re:Invent 2024: AWSによるAmazon EKSでのKubernetesワークロードセキュリティ強化
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Securing Kubernetes workloads in Amazon EKS (KUB315)
この動画では、Amazon EKSにおけるKubernetesワークロードのセキュリティ確保について、クラスター、インフラストラクチャ、アプリケーションの3つのレイヤーから詳しく解説しています。Cluster Access ManagementやPod Identityなどの新機能の仕組みや利点が説明され、AWS Systems ManagerやAmazon GuardDutyとの統合による具体的なセキュリティ強化方法が紹介されています。特に注目すべきは、KubernetesのRBACの制限を克服する新しいオープンソースのアクセス制御言語CEDARのデモンストレーションで、より柔軟な認可制御の実現方法が示されています。Cloud Native Computing Foundationの2023年調査で84%が本番環境でKubernetesを使用または評価中という事実も紹介されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Amazon EKSにおけるKubernetesワークロードのセキュリティ確保:セッション概要

みなさん、こんにちは。Micah Hauslerです。ここはcube 315、Amazon EKSにおけるKubernetesワークロードのセキュリティ確保についてのセッションです。私はAWSのPrincipal Software Engineerとして、KubernetesとKubernetesのセキュリティに携わっています。上流のKubernetesにコントリビュートしており、Kubernetes Security Committeeのメンバーでもあります。セキュリティレポートを受け取り、評価し、Kubernetesの修正を行っています。私はGeorge Johnで、Amazon EKSチームのProduct Managerです。本日はこのような機会をいただき、大変嬉しく思います。また、皆様には貴重なお時間を割いていただき、ありがとうございます。

本日のセッションでは、少し異なるアプローチを取らせていただきます。Amazon EKSで実行されているワークロードを、いくつかの異なるレイヤーからどのように保護できるかについて見ていきます。まず、全体像を把握し、クラスターレベルで利用可能なコントロールについて見ていきます。クラスターへのアクセスをどのように保護するか、そしてクラスター内で実行されているアプリケーションに、S3バケットやDynamoDBなどのAWSリソースにアクセスするための権限をどのように割り当てるかについて見ていきます。最後に、第一セクションでは、セキュリティ分野におけるさまざまなAWSサービスと、それらがAmazon EKSとどのように統合されているかを見ていきます。
インフラストラクチャーレイヤーについて、もう少し深く掘り下げていきます。ここでいうインフラストラクチャーとは、クラスターで実行されるEC2インスタンス、つまりワーカーノードのことを指します。また、ネットワーキングVPCについても見ていき、インフラストラクチャーレイヤーを保護するために利用可能なコントロールとメカニズムについて説明します。そして最後に、アプリケーションレイヤーに入っていきます。アプリケーションを構成するイメージとPodを保護するためのベストプラクティスとコントロールについて説明します。
一点お伝えしたいのは、本日のセッションでは、実際にEKSとAWSで利用可能なコントロールと機能に焦点を当てているということです。セッションの最後に、EKSベストプラクティスガイドというリソースを共有させていただきます。これには、クラスターを保護するために利用可能なKubernetesの機能とツールについて説明されており、セキュリティ確保に関する全体像を把握していただけます。
Kubernetesの採用拡大とAmazon EKSの役割


ここ数年、Kubernetesの採用が急激に増加しています。Cloud Native Computing Foundationの2023年の年次調査によると、回答者の84%が本番環境でKubernetesを使用しているか、評価中とのことです。 これはAmazon EKSでも同様の傾向が見られており、毎年、お客様は数千万のクラスターを実行しており、この数字は増加し続けています。

6年以上前にEKSをローンチした際、それは「大規模なKubernetesの管理は難しい」というお客様からのフィードバックに応えるものでした。当時、お客様はKubernetesコントロールプレーンの監視、スケーリング、管理に多くの時間を費やしており、さまざまなサービスとネイティブに連携する方法を求めていました。それ以来、EKSはAWS上でKubernetesを実行する最も信頼できる方法として確立されました。私たちは、Kubernetesコントロールプレーンの管理だけでなく、クラスターに関するさまざまな側面における面倒な作業から、お客様を解放しています。

クラウドでの安全な運用は、共有責任モデルに基づいています。AWSはクラウドの安全性に責任を持ち、お客様はクラウド内での安全性に責任を持ちます。下層の3つのレイヤーは、すべてAWSとEKSが管理しています。Kubernetesクラスターコントロールプレーン、それが動作するインフラストラクチャ、リージョン、ローカルゾーン、コントロールプレーンが利用する基盤サービス(コンピューティング、ストレージ、ネットワーキング)、そしてコントロールプレーンで動作するAPIサーバーやetcdデータベースといったKubernetesのコンポーネント - これらはすべて私たちの責任です。パッチ適用、スケーリング、管理を行い、可用性と耐障害性を確保します。

その上のレイヤーは、お客様のVPC内で動作するEC2インスタンスとワーカーノードに関するものです。オペレーティングシステムのパッチ適用、監視、ヘルスチェック、Auto Scalingなどのクラスター機能、さらにはkubeletやコンテナランタイムといったワーカーノード上で動作するKubernetesコンポーネント - これらはすべてお客様の責任となります。ただし、AWSとEKSは、セキュリティグループ、Podサブネット、プライベートエンドポイントアクセス、EKS最適化AMIなど、データプレーン、VPC、そしてそこで動作するものを簡単に保護できるツールを提供しています。とはいえ、最終的にはお客様の責任となります。 基本的な部分を説明したところで、最初のレイヤーであるクラスターレベルのコントロールについて見ていきましょう。
クラスターレベルのセキュリティコントロール:認証と認可

EKSをローンチした際、私たちはクラスターへの認証をKubernetesネイティブな方法で提供したいと考えました。 そこで、aws-authというConfigMapを作成し、IAMプリンシパルとKubernetesのパーミッションのマッピングを定義できるようにしました。このアプローチにはトレードオフがありました。一方では、別個のアイデンティティプロバイダーを維持する必要なくIAMを使用でき、多要素認証やCloudTrailによる監査など、IAMのすべての利点を活用できるという利点がありました。

しかし一方で、必要なパーミッションを持つEKSクラスターを作成する際に、異なるAPIセットを扱う必要がありました。例えば、クラスターの作成にはEKS APIを使用し、その後マッピングの設定やConfigMapのセットアップにはKubernetes APIに切り替える必要がありました。これにより、必要なパーミッションを持つクラスターのブートストラップを自動化したり、Infrastructure as Codeツールを使用したりすることが難しくなっていました。ConfigMapによる方式のもう一つの課題は、やや脆弱だったことです。ConfigMapでタイプミスをしたり、正確なフォーマットに従わなかったりすると、誤ってユーザーをロックアウトしてしまう可能性がありました。さらに、EKSクラスターの作成に使用されるIAMエンティティを作成すると、自動的にスーパーユーザーアクセス権が付与されてしまいます。


これらの課題に対処するため、昨年のre:Inventで私とMikeがステージで予告した直後に、Cluster Access Managementという機能をリリースしました。 Cluster Access Managementの役割は、APIを統一することです。これにより、EKSとKubernetesのAPIを行き来する必要がなくなり、クラスターの作成、権限の設定、クラスターの準備までを単一のAPIで行えるようになりました。設定が簡素化され、ユーザーやEKSにアクセスする必要のある他のAWSサービスにとって、セットアップ全体がより簡単になりました。さらに、クラスターを作成するIAMプリンシパルに自動的に付与される権限を、きめ細かく制御できるようになりました。

実際の背後の仕組みを見てみましょう。まず、IAMと連携してIAMプリンシパル(ロールまたはユーザー)を作成し、その後、この機能の一部として導入された新しいAPIを利用します。同じ機能はコンソールからも利用可能で、EKSコンソールまたはAPIのいずれかを使用できます。主に2つのエンティティを作成します。まず、作成したIAMエンティティと関連付けるAccess Entryを作成し、次にAccess Policyを作成してAccess Entryの権限を指定します。



最初の2つのステップが完了すると、Cluster Access Management機能のセットアップは完了です。ユーザーがAPIサーバーにアクセスしようとすると、IAM AuthenticatorまたはCLIのget tokenオペレーションによってAWS STSが呼び出されます。リクエストがコントロールプレーンのAPIサーバーに到達すると、Webhookがリクエストを受け取り、STSトークンを確認して、そのトークンに関連付けられたユーザーIDを探します。Access Entryと一致すれば、認証は完了です。 認可については、一連のAuthorizerで確認が行われ、ユーザーIDがAccess EntryとAccess Policyに一致すれば、認可が許可されてリクエストが処理されます。 Cluster Access Managementは、APIとコンソールの両方から利用可能で、柔軟な運用が可能です。
インフラストラクチャレイヤーのセキュリティ:ネットワークとアクセス管理

ここまでは、クラスターへのアクセスの設定方法についてお話ししました。次は、クラスター内で実行されるアプリケーションについて見ていきましょう。多くの場合、S3バケット、DynamoDBテーブル、その他のAWSリソースなど、AWSリソースへのアクセスが必要になるでしょう。アプリケーションに適切な権限を割り当てるにはどうすればよいのでしょうか?以前から利用可能で、現在も使える選択肢の1つが、IAM Roles for Service Accounts(IRSA)です。IRSAは2019年にリリースされ、Podに対してきめ細かなAWS権限を付与することができます。同じEC2インスタンス上で複数のアプリケーションに属する複数のPodが実行されている場合でも、IRSAを使用することで、AWS権限を分割することができます。
これにより、同じインスタンス上で実行される複数のアプリケーションに属する複数のPodに対して、それぞれ異なる権限セットを持たせることが可能になります。IRSAの開発目標は、AWSでサポートしている様々なKubernetesデプロイメントモデルで動作させることでした。IRSAは、クラウド上のEKSマネージドサービス、EKS Anywhere、EC2インスタンス上の自己管理型Kubernetesクラスター、Red Hat OpenShift Service for AWS(ROSA)で動作するように設計されています。
私たちはIRSAを構築する際に、EKS APIへの直接的な依存を避け、IAMのような基盤サービスを活用しましたが、これにはいくつかのトレードオフがありました。その1つは、IAMに依存していたため、特権的な操作であるIAM OIDCプロバイダーを作成する必要があったことです。特に規制の厳しい業界のお客様から、クラスター管理者がIAMの権限を持っていないことが多いという声を聞きました。これは、クラスター管理者がIAM管理者に連絡を取る必要があることを意味し、IRSAのセットアップに関して多くのやり取りが発生し、ユーザーフレンドリーとは言えない状況でした。

もう1つの課題はスコーピングでした。IRSAのロールを使用または作成する際、通常そのロールを制限し、どのクラスターがそれを引き受けることができるかを指定する必要があります。つまり、後で新しいクラスターでロールを使用したい場合、IAMロールに戻ってトラストポリシーを更新し続ける必要があります。同様に、クラスターからロールを取り消したい場合も、ロールのトラストポリシーを変更する必要があります。また、ロールを使用できるクラスターの数にも制限があります。これらの課題に対処するため、昨年私たちはPod Identityという機能をリリースしました。
Pod Identityは信頼関係を簡素化し、EKSサービス全体で引き受けることができるロールを作成できるようにします。以前は、ロールを作成する際に、それを引き受けることができるクラスターを指定する必要がありました。しかし、Pod Identityを使用すると、使用しているクラスターに関係なく、サービスがそれを引き受けることができるように指定できます。必要に応じて、特定のクラスターに制限することも可能です。IAMロールセッションタグをサポートすることで属性ベースのアクセス制御などの新機能を提供し、ポリシーとロールをクラスター間で再利用できるようにし、必要なすべての権限を持つクラスターを一度に作成することを可能にします。

強調しておきたいのは、クラスターアクセス管理の古い方法としてConfig Mapがありますが、IRSAが時代遅れになったわけではないということです。私たちは両方の方式をサポートし続け、IRSAを廃止する予定はありません。IRSAはPod Identityと並行して存在し続けます。Pod IdentityはクラウドのEKSマネージドサービス向けに特別に設計されており、EKS AnywhereやEC2上の自己管理型Kubernetesクラスターでは機能しません。これは、ユースケースやニーズに応じて、より多くの選択肢を提供することが目的です。
アプリケーションレイヤーのセキュリティ:Podとイメージの保護

Pod Identityのフローを見てみましょう。前提条件として、すべてのワーカーノードでPod Identityエージェントをデーモンとして実行する必要があります。S3バケットにアクセスする必要があるアプリケーションをクラスターにデプロイしたい場合を簡単な例として考えてみましょう。これは任意のAWSリソースでも構いませんが、ここではS3を簡単な例として使用します。まず、IAMとやり取りしてIAMロールを作成します。これには2つの部分があります:パーミッションポリシーとトラストポリシーです。パーミッションポリシーは、この例ではS3のような、ロールがアクセスできるものを指定します。
Pod Identityは、IRSAとはTrust Policyの部分で異なります。Pod IdentityのTrust Policyでは、このロールがサービスとしてのEKSによって引き受けられることを指定します。新しいサービスプリンシパルを導入しましたが、これは一度だけの作業です。このロールが将来クラスターA、B、Cのどこで使用されても、そのまま機能します。その後、以前作成したIAMロールとサービスアカウントをマッピングするPod Identity Associationを作成します。この時点でサービスアカウントが存在している必要はなく、後から作成することができます。これは、アプリケーションチームが後で使用するための権限を全て準備した状態でクラスターをセットアップしたいクラスター管理者にとって有益です。この機能は次のように動作します:
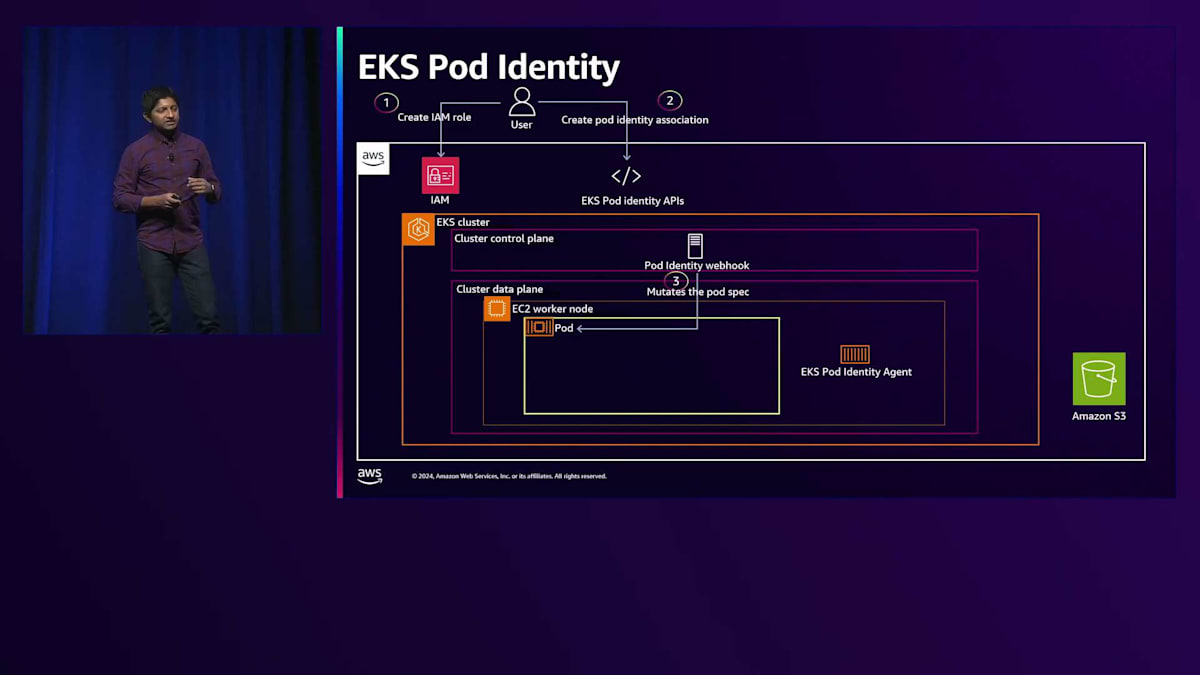



開発チームがアプリケーションをデプロイすると、Podが起動し、このPodに以前Pod Identity Associationを通じてマッピングされたサービスアカウントが関連付けられていることを検出すると、Webhookがリクエストをインターセプトし、Podの仕様に既知の環境変数を追加する形で変更を加えます。AWS SDKが起動すると、これらの環境変数を認識し、Podにマウントされているサービスアカウントトークンを取得してマウントします。そして、Pod Identity Agentにトークンを渡し、サービスアカウントトークンを送信します。その後、Pod Identity AgentはPod Identity用のAssume Roleを呼び出します。これはPod Identity APIの一部として新たに導入されたAPIです。このAPIは渡されたサービスアカウントトークンを検証し、検証が成功すると一時的なAWS認証情報を返し、それがPodに注入されます。アプリケーションはこのAWS認証情報を使用してAmazon S3にアクセスできるようになります。

昨年のローンチ以降のPod Identityの新機能についてですが、Pod Identityは現在、すべての商用AWSリージョン、中国、そしてUS GOVクラウドリージョンで利用可能になりました。また、Agentそのものをオープンソース化しました。ローンチ時にはAmazon EKSアドオンとしてのみ利用可能でしたが、Helmチャートとしてデプロイしたい、あるいは独自のAMIに組み込んでカスタムAMIを作成したいというお客様からのフィードバックを受けて、Agentをオープンソース化しました。さらに、EKSアドオンでのPod Identityのサポートも導入しました。アドオンはクラスター内で実行できる運用ソフトウェアで、通常このソフトウェアはAWSリソースにアクセスするためのAWS権限が必要です。これまではIRSAを通じてのみセットアップ可能でしたが、現在はPod Identityも利用可能となり、アドオンのセットアップ体験が大幅に簡素化されました。

問題を特定し警告を発するために利用できる制御機能についてお話ししましょう。まず、APIサーバー自体に入ってくるアクセスリクエストを見ていきます。EKSクラスターを作成すると、コントロールプレーンで実行されているAPIサーバーであるクラスターエンドポイントが提供されます。APIサーバーに入ってくるすべてのリクエストは、コントロールプレーンの監査ログに記録され、CloudWatchで利用可能になります。これは有効にする必要のあるオプションですが、コントロールプレーンのロギングを有効にすると、ログは自動的にCloudWatchに流れます。CloudWatchにログがあれば、CloudWatch Logs Insightsを使用してさらに分析することができます。プレゼンテーションの最後に、セキュリティのベストプラクティスを共有しますが、その中には「Detective Controls」というセクションがあり、私たちが有用だと感じた事前構築されたCloudWatch Logs Insightsのクエリがいくつか含まれています。また、ログがCloudWatchにあることのもう一つの利点は、HTTP 403 Forbiddenや未認証アクセスの増加を検出するためのアラームを設定できることです。
CEDARによる新しい認可システム:柔軟な属性ベースのアクセス制御
先ほど、クラスターのAPIサーバーエンドポイントに入ってくるリクエストについて見てきました。次は、EKS APIに入ってくるリクエストについて説明しましょう。EKS APIとは、クラスターの作成、削除、更新に使用するEKSサービスAPIのことで、KubernetesのAPIではありません。これらはすべてAWS CloudTrailに記録され、CloudTrailログとCloudTrail Insightsを使用して分析することができます。最後に、Amazon Detectiveがあり、これを使用してVPC Flow Logsを分析または可視化することができます。

暗号化に関して、Amazon EBSやAmazon EFS、FSx for LustreなどのネイティブなAWSストレージオプションでは、AWSマネージドキーまたはカスタマーマネージドキーを使用した保存時の暗号化をサポートしています。また、Kubernetesクラスターに保存される機密情報は通常、Kubernetes Secretsオブジェクトに格納されます。EKSでは、AWS Key Management Serviceのキーまたは独自のキーを使用してSecretsオブジェクトを暗号化することができます。キーがKMSにあることで、KMSが提供する自動ローテーション機能のメリットを得ることができます。

その他のクラスターレベルのコントロールについてですが、まず1つ目はKubernetesクラスターエンドポイントです。Kubernetesクラスターエンドポイントと言うのは、各クラスターで利用可能なAPIサーバーエンドポイントのことです。デフォルトではパブリックモードになっており、ワーカーノードなど、VPCからAPIサーバーにアクセスする必要があるトラフィックは、一旦VPCを出て、Amazonのネットワーク内を通り、APIサーバーに戻ってくる形になります。完全にプライベートにして、トラフィックを常にVPC内に留めたい場合は、そのように設定することができます。
これを実現するには、エンドポイントをプライベートモードに設定するオプションがあります。次はEKS APIについてです。VPCから発生するトラフィックがプライベートエンドポイントを介してEKS APIにアクセスする必要がある場合、約1年前にリリースしたPrivateLinkの機能を活用できます。EKSサービスでPrivateLinkを利用することで、そのプライベート接続を実現できます。
次の考慮事項は、可能な限りマネージドコンポーネントを使用することです。EKSアドオンやEKS最適化Amazon Machine Images(AMI)は、私たちが責任を持つコンポーネントです。常に問題を監視しており、脆弱性が見つかった場合は、パッチを適用して新しいバージョンを提供することが私たちの責任です。これらをクラスターに適用するためのAPIが用意されていますので、可能な限りマネージドコンポーネントを活用してください。Security Hubでは、クラスターのセキュリティスキャンが可能で、クラスターのセキュリティ状態を確認するための8つの事前定義されたチェック項目が用意されています。



ここでMiaをお招きしましょう。次のセクションはインフラストラクチャーレベルのセキュリティコントロールについてです。Georgeが説明したように、クラスターとインフラストラクチャーを分けて考えています。インフラストラクチャーとは、コンテナが実行される場所のことを指します。まず最初にご紹介したいのは、昨日リリースされたばかりのAmazon EKS Auto Modeです。EKS Auto Modeは、Kubernetesクラスターインフラストラクチャー全体を自動化するEKSの新機能です。Auto Modeでは、ノードの作成とデプロイをAWSが担当し、ユーザーはPodを作成するだけでよくなります。
これにより、パフォーマンスを向上させリソースを最適化することが可能になります。私たちが作成したオープンソースプロジェクトのCarpenterを使用することで、Podに必要なノードを完全に自動管理します。特定のメモリやCPUを必要とするPodを特定のAWSゾーンで定義すると、そこにノードを作成します。Kubernetesのデプロイメントをスケールアップしてレプリカを追加すると、最適なタイプのEC2ノードを作成します。また、実行中のワークロードに最適なタイプのノードを見つけて統合します。

これにより、ノードグループの作成やゾーンの選択について考える必要がなくなり、クラスターの管理が簡素化されます。 EKS Auto Modeの設定を作成するためにKubernetes APIを使用するだけでよいのです。これにより運用の負担が軽減されます。AWSが作成して提供するマシンイメージの更新について考える必要もありません。ノードの最大寿命は21日間で、21日以上実行されているワークロードがあっても、そのノードは自動的にリサイクルされ、アプリケーションは最新のAmazon Machine Imageとセキュリティパッチが適用された別のノードに優しく移行されます。
すべてのノードを最新の状態に保つことに時間を費やす必要がないため、アジリティが向上しイノベーションを加速することができます。これらの運用作業をAWSに任せることができます。ノードの優しい再起動と移行により、アプリケーションのパフォーマンスと可用性が向上します。Auto Scaling Groupにどのようなスケーリングポリシーを適用するか考える必要はありません - すべて自動的に処理されます。また、ワークロードに最適なノードタイプを決める必要もありません。KubernetesのPodのリクエストに基づいて最適なものを判断します。

Georgeが先ほど説明したように、私たちには共有責任モデルがありますが、EKS Auto Modeではこれが少し変わります。以前の例では、EKS Managed Node Groupsを使用する場合、より多くの責任がユーザー側にありました。このモデルでは、コンテナとVPCインフラストラクチャのセキュリティ、そして追加でインストールするアドオンの管理だけがユーザーの責任となります。kubelet、Container Network Interface、kube-proxyなど、多くのアドオンがEKS Auto Modeに自動的に含まれており、これらは私たちが自動的に管理します。ただし、その他のアドオンは引き続きユーザーの責任となりますが、管理する必要のある項目は大幅に減少しています。

クラスターのセキュリティに関して議論すべきもう一つの重要な側面は、クラスターのネットワークセキュリティです。クラスター内でコンテナやPodでアプリケーションを実行する場合、主に2つの設定が利用可能です。
1つ目は、Kubernetes Network Policyを活用する方法です。これはKubernetesインターフェースの一部で、AWS VPC Container Network Interface(CNI)プラグインによって実現されています。Kubernetes APIで、あるネットワーク名前空間のPodが別のネットワーク名前空間のPodとどのように通信できるかを定義するルールを設定できます。これにより、Podラベルレベルでの詳細な制御と、ホスト名やTCPポートなどのL7仕様が可能になり、EKS VPC CNIのEBPFを使用してホスト上で実施されます。別のCNIプラグインを使用している場合は、異なる実施レイヤーで異なるテクノロジーが使用される可能性があります。

2つ目の方法は、Security Groupsを使用する方法です。これはEC2で使用されているものと同じSecurity Groupsですが、KubernetesのPodにも適用できます。Elastic Network Interface(ENI)を使用するKubernetesの各Podは、EC2インスタンスに接続され、Pod単位のEC2 Security GroupがそのPodのネットワークインターフェースに紐付けられます。これにより、ホスト上で変更できない外部メカニズムとして、Podが実行できるネットワーク呼び出しを制御することができます。
先ほど述べたように、CloudTrailを使用した検知制御が利用可能です。インフラストラクチャレイヤーに焦点を当てたもう一つの検知制御として、Amazon GuardDutyがあります。GuardDutyはAmazon EKSと優れた統合機能を持っており、最初の統合機能は監査ログ保護のために構築されました。Kubernetesは APIサーバーであるため、Pod名、ユーザー作成の詳細、その他のメタデータなど、すべてのリクエストに対して監査ログを生成します。このログはアカウントに送信できますが、GuardDutyを使用すると、機械学習と既知の攻撃パターンを使用して分析することもできます。

私たちは、GuardDutyチームと頻繁に協力して、Kubernetesの新しい開発や、潜在的な設定ミスや攻撃パターンを特定しています。GuardDutyは、匿名ユーザーに誤ってKubernetes APIへの管理者アクセスを設定してしまうなどの設定ミスや、その他の既知の攻撃パターンを検出した場合にアラートを発します。これは、すべてのクラスターに対してアカウントレベルで有効にできる強力な保護メカニズムです。Amazon GuardDutyの検知制御の2つ目の側面は、ランタイム保護です。これは、EKS Add-onsを通じて各ホストにエージェントをデプロイし、ファイルの変更やその他のヒューリスティックを通じて既知の攻撃パターンを監視します。これらはKubernetes監査ログには現れないかもしれませんが、Linux監査ログで検出できる可能性があります。
インフラストラクチャスコープのセキュリティ制御をさらに強化するために、AWS Systems Manager(SSM)を使用してインスタンスへのアクセスを制限し、最小限に抑えることをお勧めします。AWSコンソールを通じてVMを起動した経験がある方は、おそらくSSHを使用したことがあると思います。これには、SSHキーの生成、インスタンスの設定、Security Group上のポートの開放、IPアドレスの取得、ホストへの接続などが含まれます。
セキュリティグループを設定し、ホストへの接続用のIPアドレスを取得する際、自宅とオフィスの間でIPアドレスが変わる可能性があるため、わざわざIPアドレスを調べたくないという理由で、世界中からのアクセスを許可するインバウンドセキュリティグループルールを設定してしまうことがあります。これは理解できる対応ですが、本番環境では避けるべき方法です。
AWS Systems Managerを使用すると、SSHを無効にしてSSMでホストにアクセスすることができます。SSMエージェントはSSMサービスに接続し、SSM Session Managerを使用することで、ポートを開放することなくSSM経由でインスタンスにログインできます。これは必ずしもAmazon EKS固有のものではありませんが、誤って設定されたポートが世界に公開されるのを防ぐことができるため、強く推奨されるベストプラクティスです。インターネット上のボットが常にグローバルIPスペースをスキャンしてポート22をリッスンしているかどうかを確認しているため、SSHを公開する必要はありません。
コンテナ最適化されたオペレーティングシステムの使用をお勧めします。Amazon Linuxを使用したAmazon EKS最適化AMIがあり、また、Amazon Linuxと同じカーネルを使用しながらより堅牢なコンテナファーストOSを提供するBottlerocketもあります。EKS Auto ModeはBottlerocketを内部で使用しています。Bottlerocketは汎用的ではなくパッケージマネージャーを持たない、よりロックダウンされたOSです。パッケージを最新の状態に保つ代わりに、新しいパッケージやセキュリティパッチが必要な場合は新しいインスタンスを作成します。
また、CIS Amazon EKS Benchmarkを使用してクラスター構成を検証することをお勧めします。このベンチマークを使用すると、必要に応じてパブリックアクセスが無効になっていることを確認したり、クラスターアクセス管理が適切に実装されていることを確認したりなど、クラスター構成のさまざまな側面を検証できます。kbenchなどのオープンソースツールを使用して、構成を検証することができます。
CEDARポリシーの実装と動作デモンストレーション

クラスターのアプリケーションスコープのセキュリティコントロールに移ると、Podセキュリティが重要になります。これに対する最も効果的なメカニズムの1つは、ネイティブなKubernetes Pod Security Standardsか、外部のポリシーアズコードソリューションを使用することです。KyvernoやOpen Policy Agent Gatekeeperなどのオープンソースソリューションを使用して、セキュリティ基準をコードとして適用することができます。
特権コンテナを制限することは非常に重要です。ここで特に「制限する」という言葉を使っているのは、特権コンテナを完全に使用禁止にすべきだと考える人がいるからです。特権コンテナについてご存じない方のために説明すると、Dockerを特権フラグ付きで実行すると、コンテナに対してホスト上の様々なLinuxデバイスと特権昇格へのアクセス権が付与されます。これが必要な場合もあります。例えば、AWS VPC CNIはPodのネットワークネームスペースを設定するために特権が必要です。EBSやEFSのCSIエージェントも特権が必要かもしれませんが、それは許容できる範囲です。
Kubernetes APIと通信する必要のないWebトラフィックを処理するアプリケーションの場合、Service Accountトークンのマウントを無効にすることをお勧めします。デフォルトでは、KubernetesはAPIサーバー認証用のトークンを全てのPodにマウントしますが、必要ない場合は無効にしましょう。同様に、必要でない場合はhostPathの使用も制限してください。過去にContainerD、Kubernetes自体、そしてrunC(コンテナランタイムエージェント)に関連して、ホストマウントに関する数多くのCVEが報告されているため、必要でない場合は無効にするのがベストです。ホストマウントが不要な場合は、無効にしましょう。
Podの設定を定義する際、Podのアプリケーションがファイルシステムに書き込む必要が全くない場合は、コンテナのファイルシステムを読み取り専用に切り替えることを検討してください。これにより、アプリケーションが潜在的に抱える可能性のある攻撃ベクトルの全範囲を排除でき、それらについて心配する必要もなくなります。

もう一つ考慮すべき点はイメージのセキュリティです。実行するイメージは、おそらくAmazon ECRか他の場所からプルされています。これらを定期的に脆弱性スキャンすることを強くお勧めします。Amazon ECRでは、ネイティブのAmazon Inspector統合を使用して、イメージのスキャンを実行し、システムパッケージや言語パッケージに関わらず、アプリケーションにセキュリティ脆弱性が見つかった場合にレポートを受け取ることができます。ECRを使用する際、VPC外からのECRアクセスが不要な場合は、PrivateLinkを使用してイメージがプライベートリンク経由でのみ取得できるようにすることができます。これは、多くのお客様が活用している優れた制御方法です。
読み取り専用ファイルシステムと同様に、コンテナの構築時に設定する内容として、イメージを非rootユーザーで実行するように設定することをお勧めします。Dockerfileでビルドする際のデフォルトではrootユーザーを使用しますが、特定のポートでリッスンするWebコンテナの場合、必ずしもrootとして実行する必要はありません。非rootユーザーに変更することで、クラスター内でLinuxプロセスが実行される際の権限が制限され、望ましくないセキュリティイベントがエスカレートする可能性が大幅に低下します。

次にお話ししたいのは、私たちが非常に期待している新しい機能についてです。Kubernetesには組み込みの認可機能があります。Kubernetesを使用したことがある方なら、RBACつまりロールベースのアクセス制御を設定し、Podにクラスターでの管理権限を与えたり、人間にクラスターの管理権限を与えたりするためのRBACポリシーを書いた経験があるでしょう。RBACポリシーを書いたことがある方なら、その制限にも気付いているはずです。この8年ほど、KubernetesでRBACは素晴らしく機能してきましたが、最近になってRBACの制限が目立つようになってきています。
RBACポリシーを書いたことがある方ならご存知の通り、RBACは許可のみで、拒否の設定ができません。例えば、プラットフォームチームとして、開発者や開発者グループにクラスター内の一部のDeploymentを管理する権限を与えたいが、kube-systemネームスペースのDeploymentやDaemonSetは管理させたくない、という場合、プラットフォーム管理者にとってはかなり面倒な作業になります。開発者のために各ネームスペースでRBACポリシーを作成する必要があります。Kubernetes Cluster Roleを作成する場合、すべてのネームスペースに対するすべての権限か、特定のネームスペースに対する権限のどちらかを与える必要があります。条件付けも拒否もできないのです。
CEDARは、AWSが構築したオープンソースのアクセス制御言語とランタイム評価エンジンです。これは数年前のre:Inventで発表されました。Amazon Verified Permissionsという管理サービスもあります。CEDARは独自のアプリケーションで使用でき、誰がどのリソースに対してどのようなアクションを許可できるかを定義できます。この数ヶ月間、私たちはCEDARを使用してKubernetesの認可を再構築した新しいプロトタイプを開発し、オープンソース化しました。これはGitHubで利用可能です。

CEDARがどのようなものか、簡単にお見せしたいと思います。CEDARのコードを見たことがない方でも大丈夫です。CEDARは非常に読みやすい言語です。CEDARポリシーには3つの部分があります。まず効果(effect)があります。このポリシーは実際には使用されない例示用のものですが、CEDARで何ができるかを示すために、効果があります。permitまたはforbidで、これはpermitポリシーです。次に、どのプリンシパルがアクションを実行できるかを定義するメインセクションがあります。
このメインセクションでは、どのプリンシパルがアクションを実行でき、ポリシーが何に適用されるかを定義します。このポリシーが適用されるアクションまたはアクションのセットを定義できます。ここでは、プリンシパルは特定のものではなく、カスタムユーザータイプとして定義しています。アクションはgetまたはlistのリストに含まれています。つまり、getまたはlistアクションのいずれかです。リソースは私が許可したカスタムリソースタイプですが、Kubernetes RBACではできない条件付けが可能になっています。
このPolicyには、特定のグループにいるPrincipalに対してのみ効果を持たせるWhen句があります。ここではカスタムのグループタイプとそのグループのIdentifierを定義しています。このConditionのもう一つの部分として、リソースが持つある特定のフィールドが「cool value」と等しくなければならないという条件があります。最後に、Policyの適用を否定するUnless句という構文的な簡略表現があります。これはWhen句で「and」や「not equals to」を書く必要がなくなるため、より簡単になります。このPolicyは、リソースのmy kindという属性が「secret」と等しくない限り有効になります。つまり、その属性が「secret」の場合、このPolicy全体が適用されません。


ここで、私が事前に作成したいくつかのPolicyを紹介し、その動作を見ていきたいと思います。最初のPolicyは認可(Authorization)Policyです。これはKubernetesユーザーであるPrincipalに対して、アクションの実行を許可します。実行可能なアクションには、create、list、watch、update、patch、deleteがあり、対象となるリソースはKubernetesリソースです。RBACポリシーを書いたことがある方なら、metricsやliveness checksのようなnon-resource URLと、リソースの違いをご存知でしょう。Secret、Pod、Config Map、CRDなど、これらはすべてリソースです。
このPolicyはリソースに対して作用しますが、これは特定の条件下でのみ適用されます:Principalの名前がsample userである場合、操作対象がNamespaceリソースである場合(Node、Validating Admission Configuration、その他のKindsタイプのような、Namespaceを持たないリソースは除外されます)、Namespace名がdefaultである場合、APIグループが空(つまり、PodやConfig Mapなどが存在するKubernetesのコアAPIグループ)である場合、そしてAPIリソースがConfig Mapである場合です。このPolicyでは、sample userがConfig Mapに対してこれらすべてのverbを実行することを許可します。これはRBACでもほぼ同様のことができますが、これはpermitであってforbidではありません。

次に、forbid句を持つ2番目のPolicyを追加します。これは「requires labels」グループに属するユーザーに対して、リクエストにラベルセレクターがない限り、すべてのKubernetesリソースのlistingとwatchingを禁止するものです。Kubernetesリソース(Podやその他のリソース)をリストする際、kubectlコマンドで-Lオプションを使ってkey equals valueのようなラベルセレクターを指定できることをご存知かもしれません。この例では、ownerキーがリクエスト者の名前と等しいというラベルセレクターがない限り、すべてのリクエストを禁止します。これはRBACではできない、属性ベースのアクセス制御(ABAC)の例です。

次のPolicyは、Kubernetesの認可だけでなく、Admission(受付制御)に関するものです。Kubernetes Admissionは、リソースの変更(作成、削除、更新)を制限できるKubernetesの別の機能です。ここでも「requires label」グループのユーザーに対して、リソースにメタデータがない限り、リソースの作成、更新、削除を禁止します。Kubernetesリソースを設定したことがある方なら、Object MetaにメタデータオブジェクトとLabelsがあることをご存知でしょう。そのラベルの1つとして、ownerがPrincipal nameと等しくなければなりません。

最後に、Updateに対しても同様のForbidを行いますが、今回は上書きを防止します。Updateのアドミッションリクエストを受け取ると、新しい状態と古い状態という2つのリソースを取得します。

自分が所有していないリソースを誰かが上書きすることを防ぎたいので、古いオブジェクトのメタデータにオーナー名がない場合はForbidとします。これが私たちのポリシーです。すでにローカルのKubernetesとDocker Kindクラスターにこれを作成済みなので、実際にどのように動作するか見ていきましょう。



ここにサンプルユーザーとして作成したKubeconfigがあり、kubectl auth whoamiというKubernetesクライアントコマンドを使用しています。これは、あなたが誰であり、どのグループに所属しているかを返すだけのコマンドです。私はサンプルユーザーで、先ほどポリシーで見たsample group requires labelsグループとsystem authenticatedグループに所属しています。クラスターの管理者として(先ほどのKubeconfigではなく)、 デモンストレーション用にConfigMapを作成したいと思います。そこで、other-configという名前のConfigMapを作成し、keyとvalueにfoo barを設定しました。 次に、作成したConfigMapにownerとしてsome userというラベルを付けます。これは私たちのサンプルユーザーではなく、別のユーザーということです。


では、存在するConfigMapとそのラベルを確認してみましょう。3つあります:Kubernetesによって自動的に作成されたkube-root-ca(ラベルなし)、some userが所有するother-config、そしてデフォルトが所有するtest-configです。これらのどれも私たちのサンプルユーザーの所有ではありません。 サンプルユーザーとしてkubectl get cmまたはconfig mapを実行しようとすると、アクセスが拒否され、どのポリシーによってリクエストが拒否されたのかも表示されます。ここでは、21行目1列目のlabel enforcement policyによってリクエストが拒否されたことがわかります。これで、アクセスが拒否された理由と、どのポリシーによって拒否されたのかが分かりました。


other-configにstage equals testというラベルを追加しようとしても、所有者ではないため拒否されます。サンプルユーザーとして ConfigMapを作成し、k1=v1というリテラルで再度試みても、このConfigMapにラベルがないため拒否されます。これはアドミッションの拒否で、admission webhookによって拒否されたことが分かります。ここまでのところ、このポリシーは非常に効果的に機能しています。


では、このユーザーとして実際にどのように操作を行うのでしょうか?ここに、ローカルにある「sample-config」というファイルのConfigMapのサンプルがあります。owner=sample-userというラベルが付いており、stageがtestというダミーデータが含まれています。では、このsampleユーザーとしてこれを作成しようとするとどうなるでしょうか?成功しました。これは素晴らしい結果です - まさに私たちが望んでいたことです。次に、sampleユーザーとしてConfigMapをリストアップする場合、ラベルセレクターを使用して - 以前ラベルセレクターなしで試したことを覚えていますが - 実行すると成功しますが、自分が所有するものだけが表示され、他のものは見ることができません。
Cedarについて注意すべき点として、現時点ではプロトタイプ段階であるということです。皆様からのフィードバックをお待ちしています。Amazon EKSへの統合をご希望の方は、ぜひお聞かせください。ダウンロードして試していただけます - すべてオープンソースです。気に入った点、気に入らない点、そして今後期待する点について、皆様のご意見をお聞かせいただければ幸いです。現時点では、私たちが非常に期待しているオープンソースプロジェクトであり、皆様からより多くの情報をいただきたいと考えています。
Amazon EKSのリソースとロードマップ:今後の展望

最後に、講演の中で触れたリソースをご紹介します。AWSドキュメントにEKSのベストプラクティスガイドがあります。ここにQRコードがありますので、これまでお話ししたベストプラクティスや、AWSやAmazon EKSに限らないKubernetes特有のベストプラクティスについて、さらに詳しく読むことができます。また、EKS Workshopもあります。これは、KubernetesやAmazon EKSを初めて使用する方向けの素晴らしいガイド付きツアーで、EKSクラスターの作成方法を学ぶことができます。クラスターの作成、設定、モニタリングスタックなどのアドオンのインストールについて、丁寧に説明されています。さらに、EKS Blueprintsも提供しています。これは、TerriformとAWS CDKのサンプル設定で、Amazon EKSを素早く使い始めるのに役立ちます。

最後に、パブリックロードマップもご用意しています。GitHubのAWS organizationにあるcontainers-roadmapでは、ユーザーからの機能リクエストや、私たちが検討している課題のリストをご覧いただけます。そこでAmazon EKSに望む機能に投票したり、ユースケースについて教えていただくことができます。Amazon EKSへのCedar統合についても項目がありますので、もしご興味があれば+1をお願いします。また、更新情報を購読すると、機能の開発状況や実際のリリース時に通知を受け取ることができます。私たちのProduct Managerは、最も人気のある課題を把握するためにこれを常に活用しています。+1の数で並び替えることで、Amazon EKSで最もリクエストの多い機能を確認することができます。以上で終わりです。本日は時間を取っていただき、ありがとうございました。Georgeと私は講演後、外でQ&Aに対応させていただきます。ありがとうございました。re:Inventでの素晴らしい1週間をお過ごしください。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion