re:Invent 2024: AWSのEC2 Nitroネットワーキングの内部構造を解説
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - EC2 Nitro networking under the hood (NET402)
この動画では、EC2インスタンスのネットワーキングの仕組みについて、Nitroシステムを中心に詳しく解説しています。1つのパケットがアプリケーションからNitroを通過する流れ、フローの確立後の最適化、複数フローの処理方法など、EC2のデータプレーンの動作を包括的に説明しています。特にNitroの進化により、V3以降での通信時の暗号化追加や、V5でのENA Flow Steeringの実装など、世代ごとの改善点にも触れています。また、Burst帯域幅とBaseline帯域幅の違い、Connection Trackingの仕組み、Network Address Unitsによるメモリ最適化など、パフォーマンスチューニングに関する具体的な知見も提供しています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
EC2ネットワーキングセッションの開始と参加者の確認

おはようございます。Re:Inventへようこそ。NET 402へようこそ。月曜の朝一番から400レベルのセッションで盛り上がっていきましょう。私はJohn Pangleと申します。EC2のSenior Product Managerで、インスタンスネットワーキングを担当しています。本日は同僚のScott Wainnerと一緒に登壇させていただきます。

まず手を挙げていただきたいのですが、エンジニアリングや設計の分野からいらっしゃった方はどのくらいいますか?かなりの人数がいらっしゃいますね。運用担当の方は?何人かいらっしゃいますね。皆さんにもお役立ていただける内容をご用意しています。アプリケーション開発者の方は?こちらも何人かいらっしゃいますね。今日は皆さんにとって何か持ち帰っていただけるものがあると思います。
Nitroシステムの進化と重要性

なぜ私たちがここにいるのか、と思われるかもしれません。Product ManagerとSolutions Architectとして、Scottの仕事は顧客のワークロードのパフォーマンスを最適化し改善することに焦点を当てています。私の仕事は、インスタンスネットワーキングの観点から、データプレーンにおける新製品やイノベーションを開発・提供し、ネットワークのパフォーマンスと接続性を継続的に進化させることです。本日は、VPCネットワーキングの観点からNitroについて詳しくご説明します。というのも、データプレーンとVPCネットワークは密接に関連しているからです。
このデータプレーンは何百万台ものサーバーを支え、1秒間に何千億ものパケットを処理しています。AmazonストアやNetflix、そして皆さんのワークロードなど、よくご存知のアプリケーションすべてを実行しています。EC2のデータプレーンは非常に複雑ですが、一部のお客様にとってはブラックボックスになっているかもしれません。そこで、このデータプレーンの仕組みを理解するためのコツやヒントをご紹介し、ワークロードの最適化に役立てていただきたいと思います。

本日のアジェンダを簡単にご紹介します。まず、EC2インスタンスを通過する1つのパケットの流れを理解するためのパケット分析から始めます。ネットワークは1秒間に何十億ものパケットを処理していますが、1つ1つのパケットが重要で、その流れを理解することが不可欠です。単一パケットの分析から、接続確立後にフローがどのように最適化されるかを理解するための単一フロー分析へと進みます。そこから、インスタンスが多数のフローをどのように処理するかについて、マルチフロー分析へと話を進めます。さらに、レイテンシーとCPUの観点からの最適化方法を理解するための追加のツールやテクニックをご紹介し、最後に実践的なアクションプランをお伝えします。


まず、Nitroとは何かについてお話ししましょう。Nitroは多くのものを包含する包括的な用語です。Nitroは、ネットワーキング、ストレージ、ブロックストレージ、ローカルストレージ、セキュリティなど、様々な機能を実現するチップシステムです。 2010年代初頭にNitroのアイデアを思いついた時、私たちは新たなトレンドに気づきました。世代を重ねるごとにサーバー密度が継続的に向上し、ホストCPUにより多くのインスタンスを配置できるようになっていました。しかし、お客様がEC2インスタンスにより多くの機能を求めるようになるにつれ、ネットワークI/O、ストレージI/O、セキュリティ機能の比重が大きくなっていったのです。



2013年、私たちは大胆な決断を下し、C3インスタンスでEnhanced Networkingの機能をオフロードし、サーバーからNitroチップにプロセスを移行しました。ネットワーキング、ストレージ、セキュリティをオフロードし、ホスト上には軽量なHypervisorのみを残しました。 しかし、それで終わりではありませんでした。 現在までに、私たちはC4から始まり、最新のNitro V5 C7gnまで、5世代のNitroをリリースしており、さらに開発を続けています。Nitroの各世代で、帯域幅、パケットレート、そしてセキュリティの面でパフォーマンスを継続的に向上させています。特にNitro V3以降は、すべてのNitro機能に対して通信時の暗号化を追加しました。
EC2データプレーンの概要とパケット分析の導入

ここで、本日のお話の概要を簡単にご説明させていただきます。まず、Packet分析について、つまり1つのパケットがEC2をどのように流れていくのかについてお話しします。

その後、Flow分析に移り、コネクションが確立された後のフローがどのようになるのかを見ていきます。そして最後に、複数のフローについて説明します。ここからは、Packet分析の説明をScottに引き継ぎたいと思います。

ありがとう、John。このセグメントでは、1つのパケットがアプリケーションからカーネルを通り、ドライバーを経てNitroに入り、最終的にホストから出ていくまでの過程を見ていきます。このプロセッシングスタックに焦点を当てます。その後、 Nitroで表現されるVPCのカプセル化の仕組みを説明し、Nitro内でのパケット処理、そしてNitroのステートマシンについて見ていきます。

それでは、このプロセスについて詳しく見ていきましょう。このプレゼンテーションでは、スタックの表現として次のようなものを使用します:アプリケーション、カーネル、ドライバー、Nitro、そしてコンピュートホスト間でパケットを移動させる実際のEthernetです。ここに境界線があります - この境界線より上にあるものはすべてお客様のインスタンス、つまり私たちが関与しないCPUです。私たちはNitroとインターフェースするためのドライバーを提供します。Nitroはホストの下に配置されるNitro Cardであり、そのため明確な区分があり、Nitroの一部として提供されるドライバーがここで使用されることになります。
VPC構造とパケット処理の詳細



このスタックの表現は、スライドを通して右上隅に表示し続け、ホストからNitro Cardまでパケットがスタックを下っていく際に、私たちが説明している部分を強調表示していきます。まずは会話の概要とフレームを理解するために、VPCの構造から始めましょう。クライアントがあり、Internet Gatewayを通して通信し、そしてVPCがあります。

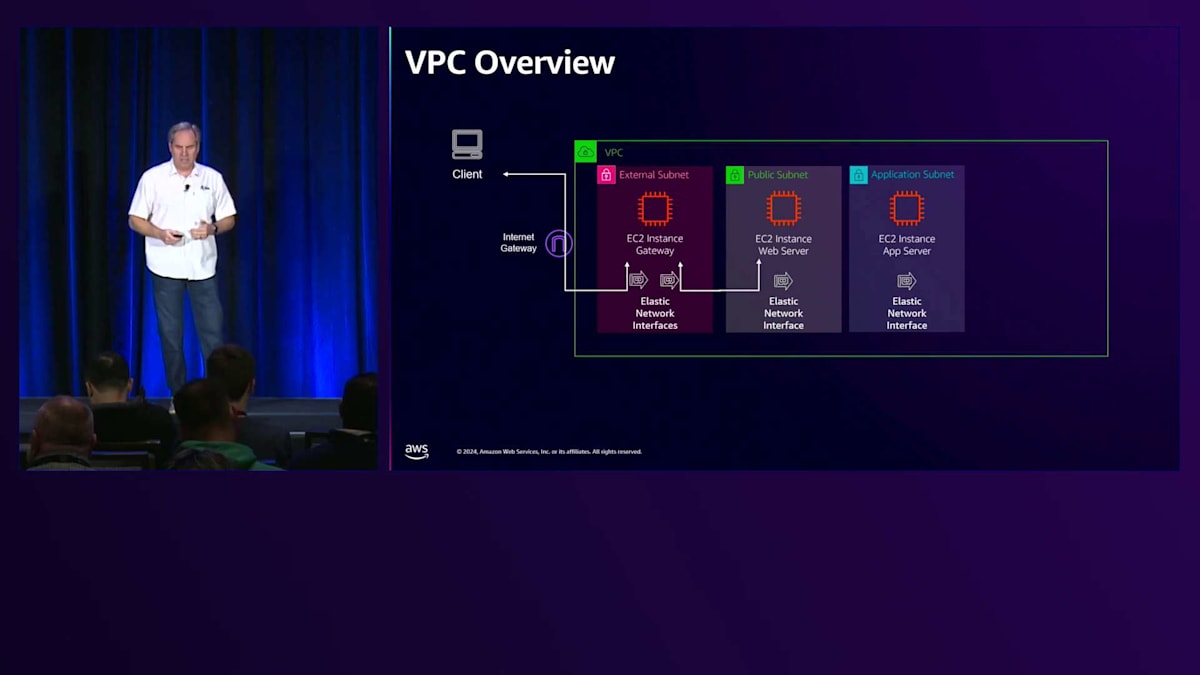

これは典型的なVPCの相互作用で、何らかの形のゲートウェイを持つことになります。この例では、2つのインターフェースを持つゲートウェイを示しています。これはファイアウォール、ルーター、あるいは何らかのプロキシタイプのインスタンスかもしれませんが、これが外部サブネットです。そこからWebサーバーへの相互作用があります。これは参考として使用される可能性のある3層アーキテクチャのフロント部分です。Webサーバーから、その後ろにあるAppサーバーと通信することになります。これはElastic Network Interfaceを使用するビジネスロジック層にあたります。そして最後にデータベースシステムへと続きます。これを扱うには様々な方法がありますが、Nitroの具体的な処理要素について説明する際の参考フレームとしてこれを使用したいと思います。



次のセクションでは、WebサーバーとAppサーバーの間のこの特定の部分、特にWebサーバーを出てAppサーバーに向かい、そして戻ってくるパケットに焦点を当てます。パケット処理から始めますが、ここではIPの送信先、IP送信元、プロトコル、送信先ポート、送信元ポートとして表現されているパケットを取り上げ、これを参考として使用していきます。NitroがAWSのシステムとどのように連携するかを理解することは非常に重要です。

作成するパケットから始めましょう。Webサーバーから、例としてcurlを使用してAppサーバーへのAPIを叩きます。ファイルを取得する際、DNS解決により送信先IPアドレスを取得します。アプリケーション自体は、ポート80やポート443などのポートを指定します。TCPソケットを開くことになりますが、これはすべてカーネルのオペレーティング層からデバイスドライバーで行われます。これにより5-tupleが生成されます。Nitroでこのパケットの処理を開始する際に非常に重要になるので、この5-tuple(送信元IP、送信先IP、プロトコル、送信元ポート、送信先ポート)を覚えておいてください。


パケットを受け取ると、オペレーティングシステムから特定のデバイスへのルーティングを決定します。この場合、ens5という形で表現されるかもしれません。これは Elastic Network Interface にマッピングされます。Elastic Network Interface は実際には Nitro 内にあり、これはすべて Elastic Network Adapter の一部です。Nitro カードには Elastic Network Interface の表現があり、これがカーネルオペレーティングシステム内のデバイスと関連付けられています。


そこから、宛先パケットを取得し、次に Nitro 内でどのようにステートマシンを構築するかを決定します。このパケットはオペレーティングシステムを出て、Elastic Network Interface に入ってきます。右側に示されているように、まず最初にそのパケットがどのキューに入るかを判断する必要があります。この Elastic Network Interface には送信用のキューセットがあり、その送信キューセットに関連付けられた受信用のキューセットがあることがわかります。パケットをリングに配置してオペレーティングシステムに受け渡すための送信リングと受信リングがあります。

その下にあるネットワークインターフェースでは、パケットを別の Compute インスタンスに送信します。重要なポイントは、5-tuple でハッシュを行うということです。この 5-tuple ハッシュによって、キューの割り当てと Nitro に関連付けられたプロセッサーが決定されます。この 5-tuple は、キューへのパケット処理をどのように行うかを理解する上で非常に重要になります。



パケットを受け取ると、私たちは Nitro の中にいて、ここで VPC の表現を持っています。VPC は Nitro カード内でサブネットとして表現されています。パケットに到達すると、このパケットを初めて見たときに行う必要のある処理がいくつかあります。まず最初に、サブネットに関連付けられたルートテーブルを確認します。Nitro 内でも、この場合は隣接する App サーバーにのみ向かうため、ローカルルートを行うだけかもしれません。次に考慮しなければならないのは、サブネットに関連付けられた Network Access Control List です。これも Nitro 内の設定された状態です。そして最後に、このパケットの送信を許可するかどうか、またはどこからの受信を許可するかを定義する Security Group があります。
Nitroカードにおけるパケット処理とフロー確立

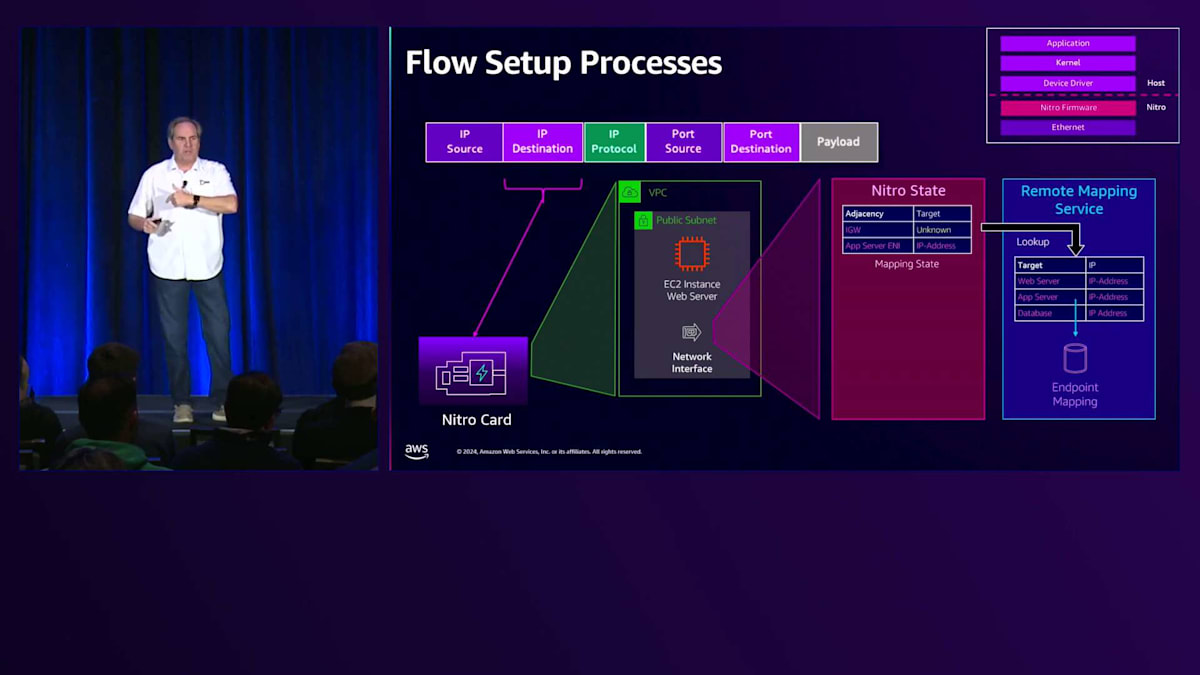
この Nitro の設定が使用されることになります。Nitro の状態は Console や API を通じて設定します。しかし、このパケットを初めて見たため、Nitro の状態を構築する必要があります。そのためには、この VPC 構成内の別の場所、つまりネットワーク内のどこか別の Nitro カードにこのパケットを送信する必要があります。これを行うために、その IP アドレスの検索を行い、マッピングサービスを使用します。基本的に、その宛先 IP アドレスを検索して、この Nitro カードのネットワーク内のどこにパケットを転送する必要があるかを判断します。


その回答を受け取ると、Nitroで隣接関係を構築し、その状態を記憶することができます。これは後半でMulti-flowについて説明する際に重要になってきます。また、コネクション追跡メカニズムというものもあります。この時点では、パケットは片方向でしか確認されていません。これは契約(Contract)と呼ばれるもので、基本的にWebサーバーとAppサーバー間の関係を定義し、その状態を追跡するものです。最後に、Flow Cacheを構築します。Flow Cacheは、Nitroを通じてパケットを高速化できるメカニズムの1つです。


ここでの目的は、Nitroの状態を構築することです。最初のパケットが通過する際は、処理パスにいることになります。これは初めて見るパケットなので、最初に発信されるパケットのために全ての状態設定を行う必要があり、この時点では処理が必要なため、1秒あたりのパケット数は少なくなります。パケットはWebサーバーから出て、Appサーバーに到達し、Appサーバーが処理を行い、その後レスポンスが返ってきます。



レスポンスが戻ってくると、今度はNitroカードに逆方向のパケットが入ってきたことがわかります。この時点で、コネクション追跡が確立されます。また、Flow Cacheが完了したことも確認でき、これによってこのトランザクションの残りのパケットを全て高速化できるようになります。これが加速フローと呼ばれるものです。このパケットはNitroを通って戻り、Receive Ringに配置され、Receive Queueの1つに整列された後、Elastic Network Interfaceを通じてオペレーティングシステムのドライバーに渡されます。


受信側では5-tupleハッシュがあり、これによってReceive Queueに割り当てられ、そのQueueでパケットを受信することになります。これらのパケットがどのQueueに到着するかに注目してください。パケットの受信方法には様々な方法があり、Johnが後ほど詳しく説明します。ということで、1つのトランザクションが完了したので、このフローについてJohnに戻したいと思います。トランザクションが完了し、加速パスに入りました。加速パスにいる時は、Nitroに必要な作業が少なくなるため、システムのパフォーマンスが向上するという重要な機能を理解することが大切です。
単一フローの仕様と性能特性

加速パスに入ったら、単一のFlow仕様またはインスタンスが単一のFlow内で何ができるかを理解する必要があります。そこから、お客様がよく直面する一般的な課題についてお話しします。最も多く耳にするのはMicroburstsに関することなので、その管理方法についてのヒントとツールをご紹介します。また、接続を切断したり影響を与えたりする可能性のあるFlow状態の異常についても説明します。最後に、Whale Flowsについて説明します。Whale FlowsはTCPやUDPでは一般的かもしれませんが、より詳細な検討が必要なその他のエッジケースも存在します。
まず、単一のフローの仕様についてお話ししたいと思います。デフォルトでは、EC2インスタンスを通過するフローの大部分は、最大5ギガビット/秒までの通信が可能です。これは、外部インターネットからEC2インスタンスへの、またはその逆方向のフローを指します。また、これは任意の2つのAvailability Zone間や、2つのリージョン間でも同様です。

Availability Zone内では、一貫した利用体験を提供し、インフラを保護するために、この制限を5ギガビットに設定しています。これにより、ネットワークの輻輳やホットスポットを回避し、日々安定したパフォーマンスを確保することができます。
外部フローやデフォルトフローの他に、Cluster Placement Groupフローと呼ばれるものがあり、TCPで最大10ギガビット/秒、UDPで8ギガビット/秒まで通信が可能です。Cluster Placement Groupは、EC2インスタンスを物理的に近接して配置する起動メカニズムで、最大10ギガビット/秒を実現できます。さらに、最近発表されたENA Expressという機能があります。ENA ExpressはENAの拡張機能で、SRDまたは高度な輻輳制御アルゴリズムを使用して、単一フローで最大25ギガビット/秒を実現します。どこでも機能する外部フローや、起動設定に基づいて機能するCluster Placement Groupとは異なり、ENA Expressはインスタンスレベルの機能で、EC2インスタンスの起動時または変更時に設定する必要があります。


では、これが理論上どのように見えるか確認してみましょう。この緑の線がCluster Placement Groupフロー、黄色の線が外部フローつまり5ギガビットフローを表しています。このグラフは、X軸にパケットサイズ、Y軸に実際の帯域幅を示しています。64バイトや128バイト程度の小さなパケットサイズでは、実際にはパケット/秒の制約を受けることになります。パケットサイズが大きくなるにつれて、ビット/秒の制約を受けるようになります。これは、Nitroの性能やNitroプロセッサの世代だけでなく、EC2インスタンスの仕様にも依存します。両者とも、パケット/秒の制約からビット/秒の制約に移行するまで、同様の傾向線をたどります。

実際の例を見てみましょう。Nitro V2とNitro V4を代表する複数世代の改良を示すc5.largeとc7i.largeを起動して実行しました。ピンク色の線とC7を表す赤い線が示すように、新しい世代のNitroを搭載したc7i.largeは、古い世代のNitroを搭載したc5.largeと比べて、パケット/秒の性能をより早く達成できます。ただし、どちらも先ほど説明した理論的な傾向線と同様に、最初はパケット/秒の制約を受け、パケットサイズが大きくなるにつれてビット/秒の制約を受けるようになります。
Microburstとネットワークバーストの理解


Microburstについて話しましょう。Microburstの課題に直面したことはありますか?それが何なのか、どうやって診断するのかご存知ですか?EC2インスタンスでは、いつどのように発生するかを理解していないと、診断がとても難しい場合があります。 しかし、Microburstについて話す前に、実際のNetwork Burstとは何かについて説明する必要があります。こちらのグラフでは、X軸に時間スケール、Y軸にスループットを示しています。約6秒間にわたって、毎秒10ギガビットのデータを送信しています。

実際にはここに示されているように、スループットがスパイク状に上昇し、その後下降するという形になります。ただし、ENAメトリクスやCloudWatch経由のインスタンスメトリクスを使用している場合、Enhanced Metricsを通じて60秒間のタイムラインで見ると、1ギガビット/秒としか表示されません。つまり、平均化の効果によってスループットが平滑化されているのです。メトリクスを見ると1分間で1ギガビットしか送信していないように見えますが、実際には6秒間で10ギガビットを送信し、その後その数値が平均化されているのです。




この理論を検証してみましょう。 c7i.largeインスタンスを使用して送受信のテストを行い、その出力をCloudWatchに送信しました。ビット/秒からメガバイト/秒に変換するためにMetric Mathを使用しました。 こちらは、9000バイトのパケットサイズで単一ストリームを使用して6秒間実行したテストです。出力を見ると、それぞれの6秒間で約9.5ギガビットを記録しています。 その6秒間全体でも、同様に9.5ギガビットを維持しています。 これをCloudWatchでMetric Mathを使って計算すると、平均で1ギガビット/秒未満という結果になります。このように、Microburstについて理解する前に、Network Burstがどのように発生するかを理解することが重要です。

同様のテストをもう一度実施しました。今回は8つのフローを使用し、各フローで10ギガビット/秒を目標とし、それぞれ9000バイトのパケットサイズを使用しました。

この場合、バックオフや輻輳制御を通常行うTCPのオーバーヘッドを避けるためにUDPを使用しています。ここで分かるのは、各フローが約3ギガビット/秒に制限され、合計で26ギガビット/秒の送信スループットになるということです。しかし、これはc7i.largeインスタンスで、最大で10ギガビット/秒しか処理できません。10ギガビットのインスタンスで26ギガビットを送信しようとすると、うまく動作せず、パケットドロップが発生することになります。

この問題の実際の原因は何でしょうか? この問題は、パケットがNitroで処理できる速度よりも速く到着する時に発生します。その結果、先ほど簡単に説明したキューが滞留していきます。最終的に、これらのキューが満杯になり遅延が発生し、その後パケットドロップが起き、それに応じてメトリクスにも影響が出ます。

これを防ぐためのメカニズムが存在します。 キューやカーネル内で使用できる輻輳制御があり、これによってマイクロバーストをより効果的に管理し、パケットドロップを防ぎ、一貫したネットワークパフォーマンスを最適化することができます。一般的な解決策としては、RXQの深さを増やしてメモリ内により多くのパケットを保持できるバッファを確保することが挙げられます。もちろん、メモリ内により多くのパケットを保持することで遅延が増加するというデメリットもあります。送信側では、QDiscやFair Queuingを使用するLinuxカーネルの機能であるTraffic Controlを使用して、システム全体のスループットや個々のフローのQEスループットをレート制限することができます。さらに、Nitro v4では、ENA Expressという機能があり、輻輳制御アルゴリズムを通じて入力側のマイクロバーストを効果的に管理します。

例を見てみましょう。 16 CPUを搭載したc6i.8xlargeインスタンスがあります。デフォルトでは、ほとんどのインスタンスでCPU数と同じ数のキューをサポートしています。一部のアクセラレーテッドインスタンス、つまりネットワーク強化インスタンスでは、最大32キューをサポートしています。最新世代のNitroドライバーでは、デフォルトでWide LLQという機能により、TXリング深さは512となっています。RX側では、デフォルトで1024となっています。いずれの場合も、キューの深さやリングの深さを増やしてより多くのパケットを保持することができます。TX側では、Wide LLQを無効にする必要があります。これは主にヘッダー内でより多くのディスクリプタやオプションを持つことを可能にする機能です。IPv4を使用している場合、ディスクリプタはそれほど多くないのでWide LLQを無効にできます。ただし、IPv6を使用している場合は、ディスクリプタが追加されるためWide LLQを有効にする必要があり、その場合TXリング深さは512に制限されます。



Traffic Controlは送信側の機能で、カーネルからネットワークスタックに実際に送り出すパケット数をレート制限することができます。 このテストでは、10本のストリームでiPerfテストを10秒間実行し、各ストリームで10ギガビット/秒、合計93ギガビット/秒を送信しようとしました。これは26ギガビットどころか93ギガビットも処理できないc7i.largeインスタンスでの実行なので、フローのフラッディング、マイクロバースト、パケットドロップが発生することになります。

これに対して、Traffic Controlを有効にし、トラフィッククラスを設定し、Fair Queuingを有効にすることができます。 インスタンスの仕様制限が10ギガビットなので、最大入力を約10ギガビットに設定し、個々のフロー制限またはキュー制限を1ギガビット/秒に設定します。この設定により、カーネルが全体で10ギガビット以上を送信しないようにシステム全体をレート制限すると同時に、単一のフローが1ギガビットを超えないようにすることができます。


このカーネル設定を実装した後で同じテストを実行したところ、各ストリームは約964メガビット(1ギガビット/秒をわずかに下回る速度)となり、システム全体のスループットは9.6ギガビット/秒で、10ギガビット/秒を下回る結果となりました。
ENA ExpressとWhale Flowsの解説


最後にご紹介したい機能は、2022年にローンチされたENA Expressです。この機能は25ギガビット/秒のフロースループットを実現し、SRDベースの輻輳制御機能を備えています。機械学習やAIアプリケーションを支えるEFA(Elastic Fabric Adapter)をご存知の方もいらっしゃると思いますが、SRDはNitroカード上の輻輳制御を担うNitro内部のプロトコルです。私たちはEFAとML(機械学習)アプリケーションで使用していたこの機能を、TCPやUDPベースのアプリケーション向けに移植し、一般的なアプリケーションの輻輳制御を可能にしました。これにより、通常のアプリケーションでも輻輳制御が可能になり、インキャストシナリオやインバウンドのマイクロバーストにも適切に対応できます。また、輻輳制御をカーネル層ではなく、Nitroファームウェアの下位層で直接実行するため、P99以上のテールレイテンシーの改善にも役立ちます。

この機能はNitro V4以降のインスタンスでサポートされており、ローカルゾーン内で利用可能なオプトイン機能です。 このプレゼンテーションでは右下に重要なポイントを示していますが、これらは最後にもう一度参照する予定です。今メモを取っていただいても構いませんし、後ほど再度ご確認いただくこともできます。


ここからは、フロー状態の異常について2つお話ししたいと思います。まず、VPCのミューテーションについて説明します。先ほど説明したように、1つの接続は状態に基づいて確立されます。ここではWebサーバーとNitroステートマシン(あるいはNitro設定)があり、そこにはルーティングテーブル、アクセスコントロールリスト、セキュリティグループが含まれています。 ACLはステートレスで、単一方向のトラフィックのみを許可し、戻りトラフィックは許可しません。ACLが更新された場合、NitroやEC2インスタンスがその変更を認識する必要があります。そのため、より制限の緩いACLからより制限の厳しいACLに変更する場合、その接続が切断される可能性があります。逆に、より制限の厳しいACLからより制限の緩いACLに変更する場合は、処理パスでパケットを再評価する必要がありますが、接続は切断されません。

同様に、セキュリティグループはステートフルであり、受信パケットは送信が許可され、その逆も同様です。 これは実際に受信した最初のパケットに依存します。この例では、セキュリティグループが任意のソースIPアドレスからTCPプロトコルで443というポート範囲への通信を許可しています。オープンな(トラッキングされていない)セキュリティグループからトラッキングされるセキュリティグループに変更する場合、そのセキュリティグループを適用してパケットを再処理します。しかし、逆に閉じたセキュリティグループからよりオープンなセキュリティグループに変更する場合は、その状態を破壊せず、ステートフルな接続として継続して動作します。


Untracked Connectionについて、重要な点を詳しく説明させていただきます。ここでは、インバウンドとアウトバウンドのルールに関するSecurity Groupの設定を見ていきます。 複数のTCPプロトコルがあり、HTTPのポート80には0.0.0.0/0とIPv6用の::/0が設定されています。この場合、インバウンドとアウトバウンドの両方で、すべてのIPアドレスからのアクセスが許可されています。一方、ポート22とSSH機能については、開発環境からのトラフィックのみを許可したいため、特定の送信元IPアドレスからのトラフィックのみを許可しています。これがTracked Connectionであり、対してポート80はUntracked Connectionとなります。なお、ICMPなどの一部のプロトコルは常にTrackedとなります。

Untracked Connectionの重要な点は、Security Groupの評価が不要となるため、アプリケーションのパフォーマンスが向上することです。もちろん、Security Groupはアプリケーションのセキュリティにとって重要で不可欠な要素ですが、3層アーキテクチャのフロントエンドに配置されているようなネットワークアプライアンスを実行する場合など、特定の状況では、OpenまたはUntracked Connectionを使用することで、処理をEC2ホスト上で動作する実際のFirewallにプッシュすることができます。これはダムの水門を開放するようなもので、Nitroにできるだけ多くの作業を許可し、ホストCPUやビジネスロジックにその処理を押し上げることができます。


最後にこのセクションでは、最小ドライバー要件について説明します。Nitro V3からNitro V4への移行に際して、 アクセラレーテッドパスを活用するには、最小限のENA Driverバージョンが必要です。これはNitro V5では必須要件となっていますが、Nitro V4では推奨事項となっています。バージョン2.22.0.9以降では、Nitroに組み込まれたハードウェアアクセラレーション機能を活用できる機能が搭載されています。このバージョンを使用しない場合、継続的に処理パスで動作することになり、システム全体のパフォーマンスに影響を与える可能性があります。




では、このFlow Analysis セクションでWhale Flowsについて説明していきましょう。従来のTCP/UDPフローはNitroに入ってきます。 そしてNitro Cardのキューに到達しますが、ここで少し異なる点があります。この場合、送信元IP、宛先IP、トンネル、そして内部IPパケットと内部IPペイロードがあります。 1つのパケット(このブルーのパケット)があり、そしてもう1つのパケット(このピンクのパケット)があります。ご覧のように、何か異なる点があります。 この場合、トンネル内に2つの異なるユニークなIPアドレスまたはIPペイロードがありますが、同じ共通の3-tupleを共有しています。


Scottが先ほど非常に重要な指摘をしましたが、5-tupleに基づいてフローを評価し理解することが重要です。この場合、一般的なIPパケットでは、実際には3-tupleフローで評価を行っています。そのため、ここでブルーパケットと ピンクパケットまたはパープルパケットというユニークなパケットがあっても、実際には同じ一般的な3-tupleを持つことになり、キューやNitro上で同じように扱われることになります。


つまり、ペイロード内の一意なIP 5タプルパケットですが、GREやIPSecなどの外部IPトンネルプロトコルでは、Nitroとキューがこれを3 タプルとして扱います。そのため、これらは実際には単一のフローとして表現されます。このように、これまで説明してきた単一フローに関する考慮事項は、GREトンネルやIPSecトンネル、あるいは3タプルフローのように見える他の一般的なIPプロトコルにも適用されます。



では、この制限をどのように解決できるでしょうか?トンネル内には依然として一意な 5タプルパケットが存在しますが、UDPベースのカプセル化プロトコルを使用することができます。VXLANはデータセンターを拡張するためにオンプレミスでよく使用されています。 GENEVEは最近開発された新しいプロトコルで、まだ普及を目指している段階です。また、Telco分野ではGTPがよく使用されており、MPLS over UDPも存在します。実際の運用環境に応じて、異なるUDPベースのプロトコルを使用することで、各フローが Nitroのキュー内で個別に処理され、全体的なパフォーマンスを向上させることができます。


つまり、これらは個別の単一フローとして扱われます。この場合、一意なトンネルを持つUDPヘッダー があり、それぞれが一意な5タプルとして扱われ、最終的にNitroで異なるハッシュ処理が行われ、キューにも異なる形でハッシュされることで、負荷をより均等に分散させることができます。 これで単一フローの説明を終わります。自然な流れで単一フローから複数フローへの分割について説明してきましたが、ここでScottにマルチフロー分析について説明してもらいましょう。
マルチフロー分析とバースト帯域幅の仕組み

トンネリングメカニズムを使用する際は、トンネル内で何が起きているかを理解することが非常に重要です。なぜなら、GREパケットやIPSecトンネルパケットは単一フローとして扱われ、Nitroで処理されて特定のキューに送られることになるからです。そして、その特定の キューを扱うことになりますが、後ほどJohnが、インスタンス内の複数のキューとプロセッサーでの複数フローの扱い方について説明します。
フローの数について見ていきましょう。これまで説明してきたフロー数、バーストバンド幅、ベースラインバンド幅、これらの属性は仕様で定められており、最後のQRコードで確認できます。また、1秒あたりのパケット数や共有Nitroリソースは、必要なサービス品質を確保するために使用しているメカニズムです。しかし、変数が非常に多いため、私たちの推奨事項は、アプリケーションが必要とするパケット/秒とNitroリソースを確実に得られるよう、徹底的にテストを行うことです。

Johnが説明したように、ここでに示されているような複数のフローについて説明していきます。ここにはいくつかのトンネルフローがあります。5タプルを使用して、それらをハッシュ化すると一意になり、異なる受信キューと送信キューに割り当てることができます。これにより水平方向のスケーリングが可能となり、複数のキューにフローを分散させることができます。そして、インスタンス側のCPUに受け渡される際には、複数のCPUに分散されます。これらのフローハッシュを使用し、異なるメカニズムで独立したキュー割り当てを行うという点がユニークな特徴です。
フロー対称性という概念がありますが、これは重要ではありませんが、User Enhanced Metricsを使用する際に知っておくべき点です。Nitro V3のような古いNitro Cardでは、キューの独立した割り当てを使用していました。つまり、特定のフローの送信がキュー0で行われ、戻りがキュー4で行われる可能性がありました。一方、Nitro V4以降では対称的な方式に戻したため、メトリクスが整合するようになりましたが、この点は覚えておいてください。


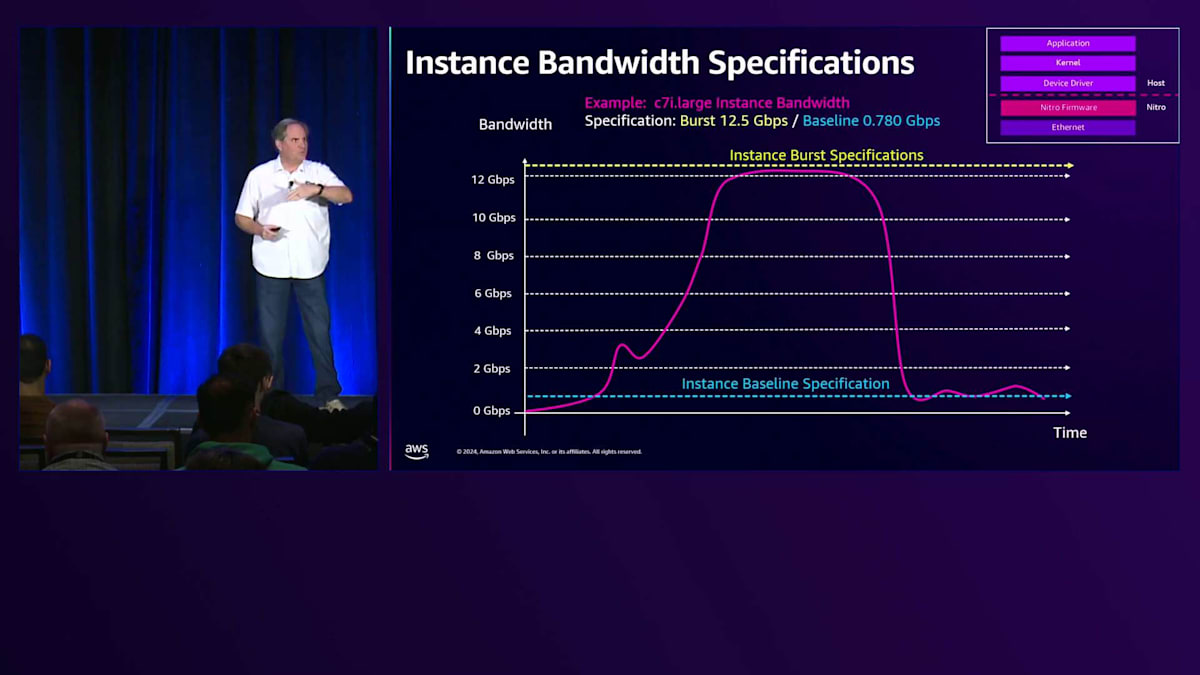
バーストバンド幅について見ていきましょう。ここでも複数のフローについて話していますが、これはインスタンスレベルの話です。バーストバンド幅とは何を意味するのでしょうか。ここでc7i インスタンスを例に説明します。バースト仕様は12.5 Gbps、ベースラインは780 Mbpsです。これらをマッピングすると、このインスタンスに適用される制限が見えてきます。例として、WebサーバーからAppサーバーへの仮想的な転送を考えてみましょう。この場合、ゼロから転送を開始します。

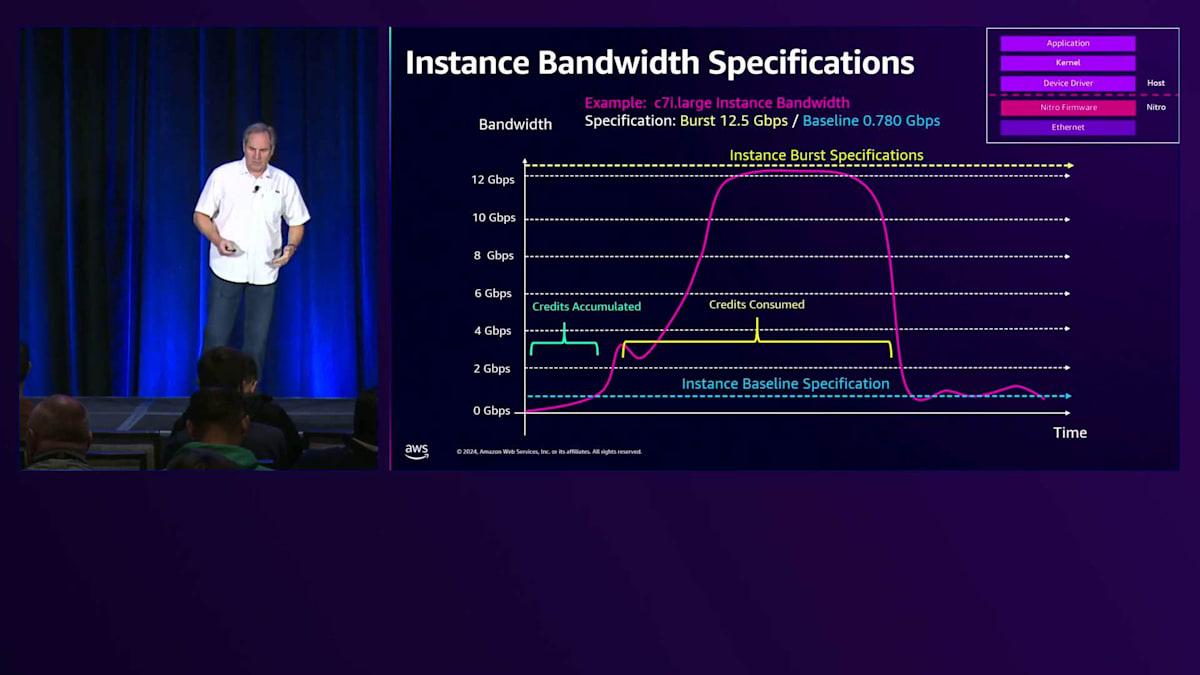
インスタンスを起動すると、バースト用のクレジットが付与されます。さらに、トラフィックがベースライン以下である限り、クレジットが蓄積され、ベースラインを超えてバーストする際にそれらのクレジットを使用できます。クレジットが消費されるまでバーストを継続でき、バーストバンド幅の上限まで到達可能です。ただし、バーストモードをどれだけ維持できるかが問題です。クレジットをすべて消費すると、ベースラインに戻されます。
これは設計上の選択において重要なポイントです。アプリケーションのワークロード要件が周期的であることがわかっている場合、小さめのインスタンスを選択し、短時間のバースト特性を活用することができます。しかし、トラフィックを常時処理する持続的なワークロードがある場合は、その負荷を維持できるようにベースラインに注意を払う必要があります。


それでは、このBurst帯域幅の機能について見ていきましょう。 これは、Ingressの合計またはEgressの合計を表しています。これらは別々に監視される2つのメトリクスで、Burstクレジットの可用性を確認していきます。 ここでは、12.5 Gbpsのバーストに焦点を当てていきます。送信側から受信側に大きなMTUを送信して、Burst制限に到達させ、その後インスタンスの仕様による制限がかかるのを確認します。


テストをセットアップしました。この例では、9000バイトのパケットを使用して1秒間のBurstを1ストリームで実行します。ご覧の通り、ここではCluster Flow の制限に制約されています。 しかし、2つのストリームを使用すると、9000バイトの制限は1秒間のままですが、Burst制限まで到達できることがわかります。これはMulti-Flowであり、Cluster Placement Groupの10 Gbpsの制限を超えることができます。2つのフローがほぼ均等にバランスされ、インスタンスの合計でBurst仕様の上限まで到達することができます。



これは公開情報で、Enhanced Network Metricsで実際に監視することができます。これらは、Bandwidth Allowance InとBandwidth Allowance Outのメトリクスです。 ここまでBurstについて多く説明してきましたが、次はBaseline帯域幅について見ていきましょう。同様に、BaselineはIngressの合計またはEgressの合計です。 Baseline機能でMulti-Flowテストを実行した場合の動作を見てみましょう。すべてのクレジットを消費したことを確認するため、一定期間このテストを実行します。クレジットを使い切ると、トラフィックはBaselineに制限されます。


ここでは、600秒間テストを実行し、9000バイトの大きなフレームを使用して2つのストリームで実行しています。ご覧の通り、現在はBaseline容量に制限されています。長時間の低負荷ワークロードを実行していますが、その期間中Baseline容量を維持することができます。 これがインスタンスの合計Baselineフロー制限で、2つのストリームがほぼ同等の能力を共有していることがわかります。このテストは、すべてのクレジットを消費した直後に実行されました。そのため、テストを停止して5分後に再開すると、すでにいくらかのクレジットが回復しているのがわかります。




BaselineとBurst機能を総合的に見ると、一定期間テストを実行した場合、CloudWatchで長期間のデータを収集した結果は次のようになります。 最初の部分では、蓄積されたクレジットを消費しているのがわかります。 その後、Burst制限に到達し、そのインスタンスのBurst制限で維持されます。これは仕様で定められており、詳細へのリンクを提供します。 最後に、すべてのクレジットを使い切ると、トラフィックは減少し始め、Baselineレベルに落ち着きます。このBaselineが、その後の継続的なスループットを決定します。



では、Packets Per Second(PPS)について説明していきましょう。先ほどと同様に、Ingressの合計とEgressの合計について、同じようなテストを行います。ただし、このケースでは小さなMTUを使用します。 128バイトのパケットを使用し、キューをまたいで集計されるインスタンス制限とフロー制限を確認します。 このケースでは、1つのフローと1つのキューを使用し、128バイトのパケットでテストを行います。テスト時間は10秒で、このインスタンスで約928メガビット/秒のターゲットPPSに到達することがわかります。つまり、このケースでは約1000Kパケット/秒というPPSの制限に達しているわけです。

次に、2つのキューを使用して10秒間の2回目のテストを行うと、同じく928メガビット/秒の容量に達します。ここでも再びインスタンスの集計フロー制限である972,000パケット/秒に達しています。つまり、インスタンスのPPS制限に達しているということです。繰り返しになりますが、これはターゲット値であり、保証値ではありません。この制限は、インスタンスのPPS処理能力を表しています。



理解しておく必要があるのは、 トラフィックをどれだけ速くアクセラレーテッドパスに乗せられるか、どれだけの接続を確立しているか、そしてそれらの属性をどれだけの頻度で変更しているかということです。インスタンスは、 約1000バイトの最大パケットサイズに達するまでは小さいパケットでPPS制限を受け、その後はビット/秒の制限に達し始めます。2つのフローは現在、 そのプロファイル内でほぼ均等に制限されています。

これによって、PPSで何が起きているかがわかります。これらのメトリクスはEnhanced Metricsで確認できます。ドライバーからPPS許容値超過の情報を取得でき、共有Nitroリソースについて理解することができます。 この例では、64コアのホストがあり、16コアのインスタンスを起動すると、ENI、受信・送信キュー、リングを取得し、Nitroにはサイクルタイムがあります。コアの約25%を使用しているため、Nitroのサイクルタイムの25%が保護されています。


ただし、その制限に固定されているわけではありません。サイクルパスで時間が利用可能な限り、追加のNitro処理サイクルを活用することができます。 繰り返しになりますが、PPS許容値超過により、アクセラレーテッドフローを最大限活用できます。大きなパケットと長期的なフローを使用することで、Nitroのサイクルタイムを最大限活用できます。同じホストに他のユーザーが配置された場合、 そのユーザーも保護されたリソースを取得し、同様にバーストが可能です。Nitroの追加サイクルタイムは、すべてのユーザーが機会的に活用できます。共有テナンシーの観点から、リソースの分離、競合の軽減を行い、あなたと隣接ユーザーのスループットを最大化しようとしています。
ネットワークパフォーマンスの最適化とモニタリング

これらのメトリクスはPPS超過メトリクスとともに利用可能です。ここで、チューニングとモニタリングツールについて、Johnに説明を戻したいと思います。これまで単一接続、単一フロー、そして複数フローについて見てきましたが、インスタンスと3層アーキテクチャを設定した後は、その先の管理方法を理解することが重要です。レイテンシーはその考慮事項の1つですが、これと並行して考えるべきなのがホストのCPU管理です。これらは密接に関連しており、さらにキュー管理とも関係があります。


レイテンシーに関しては、物理法則や光速を超えることはできません。そのため、Cluster Placement Groups(CPG)を使用することで、インスタンス同士をできるだけ近接して配置し、インスタンス間の距離を短縮して可能な限り低いレイテンシーを実現できます。アプリケーションスタックにおける他の機能には、ドライバーの機能があります。DPDKはホストカーネルをバイパスし、ユーザースペースでパケット処理を行うことで、カーネルによるレイテンシーのオーバーヘッドを削減します。また、TCPスタックのオーバーヘッドを削減するために、TCPの代わりにUDPなどのプロトコルを使用することもできます。


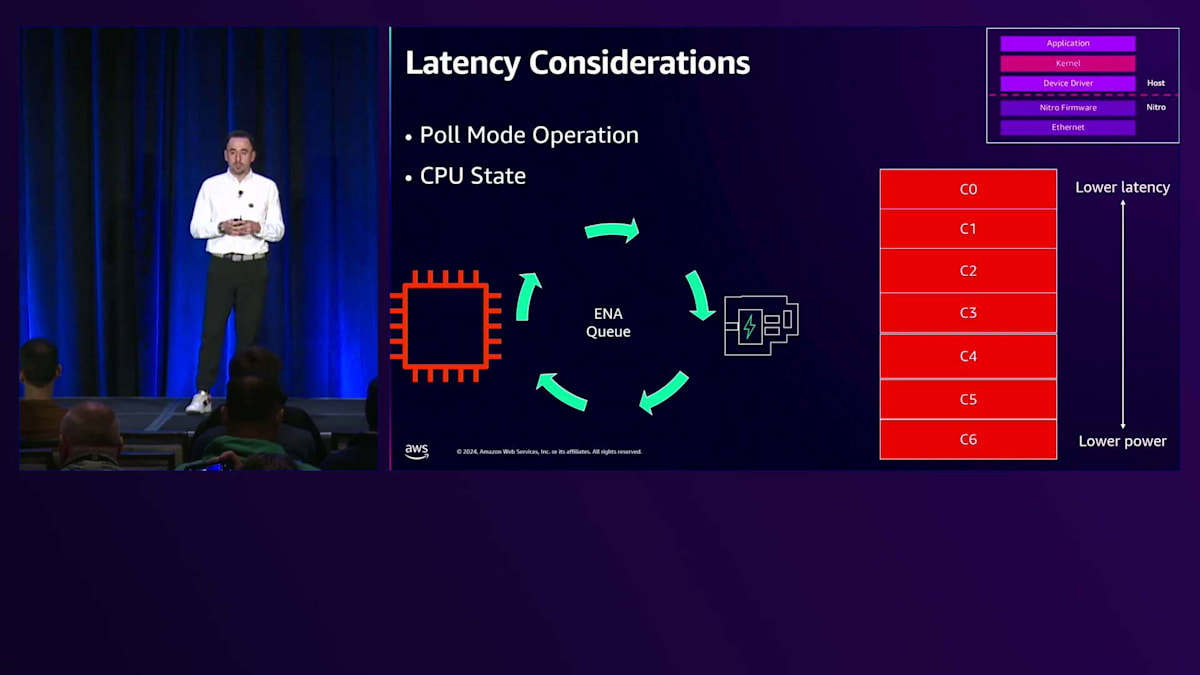
カーネルに関して、Poll Mode Operationと呼ばれる機能もあります。Poll Mode Operationでは、ホストCPUがタイトループで継続的にキューからパケットを取り出します。パケットを受信すると、それらはホストCPUによって取り出され処理されます。より深いCステート(C6など)を使用することもできますが、これは消費電力は低くなるものの、C6からC5へ、さらにスタックの上位へ移行する際に追加の時間、つまりレイテンシーの遅延が必要になります。ホストCPUをC0に設定すれば最低のレイテンシーが得られますが、その代わりに消費電力とのトレードオフが生じます。



割り込みに関して、デフォルトではパケットがリングに到達してキューに入ると、キューはネットワークAPIを呼び出してホストCPUに通知し、そのパケットを処理する必要があることを示します。割り込みはパケットを受信するたびにリアルタイムで発生します。ここで利用できるのが割り込み調整で、これにより頻度を下げることができます。TXとRXのデフォルトである20〜64マイクロ秒から頻度を下げることができますが、これには他の影響もあります。常にパケットを受信している場合、実際には処理が遅くなります。そのため、Dynamic Interrupt Moderationをサポートしており、これはレイテンシーと割り込み頻度のバランスを取ることを目的としています。多くのパケットを受信している場合は割り込みを増やし、受信が少ない場合は低い頻度で動作します。パケット量に応じて割り込みの動作が変わります。

パケットの受信が少ない場合は、高い割り込みモードで動作せず、その場合はCPU使用率が実際に低下します。割り込みはキューから発生します。

デフォルトでは、すべてのインスタンスでReceive Side Scaling(RSS)がサポートされています。ただし、ネットワーク操作に単一のキューと単一のホストCPUを使用したい場合もあります。この場合、すべてのパケットは単一のキューで受信され、単一のホストCPUで処理されます。デフォルトで有効になっているRSSでは、 Scottが先ほど説明したように、CRC32またはToeplitzハッシュを使用して、すべての異なるキューからホストCPUで利用可能なキュー数またはCPU数まで、フローを分散させることができます。Nitro V3以降では、このハッシュを評価および操作して、パケットの着地点を決定できるため、特定のワークロードアプリケーション向けに特定のキューを使用することが可能になります。

RSSに加えて、Receive Packet Steering(RPS)という機能があります。RPSはカーネル操作で、パケットをホストCPU全体にさらに分散させることができます。左側の例では、RSSを使用して8つのキューを8つのホストCPUに分散させ、残りの8つのCPUでNetwork Business Logicを実行しています。RPSを使用すると、パケットを処理する8つのCPUから他の8つのCPUにパケットを分散させることができ、負荷をより効果的に分散させることが可能です。



数ヶ月前に新しく導入された機能として、ENA Flow SteeringまたはN-tuple Filteringがあります。これはNitro V5でのみ利用可能です。このスライドでは、RPSとFlow Steeringを備えたC8g.8xlargeインスタンスを示すように更新しました。 ポート22へのSSHトラフィックや一般的なTCPパケット、一般的なUDPパケットを受信する場合、これらは設定されたハッシュ(CRC32またはToeplitz)を使用して、それぞれのキューに分散されます。 しかし、特定のトラフィックルーティングを定義することができます。例えば、ポート22のSSHトラフィックをキュー0に、TCPトラフィックをキュー1に、UDPトラフィックを別のキューに振り分けることができます。N-tuple Filteringを使用すると、シングルチューブルから5チューブルまで、非常に具体的なパラメータでフロータイプを設定でき、CPU全体でのトラフィック分散を細かく制御できます。ルール数は、インスタンスのCPU数に基づいて制限されます - 16個のCPUの場合、最大16個の個別ルールを設定できます。


モニタリングに関して、これまでbandwidth in/out allowance exceeded、PPS allowance exceededについて説明してきましたが、connection tracking allowance exceededとavailableのメトリクスもあります。link local allowanceのメトリクスもありますが、今日は触れません。これらのメトリクスはすべてツールでネイティブに利用可能で、 CloudWatch agentを使用してCloudWatchにエクスポートし、アラートやモニタリングに活用することもできます。




先ほど簡単に触れたConnection Trackingについて説明します。Connection Trackingは EC2インスタンスに到達する様々なフローの状態を監視するために使用されます。Nitroファームウェア内で、各EC2インスタンスの接続数をカウントおよびインデックス化し、 ENAドライバー内でそれをメトリクスとしてエクスポートしています。connection tracking allowance availableとexceededの両方のメトリクスを追跡しています。利用可能な接続を使い果たすと、availableメトリクスは0になり、exceededメトリクスが増加し始めます。 これは接続を使い果たした時に問題となる可能性があります。この問題に対処するため、約1年半前に設定可能なアイドルタイムアウトを導入しました。これにより、TCPの設定可能なアイドルタイムアウトを現在のデフォルトの5日間から最短60秒まで調整できます。同様に、UDPについても、単一ストリームの双方向タイムアウトを180秒から60秒まで調整できます。

もう1つの制約はメモリです。具体的にはNitro内のステートマッピングに関するものです。また、メモリはNetwork Address Unitsにも使用されます。先ほどScottが説明したように、接続を確立する際にはリモートインターフェースを検索する必要があります。新しいインスタンスと通信しようとする際、Nitroカードはそれらのインスタンスの場所を特定するためにマッピングサービスを呼び出します。


VPC内には通信を行うインスタンスがすべて存在しますが、実際には通信を行わない数百、数千、あるいは数十万のインスタンスが存在する可能性があります。このような場合、 通信を行うインスタンスの場所のみを検索し、通信を行わないインスタンスの場所は読み込みません。これによってメモリを最適化し、現在のクラウドでは前例のない規模までVPCを拡張することができます。デフォルトでVPC内に128のNetwork Address Unitsをサポートしており、Pure VPCでは256まで倍増できます。デフォルトで256,000のNetwork Address Unitsをサポートしており、モニタリングセッションを含めて512,000 Network Address Unitsまでスケールアップできます。
まとめとアクションプラン、関連セッションの紹介


本日ご説明したのは、アプリケーション層から始まる一連の流れです。アプリケーション層でできること、そしてネットワークからの割り込みを プロセスを特定のCPUに割り当てて分離する方法をお見せしました。次にFlow Controlに進み、カーネルを使用してキュー構造と送信を管理する方法を説明しました。 さらにドライバーの層に進み、ENAの各種ドライバーの関連性について説明し、最後にNitroでのフロー状態について説明しました。


これらを踏まえて、ここから持ち帰っていただきたいアクションプランをご紹介します。まず、トラフィックタイプを把握してください。IPsecやGREなどのトンネルを使用するWhale Flowsがあるかどうかを確認してください。TCPやUDP Flow Entropyがあるか、フローに十分なエントロピーがあるか、単一のホットフローがあるのか、それとも多数のフローがあるのかを特定してください。トラフィックタイプを把握したら、 それぞれのトラフィックタイプのプロファイルを作成します。これには、1秒あたりのパケット数、ビット数、接続数が含まれます。このトラフィックプロファイルがあれば、Nitroを通過するトラフィックに制約があるかどうかを理解し始めることができます。


トラフィックプロファイルタイプが分かったら、インスタンスを選択できます。ここでは、 BaselineとBurstの仕様を確認し、Nitroのパフォーマンスを検討します。達成可能な1秒あたりのパケット数と、必要なインターフェース数を確認するためのテストを行う必要があります。これらのインターフェースにはセキュリティグループを関連付けることができ、インターフェースごとに異なるプロパティを持つことができます。 最後に、インスタンスのチューニングとモニタリングを行います。これには、Johnが言及したドライバーのチューニング、適切なドライバーの選択、より詳細な指標を得るためのCloudWatch Agentのインスタンスへの導入などが含まれます。また、CloudWatchからVPCの指標も取得できます。

ここでは、私たちが用意したQRコードやナゲットをご覧いただけます。 Nitroチューニングガイドがあり、さまざまな世代のNitroについて説明しました。EC2をNitroの世代にマッピングするユーザーガイドもあります。ENAのベストプラクティス、ドライバーのベストプラクティス、Connection Tracking、Network Address Unitsについても取り上げました。また、CloudWatchの機能、ENA Express、Microburstのトラブルシューティングと管理方法、そしてバーストとベースラインの帯域幅に関する様々なネットワーク仕様についても説明しました。

AWSのDay Oneですが、re:Inventの一環でもあります。 いくつかの追加セッションをご紹介したいと思います。Distinguished EngineerやVPたちが、ComputeとNetworkingの分野における最新の開発について講演します。NET301では、高度な設計と新機能について取り上げます。私たちの同僚が、この1年間に発表した素晴らしい最新機能について説明します。また、NET317のアプリケーションネットワーキングのセッションや、さまざまなNitroの機能や最近発表したGravitonインスタンスの新世代について見ていくComputeトラックもあります。

以上で終わりとなります。皆様、お時間をいただきありがとうございました。アンケートへのご協力をお願いいたします。ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion