re:Invent 2023: AWSが語るAZ障害からの自動回復 - zonal autoshiftの紹介
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - Using zonal autoshift to automatically recover from an AZ impairment (ARC309)
この動画では、AWSのDeepak SuryanarayananとGavin McCullaghが、Availability Zone (AZ)の障害からの自動回復について解説します。AWSが内部で使用しているツールや手法を公開し、新機能のzonal autoshiftを紹介。グレー障害への対処、サイロ化モデルと非サイロ化モデルの比較、事前スケーリングの重要性など、AWSの長年の経験から得られた貴重な知見を共有しています。AZレジリエンスを実現するための具体的な設計方法や、practice runの活用法も学べる内容です。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
AWSのDeepak SuryanarayananとGavin McCullaghによる自動AZ回復の紹介


みなさん、こんにちは。私の名前は Deepak Suryanarayanan です。AWS の Amazon Route 53 Application Recovery Controller の General Manager を務めています。ここは ARC 309 のセッションです。今日のセッションは、皆さんが見たセッションタイトルから少しアップグレードされています。ここに「automatically」という言葉が追加されているのがお分かりでしょうか。つまり、「AZ 障害から自動的に回復する」というタイトルになっています。これは、後ほど詳しくお話しする新機能を本日リリースしたためです。私が AWS で行っている仕事は、顧客に影響を与えるイベントをより少なく、より短くすることです。その一環として、私のチームは内部の AWS サービス向けにツールとプロセスの両方を構築・運用し、 また、お客様向けに機能を提供しています。
今日のお話の多くは AZ、つまり Availability Zone に関するものです。現在、複数の AZ にデプロイしている方は手を挙げていただけますか? はい、素晴らしいですね。では、AZ 回復プロセスにどの程度自信がありますか?とても自信がある方は手を挙げてください。はい、素晴らしい。少なくとも1人の方が手を挙げているのが見えますね。このセッションでは、AWS が AZ を効果的に使用する方法や、AZ の起源について多くのことを聞くことができます。そして、それらを皆さんのマルチ AZ 環境に適用していただければと思います。また、本日リリースした AZ 回復を支援する機能である zonal autoshift についても後ほど詳しくお話しします。それでは、このプレゼンテーションの最初の部分について、Gavin にマイクを渡したいと思います。
AWSにおけるAvailability Zone (AZ)の起源と重要性

ありがとう、Deepak。私の経歴を少し紹介させていただきます。私の名前は Gavin McCullagh です。AWS に入社して約12年になります。 最初はアイルランドのダブリンオフィスで、Amazon のロードバランシングを担当するチームで働いていました。その直後、Amazon の DNS も担当しました。私たちは非常に中心的なインフラチームで、ロードバランサーの背後で働くすべてのサービスチームが、AZ 内で何らかの問題が発生した際に確実に回復できるようにすることに多くの時間を費やしていました。最近では Route 53 にも携わっており、Amazon 内のインシデントに対する call leader チームの一員でもあります。これから、Amazon が Availability Zone をどのように使用しているかについてお話しします。



まず最初の質問ですが、AZ にデプロイしているかどうか聞いたときに多くの手が挙がりましたね。ここで簡単に、 なぜ Amazon が 2007 年頃に Availability Zone を一般に公開したと私が考えているかについて、背景をお話しします。私たちはしばらくの間、複数のデータセンターを使用していたので、どちらかというとその概念に名前を付けただけのようなものでした。2006年から2007年頃の Amazon の小売事業を想像してみてください。急速に成長している会社で、顧客にとって信頼性が非常に重要だということに気づき始めていました。人々はウェブサイトに依存し始めており、 何らかの問題が発生すると本当にビジネスに影響を与えるのです。



避けられない障害は必ず発生します。それは受け入れなければなりません。しかし、私たちにとって本当に重要な指標は、何らかの障害が発生したときに何が起こるか、あるいはどれだけ早く回復できるかということです。この時点でいかに重要になっていたかを少し説明しますと、2007年頃、Amazon は次のようなことを行っていました。大規模なオンライン小売ウェブサイトを運営していました。 Amazon Kindle を発売しました。Amazon Prime Shipping がちょうど始まったところでした。AWS という、まだあまり知られていない新しいものがありました。 Slashdot をよく読む人たちの中には S3 や SQS について聞いたことがある人もいましたが、まだかなり小規模でした。 Amazon Video on Demand と呼ばれるものがありました。これは現在の Prime Video です。そして、会社の収益は順調に成長していました。

2011年に入社した時、先ほど申し上げたように、ロードバランサーチームに配属されました。その年のこの時期に初めてオンコール当番になった時、Q4ピークと呼ばれるものについてアドバイスをもらいました。これは、Black FridayやCyber Mondayなど、トラフィックが多く、注文が殺到し、誰もが特に注意深く状況を見守っている時期のことです。彼が基本的に言ったのは、Q4では「数分が数百万ドルを意味する」ということでした。つまり、何か影響のあるイベントが進行中の場合、迅速かつ断固とした対応が必要で、本当に素早く回復しなければならない、なぜなら数分の差が文字通り数百万ドルの売上の差になるからです。これはDublinにいた私のメンターで、私はなぜかこの言葉を忘れられませんでした。ただし、これを文脈で理解することが重要です。

数分が数百万ドルを意味するわけではありません。誰にでも当てはまるわけではないし、たとえあなたが所有しているサービスがあったとしても、すべてのサービスに当てはまるわけではありません。本当に最高の回復時間を得るためには、冗長性が必要です。これについては後ほど詳しくお話しします。それにはコストがかかります。だから、アプリケーションやビジネスにとってのトレードオフを考える必要があります。この点で勝つべき戦いを適切に選ぶ必要があるのです。
Recovery-Oriented Computingとデータセンターの冗長性



繰り返しになりますが、すべては回復までの時間に関わることです。Amazonが長年提唱してきた哲学は、業界文献にもあるrecovery-oriented computing(回復指向コンピューティング)です。簡単に言えば、壊れたものを修理しようとするのではなく、すべてのものの冗長コピーを確保し、1つが壊れたら、そこから離れて、顧客体験を素早く回復させ、その後修理するということです。これは、障害のあるホストを意味するかもしれません。通常、ロードバランサーのヘルスチェックを使用してホストを外します。ラック全体が故障することもあるかもしれません。場合によっては、データセンター全体に障害が発生することさえあるかもしれません。

AWSで働くことの本当にクールな点の1つは、データセンターを管理し設計する人々と話ができることです。これらの信じられないほど回復力のあるデータセンターを構築するために投入されているエネルギーと投資は驚くべきものです。電力やネットワークの冗長性があり、電力の問題が発生した場合はUPSがすぐに作動します。UPSが対応できる時間内に回復しない場合は、バックアップ発電機が起動し、何時間も稼働し続けます。冗長な冷却システムもあります。データセンターには膨大な量の冗長性が組み込まれているのです。


しかし実際には、完璧なデータセンターを構築することは決してできないと認めざるを得ませんでした。常に何かしら問題が発生する可能性があります。これらは一般的なイベントではありませんが、確かに存在します。そのため、Amazonとしては、顧客に最高の信頼性を提供したいのであれば、1つのデータセンターに依存することはできないと考えました。そこで私たちが辿り着いた設計、皆さんもかなり馴染みがあると思いますが、それがAvailability Zonesです。
さて、この話を始めるにあたって、「東海岸に1つ、西海岸に1つデータセンターを置けばいい」と思うかもしれません。当時のAmazonはずっと小規模だったことを覚えておいてください。そうすることもできたでしょう。しかし、問題は、これを効果的に行うためには、複数のデータセンターがactive-activeで動作し、顧客がAZ 1、2、3のどれと通信しているかを気にしなくて済むようにすることが本当に望ましいということです。そしてそれは素晴らしいことです。顧客が「このアイテムをショッピングカートに追加」をクリックしたとき、たまたまその時にAZ 1とAZ 2の間で切り替わったとしても、他のAZのショッピングカートにもそのアイテムが入っていることが望ましいのです。
そのため、必要なのは同期データレプリケーションです。つまり、AZ 1で書き込みが行われた場合、先に進んで書き込みを確認する前に、AZ 2と3でも書き込みが行われるということです。そうすることで、データの不整合が生じることはありません。AZの目的は、同期書き込みができるほど近接していることです。AZ間の一般的な往復時間は1ミリ秒程度です。これにより、AZ間で迅速に書き込みを行うことができます。もし国を横断するような距離だと、50ミリ秒程度のレイテンシーになってしまいます。そのような状況で同期書き込みを行い、パフォーマンスを良好に保つのは非常に難しいです。
AWSのAvailability Zone設計と同期データレプリケーション

つまり、これらは同期書き込みができるほど近接していますが、同時に近すぎないようにしています。洪水などが発生した場合に複数のAZが同時に障害を起こさないよう、通常は数マイル離れています。そして長年にわたり、少し規模が大きくなりました。 通常、AZは1つのデータセンターと考えることもできますが、大規模なregionでは実際にはより頻繁に複数のデータセンターになっています。同じAZの一部である場合、それらは通常より近接しています。なぜなら、それが私たちの望むところだからです。私たちは迅速さを求めています。しかし、実用的な観点からは、依然として単に大きなAZとして考えることができます。

さて、時間の経過とともに私たちが気づいたことがいくつかあります。これも特に秘密ではありません。業界では、ハードな障害とグレーな障害の区別がよく見られます。ホストの電源が切れたり、アプリケーションが通常リッスンしているポートでの応答が停止したりした場合、それは非常に明確な障害です。ヘルスチェックプローブは、このホストが健全でなくなったことを非常に簡単に判断できます。ロードバランサーのヘルスチェックや単純な方法を使用して、このような種類の障害を検出するのは比較的簡単です。

グレーな障害はより対処が難しく、分散システムではより一般的になります。問題は、誰が見ているかによって、何かが健全かどうかという質問が曖昧になる可能性があることです。例えば、ホストの応答が著しく遅くなった場合、それはまだ健全と言えるでしょうか?それは呼び出し元とそのレベルのレイテンシーに満足しているかどうかによります。あるいは、断続的に障害が発生している場合もあります。通常、単純なヘルスチェッカーは何かを不健全と判断する前に複数回チェックするので、10%のリクエストで障害が発生していても、サービスを継続しヘルスチェックに合格し続けることができます。

私たちのアプローチは、インフラの観点からデータセンターやAvailability Zone (AZ)の障害に対処できるよう、十分な冗長性を確保することです。これらのグレー障害がひとつのAZ内に封じ込められるようにし、そのデータセンターから離れて状況を調査できるようにしています。皮肉なことに、複数のデータセンターにまたがる超耐久性のあるシステムを構築した後、それらはグレー障害を引き起こす傾向があります。適切に設計されたマルチAZシステムでは、ハード障害はほとんど見られません。通常見られるのはグレー障害です。


これをより具体的に理解するために、AZでのグレー障害の実際の例を見てみましょう。私は約10年から12年間、32のAWSリージョンにわたってこれを観察してきました。そのため、かなりの経験に基づいています。ほとんどのリージョンでは、重大なAZのグレー障害は数年に一度程度で、多くの場合、ほとんどの顧客は気づきません。複数のデータセンター環境で、インスタンスが詰まった1つの部屋を失ったとしても、それは全体のAZの5%から10%程度にすぎません。複数のデータセンターがあり、そのうちの一部だけが影響を受けるからです。多くの顧客はそれに気づきもしませんが、最高の耐障害性を求めるなら、それでも対処できるようにしたいかもしれません。
AZにおけるハード障害とグレー障害の違い


AZ全体がダウンすることは極めて稀です。過去10年間で、特に小さなリージョンで1件だけ追跡できる事例があるかもしれませんが、それは非常に珍しい状況です。もしそれがあなたの想定モデルなら、それをグレー障害の方向に調整し、そのような完全な障害を想定しないようにする必要があります。実際の例としては、AZ内のインスタンスの比較的小さな割合(1%、5%、または10%など)が電源を失うことがあります。そのAZにある程度の規模のフリートがある場合、いくつかのインスタンスを失う可能性があります。非常に小規模なフリートを持っていて、非常に運が悪い場合は、より多くを失う可能性があります。

AZ内で断続的なパケットロスが発生することがありますが、これは混雑やネットワークデバイスの障害が原因です。通常、修正には数分かかります。同様に、断続的な接続障害が発生することもあります。これらはすべてグレー障害で、ホストはおそらくまだほとんど機能していますが、依存関係への接続に問題が生じています。また、1つのAZでDNSルックアップの障害が見られることもあります。繰り返しになりますが、これらはすべて1つのAZ内に限定されているため、冗長性があれば、そのAZから離れることができるはずです。時々、AZでEC2の起動に断続的な障害が発生することもあります。


アプリケーションがマルチAZで設計されている場合、これらのグレー障害の典型的な結果は、アプリケーションは引き続き機能しますが、一部のリクエストで断続的に遅延が増加したり、いくつかのリクエストでエラーが発生したりすることです。これが、ここで対処しようとしている問題の種類です。問題が1つのAZに限定されている場合、そこから離れて、問題の修正方法を考えることができます。
AWSにおけるAZレジリエンス設計の原則

では、AWSでAZレジリエンスをどのように設計するのでしょうか?これは長いトピックで多くの詳細がありますが、考慮すべき高レベルのトピックだけを簡単に説明します。まず最初に、おそらく明らかなことですが、アプリケーション全体を俯瞰的に考えることです。通常、複数のレイヤーと複数のコンポーネントが関与しているため、すべての要素について本当によく考える必要があります。
時々、オンプレミスからアプリケーションをリフト&シフトするお客様を見かけますが、これは全く合理的なことです。しかし、多くの場合、オンプレミスでは単一のホスト上の単一のリレーショナルデータベースに依存しており、手動でフェイルオーバーする必要があります。これはよくある設定ですが、課題は、これが迅速にフェイルオーバーしたい項目の1つになるということです。可能であれば、自動フェイルオーバーにしたいでしょう。したがって、アプリケーションのすべてのコンポーネントを検討し、障害が発生したAvailability Zone(AZ)に残るものがないことを確認することが重要です。


これは、単一のAZ依存がないことを確認することに関連しています。テスト環境でコストを抑えるのに非常に便利な単一AZまたはDSデータベースを使用する場合がありますが、これらは高度にレジリエントなアプリケーションには適していません。したがって、1つのAZでのみ実行されるものに注意してください。AZ間に分散する場合、 各AZに同等の容量があることを確認することが本当に重要です。時々、1つのAZに容量が集中し、他のAZよりも多くなってしまうことがあります。そうしてしまい、そのAZに障害が発生すると、残りのAZの容量が少ないため、困難な状況に陥ることになります。

必ずしも明らかではありませんが、本当に強調する価値があるのは、AWSがAZ内にサービスを構築する際、1つのAZが消えてしまっても他のAZが継続できるよう、十分な容量を事前にスケールして運用しているということです。多くの容量を失うため、レイテンシーが若干低下するかもしれませんが、スケールアップせずに負荷を処理できる十分な容量がオンラインで確保されています。これは非常に重要な原則であり、ほぼすべてのAWSサービスがこれを念頭に置いて構築されています。例えば、DynamoDBやS3を考えてみましょう。これらのサービスは、ほとんどの場合、常に容量の約66%で稼働しています。なぜなら、いつでもAZを失っても継続できるように構築されているからです。

独立したAZで構築し、容量を分散させ、事前にスケールされていることを確認したら、ゾーン間の連携を最小限に抑えることが重要です。その理由は、連携がマルチゾーン障害を引き起こす傾向があるからです。例えば、一度に1つのAZにのみデプロイすることをお勧めします。これにより、「1つのAZにデプロイしたら問題が発生したが、ロールバックするよりもそのAZから離れる方がはるかに早いことがわかっている」と言えるからです。もう1つ考慮すべき点は、キャッシュを使用する場合、AZごとに個別のキャッシュを使用することです。キャッシュも時々問題を引き起こす可能性があり、リージョン全体に問題を引き起こしたくないからです。

ほとんどのアプリケーションにおいて、リージョン全体で一貫性を保つ必要がある部分に特に注目しましょう。それは通常、データベースです。アプリケーションによっては、どのAZにいても一貫性を保つ必要があるデータストアがあります。例えば、ショッピングカートの場合、どのAZにいても一貫性が必要です。この部分には細心の注意を払う必要があります。データベースは、AZに問題が発生した場合でも、データ損失なしにほぼ即座に復旧できる必要があります。通常、私たちの設計では、これを行う際にクォーラムやリーダー選出を使用します。
AWSサービスの場合、新しいAWSサービスを構築する際、データベースサービスを作っているのでない限り、新しいロードバランサーや新しいデータベースサービスは作りません。私たちは通常、DynamoDB、Aurora、RDSなどのサービスを使用します。これらのサービスはAZの障害からの復旧を設計に組み込んでいるので、私たちが考える必要はありません。もちろん、オンプレミスから移行する場合、最初はリフト&シフトを行うかもしれませんが、少なくとも復旧方法を把握することが最優先事項の一つであるべきです。理想的には、これらのマネージドデータベースサービスに切り替えることです。
AZのグレー障害の検出と対応方法


次に、AZのグレー障害をどのように検出するかについて話しましょう。 私たちが通常行う方法は、特定のサービスに対して、顧客体験を見ることです。左の列は、ほぼ誰もが必ず見るものです。しかし、他の3つの列はやや斬新で、顧客体験を見たいと考えています。それが一番左の列です。しかし、他の3つの列は、特定のAZにいる顧客の現在の体験を示しています。ここで各AZに対してカナリアを実行している理由は、問題がある場合に
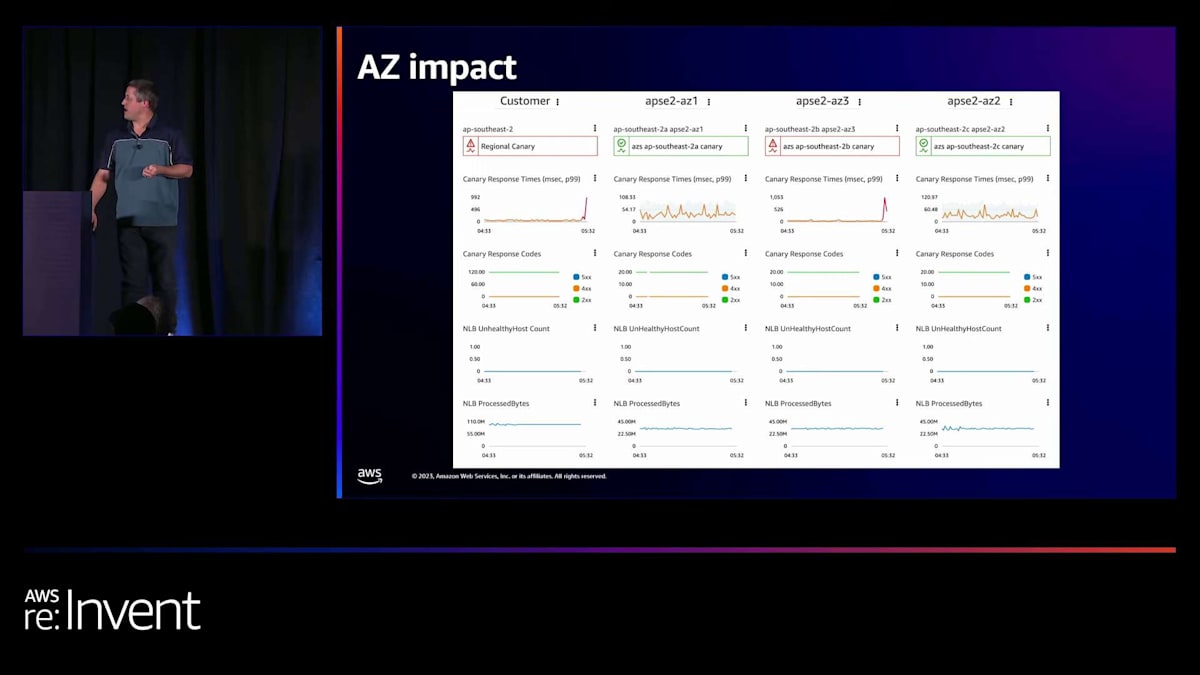
顧客体験が損なわれているのを確認できるからです。 各AZのパフォーマンスを比較することで、問題がどこにあるかを把握し始めることができます。本質的に、ここでは外れ値検出を行っています。サービスの3つのレプリカがあり、そのうちの1つが外れ値かどうかを確認しています。常にそうとは限りませんが、そうである場合、このイベントから回復するための論理的な対応は、AZ 3を切り離すことです。



グレー障害を検出したら、どのように対応すればよいでしょうか? このサービスはかなり標準的です。クライアントは3つのコンポーネントロードバランサーとして示されているリージョナルロードバランサーと通信しています。その背後にコンピュートインスタンスがあり、すべてのAZでほぼ100%の成功率を見ています。そしてそれらはすべて同じです。 全体の成功率はほぼそれらの平均です。しかし、何かが起こり、3番目のAZで成功率の低下に気づきます。
さて、私たちの全体的な成功率が低下しました。まだ96%ですが、「それほど悪くない」と思うかもしれません。しかし、eコマースウェブサイトを運営していて、ページ読み込みの3%が失敗しているとしたら、それは良くありません。これは、迅速に解決したい「グレー障害」の問題の一種です。ほとんどのAWSサービスで3%の失敗率があれば、電話が鳴り始めるでしょう。ですから、これは迅速に修正する必要があるものです。多くのアプリケーションでは、「まあ、様子を見よう」というのも合理的かもしれません。
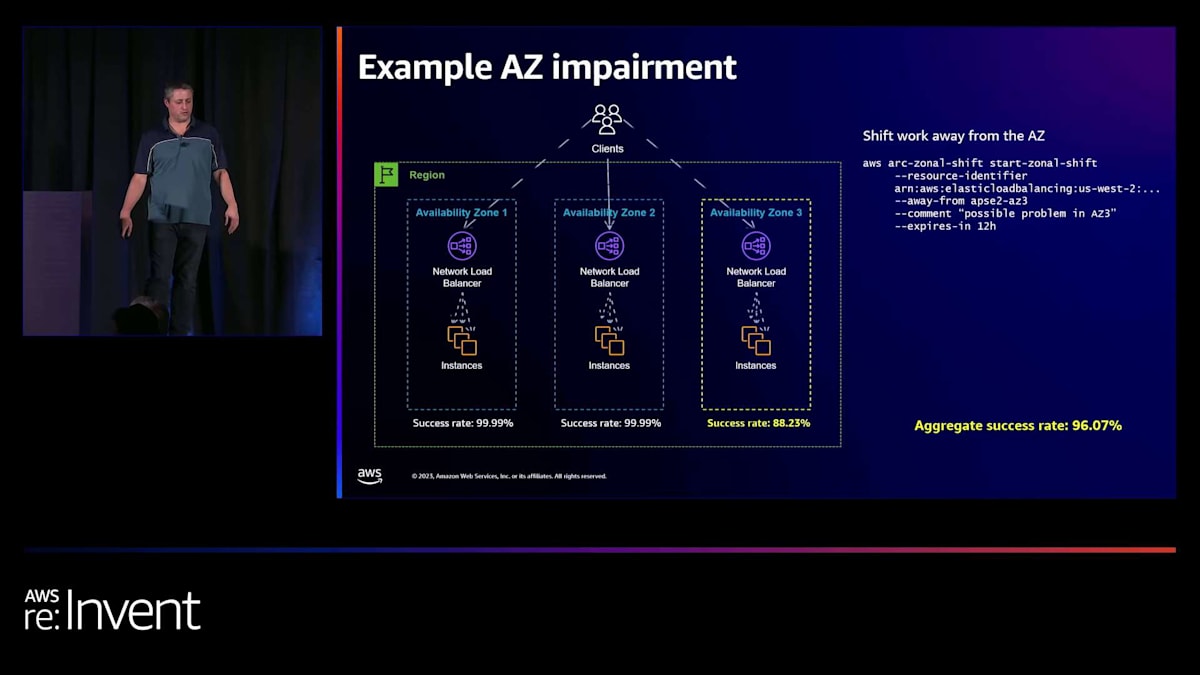


昨年私たちがリリースした製品は、基本的にAWSで10年以上使用してきたツールをお客様に提供するもので、zonal shiftと呼ばれています。アイデアは、一時的にそのゾーンからトラフィックを離すことです。zonal shiftを開始すると、 進行中に全体的な成功率が上がり始めるのが分かります。これはトラフィックが離れていっているためです。 起こっていることは、クライアントが自然に再接続する際、ゾーン1と2に再接続しているということです。
AWSサービスにおける共有責任モデルとAZ回復
現在、ゾーン1と2は以前よりもかなり多くのトラフィックを受けており、これは念頭に置いておく重要なポイントです。おそらく1と2のトラフィックは約50%増加し、ゾーン3からのトラフィックは減少しています。まだ問題自体は解決していません。ゾーン3はまだ80%から88%の成功率を示しています。しかし、全体的な成功率、つまりお客様の成功率は正常に戻っています。これが回復指向のコンピューティングです。単に問題から離れることで、まずお客様の問題を解決し、その後でAZ 3で何が起こっているのかを調査します。そのインスタンスにデプロイメントがあったのかもしれませんし、インフラの問題かもしれません。分かりません。

ここには興味深いトピックがあります。セキュリティの話でよく聞く「共有責任」という表現をご存じかもしれませんが、ここにも当てはまります。これは本質的に、AWSが管理できる範囲、AWSがお客様に代わって決定を下す範囲、そして場合によってはお客様が決定を下すか責任を負う必要がある範囲の境界線の問題です。同じようなパターンがここにも存在します。

いくつかの例を挙げて説明します。少し変わった視点ですが、他のAWSサービスの上に新しいAWSサービスを構築する立場から話をします。新しいAWSサービスを構築していると想像してください。自前のロードバランサーフリートを構築したり、独自のデータベースサービスを構築したりするのではなく、既存のAWSサービスを使用します。つまり、AWSサービスを構築しながら、同時にAWSの顧客でもあるという立場です。

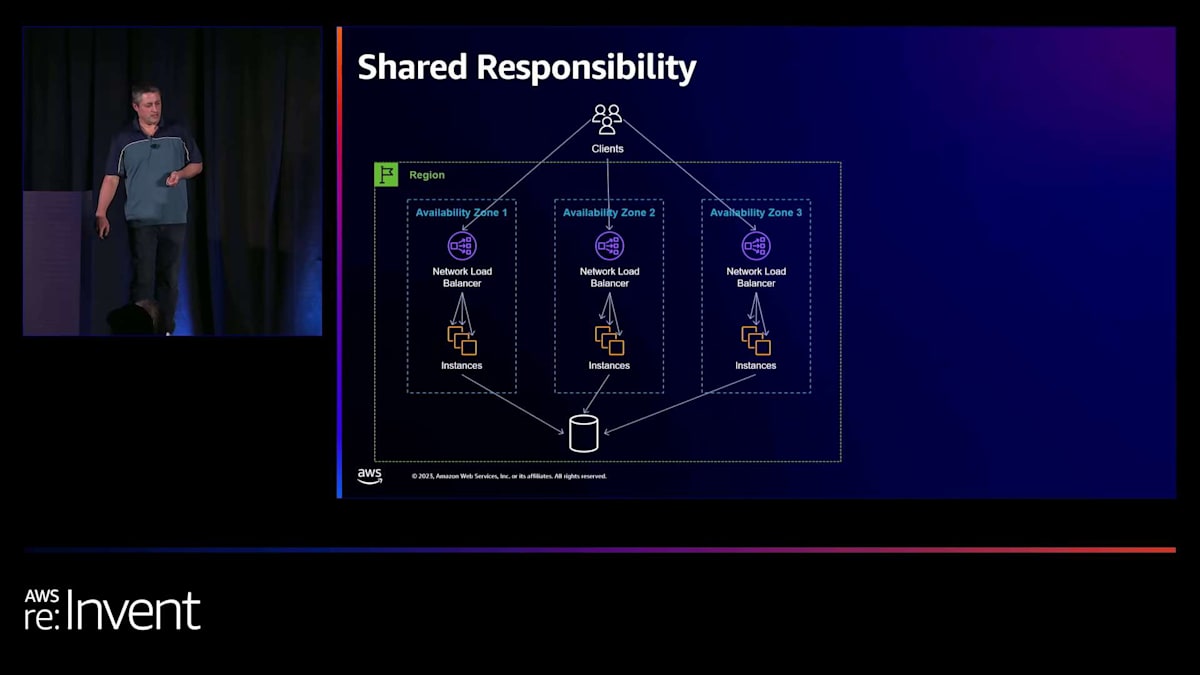
AZの障害から素早く復旧するためには、2つのことが必要です。まず、3つのAZで運用している場合、いつ起こるかわからないイベントに備えて、キャパシティを1/3削減できる準備をしておくことです。そして、障害が発生していることを迅速に検知し、対応するための行動を取れることが重要です。 これらの3つのレイヤーについて、共有責任モデルの観点から考えてみましょう。

ロードバランサーのレイヤーでは、ELBの管理されたロードバランサーを使用します。独自のカスタムロードバランサーを運用しているお客様はAWSでもそれほど多くありません。ELBを選択した場合、1つのAZを失っても対応できる十分なキャパシティを、こちらが要求しなくても自動的にスケールしてくれます。マルチゾーンのロードバランサーを構築すれば、1つのゾーンに問題が発生しても、他のゾーンで自動的にカバーしてくれます。そのため、このロードについては心配する必要がありません。ELBは検知と復旧も行います。そのAZでロードバランサーサービスに問題が発生した場合、自動的に切り替えてくれます。データベース側では、

DynamoDBを選択しました。 これは管理されたリージョナルサービスです。DynamoDBは1つのAZが停止しても対応できる十分なキャパシティを確保しています。サービスは継続され、十分なキャパシティがあり、検知と復旧も自動的に行われます。これはAWS側の責任範囲です。
中間のコンピュートレイヤーは、少し複雑になります。1つのAZ、つまり約1/3のインスタンスが失われても対応できるだけのEC2インスタンスを確保したいところです。しかし、最終的にはお客様がEC2インスタンスをいくつプロビジョニングするかを決定します。ここがEC2のお客様である私の責任となる部分で、どれだけのキャパシティを持つか、そしてAZの障害に対応できる十分なキャパシティを確保することは私の役割です。同様に、その決定を下すのは私なので、グレーな障害が発生した際にシフトするかどうかの判断にも関与する必要があります。コスト面を考慮して余裕を持たせずに運用する場合、「これはグレーな障害だから、フェイルオーバーしたくない」と判断できる必要があります。そのため、理想的にはこの判断にお客様が関与する必要があります。
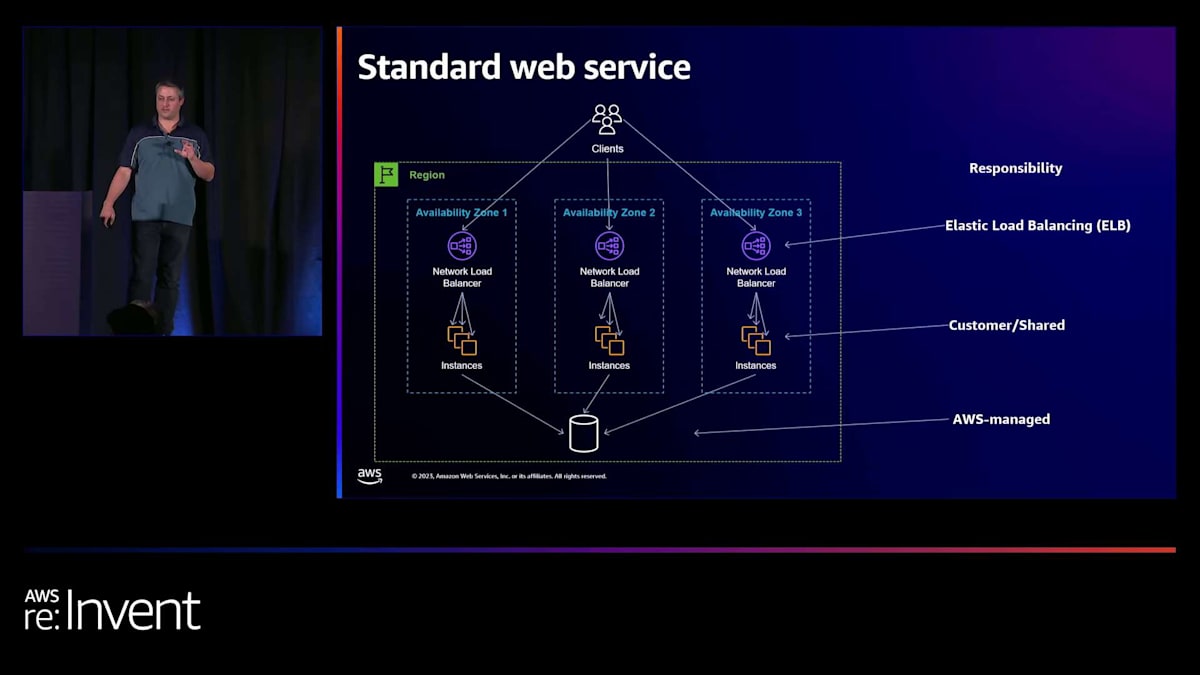
AWSは、アプリケーションやその冗長性について知らない状態でこのような判断を下すのは難しいと考えています。 Elastic Load Balancingは2つのレイヤーを処理していますが、中間の第3のレイヤーはより顧客との共有モデルになっていることに注目する価値があります。Elastic Load Balancingはこれらのインスタンスのヘルスチェックを行いますが、これは完全な障害には効果的です。しかし、通信の遅延などのグレーな障害の場合、ヘルスチェックが必ずしも失敗するとは限りません。そのため、ELBは確かに役立ちますが、必ずしも問題を完全に解決するわけではありません。
マイクロサービスアーキテクチャにおけるAZサイロ化モデル

共有責任モデルがどのサービスに適用されるかを知っておくと便利です。AWSがAZを提示せず、単に実行するだけの地域サービスが一連あります。S3はその一例で、特定のゾーンにデータを置くのではなく、地域サービスに置きます。これらはAZ全体で実行されますが、そのことを気にする必要はありません。DynamoDB、Lambda、API Gateway、SQSも同様です。これらのサービスでは、AZに問題が発生した場合、それに対処するのはAWSの責任であり、ユーザーは心配する必要がありません。これは非常に価値のある特性です。
EC2の場合、先ほど述べたように、AZの問題から迅速に回復したい場合は、ユーザー側の責任がより大きくなります。RDSの場合、マルチAZかシングルAZのデータベースを選択できます。回復できるようにしたい場合は、おそらくマルチAZのRDSデータベースを選択する必要があります。


Deepakにバトンを渡す前に、AWSサービスを構築する際に使用する他のアーキテクチャをいくつか紹介して、私たちが何をしているのかについてのアイデアを提供したいと思います。 これは私が本当に気に入っているものです。少なくともAZの回復という観点では、何も所有する必要がないからです。ここでは意図的に3つの地域サービスを選んでいます:API Gateway、Lambda、DynamoDB。これらはすべてAZの回復に関するすべての責任を負っています。私の側でゾーンシフトをする必要はありません。彼らが私のためにすべてを管理してくれます。これらの問題に対して事前にスケーリングする必要もありません。
これは、おそらくLambdaやAPI Gatewayのチームが十分に強調していないことの一つかもしれません。私たちは、これらの問題を単に解消できるように、大量の予備容量を構築しています。そのため、共有責任表では、すべてが緑色になっています。API Gatewayが対処し、Lambdaが対処し、DynamoDBが対処しています。



これは先ほど話したWebサービスです。ロードバランサーを使って比較的シンプルにセットアップし、その背後にバランスの取れたフリートを配置します。容量を事前にスケーリングし、管理されたAZ耐性のあるデータベースを使用します。 ここで私たちが試みているのは、顧客にできるだけ少ない責任を持たせるか、あるいはAWSが差別化されていない重労働をできるだけ多く処理できるようにする方法を見つけることです。同じ原則が内部サービスを構築する際にも適用されます。
私たちは、100のチームに問題対応を依頼するよりも、1つのチームがその問題を担当できるようにしたいと考えています。現代のAWSリージョンには数百のAWSサービスがあり、それらの多くは複数のマイクロサービスで構成されています。このようなイベントが発生した際に、すべてのチームを迅速に対応させるのは困難な仕事です。そこで私たちは、すべてのチーム間で合意を形成します。私たちは皆、このイベントに対応できるようにスケールを確保します。そして、中央のインシデント対応チームに、問題を検出し全員をシフトさせる責任を与えます。これにより、対応時間が驚くほど短縮されます。
デカップルされたマイクロサービスモデルとAZ回復の課題

顧客と話をすると、大企業では同様の状況が珍しくありません。1つのリージョンで50、100、あるいは200のサービスが稼働しており、同じような状況に直面しています。そのため、検出と対応を一元化することは非常に有用です。 本質的に、私たちは責任モデルを少し変更しているのです。インシデント対応チームが検出と復旧の問題を扱います。ただし、スケーリングについては、依然としてそれらのサービスチームがお客様として担当します。



よく目にするのは、マイクロサービスアーキテクチャです。私たちも、多くの顧客も、これらを多数構築しています。実際には、このような単一のWebサービスではありません。時間とともに、ステートレスなフロントエンドサービスと、その背後に多くの機能を持つ形に成長していきます。 背後に1つ、2つ、3つのマイクロサービスがあるかもしれません。実際、大規模なケースでは、50や100のマイクロサービスが背後にあることがよくあります。 ここでの課題は、より多くの調整問題を生み出していることです。

内部的に、アーキテクチャ的にこれを扱う2つの方法があります。1つ目は「サイロ化モデル」と呼んでいるもので、マイクロサービス間の呼び出しをAZ内でサイロ化します。これについては後ほど図で説明します。もう1つは、より分離されたモデルです。これらの概念について簡単に説明します。AZサイロ化モデルでは、クライアントがAZ 1にかなりランダムに呼び出しを行うのがわかります。 DNSが指示したAZを選択します。これらのホストがバックエンドのマイクロサービスを呼び出す際、すべてがAZ 1に現れることに注目してください。クライアントがAZ 2にヒットした場合、すべてのバックエンドマイクロサービスの呼び出しもAZ 2に着地します。AZ 3の場合も同様に、すべてのバックエンドマイクロサービスの呼び出しがAZ 3に着地します。

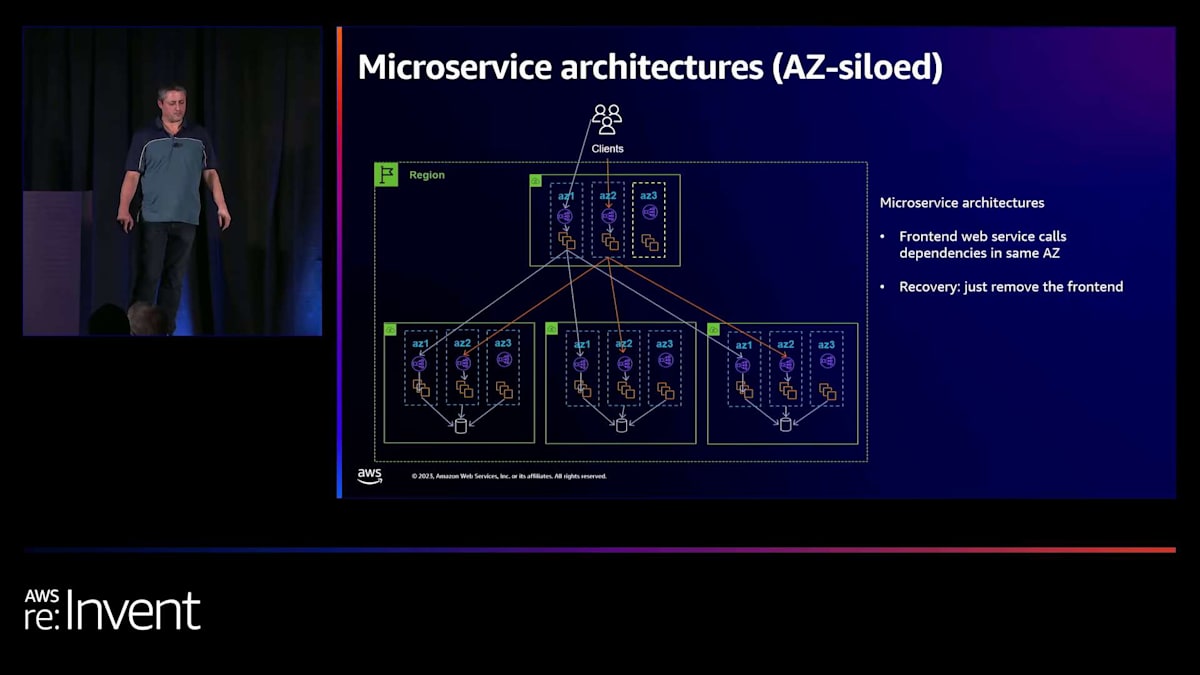
この素晴らしい点は、AZの障害から回復したい場合、フロントエンドでAZ 3を切り離すだけで、 バックエンドに全く変更を加えることなく、AZ 3のすべてのバックエンドが静かになり始めることです。これは特にこのようなマイクロサービスモデルにとって非常に便利な特性です。 実際のイベントが発生した際に変更する必要のある項目が少なくて済むのです。ただし、容量の問題についても考慮する必要があります。なぜなら、AZ 1とAZ 2のすべてのマイクロサービスが増加したトラフィックを受けることになるからです。

時間が経つにつれて、このモデルには一定のポイントまでスケールアップできるものの、その後は少し難しくなるという問題があることがわかりました。ほとんどの顧客やチームがマイクロサービスを構築したい理由は、多くのチームが独立して運用でき、お互いの業務に干渉せずに済むからです。サイロ化されたモデルを運用する難しさは、フロントエンドサービスがAZ 4に容量を追加することを決めた場合、他のすべてのマイクロサービスもそれに追随してAZ 4にデプロイしなければならないことです。これは理想的ではありません。特に、その決定に20〜30のチームが関与している場合はなおさらです。

同様に、デプロイ時に(私はチームがこれを行うのを見たことがありますが)、その日のAZにデプロイするということがあります。フロントエンドサービスがAZ 1にデプロイしている場合、何か問題が起きるリスクがあり、そこから離れたいと思うかもしれません。しかし、バックエンドサービスの1つが同時にAZ 2にデプロイしている場合、複数のゾーンを同時に壊してしまう可能性があります。これは本当に避けたいことです。つまり、これはチーム間でより多くの共有された調整責任につながります。 そして、これがこのアプローチのデメリットの1つです。これは本当にトレードオフなので、使わないでくださいとは言いませんが、

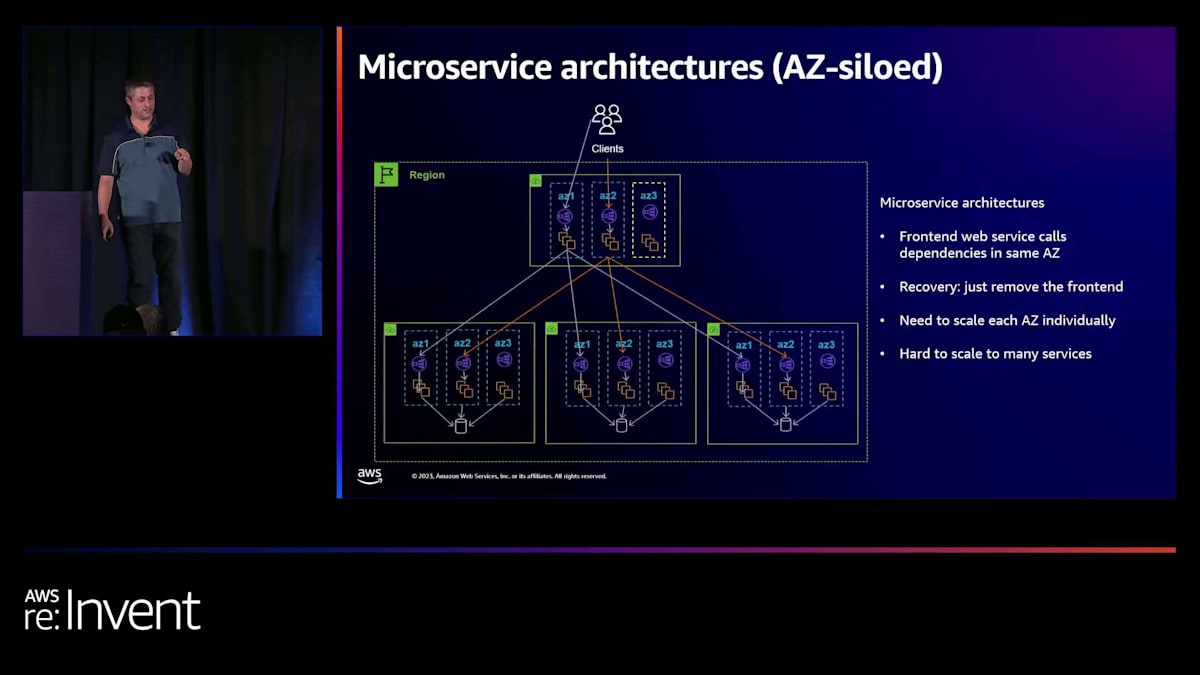
ただ、その境界について考えてみてください。ある時点で難しくなりすぎると思います。しかし、これを実行することが最近非常に簡単になりました。数週間前、AWS Network Load Balancer (NLB)が Availability Zone DNS affinityと呼ばれる機能をリリースしました。これが実際に行っていることは、 オンにすると透過的にこのサイロ化されたアーキテクチャを実装することです。ここの左下のロードバランサーを見ると、フロントエンドサービスがそのサービスのリージョン名を検索すると、常にAZ 1のIPが返されます。その利点は、このサイロ化が自動的に行われることです。つまり、非常に簡単にオンにできます。以前は各ゾーンのフリートを明示的にAZに呼び出すように設計する必要がありましたが、今ではNLBでこれを簡単にオンにできます。


もう1つの選択肢は、 デカップルされた、つまり非サイロ化モデルです。ここでは、これらのロードバランサーやサービスはそれぞれ、どのAZにあるかに関係なく、お互いをリージョナルとして呼び出します。これにより、より高度なデカップリングが可能になります。サービスはお互いをリージョナルユニットとして扱います。つまり、フロントエンドサービスが他のサービスのAZ 3を呼び出せないという制限がないため、これらのマイクロサービスそれぞれがAZ 3から独立して回復する必要があります。繰り返しになりますが、これはある種のトレードオフです。 小規模な緊密なチーム、2〜3のマイクロサービスから始めて、このサイロ化モデルがうまく機能するかもしれません。時間が経つにつれて規模が大きくなり、チーム間でより多くの自由を求めるようになると、必ずしもスケールしないかもしれません。しかし、非常に簡単な回復パスを提供してくれます。
AWSのAZ回復に関する主要な学びと推奨事項


再度、この共有責任モデルを見てみましょう。Amazonでは、デカップルされたモデルの場合、インシデント対応チームがフロントエンドサービスだけでなく、すべてのマイクロサービスも処理できる準備ができていれば、それほど問題にはなりません。すべてのチームに反応を求める必要はありません。 Deepakにバトンタッチする前に、私たちの経験からいくつかの簡単な学びをお伝えします。各アプリケーションの設計を慎重に考えることが非常に重要です。ロードバランサー層、データベース層、コンピューティング層がAZの障害からどのように回復するかを考えてください。キャッシュがある場合、それはどうなるでしょうか?理想的には、AWS Fault Injection Serviceを使ってテストするなどして、それを正しく理解することが重要です。そうすることで、通常、AZの障害時にダウンすることはありません。ただし、低レベルのグレー障害が発生する可能性はあります。
2つ目は、グレーの障害を、それが何であるかや解決方法を心配せずにハードな障害に変えることができるということです。単にAZがダウンしていると仮定し、原因を突き止めるまでそこへのトラフィックを止めるのです。一般的に、AWSサービスに代わってシステムを構築する際は、マネージド型のリージョナルサービスを好む傾向があります。多くのサービスでAWS Lambdaパターンを使用しているのは、運用がはるかに簡単だからです。また、これを行う際には、必ず事前にスケールアップしておくようにしています。AZから離れる際に、オートスケーリングによるスケールアップを待つことなく回復できるようにしたいのです。十分な容量があれば、安心して移動でき、うまく機能することがわかっているので、その後で離れたAZで何が起きているかを心配し始めればいいのです。理想的には、多くのサービスが関与している場合、中央のチームが検出してシフトを行うことが本当に役立ちます。
もう1つは、このプロセスを18ヶ月も間隔を空けて行うべきではないということです。定期的なテストサイクルを設けることが重要です。ここでDeepakに引き継ぎ、auto shiftについて話してもらいます。内部でツールを構築する中で、それらをより外部に公開し始めているのです。Deepakが話すツールは、これらの学びから得られた知見に基づいています。では、お願いします。
Zonal ShiftとZonal Auto Shiftの紹介
ありがとう、Gavin。Gavinが言ったように、多くのツールを外部にも公開しようとしています。これにより、お客様もAZの障害から回復できるよう支援したいと考えています。私が詳しく話すのは、zonal shiftについてです。これは、クライアントトラフィックをAZから確実にシフトする方法です。この機能は昨年リリースされました。


次にzonal shiftについて説明します。Gavinが説明したアーキテクチャタイプに戻ると、サイロ型アーキテクチャでは、zonal shiftはフロントエンドに適用されます。これにより、この場合AZ 1を通過するトラフィックをブロックします。非サイロ型アーキテクチャでは、実際には実行中の各マイクロサービスに適用する必要があります。これらの各マイクロサービスについて、AZ 1に対して行います。

これらのモデルでは、AZ 1で障害が発生し、グレーの障害がある場合、それをハードな障害に変え、アプリケーションのそのAZを使用停止にします。Zonal shift自体は、呼び出す単純なAPIです。リソースを再構成せずにトラフィックをシフトするためのものです。つまり、実際には何も再構成せず、リソーステンプレートに変更はなく、リソースにドリフトは発生しません。イベントを検出したらzonal shiftを適用し、イベントが過ぎ去ったら元に戻します。リソースには実際の変更はありません。


ご想像の通り、このタイプのAPIはイベントが進行中の際に呼び出されます。Zonal Shiftの背後にあるサービスは既に事前にスケールされており、顧客がAPIを呼び出す際の追加負荷に対応できるようになっています。これはリージョナルAPIです。 Gavinがリージョナルモデルとゾーナルモデルについて話したように、これはAWS側の共有責任モデルの一部であり、イベント中でもAPIの可用性を維持します。


実際には、これはリソースごとにZonal Shiftを適用することで機能します。 この場合、AZ 2のElastic Load BalancerノードにZonal Shiftが適用されていることが示されています。有効期限に注目することが重要です。これは一時的なアクション、つまりこの場合はAZ 3からのトラフィックを一時的にシフトさせるものです。イベントが有効期限前に終了すると予想される場合は、その時点でZonal Shiftをキャンセルします。もしイベントがそれを超えて続く場合は、もちろんZonal Shiftを継続し、 有効期限をリセットすることができます。



Zonal ShiftはAmazon Route 53 Application Recovery Controllerの一部です。Recovery Controllerサービス自体には2つのコンポーネントがあります。マルチリージョンアプリケーションとマルチAZアプリケーションの復旧を支援するコンポーネントがあります。今日議論しているのは、もちろんZonal Shiftを使用したマルチAZの部分です。Zonal Shiftをどのリソースで使用できるでしょうか?Application Load Balancer またはNetwork Load Balancerで使用できます。これらは現在サポートしているマルチAZコンポーネントです。これらはクロスゾーン無効モードでサポートされています。この機能は標準パーティションのすべてのリージョン および中国リージョンで利用可能です。残りのリージョンでもまもなく利用可能になる予定です。

さて、Zonal Shiftをローンチしてから1年以上が経ちました。顧客から多く寄せられたフィードバックは、「多くの場合、AZ内のAWSの潜在的な影響に対応しているのですが、それをどうやって知ることができますか?多くの異なるアカウントでサービスを実行している中で、それを確実に検出するにはどうすればいいでしょうか?そして、AWSが潜在的な影響を知っている可能性が高いのであれば、なぜAWSが自動的に私のリソースにZonal Shiftを適用するボタンを押せないのでしょうか?」というものでした。このフィードバックに基づいて、今日私たちが発表したのがこれです。

Zonal Auto Shiftを導入しました。私たちが自動的にボタンを押すことになります。ただし、いくつかの重要な注意点があります。AZに潜在的な影響がある場合に実行します。つまり、この影響が見られる場合、アプリケーションのためにAZから容量を取り去ることになります。アプリケーションの健全性に影響を与える可能性があるため、これはオプトイン機能となっています。

例えば、残りのAvailability Zoneに追加のトラフィックを処理するのに十分な容量がない場合、実際にエンドユーザーにとっては状況を悪化させる可能性があります。そのため、私たちはお客様にオプトインしていただき、お客様に代わってボタンを押すことを承認していただきたいのです。これは現在サポートされているリソース、つまりNetwork Load Balancer(NLB)とApplication Load Balancer(ALB)で行うことができます。


zonal autoshiftをオンにするのは非常に簡単です。zonal shiftコンソールに移動し、リソースごとに有効にして、auto shiftをオンにするだけです。これを行うと、共有責任モデルに変更が生じます。Gavinが説明していたように、検出と回復に関してお客様が所有していた部分は、コンピューティングに関するものでした。zonal auto shiftをオンにすると、それがAWS側の責任モデルに移行し、問題を検知した場合、私たちがお客様に代わってボタンを押すことになります。
Zonal Auto Shiftの実践と注意点



もちろん、ボタンを押すということは、それに備える必要があるということです。十分な容量が必要です。容量という言葉をよく耳にすると思いますが、これは私たちがお客様とよく話し合うトピックだからです。トラフィックを移動させた場合、何が起こるでしょうか?理想的なケースでは、すべてが正常に動作し、負荷が完全にバランスが取れており、アプリケーションの各Availability Zoneが正常に稼働しています。zonal shiftが適用された場合、あるいはauto shiftが行われた場合、1つのAZの容量が削減され、残りのAZで追加の負荷が発生することになります。

これに対する準備ができていないと、クライアントにとってブラウンアウト状態を引き起こす可能性があり、それは避けたいところです。そのため、準備が非常に重要なのです。そこで、auto shiftと共に追加しているのが、practice runと呼ばれる機能です。auto shiftをオンにすると、practice runも一緒に得られ、これは必須です。practice runなしでauto shiftを使用することはできません。両者はセットになっています。
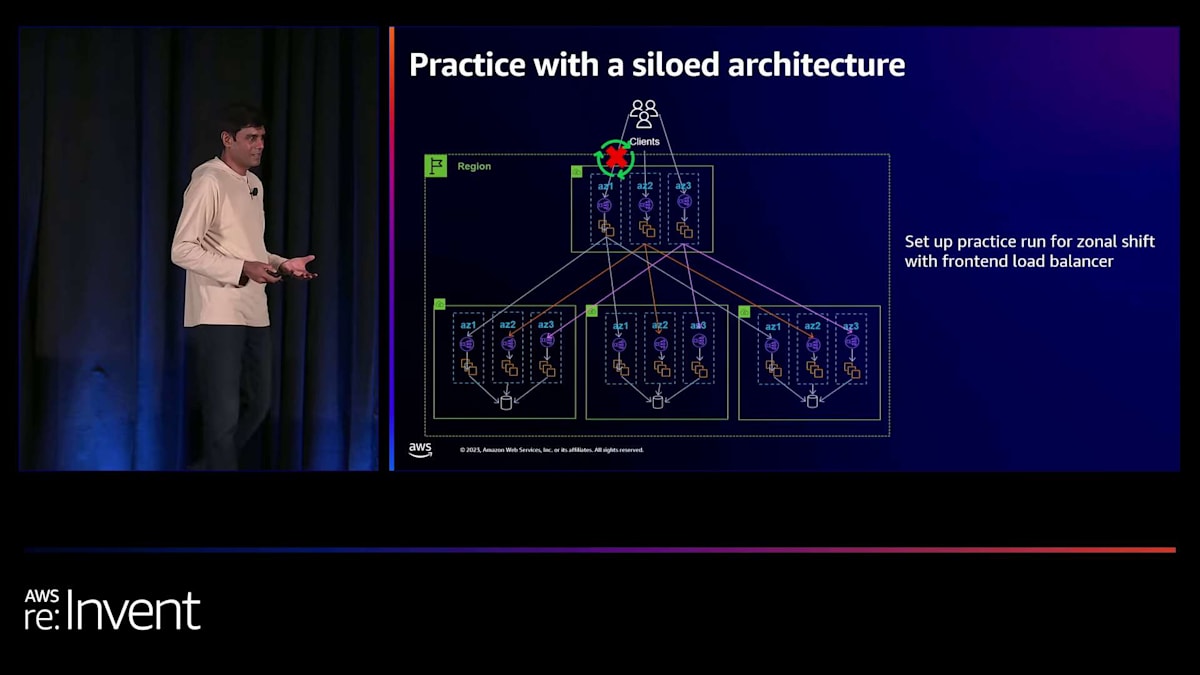

practice runの考え方は、オプトインしたリソースに対して、週に1回、自動的にzonal shiftを適用するというものです。週に1回、30分間、各リソースがこの動作を経験します。zonal shiftが適用されるのです。サイロ化されたアーキテクチャでは、フロントエンドで週に1回のzonal shiftが予想されます。おそらく、フロントエンドのロードバランサーに対してauto shiftを有効にすることになるでしょう。そこに適用されるのです。そして、サイロ化されていないケースでは、アプリケーションのフロントエンド部分とバックエンド部分の両方で、各ロードバランサーに対してこれを有効にすることになります。

また、このようなアーキテクチャでは、多くのアプリケーションが稼働し、多くのチームが関与している可能性が高いため、practice runはゲームデーのようなイベントではありません。これらのpractice runやリソースに対するzonal shiftの適用は、それぞれ独立して行われます。その理由は、各チームと各サービスが独立して観察され、AZの損失に耐えられることを確認するためです。

すでに顧客から寄せられている質問の1つは、auto shiftをオンにしなくても、practice runを独立して使用できるかどうかということです。はい、practice runをオンにすることができます。これは、APIを呼び出してzonal shiftを自分で適用するのと似ていますが、practice runではこれを自動化し、auto shiftを有効にする前にアプリケーションの動作をチェックします。

practice runをセットアップする際に、特定の時間帯や特定の日を除外できるかどうか疑問に思うかもしれません。ブラックフライデーや確定申告日、あるいはビジネスにとって重要な他の日にpractice runがシステムにエントロピーを加えることを望まないかもしれません。はい、それは可能です。除外する時間帯や日を設定できます。ただし、イベントはいつでも発生する可能性があることを忘れないでください。

したがって、除外するウィンドウや日数を減らすことも、時間の経過とともに有益です。私たちは、時間の経過とともに除外するウィンドウを減らし、最終的にはできるだけ少なくして、いつでもイベントに備えられるよう自信を築くことをお勧めします。

もう1つ重要な点は、practice runが行われ、アプリケーションの健全性が低下し始める可能性がある場合です。practice runの契約の一部として、アラームを提供していただき、そのアラームが発生した場合にpractice runを停止します。また、practice runを開始する前にもそのアラームを確認します。例えば、すでにデプロイメントを行っている場合や、環境で他の何かが進行中でpractice runを開始したくない場合、これがトリガーするアラームです。このアラームをモニタリングし、必要に応じてpractice runをブロックします。

また、autoshiftや実践的な運用が行われている場合に、それを観察することも重要であると認識しています。Amazon EventBridgeを使用して通知を設定することができます。

ここで、いくつかのトレードオフと注意点についても触れておきたいと思います。

autoshiftを設定する際、事前スケーリングに関するビジネス上のトレードオフが発生します。autoshiftをオンにすると、他のAvailability Zone(AZ)のリソースも事前にスケーリングすることに同意することになります。事前スケーリングにより、固定または制限された復旧時間が確保され、結果としてクライアントの体験が向上します。
autoshiftを使用する場合、事前スケーリングも併せて使用することを前提としています。これらの戦略は一体となっています。もし、イベントに対する応答としてautoscalingに依存する戦略を取る場合、autoshiftは適していません。ただし、その場合は復旧時間が不定になり、クライアントの体験が悪化する可能性が高くなります。これがビジネス上のトレードオフとなります。

今回、autoshiftと共にAWS Fault Injection Serviceの新機能もリリースしました。これはzonal shiftやautoshiftと補完的に使用できるものです。この機能を使用すると、停電テストを導入し、実際にAZでの電源障害をシミュレートして、その対応としてzonal shiftをどのように使用できるかを確認することができます。
AZレジリエンス設計の重要ポイントとまとめ

ここで、Gavinにバトンタッチします。Gavin、まとめをお願いします。「はい、ありがとうございます。最後に、いくつかの重要なポイントをまとめたいと思います。スライドの写真を撮りたい方は、今がいいタイミングかもしれませんね。

ここで重要な点をいくつか挙げておきましょう。先ほども述べましたが、AZレジリエントな設計が極めて重要です。AZから離れる場合、アプリケーションはグレー障害に対処できるように設計されている必要があります。事前にアプリケーションをそのように設定しておく必要があります。
我々のアプローチは、1つのAZでグレー障害を特定し、そこから離れることでハード障害に変換するというものです。実際にはそのAZへのトラフィックをブロックするのではなく、単に迂回させるだけです。AZレジリエントな設計を行う際の一般的なルールとして、どのようなデータストアや技術を使用しても構いません。ただし、特にデータベース層では、AZ障害に対処できる管理されたリージョナルサービスを好んで使用します。コストとのバランスを取る必要がありますが、これを迅速に行うためには、事前にスケーリングしておく必要があります。
ほとんどのサービスは、常時100%や98%のCPU使用率で稼働しているわけではありません。そのため、多くの場合、余裕があります。即座に切り替えができるよう、少し上乗せするだけで十分です。ただし、バランスが必要です。一部の顧客やサービスにとっては、このアプローチが適していない場合もあります。しかし、問題が発生したらすぐに切り替える、というように回復時間に制限を設けることで、ビジネスにとって重要な問題であれば、回復時間を大幅に短縮できます。
Zonal shiftは、広範囲なAvailability Zone障害を中央で検知し、作業を移動させるという役割を、お客様に代わって効果的に担います。お客様だけに影響する問題が発生した場合でも、zonal shiftは利用可能で、自分で使うこともできます。私たちは広範囲の問題を探しています。最後に重要なのは、18ヶ月や2年に1回ではなく、定期的に練習することです。1月にセットアップして、負荷テストを行い、万全の準備をしたとします。しかし、18ヶ月後、サービスが大幅に成長した後に、ついにこの状況が発生し、auto shiftがトリガーされます。しかし、トラフィックは今やはるかに大きくなっており、スケールアップを忘れていて、それ以来テストもしていないので、うまくいかない可能性があります。

そのため、私たちは練習を組み込んでいます。良好な関係を築き、定期的に練習し、これが安全であることを確認するためです。これにより、顧客に悪影響を与えるかどうか心配することなく、迅速に行動できます。なぜなら、皆が私たちと一緒に練習しているからです。以上が、お伝えしたかった主なポイントです。DeepakとI(私)はこちら側に移動して、後ほど質問にお答えします。今日はここまでお越しいただき、お話を聞いていただき、ありがとうございました。
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion