re:Invent 2024: VMwareワークロードのAWS移行 - オンプレミス依存環境の課題と解決策
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Migrating your VMware workloads with on-premises dependencies (HYB308)
この動画では、VMwareワークロードのAWS移行について、特にオンプレミス依存のある環境の移行に焦点を当てて解説しています。AWS Elastic Disaster Recovery、AWS Application Migration Service、Cirrus Migrate Cloudなど、具体的な移行ツールの特徴と使い分けについて詳しく説明されています。British American Tobaccoの事例では、Manufacturing Execution Systemsを含む工場システムをAWS Outpostsに移行し、45%のコスト削減を実現した具体的な手法と課題が共有されています。Windows Failover ClusterやLoad Balancerの移行における技術的な注意点、BGPプロトコルの必要性、Amazon S3の要件など、実践的な知見が豊富に盛り込まれています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
AWS Hybrid 308セッション:VMwareワークロード移行の概要

Hybrid 308へようこそ。本セッションではVMwareワークロードの移行、特にオンプレミス依存関係のある環境の移行についてお話しします。Venetianからご視聴の皆様、ご参加ありがとうございます。本日のセッションは3つのパートに分かれています。まず自己紹介させていただきます。私はMayur Dewaikarと申します。AWSのHybrid Computeソリューションのプロダクトマネジメントを率いています。そして本日はBrian Daughertyも参加しています。BrianはPrincipal Solution Architectで、Edge Computingの専門家の一人です。また、British American TobaccoのClaudio Kaistも参加しています。同社はVMwareワークロードのAWSへの移行について非常に興味深いケーススタディを持っており、このプレゼンテーションの一部としてお話しいただく予定です。最後にQ&Aの時間も設けたいと思いますが、時間が足りない場合は、セッション後に廊下でご質問をお受けいたします。

アジェンダは大きく3つのパートに分かれています。まず私から、お客様がAWSへのワークロード移行を検討する際の主要な動機と、利用可能な移行パスについてお話しします。次にBrianが、AWSでワークロードを移行するために利用できる様々なツールやサービスについて詳しく説明します。最後に、Claudioが実際の移行プロジェクトの詳細なケーススタディと、AWS移行後に得られた具体的なメリットについてお話しします。
AWSへのワークロード移行:動機と課題

AWSへのワークロード移行について話す際、まずその理由を理解することが重要です。VMwareは長年にわたって使用されてきましたが、最近BroadcomによってVMwareが買収され、Broadcomはライセンスに関して多くの変更を行いました。多くのお客様が急激なライセンスコストの上昇に直面し、現在のワークロードの取り扱いについて検討を始めることになりました。お客様との対話を通じて、その動機は大きく2つのカテゴリーに分類されることがわかりました。1つ目はビジネス上の要因です - コストが上昇し、レガシープラットフォーム上でワークロードを実行することのリスクが潜在的にあり、お客様はこの移行を通じてそれらを管理したいと考えています。
この移行を機に、VMwareから移行するのであれば、インフラストラクチャのイノベーションと最新化も検討したいとお考えのお客様も多くいらっしゃいます。多くのお客様が、VMwareの代替としてクラウドを検討しながら、異なるシステムやセットアップの統合を目指しています。また、データセンターのカーボンフットプリントを削減してより持続可能な運用を目指すお客様もおり、効率的なクラウドベースのインフラストラクチャへの移行がその目標達成を支援します。M&A活動においても、AWSは異なるシステムをシームレスに統合することを可能にします。
技術面では、多くのお客様がVMwareワークロードを運用する中で、長年にわたって技術的負債を抱えてきました。セキュリティ態勢、スケーラビリティ、システムの信頼性を向上させたいと考えています。多くのお客様は、インフラストラクチャ管理をビジネスの一部としたくないため、データセンターの管理から脱却したいと考えています。AWSの真の価値は、お客様自身が管理することなく、インフラストラクチャに必要な回復力と弾力性を提供することにあります。私たちは、お客様にインフラストラクチャ管理から解放されていただき、アプリケーションの開発とお客様への価値提供にできるだけ早く集中していただきたいと考えています。
VMwareからAWSへの移行オプションとアプローチ

VMwareから離れてAWSに移行することを考える際、多くの選択肢があります。大きく分けて2つの方向性についてご説明します。1つ目は、クラウドのリージョンに移行する方法です。VMware Cloud on AWSで実行しているVMwareワークロードがあり、それらの扱いを決めるのに時間が必要な場合、Broadcomは当面の間それらのワークロードの実行を継続するため、じっくりと検討することができます。
VMwareから抜け出す最も簡単な方法は、Lift and Shiftで、これは長年行われてきた方法です。AWSが登場してからの10-15年間、お客様はVMwareワークロードをEC2に移行してきました。これは低コストで労力も少なく、素早くクラウドに移行できる方法です。さらに進んで、ワークロードをReplatformしてコンテナに移行したり、マネージドデータベースを利用したり、より本格的にアプリケーションをRearchitectureやRefactoringしてServerlessなどのモダンな技術に移行することもできます。
将来的にもワークロードをオンプレミスで維持する必要がある場合は、AWS Outpostsがあります。多くのお客様は、非常に低レイテンシーで高性能が要求されるワークロードを持っており、クラウドへの移行ではそのパフォーマンスが得られない可能性があります。また、特定のデータ主権要件があり、自社でコントロールできるデータセンターの近くにワークロードを置く必要があるお客様もいます。Outpostsは基本的にお客様のデータセンター内のAWSクラウドの延長線上にあります。このようなユースケースがある場合、Outpostsは完全にクラウドに移行することなくAWSに移行できる素晴らしい方法であり、多数のサービスがOutpostsで利用可能です。

時間が限られている場合、例えば来月更新時期が来ていて早急に判断が必要な場合、最も迅速な移行アプローチはLift and Shiftです。私たちはこれを「まず移行してから、最適化とモダナイゼーションを後で行う」と呼んでいます。VMwareから抜け出してAWSに移行し、その後でそれらのワークロードをどうするか決めることができます。このプロセスは単純明快で、長年実践されてきました。環境内のワークロードの迅速な発見を可能にするアセスメントから始め、Landing Zoneをセットアップし、Lift and Shift移行をサポートします。そしてAWSに移行した後、組織のビジネス戦略に基づいてワークロードを最適化できます。多くのお客様がこれを実践しています - Maydenは最近6週間で300台のサーバーをReホストし、3Mは24ヶ月で2,200のアプリケーションを移行しました。

フルマイグレーションアプローチを選択する場合は、長期的な視点に焦点を当てます。単なる移行だけでなく、これらのワークロードの理想的な最終状態を考えます。多くの方々が、ワークロードをAWSに持ち込むのは素晴らしいが、Cloud Nativeの機能を活用し、コンテナを使用し、Serverlessを使用し、クラウドで利用可能な新機能をすべて活用したいと言います。このアプローチは、そのような長期的な戦略に焦点を当て、3つのステップがあります。まず、ビジネスケースを把握するためのアセスメントから始めます。この取り組みには時間がかかりますが、ビジネスに長期的な価値をもたらすためです。アセスメントを行い、TCOを算出し、次にMobilizeフェーズで Landing Zoneを作成し、詳細な計画を立て、組織のIT担当者のスキルアップのためのトレーニングを提供します。最後に、私たちのツールを使用して移行を実施し、クラウドに移行した後、次のステップを決定できます。移行の一環としてモダナイゼーションを行いたい場合も、それは可能なオプションです。
AWS Outpostsを活用したオンプレミス依存ワークロードの移行
アプリケーションや環境設定によっては時間がかかる場合があり、そのため綿密なプロセスが移行の過程で非常に重要になってきます。

AWS Outpostsについてお話ししたいと思います。 Outpostsは、お客様のデータセンター内にAWSインフラストラクチャを配置するものです。私たちのリージョンで運用しているものと全く同じインフラストラクチャを提供する、フルマネージドサービスです。現在3つの製品をご用意しています。まず標準的なRackがあり、これはデータセンターでよく見かける42Uラックそのもので、完全に構成済みの状態でお客様のデータセンターに搬入できる状態でお届けします。より小規模な設置面積をご希望の場合は、2種類のサーバー形状もご用意しています:2Uサーバーと1Uサーバーです。これにより、お客様自身のデータセンター内で同様のAWSサービスをご利用いただけます。

AWS Outpostsを使用した移行パスをお考えの場合、いくつかのアプローチがあります。最も簡単な方法は、アプリケーションをOutpostsにRehost(再ホスト)することです。何らかの理由でオンプレミスに残す必要があるワークロードがある場合、このアプローチが適しています。ワークロードをAWS Outpostsに移行することで、Amazon EC2、Amazon EBS、コンテナを使用したい場合はAmazon ECSやAmazon EKSといった重要なサービスにアクセスでき、シームレスにワークロードを素早く移行できます。
2つ目のアプローチは、これらのアプリケーションをReplatform(再プラットフォーム化)することです。コンテナ化を検討される場合はAmazon EKSやAmazon ECSといったサービスをご用意しています。また、マネージドデータベースサービスとしてOutpostsでAmazon RDSもご利用いただけます。3つ目のアプローチは、基本的にこれらのワークロードがAWS Outpostsに移行された後の長期的な計画を考えることです。これにより、VMから素早く脱却し、AWSでの運用に慣れながら、最終的なあるべき姿とその計画について検討する時間を確保できます。

よく話題に上がる点の1つが、移行過程におけるライセンスへの影響とその対処方法です。AWS Optimization and Licensing Assessment(AWS OLA)というサービスをご用意しています。移行を検討し始める際、私たちが環境の完全な評価を行います。すべての設定を確認し、現状のスナップショットを取得し、ライセンスとインフラストラクチャの両面で可能な最適化を特定し、ライセンスへの影響を考慮したワークロード処理の最適な方法について明確なガイダンスを提供します。これは移行時に実施するアセスメントプロセスの一部です。

以上で導入部を終わります。ここでBrianをステージにお呼びしたいと思います。BrianがVMwareマイグレーションのための様々なツールやサービスについてお話しします。ありがとうございました。
AWS移行ツールの詳細:DRS、MGN、サードパーティソリューション

皆様、こんにちは。オンプレミスのワークロードをAWSインフラストラクチャに移行する理由についてお話ししましたが、次は実際にその方法についてご説明します。3つの異なるサービスについてお話しします。1つ目はAWS Elastic Disaster Recovery(DRS)、2つ目はAWS Application Migration Service、そして3つ目は、マイグレーションに役立つサードパーティツールについてです。DRSは、パイロットライト型のディザスタリカバリを構築するために使用されるAWSサービスです。ワークロードをステージングし、継続的に更新され、プライマリデータセンターで障害が発生した場合、そのバックアップに素早く切り替えることができます。問題が解決したら、フェイルバックすることができます。これは柔軟性の高いパイロットライト型ディザスタリカバリソリューションです。
スライドでご覧いただけるように、仮想マシンでもベアメタルでも、オンプレミスサーバーからクラウドやAWS Outpostsラックに移行できます。AWS DRSを使用して、Outpostsラック間、リージョンからラック間、さらには他のクラウドスタイルのOutpostsラック間での移行も可能です。リフト&シフト型の運用が可能な、非常に柔軟性の高いサービスです。カットオーバーと最終的な移行を決定するまで、継続的なデータ同期を行うため、信頼性が高いのが特徴です。DRSを移行に使用する場合、WindowsやLinuxのシステムにインストールして使用できるため、ソース仮想マシンやソースシステムに関する大きな制約はありません。また、ディザスタリカバリと移行パスを設定すれば、高度なスキルは必要ありません。


典型的なクラウド移行やリージョン間のパイロットライト型デプロイメントがどのようなものか見てみましょう。まず、災害時の生存性を確保したい複数のソースインスタンスがある保護対象リージョンがあり、別のリージョンにパイロットライトまたはDRサイトを構築することを決定します。最初に、AWSコンソールでDRSサービスを構築してDRSをアクティブ化します。DRSサービスを構築する際、ステージングサブネット、ステージングVPC、リカバリサブネットを定義します。これらはすべて同じVPCに配置することができます。

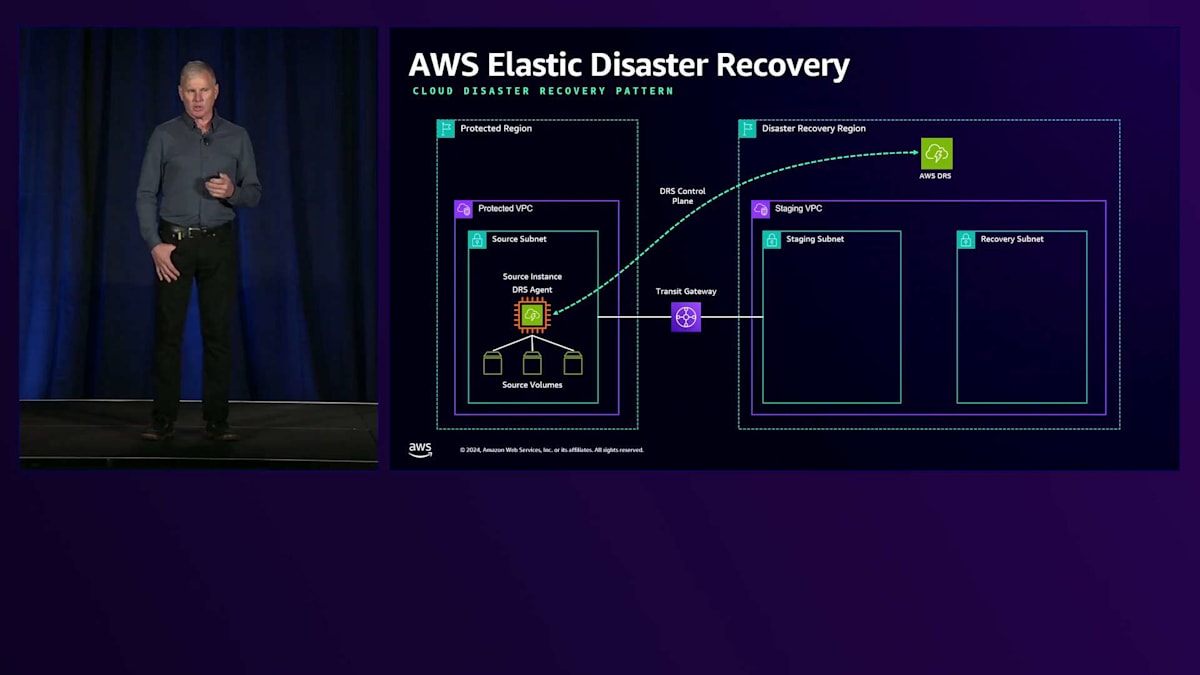


その後、VPCピアリングやトランジットゲートウェイを通じて、ソースリージョンとデスティネーションリージョン間の良好な接続性を確保します。この2つのリージョン間で接続できる状態であれば問題ありません。DRSはエージェントベースのシステムなので、ソースワークロードにDRSエージェントをインストールします。DRSエージェントは自身をDRSシステムまたはサービスに登録します。その後、DRSエージェントをインストールしたシステムからソースボリュームのレプリケーションを開始します。ステージングサブネットへのレプリケーションを実行するインスタンスを管理し、レプリケーションサーバーを通じてそれらのボリュームをステージングサブネットにレプリケートし始めます。これらのボリュームは、ディザスタリカバリのために使用する必要が生じるまで、継続的なブロックベースのレプリケーションによって維持されます。



DRSの重要な特徴の1つは、Point-in-timeスナップショットを取得できることです。過去の特定の時点に戻る必要がある場合に備えて、RTOやRPOに応じたスナップショットを保持しています。データをリージョンに移行し、Point-in-timeスナップショットで維持した後、 カットオーバーまたはフェイルオーバーを実行して、リカバリーサブネット内の別のリージョンでリカバリーインスタンスを作成できます。これにより、必要な状態に素早く復帰することができます。 そして、問題が解決した後は、元の状態に戻すことも可能です。


では次に、Outpostsへの移行がどのように行われるのか見ていきましょう。この場合も同じソリューションを使用できます。まず、工場やオンプレミスのデータセンターなどの場所から始めて、それをAWS Outpostsに移行したいとします。 Outpostsを購入すると、ワークロードをサポートするために必要な構成とサイズを決定するお手伝いをさせていただきます。Outpostsを導入する際、Outpostsラックサービスをご存知の方なら分かると思いますが、Outposts Local Gatewayと呼ばれる構成要素を通じてオンプレミスシステムと統合されます。このLocal GatewayはCustomer Gatewayに接続され、Outpost上のEC2インスタンスがオンプレミス環境と通信できるようになります。

DRSではEBSスナップショットの使用が必要で、Outpostsでは S3 on Outpostsの使用が必要となります。Outpostsを導入し、S3を構成し、オンプレミスネットワークの残りの部分に接続すれば、次のステップに進む準備が整います。

このプロセスは、リージョン間のディザスタリカバリーと似ています。まず、DRSサービスをセットアップし、Outposts上のVPCにステージングサブネットと移行サブネットを作成します。次に、VMware環境内のソース仮想マシンにDRSエージェントをインストールします。DRSに登録され、オンプレミスサーバーとOutpostsの間にルーティングパスが確立されると、 オンプレミスワークロードからOutpost上のEC2インスタンスへの継続的なブロックレベルレプリケーションを開始できます。


移行を実行する場合、すべてのワークロードが完全にレプリケートされ、準備が整ったら、目的のPoint-in-timeリカバリーのためのスナップショットを作成し、 カットオーバーテストを実行できます。テストと最終的なOutposts移行サブネットへのインスタンスのカットオーバーが完了すれば、VMware環境からOutpostsへのインスタンスの移行は成功です。必要に応じて、時間の経過とともに これらのインスタンスを削除し、オンプレミスのVMware環境を廃止することができます。その後、これらのサーバーをDRSから切断することができます。

いくつかの重要な考慮事項があります。 このマイグレーションを実現するためには、Outpost Rackには必ずEBSとAmazon S3が必要です。Outpost Rackには、オンプレミスのワークロードとEC2インスタンス間の接続に2つの異なるモードがあります。Direct DVRルーティングモードがサポートされており、これによりOutpost上で作成されたサブネットがBGP経由でオンプレミスにアドバタイズされます。ただし、オンプレミスのIPアドレスをOutpostで使用するCustomer-owned IPsモードはサポートされていません。オンプレミスのワークロードをレプリケーションする際は、最終的なワークロードと、マイグレーション期間中にレプリケーションされるワークロード両方のEBSストレージを考慮する必要があります。さらに、複数のポイントインタイムスナップショットを保持する予定がある場合は、追加のS3ストレージも考慮に入れる必要があります。

次に、AWS Application Migration Service(MGN)について説明しましょう。MGNは、事実上あらゆるソースからAWSリージョンへのワークロードのマイグレーションを可能にする包括的なツールです。これは強力なツールで、広範な自動化を実現し、マイグレーションを追跡するためのコンソールを提供します。アプリケーションを移行した後は、リージョンで利用可能なすべてのアプリケーションやサービスを活用できます。

MGNは、バックエンドで同じテクノロジーの多くを使用しているため、DRSと多くの機能や特徴を共有しています。主な違いは、MGNがAWS Migration Hubと緊密に統合されていることです。Migration Hubは、包括的なマイグレーション戦略の構築を可能にするソリューションです。AWS Migration Hubを使用すると、組織内の異なる専門分野や背景を持つメンバーを招き、アプリケーションをAWSに移行する方法を理解し、パートナーと協力してマイグレーションの道筋を構築することができます。MGNはMigration Hubの背後にあるツールで、仮想マシンをある場所から別の場所に移動するという点でDRSと同様の機能を提供します。


AWS Application Migration Service(MGN)を使用したマイグレーションの流れを見てみましょう。DRSでリージョン間のマイグレーションを示したのとは異なり、ここではソースデータセンター(おそらく工場)から始めます。MGNを使用する場合、AWSコンソールに移動してMGNサービスを作成します。これはDRSと非常によく似ており、ステージングサブネットまたはレプリケーションサブネット、そして最終的に移行した仮想マシンを配置したい場所となるマイグレーションサブネットを作成します。

MGNの特徴の1つは、Launch Templateという概念です。レプリケーションインスタンスの構成だけでなく、最終的に移行されたインスタンスがどのような構成になるかも、テンプレートを通じて定義できます。ソースネットワーク、つまりソースサイトとAWSリージョン間の良好な接続を確保する必要があります。これはインターネット経由で行うことができ、また大規模な施設の場合はDirect Connect接続を使用することもできます。

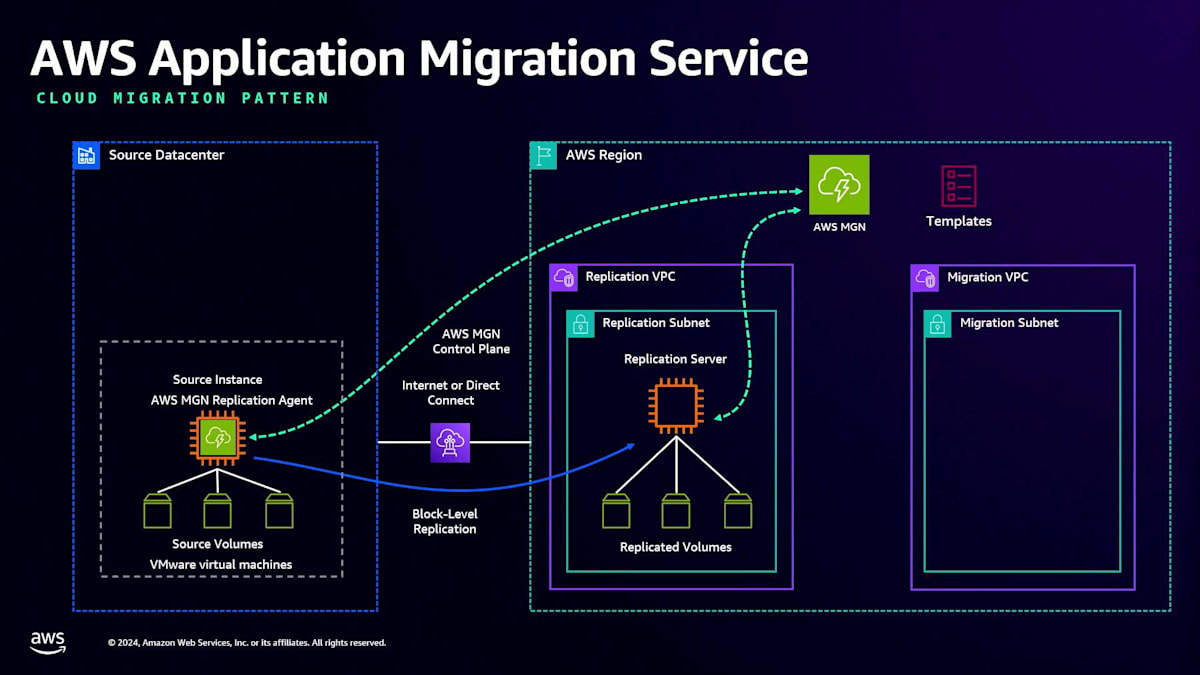

ソース上にMGN Agentをインストールすると、MGNはそれらのソースのボリュームをReplication Subnetにレプリケーションし始め、すべてのボリュームの作成とReplication Serverのスケールアップ・ダウンを管理します。MGNによってボリュームが作成されると、ソースからReplication Subnetへのブロックレベルのレプリケーションが行われます。その後、テストやテストカットオーバーを実行できるようになり、最終的にそれらのインスタンスをMigration Subnetに完全カットオーバーすることができます。



では、これをOutpostsにどのように適用するのでしょうか?DRSと同様に、Outpostに移行したいサーバーが多数存在する工場やサイトがあります。しかし、AWS MGNはアプリケーションやインスタンスをリージョンに移行するように設計されているため、MGNをセットアップし、Replication Subnet、Staging Subnet、Cutover Subnetを作成します。Agentをインストールすると、レプリケーションはソースからReplication Subnetへと行われます。
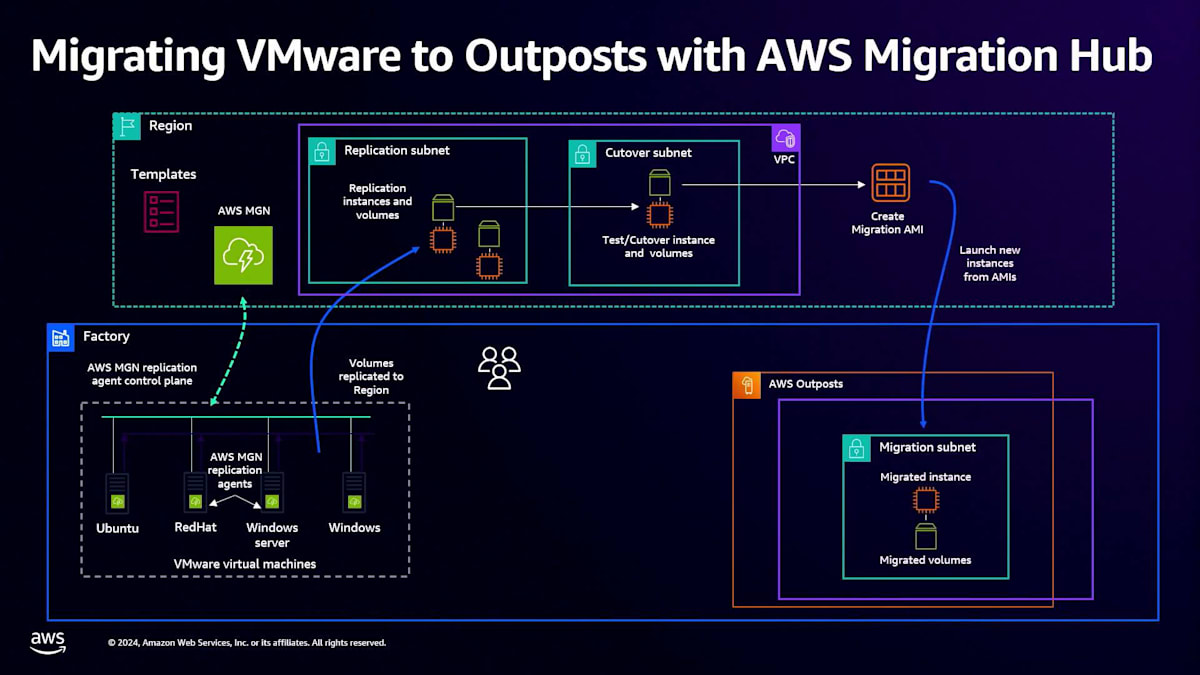
Outpostへの移行は異なる方法で行います。まず、ソースインスタンスとソースボリュームのカットオーバーを実行します。それが完了したら、そのカットオーバーされたボリュームからAmazon Machine Imageを作成します。このAmazon Machine Imageを使用して、オンプレミスのOutpost上に新しいインスタンスをデプロイできます。DRSの場合とは異なり、リージョンを経由する形になりますが、これがMGNを使用してOutpostへの移行を行う方法です。これは、リージョンへの他のクラウド移行などで既にMGNを使用している人々にとって魅力的で、使い慣れたツールとなっています。
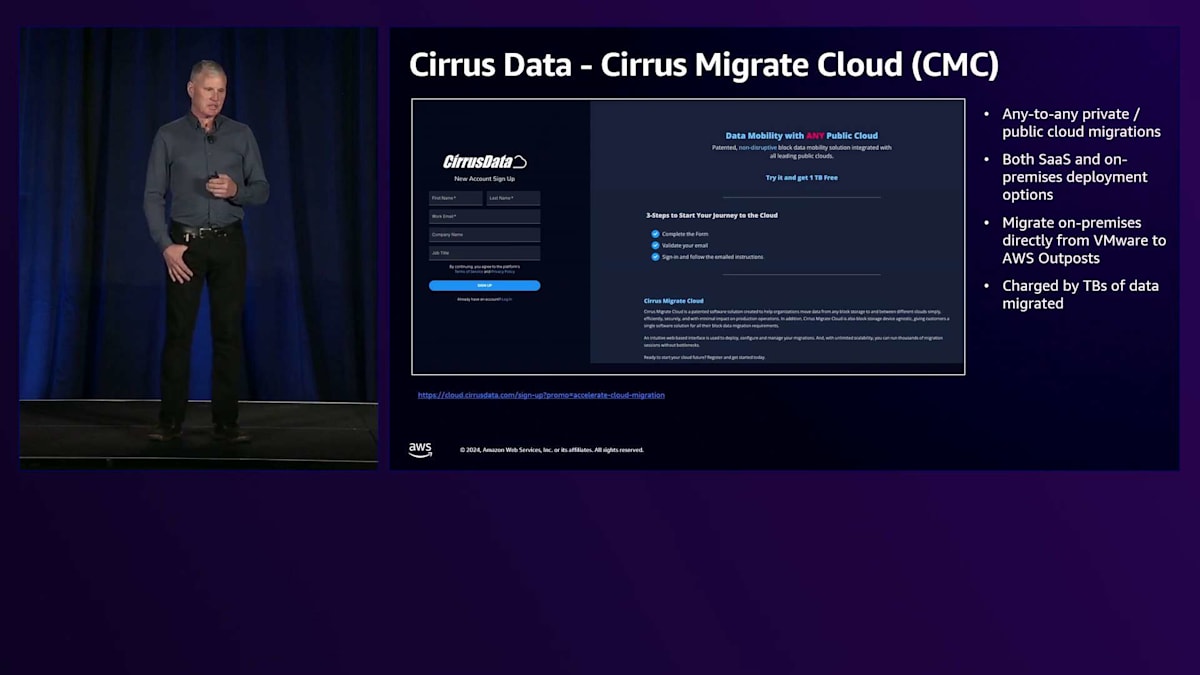
サードパーティツールについて、最近ではパートナーであるCirrus Dataと多くの協力を行っています。Cirrus DataはCirrus Migrate Cloudという、マルチソース・マルチデスティネーションの移行ツールを提供しています。また、すべてのオンプレミスやあらゆる環境間の移行が可能な類似製品も提供しています。彼らは、この製品がAWS Outpostsと非常に良く連携するよう、徹底的な取り組みを行ってきました。これはSaaSプラットフォームで、OutpostのS3に依存することなく、またリージョンを経由せずに、VMware環境からOutpostに直接オンプレミスで移行することができます。一部の顧客はこのタイプの移行シナリオを好みます。というのも、テラバイト単位で料金が発生するためです。Cirrusからライセンスを取得すると、基本的に転送したいデータ量を指定し、コストが提示され、すぐに開始できます。

Cirrus Dataアカウントにサインアップすると、AWSとの非常に堅固な統合が提供されます。AWSアクセスキーとシークレットを使用するか、AWS IAMロールを通じて統合を設定できます。つまり、アカウントを作成してライセンスを適用するだけです。



AWSとの連携を作成すると、2つのシステム間の移行を開始する準備が整います。 AWS DRSやAWS MGNと同様に、エージェントのインストールを実行します。このインストールでは、移行したい仮想マシンにエージェントをインストールします。これはAnsibleやその他のオンプレミスで使用している管理ツールを通じて管理できます。これにより、仮想マシンがCirrus DataのSaaSプラットフォームに登録されます。Cirrus Dataプラットフォームがソースを認識すると、移行オペレーションを作成できるようになります。

Cirrus Dataでは、Migrate Opsを通じて移行を作成します。YAMLを使用して、ソースをAWS Outpostsに移行する方法を定義します。これは、ソースが登録情報によって定義され、移行先がインスタンスを配置したいサブネットによって定義されるためです。このMigrate Opsのシナリオを定義し、YAMLをプラットフォームにプッシュします。この時点で、SaaSプラットフォームはOutposts上にヘルパーエージェントを作成します。このヘルパーエージェントは、VMware環境のソースからLocal Gatewayを経由してOutpostsのサブネットに直接データを転送するために使用されます。
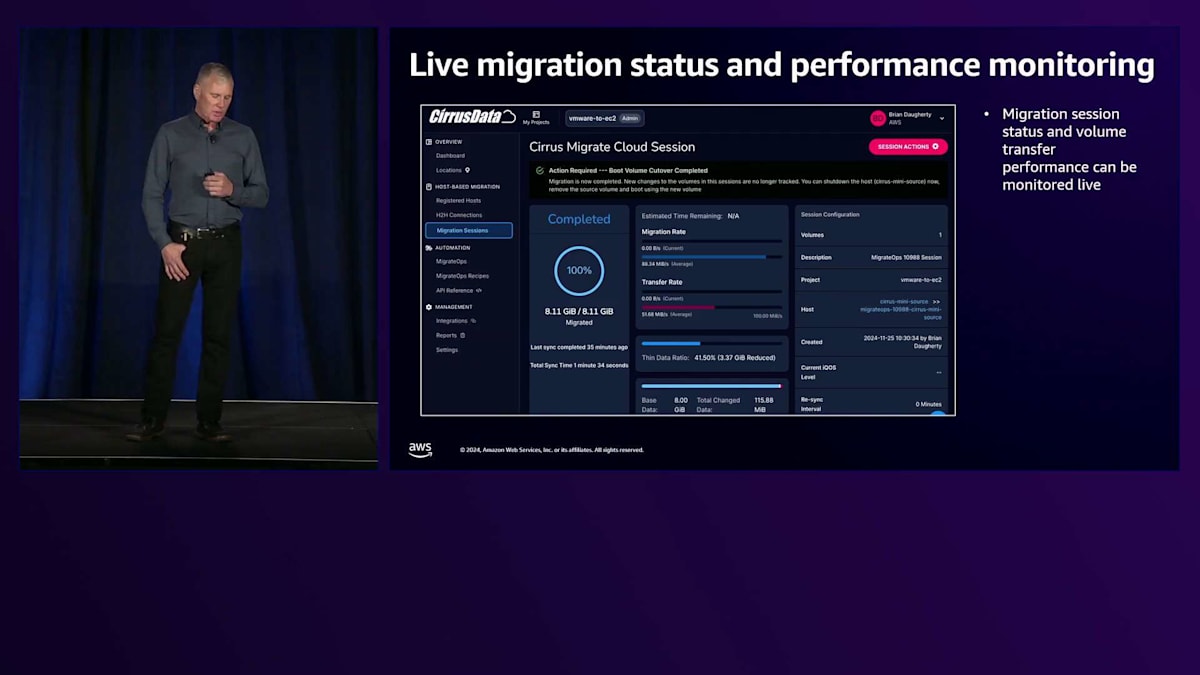
このデータ転送はTCP経由で行われます。この方式の特徴的な点は、オンプレミス環境からLocal Gateway経由でOutpostsへのルートさえあれば、その方向で移行が行われることです。Regionを経由する必要もなく、AMIやスナップショットの作成といった特別な処理も必要ありません。セッションが作成されると、SaaSプラットフォームで、どれだけのデータが移動され、どのくらいの時間がかかったかを監視できます。ソースとヘルパーエージェントが使用しているボリューム間でデータが完全に同期されると、カットオーバーの承認要求が届きます。


カットオーバーを承認すると、プラットフォームは実際のターゲットインスタンスを作成し、移行されたボリュームをAmazon EC2で起動可能なように調整し、そのボリュームをアタッチしてインスタンスを起動します。UIで実行できるこれらの操作は、すべてRESTful APIでも同様に実行できます。このプラットフォームは移行に非常に適しており、特にGitOpsの経験やGitOpsパイプラインを活用できる場合に効果的です。

ここまでで3つの異なる移行パスについて説明しました。AWS Elastic Disaster Recoveryは、すでにそれを使用していて、Amazon S3を持つOutpostsへの移行を希望する場合に適しています。AWS Application Migration Serviceは、すでにMGNを使用して他の移行(おそらく大規模なクラウド移行)を行っている場合に適した選択肢で、そのツールを継続して活用してオンプレミスからOutpostsへワークロードを移行できます。3つ目は、先ほど説明した第三者の移行ツールであるCirrus Dataです。この他にも、ローカルバックアップを実行してAWSにデプロイする機能を持つバックアップ企業なども存在します。


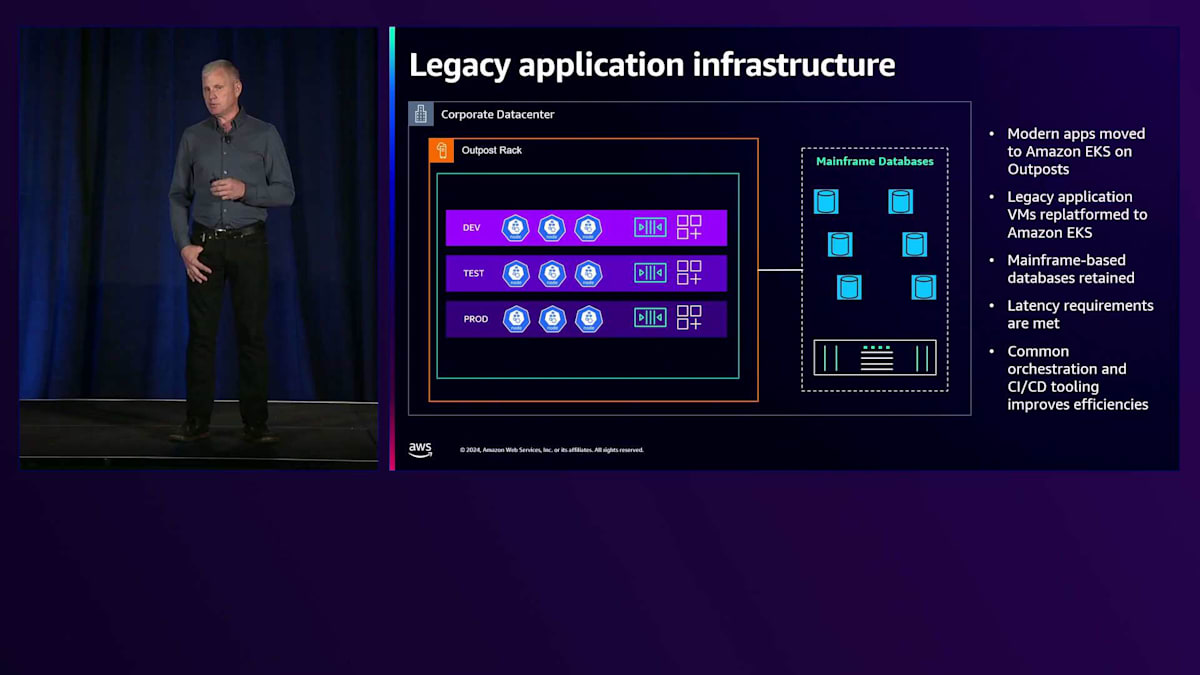
手短にお話ししますが、先ほどMayurが説明した移行パスの1つについて、具体的にはReplatforming移行についてお話しします。南米の大手銀行のお客様と協力した事例では、ワークロードをオンプレミスに保持する必要があるという課題を解決するために、多数のOutpostsを導入しました。その理由は、すべての銀行アプリケーションのバックエンドとして機能する巨大なメインフレームデータベースを持っていたからです。彼らはKubernetesを実行しており、その一部をVMware環境上で動作するKubernetesに近代化していました。また、そのバックエンドデータベースにアクセスする必要のあるキューイングサービスやその他のアプリケーションサービスを提供する仮想マシンも使用していました。彼らはAWS全体とより良く統合できるよう、AWS Outpostsベースのソリューションに移行して近代化したいと考えていました。
彼らはAmazon EKS on Outpostsに移行しました。すでに多数のKubernetesベースのアプリケーションを持っていたため、それらはAmazon EKSに比較的スムーズに移行できました。その後、以前は仮想マシンだったキューイングやその他のアプリケーションを置き換え、コンテナ化してKubernetes上で実行できるように近代化しました。これらすべてが、レイテンシーの観点からメインフレームデータベースの近くに設置されたOutpost上で実行されました。メインフレームは近代化しなかったものの、AWS Outpostsへのリプラットフォーミングを完了させました。
British American Tobacco:AWS Outpostsへの移行事例


Claudioが、異なるパス、つまりリホストのパスについて話をします。ありがとうございました。ありがとう、Brian。皆さん、こんにちは。このセッションを楽しんでいただけていることを願っています。これから20分ほど、私たちのクラウドジャーニーと、最初の工場をクラウドに移行できた経緯についてご説明します。まず、British American Tobacco(BAT)について簡単にご紹介させていただきます。私たちは120年以上にわたりタバコビジネスを展開しており、108カ国以上でグローバルに事業を展開し、52,000人以上の従業員を抱えています。Vaping、Modern Oral、加熱式タバコなど、新しい製品カテゴリーを通じて価値を提供することに取り組んでいます。

少し時間を遡って、私たちのクラウドジャーニーがどのように始まったかをお話しします。約10年前、小規模なワークロード、重要度の低いワークロード、工場以外のワークロードをクラウドに移行し始め、最終的にはワークロードの100%をクラウドに移行するまでになりました。しかし、私たちには世界中に約50の工場があり、それらの工場には少なくとも1つのデータセンターがあります。これらの工場にクラウド移行の可能性について相談するたびに、いつも反発がありました。ほとんどの場合、理由は同じでした。すべての機械を制御するPLCデバイスに接続されているためレイテンシーの低さが必要だとか、クラウドでの実行を想定していない古いアプリケーションがあるとか、あるいはインターネットが信頼できない場所に工場があるといった理由でした。
ちょうど2年前、私はAWSチームとサービスレビューミーティングを行い、工場に関する戦略や課題について話し合っていました。その時、彼らは「心配いりません。最適な製品があります - AWS Outpostsです」と言いました。私はOutpostsについて聞いたことがありませんでした。Outpostsについて説明を受けた後、私たちはそのアイデアを気に入り、工場に適していると感じました。そこでCloud and Data Centerエリアの責任者にこのアイデアを持ち込んだところ、彼も気に入って、どの工場から始められるか検討するよう指示を出してくれました。ただし、2つの条件がありました。1つ目は、これが組織にとって非常に重要で戦略的なプロジェクトになるため、私がプロジェクトマネージャーを務めること。2つ目は、失敗は許されないということでした。というのも、工場の移行は1度しかチャンスがなく、失敗すれば二度目の機会はないからです。
私たちは、影響力があり、プロジェクト管理がしやすい近隣の工場を選びました。彼らと話を始めた時は簡単ではありませんでした。というのも、彼らは不安を感じていたからです。何度も話し合いを重ねた結果、彼らは同意してくれましたが、1つ条件がありました。もし製品が本当に良くて、私たちが約束したことを実現できるのなら、最も重要なシステム - Manufacturing Execution Systems (MES)から始めるべきだと。彼らの考えは、MESシステムを移行できれば、他のすべてのシステムも移行できるはず。逆に失敗するなら、他のシステムに時間とお金を費やす前に早めに失敗した方がいい、というものでした。
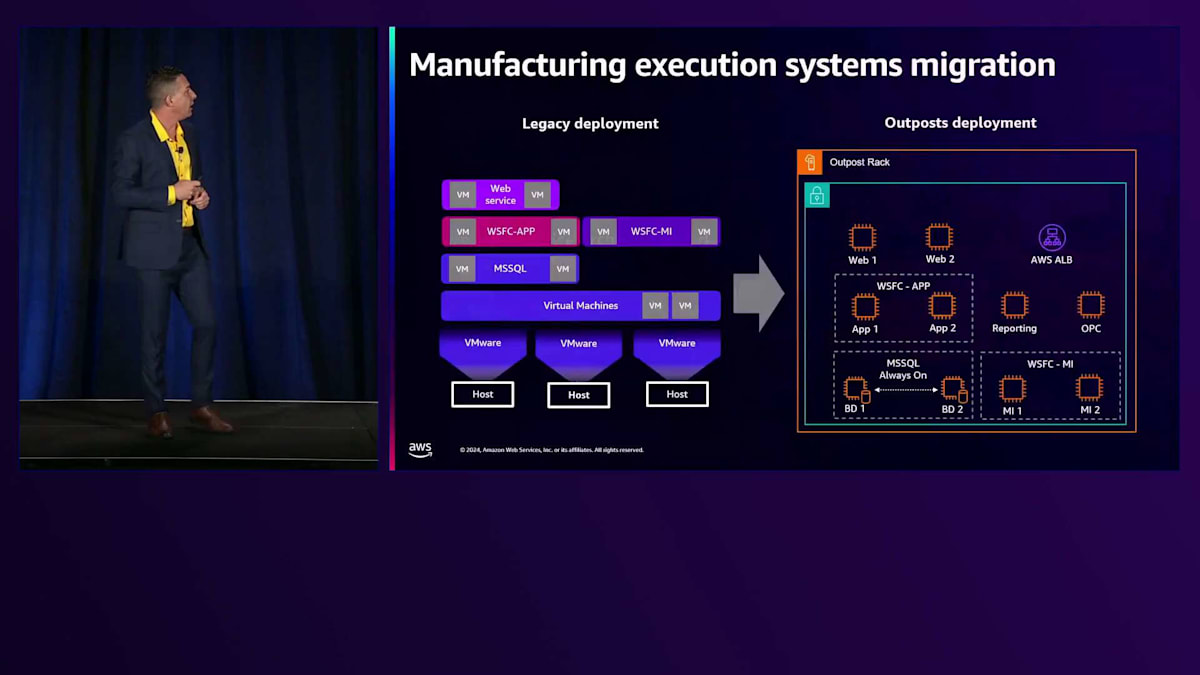
ここに示しているのが、私たちのMESシステムのアーキテクチャです。これはWindows環境でVMware上で動作していました。Microsoft SQLクラスターをAWS Outpostsに移行しました。Outpostsでは共有ストレージのサポート方法がVMwareとは異なるため、若干の変更が必要でした。Microsoft SQL Always Onに移行することで、ビジネスが要求する同じ機能性と高可用性を維持することができました。その上のレベルでは、アプリケーション用とマシンインテグレーター用の2つのWindows Failover Clusterがありました。
私たちはさらなる課題に直面しました。というのも、AWSではVMwareのようにクラスター上に仮想IPを設定するWindows Failover Clusterをネイティブにサポートしていないからです。この課題を解決するため、PowerShellスクリプトを活用しました。アクティブノードがダウンすると、Windows Failover Clusterがそのスクリプトを呼び出し、スクリプトがリージョン内のAPIを呼び出してIPアドレスをアクティブノードからパッシブノードへ、またはその逆に移動させます。同じ機能性と高可用性を維持できましたが、1つ注意点があります。PowerShellスクリプトがリージョンのAPIを呼び出す必要があるため、フェイルオーバーを実行するにはインターネット接続が必要になります。
Webサービス層では、DNS round-robinを使用したWindows Network Load Balancingで2つのWebサービスを運用していました。NLBはAWSではサポートされていないため、AWS Application Load Balancerに移行しました。もう1つの考慮点として、NLBで使用していたSticky Sessionsは、リージョンではサポートされていますが、Outpostsではサポートされていません。そのため、Webサービスの動作をアクティブ/パッシブノード方式に変更する必要がありました。AWS Lambda関数とALBを組み合わせてWebサーバーの健全性を監視することで、ビジネスが要求する同じ機能性と高可用性を実現することができました。

このスライドは大幅な簡素化を示しています。左側のオンプレミス環境では、様々な契約、ハードウェアサポート、VMwareライセンス、バックアップライセンス、テープ管理などが必要でした。一方、右側では AWS Outposts という1本の線だけになりました。これは既存のエンタープライズ契約に含まれていたため、別途契約する必要もありませんでした。
ネットワークに関しては、大きなアップグレードや変更なしで、セットアップだけを行えばよかったのです。サポートについては、オンプレミスでサポートしていたベンダーから、すでにクラウドでサポートしていたパートナーに切り替えました。結果として、ビジネスにとって大きな意味を持つ45%のコスト削減を達成することができました。

この経験から得られた教訓をお話しさせていただきます。まず発注からですが、一見シンプルに思えるかもしれませんが、AWSは発注のために多くの質問をしてきますので、要件に細心の注意を払う必要があります。データセンターのフロア容量、重量制限、ネットワークや電源ケーブルの構成、冷却システム、インターネット接続など、普段すぐに答えられないような仕様について多くの質問があります。これらの質問に答えるには時間がかかりますが、発注には必要不可欠なプロセスなのです。
AWS Outposts導入の教訓とメリット
納品に関して、私たちは定期的にデータセンターで機器を受け取ることに慣れていると思うかもしれません。しかし、Outpostsはケージの中に完全に組み立てられた状態で届くため、それを収容するための十分なスペースが必要です。AWSは Outposts を扱える人について非常に厳格です。設置に関して、私たちのケースでは、データセンターが工場内にあるため、エンジニアがデータセンターにアクセスするために複数のセキュリティトレーニングを完了する必要があり、これにもかなりの時間がかかりました。
プロジェクトの重要な側面の1つがコラボレーションです。私たちは計画を立て、早い段階からすべてのステークホルダーやアプリケーションオーナーと関わり、Outpostsとは何か、なぜ導入するのか、そしてサポートを得るための説明を始めました。人は時として詳細を忘れたり、異なる記憶を持っていたりするため、すべてを文書化することが重要です。接続性に関しては、AWS、ネットワークチーム、サイバーセキュリティチーム、クラウドチームと少なくとも1回のワークショップを開催し、Outpostsの要件とネットワーク設計の仕様をすべて理解することが不可欠です。
先ほどBrianが説明したように、OutpostsとローカルネットワーK間の通信にはBGPを使用します。私たちはそれまでBGPを使用していませんでした。あまり一般的なプロトコルではないためです。そのため、BGPを有効にする必要がありました。場合によっては、その機能を有効にするためにスイッチのライセンスを取得する必要があるかもしれません。24時間稼働の工場運営を扱う場合、専任のProject Managerを置くことが重要です。Project Managerは全てのステークホルダーと異なるチームに関与する必要があります。私たちには米国、メキシコ、ポーランド、インドにまたがるチームがあり、調整が課題でした。

アプリケーションだけでなく、ネットワークに関するAWS側の要件や制約についても、全てを理解することが重要です。Outpostsのセットアップ時に、移行時ではなく、エンドツーエンドのテストを実施することが非常に重要です。これにより、UATでの多くの問題を回避できます。私たちの場合、UAT中にネットワーク設計の一部を見直す必要がありました。その調整後、移行を進めることができました。全ての移行を継続することができたのです。
Load Balancerについては、先ほど触れたように、シンプルなトピックに見えますが独自の課題があります。現在使用しているLoad Balancerの要件と機能、そして移行で計画していることをしっかりと理解することが非常に重要です。まず、採用する移行アプローチを定義し、使用するツールを決定します。私たちの場合、Brianが既に言及したAWS Application Migration Service(AWS MGN)を使用することにしました。
しかし、開始前に誰も教えてくれなかったのですが、AWS OutpostsでAWS MGNを使用するためには、OutpostsにAmazon S3が必要でした。最初の移行を開始したところ、多くの問題と失敗に遭遇しました。そして、Amazon EBSしか持っていなかったため、S3が必要だということが分かりました。Brianが言及した回避策として、ワークロードを一旦Regionに移動し、そこからOutpostsでAMIを作成する必要がありました。これにより、カットオーバーの時間が増え、ワークロードがRegionにある間のコストも増加しました。
配置は極めて重要です - Outpostsを注文したからといって、オンプレミスの全てのワークロードをOutpostsに移行する必要はありません。私たちは全てのアプリケーションについて非常に深い分析を行い、一部のアプリケーションは直接Regionに移行できることを発見しました。Outpostsには、主に低レイテンシーの問題に関連する、本当に必要なものだけを残しました。IPアドレッシングについては、IPアドレスレンジの準備が必要です。VMwareからOutpostsにサブネットを移動することは可能ですが、設定方法によっては、私たちが行ったように同じサブネットを両方の場所に配置することはできず、非常に困難です。

サブネットをOutpostsに移行すると、Outpostsがゲートウェイとなります。同じサブネット内にサーバーとネットワークデバイスがある場合は、まずネットワークデバイスをサブネットから削除してから、サーバーを移行する必要があります。すでに分離されている場合は、よりシンプルに進められます。この移行後に得られた主なメリットについてご説明させていただきます。Infrastructure as a Serviceにより、ハードウェアの管理、購入、更新などを気にする必要がなくなり、コアビジネスに集中できるようになりました。ハードウェアに関する事項はすべてAWSに任せることができます。
Outpostsによるスケーリングは非常に簡単です。プロジェクトの途中で、ビジネスから新たにキャパシティ増強の要件が出た際の経験をお話しします。従来のデータセンターであれば、新しいサーバーの導入に数ヶ月かかっていたでしょう。Outpostsでは、AWSに注文を出すだけで数週間で新しいキャパシティが利用可能になりました。単一のベンダーと単一のコンソールで、一貫した管理体験を得ることができます。新しいサーバーのデプロイやバックアップの取得など、必要な作業はすべてAWSコンソールで行えるため、コストと複雑さが軽減されます。
リージョンで使用していたツールを、そのままOutpostsでも使用できます。リージョンにあるAWSのインフラと同じものを、オンプレミスで利用できるようになりました。ミッションクリティカルな運用のために設計された、完全な冗長性を備えた非常に高い耐障害性を持っています。このデータセンターでは、クラウドベースのバックアップと災害復旧が可能になりました。以前は十分な災害復旧計画がありませんでしたが、現在はOutpostsのバックアップが自動的にクラウドに保存されるため、数分でクラウドDRを実現できます。私たちが選択したLift-and-shift移行は完全にスムーズとはいきませんでしたが、アプリケーションの再インストールは必要ありませんでした。先ほど説明したツールを使用することで、すべてのワークロードを移行することができました。そろそろ時間になりましたので、さらにご質問がありましたら、後ほど個別に承らせていただきます。皆様、お時間をいただき、ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion