re:Invent 2023: AWSのRAGアプリケーション構築 - Bedrock知識ベースの活用と最新AI開発トレンド
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - Use RAG to improve responses in generative AI applications (AIM336)
この動画では、Amazon Bedrockのknowledge basesを活用したRetrieval Augmented Generation(RAG)アプリケーションの構築方法を学べます。foundation modelのカスタマイズ手法やRAGの仕組み、embeddingsの重要性など、具体的な技術的洞察が満載です。さらに、LangChainとの統合やAgents for Amazon Bedrockとの連携など、最新のgenerative AI開発のトレンドも押さえています。RAGアプリケーション開発の複雑さを抽象化し、簡単に構築できる方法を知ることができます。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
Retrieval Augmented Generation (RAG)の概要と本日の講演内容

さて、そろそろ始めましょう。皆様、generative AIアプリケーションでの応答を改善するためのretrieval augmented generationの使い方に関する講演にご参加いただき、ありがとうございます。ここに来られた目的がそれだと良いのですが、もしそうでなくても、今日は私たちの話を聞いていただくことになりますね。

では、始めましょう。今日は盛りだくさんの内容を用意しています。foundation modelのカスタマイズ、なぜカスタマイズを検討すべきか、一般的なカスタマイズ手法などのトピックを扱います。その後、特にretrieval augmented generation(RAG)に焦点を当て、その仕組みを詳しく説明し、データ取り込みワークフローからembeddingsの仕組みまで、様々な要素を網羅し、この会議で耳にしたかもしれない多くの概念を分かりやすく解説します。
次に、AdamとSwamiのkeynoteでお聞きになったかもしれませんが、Knowledge Bases for Amazon Bedrockをご紹介します。そして、RAGアプリケーションの構築をいかに簡単にしているかについてお話しします。最後に、knowledge basesの機能がAgents for Amazon Bedrockなど、Bedrockエコシステムの他の部分とどのように連携するか、また、RAG機能の構築にLangChainなどのオープンソースのgenerative AIフレームワークをどのように活用できるかについてお話しします。
講演者の自己紹介とKnowledge Bases for Amazon Bedrockの認知度確認
自己紹介を忘れていました。私はRuhaab Markasです。Knowledge BasesとAmazon Lexのプロダクトマネジメントを率いています。
そして私はMani Khanujaです。worldwide specialist organizationのgenerative AI specialistのテクニカルリードを務めています。今日はRuhaabと一緒に発表させていただき、Knowledge Bases for Amazon Bedrockを使ってretrieval augmented generativeアプリケーションをどのように構築できるかについて、皆様をご案内させていただきます。
では、手短に伺いたいのですが、Bedrock の Knowledge Bases について、基調講演や事前情報で聞いたことがある方は手を挙げていただけますか? はい、素晴らしいですね。かなりの方が聞いたことがあるようですが、まだ聞いたことがない方もいらっしゃるようですね。今日は皆さんに様々な内容をお届けできそうです。
Foundation Modelのカスタマイズ:理由と一般的なアプローチ

まず、foundation model をカスタマイズすることについて考える理由をお話ししたいと思います。foundation model には、モデルに直接エンコードされた膨大な事前学習済みの知識が含まれています。GPT という用語を聞いたことがある方もいらっしゃると思いますが、その P は実際にこの事前学習済みの知識を指しています。しかし、重要なのは、これらのモデルは多くの場合、皆さんの特定の会社についてはあまり詳しくないということです。
foundation model をカスタマイズする最初の理由は、特定の分野の言語に適応させるためです。例えば、ヘルスケア分野にいて、販売している全ての医療機器をモデルに理解させる必要がある場合、ほとんどの場合、それはすぐには使えません。次に、これらのモデルを会社独自のタスクでより良いパフォーマンスを発揮させたい場合があります。例えば、金融サービス会社で、決算報告書のより高度な会計や分析を行いたい場合、これらのモデルにタスクについて教え、会社固有のデータセットやタスクに特化させたいと考えるかもしれません。
最後に、外部の会社データでこれらのモデルのコンテキストと認識を向上させたい場合にカスタマイズを検討することがあります。つまり、FAQ やポリシー、その他の社内文書などの会社のリポジトリをどのように foundation model にコンテキストとして渡すかということです。これらがカスタマイズを検討する理由のいくつかです。
Foundation Modelカスタマイズの手法:プロンプトエンジニアリングからRAGまで

次に、foundation model をカスタマイズする一般的なアプローチをいくつか紹介します。ここでは一般的なアプローチをいくつか取り上げますが、これらが全てではなく、他のアプローチもあります。これらは複雑さ、コスト、実装にかかる時間の順に徐々に増加していきます。

基盤モデルをカスタマイズする最もシンプルなアプローチは、プロンプトエンジニアリングです。プロンプトとは、基盤モデルに渡すユーザー入力のことです。これらのプロンプトを巧みに作成し、改良することで、基盤モデルから適切な出力を得るよう方向づけることができます。プロンプトエンジニアリングには、プロンプトプライミング、プロンプトウェイティング、さらには異なるプロンプトをつなげるなど、様々なアプローチがあります。
プロンプトプライミングは、プロンプトエンジニアリングの最も基本的な形態で、入力や指示を基盤モデルに渡すことを含みます。時には、プロンプトを通じて基盤モデルに特定の例やタスクを渡すこともあり、これはin-context learningとして知られています。もう一つのアプローチはプロンプトウェイティングで、基盤モデルに注目してほしい特定の要素により重点を置きます。例えば、モデルに知らないことには絶対に応答しないよう指示する場合、その指示を大文字にして複数の感嘆符を追加することで、指示の特定の部分にバイアスをかけ、強調することができます。最後に、プロンプトチェーニングがあります。これは複雑なプロンプトをより離散的な部分に分解し、一つのプロンプトの出力を次のタスクの入力として渡すことを含みます。

二つ目は、Retrieval Augmented Generation(RAG)です。これは外部の知識ソースを活用して、応答の質と正確性を向上させることに関するものです。ここで「外部の知識ソース」と言う場合、おそらくこれらの知識ソースは実際には自社内のものですが、事前学習済みモデルの知識という観点からは外部のものです。つまり、基盤モデルに新しい知識をもたらすことを支援しているのです。だからこそ「外部」という言葉を使っています。このプレゼンテーションを通じてRetrieval Augmented Generationについて詳しく掘り下げていきますが、基本的な手順としては、文書の集合体からある形式のテキストを取得します。それを基盤モデルのコンテキストとして使用し、最終的に自社のデータの知識に基づいた応答を生成します。これは、基盤モデルの高度な推論能力を活用しながら、それを特に自社のデータの知識に向けて導くことを考えると、非常に強力なアプローチです。
Model Fine-tuningとFoundation Modelの再訓練:高度なカスタマイズ手法

これら2つのカスタマイズ方法は、foundation modelを拡張するものです。実際にはfoundation model自体を変更するわけではありませんが、それを可能にするアプローチもあります。例えば、model fine-tuningです。Model fine-tuningでは、特定のタスクに特化したデータセットを使って、foundation modelを適応させることができます。これは教師あり学習のアプローチで、期待される出力や結果を指定した例を用いてfoundation modelを訓練し、特定のタスクに特化したモデルを作成します。Fine-tuningを通じて、実際にモデルの重みを更新します。モデルのパラメータがこのカスタマイズに基づいて調整されるのです。

最後に、おそらく最もコストと時間がかかるアプローチとして、foundation modelをゼロから訓練する方法があります。このアプローチは、モデルの訓練に使用するデータを完全にコントロールしたい場合に用いられます。モデルが訓練された他のコンテキストから inherited biasを取り除きたい場合もあるでしょう。これにより完全なコントロールが可能になり、ドメイン固有のモデルを構築できます。当然ながら、これには大量のタスク固有のデータと多くのコンピューティングリソースが必要となり、より複雑で時間とコストのかかるアプローチの一つとなります。カスタマイズのアプローチについていくつか紹介しましたが、これらが全てではありません。ただし、モデルカスタマイズでよく見られるアプローチの一部です。今日は特にRAGに焦点を当てて説明します。
カスタマイズ手法の選択:ユースケースに応じたアプローチ



なぜカスタマイズすべきか、そしてよく使われるカスタマイズの方法について理解したところで、どのような場合にどの手法を使うべきかについての考え方を見ていきましょう。どのアプローチを取るべきかを決定するのは、より簡単になります。まず、foundation modelに実行してほしいタスクについて考えることから始まります。そのタスクは外部データからのコンテキストを必要としますか?これが最初の判断ポイントです。答えがイエスの場合、次にそのデータアクセスがリアルタイムで必要かどうかを考える必要があります。もしデータが比較的静的なものであれば


リアルタイムで変化しないよくある質問や方針などの情報は、Retrieval Augmented Generation (RAG)の典型的なユースケースです。ただし、「比較的静的」という言葉を使ったからといって、このデータが全く変化しないわけではありません。このような構成でもデータは変化し得ますが、リアルタイムで変化するわけではありません。しかし、データがリアルタイムで変化し、さらに異なるツールに接続する必要がある場合、つまりデータベースからデータを取得したり、APIやアプリケーション、ツールと対話したりする場合は、Agents for Amazon Bedrockのユースケースとなります。また、エージェントとナレッジベースを組み合わせて非常に強力な機能を構築する方法についても説明します。これらは決して相互排他的なものではありません。

次に、過去のデータを活用し、情報のスナップショットを使用する比較的単純なタスクで、事前学習済みの基盤モデルですでに高いパフォーマンスを発揮できる場合、それはプロンプトエンジニアリングが本当に役立つ場面です。プロンプトエンジニアリングの一部として、特定のコンテキスト、タスク、または指示を渡すことで、多くの場合、非常に効果的な結果が得られます。最後に、過去のデータがやや複雑で、先ほど述べたように、タスク固有でより多くのタスクトレーニングが必要な場合、それはモデルのファインチューニングが非常に重要な目的を果たす場面です。本日のキーノートで聞いたかもしれませんが、Amazon Bedrockの全ての基盤モデルに対するファインチューニング機能が発表されました。Anthropic Claudeのファインチューニングサポートも近日中に提供される予定です。
Retrieval Augmented Generation (RAG)の仕組みとユースケース

ここまでRuhaabが説明したのは、なぜカスタマイズが必要なのか、いつカスタマイズすべきか、そして特定のユースケースからどのように逆算して作業を進めるかについての非常に有益な指針でした。では次に、Retrieval Augmented Generationとは何かを理解しましょう。名前が示すように、最初の部分は検索(retrieval)で、関連情報を取得し、それを元のクエリと組み合わせて(augment)、基盤モデルに渡して正確な応答を生成します。これには多くの側面があります。大量の情報があり、「よし、全てをモデルに追加しよう」と考えた場合、何が起こるか想像してみてください。複数の問題が発生する可能性があります。
まず、モデルが受け取れる入力サイズ(コンテキスト長と呼ばれます)が不十分で、エラーが発生する可能性があります。次に、人間に大量の情報を投げかけられた場合を想像してみてください。私たちも「ああ、質問に答えるのに関連する情報を選び出さなければ」と考えますよね。時間がかかります。モデルも同じです。そのため、関連情報を提供する必要があり、ここで検索部分が非常に重要になります。大規模な知識データから関連情報を取得し、その関連コンテキストをモデルに提供し、元のクエリと組み合わせることで、モデルが質問も理解できるようにします。そしてそれをモデルに入力することで、モデルは応答を生成できます。
プロンプトエンジニアリングもここで非常に重要な役割を果たします。ユースケースに応じて、モデルにさらに指示を追加したい場合があるからです。では、Retrieval Augmented Generationのユースケースを見てみましょう。RAGを考えるときに最初に思い浮かぶユースケースは、コンテンツの品質向上です。RAGを使ってどのようにコンテンツの品質を向上させているのでしょうか?それは幻覚(hallucination)を減らすことです。例えば、Ruhaabが言及したように、事前学習済みモデルについて話すとき、これらのモデルは非常に大きく、膨大な量のデータで学習されていますが、そのデータは

ある時点からのデータだったかもしれません。それはあまり最新のものではないかもしれません。これが1つ目のポイントです。モデルには最新のデータがないため、最近の情報について尋ねると、モデルは超知的に振る舞って不正確な回答をする可能性があります。回答の質を向上させ、幻覚を取り除くために、Retrieval Augmented Generation (RAG)テクニックを使用して改善できます。
その部分は説明しましたが、もし私が自分の知識や企業のデータのみに基づいて回答してほしい場合はどうでしょうか?モデル自身の知識からの回答は望まず、このモデルの知性を活用して私のデータにのみ焦点を当てたいのです。そこで、コンテキストベースのチャットボットやQ&Aなどのアプリケーションが登場します。RAGテクニックを使用してこれらのアプリケーションを構築できます。
3つ目のユースケースはパーソナライズド検索です。なぜQ&Aだけに限定する必要があるでしょうか?このテクニックを使ってレコメンデーションエンジンを強化し、私のプロフィールや好みに基づいたアプリケーションを作成することができます。例えば、小売業の場合、私が特定の商品を購入した履歴がすでにあります。その履歴と私の好みを使って、ユーザーにレコメンデーションを表示したい場合はどうでしょうか?RAGテクニックを使えばそれも可能です。
最後のユースケースは、その仕組みから私にとって非常に身近なものです。2022年12月に、applied machine learningとhigh performance computingに関する本を書きました。その頃、generative AIも人気が出始めていたので、ある人がgenerative AIを使って約400ページの本の要約をレビューとして投稿しました。それを想像してみてください。とてもクールで気に入りましたが、重要なポイントが抜けていました。そこで、RAGテクニックを使ってテキスト要約をするのはどうでしょうか?あるいは、興味のある特定の章だけを要約して、すべての重要なポイントを確実に含めたいかもしれません。RAGテクニックを使えばそれも可能です。
Semantic Searchの重要性とEmbeddingsの役割

ユースケースについて話しましたが、次は異なるタイプのデータをどのように使用するかについて議論しましょう。様々なタイプのデータセットを扱っているかもしれませんし、異なるタイプの検索も行われる可能性があります。では、どのテクニックを使うべきでしょうか?単純に特定のルールやキーワード、フレーズに基づいてドキュメントを取得する方法もあります。それで十分なら、そのまま使いましょう。常にユースケースや手元にあるデータから逆算して作業する必要があります。
2つ目は、構造化されたデータが大量にある場合です。実際に私たちがすでに一部の顧客と構築しているユースケースを想像してみてください。自然言語の質問がありますが、データは分析データベースやデータウェアハウス、トランザクションデータにあるとします。その自然言語の質問に基づいて、foundation modelを使ってクエリを生成し、そのクエリがデータベースで実行されて結果を返します。そして、foundation modelを使ってその結果を合成し、元の質問に対する答えを提供します。ユーザーとしては、質問をして結果を得るという完全な体験を得られますが、裏側では多くのプロセスが進行しているのです。
3つ目はsemantic searchです。これは例を挙げて説明したいと思います。というのも、この話は私を高校時代、いや実際には小学校時代にまで連れ戻してくれるからです。学生時代、読解問題というものがありました。文章が与えられ、その文章に基づいて特定の質問に答えなければなりませんでした。
子供の頃の私は賢いと思っていて、文章全体を読む必要はないと考えていました。質問のキーワードを使って、文章の2、3、あるいは4段落だけを探せばいいと思っていたのです。小学校時代とある程度中学校時代まで、いつも10点満点を取っていました。しかし、高校に入ると、その10点満点が実際には3点か4点に減ってしまいました。運が良ければの話ですが。理由は、成長するにつれて与えられる文章がより複雑になり、質問も巧妙になって、もはやキーワードだけでは答えられなくなったからです。質問を理解し、著者が高いレベルで何を言おうとしているのかを理解してから、答えを試みる必要がありました。

ここで、機械のsemantic searchが重要になってきます。テキストの意味を理解し、それに基づいて答えを提供することです。これが3つ目の検索方法で、今日は主にこの3つ目の検索方法に焦点を当てていきます。semantic searchを行う、つまりテキストの意味を理解するには、素晴らしく見えますが、私が行う場合、機械のようには行いません。では、機械がこれを行えるようにするには何をする必要があるでしょうか?実際に必要なのは、テキストを数値表現に変換することです。
Amazon Titan Text Embeddingsモデルの紹介とRAGワークフロー
なぜテキストを数値表現に変換する必要があるのでしょうか?それは、入ってくる質問に基づいて類似のドキュメントやテキストを見つけたいからです。数値の部分については後ほど説明しますが、単語間の関係を保持できるような方法で数値表現に変換する必要があります。単語間の関係を保持できなければ、私や機械にとって意味をなさず、目的は達成されません。したがって、embeddingsモデルの選択が重要です。なぜなら、あなた自身でこれを行うのではなく、embeddingsモデルを使用してテキストを入力し、単語間の意味、特徴、関係を維持する数値表現に変換するからです。

これが、セマンティック検索を行う際に、数値表現に変換するためのembeddingsモデルが必要な理由です。クエリが入力されると、それに基づいて関連する結果を取得します。では、これがどのように役立つのでしょうか?簡単に要約すると、意味に基づいて結果を取得するのに役立ちます。正確なコンテキストが得られるため、役立つのです。正確なコンテキストがあり、それをモデルに与えれば、正確な結果が得られます。ここで、各要素がどのようにつながっているかを見てみましょう。まずデータがあり、それをチャンクに分割してembeddingsを作成します。embeddingsを作成するモデルの質が高ければ、それが応答や検索に影響を与え、検索が応答に影響を与えます。これがembeddingsが重要な理由です。では、どのモデルを選ぶべきでしょうか?この点について、Ruhaabに説明を譲りたいと思います。

ありがとう、Mani。embeddingsは複雑なプロセスに見えるかもしれません。実際にembeddingsレイヤーを構築することは少し気が重いかもしれません。そこで私たちは、Amazon Titan Text Embeddingsモデルの一般提供を開始しました。これは9月に発表したもので、Titan embeddingsモデルはテキスト検索ユースケースやRAGユースケースに最適化されています。英語、スペイン語、中国語など25以上の言語で利用可能です。Titan text embeddingsはAmazon Bedrockのサーバーレス体験を通じてアクセス可能なので、インフラを管理することなく単一のAPIでこのモデルにアクセスできます。非常に簡単です。モデルを指定し、コンテキストを渡し、embeddingsを構築するだけです。単一のAPIを通じて使用するのは、信じられないほど簡単です。
さて、embeddingsとは何か、そしてRAGの基礎知識を得たところで、実際に裏側で何が起こっているのかを理解しましょう。つまり、技術的な観点から何がこれを可能にしているのでしょうか?データについて質問をする前に、そのデータをRAGのユースケースに最適化する必要があります。
Knowledge Bases for Amazon Bedrockの概要と利点

これがデータ取り込みレイヤーで、このレイヤーに対応するワークフローがあります。このワークフローを右から左に見ていきましょう。まず、外部データソース、つまり企業のデータから始まります。これはAmazon S3に保存されており、さまざまなファイル形式やPDFドキュメント、非構造化データの形で存在する可能性があります。このデータを取り、チャンキングと呼ばれるプロセスを経ます。チャンキングは、データを異なるセグメントに分割することで、関連性などを最適化するのに役立ちます。これらのチャンクは、Amazon Titan Text Embeddingsなどのembeddingsモデルに渡され、最終的に目的に特化したベクトルデータベースに保存されます。


ベクトルデータベースは、embeddingsのインデックス作成と検索に最適化されており、embeddingsモデルを通じて得られる関係性と意味的な意味を維持できます。このデータ取り込みワークフローを経れば、質問をして、RAGの真の力を見る準備が整います。これで、テキスト生成ワークフローに移ります。これはユーザーが質問をすることから始まります。その質問やクエリも同じembeddingsモデルを通して、ベクトルに変換されます。そのベクトルは、同じベクトルデータソースで検索され、ベクトル類似性検索を可能にします。

これは、同じ厳格なキーワードの文脈で質問をする必要がないということを意味します。実際に意味を抽出し、質問の類似した側面とそれがどのように文書に関連するかを見ることができます。これがセマンティック検索の真の力です - 関係性を見て、意味をより深く理解することです。検索結果を得たら、それが検索部分です。ベクターデータベースからそのデータを取得し、その文脈を基盤モデルのプロンプトに渡します。 これらの返された文章でプロンプトを拡張しているのです。これが拡張部分です。最終的に、この大規模言語モデル、つまり基盤モデルが最終的な応答を生成します。

ご想像の通り、このワークフローはかなり面倒なものになりがちです。完全なRAGアプリケーションを構築するには、多くの固有の複雑さがあります。複数のデータソースを管理し、どのベクターデータベースを使用するかを考え、そのベクターデータベースに段階的な更新をどのように行うかを検討する必要があります。多くの異なる専門分野が必要です - データサイエンティスト、データエンジニア、インフラエンジニアの助けが必要です。スケーリングやDevOpsに関する情報も必要で、これらの多くが困難に思えるかもしれません。LangChainのようなオープンソースのフレームワークがこれを少し簡単にしましたが、それでもかなりの開発とコーディングが必要です。では、この複雑さをすべて抽象化するにはどうすればよいでしょうか?
Knowledge Bases for Amazon Bedrockのデモンストレーション:データ取り込みから検索まで

そこで登場するのが、Amazon Bedrockの Knowledge Bases です。RAGを実装したり、先ほど見たこのRAGアーキテクチャに基づいたアプリケーションを構築したいけれど、完全に管理された方法で行いたい。そうすれば、ビジネスのユースケースや問題の解決に集中できます。私たちは、差別化されていない重労働をすべてお客様から取り除きます。Amazon Bedrockの Knowledge Bases は、自動化されたデータ取り込み、基盤モデルやBedrock用Agentsとこれらのナレッジベースやデータソースの安全な接続、そして関連データの簡単な取得とプロンプトの拡張を支援することで、お客様をサポートします。
機能や最近の発表があり、それらについてより深く掘り下げていきます。最後の機能はソース属性です。機械に関しては、証拠が必要です。そこでソース属性が重要になります。基盤モデルが私たちのデータソースに基づいて正確な情報を提供していることを知る必要があります。

基盤モデルが正しい応答を提供していることをどのように知ることができるでしょうか?それは、私たちが提供しているこれらのデータソースに基づいて応答が生成されているからです。では、見てみましょう。まず、データ取り込みワークフローを詳しく見ていきましょう。 なぜなら、ベクターDBにデータがなければ、検索、拡張、生成を本当に行うことができないからです。

まず最初に、先ほど見たデータ取り込みワークフローについてお話しします。この場合、左から右へ進んでいきます。新しいデータがあり、次にデータソース、チャンキング、埋め込みモデル、そしてベクトルDBへの保存があります。これらすべてを自分で実装しなければならないと想像してみてください。まず、本当に優れたコーディング能力を持つリソースが必要になります。次に、コーディングをしてから、そのコードのメンテナンスをしなければなりません。オープンソースのフレームワークを使用したいと思うかもしれませんが、それはすばらしいことですが、時にはバージョン管理の部分について考えなければなりません。そのため、多くの作業が必要になります。さらに、使用しているベクトルストアの特定のAPIについても学ばなければなりません。

もし私たちがすべてを変えて、選択肢を提供し、それを選択肢に絞り込むとしたらどうでしょうか?データソースを選択するだけでよいとしたらどうでしょうか。この場合、私たちはAmazon S3をデータソースとしてサポートしています。つまり、ドキュメントが保存されているバケットを選択するだけです。私たちは増分更新をサポートしています。新しいドキュメントが入ってくるたびに、取り込みジョブの同期を開始するだけでよいのです。また、複数のデータフォーマットをサポートしています。Knowledge Bases for Amazon Bedrockでは、PDF、CSVファイル、Excelドキュメント、Wordドキュメント、HTMLファイル、Markdownファイル、そしてテキストファイルもサポートしているので、異なるデータフォーマットについて心配する必要はありません。そして、この一覧は今後さらに拡大される可能性があります。
つまり、文字通りデータを持っていて、それをS3にアップロードし、データソースとして追加するだけでよいのです。次に、ドキュメントの分割、つまりチャンキングを行うオプションを提供します。「それらのことについてよく分からないので、何も選択したくない」と思うかもしれません。それでも大丈夫です。デフォルトのチャンキングオプションがあり、300トークンで20%のオーバーラップに設定されています。つまり、選択したくなければ選択する必要はありません。しかし、特定の固定チャンクに興味がある場合は、それらを提供することもできます。そのため、2つ目のオプションとして固定チャンキングがあります。各テキストチャンクに対するトークン数とオーバーラップを指定します。オーバーラップは10〜20%の間にすることをお勧めします。
次に、埋め込みモデルを選択します。現在、Amazon Titan埋め込みモデルをサポートしており、Ruhaabがすでにカバーしているので、ここでは繰り返しません。ただ、ここで強調したいことが1つあります。25言語をサポートしていると言う時、これは非常に重要な側面です。埋め込みについて話したときを思い出してください。これらの埋め込み、つまり数値表現は、関係性を維持しています。モデルが言語を理解していなければ、単語間の関係を維持することができません。そのため、テキストが異なる言語である場合、モデル、つまり埋め込みモデルがそれを知っていて、その関係を維持できることが重要です。
次の部分はベクトルストアです。OpenSearch Serverless、Redis、またはPineconeを使用するかどうかのオプションを提供しています。つまり、ここにオプションがあり、これらすべての選択をして、Knowledge Base作成ボタンをクリックするか、SDKを使用している場合はCreate Knowledge Base APIを使用すれば、すべてが自動的に処理されます。Knowledge Bases for Amazon Bedrockを使用した、自動化され完全に管理されたデータ取り込みが行われるのです。

さて、これでデータの取り込みが完了し、使用できる状態になりました。次のステップは、アーキテクチャがどのようになっているかを見ていきましょう。こんな感じです。 ナレッジベースができ、データは準備できましたが、まだクエリを提供し、埋め込みを作成し、コンテキストを取得し、プロンプトを拡張し、foundation modelを提供し、プロンプトエンジニアリングを行い、そして応答を得るという作業が残っています。これらの作業を省略して、さらに負担を軽減できないでしょうか?そこで、最近私たちは2つの新機能、つまりAPIを発表しました。
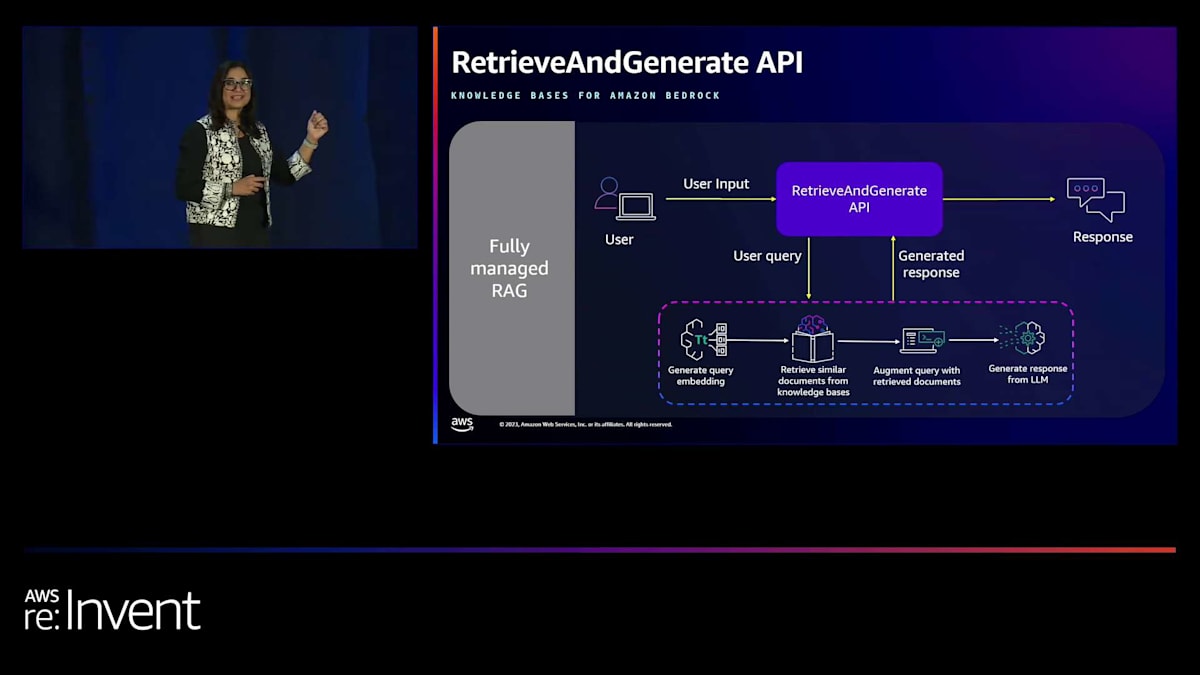
1つ目はRetrieveAndGenerateで、文字通り関連文書を取得し、モデルに供給して応答を返します。2つ目はRetrieve APIで、より多くのカスタマイズオプションが必要な場合に使用します。このアーキテクチャがどのようになるか見てみましょう。
ユーザーが質問をすると、RetrieveAndGenerate APIを呼び出し、応答を得ます。このRetrieveAndGenerate APIが作業を代行してくれます。クエリを受け取り、埋め込みモデルで埋め込みを作成し、プロンプトに追加してから、選択したモデルに供給します。現在、AnthropicのClaude InstantとClaude version 2の2つのモデルをサポートしています。これらのモデルのいずれかを選択して、生成された応答を得ることができます。素晴らしいですよね?

もし「これはいいけど、もっと制御したい。重労働はしたくないけど、少しはカスタマイズしたい」と思うなら、2つ目のAPI であるRetrieve APIがあります。このAPIは柔軟性も提供します。ここでも、埋め込みモデルを自動的に使用してクエリの埋め込みを作成し、関連するデータや文書を提供することで支援しています。
関連文書を取得したら、プロンプトの拡張を行う必要があります。モデルに基づいてプロンプトに指示を与える柔軟性があります。Amazon Bedrockが提供する任意のモデルを使用できますし、Bedrockシステムで作業していたカスタムモデルや微調整済みモデルをRetrieve APIで使用することもできます。選択肢があり、アプリケーションと意思決定ポイントを完全に制御できるようにしたいと考えています。これらは、アプリケーションから得られる回答に大きな影響を与えます。
Knowledge Basesの実際の使用例:コンソールでのQ&A機能とRetrieve API

さて、話はこれくらいにして、実際の動作を見てみましょう。コンソールでどのように見えるか確認しましょう。今から画面を共有します。 コンソールを開いて、Amazon Bedrockを検索しました。これがBedrockです。knowledge basesに移動する必要がありますが、これはorchestrationセクションの下にあります。そこをクリックしましょう。 ここでは、コンソールから何ができるかが説明されています:knowledge baseの作成、テスト、そして使用です。これらの手順を見ていきましょう。

時間を節約するために、私はすでにknowledge baseを作成していますが、それでも作成に必要な手順を説明します。最初のステップはknowledge baseの作成です。create knowledge baseボタンをクリックします。ちなみに、ここでお見せしていることは、 SDKを使っても同様に行えます。次に、名前を入力します。多くのknowledge baseを持つことになるかもしれないので、混乱を避けるために、非常に意味のある名前をつけることをお勧めします。また、意味のある説明も追加してください。

次に、ロールに権限が必要です。knowledge baseはS3のデータにアクセスし、embeddingsを作成するので、embeddingsモデルへのアクセスも必要です。また、embeddingsをベクトルデータベースに保存するので、そこへのアクセスも必要です。knowledge base用のAmazon Bedrock実行ロールにこれらの権限がすべてあることを確認してください。設定方法がわからない場合は、「create and use a new service role」オプションを選択すれば、自動的に作成されます。
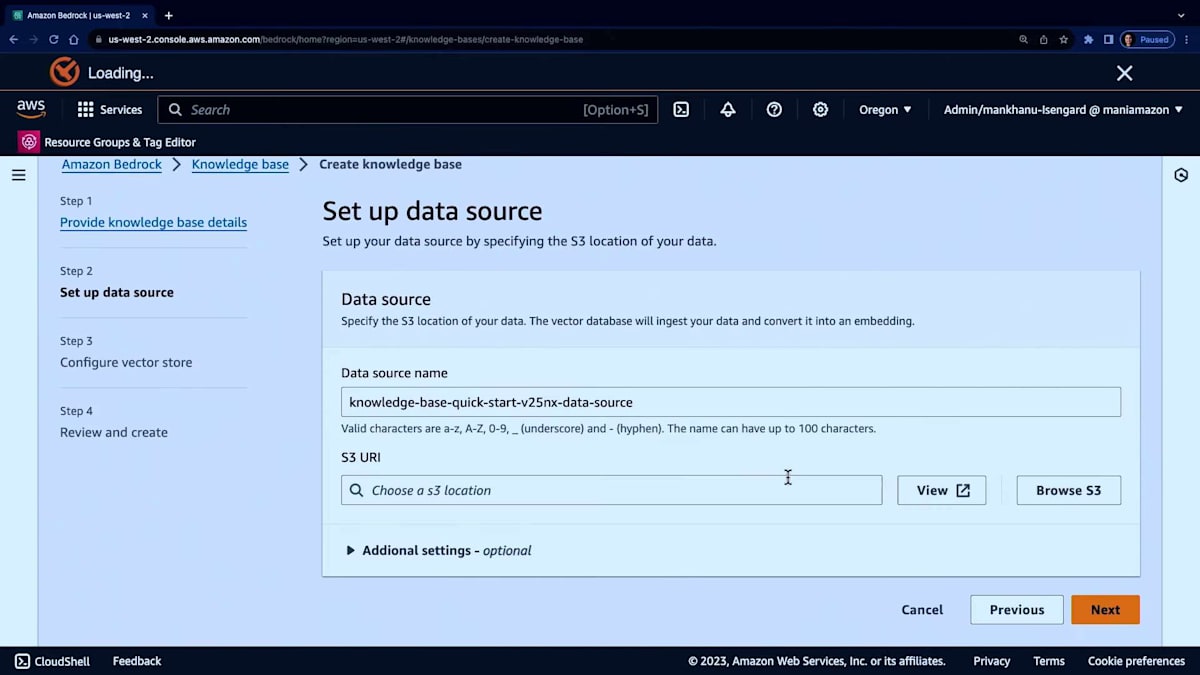


次に、データソースに進みます。意味のあるデータソース名とS3の場所を入力します。ここでは単に入力するだけです。これは実際のS3バケットではなく、デモ目的で名前を入力しているだけです。次に追加設定があります。 ここでchunking strategyを選択できます。先ほど説明したように、default、fixed size、no chunkingの3つのオプションから選べます。 fixed sizeを選んで、例えば512を選択しましょう。

通常、overlapは10〜20%程度にすることをお勧めします。現在はTitan embeddingsモデルのみをサポートしているので、それがここにあります。
ベクターデータベースを自分で作成したくない場合は、クイック作成オプションを選択することができます。これにより、Amazon OpenSearch Serverlessを使用してベクターデータベースが自動的に作成されます。これは、先ほど説明した完全マネージド型のRAG機能に沿ったものです。ただし、他のオプションも用意されています。既存のベクターデータベースやインデックスがあり、それに情報を追加したい場合は、OpenSearch Serverless、Pinecone、またはRedis Enterprise Cloudの詳細を提供して、次に進むことができます。

本日の発表でお聞きになったかもしれませんが、近々AuroraやMongoDBを含む新しいタイプのベクターデータベースをサポートする予定です。おそらく、さらに多くのベクターデータベースオプションが追加されるでしょう。これらの更新にご注目ください。


時間を考慮して、すでにナレッジベースを準備しています。 このナレッジベースはテキスト文書に基づいています。ナレッジベースを作成すると、実際にはこのページに到達します。 ナレッジベースのリストを見るには、ナレッジベースセクションに戻る必要があります。
ナレッジベースを作成したら、同期ボタンをクリックすることが非常に重要です。これは極めて重要です。なぜなら、ナレッジベースを作成したと言っても、それだけでは不十分で、同期が必要だからです。同期は、S3内のすべてのデータを検索し、文書を前処理し、テキストを抽出し、指定した戦略に基づいてチャンクに分割し、埋め込みモデルを通過させ、そしてベクターデータベースに保存する実際のプロセスです。
後でS3バケットに新しいファイルがある場合、再度同期ボタンを押すか、SDKのstart ingestion jobを呼び出すことができます。これにより、すべてが同期された状態を保つことができます。デモンストレーションのために、私はすでにこれを行っています。


それでは、テストしてみましょう。レスポンスを生成したい場合、つまりgenerate、retrieve、generateのAPIを使用する場合は、このオプションを切り替えることができます。あるいは、retrieval onlyの場合はオプションを切り替えないでおきます。まずは、レスポンスを生成する方法から始めましょう。最初に、モデルを選択する必要があります。そして、InstantモデルかClaude v2を選択できます。最近発表されたClaude 2.1も利用可能です。

モデルを選択したら、質問をすることができます。私のドキュメントは税金データに基づいているので、knowledge baseには税金関連のデータセットがすべて含まれています。そこで、「リモートで働いている場合、どの州に税金を納める必要がありますか?」と質問してみます。この質問を選んだのは、パンデミック中に多くの人がリモートワークをしていたからです。もちろん、今では多くの人がオフィスに戻っていますが、それもいいことですね。

では、結果の詳細を表示してみましょう。重要なポイントがいくつかあります。まず、非常に素早くレスポンスが返ってきます。次に、画面上ですぐに情報源の出典を確認できます。レスポンスでは、リモートで働いていても雇用主が特定の州にある場合、その州に所得税を納める必要がある可能性があると説明しています。さらに、tax homeや関連する概念についても詳しく説明しています。
モデルが使用した情報源を確認したい場合は、ここにあります。複数の情報源がある場合は、複数のタブが表示されます。これについては後ほどお見せします。そのドキュメントの場所に直接アクセスすることもできます。
次に、生成せずに検索のみを行う場合はどうなるか見てみましょう。比較しやすいように、同じ質問をしてみます。デフォルトでは、最も関連性の高い上位5つのドキュメントが検索されます。詳細を表示すると、p17.pdfファイルからの特定のチャンクと、他の関連ドキュメントを確認できます。

次に、別のPDFから別のチャンクを取得し、このretrieve APIはスコアも提供します。使用しているベクトルデータベースとスコアリング方法によって、例えばコサイン類似度を使用している場合はそれに基づいたスコアが、ユークリッド距離を使用している場合はそれに基づいたスコアが得られます。このスコアオプションも利用可能です。以上がコンソールでの使用方法についてでした。また、APIの使用方法とLangChainとの統合方法をお見せする別のデモもあります。
Agents for Amazon BedrockとKnowledge Basesの連携
重要なポイントは、Amazon Bedrockのナレッジベースを使用してRetrieval Augmented Generation(RAG)アプリケーションを構築し、それらのAPIを使用したい場合、先ほど説明した機能を使って完全にエンドツーエンドで実現できるということです。しかし、ナレッジベースに加えて動的な情報を取得する必要がある場合はどうでしょうか?例えば、多くの注文詳細を含むナレッジベースがあるが、現在輸送中の注文のステータスを提供する注文APIも呼び出したい場合や、それに関連する複数のタスクを実行したい場合はどうすればよいでしょうか?ナレッジベースをAmazon Bedrockのエージェントや他のエコシステムと統合したい場合、何をする必要があるでしょうか?それでは、Ruhaabさん、説明をお願いします。

素晴らしいです。スライドに戻っていただけますか。Maniが説明したように、ドキュメントをベクトルデータベースにアップロードし、すぐに質問とやり取りを始めるのがいかに簡単かをご覧いただきました。わずか数ステップで、完全に機能するRAGアプリケーションが完成しました。先ほど説明したように、そのドキュメントに保存される情報は比較的静的であり、バックグラウンドで一定の頻度で同期されているとしても、データベースや他のツール、システムとリアルタイムで対話する必要がある場合があります。これこそがAmazon Bedrock用エージェントの真の目的であり、ナレッジベースはエージェントと直接連携してこのユースケースを実現できます。

エージェントの真の力を考えると、思考連鎖処理などの推論能力を活用してタスクの計画と実行に使用される非常に特殊なモデルです。これらの最先端のアプローチは、アプリケーションがAPIと対話し、そのAPIのアクションを実行するために必要な情報を収集するためのダイアログを自動生成したい場合に優れています。会話の流れを定義する必要はなく、APIのパラメータは、このモデルがAPIの呼び出しに必要な引数を満たすために必要な情報を要求することで自動的に収集できます。また、ツールとの対話やそれらのアクションのオーケストレーションも可能です。
先ほど述べたように、エージェントはナレッジベースと組み合わせることもできます。これは、アクションと情報検索型のユースケースを組み合わせたい場合に有用です。単にドキュメントからコンテキストを取得し、それをツールとの対話の補足情報として使用する場合などです。最後に、エージェントとナレッジベースを使用すると、これらのワークフローはすべて完全に抽象化され、Amazon Bedrockに直接構築された完全マネージドサービスとして提供されます。

では、Knowledge BaseとAgentが連携して動作する例を見てみましょう。先ほど申し上げたように、Agentはユーザーが要求したタスクを調整できます。例えば、未提出書類のあるすべての保険契約者にリマインダーを送るようにこのアプリケーションに依頼する場合を考えてみましょう。このモデルは、タスクの実行計画を立てるために、これをより小さなサブタスクに分解します。例えば、特定の期間の請求を取得したり、このプロセスで必要な書類を特定したりします。これらの情報は、Knowledge Baseに含まれている可能性があります。
最終的に、Agentは適切な手順の順序を決定し、対話を促進し、情報を収集し、さらにエラーシナリオにも対処できます。これは、Knowledge Base、API、ツールにまたがる動的な一連のアクションを調整する非常に強力な能力であり、シームレスな体験を提供します。未決定の保険契約者全員にリマインダーを送信するように機械に依頼するという単純なことでも、その複雑さを抽象化してユースケースを可能にすることができるのです。
次に、LangChainのようなオープンソースの生成AIフレームワークを使ってKnowledge Baseを構築する方法をお見せしたいと思います。Maniに別のデモをお願いしましょう。
LangChainを使用したKnowledge Basesの実装デモ
はい、そのためにスクリーンを共有させていただきます。このデモでは、APIを使用します。多くの方がコンソール体験に加えてAPIやSDK体験を好むかもしれないからです。LangChainには多くの事前構築されたラッパーがあり、私たちはそれらを先ほどお見せした最新機能と一緒に再利用したいと考えています。では、この短い旅にお連れしましょう。
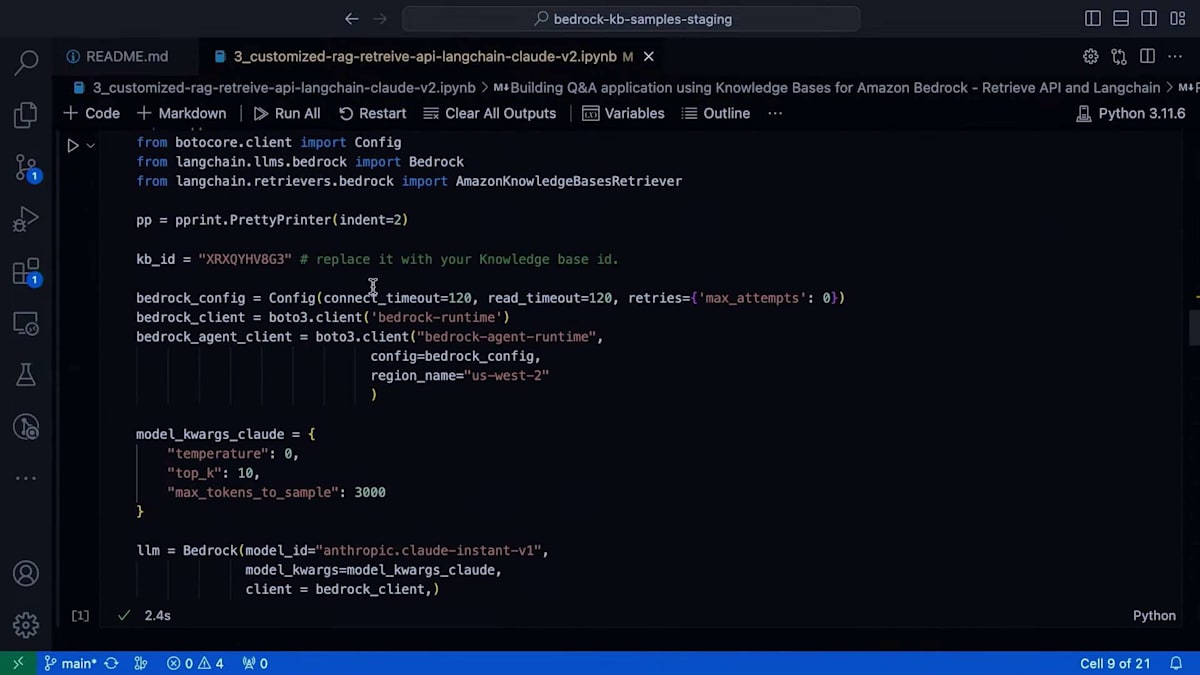
まず、最新のBoto3とLangChainのバージョンがあることを確認してください。LangChainは0.0.342以上、Boto3は1.33.2以上である必要があります。次に、セットアップを行う必要があります。他のAWSサービスと同様に、APIを使用する場合は、まずクライアントを作成する必要があります。Bedrockの場合、2つのクライアントが必要です。1つはモデルを呼び出すためのBedrock runtimeクライアント、もう1つはAmazon BedrockのKnowledge BaseのretrieveAPIを呼び出すためのBedrock agent runtimeです。

Amazon Bedrock が提供する任意のモデルに接続できるため、retrieve API にはいくつかのモデルパラメータを提供しています。モデルパラメータを指定し、モデルを選択します。実際の retrieval については、 LangChain で retrieve API を使用する場合、まず retriever オブジェクトを初期化する必要があります。LangChain から AmazonKnowledgeBasesRetriever をインポートして使用します。何を渡す必要があるでしょうか?結果の数、つまり取得したい関連ドキュメントの数と、knowledge base ID を渡す必要があります。情報を取得する knowledge base を特定するためです。
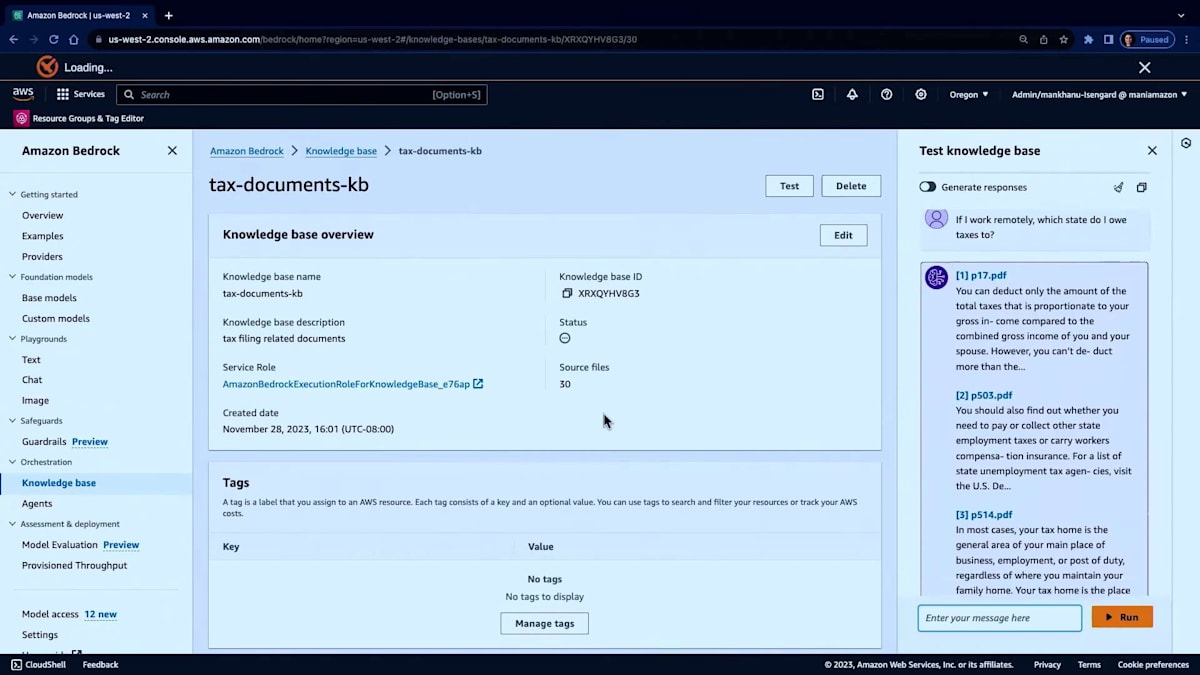

knowledge base ID の取得方法をお見せしましょう。SDK を使用している場合、API からのレスポンスとして自動的に取得でき、それを利用できます。コンソールから使用している場合は、knowledge base をクリックし、そこで knowledge base ID を取得します。そのままコピーできます。ここでも同じ knowledge base を使用しています。

関連ドキュメントを取得したら、Q&A アプリケーションを構築する場合、LangChain は retriever QA chain を提供します。大規模言語モデルを宣言し、retriever を宣言し、retrieval QA chain を使用して、すべてを一緒に渡し、質問を続けるだけです。では、その部分に移りましょう。これは、単にドキュメントを取得して関連ドキュメントを取得したい場合の方法を示しています。しかし、retrieval QA chain と統合する場合は、これを行う必要はありません。必要なのは、この retriever オブジェクトだけです。

では、統合方法を見てみましょう。はい、ここに retrieval QA chain があります。ここで、レスポンスを提供する言語モデルと、関連ドキュメントを提供する retriever オブジェクトを指定します。

また、プロンプトも提供します。これにより、独自のプロンプトや指示を提供する柔軟性が得られ、この retrieval QA chain が自動的に関連ドキュメントをプロンプトに追加します。


皆さんにお知らせしたいのですが、プロンプトテンプレートもお見せしたいと思います。特定の指示やモデル固有のプロンプトを提供できるんです。文字通り、モデルは文書に基づいた情報のみを提供すべきだと指定できます。ユースケースに応じて指示を与えられるわけです。そして、retrieval QA chainと統合したら、作成したこのQAオブジェクトにクエリを与えるだけで、答えを返し続けてくれます。
何度も初期化する必要はありません。複数のクエリを投げて答えを得る、また別のクエリを投げて答えを得る、というように、たった3つのステップで動作するQ&Aアプリケーションができあがります。モデルの初期化、LangChainを使ったAmazon knowledge base retrievalの初期化、そしてretrieval QA chainで全てをまとめるだけです。アプリケーションの準備が整いました。同じパターンを使って、LangChainが提供するconversational chainsでコンテキストベースのチャットボットを構築することもできます。ぜひ探索してみてください。同じコードに興味がある方のために、GitHubにアップロードしてありますので、リソースを共有させていただきます。
講演のまとめと今後の展望

では、Ruhaabさん、ここまでのまとめをお願いできますか?

はい、もちろんです。ありがとうございます、Maniさん。LangChainを使っても、Bedrockコンソールを使っても、どちらを選んでも同じ出力が得られるという柔軟性があり、始めるのがとても簡単だというのは素晴らしいですね。スライドに戻っていただけますか。今日カバーした内容を簡単に振り返ってみましょう。多くの内容を扱いましたので、皆さん熱心に聞いていただき、ありがとうございました。
まず、カスタマイズが重要な理由、augmentationとモデルのパラメータや重みを実際に変更する他のアプローチなど、カスタマイズの異なるアプローチについて説明しました。次に、retrieval augmented generation(RAG)について少し触れ、RAGの具体的なユースケース、そしてデータ取り込みからクエリワークフローまでの様々なコンポーネントについて説明しました。これらの多くは、Amazon Bedrockのknowledge basesを使用することで完全に抽象化されています。最後に、リアルタイムデータやデータベース、APIとの連携が必要な場合に、knowledge basesをさらに拡張する方法について話しました。agentsとknowledge basesを組み合わせることで、そのような機能を実現できるのです。

もしこの画面をすぐに撮影したい場合は、Maniが先ほどお見せしたノートブックの多くと、さらにいくつかの例がGitHubで公開される予定です。皆さんの作業の参考にしていただけますし、Knowledge Basesについてさらに詳しく掘り下げたドキュメントもあります。ぜひチェックしてみてください。
最後に、ご参加いただきありがとうございました。お役に立てたなら幸いです。私たちのLinkedInのハンドルをここに記載しています。皆さんがKnowledge Basesをどのように使用されているか、どんなフィードバックをお持ちか、ぜひお聞かせください。そして、アプリ内のアンケートへの回答をお忘れなく。ManiとI私が来年もre:Inventで講演できるよう、ご協力をお願いします。本日はご来場いただき、誠にありがとうございました。素晴らしいカンファレンスをお楽しみください。
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion