re:Invent 2024: NetflixのContent Drive - S3で実現する大規模メディアストレージ管理


はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Scaling and evolving media storage at Netflix with Amazon S3 (NFX302)
この動画では、Netflixのメディアストレージ管理システムであるContent Driveについて、その設計思想と実装の詳細が解説されています。Amazon S3上に構築されたContent Driveは、約1,455億のノードと142.5億のファイルを管理し、毎日5-6万人のユーザーがアクセスする重要なインフラとなっています。特に注目すべきは、ストレージライフサイクル管理システムの実装で、Policy Managerによる自動化された階層化戦略により、約77ペタバイトのデータをアーカイブし、70%のコスト削減を実現しました。また、P90レイテンシーを0.5秒以下に維持しながら、分散キャッシングやFollower Readsなどの最適化手法を用いて、高いパフォーマンスを確保している点も印象的です。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Netflixのコンテンツ管理:Content Driveの概要

皆様、こんにちは。NFX 302セッションへようこそ。私の同僚のAnkurと私で、Netflixのメディアストレージについて、その進化、規模、そしてデータライフサイクル管理ソリューションについてお話しさせていただきます。私はIshaと申しまして、NetflixのContent Infrastructure and Solutionsチームで働いております。 本日のアジェンダをご紹介させていただきます。まず、プロダクションライフサイクルとNetflix Studioエコシステムについて概要をお話しします。その後、本題であるContent Drive(私たちのStudioメタデータ管理プラットフォーム)について、その開発の動機、ハイレベルアーキテクチャ、設計思想とコンセプト、そして具体的な数値データを交えながら詳しくご説明します。また、グローバルStudioの文脈における、ハイブリッドストレージをサポートするための進化についても少しお話しします。その後、同僚に引き継ぎ、データライフサイクル管理ソリューションについて詳しく説明させていただき、最後に質疑応答で締めくくらせていただきます。
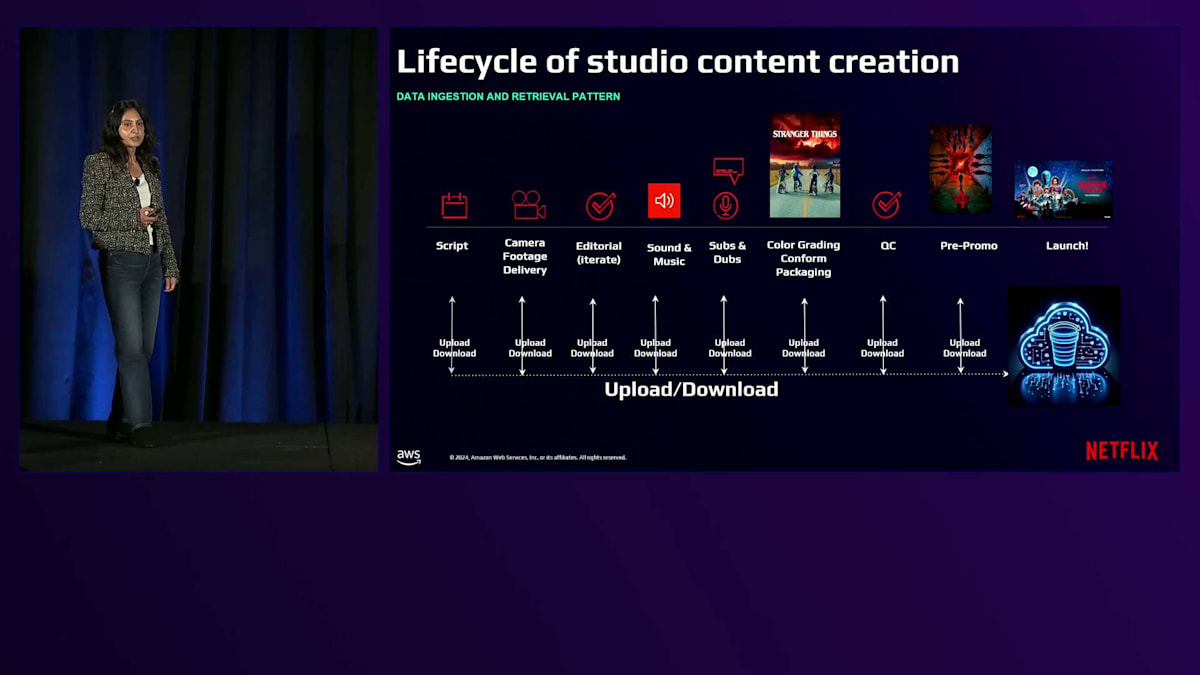
早速本題に入らせていただきます。Netflixは、クラウド上にStudioを構築することで先駆的な役割を果たし、世界中のアーティストたちが、場所を問わず世界中の人々を楽しませるストーリーやアセットを制作できる環境を実現してきました。カメラで撮影されたデータが取り込まれる時点から、様々なステージとフェーズを経ていきます。メディアは、これらすべてのステージとフェーズで頻繁なアップロードとダウンロードを伴いながら、絶え間ない変換プロセスを経ていきます。このようなグローバルに分散したプロセスをサポートするために、高効率で高性能なメディアクラウドインフラストラクチャを提供する必要がありました。

Netflix Studioエコシステムについて見ていきましょう。私たちは、Studioのアセットやデータを扱う多くのアプリケーションを持っています。これらのアプリケーションのほとんどはAWSクラウド上で動作しています。データに関して言えば、これらのメディアアセットはポストプロダクションで使用され、Netflixストリーミングプラットフォームで視聴される最終的なコンテンツを作り上げていきます。プロダクションとポストプロダクション中に生成されるすべてのデータは、Amazon S3上にオブジェクトとして保存されます。Netflixでは、ストレージインフラストラクチャ層で参照できるよう、これらのオブジェクトのIDと他の重要なメタデータを保存しています。アーティストとアーティストアプリケーションが作業を行うエッジでは、オブジェクトとアプリケーション間の変換エージェントを必要とせずにシームレスにアクセスできるよう、ファイル・フォルダインターフェースを期待しています。
Content Driveの設計と機能:ファイル管理の革新

私たちは、アーティストがStudioアプリケーションを使用する際のシームレスな体験を実現したいと考えていました。これはアーティストだけでなく、Studioワークフローにも同様のニーズがありました。良い例として、コンテンツのレンダリング中に行われるアセット変換が挙げられます。そこで私たちは、使い慣れたファイル・フォルダインターフェースを維持しながら、Netflixの何十億ものメディアファイルを保存、管理、追跡できるシステムが必要でした。このシステムでは、変換エージェントを必要とせずに自由な形式のファイルをアップロードでき、作成、管理、コピー、移動、削除、ダウンロード、共有などの管理機能を提供する必要がありました。また、プロジェクトごと、ステージごと、アセットワークフローごと、あるいはアプリケーションやユーザーごとに変更可能な動的アクセス制御の提供も求められました。さらに、異なるプロダクション部門間でのコラボレーションと共有機能も必要でした。これにより、ユーザー、アプリケーション、またはワークフローと、任意のファイル、フォルダ、またはアセットを共有できるようにする一方で、新しいメディア機能や拡張機能のサポートも確保する必要がありました。

そこで私たちは、様々なシナリオで活用できるContent Driveというコンセプトを考案しました。Content Driveを簡単に説明すると、Amazon S3の上に構築されたメタデータ抽象化層です。これはファイル・フォルダのメタデータ抽象化であり、実際にAmazon S3に保存されているオブジェクトの上にファイル・フォルダのメタデータ抽象化を作成していることに注目してください。
これにより、私たちは大きなメリットを得ることができます。例えば、基礎となるバイトデータを移動やコピーすることなく、ユーザーがデータのコピーを作成したり移動したりできる高速なファイル操作機能を提供できます。さらに、Content Driveではアプリケーションやワークフローに基づいてファイルやフォルダーのアクセス制御を動的に行うことができます。また、Content Driveはデータ転送セッションの作成と、実際の転送に必要な認証トークンの提供をサポートします。加えて、Content Driveは様々なシナリオで活用できる豊富なファイル・フォルダー通知機能を提供します。例えば、ファイルやフォルダーのアップロードが完了した際のアップロード完了通知などです。また、ユーザーがWorkspaceやアプリケーション、アセットに対して行うすべての移動や変更を監査する機能も備えています。

それでは、高レベルのアーキテクチャを見てみましょう。 システムには複数のコンポーネントがあります。まず、RESTとGraphQLのレイヤーがあり、ユーザーがファイルやフォルダーにアクセスして作成、管理、コピー、共有、ダウンロードなどを行うためのエンドポイントを提供します。File Serviceレイヤーは、このメタデータ構造を管理する主要なサービスです。Access Controlレイヤーは、これらのファイルやフォルダーを異なるユーザーやアプリケーションと共有するための機能を提供します。Data Transferレイヤーは、ファイルやフォルダーの認証トークンを生成し、アップロードやダウンロードの転送を追跡するための転送セッションを作成するために使用されます。Persistenceレイヤーは、メタデータを維持するための実際のデータベース操作を実行することで、このメタデータ構造を維持する実作業を行います。また、Objectレイヤーから通知を受け取り、アプリケーションが使用するためのファイル・フォルダー通知を送信するEvent Handlerも備えています。
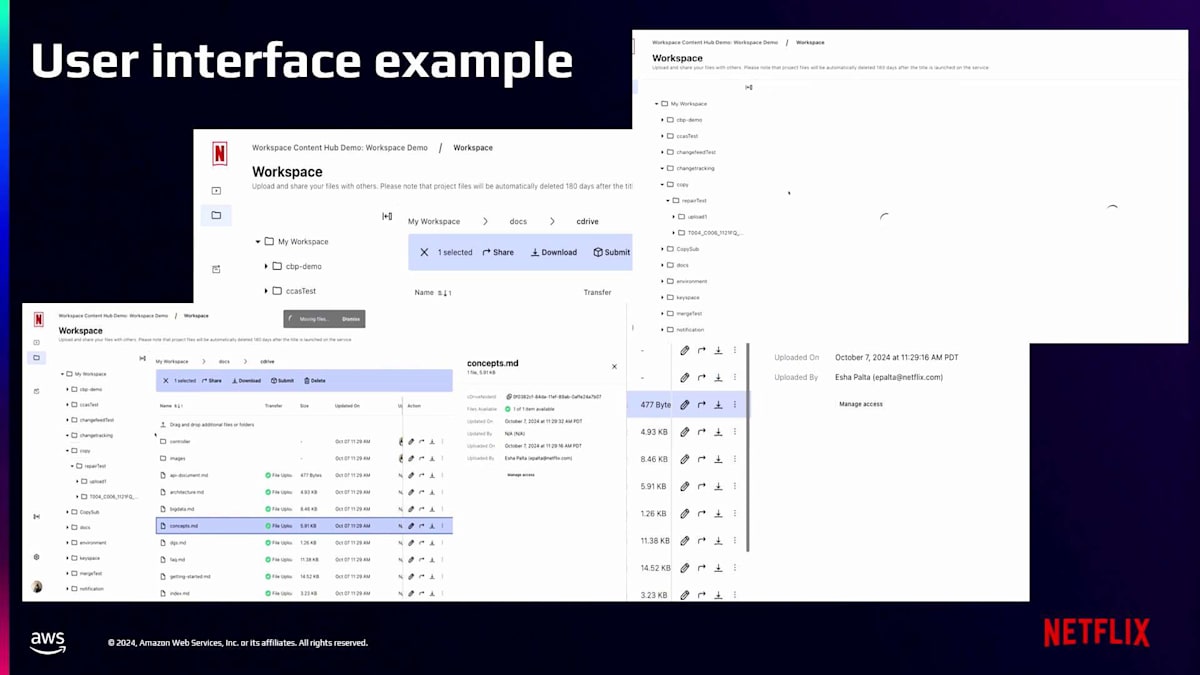
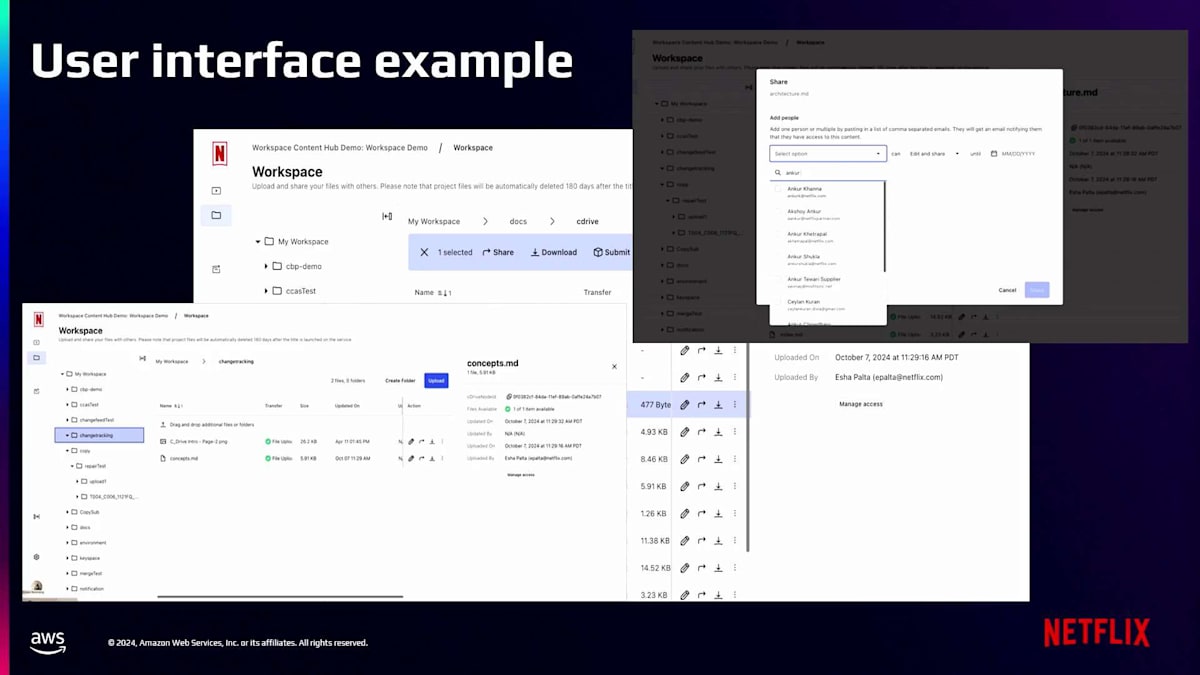
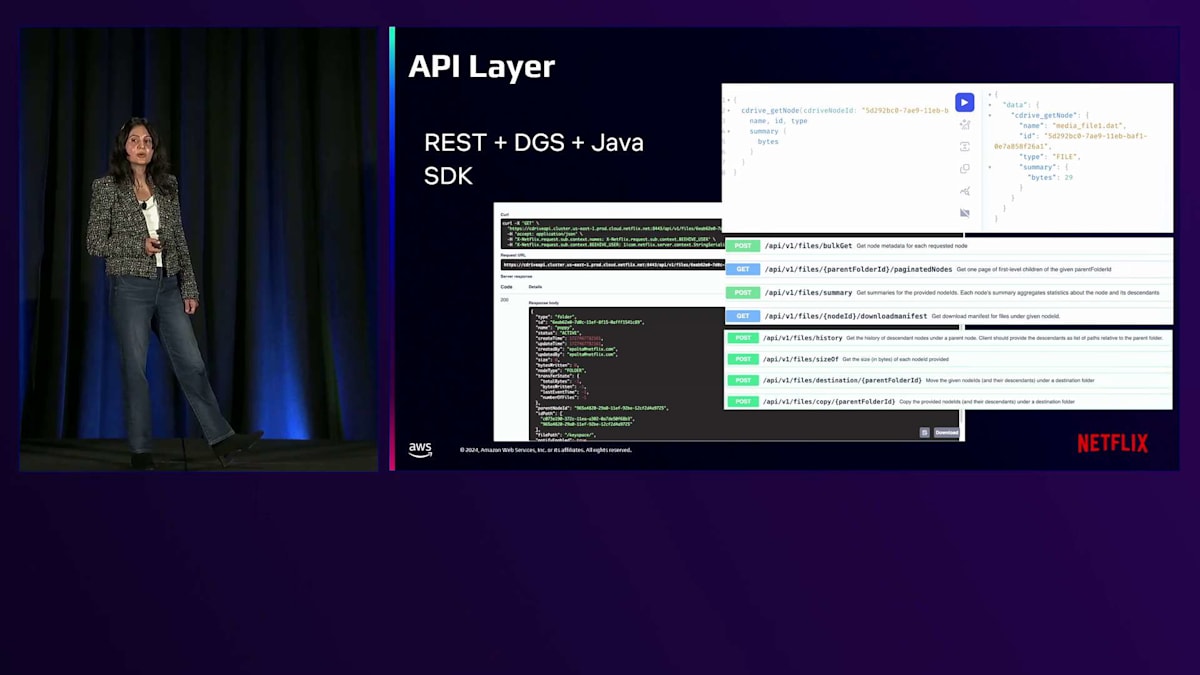
Content Driveの機能の良い例として、クラウド上の個人Workspaceにアクセスするユーザーが、 ローカルファイルシステムで行うような操作を実行できることが挙げられます。例えば、ファイルやフォルダーの作成、コピー、削除、一覧表示、共有などの操作です。先ほど述べたように、Content Driveが提供するAPIレイヤーはRESTとGraphQLのエンドポイントであり、 アプリケーションがファイルやフォルダーに対してこれらの操作を実行できるようにするJava SDKも提供しています。APIの例をいくつか紹介します。例えば、Bulk Get、ツリー全体のBulk Fetch、ツリー全体のサマリー取得、ディレクトリやフォルダーの一覧取得、サイズ取得など、多くのバッチAPIがあります。

それでは、システムの詳細を理解するために、いくつかの主要なエンティティについて掘り下げてみましょう。Content Driveでは、ファイルとフォルダーを階層的なツリー構造で保存します。これらのファイル、フォルダー、Workspace、パーティションはすべて、CNodeと呼ばれるノード構造で表現されます。CNodeには異なるタイプがあります。最上位のCNodeタイプはRootまたはWorkspaceで、これはOSのディスクパーティションに相当します。これは、その配下のファイルやフォルダーの名前空間を持つために作成されます。次に、単純なコンテナノードであるフォルダーがあります。ファイルは、Amazon S3に保存されている実際のデータの場所への参照を持つリーフノードです。また、シーケンスノードという特殊なノードの概念もあります。シーケンスは、Content Driveの特殊なノードまたはコンテナで、その配下に数百万のファイルを含むことができます。これは、短いクリップを形成するフレームの範囲を持つオフカメラ映像などの特殊なメディアファイルを表現するために作成されました。これは、消費者が基盤となるメディアを理解するのを助けるためにContent Driveに追加された特別なメディア機能です。
Content Driveが提供するもう一つの特殊なコンテナは、Snapshotです。Snapshotは、その配下のサブツリーが不変であることを保証する特殊なコンテナです。通常、アプリケーションは最終的なアセットを作成するために、ファイルやフォルダーを記録するためのSnapshotを作成します。
Content Driveの技術詳細:メタデータ管理とワークフロー
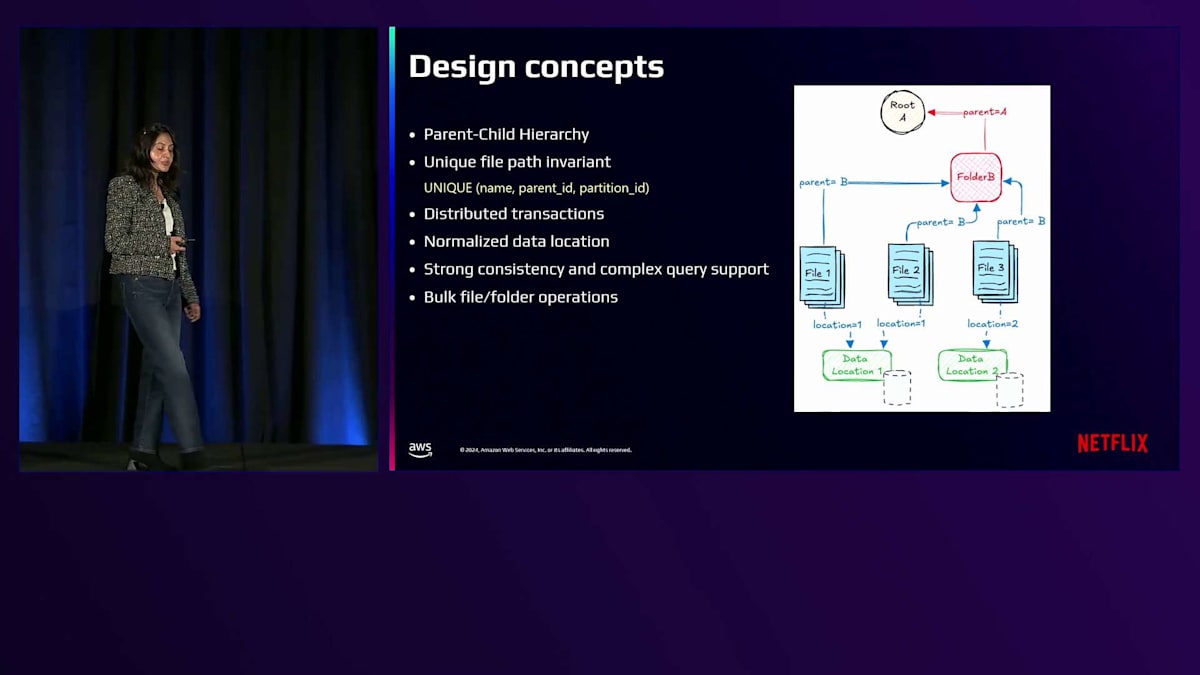
それでは、Content Driveがどのように親子階層を維持しているのか、さらに詳しい設計コンセプトを見ていきましょう。各CNodeは親への参照を保持しており、これによってContent Driveは階層的なツリー構造を維持しています。データの一貫性と正確性を保つため、型と正確性が非常に重要です。そのため、各ファイルパスが常に一意のCNodeによって表現される「一意なファイルパス不変条件」を維持しています。つまり、名前、親ID、パーティションIDの組み合わせは、Content Drive内で常に一意であることが保証されています。コピー、移動、一覧表示などの複雑な一括操作をサポートするため、分散トランザクションをサポートしています。また、ファイルのデータロケーションを正規化しており、データロケーションは1箇所にのみ保存され、各ファイルCNodeは同じデータロケーションのコピーを参照します。永続化層では強い一貫性と複雑なクエリをサポートしており、一貫性を保証しながら即時のコピーや移動操作などの一括操作を提供することができます。

CNodeはそのライフサイクルの中でさまざまな状態を遷移します。最初にCNodeが作成されると、そのファイルやフォルダのメタデータインスタンスの作成を表します。アップロードが完了すると利用可能な状態に移行し、その後、システムがファイルやフォルダ構造のチェックサムを検証すると、内部的にチェックサム検証済みの状態に移行します。CNodeはユーザーのアクションによってソフト削除されることもあり、同様にユーザーのアクションによって復元することもできます。これらはすべてContent Driveが提供するAPIです。データライフサイクル管理では、追加の状態も導入されています。例えば、CNodeは検証が完了し本番環境がローンチされると、実際のデータバイトがAmazon Glacierに保存されるアーカイブ状態に移行します。また、新シーズンの更新などの本番環境の要件に応じて一時的に復元されたり、不要になった場合はパージされたりすることもあります。

それでは、各CNodeに保存されるメタデータの種類を見ていきましょう。ここで紹介するのは限定的なメタデータの一部です。例えば、各CNodeに対して生成する一意のUUID(ノードID)があり、親への参照(親ID)があり、ファイルノードの場合はデータロケーションへの参照があり、各ノードのチェックサムとチェックサムステータスも保存しています。ワークスペースタイプについて見ていくと、CNodeでは3つの異なるワークスペースタイプをサポートしています。まず、ユーザーワークスペースとパーソナルワークスペースがあり、これらはユーザーが所有し、データへのフルアクセス権を持ちます。ユーザーは自分のローカルファイルシステムと同じように、データを共有したり任意の操作を実行したりできます。アーティストが作業中のファイルを保存するのはこのワークスペースで、データは可変です。次に、プロジェクトワークスペースまたはアプリケーション所有のワークスペースがあります。このタイプではデータはアプリケーションやワークスペース、プロジェクトによって所有され、ファイルやフォルダが明示的に共有されない限り、個々のユーザーはアクセスできません。
このワークスペースには最終的なアセットが保存されるため、アクセス制御はアプリケーションやチームによって管理されます。最後に、チームワークスペースという概念があり、これは複数のユーザーとワークスペースを共有する機能を提供します。例えば、2台のワークステーションを2人の異なるユーザーが使用している場合でも、クラウド上の同じワークスペースフォルダにアクセスできます。お互いの変更を確認でき、ローカルファイルシステムの認証を使用するかのようにこれらのファイルやフォルダにアクセスできます。

Content Driveでの認証の扱い方を見ていきましょう。認証はワークスペースタイプに基づいて行われます。ユーザーワークスペースまたはパーソナルワークスペースの場合、認証は完全にそのユーザーによって制御されます。そのユーザーは他のユーザーやアプリケーションに共有可能なアクセス権を提供できます。一方、アプリケーション所有のワークスペースの場合、Content Driveには委任認証という概念があり、認証リクエストをワークスペースを所有するアプリケーションに委任します。許可される権限には、読み取り、書き込み、共有、ダウンロードがあり、これらの権限はすべて認証サービスのアクセス制御リストとして保存されます。
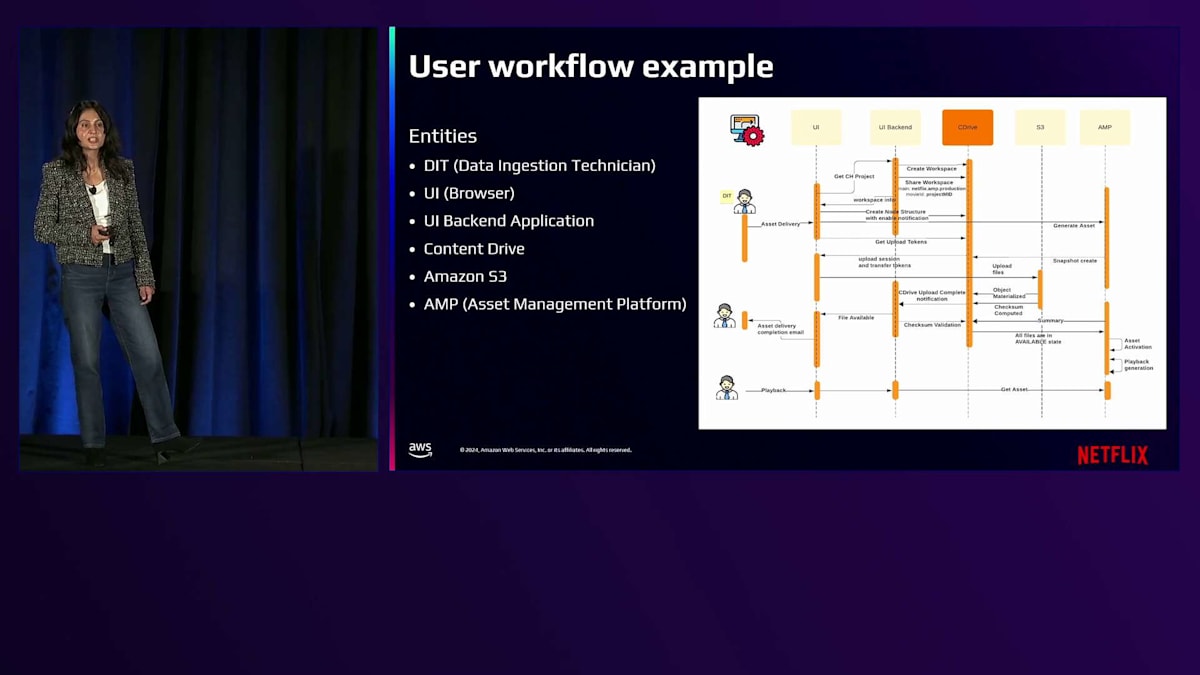
それでは、アセットが取り込まれ、システム全体を通じてどのように流れ、Content Driveがどのように活用されるのかについて、ユーザーワークフローの例を見ていきましょう。関係する主体は以下の通りです:Data Ingestion Technician(DIT)、DITがアセット取り込みに使用するワークステーション上のUI、Content Driveと通信するUIバックエンドアプリケーション、実際のバイトデータを保存するAmazon S3、そして Asset Management Platformです。アーティストがワークステーションを開いてWorkspaceを表示する際、ユーザー認証情報に基づいて個人のWorkspaceがContent Driveから取得されます。
アーティストがローカルワークステーションからファイルやフォルダをWorkspace UIにドラッグ&ドロップすると、いくつかのステップが実行されます:Content Driveでのディレクトリ構造の作成、転送追跡セッションの作成、Content Driveからの転送トークンの取得です。Workspace UIはContent Driveからこれらの認証トークンを取得し、実際のAmazon S3への転送を実行するローカル転送エージェントに渡します。データが正常に転送されると、Content Driveはオブジェクトアクセスレイヤーからオブジェクトが具現化されたというイベント通知を処理します。クラウドでデータが利用可能になると、Content Driveは転送全体の検証を実行し、アップロード完了のユーザー通知を行い、その後プロセスに基づいてオンデマンドでアセットが作成されます。

Modern Netflix Studioには、Netflixクラウド、ベンダー、またはベンダーに提供するオンプレミスインフラにまたがる様々なワークフローがあります。グローバルスタジオのコンテキストでは、ハイブリッドストレージに対してもContent Driveを活用できるようにしたいと考えています。Content Drive内の各ファイルは、図に示すように複数の場所に配置できます。ファイルがローカルベンダー環境やオンプレミスインフラで利用可能な場合、Content Driveにそのデータの表現を作成して、これらのファイルの追跡と可視性を確保できます。これにより、Amazon S3へのアップロードやバックアップ、別の場所へのファイルの展開、チェックサム検証など、多くの操作が可能になります。将来的にContent Driveは、Netflixのグローバルスタジオのどこにファイルが配置されていても、これらすべての操作に活用されることになります。
Content Driveの実績と最適化:数字で見る効果

次に、Content Driveの明確な理解とビジネス価値を示すため、いくつかの興味深い統計と数値を共有したいと思います。2024年10月時点で、約1,455億のContent Driveノードがあり、そのうち約84.8万がWorkspaceです。平均して毎週約5,000万の新しいCDriveノードが作成されています。ファイル、フォルダ、スナップショット、シーケンス、Workspaceといった概念がありますが、そのほとんどはファイルノードで、合計約142.5億のファイルが存在します。
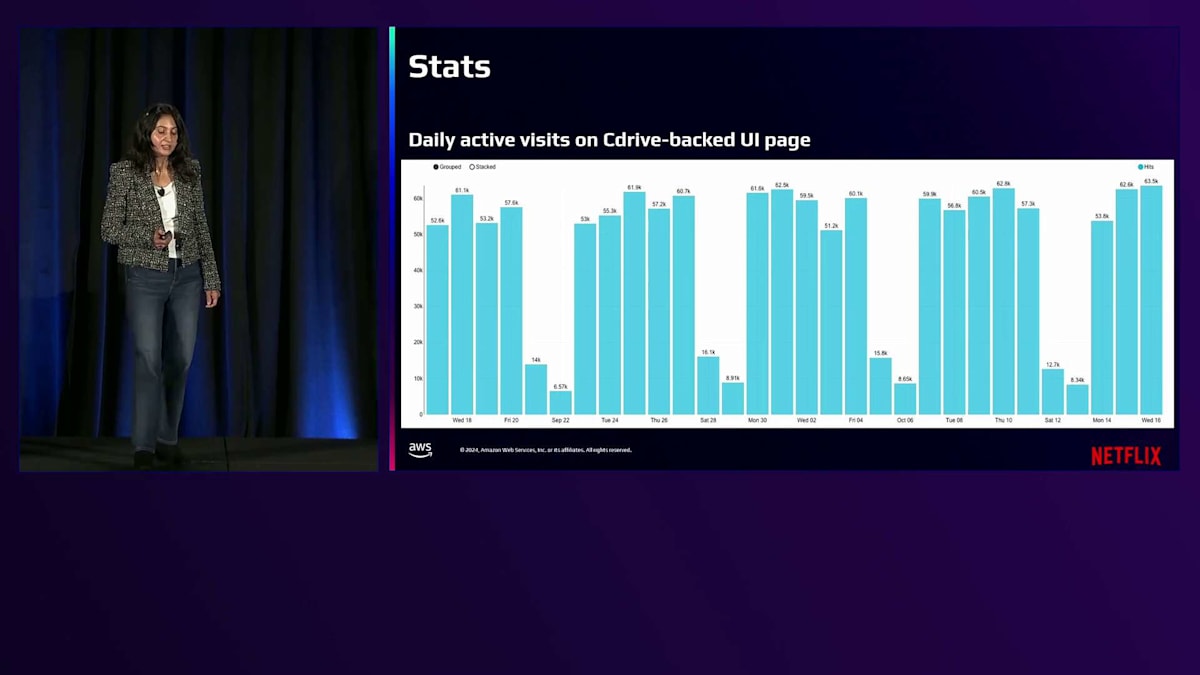

このグラフは、Content Driveを基盤とするUIページの日次アクティブ訪問数を示しています。ご覧の通り、毎日約5万から6万人のユーザーがContent DriveのUIページにアクセスして、作業を行い、進行中のファイルにアクセスしています。さまざまなスタジオ制作部門によるContent DriveのUIページへの訪問数は、ビジネスにおけるその重要性をさらに浮き彫りにしています。制作、マーケティング、ポストプロダクション、コンテンツ取得、パブリックリレーションズ、吹き替えなど、様々な部門が日常的にContent Driveを利用しています。
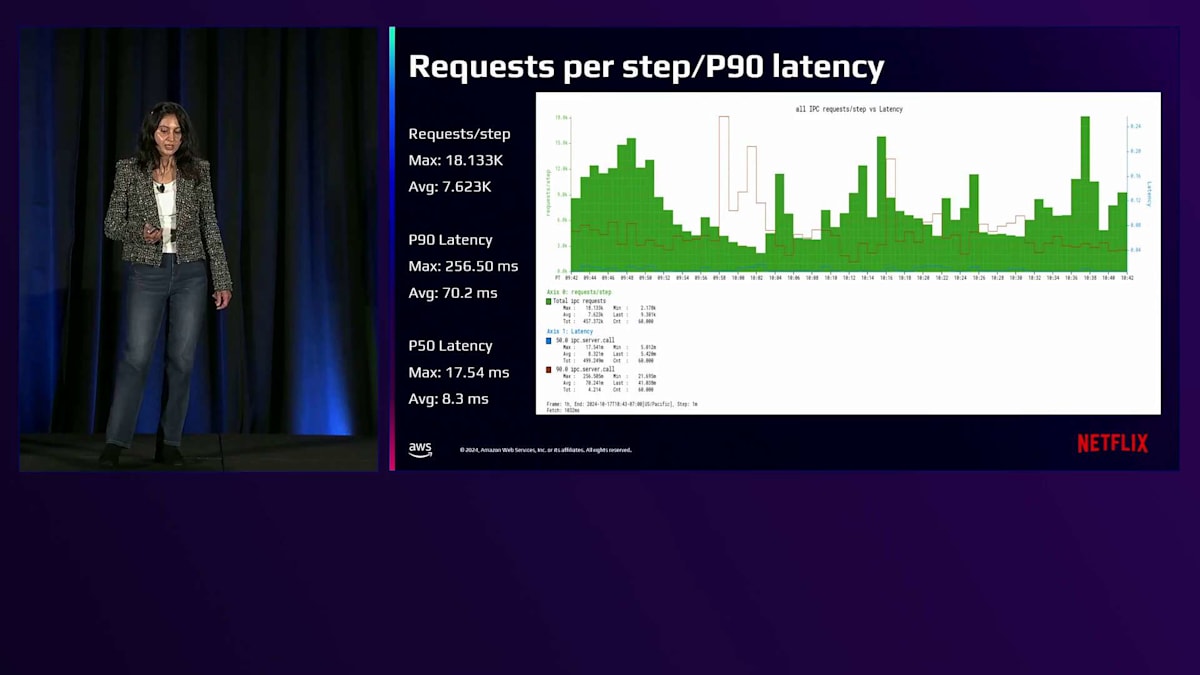
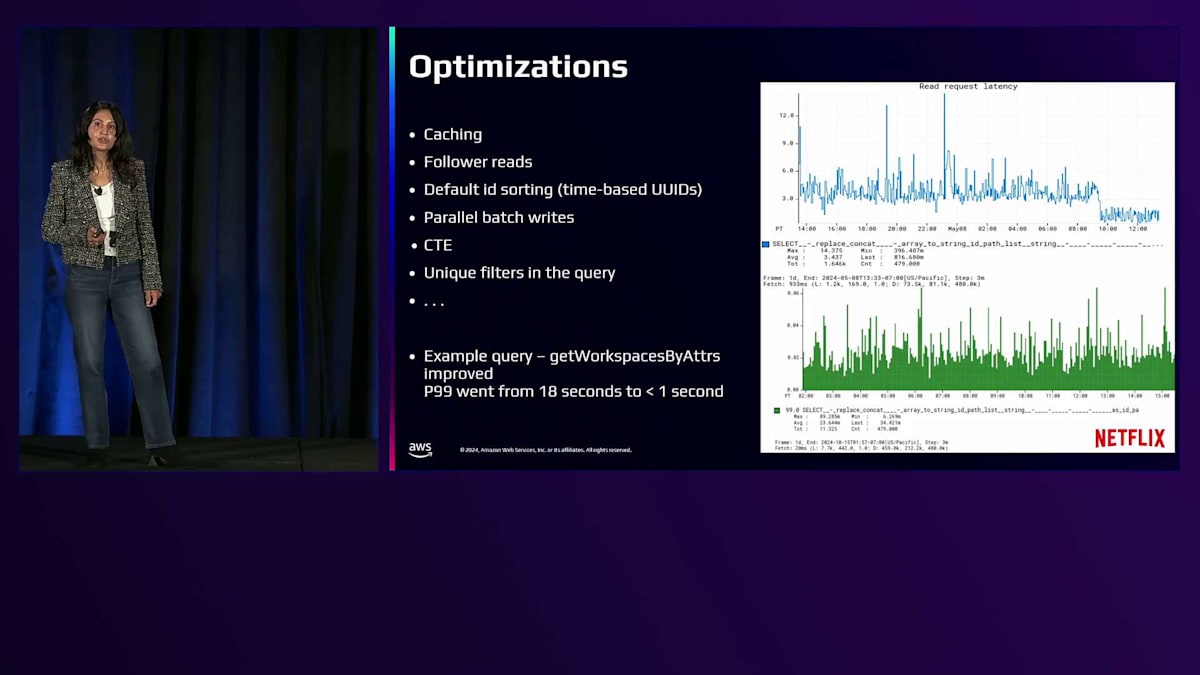
このグラフは、サーバーレベルのリクエストのステップごとの指標と、2時間のウィンドウで測定したエンドポイントの全体的なP90レイテンシーの概要を示しています。私たちは一貫してP90レイテンシーを0.5秒以下に維持しており、平均は70.2ミリ秒です。スケールに応じてさらなる改善を目指しています。ここで、システムの効率を改善するために採用した最適化のいくつかをご紹介したいと思います。スケールに応じて、リクエストごとにデータベースに問い合わせることを避けるため、永続オブジェクトに分散キャッシングを使用しています。データの鮮度にそれほど敏感でない読み取りクエリではFollower Readsを使用し、ページネーションクエリでデフォルトのID基準のソートを確実にするため、時間ベースのUUIDをノードID生成に使用しています。
非常に高いスループットを必要とするアプリケーションのために、並行バッチ書き込みのサポートを提供しています。トランザクションをデータベースにオフロードする方が有用だとわかっている場合には、Common Table Expression(CTE)を使用しています。レイテンシー改善のもう一つの例がこれらのグラフに示されており、クエリに一意のフィルターを使用することで、P99レイテンシーを18秒から1秒未満に改善できたことを実証しています。
ストレージライフサイクル管理:コスト削減への挑戦

ここで、データライフサイクル管理ソリューションの詳細について、同僚のAnkurに説明を譲りたいと思います。Content Driveの概要と、Netflixでのコンテンツの保存とアクセスについて洞察に富んだ説明をありがとう、Isha。皆さん、re:Inventへようこそ。私はAnkurです。これから数分間、Content Driveのストレージライフサイクルの提供について、技術的な課題と私たちが採用したソリューションを見ていきましょう。大まかに言えば、ストレージライフサイクル管理とは、コンテンツが最初から最終的な削除または永続的なストレージ層への移動までたどる道のりを指します。

すべては作成から始まります。カメラで撮影された映像がアップロードされる場合でも、処理中にシステムによって生成されたデータの場合でも、これが私たちがコンテンツと最初に接点を持つ場所です。コンテンツが私たちのシステムに入ると、重要な処理フェーズを経ます。ここでコンテンツにタグ付けを行い、分類し、編集してさまざまなシステム向けにエンコードし、メタデータを付与して充実させていきます。これは、Netflixで視聴できるコンテンツを作成するプロセスだと考えてください。処理フェーズの間、コンテンツはアクティブストレージ、つまり最も動的な状態にあります。ここではユーザーとの相互作用が最も多く、頻繁に修正が行われ、最高のパフォーマンスを持つストレージが必要とされます。このステージは最も多くのリソースを必要としますが、同時に最も重要なニーズにも対応しています。
コンテンツの経年や利用パターンの変化に伴い、分析とポリシーベースの判断を用いてトランジション段階へと移行します。アーカイブ内のより費用対効果の高いストレージ階層へとコンテンツを自動的に移行します。ここでは、データの不変性を長期的に保持し、何年後であっても必要に応じてコンテンツを取り出せることを確実にしています。最後に、コンテンツがライフサイクルの終わりを迎えた場合(もしそうなるのであれば)、安全な削除プロセスが必要となります。これは単に削除ボタンを押すだけの話ではありません。必要な分だけを確実に削除し、それ以上は削除しないようにすることが重要なのです。長年データを扱ってきた経験から言えば、データ管理において最も難しいのは削除のプロセスだと断言できます。

なぜ今この問題に注目するのでしょうか?私たちは成長要因が重なる完璧な嵐に直面しています。コンテンツの量は3つの主要な要因により、前年比で倍増しています。第一に、地理的な拡大により、複数の地域にまたがる新しいデータストリームが導入されました。第二に、数千のベンダーにまで規模が拡大し、それぞれが私たちのデータエコシステムに貢献しています。第三に、コンテンツ制作期間を短縮するため、アップロードとダウンロードの両面で、データ移動量が大幅に増加しています。この爆発的な成長には代償が伴います。ストレージとアクセスのコストが前年比50%増加しているのです。アクティブに使用されるデータの増加に伴い、未使用のデータ、いわゆるダークデータも比例して増加しています。これは私たちに大きな効率性の課題をもたらしています。使用するデータに対してだけでなく、ビジネス価値を生まない大量のデータに対しても、プレミアム料金を支払っているのです。
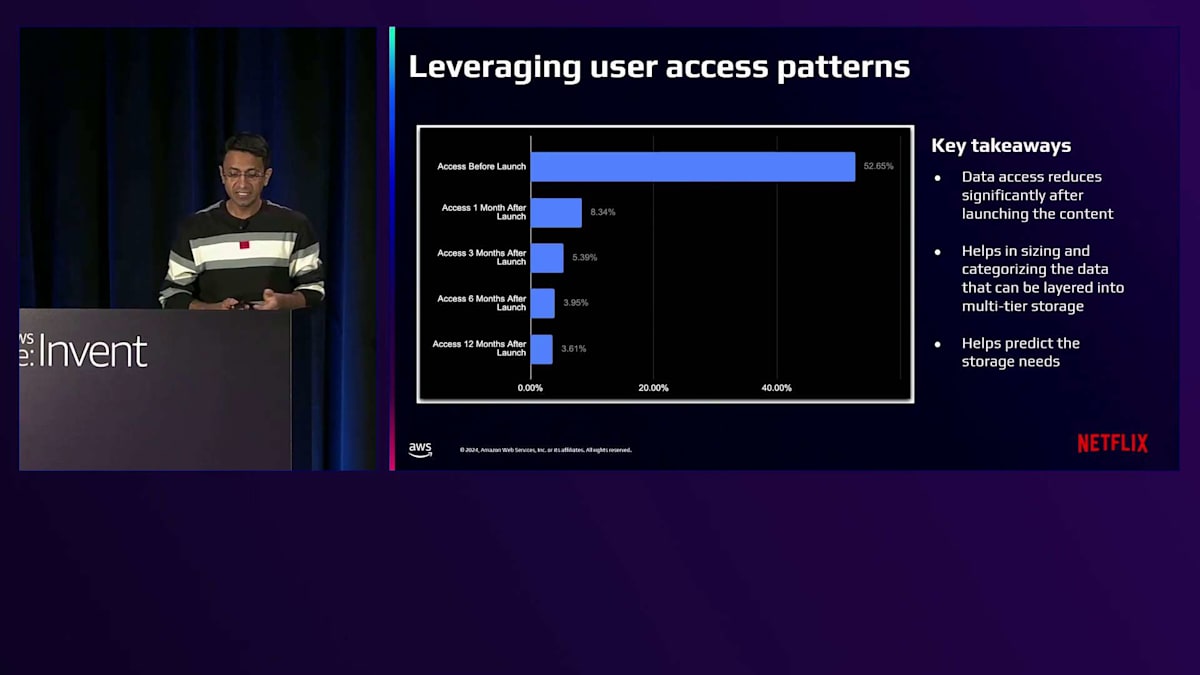
このトレンドは明確です。コンテンツのライフサイクル管理についてより賢くなる必要があります。単により多くを保存するのではなく、適切なものを保存することが重要なのです。このグラフは、時間の経過とともにコンテンツのアクセスパターンがどのように変化するかという興味深いストーリーを示しています。最初のスパイクに注目してください。全アクセスアクティビティの53%がタイトルのローンチ前に発生します。これは、コンテンツが私たちのアプリケーションによって活発に利用されている時期で、先ほど話したライフサイクルの処理フェーズにあたります。しかし、タイトルがローンチした後に何が起こるかを見てください。アクセスアクティビティは劇的に低下します。ローンチ1ヶ月後にはアクセス率は約8%に低下し、3ヶ月後には5%に、6ヶ月後には3%となり、12ヶ月後にはほとんどアクセスがない状態になります。これらのパターンは非常に価値があります。なぜなら、ストレージの振り分けについて賢明な判断を下すのに役立つからです。めったにアクセスされないコンテンツを、最も高価で高性能なストレージに保持し続ける必要があるでしょうか?これを適切に実施できた場合の影響を考えてみてください。ストレージインフラを適切なサイズに調整し、コストを最適化しつつ、最も重要な部分で適切なパフォーマンスを維持することができるのです。

この機会についての文脈を踏まえた上で、ライフサイクル管理システムを形作る重要な要件について詳しく見ていきましょう。まず何よりも、ポリシーベースの自動化が必要です。手動での介入は単純にスケールしません。セキュリティは最重要事項です。すべてのデータ移動、すべての移行は適切に承認される必要があります。ストレージと使用パターンに関するリアルタイムの洞察が不可欠です。データがどこにあるかだけでなく、どのように使用されているか、あるいは使用されていないかを理解する必要があります。システムはデータ階層化においてオブジェクトレベルの粒度をサポートする必要があります。個々のオブジェクトを、その固有の使用パターンやビジネス価値に基づいて移行できる柔軟性が必要です。アーカイブはあらゆる場合においてデータの整合性を維持しなければならず、削除は安全で、コンプライアンスに準拠し、取り消し不可能である必要があります。
私たちに必要な透明性を提供するため、包括的な編集と監査の機能が必要です。容易な取り出しは重要です。これにより、アーカイブポリシーをより広範に適用することができます。自動化は重要ですが、アドホックな一括移動の柔軟性も必要です。これにより、自動化されたポリシーに制約されることなく、即座のビジネスニーズや予期せぬ状況に対応することができます。

Amazon S3には、すでにいくつかのストレージ階層が用意されています。S3 Standard、S3 Glacier Instant Retrieval、S3 Glacier Flexible Retrieval、そしてS3 Glacier Deep Archiveです。評価の一環として、私たちはAmazon S3のIntelligent-Tieringを詳しく検討しました。これは当初、有望に思えました。S3 Intelligent-Tieringは、データの使用パターンに基づいて、データを異なる階層間で自動的に移動することでコストを最適化します。これは、まさに私たちが実現しようとしていたことと同じでした。

しかし、私たちの具体的な要件に合わない制限がいくつか見つかりました。まず、きめ細かな制御ができないという点です。S3 Intelligent-Tieringは事前に定義された期間の後にデータを自動的に階層間で移動しますが、私たちの規模では、これらの移行ルールについてより柔軟な制御が必要でした。次に、階層をスキップして移行することができません。S3 Intelligent-Tieringは、固定された順序で階層間を移動します。私たちのユースケースでは、ビジネスルールに基づいて、中間階層を完全にスキップしてデータを直接コールドストレージに移動する必要があることが多々あります。最後に、Intelligent-Tieringは、私たちが持っているデータに関する豊富なメトリクスやコンテキストを活用できません。

これらの制限により、私たちは細かな制御を可能にしながらもコスト効率の良いハイブリッドソリューションを開発することにしました。S3の基本機能を活用しながら、私たちの特定のニーズに対応するソリューションについてご説明させていただきます。私たちは、システム全体でオブジェクトレベルのカスタムタグ付け機能を構築しました。これにより、時間ベースのルールだけでなく、コンテンツタイプ、事業部門、プロジェクトフェーズ、個々のオブジェクトの特性に基づいて、階層化に関する賢明な判断を下すことができるようになりました。プロジェクトが特定のマイルストーンに達した時点で、中間階層を完全にスキップして、直接コールドストレージへの移行をトリガーすることができます。データの取り出しも、ビジネスコンテキストを活用してデータを事前に復元できるため、待ち時間を節約できます。
最も重要なのは、このフレームワークをストレージに依存しないように設計したことです。S3上に構築しましたが、同じ原則とプロセスをエッジのオンプレミスソリューションにも適用できるため、将来に向けて大きな柔軟性を持つことができます。実際には、このハイブリッドアプローチにより、S3の堅牢なインフラストラクチャと、コンテンツライフサイクル管理に必要な正確な制御と可視性の両方を手に入れることができました。
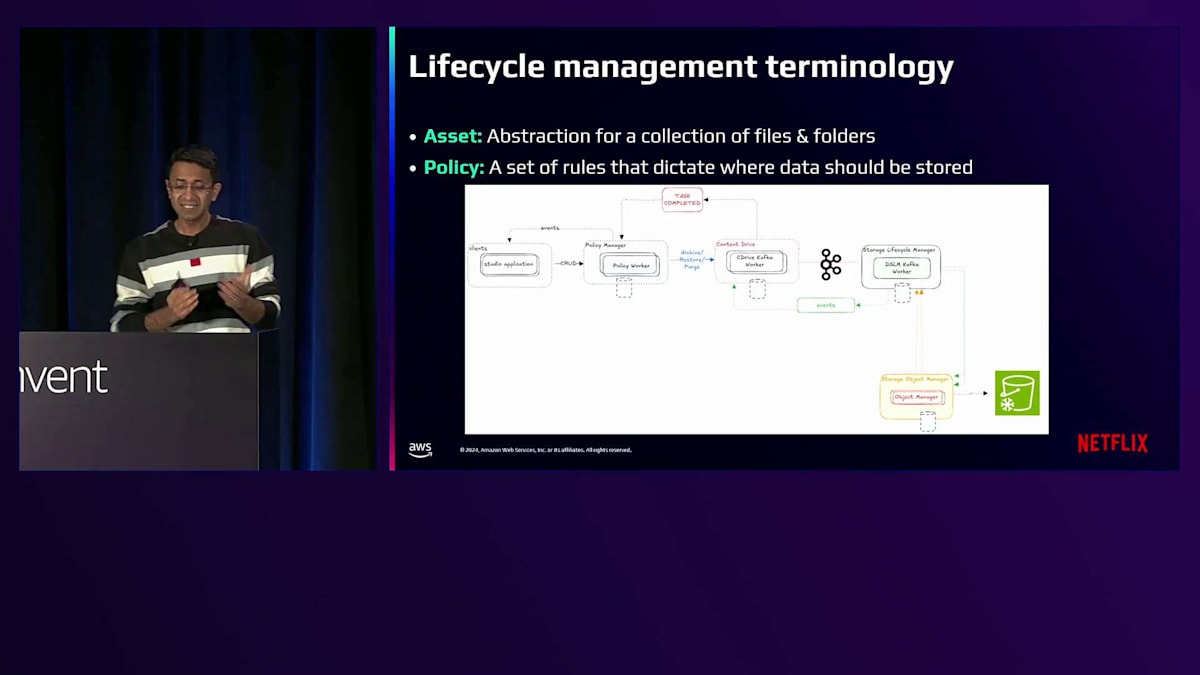
それでは、私たちのライフサイクル管理システムを構成するコンポーネントについて見ていきましょう。アセットとは、ファイルやフォルダのセットとそれらに関連するメタデータを表すスタジオの抽象概念です。各制作過程で何百万ものアセットが生成されます。制作アセットにはそれぞれ特性があります。一時的なものもあれば、他のものより頻繁にアクセスされるものもあり、時間とともに重要度が変化するものもあります。ライフサイクルポリシーとは、データをいつどこに保存または削除するかを定める一連のルールと手順です。AIの時代に突入しつつありますが、私たちのポリシーは、少なくともまだ生きているわけではありません。大まかに言うと、4つの主要コンポーネントで構成されています。まず、ビジネスコンテキストをアクションにつながるライフサイクルリクエストに変換するPolicy Managerと、先ほど説明したContent Drive(システムの頭脳)であるストレージメタデータレイヤーです。次に、ライフサイクル操作を統括するストレージライフサイクルマネージャーコンポーネントがあります。
第三に、これらのライフサイクル操作をS3へのリクエストに変換するS3抽象化レイヤーがあります。さらに、ポリシーの定義、メタデータの追跡、データ移動の管理を行う他のアプリケーションもシステムと連携しています。4つの主要コンポーネントの役割について簡単に説明しましょう。Policy Managerは、アセットのライフサイクルポリシーを保存・管理する機能を提供します。これは、アセットのライフサイクルにおける次のステップを決定するための頭脳となります。Policy Engineは、個々のポリシー定義を評価して、特定のライフサイクル操作の対象となるアセットを判断します。
この評価は通常、プロダクション中に発生する可能性のあるトリガーイベントに応じて行われ、任意のタイミングでこれらのデータ遷移を処理する機能を提供します。最終的に、Policy Execution Workersのためのタスクをキューに入れ、それらがContent Driveにアーカイブ、リストア、パージなどのライフサイクルタスクをスケジュールします。これらの遷移について、ユーザーに対して透明性を確保することが要件の一つであるため、ライフサイクルタスクを「スケジュール」すると言いました。これにより、数日から数ヶ月先の未来にこれらのライフサイクルイベントをスケジュールするという付随的な課題が生まれます。
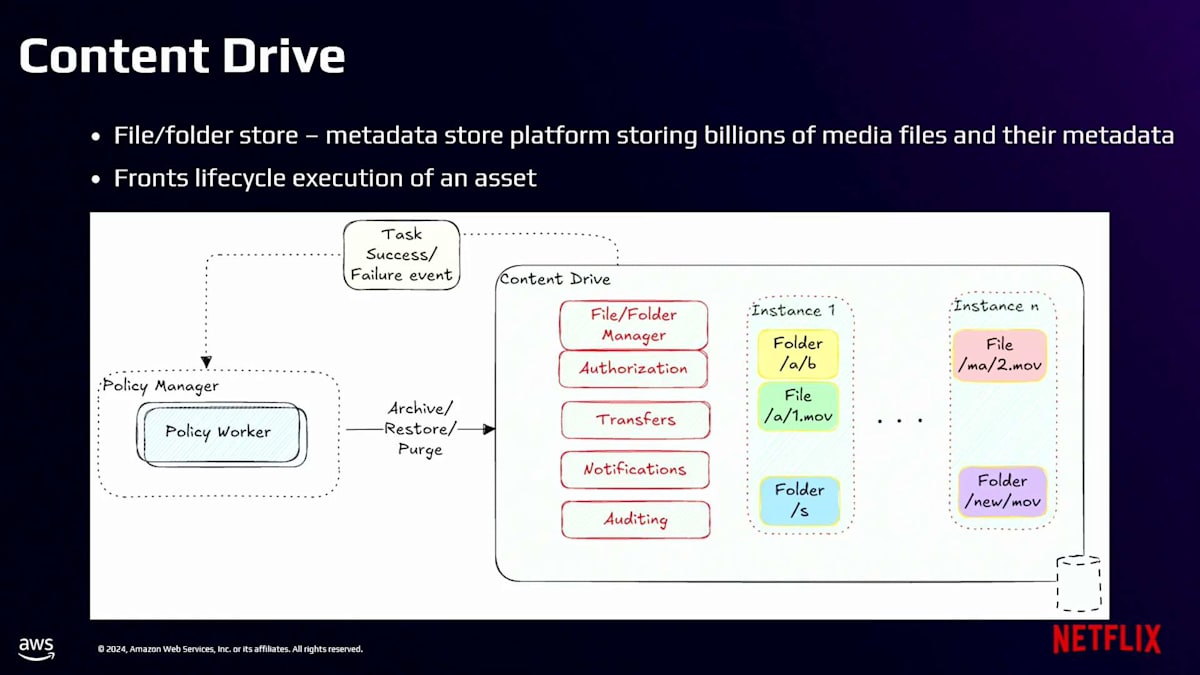
すでにNetflixのクラウドストレージレイヤーとしてのContent Driveの重要な役割について説明しました。 ここで、効率的なライフサイクル管理を可能にするContent Driveのコアアーキテクチャ機能の1つについて説明させていただきます。Content DriveはPolicy Managerからアーカイブ、リストア、パージイベントを受け取り、アセットのライフサイクル実行を担当します。メタデータとS3に保存するデータの間の明確な分離を維持することで、重要な機能を果たしています。この分離は私たちのアーキテクチャの基本であり、参照カウントシステムによって実現されています。アセットが作成または変更されるたびに、Content DriveはアセットとS3オブジェクトの関係を追跡します。
この参照カウントは、実質的にアセットレベルの重複を提供し、これらのライフサイクル操作の範囲を決定する際に重要となります。ライフサイクル操作を実行する必要がある場合、Content Driveは参照カウントに基づいて、メタデータのみを変更してS3オブジェクトはそのままにするべきか、それともS3オブジェクトに対する操作も含めるべきかを判断します。Content Driveがライフサイクル操作の影響を受けるS3オブジェクトを特定すると、この情報をライフサイクル管理システムの実行部分に引き渡します。
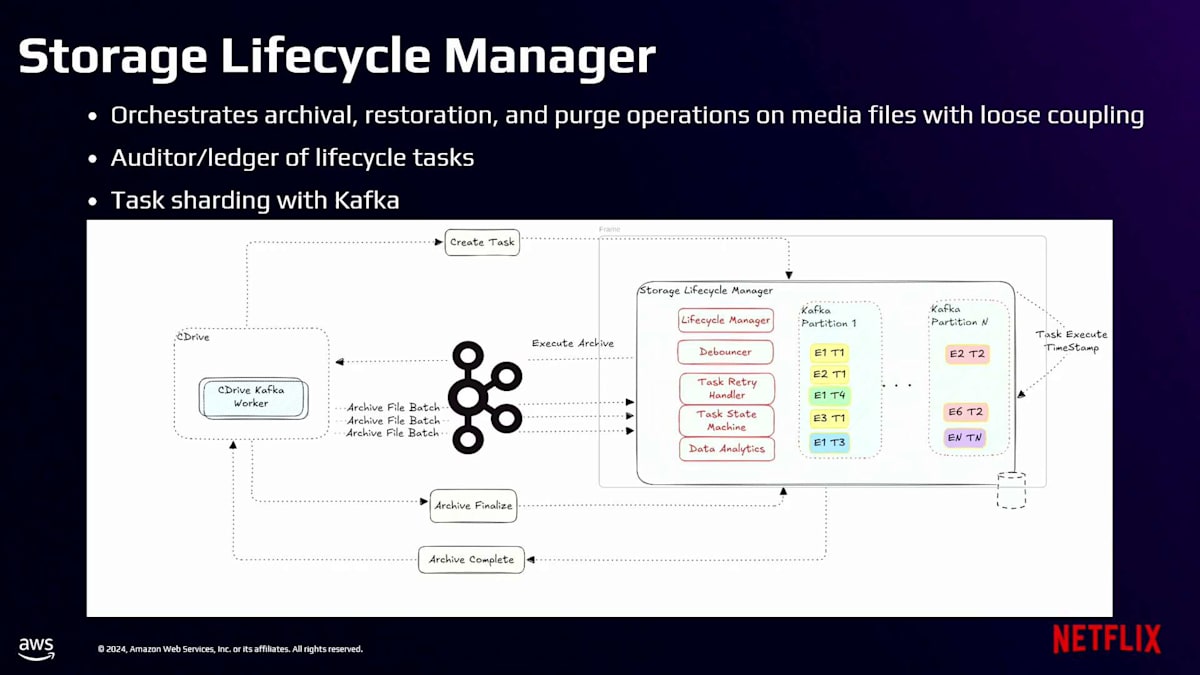
Storage Lifecycle Managerは、すべてのライフサイクル操作の背後にあるオーケストレーションエンジンです。その中核は、S3オブジェクトとやり取りするライフサイクル操作の管理を担当しています。このシステムは完全な非同期アーキテクチャを採用しています。リクエストを受け取った際、即座に処理するのではなく、まず永続化して耐久性を確保します。高いスループットを実現するため、異なるアセットの操作をクラスター内のすべてのノードに分散する分散処理モデルを実装しています。複数のノードが処理可能な状態であっても、特定のアセットは常に1つのノードだけが所有します。この重要なアフィニティは、Kafkaの組み込みパーティション割り当て機能を使用して構築されています。
このShardingアプローチにより、2つの重要な問題が解決されました。1つ目は、キャッシュ効率を向上させ、複数のノードが同じアセットを処理しようとする際に発生する競合を排除できることです。2つ目は、インフラ全体で均一なワークロード分散を実現できることです。最終的に、Storage Lifecycle Managerは、S3抽象化レイヤーと連携して、S3で定義されたライフサイクル設定に基づいて適切な移行のためにS3オブジェクトにタグを付けていきます。
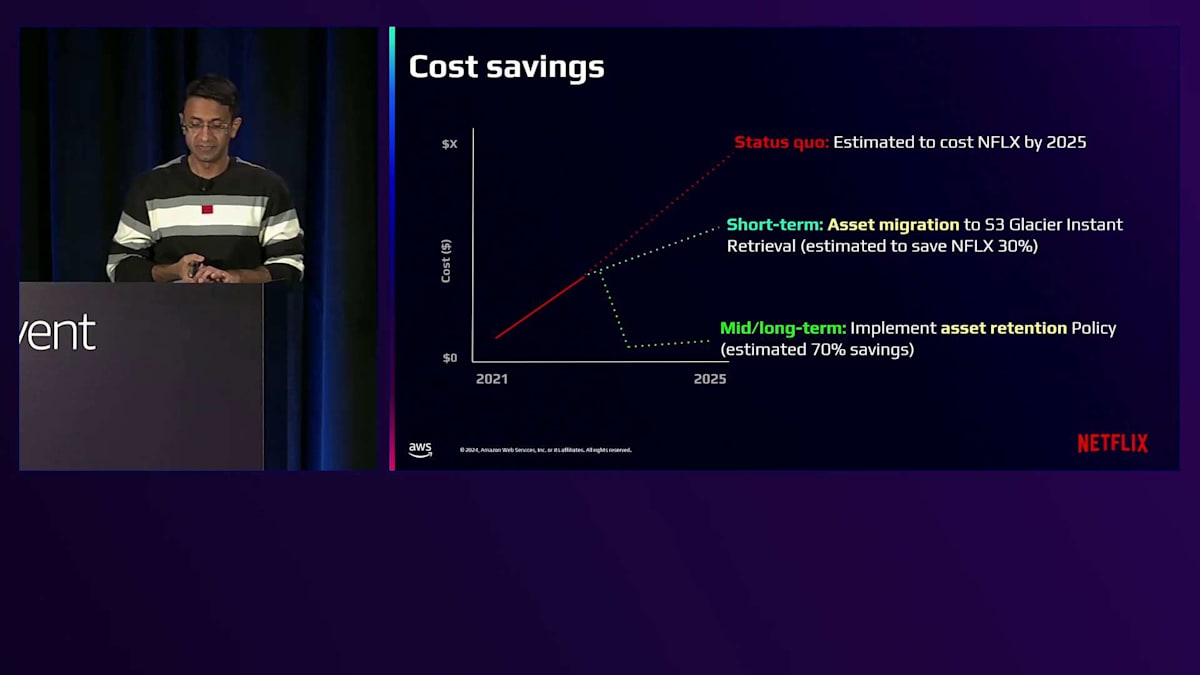
ライフサイクルの取り組みによるコスト削減効果についてご説明させていただきます。赤い線は、何も対策を講じなかった場合のコストの推移を示しており、ストレージコストが直線的に増加し続けることを表しています。これは主にデータ増加と未使用アセットの保持が原因です。しかし、私たちは2つの重要な対策を特定しました。まず短期的な対策として、S3の標準的なライフサイクル設定を使用して、Amazon S3 Glacier Instant Retrievalへのアセット移行戦略を実施しました。ライフサイクル管理システムを開発している間も、この移行だけで初期コストと比較して20〜30%のコスト削減を実現できました。古いコンテンツへのアクセス頻度が非常に低いことは既にわかっていたため、これは私たちにとってリスクの低い移行戦略でした。

さらに重要なのは、ポリシーベースのストレージライフサイクル管理により、未使用アセットの自動識別、インテリジェントな保持ルールの実装、コールドデータのより費用対効果の高いストレージ階層への移行を通じて、約70%のコスト削減が見込めることです。これらの対策によって、コストの推移が劇的に変化し、コストの安定化に向かっていることがわかります。ライフサイクル管理システムの効果を示す印象的な数字をご紹介し、次のステップについてお話しさせていただきます。
私たちは約77ペタバイトのデータのアーカイブに成功しました。積極的なアーカイブ戦略を採用しているため、この1年間で約200テラバイトの一時的な復元データが発生しました。最も印象的なのは、約33ペタバイトのコンテンツの削除に成功し、今後さらに多くの削除が予定されていることです。どのストレージシステムでも同じですが、まだポリシーの策定を待っているペタバイト単位のデータが山積みです。データ処理で最も難しいのは削除だと冗談を言いましたが、これらすべてのペタバイトがまさにその証拠です。
今後の展望として、ライフサイクル管理機能をさらに進化させる3つの重要な取り組みがあります。1つ目は、ハイブリッドストレージ環境へのライフサイクル管理の拡張です。これにより、オンプレミスとクラウドストレージをシームレスに管理でき、データ配置とコスト最適化において大きな柔軟性が得られます。2つ目は、インテリジェントなタグ付けシステムの実装です。制作段階でコンテンツにタグを付け、後のストレージライフサイクル管理システムのための手がかりを残します。最後に、メタデータの階層化を検討しています。私たちの規模では、データだけでなくメタデータのコストも無視できず、スタジオの制作ライフサイクルを通じてメタデータをどのように保存・管理するかを考えることが、次の大きなコスト削減につながります。


まとめますと、Content Driveは、Netflixのメディアアセット管理のためのクラウドネイティブソリューションです。Netflix Studioでは、メディアコンテンツの取り込み、メタデータの管理、ライフサイクルポリシーの適用、そしてコンテンツ共有のためのアクセス制御を実現できます。Content Driveは、私たちの詳細なパターン分析に基づいたS3ストレージ階層の効率的な活用により、コスト最適化を実現しています。Content Driveとそのライフサイクル管理機能についての詳細は、Netflix Tech ブログの記事をご覧ください。ご視聴ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion