re:Invent 2023: Amazon Bedrockの新画像生成・検索モデルの機能と活用事例
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - Explore image generation and search with FMs on Amazon Bedrock (AIM332)
この動画では、Amazon Bedrockの新しい画像生成モデル「Titan Image Generator」と「Titan Multimodal Embeddings」の機能と利点を詳しく解説しています。Responsible AIの観点から開発された両モデルの特徴や、OfferUpでの実際の活用事例が紹介されます。画像生成や検索の精度向上、バイアス軽減など、最新のAI技術がもたらす具体的な成果を知ることができる内容です。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
Amazon Bedrockによる画像生成と検索の革新

皆さん、おはようございます。私はRohit Mittalと申します。Amazon Bedrockチームのプリンシパルプロダクトマネージャーを務めています。本日は非常に興味深いトピックについてお話しします:「Amazon Bedrockの基盤モデルを使用した画像生成と画像検索の探求」です。私の他に2名の講演者がいます。Amazon AIチームのアプライドサイエンスのシニアマネージャーであるAshwin Swaminathan氏と、OfferUpのプリンシパルデータサイエンティストであるAndrés Vélez氏です。

画像は魅力的な表現形式です。瞬時に私たちの注目を集め、脳は100ミリ秒以内に画像を処理できます。AI分野において、最近の最も魅力的な進展の一つが視覚芸術の形で現れています。今では、テキストプロンプトを使うだけで、印象的な画像を簡単に生成できるのです。創造力を存分に発揮できます。既に、銀河系の中で馬に乗った宇宙飛行士や、視覚的に印象的なユニコーン、あるいはここに示されているような電球の中のヨットなどを見てきました。

現在利用可能な、そして今まさに生成されている視覚コンテンツの量は、特にスマートフォンの普及により急増しています。人々は1日に50億枚以上の画像を撮影しており、これは年間1.8兆枚以上の画像に相当します。これは膨大な量です。ビジネスアプリケーションのためにこれらの画像を検索したり、小売ウェブサイトの商品カタログを検索したり、あるいは数年前に家族と撮った写真を探すために過去の思い出をたどったりすることを考えてみてください。日に日に難しくなっています。
画像生成ツールの登場により、状況は爆発的に変化しました。昨年だけでも、人々はこれらのツールを使用して150億枚以上の画像を生成しており、その傾向は指数関数的に増加しています。大量のコンテンツが生成されるという大きな問題があり、従来の機械学習やキーワードベースの検索方法では、デバイス上やビジネスニーズのためにこのコンテンツを簡単に検索するための適切なツールがありません。
ここでも生成AIが救世主となっています。このコンテンツの検索と、コンテンツ作成の効率を向上させることによる印象的な画像の生成の両面で役立っています。今日のセッションでは、Amazon Bedrockがこれら2つの問題、つまり画像生成モデルを通じて印象的な画像を作成する問題と、埋め込みモデルを通じて既存の画像セットを検索する問題をどのように解決しているかを見ていきます。

本日のアジェンダでは、昨日のSwamiのキーノートで発表された2つの新しいTitanモデルについてお話しします。1つ目はTitan Multimodal Embeddings、2つ目は画像編集タスクも行うTitan Image Generatorです。その後、いくつかの使用例とアーキテクチャを見ていきます。これらはすべて、私たちのFoundation Modelをサービスとして提供するAmazon Bedrockを使用しています。最後に、Andrésが、OfferUpにとって検索がいかに重要か、そしてこれらのTitanモデルが彼らのミッション達成にどのように役立つかについて説明します。
Amazon Bedrockの概要とTitanモデルの紹介

まず、Amazon Bedrockについて簡単に説明させていただきます。Amazon Bedrockは、AI21、Anthropic、Cohere、Meta、Stability AIなどの一流企業や、Amazonが一から開発したAmazon Titanファミリーのモデルなど、最高クラスのFoundation Modelへのアクセスと選択肢を提供する完全マネージドサービスです。2日前まで、Amazon Titanモデルは主にテキスト中心でした。Titan Text LightとTitan Text Expressモデルを使ってテキストを生成したり、テキスト検索やテキスト類似性のようなユースケースに使用するTitan Text Embeddingsを利用できました。Bedrockはこれらのモデルの選択肢を提供するだけでなく、ユースケースに応じた生成AIベースのアプリケーション全体を構築するための多くの機能を提供し、さらにそれを非常にプライベートで安全な方法で行うことができます。


昨日発表した新しいモデルについて詳しく見ていきましょう。Amazon Titan Multimodal EmbeddingsとAmazon Titan Image Generatorという2つの新しいモデルは、完全に一から構築されています。1つ目のAmazon Titan Multimodal Embeddingsは、テキストと画像、またはその組み合わせを受け取り、それらをベクトルのセット、つまり数値表現で表します。これをembeddingsと呼んでいます。その主な考え方は、入力がテキストであれ、画像であれ、またはその組み合わせであれ、その意味的な内容をベクトルの形で捉えることで、非常に高速に検索できるようにすることです。
従来のキーワードを使用した検索方法では、画像に手動または自動でキーワードのセットをタグ付けし、入力されたクエリのキーワードとマッチングを試みますが、適切な精度が得られず、リソース効率も良くありません。このモデルは、検索、レコメンデーション、パーソナライゼーションなどのユースケース、特に画像のみを扱う場合に役立ちます。例えば、何億もの画像を持つストックフォトグラフィー企業では、エンドユーザーがユニークなコンテンツを見つけて購入しようとする検索が主要なビジネスです。特にコンテンツクリエイター自身にとって、発見可能性が大きな課題となっています。このモデルは、最先端のembeddingsを提供することで、それらすべてに対応し、その上に検索やレコメンデーションタイプのアプリケーションを構築できるようにします。
2つ目のモデルは、Amazon Titan Image Generatorです。ここで私たちが注力しているのは、コンテンツ作成にかかる時間を短縮することです。特に広告やマーケティングなどの業界では、製品があり、その製品のための魅力的なライフスタイル画像を生成したいと考えています。これにより、顧客が製品のメリットを見て、クリックすることで、より多くの視聴者、より多くの目に触れる機会が増え、結果的に彼らの収益増加につながります。これらのモデルはどちらも、すぐに高い精度を発揮するので、ベースモデルをそのまま使用して非常に正確な結果を得ることができます。さらに、私たちが差別化しているのは、Bedrock APIを通じてカスタマイズ機能を提供していることです。これは、これらのモデルを独自のデータでカスタマイズするためのシンプルなAPIです。
他のAWSサービスと同様に、お客様のデータはすべて高度に安全かつプライベートです。推論呼び出しを行っても、BedrockやAWSに保存されることはありません。また、第三者と共有されることもありません。Titanの場合も、モデルをカスタマイズするために使用したデータを、モデルの改善のために使用することはありません。カスタマイズされたモデルを含め、すべてが非常に安全でプライベートです。カスタマイズされたモデルは、お客様専用のセキュアなコピーとして作成されます。データに基づいて簡単にカスタマイズする方法を提供するだけでなく、例えば広告業界を例に挙げると、各ブランドには特定のスタイルや特定のブランド美学があり、それに基づいて広告画像を作成します。わずか100枚または数千枚の画像ペアでモデルをトレーニングし、Bedrock APIに持ち込んでカスタマイズされたモデルのコピーを作成すると、そのモデルは生成する画像にお客様のブランド美学を反映します。
また、画像生成モデルには包括的な機能セットを提供しています。テキストから画像への変換だけでなく、インペインティングやアウトペインティングも可能です。アウトペインティングの場合、広告やマーケティングのユースケース、あるいはeコマースの販売者向けに特化しています。例えば、製品画像を持ち込んで、ソファのような画像を簡単に作成できます。単純な背景のソファと、暖炉のある居間のような家庭的な設定のソファでは印象が異なります。より温かみのある雰囲気を作り出すことができます。シンプルなAPIを使用して、歪みの少ない非常にライフスタイル感のある画像を簡単に作成できるのです。
このモデルを使用することで高い精度が達成されます。他にもいくつかの機能があり、後ほど詳しく説明します。Amazonにとって非常に重要なもう一つの点は、AIの責任ある使用であり、すべてのTitanモデルでそれを実践しています。AIの責任ある使用とベストプラクティスを継続的にサポートするため、すべてのTitan Foundational Modelsは、トレーニングデータから有害なコンテンツを検出して削除し、推論時にユーザーからの不適切なプロンプトを拒否し、モデルが生成する可能性のある有害なコンテンツも削除するように構築されています。
モデル出力の上に追加の責任あるAIガードレールを実装する心配はありません。これは特に画像生成モデルにとって重要です。このメディアがいかに強力であるかを考えると、特定の人々にとってセンシティブであったり、有害であったり、偏見を含むようなものを生成したくありません。私たちの世界には多くの偏見が存在します。これらのモデルで私たちが試みているのは、性別、肌の色、その他のステレオタイプに関する偏見を軽減することです。
Amazon Titan Multimodal Embeddingsモデルの特徴と利点

次に、一般提供が開始されたAmazon Titan Multimodal Embeddingsモデルについて説明します。従来、多くのコンテンツ所有者は画像にタグを付け、入力されたクエリのキーワードとそれらのタグを照合しようとしていました。同様に、小売業界では、販売や検索したい多くの商品画像がありますが、多くの場合、説明が不足していたり、不適切であったり、不正確であったりします。これらはすべて発見可能性の問題につながります。エンドユーザーが販売者が売りたい適切なコンテンツを見つけられず、結果として販売者、購入者、プラットフォーム自体にとって悪い体験となってしまいます。

エンベディングが行うのは、画像から意味的な情報を捉えることです。例をお見せしましょう。この画像の左側には、製品の説明文やキーワードに基づくテキストベースの検索で「紐のない青いスニーカー」を検索した結果が表示されています。特に否定表現は難しいものです。右側のハイライトされた部分は、私たちのMultimodal Embeddingsモデルの結果です。画像自体に色や紐がないという情報が含まれているため、エンベディングで表現される情報は画像から意味を捉えています。
ユーザーがこれらのキーワードで検索すると、同じ意味空間にマッピングされるので、入力されたクエリと、顧客が探している正しい靴の画像セットを関連付けることができます。これは、エンドユーザーにとって素晴らしいユーザー体験となり、販売者にとっても適切な商品が表示されるため素晴らしい体験となります。また、小売プラットフォーム自体にとっても、顧客満足度を高め、リピーターを増やすことができます。


このモデルには主に3つの利点があります。1つ目は精度、2つ目は使いやすさ、3つ目はResponsible AIです。それぞれについて詳しく見ていきましょう。精度に関しては、先ほど申し上げたように、このモデルはベースモデル自体から構築できる検索や推奨の精度において最先端です。また、お客様がさらに精度を向上させるためのメカニズムも提供しています。特に、お客様の領域に特有のデータがある場合に有効です。
例えば、自動運転車は特定のタイプの画像を何十億枚も撮影します。それらは広角レンズの画像かもしれません。そこで、お客様の特定のユースケースの例を数百件提供することで、エンベディングの精度をさらに向上させることができます。これにより、ベースモデルのパワーを活用しながら、お客様のニーズに合わせてモデルをカスタマイズすることができます。
お客様のタイプの画像を数百枚から数千枚提供することで、精度が向上します。データとモデル自体は、お客様専用に安全かつプライベートにカスタマイズされます。また、お客様にはもう一つのレバーを提供しています。デフォルトのエンベディングサイズは1024で、これは何百ものお客様との議論や、適切な精度とレイテンシーの分析に基づいています。私たちは、これが大多数のお客様にとって適切なエンベディングサイズだと考えています。しかし、Amazon Bedrockと同様に、お客様に選択肢を提供したいと考えています。そこで、384と256のより小さなサイズのエンベディングを生成するオプションも提供しています。これにより、お客様のニーズに応じて、レイテンシーをさらに最適化したい場合は、エンベディングサイズを小さくすることができます。このオプションをお客様に提供しています。
Amazon Titan Image Generatorの機能と応用

次に、2つ目のメリットである使いやすさについて見ていきましょう。Amazon Bedrockの前提全体も使いやすさを重視しており、これはAmazon Titan Multimodal Embeddingsにも反映されています。embeddingsを生成するためのシンプルなAPIが1つあります。また、バッチAPIもあるので、何千もの画像を入力してembeddingsを生成することができます。さらに、Amazon OpenSearch Serviceとの接続性もあります。もしコンテンツがすでにAmazon OpenSearch Serviceにある場合、あるいはembeddingsの使用とコンテンツのインデックス作成をより統合的でシームレスな体験を提供するものを探している場合、Amazon OpenSearch ServiceにはAmazon Bedrockへのコネクタがあります。OpenSearchから直接このモデルを通じてembeddingsを生成し、Amazon OpenSearchが提供するベクトルDBに保存することができます。つまり、どこにも移動する必要がないのです。


3つ目のメリットは、責任あるAIです。このモデルの学習データから有害なコンテンツをフィルタリングし、人口統計学的なバイアスを軽減するのに役立ちます。これは特に、人物を含む多くの画像がある場合に重要です。特定の肌の色、性別、あるいは現実世界で見られるその他のステレオタイプ的なバイアスのみを反映する検索結果を避けたい場合に有効です。私たちには、これらすべてを最小限に抑えたり軽減したりするのに役立つ特許出願中の技術があります。これは、他のembeddingsモデルでは提供されない、もう1つのメリットや差別化要因です。

Responsible AIへの取り組みとTitanモデルの安全性
では、2つ目のモデルである Amazon Titan Image Generator を見てみましょう。これは現在プレビュー段階にあります。このモデルは多くの機能を提供していますが、主な機能はテキストから画像を生成することで、これが競合他社との差別化ポイントになっています。この分野では既に多くのモデルをご覧になったことと思いますが、私たちには多くの差別化要素があります。機能面と、提供するメリットの両面からご説明したいと思います。
テキストから画像を生成する機能では、テキストプロンプトから高品質な画像を生成します。モデルの良し悪しを判断するのは、出力結果だけでなく、どれだけ簡単に画像を生成できるかという点も重要です。長くて詳細なプロンプトを作成する必要はありません。私たちのコンセプトはシンプルさです。プロンプトを簡略化し、シンプルなプロンプトで魅力的な画像を生成できます。生成される画像は歪みが少なく、いわゆるハルシネーションも抑えられています。また、画像内にテキストを生成することもできます。例えば、「Happy Thanksgiving」と書かれたグリーティングカードを簡単に作成できます。
このモデルは複雑なプロンプトも理解します。これは先ほど述べたシンプルさとは異なります。シンプルさとは、頭の中にあるイメージを簡単に定義できるということです。しかし、場合によっては「このオブジェクトをそこに配置して、何かをさせたい」というような、2、3ステップのプロセスを指定したいこともあるでしょう。そのような複雑なプロンプトも簡単に理解し、正確な画像を生成できます。後ほど、もう少し例をお見せします。
最後にカスタマイズについてですが、先ほども申し上げたように、カスタマイズは多くのお客様が求める重要な機能です。なぜなら、どの企業も独自の専有データや、モデルに反映させたいブランドの美的感覚を持っているからです。ベースモデルでもある程度の仕事はこなせますが、お客様固有の要素を知ることはできません。そこで、わずか数百から数千の画像だけで簡単にカスタマイズできるようにしました。画像編集に関しては、inpainting を提供しており、既存のオブジェクトを別のものに置き換えたり、オブジェクトを削除したりする従来の inpainting が可能です。
また、非常に強力な自動編集機能も提供しています。これは私たちが独自に開発したモデルによるもので、詳しくは後ほど Ashwin からお話があります。この機能では、画像を入力し、加えたい修正内容をテキストプロンプトで入力するだけで、モデルがユーザーの意図と、画像内の特定のオブジェクトを理解し、修正を行います。必要に応じて、画像マスクを使用して同様の編集を行うこともできます。もちろん、特定のマスクを使用すればより正確な編集が可能です。つまり、マスクベースの編集とマスクフリーの編集(自動編集と呼んでいます)の両方が可能です。
私たちには生成的リサイズ機能があります。これは、Dollyなどのモデルでよく知られているもので、画像の境界を拡張し、テキストプロンプトで誘導することもできます。例えば、左側に画像を生成したいと指定できます。デフォルトでは元の画像の要素を維持しようとしますが、左側に何かを追加するように指示することもでき、それを試みます。私たちのoutpaintingは、広告やマーケティングのユースケースに特化しています。香水ボトルなどの商品画像を持ち込み、先ほど説明したようなライフスタイルの設定で展示したい場合に使用できます。
Amazon Bedrockを活用した画像生成と検索のワークフロー
この機能を使えば、非常に簡単にそれを実現できます。他の従来のモデルでは、それを生成するために何段階かのステップを踏む必要があり、その結果、入力した商品画像にハルシネーションや歪みが加わってしまいます。ここでは、歪みを最小限に抑えつつ、求めるものを生成する使いやすさに焦点を当てています。また、image variationsでは、入力画像を基に類似の画像を生成することができます。では、いくつか例を見てみましょう。


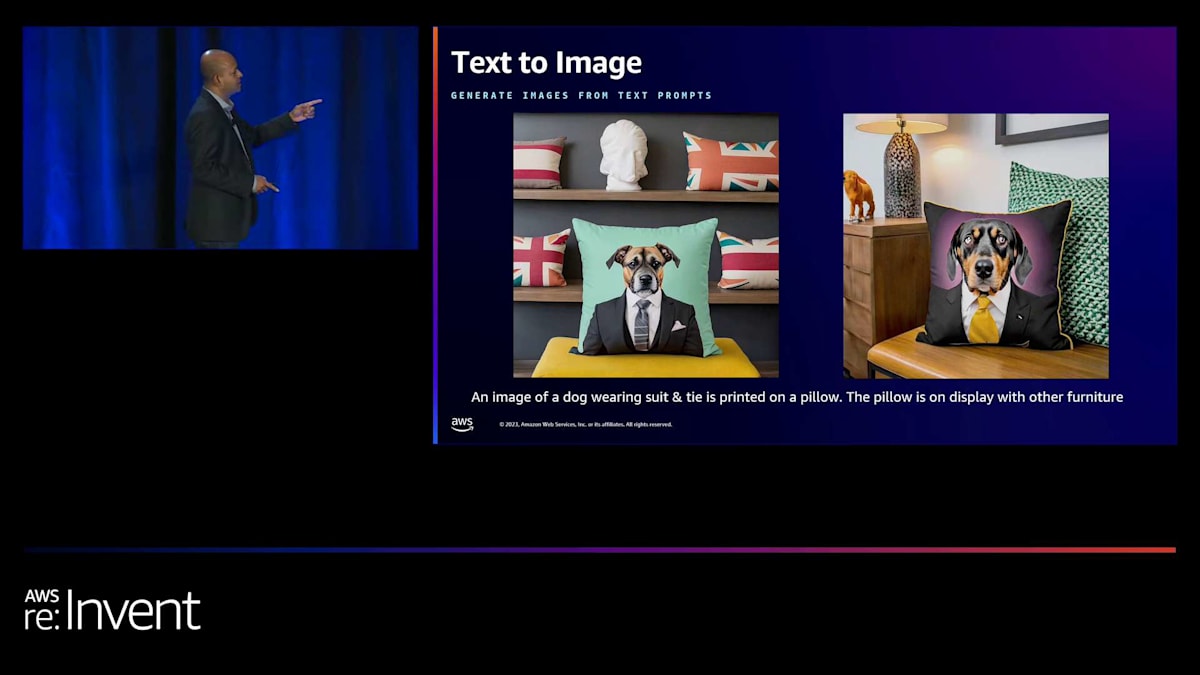
これは非常に興味深いユースケースです。ご存知の通り、ワイングラスと象のサイズは全く異なるので、これらを適切なサイズに調整し、さまざまなオブジェクトのこのような構図に反映させるのは非常に複雑な作業です。私たちは、これらの例をすべて競合モデルで試してみました。皆さんも自分で試してみて、その違いを確認できます。フェドーラを被ったトラ。これは非常に興味深いですね。ここのプロンプトを読むと、3つの部分があります。まず、スーツとネクタイを着た犬です。それを生成し、次に正しいアスペクト比とサイズでクッションにプリントされていることを確認する必要があります。そして、そのクッションが他の家具と一緒に展示されています。
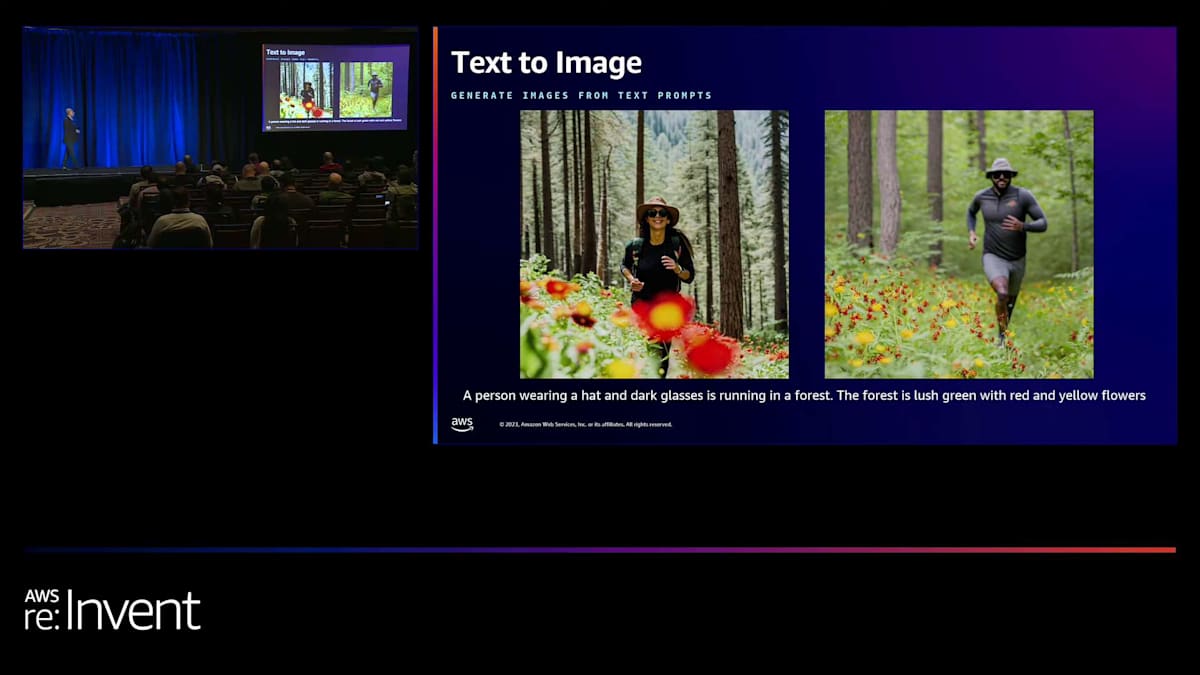
これは非常に複雑なプロンプトですが、画像の品質を見ればわかるように、正確に生成されています。これも私のお気に入りの一つで、プロンプトの複雑さを示すだけでなく、帽子とサングラスをかけた人が森の中を走っている様子、そして森自体の特徴、つまり赤と黄色の花が咲く緑豊かな森を表現しています。ここでもう一つ指摘したいのは多様性です。先ほど申し上げたように、責任あるAIは私たちにとって非常に重要で、性別や肌の色など、すべてが現実世界を反映するようにしています。
もう一つの例を見てみましょう。これも競合他社のモデルで試してみましたが、男の子と女の子の両方が帽子をかぶっていたり、誰も帽子をかぶっていなかったり、着物が正しくなかったり、両方とも男の子か女の子だったりしました。しかし、これも非常に複雑なプロンプトで、帽子をかぶった男の子が着物を着た女の子の隣に立っているという設定を定義しています。
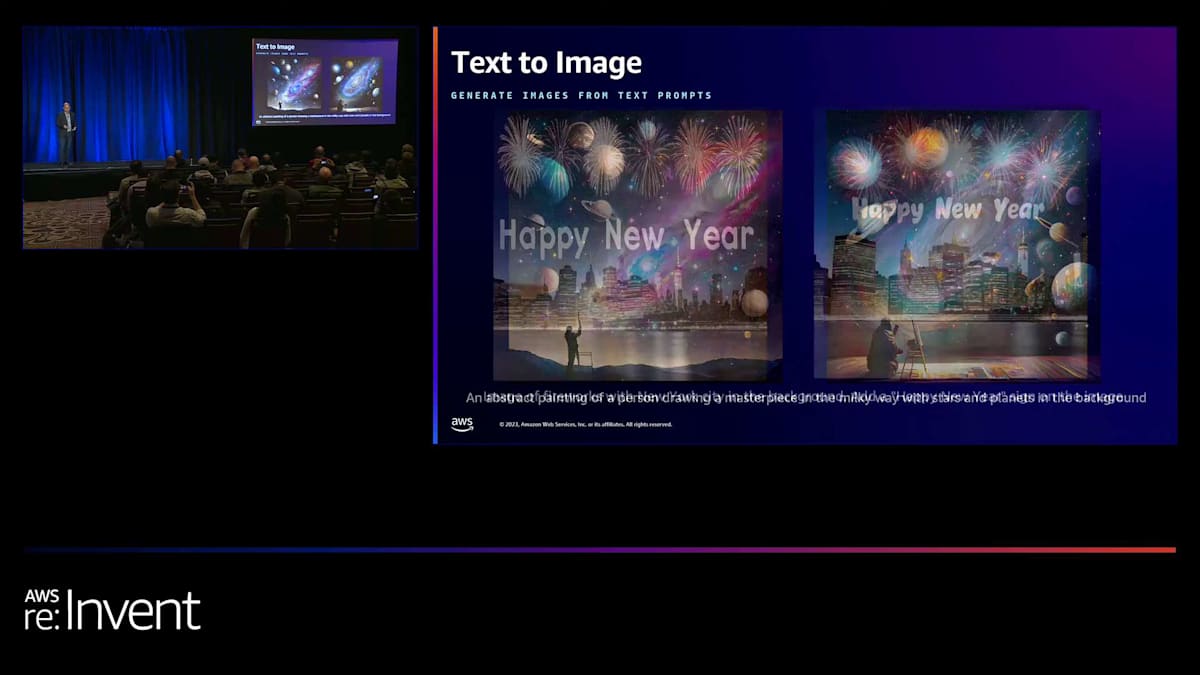
これは、アーティスティックな画像も生成できる例です。 これは、画像がテキストも生成できることを示す例です。プロンプトは「ニューヨーク市の花火の画像」です。一部のお客様は、エンドユーザーが休日やイベントで共有できるこのような挨拶カードを生成できるようにしたいと考えています。そのため、このような画像を正確に生成することができます。


昨日のSwamiの基調講演でお聞きになったかもしれませんが、私たちはイグアナが大好きです。そこで、カラフルな背景のイグアナの写真をご覧いただきます。 これらは全て、テキストから画像への変換例で、品質が良いだけでなく、複雑なプロンプトを理解し、適切な画像を生成できることを示しています。さらにイグアナを例に取ると、ここで見られるように、例えば児童書の会社だとします。特定のスタイル、例えば漫画やスケッチの画像を自動生成したいとします。そして、モデルがそれを理解できないとします。実際には理解できますが、仮に理解できないとしましょう。その場合、モデルにいくつかの例を与えて学習させれば、ユースケースに基づいてカスタマイズされた画像を生成できるようになります。
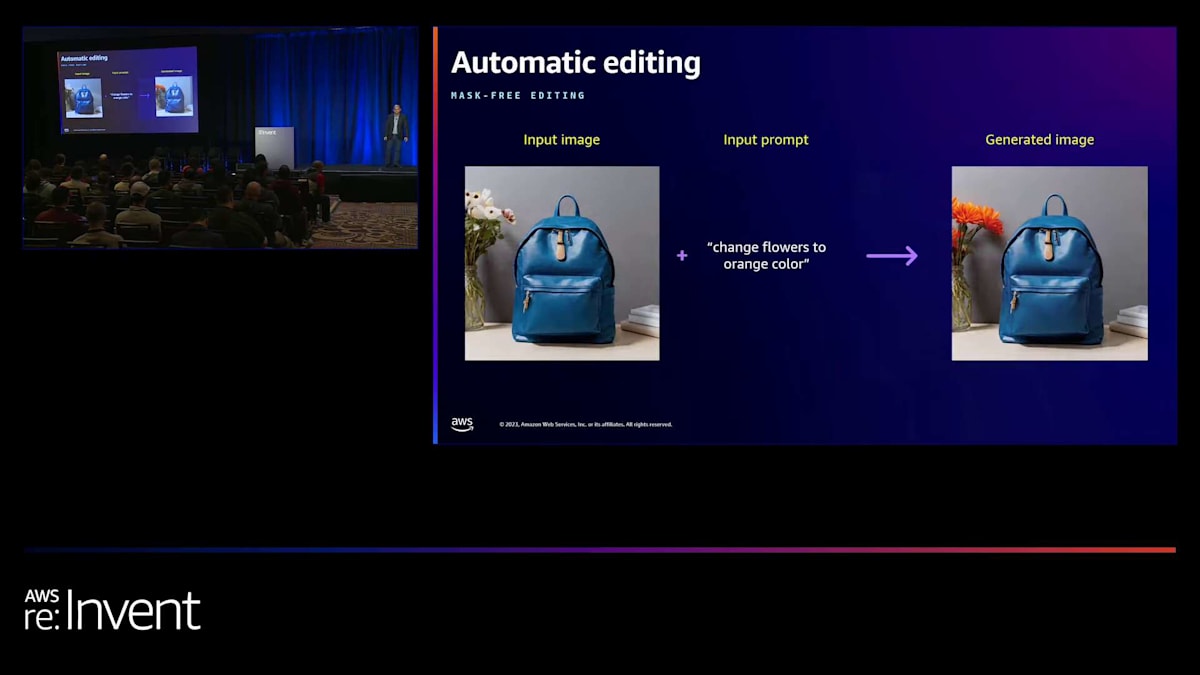


これは自動編集の例で、私たちのモデルが実際に生成した入力画像から始まり、「花をオレンジ色に変更する」というプロンプトを定義します。私たちは何について話しているのか、花がどこにあるのかを理解し、それを更新します。 インペインティングの場合も、左側の画像(これもモデルによって生成されたもの)から始まります。豊かな緑の森と背後に山がある納屋、その前に湖があります。その前に車を追加することができます。次のステップでは、 生成された画像の1つ(今は左の画像)を取り、山を変更したい場合は調整できます。湖にアヒルを追加することもできます。


前に示したようなアウトペインティングの例です。製品を持ち込んで、 好きなライフスタイルの背景を生成できます。画像のバリエーション。 これも昨日Swamiが示した例です。参照画像から、似たような画像を生成できます。また、Amazon Bedrockコンソールにある新しいImage Playgroundをご紹介します。豊富な機能を備えており、画像の生成や編集ができます。ネガティブプロンプトも提供できます。スタイルの選択、サイズの選択、生成したい画像の数(1〜5枚)、シード値の設定ができ、結果を直接得ることができます。

それでは、このモデルの利点、ユースケース、アーキテクチャについて、Ashwinに説明してもらいます。
Titan Image GeneratorとMultimodal Embeddingsの実践的応用

ありがとう、Rohit。Rohitが説明していたように、画像とデータモデルを構築する際、私たちは3つの基本原則から始め、それらを確実に実現することに注力しました。まず、非常に高い精度と品質の画像を提供し、お客様が私たちのモデルを簡単に使用できるようにすることです。次に、適切なAPIとツールを構築して、お客様が自身のアプリケーションにモデルを容易に統合できるようにすることです。最後に、Responsible AIを最優先事項として考え、お客様が安心してモデルを使用でき、適切で多様なデータ、無害な情報を提供できるようにすることで、アプリケーションに直接統合できるようにしています。
これらの各カテゴリについて、もう少し詳しく説明しましょう。先ほどお見せした画像の一部でご覧いただいたように、私たちはモデルから得られる画像の品質が非常に高くなるよう努めています。その一環として、幅広いプロンプトに対して広範な評価研究を行い、お客様が使用する可能性のあるさまざまなカテゴリーを検討しました。例えば、シーン内のオブジェクトの相対的な配置を考慮する構図や、複雑なプロンプトなどのカテゴリーです。

Rohitが示した例の中に、複雑なプロンプトの例がありました。森を走る人物が帽子をかぶり、サングラスをかけていて、森自体にも特徴がありました。私たちは、このようなユースケースに対応できるよう、モデルの生成において高い品質を確保したいと考えています。また、これらの要素を理解し、 テキスト生成もサポートできるようにしたいと考えています。誕生日カードや挨拶状、道路標識などの生成に使用したい場合、私たちのモデルを使用して適切な場所にテキストを配置し、アプリケーションに直接統合できるようにします。


アプリケーションの構築に関しては、 Amazon Bedrockのすべての機能と同様に、適切なツールと適切なAPIを提供し、お客様がAPIを呼び出してアプリケーションを生成できるようにしています。画像生成のためのシンプルなAPIを提供しており、テキストプロンプトを入力として受け取り、画像を生成します。Playgroundで見られるように、異なる解像度の画像を選択するオプションもあります。 512x512の解像度から1024x1024の解像度まで、8〜10種類の異なる解像度をサポートしています。また、異なるシードを試したり、同時に複数の画像を生成したりすることもできます。これらすべてをAPI定義の一部として提供しているので、アプリケーションに直接統合し、ワークフローの一部として使用することができます。
私たちが行った重要な取り組みの1つは、リリースした各機能について、お客様がより簡単に使用できるようにする方法を検討したことです。例えば、インペインティングを例に取ると、豊かな緑の森の画像と、その森の中にある車の画像をご覧いただきました。その車をトラックに置き換えたいとします。従来のワークフローでは、画像に入り、マスクを作成し、マウスポインターを使って画像内の車の領域をマスクし、「この部分をトラックに置き換えてください」というテキストプロンプトを使用します。私たちは、そのようなマスク出力を使用したい人々のために、そういったユースケースもサポートしています。
さらに、自動編集機能も提供しています。マスクを手動で更新する必要はなく、テキストプロンプトを使用して「車をトラックに置き換えて」と指示できます。私たちは独自の segmentation モデルを構築しました。これは世界の知識を理解し、画像内のオブジェクトを理解し、車に対応する画像内のピクセルを特定できます。そして自動的にマスクを作成し、inpainting モデルを使用してマスクを編集し、トラックを生成するという出力を行います。このように、大量のデータを簡単に生成できるよう、ワークフローを簡素化する方法を検討しました。
また、image variations を生成するための API も用意しています。山の中のトラックの画像を生成したとして、そのトラックのさまざまなバリエーションを生成したい場合や、同じ写真の異なるスタイルを生成したい場合があります。お客様にとってどうすれば簡単になるか、それも検討し、image variations を生成するための別の API を用意しました。
最後に、基本的なコアモデル自体でさらに何ができるかも検討しました。そこで、fine-tuning 機能を提供しています。お客様は独自のデータセットを持ち込むことができます。私たちはそのデータセットに特化してモデルをトレーニングし、fine-tuning を行い、そのお客様だけがアクセスできるモデルを提供します。そのデータは、私たちが独自のモデル作成に使用する他のトレーニングには一切使用されません。このモデルはお客様専用に別途ホスティングされ、お客様は完全にアクセスでき、独自のアプリケーションで実行したいアプリケーションを実行するためにモデルを呼び出すことができます。

fine-tuning ワークフローの一環として、従来の fine-tuning の方法は、画像とテキストのペアを用意し、画像とテキストのペアを API への入力として渡すというものです。これは S3 コンテナに入れることができ、API に S3 コンテナへのリンクを指定すると、私たちはその画像とテキストのペアを使用してモデルをトレーニングします。私たちが検討したことの1つは、このワークフローをどう簡素化するかということです。この場合、「お客様がテキストを持ち込まず、画像だけを提供すれば、もっと簡単にできないか」と考えました。そこで、近々リリース予定の機能の1つとして、独自の captioning モデルを用意しました。これにより、お客様の画像に自動的にキャプションを付け、それを使用して fine-tuning のための画像とテキストのペアを生成します。このように、これらのユースケースのあらゆる段階で、お客様が私たちのモデルを使用し、ワークフローに組み込むことをいかに容易にするか、全体のプロセスをいかに簡素化するかを検討しています。
広告制作プロセスにおけるAmazon Bedrockの活用例
第三に、私たちは責任あるAIの観点からモデルがフレンドリーであることを確保しています。モデル開発プロセス全体を通じて幅広い緩和策を実施し、初日から責任あるAIに対して根本的なアプローチを取っています。私たちの目標は、お客様が不適切なコンテンツや有害なコンテンツを心配することなく喜んで使用できる、安全な画像を生成することです。
データ側で広範なフィルタリングを行い、モデル作成プロセスを改善しました。これにより、モデルに入力されるデータが良質でクリーンであることを確保しています。また、システムの一部として、入力されるテキストプロンプトが有害なコンテンツを生成しないよう、ガードレールとフィルターを設けています。同様に、モデルによって作成された画像コンテンツもフィルターを通過し、不適切または暴力的なコンテンツの生成を防いでいます。
昨日のkeynoteでSwamiが言及したように、私たちはモデルに真正性追跡のための透かしを入れています。Titan Image Generatorモデルによって生成されたすべての画像には、目に見えない透かしが埋め込まれています。近々、画像がTitan Image Generatorで作成されたかどうかを確認できるAPIを提供する予定です。このようにして、生成された画像が安全で、真正性の証明があり、この環境でディープフェイクを作成しないことを保証します。

また、すでに利用可能な多くのtext-to-imageモデルで懸念されている人口統計学的バイアスにも対処しています。例えば、一緒にポーズをとるカップルの画像を生成する場合、従来のモデルはしばしばバイアスのあるデータセットに基づいて調整されています。これらのデータセットは、特定のカテゴリーの人々、肌の色、民族、または地理的位置に偏っている可能性があります。私たちのトレーニングプロセスの一環として、モデルが様々な肌の色や性別を代表する多様なデータにさらされるようにしています。これにより、モデルは幅広い人々を表現できるようになります。

弁護士などのプロフェッショナルの高品質な画像を生成する際にも、よくあるバイアスが発生します。特定の地域の弁護士に関して、肌の色や性別に関連したバイアスが内在していることがあります。私たちは、モデルが幅広い可能性を生成するよう確保しています。これにより、お客様は多様な人物のバリエーションを作成し、アプリケーションで安心して使用することができます。
私たちは、画像情報とembeddings情報を取り込み、バイアスのない空間に配置する方法に特化した特許出願中の技術を開発しました。これにより、このデータを使用して、これらの画像に見られるような多様な種類の出力を提供することができます。これらはすべて、Titan Image Generatorの一部として統合されています。
Amazon Bedrockを用いた広告コピー生成の具体的ワークフロー


では、モデルの使用例をいくつか見ていきましょう。マルチモーダル検索体験を構築したいとします。画像とテキストのペアがあり、最初のステップはインデックス作成です。Multimodal Embeddingsモデルを呼び出してembeddingsを生成します。Rohitが言及したように、異なる長さのembeddingのオプションを提供しています。低レイテンシーを求めるお客様には、より高速な検索を可能にする256の長さの小さなembeddingを提供しています。検索の高精度を優先するお客様には、1,024の長さのembeddingを使用して独自の画像データベースをインデックス化することができます。
私たちは、ベクトルDBストアとのデータベース統合を容易にしました。OpenSearchと統合することで、お客様がOpenSearch APIを簡単に呼び出せるようになりました。Amazonエコシステムのユーザーであれば、OpenSearchから当社のTitan Embeddingsモデルを呼び出し、システム全体を統合できます。また、Pineconeとの統合も提供しており、ユースケースやニーズに応じて幅広い選択肢があります。
当社のembeddingsモデルを使用することで、基盤モデルのパワーを活用しながら、高いレイテンシーや高い精度を必要とするさまざまなユースケースをサポートできます。embeddingsが責任ある方法で定義されるよう確保しています。例えば、異なる性別や肌の色のCEOの画像データベースがある場合、生成されるembeddingsがこれらの側面を公平にカバーするようにしています。これにより、ユーザーがクエリを入力した際に、性別や肌の色に関係なく、対応する画像を取得できます。
クエリのワークフローについて説明しましょう。テキストプロンプト、類似画像検索のための画像、またはテキストと画像の組み合わせを使ってデータベースを検索できます。小売のユースケースでは、緑のシャツの画像を取得したいが、異なるチェック柄や色で探したい場合があるでしょう。私たちは、画像とテキストクエリを組み合わせたこのような複雑な検索をサポートしています。Multimodal Embeddingsモデルを呼び出してembeddingsを生成し、それを検索アプリケーションに使用できます。

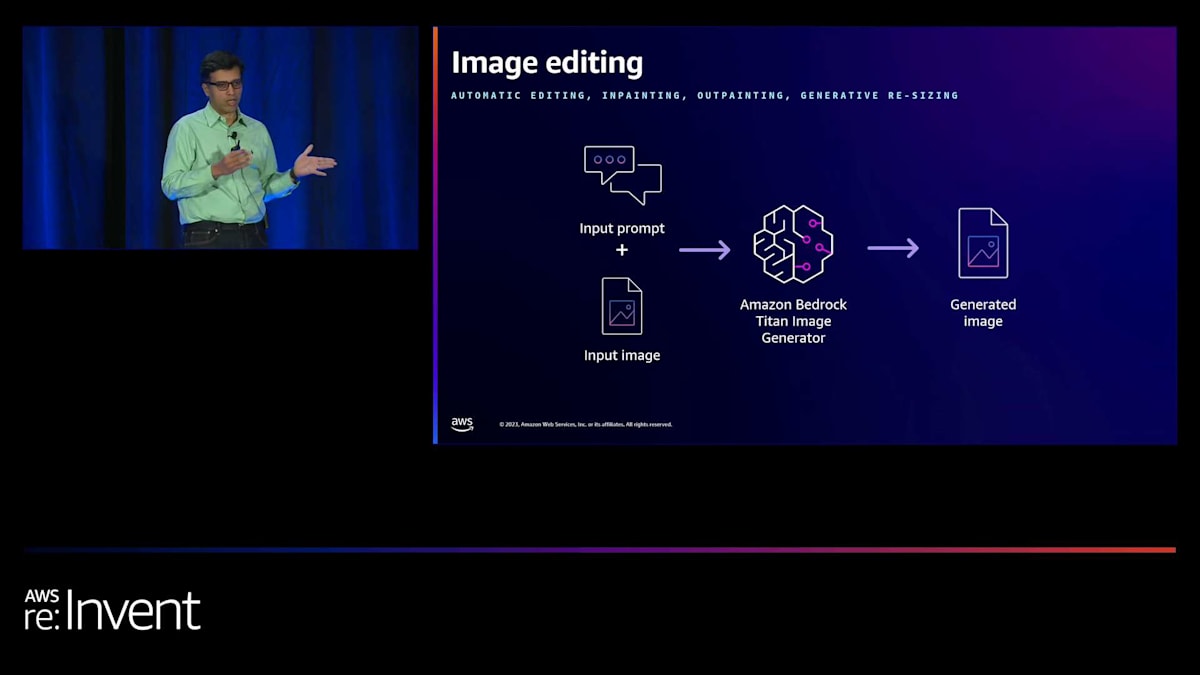
では、テキストから画像を生成するモデルの例を見てみましょう。テキストから画像へのモデルでは、入力テキストプロンプトから始まり、Bedrock APIを呼び出して画像を生成します。とてもシンプルで、お客様が簡単に使用できるようになっています。画像編集については、入力画像とマスクの組み合わせを使用できます。マスクを使用したいお客様向けにオプションを提供しています。入力画像とマスクがあれば、そのマスクを使って編集、インペインティング、アウトペインティングを行うことができます。また、テキストプロンプトからマスクを生成し、それを使ってインペインティングやアウトペインティングを行うこともできます。

広告制作プロセスの例を見てみましょう。香水ボトルのデータベースがあり、広告コピーを作成したいとします。まず、データベースから香水ボトルの良い画像を取得します。最初に上位5つか10個の検索結果を生成するかもしれません。次に、当社の画像生成モデルを使用して、広告コピーのワークフローに組み込める香水ボトルの見栄えの良い画像を作成します。その後、画像バリエーションを使用して、異なるスタイルや背景を作成できます。

最後に、Bedrock スイートのテキストモデルを使用して、広告のテキスト説明を生成できます。 Bedrock ファミリーの異なるモデルを組み合わせることで、このワークフロー全体を実行できます。Titan Multimodal Embeddings モデルを使用してデータベースを検索し、適切な香水画像のセットを見つけることができます。Titan Image Generator を使用して、バリエーションを生成したり、背景や異なるシーンを追加したりできます。最後に、Titan Text Model や他の Bedrock Text Model を使用して、広告コピーのテキスト生成を行うことができます。簡単な例を見てみましょう。

広告コピーのテキスト生成の最初のステップは、データベースを作成することです。 ワークフローの一部として、すべての香水ボトルと製品のデータベースを持つことになります。Titan Multimodal Embeddings モデルを使用して、データベースにインデックスを付け、逆インデックスを作成します。そして、「香水ボトル」のような検索クエリが与えられると、データベースを検索して最も関連性の高い情報を見つけ、調べるべきすべての香水ボトルのリストを提供します。
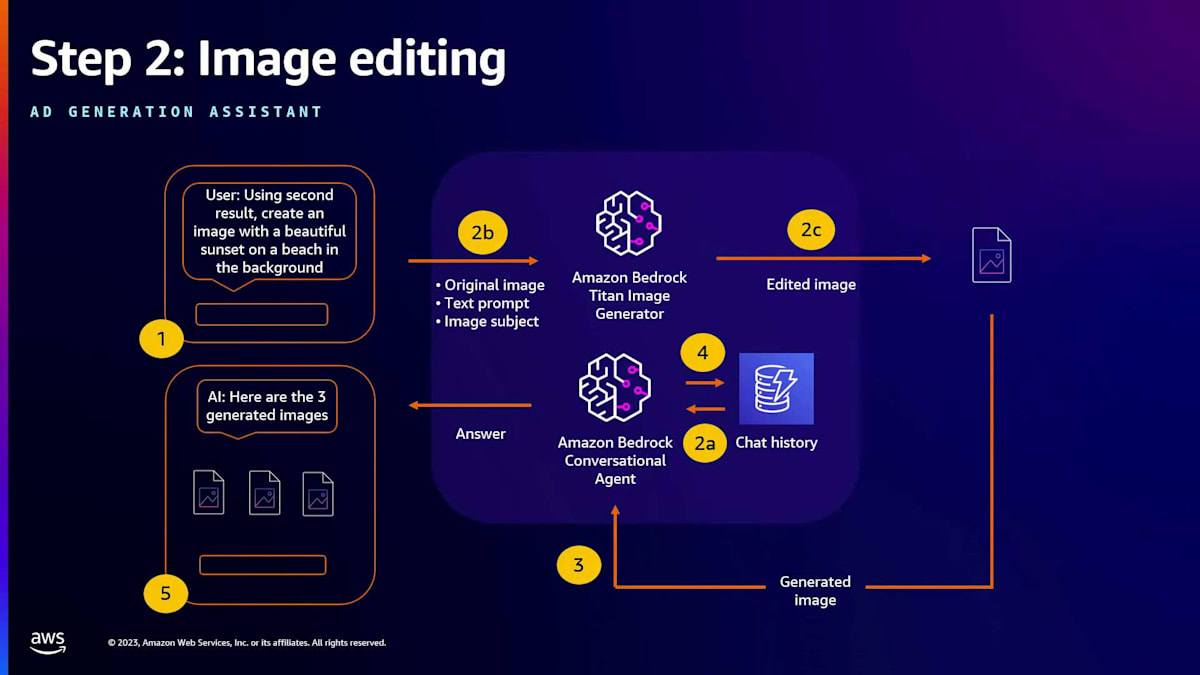
次のステップは、画像編集 API を呼び出すことです。この API を使用すると、自動マスク、インペインティング、異なる背景でのアウトペインティング、スタイル化を行うことができます。例えば、ビーチ環境、森林、都市景観の中に香水ボトルを作成することができます。製品のユースケースに視覚的に魅力的な画像を確保するために、さまざまな背景を試すことができます。
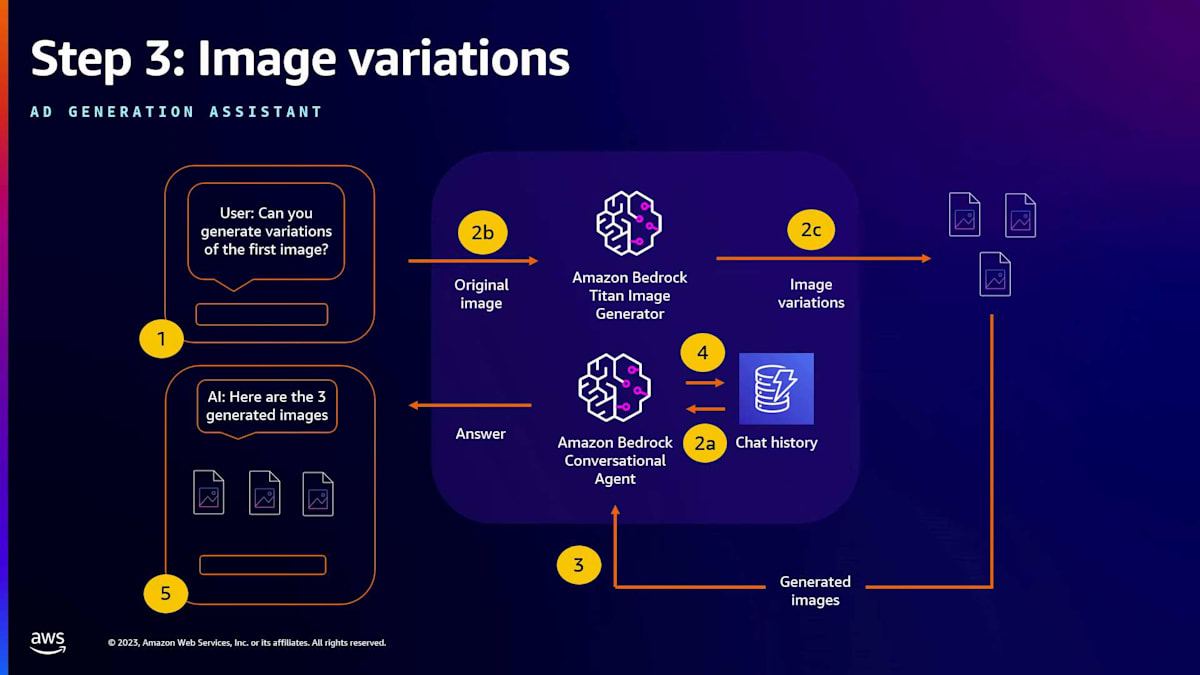

最後に、画像のさまざまなバリエーションを生成できます。異なるスタイルや背景を探索して、顧客の目を引く興味深い画像を作成できます。最後のステップは、画像テキスト生成モデルを使用することです。 ここでは、テキストを取り、Bedrock LLM テキスト API を呼び出し、検索キーワード、製品説明、または画像の背景を組み込みます。LLM は魅力的なテキスト説明を作成し、それを広告コピーに添付することで、バージョン全体を完成させます。
このアプローチにより、Titan Image Generator、Titan Multimodal Embeddings、そして Bedrock でホストされている LLM スイート全体を含む Bedrock ファミリーのモデルがシームレスに連携します。これらの実験を実行し、これらのワークフローを作成するためのワンストップソリューションを提供します。

では、Andresに引き継ぎます。Andresは、OfferUpアプリケーションでどのように活用しているかについて説明します。
OfferUpの紹介とモバイル検索の課題
皆さん、おはようございます。私はAndres Velezと申します。OfferUpのプリンシパルデータサイエンティストを務めています。本日は、OfferUpがAmazon Bedrockを使用して検索機能で革新的な体験を構築する方法についてお話しします。ちなみに、これまでにOfferUpを使ったことがある方は手を挙げてください。素晴らしいですね。
OfferUpをご存じない方のために説明しますと、2011年に設立され、現在では米国最大のローカルバイヤーとセラーのためのモバイルマーケットプレイスの1つとなっています。興味深い事実として、現在、米国の5人に1人がOfferUpを利用しています。私たちは、これらの取引のためのユニークでシンプル、そして信頼できるアプリケーションを提供することで、地域コミュニティの売買方法を変革してきました。

私たちのミッションは、モバイルデバイスで写真を撮るだけで簡単に商品を出品できるインターフェースを通じて、バイヤーとセラーをつなぐことで、ローカルコマースの選ばれるプラットフォームになることです。

今日は検索について話します。検索は、どのアプリケーションにおいても重要な要素です。検索に投資することで、複数のアプリケーション指標を活用できます。次のシナリオを想像してみてください:ユーザーがアプリケーションにアクセスして商品を検索します。結果がパーソナライズされていれば、必要なものを見つけるのに時間と労力を節約できます。このプロセスが最適化されていれば、ユーザーは必要なものを見つけ、取引を完了する可能性が高くなります。そうでない場合でも、プラットフォームを改善するための洞察が得られます。これらの変更を適用すると、ユーザー体験に具現化され、最終的にユーザー定着率の指標が向上します。

モバイル検索には独自の課題があります。まず一つ目は、幅広く短い検索クエリのタイプです。ユーザーは通常、1〜5個程度のキーワードを使用する傾向があります。
これは非常に複雑です。なぜなら、求めているものを探すための文脈が短いからです。他の検索エンジンを見ると、検索クエリにはより詳細な説明や文脈が含まれています。もう一つの課題は、ユーザーが提供するコンテンツの品質にばらつきがあることです。ここに示されている画像を想像してみてください。一部は非常に高品質で素晴らしいものですが、一方で低品質の画像を提供するユーザーもいて、これが課題となっています。タイトルや説明を見ても、一部は非常に乏しく、商品に関する十分な文脈を提供していません。さらに、限られた画面スペースも複雑さを増しており、アプリケーションで成功するには適切なランキングが不可欠です。
OfferUpにおける検索技術の進化

これらがモバイルマーケットプレイス検索における複雑さの一部です。この分野は進化し続けており、私たちOfferUpは最新の変化に追いつくために懸命に取り組んでいます。私たちはキーワード検索から始めました。 キーワード検索はアプリケーション全体で使用しています。この技術には長所と短所があります。ユーザーが提供するキーワードを使用し、エンジンでマッチングを行います。そして、実際にマッチする商品リストを取得します。この技術の上に、私たちはニューラル検索を探求しました。 ベクターデータベースの使用を開始し、Amazon OpenSearch Serviceを探求し、さらにAmazon SageMakerを使用して意味検索のためのモデルをデプロイしました。タイトルと説明を取り、埋め込みを生成し、それらの埋め込みをベクターデータベースに格納しました。

本番環境に移行する前に、この新しい技術スタックを主に2つの側面でテストしました。1つ目はレイテンシーです。会社のSLAに準拠したいと考えています。2つ目は品質です。取得された商品リストが実際に良い結果をもたらすことを確認したいのです。レイテンシーについては、 実験を行いました。OpenSearchデータベースに数百万件の商品リストをバックフィルしました。この情報をバックフィルした後、データベースに数百のRPSを適用しました。これらすべてのシナリオで、P99で約60ミリ秒未満という素晴らしい結果が得られました。私たちはAmazonのOpenSearchチームとの協力に非常に驚き、喜んでいます。素晴らしいコミュニティサポートがあるからです。

もう一つの実験は品質に関するものです。品質評価のために、 アプリケーションで最も使用される上位25のキーワード検索を使用して商品を取得しました。この情報を使用して、一定数の商品リストを取得し、関連性リコールを計算しました。キーワード検索をベースラインとしています。結果を見ると、低密度の場所では意味検索を使用することで関連性リコールが約23%増加し、高密度の場所では27%増加しています。高密度の場所とは、エリアあたりの商品数を指します。この技術に切り替えることで、非常に大きな改善が見られました。
Amazon Titan Multimodal Embeddingsモデルの導入と効果
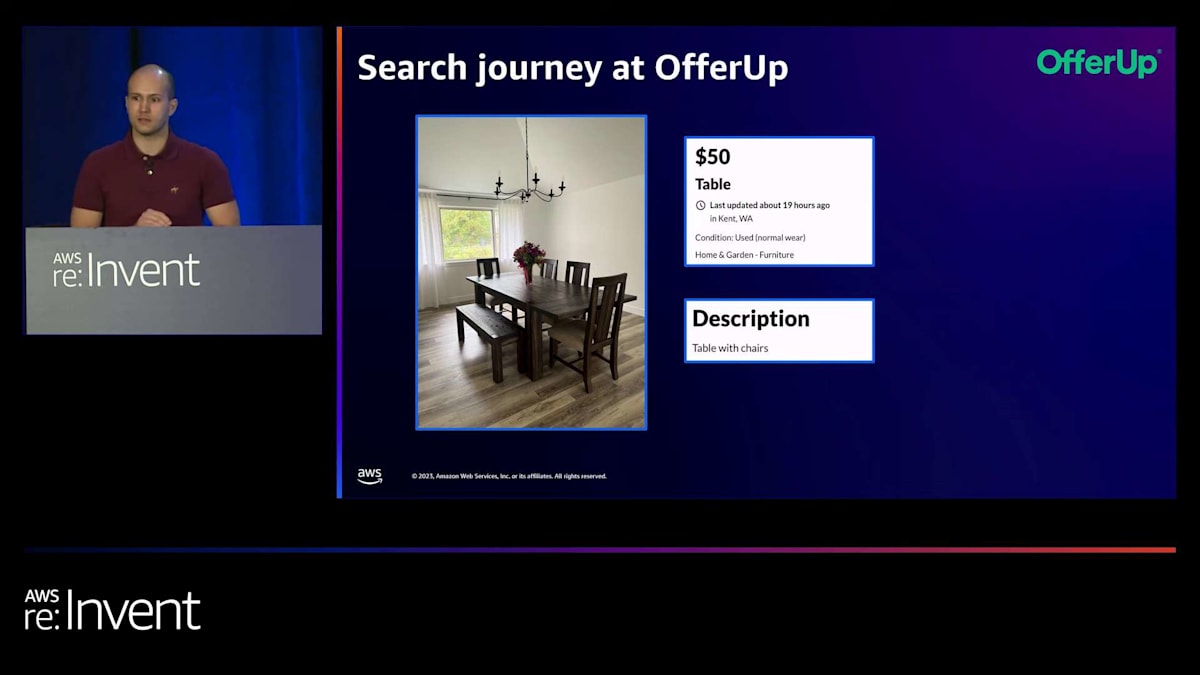
しかし、これらの数字を見てみると、素晴らしい結果だと言えますよね。ただし、これらの側面にはすべて欠けているものがあります。この画像を見てみましょう。まず、これは本当に素敵な商品です。私なら間違いなく自宅用に購入するでしょう。よく見ると、タイトルはあまり意味をなしておらず、説明文も非常に短いです。しかし、画像を見ると、

画像からは色、形、販売されている座席の数、そして座席のサイズなど、多くの詳細情報が得られます。画像はこのコンテキストについてはるかに多くの情報を提供しており、だからこそこれを考慮に入れることが非常に重要なのです。

そのために、私たちは Amazon Titan multimodal model を使用しており、この新しいコンポーネントを私たちのジャーニーに統合しました。タイトルと説明文とともに画像を取り込み、Titan Multimodal Embeddings に通し、この情報でベクターデータベースにインデックスを作成します。これにより、これらの新しいコンポーネントを使って検索することが可能になります。このマルチモーダルモデルアプローチがなければ、特定のリスティングを発見可能にすることはできませんでした。これは本当に重要なことです。

技術的な観点から見ると、AWS とのパートナーシップにより、非常に短期間で新しい技術をテストすることができました。この新技術の構築にはわずか数ヶ月しかかかりませんでした。また、先ほど説明した方法論に従って、品質の面でもテストを行いました。Titan Multimodal Embeddings モデルは、低密度の地域で約9%の改善を示しました。また、低密度と高密度の両方の地域で分散を減少させました。
OfferUpの検索技術の進化と成果
これは本当に素晴らしいことです。なぜなら、現時点では transfer learning を適用していないので、そのままの性能を発揮しているからです。分散の減少は実際にシステムをより安定させます。このジャーニーを要約すると、私たちはキーワード検索から始めました。そして、semantic search を使用したニューラル検索の探索を開始しました。これにより、低密度の地域で23%の改善、高密度の地域で関連性のあるリコールが27%増加するという素晴らしい改善が得られました。

それに加えて、私たちは新しい技術の探索を始めました。マルチモーダル埋め込み技術を探索し、これによって低密度の場所での関連性のリコールを向上させつつ、高密度の場所でのパフォーマンスを維持することができました。しかも、transfer learningを適用することなく、システムをより安定させることができたのです。では、次に何を考えているでしょうか? 私たちは、OfferUp内での検索、レコメンデーション、画像生成などをさらにサポートするために、AIツールをどのように活用できるかを研究しています。ありがとうございました。
まとめと今後の展望

ありがとう、Andres。まとめますと、Titan image generatorモデルについて、その機能、差別化要因、そして利点について学びました。また、Titan Multimodal Embeddingsモデルについても、同様にその差別化要因と利点について学びました。そして次のステップとして、OfferUpや皆様のような他のお客様との取り組みについて説明しました。これらのモデルが皆様のユースケースにどれほど有益であるかについて、何かしらのアイデアを得ていただけたと思います。私たちは、皆様と協力して、これらのモデルがGenerative AIアプリケーションの構築にどのように役立つかを見ることができるのを本当に楽しみにしています。本当にありがとうございました。
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion