re:Invent 2023: AWSのレジリエンス分析フレームワーク - 理論と実践例


はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - A consistent approach to resilience analysis for critical workloads (ARC313)
この動画では、AWSのレジリエンス分析フレームワーク(RAF)について詳しく解説します。第二次世界大戦の「消えた弾痕」の話から始まり、RAFの理論と実践的な適用方法を学べます。顧客事例を通じて、constant workパターンやヘッジングなど、具体的なレジリエンス向上策を紹介。さらに、Amazon Route 53 Application Recovery ControllerやZonal Shiftなど、AWSサービスへのRAFの実装例も解説します。レジリエンスを「目的地ではなく旅」と捉える新しい視点を得られる貴重なセッションです。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
AWSのレジリエンス戦略:Application Recovery Controllerの紹介

Arc 313へようこそ。私はJohn Formento, Jr.で、AWSのResilience Infrastructure and Solutions TeamのPrincipal Product Managerです。私たちはApplication Recovery Controllerを当社のサービスの1つとして開発しています。ご存知の方はすばらしいですし、そうでない方にもぜひチェックしていただきたいと思います。これはレジリエンスを支援するリカバリーツールです。今日は、Mike HakenとMike Golovnykhに共同発表者として参加してもらえることを嬉しく思います。彼らは登場時に自己紹介をします。

まず、いくつかの事務連絡からはじめましょう。 最近、AWS resilience lifecycle frameworkをリリースしました。QRコードをスキャンすると、ホワイトペーパーにアクセスできます。このフレームワークは、レジリエンスの取り組みをどこから始めるべきかという多くのお客様からの問い合わせに応えて開発されました。ホワイトペーパーでは、皆さんが使えるフレームワークのステップを概説しています。今日のセッションでは、そのライフサイクルの設計、実装、運用の段階に焦点を当てます。

AWSがレジリエンス指向のサービスを幅広く提供していることを簡単に強調しておきたいと思います。それぞれについて詳しく説明することはしませんが、興味のあるものを写真に撮って調べてみることをお勧めします。ただし、Application Recovery Controllerについては特別に言及しておきます。これは間違いなくチェックする価値があります。
「消えた弾痕」から学ぶレジリエンス分析の重要性

プレゼンテーションを始めるにあたり、「消えた弾痕」の話を聞いたことがある人はいますか?数人の方が聞いたことがあるようですね、素晴らしいです。この話は、同僚のMikeが数ヶ月前に教えてくれるまで私も知りませんでした。これは第二次世界大戦時のP-38 Lightning長距離戦闘機についての話です。米国政府は、これらの飛行機を空中に留め、戦闘任務後に安全に帰還できるようにする必要がありました。課題は、これらの飛行機の機動性や燃費を損なうことなく、より耐久性を高めることでした。

政府は、優れた数学者で統計学者のAbraham Waldが率いるStatistical Research Groupというチームにこの課題を与えました。彼らは、飛行機の生存率を高めつつ性能を維持するために、どこに装甲を追加すべきかを決定する問題に取り組みました。チームには、任務から帰還した航空機の弾痕分布を示すデータが提供されました。

最初の考えは、弾痕が最も集中している場所に装甲を追加することでした。しかし、Waldはこの仮定に疑問を投げかけました。彼は数学的にアプローチし、エンジンやパイロット室のような重要な部分に被弾した飛行機は全く戻ってこないことを考慮しました。これらの部分への被弾の生存確率をゼロに設定することで、戻ってこなかった飛行機にあるはずの見えない弾痕の分布を明らかにしました。

この分析により、直感に反する解決策が導き出されました。戻ってきた飛行機で弾痕が少ない部分により多くの装甲を追加するのです。なぜなら、これらが被弾すると致命的になる重要な部分だからです。このアプローチにより、飛行機の生存率は大幅に向上しました。この教訓は私たちのシステムにも当てはまります。私たちは表面的なことだけでなく、システムの真の脆弱性がどこにあるかを理解し、効果的にレジリエンスを構築するために、十分な情報に基づいたトレードオフを行う必要があります。
レジリエンス分析フレームワーク(RAF)の概要と重要性

これが、レジリエンス分析フレームワークにつながります。このフレームワークは、過去1年間の顧客とのやり取りや、システムのレジリエンス向上に関する社内での議論から得た洞察を統合した結果です。私たちは、観察された一般的な障害モードや障害カテゴリーを検討するモデルを定義しました。このフレームワークの理論と、システムを分析するために必要なステップについて説明します。その後、Mike Hakenが、このフレームワークを適用して是正措置や予防措置を実施し、システムのレジリエンスを向上させた実際の顧客シナリオを紹介します。そして、Michael Golovynkhが、Application Recovery Controllerチームがこのフレームワークをどのように運用化したかを説明します。
なぜこれが重要なのか疑問に思うかもしれません。 このQRコードは、ここで説明する以上の詳細が記載されたホワイトペーパーにつながります。このフレームワークが重要なのは、ワークロードのレジリエンスを評価し強化するための再現可能なプロセスを提供するからです。組織全体で一貫して適用でき、必要に応じて週次、月次、四半期ごとに運用化できるものです。Mikeが実装についてさらに詳しく説明します。


このフレームワークは、特定の障害カテゴリーとそのカテゴリー内の複数の障害モードに対処できる緩和策を考慮する、リカバリー指向のアーキテクチャに導きます。また、レジリエンスの目標に適した緩和策と観測可能性戦略の整合を支援します。私たちは、ワークロードに求められるレジリエンス特性を特定することから始めました。 最初は障害の分離で、潜在的な障害の影響範囲を制限するための境界を意図的に設けます。 次に十分な容量で、CPUサイクル、メモリ、その他のリソースなど、ワークロードに課される需要に対応できることを確認します。





また、タイムリーな出力も求められます。つまり、クライアントが期待する時間枠内に結果を受け取ることです。 これは、クライアントのタイムアウトを超えてアプリケーションが利用不可能と認識されるか、 適切なタイムアウト内に応答を得るかの違いになります。正確な出力も極めて重要です。システムからは期待される結果が必要です。 時には、不正確または不完全な結果は、結果がないよりも悪い場合があります。最後に、冗長性があります。 バックアップコンポーネントを持つことは、単一障害点に依存するよりも多くの場合優れています。

これらの望ましいレジリエンス特性に基づいて、SEEMSモデルを作成しました:Shared fate(共有運命)、Excessive load(過剰な負荷)、 Excessive latency(過剰な遅延)、Misconfiguration and bugs(設定ミスとバグ)、Single point of failure(単一障害点)です。これらの障害カテゴリーはそれぞれ、レジリエンス特性の1つに違反します。共有運命は障害分離境界を越えて広がり、潜在的に影響範囲を拡大します。過剰な負荷は、予期せぬトラフィックスパイクなどで十分な容量を侵害する可能性があります。過剰な遅延は、ネットワークデバイスの障害や遅いハードウェアなど、様々な形で現れ、タイムリーな出力に影響を与えます。

設定ミスとバグは、おそらく最も一般的な障害カテゴリーで、予期せぬ出力につながる可能性があります。これは、デプロイメントの失敗、誤ったセキュリティグループの変更、EC2ホストのパッチ適用の問題などが原因かもしれません。最後に、単一障害点は、それが故障すると、システム全体が利用不可能になる可能性のあるコンポーネントです。私たちはシステムでこれらを最小限に抑えることを目指しています。障害カテゴリーと望ましいレジリエンス特性を理解したところで、 このフレームワークを使用する最初のステップは、ワークロードを理解することです。
ワークロードの理解:RAFの第一歩
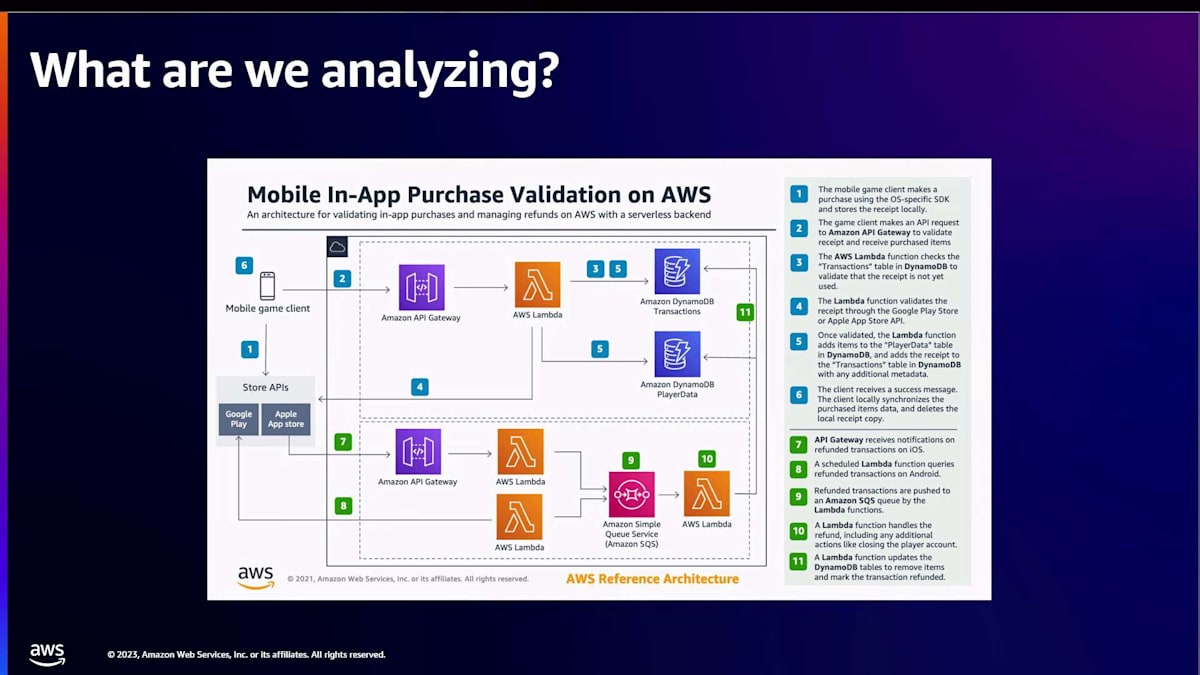
こちらは、AWSで構築されたアプリ内購入検証ソリューションの例です。通常、このような番号付きのステップでデータフローやトランザクションのライフサイクルを示すアーキテクチャ図から始めます。また、システムが提供する異なる機能を表す原子的なユーザーストーリーにシステムを分解します。この例は比較的シンプルで、わずか数個のサービスと2つのフローしかありません。しかし、eコマースウェブサイトや小売銀行のウェブサイトの場合、ユーザーストーリーがはるかに広範になることは想像できるでしょう。この場合、アプリ内購入と返金のユーザーストーリーがあります。

このアプローチにより、ビジネスにとって最も価値のあるユーザーストーリーを優先順位付けし、それに応じてレジリエンス分析作業に焦点を当てることができます。海の水を沸かそうとしているわけではありません。分析作業で意味のある進展を得ることができます。これが最初のステップであり、ワークロードを理解し、どこに焦点を当てるかを把握することです。


これらのユーザーストーリーと図の中で、以下の4つの要素を必ず明確にする必要があります。まず1つ目は、コードとコンフィグです。これはアプリケーションコードや、システムで使用される各種設定と考えることができます。2つ目はインフラストラクチャで、多くのAWSサービスやオンプレミスのコンポーネント、あるいはシステムを動かすあらゆるものが該当します。そして3つ目がデータソースで、データベースやEBSボリューム、データが保存される場所全てが含まれます。最後に4つ目が外部依存関係です。これには、組織内の他チームが提供するAPIを利用する場合や、ISVのAPIなどサードパーティのものも含まれます。例えば、システムに天気データが必要な場合、それは外部依存関係に分類されます。

ここでの主な目的は、必ずしもデータベースのコンポーネントを全て列挙することではありません。むしろ、システムを考え、図示し、理解する過程で、これらのコンポーネントの位置づけと相互の関係を把握することが重要です。これを分析の一部として活用することになります。このようにして、ワークロードを理解し、モデル化・図式化し、作業グループ全体で共通の理解を得ることができます。
SEEMSモデル:障害カテゴリーとレジリエンス特性の関係



次に、このフレームワーク、つまりSEEMSモデルを、潜在的な障害を軽減するためにワークロードにどのように適用するかを考える必要があります。そして、先ほど話した障害モードに関する質問を始めた後の最初のステップは、必要なトレードオフを見極めることです。これは、Abraham Waldが航空機で行ったのと同じです。私たちのシステムでは、通常、コストと労力の要素があります。先ほど冗長性について話しましたが、レプリカやスペアを追加するとコストが増加します。また、高度な耐障害性パターンを実装する労力もかかります。Mikeが数分後にいくつか紹介する予定です。

また、複雑さも増します。設定ミスやバグを減らすために、高度なCICDシステムを特定の方法で展開したり、異なる障害モードを理解し、事後的な指標ではなく先行指標を検出できるように、より強化された可観測性が必要になるかもしれません。運用負担も増加し、より洗練されたランブック、オンコールプロセス、イベント発生時にチームが何をすべきかを確実に理解させる必要があります。これらすべてが、重要なシステムで行う必要があるトレードオフです。

最後に、一貫性とレイテンシーがあります。多くの場合、これらのシステムはマルチリージョンアプローチやDR戦略を考え始めます。そして通常、CAPの定理と非同期レプリケーションを考え始めると、可用性よりも一貫性を重視するトレードオフが発生しますが、これは慎重に検討する必要があるトレードオフです。さて、SEEMSと障害カテゴリーを見て、ワークロードを検討し、これらの障害モードがどのように現れるかを理解し始めました。そして、軽減策を実装する際のトレードオフについても見てきました。
そして次に考えなければならないのは、特定の障害モードについて検討した場合、その発生可能性はどの程度かということです。この特定の障害モードに時間を投資すべきでしょうか?可能性とは、それが起こり得る蓋然性のことです。例えば、EC2 インスタンスがある場合、そのインスタンスの寿命の間に、おそらくパッチを当てることになるでしょう。メンテナンスも行います。ある時点で何かがうまくいかず、そのインスタンスが利用できなくなる可能性はかなりあります。一方で、RDS を使用していて複数のレプリカがある場合、利用不可能になる可能性は低いでしょう。なぜなら、何か問題が発生しても、レプリカが引き継いで問題なく動作するからです。
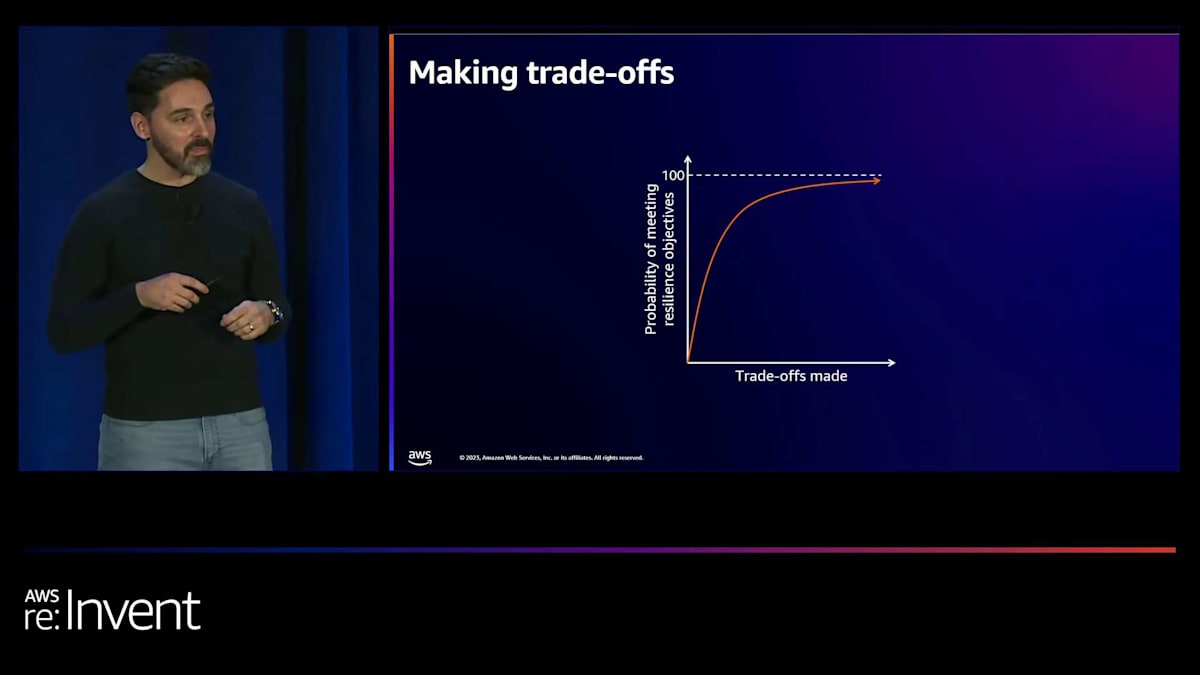
もう一つの要素は影響度です。その障害モードが顕在化した場合の損害、あるいは評判や商業的な損失を理解する必要があります。発生の可能性と影響度を考慮することで、どの障害モードに焦点を当てるべきか、そしてその対策の開発を続けるべきかを判断できます。ここで示したいのは、通常、収穫逓減の法則があるということです。 時間と労力をかけることで、ある程度までレジリエンスを高めることができます。そのトレードオフを考慮しながら、曲線の頂点に近づくにつれて、通常はより重要なシステムに注力することになります。例えば、組織内で人を検索する内部ディレクトリがある場合、それを非常にレジリエントにするために多くの時間と労力を費やす必要はないでしょう。しかし、ビジネスにとって重要で多くの収益を生み出すシステムがある場合、レジリエンスにより焦点を当て、特にビジネスを推進する重要なユーザーストーリーに注目する必要があるでしょう。
障害モードの分析と緩和策の検討

次のステップは、障害モードを特定し、どこに焦点を当てるべきかを把握したら、これらをどのように観察するかを考えることです。
可能であれば、先行指標と遅行指標の両方を持つことが重要です。先行指標とは、システムに何かが変化していることを認識し、可用性に問題が生じる可能性のある閾値に近づいているものの、まだ発生していない状態を示します。例えば、データベースの接続数をモニタリングし、特定の閾値に近づいていることを理解した上で、スロットリングを実装したり、最も使用頻度の低い接続を終了させたりして、潜在的な問題の発生を防ぐことができます。遅行指標の例としては、データベースへの接続失敗に関するアラームが挙げられます。可能であれば、両方のタイプの指標を利用できるようにすることが望ましいです。

これらをどのように観察するかを理解したら、次はそれらをどのように緩和するかを考える必要があります。一般的なアプローチには、予防的または是正的の2つがあります。 予防的とは、障害や故障の発生を防ぐための対策を講じることを意味します。これは、インフラストラクチャに過度の負荷がかかるのを防ぐためのスロットリングやロードシェディングを実装し、システムが完全に利用不可能になる状況に至らないようにすることと考えられます。是正的な緩和の例としては、トラフィックの増加が見られ、今後24時間で過度の負荷がかかると予測される場合に、必要に応じて容量を追加するために事前にオートスケーリングを開始することが挙げられます。

では、顧客事例を共有するためにMikeに引き継ぎます。Mikeは、これまでの経験から得られた例を紹介し、実際に分析フレームワークを使用して、レジリエンスの脅威を定義し、これらの顧客シナリオに対する緩和策を見つける方法を説明します。
メタデータの問題:Constant workパターンによる解決


最初の例は、メタデータの問題を抱えるワークロードについてです。彼らは大規模な対話型フリートとシャード化されたデータベースを持っていました。そのシャード化されたデータベースの各ノードは、異なるデータセットを担当していました。 データベースは成長に伴って再シャード化されるため、固定サイズではありませんでした。このシステムには、シャードのマップを管理するメタデータデータベースもありました。



コンテナ自体、つまりソフトウェアは、メタデータデータベースからマッピングデータを遅延ロードしていました。最初のリクエストを受け取ると、このメタデータデータベースにアクセスしてマッピングを取得し、必要なデータベースに接続していました。 私たちは過剰な負荷の問題を検討したいと考えました。通常のシナリオでは、ユーザーが「Smithを探したい」と言うと、そのワーカーフリートに行き、フリートがメタデータデータベースにアクセスします。データベースマッピングが返され、 SmithはSの文字なのでDB4にあることがわかります。そして、そのデータベースに接続します。


しかし、突然ユーザーが殺到した場合はどうなるでしょうか?大勢の人が一度に現れ、全員が検索を試み、すべてのワーカーノードが単一のメタデータデータベースに接続しようとしてクラッシュしてしまいます。彼らには、このシステム全体をダウンさせ、回復不能にする非常にありそうな過剰負荷のシナリオがありました。そこで私たちが提案したのは、constant workと呼ばれるパターンを検討することでした。 リクエストを受け取ったときにそのメタデータを検索する代わりに、 これらのワーカーフリートのノードすべてが60秒ごとにS3バケットのようなものからマッピングを取得するようにできます。

このアプローチでは、次のようになります: 彼らは同じことを継続的に行います。これにより、予期せぬ負荷が取り除かれます。なぜなら、彼らは常に同じことを繰り返しているからです。そのため、顧客リクエストの数に関係なく、メタデータサービスへの負荷は変わりません。

Constant workにはいくつかの利点があります。一貫した予測可能なパフォーマンスを提供し、アンチフラジリティと呼ばれる特性をもたらします。これは、何かが間違ったとき、何かが壊れたときに、実際にはより少ない作業を行うことを意味します。つまり、システムで問題が発生したとき、作業量を増やすのではなく、減らすのです。Constant workは、メタデータデータベースの過剰負荷の問題を解決するのに役立つ可能性があります。
マルチリージョン同期レプリケーションの課題と非同期レプリケーションの提案

しかし、Johnが言及したように、レジリエンスを向上させようとする際には、トレードオフを考慮しなければなりません。常時作業のトレードオフの一つは、潜在的な無駄な作業が発生する可能性があることです。変更がない場合でも多くの作業を行うことになります。そのため、潜在的なコストの増加を考慮し、理解する必要があります。なぜなら、すべてのリクエストにはコストが伴い、データ転送にもコストがかかるからです。ここでトレードオフを検討する必要があります。この問題を解決するために常時作業を実施することによるレジリエンスの向上は、そのトレードオフに見合うものでしょうか。これが最初の例です。



次の例は、マルチリージョン同期レプリケーションシステムを構築したいと考えていた顧客の事例です。彼らは、RPOゼロ、つまりリージョン間でデータ損失がゼロという回復ポイント目標を達成したいと考えていました。3つの異なるリージョンにまたがるマルチリージョン同期レプリケーションを使用する予定でした。Johnは先ほどCAPについて触れましたが、CAPの定理を聞いたことがある人はいますか?CAPの定理では、一貫性(Consistency)、可用性(Availability)、分断耐性(Partition tolerance)という3つの特性があり、そのうち2つしか同時に満たすことができないと言われています。ほとんどの分散システムでは、複数のサーバーや複数のコンポーネントがあるため、分断耐性を受け入れざるを得ません。つまり、一貫性と可用性の間でトレードオフと選択をしなければならないのです。

しかし、この顧客はCAPの定理を克服しようとしていました。障害が発生した場合、つまりこれらのうちの1つが利用できなくなった時に、障害のあるリージョンを構成から削除して可用性を回復させると言っていました。同期レプリケーションスキームでは、ノードの1つが故障すると、システム全体が故障するからです。そのため、障害時に構成をランタイムで更新したいと考えていました。そのリージョンが回復したら、障害のあったリージョンにデータを同期して戻すつもりでした。つまり、いずれにせよ、ある期間は不整合が生じることになります。彼らはこれらすべてを同時に達成しようとしていたのです。

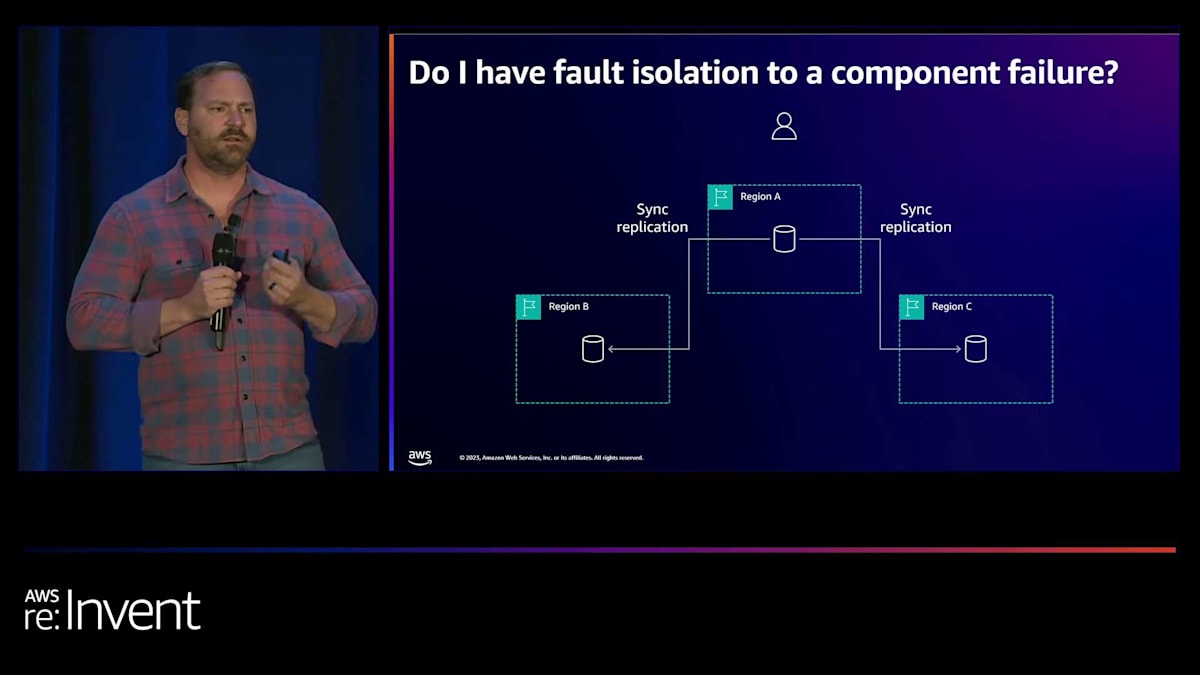
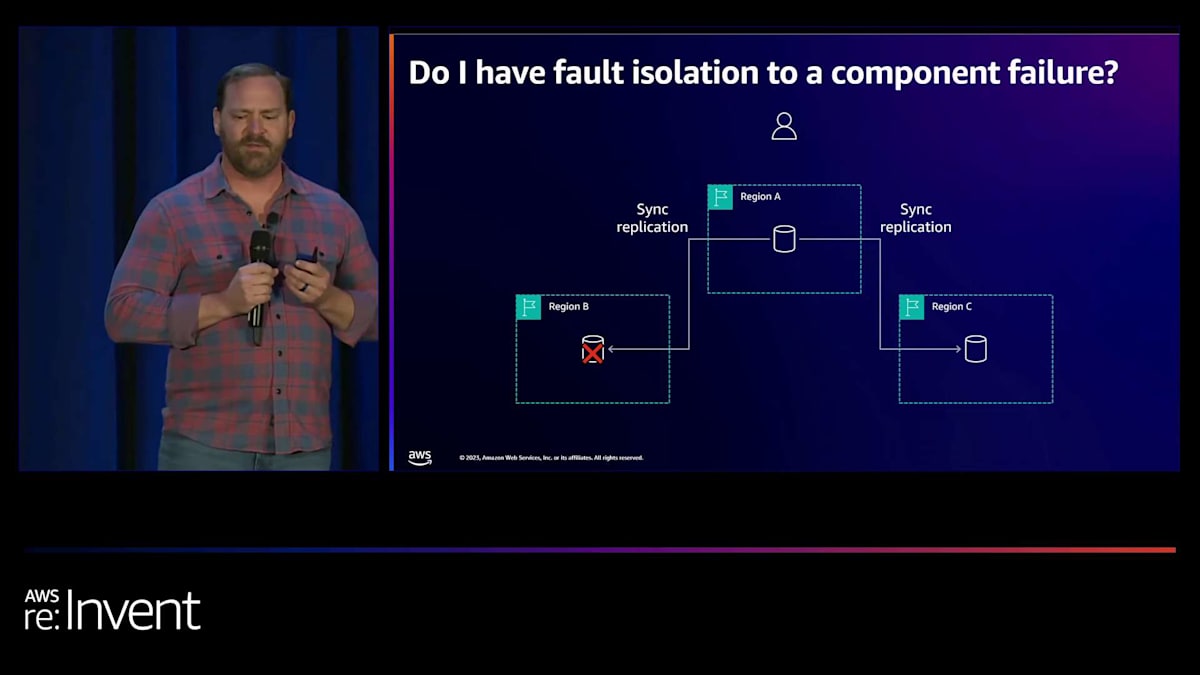
私たちがこれを検討した結果、これは非常に複雑で脆弱なシステムになることがわかりました。そこで、連鎖障害の部分をテストしたいと考えました。共通の運命があるのでしょうか?そこで、このレプリケーションが障害分離にどのような影響を与えるかを検討しました。ここでは、リージョンA、B、Cの3つのリージョンがあり、同期レプリケーションを使用しています。そして、リージョンBに何らかの理由で障害が発生した場合、例えばそのデータベースノードが故障し、ユーザーがリージョンAで書き込みを行おうとしても、できません。この操作は失敗します。つまり、リージョンBからリージョンAへの連鎖障害が発生しているのです。
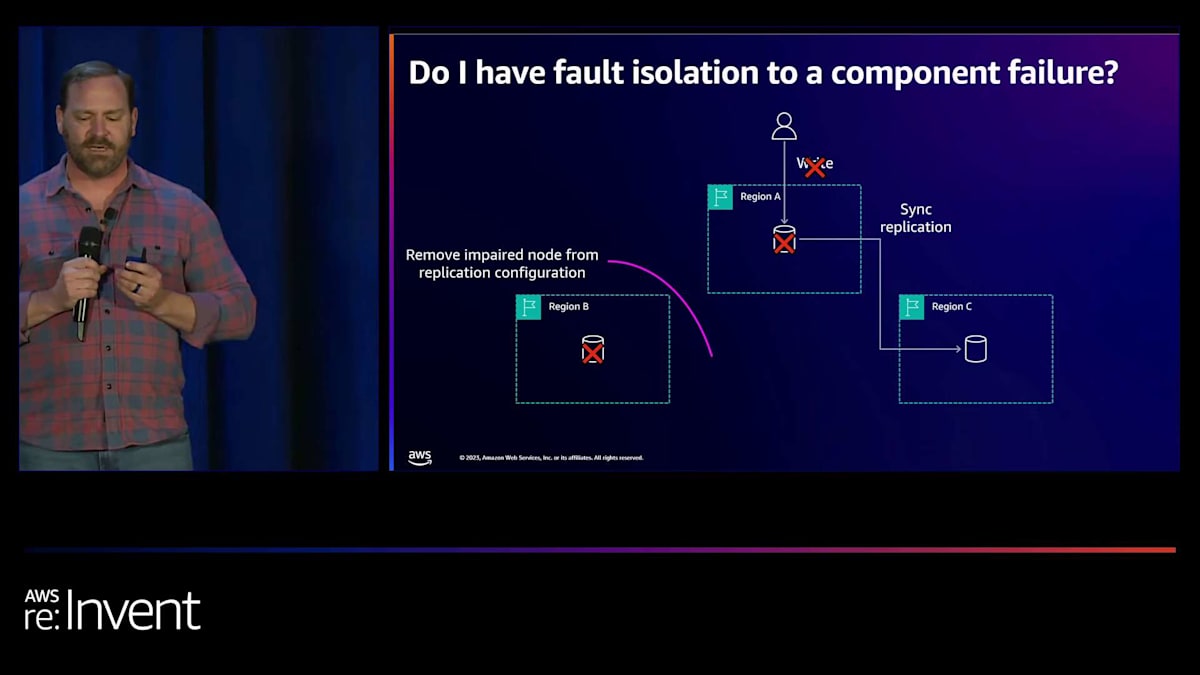
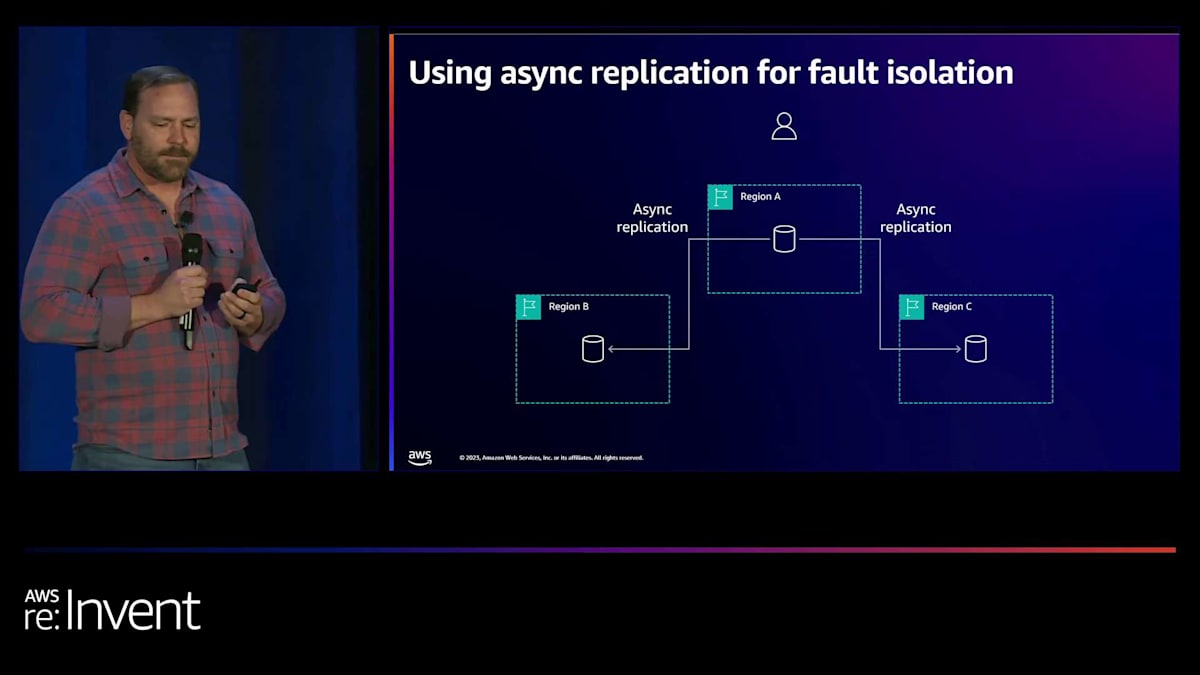
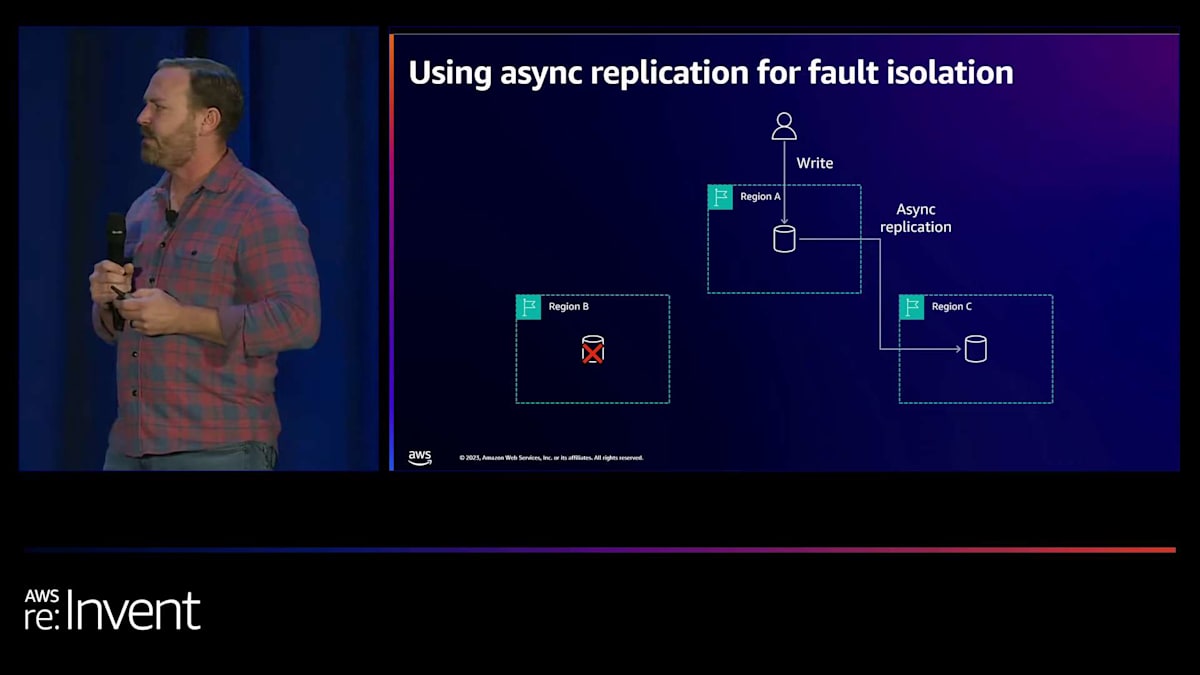
そこで彼らがしようとしていたのは、障害のあるノードをレプリケーション構成から削除することでした。そうすると、このデータベースは回復して追いつくまで不整合な状態になります。代わりに、私たちは次のように提案しました。本当に障害分離が必要で、連鎖障害を避けたいのであれば、非同期レプリケーションを使用することができます。こうすることで、リージョンBに問題が発生しても、他のリージョンで書き込みを実行できます。リージョンAで書き込みを行い、それをリージョンCに非同期でレプリケートすることができます。そして、リージョンBが回復したら、追いつくためのレプリケーションを行う必要がありますが、最終的には非同期レプリケーションの最小限のラグを伴って追いついた状態に戻ります。

これらのリージョン間でフォールトトレランスを実現し、カスケード障害を防ぐために、非同期レプリケーションを使用する計画でした。これにより、すべての書き込みが両方のリージョンにレプリケートされるのを待つ必要がないため、レイテンシーを削減できます。

非同期レプリケーションは、より高速なパフォーマンスと可用性の向上をもたらします。一方のリージョンに障害が発生しても、残りのリージョンで書き込みと読み取りを継続できます。ただし、ここでのトレードオフは一貫性です。 私たちは一貫性についてトレードオフを行い、このようなシナリオではRPOゼロを達成できないことを認識しました。ある程度の不整合に対処する必要があります。この決定を下したのは、元のデザインでも既に不整合な状態を想定していたからです。ノードの1つが故障した場合でも、追いつく必要があったのです。

私たちは、このデータの不整合の可能性を受け入れる決断をしました。これは実際にはデータ損失ではありません。そのデータは書き込まれた主要リージョンのデータベースに残っています。しかし、フェイルオーバーが必要になった場合、すべてのデータが利用できない期間に対処しなければならない可能性があります。これが私たちが行わなければならなかったトレードオフの1つでした。
分散ストレージシステムにおけるヘッジングの活用


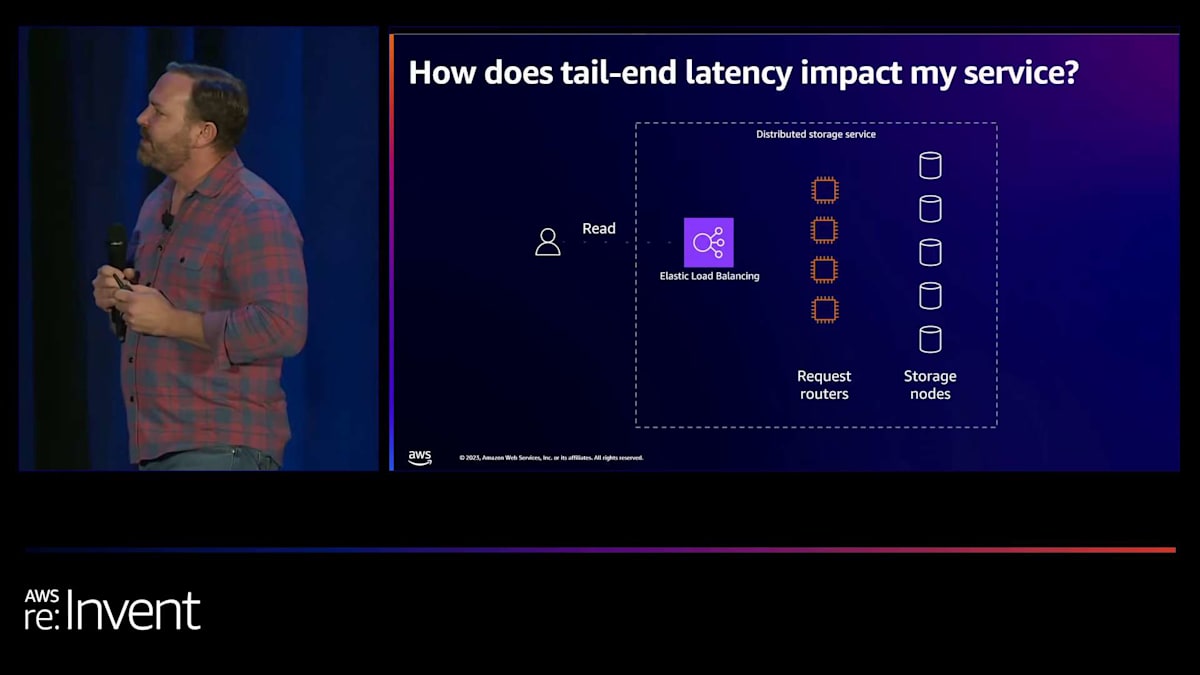
例3を見てみましょう:分散ストレージシステムです。このサービスでは、データが複数のストレージノードにシャーディングされています。 データはこれらのノード間でレプリケートされています。システムユーザーが発行する読み取りリクエストは、レプリカのいずれかに到達する可能性があります。 リクエストは通常、フロントエンドのリクエストルーターからランダムなストレージノードにルーティングされます。では、これはどのように機能するのでしょうか? ユーザーが読み取りを実行すると、いずれかのストレージノードに到達します。2回目の読み取りを行うと、別のノードに到達します。
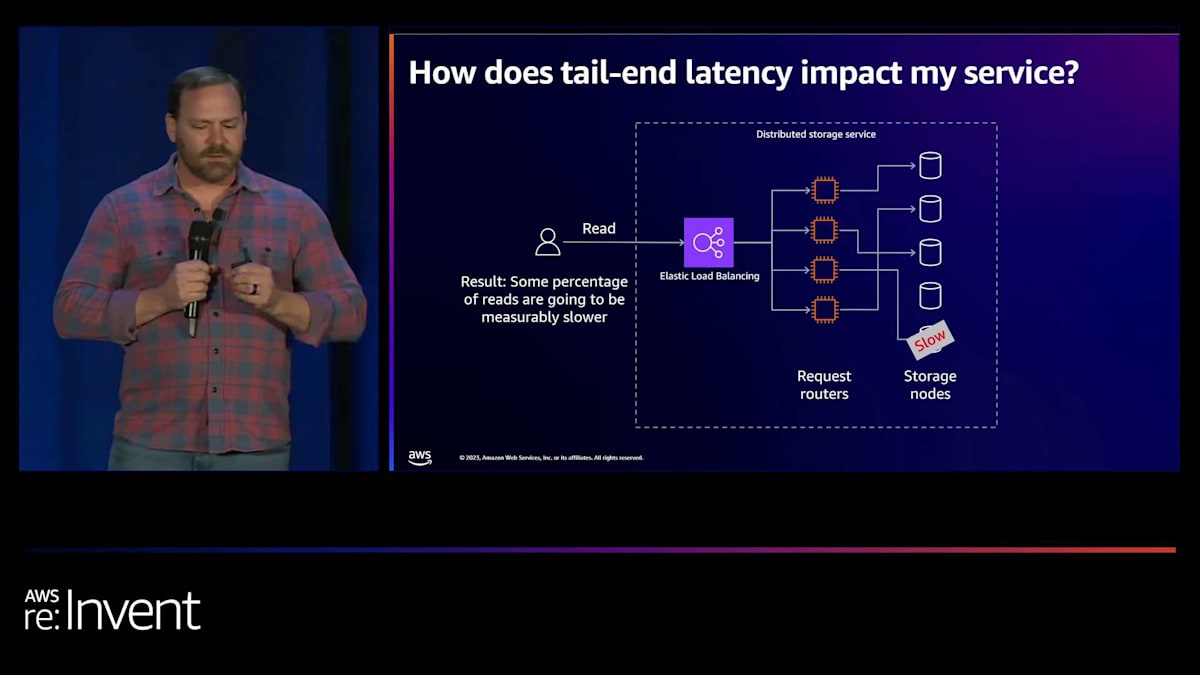
しかし、これらのノードの1つが遅い場合はどうでしょうか?システムに過度のレイテンシーがある場合、何が起こるかを考えてみました。 下部のこのストレージノードがハードドライブエラーを起こしているか、CPUやメモリに障害がある可能性があります。何らかの理由で、他のストレージノードよりもはるかに遅く応答しています。その結果、読み取りの一定の割合が明らかに他よりも遅くなります。つまり、テールレイテンシー(p90、p99、p99.9など)が他のノードと比較して著しく高くなるのです。

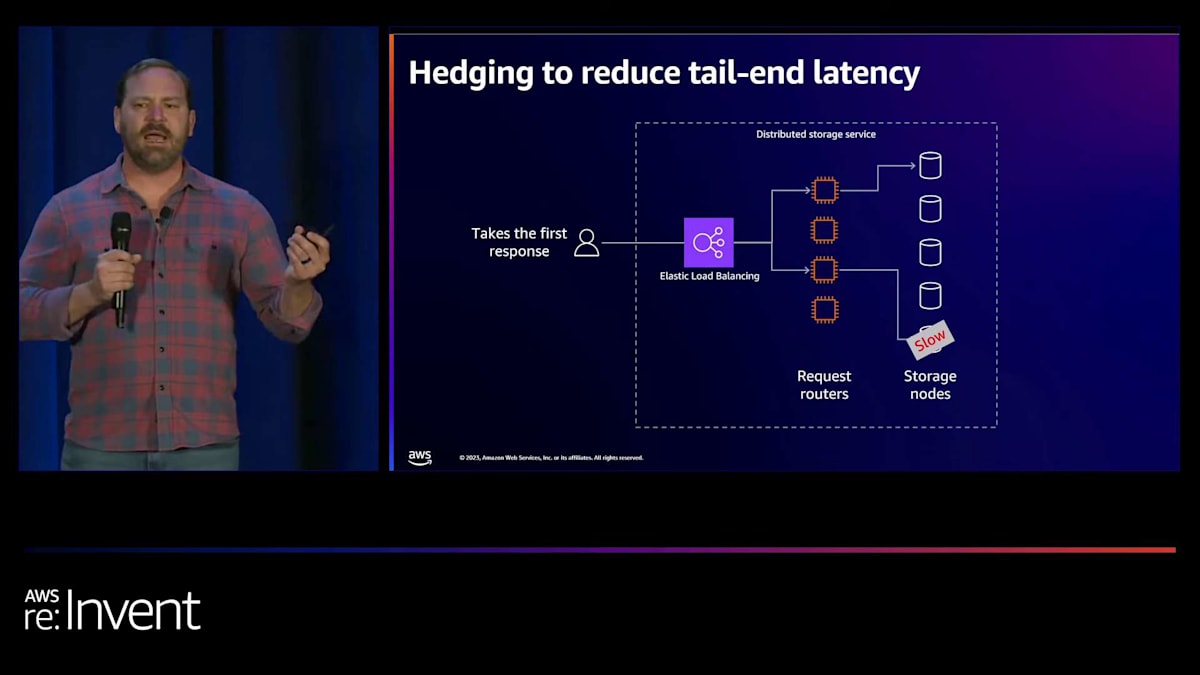
私たちは、テールエンドレイテンシーを削減するためにヘッジングと呼ばれるパターンの使用を提案しました。 ヘッジングは、リクエストを並行して送信し、それらを互いに競争させる方法です。ここでも遅いストレージノードがありますが、2つの読み取りリクエストを並行して送信します。上のリクエストが下のリクエストよりもかなり速くなっているのがわかります。 ヘッジングでは、最も速いレスポンスだけを採用します。そのため、遅いストレージノードが高いテールエンドレイテンシーで応答しても、他のリクエストからより速いレスポンスを得ているので、実際にはそれを気にする必要がありません。
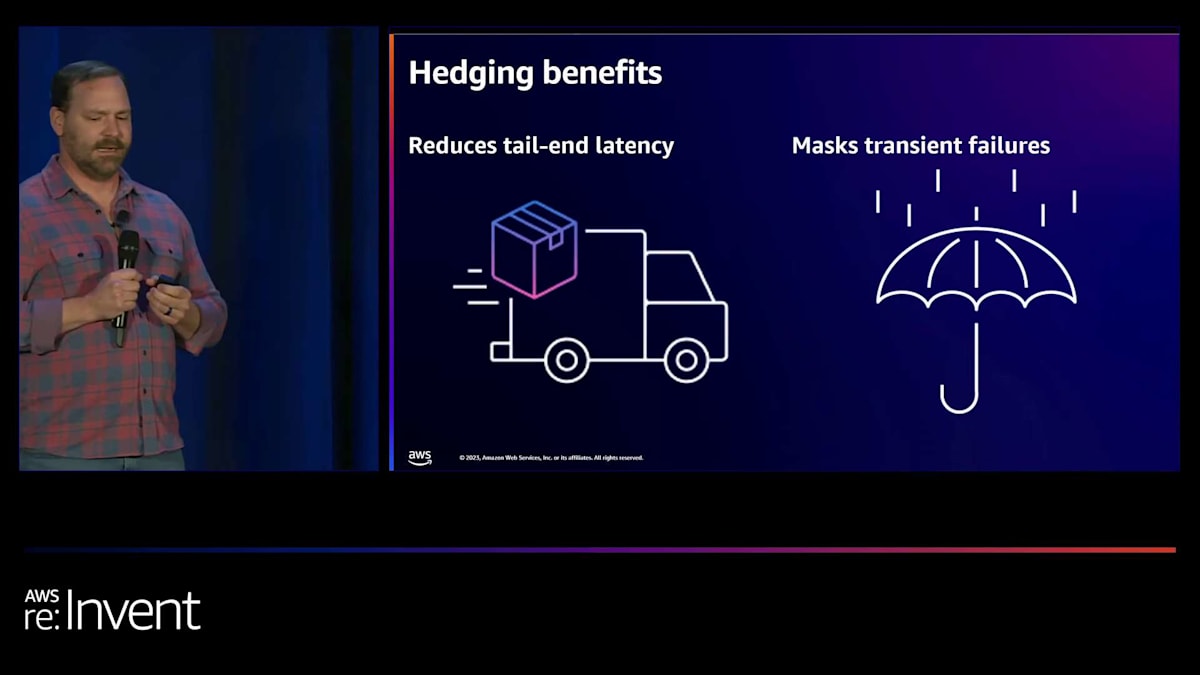

ヘッジングは、テールエンドレイテンシーを削減する能力を与えてくれます。また、一時的な障害も隠蔽します。なぜなら、ストレージノードが遅いか完全に利用不可能かは、クライアントにとってまったく同じことになるからです。最初のレスポンスだけを見ているので、そのノードが遅かったのか、単に応答しなかったのかはわかりません。ヘッジングの課題は、トレードオフとして、追加の作業が発生することです。1つの読み取りリクエストに対して、ヘッジの程度に応じて2つか3つのリクエストを行うことになります。そのため、追加の作業が発生し、潜在的にコストが増加する可能性があります。
ヘッジングで非常に注意しなければならないもう1つの点は、それらのリクエストが冪等でなければならないことです。冪等とは、リクエストを何回発行しても、常に同じ結果が得られることを意味します。読み取りリクエストは本質的に冪等なので、読み取りに関してはこれに対処できます。書き込みリクエストや変更を加えるリクエストの中には、冪等なものもあれば、そうでないものもあります。そのため、システムでヘッジングを実装する際には注意が必要です。
Multi-AZデプロイメントの改善:障害分離型アプローチ



4つ目の例、Multi-AZ deploymentを見てみましょう。3つのAvailability Zoneを使用するようにアーキテクチャされたシステムがあります。 このお客様にとって、このデザインにおいてデプロイメントの速度が優先事項でした。デプロイメントは各AZのインスタンスを同時にターゲットにします。 彼らは、デプロイメントを検証するために、pre-production環境の成功に依存するシステムを構築していました。 しかし、実際に私たちが発見したのは、多くのお客様のpre-production環境が本番環境を正確に反映していないということでした。ここにいる方で、本番環境を正確に反映した本当のpre-production環境をお持ちの方はいますか?3人、4人の手が挙がっているようですね。ほとんどのお客様は、環境間に何らかの差異を経験しています。
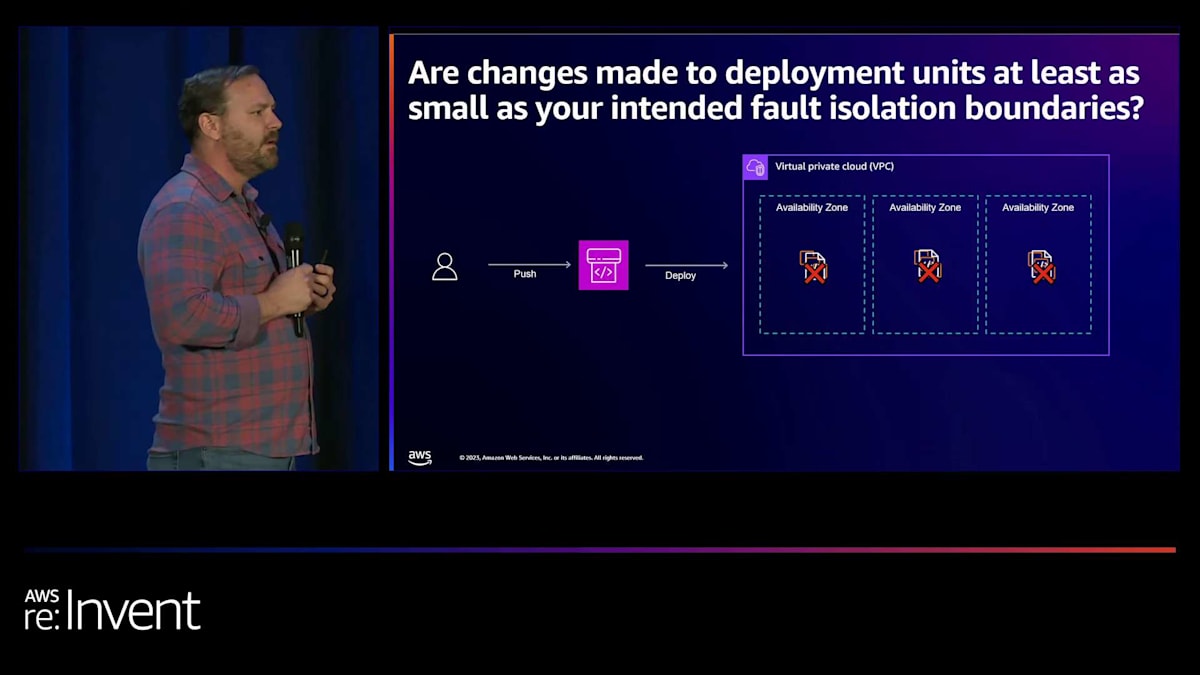
この差異は、デプロイメントが失敗した際に問題を引き起こす可能性があります。悪い変更や環境の問題、見逃したことが原因でデプロイメントが失敗し、その変更をデプロイするためにプッシュすると、3つのAvailability Zoneすべてに同時に影響を与えてしまいます。 これは大規模な障害につながります。私たちは、行っている変更、つまりそれらのデプロイメントユニットが、少なくとも意図した障害分離境界と同じくらい小さいかどうかを問う必要がありました。ここでは、Availability Zoneが障害分離境界を提供します。1つのAvailability Zoneでの障害が他のAvailability Zoneにカスケードすることは想定していません。1つのAZでインスタンスが失敗しても、他のAZのインスタンスには影響しません。
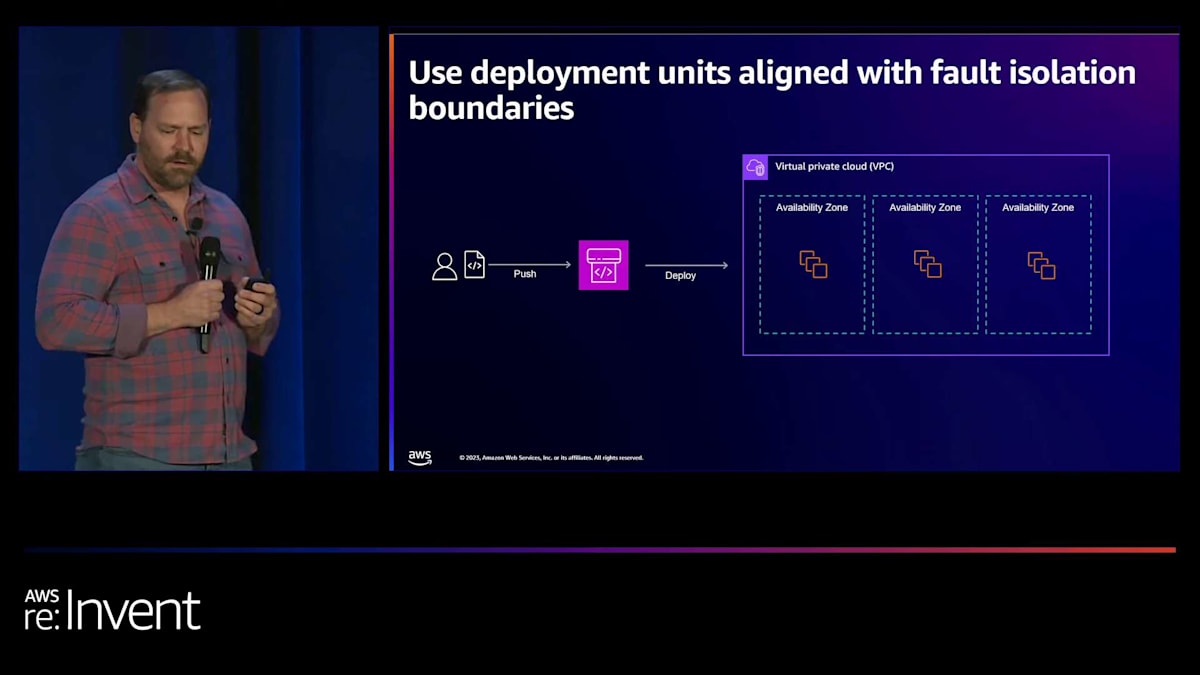
その代わりに、デプロイメントユニットをAvailability Zoneに合わせることができるかどうかを検討しました。変更をプッシュしてデプロイする際、それは1つのAvailability Zoneに適用されます。そのデプロイメントに問題があり、そこで障害が発生した場合、修正するためのいくつかのオプションがあります。Availability Zone独立型のアーキテクチャを構築している場合、つまりすべてのトラフィックをAZ内に保持している場合、ゾーンシフトのようなものを使用して、デプロイメントをロールバックする前に、トラフィックを問題のあるAZから移動させ、迅速に回復することができます。そのようなアーキテクチャを構築していない場合でも、特定のメトリクスやアラームに基づいて自動ロールバックを開始することは可能です。
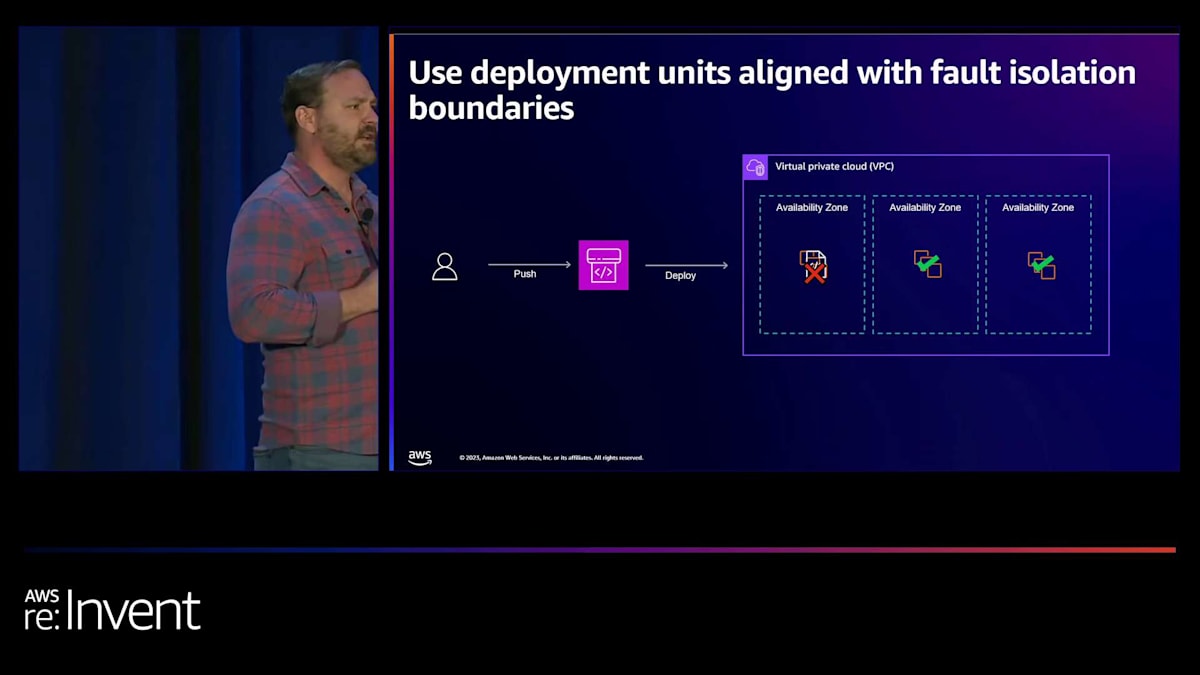
ここで重要なのは、残りの2つのAvailability Zoneが変更されておらず、障害が発生していないことです。これは必ずしも完全な障害を意味するわけではなく、すべてのインスタンスが一度に変更されたわけでもありません。しかし、各AZのインスタンスを同時に変更した可能性があり、それが障害の影響範囲を拡大させる可能性があります。デプロイが成功した場合、1つのAZずつ進め、次のAvailability Zoneへのデプロイに進む前の依存関係やゲートチェックとすることができます。


障害分離型デプロイメントを使用することで、予測可能なデプロイメント障害の影響範囲が得られます。影響範囲が常に単一のAvailability Zoneのサイズに限定されることがわかります。これは顧客体験の維持に役立ちます。失敗したデプロイメントユニットからトラフィックを素早くロールバックまたはシフトすることで、大規模な障害を起こすことなく、提供しようとしていた顧客体験を維持できます。しかし、トレードオフもあります。デプロイメントは少し遅くなる可能性があります。一度に1つのAZ全体にデプロイし、監視し、検査して、次のAZに進む前にすべてが健全であることを確認する必要があります。
このアプローチは、オーケストレーションがやや複雑になります。CI/CDシステムがどのAZにデプロイしているかを認識できるように設定する必要があります。これは、AWS CodeDeployとタグを使用して実現できます。すべてのインスタンスにAvailability Zone IDでタグ付けしておけば、それぞれに対して個別のデプロイメントを設定できます。ただし、CI/CDシステム内でのオーケストレーションは課題となる可能性があります。
eコマースサイトのレジリエンス向上:Graceful degradationの実装




最後の例として、複数の依存関係を持つeコマースサイトを見てみましょう。このサイトは、ウェブページにコンテンツを提供するために複数のバックエンドサービスを使用しています。すべてのマイクロサービスが顧客体験にとって重要というわけではありません。しかし、現在のウェブサービスでは、ページ全体をレンダリングするために各コンポーネントがロードされる必要があります。これが私たちのウェブページです。とてもファンシーですね。製品画像があり、これは1つのマイクロサービスを呼び出しています。カートに追加する機能があり、これは別のマイクロサービスです。よく一緒に購入される商品の提案があります。興味がありそうな商品のセクションがあります。そして最後に、新しいプロモーションがあります。


しかし、新しいプロモーションのマイクロサービスが失敗すると、ウェブサイト全体が読み込めなくなってしまいます。これは良い顧客体験とは言えません。私たちが望むものではありません。その代わりに、これらのマイクロサービスがすべて正常に読み込まれれば、重要なユーザーストーリーを提供できます。最も重要なのは、顧客が購入したい商品を見て、カートに追加し、チェックアウトできることです。そのため、新しいプロモーションが利用できない場合は、ウェブページの読み込みを失敗させるのではなく、単にそれを表示しないようにします。これがgraceful degradation(優雅な機能低下)の考え方です。システムのコンポーネントが遅くなったり利用できなくなったりしても、優雅に機能を低下させることができるのです。

Graceful degradationは、連鎖的な障害を防ぐのに役立ちます。先ほど見たように、あるコンポーネントの障害が他のコンポーネントやシステム全体の障害を引き起こすことは避けたいものです。

このアプローチは、特に重要な機能に対して重要です。例えば、新しいプロモーションウィジェットの障害がチェックアウトプロセスやその他の重要な操作に影響を与えることは避けたいものです。Graceful degradationを実装することで、特定のコンポーネントが失敗しても部分的な顧客体験を提供する能力を得ることができます。
ただし、トレードオフを考慮する必要があります。Graceful degradationの実装には、依存関係の相互作用について深い理解が必要です。サービス全体の依存関係マップを理解し、優雅に機能低下するよう調整することは難しい課題です。すべてのコンポーネントがどのように連携しているかを徹底的に検証する必要があります。

以上が、顧客との実例で、分析フレームワークを使用してレジリエンスのギャップを特定し、それに対処するための緩和策を提案した事例でした。ここで、AWSにおけるレジリエンス分析について話すMikeにバトンタッチします。
AWSにおけるRAFの実装:教訓と導入の判断基準

マイク、ありがとうございます。私はMike Golovnykhと申します。AWSのSenior Software Engineerとして、Resiliency Infrastructure and Solutions Organizationで働いています。今日は、私たちのチームがRAFを組織内でどのように実装したか、学んだ教訓、そして最も重要なこととして、皆さんの組織でRAFを実装すべきかどうかを判断する手助けをさせていただきます。
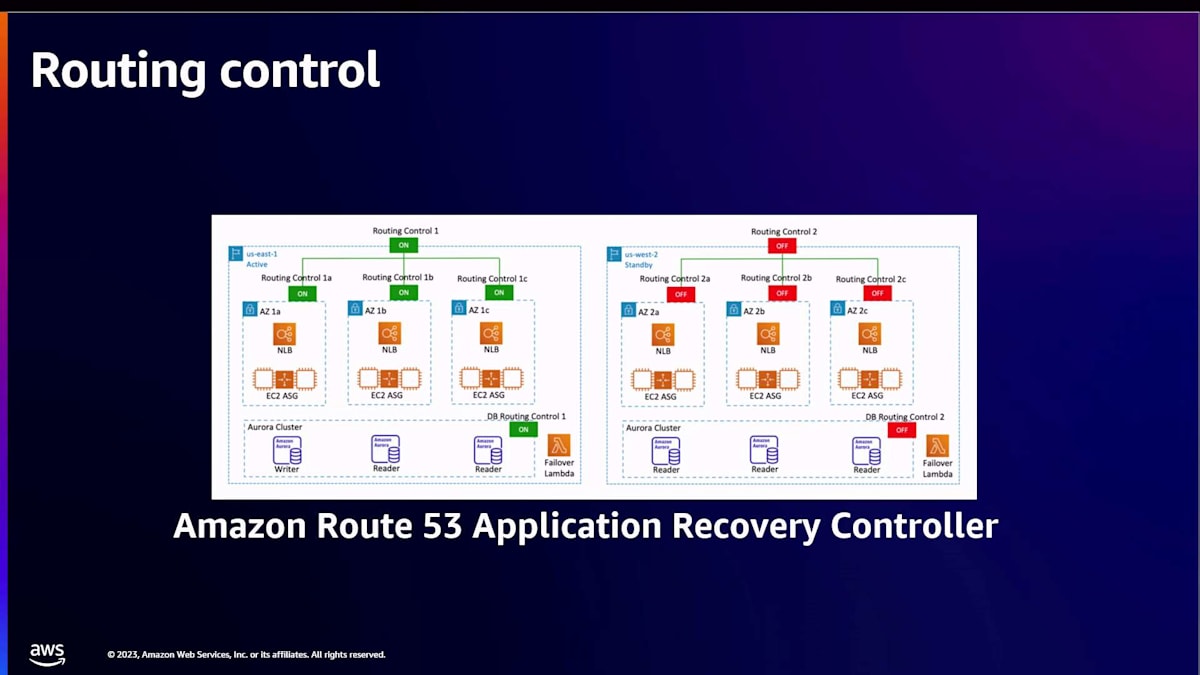
私たちがRAFを実装したサービスの一つが、Amazon Route 53 Application Recovery Controllerのrouting controlです。お客様はrouting controlを使用して、リージョンレベルのインフラストラクチャやアプリケーションの障害からアプリケーションを復旧させます。フェイルオーバーを開始し、DNSレコードを迅速かつ確実に更新するために使用されます。Routing controlは100%のSLAを提供し、2つのリージョンが障害を起こしている場合や、1つのリージョンが他から分断されているような極端なシナリオでも動作するように設計されています。
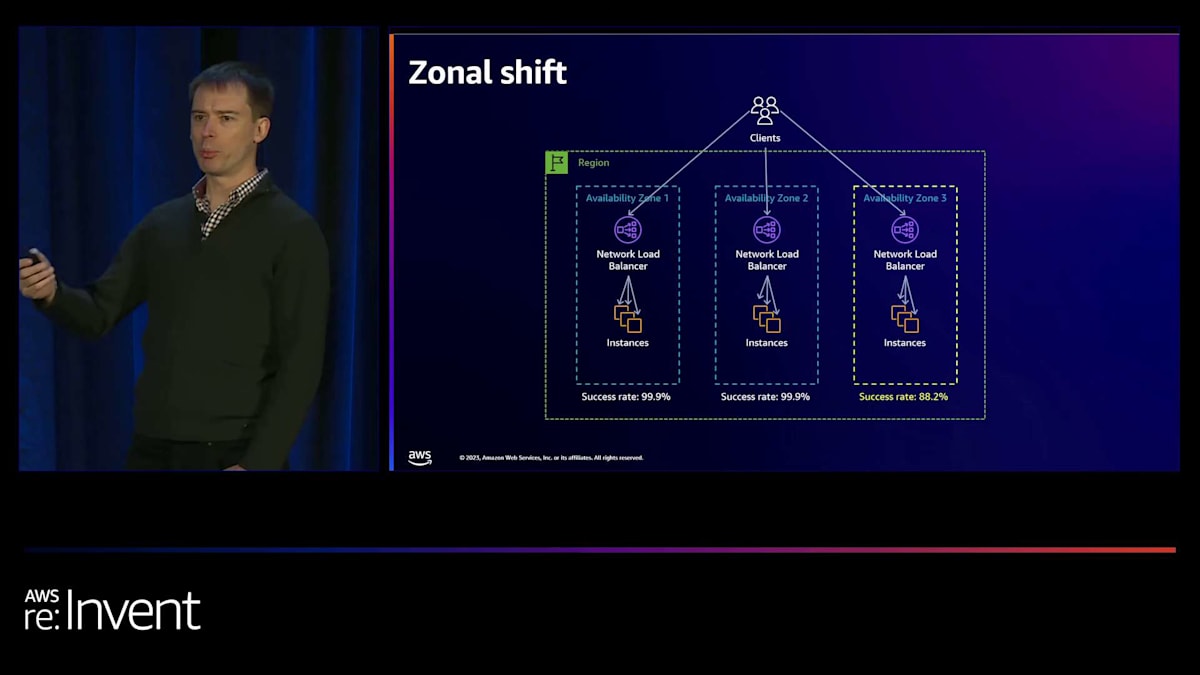
私たちがRAFを実装したもう一つのサービスは、Application Recovery Controllerの一部であるzonal shiftです。これは、お客様が単一のAvailability Zone内の障害からアプリケーションを復旧するのを支援します。Zonal shiftは無料で、AWS Elastic Load Balancingと統合されており、コントロールプレーンに依存することなく、障害のあるAvailability Zoneからトラフィックを移動させることが容易になっています。
典型的なマルチAZアプリケーションでAZ3でエラー率が上昇している場合、お客様はzonal shift APIを使用して、AZ3のEC2インスタンスから他のAvailability Zoneにトラフィックをリダイレクトできます。裏側では、zonal shiftはコントロールプレーンに依存せず、一定の作業量で Amazon Route 53のDNSレコードを更新します。これは、お客様のリクエスト数やアプリケーションの規模に関係なく機能することを意味します。
Zonal shiftは大規模に運用され、何百万ものロードバランサーとリソースを管理しています。Availability Zoneの障害時に、影響を受けたリージョンで実行しながら価値を提供します。このようなサービスの運用と機能の継続的な構築は困難であり、そのため私たちはRAFを適用して、サービスのレジリエンシーに積極的に取り組むことを選択しました。

この回復力に対して積極的に取り組むには、様々な側面を考慮する必要があります。Johnが言及したように、回復力はあらゆる規模と形で現れます。飛行機からアプリケーションまで様々です。ゾーンシフトの場合、Availability Zoneに障害が発生した時に機能しなければなりません。それが重要なのです。お客様は、他のAWSサービスの一部が障害を起こしている時でも、ゾーンシフトを頼りにできなければなりません。

多くのアプリケーションにとって、最大の回復力の懸念は可用性であり、これはしばしば障害率で測定されます。しかし、ゾーンシフトの場合はそうではありません。500エラーの数も確かに重要ですが、私たちはゾーンシフトを開始する能力を優先します。ゾーンシフトを開始する最初のリクエストが失敗しても、2回目のリクエスト、つまり最初の再試行が成功すれば許容できるかもしれません。アプリケーションにとって本当に重要なものを理解することが大切です。


もちろん、単純ではありません。耐久性、一貫性、上流の可用性、下流の可用性 - まずお客様のワークロードを明確に定義し、それらのワークロードにとって回復力の観点から重要なものから逆算して考える必要があります。私の組織で制度化したプロセスは、2週間ごとに会議を行うことです。定められたアジェンダがありますが、特定の会議や会話に合わせてこのアジェンダを調整する責任を持つファシリテーターもいます。会議にはプロダクトチームのメンバーも参加しますが、プロセスはエンジニアリングチームが主導し、所有しています。

このプロセスを進めていくと、多くのドキュメントが作成されます。Amazonでは、文書化の文化が重要だと考えています。障害モードのドキュメントを作成し、チームでレビューする時間を取ることで、単に話し合うよりも問題をより深く理解できます。「このRAFというのは、重いプロセスとドキュメントだ」と思うかもしれません。そしてその通りです。RAFには相当なエンジニアリング努力の投資が必要です。しかし、常に確実に動作する必要がある重要なアプリケーションを運用している場合、アプリケーションが複雑で様々な依存関係がある場合、そして常に変化する顧客トラフィックを扱う場合は、検討する価値があります。

一つ質問させてください:あなたのソフトウェア開発ライフサイクルにおいて、アプリケーションのローンチ後に回復力について積極的に考える時間を設けていますか?イベント後に振り返りを行うことは、私たち全員が行っていることに疑いはありません。私のチームでRAFを制度化した理由の一つは、重要なサービスの回復力についてより積極的に考える方法が欲しかったからです。

レジリエンスは目的地ではなく、旅であることを私たちは自らに思い出させます。レジリエンスを一度デザインすれば終わりというわけではありません。さて、このRAFの実装から私たちは何を学んだのでしょうか。

他のイニシアチブと同様に、RAFにも経営陣レベルのサポートが必要であることは驚くべきことではありません。RAFには、仮説的なシナリオに深く入り込み、それについて推論する意欲と能力を持つエンジニアも必要です。これは当然ながら、レジリエンスに情熱を持つ適切な人材をチームに配置することにつながります。

RAFは、ステークホルダーにとってと同様に、エンジニアにとってもプロセスであることを私たちは学びました。RAFは、エンジニアがシステムの動作について学び、レジリエンスのマインドセットを養うのに役立ちます。RAFは、運用やフィーチャー開発プロセスと統合されたときに最も効果を発揮します。ただし、プログラムの実行だけでなく、チームが最も重要だと特定した領域でシステムを改善するためにもリソースを投入する必要があります。

私のチームの例を紹介しましょう。 ある日、オンコールエンジニアがアプリケーションコンポーネント環境の1つでデプロイメントの問題を緩和しました。その問題を緩和する中で、根本原因が重要度の低い依存関係の断続的な障害にあることに気づきました。エンジニアは定期的なRAFミーティングでこの点を指摘しました。チームと一緒に障害モードのドキュメントを確認し、議論した結果、この重要度の低い依存関係がアプリケーションの迅速なスケールアップ能力を低下させる可能性が、当初考えていたよりも高いことに気づきました。これは、特定の障害モードのリスクが当初の評価よりも高いことを意味していました。

その結果、アプリケーションのクリティカルパスからこの重要度の低い依存関係を取り除く作業の優先順位を上げました。 RAFがなければ、このリスクはより長く私たちと共に存在し続けていたでしょう。

では、ここで要点をまとめましょう。ミッションクリティカルなアプリケーションを運用していて、そのアプリケーションを常に確実に稼働させることを非常に重視している場合、RAFが適しているかもしれません。たとえアーキテクチャがベストプラクティスに従っていて、十分に設計された標準操作手順(SOP)があり、優秀なオペレーターがいたとしても、あなたのアプリケーションはおそらく複雑です。顧客が様々な行動をとることで常に変化するトラフィックパターンに対応し、さまざまな依存関係を扱っています。
レジリエンシーについて事前に考えることに価値を見出し、レジリエンシーは目的地ではなく旅であるという考えに賛同するなら、RAFの導入を検討すべきでしょう。一度導入すれば、あなたのチームがアプリケーションを改善する機会を見つけ出すことを信じてください。そして、チームはあなたがそれらの機会を活用することを期待するでしょう。
ご清聴ありがとうございました。
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion