re:Invent 2024: MetaがAWSで実現したGenerative AI活用 - Ray-Ban開発事例


はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - AWS-accelerated computing enables customer success with generative AI (CMP207)
この動画では、AmazonのEC2における高速コンピューティングを活用したGenerative AIモデルの構築・デプロイについて解説しています。ヘルスケアや産業、金融など様々な業界でのGenerative AIの活用事例を紹介した後、LLMのトレーニングの大規模化やInferenceの世界的な増加、マルチモーダルLLMへの注目といった主要トレンドを解説します。また、MetaのWearables AIチームによる事例として、Ray-Ban Metaスマートグラスの開発におけるAWSの活用について詳しく紹介。24,000個のGPUを使用して15兆のトークンでトレーニングされたLlamaモデルを基に、マルチモーダル化を実現した過程や、AWS上での大規模な並列実験の実施方法などが具体的に語られています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Generative AIセッションの概要と議題

皆様、本日のセッションへようこそ。今回は、お客様がAmazonの高速コンピューティングを活用して、Generative AIのモデルをどのように構築・デプロイしているかについてお話しさせていただきます。私はAmazon EC2のSenior Product ManagerのDvij Bajpaiです。私はEC2のPrincipal Product ManagerのSamantha Phamです。そして皆様、私はMetaのAI Engineering LeadのKirmani Ahmedです。

本日は盛りだくさんの内容をご用意しています。まず、この1年間で私たちが観察してきた傾向を中心に、様々な業界におけるGenerative AIのユースケースの概要についてご説明します。次に、この分野のお客様に共通して浮かび上がってきた主要なニーズについてお話しし、これを基に、お客様が機械学習モデルのトレーニングと推論を行うためのEC2の機能開発についてご説明します。続いて、私たちが「Generative AIスタック」と呼んでいるものについて、そしてコンピューティングインフラストラクチャからオーケストレーション、さらにはSageMakerやBedrockのようなマネージドサービスまで、あらゆるレイヤーで高速コンピューティングをお客様にとってより使いやすくするための投資についてお話しします。最後に、お客様の声をお届けします。本日は特に、MetaにおけるAI研究の最前線についてKirmaniにお話しいただけることを大変楽しみにしています。
様々な業界におけるGenerative AIの活用事例
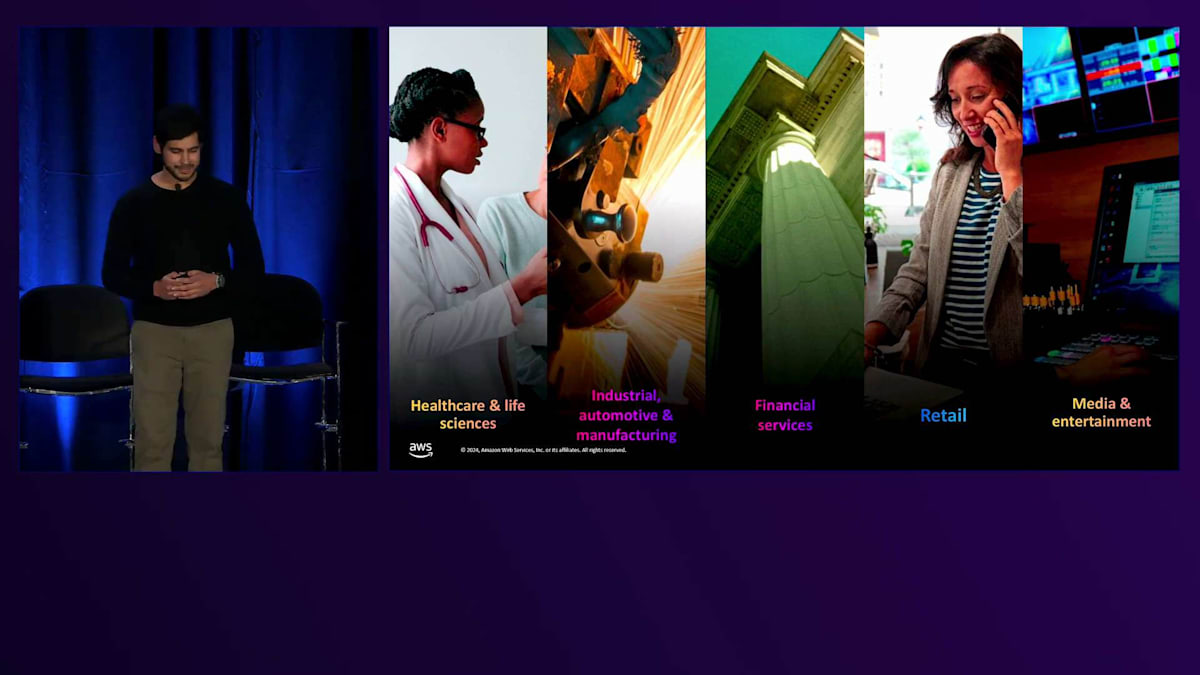
Generative AIは、ここ数年でほぼすべての業界に影響を与えています。ヘルスケア分野では、Amreのようなお客様がTransformerベースのモデルを使用して、創薬を加速するためのタンパク質設計を行っています。タンパク質や生物学の言語を機械学習モデルが学習し、新しい薬剤や治療法の候補を生成できるということは、科学界にとって画期的な発見となりました。これらは、電子カルテの文書化と処理を簡素化することで、医療システムの管理負担を大幅に軽減する可能性も秘めています。また、一部の企業では、R&Dの初期段階で研究者がアクセスしやすいように、自社の出版物でLLMをファインチューニングしています。そして、R&Dから運用、製造、医療サービスの提供に至るまで、AIがヘルスケアのあらゆる側面をどのように変革していくのか、私たちはまだ初期段階にいます。
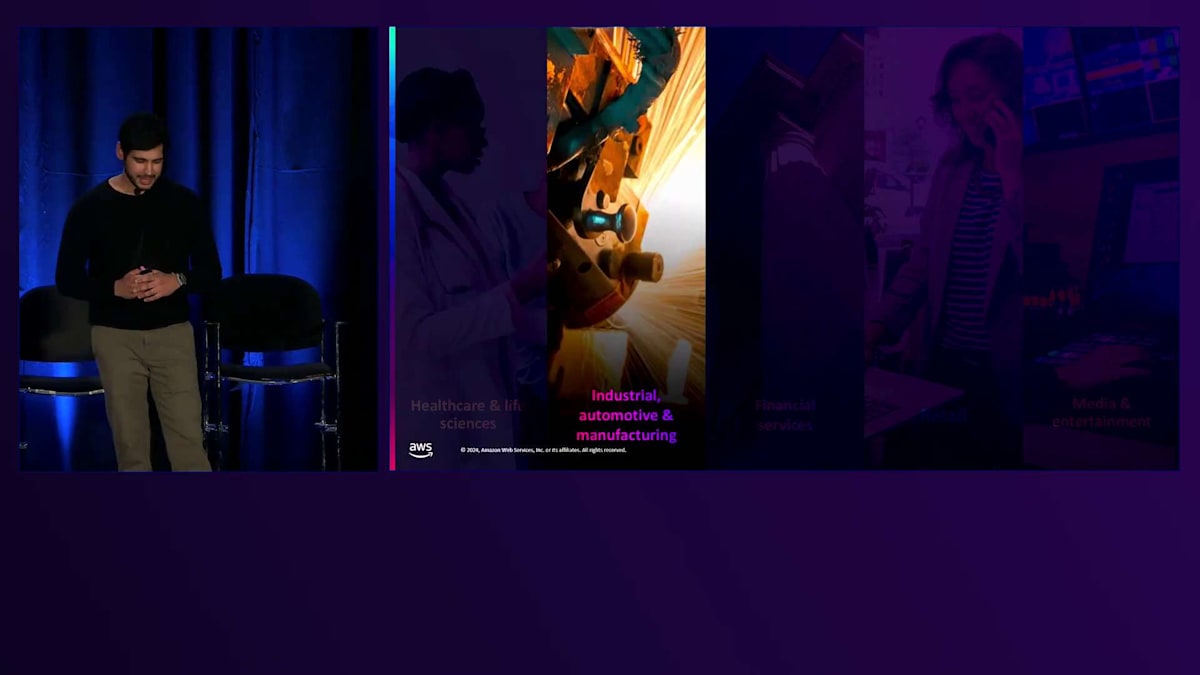
産業・自動車分野では、お客様はGenerative AIをロボティクスに統合し、周囲の世界を認識してリアルタイムでイベントに対応できるロボットを作成しています。これにより、ロボットの安全性と効率性が向上し、製造ラインの効率を改善することができます。Ferrariのような企業は、Generative AIを車両設計に活用し、顧客体験を再構築しています。これにより、お客様は実際の生産に移る前に、車両の高度にリアルな3次元レンダリングを視覚化することができます。
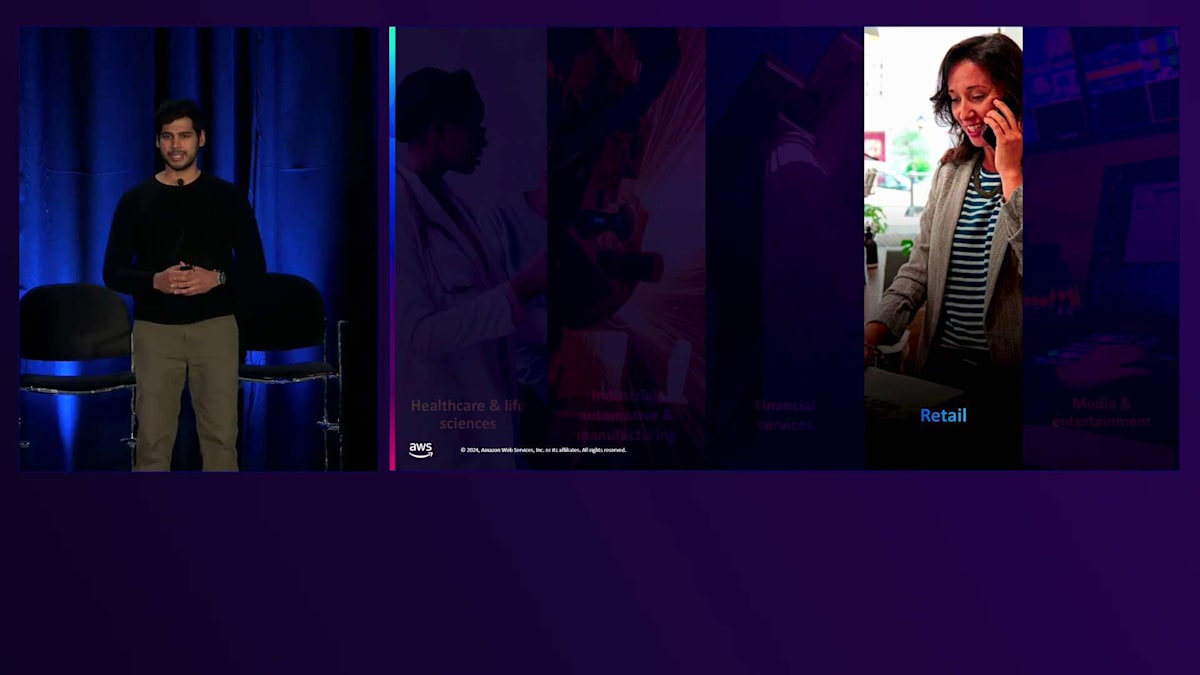
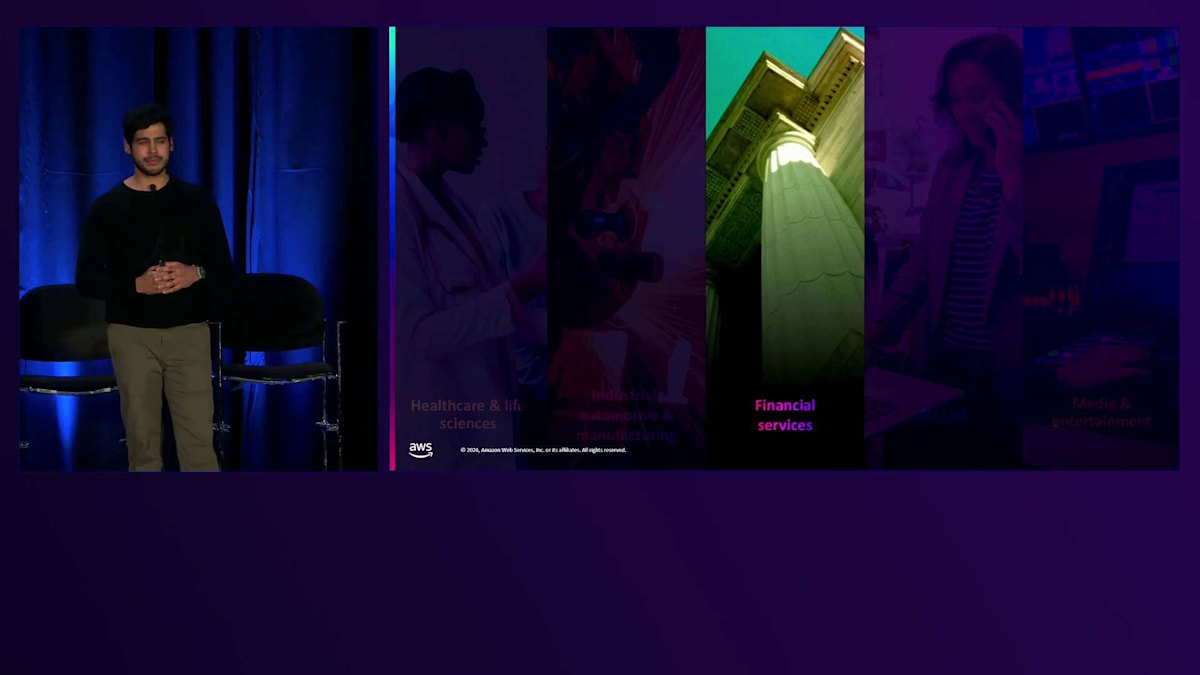
金融サービス分野では、企業は年次報告書や財務諸表でLLMをファインチューニングし、投資家がデータにアクセスしやすくしています。また小売分野では、今年初めにamazon.comのサイトでショッピング中に対話できるGenerative AI搭載アシスタントのRufusを発表しました。「油絵を始めたいのですが、どんな商品を購入すればいいですか?」といったオープンエンドな質問をRufusにすることができます。Rufusはamazon.comの商品カタログとカスタマーレビューでトレーニングされており、商品選びの際にこれらの情報により簡単にアクセスできるようになっています。
そして最後に、メディアとエンターテインメントの分野では、Adobeのような企業が、数行のテキストから映画のような体験を生み出すことができるマルチモーダルモデルを開発しています。これは、クリエイターがインテリジェントモデルと対話しながら、画像や短い動画、そして近い将来には長編映画までも、素早く作成し改良できるという点で、クリエイティブプロセスを根本的に変革しています。
Generative AI分野における3つの主要トレンド

これらは、私たちが様々な業界で目にしている多くのユースケースのほんの一例であり、その進化は続いています。私たちEC2のコンピュートレイヤーにいる者として、これらの異なるトレンドがどのように進化しているのかを観察できる興味深い立場にいます。では、この1年間で観察された3つのトレンドについてお話ししましょう。1つ目のトレンドは、LLMのトレーニングがさらに大規模化を続けているということです。最大規模のトレーニングジョブでは、1つの同期分散ワークロードで1万台以上のGPUを活用することができます。私たちは、Amazonでの次世代Foundational Modelのトレーニングをサポートするため、数十万台のアクセラレーターをサポートできるよう、クラスターの規模を拡大し続けています。この規模になると、後ほど詳しくお話しするように、効率性と信頼性が重要な焦点となります。

この1年間で見られた別のトレンドは、世界の様々な地域でLLMのInferenceが大幅に増加したことです。世界中の企業が、最も強力なLLMを自社のアプリケーションに統合したいと考えています。例えばインドの遠隔地にいても、業界で最も強力なモデルとリアルタイムでやり取りできるということを考えると、本当にワクワクします。

私たちは、これを実現するために、コンピュートのフットプリントとその経済性の拡大に注力しています。2023年がテキストベースのLLMの年だったとすれば、2024年は企業がますますマルチモーダルLLMに注力しています。これらのモデルが、ビデオやオーディオ情報のデコードに特化したアップストリームレイヤーと、より抽象的な推論に特化したダウンストリームレイヤーを持つ、真のオーディオビジュアル実体へと進化していくのを見るのは魅力的です。Kirmaniも後ほどこれについて詳しく話します。音声や動画にリアルタイムで応答できるモデルの展開は、私たちのコンピュートインフラストラクチャに新しい要件をもたらしており、これについても後ほど詳しく説明します。
AIモデルの種類とワークフロー:プロトタイピングからデプロイメントまで

これらは大まかなトレンドですが、Samantha、今日のインスタンスでトレーニングされている具体的なモデルやユースケースについてもっと詳しく教えていただけますか。マルチモーダルモデルの分野では大きな成長と進展が見られますが、テキストベースのLLMでも依然として多くのイノベーションが起きています。お客様は、数百万パラメーターから数兆パラメーターまで、さまざまなサイズのモデルを構築しています。これらのお客様は、特にグローバルな展開を開始し、特定のモデルタイプを展開するための適切なインフラストラクチャを見極めようとしている今、パフォーマンスとコストのバランスを最適化するために、モデルのサイズを変更しています。

さらに、多くのお客様が、Vision、Speech、Recommenderシステムの構築を続けていることも確認しています。これらのモデルは、Multimodalモデルや LLMと比べるとサイズは小さいものの、リアルタイムで前処理が必要な大規模なデータセットを扱うため、インスタンス上でCPUとGPUのパワーを適切にバランスを取ることが非常に重要になります。最近では、この分野のお客様も、Self-attentionによってワークロードの並列化を効率的に行えるTransformerを採用し始めています。これは、現在お客様が構築しているさまざまなタイプのモデル間に共通する要素となってきています。


次に、モデルの構想から本番デプロイメントまで、異なるモデルタイプ間でも共通するワークフローが見られるようになってきています。通常、お客様はまずPrototypingから始めます。この段階では、パフォーマンスの最適化や、モデルアーキテクチャの改善方法を試行錯誤します。これはライフサイクルの中で最も計算負荷の低い段階ですが、研究者が新しい理論を素早くテストできるよう、インタラクティブ性の高いハードウェアが必要です。次に、お客様は数千台のアクセラレータまでスケールするクラスターでPre-trainingを行います。この段階では、モデルタイプに応じて最適な並列化方法を見つけることが非常に重要になります。さらに、数千台規模のアクセラレータクラスター内の各ノード間での通信を最適化する方法を見極めることも極めて重要です。

その後、お客様はFine-tuningに移ります。Foundation Modelの開発者が提供するオープンソースの事前学習済みモデルを使用する場合は、PrototypingとPre-trainingの段階をスキップするお客様もいます。Fine-tuningでは、通常、これらの事前学習済みモデルを特定のユースケースやアプリケーションに適応させることを目指します。お客様は新しいデータを使用して、特定のユースケースに合わせてモデルのパラメータを調整し、再学習を行います。一般的に2つの方法が見られます。1つ目は、事前学習済みモデルのニューラルネットワーク全体を更新するFull Fine-tuningです。これは非常に計算とメモリを必要とする方法であるため、コストを抑えたいお客様は、Parameter-efficient Fine-tuningを選択することがあります。この方法では、パラメータの一部のみを更新するか、事前学習済みモデルの上に追加のレイヤーを設けます。


お客様がモデルを本番環境にデプロイする準備が整うと、2つの方法でデプロイを行うことが多いです。1つ目は、Real-time Inferenceです。この場合、お客様はパフォーマンスを優先し、エンドユーザーに最高のカスタマーエクスペリエンスを提供するために、可能な限りレイテンシーを最適化して低減することを目指します。2つ目の方法は、Batch Inferenceです。これは、生成されるトークンあたりの全体的なコストを削減することに重点を置き、コスト効率を最適化できる方法です。
顧客ニーズとEC2の機能開発:パフォーマンス、コスト、セキュリティ、使いやすさ

お客様が共通して重視するニーズについてお話ししましょう。先ほど説明したように、EC2インスタンス上で実行されるワークロードは実に多様ですが、お客様が一貫して重視している要素とは何でしょうか?1つ目は、トレーニング時のパフォーマンスです。より高いパフォーマンスは、トレーニング時間の短縮を意味し、モデルの開発やイテレーション、本番環境へのデプロイをより迅速に行えるようになります。Inference時には、より高いパフォーマンスによって、より大規模なモデルを低レイテンシーで実行できるようになり、エンドユーザーにリアルタイムでより魅力的なエクスペリエンスを提供することが可能になります。


Generative AI モデルの規模を、数十から数百、数千、さらには数百万のお客様へと拡大していく中で、大規模な経済性の管理が極めて重要になってきます。 そのため私たちは、新しい EC2 インスタンスごとにより高いコストパフォーマンスを実現することに常に注力しています。これにより、トレーニングやインференスに使用される1ドルあたりのパフォーマンスが、新しい世代のインスタンスでより向上することになります。3番目の重要な顧客ニーズはセキュリティです。これは Amazon において私たちが最も真剣に取り組んでいる課題です。 エンドユーザーがモデルと対話する際に、非常に個人的な情報を共有する可能性があり、そのやり取りが確実に安全に保たれる必要があります。また、モデルの開発に多大な投資をされている場合、データやモデルの重みが確実に保護される必要があります。

AWS Nitro System を通じて、業界をリードするセキュリティ機能と特長をどのように提供しているかについて、さらに詳しくお話しします。最後に使いやすさについてですが、トレーニングワークロードやインференスのニーズに応じて、数千のインスタンスのフリートを管理し、スケールアップ・ダウンすることは複雑になり得ます。そのため私たちは、スタックのあらゆる層を見直し、「差別化されない重労働」と呼ばれるものを簡素化するよう努めています。これにより、お客様は高度に専門化されたチームを揃えたり、さまざまな要素を組み合わせたりする必要なく、私たちのコンピュートを最大限に活用できます。つまり、パフォーマンス、コスト、セキュリティ、使いやすさ - これらを枠組みとして使用し、お客様がこれらの目標を達成するために EC2 で開発している機能についてお話ししましょう。
EC2インスタンスの内部構造とAWSの高性能コンピューティングソリューション
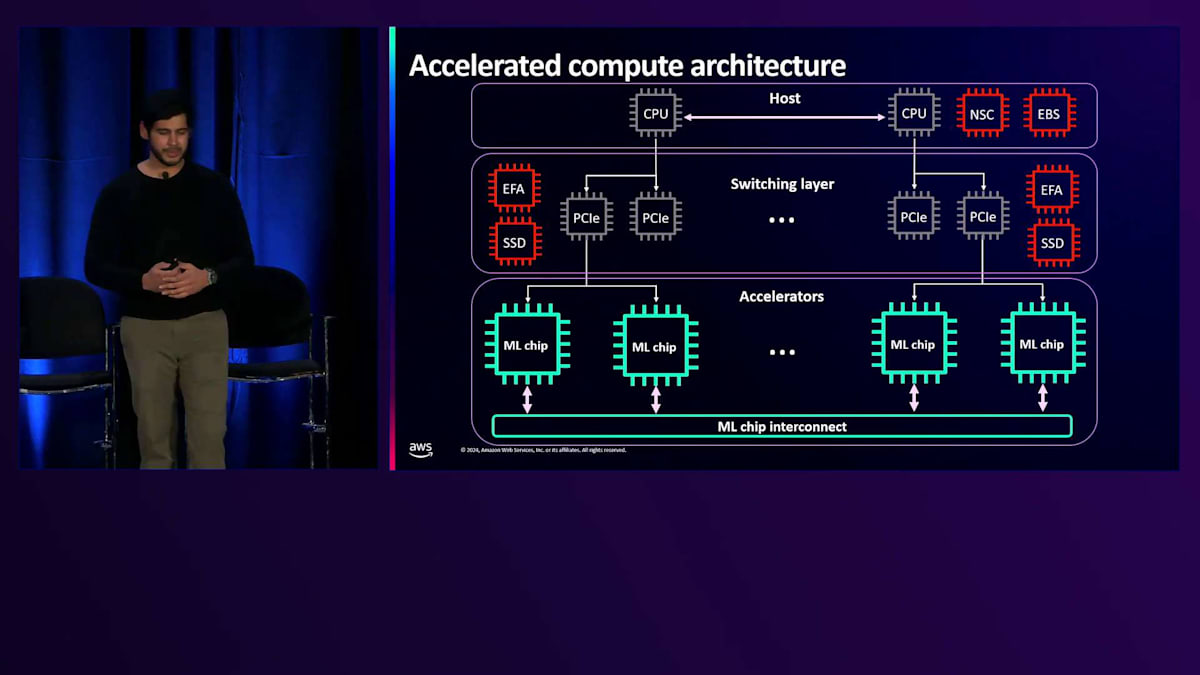
これをより具体的にする一つの方法として、EC2 インスタンスの中身を覗いてみたらどのように見えるか、という質問から始めてみましょう。 アクセラレーテッドコンピューティングインスタンスの中核にあるのは、アクセラレーター自体です。私たちは NVIDIA GPU から、Intel、AMD、Qualcomm といったシリコンパートナーのシリコン、さらには独自開発のトレーニングとインференス用 AI アクセラレーターまで、幅広いアクセラレーターを提供しています。多くのアクセラレーテッドコンピューティングインスタンスには、高性能なチップ間相互接続も搭載されており、GPU 同士が高帯域・低レイテンシーで通信できます。
アクセラレーター層の上には、GPU を直接インスタンスのネットワークやローカルストレージに接続する PCI スイッチング層があるインスタンスもあります。重要なのは、データが処理速度を低下させる可能性のある CPU を経由せずに、GPU との間で送受信できることです。そして最後に、実際にインスタンスを起動して SSH 接続する際のホストとなる CPU を備えたホスト層があります。ホスト層の主な機能の一つは、コンピューティング環境が常に安全に保たれることを確実にすることです。

アクセラレーター層についてさらに詳しく見ていきましょう。通常、お客様は AI/ML ワークロードの高速化に3種類のハードウェアを使用されています。まず CPU から始めると - CPU は時系列モデルや線形回帰モデルなど、より直列化されたワークロードによく使用されます。AWS では、AWS Graviton チップや Intel、AMD の CPU など、さまざまな種類の CPU を幅広く提供することで、CPU を使用した AI/ML ワークロードのお客様をサポートしています。
最終的に、お客様がより複雑で大規模なモデルを構築し始めると、CPUが提供するパフォーマンスでは不十分であることに気付きます。そこで、お客様はGPUによる高速化を検討し始めます。GPUを使用することで、お客様はコンピューティングをより効果的に並列化し、パフォーマンスとコストを最適化することができます。AWSでは、お客様のAI/MLワークロードを加速するための、様々な種類のNVIDIA GPUを幅広く提供しています。ただし、これらのGPUは、グラフィックスレンダリング、ビデオトランスコーディング、HPCワークロードなど、他のタイプのワークロードにもハードウェア最適化を提供するため、依然としてある程度汎用的な計算装置と言えます。そこで、カスタムAIアクセラレータを使用することで、さらなるコスト最適化とパフォーマンス向上を実現できます。これらは特にAIワークロード向けに設計されており、シリコンレベルで設計者がAIワークロードのパフォーマンスを最適化するためのアーキテクチャ上の決定を行っています。
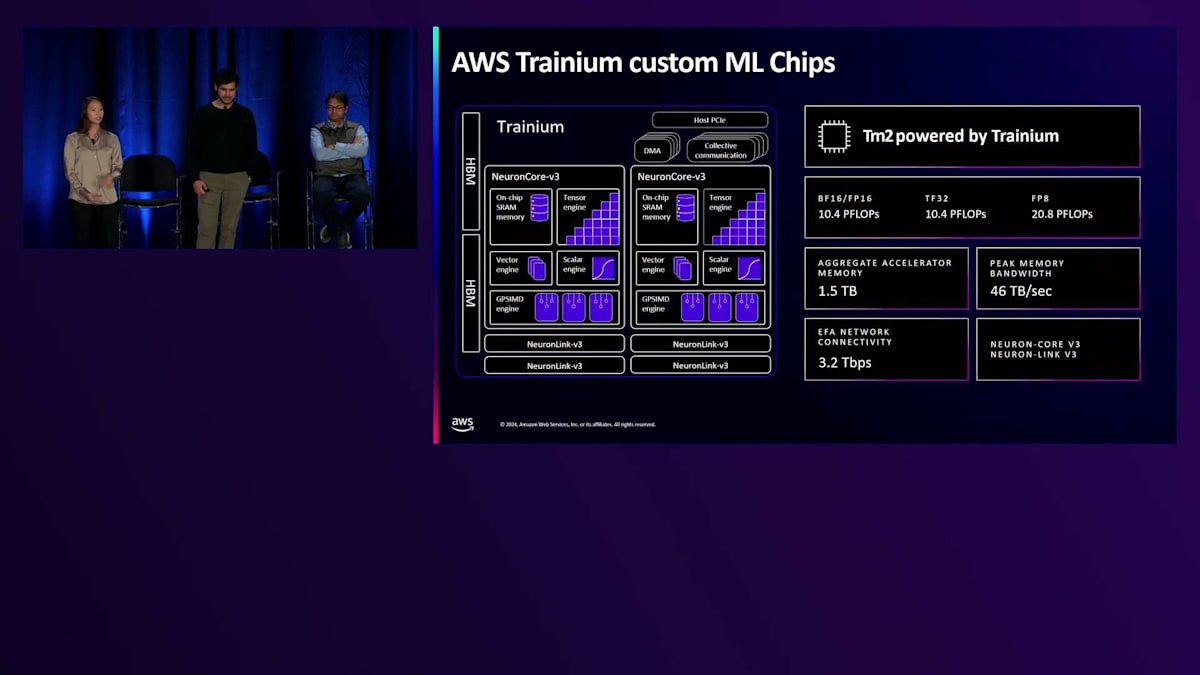
私たちは、自社開発のAWS InferentiaとTrainiumチップ、そしてIntelとQualcommの両社が提供するAIアクセラレータなど、AIワークロード向けの様々なタイプのAIアクセラレータをサポートしています。 ここで、カスタムAIアクセラレータの例として、AWS Trainiumチップを見てみましょう。今朝、私たちはTrainium 2チップを搭載したTrn2インスタンスの一般提供を発表しました。これらのアクセラレータは、最低コストで最高のMLパフォーマンスをお客様に提供するために特別に設計されています。これらは、テンサー、ベクトル、スカラー、および汎用シングルインストラクションマルチデータエンジンを含む、AIワークロードを強化するように特別に設計されたNeuronコアを使用して構築されています。
これらのインスタンスは、AI分野で私たちが目にしているトレンドを活用し、お客様のニーズに対応するために構築されました。モデルサイズは拡大傾向にあり、お客様はアクセラレータに十分なメモリを確保し、最高のパフォーマンスを提供するための十分なメモリ帯域幅を確保することに、より注力しています。そのため、Trainium 2アクセラレータは、アクセラレータあたり96ギガバイトのメモリを搭載して構築されています。16個のアクセラレータを搭載した単一サーバーで、46テラビット/秒のメモリ帯域幅で最大1.5テラバイトの集約高帯域幅メモリを実現できます。さらに、Neuron Link技術を改良し、単一インスタンス内のアクセラレータ間で最大1.5テラバイト/秒の相互接続を実現し、複数のアクセラレータにまたがる大規模モデルのパフォーマンスを最適化できるようにしました。


アクセラレータ層について説明したので、次はアーキテクチャの上層に移動して、スイッチング層にある構成要素について説明しましょう。スイッチング層について、まずネットワーキングについて説明し、その後ストレージについて説明します。私たちの高速コンピューティングインスタンスは、一般的にポートフォリオ内で最高のインスタンスネットワーキングを特徴としています。このような大規模なネットワーキングを提供しているのは、お客様が数百から数千のインスタンスにワークロードをスケールアウトすることを知っているからです。数年前、Amazonでは、これらの要件を満たすスケーラブルで効率的、かつ信頼性の高いネットワークプロトコルをどのように設計すべきかという問いを立てました。その結果、これらのインスタンスのネットワークインターフェースであるElastic Fabric Adapterの基盤となるSRDプロトコルを設計しました。
今日はSRDの2つの機能についてお話しします。1つ目は適応型マルチパスルーティングです。SRDは実際に、あるインスタンスから別のインスタンスに到達するために、ネットワークファブリック内の複数のルートにパケットを分散します。各パスのネットワークの往復遅延を測定し、特定のエリアで輻輳を検知した場合にパケットの経路を変更し始めます。輻輳はワークロードを大幅に遅くする可能性があるため、この機能は分散ワークロードの一貫した高パフォーマンスを確保するのに役立ちます。もう1つの機能は、パケットの順序外処理です。従来のHPCプロトコルでは、パケットが順序通りに到着する必要があり、ネットワークでパケットをドロップした場合、その回復のために多くのパケットを再送信する必要がありました。これはP99レイテンシーに影響を与えます。なぜなら、時折パケットをドロップすると、すべてのパケットを再送信して回復するのにかなりの時間がかかるからです。EFAは実際に、パケットを処理するNitroカードを通じて、ハードウェアレベルでパケットを順序外で処理できるため、P99レイテンシーを大幅に改善し、スケールでより一貫したパフォーマンスを提供できます。

では、なぜこれらのことが機械学習のワークロードにとってそれほど重要なのでしょうか? インスタンスのネットワーキングが重要である理由について、簡単に説明させていただきます。例えばMetaのLlama 45Bモデルを例に取ると、FP16データ型を使用した場合、パラメータ1つあたり2バイトのメモリが必要になります。つまり、45Bに2を掛けると90ギガバイトのメモリが必要になります。最もメモリ容量の大きいGPUでも1台あたり140ギガバイトまでしか搭載できないため、1台のGPUにモデル全体を収めることができず、複数のGPUに分散させる必要があり、さらには複数のインスタンスにまたがることもあります。トレーニング時には通常、データセットも複数のGPUに分散させるため、クラスター内の各GPUは常にモデルの一部とデータセットの一部を処理することになります。これは、GPUが定期的にデータを共有する必要があることを意味します。
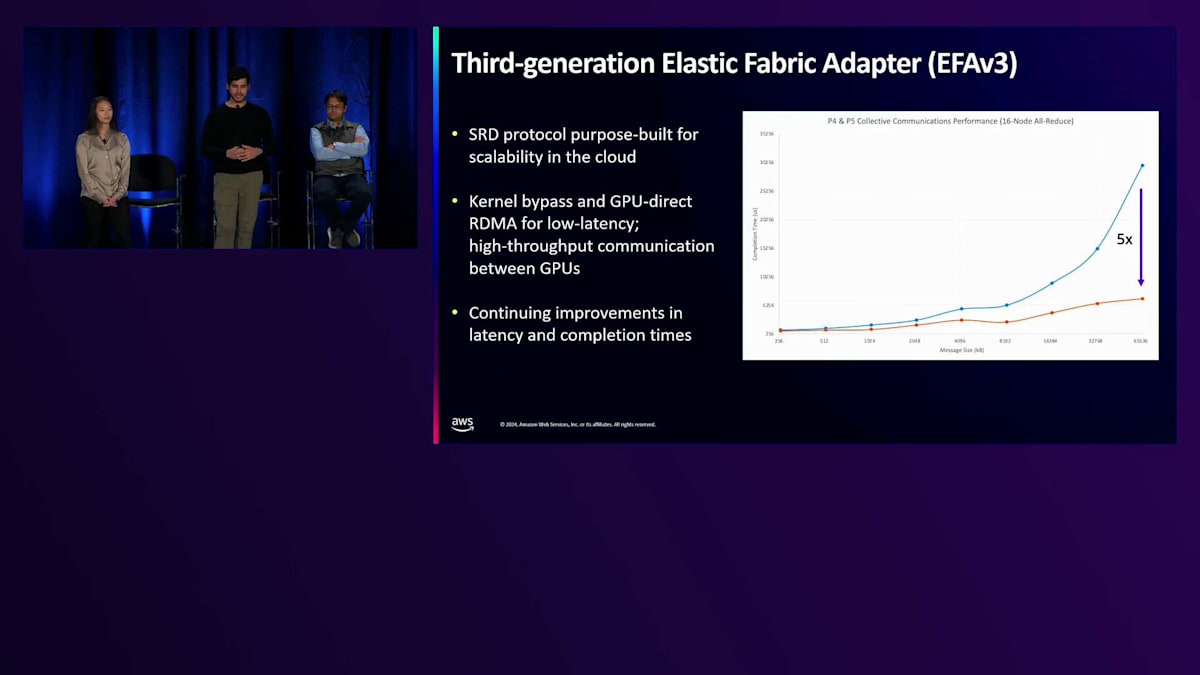
高帯域・低レイテンシーで情報を定期的に共有し、勾配を同期させる必要があります。各GPUがモデルの更新されたコピーを持ち、トレーニングを継続できるようにするためです。そのため、GPU間の帯域幅とレイテンシーの最適化が非常に重要になります。P5インスタンスをリリースした際には、Collective通信の完了時間を5倍以上改善し、大規模な分散トレーニングのパフォーマンスを向上させました。昨日発表した新しいP5nインスタンスでは、一般的なCollective処理のレイテンシーと完了時間をさらに改善しており、お客様がより効率的に大規模なトレーニングを実施できるよう、継続的なイノベーションを行っています。
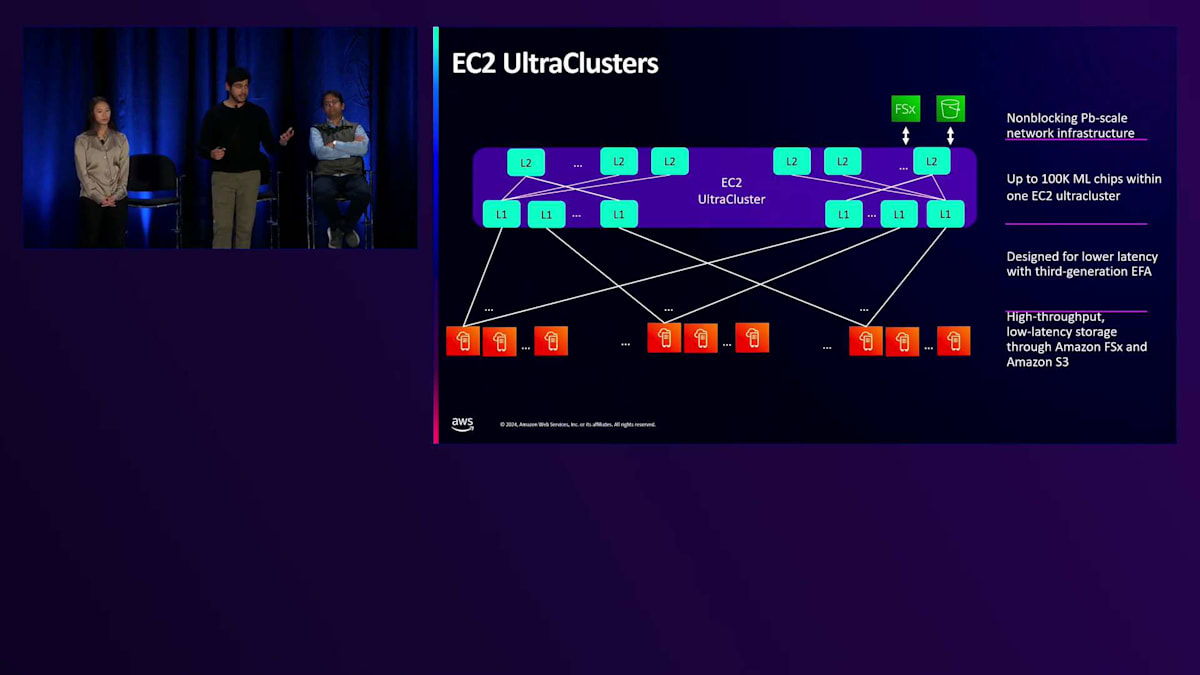
EFAインスタンスは通常、EC2 UltraClustersにデプロイされます。これは、データセンターでノンブロッキングのネットワークインフラストラクチャを表す用語です。ノンブロッキングとは、ネットワークをオーバーサブスクライブすることなく、すべてのインスタンスで持続的にピークのネットワーキングパフォーマンスを実現できることを意味し、これは大規模な分散ワークロードにおいて重要です。私たちはUltraClustersの規模を拡大し続けており、次世代のトレーニングワークロードのために数十万個のアクセラレーターをサポートする予定です。UltraClustersはまた、Amazon S3やFSxなどのストレージへの効率的なアクセスを提供し、今週初めには、EFAを通じて直接FSxにアクセスできるようになり、ストレージへの高性能なアクセスが可能になりました。

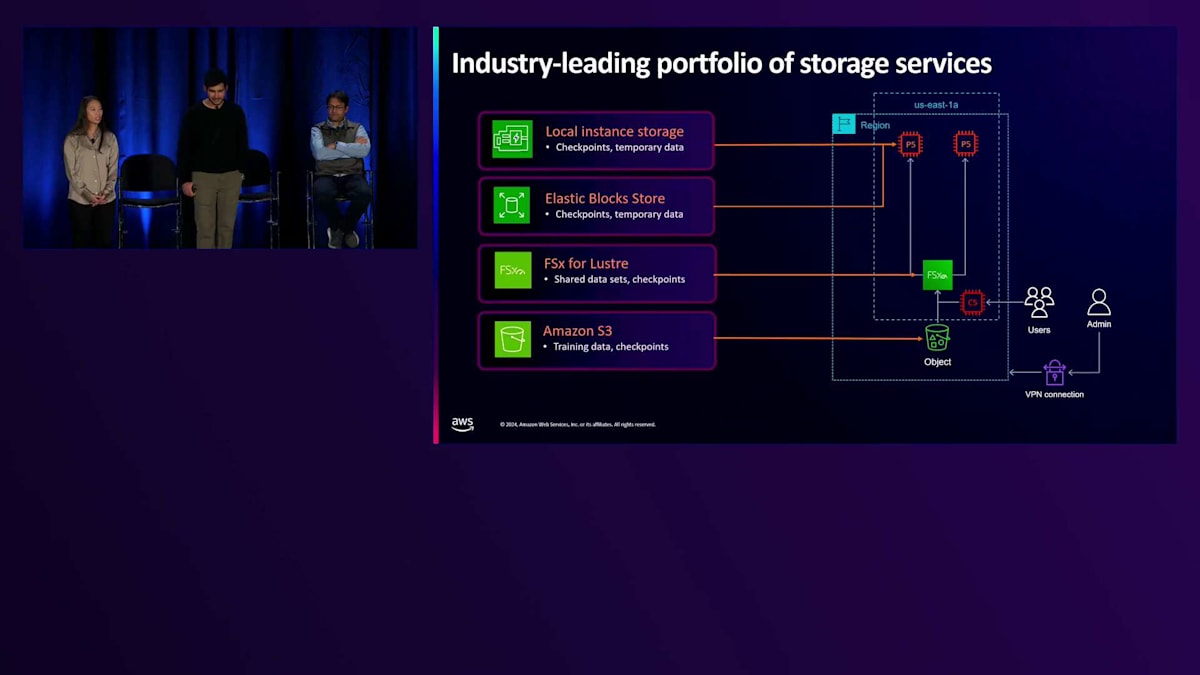
ストレージオプションについてもう少し詳しくお話ししましょう。お客様は、トレーニングクラスター内や、エンドユーザーをサポートするためにグローバルにデプロイされた本番インフラストラクチャ内で、大量のデータにアクセスする必要があります。そのため、データを最適な方法で保存することが非常に重要になります。AWSは、オブジェクトからブロック、ファイルシステムまで、さまざまなタイプのファイルに対応した最も包括的なストレージサービスを提供しています。実際のお客様の様々な機械学習ワークロードでの使用状況を見てみると、一時データやチェックポイントデータには、ローカルストレージを使用しているケースが見られます。これは、アクセラレーターと同じインスタンス上にあるSSDを使用する、コンピュートに最も近いストレージオプションです。ただし、インスタンスがシャットダウンまたは終了すると、このストレージは消えてしまう一時的なものです。そのため、お客様は一時データやチェックポイントにのみ使用し、トレーニングジョブの途中でエラーが発生した場合でも、最初からやり直す必要がないようにしています。
チェックポイントや一時データに使用されるもう一つのサービスがAmazon EBSです。EBSは生のブロックレベルのストレージオプションを提供し、これらのボリュームを複数の異なるEC2インスタンスにアタッチできるため、クラスター内の異なるインスタンス間で同じデータを簡単に共有できます。また、高度にスケーラブルなオブジェクトストレージシステムであるAmazon S3も提供しており、ここではペタバイト規模の大規模なデータセットを保存するお客様が多く見られます。ストレージサービスから最高のパフォーマンスを得たいお客様には、高性能な完全マネージド型ファイルシステムであるFSx for Lustreをご利用いただいています。先週お伝えしたように、現在ではEFAとNVIDIA GPU Direct Storageをサポートしており、データストレージをアクセラレーターメモリに直接接続することで、ストレージからアクセラレーターへのアクセスが高速化されました。これにより、お客様はファイルストレージシステムからアクセラレーターまで、最大1.2テラバイト/秒のスループットを実現できます。
AWSのGenerative AIスタックとサービス:SageMakerからBedrockまで


次に、Acceleratorレイヤーとスイッチングレイヤーの両方のコンポーネントについて説明してきましたが、ここではHostレイヤーのコンポーネントについて説明します。 先ほど述べたように、Hostレイヤーには、実際にインスタンスをホストしてSSH接続するCPUがあります。また、Hostレイヤーにはコンピュート環境のセキュリティを確保するNitroカードも搭載されています。ここで、Generative AIにおいてセキュリティが重要である理由について説明しましょう。 一般的なGenerative AIアプリケーションは、興味深いマルチパーティの相互作用です。モデルとやり取りをするエンドユーザーがいて、プロンプトを送信してレスポンスを受け取り、個人データを共有する可能性があるため、そのチャネルの機密性を確保する必要があります。また、モデルの開発に多大な投資をしているモデルプロバイダーは、知的財産とモデルの重みを常に安全に保つ必要があります。
時には、既製のモデルを特定の独自データセットで Fine-tuning した第三者が存在する場合もあります。その場合、データセットとFine-tuningされた重みの安全性も確保する必要があります。さらに、インフラストラクチャプロバイダーとしてのAmazonは、アプリケーションを実現するための基盤となるコンピュートを提供しています。

3つの機能について説明し、1つのユースケースを見ていきましょう。機能の1つは、No operator accessまたはZero operator accessと呼ばれるもので、これはNitroカード、Nitroセキュリティチップ、Nitroハイパーバイザーという3つのコンポーネントを含むAWS Nitro Systemのすべてのコンポーネントを構築する際の基本設計原則です。 これは、AmazonのオペレーターがインスタンスにSSHやアクセスする仕組みが一切ないことを意味し、これによってコンピュートレイヤーのセキュリティを確保しています。また、VPC暗号化などのサービスも提供しています。先ほどEFAについて説明しましたが、すべてのEFAトラフィックはデフォルトで暗号化されており、インスタンス間の情報も暗号化されています。Amazon KMSなどのサービスを使用してデータを保存時に暗号化することもでき、エンドユーザーからデータ、ネットワーク、コンピュートに至るまで、信号チェーンのあらゆる側面のセキュリティを確保するための様々な基盤を提供しています。

アプリケーションが信頼できる環境で実行されているという追加の保証をエンドユーザーに提供したい場合のユースケースを簡単に説明しましょう。これは、デプロイするコードを測定できるNitroTPMを使用して実装できます。例えば、インスタンスとの対話やアクセスが一切できないHermeticコードをデプロイする場合、NitroTPMはコードを測定し、既知の正常なコードの測定値と比較できます。コードの1行でも、コードベースの1文字でも変更されると、そのハッシュ関数の出力が変更され、第三者にコードが変更されたことを通知できます。これを使用することで、アプリケーションが常に信頼できる環境で実行されているという、さらなる保証を顧客に提供できます。

セキュリティやその他の機能について一般的な説明をしてきましたが、ここでインスタンスポートフォリオと、様々なユースケースに対応する異なるオファリングについて詳しく見ていきましょう。 先ほど説明したコンピュートアーキテクチャ内の様々なコンポーネントを異なる方法でパッケージ化し、顧客が特定のワークロードに対して最高のパフォーマンスとコストを実現できるよう、幅広いインスタンスタイプのポートフォリオを提供しています。これらの異なるタイプのインスタンスには、2つの大きな分類があります。1つはカスタムAIアクセラレーターを搭載したインスタンスで、先ほど述べたように、InferentiaやTrainiumなどのAWS製アクセラレーター、そしてIntelやQualcommのAIアクセラレーターがあります。2つ目はGPU搭載インスタンスで、顧客が最低コストで適切なパフォーマンスを確保できるよう、様々なNVIDIA GPUから選択できるようになっています。

ハードウェアアクセラレーテッドポートフォリオの中の様々なインスタンスラインについてお話ししましょう。まずはGインスタンスからです。 GインスタンスはNVIDIAのGPUを搭載しており、エントリーレベルの開発者向けGPUから、NVIDIAの最高性能コンピューティング・グラフィックスGPUまで、計算処理とグラフィックス処理の両方に最適化されています。これらのインスタンスは、シングルGPUのワークロードを展開したいお客様に最適です。現行世代のGインスタンスには2つの異なるタイプがあり、まずG6インスタンスから見ていきましょう。これらのインスタンスはNVIDIA L4 GPUを搭載しており、24ギガバイトのGPUメモリを備えています。先ほど説明した計算方法を使うと、約120億パラメータまでのモデル、つまり比較的小規模なDiffusionベースの生成AIモデルを展開できることになります。より大規模なモデルタイプを展開したいお客様向けには、NVIDIA L40S GPUを搭載したG6eインスタンスをご用意しています。これらのGPUは1基あたり48ギガバイトと、2倍のGPUメモリを備えており、お客様は展開できるモデルのサイズを2倍にすることができます。
G6eではインスタンスメモリも2倍に増やし、最大1.5テラバイトのインスタンスメモリを提供しています。さらにネットワーク帯域幅も4倍に増やし、最大400ギガビット/秒の帯域幅を実現しています。G6とG6eインスタンスはどちらも8つの異なるサイズで提供され、1~8基のGPUに、様々な量のvCPU、メモリ、ネットワーク帯域幅、ローカルストレージが組み合わされています。これにより、お客様は必要なリソースを過不足なく確保でき、本番環境へのモデル展開時のコスト最適化を実現できます。
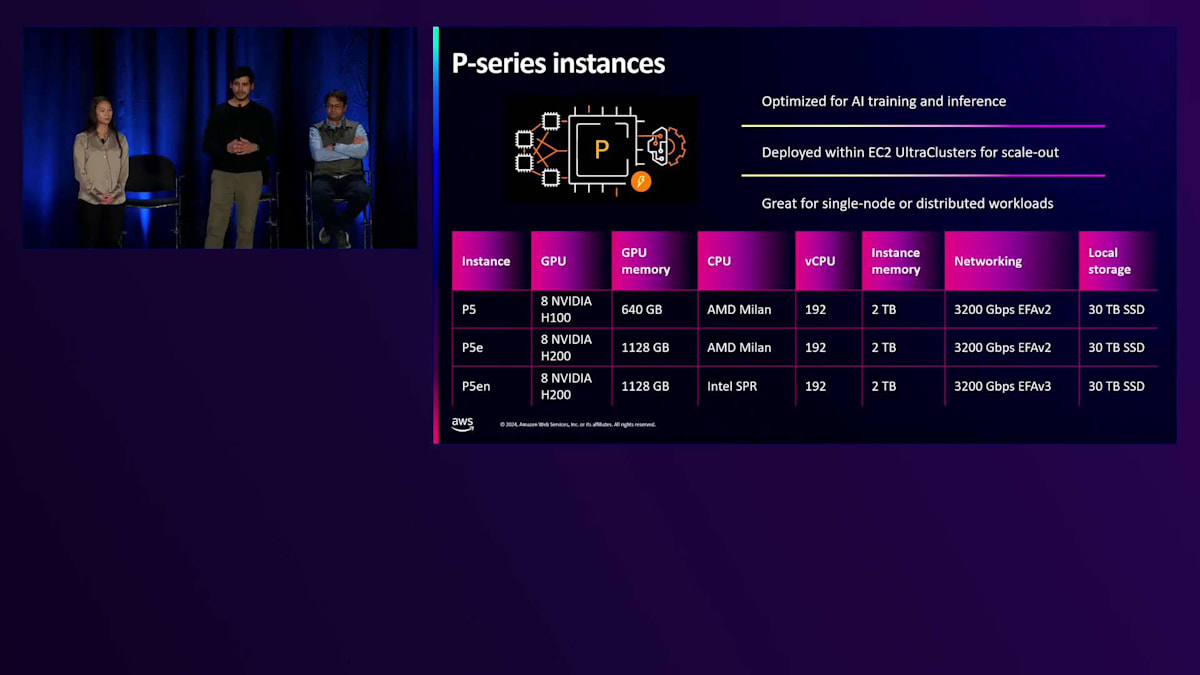
P-seriesインスタンスは大規模な分散トレーニングワークロード向けに特別に設計されていますが、LLMの推論にも非常に有用です。P-seriesインスタンスの3つの特長についてお話しします。1つ目はNVLinkで、これはP3、P4、P5インスタンスに搭載されている高性能なチップ間相互接続です。例えばP5では、任意の2つのGPU間でマイクロ秒レベルの遅延で900ギガバイト/秒の通信が可能です。これにより、先ほど説明したように、インスタンス内での集合通信を最適化できます。2つ目の特長はEFAネットワーキングで、これらのインスタンスはEC2ポートフォリオ全体で最高の3200ギガビット/秒のEFAネットワーキングを実現しています。昨日発表されたP5enでは、EFAネットワーキングをさらに最適化し、NICの使用率を向上させ、NICの遅延を低減することで、分散トレーニングのパフォーマンスを向上させています。

最後に、GPUそのものについてお話ししましょう。これらのインスタンスにはNVIDIAの最高性能GPUが搭載されています。P5では、H100とH200 GPUを搭載したHopperアーキテクチャを採用しています。これらのGPUはそれぞれ最大140ギガバイトのメモリを備えており、1つのインスタンス内で1テラバイト以上のGPUメモリを利用できます。つまり、Llamaの45Bモデルを推論用にP5enインスタンス内に余裕を持って収めることができるのです。 また、私たちはNVIDIAのBlackwell GPUについても密接に協力しており、GB200には特に期待を寄せています。GB200は、アクセラレーテッドコンピューティングにおいて新しいパラダイムを確立します。1つのNVLinkドメイン内で最大72基のGPUにアクセスできるのです。これはP4やP5の8基と比べると大きな進歩です。つまり、お客様は13テラバイト以上のGPUメモリと180ペタフロップスのFP16演算性能を1つのコンピュートドメイン内で利用でき、数兆パラメータ規模のモデルのトレーニングと推論をすぐに実行できます。
GB200についてさらに2点お話しします。1つ目は、NVIDIAのスーパーチップアーキテクチャで、CPUとGPUが1つのコンピュートモジュール内に統合されています。これにより、CPUコアとGPUコアを並列で使用できる次世代の機械学習ワークロードのための真の異種混合コンピューティングを実現します。もう1つの特長は、BlackwellがAmazonで初めての液冷プラットフォームになるということです。私たちはBlackwellをグローバルに展開するために、液冷インフラのスケーリングに注力しています。液冷により、GPU1基あたりのパフォーマンスをさらに向上させることができ、結果としてワークロードの性能が向上します。
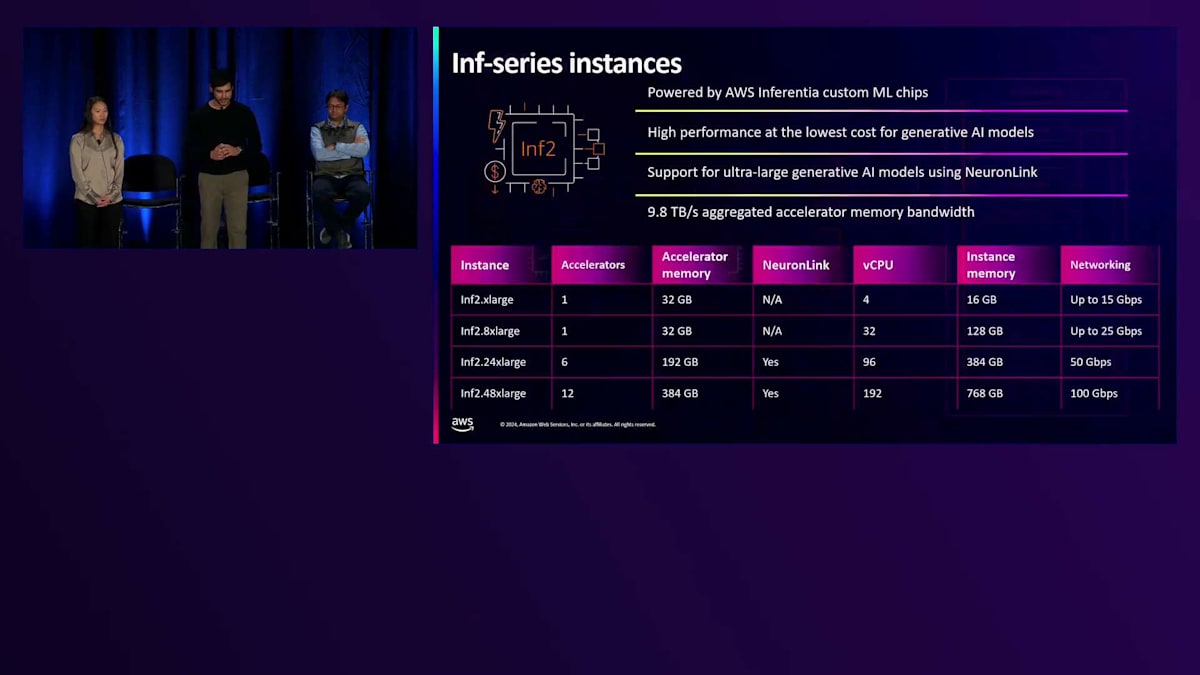
ここまでGPUインスタンスについてお話ししてきましたが、次はカスタムシリコンインスタンスについて見ていきましょう。まずは、AWS InferentiaカスタムMLチップを搭載したInf-seriesインスタンスについてお話しします。Inf1は2019年のre:Inventで初めて発表され、その後Inf2が登場しました。Inf2では、Inferentiaチップだけでなく、インスタンスタイプ全体の設計を改良し、Inf1と比べて4倍のスループットと10分の1のレイテンシーを実現しました。Inf2は、お客様の生成AIモデルのデプロイにおいて、最高のパフォーマンスと最低のコストを提供します。Gインスタンスと同様に、Inf2も16個または12個のアクセラレータを搭載する複数のインスタンスサイズをご用意しており、お客様のワークロードに最適なリソース量を選択できます。Inferentia 2チップは、アクセラレータあたり32ギガバイトのメモリを搭載し、さらにNeuronLinkで相互接続されているため、お客様は10テラバイト/秒の集約メモリ帯域幅を利用できます。これにより、お客様は単一のInferentia 2インスタンスで、最大1,750億パラメータのモデルをデプロイすることが可能になりました。では、トレーニングの側面に移りましょう。
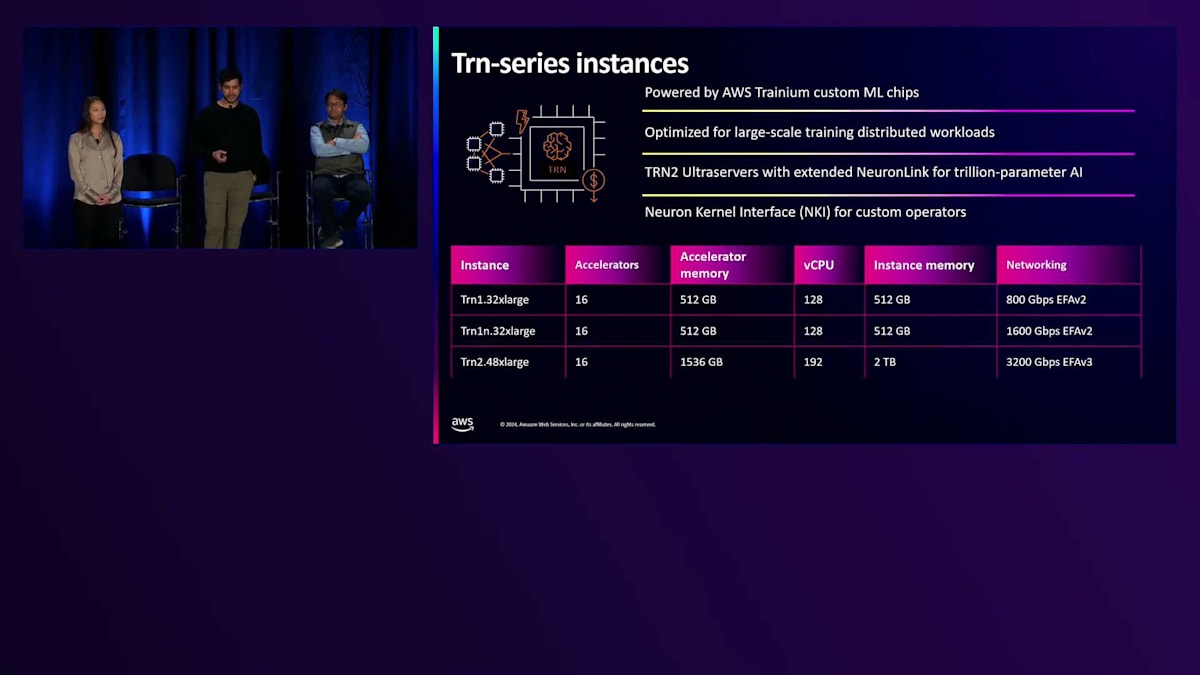
トレーニングインスタンスは、トレーニングワークロード専用に設計されています。昨日、私たちは最大40%のコストパフォーマンス向上を実現し、ポートフォリオ全体で最高のパフォーマンスを提供するTrn2の一般提供開始を発表できたことを大変嬉しく思います。各Trn2インスタンスには、NeuronLink経由で接続された16個のアクセラレータが搭載され、1テラバイト以上のアクセラレータメモリを備えています。これらのインスタンスは、最適なスケールアウトのために3,200ギガビット/秒のEFAv3も特徴としています。さらに、業界最大規模のモデルのトレーニングと推論に対応する5テラバイト以上のアクセラレータメモリを提供する、最大64個のトレーニングアクセラレータを1つのコンピュートドメインに接続するTrn2 Ultraserversのプレビュー版も発表できたことを嬉しく思います。
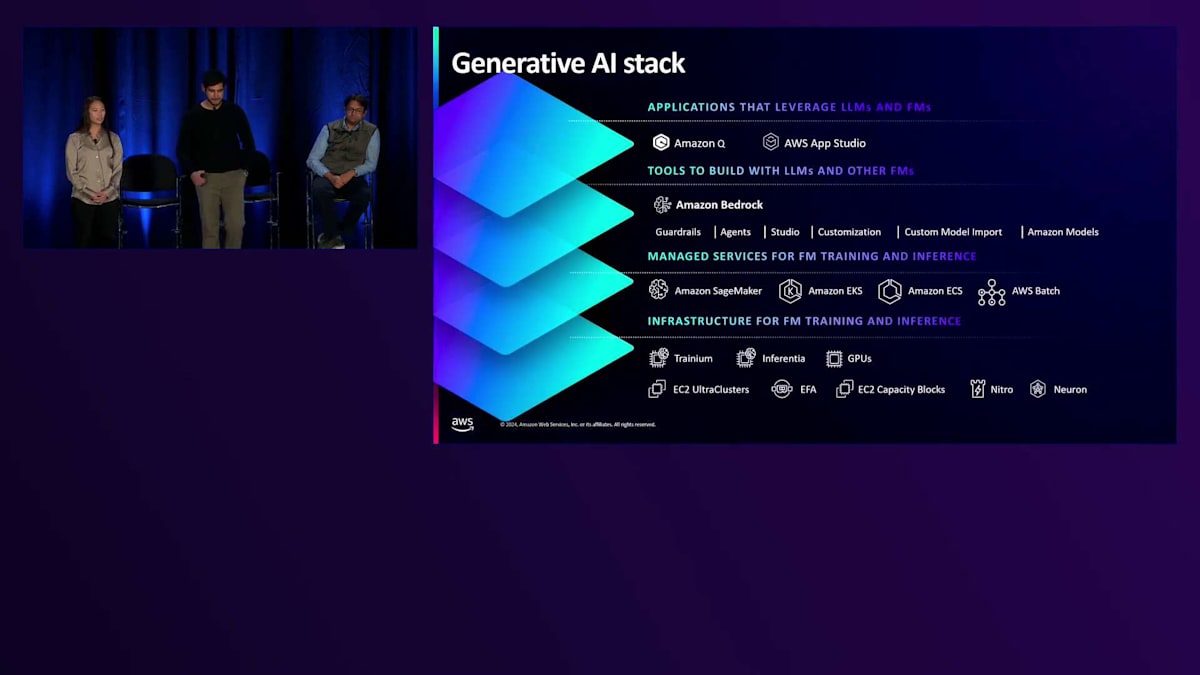
EC2の機能とインスタンスポートフォリオについて説明してきましたが、ここからは生成AIスタックと、このコンピュートリソースをお客様にとってより使いやすくする方法について説明します。生成AIテクノロジースタックの最下層には、先ほど詳しく説明したインフラストラクチャ層があります。その上には、Amazon SageMakerやAmazon EKSなど、お客様がモデルのトレーニングやデプロイ、インフラストラクチャの管理に使用できるマネージドサービスとオーケストレーションシステムがあります。その上の層には、Amazon Bedrockのような、インフラストラクチャ層を抽象化するツールがあります。これは業界をリードするFoundation Modelにアクセスし、生成AIモデルを本番環境にデプロイできるサーバーレスサービスです。テクノロジースタックの最上位層には、AIショッピングアシスタントのRufus、ビジネス生産性向上のためのAmazon Q、よりインテリジェントなAlexaなど、Foundation Modelを統合した既存のアプリケーションが含まれています。
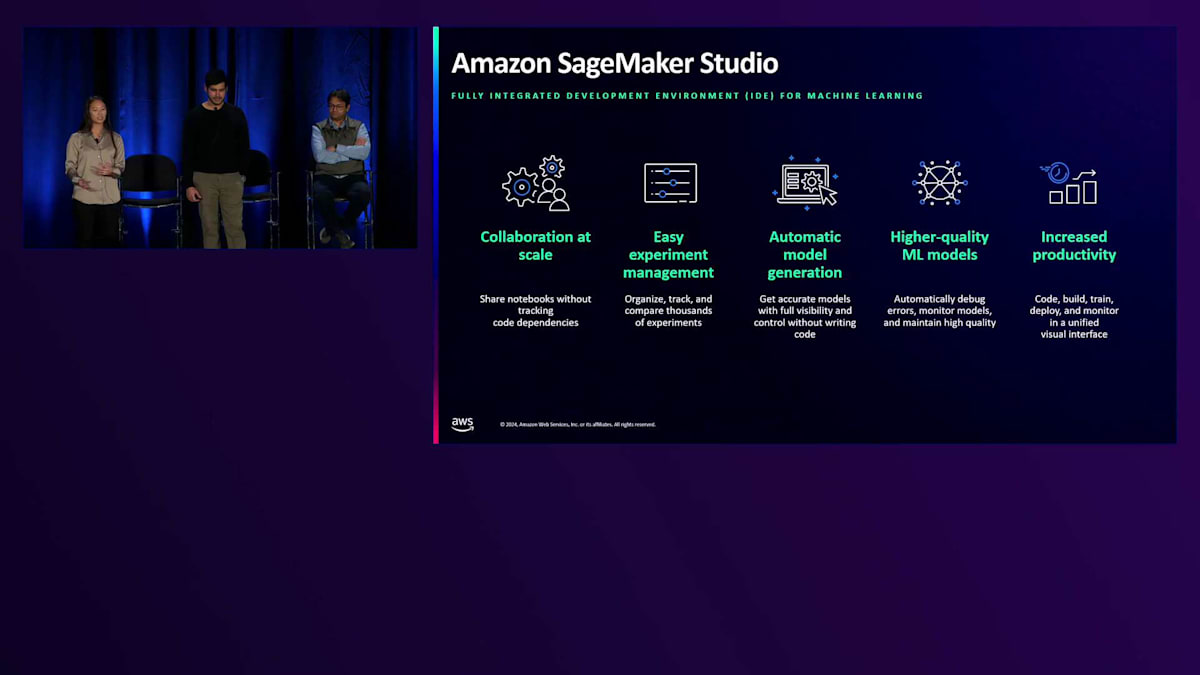
テクノロジースタックの中から、具体的な2つのサービスを見ていきましょう。まずはSageMakerです。Amazon SageMakerは、データサイエンティストやMLエンジニアがAIトレーニングのためのデータ準備、モデルのトレーニング、本番環境へのデプロイを行うためのエンドツーエンドのマネージドサービスを提供します。特にAmazon SageMaker Studioは、トレーニングジョブを開始する前のデータクレンジング、エンリッチメント、エラー検出のためのスケーラブルなツールを提供し、お客様のモデル開発をサポートします。今朝、私たちはMLサイエンティスト間のコラボレーションを強化し、より迅速な構築を可能にする次世代のSageMaker StudioであるAmazon SageMaker United Studioのプレビューを発表しました。さらに、Amazon S3やAmazon Redshiftなどのサービス間でデータを統合し、データサイロを削減できるAmazon SageMaker Data Lake Houseの一般提供開始も発表しました。

Amazon SageMakerが提供するもう一つのサービスが、SageMaker for trainingです。これは、お客様がMLモデルのトレーニングやファインチューニングを行うためのマネージドサービスで、トレーニングジョブの管理・追跡、エラーのデバッグ、インフラストラクチャの使用状況のモニタリングを簡単に行うことができます。SageMaker trainingは、トレーニングコストを最適化するため、1個のGPUから数百個のGPUまで自動的にスケールします。SageMakerの分散トレーニングライブラリを使用すると、お客様はモデルとトレーニングデータセットをGPU間で自動的に分割でき、トレーニングジョブを最大40%高速化することができます。


次に、Amazon Bedrockについてお話ししましょう。多くのお客様にとって、モデルを一からプリトレーニングすることにはあまり価値がありません。Llamaのようなすぐに使えるオプションは非常に高性能なので、これらのモデルの1つを選んで特定のデータセットでファインチューニングし、すぐに本番環境にデプロイする方が理にかなっています。私たちは昨年、このような体験のあらゆる面を簡素化するためにAmazon Bedrockをローンチしました。 専用のAPIセットを通じて、BedrockではAI21 Labs、Anthropic、Cohere、Metaなどのプロバイダーが提供する様々なモデルから選択することができ、これらのモデルの1つを選んでBedrockを使えば数分で稼働させることができます。
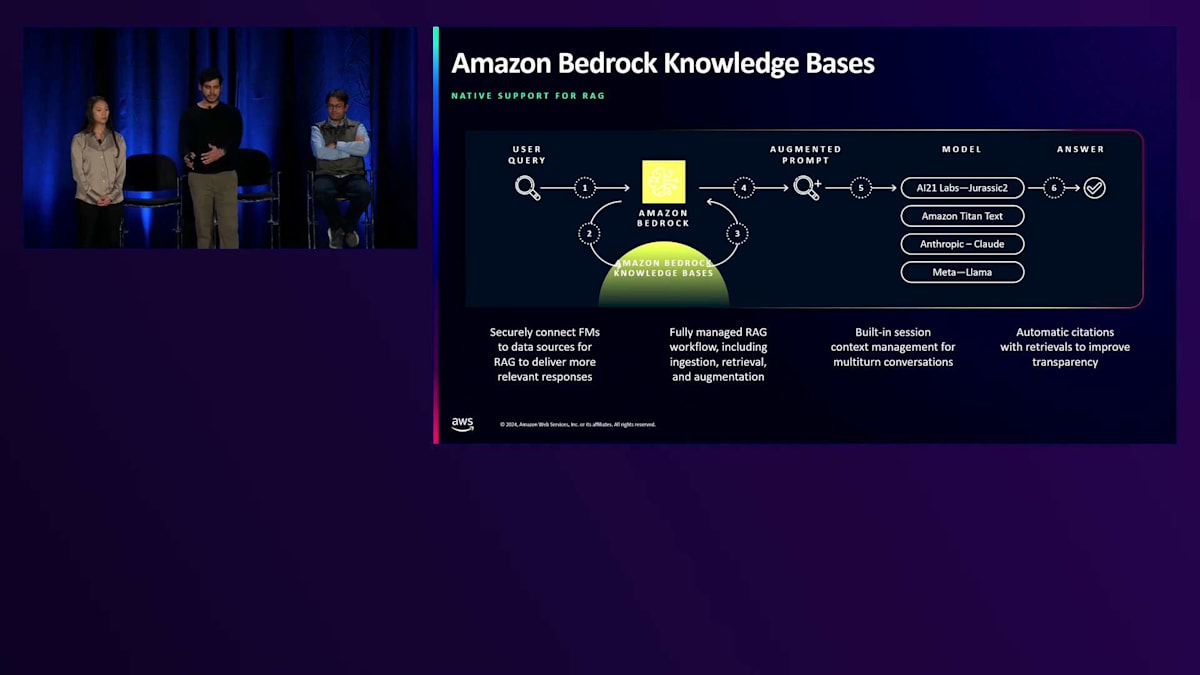
Bedrockでは、新しいテクニックや推論を一から実装することなく利用することもできます。その一例が検索拡張生成で、ユーザーのプロンプトを受け取り、 推論のためにモデルに渡す前に追加のコンテキストで補完します。これにより、モデルはすべての異なるコンポーネントをパイプラインに組み立てる必要がなく、追加のコンテキストを持っているため、より意味のある関連性の高い応答を提供できます。Amazon Bedrockのナレッジベースは、これをすぐに稼働させるためのエンドツーエンドのソリューションを提供します。
MetaのWearables AIチームによるRay-Ban Metaの開発:AWSを活用したマルチモーダルAIの構築

これまで、業界とユースケース、そしてAWSとGenerative AIスタックで提供している機能について多く話してきました。では、お客様がこれらをどのように活用しているのか見ていきましょう。ここでMetaでのチームの取り組みについてもう少し詳しく伺えればと思います。SamanthaとDvijさん、AWSの機能について素晴らしい概要説明をありがとうございました。私たちは日々AWSを使用していますが、すべてが1つのプレゼンテーションにまとまっているのを見るのは本当に素晴らしいことでした。 これからMetaでのAWSの活用方法についてお話しさせていただきます。私はKirmani Ahmedで、MetaのWearables AIチームを代表してここでお話しできることを光栄に思います。今日お話ししたい内容は、AWSとMetaがいかにして最も技術的に複雑な問題の1つを解決し、世界最高のウェアラブルAIデバイスをゼロから作り上げたかということです。



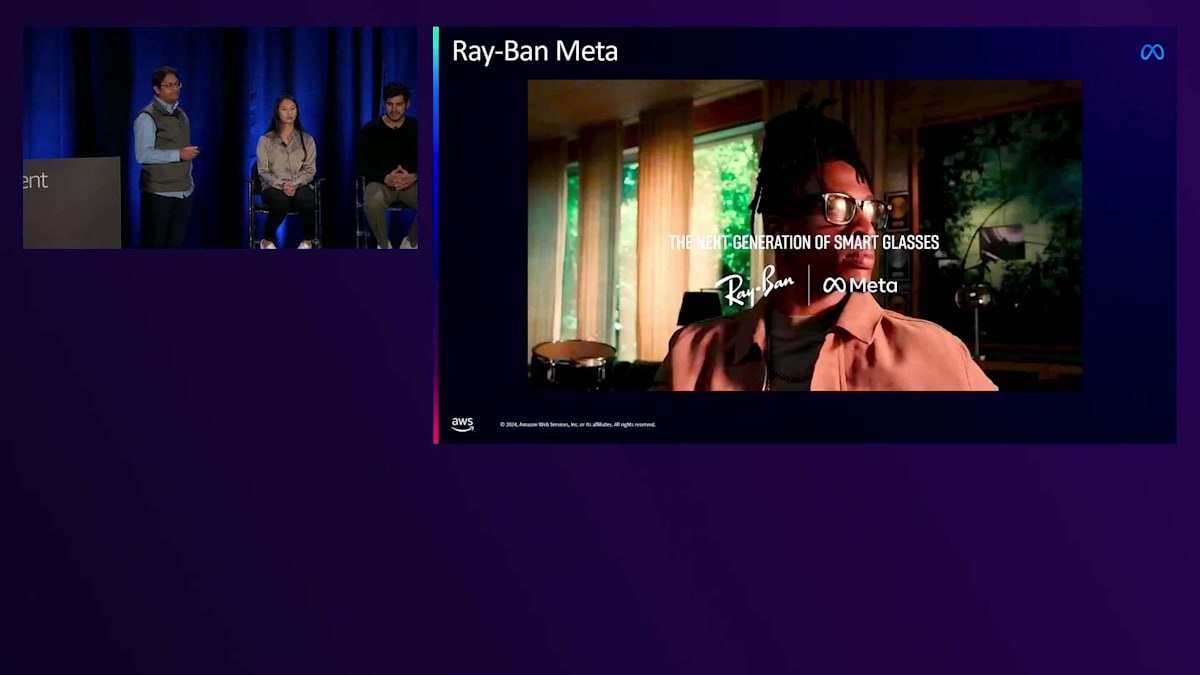



技術的な話に入る前に、製品のプレビューをお見せしましょう。Ray-Ban Metaをご紹介します。これは現在市場で購入できる最高のスマートグラスです。スマート機能を抜きにしても、まず第一に、MetaとRay-Banは見た目の良いメガネをデザインするためにパートナーシップを組みました。 クールな見た目に加えて、このメガネはスマートフォンではできない多くの機能を備えています。それらを簡単に見ていきましょう。 周囲の音を遮断することなく音楽を聴くことができ、自分の視点からライブストリーミングを配信し、作業の流れを中断することなく通話ができ、メガネから直接、あなたならではの視点を瞬時に撮影することができます。Ray-BanとMetaによる次世代スマートグラス、それがこの製品です。

ご覧の通り、このメガネを使えば、今この瞬間に存在し、やっていることに完全に没入して楽しむことができ、難しい作業はメガネに任せることができます。私がお見せした機能は素晴らしいものですが、今日このメガネで最も興奮させられる機能は、Meta AIを使用できることです。メガネを使ってMeta AIと会話すると、メガネは実際にあなたが見ているものを見て、聞いているものを聞き、目の前にあるすべてのものを翻訳・分析して、その瞬間のあなたの質問に対して可能な限り短時間で最適な回答を提供します。実際の使用例を少し見てみましょう。「Hey Meta、この建物を見て説明して」「これを見て翻訳して」「これを見て何を作ればいいか教えて」「この蝶の種類を教えて」「それはペインテッドレディーのようですね」。
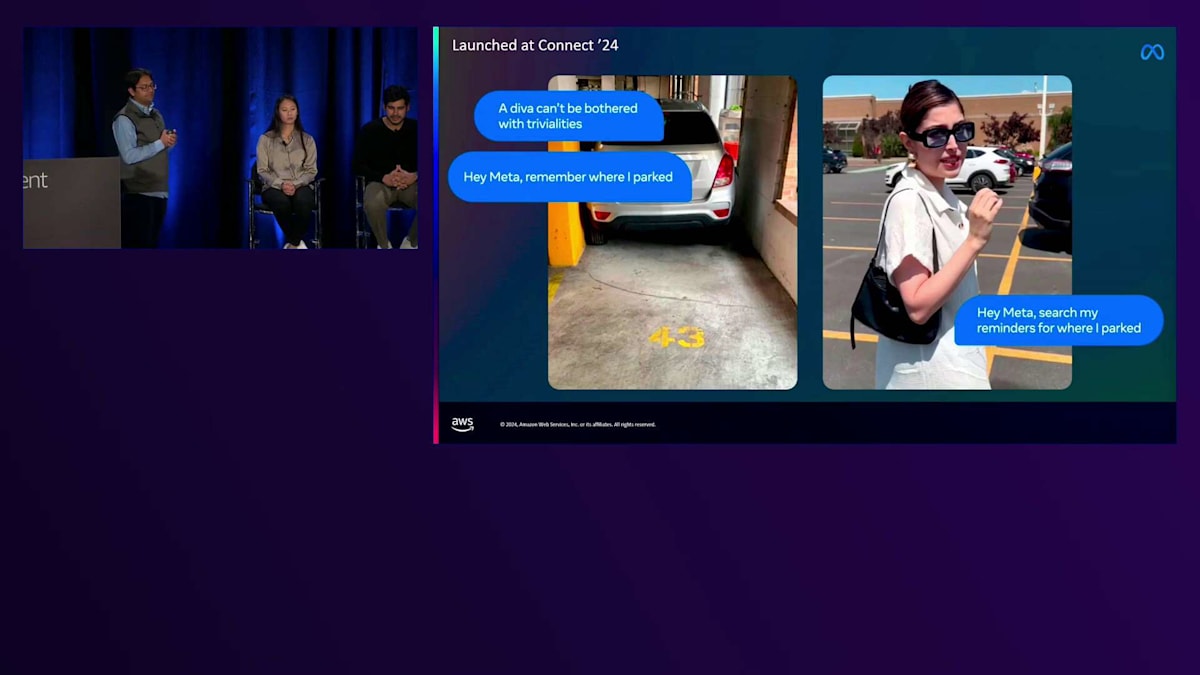

この Meta グラスは、ユーザーにとって AI の最も優れたユースケースの1つです。実際、このグラスは多くの店舗で通常の Ray-Ban よりも売れているほど人気があります。私たちは昨年の Connect 2023 でこのグラスを初めて発表した際に、多くの AI 機能を搭載して ローンチしました。そして、それ以降も数ヶ月ごとに新機能を追加してきています。例えば、Connect では Visual Reminders 機能をローンチしました。これにより、車を駐車した場所や鍵をなくした場所など、視覚的な情報を記憶することができます。 また、このグラスがユーザーに代わって行動することも可能になりました。例えば、電話番号をスキャンして自動的に発信したり、QR コードをスキャンしたりできます。これは、2024年以降に予定している長期的で魅力的な AI ロードマップの、ほんの始まりに過ぎません。

では、私たちはどのようにしてここまで辿り着いたのでしょうか。 それが今日お話ししたい内容です。私たちは目標を達成しただけでなく、非常に速いスピードで実現しました。ご存知の方もいるかもしれませんが、「速く動く」ことは Meta の核となる企業価値の1つです。では、実際にどれくらい速かったのでしょうか?一例をご紹介しましょう。Ray-Ban Meta の発売の数ヶ月前、私たちの CEO の Mark が運転中に Augmented Reality 担当の Vice President に電話をかけてきました。土曜日に子供たちと高速道路を運転中だった彼は、「数ヶ月後に発売予定のそのグラスに Meta AI を搭載して、良いアイデアかどうか試してみることはできないか」と言ったのです。これは文字通り、発売のわずか数ヶ月前の出来事でした。
その電話以来、チーム全体が Meta とスマートグラスのために結集し、そして残りはご存知の通りです。


では、このスマートグラス向けの Meta AI をどのように構築したのか、詳しく説明していきましょう。 すべては Llama から始まります。Llama はオープンソースモデルファミリーの先駆者であり、オープンソース AI イノベーションにおける革命的な存在です。私たちは過去18ヶ月で3世代のモデルをリリースし、各世代は前世代をはるかに上回る性能を実現しています。これまでに3億5000万回ダウンロードされ、先月だけでも2000万回のダウンロードがありました。そして、関連するクラウドやビジネスを大きく加速させています。 前年比で10倍の成長を達成しています。

技術的な詳細に入る前に、Llama が実際にどのようなものなのか簡単におさらいしましょう。Llama は他の大規模言語モデルと同様に、テキストを理解し生成することができます。24,000個の GPU を使用して、約15兆のトークンのテキストでトレーニングされています。これが私たちのフラッグシップモデルであり、GPU あたり約400テラフロップスの計算能力で、このモデルのトレーニングには膨大な計算リソースが投入されました。 このモデルは非常に高性能で多くのタスクをこなすことができますが、画像や音声を理解することはできず、ユーザーが見ているものや聞いているものを認識することはできません。

私たちがスマートグラスで Llama の実験を始めた時に欠けていたのがそれでした。ユーザーが見ているものを理解させる必要があり、急いでマルチモーダル化する必要がありました。直感に反するかもしれませんが、マルチモーダル Large Language Model のトレーニングは、ゼロから始める必要があるように思えるかもしれません。しかし、ここで重要な発見により、私たちは迅速に進めることができました。Vision Encoder や Image Encoder と呼ばれる別のAIモデル、つまりビジョンモデルを使用して、入力画像を基本の Llama が本来理解できるトークンのセットに変換することができるのです。それでも、視覚的なコンテキストや知識を理解させ、視覚的なクエリに適切に答えられるようにするには、かなりの量のデータでトレーニングする必要がありました。

興味深いことに、実験を始めた時に直面した課題は、モデルの構築方法に約12の選択肢があり、どれも良さそうに見えたのですが、私たちのユースケースにどれが最適なのか確信が持てなかったことです。この課題は、スマートグラスの入力が本質的にノイズの多い入力であることに起因します。スマートグラスでの使用は、キーパッドで入力する携帯電話やデスクトップでの Generative AI の使用とは大きく異なります。スマートグラスでは、多くのノイズがあり、音声も多く、信号とノイズを分離する必要があります。

そのため、スマートグラス用のマルチモーダルモデルを構築する必要があり、しかも迅速に構築する必要がありました。ここで AWS が重要な役割を果たしました。AWS は私たちの探索を洞察に変える上で不可欠でした。クラウドコンピューティングを検討する際、3つの重要な要素がありました:高速なプロトタイピング能力(Amazon のベアメタルソフトウェアプラットフォームが、GitHub や Hugging Face のリポジトリを大規模なトレーニング実験に変換する上で非常に重要でした)、高い信頼性、そしてコスト効率です。大規模な並列実験を実行する必要があったからです。そしてAWS は、これら3つすべての要件を完璧に満たしてくれました。


では、マルチモーダルモデルをどのように構築したのか、AWS がどのような重要な役割を果たしたのかを順を追って説明しましょう。私たちのマルチモーダルのレシピは3つのパートからなります。まず、適切なアーキテクチャを選ぶためのプロトタイピングと実験を行いました。次に、反復と拡張が可能な十分な基本モデルをトレーニングする必要がありました。そして3番目の最も重要な課題は、必要な精度を得るためにそれを大幅に拡張することでした。

ステップ1:開始時点で、優れたマルチモーダル LLM となり得る選択肢が約12個ありました。しかし、それらは実際にはアーキテクチャファミリーに分類されました:Google Flamingo のようなクロスアテンション型アーキテクチャや、LLaVa のようなデコーダーオンリーアーキテクチャ(これは人気のあるオープンソースの選択肢の一つです)などです。数週間にわたって何百もの実験を並行して実行しました。それぞれの実験から、何が機能し何が機能しないかを学び、モデル構築に必要な計算品質のトレードオフについての洞察が得られました。ここでも AWS のソフトウェアスタックが、私たちの迅速な進行を支援してくれました。
最終的に、私たちはこれまでの学びを集約して、独自のアーキテクチャである「AnyMAL」を開発し、最近オープンソース化しました。AnyMAL(Any-Modality Augmented Language Model)というかなり特徴的な名前ですが、現存する最高の一人称視点マルチモーダルモデルと言えます。
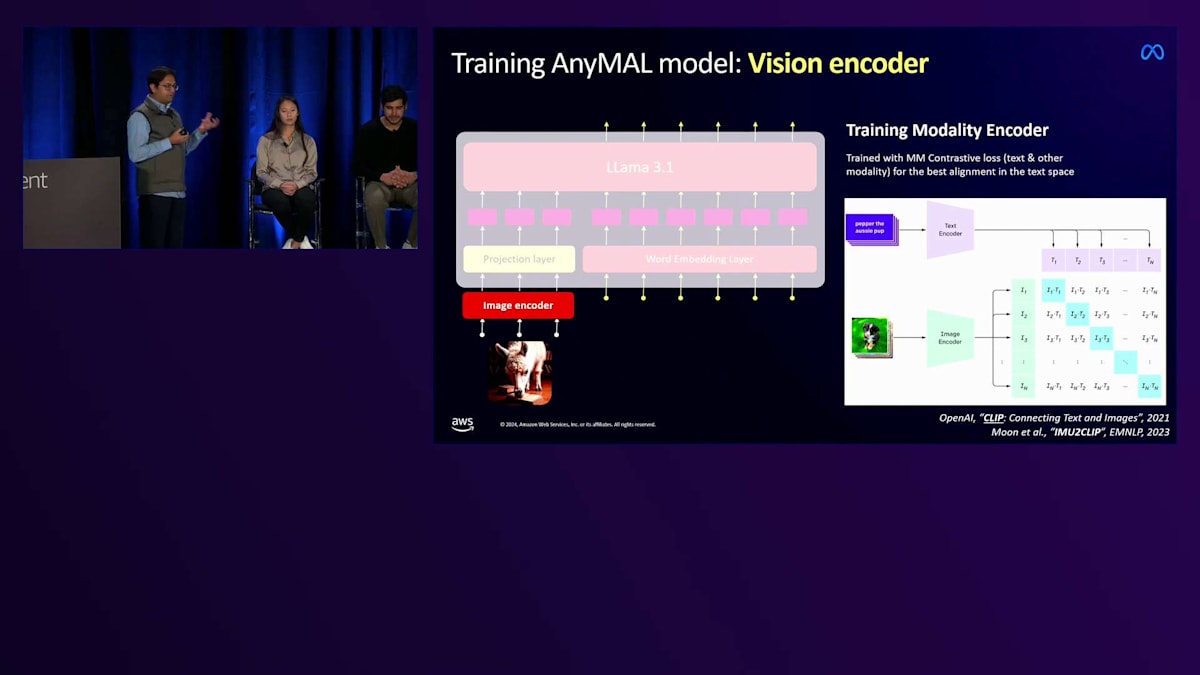
適切なアーキテクチャを選定した後の次のステップは、先ほど説明したような有能なベースモデルを訓練することでした。 このモデルは比較的小規模ではありますが、それでも数十億の画像を学習する必要があります。私たちはAWSを活用して訓練を迅速にスケールアップし、画像をLlamaが理解できる同じ表現空間に変換できるモデルを訓練しました。
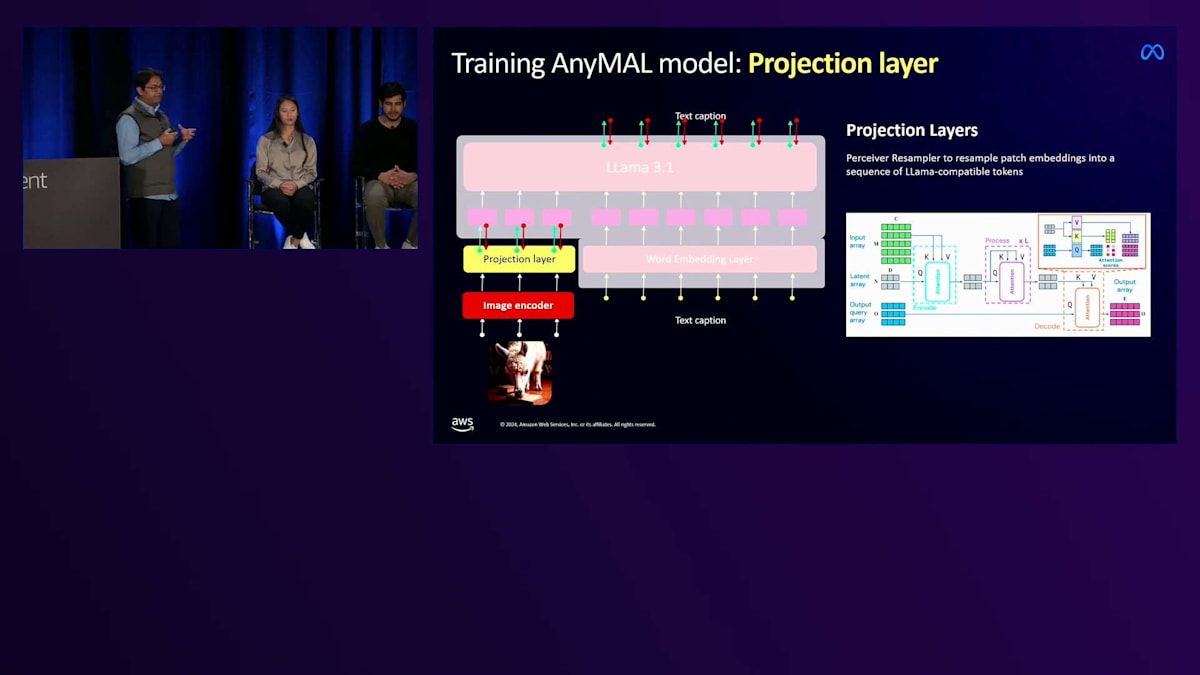
モデルの訓練が完了した後、次のステップはそれをベースとなるLlamaに接続することでした。 これは「プロジェクション」と呼ばれる事前学習プロセスを通じて行われます。この特定のステップでは、入力画像の最も正確な説明を生成するために、LlamaとVisionエンコーダーを一緒に訓練します。私たちは「キャプション・ファースト、質問は後で」という訓練パラダイムに従い、約10億枚の画像を使用して、これも非常に大規模に実行します。
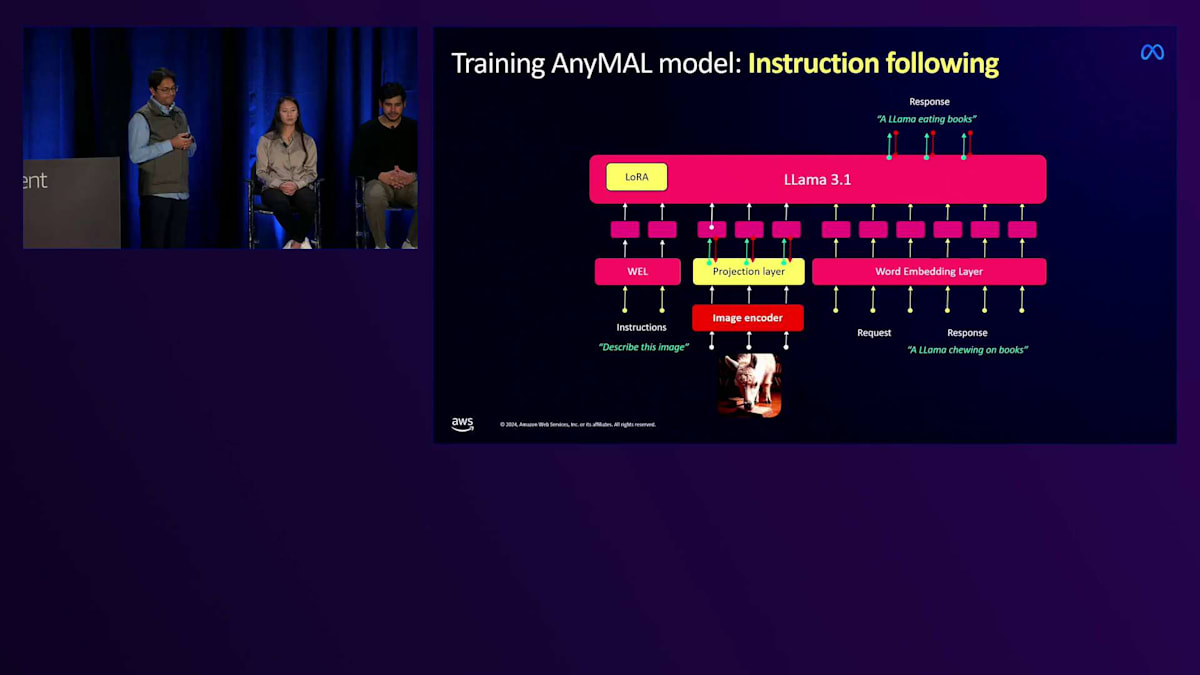
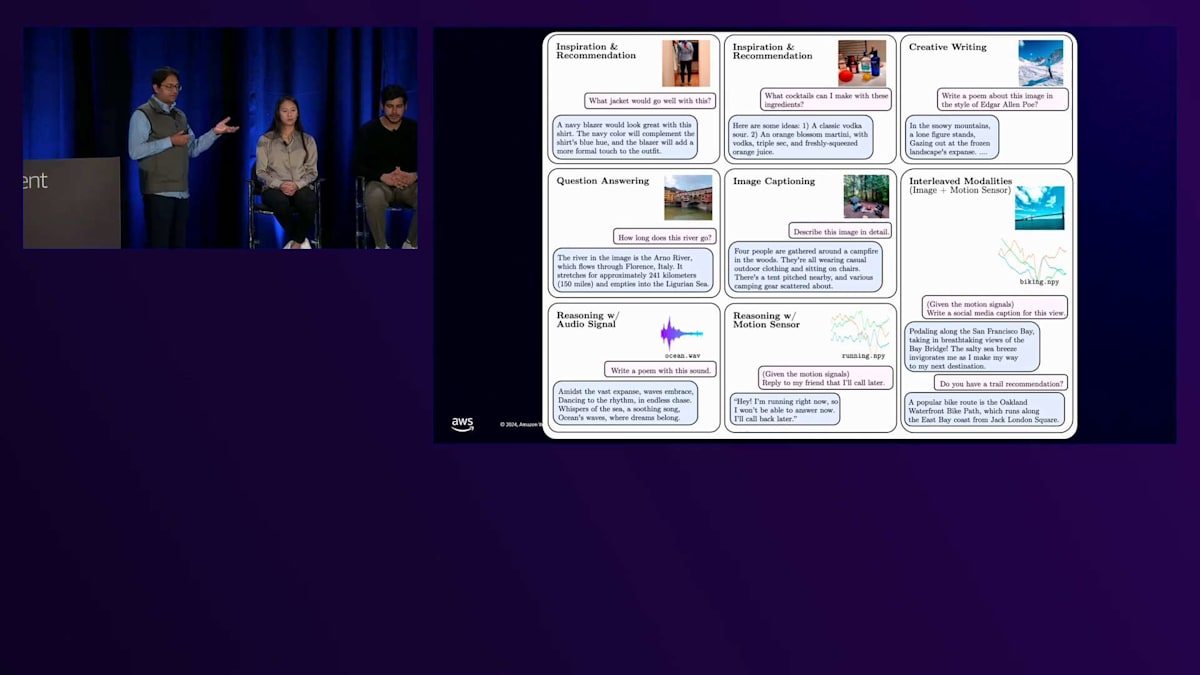
最後に、顧客が事実上あらゆる用途に使用する可能性があるため、私たちは多様なタスクでモデルのファインチューニングを行います。これは「インストラクション・チューニング」と呼ばれるプロセスを通じて行われます。スマートグラス向けのユースケースに適した約12のタスクでモデルを訓練しました。これには、インスピレーションやレコメンデーションの提供から、 目の前にあるものに基づいた文章作成、クリエイティブな編集、ビジュアル質問への回答、画像のキャプション生成、さらには音声やモーション信号への機能拡張まで含まれています。マルチモーダルLLMについて興味深い発見の1つは、モダリティを組み合わせることで、最も驚くべき結果が得られることでした。

もう1つの重要な発見は、これらのモデルが入力画像の内容に関係なく、クエリの内容に応じて適切に注目できるようになることです。 例えば、同じ入力画像に対して、ホテルの名前を尋ねれば、そこの適切なピクセルに注目し、天気について尋ねれば上を見るように注目し、ドレスについて尋ねれば、関連するピクセルに焦点を当てます。これらの発見により、品質に焦点を当てて迅速に進めることができました。

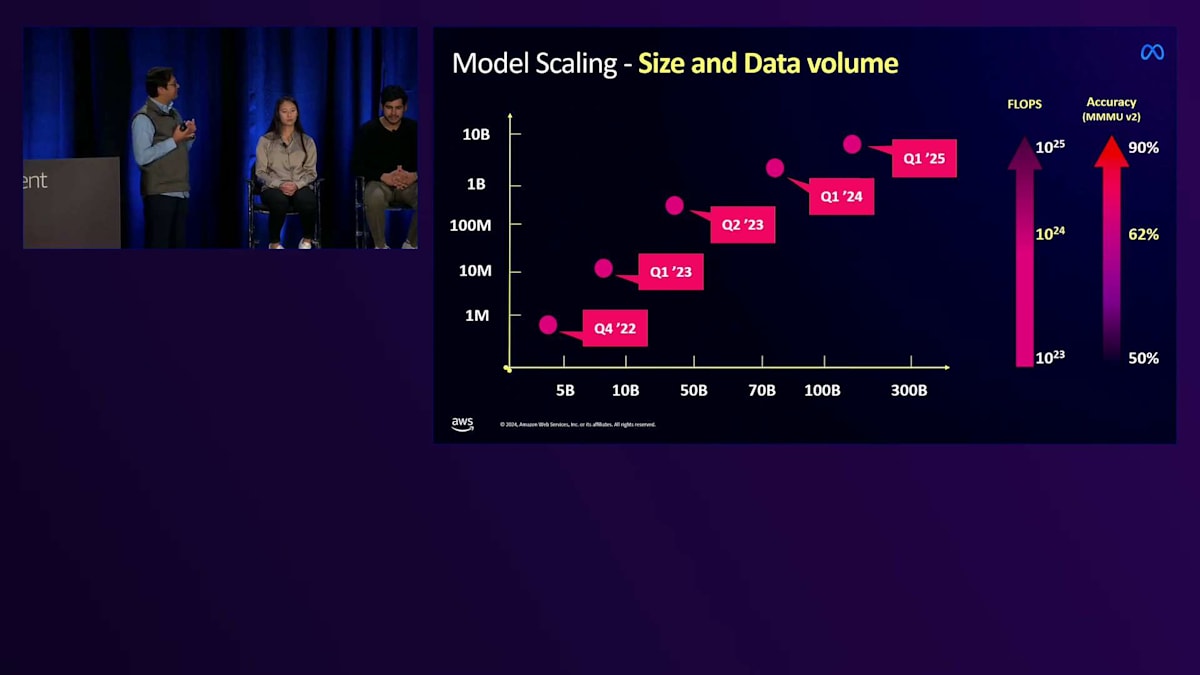
さて、最も重要なステップとして、モデルのスケーリングを行う時が来ました。私たちは適切なアーキテクチャを選び、良好なベースモデルを学習させました。最初にモデルを学習させた時は、約50億のパラメータと約100万の画像-テキストペアでした。1年足らずでそれを約800億のパラメータと30億の画像-テキストペアまでスケールアップしました。かなりの規模ですが、それでもまだ私たちの要求を満たすには十分ではありません。必要な精度に到達するには、さらに1,000億のパラメータまでモデルをスケールアップする必要があります。
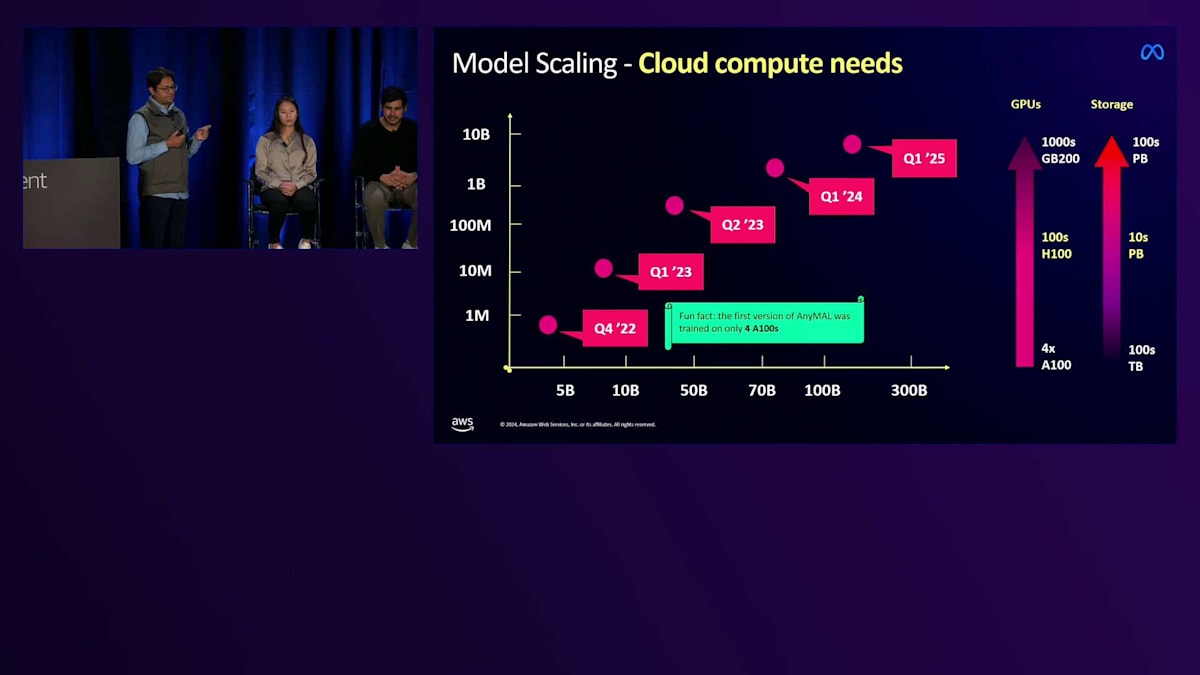
これが現在学習中の次のチェックポイントです。求める精度に到達するために必要なFLOPS数は、約2桁増加しました。製品出荷までの時間枠の中でこれだけのFLOPSを達成することは、非常に計算負荷の高い作業です。最初にモデルを学習させた時は、わずか4台のA100インスタンスでしたが、現在は数百から数千台のA100インスタンスで学習を行っており、近々H200やGB200への移行も予定しています。

計算能力がスケーリングの一つの側面だとすれば、ストレージは別の大きな課題でした。これらのマルチモーダルデータセットは、テキストのみのデータセットと比べて数百倍も大きくなる傾向があります。ストレージの必要量は、学習開始時の約100テラバイトから、1年の間に数百ペタバイトまで増加しました。このスケールに対応するために、新しい実験的なファイルシステムの開発が必要でした。しかし結局のところ、先ほど述べた3つの課題に帰着します:信頼性、スケーラビリティ、効率性です。これらの課題は、すべてのAI学習の中核となる3つの要素に密接に影響を与えます:計算、通信、メモリです。
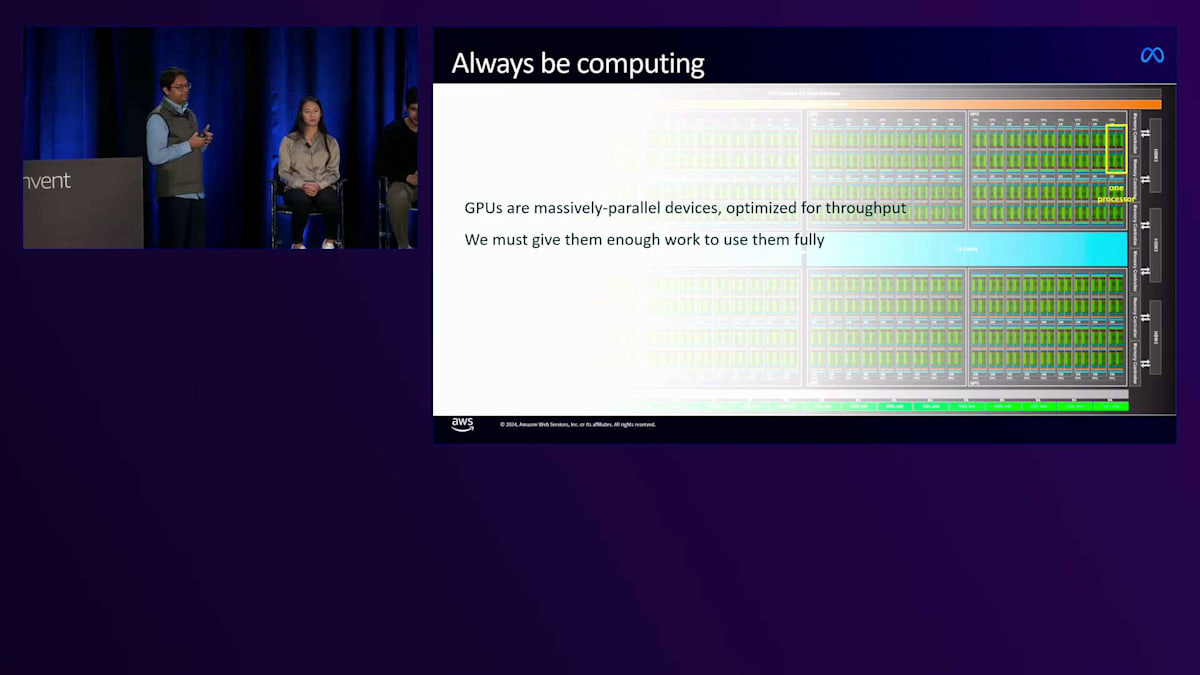
GPUで学習を行ったことのあるAIエンジニアなら誰でも、計算能力が最重要だと言うでしょう。なぜならメモリには物理的な制限があるからです。ハードウェアが提供する以上のものは得られません。通信は最適化に多大な努力が必要です。ワークロードを大幅に最適化する必要がありますが、やはり計算能力が最重要なのです。そのため、モデルの学習に必要な適切なFLOPS数を達成するには、GPUが常に計算を実行している状態を維持する必要があります。GPUは大規模な並列処理デバイスで、スループット向上のために最適化されており、それらを最大限に活用するには十分な作業量を与える必要があります。これは効率性の面でも重要な役割を果たします。

効率性の話に入る前に、最初に解決する必要があったボトルネックの一つが信頼性でした。ここでAWSチームとのパートナーシップが非常に重要でした。最初にクラスターをセットアップした時、ファイルシステムの障害、不具合のあるノード、ソフトウェアの依存関係の不一致など、いくつかのセットアップの問題に直面しました。AWSチームは、Metaのハイパフォーマンスコンピューティングチームと共に、発生したすべての問題を綿密に調査し、数時間以内に解決してくれました。
私たちは、2025年に向けて最初の1ヶ月のトレーニングで、すべてのノードで失敗を経験することが何度もありました。ホームファイルシステムをLustreに移行した日のことを鮮明に覚えています。その後、何百ものノードが数週間にわたって一切の障害なく稼働するようになりました。クラスターの利用率は数日のうちに約20倍に跳ね上がりました。これを実現してくれたAWSチームには本当に感謝しています。
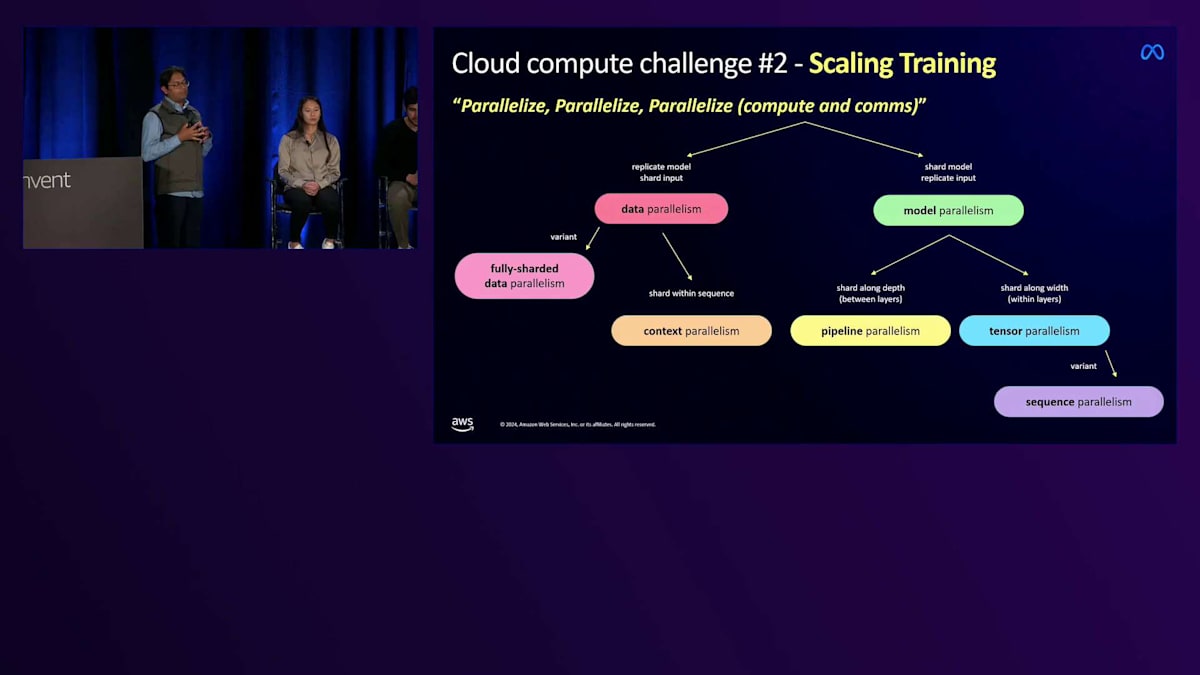

必要な信頼性を確保できた後は、トレーニングのスケールアップが必要でした。まず最初に行うべきは、並列化によるワークロードの最適化です。先ほどの講演でも触れられていましたが、並列化には主にデータ並列化とモデル並列化という2つのタイプがあります。並列化のテクニックは全部で12種類ほどあります。私たちはあらゆる最適化を実装し、最も一般的なシャーディング手法であるFSDPを、 Tensor ParallelismやModel Parallelism、最適化された量子化と組み合わせることで、約16倍のスピードアップを達成しました。

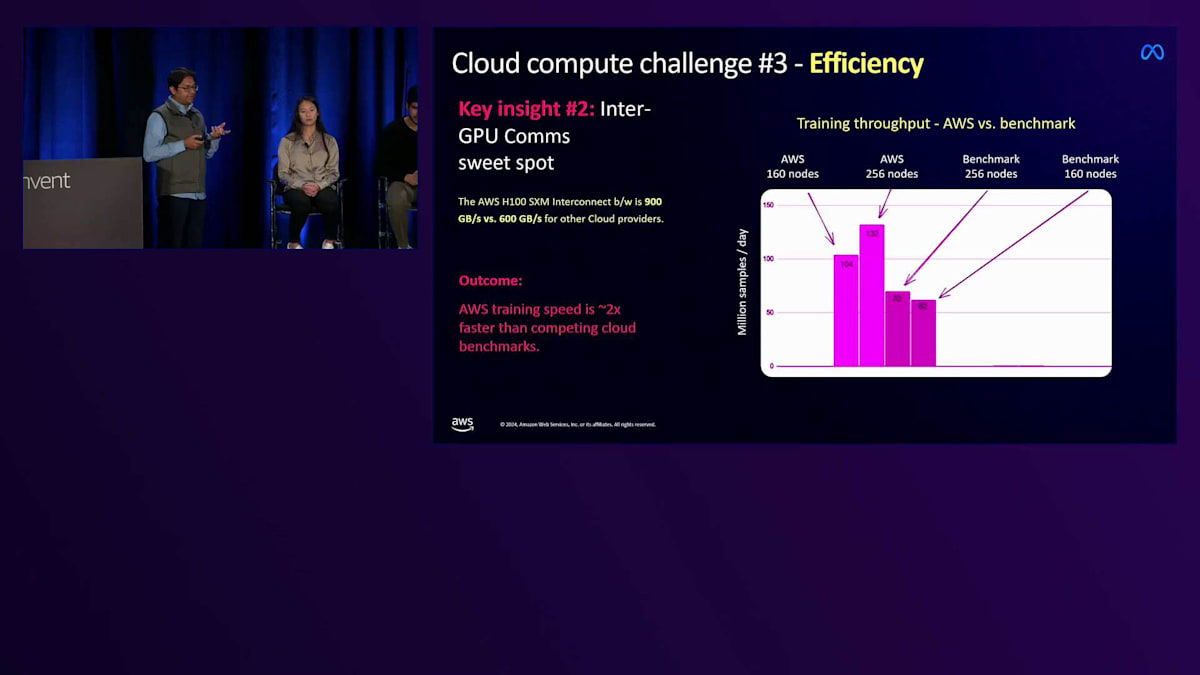
しかし、大規模トレーニングに携わった人なら誰でも、ソフトウェアだけでは限界があることを知っています。ある一定のポイントを超えると、主なボトルネックはハードウェアになってきます。ワークロードをスケールアップすると、効率性が次第に低下していきます。GPUの最大数に達すると、 さらにGPUを追加してもトレーニングのスケールアップには役立ちません。ここで重要になってくるのが、より優れたハードウェアです。私たちはすでに市場で最高のH100を使用していましたが、さらに何が改善できるのでしょうか?AWSは私たちに興味深いサプライズを提供してくれました。クラウドのベンチマークをAWSと比較したところ、ワークロードを最適化することなく、約2倍のパフォーマンス向上が得られました。これは、AWSが他のベンチマークの600Gbpsと比べて900Gbpsのインターコネクトを使用しているためでした。


2025年に向けて、マルチモーダルAIには3つの主要な課題があります。まず、AWSチームが示したロードマップに沿ってモデルをスケールアップする必要があります。マルチモーダル機能を十分に活用するために、trillion parameterモデルのトレーニングが必要です。また、動画やセッションベースのエクスペリエンスなどのユースケースに対応するため、非常に長いコンテキスト長をサポートする必要があります。そして最も重要なのは、より多くのデバイスを販売し、ユーザーがMetaの機能に継続的にエンゲージメントするようになるにつれて、ユーザー増加をサポートするためにInferenceをスケールアップする必要があるということです。

3つの重要な要素は、これまでと同じです。 ある意味で全てが一巡しているのです - trillion parameterモデルに最適なアーキテクチャを選択できるよう、迅速なプロトタイピングと実験を続ける必要があります。そのためには、H100からGB200への移行によって計算能力をスケールアップする必要があります。GB200が提供する exciting potentialは極めて重要で、より高速なInferenceによってレイテンシーを削減し、ユーザーエンゲージメントを向上させ、ユーザーフィードバックから学ぶ機会を提供することができます。
セッションのまとめと謝辞
以上で、AWSチームと本日ご参加の皆様、そしてMetaのハイパフォーマンスコンピューティングチームの皆様、さらにこれらすべての取り組みを可能にしてくれた私のホームチームに感謝を申し上げます。お時間をいただき、ありがとうございました。それでは司会にお返しします。簡単にまとめさせていただきます。まず、KirmaniさんとメタのWearables AIチームの皆様には、ワークロードに関する貴重な知見を共有していただき、感謝申し上げます。また、本日遅い時間にもかかわらずご参加いただいた皆様にも御礼申し上げます。質疑応答の時間は限られているかもしれませんが、講演後に質問がございましたら、お答えできるよう待機させていただきます。皆様、ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion