re:Invent 2024: AWSが提供するHPC戦略とPCSの詳細を解説
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - High performance computing: Reinvented to help you think truly big (CMP204)
この動画では、AWSのAdvanced Computing and SimulationのDirectorであるIan Colleが、AWSにおけるHPCの戦略とイノベーションについて解説しています。AWS Parallel Computing Service(PCS)という新しい完全マネージド型のHPCサービスの詳細や、850種類以上のEC2インスタンスタイプ、EFAによる10マイクロ秒未満の低レイテンシー相互接続技術など、具体的な技術進展が紹介されています。また、National Renewable Energy LaboratoryのMichael Bartlettが、クラウドベースのHPCクラスターの実践的な活用事例を共有し、23andMeやRivianなど、実際にAWS上でHPCワークロードを成功させている企業の具体例も示されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
AWSのHPC戦略:過去から未来へ

こんにちは。AWSのAdvanced Computing and SimulationのDirectorを務めておりますIan Colleです。簡単に言えば、AWS上のすべてのHigh Performance Computing (HPC)ワークロードを担当するチームを率いているということです。本日は私のセッションにお越しいただき、ありがとうございます。始める前に、会場の皆様に少しお伺いしたいことがあります。まず、re:Inventに初めて参加される方は手を挙げていただけますでしょうか?ようこそいらっしゃいました。次に、Supercomputing conferenceに参加されたことがある方はいらっしゃいますか?ご参加ありがとうございます。
このように異なるコミュニティが融合してきているのは、とても興味深い現象だと思います。私がAWSに入社した7年前に同じ質問をしていたら、これらは重なり合わないベン図だったでしょう。Supercomputingコミュニティとクラウドコンピューティングコミュニティは完全に分かれており、お互いが相手の動向について確信が持てない状況でした。特にSupercomputingコミュニティは、クラウドが彼らのパフォーマンス要件を満たせるのか、非常に懐疑的でした。

そして今、2024年を迎え、この1年間で私たちが実現してきたイノベーションについてお話ししたいと思います。また、HPCに対する私たちの全般的な戦略と、AWS上でHPCワークロードをどのようにサポートし続けていくのかについてもお話しし、皆様にその展望を感じていただければと思います。そして、National Renewable Energy Laboratoryのお客様にも登壇いただき、クラウドへの移行の経験と、AWSでの取り組みについてお話しいただく予定です。
HPCの定義とAWSにおける柔軟な実装


先ほど申し上げたように、まずHPCに対する私たちの考え方についてお話しします。 その後、Michaelが実際の活用事例についてご紹介します。最後に、パートナーの皆様とともに進めているイノベーションについてお話しさせていただきます。まず概要として、そもそもHPCとは何を指すのでしょうか? これは、誰に聞くかによって定義が曖昧になりがちな用語です。その理由は、HPCがサポートするワークロードの規模において非常に成功を収めてきたからだと考えています。自動車製造におけるCAEワークロード、航空宇宙分野での計算流体力学、気象予報のための数値計算、エネルギー資源における貯留層シミュレーション、金融サービスにおける日次リスク計算など、実に幅広い業界で活用されています。
このような状況を踏まえ、私たちはワークロード中心のアプローチを取ることにしています。お客様との協業においては、特定のワークロードをAWS上で効果的にサポートできることを重視しています。AWSのコンポーザブルアーキテクチャの素晴らしい点は、複数のワークロードに対して70%程度の最適化で妥協する必要がないことです。代わりに、ワークフローの一部に特化した動的なクラスターを構築し、それを終了したら、また別の加速インスタンスを使用するクラスターを立ち上げ、計算を実行して終了する、といった柔軟な運用が可能です。モノリシックなアーキテクチャに縛られることなく、これこそがAWSにおけるHPCの強みなのです。
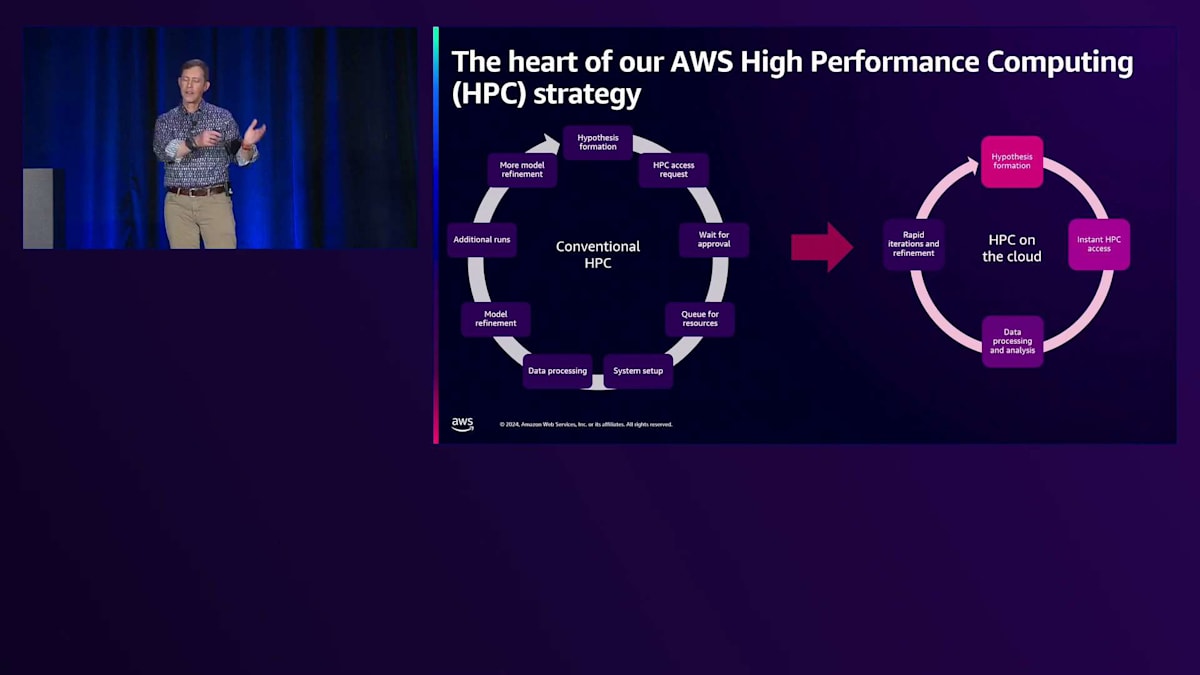
では、この柔軟性は何をもたらすのでしょうか?従来、私たちはHPCをイノベーションのためのものとして捉えてきました。高性能コンピューティングのためのハードウェアインフラ、ネットワーキング、ストレージの専門化が検討されたのは、多くの人々が重要で困難な技術的、科学的、工学的な問題を解決しようとしていたものの、それをサポートする基盤となるハードウェアやソフトウェアが見つからなかったからです。そのため、彼らは自ら構築を始めなければなりませんでした。その過程で、業界は2つの並行したトラックで発展してきました。一方では、依然として困難な問題を解決しようとする科学者やエンジニアがおり、もう一方では、それらの解決策を支援するソフトウェアやハードウェアに焦点を当てた専門家たちがいました。
従来のアプローチでは、長期の調達プロセスを経なければなりませんでした。そして、ハードウェアが調達された後も、システムのユーザーである科学者やエンジニアは、システムの使用時間を競い合わなければなりませんでした。最近、ある顧客と話をしましたが、その方は研究プロジェクトを実行するために6ヶ月もキューで待たなければならなかったそうです。場合によっては人生を変えるような技術革新が、今まさにリソース待ちで止まっているということを考えてみてください。これにどう価値をつけることができるでしょうか?

一方、AWSから弾力的に利用可能なリソースを得られる場合を見てみましょう。研究者がアイデアを思いつき、仮説を検証するために必要なリソースを立ち上げ、テストし、評価し、リソースをシャットダウンして、また新しいアイデアを考え出すという、イノベーションのサイクルが短縮されます。これにより、作業のペースを上げることができます。そのため、AWSクラウドのような動的にハードウェアインフラを割り当てる環境で、ワークフローを再考することが非常に重要だと考えています。結局のところ、私たちがこれを行うのは、科学技術の側面だけでなく、科学技術へのアプローチの考え方においても、継続的に前進するためです。この観点から、私たちは受け継いだものよりも良い遺産を残したいと考えており、クラウドの柔軟性はその重要な要素の一つだと本当に考えています。
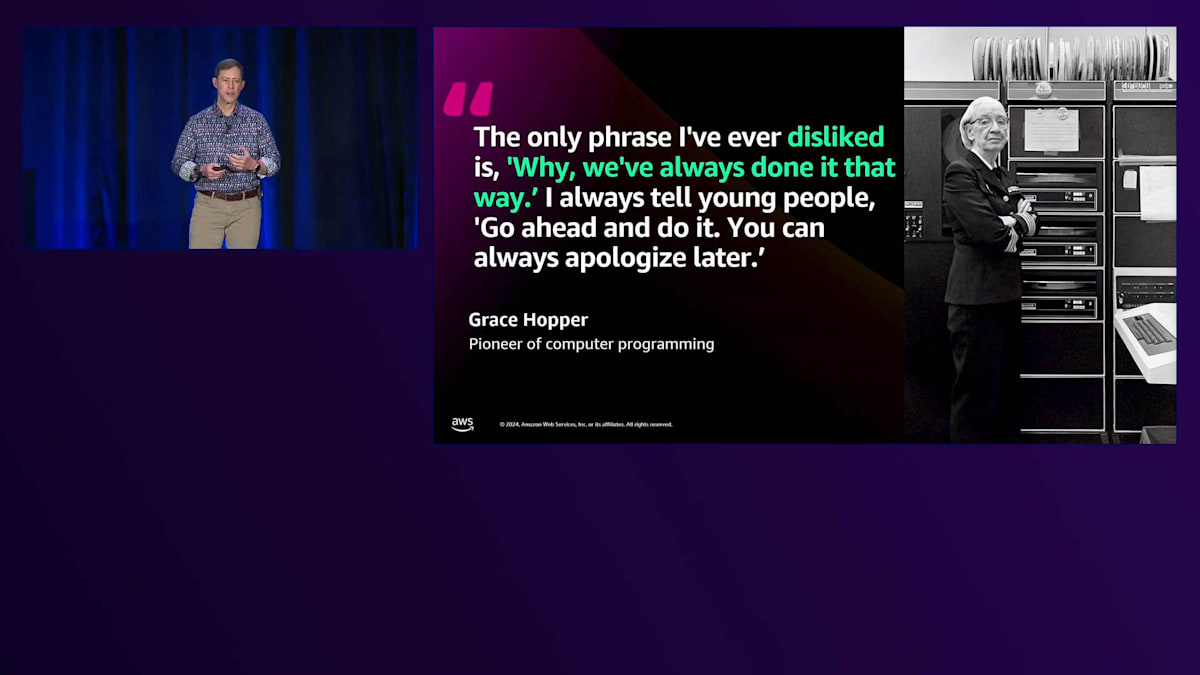
私は退役海軍の出身で、長年テック業界でキャリアを積んできましたが、Rear Admiral Grace Hopperは私の個人的なヒーローの一人です。提督のこの言葉が大好きなのは、時には物事を壊したり、非伝統的なやり方で物事を行ったりすることも良いのだと基本的に言っているからです。これは高性能コンピューティングにとても重要な意味を持ちます。なぜなら、数十年にわたって、専門家たちが「これがワークロードを実行する方法だ」と言ってきたからです。ハードウェアボックスを構築し、スケジューリングリソースによる重要な使用率アルゴリズムを通じて、そのハードウェアボックスの使用を最大化する。しかし、そのボックスを開放し、すべての問題を解決しようとする単一の一枚岩的なハードウェアアーキテクチャに制約されることなく、コンポーザブルなリソースで異なる考え方ができる環境で運用する場合、何が起こるでしょうか?

私がこのHPC組織を率いる中で、高性能コンピューティングの未来について考えるとき、私が常にチームと共有し、繰り返し強調しているビジョンは、「Project Any」と呼んでいるものです。私のプレゼンテーションから何か一つ持ち帰っていただけるとすれば、これが私たちの指針となる星だということです。理想的には、誰でも(Fortune 500のエンジニアリングアプリケーション開発者でも、大学院の研究者でも、寮にいるインターンでも)、どこからでも(オンプレミスリソースとクラウドリソースの混在でも、完全なクラウドリソースでも構いません)、どんなワークロードでも、いつでも実行できるようにしたいと考えています。私たちは、イノベーションへの制約を取り除き、将来のイノベーションを本当に加速するために必要なリソースを提供する能力を確保したいと考えています。そしてもちろん、ビジネスロジックのためのツールも追加したいと考えています。なぜなら、アカウントの支払いをする人々(以前は小切手でしたが、今は直接振り込みをしています)が行っているのは...
クラウド上のこれらHPCリソースすべてに無制限のアクセスを許可すると、1人の研究者が年間予算を3ヶ月で使い切ってしまう可能性があります。これは初期によく耳にした懸念の1つでした。しかし、AWSで実装されているコスト管理メカニズムにより、ビジネスロジックに応じた制約を設定したり、必要に応じて制約を解除したりする柔軟性が得られます。ワークロードを急増させる必要がある重要な時期かもしれませんし、支出を注意深く監視してリソースを制限する必要がある重要な時期かもしれません。私たちは、予算管理者の要求を満たしながら、コストを監視・制御しつつ、お望みのペースでイノベーションを実現するためのツールを提供しています。
クラウドベースHPCの急速な成長と技術革新


AWSでの私の在任中、HPCの広範な領域で実際に起きていることを観察するのは特に興味深いものでした。 当初、スーパーコンピューティングの人々とクラウドコンピューティングの人々は、重なり合わないベン図のような状態でした。現在では、従来型のHPCワークロードがオンプレミスのデータセンターからクラウドへと急速に移行しているのを目にしています。昨年だけでも、すべてのHPCワークロードの20%がすでにクラウドに移行していました。Hyperion Researchは、今後3~4年の間に、すべてのHPCワークロードの3分の1がクラウドで実行されるようになると予測しています。
私たちは継続的な成長を予想しており、興味深い兆候も見られます。通常であればRFPの作成時にモノリシックなオンプレミスアーキテクチャを要求していたような資金提供機関や施設が、今では完全にアプローチを見直しています。特定のレイテンシー要件やセキュリティ上の考慮事項のために、管理された床下空間に一部のワークロードを必要とする場合でも、以前と比べてその規模は大幅に縮小されています。現在では、残りのワークロードをサポートするためのElasticなクラウド予算を追加し、研究者やエンジニア、科学者たちにAWSクラウドで柔軟なコンピューティングを利用する機会を提供しています。
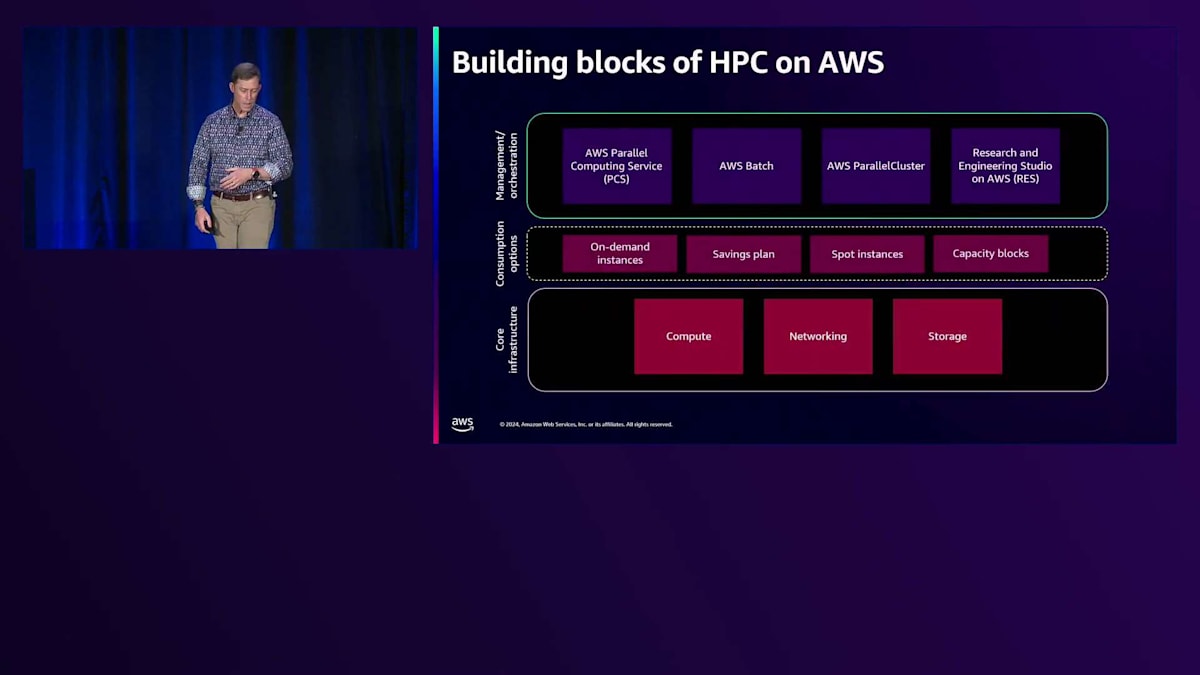
AWSにおけるアーキテクチャと、これらのレイヤーについて見ていきましょう。特に、今年の夏初めにリリースしたAWS Parallel Computing Service(PCS)という新しいサービスについて、オーケストレーションレイヤーの観点から説明します。その後、実際の計算リソースの調達方法や、ユーザーとして利用可能なオプションについて説明します。優れたHPCシステムには欠かせない、コンピューティング、ネットワーク、ストレージの各分野での私たちのイノベーションについてもご紹介します。

新しい完全マネージド型のHPCサービスであるPCSについてお話ししましょう。私たちは、以前オンプレミスを利用していたお客様が、既存のスクリプトを若干修正するだけでAWSに移行できるような、ジョブスケジューラーのファミリー全体を構想しています。これにより、Altair PBS ProのようなスケジューラーからAWS上で動作する別のスケジューラーへの変換について考える必要がなくなります。オープンソースプロジェクトとして最も統合が容易なSlurmから始めていますが、今後数年でこれを他のスケジューラーにも拡張していく予定です。AWSならではのAPI統合、CDK、AWS APIをそのまま使用することができます。
この完全マネージド型のSlurmソリューションにより、ユーザーは動的にクラスターをプロビジョニングすることができます。この初期段階では、完全マネージド型のソリューションでクラスターを提供しているため、ヘッドノードの管理やリソース管理、その他の複雑な作業について考える必要はありません。実際のコンピュートノード自体はサービスによってインスタンス化されますが、お客様のアカウントで実行されます。これにより、コスト管理が可能になり、支出をコントロールすることができますが、実際のスケジューラーやリソースの管理はすべてAWS PCS内で処理されます。

私たちがこのスケジューラーファミリーを作成している理由は、お客様がこれらのワークロードをクラウドに移行する際の障壁を取り除きたいからです。HPCのお客様との最初の対話では、パフォーマンスについての質問や、AWSで実際にワークロードを実行できるかどうかという疑問がありました。私たちはそれが可能であることを証明し、後ほど作成したコンピュートインスタンスについて説明する際にその理由を詳しく説明します。次に問題となったのはインフラストラクチャのセキュリティでした。そこで、AWS Nitro Cardの詳細について説明し、多くの国家認証でも実証されているように、AWS Nitro Cardを通じて、オンプレミスのデータセンターよりも実際にはより安全であると考えています。そして最後に価格性能比の問題がありましたが、購入オプションについて説明する際に、ほとんどのお客様が非常に満足できる価格性能比を実現できる魅力的な提案があることをご理解いただけると思います。

こちらは、AWS PCSを利用されているお客様の典型的なアーキテクチャの例です。先ほど申し上げたように、一部のお客様はクラウドに完全に移行してデータセンターから撤退し、すべてのHPCワークロードをAWSに移行していますが、まだ大多数のお客様は何らかの形でオンプレミスの環境を維持しています。そういったお客様は、データセンターへのDirect Connectを確立し、それをAWSクラウドに接続して、AWSのVirtual Private Cloudをシステムに統合することでHPCワークロードを実行しています。
AWS Parallel Computing Serviceと関連技術の詳細

PCSの強みは何でしょうか?これは重要な差別化要因の1つで、後ほど現在のParallel Clusterツールキットについても説明しますが、PCSが以前のソリューションと比べて大きく異なる点は、実行中の更新が可能なことです。以前は、セキュリティパッチの更新からOSの新バージョンまで、何か変更を加えたい場合には、すべてをシャットダウンして最初からやり直し、すべてを再起動する必要がありました。AWSの完全マネージド型サービスとなったことで、パフォーマンスの向上やセキュリティ対策、新バージョンへの更新など、どのような場合でもユーザーへの影響を最小限に抑えてシステムの更新が可能になりました。

PCSの構築にあたって、私たちは3つの異なるペルソナを想定していました。これは、AWSで新しいサービスを考える際の私たちの考え方を共有する上で非常に興味深い点です。まず、最終的なエンドユーザー、つまりこれらのリソースを使用して計算を行おうとしているHPCの研究者やエンジニアがいます。これは考えやすい部分ですが、サービスの顧客はそれだけではありません。HPCシステム管理者の必要性は依然として続いています。これは、従来のオンプレミス環境の方々から聞かれる懸念の1つでした。つまり、すべてがAWSに移行してHPCシステム管理者が不要になるのではないかという懸念です。ハードウェアのラックマウントや配線作業ではなく、AWSやクラウドの原則に基づいて作業する方法を理解する必要があるため、求められる資質は異なるかもしれませんが、全体的なアーキテクチャを作成し、ビジネスルールを実装するための人材は依然として必要です。
これらのビジネスルールにより、社内のお客様は定められたコスト範囲内でリソースを利用することができます。AWSでサービスを構築する際、私たちは直接のお客様だけでなく、私たちのサービス上に追加機能を構築する多くのパートナーのことも考慮しています。PCSを構築する際、私たちはこれらの次世代のパートナーが、お客様にとって有用な価値ある機能を構築できるよう、できる限り容易にすることに注力しています。



このサービスは、High-Performance ComputingやMLのワークロードを実行するほぼすべての方々を対象に設計されており、Parallel Computing Serviceをご利用いただけます。 これは私たちのポートフォリオにおいて、オーケストレーションレベルに新たに加わったものです。 あらゆる処理に対応できますが、High-Throughput Computingのワークロードに関しては、現時点ではSlurmが最適なソリューションではないかもしれません。ただし、将来的にはPCSが、非常に短時間で突発的なジョブを含むHigh-Throughput Computingワークロードにも対応できるようになることを目指しています。


この夏の初期リリース時点では提供していませんでしたが、チームによれば、AWS CloudFormationのサポートは最終テスト段階にあり、まもなく利用可能になる予定です。これにより、お客様がサービスを構築する際の作業が大幅に容易になるでしょう。 PCSは私たちが提供する唯一のソリューションではありません。コンテナ化されたワークロード向けのクラウドネイティブスケジューラーであるAWS Batchも提供しています。PCSが仮想化されたあるいはベアメタルのAmazon EC2インスタンスと標準的な方法でやり取りする手段を提供するのに対し、AWS Batchは、ワークロードのコンテナ化に慣れたお客様向けのサービスです。

KubernetesやAmazon EKSだけでなく、Amazon ECSもAWS Batchで数千から数百万のvCPUまでスケールアップする際の主要な方法の一つとして、お客様にご利用いただいています。これにより、コンテナ内でのジョブのBin Packingにおいて、素晴らしいスケーリングと効率性を実現できます。ゲノムマッピングから、がん治療に有望な物質の開発まで、お客様は印象的な成果を上げています。「AWS Batch scaling」でGoogle検索すれば、お客様の驚くべき成果をご覧いただけます。さらに、サーバーレスな体験をお求めの方には、AWS Fargateもサポートしており、非常に柔軟性の高い製品となっています。


今年、お客様に特に評価いただいているいくつかの重要な革新を導入しました。その一つが、Sidecarを実行する機能です。以前は単一のコンテナ内ですべてをオーケストレーションする必要がありました。今年追加されたAWS Batchでの複数コンテナのサポートは、ロボティクスや自動運転車のシミュレーションなど、複数のコンテナを必要とするワークフローを持つお客様にとって特に価値のあるものとなっています。 私が提唱してきたもう一つの機能は、大規模なジョブに関する課題への対応です。数十万あるいは数百万のvCPUを実行する際、問題のある単一のジョブがキューをブロックし、パフォーマンスに大きな影響を与える可能性があります。以前はこのような問題に対する洞察が限られていましたが、現在では、このような状況を可視化するツールを提供し、問題のあるジョブを特定して除去し、キューを効率的に動かし続けることができるようになっています。


これらのAWS Batchの改善に加えて、AWS ParallelClusterについてもお話ししました。これは、AWSでHPCクラスターを構築するお客様を支援するための私たちの最初の取り組みでした。これはオープンソースのツールキットで、今後も維持・開発を続けていきます。ただし、これからの重点は AWS PCSに移行していく予定です。というのも、お客様から完全マネージド型サービスへの強い要望をいただいているからです。


Research and Engineering Studioは、VDIインスタンスを構築するための興味深いアプローチです。HPCシステムを持っていて、それと対話的に作業したい場合、すべてのユーザーワークステーションをどうするかを考える必要があります。Research and Engineering Studioは、システムと通信するVDIインスタンスを簡単に作成できるオープンソースのツールキットです。重要な特徴の1つは、AWS Managed Microsoft Active Directoryと完全に統合されていることで、Active Directoryを通じてユーザーグループと同様にこれらのリソースへのアクセスを制御できます。

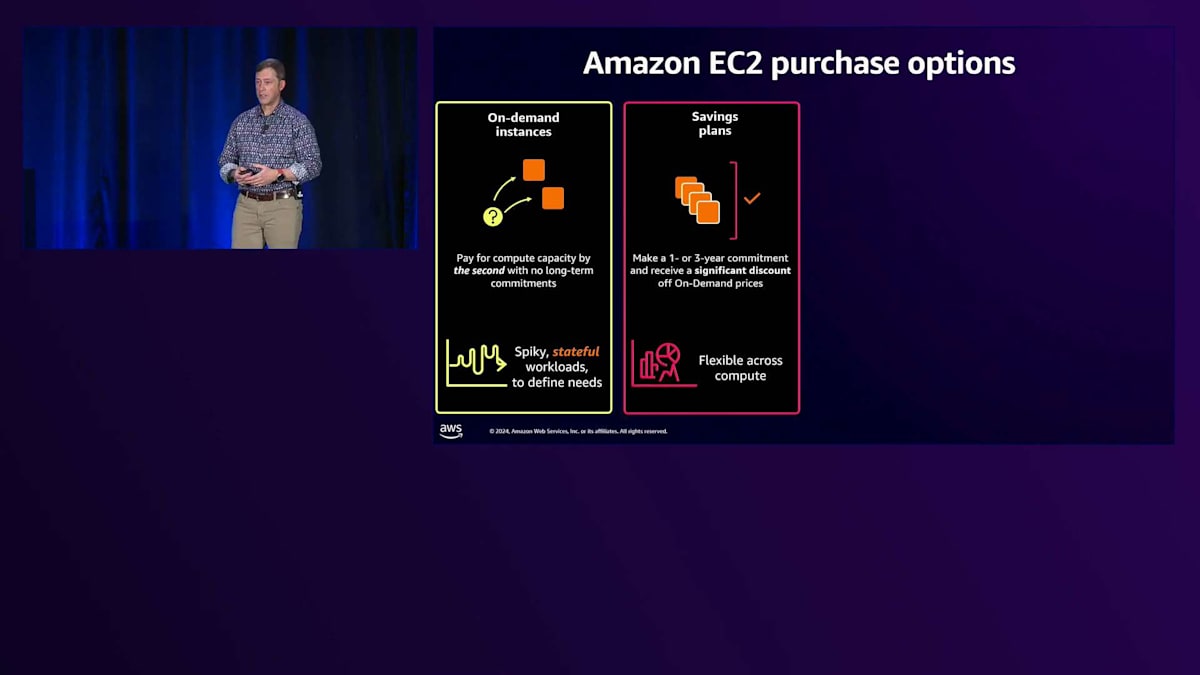

Amazon EC2の購入オプションは複数あります。1つ目はオンデマンドで、これは分かりやすいですね。リソースがすぐに必要な場合、クリックすれば特定の価格で即座に起動できます。2つ目は、多くのお客様が選択されているSavings Planです。これは、一定量のリソースに対して1年または3年の契約を結ぶことで割引が受けられます。3つ目はSpot Instancesで、余剰キャパシティを極めて大きな割引で利用できます。世界中のお客様がさまざまなユースケースでインスタンスを利用している中で、需要の谷間で生じる余剰キャパシティを大幅な割引価格で提供しています。



最近追加した新しいオプションは、GPUのキャパシティ確保の課題に対応するためのCapacity Blocksです。Capacity Blocksでは、GPUを使用したい期間を選択し、必要な週数(現在は最大6ヶ月まで延長可能)と必要なインスタンス数を指定できます。最近、よくある懸念事項に対応しました。それは、2週間のCapacity Blockを予約していて、残り1日となった時点で作業が予定通り終わりそうにないと気付いた場合どうするか、というものです。そこで、予約期間の終了時にCapacity Blockを延長できる機能を追加し、未完了の作業を完了できるようにしました。


本来であればオンデマンドインスタンスを使用したいタスクに、お客様がCapacity Blocksを使用されているのが現状です。これは、サプライチェーンの制約により、GPUのオンデマンドキャパシティが十分に確保できていないという率直な現実があるためです。そのため、入手困難なこれらのリソースにお客様がアクセスできるよう、このCapacity Blocksという形態を開発しています。

AWSの基盤技術について簡単にご説明させていただきます。 私たちのElastic Compute CloudであるAmazon EC2には、850種類以上のインスタンスタイプがあります。先ほどHPCシステムには正確なノードタイプが必要かもしれないという70%ソリューションについて触れましたが、現在では小規模クラスタに対して、コンピュートとメモリの構成を細かく調整し、その後シャットダウンすることが可能です。以前は、ラボでのテストやベンチマークのために最低1、2台のノードを購入する必要がありましたが、現在は実験用のCapacity Blocksを1、2週間確保して、コードの高速化が可能かテストし、GPUとCPUの価格性能比を計算することができます。これは、お客様が異なるインスタンスを使用する具体的な方法の一例です。


この夏に発表したGraviton4について触れたいと思います。非常に印象的な7チップレットアーキテクチャを採用しており、6年前に始めたシステムの次世代進化版です。ARMアーキテクチャの各世代で、 パフォーマンスだけでなく、ワットあたりのパフォーマンスも大幅に向上していることがわかります。これは、高性能コンピューティングリソースを利用できることに関して、お客様が非常に期待を寄せている点の一つです。すべてのワークロードやコードがARMで動作するわけではありませんが、対応するものが増えてきており、今後も増え続けると考えています。



この新しいARMチップを基盤とする具体的なインスタンスの一つが、最近リリースしたI8gです。これは驚異的なストレージコンピュートインスタンスです。High Performance Computing専用ではありませんが、Graviton4のロードマップで私たちが継続的に示しているイノベーションの一例としてご紹介したいと思います。 もちろん、コンピュートだけではありません。HPCシステムを構築するには、ネットワークとストレージネットワーキングが必要です。

Elastic Fabric Adapter(EFA)をご存じない方のために説明しますと、これは10マイクロ秒未満の低レイテンシーを実現する私たちの相互接続技術です。月曜日のPeter DeSantisの講演をご覧になった方はご存知かと思いますが、まだの方はYouTubeでぜひご覧ください。彼は、HPCとMLリソースに使用している10P10U、つまり10ペタビット/秒、10マイクロ秒未満のレイテンシーネットワークについて詳しく説明しています。これはOSバイパスを採用しており、低レイテンシーで極めて高いスループットを実現します。多くのHPCワークロード、特にMPIジョブに必要なホスト間通信を実現します。


少し自慢させていただきますと、スライドの右側を見ていただくと、これらのインスタンスがほぼ理想的なスケーリングを示していることがわかります。これは、AWSの初期の頃、多くの同僚が実現可能性を疑っていたものです。最後にストレージについてですが、NetApp ONTAPやOpenZFSを含む複数のFSxオプションを提供しています。しかし、全般的なHPCアーキテクチャでの人気を考えると、最も人気があるのはFSx for Lustreです。お客様は何十年もLustreを使用してきました。これはHPC向けのワーホースとなるオープンソースの高性能ファイルシステムです。

お客様から要望があったのは、フルマネージド版です。それだけでなく、大規模なシステムでは、メタデータの要件の限界に近づいていました。コンピューティングを動的に割り当てられるのと同様に、今ではLustreでストレージを動的に割り当て、システムを起動できるようになりました。お客様はS3という低コストのストレージからデータをハイドレートし、従来のアプリケーションが利用できるPOSIX準拠のファイルシステムを手に入れることができます。ワークフローが完了したら、コンピューティングだけでなく、ストレージもシャットダウンできます。完全に動的なクラスターが実現したわけです。


Lustreを広範に活用しているお客様の一つで、非常に興味深いユースケースとして、次世代Fireflyモデルを開発しているAdobeがあります。彼らはEKSとLustreとEC2インスタンスを使用してこれを実現し、モデリングで20倍のスケールアップを達成しました。考えてみてください - どこでこのようなスケールアップが可能でしょうか?最近、FSx for Lustreの改善点として、先ほどお話したEFA低遅延インターコネクトとの組み合わせを発表しました。以前はLustreはその上では動作しませんでしたが、今年になってEFA上でLustreファイルシステムを実行する機能を追加し、パフォーマンスが大幅に向上しました。今後もIOPS、メタデータ、そして全体的なスループットを改善するための革新を続けていきます。最後に、Amazon File Cacheについてお話しします。

これは、お客様がAWSまたはオンプレミスのファイルシステムの前に高速キャッシュを配置して、データをより迅速にキャッシュできるようにするシステムです。システムの概要を駆け足でお話ししましたが、ここからはNRELのMichaelに、クラウドジャーニーでの取り組みについてお話しいただきたいと思います。
NRELにおけるクラウドHPCの実践例
ありがとうございます、Ian。私はMichael Bartlettで、National Renewable Energy Laboratoryのクラウドエンジニアです。少し長い名前なので、通常はNRELと呼ばれています。私は数年間、クラウドでクラスターを構築してきており、時にはAWSからサポートを受けることもありました。その経験を基に、エンドユーザーの視点からParallel Computing Serviceのベータテストに参加する機会をいただきました。また、私たちの組織がクラウドでHPCをどのように研究に活用してきたか、そしてPCSがその全体像にどう適合するかについて、ここでお話しする機会もいただきました。

ご存じない方のために少し背景をお話しします。NRELは、全国各地に点在するDepartment of Energyの国立研究所の一つです。名前が示す通り、私たちは主にグリーンエネルギーや再生可能エネルギー技術、そしてこれらの技術をより商業的に実現可能にするための様々な課題に焦点を当てて研究を行っています。スマートグリッド技術やエネルギー貯蔵など、関連分野すべてが研究所の研究対象となっています。

研究所における私の所属部門について説明させていただきます。私のチームは Advanced Computing Operations グループの一部です。このグループの使命は、研究者たちが Solution Architect やソフトウェア開発者、システム管理者になる時間や予算を持ち合わせていないことが多いため、様々な科学計算技術へのアクセスを簡素化することです。私が所属する Cloud Operations チームも同じ使命を持っていますが、クラウドコンピューティング技術や、そこに存在する数多くのサービスへのアクセスを促進することに特化しています。
私たちの組織構造の素晴らしい特徴の一つは、オンプレミスの HPC システムを管理している HPC Operations チームと直接隣接していることです。これは素晴らしいことで、定期的に連携を取ることができます。これにより、異なるコンピューティングパラダイムへのアクセスを確立する方法について、一貫性のある統一されたビジョンを持つことができ、さらには、これら2つのプラットフォームのハイブリッド化についても検討を進めることができています。

私の所属する Cloud Operations チームについて、もう少し詳しくお話しします。最も興味深い点は、私たちが研究所の研究者のために働いているということです。通常、研究者と直接相談し、彼らの研究内容や解決したい課題を実際に理解した上で、効果的で最適なアーキテクチャに落とし込んでいきます。これは、私たちが過去にプロジェクトを支援してきたサービス分野のほんの一部です。私たちのチームは2012年から活動しており、研究者と対話し、その研究を理解し、効果的なアーキテクチャに変換するという直感を磨いてきました。


私たちのオンプレミスシステムも同様に、10年以上の長きにわたって存在してきました。組織的な要因により、高度な計算ニーズを持つ研究者にとって、事実上のデフォルトの計算プラットフォームとなっています。システムが長期間存在してきたことと、研究者がそれを使用する傾向にあるという、この2つの事実が組み合わさって、HPC システムを使用するスキルセットが研究者の間で普遍的になり、文化として深く根付いています。これは素晴らしいことです。なぜなら、ほとんどの研究者が HPC を活用できるスキルセットを持っているからです。このスキルセットを活用できれば、新しい言語や設定を学んだり、ワークロードを大幅に変更したりすることなく、認知的負担を増やすことなく、活用できるプラットフォームを拡大することができます。クラウドベースのクラスターが役割を果たすべき場所を特定する上で、これは非常に自然な入り口となります。クラウドベースのクラスターが最適な場所を検討するにあたり、 オンプレミスの HPC クラスターで人々が経験している課題のいくつかを見てみることにしました。
ハードウェアの調達時点で、時間の経過とともにそのハードウェアの性能が固定されてしまうという状況は、Cloudで得られる柔軟性と比べるとやや制限的です。既存のHPCシステムで自分の研究ワークロードがうまく処理できない研究者にとって、これは決して望ましい状況とは言えません。もう一つの課題は、メンテナンス期間です。データセンターのサーバーと同様に、OSのアップグレードやハードウェアのメンテナンスのために定期的にサービスを停止する必要があります。これらは必要な作業ですが、購入した目的のサービスが提供できなくなることを意味します。
最後の点は、科学研究機関である私たちにとってより特有の課題かもしれませんが、HPCシステムへのアクセシビリティに関する継続的な懸念がありました。ソフトウェア開発者である研究者の中には、HPCシステムへのアクセスが当たり前になっている人たちがいます。彼らはパフォーマンス上の理由から、計算能力を前提としたシミュレーションを行うため、HPCネイティブなライブラリを維持しています。しかし、そのソフトウェアを使用したい潜在的なエンドユーザーが、自身のHPCシステムにアクセスできないために除外されてしまうリスクが存在します。
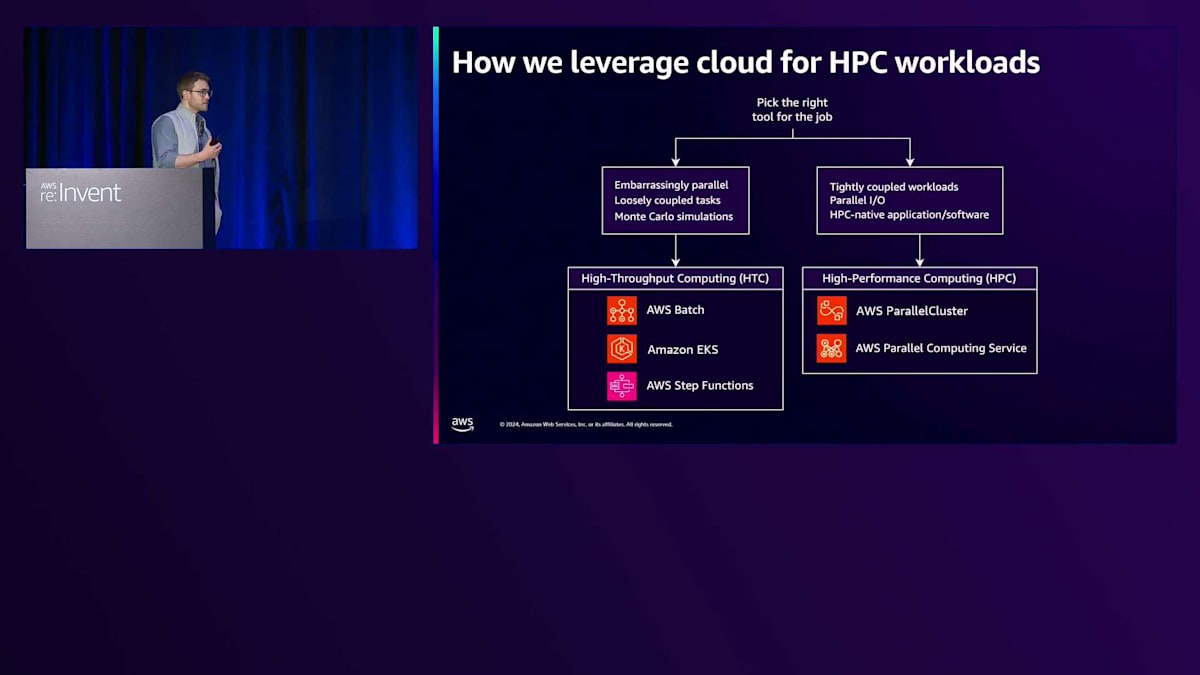
プロジェクトとの相談を重ねる中で、Cloudクラスターが彼らのニーズに合うかどうかを検討していたとき、大規模計算ワークロードという広いカテゴリーの中で、傾向が2つのカテゴリーにきれいに分かれることに気づきました:HPCスタイルのワークロードと、よりCloud-nativeなアプローチが有効な高スループット型のワークロードです。HPCスタイルのアプリケーションは一般的に識別が容易です - 個々の実行間でメッセージをやり取りする必要があるか、並行I/Oをサポートするパフォーマンスファイルシステムに依存しています。最も分かりやすい指標は、以前HPCシステムで実行されたことがあるかどうかです。これらについては単純で、クラスター管理サービスの1つを使用してクラスターを作成し、そのジョブを実行するだけです。
より疎結合で、いわゆる"embarrassingly parallel"なワークロードについては、よりCloud-nativeなアプローチを採用できます。これらは柔軟性だけでなく、パフォーマンスの面でもメリットが得られることが一般的です。例えば、コンテナ型のワークロードであれば、AWS BatchやKubernetesのようなコンテナオーケストレーションサービスを使用できます。さらに、ジョブがLambdaランタイムに適合する場合は、Step Functionsを追加するだけで、簡単に並行処理レイヤーを提供できます。

最近、このCloud-nativeアプローチで支援できたワークロードの例を紹介します。詳細は大きな図を理解する上ではそれほど重要ではありませんが、基本的に、このプロジェクトは、オープンなS3バケットで利用可能なLIDARデータセットを使用して、建物の屋根の上に太陽放射情報をマッピングしようとしていました。彼らのワークロードはすでにLambdaランタイムだったので、Step Functionsが適しているかどうかを試してみる価値がありました。彼らはこのオープンデータセットを読み込み、屋根の位置を処理し、太陽放射情報を適用して特定の地域の屋根の太陽光発電ポテンシャルを理解し、それを自身のS3バケットに書き出し、エンドユーザーがそのバケットに簡単にアクセスできるようにするソフトウェアライブラリを作成しました。

ここでのポイントは、このプロジェクトのためにHPCクラスターを構築することもできましたが、正直なところそれは過剰であり、柔軟性を犠牲にし、コンピュートノードイメージを設計し、必要なソフトウェアライブラリを確保する必要があったということです。Step Functionsと比べると、同時実行のスケーリングにおいてやや柔軟性が低くなります。Step Functionsでは単に必要な同時実行数を指定するだけで済むからです。では、これがクラウドベースのHPCに適していない例だとすれば、私たちにとってHPCが適していたケースとは何だったのでしょうか? これらが私たちの成功事例です。ここで注目すべき点は、これらのほとんどがParallelClusterツールを使用して実現されたということです。ParallelClusterは昨年8月にローンチしたParallel Computing Serviceと比べて、すでに数年の実績があります。そのため、より多くのソリューションに組み込んで活用する機会がありました。
Parallel Computing Serviceの魅力と将来計画
上の2つのポイントは、キューの混雑とシステムへのアクセス全般に関連しています。オンプレミスのキューでは通常数日から数週間の待ち時間が発生しますが、プロジェクトによってはこのキューをバイパスする必要がある場合があります。締め切りが迫っているなどの理由で長時間待てないプロジェクトの場合、私たちはそのニーズに合わせたコンピュートノードイメージを設計し、カスタマイズされたクラスターを構築することで、オンプレミスの状況を気にすることなくワークロードを実行できるようにします。
次のポイントは、その状況のより極端なケースを示しています。オンプレミスシステムは有限のリソースであるため、プロジェクトが一定期間のアクセスを申請し、承認されるものとされないものが出てくる承認プロセスが存在します。承認されなかったプロジェクトが作業を進められなくなるのを避けるため、同様の対応を行い、大幅な改修を必要とせずにワークロードを実行できるカスタマイズされたクラスターを作成することができます。
最後のポイントは、先ほど触れた特殊な課題に対応するものです。HPC対応のオープンソースライブラリを保守している開発チームの中には、AWS ParallelClusterのサンプル設定ファイルとドキュメントを提供し、エンドユーザーが適度な規模のHPCクラスターを簡単に構築できるようにしているところがあります。これにより、ユーザーは彼らのソフトウェアを試し、必要に応じてスケールアップすることができます。科学組織として再現性は重要であり、ParallelClusterを使用するプロジェクトでは設定ファイル全体を含めることで、他の人々が同一のシステムを再現し、結果を検証できるようになっています。

私たちのParallelClusterの使用経験は、 Parallel Computing Serviceのどの機能が特に魅力的かを判断する上で参考になりました。最も重要なのはInfrastructure as Codeとの統合です。Ianが言及したように、まもなくCloudFormationのサポートが開始され、他のインフラストラクチャ アズ コードツールもすぐに続く予定です。これは素晴らしいことです。なぜなら、ParallelClusterは強力なツールですが、インストールが必要な別個のソフトウェアユーティリティであり、解決しようとしている問題を考えると、その設定構文は複雑になりがちだからです。Parallel Computing ServiceのInfrastructure as Codeを使用すれば、運用チームがすでにこれらのツールを使用している場合、追加でインストールする必要がなく、既存のスキルセットを活用してクラスターを作成できます。
同様に、AWS SDKsについても、完全な状態管理機能が必要ない場合、例えばWebアプリケーションの作成やクラスターの状態を変更するためのイベント駆動型パイプラインの構築などが適したユースケースとなります。私のチームは特に、Parallel Computing Serviceコンソールへのアクセス提供に力を入れています。というのも、クライアントが自立的にインフラを構築できるよう支援し、私たちチームの仲介的な役割を減らすことに注力してきたからです。これは正式なAWSサービスなので、コンソールビューを備えており、ユーザーが必要に応じて自身でクラスターをスピンアップできるようなリースパーミッションアクセスの付与を検討しています。最後のポイントは、AWSマネージドサービスの一般的なメリットを反映しており、個々のシステムコンポーネントの管理・保守にかける時間を減らし、システムの利用により多くの時間を費やすことができます。

これまでの成功と、Parallel Computing Serviceローンチの魅力的な点についてお話ししてきましたが、ここからは近期および長期的な計画についてお話しします。最初のポイントは、Infrastructure as Codeモジュールや各種スクリプト、ユーティリティの追加です。研究者の方々は作業の進め方やスピンアップするインフラストラクチャに関して多様な好みを持っているため、そのサービスで十分にサポートされ、すぐに作業できる環境を確保したいと考えています。2番目のポイントは、先ほど触れたハイブリッド化の取り組みです。オンプレミスのスケジューラーと統合し、必要に応じて適切なジョブをクラウドにバーストできるハイブリッドスケジューラーの構築に興味を持っています。オンプレミスシステムの様々なワークロードを分析し、適切な候補を特定しました。それらは主に、ハードウェアに大きな負荷をかけない低リソースのジョブです。これらのジョブはオンプレミスのスケジューラーにとってノイズとなり、オンプレミスシステムが得意とする大規模なジョブに十分なノードとリソースを割り当てることを難しくしています。
このアイデアは、これらの小規模なジョブをクラウドにバーストアウトしてリソースを解放し、オンプレミスのスケジューラーがより早く、より頻繁に大規模なジョブを実行できるようにすることで、すべての関係者にメリットがあるというものです。また、このセットアップでは、メンテナンス期間中の中断を軽減し、システムのサービス期間中でも一部のジョブを継続して実行できるという副次的なメリットも期待しています。
最後のポイントは、特殊なハードウェアへのアクセスを可能にすることです。例えば、研究者が機械学習に特化したEC2インスタンスの使用に興味を持っている場合、その場でカスタマイズされたパーティションを作成して使用できるようになります。スケジューラーがコードやデータにより近い位置にあるため、EC2インスタンスを単独でスピンアップするよりも簡単になります。この最後のポイントは、長期的に実装しようとしている哲学的な目標であり、適切なサイジングの自動化を支援し、研究者のワークロードを実際の実行プラットフォームから抽象化しようとするものです。これには、ワークロードが実際に実行される前に予測的に特性を把握し、最適なコンピューティング環境を提案するような機械学習モデルの活用も含まれるかもしれません。
AWSのHPC成功事例と今後の展望

以上が、私の組織がクラウドベースのHPCで達成できたことの簡単な概要です。ご質問があれば、最後にお受けする時間があると思います。それでは、Ianに締めくくりをお願いしたいと思います。ありがとうございます、Michael。この具体的な業界の例が参考になったことを願っています。最後に、AWSでHPCアプリケーションを成功裏に実行している顧客のワークロード例をいくつかご紹介したいと思います。将来の持続可能性の観点から特に興味深いと思うのは、Wiskが取り組んでいるeVTOL航空機です。バッテリー密度に関する課題を考慮しながら、電動飛行という未来の飛行のあり方を再考しており、AWSで複数のワークロードを実行しています。Commonwealth Fusion Systemsは核融合発電の未来を象徴しています。これは、ジェネレーティブAIの発展に伴い、ここ数年で指数関数的に増加しているデータセンターの電力需要を考えると、非常に魅力的です。Rivianは素晴らしいパートナーで、安全性テストや電動輸送のための未来の車両設計に関する彼らの取り組みは非常に興味深いものです。23andMeは、遺伝子配列解析アルゴリズムの実行時に、AWS Batchを通じて数十万のvCPUにスケールアップしています。ほぼすべてのワークロードに適した顧客事例がありますので、お客様の特定のケースやワークロードがAWSでどのように機能するかについてご質問がありましたら、ぜひお問い合わせください。成功を収めた事例を参考に、パートナーとしてご協力させていただけると思います。

お気に入りのチップベンダーから、幅広いパートナーエコシステムを構築しています。AWSでよく話題に上がることの1つに、私たちは選択肢を重視しているということがあります。これは時にメリットにもなれば、面倒な課題にもなり得ます。850種類のInstanceがあると言うと、とても興奮するお客様もいれば、どれを選べばいいのかと悩むお客様もいます。そのため、私たちにはConsulting Partnerがいて、お客様と協力しながら、各業界に特化したパイプラインやオーケストレーションを構築し、システムの成功に最適なInstanceとクラスターアーキテクチャの選定をサポートしています。


最後に、私のチームの自慢を少しさせていただきたいと思います。先日開催されたSupercomputing Conferenceで、 私たちは7年連続でBest HPC Cloud Platformを受賞し、さらにAWS PCSがHPC分野で注目すべきTop 5テクノロジーの1つに選ばれるなど、合計6つの賞をいただきました。お客様がこのサービスでどのようなことを実現されるのか、とてもワクワクしていますし、今後もサービス改善に向けてフィードバックをお待ちしています。


そして最後に、皆様へこのような課題を投げかけたいと思います: 皆様の職場でイノベーションサイクルを向上させるために、動的に割り当て可能なComposableリソースをどのように活用されますか? ご清聴ありがとうございました。後ほど質疑応答の時間を設けていますが、もし時間の都合で質問ができない場合は、MichaelまたはPrivateまでご連絡ください。連絡先を表示していますので、ぜひセッションのアンケートにもご協力ください。皆様からのフィードバックは、次回のセッションをより良いものにするために重要です。お時間をいただき、ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion