re:Invent 2024: エッジデータを活用したGenerative AIアプリケーション構築 - AWS


はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Building generative AI applications with on-premises and edge data (HYB318)
この動画では、エッジでのGenerative AIアプリケーション構築について、AWS OutpostsやLocal Zonesを活用したアプローチを解説しています。Large Language Model (LLM)とSmall Language Model (SLM)の特性を比較し、エッジ環境ではSLMが優位な場合が多いことを示しています。特にLlama.cppを用いたSLMの実装では、トークンあたりのコストがLLMの1-3%程度に抑えられ、応答速度も向上することが具体的に示されます。また、RAGやFine-tuningを組み合わせることで、SLMの精度をLLMに近づけられることも、実際のデモを通じて説明しています。データレジデンシーやレイテンシーの要件でパブリッククラウドが使えない場合の、実践的なソリューションが提示されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
エッジにおけるGenerative AIの進化:概要と背景

みなさん、こんにちは。re:Invent 2024へようこそ。そして「Building Generative AI applications with on-premises and edge data」セッションへようこそ。私はScott Roseです。同僚のChris McEvillyとFernando Galvesと一緒に登壇させていただきます。私たちは普段、AWSのパブリックリージョンの外側、つまりエッジでソリューションの設計やアーキテクチャの構築を始めようとしているお客様のサポートに時間を費やしています。本日は、エッジにおけるGenerative AIの進化について、とてもエキサイティングなプレゼンテーションをご用意しています。多くの方々は、AWSのリージョンにおけるGenerative AIの進歩についてご存知かと思いますが、パブリッククラウドやパブリックリージョン(AWSであれ他のクラウドプロバイダーであれ)にデータやワークロードをデプロイできないお客様も多くいらっしゃいます。今日は、そういったパブリックリージョンの外側、エッジでこれを実現する方法についてお話しします。

これまでの私たちの journey は、特にモデルに関して、Generative AI ソリューションを開発・進化させることでした。私たちのアプローチは、お客様に選択肢を提供し、ユースケースに最適なモデルでデータをデプロイする最良の選択肢を提供することです。特定のソリューションを推奨するのではなく、その選択肢を提供し、最適なソリューションを設計するためにお客様と協力することを目指しています。これらのモデルとパフォーマンスを最適化して、レイテンシー、データレジデンシー、エッジでの高性能推論、ニアリアルタイムのパフォーマンスなど、お客様の目標を達成し、さらにRAGやその他のチューニングオプションでモデルを強化・微調整できるようにしています。

AWSでハイブリッドについて話す際に、はっきりさせておきたいことが一つあります。それは、パブリックリージョンと非常に一貫性のある体験を提供しているということです。多くのベンダーがオンプレミスインフラを構築する際、パブリッククラウドでのインフラの利用方法やデプロイ方法とは異なる方式を採用しています。AWSでは、特にプログラマビリティとAPIについて、エッジとリージョンの間で同一の体験を提供しています。開発者の皆様が、リージョンでもエッジインフラでも、ソリューションを再設計・再エンジニアリングする必要がないよう、この一貫性を確保する必要があります。私たちが話しているインフラは、リージョンで使用されているものと同一です。ただし、これらは物理的にお客様のデータセンター、コロケーション施設、その他のエッジロケーションに配置されており、AWSのある領域で設計したアプリケーションとインフラが、他の領域でも一貫していることが保証されています。

ハイブリッドについて話す際、活用できるいくつかのフォームファクターがあります。主なものはAWS Outpostsで、これはフルラックフォームファクターや、より小型の1Uおよび2Uサーバーフォームファクターで利用可能なオンプレミスインフラソリューションです。これらは数年前に発表され、今週のre:Inventでいくつかのエキサイティングなアップデートを発表する予定です。Outpostsに加えて、AWS Local Zonesがあります。これは多くのOutpostsインフラのラックで構成され、通常は都市部の施設に設置され、このエッジインフラ全体でマルチテナント体験を可能にします。先ほど述べたように、私たちは選択肢について議論しています。どちらか一方というわけではありません。多くのお客様が、ワークロードの分散や災害復旧を目的として、これらの様々なフォームファクターにまたがってAWSハイブリッドソリューションをデプロイしています。
SLMとLLMの比較:エッジでの選択基準

このセッションでは、かなり技術的な内容に踏み込みます。いくつかのデモをお見せしますが、このセッションの基礎となるのは言語モデルです。もちろん、これはGenerative AIの基盤です。ただし、エッジにおけるGenerative AIでは、Large Language ModelとSmall Language Modelの区別があります。Large Language Modelは通常、200億パラメータ以上のモデルを指し、Small Language Modelは200億以下のモデルを指します。Large Language ModelとSmall Language Modelの違いを見ると、それぞれに利点とトレードオフがあります。どちらが優れているというわけではありません。ただし、エッジでは、コスト、インフラのフットプリント、Generative AIの使用目的という観点から、考慮すべき別の要素があるかもしれません。
Small Language Model(SLM)は、特定のユースケース、特定の応答、限定された質問に対応するように微調整されたモデルです。一方、Large Language Modelは、より幅広い種類の質問や人との対話に使用できるモデルです。このような違いを理解した上で、どちらのモデルが最適かを判断する必要があります。今回のプレゼンテーションでは両方について触れますが、主にSLMに焦点を当てて説明していきます。

エッジでのGenerative AIには、多くのビジネス上の推進要因があります。最も多く耳にするのが、データレジデンシーとデータコンプライアンスです。これは、企業の方針や現地の法的要件、あるいは国家主権の要件により、データを地理的な境界や特定の施設の外に移動できないため、顧客がパブリッククラウドの領域にデータを置けないという問題です。また、機密データに関するコンプライアンスポリシーにより、低レイテンシーやパフォーマンスの理由で、情報を特定の場所や他のソースの近くに保持しなければならない場合もあります。これらがエッジでのGenerative AIの基本的なビジネス推進要因であり、特定のユースケースに対して導入を始めているお客様が増えています。チャットボット以外の例として、コンピュータビジョンアプリケーションがあります。センサーやモニターの高速な相互作用をモデルで調整し、それらのデバイスがモデルに基づいて正確な応答を得て行動を起こせるようにしています。

同僚のChrisにバトンタッチする前に、このサイレントセッションについて一言。質問が多く出ると思いますので、セッション後に遠慮なくお声がけください。ホール外でお待ちしていますので、ご質問にお答えします。Chris、ありがとう。このLevel 300のプレゼンテーションでは、まず、お客様が実際にエッジでGenerative AIをどのように使用しているかについてお話ししたいと思います。 アーキテクチャの観点から見ると、ユースケースは3つのカテゴリーに分類されます:カスタマーエクスペリエンス、生産性向上やクリエイティビティ、そしてビジネスプロセスの最適化です。ここでご紹介するユースケースは、すべて実際にお客様と詳しく検討したものであり、オレンジ色で強調されているものは、現在POCを実施中か本番環境への移行を進めているものです。私たちは4月にこの取り組みを開始し、エッジでのGenerative AIの可能性を探り始め、その後、お客様と深く関わりながら、エッジでの展開に何が必要で、どのように機能すべきかを理解してきました。



誰もが最初に挙げるユースケースは、一般的なものや業界・タスク特化型など、さまざまな種類のチャットボットです。コールセンターサポートでは大きな関心を集めており、音声をテキストに変換し、そのテキストを感情分析やエージェントのスクリプト遵守確認、統計作成などに活用するモデルを使用しています。同時に、エージェントが顧客との会話のトピックについてより詳しく質問したり掘り下げたりするためのツールとしても活用されています。 パーソナライゼーションも優れたユースケースで、ユーザーのデータをパーソナライズするためにモデルを使用しています。あるお客様の事例では、各顧客向けの個別レポートを生成し、エージェントをサポートするために活用しています。 銀行やFSIのお客様は、顧客とのやり取りの感情分析やレポート作成、データインサイトの取得に多大な労力を投じています。


音声からテキストへの変換は広く使用されており、私のグループでも内部的に使用しています。ChimeやTeamsでの全ミーティングノートを記録し、テキストに変換するためにSLMを使用しています。プロセス全体を効果的に自動化しており、ほとんどの場合うまく機能していますが、一部の英語コンテンツでは少し奇妙な結果になることもあります。 コンテンツ作成の人気も高まっており、マーケティング部門や営業部門、セールスキャンペーン向けのテキスト生成にモデルが使用されています。100%正確ではないかもしれませんが、ゼロから始めるのではなく、約80%の完成度の出発点を提供します。また、大量の文書を要約する機能も価値があり、特に営業目的で使用されています。これは、営業、マーケティング、エッセイなどの大量の文書を、簡単に理解できる形に要約する際に特に役立ちます。
エッジでのGenerative AIアーキテクチャ設計


コード生成は広く好まれているアプリケーションの一つで、 実際に私たちもこれらのデモでコードを書くために頻繁に使用しています。ドキュメント処理は、モデルがドキュメントを処理してインサイトを生成する、もう一つの重要なユースケースです。
私たちが詳しく検討した意外なアプリケーションの一つが、複雑なレポート作成です。ある銀行と協力した際、顧客向けの詳細な月次レポートの作成に数日かかり、1レポートあたり約5万ドルのコストがかかっていました。この工程にGenerative AIを導入するプロジェクトを開始したところ、結果は驚くべきものでした。コストは月額約1万ドルまで削減され、レポートは最終承認のみを必要とし、数時間で生成できるようになりました。

データの拡充とインサイトの生成は、特に価値のある成果を示しています。ある保健当局との協働では、当初、彼らのサービスの主なユーザーは16歳以上だと考えられており、それに応じてリソースが配分されていました。しかし、Generative AIモデルを使用してデータを分析したところ、実際の主要ユーザーは40~45歳で、十分なサービスを受けていないことが判明しました。これらの主要ユーザーに対する3つの重要な信頼領域に対処することで、救急車の出動要請を80%削減することができ、従来の方法では発見できなかった課題を特定することができました。

LLMとSLMのどちらを推奨するかという話ではありませんが、それぞれのアーキテクチャの違いとビジネスへの応用について理解することは重要です。同じトークン数の場合、SLMのコストはLLMの約1~3%です。その代わりに機能性では劣ります。SLMは単一のタスクには優れていますが、複数のユースケースを同時に処理する企業全体の言語モデルとしては適していません。あるお客様は特に、タスク固有のチューニングなしでも質問に対して知的に応答できるゼロショット機能を求めていました。これはLLMが得意とする分野で、SLMは不得意です。
お客様からのフィードバックによると(AWSは異なる見解を持っているかもしれませんが)、SLMは単一タスクに焦点を当てているため、より安全だと考えられています。RAGデータベースを使用する場合、データはモデルの外部に保存され、SLMは通常1つのタスクにのみ使用されるため、特定のユーザーに限定され、攻撃対象領域が減少します。特に驚いたのは遅延の違いで、テストによると同じプロンプトに対してSLMはLLMより約300%速いことが分かりました。これは、エッジでの低遅延ワークロードにGenerative AIの使用を検討しているお客様にとって重要であり、より優れたサステナビリティプロファイルにも貢献します。

Architectとして、お客様がSLMとLLMのどちらを採用すべきかを判断する際の考え方と、その主要な判断要因についてご説明したいと思います。まず最初の考慮点は、モデルの使用目的です。金融、ギャンブル、地理的な規制がある市場では、データの処理と保存をオンプレミスまたは国内に限定する必要があり、多くの場合LLMの選択肢が除外されます。次の考慮点は、多くのお客様が懸念されるビジネス機密性です。

データセキュリティの懸念に関しては、RAGアーキテクチャを備えたSLMを使用することで、特に銀行やFSI業界のお客様組織におけるOpsecコミュニティの懸念に対応でき、規制コンプライアンスの遵守にも役立ちます。もう一つの重要な考慮点は、お客様のCIOやCTOが、特定のタスクに対して複数のモデルを使用することを好むのか、それともデプロイメントにおいてすべてを処理する包括的な1つのモデルを好むのかということです。後者のアプローチを取る場合、エッジでの大規模言語モデルの効率的な実行には大きな課題があるため、実質的にお客様をクラウドに押し出すことになります。
モデルの制約を考える際、最初の要因はタスクの範囲であり、特定のタスクか複数のタスクかの選択が含まれます。予算の制限も重要な考慮事項です。以前、ある銀行の複雑なレポート作成に関する事例では、お客様は当初Large Language Modelを選択しましたが、運用コストが削減効果を大幅に上回ることが判明しました。TCO分析を実施した結果、特にエッジでSLMを実装することで、はるかに小規模なデプロイメントが可能となり、そのモデルの運用で月額4万ドルの節約を実現できました。

トレーニング戦略に関しては、すべてのトレーニングをRegionで実施することを一貫して推奨しています。以前、データセンターのGPUバンクでエッジでのトレーニングを実施し、モデルの再トレーニングに約30日かかっていたお客様がいました。Regionに移行後、この時間を2日に短縮し、コストを大幅に削減し、環境への影響も改善しました。これは、SLMを使用して機密データを削除してからRegionにトレーニング用のデータを送信するというデータ抽象化戦略を通じて実現できます。もう一つの有望なアプローチは、実際のデータをRegionに送信する代わりに、SLMを使用してローカルで人工データを生成する合成データの使用です。
Architectとして、モデルのパフォーマンス基準は重要な考慮事項です。エンジニアは通常、1秒間に数千トークンを処理できる最速のエンジンを目指しますが、コールセンターシステムでの経験から、ユーザーあたり1秒間に6トークンあれば十分だということがわかり、これによってはるかに小規模なデプロイメントアーキテクチャが実現できました。一部のユースケースではGPUではなくCPUでも効果的に動作します。入出力要件も重要で、モデルによって異なるコンテキストサイズの入出力を処理できます。一部のSLMは128Kのコンテキストサイズを処理できますが、約50K以上では幻覚が増加し、時にシステムのパフォーマンスに悪影響を与えることが観察されました。First Tokenまでの時間やプロンプトの応答時間を含むレイテンシーも重要な要因です。精度要件については、SLMはRAGアーキテクチャやモデルのFine-tuningを通じて追加の作業を行えば、LLMと同等の精度を実現できます。

この分析の結果、私たちのお客様は満足しており、ほとんどのData Scientistが私たちのアプローチに同意していることが分かりました。つまり、特定の業務にはSLMを使用し、企業全体での一般的な展開にはLLMを活用するというアプローチです。モデルとタスクのサイズを適切に設定し、コンテキストを考慮することが重要です。また、定期的なFine-tuningの要件やSLM向けのRAGデータベースのメンテナンスなど、隠れたコストも含めて全てのコストを考慮する必要があります。私たちは、より低コストでAWSの機能を活用できることから、すべてのトレーニングアプローチにおいてDatabase Generate Cloudを活用することをお勧めしています。
RAGアーキテクチャの実装とデモンストレーション


このセクションをより詳しく見ていきましょう。まず最初に話題にするのは、適切なLarge Language Model(LLM)またはSmall Language Model(SLM)の選択についてです。 デプロイメントアーキテクチャをどのように構築するかを検討する必要があります。コントロールプレーンの大部分をリージョンに置き、モデルの処理だけをエッジで行うハイブリッドアーキテクチャで済ませることができるのか、それとも完全にスタンドアロンのモデルが必要なのか、考える必要があります。これからの話は、完全にスタンドアロンのモデルに焦点を当てていきます。

次の問題は、モデルの最適化方法です。これについても少し話をしますが、私たちがテストした各モデルでは、正しい答えを得るためにコンテキストサイズ、Temperature、その他の設定などのパラメータについて、それぞれ異なるレシピが必要であることが分かりました。後ほど、私たちのアーキテクチャのデモをお見せします。特にSLMについては、そのままの状態で使用しても意味がありません - 必ずFine-tuningが必要です。私たちは、Fine-tuningとRetrieval Augmented Generation(RAG)を組み合わせて行うことをお勧めしています。これにより、モデルのFine-tuningを考慮しながら、コストとパフォーマンスのバランスを取ることができます。

モデルを実行するためのオープンソースフレームワークを数多くテストし、私たちが最も力を入れて取り組んできたものとしてLlama.cppを選択しました。これは最先端のパフォーマンスを提供し、適切にチューニングされた場合、ネイティブモデルとLlama.cppで実行されるモデルのトークン処理速度は、数桁の差があります。MITライセンスで運用されているため、真のオープンソースです。重要なポイントとして、52以上のモデルにアクセスでき、GGUFフォーマットに従えば独自のモデルを持ち込むこともできます。

Llama.cppの主な利点は、データストレージとトークン処理の効率性です。運用の観点から見ると、プロセス全体が1つのファイルにまとめられたC++で書かれているため、非常に高速です。これは、GPUで初期モデルを実行する場合と比べて、約10分の1の時間でモデルを起動できることを意味します。これは私たちのアーキテクチャでのスケーリングにとって重要です。なぜなら、モデルを素早く起動できるからです。ここで説明している内容はすべて、エッジのGPU上にデプロイされて実行され、リージョンには一切何もありません。
私たちはこのフレームワークを、プライバシーとセキュリティに関するお客様のフィードバックに基づいて、特定のユースケース向けに選択しました。私たちの観点から最も重要なのは、リアルタイムのパフォーマンスを提供し、環境を制御できることでした。各モデルごとにCookbookを作成して、ユースケースとモデルに最適なコンテキストサイズを決定し、さまざまなプロンプトサイズでの1秒あたりのトークン処理数を計算できます。主にコンテキストサイズに焦点を当てていますが、Mistral-7Bのような大規模モデルについては、エッジで効率的に実行できるように量子化も行っています。

これが現在のシステムアーキテクチャで、複数の異なるユースケース(クイック質問応答のためのChatbotサポート運用、大規模文書の要約、レポート生成、コード生成など)に対応できるように設定されています。これらすべてのケースで同じアーキテクチャを使用しています。システムは、Local ZonesまたはOutpostsのいずれかのハイブリッドエッジ環境内で実行されるAWS Virtual Private Cloud(VPC)で構成されています。Webサービスを実行する複数のM5インスタンスを備えたロードバランサーがあり、テストケースに応じてスケールアップまたはダウンできます。

ここでは主に、Application Load Balancer(ALB)が複数のG4dn.12xlargeインスタンス上で実行されているGPUに接続している様子を示していますが、2xlargeインスタンスも使用可能です。データがモデルに渡されると、アプリケーションから負荷が分散されます。Chatbotの場合、ALBでスティッキーセッションを使用しています。また、プロンプトのキューイングメカニズムとしてRabbitMQをテストし、GPUの負荷に基づいてプロンプトを分散させています。 運用の観点からは、アプリケーションがGUIまたはモバイルアプリ用のAPIを提供し、SLMへの読み込みを最適化するようにクエリをフォーマットし、その後、複数のGPU上でホストされているSLMにクエリを渡します。


本日のデモは1台のGPUで実行されています。 これは、Los AngelesのLocal Zoneにデプロイされているエッジで実行されているGenerative AIアプリケーションのライブデモですが、Outpost環境にもデプロイ可能です。これはPythonで書かれたシンプルなデモで、モデルを選択することができます。テストは様々なモデルで行いましたが、現在は2つのモデルが利用可能です。 70億パラメータのMistral 7Bと、17億パラメータのSmolLM2があります。




ここで簡単な質問として「What is GenAI?」と入力すると、 これがMistral 7Bの出力で、最後に入力と出力の トークン数、レイテンシー、トークン生成時間、1秒あたりのトークン数(スループット)などのメトリクスが表示されます。Mistralでは1秒あたり18トークンを処理できることがわかります。より小さなモデルであるSmolLM2を選択して同じ質問、「What is GenAI?」を入力すると、Mistral 7Bよりも高速に実行されることがわかります。ここでメトリクスを確認できます。

また、モデル間の違いを簡単に確認できる別のアプリケーションもあります。左側にはSmolLM2 1.7Bパラメータモデルが、右側にはMistral 7Bが表示されています。質問をすると、2つのスレッドが並行して実行されているため、同じプロンプトが両方のモデルに送信されます。このケースでは、パフォーマンスの違いを確認することができます。
RAGとFine-tuningによるモデル性能の向上




環境については、2種類のインスタンスを使用しています。Pythonアプリケーション用のc5インスタンスと、推論モデル用のg4dnインスタンスです。ここではg4dn.12xlargeインスタンスを使用しており、確認するとNVIDIAツールの出力に4つのGPUが表示されています。この場合、使用率がゼロの4つのGPUが確認できます。別の質問をしてみましょう。「地下鉄に行きたいのですが」と入力すると、GPUの使用率が上昇していくのがリアルタイムで確認できます。


各GPUでは、llamaサーバーが実行されています。モデルをGPU間で分散して読み込み、4つのGPUすべてを使用して推論モデルを実行しています。2つ目のモデルでも同じアプローチを適用しています。もう一度実行すると、ここで使用率を確認できます。
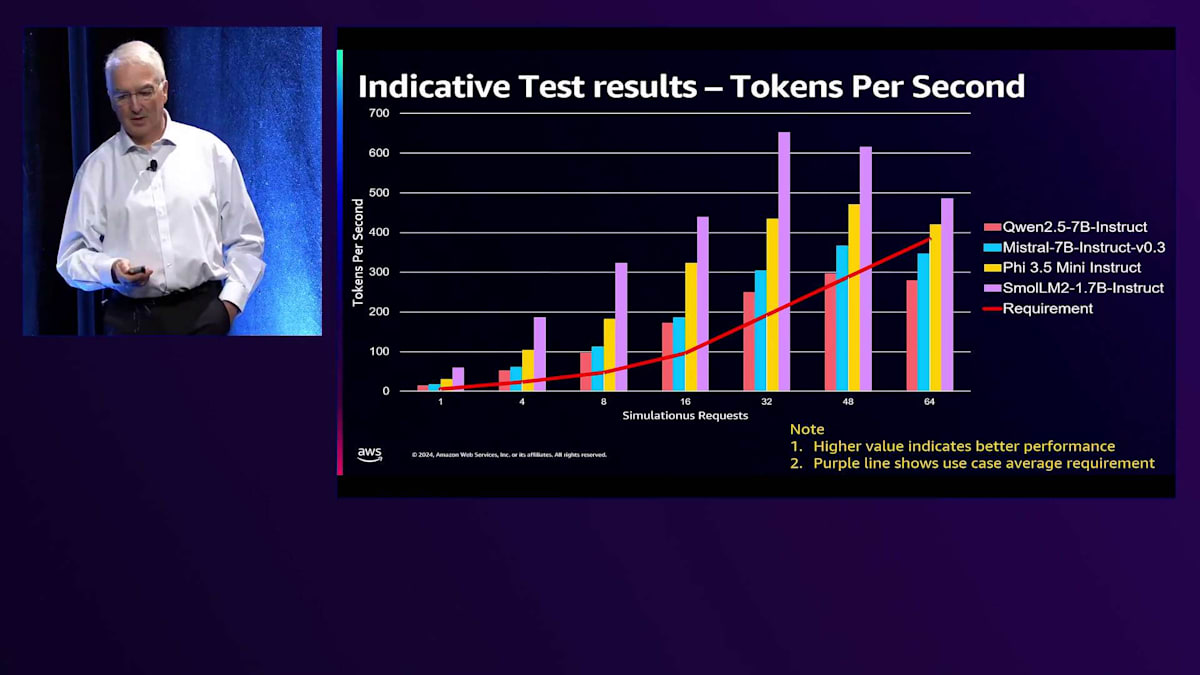
実際、私たちは多くの時間をテストに費やしてきました。4月から始めて、おそらく15の異なるモデルをテストしました。毎月リストの中身が変わっていき、エッジでどのようなことが可能かを本当に理解しようと努めています。このテストで解明しようとした質問の1つは、システムをどのようにスケールさせるかということです。ここで示されている赤い線は、顧客からの実際の要件で、コールセンターのチャットボットエージェントサポート1件あたり、最大で毎秒6トークンが必要とされています。私たちは8、16、32、48、64の同時プロンプトで、1つの質問を同時にテストしています。その数のプロンプトを同時にモデルに投げかけると、32までは全てのモデルでほぼ線形的な成長が見られ、顧客の要件をはるかに上回っています。このテストはすべて、1つのGPUの100%を使用して実施されています。
運用の観点から見ると、あるポイントでセッション数が増えるほどモデルのスループットが実際に低下し、顧客の要求水準を下回ってしまうことがわかります。エージェントが100%同時に稼働している場合、基本的に2つのGPUが必要だということがわかりました。これは想定よりもはるかに少ない数です。顧客がGPUのエンジニアリングを検討する際、多くの場合数百のGPUを想定しています。私たちはこの結果に驚き、64に到達した時点で、2つのモデルは要件を下回りましたが、より小さなモデルは依然として顧客の要求性能を上回っていました。

パフォーマンスの一つの側面はトークン毎秒でした。もう一つの観点は応答時間でした。 人間が100ミリ秒を実際に認識できるかどうかは定かではありませんが、閾値を約150ミリ秒に設定しました。32の同時セッションまでは、ほとんどのモデルがこの閾値を処理できることがわかります。32から48セッションを超えると、小規模なモデルだけが効果的にシステムに応答できています。アーキテクチャの観点から申し上げたいのは、一つの指標だけではないということです。最初のトークンまでの時間、1秒あたりの最大トークン数、そしてレイテンシーが全て組み合わさって、特定のユースケースに適したモデルを選択する答えが得られるのです。

まとめますと、私たちは顧客からの多くのフィードバックを得て、特定のユースケースではSmall Language Models(SLMs)が優れた性能を発揮する可能性が高いと考えています。これは特に規制市場で運用している場合や、データを施設外に持ち出したくないというデータ機密性要件がある顧客にとって重要です。運用環境でモデルを立ち上げる際には、Llama.cppの使用を推奨しています。これは高性能で、多くのパラメータでモデルを最適化でき、最適化の観点からモデル選択を可能にするためです。私たちが確認したところ、各SLM(そしてLarge Language Models(LLMs)も同様ですが、特にSLMsにおいて)は特定のタスクに長けています。コード生成が得意なもの、対話や人間の発話が得意なもの、レポート生成や数学的問題が得意なものなど、様々です。

私たちの観点からすると、より大規模なモデルと同じレベルまで精度を向上させるためには、必ずチューニング手法を使用する必要があります。Prompt engineeringも一つのアプローチですが、ここでは触れません。Retrieval Augmented Generation(RAG)は多くの顧客にとって非常に重要です。これはモデルの外部にデータを保持しながら、より豊富なデータセットの利点を活用できるためです。RAGはモデルの動作を改善し、質問に関連する特定のデータセットに基づいて応答を生成することを可能にします。顧客は、モデルに近づけることも学習させることもない、プライベートで安全なデータを扱うことができます。RAGのもう一つの利点として、モデルをデプロイした時点でのデータセットを持っているものの、その後は何も学習しないという問題に対処できることが挙げられます。FSIレポートや株価など、モデルを常に最新の状態に保ちたい場合、RAGアーキテクチャは非常に有効です。最新のデータを継続的に取り込むことができ、静的な一時点のデータよりもモデルをはるかに最新の状態に保つことができるためです。
Fine-tuningも非常に有用なツールで、特定のタスクやドメインにモデルを適応させることができます。データの理解方法や適切な用語での応答方法をモデルに教育するのに役立ち、特定のドメインに対して特に効果的です。ただし、モデルを複数のドメインで学習させることはできません。その場合は、LLMを検討し、そのモデルに対してデータセットで再学習させる方向に戻ることになります。これは基本的にモデルに対して心臓の手術をするようなものです。


この再学習アプローチは非常に重量級なアプローチであり、常にリージョン内で実行することをお勧めします。Fine-tuningについて話しましょう。ここでは詳しく説明しませんが、モデル自体を見てみる価値があります。「Xとは何か」というプロンプトを与えると、SLMに問い合わせを行い、SLMはかなり一般的な回答を返します。しかし、厳選されたデータセットでモデルをFine-tuningすると - そしてここで強調したいのは、データは非常に正確である必要があり、不要なデータセットは全て除外しなければならないということです - モデルに投入する本当に良質なデータセットを用意することで、チューニングプロセスが大きく改善されます。そうすると、「Xとは何か」という質問をした際に、会社のアプリケーションのコンテキストにおけるXについて、ドメイン固有の言語で回答を得ることができ、顧客にとってモデルがより有用で現実的なものとなります。

RAGに焦点を当てたいと思います。というのも、後ほどRAGのデータをお見せするからです。私たちが確認したところ、RAGはモデルの精度を大幅に向上させ、副次的な効果として、特にパラメータモデルを調整して創造性を抑制すると、モデルのHallucinationを防ぐことができます。RAGを使用すると、設定したパラメータの範囲内で、常に非常に良好な応答が得られます。また、データベースを拡張するためのモデルを非常に小規模なインフラで実行できるため、コスト効率も優れています。24時間365日稼働可能で、リアルタイムである必要もなく、応答をカスタマイズすることができます。セキュリティの観点からは、すべてのデータはSLMやLLMの外部にあるデータベースに保存されるため、そのデータベースをロックダウンすることができます。ここではSLMの使用を提案しているため、実際のユーザーベースはかなり小さくなり、データへのアクセスもそれらのユーザーに限定されるため、デプロイメント全体のセキュリティ態勢と攻撃対象領域が大幅に縮小されます。
RAGの詳細アーキテクチャとライブデモ
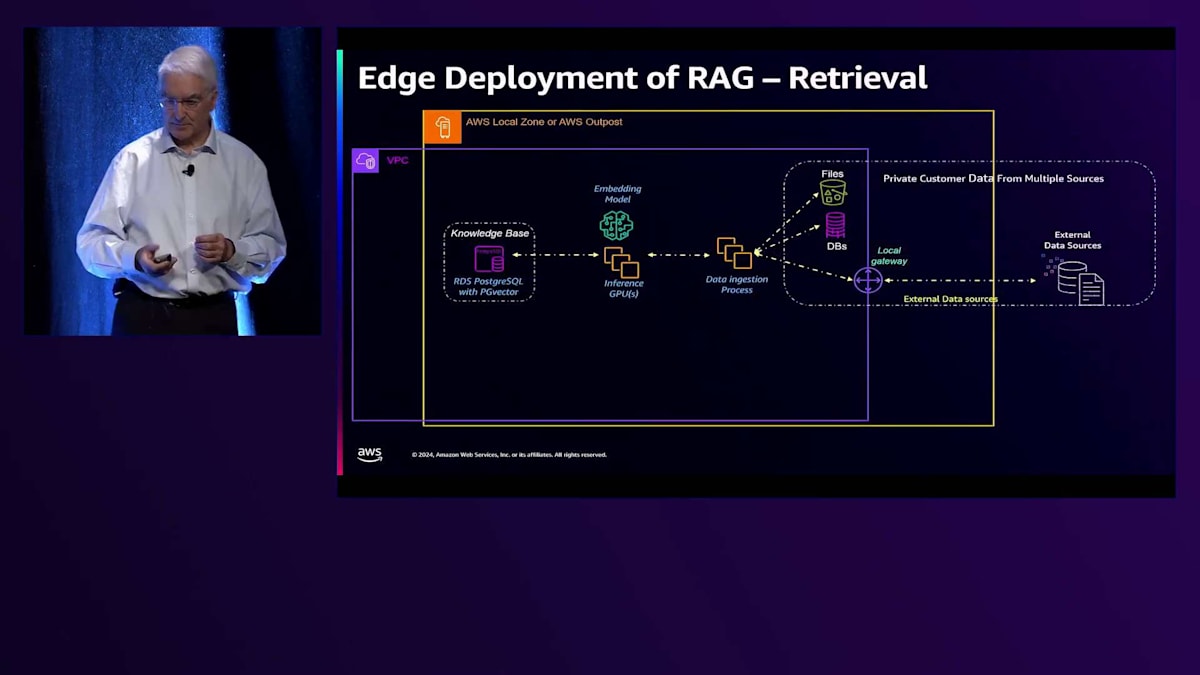

RAGのアーキテクチャを詳しく見ていきましょう。私たちには複数の異なるソースがあります。今日はPDFファイルの取り込みだけをお見せしますが、データベースを使用したり、Big DataクエリのためにEMRにアクセスしたりすることもできます。これらは新しいデータを監視してそれを取り込むプロセスに入り、その後Embeddingモデルを通してPostgreSQLのVector Databaseに格納されます。Vector Databaseとして、PG Vectorプラグインを搭載したRDS PostgreSQLを使用しています。 まず、この新しいデータを検出し、取り込みます。例えば、50ページのPDFドキュメントがある場合、50ページすべてを1つのチャンクとしてデータベースに読み込むのは目的に反します。そのため、実際には各ページを10%のオーバーラップを持たせて4つに分割するようなChunking戦略を採用し、データの関連性を保持しています。
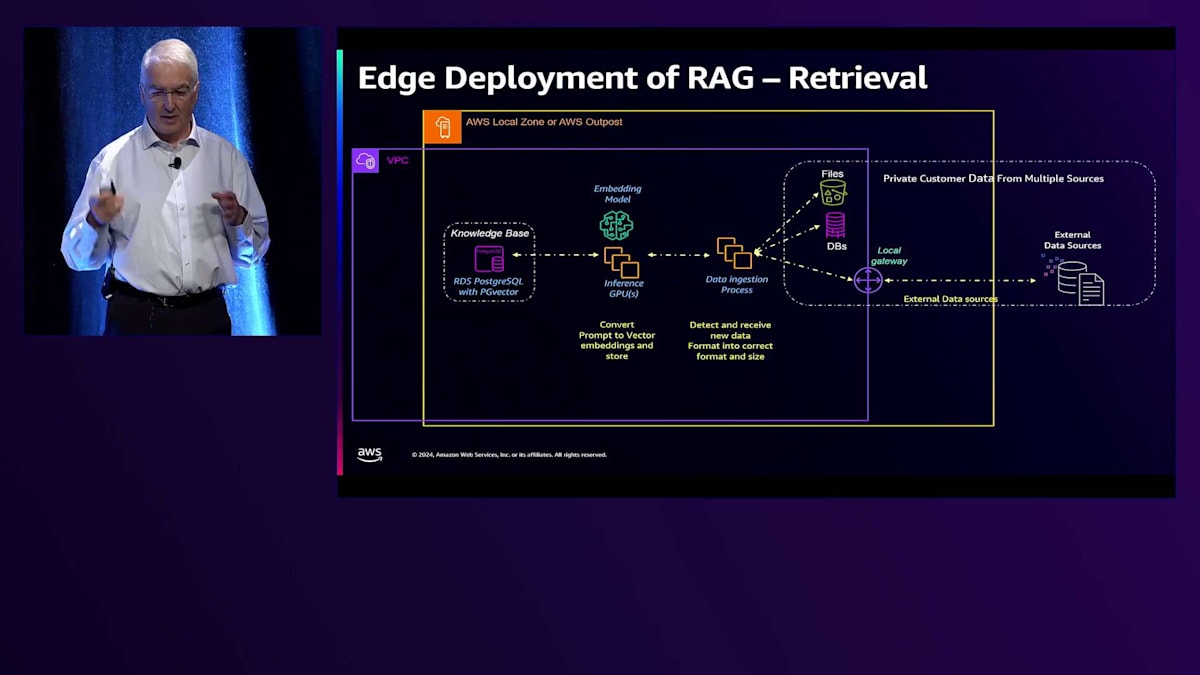
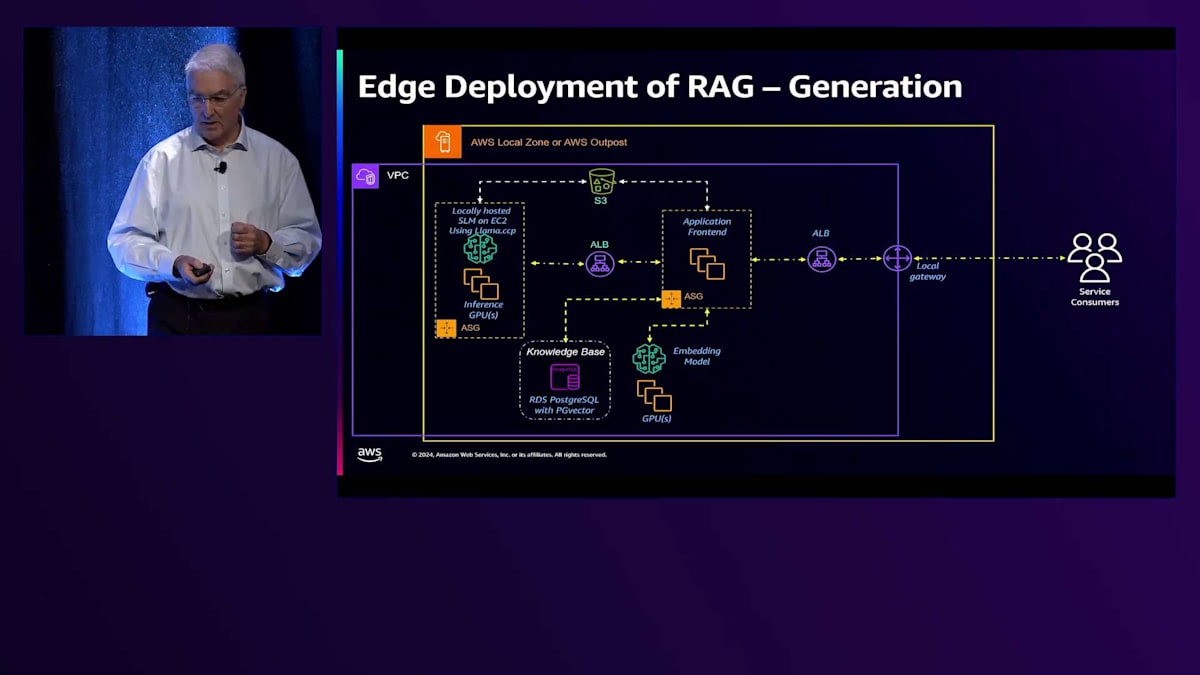
そしてそれがEmbeddingドキュメントデータベースに送られ、 Embeddingモデルがそれをベクトルのセットに変換し、チャンクとベクトルがデータベースに保存されてナレッジベースが作成されます。 一方で、他のモデルで示したのと同じアーキテクチャを使用していますが、今回はアプリケーションフロントエンドにEmbeddingモデルを追加して、プロンプトをトークンに変換し、以前に作成したナレッジベースを使用してユーザーシステムに応答します。



クエリが入力されると、GUIまたはAPIを通じてプロンプトを受け取ります。そのプロンプトは最初に Embeddingモデルによってベクトルに変換されます。そのベクトルを使用してVector Databaseを検索し、 そのクエリに適したデータのチャンクのセットを取り出します。ここでのアプローチとして、返されるチャンクの数を制限したり、逆に増やしたりすることができます。モデルに返すチャンクが多いほど、知識の幅は広がりますが、質問に対する応答が複雑になりすぎるリスクもあり、モデルが少し変な動きをする - 私はこれをHallucinationと呼んでいます。その後、プロンプトを受け取り、データベースからのデータと組み合わせるので、質問だけでなく、大量のデータがSLMに送られ、SLMがモデルに応答を返すのを助けます。では、今お見せしたものをデモンストレーションしていきましょう。

これはEdgeで実行されているRAGアプリケーションのライブデモです。 左側ではRAGを使用していないMistral 7Bモデルを使用し、右側では同じモデルにRAG情報を組み合わせています。この場合、同じリクエストを処理する2つのスレッドが並行して実行され、すべてがEdgeで実行されています。両方のモデルの比較を見るために、私たちのセッションに関する情報をアップロードしました。

「re:Invent 2024のセッションは何時から始まりますか?」と質問した場合、このMistral 7Bモデルのトレーニングデータは3ヶ月以上前に切り取られているため、この情報を持っていません。左側を見ると、セッションに関する情報がないことがわかります。しかし右側では、私たちの環境にアップロードしたため、セッションの情報を見ることができます。すべてはEdgeで実行されており、バックグラウンドではGraphとVector拡張機能が有効化されたRDSを使用しています。



実際にライブテストをしてみましょう。Anthropicについて話すと、Claude 3.5 Haikuは先月リリースされました。この情報もMistralには含まれていません。このページの情報をPDFとして保存することができます。このデモのために1ページ目だけを保存しましょう。ここでそのPDFの情報が確認できます。また、ローカルのナレッジベースも持っています。このPDFファイルをRAG環境にアップロードすることができます。



ここで、そのファイルを選択してアップロードできます。ここで起きていることは、Vector Embeddingを実行する環境とPythonアプリケーションが情報を受け取り、PDFからテキストに変換されたチャンクごとにVector Embeddingを生成し、RDSデータベースに保存されるということです。このデモで、Amazon BedrockのClaude 3.5 Haikuについて質問することができます。左側では、トレーニングデータの切り取りにより、ネイティブにサポートされていないことがわかります。右側では、アップロードしたRAG情報の使用が確認できます。入力トークンが異なっているのが分かります:こちらは75、そちらは524です。これはRDSデータベースから取得されているためです。すべてはLos AngelesのLocal Zoneのオンプレミスで実行されています。

基本的に、Edgeでモデルを実行し、RAGデータベースでモデルを実行する方法をお見せしました。これらのモデルはFine-tuningを行っていませんが、Fine-tuningを行えばさらに良い応答が得られます。RAGデータベースを使用することで、モデルの精度が向上し、データをそのモデルのデータベースに効果的に保持できることがわかります。アーキテクチャの観点からは、すべてをデータベースに保持し、デプロイメントの観点からは、チャンキングを適切に設計する必要があります。
チャンクが大きすぎると、モデルの処理が遅くなり、モデルへのコンテキストサイズが大きくなりすぎます。チャンクが小さすぎると、モデルが処理するデータが不足します。そのため、チャンキング戦略とモデルへの実装方法を慎重に検討することが重要です。私たちは、リアルタイムデータをデータベースから取得する解決策を顧客と実装しており、あるケースでは、5分以内のリアルタイムで株価データをWebから取得しています。
エッジでのGenerative AI:まとめと今後の展望
私たちが確認してきたのは、Tuningが汎用的なSmall Language Model (SLM)を取り、それを対象のデータセットと環境のコンテキストを理解できるように適応させる上で、非常に効果的だということです。Prompt engineeringは精度を向上させ、Retrieval Augmented Generation (RAG)は動的なデータをモデルで使用することを可能にします。多くのお客様の観点からより重要なのは、RAGによってデータをモデルの外部に保持でき、ハルシネーションを防ぐことができる点です。RAG情報と共にソースを含めるようにモデルを設定することで、回答を特定の文書まで遡って確認することができ、これはコンプライアンスの観点で重要です。


Tuningは、トレーニングよりもはるかに軽量なプロセスです。Tuningで実際に行っているのは、モデルの後半部分を採用することであり、これによってドメイン固有の応答が可能になります。 まとめると、私たちは3つの主要な基準に焦点を当てています:速度、レイテンシー、コスト、そして精度です。Large Language Modelsについて分かったことは、全体的に精度は非常に高いものの、トークンあたりのコストが高く、速度が遅いということです。 SLMsについて見てみると、応答の提供が非常に速い - モデルが小さいほど、応答が速くなります。コストの面では、LLMと比べてトークンあたり1〜3%程度と大幅に低くなりますが、精度は低くなります。


私たちは、ドメインに関連する新鮮なデータを継続的に取り込み、そのデータをデータベースに保持するRAGアーキテクチャの実装が非常に有用だと考えています。もう一つの戦略は、モデルのTuningまたはFine-tuningです。 これらを組み合わせることで、特定のユースケースに最適化された小規模なモデルのパフォーマンスを得られ、ネイティブで実行されるSLMとほぼ同じ速度で、同レベルの精度を実現できます。一般的なテストでは、モデルの精度はプラスマイナス1%以内で、コストはSLMとほぼ同じであることが分かっています。

ChrisとFernandoの素晴らしいデモをありがとうございました。まとめとして、エッジでのGenerative AIアプリケーションとインフラストラクチャの設計・アーキテクチャについて、実用的な情報をお伝えできたと思います。セッションの冒頭で述べたように、これはリージョンでの機能を補完するものです。ワークロードがリージョンで実行可能な場合は、そうすることを強くお勧めします。データレジデンシー、レイテンシー、その他の法的理由でリージョンで実行できない場合は、エッジの活用を検討していただきたいと思います。
Generative AIは発展途上の分野で、状況は急速に変化しています。この分野における私たちの機能も急速に進化しています。ご質問がありましたら、このセッション終了後、会場の外で数分間お待ちしています。また、多くのお客様がテストや評価を行っていることもお伝えしたいと思います。AWSにはOutpostsテストラボがあり、米国に複数、ヨーロッパに1つ、そして他の国際的な場所も検討中です。そのインフラストラクチャでワークロードをテストしたい場合は、無料でご利用いただけます。そのインフラストラクチャを活用するための定量的な技術テスト計画の構築をサポートさせていただきます。

私たちのハイブリッドチームは、従来のEdgeワークロードからGenerative AIワークロードへと機能を進化させており、これらのアーキテクチャを構築するために追求している深いレベルの取り組みをご覧いただけます。 今週のre:Inventでは、本日も含めて複数のハイブリッドEdge・ハイブリッドクラウドのセッションを開催しています。AWS OutpostsやAWS Local Zonesのインフラで実現できることを紹介するこれらのセッションやワークショップもぜひご覧ください。re:Inventモバイルアプリでアンケートフォームへのご記入もお願いいたします。EdgeインフラにおけるGenerative AIとアプリケーションに関する私たちの発展的な取り組みについて学んでいただき、ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion