re:Invent 2023: FetchのMLエンジニアが語る大規模ML運用の実践
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - How Fetch built world-class ML models to power their business (SEG301)
この動画では、AWSのDigital Native Business部門のTony CerqueiraとFetchのlead machine learning engineerであるSam Corzineが、機械学習モデルを本番環境に投入するための実践的なアプローチを紹介しています。毎秒100枚のレシートを処理するFetchのシステムを例に、エンドツーエンドのデモ作成からシャドウパイプラインの活用、そしてモデルの継続的な改善まで、具体的なパターンとベストプラクティスを解説。大規模なMLシステムの構築と運用に関する貴重な知見が得られる内容です。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
AWSのTony CerqueiraとFetchのSam Corzineによる自己紹介

みなさん、こんにちは。私はAWSのTony Cerqueiraです。今日はFetchのSam Corzineと一緒に来ました。FetchはAWSのプレミアDigital Native Business (DNB)カスタマーの一つです。私はAWSでDNBセグメントを担当しており、もちろんFetchはそこでの主要なDNBカスタマーの一つです。Fetchから来られた方はいますか?こんにちは?他のDNBから来られた方はいますか?はい、わかりました。

では、スライドを切り替えますが、AWSでは、Digital Native Businessをクラウドネイティブで生まれたビジネスと定義しています。通常、消費者向けにフォーカスしています。また、データに大きく依存した戦略を持っており、その結果、非常に焦点を絞ったデータ戦略を持っています。さらに、デジタルまたは物理的な製品を持つビジネスですが、デジタル価値に重点を置いています。

ちょっと戻りますが、デジタル戦略をDNBほど進化させていない方々にとって良いニュースがあります。ウェブサイトに新しいセクションを設けました。URLはこちらです。これは、DNBのようにビジネス戦略を組み立てたい方々へのガイダンスを提供しています。つまり、まずデータ戦略を組み立て、そこからイノベーションを進め、データへのアクセス、整理、キュレーション、そしてビジネスモデルに深く組み込む能力と接続性を持つことです。では、Samを紹介して、バトンタッチしたいと思います。
Fetchアプリの概要と日々の規模

ありがとうございます。さて、このプレゼンテーションの本題は、機械学習に関する技術的な内容です。モデリング側、つまり目標を達成するモデルの作り方と、エンジニアリング側、つまりそれらのモデルをクラウドにデプロイし、アプリに接続する方法などについてです。しかし、その前に少し紹介をさせてください。Fetchとは何か?皆さんはすでにFetchアプリをダウンロードしていると思いますが、もしまだの方がいれば、簡単に説明します。
Fetchは消費者向けリワードアプリで、ナンバーワンの消費者リワードアプリです。ユーザーは日常の買い物、例えばスーパーやコンビニでの買い物の際に、商品を購入し、買い物の最後にレシートをスキャンできます。もし我々のパートナー企業の商品を購入していれば(PepsiCoやMolson Coorsなどの大手パートナーと提携しています)、そのパートナーがオファーを実施しています。ポイントを獲得し、そのポイントをギフトカードに交換できます。全体的なコンセプトは、買い物体験を通じて小さな喜びの瞬間を作り出すことです。楽しみながらお金を節約する、それがFetchのアイデアです。
毎日の規模を簡単に見てみると、600万人がFetchアプリを開き、1100万枚のレシートがスキャンされ、4億1600万ドルの小売売上が捕捉されています。他の数字もご覧いただけますが、この発表の核心は毎日スキャンされる1100万枚のレシートについてです。これは、現時点で1秒間に100枚のレシートがシステムに入ってくるという事実に対処するための技術的な実装についてお話しします。ユーザーは全国各地で可能な限り素早くスキャンしており、私たちはその負荷全てを処理し、ユーザーが期待するポイントを確実に獲得でき、全体的に良い体験ができるようにしなければなりません。
技術的な話に入る前に、私自身について少し背景をお話しします。私はFetchのlead machine learning engineerです。しばらくの間、それはレシートスキャンを機能させるスキャンパックのtech leadを意味していました。現在はguild lead機能を担当しており、基本的に会社全体の機械学習とデータサイエンスプロジェクトを横断的に見て、うまくいっているものを特定し、そのパターンを他のプロジェクトに複製する責任があります。つまり、ある場所でうまくいったものを別の場所に移すのです。現段階では大規模なMLプラットフォームはありませんので、成功事例を複製しようとする主な方法は、このようなパターンを通じてです。今日のプレゼンテーションは、主に10枚ほどの実際のコンテンツスライドで構成されており、その大部分は私がMLプロジェクトで気に入った小さなアイデアやパターンで、それらを複製しようと取り組んでいるものです。過去数年間の経験についていくつかのストーリーをお話しし、それをもう少し具体的に説明したいと思います。
最後にQ&Aの時間を設けたいと思います。私のペース次第ですが、Q&Aの時間は30分になるか5分になるかもしれません。
機械学習プロジェクトの背景と目的

さて、なぜ機械学習なのでしょうか?既にお話ししましたが、毎週何億もの購入情報がレシートから読み取られています。FetchのUXの核心は、今アプリを開くと、下部に「スキャン」というボタンがあることです。そのボタンをクリックするとカメラが開き、レシートの写真を撮ることができます。1秒以内に、そのレシートが処理されたという応答が返ってきます。その間に、そこに見えているAIが生成したレシートの画像から構造化データに変換する必要があります。つまり、店舗名、日付、合計金額、そしてこのレシートに記載されている商品を特定し、バックエンドの残りの部分がそれを処理してポイントを付与できるようにする必要があります。
Diffusion モデルのおかげで、今日お見せする多くの画像を作成することができました。そこには多くの AI の助けがあります。私たちの ML プロジェクトの見方のもう半分は、ユーザープロファイルに関するものです。Fetch の全体的なアイデアは、インテリジェントなターゲットマーケティングができるということです。つまり、「みんなに同じクーポンを配る」のではなく、特定の購買傾向を示すユーザーに合わせてプロモーションを調整できるのです。ある業界にいて、特定の製品群を購入する人や、月に一定額を使う人をターゲットにしたい場合、私たちはそれを可能にします。そして、ビジネスのその部分をより一層データドリブンにすることにも常に取り組んでいます。
その部分については私はあまり詳しくないので、主に画面の左側に焦点を当てていきますが、非常に重要なので言及しておきたいと思います。そして、これは私たちの仮想ユーザーの Bob です。彼は Virginia に住んでいて、フライドポテトが大好きです。彼は常にフライドポテトを買い続けているので、私たちは Bob にフライドポテトでポイントを獲得してもらえるよう期待しています。
プレゼンテーションの構成と主要テーマ

さて、このプレゼンテーションは主に3つの部分に分かれています。まず、もう少し背景説明などをします。次に、エンジニアリングの詳細に入り、そして最後にデータサイエンスの詳細に入ります。私の同僚の Alec は、このプレゼンテーションを「Sam の ML モデルを本番環境に投入するためのスクラッピーな入門」と表現しました。つまり、エンジニアリングのこと、データサイエンスのこと、そして私たちがどのようにプロジェクトを進めていくかについて、少しずつ紹介していくような内容になっています。
Fetchにおける機械学習チームの発展と主要プロジェクト
素晴らしいですね。まず第一に、「誰が」そして「何を」という順番です。私たちは、チームが断然最も重要だという考えを強く信じています。実際に全ての仕事をこなすのはチームのメンバーたちなのです。今日はFetchから多くの代表者が参加していて、とても嬉しく思います。この技術の多くを構築してくれた人たちが、ここで私と一緒にこの場に参加してくれているのを見ると本当に嬉しいですね。
3年前、Fetchにはmachine learningチームがありませんでした。実は、先ほど概要をお話したドキュメントスキャンニングも、サードパーティ製のパーツを寄せ集めて何とか作り上げたものでした。会社はすでに数年存在していましたが、私たちのビジネスに特化して作られたものではないツールを何とかつなぎ合わせて使っていました。これはFetchのビジネスにとって大きな制限になっていました。まず、コスト面の問題があります。私たちにはそれらのプロセスを最適化する制御権がほとんどなく、ユーザー数が毎年倍増している中で、ある時点でこのユニットエコノミクスを変える必要があることを強く意識せざるを得ませんでした。
次に、私たちの製品の核心部分をコントロールできていませんでした。ユーザーがレシートをスキャンする瞬間、物事は非常にうまくいくか、非常に悪くなるかのどちらかです。うまくいった時、ユーザーはほとんど気づきません。これはスキャンニングの重要な部分で、ユーザーの邪魔にならないようにすることが大切です。私たちは、ユーザーにレシートを読み取るアルゴリズムが動いていることを意識させたくありません。ユーザーが気づく時は通常、アルゴリズムが失敗して何か変なことを読み取ってしまい、サポートに連絡しなければならない時です。
長い間、そういった失敗が起きた時、私たちにはアルゴリズム自体を改善するための手段がほとんどありませんでした。つまり、良いサポート体験を提供しようと努力するしかなく、それはスケールするにつれてとても苦痛になります。そこでFetchは、この問題を自分たちの手で解決する必要があると気づきました。そして当時のリーダーシップは、巨大なドキュメントスキャンニングパイプラインを構築する詳細は分からないけれど、おそらくmachine learningが関係してくるだろうと理解しました。
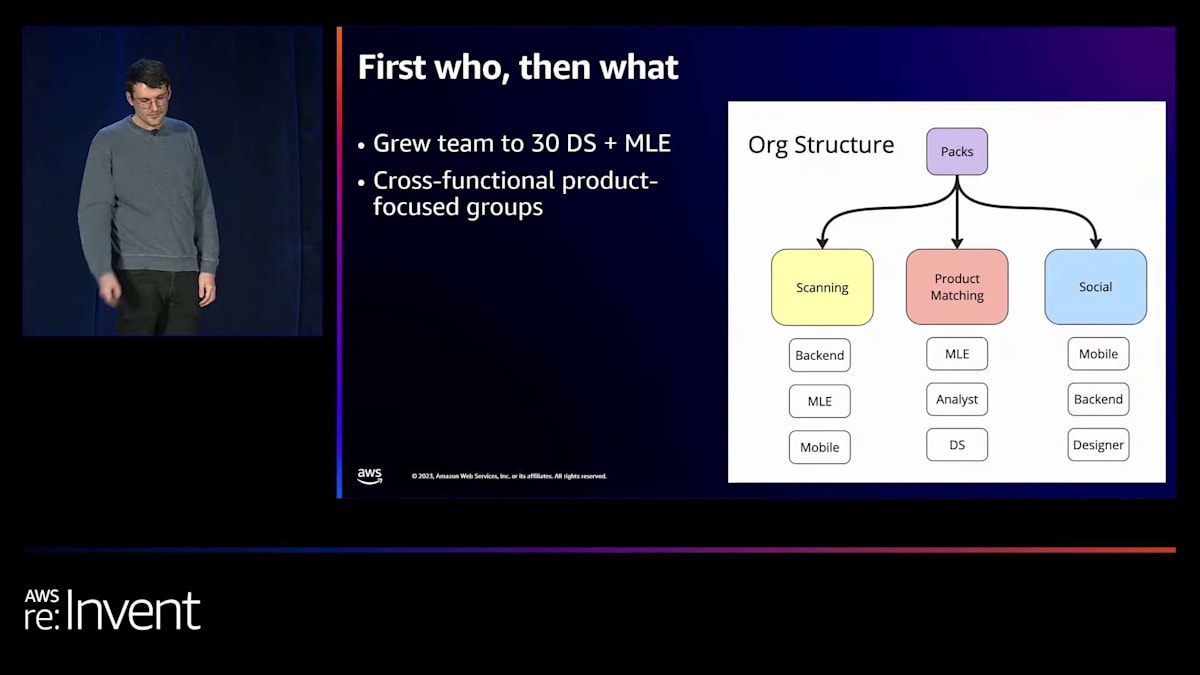
彼らは、高度な分析作業を行う少数のdata scientistから、machine learning engineeringチーム、data scienceチーム、そして実際に製品を構築できる大規模なグループへと発展させました。比較的短期間で、少数のdata scientistから30人以上のdata scientistとmachine learning engineerへと成長したのです。
組織構造について簡単に説明しますと、Fetchには「Pack」と呼ばれるクロスファンクショナルな独立プロジェクトチームがあります。リクエストを受けてモデルを提供する中央データサイエンスチームは存在せず、すべてのデータサイエンティストと機械学習エンジニアがプロジェクトチームに組み込まれています。これは今回のプロジェクト作業にとって非常に良い結果となりました。機械学習アルゴリズムを訓練する人々が、実際にそれをバックエンドにデプロイしてモバイルアプリに機能を組み込む人々のすぐ隣にいるということです。これにより、機械学習組織でよく起こる断絶が大幅に軽減されました。

これが私たちの状況です。2年半前に私が入社した時、スキャンパイプラインはありませんでした。私たちはこのチームを立ち上げ、スキャン用の機械学習モデルの構築に挑戦することにしました。ドキュメントスキャンパイプラインを構築するという大きなプロジェクトの中に、3つの主要なサブプロジェクトがあります。最初に取り組んだのは不正検出です。Fetchアプリでは、ユーザーがポイントを多く獲得しようとレシートを改ざんする自然な動機があります。大きな問題ではありませんが、システムの奥深くまで進む前に捉えたい問題です。私たちはシンプルな画像分類モデルから始めました。これが最初に本番環境に投入した機械学習モデルでした。これらはスキャン後に非同期で実行され、パフォーマンス要件は低く、単純な特徴を捉えようとするものです。
次に、ドキュメント理解があります。これは私たちがスキャンパイプラインと呼んでいるものの総称です。Fetchという領収書スキャン会社で機械学習の仕事をしていると聞くと、多くの人は自社開発のOCRを想像しますが、実際にはそれ以上に多くの要素があります。パイプラインに領収書が入るたびにOCRを行いますが、同時に領収書上のすべての単語を理解するためのテキスト分類も行います。また、すべての商品をグループ化する高度なグラフニューラルネットワークも持っています。これにより、OCRモデルから返ってくる大量の単語から、ユーザーが具体的にCheetosを買ったことなどを理解できるのです。
最後に、プロダクトインテリジェンスがあります。Fetchのユニークな点は、ユーザーが国内のどの店舗のレシートでも、いつでもスキャンできることです。小売業者と緊密に統合された網羅的な商品カタログはありません。そのため、異なる小売業者のレシートがどのようにレイアウトされているかを深く理解できるアルゴリズムの構築に多くの労力を費やし始めました。ポイントを正確に付与するためには、購入された商品を正確に知る必要があります。これらが、スキャンプロジェクトの3つの主要な柱であり、今後も発展していきます。
Streamlitを活用したMLプロジェクトの開始パターン

これは、機械学習プロジェクトを始動する際に私たちが好んで使うパターンです。Streamlitについて触れましたが、これはフルスタックのデモを構築するのに役立つPythonベースのツールです。私は、企業が始める機械学習プロジェクトはほぼすべて、プロジェクトとして考える前に、何らかのエンドツーエンドのデモから始めるべきだと考えています。スキャンチームの機械学習エンジニアとして最初に入社したとき、実用的なモデルができる前に自動化パイプラインのセットアップを始めるべきだと考えました。しかし、3ヶ月後にモデリング戦略を変更したときに、それが非常に苦痛な経験となりました。Samは、いわば行き止まりのようなAirflowパイプラインの多くを削除しなければなりませんでした。
エンドツーエンドで動作する簡単なデモを作れないのであれば、おそらくチームを組んで本格的に取り組む準備はまだできていないと言えるでしょう。

このようなデモは1〜2人で作れるはずです。速度や性能、スケーラビリティの要件を満たす必要はありません。ただ、私たちがこれを実現できると考えていて、モデルが最終的にそこに到達することを示せればいいのです。そこから良い次のステップは、Streamlitアプリを分割することです。これは優れたフルスタックデモになります。バックエンドコンポーネントを分離すると、最終段階に向けて非常に良い準備になります。
仮に不正検出パイプラインだとしましょう。画像を入力すると、これは不正かどうかをYesかNoで判定します。私たちのパターンでは、プロジェクトを始めたStreamlitアププリが、モバイルアプリが使用するのと同じバックエンドと通信し続けることができます。ただし、今やそれは単なるクライアントであり、より薄いビューレイヤーになっています。このようなツールを使えば、ハックして作った完全なエンドツーエンドデモから本番環境で動作するものまで移行できるのは、本当に素晴らしいことだと思います。
パターンについて話すとき、私たちはこれを至る所で再現しようとしています。今、Fetchで新しいMLプロジェクトを見るときはいつも、こう尋ねます:それが何なのかを示す小さなデモはありますか?社内でデプロイできますか?ドメイン専門家がそれを試せますか?ちなみに、社内のStreamlitアプリのデプロイを容易にするKubernetes operatorをオープンソースでリリースしました。GitHubで「Fetch rewards/Streamlit operator」をチェックして、スターを付けていただけると嬉しいです。私たちはこのツールを誇りに思っています。人々が私たちのプロジェクトにスターを付けてくれると、より多くのオープンソース活動ができるので素晴らしいことです。
MLモデルのデプロイとスケーリングのエンジニアリングパターン
はい、素晴らしいですね。では、プロジェクトを進めていて、Streamlitアプリを動かしているとしましょう。モデルはまだ完璧ではありませんが、これで行けると感じています。6ヶ月から1年ほど時間をかければ、望んでいた結果が出始めるだろうと考えています。この段階で、私はプロジェクトを二つの部分に分けて考えるようにしています。一つは、モデルをデプロイし、スケールさせ、アプリケーションと統合するエンジニアリングの部分。もう一つは、モデルの精度を80%から、本番環境で必要な99%まで引き上げるモデリングの部分です。

まずは、Fetchで好んで使用しているエンジニアリングのパターンについてお話しし、その後、時間をかけてモデルを改善するためのパターンについて話し合いましょう。素晴らしいですね。では、マイクロサービスのパターンについて。この図はシンプルですが、私自身、苦い経験を通じて学んだものです。基本的に、Fetchでは現在、ほとんどのバックエンドサービスがGoで書かれています。非常に高性能で並行処理に優れたサービスです。
しかし、機械学習アプリケーションを構築し始めると、ほぼ間違いなく、機械学習ライブラリはPythonで書かれています。そこで、「どうしよう?」というジレンマに陥ります。バックエンドエンジニアは全員Goを使っているのに、私にはこのPythonスクリプトがあって、ネット上の人々はPythonスクリプトをデプロイするにはFlaskアプリのようなものを使うべきだと言っている。ドメインをどう分割し、これらすべてを実現するかが非常に混乱してきます。
そこで私たちは、Amazon SageMaker endpointsを多用しています。これを使えば、トレーニングしたモデルを、引数を与えて期待する応答を得られるlambdaのようなものに簡単に変換できます。しかし、モデル自体は、デモでは見られないかもしれませんが、ほとんどの場合、ビジネスドメインにうまくマッピングされません。例えば、画像分類器を作って「はい、この画像分類器をデプロイしました」と言っても、「これはサービスで、会社の誰でも私の画像分類器を使えます」とは言えません。
そのようなアプローチは、ほぼ確実に失敗につながります。ドメイン駆動設計から学んだように、チームの境界、サービスの境界を主要なビジネス要素にマッピングすべきだからです。このパターンを見ると、Goサービスが外部世界と対話し、「私はスキャニングサービスです」または「私はプロダクトインテリジェンスサービスです。これこれの機能があり、機械学習について知らなくても使える高レベルのスキーマインターフェースがあります」と言っているのが分かります。
そして、任意の数の機械学習モデルを呼び出すことができます。スキャンを実行すると、誰かが何かを返す前に、1秒以内、あるいはしばしばそれよりも速く4つのディープラーニングモデルが呼び出されます。しかし、これらはすべて舞台裏で隠れています。Fetchの他のサービスでさえ、それについて知りません。つまり、多くのサービス契約を変更することなく、新しいモデルを入れ替えたり、パイプラインに新しいモデルを追加したり、機能の仕方を拡張したりすることができるのです。
バックグラウンドの部分は非常に速く変化します。結果的に、RPCフレームワークのようなものに感じられます。Go Serviceのすべてのエンドポイントと通信するライブラリがあり、そしてGo Serviceが残りの世界と通信します。もう一つの注意点は、これらのSageMakerエンドポイント内で多くのことを行いたくなる誘惑があることです。「これらの中で大量の後処理を行おう」と言い始めるかもしれません。人々に返す前にこれらのレスポンスをすべてクリーンアップする必要があり、SageMakerエンドポイントが実際のバックエンドサービスのように感じられる滑りやすい坂道になる可能性があります。
スキャンのロールアウト中、私たちは実際にSageMakerエンドポイントの1つの中に巨大なライブラリを持つ点に到達しました。そして、このような方法でデプロイしたくないと気づきました。なぜなら、そのライブラリの代わりに、パイプラインに別のモデルを追加したいからです。ユーザーの約5%に対してプロダクショントラフィックを提供していた瞬間があり、これらのモデルの1つがそのサーバー内から別のモデルを呼び出していました。これは大きなパフォーマンスの問題です。なぜなら、SageMakerエンドポイントには可能な限り高度にGPUを利用することに集中してほしいからです。すべてのものの効率を最大化したいのです。そして、Pythonは並行処理が得意ではありません。
SageMakerエンドポイント内で多くの接続を開いたままにすると、エンドポイントのスケーリングが非常に悪くなります。私たちは「この製品の核心部分の動作を基本的に変更する大規模なロールアウトの最中だ」と言っていました。このものに大量のトラフィックが当たっていて、そこから3つ目のサービスを分離したいと思っていました。基本的に、大規模なロールアウトの最中にこれを行わなければなりませんでした。そして、皆さんにはそのような経験をしてほしくありません。そこで、私の大きなアドバイスは、「モデルエンドポイントの1つが大きくなりすぎていると感じたら、それがモノリスのように感じ始めたり、より多くのロジックをそこに押し込んでいるなら、それをLambdaや小さなエンドポイントに分割するか、可能であれば高速バックエンドサービスにプッシュして数ミリ秒を節約しましょう」ということです。
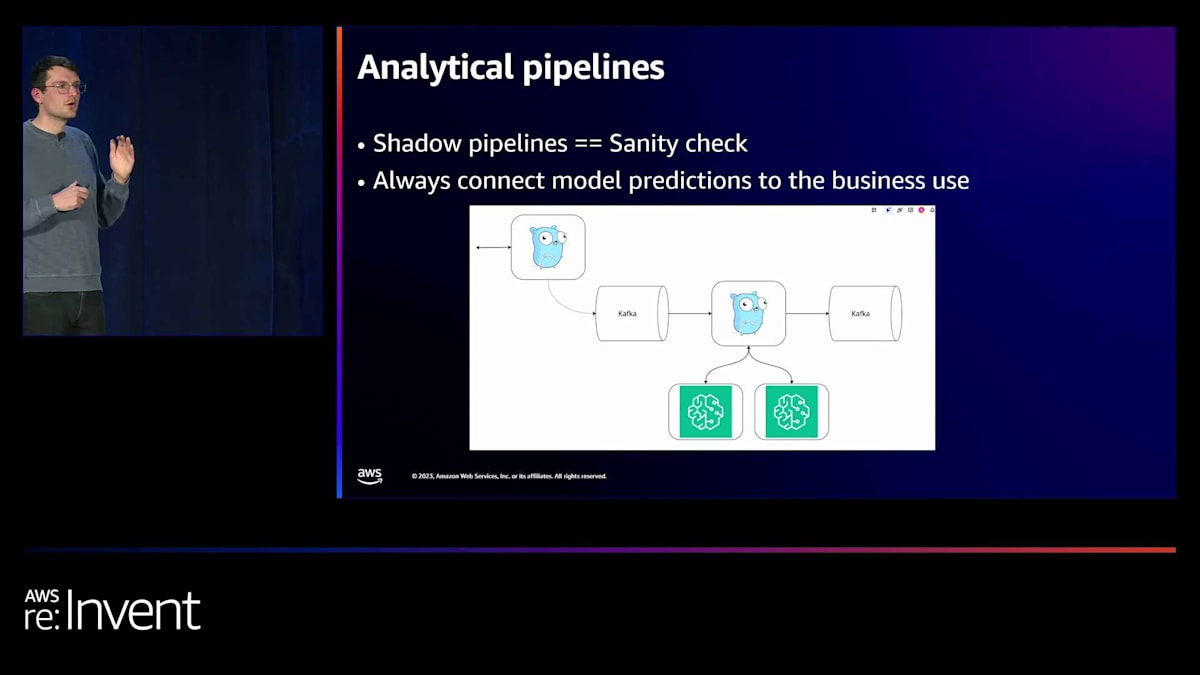
私が本当に好きな次のパターンはシャドウパイプラインです。 Fetchで何かを行うために機械学習モデルをロールアウトするとき、ほぼ常に何らかのヒューリスティックプロセスを置き換えています。何かを行うために人々が書いたルールがあります。私たちが望む使用事例の量にスケールしないと判断した、寄せ集めのヒューリスティクスとビジネスロジックがたくさんあるかもしれません。しかし、モデルは様々な方法で驚かせることがあります。それらはある程度ブラックボックスのようなオブジェクトであり、デプロイするときに「精度の数字に自信がある」と言うかもしれません。しかし、実際にプロダクショントラフィックの全範囲で実行し、人々が本当にこれに送信するものの分布を見るまでは、驚くことになるでしょう。
効果的なMLモデリングのためのデータ戦略
私たちは、このパターンをいくつかのサービスに組み込みました。メインのGoサービスが、外部と通信する同じものですが、短いTTLを設定してKafkaトピックにリクエストを転送します。それが、来週や来月にプロダクションにプッシュする予定の新しいものによって処理されます。そして、そのサービスは、コール・レスポンスパターンのように応答するのではなく、新しいKafkaトピックに予測を書き込みます。これにより、発生している事象の基本的な分析を行い、予想される負荷に対応できることを証明することができます。
多くの負荷テストを行うことができます。次のスライドには負荷テストに関するメモもありますが、システムがすでにかなりの期間、プロダクションの負荷を処理してきたことを知るほど、自信を与えてくれるものはほとんどありません。新しいスキャンパイプラインをトラフィックの100%にロールアウトした時、私たちはすでに1ヶ月ほどプロダクションのトラフィック100%を処理していました。これにより、私がこれまで経験した中で最も安心感のあるロールアウトの一つとなりました。まるで、「よし、切り替えよう。これでプロダクションだ」という感じでした。見逃した大きな問題がないことを願いましたが、クレイジーなカオス的スケーリングの問題は一切ありませんでした。

さて、モデルサーバーでのスケーリングについてもう少し補足します。まず第一に、リクエストが非常に長く感じます。 Fetchでは、パフォーマンス重視のエンジニアリング組織です。10ミリ秒のサーバーを目指すという話をよく耳にします。これは私が入社した時に驚いたことですが、他のエンジニアリング組織と比べると低い数字に感じます。しかし、そこにバーを設定することで、アプリがユーザーにとって本当に高速に感じられるようになります。ユーザーがアプリを操作しながら、バックエンドで何らかのデータベース呼び出しを待つという問題がなくなります。
しかし、ディープラーニングモデルを実行している場合、特に複数のディープラーニングモデルを実行している場合、これらのアーキテクチャの多くは、10ミリ秒以下で実行できれば、博士号か10億ドル企業を手に入れられるほどです。単純に遅いのです。現実には、普段よりも多くの接続を開いていることに対応するために、アーキテクチャの一部を変更する必要があります。重要な落とし穴は、ほとんどすべてのモデルサーバーに隠れたキューがあることです。Goサービスの背後には、サーバーがあり、そしてキューがあり、その中で多くのワーカーが動作しています。
私がこの分野を始めたばかりの頃、これらのキューがあちこちに存在することに気づきませんでした。これらは良い理由があって存在しています - GPUへのリクエストの出し入れを可能な限り効率的に行うためです。それには転送コストが伴います。MLモデルを呼び出す際には、バッチ処理によって多くの改善が得られます。間違いなく、保持するレコード数や保持時間についてデフォルト設定されたキューが存在します。
左側に表示されているのは、私たちがロールアウトの準備をしていた際に非常に混乱し、難解だと感じたロードテストです。基本的に、3つの連続した異なるレベルのトラフィックを送信しています。2回目と3回目の実行では、RPSがほぼ同じポイントでピークに達していますが、レイテンシーは約2倍になっています。これは、リクエストがキューに留まっているためです。これらのワーカーのスループットは、基本的に固定された数値です。ほとんどのモデルサービスでこの数値を見つけることができますが、サービスは喜んでリクエストを受け続け、モデルサーバーの設定にぶつかってシステム全体が崩壊するまで、どんどん遅くなっていきます。
良いニュースは、Amazon SageMakerのようなサービスには、requests per secondに基づいた事前構築された自動スケーリングポリシーがあることです。これは、CPUやGPUの使用率などでオートスケーリングを行うよりも、ほとんどの場合優れたルールとなります。インスタンスが最大容量で動作している数値があり、それを超えるとバックアップが始まってシステムがダウンし、それ以下だとリソースが十分に活用されていないという状況です。そのため、よほどの理由がない限り、requests per secondでオートスケールすることを強くお勧めします。

素晴らしいですね。さて、約束通り、ここからは本番環境でのモデル運用に話を戻します。エンジニアリングの部分はほぼ解決されたと仮定して、今度はモデルが実際に優れている必要があります。幅広いデータを送信したときに、期待通りの結果を返す必要があるのです。 では、モデリングについて話しましょう。まず何よりも、機械学習プロジェクトで最も重要なことは、データを把握することです。これは陳腐な言い方で、誰もが言うことかもしれませんが、実際のところ、Fetchでの機械学習プロジェクトを見ると、例外なく、ドメインを適切に反映した良好なトレーニングデータセットを得ることが大きなブレイクスルーとなります。
特に事前学習済みモデルがどんどん良くなっていく中で、多くの場合、既製の事前学習済みモデルを使用し、少し微調整するだけでドメイン適応ができます。しかし、データがなければ、どうしようもありません。ある目的のモデルを別の目的に変えることはできません。最初のスライドで示したStreamlitの段階で、「これが機能するかどうかわからない」という状況であれば、大企業でない限り、すぐにアノテーターを雇うべきではないでしょう。それは始めるのに大変な作業です。お金をかける必要があり、多くの時間もかかります。
そのため、Fetchで成功した機械学習プロジェクトのほとんどは、私たちの問題の模擬版のようなデータセットを巧妙に収集する方法を思いついたことから始まっています。
NLPやテキスト関連のタスクでは、多くの場合、RegExや領収書のレイアウトに関する巧妙なルールを使用します。不正検出モデルをトレーニングする場合、すべての領収書を一つ一つ確認する時間がなくても、どの領収書が不正である可能性が高いかを合理的に推測するための良いアイデアがあるかもしれません。スクレイピングで集めたデータセットを使用して事前学習済みモデルをファインチューニングすることが、プルーフオブコンセプトを得るための最良の方法です。モデルが少量の急ごしらえデータで適応できれば、より高品質なデータを与え始めるとほぼ確実に改善されるでしょう。
これが、プロジェクトを始める前に一つの巧妙なアイデアを思いつく必要性です。プロジェクトが成功する可能性があるかどうかのリトマス試験のようなものです。しかし、ヒューリスティックだけでは完全には達成できません。なぜなら、もしそれだけで達成できるのであれば、単にそのヒューリスティックを実行するだけで済むからです。コードベースに書き下せる巧妙なルールよりも優れたものが必要です。そこから、何らかの形でアノテーターと関わる必要があります。
ディープラーニングプロジェクトを行う場合、内部で行うか外部で行うか、そしてどのようなプロセスを設定するかを決めるには多くの要素があります。エンジニアリングプロジェクト内では、非常にプロセス指向的なものになります。プログラマーのように、何かを素早くハックして、気に入らなければすべてを元に戻したり、一日かけてプロジェクト全体をリファクタリングして全てを変更したりするようなことはできません。アノテーションチームはそのような見方をしません。毎日要件を変更すると、週単位あるいは月単位の長いサイクルが必要になってしまいます。
とはいえ、アノテーション要件を正しく設定することは非常に重要です。ビジネスで解決すべき問題をまだ把握しようとしている段階であれば、アノテーションの取得方法を考えることで、実際に問題自体が何であるかを理解することができます。デモが完成し、モデリングアプローチに自信がついたら、早めにアノテーターと関わりを持ちましょう。そして、できるだけ早い段階でステークホルダーと関わり、要件で見落としていた小さな問題点を見つけてください。アノテーションパイプラインを12ヶ月間実施した後よりも、最初の1ヶ月で変更する方がはるかに簡単です。
私が携わったスキャニングプロジェクトの例を挙げましょう。我々は全ての要件を集めたと思っていました。店舗名、合計金額、税金が必要だと言いました。しかし、アノテーションを6ヶ月間行い、本番環境に移行する準備ができた時点で、ビジネスの特定の部分にとって決定的に重要な支払いに関する追加フィールドがいくつかあることに気づきました。これは良い気分ではありません。なぜなら、完全にアノテーションされた何千ものデータが、定義上、間違っていることになるからです。別のものだと言っていたのですから。
階層構造や特殊なケースを忘れてしまった場合、それを忘れたということは、データが何かを欠いているだけでなく、それらの要素が実際には別のものであるとデータが示していることになります。私たちは今でもその影響に悩まされています。追加したかった特定のフィールドがありますが、それを見逃してしまったため、単に追加したり文書の1行を変更したりするだけでなく、何千もの領収書を再作業しなければなりません。そして、もし間違えてしまえば、再び作業をやり直さなければならず、それは楽しいことではありません。
クールな機械学習モデルのトレーニングとデプロイに集中したい人にとって、データの悪い決定に時間を費やすのは最善の方法ではありません。ですので、これらのタスクをどのように注釈付けし、説明するかについての要件文書を作成し、早い段階で反復することを試みてください。モデルの初期バージョンがトレーニングされている間、機械学習パイプラインの説明方法に本当に自信を持てるよう、注意深く見守ってください。
本番環境でのMLモデル分析と継続的な実験

素晴らしいですね。シャドウパイプラインも周りにあります。機械学習モデルから出力される予測の分析について話しましょう。モデルがあれば、トレーニングスクリプトから出力される精度の数値がほぼ常にあります。例えば、テキストの一部を見て、事前に定義されたクラスのリストに分類するテキスト分類器かもしれません。多くのプロジェクトの初期段階では、素晴らしい成果を上げているように見えるモデルを得ることがあります。99%の精度で、すべてのケースを的確に処理しているように感じます。保留しておいたすべてのデータで良好な結果が出て、完璧で精度要件をはるかに超えていると思い、本番環境に移行する準備ができたと感じます。
Fetchが扱う規模、つまり週に1億件の領収書という規模では、数え切れないほど多くのケースがあります。
つまり、トレーニングセットやテストセットでは捉えきれなかった数え切れないエッジケースがあるということです。シャドウパイプラインを実行する際は、ヒューリスティックなビジネスルールや既製のソリューションを組み合わせたものなど、どのようなベースラインがあっても、分布分析を行ってください。現在のシステムが示すものと、新しい改良されたシステムが示すものを比較してください。もしそれらが桁違いに異なっていれば、何か悪いことが起きています。99%の精度があっても、本番トラフィックを比較すると桁違いの差が見られる可能性があります。
例えば、スキャンパイプラインの一部をロールアウトしていた時、特定の小売店が表示される時間の割合について簡単な統計を取っていました。店舗名の精度が99%に達していたにもかかわらず、データ上でMcDonald'sのレシートが50%減少していることに気づきました。これは非常に考えにくいことです。人々はMcDonald'sに行くのをやめているわけではありません。彼らはMcDonald'sが大好きなのです。そこで、さらに調査する必要がありました。ここで便利な調査員の出番です。分布に非常に奇妙なものがあることに気づいたら、今度はズームバックして、システム間で意見が一致しない箇所を見つけます。これらが、解決すべき本当のビジネス上の問題なのです。

これが私が見るすべてのMLプロジェクトの核心です。何かを予測させ、おかしそうな箇所を見て、個々の予測を掘り下げ、エラーを潰していきます。ほとんどの場合、トレーニングデータの修正、より多くのトレーニングデータの取得、またはモデルの微調整が必要になるでしょう。
最後に重要なのは、絶え間ない実験です。Fetchはソフトウェアエンジニアリング組織として始まりましたが、機械学習に多額の投資を始めました。MLプロジェクトに取り組む際の異なるワークフローに慣れる必要がありました。ソフトウェアは予測不可能な場合がありますが、機械学習モデルでは、1ヶ月間何も大きく改善しないことがあります。これは、人々が実験的な作業を行い、異なるアイデアを試し、精度の大きな飛躍を探しているためです。このようなワークフローに慣れていない組織では、これを伝えるのが難しい場合があります。

データサイエンティストが行っているすべての実験を記録するためのワークフローをどのように設定するかについて、早い段階で考えてください。 うまくいかなかった場合でも、様々なアプローチを試したことを示し、取り組んでいることを伝えてください。優れた実験追跡ソフトウェアがたくさんあります。現在、Fetch内ではCometを使用してトレーニングの実行とスコアを追跡しています。試したこと、なぜそれが機能すると思ったか、なぜ機能しなかったと思うかを説明する最小限のドキュメントを書くことができます。このコミュニケーションパターンは、科学者が問題について熱心に考えるという概念に慣れていない可能性のある組織により適合させることができます。
Fetchの機械学習の成果と今後の展望


結論として、現在、4つの異なるプロジェクトチームが本番環境で機械学習モデルを実行しています。 レシートをスキャンするたびに約10個のMLモデルが実行され、そのうち4つのモデルがホットパスで実行され、さらに4〜5つのモデルが次の1秒以内に起動します。ここまで来るのは膨大な作業量でしたが、私たちはとても誇りに思っています。Fetchの歴史上初めて、人々がデータの問題を持ってきたときに、それを解決するための本当に強力なレバーを持っていると感じられる立場にいます。

パートナーが特定の種類のプロモーションを実施したい場合や、何か問題があるように見える場合、私たちは手をこまねいているわけではありません。新しいモデルを素早く作成し、現在の取り組みを調整するために必要なすべての要素が整っています。これは、ビジネス面で私たちにとって大きなブレイクスルーとなりました。 最後に、私たちの今後の方向性についてお話しします。スキャンパイプラインは大きな成果を上げましたが、Fetchの将来を見据えた大きな取り組みの多くは、パーソナライゼーション、ディスカバリー、レコメンデーションシステムのレベルアップです。ユーザーが私たちに提供してくれる購買情報の量は驚異的で、世界最高レベルのレコメンデーションモデルを持つべきだと強く感じています。ユーザーがスーパーマーケットで購入するものすべてを教えてくれるのですから、最低限、彼らの好みを適切に理解し、喜んでもらえるオファーを確実に提供する必要があります。私たちは、スキャンチームから得られたパターンを、ユーザーに多くの喜びをもたらすこれらの新しい課題に適用しています。
これらのパターンをXISの領域に移行することは、非常にエキサイティングな取り組みです。来年のre:Inventで、このようなトピックについて再び話す機会があることを強く願っています。Stateful MLサービスは、現在ベクトルデータベースへの投資が盛んに行われている、もう一つの注目分野です。私たちは、ベクトルデータベースを私たちのモデルと連携させる方法を模索しており、これは非常に興味深い取り組みとなっています。
最後に、generative AIについて触れたいと思います。今日はgenerative AIについてあまり多くを語りませんでしたが、皆さんはこの週に既に十分お聞きになったと思います。実は、私たちは既に小規模なgenerativeモデルを本番環境で運用しています。週に1億件のレシートに対してgenerative AIモデルを実行するのは非常に難しい課題です。コストがかかり、処理速度も遅く、その他の課題もありますが、先ほど説明したような重労働を避けたい一回限りのユースケースには非常に適しています。例えば、ちょっとしたプロンプトエンジニアリングで、アノテーションチームの設置を回避できる場合があります。
ビジネス内部で使用する一回限りのデータタスクがあり、「これをコアのホットパスモデルにプッシュするのではなく、追加データを解析するために非同期フローで使用する」というようなケースがあります。初期の結果は非常に有望で、コアのMLパイプラインを補強するようなものです。これまでの観察結果に満足しています。
プレゼンテーションの締めくくり

サム、ありがとう。サムに大きな拍手をお願いします。また、時間があればアンケートにご協力いただけると幸いです。よろしくお願いいたします。皆様、ご参加いただきありがとうございました。
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion