re:Invent 2024: AWSが生成AIワークロードのスケーリング手法を公開
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Scaling generative AI workloads with efficient model choice (AIM397-NEW)
この動画では、Amazon Bedrockにおける生成AIワークロードのスケーリングについて、3つの重要な機能が紹介されています。1つ目のIntelligent Prompt Routingは、プロンプトを最適なモデルに振り分ける機能で、Claude SonnetとClaude Haiku間などでの効率的なルーティングを実現します。2つ目のModel Distillationでは、大規模なTeacher Modelの知識を小規模なStudent Modelに転移させ、精度を2%未満の損失に抑えながら処理速度を最大500%向上させることができます。3つ目のAmazon Bedrock Marketplaceでは、30以上のプロバイダーから提供される100以上のモデルを利用可能で、Robin AIやSony Groupによる具体的な活用事例も紹介されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Amazon Bedrockによる生成AIワークロードのスケーリング:課題と新機能


私はAmazon Bedrockのプリンシパルプロダクトマネージャーを務めており、本日は同僚のJohn Liuとともに、効率的なモデル選択による生成AIワークロードのスケーリングについてお話しさせていただきます。また、Robin AIのRichardさんとソニーグループのOba Masahiroさんにも、Bedrockの活用事例についてお話しいただく予定です。本日のアジェンダを簡単にご紹介させていただきます。まず、皆様が生成AIアプリケーションを構築する際に直面する課題についてお話しします。その後、昨日発表された3つの機能、すなわちIntelligent Prompt Routing、Model Distillation、そしてAmazon Bedrock Marketplaceについて詳しくご説明いたします。

生成AIアプリケーションを構築する際に皆様が直面する課題は、Foundation Modelからの応答の品質、コスト、そして応答速度という3つの要素の最適化です。大規模なFoundation Modelは応答の品質が高く、より正確ですが、運用コストが高く、時には応答に時間がかかることがあります。一方、小規模なモデルは高速で費用対効果が高いものの、大規模モデルの精度には及びません。私たち全員が望んでいるのは、より高速で安価な小規模モデルの特性と、大規模モデルの精度を兼ね備えたものです。私たちは、まさにそれを実現するための新機能を導入しています。
Intelligent Prompt Routingの仕組みと活用事例

まず、Intelligent Prompt Routingについてお話しします。この機能により、アプリケーションで複数のFoundation Modelを使用し、各プロンプトを最適なモデルに振り分けることができます。複数のFoundation Modelを組み合わせることで、単一のFoundation Modelを使用する場合と比べて、より高い精度とより低いコストを実現できます。この機能はプレビューとして発表されました。現在、プレビューで2つのルーターを提供しています。1つはAnthropicルーターで、Claude Sonnet 3.5とClaude Haiku間でリクエストをルーティングできます。もう1つはMetaプロンプトルーターで、Llama 3.1ファミリーの8ビリオンモデルと70ビリオンモデル間でリクエストをルーティングできます。近々、さらに多くのモデルとモデルファミリーのサポートを追加する予定です。

Intelligent Prompt Routingの仕組みについてご説明します。必要な入力は3つあります。1つ目は、あらゆる生成AIアプリケーションの基本となるプロンプトです。2つ目は、生成AIアプリケーションで使用したいモデルの選択です(これらのモデルは同じモデルファミリーに属している必要があります)。3つ目は、大規模モデルと小規模モデルの間で許容される応答品質の差であるルーティング基準です。これらの入力をプロンプトルーターに提供すると、まずプロンプトの内容を理解するためにエンコードを行います。その後、私たちが訓練したモデルを使用して、そのプロンプトに対する各モデルのパフォーマンスを予測します。各モデルのパフォーマンスを予測した後、提供されたルーティング基準を使用して適切なモデルにルーティングします。
具体例を挙げて説明させていただきます。プレビューで発表したAnthropicプロンプトルーターは、Claude Sonnet 3.5とClaude Haiku間でルーティングを行います。デフォルトルーターの応答品質閾値、つまりルーティング基準は0%に設定されています。これは、Claude HaikuのパフォーマンスがSonnet 3.5と同等の場合にのみ、プロンプトルーターがClaude Haikuにルーティングすることを意味します。それ以外の場合は、すべてSonnet 3.5にルーティングされます。これにより、HaikuがSonnet 3.5と同等のパフォーマンスを発揮できる場合に、より低コストでSonnet 3.5の精度を実現できます。現在、応答品質閾値は固定されていますが、近々設定可能になる予定です。例えば10%など、より高い数値に設定することもできます。応答品質を10%に設定すると、Claude HaikuのレスポンスがClaude Sonnet 3.5の性能の10%以内である場合に、プロンプトルーターはClaude Haikuにルーティングします。この数値は、ユースケースやアプリケーションに応じて設定することができます。

Intelligent Prompt Routingの利点をご紹介します。Prompt Routingアプリケーションで使用するモデルを自由に選択できますが、同じモデルファミリーからの選択である必要があります。Bedrockのinvokeおよびconverse APIを通じて、単一のサーバーレスエンドポイントからPrompt Routerにアクセスできます。また、生成AIアプリケーションで使用する最大モデルと最小モデル間の許容可能な応答品質の差という、独自のルーティング基準を定義することができます。将来的には、Ground Truthデータを提供することで、アプリケーションに合わせてこのPrompt Routerの予測を調整することも可能になる予定です。

それでは、このPrompt Routingの実際の動作例を見てみましょう。ここでは、Anthropic Prompt Routerを選択しています。
Amazon Bedrockコンソールの左側を見ると、Claude Sonnet 3.5とClaude Haiku間でルーティングが行われており、応答品質の差は0%に設定されています。このPrompt Routerに簡単な質問をしてみました:「Twitterに投稿できる携帯電話の7種類のマーケティングコピーを考えてください」。これは基盤モデルにとってはとても単純なタスクで、携帯電話のマーケティングコピーを生成するものです。ご覧のように、このリクエストはPrompt RouterによってClaude Haikuにルーティングされました。

次に、このPrompt Routerにより複雑なプロンプトを与えてみました。「1Lの容器と4Lの容器があり、どちらにも目盛りがない場合、2Lを計測するにはどうすればよいですか?1Lの容器と4Lの容器を使って2Lの水を計測する方法を、ステップバイステップで説明してください」と尋ねました。 これは計算を必要とするより複雑なクエリなので、より良い応答を得るためにClaude Sonnet 3.5にルーティングされたことがわかります。

では、Intelligent Prompt Routingが活用できる顧客のユースケースについてお話ししましょう。 Intelligent Prompt Routingは、企業のチャットボットや生成AIアプリケーションの構築に特に効果的です。チャットボットには様々なクエリが寄せられますが、すべてのクエリを最も性能の高い大規模モデルで処理する必要はありません。Intelligent Prompt Routerを使用することで、シンプルなクエリは大規模モデルと同等の性能を発揮する小規模モデルに送り、より複雑なクエリのみを大規模モデルに送ることができます。
例えば、あなたの会社が Intelligent Prompt Router を使用して旅行用 Chatbot を開発しているとします。この Chatbot が「ヨーロッパのおすすめの観光地を教えて」や「夏に訪れるのにおすすめの観光地を教えて」といった単純な質問を受け取った場合、通常は Claude Haiku や Llama 8 billion のような小規模なモデルに送信されます。しかし、複雑な条件を考慮した旅程を立てるように依頼された場合は、Claude Sonnet 3.5 や Llama 70 billion のような大規模なモデルにルーティングされます。
Model Distillationによる効率的なモデル最適化


次に、Model Distillation についてお話ししたいと思います。Model Distillation とは、Teacher Model と呼ばれる大規模なモデルの知識を、より小規模で、コスト効率が良く、高速な Student Model と呼ばれるモデルに転移させるプロセスです。Model Distillation はどのように機能するのでしょうか?まず、プロンプトを Teacher Model と呼ばれる大規模または高度なモデルに入力します。Teacher Model が応答を生成します。そして、これらのプロンプトと応答を使用してデータセットを作成し、それを用いて小規模なモデル、つまり Distilled Model の Fine-tuning を行います。


大規模モデルから小規模モデルへの知識の蒸留プロセス全体を自動化することに加えて、Amazon Bedrock Model Distillation は、独自のデータ合成技術を提供し、多様で高品質なデータセットを生成してモデルの蒸留を行うことができます。その方法をご説明しましょう。まず、Model Distillation に自社の本番データを使用することができます。Model Distillation に自社の本番データを使用するには、Amazon Bedrock の Invoke および Converse API で Invocation Logs を有効にする必要があります。

Amazon Bedrock の Invoke および Converse API で Invocation Logs を有効にする際、リクエストデータのフィルタータグを設定することもできます。これらのリクエストメタデータフィルターを使用して、後で Invocation Logs をフィルタリングすることができます。Invoke および Converse API の Invocation Logs を有効にすると、Amazon Bedrock Model Distillation を実行する際に、Invocation Logs へのリンクを提供するだけで、大規模な Teacher Model を使用して既に生成した本番データを使用して、小規模な Distilled Model の Fine-tuning を行うことができます。
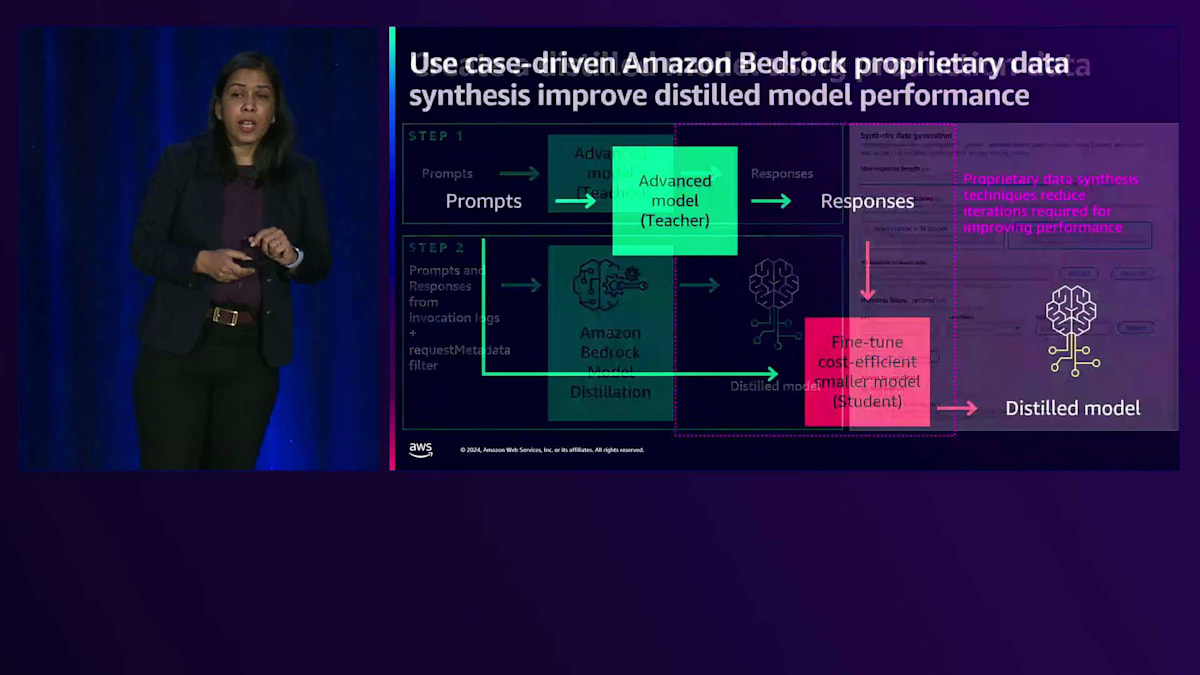
ここでメタデータフィルターを追加して、Distilled Model の Fine-tuning に最も適したデータをフィルタリングすることもできます。また、プロンプトのみにアクセスを提供するか、プロンプトと応答のペアにアクセスを提供するかを選択することもできます。プロンプトと応答のペアへのアクセスを提供する場合、Amazon Bedrock はそのデータを使用してモデルの蒸留を行います。プロンプトのみへのアクセスを提供する場合、Amazon Bedrock は Teacher Model を使用して応答を生成します。ここで重要なポイントは、これらの Invocation Logs または本番データは、Model Distillation の Teacher Model として使用する予定のモデルと同じモデルで生成する必要があるということです。また、Amazon Bedrock の独自のデータ合成技術を使用して、より多くのデータを生成することもできます。データ合成技術は、依然として大きな課題の一つである、より多くのデータを生成することができます。

お客様が独自にモデルの蒸留や Fine-tuning を行う際には、プロンプトを提供するだけで Amazon Bedrock がユースケースを理解し、独自の技術を用いて最適な合成データを生成して活用します。

仕組みについてご説明します。Amazon Bedrock Model Distillation にプロンプトを提供すると、類似のプロンプトを生成し、元のプロンプトと新しいプロンプトを使用してレスポンスを生成します。プロンプトとレスポンスのペアで構成されるゴールデンラベルデータセットを提供した場合、Teacher モデルは提供されたゴールデンデータセットを使用して類似のレスポンスを生成します。Amazon Bedrock Model Distillation では、蒸留モデルを作成するためのデータセットの作成方法を選択することができます。

Amazon Bedrock Model Distillation に関して説明した機能は、すべて Amazon Bedrock モデルコンソールの単一のフローで利用できます。まず Teacher モデルを選択します。この例では Llama 3.1 405B モデルが表示されています。次に Student モデルを選択します。現在、Amazon Bedrock Model Distillation では、Amazon、Anthropic、Meta の3つのモデルファミリーを提供しています。なお、Teacher モデルと Student モデルは同じモデルファミリーから選択する必要があります。
Teacher モデルと Student モデルを選択したら、小規模なモデルの Fine-tuning に使用するデータセットの生成方法を選択できます。大規模モデルで生成された既存の本番データである Invocation logs を使用するか、いくつかの例を提供してデータ合成を行うかを選択できます。Amazon Bedrock は、蒸留モデルを作成するために、より多くのデータを生成して小規模なモデルの Fine-tuning を行います。また、出力メトリクスを保存するための S3 の場所も指定できます。
Amazon Bedrock Marketplaceの導入とユースケース

ここで、Robin AI の CEO である Richard をステージにお招きして、Robin AI での Amazon Bedrock Model Distillation の活用についてお話しいただきます。皆さん、こんにちは。Robin AI の CEO 兼創業者の Richard Robinson です。私たちは AI を活用した法務サービスを提供する企業です。顧客の契約書に関する重要な質問に答えることができる AI を開発しています。例えば、顧客が保有する多数の契約の中から、今後3ヶ月以内に自動更新される契約を特定したり、データプロバイダーを変更する際にサプライヤーへの通知が必要な契約を見つけたりするなど、企業が膨大な非構造化データについて答えを必要とする重要な質問に対応しています。
このような法務サービスを提供する上での大きな課題は、質問に対する回答の正確性が極めて重要だということです。私たちは最先端の精度レベルを実現しており、その精度には様々な側面があります。この場合特に重要なのは、回答がどれだけ詳細か、引用や出典の参照が適切になされているか、そして回答が有用な形で作られているかということです。精度に重点を置くことは非常に重要ですが、その結果として利用可能な最大規模のモデルを使用せざるを得なくなります。ご存知の通り、そうしたモデルは他のモデルと比べて処理が遅く、通常はコストも大幅に高くなります。

私たちは、極めて高い精度と、信じられないほど低いコスト、そして驚くほど低いレイテンシーを同時に実現するという、理想的な状況を目指しています。これを実現するために、Amazon Bedrockのモデル蒸留プロセスを活用しました。最初は、呼び出しログに依存するという、かなり素朴なアプローチを取りました。教師モデルからの応答を使用して、より小さなモデルをファインチューニングしたのです。教師モデルとしてLlama 3.1 405Bを選び、同じモデルファミリーの小規模モデルを生徒モデルとして選択しました。結果は4つの基準で評価しました:正確性、有用性、完全性、明確性です。精度は1から5のスケールで測定し、数字が大きいほど良いとしました。蒸留モデルは、教師モデルを含む他のモデルと比較して、すでに相対的な同等性を示していますが、まだ私たちが望む精度レベルには達していません。確かに高速な処理と低レイテンシーを実現し、毎分多くのトークンを処理し、大幅なコスト削減を達成していますが、精度についてはまだ改善の余地があります。

次に私たちが行ったのは、Amazon Bedrockの蒸留データ合成技術を使用して、小規模モデルのファインチューニングに使用するデータの量と多様性を向上させることでした。新しい蒸留モデルは、教師モデルの精度の約98パーセントで動作しながら、速度とコストに関して期待していた全てのメリットを実現しています。数千または数十万件の契約書を処理する場合、その長さゆえに数百万のトークンを含むことになりますが、66パーセントのコスト削減は私たちのビジネスに大きな影響を与えます。また、結果をより速く生成できることで、ユーザー体験も大幅に向上します。

データ合成技術で良好な結果を得た後、チームは異なるモデルファミリーでの実験を行いました。Amazon Novaモデルを導入しましたが、これはカンファレンスでの発表前にチームと協力する機会に恵まれたものです。そして、非常に優れたパフォーマンスを確認しました。これは私たちの評価の中で最も良い結果でした。私たちのチームがキュレーションした約10個のゴールド・エグザンプラー、つまりゴールデンな質問-回答ペアを提供しました。その後、同じパイプラインを通じて教師モデルからの応答を使用し、データ合成技術を再び活用してそのデータセットを拡張し、多様化しました。蒸留モデルは教師モデルを超えるパフォーマンスを示しましたが、定量的なデータではこのモデルがどれほど改善されたかを完全には捉えきれていません。私たちのチームの定性的な評価では、このモデルが断然最も優れており、当初目指していたコスト削減と時間短縮を同時に実現しています。



ここまでのまとめとして、インテリジェントなプロンプトルーティングによってサービスモデル間でプロンプトを効率的にルーティングする方法と、モデル蒸留によって精度、速度、コストのバランスを取る方法をご紹介しました。次は、モデルの選択によってGenerative AIワークロードをさらにスケールする方法をお伝えします。モデル選択がなぜ重要かを理解するために、2023年に顧客が本番環境に導入しているユースケースをいくつか見てみましょう。私たちは、より細分化されたユースケースを目にしています。例えば、製造業の文書に対して英語と日本語の翻訳を導入している顧客がいます。また、金融リサーチアナリストが様々なデータや規制関連文書を調査し、それらの用語を理解するためにLLMを活用して情報を要約しようとしているケースも見られます。

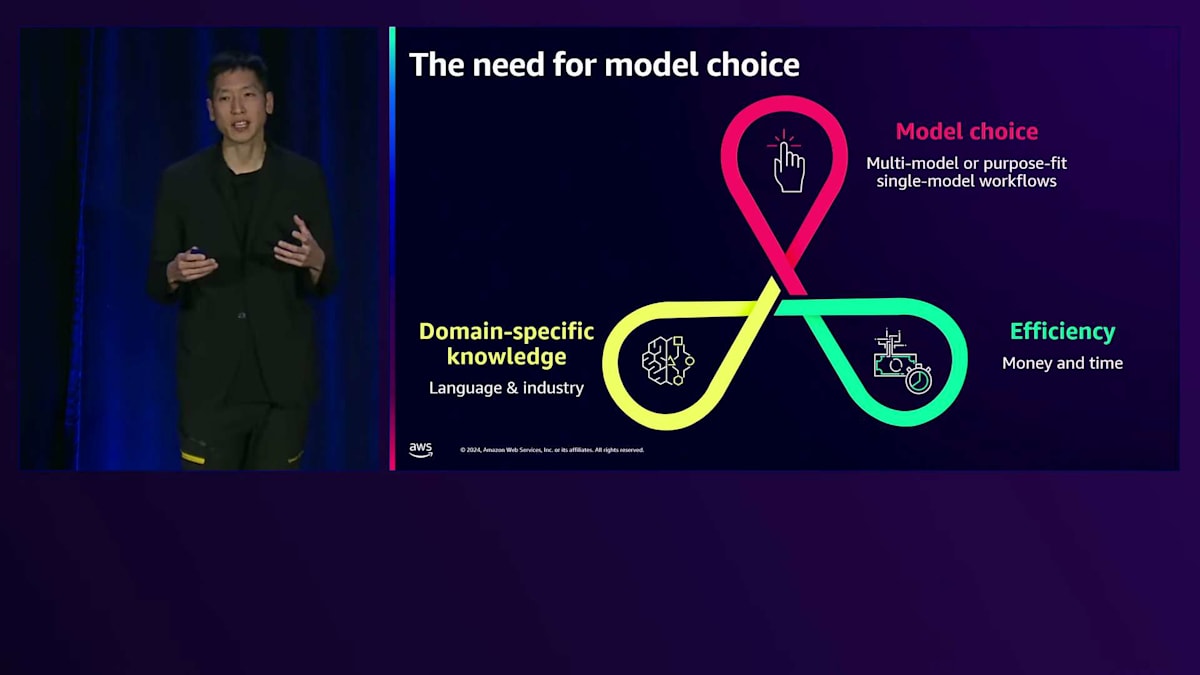
最後に、デジタルコンパニオンをリリースするお客様が増えていますが、これらのコンパニオンに関しては、人々の表現方法のニュアンスを捉えることが重要です。特に、ローカル言語の俗語のニュアンスは非常に重要で、汎用的なサービスモデルがより強力になってきているとはいえ、特にアジアや東南アジアの言語では、お客様がそれらの地域特有の言い回しを捉えたいと考えています。これは結局のところ、モデル選択の必要性につながります。 モデル選択により、お客様は単一のプラットフォームで複数のモデルを検討し、自分たちのワークフローに最適なモデルを見つけることができます。これらのモデルは、金融や法務などの業界固有の知識、英語・日本語・韓国語間の翻訳のための言語固有の知識、あるいはタンパク質配列の生成といった専門的なタスクなど、ドメイン固有の知識がもたらす利点があります。また、これらのモデルは、モデルの実行コストと実行時間の両方を考慮した、さまざまなレベルの効率性をお客様にもたらします。

考慮すべき異なる側面があります:お客様が実行している小規模なモデル、先ほど説明したDistilledモデル、プロバイダーによってすぐに使える状態に微調整されたDistilledモデル、あるいはお客様自身がカスタマイズしたい公開モデルなどです。私たちは Amazon Bedrock Marketplace をローンチしました。 これにより、100以上の公開モデルおよび独自モデルをサーバーフルな提供形態でBedrockに導入しています。

これらのモデルは30以上のプロバイダーから提供されており、さまざまな観点から選択することができます。例えば、 IBMのGranite 3モデルやLGA I ResearchのXO 13.0モデルなど、エンタープライズプロバイダーの最新モデルにアクセスできます。また、Hugging Faceからさまざまな公開モデルにアクセスすることもできます。言語翻訳については、UpstageやPreferred Networksが提供する、英語からアジア言語やヨーロッパ言語への翻訳に特化したモデルがあります。また、Matt Garmanのキーノートで言及されたEvolutionary ScaleのESM 3モデルのような、タンパク質配列の生成といった特定のタスクに特化したモデルもあります。さまざまなモダリティについては、高品質な画像生成のためのStability AIのStable Diffusion 3.5 Largeモデル、音声分野ではCAMB.AIのMAR 6モデルによる音声吹き替えなどにアクセスできます。

これらのモデルはすべて、Amazon Bedrockの利点を備えています。 BedrockのシンプルなAPI、Converse API、Invoke APIで使用できます。Converse APIと互換性のあるモデルは、Amazon Bedrock Agents、Amazon Bedrock Knowledge Bases、Guardrailsなどの Amazon Bedrockのツールと併用できます。インフラストラクチャに関しては違いがあります。Bedrockはサーバーレスインフラストラクチャで知られていますが、Amazon Bedrock Marketplaceはサーバーフルな提供形態で提供され、お客様はインスタンスタイプを選択し、ニーズに合った数のインスタンスを定義できます。これらのインスタンスはお客様のアカウントにデプロイされたSageMakerエンドポイントの背後に配置され、お客様はSageMakerのオートスケーリングポリシーを使用してスケーラビリティを設定できます。

Fine-tuningについては、モデルがFlan、Mistral、またはLlama 2や3のアーキテクチャに適合する場合、お客様はモデルをFine-tuningし、Bedrockのカスタムモデルインポート機能を使用してそれらのモデルをBedrockに取り込むことができます。お客様にとってのメリットは何でしょうか? これらすべてのモデルを見つけることができる単一の場所であり、InvokeやConverse APIといった単一のAPIでアクセスできます。AgentsやKnowledge Basesといったアマゾンのシンプルなツールをこれらのモデルで使用でき、独自のスケーラビリティを設定することができます。




Amazon Bedrock Marketplaceの利用を開始するには、新しくリリースされたモデルカタログにアクセスします。ここでは、私たちが提供するサーバーレスモデルと、Bedrock Marketplaceのモデルの両方を確認できます。各モデルパートをクリックしてプロバイダーについて詳しく確認し、その後オファーやプロバイダーが設定したUA(利用規約)または使用許諾契約の条件を確認できます。これらを承認した後、エンドポイントを設定し、インスタンス数を指定し、インスタンスタイプを選択して、エンドポイントをデプロイします。数分以内にAmazon Bedrock内でこのエンドポイントの使用を開始できます。これが本日ご紹介するコンソールでの操作方法です。もちろん、APIやCLIを通じてこれらの操作を行うこともできます。
Sony GroupのGenerative AI戦略とAmazon Bedrock活用事例


Amazon Bedrock Marketplaceのメリットを理解するために、お客様がAmazon Bedrock Marketplaceのモデルをどのように活用しているのか、いくつかのユースケースを詳しく見ていきましょう。まず、10万社以上のお客様にサービスを提供するAIファーストカンパニーのZendeskについてです。彼らは顧客体験の自動化、業務の最適化、チームのサポートを支援しています。世界中の顧客が現地の言語で顧客サポートを受けられるようZendeskに依存しており、そのためZendesk AIには多言語対応が重要となっています。
Zendeskは、ユースケースに最適なモデルを探しています。この特定のケースでは、Amazon Bedrock経由で22言語以上の翻訳が可能なWIDN.aiの高性能モデルの統合を計画しています。Zendeskが検討しているユースケースには、AIエージェントを使用して顧客向けFAQを現地の言語に翻訳することが含まれます。もう一つの社内向けユースケースとして、LLMを使用して機密情報やPII(個人を特定できる情報)を編集することも検討しています。

次にご紹介したいのは、Upstageのソーラーモデルを使用して校正方法の近代化を目指す韓国の主要新聞社のケースです。ジャーナリズム業界では、記事を迅速かつ正確に生成することが不可欠です。しかし、現在の校正プロセスは依然として非常に時間がかかり、専門の校正者に依存しています。これはコストがかかるだけでなく、空白やタイプミスなどの基本的なエラーを見落としたり、より難しい分野では文脈的に不適切な単語が選ばれたりするなど、人的な限界があります。例えば、政府の政策行動を説明する際に「discuss」と「evaluate」という言葉を使用する場合、それぞれ異なる意味を持つため、特定の記事に適した微妙なニュアンスの言葉を選ぶ必要があります。Upstageのモデルを使用することで、この企業は校正の精度を57.9%向上させ、エラーの検出と修正の率を95%まで達成する見込みです。

ここで、SonyのGeneral ManagerであるMasahiro Obaさんに、彼らのユースケースについて詳しくお話しいただきたいと思います。ありがとうございます、John。そしてAmazon Bedrockチームの素晴らしい進化、おめでとうございます。パートナーとしてここに参加できることを大変嬉しく思います。Sony Groupには6つの多様な事業部門があります。ゲーム、映画、音楽などのエンターテインメント事業、電子機器や半導体の製造を行っています。また、日本では金融サービス事業も展開しています。私たちの目的は、創造力とテクノロジーの力で世界を感動で満たすことです。私たちは、Generative AIが非常に革新的な技術であり、Sony Group全事業の成長ドライバーになると考えています。そのため、Amazon Bedrockを活用してGenerative AIの民主化を推進しています。Generative AIは強力で、各事業部門がGenerative AIに対して独自の期待を持っています。


Sony Groupの本社として、私は5層からなるAIスタックを推進しています。これはアプリケーションだけでなく、教育や安全性のためのガードレール、データ活用、そしてLLM機能を提供するプラットフォームで構成されています。このAIスタックをSony Group全体に展開しているところです。 今回は、Generative AIの民主化に向けたソリューションについてお話しします。私たちには2種類のソリューションがあります。1つ目は、社内で開発したWebアプリケーションを備えたEnterprise LLMです。これはAmazonのテクノロジーを活用した、Sony Group全体向けのクラウドネイティブで自動スケーリング可能なアプリケーションです。この環境は、27,000人のアクティブユーザーが日常的にGenerative AIを最大限活用している、最大規模の企業向けアプリケーションとなっています。

Enterprise LLMに加えて、Playgroundと呼ばれるアプリケーションも展開しています。 これはGenerative AIのビジネスインパクトを評価するための非常に柔軟な環境です。チャット型アプリケーションだけでなく、LLM機能をビジネスプロセスに組み込むことができるAPIサービスもサポートしています。成功の鍵は、各ユースケースに適したLLMを使用することです。現在、私たちの環境では70以上のモデルを提供しており、Amazon Bedrockは私たちのLLMの最も重要なソースとなっています。


Sony GroupにおけるGenerative AIのユースケースは、10のユースケースの下、5つの進展領域に分類されています。 ご覧の通り、Sony Groupには多様なユースケースがあります。典型的なユースケースとしては、AIアシスタントによるユーザー問い合わせの自動化があります。 AIアシスタントの場合、特定のドメイン知識による最適化が必要となるため、ベースモデルの選択が非常に重要です。このケースでは、大規模なパラメータを持つ高性能なモデルが必ずしも最適な選択とは限りません。企業での利用においては、パフォーマンス、コスト、チューニングのしやすさが非常に重要です。

Generative AIやモデル自体に対するユーザーの期待は、それぞれ異なります。私たちは多様なモデルの選択肢を提供するため、 Amazon Bedrockを通じて多くのモデルをサポートしています。特定の言語や特定のタスクに特化したモデルを必要とするユーザーもいます。ここで、特殊なモデルに対する私たちの期待をいくつか共有させていただきたいと思います。特に、特定のドメインに特化したドメイン固有モデルについてです。Sony Groupは多様なビジネスポートフォリオを持っており、各事業部門で業界特化型モデルへの強いニーズがあります。なぜなら、ドメイン固有モデルはチューニングコストを削減し、ビジネスへの適応速度を向上させることができるからです。
Small Language Modelsについては、個人向け電子機器や半導体を扱っています。デバイス上で小規模モデルを実装することで、お客様への提供価値を高める機会があります。Small Language Modelsは、私たちの製品に新たな可能性をもたらします。軽量モデルは、スマートAIアシスタントの開発における総コストとパフォーマンスのバランスを取る上で非常に有用です。軽量モデルにより、企業内で多くのAIエージェントを効率的に展開することが可能になります。これらが特殊なモデルに対する主な期待であり、だからこそ私たちはAmazon Bedrock Marketplaceに大きな期待を寄せているのです。

例えば、Sony Groupはグローバル企業として多くの地域でビジネスを展開しています。 ローカル言語やローカルタスクに最適化されたモデルは、私たちにとって非常に重要で有用です。日本にも日本語や日本国内のスタイルに特化した優れたモデルがあります。KARAKURIやPreferred Networksは特殊化されたモデルを開発しており、私たちはMarketplaceを通じてこれらの優れたモデルを私たちのエコシステムに取り入れることができることを大変嬉しく思っています。


最後に、参考までに私たちの最新の生成AIアーキテクチャについてご紹介させていただきます。 先ほど申し上げた通り、私たちのプラットフォームはAmazon Web ServicesとAmazon Bedrockを基盤として構築されています。このプラットフォームは、Workspace、モニタリング、そしてAPIサービス群という5つのコンポーネントで構成されています。また、PipelineとLLMの機能も備えています。 この色とりどりの画面がBedrock Marketplaceです。ご覧の通り、Amazon Bedrock Marketplaceを通じて、様々なモデルを既存のエコシステムに簡単に組み込むことができます。このMarketplaceによって、より多くの自由度と幅広い選択肢が得られると期待しています。これが私たちにとってのMarketplaceの価値であり、その価値を最大限活用していきたいと考えています。

Dr. J、ありがとうございました。本日のまとめとして、2025年、あるいは今日においても、生成AIワークロードをスケールするための3つの重要なポイントについてお話ししました。まず、Intelligent Prompt Routingから始めて、精度や速度など、様々な基準に基づいて、どのモデルにプロンプトをルーティングするかを決定できることをご説明しました。次に、Model Distillationについてお話しし、RAGなどのユースケースにおいて、親モデルと比較して2%未満の精度損失で、処理速度を最大500%向上させ、実行コストを75%削減できることをご紹介しました。最後に、Amazon Bedrock Marketplaceについて説明し、生成AIワークロードを実現するための様々なモデルを選択できることをお伝えしました。

本日は午後のセッションにご参加いただき、ありがとうございました。残りのre:Inventもお楽しみください。皆様、ご来場ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion