re:Invent 2024: AWSがGraviton4でAI/ML性能を30%向上 - EC2セッション


はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Optimize your AI/ML workloads with Amazon EC2 Graviton (CMP323)
この動画では、AWS GravitonのAI/ML分野での活用について詳しく解説しています。Graviton4では前世代から30%のパフォーマンス向上を実現し、最大192 vCPUまでスケール可能になりました。PyTorchなどのMLフレームワークでの最適化事例や、AnthropicがGravitonを活用してデータ処理パイプラインを200ペタバイト規模まで拡張した事例が紹介されています。また、SprinklrやDatabricksでの導入事例では、最大30%のコスト削減や3.5倍の価格性能比向上を達成しています。Vector Data StoreやRetrieval Augmented Generationなど、生成AIの実用的なユースケースにおけるGravitonの活用方法も具体的に解説されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
AWS Gravitonを活用したAI/MLワークロードの最適化



ビルダーの皆様、今朝はお越しいただきありがとうございます。この1週間、そして私がAWSに在籍している数年間、皆様との会話を通じて、皆様がビルダーであることを実感してきました。 ビルダーとして、私たちは仕事をするためのツールを必要としており、AI/MLワークロードをできる限り効率的に実行することが目標です。 「持っているツールがハンマーだけだと、すべての問題が釘に見える」という古い格言があります。これは、1つのツールですべてを解決しようとすることへの警告的な教訓です。ご存知の通り、AI/MLは非常に多様なワークロードの集まりですので、仕事に適したツールを選ぶ必要があります。

私はツールが大好きで、妻に言わせると少し度が過ぎるくらいなのですが、あらゆるツールが揃った工具小屋があれば素晴らしいと思います。そこで生成AIを使って、「もしAWSが工具小屋を作ったら、どんな感じになるだろう?」というイメージを生成してみました。 そしてこれが私が思い描いた、素晴らしいツールが詰まった工具小屋です。考えてみると、これはクラウドに私たちが持っているものと似ていますね。AWS Cloudには、AI/MLワークロードを実行するための幅広く深いAI/MLサービスとインフラストラクチャのポートフォリオがあります。

本日の私たちの役目は、皆様がここを出た後に、どのサービスを、そしてより具体的には、どのインフラストラクチャがAI/MLワークロードに最適な価格性能比を提供するかについて、十分な情報を得た上で判断できるようにすることです。従来型のMLから生成AIまで、さまざまなサイズのモデル、異なるデータタイプ、異なるビジネス目標や技術的目標など、多くの変数が絡み合っています。いつも同じツールばかり使っているとすれば、おそらくワークロードの一部をより効率的に実行する機会を逃しているでしょう。
Graviton3のAI/ML性能向上とソフトウェア最適化の重要性

AI/MLは連続的なコンピュートを使用します。このパイプラインを見てみましょう。これは非常に高レベルな抽象的なパイプラインです。基本的に、構造化データであれ非構造化データであれ、データを取り込み、そのデータを準備する必要があります。これはプロセスの中で非常に重要な段階です。なぜなら、モデルのトレーニングに多くの時間と労力を投資するのであれば、そのモデルにバイアスがなく、トレーニングプロセスに可能な限り良質なデータを投入したいからです。その後、モデルを評価する必要があります - 期待通りの性能を発揮しているか、除去したいと考えていたバイアスを除去できたかどうかを確認します。そこにフィードバックループがあるかもしれません。問題がある場合は、追加のデータ準備や追加のトレーニングが必要になるかもしれません。


最終的に、推論段階に到達します。従来型のAI/MLではパターンマッチングや意思決定を行い、生成AIの場合はテキスト、ビデオ、音声など、新しい出力を生成することになります。 これらすべての基盤となるのがソフトウェアです。ソフトウェアなしでは何も起こりません。データの取り込みと準備のツール、データ分析、フィルタリング、検索ツール、そしてトレーニングと推論ワークロードを支えるツールがあります。 ここでのポイントは、最大限のパフォーマンスを確保するためのMLフレームワークと最適化された数学ライブラリです。先ほど述べたように、これらはCPUがワークロードの一部に対して有効で魅力的な選択肢となる場合から、AWS TrainiumやInferentiaのようなAWSの目的特化型アクセラレーターまで、連続的なコンピュートによって支えられています。これらは素晴らしいテクノロジーです。


このセッションでは、汎用CPUに焦点を当て、特に私たちの汎用CPUであるAWS Gravitonについてお話しします。 AWSは、お客様のワークロードを実行するための、最も幅広いAI/MLインフラストラクチャのポートフォリオを提供しています。このスライドの上部には、AWS Siliconが示されています。左側には最大40%の価格性能比を実現するAWS Gravitonがあり、後ほど、Gravitonでのお客様のAI/ML活用の具体的な事例をご紹介します。右側には、推論用チップのAWS Inferentiaと学習用チップのAWS Trainiumがあります。また下部には、Intel、AMD、NVIDIA、Qualcommといった私たちのシリコンパートナーからのシリコンオプションも示されています。

Gravitonは、この時点で6年の歴史があります。最初のGravitonは2018年のre:Inventで発表されました。昨年、第4世代プロセッサーのGraviton4を発表し、この4世代を通じて4倍のパフォーマンス向上を実現しました。これは非常に印象的な成果です。
各世代での改善を見ると、Graviton2と比較してGraviton3で25%のパフォーマンス向上、そしてGraviton4で30%のパフォーマンス向上を達成しています。これらの具体的な詳細と、AI/MLワークロードへの適用について、これから詳しく見ていきましょう。
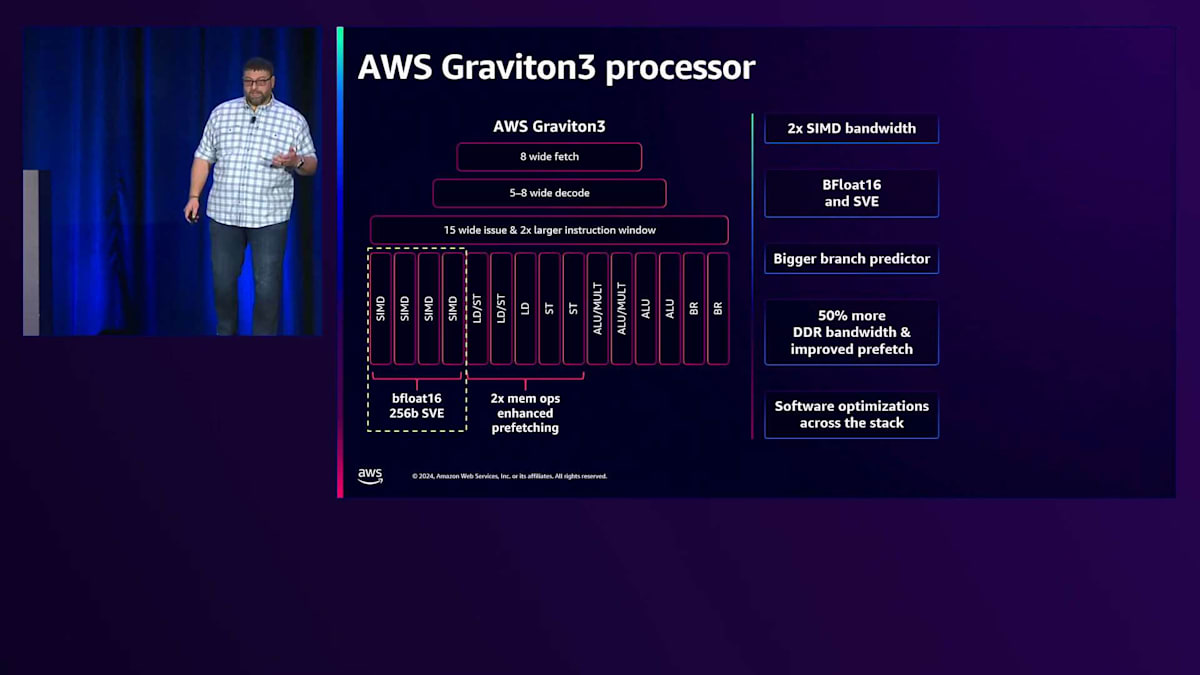
これはGraviton3 CPUのフェッチ実行ユニットの概要です。AI/MLに優れたパフォーマンスをもたらすGraviton3での具体的な変更点をいくつかご説明したいと思います。 Graviton3では、SIMDエンジンの幅を2倍に拡張し、前世代のNeon SIMDエンジンに加えてSVEを導入しました。AI/MLの高速化に適したBFloat16データ型をネイティブにサポートしており、これについても後ほど詳しく説明します。より大きな分岐予測器を搭載し、前世代よりも大規模で複雑なアプリケーションを処理できるようになりました。また、Amazon EC2において初めてDDR5メモリを搭載したプロセッサーとなり、最新技術が最初にGravitonプロセッサーに採用され、最大50%の帯域幅向上を実現しています。MLワークロードはメモリ集約型なので、このような強力な計算能力を詰め込む中で、いわば「野獣に餌を与える」ように、メモリ帯域幅を増やす必要がありました。
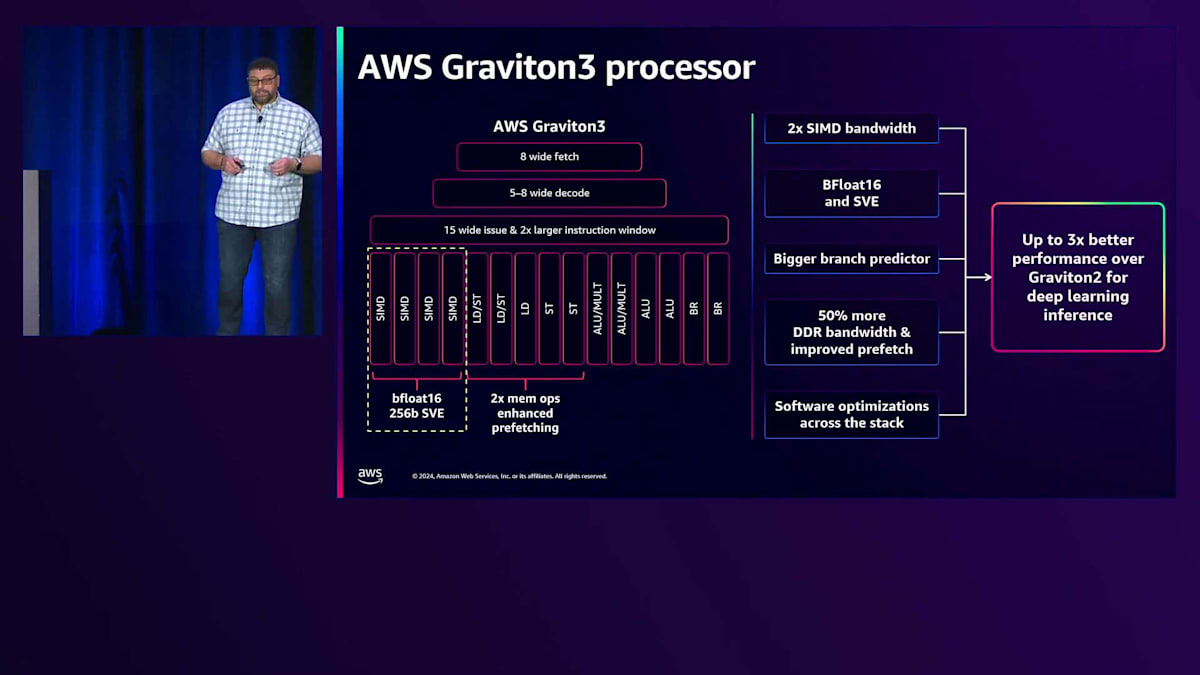

これらのハードウェア機能を活用するには、ソフトウェアの最適化が必要で、これについても後ほど詳しく説明します。 これらのソフトウェアの最適化とハードウェアの革新を組み合わせることで、ディープラーニングの推論において、Graviton2と比較してGraviton3で最大3倍のパフォーマンスを実現しています。
SprinklrとDatabricksにおけるGravitonの成功事例
顧客事例をご紹介します。Sprinklrは当初Graviton2を採用し、Graviton3が登場した際には、様々なAIワークロードに対してこれを採用することができました。すでにGravitonでARMベースのプロセッサへの移行を経験していたため、非常にスムーズな移行が可能となり、スループットが20%向上、レイテンシーが30%削減、そしてコストを最大30%削減することができました。このケーススタディが公開された後、彼らはこのパフォーマンス向上による波及効果を検証しました。その結果、顧客からの問い合わせ解決が50%速くなり、サポートエージェントの生産性が40%向上し、同社とその顧客に対して実質的で大きな利益をもたらしたことが分かりました。

もう一つの例はDatabricksです。2022年、彼らはクエリエンジンにGravitonのサポートを追加し、Photonクエリエンジンで最大3.5倍の価格性能比を達成しました。今年に入り、MLランタイムプラットフォームにもGravitonのサポートを提供しました。下のグラフを見ると、Graviton3でハイパーパラメータチューニングを行うAutoMLの場合、同等のインスタンスタイプと比較して63%多くの実行が可能でした。これにより、同じ期間内でより広範な問題空間を探索し、より高いF1精度スコアを達成することができました。また、Spark MLlibの様々な機能では、30-50%の高速化を実現しました。
Graviton4の進化と多様なインスタンスタイプの提供

現在のGraviton4は、Graviton3のすべての機能を基盤として構築されています。Graviton3が64コアだったのに対し、Graviton4プロセッサは96コアを搭載し、デュアルソケット対応となったため、1つのシステムで最大192 CPUまで拡張できます。Graviton3がNeoverse V1だったのに対し、こちらはNeoverse V2コアをベースとしており、より高性能なコアとより多くのコアを実現しています。また、コアあたりのL2キャッシュを2MBに倍増させました。7チップレット設計を採用し、DDR5-5600の12レーンを備えています。Graviton3は8チャネルのDDR-4800でしたが、ここではチャネル数を増やし、より高速化しています。計算性能の向上に伴い、そのパフォーマンスを活用するためのデータ入力能力も向上させる必要がありました。最後に、ネットワークとストレージへの接続のために96レーンのPCIe gen5を搭載しています。

インスタンスの観点から見ると、最大30%のパフォーマンス向上が得られます。
このパフォーマンス向上は、CPU自体を考慮した場合のコアあたり30%の向上です。さらに、チップあたり50%増加し、1つのインスタンスに2つのチップを搭載することで、最大48 XLで192 vCPUまで、最大3倍のvCPU数を実現しています。メモリ容量は最大6倍となり、今年初めに発表されたX8gインスタンスでは3テラバイトのメモリを搭載し、チャネル数の増加とチャネル速度の向上により、75%のメモリ帯域幅の向上を実現しています。


Graviton4のML性能をGraviton3と比較すると、15〜28%の向上が見られます。こちらのチャートでは、様々なMLフレームワークと機能における性能向上を示しています。このスライドについては後ほど詳しく説明させていただきます。MLフレームワークについてより詳しいコンテキストをご説明したいと思います。そうすることで、なぜこの性能向上が印象的なのかがよりよくご理解いただけると思います。

ここに2つの引用がありますが、AnthropicについてはNovaが後ほど詳しく説明してくれますので、そちらは割愛させていただきます。DataStaxは、これまでAstra DBサービスをGraviton3上で運用してきました。その結果、スループットと性能の大幅な向上、そしてコスト削減を実現することができました。Graviton3への移行に投資したことで、Graviton4が利用可能になった際にもスムーズに対応することができました。Graviton4でテストを行い、さらなる性能向上とコストパフォーマンスの改善を実現することができたのです。
では、Graviton3とGraviton4を搭載したインスタンスについて見ていきましょう。AI/MLで使用する際に注目すべきこの2世代のプロセッサについてです。第7世代ファミリーのすべて - 7は第7世代を表し、GはGravitonを示します。7Iであればインテル、7AであればAMDを示すことになります。第7世代では、C、M、Rインスタンスがあります。第8世代のGraviton4ベースのインスタンスでは、5種類のインスタンスタイプがあります。日曜日にI8gを導入したことで、現在C、M、R、X、Iが利用可能です。これらはAWSのリージョン全体で利用可能ですが、すべてのインスタンスがすべてのリージョンで利用できるわけではありません。Monday Night Liveのキーノートをご覧になった方はご存知かと思いますが、Dave Brownが発表したように、過去2年間で導入したCPU容量の50%以上がGravitonベースとなっています。
MLフレームワークとライブラリの最適化:PyTorchを中心に


ここで話題をMLフレームワークとライブラリに移したいと思います。優れたハードウェア機能があっても、ソフトウェアでサポートされておらず、必要な方法で利用できなければ意味がありません。ソフトウェアの観点からアーキテクチャを見ると、これらがソフトウェアから見える機能であり、したがってMLフレームワークと最適化された数学ライブラリでサポートされていることを確認する必要があります。


まず第一にVector Processing Engineです。Graviton3と4の両方がSVE(Scalable Vector Engine)を搭載しているため、そのサポートを確保する必要があります。Matrix Multiply Accumulate命令とDot Product命令も備えています。さらに、AI/MLに有益なネイティブデータ型として、特にBFloat16があります。これはFP32と同じダイナミックレンジを持ちながら、半分のスペースしか占めません。これにより、モデルをより小さくすることができ、メモリ帯域幅やキャッシュへの負荷を軽減することができます。この機能だけでも最大2倍の性能を実現できます。
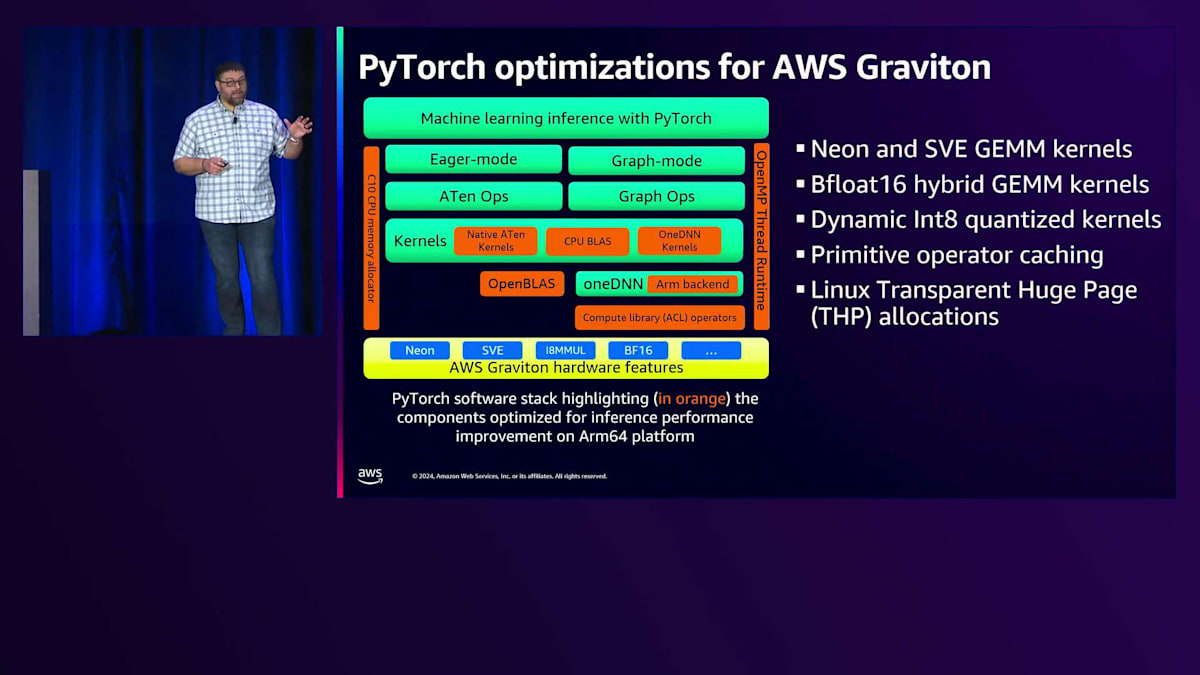
ここで少し PyTorch について具体的に見ていきましょう。このダイアグラムでオレンジ色で示されている部分は全て、ARM アーキテクチャと AWS Graviton 向けに大幅な最適化が施されています。私たちのソフトウェアチームは、Arm および上流コミュニティと協力して、これらの最適化を上流に反映させ、皆様が簡単に利用できるようにしました。Neon や SVE の GEM カーネル、BFloat16 GEM カーネル、動的な整数量子化カーネルが実装されています。また、ハードウェアやモデルの実行状況に基づいて最適なパフォーマンスを自動的に選択するヒューリスティックモデルも備えています。さらに、オペレータの重複を減らしメモリフットプリントを削減しながらパフォーマンスを向上させるプリミティブオペレータのキャッシングも実装しています。そして大規模なデータセットを扱う際には、ページテーブル処理が非常に重要になってきます。
ページテーブル操作はパフォーマンスの観点から非常にコストがかかる可能性があるため、できるだけ最小限に抑える必要があります。Transparent Huge Page の割り当ては、このパフォーマンス最適化の実現に役立ちます。

PyTorch のコンパイルフローを見てみましょう。torch.compile は、以前のデフォルトだった Eager モードを Torch Inductor に置き換える新機能で、先ほど説明した性能最適化にアクセスすることができます。これにより、コンパイルされたオペレータに対して oneDNN プリミティブを選択し、オーバーヘッドを最小限に抑えて可能な限りオペレータを融合させ、さらに cosine や Gaussian 関数などには ATen VEC バックエンドを使用することが可能になります。

これらの機能は、最新バージョンの PyTorch を使用するだけで簡単にアクセスできます。これらの最適化を活用するために必要なランタイム設定をいくつかご紹介します。大規模な入力データに対しては、BFloat16 Fast Math カーネルと THP アロケーションを使用できます。小規模な入力データに対しては、OpenBLAS バックエンドと軽量ランタイムを使用できます。これらのオプションは、大規模または小規模な入力それぞれに対して約2倍のパフォーマンス向上をもたらします。表示されている QR コードをスキャンすると、セットアップに関する詳細なリソースに直接アクセスできます。これらのリソースは後でも見つけられるよう、ハッシュタグ CMP323 を付けて投稿しておきます。

PyTorch に限らず、他の ML フレームワークでもこれらの最適化を実装してきました。これらの最適化が含まれている推奨最小バージョンをご紹介します。これらのフレームワークをお使いの場合、より新しいバージョンを使用することをお勧めしますが、少なくともここで紹介するバージョンから最適化が開始されています。

このソフトウェアへのアクセスについては、Python wheelsとAWS Deep Learning Containersを通じて利用可能です。試してみたい場合、始めるための最適な方法の1つは、Hugging Faceのモデルを使用することです - AWS Graviton上で標準的なHugging Faceモデルを実行して、お使いのモデルでどのような可能性があるか評価することができます。GitHubには詳細な技術ガイドがあり、また多数のブログやユーザーガイドも用意されており、迅速かつ効率的に始められるようサポートしています。MLワークロードの実行環境を選択する際は、完全な自己管理型か、マネージド型のオプションを選べます。AWS GravitonはAmazon EC2上で利用可能で、Amazon ECSやAmazon EKSを通じたコンテナ化、さらにはAmazon SageMaker MLサービスを通じても利用できます。

これらのソフトウェア最適化により、様々なフレームワークで以下のような性能向上を達成することができました。JAXではバージョン0.4.36以降で約1.5倍の性能向上、ONNX Runtimeで約1.6倍、Llama.cppで2倍以上の性能向上を実現しています。先ほど言及したtorch.compile機能は2倍の性能向上を実現し、PyTorchのバージョン1.13から2.0シリーズにかけて、ソフトウェアの改良により全体で3.5倍の性能向上を達成しています。人気のあるフレームワークはすべて最適化され、すぐにお使いいただける状態になっています。
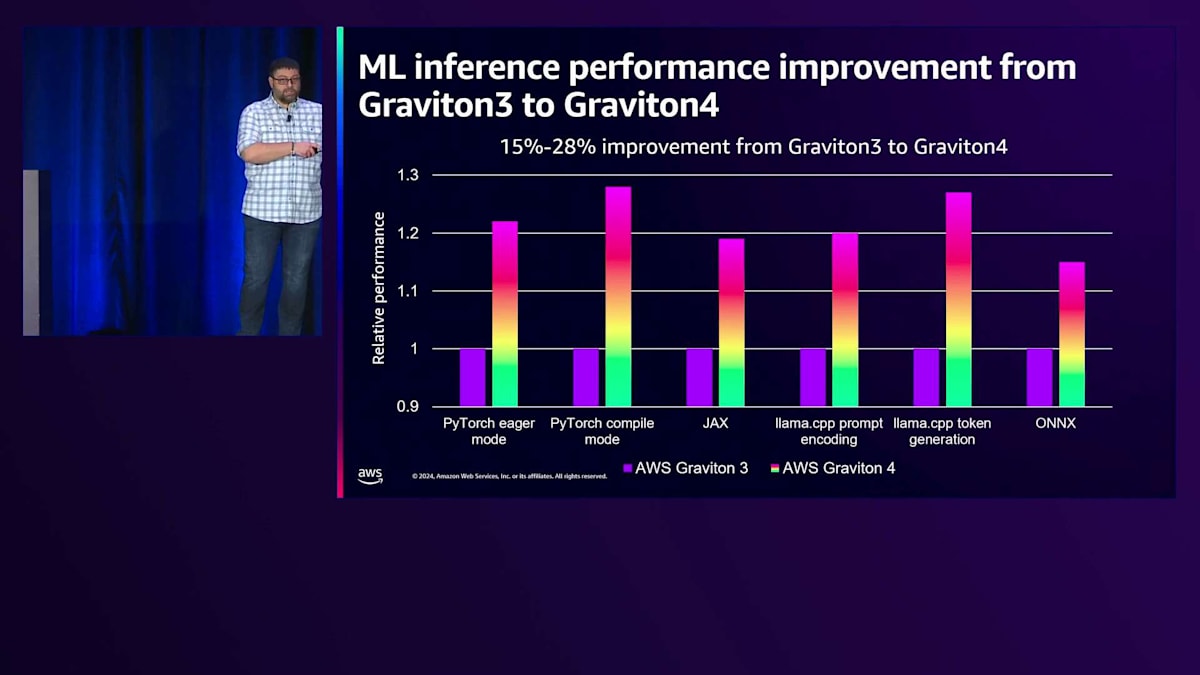
このスライドに戻りますが、AWS Graviton4は、今お話しした性能向上をさらに発展させています。AWS Graviton3におけるソフトウェアの改良による1.5倍から3.5倍の性能向上に加えて、AWS Graviton4ではさらに15から28%の性能向上を実現しています。


これでMLフレームワークとライブラリについての説明は終わりです。 ここで、同僚のShengcaiに引き継ぎたいと思います。彼は生成AIのテキスト生成、Retrieval-Augmented Generation、そしてデータの取り込みと準備について説明します。その後、AnthropicのNovaからお話を伺い、最後に私が締めくくりを行います。
AnthropicのNovaが語る生成AI推論ワークロードとGravitonの活用
ありがとうございます、Jeff。皆さん、こんにちは。Shengcaiです。これからのセクションでは、生成AIの推論ワークロードにより焦点を当てて説明させていただきます。3つのセクションに分かれています。まず、生成AI推論ワークロードから始めて、次のトークン生成に焦点を当てます。次に、今日の生成AI分野で非常に重要な要素であるベクターデータベースについてお話しします。そして、データ取り込みとデータ準備におけるML課題について説明し、Novaを招いて、AnthropicがどのようにGravitonを使用してこれらの課題に取り組んでいるかについてお話しいただきます。 では、生成AI推論ワークロードについて説明していきましょう。
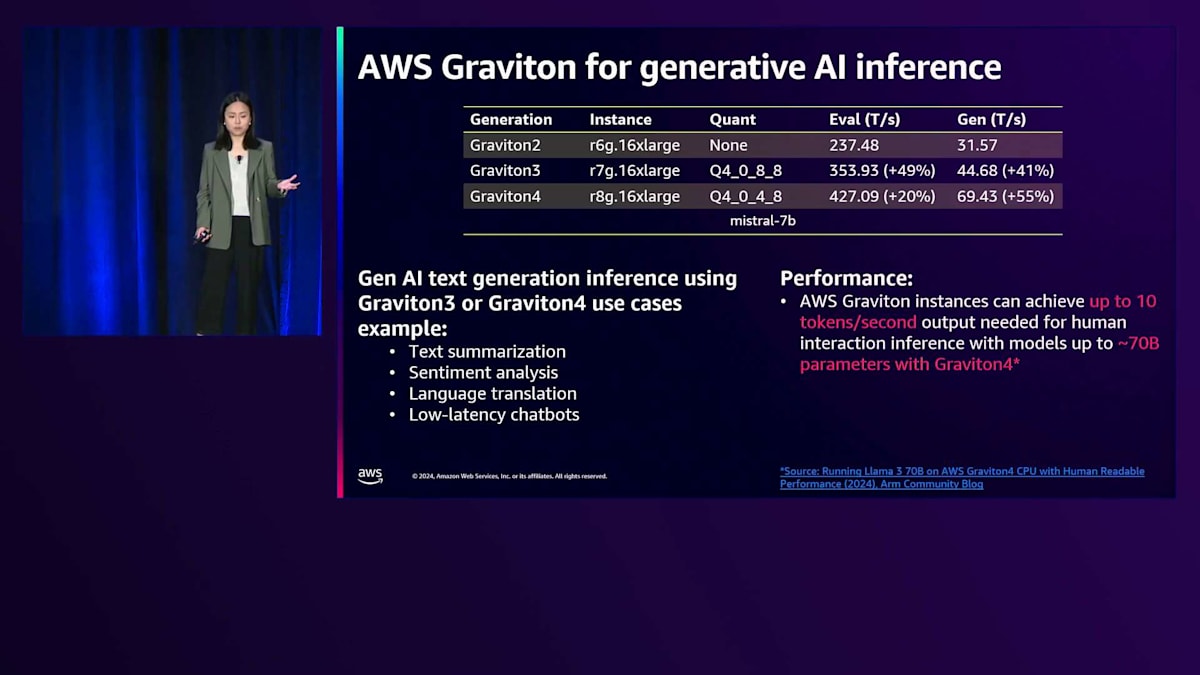
Generative AIの推論ワークロードについて、私たちはGraviton2からGraviton4にかけてMistral 7Bモデルの生成をテストしています。推論結果を向上させるためにハードウェアのジャンプチャネルを活用できるよう、モデルの重みをブロックレイアウトに再配置することが推奨されています。Graviton3は8x8のブロックレイアウトを、Graviton4は4x8のブロックレイアウトを採用しています。量子化を進めることで、次のトークン生成速度は前世代と比べて55%向上し、秒間約70トークンにまで改善されました。
Graviton3とGraviton4におけるハードウェアとソフトウェアの改良により、テキスト要約や感情分析、低レイテンシーのチャットボットなど、より高度な推論ユースケースに対応できるようになりました。パフォーマンス面では、計算負荷の高いLlama3 70Bモデルを単一のGraviton4インスタンスに成功裏にデプロイしました。これにより、人間の読書速度をわずかに上回る秒間10トークンの速度を達成し、次のトークン生成における約100ミリ秒というサービスレベルアグリーメントを満たすことができました。
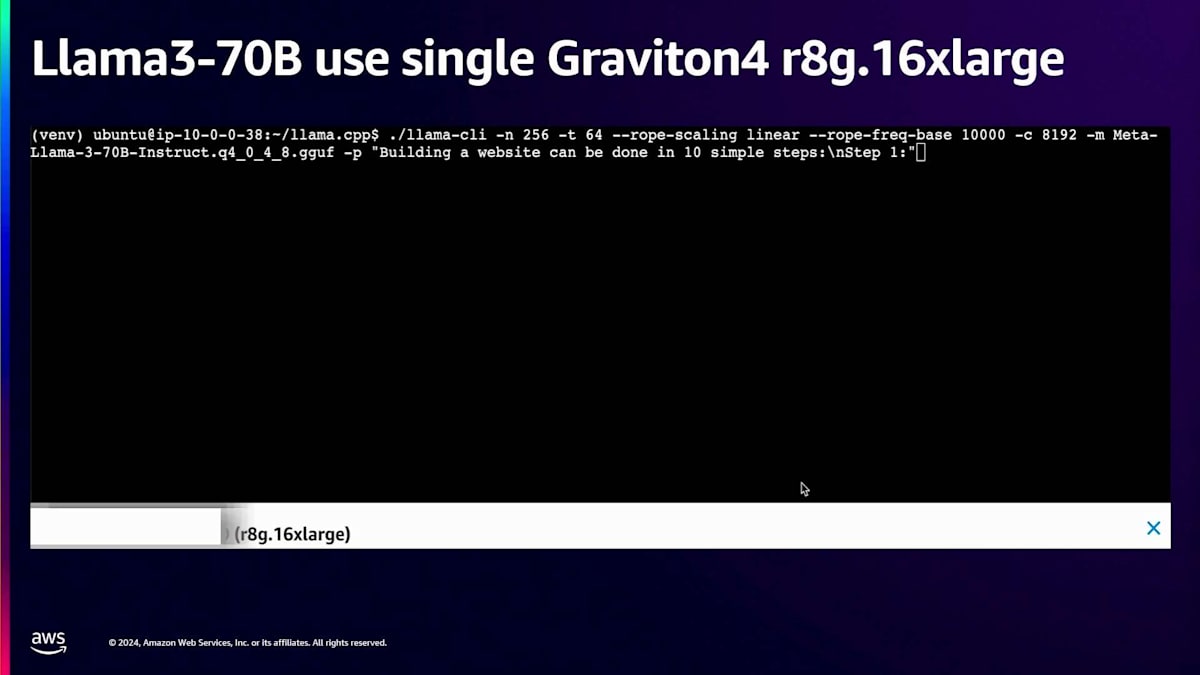
次のセクションでは、Llama.cppを使用して単一のGraviton4 r8g.16xlargeインスタンス上でLlama3 70Bモデルを実行するクイックデモをお見せします。Llama.cppフレームワークを使用しているため、パフォーマンスを調整・改善できる複数のパラメータが提供されています。vCPUに合わせてスレッド数を64に設定しました。スタートボタンをクリックしたら、トークンがどれだけ速く生成されるか、そしてそれが読みやすさの要件を満たしているかどうかを、ビデオと一緒に確認してみましょう。
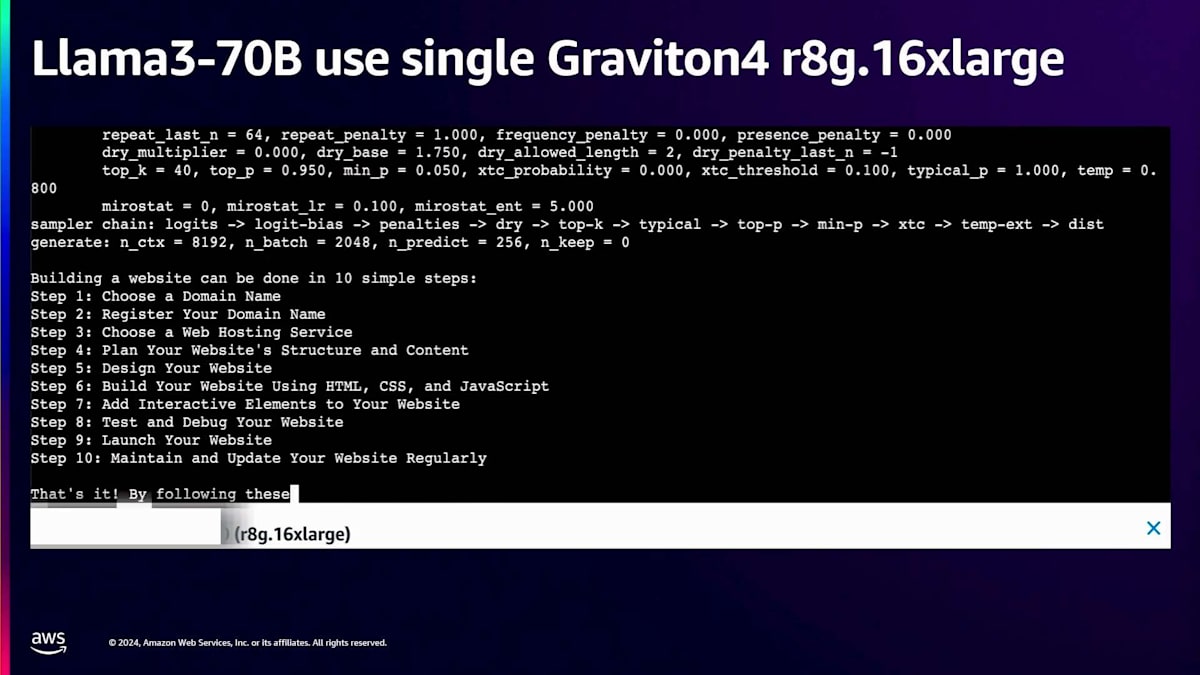
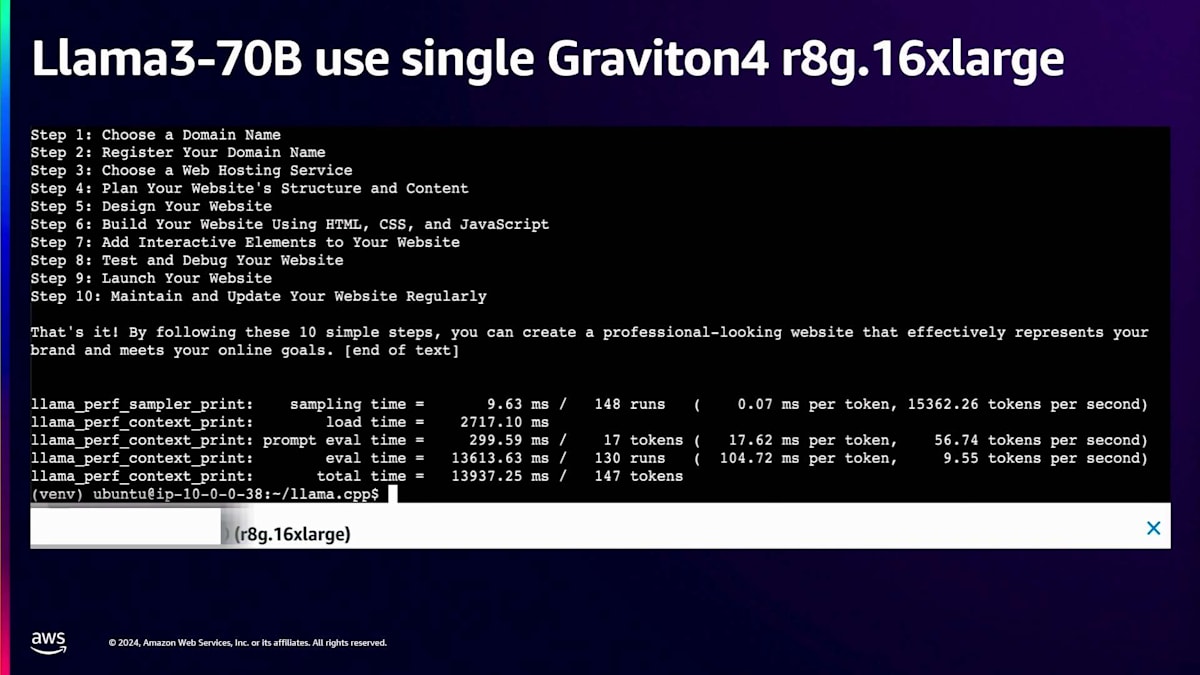
それでは始めましょう。開始すると、メタデータとシステム情報が表示され、その後プロンプトと次のトークン生成が続きます。下部にはこれまでのベンチマーク結果が表示されます。ご覧の通り、単一のr8g.16xlargeインスタンス上で秒間9.55トークンを達成しており、これは非常に印象的な結果です。
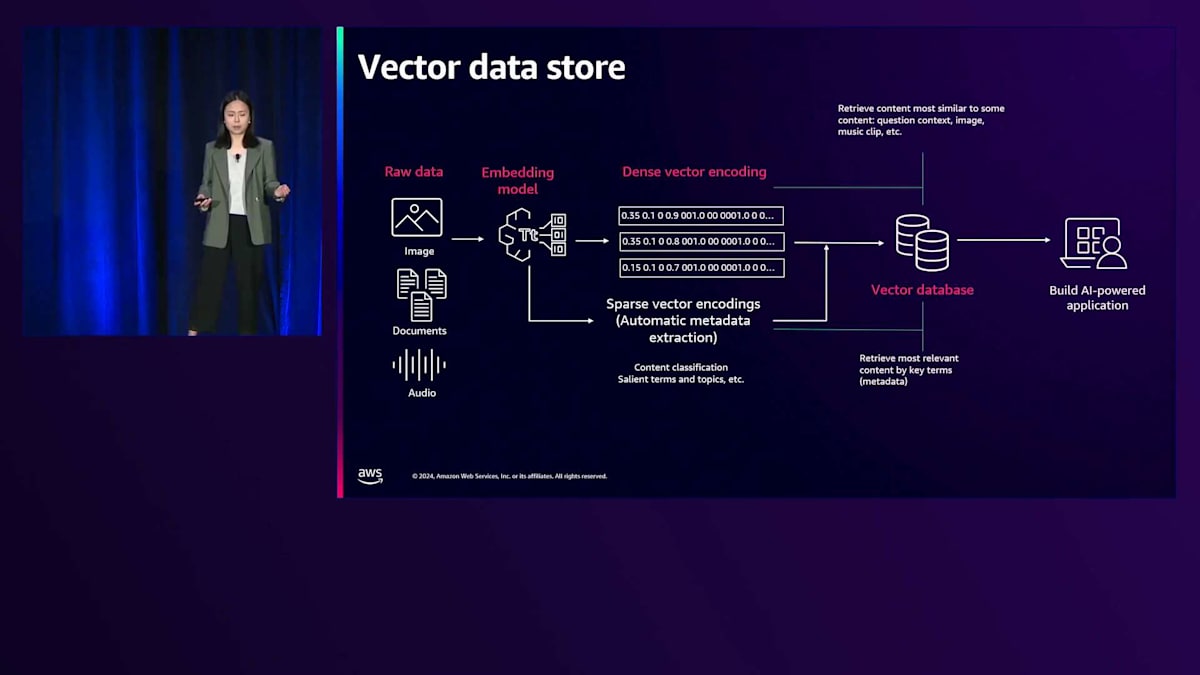
では次に、今日のGenerative AIワークロード、特にRetrieval Augmented Generationに不可欠なVector Data Storeについてお話しします。埋め込みモデルは、構造化データと非構造化データを取り込み、アセットの意味とコンテキストを捉えたベクトルにエンコードします。Vector Data Storeは、インデックス付けされたベクトルをN次元空間における高次元の点として保存・検索できるほか、最近傍点のより高速な検索を可能にする機能も備えています。Vector Data Storeを使用することで、従来のキーワードベースの検索よりも高速に関連情報を見つけることができる主題的類似性検索が実現可能になります。

Vector データストアは通常、より高いメモリ帯域幅を必要とします。先ほどJeffが説明したように、Gravitonインスタンスは世代を重ねるごとに進化し、メモリもDDR4からDDR5にアップグレードされ、より高速なベクトルの取得と比較のためにチャネル数も増加しました。また、頻繁にアクセスされるベクトルのレイテンシーを低減するため、コアあたりのL2キャッシュも改善しています。これは特にGraviton3とGraviton4において、ベクトル類似度計算を加速する上で重要です。I/Oとストレージネットワーキングの高速化のため、PCIeサポートもジェネレーション4からジェネレーション5にアップグレードされました。さらに、コア数を増やすことで、全体的なCPUの最適化とベクトル演算の並列化も向上しています。Graviton3は、高次元空間における浮動小数点演算を高い同時実行性で改善し、Graviton2と比較して60%のパフォーマンス向上を実現しています。
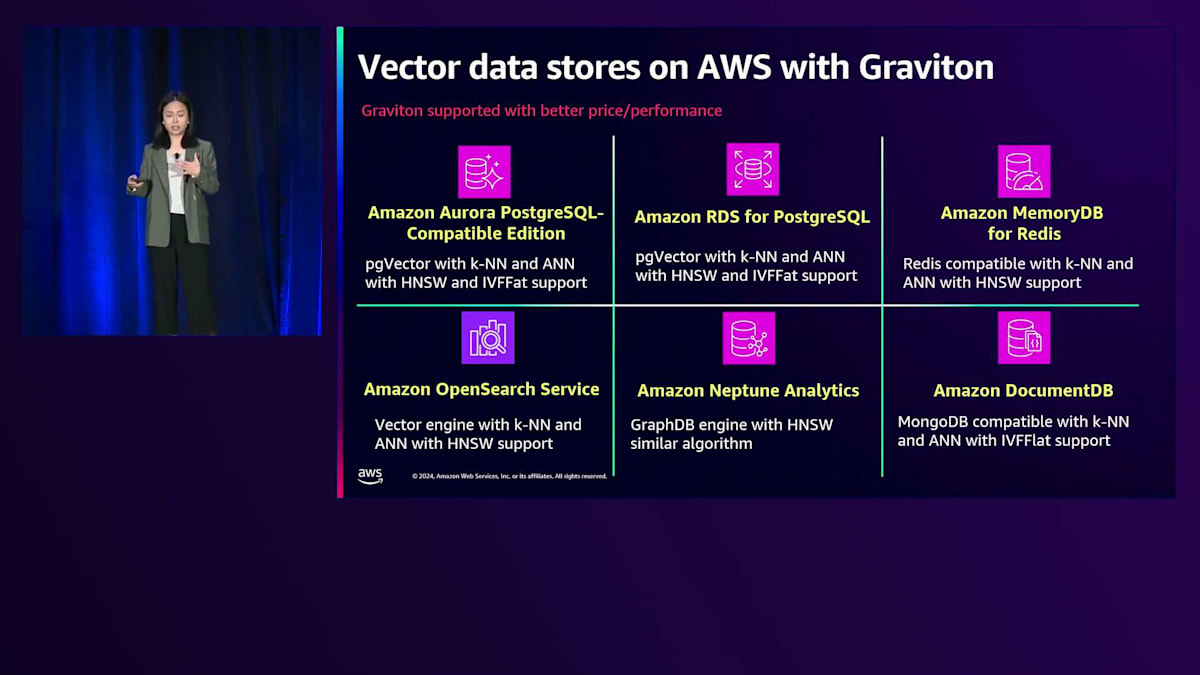
AWSでは、ベクトル演算の並列化はさまざまな方法で実現できます。AWS EC2インスタンス上で自己管理型のベクターデータベースを実行することもできますが、AWSはベクターデータベース機能を備えた複数のマネージドサービスも提供しています。例として、Amazon Aurora RDSを取り上げましょう。これはpgVectorをサポートしており、100万ベクトルと64,000次元までスケールアップが可能です。

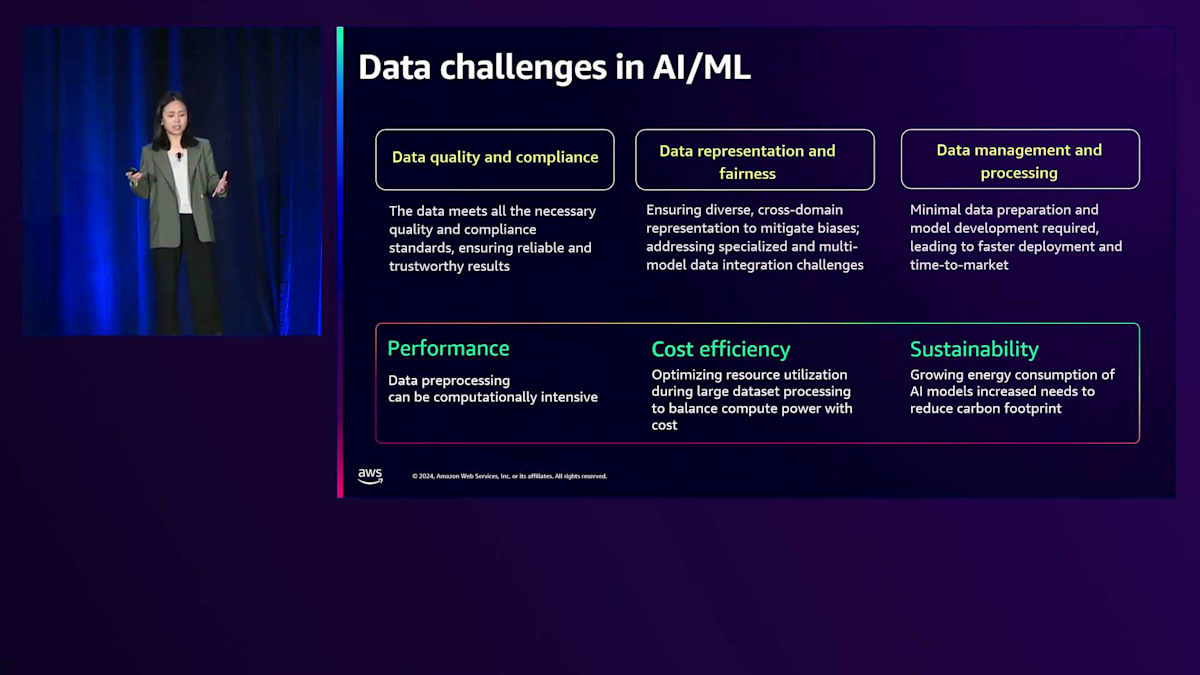
生成AIのインフラについて説明してきましたが、次はAI/MLとデータについて見ていきましょう。まずはデータの課題について説明します。データのコンプライアンスを確保しながら、データ品質を維持することが重要です。データにバイアスがなく、解決しようとしている問題を正確に表現できることが不可欠です。データの保存や保守を含むデータ準備パイプライン全体を通して、データ管理とデータ処理が重要な課題となります。特に大規模なデータセットを処理する場合、データ処理は非常に計算負荷が高くなるため、計算能力とコスト効率のバランスを取るためにリソース使用の最適化が重要です。さらに、AIモデルのエネルギー消費と炭素排出量削減の必要性も増大する懸念事項となっています。
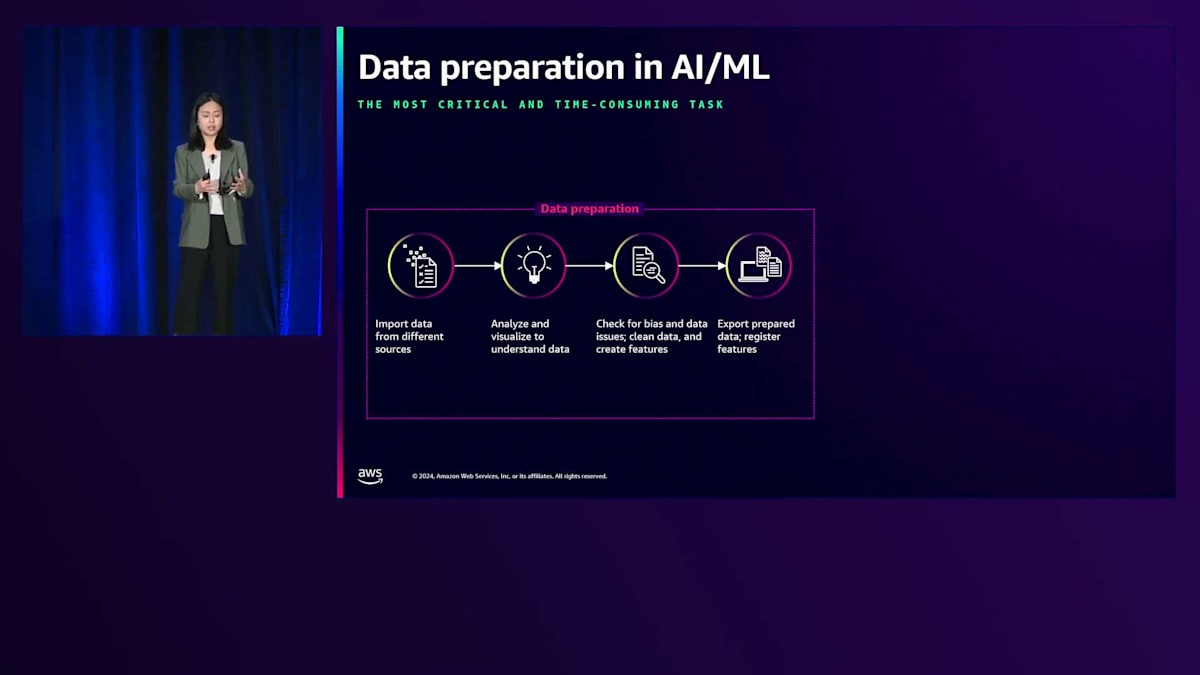
これらのデータの課題は、最も重要で時間のかかるタスクであるデータパイプライン全体に及びます。まず、さまざまなソースからデータを取り込み、次にデータを分析・可視化してデータを理解し、バイアスをチェックし、データの問題に対処してからクリーニングとFeature Engineeringを行います。その後、すべてが良好であればそのデータを使ってモデルのトレーニングを行いますが、これは一度きりのプロセスではありません。許容できない精度が検出された場合、モデルの精度を向上させるためにデータ品質を改善する必要があり、データ準備をやり直す必要があるかもしれません。
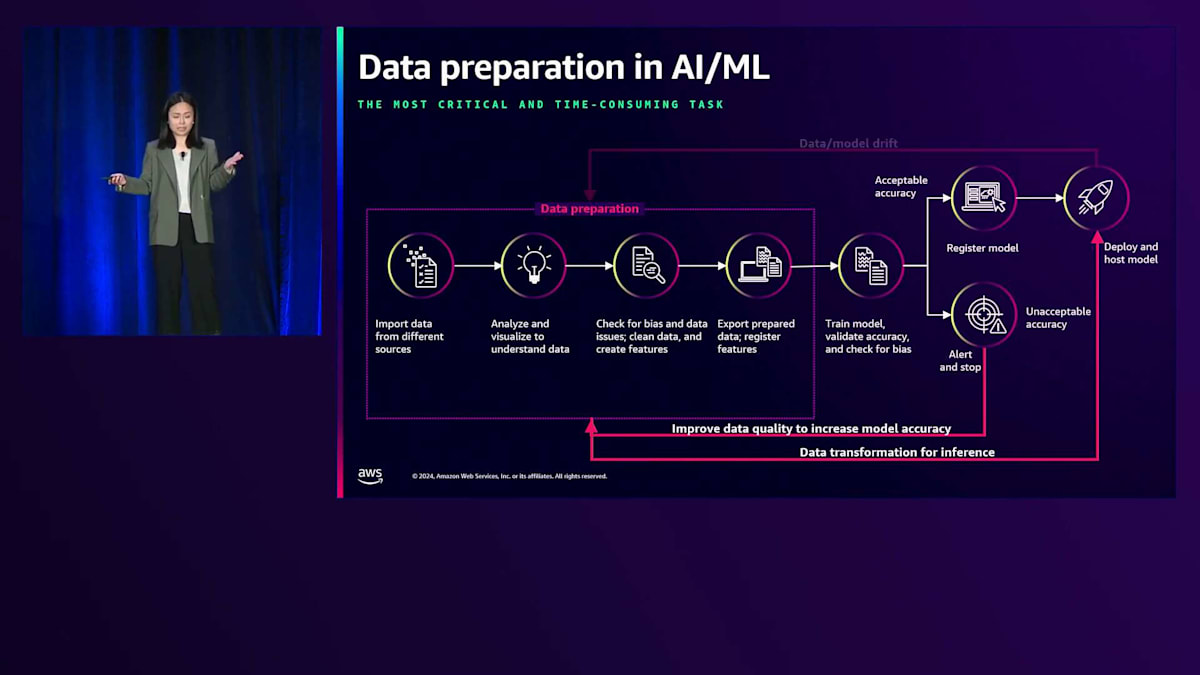
すべてが良好な場合は、推論ワークロード用にモデルをデプロイしますが、本番環境でもデータ準備が必要になる場合があります。しかし、最初は問題なく見えても、時間とともにデータとモデルの両方がドリフトする可能性があり、追加の準備サイクルが必要になることがあります。これらの課題について説明してきましたが、次はこれらの課題にGravitonでどのように対処できるかを見ていきましょう。Nova DasSarmaをお迎えして、彼らがどのように取り組んでいるかについてお話しいただきます。
Anthropicのデータ処理パイプラインにおけるGravitonの活用と最適化戦略

ありがとうございます。JSIの皆様に感謝申し上げます。おはようございます。こんなに早い時間にお集まりいただき、ありがとうございます。 Anthropicのノヴァと申します。もしかしたらご存じない方もいらっしゃるかもしれませんが、私どもはClaudeを開発しているAI研究・安全性企業です。本日は、Gravitonについて、特に私たちのデータ処理パイプラインでの活用方法についてお話しさせていただきます。この1年間で、私たちは多くのワークロードをIntelからGravitonに移行しており、様々な面で大きな効果を上げています。


私たちの目標についてですが、最も重要なのはコスト効率の良いスケーリングを実現することです。また、副次的な効果として、多くのワークロードで同じパフォーマンスを維持しながら消費電力を40%削減できるという、サステナビリティの向上も実現しています。これはコストと炭素排出量の両面に反映されています。 AWSでワークロードを実行している場合、Gravitonで最適化することができます。私たちは様々なインスタンスタイプを使用しています。一般的な用途のワークロードには、m7gd.4xlargeを使用しています。これは標準クラスのインスタンス、つまりディスクを搭載した小型のGravitonです。これは特に、大規模なインスタンスフリートでのダウンロードやHTML処理など、IO負荷の高いワークロードに効果的です。
高性能コンピューティングには、C7g.xlargeインスタンスを使用しています。高性能コンピューティングにこのような小さなインスタンスを使用する理由を不思議に思われるかもしれません。これは主にワークロードの集中度に関係しています。私たちは、多数のスレッドレベルでの並列処理ではなく、インスタンスレベルでの並列処理を実現するため、多数の小さなインスタンスを使用して、インスタンスごとの高いパフォーマンスを実現する方法を好んでいます。
このアプローチは、前処理の後に抽出やリキューイングを行うようなリンク抽出などのタスクに効果的です。メモリ集約型のワークロードには、R8g.48xlargeインスタンスを使用しています。これは大規模なSparkシャッフルなどの操作に特に適しています。また、異なるインスタンスタイプのプロビジョニングにはKarpenterを使用しています。これらのファミリーは私たちの主力インスタンスタイプですが、Karpenterは柔軟なインスタンスプロビジョニングを提供し、特定のサイズが利用できない場合や、ワークロードをより少ないインスタンスに効率的にパッキングできる場合のインスタンス割り当ての最適化を支援します。

これは私たちのインジェストとデータ処理パイプラインに関連しています。モデルをトレーニングする際には、大量のテキストを処理し、それを基本的にはfloat型であるトークンに変換する必要があります。私たちの運用規模についてお話ししましょう。 昨年は、ペタバイト規模の重複排除処理を実行しており、多数のi4iインスタンスを使用して4〜5日で処理することができました。今年は、データセットを200ペタバイトまで大幅にスケールアップしながら、総処理時間を短縮することができました。この改善は、インスタンスの総数を増やしたことと、i4iから第8世代のGravitonインスタンスへの移行など、より強力なハードウェアを活用したことの両方によるものです。
これらの改善による影響は大きなものでした。私たちの研究者は、シャッフル、フィルタリング、エンドツーエンドのデータパイプラインを実行する際に、反復的に作業を行います。並列処理の戦略は様々ありますが、人間はそれらを上手く管理することが得意ではありません。実験の反復時間が4-5日から1-2日に短縮されたことで、研究能力が大幅に向上しました。この効率化により、200ペタバイト規模であっても、ミスを発見した際にパイプライン全体を簡単に再実行できるようになりました。

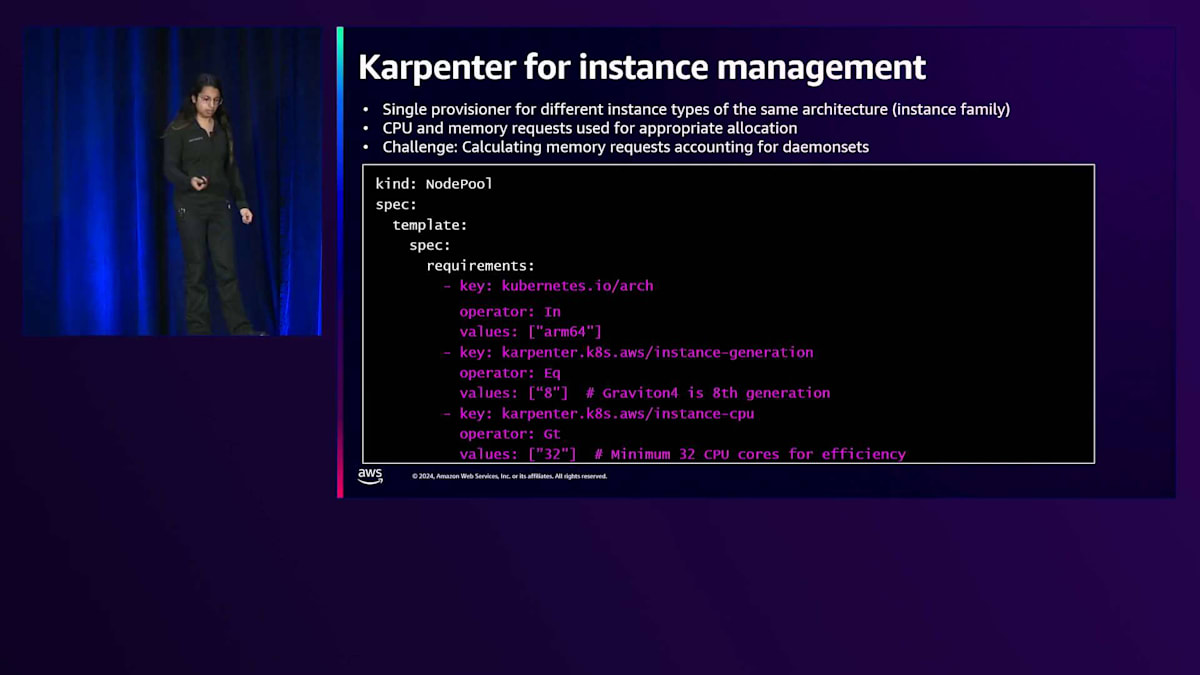
では、これをみなさんのワークロードに実装するために必要なことについて説明しましょう。「バッテリー同梱」型のソリューションについては多く耳にしていますが、DevOpsやその他のプラクティスに統合するためには、いくつかの作業が必要な領域があります。Dockerビルドパイプラインとコンテナ化環境について見ていきましょう。 インスタンス管理にはKarpenterを使用し、これらをフリートに組み込んでいます。アーキテクチャをarm64に設定し、特定の世代とサイズの要件を指定する新しいノードプールを実装しました。これが私たちのクラスプロビジョナーで、効率性を考慮して特定サイズ以上のインスタンスを探します。ワークロードを基盤ではなくタイプで理解するため、異なるインスタンスタイプに対して単一のプロビジョナーを持つことを目指しています。
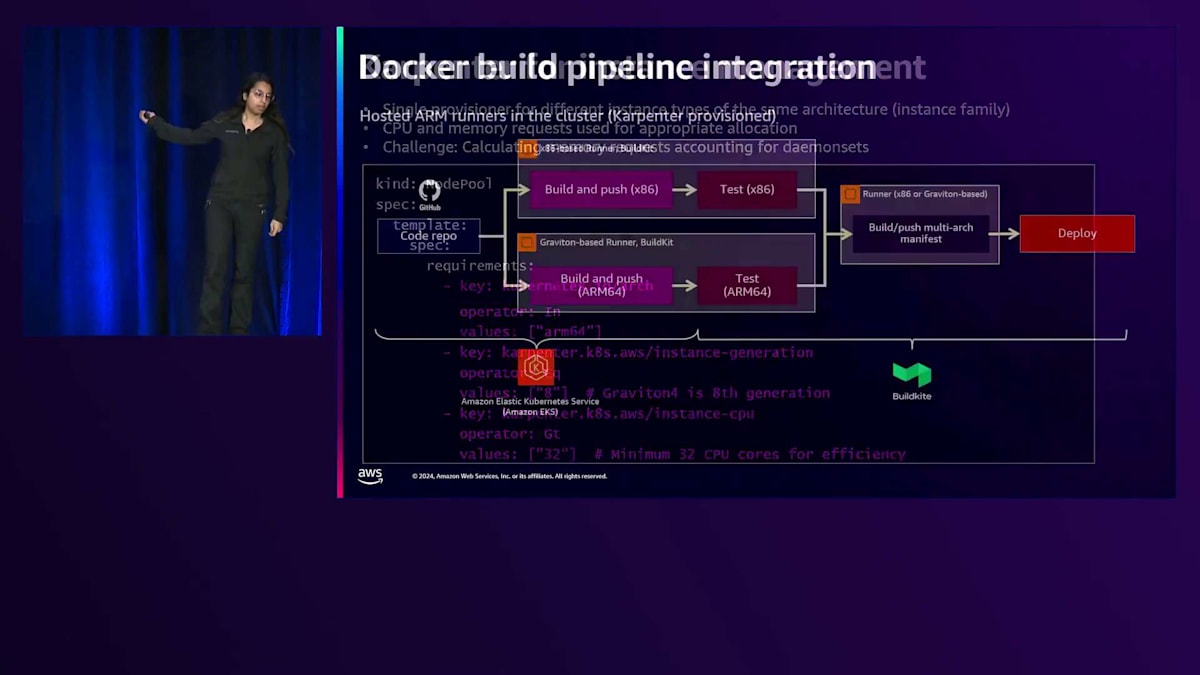
Dockerビルドパイプラインについては、以前は直接的なフロースループロセスでした。現在は、x86ベースのランナーとGravitonベースのランナーに分割しています。BuildKitを使用してDockerをビルドし、その後ビルドとプッシュの操作、テスト、そしてこれらをマルチアーキテクチャマニフェストに統合します。
これらのステップが完了すると、このマルチアーキテクチャマニフェストをビルドしてプッシュできます。ここでマルチアーキテクチャを採用している理由は、まだIntelでも作業を行っており、スポットインスタンスの可用性などの要因に基づいて、ジョブに適したシェイプを選択できる柔軟性を持たせたいからです。GravitonとX86を同じワークロードで組み合わせるために、すべてがJavaベースでJVMがあるため、統一されたイメージを使用しています。
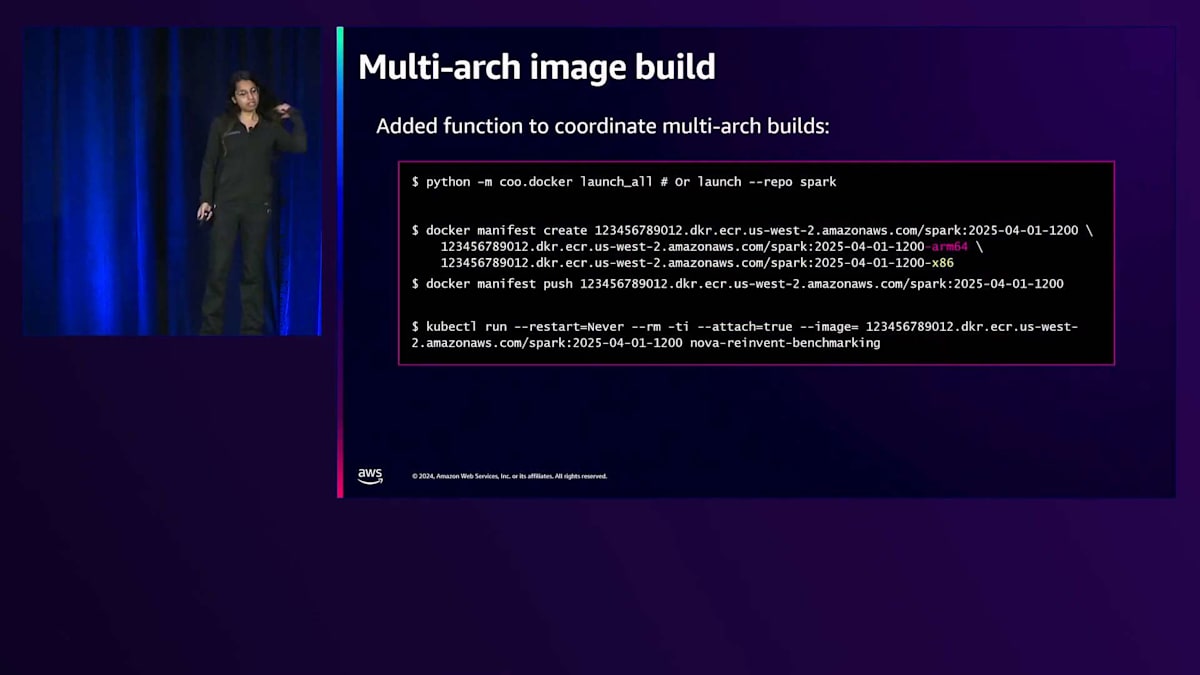
これが実際にコンポーネントをクラスターにローンチする際の様子です。私たちは内部ツールを使用し、特定のリポジトリでこれらをローンチします。最終的には、arm64とx86のプッシュされたイメージを1つのマニフェストにまとめるmanifest createを行います。kubectl runを実行するだけで動作するはずです。これはとても良いことですね。私はこのプロセスがもっと難しいものになると思っていましたが、そうではありませんでした。


マイクロアーキテクチャの最適化と、最高のパフォーマンスを得るために必要なオブジェクトレベルの対応について、詳しくお話ししましょう。私たちはPythonを使用していますが、Rustも使っています。テキスト処理やリンク抽出、IO集中型の処理にはRustが最適なんです。Rustコードでは、Large System Extensionsを必ず有効にしてください。これらのほとんどは、特定のCPUをターゲットにすると自動的に有効になります。今回の場合、Neoverse N1をターゲットにしたことで20%のスピードアップを達成できました。Neoverse N2もターゲットにすることができます。
カーネルでのSVEサポートを得るため、Amazon Linux 2023に移行しました。以前は Amazon Linux 2を使用していましたが、SVEサポートが利用できませんでした。求めるパフォーマンスを得るには、最新のAMIを使用するようにしてください。また、TLSのパフォーマンス向上のため、ベクトル化されたTLSをサポートする最適化ライブラリであるaws-lc-rsを採用しました。
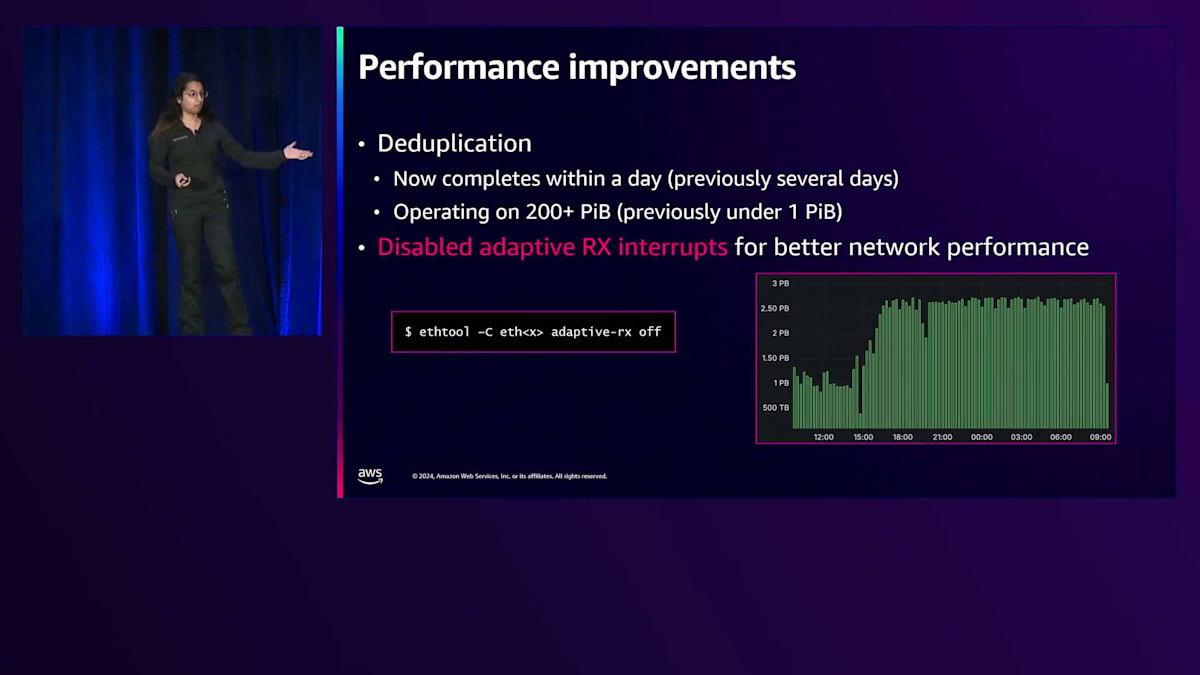
このグラフを見ると、デプロイ前後のパフォーマンスの違いがわかります。これは複数の異なる最適化を同時に組み合わせた結果です。デプロイを進めるにつれて、スループットが増加していることがわかります。このパイプラインでは、1ペタバイトから約2.8ペタバイトまで、1分あたりの処理能力が向上しました。高速化を進める中で直面した課題の1つは、CPUがネットワークの処理速度を上回ってしまう場合があることでした。CPUがENAやネットワークカードの処理速度を上回れない場合、パケットのAdaptive Receiptは重要な最適化となりますが、これらのコアでは最適化されているため、それを無効にすることでより良いネットワークパフォーマンスが得られます。

これが私たちのデータ戦略にとって何を意味するのか、お話ししましょう。最大の利点は、より大規模なデータセットでこれらのフィルターを実行できることです。私たちは意味的な重複排除などを行っています。ここでベクトルについて話しましたが、大量のテキストのEmbeddingを取得し、それを使ってクラスタリングやフィルタリングを行い、モデルにとってより良いデータセットを生成することは、私たちにとって非常に重要です。以前は、データのサブセット内で重複排除を行うShard重複排除によってスケーリングを行っていました。
画面上の図を見ると、異なる色が表示されており、Shard内での重複を検出しています - オレンジ同士、青同士、紫同士です。しかし、Shard間にはまだ重複が存在しており、結果として重複が残ってしまう可能性があります。グローバルな重複排除は私たちにとって重要です。多対多でスケールアップするには、より多くのデータをキャッシュに入れることや、さまざまな改善が必要でした。


グローバルな重複排除の方がより良い結果を示しており、データ量が大幅に削減される一方で、データの質は向上していることがわかります。多くの場合、重複排除率はデータ量に対して線形的にスケールするわけではなく、データソースによって非常に特殊なスケーリングパターンを示します。重複排除に関する実験を行うのは困難でした。数十ペタバイト規模での実験が可能になったことは、より良いモデルを作成する上で非常に有益であり、それはのような結果に反映されています。
ワークフローの適応についてお話ししましょう。私たちは純粋なDockerベースのビルドプロセスからNixビルドプロセスへと移行しました。システムアーキテクチャの最適化を活用するため、ワークフローのすべてをファイル化したいと考えました。変更点の1つは、パッケージソフトウェアの使用から、使用するインスタンス上ですべてをビルドする方式への移行でした。これはNixでは簡単で、アプリケーションのインストールリストを含むDockerfileから、パッケージ宣言のリストを含むNixファイルへと移行しました。基本的にはCPUのターゲットを変更するだけで、コンパイラが必要なものをすべて取得してくれました。
社内ではJAXを広く使用していますが、使用していたバージョンではJAXのARM対応が利用できませんでした。新しいイメージでJAXを利用できるようにするため、バージョンをアップデートする必要がありました。また、ARMで実行できないワークロードにも遭遇しました。結果として、ワークフローにアーキテクチャ固有のノードセレクターを実装することになりました。それまでは、クラスターの任意のノードで何でも実行できると広く想定していました。特にレガシーソフトウェアを扱う場合、Intelの数学拡張機能が必要なことがわかっている場合には、アーキテクチャ固有のノードセレクターを設定することが有用です。

他の数字も見てみましょう。 私たちの数字は、ステージで見た他の例ほどドラマチックではないかもしれませんが、数十万コア規模での20%のコアあたりの削減は、私たちにとって大きな意味があります。コアあたり30%の電力使用量削減は、カーボンフットプリントの削減とパフォーマンス全体の向上につながっています。これまで様々なチップで最も困っていたのは、サーマルスロットリングでした。CPUに多くの電力を投入して熱に変換されると、シングルコアのパフォーマンスが低下する可能性があります。Graviton 4ではこのようなサーマルスロットリングの問題に遭遇していません。これは私たちにとって大きなメリットとなっています。

私たちは、研究をスケールアップする際のサステナビリティを非常に重視しています。大規模モデルを構築するという野心的なプロジェクトを追求する際に、コストや環境への影響を比例的または線形的に増加させないよう取り組んでいます。 ここで、Gravitonが特に優れている点について説明しましょう。一つの利点は、大量のコア数を持つことで、これは完全な並列処理が可能なワークロードに有利です。シャッフルやフィルター処理は、同一ドメイン内に数百のコアがあることで大きな恩恵を受けられるタスクです。
スケールアップについて話しましょう。これらの大規模なCPUインスタンスの素晴らしい点は、シャッフルなどの一部のワークロードのチャンクサイズを大きくできることです。つまり、インスタンス内でより多くの作業を実行できるため、ネットワーク操作のためにインスタンスの外に出る必要がありません。これは非線形的な増加であり、より大きなインスタンスを使用してその利点を活用できる場合は、間違いなく価値があります。これがX8gを好む理由の一つで、GravitonとLargeコアを備えた高メモリインスタンスだからです。ネットワークパケット処理能力が向上している点も重要で、簡単に言えば、ネットワークカードからより良いパフォーマンスを引き出せるということです。
ENAとEFAによるエンドツーエンドの最適化、そしてネットワークアダプターとEFAは、広範なパフォーマンスチューニングなしでも優れたパフォーマンスを実現する上で重要です。他のCPUでもENAから良好なパフォーマンスを引き出すことはできますが、Gravitonは特に分散データ取り込みに効果的に機能します。

Gravitonに関する今後の計画について、私たちはアクセラレーターベースのGravitonインスタンスに興味を持っています。現在、P5やTrainumを使用していますが、同じプロセッサーレベルの最適化を活用することができません。この混合フリートのために、現在も最適化コストが発生しています。Gravitonが私たちのフリートでより広く採用され、現在使用している他のコンポーネントの一部を段階的に廃止できることを楽しみにしています。また、一貫性と性能向上のため、コアインフラストラクチャのより多くをC7gやC8gインスタンスに移行したいと考えています。
昨夜このトークについて考えていた時、Prometheusインフラの一部をIntelのC5インスタンスからC7gに移行したところ、Write-Ahead Logのリプレイで大幅なパフォーマンス向上が見られました。これは私たちにとって重要です。なぜなら、非常に大規模なクラスターを持っており、PrometheusのWrite-Ahead Logが膨大なため、単一のインスタンスがダウンした場合に観測可能性を常に復元できるとは限らないからです。これは、それらのワークロードでSpotを使用しない理由の一つでもあります。より多くのものにSpotを使用したいと考えており、昨夜のテストによれば、これは順調に進んでいます。
私たちは、このプラットフォームにコアインフラストラクチャをさらに移行したいと考えています。標準的なCPUを使用するその他の多くのユースケースがあり、Dockerイメージをマルチアーキテクチャに移行していくにつれて、これらが役立つことを期待しています。
Graviton移行のための実践的アドバイス

皆さんに実践的なアドバイスをお伝えしたいと思います。まず、実際に試してみることをお勧めします。マルチアーキテクチャイメージの作成は、特に難しいものではありません。インタープリター型言語や、コンパイル言語を使用している場合でも、Nを使用してマルチアーキテクチャビルドができないか検討してみてください。私たちの場合、ビルドプロセスの定義は予想以上に簡単でした。
ベンチマークワークロードの開発は必須です。新しいインスタンスを導入する際、私たちは何度もこのプロセスを経験してきましたが、パフォーマンスの向上が不確かな場合もありました。私たちの場合、事前に決められたデータセットを使用してシャッフル操作を行い、そのワークロードを再実行します。これにより、ニーズに最適なインスタンスタイプを特定しやすくなります。
インスタンスのサイジングとメモリ比率の違いには注意が必要です。純粋なCPUに基づいてワークロードを選択する場合がありますが、メモリ比率が異なる可能性があります。同じファミリー内で選択することで、適切な比率を維持できます。Sparkのようなメモリがボトルネックになる可能性があるものを使用している場合は、インスタンスファミリーセレクターを指定するようにしてください。ビルドとデプロイメントのパイプラインは、最後の仕上げで課題となることが多いので、早い段階から注意を払うことが重要です。
今日お話したパフォーマンス最適化の側面は興味深く、様々なアプローチが可能です。私たちはAmazonが提供するRustとGravitonのベストプラクティスガイドに従い、それは上手く機能しました。しかし、最も時間を費やしたのはビルドプロセスの確立でした。そのため、これを考慮に入れ、早い段階からチームを巻き込むことが重要です。移行中のモニタリングと可観測性の重要性も軽視しないでください。ノードセレクターの問題が発生した際、スケジューリングされていないことに気づかず、問題になってから発覚しました。セッション後、質問を受け付けますので、よろしくお願いします。
AI/MLにおけるAWS Gravitonの利点と今後の展望

私は登壇前に何人かのClaudeユーザーと話をしていたので、AnthropicのNovaからGravitonの活用方法について、そして彼らがどのように運用しているのかその内部を見られることを楽しみにしています。では、なぜAI/MLにAWS Gravitonを使用するのでしょうか? 基本的に、幅広いインスタンスタイプ、ファミリーサイズが利用可能で、リージョンの可用性も広いため、非常にアクセスしやすいのです。AWSアカウントをお持ちの方なら誰でも - この会場の皆さんは持っていると思いますが、もしお持ちでない方は作成して、今日の午後にはこれらを試すことができます。
最適化されたサポートがすぐに使える形で、幅広いMLフレームワークをサポートしています - 私たちは、お客様が独自のユースケースでGravitonのパフォーマンスを実現できるよう、できるだけシームレスで迅速、簡単にしたいと考えています。期待通りに動作しないものがありましたら、アカウントチームを通じて私たちに連絡してください。改善できるよう、ぜひ知らせていただきたいと思います。AI/MLフレームワークは基盤となるアーキテクチャを抽象化するので、通常、モデルはそれとインターフェースを取り、NovaがX86からARMへの移行について話したことの一部は、実際にフレームワークで処理され、より迅速で簡単になります。
他のプロセスと並んでMLを統合できる容易さは重要です - 時にはCPUで実行される他の機能と並んで推論処理を行う必要があります。それらを組み合わせて、他のワークロードのすぐ隣で推論のユースケースを実行できることは非常に有益です。最終的に、最適化された価格性能比が重要です。AI/MLには多くの計算が必要で、ワークロードを展開し、うまくスケールさせていく際には、できるだけ効率的に行いたいものです。

AI/MLにCPUを使用する場合、考慮すべき変数が多くあります。Cheng Caiから聞いたように、最大700億パラメータまでの生成AIテキスト生成は、単一のGravitonノードで実行できます。データの取り込みと準備に関しては、AnthropicのNovaから聞いたように、彼らはパイプライン内で広範に活用しています。Retrieval Augmented Generation (RAG)のためのVector DBは、モデルを強化する人気の方法です。GravitonはVector DBを実行するための優れたプラットフォームで、自己管理型でもShengcaiが話したマネージドサービスを通じてでも利用できます。また、自然言語処理、分類、ランキング、クラスタリングなどの従来型のクラシカルなAI/MLワークロードにも優れています。


さて、行動を呼びかけたいと思います。私はNovaのバージョンが気に入っています - Gravitonは単に動作する、それほど難しくなかった、とにかくやってみよう、すべて良いことばかりだと。冗談はさておき、AI/MLパイプラインについて考えてみてください。アクセラレータが不要かもしれない場所で、アクセラレータを使用している可能性はありませんか?CPUを使用できる場合、それはよりコスト効果が高くなります。アクセラレータは素晴らしい技術ですが、明らかな理由でCPUよりも高価で、その投資からROIを得るためには、それらを忙しく保つ必要があります。多くの人々がまずGPUやアクセラレータについて考えます - あのハンマーのたとえを思い出してください。しかし、ワークロード内の多くの機能に対してCPUが高い能力を持っていることを忘れないでください。

自分のワークロードを見直して、Gravitonが役立つ可能性のある部分を確認してみましょう。使用しているフレームワーク、モデル、モデルのサイズを確認し、CPUが適しているかどうかを検討してください。ここでは、さまざまなフレームワークと利用可能な最適化について詳しく説明しました。もしこれらが皆さんのワークロードと重なる部分があれば、価格性能比を最適化する道筋はかなり明確になるはずです。 基本的には価格性能比を評価してください。先ほどの工具箱の例に戻りますが、クラウドでは、AWSアカウント内で必要なものがすべて手に入り、実験や評価が容易にできることを当たり前のように考えています。Gravitonインスタンスを素早く起動できます - これまで使ったことがない方でも、すぐに起動して実験を始め、特定のワークロードで達成できる価格性能比を素早く判断することができます。わずかな投資で、かなりの節約を実現し、上司から高く評価されることも可能かもしれません。
最後に、本日は皆様のお時間をいただき、ありがとうございました。セッションのアンケートにぜひご協力ください。皆様からのフィードバックを大切にしています。すべてのフィードバックを確認させていただきます。特に良かった点や、できれば避けたいですが、気に入らなかった点がありましたら、具体的にコメントをお願いします。評価だけで具体的なフィードバックがない場合、改善のしようがありません。何について言及されているのかわからないのです。それでは、ご参加ありがとうございました。残りのre:Inventもお楽しみください。このあと質問を受け付けています。では、良い一日を。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion