re:Invent 2024: Mercado LibreのNoOps実現 - EKSで構築した開発者プラットフォーム「Fury」
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - How Mercado Libre engineers achieve a NoOps experience with Amazon EKS (DOP328)
この動画では、Platform Engineeringの概念と実践例について解説しています。Platform Engineeringは開発者向けの抽象化レイヤーを構築するプラクティスで、コスト効率とインフラ利用の効率性向上を目指します。特に、Mercado LibreのSenior Software ExpertのMarcos Pinheiroが、同社の内部開発者プラットフォーム「Fury」の詳細を紹介しています。Furyは1日23,000回のデプロイと1分間に9億件のリクエストを処理し、NoOpsの体験を実現。EKSとNoOpsストラテジーの組み合わせにより、クラウドのコンピュート費用を30%以上削減することに成功しました。Blue-Green、Canary、Safe、Migrationsなど複数のデプロイメント戦略を提供し、開発者がKubernetesの複雑さを意識することなく、効率的な開発を可能にしています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Platform Engineeringの概要と利点

皆様、本日は貴重なお時間をいただき、ありがとうございます。私はAWSのSenior Solutions ArchitectのThiago Marinelloです。本日は、Mercado LibreのSenior Software ExpertのMarcos Pinheiroさんをお迎えできることを大変嬉しく思います。MarcosさんにはMercado Libreが開発者向けにNoOpsの体験をどのように実現しているかについてお話しいただきます。

Mercado Libreの取り組みについてお話する前に、Platform Engineeringとは何かについて考えてみましょう。 プラットフォームを構築する際に実装できるベストプラクティスとそのメリットについて見ていきましょう。自動車産業を例に挙げると、このプラットフォームという考え方は決して新しいものではありません。多くの産業界では、機能を作り、それを再利用し、その上に製品を構築するというコンセプトを採用しています。自動車メーカーは車のプラットフォームを構築し、その上に新製品を開発することで、市場投入までの時間を短縮し、顧客に新製品を届けることができています。

ソフトウェアやインフラストラクチャにおけるPlatform Engineeringでも、同じ考え方が当てはまります。 Platform Engineeringとは、開発者向けの抽象化レイヤーを特定し構築する一連のプラクティスであり、コスト効率とインフラ利用の効率性を高めることを目指すものです。画面に表示されているPlatform Engineeringの定義は非常に的確です:「セルフサービスのAPI、ツール、サービス、ナレッジ、サポートの基盤であり、魅力的な社内プロダクトとして構成されたもの」。この定義が優れている理由は多くあります。まず、プラットフォームとして実装されるもの(抽象化とAPIとしてのツールやサービス)だけでなく、ナレッジとサポートを通じてプラットフォームの採用をどのように促進するかについても言及している点です。
開発者がプラットフォームを採用するためのサポート体制を整えることは非常に重要です。さらに、「魅力的な社内プロダクト」という表現に注目すると、プラットフォームをプロダクトとして捉える視点が興味深いですね。外部顧客向けのプロダクトを開発・管理するのと同じように、社内プラットフォームについても同様に考えるべきです。プラットフォームをプロダクトとして扱い、社内の顧客である開発者を顧客として扱うのです。AWSを利用して独自のプラットフォームを構築している多くのお客様の例を見ると、プロダクトとして捉えているケースの多くが成功を収めています。
DevOpsからPlatform Engineeringへの進化

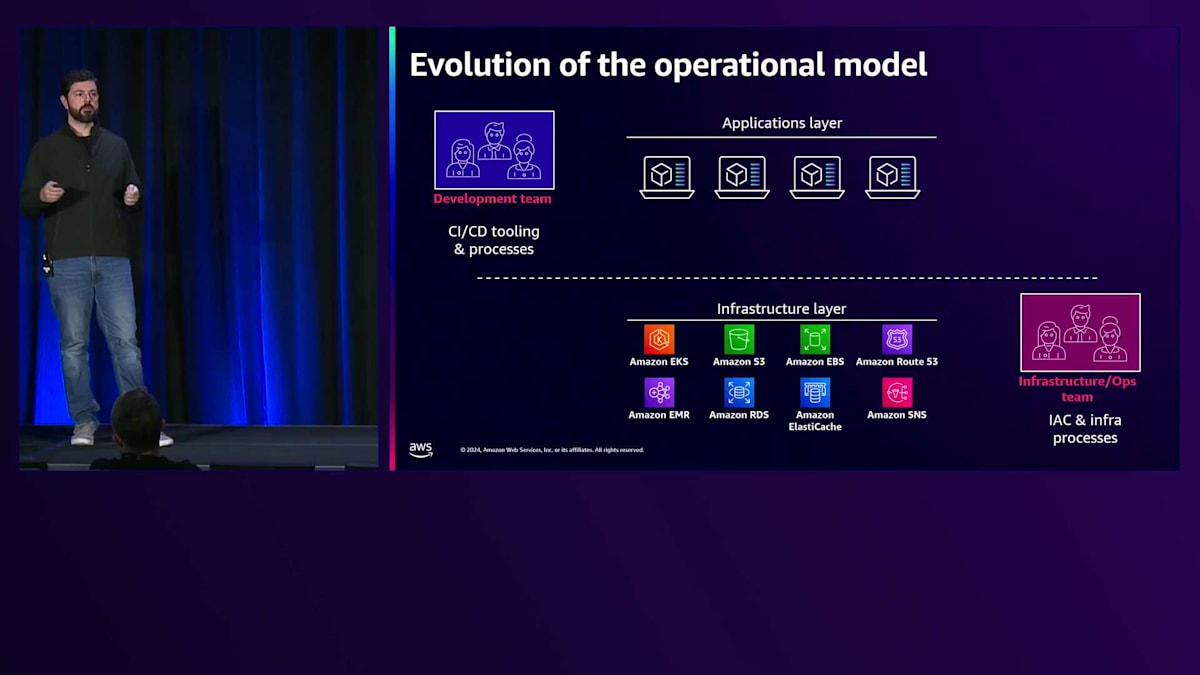
では、私たちはどのようにしてここまで来たのでしょうか?企業には基本的に2つの異なるチームがあります:開発チームとインフラチームです。前者は最終顧客に価値を提供することを担当し、後者はインフラを維持・運用することを担当しています。 企業によってアプリケーションも様々です。多種多様なアプリケーションには、それぞれ異なるリソース要件、状況、規模、メモリ要件、ストレージ要件、ネットワーク要件があり、GPUが必要な場合もあればそうでない場合もあります。開発チームがアクセスする必要のあるものは数多くあり、インフラチームはこれらの要件に対応しながら、すべてを正常に稼働させる必要があります。
私たちは2つの異なるチームというモデルを発展させ、より良い結果を出すためにコミュニケーションを取るチーム編成であるDevOpsについて考え始めました。
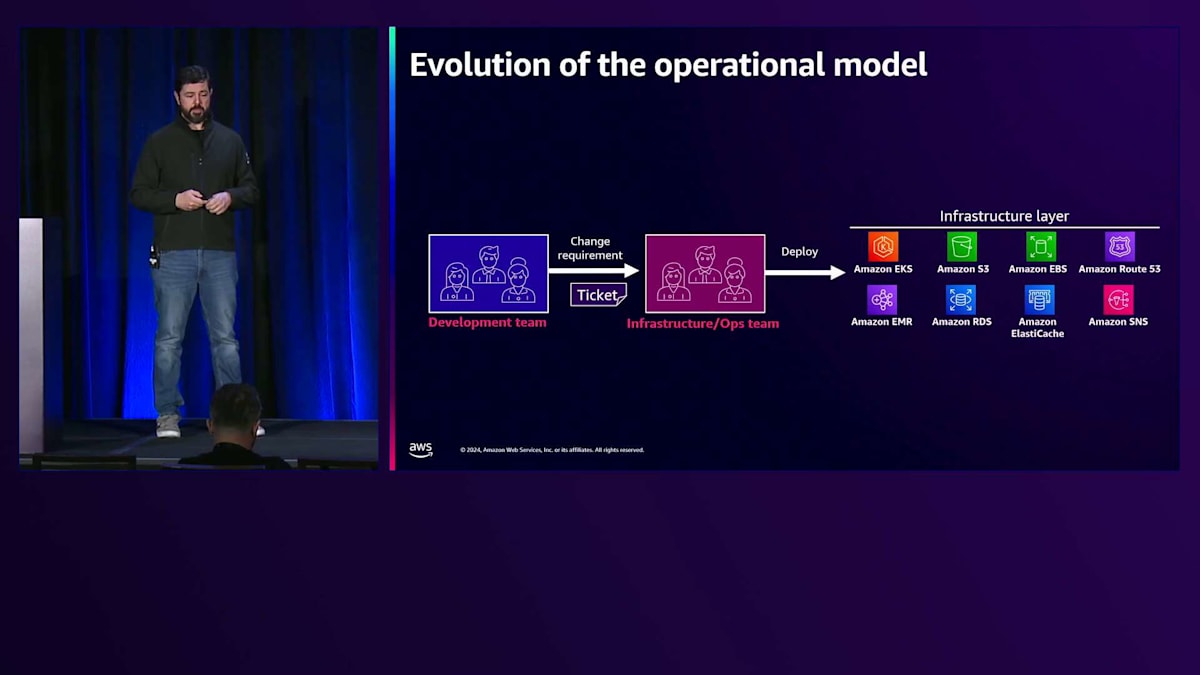
しかし実際には、開発チームが運用チームに対して多くのリクエストを作成し始めるということが起こります。 これにより、様々なリクエストによってチームが圧倒される状況が生まれ、この方法では会社の規模を拡大することが難しくなります。これは様々な理由で複雑になってしまいます。

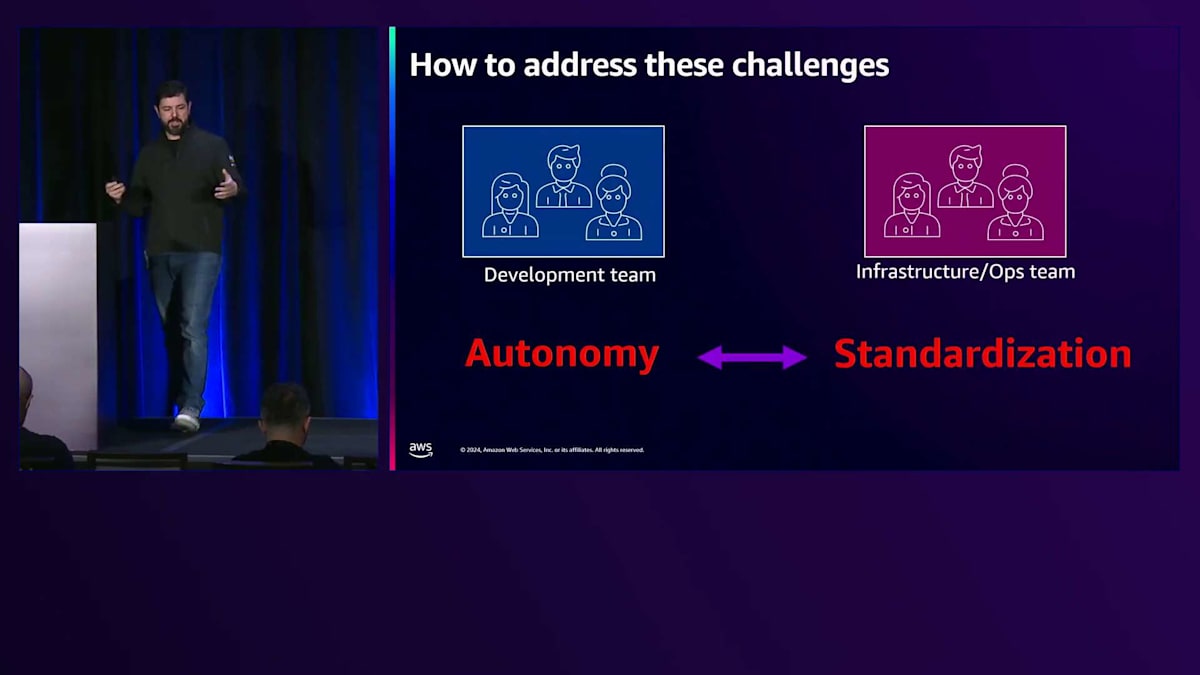
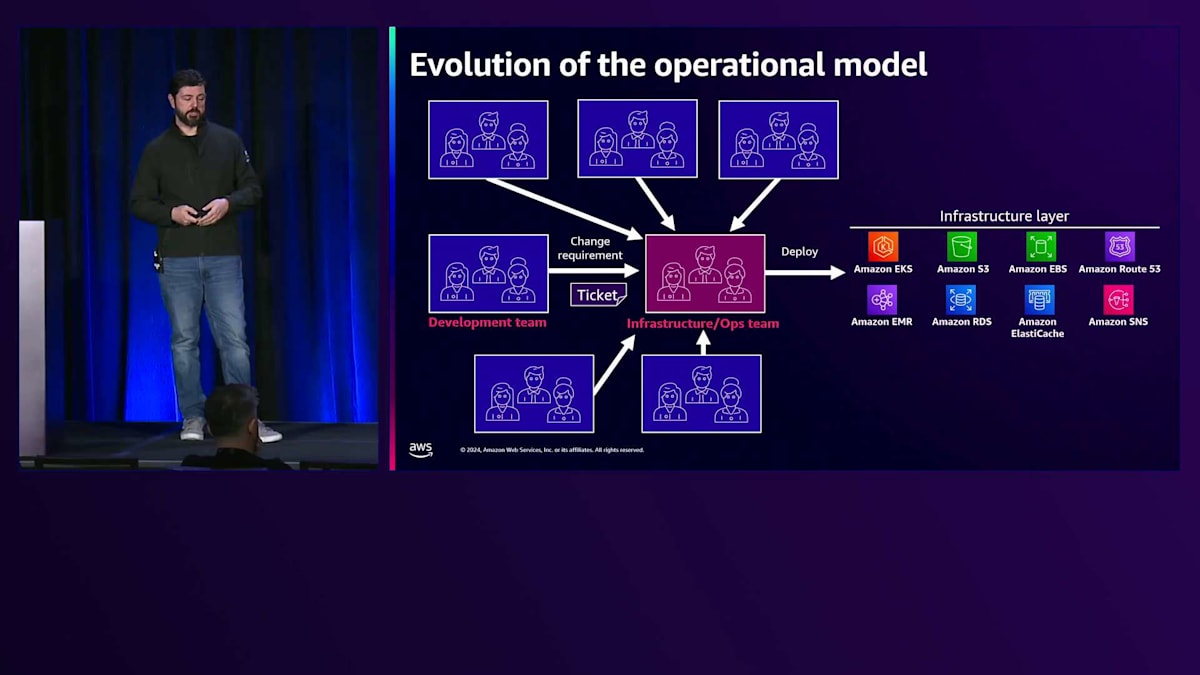
このシナリオでは、複数のチームが異なることを要求する中で実装が困難な多くの標準に対処する必要があります。また、 様々なチームをサポートするために、異なる種類のツール、フレームワーク、ライブラリに対応しなければならず、インフラストラクチャを一元的に把握する方法がありません。 これらの2つのチーム間には対立や緊張関係が存在し、基本的には自律性と標準化の間の葛藤となります。開発チームは昨日リリースされた最新のWebフレームワークを使用したがりますが、運用チームはインフラストラクチャと本番環境で実行されているものに対してより多くの制御とガバナンスを求めており、そのバランスを見つける必要があります。
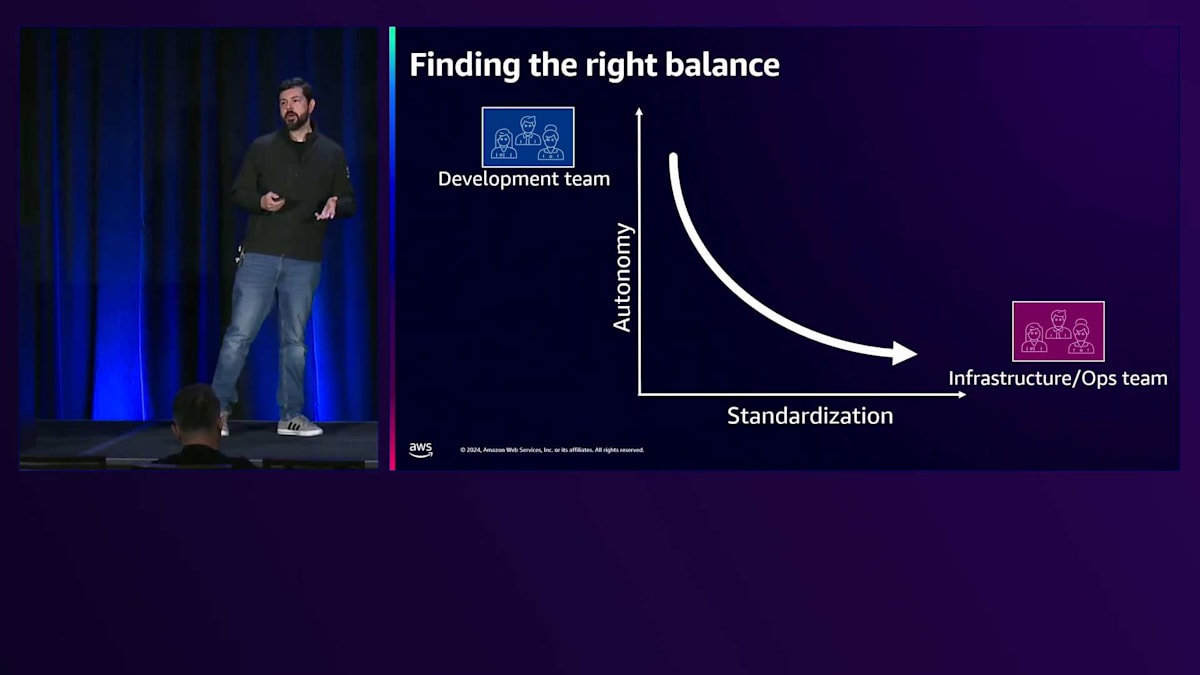

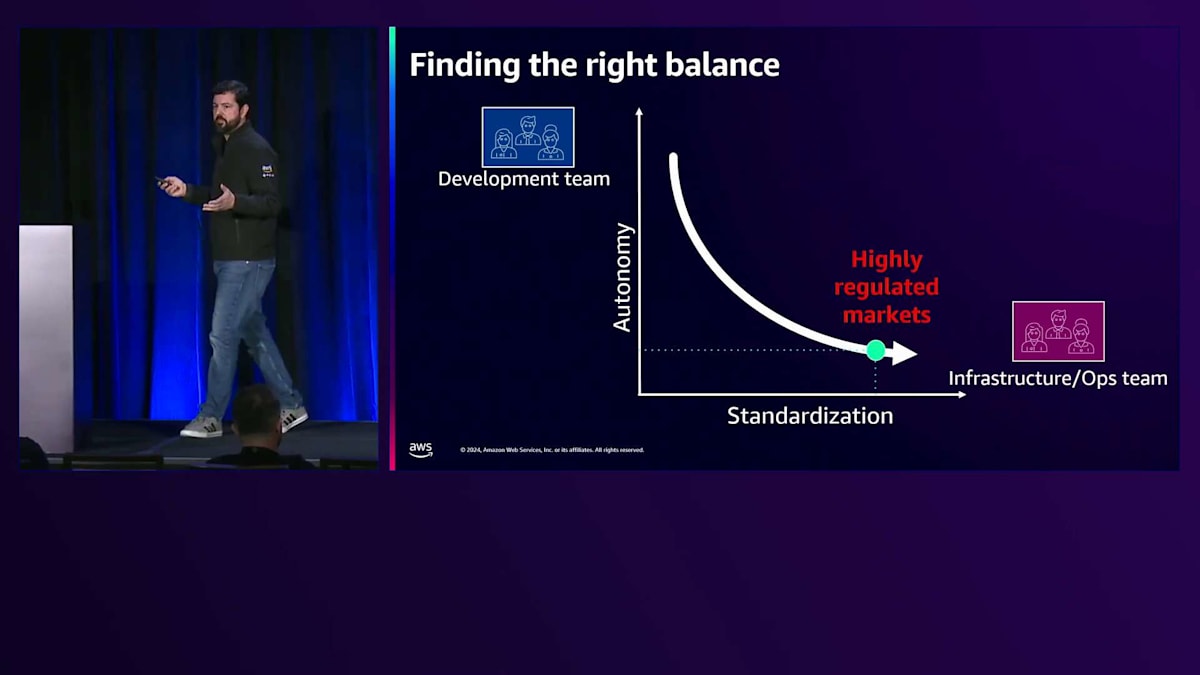
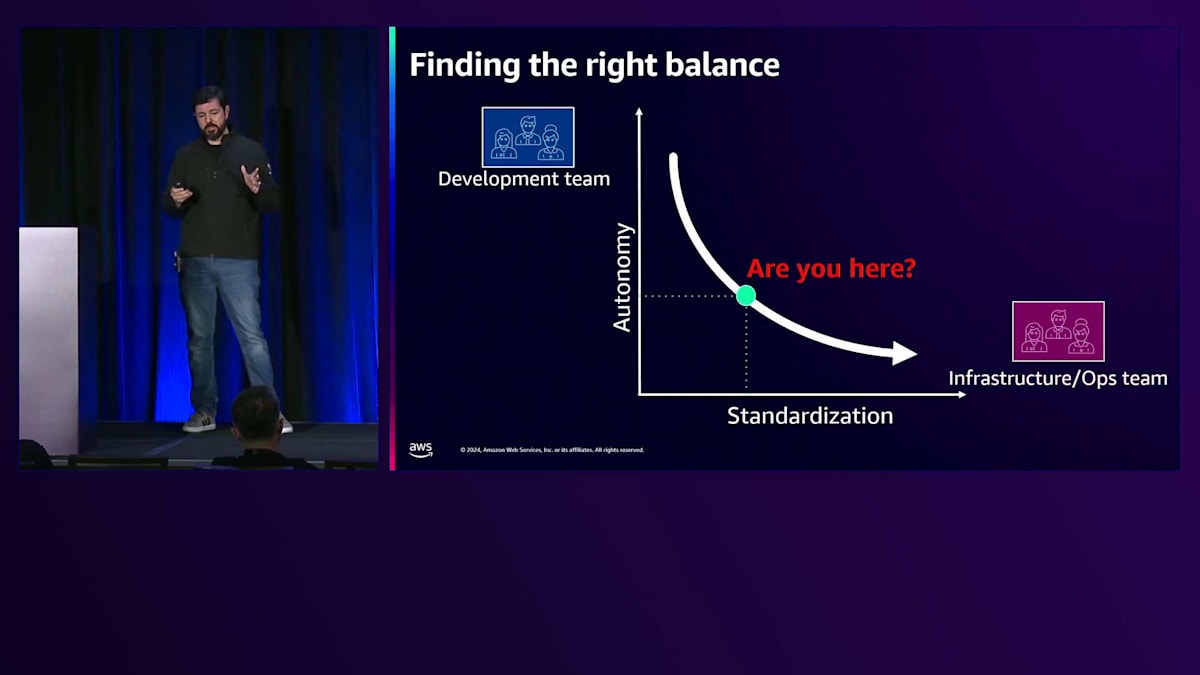
おそらく、スタートアップ企業であれば、 自律性は高いものの標準化が低いこの位置にいるでしょう。これは典型的なスタートアップの状況です。なぜなら、より速く成長することだけを考え、新規顧客の獲得に注力していて、標準化についてはあまり考えていないからです。一方で、 大企業、特に金融やヘルスケアなどの規制産業にいる場合、多くの標準を実装し、様々な要件や規制に準拠する必要があるかもしれません。 目指すべきは、このバランスを見つけることです。2つの異なるチームで協力して、この曲線の中間地点で活動することも可能で、それは非常に良いことです。しかし、それでもまだ自律性と標準化の両方を持つことの潜在的な利点を全て活用できているわけではありません。そしてここで、Platform Engineeringが両方の側面を実現する道を開きます。


私たちは多くの顧客がプラットフォームを実装する様子を観察し、 そこにはいくつかの利点があることがわかりました。1つ目は速度です - 彼らはより迅速に物事を進められるようになりました。プラットフォームがあることで、開発者がコーディングを始めてから本番環境にデリバリーするまでの時間が大幅に短縮され、市場投入までの時間を削減できました。 また、より良いガバナンスを実現することもできました。ここでガバナンスと言う時、セキュリティ、コンプライアンス、スケーラビリティや信頼性を指しています。これらの要素は部分的にプラットフォーム内に実装できるため、開発者はこれらのインフラストラクチャの詳細について考える必要がなくなります。


効率性に関して、このように全てを一箇所に集中させることで、コストを把握し、マルチテナント環境を管理してコストを削減することができます。これはクラウドコストだけでなく、チームのコストも含まれます。チームがすべてのことに精通する必要はありませんし、クラウドの全てのサービスのエキスパートになる必要もありません。開発チームはアプリケーションの開発に、Platformチームはプラットフォームの開発と進化に集中できます。これにより、お客様からは、プラットフォームを使用することでスケールメリットを実現できるとの声をいただいています。プラットフォームは投資であり、短期的な投資ではありませんが、時間とともに新しいアプリケーションを作成して本番環境にデプロイするコストが大幅に削減され、投資は確実に回収できます。
Platform Engineeringの実装における課題とベストプラクティス

3年前、私たちはPlatform Engineeringについて考え始め、耳にするようになりました。それまでは業界で一般的な用語ではありませんでしたが、トレンドになり始めました。現在では、様々な企業や組織からの報告で、このような実装とプラットフォームの活用が成果をもたらしていることが示されています。Puppet by Perforceのレポートによると、生産性の向上、ソフトウェアの品質向上、デプロイのリードタイム短縮が実現されています。


プラットフォームの導入を決めた場合、以下の課題に注意を払う必要があります。まず責任の所在について - プラットフォームの所有者を明確に定義する必要があります。通常、社内にPlatform開発チームを置き、彼らが責任を持ち、顧客がいることを認識する必要があります。開発者はこのチームと協力してプラットフォームを進化させるべきです。顧客にとって有用なものを定義し開発したい場合は、顧客起点で考える必要があります。
抽象化のレベルも一つの課題です。プラットフォームがどこで終わり、アプリケーションがどこから始まるのかという明確な定義がないからです。あるチームはKubernetesクラスターを求め、別のチームはAWSアカウントだけをプラットフォームとして求めるかもしれません。抽象化には様々なレベルがあり、それらのチームと議論して合意を得る必要があります。時には同じ会社内でも異なるレベルが存在し、それと共存していく必要があります。
プラットフォームの採用も非常に重要です。最新技術を使った素晴らしいプラットフォームを開発しても、誰も使いたがらないという状況ほど悪いことはありません。顧客と対話し、サポート体制を整える必要があります。社内トレーニングに投資すべきで、それは優れたドキュメントや社内ウェブサイトの動画など、開発者がプラットフォームの価値を理解し活用するのに役立つものである必要があります。
トラブルシューティングも重要な要素です。開発者は自分たちの環境でソフトウェアを開発しているからです。「このプラットフォームを使えば、コードを書くだけで本番環境にデプロイできます」と言うのは良いのですが、問題が発生してデバッグや状況確認が必要になった時に、「Kubernetesクラスターに入って確認してください」とは言えません。開発者はそれを望まないでしょう。そのため、開発者向けの可観測性ツールやトラブルシューティング支援ツールに投資することが重要です。



プラットフォームの構築や導入を決める際のベストプラクティスをご紹介します。 まず、顧客と共に構築することが非常に重要です。プラットフォームチームは社内の顧客である開発者と密接に連携し、会社にとって最適なプラットフォームとは何かを一緒に定義する必要があります。 また、すべての問題を解決しようとするプラットフォームを作ろうとしないことです。小さく始めて、プラットフォームで解決できる会社の課題を一つ考え、実際の顧客と共にプラットフォームが役立つビジネスケースを特定し、そこから開発、検証、成長を始めていきましょう。

すべてのワークロードに一つのサイズが適合するわけではありません。アプリケーションによって異なる設定や異なるリソースセットが必要になることがあり、プラットフォームが一つのオプションしか提供していない場合、それらに対応できません。そのため、プラットフォームは開発者に選択肢と異なる種類の抽象化を提供する必要があります。

例えば、開発者がKey-Value Storeデータベース、ドキュメントデータベース、SQLデータベースを使って何かを開発する必要がある場合、プラットフォームはそれらのオプションを提供し、 さらにエスケープハッチも用意する必要があります。これは重要なポイントです。優れたプラットフォームを持つ会社でも、開発者の18〜19%がプラットフォームを採用・使用するだけです。残りの開発者がプラットフォームを使用しないのは、使いたくないからではなく、異なるビジネス要件があるからです。ビジネスの要求で異なる技術を使用する必要がある場合もあるため、開発者にビジネス要件の正当性を説明してもらいながら、異なるリソースを使用できる出口やエスケープハッチを提供することが重要です。


ドキュメントと教育は重要な要素です。 ドキュメントは自動生成するか手書きするかは選べますが、良質なドキュメントを提供することが大切です。開発者はドキュメントを書くのは好みませんが、良いドキュメントを読むのは大好きです。開発者向けに、ドキュメントだけでなく、教育、トレーニングビデオなど、プラットフォームの使用を支援するものを十分に提供することが重要です。 プラットフォームを製品として扱うというマインドセットも非常に重要で、これによってプラットフォームを製品として適切にケアし、会社と開発者の利益のためにより良く進化させることができます。
Mercado LibreのInternal Developer Platform「Fury」の概要

それでは、Mercado Libreの社内開発者プラットフォームの構築方法について、Marcosにお話しいただきたいと思います。ありがとうございます。皆さん、こんにちは。Thiagoの紹介にもありました通り、私はMercado LibreのシニアソフトウェアエキスパートのMarcos Pinheiroです。本日は、Mercado Libreのプラットフォームと、社内でのKubernetesの実装についてお話しできることを大変嬉しく思います。ご存知ない方のために説明しますと、Mercado Libreはラテンアメリカを代表するEコマースおよびフィナンシャルサービス企業です。Time Magazine、Fortune Magazine、そしてKantar Brandsから、世界で最も価値のある影響力のある企業の一つとして認められています。Mercado Libre内には複数のビジネスユニットがあり、マーケットプレイスでは6,000万人以上のユニークバイヤーと4億点以上の商品取引があります。Mercado Pagoと呼ばれる当社のフィンテックサービスは、5,000万人以上のアクティブユーザーを抱え、約60億ドルの与信ポートフォリオを持っています。

現在、Mercado Libreはラテンアメリカの8カ国に展開しています。IT部門の規模を見ると、全社員6万人のうち、1万6,000人がIT部門に所属しています。これらの人々は開発者やテクニカルリーダー、エキスパートとして、3万5,000のマイクロサービスを維持し、1日あたり約2万3,000回のデプロイを実施し、1日10万件以上のPull Requestを作成しています。また、パブリックと社内を合わせたトラフィックレイヤーでは、1分間に9億件以上のリクエストを処理しています。これらは非常に印象的な数字だと考えています。

これらすべての人員とアプリケーションをサポートするために、私たちはFuryを使用しています。FuryはMercado Libreの Internal Developer Platform(IDP)で、約10年前に誕生しました。Furyは開発のライフサイクル全体、つまりコードから本番環境までの過程で開発者をサポートしています。現在、Furyはセルフサービス方式で30以上のサービスを提供しており、そのほとんどが抽象化されたもので、クラウドコストの削減や社内のセキュリティ基準の適用を支援しています。

これらの機能により、NoOpsスタイルで認知負荷を軽減し、技術的な生産性を向上させています。こちらの図は、開発者向けのゼロからプロダクションまでの流れを示しています。3つのステップで、すべては開発者がアプリケーションを作成する必要があるところから始まります。Node.js、Java、Kotlin、Pythonなどの技術とアプリケーション名を入力すると、バックグラウンドでGitリポジトリを作成し、アラームメトリクスを含む完全な監視スタックをセットアップし、アプリケーションログを受け取るクラスターを割り当て、選択した言語用のマネージドパイプラインを準備します。

その後、開発者は当社のFury CLIを使用して、このGitリポジトリをローカルにクローンし、エンドポイントと単体テストを含む初期のスキャフォールディングを作成できます。開発者がこのコードをリモートリポジトリにプッシュすると、PR(Pull Request)が作成されるか、Furyのバージョン作成が実行されると、どちらのアクションもパイプラインをトリガーし、単体テストの実行やLintの適用、x86とARMという2つの異なるCPUアーキテクチャでのアプリケーションイメージのビルドなどのステップが実行されます。
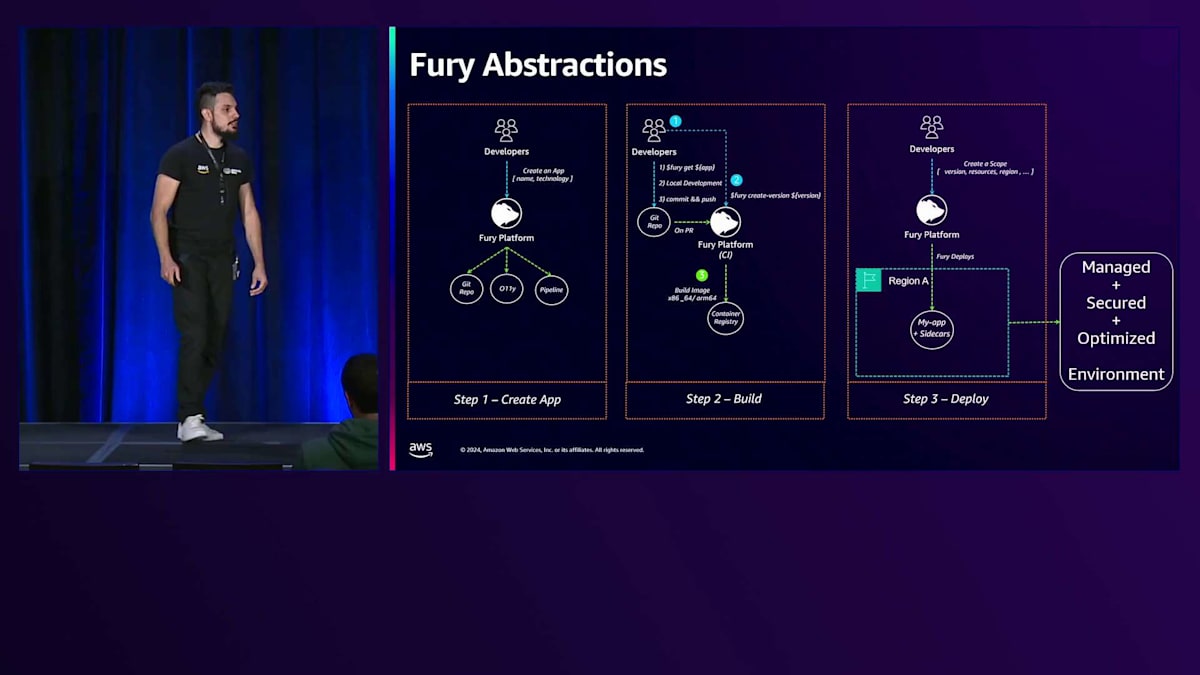
バージョンが作成されると、開発者はそのコードを公開する必要があるため、Scopeを作成します。Scopeは、Furyの用語で、特定のバージョンでアプリケーションコードを実行するワークロードまたはレプリカのプールを指します。バージョンを選択し、コンピューティングリソースを入力し、リージョンを選択することで、Furyはトラフィック認証、ログ、メトリクスなどを解決するためのSidecarと共に、管理された安全で最適化された環境でこのアプリケーションをデプロイします。ここで開発者はクラウドやKubernetesの専門知識を持つ必要はありません。すべてがFuryプラットフォームによって管理されているからです。
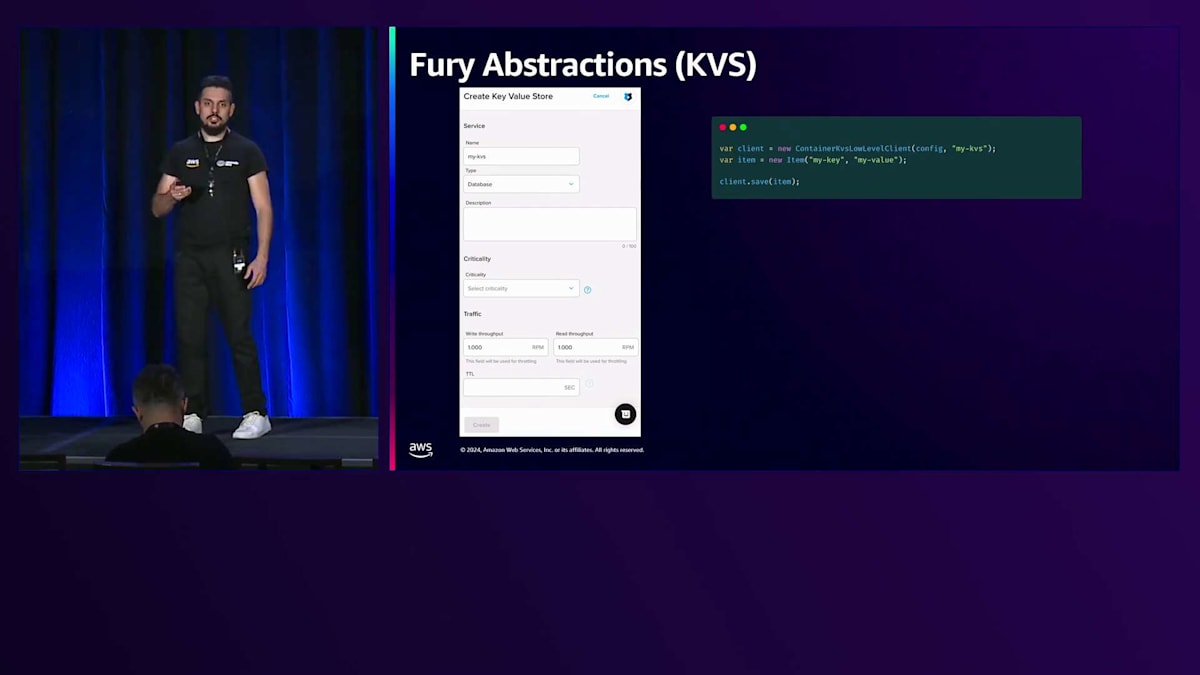
Furyの抽象化は開発者向けだけでなく、アプリケーション向けにも提供されています。例を挙げましょう。私たちのKVSはKey-Value Storeサービスで、アプリケーションがキーバリュー形式でデータを保存できるようにするFuryの抽象化データベースです。このフォームに名前、タイプ、説明などの情報を入力することで、KVSデータベースを作成できます。その後、開発者はKVS SDKを使用してこのAPIをコピーし、KVSクライアントを初期化して、アイテムを作成し、コード内にアイテムを保存することができます。
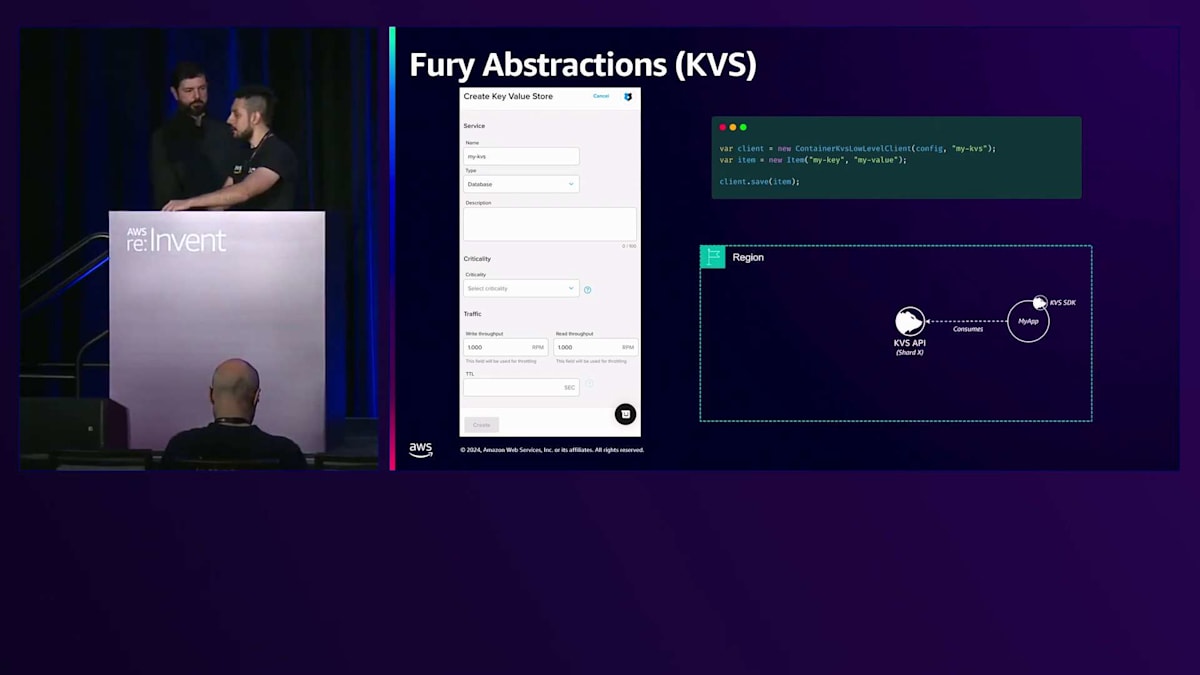
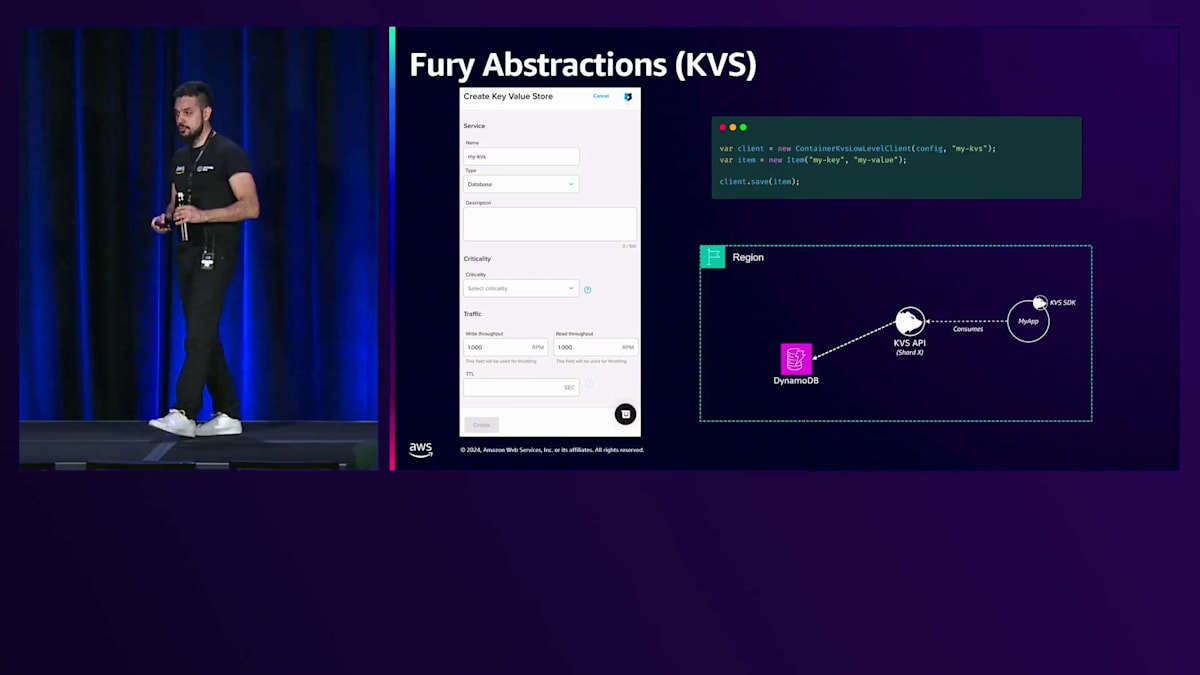
裏側では、アプリケーションがKVS SDKを使用してキーを利用しています。2018年まで、この情報はApache Cassandraクラスターに保存されていました。 しかし、その年以降、私たちはDynamoDBに切り替えましたが、この変更は開発者にとって完全に透過的でした。コードは同じままで、KVS SDKも変わらず、バックエンドでDynamoDBに切り替わっただけだったからです。

開発者はクラウドプロバイダーと直接やり取りすることはなく、UIやCLIを通じてFuryを使用します。アプリケーションはSDKを使用して私たちのAPIを利用しますが、Furyの抽象化は単なるプロキシではありません。クラウドサービスの前に単にプロキシとして存在する意味はないのです。私たちの考えは、ベストプラクティスを組み込み、複数のクラウドサービスを組み合わせ、開発者に単一の抽象化として提供することで、サービスを拡張することにあります。

ただし、今回は特に私たちのコンピューティングモデルについてお話ししたいと思います。 Kubernetesを導入する前の運用方法をご紹介しましょう。この図では、開発者がFuryとやり取りしてワークロードをリクエストしています。Furyはこのリクエストをインスタンスベースのコンピュートレイヤーに転送します。このレイヤーはAmazon EC2 APIを通じてEC2インスタンスをリクエストし、アプリケーションコンテナだけでなく、私たちのSidecarも起動するためのDocker Composeファイルを生成します。このアプローチは10万以上のEC2インスタンスで機能していましたが、効率性に関していくつかの改善の余地があることがわかりました。
FuryによるKubernetesの活用とNoOps環境の実現
このアプローチの最初の問題点は、1つのレプリカが1つの専用EC2インスタンスとなり、レプリカが常時基盤リソースの100%を使用しているわけではないため、未使用のリソースが発生してしまうことです。2つ目の問題は、アイドル時間に関連しており、3つの例を挙げることができます。1つ目はTest Scopeで、開発者がProductionにデプロイする前にコードを公開するための独立した環境を作成する必要がある場合です。これは良い方法ですが、開発者は常にこれらのScopeをテストしているわけではないため、24時間365日インフラが稼働している状態となります。2つ目の例は、Furyのコンシューマーに関するものです。Scope typeのコンシューマーはFury上の特殊なレプリカプールで、トピックをサブスクライブし、メッセージブローカーが各メッセージに対してこれらのコンシューマーにリクエストを送信しますが、すべてのコンシューマーが常時メッセージを処理しているわけではありません。
最後に、Jobs Scope typeがあります。ここでは1つのレプリカしかありませんが、開発者はコンソールでCronルールを設定して、Jobの実行時間に基づいて特定のエンドポイントをトリガーすることができ、これも24時間365日稼働しています。私たちはこの問題を緩和するため、Right-sizerのような機能をFury上で開発しました。これは、利用可能なキャパシティが使用リソースに適合しない場合に、Scopeのフレーバーを縮小することを開発者に推奨するものですが、十分ではありませんでした。

このユースケースを見ると、この問題に対してさまざまな解決策を考えることができます。例えば、コンシューマーにはAWS Lambdaを、JobsにはAWS Batchを使用するなどです。しかし、私たちのアイデアは、35,000のマイクロサービスを抱える中で、開発者に対して透過的な1つのテクノロジーだけを使用してFuryを拡張することでした。これらすべてのアプリケーションに変更を要求することは合理的ではありませんでした。研究を行い、様々な製品をテストした結果、最終的にAmazon EKSを選択しました。 現在、私たちには3つの新しいアクターがあります:EKSクラスター、各クラスター内のCompute API、そしてクラスターベースの新しいCompute Layerです。
ここでのCompute Layerの役割は、FuryからKubernetesを知らないクラスターの概念を抽象化することです。Compute LayerはAPI Serverと直接やり取りせず、代わりにCompute APIとやり取りします。このAPIを開発した理由は2つあります。1つ目は、Breaking Changesが発生する可能性のある新しいEKSバージョンをクラスタープールに導入する際、アーキテクチャ内で同じ標準を維持しながら、その特定のKubernetesバージョンと通信するための新しいCompute APIリリースを生成できることです。2つ目の理由は、EKSから他のソリューションに変更する場合に関連します。

2つ目の理由は、EKSから他のコンテナオーケストレーターに変更する場合に何が起こるかということです。その場合、アーキテクチャへの影響を軽減しながら、特定のコンテナオーケストレーターと通信するための新しいCompute APIを生成してリリースすることが可能です。このアプローチを使用することで、Kubernetesを Furyのバックエンドエンジンとして使用することが可能になり、開発者はEKSを使用していることを意識することなくKubernetesを利用できます。また、以前の図ではFuryのデータプレーンは1つだけでしたが、現在は各クラスターごとに1つのデータプレーンを持つCompute Shardsも導入しています。これは有益です。なぜなら、重要度とScope Typeに基づいて、すべてのワークロードを明確に定義されたクラスターに分散させることが可能になり、Job Test、Job Production、Job Critical、Consumers Test用のクラスターなどを持つことができるからです。
これにより、例えばCompute APIを変更する必要がある場合など、社内の変更をデプロイする際に役立っています。一部の変更は、最も重要度の低いクラスターから開始し、最も重要度の高いクラスターへと段階的に適用することで、重要なアプリケーションへのリスクと影響を軽減しています。また、これはControl Planeのアップグレードにも役立ちます。Control Planeのバージョンをその場でアップグレードする代わりに、イミュータブルインフラストラクチャの概念を適用できるからです。例えば、AWSで利用可能な最新バージョンを使用して新しいEKSクラスターを作成し、そのクラスターをテストして、新しいワークロードを受け入れるためにCompute層に登録することができます。開発者がBlue-Greenデプロイメントを実行する際、このような新しいKubernetesクラスターにワークロードを移行できます。インスタンスベースの古い環境から新しい環境へとワークロードの移行を開始した当初は1つのクラスターだけでしたが、現在では130以上のEKSクラスターを持ち、全スコープの70%を移行しています。

デプロイメントに関して、Furyは4つの主要なデプロイメント戦略を提供しています:Blue-Green、Canary、Safe、そしてMigrationsです。 Blue-GreenとCanaryは広く知られたデプロイメント戦略ですが、SafeとMigrationsはFury特有のデプロイメント戦略です。Safeは基本的にはBlue-Greenと同じ仕組みですが、古いプールと新しいプール(BlueとGreen)のメトリクスとトラフィックメトリクスを比較するため、オリジナルのBlue-Greenと比べて slower です。異常が検出された場合、開発者にロールバックを提案します。開発者が50分以内に対応しない場合、自動的にデプロイメントをロールバックします。一方、Migrationsは主にFuryチームがリージョン間、クラウド間、環境間でアプリケーションを移行する際に使用します。このストラテジーは、インスタンスベースの古い環境からクラスターベースの新しい環境へとワークロードを移行する際に広く活用しており、Blue-Greenデプロイメントと同様のゼロダウンタイムなどの保証を提供します。
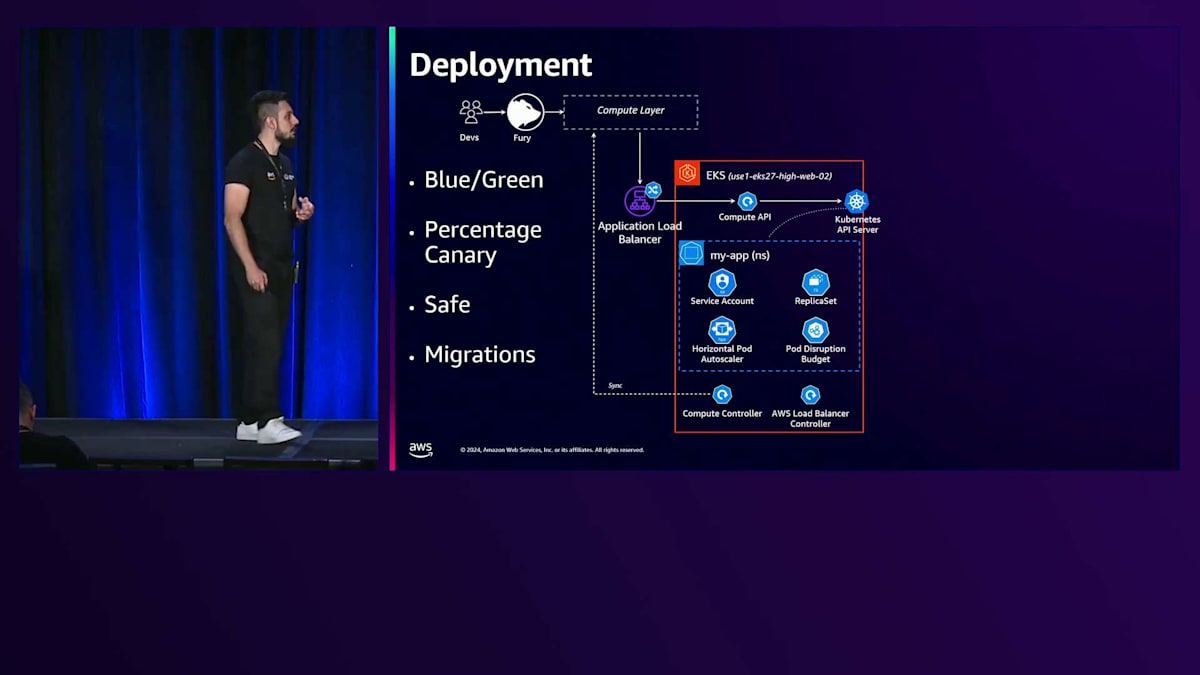
ここでは、開発者がBlue-Greenデプロイメントを実行する際に、私たちのElastic環境内で何が起こるのかについて、より詳しく説明します。Compute層とCompute APIの間には、Application Load Balancerがあります。このロードバランサーは、AWS Load Balancer Controllerによって作成され、クラスターをスキャンして、AWS固有のアノテーションを持つすべてのIngressオブジェクトに対して、Application Load Balancerを作成し、Compute Serviceの背後にあるすべてのPodをAWS Load Balancer Target Groupのターゲットとして登録します。Compute APIがこのリクエストを受け取ると、Namespace、Service Account、HPA、PDBなどのオブジェクトをAPI Serverリクエストに変換します。Namespace、Service Account、Horizontal Pod Autoscaler、Pod Disruption Budget、そしてReplicaSetが重要なコンポーネントとなります。
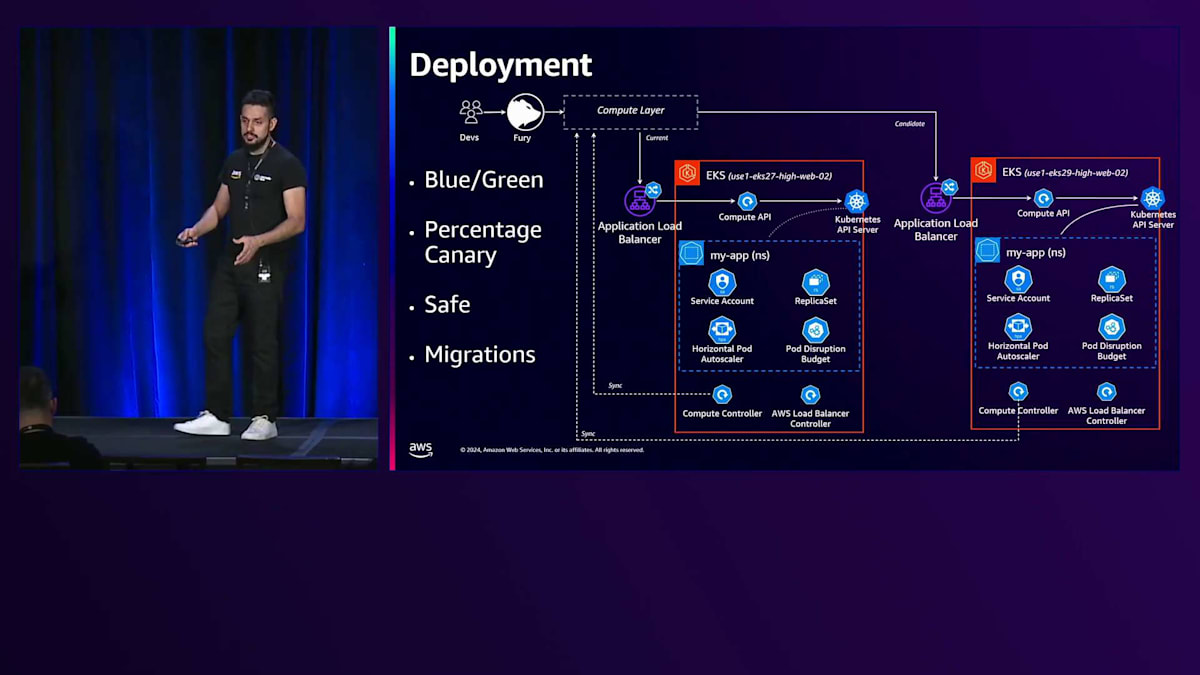
プラットフォームレベルですでにDeploymentを持っているため、KubernetesからはSelf-healing機能だけが必要でした。そのため、DeploymentオブジェクトではなくReplicaSetを使用しています。ReplicaSetで要求されたすべてのPodが準備完了状態かどうかを判断するために、Compute Controllerと呼ばれる独自のKubernetesコントローラーを開発しました。これはクラスターの状態を外部の状態(この場合はCompute層)と照合します。同じリージョン内の各クラスターについて、すべてのCompute層が作成、変更、終了されたPodを中央のCompute層と同期します。
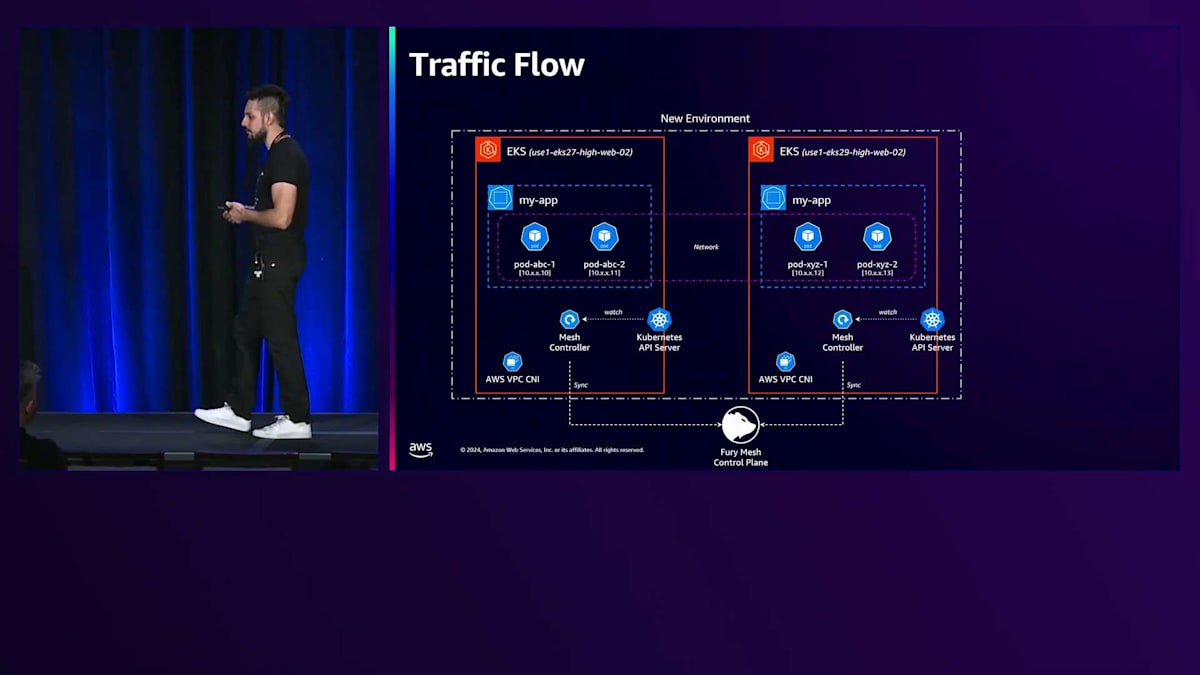
これにより、開発者がBlue/Greenデプロイメントを実行する際に、例えばクラスター間でワークロードを移動するなど、さまざまなアルゴリズムを適用できます。Compute層がデプロイメントを受け取ると、これらのワークロードを受け入れるのに最適なクラスターを分析し、同じクラスターまたは同じ特性を持つ別のクラスターを選択できます。異なるクラスター間でアプリケーションが通信できるように、Fury内のトラフィックフローについてご説明します。Furyは何年も前からトラフィックソリューションとしてService Meshを採用しています。以前は、ほとんどのServiceツールがnon-Kubernetesワークロードや一部のFuryの要件をサポートしていませんでした。これは、アーキテクチャにKubernetesを導入した際に重要になりました。なぜなら、PodをService Meshと同期するコンポーネントが存在しなかったからです。
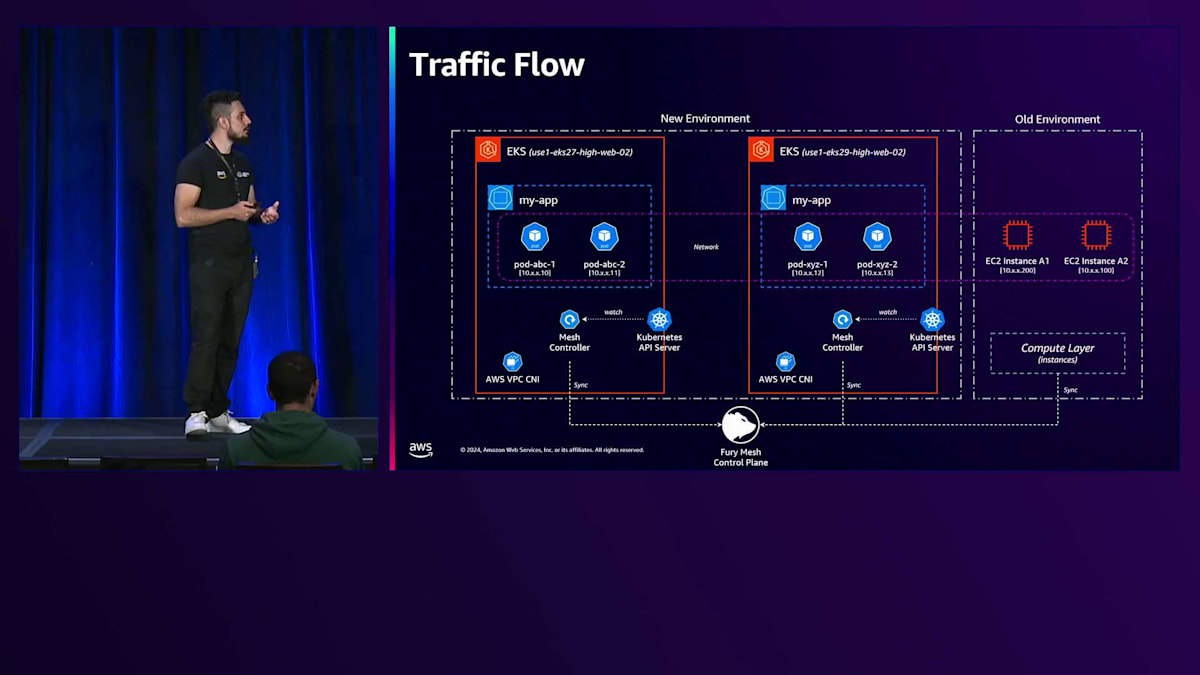
この問題を解決するため、私たちはAWS VPC CNIをメインのCNIとして採用しました。これにより、各Podに1つのルートと可視化されたVPC IPを割り当てることが可能となり、ネットワークアクセスがシンプルになりました。ネットワークの観点からは障壁がなくなったのです。そして、Mesh Controllerと呼ばれる新しいカスタムKubernetes Controllerを開発し、作成・終了される全てのPodをService Mesh内の独自のControl Planeと同期させました。これにより、新環境内のアプリケーション同士の通信や、異なる環境間の通信が可能になりました。
Furyのスケーリング戦略とデモンストレーション

Furyにおいて、スケーリングは重要な機能の一つです。Kubernetesを使用することで、より多くの異なるスケーリング戦略を提供することが可能になりました。私たちのスケーリングポリシーの大部分はCPUメトリクスに基づいており、バックグラウンドではHorizontal Pod Autoscalerを使用しています。しかし、リアクティブなスケーリングに依存できないアプリケーションの場合はどうでしょうか?そこで私たちは、予測CPUメトリクスを開発しました。これは、各アプリケーションのCPUパターンを学習し、将来のCPU使用率を予測できるモデルです。このアプローチを使用することで、スパイクが発生する前にReplicaをスケールアウトすることが可能になります。このモデルをHorizontal Pod Autoscalerポリシーに接続するため、カスタムKubernetesメトリクスアダプターを開発しました。さらに、RPSメトリクスのサポートも提供しています。
GPUなどのアクセラレーターを使用するアプリケーションは、通常GPUリソースを大量に消費しますが、CPU使用率は最小限に抑えられます。そのため、標準のCPUベースのスケーリングポリシーが機能しない可能性があります。この課題に対応するため、開発者がプラットフォーム上でRPSを使用できるようにサポートを構築しました。また、VPAとGPAを組み合わせた垂直スケーリングも使用していますが、実行中のPodを変更する代わりに、VPAからすべての推奨事項を取得し、これらのリソース変更を含む新しいBlue-Greenデプロイメントと新しいReplicaプールを推奨するためにFury by Sizerに取り込んでいます。
Zero Scalingという機能は、アイドル状態の問題に対処するために実装されました。クラスター内には、アプリケーションがリクエストを受信していないことを検出できるワークロードのセットがあります。開発者がこの機能を有効にすると、Replica Setのカウントをゼロに変更できます。同じアプリケーションセットがアクティビティを識別し、HEPAポリシーで設定された最小値までReplicaをスケールアウトすることができます。
クラスター内のKubernetesアプリケーションをスケーリングする方法は2つあります。クラスター内のNodeのスケーリングには、Karpenterをメインのクラスタースケーラーとして使用しています。Karpenterを選んだ理由は、Node内でAWS Spotインスタンスの比率を仮想ドメインで使用するなどの機能が標準で備わっているためです。クラスターシャーディングに合わせて、クラスター内でSpotインスタンスをどの程度使用するかを決定できます。テストクラスターでは100%をSpot、本番クラスターでは80%をSpot、20%をオンデマンド、ミッションクリティカルなクラスターでは異なる割合を設定することが可能です。
GPAと共に、Cluster Proportional Autoscaler (CPA)を使用してオーバープロビジョニングの概念を適用しています。ワークロードのスケーリングが必要で、クラスター内に空きスペースがない場合、Karpenterが新しいノードをプロビジョニングするまで数分待つのではなく、数分ではなく数秒で済むPreemptiveポッドを置き換えます。このPreemptされたポッドがトリガーとなって、Karpenterが新しいノードを作成します。


開発者はKubernetesを使用しますが、開発者とKubernetesの間に中間レイヤーとしてFuryがあります。ここでは、Kubernetesをベースとして、命令的な方法でクラスター内のすべての変更をデプロイします。クラスターをFuryに登録する前に、本番クラスターに昇格させる必要があります。クラスターの引数は、FluxCDを使用してKopsの概念を適用し、ソースオブトゥルースとして新しいGitリポジトリを作成する宣言的な方法を使用します。変更が発生するたびに、このGitリポジトリのFluxCDが外部ステージと内部ステージを照合し、クラスター内のオブジェクトの作成、削除、変更を行います。つまり、同じクラスターに対して、ワークロードをデプロイする2つの異なる方法があるということです。
それでは、Furyの実際の動作を見てみましょう。先ほど説明した内容と同じように、アプリケーションの作成、Scopeの作成、バージョンの作成、そしてアプリケーションのデプロイを行う様子を動画で用意しました。
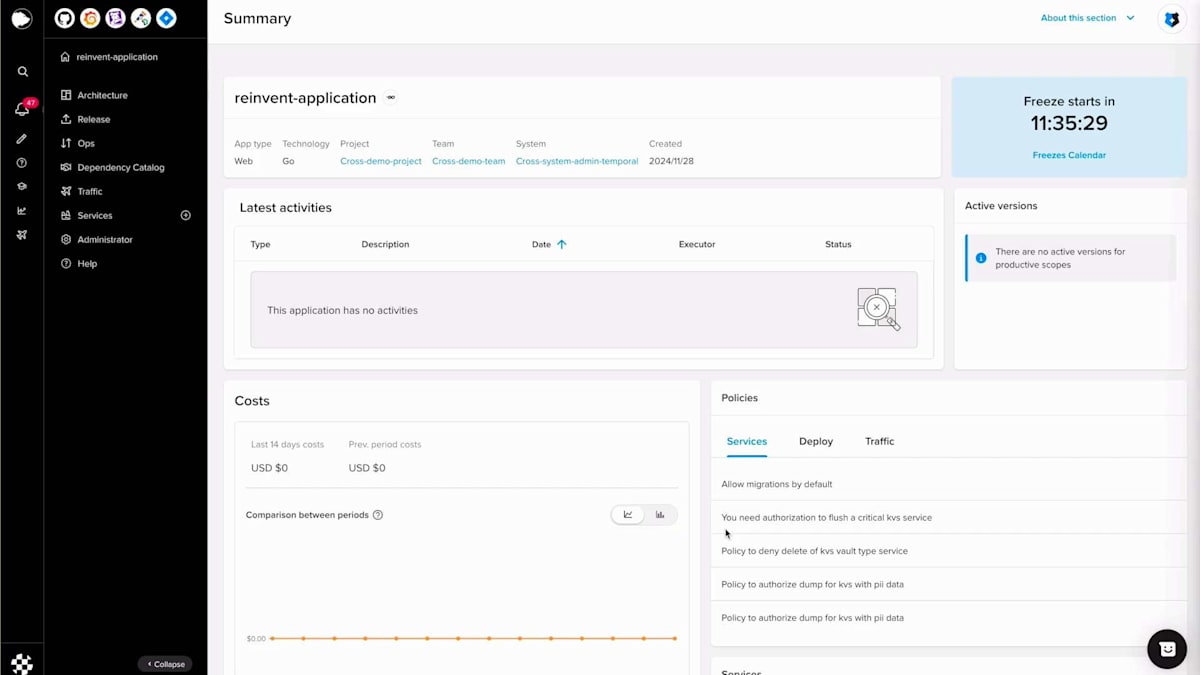
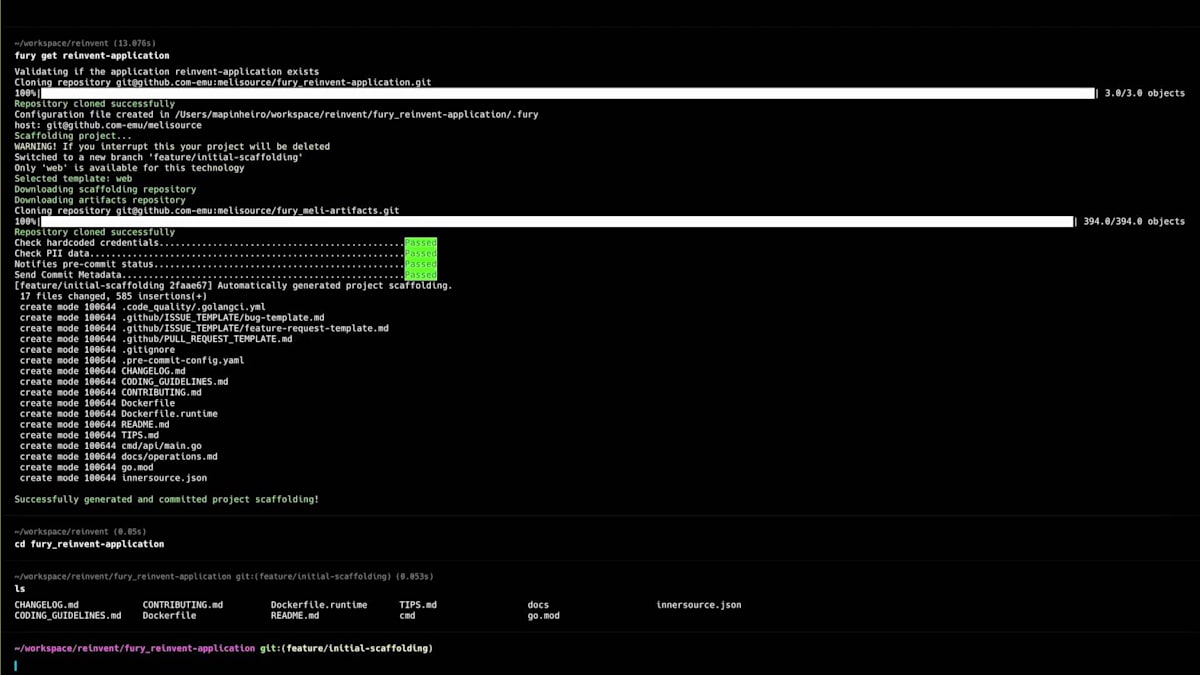
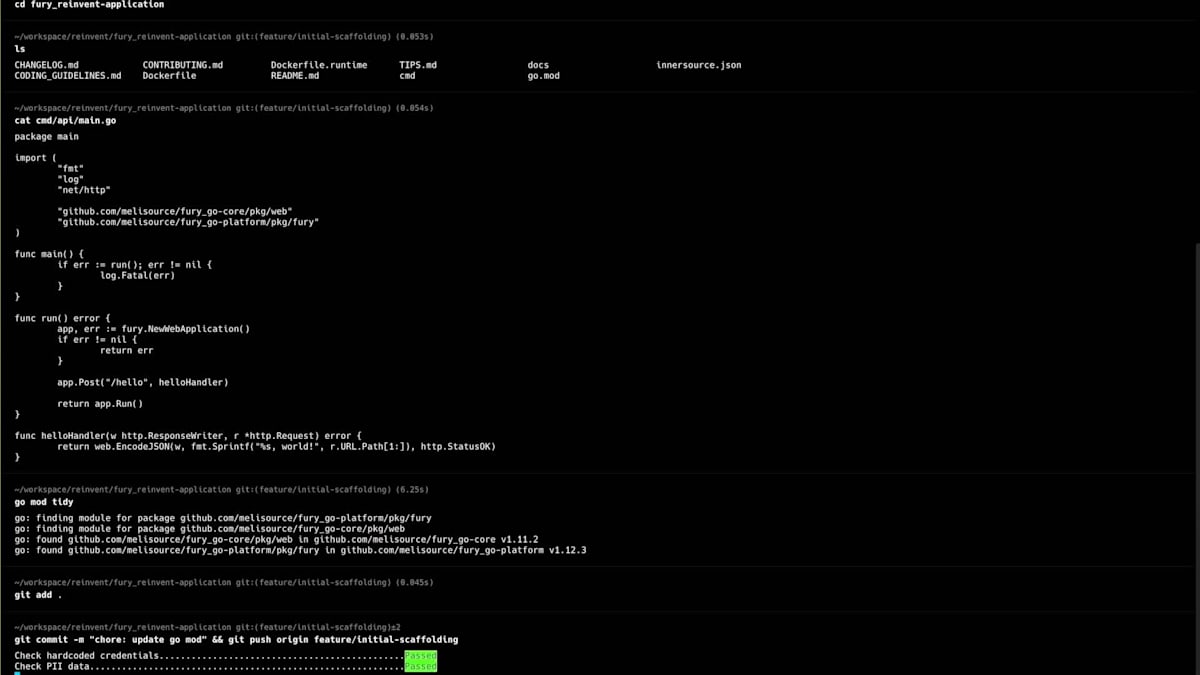
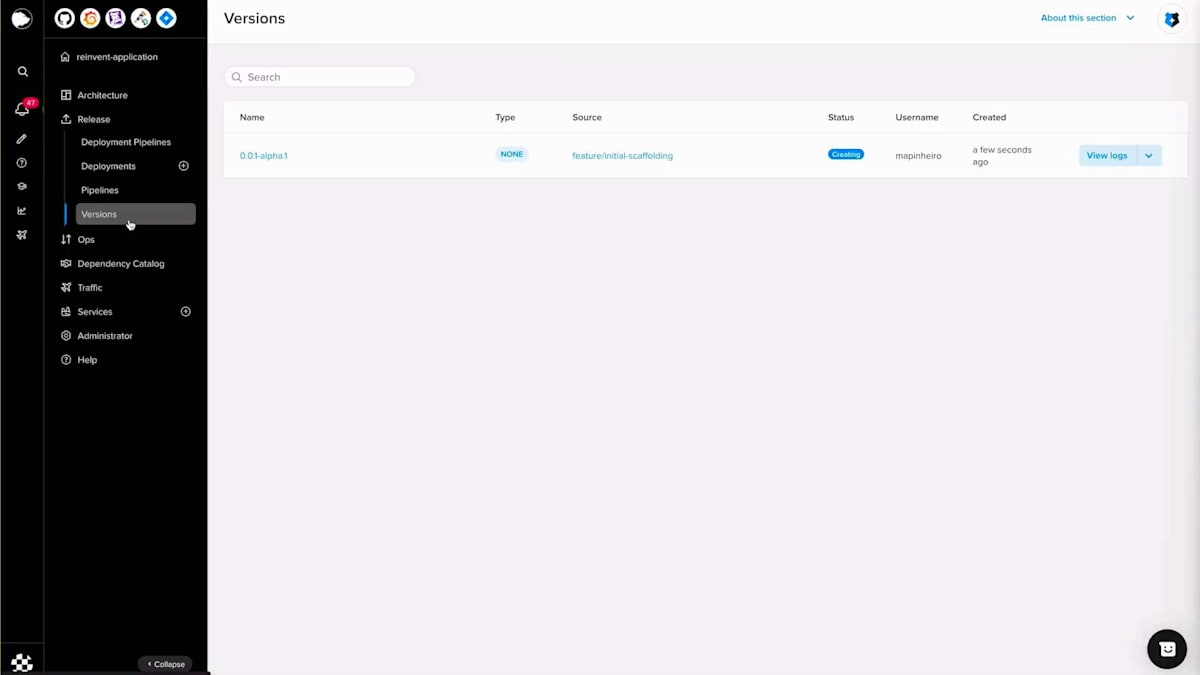
3分に収めるために、一部をカットしたり早送りしたりしています。ここでは、アプリケーションを作成し、名前、説明、使用する技術を選択し、メタデータを入力しています。 こちらがメインページです。その後、Furyコマンドを実行してリポジトリをローカルにクローンし、初期のスカフォールディングを作成します。 ここで作成されたファイルと、Fury getで作成されたシンプルなエンドポイントが確認できます。これでコミットしてプッシュし、Fury create versionタグを実行して、この場合はalpha oneを作成できます。その後、バージョンセクションに移動し、バージョンが作成されたら、このバージョンを本番環境にデプロイできます。
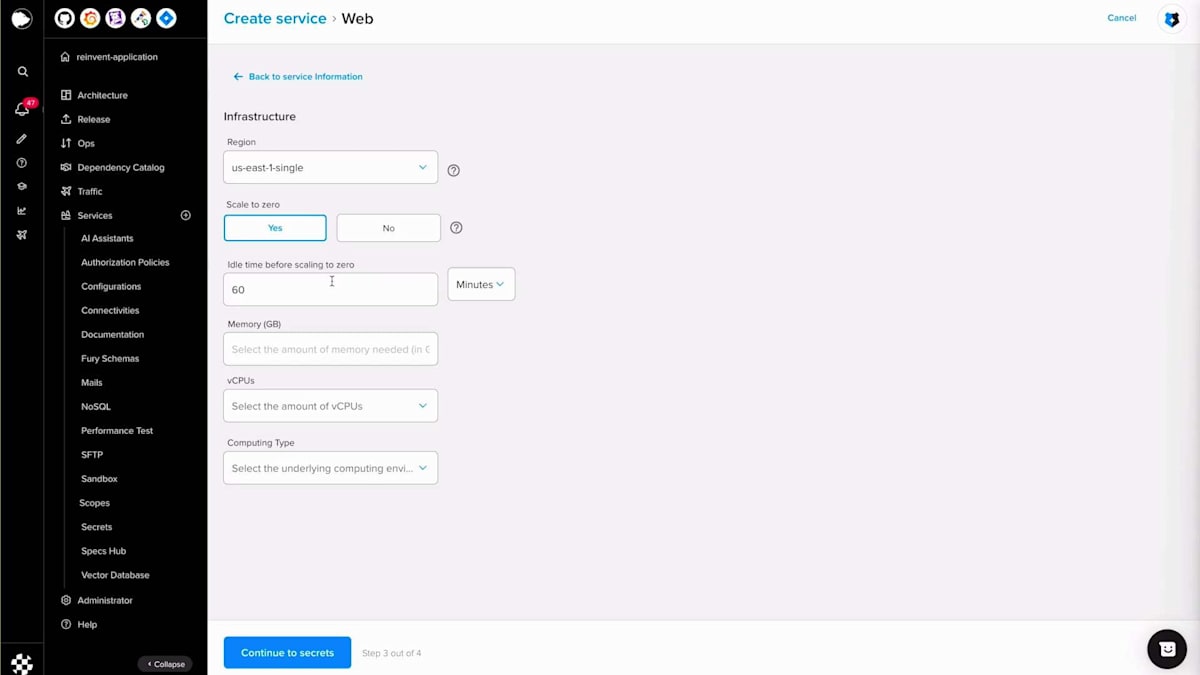
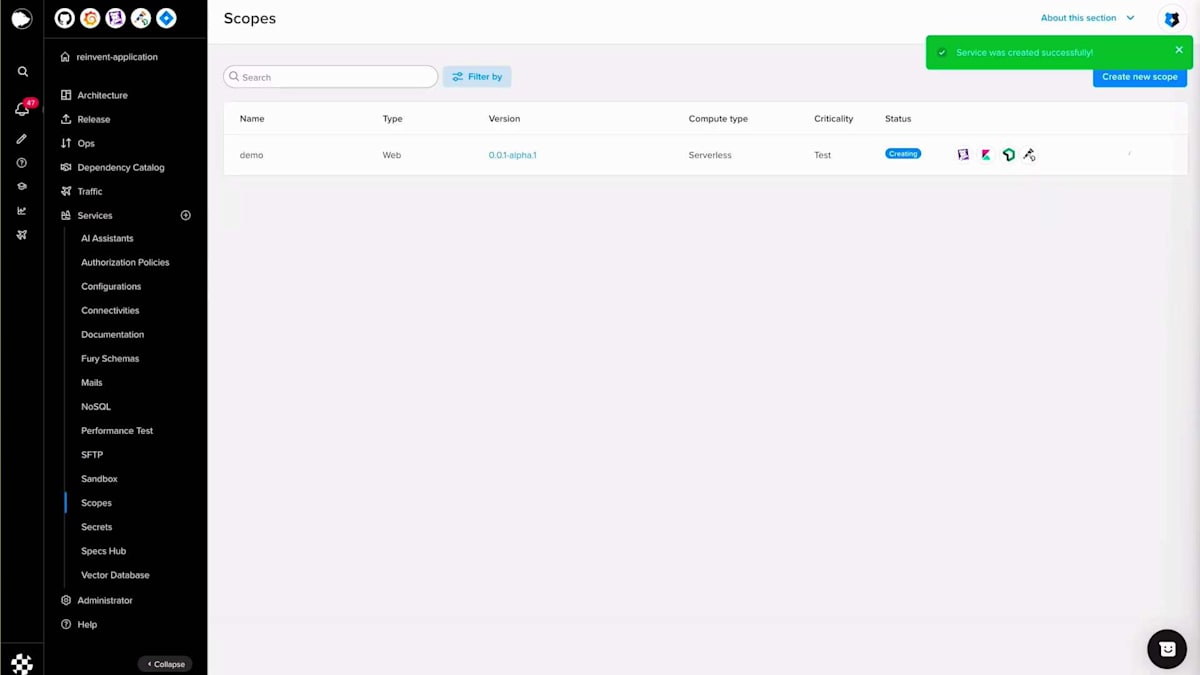
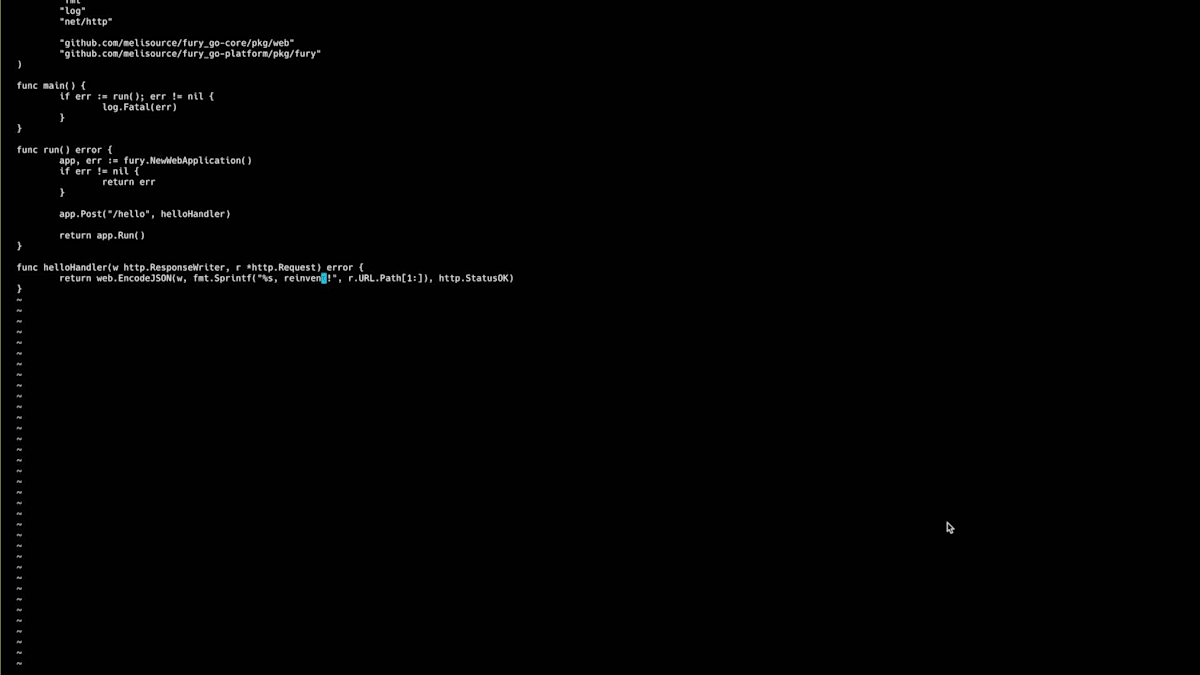
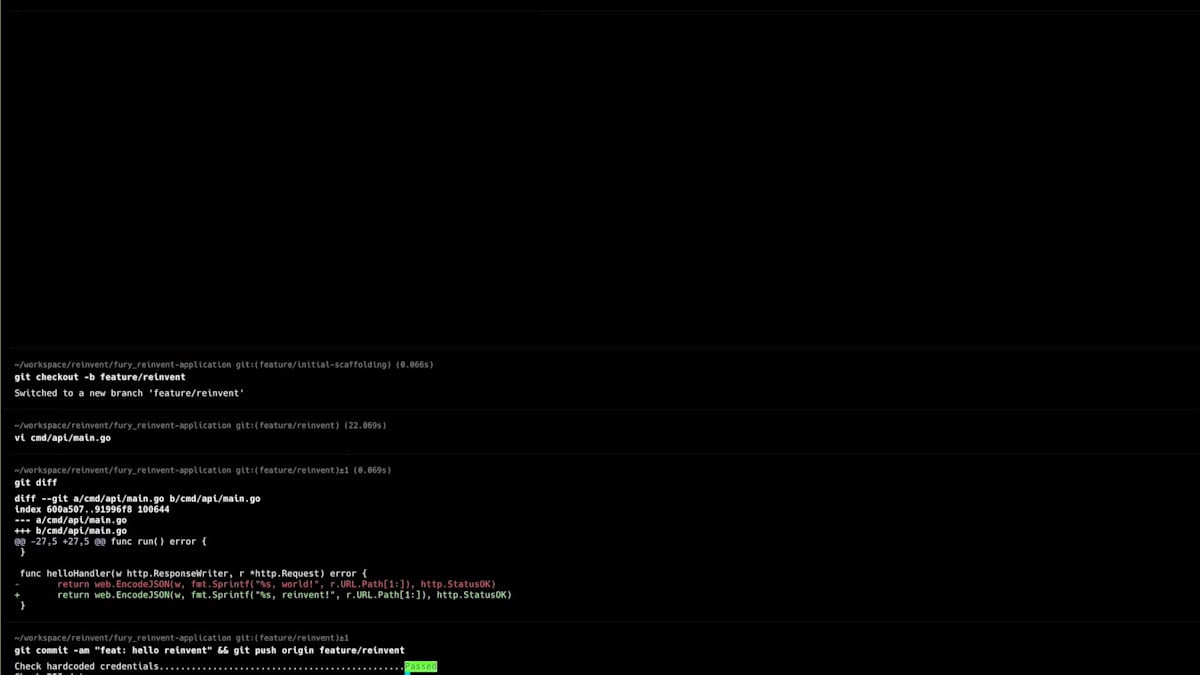
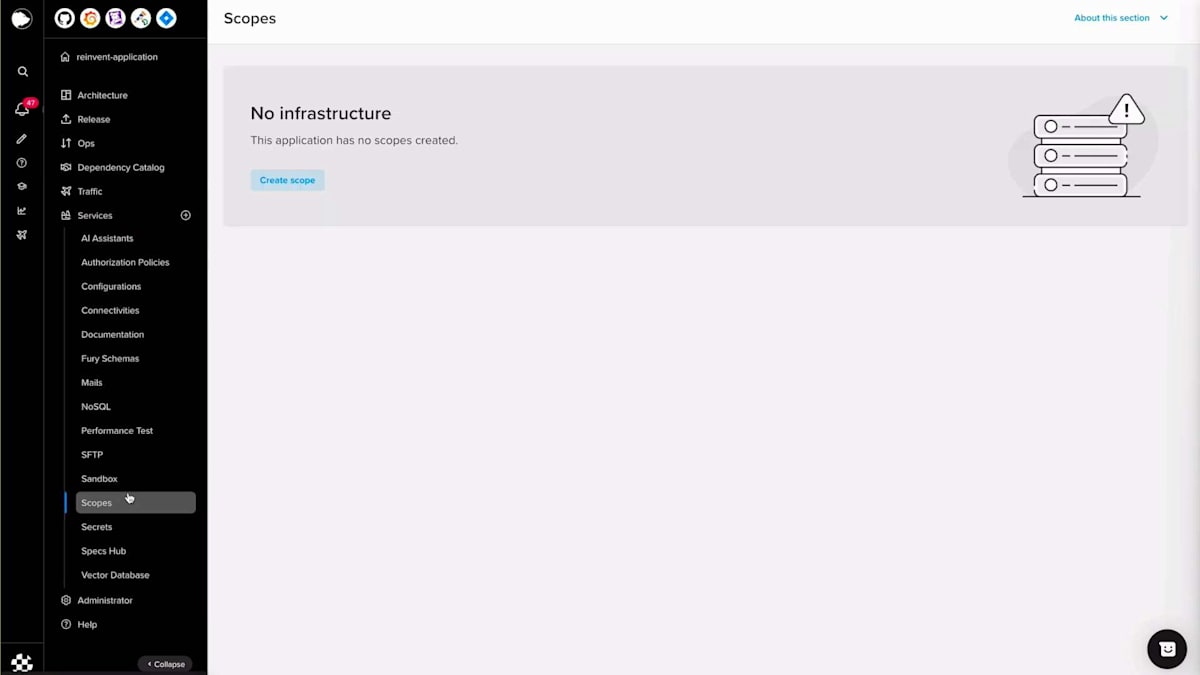
Scopeセクションに移動し、重要度を選択し、Scope名を入力し、バージョンを選択して、設定を行い、例えばスケールをゼロに設定し、コンピュートリソースを設定します。この場合、追加するシークレットはないので、Scopeを作成しましょう。 Scopeが作成されアクティブステータスになったら、生成されたドメイン名を取得して、すべてが正常に動作するかテストの呼び出しを行うことができます。helloエンドポイントはスカフォールディングコードで生成されたポイントで、正常に動作しています。次に、何か変更を加えてBlue-Greenデプロイメントを行ってみましょう。hello worldを「reinvent」に変更してみましょう。ここで差分を確認でき、同じように、コードをコミットし、プッシュして、Fury create version alpha twoを実行できます。
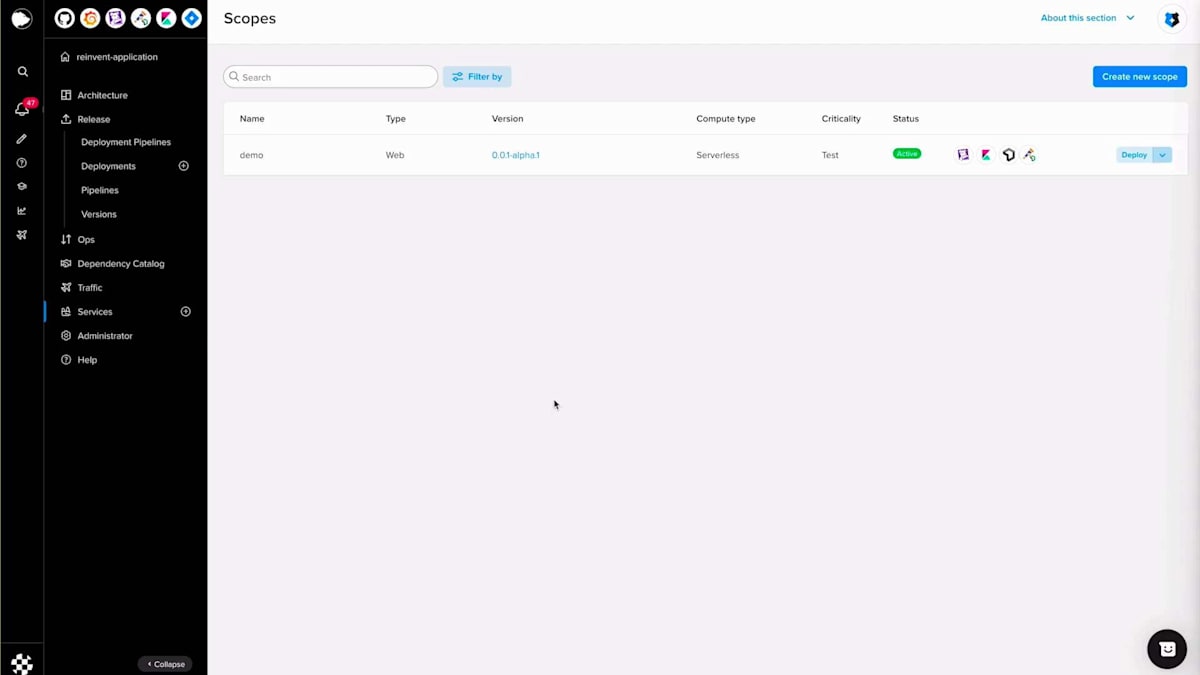
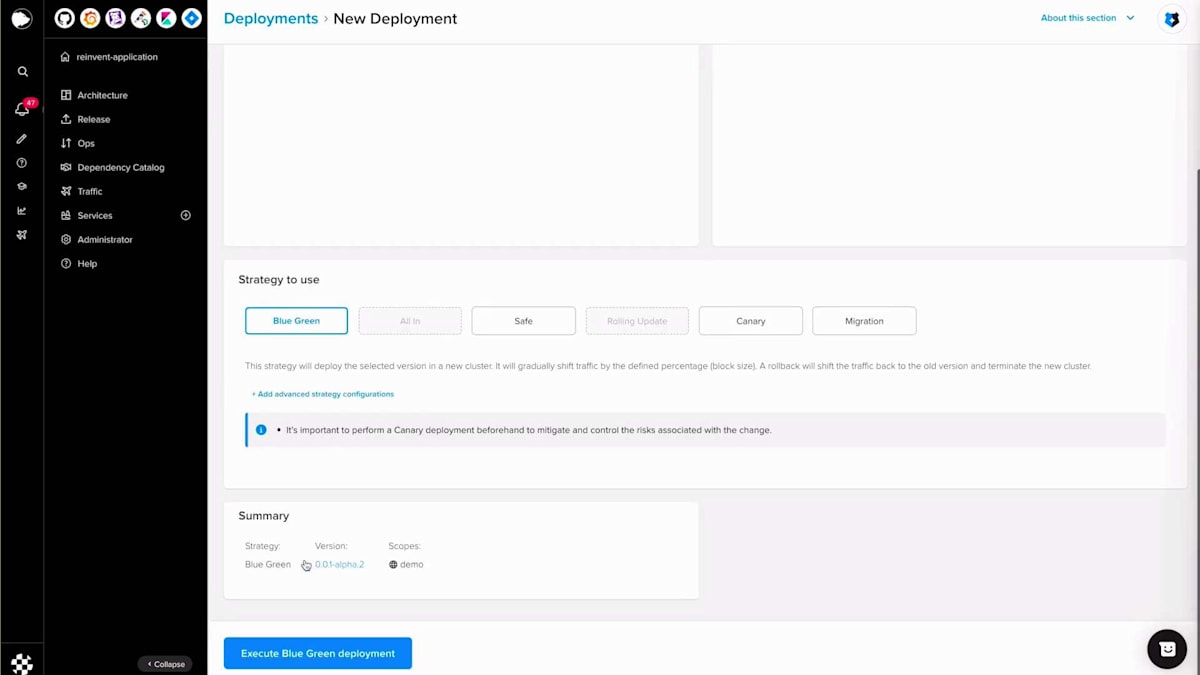
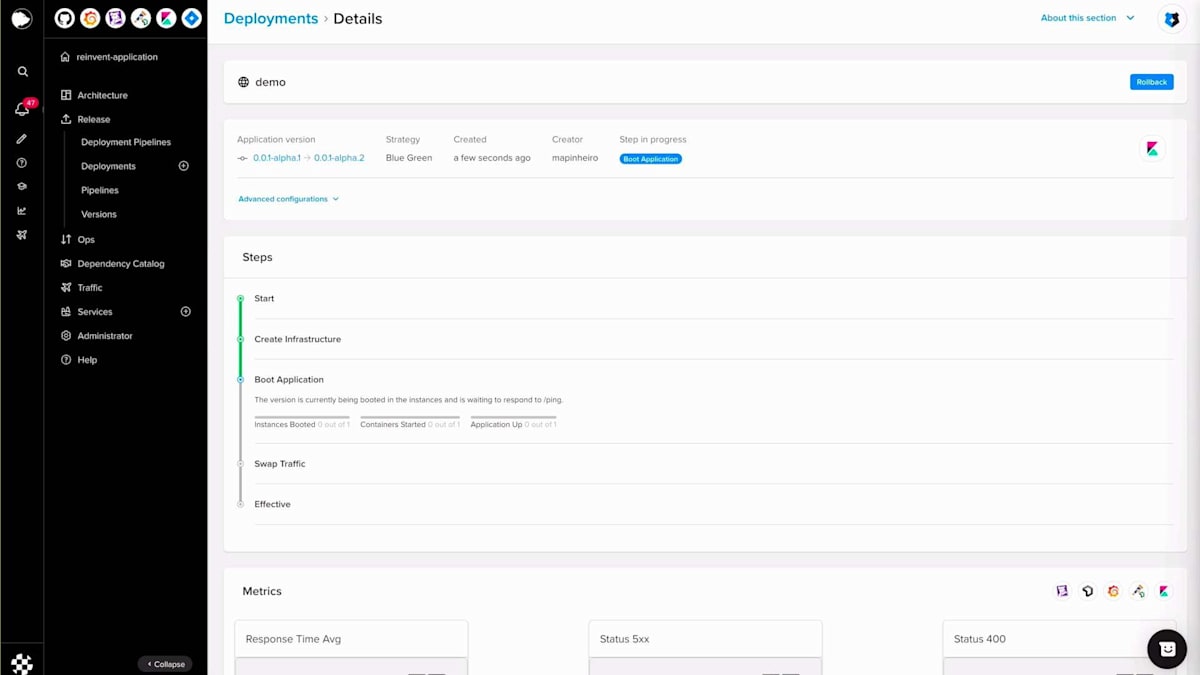
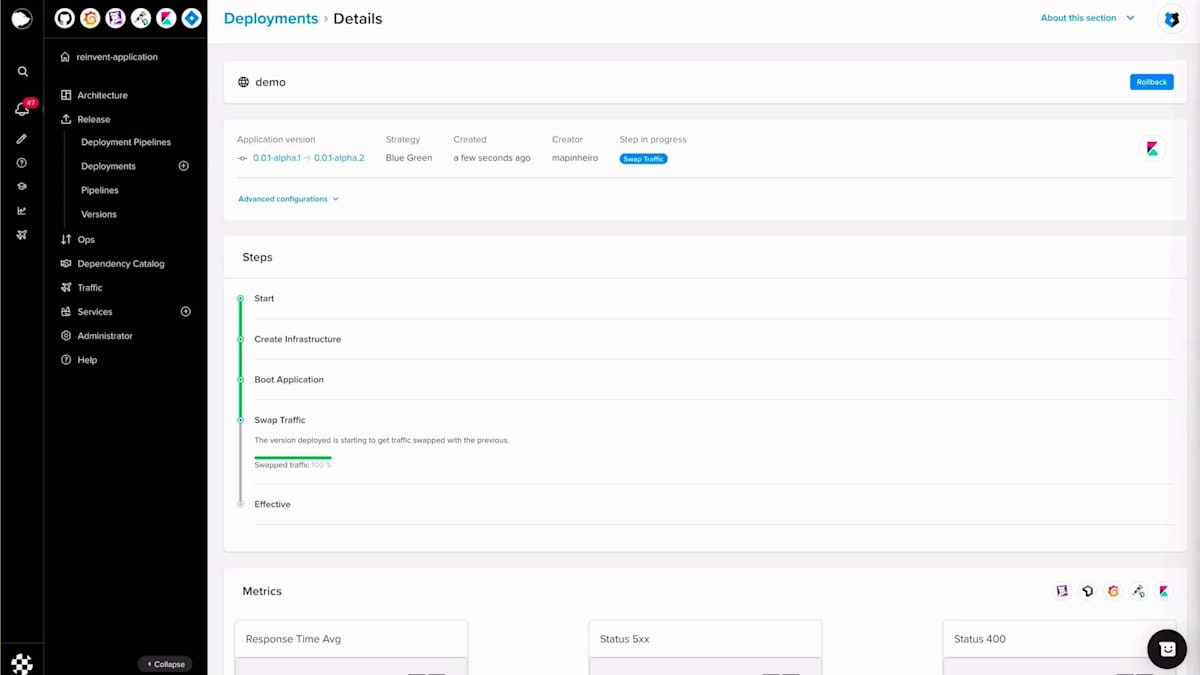
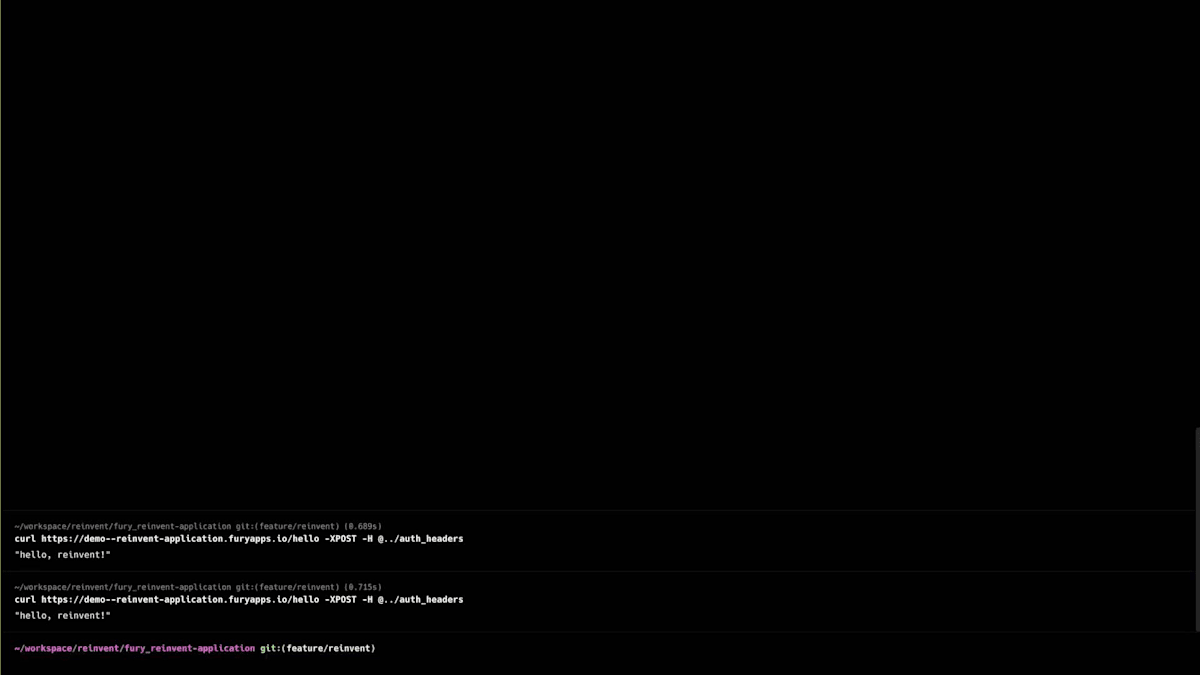
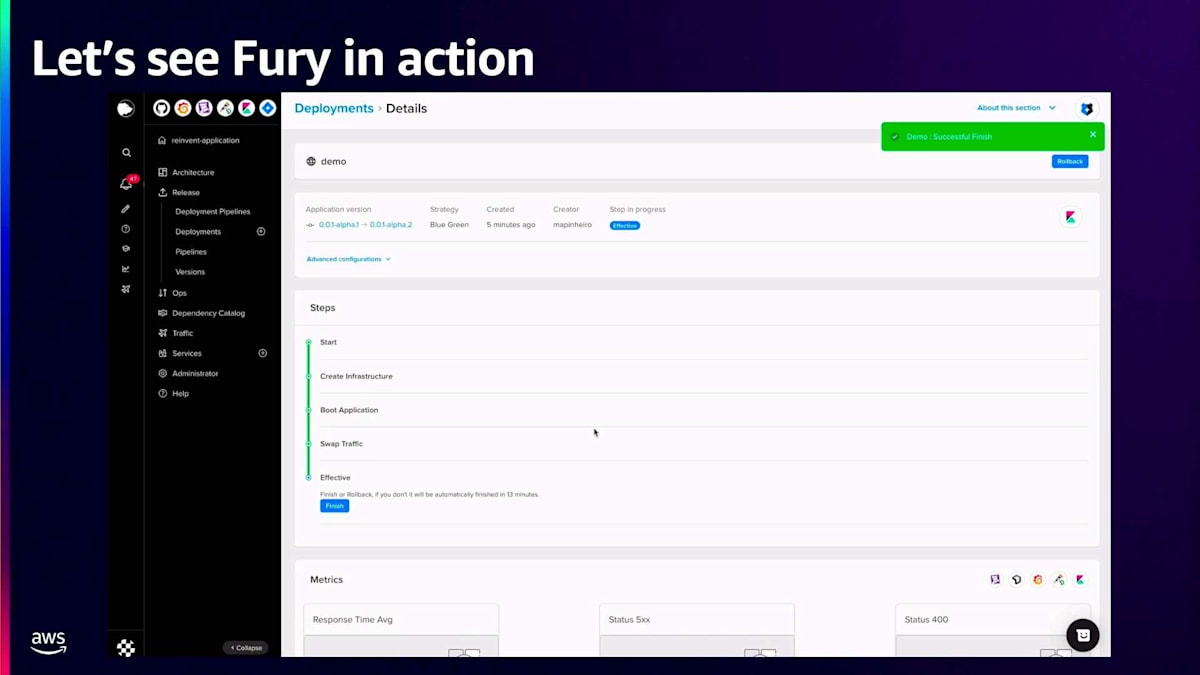
このバージョンを作成したら、デプロイセクションに移動し、バージョン、スコープ、そして今回の場合はBlue-Greenというストラテジーを選択します。Blue-Greenデプロイメントを実行する前に、いくつかの属性を設定することができます。アプリケーションステップでは、FuryはこれらのPodがReady状態になるのを待ち、トラフィックのスワップはトラフィックを移行するプロセスです。トラフィックのスワップが100%になったら、再度呼び出しを行うと、今度は「hello reinvent」が表示されます。その後、Blue-Greenデプロイメントを完了して古いプールを破棄し、新しいプールのみを維持することができます。



このビデオをご覧いただくと、開発者にとってはYAMLを管理する必要もなく、コントロールプレーンを管理する必要もなく、データプレーンを管理する必要もないことがわかります。つまり、認知的負荷がなく、NoOpsの体験により、日々の生産性が向上しています。これは私たちのコンピュートモデルだけでなく、カタログで提供しているほとんどのサービスにも当てはまります。結論として、Furyはこれらのワークロードのほとんどを支える基盤であり、99.95%のアップタイムを実現しています。また、NoOpsストラテジーを採用することで、開発者に変更を要求することなく、Docker ComposeベースのワークロードをKubernetesに透過的に移行することが可能となり、イノベーション、創造、そして迅速な切り替えが可能になりました。さらに、EKSとNoOpsストラテジーの組み合わせにより、クラウドのコンピュート費用を30%以上削減することができました。以上です。セッションをお楽しみいただけたと思います。ありがとうございました。では、Thiagoに戻したいと思います。皆様、本日は何か学びを得ていただけたと思います。ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion