re:Invent 2023: AWSが語るAmazon EKSの進化と将来像 - セキュリティ強化と自動化


はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - The future of Amazon EKS (CON203)
この動画では、AWSのKubernetes製品チームリーダーNathan Taberが、Amazon EKSの過去5年間の進化と今後の展望を語ります。SlackとAnthropicの事例を交えながら、EKSの新機能や改善点を紹介。特に、Pod Identity、Cluster Access Management、VPC CNI Network Policyなどのセキュリティ強化や、KarpenterによるノードのオートスケーリングなどEKSの最新動向がわかります。また、機械学習ワークロードへの対応や、クラスター管理の自動化など、EKSの未来像も垣間見ることができます。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
AWSにおけるKubernetesの未来:セッション概要と背景

はい、まだ何人か到着中ですね。ありがとうございます。皆さん、こんにちは。お越しいただきありがとうございます。CON 203、AWSにおけるKubernetesの未来についてのセッションです。私はNathan Taberと申しまして、AWSのKubernetes製品チームを率いています。今日はここにいらっしゃる皆さんのために来ました。とてもワクワクしています。本日は特別ゲストとして2名をお迎えしています。SlackのDirector of EngineeringであるAlex Demitriさんと、AnthropicのSystems LeadであるNova DasSarmaさんです。お二人のお話を楽しみにしています。素晴らしい講演を用意しました。

では、少し内容について触れてみましょう。 アジェンダは何でしょうか?こんなに急速に進化し、私たち全員に大きな影響を与えているものの未来について、どのように語り始めればいいのでしょうか?AWSでは、常に次に何をすべきかを考えています。私は時間の大半を次の一手を考えることに費やしています。ある意味、何かを行うと決めた時点で、私の頭の中ではすでにそれを出荷したも同然なのです。6ヶ月後に振り返ってみると、「ああ、実際にそれを出荷したんだ」と思うことがあります。頭の中では常に先のことを考えています。6ヶ月後に何をするか、1年後に何をするか、2年後に何をするか、といった具合です。
これは非常に難しいです。なぜなら、時には状況が変化するからです。re:Inventの動画に載せるスライドに、2年後に誰かが見返して「あの時、これをすると言っていたのに実際にはやらなかったじゃないか」と言われるようなことを載せるのは難しいです。トラブルに巻き込まれたくありません。しかし同時に、私たちがどのように考えているかについて少し洞察を与えたいとも思います。私たちは何を考えているのか、何を見ているのか、世界をどのように見ているのか、そしてそれをどのように整理して組み立てていくのか。この講演を通じて、私たちの頭の中にあるものや、Kubernetesについてどのように考えているか、そしてお客様をより良くサポートするためにどのように考えているかについて、いくつかのヒントを得ていただければと思います。
もちろん、Amazonでは顧客に非常にこだわっています。KubernetesチームやほとんどのAWSチームが行ってきたことで、顧客の要望に基づいていないものはほとんどありません。だからこそ、今日はSlackのAlexさんとAnthropicのNovaさんにここに来ていただいたのです。なぜなら、私たちがどこに向かっているのかを知るためには、お客様の声を聞く必要があるからです。AWSからより良く、より速く進むために何が必要かを考える必要があります。Slackにはアプリケーションのスケーリングについて、Anthropicには安全な方法でAIをスケーリングする方法について話していただきます。そして私は、過去、現在、未来という3つのことについて話します。これにより、私たちが何を構築しているのか、どこに向かっているのか、そして何を考えているのかについて、皆さんにイメージを持っていただけると思います。
Kubernetesの人気と採用理由
では、始めましょう。まず最初に、Kubernetesは非常に人気があるということです。大成功を収めたと言うのは控えめな表現でしょう。KubernetesのガバナンスorganizationであるCloud Native Computing Foundationが調査を行い、昨年の調査では、企業organizationの64%が本番環境でKubernetesを使用していることがわかりました。さらに、これらのorganizationの25%がKubernetesを評価またはパイロット運用していました。つまり、大多数のorganizationがKubernetesをビジネスの一部として導入し、アプリケーションを実行する上で中核的な部分にしようとしているのです。

では、なぜ人々はこのものを使うのでしょうか? これはオープンソース技術です。運用が複雑で、使ってみるとわかりますが、ちょっと変わった特徴がいくつかあります。皆さんの多くが使ったことがあると思いますが、こういった奇妙な点に遭遇したことがあるでしょう。しかし、それには十分な理由があるのです。私たちが顧客と話をすると、Kubernetesを使う理由が4つあることがわかります。1つ目は、より良いイノベーションを実現し、顧客のためにイノベーションを起こすことです。イノベーションをどのように起こすのか?それは、素早く動き、安全かつ迅速に変更を加えられることです。これが最も重要なポイントです。全ての開発チームが変更を加える方法について、システムと標準があれば、そういった変更が可能になります。
2つ目の理由は、固定費を削減することです。静的リソースの使用や、VMごとに1つのプロセスを実行するようなことから、コンテナを使用した動的な共有リソースへと移行することです。つまり、物事を分割し、複雑な契約を排除し、管理のオーバーヘッドを減らし、コストを下げるのです。3つ目の理由は、組織全体を活性化することです。Kubernetesは、アプリケーションのオーケストレーションのためのAPI標準を提供します。顧客は「AWSクラウドの異なるリージョンで実行している場合でも、まだオンプレミスで実行しているワークロードがある場合でも、そして...」と言いたいのです。あまり大声で言うべきではありませんが、他のクラウドもあります。そうですね、re:Inventですから。でも、実際にそういうことはあるんです。様々な場所で実行されるワークロードがあり、それらすべての場所で実行できる標準があるのは非常に便利です。
一貫した方法ですべての場所で実行でき、ベストプラクティス、ガバナンス管理、セキュリティ、モニタリング、コスト管理、そしてこれらの複雑なことすべてを確立できる標準があるのは非常に便利です。そして、それらがどこで実行しても機能するのです。AWSだけを使っていたとしても、私はAWSが大好きで、明らかにAWSに全面的に賭けていますが、ある会社を買収し、別の会社を買収し、あるいは合併があって、突然システムリーダーとなり、別の環境で運用している他のチームを管理しなければならなくなったとしたらどうでしょう?そういった場合、どうすればいいのでしょうか?Kubernetesを使えば、そのクロス環境の標準化について考え、将来に備え、リスクを軽減することができるのです。
Amazon EKSの5年間の進化と成果
リスク軽減は、CIOやCTO、企業ジェットで飛び回る大物だけが考えることではありません。リスクは、エンジニアが考えることであり、開発リーダーや開発チームが考えることでもあります。ただ、私たちはそれを通常「技術的負債」と呼んでいます。そして、これもKubernetesの大きな利点です。つまり、その技術的負債を減らすのを助けてくれるのです。AWSでは、Kubernetesに多くの投資をしてきました。Amazon EKSは今年の6月に5周年を迎えます。一般提供開始から5年目です。2017年のre:Inventで初めてEKSを発表したときに私もここにいたことを嬉しく思います。それは本当にエキサイティングな瞬間でした。

この5年間、私たちはEKSに大きく投資し、AWSのパフォーマンス、スケール、信頼性、可用性の最高峰を体現するものにしてきました。そのため、CNCFと話をしたり、このデータを持つ顧客を見たりすると、他のどの場所よりもAWS上で多くのKubernetesワークロードが実行されていると言われています。 そして、私たちのデータを見ると、毎週数十億のEC2インスタンス時間がEKSで実行されていることがわかります。これは信じられないことです。なぜなら、このサービスを立ち上げたときは、ただの小さな新興サービスで、顧客がKubernetesコントロールプレーンをより良く実行できるよう支援するだけだったのに、それが一転して文字通り数十億のEC2インスタンス時間になったのですから。これは驚くべきことです。

これらの顧客は何をしているのでしょうか?想像できるあらゆることを行っています。レガシーの.NETやJavaアプリをクラウドに移行したり、データ処理を行ったり、リアルタイムのバックエンドを構築したり、Webフロントエンドを作ったりしています。最近では、機械学習やAI/MLがEKSとKubernetesの主要なユースケースとして浮上しています。生成AI、ロボット工学など、多岐にわたります。個人的には、自動運転車が大好きです。本当にクールだと思います。現在、EKSで多くの自動運転車のトレーニングが行われているのを見るのは、とてもワクワクします。機械学習やKubeRay、Spark、Kubeflowなどのツールを使って未来の技術に取り組んでいる企業を見るのは、本当に素晴らしいことです。
Kubernetesスタックの構造と顧客支援の目標
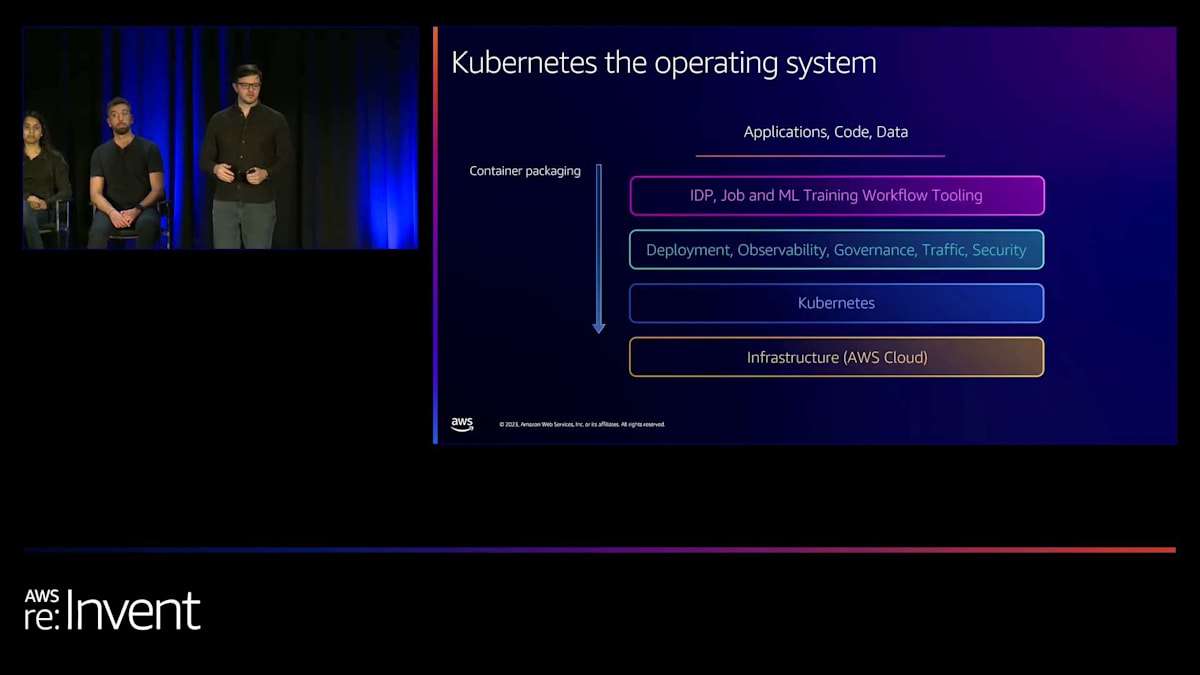
しかし、私たちチームが注目しているのは、ユースケースだけでなく、Kubernetesがスタックのどこで動作しているのか、そして顧客が何をしているのかということです。これは重要なポイントです。私たちが顧客のために何をすべきか、どうすれば差別化されていない重労働を取り除けるかを考える上で重要です。インフラストラクチャがあり、その上にKubernetesが乗っていて、異なるインフラストラクチャを横断的にオーケストレーションし、それらをすべて結びつけるのを助けています。 そして顧客は、デプロイメント、可観測性、ガバナンス、トラフィック制御、セキュリティ制御など、さまざまなものをKubernetesの上に重ねています。
これらの多くはKubernetes内で動作しています。実際、CNCFを見ると、Kubernetes内または隣接して動作する599のオープンソースカタログプロジェクトがあります。そのうち173は実際にオープンガバナンスでCNCFが直接運営しています。これは、Kubernetes上でこのプラットフォーム層を実行するためのたくさんのものです。さらに、AWSサービスからKubernetesにこれらの機能の一部を提供するための統合を多数構築しています。そしてさらに上の層には、IDP(統合開発者プラットフォーム)があります。これは、アプリケーションをどのようにパッケージ化し、デプロイメント、可観測性、ガバナンスなどを備えたKubernetes上で実行するか、データ処理ジョブをどのようにオーケストレーションするか、機械学習ワークフローをどのようにオーケストレーションするかということです。これが、顧客がパッケージングとコンテナを使用し、このスタック上で実行している異なる層です。そして、これが私たちが考えていることです。顧客がこれをもう少しうまく行えるようにするにはどうすればよいかということです。

AWSでKubernetesを実行する顧客を支援するための3つの目標があります。差別化されていない重労働を取り除き、物事を簡素化し、クラウドの規模、安定性、セキュリティへの完全なアクセスを提供すること。そして、Kubernetesのオープンソース標準を維持し、599のCNCFプロジェクトとの互換性を確保し、コミュニティやパートナーからの新しいイノベーションへのアクセスを可能にし、コミュニティ標準を維持・改善することです。全体的な目標は、お客様が自身の専門知識に集中し、信頼性の高いシステムを大規模に構築し、リスクプロファイルを低減できるようにすることです。


Amazon EKSは、AWSがKubernetesをサポートする方法の一つです。おそらく最も重要な方法でしょう。 しかし、他にもたくさんの方法があります。
AWSのKubernetesサポート:EKSとその他の取り組み
EKSはその管理の分野に該当します。これは、お客様のためにKubernetesを管理する方法だからです。また、Kubernetesのディストリビューションも提供しています。多数の統合機能を構築しており、AWSの各部分とKubernetesを統合するための20以上のオープンソースプロジェクトがあります。CSIドライバー、CNI、ロードバランサーコントローラー、ACKなど、あらゆるものが含まれます。また、アップストリームでの開発も行っています。コードをプッシュし、アップストリームで開発を行っています。CNCFおよびKubernetesプロジェクト全体のセキュリティ支援を提供し、セキュリティ評議会に参加して問題や重大な脆弱性をレビューし、非公開の問題に対処して、AWSでもそれ以外の場所でKubernetesを実行している場合でも、お客様の安全を確保しています。また、直接的なスポンサーシップも提供しています。コミュニティにプロジェクト構築のための資金を提供し、コミュニティプロジェクトのコスト削減と可用性向上を支援するシステムの構築をサポートしています。

EKSが主要なものですが、現在ではEKSはあらゆる場所で稼働しています。Distroがあり、EKS Anywhereがあります。これはオンプレミスでKubernetesを実行するためのツールチェーンです。EKSは現在、Snow、Outposts、ローカルゾーン、Wavelength、そしてもちろんAWSリージョンで稼働しています。目標は、一貫したパフォーマンスのKubernetesが必要な場合、どこで実行するにしても選択肢を提供することです。
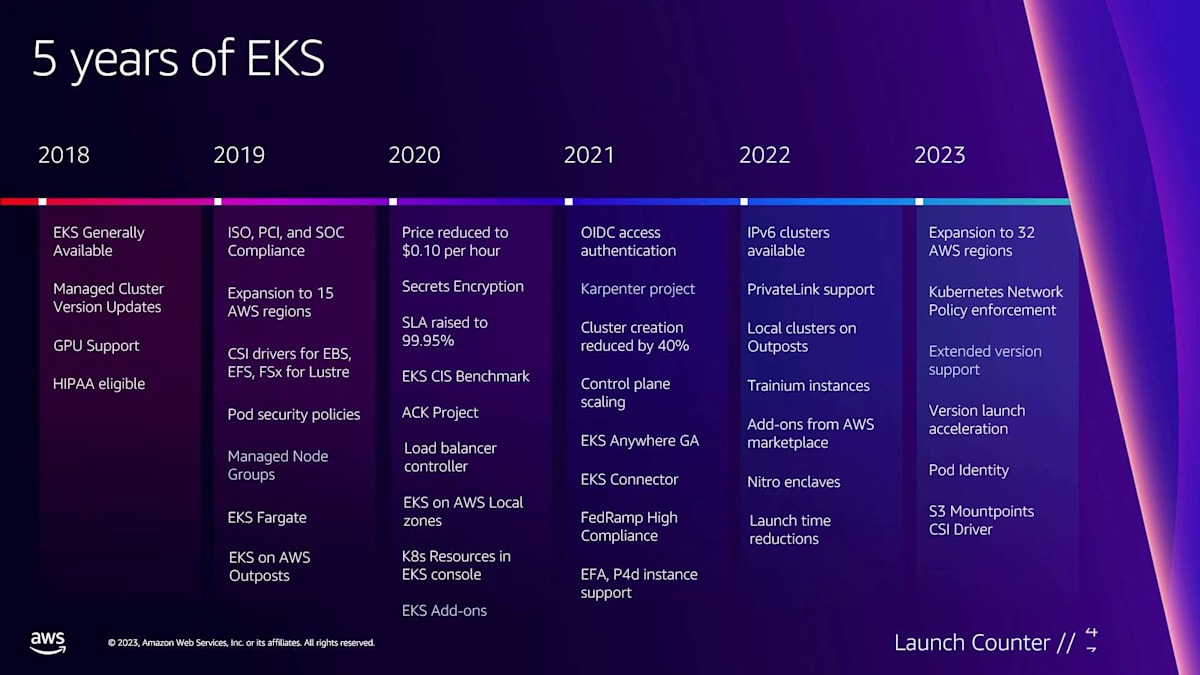
このスライドを全て説明するのは難しいかもしれません。内容が多すぎるんです。振り返ってみると、過去5年間でこの製品にどれだけの開発が行われたかを共有したいと思いました。2018年にEKSを発表して以来、222以上の異なるローンチを行ったと数えました。価格の引き下げからコンプライアンス、新しいプロジェクトの立ち上げ、クラスター作成時間の短縮、新しいインスタンスとリージョンのサポート、そして新しい重要な機能の追加まで、あらゆることが含まれています。
では、ここでマイクをSlackのAlexに渡します。彼がSlackでEKSを使用して大規模なシステム開発を行っている方法について話してくれます。
SlackのAlex氏によるEKS活用事例:Bedrockプラットフォームの紹介


SlackでEngineering Directorを務めており、内部のお客様を喜ばせることに情熱を注ぐいくつかのチームをリードする喜びを感じています。Amazonが顧客を喜ばせたいのと同じように、私たちはコアインフラチームとして内部のお客様を喜ばせたいと考えています。スケーラブルで信頼性の高いコンピューティングインフラを専門としており、AWSおよびEKSと密接に連携しながら、これからお話しする課題から現在の状況に至るまでの道のりを歩んできました。
数年前、私たちは主にChefを構成管理ツールとして使用した仮想マシンベースのインフラストラクチャを運用していました。これらのシステムの運用とOSのアップグレードは、お客様にとって非常にコストがかかるものでした。社内のお客様は、これらのOSアップグレードを行うために多くの苦労を強いられていました。昨年、GovSlackの提供を誇らしげに発表した際、これにより社内のお客様がVMを管理するための労力がさらに増加することになりました。

そこで私たちは、Slackのアプリケーションを取り込み、開発者がより正確にテストでき、環境の拡張性と柔軟性を大幅に向上させる良いソリューションは何かと自問し始めました。Amazon EKSを検討し、私たちが抱えていた問題に立ち返ると、Slackはインフラストラクチャの複雑さに直面していました。これは主にChefによる構成管理の問題に起因していました。開発者にとって、インフラストラクチャ・アズ・コードの経験はモノリシックなものでした。これらの変更をテストするのは非常に困難でした。開発者が自信を持ってコードを正確にテストできるようにするため、時にはテストが十分に堅牢ではないという理由で、コードをそのままリリースすることもありました。

そこで私たちは、EKSを使って構築するプラットフォームで、複雑さの多くを抽象化しつつ、解決したい信頼性と拡張性の懸念や問題の一部を維持するものは何かと自問し始めました。これが、私たちが「Bedrock」と呼ぶものを生み出しました。簡単に説明すると、BedrockはAmazon EKSを裏で活用するPlatform as a Serviceです。ビルド、デプロイ、ランタイム環境を処理します。今日この場にいる素晴らしいエンジニアチームが、Papiと呼ばれる優れたKPIや、ランタイム環境、Golangライブラリを可能にする素晴らしい抽象化を構築しました。
ここに示されている機能は、アプリケーションのコンテナのライフサイクルがどのように実現されるかを示しています。お客様のために解決したい最大の問題の1つは、インフラストラクチャの複雑さやネットワーキングを心配することなく、アイデアを構想から本番環境まで実現できるようにすることです。私たちの約束は、これらすべてが単一のYAMLファイルによって実現されるということです。

これがユーザーインターフェースです。これは明らかに単純化されたファイルですが、社内の開発者が新しいアプリケーションを立ち上げたり、以前VMで動作していたアプリケーションをBedrockに変換したりする際に提示されるものです。イメージ、Dockerファイル、そしてクラスターの呼び出しがあります。私たちは、Nebulaと呼ばれるソフトウェア定義ファイアウォールに準拠するために、独自のクラスターを運用しています。KubernetesノードにEC2ノードを使用することが重要です。私たちのチームがこれらのクラスターを作成し、後ほどKarpenterを使ってこれらのEC2ノードをどのように作成し維持するかを見ていきます。
Bedrockの内部構造とKarpenterの活用
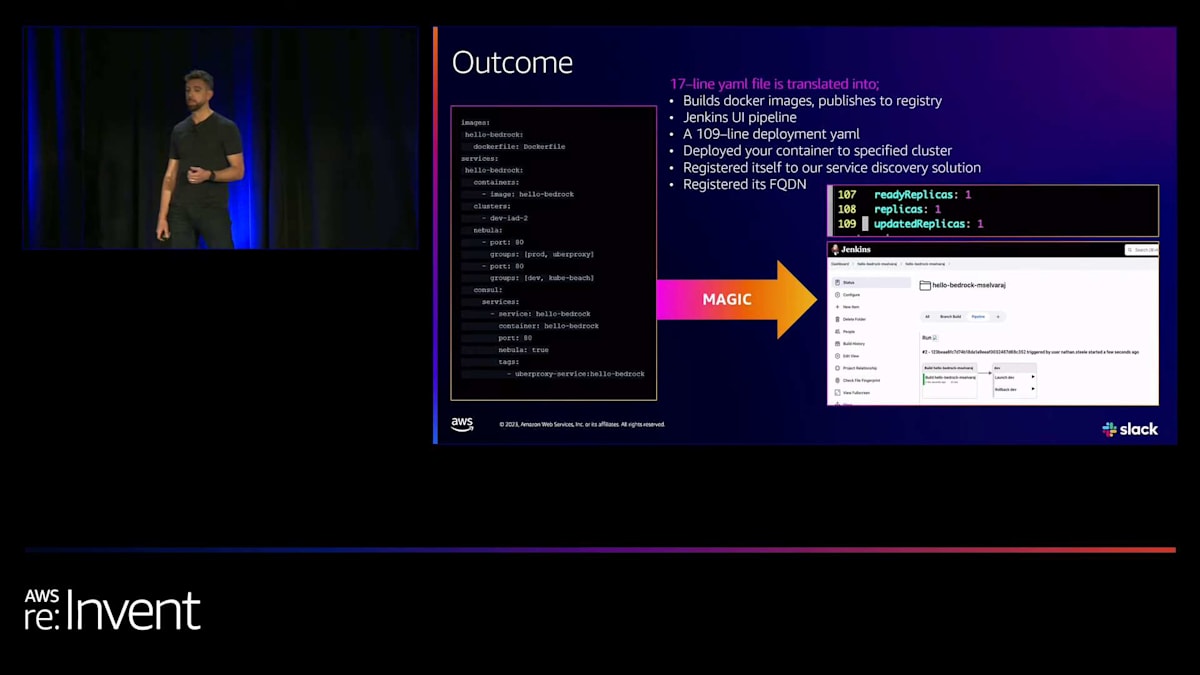
開発者にとっては、Nebulaというソフトウェア定義ファイアウォールに準拠した、セキュアな共有VPCネットワークに対して開放したいポートを指定するだけです。そして、コンソール上でサービスの内容とその検出方法を少し記述するだけです。ご覧のように、比較的読みやすく使いやすいものになっています。 では、この魔法はどこで起こるのでしょうか?アプリケーションによってファイルは長くなりますが、この簡単な17行のYAMLファイルは、Dockerイメージのビルド、レジストリへの公開に変換され、そしてJenkinsが起動します。パイプラインがあり、デプロイメントが行われます。コンテナは特定のクラスターに移動し、サービスディスカバリーソリューションであるFQDNに自身を登録し、準備完了となります。

最近、このYAMLファイルをテンプレート化することにも成功し、チームにより柔軟性を提供し、メンテナンスの負担を軽減しました。 内部を見てみると、どのようになっているでしょうか?上部には、この機能を実現するために重要なSlackの他のチームやアプリケーションを表す複数のボックスが見えます。私たちは、プロダクトエンジニア、つまり内部顧客のために、多くの部分を抽象化したいと考えています。彼らがこれらすべてを機能させることを心配せずに、シンプルでありながらスケーラブルで効率的なシステムを提供したいのです。
サービスディスカバリーにはConsul、FQDN解決にはUberproxy、そしてSlack内の他のシステムとの通信を可能にするソフトウェア定義ファイアウォールNebulaがあります。これはBedrockにとって重要で、開発者がSlackのエコシステムへの直接接続を持つことで、正確性と自信を持ってテストできるようにします。Ops-Jenkinsと共に、これらが機能を実現する上部を形成しています。また、アプリケーションのモニタリング、可視化、観測性のためにGrafanaとPrometheusを使用しています。

Bedrock CLIとAPIは、インフラストラクチャ開発者によって社内で開発されました。また、kube-beachesというSSH可能なVMがあり、より高度な顧客が追加タスクを実行し、ゼロトラストネットワークポリシーを犠牲にすることなく、制御された安全な環境でEKSを操作できるようにしています。ノード管理にはKarpenterを使用しており、これには非常に興奮しており、強くお勧めします。 AWSと提携してこれをオンボードし、クラスターに大成功で導入しました。
スタックの一部と、これらのKubernetesクラスターに新しいノードをプロビジョニングする方法が見えます。構成管理ツールとして引き続き使用しているChefから始まり、これらのノードをプロビジョニングする別の社内サービスであるPoptartがあります。このプロセスの多くはSlackチャンネルで見ることができ、何が起こっているか、ノードがどのようにプロビジョニングされるか、そして失敗があるかどうかを確認できます。
私たちのすべてのノードは不変と見なされ、14日以上生存することを許可していません。これを実現するために、ノードの寿命を管理するサービスアノテーションを使用し、Karpenterのおかげでカオスエンジニアリングツールを統合しています。これにより、障害が発生した場合でも、より自信を持って対応できるようになりました。では、そのメリットについて話しましょう。
Bedrockの利点とクラスター管理の改善

Karpenterのダイナミックな性質とリソース要件に基づいてノードを割り当てる能力により、より効率的にパッキングされたクラスターを実現できました。同時に、多くの方々と同様だと思いますが、この1年間でAWSの請求額を大幅に削減し、より適切なサイズ設定ができるようになりました。
誰かがクラスターを停止したり、Terraformファイルでオートスケーリンググループを変更したりするような、インシデントや厄介な状況を経験することがなくなりました。Karpenterのダイナミックな性質により、もはやこれらの問題に対処する必要がありません。ノードのドレイニングが速くなり、プロビジョニングのローテーションが速くなり、インシデント発生時の復旧が迅速になりました。クラスターが侵入されたり問題が発生したりしても、EC2 VMで経験した長い時間ではなく、数秒から数分で復旧できるようになりました。
KarpenterはEC2 APIに直接接続するため、非常に高速です。AWSに容量がある限り、アプリケーションをスケールでき、コアインフラストラクチャ開発の観点から、外部および内部のお客様の要求に応えることができます。では、クラスターのアップグレードについてもう一度見てみましょう。これが私たちのKubernetesクラスターの管理方法です。Kubernetesは非常に速いバージョンアップグレードスケジュールを持っており、EKSも多くの新機能をリリースしています。私たちは常に最新の機能を使用したいと考えており、内部のお客様がアプリケーションを開発する際に最高の機能を提供できるようにしています。
私たちのチームは内部で、お客様に影響を与えることなくこれらのアップグレードを実行する素晴らしい仕事をしてきました。バージョンを特定し、特定のソーキング期間を経て、各環境で10%、25%、50%、100%のロールアウトを行い、すべてが問題ないことを確認します。この過程をSandbox、Canary、Development、Productionの各環境で実施することで、ロールバックが必要な場合にも自信を持って対応できます。

では、このプロジェクトの現状について話しましょう。私たちは非常に誇りに思っています。これは社内のエンジニアたちの多大な努力の結果です。このプロセスに参加してくれたTPMたちに大きな感謝を捧げます。数字が物語っています。メモリーは数えきれませんでしたが - 試してみましたが、これがほぼ全てです。現時点で、Slackアプリケーションの80%がBedrockとAmazon EKSで稼働しており、今日お話しする全ての機能を活用できることを誇りに思います。
Bedrockの成果とFinOpsへの貢献

これらは、インフラの観点だけでなく、社内のお客様にとっても個人的な勝利です。今では、インフラのコードが他のインフラと同様にリポジトリに存在し、以前のモノリシックなアプローチと比べてはるかに柔軟性が高くなりました。BedrockとEKSを使用することで、ゾーンの回復力のためのAZリバランシングとAZドレイニングがはるかに容易になり、これも特定の側面における災害復旧戦略の一部となっています。
もう一つの大きな成果は、GovSlackの立ち上げです。これは素晴らしい取り組みでした。その一環として、全体的なコンプライアンスの確立がありました。以前は、各サービス所有者がVMでAppArmorを使用してアプリケーションをプロファイリングするのに多大な労力が必要でした。私たちは、AppArmorを使用してKubernetesインフラ全体をプロファイリングすることで、これを抽象化しました。これにより、開発者はコードの作成とアプリケーションに集中できるようになりました。
FinOpsの側面について最後に一言。全員ができる限り効率的であることが非常に重要です。Bedrockを使用することで、Kubecostを統合することができました。これは素晴らしいツールです。これにより、より良いチャージバックモデルを作成でき、各サービス所有者が何にどれだけ、どこでお金を使っているかを確認できるようになりました。これにより、私たち全員がより効率的に運営できるようになりました。以上で、Nathanに戻します。
EKSの可用性拡大とバージョン管理の改善
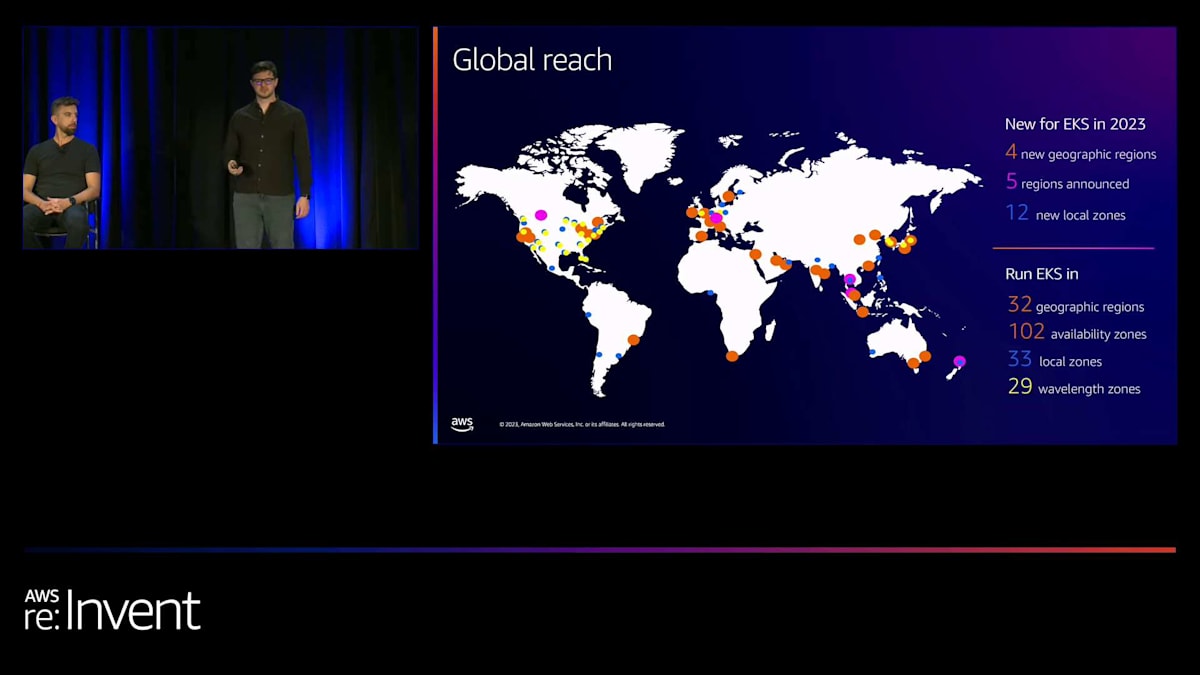
Alex、ありがとうございました。素晴らしいですね。Bedrockは素晴らしいシステムです。Alexは、Kubernetesの上に構築する方法について多くを語りましたが、私たちがEKSで顧客がKubernetesの上に構築するのを支援するために取り組んできた最大の課題の1つは、その可用性の拡大です。先ほど、リージョン、Outposts、Local Zonesでの実行について少し触れました。 このマップは本当に驚くべきものです。現在、EKSは全てのAWSリージョンで利用可能になっており、実際に今年最初の新しいリージョンであるTel Avivでも立ち上げました。これは非常にエキサイティングで、今後さらに増えていく予定です。実際、AWSは5つの新しいリージョンを発表しており、EKSはそのすべてで利用可能になります。
現在、EKSは32のリージョン、102のアベイラビリティーゾーン、33のローカルゾーン、そして29のWavelengthゾーンで利用可能です。つまり、お客様に近い場所が必要な場合、世界中のほぼどこでもEKSクラスターを配置できるということです。これらの場所でも足りない場合は、OutpostsやEKS Anywhereを使用して、EKSでエッジまで到達することができます。このように、EKSがこれほど多くの場所で利用可能になったことを、私たちは非常に嬉しく思っています。

これから数分間、先ほどお話しすると言った内容について詳しく説明します。つまり、私たちが取り組んできた大きな成果についてです。これらの様々なイノベーションから、次に何を構築するかを考えていただければと思います。先ほど述べたように、これらのクラウドリージョンでも足りない場合、私たちはEKS Anywhereの対応範囲と機能を拡大してきました。現在、EKS AnywhereはSnowデバイスでサポートされ、出荷されています。もともとストレージだけだったSnowは、エッジコンピューティングにまで拡張され、EKS AnywhereはすべてのSnowデバイスに搭載されています。また、EKS Anywhereを使用して、VMやベアメタルを使用し、Tinkerbellプロビジョニングを内蔵した自社インフラ上にベアメタルノードをプロビジョニングすることもできます。さらに、EKS Anywhereのサブスクリプションプロセスも改善しました。以前は、私たちに電話をかける必要がある手動プロセスでしたが、現在はEKSコンソールで直接EKS Anywhereにサブスクライブできるようになりました。これはより便利で、AWSの好むやり方に沿ったものです。
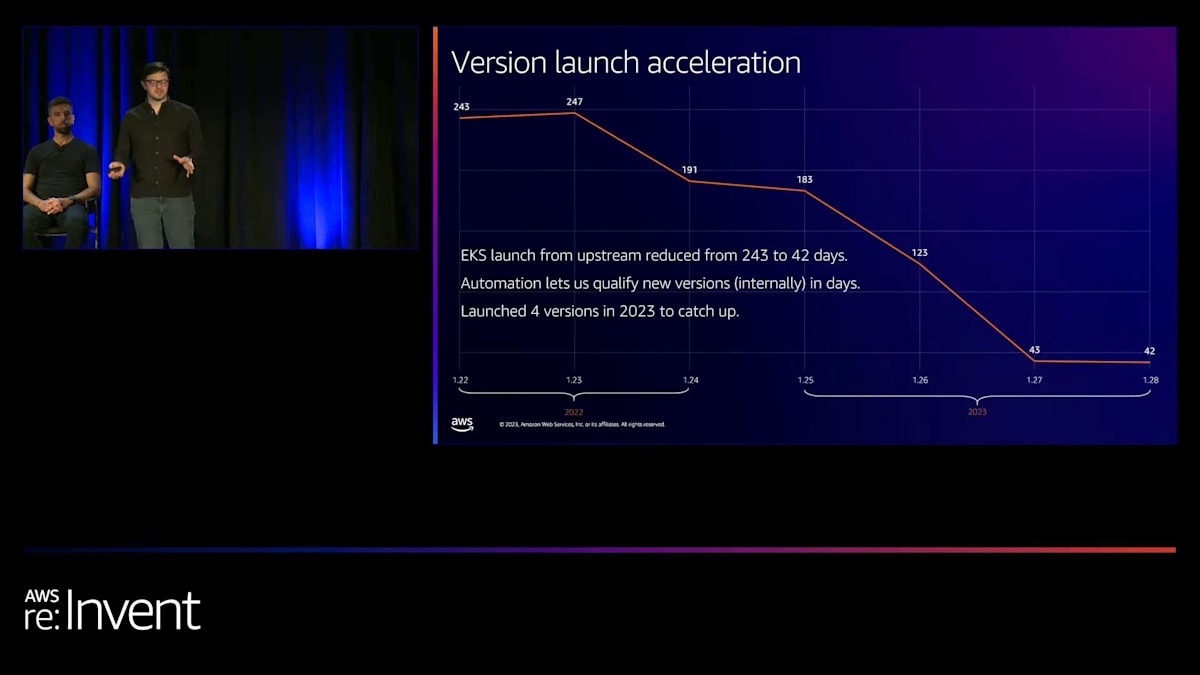
リージョンに加えて、バージョンも非常に重要です。Alexが言及していたように、Slackは最新バージョンを使用したがります。正直に言うと、1年前のEKSは少し遅れていて、新しいバージョンのリリースまでに上流から約240〜250日かかっていました。それは本当に遅く、お客様から「最新の素晴らしい機能にアクセスしたい」という声がありました。そこで今年、大きな取り組みを行い、過去4バージョンで上流からの遅れを243日から42日に短縮しました。今年は4つのバージョンをリリースしてKubernetesに追いつき、新しいバージョンをより迅速に認定してロールアウトできる新しい自動化スイートを社内で構築しました。
EKSの新機能:延長サポートとAWS Managed Services


おそらくこれは、グラフが下がっているのが良いことを示す唯一の例だと思います。通常はグラフが右上がりになることを望むものですが、このグラフは実際に良いものなんです。そう私のチームが言うので、ここに入れました。最新バージョンへのこの改善は、新たな課題を生み出しました。今度は、これらの最新バージョンに移行してアップグレードする必要があり、多くのお客様から14ヶ月のサポート期間では次のバージョンに移行するには十分ではないという声がありました。そこで10月に、Amazon EKSの延長サポートを発表しました。これにより、1.23以降の任意のKubernetesバージョンを、AWSからの完全なサポートを受けながら最大26ヶ月間実行できるようになりました。
延長サポート中の任意のバージョンで、いつでもクラスターを作成したりアップグレードしたりできます。コントロールプレーン、コンポーネント、AMIのセキュリティパッチを提供します。これは現在、バージョン1.23で無料プレビューとして利用可能で、2024年初頭に1.23以降のバージョンでこのソリューションをGA(一般提供)する予定です。今後のEKSの全バージョンで引き続き利用可能になります。お客様に必要な追加の時間を提供できるため、私たちは非常に興奮しています。ここでの目標は、お客様のフィードバックに基づいて、年に1回新しいKubernetesバージョンをリリースできるようにすることです。
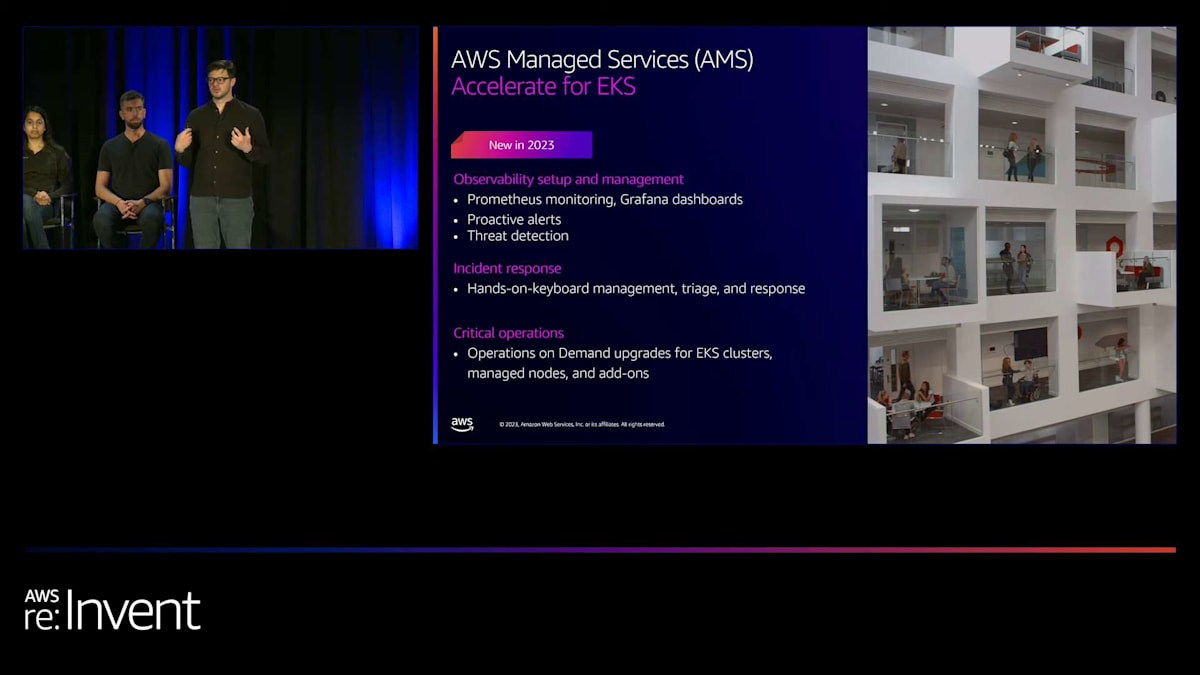
お客様から指摘されたもう一つの問題は、特にスタッフやオートメーションが限られている場合に、複数のクラスターをアップグレードすることの難しさでした。これに対処するため、私たちはAWS Managed Servicesチームと協力して、EKS向けのAMS Accelerateプログラムを作成しました。このプログラムは、迅速に移行し、規模を問わず人員や専門知識が不足している可能性のある運用タスクを実行するのに役立つ、実践的なSREリソースを提供します。観測可能性のセットアップと管理を支援し、実践的なキーボードインシデント対応を提供し、クラスターのアップグレードなどのオペレーションをオンデマンドで実行します。これはAWSからの魅力的なオファリングであり、必要とする人々にとって大きな価値があると信じています。私たちは、この追加サポートを提供するためにこれらのチームと協力できることを嬉しく思います。
さて、セキュリティについて少し話しましょう。今年、EKSチームではセキュリティに大きな焦点を当てており、セキュリティを改善するために行ってきたいくつかの取り組みについてお話ししたいと思います。

EKSのセキュリティ強化:Pod IdentityとNetwork Policy
まず最初に紹介するのは、AWS Pod Identityです。これは昨日ローンチしたばかりで、導入できることを非常に嬉しく思います。Pod Identityが行うのは、KubernetesアプリケーションにIAMロールを取り込む方法のパターンを活用し、ポッドに他のAWSリソースへのアクセスをAWS IAMロールを使用して提供することです。これに対するソリューションとして、IAM Roles for Service Accountsを数年前から提供していますが、うまく機能はするものの、スケーリングが難しい場合がありました。Pod Identityは、この機能をEKSにより深く組み込むことで改善しています。実際に、OIDCプロバイダーをセットアップする必要なく、EKSサービスから認証情報を所有し、提供しています。
クラスターとアプリケーションに必要なすべてのロールを一元的にマッピングできます。これにより、YAMLファイルにアノテーションを付ける必要がなくなり、複数の信頼ポリシーを作成したり、クラスター間でロールを複製したりする必要がなくなります。また、セッションタグのサポートも追加しました。これにより動的なロールが可能になります。例えば、アプリケーションにS3バケットへのアクセスを提供する基本的なロールを持ち、クラスターがprodまたはdevとしてタグ付けされているかどうかに基づいて、アクセスできる特定のバケットを決定するためにセッションタグを使用できます。全体として、Pod Identityは、すべてのKubernetesアプリケーションにIAMを追加しやすくし、セットアップと設定を簡素化します。

さて、IAMをクラスターに導入する方法について話しましょう。私たちは間もなくCluster Access Managementという機能を発表し、リリースする予定です。これは2023年中に提供開始される見込みです。この機能を使えば、EKS APIを使ってクラスター内のさまざまなIAMロールマッピングを管理できるようになります。AWS auth config mapを廃止し、EKS APIを使ってクラスター内のすべてのRBACパーミッションを設定できるようにします。私はこの機能にとてもワクワクしています。これによって多くの素晴らしい可能性が開けるでしょう。チームもこの機能に非常に興奮していて、今日のre:Inventで紹介してほしいと言ってきたほどです。ですので、皆さんは近々リリースされる機能の先行プレビューを見ることができます。これによってEKSの使いやすさが大幅に向上すると思います。

次に、VPC CNI Network Policyについて話しましょう。Network policyはトラフィック制御とルーティング管理にとって非常に重要で、クラスター内の特定のポッドが他のポッドと通信できるようにします。これまでは、network policyを実装するためにCiliumやCalicoなどのエージェントをインストールする必要がありました。今年、私たちはこの機能をVPC CNIにネイティブに組み込みました。これを実現するために、eBPFデータプレーンを構築しました。これは、AWSが将来何を計画しているかを示唆するものでもあります。このデータプレーンを使って、ネイティブなKubernetes network policyを実装しました。
ネイティブなKubernetes policyを定義すると、それがすでにVPC CNIに含まれています。私たちがポッド内のすべてのトラフィックに対してそのポリシーを実装します。これは追加のエージェントを実行したり、設定したり、スケールしたりする必要なく含まれています。また、VPCセキュリティグループとも統合されています。この機能は現在GA(一般提供)されており、今年の初めにリリースしました。私たちはこの機能にとても興奮しています。

EKSの統合と接続性の向上:ACK、アドオン、可観測性
では、統合と接続について話しましょう。クラスター内で実行できる599のものがあり、また皆さんはre:Inventに参加していますよね?ですので、「ワオ、200以上のAWSサービスがあり、新しいサービスも発表されている。Kubernetesでそれらをもっと簡単に使えたらいいのに。Kubernetesを使ってデータベースをプロビジョニングしたり、ストレージバケットをプロビジョニングしたり、他のAWSリソースをプロビジョニングしたい」と考えているかもしれません。AWS Controllers for Kubernetes(ACK)は、KubernetesのAPIを使って他のAWSリソースをプロビジョニングおよび管理できるようにするCRDとコントローラーのセットです。
これは非常に便利です。なぜなら、KubernetesアプリケーションでSQSを使いたいかもしれません。AWSによって実装されたキューを使って、クラスターにさまざまなデータを送信したいかもしれません。しかし、CloudFormationやTerraformを使ってすべてのAWSのものをセットアップし、その後クラスターに入ってすべてのクラスターのものをセットアップし、それらすべてを接続するのは望まないかもしれません。それは本当に複雑です。ACKを使えば、Helmチャートを定義するときに、「このAWSリソースも定義したい」と指定するだけで、実際にそれを行うことができます。そして、それらの異なるリソースのエンドポイントと値を、Kubernetes内でネイティブに接続できます。
私たちはACKにとてもワクワクしています。現在、21のGAサービスをサポートしており、さらに11のサービスがプレビュー中です。最近、EventBridge、SQS、SNSという3つの新しいサービスを追加しました。このプロジェクトは継続し、私たちは非常に熱心に取り組んでいます。
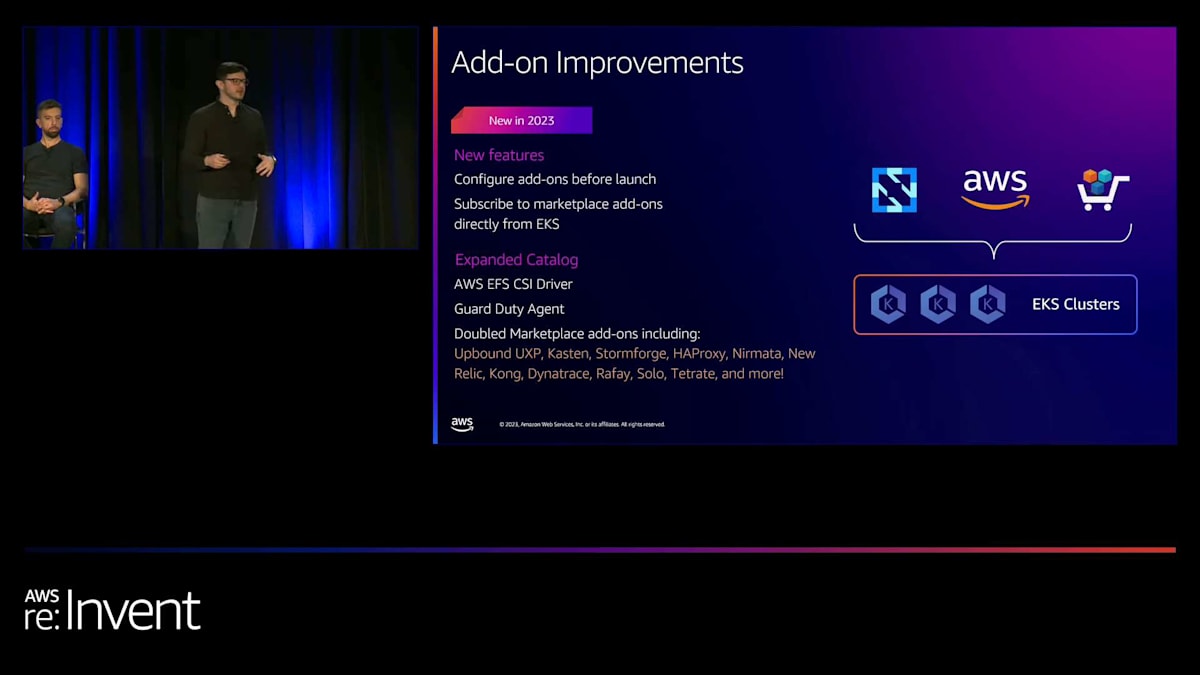
ACKに加えて、多くの補助的なものがあります。私がそのサーベイを見たとき、クラスターで実行されているものの約60%が、私たちが補助的ワークロードと呼ぶものでした。それらはアドオンであり、アプリケーションの実行を支援するものです。私たちはEKSアドオンを構築し、顧客がさまざまなコンポーネントをクラスターに簡単に持ち込み、クラスターを起動し、ライフサイクル管理を行えるようにしました。より簡単なアップグレードを行うために、今年アドオンにいくつかの改善を加えました。
私たちは、この機能の力とビジョンを引き出す重要な改善点をいくつか追加しました。アドオンの起動前に設定できるようになり、EKS APIを通じてアドオンを起動する際にカスタム値をチャートに追加できるようになりました。また、昨年のre:Inventで、AWS Marketplaceとの統合を発表しました。ベンダーのアドオンをクラスター上で直接開始できるようになり、それらのアドオンへの登録機能も追加しました。無料か有料かに関わらず、EKS APIとEKSコンソールを通じて直接アドオンに登録できるようになりました。

カタログを拡充しました。アドオンは大規模なカタログがあるときに最も効果を発揮するからです。EFS CSIドライバー、GuardDutyエージェントを追加し、サポートされるMarketplaceアドオンの数を2倍に増やしました。
アドオンに加えて、可観測性のための機能も多数追加しました。CloudWatchは、コンテナとEKS専用の新しい可観測性スイートである「Enhanced CloudWatch Observability」を発表しました。これにより、コンテナレベルのパフォーマンスメトリクス、クラスターレベルのパフォーマンスメトリクス、ログ、完全なクラスターダッシュボードが提供され、事前定義されたアラートや警告を設定し、クラスター全体を詳細に調査できます。非常に優れています。新しいエージェントも新しいアドオンとして立ち上げられ、現在利用可能です。2週間前に立ち上げたばかりです。チェックする価値のある素晴らしい製品です。

同時に、新しい「Agentless Prometheus Metrics Collection」をローンチしました。これは昨晩、ここre:Inventで発表されたばかりです。私たちはこれにとてもワクワクしています。Prometheusを使用している場合、AWS Managed Service for Prometheusを使用している場合、エージェントレスな方法でPrometheusメトリクスを収集し、完全にサーバーレスでクラスター内で処理し、AMPにエクスポートできるようになりました。どのクラスターでも機能し、1クリックで有効化でき、クラスターやアプリケーションに合わせてスケールし、AMPとネイティブに統合されています。非常にクールなローンチです。AMPチームが今週中に詳しく説明すると思います。彼らとパートナーシップを組んでこれを利用可能にできたことを非常に嬉しく思います。
Alexが言及したKarpenterについてですが、Karpenterはコンピュートとノードの自動プロビジョニングシステムです。Karpenterにいくつかの機能を追加しました。最も重要なのは、KarpenterをSIG Autoscalingに提供したことです。Karpenterが現在CNCFの一部になったことを非常に嬉しく思います。実際にはKubernetesプロジェクトの一部になりました。そして、それと同時に、Azureがサポートを発表しました。re:Inventでこんな話をするのは変かもしれません。Azureの話をしているなんて。正しい会議に来ているのかと思われるかもしれません。でも、私たちはこのことを本当に嬉しく思っています。
多くの顧客が成功を収めているのを見てきました。Karpenterを使用することで、クラスター上で実行しているノードの数を25〜40%削減できた顧客もいます。このプロジェクトは、将来的にノードのオートスケーリングのゴールドスタンダードになると考えています。CNCFに参加することはその大きな一歩であり、これによってKubernetesの一部となり、さらにAzureのような他の企業もこのプロバイダーを構築することができます。これは顧客に追加の保証を与えます。Karpenterは長期的に存在し、これが進むべき道であり、そのコミュニティの成長を見るのが非常に楽しみです。
AnthropicのNova氏によるEKSを活用した機械学習インフラの紹介
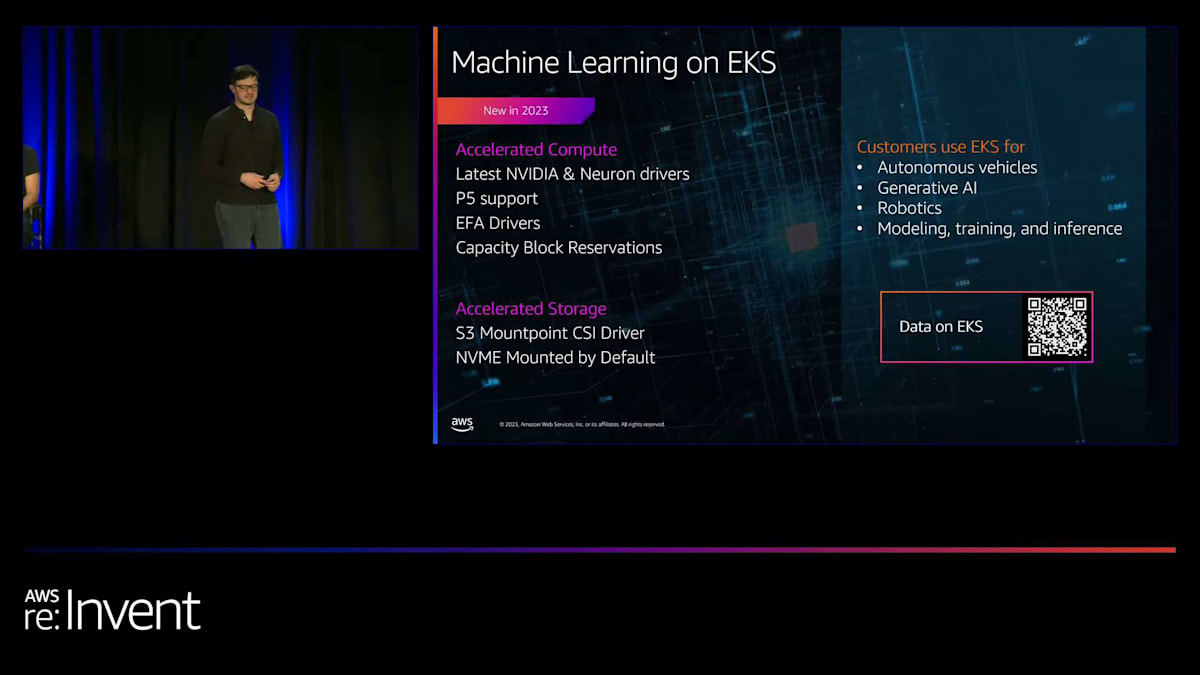
そして、機械学習の話題なしでは講演は終われませんね。先ほど申し上げたように、機械学習は最も急成長している新興のユースケースの1つであり、EKSでの機械学習をより簡単にするために多くの投資を行ってきました。最新のNVIDIAとNeuronのドライバーを追加し、P5のサポートを追加し、EC2上のElastic Fabric Adapter(EFA)用のドライバーを追加し、さらにキャパシティブロック予約のサポートも追加しました。機械学習がどのように普及しているかを見るのは本当にクールです。企業がどのようにEKSを機械学習に使用しているかについて、少し洞察をお伝えしましょう。

では、AnthropicのNova DasSarmaさんをお迎えします。ありがとうございます、Nathan。Anthropicについてご存知の方もいらっしゃるかもしれません。私たちはAIの安全性と研究を行う企業です。Claudeのような信頼性が高く、解釈可能で、操縦可能なAIシステムを構築しています。最近Claude 2.1をリリースしました。私たちのミッションは、最先端のシステムを構築し、その動作を研究し、責任を持って展開し、安全性に関する洞察を定期的に共有することで、AIが人々と社会の繁栄を助けることを確実にすることです。

これをAmazon EKSで実現しています。トレーニングからデータ、推論まで、すべてのアプリケーションがKubernetes上で動作しています。トレーニングでは、Kubernetes内の個々のオブジェクトで数万のポッドにスケールアップします。データワークロードの一部として柔軟なインスタンスタイプを利用し、また本日他の方々が話されたように、コスト最適化と、とにかく使用したいインフラの利用率向上のためにKarpenterを利用しています。また、EKSとAmazon S3を統合して、状態をKubernetesの外に移動し、Kubernetesにアプリケーションのスケーリングを任せながら、S3に静的な状態を保持させる方法についても少しお話しします。

では、今日のLLMのトレーニング方法はどうなっているでしょうか?簡単な図をお見せします。スライドの準備時間が足りなくなってしまったので、Claudeにこれを書いてもらいました。最近ファンクションコーリングをリリースしたので、すべてのTerraformをそこに入れたら、これが出てきました。説明させていただきます。プロセスは、スクレイピングやその他のソースから得た生データから始まります。DaskとSparkのワークロードの両方に対して、Spot EC2インスタンスをプロビジョニングするためにKarpenterを使用します。これらはすべてEKS上にあり、生データバケットからデータを取得し、それをトークン化し、S3のトークン化バケットに戻し、そこからP4dや新しいP5、Trainiumインスタンスなどの高速EC2インスタンスに戻します。これらはすべてEKS内にあります。

その後、再びS3を利用します。ここでS3とEKSを行ったり来たりしているのがわかると思います。モデルのチェックポイントを保存するためにS3を使用しています。実は、PVは使用していません。S3から直接十分なパフォーマンスを得られることがわかったからです。これはとてもエキサイティングなことですね。 データ処理についてもう少し詳しくお話しします。私たちは複数のインスタンスクラスを使用しています。以前は、cluster-autoscalerを使用し、特定のSparkジョブ用にR5インスタンスグループなどを構成していました。しかし、特定の方法で容量が不足したり、CPUとメモリの比率を変えてスケールしたいことがよくありました。

Karpenterを使うと、私たちが考えている制約をそのまま表現でき、個々のインスタンスタイプを考える必要がなくなります。また、Spot、On-Demand、Reserved Instancesを一緒に使用できるため、コスト最適化にも役立ちます。データ処理のユースケースによっては、あるケースではより多くのネットワークが、別のケースではより多くのストレージが必要になることがありますが、Karpenterはそれを可能にします。そのため、私たちはKarpenterをかなり活用しています。 そして、ここに大きな数字があります。Karpenterで柔軟なインスタンスタイプを利用できるようになり、さらにSpot Instancesをより一般的に使用できるようになったことで、On-Demandインスタンスを使用していた前年比で40%のコスト削減を達成しました。


スライドでは触れませんでしたが、cluster-autoscalerの調整は必要ありません。 cluster-autoscalerはしばしば様々な形で行き詰まることがありますが、Karpenterはそうはなりません。常に機敏に動作し、必要なくなったインスタンスは必ず削除されます。これは重要なポイントで、autoscalerが時々苦労する部分です。そのため、私たちのユースケースにとてもよく合っています。 また、ここでもS3について触れました。アプリケーションにとって単一の信頼できるソースがあるのは素晴らしいことで、私たちにとってそれがS3です。データ、チェックポイント、評価結果の保存にS3を使用しています。
PVに同期する必要がないため、状態をより抽象的に考えることができ、データとアプリケーションを別々にスケールできます。これを実現するために、S3から非同期処理を行っています。つまり、スループット重視のレジームを維持し、レイテンシーをあまり気にしないようにしています。このアプローチではPV管理が不要になるのも魅力的です。スクラッチディスクなど、いくつかの用途でPVを使用していますが、現在ではPVコントローラーの同期に阻害されることはなくなりました。これはとても良いことです。

そして、ここにEKSを使用する上でのいくつかのヒントとコツがあります。 まず、シンプルに考えることが重要です。私たちは、Claudeのようなモデルのトレーニングを、数万のノード、数万のポッドを使用してStatefulSetでスケールすることに成功しました。実際、多くのワークフローでCRDを使用していませんが、それでも私たちが行う多くのタスクに対して十分にスケールアウトできています。
プリエンプションを最適化しましょう。ステートをアプリケーションとは別に考えていなければ、スポットインスタンスは使えません。また、ワークロードが時々中断されることを想定して最適化していなければ、Kubernetesのスケールアウト機能などを活用することもできません。スケールアップする際、特にトレーニングについて考えると、大規模になるとよくないことが起こりがちです。トレーニング中にノードがダウンすることもあるでしょう。アプリケーションを、いくつかのサーバーに存在するものというよりも、目指すべき状態として考える必要があります。
ステート管理についてはすでに話しましたが、非同期的に考えることも重要です。Amazon S3を本来の使い方で使用したいものです。その使い方とは、スループットの境界領域で使用することです。複数のプレフィックスを使用するなどして、必要なパフォーマンスを得るためにスケールアップできます。現在、高速PVをマシンに接続する必要がないのは、S3からデータをプリロードし、適切なバッファを保つようにアプリケーションを設計しているからです。これにより、ネットワークカードからの入力を最大限に活用できています。この点については、後ほどこのカンファレンスで詳しく話します。
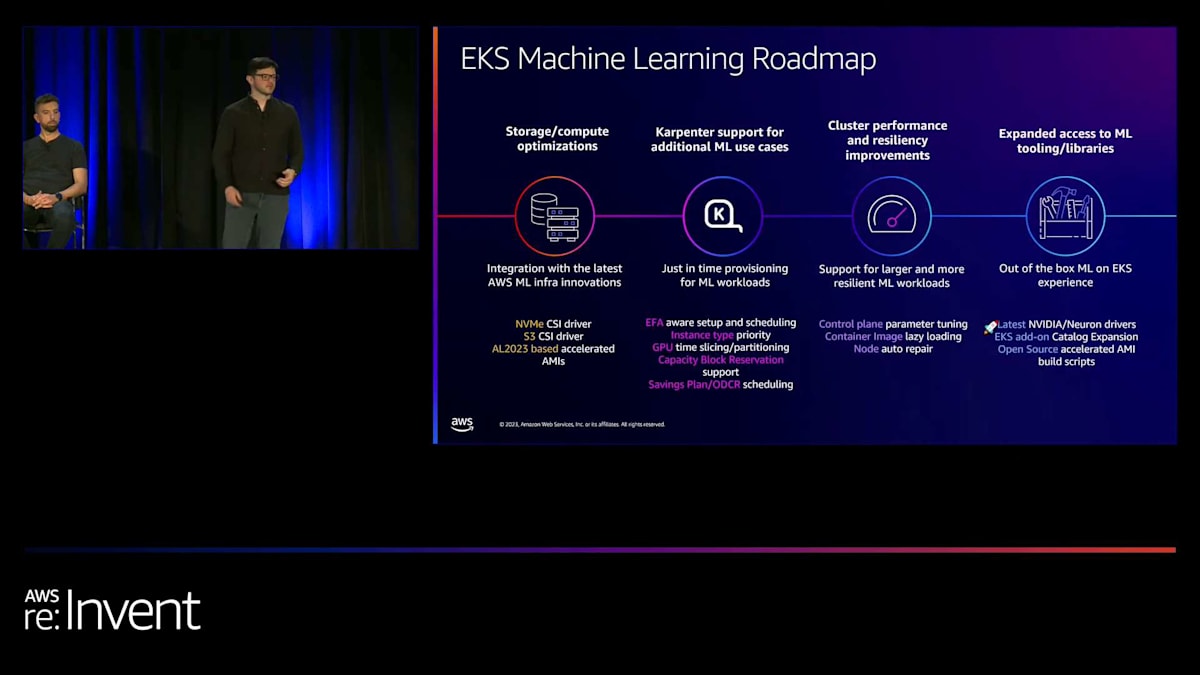
EKSの今後5年間の展望:管理、統合、効率性の向上

ありがとう、Nova。それはかなりクールですね。実際、そのシステムがどれほどクールなのかを控えめに言っているように思います。そして、大規模になるとあらゆるものが壊れる可能性があるので、そのスケールを想定して設計する必要があるというのはその通りです。ここで、私たちが今後どのような方向に進むと考えているかについて少し話したいと思います。どうやって未来を予測できるでしょうか?そこには何があり、どこに向かっているのでしょうか?私たちはどのように考えているのでしょうか?
EKSの今後5年間について。もちろん、EKSが今後5年以上存続することを期待していますし、そうなると思いますが、今日は5周年を祝っているので、次の5年間とその先についてお話ししましょう。AWSが行う3つのことがあると思います。まず、より多くのものが管理されるようになります。私が「クラスターベンディングマシン」と呼ぶアプローチを取ることになるでしょう。これは、多くの方々がすでに構築しているかもしれませんし、多くの顧客も構築しているのを目にしています。
これは、開発者が直接使用するクラスターを提供するベンディングマシンかもしれません。あるいは、内部でクラスターを提供し、それらのクラスターをプラットフォームチームが使用し、さらに上位のスタックで抽象化するベンディングマシンかもしれません。いずれにせよ、アプリケーションの準備ができたクラスターを顧客がより簡単に提供できるようにすることが目標です。そのクラスターベンディングマシンを構築するために必要なコンポーネントは何でしょうか?
お客様のアップグレードをより手厚くサポートし、アップグレードの自動化を進めています。先ほど、Extended Version Supportはまだ始まったばかりだとお話しました。2024年以降、アップグレードの自動化や、クラスター内のすべてのコンポーネントとアドオンをまとめる方法、クラスターの状態を最新に保つ方法など、さまざまな計画を立てています。
私のように、1〜2週間クラスターを見ないでいて、後でコンソールを開いてkubectlを実行し、各コンポーネントのバージョンを確認すると、「なんてこった、すべてが古くなっている。これをどうやって最新の状態にすればいいんだ?」という経験をしたことがあるでしょう。これらのコンポーネントを最新の状態に保つだけでも、フルタイムの仕事になってしまいます。お客様の中には、EKSクラスターごとに40、50、60もの異なるコンポーネントを実行している方もいます。そこで、クラスターの状態をどのように最新に保ち、アップグレードボタンを押したときに、問題なく動作するという確信をどのように持っていただけるか、ということが重要になってきます。
これは非常に重要なポイントで、将来的には、アップグレード後の動作に自信を持っていただけるような機能や、より多くのコンピュートやコンポーネントの管理、煩雑な作業の軽減などが提供されるのではないかと予想しています。re:Inventで皆さんと話をしていると、EKSで同じようなことをされているので、私たちがどのようにサポートできるか考えているのがおわかりいただけると思います。というのも、それは必ずしもお客様自身で行う必要がないかもしれないからです。
次に、AWS、データセンター、エッジのためのより多くのKubernetesについてです。AWSクラウドとの深い双方向の統合を構築しています。今日すでにいくつか触れましたが、Capacity Block Reservationsや各種機械学習ツールとのより良い統合、IAM、Observability、ネットワーキングツールとのより良い統合などがあります。今日は触れませんでしたが、AWS GuardDutyとの統合にも非常に期待しています。GuardDutyは脅威に関する洞察を提供するサービスです。
これらの洞察は複数のクラスターにまたがっており、今年の1月か2月にEKSのランタイムモニタリングを発表しました。これは非常にクールな統合で、世界のある地域にある顧客のクラスターで発生した脅威アクターに関する洞察を取得し、その脅威を一般化して、別の顧客で同様の事象が発生した場合に認識することができます。これは、AWSでワンクリックで有効にできる統合で、クラスターに組み込まれて、これまでにない洞察を提供します。
これらは、セキュリティ、ガバナンス、開発者の生産性向上のために検討している双方向統合のタイプです。クラスター間のワークロードの移行、オンプレミスからクラウドへの移行、そして以前はモノリシックで運用が困難だったシステムをコンテナ化して効率化するサービスの提供に焦点を当てています。また、ハイブリッドノードとクラスター管理の改善、オンプレミスからクラウドへの移行の負担軽減にも取り組んでいます。ただし、一部のものはオンプレミスに残る可能性があることも認識しています。
トレーディングフロアのようなものをオンプレミスで運用する必要がある顧客もいます。私たちの目標は、実行場所に関係なく一貫した管理体験を提供することです。また、スケールでの効率性についても考えています。GuardDutyが脅威を認識するという話をしましたが、効率性についても同様のことを検討しています。ある場所で機能するパターンを見つけ、効率性を向上させるためのヒント、アイデア、提案を提供し、それらの洞察をクラスターチューニングに適用し、集中的な可観測性、トラブルシューティング、深堀り分析を提供したいと考えています。これらのイノベーションの一部は、CloudWatchやAmazon Managed Service for Prometheus (AMP)で登場し、顧客が大規模な環境全体を監視しトラブルシューティングするのを支援する方法を検討しています。

機械学習については、多くの顧客がEKSとKubernetesを急速に採用している大きなユースケースですが、私たちは多くの機能のロードマップを持っています。これには、NVMEとS3マウントポイントの新しいCSIドライバー、AL 2023アクセラレーテッドAMI、大規模な機械学習ワークロード向けのコントロールプレーンの最適化が含まれます。また、最新のNVIDIAとNeuronドライバーの提供、より多くの機械学習ツールと機能を備えたEKSアドオンカタログの拡張、Elastic Fabric Adapter (EFA)、GPUタイム価格設定、キャパシティブロック予約、Savings PlanなどのEC2機能へのアクセスも提供しています。機械学習のための包括的なロードマップがあり、顧客がモデルを構築し、大規模なトレーニングと推論を行うのを支援します。


では、実際にどのように未来を予測するのでしょうか? 私たちが何をするかの未来を予測する最良の方法は、あなたや他の顧客が何をしているかを見ることです。私たちは、差別化されていない重労働、つまり繰り返し行っていることや類似のプラットフォームを構築している場所を追跡します。そして、それをより速く、より確実に、より効率的に行う方法を検討しています。
フィードバックを提供し、他の人々が何を求めているかを知る良い方法は、EKSのパブリックロードマップです。このロードマップでは、追跡している多くの項目があります。問題を提出したり、フィードバックを提供したり、何をすべきか尋ねたりすることができます。いくつかの統計を数えてみました:ロードマップを開始して以来、408以上のEKS項目を出荷し、すべてのAWSコンテナサービスで追跡されている項目は合計で850近くになります。アイデアがある場合や、他の人が何を考えているかを知りたい場合、あるいは私たちが構築しているものについて協力したい場合は、EKSロードマップをぜひチェックしてください。私たちのチームと私は毎日そこで顧客と対話し、協力し、より良い構築方法を尋ねています。
EKS学習リソースとre:Inventセッションの紹介

EKSを始めたばかりの方や、もっと深く学びたい方のために、いくつかのおすすめリソースがあります。プロダクション環境への移行やEKSを大規模に運用するための詳細なベストプラクティスをまとめたガイドがあります。これは、私たちのチームのエンジニアを含む専門家たちが、クラスターやアプリケーションを運用・チューニングするための最適な方法を見つけ次第、定期的に更新しています。また、200レベルから400レベルまでのトレーニングをカバーするEKSワークショップもあり、開発者向けの新しい開発ワークショップモジュールを追加することにワクワクしています。現在のワークショップはプラットフォーム所有者向けですが、開発者向けの特別なモジュールを追加する予定です。さらに、TerraformやAWS CDKと連携して完全なクラスターをデプロイするためのフレームワークと例を提供するEKS blueprintsもあります。

開発について少しお話ししたいと思います。多くの人がKubernetesを使用していますが、初心者の方やEKSとAWSを始めたばかりの方もいらっしゃると思います。新しいEKS学習パスを用意しており、Skill Builderで知識を広げ、学習プランに従うことができます。EKSバッジを獲得でき、これはあなたのスキルを証明するもので、ソーシャルメディアや履歴書に掲載できます。実際に、Amazon EKSの知識を習得し、多くの認定資格を取得したことを証明できます。これはAWSが今年から開始する新しいプログラムです。

re:Inventはまだ続きます。今日は月曜日ですが、信じられますか?今週はEKSについてもっと学びたい方のために、素晴らしい講演がいくつか用意されています。プラットフォームエンジニアリング、AIの未来、EKS上で生成AIを構築する方法に関するワークショップ、Karpenterに関する深掘りセッション、そしてPinterestによる大規模データ処理に関する素晴らしい講演があります。

ちょうど時間になりましたので、私と発表者たちは外にいますので、質問がある方はお気軽に声をかけてください。今日はみなさんに来ていただき、私たちの講演を聞いていただき、本当にありがとうございました。
(聴衆拍手)
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion