re:Invent 2024: AWSのHPCサービスで実現する製品開発の加速


はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Drive innovation and results with high performance computing on AWS (CMP203)
この動画では、AWSにおけるHigh Performance Computing(HPC)の活用について、AWSのSrinivas Tadepalliが解説しています。MerckのHarsha GurukarとPhysicsXのJake Mulleyによる事例紹介を通じて、HPCがどのように製品開発やイノベーションを加速させているかを具体的に示しています。MerckではHPCを創薬プロセスに活用し、PhysicsXではLarge Physics Modelsを用いて製品設計の最適化を実現。また、AWS ParallelClusterやAWS Batchなどの主要なHPCサービスの詳細や、HPCとAIの融合事例としてNVIDIAとの協業によるEarth-2プラットフォームでの気象予測についても紹介されています。7年連続でベストクラウドHPCプラットフォームに選ばれたAWSのHPC関連サービスの全容が理解できる内容です。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
AWSにおけるHigh Performance Computingの概要

みなさん、こんにちは。セッション CMP 203「AWS上でのHigh Performance Computingによるイノベーションと成果の実現」へようこそ。私はSrinivas Tadepalliと申します。Advanced Computing(High Performance Computing、Accelerated Computing、Quantum Computingワークロード)のワールドワイドGo-to-Marketチームを率いています。本日は、MerckのHarsha GurukarさんとPhysicsXのJake Mulleyさんという2名のお客様にもご参加いただけることを大変うれしく思います。後ほど、彼らにAWSでの取り組みについてお話しいただく予定です。

これから45分ほどのお時間で、以下の内容についてお話しさせていただきます。まず、様々な業界のお客様がAWS上で実行している一般的なHPCワークロードについてご紹介します。次に、これらのお客様が利用している主要なHPCサービスについて詳しく見ていきます。その後、HarshaさんがMerckのAWSでの取り組みについて、続いてJakeさんがPhysicsXの取り組みについてお話しします。その後、私から、HPCとAIワークロードの融合について、私たちが注目している興味深い側面についてお話しし、最後にまとめで締めくくりたいと思います。
HPCワークロードの多様性と特性

High Performance Computingは私たちの身の回りのあらゆるところに存在します。製品設計の分野では、私たちが運転する自動車や搭乗する航空機など、様々な企業が有限要素解析や計算流体力学といったHPCアプリケーションを使用して適切な製品設計を行っています。ヘルスケアライフサイエンスの分野では、後ほどHarshaさんからお話があると思いますが、Merckをはじめとする多くのお客様がミッションクリティカルなモデリングやシミュレーションのワークロードにAWSを活用しています。気象・気候も、長年お客様にAWSをご利用いただいている重要な分野の一つです。半導体設計の分野では、フロントエンドのEDA設計やバックエンドのワークロードを通じて、チップの設計から市場投入までの時間短縮を実現しています。エネルギー分野では、多くのお客様が地下の石油や天然ガスの埋蔵場所を特定するために、地震探査処理や貯留層シミュレーションなどのワークロードを使用しています。

金融リスクシミュレーションの分野では、保険、銀行、クオンツトレーディングなど、多くのお客様がAWSを利用しています。学術研究も、長年HPCが活用されている重要な分野です。そして最後に、Generative AIとLarge Language Models - これらも私たちの視点では、大規模な基盤モデルのトレーニングに同じインフラストラクチャ(コンピューティング、ストレージ、ネットワーキング)を使用するHPCワークロードの一つと考えています。 ここでご紹介したのは、長年にわたり日々の本番ワークロードにAWSを活用している、様々な業界のお客様のごく一部です。
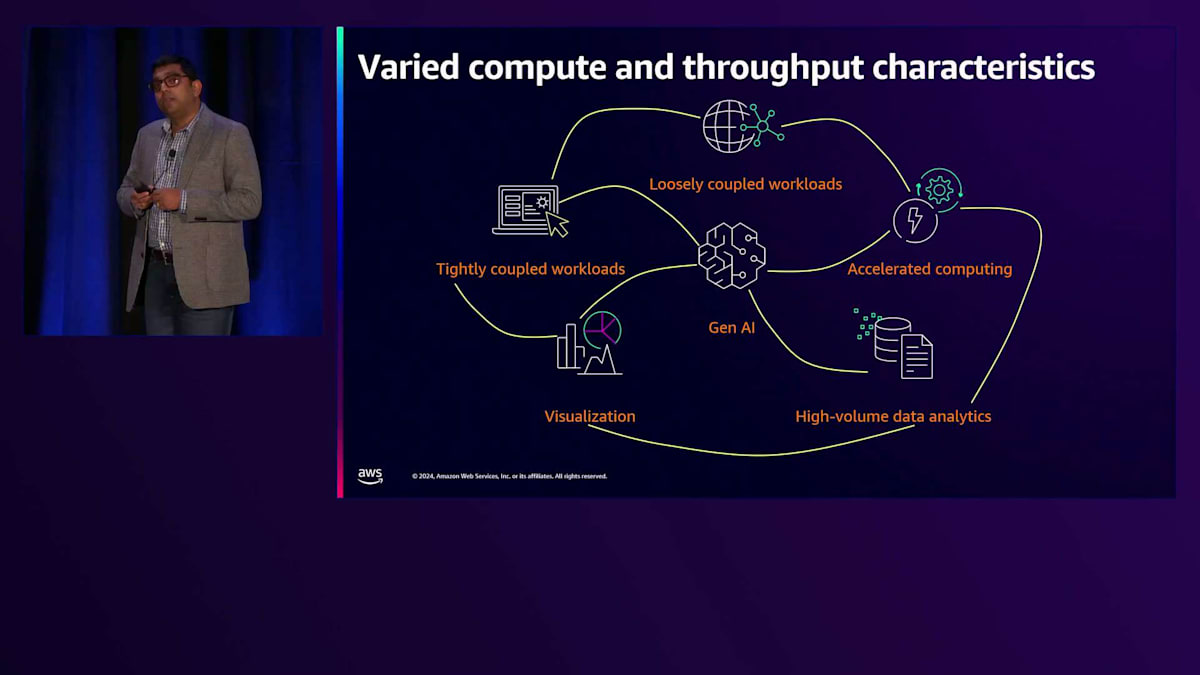
これらのAdvanced Computingシミュレーションワークロードの興味深い特徴の一つは、それぞれが異なる計算処理能力とスループット特性を持っているということです。例えば、自動車や航空宇宙分野の製品設計・エンジニアリングシミュレーションは、私たちは「密結合ワークロード」と呼んでいます。これは、単一のHPCジョブを複数のコンピュートノードやGPUノードにスケールアップして実行時間を短縮するという意味です。同様に、ゲノミクスや金融サービスでのMonte Carloシミュレーションなどの分野では、これらを「疎結合ワークロード」と呼んでいます。数千、数万、時には数十万のジョブを完全な並列処理で実行するものです。
この10年ほどで、私たちは加速コンピューティングの台頭を目の当たりにしています。お客様は、ワークロードを高速化するために専用のアクセラレーターやGPUを使用するようになってきました。また、VDIや大規模なレンダリングなど、コンピュートフォーム全体にわたる可視化ワークロードも増えています。これらの異なるワークロードは、それぞれ特性が異なるため、コンピュート、ストレージ、ネットワーキング、そしてオーケストレーションに関して、異なるニーズが生じています。
AWSのHPCサービススタックとセキュリティ


では、これらをAWSで実行する場合について見ていきましょう。基本的には、コンピュートとネットワーキングから始まるサービススタックがあります。その上にストレージがあり、さらにこれらのコンピュート、ストレージ、ネットワーキングを統合するためのオーケストレーションツールが必要になります。最終的に、その上でエンドユーザーアプリケーションが実行されます。 もう少し詳しく見ていきましょう。コンピュートとネットワーキングの面では、お客様はCPUノード、GPUノード、FPGAノード、カスタムASIC、そして低レイテンシーネットワーク用のElastic Fabric Adapter(EFA)を使用しています。これについては後ほど説明します。その上には、EFS、EBS、S3、FSx Lustreなど、様々なストレージサービスがあります。
オーケストレーションに関しては、お客様はSlurm、EKS、あるいはその他のお好みのオーケストレーションツールを選択できます。その上で、LLMトレーニング、モデリングとシミュレーション、気象・気候アプリケーションなど、様々な種類のワークロードが実行されています。

このスタックの構成をより具体的に見ていくと、 コンピュートでは、後ほど詳しく説明するHPC7aなどの特定のCPUタイプや、NVIDIA H100 GPUを搭載したP5インスタンスを選択できます。ストレージについては、FSx for Lustreを推奨サービスとしており、これについても詳しく見ていきます。オーケストレーションでは、AWS Parallel Computing Service、AWS ParallelCluster、またはパートナーソリューションを利用できます。最後に、分子動力学シミュレーション用のNAMD、Fluent、Star CCM+などのエンドユーザーアプリケーションがあります。これらのISVパートナーのアプリケーションは、モデリングとシミュレーションのワークロードを実行します。
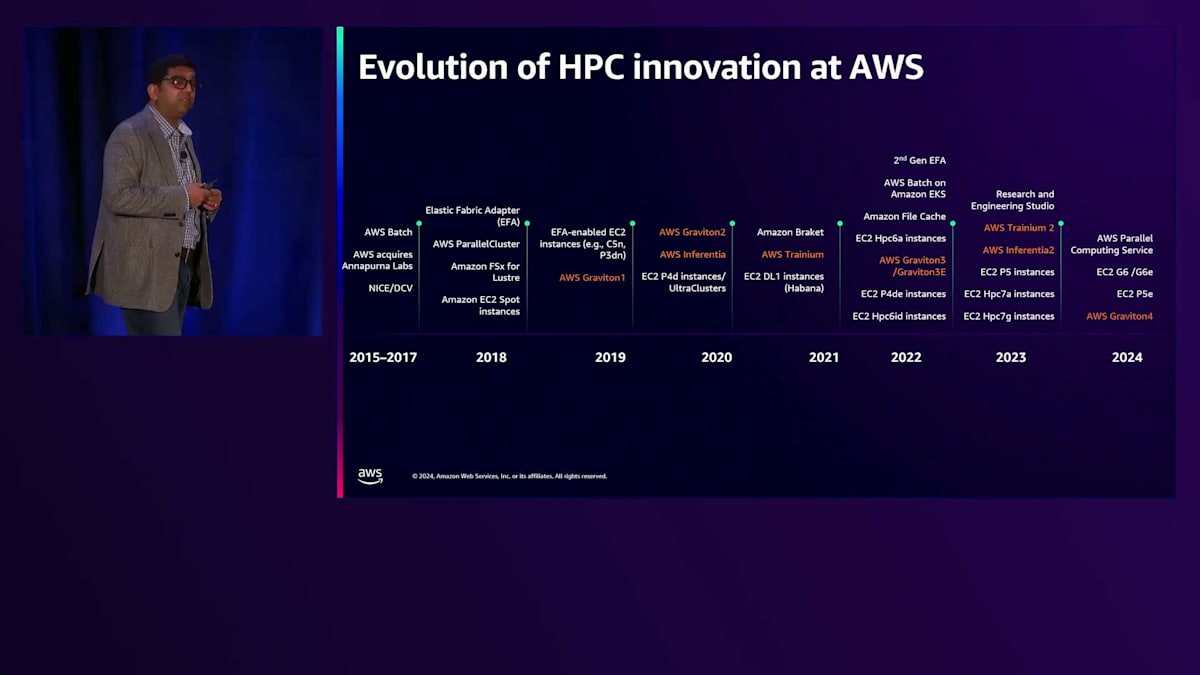
AWSは、AWS Batch、NICE DCV、そしてAnnapurna Labsの買収から始まり、約10年にわたってHPCとAdvanced Computingに投資を続けてきました。現在では、お客様のミッションクリティカルなHPCワークロードを実行するための数十のサービスを提供しています。オレンジ色でハイライトされているサービスは、汎用コンピューティング向けのAWS Graviton、大規模トレーニング向けのAWS Trainium、推論向けのAWS Inferentiaなど、カスタムシリコンイノベーションを表しています。
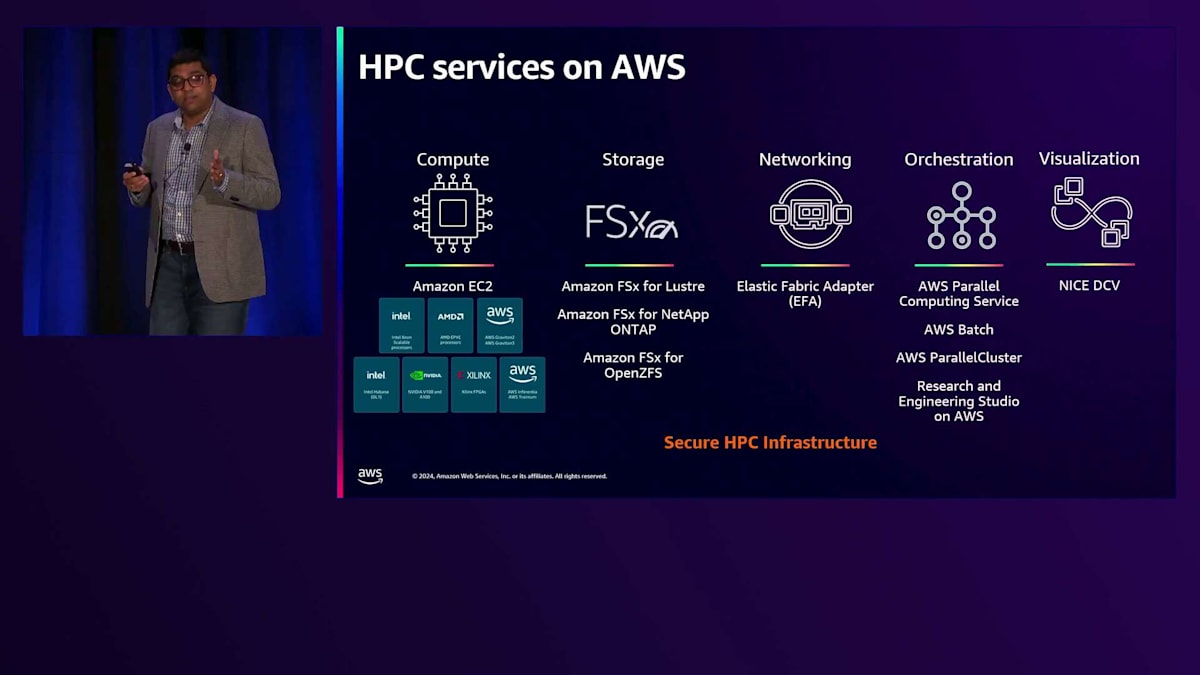

AWSにおけるHigh Performance Computingは、5つの柱に集約されます:Compute、Storage、Networking、Orchestration、そしてVisualizationです。これらのサービスはすべて、セキュアなHPCインフラストラクチャを通じて提供されています。これらのサービスの詳細に入る前に、セキュリティについて少しお話しさせていただきたいと思います。AWSでは、セキュリティを最優先事項としています。スピードと俊敏性を実現するセキュリティ自動化を通じて、エンドツーエンドのセキュリティとガイダンスを提供し、お客様の本番環境やミッションクリティカルなワークロードを実行するための最も安全なインフラストラクチャを提供しています。

こちらは主要なセキュリティサービスの概要で、AWS Identity and Access Management(IAM)、検知と対応、ネットワークとアプリケーションの保護、データ保護、そしてコンプライアンスが含まれています。これらの詳細はすべて当社のウェブサイトでご確認いただけます。
AWSのHPC向けコンピューティングリソース

それでは、Computeの提供内容について見ていきましょう。AWSは現在、750種類以上のインスタンスタイプを提供しています。High Performance Computing分野では、あらゆるHPCワークロードに対して最高の価格性能比を実現する一連のインスタンスを特別に設計しています。HPC7aインスタンスは、AMD GENOAを採用した第7世代のAMDプラットフォームベースのインスタンスで、192個の物理コア、768ギガバイトのシステムメモリ、そして300ギガビットのEFAを提供します。AWSのこれらのHPCインスタンスの注目すべき点は、お客様のご要望に応じて、ハイパースレッディングがデフォルトでオフになっていることです。
同様に、HPC7gは私たちのGraviton ARMベースのインスタンスで、計算流体力学、計算化学、分子動力学、気象・気候アプリケーションなどのワークロードを実行するために特別に設計されています。また、Intel Ice Lakeプラットフォームをベースとしたデータ・メモリ集約型インスタンスのHPC6idも提供しています。HPC分野では、これをファットノードと呼んでいます。というのも、コア数は少なめですが、データやメモリ集約型アプリケーションを実行するための大容量のシステムメモリとローカルディスクを備えているという特徴があるからです。さらに、半導体分野のお客様向けに、チップ設計やEDAワークロードを実行するために特別に最適化された高周波ノードも用意しています。

昨年のre:Inventで事前発表したGraviton4インスタンスは、数ヶ月前に一般提供が開始されました。Graviton4は、最新世代のEC2インスタンスです。
最新世代のGraviton4は、様々なコンピュートファミリーでご利用いただけます。最大規模のノードは、ARM Neoverse V2を搭載し、コアあたり2MBのL2キャッシュ、12チャネルのDDR5、そして96レーンのPCIe Gen5を備え、秒間約半テラバイトのメモリ帯域幅を実現しています。これはシングルソケットの場合で、デュアルソケットノードではテラバイト級のメモリ帯域幅となり、様々なHPCアプリケーションの実行に最適な環境を提供します。
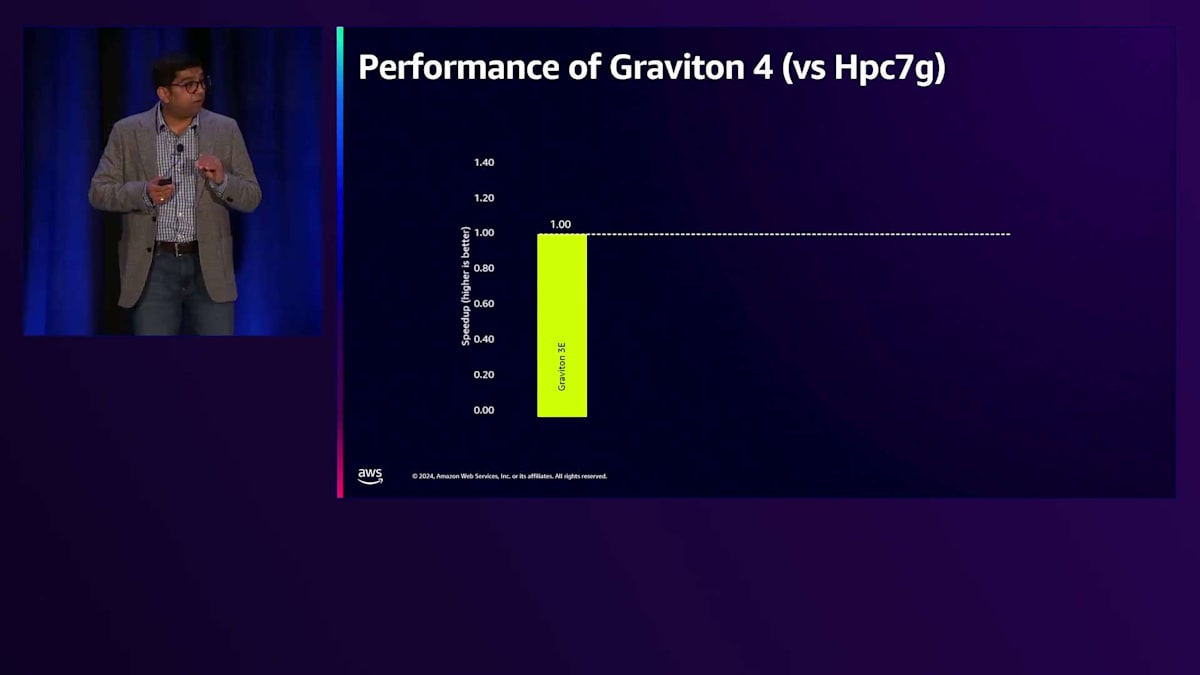
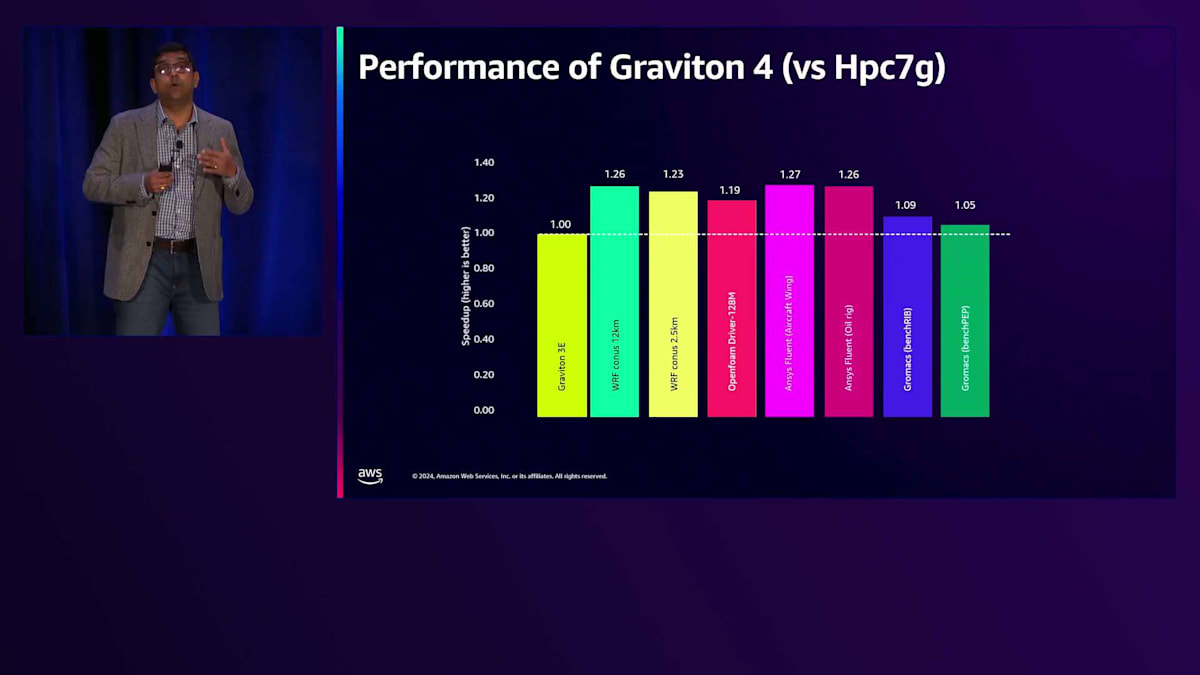
それでは、前世代のGraviton3ベースのHPC7gインスタンスと比較して、Graviton4のパフォーマンスがどのように向上しているか見ていきましょう。 Graviton3(HPC7g)のパフォーマンスを基準として、様々なアプリケーションでの性能を正規化してみました。 最初の2つのアプリケーションは、気象・気候業界で広く使用されているWRF(気象研究予報モデル)です。これらのアプリケーションでは、世代間で平均23〜25%以上の性能向上が見られます。OpenFoamやANSYS Fluentアプリケーションでは、世代間で19〜27%のパフォーマンス向上が確認されています。計算化学の分野でも、Gromacsなどのアプリケーションで、価格性能比で5〜10%の改善が見られています。

次に、HPCとVDIワークロード向けのGPUノードについて見ていきましょう。AWSは13年以上にわたってNVIDIAと提携し、お客様に最新のGPUインスタンスを提供してきました。ここでご紹介するのは、NVIDIA H200(Hopper 200プラットフォーム)を搭載した最新のP5eインスタンスです。P5インスタンスは一世代前のH100ベースのインスタンスです。また、Gファミリーのインスタンスとして、L40SベースのG6eとL4ベースのG6もご用意しています。昨日、P5eインスタンスの更新版としてP5enインスタンスを発表しました。これは8台のH200ノードとEFA V3を搭載し、3200Gbpsのネットワークスループットを実現し、HPCやAIワークロードに対して非常に低いレイテンシー、高帯域幅、高スループットを提供します。
MerckのAWSを活用したHPC事例

大規模なAPIワークロードの実行には計算能力が非常に重要ですが、AWSでは高性能で高スループット、低レイテンシーのネットワークも必要不可欠です。私たちのネットワークプロトコルであるEFA(Elastic Fabric Adapter)は、OSバイパス機能とGPU Direct RDMA機能を提供し、アプリケーションがCPUをバイパスして他のノードやCPUノード、GPUノードのメモリに直接アクセスすることを可能にします。右端のグラフは、STAR-CCM+というCFDアプリケーションのパフォーマンスと線形スケーラビリティを示しています。14億セルのモデルを400ノードまでスケールアップし、ほぼ線形のスケーリングを実現しており、単一のジョブで約40,000コアつまり400ノードで実行することができます。

最後にストレージオプションについて見ていきましょう。Amazon S3、Amazon EFS、Amazon EBS、そしてHPC向けの様々なバージョンを提供しています。HPCのお客様は常に高性能なファイルシステムを必要とするため、Amazon FSx for LustreやAmazon FSx for NetApp ONTAPといったHPCアプリケーション向けに特化したサービスを提供しています。どちらもサブミリ秒のレイテンシーを実現します。POSIXの依存関係が必要なワークロードには、FSx for Lustreをお勧めします。NFSとSMBの両方のサポートが必要なアプリケーションには、NetApp ONTAPをお勧めします。

オーケストレーションスタックについて説明を進めていきますと、私たちには顧客のあらゆるニーズに対応する4つの異なるサービスがあります。その中で顧客が最も長く使用してきたのが、AWS Batchです。これは完全マネージド型のクラウドネイティブスケジューラーで、他のAWSサービスと完全に統合されており、大規模なスケーラビリティとリソースプロビジョニングの最適化を実現します。
AWS Batchは、特に大規模なスケールアウトアプリケーションの実行において、最高のコストパフォーマンスを提供します。AWS Batchに関する興味深い事例として、フランスを拠点とするInstitut Pasteurの例があります。彼らは200万のGravitonコアをスピンアップし、地球上のすべてのウイルスのインデックスを作成することができました。この取り組みは、2週間前に開催されたSupercomputingカンファレンスで、最優秀クラウドHPCユースケース賞を受賞しました。この顧客は、複数のリージョンにまたがる200万のGravitonコアにスケールするためにAWS Batchを活用したのです。
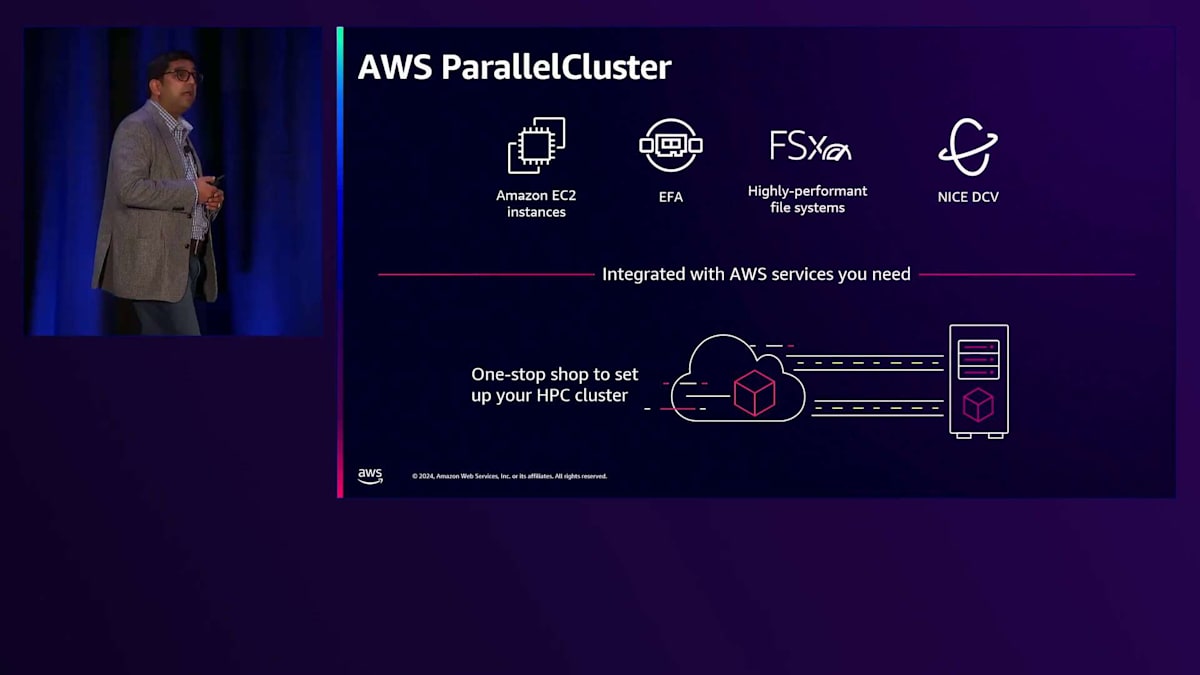
密結合アプリケーションの実行に特化した別のサービスとして、AWS ParallelClusterがあります。AWS ParallelClusterは、AWSが管理・保守しているオープンソースツールです。このサービスは長年にわたって多くのお客様にご利用いただいています。ParallelClusterは、コンピューティング、ストレージ、ネットワーキング、可視化など、さまざまなサービスを一つにまとめています。
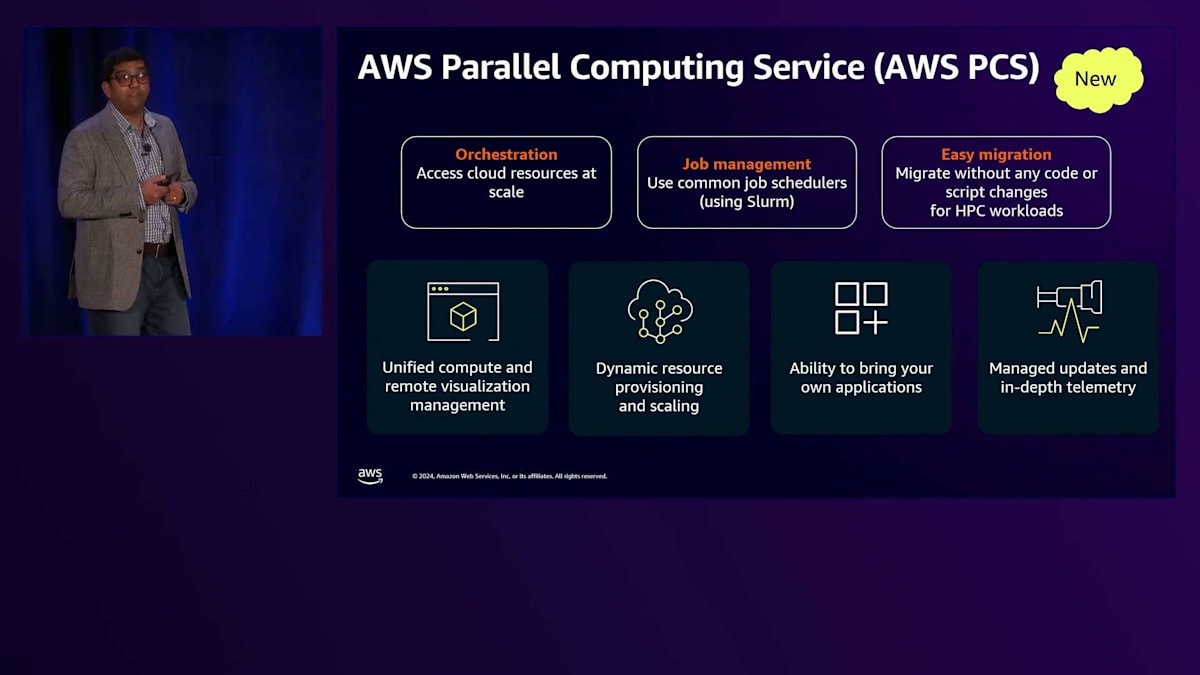
ParallelClusterは素晴らしいサービスで多くのお客様に長年ご利用いただいていますが、ParallelClusterの優れた機能をすべて備えた完全マネージド型サービスの提供を求める声が多くありました。これらのニーズに応えるため、数ヶ月前にAWS Parallel Computing Serviceをローンチしました。これは完全マネージド型のオーケストレーションで、AWSのリソースに大規模にアクセスする機能を提供します。Slurmを使用したジョブ管理機能を提供し、近い将来さらに多くのスケジューラーが追加される予定です。また、コードやスクリプトの変更を必要とせずに、お客様の簡単な移行をサポートします。
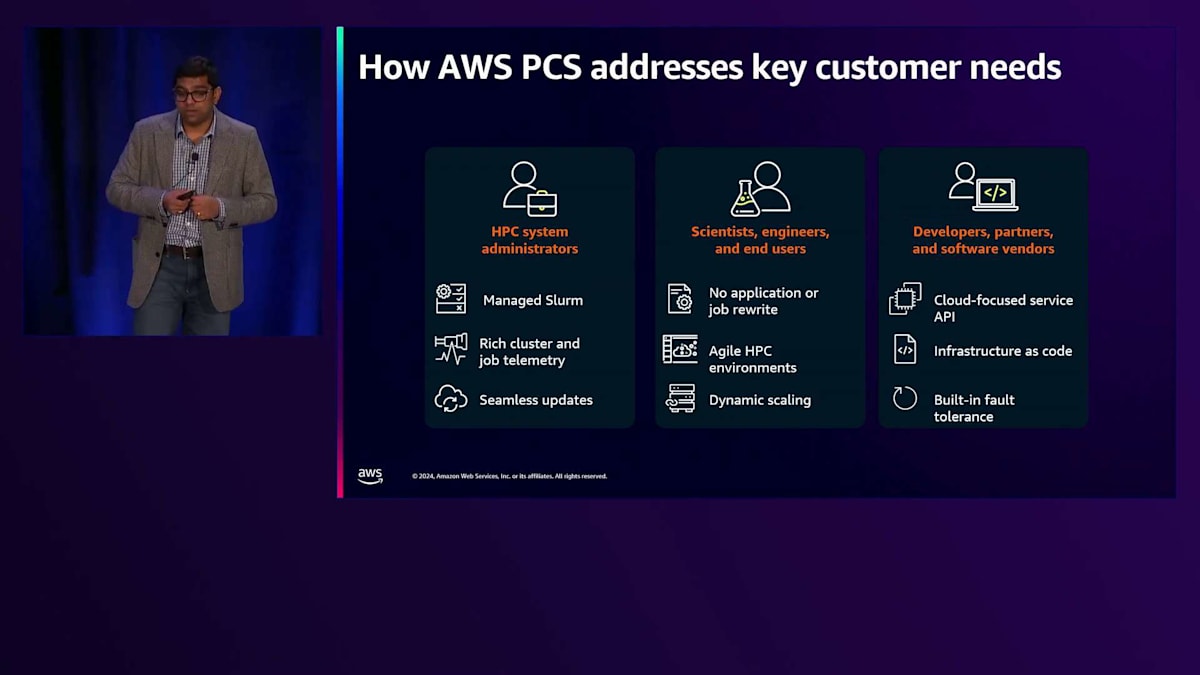
AWS Parallel Computing Serviceの興味深い点は、統合されたコンピューティングとリモート可視化機能を提供し、リソースプロビジョニング能力を動的にスケールアップ・ダウンできること、そしてお客様独自のアプリケーションを持ち込める点です。すべてのクラスターとジョブについて詳細なテレメトリを提供します。AWS Parallel Computing Serviceのもう一つの重要な点は、HPCインダストリーにおける様々な立場の方々のニーズに対応していることです。システム管理者の方々、科学者やエンジニアといったクラスター上でアプリケーションを実行するエンドユーザー、あるいはAWS PCS上でアプリケーションを開発したい開発者やISVパートナーなど、それぞれのニーズに応えることができます。

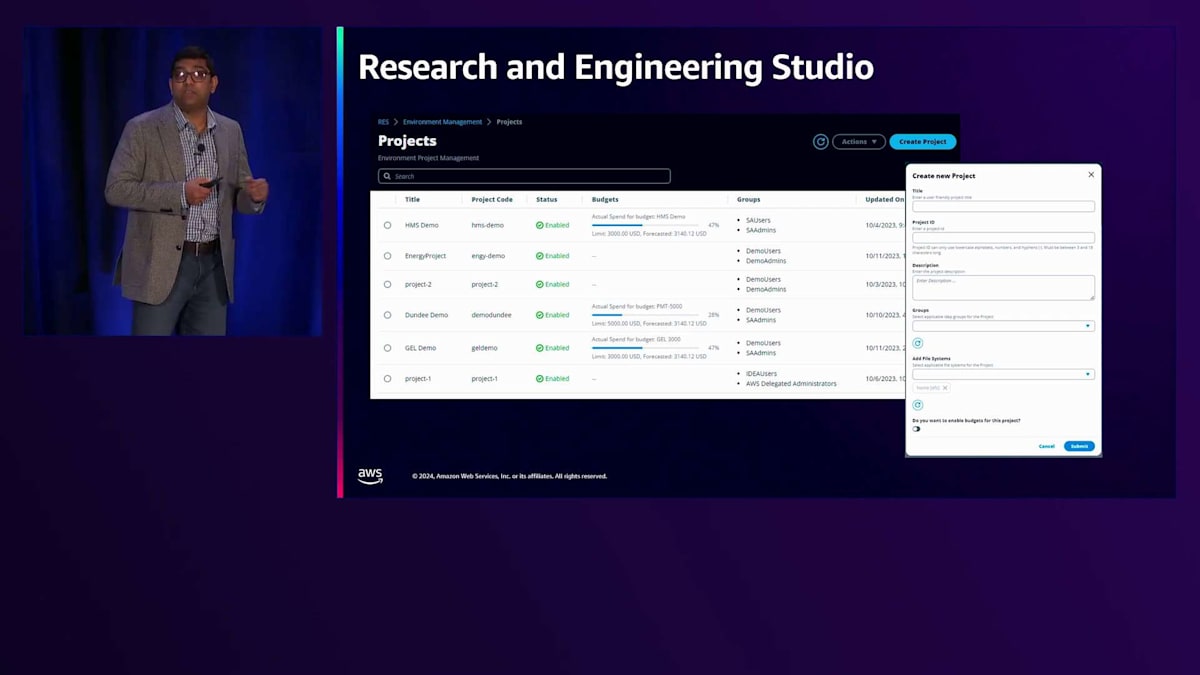
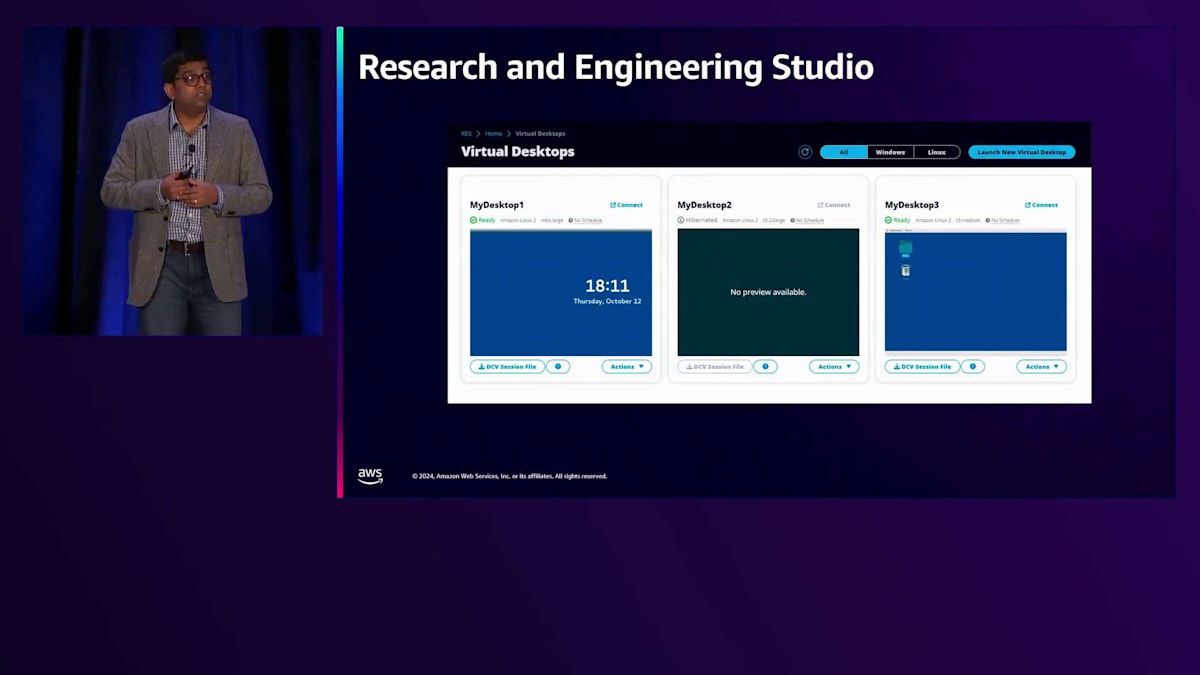
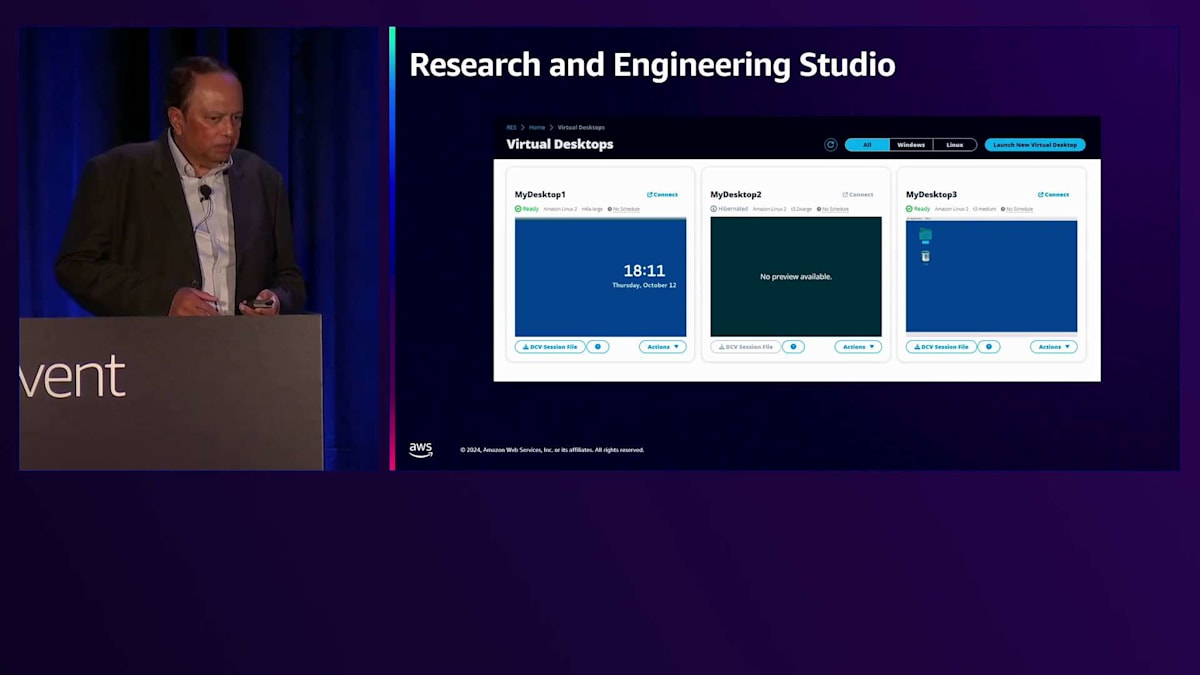
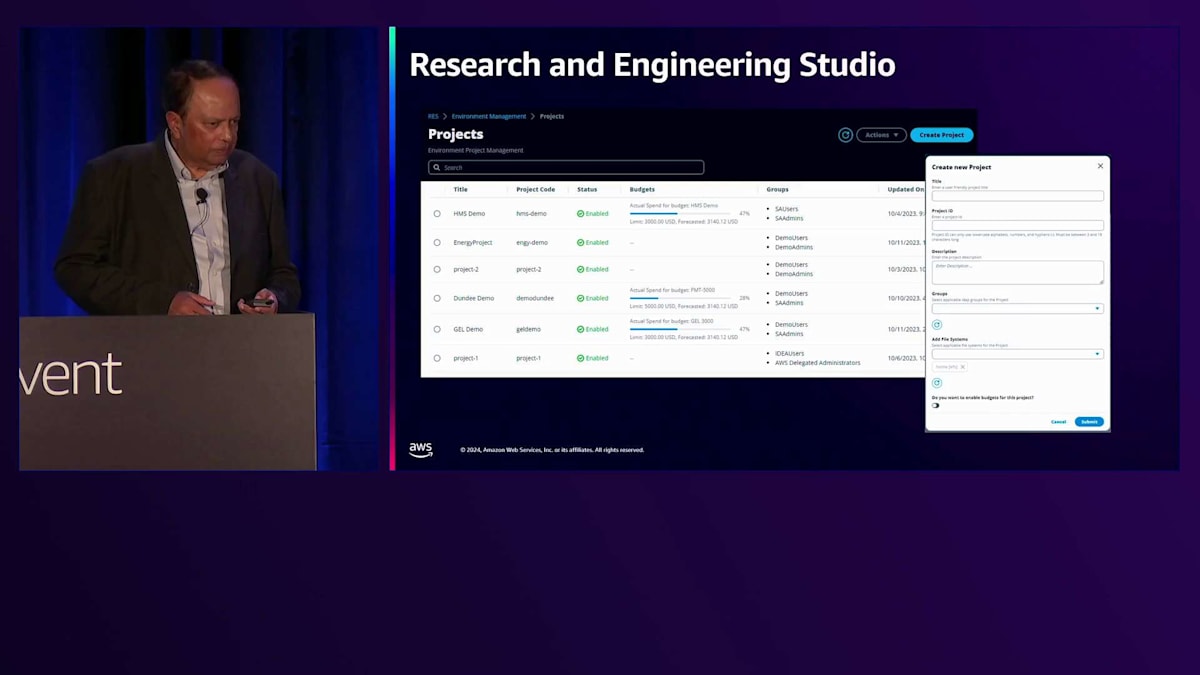
最後に、Research and Engineering Studio についてご紹介します。これは、コストや予算の配分・管理を含め、お客様がプロジェクトを簡単に管理・デプロイできるようにするポータルです。名前が示す通りポータルであり、このようなUIを備えています。お客様は簡単にプロジェクトを作成し、ユーザーをこれらのプロジェクトに割り当て 、権限を設定することができます。これにより、AWS Parallel Computing Serviceと連携することが可能になります。Research and Engineering Studioをフロントエンドのポータルとして、AWS Parallel Computing Serviceをオーケストレーションツールとして使用し、HPCクラスターの起動と停止を行うことができます。また、Research and Engineering Studio は、HPCアプリケーションと連携して仮想デスクトップ環境を管理するためにも、お客様によって活用されています。
PhysicsXのLarge Physics Modelsとその応用


これらの様々なサービスの実際の活用例を見ていただくために、MerckのHarsha Gurukarさんをご紹介したいと思います。彼は、Merckが本番環境のワークロードを大規模に実行するためにAWSをどのように活用しているかについてお話しします。こんにちは。これから、オンプレミスからAWSへの移行の旅についてお話ししたいと思います。これは、私が話をする多くの方々の共感を呼ぶ内容です。というのも、Merckには1990年代初頭からHPCチームがあり、オンプレミスで非常に成熟したワークロードを運用してきました。そのような環境を別の場所に移行するのは大変な作業です。 まずは、創薬の過程 がいかに複雑かについてご説明させていただきます。一般的に、創薬は発見から始まり、前臨床、初期開発、そして複数段階の臨床試験へと進んでいきます。これらの各段階が複雑です。
例えば、創薬の段階では、まずどの疾患をターゲットにするかを決定し、その疾患におけるバイオマーカー(通常はタンパク質)を特定します。次に、そのタンパク質の構造を変化させるか、疾患を治療するための化合物を届けるために、特定のタンパク質とドッキングするメカニズムを解明します。医薬品を市場に出すまでには8~10年の期間と10億から20億ドルの費用がかかり、非常に高額で時間のかかるプロセスとなっています。コストや市場投入までの時間を削減できる部分があれば、それは重要な意味を持ちます。これは単に財務的な側面だけではありません - 私たちは、必要としている患者さんに一日でも早く医薬品を届けることを信念としています。

これを実現するために、私たちのR&Dは非常に革新的でなければならず、R&Dに適切なツールを提供する必要があります。High Performance Computing(HPC)は、そのような能力を提供する適切なツールの1つです。Merckには30年にわたるHPCの経験がありますが、今こそ近代化し、より良い発明を始め、次のステージに進む時です。その答えがクラウドなのです。
価値提案という観点では、AWSで得られるオンデマンドサービスにより、予算予測、調達、セットアップという長期にわたるプロセスは過去のものとなります。これらは必要なくなります - 予算管理は依然として必要ですが、設備投資ではなく経費になります。システム管理も必要ですが、データセンターのハードウェアではなく、Infrastructure as Codeとなります。研究者がITについて考える時間を減らし、研究成果について考える時間を増やすことができるため、生産性自体も向上するでしょう。

これを実現するためには、自動化を行い、データを別の場所に移動したり、どのCPUを使うか、どのClusterを使うか、あるいは共有インフラで順番待ちをしたりすることに時間を費やすのではなく、研究をサポートするサービスを提供する必要があります。AWSサービスには、研究者の生産性を向上させるための多くの機能が用意されています。
成功基準として、最初に注目したのはユーザー採用です。既存のユーザーに加えて、HPCのスキルセットを持っていない、もしくはクラウドのスキルセットも持っていないラボの化学者や生物学者など、多くの潜在的なユーザーがいます。採用の鍵となるのはユーザーインターフェースです。ウェブサイトにアクセスし、ウェブインターフェースで数個のオプションを選択し、結果を待つだけです。その過程で、ジョブの状況や進捗状況を常にモニタリングし、情報を提供します。もう一つ重要な側面は指標です。成功の測り方についてご説明しましょう。
私たちは、移行したプラットフォームの数、移行したユーザー数、廃止したオンプレミスストレージの量などの指標を追跡しています。FinOpsについては、チャージバックモデルは採用していませんが、支出の予測は必要です。ユーザーコミュニティに対して、ジョブごと、ユーザーごとの総保有コストとクラウド消費コストを公開しています。

では、これをどのように資金調達しているのでしょうか? オンプレミスのインフラがあり、クラウドへの移行に向けた価値提案を確立しました。企業が後援し、取締役会が後援するIT近代化プログラムがあり、多くの組織と同様に、コンサルティング会社を招いてランドスケープを評価しました。彼らがHPCを調査した際、その大規模なインフラ使用量から「Big Rock(大きな岩)」としてラベル付けし、別枠で検討することにしました。その後、この「Big Rock」をさらに分析し、財務的価値とビジネス価値の両方を特定しました。財務的価値には、蓄積された技術的負債の軽減、データセンターコストの削減、システム管理者コストの潜在的な削減が含まれていました。ビジネス価値については、システム上で年間4,000万時間以上の待ち時間が発生していることが判明しました。理論的には、AWSでこれを大幅に削減できます。研究者がイノベーションを起こし、医薬品をより早く市場に投入することで早期の収益実現の可能性があることを示すと、注目を集めることができます。
このビジネスケースは、承認されるまでに何度もの審査を経ました。このプロセスの中で、価値の証明を求められました。私たちは、オンプレミスで通常90日かかるワークフローを選び、30時間以内で結果を出せることを実証しました。これは、ビジネスケースに実際の価値があることを示す優れた実証実験となりました。本日ここにいる何人かのロックスターを含む私たちのチームは、自分たちだけでは対応できないことを認識しました - それには6〜8年かかっていたでしょう。そこで、AWS Professional Servicesに重要な作業を依頼し、私たちのチームは監督役を務めることにしました。
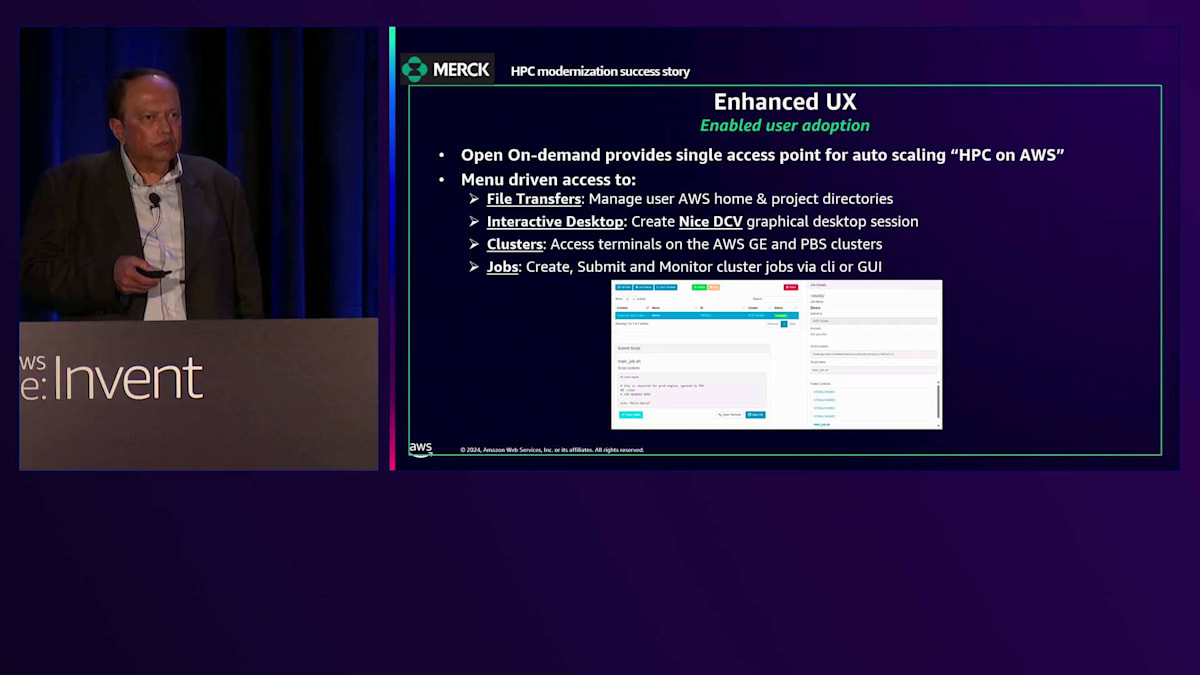
過去18ヶ月間の成功事例をご紹介します。 最初に取り組んだのは、ユーザー採用の促進でした。HPCリソースへの単一アクセスポイントを提供するオープンソースツールのOpen OnDemandをカスタマイズしました。これにより、一定の制限内でドラッグ&ドロップによるファイル転送が可能になりました。ただし、大容量データの転送には依然として管理者のサポートが必要でした。
次に、NICE DCVを使用して可視化用のインタラクティブデスクトップを作成しました。NICE DCVにはCPUとGPUのオプションがあり、ユーザーは必要に応じて選択できるようにしました。また、Grid EngineとPBS Proという従来型のジョブスケジューラーでクラスターへのアクセスを提供しました。Open OnDemandの一部として、HPCやクラウドに不慣れな人でもジョブの作成、投入、監視ができるGUIも用意しました。これによりユーザー採用が促進されました。パワーユーザーにはコマンドラインインターフェースが必要でした。というのも、彼らは代替手段の話をした時点で即座に疑問を投げかけてきたからです。ただし、後に彼らから、全員が頻繁に使用するカスタムワークフローの要望があり、その機能も実現しました。グラフィカルユーザーインターフェースは、コマンドラインに慣れていない新規ユーザーにとって確実に役立ちました。

その後、リフト&シフトを意識的に実施することを決めました。30年以上の歴史があるため、研究者から研究者へと受け継がれてきた多くのレガシーワークフローがあり、彼らはこれらのコマンドラインベースのツールの使用に精通しています。また、研究者にも私たちと同様に期限があり、新しいものを学んで検証する時間がありません。そこで、単なるリフト&シフトだけでなく、自動スケーリング機能も提供することで彼らを惹きつけました。オンプレミス環境を複製し、同じストレージパス、モジュール、ツールを維持しました。結果として、コマンドラインに慣れた研究者は、オンプレミスのヘッドノードの代わりにAWSのヘッドノードにログインするだけで、わずかな調整で全てが動作するようになりました。これは投資に対する成果を示す必要があった私たちにとって、手の届きやすい目標となりました。クラウドソリューションは、既存のワークロードを最小限のテストで使用でき、クラウドの柔軟性を迅速に実装し、オンプレミスの技術的負債を削減できるという大きな価値をもたらしました。

オンプレミスでのデータライフサイクル管理は困難な課題でした。研究者は削除せずにデータを保存する傾向があり、30年の歴史から大量のテープバックアップがあります。データの削除やデータ保持ポリシーの実装を試みましたが、効果がありませんでした。複数のサードパーティベンダーを評価しましたが、私たちの環境に合う解決策はありませんでした。40~50ペタバイトのデータが様々なアドホックなストレージソリューションに分散しており、データライフサイクルを効果的に管理することは不可能でした。しかし、AWSのストレージサービスがこの課題に対する明確な解決策を提供してくれました。過去3年間作成されていないか、過去1年間アクセスされていないデータについて研究者に相談しました。「過去3年間作成されておらず、1年間使用されていないデータは、ユーザーの関与なく自動的にアーカイブします。必要な場合は、このEC2インスタンスにログインしてください」という形で対応しました。
バックグラウンドでは、AWSゲートウェイを使用してデータを公開しました。研究者はデータを手放したがらないため、これは迅速な解決策となりました。私たちが実施しなかったのは保持ポリシーの設定です。全てをAmazon S3に配置して自動的に階層化され、保持ポリシーも設定できます。しかし、5年保持を望む人、10年、35年、さらには100年保持を望む人がいるなど、多くの質問と混乱があったため、実装しませんでした。AWSサービスはいつでも保持ポリシーを設定できるため、これは後回しにすることにしました。

今後のデータライフサイクル管理については、すべてを直接クラウドに移行し、保持ポリシーと階層化ポリシーを最初から適用していきます。 Data Scienceノートブックは、オンプレミスで広く使用されていたもう一つのプラットフォームでした。最初はR Studioから始まり、その後別の署名アプリを導入しました。オンプレミスでPosit Workbenchもセットアップしましたが、保証期限が切れそうなハードウェア上で動作していました。そこで、クラウド上にセットアップし、ユーザーを一人ずつ移行していきました。GitHubやHPCクラスターと統合できたことは大きなメリットで、大規模なデータセットを扱うユーザーはネットワーク内からHPCにスケールアップすることができるようになりました。
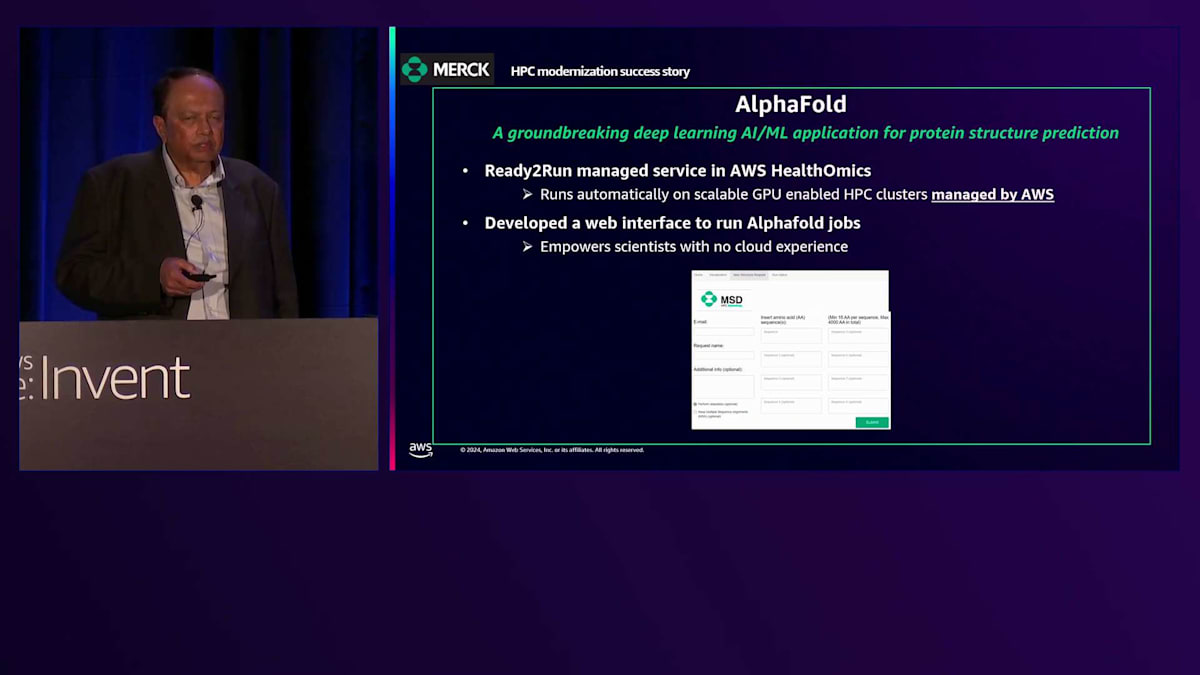
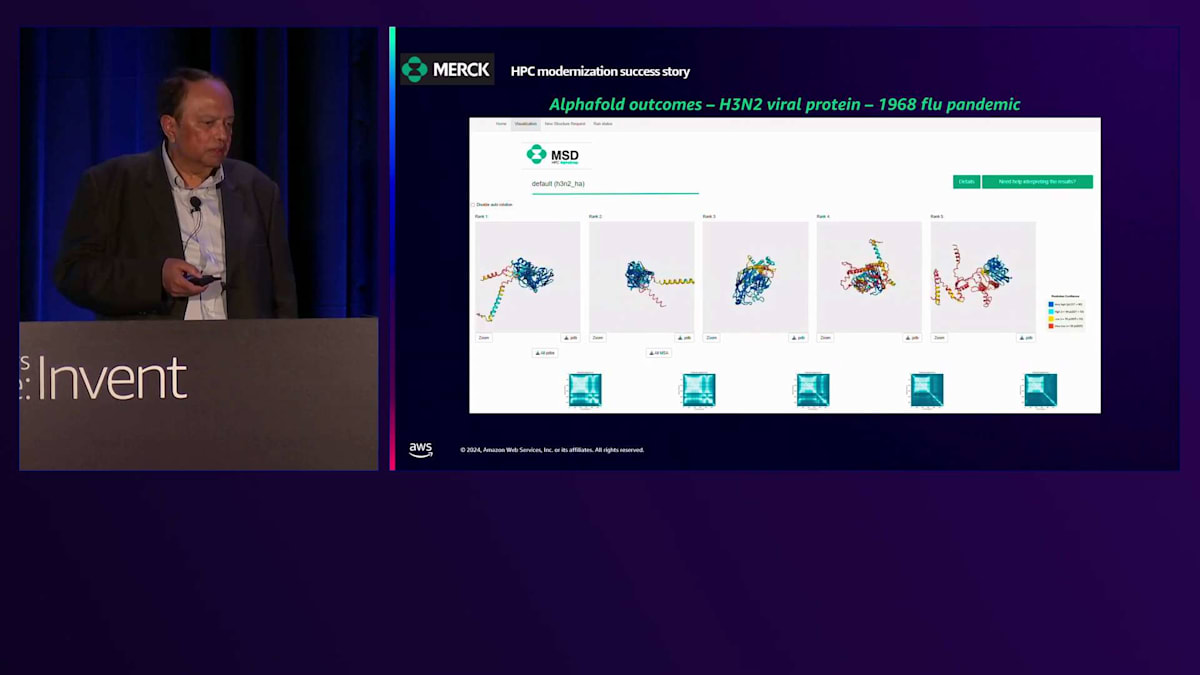

AlphaFoldは、タンパク質構造予測のための画期的なAI/MLアプリケーションです。AWS HealthOmicsでは、AlphaFoldをすぐに実行できるサービスとして提供しています。私たちはこれにWebインターフェースを追加し、基本的にはShinyアプリを使って、ユーザーが簡単にアクセスして結果を得られるようにしました。 数時間後、処理が完了すると通知が届き、5つの異なる予測結果が提供されます。 ユーザーは処理完了のリンクをクリックすると、結果を確認することができます。このShinyアプリにより、HPCやクラウドに詳しくないユーザーでもAlphaFoldを利用できるようになり、現在では広く使用されています。
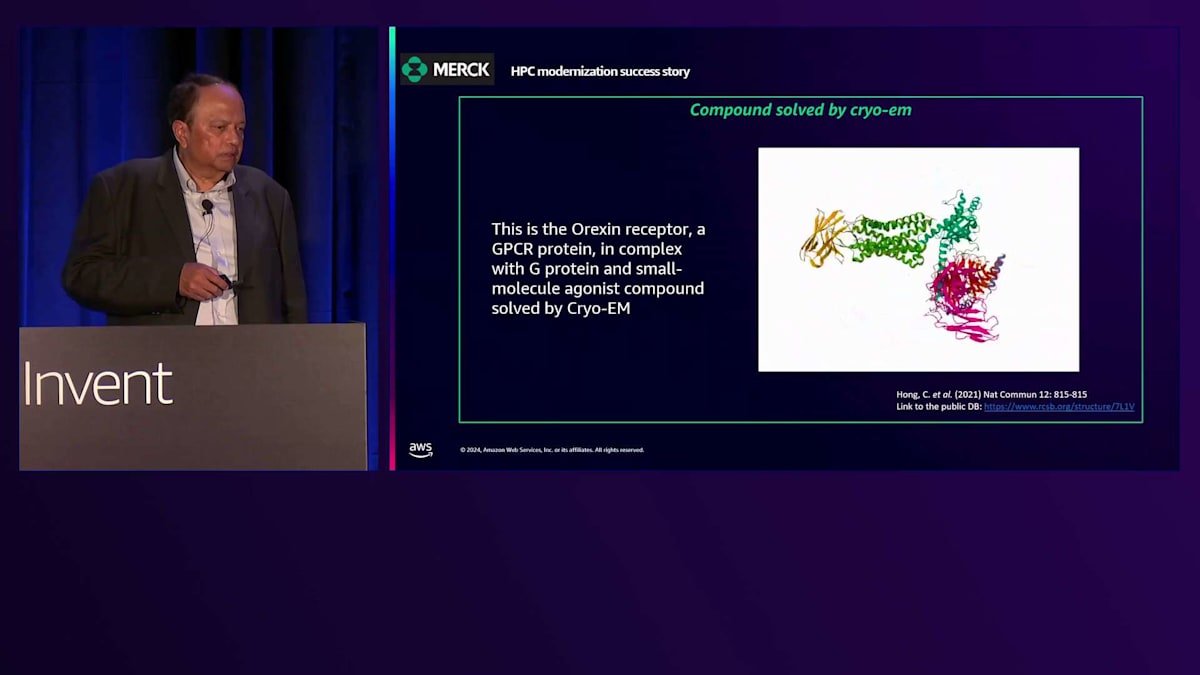
最後のユースケースはCryo-EMで、1日約16テラバイトという膨大なデータを生成します。現在さらにCryo-EMの機能を追加しているため、1日32テラバイトになる可能性もあります。データ管理の課題は非常に大きく、バックアップの方法、データの移動、計算処理などが問題となります。私たちは、Cryo-EM装置のオンボードキャッシュから直接AWSにデータを転送し、そこで計算を行う方法を見出しました。S3でバックアップを行うため、データ管理は自動化され、研究者の負担にはなりません。これらすべてを短期間で実現できたことで、オンプレミスのインフラを削減できるという副次的な効果もありました。外部ベンダーから取得するデータにも同じアーキテクチャを使用しています - ベンダーが私たちのバケットにデータを置くだけで、あとは私たちが処理します。 これはCryo-EMによって解明されたコンポーネントの一例です。
これはOrexin受容体です。皆様ありがとうございました。それでは、PhysicsXのJakeに引き継ぎたいと思います。Jake、お願いします。緑のスライドから始めてください。SrinivasとHarshaの温かい紹介、ありがとうございます。
PhysicsXのAWS活用事例と物理学ベースの機械学習

簡単に自己紹介させていただきます。私はJake Mulleyで、PhysicsXのCloudエンジニアリングを率いています。これから10分ほどで、PhysicsXとは何か、私たちが何をしているのか、そしてAWSをどのように活用しているのかについてご紹介させていただきます。まず、PhysicsXについて説明させていただきます。 PhysicsX:複雑な物理製品や機械の設計、製造、運用を加速するAIを構築しています。私たちは、コンピュータ支援エンジニアリングシミュレーション、AI計画、ジェネレーティブデザイン、制御の分野で活動しています。組織としての私たちの目的は、人間の想像力を超えて、現代の最も重要な課題に取り組むことです。再生可能エネルギー、材料、半導体、自動車、航空宇宙など、先端産業分野で活動を展開しています。
私たちの研究から、明確な仮説が得られています。従来のエンジニアリングのあり方を変革できると考えています。具体的には、シミュレーションから推論へと移行し、シミュレーションの実行コストを削減することで、製品設計・開発のイテレーション時間を「時間や日単位」から「秒単位」へと短縮できます。製品設計は通常、CAEに依存するプロセスがボトルネックとなっており、物理的な設計の全ての組み合わせを検証するには多大な時間と労力が必要です。そこで私たちは、物理プロセスの挙動を再現することを学習し、イテレーションあたりの計算量を大幅に削減して短時間で実行できる Large Physics Models(LPMs)を開発してきました。組織としては比較的若く、設立から約5年ですが、ソフトウェア、データサイエンス、機械学習、シミュレーション、AIリサーチにわたる学際的なチームで100名以上のメンバーが在籍しています。

従来のCAEと従来のメタモデルを見てみましょう。従来のCAEは、一般的なエンジニアリングや数学的モデリングから生じる微分方程式を数値的に解きます。しかし、これには典型的な課題があります。CAEシミュレーションを実行するための準備に長時間かかり、データ処理も膨大です。さらに、計算時間も時間や日単位でかかり、設計の探索も制限されます。ジェットエンジンのような物理的な製品を設計する場合、フィードバックループに数日かかり、必要な最適な出力を得るためにこのサイクルを繰り返し実行する必要があります。また、作業対象のドメインに関する専門知識も必要です。従来のメタモデルについても、Reduced Order Modelやシミュレーションのレスポンスサーフェスを使用して計算を高速化できますが、これらにも課題があります。数値シミュレーションと比べて精度が大幅に低下したり、Deep Learningでは非線形の挙動や複雑なダイナミクスの捕捉が困難だったり、物理的な制約条件を犠牲にしなければならないことが多いのです。

これが Large Physics Model です。1つまたは複数の物理プロセスの挙動を再現することを学習します。例えば、航空機を設計する場合、LPMsは航空機の翼の設計と、その表面上の圧力場および内部の構造応力との関係を学習できます。従来のCAEや従来のメタモデルと比較して、これらのモデルは実行時間が短く、イテレーションを高速化できます。計算量も大幅に削減され、日や時間単位から分や秒単位へと変わります。さらに、次のスライドで見るように、このプロセスを自動化することができます。これにより、より多くの設計を探索でき、リアルタイムのプロセス最適化を通じて、より最適化された設計が可能になります。また、私たちが協業している企業の製造スループットを向上させることもできます。さらに、時間とともにモデルは改善され学習を続けます。これを私たちはActive Learningと呼んでいますが、既知の制約の中で組織の知識を蓄積し、物理的な製品設計を探索することができます。これはすでに、私たちの顧客を通じて日常的に使用される製品に応用されています。
Large Physics Modelsは単一のモデルではありません。人々が使用できる多くのモデルがあり、私たちの学びと経験から、すべてのユースケースに適合する単一のモデルは存在しないことがわかっています。Large Physics Modelsを使用することで、従来のCAEプロセスを使用してデータパイプラインを一から再構築するのではなく、非常に迅速に構築、デプロイ、変更、実験を行い、物理的な製品の設計においてよりアジャイルになることができます。
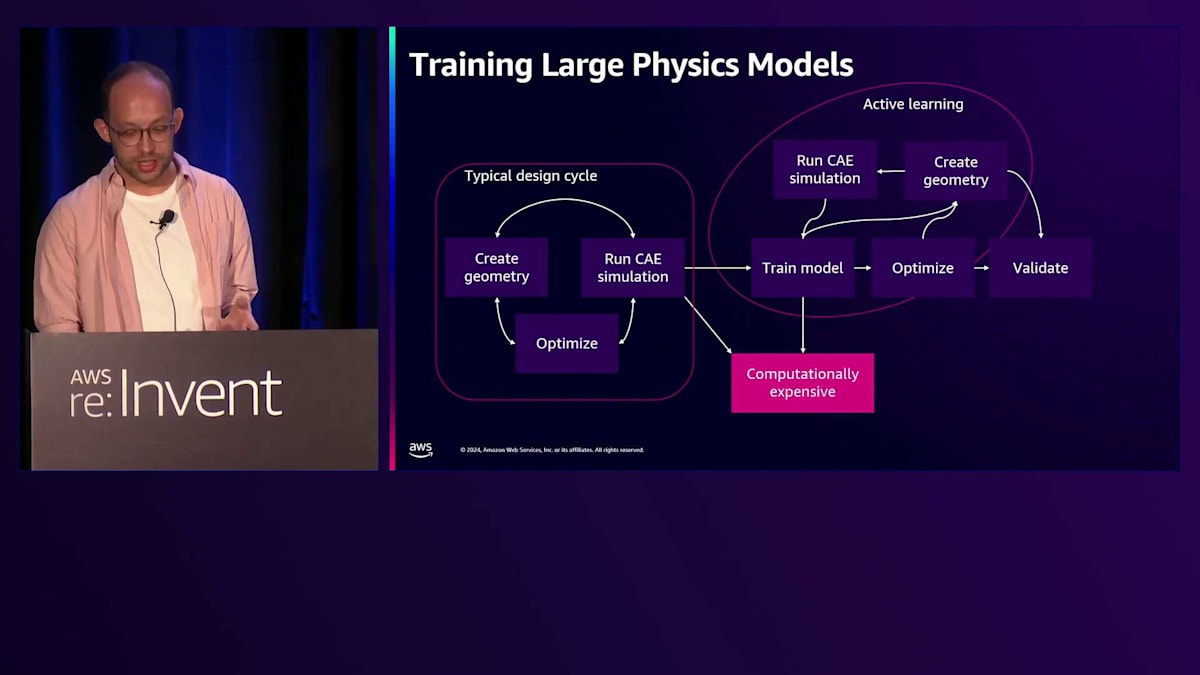
このダイアグラムを見てみましょう。これは、右側にActive LearningとLarge Physics Modelsを組み込んだ、典型的な製品設計サイクルを示しています。左側では、ジオメトリを使用してベースラインを作成し、CAEシミュレーションを実行して最適化します。満足のいく結果が得られたら、それを使用してモデルを学習させ、Active Learningループを通じて、最適化、シミュレーション、学習を継続的に行い、より迅速に最適化された設計を作成します。私たちは、社内でも顧客とも同じフローを使用して、チームや既存のワークフローを強化し、設計を改善してきました。一般的に、製品の市場投入までの時間はCAEの実行回数とその所要時間に関連付けられますが、Active Learningループを使用すれば、従来の方法と同じCAE実行回数でも製品開発時間を短縮できると考えています。自動化されているため、あなたがre:Inventに参加している間も、週末の真夜中に自己学習を続けます。また、従来の方法と比べて、より多くの次元と出力を探索することができます。


実例を見てみましょう。これは、新しいタイプの人工心臓を開発しているMedTechスタートアップと私たちが行った取り組みです。これはLVAD(Left Ventricular Assist Device)と呼ばれるものです。通常、大きな心臓ポンプが必要な場合、胸から管が出ているため、感染症などの合併症を引き起こす可能性があります。このMedTechスタートアップの目的は、機械的なポンプ作用によって引き起こされる出血や血栓などの血液損傷に関連する合併症を減らすことです。

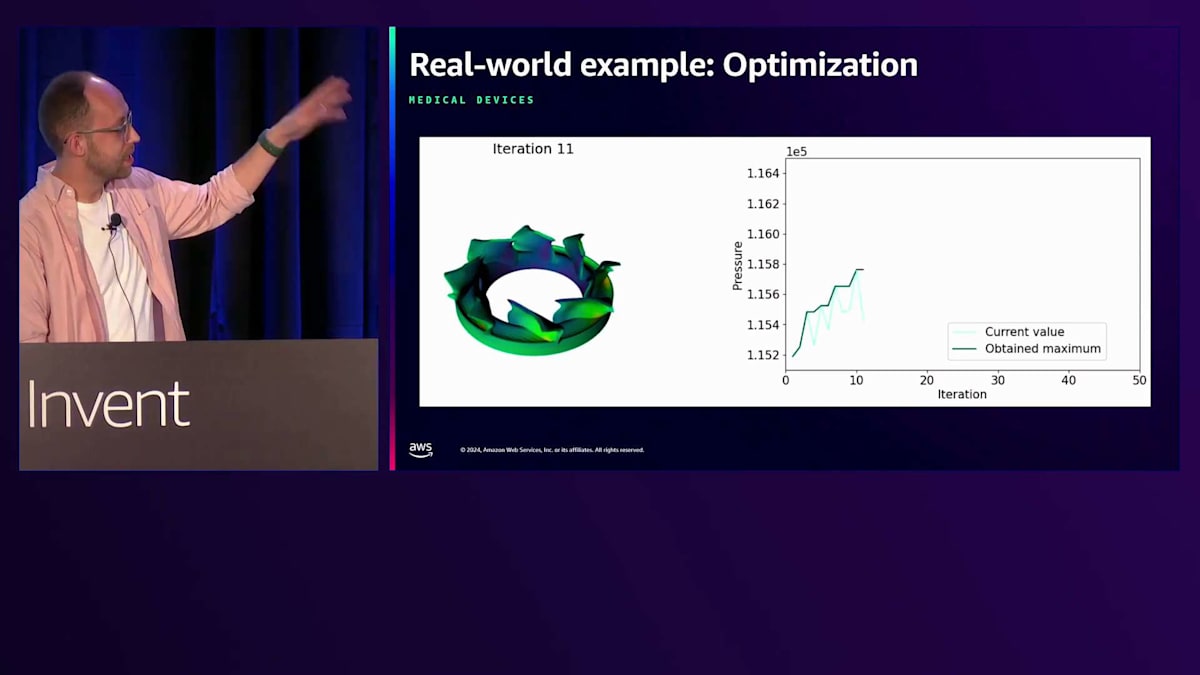
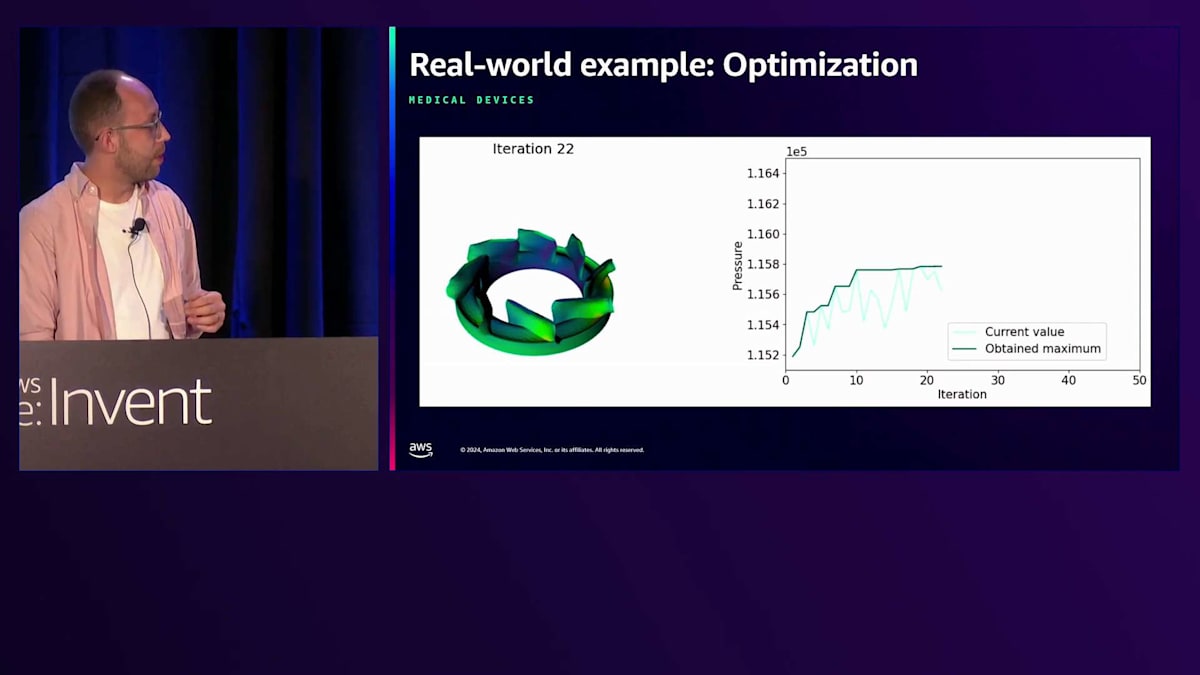
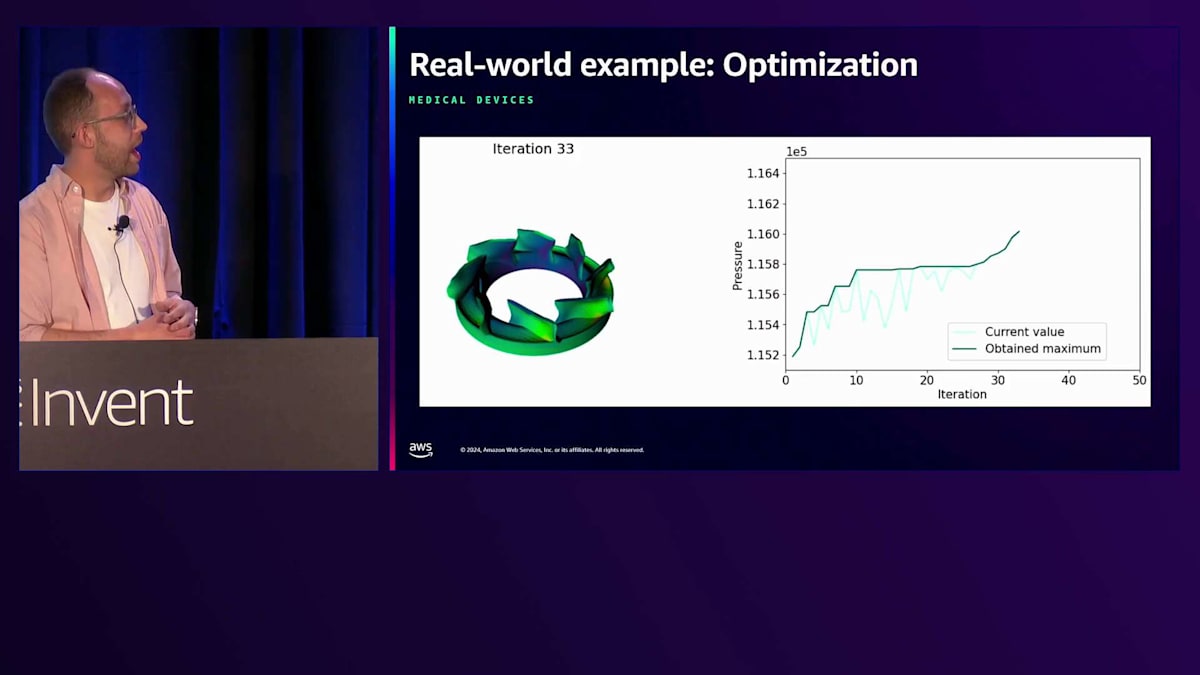
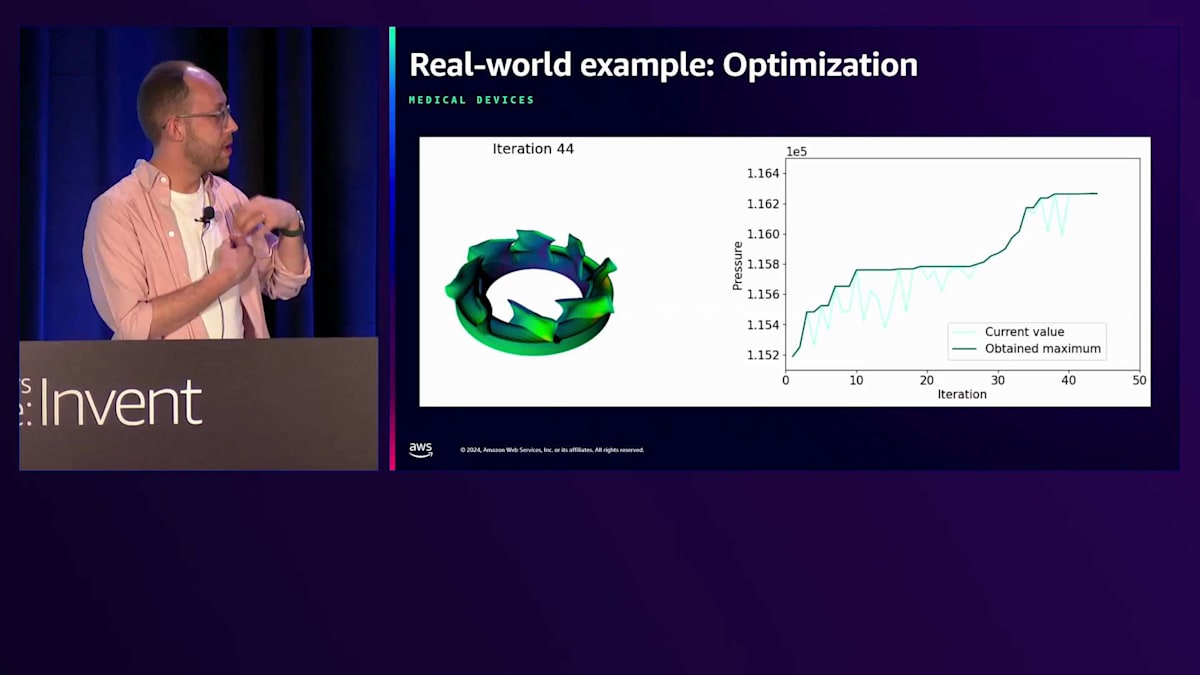
このスライドは、もし動画が始まれば表示されるはずですが、動かないかもしれません。ご覧のように、Active Learningのループを通じて自己学習を繰り返しているところです。これはリアルタイムで、速度を変更していません。私が話している間に、このデバイスに適切な圧力を計算するために、20回近くの反復処理が行われているのがわかります。このハートポンプは現在、豚での試験段階にあり、将来的にはヒトへの移植が期待されています。この特殊なデバイスは従来の心臓ポンプよりもはるかに小さいため、胸から出るワイヤーもなくすことができ、さらに合併症のリスクを減らすことができます。

結局のところ、私たちがここにいる理由は、これがAWS上に構築されているからです。そこで、私たちのアーキテクチャを見てみましょう。この数年間、私たちは何百ものコアと多数のGPUを持つオンプレミス環境を、先ほどSrinivasが話していたAWSサービスを使って拡張してきました。私たちは通常、Machine LearningとCAEシミュレーション用のHigh-Performance Computeという2種類のワークフローを持っており、現在、社内および顧客向けのEnterprise SaaSプラットフォームを構築中です。これにより、私たちのLarge Physics Modelsへのアクセスを提供し、顧客が自身の要件に応じてセルフサービスで利用できるようにしています。

High-Performance Computeのアーキテクチャを見ると、SLURMを使用したAWS ParallelClusterを使用していることがわかります。ParallelClusterの素晴らしい点の1つは、すべてが既にセットアップされていることです。また、SLURMコンポーネントは研究者やチームが普段から使い慣れているものなので、これらのツールを使用するための学習曲線がありません。私たちは計算コアを最大限に活用するために、数百台のhpc7a.g6xlargeでスケールしています。hpc7aには物理コアがあり、これはシミュレーションソフトウェアに必要です。また、ノード間の通信速度を向上させるためのEFAや、S3データへの高速アクセスのためのAmazon FSx for Lustreも使用しています。さらに、シミュレーションエンジニアが出力を確認する際にクラスター内で完結できるように、可視化ノードも用意しています。

そして、Machine Learningアーキテクチャを見ると、EC2モードでマルチノード並列処理のためにAWS Batchを使用しています。
GPUアクセスについては、大規模な実行には16台のP5、もしくは8台のP4Dの間でスケーリングを行っています。p4.24xlarge instancesを使用する大規模な実行では、トレーニング時に64から128のGPUを使用し、高速・低レイテンシーのデータアクセスにはAmazon FSx for Lustreを、そしてNVIDIA GPUDirectを通じた高速なノード間通信にはEFAを活用しています。これが私たちのアーキテクチャの概要です。

物理学に基づいた機械学習は、人々のデザイン、最適化、製造の方法を変革しています。シミュレーションのデータセットでモデルを学習させることで、まだ実行していないシミュレーションの結果を予測し、最適な出力を得るためにデザイン空間をさらに探索することができます。推論は1秒未満で実行できるため、30分程度で20-30のデザインを評価できることから、より明確な物理的デザインをより迅速に、そしてはるかに低コストで得ることができます。物理学と機械学習は、世界を正確にモデル化するという共通の目標を持っているため、物理学に基づいた機械学習は理にかなっているのです。
HPCとAIの融合:気象・気候モデリングの事例と総括

ここで締めくくりのために戻りたいと思います。ありがとう、JakeとHarsha。この30分間で、MerckやPhysicsXのようなお客様がHPCとAIを組み合わせてイノベーションを加速させている様子をご覧いただきました。冒頭に戻りますが、HPCとAIの融合が見られる3つ目の領域である気象と気候について触れたいと思います。

この分野で私たちが取り組んでいることは、気象・気候モデリングという領域がどのように変化しているかを見ると、これは約30年にわたって典型的なHPCワークロードでした。お客様は従来の高性能コンピューティングを使用してこれらの気象モデルを大規模に実行してきました。ここ数年、AmazonのPreDiff、Earthformer、NVIDIAのFourCastNet、GoogleのGraphCast、HuaweiのPangu-Weatherなど、物理ベースの気象モデル全体にMLが導入されてきています。これらの異なるモデルはすべて、気象と気候予測にAIとML技術を取り入れています。

この特定の取り組みでは、NVIDIAと協力して、気象・気候モデリング用に彼らのEarth-2プラットフォームを採用しました。Earth-2は従来の物理ベースのシミュレーション、可視化、そして従来の物理ベースのシミュレーションへのMLモデルの導入をカバーする完全なスタックプラットフォームです。様々な物理学向けの物理-MLモデルを提供するリポジトリであるModulus、主に気象の推論やトレーニングパイプラインに使用されるEarth Studio、そして最後に、主にフォトリアリスティックなレンダリングに使用されるOmniverseといった、異なるアプリケーションのコレクションを持っています。

これが実際のパイプラインです。数週間前に、 AWSでEarth-2を実行して、リアルタイムの天気予報を行い、そのデータをダウンストリームアプリケーションに活用する方法を最適化する方法についてのブログを公開しました。例えば、一般的な天気予報以外の気象データの実用的な応用例として、エネルギー取引があります。このブログでは、AI/MLモデルを使用したリアルタイムの天気予報と、そのデータをエネルギー取引アプリケーションに活用する方法について説明しています。
これは中期的な天気予報の簡単なスナップショットです。上部には地表風速のUおよびV方向の成分が示されており、右側にはアンサンブル結果が表示されています。多くの場合、単一のシミュレーションだけでなく、数百、時には数千のシミュレーションを実行します。右側では、それらすべての結果のアンサンブルをご覧いただけます。

ご覧の通り、この45分間で AWS HPCサービスについてお話ししてきました。MerckやPhysicsXがこれらのサービスをどのように活用し、組織内でイノベーションを加速させているかをご覧いただきました。お客様がこれらのアプリケーションを成功裏に実行できる重要な要因の1つが、強力なパートナーエコシステムです。これは、ISVパートナー、ハードウェアパートナー、コンサルティングSIおよびGSIパートナーにわたる私たちのパートナーエコシステムの一部をお示ししたものです。

この 45分間でご覧いただいたすべてのイノベーション - 先ほども申し上げましたが、AWSは約10年にわたってHigh Performance Computing分野に投資を続けてきました。2週間前の最近のSupercomputing conferenceでは、AWSは7年連続でベストクラウドHPCプラットフォームに選ばれ、お客様のために行っているこれらすべてのイノベーションが認められました。

以上で本日のプレゼンテーションを終わらせていただきます。最後にアンケートにご協力いただければ幸いです。 ご清聴ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion