re:Invent 2024: AWSのセルフサービス分析でデータ活用を加速
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Scale with self-service analytics on AWS (ANT334)
この動画では、組織のAnalyticsをスケールするためのAWSのセルフサービス分析ソリューションについて解説しています。Amazon DataZoneによるデータディスカバリー、Amazon Redshift MLを活用した機械学習モデルの構築、Amazon QuickSightによるGenerative BIなど、技術的な専門知識がなくても高度な分析を可能にする機能を紹介しています。特に注目すべきは、今年新たに発表されたAmazon SageMaker Unified Studioで、データの準備から分析、モデル構築、アプリケーション開発までを統合環境で実現できる点です。また、Zero-ETL統合やLakehouseアプローチにより、複雑なデータパイプラインの構築なしでデータ活用を可能にする方法も詳しく説明されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
セルフサービスAnalyticsの現状と課題

皆様、こんにちは。本セッションへようこそ。今日のデータ駆動型の世界では、組織のAnalyticsをスケールする能力は、もはや優位性ではなく必要不可欠なものとなっています。本日は、AWSがどのようにしてセルフサービスAnalyticsを革新し、組織内のすべてのチームがデータエキスパートとなれるよう支援できるかについてご紹介します。私はPrincipal Analytics and AI Solutions ArchitectのSrikanth Sopiralaです。本日は同僚のDataZoneのSenior Product Manager TechnicalであるUtkarsh Mittal、そしてPrincipal Solutions ArchitectのRaghavarao Sodabathinaと共に登壇させていただきます。このセッションでは、AWSのAnalyticsサービスを活用して、データインサイトを民主化し、組織全体でイノベーションを推進する方法についてお話しします。

まずは、皆様のセルフサービスAnalyticsの現状を把握するため、いくつかアンケートを取らせていただきたいと思います。皆様の組織における現在のセルフサービスAnalytics機能をどのように評価されますか?A - 存在しない。Aの方はどれくらいいらっしゃいますか?お一人ですね。B - 基本的なレベル(限定的で、ユーザーも少数)の方は手を挙げていただけますか?何名かいらっしゃいますね。C - 中級レベル(ツールは揃っているが、ユーザーベースは成長中)はいかがでしょうか?はい、ありがとうございます。そしてD - 上級レベル(幅広いツールを活用)の方は?素晴らしいですね。予想通り、多くの方がBとCのレベルにいらっしゃるようですね。

もう一つアンケートを取らせていただきます。セルフサービスAnalyticsの導入やスケーリングにおいて、最も大きな課題は何でしょうか?データガバナンスとセキュリティの懸念 - 手を挙げてください。素晴らしいですね。データツールに関するユーザースキルとトレーニングの不足 - 何名か見受けられます。ツールやインフラの制限 - これはクラウドが解決できる部分ですね。そして従来のBIプロセスからの変更に対する、エンドユーザーやビジネスユーザーからの抵抗 - どれくらいいらっしゃいますか?予想通りですね。これらの情報は、本日のプレゼンテーションの良い導入となりました。
セルフサービスAnalyticsの定義と構成要素

それでは、アジェンダに入っていきましょう。まず、セルフサービスAnalyticsとは何かについて共通認識を持ちたいと思います。これは非常に広範なトピックですので、その本質と基盤となる要素について焦点を当てていきます。次に、AWS上でのセルフサービスAnalytics、つまりAWSがどのようにセルフサービスAnalyticsをサポートできるかについて説明し、最後に活用可能なリソースをご紹介します。
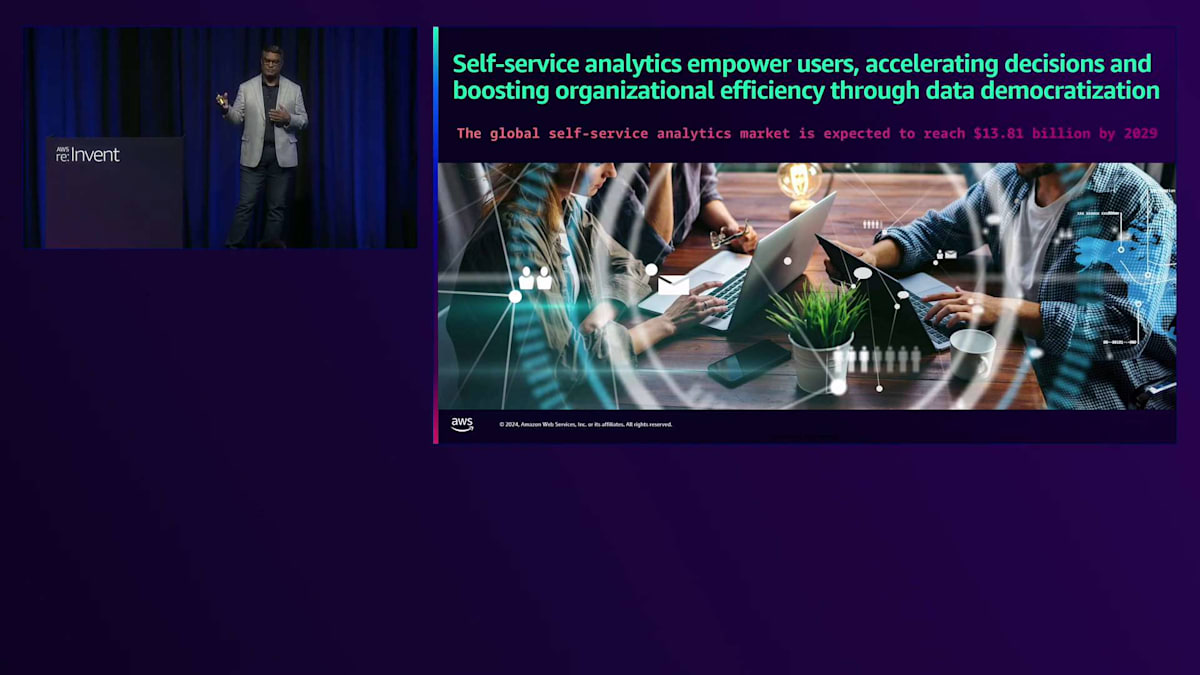
では、セルフサービスAnalyticsとは何でしょうか?セルフサービスAnalyticsは、組織内のデータエキスパートだけでなく、すべての人々にデータツールを提供します。これにより、ITチームだけでなく組織全体が迅速に意思決定を行い、イノベーションを推進することができます。グローバルなセルフサービスAnalytics市場は2029年までに138.1億ドルに達すると予測されており、これは驚くべき数字です。さらに驚くべきことに、ビジネスユーザーの70%が、組織のITやデータチームに頼ることなく、セルフサービスAnalyticsツールを使用してデータ駆動型の意思決定を行いたいと考えています。

しかし、今日の世界では、Self-Service Analyticsがあらゆる組織にパワーを与えることを約束しているものの、データ民主化への道のりには大きな障壁が存在します。ビジネスが持てる可能性を最大限に発揮しようとする際、重要な課題に直面します。その一つが広範なETLパイプラインです - 私たちはETLパイプラインの構築に多くの時間を費やし、それらはますます複雑になっています。データの準備はSelf-Service Analyticsにとって完全な障壁となっています。また、データが至る所に散在しているという問題もあります。データセットを見つけ出す能力が大きなボトルネックとなっています。組織のデータ規模が拡大するにつれ、Self-Service Analyticsを実現するためのツールのスケーラビリティとパフォーマンスは、ほとんどの組織にとって限定的です。4番目の課題は技術的な複雑さです - 従来の分析ツールは一般的にITチームによって管理され、特別な専門知識とスキルを必要とします。

このアクセシビリティの制限により、組織全体での導入が制限されています。さらに、エンドユーザーが利用できる高度な分析機能が限られているため、組織全体にMachine Learning機能を提供することも課題となっています。
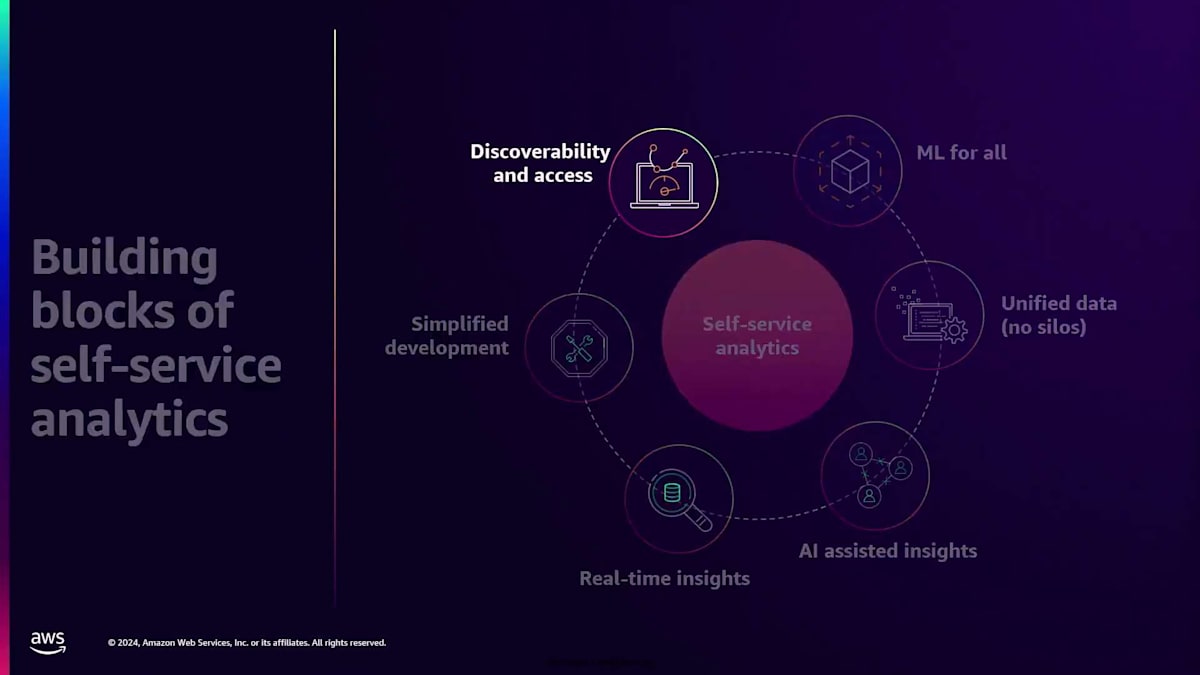
これらがSelf-Service Analyticsの基本的な構成要素です。最初の構成要素は、ユーザーがOLTPシステムなどのデータソースから独立して分析にアクセスできるようにするリアルタイムインサイトに焦点を当てています。2番目の構成要素は、AI支援によるインサイトです。多くのお客様が人工知能、Generative AI を活用し、データをより深く理解したいと考えているためです。3番目の構成要素は統合データで、データを1か所に保持することで長年の課題であるデータサイロの問題に対処します。4番目の構成要素はデータの発見可能性に対応するもので、データが統合されると適切なデータセットを見つけることが重要になります。最後に、ML for allは、専門的なスキルが限られているため、データサイエンスの専門知識を必要とせずにエンドユーザーがMachine Learningにアクセスできるようにすることを目指しています。
AWSによるZero-ETLとデータ統合の実現

データをキュレーションしてすべてを整えたら、開発を簡素化し分析を構築するための体験を提供することが重要な構成要素となります。これらの構成要素それぞれについて詳しく説明し、AWSがどのように役立つかをご説明しましょう。最初の構成要素はZero-ETLです。 Zero-ETLは、分析システムとトランザクションシステム間のデータ統合を簡素化し、トランザクションを加速・最適化し、エンドユーザーにより良い成果をもたらすことで、Self-Service Analyticsを実現します。

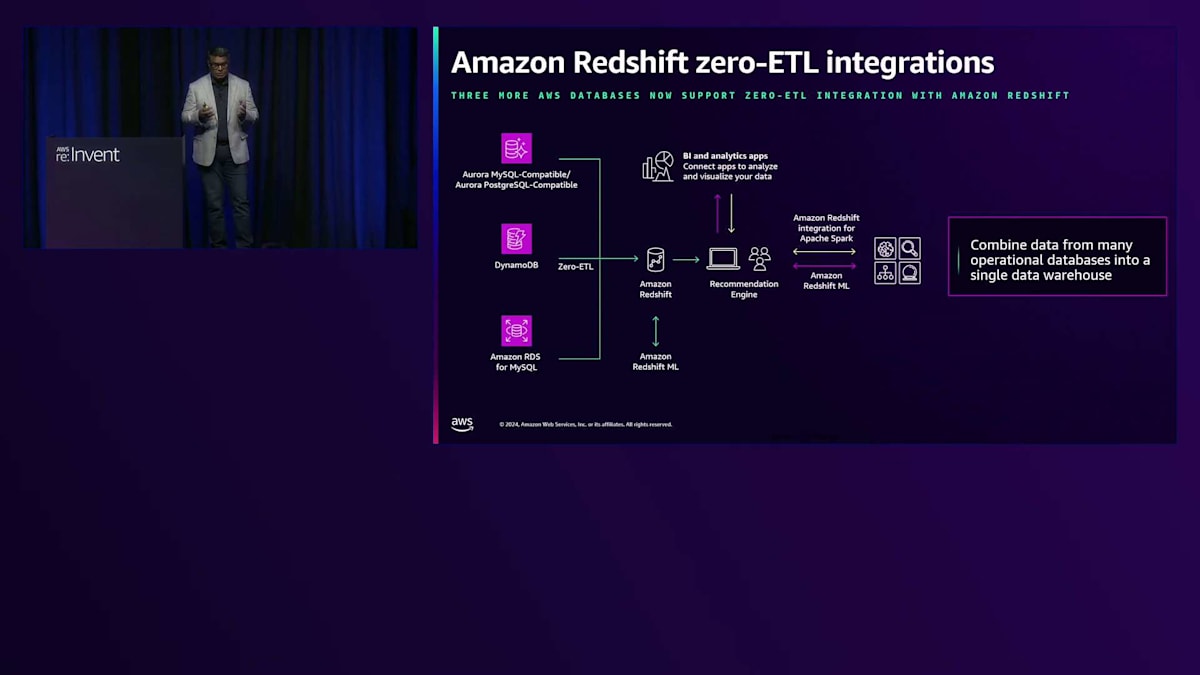
AWSでは、 異なるシステム間のZero-ETLをより簡単にするための取り組みを行っており、複雑なETLパイプラインなしでデータをポイントAからポイントBに移動できるようにしています。Zero-ETL統合により、トランザクションデータと分析データを分析目的で1か所に集めることができます。簡単なユースケースを考えてみましょう: 組織内のビジネスアナリストがデータベースのデータを分析する必要があるものの、技術的なスキルが不足している場合を想定します。これがZero-ETLが役立つ場面です。Amazon Aurora PostgreSQLにデータがある場合、数回のクリックだけでソースとターゲット間の簡単な接続を有効にし、すぐにZero-ETLの活用を開始できます。

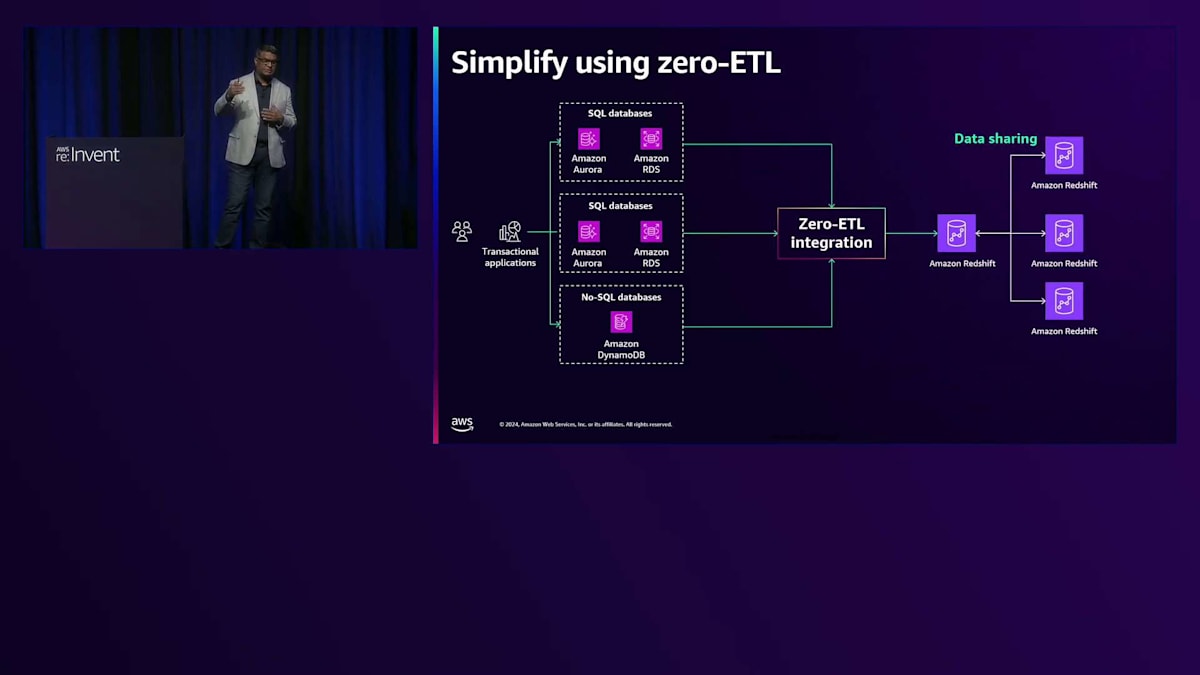

Zero-ETLによるセルフサービス分析に加えて、Amazon Redshiftでデータをキュレーションし、データ共有を活用することで、各事業部門向けのセルフサービス分析を実現することができます。また、Amazon S3からAmazon Redshiftへの自動コピーも素晴らしい機能の一つです。私たちはRedshiftへのデータ取り込みを常に高速化するよう取り組んでいますが、自動コピー機能を使えば、S3にドロップされたファイルを定期的にAmazon Redshiftへ自動的にコピーすることができます。これは、ビジネスアナリストや技術に詳しくないユーザーがAmazon Redshiftにデータを取り込む際の強力なツールとなります。


AWSにはネイティブなデータベースがありますが、SalesforceやSAPなどのサードパーティソースにも価値のあるデータが存在します。最近、Salesforceからのゼロ-ETL機能を発表し、増分CDCデータを自動的にデータレイクやRedshiftデータウェアハウスに取り込むことができるようになりました。以前は、これらのサードパーティ製品へのコネクタがありましたが、今回はセルフサービス分析機能を強化するためにZero-ETLを実現しました。まとめると、Zero-ETLはエンドユーザー向けのセルフサービス分析を実現する強力なツールです。
これは簡単で信頼性が高く、迅速な導入が可能だからです。複雑なデータパイプラインを構築する必要がなく、低レイテンシーのデータ統合を提供します。Zero-ETLは、すべてのデータを1つの場所に統合することで、統一された洞察を提供します。さらに、複雑なETLパイプラインの作成と維持が不要になるため、コストが最適化され、リソースと経費の節約にも役立ちます。
Amazon Lakehouseとデータ民主化

2番目の構成要素は、サイロのない統合データです。ここでLakehouseが登場し、柔軟なスキーマオンリードオプションですべてのデータを取得し、セルフサービスを可能にする統合プラットフォームを提供します。このアプローチにより、複数のサイロを持つのではなく、1つのコピーを維持しながら、分析機会のスケーラビリティを確保することができます。
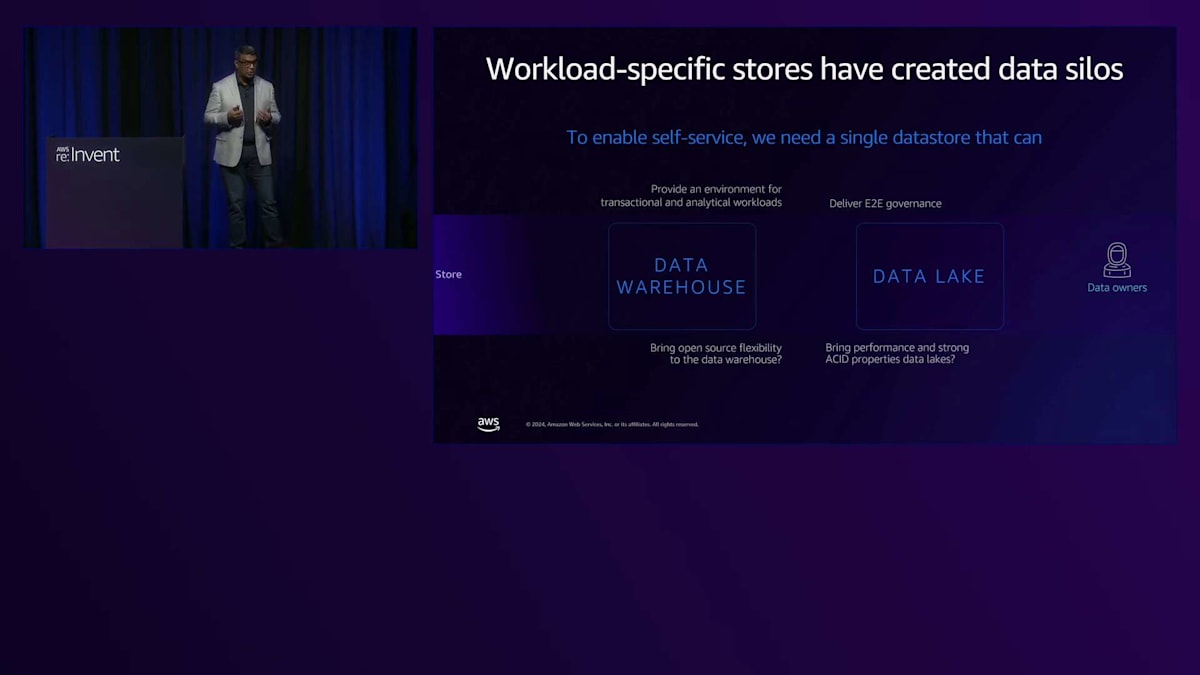

長年にわたり、私たちはデータウェアハウスとデータレイクを構築し、異なる事業部門向けにサイロを作成してきました。お客様から寄せられている声は、Amazon Redshiftのようなパフォーマンス要件やACID準拠を備えながら、トランザクションデータと分析データの両方を1つの場所で提供することで、セルフサービスを実現したいというものです。これが、私たちがLakehouseアプローチを再考している理由です。核となるコンセプトは、データの単一コピーを維持することです。半構造化、構造化、非構造化データを問わず、1つの場所に保存することで、継続的なサイロの必要性をなくします。今朝、Mattが、このコンセプトとしてAmazon LakehouseとSageMaker Lakehouseを発表しました。



SageMaker Lakehouse は、データの構造に関係なくゼロETLでデータをLakehouseに取り込めるため、セルフサービス性を実現できます。主な特徴は3つあります:すべてのデータを一箇所に集約できる統合データ、Apache Icebergとのオープンな互換性、そしてデータAIとガバナンスを通じたセキュリティです。Lakehouseは統合Studio へのアクセスを提供し、開発を簡素化し、サードパーティ製品がセルフサービス方式でデータにアクセスすることを可能にします 。

ゼロETLとフェデレーションをLakehouseにどのように統合できるか見ていきましょう。ゼロETLアプローチを使用してデータをLakehouseに取り込むことができ、また、エンドユーザーやビジネスアナリストがセルフサービス分析を実行できるようにLakehouseへのフェデレーションも可能です。Lakehouseの基本的な考え方は、データの単一コピーを持ち、分析 のための一元的な場所を提供することです。ユーザーは、Apache Iceberg準拠の環境で、好みのツールを使用して一箇所で簡素化された開発を行いたいと考えています。Lakehouseは、必要なツールとリアルタイム分析機能を備えたインタラクティブな分析を提供し、ビジネスアナリストがデータにアクセスするために何週間も待つ必要がないようにします。S3ベースのデータレイクであるため、セルフサービス分析に対してコスト効率が高くスケーラブルです。
3つ目のビルディング ブロックについて説明しましょう。ビジネスインテリジェンスのためのセルフサービス分析は新しいものではありませんが、Generative Business Intelligence は分析に真のセルフサービス機能をもたらします。誰もがBIエキスパートというわけではないため、自然言語インターフェースは不可欠で、ユーザーは単純に自然言語コマンドを使用してダッシュボードを作成できます。これには自動インサイト生成とダイナミックな可視化が含まれます。


QuickSightは長年にわたって、ビジネス インテリジェンス機能を提供してきました。データレイクやLakehouseへのアクセスを備えた、すべてのエンドユーザー向けの統合BIを提供しています。これから説明するのは、ビジネスインテリジェンスのセルフサービス分析において画期的な QuickSight Qについてです。議論すべき重要な側面が4つあり、まずはAIを活用したダッシュボード作成エクスペリエンスから始めます。
最初は、BIエキスパートでなくても自然言語を使用してコンテンツを素早く作成できる、AIを活用したダッシュボード作成エクスペリエンスです - これはセルフサービス分析に不可欠です。次に、後ほど説明するデータストーリーテリングがあり、これもQuickSightにおける重要なセルフサービス実現要素です。さらに、オンデマンドの回答機能があります - 巨大なダッシュボードをCIO、CEO、CTOに提供する際、膨大な情報の中から必要な情報を探す代わりに、単純に自然言語で質問できることを想像してください。このAIを活用したQ&A機能により、組織全体に真のセルフサービス分析が提供されます。最後の側面は、これらの機能をアプリケーションに拡張して組み込む機能です。
QuickSightによるGenerative BIの革新
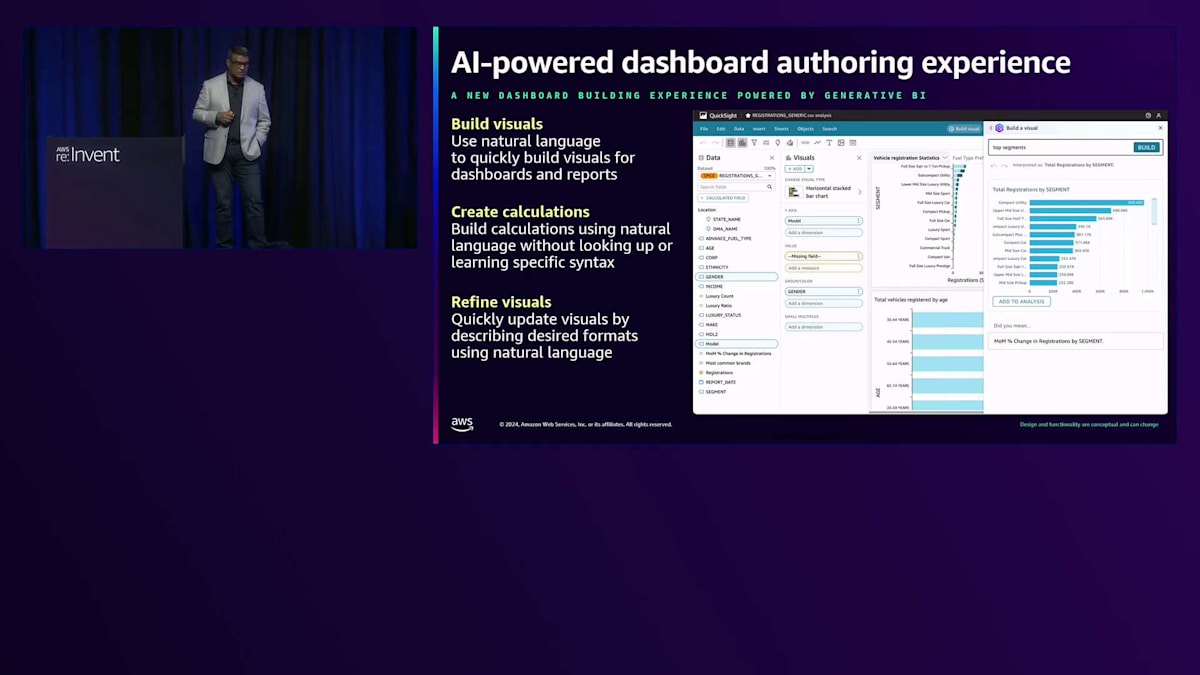
それでは、各機能について詳しく見ていきましょう。AI搭載のオーサリング体験について、BIは常にセルフサービスの性質を持っていましたが、現在では自然言語を使って簡単にビジュアルを作成し、分析やダッシュボードに追加できるようになりました。BIの専門家である必要はありません。シンプルな自然言語コマンドは、Amazon Bedrockを通じて生成AIを使用してバックグラウンドで処理され、データセットのビジュアルを作成します。計算の作成やビジュアルの調整(円グラフを積み上げ棒グラフに変換するなど)も、すべて自然言語コマンドで行えます。

アシスト付きストーリーテリング機能は、私のお気に入りの一つです。シンプルなプロンプトを使って、ダッシュボードから直接、経営陣向けのMBRやPowerPointを作成できます。ダッシュボードやビジュアルを選択するだけで、データストーリーを物語形式で素早く生成できます。この素晴らしい機能により、経営陣やお客様と共有するためのPowerPointやPDF形式のファイルを作成できます。必要に応じて内容や箇条書きを修正し、ストーリーをカスタマイズすることもできます。

AIアンサー機能は、オンデマンドのデータ質問を可能にする特に重要な機能です。15,000人のユーザーベースにダッシュボードを公開する場合、ユーザーはデータに直接アクセスできなくても、ダッシュボードにはアクセスできます。Amazon QuickSight IQを使用すると、ユーザーは自然言語でダッシュボードに関する質問をすることができ、ビジュアルまたはナラティブ形式で回答が生成されます。
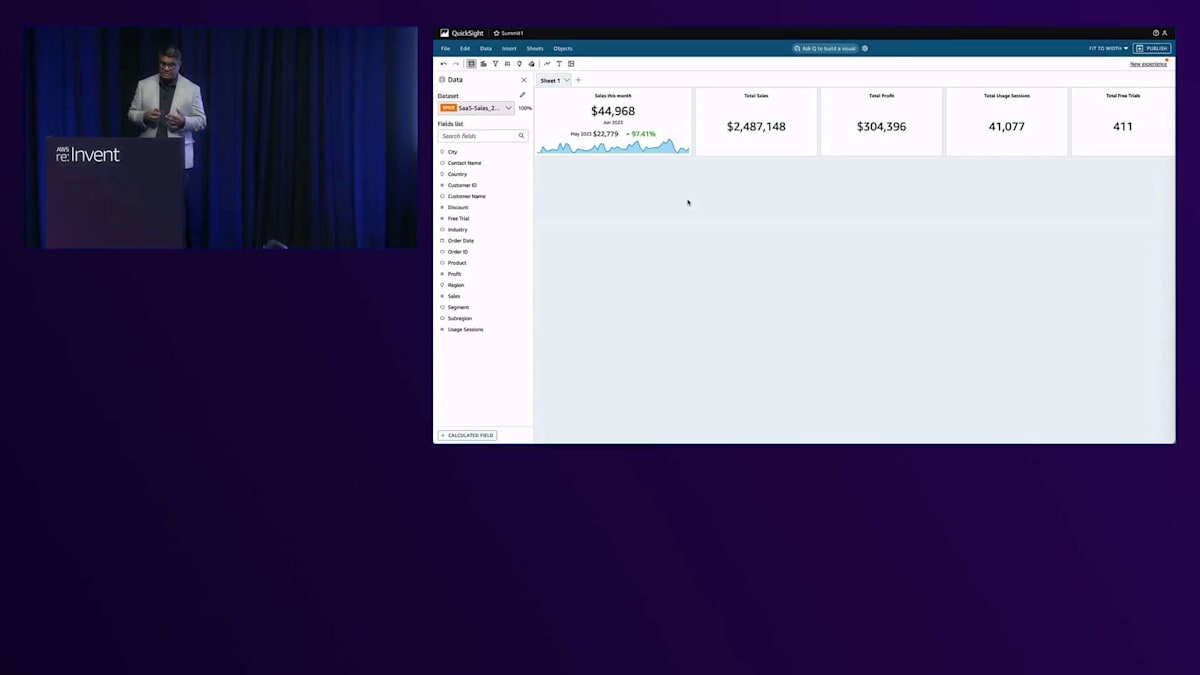
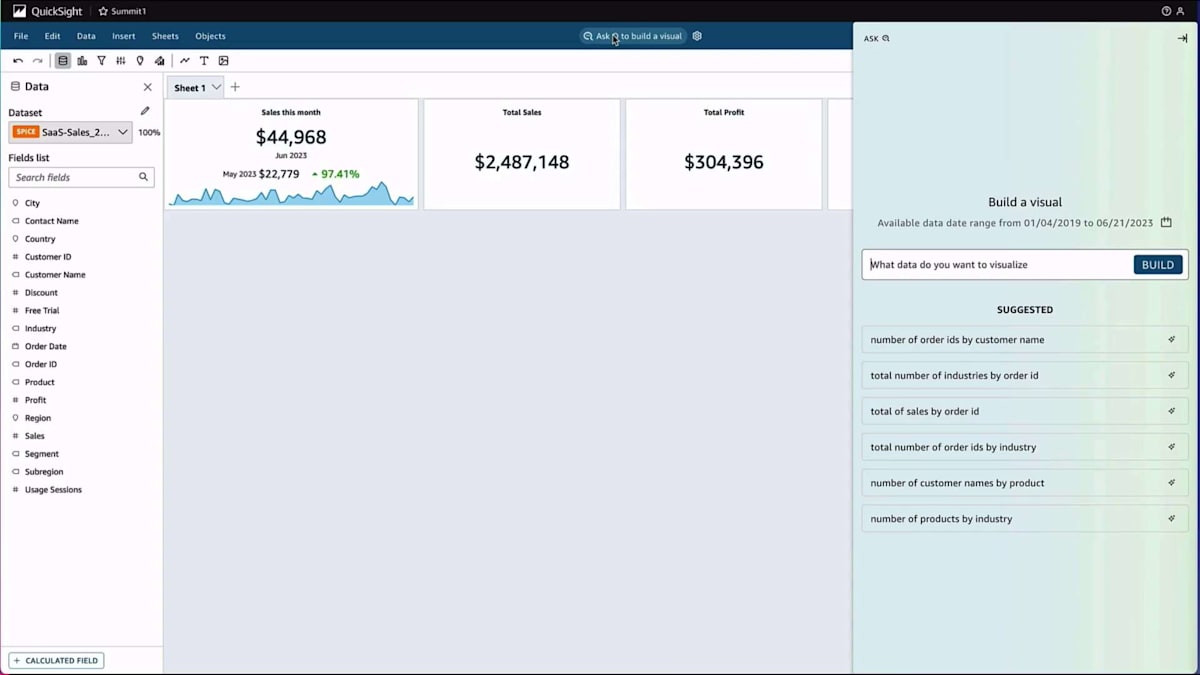

ビジネスアナリストが生成BIの力を活用して、シンプルな自然言語でビジュアルを作成する方法をデモンストレーションしましょう。まずビジュアルを作成し、その後、それを修正する方法をお見せします。この機能は、QuickSightダッシュボードの作成者とダッシュボードの閲覧者の両方が利用できます。 ここでは、自然言語を使用してビジュアライゼーションを作成しています。月次の売上と利益を表示するようにプロンプトを入力するだけです。 システムは自動的にQuickSightのデータに基づいてビジュアルを作成します。このビジュアルを分析に追加したり、修正したり、予測を作成したり、異常検出を実行したり、ダッシュボードに追加したりすることができます。

これは真のセルフサービスを示しています。BIの専門家である必要はないのです。都市と製品ごとの売上合計(これによりマップが生成されます)や、セグメント別の地域売上などのビジュアライゼーションを作成できます。また、シンプルな自然言語コマンドを使用してビジュアルタイプを変更することもできます。ビジュアルメニューから選択するだけでSankeyダイアグラムを作成することも可能です。目標は、エンドユーザーが必要なものを素早く作成できるツールを提供することです。
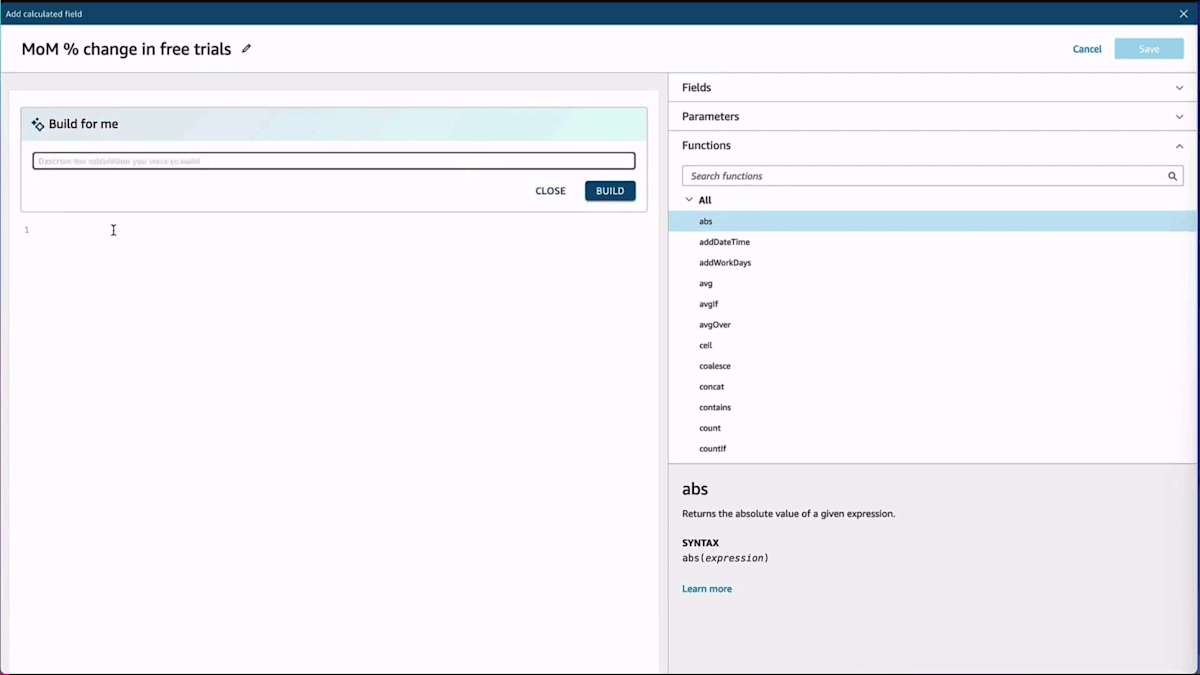

自然言語を使って、トライアル数の月次変化率のような計算を作成することができます。通常の方法でも作成できますが、ここでは自然言語を通じて行っています。これらのフィールドは他のダッシュボードでも使用でき、必要に応じて修正することができます。 例えば、折れ線グラフがあるけれど積み上げ棒グラフの方が良いと思った場合、自然言語でその変更をリクエストするだけで、積み上げ棒グラフを作成してくれます。ここでも重点は、専門家である必要のないエンドユーザーのためのセルフサービス分析を実現することです。最後に紹介したい機能は、データストーリーテリングです。ストーリーテリングでは、このデータを使ってストーリーを作成することができます。



データストーリーを作成してビジュアルを追加し、それを QuickSight のデータストーリーに組み込むことができます。ダッシュボードのナラティブを生成するための簡単な自然言語プロンプトを作成できます。これは特に、ダッシュボードを細かく見たくないエンドユーザーにとって便利です。なぜなら、 インサイトに素早くアクセスできるからです。ダッシュボードごとに包括的なナラティブを作成し、何を達成しようとしているのかの説明を提供します。これらはすべて QuickSight 内の Generative AI によって実現されています。



ストーリーのさまざまな側面を、より多くのチャートを挿入したり、追加の機能にアクセスしたりすることで修正できます。 例えば、利用可能なデータに基づいて次のステップを提供し、推奨事項を示してくれます。箇条書きを追加したり、データストーリーを必要に応じてフォーマットしたりすることができます。この機能の主な目的は、 セルフサービスの特性を維持しながら、これらのビジュアルを素早く作成してエンドユーザーと共有できるようにすることです。

Matt が今朝言及した2つの機能について説明したいと思います。これまで、構造化データと QuickSight でのセルフサービス分析の方法について説明してきました。 非構造化データについては、QuickSight の構造化データに非構造化データを追加する機能を実装しました。これは、ビジュアルを作成していて、それに関連する文書、契約書、PDF、銀行取引明細書などがある場合、質問をする際にそれらを追加できるということです。これにより、質問をする際にビジュアルと関連する非構造化文書の両方に同時にアクセスできます。



もう1つの注目すべき機能は、データストーリーにあります。データストーリーについて説明し、 デモを見ましたが、データストーリーに非構造化データを追加することができます。これらの文書でデータストーリーを補完し、セルフサービス の特性を実現します。これには、ビジネス、MBR、その他のドキュメントに関するストーリーが含まれ、関連文書をナラティブに追加します。
Generative BIにより、QuickSightは既にセルフサービスを提供していますが、さらに強力なセルフサービス分析を実現できるようになります。自然言語でのクエリ、素早い質問、そしてダイナミックな可視化機能を提供します。自然言語で質問して可視化を作成したり、データストーリーのような説明文を生成したり、予測分析のための予測や異常検知を活用したりすることができます。これらのツールはすべて、QuickSightを使用するエンドユーザーやビジネスアナリストが利用でき、そこにセルフサービスの真価が発揮されます。
Amazon DataZoneによるデータディスカバリーの簡素化



ここで、データディスカバリーについて説明する私の同僚のUtkarsh Mittalに引き継ぎたいと思います。私が説明した機能は、適切なタイミングで適切なデータにアクセスできれば、真のセルフサービス分析を実現できます。今日の世界では、データは至る所にありますが、組織内の何百、時には何千ものデータサイロに分散しています。今日のデータユーザーが直面している課題は、分析のユースケースに必要な適切なデータを適切なタイミングで見つけることです。適切なデータを見つけることができたとしても、適切なビジネスコンテキストで理解し、そのデータへの信頼を構築できることを確認する必要があります。データ管理者に依頼して何日も何週間もアクセス権を待つことなく、セルフサービスでデータにアクセスする方法を知る必要があります。

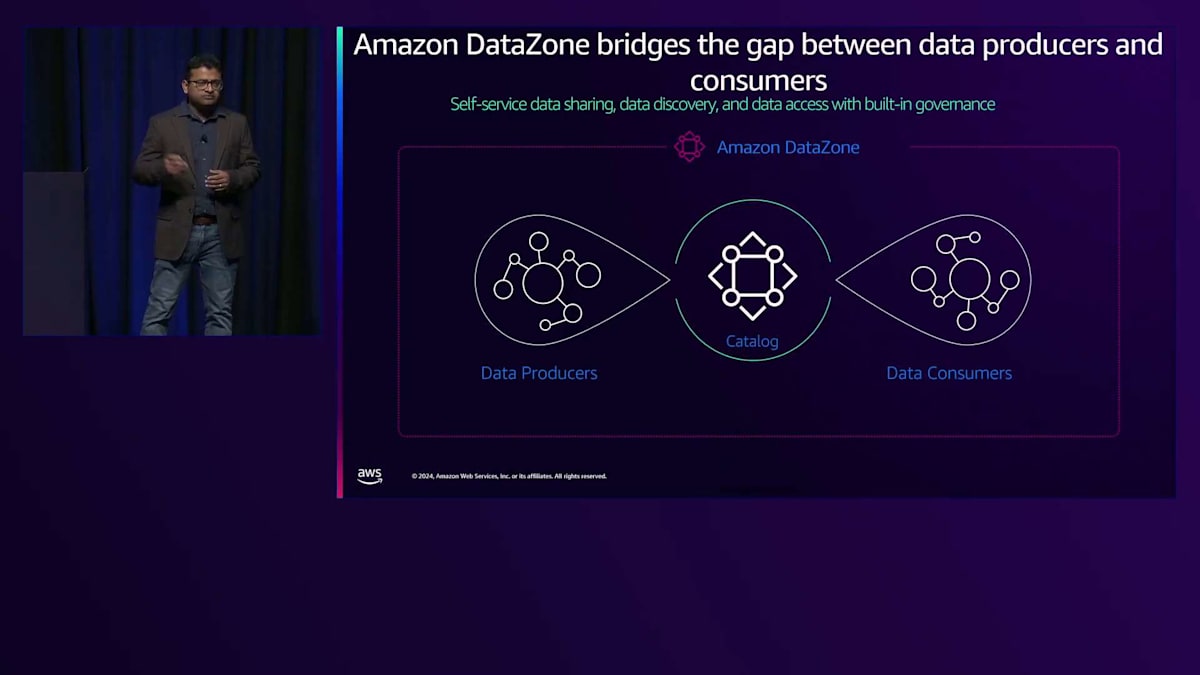
最後に、データへのアクセスを得た後は、選択したツールでそのデータを活用する方法を知る必要があります。Amazon DataZoneがデータディスカバリーとデータアクセス管理を簡素化することで、どのようにセルフサービス分析を実現するのか見ていきましょう。どの組織でも、一方にはデータサイエンティストやデータエンジニアなどの新しいデータを生成するデータプロデューサーがおり、もう一方にはビジネスアナリスト、データアナリスト、ビジネスユーザーなどのデータを利用したいデータコンシューマーがいます。Amazon DataZoneは、このデータプロデューサーとデータコンシューマーの間のギャップを埋めます。データプロデューサーが組織全体のユーザーとデータを共有できるようにする一方で、データコンシューマーがそのデータを見つけ、ビジネスコンテキストで理解し、セルフサービスでアクセスを取得し、選択したツールで利用できるようにします。


Amazon DataZoneの主要な機能の1つは、ビジネスデータカタログです。これは企業全体のビジネスデータカタログで、AWSにあるデータでも、サードパーティのソースにあるデータでも、すべてのデータを一元化できます。DataZoneは、データプロデューサーがデータをオンボードできるセルフサービス機能を提供します。

これらの機能により、データプロデューサーはカタログをビジネスコンテキストで充実させることもできます。テーブルやカラムのビジネス説明やビジネスラベルを含むビジネスメタデータを自動生成する生成AIの機能を提供します。これは、データプロデューサーにとって非常に強力な機能となり得ます。というのも、時間のかかるカタログへの情報の手動追加が不要になるからです。また、データ品質やデータリネージを追加することもでき、これにより組織全体のユーザーがデータへの信頼を構築できるようになります。
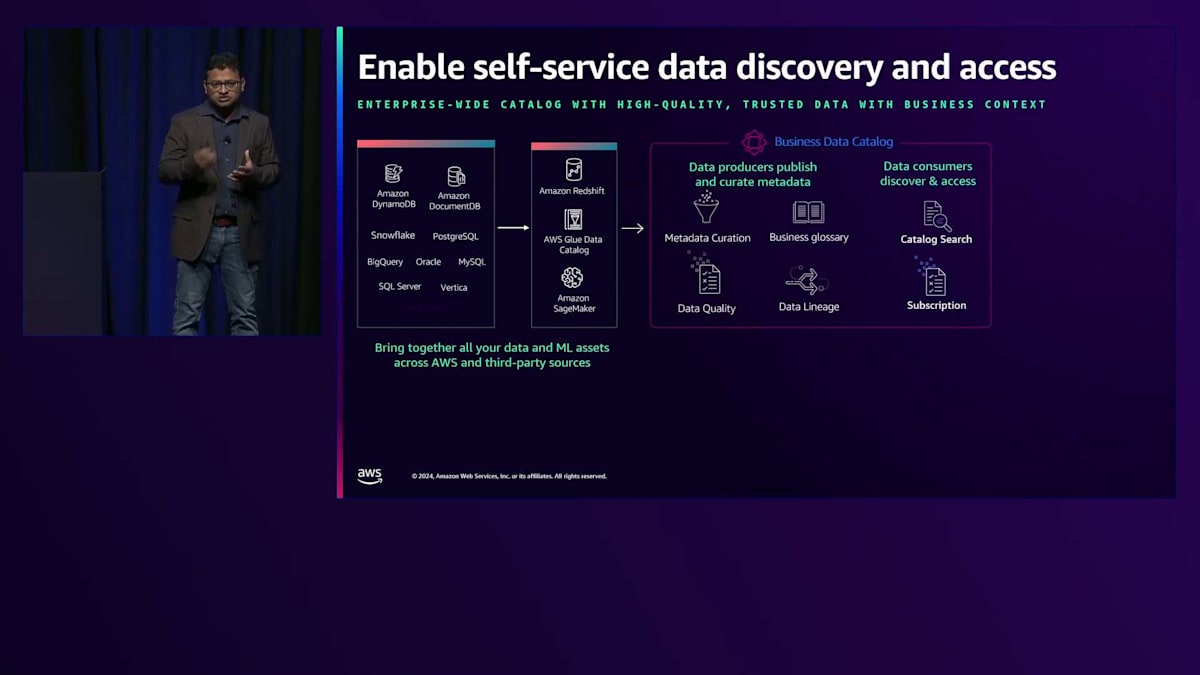


データコンシューマー側では、DataZoneは強力なカタログ検索機能を通じてこのカタログを公開し、ビジネス用語を使用してデータを見つけることができます。データコンシューマーがセルフサービスでデータへのアクセスをリクエストできるサブスクリプションワークフローを提供します。アクセスが承認されると、DataZoneは基盤となるシステムの権限を管理することで、データコンシューマーに自動的にアクセス権を付与します。アクセス権を取得すると、データコンシューマーは好みのツールでデータを利用できるセルフサービスツールを使用できるようになります。


DataZoneがどのようにセルフサービス分析を実現するのか、短いデモをご覧いただきましょう。ここでは、私が説明したすべての機能を体験できるDataZoneポータルにログインしています。最初に行うのはプロジェクトの選択です。プロジェクトは、DataZoneでデータを扱う方法です。右側には、Amazon SageMakerを含む、このプロジェクトで利用可能なツールが表示されています。デモに技術的な問題が発生しているようです。お見せしたかったのは、DataZoneを使ってカタログ内のデータを見つけ、データコンシューマーがビジネスコンテキストで簡単に理解し、データへのアクセスをリクエストし、承認後は好みのツールでそのデータを利用開始できる方法でした。
Amazon Redshift MLを活用したセルフサービス分析

それでは、私の同僚のRaghavarao Sodabathinaにバトンを渡したいと思います。皆さん、こんにちは。私はAWSのPrincipal Solutions Architectです。AWSで約5年間、お客様のセルフサービス分析の構築をサポートしてきました。一つ質問させてください:セルフサービス分析で複雑なビジネス課題を解決できることをご存知の方は何人いらっしゃいますか?手を挙げてください。何人かの手が挙がっていますね。ありがとうございます。では、セルフサービス分析でそれらの複雑な課題をどのように解決するかをご存知の方は?手が挙がっていませんね。ありがとうございます。

Amazon Redshift MLを使用してセルフサービス分析ソリューションを構築し、複雑な課題を解決する方法についてお話しします。セルフサービス分析を実現するための様々なツールについて説明し、リファレンスアーキテクチャをご紹介し、AWSでセルフサービス分析を始めるためのリソースについてお話しして締めくくりたいと思います。まずはAmazon Redshift MLから始めましょう。Redshift MLでは、SQLを使用して簡単にMLモデルを作成できます。ユースケースに基づいてMLアルゴリズムを選択できます。Redshift MLはデータの前処理、モデルの構築、モデルのチューニング、デプロイを行うことができます。推論はRedshiftクラスターに含まれているため、トレーニングにのみ料金が発生します。


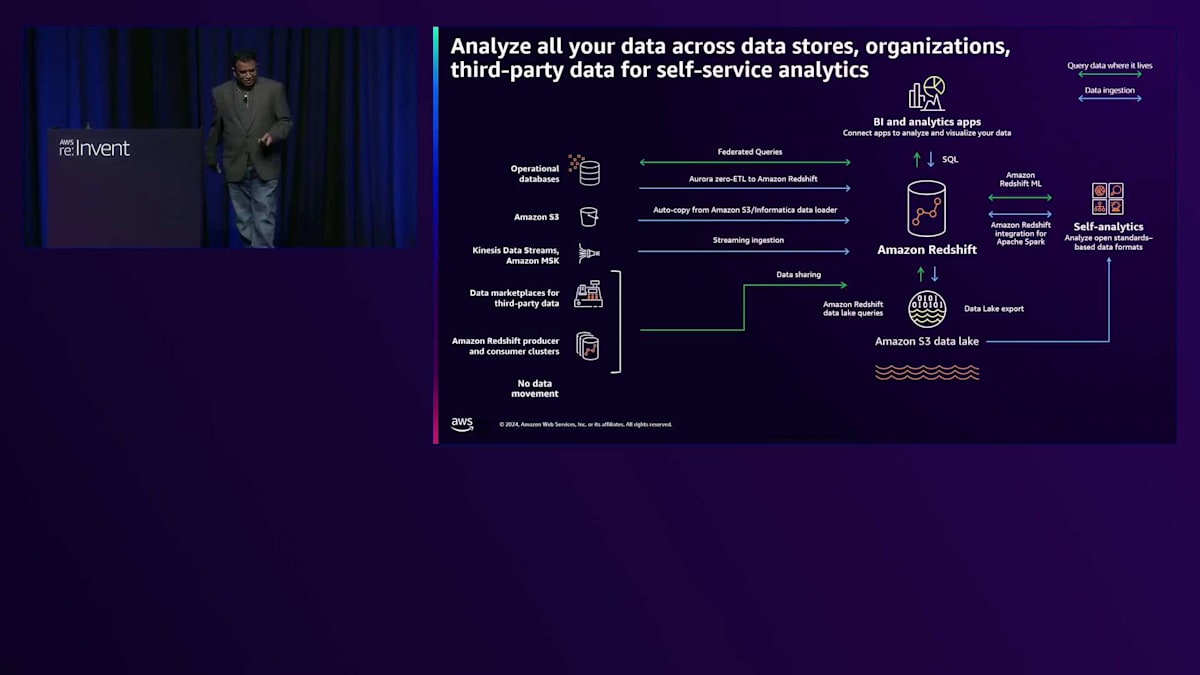
Redshift MLで何ができるかわかったところで、どのように行うかについて説明しましょう。Amazon Redshiftは、通常集計を含む履歴データの保存に使用されるクラウドデータウェアハウスです。様々なデータソースからAmazon Redshiftにデータを取り込むことができます。データがAmazon Redshiftに取り込まれると、SQLを使用して分析を実行し、データからインサイトを得ることができます。また、これからお話しするRedshift ML機能も備えています。Redshiftのイノベーションについてもっと知りたい方は、ちょうど今、午後1時30分からANT349というセッションが行われています。このセッションはYouTubeでご覧いただけます。

Amazon Redshift MLでできることについてお話ししましょう。予測分析やパーソナライゼーション、顧客離反など、高度な分析ユースケースに対して教師あり学習を活用できます。これらは、データウェアハウス内のデータを活用できるユースケースの一例です。

MLワークフローについて見ていきましょう。MLワークフローは複雑になる可能性があり、スライドを見ていただくと、まずデータの準備から始めて、モデルのアルゴリズムを選択してから、モデルの構築とトレーニングを行う必要があります。モデルを構築したら、ビジネス目標に基づいて期待する出力が得られているかを確認するため、モデルの評価指標を確認します。その後、デプロイと管理を行います。一般的に、モデルのトレーニングにはMLエンジニアやデータサイエンティストの支援が必要となります。

では、Amazon Redshift MLの仕組みについてお話ししましょう。データアナリストやデータベースエンジニアは、Amazon Redshiftデータウェアハウスに保存されているデータを使用して、シンプルなSQLクエリでMLモデルを作成できます。例えば、顧客離反を予測するモデルを作成する場合、Amazon Redshiftデータウェアハウス内の1つまたは複数のテーブルの列に対してクエリを実行できます。顧客プロファイルテーブルをモデルトレーニングの入力として使用し、顧客が離反したかどうかを示すターゲット列を設定できます。

簡単なユースケースを見てみましょう。顧客プロファイルデータに保存された履歴データを使用して、顧客予測モデルを構築したいとします。通常、ビジネスアプリケーションのデータは、Amazon RDSやPostgreSQLサーバーを使用したAmazon Aurora、あるいはSQL ServerやOracleなどの商用データベースのような関係データベースに保存されています。この顧客プロファイルデータをデータウェアハウスに取り込んで、履歴データを集計し、すぐに使用できるモデルを作成したいと考えています。モデルの出力に基づいて、顧客離反が発生している箇所を可視化し、即座に対応できるようにしたいと考えています。



アーキテクチャを見てみましょう。右側を見ると、先ほど述べたように、通常はAmazon Auroraデータベースのような関係データベースに保存されているビジネスアプリケーションがあります。ETLデータ処理パイプラインを作成することなくデータを取り込むことができます。図のように、Amazon AuroraとAmazon Redshift間のZero ETL設定を数回クリックするだけで有効にできます。そうすると、Amazon Redshift MLでデータを確認できます。モデルのトレーニングが完了したら、Amazon QuickSightを使用してダッシュボードとしてこのデータ出力を利用したり、他のビジネスアプリケーションと共有できるようにデータAPIを作成したりできます。

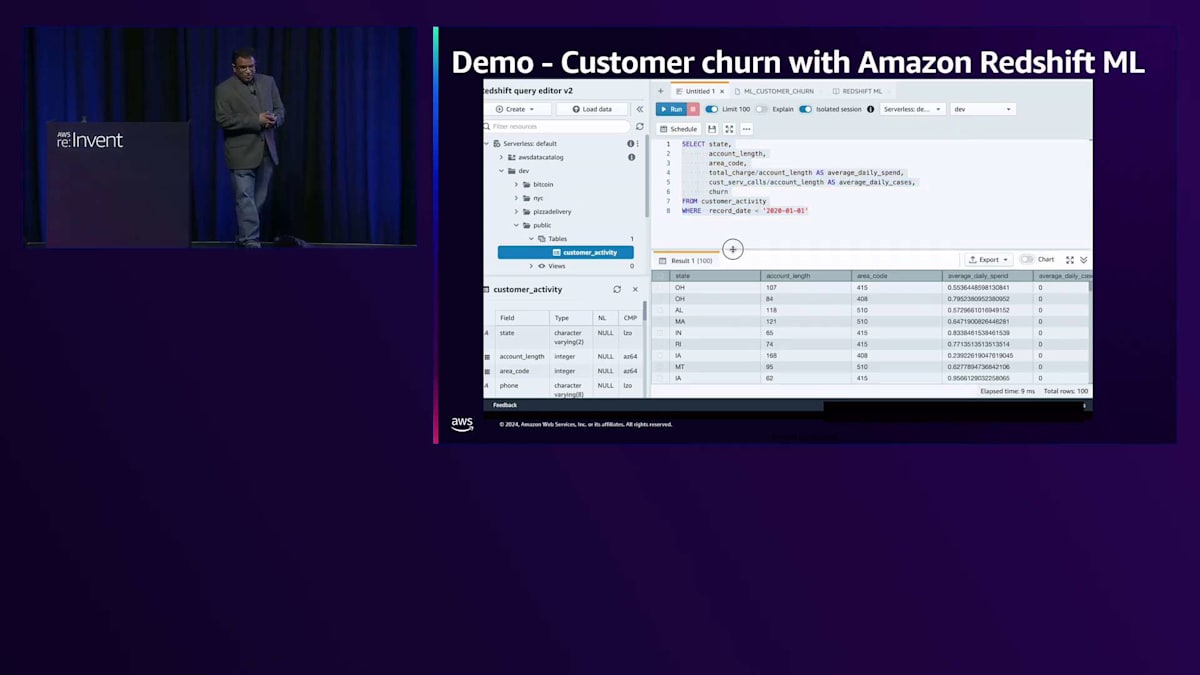
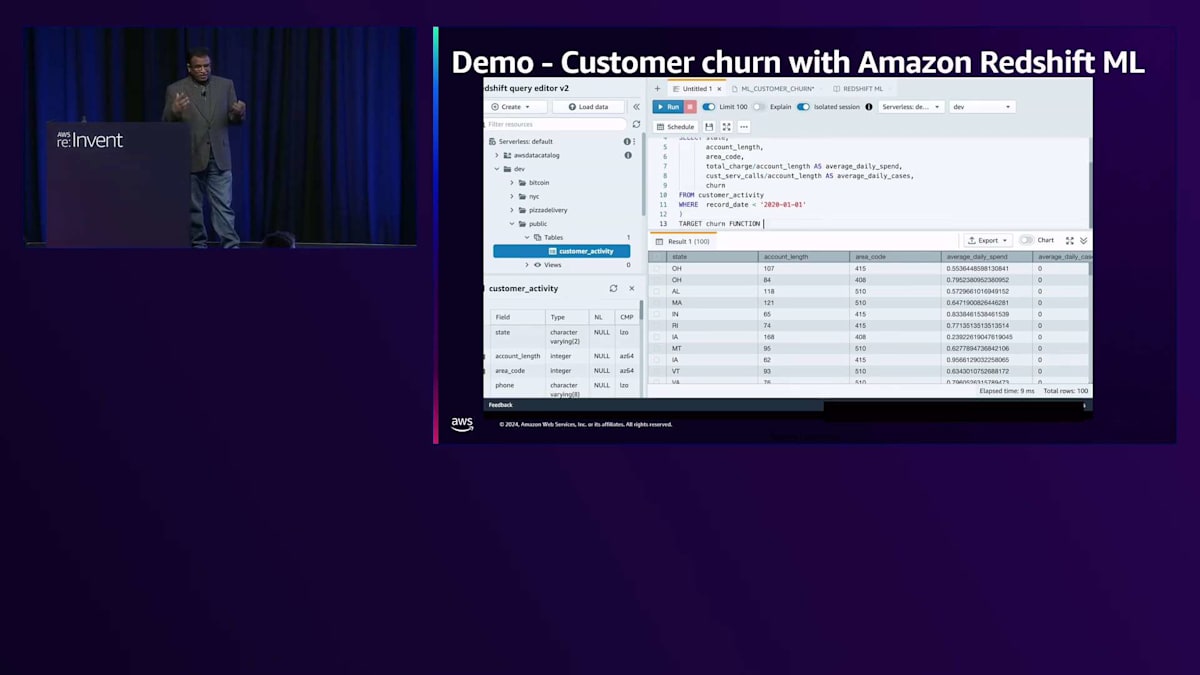
それでは、デモを簡単に見てみましょう。より詳しく学びたい方は、実際に体験できるAmazon Redshift MLワークショップがあります。ここでは、Customer Activity Tableに保存されている顧客プロファイルデータを使用しています。ターゲットをカラムとして指定し、それを関数として使用しています。この関数が作成されるMLモデルとなります。モデルがデプロイされると、バックグラウンドでAmazon Redshift MLはSageMaker Autopilotを使用して、この顧客データに対して複雑な実験を実行し、最適なモデルを導き出します。


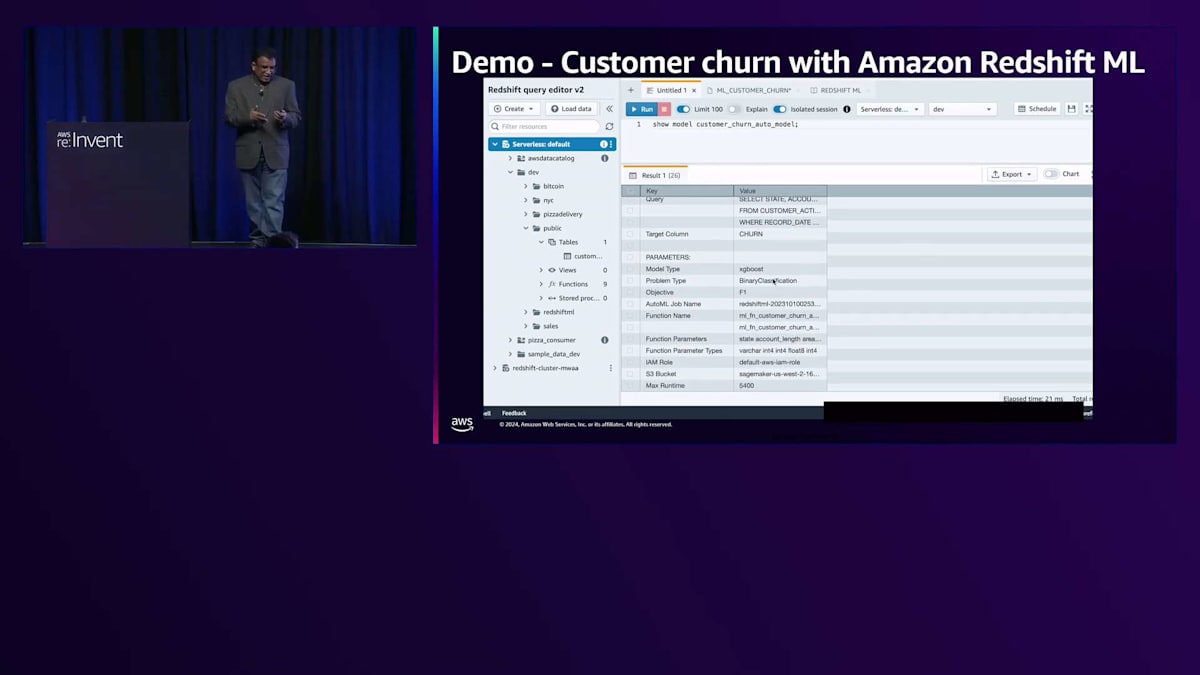
結果を見ると、モデルがトレーニング中か準備完了かが表示されます。ここでは単にSQLクエリを実行してモデルを確認しています。モデルが作成されると、現在はトレーニング中であることがわかります。別のクエリを実行すると、モデルが準備完了となり、使用しているアルゴリズムも確認できます。今回はXGBoostです。モデルが作成されデプロイされると、この関数はSQLクエリとして呼び出せるようになり、モデルからの結果を確認できます。

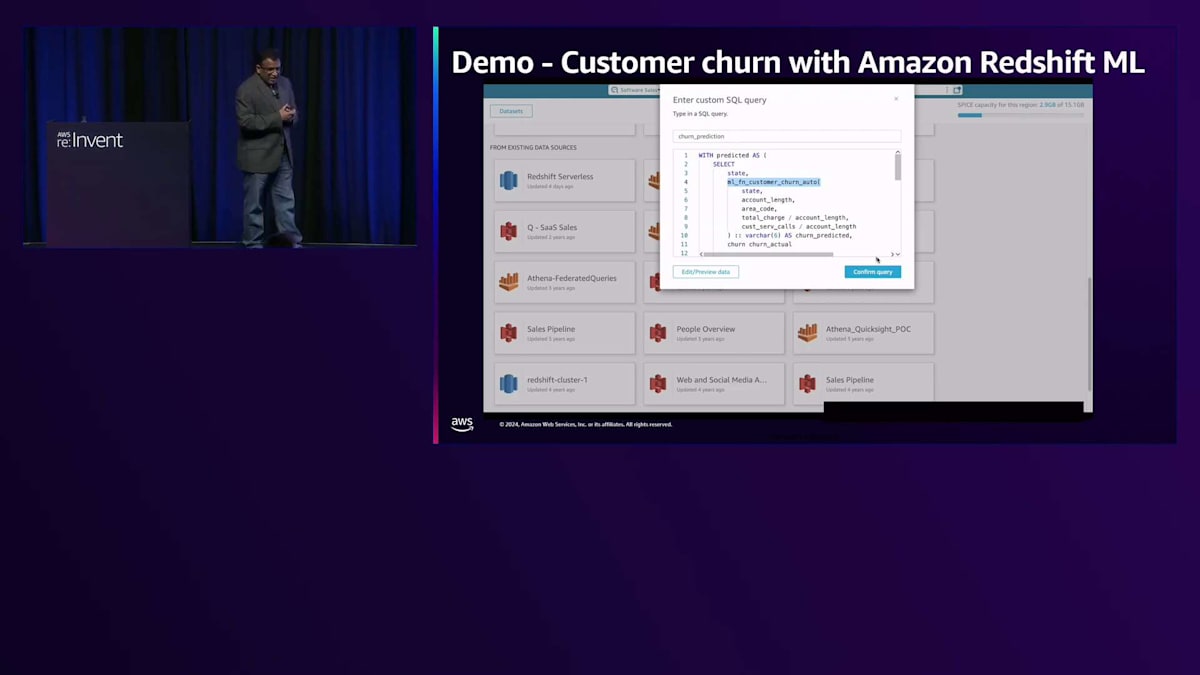
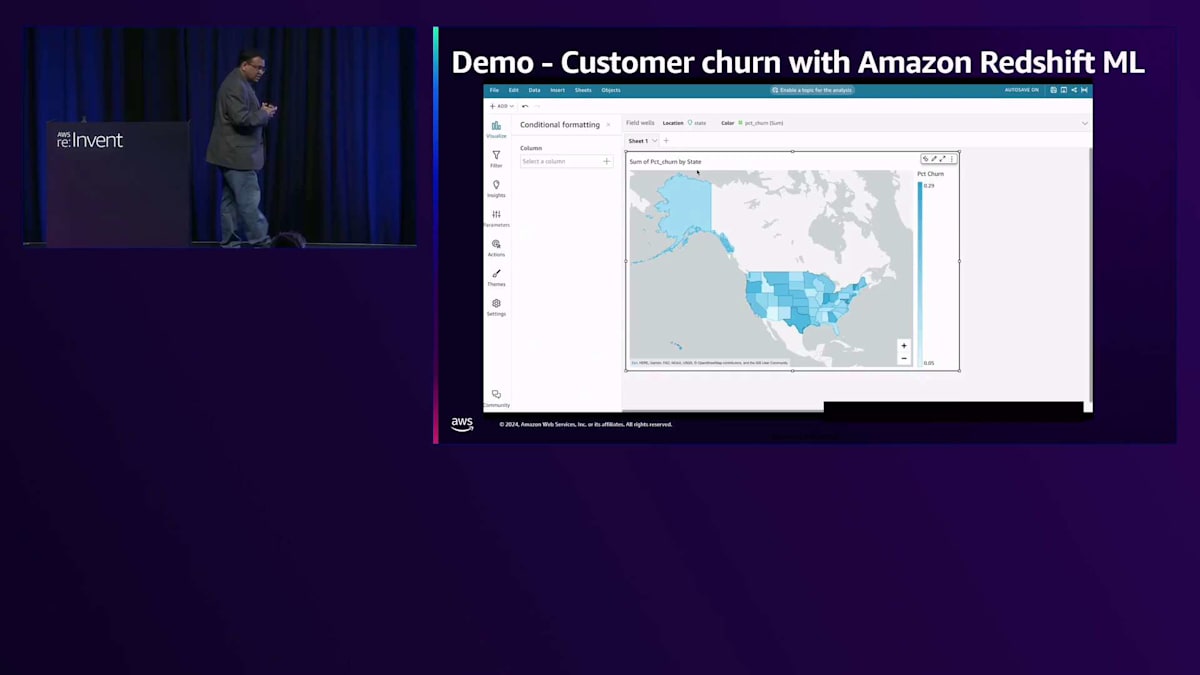
次に、その関数を呼び出してCustomer Activity Tableから顧客データを取得するモデルを実行します。MLモデルである関数が、結果がtrueかfalseかを教えてくれます。このML出力を使って、QuickSightダッシュボードを作成し、この結果をビジュアライゼーションとして素早く表示できます。そうすることで、顧客の解約がどこで発生しているかを把握でき、顧客維持のための最適なアクションを決定できます。このビジュアライゼーションでは、州レベルで確認することができ、この画面を見ると、インドやその他の州で顕著な顧客の解約や活動が発生していることがわかります。


マーケティングチームはこれらの地域で何が起きているかを分析し、適切な対策を講じることができます。まとめると、Amazon Redshift MLを使用することで、複雑なビジネス上の課題を迅速かつ簡単に解決できます。SQLでMLモデルを構築し、ユースケースに応じて最適なMLアルゴリズムを選択できます。モデルの予測はRedshiftクラスターに含まれているため、モデルのトレーニングにのみ費用が発生する形で、MLモデルを試し、チューニングし、デプロイすることができます。
AWSの統合開発環境によるセルフサービス分析の実現

それでは次のビルディングブロックについて詳しく見ていきましょう:Data Engineering、SQL Analytics、Machine Learning、そしてGenerative Developmentです。これらはデータユーザーが日常的に実行する機能の一部です。データユーザーがこれらの機能を独立して実行できるようにするには、ユーザーフレンドリーなローコード/ノーコードツールを提供する必要があります。例えば、データ処理にはEMR Studio、SQL分析にはRedshift Query Editor、機械学習にはSageMaker Studio、アプリケーション開発にはBedrock Studioを使用できます。

組織は通常、チームやプロジェクト単位で運営されています。 AWS IAMやAuth0などのIdentity Providerを使用して、これらのツールにユーザーを招待することができます。これらのツールはすべてGit統合機能を備えており、複数のデータユーザーが特定のユースケースで協働することができます。これは責任ある形でのセルフサービスを実現しています。というのも、ユーザーが作業を行うために必要なコンピューティングリソースとツールを提供し、これらの機能へ素早く簡単にアクセスできるようにしているからです。


それでは、各ツールを個別に見ていきましょう。データ処理、SQLアナリティクス、機械学習、開発に利用できるツールについてお話しします。Amazon EMRを使用すると、Apache Spark、Hive、Presto、Flinkなどのビッグデータ処理フレームワークを簡単に利用できます。また、EMRはAmazon S3データレイクに保存されているデータを直接処理することができます。AWS Glueはデータ統合サービスで、Apache Spark、Python、Scalaを使用してデータ処理のニーズに対応します。AWS Glueはビジュアルツールも提供しており、ビジネスアナリストはドラッグ&ドロップのインターフェースで複雑なデータ処理ジョブを構築でき、データエンジニアはJupyterノートブックでコーディング体験を得ることができます。

EMR Studioを使用したセルフサービス分析についてお話ししましょう。AWS SSOを使用するか、IAMやAuth0などのIdentity Providerとのサムル連携を構築することで、データユーザーをEMR Studioにオンボーディングできます。EMR Studioは、完全マネージド型のJupyterノートブックとGitリポジトリ統合機能を備えており、簡単にコラボレーションができます。ノートブックでリアルタイムの共同編集が可能で、EMR Studioを使用してユースケースに応じてEMRクラスターの閲覧、作成、削除を行うことができます。

次にGlue Studioについて見ていきましょう。Glue Studioは、Apache Spark、Python、Scalaをサポートするサーバーレスインフラストラクチャを提供します。バッチデータ処理、マイクロバッチ処理、ストリーム処理を実行できます。ローコード開発を好むデータエンジニア向けのビジュアルETLエディタでデータを変換したり、コードベースの体験を望むユーザー向けにノートブックを使用したりできます。Apache SparkやScala開発用のIDEも使用でき、複数のカラムの結合や欠損値の処理など、多くの組み込み変換機能が用意されています。

すべてを総合すると、IDE レベルでは、オーケストレーションワークフローと共にGlue StudioまたはEMR Studioを使用できます。AWS Glueワークフロー、AWS Step Functions、Amazon MWAAを利用でき、ランタイムとしてAWS GlueまたはAmazon EMRを選択できます。Apache Sparkに精通している場合はAWS Glueをお勧めしますが、HadoopやHiveなどの他のビッグデータフレームワークを使用したい場合は、Amazon EMRがより適切な選択となります。

Amazon Redshiftを使用したセルフサービスSQLアナリティクスについてお話ししましょう。ビジネス分析のために、生成AIを活用したRedshift Query Editorを使用できます。ビジネスアナリストは、SQL構文の知識がなくても自然言語を使ってSQLクエリを作成し、それをQuery Editorですぐに実行して、即座にインサイトを得ることができます。


自然言語で質問を投げかけることでSQLクエリを作成でき、素早く結果を得るためのコーディング推奨事項が提供されます。 Amazon SageMaker AIによる機械学習については、既存のSageMakerを「SageMaker AI」と呼んでいます。SageMaker Aと混同しないようにしてください。SageMakerには、データ準備、モデル構築フェーズ、トレーニングとチューニング、デプロイメントと管理という4つのカテゴリーに分類される幅広い機能が備わっています。これらの4つのカテゴリーを使用して、SageMaker Studioで完全なエンドツーエンドの機械学習パイプラインを構築できます。

SageMaker StudioにはJupyterLabが付属しており、インタラクティブな開発のために完全マネージド型のJupyter notebookを数秒で起動できます。また、Data Wranglerを使用した低コードのデータ準備機能もあり、MLモデル用のデータ準備を素早く構築できます。モデルを選択するか、Foundation Modelを含む約300の公開モデルがSageMaker JumpStartで利用可能です。さらに、SageMakerはTensorFlow、PyTorch、Apache MXNet、Hugging Faceなどの主要なフレームワークをサポートしています。SageMaker Studio内ですべてのMLモデルを監視し、Amazon SageMaker Studioを使用してエンドポイントをデプロイできます。

AWSの生成AIスタックについて説明しましょう。最下層では、RecordMLハードウェアを提供しています。独自のFoundation Modelを構築したい場合は、本日の基調講演で触れられたように、AnthropicがFoundation Model構築に使用しているこのハードウェアを利用できます。Amazon Bedrockには多くのFoundation Modelが用意されており、これらを使用してデータを活用した生成AIアプリケーションを構築できます。生成AIでは、Prompt Engineering、RAG、Fine-tuningなど、さまざまなデザインパターンを実装できます。ビジネス向けのAmazon Qは、SalesforceやSharePointなどの企業データソースと連携して多くのタスクを自動化し、AWSサービスに関するインサイトを提供します。Amazon Q Developerを使用してコードを作成することもできます。
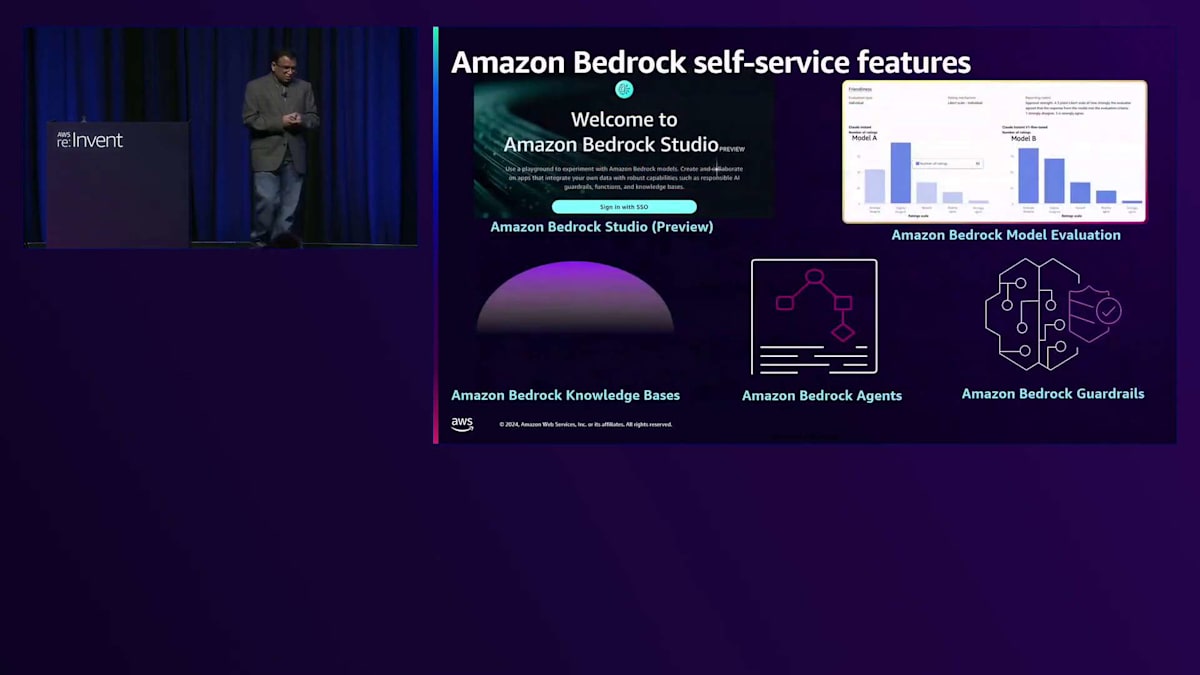
現在、様々なAPIを使用して生成AIアプリケーションを構築できるBedrock Studioがあります。Amazon Bedrockには、ユースケースに最適なモデルを素早く評価できるModel Evaluationが含まれています。Amazon Bedrock Knowledge Baseは、生成AIアプリケーションを構築するために、ドメイン中心のデータと接続するRAGデザインパターンを自動化できます。Bedrock Agentsは複雑なタスクを自動化できます。例えば、クライアントのオンボーディングパイプラインを構築する場合、Amazon Bedrock Agentにこれらのプロセスの自動化を依頼できます。最後に、Amazon Bedrock Guardrailsを使用することで、責任あるAIポリシーの構築、ワードフィルターの実装、特定のトピックの拒否、PIIデータの検証が可能です。

次は、Amazon SageMaker Unified Studioについてお話しましょう。これは本日のKeynoteで取り上げられ、また先ほどSrikanthがデータディスカバリーとデータ検索のためのビジネスカタログを備えたLakehouseとデータについて説明しました。Amazon SageMakerは統合開発環境を提供するもので、現在パブリックプレビュー中です。
データの準備、処理、分析、モデル構築、アプリケーション開発といった作業を、ノートブックやクエリエディタなどのツールを様々なAWSデータサービス全体で統合して実行できます。データ処理やSQLアナリティクスのためのAmazon EMR、AWS Glue、Amazon Athena、Amazon Redshift、機械学習のためのAmazon SageMaker AI、開発のためのAmazon Bedrockとシームレスに連携します。将来的には、ストリーミング、検索、Business Intelligenceサービスもサポートする予定です。

EMR StudioやGlue Studioと同様に、AWS SSOを使用するか、お客様のIdentity Providerで認証を構築してデータユーザーをオンボーディングできます。データユーザーは、SageMaker Unified Studioプロジェクトで、既存のプロジェクトを利用するか、ビジネスユースケースに基づいて新しいプロジェクトを作成できます。職務や役割に応じて、他のデータユーザーとコンピューティングリソース、データ、コードを共有して、複雑な問題を解決することができます。

Amazon SageMaker Unified Studioのインターフェースには、様々なツールが用意されています。IDEとアプリケーションの下には、JupyterLab、クエリエディタ、ビジュアルETLツールがあります。機械学習の下には複数のオプションがあります。メインタブは「Discover」「Build」「Govern」の3つです。Discoverではデータの探索が可能で、Buildではセルフサービス分析を実現するための様々なツールを使用できます。Governでは、データスチュワードがユーザーの役割に基づいてツールアクセスのポリシーを作成できます。

Amazon SageMaker Unified Studioでのデータ処理については、Amazon Qによる提案機能を備えたノートブックを使用できます。SQLアナリティクスについては、統合スタジオ内に自然言語でSQLアナリティクスを作成できるクエリエディタがあります。機械学習については、SageMaker AIが統合スタジオ内で様々なツールを提供しています。Bedrockについては、現在プレビュー中のBedrock IDEがあり、現行のBedrock Studioの機能をすべて含んでいます。


これらのツールはすべて、ツールの使用方法やコラボレーションに関する提案を提供するAmazon Q Developerによってサポートされています。顧客体験を向上させるためにパーソナライズされたレコメンデーションモデルを組織内の複数のユーザーが構築したいという複雑なユースケースを考えてみましょう。 複数の担当者が相互にやり取りできる統合された開発環境を提供したいと考えています。




このプロセスは、ビジネスアナリストがSQLエディターを使用してデータ探索を行うところから始まります。次にデータエンジニアがビジネスアナリストの作業を確認し、 Notebookやビジュアルツールを使用してデータ処理を行います。その後、機械学習エンジニアやデータサイエンティストが SageMaker AIやNotebookを使用してMLモデルを構築します。ML Appsエンジニアはこれらの モデルをモデルメトリクスと照らし合わせて評価し、ビジネスユースケースに最適なモデルを選択します。最後に、アプリケーション開発者が 推論エンドポイントをビジネスユースケースと統合します。

このアプローチにより、様々なビジネスユーザーがNotebookやコードを各担当者間で共有しながら、複雑な問題を協力して解決することができます。このコラボレーションは、SageMaker Unified Studioプロジェクト内で行われ、チームメンバー全員が効果的に協力することができます。これらの人々が互いに協力し合うことで、より深い洞察が得られ、より良い意思決定が可能になります。GitHubを通じてコードを共有する必要がなく、全員がUnified Studioプロジェクトにアクセスしてビジネスアナリストの作業を確認でき、データチームが更なるデータ処理を進め、データサイエンティストがモデル構築の準備が整っているかを判断できるため、運用効率が向上します。

これは、1つのビジネスプロセスがあり、各ビジネスプロセスにデータ関連の作業に必要なツールが揃っているというモジュラーなアプローチを表しています。Unified Studioにはこれらのツールが装備されており、複雑な問題を効率的に解決することができます。まとめると、専門的なツールやエディターを使用して統合開発を シンプルにすることで、ビジネス価値の創出に焦点を当てています。このため、インフラストラクチャの管理やツールについて心配する必要はなく、オンボーディングプロセスを完了するだけです。これらのツールはすべてAmazon SageMaker Unified Studioに付属しています。


ここで、いくつかの追加リソースをご紹介したいと思います。 例えば、AWS Glue Studioを使用したセルフサービス分析に関する優れたブログがあります。また、先ほど言及したEMR Studioについての情報や、その使用方法に関する有用なブログもあります。Amazon SageMakerについてもっと学びたい場合は、いくつかのセッションが用意されています - このスライドを写真に撮ることをお勧めします。 これらのセッションのいずれかに参加することができます。今回はAmazon SageMakerのセルフサービス分析の側面について概要レベルでしか説明していませんが、Amazon SageMaker Lakehouse、Amazon SageMaker Business Catalog、またはAmazon SageMaker Unified Studioについてより詳しく学べる個別のブレイクアウトセッションがあります。
皆様、お時間をいただきありがとうございました。モバイルアプリでのアンケートにご協力をお願いいたします。質問がございましたら、私どもはしばらくこの壇上におりますので、お気軽に前までお越しください。どのようなご質問にも喜んでお答えさせていただきます。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion