re:Invent 2023: DraftKingsに学ぶ大規模.NETアプリの近代化戦略


はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - Modernize .NET apps at scale: DraftKings principles for success (XNT307)
この動画では、DraftKingsの成功事例を通じて、大規模な.NETアプリケーションの近代化への取り組みを学べます。Kubernetesへの移行、非同期処理の活用、マイクロサービスのスケーリングなど、具体的な技術的課題とその解決策が紹介されます。また、エンジニアの生産性を大幅に向上させるisolated testingの導入や、複数のクラウド環境での一貫した開発アプローチなど、ここでしか聞けない貴重な知見が満載です。AWSが提供する近代化支援ツールについても詳しく解説されています。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
AWSとDraftKingsによる.NETアプリケーションの近代化への取り組み

みなさん、ようこそ。本日は、DraftKingsの成功の原則と、大規模な.NETアプリケーションの近代化への取り組みについてお話しします。私はChris Evilsizerで、AWSのMicrosoft Workloadsの主任近代化スペシャリストです。一緒に登壇するのは、AWSのMicrosoft Workloads製品部門のシニアマネージャーであるManikandan Srinivasanと、特別ゲストとしてDraftKingsのアーキテクチャ部門シニアディレクターのDave Musicantです。


今日は、実際の世界での近代化と、AWSチームがDraftKingsの取り組みをどのように支援したかについてお話しします。Daveは、DraftKingsの近代化の物語を共有し、近代化の取り組みに関する具体的なアドバイスを提供します。Manikandanは、近代化の取り組みを支援するためのAWSのツールとリソースについて説明します。 本日のセッションの目標は、皆さんに近代化への第一歩を踏み出す勇気を与えること、あるいはすでに取り組んでいる方々を支援することです。重要なのは、皆さんが一人ではないということです。AWSには、近代化の取り組みを前進させ、加速し、成功に導くためのツール、リソース、そして経験があります。
近代化の必要性とAWSのサポート



今朝ここにいらっしゃる理由はいくつかあるでしょう。 一つは、パフォーマンスを向上させ、インフラコストを削減したいということです。Daveは、DraftKingsでどのようにしてそれを達成したかを示します。 もう一つの理由は、近代化が必要なワークロードを特定し、次に何をすべきか悩んでいるかもしれません。どうすれば他の人々にあなたのビジョンを納得させることができるでしょうか?DraftKingsでDaveがどのように行ったか、そしてAWSがビジネスリーダーに近代化が開発を加速し、コスト削減につながることを納得させるためのツールとリソースをどのように提供しているかについてお話しします。


また、Microsoftやその他の独自ワークロードのライセンスコストを削減するよう求められているかもしれません。このプロセスをどのように始めるか、そしてDaveの成功事例がどのように皆さんの指針となるかについて議論します。 では、私たちがパートナーシップを通じてDraftKingsをどのように支援したかについてお話ししましょう。約4年前、DaveがDraftKingsチームに加わりました。当時、そのチームはAWSのアカウントチームを十分に活用していませんでした。Daveが最初に行ったことの一つは、Windowsの近代化とKubernetesについて支援が必要だと技術アカウントマネージャーに相談することでした。
これがアカウントチームとの深い関わりの始まりでした。3年前のre:Inventで、AWSで.NETワークロードを運用することについて初めて話し合いました。そこから、DaveはKubernetesに関する深いセッションを行いました。2年前、私たちはDaveがコミュニティと学びを共有するブログ記事を書きました。また、Daveは彼らが欲しかったツールやリソースについて私たちのサービスチームにフィードバックを提供しました。これについては、今日Manikandanが説明します。

それでは、Dave Musicantをご紹介します。Dave、よろしくお願いします。
DraftKingsの近代化の目的と課題
ありがとう、Chris。まず最初に、これは私一人の成果ではなく、私たちみんなの成果だということを明確にしておきたいと思います。これは間違いなく、チーム全体の大規模な努力の結果です。そして、それが私が今日お話しする内容の一つになります。どのような近代化を目指すにせよ、この移行を成功させるためには、チームワークが絶対に不可欠なのです。
皆さんもご存じの通り、技術の変革は難しいものです。特に大規模になるとなおさらです。素早く動く企業で、多くの異なるチームがそれぞれ少しずつ異なる構造を持ち、独自のロードマップやデッドラインを抱えている場合、それは非常に困難です。私たちも間違いを犯しましたが、私たちが学んだ教訓が、皆さんが同じ落とし穴を避けるのに役立てば幸いです。

最も重要なことの一つは、近代化の目的、つまりなぜこれを行うのかを明確にすることです。これは非常に重要です。なぜなら、それによって自分たちがどこに向かっているのかを理解できるだけでなく、このビジョンを他の人々にどのように伝え、支持を得るかを理解するのにも役立つからです。さらに、自分たちがどこから来たのか、どんな問題を解決しようとしているのかを理解し、その過程でより柔軟に対応できるようになります。
このようにすれば、実際に正しい方向に進んでいるかどうかを評価することができます。DraftKingsにとって、私たちの「なぜ」は、いくつかの重要な点に集約されていました。私たちは、ソフトウェアのスケーラビリティを向上させ、そのソフトウェアを進化させる能力を高め、より強靭になりたいと考えていました。しかも、運用コストを削減しながらです。同時に、開発者の効率を維持し、向上させ、より少ないリソースでより多くのことができるようにしたいと考えていました。
これを基盤として考えることが重要です。つまり、積み重ねていくものです。何をするにしても、常に改善し、成長し続けられるようにすることが大切です。会社は常に何をすべきか、どのように行うかを変化させていきます。組織構造も変わるでしょう。ですので、自分たちのために成長の余地を作っておく必要があります。最後に、私たちの場合、規制要件があるため、特定のワークロードをオンプレミスに置かなければなりません。すべてをクラウドに置くことはできません。そこで、開発者がオンプレミスとクラウドのワークロードを全く同じように扱えるようにしたいと考えました。開発者はワークロードがオンプレミスにあるかクラウドにあるかを気にせずに、同じ方法で開発・デプロイできるようにしたかったのです。
組織全体の賛同を得るための戦略

この「なぜ」を理解することで、次のステップである賛同を得ることにもつながります。ここで重要なのは、これが本質的に破壊的な変化だということを認識することです。技術を変更し、人々のやり方を変えるということは、本質的にリスクを伴い、少し怖いものです。特に、誰も経験したことのない新しい複雑な技術について話すときはそうです。そのため、明確なメッセージを作り、人々に伝えることが非常に重要です。それによって、彼らに求められていることだけでなく、彼ら自身や会社が得られるメリットも理解してもらえるのです。
DraftKings社内では、Chrisが言及していた「Spark」という内部ブランドを作りました。これによって会話の内容が大きく変わりました。「うーん、このKubernetesって本当に複雑だね。Horizontal pod autoscalingって何?」というような会話から、「Sparkって素晴らしいね。どうやったら参加できるの?イノベーション、レジリエンス、安定性を促進するんだって。そういったものが欲しいよね、素晴らしい」というような会話に変わったのです。そして、組織構造を活用することも重要です。単に「エンジニアの皆さん、この技術に取り組みたい、ワクワクしてほしい」と言うだけではありません。そのエンジニアたちは特定の製品や異なるビジネスドメインで働いており、ロードマップや締め切り、日々こなさなければならないタスクがあります。そんな彼らに時間を割いてもらうことになるのです。
これは彼らだけの問題ではなく、リーダーシップの問題でもあります。全員のロードマップの中にスペースと時間を確保し、ソリューションに向けて協力できるよう、調整を図ることが重要です。それと同時に、これが理解可能で管理可能なもの、そして人々が取り組めるものであることを確認する必要があります。そのため、異なるフェーズに分けることが非常に重要です。各フェーズでもポジティブな効果が得られるようにし、私たちがどのようにそれを行い、各段階でどのような成果とメリットを得たかについてお話しします。
例えば、Windows Frameworkから.NET CoreのKubernetesに移行しようとする場合、私たちがそうしたように、いくつかのフェーズに分けることができます。まず.NET Coreに移行し、そこでasyncを全面的に活用することで得られた素晴らしいメリットについてお話しします。次にWindowsからLinuxへの移行で、スケーリングとコスト面でのメリットがありました。そして最後にKubernetesへの移行です。これは技術的に見ても動く部分が少なくなり、開発者なら誰でも知っているように、成功の可能性が高くなります。また、人々のやり方や、仕事、プロセス、アプローチの中で変更しなければならない量についても考慮しています。
段階的なアプローチとデータ駆動型の意思決定
これらのフェーズの中で、アプローチ方法については非常に意図的かつ的確である必要があります。「さあ、すべてを変換する自動化を構築しよう」と単純に始めるべきではありません。2つのマイクロサービスや小規模なアプリケーションならそれでも機能するかもしれませんが、実際の企業組織では上手くいきません。チームごとに作業方法が大きく異なります。すべてのマイクロサービスが全く同じというわけではありません。異なるサードパーティライブラリを使用したり、異なるアクセスパターンや異なるデータ構造を扱ったりしています。そのため、それらの間には大きな違いがあります。

まずは主要なチームをいくつか選んでパイロットを行い、それらの間の一般的な共通点を本当に証明し理解することから始めるべきです。そこから、多くのチームに提供できるような runbook を作成し、チームが自分たちで作業を始められるようにします。そして、彼らからフィードバックを集めます。最終的に、それを基に自動化を構築できます。私たちがどのようにそれを行い、どのような利点を得たかを詳しく説明します。そして、これに関連して、先ほど話した「なぜ」を思い出してください。「なぜ」を使用する上で重要なことの1つがデータ収集です。データ駆動型であることが重要です。
データは多くの面で役立ちます。その1つは、現在の問題を理解し、それらを測定できるようにすることです。例えば、ロールバックが多すぎる、インシデントが多すぎる、あるいはこれらのものをサポートし維持するのに時間がかかりすぎるなどと言えるかもしれません。それらについて多くのデータを収集する必要があります。これは、それらの問題を成功裏に解決したかどうかを理解するのに役立つだけでなく、途中で間違った方向に進んでいる場合や、解決策が適切でない場合にも調整できるようにします。データを収集しているからこそ可能なのです。
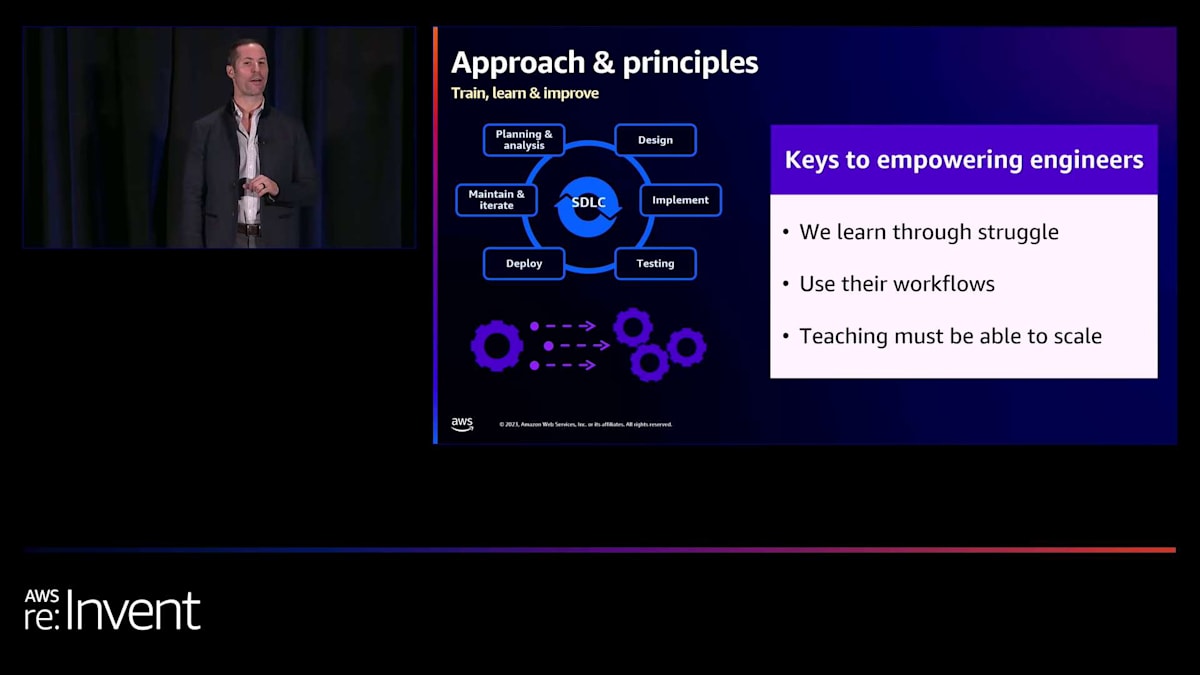
データに関するもう1つの本当に素晴らしいことについてもお話しします。私たちには誤解があり、このようなことへのアプローチについていくつかのアイデアがありましたが、データは私たちが間違っていることを示しました。そのおかげで、変更を加え、そのギャップを埋めることができました。覚えておいてください。正式に定義された Software Development Life Cycle (SDLC) がなくても、すべてのエンジニアリングチームには SDLC があります。アイデアの段階から、ソフトウェアを本番環境で実行し、それを維持するまでの方法があります。それは彼らが仕事を成功裏に行うために構築した方法であり、習慣であり、彼らが快適に感じているものです。
先ほど述べたように、変更は混乱を招きます。人々にとって怖いものです。また、仕事を成功裏に行うために構築したものをどのように変更するかを考えなければならないことも意味します。そのため、エンジニアや各チームが新しい作業方法や新しい技術に慣れるようにトレーニングする方法を本当に考える必要があります。そこでの重要な原則の1つは、私たちは苦労することで学ぶということです。単にマニュアルやドキュメントを作成して「はい、これを読んでください。これがやり方です」と言うだけでは十分ではありません。人々はそれを覚えません。多くのことを内面化しないでしょう。
新しい人材を迎え入れ、他の人々が去っていくとき、多くの知識が失われてしまいます。なぜなら、十分な「理由」が含まれておらず、彼らの働き方に合っていないからです。そして、これが2つ目のポイントですが、人々は学んだことを全く異なるシナリオに適用するのに苦労する傾向があります。そのため、トレーニングを行う際は、彼らの働き方、仕事の進め方に合わせて構築されていることを確認する必要があります。そして、これがスケーラブルであることを確認しなければなりません。モダナイゼーションを担当するチームがどれだけ大きくても、全員をワークショップに通すのに時間を費やすことはできません。また、新しい人が会社に入ってくるたびに、ワークショップを開催する必要があってはいけません。そのため、これはスケーラブルでセルフサービス型である必要があります。私たちがどのようにそれを実現したかについてお話しします。
.NET FrameworkからCoreへの移行:MS Buildの活用
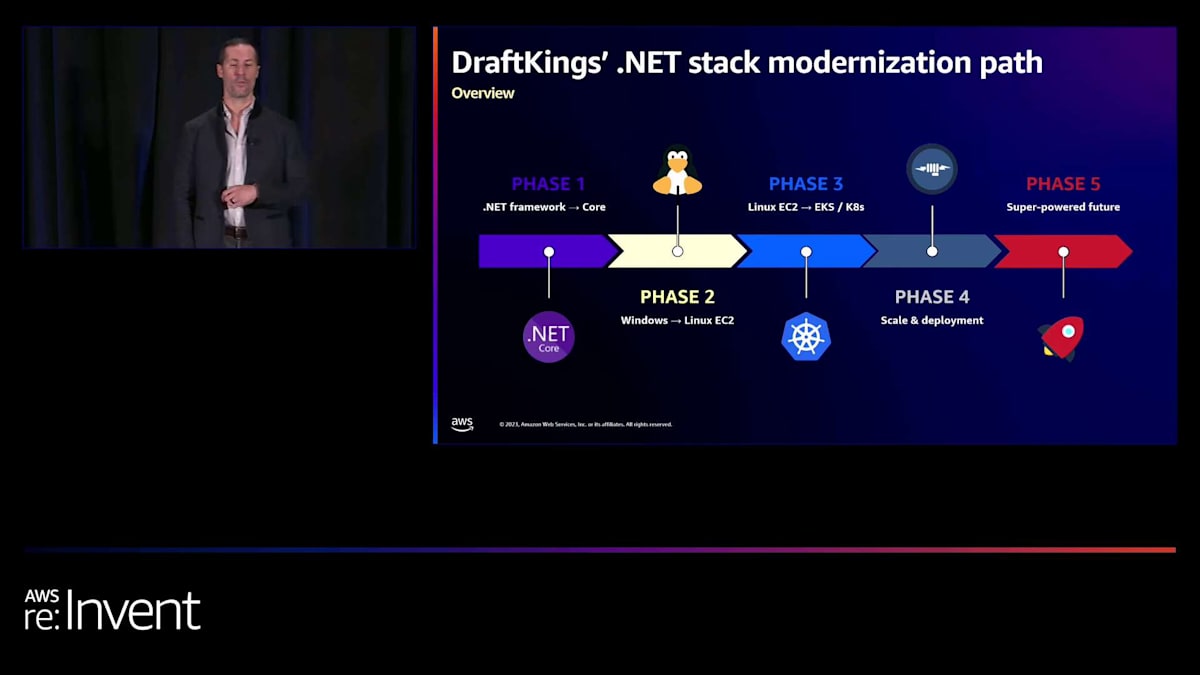
DraftKingsでは、これをいくつかの異なるフェーズに分けました。それぞれが基礎となり、互いに積み重なっていくものであることを確実にしました。そして、先ほど述べたように、私たちに runway を与えてくれました。まず、.NET Frameworkから.NET Coreへの移行から始めました。そして、非同期処理によって得られた素晴らしい利点についてお話しします。次に、WindowsからLinuxへの移行を行いました。ここでは、コストと拡張性に関する素晴らしい利点についてお話しします。そして、ここで本当に強固な基盤を築き、私たちの働き方を大きく変えました。Kubernetesへの移行、クラウドではAmazon Elastic Kubernetes Service (EKS)、オンプレミスではRancher Kubernetesを採用しました。
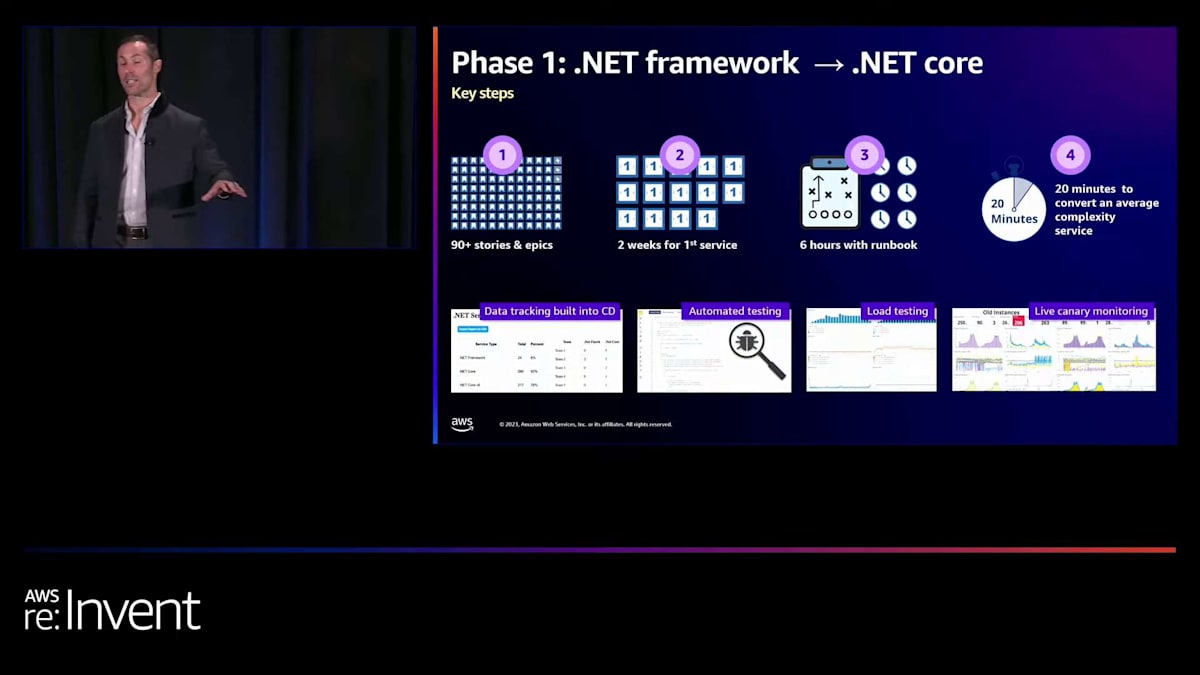
そして、その基盤の上に、本当に多くの興味深いことを行うことができるようになりました。スケーリングとデプロイメントで行ったことについてお話しし、そして現在取り組んでいるスーパーパワーを持った未来についてもお話しします。Frameworkから Coreへの移行について、最初に気づくのは、まさに先ほど話したことです。それは、非常に意図的で的を絞ったアプローチ方法です。多くの人が、これは過剰だと思うかもしれません。マイクロサービスを簡単に変換できるじゃないかと。確かにそうです。しかし、私たちが目指しているのは、ラップトップ上でマイクロサービスを動作させることではありません。本番環境で使えるようにする必要があります。安定性、耐障害性、観測可能性、モニタリングなど、多くの要素がそこに関わってきます。
そこで、DraftKingsのマイクロサービスのために長年にわたって構築されてきたカスタム要素をどのように管理できるか、開発者がそれらを扱いやすくするためのソリューションをどのように見つけられるか、サードパーティライブラリをどう扱うかなど、多くの作業を行いました。そして、数チームでパイロットを実施しました。それらを動作させるのに数週間かかりました。繰り返しますが、ラップトップ上で動作させるのではなく、本番環境で使えるようにするためです。そこから、マイクロサービスを一貫して変換できるランブックを作成することができました。そして、それをクラウドソーシングに活用しました。具体的には2つの方法で活用しました。1つは、サポートチャンネルを設置し、変換を行った全員が deputized されました。彼らは実際に、私たちが他の人々の変換を手伝い、そこからデータを収集するのを助けてくれました。
そこから、自動化を構築することができました。自動化によって、マイクロサービスの変換がわずか1分程度で行えるようになりました。そして、平均して合計20分程度で、人々はマイクロサービスの細かな違いをすべて処理できるようになりました。データ収集を覚えていますか?私たちは Continuous Deployment (CD) パイプラインにデータ収集を組み込みました。そのため、本番環境で何が.NET Coreに変換されているかを見るだけでなく、それをチームに紐付けることができました。これはチームにとって素晴らしい動機付けとなりました。彼らは自分たちの内部での進捗だけでなく、他のチームと比較して、誰が最も速く変換できるかを競い合うことができたのです。
しかし、現実の世界では必ずしも全てが完璧にいくわけではありません。そのため、テストは非常に重要です。この後の話でも、私たちが後になって発見したことがいくつかあることがわかるでしょう。私たちは、エンジニアのために優れた自動テストと負荷テストの機能を確保し、マイクロサービスへの変換を行う際に適切に機能するようにするための指針を提供するために、多くの時間と労力を費やしました。
WindowsからLinuxへの移行とKubernetesの導入

エンジニアがカナリアデプロイを行えるようにダッシュボードを設定しました。「トラフィックの25%を新しいインスタンスに送ります」と言えば、レイテンシー、スループット、エラーの数が適切かどうかを簡単にモニタリングできるようにしました。これにより、顧客や製品への影響を最小限に抑えることができます。
先ほど述べたように、重要なポイントは「async all the way」です。まず第一に、これはI/Oバウンドの処理に適しています。例えば、ソケットに入ってくるRESTコールやデータベースへのアクセスなどが考えられます。以前の.NET Frameworkでは、これらは同期的な呼び出しでした。つまり、高いスループットを得るためには、スレッドプールに関する興味深い工夫をするだけでなく、通常はより多くのコアを使用する必要がありました。これは並列処理、つまり多くのコアを使って並行してワークロードを実行することを意味します。
Microsoftは「async all the way」で素晴らしい仕事をしました。同期コンテキストと呼ばれるものを作成し、単一のコアで多くのワークロードを並行して実行できるようにしました。ただし、これにはいくつかの注意点があります。一つは、本質的に少しオーバーヘッドが加わることです。そのため、どのような種類の処理をこの方式に変更するか、そしてそのことを考慮に入れる必要があります。二つ目は、もはやout引数を使用できないことです。これは、適切に機能させるために同期コンテキストをレスポンスにマーシャリングする必要があるためです。代わりに、タプルの使用が推奨されています。

また、以前の同期コードが適切に機能するようにするために組織として行ったことが、もはや必要ないことを考慮する必要があります。例えば、私たちは以前、スレッドプールを保護するために同時実行制限機能を多く使用していました。これは以前は非常に役立ちましたが、「async all the way」に移行すると、実際にはパフォーマンスを低下させてしまいました。上のグラフを見れば、「async all the way」に移行した時点がはっきりとわかるでしょう。レイテンシーの面で大きな改善が得られました。
Kubernetesを活用した運用効率の向上
しかし、先ほど申し上げたように、現実の世界では必ずしも全てが完璧にはいきません。当時、実際にはバグがあり、Kestrelの間違ったバージョンを取り込んでしまうことがありました。その結果、間違ったソケットライブラリを使用することになり、多くのマイクロサービスで非常に不安定で低いパフォーマンスが発生しました。しかし、私たちは非常に良いテストを行い、優れた可観測性を持っていたため、これを発見し、迅速に診断して修正することができました。右下を見ると、マイクロサービスから安定した高いパフォーマンスが得られていることがわかります。

ここで見ているのは、変換した一つのマイクロサービスの実際の本番環境の数値です。左側は.NET Coreで完全に非同期化する前、右側はその後です。注目すべきは、同じスループットを処理するのに必要なインスタンス数が以前の10分の1になっていることです。しかし、実際にはそれ以上です。メモリを見ると、以前はインスタンスあたり8ギガバイトのメモリを使用していましたが、今では約200メガバイトしか必要ありません。そしてCPUは、以前必要だった量の10分の1を使用しています。これは完全な非同期化の本当に驚くべき利点です。


そこから、次のステップとしてLinuxに移行することを決めました。これはコンテナへの移行への踏み石でした。ここで私たちは誤算をしてしまいました。これは簡単で簡素な、ほんの少しの変更で済むと思っていました。ほとんどの変更は本当にマイクロサービス内に限定されると考えていました。しかし、そうではありませんでした。OSがほぼすべてのものに組み込まれていることが判明しました。
環境の状態に関しては、ほとんどの開発者がWindowsラップトップを使用していました。ほとんどは問題なく動作しましたが、時々違いが生じることがありました。なぜなら、本番環境やテスト環境ではLinuxで動作していましたが、彼らのラップトップではWindowsだったからです。そのため、問題が発生することがありました。CIでは、以前はWindowsエージェントを使用していましたが、今度はLinuxエージェントに切り替える必要がありました。そして、テスト環境のようなものもありました。インスタンスを自動的に立ち上げる自動化がありましたが、それらはWindowsだったため、Windows固有のコードがたくさんありました。それを移行する必要がありました。
そして、プロビジョニングです。TerraformにはWindows固有の多くのものが組み込まれていました。さらに、マイクロサービス内では、明らかなのは大文字小文字の区別でした。Windowsでは大文字小文字は関係ありませんが、Linuxでは異なるファイルやプロパティとして扱われます。認識されないのです。
また、設定、ログ記録、メトリクス、暗号化にも対処する必要がありました。インスタンスでは、Windows APIを使用して暗号化とPCIフィルタリングを行っていました。
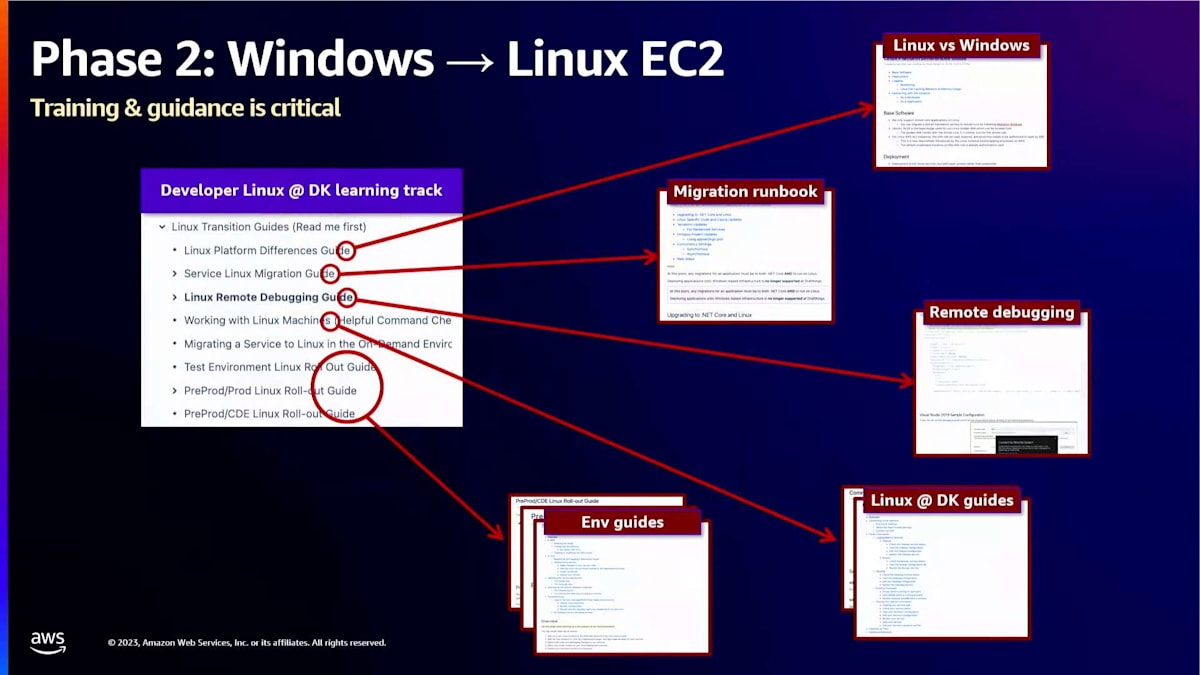
OSの変更は非常に大規模なものではありませんでしたが、それでも開発者の作業方法に変化をもたらしました。私たちは開発者向けのトレーニングとガイダンスを作成するために多大な労力を費やしましたが、それをクラウドソーシング化もしました。多くの人々に権限を与え、この移行や以前の仕事から得たアイデアや学びを共有するよう促しました。このアプローチにより、5〜10人の小さなチームに頼るのではなく、多様なエンジニアのための優れたガイダンスを構築することができました。
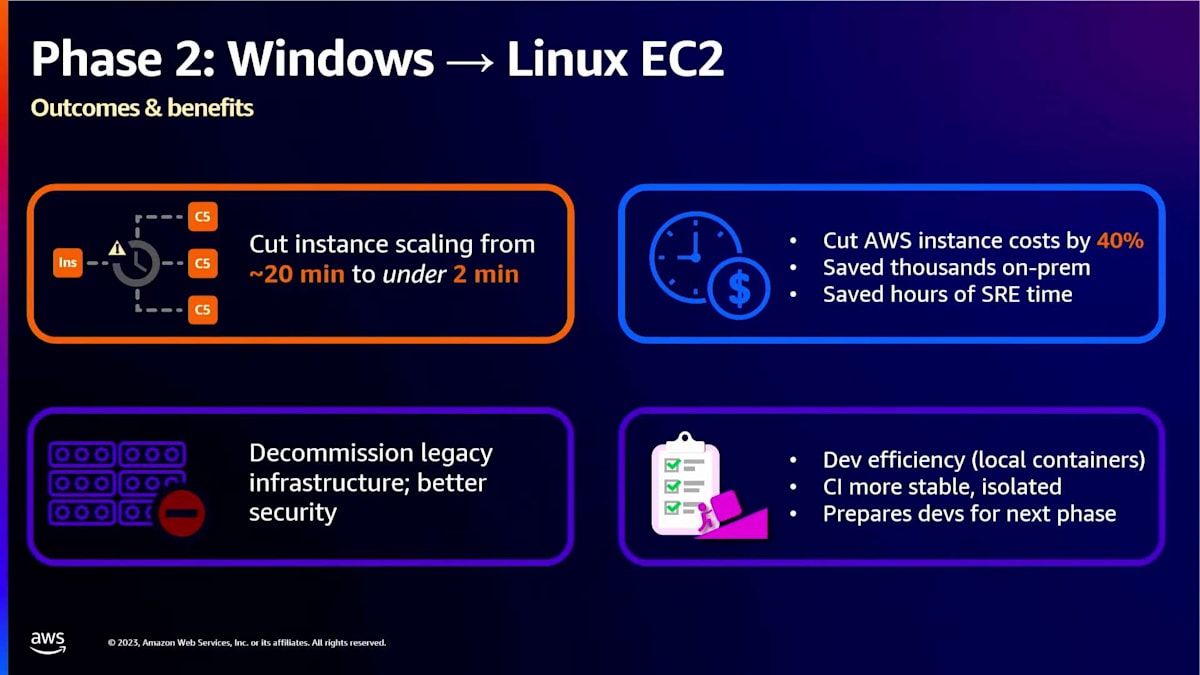
得られた大きな利点の一つはスケーリングに関するものでした。以前は、Windowsインスタンスの起動に約20分かかっていました。Linuxでは、これを2分以下に短縮でき、大幅な改善となりました。さらに、大きなコスト削減も実現しました。AWSは、Windows EC2インスタンスの代わりにLinuxに切り替えることで、大幅なコスト削減を提供しています。すべてのインスタンスタイプで平均すると、約40%の削減となりました。オンプレミスでも、もはやWindowsライセンスを購入する必要がなくなったため、コスト削減が見られました。
また、私たちは労力も節約しました。以前は、Site Reliability Engineering(SRE)チームがオンプレミスでWindowsインスタンスのインストール、サポート、メンテナンス、管理に多くの時間と労力を費やしていました。Linuxに移行することで、彼らは多くの時間を節約できました。開発者にとっては、より効率的で一貫性のある環境を提供しました。これらのものをローカルでコンテナ内で実行するようになり、手動でセットアップする必要がなくなりました。IDEから簡単に起動できるようになったのです。
エンジニアの生産性向上:Isolated Testingの導入
このアプローチは、環境がContinuous Integration(CI)上でも開発者のラップトップ上と同じように動作することを意味しました。コンテナ内の内容を制御できるからです。すべてがコンテナ内で分離されているため、CIはより安定しました。この準備が次のフェーズ、つまりKubernetesへの移行の舞台を整えました。

先ほど述べたように、Kubernetesは多くの人にとって intimidating かもしれません。さらに重要なのは、これがマインドセットの転換を表しているということです。古い世界では、静的なビューを定義していました。「このものの3つのインスタンスをC5.2x largeにデプロイします。これだけのRAMとCPUを持ちます」というように。変更に対処するためのモニターやアラートを設定したり、スケーリングのためのスクリプトを書いたりしていました。Kubernetesはこれとは大きく異なります。Kubernetesに静的な要求を伝えるのではなく、何が良いか、何が悪いか、世界の状態がどうあるべきかを伝えます。するとKubernetesは「わかりました。それを扱う方法について教えてくれたすべてのことを考慮して、私が面倒を見ます」と言います。これは、エンジニアがこれらのシステムを管理し、考える方法における大きな転換を表しています。
私たちは、この新しいアプローチを成功裏に実装するためには、エンジニアたちがこれに慣れるよう訓練することが極めて重要だと認識していました。そこで、私たちは「リファレンスワークショップ」と呼ぶものを作成しました。これらのワークショップの1つは、例えば、実際のワークフローを模倣するように設計されています。エンジニアたちは、まずローカルでマイクロサービスを作成するためのスキャフォールディングから始めますが、そこには問題があり、テストが全て失敗します。エンジニアは、全てのテストをパスさせるために取り組まなければなりません。それができたら、CIにプッシュしますが、実はCIにも問題があるのです。そのため、CIの問題も修正して動作させる必要があります。
次に、デプロイメントを使用してワークショップクラスターにプッシュします。このワークショップクラスターでは、様々な問題を引き起こします。何も起動しない、データベースに接続できない、リソースが不足している、再起動ループに陥るなど、実際の本番環境のマイクロサービスで遭遇する可能性のある問題ばかりです。このアプローチにより、エンジニアたちは問題を解決し、ツールの使い方を学ぶ必要に迫られますが、同時に彼らの実際のワークフローに沿った内容になっています。したがって、これを首尾よくこなせば、彼らの実際の業務でもより成功を収めることができるでしょう。また、このワークショップはスケーラブルでセルフサービス型なので、チームを組んで指導する必要もありませんでした。
ワークショップを通じたエンジニアのスキル向上

先ほどのデータを覚えていらっしゃるでしょうか。私たちはこれに関する情報を収集することができました。エンジニアたちがこれらのワークショップを受講したかどうか、そして首尾よく完了したかどうかを把握していました。これにより、私たちは最初の大きな洞察の1つを得ることができました。皆さんの中にも、何かを変換する際に「これはそれほど重要ではないから、若手エンジニアに任せよう。彼らでも簡単にできるだろう」と考えた経験がある方もいらっしゃるかもしれません。多くの人がそう考えますし、私たちも同じでした。しかし、実際にはそれには多くの問題が伴う可能性があります。
非常に経験の浅いエンジニアは、通常、会社にも新しく入ったばかりです。彼らは多くのドメイン知識や、コードの変更の背景にある理由についてのスキルが不足しています。そのため、彼らは問題に直面しました。しかし、私たちが発見したのは、このワークショップでそのギャップを埋められるということでした。このワークショップを受講したエンジニアは、同じレベルと在籍期間でワークショップを受講していないエンジニアと比べて、サービスをKubernetesに変換するのに40%少ない時間で成功することがわかりました。

私たちは、これが人々にとって参考になるという素晴らしいフィードバックも得ました。これはワークショップのためだけでなく、日々の仕事をする上で常に参照するものだということでした。私たちにとってもう一つ重要だったのは、エンジニアたちに新しい方法で働くトレーニングをするだけでなく、この新しいアプローチを使用して成功するために、彼らが学び、実行しなければならない多くの追加タスクやスキルを加えないようにすることでした。そこで、HelmやMS Buildの変更、GitOpsなどのテクノロジーをどのように使用したかについて少しお話しします。
また、先ほど述べたように、私たちにはオンプレミスのデータセンターとクラウドがあります。そこで、エンジニアが両方の環境で全く同じように対処できるようにするために行ったことについてもお話しします。このパスで標準化されたものに移行することで、多くのサードパーティツールやオープンソースツールを使用することができ、それらは非常に簡単に使えるものでした。例えば、observabilityの分野では、ほとんど労力をかけずにすぐに使えるようなものがありました。そして、この標準化によって本当にクールだったのは、エンジニアたちが以前はできなかったことを可能にできたことです。例えば、私たちはSOX準拠の会社ですが、エンジニアたちを可能にするために行ったことの一つについてお話しします。
Kubernetesによる運用効率とコスト削減の実現
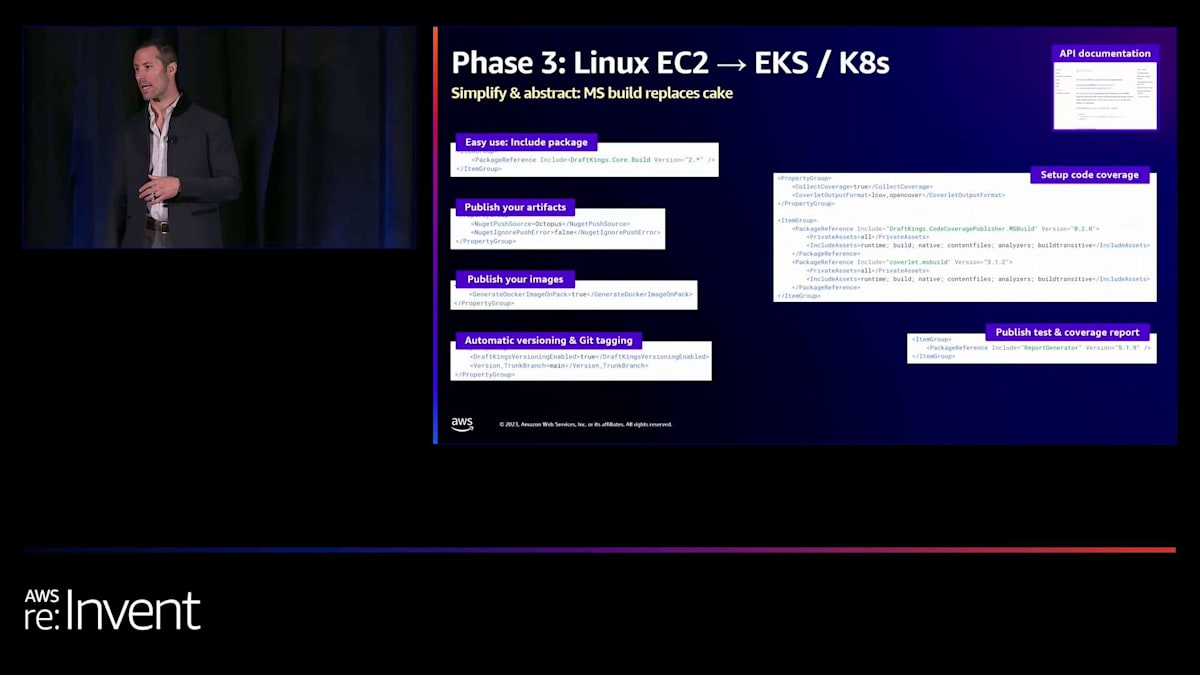
最初に取り組んだのは、マイクロサービスの構築方法でした。以前は、Cakeというテクノロジーを使用していました。多くの人がこれを使用していることは知っています。Cakeは一般的にはうまく機能しますが、いくつかの問題がありました。一つは非常に複雑で、ドキュメントがあまり良くないことです。エンジニアたちは理解するのに多くの苦労をしていました。また、良いデフォルト設定で他の人のためにパッケージ化し、必要な場合にクリーンかつ簡単にオーバーライドできるようにするのも難しいです。そのため、結果的に全員のCakeファイルが少しずつ異なっていました。そして、組織全体に何らかの変更を展開する必要があったとき、それができませんでした。全員のCakeファイルが少しずつ異なっていたため、全員に手動で変更してもらう必要がありました。
さらに、おそらく最大の問題の一つは、Cakeが人々のラップトップ上でCIと同じように動作しないことでした。その結果、違いがあるだけでなく、ラップトップ上で再現できないため、トラブルシューティングが非常に困難でした。MS Buildに移行することで、いくつかのことができるようになりました。一つは一貫性があることです。どこでも同じように動作します。また、エンジニアにとって理解しやすい、シンプルで簡単なものでもありました。パッケージを取り込むだけで、csprojを通じて設定できます。そして、アーティファクトやコンテナイメージで何を公開するかを制御したり、バージョニングやGitタグ付けを行ったり、コードカバレッジやテスト結果の自動レポートをセットアップしたりすることができました。そしてここでもう一つクールなのは、先ほど述べたように、私たちは標準に固執したことです。そのため、多くのドキュメントを書く必要がありませんでした。Microsoftがすでに書いていたので、私たちはそのドキュメントを使用しただけです。

次の分野はHelm Chartsでした。Kubernetesに移行すると、設定にはYAMLsと呼ばれるものを使用します。これは良いフォーマットで、一般的に人々にとって理解しやすいものです。しかし、いくつかの欠点があります。その一つはCakeと同様です。多くの異なるYAMLファイルができてしまいます。人々はそれらをコピーアンドペーストし、少し修正します。そのため、変更を全体に展開しようとすると同じ問題が発生します。もう一つは、型チェックのようなものが組み込まれていないことです。ユニットテストのようなことができません。Helmの素晴らしい点は、これらをパッケージ化してテンプレート化できることです。そのため、適切なデフォルト設定を入れつつ、人々がそれらをオーバーライドできるようにすることができます。
また、スキーマも備えています。これにより、単に整数や文字列かどうかだけでなく、型チェックも可能になりました。さらに、特定のフォーマットに関するチェックもできるので、設定ミスを防ぐことができます。しかし、それ以上に優れているのはユニットテストです。マイクロサービスの設定プロパティを設定したのに、予想外の結果になった経験はありませんか?ユニットテストを使えば、そういった問題を防ぐことができます。実際に、このユニットテストを構築し、パイプラインに組み込みました。これにより、開発者は期待通りの動作をする再現性のある設定を作成できるようになりました。

コンテナに移行する際の重要なポイントは、 EC2インスタンスとは全く異なる動作をすることです。コンテナは不変であり、実行中に変更を加えるべきではありません。
VMと比較すると、コンテナの扱い方は異なります。以前は、SREがChefを使用して本番環境でセキュリティパッチなどのタスクを実行していました。これは効果的に最新の状態を保つ方法でしたが、多大な労力を要し、リスクも伴いました。コンテナに移行する際、セキュアで最新の状態を保つ必要がありました。そこで、CVEをスキャンし、その他のチェックを行うパイプラインを構築しました。これらのコンテナは、デプロイメント用のゴールデンイメージとして認証されます。
Kubernetesを基盤とした標準化のもう一つの重要な利点は、Open Policy Agentの使用です。SOCKS規制の対象組織として、顧客や組織に金銭的損害を与える可能性のある変更には慎重でなければなりません。以前は、特定のサービスをエンジニアがスケーリングできず、チケットを発行して他の人に対応を依頼する必要がありました。KubernetesとOpen Policy Agentを使用することで、マイクロサービスごとに特定のゲートやルールを設定できます。最小限の運用閾値を定義することで、エンジニアはコンプライアンスの懸念なく、安全な範囲内でスケーリングを行うことができます。
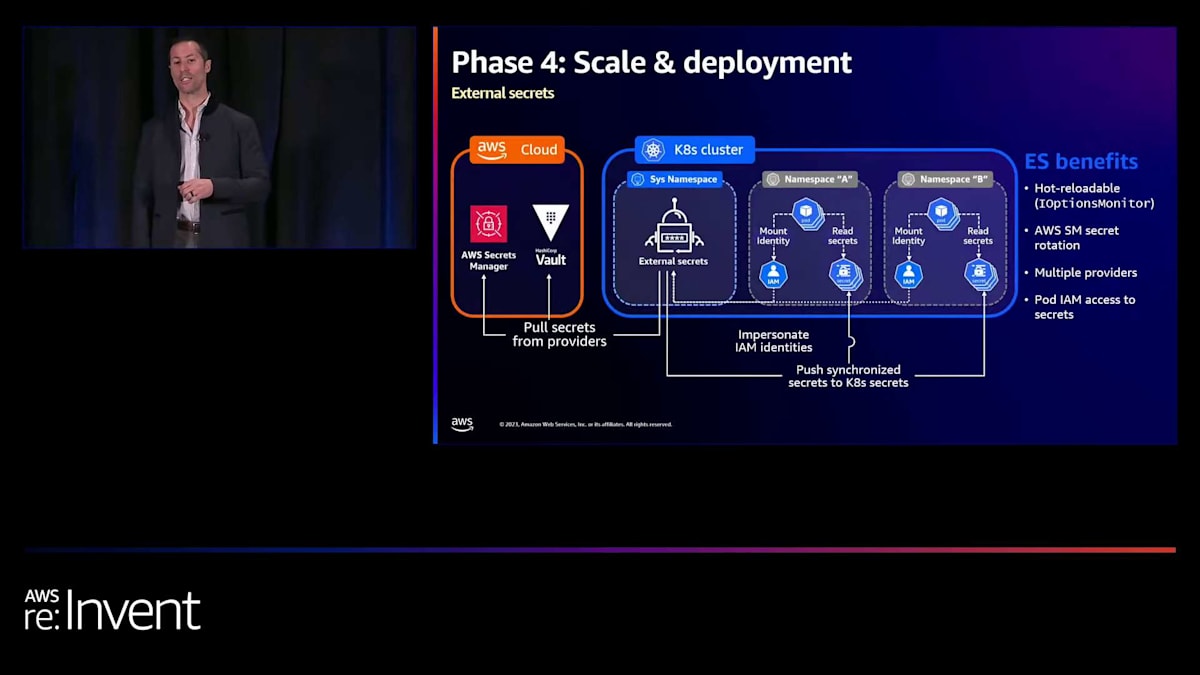
そこから、私たちは革新的なソリューションの開発に取り掛かりました。多くの組織では、合併や買収、レガシーコード、チームの自律性などの理由で、さまざまな方法でシステムが実装されています。その結果、VaultやAWS Secrets Managerなど、異なるプロバイダーにシークレットが保存されることがあります。通常、これには適切なプロバイダーからシークレットを取得するコードを書く必要がありますが、複数の言語やランタイムにまたがると難しくなります。私たちはExternal Secretsというテクノロジーを発見し、この問題に対処しました。これにより、IAMロールをポッドにマウントでき、External SecretsがそのIAMロールを使用してシークレットをリクエストできるようになります。これによりマイクロサービスからプロセスが抽象化され、マイクロサービスが詳細を知る必要なく複数のプロバイダーをサポートできます。シークレットはKubernetesのシークレットとしてポッドにマウントされ、すべてのマイクロサービスで一貫性が確保されます。また、ホットリロードも可能になり、AWS Secrets Managerのシークレットローテーションと.NET CoreのiOptionsMonitorを使用することで、新しいシークレットが自動的に取得されます。
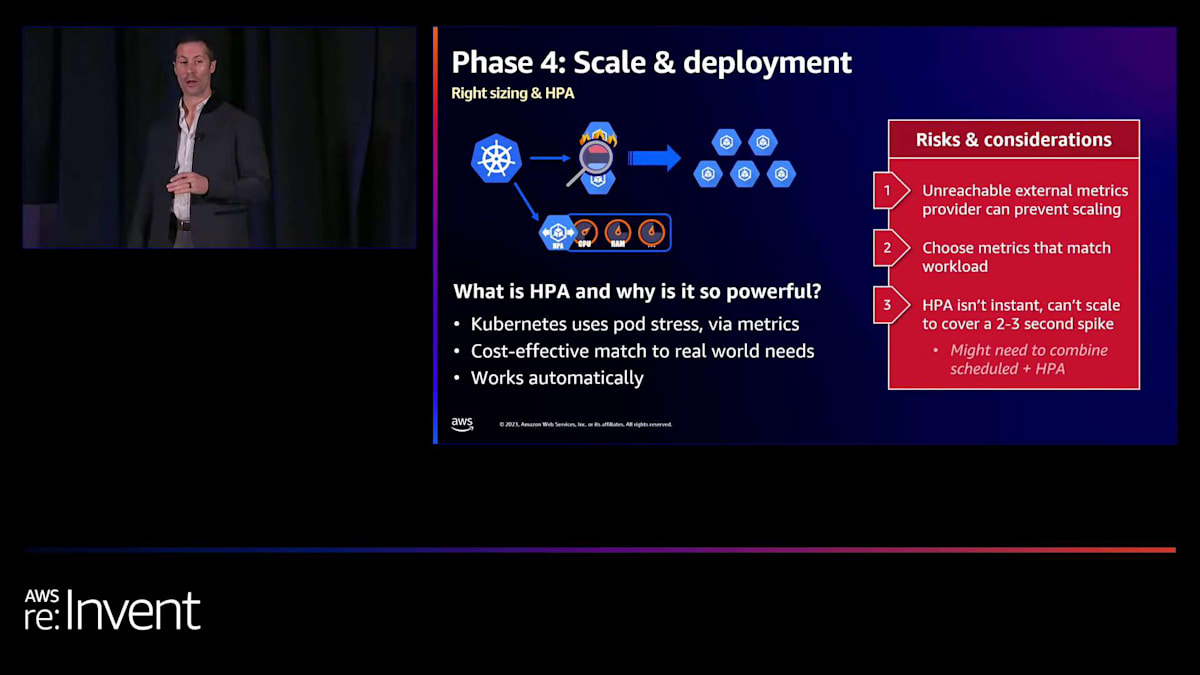
もう1つの大きな利点は、Horizontal Pod Autoscaling(HPA)でした。これはKubernetesの良い動作と悪い動作の観点と一致します。サービスが悪い状態に入りつつある(例えばCPU使用率が80%に達する)ときを示す指標を定義し、それにどう対処するかを指定できます。そうすると、Kubernetesは人間の介入なしにこれらの状況を自動的に管理できます。これは、エンジニアの関与が必要だったモニターやアラートを設定する以前のアプローチとは異なります。ただし、考慮すべき注意点もあります。外部メトリクスプロバイダーを使用していて、それにアクセスできなくなると、Kubernetesがサービスを適切にスケールする能力に影響を与える可能性があります。フォールバックを用意しておくことが重要です。また、ワークロードに合ったメトリクスを選択することも大切です。CPU集約的でないタスクにCPUをメトリクスとして使用しないでください。最後に、HPAはすべてのスケーリング状況を解決できるわけではありません。特に、突然の大規模なアクティビティの急増を伴う状況には対応できません。
例えば、NFLの試合中に誰かがフットボールをファンブルし、それがタッチダウンに返されると、瞬間的に大規模なスパイクが発生します。これはHorizontal Pod Autoscaler(HPA)には速すぎます。なぜなら、HPAはサービスがスケールアップし、準備が整い、ロードバランサーに組み込まれる速度でしかスケールできないからです。通常、これを他のソリューションと組み合わせて使用することをお勧めします。私たちの場合、スケジュールされたスケーリングを使用しています。これにより、そのような予期せぬスパイクに対処できるよう、最小数を増やします。
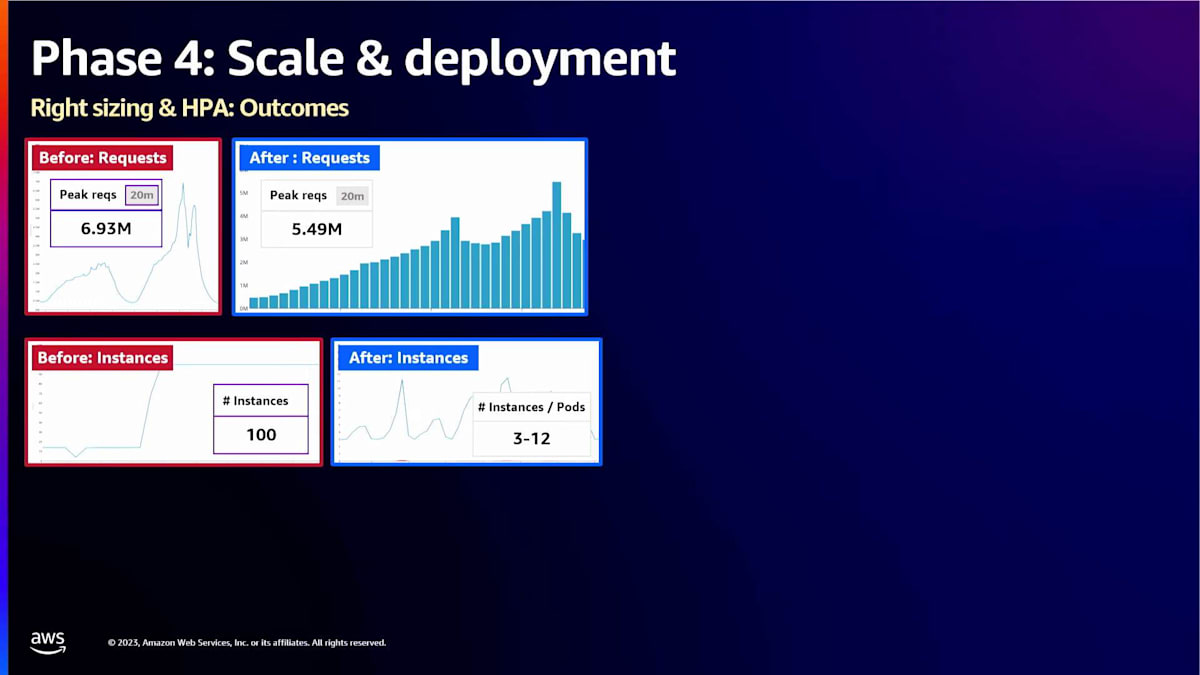
私たちが達成したクールな利点と成果をいくつか紹介しましょう。これは実際の数字なので、リクエスト数は完全に一致しませんが、かなり近いものです。 以前は、100インスタンスに固定する必要がありました。これが、私たちが持っていたすべてのアクセスパターンでこのトラフィックを一貫して適切に処理できる唯一の方法でした。右側を見ると、興味深いことに気づくでしょう。もはや単一の数字ではありません。チームは大規模な負荷テストを行い、通常のトラフィックに対しては3インスタンスが必要であることを確認しました。これは非常に快適に動作しました。しかし、彼らはKubernetesがそのトラフィックの変化にどのように対処できるかも定義しました。この期間中、実際には最大12インスタンスまでスケールアップしました。必要な時だけそうし、必要がなくなるとスケールダウンしました。このアプローチにより、ハードウェアのコストと管理に必要な人員の時間を大幅に節約できます。
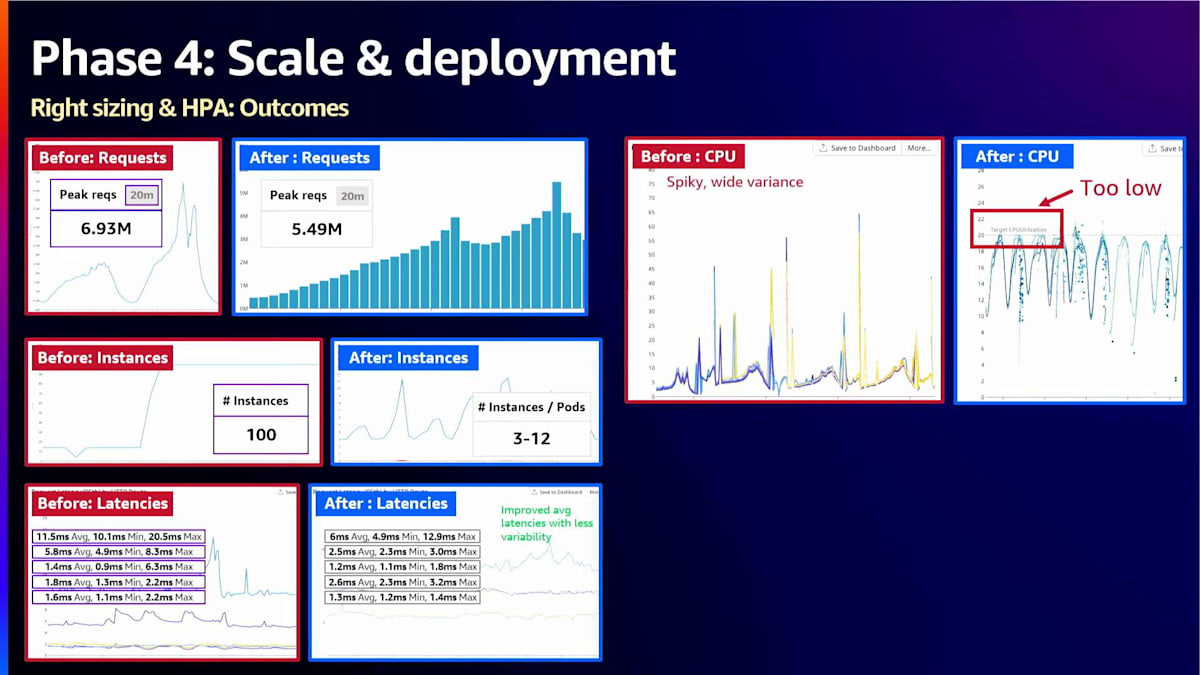
もう1つ興味深い点は、これが完全に非同期で動作していることです。 インスタンス数が10分の1以下になったにもかかわらず、レイテンシーに多くの利点と改善が見られました。もちろん、CPUの使用率もはるかに安定し、予測可能になりました。しかし、まだ慣れていく過程で学ぶべきことがあります。これを実装したチームはおそらくCPUの設定を低すぎにしていますが、それは問題ありません。彼らはまだ慣れている途中なので、時間とともに調整していくでしょう。
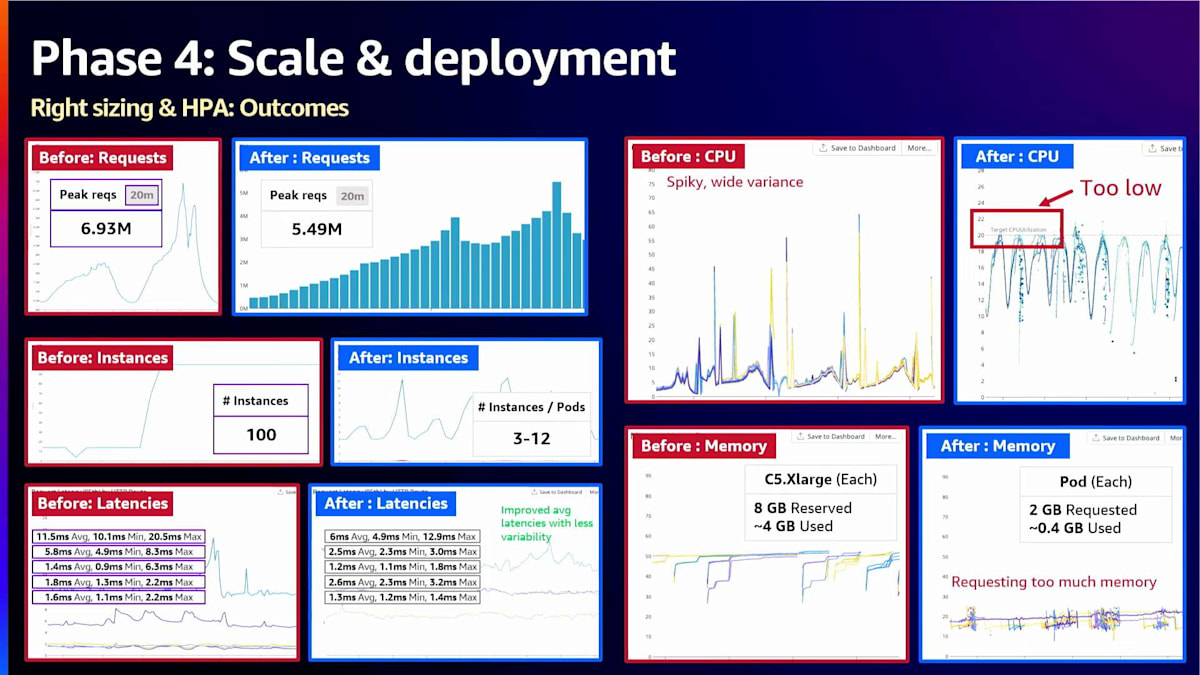

メモリ使用量についても同様です。私たちは大幅に少ないメモリを使用しており、うまく動作しています。しかし、少し低すぎる設定にしたことで、まだコスト削減の余地が残されているかもしれません。 ここから、エンジニアの生産性を大幅に向上させるための非常にクールな取り組みに移っていきます。
マルチクラウド環境での一貫した運用の実現

私たちが取り組んだ最もクールなことの1つが、isolated testingです。 実は、このプロジェクトに取り組んだJohnが今日この会場にいます。彼はこれに関して素晴らしい仕事をしました。isolated testingによって、いくつかのクールなことが可能になりました。大きな利点の1つは、マイクロサービスに対して複数のエンジニアが同時に作業してテストを実行したい場合、お互いに干渉することなく、まったく同じタイミングで実行できることです。データは再現可能なので、スピンダウンしてスピンアップするたびに、以前とまったく同じ状態でクリーンに開始されます。


これは同じマイクロサービスで作業する2人にとってだけでなく、同じ依存関係を持つマイクロサービスで作業する人々にとっても有益です。お互いの邪魔をせず、環境が安定し、一貫性があり、再現可能であることを確認できます。また、カオステストやストレステストを導入することもできます。 ネットワークの問題、レイテンシー、依存関係のダウンなど、本番環境で見られるようなあらゆる種類の問題を引き起こすことができます。他の人の作業に影響を与えることなく、環境を非常に悪い状態にするような問題のあるシナリオを作成できます。シャットダウンしてスピンアップし直せば、カオスが起こらなかったかのようになります。
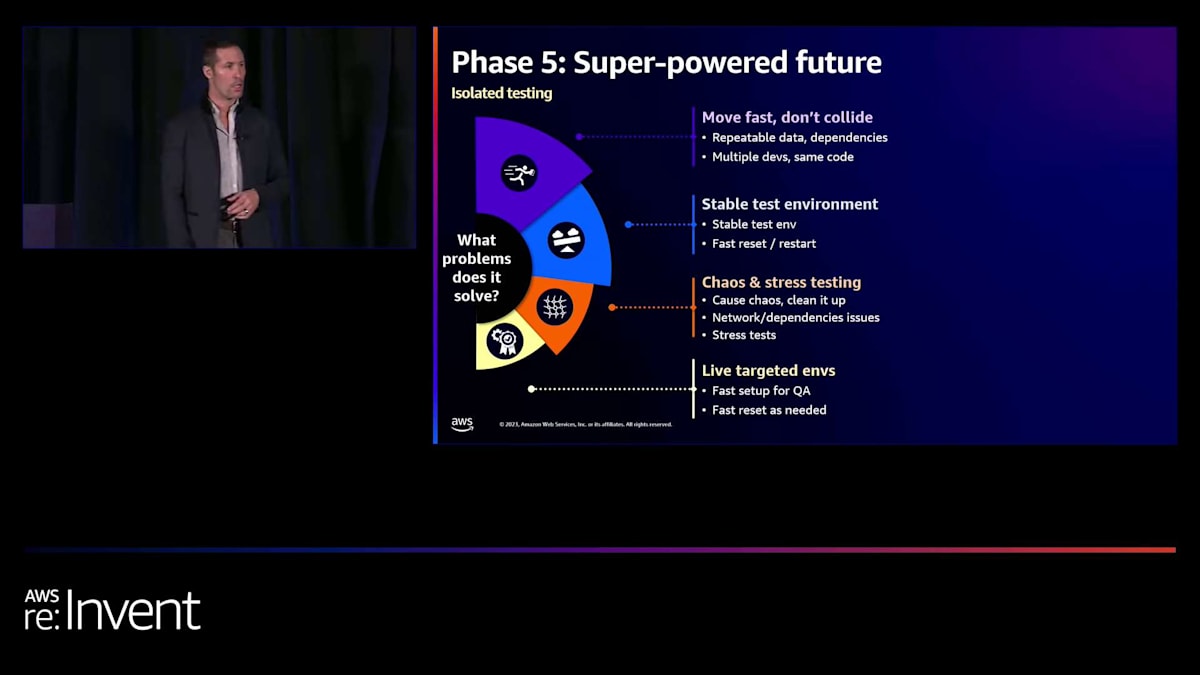
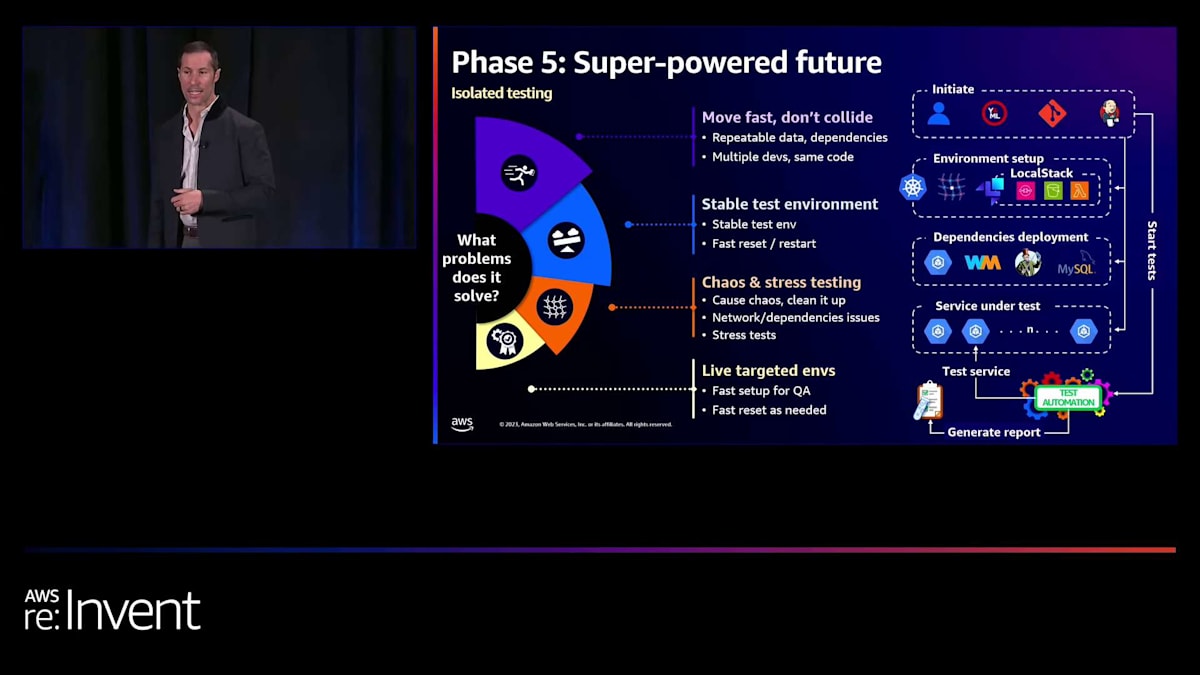
また、ライブのターゲット環境を作成する機能もあります。品質管理エンジニアがこれらのマイクロサービスに対して繰り返しテストしたい場合、これをスピンアップできます。あるいは、フロントエンドエンジニアがこれらをスピンアップして、実際にアプリケーションからアクセスすることもできます。 これらのテスト環境ではLocalStackを実行しているので、問題を引き起こしたりコストを発生させたりすることなく、AWSリソースもテストできます。SQSやLambda関数などをその場でテストできます。
また、マイクロサービスをモックする機能もあります。別の依存関係全体を立ち上げたくない場合、必要な応答の種類が分かっているので、代わりにモックすることができます。その周りに条件を設定したり、モックと実際のサービスの両方を実行したりすることができます。これは実際の環境なので、HPAやスケーリングなどもテストできます。より多くの負荷をかけると、適切に応答しているかをテストできます。そして、自動テストを実行してレポートを生成することができます。

これから得られる次の大きな利点は、皆さんもきっと経験したことがあるものです。複数の異なる環境や複数のクラウドを使用する理由はたくさんあります。私たちの場合、先ほど述べたように、規制要件があり、一部のものはオンプレミスでなければならず、他のものはクラウドで可能です。
そのため、純粋なAWSソリューションを構築することはできません。しかし、合併や買収などの理由もあります。複数のクラウドを持っているかもしれませんが、AWSをハブにしたいと考えているかもしれません。そして、エンジニアが全てを全く同じ方法で扱えるようにしたいと思うでしょう。私たちにとって、その基盤が本当にそれを可能にしました。
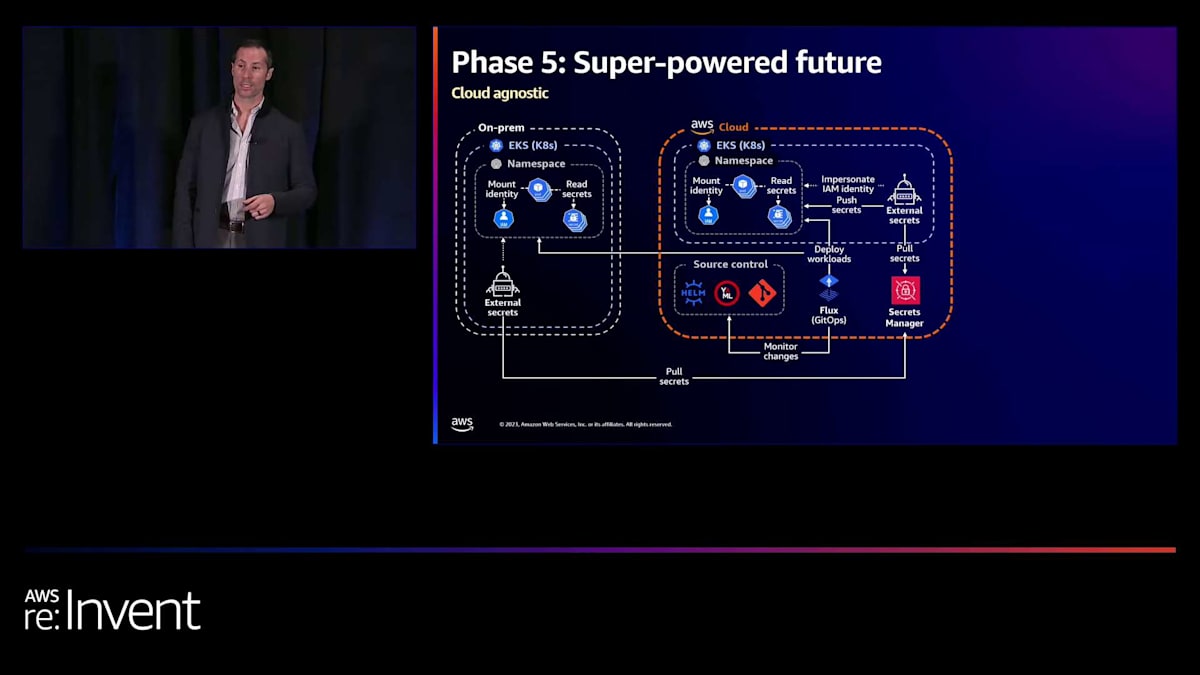
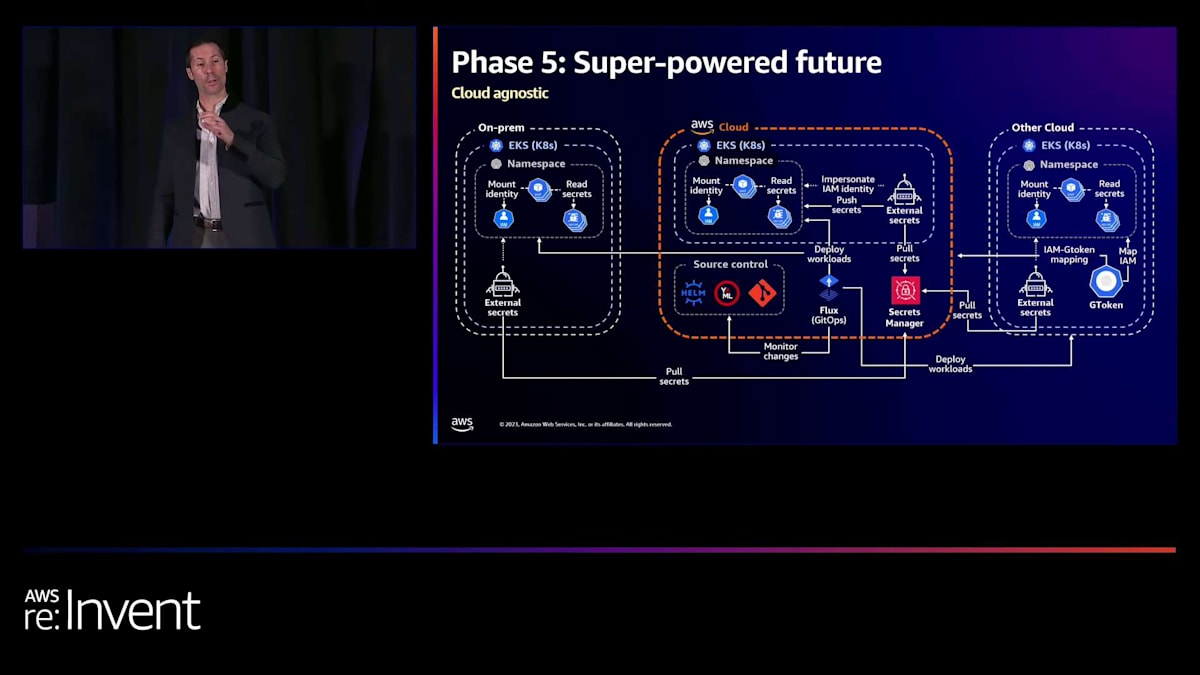
覚えておられるかもしれませんが、オンプレミスでもIAMロールを使用できるようになりました。AWS リソースを安全かつセキュアに呼び出すために特別なことをする必要はありません。External Secrets と OIDC を使用することで、それが可能になります。さらに、 別のクラウドもあり、そのクラウドの Kubernetes バージョンの ID を IAM にマッピングできるようになりました。そのため、その他のクラウド環境にあるすべてのマイクロサービスは、別の環境にいることを意識する必要さえありません。SQS を呼び出したり、他のマイクロサービスを呼び出したり、他のマイクロサービスから呼び出されたりしても問題ありません。
これが本当に重要なポイントの1つです。つまり、自分たちの「なぜ」を理解し、それに基づいて基盤を構築することで、最初には思いもつかなかったことに対して、時間とともに継続的に能力を向上させていくことができるのです。では、Maniに引き継ぎます。
AWSが提供するモダナイゼーションツールとサポート
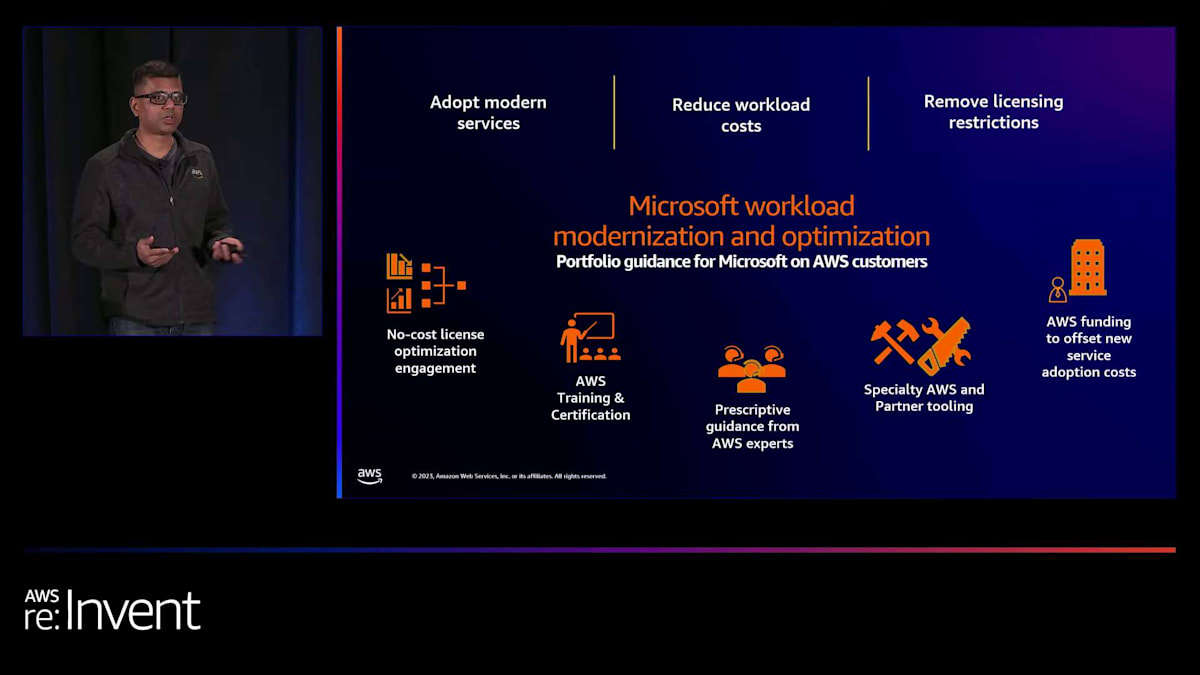
ありがとうございます。非常に洞察に富んだお話でした。Dave、貴重なお知恵を共有していただき、ありがとうございます。それでは、この点についてAWSがどのようにお役に立てるかについてお話しましょう。Daveが言及したように、彼のチームは多くの実験を行い、そこから多くのことを学びました。そして、このモダナイゼーションの旅を経験しました。私たちはDraftKingsのようなお客様から学んだことを活かし、AWSの観点から、この旅をサポートするための適切なテンプレートや具体的なガイダンスを提供しています。
これには、実際に行うことができるAWS Training and Certificationが含まれます。私たちのソリューションアーキテクトやエキスパートがお客様のアプリケーションを確認し、モダナイズされた世界への移行方法について具体的なガイダンスを提供します。また、モダナイゼーションの旅を進める際のコストの一部を相殺するのに役立つAWSの投資やプログラムもご利用いただけます。ChrisとI私はセッション後にここにいますので、プログラムに関するご質問にお答えさせていただきます。

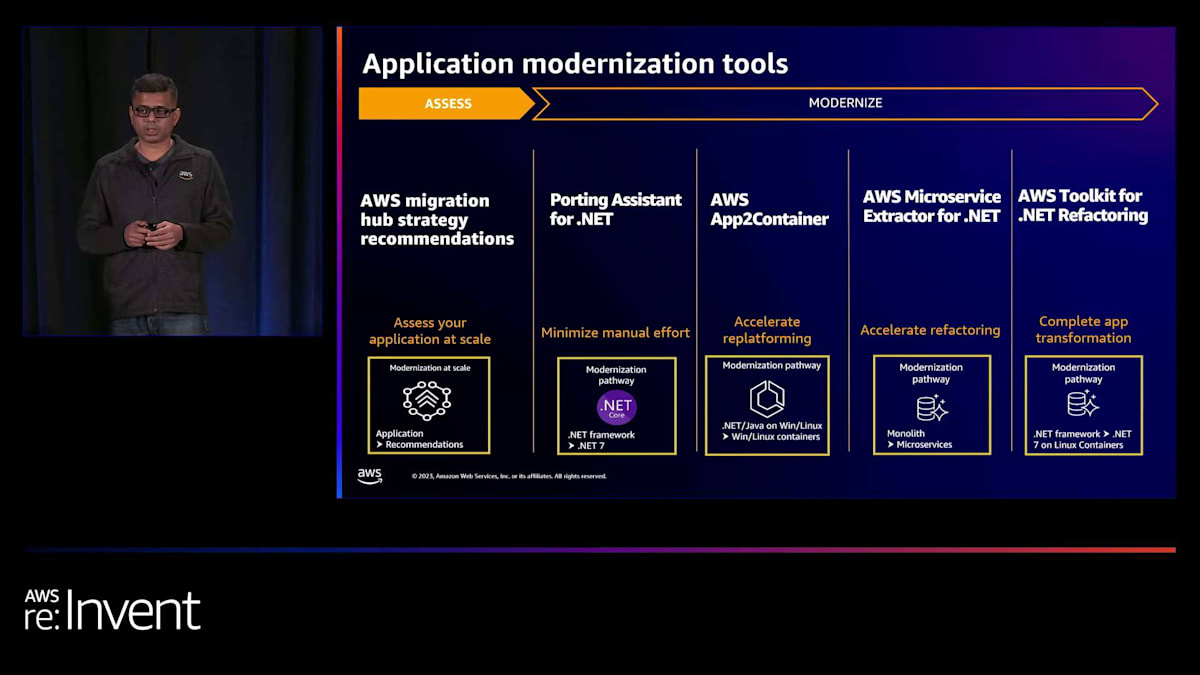
次に、モダナイゼーションツールについてお話しします。Daveは彼らがカスタムビルドしたすべてのことについて話しました。私たちはDraftKingsやそれに類似したお客様から多くのことを学び、この旅を加速するのに役立つ製品を実際に開発しました。それでは、私たちが行ったことの概要をご説明しましょう。お客様がモダナイゼーションの旅を始める際、通常はアセスメントから始めます。アセスメントを始める際、お客様はアプリケーションインベントリを確認し、どのアプリケーションがあり、どのようなモダナイゼーションの道筋があるかを把握しようとします。
アセスメントをサポートするために、私たちはMigration HubのStrategy Recommendationsという製品をリリースしました。これは基本的に、アプリケーションインベントリを確認し、それらのアプリケーションを理解した上で、適切なモダナイゼーションの道筋を提供します。例えば、アプリケーションをリファクタリングし、.NET Frameworkから.NET Coreに移行してEKSにデプロイすることを検討するかもしれません。あるいは、モダナイゼーションの道筋として、アプリケーションをWindows containersで動作するようにリプラットフォームしてデプロイすることを検討するかもしれません。
つまり、アセスメントをサポートするためにStrategy Recommendationのような製品を使用できます。モダナイゼーションの旅を進める際、お客様は通常複数の道筋を辿ります。Daveはここでリファクタリングの道筋について話していました。お客様がFrameworkからCoreに移行したい場合です。これを促進するために、私たちはPorting Assistant for .NETという製品を提供しています。これは基本的に、.NET Frameworkアプリケーションを分析し、理解した上で、.NET Frameworkから.NET Coreへの移行の道筋を提供する分析ツールです。既存の互換性の問題を特定し、.NET Coreに移行するために切り替える必要のある適切なライブラリを示します。これは基本的に、.NET Frameworkから.NET Coreへの移行を支援し、その過程を加速するためのツールです。
場合によっては、お客様がアプリケーションをコンテナ上で、例えばWindowsコンテナ上で実行したいと考えることがあります。Windowsコンテナ上で実行する理由は多くあります。そのようなお客様を支援するために、AWS App2Containerという製品があります。これは、実行中のアプリケーションを取り込み、スキャンして、
Amazon Elastic Container Service (ECS)やAmazon Elastic Kubernetes Service (EKS)上で実行できるようにアプリケーションを移行するのを支援します。適切なコンテナイメージとデプロイメントアーティファクトを作成し、それらのアプリケーションをEKS、ECS、またはApp Runnerにデプロイするのを支援します。お客様がよく検討するもう一つの方法は、モノリスアプリケーションをマイクロサービスに分割することです。これには、AWS Microservice Extractor for .NETという製品があります。
AWS Microservice Extractor for .NETは、.NETアプリケーションをスキャンし、アプリケーションの構造を視覚的に表現します。これには、すべての名前空間、クラス、メソッド、およびそれらの相互依存関係が含まれます。これにより、モノリスをマイクロサービスにどのように分割するかを決定するのに役立ちます。進みたい方向を確認したら、単に右クリックして「Extract to Microservice」を選択するだけです。Microservice Extractorが作業を行い、新しいソリューションを作成します。これにより、アプリケーションをより小さな部分に分割するプロセスが簡素化され、より速いペースで移行できるようになります。
最後に、AWS Toolkit for .NET Refactoringがあります。これはVisual Studioのプラグインです。.NET Frameworkで実行されているアプリケーションを.NET Coreに移行するのを支援します。さらに、テストデプロイメントも支援します。例えば、アプリケーションを移行した後の動作を理解したい場合や、ECS上でテストデプロイしたい場合、このツールキットを使用して行うことができます。要約すると、AWSには、アプリケーションをより最新の、オープンソースの、クラウドネイティブなサービスに移行・変換する際の変革の旅を加速するための適切なツール、プログラム、インセンティブがあります。さらに質問にお答えしますので、セッション後もこちらにいます。
質疑応答セッションの案内
それでは、質疑応答の時間に移りましょう。皆様、ご来場ありがとうございました。
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion