要がある代わりに、単にTelcoのコンソールにログインして、0800番号が指し示す直通番号を変更するだけでよかったのです。移行作業は20分から30分程度の簡単な作業となり、その後はその日のうちにビジネス部門による追加のチェックアウトを行って、すべてが正常に動作していることを確認しました。多くの移行作業では、プロセスに自信があったため、チェックアウトを行いながら実際の顧客からの通話も受けていました。
これにより、ビジネス部門はサービスの運用方法と移行の進め方について大きな信頼を寄せるようになりました。この信頼を示す重要なポイントが2つあります。従来、私たちの組織は大規模な移行作業に関してはリスク回避的で、通常は小規模から始めて徐々に規模を拡大していく方法を取っていました。しかし今回は、ビジネス部門に大きな信頼を得ていたため、最大規模のコンタクトセンターを最初に移行しました。これにより、その1回の移行から他のすべての移行に活用できる大量のデータを得ることができました。
もう1つの重要な決定は、年間で最も忙しい時期であるBlack Fridayの週末の前日に、不正対策部門の移行を実施したことです。Black Fridayには膨大な数の電話を受けましたが、彼らはそれほど自信を持っていたため、私たちにそのような決定を許可してくれました。22回の移行のうち、巻き戻しを行ったのは1回だけでした。これは私たちの変更とは無関係のサードパーティシステムの問題であることが判明しました。巻き戻しを行っている最中にも、ビジネス部門は既に翌週の計画を立てるのを手伝ってくれており、その移行は無事成功しました。これにより、リスクの低い、クリーンで安全な移行方法を実現することができました。

移行に関してもう1つの大きな決定は、「移行しながら最適化するか」それとも「移行してから最適化するか」という選択でした。これは多くの大規模な変革プログラムが直面するジレンマです。私たちはスピーディーに進めたいと考えていましたが、同時にサービスの改善も進めたいと強く意識していました。皆さんは、大規模なビジネスケースを構築する、このような大規模な変革プログラムに何回携わったことがありますか?
大規模な事業計画を立て、その後2年間の開発を予定する変革プロジェクトに携わったことはありますか?サービスの将来像について壮大な計画を立てても、移行が完了した後に予算が打ち切られて立ち消えになってしまうことがあります。私たちも、Amazon Connectへの移行後に実現したいと考えていた大きな計画があったため、同じことが起きるのではないかと心配していました。結局、移行を先に行い、その後で最適化を進めるという決断をしたのは、データの問題が理由でした。従来のプラットフォームでは、意味のあるデータが得られませんでしたが、Amazon Connectに移行すれば確実にデータが取得できることは分かっていました。
移行と最適化を同時に行うと、コンタクトセンターが実際にどう機能しているかという証拠に基づくのではなく、どう機能していると思い込んでいるかに基づいて、間違った判断をしてしまう可能性がありました。そこで、まず移行を完了させるというアプローチを取りました。移行完了後、データ主導のアプローチで実験を開始し、さまざまな機能についての検証を行いました。ここで、Amazon Connectのコストモデルと運用方法の強みが活きてきました。Amazon Connectの機能やサービスを有効にして数週間実験を行い、当初の価値に関する仮説が正しいかどうかを確認し、必要に応じて機能をオフにすることができました。機能を使用している間だけ課金されるため、製品が謳い文句通りの機能を持っているかを確認するために3年契約を結ぶ必要はありませんでした。
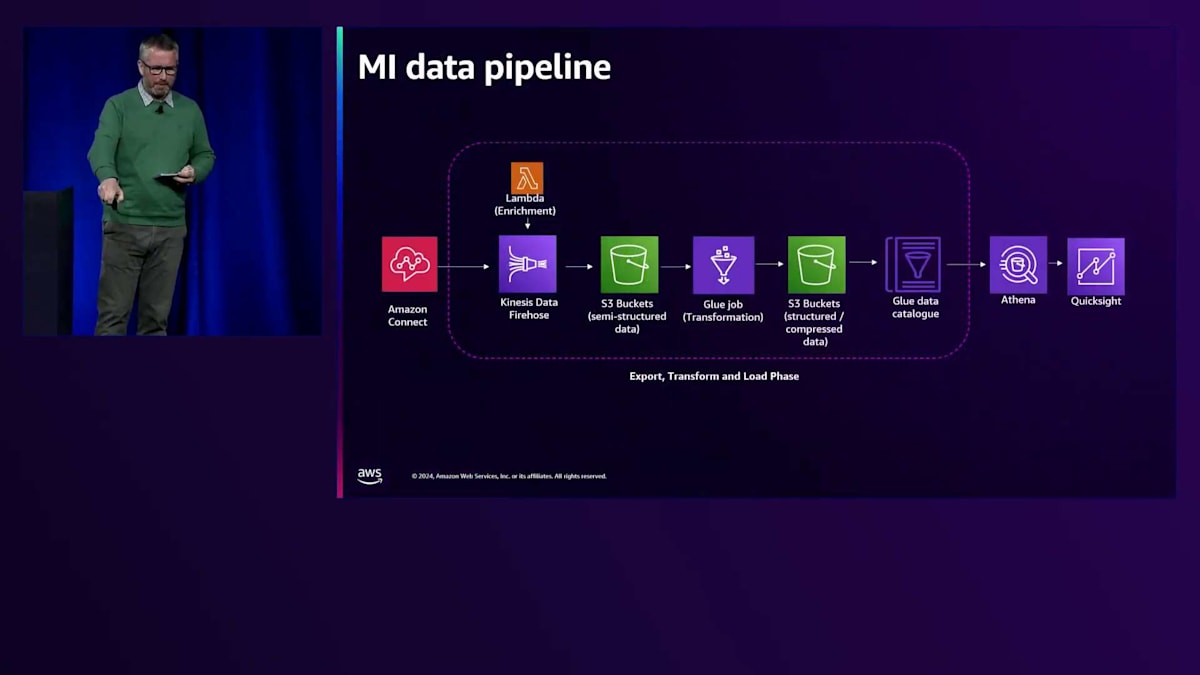
Amazon Connectへの移行の大きな理由の一つは、データにアクセスし、それを意味のある形で活用できることだと何度か触れてきました。先ほど述べたように、従来のプラットフォームでは、データはさまざまなアプリケーションに分散していました。すべてのアプリケーションが中央のデータ機能にフィードされ、複雑な分析を行うまで、そのデータを活用することはできませんでした。Amazon Connectに移行した大きなメリットは、データがすべて一箇所に集約されることでした。ただし、そのデータから意味のある洞察を得るためには、やはりある程度の作業が必要です。
Amazon Connectから、私たちは3つの重要な情報を取得していました。1つ目は、通話がどのように行われ、どのように機能したかというすべての情報を提供するContact Trace Record、2つ目は、すべての通話を文字起こしした通話トランスクリプション(エージェントと顧客の両方の発言の文字記録を提供)、そして3つ目は、エージェントの視点から何が起こったのか、誰が対応したのか、どのように行動したのかの詳細を提供するエージェントデータです。これらのデータを、多くの方がご存知のETL(Export、Transform、Load)プロセスに投入しました。このプロセスでは、AWS Lambdaを使用してデータを強化しています。
データ強化の例をいくつか挙げると、Contact Trace RecordでエージェントのログインIDを確認し、実際の名前といったより意味のある情報を照会して取り込むことができます。また、お客様が電話をかけてきた番号に基づいて、そのブランドを特定することができます。私たちは複数のブランドを持っており、電話番号は通常、個々のブランドに紐づいているためです。その後、データを構造化し、レポートの結果を高速化するために圧縮し、データディクショナリを構築しました。これにより、Amazon Connectが理解する個々の属性を取り、ビジネスがより理解しやすい名前とメタデータを付与し、コードベースの属性を意味のある説明に変換することができました。
私たちが実際にこれを行う必要があった例として、放棄コールの事例があります。放棄コールは単純にクエリできるものではありませんでした。ビジネスの観点から、何をもって放棄コールとするのか、お客様が意図的に切断したのか、通話が失敗したのか、あるいは他の要因があったのかを定義する必要がありました。これらすべてを導き出し、Amazon Athenaでデータポイントを組み合わせるSQLクエリを作成して放棄コール報告を生成し、Amazon QuickSightを通じてビジネス部門に提供する必要がありました。これは以前の状況と比べると大きな改善でした。先ほど申し上げたように、以前はデータがありませんでした。今では一箇所にすべてのデータがありますが、技術的な開発が必要でした。プロセスは速くなりましたが、主に技術的なプロセスであり、技術チームはコードやSQLの書き方を理解する必要があると同時に、意味のあるデータポイントを理解するために、普段以上にビジネスについて理解する必要がありました。そのため、フラストレーションの性質が変化したのです。
データ駆動型コーチングによる顧客体験の向上

フラストレーションは、データがないことから、データはあるものの期待していたよりもアクセスが難しいということに変わりました。良いニュースは、それが変わってきているということです。私たちは新しいAmazon Connect Zero-ETLデータレイクの実験を始めています。このスライドで目立つのは、以前は私たちが自分でコーディングして開発していた長いETLの部分が、今ではすぐに使える形で提供されているということです。同じ3つのデータがConnectから取り出されてデータレイクに送られていますが、データレイクが重要なタッチポイントをすべて把握し、意味のある形で提示する作業を行っています。
依然としてAthenaクエリを書く必要はありますが、SQLクエリはずっとシンプルになりました。これにより、より迅速にデータ主導の意思決定を行うことができるようになりました。放棄コールの例を見てみましょう。これは今では簡単に取得できるデータポイントです。放棄コールとは何かを定義する必要はなく、自動的にクエリできる状態になっています。また、新しいデータポイントの実験も始めています。現在特に注目しているのは、エージェントの話すスピード、お客様の話すスピード、エージェントがお客様の話を遮る回数などです。これらの要素の組み合わせによって、通話中のお客様の感情がポジティブになるのかネガティブになるのかを分析しています。
これは、はるかに技術的ハードルの低いプロセスでした。また、ドラッグアンドドロップ機能も利用できるようになりました。ビジネスレポートは今でも作成していますが、以前のモデルでは数週間かかっていたものが、今では数日で完成します。カスタムのアドホックレポートを作成するためのドラッグアンドドロップ機能が使えるようになりました。主要な指標のリストが片側に表示され、それを単純にドラッグしてテーブルを作成できます。Excelでピボットテーブルを作るのと同じくらい簡単で、アドホックレポートの作成プロセスがずっとシンプルになりました。以前お話しした顧客の行動分析も、通常数週間かかっていたものが数日で完了できるようになりました。
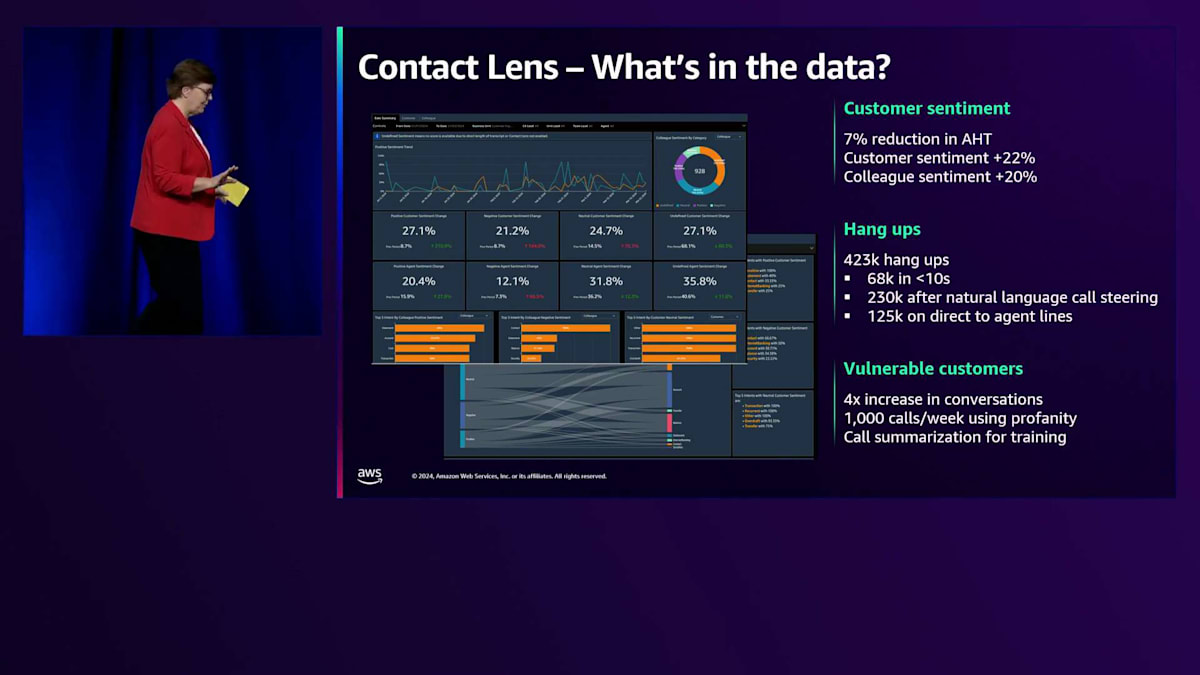
ここでJillに引き継ぎ、このデータを使って何をしているのかについてお話ししてもらいます。組織全体でデータをどのように活用しているか、3つの例を挙げてご説明したいと思います。その前に、NatWestでのコーチングの従来の方法について説明させていただきます。おそらく他のコンタクトセンターと同様に、チームリーダーが複数のテレフォニーエージェントを担当し、通話をサンプリング的に聞いてコーチングニーズを判断していました。良い通話か悪い通話かを判断できましたが、それはごく少数のサンプルに限られていました。Stevenが言及したように、現在では全ての通話を文字起こしするため、年間2,500万件のデータポイントを持っています。
私たちが最初に取り組んだのは、データに基づくコーチングによってSentimentを向上させることができるかどうかを確認することでした。すべてのAgentに同じ時間をかけるのではなく、本当にコーチングを必要とするAgentに特化したコーチングができないかと考えたのです。Sentimentについてご存じない方のために説明すると、文字起こしされた通話それぞれにSentimentスコアが付与されます。システムは発言された言葉を聞き、ポジティブ、ネガティブ、ニュートラルとして識別し、お客様とAgentそれぞれのスコアが算出されます。私たちは、このデータに基づくコーチングを通じて、お客様のSentimentを向上させることができるかどうかを確認したいと考えました。
この取り組みを進めていく中で、必ずしもネガティブなSentimentだけを見る必要はないことに気づきました。重要なのは、お客様が通話を始めた時点でどのようなSentimentであっても、Agentが通話の終わりにはよりポジティブな、あるいは場合によってはマイナス度を軽減できるかということでした。なぜなら、お客様の中には深刻な経済的困難を抱えて連絡してこられる方もいるからです。私たちはアフルエント向けのコンタクトセンターの1つでデータに基づくコーチングを実施し、お客様のSentimentを向上させることができるか試してみました。画面でご覧いただけるように、かなり大きな効果が出ました。そしてAgent側のSentimentも向上しました。Agentたちはこのデータに基づくコーチングを望んでおり、通話においてより自信を持てるようになりました。さらに嬉しい驚きとして、AHTの削減も確認できました。
これは非常に有益でした。というのも、私たちはPay-as-you-goモデルのメリットについて多く語ってきましたが、翌月以降、財務的なメリットが表れ始め、お客様もAgentも、より満足度が高まったからです。これは私たちが本当に注力している取り組みの1つで、ビジネス部門の1つが現在、Customer Sentimentを目標指標として採用していることを嬉しく思います。彼らはNPSを見るのではなく、これを重要なデータポイントとしているのです。
データの価値を示す2つ目の取り組みは、切断に関するものです。私たちには相当数の切断があり、以前のLegacyプラットフォームでもこの数字は把握していました。人々は「これは単にお客様が早い段階で電話してきて、玄関のチャイムが鳴るなどして気が散り、切断してしまうだけだ。大丈夫、また電話してくれて良い体験をしてもらえるから」と言っていました。しかし今では、このデータを本当の意味で理解できるようになり、その想定は完全に間違っていたことがわかりました。私たちは、お客様が切断するタイミングを10秒、20秒、30秒といった具合に調べ始めました。切断するお客様の16%が短時間で切断していることに関して、データに大きな変化はありませんでした。
データを深く分析していくと、一部のお客様がIVRの中で、私たちも経験したことがあるような悪循環に陥っていることがわかりました。彼らは単に切断しているのではなく、IVRから抜け出せずに諦めてしまい、非常にネガティブな顧客体験をしていたのです。わかったことは、お客様は私たちがIntentとして認識できる発話を試みていたのですが、私たちがそれを認識できていなかったということです。現在、私たちはそれらのデータをすべて活用して、Natural Language Call Steeringを改善しています。これは私たちにとって、このレベルのデータに取り組み始める上で本当に重要な洞察となりました。
最後の例として、Vulnerable Customerに関する取り組みをご紹介します。Vulnerable Customerとは、追加のサポートを必要とするお客様を指す銀行用語です。身体的な障害や精神的な障害、あるいは死別や離婚など、人生の特定の時期にコンタクトセンターから追加のサポートを必要とする状況全般を指します。私たちはContact Lensを使用して、これらのデータポイントを特定するための多くのルールを構築しました。「あなたはVulnerable Customerですか?」といった質問をお客様にすることは避けたかったのです。そうではなく、プロアクティブに特定して、必要な追加サポートを提供したいと考えました。
経験豊富なコールセンターのエージェントやチームリーダーに協力を仰ぎ、特定すべきIntentの構築を依頼しました。彼らの支援を得てこのシステムを開発し、現在は経験豊富なエージェントが作成した拡張Intentに基づいてデータを分析しています。その結果、Vulnerable Customerの特定率は4倍に向上しました。しかし、ここでもデータから予想外の発見がありました。エージェントが顧客から多くの暴言を受けていることが判明したのです。これにより、追加のコーチングを実施するとともに、許容できる行為と許容できない行為について、エージェントに明確に説明することができました。このデータを通じて、コーチングの改善を図ることができたのです。これらの事例が、2,500万件のデータポイントをどのように活用しているかを具体的に示せたことを願っています。
AIとAmazon Q in Connectの活用:現状と将来展望
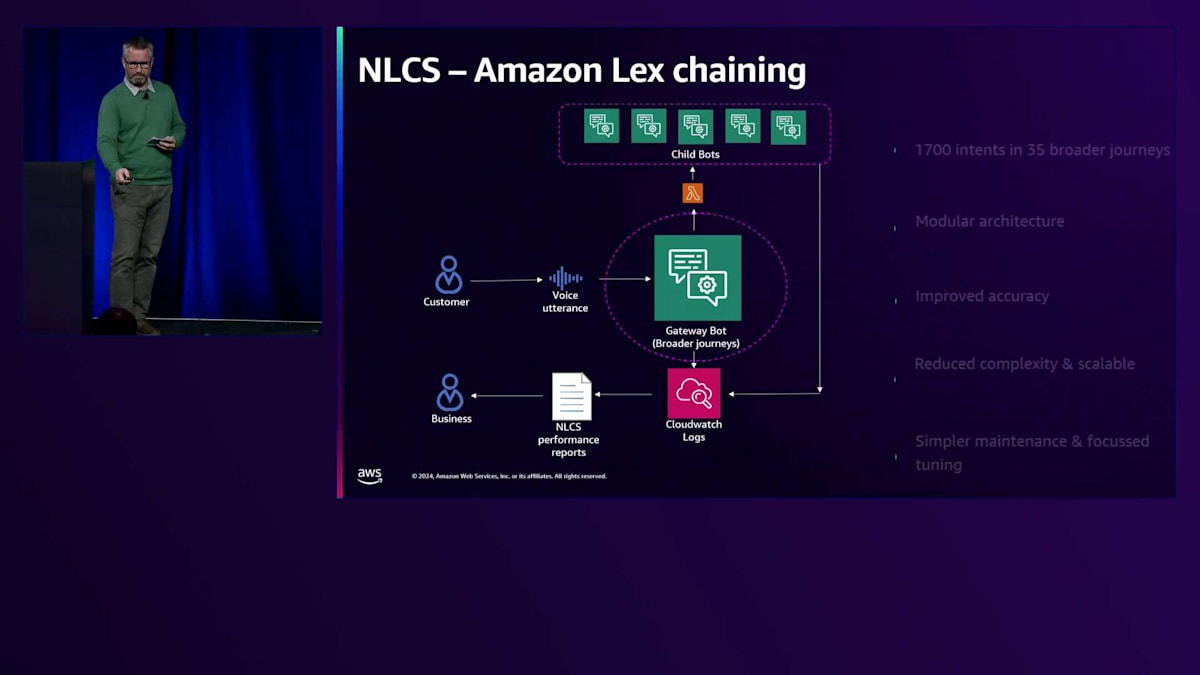
では、AIに関する取り組みについて説明するStevenにバトンを渡したいと思います。 ありがとうございます。Amazon Q and Connectについてお話しする前に、Lexチェーニングについて少しお話ししたいと思います。これは、先ほどJoeが話していた内容に関連します。NLCSにおける顧客とLexのインタラクションを制御する当初の設計では、単一のLexボットを使用していました。冒頭で私が述べ、Jillも言及したように、サービス内には1,700以上のIntentが存在します。
当初の単一ボットモデルでは、これほど多くのIntentを扱うにはスケールしないことが分かりました。Lexから返されるIntent認識の精度が非常に低く、Intentを追加するほど悪化していきました。さらに問題だったのは、このボットの変更がコードと開発の観点から非常に複雑になっていたことです。ボットが大きくなりすぎて、既存の機能を壊していないことを確認するために、比較的単純な変更でも広範なテストが必要になっていました。
私たちはAmazonに相談し、Lexチェーニングというアイデアを一緒に開発しました。この実装時点で、このような方法でLexボット同士を連携させたのは私たちが初めてだと考えています。このフローでは、顧客が発話した際、1,700のIntentと照合するのではなく、35の高レベルIntentのみを確認します。高レベルIntentが判定されると、その特定のIntentを専門とする子ボットに処理を引き継ぎます。例えば、顧客が支払いを行おうとしている場合、その高レベルIntentは子ボットに引き継がれ、顧客が既存の受取人に即時支払いを行おうとしているのかどうかを判断します。これによりIntentが分解され、よりシンプルでモジュラーなアーキテクチャが実現されました。
私たちは、多くのお客様が理解できないことを話していたため、CloudWatchを通じてNLCSのログを収集し始めました。このような状況で、顧客の行動をよく知らない技術チームに分析させるのは適切ではないと考えました。そこで、ビジネス部門が自ら分析できるようにしたいと考えたのです。そこで分かったのは、お客様は私たちが予想するような言い方をほとんどしないということでした。例えば、お客様は「残高を教えてください」とは言わず、代わりに「口座にいくらありますか?」と言います。同様に、私たちが意図やジャーニーと呼んでいる「住所変更」という言葉ではなく、「引っ越しました」と言うのです。
私たちは、Federated開発モデルと呼ぶものを導入しました。ビジネス部門は、生成されたNLCSレポートを活用して、どのような変更を加えるかを決定し、自らコードを書くようになりました。必要に応じてサポートは提供しますが、彼らは主に独立して作業を行い、コードを私たちに持ち帰ります。そのコードを次のリリースサイクルに組み込み、テストして、リリースします。これにより、NLCSの変更が年に2、3回で数ヶ月かかっていたものが、現在は2週間ごとのリリースサイクルで行えるようになり、悪い体験への対応能力が大幅に向上しました。
このアーキテクチャについて一つ警告があります。Lexのループが非常に作りやすいのです。ブレイクアウト条項に注意を払い、お客様がどのように反応するかを考慮する必要があります。最初にデプロイしたときに痛い目に遭いましたが、子ボットが親ボットに戻し、親ボットが子ボットに戻すというループにお客様を閉じ込めてしまう可能性があります。幸いなことに、データがあれば、通常これをすぐに把握することができます。

次は、Amazon Q and Connect について説明します。私たちは、AIを活用することで、エージェントがお客様に対して適切な結果をより迅速に提供できるようになるという仮説を立てました。お客様に代わって取るべき適切なアクションに導きたいと考えました。これにより、通話のAHTが削減され、翌月には直接的なコスト削減効果が現れると考えました。また、時間の経過とともに、お客様にとってより使いやすい体験を作り出すことで、サービスのNPSが向上することも期待しました。

そこで、実験を行うことにしました。 これが、私たちのQ and Connectの実験のアーキテクチャです。お客様がエージェントと通話している間、Q and Connectはバックグラウンドでお客様の発言をすべて聞いています。リアルタイムで、会話の現在のパートを意図にマッピングしようとしています。重要なのは、お客様が最初にキューに入ったときに検出された意図だけでなく、会話の現在のパートを分析していることです。これは、意図が変化する可能性があることを認識しているためです。
お客様が電話をかけてきた理由が、私たちが当初想定していた意図とは異なることがよくあります。また、複数の意図やキューが存在することもあり、それらに継続的に対応していく必要があります。支払いに関する例を挙げると、お客様が退職する同僚へのプレゼント代を支払うために電話をかけてくることがあります。これは一見単純な要件に見えますが、実際には3つの異なる処理が必要です:残高照会で資金の確認、同僚への支払い先の新規登録、そして実際の支払い処理です。
Qが意図のジャーニーの中で進行していく中で、Bedrockから情報を受け取りながらアドバイスを適応させていきます。Bedrockは主に2つの重要な情報をQに返します:1つ目は、エージェントが顧客に直接読み上げることができる実際のフレーズです。2つ目は、問題解決方法についての分かりやすい説明で、エージェントが解決策を理解できるような形で提供されます。
また、画面下部で見られるように、Amazon Q in Connectは私たちのナレッジリポジトリ(私たちはEllaと呼んでいますが、これはエージェントのナレッジです)にも問い合わせを行っています。ここでは、AIが解決策を導き出すために使用したすべての記事を取得しています。これらの記事は、お客様が個々の解決策についてより詳しく知りたい場合に参照できるようになっています。右側には、エージェントのデスクトップに直接表示されます。この具体例では、お客様がクレジットカードの利用停止を希望している場合(紛失や盗難など)を示しています。上部では、BedrockがQに対してエージェントが顧客に直接伝えられる内容と、問題解決方法の明確な説明(Mastercard Control Panelでカードを停止する方法)を提供しています。また、お客様自身でも実行可能であることを強調し、下部には、エージェントが次のステップを判断するために直接参照できるS3バケットに保存されている関連記事へのリンクが表示されています。

では、実験はどのように行われたのでしょうか? 最初の実験はカード事業部門で実施し、10人のスーパーエージェント(通常の業務ではEllaを参照する必要がないほど経験豊富なエージェント)を選びました。彼らにこのシステムを使用してもらい、得られた回答の評価(正確性、通常の対応との一致度、有用性)を依頼しました。約30,000件の記事から12,000件の静的記事とフローベースの記事を投入し、意図を判断するために顧客側の会話をQに入力しました。結果として、意図認識率は58%と低く、さらに悪いことに、適切な解決策が得られたのは3分の1程度でした。最も深刻だったのはレイテンシーの問題で、反応が非常に遅く、より迅速な対応を目指していた私たちの目的に反して、エージェントから悪い評価を受けました。

アジャイルの精神に則り、一旦立ち止まって考えた後、2回目の実験を実施しました。 2回目の実験では、記事数を12,000件から、パイロットの対象範囲に特化した1,000件に絞り込みました。また、自社のフロープロセスが複雑すぎると考え、フローベースの記事を除外して静的記事に焦点を当てました。検索しやすいようにコンテンツを構造化し、意図の判断にエージェント側の会話を入力しました。その結果、意図認識率はわずかに向上し、これは非常に興味深い発見でした - 私たちは、顧客が実際に使用している言葉に対して、顧客が本当にやりたいことを判断する上でのエージェントの重要な役割を過小評価していたのです。これにより精度は約50%まで向上し、さらに重要なことに、応答速度が大幅に改善されました。

次に私たちが行っているのは、今後の方針を評価することです。 ボードには、このアプローチを取ることで得られた利点と、私たちが達成した成果のいくつかの例が示されています。
このアプローチを取ることで、私たちは大きな学びを得ることができましたが、最も多くを学んだのは自社のナレッジ記事についてです。Amazon Qから最大限の効果を得るためには、Large Language Modelと連携できるように記事を構造化する必要があることに気づきました。これは、おそらくLLMベースのプロセスすべてに当てはまることでしょう。そこで私たちは、記事の再構築、メタデータの追加、不要な要素の削除を進めています。
例えば、これらの記事は、多くの場合、経験豊富なエージェントが、プロセスを知っているけれどリマインドが必要な他の経験豊富なエージェント向けに書いていました。ビジネス特有の言葉を多用し、「プロセス24」のような用語を、その実際の意味を説明することなく使用していました。そこで、そういった専門用語をすべて取り除き、記事を書き直しています。年末から来年初めにかけて3回目のパイロットを実施する予定で、大幅な改善が見込まれています。もし他の方々がAmazon Qの導入でより進んだ段階にいらっしゃるなら、ぜひお話を伺いたいと思います。私たちはこれに大きな価値を見出していますので、Amazon Qでこの段階を超えて素晴らしい経験をお持ちの方がいらっしゃいましたら、後ほどお声がけください。

最後に、AIの分野で特に期待している2つのことについてお話しします。1つ目はコールサマリーです。Jillが言及したように、私たちの方針は、本当に必要な時にお客様がエージェントに繋がれるようにすることです。しかし実際には、本当に必要とされる会話というのは非常に複雑なものです。様々な事項を探り、異なる方向性を検討し、多くのフォローアップアクションが必要になる可能性があります。そのため、エージェントはこれらの会話に多くの時間を費やし、次の電話に対応する前に内容を書き起こす必要があります。私たちは、AIエンジンにコール後のサマリー作成を任せ、エージェントは内容を読んで適切な要約になっているかを確認するだけで済むように、実験を行っています。
もう1つ期待しているのは、すでに実験を開始しているAgent Evaluationです。Jillが言及したように、私たちは年間2,500万件の通話を処理しており、それらすべてを個別にレベルで分析することは不可能です。チームリーダーが、学習ポイントやプロセスから少し外れている部分を特定するために、チームメンバーの通話をすべて聞くことは不可能です。Agent Evaluateでは、通話と比較できるルールの作成実験を開始しました。例えば、エージェントが追加サポートが必要な可能性のある脆弱性を探るための質問をお客様にしたかどうかをチェックしたり、規制産業である私たちの業界で、エージェントが「投資価値は上下する可能性があります」といった必要な免責事項を述べているかを確認したりしています。
マクロレベルでこれらのことが自動的に行われるようになり、チームリーダーは追加のサポートを必要とするエージェントとサービス提供の改善について、意味のある会話を持つことができるようになります。これら2つのポイントが特に期待されることですが、まだre:Inventで発表される内容は見ていませんし、Chrisもre:Inventでの発表内容については教えてくれません。本日は皆様、ご清聴ありがとうございました。お楽しみいただき、何か学んでいただけたことを願っています。この後お話をご希望の方は、ホールでお待ちしております。Jillを代表して、本日このような機会を与えてくださったAmazon、特にChrisのサポートに感謝申し上げます。皆様、誠にありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion