re:Invent 2023: AWSがClean Rooms MLと差分プライバシー機能を発表
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - [LAUNCH] AWS Clean Rooms ML and AWS Clean Rooms Differential Privacy (AIM241)
この動画では、AWS Clean Roomsの新機能であるMachine LearningとDifferential Privacyについて詳しく解説しています。The Weather Companyの事例を交えながら、データのプライバシーを保護しつつ、パートナー間でのデータコラボレーションを実現する方法を紹介します。市場投入までのスピード向上や、ルックアライクモデルの構築、差分プライバシーを用いた安全な分析など、具体的なユースケースと参照アーキテクチャも示されており、エンジニアの方々にとって興味深い内容となっています。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
AWS Clean Roomsの新機能紹介:プライバシー強化と機械学習


みなさん、こんにちは。私はTia Whiteと申します。AWSのAI/ML、AdTech、MarTechの General Manager を務めております。本日は、AWS Clean Roomsの既に強力なプライバシー強化機能をさらに向上させる素晴らしい機能についてご紹介できることを大変嬉しく思います。今日は、AWS Clean RoomsのSenior Solution ArchitectであるRyan Maleckyさん、 そしてThe Weather Companyから、Data ProductsのHead であるJulianne Jenningsさん、Customer Data Product ArchitectureのHead であるSam Tahaさんという素晴らしいリーダーたちにも登壇していただきます。

本日のアジェンダは盛りだくさんです。まず、2023年を通じてAWS Clean Roomsに継続的に行ってきた投資について詳しくお話しします。次に、プライバシー強化型データコラボレーションの重要性とメリットについて議論します。そして、最近リリースしたAWS Clean Rooms Machine LearningとAWS Clean Rooms Differential Privacyについて探っていきます。AWS Clean Rooms Differential PrivacyについてはAWS Clean Rooms DPまたは単にDPと呼ぶかもしれません。最後に、お客様であるThe Weather Companyから直接お話を伺います。
デジタルデータの爆発的増加とプライバシー保護の課題

COVID前後で、あなたの生活がどのように変化したか少し考えてみてください。COVIDは私たちの生活を劇的に変えました。食料品のような必需品でさえ、買い物の仕方を考えてみてください。友人や家族とのつながり方や、娯楽の楽しみ方についても考えてみてください。 COVIDによって私たちの生活の多くの側面が変化しましたが、ポジティブな結果の一つはデジタルデータの爆発的な増加とアクセシビリティの向上でした。
これを具体的に説明しましょう。世界中で作成、キャプチャ、コピー、消費されるデータの総量は、週平均30%以上の複合成長率に達すると予測されています。2020年には64.2ゼタバイトのデジタルデータがありました。2025年までに、業界はこれが180ゼタバイト以上に達すると予測しています。つまり、データは力であり、かつてないほど多くの力があなたの手の中にあるのです。
この成長は、動画ストリーミング、ソーシャルインタラクション、買い物の習慣、さらには子供たちの教育方法といったデジタルエンゲージメントによって引き起こされています。企業はこのデータがどのようにビジネス成果を推進できるかを理解する必要があり、パートナーと協力してインサイトを生成し、その価値を引き出したいと考えています。しかし、データは断片化され、異なるリポジトリ、アプリケーション、チャネル、部門に存在しており、相互運用性とスケールの課題を生み出しています。
データの取得を大幅に制限すると、アイデア創出、デリバリー、そして最も重要な意思決定が遅くなることは明らかです。しかし、企業が直面する最も重要な課題は、ユーザー、消費者、顧客のデータをいかに保護するかということです。多くの組織は、コンプライアンスを維持し、強力なプライバシー体制を確保しながら、機密データの収集、保存、使用方法をより適切に管理する方法を必要としています。
データコラボレーションの課題とAWS Clean Roomsの解決策

私に関する興味深い事実をお話しします。水曜日にAWSでの2周年を祝ったばかりです。それ以前は、6年以上にわたってカスタマーでした。私は物語を語るのが好きなので、これまで働いてきた企業を守るために、抽象的な仮説の話を使います。私のキャリアの全ては金融サービス業、つまり厳しく規制された業界で過ごしてきました。キャリアの最初の数年間は、エンジニアリング組織や大規模な変革をリードするエンジニアリングに携わっていました。金融機関で働いた最後の5年間は、applied AIグループをリードし、機械学習と人工知能を大規模に適用することに焦点を当てていました。
キャリアの前半はデータ生産者、後半はデータ消費者でした。データ消費の部分は特に難しく、組織外の人々と協力する際はなおさらです。仮説的な例を挙げると、私がクレジットカード会社で働いていて、Neiman Marcusのようなブランドとコブランド契約を結んでいた場合、よく協力する必要がありましたが、それは困難でした。どのようにデータを共有するのか?どのように迅速に動くのか?基礎となるデータを保護しながら、ビジネスに大きな影響を与えるにはどうすればよいのか?多くの場合、何ヶ月も、四半期も、時には1年近くかかる長期的な契約合意を経て、ビジネス開発が停滞していました。
これにより、企業が収益に影響を与えるために協力する方法と、顧客のプライバシーを保護する方法との間に本質的な緊張関係が生まれました。時にはこれらのメカニズムにより、企業はデータをコピーする必要があり、それはコストがかかり、先ほど述べたように、顧客を保護するために長期的なプロセスを経る必要がありました。しかし、顧客もまた可能な限りデータの移動を制限したいと考えています。彼らは誤用や漏洩を防ぎたいのです。結果として、彼らはしばしば協力しないことを選択し、それは機会の損失を意味します。
もし、決断や妥協をする必要がなかったらどうでしょうか?もし、すべてを手に入れられたらどうでしょうか?データと知的財産を保護しながら協力できるソリューションがあると言ったらどうでしょうか?実験し、革新し、生産性を生み出し、従業員に力を与え、そして何よりもビジネスに大きな影響を与えることができます。データクリーンルームを使えば、まさにそれが可能になります。パートナーと協力して価値ある洞察を引き出しながら、ビジネスに大きな影響を与えることができるのです。
AWS Clean Rooms MLとDifferential Privacyの導入
顧客の優先事項を理解するため、今年の夏にアンケート調査を実施しました。主にマーケティングと広告業界から約50社のAWSの既存顧客に質問しました。まず、データコラボレーション製品に関連して、意思決定において最も重要な側面は何かを尋ねました。圧倒的な回答は、消費者または顧客のデータ保護でした。2つ目の質問は、データコラボレーション製品を選択する際の意思決定プロセスで最も重要な基準についてでした。そして、答えは何だったと思いますか?プライバシーの強化でした。この回答は、re:Inventの前や、ここre:Inventで皆様のような顧客と交わした数多くの会話によって裏付けられています。

企業が直面するこの課題が、ちょうど前回のre:Inventで私たちがAWS Clean Roomsを発表した理由です。皆さんには有利な点があります。なぜなら、皆さんのデータはすでにAWS上にあると想定されるからです。そして、私たちは巨大なクラウドプロバイダーなので、皆さんのパートナーのデータもおそらくAWS上にあるでしょう。AWS Clean Roomsは、企業とそのパートナーが、基礎となるデータを共有したりコピーしたりすることなく、より簡単に、安全に、そしてプライバシーを強化する方法で、彼らの集合的なデータセットを分析し、協力することを支援します。AWS Clean Roomsを使用すると、顧客は数分で安全なデータクリーンルームを作成でき、価値創出までの時間を短縮し、長期的なプロセスの負担を取り除くことができます。広告キャンペーン、投資判断、研究、実験に関する有意義な洞察を生み出すために、他の企業と協力することができます。
昨日、Swamiが基調講演で発表したAWS Clean Rooms Machine LearningとAWS Clean Rooms Differential Privacyについて、皆さんにお知らせできることを嬉しく思います。これらにより、私たちが提供するプライバシー強化機能をさらに向上させました。今日は、最近発表されたこれら2つの機能について詳しく見ていきます。AWS Clean Rooms MLはパブリックプレビューで利用可能です。
AWS Clean Rooms MLの機能と利点

この機能を今日から使用して、パートナーと協力し、プライバシー強化機械学習を適用することで、基礎となるデータを共有せずに予測的な洞察を生成できます。この機能により、機械学習開発ライフサイクル全体(トレーニング、構築、デプロイ)を通じてデータを共有する必要がなくなります。最初に利用可能なモデルは、企業がルックアライクセグメントを作成するのに特化しています。AWS Clean Rooms ML ルックアライクモデリングを使用すると、自社のデータを使用して独自のカスタムモデルをトレーニングし、パートナーを招待して少量のレコードまたはシードデータを持ち込み、ルックアライクセグメントを生成できます。
この機能は、eコマースやストリーミングビデオなど、幅広いデータセットにわたってテストされました。私たちは顧客の精度向上を支援できます。テストを通じて、私たちのベンチマークは平均して業界標準を25〜36%上回りました。つまり、使いやすさだけでなく、市場投入までの速さ、そして高精度な出力も得られるのです。これは数百万ドルの節約につながる可能性があります。ヘルスケアのルックアライクモデリングは今後数ヶ月で登場する予定ですので、ご期待ください。
AWS Clean Rooms Differential Privacy(AWS Clean Rooms DP)もパブリックプレビューで利用可能です。これは、数学的に裏付けられた厳密で直感的な機能を使用して、ユーザーのプライバシーを保護するのに役立ちます。差分プライバシーは、データプライバシー保護の厳密な数学的定義です。しかし、この技術の設定は複雑で難しい場合があります。
AWS Clean Rooms Differential Privacyは直感的で、完全に管理された機能であり、ユーザーの再識別を防ぐのに役立ちます。差分プライバシーの経験がなくても使えるように、この管理機能を構築しました。現在、オープンソースバージョンも利用可能ですが、私が継続的に会う多くの顧客は、差分プライバシーの専門知識が不足しているため、難しいと感じています。

AWS Clean Roomのディファレンシャルプライバシーは、クリーンルームのコラボレーションから個人のデータの寄与を隠し、出力を集計します。これにより、広告、投資決定、臨床研究など、幅広い分野でインサイトを得るための多様なSQLクエリを実行できます。既存または新規のコラボレーションでカスタム分析ルールを通じて、AWS Clean Roomsディファレンシャルプライバシーをセットアップできます。それでは、これらの機能について詳しく見ていきましょう。
AWS Clean Rooms MLの実用例と適用可能性
皆さんの中で、機械学習の経験が本当にある方がどれくらいいるかわかりませんが、人工知能と機械学習は世界中で大きな話題となっています。しかし、これは難しい課題です。まず、スキルセットが必要ですが、現在の市場では誰もがAIに取り組みたがっているため、そのスキルを持つ人材を維持し、関与させ続けるのは困難です。さらに、これは長期的なプロセスであり、特にプライバシーを保護する方法で行うのは難しくなる可能性があります。私たちは、この完全に強化された既製のモデリングプライバシー強化機能を立ち上げており、クリーンルームの構造でこれを行う最初の企業となります。
顧客が直面する課題の1つは、ユーザーのプライバシーと知的財産を保護したいということです。なぜなら、そのモデルはIPだからです。パートナーと機械学習モデルを構築・実行する際、モデル構築にデータセットを使用することを犠牲にしたくありません。AWS Clean RoomのMLは、機械学習開発ライフサイクルのデータ共有部分を不要にします。また、顧客は自社の最優良顧客に似たユーザーを、ファーストパーティデータを明かすことなく見つけたいと考えています。今や、彼らのデータでカスタムトレーニングされ、再利用されることのないAWS構築モデルを適用できます。

AWS Clean Rooms MLを使用すると、これらのトレーニング済みモデルの完全な制御と所有権を保持できます。これには、モデルの使用時期、セグメントの生成時期、削除時期が含まれます。あなたのデータは、あなたのモデルのトレーニングにのみ使用されます。私たちはそれを再利用したり、共有したり、利用したりすることはありません。それはあなただけのものです。顧客はパートナーとMLルックアライクモデリングを使用したいと考えていますが、先ほど述べたように、リソースや時間がありません。AWS Clean Rooms MLを使用すれば、数ヶ月ではなく数日でこれを実現できます。最後に、顧客は機械学習モデルの柔軟性と設定可能性を求めており、パートナーと予測インサイトを生成したいと考えています。AWS Clean Rooms MLは、直感的な機械学習コントロールを提供し、あなたとパートナーが特定のユースケースにより適した結果を調整できるようにします。

これらは、この機能を使用できる方法のほんの一例です。この機能の適用には無限の可能性があることをご理解ください。私のチームと私は、より深く掘り下げて、どのように協力できるかを考えるために、皆さんとお会いできることを楽しみにしています。例えば、United Airlinesは、ロイヤルカスタマーに関するデータを活用し、Booking.comのようなパートナーと提携して、類似の特性を持つユーザーにプロモーションを提供し、より高いコンバージョン率を達成できます。自動車ローン会社と自動車保険会社は、最近車をリースし、保険も必要としている見込み客を特定できます。ブランドとパブリッシャーは、市場にいる顧客のルックアライクセグメントをモデル化し、非常に関連性の高い広告体験を提供することで、広告費用対効果を高めることができます。研究機関と病院ネットワークは、既存の臨床試験参加者に似た候補者を見つけることができます。これは現在、ヘルスケアとライフサイエンスの分野では非常に面倒で時間のかかるプロセスであり、高度に手動で行われています。
AWS Clean Rooms Differential Privacyの概要と重要性

AWS Clean Roomの機械学習は非常に使いやすく、意図的にそのように設計されています。まず、コラボレーターがカスタムモデルをトレーニングするためのデータを提供します。そして、レコードに似たデータセット(シードとも呼ばれます)を持つ別のパートナーを招待します。一緒にlookalike segmentを作成し、その出力は単純にS3に配信され、必要に応じて使用できます。本当にシンプルなのです。
さて、ここからは私がこの仕事を始めたときに思い出す話題に入ります。「えっ、何?何をしてほしいの?」と言ったことを覚えています。
私は何をすべきか、そしてdifferential privacy(DP)が何を意味するのかわかりませんでした。以前、プライバシーを重視する金融機関で働いた経験はありましたが、完全に理解するには時間が必要でした。最初の3〜4ヶ月は、学術論文を読み、科学者に相談して、その潜在的な利点と応用を理解しようと努めました。
発売された製品について説明する前に、differential privacyが実際に何であるかを説明させてください。本質的に、DPは個人データのプライバシーを保護するためのフレームワークです。その主な利点は、分析されたデータセットに単一のユーザーが存在するかどうかを曖昧にするために、制御された量のランダム性を導入することで、個人レベルでデータを保護することです。特に、個人を数人追加または削除してもほとんど影響がない大規模なデータセットに有用ですが、それでも統計的に健全な出力を可能にします。DPは、count queries、ヒストグラム、ベンチマーキング、A/Bテスト、さらには機械学習にも適用できます。
Differential privacyにより、データの匿名化やクエリ監査への依存を減らしながら、パートナーとのデータ分析のコラボレーションが可能になり、ビジネスに影響を与える洞察を生み出す新しい道が開かれます。DPの実世界での応用例として、米国国勢調査局が挙げられます。彼らはDPを使用して、米国人口に関する機密データを分析し報告しています。最新の国勢調査報告では、住宅ユニットと収入データにdifferential privacyを適用し、個人のプライバシーを侵害することなく統計分析を公開することができました。
最近の米国大統領令では、AIの安全で信頼できる開発と使用に関して、Differential Privacy(差分プライバシー)をプライバシー強化技術(PET)の重要な要素として特定しました。10月24日までにその具体的な使用に関するガイドラインが発表される予定ですが、これはAWSがこのようなプライバシー保護機能を市場に提供する上で先駆的な立場にあることを示しています。

Differential Privacyの実用的な応用例として、企業やパートナーと協力して集合的なデータセットを分析する際に、個人の属性を共有せずに行うことが挙げられます。Differential Privacyは、SQLクエリの結果に実行時に慎重に調整されたエラーを加えることで、個々の貢献を隠しつつ、意図された使用目的に対するクエリの有用性を維持します。具体的な要件に基づいて、分析に加えるエラーの量や、個人のプライバシーを保護しながら実行できるクエリの数の閾値など、Differential Privacyのパラメータを設定できます。

図に示されているように、Differential Privacyの適用を増やすことでより多くの洞察が得られるほど、データセット内の特定のユーザーの存在や不在をより効果的に隠すことができます。AWS Clean Rooms DPは非常に直感的に設計されています。私たちの推奨設定をそのまま使用するか、いくつかの入力を調整して、ユースケースに最適なDifferential Privacyアプローチを決定することができます。
AWS Clean Rooms Differential Privacyの実装と使用方法

AWS Clean Rooms DPは、お客様が正確かつ迅速に大規模な差分プライバシーを適用できるよう支援するために開発されました。多くの企業が差分プライバシーの使用を望んでいますが、専門知識が不足していることがよくあります。今や、このソフィスティケートされた手法をデータセットに適用し、プライバシー保護を強化することができます。AWS Clean Rooms DPは、差分プライバシーの実装に必要な労力を軽減する完全マネージド型の機能です。パラメータを推奨しつつ、必要に応じて調整する自由度も提供します。
AWS Clean Rooms DPにより、企業はパートナーと協力して、柔軟で設定可能な制御を使用し、特定のユースケースに関する洞察を生成できます。さらに、高度なSQLクエリをサポートし、その重要性と利点を理解しています。これらは、AWS Clean Rooms DPのユースケースのほんの一部であり、企業が効果的かつ効率的に差分プライバシーを活用できるようにします。

AWS Clean Rooms Differential Privacyを使用して、以下のことを実現できます:共通の顧客を明かすことなく、マーケティングパートナーとのユーザーの重複を特定し、広告支出を計画する。メディアパブリッシャーとのマーケティングROIを測定し、集計された洞察に基づいてキャンペーンを最適化する。基礎となるユーザーデータを明かすことなく、ドライバー層に関する市場洞察を用いて自動車保険契約を補完する。そして、非常にセンシティブな患者データを明かすことなく、医療機関と協力して臨床試験の洞察を進展させる。

AWS Clean Roomsは、開始するだけでなく、インパクトのある結果を得るために、3つの簡単なステップを踏みます。コラボレーションをセットアップする際、AWS Clean Roomsでテーブルを設定しながらDifferential Privacyをオンにします。そこから、直感的なコントロールを使用してパラメータを設定するか、デフォルト設定を使用するオプションがあります。その後、パートナーは通常通りクエリを実行でき、彼らにとっては変更はありません。Differential Privacyは各クエリ結果に適用されます。AWS Clean Rooms Differential Privacyは、データをクエリするための追加の設定やパラメータ設定を必要とせず、パートナーがこの素晴らしい製品をデータコラボレーションに引き続き簡単に使用できるようにします。
AWS Clean Roomsデモ:Differential Privacyの適用

では、楽しい部分に入りましょう。ライアンに引き継ぎます。

ありがとう、ティア。私はライアン・マレッキーです。AWS Clean Roomsチームのシニアソリューションアーキテクトを務めています。本日は、AWS Clean Rooms Differential PrivacyとAWS Clean Rooms Machine Learningの初お披露目をさせていただきます。

このデモでは、サービスの両面、つまりコラボレーションの両側面をお見せするために、2つのブラウザウィンドウを行き来します。分かりやすくするため、また舌をかまないようにするため、少しシナリオを用意しました。
コーヒー会社がストリーミングサービスで広告キャンペーンを実施したいという事例をお見せします。まず、AWS Clean RoomsのDifferential Privacyを使って、共通の顧客がいるかどうかを確認し、コーヒー会社が狙っている層に望むメッセージを届けられるようにします。そして、デモの後半では、新規顧客にリーチする方法をお見せします。



AWS Clean Rooms Differential Privacyの使用の大まかな流れは、まずお客様がAWS Clean Roomsの利用を開始することから始まります。自社のデータにDifferential Privacyを適用する最初の顧客は、Clean Roomサービスにデータを関連付け、いくつかの設定を行います。 そこから、このデモの2番目の顧客であるコーヒー会社が、自社のデータを関連付けてクエリの実行を開始します。実行される各クエリは、クエリ予算、つまりプライバシー予算の一部を消費します。十分な数のクエリを実行すると、 予算全体を消費し、それ以上クエリを実行できなくなります。


では、サービスの使用方法をご案内します。AWS Clean Roomsについてもっと詳しく知りたい方は、この講演の最後にリンクする資料をご覧ください。まず、AWS Clean Roomsを開いて、 コラボレーションを設定します。コラボレーションは、 分析に参加できるアカウントの集合、データを提供できる人、クエリの実行や結果の受け取りなどの様々なアクションを実行できる人を定義する論理的な境界と考えることができます。請求の責任者を設定することもできます。また、ログ記録を有効にするかどうか、暗号計算などの高度な機能を使用できるかどうかなども設定できます。これらはすべて、クリーンルームのインスタンスレベルであるコラボレーションレベルで定義されるため、各データセット所有者は自分のデータがどのように使用されるかを把握できます。
AWS Clean Rooms MLデモ:ルックアライクモデリングの実践



次に、別のアカウントに移ります。この明るい背景のアカウントは ストリーミングサービスプロバイダーのものです。ここでは、ストリーミングサービスプロバイダーが すでに自社のアカウントに持っているデータ(S3に保存され、AWS Glueデータカタログにカタログ化されている)をクリーンルームサービスにマッピングする設定済みテーブルを作成しています。ここでは、 メールアドレス、電話番号、内部IDなどのデータがあることがわかります。これから、このデータを使って設定済みテーブルを作成します。

さて、設定済みのテーブルは、アカウント内の既存データへの参照に過ぎません。次に、分析ルールを設定していきます。分析ルールは、AWS Clean Roomsでデータをどのように使用できるかを制御します。分析ルールにはいくつかの種類がありますが、今回は差分プライバシーが有効になっているカスタム分析ルールを使用します。


次のステップでは、差分プライバシーを有効にすることを選択します。また、プライバシーを保護するユーザーを表す列も選択します。この場合、subscriber_id列を選びます。次に、実行可能なクエリの種類を決定するクエリコントロールを指定します。AWS Clean Roomsのカスタム分析ルールでは、テンプレートを許可するか、特定のアカウントが作成した任意のクエリを許可するかを選択できます。今回は、よりデモを面白くするために、コーヒー会社からのクエリを許可するオプションを選びます。




これで分析ルールの設定が完了しました。すべての設定を確認し、テーブルに適用します。この時点で、設定したテーブルをコーヒー会社とのコラボレーションであるClean Roomのインスタンスに関連付けます。関連付けが完了すると、テーブルが利用可能になります。ここでは、AWS Clean Roomsがストリーミングサービスのアカウント内のデータにアクセスできるように権限を設定しています。デフォルトでは、AWS Clean Roomsにはデータへのアクセス権がないため、サービスに明示的に許可を与える必要があります。


ここからは、AWS Clean Rooms Differential Privacyのセットアップの後半として、2つのプライバシー設定を行います。ここで設定する2つの項目は、プライバシー予算とノイズです。予算については、毎月リセットするかどうかを選択できます。今回はリセットしないことにします。ノイズとプライバシー予算については、これらの範囲から選択でき、その選択によって実行可能なクエリの数が変わってきます。クエリの種類や集計関数の種類によって、プライバシー予算の消費量が異なります。平均のような操作は多くの予算を消費しますが、count distinctのような操作は比較的少ない予算で済みます。

ノイズの量(つまり誤差の量)を変更することで、与えられた予算で実行できるクエリの数を変更できます。ノイズ設定が低い場合、実行できるクエリは比較的少なくなります。ノイズ設定を高くすると、より多くのクエリを実行できるようになります。したがって、ユースケースの種類や必要な精度に応じて、これらの設定を調整できます。予算についても同様です。コラボレーターを十分に信頼している場合は、より多くのクエリを実行し、より多くのインサイトを生成できるように、大きな予算を設定できます。そうでない場合は、より小さな予算を設定できます。これで差分プライバシーの設定が完了しました。


ストリーミングサービスプロバイダー側から、実行されたクエリとその予算の残りを監視できます。ここで、コーヒー会社側に切り替えてクエリの実行を始めます。コラボレーションで利用可能なすべてのデータを見ることができます。 差分プライバシーの設定と、残りの予算で実行できるクエリの数も確認できます。また、コラボレーション内のすべてのテーブルのスキーマと分析ルールも見ることができます。クエリを直接書くこともできますし、すべての関係者によって事前承認されたテンプレートを使用することもできます。これは、コラボレーションで実行するクエリが正確にわかっている場合に便利です。

ここでは、特定のIDを選択するクエリを実行しようとしています。 差分プライバシーが有効な場合、集計インサイトを生成するクエリのみが許可されるため、これはブロックされます。サービスは許可されていないクエリを自動的にブロックします。そこで、これをcount distinctと集計クエリに変更すると、クエリの実行が始まります。AWS Clean Roomsで初めてクエリを実行する際は、コラボレーション専用のコンピュート環境をスピンアップするため、数分かかります。

そこで待つ代わりに、 事前にセットアップしておいたコラボレーションに切り替えます。この2つ目のコラボレーションでは、すでにいくつかのクエリを実行しており、環境が整っています。

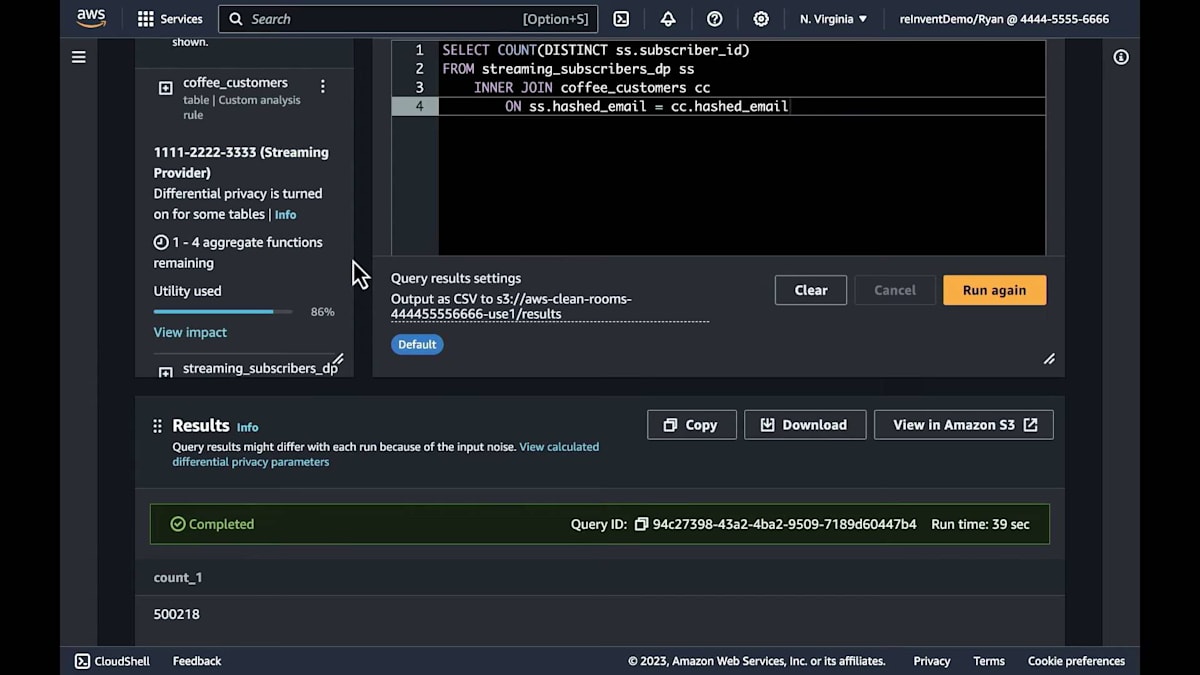
この準備された環境では、 プライバシー予算のほとんどを使い切っていることがわかります。予算の約86%が消費されています。ここで、ストリーミングプロバイダーとコーヒー会社の共通ユーザー数を調べるクエリをいくつか実行します。最初のクエリを実行すると、約50万人の共通ユーザーがいることがわかります。 正確には50万218人です。そして、予算の一部を消費したことがわかります。つまり、最大でもあと3回しかクエリを実行できません。


このクエリをもう一度実行すると、結果が返ってきます。先ほどは50万218人でしたが、 今度は50万212人です。つまり、わずかな差があります。 3回目を実行すると、50万220人という結果が出ます。つまり、毎回ほぼ同じ結果が得られています。ここで少し反則をします。データ内にRyan@example.comが存在するかどうかを調べるクエリを実行してみます。差分プライバシーが有効でなければ、結果からこのユーザーがデータセットに含まれているかどうかがわかってしまうでしょう。



ここで得られる結果は、ノイズが加えられているため、曖昧なものになります。そのユーザーがデータセットに存在したかどうかを判断することができません。この点を強調するために、次に私が生成したすべてのデータをグラフにプロットします。ここに、私が書いた小さなスクリプトがあります。これは、そのデータセットに対して20回のクエリを実行した結果のすべてです。結果が非常に似通っていることがわかります。これは50万件の結果のスケールでズームインしたものですが、結果セットが重なり合っているのが見てとれます。しかし、十分な回数のクエリを実行すれば、そのノイズを平均化することができます。ここでバジェットが関係してきます。
すべてのクエリを実行してバジェットを使い果たしてしまうと、このクエリをもう一度実行しようとしても、サービスがブロックします。これがバジェットの役割で、機密性の高い洞察にアクセスできるほど多くのクエリを実行できないようにするのです。以上が、AWS Clean Rooms Differential Privacyについての説明でした。次に、AWS Clean Rooms Machine Learningについて見ていきましょう。
The Weather Companyの事例:AWS Clean Roomsの活用

この例では、コーヒー会社とストリーミングプロバイダーが協力を始め、コーヒー会社は新規ユーザーにリーチしたいと考えています。つまり、すでに知っているユーザーではなく、ロイヤリティプログラムの顧客、例えば紅茶ファンに似たユーザーを見つけたいのです。これを実現するために、まずストリーミングサービスプロバイダーがユーザーのデータセットを関連付けます。つまり、番組を視聴している加入者のデータでモデルをトレーニングします。

次に、コーヒー会社がシードデータ、つまりより多くリーチしたい顧客に似た紅茶愛飲者のリストを提供します。そして、モデルをトレーニングし、ルックアライクセグメントを生成します。これは、コーヒー会社が提供したユーザーに似たストリーミングサービスプロバイダーのユーザー群です。最後に、その結果がストリーミングサービスプロバイダーに返されます。彼らはそれを自社のシステムに取り込み、広告ターゲティングに使用することができます。


では、デモ環境に戻りましょう。ここでは、ストリーミングサービスプロバイダーから始めます。まず、機械学習モデルのトレーニングを開始します。最初のステップは、データセットを指定することです。先ほど設定済みテーブルで示したように、まず自分のアカウントにすでにあるデータセットをClean Roomサービスにマッピングします。ここでは、加入者の視聴履歴、つまり誰がどの番組をいつ見たかを示すデータセットがあります。
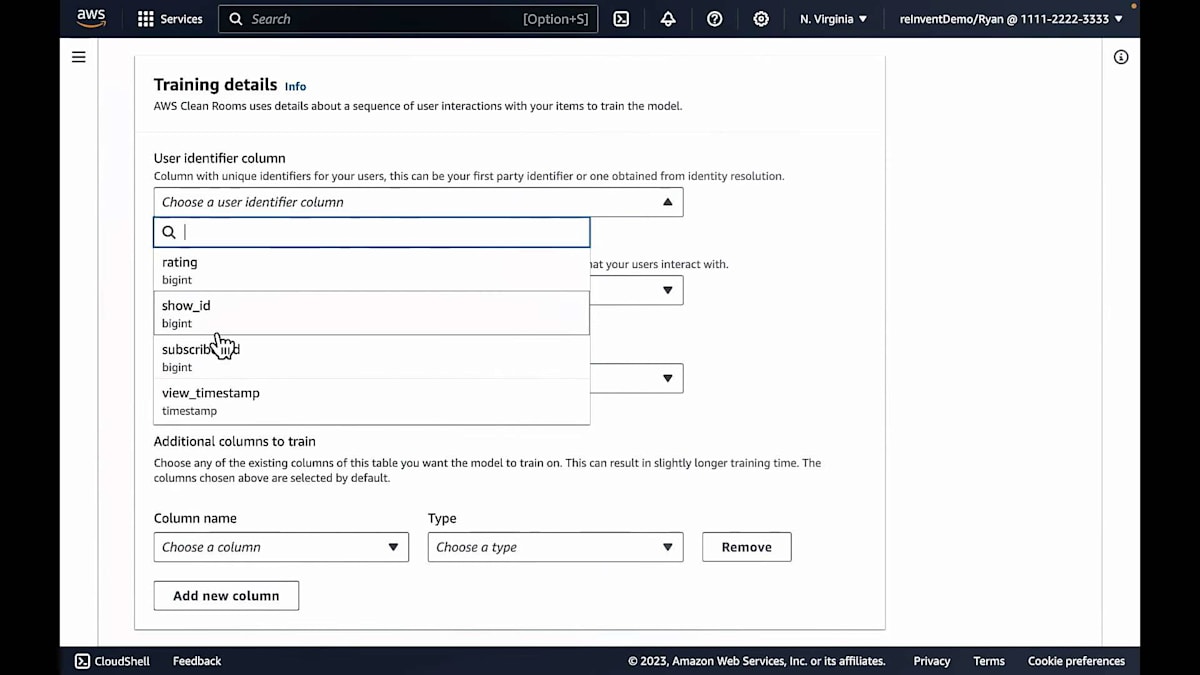
データのスキーマの詳細を確認し、次にデータセットのスキーマをモデルがトレーニングに使用するフィールドにマッピングします。まず、ユーザーを識別する列を選択します。次に、ユーザーが操作する番組、つまりアイテムを識別する列を選択します。そして、タイムスタンプの列を選択します。



これらに加えて、モデルの精度を向上させるために使用できる追加の列も取り込むことができます。ここではレーティングを追加していますが、さまざまな数値列やカテゴリ列を取り込むことができます。次に、AWS Clean Roomsサービスにデータへのアクセス権限を与えるロールを指定し、トレーニングデータセットを作成します。



次のステップはモデルのトレーニングです。そのデータセットを使って、類似モデルを作成します。使用したいデータセットと、そのデータセットからのデータの日付範囲を指定します。ほとんどの場合、データプロバイダーは定期的にこれらのモデルを再トレーニングして、新しいユーザーや新しい活動を取り込み、もはやアクティブでないユーザーをモデルから除外することが期待されます。ここでは1年間の時間範囲を選択しています。


次の設定は暗号化です。AWS Clean Rooms MLは常にデータを暗号化します。サービスが使用するAWS KMSキーを提供するか、提供しない場合はサービスがキーを作成して代わりに使用するかを選択できます。モデルのトレーニングには、データの量に応じて時間がかかる場合があり、小規模なデータセットで1時間から、非常に大規模なデータセットで数日かかることもあります。ここでは、すでに準備したモデルに移ります。

このモデルを見る際にまず行うのは、トレーニングプロセス中に生成されたメトリクスを確認することです。これらのメトリクスを使用して、モデルが有用かどうか、あるいはデータのクリーンアップや追加の次元の取り込みが必要かどうかを評価できます。モデルに満足できれば、次に設定済みモデルを作成します。これには、データコラボレーションプロセスに関連するいくつかの設定が含まれます。

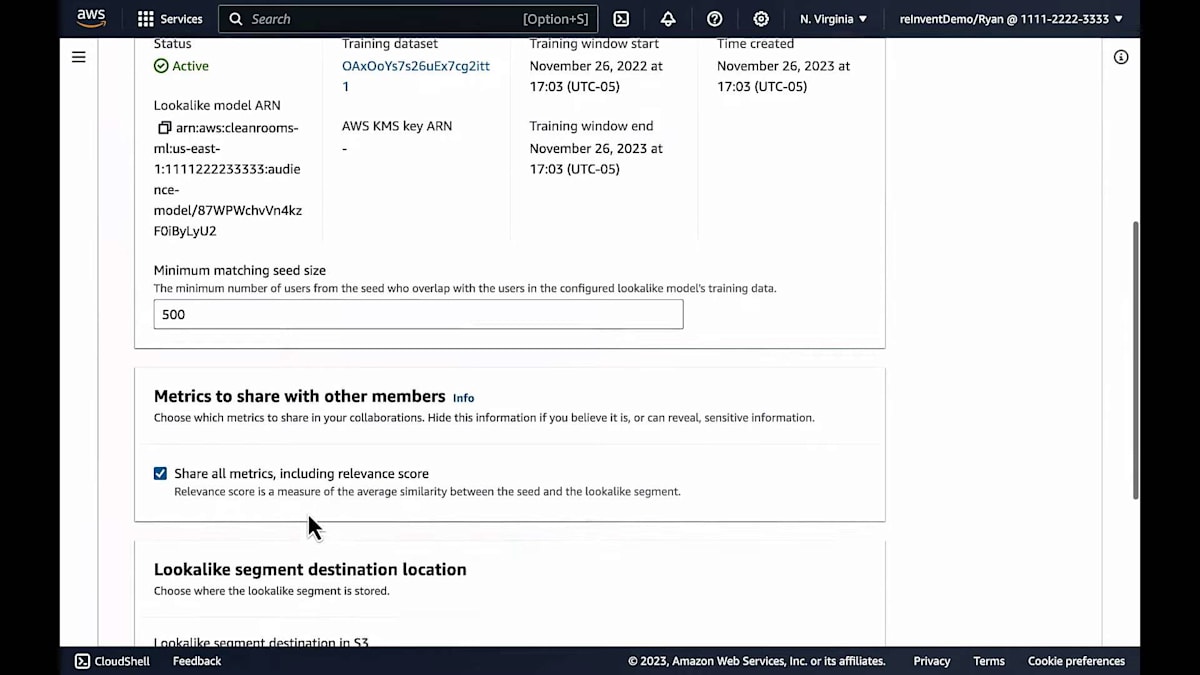

設定済みのモデルに関しては、名前を入力し、設定したいモデルを選択します。そして、シードオーディエンスのサイズや、lookalike を生成するための最小共通ユーザー数など、いくつかの値を入力します。また、relevance metrics を共有するかどうかも選択します。これらの指標については後ほど詳しく説明しますが、非常に重要なものです。これで設定済みモデルが作成され、パートナーとのコラボレーションを開始する準備が整いました。今回の場合は、コーヒー会社とのコラボレーションです。

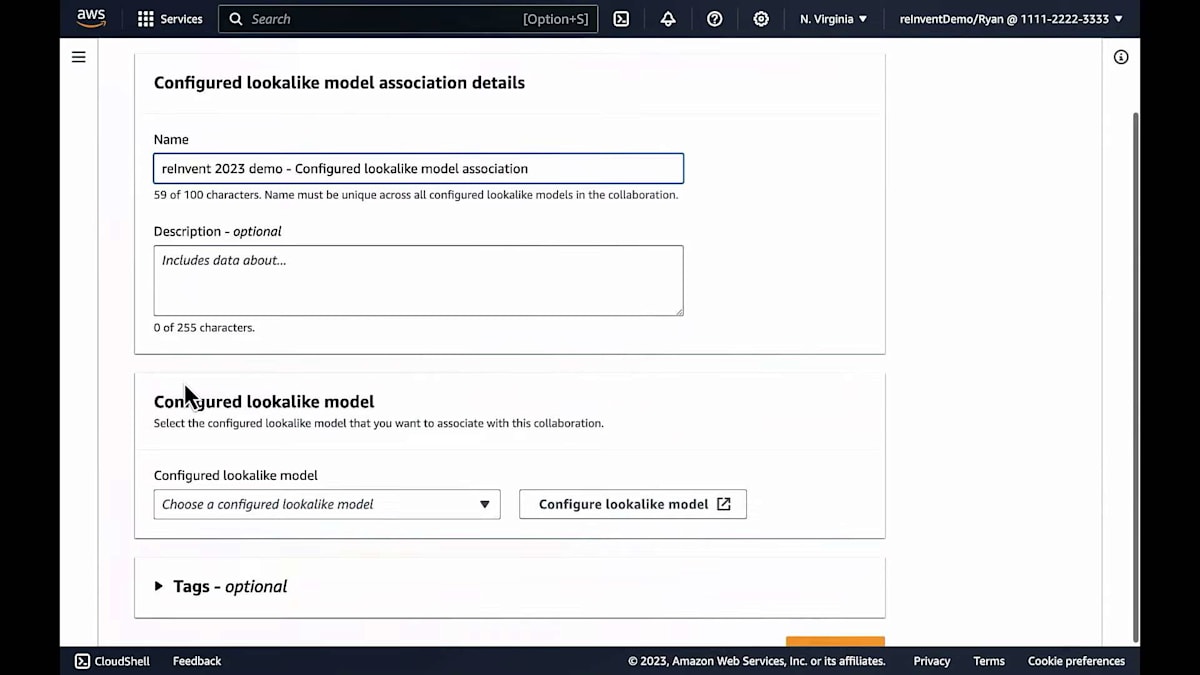



先ほどデモでお見せしたのと同じコラボレーションに入ります。そして、その設定済みモデルを関連付けます。コラボレーションには、場合によっては異なるパートナーから複数のモデルを関連付けることができます。モデルの関連付けが完了すると、ストリーミングサービスプロバイダーの役割は終了です。ここで、コーヒー会社のアカウントに戻ります。コラボレーションに移動し、ML タブに戻ります。ここで、先ほど関連付けたモデルを確認できます。
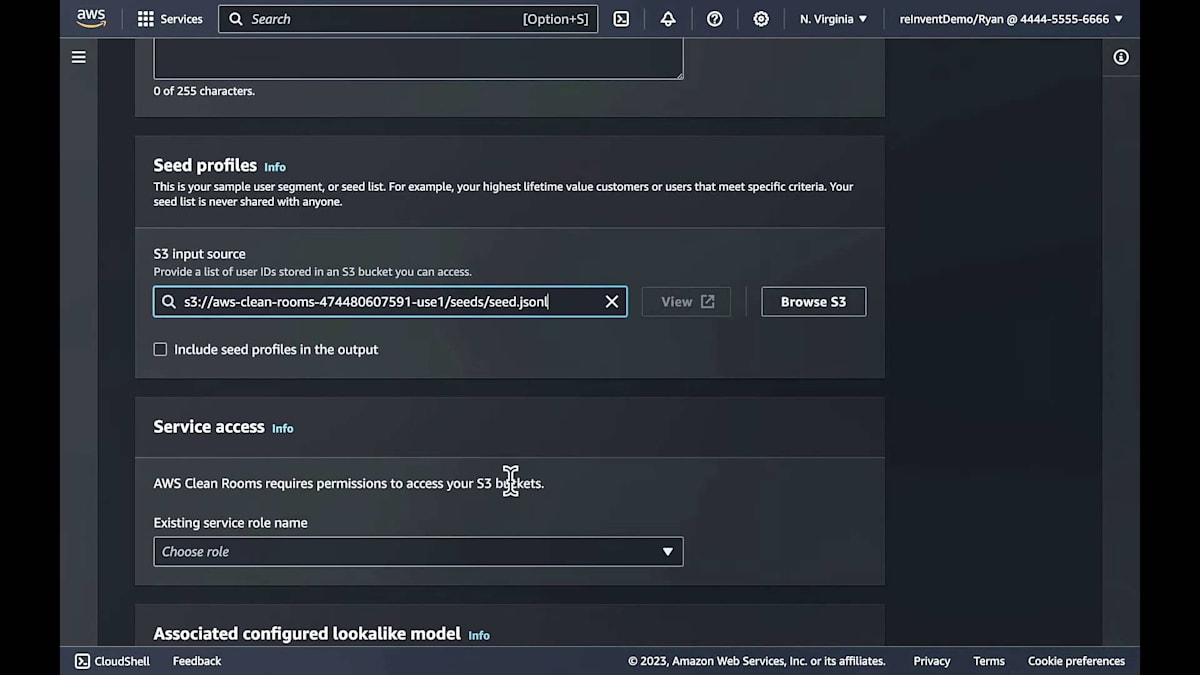


次に、モデルからセグメントを作成します。セグメントを作成する際の重要なポイントは、すでにアカウントにあるシードデータを提供することです。これは AWS Glue データカタログにある必要はなく、Amazon S3 上のオブジェクトでも構いません。再度、サービスにデータへのアクセス権限を与え、使用したいモデルを指定します。これでセグメントを作成できます。セグメント作成プロセスには数分かかります。


更新すると、作成中であることが確認できます。もう一度更新すると、トレーニングが完了したことがわかります。次に、プロセスが成功したかどうかを確認します。ここでの重要な指標は relevance metric です。これは、ストリーミングサービスプロバイダーのユーザー群の様々な部分が、提供されたシードデータにどれだけ類似しているかを示しています。約5%のところで50%のスコアとなり、そこから急激に下がっていることがわかります。これは、エクスポートしたいオーディエンスのサイズの目安となります。目的によっては、より大きなまたは小さなエクスポートを選択することもありますが、ここでは5%が良好な relevance metric を示しています。


そこで、上位5%をストリーミングサービスプロバイダーに渡すセグメントとしてエクスポートすることにします。ここで注目すべき点は、コーヒー会社側には S3 ロケーションが表示されていないことです。ストリーミングサービスプロバイダー側から見ると、データが彼らのアカウントに配信されたため S3 ロケーションが表示されています。そして、S3 上のそのオブジェクトを確認することができます。
これで、AWS Clean Rooms MLのデモが終了しました。次に、Julianne JenningsとSam Tahaにバトンタッチします。私は約6ヶ月間彼らと一緒に仕事をする機会があり、AWS Clean Roomsで彼らが行っている素晴らしい取り組みについて皆さんにお聞かせできることを本当に楽しみにしています。
The Weather Companyのデータプロダクト戦略とAWS Clean Roomsの役割

皆さん、こんにちは。本日は、2つの企業がAWS Clean Room Solutionを活用して、The Weather Companyにとって不可欠な機能を提供している事例についてお話しできることを嬉しく思います。ご存じかもしれませんが、The Weather Companyは毎分、ほとんどのアメリカ人に最も正確な天気予報を提供しています。実際、アメリカで最も信頼されているブランドトップ10に選ばれています。つまり、私たちはパブリッシャーサイトと言えます。簡単に言えば、私たちのサイトで広告枠を販売し、ブランドと訪問者をつなげているのです。
The Weather Companyでの私の役割は、そのブランドと訪問者をつなげるデータプロダクトを作ることです。少し詳しく説明させていただきますと、データプロダクトというのは、様々な異なるデータソースを組み合わせて、ブランドが広告キャンペーンで使用できるターゲティングセグメントを作成することです。これにより、ブランドはKPIにつながり、リーチしたいオーディエンスを見つけることができます。今日の私の目標は、現在Clean Rooms Solutionを使用している顧客の実例を紹介し、私たちの学びをお伝えすることです。
さて、ここで挙手をお願いします。皆さんが目を覚ましているか確認させてください。顧客のために魅力的な体験を作る責任がある方は?はい、1人、2人、3人。素晴らしいですね。次の挙手です。これらの魅力的な体験を作るために、組織横断的に法務、プライバシー、調達、運用などと協力しなければならない方は?そうですね、時間がかかることもありますよね。
そして、製品オーナーや製品マネージャーの方はいらっしゃいますか?はい、2人。素晴らしいです。製品マネージャーとして皆さんが望むのは、市場投入までのスピードですよね。では、SamとI私がClean Room Solutionに求めていた3つの例をお話しします。まず1つ目は、市場投入までのスピードです。長期にわたる契約や調達、さまざまなデータベンダーとのやり取りに費やす時間が少なければ少ないほど、広告主向けのソリューションをより早く市場に投入できます。これが1つ目です。2つ目は使いやすさです。私のようなビジネスユーザーだけでなく、エンジニアにとっても直感的に使えるプラットフォームを探しています。そして最後に、このソリューションがどれだけ迅速にインサイトを計算できるかを理解したいと思います。

はい、それでは例を挙げてみましょう。私はこの10年ほどアドテク業界で働いてきましたが、これらのレガシープラットフォームでは、洞察を得るまでに多くの時間がかかります。例えば、エンジニアのSamのロードマップに乗せてもらう必要があるかもしれません。そして、彼のスケジュールの優先順位を競わなければならないかもしれません。最終的に彼のチームが「よし、分かった」と言ってくれたら、データセットを取り、特定のベンダーがデータセットを取り込むために必要な適切なスキーマに入れることができます。そして、データセットを取り込み、すべてが上手くいったかどうかを確認し、場合によっては24時間待つ必要があります。

皆さんもこの状況に共感できると思います。そして最後に、セグメントを作成できます。セグメントを作成したら、そのデータセットのオーバーラップ、高いインデックスを示す項目、またはキャンペーンの効果について、顧客にインサイトを提供できます。この全プロセスは、データプロダクトマネージャーの1日の仕事として聞くと非常に労力を要するものですが、2〜3ヶ月かかることもあります。これは決してスピーディーなソリューションとは言えません。そこで、AWS Clean Roomsソリューションが私たちの全ての要件を満たしてくれました。


そういうわけで、データプロダクトを作成する上で最も複雑な要件の1つを解決するためにAWSに頼ることにしました。それは、サードパーティのデータプロバイダーを選択することです。私たちには素晴らしいファーストパーティデータがあり、膨大な規模を持っています。しかし、ブランドのKPIによっては、サードパーティのデータセットで補強する必要があるかもしれません。過去には、皆さんも経験があると思いますが、推測とベンダーのセールストークに頼らざるを得ませんでした。どのベンダーを選ぶかという決定に数学的根拠はありませんでした。また、データプロバイダーと何かをテストしたい場合、データセットをコピーして複製する必要があるかもしれません。

AWS Clean Roomsソリューションを使えば、どのデータプロバイダーが自社の製品に最適かを、推測ではなく数学的に答えを得ることができます。私たちが作成したClean Roomの提供は素晴らしい基盤です。しかし、ここで止まるつもりはありません。私は自社の製品をさらにパワーアップさせたいと考えています。今日発表される2つの新しいサービスが、それを実現するのに役立つと信じています。では、機械学習をどのように活用できるか、もう1つ実践的な例を挙げてみましょう。
Weather.comには多くの自動車広告主がいますが、その中の1社が新しいターゲット可能なオーディエンスを探しているとします。例えば、SUVを購入する可能性のある10代の子供を持つ親をターゲットにしたいとします。そこで、lookalike(類似)オーディエンスを作成したいと考えています。私たちのインベントリに機械学習を適用することでこれを実現できます。そのインベントリをcollaboration room(コラボレーションルーム)に入れます。そして、自動車会社がシードオーディエンスをコラボレーションに入れることで、lookalike オーディエンスを作成できます。これにより、広告主はWeather.comで新たにターゲット可能なオーディエンスを手に入れることができます。
でも、そのキャンペーンは効果があったのでしょうか?その新しいセグメントは成果を上げたのでしょうか?広告主に対して、そのセグメントやキャンペーンの効果を伝える必要があります。差分プライバシーを使えば、個人情報を危険にさらすことなくそれが可能になります。では、Samに引き継いで、どのようにしてそれを実現できるかの参照アーキテクチャについて説明してもらいましょう。
パブリッシャーと広告主のコラボレーション:AWS Clean Rooms MLの参照アーキテクチャ

ありがとうございます。皆さん、こんにちは。最初の参照アーキテクチャでは、パブリッシャーと広告主の間のクリーンルームでのコラボレーションシナリオについて説明します。 両者がクリーンルームに集まり、広告キャンペーンを計画し、AWS Clean Rooms MLを使ってルックアライクオーディエンスを構築し、それを広告キャンペーンで使用します。ここに示す参照アーキテクチャを見ると、左側にパブリッシャーとしてThe Weather Companyがあり、右側に広告主としてお気に入りの自動車会社があります。両者は異なるAWSアカウントに存在し、クリーンルームがその中間に位置しています。ここで重要なのは、このコラボレーション中、異なるAWSアカウント間でデータのコピーや共有が行われないということです。The Weather Company環境に注目すると、一番左に天気アプリケーションがあります。
これらは、ユーザーが天気情報やデータを取得するためのWebおよびモバイルアプリケーションです。また、ユーザーがアプリケーションを利用する際に広告も配信しています。Customer Data Platform(CDP)は、インタラクションデータ、ファーストパーティデータ、ユーザーシグナルを収集しています。CDPは、ほぼリアルタイムで顧客データをAWS Lake FormationとAmazon Redshiftで構築されたデータレイクにストリーミングしています。
規模と量のイメージをお伝えすると、天気アプリケーションを利用する月間アクティブユーザーは4億人で、1日に約10億のイベントを処理しています。1日に1テラバイト以上のデータがデータウェアハウスとデータレイクに入ってきます。パブリッシャーと広告主のこのコラボレーションでは、AWS Clean Rooms MLでトレーニングされる顧客データを提供します。顧客IDと各顧客のユーザーシグナルを取り込み、データセットにキュレーションして、Clean Rooms MLに送り、モデルをトレーニングします。
モデルがトレーニングされ、評価され、満足できる結果が得られたら、そのモデルをクリーンルームに関連付けます。これでパブリッシャー側のコラボレーションは完了です。広告主側に移ると、彼らは自社の顧客IDをシードデータとしてコラボレーションに持ち込みます。これがMLモデルに送られ、出力としてルックアライクオーディエンスセグメントが生成されます。それをクリーンルームから出力し、アドサーバーにアップロードします。そこから、そのオーディエンスを広告や targeting に使用することができます。

要約すると、AWS Clean Rooms MLを使用して、広告主とパブリッシャーの間の顧客IDの有機的な重複よりも大きなルックアライクモデルを構築しました。次に、差分プライバシーのリファレンスアーキテクチャに移ります。
広告キャンペーン測定のための差分プライバシー適用:参照アーキテクチャ
この連携でも、パブリッシャーと広告主という同じ2つのプレイヤーを含むクリーンルームを使用しています。ただし、この場合、広告主は広告キャンペーンの結果に対する測定と分析を行いたいと考えています。これは先ほど話した計画のユースケースとは異なる展開です。The Weather Companyの環境に焦点を当てると、広告サーバーのログをデータレイクに取り込んでいます。広告インプレッションを取得し、広告主が測定したいキャンペーンに関連付け、広告インプレッションを設定済みテーブルとしてクリーンルームに取り込みます。
設定済みテーブルに差分プライバシーを適用します。これにより、設定済みテーブルに注入したいノイズの量のしきい値を設定できるようになります。また、広告主がデータに対して実行できるクエリの数や分析の量に関して、差分プライバシーの予算を設定することもできます。パブリッシャー側の連携が完了したら、広告主側に移ります。広告主は、購入データやキャンペーンデータを設定済みテーブルとして連携に持ち込みます。
これが完了すると、広告主は他の一般的なSQLエディタと同じように、SQLを使用して結合されたデータセットに対してクエリを実行できるようになります。差分プライバシーの設定とコントロールを実装しているため、個々のユーザーに関するデータは制限され、利用できなくなります。
そのため、個人データは公開されず、この連携の最後には、実行された分析とクエリをAmazon S3に出力し、必要に応じてお気に入りのBIやビジュアライゼーションツールにダウンロードしてレポートを作成することができます。最後に、クリーンルームと新しいMLサービスの使用に関して、私たちはとてもワクワクしています。皆さんにもこのサービスを検討していただくことをお勧めします。きっと気に入っていただけると思います。特に、法務部門の方々にも喜んでいただけるでしょう。書類作業や手続きが大幅に減るからです。ありがとうございました。
The Weather Companyが得た主な学び:AWS Clean Roomsの利点


Sam、ありがとうございます。結局のところ、これらの製品やサービスによって、プロダクトマネージャーである私は、より速く、よりスケーラブルに、そしてより効率的に製品を構築できるようになります。予測モデルを作成するのにかかる時間を短縮できることを、本当に楽しみにしています。これは私たちにとって非常にエキサイティングなことです。ここで締めくくりとして、data clean roomsを使用して得た主な学びについてお話しします。既存のAWSコントラクトでAWSサービスを利用できたことが素晴らしかったです。実際、Samとこのサービスについて聞いたとき、その日のうちに社内で概念実証を行い、さまざまなデータセットを試すことができました。これが私たちのニーズに本当に合っていることにすぐに気づきました。
推測作業を排除でき、製品化までのスピードを上げられたことが気に入りました。ご存知の通り、私は顧客の問題を解決するために行動を起こすことに強いこだわりがあります。このサービスのおかげで、それが可能になりました。では、締めくくりをTiaに戻したいと思います。ありがとうございました。
AWS Clean Roomsの可能性と今後の展望


Julianne、私たちのLPについてはよくご存じだと思います。ここで締めくくりに入りますが、時間通りにセッションを終えられるよう、記録的な速さで行います。まず、AWS Clean Roomsは、ビジネスの進め方、社内でのコラボレーションの方法、さらには外部データの活用方法に大きな影響を与える可能性があります。コピーを最小限に抑え、短時間で共同データを共有し、強力なセキュリティとプライバシーの姿勢を保ちながら行うことができます。最初のAWS Clean Rooms MLモデルでは、機械学習関連の側面でIPを共有することなく、また基礎となるデータを保護しながら、類似セグメントを作成できます。
最後になりましたが、決して重要性は劣りません。AWS Clean Rooms Differential Privacyは、数学的に厳密な制御を簡単に使用できる方法で、ユーザーのプライバシーを保護するのに役立ちます。詳細をお知りになりたい方は、こちらのQRコードからAWS Clean Roomsのebookをダウンロードしてください。AWS Clean Rooms MLとAWS Clean Rooms Differential Privacyについてもっと読んでみてください。re:Inventの終わりに近づいていますが、re:Inventブースに立ち寄って機能デモをご覧ください。引き続き関心を持ち続けてください。私たちにどのようなお手伝いができるか教えてください。皆様とパートナーシップを組ませていただければ幸いです。素晴らしい一日をお過ごしください。
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion