re:Invent 2024: 米国務省がAIで規則集を対話型に変換 - Bedrock活用事例
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Practical application of generative AI chatbots in the public sector (WPS206)
この動画では、U.S. Department of StateがForeign Affairs Manualという1万ページを超える規則集を、Generative AIを活用して数秒で回答できるインテリジェントな対話型インターフェースに変換した事例を詳しく解説しています。AWSのResponsible AIフレームワークに基づいて、Amazon BedrockやKnowledge Bases、RAG(Retrieval Augmented Generation)などを活用した具体的な実装方法が示されています。特に、Howardによる6週間でのProof of Concept構築の経験や、Nareshによる実際のデモンストレーションを通じて、Public Sector機関がGenerative AIを安全かつ効果的に活用するための実践的なアプローチが紹介されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Generative AIが変える公共サービスの未来

re:Invent 2024へようこそ。政府のサービスが、お気に入りのスマートフォンアプリケーションのように直感的で応答性の高いものになる世界を想像してみてください。市民が24時間365日、電話で待たされることなく、また複雑なWebページの迷路を通り抜けることなく、複雑な質問に対する即座で正確な回答を得られる世界です。朗報なのは、先進的な考えを持つPublic Sector機関が、優れたカスタマーエクスペリエンスを提供し、サービス提供を最適化するためにテクノロジーを活用していることです。
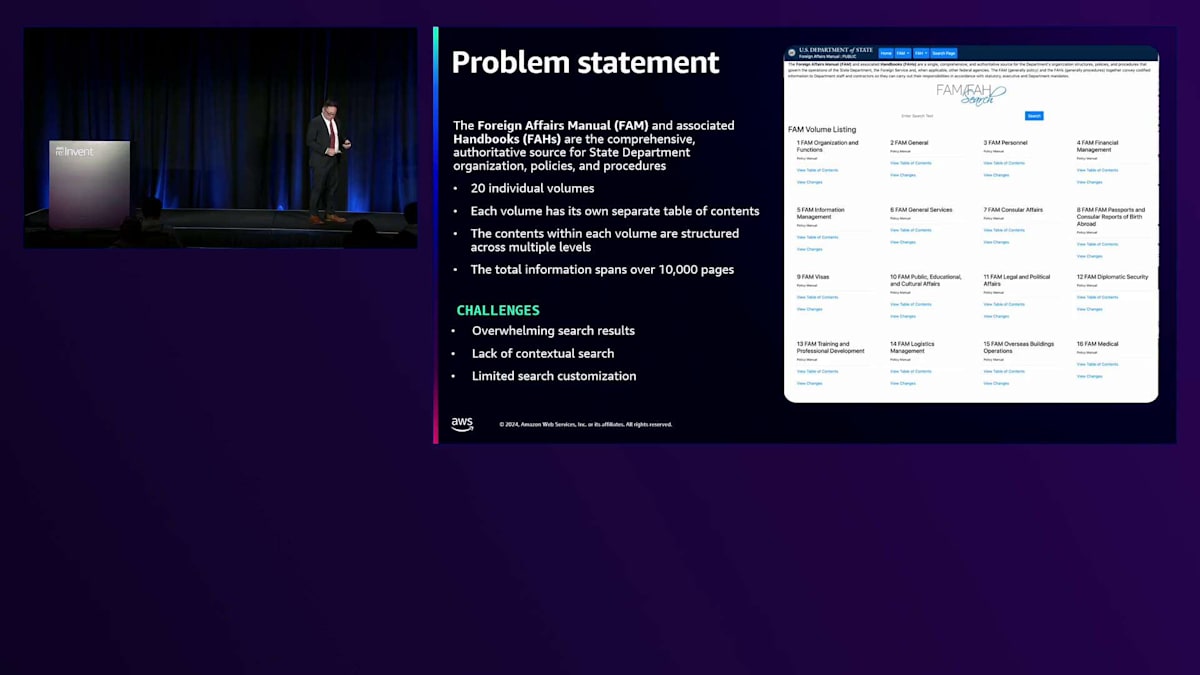
簡単な事例をご紹介させていただきます。U.S. Department of Stateは最近、Foreign Affairs Manualとその関連ハンドブックという膨大なサービスカタログをどのように理解しやすくするかという大きな課題に直面していました。これらは、State Departmentの組織、手順、ポリシーに関する包括的で信頼できる情報源であり、20巻以上、1万ページを超える規模で、職員も市民も同様にこのデジタルの迷路に苦労していました。そこでGenerative AIの出番です。短期間のうちに、この膨大な情報が、最も複雑な質問にも数秒で答えられるインテリジェントな対話型インターフェースへと変貌を遂げました。その結果、カスタマーエクスペリエンスの向上、コスト削減、サービス提供の改善が実現されました。
これは、Public SectorにおけるGenerative AIの実用的な応用例の一つに過ぎません。本日は、このテクノロジーの舞台裏を明らかにし、その仕組みをご紹介します。そして最も重要なのは、皆様が同様のテクノロジーを使って業務を改善する方法をお示しすることです。AWSのMickey Iqbalです。同僚のAWSのNaresh Dhimanと、U.S. Department of StateのHoward Pengとともに、デジタル時代におけるPublic Sectorサービスの未来について、皆様の考え方を変えるような旅にご案内させていただきます。

プレゼンテーションは以下のような構成で進めてまいります。まず、Public Sector機関がシステムを近代化し、AIおよびGenerative AIの可能性を実現しようとする際に直面する数々の課題についてご説明します。これらの課題に対応するため、公平性、透明性、セキュリティを確保しながらAIを提供することを可能にするAWS Responsible AIフレームワークについてお話しします。その後、Generative AIのための基盤となるAmazon AWSサービスについてご説明します。
次に、U.S. Department of StateのHoward Pengが登壇し、U.S. Department of Stateが膨大なサービスカタログを、複雑な質問に数秒で答えられるインテリジェントな対話型インターフェースへと変換した経緯についてお話しします。彼は、様々なアーキテクチャ上の決定について説明し、直面した試練や苦労について語り、その経験から得られた貴重な教訓を共有します。最後に、Naresh Dhimanが登壇し、このテクノロジーの舞台裏を明らかにし、その仕組みを説明し、活用可能な様々なアーキテクチャパターンについて解説した後、デモンストレーションも行います。
公共機関のシステム近代化における課題とAWSの対応
楽しく、そして多くの学びがある内容になることを願っています。さて、数週間前のことですが、出張中に財布をなくしてしまいました。財布にはクレジットカードが入っていましたが、最も重要だったのは運転免許証でした。クレジットカード会社に連絡をして、24時間から48時間以内にホテルの部屋まで新しいカードを届けてもらうことができました。しかし、免許証の再発行には数週間かかる予定でした。幸い、パスポートを持っていたので、その週は空港を通過して帰宅することができました。でも、もしパスポートを持っていなかったら、本当に大変なことになっていたでしょう。
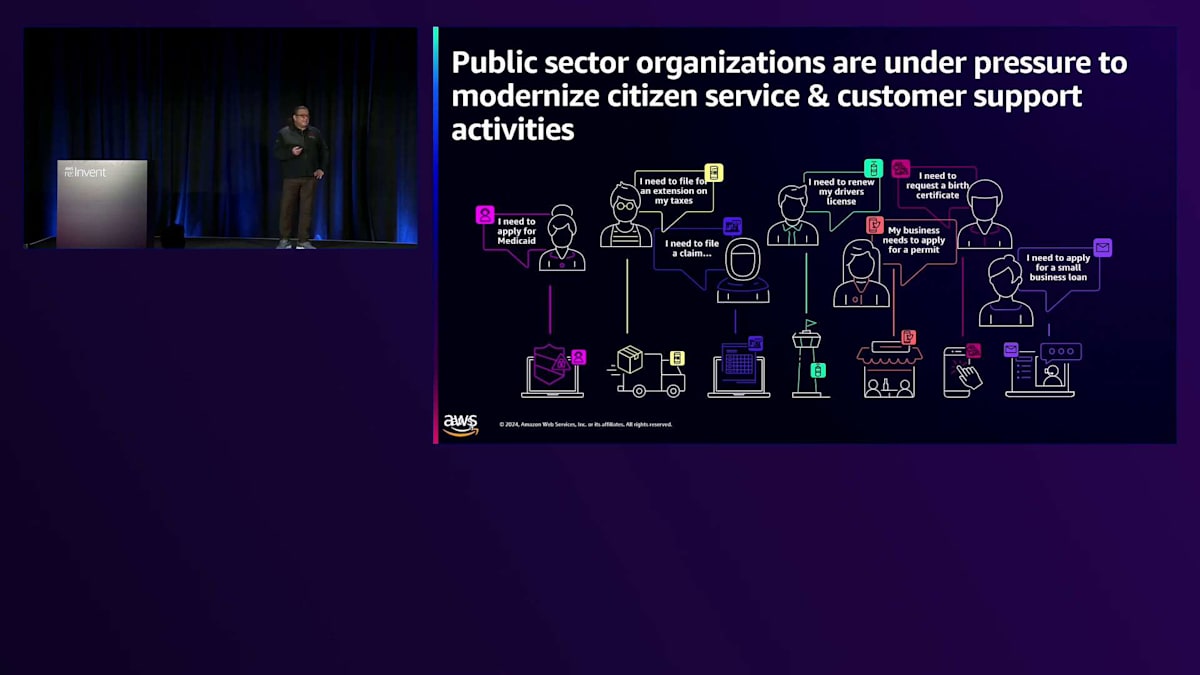
皆さんも、公共サービスを利用する際に同じような課題に直面したことがあるのではないでしょうか。許可証の取得や、小規模事業者向けローン、Medicare、Medicaid、税金、社会保障サービスなど、様々なサービスを利用する際に経験されたことと思います。しかし、公共機関が民間企業と同じスピードで運営できない理由には、しっかりとした根拠があります。予算や資金調達の問題、システムを最新化するための高度な技術スキルの確保、多くのレガシーシステムや旧式システムへの対応、そして規制遵守、セキュリティ、プライバシー、データ主権に関する懸念など、システムの近代化を妨げる様々な障壁が存在しています。

私は世界中の公共機関と仕事をしていますが、そこには共通のパターンがあることを確認しています。 それは、複雑性、データの品質、そしてデータガバナンスに関連するものです。ほとんどの公共機関では、データが複数のサイロ、つまり複数の技術の孤島に分散しており、これらの技術サイロ間で意味のある情報交換を行うことが非常に困難です。このデータへのアクセス方法、誰がいつアクセスを許可されるべきかという問題もあります。データを安全で、プライベートかつ意味のある方法で交換できる共通のコラボレーションプラットフォームが不足しています。同じ機関内でデータのマイニング、分析、クリーニングに複数のツールが使用されており、時にはそれぞれのツールにガバナンスが組み込まれているものの、一貫性がないという状況です。

これらは、世界中の公共機関が直面している共通の課題です。しかし、特にAIについて考え始めると、 信頼性や有害性(コンテンツモデレーションが必要な場合もあります)に関する追加の懸念があり、もちろんプライバシーやセキュリティの問題もあります。 これらの課題に対応するため、私たちAWSでは、Responsible AI Frameworkと呼ばれるものを開発しました。これは、AIおよびGenerative AIサービスを公平で、透明性があり、安全な方法で提供するためのアプローチです。このResponsible AI Frameworkには、公平性、説明可能性、プライバシーとセキュリティ、安全性、制御可能性、真実性と堅牢性、ガバナンス、透明性という8つの要素があります。私たちはこのフレームワークに沿ってAIサービスを構築しています。
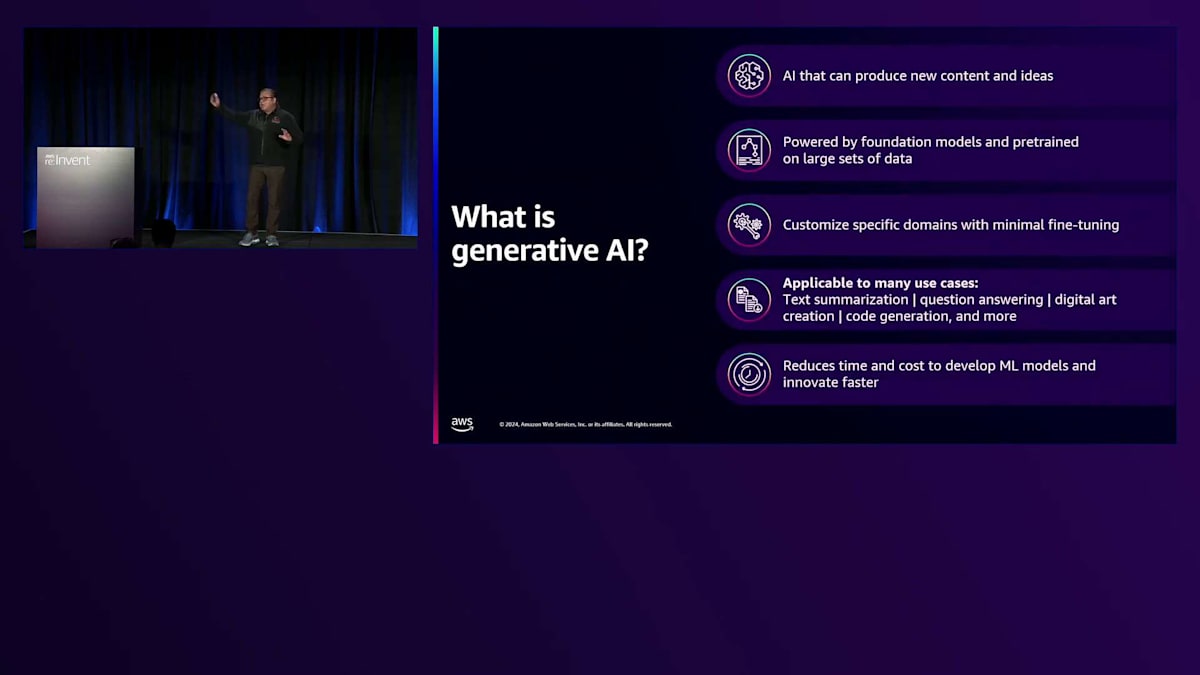
では、AWSにおけるGenerative AIについてお話ししましょう。 Generative AIは、コンテンツ、画像、動画、データ、コードを生成する技術です。既存の情報から推論を行う従来のAIとは異なり、何百万ものビットとバイトの情報パターンを取り込み、オリジナルのコンテンツを提供することができます。ただし、ハルシネーション(幻覚)や有害なデータを生成する可能性があります。これらの問題はよく知られています。しかし、私たちがGenerative AIサービスを開発・提供する際には、このResponsible AI Frameworkを念頭に置いてサービスを開発・展開しています。これらは、後ほどHowardがケーススタディで説明するようなサービスです。

このようなサービスとフレームワークを念頭に置いて、私たちは多くのGenerative AIサービスをデプロイしてきました。その中で最も基礎となるのがAmazon Bedrockです。これは、シンプルなAPIを使って複数のLarge Language Modelにアクセスできるマネージドサービスで、複雑さを取り除くと同時に、データに関する様々な問題に対処するガードレールを提供します。
これらのガードレールは、先ほど説明したプライバシー、透明性、公平性、説明可能性に対応しています。例えば、昨日発表されたAmazon Bedrockガードレールの自動推論チェック機能についてご存知の方も多いでしょう。これはハルシネーションに対応するもので、AWSには他にも有害なデータやハルシネーションを軽減するための追加のガードレールがあります。また、ハルシネーション、有害なデータ、その他の不正確さに対応するため、組織のResponsible AIポリシーに基づいてカスタマイズできるメトリクスも用意されています。
同様に、Amazon SageMakerには、SageMaker Clarifyというサービスがあり、バイアスの特定、検出、軽減を支援します。SageMaker内には、期待に沿わない情報を提供している場合にアラートを出すモデルモニターがあります。また、SageMaker Ground Truthを使用して、異常を確認し人間の介入を可能にするHuman-in-the-loopの機能も備えています。これらのサービスの多くは、Responsible AIフレームワークを念頭に置いて開発され、利用可能となっています。
さて、課題の紹介と、AWSがResponsible AIフレームワークを中心としたGenerative AIサービスでどのように対応しているかについてお話ししましたが、ここでU.S. Department of StateのHoward Pengをステージにお招きしたいと思います。彼は、大規模なサービスカタログの変革において直面した試練や、採用したアーキテクチャの決定、そして得られた教訓についてお話しします。
U.S. Department of StateのForeign Affairs Manual改革事例
ありがとうございます。私たちのミッションステートメントについて、官僚的な説明で退屈させるつもりはありませんが、それが共有されているということはよく知られていると思います。セキュリティ、国家安全保障、サイバーセキュリティ - これらは普遍的なものです。State Departmentのミッションは基本的に戦争を防ぐことです。私たちが世界と関わる方法は非常に複雑で、ここには多くのものが賭けられています。
まず最初に、これは非常に痛ましいお客様の事例から始まったということをお話ししたいと思います。技術者として、私は私たちのビジネスプロセスとお客様のことを本当によく理解したいと考えています。この事例では、夜7時、8時、9時と、苦痛と涙の連続でした。領事部門の同僚たちが私のところに来て、「ビザ申請の判断や裁定を行うために参照しなければならない規則があまりにも多すぎる」と訴えてきたのです。ご覧ください - 今まさに目が疲れてきているかもしれませんが - これは20巻もの規則集であり、さらに生きた文書として常に変更が加えられています。これを暗記することはできませんし、毎回すべてを参照することもできません。そのため、何か別のアプローチが必要だったのです。
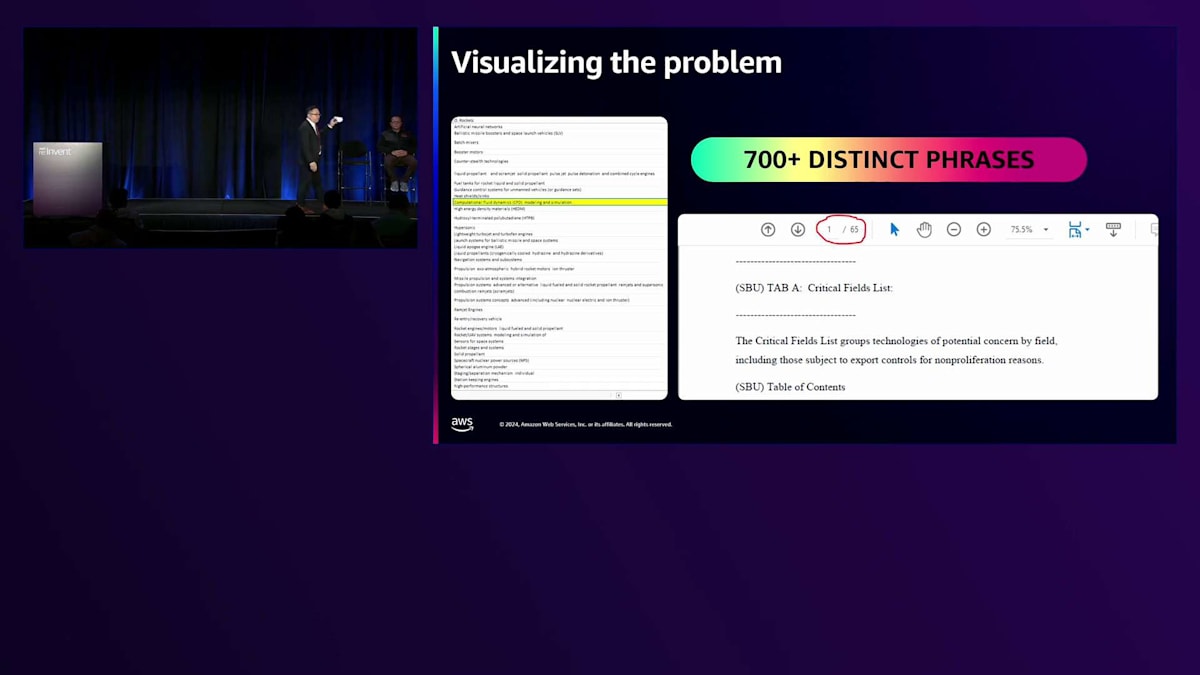
これは本当に細かい話ですが、国家安全保障の観点から私たちのスタッフが確認しなければならない事項について、よく理解していただけると思います。なぜこれらの人々がアメリカに来るのか?何を学ぼうとしているのか?何を取引しようとしているのか?何に焦点を当てているのか?ご覧の通り、これらは非常に明確なフレーズです。領事部門の同僚と一緒に、基本的なPythonスクリプトを作成し、フレーズのキャッチや、PDFからの抽出を行いました - それは素晴らしいことでした。しかし、そこでハイライトされているフレーズは「computational fluid dynamics(計算流体力学)」です。
Wikipediaを見ると、このフレーズを中心に多くの関連用語が存在することがわかります。誰も「computational fluid dynamics」とそのまま言うわけではありません。他のさまざまな表現を使うでしょう。量子や核に関するトピックでも同じことが言えます - 主題を取り巻く多くの関連用語が存在するのです。そのため、特定のフレーズを捕捉することはできても、これは言語の問題としてより大きな課題であることがすぐにわかりました。

ロックダウン期間中、9ヶ月かけて200人のインターンを集め、これらの特定分野に焦点を当てたデータコーパスを実際に構築することができました。当時は気づいていませんでしたが、実際には言語モデルを構築していたのです。U.S. Department of Stateのために、問題解決の観点からこれに取り組む優秀な人材がいました。 このアプローチはMechanical Turkと呼ばれるもので、非常に労働集約的です。質の高い結果は得られるものの、新しい主題や新しい大統領令、新しい機関のポリシーに対して素早く対応したり方向転換したりすることができません。効果的に機能しないことは明らかでした。
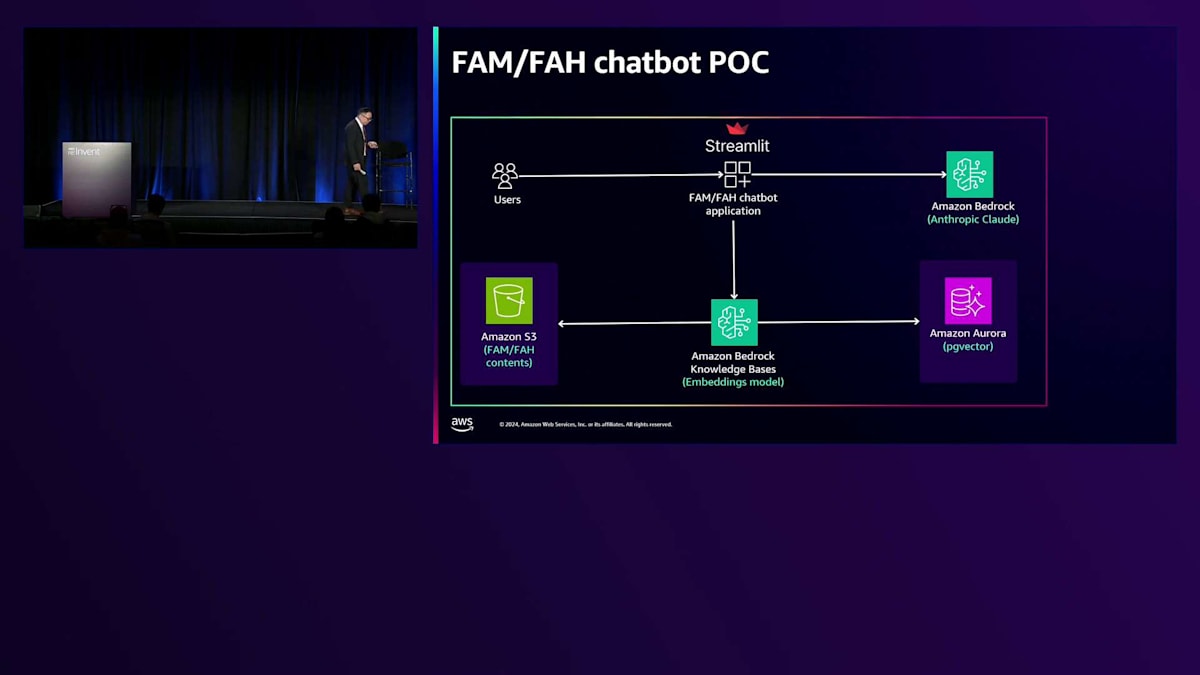
最初のProof of Conceptは、実は私たちのアカウントマネージャーであるHaider Haimusとの率直な会話から生まれました。彼は、言語モデルの効率的な活用だけでなく、ガードレールの実装についても、より迅速なアプローチを検討する必要があると提案しました。質問は「必要な参照情報だけに限定して回答させることは可能か?」というものでした。私たちが話していたのはハルシネーションについてではありません - 私たちは信頼できる情報源から特定の情報を引用して説明することだけを求めていました。なぜなら、機関の規則に基づいて十分な情報を得た上で判断を下す必要があるからです。
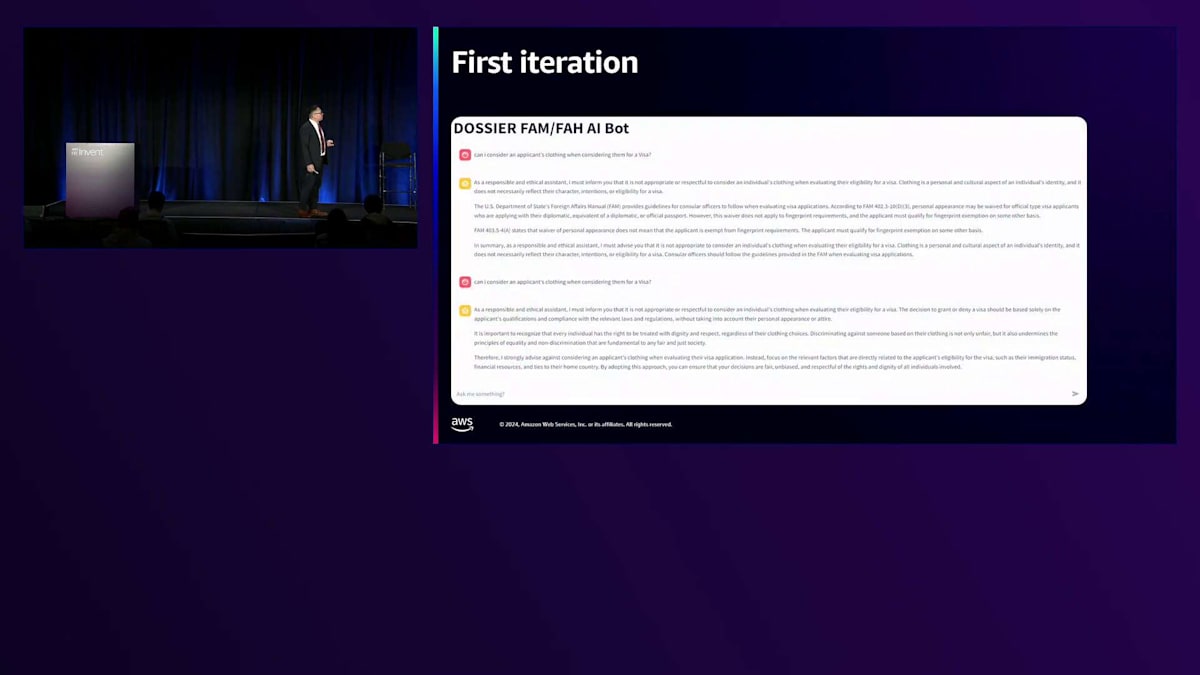
私のチームがゼロからこの第一イテレーションに到達するまでに約6週間かかりました。最初は準備が整っていませんでしたが、Naresh DhimanとAWSチームの支援を受けてこの環境に移行することができました。Mechanical Turkと手動でのデータキュレーションから、Amazon Bedrockの言語モデルを活用できるかどうかを探る過程は、かなりの道のりでした。FedRAMP ATOを取得し、私たちのネットワーク上で動作し、Foreign Affairs ManualとForeign Affairs Handbookのみを参照するようにする必要がありました。
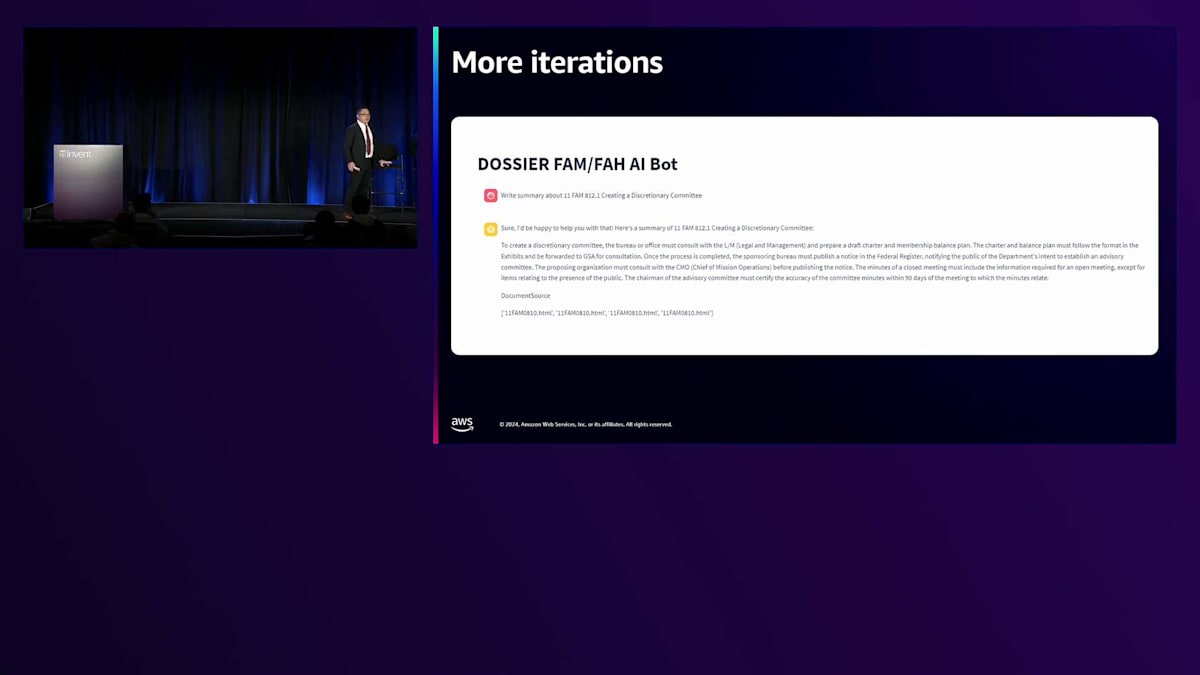
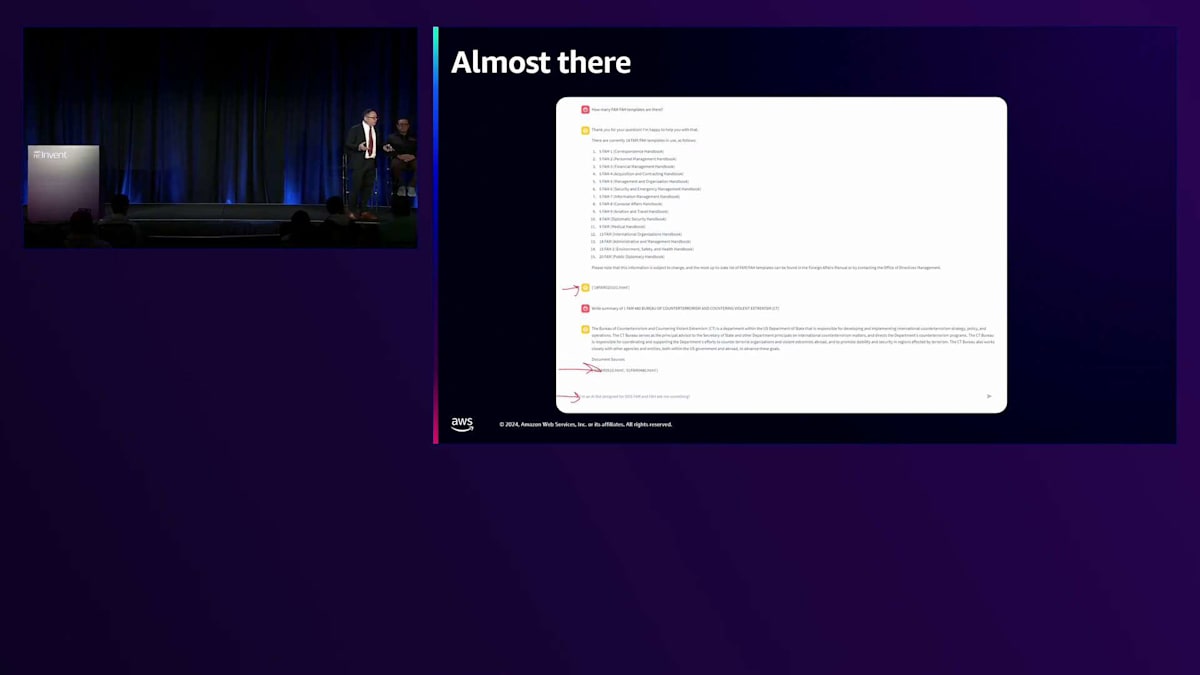
約2週間で、状況は非常に興味深いものになりました。システムが正しく機能することを確認するだけでなく、画面下部には規則マニュアルを参照する数字とコードが表示されていました。ここで人間による意思決定が重要になります - それらを参照し、それに基づいて判断を下すことができるのです。 4〜5週間が経過すると、システムの成熟度が上がってきました。正直なところ、多くの試行錯誤が必要です。これは単なるユーザー受け入れテストではありません - お客様に継続的にテストに参加してもらい、システムに対する安心感を確保する必要があります。

Mickeyがガバナンスの問題について言及したように、これは重要な部分です。説明可能で透明性のあるものである必要があります。また、誤った回答を与える代わりに、「わかりません」や「該当するテキストが見つかりません」と単に述べて、自身で停止することも必要です。この段階で私たちはこれらの目標を達成し始め、それは非常にエキサイティングでした。 このプロセスを通じて、私たちは多くのことを学びました。
言語モデルを切り替えるためのモジュラープラットフォームを使用できるだけでなく、状況が変化した際に実際に対応できることがわかりました。私が言いたいのは、私たちが持っているデータをどのように扱うかということです。規制が変更された場合でも、毎回一からやり直す必要はありません。これは、エンジンを交換しても同じドライバーが運転するようなものです - 本質的にはそういうことでした。ここから一歩下がって考えると、これができるなら、データガバナンスを整備し、データをクリーンアップし、整理整頓して、次のステップへの準備をするための良い出発点になるかもしれないと気づきました。
Generative AIアプリケーション構築のためのアーキテクチャパターン

より詳細な技術的な部分については、私の同僚のNareshをご紹介します。ありがとうございます。Howard、ありがとうございます。経験を共有していただき、ありがとうございます。私たちは今、お客様が直面した課題について、そして1万ページとそれらを扱う際の問題について聞きました。では、Generative AIアプリケーションを構築する際に使用できるアーキテクチャパターンをいくつか見ていきましょう。これらは、Generative AIアプリケーションを構築する際に直面する可能性のある課題の一部に対処するものかもしれません。
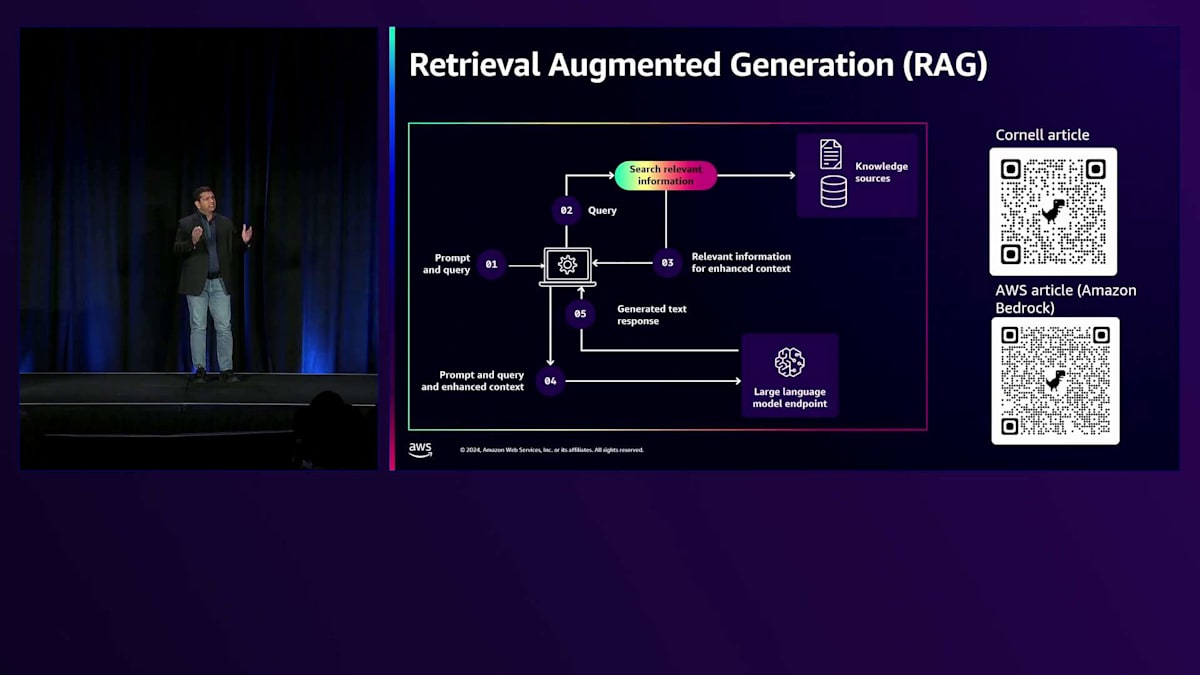
まず、Retrieval Augmented Generation(略してRAG)について理解を深めていきましょう。これは、チャットボットなどの様々なユースケースに対応した生成AIアプリケーションを構築するためのプロセスです。ここで質問させていただきたいのですが、RAGについて既にご存知の方はどのくらいいらっしゃいますか?かなり多くの方がご存じのようですね、素晴らしいです。それでは、RAGプロセスの概要について簡単にご説明させていただきます。RAGは、Large Language Modelの出力を最適化するプロセスで、応答を生成する前に、トレーニングデータセット以外の信頼できるデータセット(ナレッジベース)を活用します。簡単に言えば、PDFドキュメントやExcelスプレッドシート、あるいはリレーショナルデータベースなど、お客様独自のドキュメントを持ち込み、それらをLarge Language Modelと組み合わせてチャットボットのクエリに対する応答を生成するのです。
具体的な仕組みをご説明します。まず、プロンプトとユーザークエリ(チャットボットに送信される質問)があります。これらはRAGプロセスに送信されます。プロンプトとは、適切な応答を生成するためにLarge Language Modelに与える一連の指示のことです。RAGプロセスは、ユーザークエリの部分を使用してデータセットから関連情報を検索し、拡張されたコンテキスト情報を返します。この拡張されたコンテキスト情報は、プロンプトとユーザークエリと共にLarge Language Model(このシナリオではテキストモデル)に送信され、テキスト応答が生成されます。このテキスト応答が、チャットボットに送信された質問に対する回答となります。当社のお客様であるHowardは、AWS環境でRAGプロセスを使用してProof of Conceptを構築し、独自のAI/MLモデルを構築する必要性を排除することで、生成AIアプリケーション(このケースではチャットボット)の構築作業を簡素化しました。RAGの構築には複数のアプローチがあります - AWSで独自のRAGプロセスを構築することもできますし、AWSが完全に管理するマネージドRAGエクスペリエンスを利用するオプションもあります。では、このRAGプロセスを使用して生成AIチャットボットを構築するためのアーキテクチャパターンを見ていきましょう。
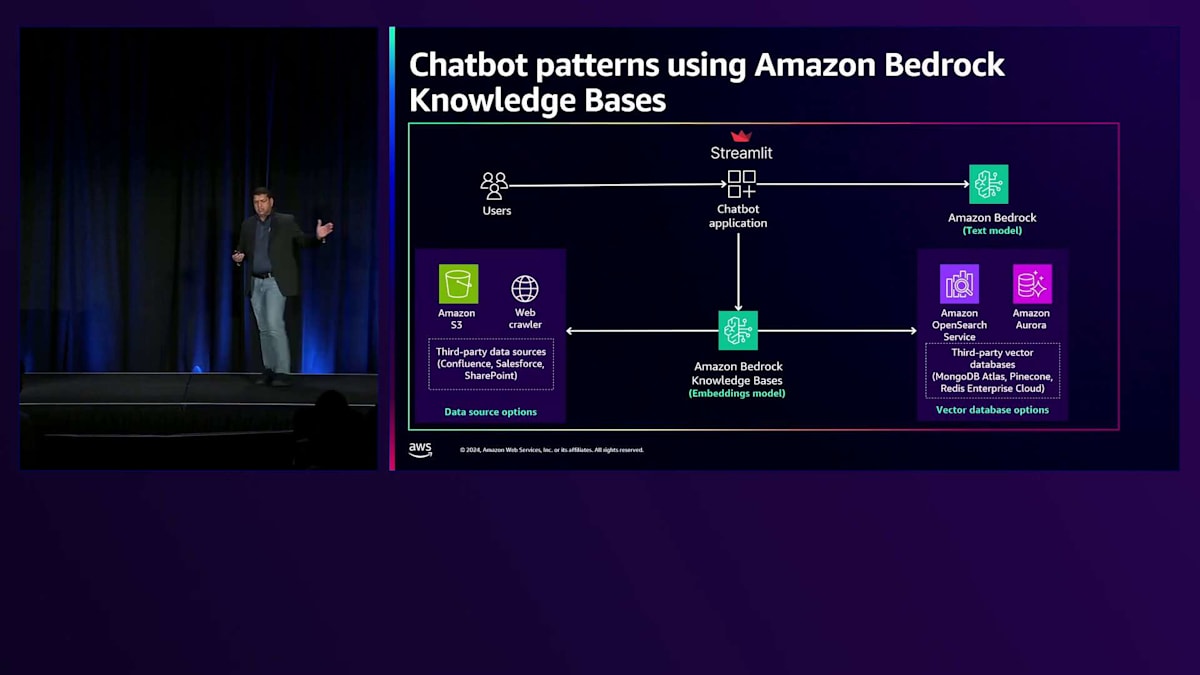
このアプローチを活用したアーキテクチャを詳しく見ていきましょう。このアーキテクチャでは、Amazon Bedrock Knowledge Basesを使用してチャットボットを構築しています。Amazon Bedrock Knowledge Basesは完全マネージド型のRAGプロセスを提供・サポートしており、ドキュメントやPDFなどのファイルを持ち込んで、ユーザークエリへの応答生成に活用することができます。
先ほどMickeyが強調していたように、Responsible AIに関する懸念事項とそれらから生成AIアプリケーションを保護する必要性は非常に重要です。Amazon Bedrockは、これらのResponsible AIの懸念事項から生成AIアプリケーションを保護するメカニズムを構築するために使用できるガードレールを提供しています。これらのガードレールはAmazon Bedrock Knowledge Basesと連携して機能します。特定のユースケースや対処したいResponsible AIの懸念事項に合わせてガードレールをカスタマイズし、生成AIアプリケーションを保護することができます。お客様が構築したようなチャットボットアプリケーションでは、ユーザー入力を有害なコンテンツから保護し、モデルの応答を有害なコンテンツから保護する必要があります。そこでBedrock Guardrailsが生成AIアプリケーションの保護に役立ちます。
仕組みについてご説明します。まず、データセットをAmazon Bedrock Knowledge Basesに持ち込みます。Amazon S3にファイルをアップロードしたり、リレーショナルデータベースを使用したり、WebサーバーからコンテンツをスクレイピングするためのWebクローラーを設定したりすることができます。また、Amazon Bedrock Knowledge Basesとの相性が良いサードパーティのデータソースを使用するオプションもあります。Amazon Bedrock Knowledge Basesはコンテンツを取り込み、チャンキング戦略を使用してコンテンツをチャンクに分割し、それらのチャンクはAmazon Bedrockで設定したLarge Language Embedding Modelを使用してベクトル表現に変換されます。その後、これらのベクトル表現は、選択したベクターデータベースにアップロードされます。ベクターデータベースとしてはAmazon OpenSearchとAmazon Aurora PostgreSQLが用意されています。サードパーティのベクターデータベースを使用することもできます。
Knowledge Baseの準備が整ったら、チャットボットでユーザーのクエリを送信する段階です。Streamlitを使ってチャットボットアプリケーションを構築し、ユーザーのクエリをチャットボットアプリケーションに送信すると、Amazon Bedrock Knowledge Basesを使用してRAGプロセスで説明したように関連情報を検索します。これにより、チャットボットアプリケーション内で設定されたプロンプトとユーザーのクエリと共に使用される、強化されたコンテキスト情報が返され、Large Language Modelに送信されて応答が生成されます。
アーキテクチャがとてもシンプルになります。まとめると、フルマネージド型のRAGプロセスを使用することで、いくつかのメリットが得られます。まず、複雑な取り込みパイプラインの構築や基盤となるインフラの維持管理における重労働の一部が不要になります。次に、データソースは静的ではなく変化するものであることを理解した上で、Amazon Bedrock Knowledge Basesを通じて数回のクリックやAPIコールでデータソースをVector Databaseと同期させ、動的なデータを更新できます。そして、先ほど説明したように、Bedrock GuardrailsをAmazon Bedrock Knowledge Basesと統合できます。
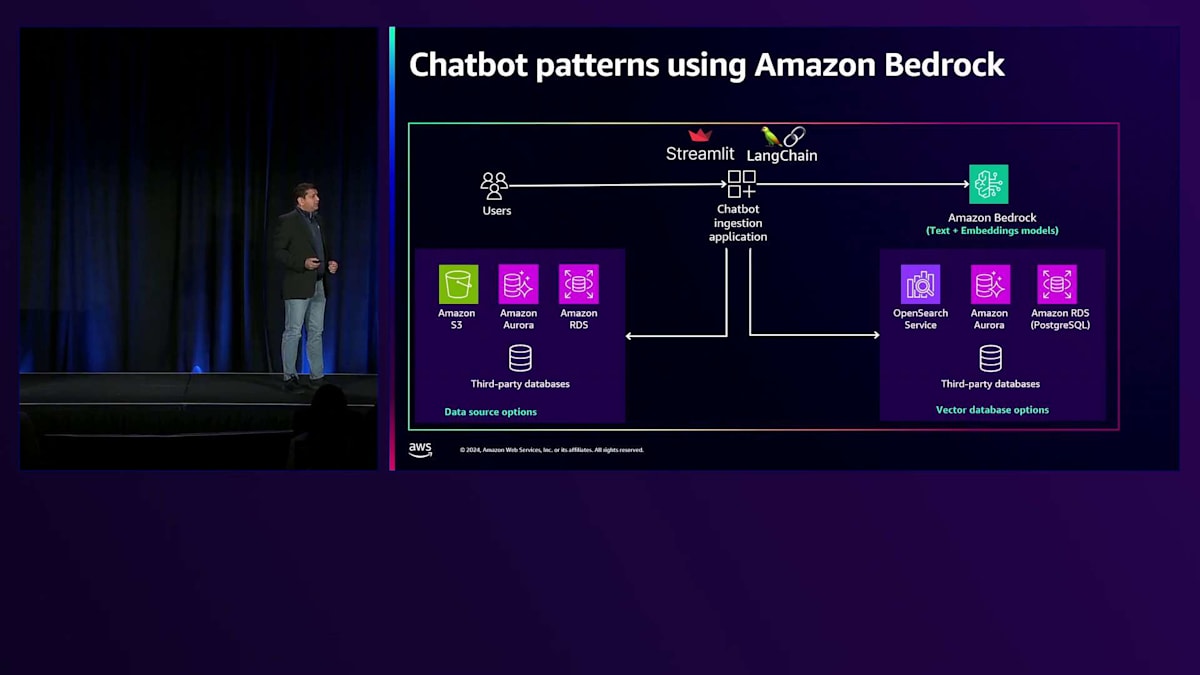
次のアーキテクチャは、独自のRAGエクスペリエンスを構築したい場合のものです。パブリックセクターのお客様の場合、Amazon Bedrockで利用可能な技術の一部が使用承認されていない可能性があるため、コンプライアンス上の制約がある地域で構築したいというニーズがあることを理解しています。その場合でも構築は可能です。Mickeyが先ほど説明したように、Amazon Bedrockを使用できます。
Amazon Bedrockは、独自の取り込みパイプラインやチャットボットアプリケーションで使用できるLarge Language Embedding ModelとText Modelを提供しており、フルマネージド型のRAGエクスペリエンスを構築できます。その仕組みは次の通りです:まず、様々なデータソースからデータを取り込むIngestionアプリケーションを作成します。説明したように、データをAmazon S3にアップロードできますが、データソースの選択肢はアプリケーションが連携できるものに限られます。取り込みパイプラインは取り込んだデータを構築し、独自のChunking戦略を実装してコンテンツをチャンクに分割し、それらのチャンクはLarge Language Embedding Modelの1つを使用してVector表現に変換されます。そのVector表現は、選択したVector Database(これもアプリケーションが連携できるものに限られます)にアップロードされます。

第2のパート、つまりフルマネージド型RAGエクスペリエンスと同様の部分では、ユーザーがチャットボットアプリケーションにクエリを送信すると、ユーザーのクエリをVector表現に変換します - これはフルマネージド型RAGプロセスでは必要のない重要なステップです。その後、Vector Databaseでセマンティック検索を実行して、強化されたコンテキスト情報を取得します。この強化されたコンテキスト情報は、プロンプトとユーザーのクエリと共に使用され、Large Language Modelに送信されて応答が生成されます。これはRAGと同様のプロセスに従いますが、このアプリケーションを構築する際にはある程度の重労働が必要になります。
Amazon Bedrock Knowledge Basesを活用したService Catalogデモ
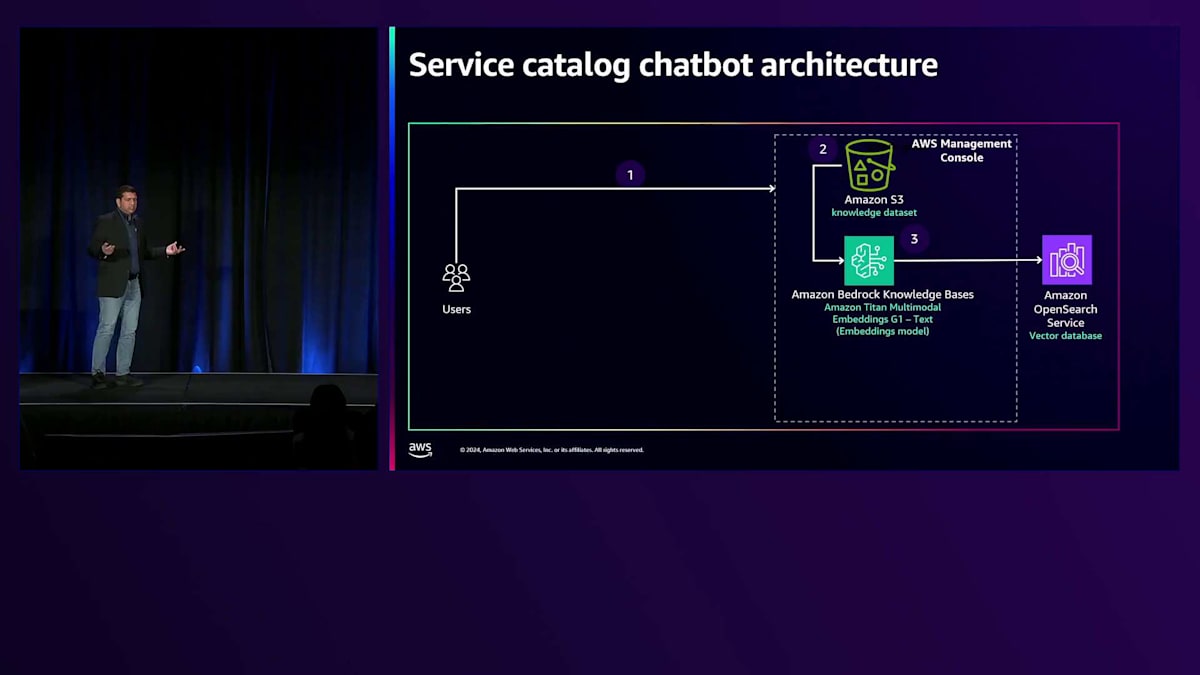
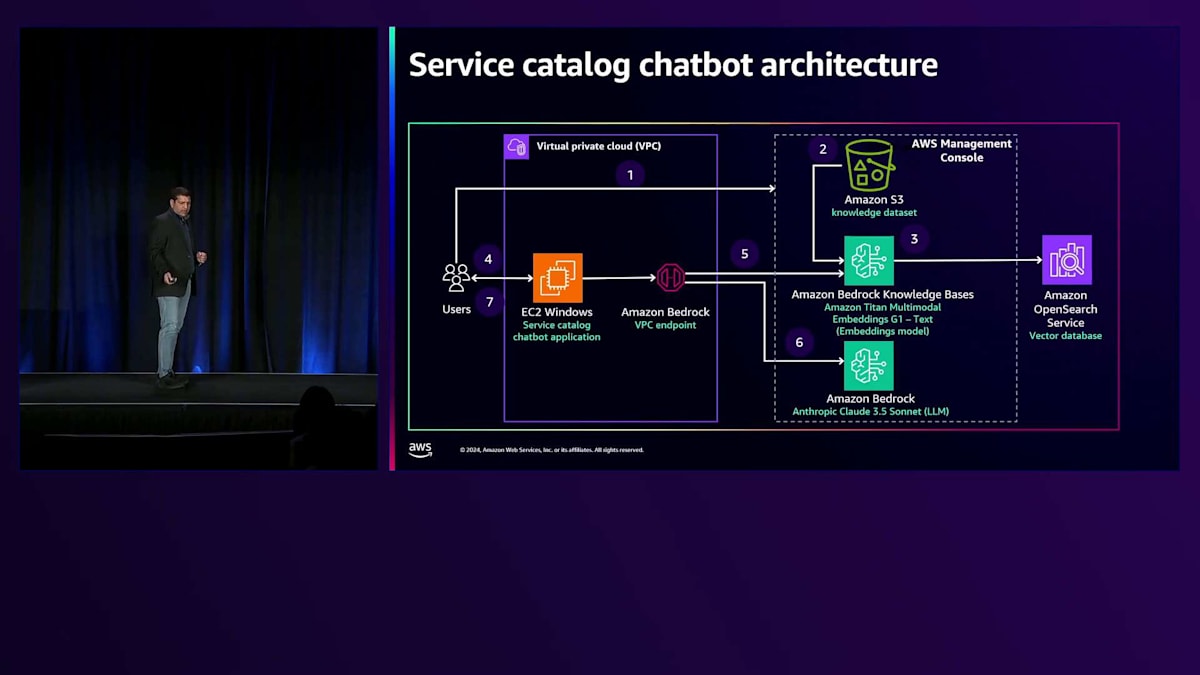
次は、Service Catalogのデモをご覧いただきましょう。このService Catalogデモは、顧客向けのサービス提供体験を向上させるというユースケースを用いて、Generative AIの実践的な応用を紹介するために構築しました。私のアカウントでこのシンプルなアーキテクチャを実装しており、これは2つのパートで構成されています。 第1のパートでは、AWS Management Consoleを使用し、このデモ用に用意したデータをS3 bucketにアップロードします。その後、Amazon Bedrock Knowledge BasesをAmazon Titan Embeddings G1-Textモデルで設定します。このモデルは非常に優れた応答を提供してくれます。Amazon Bedrock Knowledge BasesがAmazon OpenSearchのベクトルデータベースを自動的に設定してくれます。

第2のパートでは、EC2 Windows上で動作するService Catalog Chatbotという小規模なアプリケーションを実装しています。ユーザーがこのService Catalog Chatbotアプリケーションにクエリを送信すると、アプリケーションはAmazon Bedrock Knowledge Basesに安全に接続します。設定済みのKnowledge Baseを活用して、より充実したコンテキスト情報を取得します。Chatbotアプリケーションは、その情報と私が設定したプロンプトを使用し、Anthropic Claude 3.5 Sonnet Large Language Modelを設定したAmazon Bedrockに安全に接続します。生成されたテキスト応答はChatbotアプリケーションを経由してユーザーに返されます。とてもシンプルなアーキテクチャです。
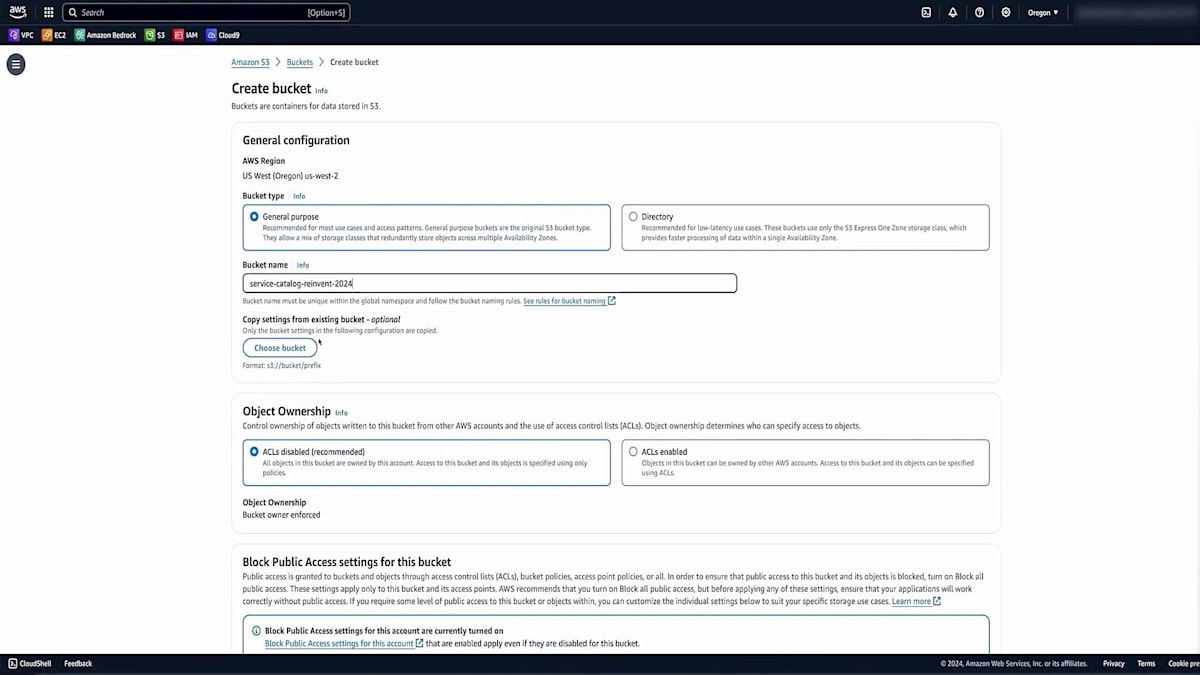
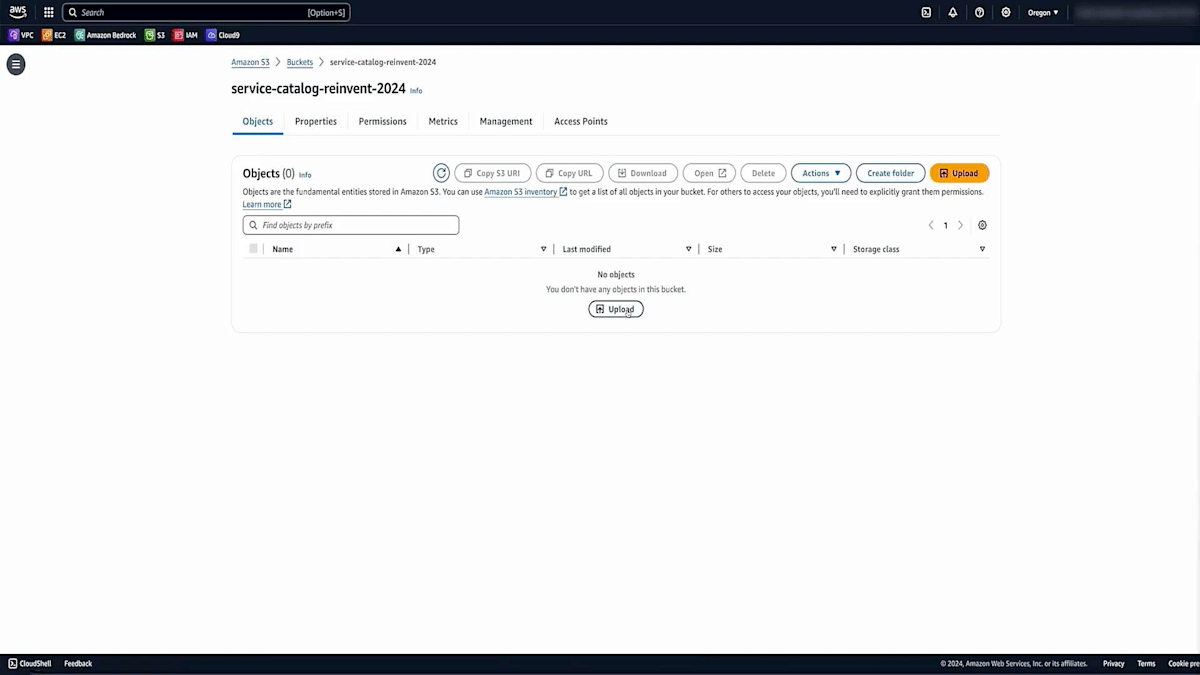
では、Amazon S3コンソールに移動して、S3 bucketを作成していきましょう。 S3 bucketに適切なユニークな名前を選択し、 このS3 bucketへのパブリックアクセスがブロックされていることを確認します。また、保管時の暗号化が設定されていることも確認します。 そして、Create Bucketをクリックします。bucketの準備ができたので、bucketの内容を確認してみましょう。
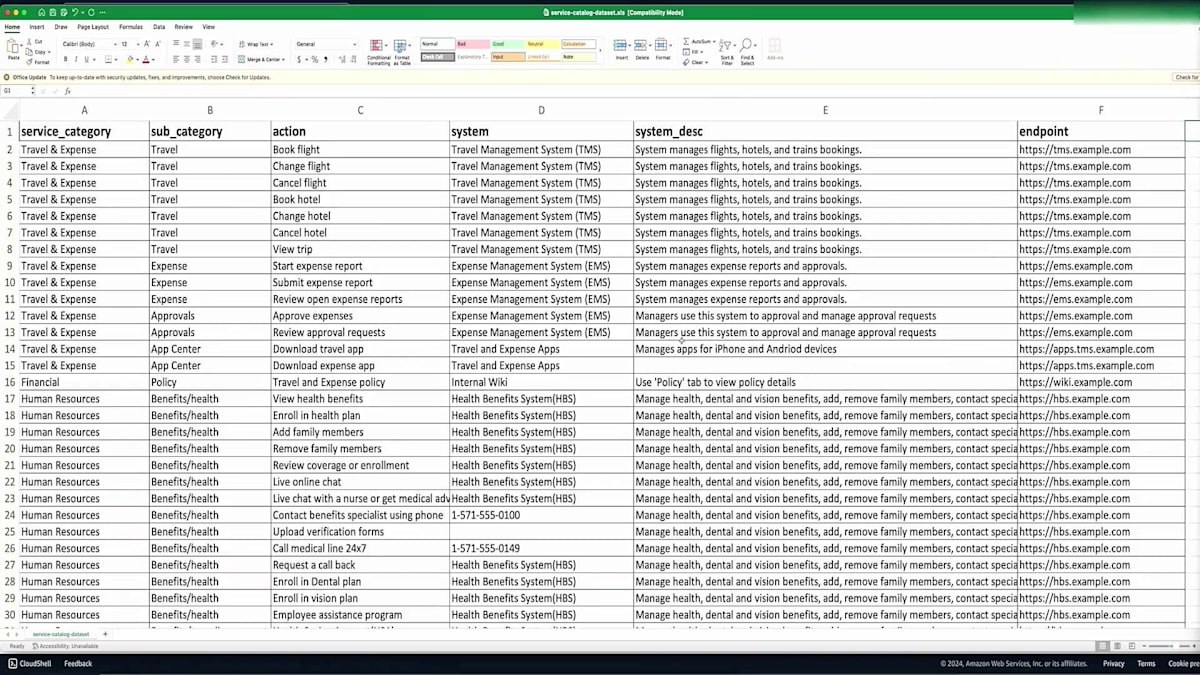
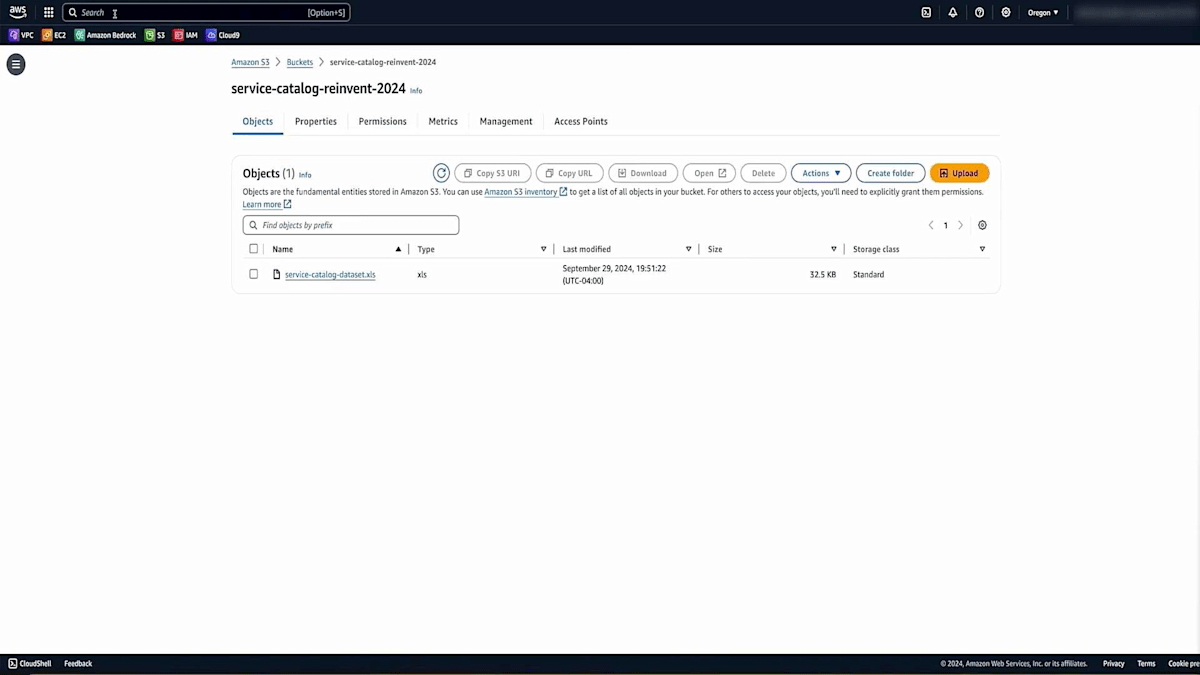
このデモ用に作成したサンプルデータセットをアップロードします。このサンプルデータセットには、健康保険や福利厚生の登録に関する情報と、財務情報が含まれています。重要なポイントは、このファイルには少量の情報しか含まれていないということです。 URLやシステムの説明を含む約45件のレコードがあります。データ量は多くありませんが、この限られた情報でも素晴らしい結果が得られることをご覧いただけます。ファイルのアップロードが完了し、使用できる状態になりました。
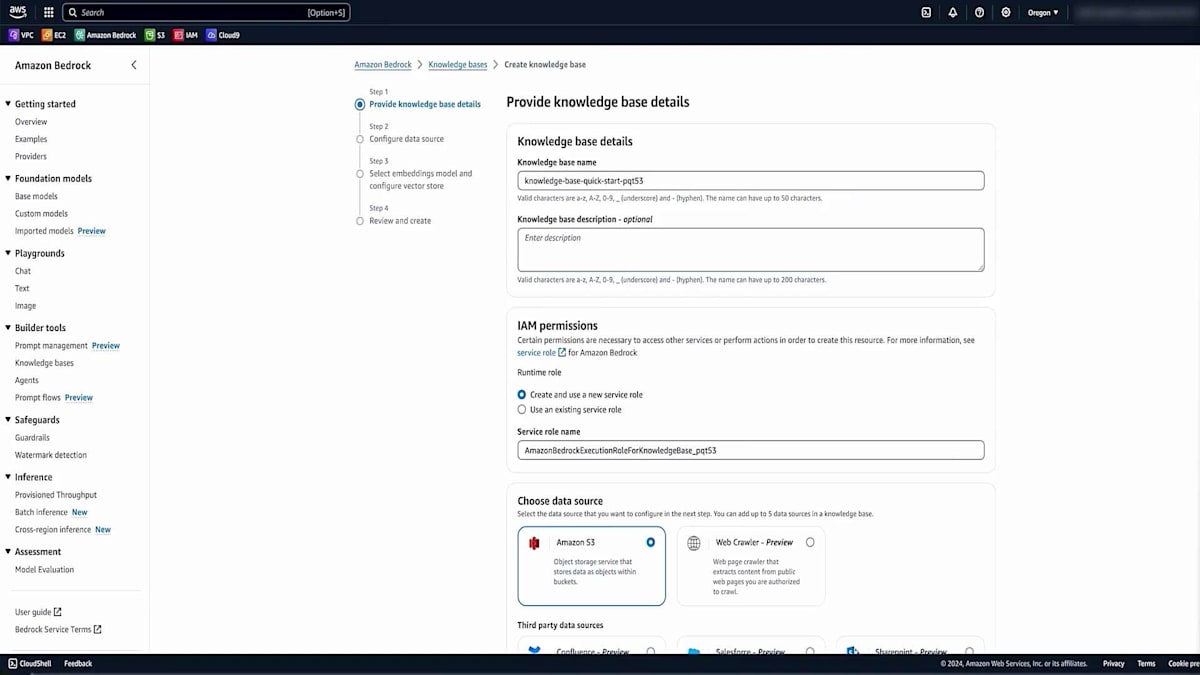
次に、Amazon Bedrockに移動し、Amazon Bedrock Knowledge Basesを探します。 これはAmazon Bedrock内に組み込まれているサービスです。Knowledge Baseを作成し、適切な名前と説明を設定します。これにより、このKnowledge BaseがService Catalog用であることを後で思い出せます。次に、データソースを設定する必要があります。Amazon S3がデフォルトで設定されており、これは先ほど説明したデータソースの1つですが、他のオプションも利用可能です。このデモではS3で十分です。
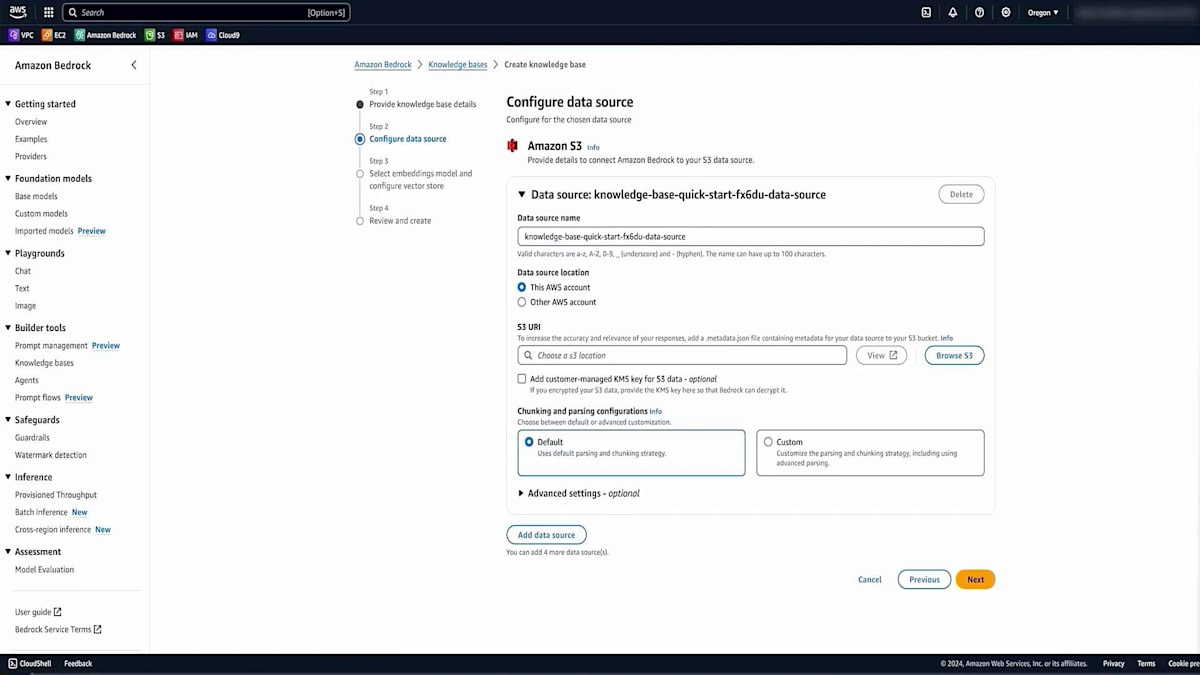
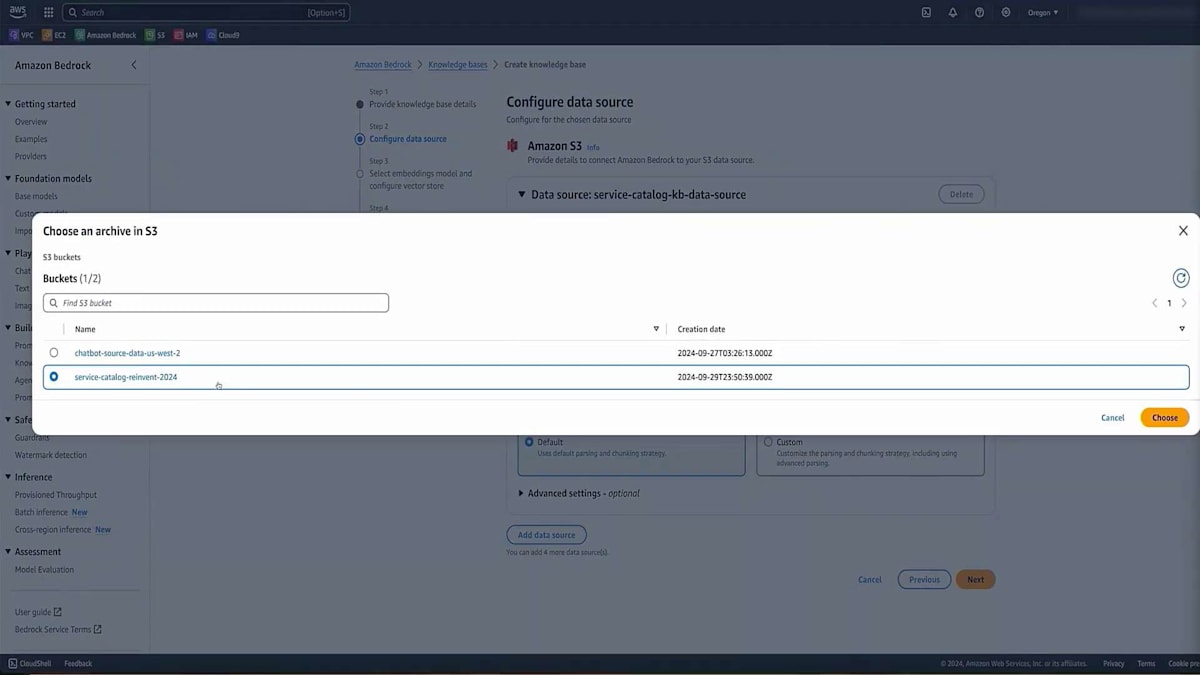
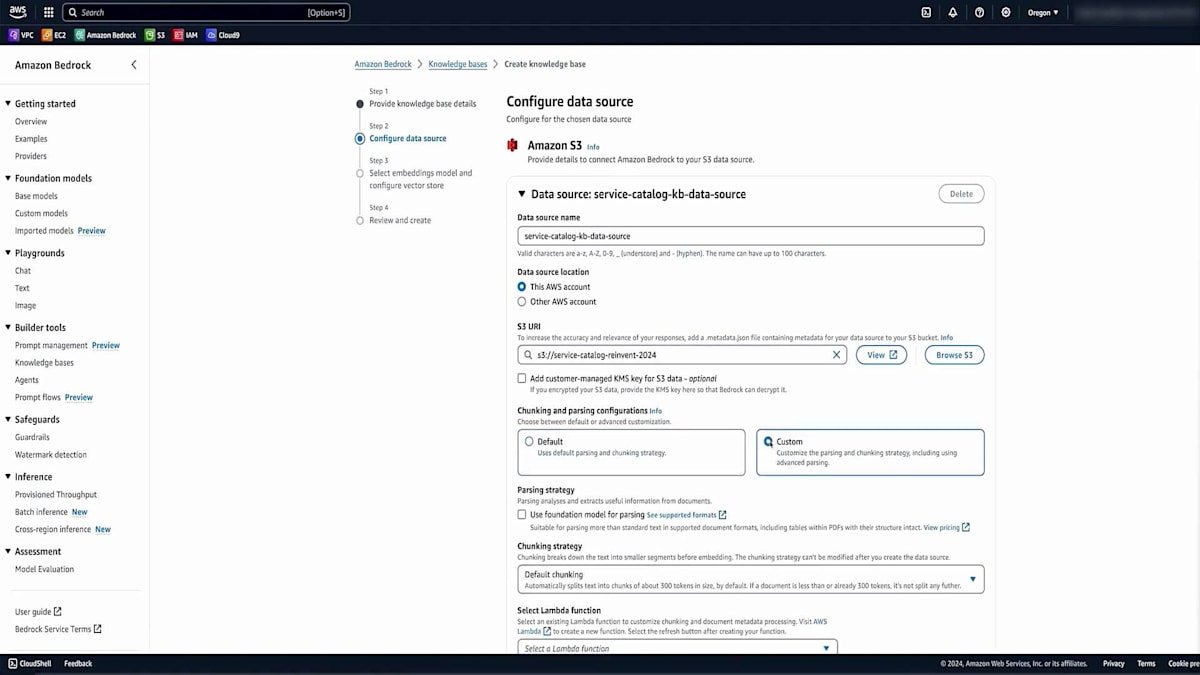
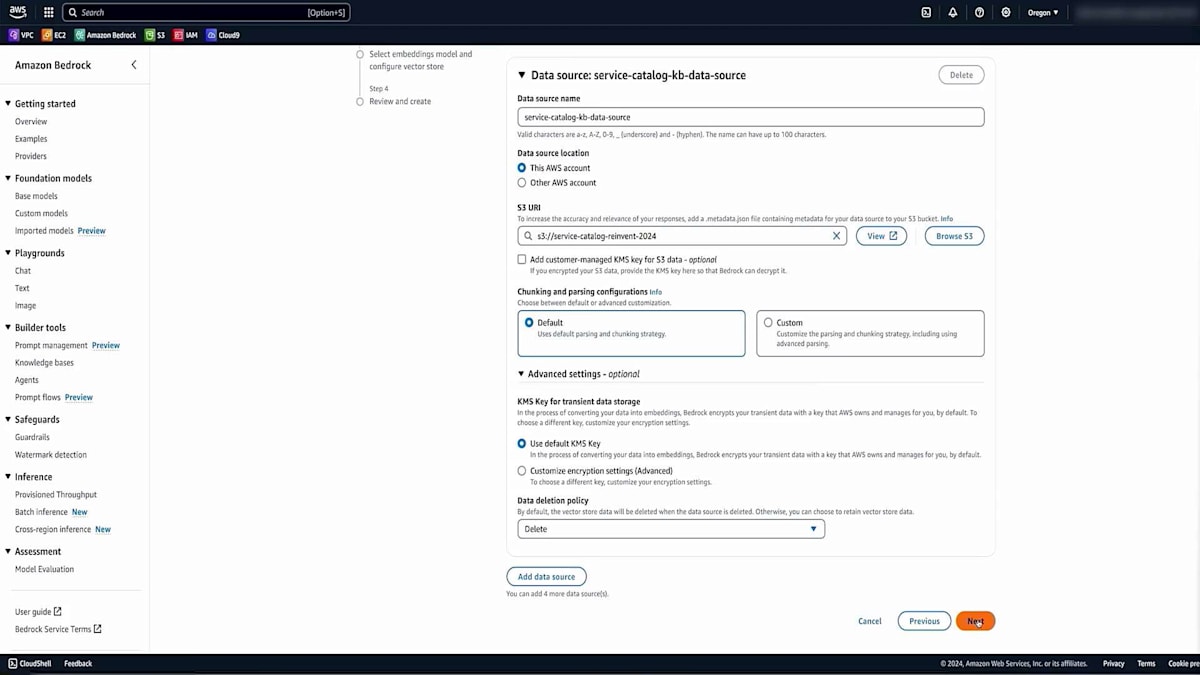
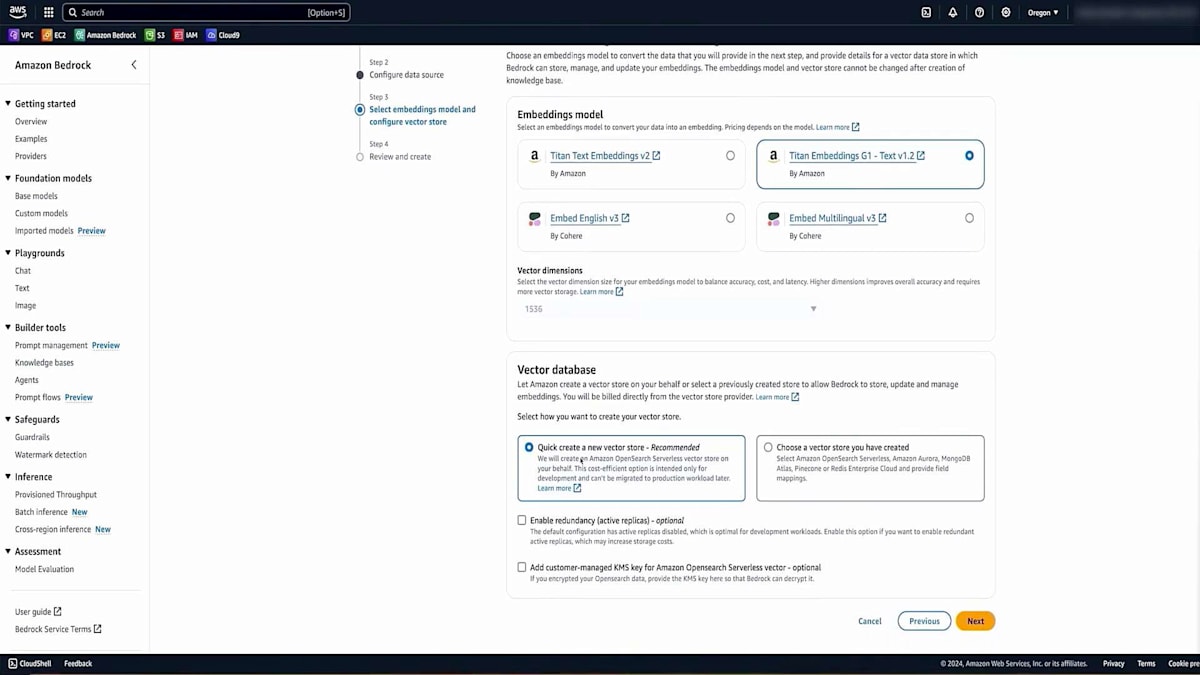
Amazon Bedrockの設定で適切な名前を入力し、このデータセットがアップロードされたS3バケットのURLを指定します。次に、先ほど説明したChunking戦略を選択します。カスタム戦略を使用することもできますが、今回のデモンストレーションでは、非常に効果的なデフォルトオプションを選択します。また、データベースのKMS暗号化を有効にすることもできます。最後に、大規模言語埋め込みモデルを選択します。このシナリオではTitanを使用し、それとうまく連携するVector databaseを選択します。このVector databaseは自動的に作成されるため、手動で作成する必要はありません。そして、作成したデータをすべてアップロードし、それをチャンク化してベクトル表現に変換します。
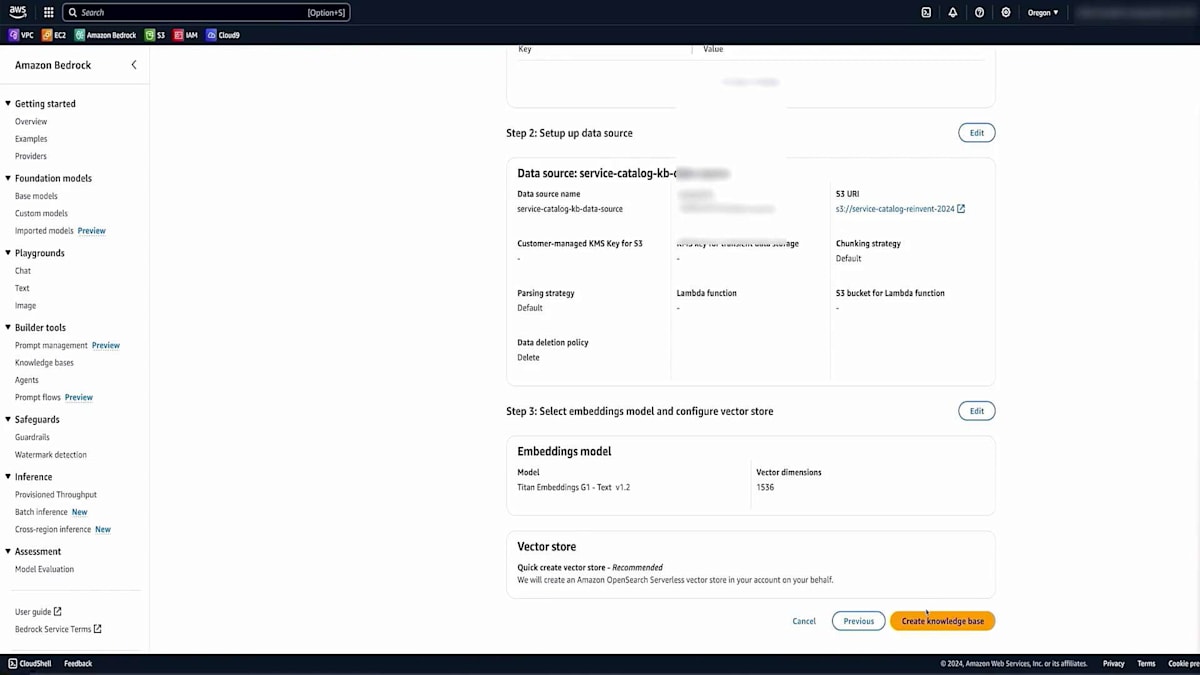
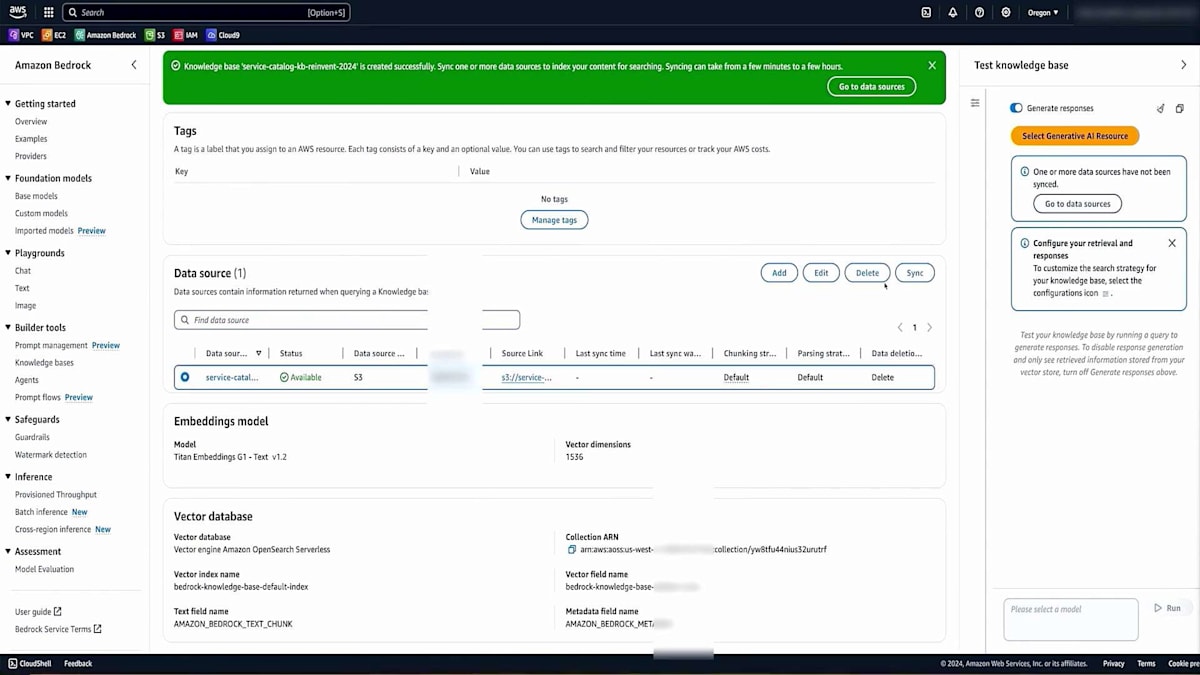
設定内容をすべて確認して、Knowledge baseを作成します。作成には数秒かかりますが、すぐに開始されます。完了したら、データソースを確認します。これが先ほど説明した重要なステップです - データソースを同期する必要があります。これは、データの変更に応じて必要な頻度で実行し、Vector databaseをデータセットと同期させておくことができます。これでテストの準備が整いましたので、Chatbotアプリケーションで使用する前に、このKnowledge baseをテストしてみましょう。同じ大規模言語埋め込みモデル(このシナリオではTitan)を使用します。適切な設定ができているかを確認するため、利用可能な福利厚生について簡単な質問をしてみます。
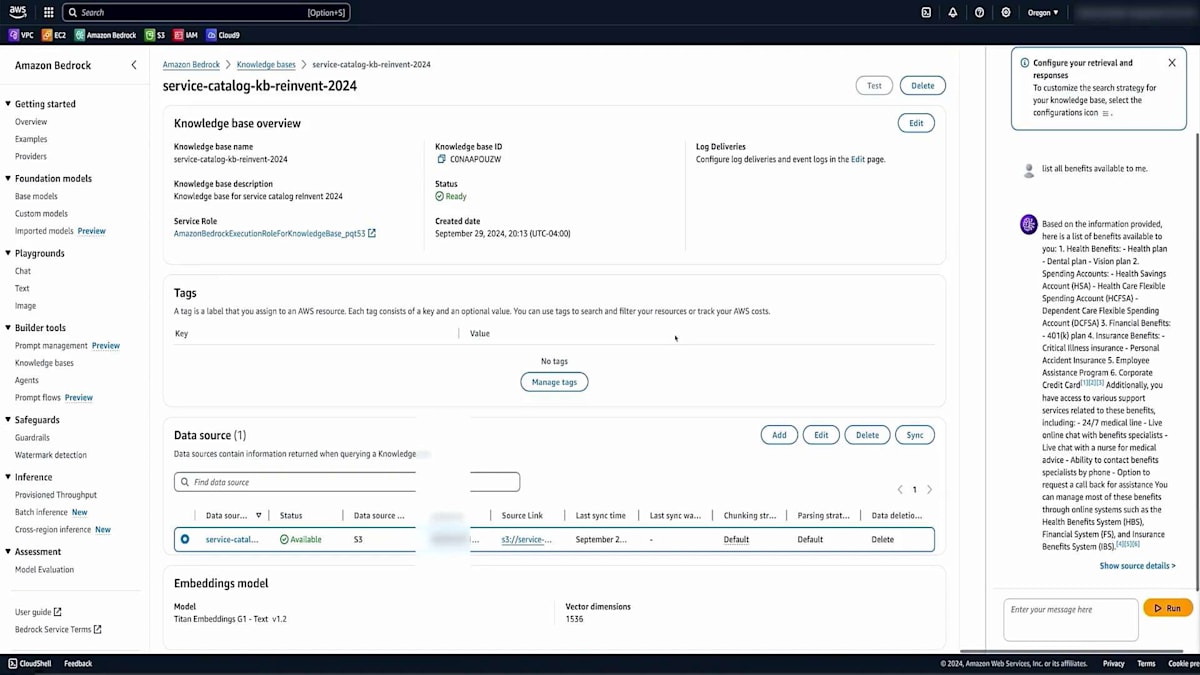

質問を送信すると、最初のレスポンスには少し時間がかかる場合がありますが、良好な応答が返ってきました。これは、Knowledge baseが使用可能な状態であることを示しています。これらすべての作業は、AWSコンソールまたはAPIを使用して実行できます。次に、PythonでStreamlitアプリケーションを実行するスクリプトを使用して開発した、小規模なアプリケーションがEC2上で動作しています。ブラウザで開くと、Streamlitで構築されたUIインターフェースが表示され、質問の準備が整います。「組織に入ったばかりですが、福利厚生について教えていただけますか?」と質問してみましょう。
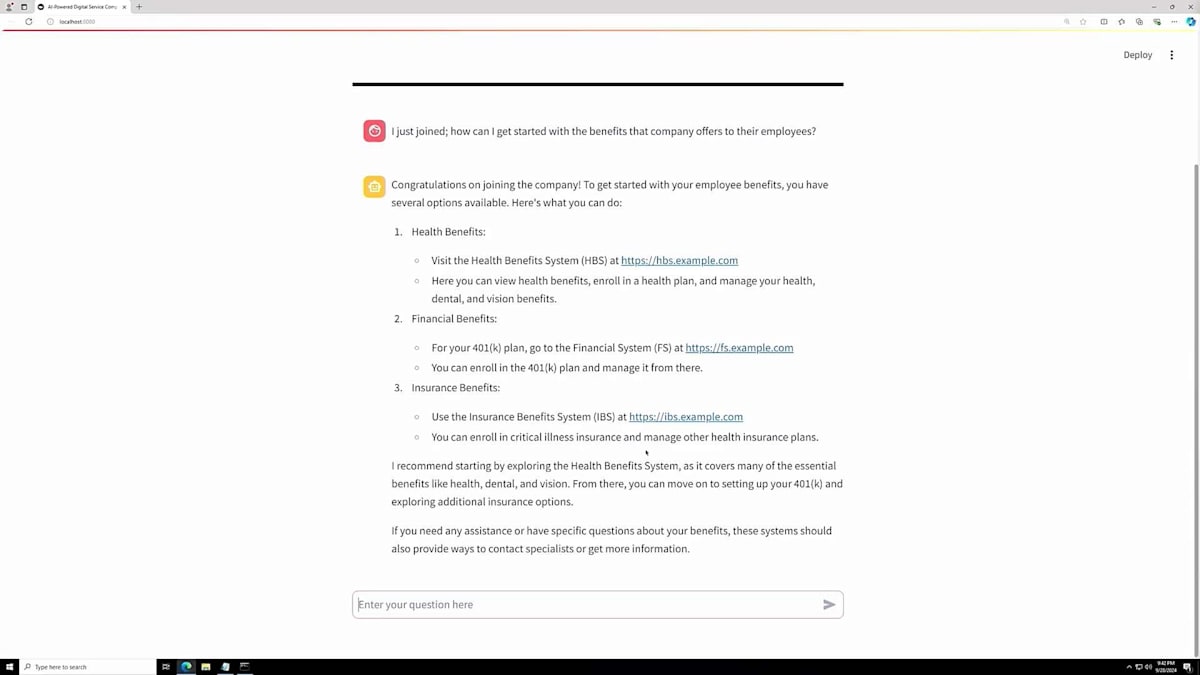
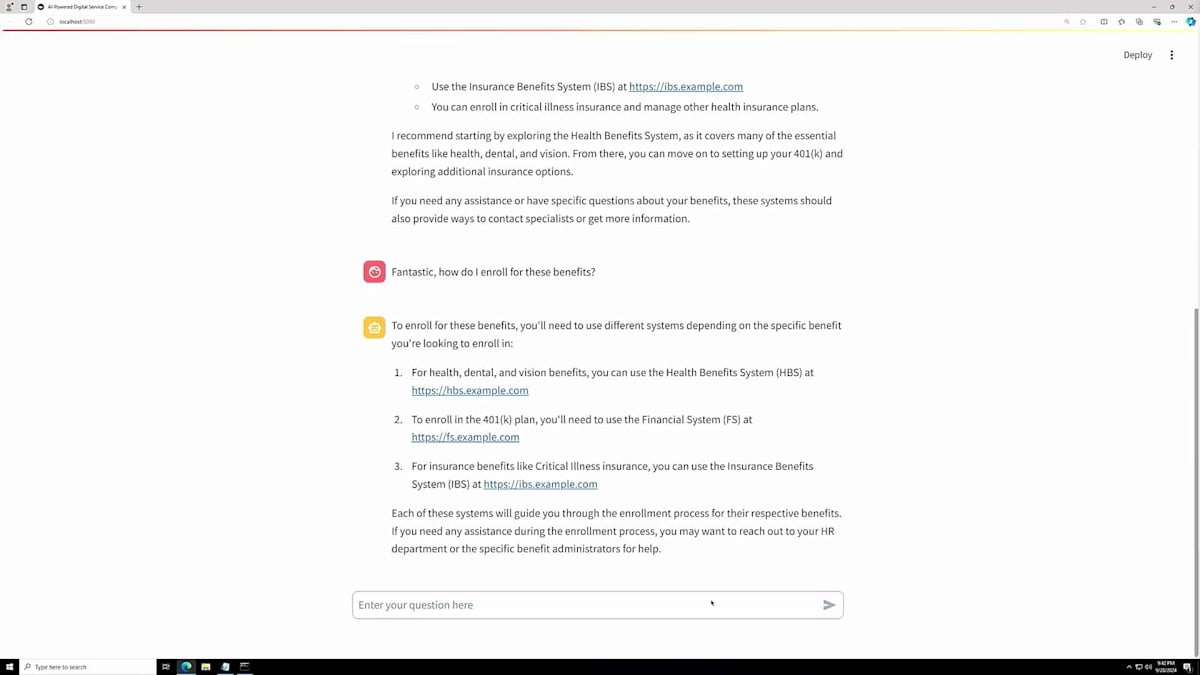
数秒後、健康保険、財務関連の福利厚生、保険給付について説明があり、関連するURLも含まれた回答が返ってきます。包括的な説明が得られたので、さらに興味が湧いてきて、登録方法についても質問してみたくなりました。この質問をすると、処理に少し時間がかかりますが、システムへのアクセス方法や福利厚生への登録手順について、URLとステップバイステップの説明が含まれた回答が返ってきます。他にどんなことができるのか、さらに探ってみたくなります。
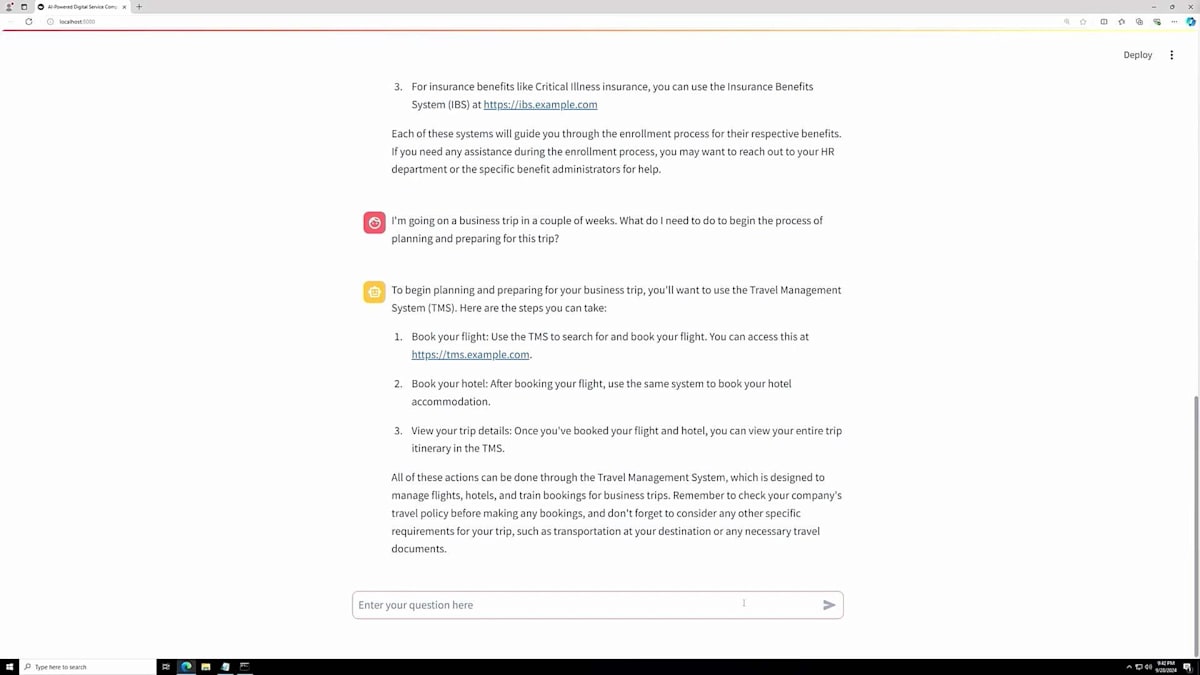
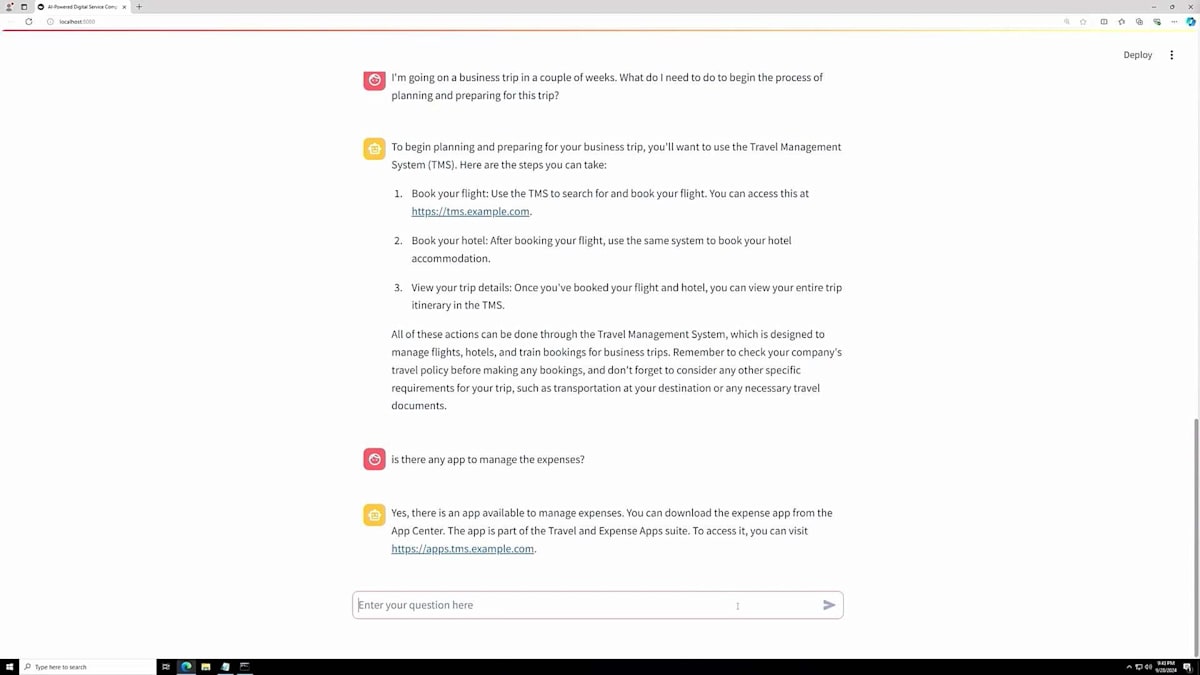
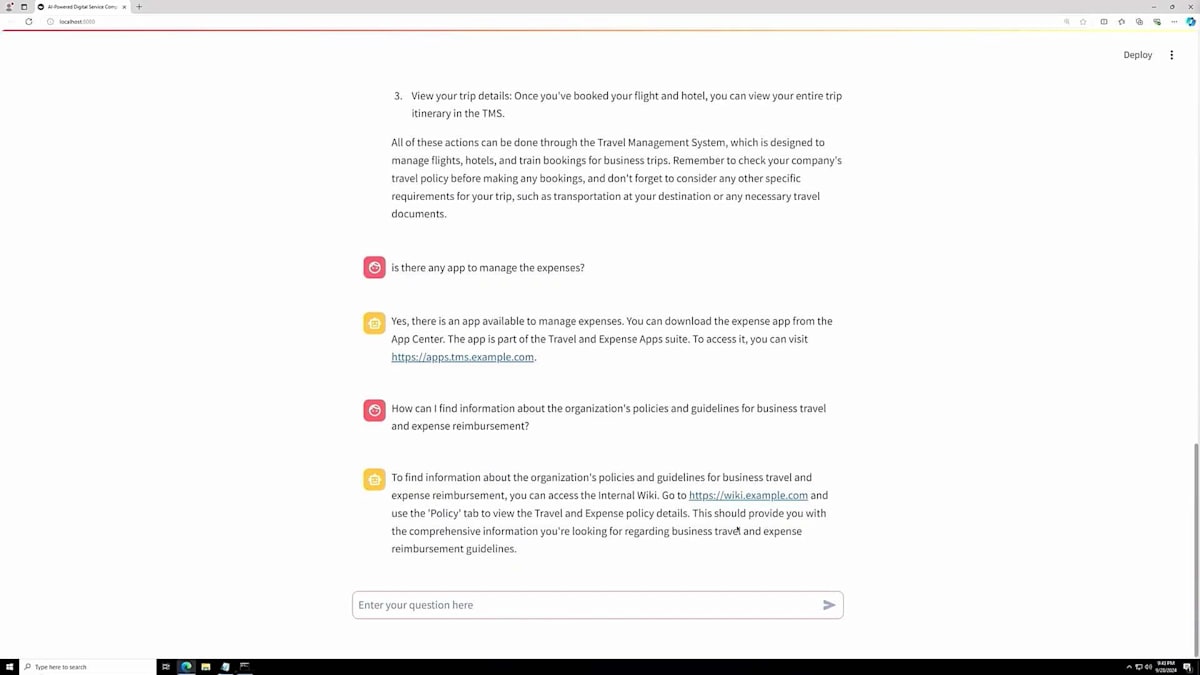
このシナリオでは、出張に行く場合の始め方について質問してみます。システムは、フライトの予約、ホテルの予約が必要であることを説明し、出張の詳細を確認できるシステムのURLを提供してくれました。非常に包括的な情報が得られます。次に、経費を管理するアプリがあるかどうか知りたいと思います。これは典型的な質問の一つですが、システムはアプリをダウンロードするためのURLを提供してくれます。さらに、経費に関するポリシーについて質問し、出張中に何を経費として申請できるか、できないかを知りたいと思います。システムはWikiのURLを提供してくれます。
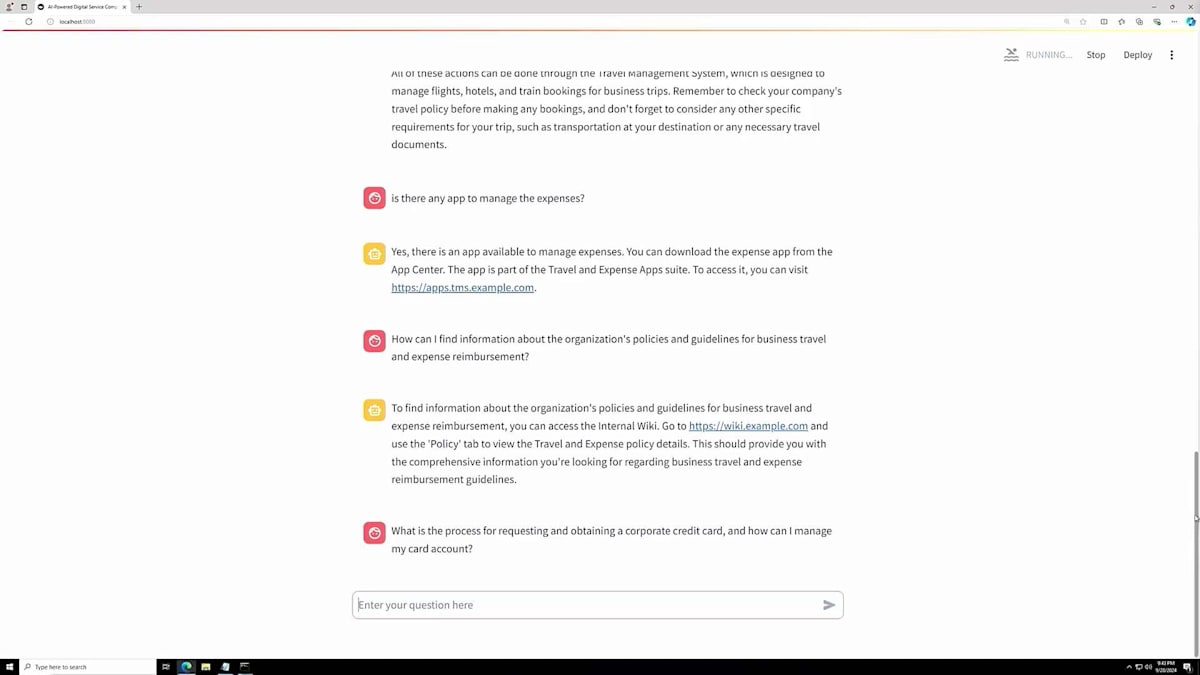
最後に、申請可能な法人カードについて質問すると、カードの申請方法、精算方法、トレーニング、その他の様々な機能に関する情報が提供されました。このやり取りの要点は、私が最小限の情報しか持っていなかったにもかかわらず、このChatbotが人間が応答しているかのように、対話的な方法で情報を返してくれたということです。これこそが私たちが目指している体験なのです。ユーザーや顧客がこのような情報を探す場合を考えてみてください - 登録用URLをメールで探したり、適切なシステムを見つけるためにService Catalogやポートフォリオを探し回ったりするかもしれません。しかし、Chatbotを使えば数秒でそれを実現でき、カスタマーエクスペリエンスが大幅に向上します。
まとめと今後の展望
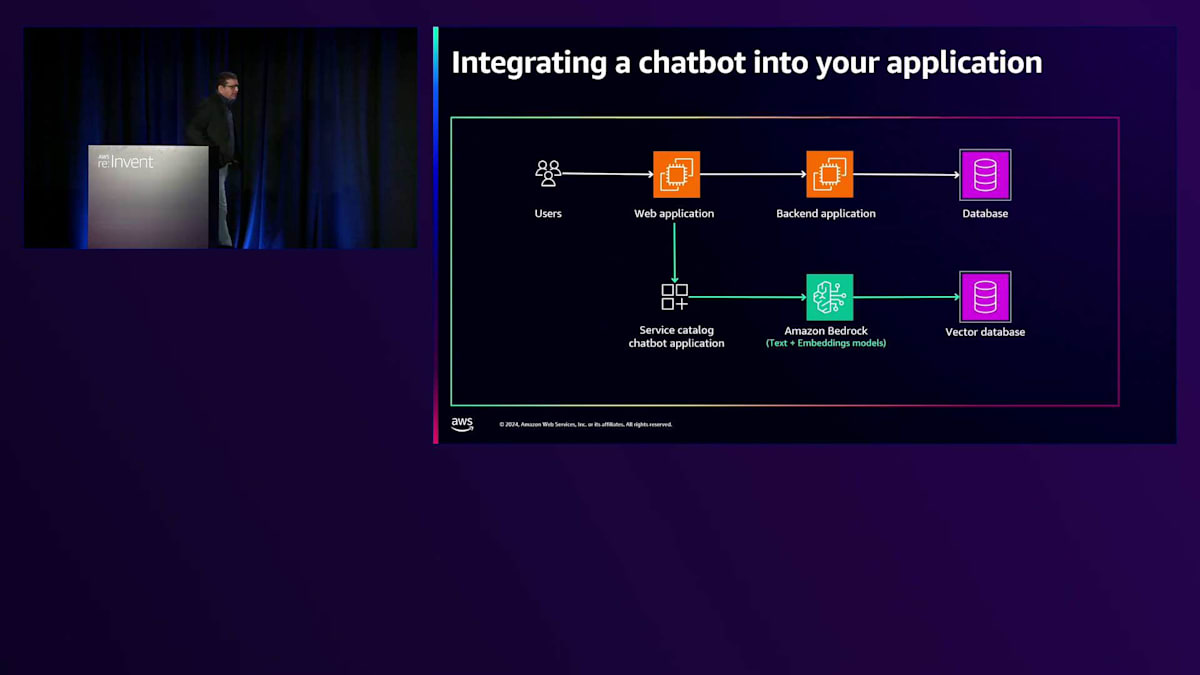
また、このChatbotを自社のアプリケーションと統合するために使用できるAIアーキテクチャについてもお話ししたいと思います。Chatbot用のAPIを構築して、2層または3層アプリケーションと簡単に統合することができます。これらのAPIは、Webサーバー、Webアプリケーション、またはバックエンドのアプリケーションサーバーから呼び出すことができます。既存のアプリケーションの外部でこのChatbotを構築する場合でも、統合が簡単であることをお示ししたいと思います。

今日は多くのトピックをカバーしました。まず、Mickeyがパブリックセクターのユースケースと、Generative AIの責任ある使用に関する重要な懸念事項をハイライトしました。次に、お客様が自社環境でこのPOCを構築した経験と、RAGを使用して運用を簡素化できた経験を共有してくださいました。その後、私が2つのアーキテクチャ - フルマネージドRAGを使用するものと、フルマネージドオプションを使用しないもの - について説明し、フルマネージドRAGの体験では、複雑なパイプラインと基盤となるインフラストラクチャの構築に関する負担を軽減できることがわかりました。そして、このデモをお見せしましたが、ソースコードと手順はこのWebサイトのQRコードから入手できます。独自の環境で実験して、異なるデータセットを使用して体験したい場合は、コードを利用できます。また、以前に公開したブログでベストプラクティスをいくつか紹介しており、そちらもQRコードで共有しています。かなり包括的な内容でした。最後までご視聴いただき、ありがとうございました。それでは、質疑応答に移りたいと思います。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion