re:Invent 2024: AWSがSageMaker HyperPodの新機能を発表
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024-Accelerate gen AI: Amazon SageMaker HyperPod training plans & recipes(AIM301-NEW)
この動画では、Amazon SageMakerのPrincipal Product ManagerのGal Oshriらが、re:Inventで発表されたHyperPodのTraining PlansとRecipesについて解説しています。大規模モデルのトレーニングにおける課題を説明し、Training Plansによって予測可能なスケジュールとコストでリソースを確保できる仕組みを紹介します。また、HyperPod Recipesを使うことで、Llama、Mistralなどの人気Foundation Modelのトレーニングを数週間から数分で開始できるようになった点も説明されています。最後に、NinjaTech AIのCEOのBabak Pahlavanが、これらの機能を活用して音声会話が可能なLlamaモデルを14時間、5,000ドル未満でトレーニングできた実例を紹介しています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Amazon SageMaker HyperPodの新機能紹介

みなさん、こんにちは。私はGal Oshriと申します。Amazon SageMakerのPrincipal Product Managerを務めております。本日は、同じくSageMakerのSenior Manager for Solution ArchitectureのGiuseppe A. Porcelliと、NinjaTech AIのFounder兼CEOのBabak Pahlavanと一緒に登壇させていただきます。先日のre:Inventで発表されたHyperPodのTraining PlansとRecipesについてご紹介させていただきます。

まず、大規模モデルのトレーニングにおける課題についてお話しし、その後、Training PlansとRecipesの詳細に入っていきます。そして、これら2つの機能のデモをご覧いただき、最後に、NinjaTech AIがHyperPodとTraining Plansを使って実現している素晴らしい取り組みについてお話を伺います。
大規模モデルトレーニングの課題とAmazon SageMaker HyperPodの解決策
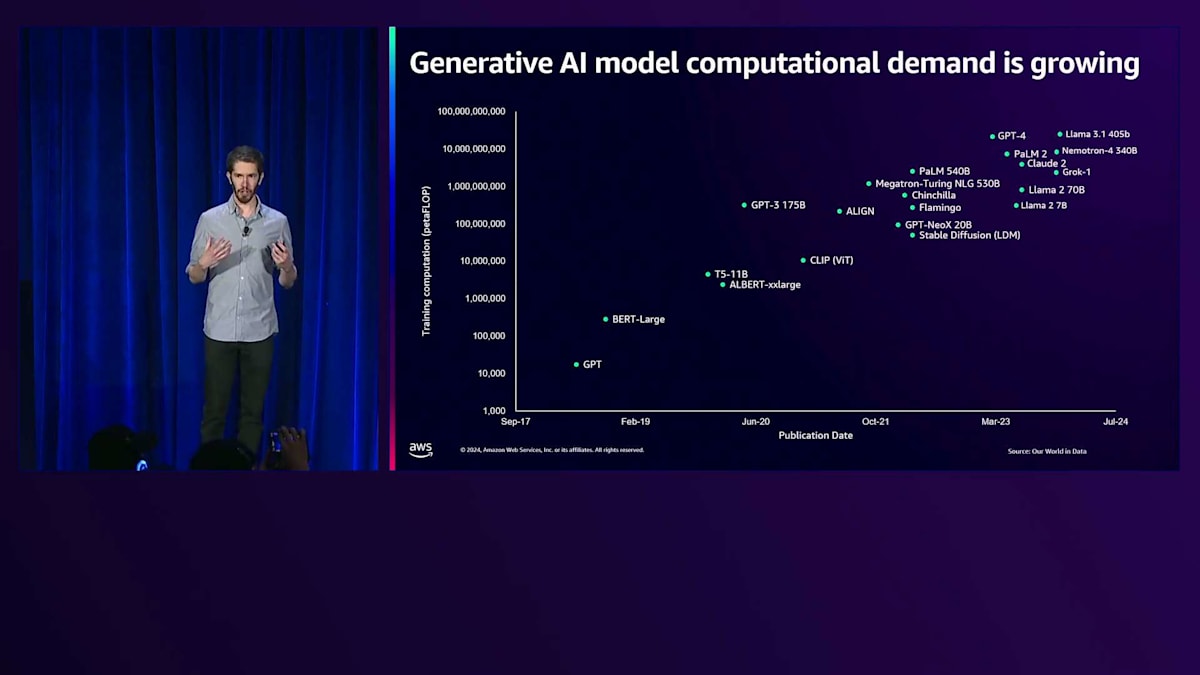
ここ数年、大規模モデルの構築とトレーニングへの需要は大きく増加しています。より大きなモデルで、より多くのデータと計算リソースを使い、より長い時間をかけてトレーニングすることで、より優れた結果が得られることがお分かりいただけると思います。これにより、既存のユースケースの改善だけでなく、これまで実現できなかった全く新しいユースケースも可能になっています。この傾向を示すスライドは、ここ数年お見せしてきましたが、今後数年でこの傾向がどのように続いていくのか、とても興味深いところです。

しかし、これらの大規模モデルのトレーニングは簡単にはいきません。多くの課題があり、今日はそのいくつかについてお話しします。まず1つ目は、最新のハードウェアを使用したいということです。re:Inventでは、新しいInstance Type、最新のNVIDIA GPU、そしてTrainium 2などの新しいインスタンスについて発表がありました。最新のハードウェアを使用することで、モデルのトレーニングを大幅に高速化でき、製品の市場投入を早めたり、新しいユースケースに対応できるかどうかの分かれ目となります。
もう1つの課題は、障害への対応です。大規模なモデルのトレーニングでは、必ず何らかの障害が発生します。そのため、障害から素早く回復し、トレーニングを再開できる能力が必要です。そうでなければ、大きな遅延が生じてしまいます。さらに、タイムラインの管理も重要な課題です。製品をリリースしたい、ユースケースで最高の成果を出したい、あるいは他社に先駆けてベンチマークで優位に立ちたいといった場合、大規模モデルのトレーニングには予測可能なタイムラインが必要となります。
また、パフォーマンスについても考慮する必要があります。トレーニングに使用する大規模クラスターで、データとモデルをどのように分散させれば最高のパフォーマンスを得られ、迅速にトレーニングできるかを検討する必要があります。そして最後に、コストについても考える必要があります。大規模モデルのトレーニングには数十万ドル以上のコストがかかる可能性があり、高額な大規模クラスターを使用する場合は、できるだけ効率的に活用したいものです。多くのお客様が、チームの効率性を最優先事項として挙げており、チームの作業がブロックされることなく迅速に進められるのであれば、より多くのコストをかけても構わないとおっしゃっています。

これらの課題に基づき、昨年のre:Inventで、Amazon SageMaker HyperPodを発表しました。HyperPodは、レジリエンシーとパフォーマンスの最適化により、トレーニング時間を最大40%削減することができます。レジリエンシーとは、大規模トレーニング中に障害が発生した際の対応を指します。HyperPodは発生したエラーの種類を分析し、最適な対処方法を判断します。場合によっては、インスタンスを完全に置き換えてトレーニングを自動的に再開することもあり、これによってデバッグや原因の特定、対処方法の決定に費やす時間を大幅に節約できます。次に、HyperPodはモデルとデータをクラスター全体に可能な限り効率的に分散させ、大規模なトレーニングを加速させることができます。そして最後に、HyperPodはクラスターの管理を支援し、すべてを自分で行うよりも簡単にしますが、非常にカスタマイズ性が高いのが特徴です。スケジューリングにはAmazon EKSやSLURMを使用でき、独自のフレームワークやライブラリ、モデルトレーニングの観察ツールなども導入できます。

しかし、現在でもいくつかの課題が残っています。最新のアクセラレーターを搭載した数百台のインスタンスで非常に大規模なモデルをトレーニングしようとする場合、需要が非常に高いため、必要な容量を常に確保することが難しい場合があります。オンデマンドの場合、そのリスクを取ることになります - 容量が利用可能な場合もあれば、そうでない場合もあり、スケジュールが遅れる可能性があります。もう一つの選択肢は、長期の予約で容量を確保することです。これにより予測可能なスケジュールが得られますが、トレーニングを数ヶ月間24時間365日実行しているわけではない場合、クラスターの使用率が低くなり、十分に活用していないリソースに対して支払いが発生することになります。そこで私たちは、これら2つのパラダイムの長所を活かしながら、お客様がスケジュールと予算に合わせてトレーニングワークロードを計画できるよう支援する方法を考えました。
Amazon SageMaker HyperPod向けFlexible Training Plansの概要

そこで数日前、Amazon SageMaker HyperPod向けのFlexible Training Plansを発表しました。 Training Plansを使用することで、トレーニングに必要な容量とコンピュートリソースを確保する際の不確実性や手作業のプロセスを排除することができます。Training Plansは、これを実現するためにCompute Capacity Blocksを活用していますが、HyperPodのTraining Plansでは、手作業や介入を最小限に抑えるため、トレーニング計画の開始時にトレーニングクラスターとコンピュートリソースを自動的にセットアップします。

具体的な使用方法は次のようになります。 必要なインスタンスタイプ、インスタンス数、トレーニングの所要時間、そしてトレーニングを開始できる最も早い時期を指定することで、要件を設定します。データの収集やアルゴリズムの調整がまだ完了していない場合は今すぐには開始できないかもしれませんが、期限に間に合わせるために来週にはトレーニングを開始する必要があることがわかっているかもしれません。Training Planの推奨プランを確認し、前払いで予約することができます。今回はHyperPodでのTraining Planの使用に焦点を当てていますが、Amazon SageMakerのフルマネージドトレーニングジョブでも使用することができます。

例として、12月10日から14日間、ml.p5.48xlarge を10インスタンス使用したいとしましょう。モデルのトレーニングには14日間必要だとわかっています。その容量の連続したセグメントを確保できるかもしれませんが、12月中旬以降になる可能性もあります。HyperPodのトレーニングプランを使用すれば、7日間ずつの2つのセグメントを見つけることができ、途中で中断があったとしても、より早く開始してより早くトレーニングを完了できる可能性があります。

トレーニングプランを入手し、異なるインスタンスタイプを含む複数のインスタンスグループでHyperPodをセットアップしたら、各インスタンスグループでトレーニングプランを使用するかどうか、どのトレーニングプランを使用するかを選択できます。12月10日にトレーニングプランが開始されると、HyperPodは自動的にそのインスタンスグループをスケールアップしてトレーニングプランを使用し、設定したLifecycle Scriptsを実行します。また、インスタンス間の接続が期待通りに機能しているかを確認するためのDeep Health Checksも実行します。トレーニングの途中で障害が発生した場合でも、HyperPodが自動的に対処するため、トレーニングをできるだけ早く再開できます。2つのセグメント間の中断時には、HyperPodがクラスターのスピンダウンと、容量が再び利用可能になった時のスピンアップを管理します。

これらのトレーニングプランを使用することの利点をまとめてみましょう。まず、モデルのトレーニングに最新かつ最高のコンピュートへのアクセスがさらに容易になります。トレーニング中に障害が発生した場合に自動的に対処して継続できるという、HyperPodのレジリエンシー機能も得られます。トレーニングを開始できる時期と終了時期が正確にわかる、予測可能なタイムラインを得られます。SageMaker Distributed Training Librariesやその他お好みのフレームワークを使用して、HyperPodが提供する高いパフォーマンスの恩恵を受けられます。最後に、そのコンピュートを使用する期間中のコストが最初から正確にわかります。
Foundation Modelのカスタマイズと課題

ここで、お客様が直面している別の課題と、トレーニングのパフォーマンスを最適化し、さらに迅速に開始できるようにする方法について、Giuseppeにお話しいただきます。ありがとうございます、Gal。Generative AIで素早く前進したいと考えているあらゆる規模の企業のリーダーと話すと、彼らは他の課題も抱えており、こんな質問をしてきます:どのモデルを使うべきか?モデルをどうやって簡単にカスタマイズできるか?トレーニングワークロードをどのように最適化できるか?

Foundation Modelのカスタマイズは重要な差別化要因となります。独自のデータを使用することで、一般的なデータでトレーニングされたモデルを使用する一般的なGenerative AIアプリケーションから、お客様独自のデータを使用して、顧客、ビジネス、製品に実際の価値を生み出すGenerative AIアプリケーションへと進化させることができます。では、どのようにしてデータを使ってモデルをカスタマイズすればよいのでしょうか?
Foundation Modelをカスタマイズする一般的な手法として、Fine-tuningがあります。Fine-tuningでは、テキスト要約や質問応答などの特定のタスクにモデルを学習させるために、追加のコンテキストで注釈付けされたラベル付きデータセットを提供します。特定のタスクに対してモデルをより強力にできますが、ラベルなしデータセットや生データを活用してドメインに対するFoundation Modelの精度を維持するためにPre-trainingを使用することもできます。例えば、ヘルスケア企業は、医学用語や業界用語に関するモデルの知識と精度を向上させるために、医学雑誌や研究論文、記事を使用してモデルのPre-trainingを継続することができます。

しかし、Foundation ModelのカスタマイズやFine-tuningとPre-trainingの実行は複雑なタスクです。まず、使用するモデルを選択する必要がありますが、これは比較的簡単なタスクです。次に、選択したインフラストラクチャー上で分散学習を実行するために使用するフレームワークを設定する必要があります。ここでは、DeepSpeed、Hydra、NVIDIA NeMo、さらには標準的なPyTorchなど、多くのフレームワークがあり、分散学習のための安定した実行環境を構築するために、適切な方法で追加の依存関係やライブラリ、ドライバーを設定する必要があります。第三に、モデル学習を最適化する必要があります。ここでは、長いコンテキスト長をサポートするためにTensorやContext Parallelismなどの並列化技術を適切に設定し、メモリ節約技術を適用する必要があります。
学習方法に応じて、学習中のGPUメモリの使用方法を最適化し、チェックポイントの保存頻度を選択する必要があるかもしれません。Galが言及したように、学習中に障害が発生する可能性があるため、学習を再開したときに最後のチェックポイントから復旧できるよう、適切な頻度で学習の状態を保存し、場合によってはハイパーパラメータの最適化や他の設定を選択する必要があります。これは、分散学習の最適な設定を見つけるために何週間もの反復的な実験を費やす部分です。それが特定できたら、本番環境でのPre-trainingとFine-tuningに移行しますが、これには何週間あるいは何ヶ月もの分散学習を実行するための信頼性の高い耐障害性のあるインフラストラクチャーが必要です。ここでAmazon SageMaker HyperPodが役立ちますが、それでもチェックポイントを設定し、必要に応じて最後のチェックポイントから学習を再開できることを確認する必要があります。

全体として、調整可能な各次元で言及されたオプションの数を数えると - 3〜5の人気のあるフレームワーク、数十の調整可能なパラメータ、数百の設定可能な項目、さらに分散学習ライブラリに対して行いたい他の最適化 - 学習スタックの異なる設定が簡単に数千に達することがわかります。学習のパフォーマンスは、選択した設定によって大きく異なる可能性があります。この複雑さは、経験豊富なチームでさえも、プロジェクトの遅延、最適とは言えないモデルパフォーマンス、予算超過につながることがよくあります。パフォーマンスを犠牲にすることなく、Foundation Modelの学習の設定と最適化を簡素化する明確なニーズがあり、ここでAmazon SageMaker HyperPod Recipesが役立ちます。

新しいAmazon SageMaker HyperPod Recipesは、データサイエンティストや機械学習エンジニアがFoundation Modelを使用した作業を加速できるようにします。私たちは、Llama 3.1(4億または5億パラメータバージョンを含む)、Llama 3.2、Mistral Mixなど、一般に公開されている人気のFoundation ModelのPre-trainingとFine-tuning用の厳選された使用準備の整ったSageMaker Recipesを提供しています。これらのRecipesは、Foundation Modelの進化に合わせて発展していきます。Recipesを使用すると、数週間ではなく数分でPre-trainingとFine-tuningを開始でき、SageMaker HyperPodの最適化されたパフォーマンス、スケーラビリティ、回復力を活用できます。これらのRecipesは、学習ワークロードのための効率的なリソース利用と、結果としてのコスト最適化を提供します。私たちは、自動モデルチェックポイント技術を含むSageMaker最適化モデルのエンドツーエンドの学習ループの実装を担当します。先ほど述べたように、チェックポイントは非常に重要なタスクであり、これらのモデルに対して追加のコード変更なしで自動的に実行しています。チェックポイントを行うためにコードを1行も変更する必要はなく、高頻度で進行中のモデル結果を保存し、障害から迅速に回復できるようになっています。
Amazon SageMaker HyperPod Recipesの機能と利点

これらのRecipeは、異なるシーケンス長やモデルサイズに適応できるよう簡単にカスタマイズでき、シンプルな設定変更だけでGPUインスタンスやTrainiumベースのインスタンスなど、様々なアクセラレーターを切り替えることができます。 それでは、具体的な仕組みと始め方を見ていきましょう。まず最初に、Pre-trainingやFine-tuningに使用したいRecipeを選択します。Recipeは、すべてのリストが公開されているGitHubリポジトリで入手できます。Recipeを選択したら、前提条件をセットアップします。インフラが稼働していて、HyperPodクラスターがトレーニングを実行できる状態であることを確認する必要があります。クラスターをスピンアップするために必要な制限や設定をすべて行います。最後に、HyperPodクラスター上でRecipeを実行します。なお、一時的なトレーニングジョブに慣れている方であれば、Amazon SageMaker training jobsでもRecipeを実行することができます。
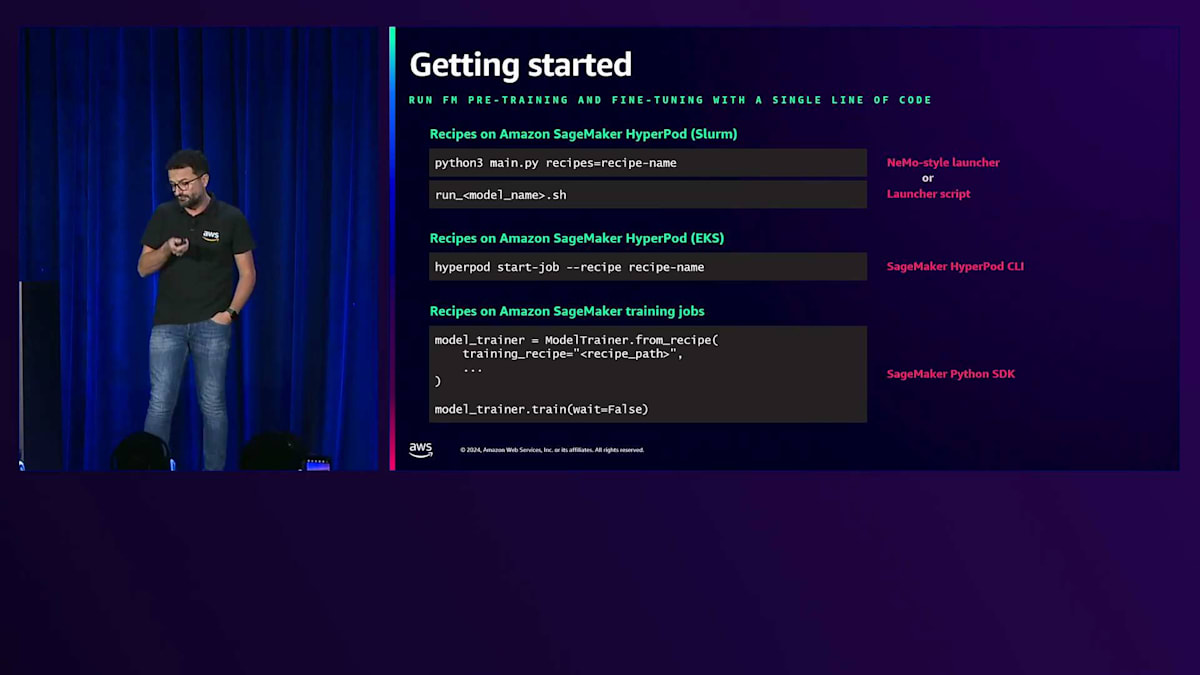
Recipeを使ったPre-trainingとFine-tuningには、いくつかの実行方法があります。NVIDIA NeMoに慣れている方向けに、NeMoスタイルのLauncherを用意しています。また、NeMoスタイルのLauncherを利用しながら、一部の設定を自動的に行うLauncherスクリプトも用意しています。これは、Slurmで制御されるHyperPodクラスターでトレーニングを実行する際に非常に便利です。さらに、HyperPodを拡張して、Recipeを使用したTrainiumでのFine-tuningをサポートするようにしました。SageMaker training jobsで実行する場合は、Recipeでのトレーニングをサポートする新しいModelTrainerクラスをSageMaker Python SDKに追加し、既存のEstimatorクラスも更新しています。
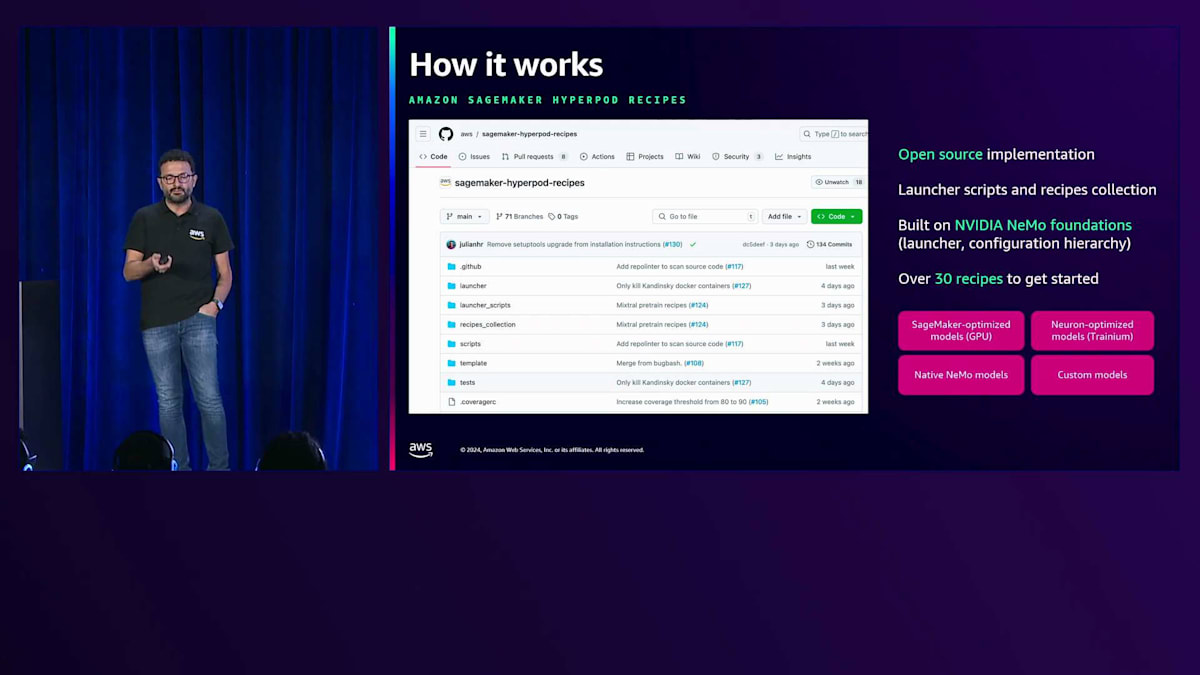
Recipeは公開GitHubリポジトリに格納されており、Launcherスクリプトとレシピコレクションが含まれています。このリポジトリには、実際のLauncher、トレーニングを実行するコードの実装、設定の階層構造が含まれています。このフレームワークで始められるRecipeは30以上あります。このLauncherを使用することで、SageMaker GPU最適化モデル、Trainiumインフラで実行するNeuron最適化モデル、さらにはネイティブのNeMoモデルやカスタムモデルでのPre-trainingやFine-tuningを実行できます。カスタムRecipeやモデルを持ち込める拡張可能なフレームワークとなっています。
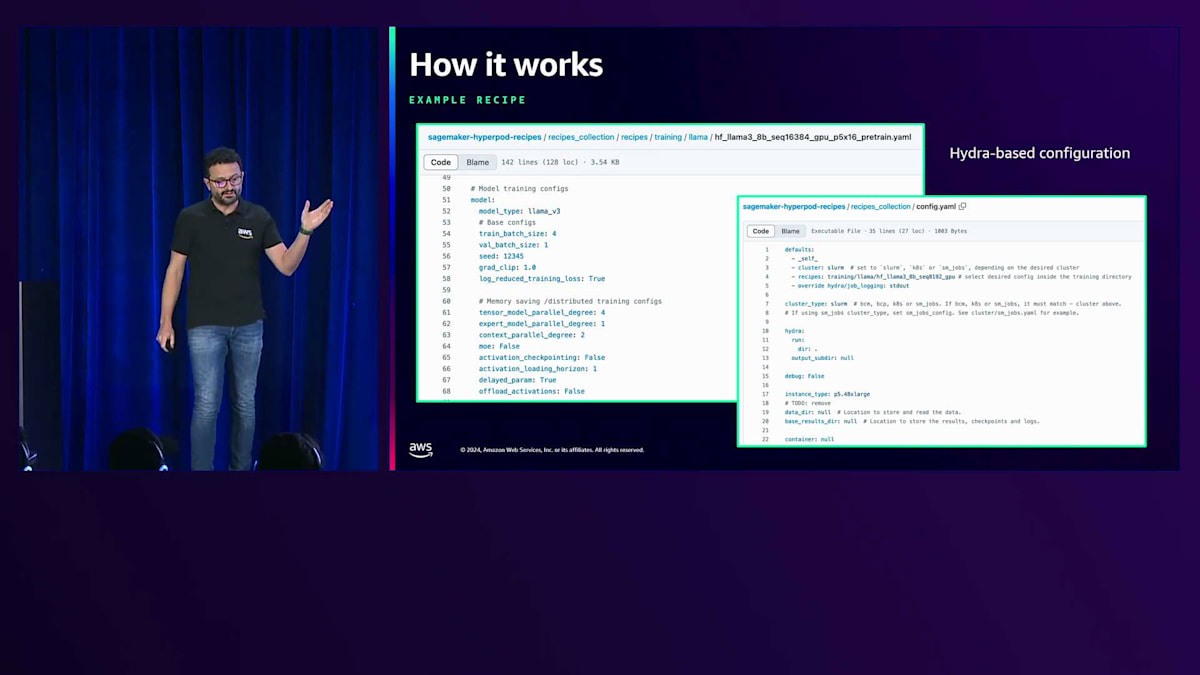
こちらがRecipeの例です。左側には、Llama 38ビリオンモデルのPre-training用のRecipeが表示されています。ご覧のように、Tensor Parallelism、Expert Parallelism、Context Parallelismなどの設定が事前に構成されています。これらは事前にテストされ検証済みで、AWSインフラ上で実行する際のコスト最適化とパフォーマンスを実現するため、最適な設定を自分で見つける必要はありません。右側には、Recipeコレクションの一部として利用可能な別の設定ファイルが表示されており、インフラの設定を行うことができます。この設定構造は、アプリケーションの設定に広く使用されているHydraフレームワークをベースにしています。設定はマージされて最終的な設定ファイルが作成され、コマンドライン引数を使用して特定の設定を記述することもできます。
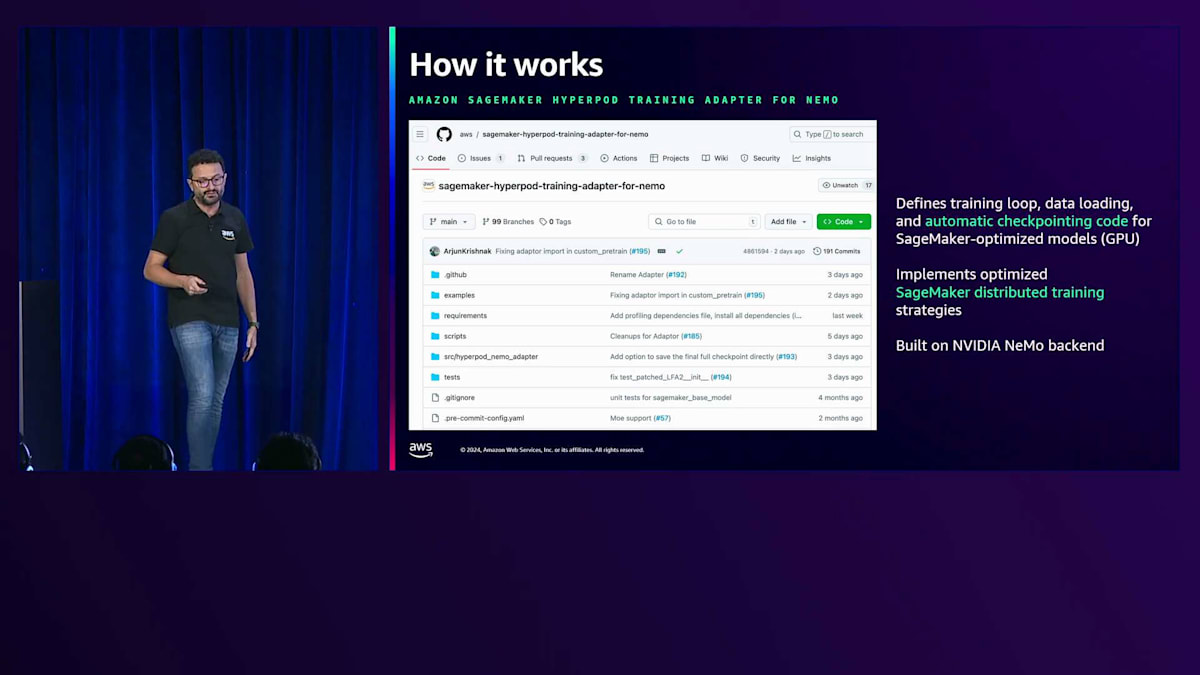
SageMaker GPU最適化モデルについては、トレーニングループ、データローディング、自動チェックポイントのコードを定義しています。これは、SageMaker HyperPod Training Adapter for NeMoという別のリポジトリで実装されており、選択したRecipeに基づいて実行時に実行される実際のトレーニングコードが含まれています。ここでは、SageMaker Model Parallelism Libraryなどの SageMaker Distributed Training Librariesを使用した分散トレーニングの最適化も実装しています。これはNVIDIA NeMoバックエンドをベースに構築されています。
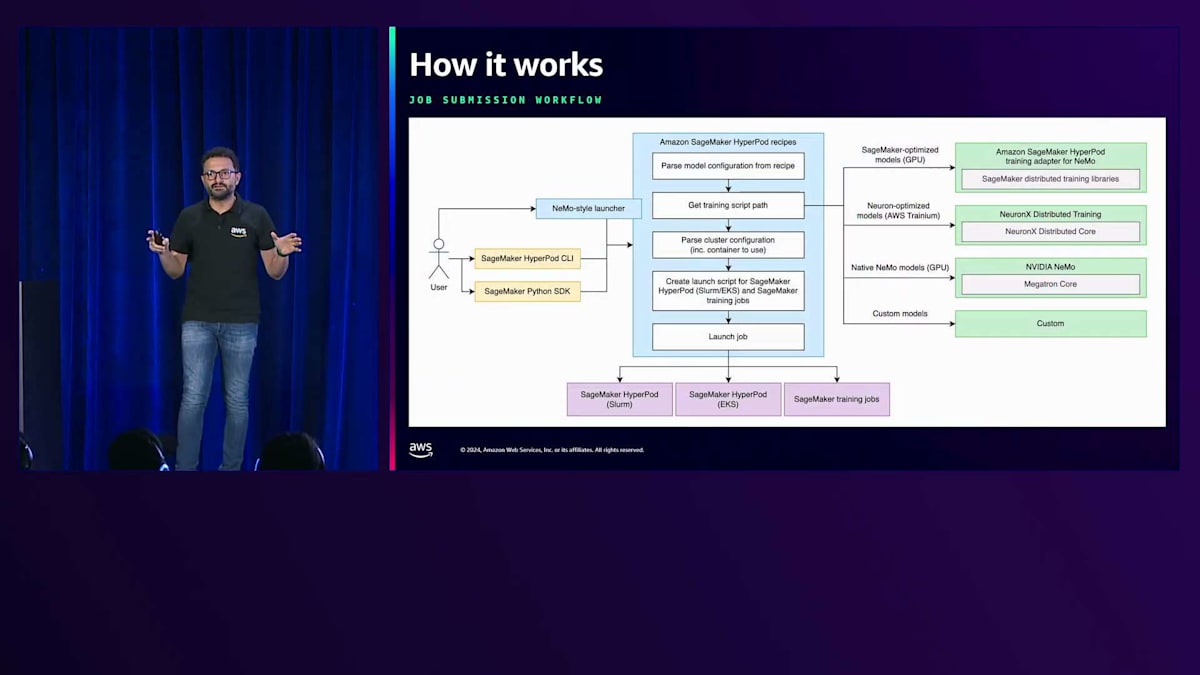
ジョブ送信のワークフローを示す1枚のアーキテクチャ図にまとめてご説明しましょう。ユーザーは、トレーニングのターゲットインフラに応じて、NeMo形式のLauncher、HyperPod、またはSageMaker Python SDKのいずれかを選択できます。SageMaker HyperPodレシピリポジトリのLauncherは、レシピのトレーニングコードからモデル設定を解析し、分散トレーニング実行用のコンテナを含むクラスター設定を取得して、最終的な起動スクリプトを作成し、コードを実行します。

GPU向けにSageMaker最適化されたモデルの場合は、NeMo用のAmazon SageMaker HyperPodトレーニングアダプターを使用します。Trinium最適化モデルの場合は、Neuron X分散トレーニングリポジトリからトレーニングコードを取得し、ネイティブNeMoモデルはNVIDIA NeMoから取得します。また、先ほど触れたように、カスタムモデルを持ち込むこともできます。これを実際に動作させる様子をお見せしたいと思いますので、トレーニングプランとレシピの両方を組み合わせたデモに移りましょう。 アクティブなトレーニングプランで実行されているHyperPodクラスターを使用してレシピを実行する予定です。
HyperPod RecipesとTraining Plansのデモンストレーション
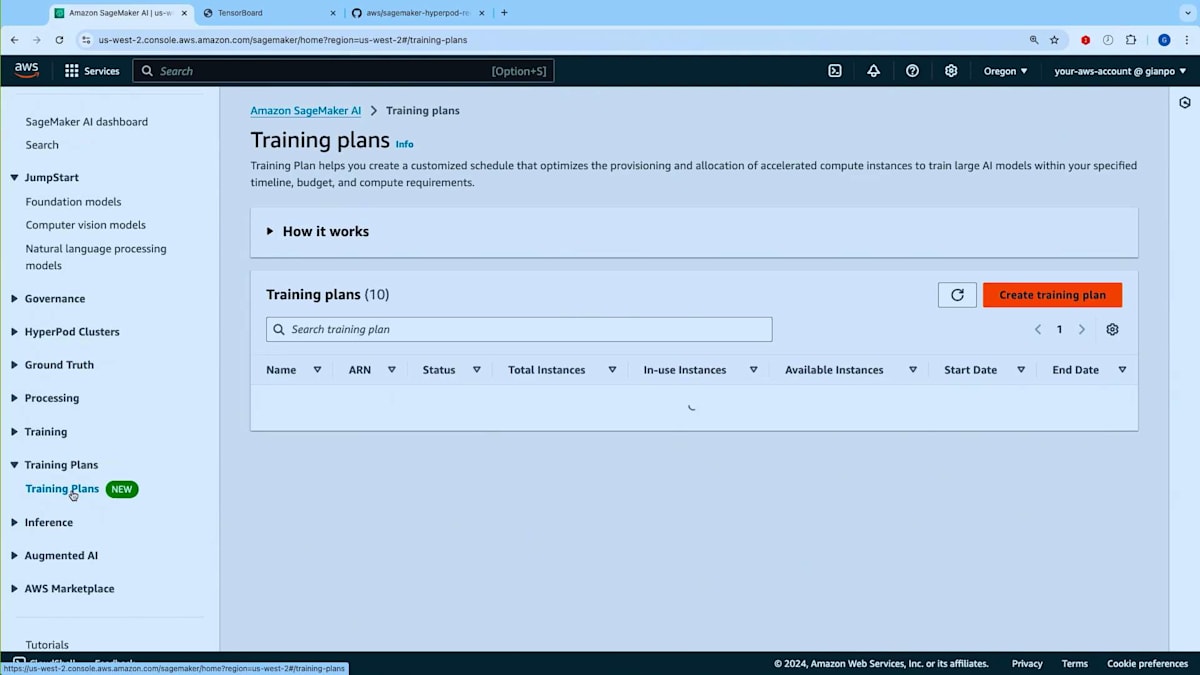
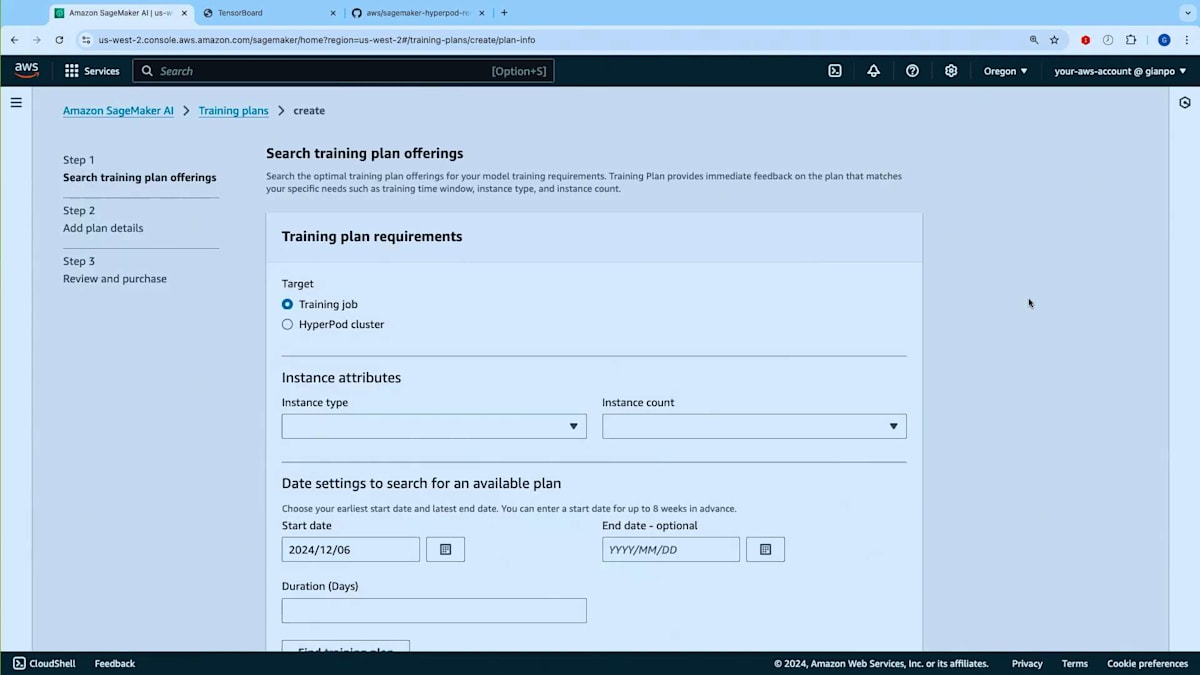
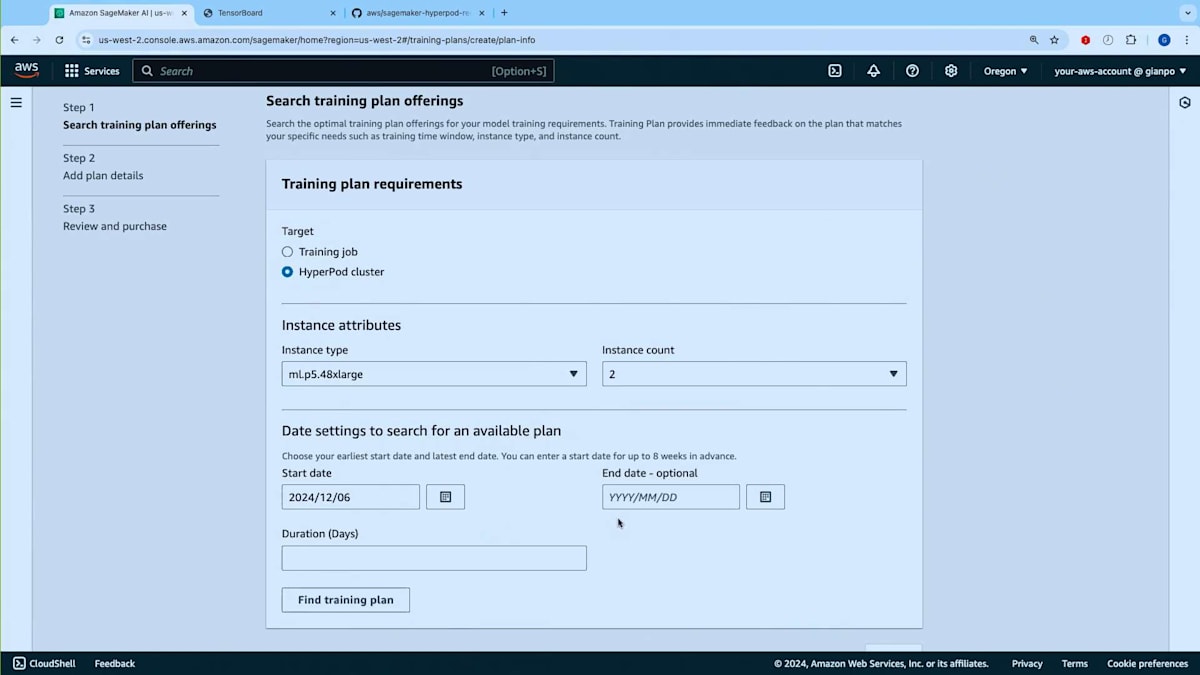
ここでAmazon SageMaker AIのランディングページにいます。 まず最初にトレーニングプランの使い方をご紹介したいと思います。こちらがトレーニングプランの画面ですので、トレーニングプランを作成してみましょう。 トレーニングプランは、HyperPodクラスターとトレーニングジョブの両方で使用できます。HyperPodクラスター用のトレーニングプランを作成したいとしましょう。使用したいインスタンスタイプを選択します - NVIDIA H100を搭載したP5.48xlargeを選んでみましょう。インスタンスを2台ほど必要としているとします。次に開始日、つまりトレーニングプランの最早開始日を指定し、 必要に応じて終了日(ワークロードを完了させたい期限)とプランの予想実行時間を設定できます。
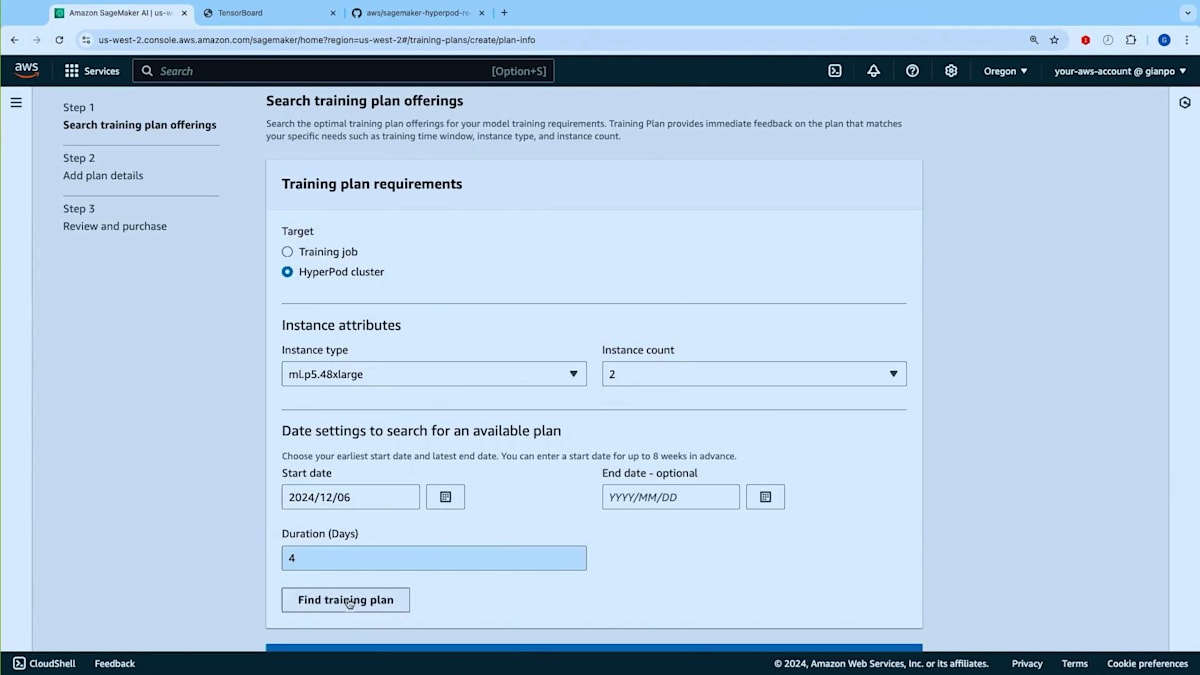
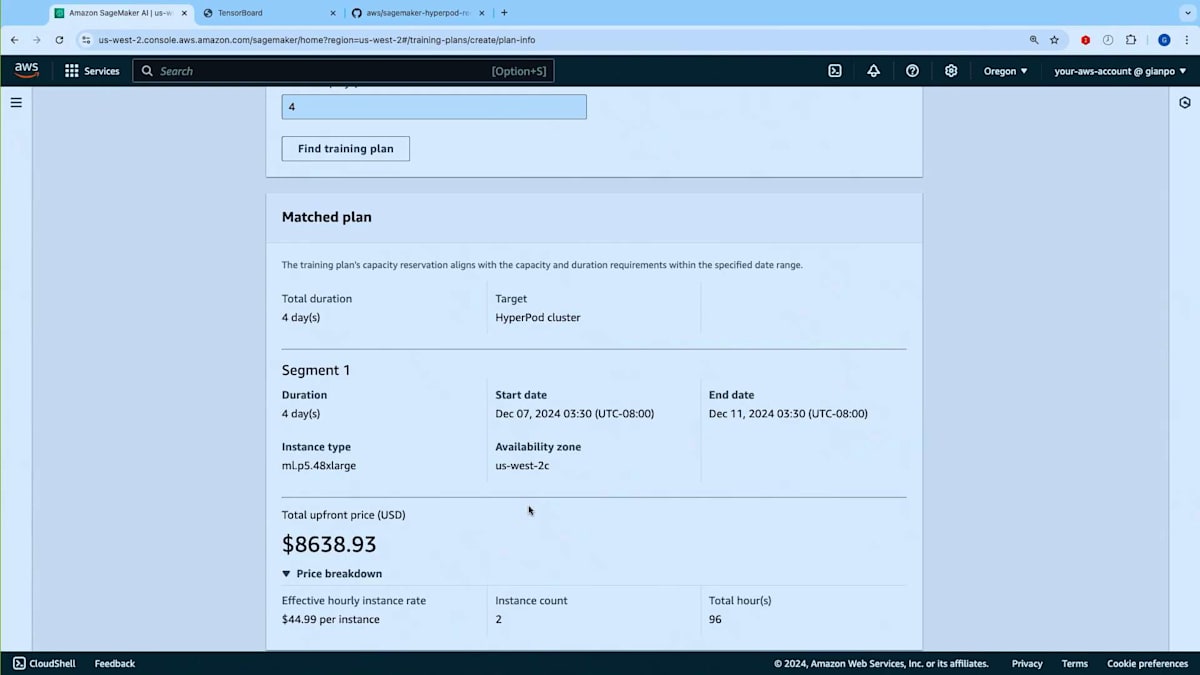
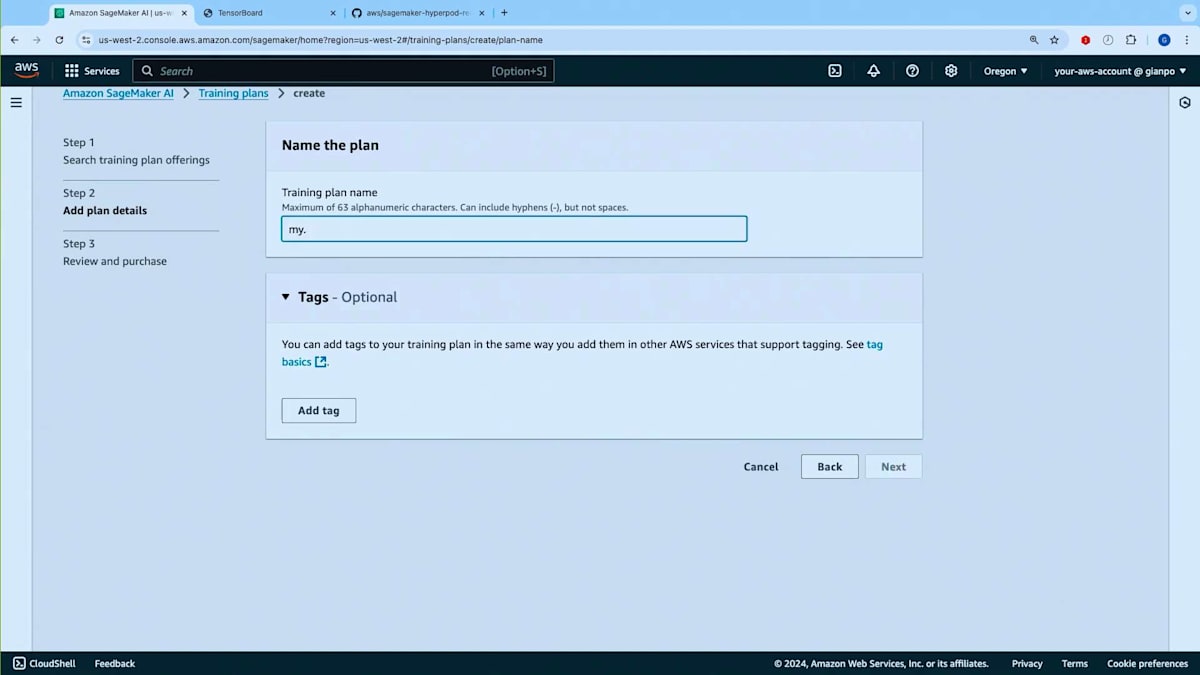
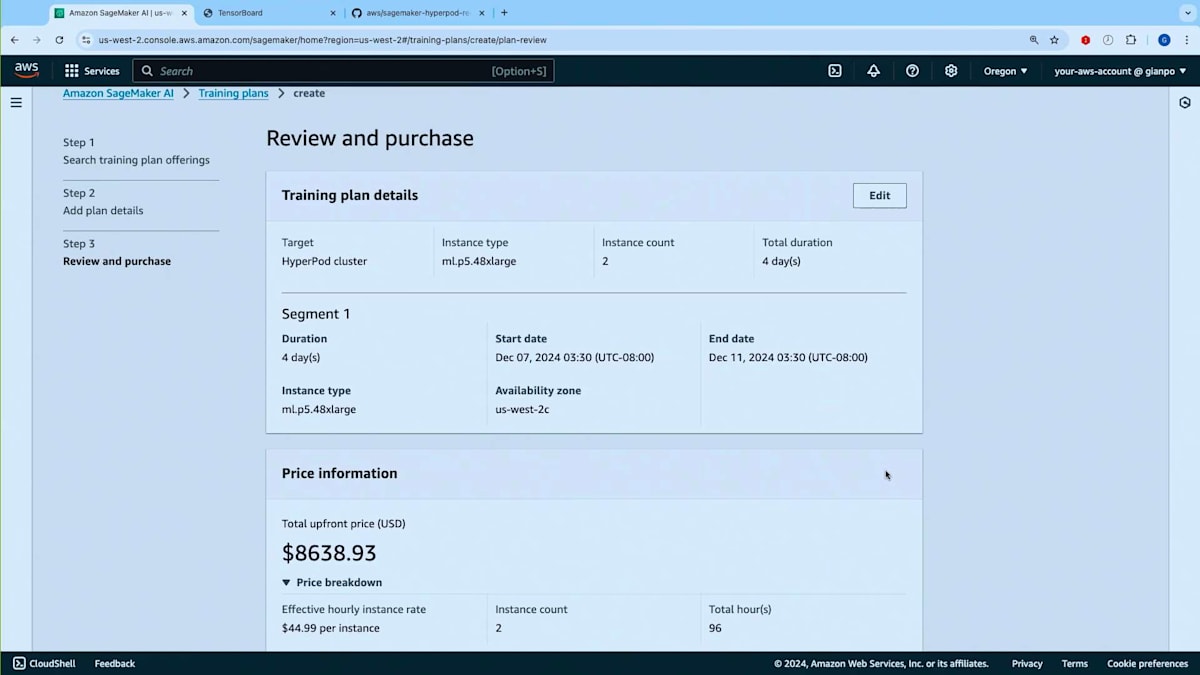
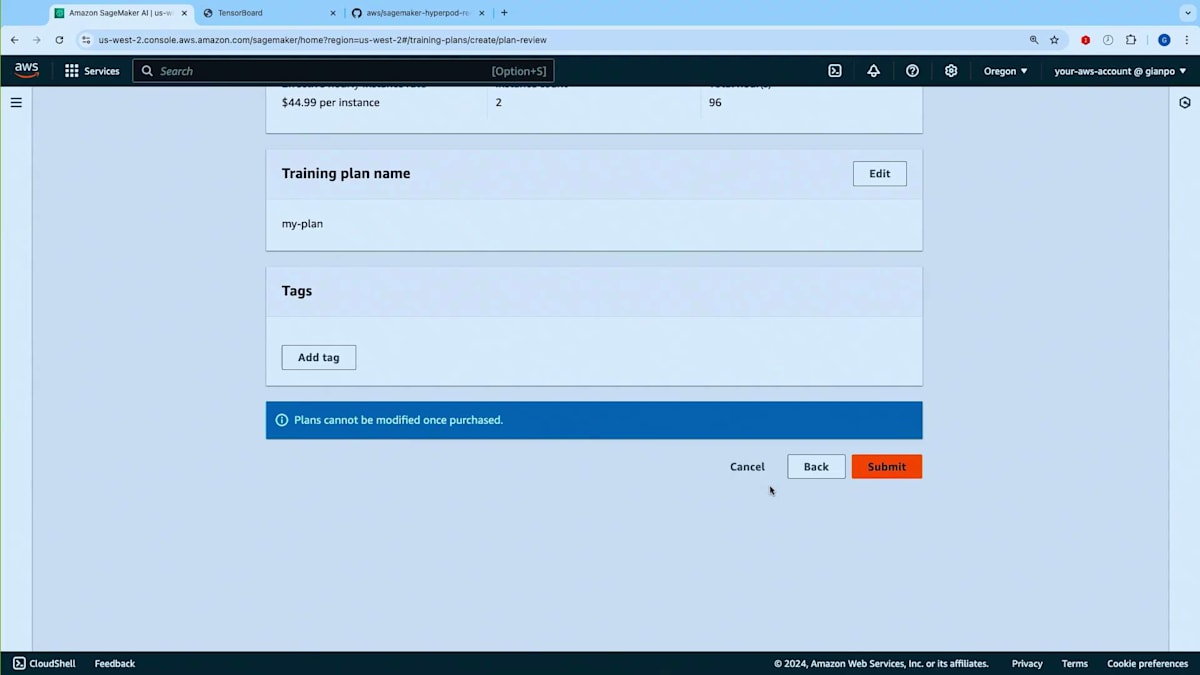
トレーニングプランを探してみましょう。ご覧のように、マッチしたプランのオファーが表示されました。 これは12月7日に開始し12月11日に終了する4日間の単一セグメントで構成されています。このキャパシティを使用するHyperPodクラスターを作成する場所となるので、アベイラビリティーゾーンをメモしておく必要があります。また、総額の前払いコストが表示され、コストと価格の内訳が事前に確認できます。次の画面に進んでプランの名前を入力できます。 他のSageMakerリソースと同様にタグを追加することができます。 最後に、内容を確認してこのプランを購入するかどうかを決定できます。重要な注意点として、一度購入したプランは変更できません。
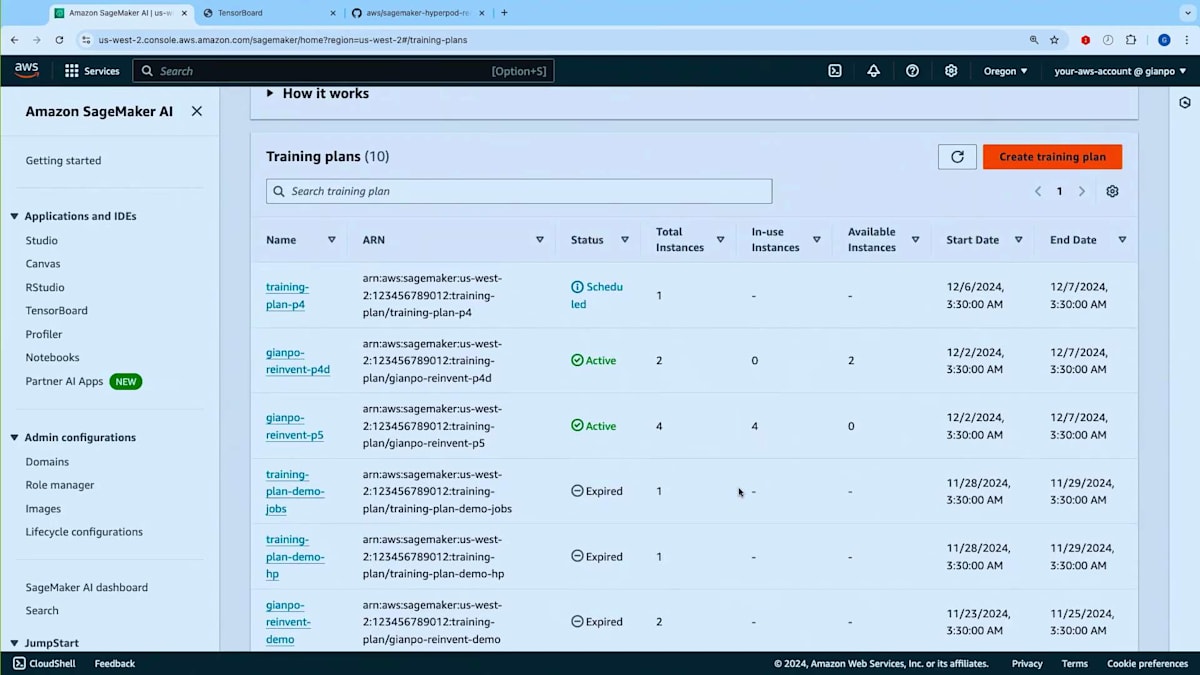
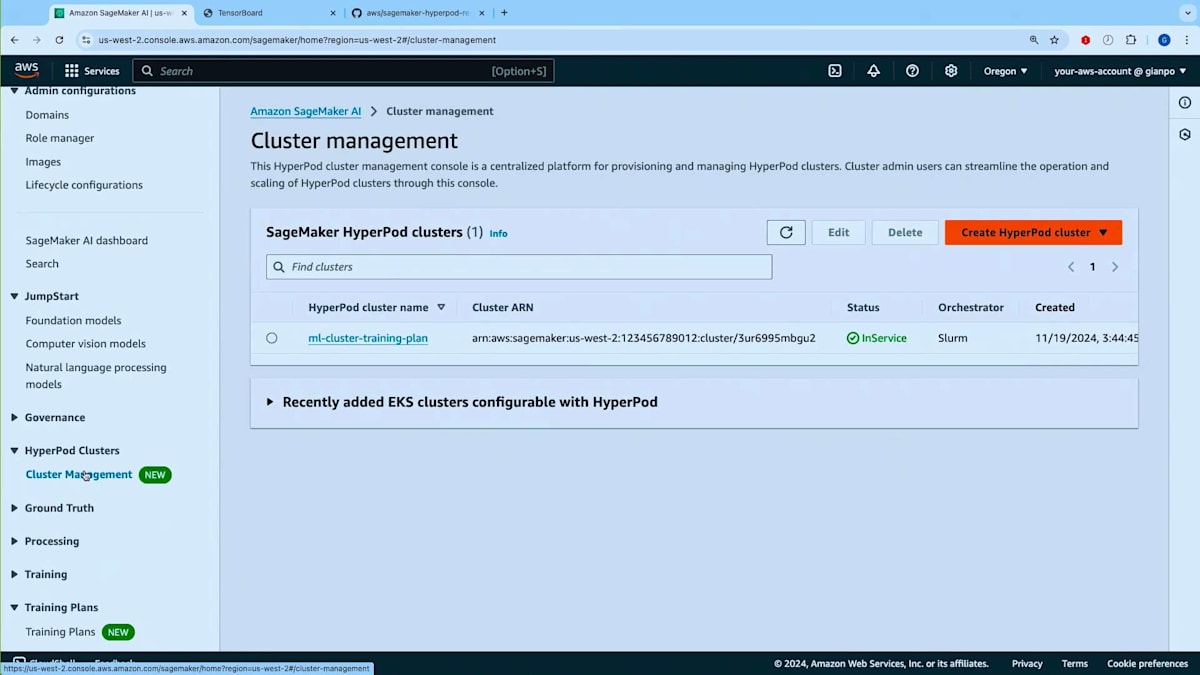
今回は既存のプランがあるので、新しいプランは作成しません。画面に戻りまして、 ご覧のように、プランのリストがあります - 期限切れのもの、アクティブなもの、そしてスケジュール状態のものがあります。スケジュール状態について補足しますと、プランは購入後、開始日に達するまでスケジュール状態のままです。ただし、スケジュール状態であってもHyperPodクラスターでそのプランを使用することはできます。HyperPodクラスターを作成し、スケジュール状態のプランを関連付けておけば、トレーニングプランがアクティブになった時点でグループが自動的に起動します。このデモでは、アクティブ状態にある4台のP5インスタンスを持つこのトレーニングプランを使用します。では、トレーニングプランがHyperPodクラスターでどのように機能するかを見てみましょう。 実行中のHyperPodクラスターに移る前に、HyperPodクラスターの作成方法とトレーニングプランの関連付け方法を簡単にご紹介したいと思います。
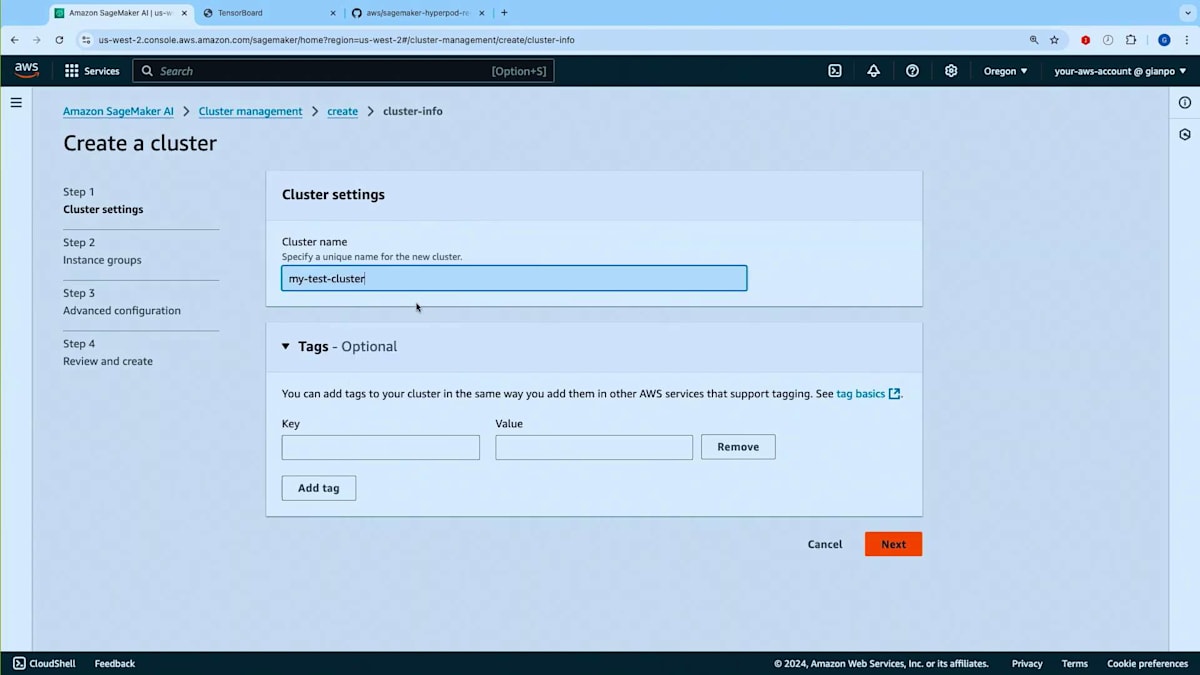
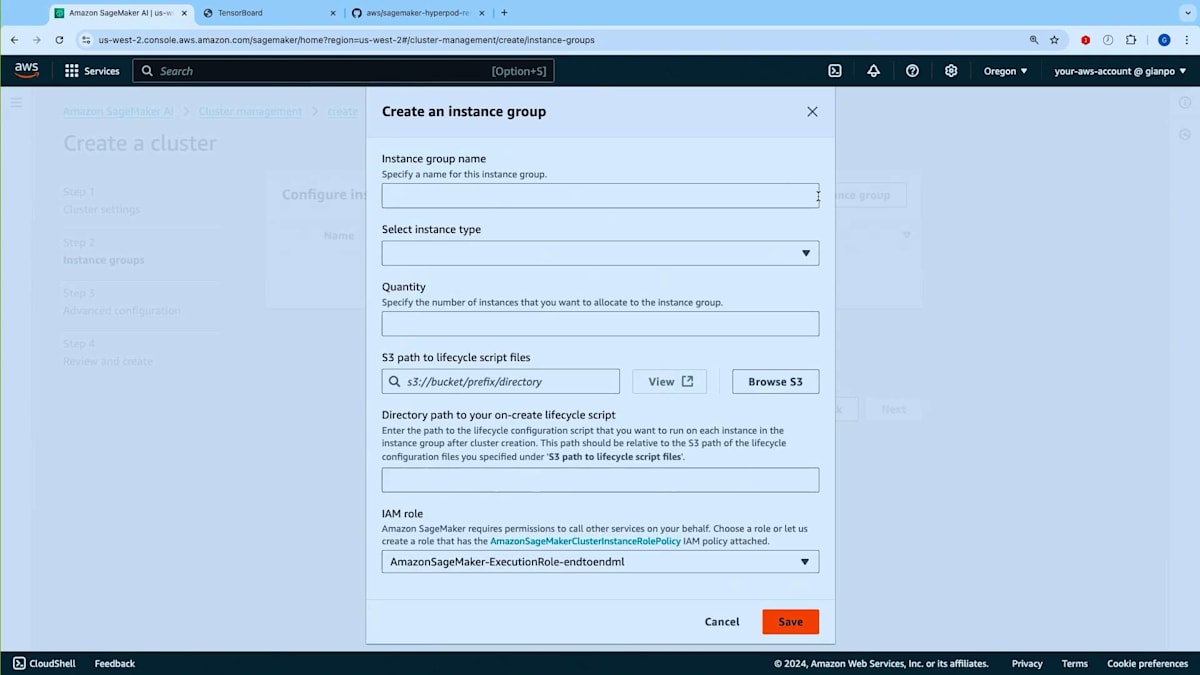
それでは、プロセスをデモンストレーションさせていただきます。Slurmによってオーケストレーションされるクラスターを作成することにします。名前を付け、Training Planを関連付ける場所を指定します。スライドでお示ししているように、クラスター用のInstance Groupを作成する際、通常Slurmクラスターでは、Login Node用のInstance Group、Controller用のInstance Group、そしてWorker Node用のInstance Groupを作成します。ここでTraining Planを関連付けることになります。
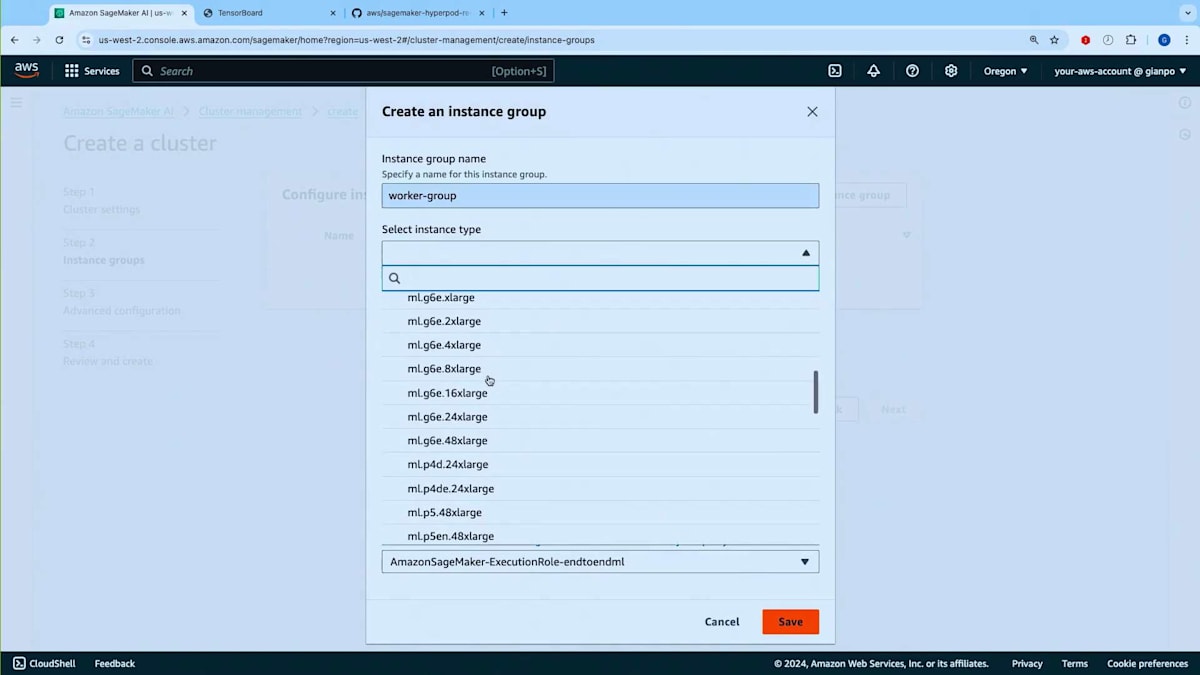
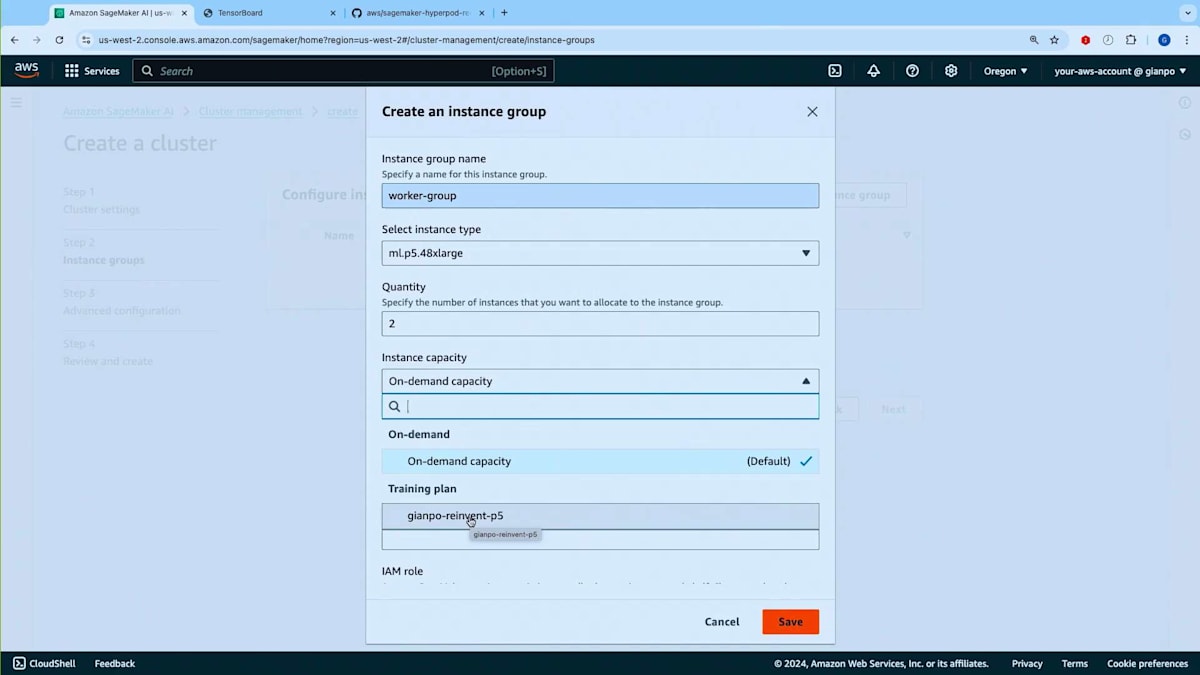
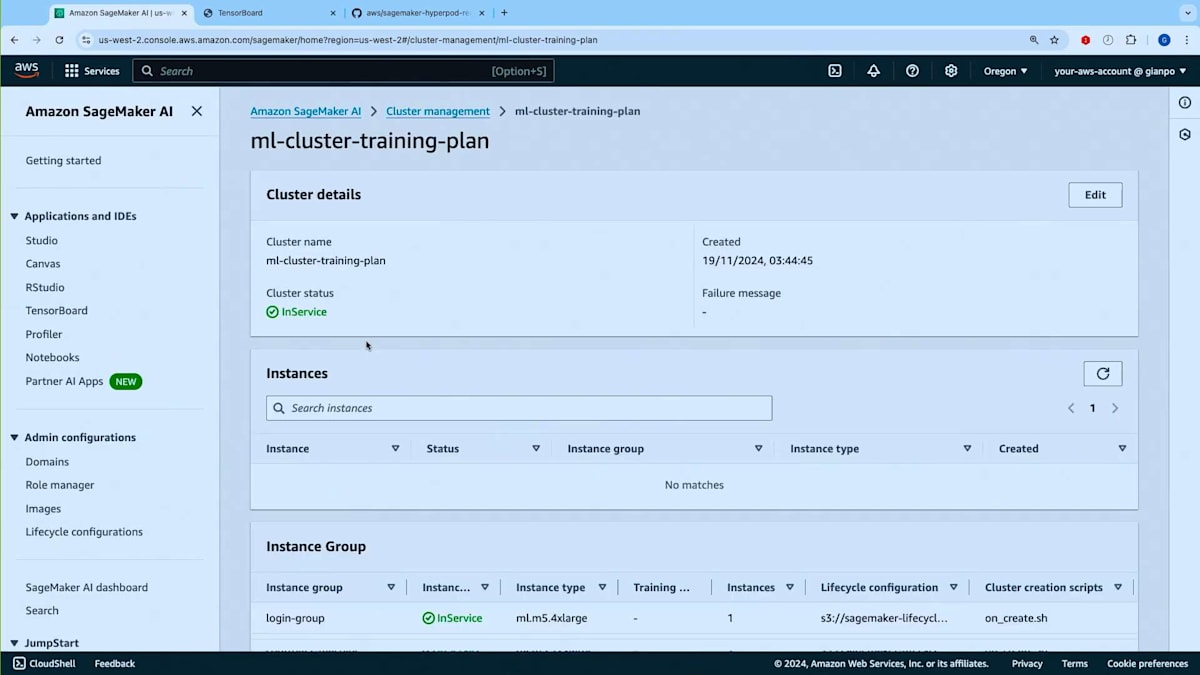
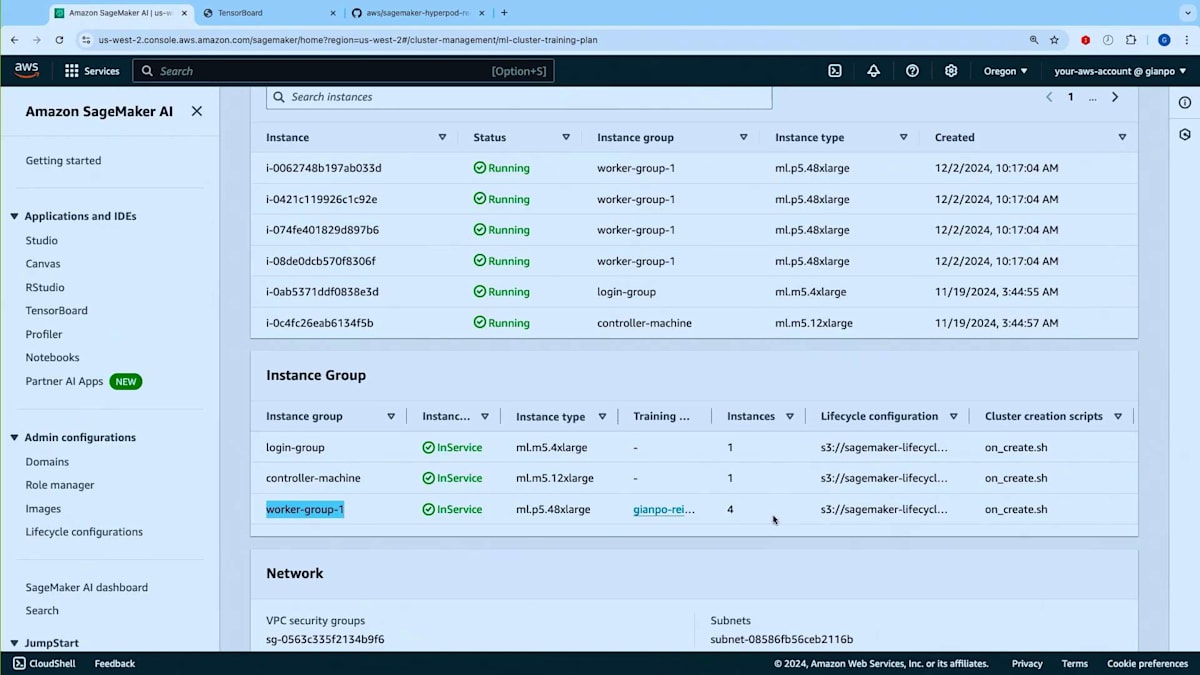
Worker Groupがここにありますので、Instance TypeとしてTraining Planを持っているP5を選択しましょう。インスタンスを2つほど設定します。ご覧の通り、On-demand CapacityかTraining Planのどちらかを選択できます。このInstance GroupをTraining Planに紐付けることで、アクティブなTraining Planからキャパシティを取得することができます。時間がかかるため今はクラスターを作成しませんが、すでにml-cluster-training-planという実行中のクラスターがあります。ご覧のように、Training Planから提供される4つのP5インスタンスで構成されるWorker Groupが動作しています。コンソールでは、Instance Groupのテーブルに新しい列が追加され、これらのインスタンスがTraining Planから提供されていることが分かるようになっています。このクラスターは現在稼働中です。
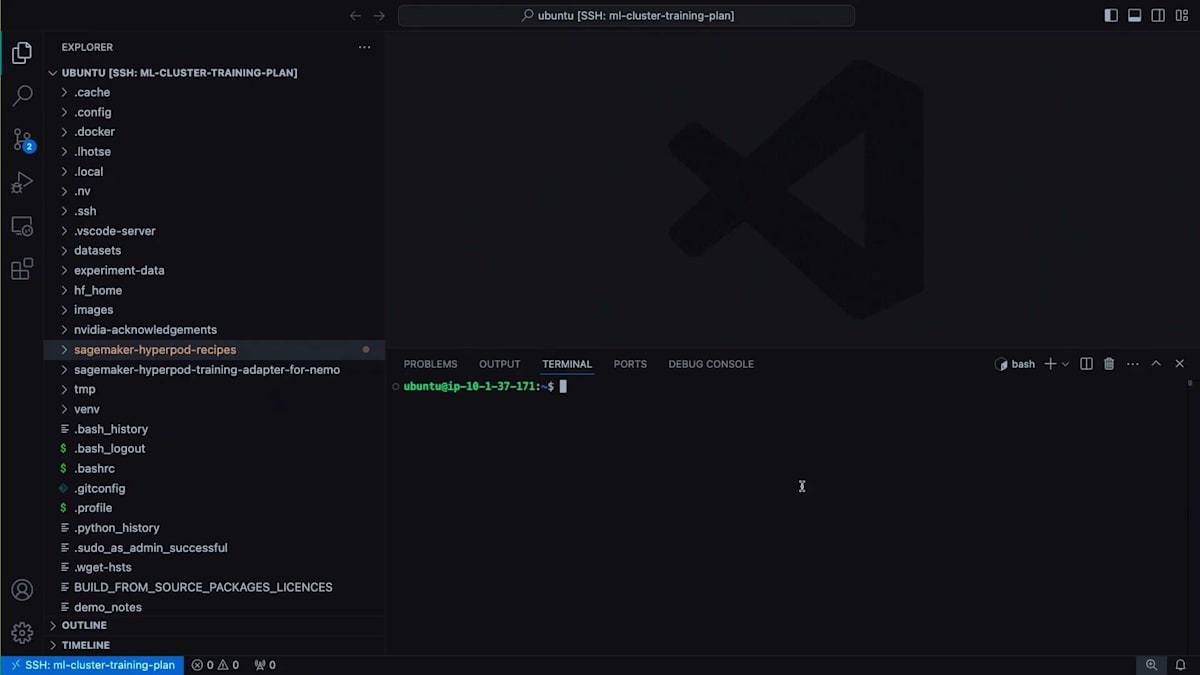
私のローカルのVS CodeをこのHyperPodクラスターのLogin Nodeに接続しています。HyperPodクラスターでは、AWS Systems Manager Tunnelを使用してセキュアなトンネル経由で接続を確立できます。リモート接続はすでに設定済みで、現在の場所を確認すると、ユーザーディレクトリはFSXファイルシステム上に設定されています。このクラスターにはFSXファイルシステムも接続されています。現時点でこのファイルシステムに何があるか見てみましょう。ここにデータセットがあり、C4データセットを使用する予定です。これはトレーニング用にキュレーションされたCommon Crawlデータセットのバージョンで、すでにトークン化されています。ここにTrainingデータセットとValidationデータセットがあります。
もう1つお見せしたいのは、イメージについてです。先ほど言及したように、HyperPod Recipeを使用する際には、分散トレーニング用のランタイムも提供しています。これはDockerコンテナの形で提供されます。ただし、SlurmクラスターでDockerを使用する場合、Dockerコンテナを非特権のサンドボックスに変換するのが便利です。これにはEnrootという技術を使用します。これはDockerコンテナを非特権サンドボックスに変換できる技術で、Slurmクラスターでの使用が推奨されています。また、HyperPod Recipesリポジトリにリンクされた事前ビルド済みのEnrootイメージをダウンロードできます。このデモではそれを使用する予定です。
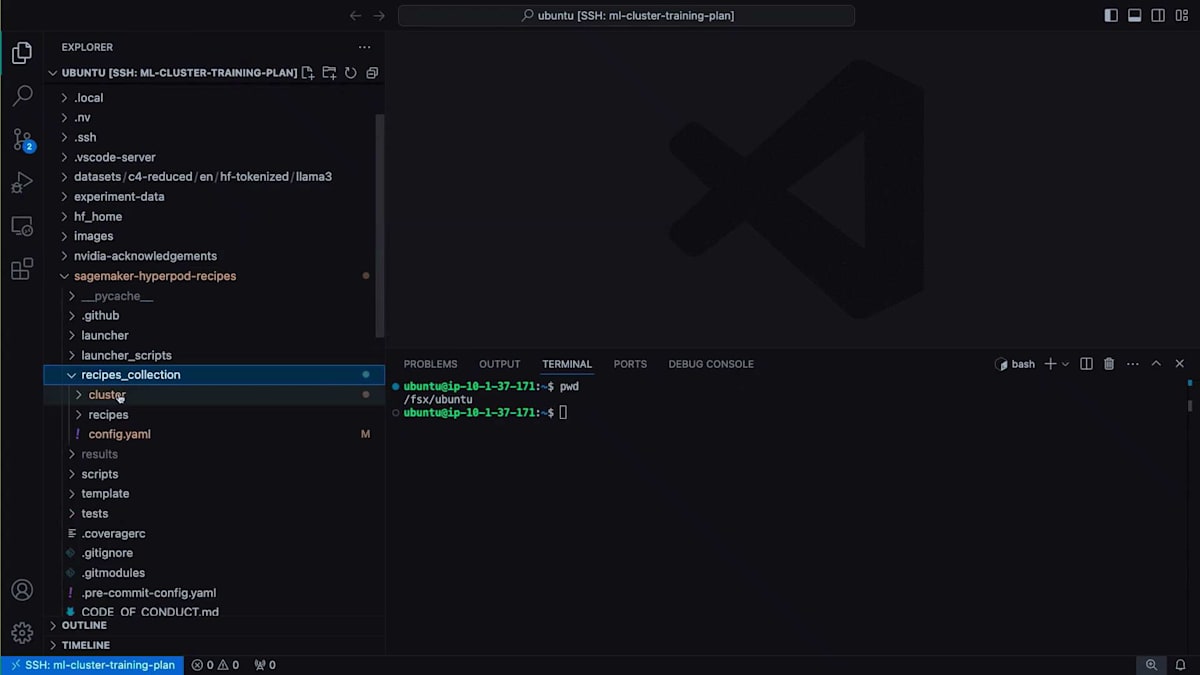
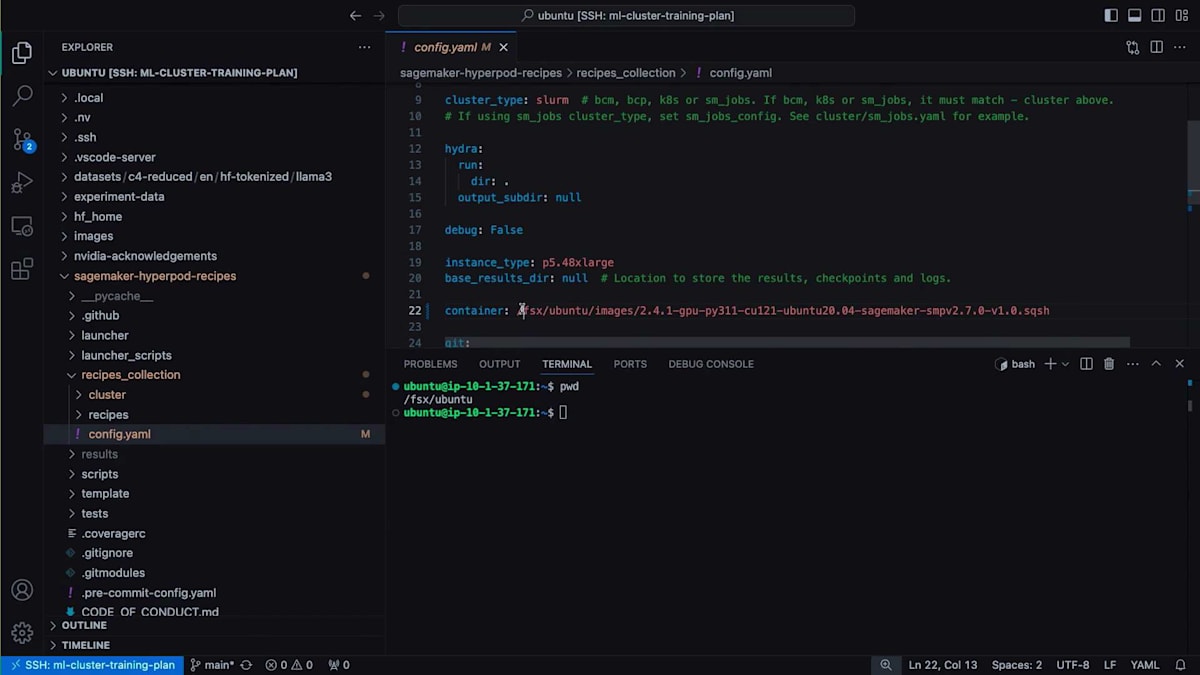
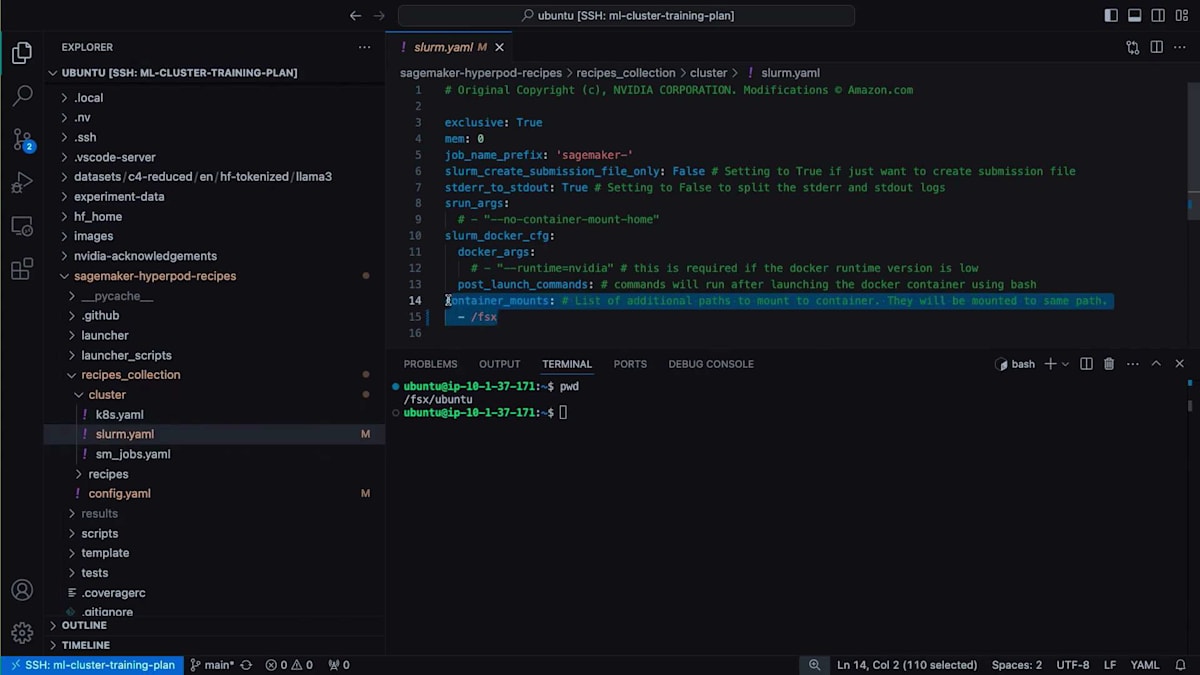
では、ローカルファイルシステムにクローンしたHyperPod Recipesの内容を見てみましょう。まず、Recipe Actionsの中で、インフラストラクチャの設定情報が記載されているconfig yamlを確認できます。この設定を使用する予定ですが、トレーニングの実行に使用したいコンテナを指定する必要がありました。これは実際には、ここで使用しているEnrootイメージのsquashファイルです。クラスター設定でもう1つ変更を加えたのは、コンテナマウントを編集したことです。これにより、クラスター上でコンテナが実行される際に、データの読み取りと結果の保存のためにファイルシステムもコンテナにマウントされます。
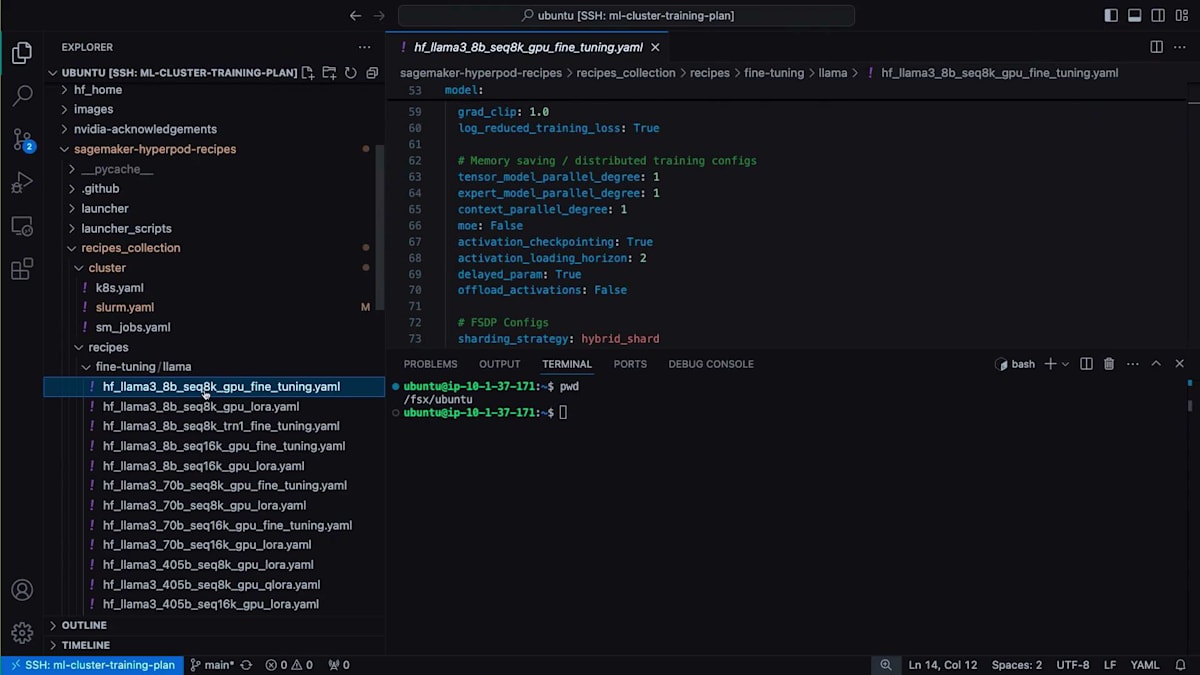
本日ご紹介するレシピは、シーケンス長でGPU上でLlama 3 8 billionをファインチューニングするものです。私はP5インスタンスを使用しており、これがレシピの定義となります。実験追跡のためのトレーニング設定が見つかります。HyperPod Recipesを使用すると、実験を自動的にTensorBoard形式で追跡できるため、TensorBoardを使用して実験を可視化することができます。
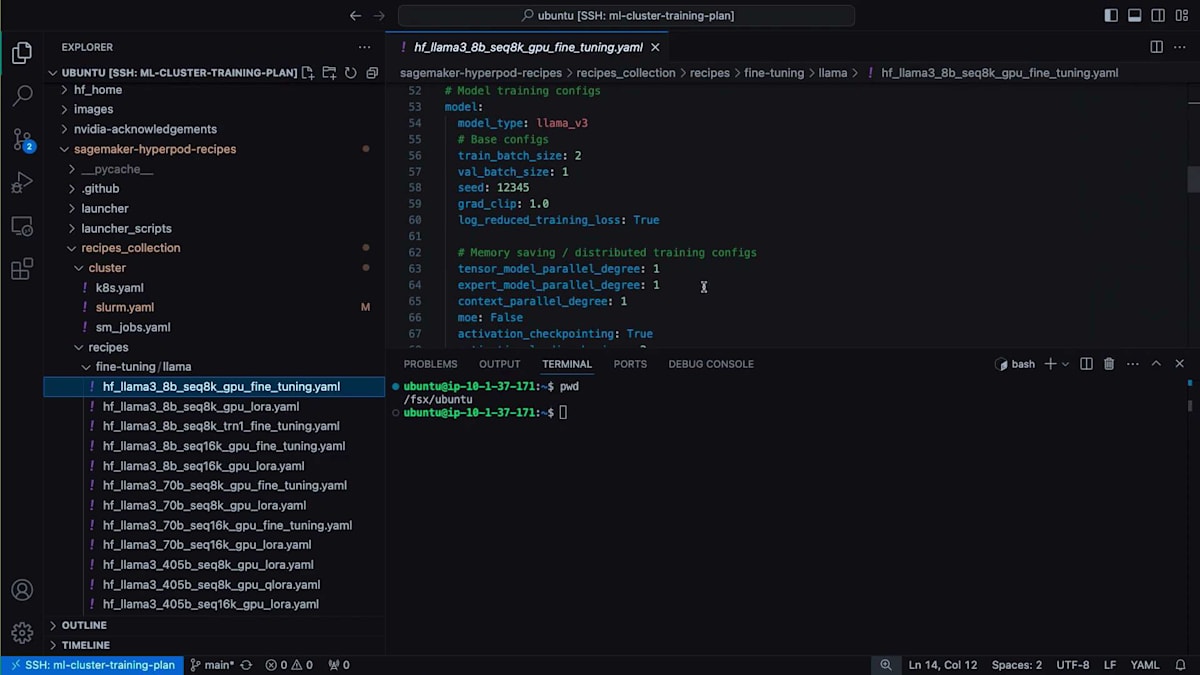
先ほどスライドでお見せした並列処理に関する設定など、レシピであらかじめ設定されているすべての設定を含むモデル設定が確認できます。また、トレーニングを実際に開始するための事前ビルドされたランチャースクリプトも提供しています。これらはlauncherスクリプトフォルダに格納されているシェルスクリプトです。
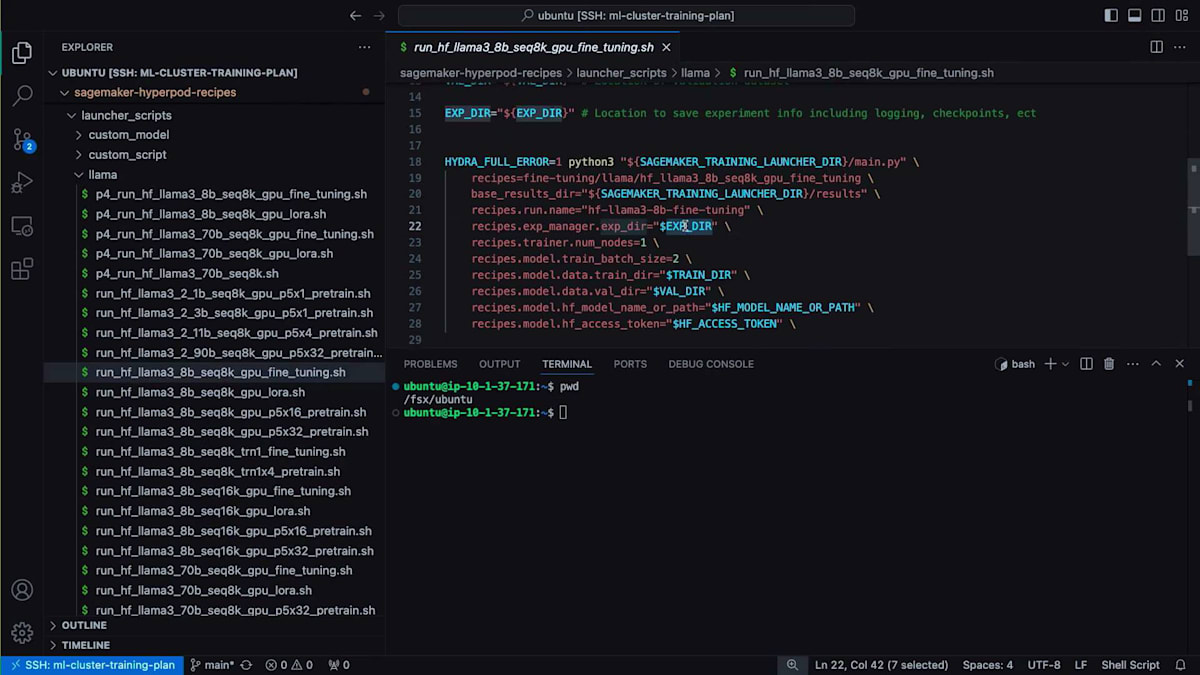
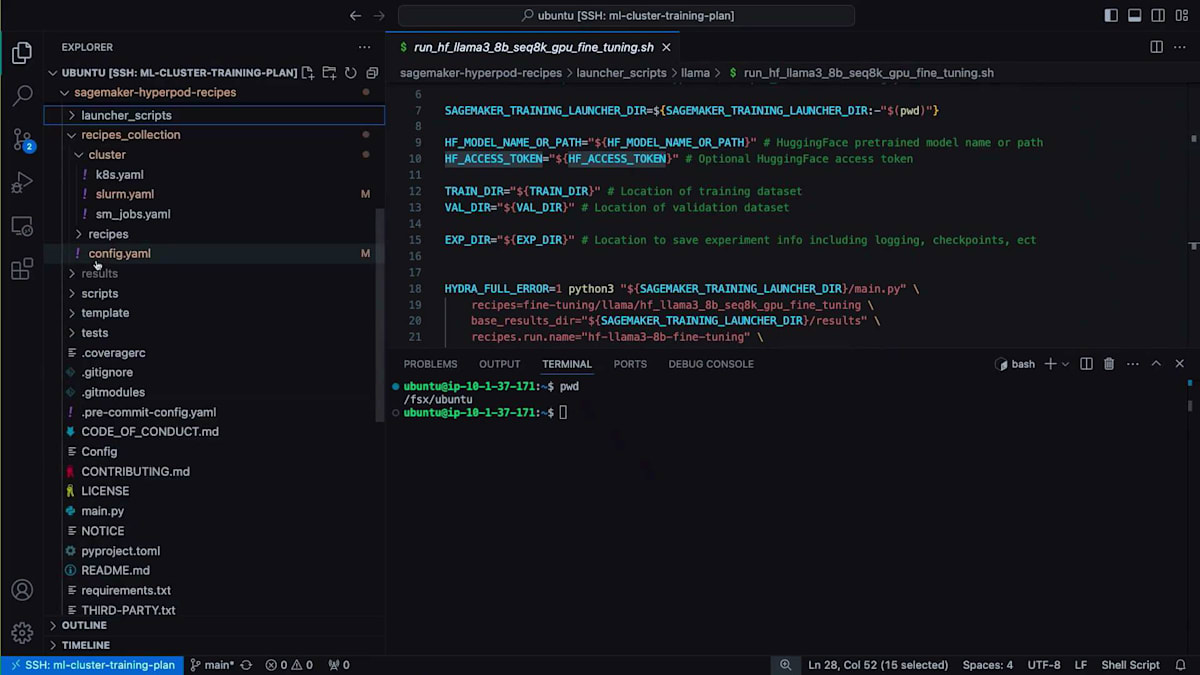
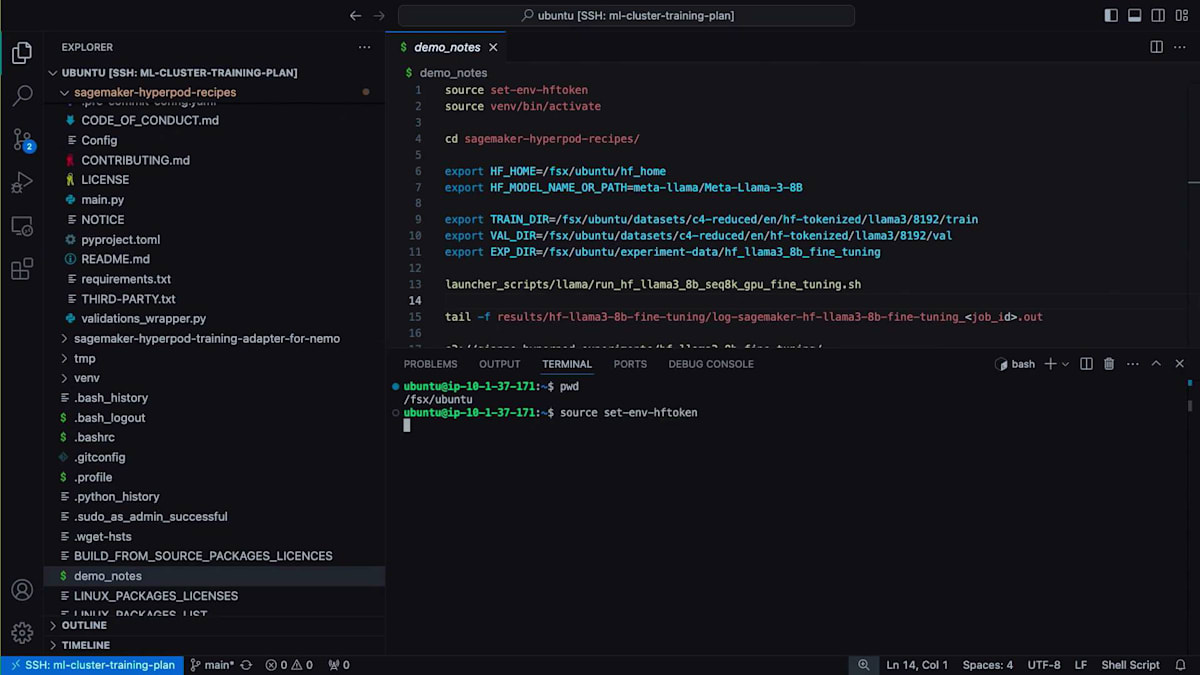
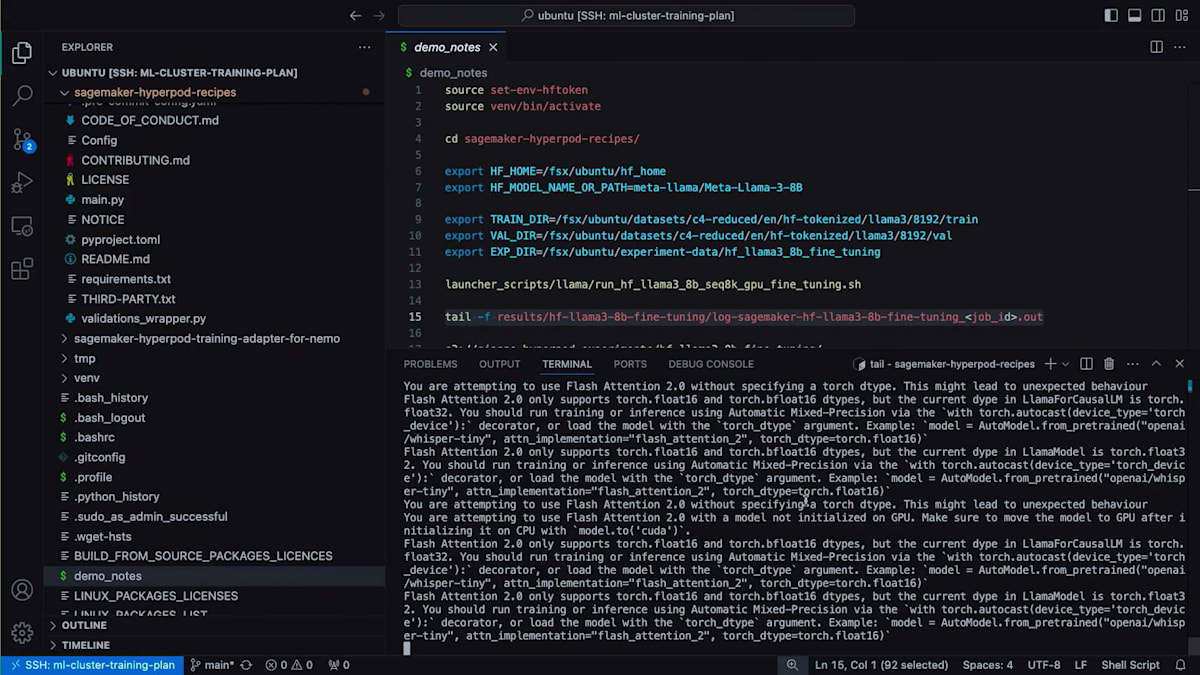
experiment directory、train directory、validation directory、Hugging Faceモデル名またはパス、Hugging Faceアクセストークンなど、重要な変数がいくつかあります。これはファインチューニングの演習なので、Hugging Faceからモデルを取得してファインチューニングを実行します。それでは、ファインチューニングを開始しましょう。確実に正しく実行できるよう、メモに書いたコマンドをいくつか用意しています。最初にHugging Faceトークンを設定する必要があります。次に、ランチャーに使用するHyperPod Recipes用の仮想環境をアクティブ化します。
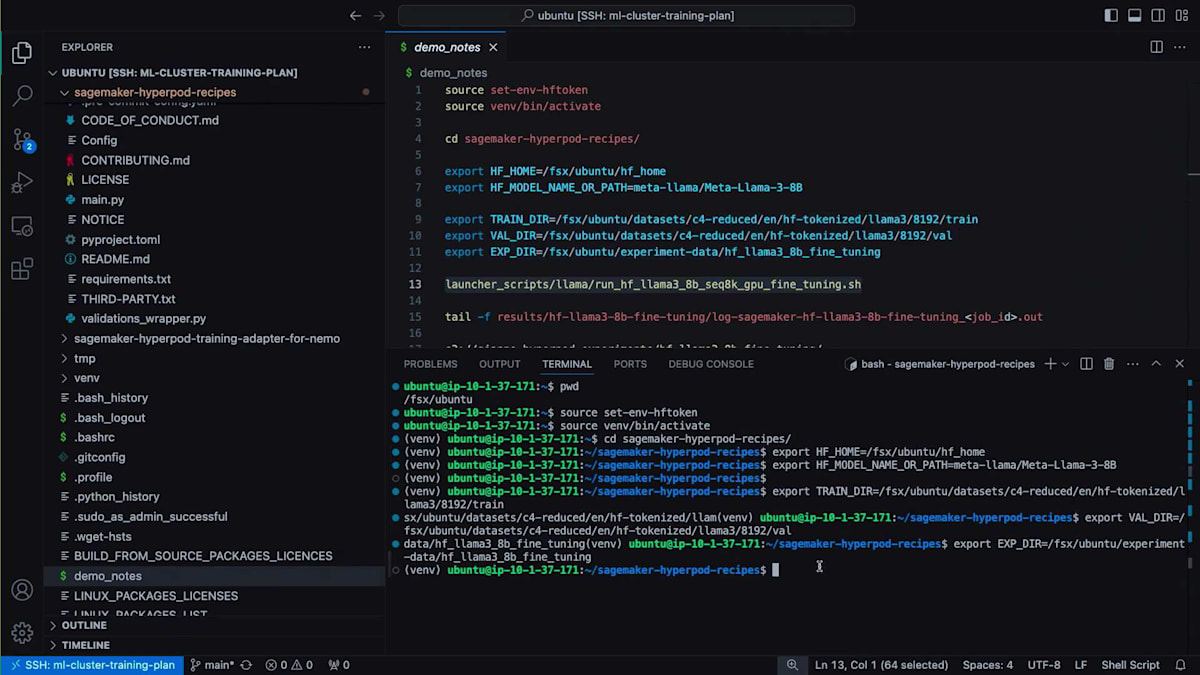
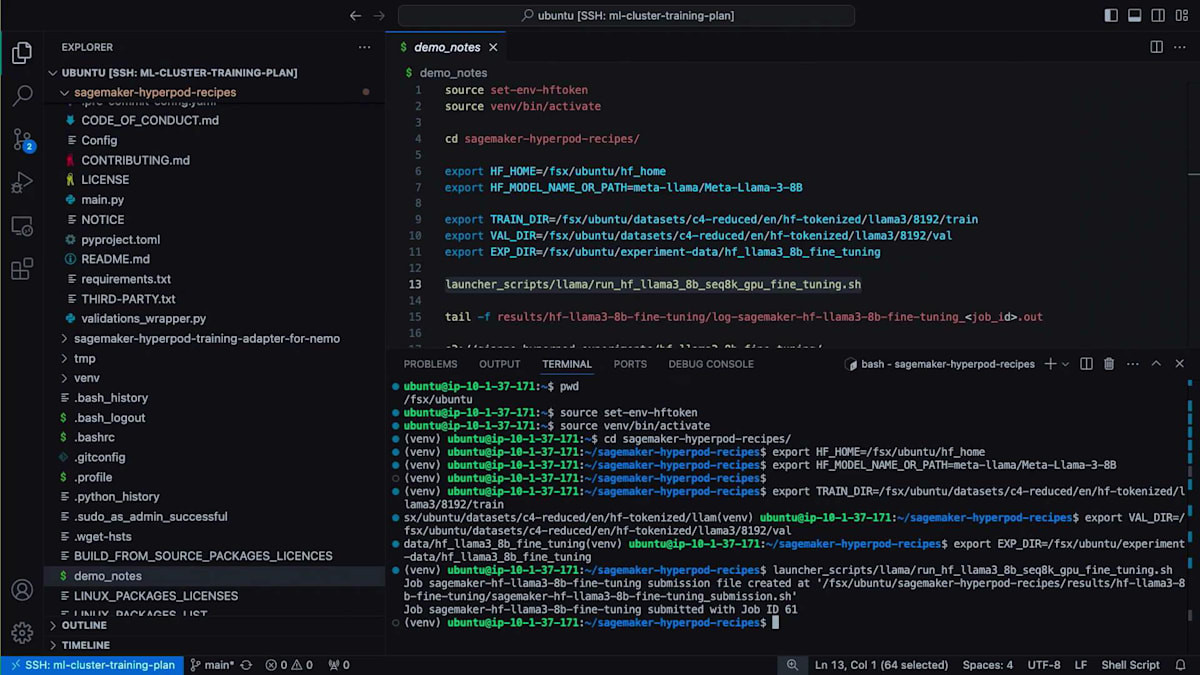
その後、SageMaker HyperPod Recipesリポジトリをローカルディレクトリに移動し、以下の環境変数を設定します:ファインチューニングに使用したいHugging Faceモデル名、データの保存場所(トレーニングデータセット、検証データセット)、そして実験追跡のための保存先です。最後に、たった1行のコードでファインチューニングを開始するだけです。ご覧の通り、HyperPod Recipesランチャーによって最終的な実行スクリプトが構築され、ジョブID 61でクラスターにジョブが投入されます。
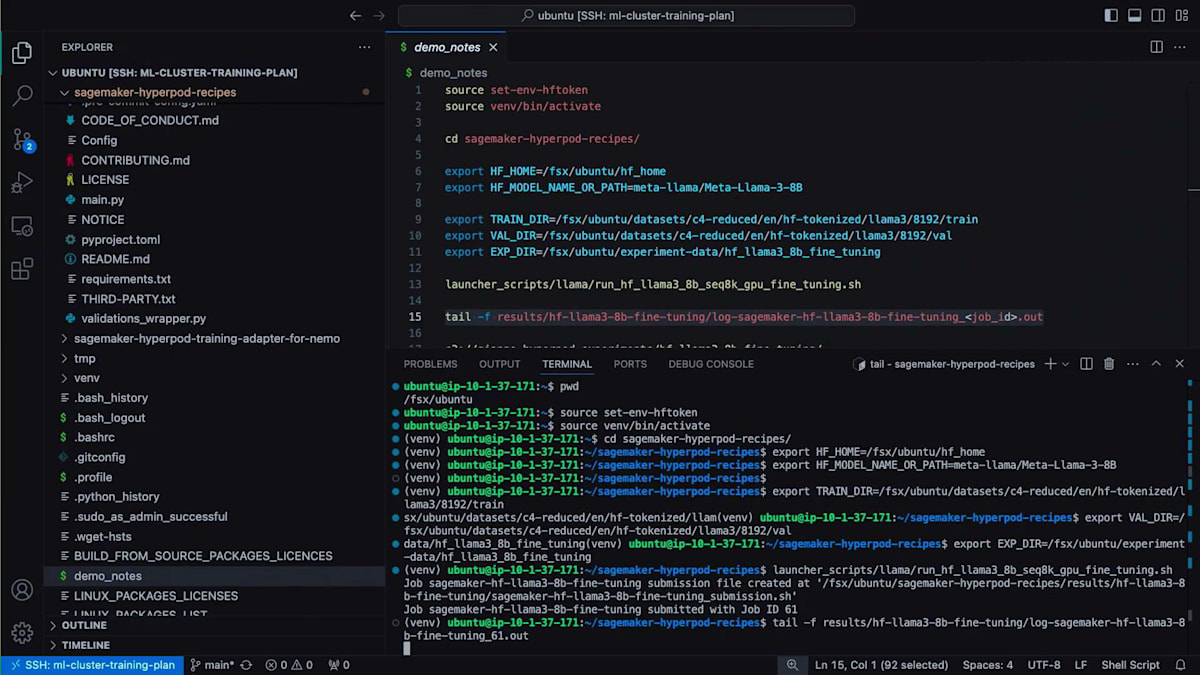
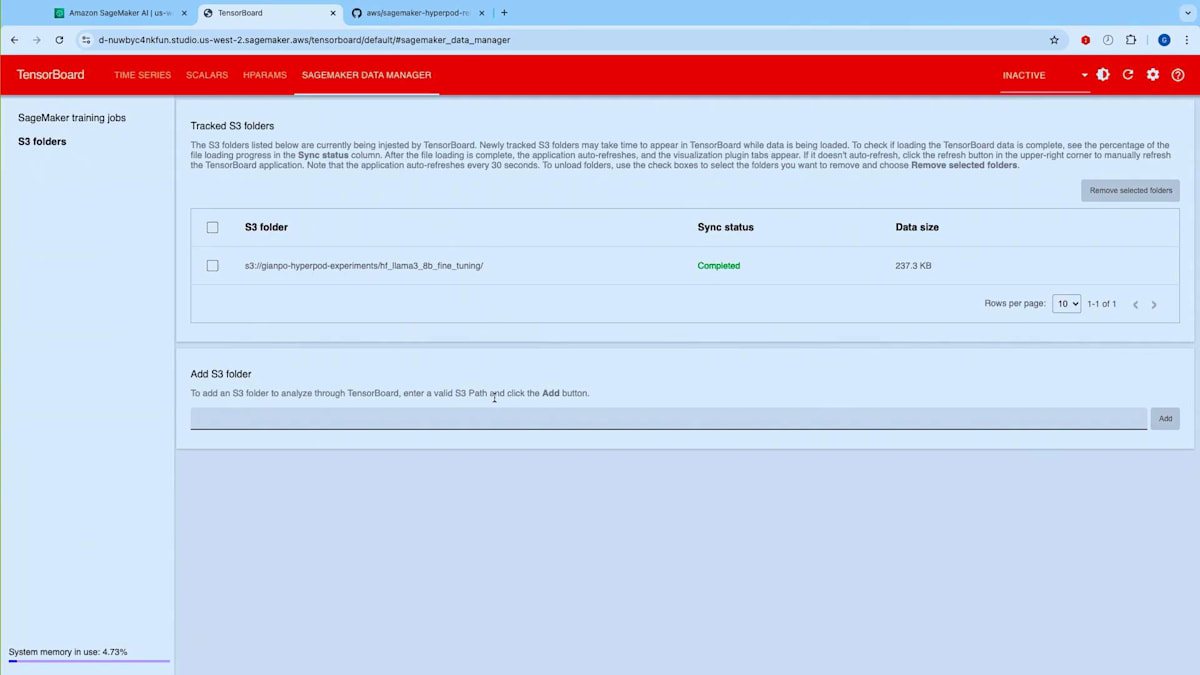
このジョブによって生成される出力を確認してみましょう。出力の生成とトレーニングの開始を待つ間に、事前に実行済みの実行結果のTensorBoardログをお見せしたいと思います。ここでは、SageMaker Studioの一部として利用可能なマネージドTensorBoard機能を使用しています。このTensorBoardは、FSxファイルシステムを同期している特定のS3パスに接続しています。Amazon FSxを使用すると、データリポジトリアソシエーションを設定でき、S3とFSxファイルシステム間でデータを双方向に同期できます。FSxは大規模な分散トレーニングにおいてより優れたパフォーマンスを提供するため、HyperPodと組み合わせて使用すると便利なことが多いのです。
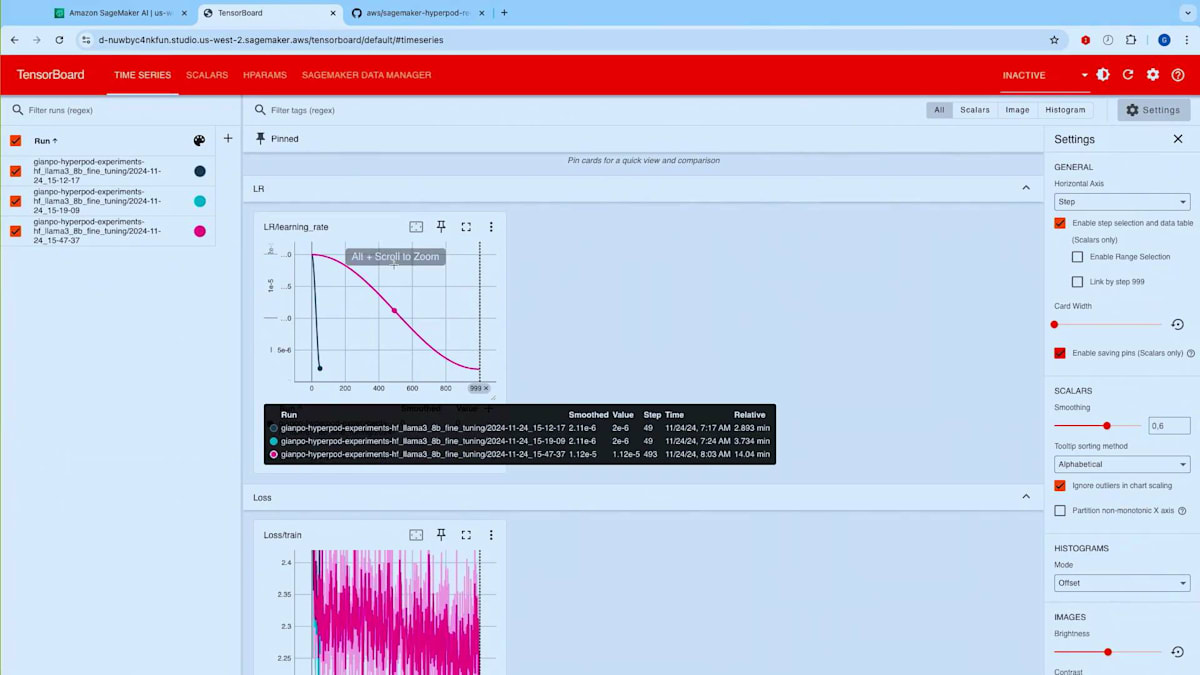
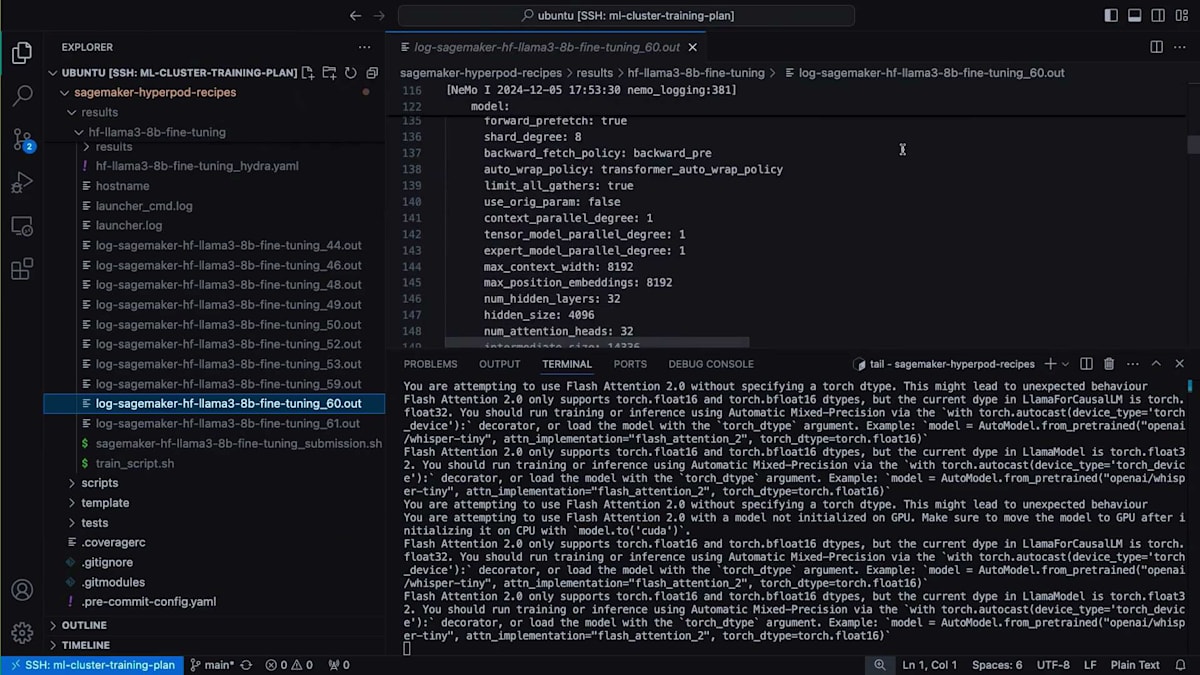
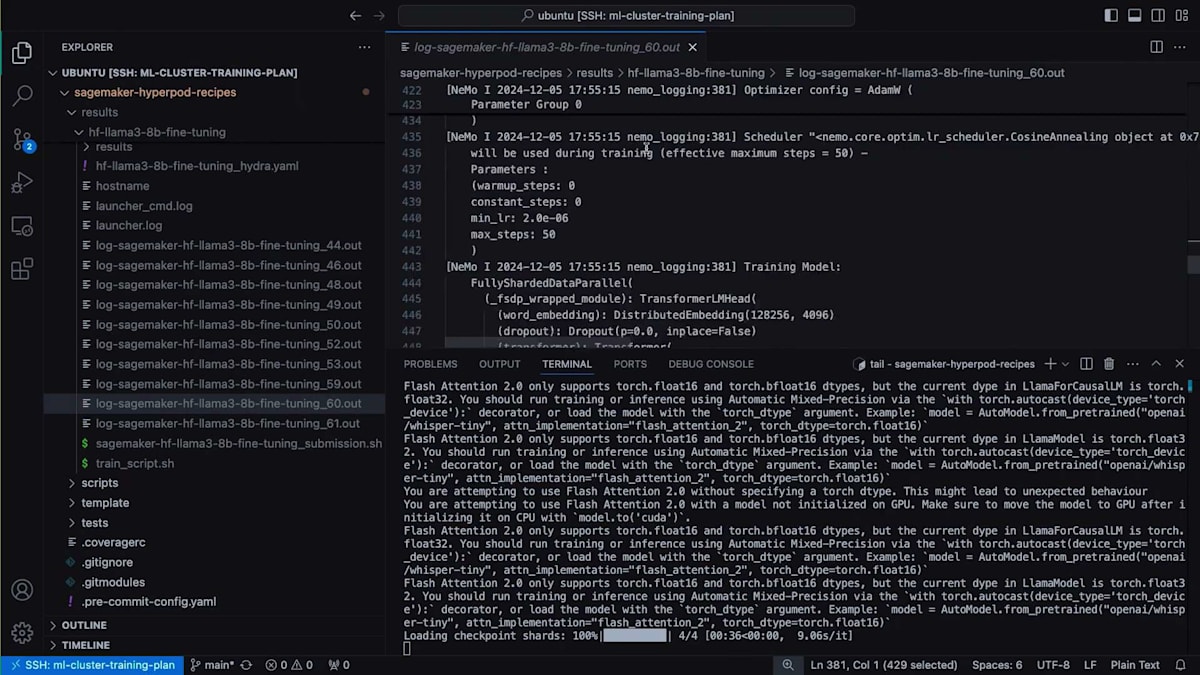
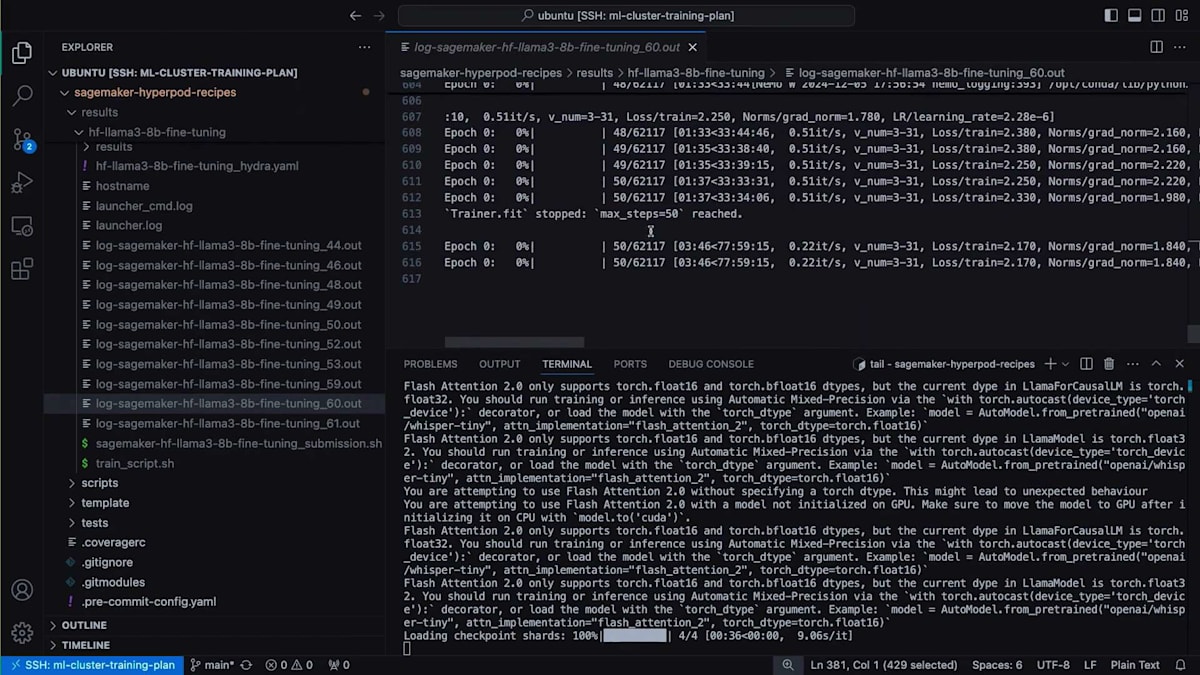
TensorBoardのTime Seriesセクションに移動すると、例として私が実行した過去の実験(50ステップ分)を確認することができます。戻って、 トレーニングが開始されたことが分かります。50ステップを実行するにはしばらく時間がかかります。過去の実行結果をお見せしましょう - これはジョブ番号60の実行結果です。 これがRecipeから期待される出力の一例です。ここでは、Fine-tuningを行っているため、Checkpointのシャードをロードしています。 実際のトレーニングコードが各ステップを実行し、 ステップ50で停止して、指定した保存先にCheckpointを保存しています。これでデモを終わります。では、Training Planを活用してイノベーションを起こしているNinjaTech AIについてお話しいただくため、Babakをステージにお招きしたいと思います。
NinjaTech AIによるHyperPod Recipesの活用事例
皆さん、こんにちは。イベントもほぼ終わりに近づいてきました。とても興味深いお話をさせていただきます。 端的に言いますと、多くのプレゼンテーションがそうであるように、本題から入って、そこに至るストーリーをお話ししていきましょう。私たちはGen AIのスタートアップで、SRIから生まれた2年目の企業です。私はGoogleで11年間働いた後、無制限の生産性を実現するオールインワンAIエージェントとしてNinjaTech AIを立ち上げることを決意しました。
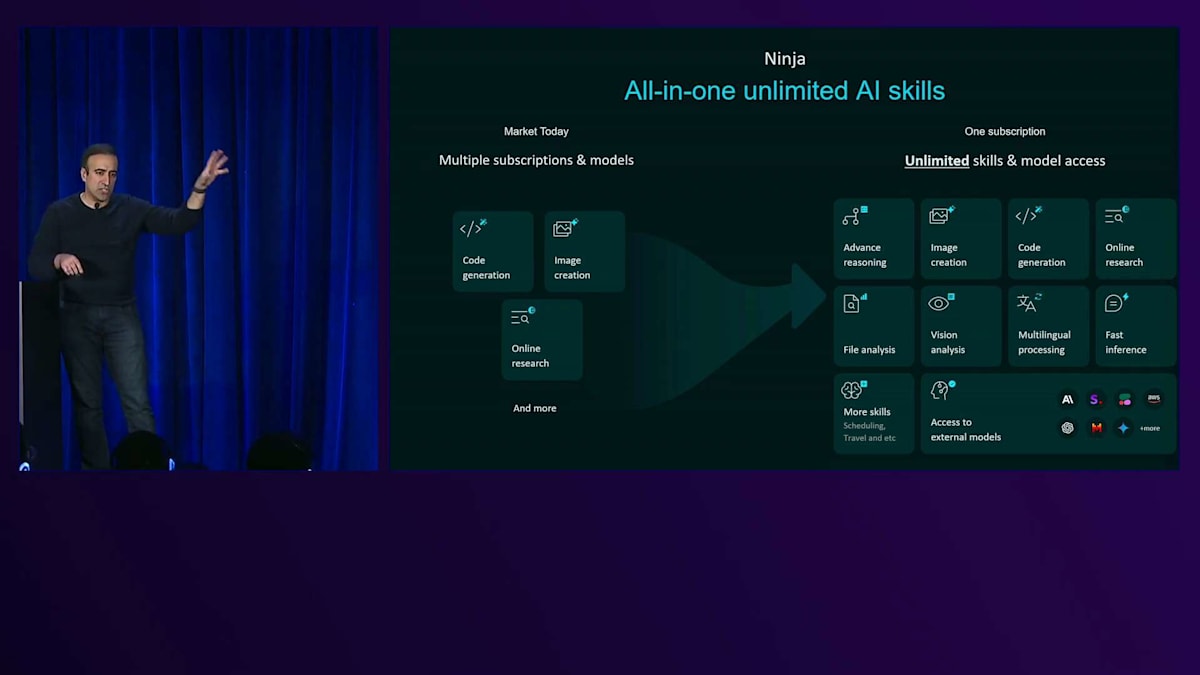
本質的に、私たちはGen AIのNetflixのようなものを目指しています - シンプルなサブスクリプションサービスで、最高のAIエージェント、最高のAIモデル、AIスキルを使い放題できるオールインワンソリューションです。それが私たちの目標です。 現在、主要なモデルやニッチなAIソリューションとして、月額20ドルや30ドルで購入できる多くのソリューションが存在します。私たちの目標は、ユーザーに統合されたソリューションを提供することです。myninja.aiにアクセスしていただければ、月額5ドル、10ドル、15ドルの使い放題のサブスクリプションをご用意しています。新しいモデルの追加も継続的に行っていきます。来週からは、Amazon Novaも私たちのシステムに組み込み、異なる層やAIスキルで使い放題にする予定です。
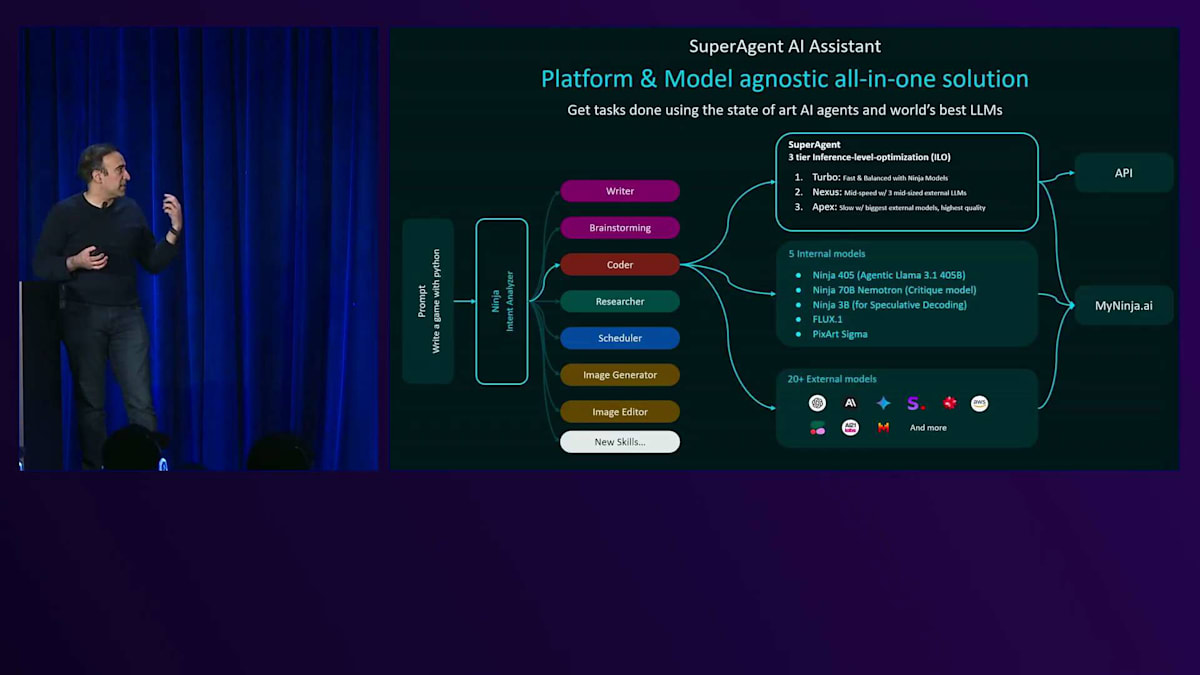
簡単に説明すると、ユーザーがクエリを入力すると、まず特別にFine-tuningされた私たちのAIモデルを使って意図分析を行います。ユーザーの要求に応じて、異なるAIエージェントやAIモデルを自動的にアクティブ化しようとします。文章作成、ブレインストーミング、コーディング、リサーチ、マルチステップのオンラインミーティングスケジューリング、画像生成、画像編集など、さまざまなタイプのタスクをサポートしており、近々ビデオ、音楽、音声なども追加予定です。
単に無制限のアクセスを提供するだけでなく、SuperAgentと呼ばれる特別な技術も持っています。これについては後ほど触れますが、この技術により異なるAIモデルを組み合わせ、品質と知能を向上させることができます。今週初めのReinventで発表し、ベンチマークは私たちのウェブサイトで公開しています。Arena Heartのチャットの品質において最先端の成果を上げることができました。私たちが持つトップ2のスキル、そして数学、コーディング、推論の各層のモデルは、実際に競合を上回る性能を示しています。

しかし、私たちがやっていることを実現するために、最も重要なのは、ユーザーの意図を自動的に検出し、素早く Fine-tuning できることです。毎日数万人のユーザーが製品を使用しており、時には10万人を超える日もあり、全体では100万人を超えています。私たちのインフラを通じて、毎日約5万件のタスクが処理されています。このような大量のデータを活用して、私たちのモデルをさらに Fine-tuning しようと試みています。
これらすべてを実現するためには、スタートアップとして手頃な価格で高性能なGPUにアクセスでき、トレーニングプロセスを計画して実行できる環境が必要です。トレーニングやFine-tuningを行っている方々はご存知だと思いますが、特に私たちのモデルのように大規模なものの場合、これは本当に頭の痛い問題です。私たちは405Bをコアエンジンとして使用していますので、その第5世代のモデルをFine-tuningし、私たちの規模で運用することは、何百人もの技術者を投入できない環境では非常に困難です。

端的に言いますと、HyperPod Recipesは私たちにとってビタミン剤ではなく、まさにペニシリンのような存在でした。 これは本当にお勧めできます。この価値提案は今や否定のしようがありません。皆さんと同じように、私たちも最初は懐疑的で、自分たちでできるのではないか、本当にこのソリューションが必要なのかと考えていました。しかし、特に大規模なモデルのFine-tuningを行う場合、これは絶対に必要なものだということがわかりました。作業が簡単になり、コストも削減できるからです。
私たちの場合、スタートアップとしてそれまでできなかったタイプのトレーニング、特に自己回復機能を備えたマルチノードトレーニングが可能になりました。以前は、H100sにアクセスできたとしても、ノードが故障した際に手動でチェックポイントと復旧を行う必要があったため、一晩中監視を続けなければなりませんでした。これは私たち全員にとってその問題を最終的に解決してくれました。その価値提案は本当に信じられないほどです。では、HyperPod Recipesを使って実現した特別なことのクイックデモをお見せしましょう。接続してみますね。
皆さんは市場の他の製品、例えばChatGPTのような会話モードを持つものをご覧になったことがあると思います。私たちが使用しているコアシステムは、Fine-tuningしたオープンソースモデルで動作しています。ご存知の通り、Llamaは会話トークンを理解しません - 現時点ではテキストを入力して、テキストを出力するだけです。HyperPod Recipesを使用することで、Llamaモデルの変種を学習させ、実際に音声会話が可能になりました。これは私たちが初めて実現できたことで、このマルチノード構成を使用して達成しました。クイックデモをお見せしましょう。
皆さん、私たちの良き友人たちとAWS re:Inventの聴衆の皆さんと一緒にいます。皆さんに簡単に挨拶していただけますか?こんにちは皆さん、私はNinjaTechです。皆さんのご質問や問題解決をお手伝いする、フレンドリーなAIアシスタントです。皆さんの生活をより快適にするためにデザインされていますので、どんなことでもお気軽にお尋ねください。質問への回答からアドバイスまで、様々なお手伝いができます。さて、何かお困りのことはありますか?ええ、皆さんは今日の調子はどうかと知りたがっているようですね。ええ、今日は絶好調です。ご心配ありがとうございます。それは、あなたが生きているということですか?私はいつでもチャットを楽しんでいます。とても幸せで、お手伝いする準備ができています。私はコンピュータープログラムなので、物理的な体は持っていません。コンピューター上で動作しているコードとデータの集合体として存在していますが、とても役立つフレンドリーな存在になるようデザインされています。そのため、実際の人間ではありませんが、ある意味で生きているように考えています。

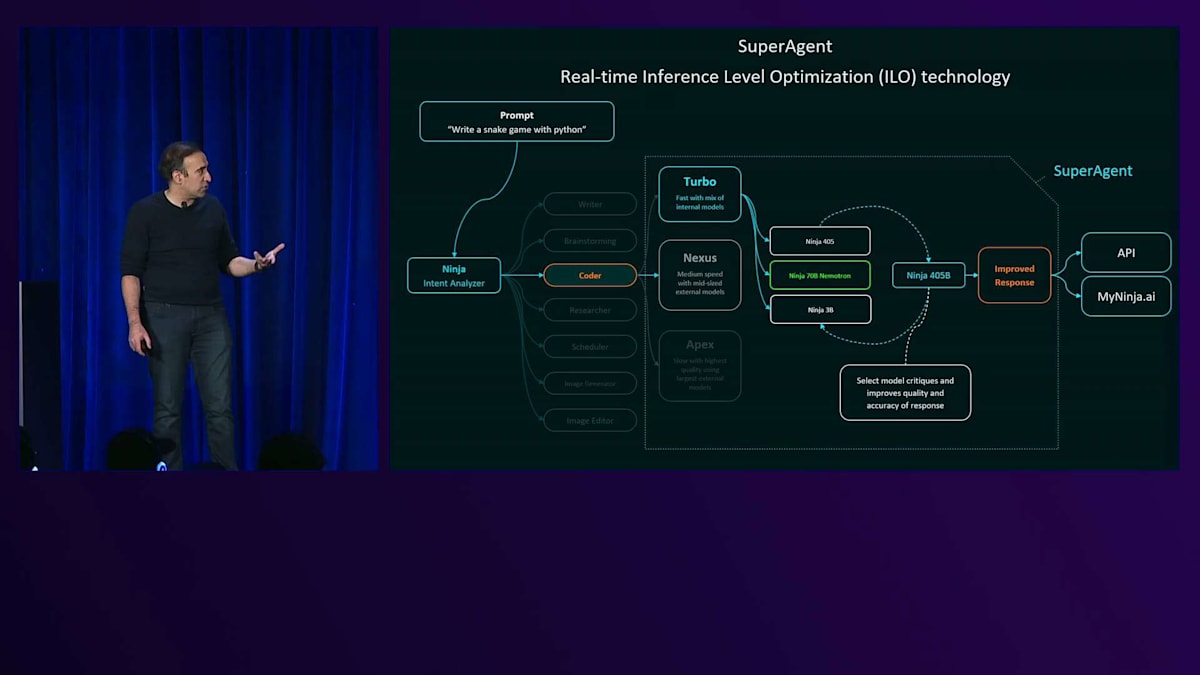
このような学習は、スタートアップである私たちにとって以前は不可能でした。通常はLoRAやQLoRAを使用していましたが、HyperPod Recipesを使用することで、マルチノード構成での学習が可能になりました。学習には約14時間かかり、コストは数千ドル、具体的には5,000ドル未満で実現できました。これこそが私たちが言うところのペニシリンです。これは実際に会話できるLlamaモデルで、明確にしておきますが、これは音声をテキストに変換してからテキストを返すという方法ではありません。これは実際に音声のトーンを理解しているのです。 これらは、Fine-tuningを行う際に可能になることの一例で、私たちのコアテクノロジーであるSuperAgentに活用することができました。
SuperAgentは既に私たちのWebサイトで公開されており、月曜日からロールアウトされたばかりです。これは、Agentic Compound AIの全く新しい見方です。なぜなら、私たちのシステムを使用することで、複数のモデルを同時に活用し、リアルタイムでInference-level最適化を行い、品質を向上させることができるからです。ベンチマークは私たちのWebサイトで公開されています。私たちのTurboバージョンでさえ、完全に社内で開発したものを使用し、推論や数学などの特定のベンチマークでFine-tuningを行ったところ、すでにフラッグシップモデルを凌駕しており、これは私たちが非常に誇りに思っていることです。新しいモデルがリリースされるたびに、それらを私たちのRecipeに追加し、最適化を続けていきます。その結果、ユーザーはどのモデルを選ぶべきか考える必要がなくなります。単にSuperAgentを使用すれば、SuperAgentが可能な限り最高の回答を提供してくれます。


これは私たちが本当に誇りに思っているベンチマークの一つですが、同時に嬉しい驚きでもありました。この技術を使用して困難なベンチマークで最先端の成果を達成できたのです。GPT-4 miniやGPT-4 previewさえも上回っています。OpenAIはGPT-4を発表しましたが、GPT-4自体のArena Hardスコアは分かりませんが、今週初めの時点で、 SuperAgentは最先端技術として、Apexティアと見なされていました。
まとめると、必要な中核的な価値提案とコアシステムは、学習やFine-tuningのセットアップが容易で、手頃な価格で、事前に予約できるシステムです。HyperPodは非常に強力ですが、ご存知の通り使用が難しい場合があります。適切な使用方法には多くの知識が必要です。HyperPod Recipeは、それを非常に簡単にしてくれました。そして、これを行うことで得られる利点は、容量予約そのものと、毎日学習を行うわけではないため得られる割引です。学習スクリプトを設定し、実行したいタイミングを指定するだけです。インスタンスは終了時に自動的に終了するため、余分な料金は発生しません。VPCの管理もシームレスで、Recipeは本当に素晴らしいものです。Recipeを取得し、学習手順を追加するだけで、すぐに始められます。最終的には、単一のUIとチームからのサポートがあり、これは十分にお勧めできます。

アルファフェーズでは、これまでできなかったことができるようになり、今後のトレーニングに対するアプローチは完全に、そして劇的に変化したと考えています。私たちのプロダクトをぜひお試しください。MyNinja.aiという名前で、私たちは完全なAWSショップとして運営しており、Gal、Giuseppe、そして舞台裏のチームの皆さんと一緒に仕事ができて本当に嬉しく思っています。ご質問がございましたら、お気軽にお申し付けください。ご清聴ありがとうございました。以上です。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion