re:Invent 2024: AWSがS3 Glacierで実現するCold dataの効率管理とコスト削減
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Maximize the value of cold data with Amazon S3 Glacier storage classes (STG207)
この動画では、Cold dataの効率的な管理とコスト削減について、Amazon S3 GlacierのシニアテクニカルプログラムマネージャーのGayla BeasleyとAmazon S3のプリンシパルプロダクトマネージャーのAndrew Pohlが解説しています。IDCの推定では世界のデータの70〜80%がCold dataとされる中、S3 Glacier Instant Retrieval、S3 Glacier Flexible Retrieval、S3 Glacier Deep Archiveなど、アクセス頻度に応じた最適なストレージクラスの選択方法や、Amazon S3 Lifecycleを活用したデータ移行戦略について詳しく説明しています。また、Canvaの事例では、適切なストレージクラスの選択により月額300万ドルのコスト削減を達成した具体例も紹介されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Cold dataの重要性と本セッションの概要

今日は私たちの大好きなテーマの1つである、Cold dataについてお話しします。この会場にもCold dataをお持ちの方がいらっしゃるようですね。これが今夜のテーマです。こんばんは。私はAmazon S3 GlacierのシニアテクニカルプログラムマネージャーのGayla Beasleyです。私はAndrew Pohlと申します。Amazon S3のプリンシパルプロダクトマネージャーを務めています。Cold dataについてお話ししていきましょう。

Cold dataとは、四半期に1回程度しかアクセスしないデータのことを指します。一般的に時間の経過とともにアクセス頻度が下がっていくものの、何らかの理由で保持しておきたいデータです。まず初めに、本日はお集まりいただき、ありがとうございます。17時30分という少し難しい時間帯ではありますが、皆様とこのテーマについて話し合えることを大変嬉しく思います。Cold dataが重要である理由についてお話しした後、Amazon S3でのデータ保存について、特にアクセス頻度が低下していくデータのコストを削減するためのベストプラクティスについて説明します。後半では、Gaylaが再び登壇し、データの復元について、そしてS3からデータを取り出す際のパフォーマンスの考慮点やベストプラクティスについてご説明します。

Cold dataは無視できない存在です。なぜなら、ビジネスが成長するにつれて、おそらく皆様はますます多くのデータを蓄積しているからです。そして、そのデータは古くなるにつれて、通常アクセス頻度が低下していきます。実際、IDCの推定によると、世界のデータの70〜80%がCold data、つまりアクセスされていないデータだとされています。私たちが顧客の傾向として見ているのは、将来的な使用のためにそのデータを保持しているということです。現在、AI/MLという大きなトレンドがあり、新しいアプリケーションで新しい使い方が見つかることで、そのデータの価値が時間とともに増加しているのです。
Amazon S3のストレージクラスとCold dataの管理方法

お客様がデータを保存する理由は様々ですが、主に3つの大きなマクロユースケースに分類されます。1つ目は保存で、メディアファイル(動画や画像)や、将来的な価値があるとわかっているデータレイク内の履歴データなどを保存するケースです。これらのデータにアクセスできる必要がありますが、同時に、データ量が増えても費用が指数関数的に増加しないよう、コストを抑える必要があります。また、多くのお客様がバックアップのユースケースを持っています。バックアップの場合、実際にはデータを復元する必要がないことを願っていますが、復元が必要になった際には、Recovery Time Objective内に確実に取り出せることが極めて重要です。

最後に、コンプライアンスのためにCold dataを保存するお客様もいます。政府による要件や自主的な方針により、データの保持が求められることがあります。これは5年から10年以上、場合によっては永久に保持する必要があるかもしれません。そのような長期間データを保存する場合、コストが膨らまないよう、十分に低いコストを維持する必要があります。約6ヶ月前、あるお客様から興味深い話を伺いました。パンデミック期間中、彼らは削除するデータを探してリテンション期間を短縮していたそうです。確かに経済的に不確実な時期で、コストを削減する必要がありました。しかし、データを削除している最中に、ある人が「新しいAI/ML機能や他の可能性を考えると、このデータを早急に削除してしまって良いのだろうか」という疑問を投げかけたそうです。

彼らは過去を振り返り、データを削除するのではなく、コスト削減に重点を置くことを決めました。というのも、そのデータには将来的な価値があることは分かっていたものの、具体的にどう活用するかまではまだ見えていなかったからです。パンデミックや最近の経済的な不確実性を経験された方々にとって、コスト削減を目指す中でこの状況は共感できるのではないでしょうか。もちろん、データを削除することもコスト削減の一つの方法です。


Amazon S3では、リージョナルなストレージクラスのオプションが用意されているのが心強いところです。これらはすべてリージョナルなストレージクラスで、最低でも3つのAvailability Zoneにまたがってデータを保存します。左から右に見ていくと、左側はより頻繁にアクセスされるデータ向けで、アクセスコストを抑える代わりにストレージコストが高くなります。右に移動するにつれて、アクセス頻度の低いデータに対してストレージコストを削減できます。S3では、長期間データを保持する場合、これらの低温ストレージクラスにデータを移行することで、ここで強調している一番右のGlacierについて、これから詳しく説明しますが、コストを抑えることができます。
データのアクセス頻度が下がるにつれてこれらのストレージクラスにデータを移行すると、アクセスコストは上がりますが、データの保存コストは下がります。S3 Glacier Flexible RetrievalやS3 Glacier Deep Archiveに移行し、ミリ秒単位のアクセスを数時間や数日に変更してもよいという場合、アクセスコストも削減できます。データへのアクセスに時間がかかることを許容できれば、アクセスコストをそれほど高くせずにストレージコストを下げるという、いわば両方のメリットを得ることができます。

では、Glacierストレージクラスについて詳しく見ていきましょう。左から順に、S3 Glacier Instant Retrievalは即時アクセスが可能で、アプリケーションは同じGET APIコールを使用してデータにアクセスできます。つまり、Instant Retrievalにデータを移行しても、アプリケーションを変更する必要がありません。これは医療画像やユーザー生成コンテンツなどのユースケースに最適です。例えば、私が病院に行って3年前のレントゲン写真を見る必要がある場合、医師は何時間も待ちたくないでしょうから、その場で確認できることが理想的です。ミリ秒単位でレントゲン画像を取り出して確認できます。古い画像はあまりアクセスされないため、アクセスが少ないことでコストを抑えながら、S3 Glacier Instant Retrievalに保存することでストレージコストも削減できます。
S3 Glacier Flexible Retrievalはストレージコストがより低くなりますが、データの取り出しに数分から数時間かかります。これは大量のデータを取り出す必要がある場合に非常に便利です。5~12時間かかるBulkオプションを使えば、無料で取り出すことができます。お客様は、AI/MLアプリケーション用に大量のデータを復元したい場合、データ復元のコストを増やすことなくこれを実行できます。最後に、S3 Glacier Deep Archiveは、テラバイトあたり約1ドルという最も低いストレージコストを実現します。これはコンプライアンスなどの長期保持ユースケースに最適で、データへのアクセスがほとんどないことが分かっていて、コストを抑えるために最も低いストレージコストを求めている場合に適しています。
Amazon S3 Lifecycleを活用したCold dataの最適化

これは、どのようにしてデータをこれらのストレージクラスに取り込むかという疑問につながります。そこで登場するのが Amazon S3 Lifecycle です。 バックアップデータなどの一部のデータについては、すでにコールドデータであることが分かっているため、適切なストレージクラスに直接アーカイブすることができます。

コールドデータをアーカイブする場合、Lifecycle を使用する必要は実はありません - 最も適切なストレージクラスに直接保存できます。しかし、多くのデータは時間とともにコールド化していきます。最初の30日から90日の間は頻繁に使用されますが、その後アクセス頻度が低下します。そのために、3つの Lifecycle 移行オプションが用意されています。


簡単な例を説明させていただきます。0日目にオブジェクトを作成したとします。90日後、アクセスパターンが月間5%未満に減少したことが分かったとします。Storage Class Analysis や Storage Lens を使用してアクセスパターンを確認できます。この場合、90日後にデータを S3 Glacier Instant Retrieval に移行する Lifecycle 移行ポリシーを設定できます。これは、まだミリ秒単位のアクセスが必要な場合の選択肢です。 さらに90日後、つまりオブジェクト作成から180日後に、そのミリ秒単位のアクセスが不要になったとします。ポリシーの下に別の Lifecycle 移行ルールを作成して、180日後にそのデータを S3 Glacier Deep Archive に移行することで、さらにストレージコストを削減できます。最後に、7年後にデータが不要になった場合、Lifecycle の有効期限切れを使用して、ポリシーの下に別のルールを設定し、データを削除することができます。
Lifecycle には、実際に移行または削除するストレージを選択するのに役立つ複数のフィルターがあります。主要なものは、Bucket Prefix と Object Tag です。データの整理方法を事前に考えておけば、同様のアクセスパターンを持つデータを同じ Prefix や Bucket に配置でき、後々これらのポリシーを設定する際にとても便利です。それができていない場合や、1つの Prefix や Bucket の下で異なる顧客のデータを管理している場合でも、Object Tag を使用してデータにタグを付け、そのタグに基づいてデータを移行できます。
さらに2つのフィルターがあります。後ほど詳しく説明する Object Size と、Number of Versions です。Number of Versions については、作成した複数のバージョンを確実に確認するために重要な Versioning を有効にした場合、すべてのバージョンを永久に保持する必要はありません。というのも、それによってコストが大幅に増加する可能性があるからです。例えば、次々とバージョンを作成して突然20個のバージョンができた場合、ストレージコストは20倍になります。このフィルターを使用すると、バージョンの有効期限を設定しながら維持したいバージョン数を選択でき、時間でも設定できます。30日後にそれほど多くのバージョンを持ちたくない場合は、このフィルターを使用して保存するバージョン数を制御できます。

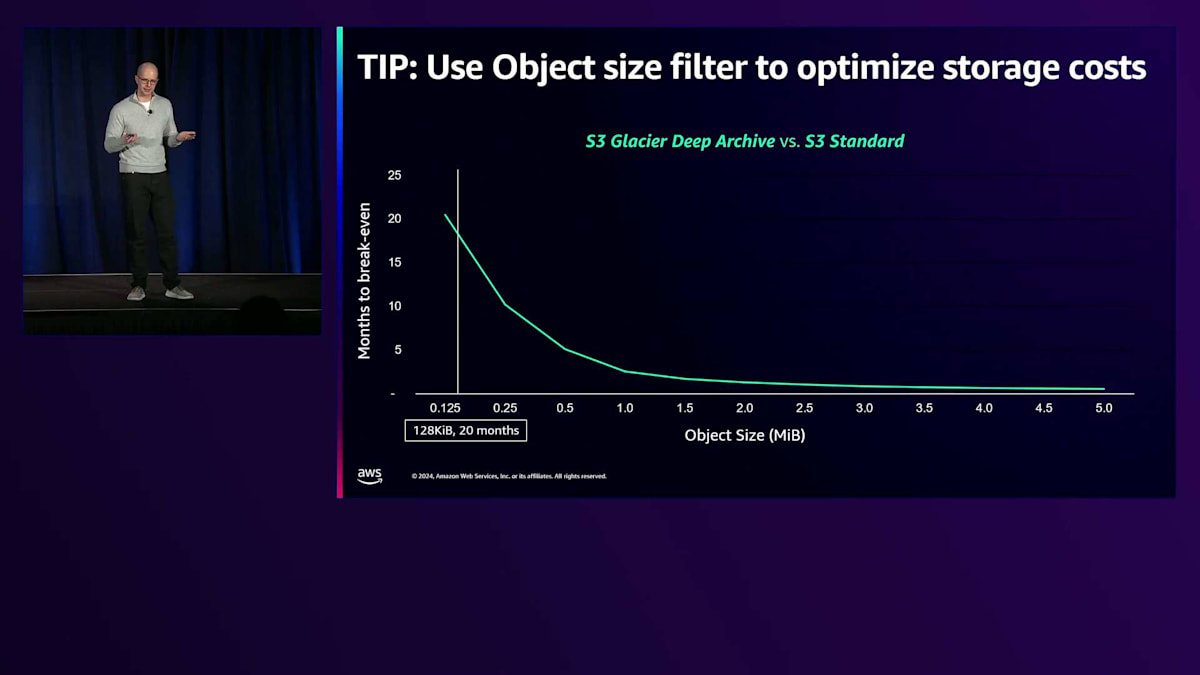

それでは、オブジェクトサイズとその重要性について説明しましょう。 このチャートでは、X軸にオブジェクトサイズ、Y軸にブレークイーブンまでの月数を示しています。これを説明する最適な方法は例を挙げることです。私たちがブレークイーブンについて考える際、お金を節約するまでにかかる時間を基準にしています。簡単な例を挙げると、S3 StandardからS3 Glacier Deep Archiveにデータを移行する場合、S3 Standardでは月額23ドル支払っていて、S3 Glacier Deep Archiveでは月額1ドルで済みます。これは月額22ドルの節約になります。しかし、Glacierへの移行に22ドルかかる場合、実際にお金を節約できるまでに1ヶ月かかることになります。 128キロバイトサイズのオブジェクトを移行する場合、同じ移行でもお金を節約するまでに20ヶ月かかってしまいます。多くのお客様にとって、20ヶ月は長すぎます。S3 Glacier Deep Archiveにデータを移行するための先行投資をして、その20ヶ月を待つことを望まないのです。そのため、多くのお客様はより早くブレークイーブンに達する大きなオブジェクトに焦点を当てています。例えば、2メガバイトのオブジェクトを移行すると、1.5ヶ月でお金を節約できます。これはずっと良い結果に見えますね。
この話題について最後に一つ触れておきたいのは、最近デフォルト設定を変更し、128キロバイト未満のすべてのオブジェクトは、どのストレージクラスにも移行しないようにしたことです。これは主に、お客様から20ヶ月以上早くブレークイーブンに達したいという要望があり、予想以上に時間がかかることに驚かれることがあったためです。この新しいデフォルト設定により、現在は20ヶ月が基準となっています。

デフォルト設定の変更は、互換性を損なう変更を避けたいため、私たちは非常に慎重に行っています。今回の場合、オブジェクトサイズフィルターを使用して最小オブジェクトサイズを128キロバイト未満に設定することで、128キロバイト未満のオブジェクトを移行できる機能と組み合わせました。ブレークイーブンを理解し、7年以上データを保存する予定のお客様の中には、すでに計算を済ませて64キロバイト以上のオブジェクトを移行したい方もいます。これはオブジェクトサイズフィルターを使用すれば今でも可能です。一方、デフォルト設定に頼りたいお客様にとっては、より簡単になりました。

オブジェクトサイズについて説明したところで、実際のお客様の事例をご紹介したいと思います:Canvaです。Canvaは、ユーザーがあらゆるものを作成・公開できるデジタルデザインプラットフォームです。2013年にサービスを開始し、1億人以上のアクティブユーザーまで成長したため、データ量も増加の一途をたどっていました。彼らはすでに一部最適化を行っており、データの大部分にStandardとInfrequent Accessを使用していましたが、S3 Glacier Instant Retrievalを使用することでさらなる節約ができると考えました。
彼らはアクセスパターンを分析し、S3 Glacier Instant Retrievalでより多くの節約ができることを発見しました。しかし、オブジェクトサイズも検討した結果、6ヶ月以内にブレークイーブンに達するためには、400キロバイト以上のオブジェクトサイズのデータを移行する必要があることがわかりました。ストック画像や公開中のデザインなど、Frequent Accessから移行できないデータも多くありましたが、ユーザーがアップロードした画像はより早く「コールド」になっていたため、そのデータの大部分をS3 Glacier Instant Retrievalに移行することができました。また、ログとバックアップを調べた結果、即時アクセスは必要ないと判断し、そのデータをS3 Glacier Flexible Retrievalに移行してさらなる節約を実現しました。最終的に、6ヶ月以内のブレークイーブン期間を維持しながら、これらの移行により月額300万ドルの節約を達成することができました。
Intelligent-Tieringとストレージコスト削減のベストプラクティス

Canvaのように、多くのお客様はS3のデータを連続体として捉えています。つまり、データは最初にS3 Standardに保存され、お客様がアクセスしている間はそこにとどまり、その後時間の経過とともに他のストレージクラスへとライフサイクル移行していくというものです。これは2022年の素晴らしい事例なので、もう一度ご紹介させていただきます。NASCARはストックカーレース会社ですが、レース当日は大量の生映像を取得し、それを処理してプロキシを作成するなど、様々な作業を行います。しかし2日目には、ほとんどの映像の使用が終わっているため、そのデータを直接S3 Glacier Instant Retrievalに移行することができ、大幅なコスト削減を実現しました。
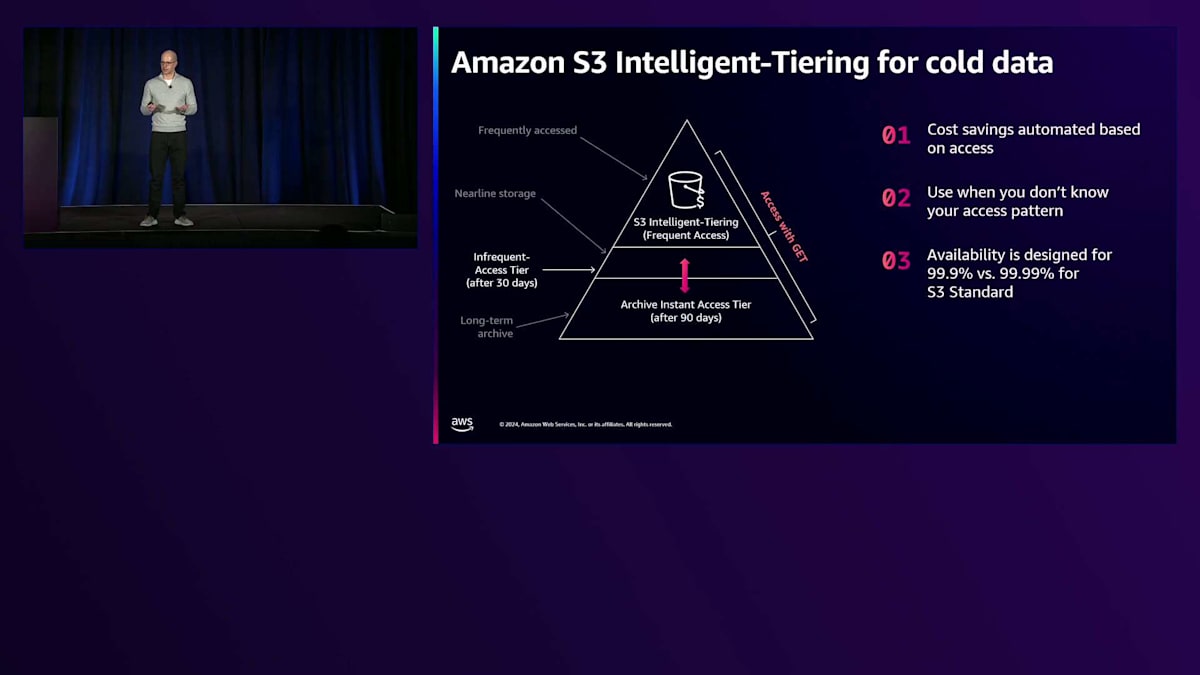
すべてのお客様がNASCARのようなケースではありません。アクセスパターンが分からないユースケースもあるでしょう。そんな場合でもコスト削減の方法があるのは朗報です。 実際、より多くのお客様から、ストレージのコスト削減を簡単に実現する方法が欲しいという声を聞くようになってきました。そこで登場するのがIntelligent-Tieringです。これは、アクセスパターンが不明な場合や、アクセスパターンを把握したい場合に使用するストレージクラスで、自動的にコストを削減しながらそれを実現できます。データにアクセスしない期間が続くと、より低コストの下位層に自動的に移行されます。例えば、90日間アクセスのないオブジェクトは、Archive Instant Accessティアに移行されます。
このArchive Instant Accessティアは、価格面でS3 Glacier Instant Retrievalと同等です。素晴らしいのは、データへのアクセスに同じGET APIを使用できることで、この点は変わりません。アプリケーションの修正なしでこのデータを利用できるのです。
Intelligent-Tieringを使用したくない場合はどんな時でしょうか?まず、NASCARのように初日以降はほとんどデータにアクセスしないことが分かっている場合です。この場合、Lifecycleを使用すれば、データを90日ではなく2日目という早い段階で移行でき、さらなるコスト削減が可能です。次に、S3 StandardよりもIntelligent-Tieringを選択しない理由として、可用性の設計が低いことが挙げられます。StandardのAA.99%に対して99.9%です。これは、10,000回に1回の失敗率に対して、1,000回に1回のリクエストが失敗して再試行が必要になることを意味します。パフォーマンスに非常に敏感なアプリケーションの場合、これは検討すべきトレードオフとなります。ただし、多くのデータレークのお客様は、パフォーマンスの違いが比較的小さいため、コスト削減のメリットを重視してIntelligent-Tieringを選択しています。

Intelligent-Tieringについて、もう一つお話ししたい点があります。それは、Archive AccessティアとDeep Archive Accessティアにオプトインできる機能です。私はアーカイブデータが好きなので、この機能にとても興奮しています。Intelligent-Tieringを使用すると、Glacier Deep Archiveへのデータ移行と同様のコスト削減が可能ですが、移行のための費用は発生しません。これはバケットに適用できる設定です。ここで重要なのは、移行されたデータにアクセスする際には、Gaylaが説明する予定のRetrival APIリクエストを使用する必要があるということです。



S3での有効化方法をご説明します。S3コンソールでバケットのプロパティに移動し、バケット配下のプロパティを選択します。 Lifecycleルールと同様に、PrefixやTagでフィルタリングすることができます。これはバケットポリシーなので、すでにバケットでフィルタリングされていることを覚えておいてください。 最後に、多くのお客様にとって重要なポイントをお伝えします。オブジェクトにアクセスがない場合、何日後に移動するかを選択できます。多くのお客様にとって、Archive AccessとDeep Archive Accessのデフォルト値である90日と180日では短すぎます - オブジェクトが作成されてからわずか180日後にアプリケーションが失敗するのは避けたいところです。
この例のように、約2年(730日)という最大値まで待つように設定すると、GETリクエストですぐにアクセスできないデータでも、多くの場合は許容できます。多くのお客様はこのアプローチを好んでいます。例えば、データレイクを保存している場合で、2年間アクセスされていないデータがあるとします。インターンが2010年から2015年のデータに対して「select star」を実行して、すべてのデータを取得するようなことは避けたいものです。この機能を有効にしておけば、アクセスのないデータは自動的に下位の階層に移動され、そのデータを頻繁アクセス階層に戻すかどうかを、コストを考慮しながらビジネス判断することができます。

ストレージセクションで説明した主なポイントを振り返りましょう。まず、LifecycleやIntelligent-Tieringを使用してストレージコストを削減することです。次に、取り出しのニーズに基づいてGlacierストレージクラスを選択することです - ミリ秒単位でデータが必要な場合はGlacier Instant Retrievalを使用し、そうでない場合はFlexible RetrievalやDeep Archiveを使用してより多くのコストを節約できます。最後に、大きなオブジェクトを移動することで、データ移動のコストが少なくなり、より早く収支が合うようになります。ここで、Gaylaを壇上に招いて、Glacierにデータを取り込む方法についてお話しいただきます。私は時々必要になるGlacierからのデータ取り出しについてサポートさせていただきます。
S3 Glacierからのデータリストアプロセスと最適化手法

お客様がリストアを選択する理由について、いくつかの共通したテーマが見られます。メディア企業であれば、新しいコンテンツを生成するためにアーカイブされたコンテンツや映像にアクセスしたい場合や、新しいコンプライアンス要件を満たすためにバックアップをリストアする必要がある場合があります。Andrewが言及したように、Machine Learningプラットフォームを構築したり、アーカイブデータの分析を行うために、コールドデータやアーカイブデータをリストアするお客様も増えています。


このように、リストアが必要になる理由は様々ですので、これからその方法についてご説明します。 データがS3 Glacier Instant Retrievalにある場合は非常にシンプルです。S3の同期階層であるStandard、Intelligent-Tiering、Standard-IAで使用するのと同じGETリクエストを使用します。データがS3 Glacier Flexible RetrievalやDeep Archiveにある場合、 リストアリクエストを送信する必要があります。これは通常、数時間から数日の取り出し時間を許容できるお客様に適しています。一方、Andrewが指摘したように、S3 Glacier Instant Retrievalは即時アクセスを目的としています。

Instant Retrievalの例をご紹介しましょう。ユーザー生成コンテンツを扱うアプリケーションを運用していて、私のように犬が大好きなお客様が様々な犬の写真をアップロードしているような状況を想像してください。そのような画像や動画は、永久に、あるいは少なくともお客様がアカウントを持っている間は保持する必要があり、お客様は定期的にそのデータにアクセスできることを期待しています。このようなコンテンツには、ミリ秒単位でアクセスできるInstant Retrievalが最適なユースケースとなります。ストレージのTCOを削減しながら、お客様のニーズである即時アクセスを実現できるからです。


しかし、データがS3 Glacier Flexible RetrievalやS3 Glacier Deep Archiveにある場合は、リストアリクエストを行う必要があります。その方法について説明しましょう。 まず、リストアを開始し、次に完了を確認し、最後にリストアされたデータにアクセスするという3つのステップがあります。 それぞれのステップについて詳しく説明していきます。S3 Glacier Flexible Retrievalからリストアを開始する場合、まず時間とコストのバランスを考慮して最適なリストアタイプを決定する必要があります。次に、すべてのリクエストを開始するのにかかる時間を見積もり、最後にS3 Standardに一時コピーを保持しておく日数を決定する必要があります。


リストアタイプの選択について - Andrewは既にBulk Retrievalについて説明しましたが、無料で利用できる最高のコスト削減機能の1つなので、ここでもう一度強調しておきたいと思います。S3 Glacier Flexible Retrievalから大量のデータをリストアする必要があり、5〜12時間待つ時間的余裕がある場合は、Bulk Restoreが最適な選択肢です。 コスト削減効果が最も高いため、デフォルトのオプションとして検討すべきです。

しかし、もう少し早くデータを取り戻す必要がある場合は、Standard Restoreを使用することになります。 Standard Restoreは、数分から5時間程度でデータを取り戻すことができます。後ほどご紹介するBatch Operationsを使用すれば、数分でデータを取り戻すことも可能です。これがより高速なオプションです。最後に、緊急に必要な少数のオブジェクトを数分で取り戻したい場合は、Expedited Restoreを使用できます。Expedited Restoreの使用を予定している場合は、5分ごとに少なくとも3つのリストアリクエストを保証するProvision Capacity Unitsの購入をお勧めします。また、S3 Glacier Deep Archiveについても触れておきたいのですが、Standard Restoreを使用する場合は約12時間、Bulk Restoreは約48時間でデータを取り出すことができます。

では、これらのリストアをどのように開始するのか見ていきましょう。 数百から数百万のオブジェクトをリストアする場合、その開始時間を考慮することが重要になります。S3 Glacierは1秒あたり1,000トランザクションをサポートしており、これは1日あたり約8,600万リクエストに相当します。ここで覚えておくべき重要なポイントは、数千万から数億のリクエストがある場合、それを全体の所要時間に考慮する必要があるということです。

例えば、S3 Glacier Flexible Retrievalでリストアを開始する場合、最後のリクエストから3〜5時間で完了すると想定しているとします。ここで重要なのは「最後のリクエスト」というキーワードです。最初のリクエストを今行った場合、4,000万件のリクエストがあるとすると、最後のリクエストが送信されるまでに12時間かかることになります。そうなると、実際の所要時間は15〜17時間に延びてしまいます。 このような場合にS3 Batch Operationsが役立ちます。1秒あたりのトランザクション数(TPS)が1,000未満の場合、リクエストの送信にさらに時間がかかることになります。実際のケースでは、お客様が25 TPSでリクエストを発行していた場合、処理時間が40倍近くに増加することもありました。

朗報なのは、S3 Batch Operationsを使用すれば、ソフトウェアの最適化やマルチスレッド化を行う必要がないということです。それらは自動的に最適化されます。ソフトウェアのチューニングを行う代わりに、S3 Batch Operationsを使用することで、リストアリクエストの毎秒の処理数を自動的に最大化できます。さらに、失敗した場合の自動再試行も行い、ジョブに問題があった場合には完了レポートを提供します。これは、リストアしたいキーのリストを含むマニフェストを作成することで機能します。マニフェストは手動で作成するか、プレフィックスやバケットなどのフィルターを適用して作成できます。マニフェストを送信すると、各マニフェストが1つのバッチジョブに関連付けられます。同時実行ジョブを実行することもできますが、TPSが分散されるので注意が必要です。より緊急性の高いジョブがある場合は、そちらを先に送信することをお勧めします。

最後に考慮すべき点は、一時コピーを保持する日数です。コピーは1日から100万年まで保持期間を選択できます。リクエストの開始にかかる時間と、そのリクエストの処理にかかる時間に加えて、リストアされたデータの処理にかかる時間も考慮する必要があります。例えば、リストアされたデータの処理に30日かかると思っていたのが、実際には5日程度で済むことがわかった場合、残りの25日間もデータをS3 Standardに保持しておく必要はないでしょう。このような状況に対する解決策があります。新しいリクエストを発行することで、S3 Glacierは完了後に元の保持期間を上書きします。リクエスト料金は発生しますが、追加料金は発生しません。


これがステップ1のリストアの開始でした。次に、リストアが完了したことを確認する必要があります。そのための方法がいくつかあります。 S3では、ステータスを確認するための複数のオプションを提供しています。S3コンソールを使用する方法、CLIでhead objectコマンドを使用する方法、head object APIを使用する方法があります。また、list APIでも確認できます。さらに、AWSのS3 events notificationなどの通知オプションを使用することもできます。

通知サービスを使用することで、ワークフローを自動化したい場合に役立ちます。これについては次に説明します。 Amazon S3では、リストアの開始と完了の通知イベントを作成します。これらをAmazon EventBridgeに発行し、そこからSNSトピック、SQSキュー、またはLambda関数をトリガーするように設定できます。これにより、データの準備が整い次第、GETコールの発行やオブジェクトのコピーなど、次のステップに自動的に進むことができます。


すでにRestoreの開始について説明しましたが、Restoreの完了を確認する必要があることも分かっています。ここからが面白い部分です:Restoreしたデータへのアクセスについてです。オブジェクトがGlacierからRestoreされると、一時的にS3 Standardストレージに保存され、S3の同期階層にある他のオブジェクトと同じようにアクセスできます。ただし、これは一時的なコピーであることを覚えておいてください。そのデータをGlacierから削除したい場合は、別のバケットに移動するか、同じ場所にコピーすることができます。ただし、同じ場所にコピーする場合は、複数のバージョンが作成される可能性があるので、Glacierに残したくない場合はバージョンセットを確認する必要があります。


具体的な事例として、DeluxeがS3 Batch Operationsを使用してストレージコストとRestoreコストを削減した方法をご紹介します。私たちは、他のコンテンツクリエイター向けにメディアを処理することを事業モデルとするこのメディア企業と協力しました。彼らはマイクロサービスを使用してGlacierからのRestoreリクエストを開始していました。S3 Batch Operationsを使用してこれらのマイクロサービスを効率化することで、大きなメリットが得られることに気付きました。S3 Batch Operations導入前は、マイクロサービスがリクエストを受け取るたびにRestoreリクエストを発行し、ピーク負荷に合わせてスケールする必要がありました。また、その日のうちに情報を処理する必要がある場合は緊急のリクエストが発生し、Expedited Restoreが必要となり、Standard Retrievalを使用した場合よりも遅いRestoreと高いコストが発生していました。



彼らはRestoreの開始をBatch Operation workflowに変更し、CSVマニフェストを使用してマイクロサービス上でリクエストを集約できるようにしました。このサービスは5分ごとにStandard Restoreを使用してRestoreのバッチジョブを作成できます。グラフを見ると、以前のバージョンでは約3時間後にデータの処理を開始できましたが、S3 Batch Operationsに切り替えると、20分程度で処理を開始できるデータが戻ってくるようになりました。これにより、Deluxeはマイクロサービスを効率化できただけでなく、グラフが示すように、Restore速度を数時間から数分に短縮することができました。この改善は、S3 Batch OperationsがS3 Glacier Flexible RetrievalからのRestoreを行い、Restoreが数時間ではなく数分で完了し始めるようになったためです。


このレッスンの重要なポイントをお伝えしましょう。データ資産を保護したい場合、Amazon S3 Glacierを使用して低コストで実現できます。自分に適したストレージクラスを選択することが重要です。また、コールドデータから価値を生み出す方法を探ることも大切です。最後に、S3 Batch Operationsを使用して大規模なRestoreを最適化すれば、うまく進めることができます。このQRコードにアクセスすると、Amazon S3 Glacierに関する追加情報を得ることができます。ご参加ありがとうございました。このQRコードを表示したままにしておきますので、ご質問がある方は横でお待ちしています。本日はご参加いただき、ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion