re:Invent 2024: AWSが語るOpenSearchの進化とLinux Foundation移行


はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - OpenSearch: A journey from fork to Linux Foundation (OPN201)
この動画では、AWSのOpenSearch Product DirectorのCarl MeadowsとSenior ManagerのPallavi Priyadarshiniが、OpenSearchのフォークから現在までの道のりを解説しています。2021年のElasticのライセンス変更を受けてOpenSearchをフォークし、3年半で75のパートナー、7億回以上のダウンロード、1,000人以上のコード貢献者を獲得するまでに成長しました。2024年にはLinux Foundationへの移行とOpenSearch Software Foundationの設立を実現し、よりオープンなガバナンスを確立。Vector Database機能やGenerative AI検索、Hybrid Search、Query Engineの改善など、9つの重点テーマに沿って技術的イノベーションを進めており、OpenSearch 2.17では1.3と比べて6.5倍の性能向上を達成しています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
OpenSearchプロジェクトの概要と本日の講演内容



AWS の OpenSearch の Product Director を務めております Carl Meadows です。本日は、OpenSearch のエンジニアリング部門を率いる Senior Manager の Pallavi Priyadarshini も一緒に登壇します。Product Director として、Amazon OpenSearch Service および Prometheus と Grafana Services、そして AWS のオープンソース OpenSearch プロジェクトへの参画を統括しています。本日は OpenSearch について、フォークから Foundation 設立までの道のりをお話しさせていただきます。皆様にお越しいただき、大変嬉しく思います。アジェンダとしては、まず OpenSearch の背景、コミュニティパートナー、Software Foundation についてお話しし、その後 Pallavi がイノベーションの道のりと今後のロードマップについて説明します。最後に、皆様がどのように参加できるかについてお話しさせていただきます。
OpenSearchの誕生と成長:フォークからFoundationまでの道のり
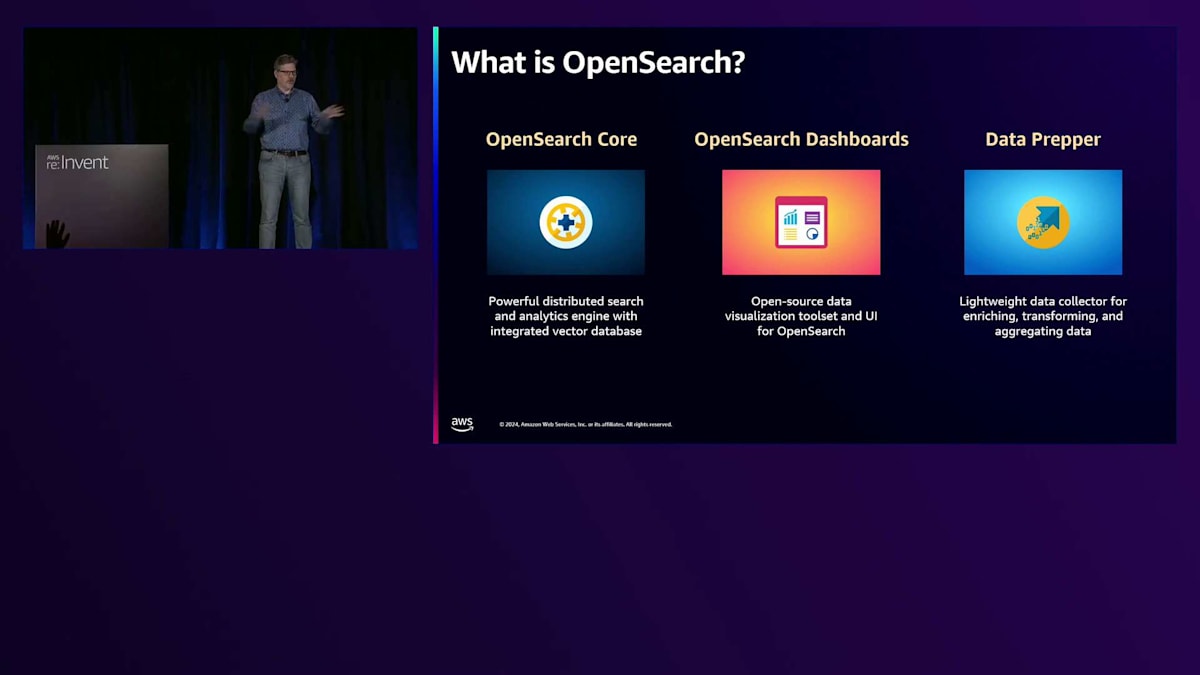
2021年、Elastic が Elasticsearch のライセンスを変更した後、私たちは Elasticsearch 7.10 から OpenSearch をフォークし、コミュニティ主導のプロジェクトを構築することを目指しました。AWS がこのフォークを AWS 管理プロジェクトとしてリードする中で、コミュニティを構築するためのメカニズムを整備しました。この点については Pallavi が詳しく説明しますが、OpenSearch の核となるのは 120 以上のリポジトリを持つ 3 つの主要ソフトウェアプロジェクトです。1つ目は OpenSearch Core で、これは Vector データベース機能を統合した分散型の検索・分析エンジンです。Apache Lucene という OpenSearch の基盤となる検索ライブラリ上に構築されています。2つ目は OpenSearch Dashboards で、ログの発見、データの可視化、Search Workbench の利用、異常検知やアラームの設定、そしてそれらの Observable な体験を可視化できるフロントエンドコンポーネントです。
3つ目は Data Prepper です。Data Prepper は、私たちが一から構築した非常に軽量なデータコレクターです。複数のデータソースからプッシュとプル両方のメカニズムでデータを収集し、OpenSearch に簡単にデータを取り込み、変換、エンリッチ、集約し、OpenSearch クラスターやコレクション、S3 など適切な送信先にルーティングすることをサポートします。複数のデータを簡単に取り込めるように設計されています。例えば、マネージドサービスにおける DynamoDB や DocumentDB とのゼロ ETL 統合では、Data Prepper をバックエンドで使用して DynamoDB からデータを取り出し、変換して、OpenSearch 上で検索アプリケーションを構築するために必要なフォーマットに整えています。

お客様やユーザーが OpenSearch の新しい興味深い使い方を見つけ出すたびに、いつも感心させられます。OpenSearch は非常に柔軟なプラットフォームで、開発者は様々なことができますが、主に 4 つの重要な分野に分類されます。1つ目は検索エンジンとしての利用です。これは元々の設計意図であり、現在も検索体験の構築や高い関連性を持つ結果の提供に非常に人気があります。ファジー検索、ファセット検索、オートコンプリート、ハイブリッドおよびベクトル機能を含む、検索体験のための豊富な機能セットを備えており、Vector 検索とフルテキスト検索、Semantic 検索を組み合わせて実装できます。この分野では多くのイノベーションが見られ、非常に人気があります。というのも、最近では多くの人々が検索の方法を見直しており、フルテキスト検索で必要だった手動チューニングなしでも、モデルがお客様の意図をより良く理解できるようになってきているからです。この分野では多くのイノベーションと人気が見られ、これは OpenSearch が AI/ML アプリケーションのバックエンドとしてよく使用される理由にもつながっています。
OpenSearch は、レコメンデーションシステム、不正検知システム、Chat RAG など、より多くの AI/ML 駆動の検索問題に頻繁に使用されています。分析面では、大量のデータの処理、集計の実行、インサイトの発見、大規模なデータセットに対する高速なフォレンジックおよび検索分析が得意です。これは特にログ分析や Observability のユースケース、そしてベンダーやお客様が膨大なデータの中からインサイトを見つける必要があるセキュリティ分析で人気があります。例えば、OpenSearch に参加し、OpenSearch 上に構築された人気の商用製品として Wazuh があります。そのバックエンドは完全に OpenSearch によって支えられています。

Version 1.0のリリースから3年半前にプロジェクトをフォークして以来、このプロジェクトは大きく成長してきました。120以上のリポジトリを持ち、75のパートナーが OpenSearch 上で商用ソリューションを構築しています。これらのパートナーには、Oracle、DigitalOcean、Aiven、NetApp Instaclustrなどのサービスプロバイダーから、検索アプリケーションやエクスペリエンスの構築を支援するコンサルティングやプロジェクト作業を行うシステムインテグレーター、さらにはWazuhのような独自の製品を構築する他のISVまで含まれています。これまでに21回のローンチを行い、7億回以上のダウンロード数を記録し、opensearch.orgでは140万ページビューを達成しています。パブリックSlackチャンネルは3,000人近くのメンバーを抱え、より永続的な技術的投稿のためのフォーラムには6,000人以上のメンバーがいます。1,000人以上からコード貢献を受け、現在ではAWS従業員ではない43人のメンテナーが OpenSearch プロジェクトに参加しています。

このような成長に伴い、プロジェクトの継続的な成長とイノベーションを実現しながら、人々が参加しやすい環境を作るために次のステップを踏む時期が来たと認識しました。誰もがより平等な立場で参加できる中立的な財団に移行する必要性が明確になってきたのです。さらに、多くの企業がベンダー管理のプロジェクトに多大な投資をすることに対して、当然の懸念を持つようになってきました。AWS管理のプロジェクトとして、AWSが方針を変更する可能性のあるプロジェクトに大きく賭けることを企業が警戒するかもしれません。 そこで、9月に OpenSearch を Linux Foundation のトップレベルプロジェクトとして移行することを決定しました。技術的なコードを貢献してきた多くのメンバーで構成される Technical Steering Committee を設置し、Linux Foundation の強みを活かしてプロジェクトの成長と継続的な構築を支援しながら、より多くの人々を招き入れ、持続可能なガバナンスモデルを構築するためのプロセスを確立しました。

同時に、プロジェクトの推進と支援を目的とした別組織として OpenSearch Software Foundation を設立しました。OpenSearch Software Foundation は、AWS、Uber、SAPなどのプレミアムメンバーと、プロジェクトを財政的に支援する他の一般メンバーで構成されています。この財政的支援は、開発者教育の推進、OpenSearch カンファレンスの開催、ウェブサイトの魅力向上、より良いブログの作成、そして採用の促進に役立てられています。ただし、OpenSearch Software Foundation は技術プロジェクトとは別個のものであることを明確にしておきたいと思います。OpenSearch を使用したり、プロジェクトに技術的な影響を与えたりするために、OpenSearch Software Foundation のメンバーになる必要はありません。
プロジェクトに技術的な影響を与えるには、コードを提供し、コミュニティと協力し、メンテナーとして選出されてプロジェクトへのアクセス権を得るというプロセスに従うことが重要です。Technical Steering Committee の議長は Anandi で、彼女は governing board のメンバーでもあり、プロジェクトを代表しています。プロジェクトが監査のための資金などのリソースを必要とする場合、彼女がその要請を governing board に持ち込むことになります。governing board の議長として、私はプロジェクトの推進と構築に関わっています。
OpenSearchのイノベーションの軌跡:2021年から2023年まで

ここからは Paul に引き継ぎたいと思います。Paul は AWS のエンジニアリングリーダーで、OpenSearch Core やその他のイニシアチブを統括しています。彼女が、これまでの私たちのイノベーションについて説明し、その後、私が締めくくりを行います。ありがとう、Carl。オープンソースコミュニティのサポートを受けて OpenSearch が取り組んできたイノベーションの旅と、プロジェクトの未来を共に築くためにそのコミュニティをエンパワーするために私たちが行っていることについて、ご説明できることを嬉しく思います。
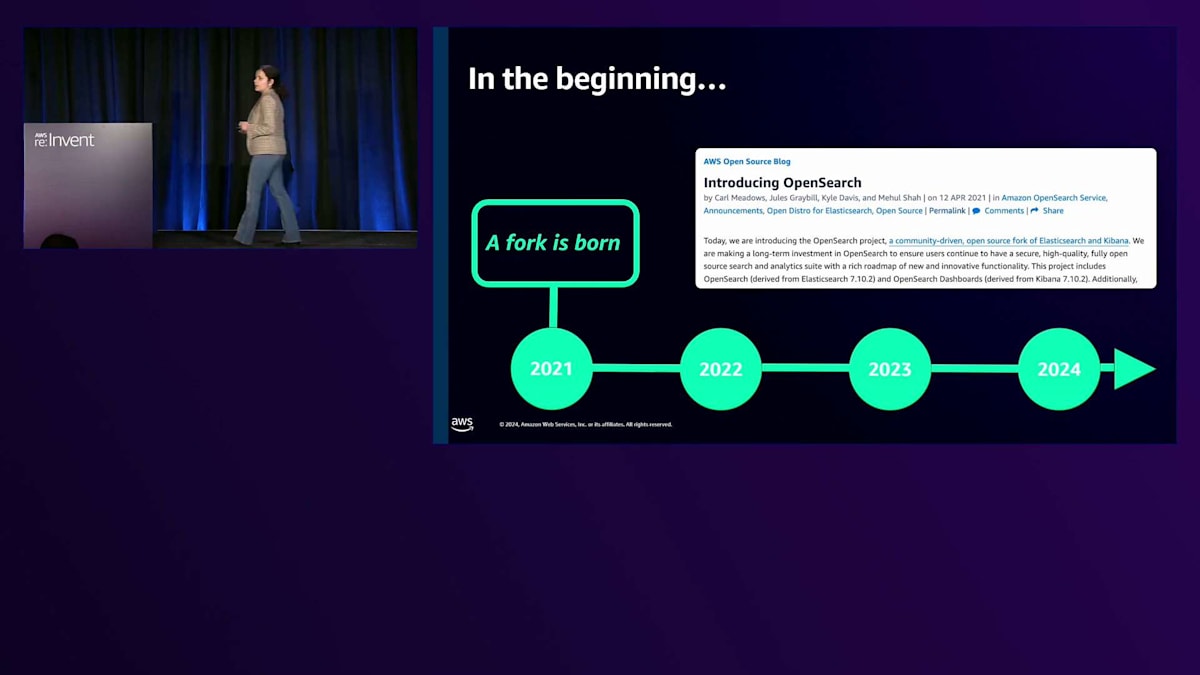

Elasticが2021年にElasticsearchのライセンスをより制限的なものに変更した際の対応については、すでにCarlが説明しました。その時、ユーザーがよりオープンソースな選択肢を求めていたため、AWSはフォークをリリースすることを決定しました。 OpenSearchフォークをリリースするというこの旅は、エキサイティングでありながら、多大な労力を必要としました。フォークの規模と複雑さは膨大で、このプロジェクトを立ち上げるために650のプルリクエスト、56,000のファイル、そして450万行のコードが修正されました。2021年のOpenSearch 1.xラインのリリースでは、コミュニティが望むすべての配布形態で利用可能で、相互運用性のある安定したリリースを実現することに重点を置きました。
安定したリリースと堅牢なビルドシステムが整った2022年は、まさに「聞く」と「学ぶ」の年でした。AWS内のOpenSearchプロジェクトチームとAWSのプロジェクトスポンサーは、より多くのユーザーやコントリビューターにこのコミュニティの一員となってもらうよう呼びかけ、オープンソースコミュニティを活性化する方法を学ぶことに多くの時間を費やしました。 意外に聞こえるかもしれませんが、AWSはそれまでOpenSearchのような規模と軌跡を持つオープンソースプロジェクトを主導した経験がありませんでした。AWS内のチーム、そしてより重要なことに、パートナー、組織、外部のコントリビューターとの信頼関係を築くための適切なアプローチを学ぶ必要がありました。私たちは、ユーザーフォーラム、ブログ投稿などの公開コミュニケーションチャネルを活用してコミュニティとの信頼関係を築き、イノベーションの手段としてGitHubを積極的に活用しました。


2023年には、私たちは真のオープンソースファーストの考え方を採用し、強力なオープンソースコミュニティの真の可能性を実感しました。2023年初頭、CNNアルゴリズムやVector Databaseの機能における初期のイノベーションにより、Generative AIの台頭がオープンソースを最前線に押し上げました。私たちは検索パフォーマンスやHybrid Searchを含むVector Databaseのさらなるユースケースへの投資を始めることが重要だと考えました。 コミュニティの一部として起こっていたすべてのイノベーションに加えて、もう一つの重要な変化がありました。それは、よりオープンで透明性の高いガバナンスへの推進です。2023年には、オープンで透明性の高いガバナンスを推進するためのリーダーシップ委員会が設立され、これが2024年のLinux Foundationへの移行につながる基盤となりました。

アクティブなオープンソースコミュニティを構築するための取り組みは実を結びました。2023年は複数の分野で大きな進展を遂げて締めくくりました。検索パフォーマンスやVector Database、Hybrid Searchにおける大きな進歩など、検索とGenerative AIの改善が最も注目を集めました。コミュニティは大きく成長し、25以上の組織からメンテナーが参加するようになりました。プロジェクトのウェブサイトopensearch.orgは月間100万人の訪問者を達成し、多くの新しいコントリビューターや外部ユーザーがコードを提供するためにOpenSearchに参加する一方で、既存のコントリビューターはさらに深く関与するようになりました。Aivenはコードの重要な部分を提供し、Intelは新しいZastanard圧縮の形でパフォーマンスの改善に貢献しました。

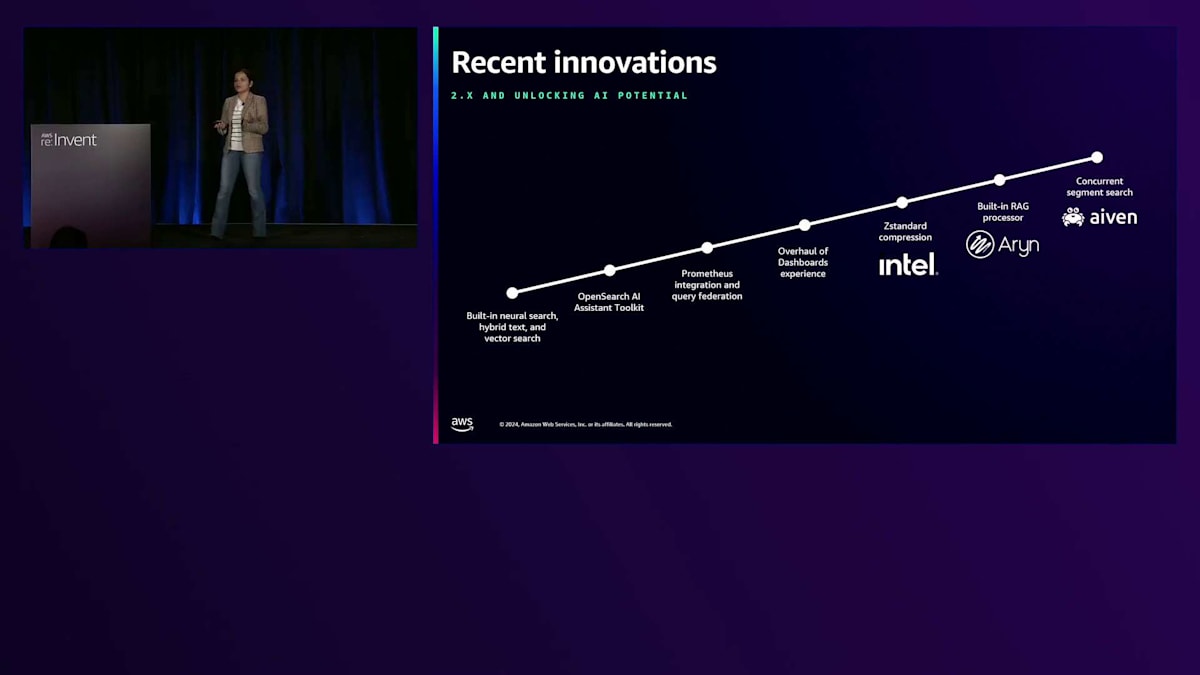
2024年には、Carlが既に説明したように、より中立的なLinux Foundationへの移行と、多様なステークホルダーで構成されるGoverning BoardとTechnical Steering Committeeの設立について説明しました。現在、私たちは非常に活発なオープンソースコミュニティを持っており、これが今後のすべてのイノベーションの基盤となります。このタイムラインが示すように、オープンソースの取り組みの初期段階では、多くの貢献がAWS内部からのものでした。しかし、時間の経過とともにオープンソースプロジェクトとして成熟するにつれ、外部のユーザーやコントリビューターからのイノベーションが増えていきました。
OpenSearchの技術的進化と2024年以降のロードマップ

私たちが構築したオープンソースコミュニティは、将来へのロードマップを確立しています。これは完全にコミュニティ主導のロードマップです。2024年9月、私たちは様々な分野で進行中のイノベーションをより良く整理するため、9つのテーマを導入してロードマップのプロセスを刷新しました。これらのテーマは、VectorとGenerative AI検索、使いやすさ、Observability、セキュリティ分析、コストパフォーマンスとスケール、安定性・可用性・回復力、セキュリティ、モジュラーアーキテクチャ、そしてリリースとプロジェクトの健全性です。これらの各テーマは私たちにとって重要であり、コミュニティがこれらのテーマに沿ってイノベーションを整理できるよう、バックグラウンドでメカニズムを構築しました。
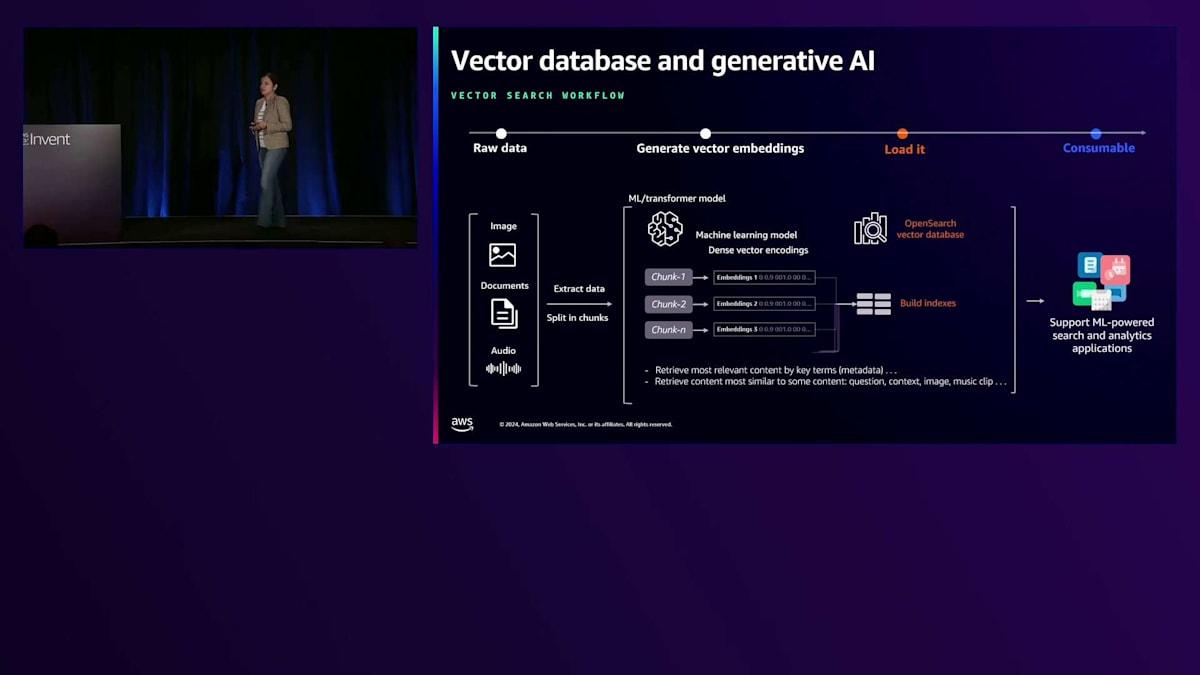
数分かけて、コミュニティが2025年以降の技術的方向性を作り上げた各テーマについて説明していきます。まず、VectorとGen AIについて説明します。 先ほど述べたように、2023年のGenerative AIとLLMの台頭により、Vector DatabaseとしてのOpenSearchに新たな機会が生まれました。
現在では、音声、動画、文書などの企業の非構造化コンテンツをチャンク分割し、Transformerモデルを通してEmbeddingを生成することができます。OpenSearchはこれらのVector EmbeddingをkNNインデックスとして保存できます。これらのVector EmbeddingをOpenSearchに保存すると、幅広いAI/MLベースの検索ユースケースで利用できるようになります。
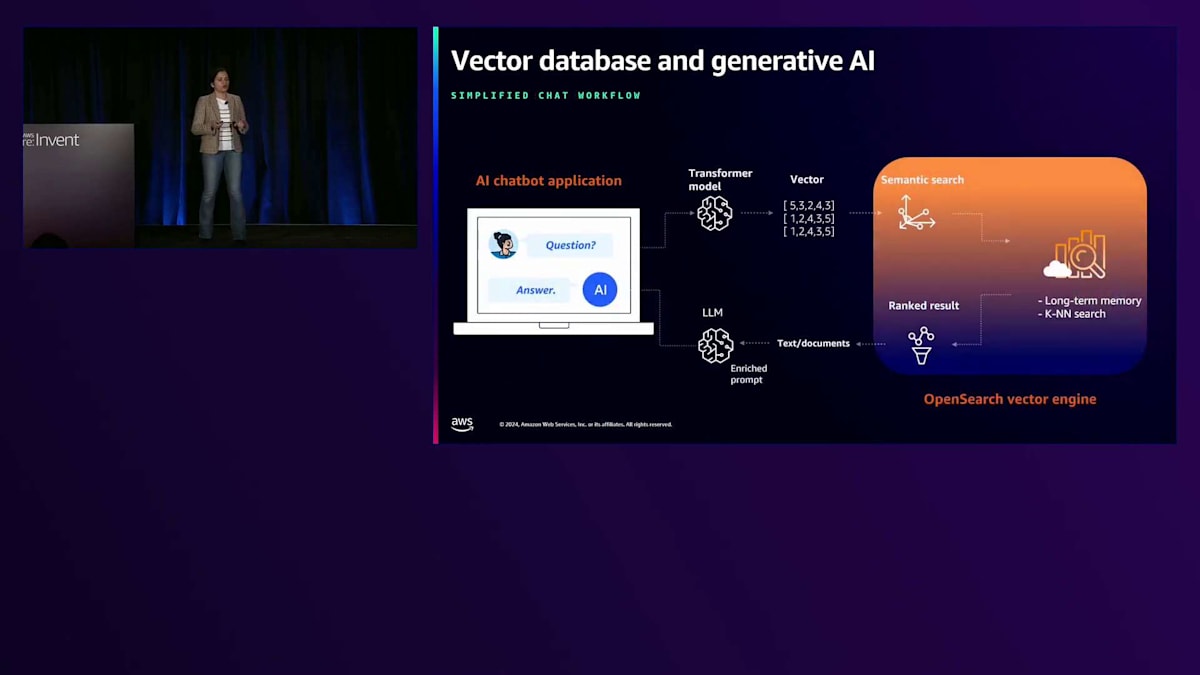
この図は、Chatbotアプリケーションの構築という、新しい検索のユースケースを示しています。Chatbotアプリケーションを使用すると、自然言語でクエリを入力できます。この質問はTransformerモデルを使用してVector Embeddingに変換され、OpenSearch内のkNNアルゴリズムを使用したSemantic Searchフローを通じてランク付けされた結果を返します。これらのランク付けされたドキュメントは、LLMへの豊富なプロンプトとなり、ユーザーに回答を返します。前のスライドはインデックス作成の側面を示し、このスライドは新しい検索ユースケースがどのように実現されるかを示しています。

Vector DatabaseとしてのOpenSearchは、広く採用され、大きな成功を収めています。現在、Vector検索の価格対性能を向上させるため、複数のイノベーションがロードマップに組み込まれています。メモリ使用量の少ない環境でVector検索を最適化するため、2段階のkNN検索を実装しています。第1段階ではメモリ内の量子化インデックスを使用し、第2段階ではディスクに保存された完全精度のVectorに基づいて結果を再ソートします。また、Product Quantizationを使用したVectorのメモリ最適化や、Vector Embeddingのインデックス構築時間を高速化するためのGPU活用にも取り組んでいます。Vector Indexに対するWarm TierやCold Storeの統合を進めており、より賢いデフォルト値やハイパーパラメータ、Auto-tuneとの統合により、すぐに使える優れた体験を提供したいと考えています。
AI/ML検索のユースケースに焦点を当てると、ロードマップには様々な開発計画が含まれています。Neural Searchは重点的に改善を進めている分野の一つで、SageMaker、Cohere、OpenAIなどのInferenceサービスを使用したバッチオフライン処理のサポートを含みます。多言語サポートを備えたより効率的なSparseモデルの実現に向けて取り組んでいます。開発者を中心に据えた取り組みを行っており、初心者ユーザーでもAIを活用した検索体験を作成できるLow-codeの検索フロービルダーの構築を目指しています。
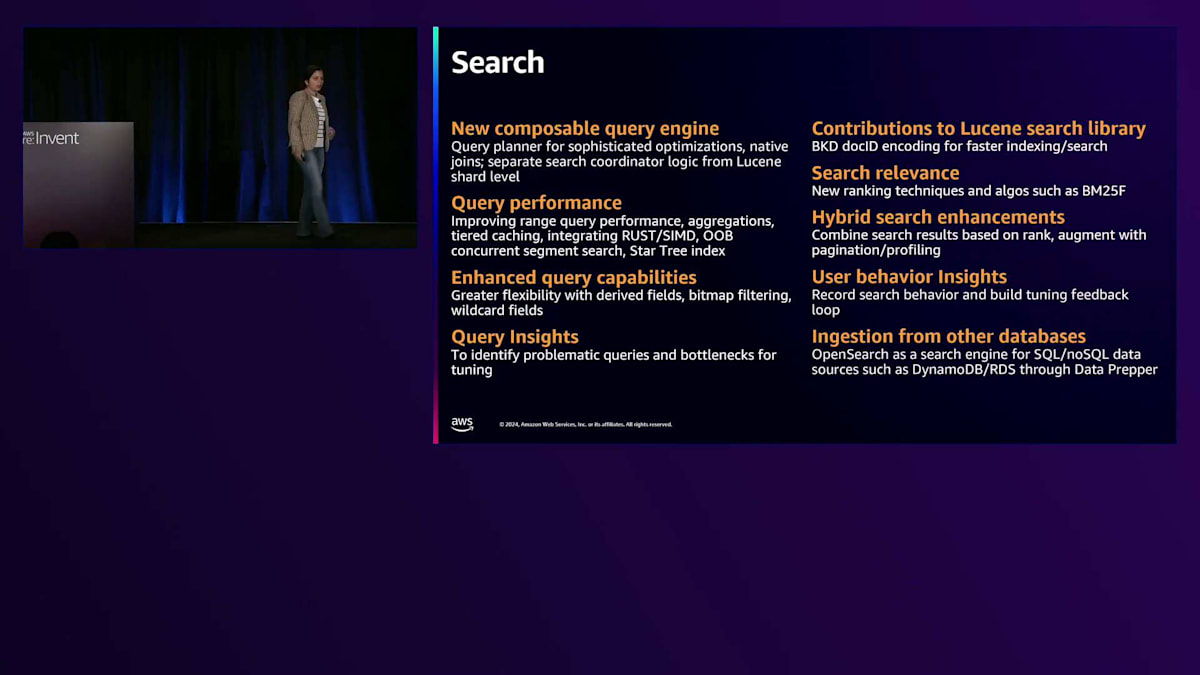
OpenSearchの本質は検索エンジンであり、その上に検索と分析のより複雑なユースケースを構築しています。OpenSearchのQuery Engineが柔軟で高性能であることを確実にしたいと考えています。Query Engineをより分散化し、さまざまなエンジンをプラグインできるように構成可能にすることで、改善を図る複数の取り組みが計画されています。クエリ実行をより最適化するため、OpenSearchへのLogicalおよびPhysical Query Plannerの導入作業が開始されています。
クエリのパフォーマンスは私たちの重要な注力分野です。ほとんどの検索・分析ユースケースでは、Query Engineが提供する一般的な操作を利用しており、テキストから日付ヒストグラム集計まで、さまざまなクエリ操作のパフォーマンス向上に焦点を当てています。より複雑なワークロードに対しては、RUSTやSIMDなどの最新技術の採用を進めています。大量のクエリ結果に対しては、結果をディスクにスピルするTiered Cachingや、Concurrent Segment Searchなどの新しいイノベーションを導入しています。
クエリパフォーマンスに関してはロードマップに多くの項目がありますが、新しいタイプのワークロードがOpenSearchに導入されるにつれて、コアのクエリ機能も強化しています。新しいField Typeを導入しており、Query Insightsは、オープンソースですべてのプリミティブを備えた新しいイニシアチブとして開発中です。Query Insightsの一環として、クエリパフォーマンスのボトルネックを特定し、クエリを微調整するためのすべての情報を提供したいと考えています。さらに重要なのは、AIテクノロジーと統合してレコメンデーションエンジンを構築することです。
私たちは、OpenSearchのクエリエンジンだけでなく、Luceneにおいても深く取り組みを進めており、そこでも積極的な貢献を行っています。最近の例として、検索とインデックス作成の両方に役立つBKD docIDエンコーディングがあります。BM25Fのような検索の関連性を向上させる新しいアルゴリズムにも取り組んでいます。Hybrid searchの改善も計画されており、ユーザー行動の洞察は検索体験を微調整するためのフィードバックループの構築を支援する別のイニシアチブです。私たちは、OpenSearchがRDS、DynamoDBなどのSQLやNoSQLデータベースなど、他のすべてのデータベースにとって選ばれる検索エンジンとなることを目指しており、Data Prepperを通じてこれらのデータベースとのより良い統合のためのイニシアチブを進行中および計画中です。

先ほど申し上げたように、検索パフォーマンスは私たちにとって重要な注力分野です。なぜなら、これは検索や分析ワークロードに必要な多くのクエリ操作の基盤となるからです。OpenSearch Benchmarkをオープンソースの第一級のベンチマーキングツールにするために、大きな投資を行ってきました。略してOSBと呼ばれるOpenSearch Benchmarkは、新しいワークロードの追加が可能で、予測可能性があり、毎晩結果を投稿し、テラバイト規模のデータにまでスケールできます。OpenSearch Benchmarkに新しいワークロードを導入し、このグラフは私たちのBig Fiveワークロードからのベンチマーキング結果を示しています。Big Fiveワークロードは、検索と分析ワークロードで一般的な約4,541のクエリ操作を捕捉し、クエリのレイテンシーを示し、コアクエリエンジンの最適化への戦略的な投資を実証しています。2024年9月にリリースされたOpenSearch 2.17は、OpenSearch 1.xラインの最後のリリースであったOpenSearch 1.3と比較して6.5倍のスピードアップを達成しました。

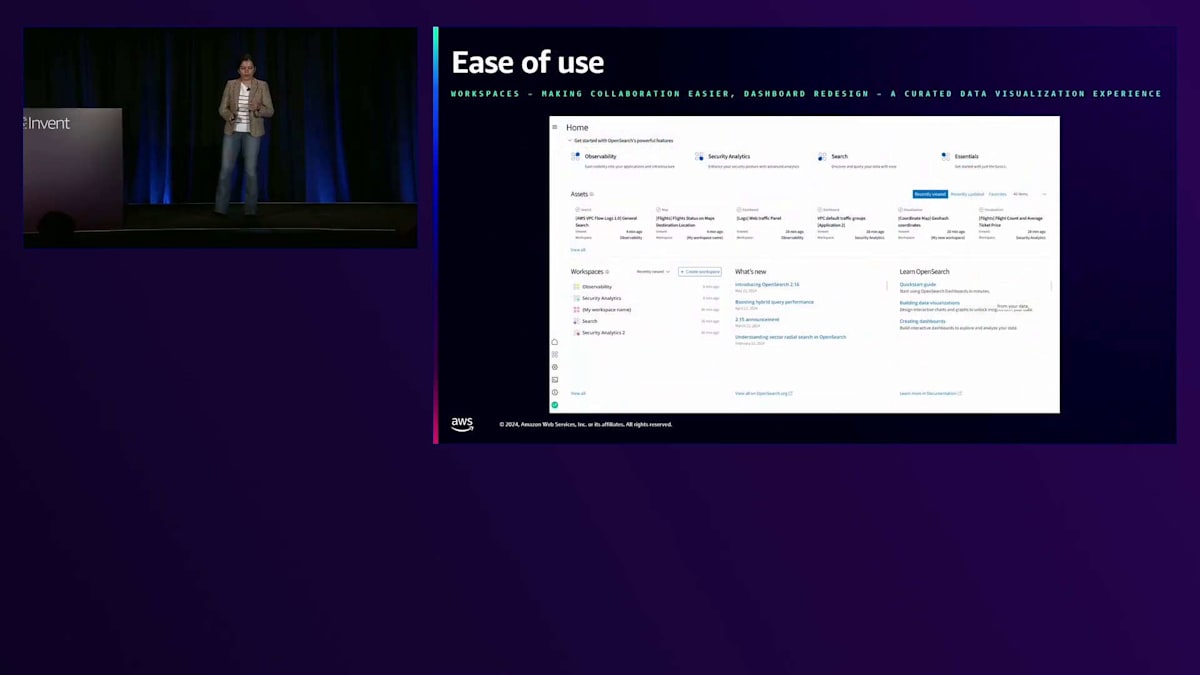

使いやすさは、Dashboardsエクスペリエンスの改善においてもう一つの重要なテーマです。マネージドサービスで最近立ち上げられた機能がある一方で、私たちはオープンソースでプリミティブを構築しています。オープンソースでマルチデータソースとバージョンデカップリングのサポートを構築しました。Dashboardsでワークスペースを使用してより良いコラボレーション体験を構築しており、最も重要なのは、ダッシュボードのルックアンドフィールを向上させたことです。より現代的なUIを備えています。
次に、Observabilityとセキュリティ分析に移ります。ロードマップには、ログ、メトリクス、トレースの相関付けを容易にするための多くの計画があります。すでにOpenTelemetryとの統合があり、最近公開されたDiscoverでSQLとPiped Processing Language(PPL)による共通のエクスペリエンスを提供したいと考えています。Discoverを、クエリの微調整、可視化の作成、アラートの発信、レポートの生成ができる中心的な分析ハブにしたいと考えています。OpenSearch外に保存されたデータの低コストストレージのためのApache Sparkとの統合は、継続的な投資分野です。Data Prepperの機能強化は、より多くのデータ取り込み方法をサポートし、Apache Kafkaなどのより多くのシンクをサポートするために計画されています。セキュリティ分析では、脅威検出のためのより統合されたエクスペリエンスと、Generative AIワークフローとの統合を提供します。

コスト、パフォーマンス、スケールに関して、OpenSearchの素晴らしさは、その高度な機能やベンチマークだけでなく、低コストで大規模に実行できることにあります。検索やインデックス作成のパフォーマンスを含む、さまざまな分野でパフォーマンスの改善を続けています。最近、インデックス作成のパフォーマンスを向上させるセグメントレプリケーションに取り組み、さらなる改善を計画しています。デプロイメントの微調整のためにアプリケーションをより理解するため、アプリケーションベースのテンプレートを導入しています。シャード管理は、オンラインシャード分割とより良いシャード配置の決定のために、さらなるイノベーションを計画している分野です。Pull型の取り込みは、主要なイニシアチブとして始まったばかりです。現在、インデックス作成はPush型モデルで動作していますが、スパイクにより適切に対応できる、あるいは異なるワークロードの優先順位付けを可能にするPull型インデックス作成の代替APIを導入したいと考えています。リモートストアとの統合は、ホット、ウォーム、コールドデータ機能を備えたより知的なデータの階層化と、リモートストアとのより良い統合を導入したい別の分野です。スナップショットは、リモートストアとの統合の結果としてより効率的になっており、管理APIもより効率的になっています。

安定性、可用性、そしてレジリエンシーの観点から、私たちはOpenSearchのデプロイメントが大規模でも安定して耐障害性を持つことを目指しています。クエリ実行の各フェーズの可視化を提供しており、クエリの洞察についてはすでにクエリのレジリエンシーの一部として対応済みです。クエリがLuceneレイヤーの深部で実行されている場合でも、ハードキャンセルや検索のバックプレッシャーのための新しいメカニズムを導入しています。ワークロード管理については、ユーザーがマルチテナント環境でOpenSearchを運用している状況を踏まえ、テナントの分離やテナントベースの優先順位付けが可能なQuery Groupsを導入しています。テナントIDに基づいてサービス品質を定義することもできます。クラスタステート管理は、Remote Storeとの連携を改善し、クラスタステートを軽量化する取り組みを行っている分野です。また、OpenSearchが利用できない場合のDead Letter Queueの改善など、Data Prepperのレジリエンシーも向上させています。

セキュリティは、Secure by DesignとSecure by Defaultの原則に従って、私たちの取り組みすべてに組み込まれています。セキュリティ関連の作業の大部分はオープンソースで行われています。OpenSearchのプラグインアーキテクチャでは、プラグイン間でリソースを共有する新しい方法を導入しています。また、管理者がプラグインのインストール前に、そのプラグインが要求する権限を完全に把握できるようにしたいと考えています。
権限の評価に関して、OpenSearchの使用方法が複雑化し、インデックスが多すぎたり、ユーザーにマッピングされるロールが数多く存在したりする状況を踏まえ、権限評価のパフォーマンス向上に取り組んでいます。インデックスレベルの暗号化については、ユーザーがマルチテナント設定でOpenSearchを運用する傾向があるため、異なるインデックスに対して異なる暗号化キーを使用できるようにしたいと考えています。
セキュリティの設定は多くのユーザーにとって課題となる分野であり、その簡素化に取り組んでいます。オープンソースに根ざした統一されたセキュリティモデルを持ち、マネージドクラスターやサーベイランスのデプロイメントは、OpenSearchのオープンソースセキュリティ構造から派生したものとして位置づけたいと考えています。また、Open Policy Agentのような新しいオープン標準との統合を容易にするため、認可などのセキュリティプリミティブをプラグ可能にしたいと考えています。

これらすべてのテーマに取り組む中で、OpenSearchの基盤となるアーキテクチャの堅牢性も確保したいと考えています。当初、OpenSearchのアーキテクチャはクラスターベースのデプロイメントに特化していましたが、現在はServerlessベースのデプロイメントに向けて移行を進めています。これは、OpenSearchのモノリシックなサーバーモジュールを分割し、異なるコンポーネント間の密結合を解消することを意味します。

リリースとプロジェクトの健全性は大きな推進力となってきました。というのも、プロジェクトは122のリポジトリにまで大きく成長したからです。私たちは中央集権的な管理を望んでおらず、異なるユーザーや異なるコンポーネントがトリアージミーティングを独自に運営できるようにしたいと考えています。最近まで巨大なモノリスだったOpenSearchコアにコンポーネントを作成しました。これにより、各リポジトリやコンポーネントが独自のオペレーションを実行できるようになりました。主要なリポジトリの健全性指標を追跡できる新しいOperationsダッシュボードを公開しました。リリースに関しては、6週間ごとにリリースを行っており、OpenSearch 2.17以降は手動での承認プロセスを廃止しました。ワンクリックリリースシステムを構築し、誰でもリリースできるようにすることを目標としています。また、OpenSearchの一部である全てのリリースパイプラインの健全性を把握する新しいリリースダッシュボードも公開しました。
OpenSearchコミュニティへの参加方法と今後の展望


このプレゼンテーションの最後のセクションに移りたいと思います。Carlが、OpenSearchにどのように参加し、より深く関わっていけるかについてご説明します。 プロダクトマネージャーとして、そして製品を愛する者として、私が重視していることについてお話ししたいと思います。それは、変更をどのように提案し、アイデア出しや適切な製品の構築にコミュニティを巻き込んでいくかということです。これは、コミュニティメンバーにもOpenSearchプロジェクトのプロダクトマネージャーにも当てはまります。私たちは全てオープンな環境で作業を行っています。
いくつか触れておきたいポイントがあります。大きな新しいアイデアや提案については、一般的にRFC(Request for Comments)から始めることをお勧めしています。RFCは誰でも作成できます。必ずしも実際に貢献する人である必要はありませんが、もしそうであればなお良いでしょう。圧縮のための新しいCodecを導入したい、異なるデータタイプのインデックス作成方法を変更したいなど、アイデアがあれば、まず問題点を挙げ、目標や目的、アイデアを概説し、それをRFCとしてGitHubに投稿します。これにより、コミュニティの他のメンバー、メンテナー、コントリビューターがそのアイデアにコメントし、改良することができます。小規模な機能については、エンジニアリングチームと直接やり取りするためのGitHub issueとして機能リクエストを作成できます。

私たちの目標は、開発コミュニティ全体が試してみることです。コミュニティの参加を最大限に高めるため、貢献やコメントをする際の手続きを非常に軽量で簡単かつ魅力的なものにすることを目指しています。私たちのRFCは皆さんに公開されており、計画しているアプローチについてコミュニティ全体で良好なコンセンサスが得られるよう、コメントを付けることができます。次のスライドで説明するパブリックロードマップですべてが確認でき、コメントを提供したり、今後の予定や提供方法を確認したりすることができます。

次のステップとして、コンセンサスが得られた後、メンテナーがその作業を承認としてフラグを立てます。これらはすべて、誰かがコードを書き始める前に行われるべきです。全員の意見が一致し、メンテナーが有効とマークすると、その機能はロードマップ項目としてタグ付けされ、パブリックロードマップに表示され、Meta issueと各作業ストリームの個別のissueに分解され始め、そこから作業を開始できるようになります。
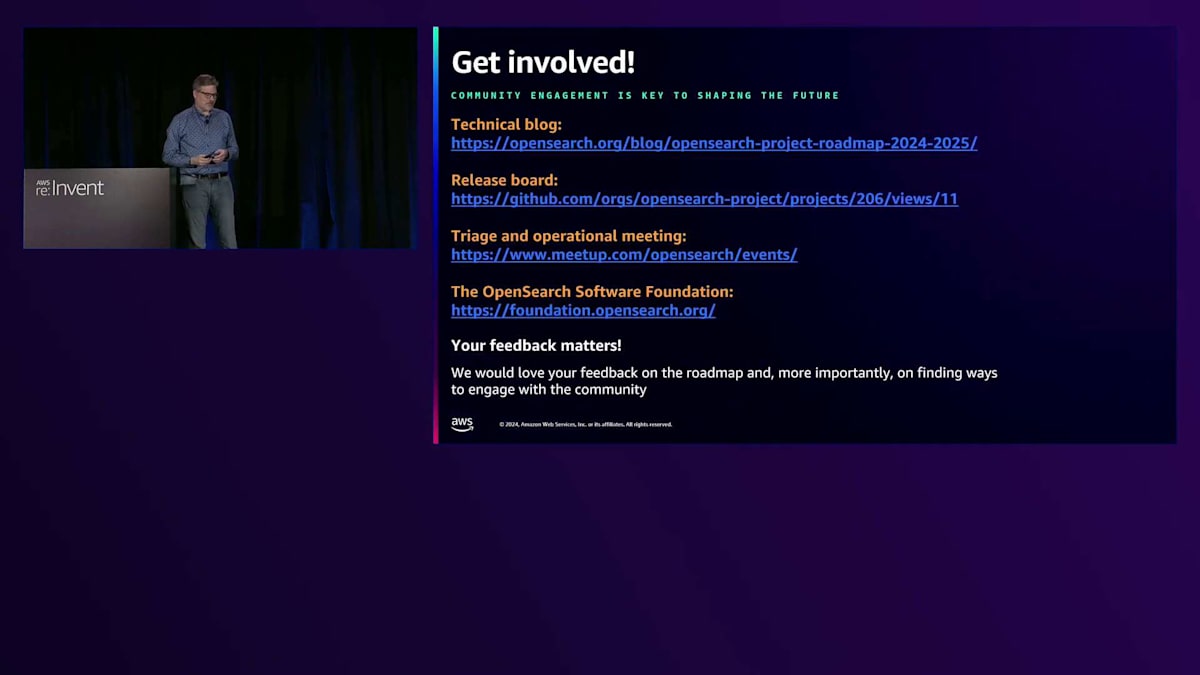
私が人々の関わり方を優先順位付けするとすれば、まず第一に製品を使用することです - OpenSearchを使ってみて、それを使って何かを構築してみてください。誰もが使えて役立つこのオープンソースプロジェクトを持つことが最も重要です。次に、コミュニティに参加し、ロードマップへのフィードバックを提供し、技術ブログを書き、コードを書くことです。コミュニティへの貢献方法は多岐にわたり、どのような形でも歓迎します。そして、OpenSearch Conイベントに参加し、最後にOpenSearch Software Foundationに関わっていただければと思います。

約1ヶ月前にPaul Levineのチームが公開した技術ブログでは、彼女がここで説明した内容や、これらの焦点領域にロードマップをどのように分解しているかについて、より詳しく説明しています。常に更新されているリリースボードがあり、そこではカテゴリー別に分類された実際のロードマップと、計画されたリリースにタグ付けされたすべてのMETA issueが掲載されています。issueやRFCに直接アクセスして、すべてのコメントを確認することができます。Meetupページでは、先ほど話した異なる領域に関するトリアージと運用ミーティングを公開しています。Vector Database、Core Search、Observabilityに興味がある方は、これらのトリアージミーティングに参加して、issueの優先順位付けの方法を確認したり、その分野で活動する他の貢献者と話し合ったりすることができます。

昨年は3つのOpenSearch Conイベントを開催しました - ヨーロッパ、インド、北米です。Linux Foundationに加入した今、これらをさらに拡大していく予定です。OpenSearch Con Europeの日程を発表しましたが、4月末にAmsterdamで開催される予定です。Call for Papers(講演募集)を近々、おそらく今週末までには公開する予定です。OpenSearchについて発表したいことやアイデアがある方は応募してください。もしかしたらAmsterdamに来て、楽しみながら講演ができるかもしれません。パブリックのSlack、コミュニティフォーラム、イベント、Meetupページ、そしてドキュメントもあります。このQRコードには、GitHubからマーケティングサイトまで、私たちが話したすべてのリンクが含まれています。Amazon OpenSearch Serviceの一部としてOpenSearchをどのように利用できるかに興味がある方は、明日の正午に私と私たちのGeneral Managerが講演を行います。場所はMandalay Bayではありません。
皆様のご来場に感謝いたします。皆様がOpenSearchに貢献し、使用していただけることを楽しみにしています。現在の進展と勢いに大変興奮しており、ご来場いただいた皆様に感謝申し上げます。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion