re:Invent 2024: AWSが語るRedshift ServerlessとData Sharingの進化
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - AI-powered analytics with Amazon Redshift Serverless & data sharing (ANT328)
この動画では、Amazon Redshift ServerlessとData Sharingを活用したマルチウェアハウスアーキテクチャについて解説しています。AI駆動のスケーリングと最適化により、最大10倍の価格性能比を実現し、ワークロードに応じて64から128 RPUまで自動的にスケールする機能が紹介されています。実例として、Hiltonの事例が詳しく共有され、31,000人のユーザーが79カ国から利用する大規模システムを、96 RPUの5ノードクラスターで運用し、60万クエリの99%を30秒以内に処理できた実績が示されています。また、Data Sharingの新機能として書き込み機能が追加され、Data MeshやHubとSpokeモデルの実装がより柔軟になったことも解説されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Amazon Redshift Serverlessによるデータ活用の革新

データが単に保存・共有されるだけでなく、積極的に活用され、AI-powered computeのスケーリングによってリアルタイムで生データを実用的なインサイトに変換できる世界を想像してみてください。本日は、Amazon Redshift Serverlessを使用したAI-drivenスケーリングの能力と、シームレスなData Sharingを活用したスケーラブルなMulti-warehouseアーキテクチャについて探っていきます。これらは組織のコラボレーション、イノベーション、成長の方法を変革する可能性を秘めています。それでは、スケーラブルでインテリジェントなデータシステムの構築方法について詳しく見ていきましょう。

皆様、こんにちは。このセッションへようこそ。私はSenior Product ManagerのSaurav Dasです。共同発表者は、Amazon RedshiftのPrincipal Product ManagerでServerlessを率いるAshish Agrawalです。また、お客様スピーカーとして、HiltonのDirector of Platform ArchitectureであるPraneeth Mandadiをお迎えし、彼の経験についてお話しいただきます。 こちらが本日のアジェンダです。これはレベル300のセッションです。Multi-warehouseアーキテクチャの構築に関する高度な概念を説明し、実世界の例を紹介した後、実際の動作を確認するための事前録画デモをご覧いただきます。その後、PraneethがHiltonでのAmazon Redshiftの興味深い経験と、ワークロードのパフォーマンスをどのように改善したかについて共有します。最後に、Ashishがベストプラクティスで締めくくります。
データプラットフォームの進化とGenerative AIの影響

手を挙げていただきたいのですが、環境内でデータの複雑さを経験している方は何人いらっしゃいますか?たくさんの手が挙がりましたね。では、環境内で常にデータが変化していると感じている方は?素晴らしい。このセッションはまさにそういった方々のためのものです。Generative AIの出現により、既存のワークロードはスケールする必要が出てきます。新しいデータセットを取得し、新しいアプリケーションと統合し、さらに規制にも準拠する必要が出てくるでしょう。組織ごとに異なる要件や目標があるため、成功への画一的なレシピは存在しません。
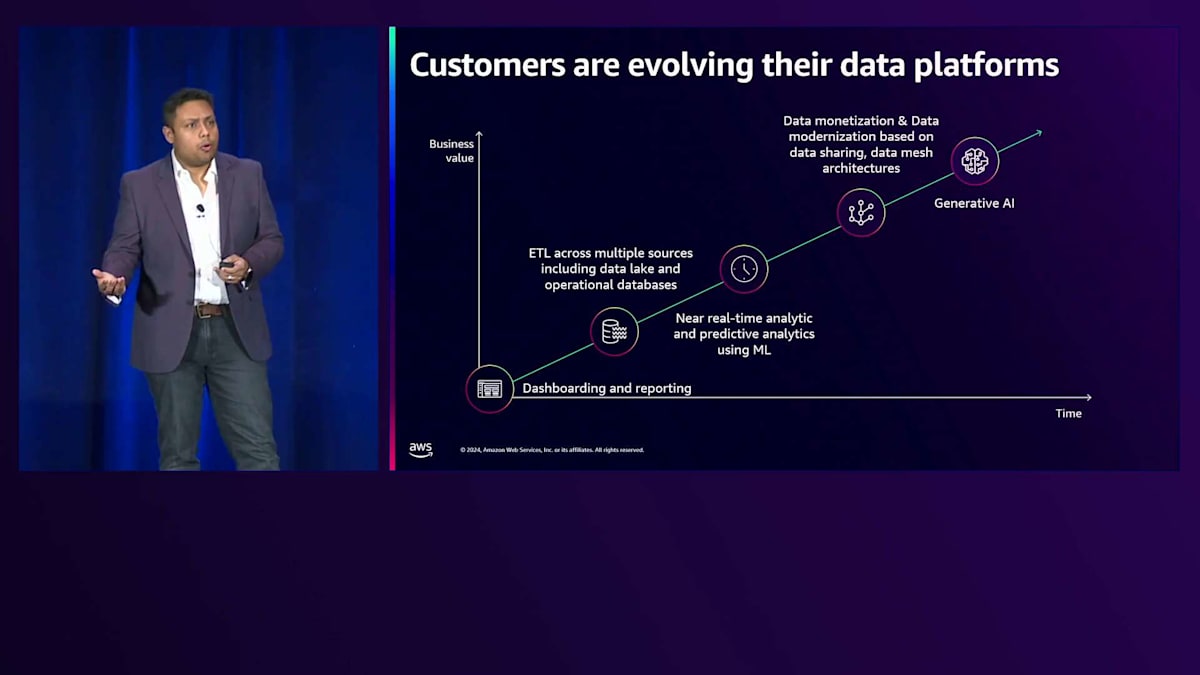
データプラットフォームを進化させ、データの力を活用しようとする際の顧客の典型的な journey を見てみましょう。最初はダッシュボードとレポーティングのユースケースから始まります。組織全体にデータが広がるにつれ、ETLパイプラインの構築を始め、複数のソースからデータを取り込み、運用ストアやData Lakeからデータウェアハウスにデータを取り込みます。データニーズが成長するにつれ、顧客はリアルタイムのインサイトを求めるようになります。予測分析のためにML機能との統合を試みます。次の段階では、データの収益化を目指します。Data MeshアーキテクチャやData Sharingを使用したさまざまなMulti-warehouseアーキテクチャを構築して、データフットプリントをスケールし始めます。組織内に大量のデータがあり、誰もがアクセスを必要とするため、アクセスの民主化が必要になります。そして今、Generative AIの時代が到来し、会話型エクスペリエンスの構築とさらなるデータの保存に取り組んでいます。

Generative AIアプリケーションのユースケースを見てみましょう。チャットベースのアシスタントを構築しようとする場合、まず大量のトレーニングデータをクラウドデータウェアハウスに保存する必要があります。これは、チャットアシスタントがデータウェアハウスに保存されているデータからユーザークエリに関するリアルタイムのインサイトを得る必要があるためです。これがGenerative AIが構築しているコンテキストです。何をするにしても、データが準備できていなければ、Generative AIアシスタントが使用するLarge Language Modelは期待通りの結果を出せません。Amazon Redshiftは、スケーラビリティを提供することで、そのような強固なデータ基盤を実現できると考えています。
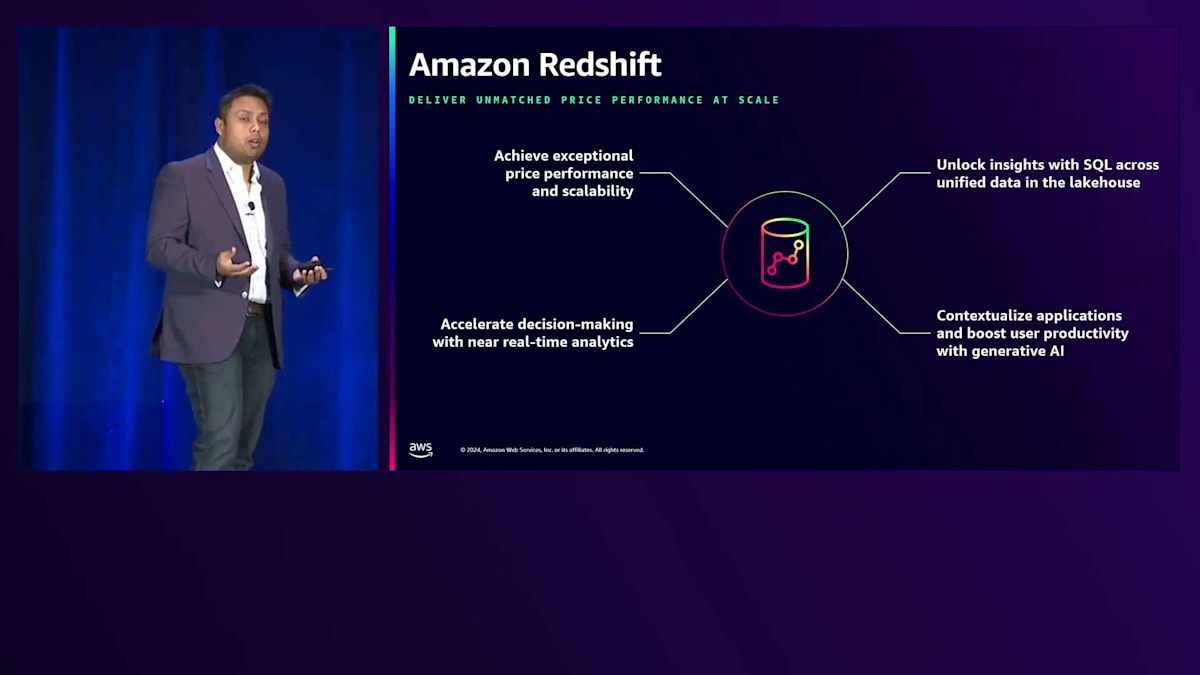
そのため、強固なデータ基盤が必要不可欠となります。 Amazon Redshiftは、増大するワークロード需要に対応できるスケーラビリティとコストパフォーマンスを提供します。リアルタイムでインサイトを得ることができ、本日発表したばかりの安全な機能を備えた統合Lakehouseへのアクセスを提供し、さらにGenerative AIアプリケーションに必要なコンテキストも提供します。これらすべてに加えて、Amazon Redshiftには組み込みのセキュリティ機能があり、今日では必須となっているセキュリティ面での安心感を提供します。
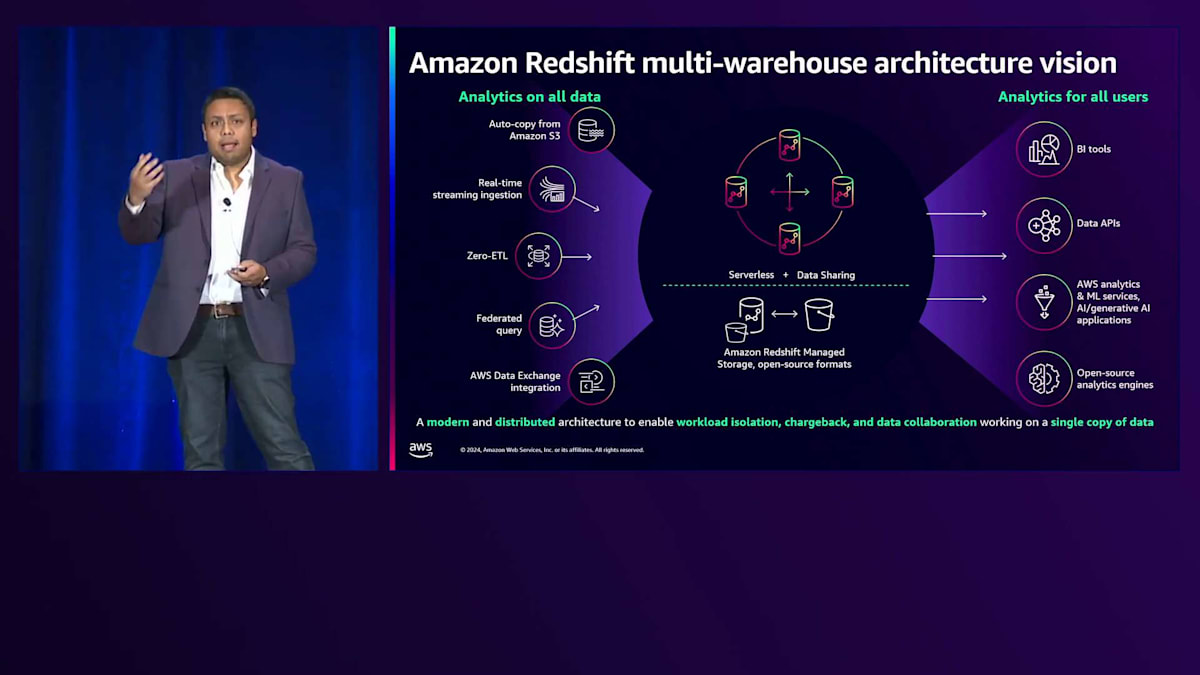
スケーラブルなデータプラットフォームを構築するための、この背後にあるMulti-Warehouseのビジョンとアーキテクチャをご紹介したいと思います。 このMulti-Warehouseのビジョンでは、様々なメカニズムを使用してデータ取り込みを行いながら、あらゆる種類のデータを分析できます。Data Lakeからのauto-copyやcopyジョブ、異なるデータストアからのZero-ETL、あるいはストリーミングアプリケーションがある場合はストリーミング取り込みを使用できます。このデータは、様々なBIツール、AIアプリケーション、API、またはサードパーティのエンジンを通じて利用することができます。このビジョンの中核となるのが、Amazon Redshift ServerlessとAmazon Redshift Data Sharingによって実現されるMulti-Warehouseアーキテクチャであり、本日のプレゼンテーションではこれに焦点を当てていきます。
Amazon Redshift ServerlessとData Sharingの機能強化


このビジョンには2つのコンポーネントがありますが、まず1つ目のコンポーネントであるAmazon Redshift Serverlessについてお話ししましょう。 2年前に私たちはAmazon Redshift Serverlessをリリースし、お客様はインフラストラクチャを管理することなく、簡単に分析を実行してスケールできるようになりました。現在、数万のお客様がAmazon Redshiftで数十億のクエリを実行しています。統計からわかるように、ほとんどのお客様は2024年には2023年と比べて4倍以上のクエリを実行しています。Amazon Redshift Serverlessは自動的にキャパシティをプロビジョニングしてスケールし、使用した分だけ支払えばよいため、大きな注目を集めています。

私たちはそこで満足せず、Amazon Redshift Serverlessをさらに強化し続けています。 安全な接続のためのAWS PrivateLinkのサポートを追加し、最大10倍のコストパフォーマンスを実現するAI駆動のスケーリングと最適化を最近導入しました。これについては、後ほどAshishが詳しく説明します。RPUの範囲を以前の2倍の1024 RPUまで拡大し、さらに10のAWS Regionにフットプリントを拡大しました。

2つ目のコンポーネントは、Amazon Redshift Data Sharingです。 Data Sharingを使用すると、実際にデータをコピーすることなく、複数のデータウェアハウス間でライブのトランザクションデータを共有できます。Amazon Redshift Data Sharingでは、プロビジョニングされたクラスターからServerlessエンドポイントへ、またはその逆、あるいは同じAWSアカウント内、AWSアカウント間、AWS Region間のあらゆる組み合わせでデータを共有できます。これにより、読み取りワークロードをスケールでき、組織がデータへのアクセスをスケールして民主化しながら、消費者に対して課金したい場合に必要となるワークロード分離とChargebackのようなユースケースを実現できます。また、パブリックデータセットを購読できるAWS Data Exchangeのサポートも追加しました。これは最も人気のある機能の1つで、お客様は毎日数千万のData Sharingクエリをamazon Redshiftで実行しています。

パフォーマンスに関して、お客様はAmazon Redshift Data Sharingを使用してマルチウェアハウスアーキテクチャを構築しており、主に2つのアーキテクチャが注目されています。1つは、同じ組織内の営業、マーケティング、研究などの異なるビジネスユニットが、同一アカウントまたはクロスアカウントで同じデータセットでコラボレーションを行うData Meshです。もう1つは、データを中央のData Warehouseに集約し、そこからBIツールやダッシュボードのユースケース向けにアクセス制御を民主化するアーキテクチャで、Amazon Redshift Serverlessを使用します。

ユーザーにアクセスを提供する必要があるダッシュボードのユースケースでは、Data Meshに似た人気のあるアーキテクチャであるHubとSpokeモデルを使用します。私たちはData Sharingの機能を継続的に強化してきました。今年初めには、コンシューマー側で共有テーブルに対するIncremental Materialized Viewのサポートを導入しました。これは、増分データを処理することで完全な更新を避けられるため、低レイテンシーを必要とするダッシュボードワークロードにとって重要です。また、データベースやスキーマレベルでのスコープ付き権限も導入し、既存のオブジェクトだけでなく、それらのスキーマやデータベース配下に今後作成される可能性のあるオブジェクトへのアクセス権も付与できるようになりました。
現在では、コンシューマー管理者がData Share内の特定のテーブルやビューへのアクセスをコンシューマーユーザーやロールに付与できるオブジェクトレベルの細かな権限制御が可能になっています。これらの権限を確認するために、SHOW GRANTSという新しいSQLインターフェースを導入し、特定のロールやユーザーに対するスキーマレベル、データベースレベル、オブジェクトレベルでの権限を確認できるようになりました。また、AWS Lake FormationとのData Sharing統合の対象地域を11リージョン追加で拡大しています。

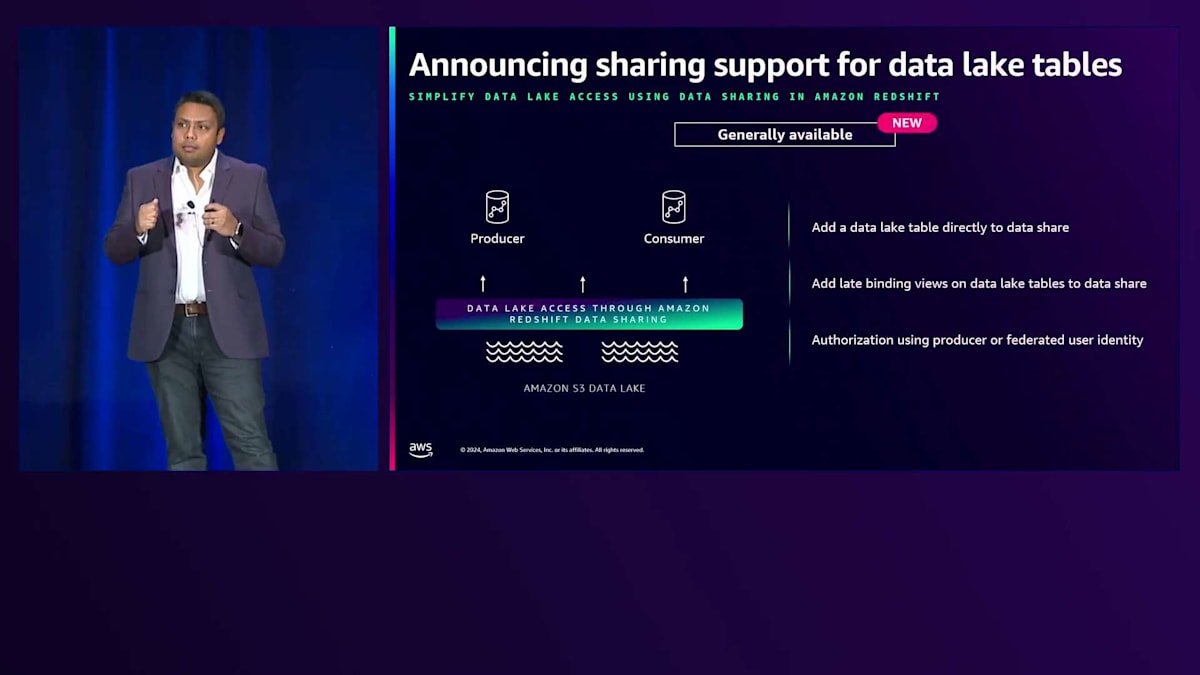
Data Sharingが広く使用されていることを考えると、パフォーマンスは極めて重要です。2024年には、2023年と比較してAmazon Redshift Data Sharingの読み取りクエリのパフォーマンスが、初回実行時で146倍、ストリーミングアプリケーション中にプロデューサーが更新される場合で最大4倍向上しています。イノベーションはパフォーマンスの改善にとどまりません。これまでData Sharingはネイティブテーブルのみをサポートしていましたが、現在ではData Lakeテーブルもサポートしています。Data Lakeテーブルを直接Data Shareに追加してコンシューマーにアクセスを提供できます。さらに、ネイティブテーブルと同様に、Data Lakeテーブル上にLate Binding Viewを作成してData Shareに追加することもできます。
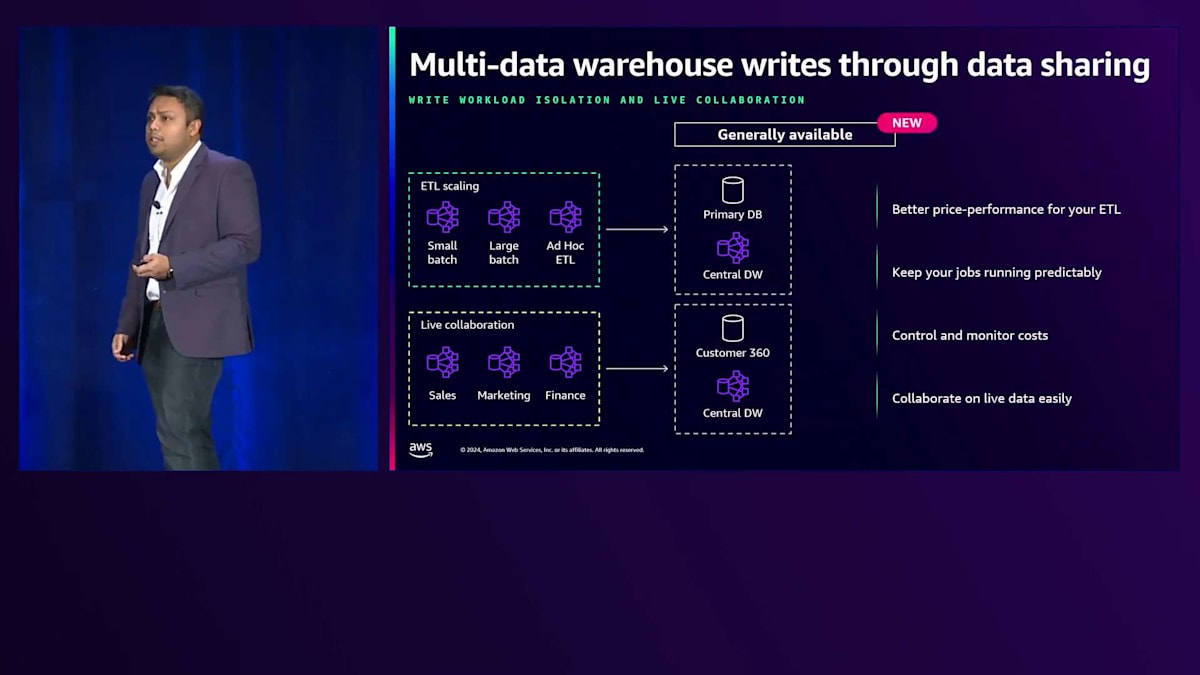
昨年のre:Inventでは、プレビュー段階であったData Sharingを通じたマルチウェアハウス書き込み機能という、Data Sharingでの書き込み操作を実行する機能を紹介しました。この機能が一般提供開始となったことをお知らせできることを嬉しく思います。この新機能により、異なるRedshiftウェアハウスから別のRedshiftデータベースへの書き込みが可能になり、わずか数クリックで書き込まれたデータがそのセットアップ内のすべてのウェアハウスで利用可能になります。Data Sharingでの読み取りワークロードのスケーリングと同様に、ETLワークロードと処理のスケーリングが可能になりました。これにより、各種ワークロードに異なるコンピュートを割り当て、分離し、適切にサイジングし、書き込み操作に関して各コンピュートの使用量に応じてChargebackすることができます。
マルチウェアハウスアーキテクチャの実装デモ



実装は簡単で、SQLインターフェースにもほとんど変更はありません。まず、Data Shareに追加するスキーマに対して、最低限のUsage権限を付与することから始めます。書き込み操作の場合は、Create、Alter、Drop権限を追加します。スキーマ配下のオブジェクトを追加でき、スキーマにScope権限を定義している場合は、個々のオブジェクトに対する権限を指定する必要はありません。ただし、必要に応じて、Write、Update、Insert、Delete操作を含む特定のオブジェクトに対する権限を指定することもできます。権限設定が完了したら、Namespace、アカウント、または一連のNamespaceのいずれかにアクセス権を付与します。クロスアカウントのData Sharingで書き込みアクセスを行う場合は、追加のステップが必要です。Producerの管理者は、デフォルトで設定されている読み取りアクセスに加えて、明示的に書き込みアクセスを許可する必要があります。


クロスアカウントのData Sharingにおいて、Consumer側では、ConsumerのSecurity Adminが Data Shareを承認する必要があります。これは、Consumerの管理者が管理する必要があるセキュリティチェックとして実装された拒否権として機能します。これが完了すれば、以前と同様にData Shareからデータベースを作成できます。これは権限の有無に関係なく実行できます。

権限付きで作成する場合、先ほど説明した詳細なオブジェクトレベルの権限を付与できるようになります。これにより、データベース全体へのアクセス権を付与していない場合でも、Data Share内の特定のオブジェクトへの詳細なアクセス権を提供できます。ルールを通じてアクセスを分離し、必要に応じて特定のユーザーに権限を付与することができます。このようなアクセス制御の柔軟性を提供しています。また、コンソールの操作性も改善し、より直感的に使えるようになりました。

ここで、Ashishに引き継ぎたいと思います。彼はAmazon Redshift Serverlessを使用したAI駆動のスケーリングについて、そしてマルチウェアハウスアーキテクチャの実例について詳しく説明します。データウェアハウスのキャパシティのスケーリングで苦労した経験のある方はどのくらいいらっしゃいますか?また、自社のデータウェアハウスがリソース不足、過剰プロビジョニング、あるいは比較的高額な費用がかかっていると感じている方はどのくらいいらっしゃいますか?多くの手が挙がっているようですね。ご安心ください - その問題の解決をお手伝いします。

SauravがAmazon Redshift Serverlessの利点について説明しましたが、新しいAI駆動のスケーリングと最適化により、10倍優れた価格性能比を実現できるようさらにスマートになりました。これは3つの具体的な方法で役立ちます。画面のスライダーで見られるように、コストの最適化、パフォーマンスの最適化、そしてその中間のバランスという価格性能目標を達成します。まず、ワークロードを包括的に分析し、ワークロードの要件とリソース要件について継続的に学習して、それに応じてサイジングを行います - 手動でのサイジングは不要で、真にServerlessです。次に、リソース集約型のクエリが突然発生した場合、価格性能目標に基づいて、それを可能な限り高速に実行するために、ほぼリアルタイムで十分なキャパシティを賢く割り当てます。
3番目のポイントとして、実際の運用環境においては、データが増加しても一貫したパフォーマンスを維持したいというニーズがあります。今日は1テラバイトのデータをクエリでスキャンしているかもしれませんが、明日さらにデータをロードすれば2テラバイトになるかもしれません。そのような状況でもビジネスに必要なパフォーマンスを維持する必要があります。このAI-driven scalingと最適化は、まさにこのようなシナリオに対応します。インテリジェントかつスマートに、Price-performanceターゲットを満たしながら、一貫したパフォーマンスを提供します。

コンソールを見ると、既存のBase capacityと、新たに追加されたPrice-performanceターゲットという2つのオプションがあることがわかります。要件に応じて、左側の最初のオプションはコストを最適化します - 優れたパフォーマンスを維持しながら、コストを優先します。限られた予算内で良好なパフォーマンスが必要なワークロードに適しています。一方、パフォーマンスを最適化するオプションは、コストよりもパフォーマンスを優先し、最高のパフォーマンスを提供しますが、コストは増加する可能性があります。このオプションは、FCCレベルのサポートが必要なワークロードや、可能な限り早くレポートを実行する必要がある場合など、クリティカルなワークロードに最適な結果をもたらします。
私たちの推奨は、すべてが動的な性質を持っているため、バランスを保つことです。いつでも変更は可能ですが、効果が現れるまでには時間がかかります。
Hiltonにおける Amazon Redshift Serverlessの活用事例

それでは、この仕組みについて詳しく説明させていただきます。 最初のコンポーネントは、Workload forecasterです。1日や2週間といった期間にわたってパターンを観察し、要件を継続的にモニタリングします。What-if分析を実行し、ワークロードのP50とP90を予測して、より高速に実行できるか、またはコストを削減できるかを判断します。Price-performanceターゲットを満たすための最適なキャパシティを見つけるためにワークロードを評価します。これは、優れた科学者の思考をシステムに組み込んだようなもので、サンプリングと分布予測モデルを使用してAI-driven scalingを実現しています。

2番目のコンポーネントは、リソースを大量に消費するクエリが入ってきた際のリアルタイム分析とスケーリングです。これは、AI-driven scaling最適化機能内のQuery forecasterによって実現されています。クエリのプロパティと必要なリソースを追跡し、What-if分析を実行して、キャパシティを増減することで、Price-performanceターゲットを満たしながら、速度向上やコスト削減が可能かどうかを判断します。これはSQLテキストに紐づいているわけではなく、より多くのリソースを必要とするMerge joinやHash joinなどの結合タイプのようなプロパティに基づいています。スキャンされるブロック数やDB値などの統計情報を考慮し、50以上のプロパティを追跡して、自動的に私たちに代わって判断を下します。
クイックなリアルタイム回答のための3つの特定のモデルがあります。Cacheモデルは、完全に一致するクエリに対して計算要件を記憶することで、繰り返しのクエリを処理します。ローカルで学習されたモデルは、クエリのテキストは同じでリテラル値が変化する類似クエリを処理します。全く新しいクエリに対しては、グローバルに学習されたモデルがあります。これらのモデルはすべて、実世界の課題解決を支援するために適切に構築・設計されています。

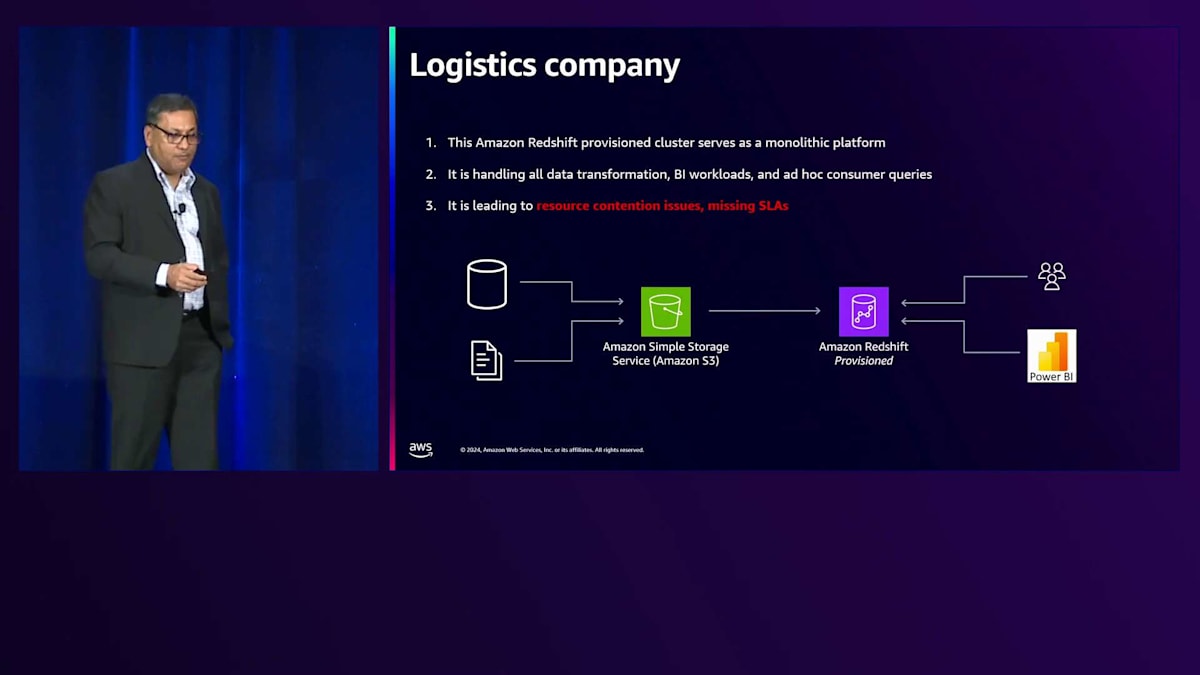
Amazon Redshift Serverlessのデータ共有について、そしてAIを活用してServerlessを強化し実世界の問題を解決する方法について学んできましたが、ここで実際のお客様の実装例をご紹介したいと思います。皆様のニーズに合うかどうかを評価していただけるよう、これらのアーキテクチャをご紹介します。 最初の例は、モノリシッククラスターを使用している物流企業です。これは業界でよく見られるパターンで、データがS3に格納され、Amazon Redshiftのプロビジョニングされたクラスターにデータをロードしてから変換を行うELTを実行します。これは上手く機能しますが、課題はデータセットが増大していることです。この物流企業には2種類のデータセットがあります。1つは入ってくる実際の注文で、これは小規模です。もう1つは荷物の位置や状態に関する継続的な更新を含む配送追跡の更新で、これは5倍の規模があります。同じユーザーがこれらのデータセットにクエリを実行することで、2つの要件が生まれます。さらに、データ変換が同時に行われており、データ自体も増加しています。
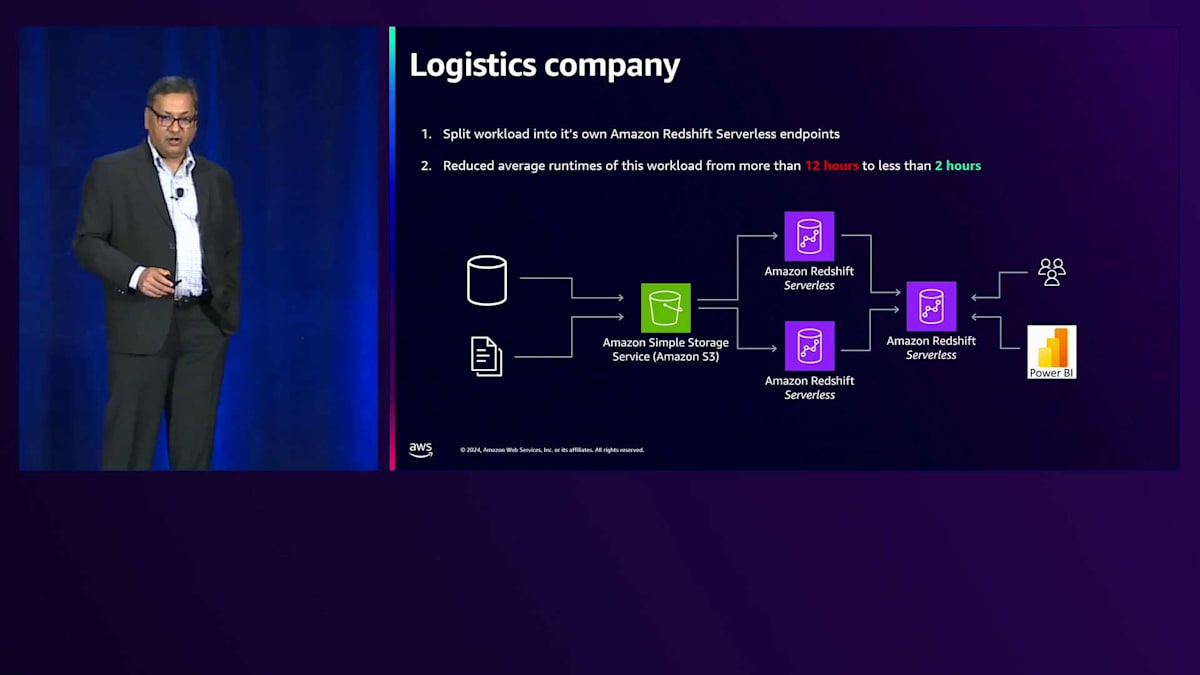
ビジネスの成長に伴いユーザーも増加し、クエリも増えていったことで、リソースの競合が始まりました。これが、このお客様が直面していた問題でした。私たちはお客様と一緒に座り、ワークロードを確認し、このマルチウェアハウスアーキテクチャを使用してワークロードを分割することを提案しました。
同じアプリケーションのワークロードを分割しました。2つのユースケース用のデータを、それぞれ別のAmazon Redshift Serverlessインスタンスにロードしました。これによりワークロード分離が実現できたからです。2つのデータセットはそれぞれのニーズに合わせてサイズ設定され、Serverlessの自動スケーリング機能を活用し、Power BIユーザーやアドホッククエリのためにデータ共有を使用しました。結果として、以前は最大12時間かかっていたお客様のワークロードが2時間で完了するようになり、パフォーマンスが向上し、ビジネスニーズを満たし、コスト削減も実現できました。
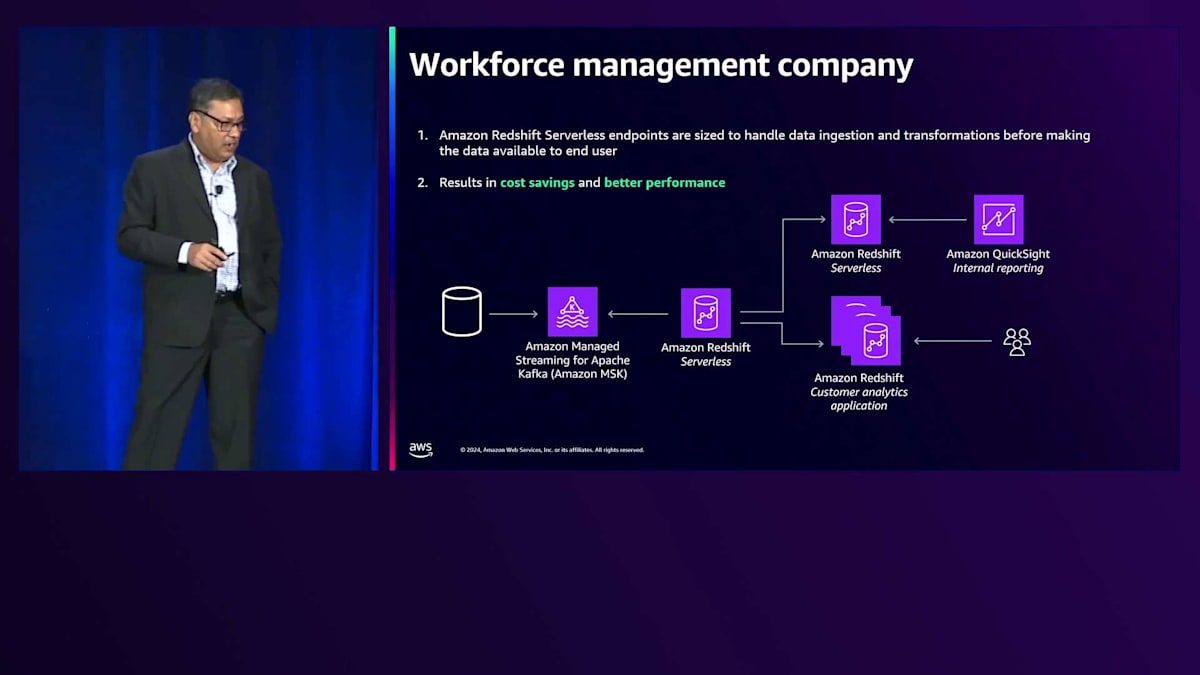
もう1つの例は、Amazon MSK(Amazon Managed Streaming for Apache Kafka)を使用して運用データセットを取り込み、Serverlessで変換を行っていた人材管理企業です。彼らには異なるニーズを持つ2つのユースケースがありました。1つは、コンプライアンス報告のために収集している労働力データに関する洞察を外部顧客に提供すること、もう1つは顧客分析のための社内ユーザー向けでした。彼らはインスタンス間でデータ共有を実装し、開始当初からコスト削減と優れたパフォーマンスを実現していました。
3つ目の事例は、不正検知分析のユースケースを持つ金融企業です。このお客様は、データが取り込まれてから5分以内にレポートを作成する必要がありました。社内のさまざまなユースケースに応じて、データの変換から、社内のアドホックユーザーや不正検知のための外部ユーザー向けの異なるレポーティングニーズまで、データセットは多岐にわたっていました。Amazon S3と運用データベースからAmazon Kinesis Data Streamsを使用してデータをロードし、真のData Meshアーキテクチャを採用して、Amazon Redshift ServerlessとAmazon Redshiftプロビジョニング型を実装し、2つのRedshift Serverlessインスタンス間でデータを共有してニアリアルタイムのレポーティングとアドホック分析を実現しました。
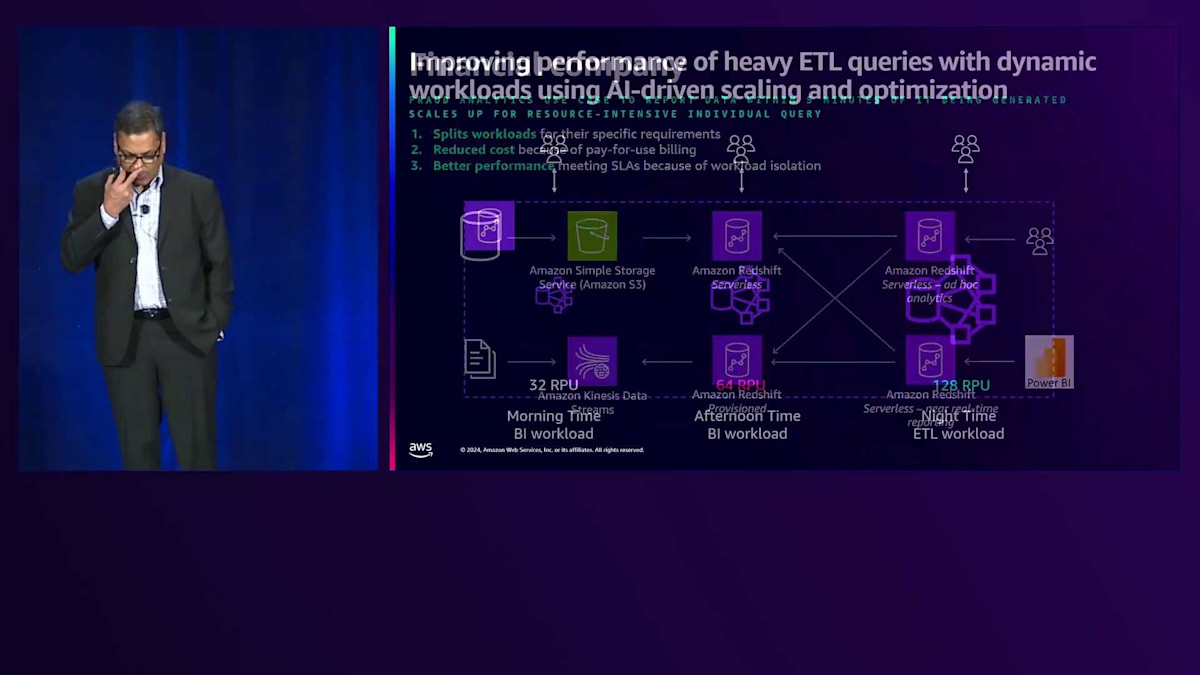
ワークロードの分離という利点により、各インスタンスが独立して稼働し、リソースの競合がほとんどまたはまったく発生しませんでした。自動スケーリング機能により、3つのServerlessインスタンスすべてが恩恵を受けました。特にBIワークロードでは、需要が変動的で、ユーザー数やデータ成長を予測できない性質がありました。結果として、パフォーマンスが向上し、5分以内というSLAを達成し、お客様にとって大幅なコスト削減を実現することができました。
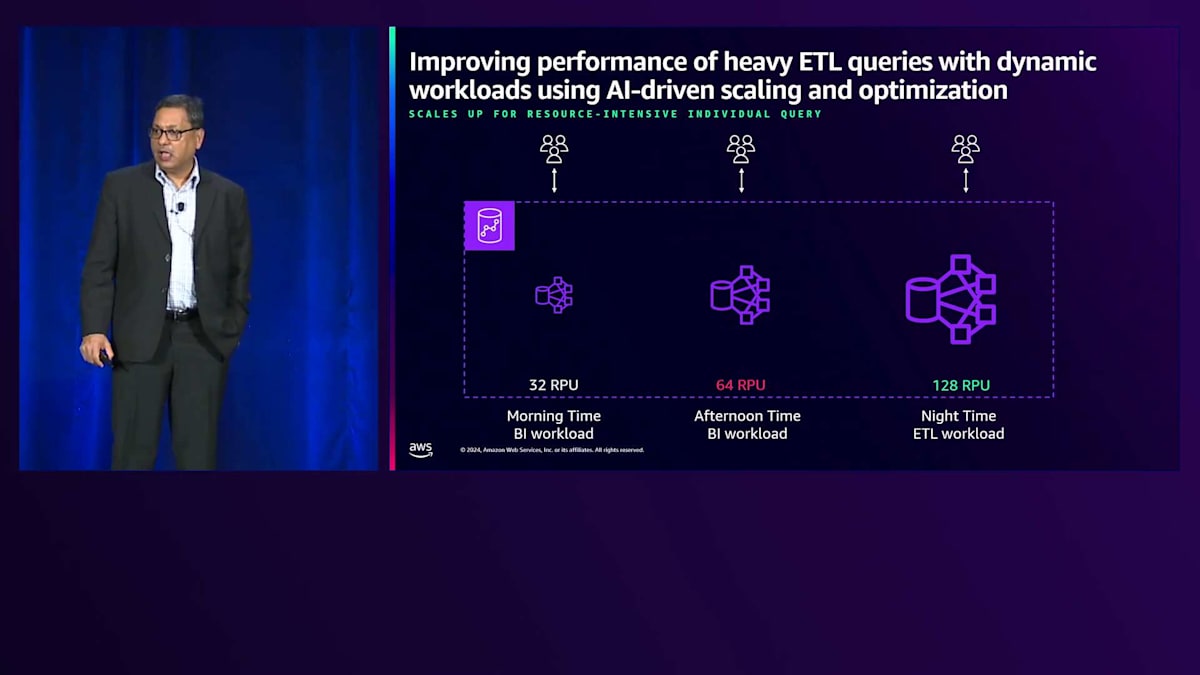
これらの実際のユースケースからいくつかのパターンが見えてきました。多くのお客様にとって非常に一般的なシナリオとして、ETLジョブは通常より多くのリソースを必要とし、特定の時間帯に実行されます。例えば、夜間のピーク時にはより多くの容量を必要とするETLワークロードがあり、日中にはより少ない容量で済むレポーティングやBIワークロードが実行されます。

キャパシティ管理の課題は、適切なサイジングにあります。オーバーサイジングしてより多くのコストを支払うか、アンダーサイジングしてパフォーマンスを犠牲にするか、あるいは今日の世界では非常に困難な手動での対応を行うかのいずれかです。Amazon Redshift ServerlessとそのAI駆動のスケーリングおよび最適化機能により、コストとリソースの測定単位であるRPU(Redshift Processing Units)を自動的に64まで拡張します。パターンを事前に学習するため、ETLジョブが開始される前でも、夜間に128 RPUまで自動的にスケールアップして、価格とパフォーマンスの目標を達成し、特にETLワークロード向けに一貫したパフォーマンスを提供できます。その後、自動的に32 RPUまで縮小します。これがAI駆動のスケーリングと最適化による最適なコスト達成の仕組みです。

ここで、私が説明したことを実際にデモンストレーションするために、Sauravに戻っていただきましょう。これらの素晴らしい機能について考えているかもしれませんが、実際の動作を見てみましょう。このデモは時間の制約とインターネット接続の問題の可能性があるため、録画されています。また、データのロードを待つ時間を省くために、いくつかのセグメントを早送りしています。ご覧のように、AI駆動のスケーリングが有効化された3つのServerlessエンドポイントがあります。右上にはデータのオーナーである、価格とパフォーマンスのバランスが最適化されたメインプロデューサーがあります。
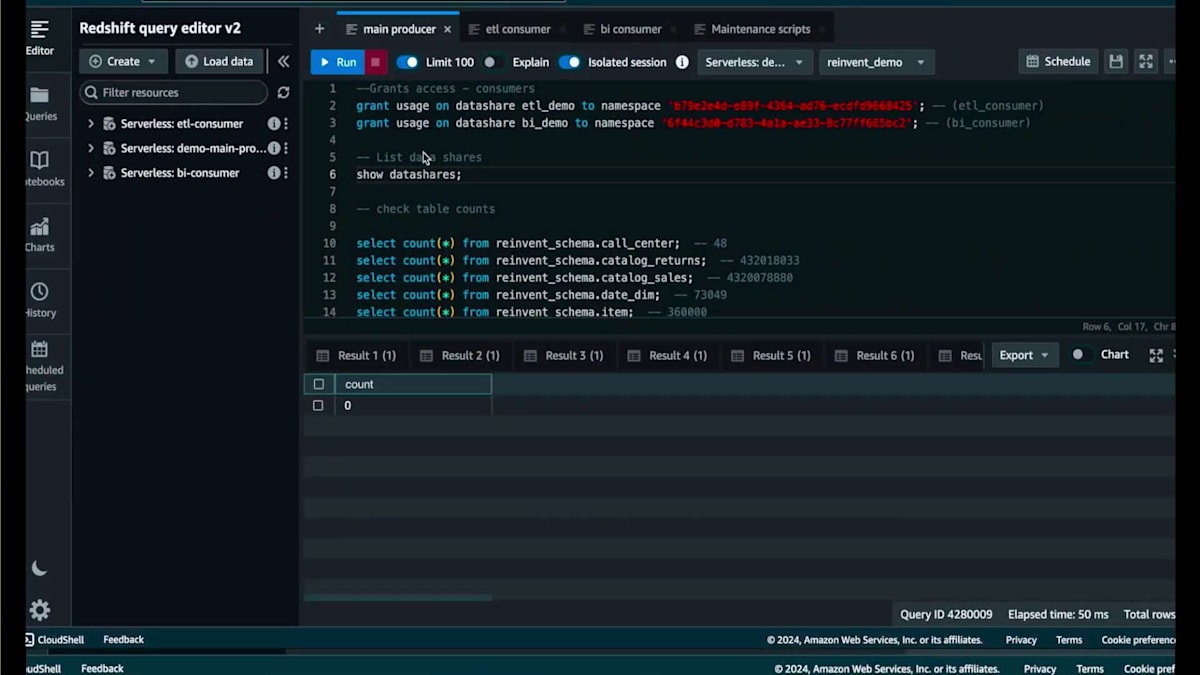
私には2つのConsumerがあります。1つは、ETL Demo Data Shareを通じて書き込み権限を持つコピージョブを実行するためのパフォーマンス重視のETL Consumer、もう1つは、BI Demo Data Shareから読み取り専用権限で集計クエリを実行する、アドホックユーザー向けのコスト重視のBI Consumerです。これら2つのData Shareに対して、それぞれのNamespaceに使用権限を付与しました。メインのProducerで「show datashares」コマンドを実行すると、これらを確認することができます。
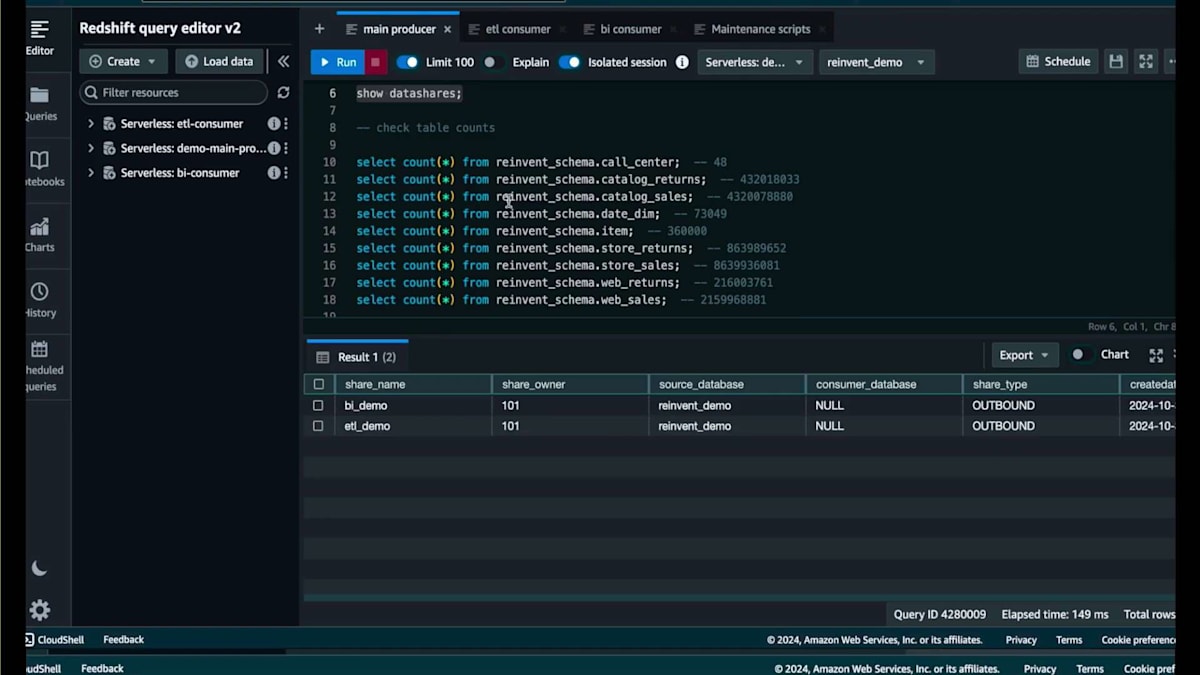
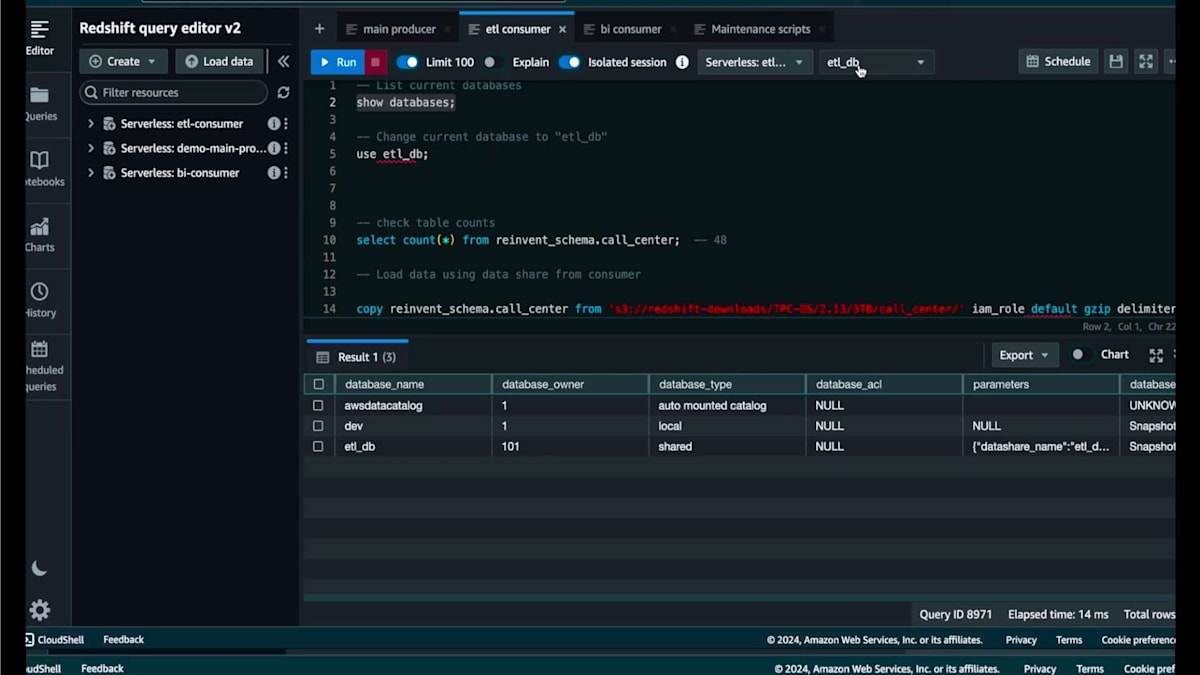
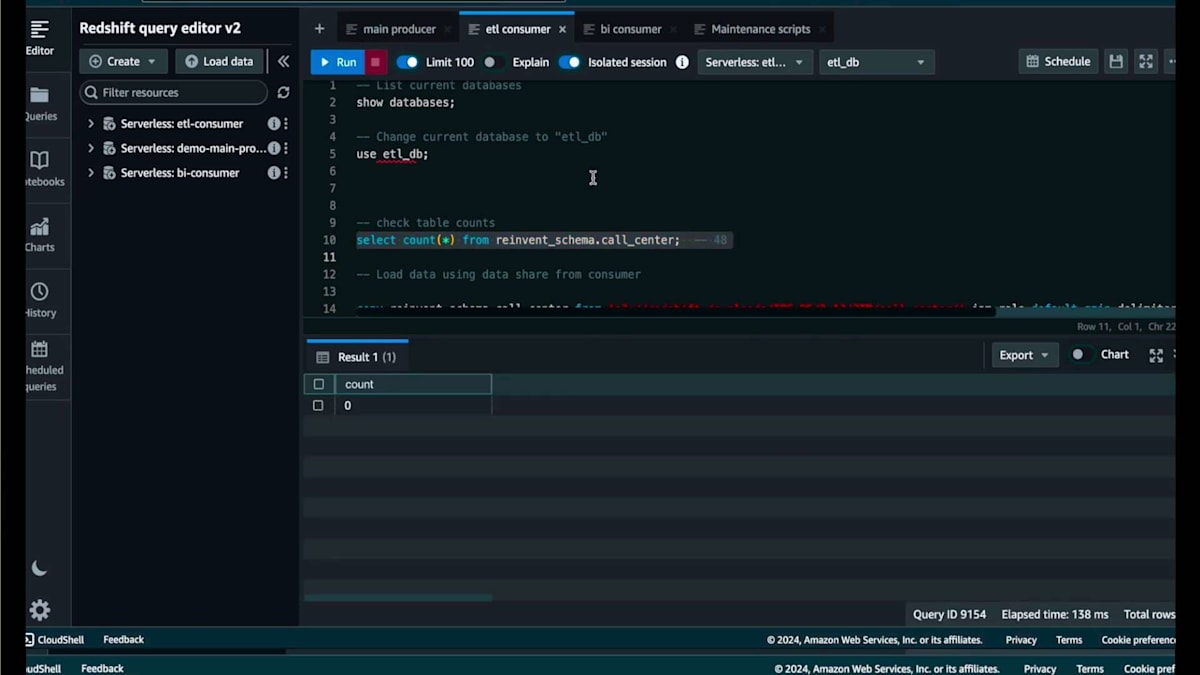
ここには小売企業のデータを含む一連のテーブルがあります。カタログデータ、コールセンターデータ、店舗とWebチャネルの両方の販売データとリターンデータが含まれています。まずはコールセンターのテーブルから始めましょう。現在、メインのProducerには0件のレコードがあります。これらのテーブルはすべて共有されており、書き込み権限を持つData Shareから作成されたETL Databaseを使用してETL Consumerで件数を確認しても、同じく0件となっています。
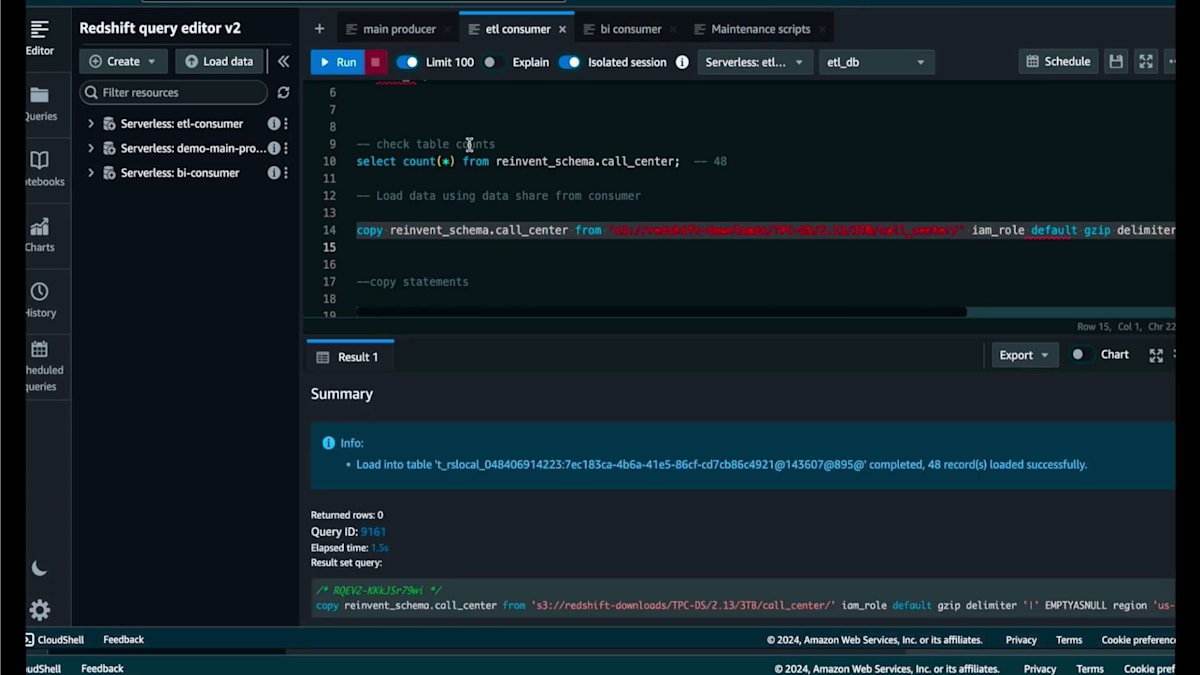
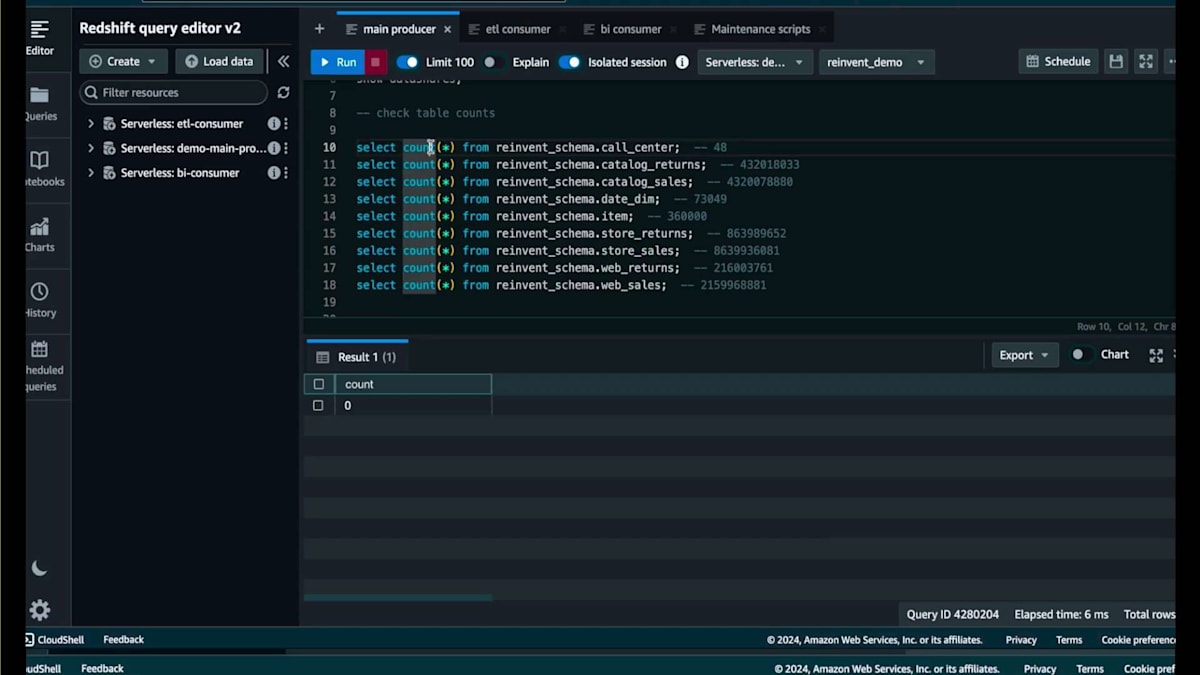
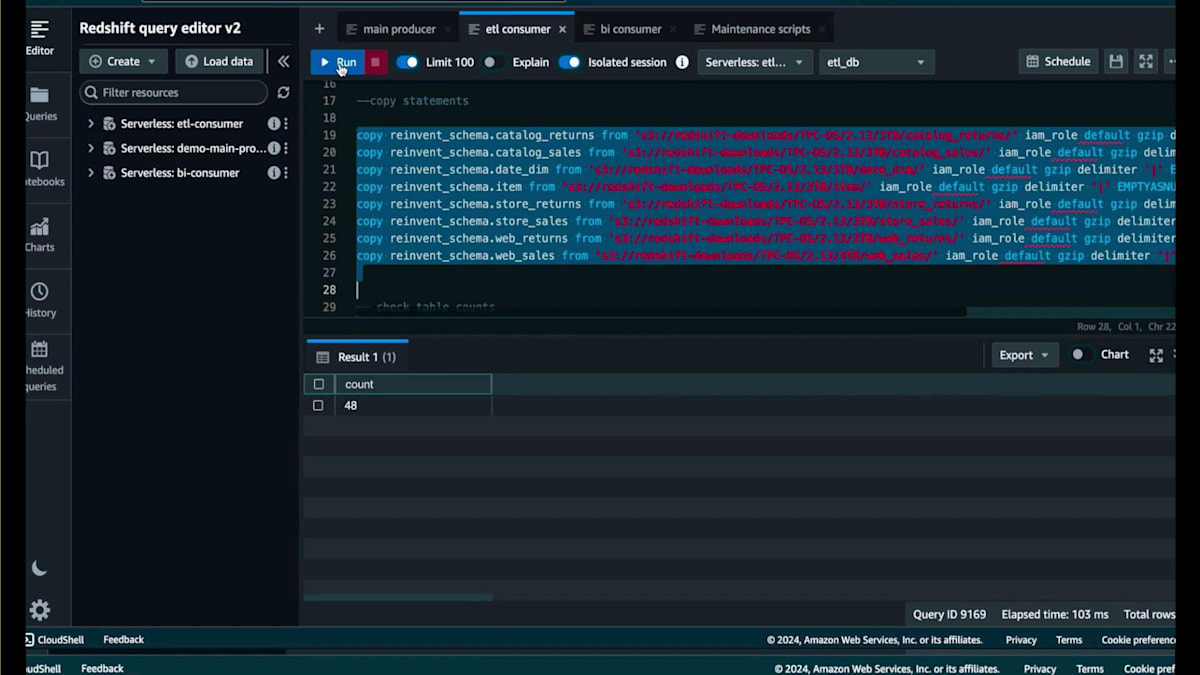
ここで、シンプルなCopyコマンドを使って40数件のデータを取り込んでみましょう。ジョブはすぐに完了し、48件のレコードが表示されます。再度件数を確認すると、48件のレコードが表示されます。メインのProducerに戻ると、先ほど0件だった同じテーブルが今度は48件を表示しています。さらにスケーリングのデモを続けましょう。Consumerに戻ると、数十億件のレコードを取り込む必要があるテーブルがあります。Copyジョブを開始し、実行中にSurplusダッシュボードとコンソールのリソースモニタリングページを確認してみましょう。
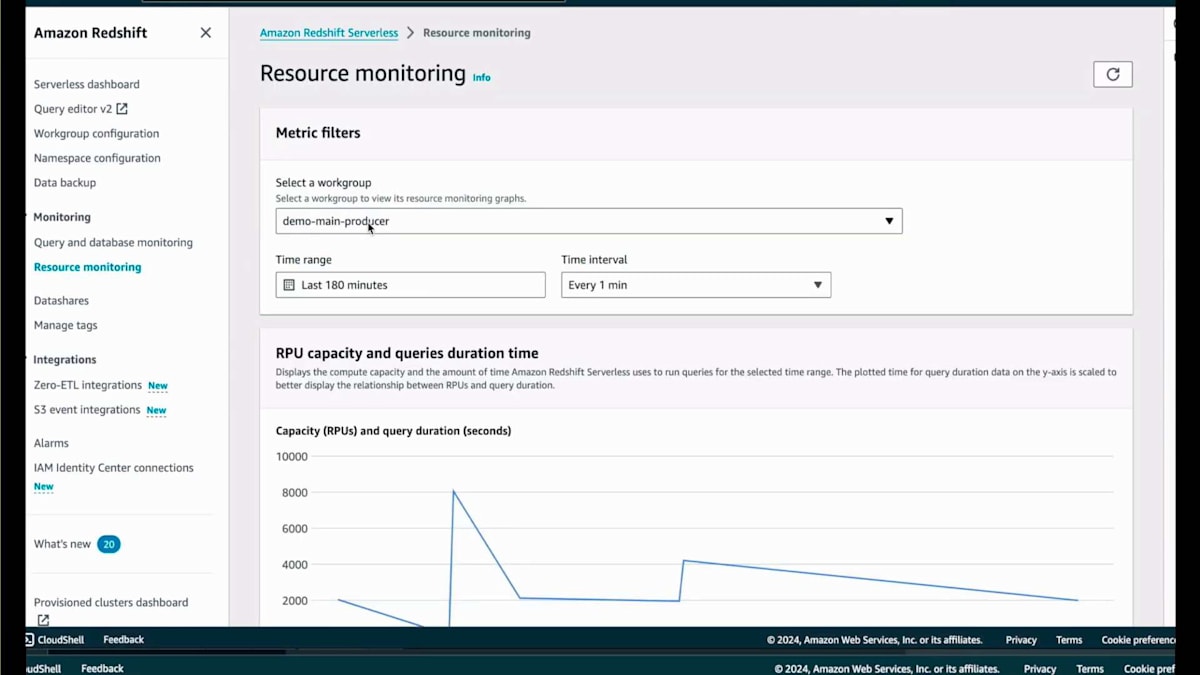
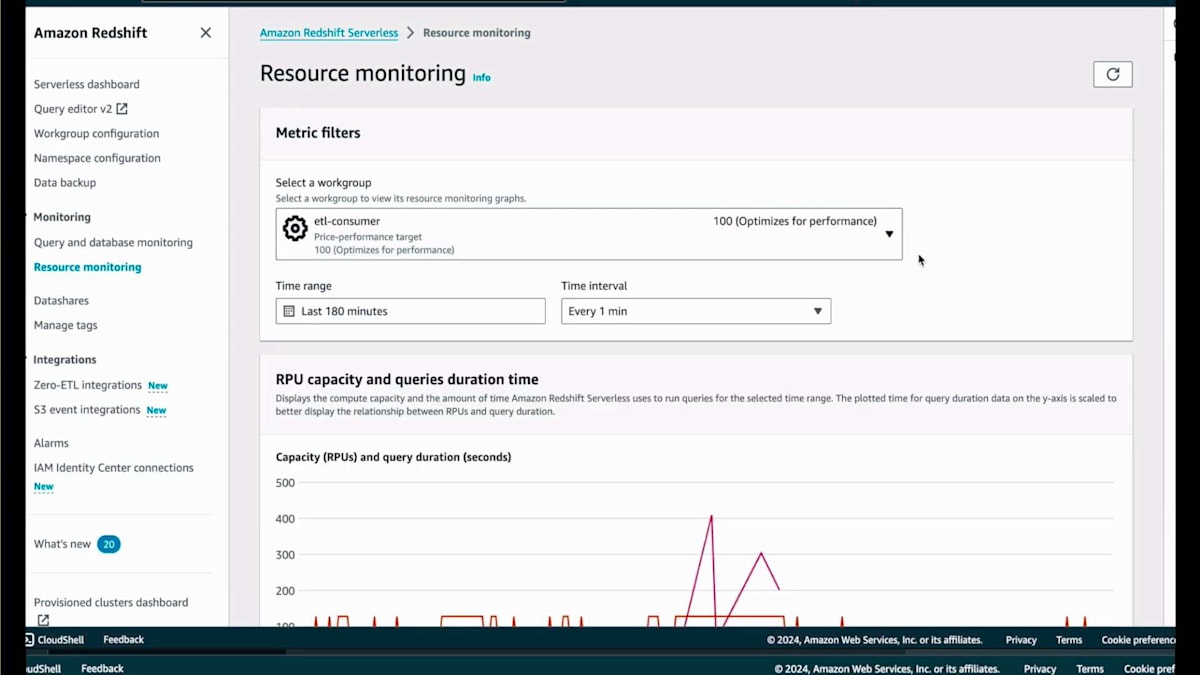
では、Surplusダッシュボードとリソースモニタリングページをご覧いただきましょう。リソースモニタリングページに移動すると、私が持っているさまざまなService Endpointとその設定が表示されます。ここでConsumerを選択します。Consumerを選択すると、RPU使用量とその時間経過に伴うスケーリングの様子が表示されます。しばらく操作を行い、複数回の反復を経て、これらのCopyジョブに対して最適化されたパフォーマンス設定が128 RPUであることを自動的に判断しました。もちろん、これはワークロードに応じた相対的な値であり、ワークロードのニーズによってはさらにスケールする可能性があります。
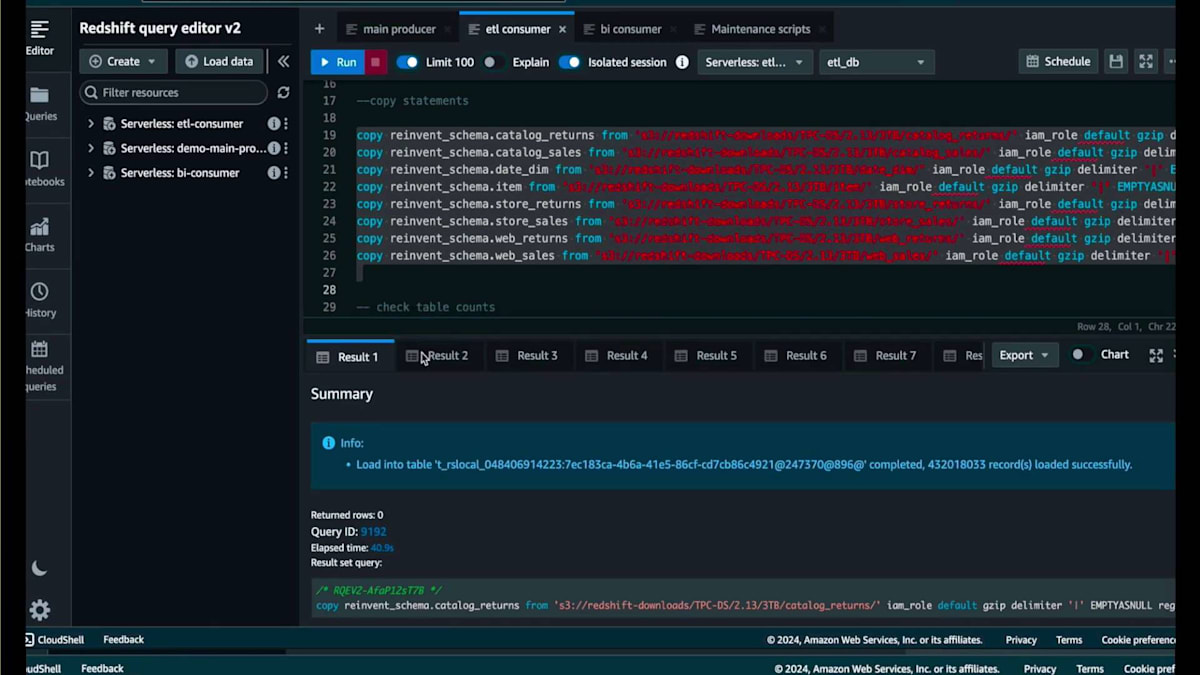
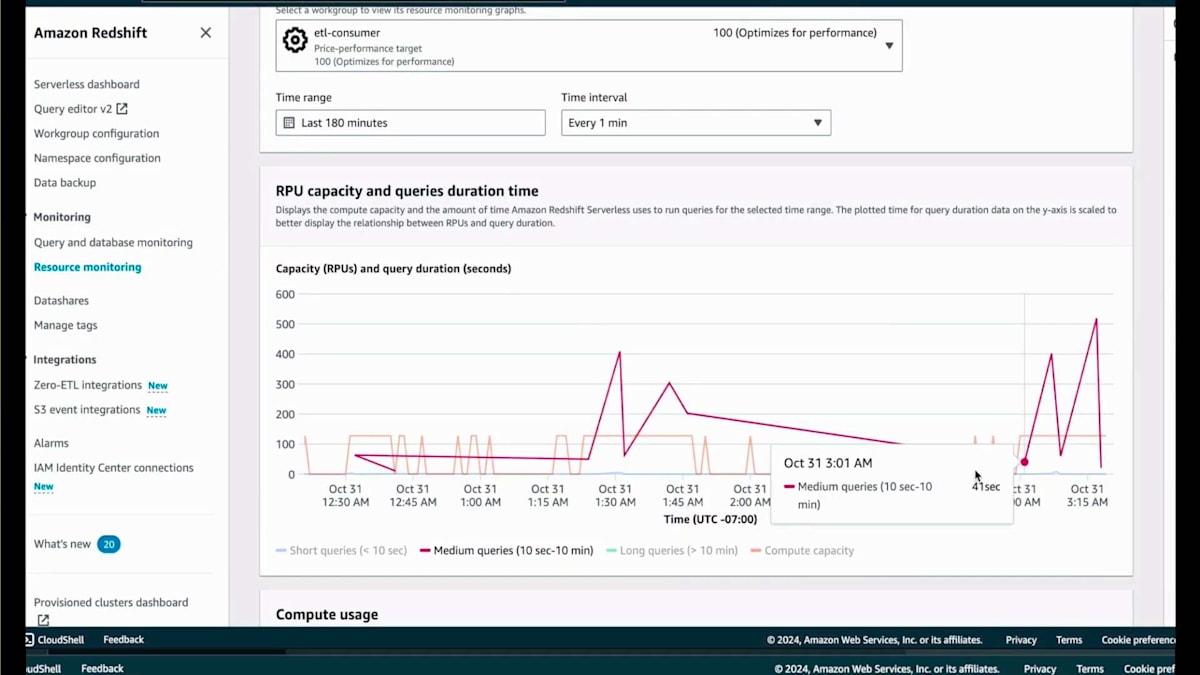
ここに戻ってきて、ジョブが完了したことがわかります。お待たせしたくなかったので、このデモを早送りしました。取り込まれたレコードは数十億件に及び、80億件、40億件、20億件といったテーブルもあります。このデータは取り込まれ、すぐに使用可能な状態です。そのダッシュボードに戻って時間を早送りすると、これらのCopyジョブを実行するために128 RPUが必要だと判断したため、再び128 RPUをベースとして使用していることがわかります。
それでは、Query Editor v2に戻って、Read Data Shareを使用しているBI Consumerを見ていきましょう。現在、Data Share bi_demoから作成されたBIデータベースにいます。これにはコンソールのドロップダウンからアクセスできますし、SQLの'use'コマンドを使用してもアクセスできます。ここには、現在と前年の売上を比較する集計クエリがいくつかあります。これらはすべて、先ほど取り込んだデータに対する読み取りクエリです。これらすべてを一度に実行しますが、実行には少し時間がかかります。コンソールに戻って、ServerlessのAI駆動のCompute Scaling機能によってコンピュートがどのようにスケーリングされているか、Resource Monitoringで確認してみましょう。
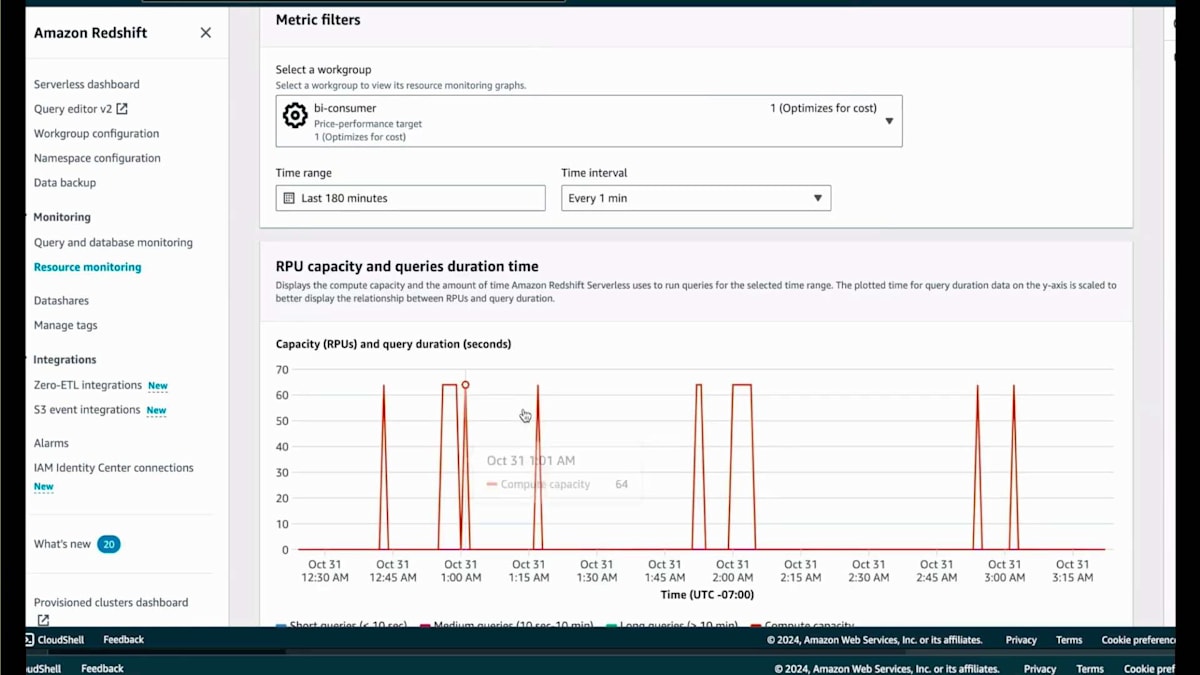
BI Consumerを選択すると、コスト最適化を指定したため64 RPUになっていることがわかります。これはアドホックユーザー向けで、コンピュートにあまりコストをかけたくないためです。そのため、最適なRPUを判断しますが、この場合は64 RPUとなっています。ここでデモを一旦中断して、カスタマースピーカーのPraneeth Mandadiさんをお招きし、Hiltonのデータプラットフォームアーキテクチャのスケーリングについての取り組みをお話しいただきます。
Hiltonのデータプラットフォーム進化とビジネス価値
皆様、こんにちは。HiltonのPlatform Architecture DirectorのPraneethです。本日は、Amazon Redshift Serverlessの実装におけるHiltonの取り組みと、Serverlessアーキテクチャとそのサービスが複雑な課題をどのように解決したかについてお話しさせていただきます。始める前に、皆様の中でHiltonや他のホテルに宿泊された方はどのくらいいらっしゃいますか?予約をすると予約データが生成され、実際にホテルに滞在したり予約を変更したりすると、裏側で大量のデータが生成されます。チェックアウト時には、より財務的な性質を持つ別のデータセットが生成されます。今日お話しするアプリケーションは、このような情報を活用して、不動産オーナーをサポートするための分析を行っています。

Amazon Redshift Serverlessは2年前に一般提供が開始されました。画面に表示されているスライドは、Serverlessへの移行を始める前の現行の実装を示しています。複数のビジネスアプリケーションが直接アクセスする2つのProvisioned Clusterがありました。これはDC2、DS2ノードタイプの時代に構築されたものです。1つはETLベースのクラスターでETLが実行され、もう1つは重要なアプリケーションをサポートするために特別に設定されたCompute Clusterでした。

さて、Serverlessの検討のきっかけとなったアプリケーションについて、アーキテクチャの観点から課題となった3つの基本要件がありました。まず、このアプリケーションは約80カ国の不動産オーナーが使用するため、世界中の35,000人以上のユーザーがアクセスできる必要があります。次に、その数に伴い高い同時実行性が求められます。つまり、いつでも100~150人の不動産ユーザーが同時にダッシュボードの実行ボタンをクリックする可能性があるということです。
ユーザーがExecuteボタンを押した時、30秒以内に結果が表示されなければなりません。これらのDashboardは複雑なクエリを生成します - 1つのDashboardで100から150行のSQLクエリが並列で生成されます。つまり、各Dashboardは結果としてAmazon Redshiftに対して数百のクエリを生成することになります。
私たちは、既存のRedshiftのProvisioned環境が、30秒以内に実行して結果を得る必要があるこれらの複雑なクエリをどのようにサポートできるか分析を始めました。これは高スケール、高パフォーマンスな環境であるため、これらの要件を満たすことができないことが明らかになりました。アーキテクチャの観点から重要な考慮事項の1つは、私たちのData Warehouseのデータ全てがRedshiftに格納されているということです。アーキテクチャ上の最大の課題であるデータのコピーを必要としないソリューションを開発したいと考えていました。
もう1つの重要な要因は、世界中にPropertyユーザーがいることです。例えば、中国から操作しているユーザーは、ESTタイムゾーンから見ると既に2時間遅れています。データのトランザクションをリアルタイムで取得できたとしても、そこからFactsとDimensionsを作成する必要があります。Serverlessを使用する前の実装では、このデータを全てMicroStrategyのCubeに取り込んでいました。MicroStrategyの上に構築されたこのアプリケーションは、2年分のトランザクションデータを取り込むのに8時間かかっていました。MicroStrategyへの取り込みとCubeの更新が完了する頃には、中国にいるユーザーは36時間前のデータを見ることになっていました。
このアプリケーションの重要な要件の1つは、太陽に従うことです。世界中のユーザーが36時間も待つのではなく、最大でも1~2時間以内に自分のデータを確認できるようにしたいと考えています。これを念頭に置いて、私たちはServerlessの検討を始めました。Serverless導入前に、既にProvisioned Clusterでデータ共有の部分をテストしていました。先ほどのスライドで説明したように、2つのProvisioned Cluster間でETLを実行していました。そのETL部分をData Sharing機能で置き換えることを試み、うまく機能しました。

私たちはData Share機能に精通しており、この製品要件が出てくる前からそれを探り始めていました。ServerlessとData Share、そしてその機能がこの問題を解決するのに役立つと考えました。そこでAWSチームの支援を受けて、この特定の問題を解決するためにどのようなアーキテクチャを開発できるか検討を始めました。 最初のPOCとして、専用のProvisioned Clusterをセットアップすることから始めました。Serverlessに移行する前にどの程度のストレステストができるかを確認したかったため、Provisioned Clusterを選択しました。7ノードの専用Provisioned ClusterをセットアップしてData Shareを有効にしました。同時接続数が少ない時は非常に良いパフォーマンスを示しましたが、ユーザーを追加して同時接続数が増えると、計算能力ではなくI/Oが懸念されたため、スケールできませんでした。
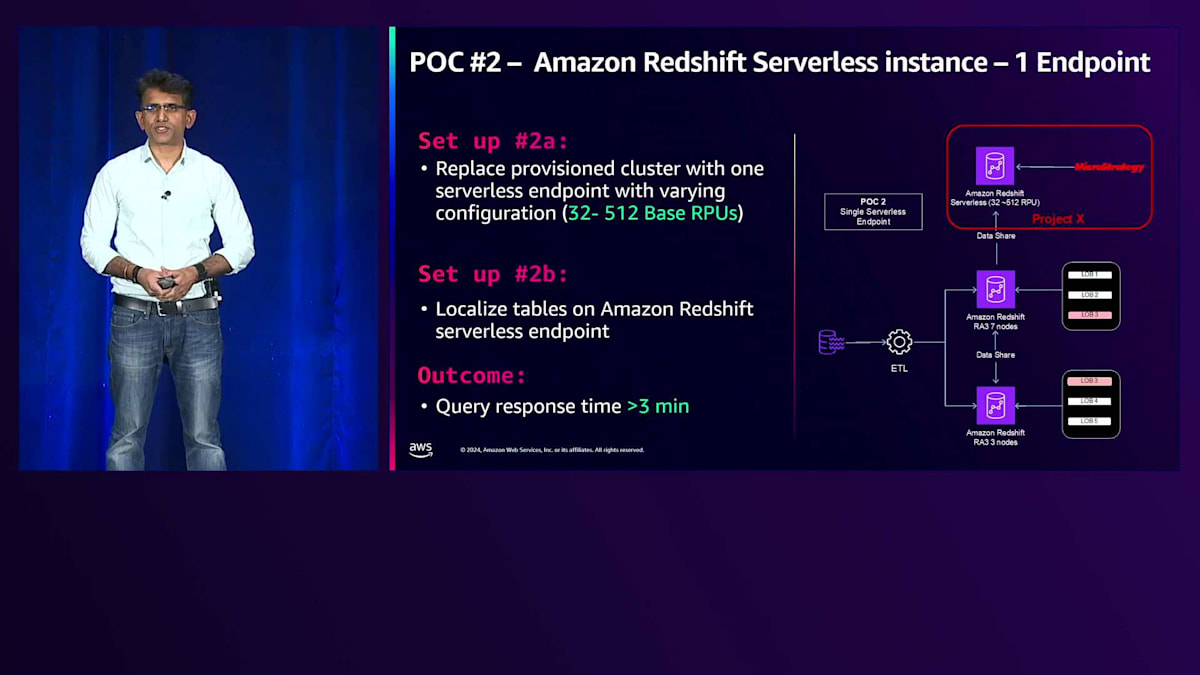
このタイプのワークロードに対して、Provisionedクラスターで得られた最大応答時間は約5分でした。これは30秒というSLA要件を満たしていませんでした。 そこで、2番目のPOCとして、ProvisionedクラスターをSingle-nodeのServerlessクラスターに置き換えることにしました。RPUはスケーラブルで、32から始めて最大512 RPUまで拡張し、様々なRPUレベルでアプリケーションをテストしました。Provisionedと比較すると、この構成の方が良好で、応答時間は約3分となりました。最初はData Shareを活用していましたが、高速であったものの、目標とする30秒の応答時間には届きませんでした。そこで、重要な数秒を短縮するため、Serverlessクラスター上でテーブルをローカライズすることを試みました。テーブルのローカライズ、データの共有、そしてProvisionedクラスター上で定期的にFactsテーブルとDimensionsテーブルを更新する方式を採用し、アプリケーションへの影響がないことを確認しました。ビューの切り替えメカニズムによるスイープ時にもアプリケーションへの影響がないよう配慮しています。

この構成でも応答時間は3分程度で、まだ十分ではありませんでした。そこで、Network Load Balancer(NLB)の配下に複数のAmazon Redshift Serverlessクラスターを配置する構成に拡張しました。
これまでは、RPUによって計算能力を変更する垂直スケーリングのみが可能でした。クラスターを上下にスケールできましたが、マルチクラスターによる水平スケーリングはできませんでした。今では、RPUを変更することで垂直方向と水平方向の両方でスケーリングが可能になりました。この構成をテストする際、3ノードクラスターから始めて5ノード、7ノードと増やし、その後3ノードと5ノードに戻すという検証を行いました。本番環境でこの検証を実施し、テストシナリオ全体を通じて同じデータ量とユーザー数を維持しました。
私たちのアプリケーションに最適なスイートスポットを見つけることができました。垂直スケーリングであれ、ノード数による水平スケーリングであれ、コンピュートには常にアプリケーションに適した数値があります。例えば、96 RPUのCPUリソースを必要とするアプリケーションの場合、200 RPUを提供しても、必要なコンピュート量は変わらないためメリットが得られない可能性があります。同様に、水平スケーリングでも、9つのクラスターを起動できたとしても、アプリケーションの計算要件とワークロードに基づくと、3ノードか5ノードで最適なパフォーマンスが得られる可能性があります。私たちのワークロード、ユーザーベース、データ量に対しては、96 RPUの5ノードクラスターが最適であることがわかりました。
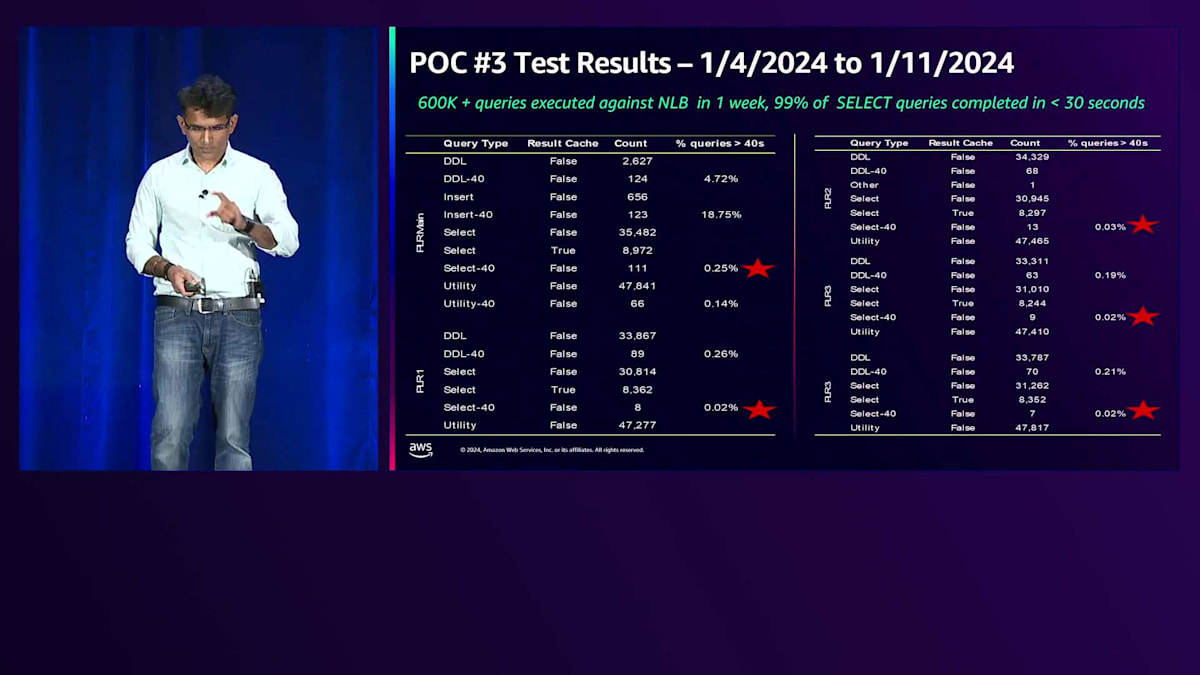
テスト結果の一つをご紹介します。 これは5ノードクラスターでの本番環境における1週間の実行結果です。この期間中、60万のクエリがこのクラスターにヒットし、NLBが5つのノードに均等に負荷を分散していました。アスタリスクが付いているエントリーは、42秒の制限時間を超えたSelectクエリを示しています。ご覧の通り、40秒を超えたクエリは1%未満で、ここには示されていませんが、30秒を超えたクエリも1%未満でした。つまり、60万クエリのうち99%が30秒以内に結果を返すことができました。これにより、私たちのアーキテクチャがスケーラブルで、応答時間要件を満たしながら目的を達成できることが証明されました。

このアーキテクチャを約9ヶ月前にデプロイしましたが、画面に表示されているメトリクスをご覧ください。10月の時点では、500人のユーザーと96 RPUの3ノードクラスターでスタートし、現在は5ノードに拡張しています。現在、このクラスターには31,000人のユーザーがデプロイされ、79カ国から24,000人のアクティブユーザーが64の本番環境のレポートにアクセスしています。大きな変更を加えることなく、このアプリケーションプラットフォームにダッシュボードを追加し続けてきました。デプロイから3、4ヶ月後に2ノードを追加しただけです。RPUは依然として96のままです。一時期128まで増やしましたが、必要性を感じなかったため元に戻しました。平均実行時間は10秒です。これらの数値はビジネスチームとプロダクトチームの月次ニュースレターから得たものです。
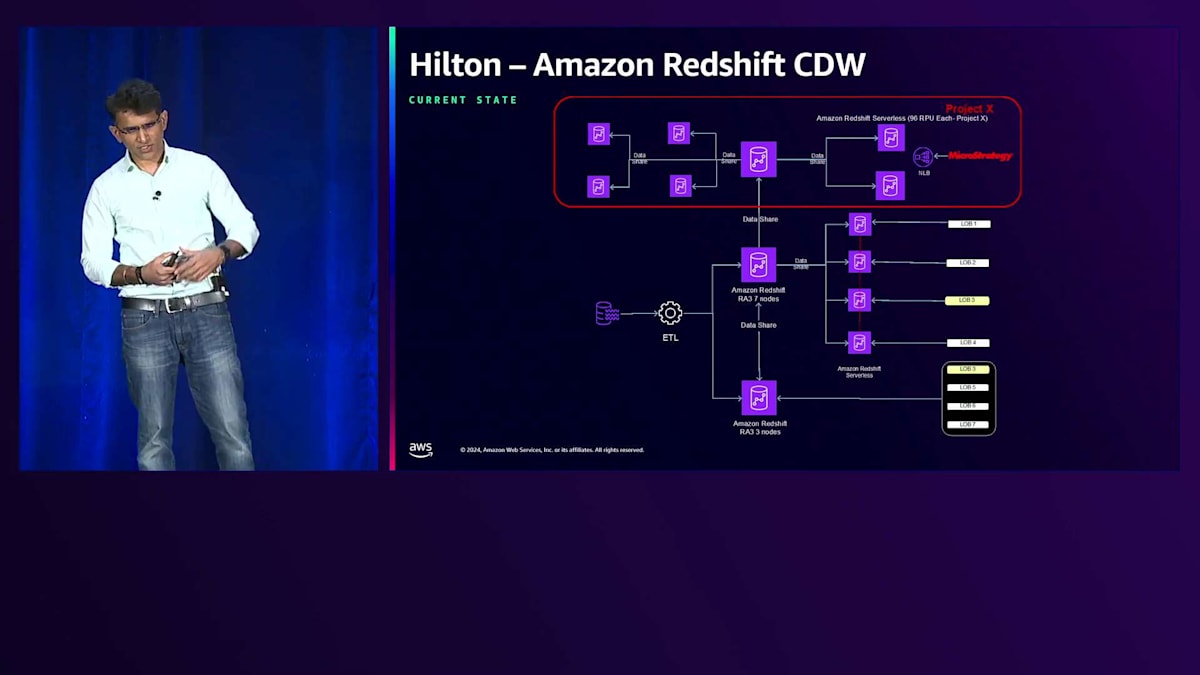
データプラットフォームとアーキテクチャの観点から、現在どのような状況なのでしょうか? 上部に表示されているのが、先ほど説明したアプリケーションの現状です。5ノードと説明しましたが、7ノード表示されているのが見えると思います。これは、スタンバイとして2ノードを追加したためですが、これらはパラメータグループには追加していません。Data Shareの一部としてノードを追加しましたが、セットに追加していないため、コストは発生していません。ワークロードが増加したり必要性が生じたりした場合は、数分で有効化できる状態です。
下部のセクションについて、最初のスライドを思い出していただければ、2つのプロビジョンとビジネスラインLOBが直接クラスターにアクセスしている様子をお見せしました。現在、ETLクラスターの1つについて、HubとSpokeモデルの実装を開始しています。ワークロードを分離し、専用の単一ノードクラスターをスピンアップすることで、ETLに影響を与えることなく、消費クエリにも影響が出ないようにしています。
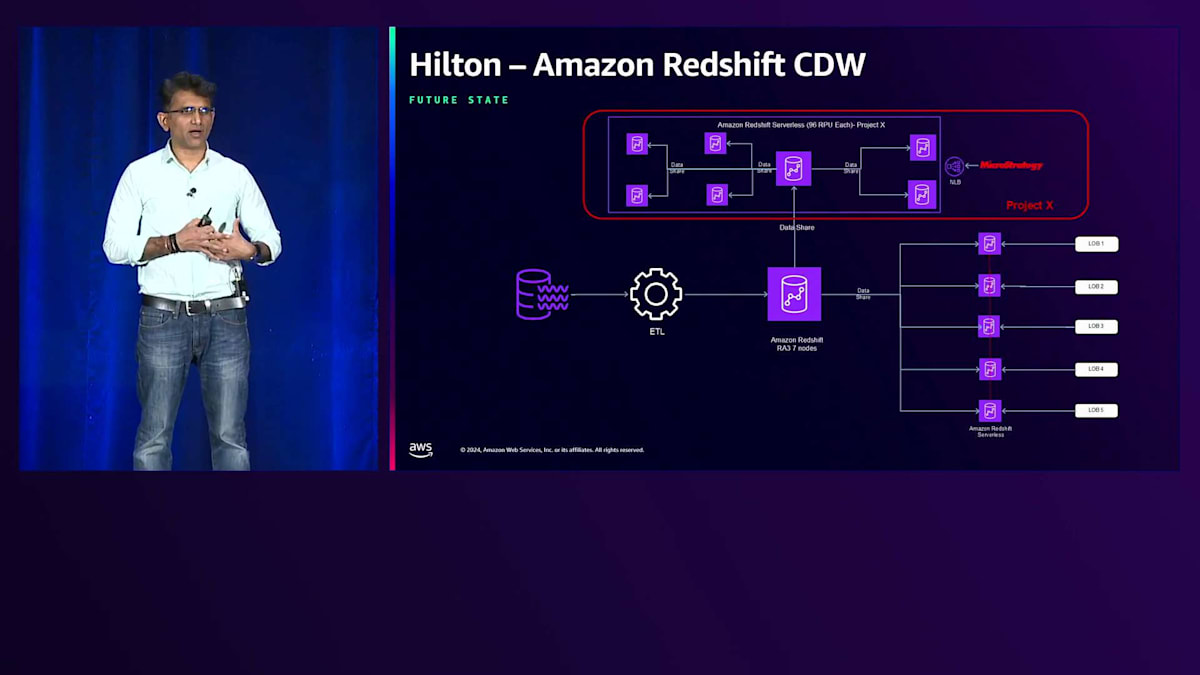
これが現状ですが、最終的に達成したいターゲットアーキテクチャがあります。すべてが整った状態で、ETLを効果的に実行できるよう、コアとなるETLクラスターに消費アプリケーションからのアクセスを一切させたくありません。私たちは22分ごとにETLを実行し、ウェアハウスへのニアリアルタイムなデータ取り込みを行っています。ETLと消費クエリが互いに影響を与えないようにしたいのです。消費者の中には、単純にクエリを実行する技術系ユーザーもいれば、独自のETLを実行するユーザーもいます。
MeshモデルやHubとSpokeモデルについて説明したServerlessの実装に関するプレゼンテーションを思い出していただければ、これはHubとSpokeアーキテクチャを表しています。サーバー上で利用可能になった新機能により、Data Shareにデータを書き込むことができるようになり、これをData Meshアーキテクチャに変換できます。以前は制限がありましたが、Data Shareに書き込み機能が追加されたことで、組み合わせてMeshアーキテクチャに変換できるようになりました。
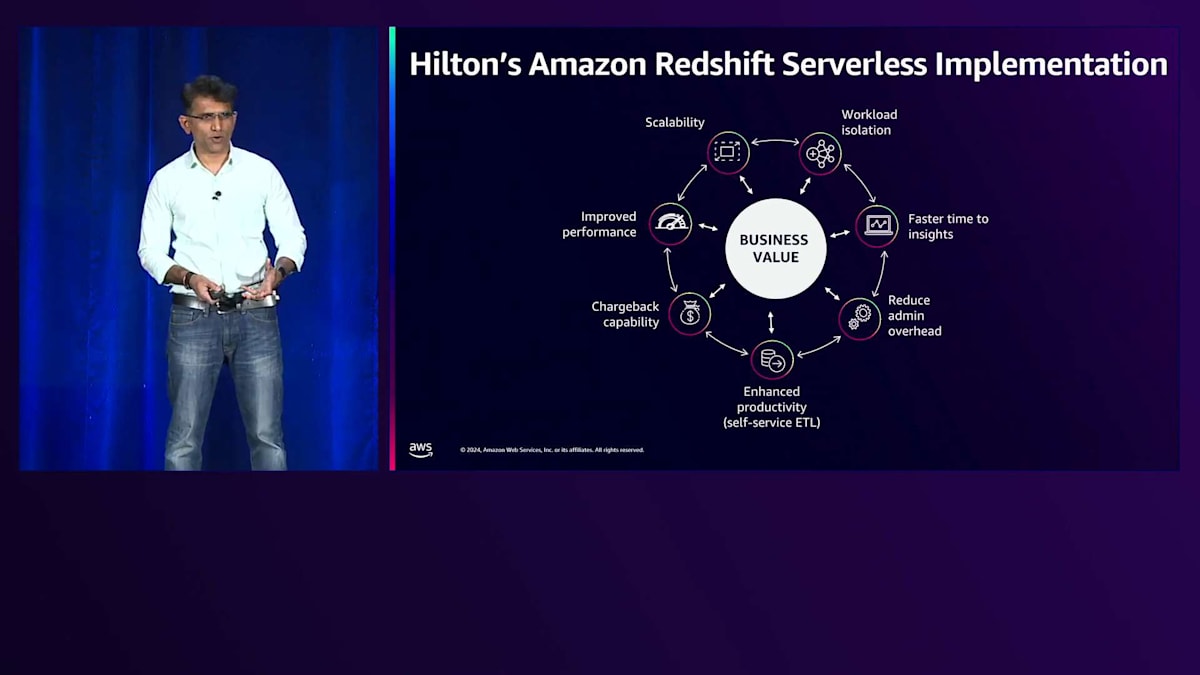
これらのアーキテクチャソリューションを実装して成功を収めましたが、具体的にどのようなビジネス価値が得られているのでしょうか?VPにプレゼンする際、最初に問われるのはビジネス価値についてです。そこで、この点について説明させていただきます。このHubとSpokeモデルのアーキテクチャで、どのような価値が得られているのでしょうか?まず第一に、ワークロードの分離です。ETLと利用者のクエリが同じクラスターに集中することは、アーキテクトが日々直面する大きな課題の一つでした。ServerlessのHubとSpokeモデルでは、このワークロードの分離が実現され、ETLがスムーズに実行されることでビジネスサイドも満足しています。
二つ目のメリットは、Data Shareを活用することで、より迅速なインサイト取得が可能になった点です。データ共有によってリアルタイムでデータにアクセスできるため、ユーザーは自分のクラスターにデータが移動するのを待つ必要がありません。専用クラスターを用意することで、セルフサービスアーキテクチャを実現し、より明確な責任分担が可能になりました。最初は3ノードから始まり、1-5ノード、1-7ノード、そして2つのスタンバイノードへと発展しました。ノードの追加や削除、RPUの増減にかかる時間はわずか3-5分で、従来のProvisioned Clusterと比べて大幅に短縮されています。
セルフサービスETL機能により、生産性も向上しました。ETL開発者を含むビジネスアプリケーションに専用のクラスターと実験環境を提供することで、これまでの制約や規制から解放されました。最大のビジネス価値は、チャージバック機能にあります。Provisioned Clusterでは、各アプリケーションがプラットフォームのコストにどの程度寄与しているかを把握することが不可能でした。現在は、Serverless実装により、各サービスクラスターごとのコストが明確になり、アプリケーションチームと協力してコストの最適化と削減が可能になりました。このパフォーマンスと拡張性の向上には、さらなるメリットも伴っています。
大きな利点は、スケーラブルなコンピュートRPUによるパフォーマンスの向上で、スケールアップとスケールダウンが可能になったことです。一般提供が開始された新機能により、RPUを変更することなく、AIが価格とパフォーマンスを調整できるようになりました。これは、先ほど議論した拡張性に関するもう一つの利点です。このクラスターをアーキテクチャとしてスケールするのが非常に簡単になり、データベース管理者と何時間も費やしてスケールアップやスケールする必要がなくなりました。これがHiltonの取り組みと、Amazon Redshift Serverlessとこの機能が問題解決にどのように役立ったかの簡単なまとめです。ありがとうございました。ここでAshishにバトンタッチします。
マルチウェアハウスアーキテクチャ実装のベストプラクティス


PraneethとHiltonチームには、私たちを信頼し、Amazon Redshift ServerlessとData Sharingを実装して、ビジネスを支援しながら顧客の生活を向上させてくれたことに感謝します。次に、実装から学んだベストプラクティスについてお話しします。マルチウェアハウスアーキテクチャとデータ共有を実装する際の最初のプラクティスは、各データセットとData Shareの所有権を明確に定義することです。責任の所在を明確にするため、データスチュワードを任命することが重要です。セキュリティとガバナンスモデルを導入し、それらを適切に文書化してください。二つ目のプラクティスは、Data Meshアーキテクチャに基づいたリアルタイムデータ共有の実装です。これにより、データの民主化が促進され、ユースケースが増加し、組織やビジネスで生成されるデータからより多くの価値を引き出すことができます。

AIによる自動スケーリングと最適化により、安定したワークロードでも、変動するワークロードでも、予測不可能なワークロードでも、サイジングの悩みから完全に解放されます。最適な価格性能比を実現できます。Amazon Redshift QMRルールを実装することで、リソースをコントロールし、最高のパフォーマンスを得るためにクエリを監視できます。データセキュリティを確立し、最小権限の原則に基づいたIAMロールを使用し、Amazon AWS Lake Formationを活用してセキュリティとガバナンスを実装します。これにより、Data MeshとHub and Spokeアーキテクチャの両方に対応できます。

コスト管理は誰もが気にかけている事項だと思います。AWS Anomaly Detectionを実装することで、コストや使用量に関する予期せぬ事象が発生した場合、異常として検知されます。データシェアの自動レポートを生成し、Amazon Redshift Serverlessデータウェアハウスが提供するコスト管理機能を活用しましょう。これを実装することで、常に予算内に収めることができます。最大RPU時間の制限設定、最大RPU容量の設定が可能で、スケーリングをコントロールできます。最後に、ユーザーからレビューとフィードバックを得ることが重要です。各ビジネスはユニークであり、ビジネスや個人のニーズも独自のものです。ユーザーと対話し、フィードバックを得て、時間とともにプラクティスを進化させていきましょう。
Amazon Redshift Serverless活用のためのリソースと結び



モノリシックアーキテクチャからこのマルチウェアハウスアーキテクチャへの移行は、Amazon Workload ReplicatorやTest Driveを使用してテストできます。環境内のワークロードの再生を非常に簡単にキャプチャできます。Amazon Redshift Serverlessを初めて利用される方には、300ドルの無料クレジットが用意されています。ここでいくつかのリソースをご紹介します。1つ目はAIによるスケーリングと最適化に関するブログ、2つ目は2つのノートブックを含むGitHubリポジトリです。価格性能の向上を実際に体験できます。これらのノートブックをダウンロードし、Amazon Redshift Serverlessにインポートして実験してみてください。AIによるスケーリングと最適化がどのように機能するか、そして詳細なブログでも説明されているマルチウェアハウスアーキテクチャを使用して適切なワークロードをどのようにスケールするかを確認できます。
本日はご参加いただき、ありがとうございました。モバイルアプリケーションでフィードバックをご記入ください。質疑応答は会場の外で承ります。本日は誠にありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion