re:Invent 2025: Amazon Auroraの10周年記念、アーキテクチャとI/O-Optimized等の新機能解説
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
re:Invent 2025 の書き起こし記事については、こちらの Spreadsheet に情報をまとめています。合わせてご確認ください
📖 re:Invent 2025: AWS re:Invent 2025 - Deep dive into Amazon Aurora and its innovations (DAT441)
この動画では、Amazon Auroraの10周年を記念し、Senior Principal EngineerのTimが最新のイノベーションを紹介しています。Auroraのログベースアーキテクチャ、3つのアベイラビリティゾーンにまたがる6コピーのストレージ、global databaseのスイッチオーバーが約30秒に短縮されたことなど、基盤技術を詳しく解説。Aurora PostgreSQLの動的データマスキング、I/O-Optimizedによる最大2.7倍のパフォーマンス向上、tiered cacheを活用したOptimized Reads、zero-ETL統合、blue-greenデプロイメントによるメジャーバージョンアップグレード、AWS Organizations Upgrade Rollout Policyなど、実用的な新機能を豊富なベンチマーク結果とともに紹介。さらに、数秒でクラスター作成が可能なExpress Configuration、agentic AI向けのメモリ活用、Aurora DSQLとの比較など、幅広いトピックをカバーしています。
※ こちらは既存の講演の内容を最大限維持しつつ自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますのでご留意下さい。
本編

DAT441へようこそ:Aurora 10周年とセッション概要
私の名前は Tim です。Aurora の Senior Principal Engineer をしています。DAT441 へようこそ。ここでは Amazon Aurora とこの年の革新について話していきます。このトークは毎年やってきたんですが、今年は少し違う形になります。理由は2つあります。1つ目は、もし以前このトークを見たことがあれば、いつもと違うプレゼンターなんです。私は Grant ではないんです。そして2つ目は、Aurora が今年10周年を迎えたということです。
もしまだご存知でなければ、Aurora の10周年を祝ったということです。ありがとうございます。そして Aurora おめでとうございます。そのケーキは世界の反対側からでも美味しかったです。ライブストリーミングイベントをやって、10年間ずっと私たちと一緒に働いてくれた人たちを見ることができて、たくさんのクールなデモを見ることができました。もし興味があれば、ぜひそのライブストリームをチェックしてみてください。QR コードでまだアクセスできます。

でも、もしこのトークを見たことがなければ、少し方向付けをしたいと思います。では Amazon Aurora とは何でしょうか? Aurora はクラウドネイティブなリレーショナルデータベースで、ハイエンドな商用データベースのスピードと可用性と、オープンソースのシンプルさとコスト効率を組み合わせたものです。完全にマネージドで、MySQL と PostgreSQL にそれぞれ完全互換です。サーバーレスと機械学習アプリケーションにプラグインできるツールがたくさんあります。互換性があるので、Aurora を使うためにアプリケーションを変更する必要がありません。そして PostgreSQL や他のデータベースのすべての拡張機能も動作します。

Aurora ファミリーの最新の追加は、Aurora DSQL という3番目のエンジンです。これは Distributed SQL の略です。 このトークでは DSQL について深く掘り下げることはありませんが、最後の方で少し話します。もし DSQL に興味があれば、最後に見るべき他のトークをいくつか紹介します。

Auroraのアーキテクチャ:ストレージ分離とマルチAZ構成の仕組み
私はエンジニアなので、これは技術的なトークです。少し技術的になる必要があります。 まず Aurora のアーキテクチャについて話します。これは今日話すことの多くの基礎になっていて、かなりクールだと思います。もし興味がなくても、残念ですが、とにかく私がオタク的に話すのを聞いてください。 ここに今日何度も見ることになる一般的な図があります。3つのアベイラビリティゾーンです。下部には Aurora ストレージがあります。これが本当に Aurora を特別にしているものです。

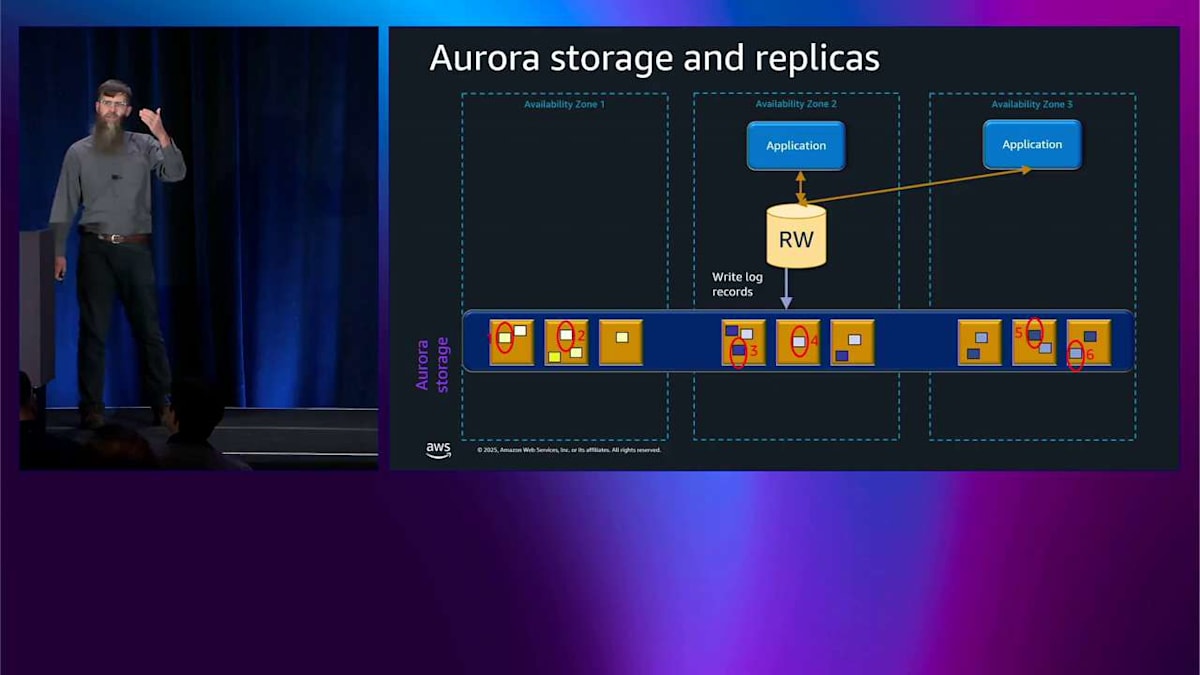
まず最初に見えるのは、この大きな青いボックスが3つのアベイラビリティゾーンすべてをカバーしているということです。つまり、Aurora では最初からすぐに3つのアベイラビリティゾーンのストレージを備えているということですね。 ここには黄色いボックスがたくさんあって、これはストレージノードを表しているんですが、実際にはこの9個よりもはるかに多くのノードがあります。アプリケーションは2つの異なるアベイラビリティゾーンで動作している2つのアプリケーションノードを持っていて、ここの読み書きノードと直接通信し、ストレージとも直接通信しています。
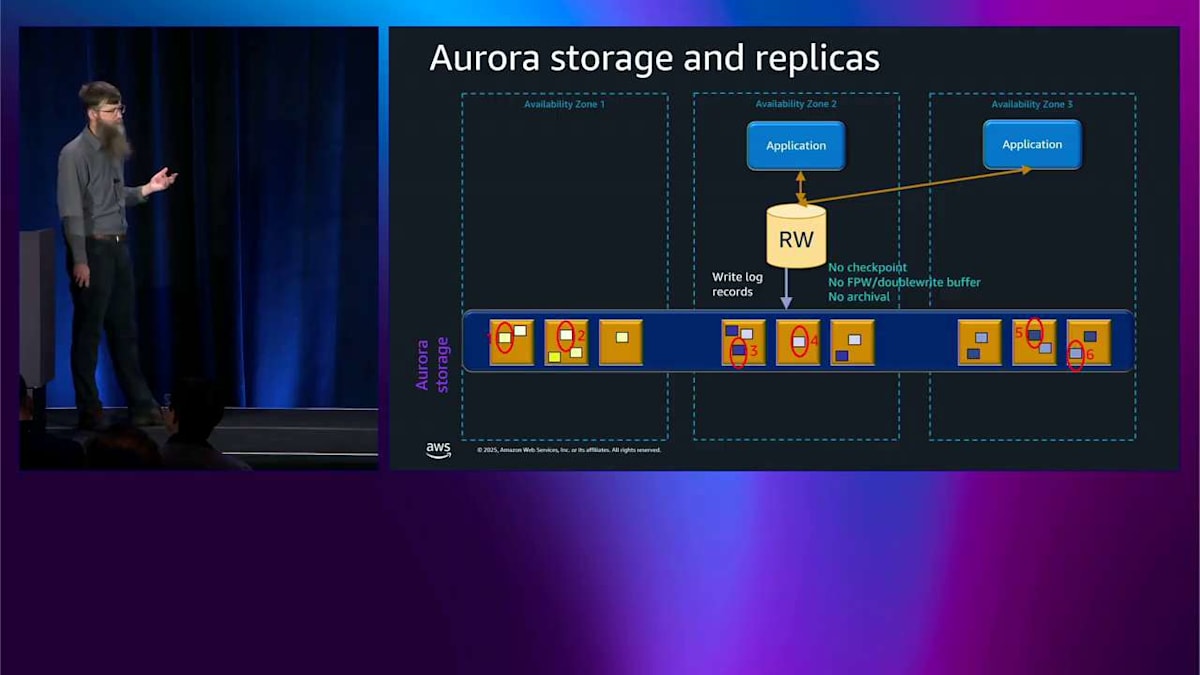
では、このストレージに何を書き込んでいるのかというと、ログレコード、つまりデータベースログレコードを書き込んでいます。これらはデータベースが通常書き込むデータの一部を変更するための指示です。このストレージの特別な点は、これらのログレコードをデータベースページに変換する方法を理解しているということです。 つまり、従来のデータベースのようなチェックポイントもなければ、フルページライトもなく、ダブルライトバッファもなく、ログアーカイブもないということです。従来のデータベースで通常発生するようなこれらの種類の問題はここでは発生しません。
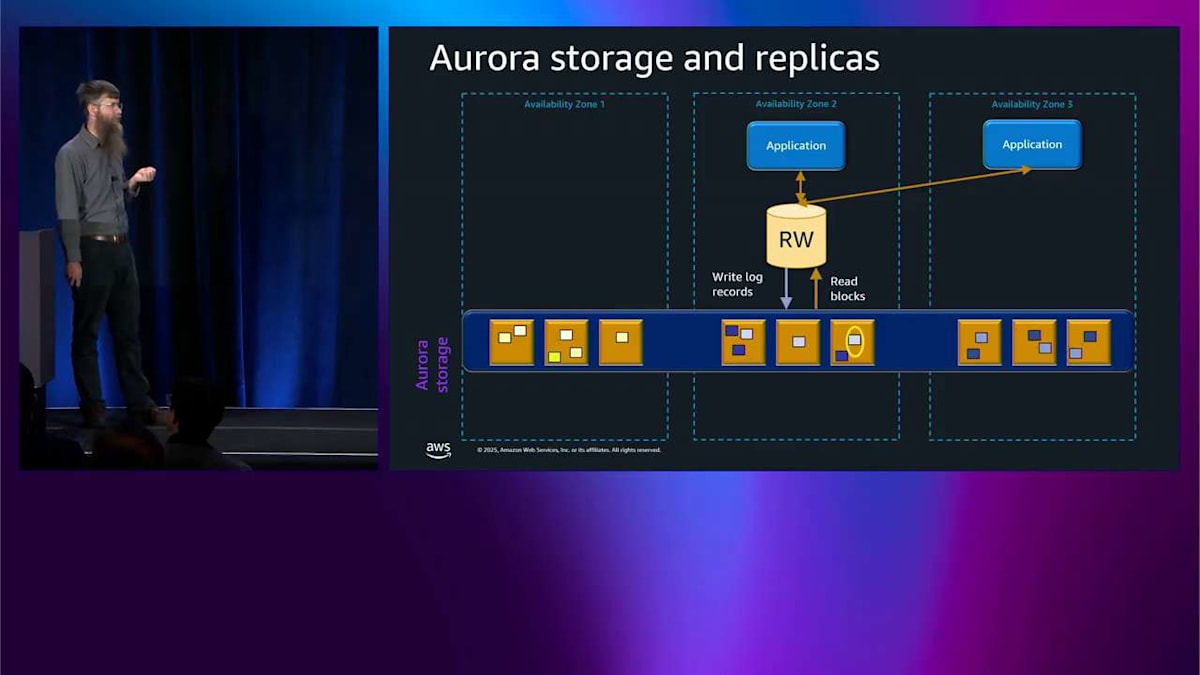
ここで私の色分けも見えると思いますが、データの各部分について6つのコピーが6つのストレージノード全体に書き込まれています。1回書き込むたびに、3つのアベイラビリティゾーン全体で6つのコピーが得られ、これも最初からすぐに備わっています。 ログレコードを書き込みますが、データベースページを読み戻します。これはストレージがそれらのログレコードをページに変換できるからです。
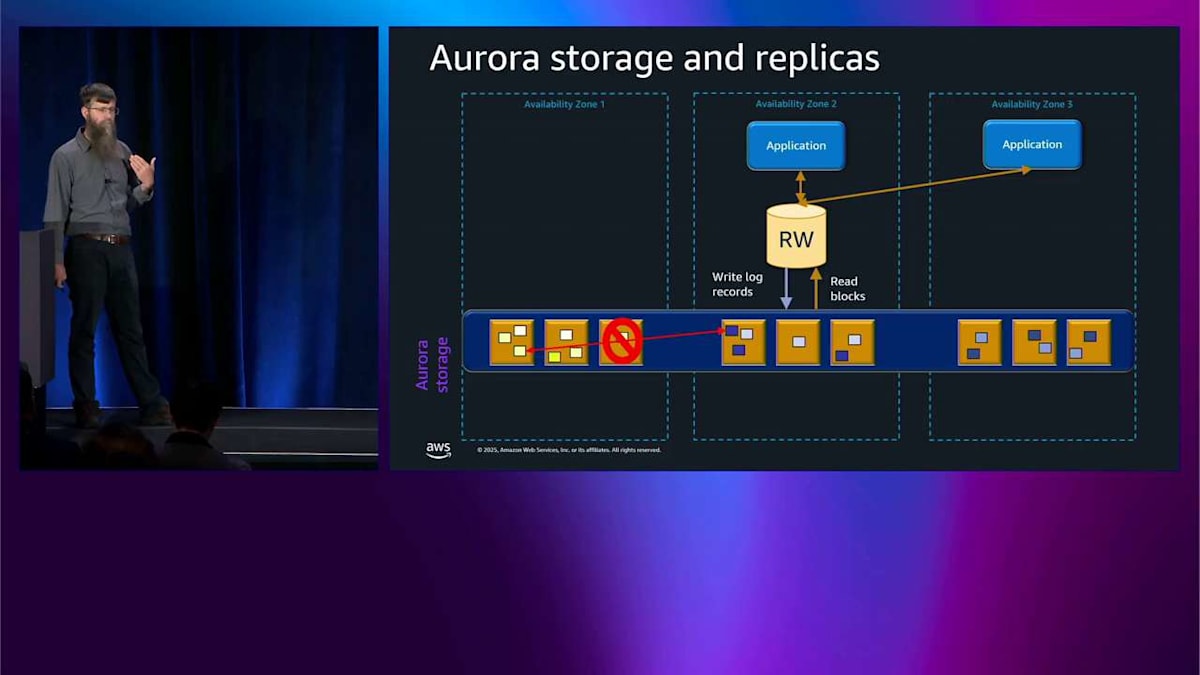
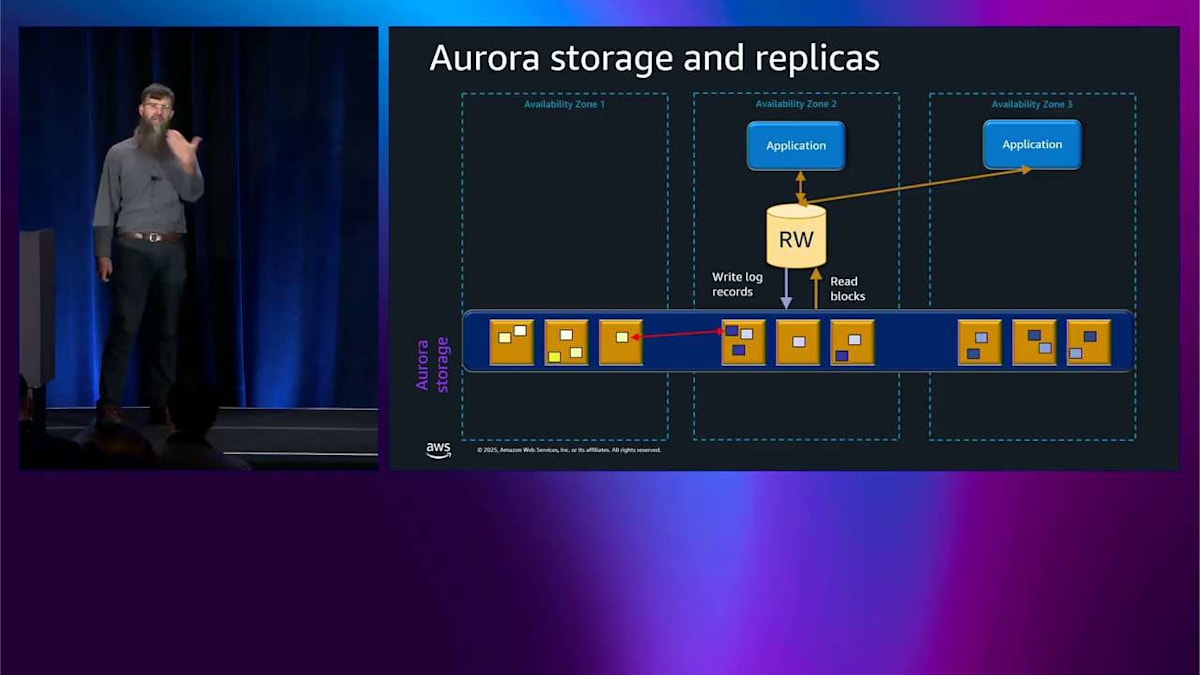
では、ログレコードの一部が破損したり、見落とされたりした場合はどうなるのでしょうか? まあ、別のアベイラビリティゾーンにある別のストレージノードからピアツーピアで修復するだけです。 では、ストレージノード全体がなくなった場合はどうなるのでしょうか? やはり、別のノードからピアツーピアで修復するだけです。これはすべてデータベースエンジンの内部で起こっていて、それが起こっていることさえ知りません。

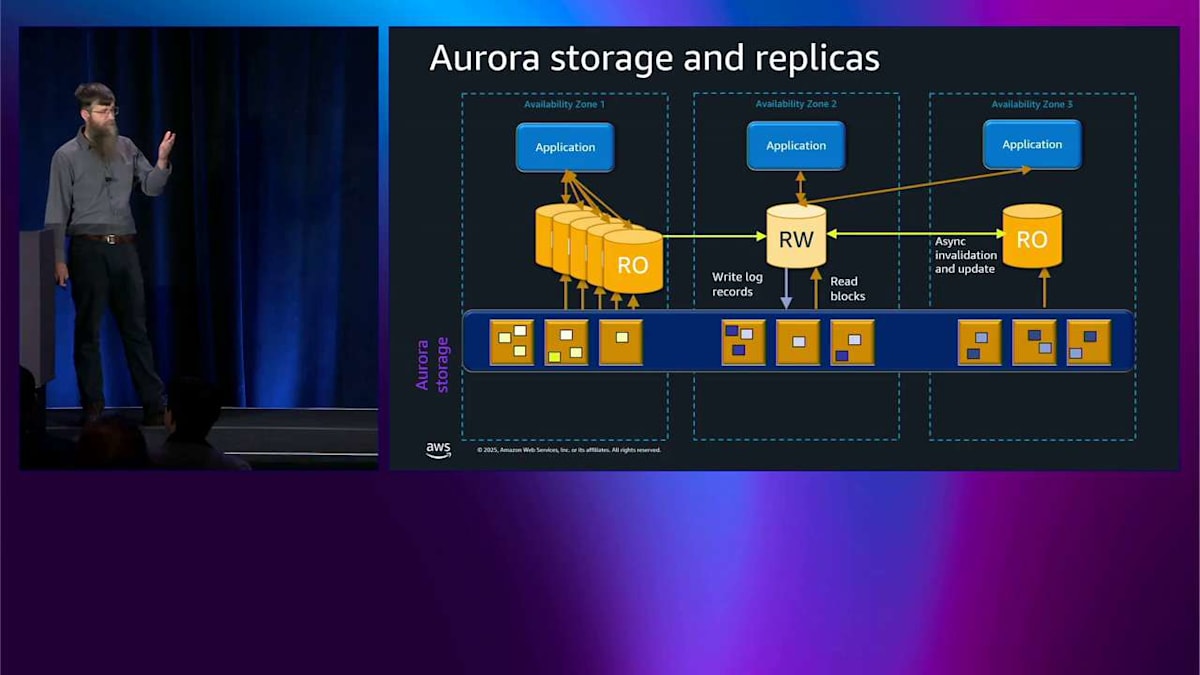
別のレプリカを追加することができます。ここでは読み取り専用のものです。 これは同じストレージから読み取っているので、この2つの間に一貫性のラグはありません。同じストレージです。これら2つのヘッドノード間で非同期の無効化と更新を行っています。つまり、読み書きノードでトランザクションを実行すると、読み取り専用ノードはわずか数ミリ秒以内にそれについて知ることになります。これらのレプリカは最大15個まで追加でき、異なるアベイラビリティゾーンに配置することも、同じアベイラビリティゾーンに配置することもできます。
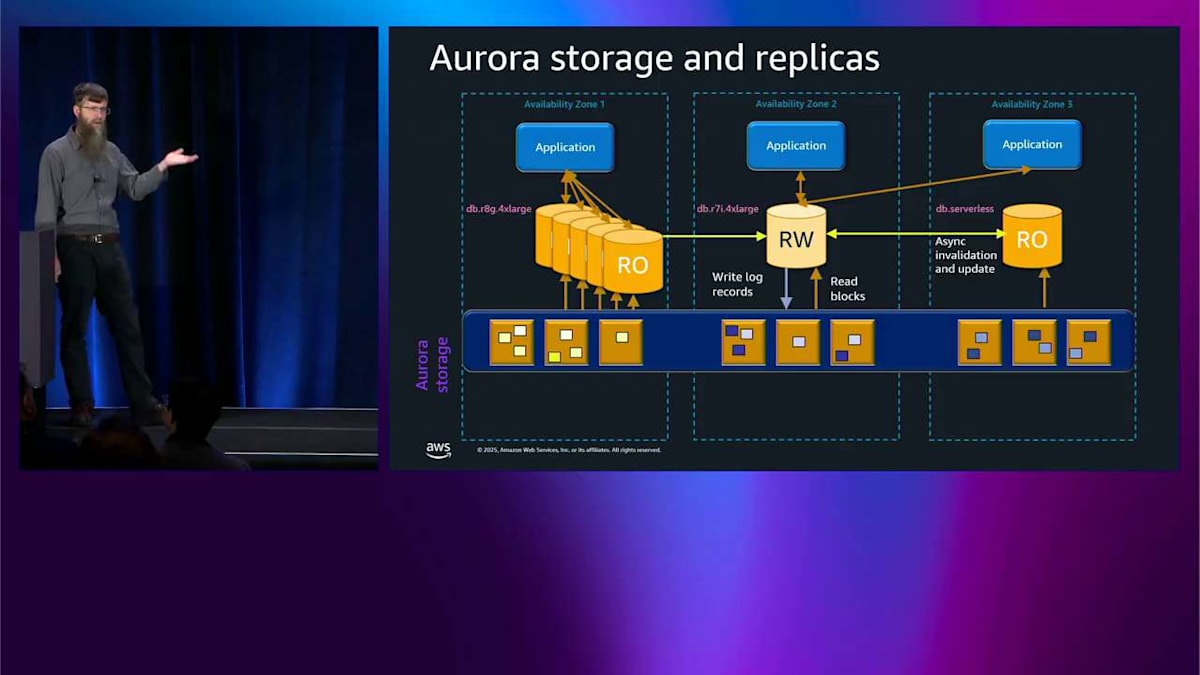
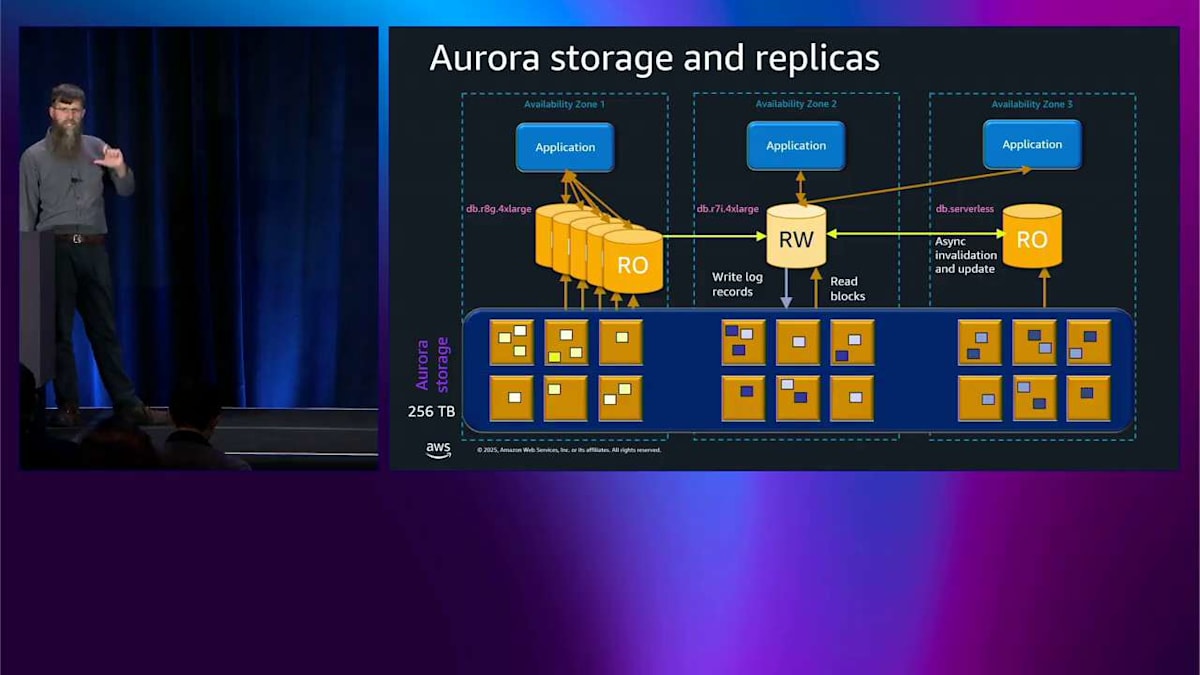
繰り返しになりますが、これは非破壊的です。クラスタやその他のレプリカをリブートする必要はありません。好きなように追加したり削除したりできます。 これらのレプリカはサイズも種類も異なるインスタンスにすることができます。ここには Graviton プロセッサの R6G があり、Intel の R7i があり、そして後でもっと詳しく説明する db.serverless もあります。



ストレージは自動的に 256 テラバイトまで拡張されます。このスペースをプロビジョニングする必要もなく、パフォーマンスをプロビジョニングする必要もありません。これは完全に弾力的で自動的です。 何か問題が発生した場合、例えばヘッドノードの可用性ゾーン全体を失った場合、そのレプリカの 1 つを自動的に昇格させて読み取り・書き込みノードにすることができます。 アプリケーションは Route 53、つまり DNS サーバーをチェックし、エンドポイントを変更して、読み取り・書き込みノードと通信を開始します。さらに高速なフェイルオーバーが必要な場合は、通常 DNS を待つため約 30 秒かかりますが、JDBC、ODBC、Node.js などの高度な高速ドライバを使用できます。 これらは数秒以内に切り替えることができるため、最大 66 パーセント高速化されます。これが Aurora アーキテクチャの駆け足ツアーです。
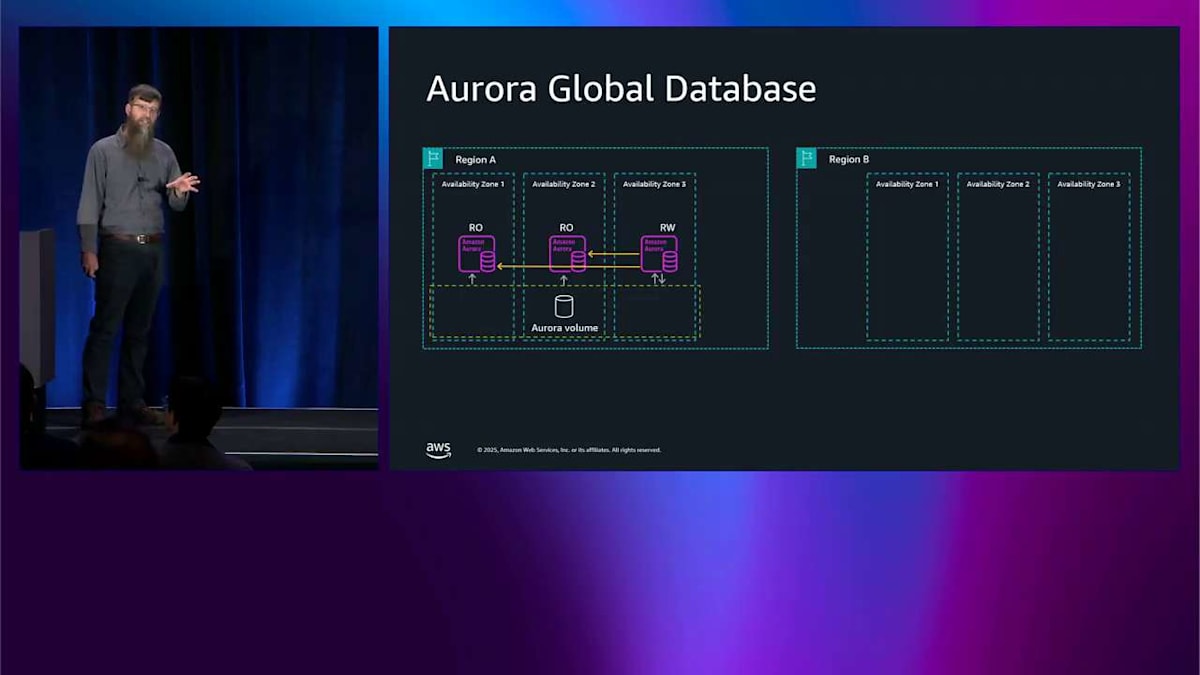

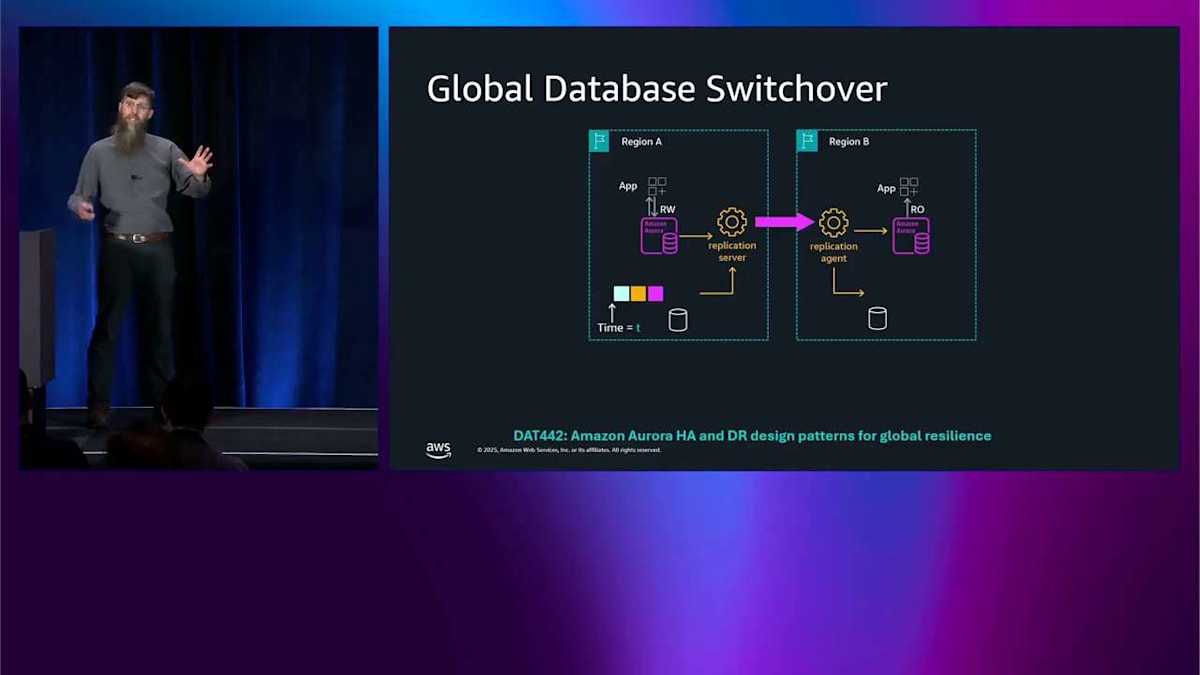
Global Databaseとスイッチオーバー:マルチリージョン展開の進化
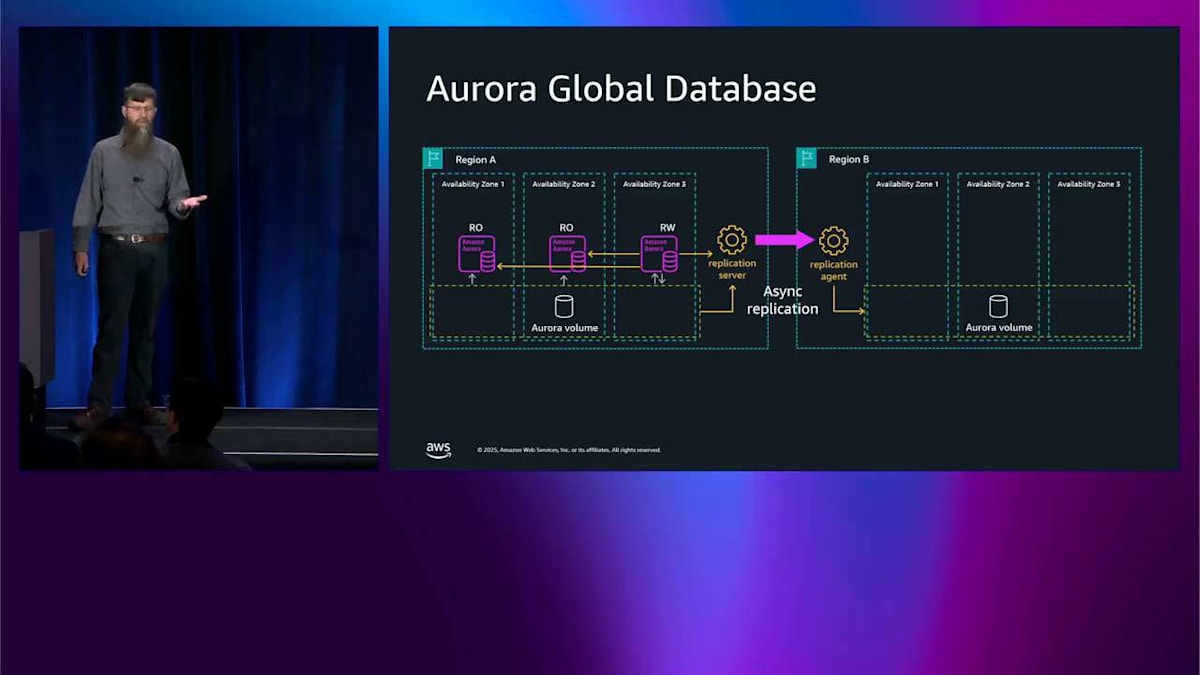
後でテストして、理解できているか確認しますね。 これが可能にすることの 1 つは、マルチリージョンに対応することです。これは左側と同じ図で、右側には global database と呼ばれる別のリージョンがあります。別のリージョンを追加するとき、ここで最も基本的にできることは ストレージを非同期的にレプリケートすることです。よく見ると、オレンジ色の矢印がレプリケーションサーバーを通り、レプリケーションエージェントに向かっています。これらはあなたが管理するのではなく、私が管理するものです。ヘッドノードからではなく、ストレージから来ています。ヘッドノードは関与していないため、アプリケーションは global database が起こっていることを知らず、変更を加える必要もありません。 レプリケートしているため、書き込みするとき、ログレコードはレプリケーションサーバーとエージェントを通り、反対側のストレージに入ります。
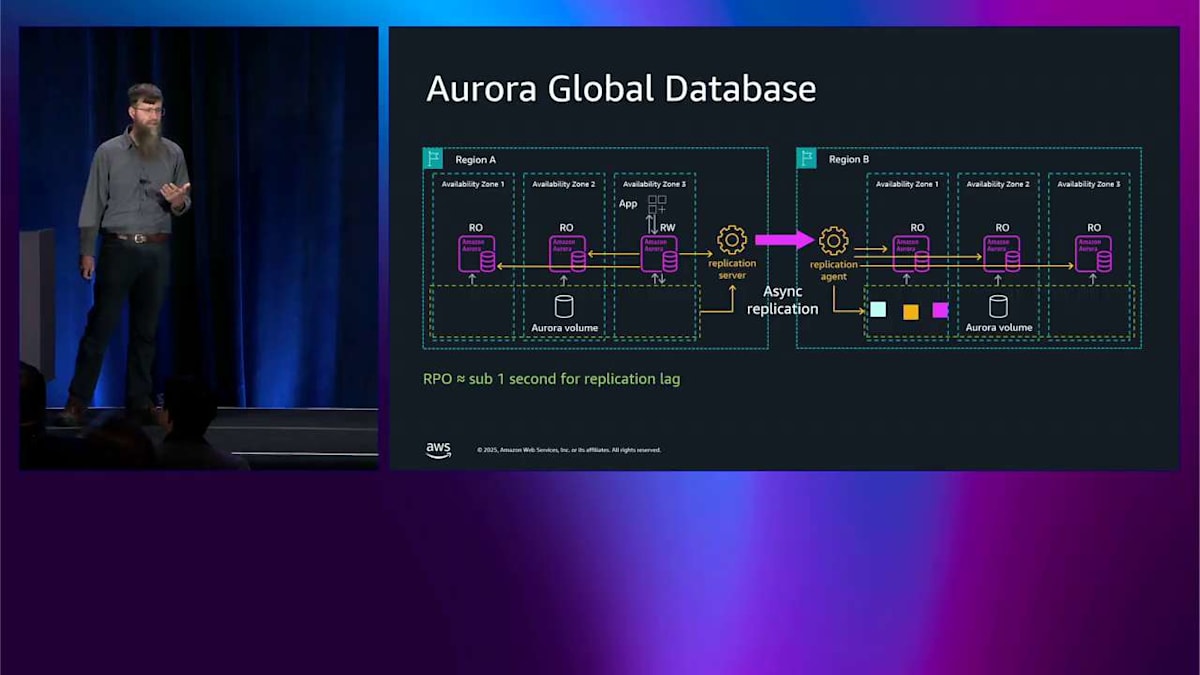
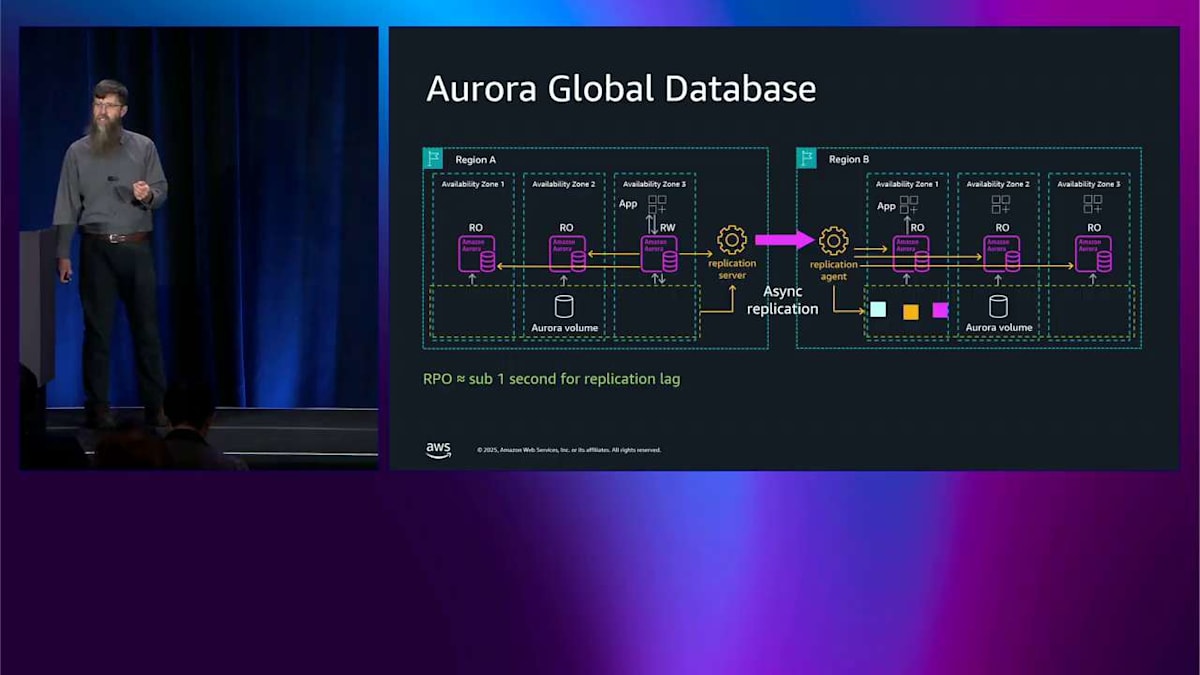
これで B リージョンの反対側にもレプリカを作成できます。 これは単一ライターシステムなので読み取り専用になり、RPO ラグ内で同じデータを見ることができます。これは通常、選択した 2 つのリージョンに応じて 1 秒未満です。これらのリージョンは最大 15 個、または好みに応じて最大 10 個持つことができます。アプリケーションを別のリージョンで実行することもできます。 これは低レイテンシーのリージョンローカル読み取りを行うための本当にクールなパターンなので、クロスリージョンレイテンシーについて心配する必要はありません。
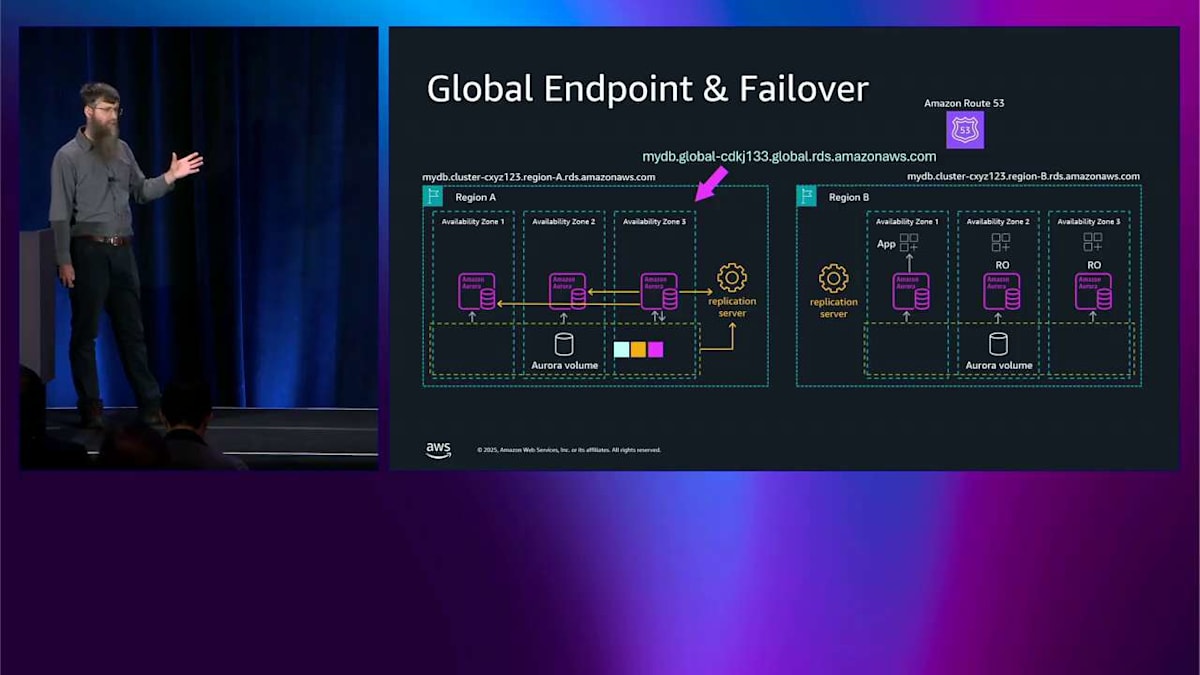
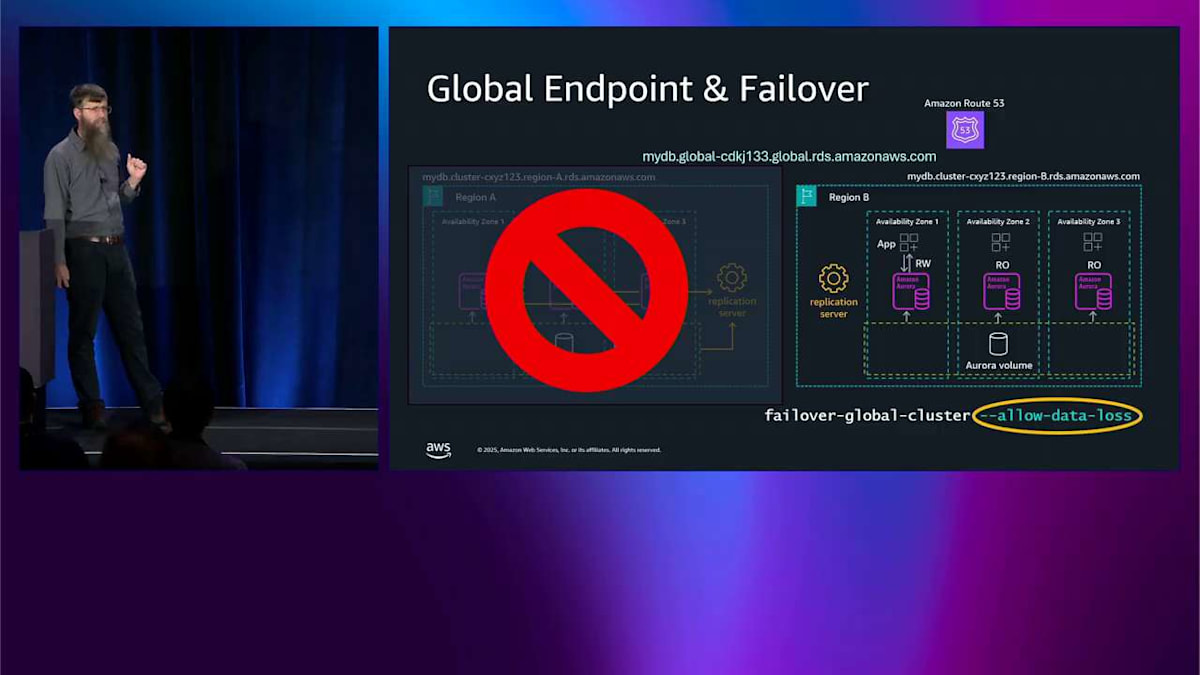
global database が登場すると、どのリージョンと通信したいのか、そしてライターがどこにあるのかをどうやって知るのかという質問が出てきます。そこで global endpoint が登場します。 これは現在ライターであるリージョンを指す DNS 名です。現在は A リージョンです。では、A リージョンに問題が発生した場合はどうなるでしょうか。フェイルオーバー操作を実行します。Tim よ、フェイルオーバーして B リージョンをプライマリリージョンにしてくれと言うわけです。そのインスタンスの 1 つを昇格させてライターノードにします。右下に allow data loss フラグがあるのが見えます。 これは、これが非同期レプリケーションだったため、強制フェイルオーバーを実行するときに非同期レプリケーションウィンドウ内に少量のデータが失われる可能性があることを思い出させてくれます。
フェイルオーバーを実行して、そのノードをライターに昇格させたら、Route 53 のデータプレーン API を使ってグローバルエンドポイントの DNS 名も更新します。これは本当に信頼性が高くて本当に高速です。自分たちで DNS を運用するよりもはるかに優れています。これがフェイルオーバー操作で、何か壊れたときに発生します。グローバルデータベースのスイッチオーバーは、何も壊れていないときに発生します。2 つのリージョンがあって、どちらも健全な状態で、単にライターを移動したいだけです。例えば、リージョン A からリージョン B に移動するかもしれません。おそらく、オペレーションで太陽を追いかけたいからです。ここで最近改善を発表しました。RTO が約 5 分から約 30 秒に短縮されたので、その仕組みについて説明したいと思います。
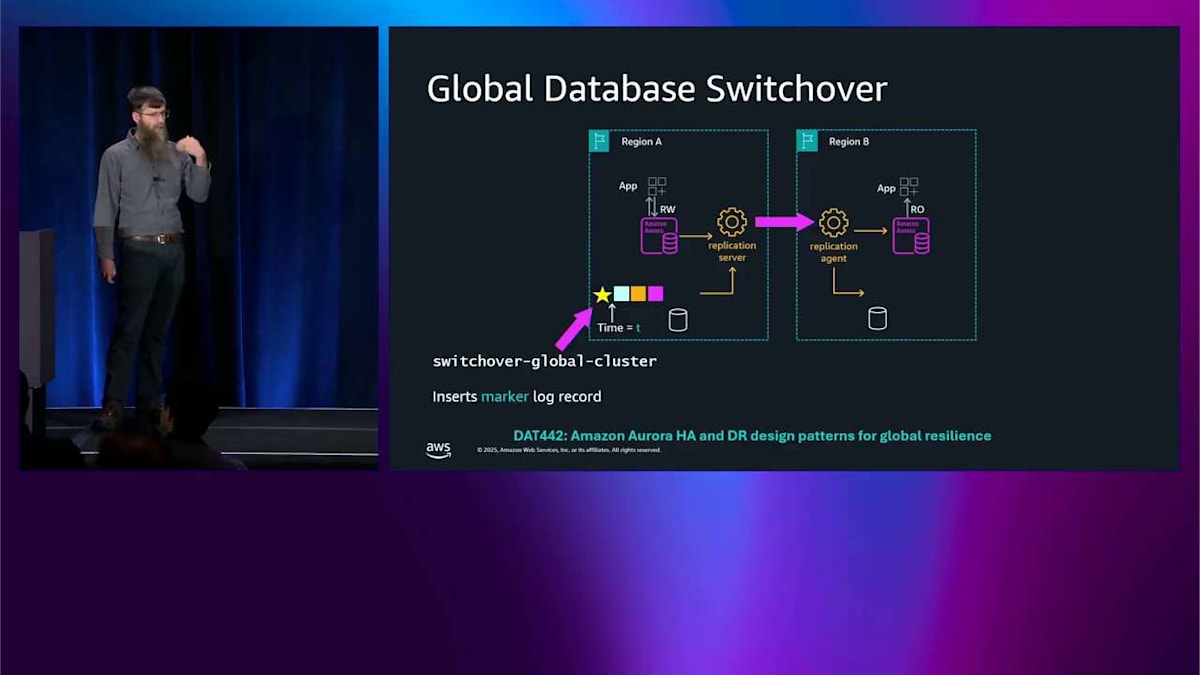
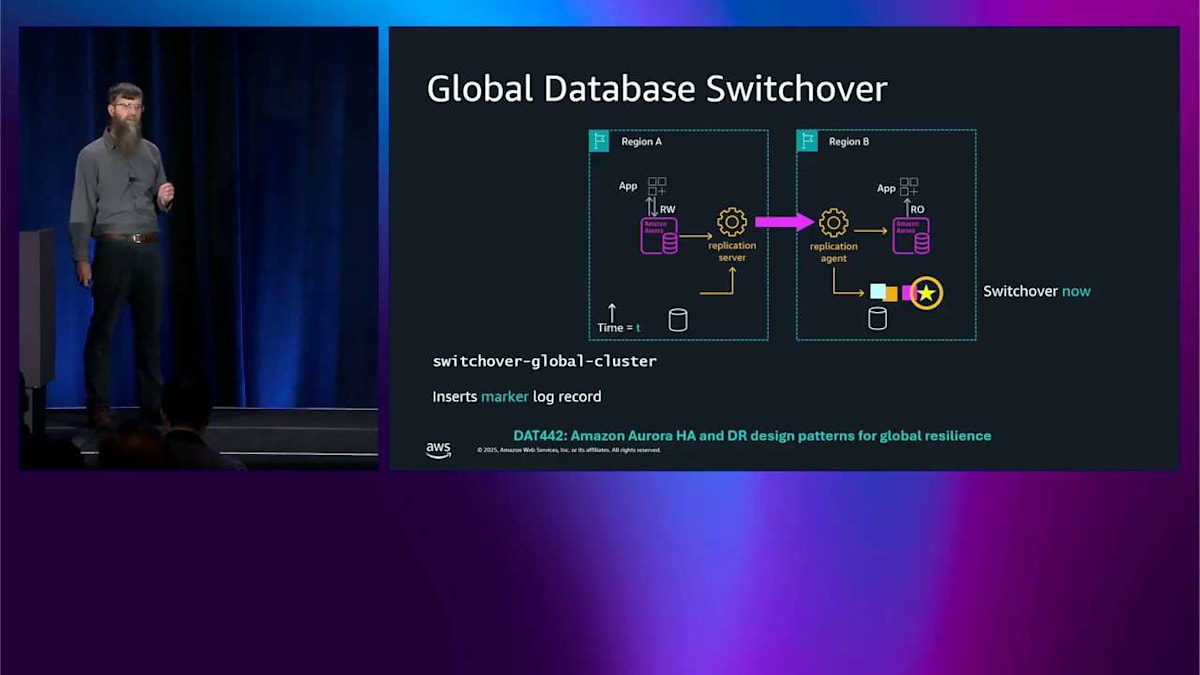
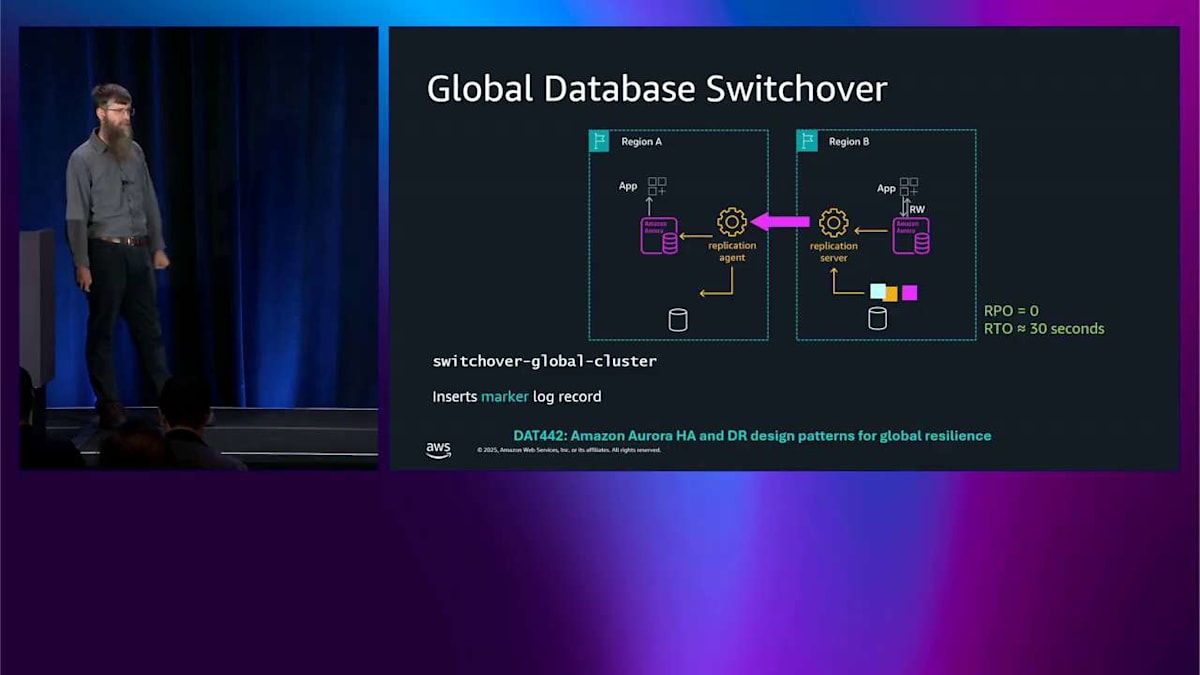
左下隅を見ると、色付きの四角があります。これらはログレコードで、時系列で並んでいます。これはこれより前に書き込まれて、これより前に書き込まれています。このポイントでスイッチオーバーを実行したいので、このログストリームに特別なログレコードを 1 つ書き込みます。これが私の小さな星です。これは通常のレプリケーション機構を通じて流れます。2 番目のリージョンで出現すると、2 番目のリージョンはそれを見て、今スイッチオーバーしろと解釈します。Aurora のログベースアーキテクチャを使用して、本当に高速なスイッチオーバーを実現できます。RPO がゼロで、データを失わず、RTO が約 30 秒です。もっと詳しく知りたい場合は、DAT441 があります。昨日開催されたので、そこで録画を見ることができます。
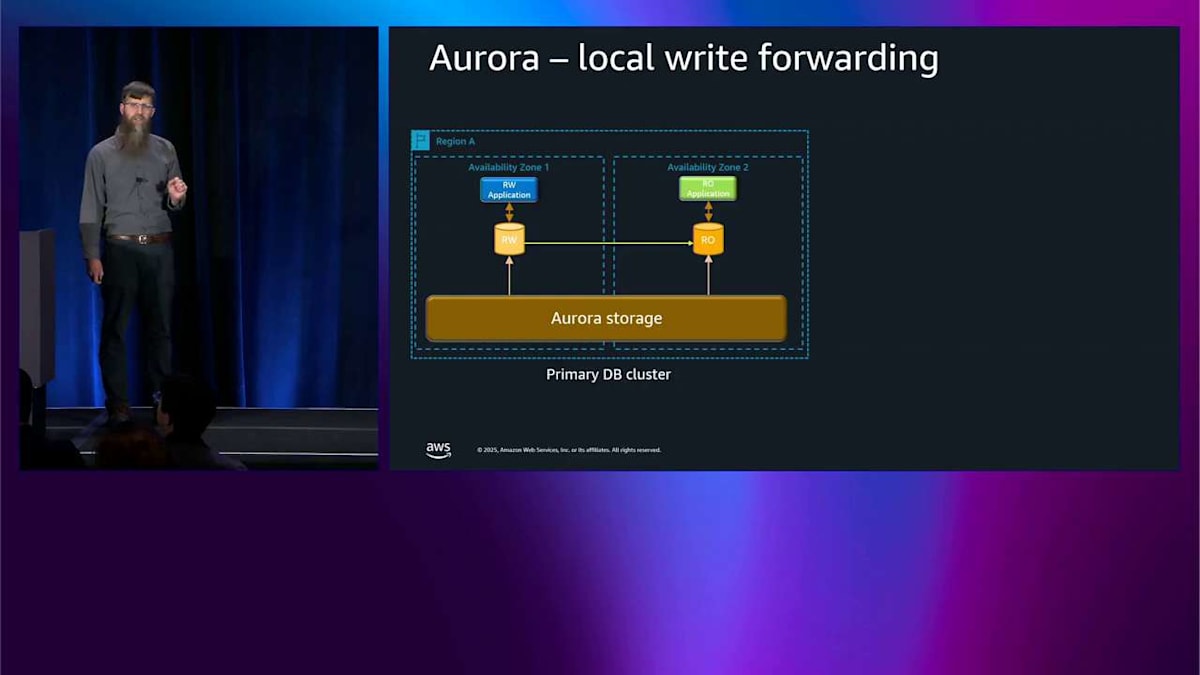
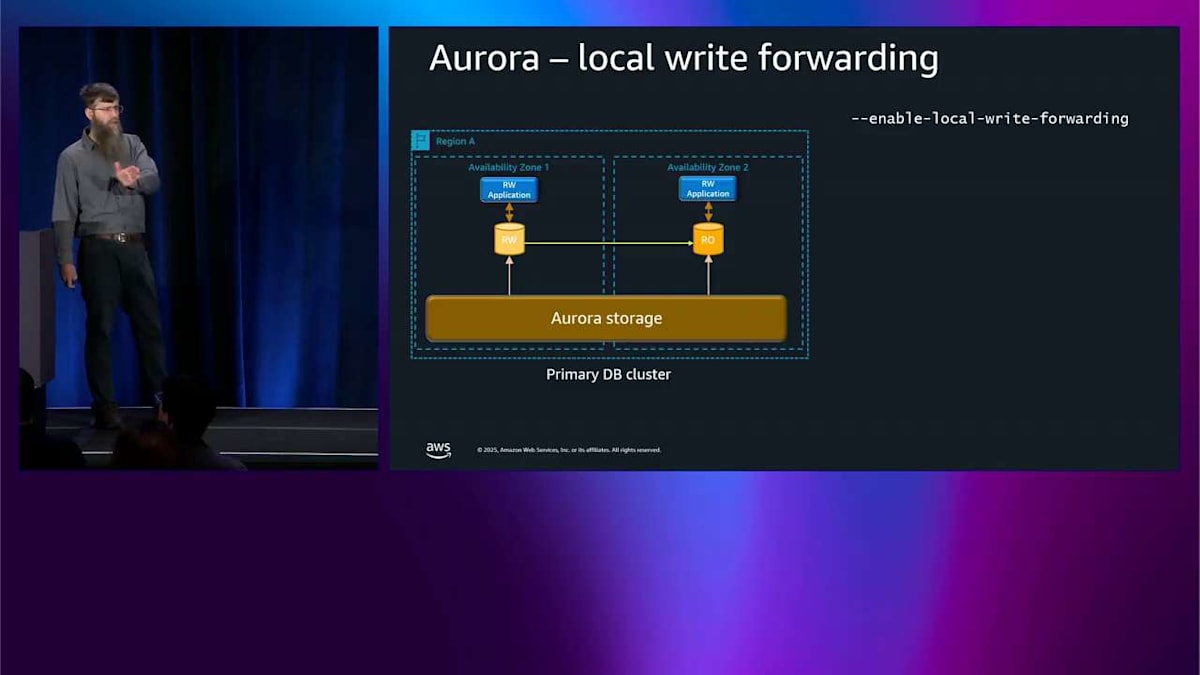
Local Write ForwardingとGlobal Write Forwarding:一貫性モデルの選択
では、ローカルライト転送についてです。この図は 2 つのアベイラビリティゾーンを示していて、2 つのアプリケーションノードと 2 つのレプリカがあります。私が本当にやりたいのは、2 番目のアベイラビリティゾーン、アベイラビリティゾーン 2 から書き込みできるようにすることです。しかし、シングルライターシステムを持っているので、その書き込みを読み取り専用ノードに送ろうとしても、うまくいきません。そこで、ローカルライト転送をオンにできます。これはアクティブ・アクティブシステムにはなりません。何が起こるかというと、アベイラビリティゾーン 2 から書き込みを送ると、その書き込みを反対側に転送します。通常通り正確に書き込みを実行して、その結果をもう一度引き戻します。
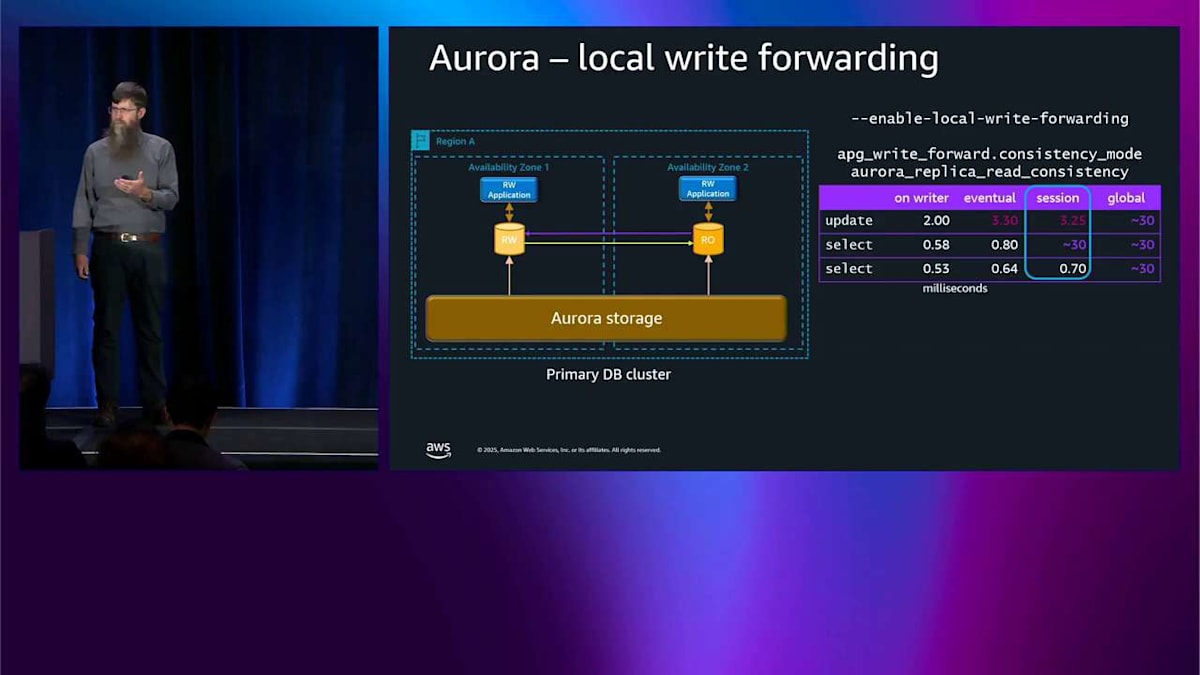
これは私が行った実験です。よく出てくる質問の 1 つは、一貫性についてどうやって知るのかということです。これは非同期レプリケーションだったからです。3 つの異なる一貫性モード、または可視性モードがあります。デフォルトはセッションです。私のテストはセッション内で更新を実行して、その後、更新したばかりのものを選択して、その後、更新したばかりのものをもう一度選択します。セッション可視性モードでは、更新を実行したのが見えます。反対側に行き来する必要があったため、数ミリ秒かかりました。最初の選択を実行したとき、反対側で起こっていることが戻ってくるのを待つ必要がありました。
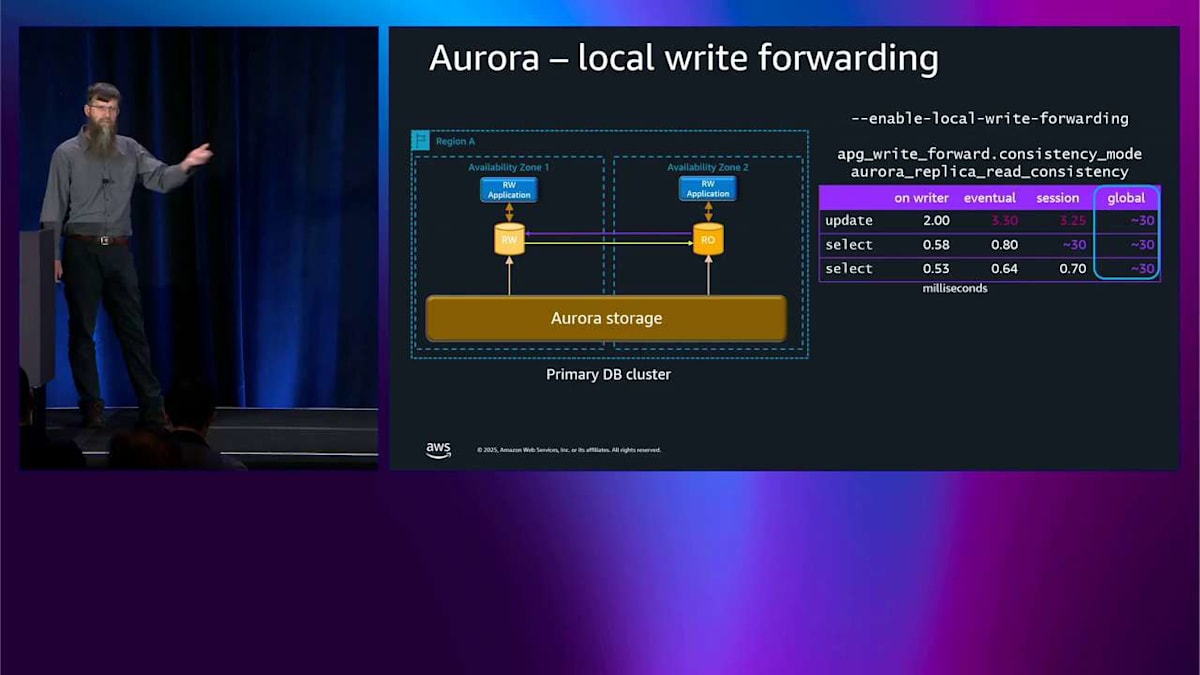
イベンチュアル一貫性モードでは、これはシートベルトなしモードのようなもので、自分たちの書き込みを読むのを待ちません。更新を実行して、それがどのくらい時間がかかったかは関係なく、その後、選択を実行したとき、反対側で起こっていることを待たなかったため、本当に素早く戻ってきました。この場合、自分たちの書き込みを読まなかったかもしれません。それはアプリケーションにとって少し混乱するかもしれないので、注意する必要があります。もう 1 つのオプション、極端な反対側は、グローバル一貫性です。クラスター全体で起こっているすべてのことを常に待ちます。最初の更新はかなり時間がかかったのが見えます。戻ってくるのを待つ必要があったからです。その後、選択も同じ時間がかかりました。
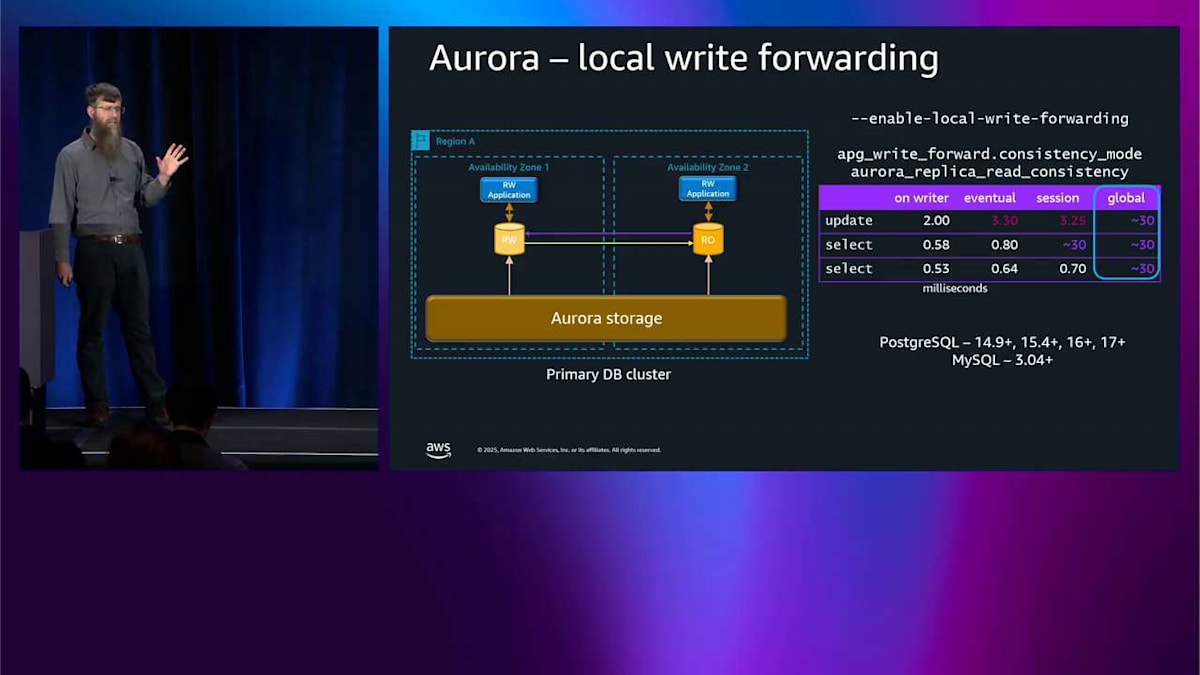
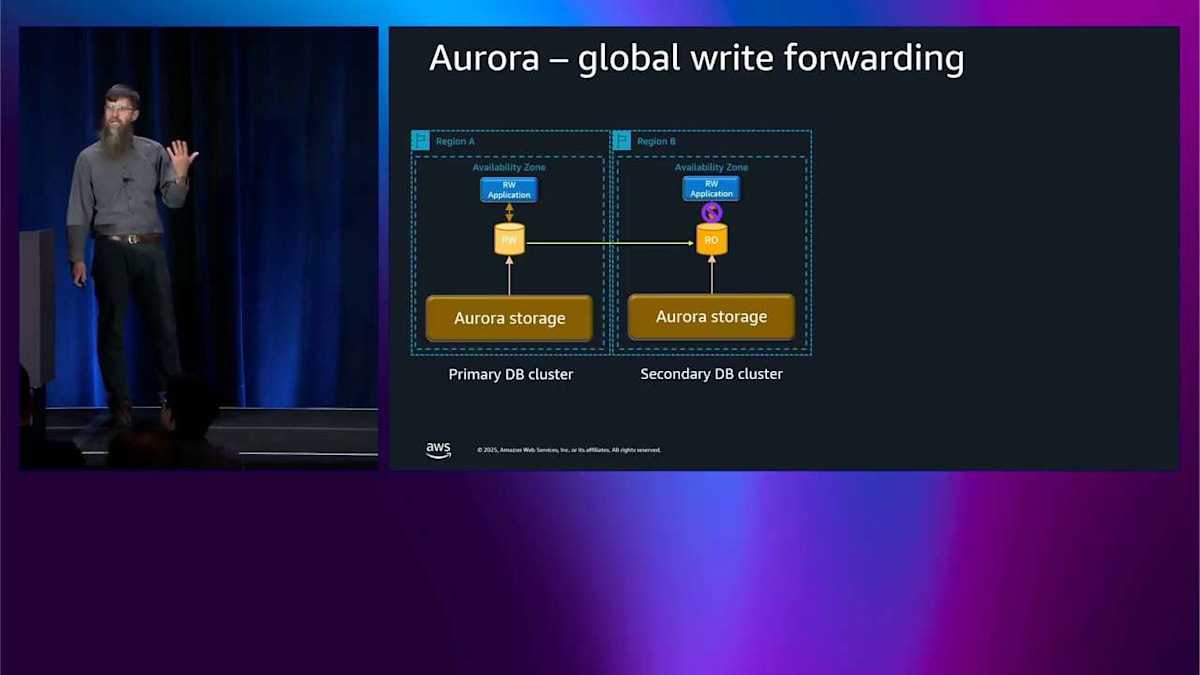
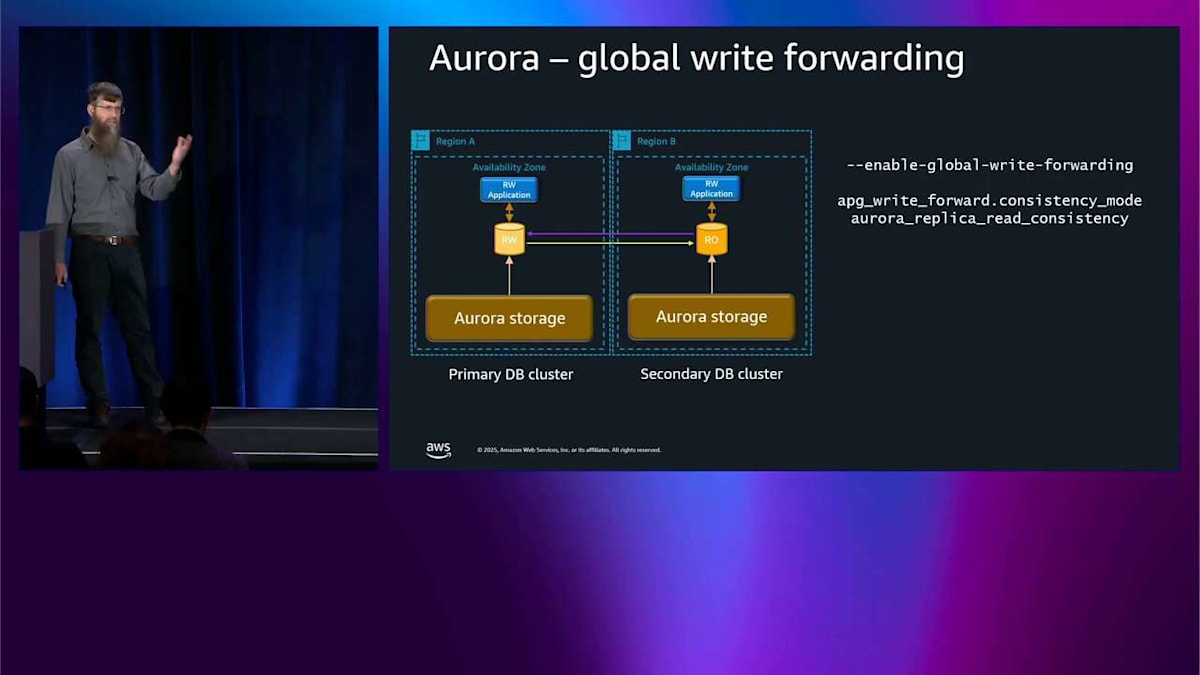
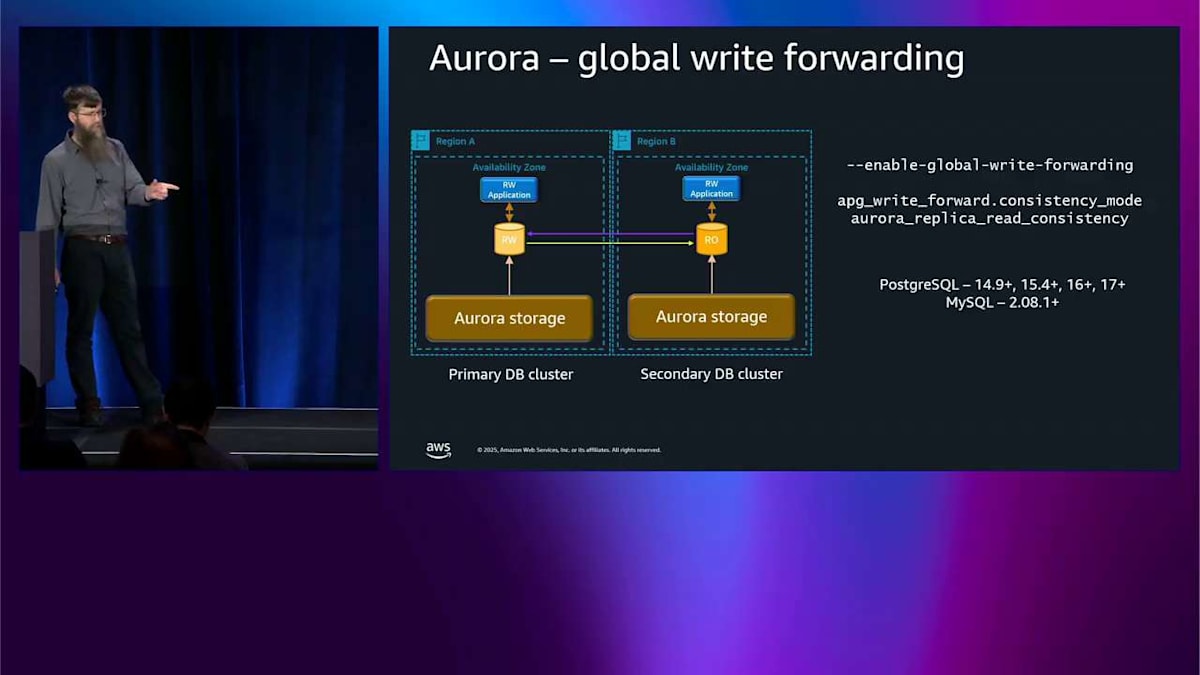
Right forwarding は便利ですが、一貫性モデルに注意する必要があります。 これを拡張して、global write forwarding について説明することができます。似たような構図ですが、今回は2つの availability zone ではなく2つのリージョンがあります。同じ問題があります。読み取り専用ノードが書き込みを試みることができません。Global write forwarding をオンにしたいのです。同じことが起こります。クエリをライターリージョンに転送して、実行してから、また戻してきます。 同じ一貫性モードと、認識する必要がある同じ考慮事項があります。明らかに、レイテンシーの数字は異なります。なぜなら、クロスリージョンについて話しているからです。
Auroraストレージの内部動作とI/O-Optimizedの技術革新
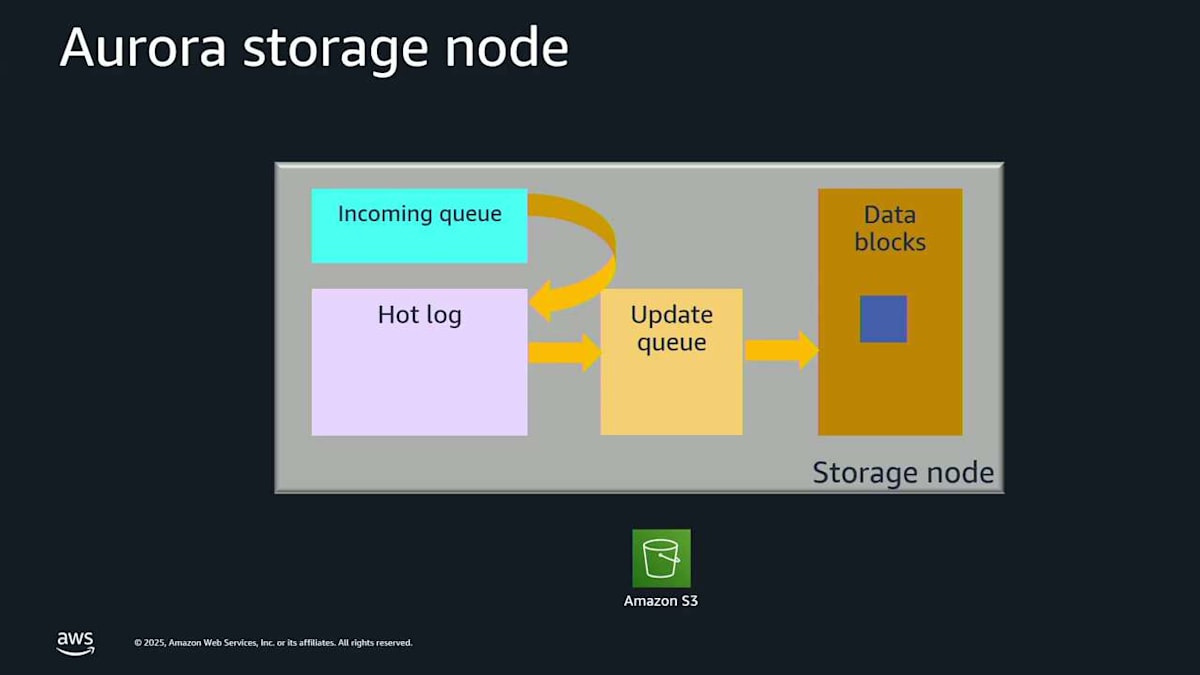
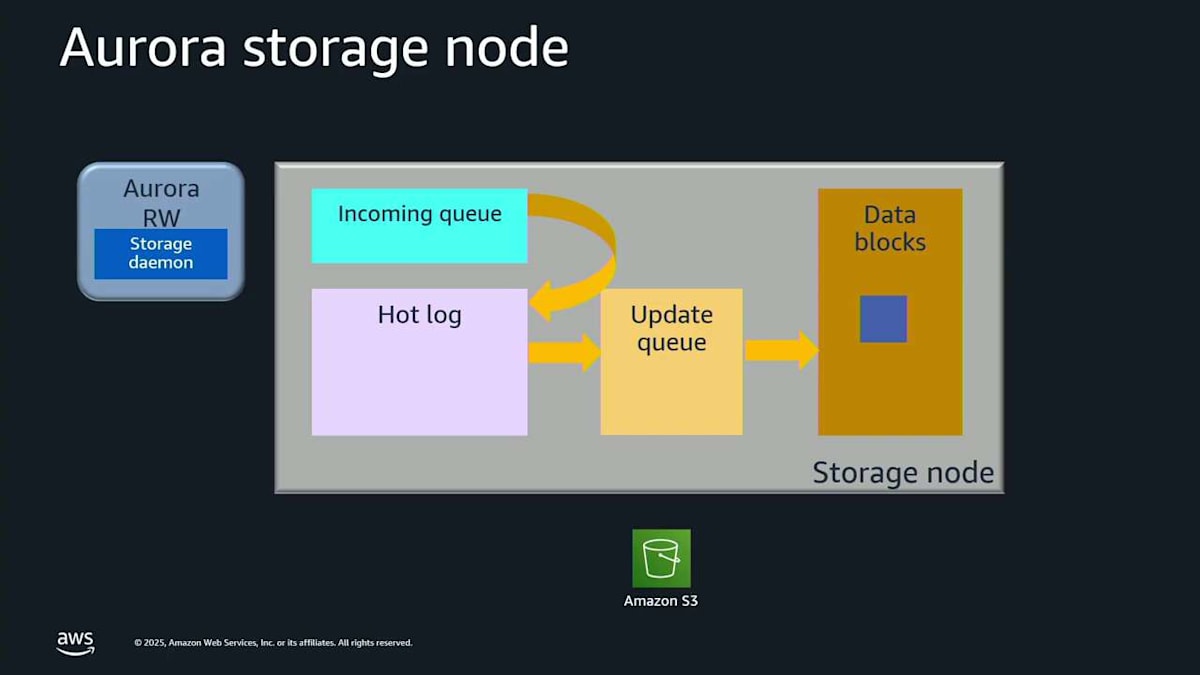
これが global write forwarding です。繰り返しになりますが、ほとんどの最新エンジンバージョンで利用可能です。では、ストレージについてもう少し掘り下げて、どのように機能するかを説明します。ここでは Aurora ストレージノードの内部で何が起こっているかを見ています。読み取り・書き込みノードがあり、小さなストレージデーモンが実行されています。これは基本的に、エンジンがストレージと通信できるようにするドライバーです。
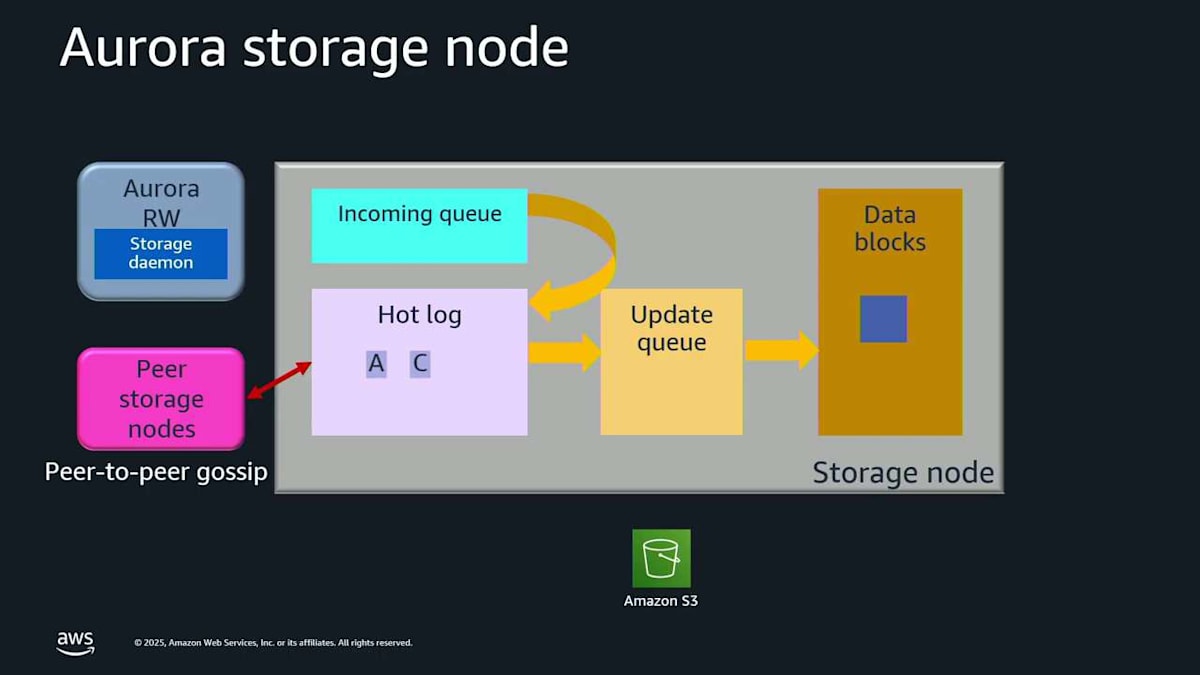
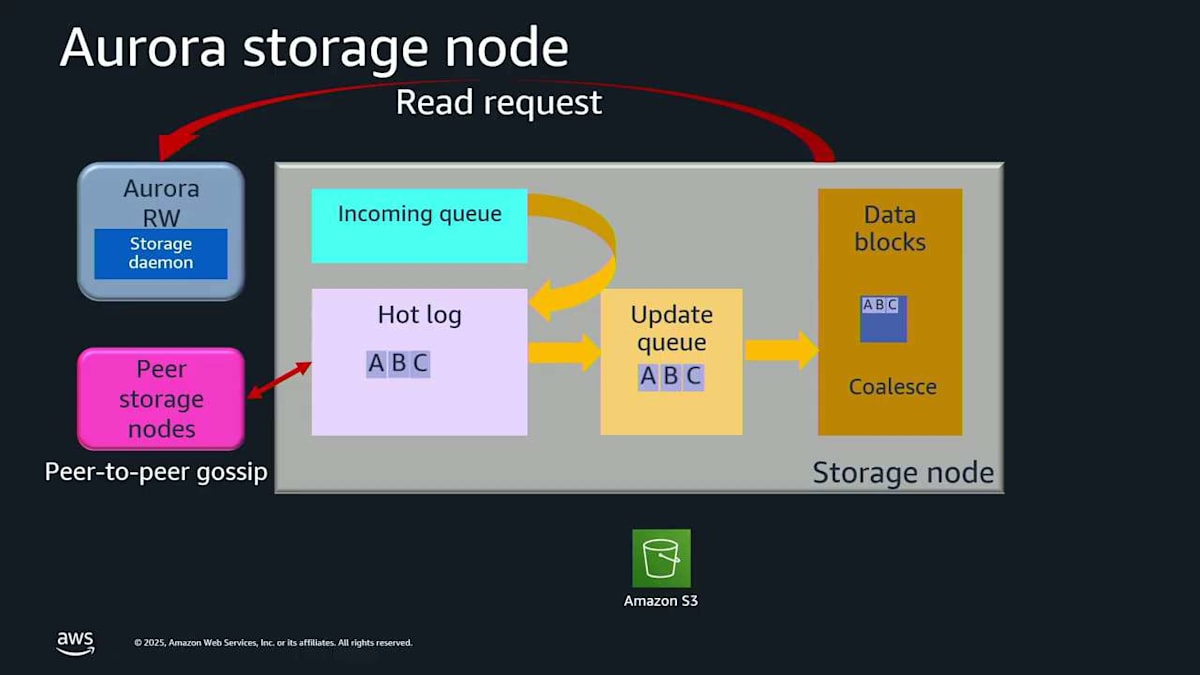
A というログレコードを書き込もうとしています。ストレージノードに入ってきます。覚えておいてください。これは6つのストレージノードのうちの1つなので、実際には6回起こっています。これはメモリ内の incoming queue に入ります。incoming queue からそれを drain して、ディスクに行く hot log に移します。これでそれがディスク上で安全なので、確認応答できます。そしてまた同じことをします。ここに record C が来ます。incoming queue に入り、hot log に下がり、確認応答され、すべて良好です。さて、あなたのアルファベットが私のように良ければ、真ん中に B がないことに気付くでしょう。おそらく転送中に遅延しただけなので、他のストレージノードからピアツーピアで取得できます。ここに B が来ます。 これで A、B、C がすべて順序通りで、ギャップがありません。これらをアップデートキューに移動して、これらのログレコードをページに戻すことができます。これを coalescing と呼びます。これはすべてストレージ内で本当に素早く起こっています。
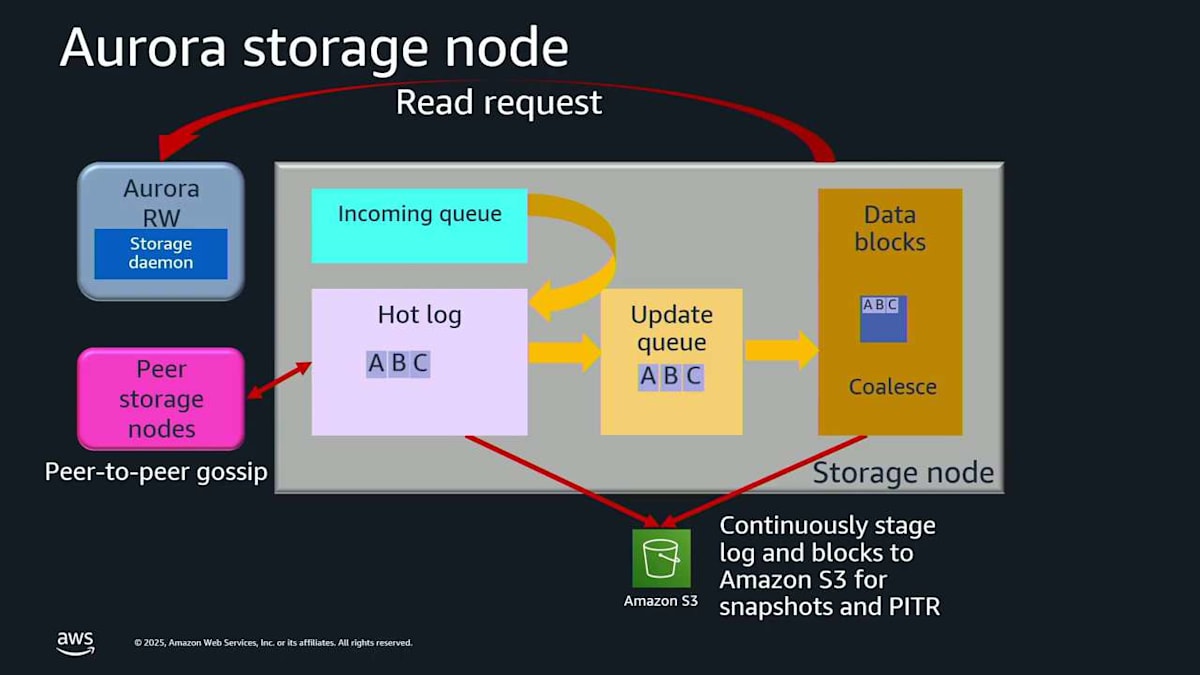
読み取りリクエストが必要な場合、それは準備ができているので、読み取りレイテンシーは影響を受けません。このストレージノードは、これらのログレコードとデータベースページのすべてを継続的に Amazon S3 に落とし込んでいます。これは continuous backup なので、保持期間内の過去35日間のいつでも point-in-time restore を実行できます。
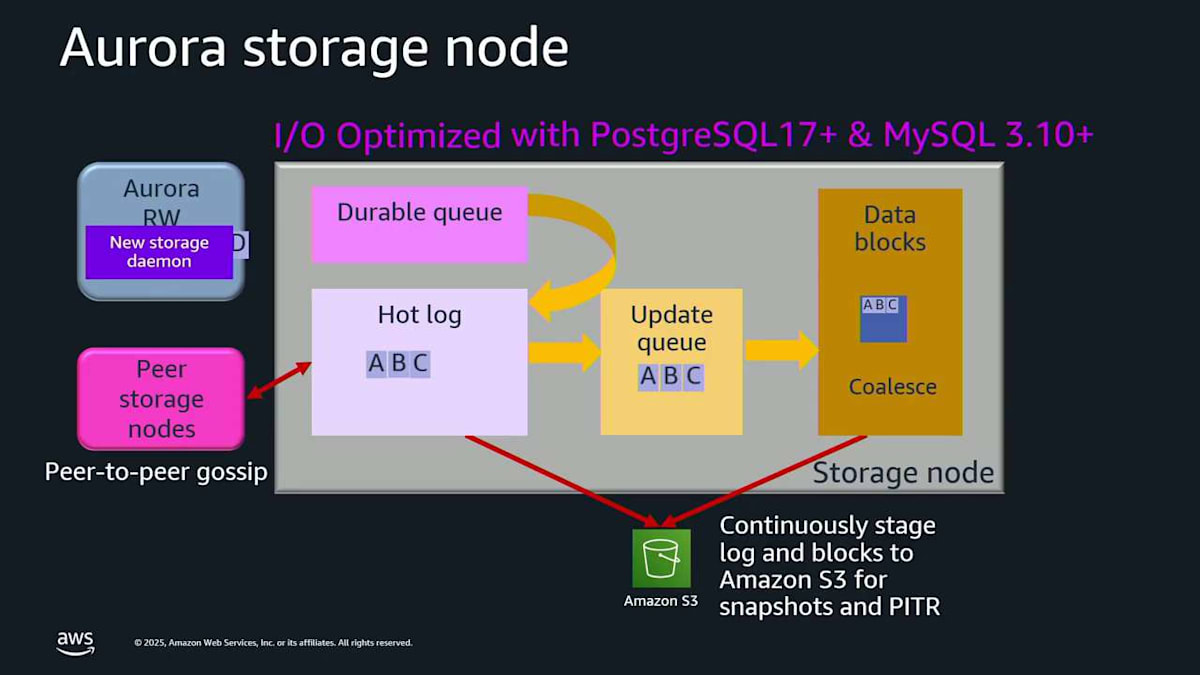
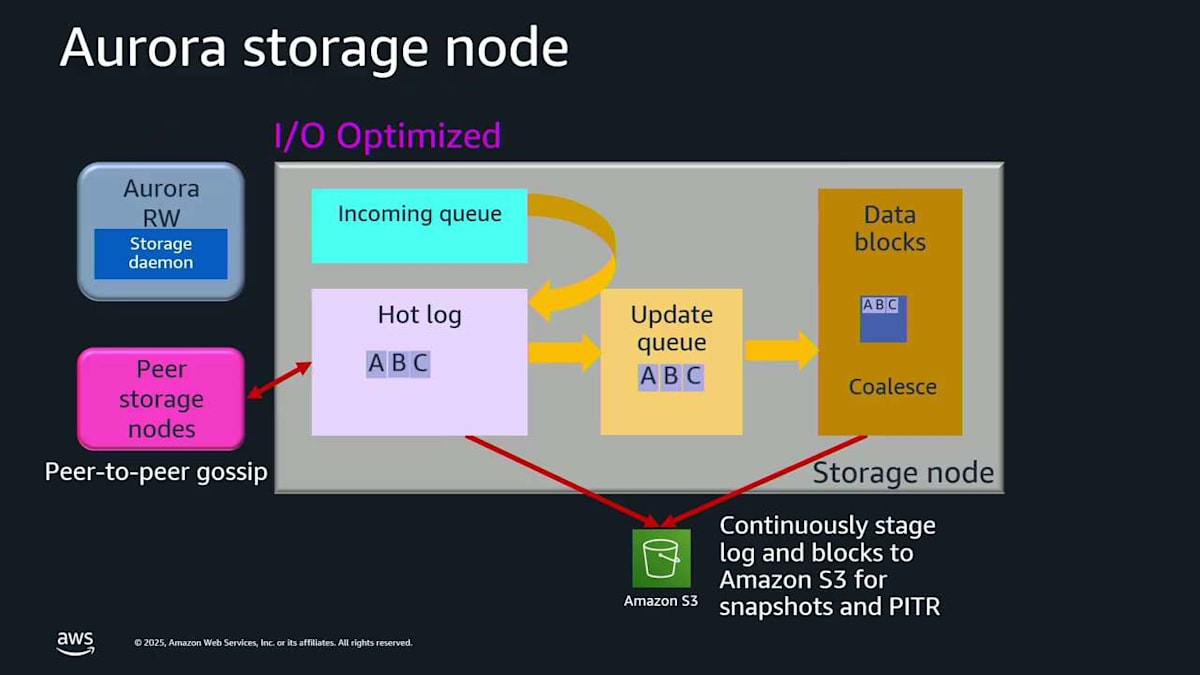
では、I/O-Optimized について説明します。これは設定オプションで、I/O集約的なアプリケーションのスループットを増やすために、これの一部を変更します。何が起こるかというと、左側のストレージドライバーを変更するので、より積極的にバッチ処理を行います。これは I/O集約的なアプリケーションに本当に良いです。新しい最新エンジンバージョンでは、これを次のレベルに上げることができます。 incoming queue を durable queue に変更しました。これで log record D を書き込もうとすると、それが入ってきて、そのボックス内に直接 durably queue されます。hot log に下がるのを待つ必要がないので、直接確認応答できます。つまり、やらなければならない作業が少なくなるため、レイテンシーが低下し、jitter が低下し、パフォーマンスが向上します。これについての結果は、すぐに見ることになります。

Aurora PostgreSQLの最新機能とパフォーマンス向上
Aurora PostgreSQL は完全に PostgreSQL と互換性があるため、常に上流から PostgreSQL の更新を取り込んでいます。 ここにある機能の長いリストについて説明したいのですが、これは非常に長いリストで、多くの機能が抜けているので、探している機能がここにない場合はご容赦ください。PostgreSQL バージョン 17.6 までサポートしており、これは先週リリースしたばかりです。ローカルディスク付きの RAGD インスタンスタイプをサポートしています。これについては今日詳しく説明します。上流からのパフォーマンス改善がたくさんあります。相関サブクエリキャッシュ、アダプティブジョイン、その他多くのものです。共有プランキャッシュがあります。これは複数の PostgreSQL プロセッサが実行されている場合に、それぞれがクエリを計画する必要があり、共有キャッシュを参照することができ、これにより大量のメモリが節約されます。大規模なインスタンスと大規模なレプリカの読み取り可用性を改善し、より高速にブートアップできるようにしました。FIPS 140-3 セキュリティ暗号化を全体的にサポートするようになりました。多くの拡張機能が更新されており、pgvector が特に興味深いものです。ボリュームサイズは最大 256 テラバイトまでサポートしています。先ほど申し上げたように、他にもたくさんのものがありますが、今日は特にいくつかに焦点を当てたいと思います。
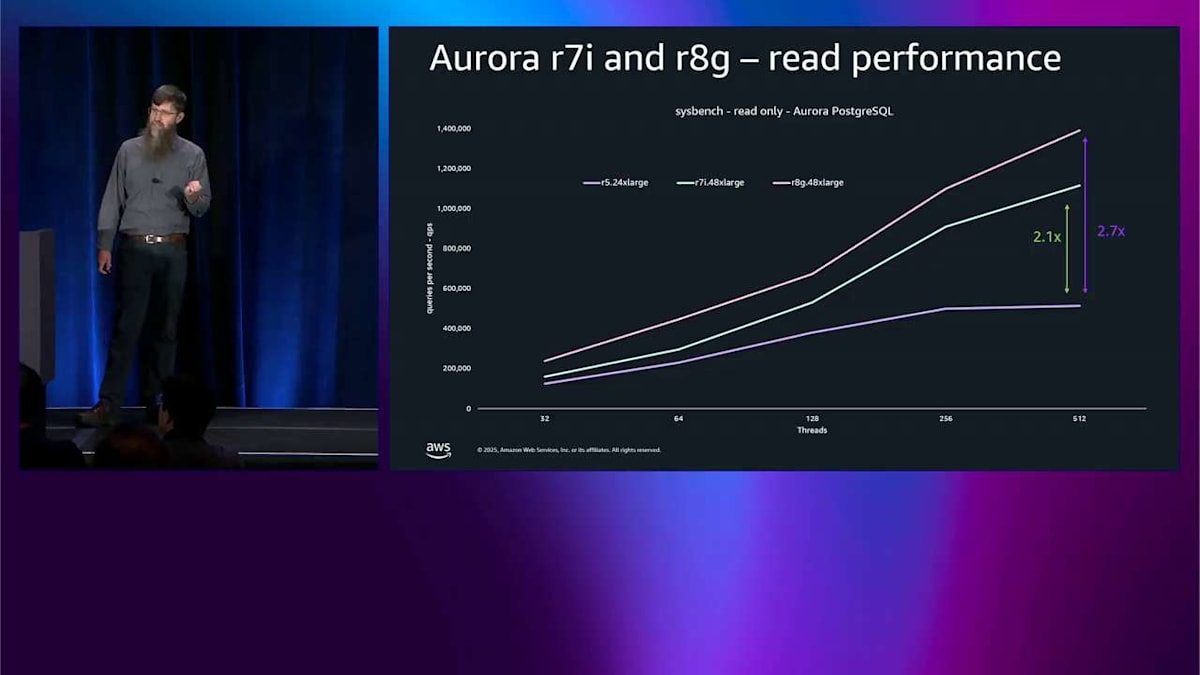
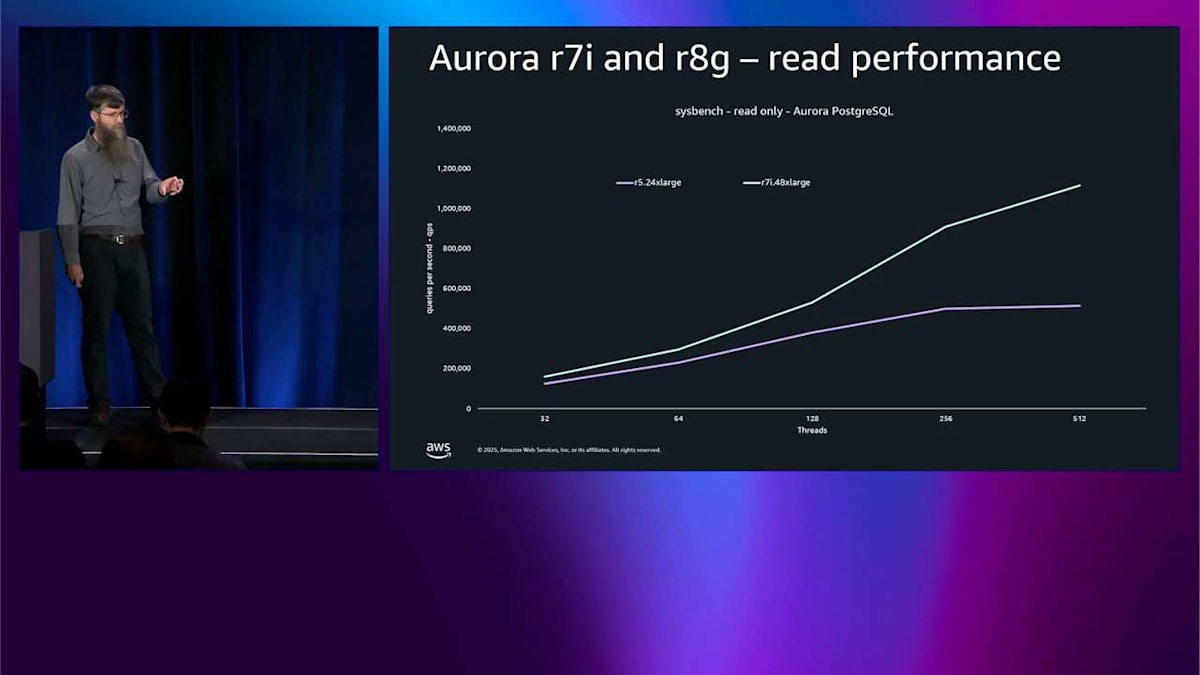
異なるインスタンス世代における Aurora PostgreSQL のパフォーマンスとスループットを見てみましょう。これは sysbench の読み取り専用テストで、基本的には全てメモリ内で実行される CPU テストです。紫色の線は r5.24xlarge を示しており、これは Aurora が誕生した 10 年前に持っていた最大のインスタンスです。青色の線は r7i.48xlarge を示しており、これは 2 倍大きく、2 世代新しく、まだ Intel です。Y 軸はクエリ毎秒で、高いほど良いです。基礎となるインスタンスをいくつかアップグレードするだけで、CPU バウンドなパフォーマンスで 2.1 倍の改善が見られます。非常にシンプルです。

次に r8g を追加します。これは Graviton バージョンで、次世代、現在の 48xlarge です。同じサイズで、ベースラインに対して 2.7 倍の改善を得ることができます。 これは線形スケーリングより優れています。他に何もしなくても、私たちが提供している通常のスケーリングルールに従うだけで、10 年間で 2.7 倍を得ることができます。これはかなり素晴らしいです。
動的データマスキング:機密データ保護の新しいアプローチ
今日お話しする最初の新機能は Aurora PostgreSQL の動的データマスキングです。
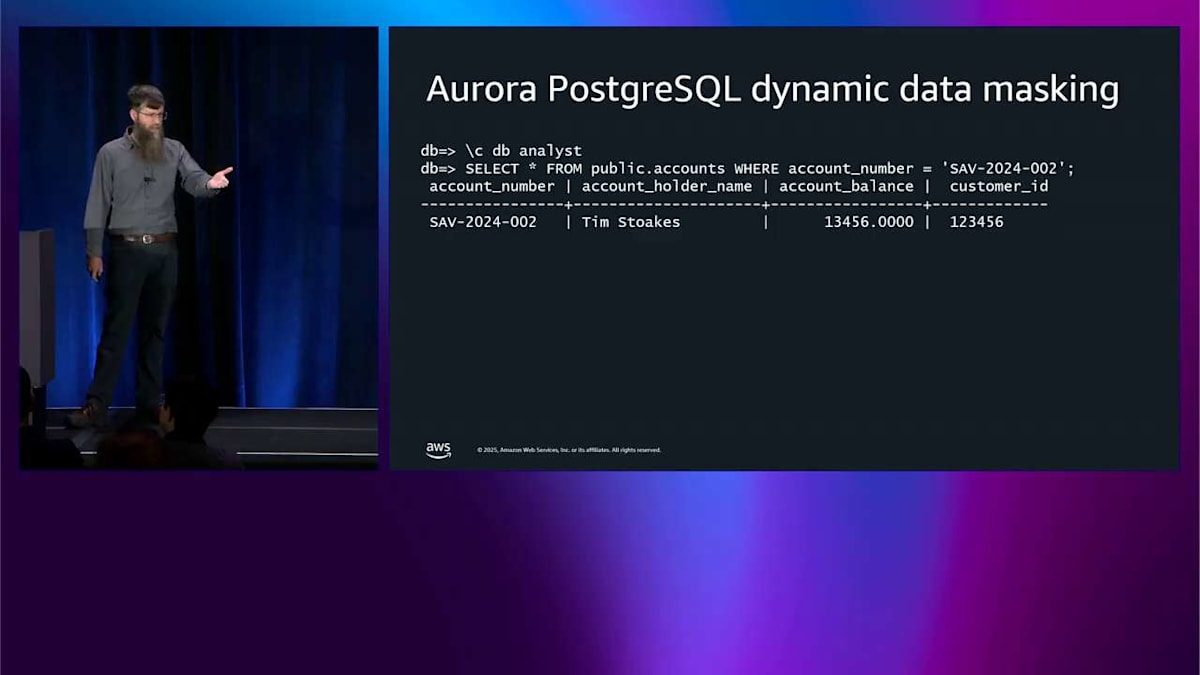
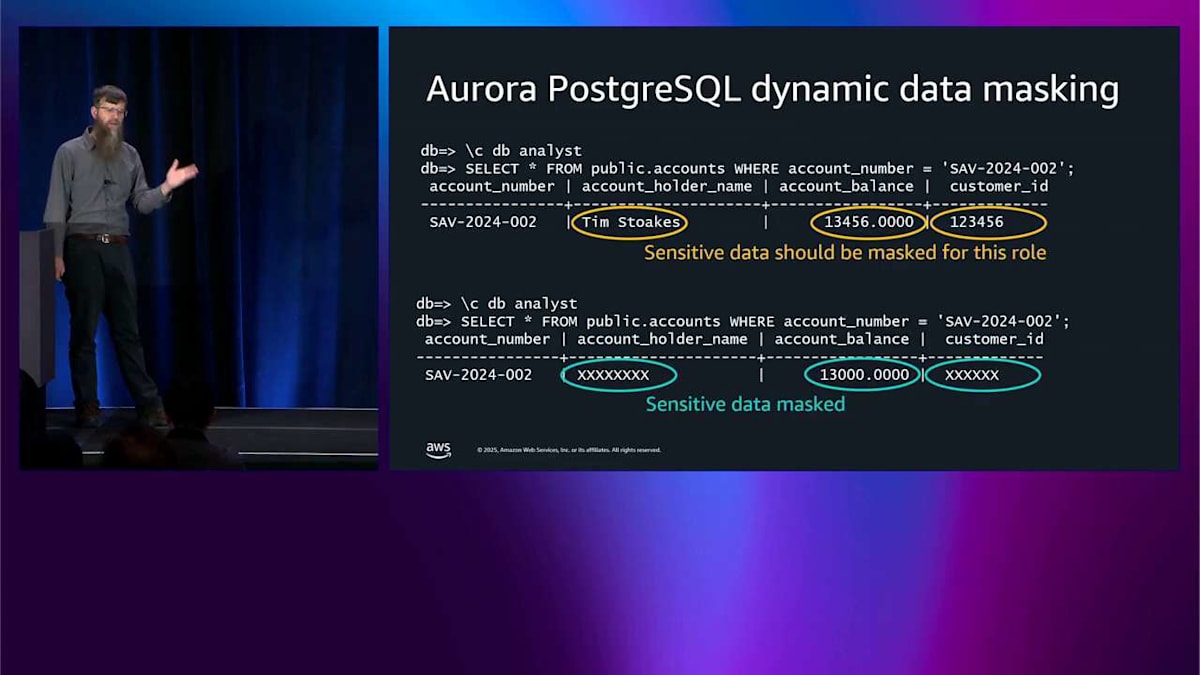
これは Aurora を使用していて、機密データを保護する必要がある組織向けです。 例えば、アカウント番号、アカウント保有者の名前、その他の個人識別情報があるかもしれません。また、アカウント残高もあり、これをアナリストに提供したいかもしれませんが、彼らは正確な残高を必要としません。残高の丸められたバージョンが必要なだけです。それが動的データマスキングの用途です。 物事をマスクして X にすることができます。または、異なる関数を適用して丸めを行うことができます。それが動的データマスキングが行うことですが、SQL の完全な表現力を持つことができるため、結合を行うことができ、すべてのインデックスを使用することができ、そのようなすべてのことができます。
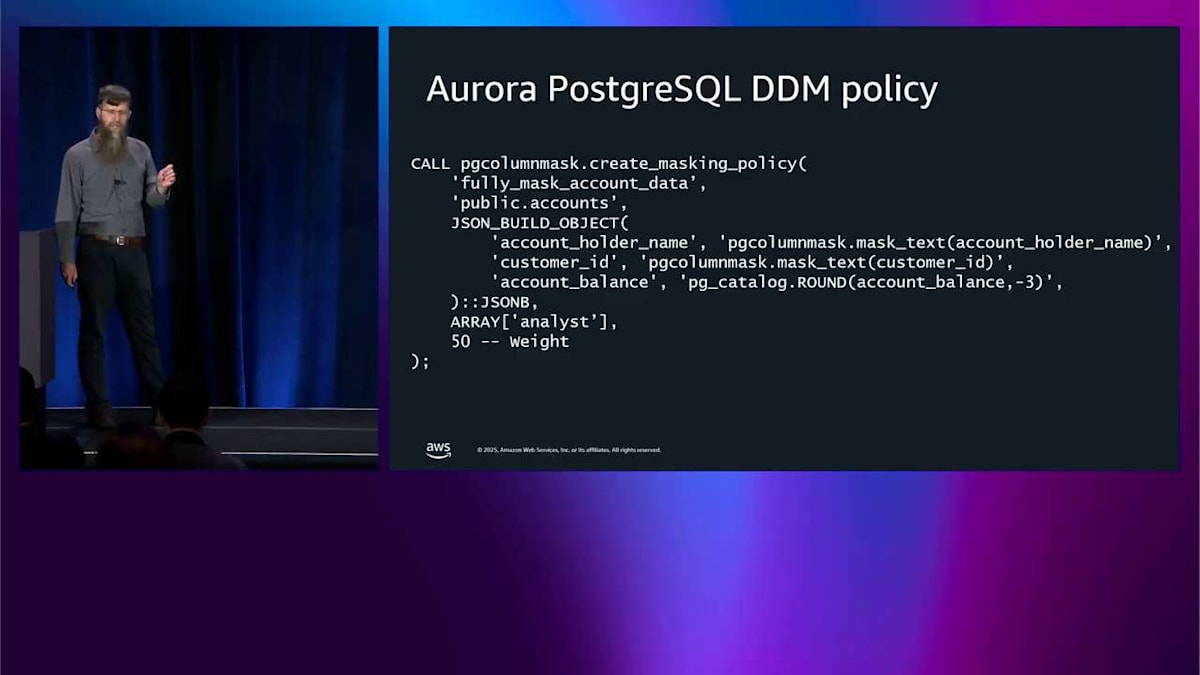
どのように動作するのか見てみましょう。これは Aurora の新しい PG column mask extension で実装されています。 この例では「fully masked account data」と呼ばれるマスキングのポリシーを定義します。これを accounts テーブルに適用して、マスキングする列のリストを指定します。例えば、customer ID one はマスキングして X に変換し、account balance one にはこの round 関数を適用します。これがマスキングの方法です。このリストにある全てのロールに適用します。このリストには analyst という 1 つのロールだけが含まれており、重みは 50 です。この重みはポリシーが重複している場合に使用され、どのように適用するかを決定します。
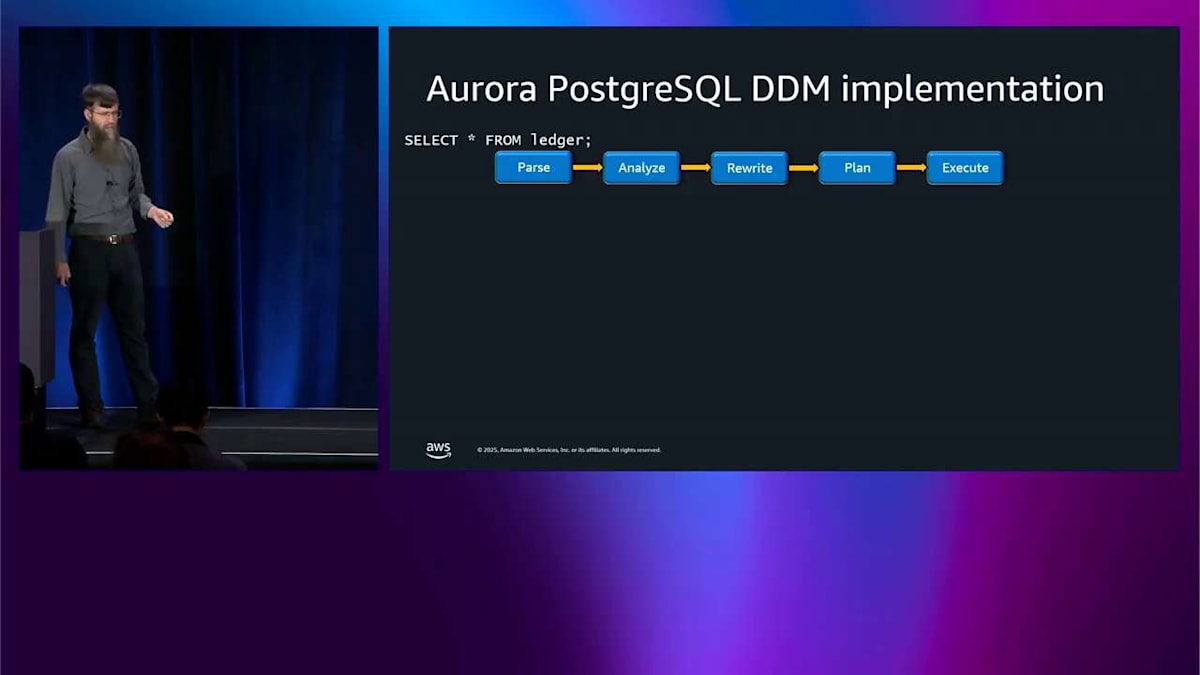
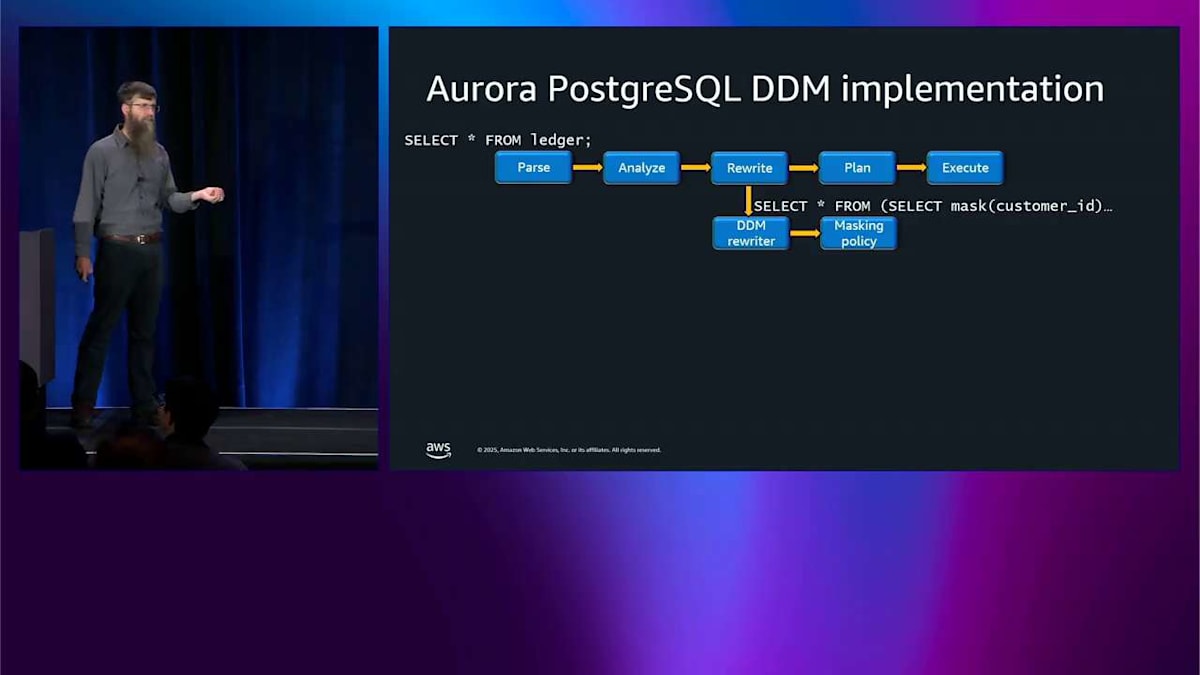
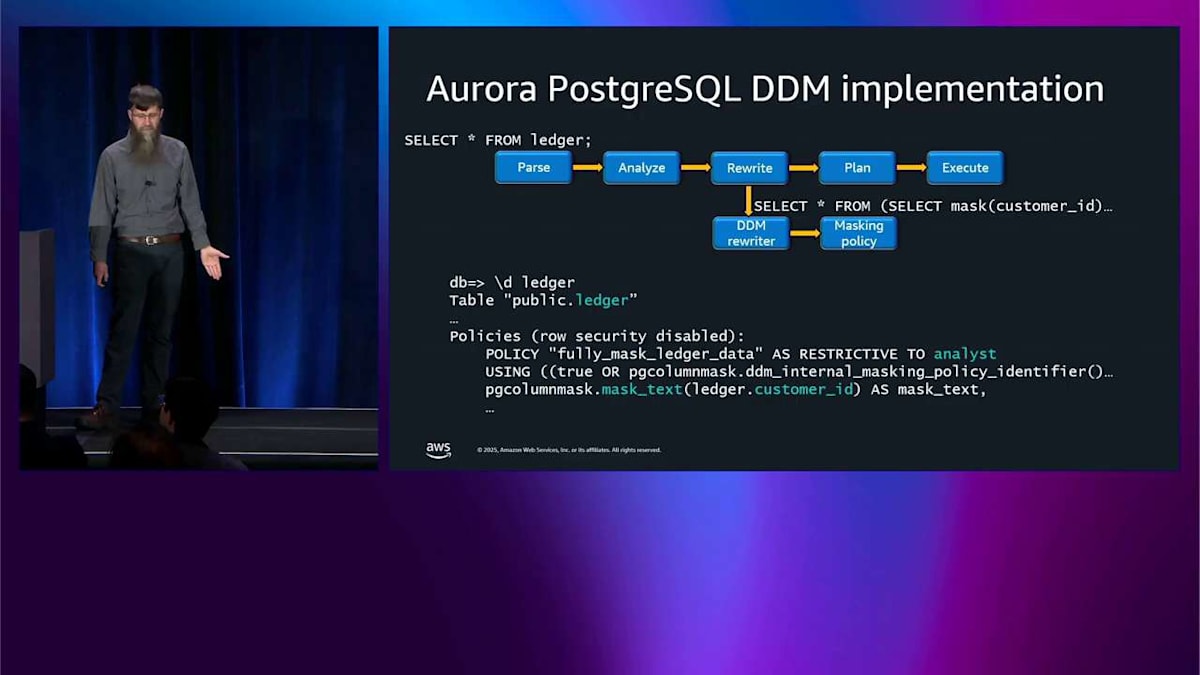
これはすでにかなり便利ですが、実装方法についても話したいと思います。これは興味深いと思うからです。 この select クエリがあります。これは実際にどのように動作するのでしょうか。PostgreSQL の内部には、parse、analyze、rewrite、plan というパイプラインがあります。 Dynamic data masking はクエリの rewrite レイヤーに接続されます。マスキングされた結果を取得するようにクエリを書き直します。取得した結果をマスキングするのではなく。 これにより、非常に良いパフォーマンスを実現でき、インデックスも引き続き機能します。これは非常に重要です。 ここの describe 出力でこれを確認できます。その列に適用されているマスク関数を見ることができます。

Aurora MySQLの最新アップデートと機能強化
Aurora MySQL については、upstream を追跡しています。ここにあるリストについても同じ話です。もしあなたの好きな機能がここにないとしたら申し訳ありません。リストが長すぎるだけです。 数週間前に 3.11 をリリースしました。これにより MySQL 8.0.43 の互換性が得られます。また、3.10.0 の長期サポート版もリリースしました。これにより、メモリ内リレーログキャッシュが得られ、バイナリログレプリケーションを使用している場合、ログレプリケーションスループットが最大 40 パーセント改善されます。これは本当に素晴らしいです。先ほど話した高度な rapid drivers も搭載されており、MySQL 用に ODBC もサポートするようになりました。256 テラバイトのボリュームサポートもあり、個人的に素晴らしいと思うのは global database secondary readers です。global database で何か起こった場合、これらのリーダーはより長くアップしたままで読み取りを提供できるようになりました。つまり、グローバルな問題がある場合、読み取り可用性が向上します。

Aurora Serverless:高速スケーリングとPlatform Version 3によるパフォーマンス革命
では Aurora Serverless についてです。これはあなたのワークロードのために、ほとんどの人に検討してもらいたいインスタンスタイプです。インスタンスサイズについて心配する必要がないため、フリートの管理が簡単になります。これは以前 Aurora Serverless V2 と呼んでいたものです。V1 はサポート終了したので、今は単に Aurora Serverless と呼んでいます。ネーミングは難しいですね。申し訳ありませんが、名前についてはご容赦ください。

では Aurora Serverless とは何でしょうか。 これはエラスティックなインスタンスタイプです。4X large のようなインスタンスタイプと考えることができますが、CPU とメモリをプラグイン・プラグアウトでき、システムが必要に応じて自動的に行います。これを行うたびに、影響はありません。エンジンを再起動しているようなことではありません。毎秒、このインスタンスのメモリ、CPU、ネットワークをスケーリングアップ・ダウンしています。これを ACU(Aurora Capacity Unit)という単位で測定します。これは 2 ギガバイトの RAM と、それに伴う関連するメモリ、CPU、ネットワークを表します。

ここの右側には Lambda があって、小さな Serverless インスタンスと通信しています。それから別の Lambda がやってきて、そのインスタンスと通信したいんですが、大量のクエリを送ってくるので、大きすぎるんです。だからちょっとスケールアップする必要があります。それから大きな分析ジョブがやってくるかもしれないので、さらにスケールアップする必要があります。スケールアップとダウンを繰り返していて、これは1秒単位で課金されるので、スケールダウンすると、スケールアップした分の料金はもう払わなくていいんです。
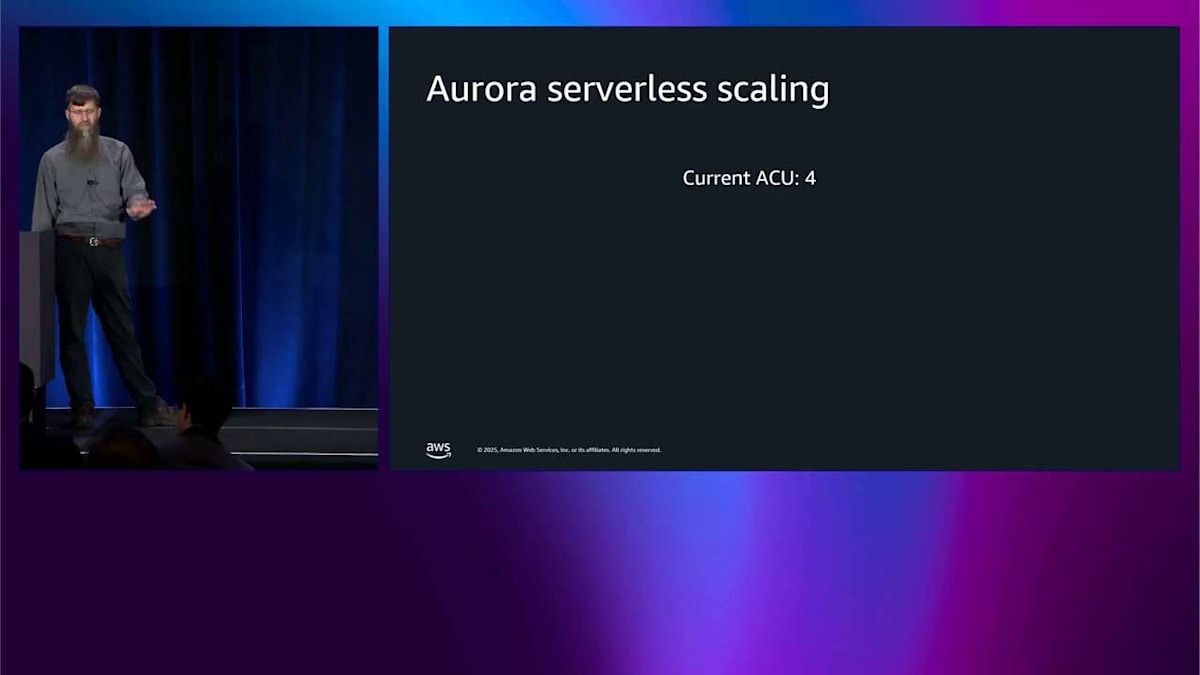

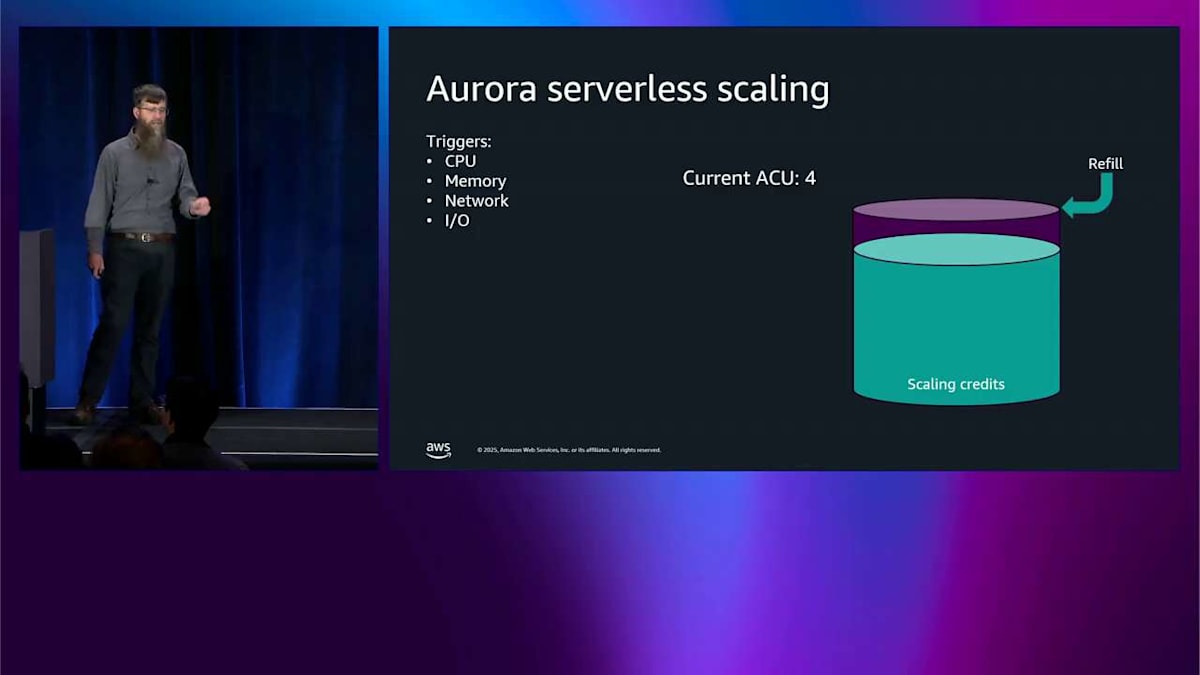
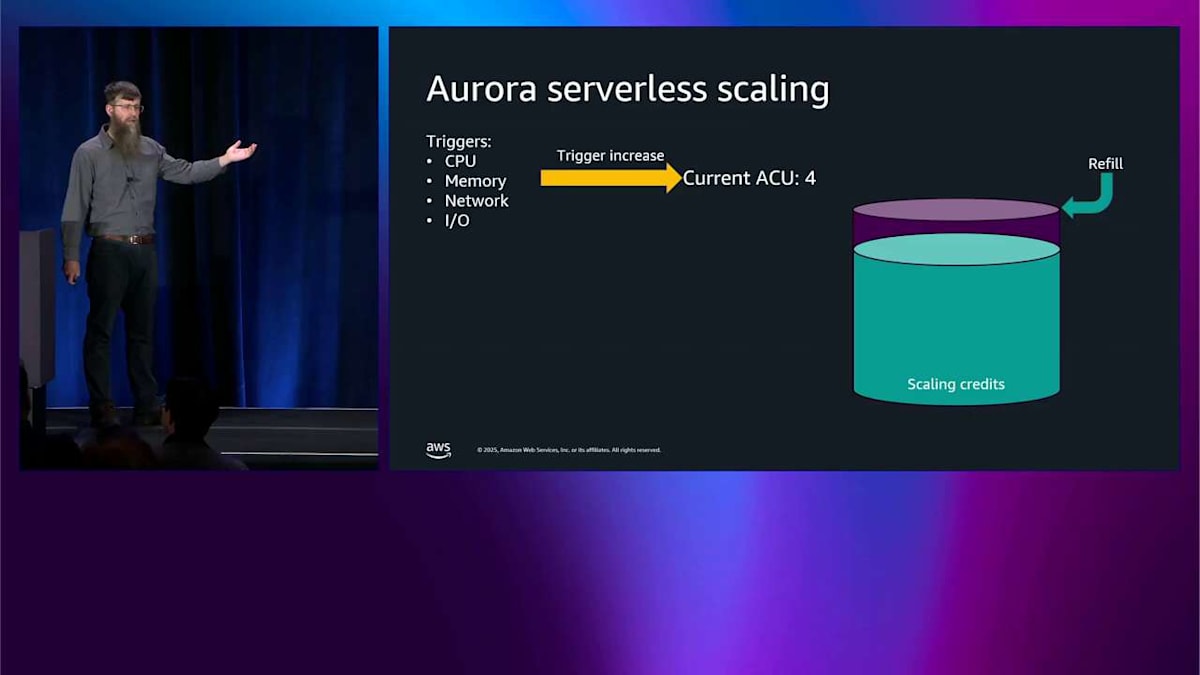
具体的な例をここに示します。4つの ACU、Aurora Capacity Units から始めます。 これらのトリガーの変化を監視しています。CPU、メモリ、ネットワーク、I/O です。それから横にこのクレジットのバケットがあります。これがスケーリングメカニズムの仕組みです。 このスケーリングバケットは定期的に満たされます。満杯になると、今スケールする必要がある場合、設定した最大 ACU リミットまでスケールアップするためのクレジットがこれだけあるということを意味します。 さあ、スケールする必要があります。何かトリガーしました。もっとメモリを使いたいのかもしれません。だからこのバケットからクレジットを消費します。4つ消費して、それからもっと消費します。
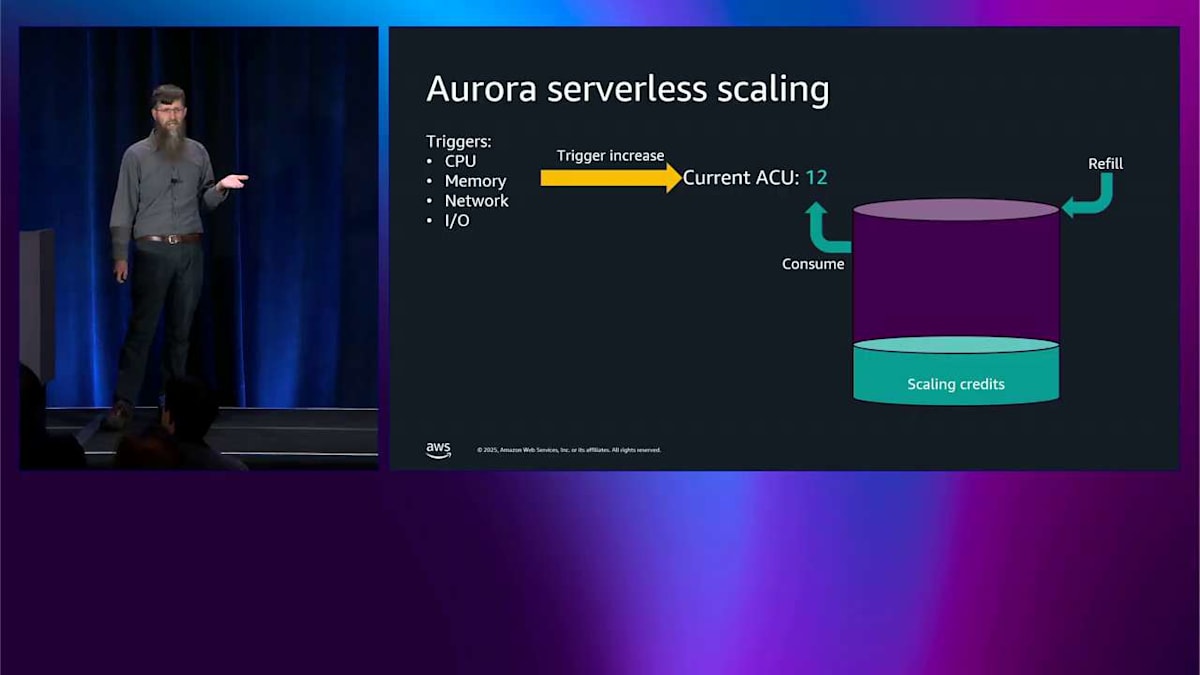

だからインスタンスは 12 までスケールアップしました。これは本当に速いんです。1秒未満で完了しています。でもスケーリングクレジットは減ってしまって、後で補充されます。 最近やったことは、この応答性を向上させることなんです。より高速なスケーリングを提供しました。 トリガーは 1秒未満で応答するようになり、バケットサイズは最初から大きくなり、補充も速くなりました。
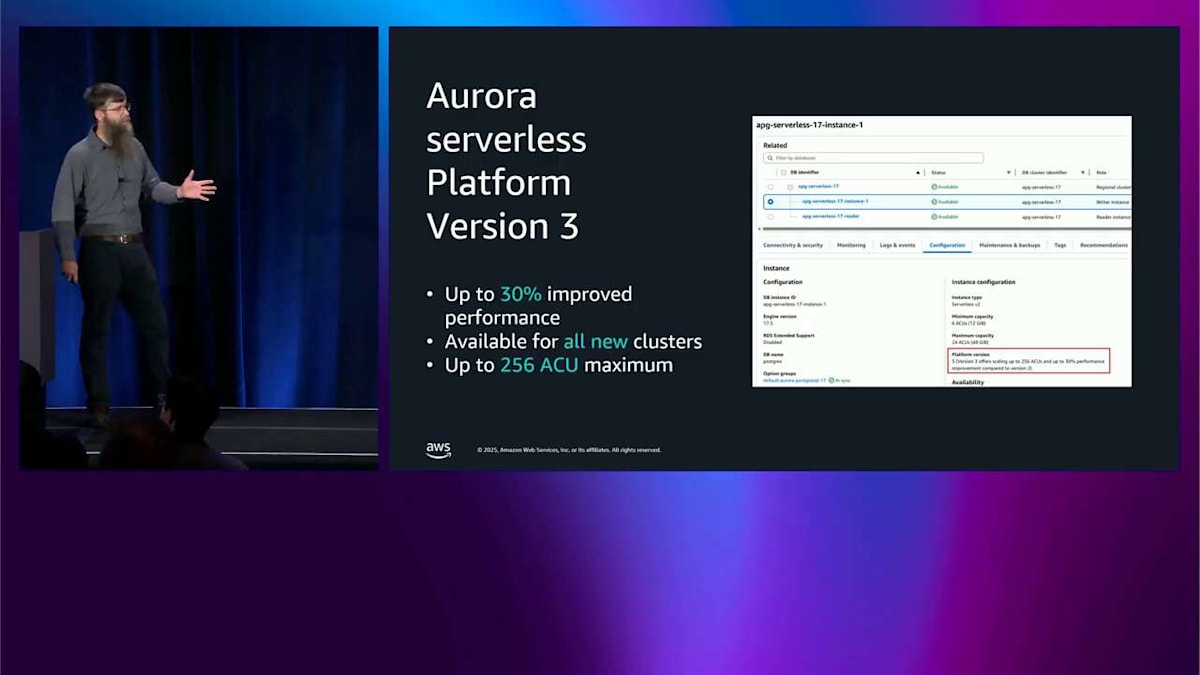
ここで話したいのはこれのパフォーマンス例についてです。Aurora Serverless で最近やったもう一つのことは、Platform Version 3 を導入したことです。 これにより最大 30% のパフォーマンス向上が得られます。これはすべての新しいクラスターで利用可能なので、バックアップやクローンから復元するか、新しいクラスターを作成するだけで、これが得られます。もう選択する必要があるオプションでもありません。これにより最大 30% のパフォーマンス向上が得られます。
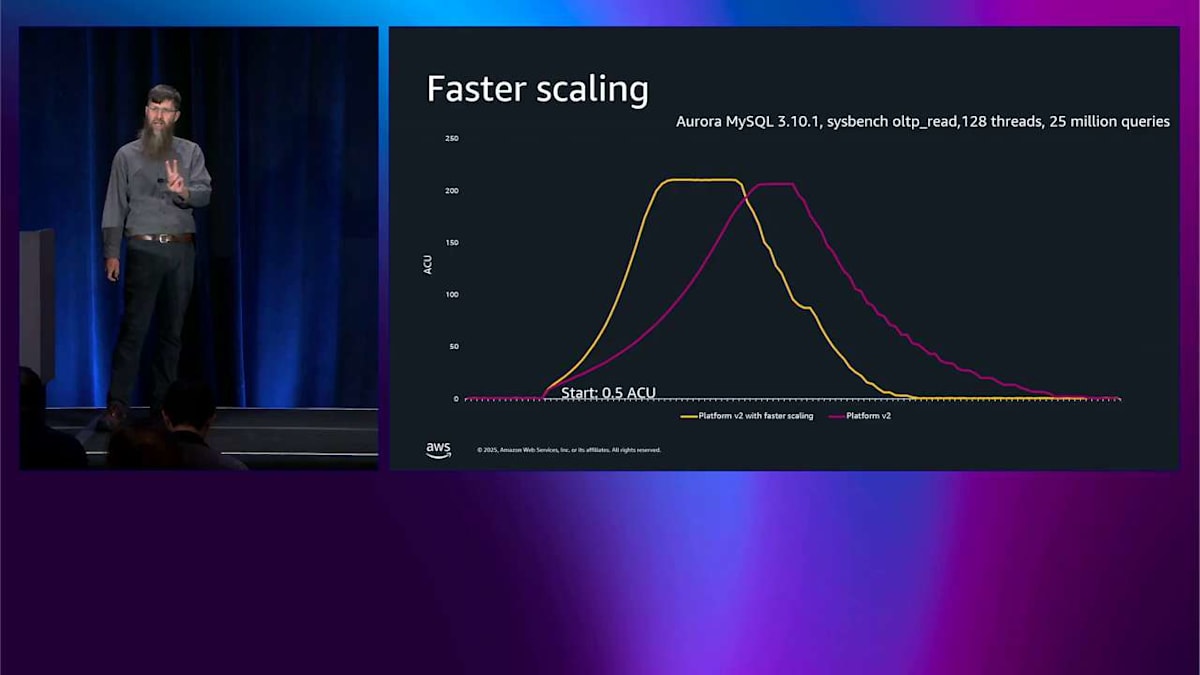
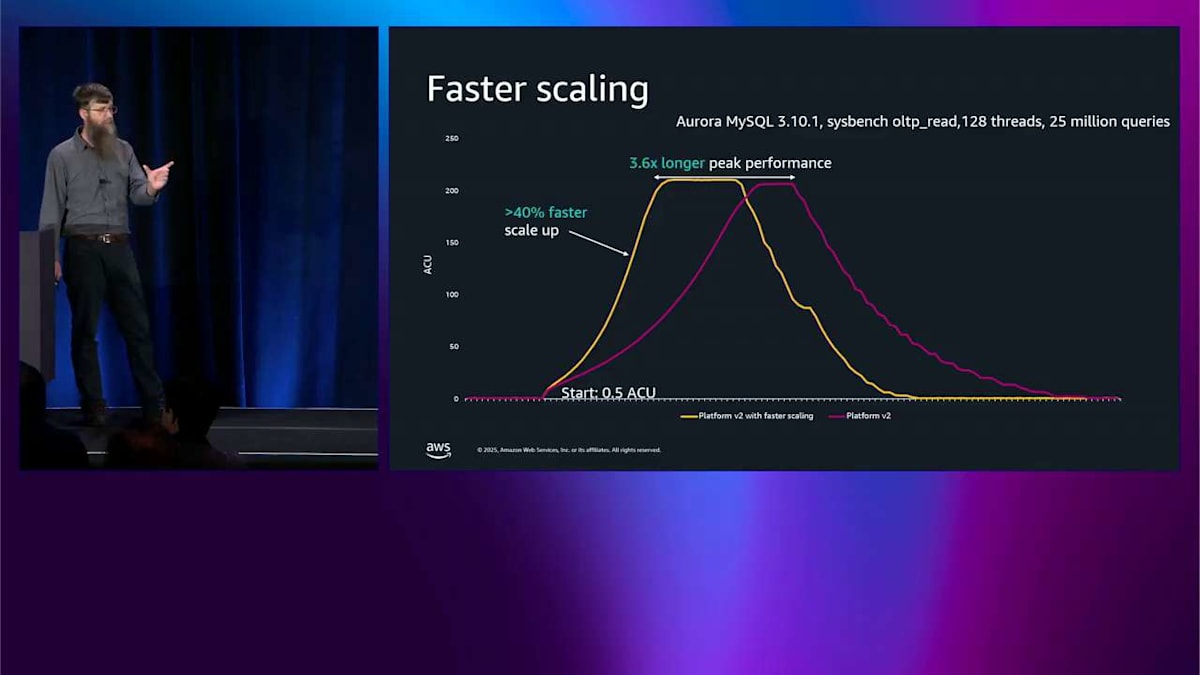
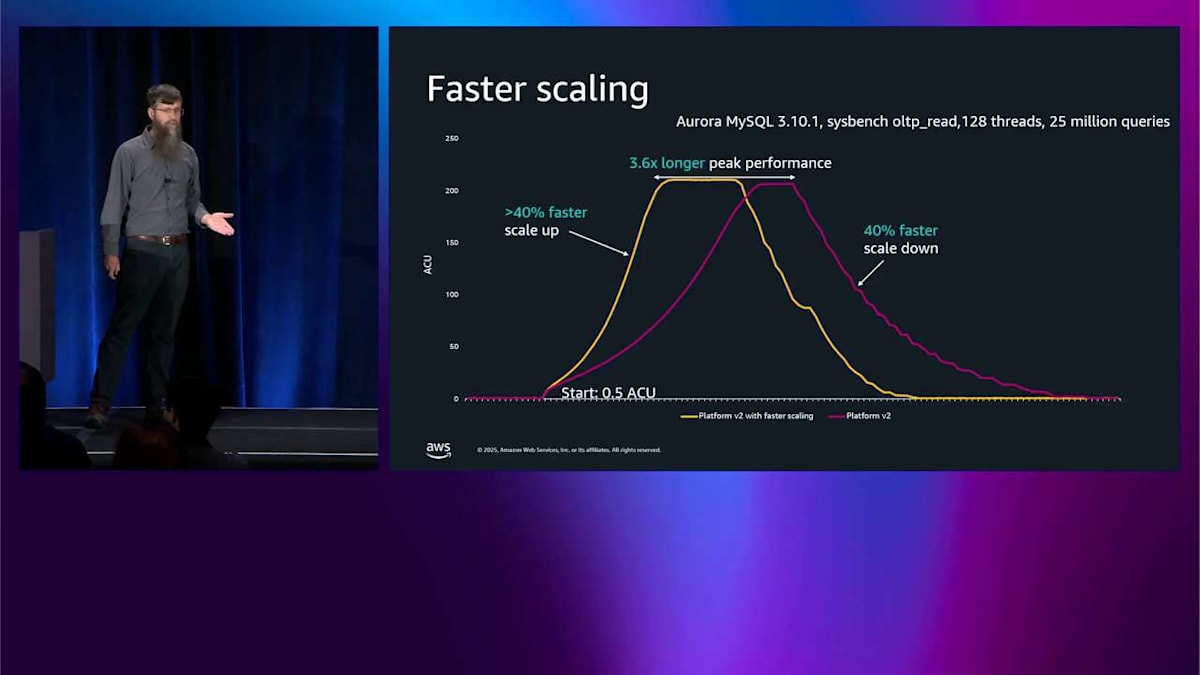
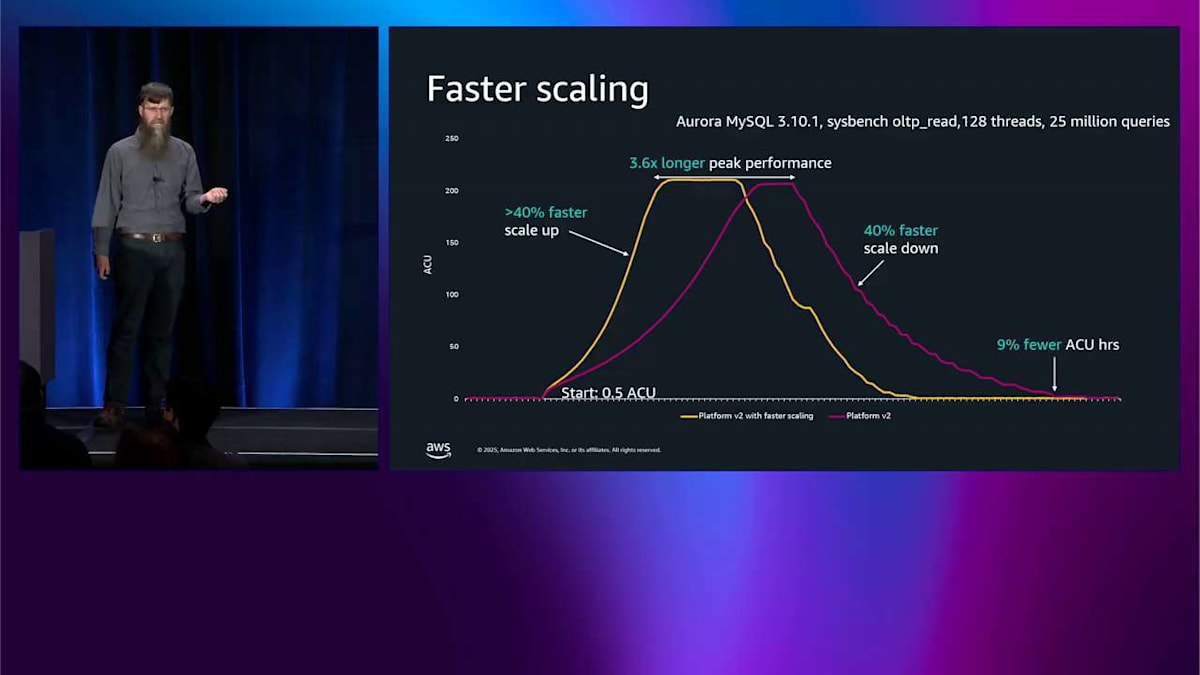
これら 2 つのことを組み合わせて見てみましょう。最初のテストはより高速なスケーリングのためだけのものです。 これは Platform Version 2 で、黄色いのが高速スケーリング、赤いのが高速スケーリングではありません。これは sysbench 読み取りテストなので、かなり強く押し進めて、210 程度の ACU まで上がります。最初に気づくことは、黄色い曲線がはるかに急勾配だということです。赤い曲線よりもはるかに速くスケールアップしています。 それからより速くスケールアップしたので、上部のピークパフォーマンスがより長く実行されるので、ワークロードを 3.6 倍長く完了させることができます。 それから 40% 速くスケールダウンもしました。 すべてを統合すると、最後の方で 9% 少ない ACU 時間を使用したことに気づきます。これが支払う対象なので、このテストでは 9% 少なく支払っているんです。
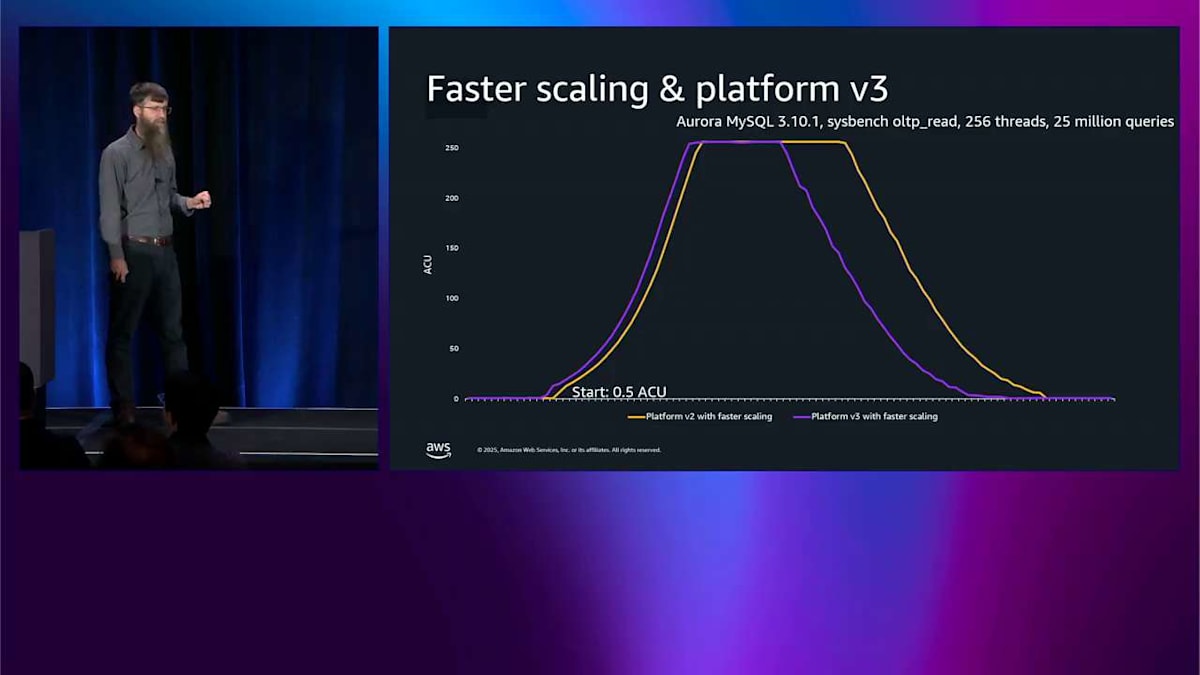
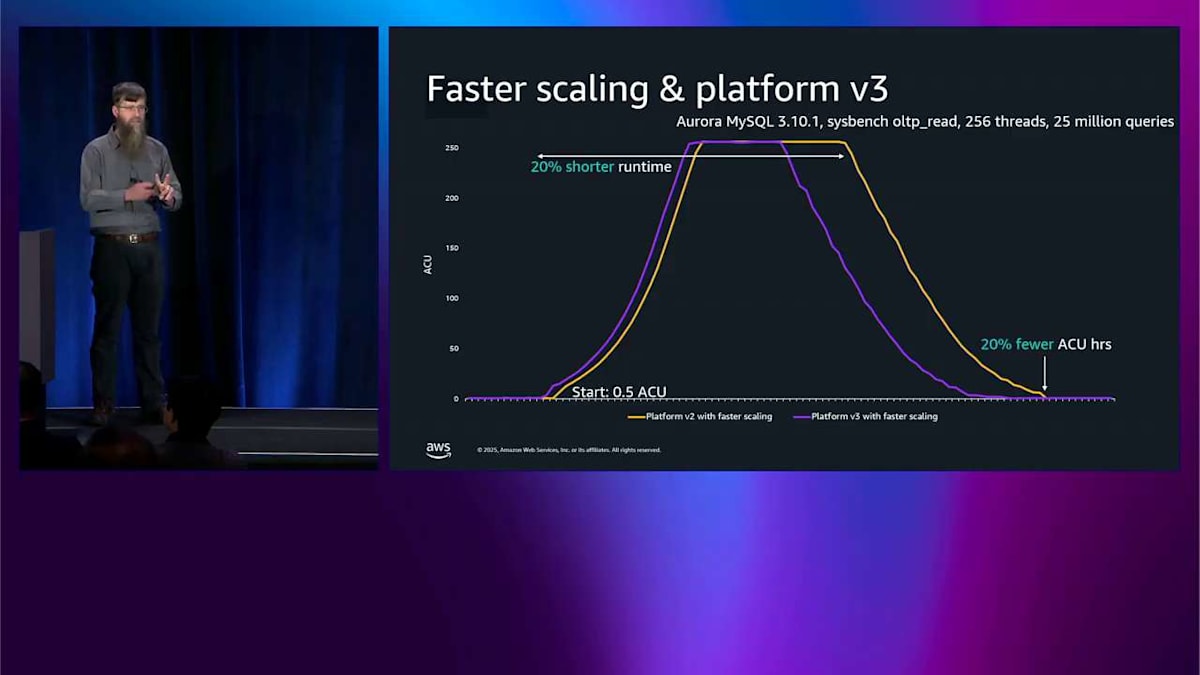
素晴らしい、これが高速スケーリングを備えた Platform Version 2 ですね。では、新しい Platform Version 3 を有効にしましょう。高速スケーリングは引き続き使用します。これは似たようなテストですが、少し負荷が高いので、さらに強くプッシュできます。紫色の線を見てください—これが高速スケーリングを備えた Platform Version 3 で、黄色いのが Platform Version 2 です。まず気づくのは、紫色のラインは 20% 短い時間で実行されます。なぜなら、より高速だから、同じジョブを完了するのに長く実行する必要がないからです。そして最後に、スケールダウンしたので、ACU 時間を 20% 削減しました。つまり、請求書が 20% 削減されるということです。これら 2 つの機能—高速スケーリングと Platform Version 3—を組み合わせることで、新しいクラスターを作成するだけで、両方を追加の手間なく手に入れることができます。
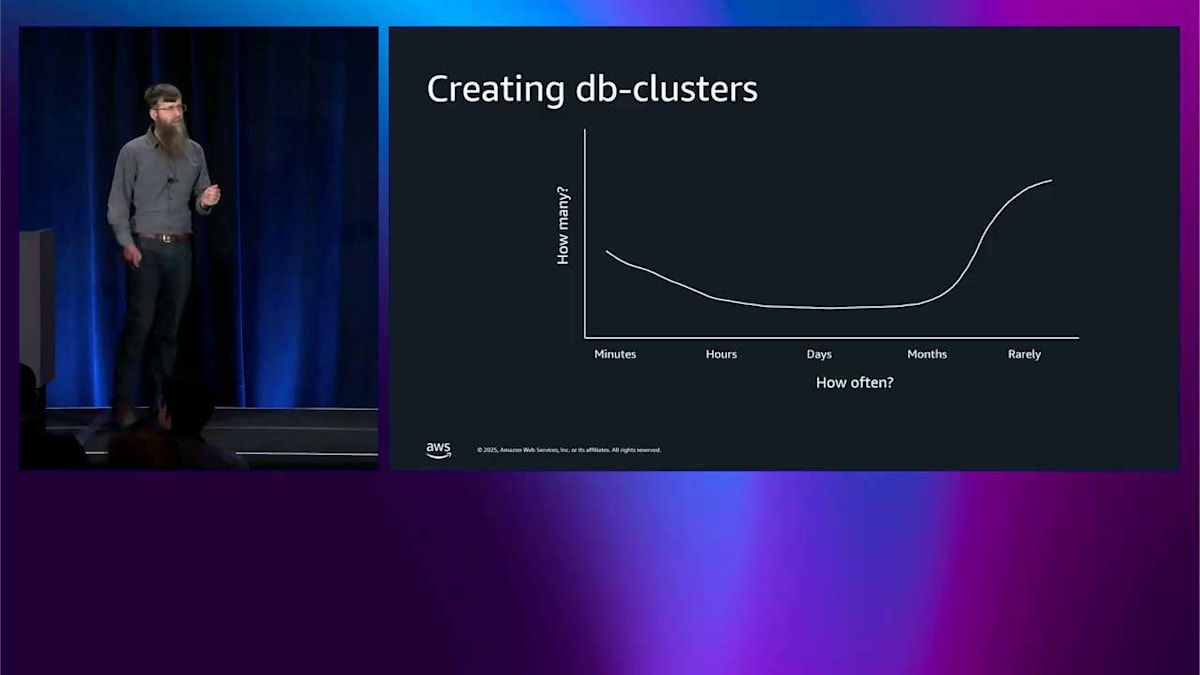
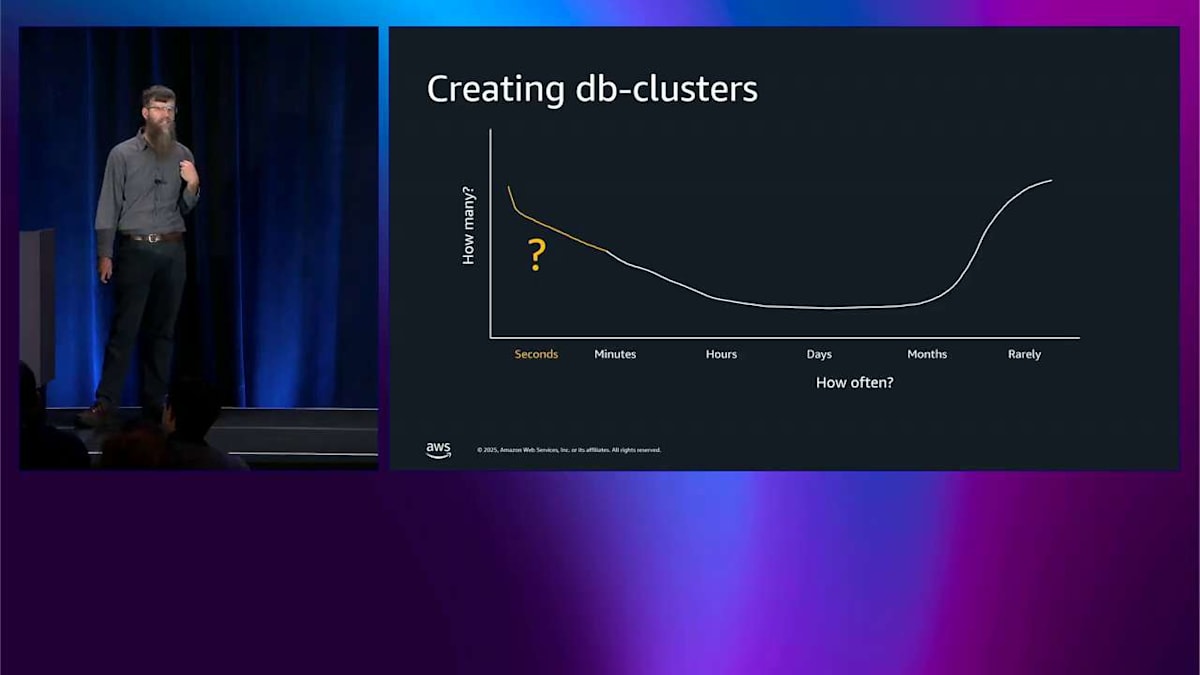
Express ConfigurationとInternet Access Gateway:数秒でデータベースを作成する新時代
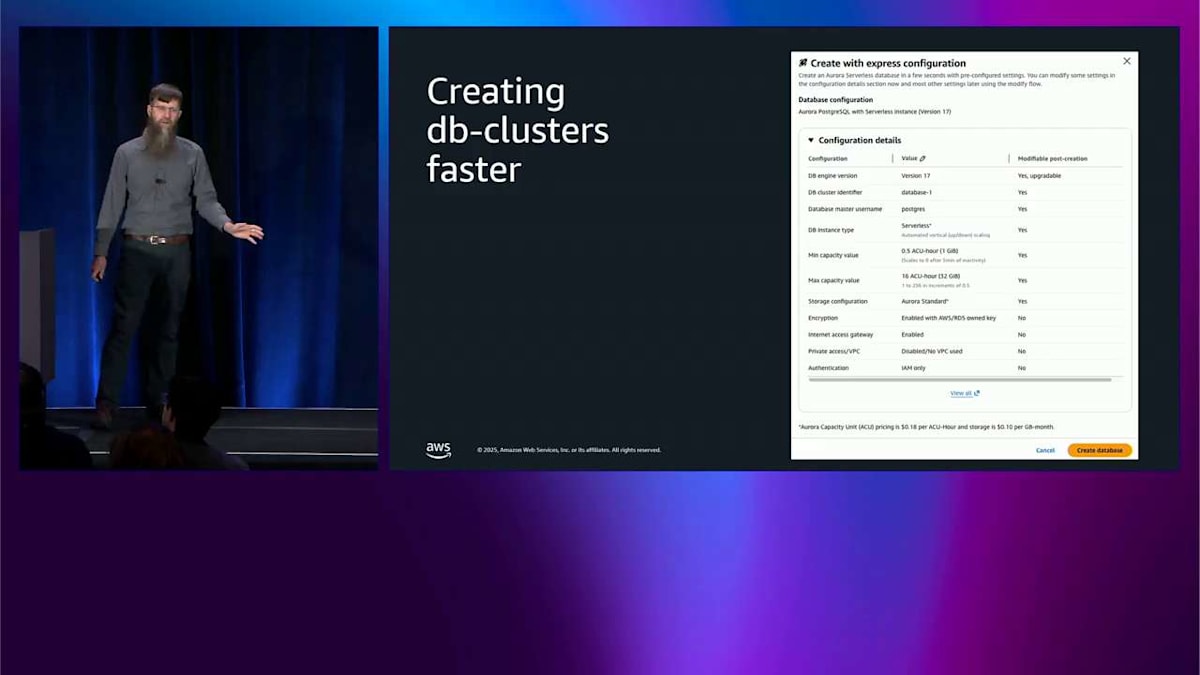
では、Aurora の最新イノベーションの 1 つについて話しましょう。これは昨日発表されたばかりで、事前発表されたものです。Aurora Create with Express Configuration です。ここにいる人たちの中で、どのくらいの頻度でデータベースクラスターを作成していますか?私の推測では、もちろん完全に正確なこの手描きの図は、ここにいるこの人口を表しています。右側には、データベースクラスターを作成することがほとんどない、基本的には決してない、という起業家精神を持った人たちがいます。真ん中には、週に 1 回くらいの頻度で作成する人たちがいます。しかし、ほぼ毎秒何かを作成したいというこの人口があります。これが CI/CD の人たちですね?本当にアジャイルで、本当に素早くやりたいわけです。そのオレンジ色の部分に対処したいのです。ここが Create with Express Configuration の出番です。これは昨日事前発表されたもので、Aurora PostgreSQL 向けに近日中に提供される予定です。
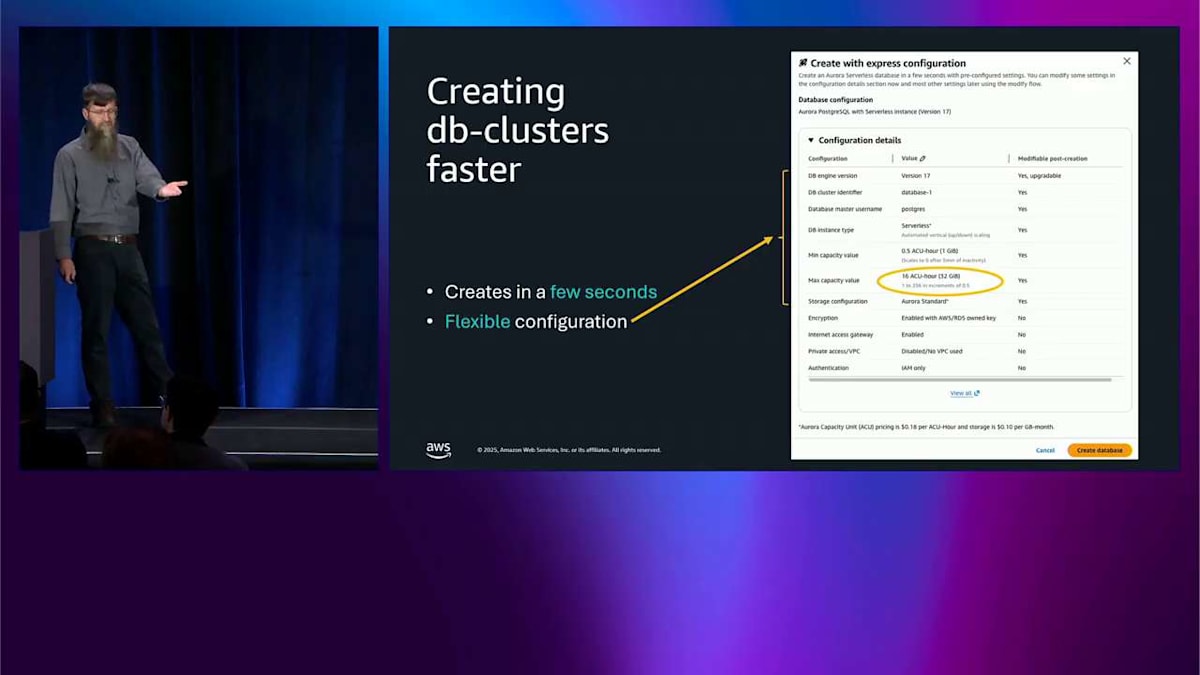
これが行うことは、データベースクラスターを数秒で作成できるようにすることです。これにより、CI/CD パイプラインでこれを使用することについて、心を開くことができます。agentic AI アプリケーションから使用できます—必要に応じて、そのインタラクションごとに新しいデータベースを作成できます。ここでいくつかのことが見えます。設定できるこれらのフィールドは、数秒で作成されます。柔軟な設定があります。これは Serverless で、必要に応じて 16 ACU から始まります—これは編集可能なフィールドです。名前を変更できます。現在のところ、PostgreSQL のバージョンはいくつか選択できるだけですが、右側の列に「Modifiable post-creation」と書かれているのが見えます。つまり、ほとんどのものについてはイエスです。ここのデフォルトが気に入らなくても、クラスターが作成されるとすぐに、必要に応じて変更できます。
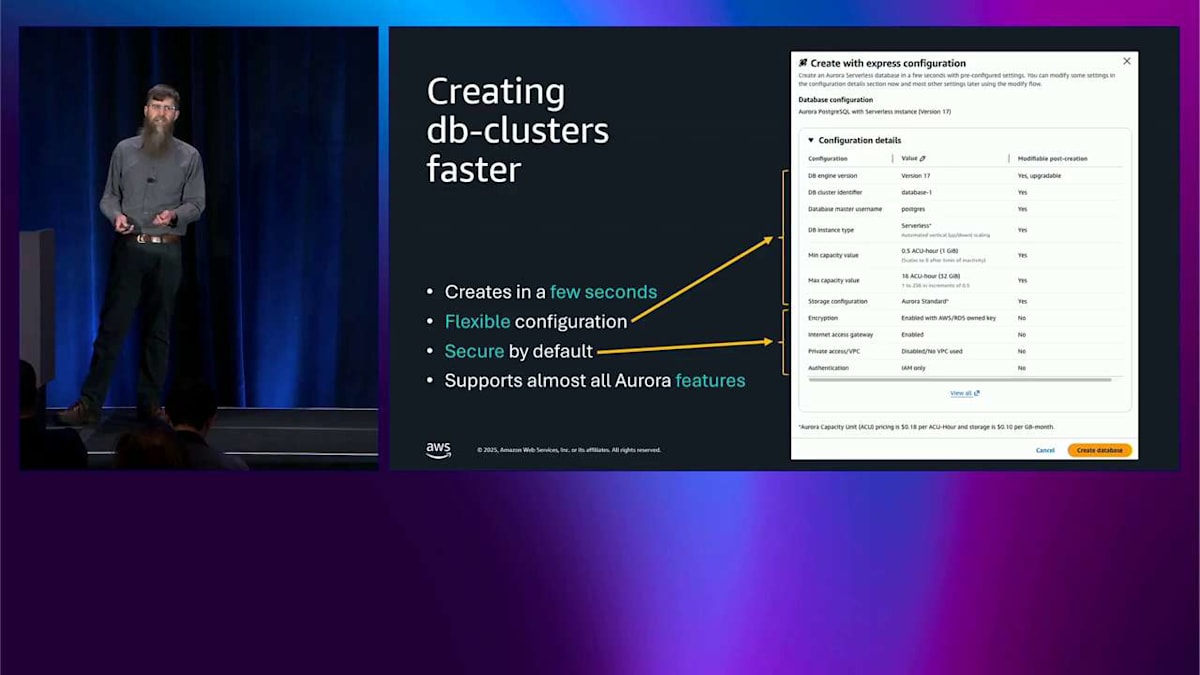
これは 16 ACU から始まります。これは多くの人にとって良いです。しかし、プロビジョニングされたシステムが必要な場合は、問題ありません—Serverless のものを立ち上げて、それに切り替えるだけです。前に話したようにフェイルオーバーできます。そして、デフォルトでセキュアなので、暗号化と IAM がデフォルトでオンになります。そして、ほぼすべての Aurora 機能をサポートしています。これは、私たちが作成している通常の Aurora データベースクラスターです—特別なものではありません。つまり、Global Database を実行できます。これは前に話したもので、zero-ETL、そして前に話したすべての他の機能ができます。バックアップは同じように機能します。すべて同じです。

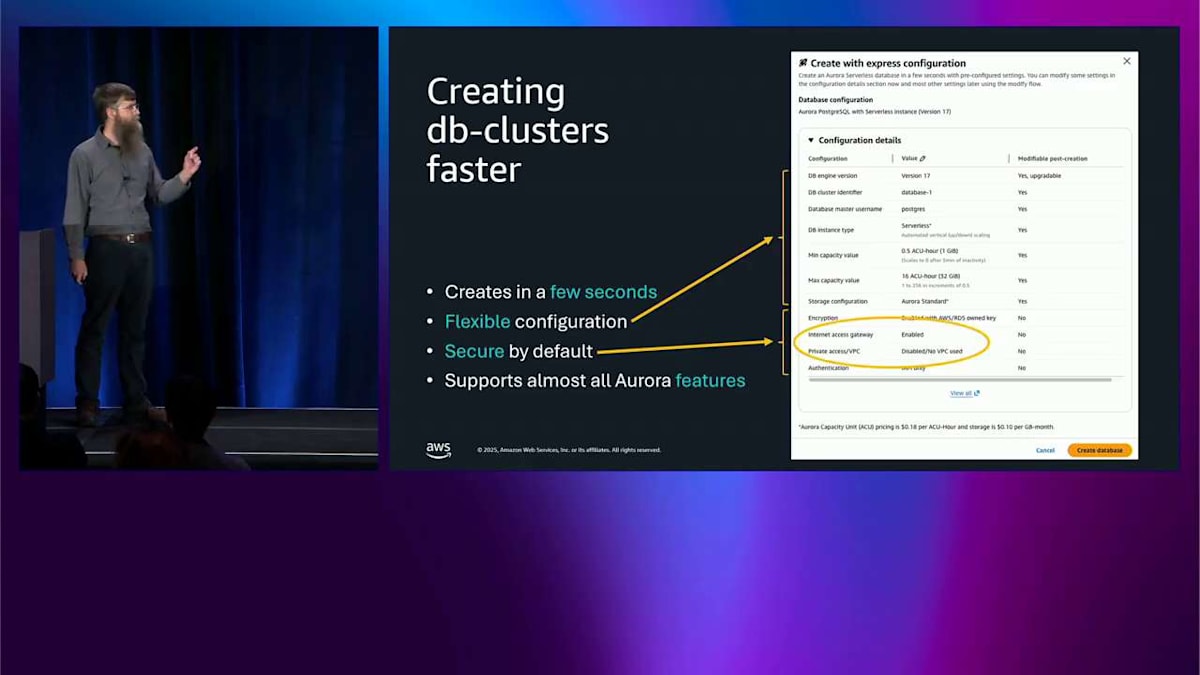
もう少し詳しく話したい新しい部分の 1 つは、下部にあるこの VPC なしのものです。これはかなり興味深いです。VPC がない場合、データベースインスタンスにアクセスする方法が必要です。おそらく、データベースインスタンスをインターネットに置きたくないでしょう。これは通常、良い実践ではありませんよね?つまり、Aurora Internet Access Gateway は、私たちが構築した新しいコンポーネントで、これに対処することができます。
これは Aurora クラスターへのアクセスを提供する高可用性エンドポイントです。PostgreSQL ワイヤープロトコルに互換性があり、重たいプロキシではないので、心配するような大きなレイテンシーはありません。つまり、VPN や VPC について心配することなく、ノートパソコンからどこからでもデータベースクラスターにアクセスできます。これにより、あなたと開発者が必要なことを行うための摩擦が大幅に軽減されます。


これは Amazon IAM と統合されており、AWS Shield とも統合されているので、不正行為防止やデータを保護するその他の方法など、提供される機能について話すことができます。Internet Access Gateway は Express 設定を作成するときにデフォルトでオンになります。ただし、ここで行った素晴らしいことについて話す必要があります。agentic AI のトークについて見たい場合は、下の方に別のものがあります。明日私の話を聞きたければそこを見てください。Aurora について最後の1分間で話したい本当に興味深いことが2つあります。
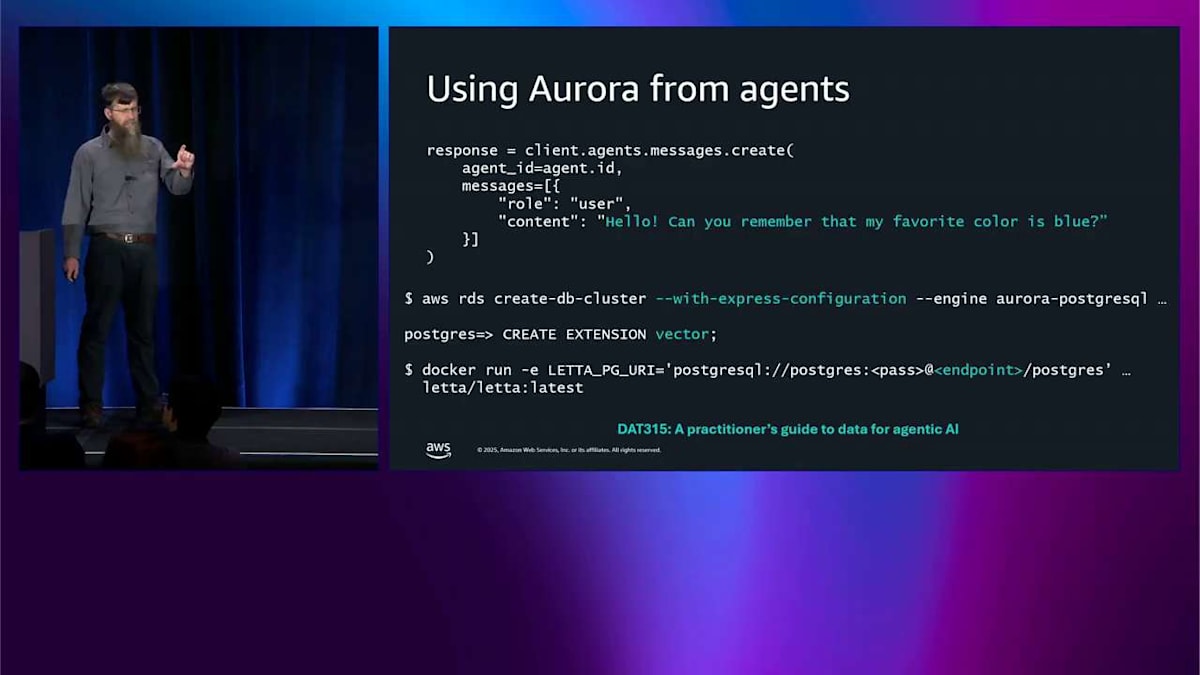
agentic AI の重要な要素はそれがループであるということです。つまり、これが機能するにはメモリが必要です。さて、私はデータベースであり、Aurora はメモリとして非常に優れていると考えています。では、どうすればいいでしょうか?「その好きな色は青です」というような何かを覚えておきたいのです。これらのオープンソースフレームワークのいずれかを使用できます。私たちはすでに Vercel や LangChain のような多くの人々とパートナーシップを結んでいます。これは LangChain で行う例です。ここではわずか3行です。先ほど話した Express 設定でデータベースクラスターを作成しました。これには数秒かかります。その後、pgvector 拡張機能を有効にします。LLM 用のベクトル埋め込みを行いたいからです。ただし、それを行う必要はありません。その後、LangChain をオンにして Docker コンテナーを起動し、PostgreSQL エンドポイントを指すだけです。完了です。これで Aurora PostgreSQL を agentic AI メモリに使用しています。
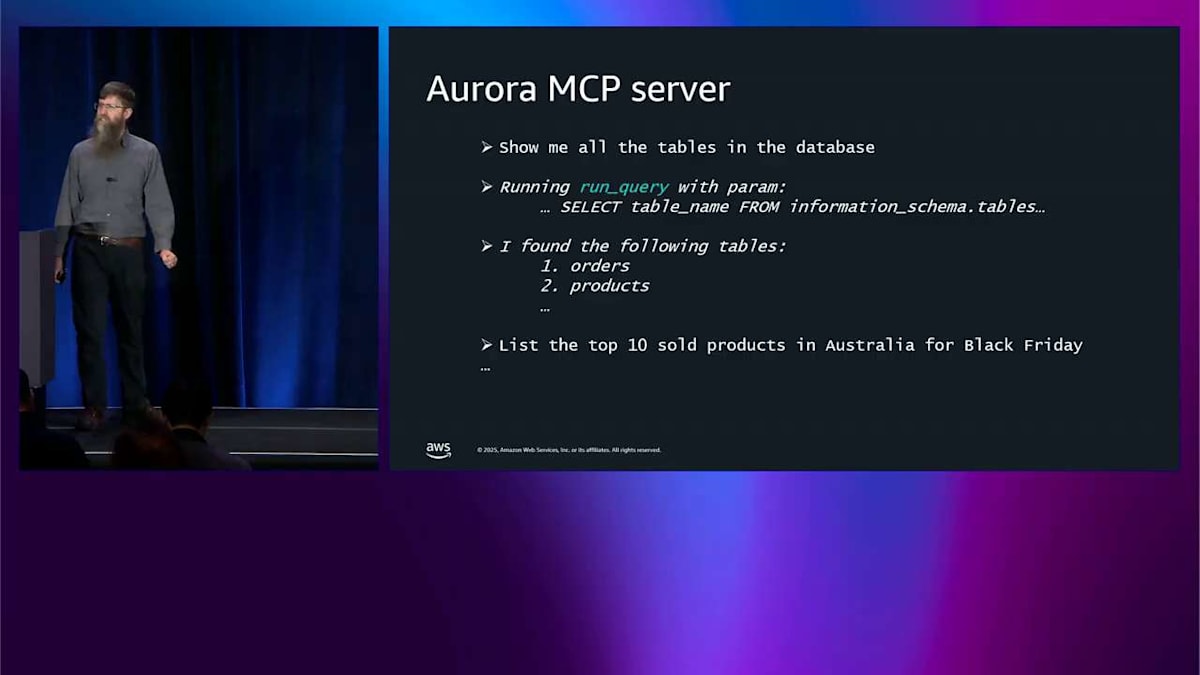
これは LangChain の例ですが、LangChain やその他すべてのようなあなたが選択した他のフレームワークについて、読むことをお勧めするブログ投稿やその他のものがたくさんあります。もう1つのことは MCP servers です。これは Model Context Protocol servers の略です。これはエージェントが通信する必要があるツールを見つけるための接着剤です。AWS は少し前にすべてのデータベース用の MCP servers をオープンソース化しました。これにより、Aurora データベース内で何が起こっているかのスキーマを理解し、自然言語クエリを SQL クエリに変換する自然言語クエリを実行できます。これは、データベースが初めてで、探索して周りを見回ろうとしている場合、または多くの場合、パワーユーザーの場合に非常に便利です。これはあなたをはるかに効果的にします。

パッチ管理とBlue-Greenデプロイメント:ダウンタイムを最小化するアップグレード戦略
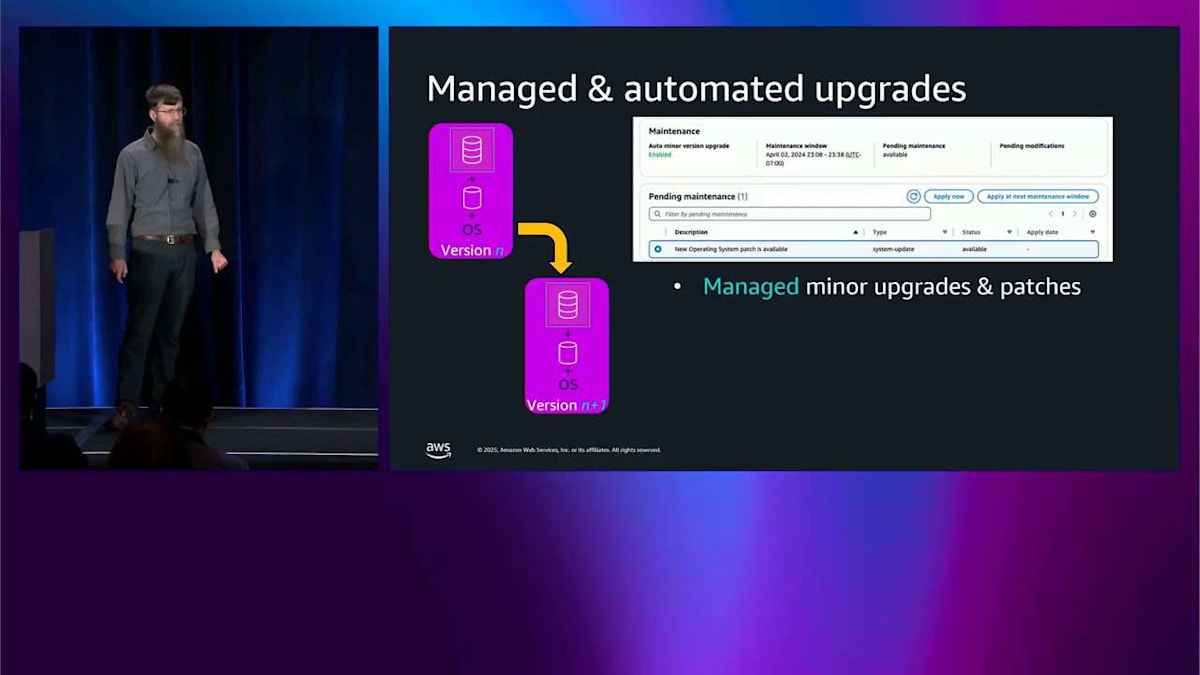
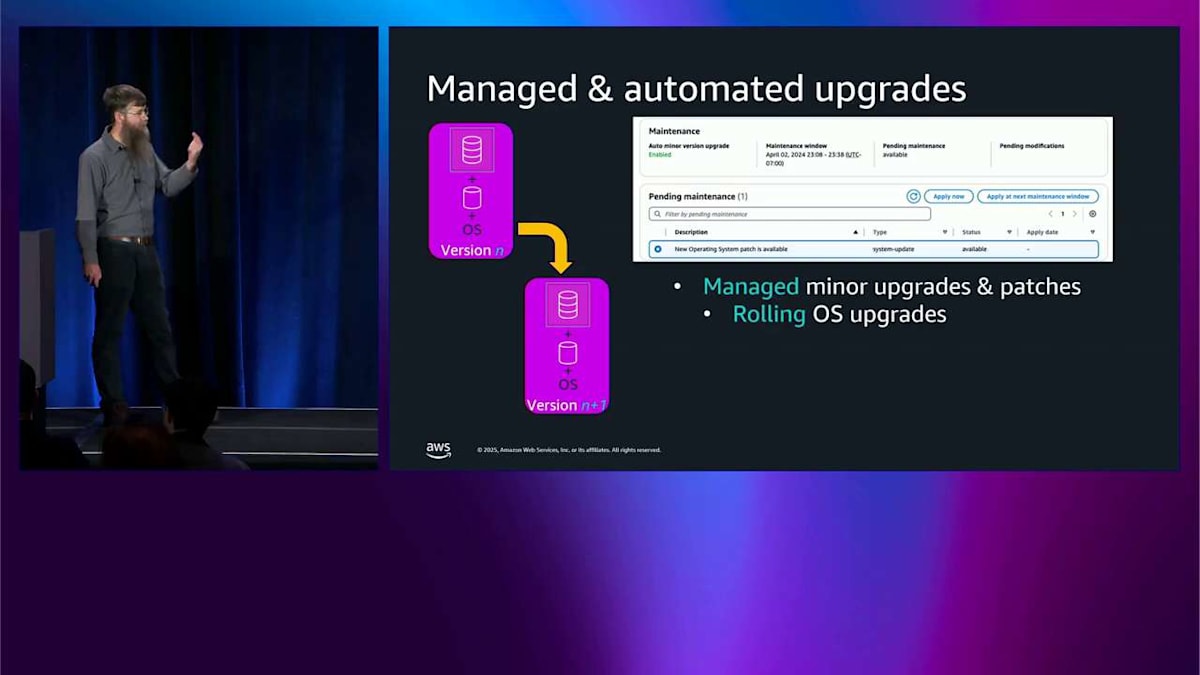
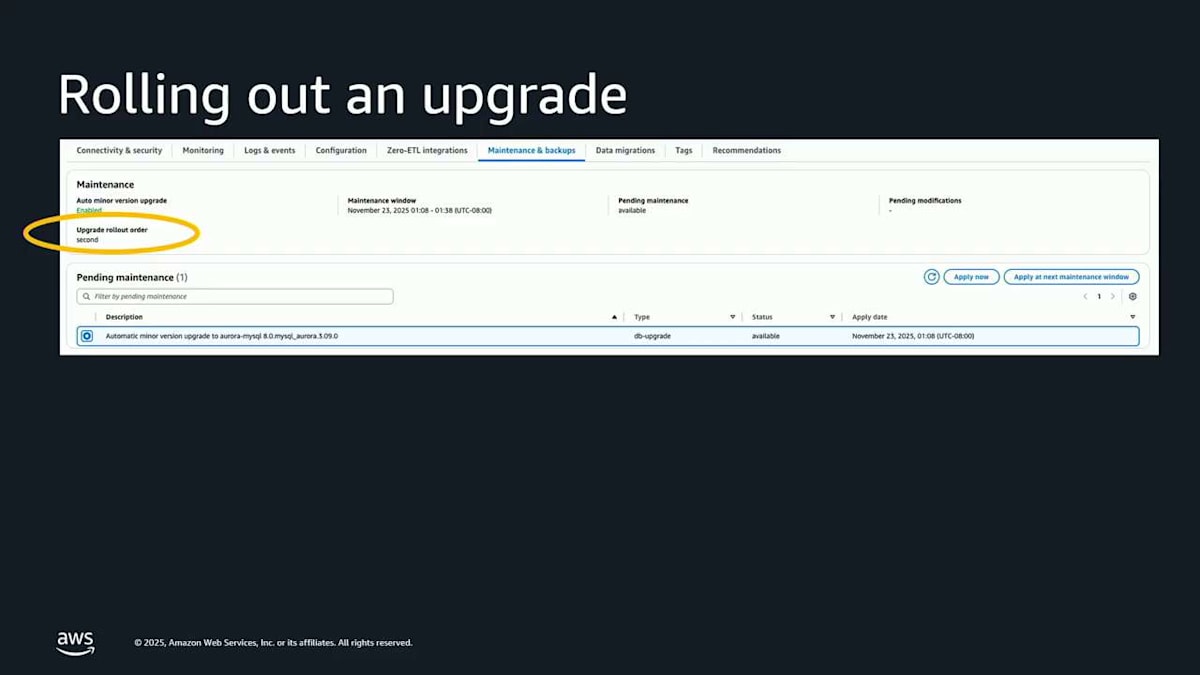
これで生成 AI についてはおしまいです。パッチとアップグレードは、おそらくもっと多くの人々の心に近いものです。うまくいけば、私はあなたを説得しました。そしてあなたはすでに多くの Aurora クラスターを実行しており、今はそれらをアップグレードしてパッチを適用し、安全で最新の状態に保つ方法について心配しています。Aurora は常にここで管理されたエクスペリエンスを提供してきました。保留中のメンテナンスアクションを示すコンソールスクリーンショットがあり、今すぐシステム更新を適用する必要があることを示しています。これは、単に実行をクリックするだけで実行される管理フローです。今、私たちは何が違うのでしょうか?オペレーティングシステムのパッチはローリング方式で行われるようになりました。つまり、クラスター内に複数のノードがある場合、それらをロールスルーするだけで、可用性が向上します。素晴らしいですね。
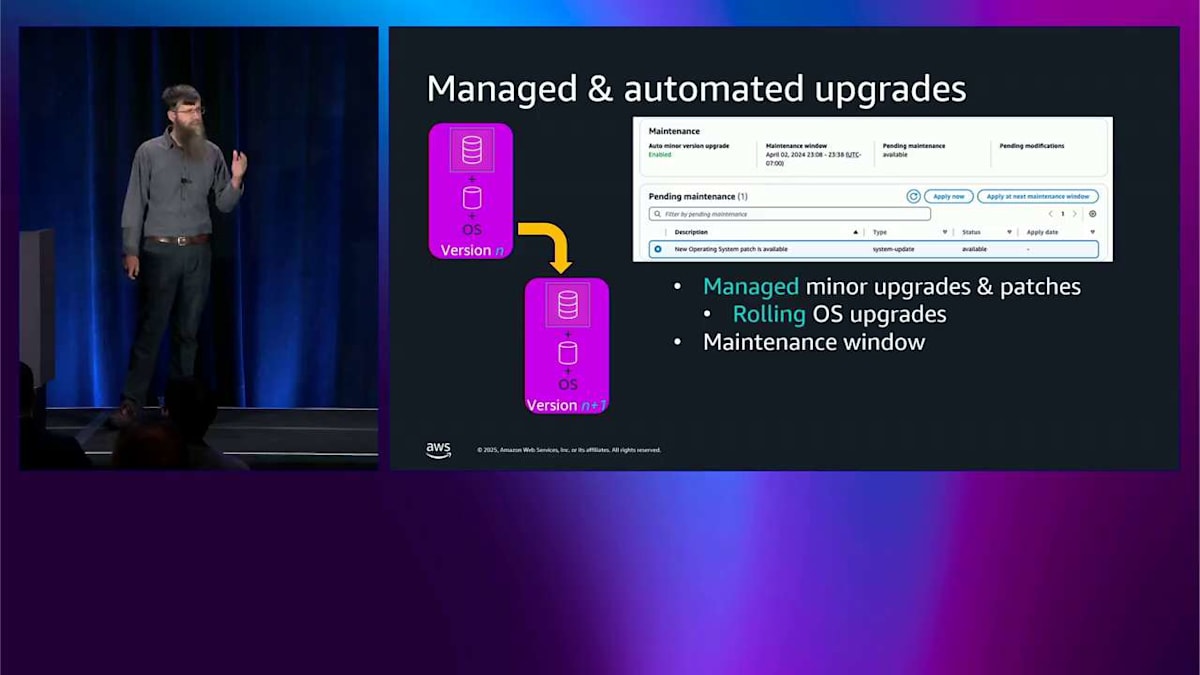
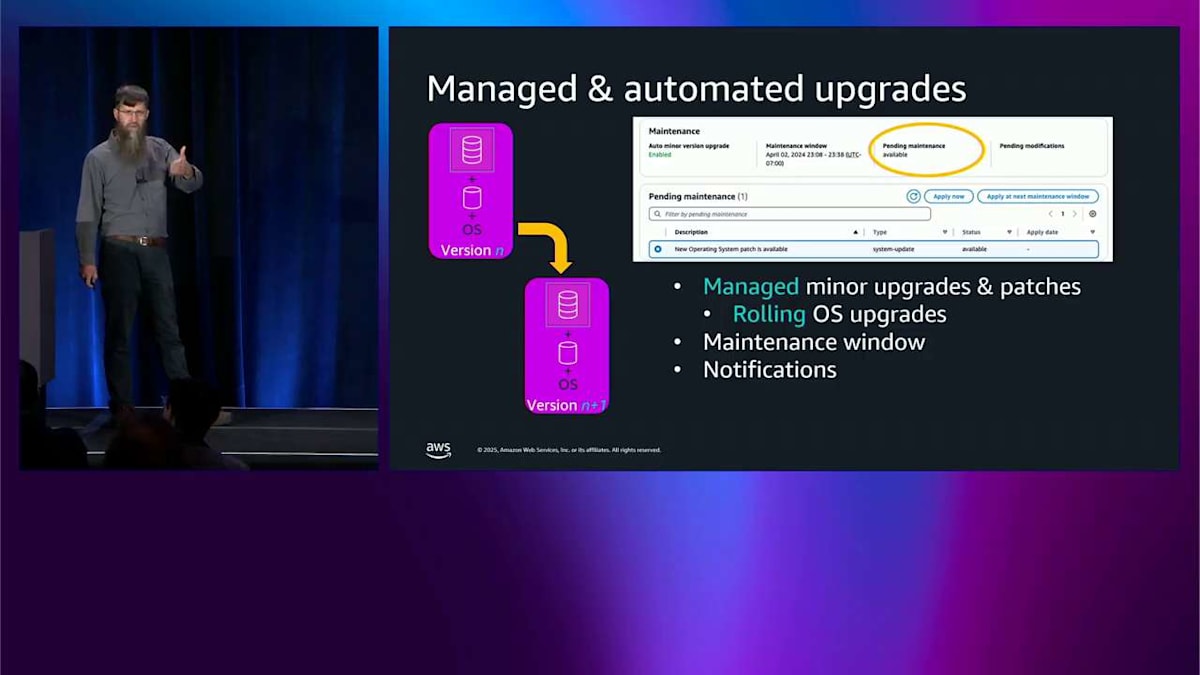
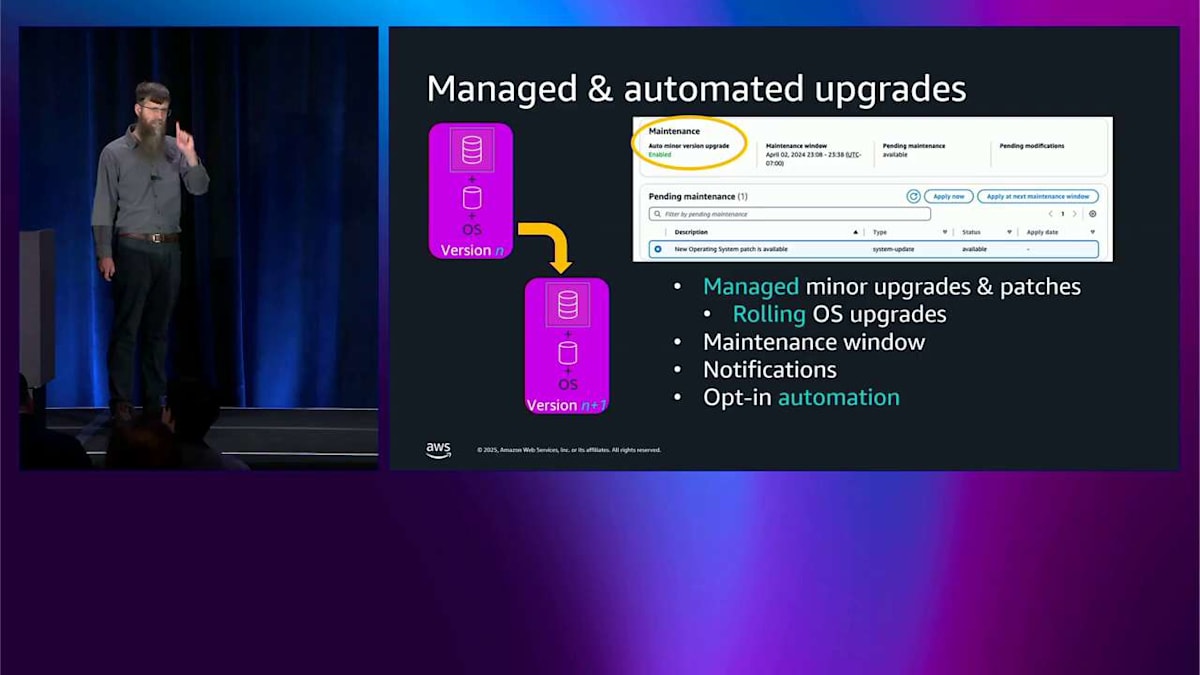
メンテナンスウィンドウは、いつでも設定できるようになっています。これにより、この特定のインスタンスでメンテナンスを実施したい曜日を設定できます。通知が送られてくるので、それが実行されるかどうかを知ることができます。これは AWS Health にポップアップで表示されます。自動化するかどうかを選択できます。Terraform などで自分たちで制御したいという理由で、自動化を選ばない人もいますが、それも全く問題ありません。これは 1 つのデータベースクラスターで、かなり管理しやすい状態です。しかし、クラスターのフリートを持つようになると、皆さんを説得して Aurora を気に入ってもらって、たくさんのクラスターを持つようになります。開発用のものもあれば、QA 用のものもあり、本番用のものもあって、それらのアップグレードをシーケンスしたいと思うかもしれません。
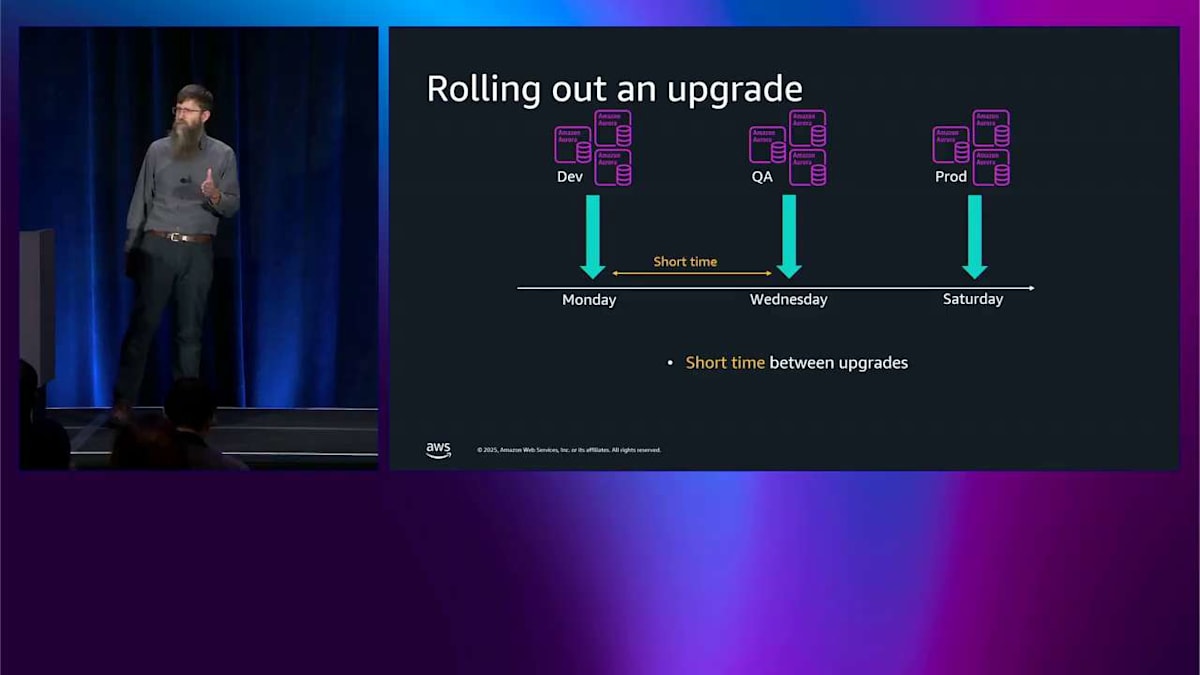
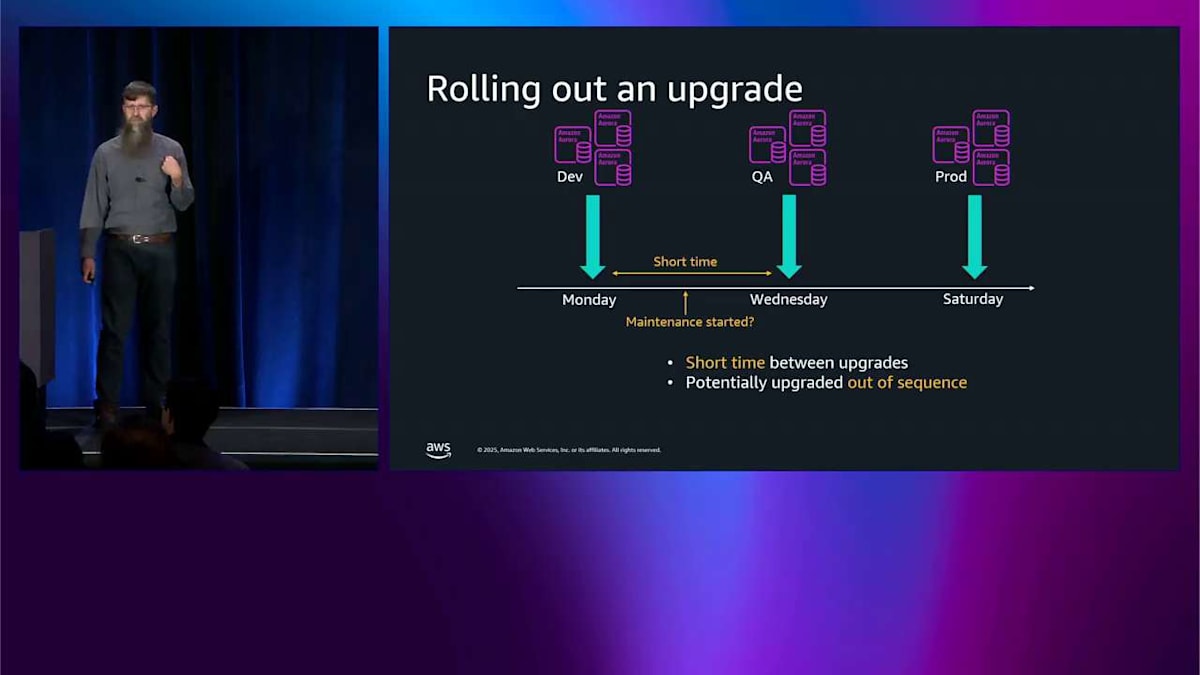
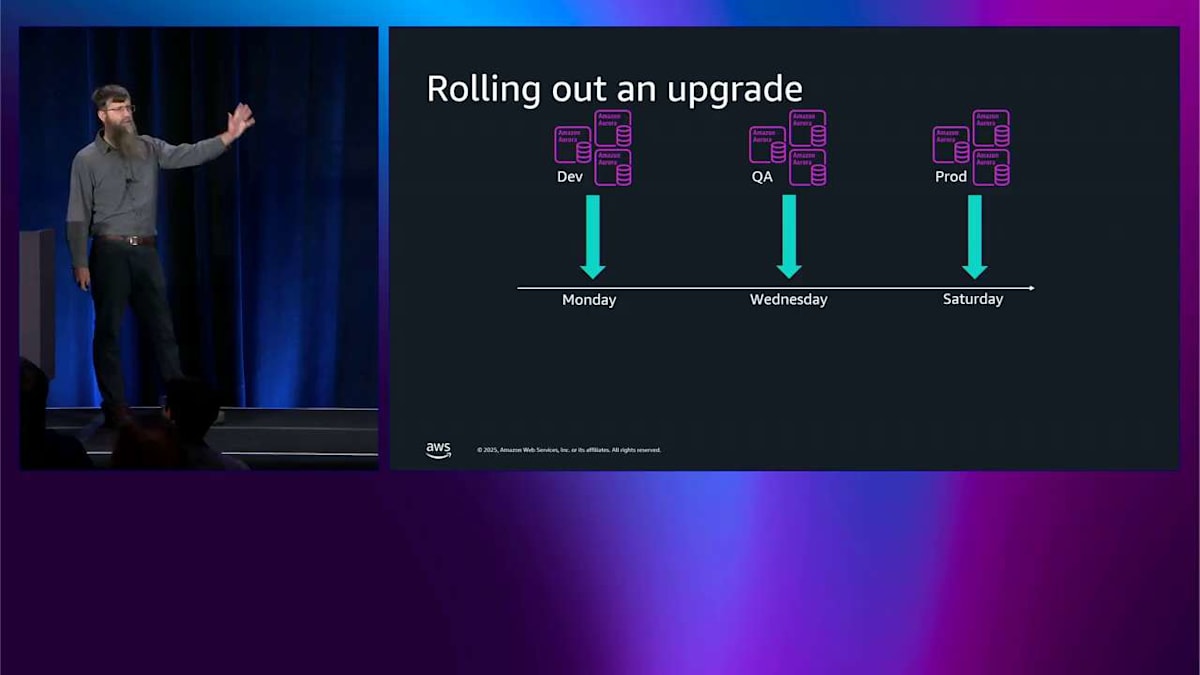
もし今日これを自分たちでやろうとしたら、開発用のものは月曜日に実行したいとします。そして QA 用のものは数日後に実行したいので、何か問題が起きた場合に備えて、ある程度の時間を確保できます。本番用のものは土曜日に実行したいので、営業時間外にできます。月曜日から水曜日までの間は時間が短いので、対応する時間もあまりありません。また、データベース内で何が起きているのか、どれが開発用でどれが QA 用なのかは分かりません。ですから、火曜日にメンテナンスを通知するかもしれません。そしてこのようなセットアップがあれば、QA 用のものが開発用のものの前にアップグレードされてしまい、それはおそらく皆さんが望んでいることではありません。私たちが行ったのは、AWS Organizations Upgrade Rollout Policy をちょうど先週発表することで、この問題に対処することです。ここに同じ 3 つの環境があり、私たちが行ったのは、それらを 3 つのウェーブに分けることです。第 1 ウェーブ、第 2 ウェーブ、最後のウェーブです。


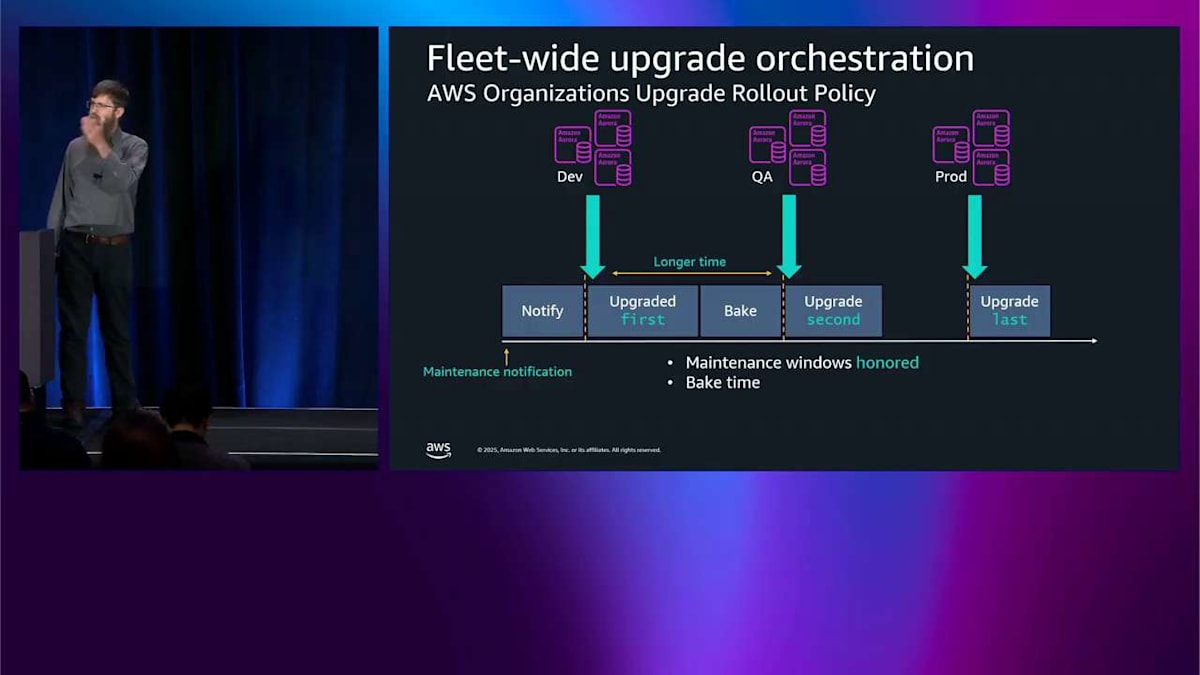

これは実は皆さんが私に表現しようとしていたことそのものです。ここで起こることは、まず、以前と同じようにメンテナンス通知で皆さんに通知します。そして、第 1 ウェーブのすべてのリソースのメンテナンスウィンドウが来るまで待ちます。その後、第 1 ウェーブのすべてのインスタンスをアップグレードします。その後、以前よりもはるかに長い時間待つので、対応する時間ができます。その後、第 2 ウェーブのリソースのメンテナンスウィンドウが来るまで待ってから、それらをアップグレードします。さらに長い時間待った後、最後のウェーブについても同じことを行います。

1 つのウェーブから次のウェーブへ何か問題が起きた場合、実際にはブロックしていませんが、皆さんが再度オプトアウトできるように十分な時間を与えています。タグをオフにするか、自動マイナーバージョンアップグレードをオフにすることができます。これらのものをシーケンスでアップグレードしているので、アップデートをリリースする曜日がどれであっても、皆さんにとってはシーケンスで実行されます。では、どうやってこれに参加するのでしょうか。AWS Organizations をまだ有効にしていなければ有効にする必要があり、アカウントを組織に入れる必要があります。自動マイナーバージョンアップグレードを有効にして、メンテナンスウィンドウをチェックするなど、通常行うことを行う必要があります。
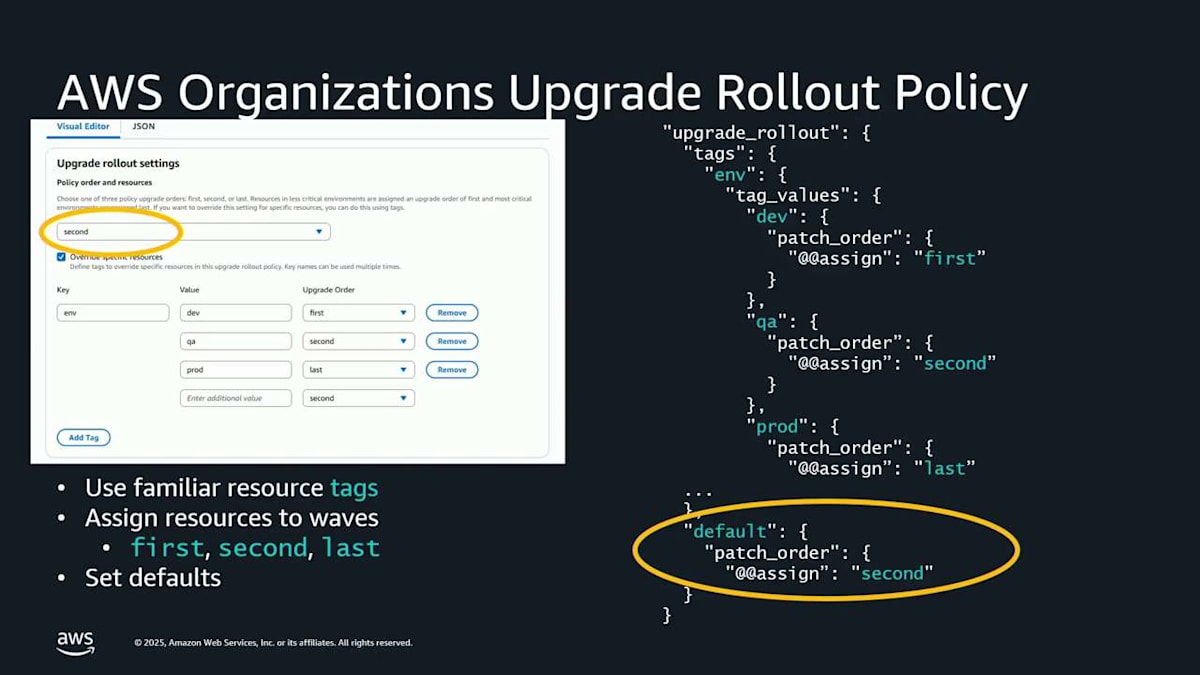
興味深い部分は、ポリシーを設定する必要があるということです。左側にはコンソール版があり、右側には同じものの JSON 版があります。これは、タグを関連付けることを許可していることを示しています。皆さんはおそらくすでにリソースにタグを使用しています。ここでは env というタグを作成します。これは特別な単語ではなく、好きな名前を付けることができます。env というタグを持つすべてのリソースが、例えば prod という値を持つ場合、それを最後のウェーブに入れたいと言っています。認識できないタグがあるか、タグがまったくない場合、デフォルトが適用されます。この場合、デフォルトは第 2 ウェーブです。タグをまったく使用したくない場合は、デフォルトを受け入れるだけで、すべてが一度にアップグレードされます。
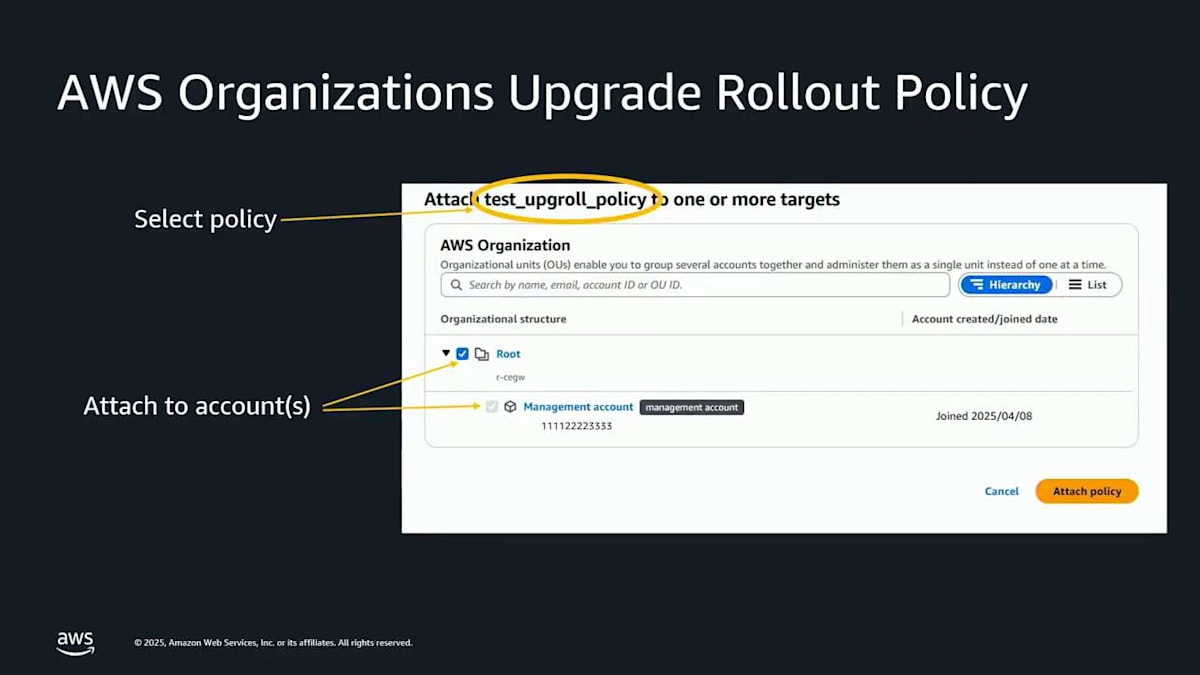
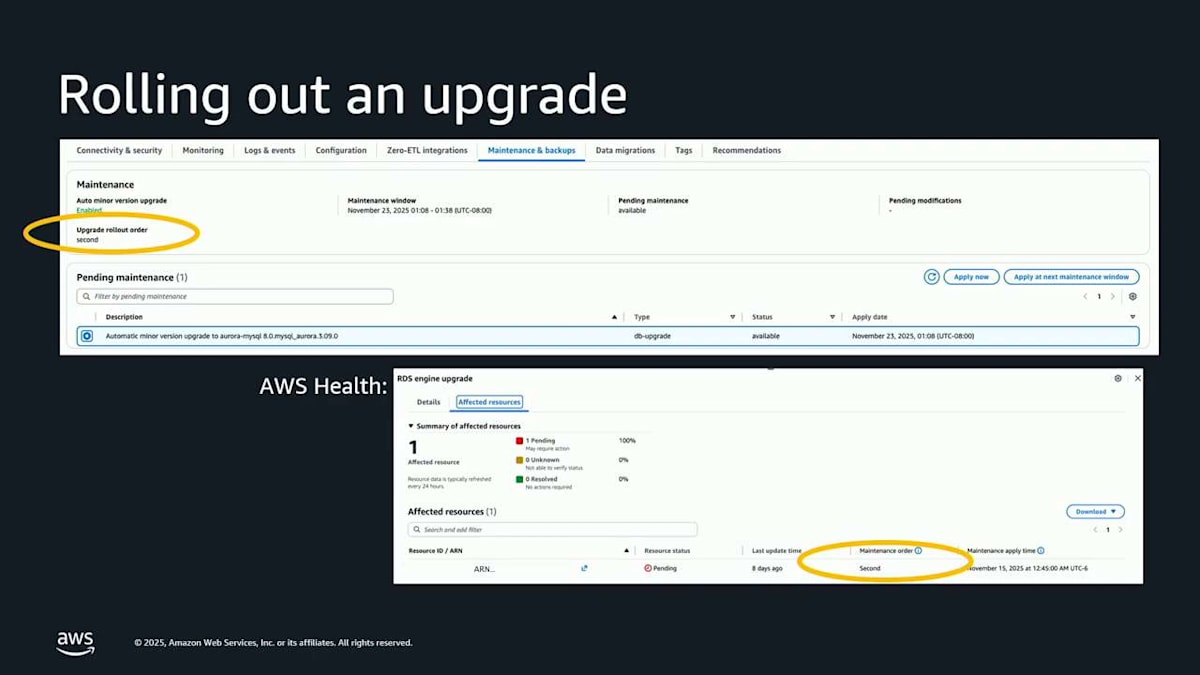
このポリシーを作成したら、組織全体のルートに、または組織内の個別のアカウントに、このポリシーをアタッチすることができます。つまり、ここで選別することができるということです。その後、アップグレードが実際にロールアウトされようとするとき、通常の方法でこれが表示されます。左上の保留中のメンテナンスアクションに、これが第2波で実行されることが表示されます。また、AWS Health でも同じ情報が表示されます。この場合、第2波の情報を含むヘルスの通知が届きます。これは本当に役に立つと思いますので、ぜひ試してみてください。これが AWS Organizations Upgrade Rollout Policy です。

では、blue-green デプロイメントについて話しましょう。私が今まで話してきたこれらのテクニックはすべて、互換性のあるアップグレードをロールスルーしている場合には素晴らしいものです。しかし、オープンソースからのメジャーバージョンアップグレードが来ると、これらは定義上、一般的に互換性がありません。つまり、大量のダウンタイムなしにインプレースでこれらを実行することはできませんし、おそらくあなたもそうしたくないでしょう。では、blue-green デプロイメントとは何でしょうか。ここでは、上部に本番環境があり、いくつかの Aurora ノード、共有ストレージ、そしてアプリケーションがエンドポイントを通じてそれと通信しています。
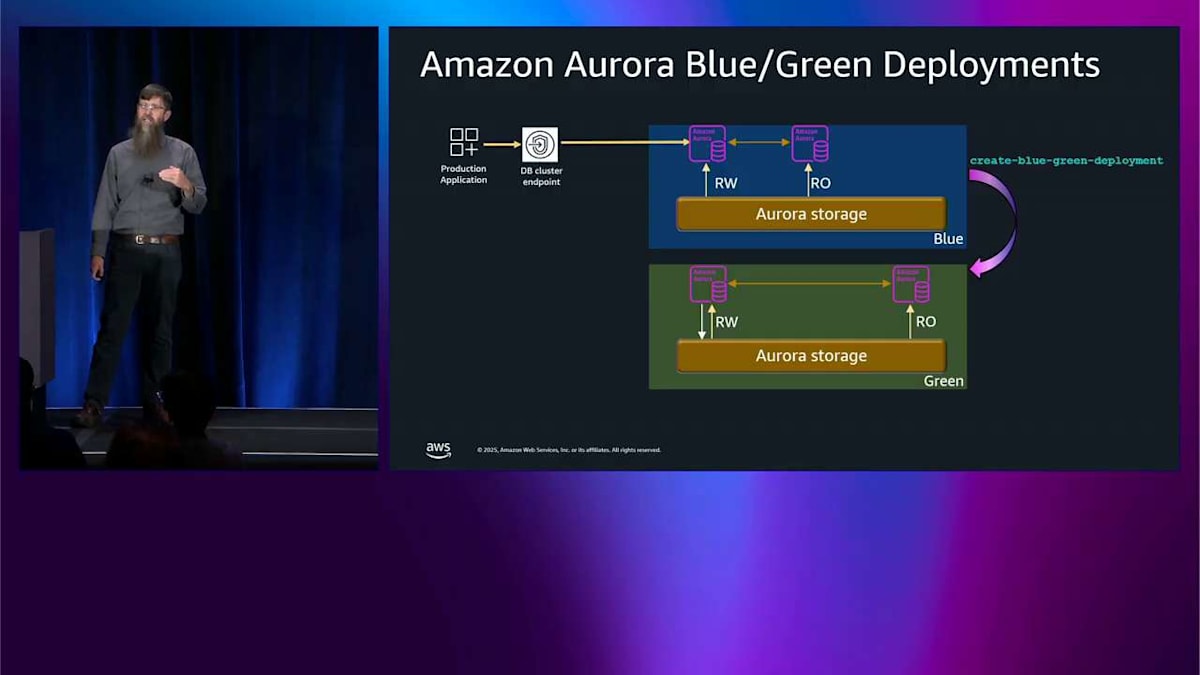
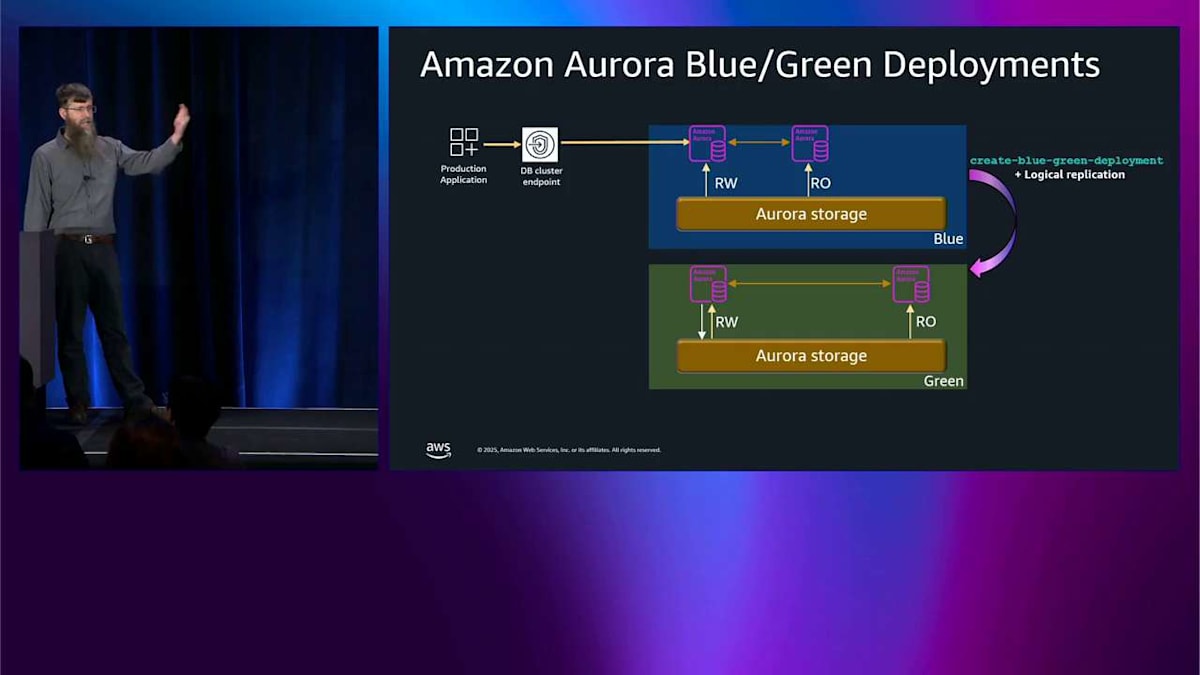
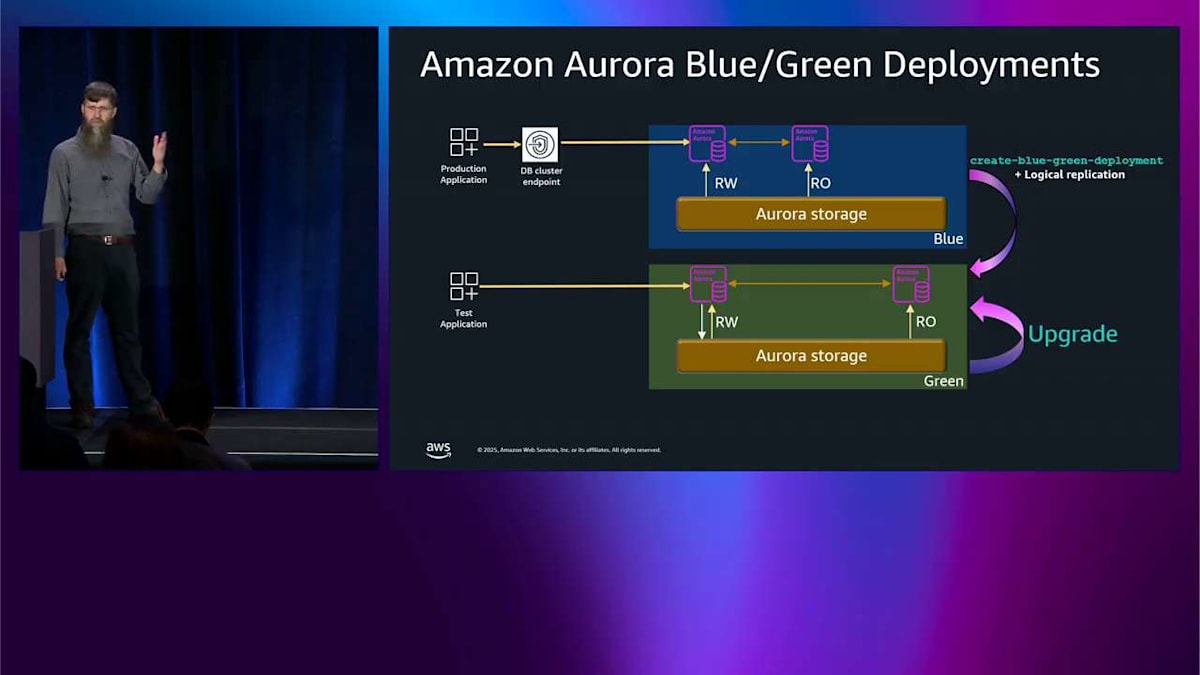
blue-green デプロイメントを作成したいとき、本番環境の完全なコピーをワンクリックで作成します。すべてのノードを同じにして、論理レプリケーションを使用してすべてのデータを同期し、この blue-green を実行し続ける限り、同期を保ちます。blue に入ってくる新しい書き込みはすべて、既に green にプッシュされます。それが完了したら、その green 環境をアップグレードして、テストアプリケーションでテストすることができます。好きなことができます。ここで1時間過ごすこともできますし、この状況で1週間過ごすこともできます。どちらでもかまいません。
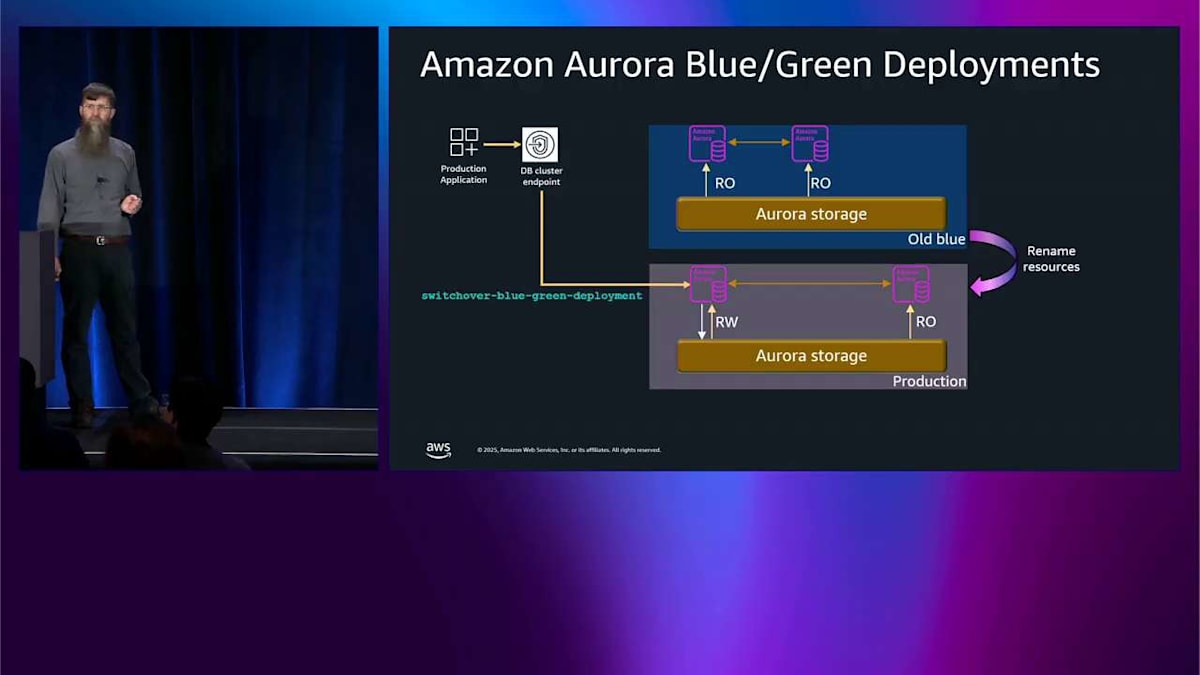
アップグレードが期待通りに機能していることに満足したら、CLI またはコンソールを通じて blue-green スイッチオーバーと呼ばれるものを実行でき、AWS リソースの名前をすべて変更して、後で混乱が生じないようにします。論理レプリケーションを最初にドレインして、データを失わないようにします。エンドポイントを切り替えます。本番クラスタはそのエンドポイントとの通信を続けます。今では、以前 green 環境と呼ばれていたものと通信しています。古い blue 環境はまだそこに残っているので、何か問題が発生した場合のルックバックプランがあります。
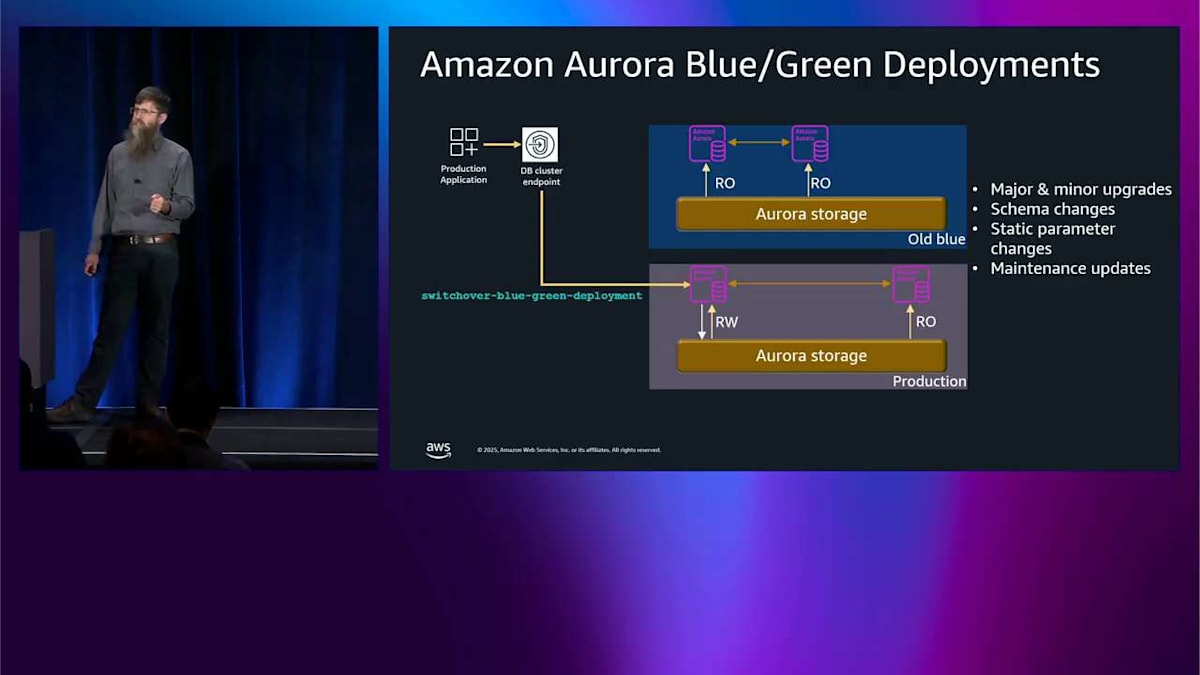
何らかの理由でスイッチオーバーがタイムアウトした場合、通常スイッチオーバーは1分未満ですが、自動的にそれを元に戻して、元の blue 環境に戻すので、何も対処する必要がありません。これが Aurora blue-green です。これらのメジャーバージョンアップグレードを実行するときに可用性を高めるための素晴らしい方法です。古いバージョンにとどまるよりも、バージョンアップグレードを実行してもらう方がいいです。誰もそれを望んでいないと思います。バージョンアップグレードだけでなく、スキーマの変更、静的パラメータの変更、メンテナンスアップデート、およびインプレースで実行するには危険すぎると思われる他のすべてのもの、そして blue-green の保護が必要なものに対しても役立ちます。blue-green デプロイメントを使用できます。
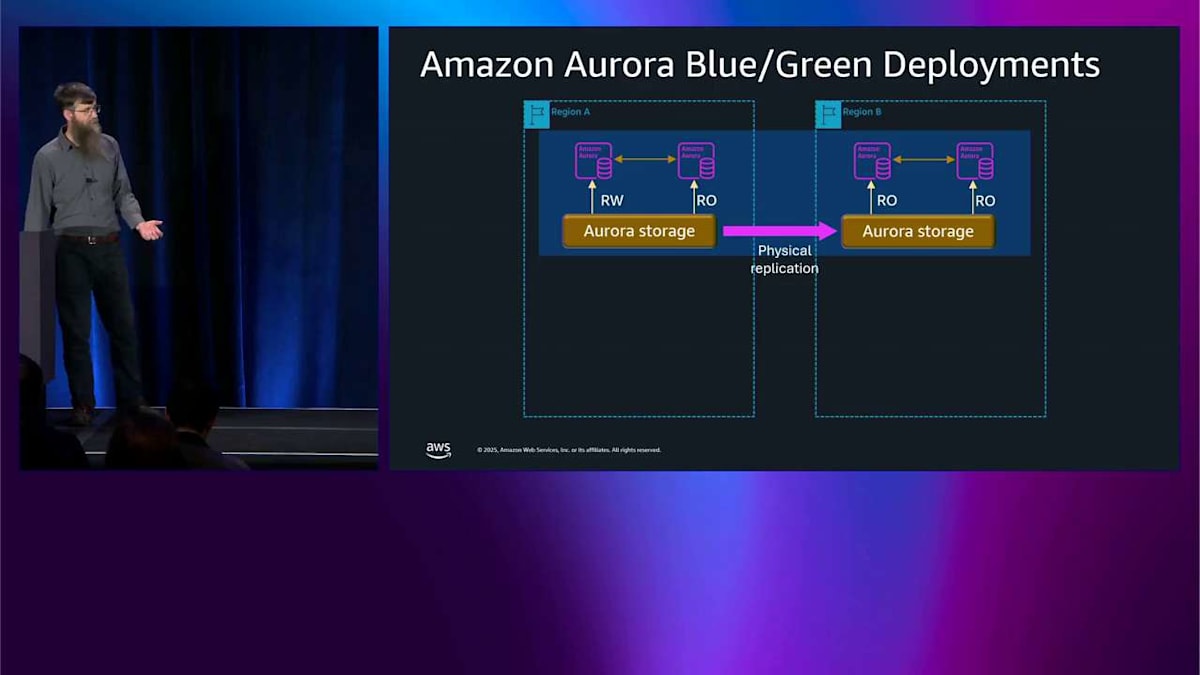
では、先ほど Blue/Green について話した興味深いことなんですが、グローバルデータベースのサポートです。今、2つのリージョンの構成になっています。
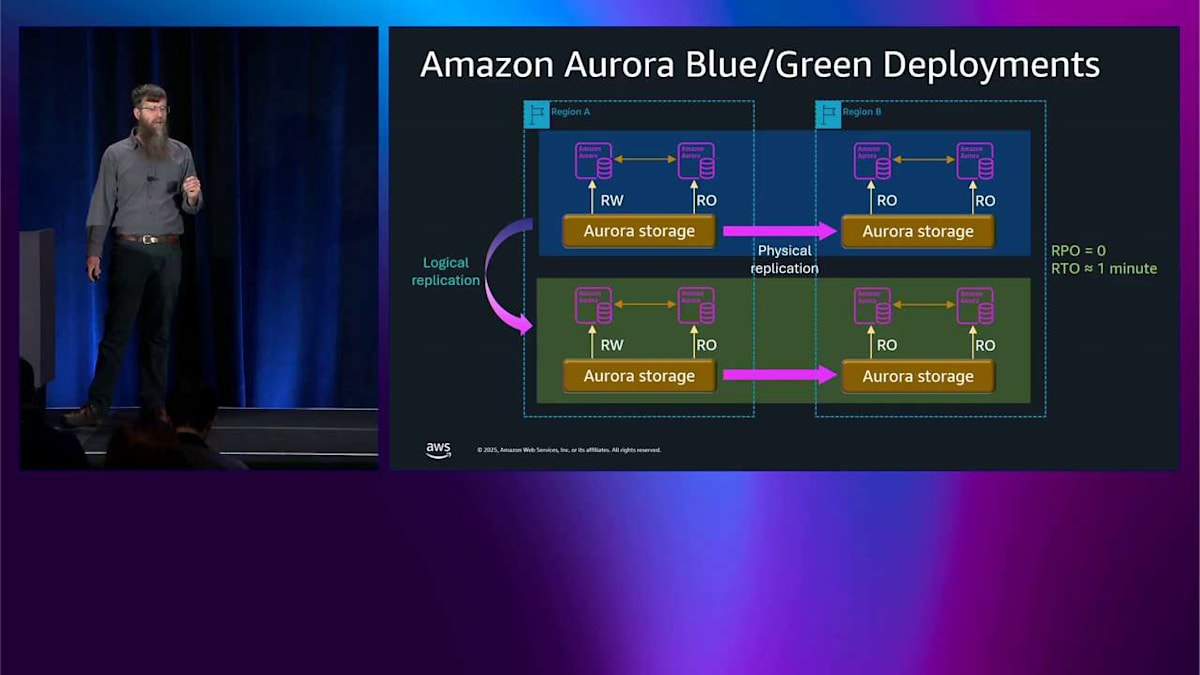
覚えておいてください、最大で5~10個のセカンダリリージョンまで可能なんですが、物理レプリケーションを備えたグローバルデータベースがあります。メジャーバージョンアップグレードをしたい場合、今は Blue/Green を使ってそれもできるようになりました。同じ考え方が適用されます。グリーン環境を作成して、ロジカルレプリケーションで同期を保ちます。さっき説明したことがすべて同じように機能します。 結果として RPO がゼロになります。つまり、データを失わないということです。そして RTO は約1分なので、スイッチオーバー時間は約1分です。グローバルクラスター全体がメジャーバージョンアップグレードを実行でき、このように管理できます。これはかなり新しい機能なので、ぜひ見てみることをお勧めします。





Zero-ETL統合:ストレージレイヤーからの高速データレプリケーション
では、Aurora がストレージを分離することで実現される別の素晴らしい機能について話しましょう。 これが Aurora の zero-ETL で、extract、transform、load の略です。左側に Aurora PostgreSQL インスタンスがあります。 右側に Amazon Redshift があって、PostgreSQL から Redshift にデータを取得したいとします。例えば、本当に低レイテンシーでこれをやりたいんです。それに伴う ETL パイプラインを管理してほしくないんです。なぜなら、それは大変な作業で、脆弱で、高くつく可能性があり、時間がかかるからです。ですから、zero-ETL 統合を追加できます。これは実行できる CLI です。 それが行うことは、Aurora クラスターと Redshift クラスター間にパイプラインを作成するようにシステムに指示することです。それだけです。5~10秒のレプリケーションラグが発生します。 つまり、PostgreSQL 側に何かを書き込むと、5~10秒以内に Redshift 側に表示されます。これは ETL パイプラインにとって本当に良いターンアラウンドタイムです。

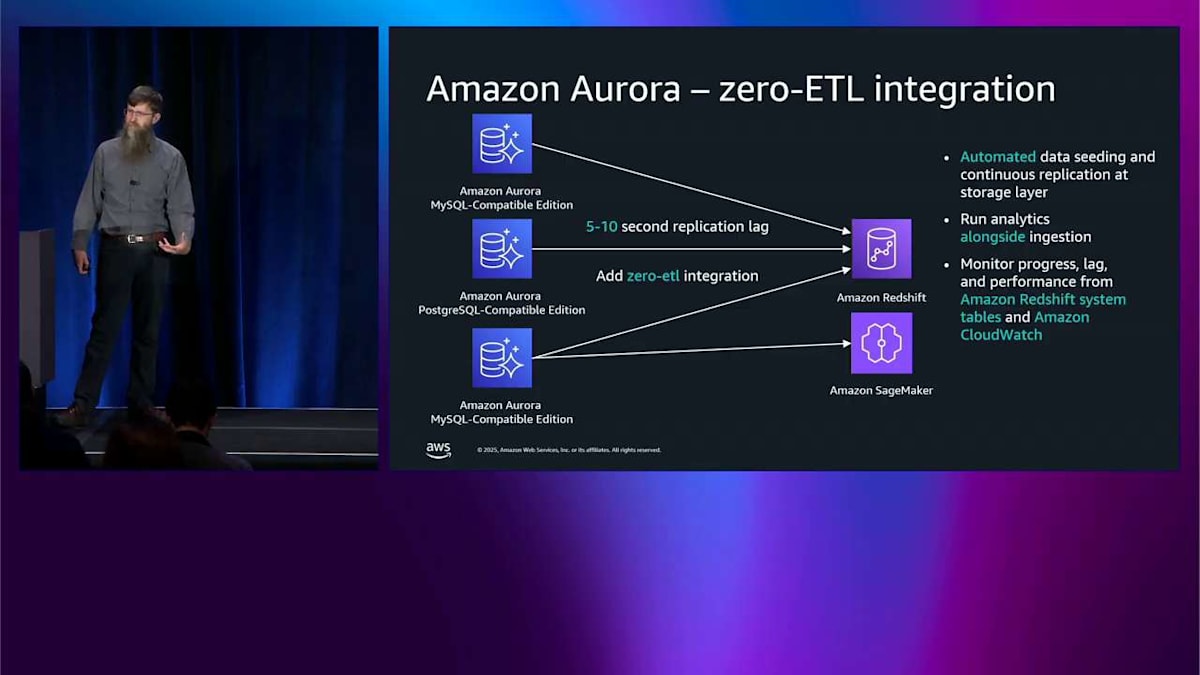
もしこれを自分でやるなら、データシーディングについて心配する必要があります。つまり、空の状態からこれをどのように開始するかということです。また、このパイプラインのメンテナンス方法についても心配する必要があります。zero-ETL ではそのすべてを処理します。複数の Aurora インスタンスがあるため、状況はもう少し興味深くなります。MySQL と PostgreSQL の異なるものかもしれません。同じ Redshift に入ります。同じデータレイク内にあるかもしれません。さらに多くのものを取得することもできます。また、Aurora MySQL から Amazon SageMaker にも同じテクノロジーを使用して移動できます。これはかなりクールだと思いますが、内部でどのように機能するかがさらに良いと思います。それが私が掘り下げたいことです。内部でどのように機能するかです。

MySQL について話しているのは、それが私がより好んで話すものだからです。以前、Aurora が何が起こっているかの物理トランザクションログをどのように理解するかについて話しました。しかし、CDC ストリーミング、つまり change data capture ストリーミングを行うには、物理ログではなくロジカルログが必要です。これは Aurora が従来扱う方法を知っていたものではありません。ですから、その CDC ログをキャプチャする必要があります。また、最初にこのデータをシードできる必要があります。変更ログがあっても、その変更の基礎となるものがなければ意味がないので、シードする必要があります。

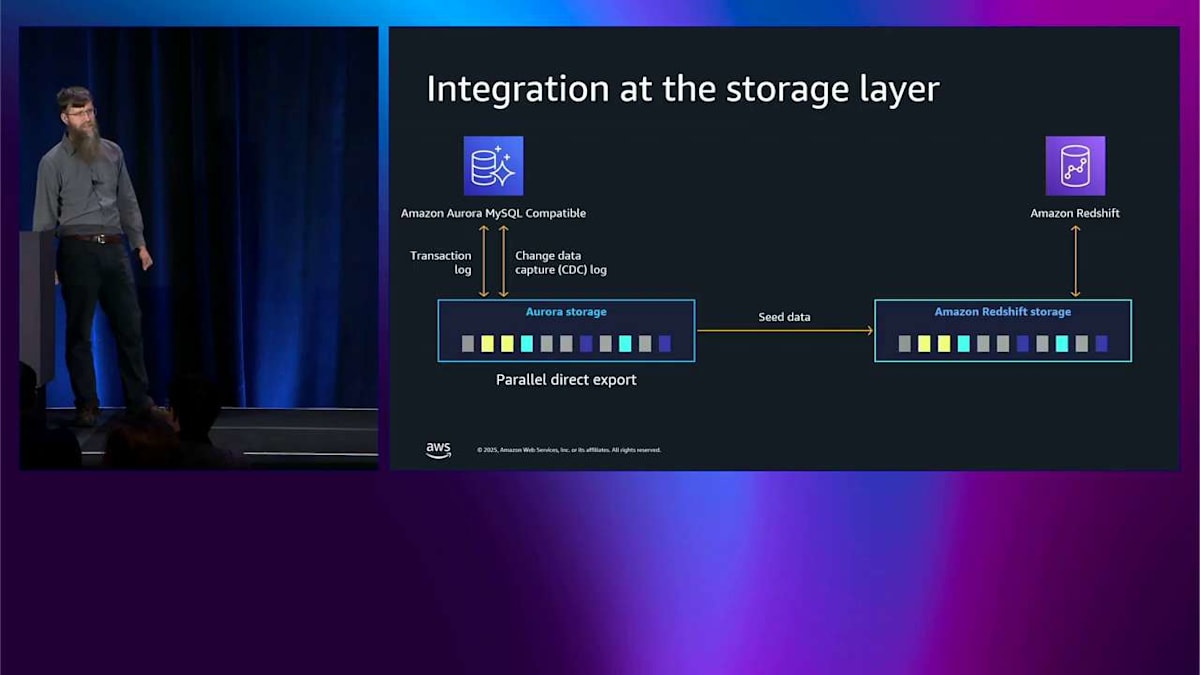

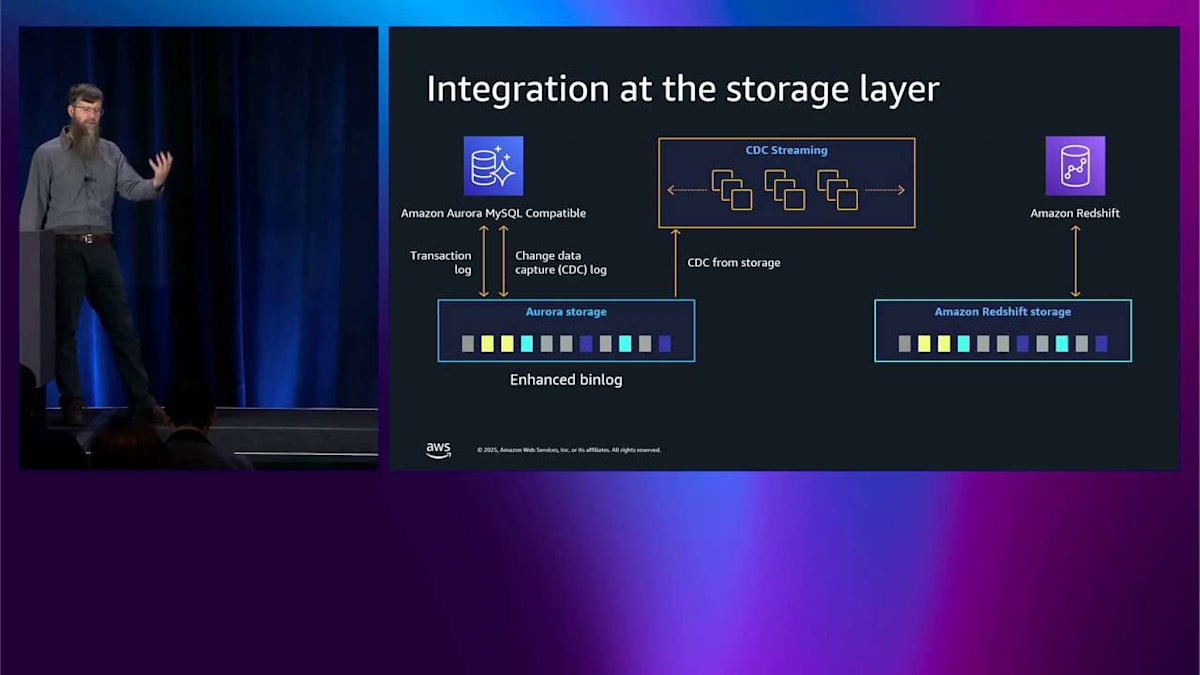
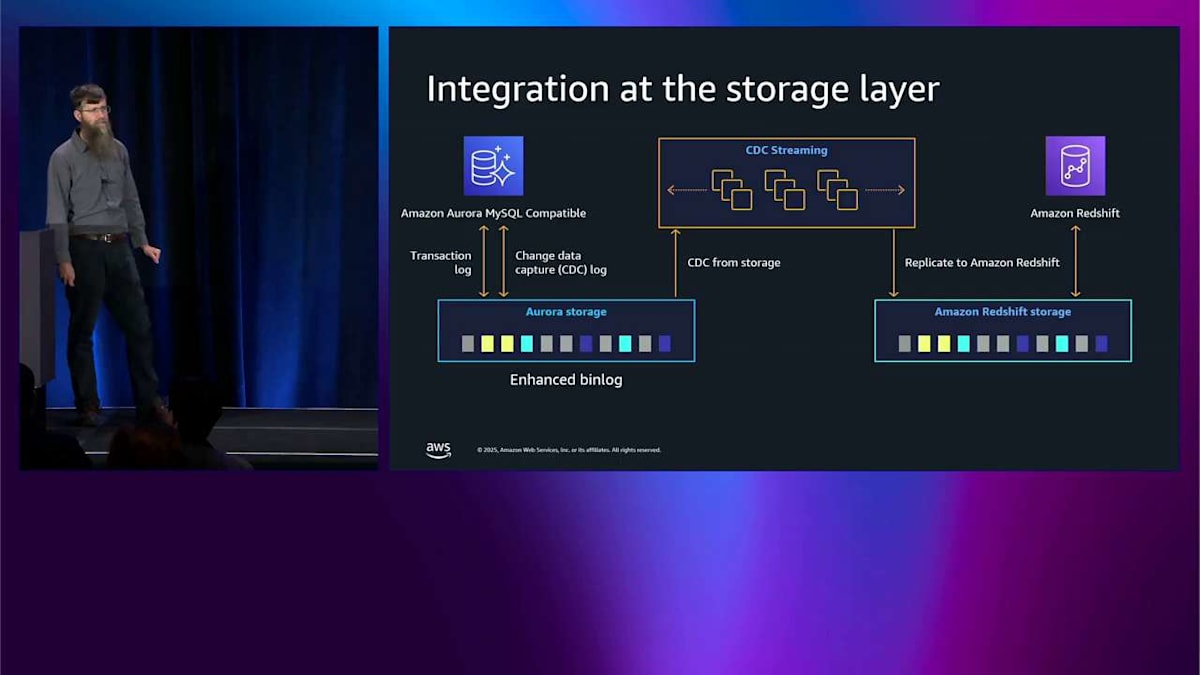
まず、ストレージレイヤーから始めることができます。そこで並列ダイレクトエクスポートを行います。これは、すべての個別のストレージノードが直接 Redshift ストレージにエクスポートして、シードを作成するというものです。ヘッドノードは関与せず、非常に高速に実行され、ヘッドノードのパフォーマンスにはまったく影響しません。シードを作成したら、 その後、エンハンスドバイナリログと呼ばれるものを使用できます。これは MySQL のバイナリログ、または PostgreSQL のライトアヘッドログです。同じように機能しますが、ここでは論理レプリケーションログの形式に関する知識をストレージに組み込んで、その仕組みを理解できるようにします。ストレージノードがエンハンスドバイナリログを理解すると、CDC ストリーミングサーバーをスピンアップします。 これらはヘッドノードではなく、ストレージから CDC ログを読み取ります。ヘッドノードでこれをオンにしても、パフォーマンスに悪影響を与えません。これは MySQL ベースのシステムで一般的に起こることです。その CDC ストリーミングフリートはフィルターを適用し、不要なテーブルを破棄し、すべての変更を行い、そのデータを Redshift にプッシュします。MySQL ヘッドノードと Redshift の間に矢印はありません。すべてストレージを通じて行われるため、パフォーマンスへの影響を感じることはありません。 これはかなりいいと思います。




I/O-OptimizedとOptimized Reads:予測可能な価格とTiered Cacheによる劇的なパフォーマンス改善
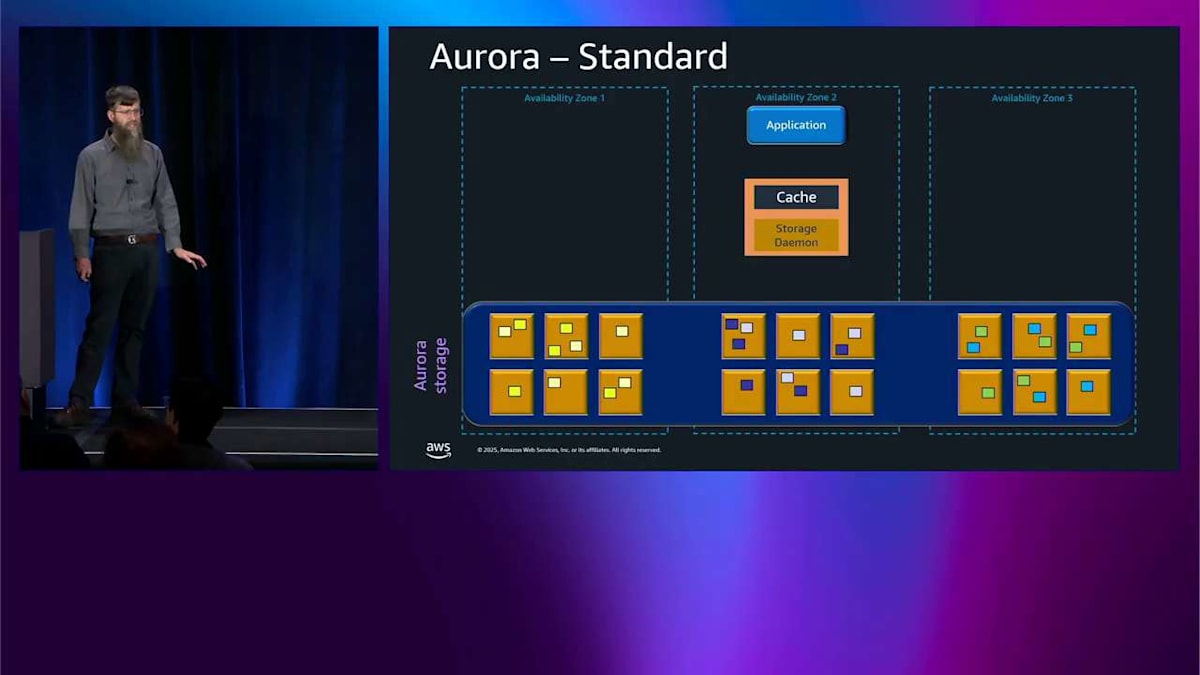
Aurora ストレージタイプについて少し話しましょう。以前 I/O-Optimized について話しましたが、 もう少し詳しく説明します。これが Aurora Standard で、何も選択しない場合に得られるものです。以前と同じ図を見ていますが、いくつかの IO のライフサイクルと、それがどのくらいの費用がかかるかについて話します。アプリケーションは select を実行します。これは読み取り専用です。 ヘッドノード内には、キャッシュがあります。そのキャッシュにヒットすると、インスタンスを実行するのに数ミリ秒以外の費用はかかりません。IO はありません。またはキャッシュをミスして、ストレージに移動してデータベースページを読み取ります。 これは 8 キロバイトまたは 16 キロバイトで、データベースエンジンによって異なり、1 セントの一部の費用がかかります。書き込みを行うとき、これらのログレコードを書き込んでいることを覚えておいてください。これらはさまざまなサイズにすることができ、さまざまな方法でバッチ処理できます。 4 キロバイトまでの書き込みを行うと、1 ペニーの一部と同じ費用がかかります。


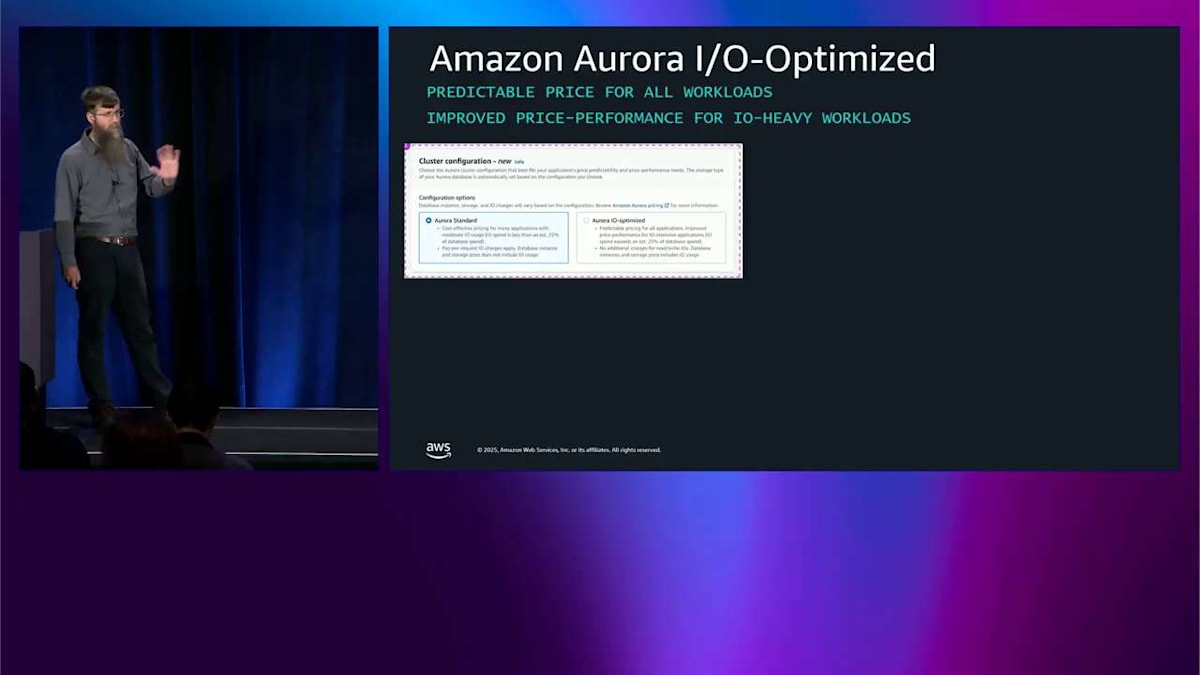
複雑さは、異なるタイプの書き込みを行うときに生じます。異なる方法でバッチ処理する可能性があり、 1 つの IO にバッチ処理されない可能性があります。4、8、または 16 キロバイトのサイズであるため、最大 4 つの IO にバッチ処理される可能性があります。 これは予測不可能な価格設定モデルで、時々はかなりうまくいきますが、時々は予測不可能性が好きではありません。そこで、これをより予測可能にするにはどうすればよいかというオプションを提供したいと考えました。これが昨年 Aurora I/O-Optimized が登場した理由です。
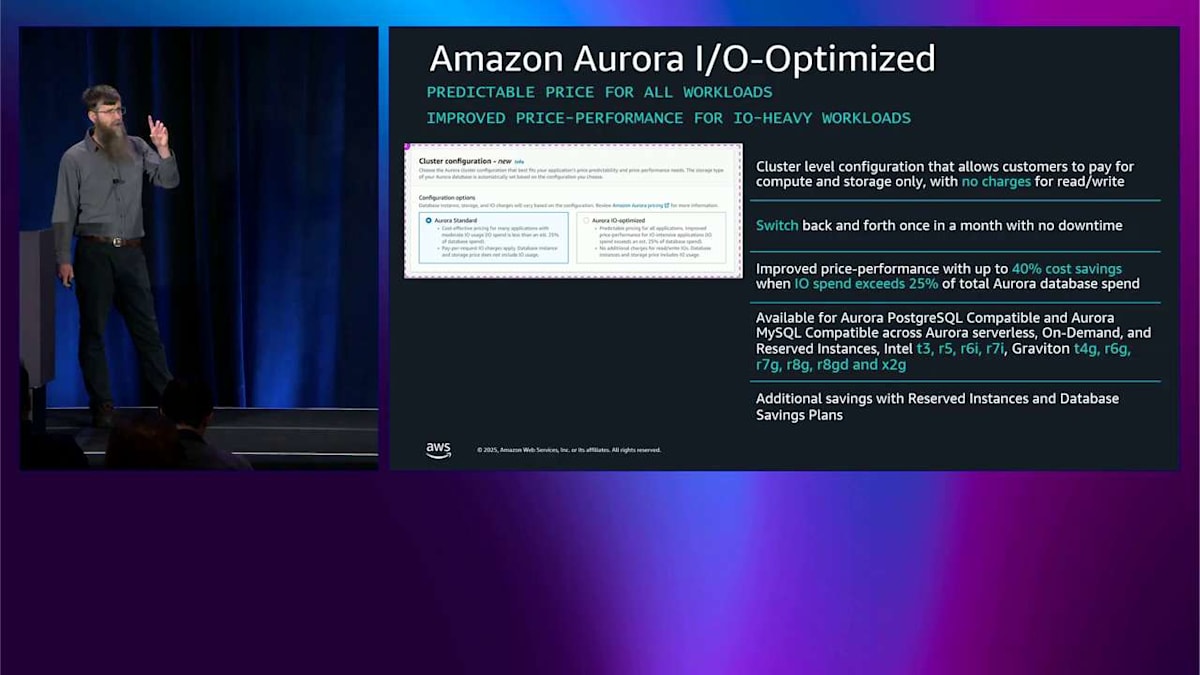
これは価格設定の選択肢です。クラスターを作成するときはいつでも、またはその後いつでも選択できます。月に 1 回、問題なくオンラインで切り替えることができます。これが行うことは、システムのパフォーマンスの方法と構築方法の両方を変更することです。インスタンスレベルではなく、クラスターレベルの設定です。ストレージ側の変更もあり、これらのストレージは共有されているためです。
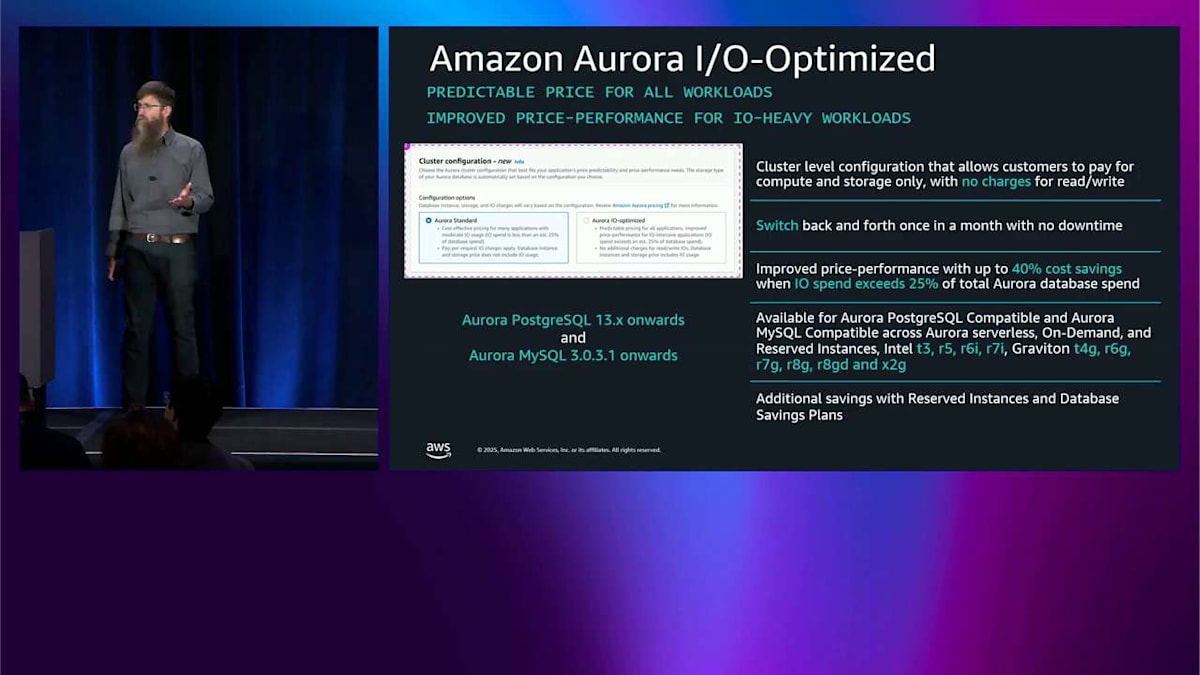
すでに Aurora を使用している場合は、Aurora の請求書の IO の割合を確認することをお勧めします。その IO の割合が 25 パーセント以上の場合は、I/O-Optimized を確認してください。実際にお金を節約できる可能性があります。役に立たないものを売ろうとしているわけではありません。実際にお金を節約でき、より良いパフォーマンスが得られ、予測可能性が得られると思います。IO の割合が 25 パーセント未満の場合でも、確認してみてください。パフォーマンスも気に入るかもしれません。


これは過去18ヶ月程度の最新のエンジンバージョンすべてで利用可能で、また今朝のキーノートをご覧になった方はお分かりかと思いますが、新しく発表されたデータベースセービングスプランとも互換性があります。 では、これはお金の面ではどのように機能するのでしょうか?左側には、先ほど説明した Aurora Standard があります。これは通常の AWS の方法で、使用した分だけ正確に支払うというものです。コンピュートに対して支払い、ストレージはギガバイト月単位で支払い、そして IO に対しては地域によって異なるレートで支払います。
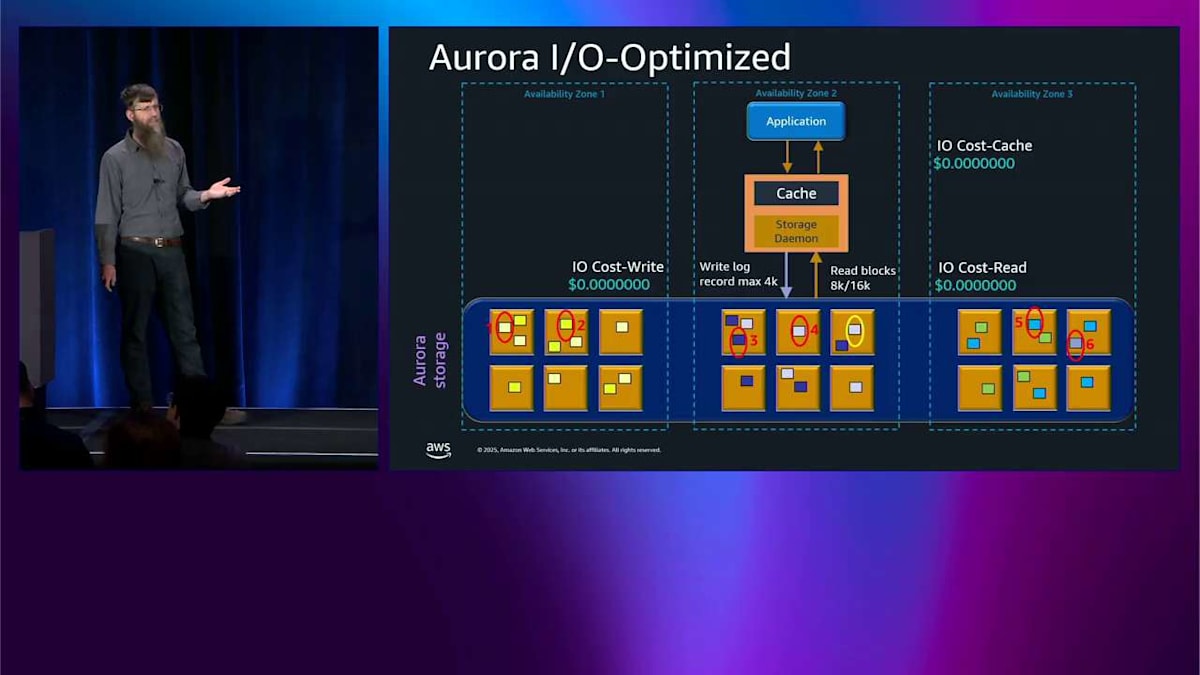
I/O-Optimized SKU を選択した場合、コンピュートに対してはやや高めのプレミアムを支払い、ストレージに対してもプレミアムを支払いますが、IO に対しては何も支払いません。ゼロコストです。そこに表示されているパーセンテージの数字を見ると、少し心配になるかもしれませんが、思い出していただきたいのは、IO の割合が約25パーセント以上であれば、これは実際にお金を節約できる可能性が高いということです。
もう一度この例を見てみましょう。すべての数字がゼロなので、非常に簡単に説明できます。キャッシュヒットするかミスするか関係ありませんし、ライトをどのようにバッチ処理するか関係ありません。ただゼロなのです。非常に簡単に理解でき、非常に予測可能です。
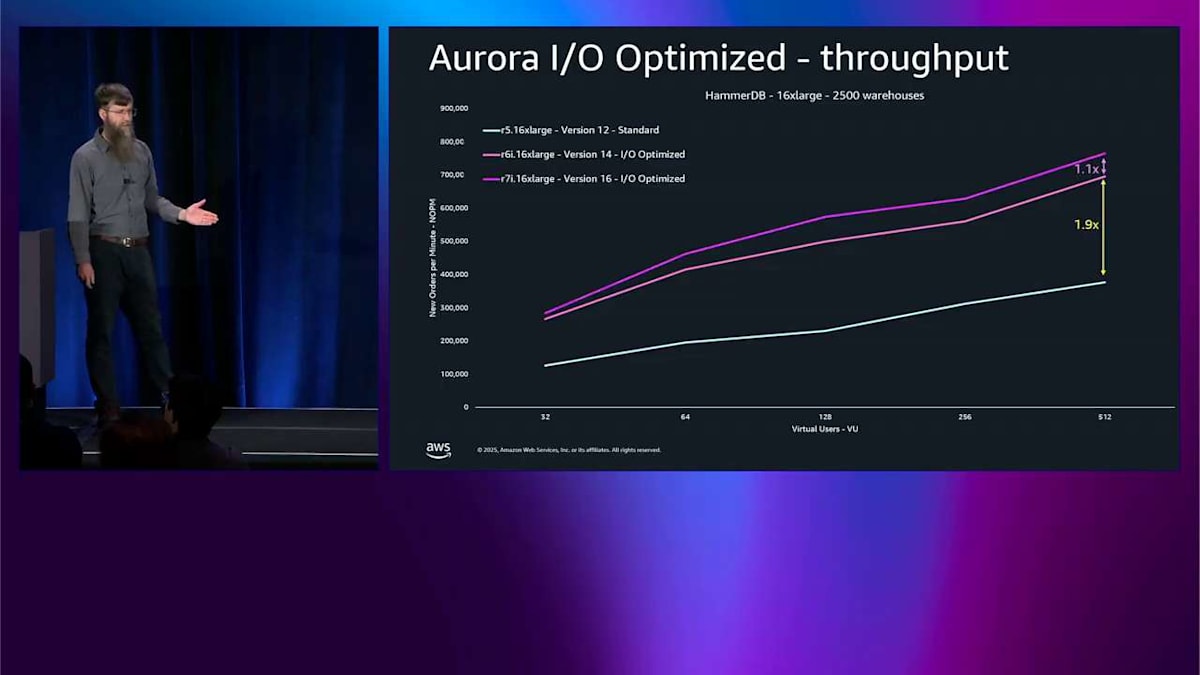
では、I/O-Optimized の価格設定の部分だけでなく、それがパフォーマンスにどのような影響を与えるかを見てみましょう。これはスループットです。これは16 X-large での HammerDB テストで、最大のボックスではありませんが、かなり大きなボックスで、かなり負荷をかけています。Y軸は NOPM で、これはこのベンチマークのメトリクスです。高いほど良いです。古いインスタンスタイプである R5 から始まります。これは PostgreSQL バージョン12で、拡張サポートバージョンの古いベースラインです。まあまあ見えます。
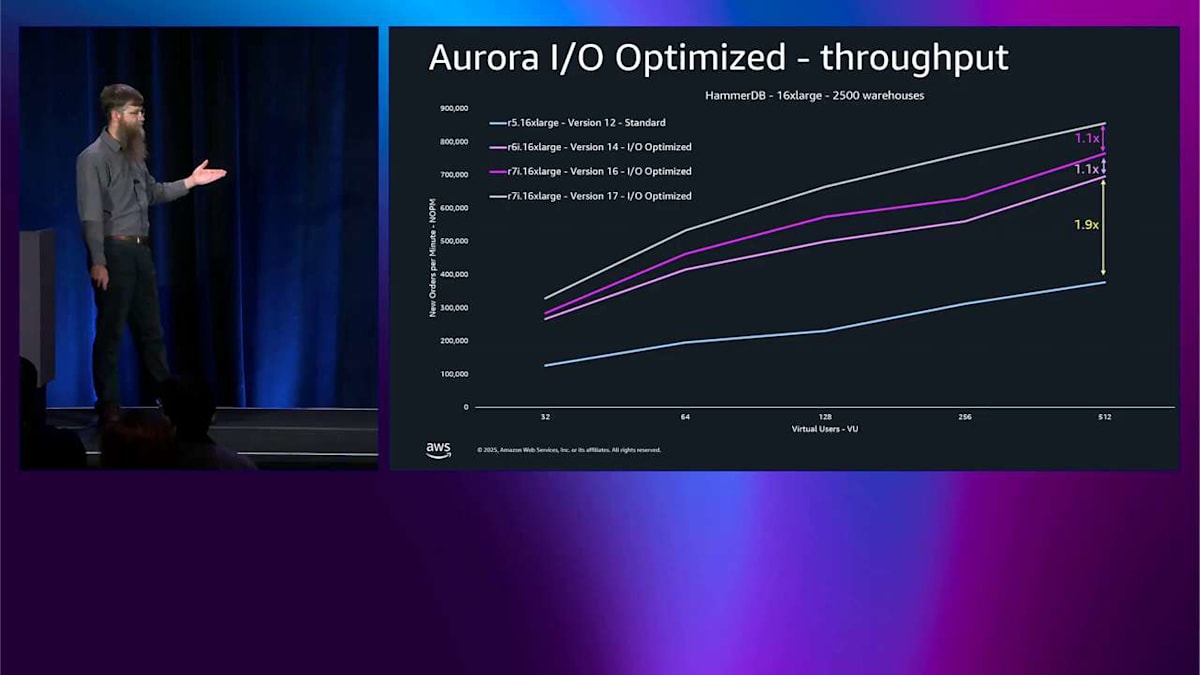
次に R6i 16 X-large、バージョン14に切り替えます。post-crisis バージョンではそれほど大きな違いはありませんが、I/O-Optimized をオンにしました。I/O-Optimized をオンにして1世代上げるだけで、基本的に1.9倍の改善が得られました。R6i はまだそれほど新しくありません。R7i に切り替えて、バージョン16 post-crisis、アップグレードするだけでさらに10パーセント得られます。バージョン17、最新のものに切り替えて、同じインスタンスで、さらに10パーセント得られます。
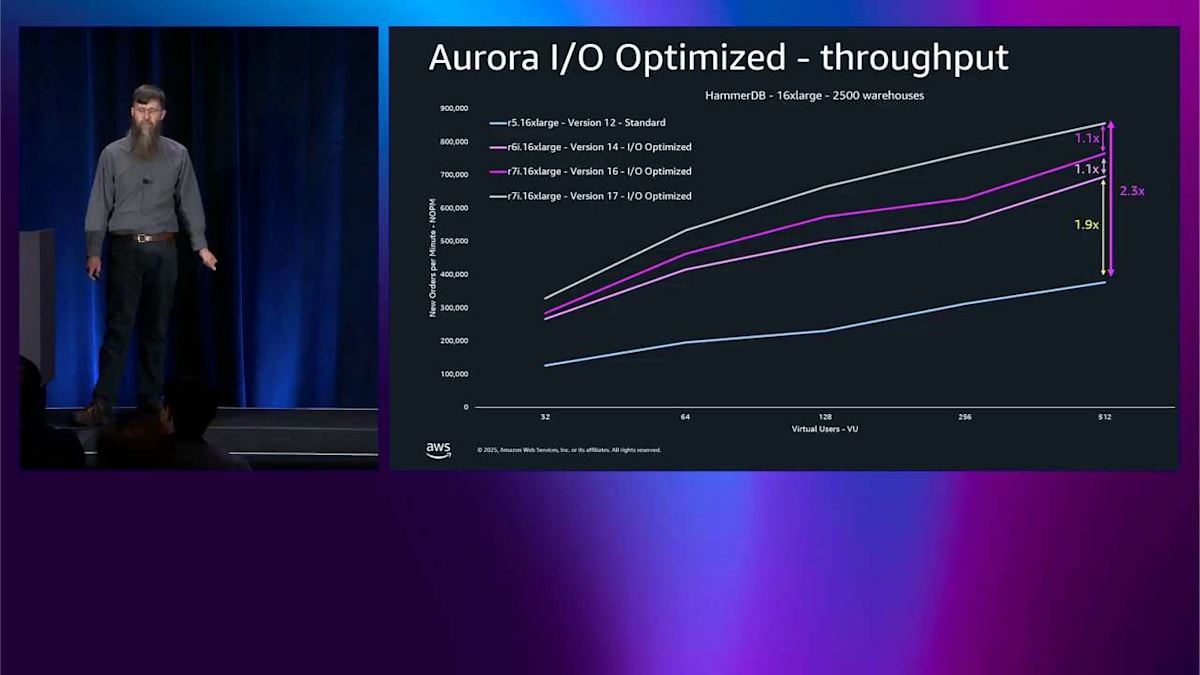
その時やったのは PostgreSQL のバージョンアップだけで、おそらく blue-green でやったんでしょう。それはさらに良いですね。スループットにとって良い。全体的にスループットが 2.3 倍改善されました。I/O-Optimized をオンにするだけで、おそらくシステムをこんなに酷使している場合は請求額も減らせますし、PostgreSQL を何バージョンかアップグレードするだけでこの結果です。
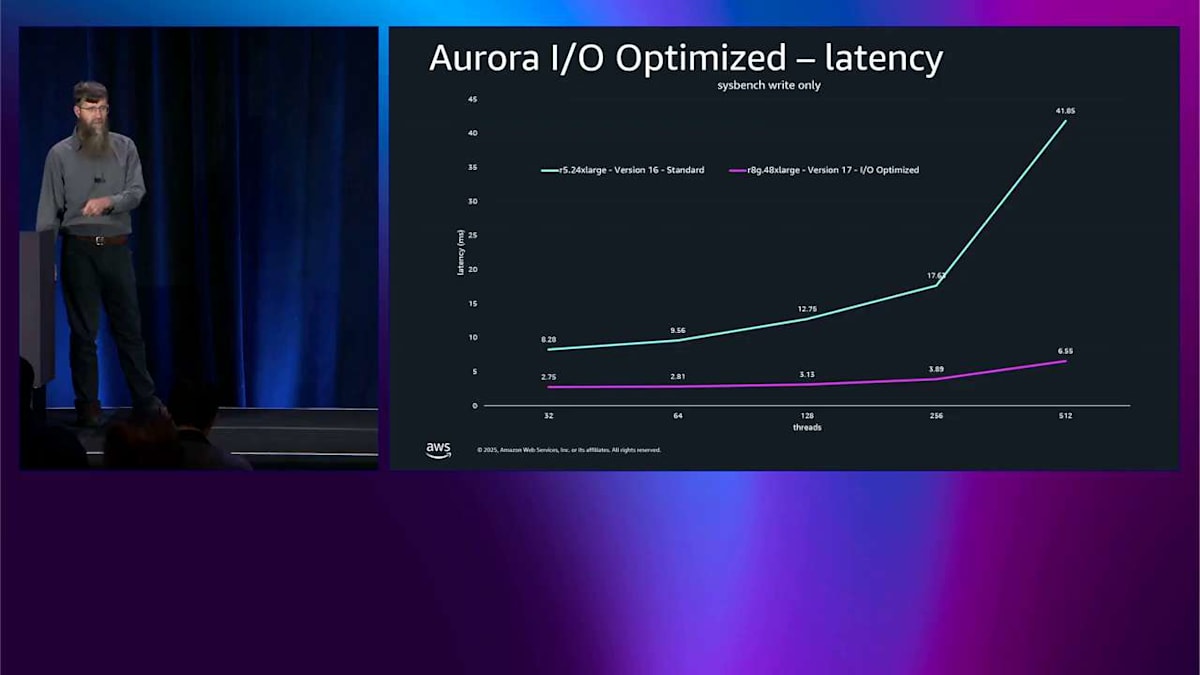
では、同様のテストのレイテンシを見てみましょう。これは実は I/O-Optimized を作った理由なんです。スループットの方はボーナスポイントみたいなものです。ここが本当の価値があるところです。これは suspension read-only です。Y 軸がレイテンシなので、低いほど良いです。青い線は R5 twenty-four X-large、PostgreSQL version sixteen です。右側に向かって飽和していくのが見えますね。レイテンシが上がってきて、これは好ましくありません。
ピンク色の線は R8G forty-eight X-large、version seventeen で I/O-Optimized です。この線がほぼ平らなのが見えますね。これがレイテンシグラフで本当に欲しい形です。
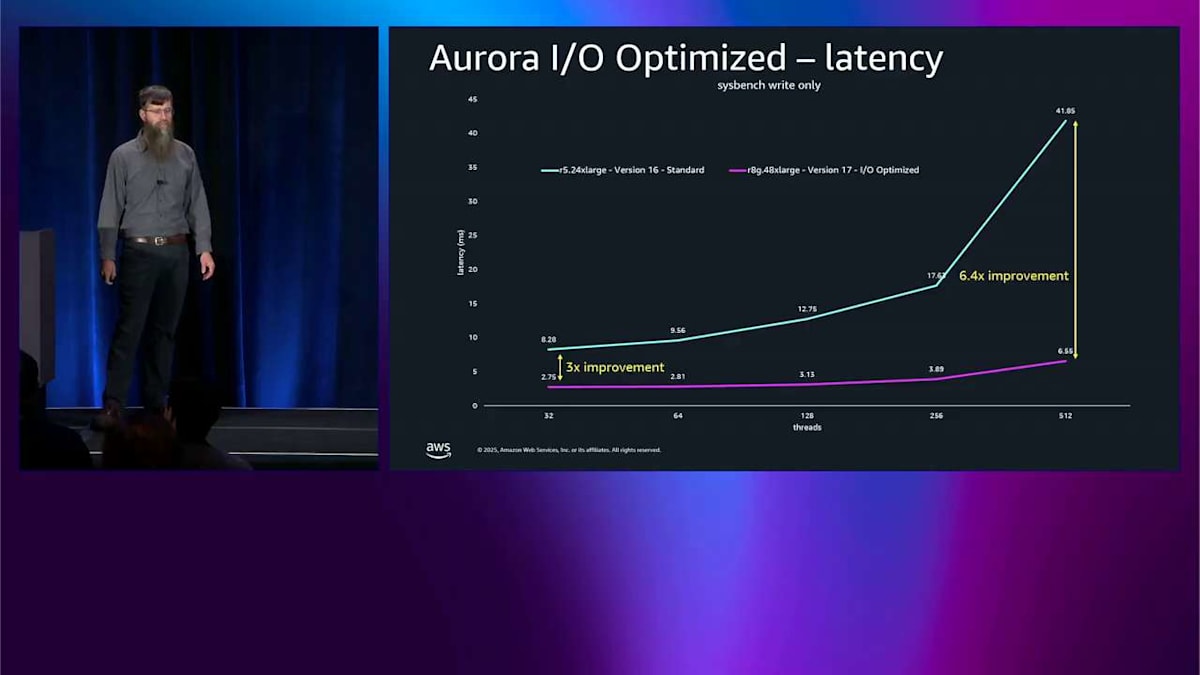
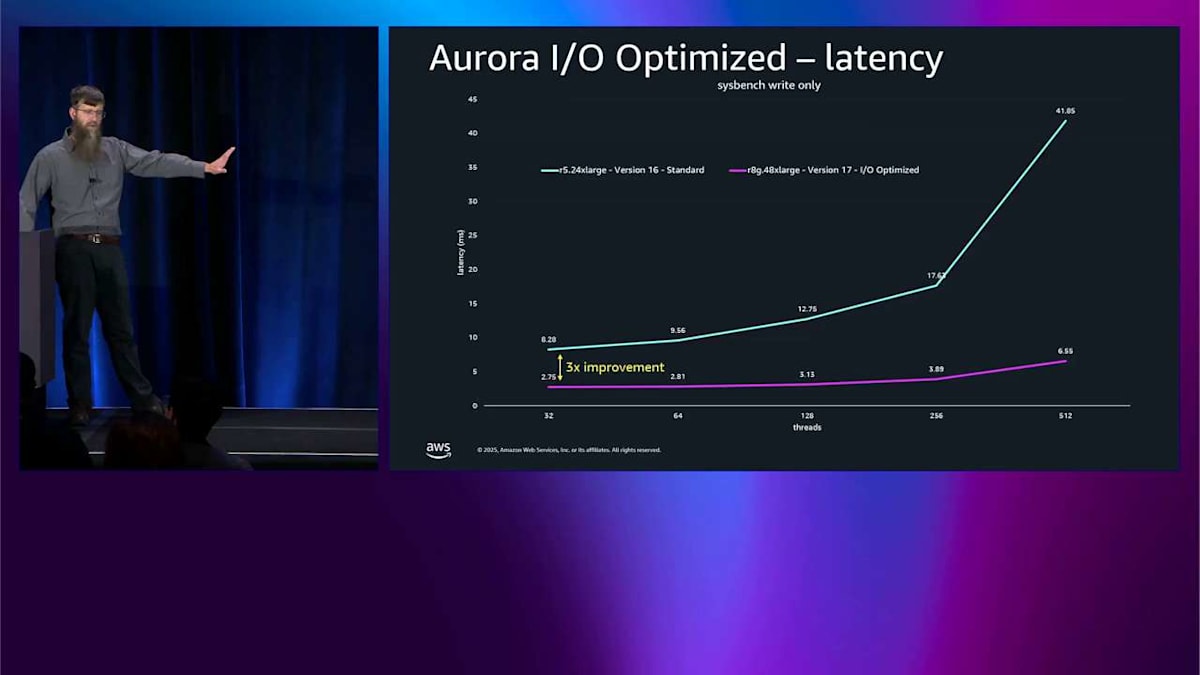
低い方の端では、レイテンシが 3 倍改善されています。これだけでも私は非常に満足です。でも高い方の端ではさらに良くて、レイテンシが 6.4 倍改善されています。
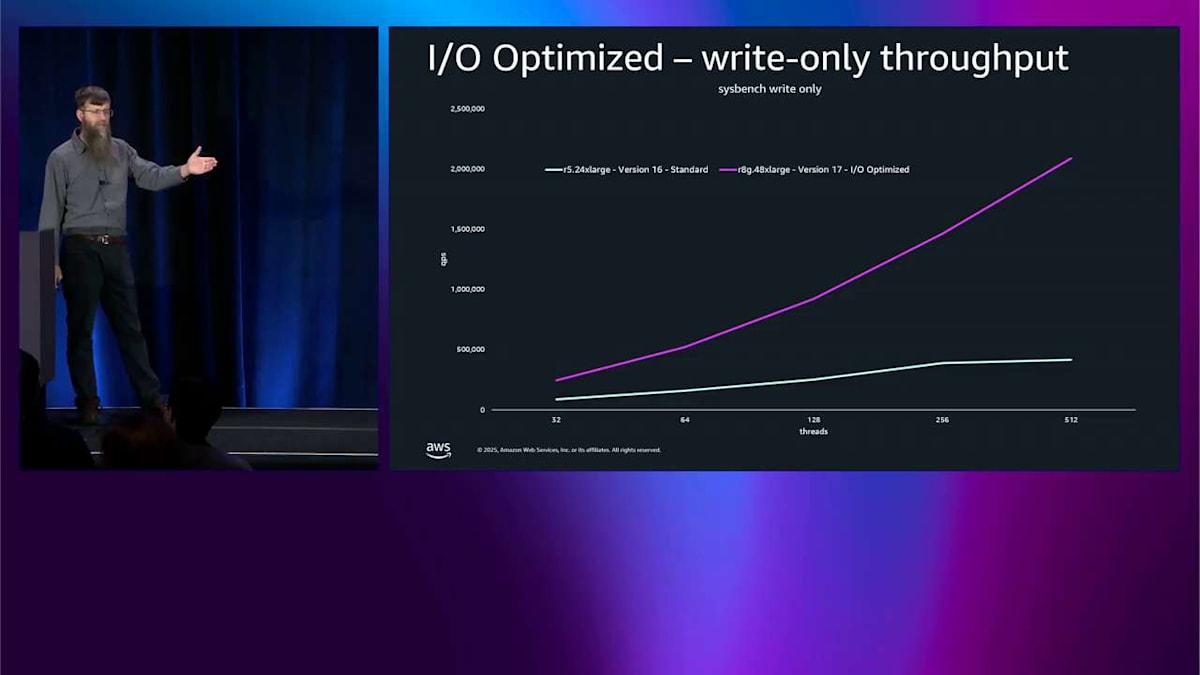
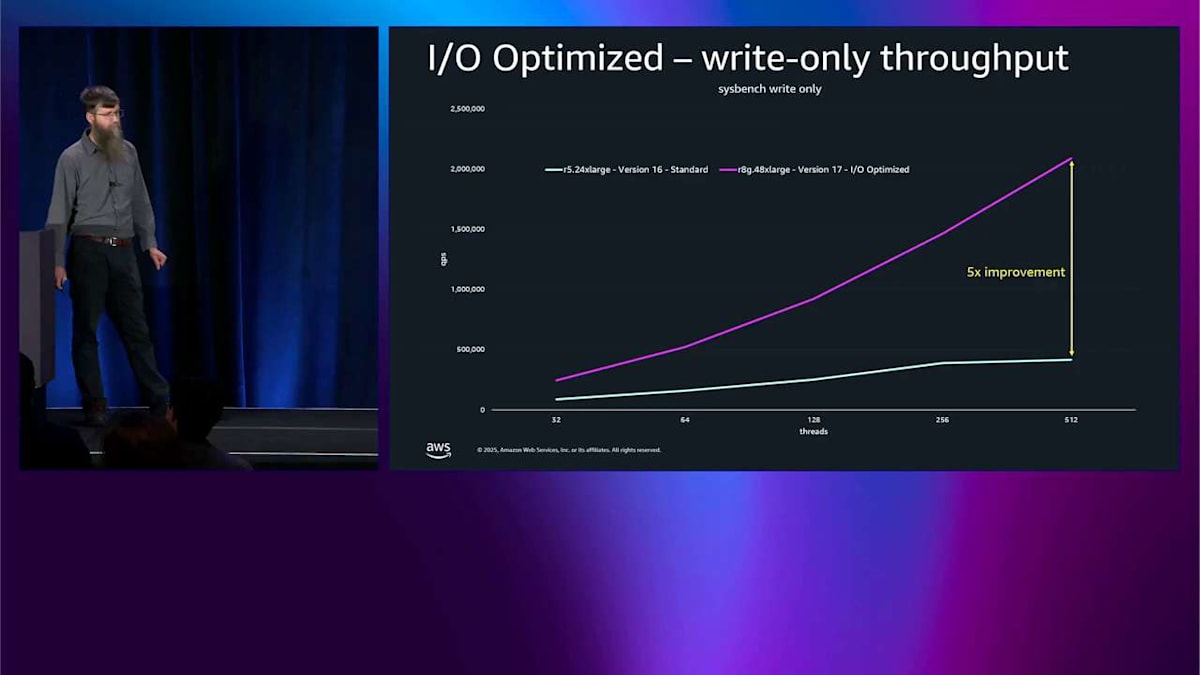
下の方にスレッド数があるので、より強くプッシュするほど、これはより良くなります。レイテンシ用に最適化しました。では、これをスループットに戻すと、同じテストをもう一度見ることができます。そして、I/O-Optimized をオンにして R8G に移行するだけで、同じ 2 つのベースラインでスループットが 5 倍改善されるということが言えます。
I/O-Optimized を今日試してみてください。そして、気に入らなかったら、それで大丈夫です。すぐにオフに戻すことができます。すべてオンラインで、フェイルオーバーはありません。

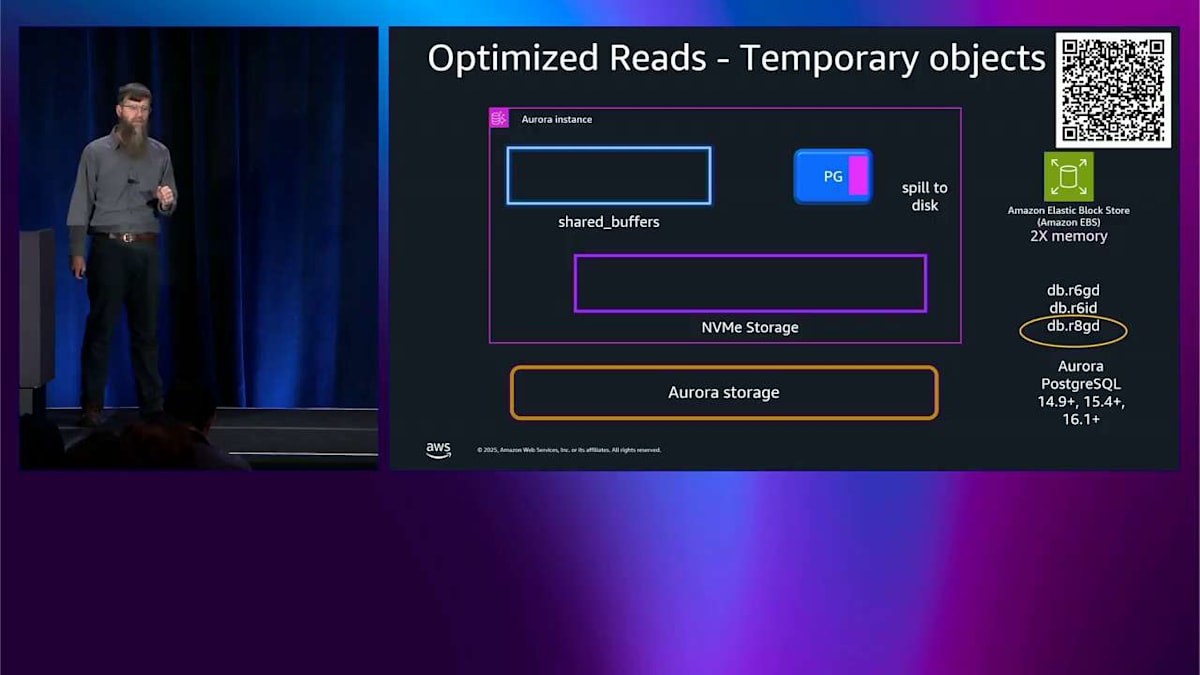

R8GDインスタンスとTiered Cache:一時オブジェクトと読み取り最適化の実践
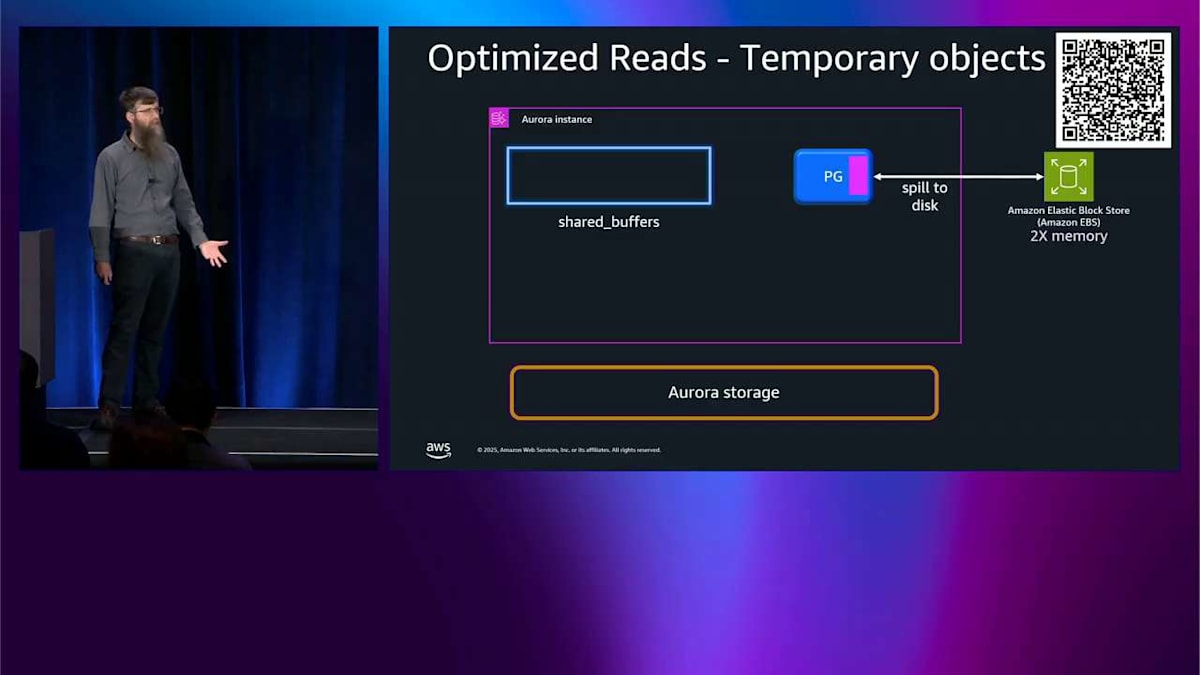
すべてオンラインで、フェイルオーバーとかそういったものはありません。 では、ここまでが書き込みについてでした。読み込みについても話したいので、忘れてませんよ。パズルの一部は一時オブジェクトです。 PostgreSQL が本当に大きなインデックス再構築や本当に大きなソートをしているとき、メモリが足りなくなってディスクに構築する必要があるかもしれません。通常のシステムではそのディスクは EBS ディスクなので、パフォーマンスに関する考慮事項があります。 D インスタンス、例えば R8GD を選ぶと、データベースインスタンスの内部にローカル NVMe インスタンスストレージデバイスがあります。 その場合、ディスクにスピルするときは、そこにスピルします。メモリ内に割り当てるメモリサイズの最大 6 倍までです。つまり、当然ながらレイテンシーはそこではずっと低くなります。これらの一時オブジェクトを使用するワークロードのパフォーマンスを劇的に改善します。
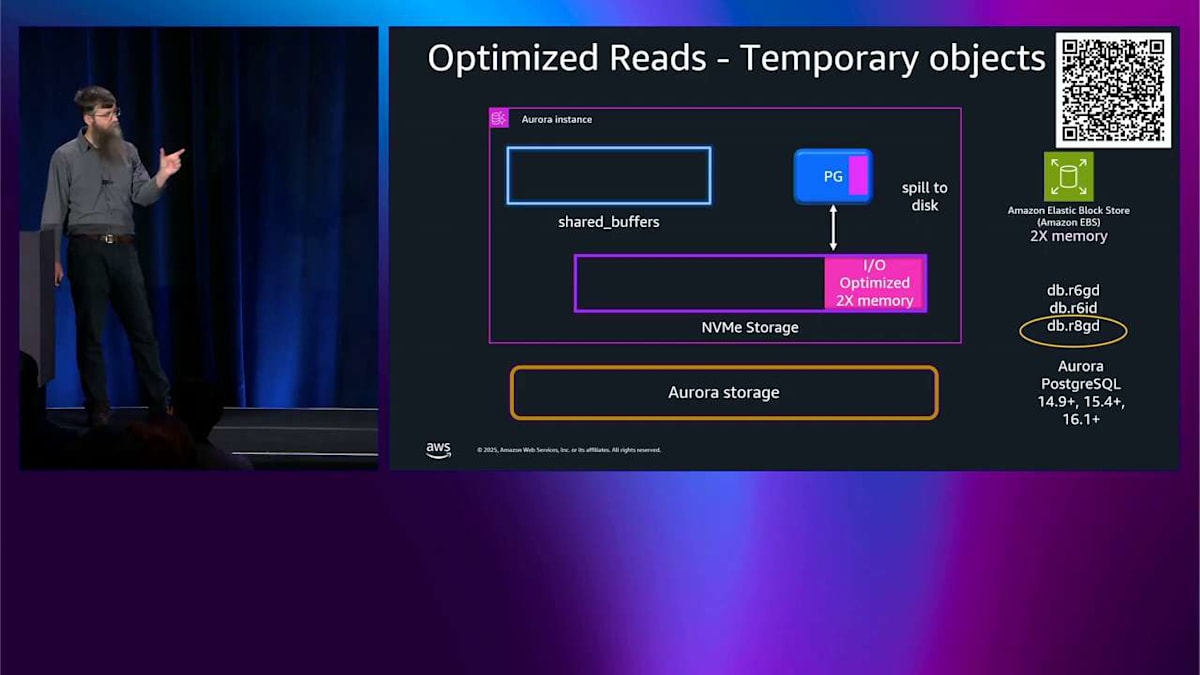
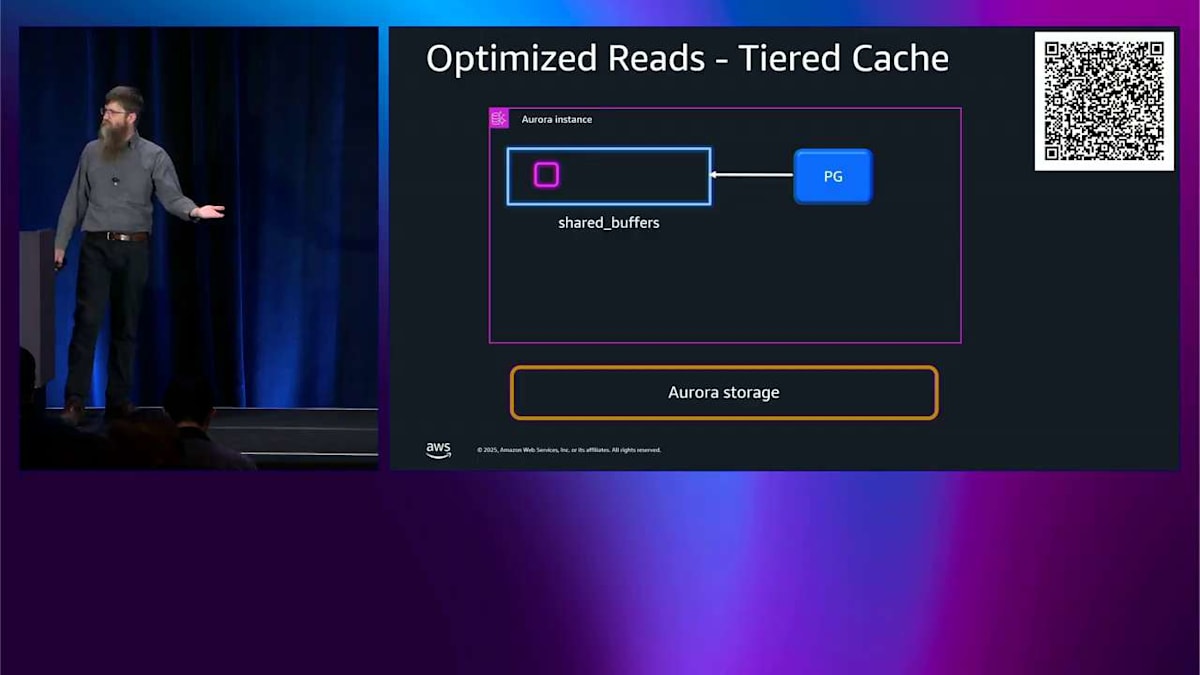
では、I/O Optimize をオンにすると、 その 6 倍をメモリの 2 倍に減らします。それでも良いし、同じように機能しますが、メモリの 2 倍だけです。では、ポイントは何ですか?なぜ左側にこんなにスペースを節約したのか?それが話したいことです。 そのスペースに tiered cache と呼ばれるものを入れます。通常の Aurora PostgreSQL を使っていて読み込みをすると、 まずメモリ内の shared buffers を見ます。そこにあれば、それを読み込んで完了です。問題ありません。shared buffers にない場合は、ストレージに行って、それを shared buffers に読み込んで、エンジンに渡して、完了です。
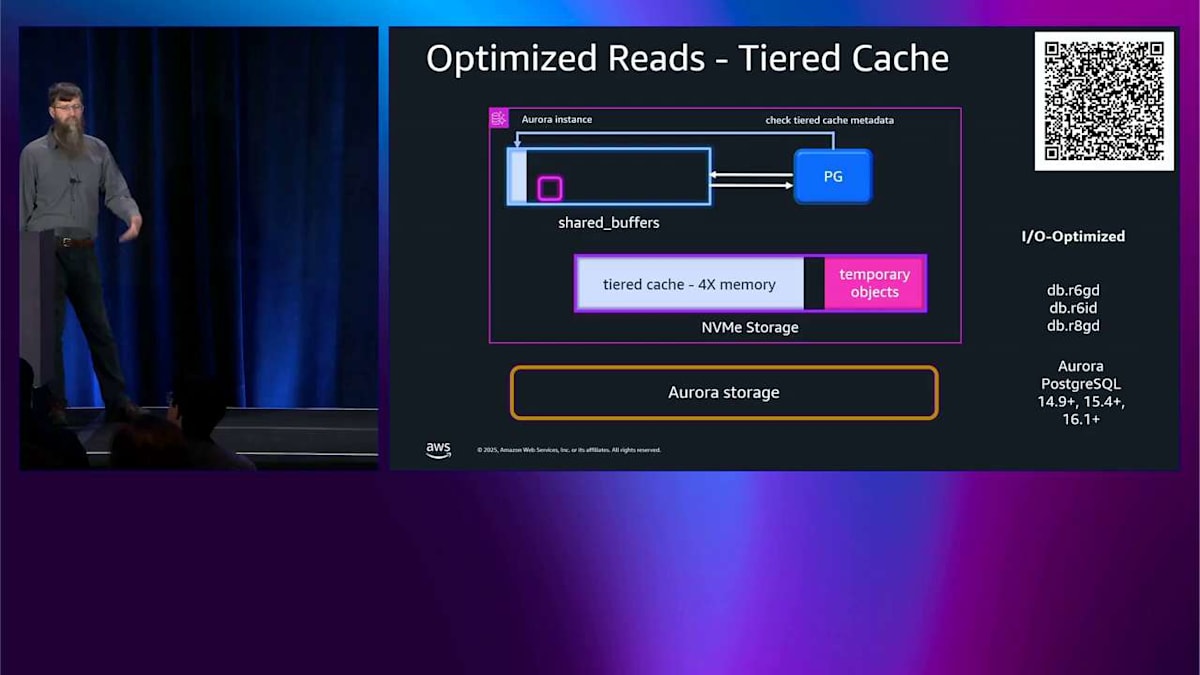
Optimized Reads をオンにして、これらの D インスタンスの 1 つを使うと、そのスペースにディスク上にあるメモリ量の 4 倍の量を割り当てます。そして、shared buffers を使うのと同じように使います。今はキャッシュです。そして、メタデータを処理するためにメモリの少しを使います。 では、PostgreSQL が何かを読む必要があるとき、そのメタデータをチェックして、欲しいものがディスクキャッシュにあるかどうかを確認します。この場合、ありません。では、ストレージから直接メモリバッファに読み込んで、前と同じようにエンジンに返します。この例では、tiered cache があったという事実は役に立ちませんでした。でも、今は shared buffers にあります。それは良いです。
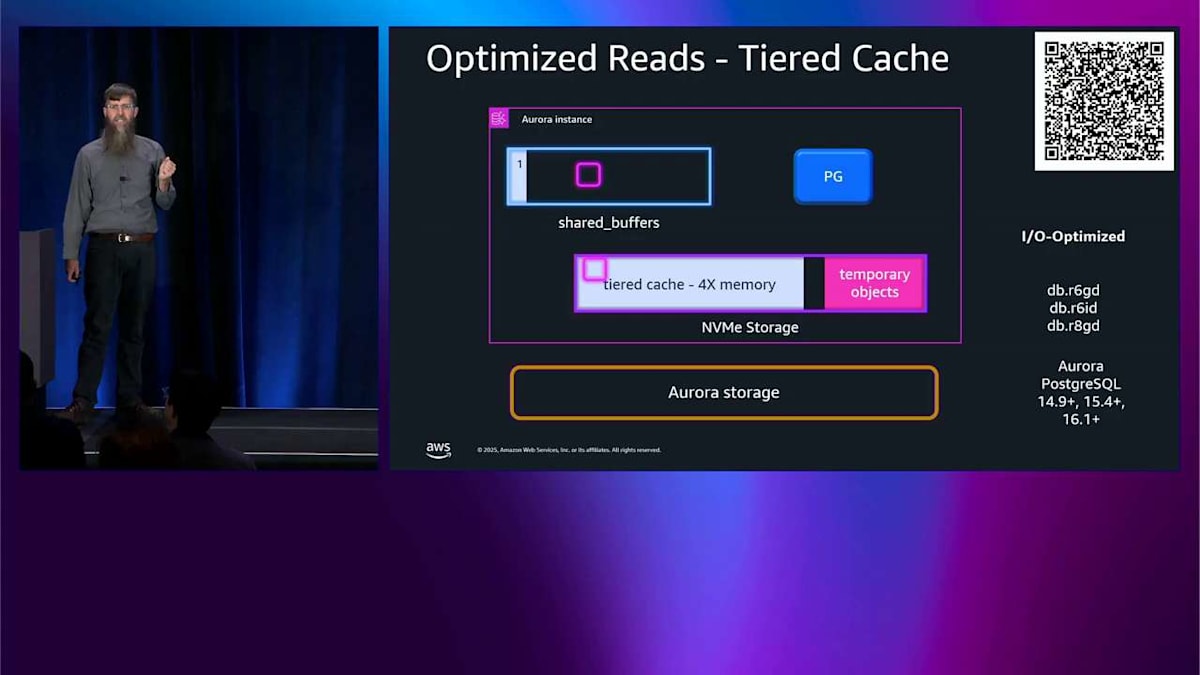

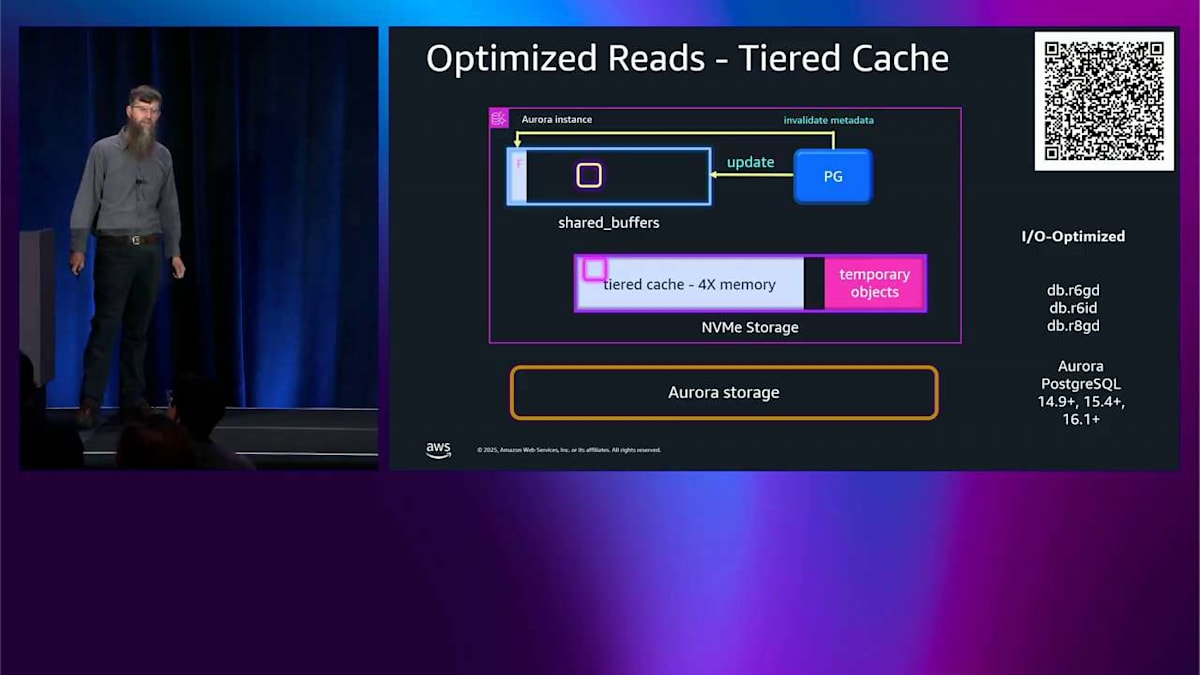
最終的に、shared buffer がいっぱいになり、そのデータをどこかに削除する必要があります。ただ捨てるのではなく、tiered cache に削除します。そこにメタデータの小さな部分を保持して、これを行ったことを覚えておきます。では、そのデータを読もうとするとき、そのメタデータをチェックして、 そこにあることを確認して、tiered cache からそれを取得するだけで、素晴らしく高速で、低レイテンシーになります。では、更新をすると、tiered cache に持っているそのコピーを無効にする必要があります。 でも、常にそこに書き込みに行きたくはありません。パフォーマンスにとって相当悪いでしょう。では、本当にやることは、そのメタデータビットをフリップするだけです。 tiered cache にそのデータがあるという事実を忘れるようにします。それが私たちがすることです。では、それを読もうとするとき、関係ありません。そこを見に行くことはありません。
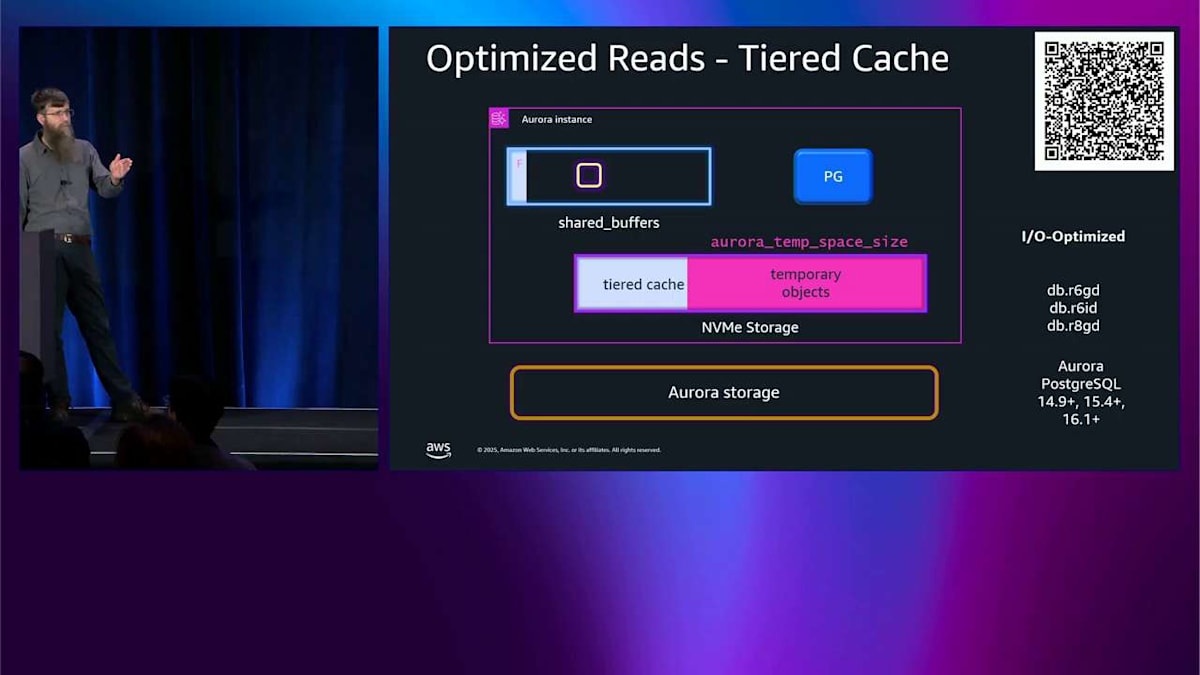
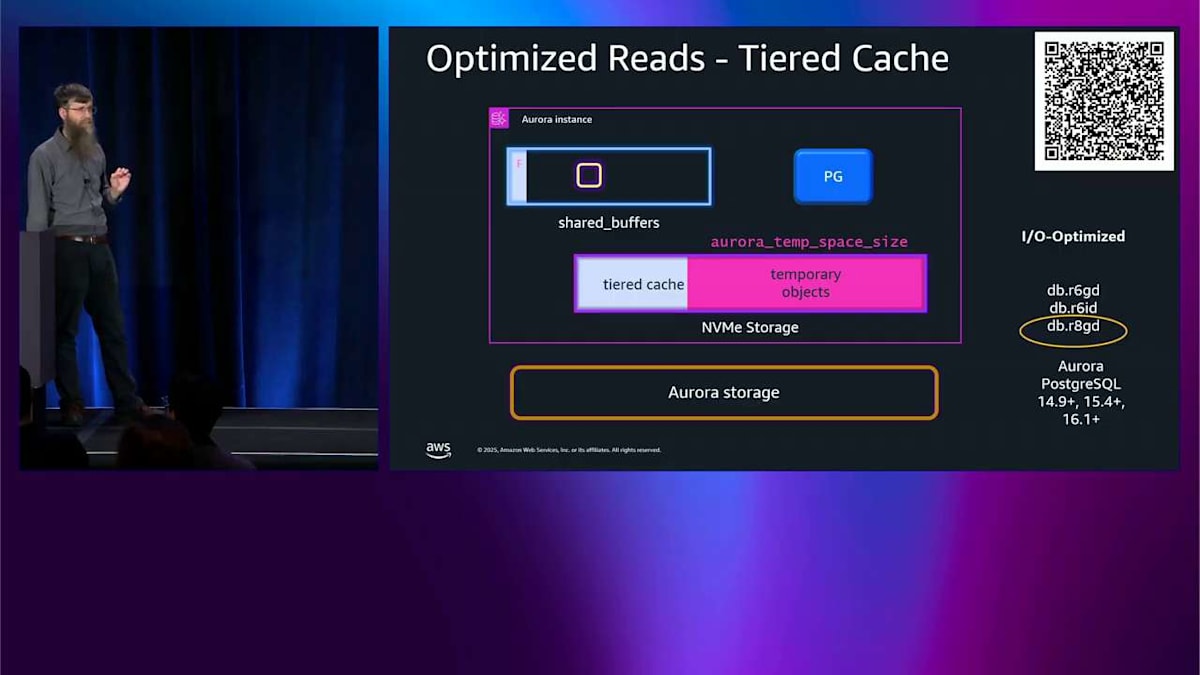
最近、tiered cache と 一時オブジェクトのサイズを変更する機能を追加しました。ディスクにかなりスピルする必要があることがわかっているワークロードが来ると、一時スペースを増やすことができます。その後、そのワークロードが終わると、それを戻して、素晴らしく大きな tiered cache を持つことができます。では、それは今、エラスティックで動的です。 R8GD インスタンス、それは新しいものです。そして、それは R6GD と同じ価格なので、まったく同じ価格です。では、R6G に対してパフォーマンスが 165% 改善されると思います。同じ価格で、tiered cache を使っていれば確認してみる価値があると思います。そして、使っていなければ、多分見てみる価値があります。
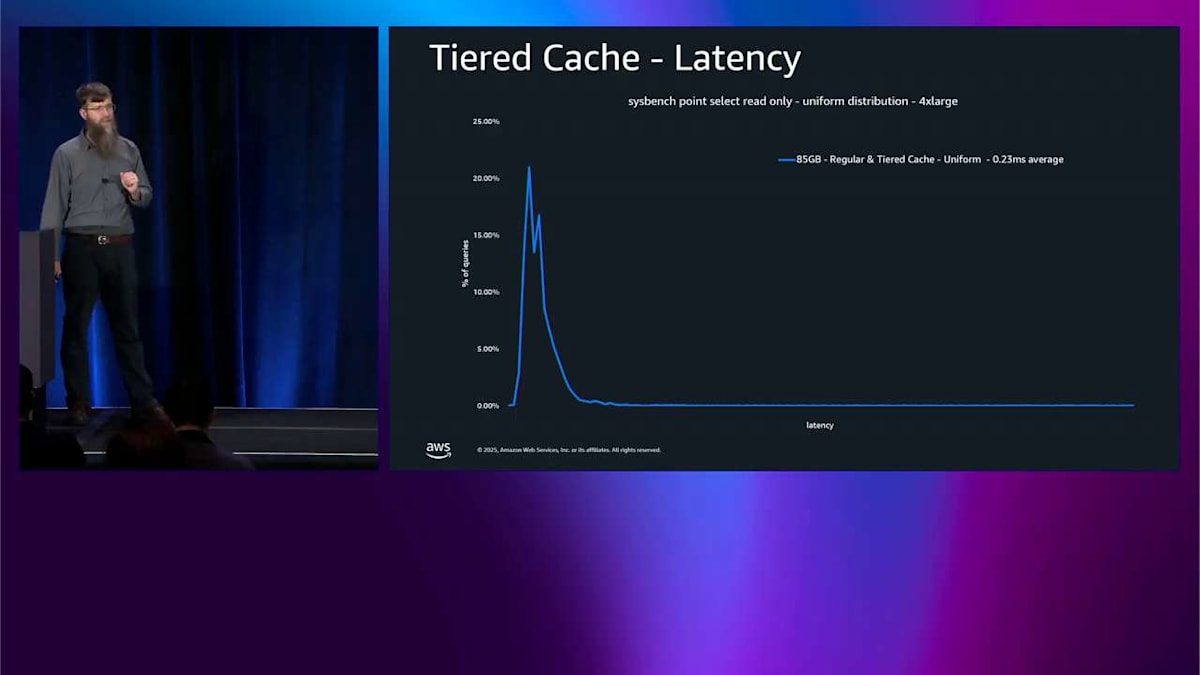
では、パフォーマンスの例をいくつか見てみましょう。これはヒストグラムなので、の左側に向かって、できるだけ高くなるのが理想的です。これはレイテンシーのヒストグラムです。ここで sysbench のポイントセレクトを実行していて、均一分布を使っています。これは本当にひどいテストで、本当にランダムなんです。通常のテスト、通常のシステムが実際にやることとは全く違います。そしてこれはすべてメモリに収まるので、左側に本当にタイトなスパイクが見えるわけです。レイテンシーは良好です。
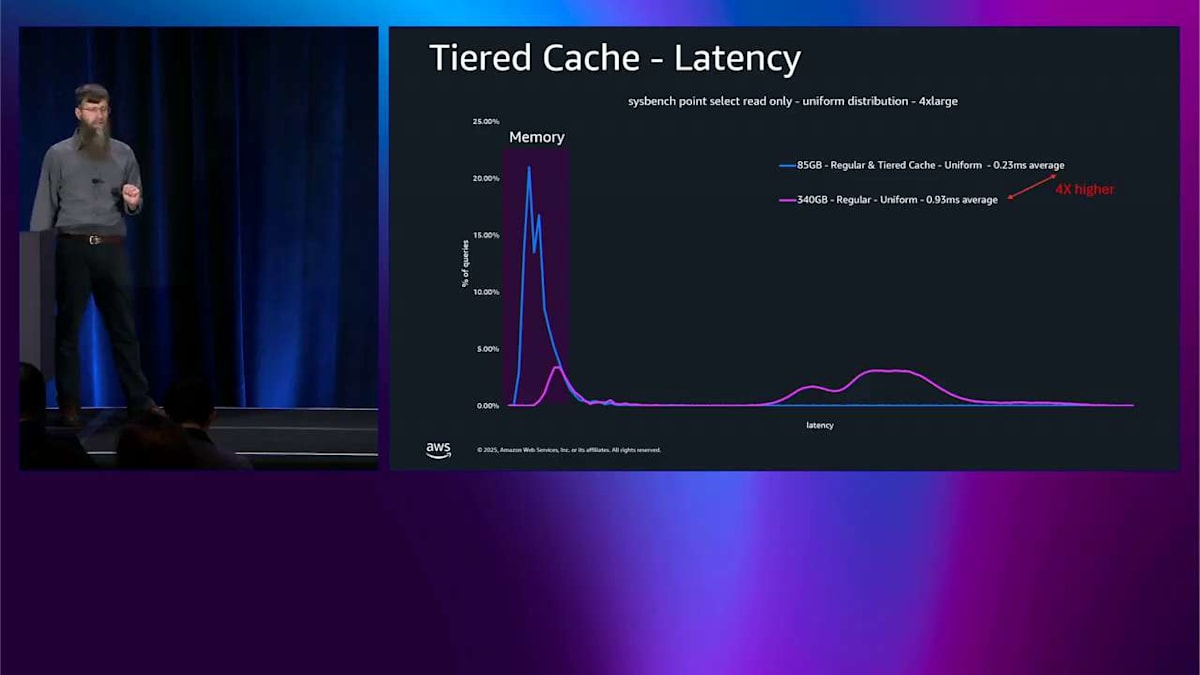
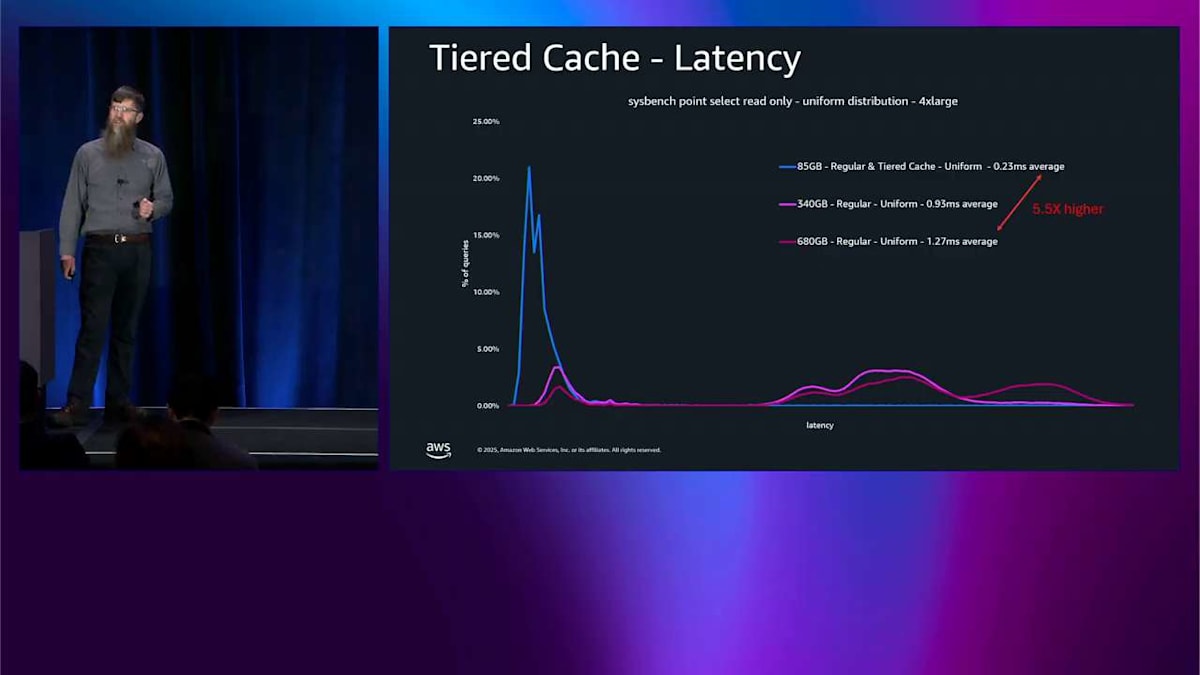
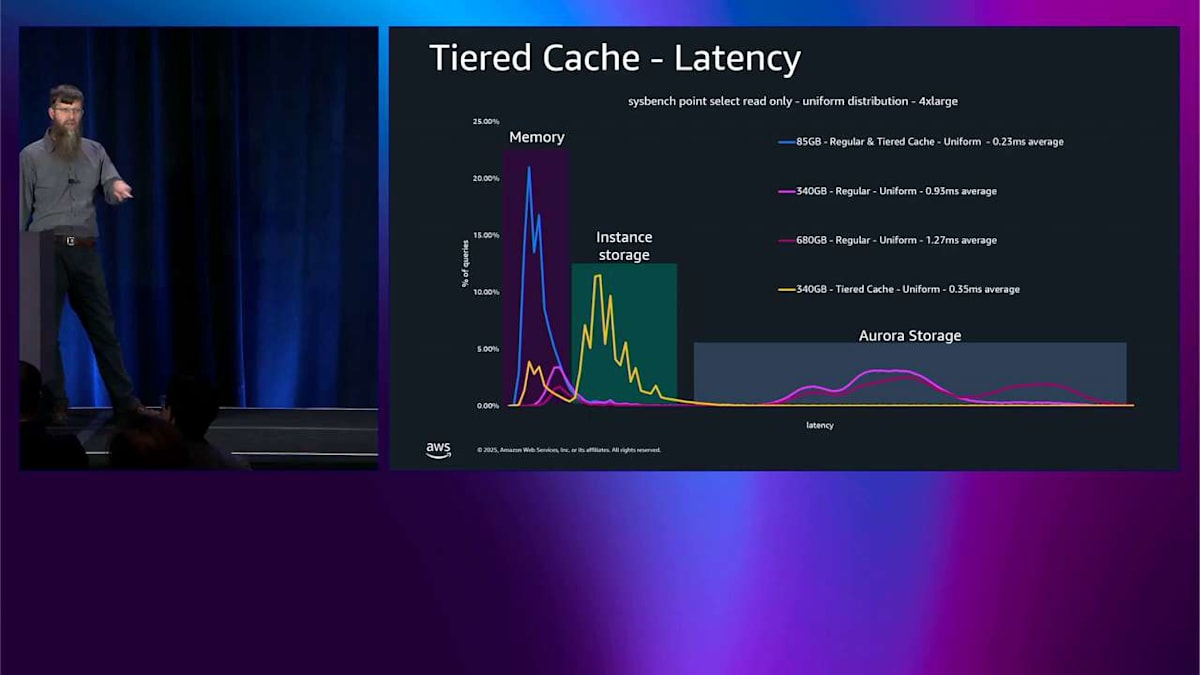
次に、もっと大きなテストを実行します。340ギガバイトで、これは 4X large のメモリには収まりません。そうすると、右側にスパイクが見えます。ここで Aurora ストレージから読み込んでいるんです。レイテンシーは 4 倍高くなっています。では、そのテストのサイズをもう一度増やします。同じようなパターンが見えます。Aurora ストレージから読み込んでいて、レイテンシーはベースラインと比べて約 5.5 倍になっています。では、tiered cache をオンにします。その 340 ギガバイトのものを見て、その黄色いスパイクを見てください。それはその空間、中程度のレイテンシーの領域にあります。メモリよりは少し悪いですが、Aurora ストレージよりはずっと良いです。そこがすべての読み込みが来ている場所です。Aurora ストレージ側に黄色でスパイクがまったくないことに注意してください。それはすべてが tiered cache に収まっているからです。ですからメモリベースラインと比べてレイテンシーの増加はわずか 1.5% です。
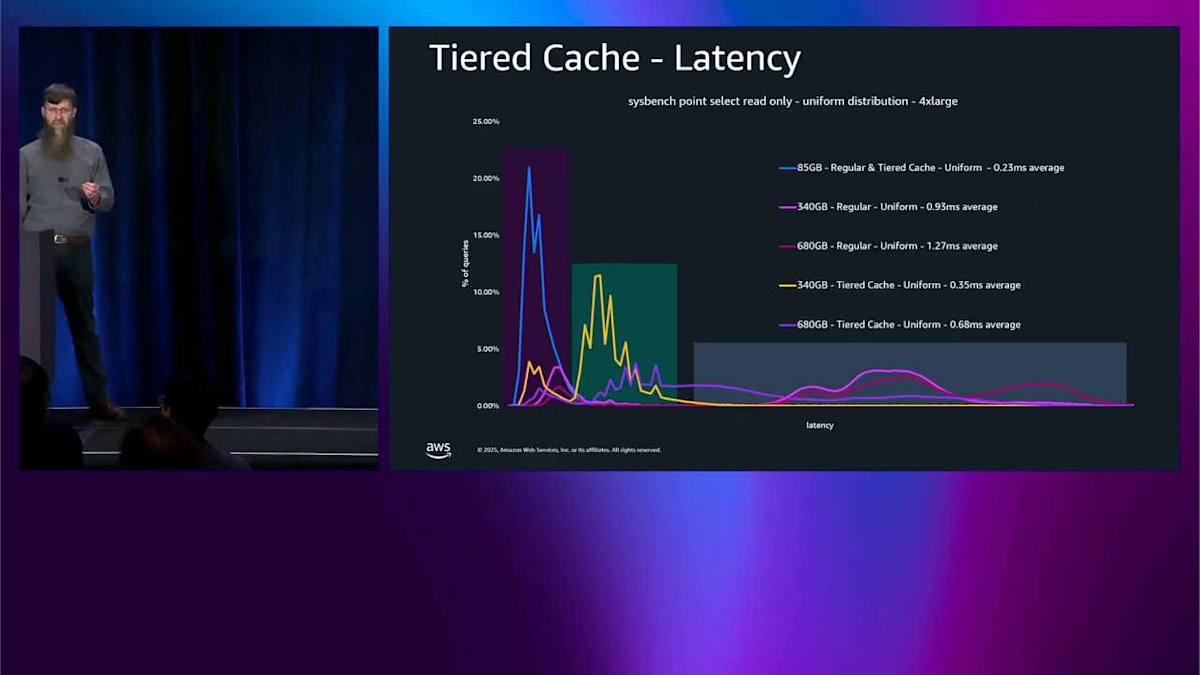
では、その本当に大きなテスト、メモリにまったく収まらないものに移ります。右側に紫色の読み込みがいくつか見えますが、それほど多くはありません。全体的には、メモリに収まるものと比べてレイテンシーの低下はわずか 3 倍です。メモリに収まるには 8 倍大きすぎるものに対してです。
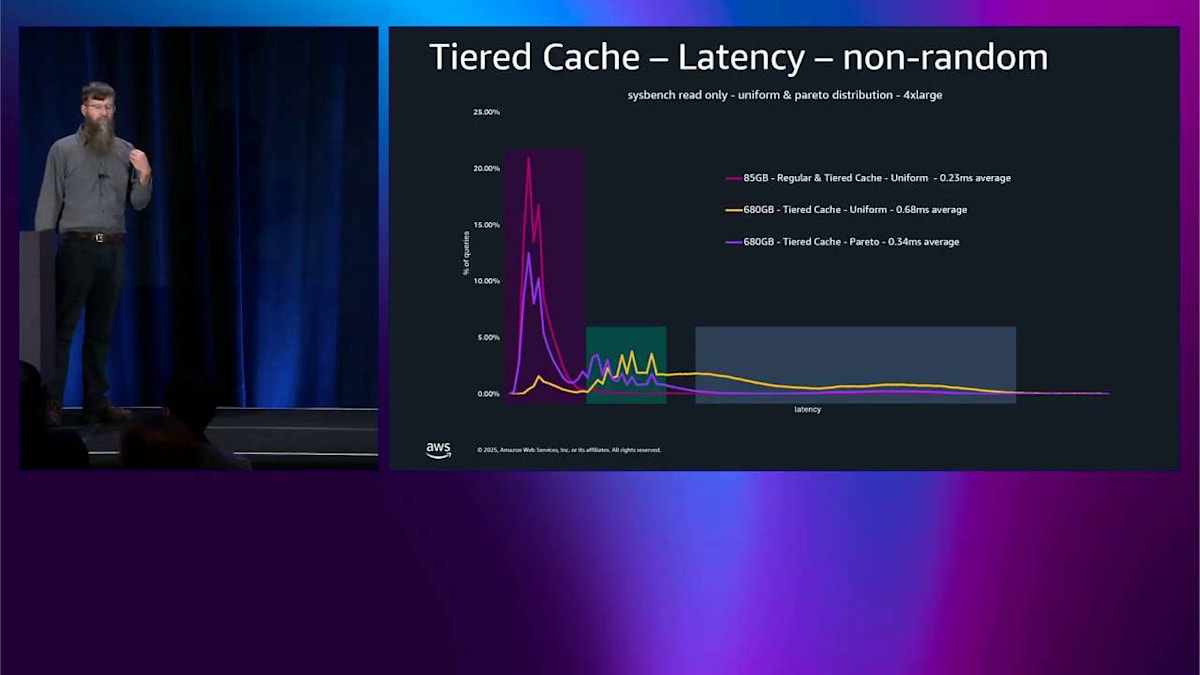
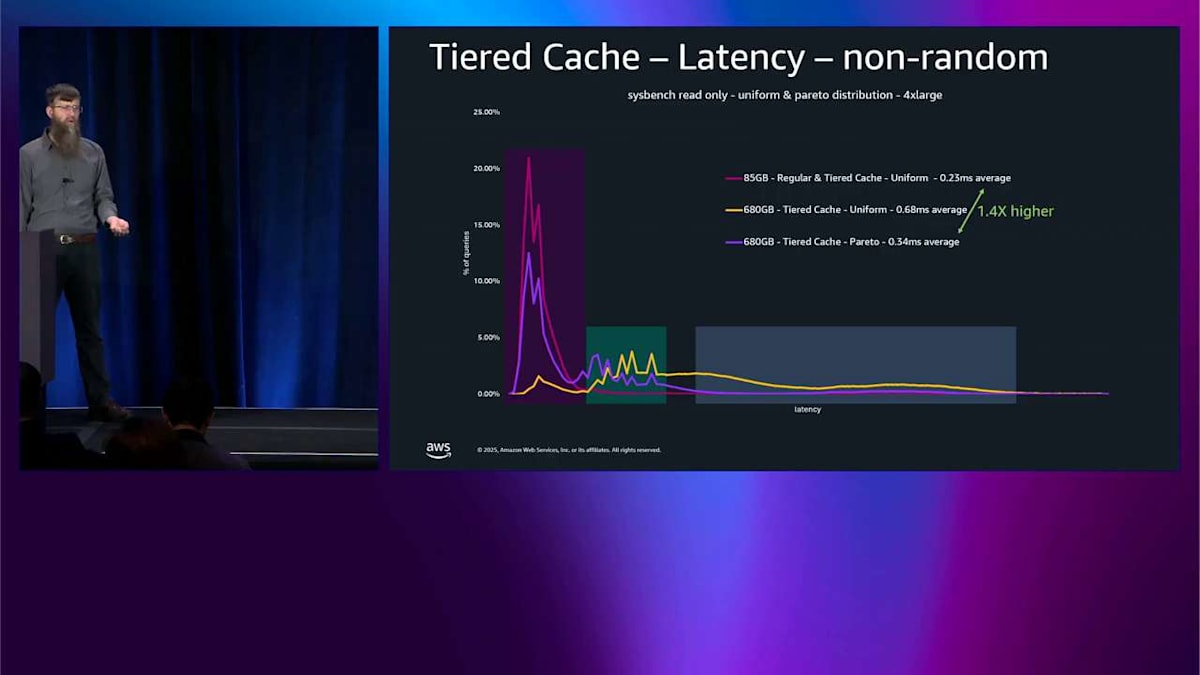
これは本当に素晴らしいアプローチです。ですが、これは均一ランダム分布だったので、今は Pareto ランダム分布を見てみます。これはおそらくあなたのアプリケーションがやっていることに近いものです。そしてそれはさらに良いことが見えます。ここで tiered cache がオンになっている同じセットのテストがあります。そしてメモリに収まるものと比べて、その巨大なテストに対してレイテンシーの低下がわずか 1.4 倍であることが見えます。より合理的な分布では、本当に強力です。
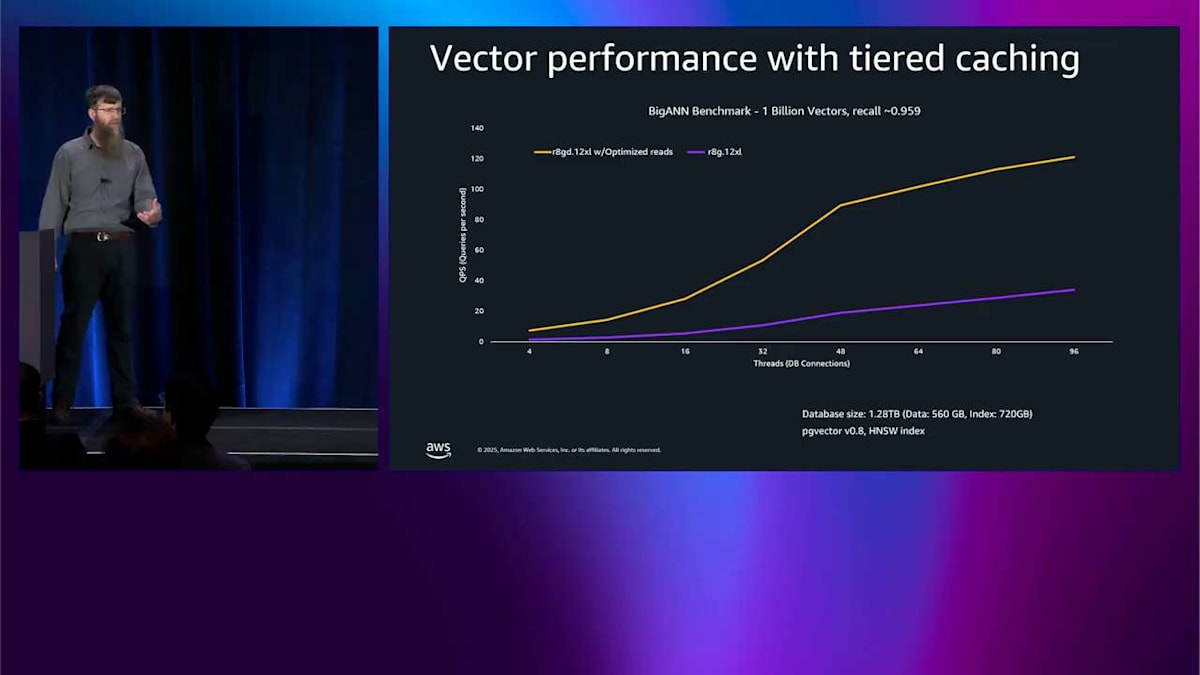
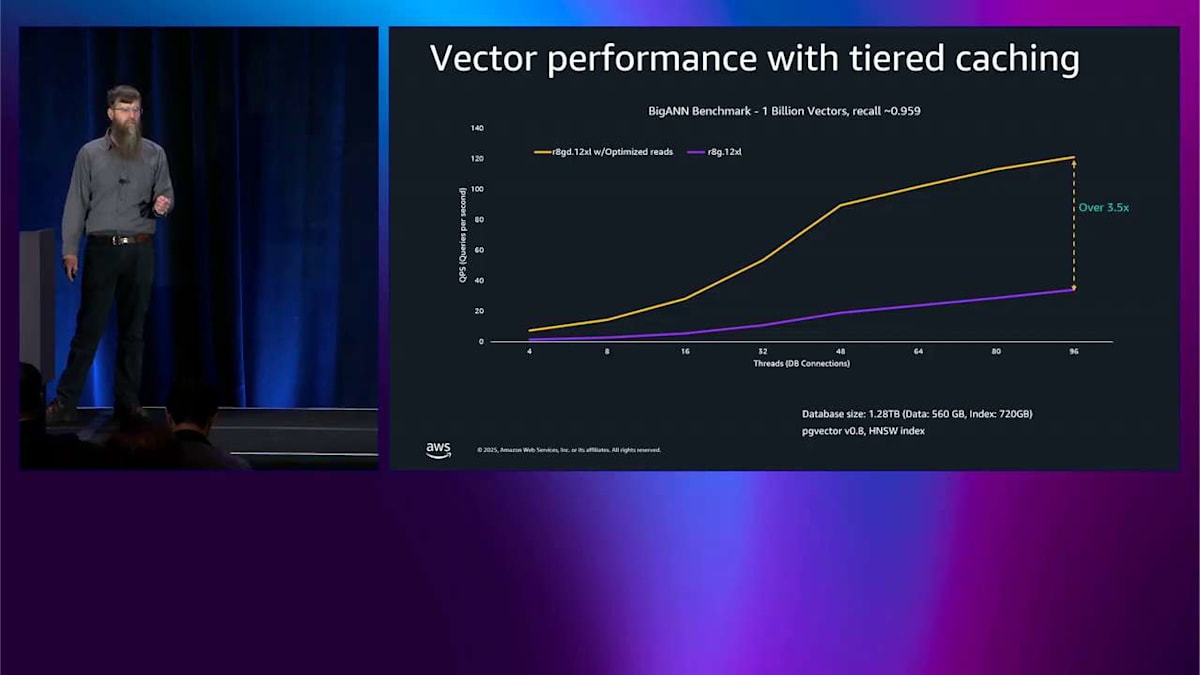
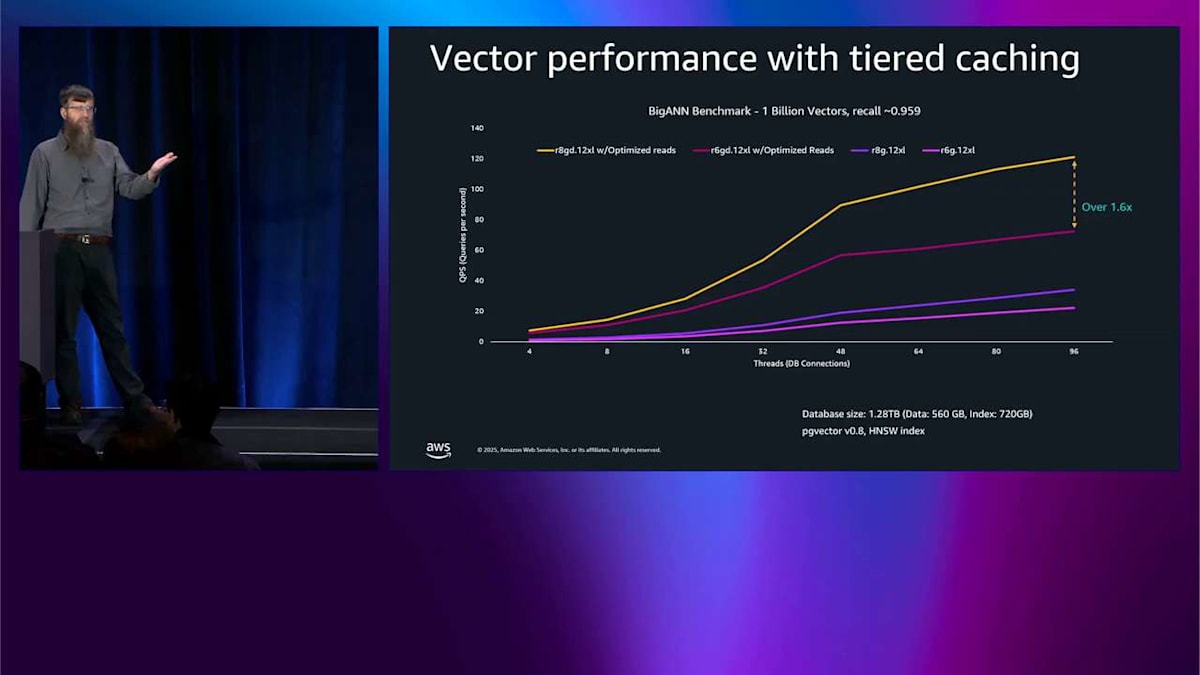
実際のユースケースを素早く説明するために、これは PG vector ベンチマークで、本当に良いリコールを持つより大きなベンチマークです。そして R8GD と R8G を比較しています。つまり、最適化された読み込みと最適化されていないものです。1 秒あたりのクエリ数で 3.5 倍以上の改善が見えます。では、R6GD を追加して比較します。R6GD と R8GD を比較するだけです。覚えておいてください、彼らは同じ価格です。そしてそれはベクトルでも 1.6 倍以上の改善をもたらします。
Aurora DSQLの紹介:アクティブ・アクティブアーキテクチャとPostgreSQLとの違い
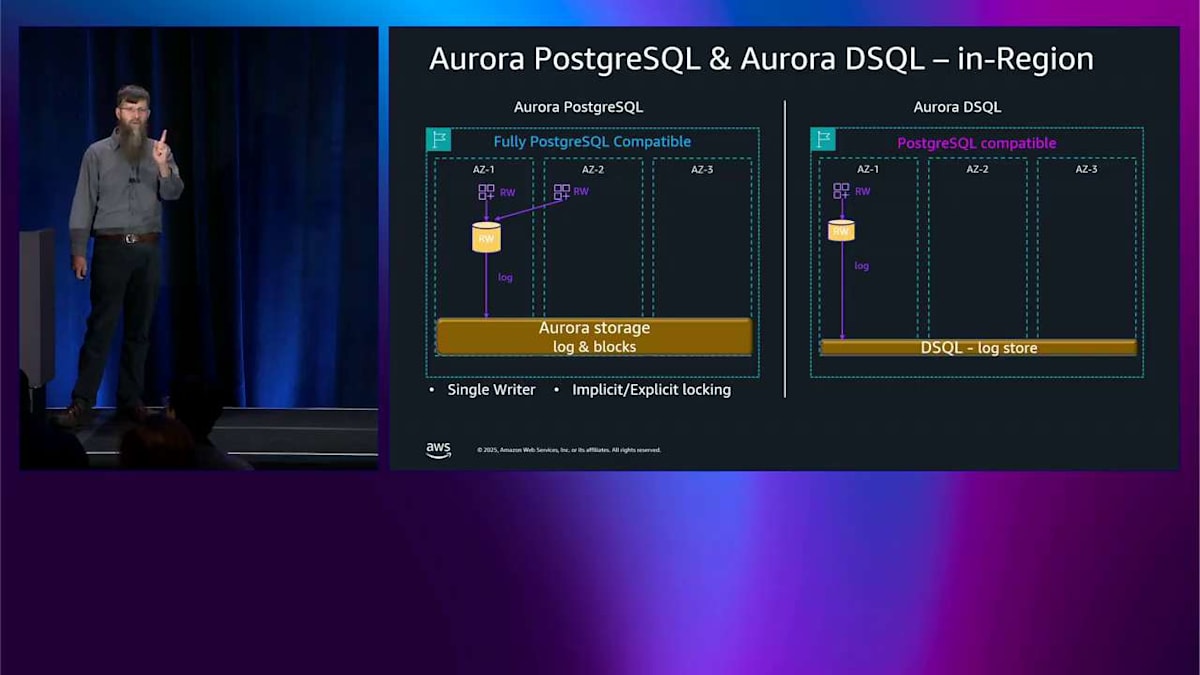
では、Aurora MySQL と Aurora PostgreSQL についてはここまでです。これからしばらくの間、Aurora DSQL についてお話しします。先ほどのような深掘りではなく、これら2つのエンジンの違いについて、どのように考えればいいのかがわかるような概要をお伝えします。 左側は Aurora PostgreSQL で、完全に Aurora であり、完全に PostgreSQL と互換性があります。右側は Aurora DSQL です。共通点は、どちらも3つのアベイラビリティゾーンにまたがるストレージを持っているということです。クエリが入ってくると、クエリ処理コンポーネント、つまり先ほど言及した head node に書き込まれ、いくつかのログレコードがこのストレージに書き込まれます。ここまでは同じように見えます。
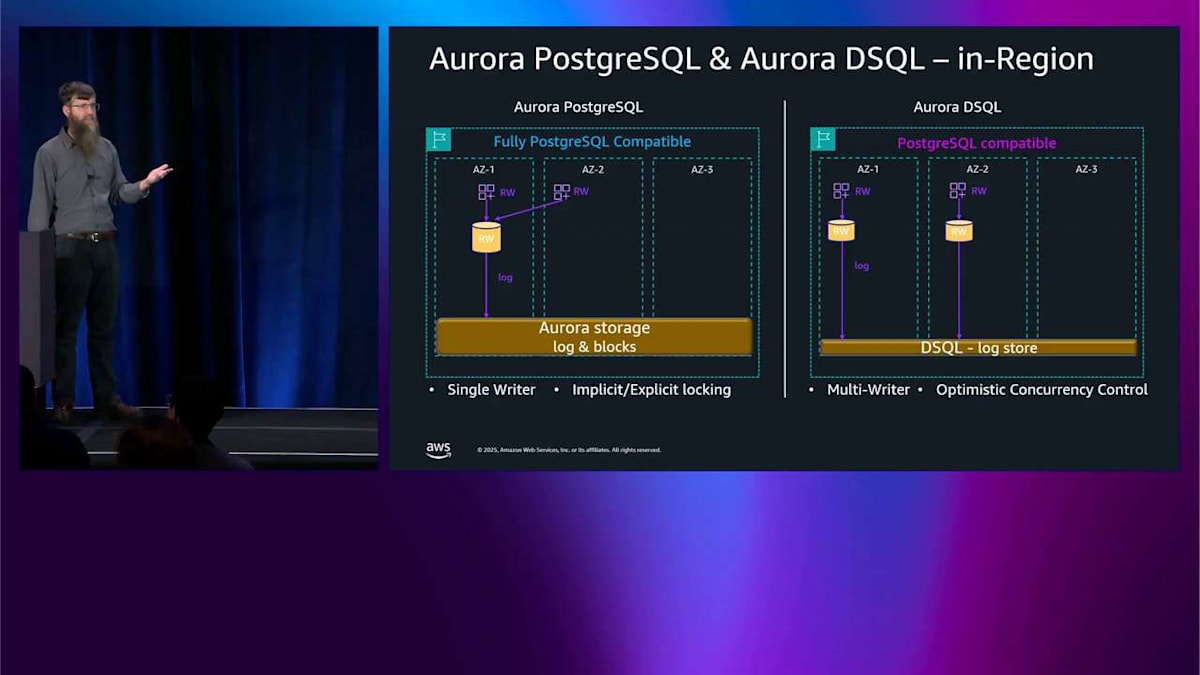
次に、2番目のアプリケーションから来る2番目のクエリを追加します。 先ほど説明した Aurora PostgreSQL では、ライターは1つだけなので、同じ場所に行く必要があります。競合に対処するために、暗黙的または明示的なロックを使用します。 DSQL 側では、新しいクエリプロセッサーをスピンアップします。これはアクティブ・アクティブなので、ここで複数の書き込みができます。オプティミスティック同時実行制御を使用します。少し競合状態が発生し、その1つがバックオフして失敗し、再試行する必要があります。
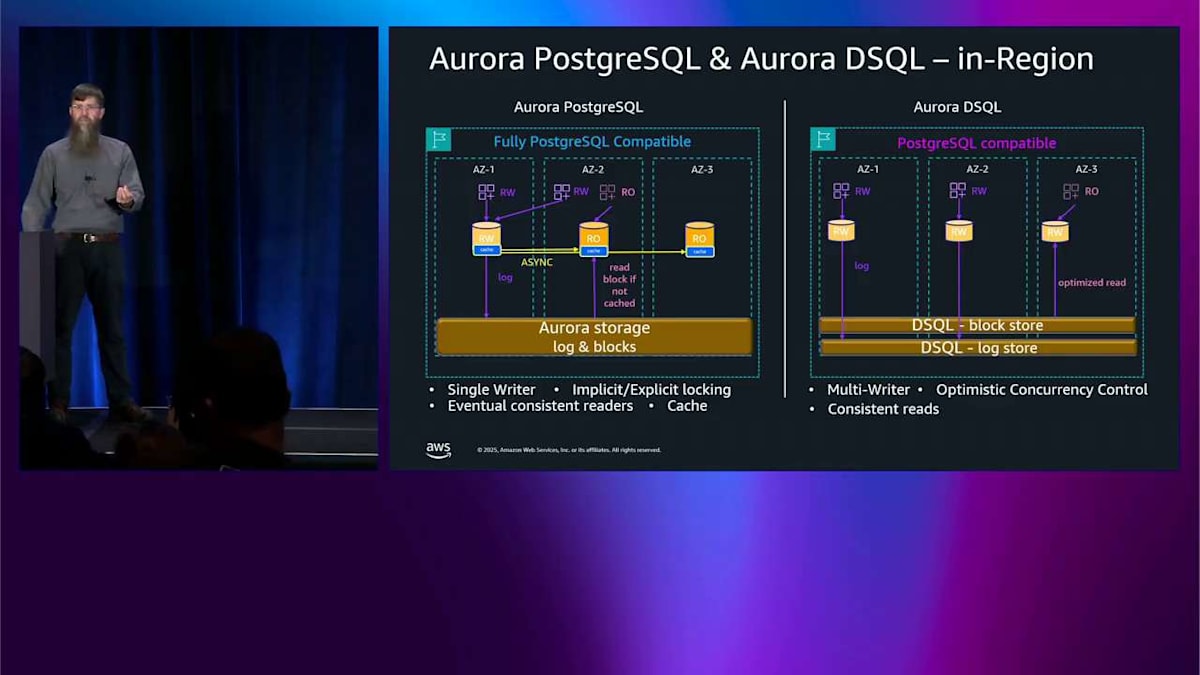
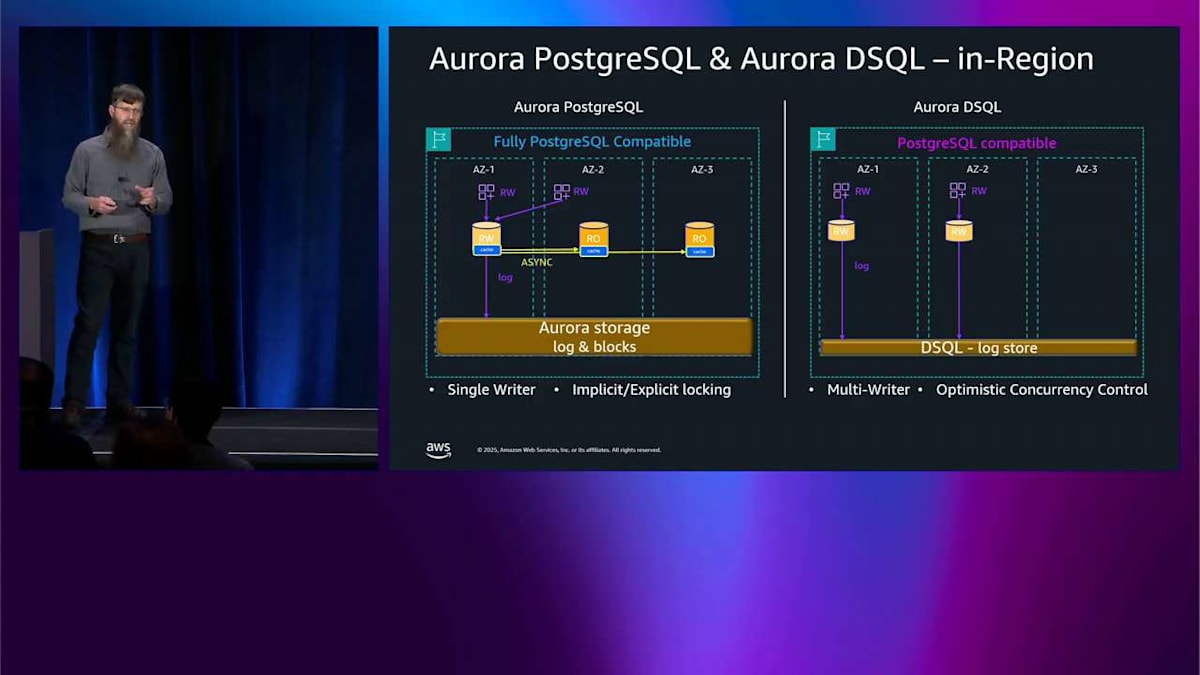
スケールアウトしたい場合は、先ほど Aurora PostgreSQL について説明したようにレプリカを追加できます。 これらの各レプリカの間には非同期レプリケーションがあるため、先ほど説明した一貫性の問題があり、キャッシングがあるため、パフォーマンスが良好です。その後、アクセスパターンに応じてキャッシュから外れる可能性があります。最適化された読み取りについて説明したように。DSQL 側では、これを異なる方法で行います。読み取りを処理するための独自の分散ブロックストアを持っており、それは独立してスケールします。つまり、head node 内にキャッシュはありませんが、私が最適化された読み取りと呼ぶものをプッシュダウンする機能があります。いくつかのクエリ述語をプッシュダウンして、読み取りでそれほどチャットする必要がないようにする必要があります。
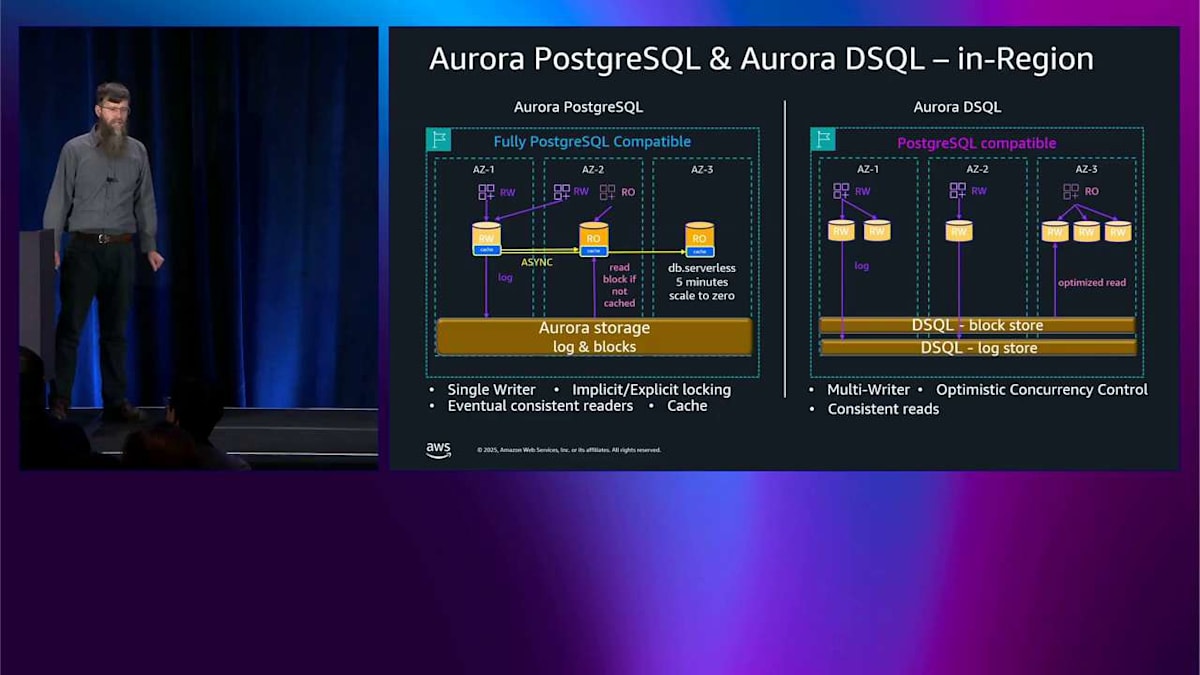
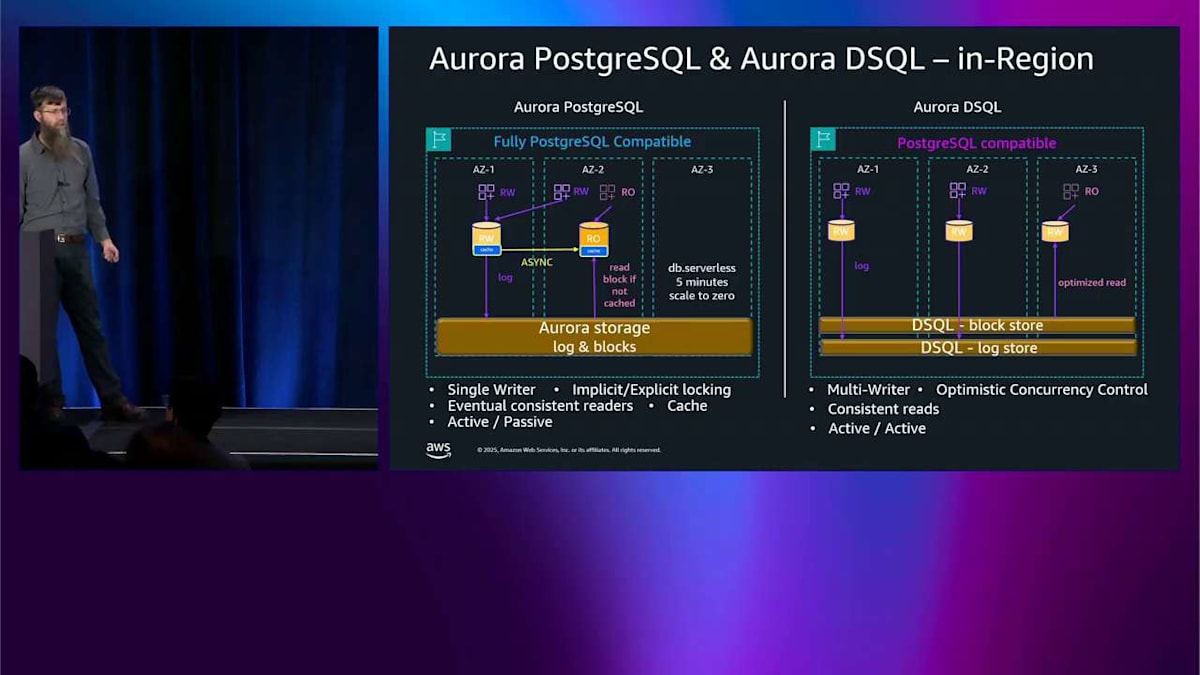
さらにスケールアップすると、Aurora DSQL はクエリプロセッサーを追加し続け、Aurora PostgreSQL は 先ほど説明したサーバーレスのことができ、それは非アクティブ状態が5分続いた後、ゼロまでスケールダウンできます。DSQL が何もしなくなった後、ゼロまでスケールダウンするのと同じ方法で できます。ここで明らかに見えるのは、左側の Aurora PostgreSQL は明示的なロックを使用したアクティブ・パッシブアーキテクチャであり、右側の Aurora DSQL はアクティブ・アクティブアーキテクチャです。これはすべて1つのリージョン内です。
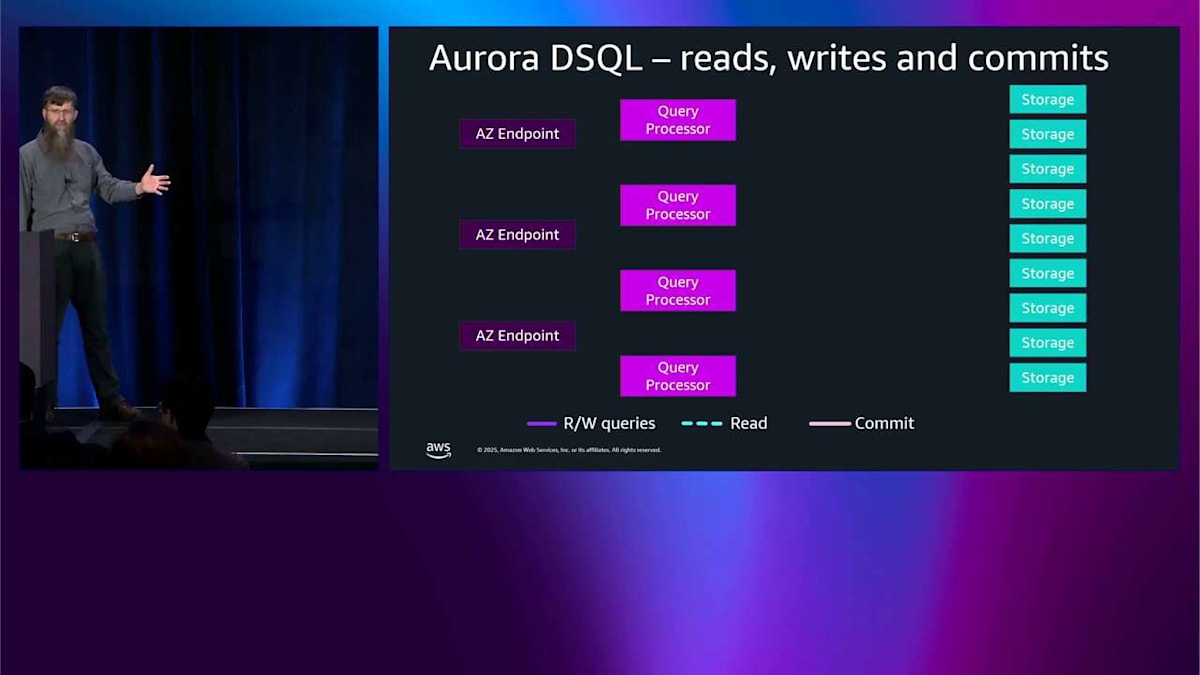


これからは読み取りと書き込みについて話し、もう少し深掘りしてみます。 アベイラビリティゾーンが3つあります。3つの AZ があるからです。読み取りが入ってくると、AZ エンドポイントを通ります。選択したクエリプロセッサーに行きます。 クエリプロセッサーは、このクエリが関心を持つデータを読み取るために、これら3つのストレージサーバーから読み取る必要があると言います。それでは、読み取りをフェッチして、完了です。問題ありません。

では、ライト操作を実行したいとします。このクエリはライト操作なので、クエリプロセッサーはこのトランザクションの一部として発生するすべてのライト操作をスプーリングしていきます。トランザクションがコミットされるまで、他のコンポーネントとは通信しません。そしてトランザクションがコミットされると、adjudicator と呼ばれるコンポーネントと通信する必要があります。 複数のライトクエリが同時に実行される可能性があることを覚えておいてください。adjudicator は誰が成功して誰が失敗するかを決定するコンポーネントです。この場合、いろいろなものに触れているので、これらがシャーディングされているため、2つの adjudicator と通信する必要があります。adjudicator は「よし、このコミットはいいですね」と言います。そしてスプーリングされたライト操作を journal の1つに送ります。journal は複数の AZ にわたってこれらのログを保存しています。その後、journal は影響を受けるストレージシャードに必要な更新をプッシュします。すべてではなく、変更の影響を受けるもののみです。これはスケーラビリティにとっても重要です。
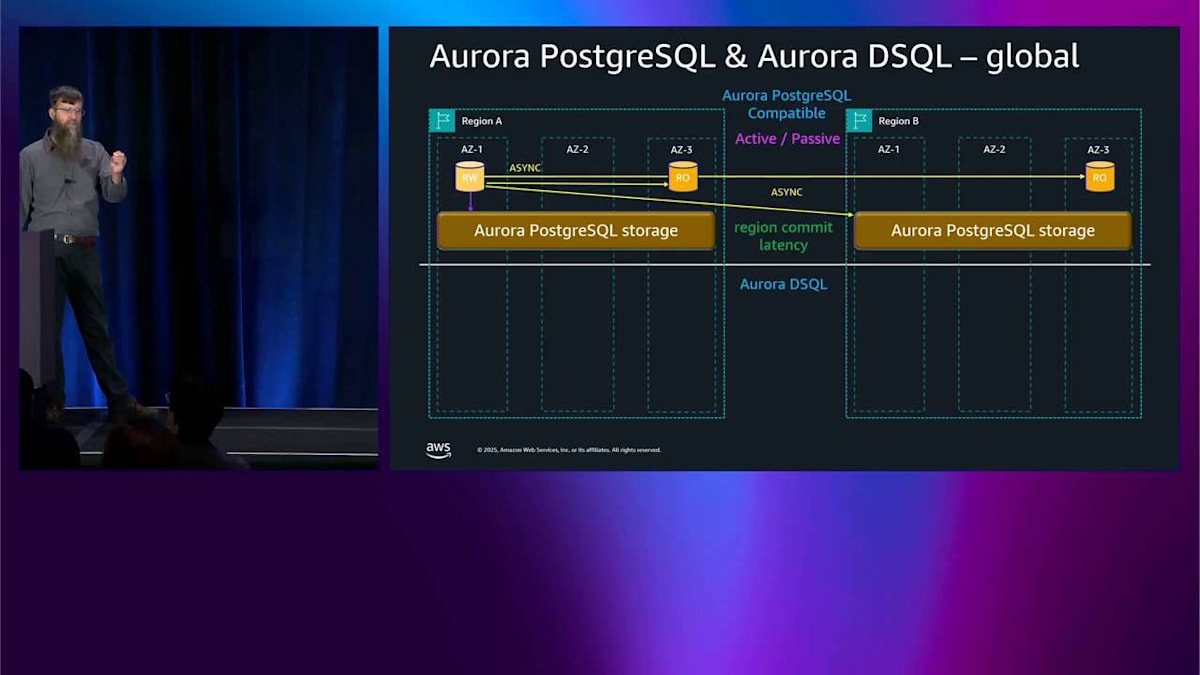
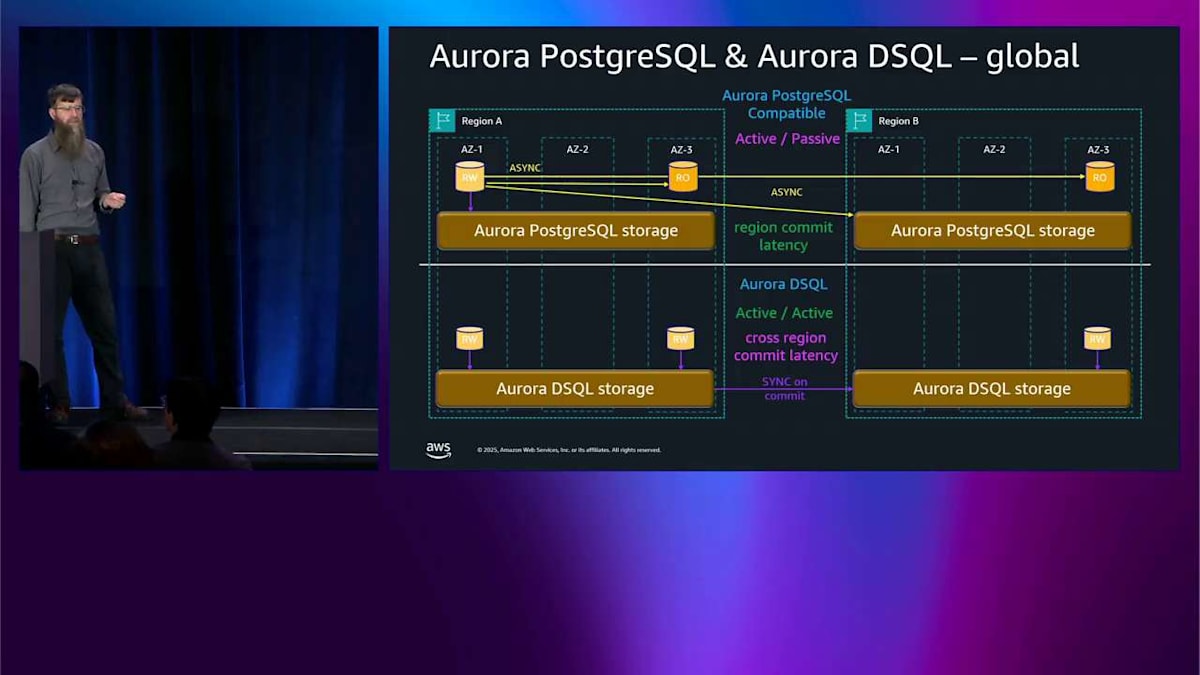
では、グローバルな話、マルチリージョンの話を簡単に説明します。上部には Aurora PostgreSQL があり、下部には DSQL があります。 レプリカがあり、遠い側には読み取り専用があります。非同期レプリケーション、アクティブ・パッシブです。これについてはもう何度も話しました。つまり、コミットするとき、コミットレイテンシーはリージョン内の構成になります。なぜなら、リージョン間のレイテンシーは非同期だからです。Aurora DSQL では、物事は少し異なります。コミットするとき、他のリージョンと同期的に通信します。つまり、コミットするたびに、コミットレイテンシーはクロスリージョンレイテンシーになります。 これが Aurora DSQL と Aurora PostgreSQL の間で考慮すべき基本的なポイントです。


まとめ:さらなる学習リソースとフィードバックのお願い
Aurora DSQL についてもっと学びたい場合は、私の話を聞くのをやめて、これらの他のトークを聞くことをお勧めします。 チョークトークやブレークアウト、ワークショップなど、選択肢がたくさんあります。見逃した場合は、録画もあります。それでは、これが Aurora がどのように内部で機能しているか、そして過去1年間に何をしてきたかについて、皆さんに感覚を与えてくれることを願っています。もちろん、私がこれをしているのは、皆さんと話をして、皆さんが何を望んでいるかを教えてくれるからです。ですから、その後また私と話をして、来年何を望んでいるかを教えてください。また、アンケートで、次回これをどのようにより良くできるかを教えてください。これが本当に私たちの評価方法です。 お時間をいただきありがとうございました。また会いましょう。
※ こちらの記事は Amazon Bedrock を利用し、元動画の情報をできる限り維持しつつ自動で作成しています。
Discussion