re:Invent 2024: AWSが解説 Terraformでサーバーレスデプロイを加速


はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Accelerate serverless deployments using Terraform with proven patterns (SVS320)
この動画では、AWSのPrincipal Solutions ArchitectであるAnton AleksandrovとServerless.tfフレームワークの作者Anton Babenkoが、TerraformでServerlessアプリケーションを構築・運用する方法について解説しています。Infrastructure as Codeツールとしてのterraform-aws-lambdaモジュールの活用法や、SAM、LocalStackを使ったローカルテスト手法、さらにTerraform stacksを用いた複数環境へのデプロイメント管理まで、実践的な内容をカバーしています。特に、Parameter StoreやTerragrunt、Terramateなど、チーム間での設定共有における具体的な選択肢の比較や、Serverlessアプリケーションにおけるモジュール化の重要性について、豊富な実例とともに説明されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Serverlessアプリケーション構築におけるTerraformの活用:セッション概要

みなさん、ご参加ありがとうございます。会場が満員で嬉しく思います。私はAnton Aleksandrovと申します。AWSのServerlessを担当するPrincipal Solutions Architectです。今日の共同発表者も同じくAntonです。一石二鳥ですね。彼はAnton Babenkoで、serverless.tfフレームワークの作者です。本日は、Serverlessアプリケーションの構築にTerraformを活用する方法についてお話しします。ちょっとネタバレになりますが、今日は盛りだくさんの内容をご用意しています。セッションの最後に、本日の内容やスライドを含むページへのQRコードをご紹介します。59分後にスライドをお渡ししますので、写真を撮っていただいても構いませんが、59分後には全てのスライドをご覧いただけます。


このセッションにご登録いただいた際、長い概要文をご覧になったと思います。 その約束を果たすため、最も重要なポイントを選んで今日のアジェンダを組み立てました。TerraformでServerlessアプリケーションをどのように構築・テストするのか、どのようにスケールさせ、デプロイするのか、そして最後に、来週からでも実践できる具体的なアクションアイテムをお持ち帰りいただけるようにしたいと思います。ちょっとお聞きしたいのですが、すでにTerraformをお使いの方は手を挙げていただけますか?はい。Serverless用にTerraformを使っている方は?はい、少し少なくなりましたね。素晴らしい、まさに適切な場所にいらっしゃいました。
Serverlessが従来のインフラストラクチャ概念を再定義する

大きな疑問:なぜこのセッションが必要なのでしょうか?Serverless向けのTerraformについて、なぜ専用のセッションを満員にして開催する必要があるのでしょうか?それは、Serverlessアプリケーションが少し異なるからです。従来のアプリケーションを考えると、通常アプリケーション層があり、そこにアプリケーション開発チームがいます。そしてインフラストラクチャ層があり、これは通常かなり厚みがあります。インフラチームとアプリケーションチームの間には明確な分離があり、必ずしも仲が良いわけではありません。DevOpsは永遠の課題ですが、彼らは協力する方法を学んできました。ただし、プロセスやツール、時には使用する言語さえも必ずしも一致していません。そのため、密結合な手作業のワークフローと長いサイクルが生まれます。皆さんもご経験があるのではないでしょうか。

これをServerlessの世界に持ち込むと、特にInfrastructure as Codeについて考えるとき、インフラストラクチャの概念が再定義されます。EC2インスタンスやRDSといった従来型のインフラは依然として存在しますが、その層は大幅に薄くなっています。インフラストラクチャは本質的にアプリケーションの構成要素となります。Lambda関数は技術的にはInfrastructure as Codeを使用して作成されますが、これは従来のインフラストラクチャとは異なります。アプリケーション開発者が所有し、必要に応じて変更できる柔軟性を求めるものです。そのため、Serverlessの世界では、この定義が少し変化します。これらはただのインフラストラクチャリソースではなく、アプリケーションリソースなのです。Infrastructure as Codeツールはもはやインフラチームの専売特許ではありません。アプリケーション開発チームがInfrastructure as Codeを採用するケースが増えています。これにより、より効率的にアプリケーションを構築できるからです。そしてInfrastructure as Codeは、もはやインフラストラクチャだけを表すものではなく、統合のコード化も表すようになっています。なぜなら、Serverlessの世界では、これらの構成要素を定義するだけでなく、構成要素間の接続もTerraformなどの同じツールを使用してInfrastructure as Codeとして定義されるからです。
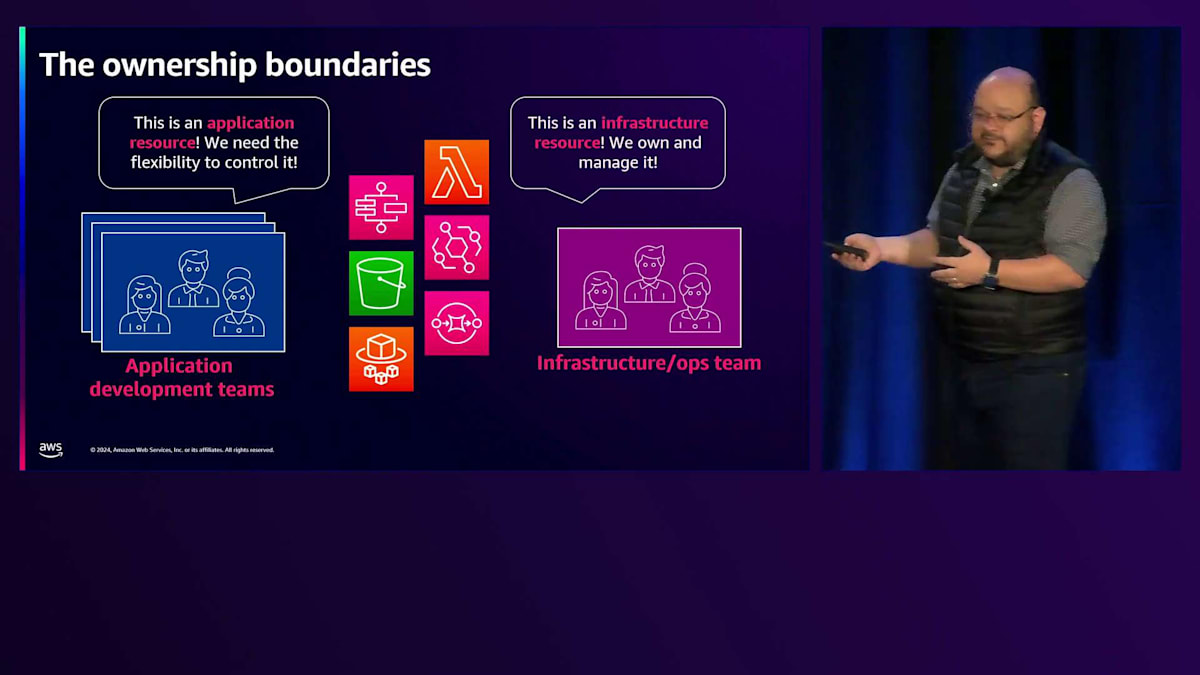

これにより、アプリケーション開発チームがInfrastructure as Codeを使用し、インフラチームも引き続き自分たちのInfrastructure as Codeツールを使用する、そして両者が協力する必要がある、という新しい興味深い世界が生まれています。アプリケーションチームはLambda関数やEventBridgeルールなどの多くをアプリケーションリソースとして考えますが、インフラチームはそれらを自分たちのインフラストラクチャとして捉え、より多くの制御を望みます。 では、彼らはどのように協力すればよいのでしょうか?答えは、Terraformです。アプリケーション開発者とインフラチームの両方が同じツールを使用する場合、多くの成功事例を見てきました。これが今日のセッションのテーマです。このセッションの参加者の皆さんに、Terraformとは何かを説明する必要はないでしょう。それは別のセッションに譲ります。Serverlessについても同様です。Lambda関数について知っていれば十分です。そしてS3バケットについても、このセッションに必要な知識は十分お持ちだと思います。シンプルなシナリオから始めて、徐々に複雑な議論へと進めていきましょう。
TerraformによるServerlessアプリケーションの基本構築

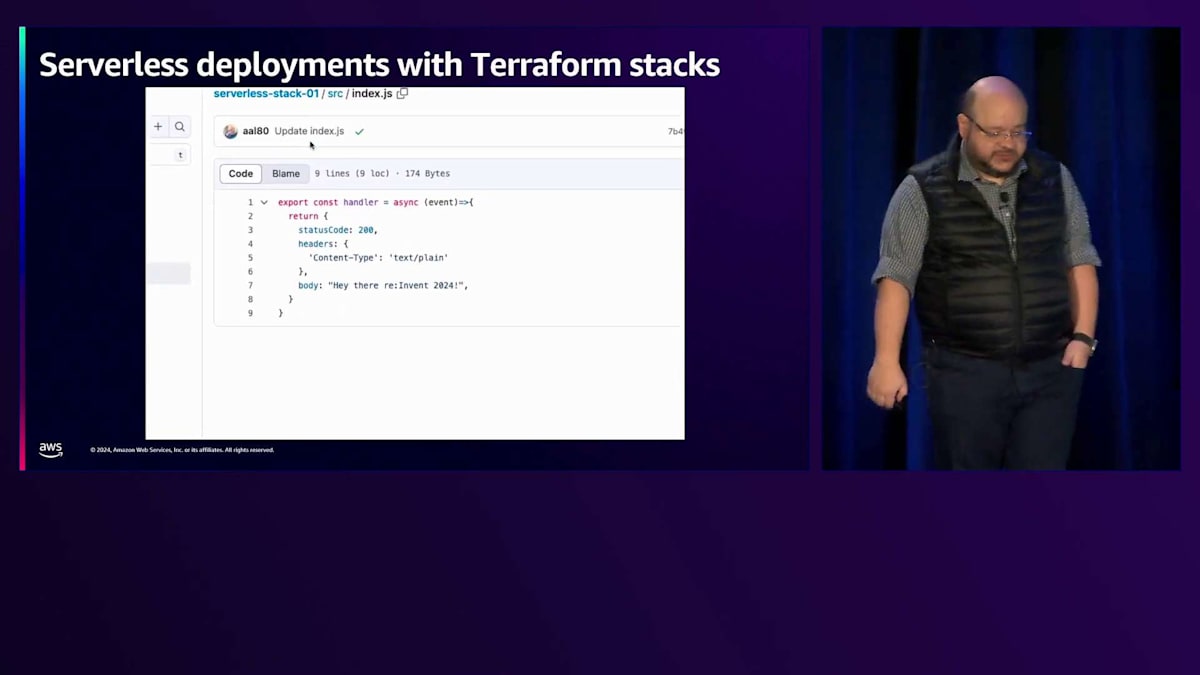
それでは実際に何かを作ってみましょう。かなりシンプルなアプリケーションを構築していきますが、ネタバレになりますが、このアプリケーションの動作は見せません。なぜかというと、ビジネスロジックには興味がなく、このアプリケーションのインフラ部分のコードに注目したいからです。PythonやNodeなど、どの言語で書かれているかは重要ではありません - このアプリケーションの定義に焦点を当てていきます。

基本的な挨拶アプリケーションで、Amazon SQSからメッセージを受け取り、AWS Lambda関数を使用します。そのメッセージに基づいて、Amazon S3バケットから画像を取得し、HTMLに変換して、別のS3バケットに保存するというシンプルなものです。繰り返しになりますが、このセッションではビジネスロジックには触れないので、実際の動作は見せません。
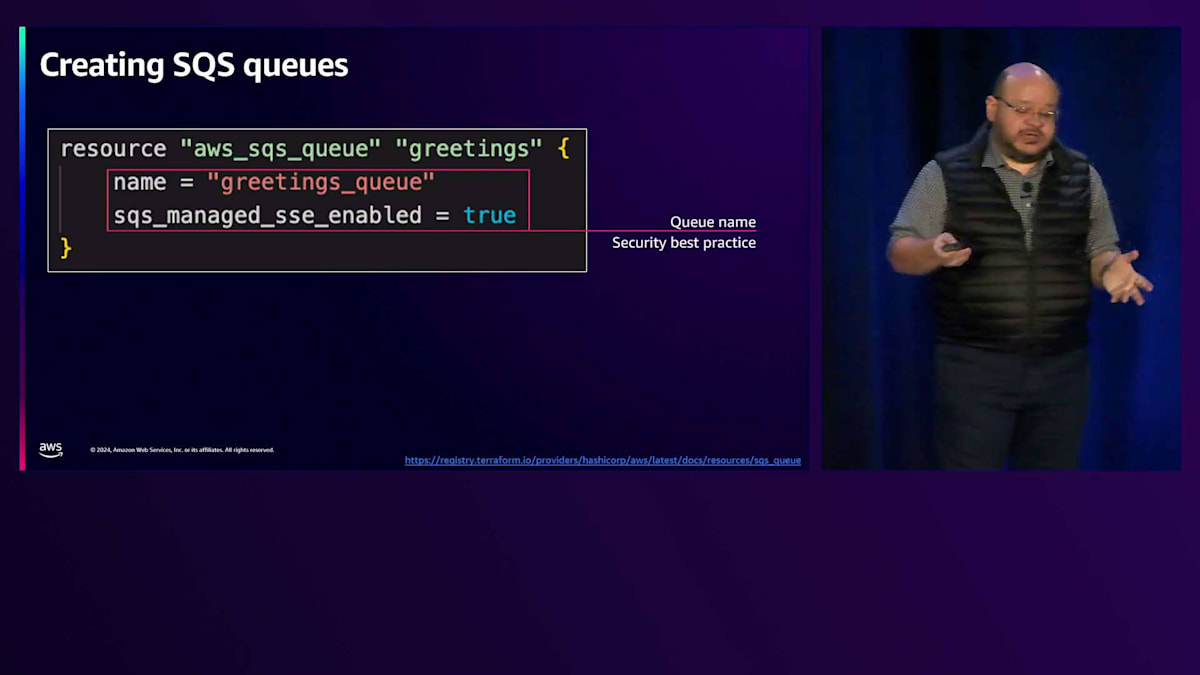
では、このアプリケーションを構築するためにTerraformの観点から何が必要でしょうか?まずはSQSキューというシンプルなところから始めましょう。これが挨拶用キューを作成するためのTerraformリソースです。ここで興味深い点が1つあります - キュー名だけでなく、sqs_managed_sse_enabledがtrueに設定されています。つまり、インフラストラクチャコードを使用して、リソースを定義するだけでなく、そのリソースのベストプラクティスも実装しているのです。

他のタイプのリソースでも同じことが言えるか見てみましょう。S3バケットをいくつか追加していきます。図を覚えていますか?これがTerraformでインフラストラクチャコードを使用してS3バケットを作成する方法です。S3バケットを作成する際、AWSとして推奨するベストプラクティスがいくつかあります。例えば、所有権制御とアクセス制御を定義することを強く推奨しています。そのため、これらのリソースを構築するTerraform設定を作成する際に、これらのベストプラクティスをリソースにエンコードすることができます。

Lambdaでもう少し複雑な部分に入っていきましょう。Lambda関数を作成する前に、その関数が実行できる権限を定義する実行ロールを作成する必要があります。ここで、ユースケースを思い出してください - 2つのステートメント、つまり2つの権限があります:私の関数はソースバケットからオブジェクトを取得し、デスティネーションバケットにオブジェクトを配置できます。これは私のお気に入りの機能の1つで、最小権限の原則です。ソースからの読み取りとターゲットへの書き込みのみが許可されています。これはすべてのセキュリティレビュー担当者が求めることで、最小権限の原則に準拠することです。そしてTerraformを使えば、これは非常に簡単に実現できます。
Lambda関数の作成とデプロイ方法の多様性


さて、実行ロールができたので、実際にLambda 関数を作成していきましょう。インフラストラクチャコードを使わずにLambda関数を作成した経験がある方なら、関数の種類に応じて3つの異なる方法があることをご存知でしょう。 最も簡単な方法は、ZIPパッケージを作成することです。つまり、コードをZIP化してLambdaサービスにアップロードすると、Lambda関数が作成されます。これは、ZIP化したサイズが50メガバイトまで、解凍後が250メガバイトまでの関数に最適です。確かに制限はありますが、通常、プロトタイプ作成や比較的小規模なものを構築する際には、これが最も簡単な方法です。

もう1つのアプローチは、関数が大きくなってきた場合です。 この場合も同様にZIP化しますが、Lambdaに直接デプロイするのではなく、S3にアップロードします。S3から Lambda関数を作成することで、ZIP化された関数の50メガバイトという制限を超えることができ、さらにS3にデプロイされたすべてのパッケージの履歴も残すことができます。つまり、デプロイされたパッケージの履歴を保持する必要がある場合は、そのままS3で確認できるわけです。

3つ目のオプションは、すでにコンテナエコシステムを利用している場合です。 コードをコンテナとしてビルドすることが好みの場合は、Docker buildを実行し、それをAmazon ECRにデプロイして、ECRからLambda関数を作成することができます。これは、サイズが最大10ギガバイトまでの関数に適しています。つまり、関数が大きい場合や、大規模なフレームワークやLLMフレームワークを使用する場合は、このアプローチを選択すべきです。

では、Terraformの観点から見てみましょう。一番上に、シンプルなアプローチが見えます。 これは、関数のソースディレクトリをパッケージ化するために使用するものです。パッケージ化が完了すると、その下に関数の設定が表示されます。関数名やロール、ハンドラーなどの設定があり、一番下にfilenameとコードハッシュがあります。基本的に、一番上で作成したパッケージ、つまりZIPファイルを参照しているわけです。とてもシンプルですね。

S3やECRを通じて関数を構築する場合など、異なる方法でビルドする場合でも、 この設定の大部分はそのまま変わりません。ただし、アプローチによって、S3バケットからコードを取得する場合はS3のソースを定義したり、イメージのURIを指定したりすることができます。このように、すべてのオプションがサポートされています。
さて、この時点でアプリケーションを構築し、キュー、いくつかのBucket、Lambda関数、そして権限の設定が完了したとしましょう。次のステップは何でしょうか?開発者として論理的な次のステップは、テストですね。デプロイメント前のテストは絶対に忘れてはいけません。開発者はデプロイ前にローカルでテストを行うことを好むので、私もまずは全体のセットアップをローカルでテストしたいと思います。
ローカル環境でのServerlessアプリケーションのテスト手法


そのために使えるツールが、 AWS SAMです。このツールをご存知の方も何人かいらっしゃいますね。これはインフラストラクチャ・アズ・コードの一部として提供されているCLIツールです。インフラには SAMではなくTerraformを使用していますが、それでもSAMを使えば関数やAPIをローカルでテストすることができます。 Dockerイメージをダウンロードして、Lambda環境をシミュレートし、実際にコードをローカルで実行することができるんです。
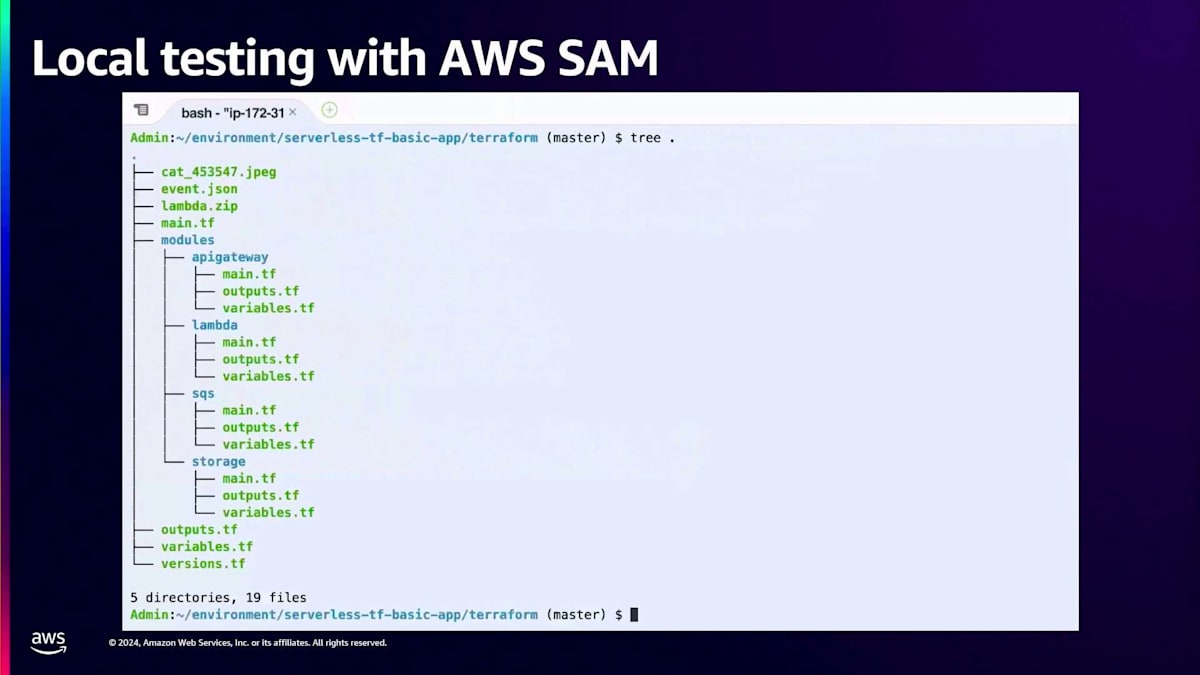

簡単なデモをお見せしましょう。ここではAWS CLIを使用し、最新バージョンのTerraformとSAM CLIを使っています。 ご覧の通り、私は今、モジュールやmain.tfなどを含む適切なTerraform構造の中にいます。実行しているコマンドは「SAM local invoke」で、関数名を指定しています。この関数は Terraformの設定で定義されています。
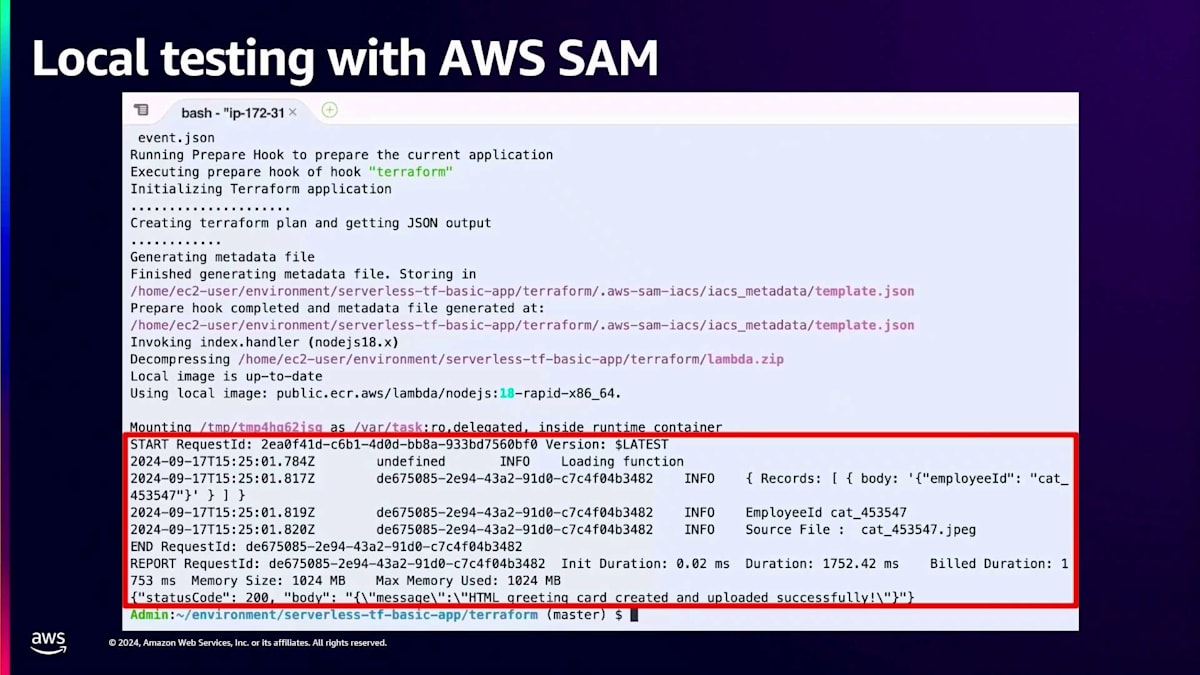
画面の一番下に興味深い出力が表示されているのがわかりますね。関数からのレスポンスが確認できます。 もしコンソールや他の方法でLambda関数を実行したことがある方なら、このようなログは見覚えがあるはずです。実行の開始、終了、employee ID、ソースのJPEGファイル、そして生成されたHTMLの本文が確認できます。これら全てがローカルで完全に実行されたんです。パフォーマンステストをローカルで行うのは適切ではないかもしれませんが、ビジネスロジックのテストには最適です。terraform applyでクラウドにデプロイする前に、ビジネスロジックをローカルでテストできるわけです。

SAMはLambdaとAPI Gatewayをローカルでシミュレートする必要がある場合に優れています。もし追加のサービスを含むより大きなエコシステムをシミュレートする必要がある場合は、LocalStackというプロダクトがあります。 インターネットで見つけることができますし、実際に展示会場にも出展していますので、興味のある方は直接話を聞くことができます。LocalStackは、Lambdaを含む数十のAWSサービスをローカルでシミュレートできるというコンセプトです。Antonもこれについて話す予定です。
Terraformを用いたServerlessアプリケーションのスケーリングと最適化

アプリケーションを構築し、テストも完了しました。スライドで説明してきた中で、多くのベストプラクティスについて触れてきました。当然出てくる疑問は、「これらのベストプラクティスをどうやって知ることができるのか?」「50のエンジニアリングチームを抱える私の会社や組織は、どうやってこれらのベストプラクティスを知ることができるのか?」ということです。つまり、次の問題は「どうやってスケールするか?」ということです。ここでスケーリングと言う場合、1秒あたり5リクエストから500リクエストへの拡張のことを指しているわけではありません - それはServerlessがほぼ自動的に処理してくれることです。

私が話しているのは成長に伴う課題についてです。開発チームが非推奨になっていない承認済みのランタイムだけを使用するようにするにはどうすればよいでしょうか?適切で一貫性のあるプロジェクト構造をどのように確保すればよいでしょうか?ベストプラクティスをスケールさせるにはどうすればよいでしょうか?タグを統一的に適用するにはどうすればよいでしょうか?オーナー不明リソース(私が「孤立リソース」と呼んでいるもの)について議論することが本当によくあります - 例えば500個のFunctionやその他のリソースがあるのに、それらがどこから来たのか全く分からず、オーナーを探さなければならないという状況です。

では、Terraformを使用している組織でこれらの成長課題を効率的に解決するにはどうすればよいでしょうか?答えは言うのは簡単ですが、実行にはある程度の労力が必要です:それはModularizationです。これは標準的なTerraformのプラクティスです。Terraformを使用している方なら、Modularizationについてご存知でしょう。ここではServerlessのコンテキストでのModularizationについて説明します。Modularizationの考え方は、通常のソースコードと同じです - アプリケーション全体を1つのファイルに書くことはしないでしょう。それは機能するかもしれませんが、確実にスケールしません。インフラストラクチャーのコードを小さな部分に分割し、それらの部分間の相互作用と接続を定義する必要があります。



これにより、今日お話ししたい3つのメリットが得られます。1つ目はベストプラクティスです。モジュールを使用してサービスリソースを作成する際、組織内の複数のチームにわたってそれらのベストプラクティスを適用できます。2つ目は再利用性です。モジュールは本質的に、ベストプラクティスを念頭に置いて作成された、カプセル化された部品であり、再利用が可能です。3つ目は構成可能性です。これらのモジュールを単に再利用するだけでなく、これからご覧いただくように、組み合わせることができます。

Terraformにあまり馴染みのない方のために、例を見てみましょう。Terraformモジュールは基本的に入力のセットです。入力を定義し、出力を定義し、作成する必要のあるリソースも定義します。これらのファイル名 - variables、outputs、main.tf - は慣習的なものですが、好きな名前を付けることができます。main.tfとして書いても問題ありません。基本的に、モジュールは入力、作成するリソース、出力によって定義されます。例えば、ここではFunction名を入力として受け取り、そのFunction名でLambda Functionを作成し、そのFunctionのARNを出力しています。これはおそらく最もシンプルな例です。Terraformの経験者の方は、おそらく「これは本当に役に立たないモジュールだ」と思っているでしょう。なぜなら、単に名前のような1つの変数を受け取って、それをリソースに適用しているだけだからです。

これをさらに発展させましょう。新しい変数を導入し、その変数をruntimeと呼び、デフォルト値を設定します。これにより、モジュールの利用者は独自のランタイムを選択できますが、同時にデフォルト値も提供されています。これは非常に重要なポイントです。このモジュールを使用する開発者はこれを変更できるでしょうか?はい、できます。しかし、必ずしも変更する必要はありません。これがベストプラクティスです。つまり、モジュールによって提供されているため、開発者はこれを理解するために精神的リソースを費やす必要がないのです。
複数環境・チーム間でのTerraform設定の共有と管理
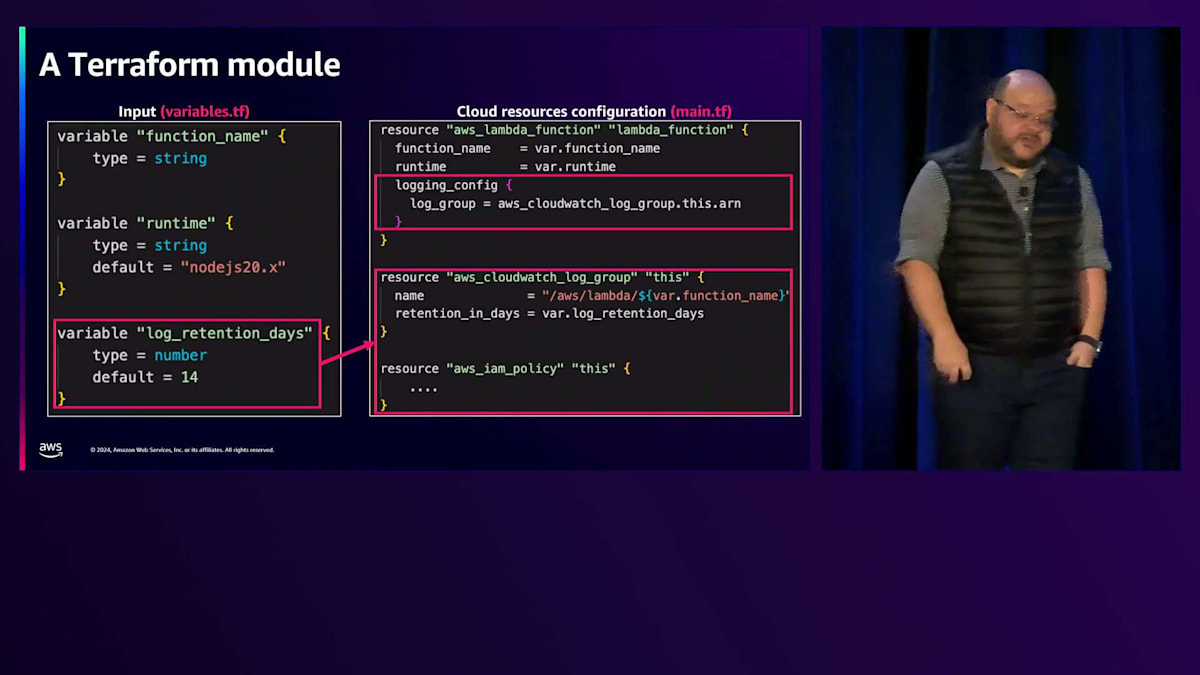
もう一歩進めましょう。よく使われる例としてログの保持日数があります。CloudWatchを使用する場合、デフォルトではログは永久に保持されます。そのストレージ料金を永久に支払い続けたいとは思わないでしょう。インフラストラクチャコードテンプレートで適用できるもう一つの例として、ログを何日間保持したいかという設定があります。左側で変数が確認できますが、右側ではいくつかの興味深いことが起こり始めています。リソース、つまりLambda関数リソースのlogging configプロパティを変更するだけでなく - これは以前見たことがありますが - 追加のリソースも作成しています。設定変数に基づいて、モジュール内で一連のリソースを作成し、本質的にこのモジュールがLambda関数をどのように定義するかを変更しているのです。

こちらは、オブザーバビリティのシナリオでよく適用される別の例です。より拡張されたロギング設定があり、デフォルトのログレベル、システムログレベル、ログのフォーマット、ロググループ、そしてトレースの有効化を定義します。これらのモジュールを使用する開発者として、主にビジネスロジックに関心があります。オブザーバビリティとセキュリティは重要ですが、まず最初にコードを書きたいものです。このアプローチにより、開発者は設定されたベストプラクティスに基づいてコードを作成でき、また会社全体での標準化も実現できます。

もう一つの例は、Layerの使用です。LayerはLambdaの機能で、関数コードとは切り離された形で、追加のコードやライブラリを別のレイヤーとして注入することができます。例えば、開発者の生産性向上のためのオープンソースフレームワークであるPowerToolsのレイヤーがあります。組織内のすべての開発チームに、必要なPowerToolsのバージョンを自分で把握させるか、あるいはPowerToolsが組み込まれたLambda関数作成用のこのモジュールを提供するかのどちらかです。PowerToolsの新しいバージョンがリリースされた際には、モジュールを更新するので、自動的に最新バージョンを取得できます。これはPowerTools以外にも、様々なオブザーバビリティフレームワークやセキュリティ・ガバナンスフレームワークにも適用できます。Layerは多くの異なる機能をもたらします。


これらのベストプラクティスをすべて実装し、Terraformモジュールとしてラップした後、次は何でしょうか? そのモジュールには、開発者が変更できる変数があり、開発者が組み合わせ可能なアーキテクチャに持ち込めるアウトプットがあります。モジュール内では、ベストプラクティスとして何を使用するかを定義するのは、作成者次第です。これは1つのモジュールに過ぎず、このような複数のモジュールを作成することができます。

私がよく目にする3つの例を紹介します。Lambda関数と定期的なスケジューラーの組み合わせは一般的なタスクです。これはLambdaがゼロまでスケールダウンし、使用していない時は料金が発生しないためです。処理のために1日1回Lambda関数をトリガーするのは一般的なシナリオで、Terraformモジュールを使用して再利用可能なものを作成できます。また、SQSキューとRedriveの組み合わせも非常に一般的なシナリオです。SQSからのメッセージを再試行する必要がある場合があるためです。先ほど説明した基本的なLambda関数からモジュールを構築することができます。

そして、興味深いことが起こり始めます。これらは3つの異なる組み合わせ可能なモジュールで、それぞれが独立しています。これら3つのモジュールとサーバーレスアーキテクチャの違いは何でしょうか?矢印を2つ追加するだけで、アーキテクチャになります。定期的な処理を行う関数があり、RedriveをサポートするSQSにデータをプッシュし、そしてそれを非同期で追加処理するLambdaにプッシュします。これらは3つの分離されたパターン、3つの分離されたモジュールで、サーバーレスアーキテクチャのために好きな方法で組み合わせることができます。

これらのTerraformモジュールのライフサイクルは、企業やTerraformモジュールの扱い方によって異なります。業界で一般的に成功しているのは、プラットフォームチームの存在です。必ずしも明確に定義されているわけではありませんが、最初は数人のサーバーレス愛好家たちから始まり、時間とともにサービスプラットフォームチームへと発展していきます。これらの人々がモジュールを作成し、gitのような単純なリポジトリに格納します。モジュールはアプリケーション開発チームによって使用され、これらのモジュールはインフラストラクチャというよりもアプリケーションコンポーネントを表現するため、開発者は時間とともにこれらのモジュールに貢献するようになります。
プラットフォームチームに機能リクエストを開いて変更を依頼することと、開発チームが検証可能なプルリクエストを開くことは、まったく異なります。その結果、これらの開発チームは、サーバーレスアーキテクチャを適切に実装する際の認知的負荷が大幅に軽減されます。これらのモジュールからベストプラクティスを得て、それらを再利用してアーキテクチャを構築することができます。


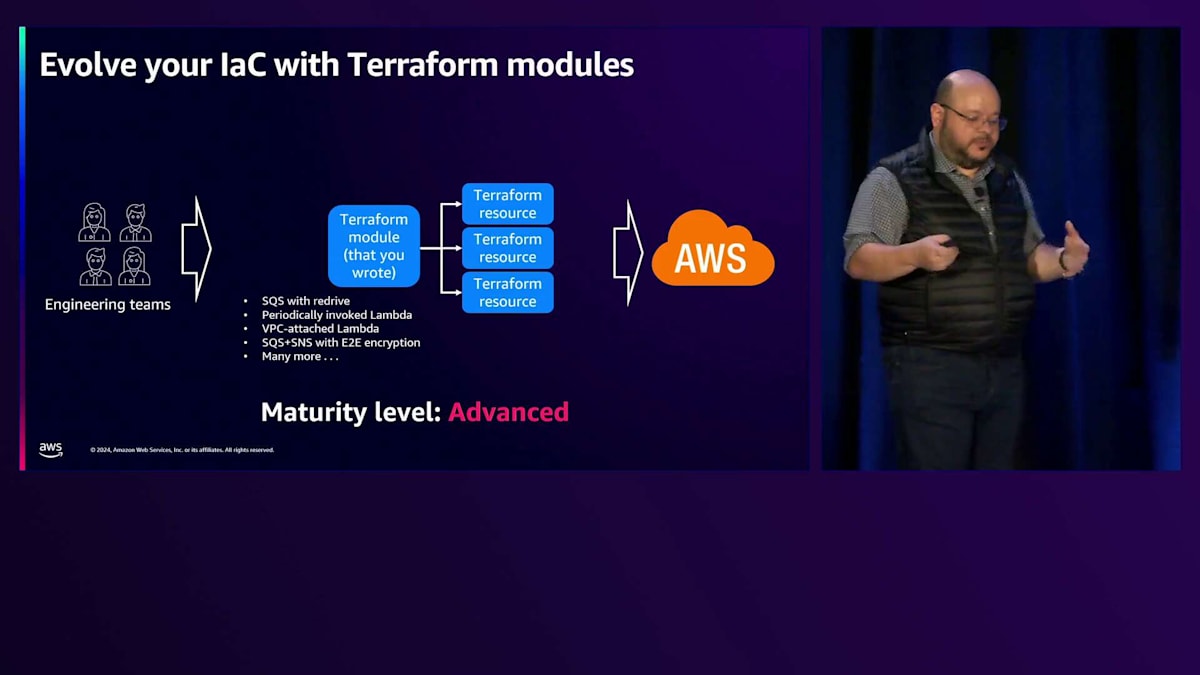
スケールへの道のりをまとめると、 組織は通常、Terraformリソースから始めます。私たちもそこから始めました。旅を始めるとき、AWSプロバイダーのドキュメントを参照し、プレーンなTerraformリソースを使ってアプリケーションを構築します。これを私は初心者レベルの成熟度と呼んでいます - 私たち全員がここから始めたのです。Terraformの経験を積んで成熟していくと、自分のTerraformモジュールを書き始めます。個人的に、あるいは組織の他の部分で再利用する必要があるものを構築します。これには、Redriveを備えたSQS、定期的に呼び出されるLambda、特に規制産業で一般的なシナリオであるVPC接続型Lambdaなどが含まれます。これを私は上級レベルと呼んでいます。次のレベルは、モジュールを書いているのが自分だけではないことに気づくときです - オープンソースのものも含め、モジュールを作成している巨大なコミュニティが存在しています。

ここからは、自分で書いたモジュールやインターネット上で見つけたモジュールを組み合わせてアプリケーションを構築していきます。ソースコードで行うように、NPMやMavenからフレームワークや依存関係を取得できるのと同じように、Terraformモジュールでも全く同じことができます。モジュールの中には自分で書いたものもあれば、コミュニティによって作成されたものもあり、本質的にはそれらの検証済みモジュールを使ってベストプラクティスを実装しながらアプリケーションを構築していくのです。これが、私が言うところのパワーユーザーです。

そのようなフレームワークの1つが、serverless.tfです。これはコミュニティプロジェクトで、100%オープンソースかつ独自の考えに基づいています。 独自の考えというのは、数年前に私がTerraformでサーバーレスアプリケーションを構築する際に人々が何を必要としているのかを調査したところ、アプリケーションの開発、パッケージのビルド、デプロイ、セキュリティ確保など、すべてのツールが不足していることが分かったことから始まりました。serverless.tfのURLには、ドキュメントと全体的なリンクが掲載されています。

Serverless.tfは、 このスライドに示されているような最も一般的なサービスのTerraformモジュールで構成されています。メインとなるのは明らかにAWS Lambdaです。Lambdaは非常に多くの異なる用途に使用されているようで、Lambdaだけで本が書かれているのも驚くことではありません。実に多くのことができるからです。これらのサービスはすべて、さまざまなアーキテクチャを実現するために組み合わせて使用されています。

これから20分間、様々なサービスの機能とTerraformのユースケースについてお話しします。不明な点があれば、後ほど話し合える機会があると思います。これらのプロジェクトを使用している皆様、そしてプロジェクトに貢献してくださっている皆様に、心から感謝申し上げます。Terraform AWS Lambdaモジュールは、異なる環境向けのLambdaパッケージを作成する方法がほとんどなかったことから始まりました。重要な点は、archive fileというデータソースを使用しても、異なるプラットフォーム向けのビルド、異なるパッケージのインストール、異なるアーキテクチャ向けのビルドなど、実際に必要なユースケースの50%も満たせないということです。そのため、このパッケージが作成されました。現在では非常に広範なものとなり、毎日何千人もの人々が使用しています。


異なるランタイムに特化したパッケージング機能が追加されました。例えば、Node.jsを使用する場合、ランタイムとしてNode.js 20を使用したいと指定するだけで、ソースパスを指定するだけでよいのです。そのソースパス内でpackage.jsonがあるかどうかを確認し、依存関係をインストールしてパッケージを作成します。これがかなりの作業量になることは想像できると思います。これが、私たちが最初に組み込みたかった機能の1つでした。その後、Pythonでも同様のことを行い、時間とともに他のランタイムのサポートも追加しました。また、異なるビルド機能もサポートしています。例えば、Docker内でパッケージをビルドしたり、独自のDockerfileを提供したり、プライベートGitリポジトリやプライベートNPMパッケージにアクセスするためにSSHエージェントを通したりすることができます。また、 PythonとPoetryを使用したビルド機能も追加しました。
このモジュールでは、"poetry install"を指定した際に何が起こるべきかを理解し、その作業を実行します。ソースパスはさまざまなタイプを取ることができます - 異なる構造のリストであったり、特定のファイルを指定したりすることができます。Sourcesは、これらのステップを順番に実行してビルドし、最後に一つのアーティファクトを生成します。そのアーティファクトは、すぐにデプロイすることも、後でデプロイするためにAmazon S3にコピーすることもできます。これがLambdaモジュールの非常に重要な機能です。


もちろん、Rustについて触れない訳にはいきませんよね。つまり、すべてをRustで書き直そうということです。terraform-aws-lambdaモジュールを使えば、今やこれが可能になりました。cargo-lambdaライブラリを使用してパッケージをビルドする方法があるからです。このモジュールを使用してRust Lambdaパッケージをビルドする方法も示されています。これらはすべてオープンソースです。
もう一つの重要な側面はテストです。先ほどAntonが言及したように、AWSにデプロイしてAWSエンドポイントを呼び出す代わりに、LocalStackを使用して環境をエミュレートすることができます。様々なデータサービスのローカルコピーを持つことができます。Lambdaファンクションに対して、特定の名前を持つバケットからソースを取得するよう指示することができます - この場合、必ずhot reloadという名前にする必要があります。アプリケーションが配置されているフォルダへのキーを提供します。そして、実際のAWSではなく、LocalStackがデプロイされているlocalhostに向かうよう指示するため、TerraformとAWS CLIのラッパーをインストールします。その後、AWS localのCLIラッパーを使用して、このLambdaファンクションを通常通り呼び出すことができます。re:Inventでこんな話をするのは少し皮肉に聞こえるかもしれませんが、AWSを完全に使用しないことが可能になります。LocalStackをローカルで実行することで、かなり良好なテストカバレッジを得ることができます。ビジネスロジックをラップトップ上で非常にうまくテストできるため、私はこの方法が非常に有用だと感じています。ただし、パフォーマンステストやその他のタイプのテストには、LocalStackは適していません。

クロスサービス統合について話しましょう。serverless.tfやterraform-awsモジュール、あるいは他のTerraformモジュールが提供するパッケージを使用していない場合、API Gatewayのためだけに約10個のTerraformリソースを作成する必要があります。様々なリソース、メソッド、統合、デプロイメントなど、多くのものを作成する必要があります。さらに、多くのIAMリソースも作成する必要があります。Lambdaファンクションや他のIAM関連のポリシーやロールが必要です。API GatewayがLambdaファンクションと通信するという単純なパターンを実装するために、約20の異なるリソースをどのように接続するかを理解する必要があります。

serverless.tfや実際にはほとんどのTerraformモジュールが提供するソリューションを使用する場合、数個のモジュールを呼び出すだけで済みます。この場合、API Gatewayを呼び出し、API GatewayのルートがどのようにしてそのルートがどのようにLambdaファンクションと統合されるべきかを指定します。そして、特定のAPI Gatewayエンドポイントからの呼び出しを許可したいため、Lambdaファンクションにトリガーを許可する必要があります。基本的にはそれだけです - 内部の複雑さに対処したり、Terraformコードを書いたり、ユーザーとしてロジックに精通している必要はありません。数個のモジュールを呼び出すだけで、それで終わりです。

Serverless Landには、多くのインテグレーションパターンの実装方法について詳細な説明があります。1年前、あるいは2年前くらいに、私がこれらのパターンを投稿したと思います。もし新しいパターンを追加したり、動作しなくなったものを修正したりしたい場合は、ぜひ貢献してください。
このウェブサイトは、一般的なサービスについて学ぶ際にとても役立つと感じています。また、AWS固有の機能についても豊富な情報が掲載されていますので、ぜひチェックしてみてください。

では、実際に効果的なプロジェクト構造について話しましょう。プロジェクトの構造化には無限の方法があることは理解していますが、私の経験と一般的なベストプラクティスに基づいて、いくつかの重要なポイントを強調したいと思います。まず、Infrastructure as Codeとアプリケーションコードを近接して配置する場合、別々のフォルダに分けつつも1つのリポジトリにまとめるMonorepoの方が格段に効果的です。これは本当に重要なポイントです。また、プロジェクトはモジュール化を心がけてください。そうすることで、あるスコープがどこで終わり、次のスコープがどこから始まるのかが簡単に理解できます。PythonファイルとTerraformファイルを1つのフォルダに入れて混乱を招くようなことは避けましょう。それは楽しくありません。

環境ごとにディレクトリを分けることで、異なる設定を含む各フォルダによって、特定の環境がどのように構成されているかを理解しやすくなります。すべてを1つのフォルダに入れるよりも理解しやすいでしょう。また、専用の変数ファイルを用意すると、異なるソースや異なるリージョンに対して非常にきめ細かな変数ファイルを提供するスクリプトを実装できます。このような構造は理解を深めるのに非常に効果的です。


例えば、変数の値をインラインで指定する場合、1回だけ行う必要がある場合は許容できますが、スケールするのは非常に難しく、時間とともに維持するのは事実上不可能です。これらのファイルをTFVARsで管理することで、比較が可能になり、全般的により良い結果が得られます。このプロジェクト構造を見ると、TFVARファイルとリソース設定が全く同じ名前で構造化されている場合、どのTerraformモジュールがどのような値を持っているのかを簡単に理解できることがわかります。

ここでの構造は、environmentsフォルダがあり、その中に異なるTFVARファイルが格納されており、実行しようとしているモジュールに応じて特定のファイルが読み込まれます。この情報を共有する方法について見ていくと、さらに興味深い展開があります。多くの人にとって、デフォルトの方法はTerraform remote stateを使用することです。異なるチーム間で値を受け渡す必要がある状況を想像してみてください。例えば、API Gatewayの設定やパラメータを担当するエッジチームがあり、一方でLambda関数とその設定に特化して作業する複数のアプリケーションチームがいます。しかし、彼らはAPI Gatewayのパラメータへのアクセス権を必ずしも持っているわけではなく、Lambda関数の実行を許可するためのAPI GatewayのARNを知らないかもしれません。もちろん、調査して尋ねることはできますが、この分離が現時点では明確でないと想像してください。また、インフラチームが管理するVPCやRDSなどの従来型のリソースもあります。そこで、Lambda ARNを添付できるかどうかメッセージを送って確認する方法がありますが、この方法にはデメリットがあります。

Bobはメールを使うべきではありません。Bobは別の方法を使うべきです。なぜなら、Slackで誰かに「これをどうすればいいの?」と尋ねるのは簡単に理解できるからです。誰かに何をすべきか尋ねる方が便利だと感じる状況は誰にでもあります。しかし、インフラを扱う際の正しい方法は、専用の依存関係の自動化・管理ツールを使用することです。そのようなツールは数多く利用可能です。

次のスライドでは、AWS Systems Manager Parameter Store、Terragrunt、そして先ほど言及した標準的なAWS Systems Manager Parameter Storeについて見ていきましょう。インフラチームがRDSデータベースのようなリソースを作成し、既知の場所に既知の名前でSSMパラメータを公開する状況を想像してください。そうすると、アプリケーション開発チームは、このデータソースから単純に読み取るだけでよいのです。このように、彼らは全く会話する必要がなく、そのデータソースにある情報を読み取り、環境変数を通じてLambda関数を設定し、この情報を渡すだけです。これはどのような規模でも実装が非常に簡単です。時には、誰がこの情報を読み取れるようにすべきか、または機密情報を置こうとする場合に課題が生じることがあります。これは可能ですが、より良い方法もあるので注意が必要です。ただし、多くのタイプの情報に対して非常に強力な方法です。
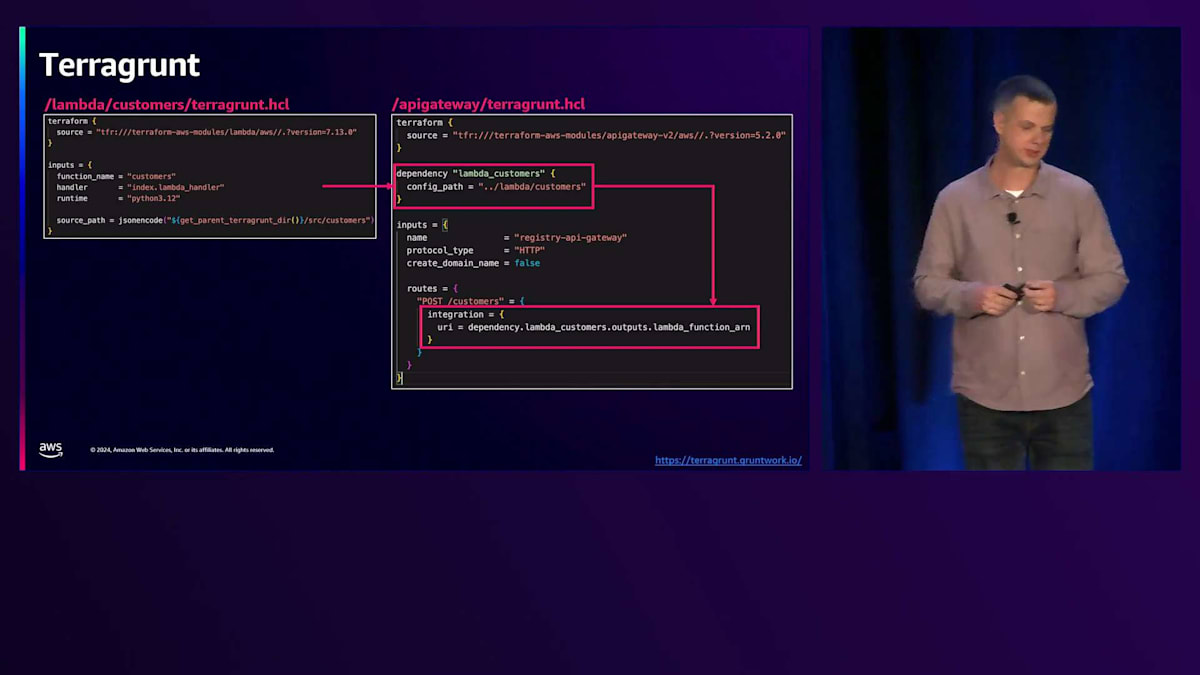
別の方法であるTerragruntを見てみましょう。Terragruntは長年存在しており、私も何年も使用してきました。Terraformモジュールの深い部分に立ち入る必要性を抽象化する方法に私は非常に満足していました。この例では、Lambda関数とAPI Gateway間の設定を受け渡すために、Lambda関数のTerragrunt HCL設定ファイル内にこのLambda関数を作成するだけです。API Gatewayの設定内で、このローカルディレクトリにあるLambda関数への依存関係を指定し、そのモジュールの出力からLambda関数のARNを取得したいと指定するだけです。これだけです。ご覧の通り、Terraformコードも、複雑な構文も、余計なものも必要ありません。この例は非常に良いと思いますし、これがTerragruntを使用する最大の利点の一つだと考えています。

また、まだあまり知られていませんが、Terramateというツールについても言及したいと思います。これも非常に似たようなフローを持っており、Lambda関数のスタック設定を定義し、このスタックからどのような出力をエクスポートする必要があるかを指定します。この場合、Lambda関数のARNを出力として出力します。そして、API Gatewayスタック内で、このAPI Gatewayモジュールへの入力がLambda関数から来るべきだと単純に指定します。構文は少し理解が難しく、パイプラインでの実装が難しい場合もありますが、一般的に、これは私が考える適度な分離レベルです。見ての通り、API Gatewayモジュールは、Terragruntのように渡される環境変数に依存することなく、変数参照を使用してこの情報をネイティブに操作します - これは純粋なTerraformコードです。これはTerramateの非常に優れた機能です。なぜなら、Terramateなしでも実行できる有効なTerraformコードを生成するだけだからです。以上で私の説明は終わりです。Anton Aにクリッカーを渡して、彼に続けてもらいましょう。ありがとう、Anton B。
Terraform Stacksによる複数環境へのデプロイメント管理

それでは、デプロイメントのスケールについて話しましょう。ついにデプロイメントの部分に到達しました。Terraform applyを実行すると、インフラストラクチャの設定がクラウドにデプロイされ、定義した場所にステートファイルが保存されます。複数のデプロイメントがある場合に、興味深い課題が発生し始めます。複数のチームがそれぞれ独自のTerraformスタックを管理していて、相互依存関係がある場合はどうでしょうか?サービス開発チームとして、作成されたLambdaモジュールを使用しているかもしれませんが、それでもインフラストラクチャチームがVPCやEC2インスタンスへの変更を許可しているとは限りません。

Terraformは、Infrastructure as Codeの設定をデプロイする際には素晴らしいツールです。しかし、通常のTerraformを使用する際には一般的な課題があり、それはParameter Storeで対処されているのを見てきました。Parameter Storeにシークレットを保存してはいけません。問題は、Terraformネイティブな、つまりTerraform自体が提供する何かがあるかということです。複数のチームがある場合に課題が発生します。本質的に、すべてが複数になります - 複数のチーム、複数のチーム間でのインフラストラクチャコード設定の依存関係の管理方法、開発、ステージング、テスト、受け入れ、本番環境といった複数の環境があり、おそらく異なるリージョンに半ダースほどの本番環境があるでしょう。

セキュリティとガバナンスの観点から、一部の要求の厳しいエンタープライズ顧客はスタンドアロンアカウントへのデプロイを要求する一方で、共有アカウントでも問題ない顧客もいるため、複数のアカウントにデプロイする必要があるかもしれません。クラウドアプリケーションを複数のリージョンで構築しているでしょう。これらは、Terraformをスケールして使用する際に克服する必要がある興味深い課題です。ここで質問ですが、Terraform stacksをすでに見たり探索したりしたことがある方は何人いますか?4人ほど見えますね。

これはHashiCorpが約2ヶ月前に発表した真新しい機能です。今日のまとめとしてこの機能について話したいと思います。なぜなら、この機能がServerlessの世界に驚くほどうまくマッピングされると考えているからです。Terraformはこのstacksという概念を導入しました。昨年のブログ投稿で簡単に触れられていましたが、今年になって本格的に公開されました。私の記憶が正しければ、まだパブリックベータ版ですが、今年のHashiConfで多くの話題に上がりました。

Terraform stackの考え方は、本質的にコンポーネントのようなリソースのコレクションです。これが公式な用語です。アプリケーションを定義するInfrastructure as Codeも目にすることでしょう。これにはAPI Gateway、Lambda、S3、その他のクラウドリソースなどが含まれ、これらのコンポーネントは基本的にモジュールにマッピングされます。ご覧の通り、コンポーネントはモジュールへの参照と設定プロパティの組み合わせです。

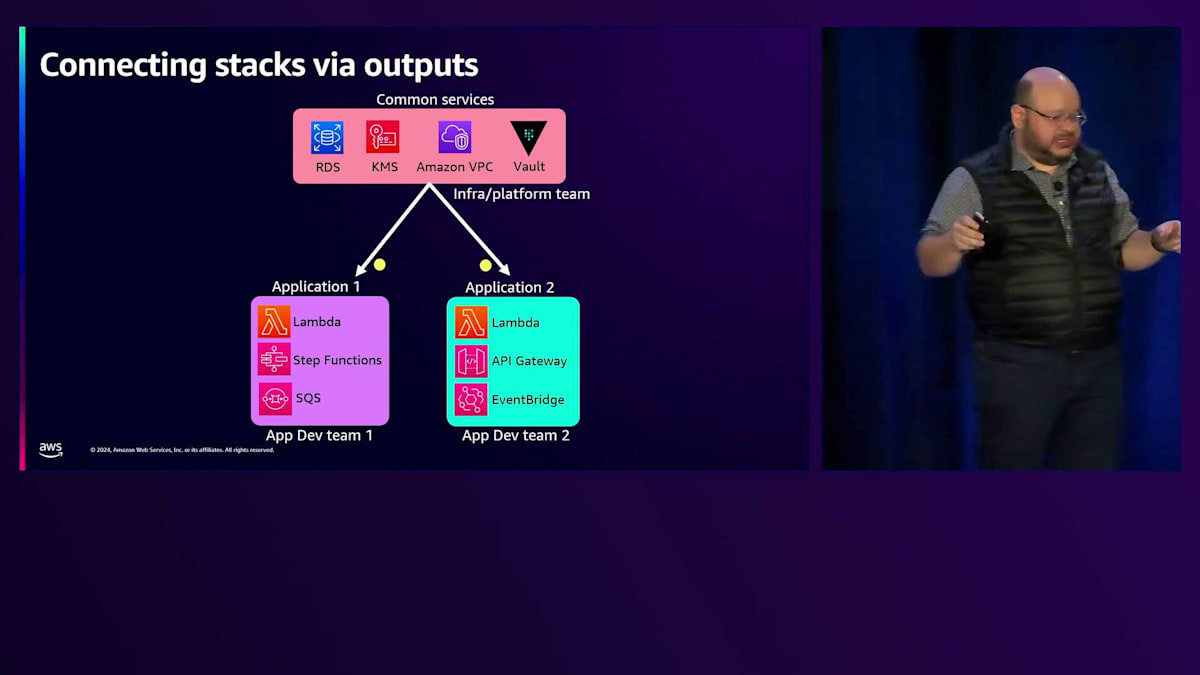
アプリケーションを複数のコンポーネントで定義した後、次に直面する課題は複数の環境や複数のデプロイメントの問題です。スタックの一部として、コンポーネントを定義し、そのスタックの複数のデプロイメントを定義すると、各デプロイメントは完全な複製となります。 素晴らしいのは、これらのスタックがOutputsを使って接続されていることです。例えば、RDSやKMS、VPC、Vaultなどの従来型のリソースを扱うCommon ServicesのTerraform設定があり、そこにいくつかのサービスアプリケーションがあるとします。

時として、そのCommon Servicesレイヤーで変更が発生することがあります。その変更が起きた時、つまりOutputが変更された時、それはアプリケーションに自動的に反映されます。心配はいりません - 自動的にApplyされることはなく、すべてが正常に動作することを確認できます。Applyは自分で実行する必要がありますが、アプリケーションは設定の更新を自動的に受け取ります。これは「更新したから最新版をPullしてね」とメールやメッセージを送ることなく、チーム間の依存関係を管理する上で非常に便利です。

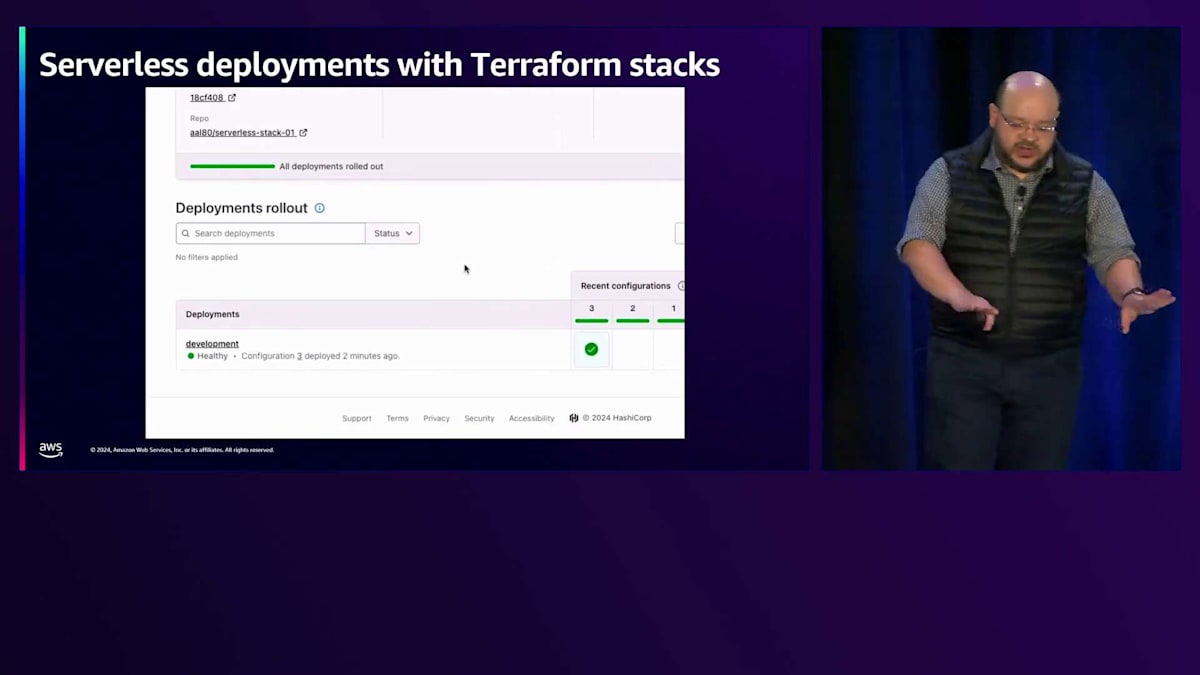
では、これらの構成要素を全て接続する方法を見てみましょう。シンプルなスタックを想像してください:API GatewayからLambdaを経由してS3へという流れです。 画面に表示されているように、Terraformを使用して定義する方法をご覧ください。上部にIdentity Tokenがあり、その下に2つのデプロイメントがあります。1つは開発環境用で、us-east-1リージョンにデプロイし、開発環境専用のRoleを使用します。
Productionデプロイメントについては、ご覧の通り、実際にはUS East 1とUS West 1の2つのリージョンで実行されます。これは異なる設定を持つ別のデプロイメントです。Productionでは異なるRoleを使用します(これは理にかなっています)、また異なるTagsも設定できます。Productionデプロイメントに対して、environment equal developmentのような追加のTagsを設定することもできます。基本的に、同じコンポーネントを使用しながら、異なる設定を持つ複数のデプロイメントを定義しているわけです。


結果として、2つのデプロイメントが得られます。開発用デプロイメントはUS East 1に3つのリソースを持ち、本番用デプロイメントは2つの異なるリージョンに同じコンポーネントを持つことになります。 では、これが実際にどのように動作するのか見てみましょう。この全体の動作を示す短いデモをご用意しています。 先ほど申し上げたように、私たちはコードではなくInfrastructure as Codeに注目しているので、まずは「Hey there re:Invent 2024」と表示する非常にシンプルなLambda関数から始めましょう。



これが私のS3コンポーネントです。これは単にモジュールへのマッピングで、Lambdaコンポーネントも持っています。つまり、S3バケットとLambda関数という2つのコンポーネントがあり、API Gatewayはまだありません。 これが開発環境のデプロイメントの定義で、先ほどのスライドでご覧いただいたものと全く同じです。 ここでTerraform Cloudに切り替えると、開発環境のデプロイメントがすでにデプロイされているのがわかります。これが私たちのスタート地点です。 最初に行うのは、異なるロールを持つプロダクション環境のデプロイメントを貼り付けることです。つまり、異なるプロダクション環境のデプロイメントを定義しているわけです。


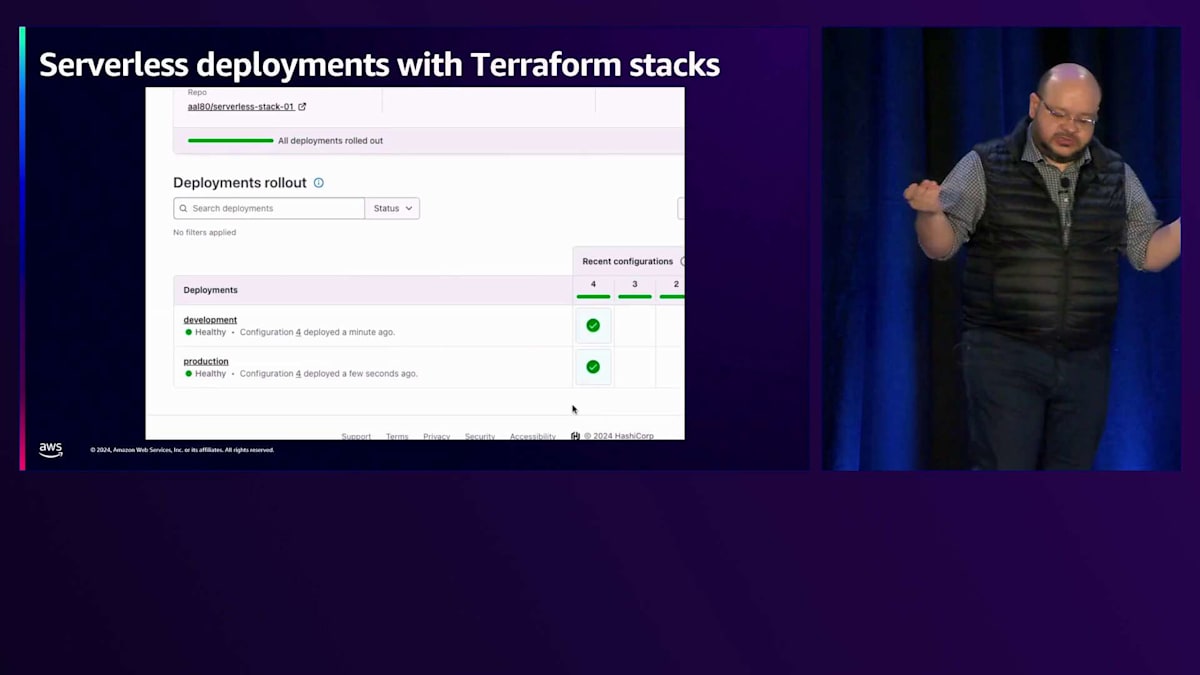
変更をコミットしてから数秒後、Terraform Cloudがそれを検知したのがわかります。開発環境のデプロイメントは変更がないため、すぐに緑色になります。 一方、プロダクション環境では2つの異なるリージョンを使用しているため、Lambda関数とS3バケットへの変更を確認できます。プランを承認すると、リソースの数に応じて数秒以内に、 標準的なTerraform applyが裏で実行され、緑色になります。



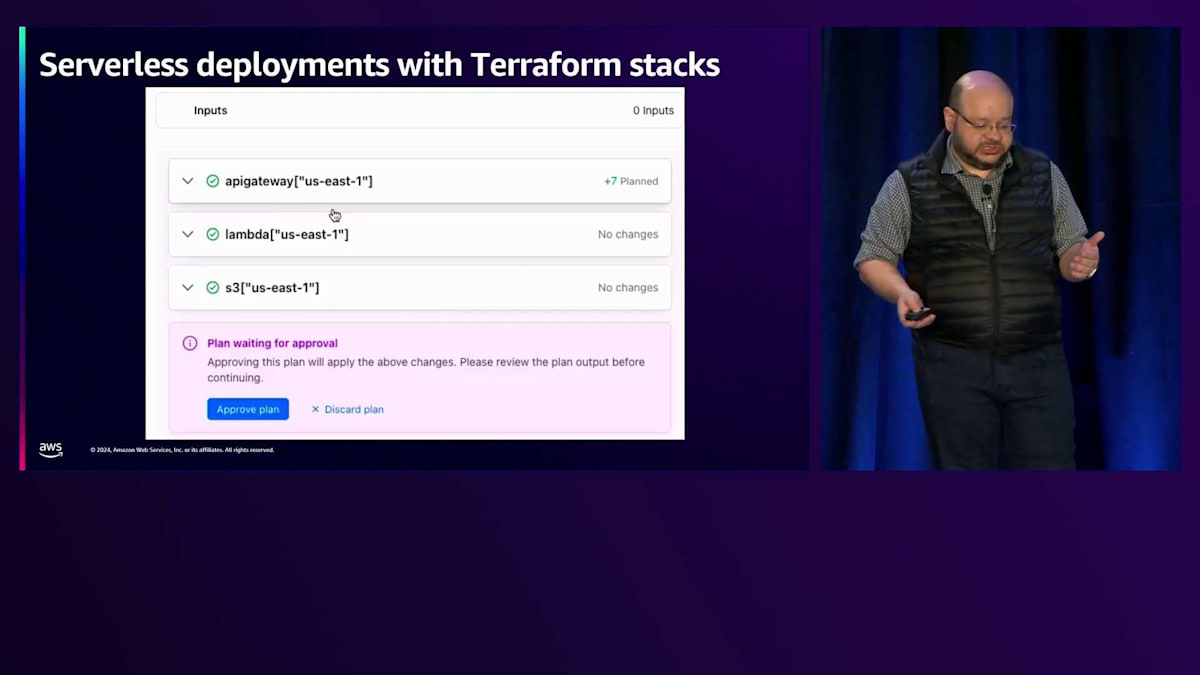
さらに変更を加えてみましょう。追加のデプロイメントを行い、新しいコンポーネントも追加します。 コンポーネントにAPI Gatewayを追加しますが、これから何が起こるか予想できると思います。このAPI GatewayはLambda関数から参照されるため、これらのコンポーネント間にクロス依存関係が生まれます。 この変更をコミットした瞬間、開発環境とプロダクション環境の両方が処理されているのがわかります。 開発環境では、LambdaとS3に変更はありませんでしたが、API Gatewayが追加されました。まずは開発環境のプランを承認し、プロダクション環境はまだ承認していません。


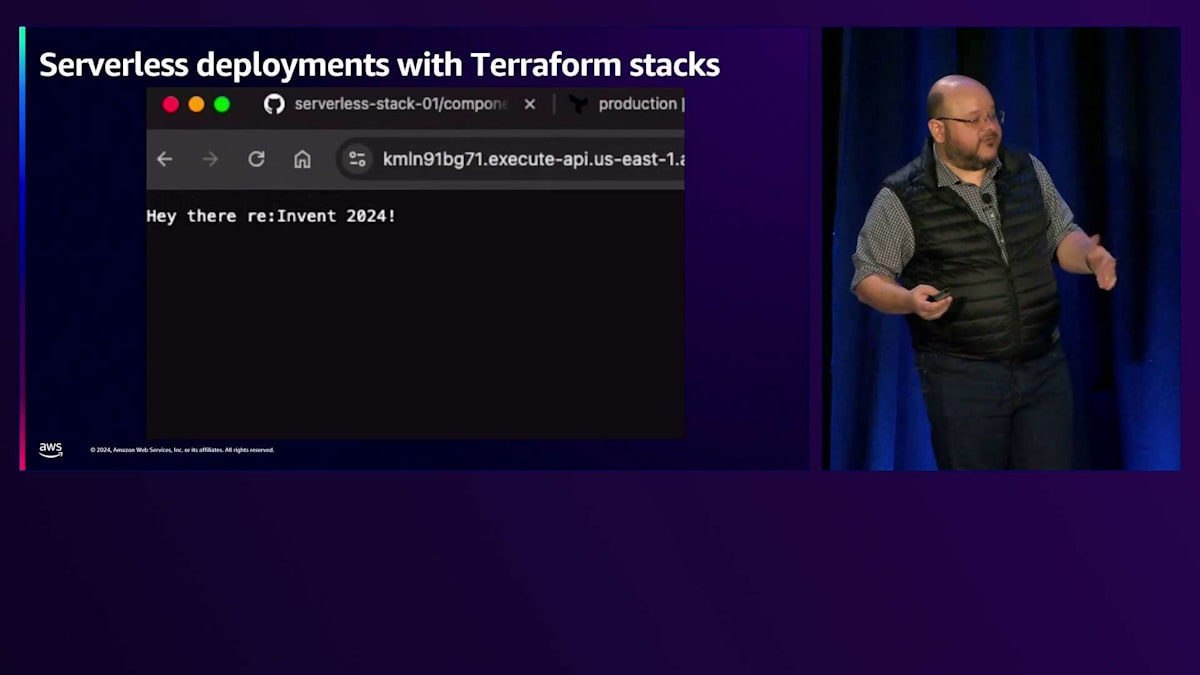
プロダクション環境は別途承認する必要があり、2つの異なるリージョンにデプロイしているため、より多くのリソースが追加されているのがわかります。1つの変更を行い、それが複数のデプロイメントに適用されました。数秒以内に、これらの変更が適用され、両方の環境が緑色になり、すべてがgitに記録されています。 たった今デプロイされたリソースに移動し、新しく作成されたAPI GatewayのURLを取得して、 ブラウザに貼り付けると、"Hey there re:Invent 2024"というメッセージが表示されます。これが私のソースコードです。

これが、複数のコンポーネント間の依存関係を管理し、さらに複数の環境や複数のアカウントにデプロイするためのTerraformネイティブな方法です。異なるチーム間でTerraformの依存関係を大規模に管理できるため、ぜひ検討してみてください。残り時間は約5分です。 そろそろまとめに入りましょう。質問がある方は、このあと外でお待ちしています。私たちはこういった話題について話すのが大好きなんです。
セッションのまとめと次のステップ

最後にまとめますと、本日は多岐にわたるトピックをカバーしました。TerraformやSAM、LocalStackなどのツールを使用することで、組織が既に慣れ親しんでいるツールを活用しながら、効率的にServerlessアプリケーションの構築とテストが可能になります。もしServerlessアプリケーションを構築したいと考えていて、既にTerraformに精通しているのであれば、それは素晴らしいことです - Terraformを使ってServerlessアプリケーションを構築してください。Lambdaの同時実行数など、いくつか新しく学ぶ必要がある事項はありますが、Infrastructure as Codeの知識をゼロから構築し直す必要はありません。Infrastructure as Codeの知識は不可欠です。

既に使い慣れているツールを活用できる - モジュール化が可能です。Terraformの設定により、再利用可能なコンポーネントとパターンを構築できます。これは Serverlessの世界では極めて重要です。この点は幾ら強調してもし過ぎることはありません。私が関わるお客様の中で最も成功している手法の1つです。モジュール化を行い、組織内でこれらの検証済みモジュールを提供することで、複数のチームが存在する組織での効率性が大幅に向上します。

3つ目のポイントは、皆さんは一人ではないということです - ここに集まった人数を見てください。320人以上の方々がいらっしゃいますし、さらに多くの方が列をなしていました。このセッションは別の建物でもリアルタイムでストリーミング配信されています。Serverlessにおいてもテラフォームを使用する巨大なコミュニティが存在します。そのコミュニティを活用し、その一員となってください。参加者が増えれば増えるほど良いのです - AWSの一部として構築したオープンソースのコミュニティプロジェクトやサンプルを活用して、皆さんの journey を加速させてください。私たちは多くの再利用可能なパターンを構築し、皆さんが使えるように公開しています。

次のステップとして - QRコードをお約束しましたが、私は約束は必ず守ります。 このQRコードには、今日ご覧いただいた内容のすべてと、さらにカバーできなかった内容も含まれています。ServerlessアプリケーションでのTerraformの使用に関するガイドがオンラインで公開されています。2時間後にこのトピックに特化したワークショップが開催されます - まだ席に余裕があれば参加できますが、オンラインでも受講可能です。Terraformプロバイダーのベストプラクティス、Anton BabenkoによるTerraformリソース、そしてServerlessアプリケーションのガバナンスガイドへのリンクも含まれています。Terraformはガバナンスに最適なツールであり、このリンクを通じて再利用可能な豊富なコンテンツを提供しています。

他にも3つのセッションをお勧めします。「Building Serverless Applications Using Terraform」ワークショップは、基本的に今回のトークのハンズオン版で、2時間強後にMandalay Bayで開催されます。そこに行けない場合でも、オンラインで公開されています。「Best Practices for Serverless Developers」は、2時間後にこの部屋で行われる素晴らしいセッションです。そして「Implementing Security Best Practices for Serverless Applications」は、開発者がビジネスシナリオに集中している間にミスを起こさないよう、TerraformやInfrastructure as Codeツールをどのように使用するかを示す非常に優れたセッションです。


AWSのServerlessの学習の旅を続けてください。serverless.tfには豊富なリソースがあり、Serverlessのスキルをアピールしたい方向けのバッジや、Serverless kung fuもご用意しています。ご参加いただき、ありがとうございました。お役に立てれば幸いです。ご質問がございましたら、すぐ外でお待ちしておりますので、お気軽にお声がけください。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion