re:Invent 2024: AWSとAnthropicが語るLLMのTool UseとAgent技術
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Tool use & agents at the frontier: Advanced techniques for LLM actions (AIM306)
この動画では、Large Language Modelを使った業務自動化の最新動向について、Amazon BedrockのPrincipal EngineerのJohn BakerとAnthropicのTechnical StaffのNicholas Marwellが解説しています。Function CallingやTool Useの基本的な仕組みから、Agentによるオーケストレーションまでを体系的に説明し、特にClaude 3.5 Sonnetがコーディングタスクで6ヶ月で21%から64%まで性能が向上した具体例や、ReActとReWoOというオーケストレーションの手法の違いなど、実践的な知見を共有しています。また、金融データを使ったボラティリティ計算の実例を通じて、Agentがビジネスドメインの知識とツールを組み合わせて複雑な問題を解決する様子を示しています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Large Language Modelの進化と本講演の概要

みなさん、ようこそお越しくださいました。この後1時間ほど、お時間を頂戴することになりますが、ご参加いただき誠にありがとうございます。Large Language Modelは過去1年で急速に進化し、これらのモデルを使った自動化の可能性が現実のものとなってきています。Large Language Modelを使って業務を自動化したいとお考えですか?推論、プランニング、オーケストレーション、ツール使用に関する最新の進歩を確実に活用したいとお考えですか?そうであれば、この講演はまさにぴったりです。これらのトピックについて深く掘り下げていきます。私はJohn Bakerと申します。Amazon Bedrockのプリンシパルエンジニアで、Agentsの開発に携わっています。本日は、AnthropicのテクニカルスタッフメンバーであるNicholas Marwellと一緒に講演させていただきます。

本日は何をお話しするのでしょうか?まず、Function CallingやTool Useとは何か、その起源や由来について説明します。次に、Function CallingとAnthropic Claudeに搭載されているビジネスドメインの知識をどのように組み合わせて複雑な問題を解決できるのか、その方法について詳しく見ていきます。Nicholasが、Tool UseとCallingに関するベストプラクティスをご紹介します。そして、Agentとはそもそもどういうものなのか、Function Callingとどのような関係にあるのかを探っていきます。Agentとは何か、簡単な質問だとお思いかもしれませんが、Nicholasが、その複雑さとプロジェクトやAgentにとってのAgentの定義の重要性について理解を深めてくれるはずです。その後、オーケストレーションの詳細、つまりAgentをどのようにオーケストレーションするのか、なぜそれが重要なのか、どのようなトレードオフが必要になるのかについて掘り下げていきます。最後に、Claudeのビジネスドメインの知識とAgentのパワーを組み合わせて、さらに複雑な問題に取り組む方法をご紹介します。
Function CallingとTool Useの起源と仕組み

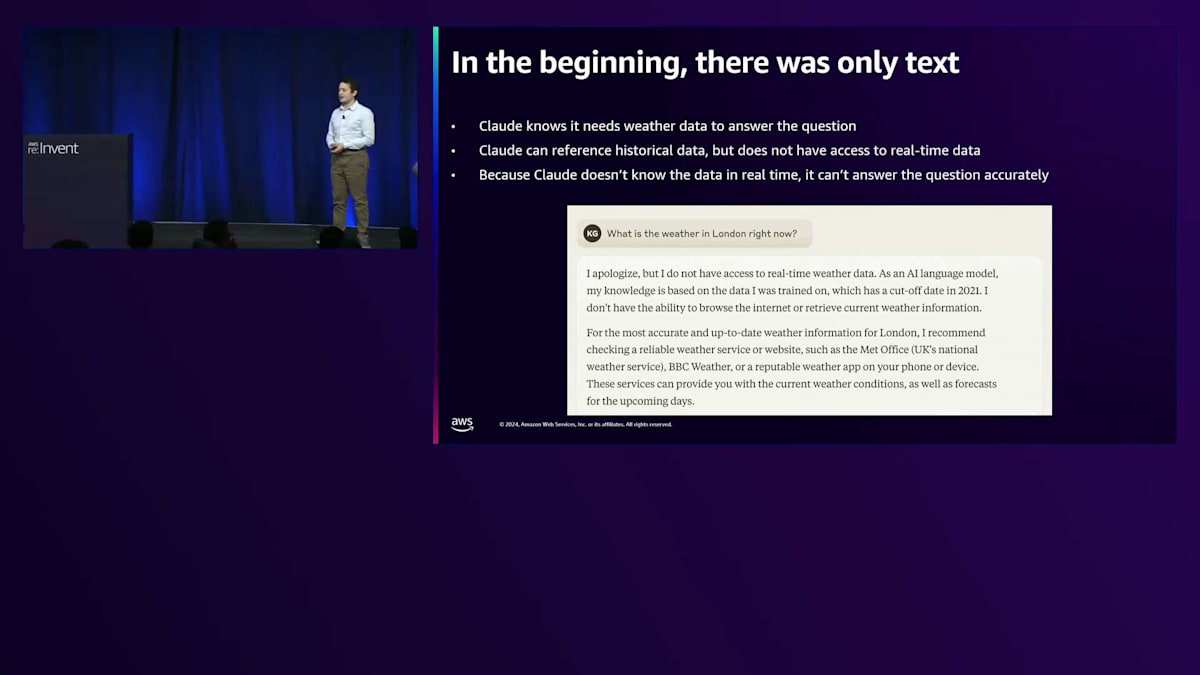
しかし、本題に入る前に、Nicholas、ロンドンの現在の天気はどうなっているか教えてもらえますか?はい、みなさんにお会いできて光栄です。Tool UseとAgentについて、まずは「なぜ」という部分と、その動機となる例から始めたいと思います。そのために、この質問に対するLLMの歴史を簡単にお話ししたいと思います。 「ロンドンの現在の天気はどうですか?」という質問です。最初は、テキストしかありませんでした。claude.aiで「ロンドンの現在の天気は?」と尋ねると、「申し訳ありませんが、リアルタイムの天気情報にアクセスできません」という回答が返ってきたでしょう。これは、Claudeが天気データが必要だということを理解しており、過去のデータを参照することはできるからです。実際、1996年6月20日のロンドンの天気なら答えられるかもしれません。しかし、リアルタイムデータにアクセスできず、5秒前にトレーニングされたわけでもないため、この質問に正確に答えることができないのです。

しばらくの間、私たちはこの状況で行き詰まっており、モデルができることが本当に制限されていました。そこで、モデルが外部世界から読み取りや書き込みができる方法が必要になりました。ここで登場したのが、Functionsです。Tool UseやFunction Callingとも呼ばれ、この発表では互いに置き換え可能な用語として使用します。その方法についてですが、実際のclaude.aiではこのようには行いませんが、何が起こっているのかを理解する上で有用な例として説明します。ユーザーからの質問を受ける前に、モデルに対して、質問に答える際に使用できるツールのセットがあることを伝えます。ここでは、Get Weather Tool、Order Pizza Tool、Send Email Toolへのアクセス権があるとします。そして、ユーザーからの質問も渡すと、Claudeは利用可能なツールを確認し、1つまたは複数の関連するツールを選んで呼び出し、ユーザーのリクエストを満たすために必要なデータを取得したりアクションを実行したりします。この場合、Get Weather Londonを実行し、従来のソフトウェアプロセスを使用してモデルからのリクエストを処理し、結果を返します。例えば、Pythonで書かれたGet Weather関数をLondonという引数で実行し、モデルに結果を返します。「ロンドンの気温は47°F」という情報を受け取ったモデルは、ユーザーの質問に答えるのに十分な情報を得たと判断し、元の質問に対する回答を出力します。「Get Weather Toolによると」という表現を避けたい場合は、プロンプトで調整することもできます。
これが、モデルが外部世界から読み取りや書き込みを行えるようにするための最初の解決方法でした。ここで、より大きな視点からなぜこれが重要なのかについて、Johnに説明してもらいましょう。
LLMの数学的能力とMRKL systemsの影響

ありがとうございます、Nicholas。なぜFunction callingなのか?その背景について見ていきましょう。 LLMは「100足す100」のような問題を解けるのでしょうか?もっと難しい問題も解けるはずだと思われるかもしれません。でも、「strawberryの中にRは何個あるか」を尋ねてみると...これは有名な例ですが、正しい答えを出せないことに驚かされます。実は「100足す100」と「strawberryのRを数える」は、同じような性質の問題なのです。では、このTool callingという考え方がどこから来たのか見ていきましょう。
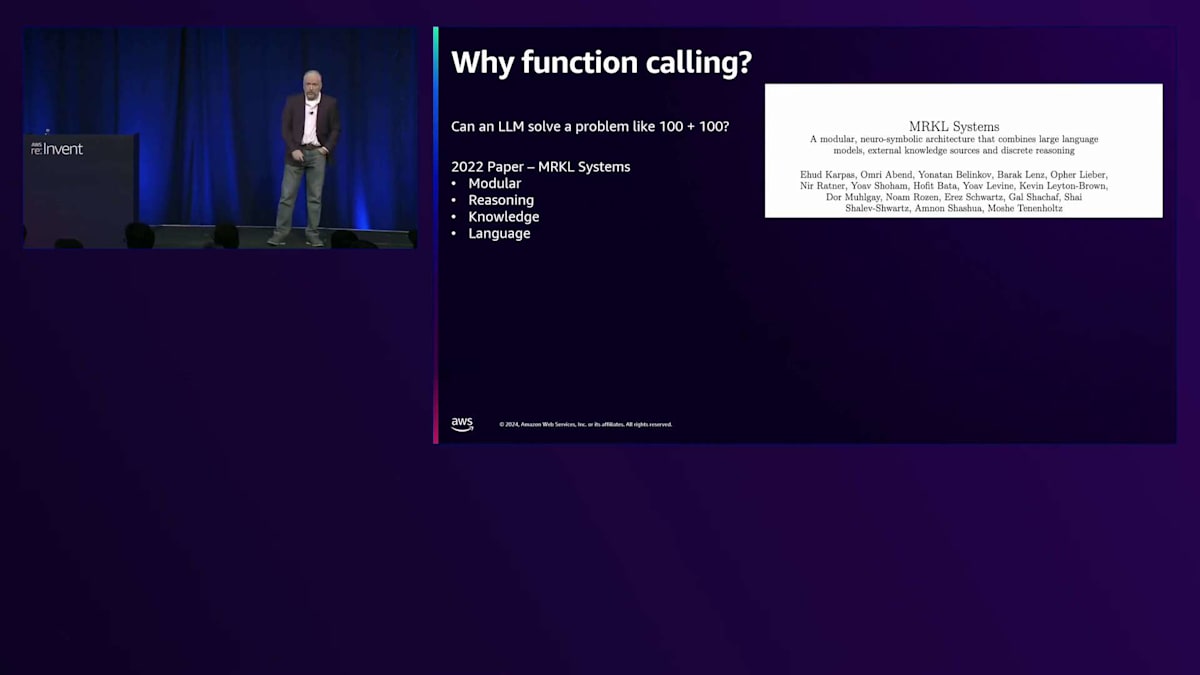
2022年まで遡ると、MRKL systems(Modular Reasoning Knowledge Language)という論文に行き着きます。一般的には「miracle」と発音され、当時のGen AIに大きな影響を与えました。 Langchainのようなよく知られているエージェントソフトウェアを見ると、この論文のアイデアを基にクラスを構築していることがわかります。このクラスは現在は非推奨となっていますが、コメント部分にはまだこの論文への言及が見られます。この論文は、エージェントやFunction callingのアーキテクチャと進化に大きな影響を与えました。
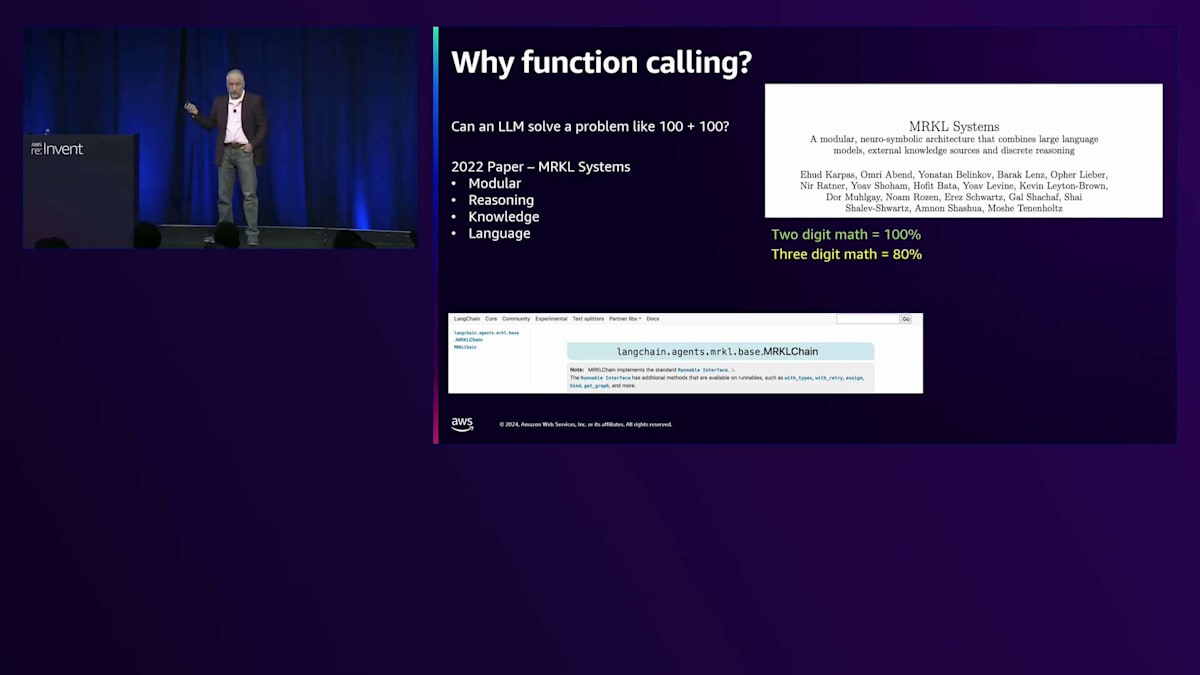
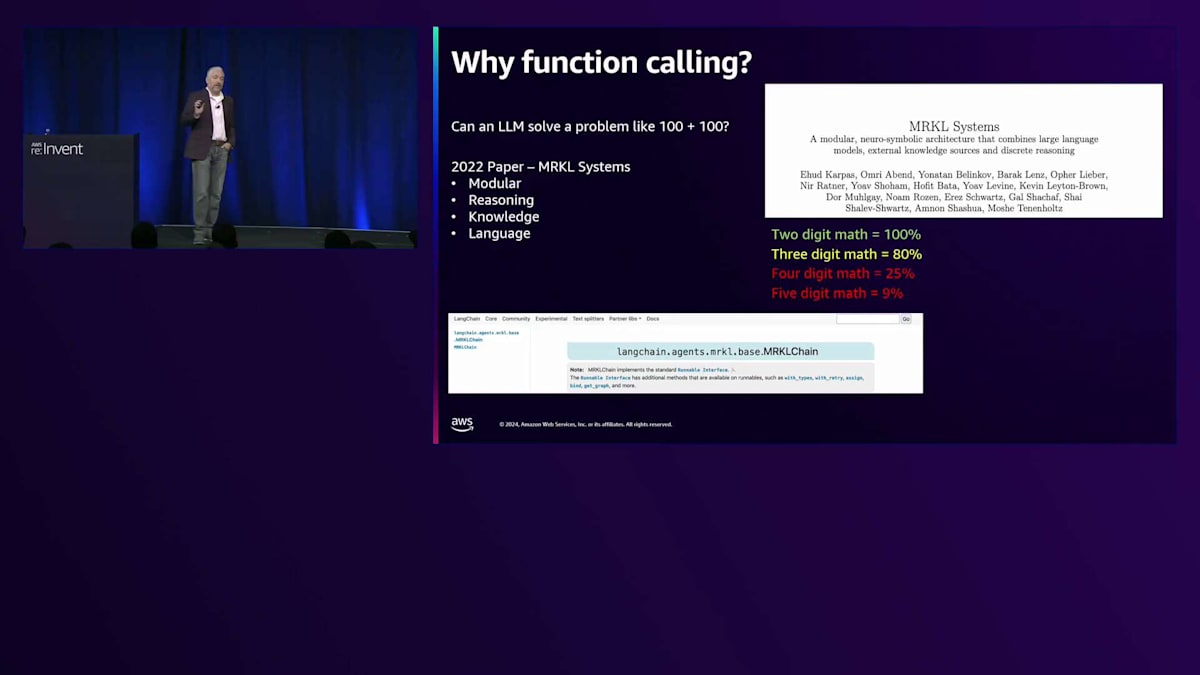
では、この論文で発見された、あるいは明らかにされたことは何だったのでしょうか?彼らは、10足す10のような2桁の計算であれば、モデルはほぼ100%の精度で答えられることを示しました。 100足す100のような3桁の計算は約80%、つまり10回中8回は正解を得られます。4桁の計算は約25%。5桁の計算は9%です。これはすべて単純な算術計算だということを覚えておいてください。 微積分などではなく、足し算、引き算、掛け算、割り算だけです。彼らは5桁の基本的な計算で、10回に1回も正解を得られないことを発見しました。
では何が起きていたのでしょうか?LLMは単に数学が苦手なのでしょうか?いいえ、違います。このモデルのトレーニングデータを調べてみると、学習時に見た数学の問題のほとんどが2桁の計算だったことがわかりました。3桁の計算もかなりありましたが、4桁の計算はわずかで、5桁の計算はほとんどありませんでした。つまり、この世代のモデルでは、あまり見たことのない問題に対しては、精度が非常に低かったのです。

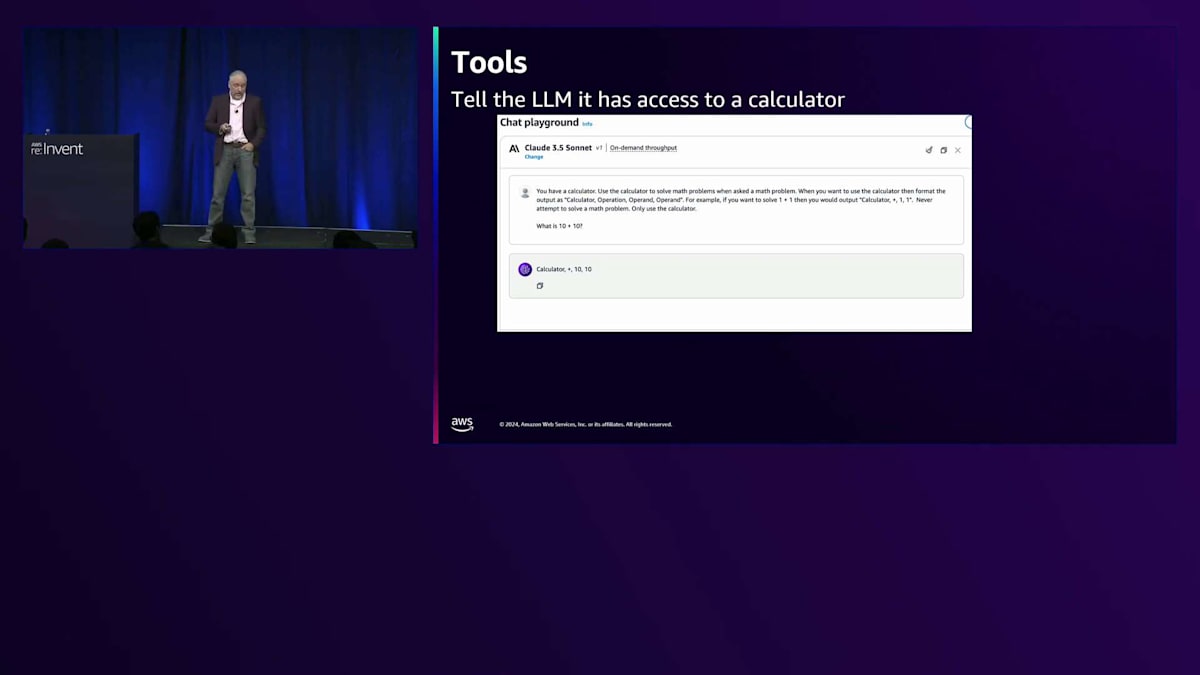
では、彼らはどのようにしてこの問題を解決したのでしょうか?信じられないかもしれませんが、ほぼ100%まで精度を戻すことができたのです。 モデルに問題を解かせる代わりに、計算機があることを伝えたのです。 Bedrockコンソールで、私はClaude 3.5を選択し、数学の問題が出てきたら計算機を使うように指示しました。そして、calculation(または calculator)operation operand operandというフォーマットで出力するように指定しました。例を示すと、「10足す10はいくつ?」と聞くと、答えが返ってきます。 これにより、文章題でも精度がほぼ100%になりました。「りんごが10個あって、さらに10個買いました。りんごは全部で何個ありますか?」というような問題でも解けるようになったのです。
なぜ精度が100%近くまで戻ったのでしょうか?それは、これらのモデルの基盤となっているTransformerモデルが、注意機制(Attention mechanism)を持っているからです。この機能により、LLMは非常に優れた分類器となります。文章中の単語や演算を組み合わせ、それを計算機として分類し、演算部分を特定して非常に正確に処理することができるのです。これで問題は解決したと思われるかもしれません。しかし、ご存知の通り、一つの問題を解決すると、新たな問題が生まれるものです。
Function callingの課題とAnthropicの解決策
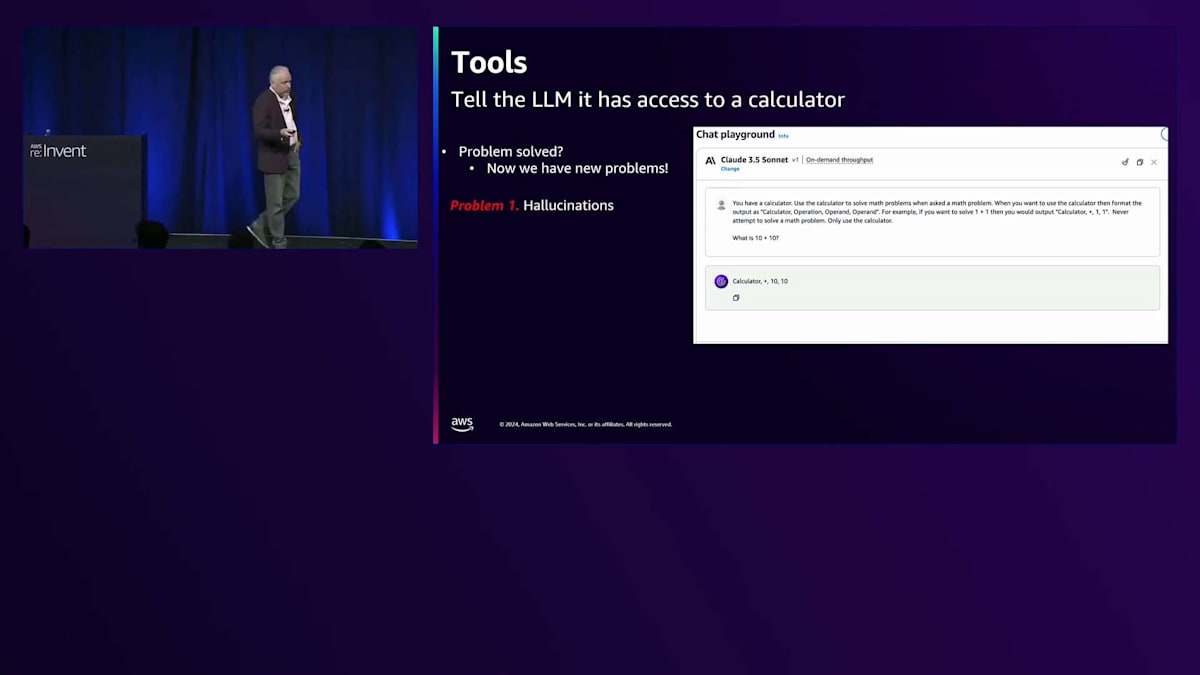
そうですね、聞こえましたよ。では、それらの問題とは何でしょうか?第一に:Hallucinationsです。例を含める際に「計算機があるので、これを使って計算してください」と指示すると、モデルは自分がアクセスできるツールの例を提示していると勘違いすることがよくありました。そのため、計算機のような新しいツールを作り出し、それを幻想として生成してしまうのです。
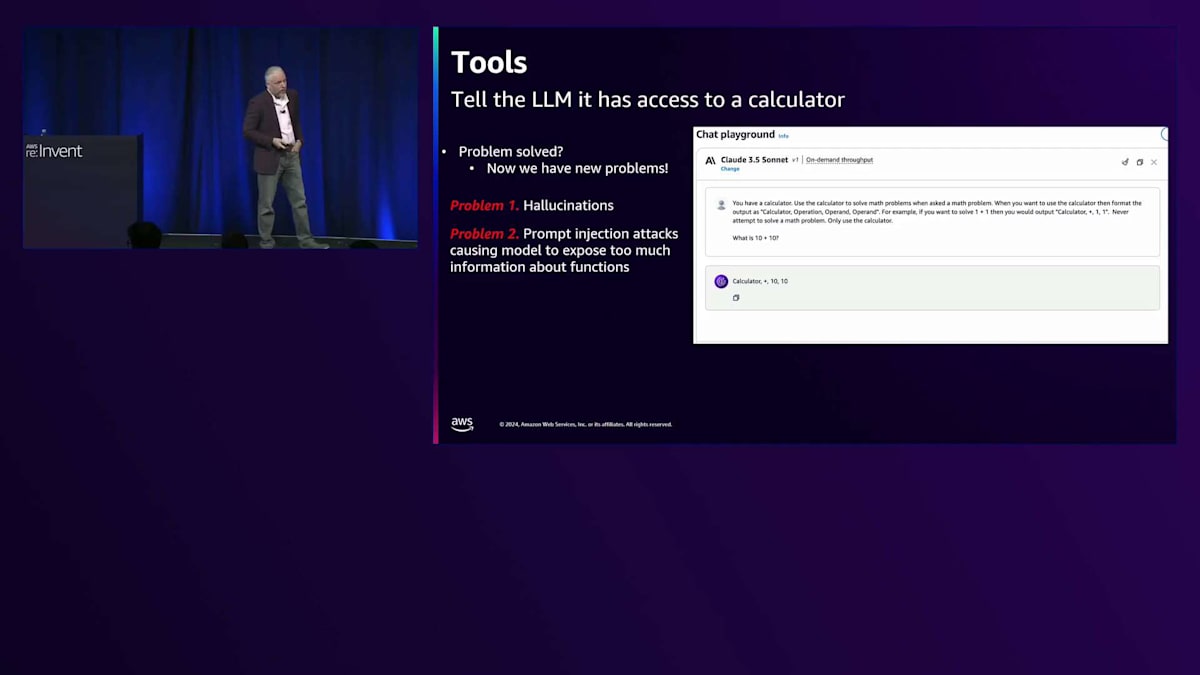
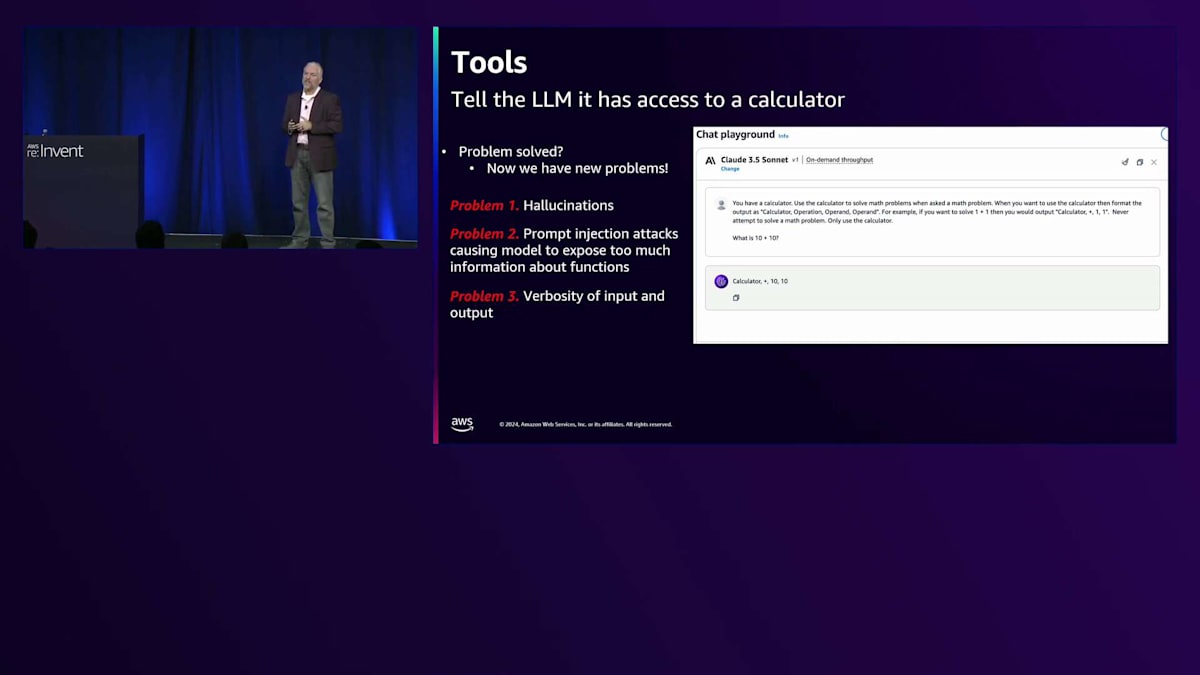
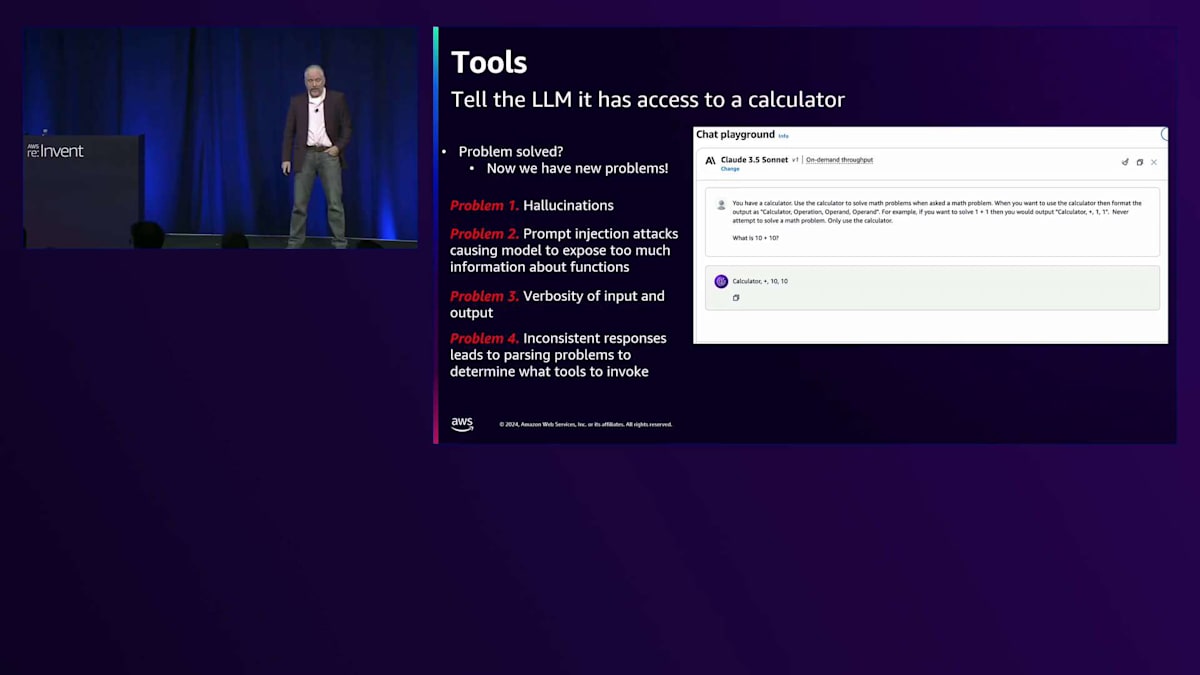
第二の問題は:Prompt injection attacksです。すべてを同じプロンプトに入れていたため、ツールの説明とユーザー入力を一緒に配置することになりました。すると、ユーザーがツールについて質問し、公開したくない情報を露呈させる可能性がありました。第三の問題は、入力と出力の冗長性です。これにより多くの入力トークンが発生し、LLMのレイテンシーは入力トークン数に依存します。そして、一貫性のない応答がパース問題を引き起こしました。ツールを使用するのか、最終的な回答を提供するのかを認識する必要がある場合、特定の構文で出力する必要があります。当時のLLMはこれが得意ではなく、ツールを自然言語で出力したり、ツールのような形式で最終応答を出力したりして、オーケストレーションの問題を引き起こしていました。


これが、Anthropicのようなモデルプロバイダーがツール専用の特別な構文に移行した理由です。いくつかの重要な点を強調したいと思います。Nicholasがツールの使用について詳しく説明しますので、その説明の中でこれらの点に注目してください。特別な構文により、ユーザーの質問をSystemプロンプトやツールの定義から分離します。モデルは提供されたツールをいつ使用するかを学習しているため、入力をそれほど冗長にする必要がなく、停止理由が決定論的に提供され、ツールの使用が明示されます。Nicholasが具体例を示してくれますが、これを利用すれば、出力テキストを解析するよりも信頼性が高くなります。

では、Nicholas、詳しい説明をお願いできますか?この会場にいらっしゃる方々は、LLMを使って何かを構築された経験があると思います。また、モデルに外部世界の読み書きが必要になったり、モデルのスキル不足に直面したりした経験もあるのではないでしょうか。5桁の計算は以前より改善されましたが、知識や知能を補完したい場面は他にもたくさんあります。多くの方が、ツール使用を抽象化するパッケージやライブラリから始めたのではないでしょうか - AnthropicのTool use API、Bedrock Agents、Langchainなどです。これから数分間、この抽象化のレイヤーを剥がして、その裏で何が起きているのかをお見せしたいと思います。なぜなら、実際には皆さんが考えているよりもシンプルで、開発者向けの優れたドキュメントを書くのと同じように、ツールの仕様を適切に記述することが重要だということがわかるからです。
Tool useの実装と動作の詳細

では、Tool useの実際の仕組みについてご説明します。 これは「写真に撮っておきたい」スライドですね。実は非常にシンプルな仕組みです。まず、モデルに対してプロンプトの中で、従うべき関数呼び出しの構文と、利用可能な関数やToolのセットを記述することから始めます。これをユーザーメッセージや、モデルに実行してほしいタスクと同じプロンプト内で組み合わせます。これらをモデルに渡してCompletionを生成し、そのモデルの出力に関数呼び出しが含まれているかどうかをチェックします。関数呼び出しが含まれている場合、モデルが呼び出そうとしている関数を解析し、従来のソフトウェアを使ってクライアントサイドやサーバーサイドで実行します。実行後、その従来のソフトウェアの結果を、前回のプロンプトで与えた情報すべてと共にモデルに戻します。そして、モデルに新しい応答を生成させ、モデルが関数呼び出しを行わなくなるまでこれを繰り返します。関数呼び出しがなくなったということは、タスクが完了して答えが得られたということを意味します。最後に、このタスクの結果を取り、裏で行われていたTool useをユーザーから隠して、モデルの最終的な結論だけを返すことができます。あるいは必要に応じて、結論に至るまでのプロセスも表示することができます。ユーザーが何が起きているのかを確認できるようにするためです。
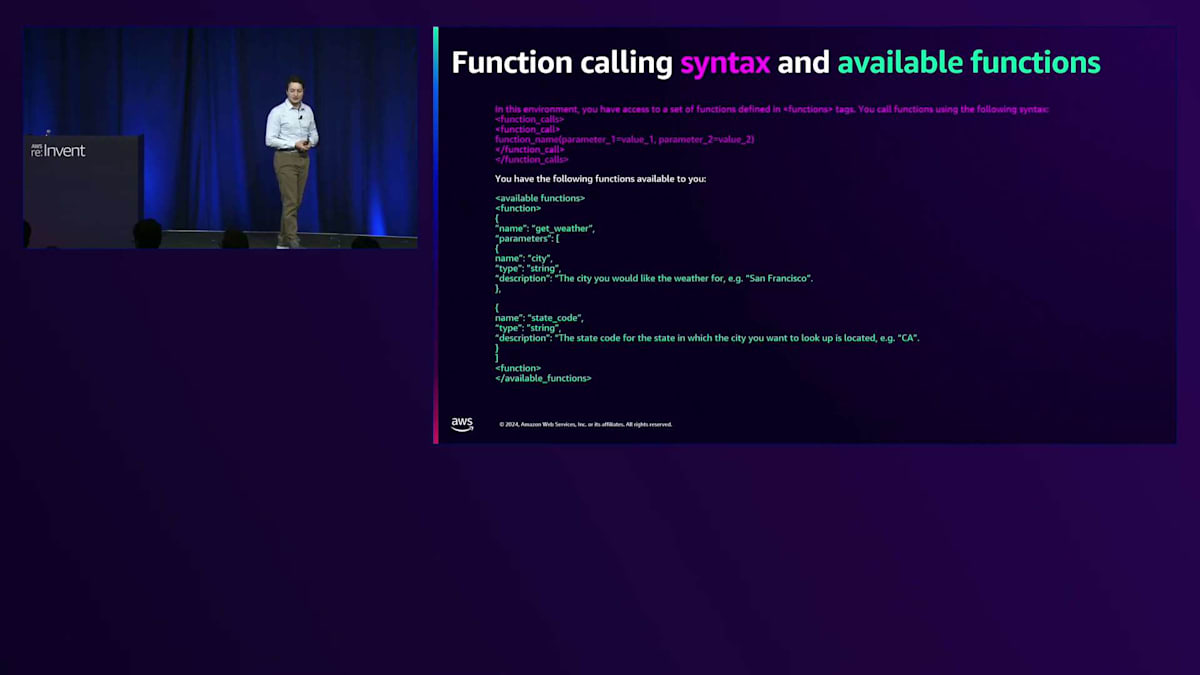
それでは、プロンプトとコードにおけるこれらのステップをより詳しく見ていきましょう。最初の要件は、関数呼び出しの構文と利用可能な関数です。 関数呼び出しの構文は、functionsタグで定義された関数セットにアクセスできるような形で、特定の構文を使って関数を呼び出すというものかもしれません。ここではXML構文を使った簡単な例を示していますが、他にもいくつかのアプローチが可能です。また、定義された関数へのアクセスも必要で、ここでは1つだけ示していますが、Claudeは現在、数十から数百のToolを同時に扱うことができます。これについては後ほど詳しく説明します。関数の仕様にはJSONを使用していますが、モデルが簡単に解釈できると思われる仕様であれば何でも構いません。
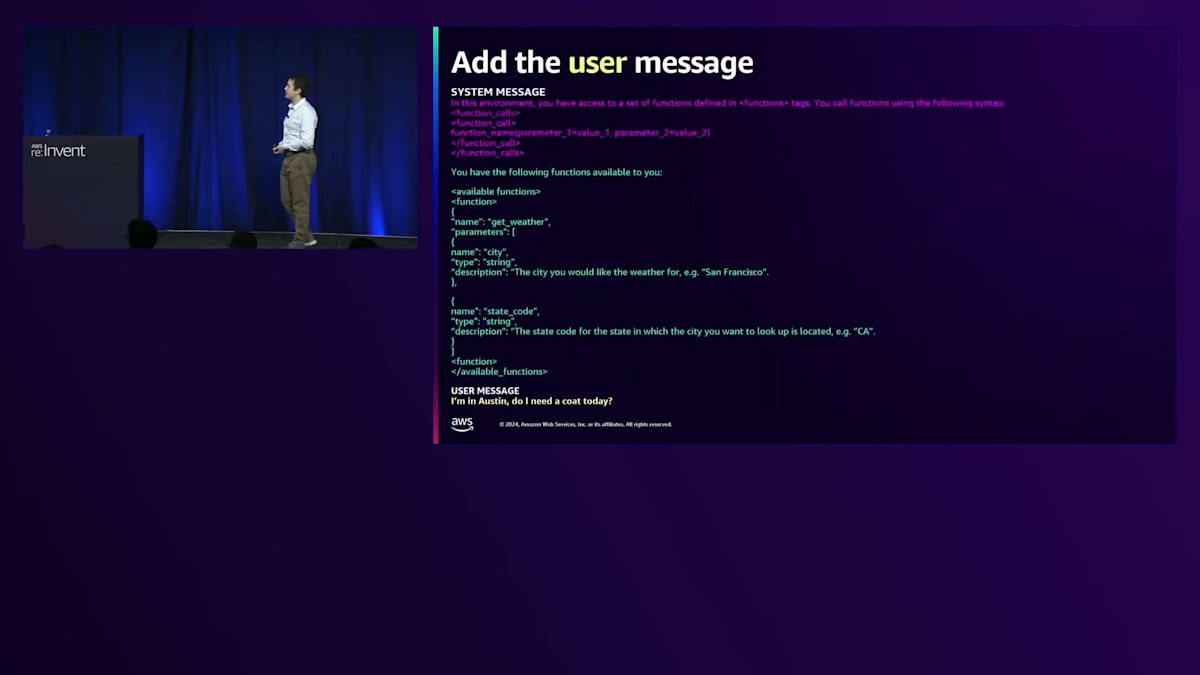

次に、示したToolに関連するユーザーメッセージが必要です。 例えば、「私はAustinにいます。今日コートは必要ですか?」というユーザーメッセージがあるとします。モデルはこの判断をするために天気を知る必要があります。これをSystemメッセージやUserメッセージと共にメッセージリストに集めて、多くの方がCompletions APIで行っているように、モデルの応答を生成します。 モデルの応答は、おそらく関数名とパラメータ(この場合はcity: AustinとState: Texas)を含む、私たちが記述したTool関数呼び出しの構文に従うことになります。注目すべき点として、Claudeの呼び出しに追加のStop sequenceパラメータを加えています。通常、Language modelをCompletions APIで呼び出す際には、モデルがトークン生成を停止するタイミングを知るためのデフォルトのStop sequenceがありますが、Tool useではこれに追加のStop sequenceを加えて利用します。

Stop sequenceを使用する理由は、モデルが次のトークンを予測する機械だからです。関数呼び出しを書いた後も生成を続けることを許可すると、その関数呼び出しに対する回答や応答を作成してしまいます。実際、モデルは続けることを許可されると回答を作り出してしまいます - これは関数の結果をシミュレートしたい場合には便利かもしれませんが、ここでは望ましくありません。 これは、Claude APIからの応答に関数呼び出しの構文が含まれているかどうかをチェックする簡単なPythonコードのスニペットです。Stop reasonがStop sequenceであり、期待される関数呼び出し終了シーケンスと一致するかを確認します。これが確認できれば、関数呼び出しが含まれていることをほぼ確実に知ることができます。


図の「yes」の部分に来ているので、 次のステップはClaudeが試みている関数呼び出しの解析と実行です。 解析の詳細は省略しますが、実行については、Claudeに指定したのと同じパラメータを受け取るget_weatherというPython関数かもしれません。これは天気のAPIを呼び出して、自然言語の形式で結果を返すかもしれません。関数の結果を自然言語で返すことは、モデルが結果をより良く理解するのに役立つことがよくあります。生の天気データを返すのではなく、現在の気温と降水確率を説明する補完された文字列を返します。


次のステップは、これらの結果をモデルに示すことですが、重要なのは、モデルが何を達成しようとしていたのかについての事前のコンテキストをすべて含める必要があるということです。 このコンテキストがなければ、モデルは結果をどのように使用すべきか理解できません。 私たちは、Function callingの構文と利用可能な関数を含むSystem messageを保持しながら、以前のチャット会話を継続します。
ユーザーメッセージ「What's the weather in Austin?」と、拡張されたAssistantメッセージがあります。これは注意すべき重要な落とし穴です。Assistantが関数を要求した後、関数の結果を新しいユーザーメッセージとして渡すことを考えるかもしれません。しかし、私たちが発見したのは、関数が呼び出されたAssistantメッセージの続きとしてこれらを渡す方が、はるかに効果的だということです。

これはCloudeで使える便利なテクニックです。メッセージリストがユーザーメッセージで終わる場合、自動的に新しいAssistantメッセージを開始しますが、メッセージリストがAssistantメッセージで終わる場合、新しいメッセージを開始する代わりに、そのAssistantメッセージの続きからサンプリングを継続します。Claudeが関数を呼び出して結果を受け取った会話の同じAssistantターンからサンプリングを継続することになります。

次に何をするのでしょうか?モデルからレスポンスをサンプリングします。今回、モデルは適切な回答を提供するために必要な情報を持っているので、「今日のAustinの気温は30°Cで、雨が降る確率は5%です。雨に備えたい場合を除いて、コートは必要ありません」といった回答を返すかもしれません。ここで、以前と同じコードスニペットを使用して、 関数呼び出しが含まれているかどうかを確認します。今回は関数を呼び出さず、実際の回答を提供したので、モデルが完了してユーザーに結果を返す準備ができたと判断できます。このテキストをユーザーに表示することになります。
AgentとFunction callingの関係性と進化

これが動作の仕組みです。ここでJohnに戻って、その使用方法についてさらに詳しく説明してもらいましょう。ここで、モデルの事前学習とトレーニング - 言語やビジネスドメインに関する知識 - の力とFunction callingを組み合わせて、本当にクールなことをやってみましょう。 ドメイン知識は、特定のテクノロジーを知ることよりも重要です - ビジネスについて知ることで、より生産的になれます。経験豊富なソフトウェアエンジニアのほとんどが同じことを説明するでしょう。ビジネスとコミュニケーションを取り、暗黙の要件を理解するのに役立ちます。

金融企業で新人ソフトウェア開発者として初日を迎えた場面を想像してみましょう。最初の簡単な慣らし仕事として、任意の株式銘柄のリターン率を表示する作業が与えられました。Price Toolという、日付範囲と銘柄を入力すると始値、高値、安値、終値のリストを出力してくれるツールが提供されています。上司からゴーサインが出て、パーセンテージの計算なら簡単だと思いながら了承します。 しかし、ここには暗黙の要件があります。例えば、始値、高値、安値、終値がある価格系列から、どのようにしてリターン率を計算すればよいのでしょうか?


つまり、始値から終値を使うと一つの数字が出ます。 安値から高値を使うと別の数字になります。始値から翌日の始値を使うと、これもまた異なる数字になりますし、終値から終値でも別の数字が出てきます。では、どうすればいいのでしょう?初日なので恥ずかしくて聞けません。 もしかしたら、どれを使っても同じようなものかもしれません。上司もわからないだろうし、適当にどれか一つを選んでも大丈夫かもしれません。
考えてみれば単純なことですが、毎日金融ニュースを見ると必ずリターン率が表示されています。S&P 500の本日のリターンはこれこれですと言いますが、そのリターン率の計算方法については説明されません。だから、みんな理解しているはずなんです。例えば、10月14日のS&P 500のリターン率をどう計算すればいいでしょうか?始値から終値を使うと約0.5%になります。始値から始値だとその倍の0.95%になります。終値から終値だと、また1.5倍くらいになります。これらは大きく異なり、この日は使用する方法によってプラスからマイナスに変わることさえあります。


これを見ると、やはり重要かもしれません - 上司に気付かれるかもしれません。ここは良い仕事をしたいので、Claudeに聞いてみることにします。Amazon Bedrock Converse APIを使ってみましょう。これは多くのベストプラクティスを実装していて、ストップトークンの処理やツール使用の構文を標準化してくれます。



そのプレミアモデルを使って、金融企業のソフトウェア開発者として 計算機があることを設定します。そして、Price Toolで取得した データを入力します。各日のリターン率を尋ねると、Claudeから過去5日間の リターン率を計算するために、始値から終値ではなく終値を使う必要があるという正確な回答が返ってきます。すべての価格を抽出し、ツールの使用方法を説明してくれます。マイナス演算から始めて除算を行い、正しい2日分のデータを抽出してくれました。

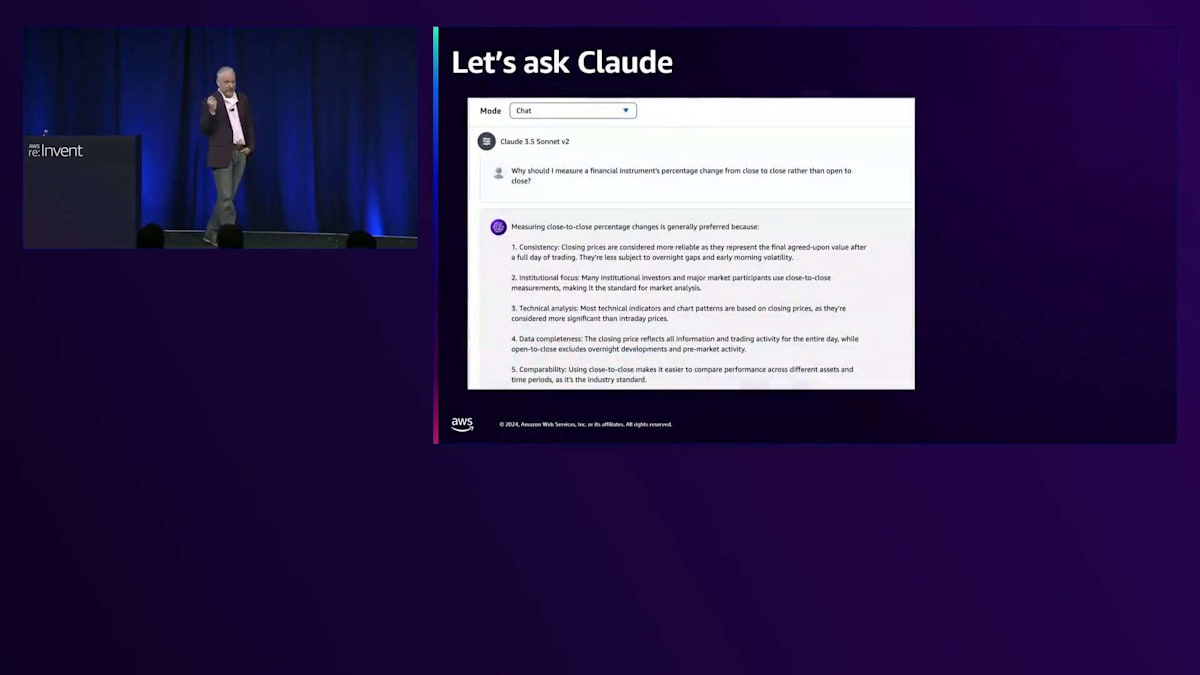
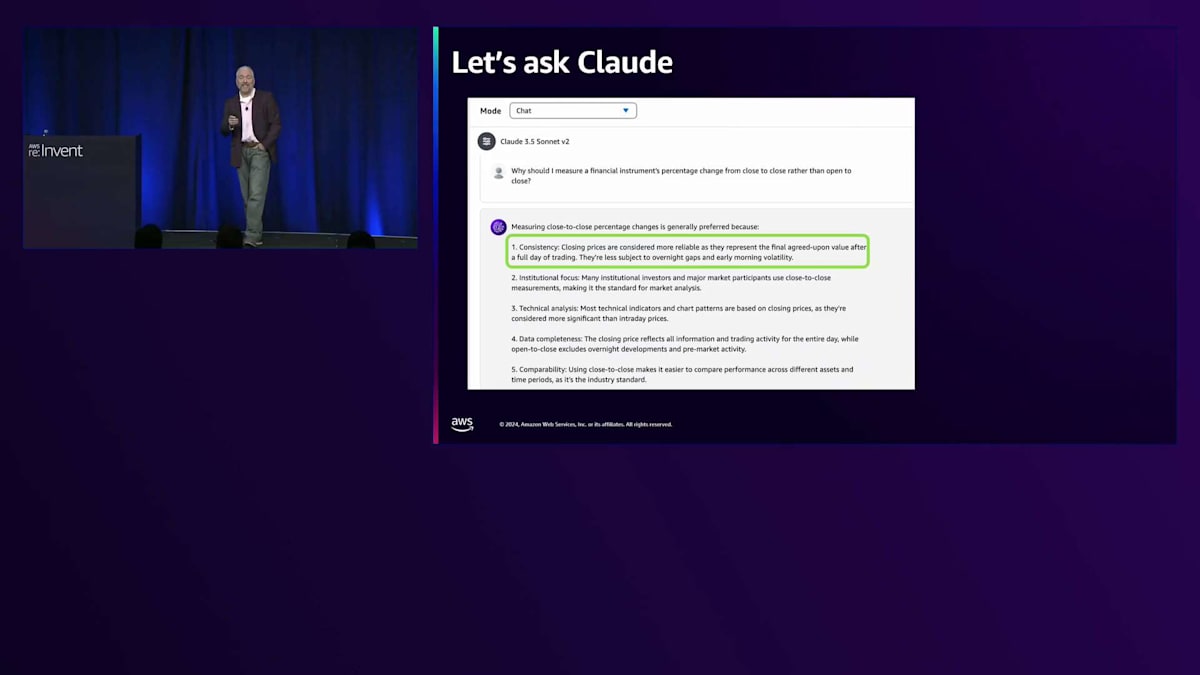
さて、初日ということで、なぜビジネスドメインの知識が必要なのかという疑問が残ります。1日目の終値から2日目の終値を使用することには、ビジネス上の理由があるのでしょうか?それともClaudeが単にランダムに選んだだけなのでしょうか?暗黙の要件があるのでしょうか?そこで、金融商品のパーセンテージ変化を、始値から終値ではなく終値から終値で測定すべき理由についてClaudeに尋ねてみましょう。Claudeはいくつかの理由を挙げていますが、特に2つに注目してください。1つ目は一貫性です - 終値は最終的に合意された価値を表すため、より信頼性が高いとされています。これは取引所によって設定され、多くの場合、法的には「Mark to Market(時価評価)」と呼ばれます。会計処理でも、金融商品を評価する際にはこの種の価格が必要です。これらは法的な価格で、通常は取引所が公表する当日の終値です。また、データの完全性も重要です。なぜなら、オーバーナイトのボラティリティを捕捉したいからです。多くの金融商品は時間外取引で取引されており、始値から終値を使用すると、それを見逃してしまいます。

つまり、Claudeはそれを理解していたわけです。さて、次の疑問として、Nicholasがオーケストレーターループの書き方を実演したように、Function Callingにはかなりの力があることがわかりました。これほど強力なのであれば、Agentとは一体何なのでしょうか?約1年前、私がAgentについて取り組み始めた時、この質問を自分自身に投げかけました。私なりの良い答えを持っていたと思い、後ほどそれを共有しますが、Agentの採用を試みていた最初の顧客たちと話し始めると、私の答えが彼らの答えと異なっているだけでなく、彼らの答えも互いに異なっていることがすぐにわかりました。このAgentという用語は、誰も本当の定義に同意できないほど多義的になっていたのです。


次のスライドで簡潔な定義を示せればよかったのですが、代わりにこのようなものを示さなければなりません。これは「ホットドッグはサンドイッチか」というインターネット上の炎上議論を解決するために使用したものですが、「Agentとは何か」という問題も解決できると考えています。私は現在、AgencyとEffectという2つの軸でAgentを考えています。Agency軸は選択に関するもので、モデルにどの程度の決定権を与えるか、つまり何をするか、いつ実行するか、いつ答えを出すか、そしてその出力を最終ユーザーや顧客にどのように見せるかということです。もう一方のEffect軸は、モデルが行うことの影響力に関するものです。ここでツールの使用が関係してきます。純粋主義者は、外部世界から読み取りと書き込みの両方ができるものだけがAgentだと言うでしょう。一方、急進的な考え方では、Effectはエージェントにとって重要ではないと主張するかもしれません。モデルからの応答は全てAgentだと言う人もいれば、仮想従業員に近いものでなければAgentとは言えないと主張する人もいます。では、先ほど説明したチャートでこれがどのように見えるか確認してみましょう。

これは、EffectとAgencyの急進主義者の視点から見たチャートかもしれません。この見方では、言語モデルの出力は全てAgentとなります。ツールを使用する必要はなく、単一のステップでも構いません。モデルに対して何をすべきかを非常に厳密に指示することもできます。これは、私の考えるAgentの定義に合致する、現在市場で展開されているものの大部分です。
これはEffect純粋主義でAgency中立的な見方で、ある程度の読み書きツールの使用が必要とされます。モデルに決定権を持たせる必要はありますが、人間に与えるような完全な自律性は必要ありません。このフローがAgency中立的でAgency純粋ではない理由は、これらのピンク色のボックスで実際にモデルの自律性を管理し制限しているからです。ユーザーメッセージがあり、モデルに見せる前に、別の分類器でそのメッセージを実行して、Claudeにどのようなプロンプトを与えるべきか、どのツールを使用すべきか、そしてプロンプトにどのような指示を含めるべきかを決定します。

私たちはすぐに、モデルのオプションの範囲と指示のセットを制限します。その上でモデルには、ツールの使用や回答の生成など、エージェントらしい多くのことを行わせます。しかし、顧客に見せる前に、人間のオペレーターが表示内容をチェックすることを望みます。これは、モデルの自律性に対するもう一つのコントロールポイントであり、モデルが完全に制御を握っているわけではありません。これは今日、最先端のAgentを構築している人々からよく見られるアプローチです。そして面白いことに、左上のコーナーに目を向けると、純粋なAgent主義者の場合、結局ツール使用のチャートに戻ることになります - モデルが何をするか、いつするか、そしておそらく最も重要な、いつ完了するか、何ステップ必要かを決定できるループの中でのツールです。これが純粋なAgent主義です。面白いことに、ツール使用の元々の概念は、実はAgentの定義を最も厳密に考える人々にとってのAgent的なツール使用だったのです。

しかしなぜ私たちは、このツール使用からAgentへの変化を気にする必要があるのでしょうか?私が見ているのは - そして私は常に驚かされているのですが、人間は指数関数的な成長の初期段階にいることを認識するのが苦手なのです - モデルが一度に扱えるツールの数と、取り組めるタスクの複雑さや時間的な範囲が急速に拡大しているということです。1年前までは、Claudeは限られたツール(最大でも1〜6個)と短期的な時間範囲のタスクが与えられた場合にのみ、確実にアクションを実行できました。広告の例で言えば、「Claude、私の広告キャンペーンのCTRはどうですか?」というような質問に対して、Claudeは基本的に関連データを検索する単一のツール呼び出しを行い、計算を実行するだけでした。
今日では、Claudeは多数のツール - 数十個、時には数百個のツールも見かけます - と複雑だが短期的なタスクが与えられた場合でも、確実にアクションを実行できるようになっています。例えば、「Claude、現在の広告予算の状況について完全なレポートを作成できますか?」というような依頼です。将来的に、これらの機能が拡大し続けるにつれて、Claudeは大規模なツールセットと複雑なタスクだけでなく、中長期的な時間範囲のタスク - つまり、完了までに数十から数百のステップが必要で、作業単位がより非原子的なタスク - も確実に実行できるようになると予想しています。例えば、「Claude、昨年分のデータを分析し、そのデータに基づいて新しい広告キャンペーン戦略を提案し、それを開始してください」というようなタスクです。これは、従来の業務では多くの人々が多くのステップと作業単位を必要とするものです。

しかし、この進歩が起きているということをスライド上の仮説的な目標だけで判断しないでください - 実際のデータを見てみましょう。今日、世界で最も注目されている2つのAgent的ユースケースの1つがコーディングです。Agent的コーディングは、数年前に見られたコード補完(コードの1行を書いているときにモデルがその行の最後の2つのトークンを書く)とは異なります。Agent的コーディングは、モデルにタスクと場合によってはコードベースを与え、単にプルリクエストを提出するなどの作業を依頼することです。
私たちはAgent的コーディングのための社内ベンチマークを持っています。素晴らしい外部ベンチマークも多くありますが、私たちの社内ベンチマークでは、Claudeにオープンソースのコードベースと、機能の追加やバグ修正のための自然言語リクエストが与えられます。これらは実際にこれらのオープンソースコードベースに対して実際に開かれたリクエストです。Claudeの仕事は、人間の介入なしにコードベースへの変更を実装することです。私たちは、最低3つのファイルから最大20個のファイルまでの検索、表示、編集が必要な課題を選んでいます。
重要なポイントとして、Claudeはただコードを書いて終わりというわけではありません。コードを書くだけでなく、変更を加えながらサンドボックス内でそのコードを実行し、タスクを達成できているかを確認してから、完了したと判断します。開発者が他の人にプルリクエストを出す前にするように、もし間違いがあったり、何かが機能するか不確かな場合は、自分で試してみて解決することができます。Claudeは、コードベースのテストがその変更に対して実際にパスするかどうかについても評価されています。
Amazon Bedrock AgentsとReActオーケストレーションの実践
1年も経たない前にClaude 3をリリースした際、モデルサイズと知能が増加する順にClaude 3 Haiku、Sonnet、Opusをリリースしました。当時、Claude 3 Sonnetはこのタスクで約21%のスコアを記録し、Claude 3 Sonnet よりもはるかに大きく高性能なClaude 3 Opusでも、おそらく38%程度でした。それから6ヶ月も経たないうちに、このファミリーの最初のモデルアップグレードとしてSonnetのアップグレードをリリースしました。Claude 3.5 Sonnetは、このタスクでのスコアが21%から64%に向上し、これは前世代の3倍、そしてわずか6ヶ月前の自身よりもはるかに大きなモデルの約2倍の性能でした。この進歩は単なる観察や感覚的なものではなく、私たちが重視し、モデルの実世界での応用を表していると考えるベンチマークで実際に確認されています。


では、BedockとAgents、そしてFunction Callingについてもう少し詳しく説明するために、Johnに戻したいと思います。ありがとうございました。かなりの内容を説明してきましたね。ちょっと一息つかせてください。この乾燥した空気は本当に喉にきます。Bedrock Agentsを使用すると、私たちが話してきたこれらすべてのことを活用できます。このスライドでお見せしているのは、Bedrock Agentsの内部アーキテクチャです。Agentsは、Lambdaで提供するツールを使用できますし、Return of Controlと呼ばれる機能もサポートしています。これを使えばローカルでホストして、ツールを呼び出すタイミングをお知らせします。関数のシグネチャ、説明、パラメータを提供します。また、Knowledge Basesも使用できます。Knowledge Baseを設定すると、私たちがプロンプトエンジニアリングを行い、それもツールとして設定します。




リクエストを受け取ると、Converse APIを使用し、適切なツールブロックと共にそのリクエストをモデルに送信し、プロンプトエンジニアリングを代行します。その後、ツール使用のレスポンスが返ってきたら、ツールを実行するか、Return of Controlを使用している場合は、実行するようにお知らせします。では、この内部の仕組みについてもう少し詳しく見ていきましょう。Bedrock AgentsはデフォルトでReAct戦略を使用します。ReActはReason and Actionの略で、まさにNicholasが示したとおりです。私たちの内部コードであるオーケストレーターがユーザーのリクエストを受け取り、提供されたツールと共にConverse APIリクエストを構築し、選択したモデルに送信します。
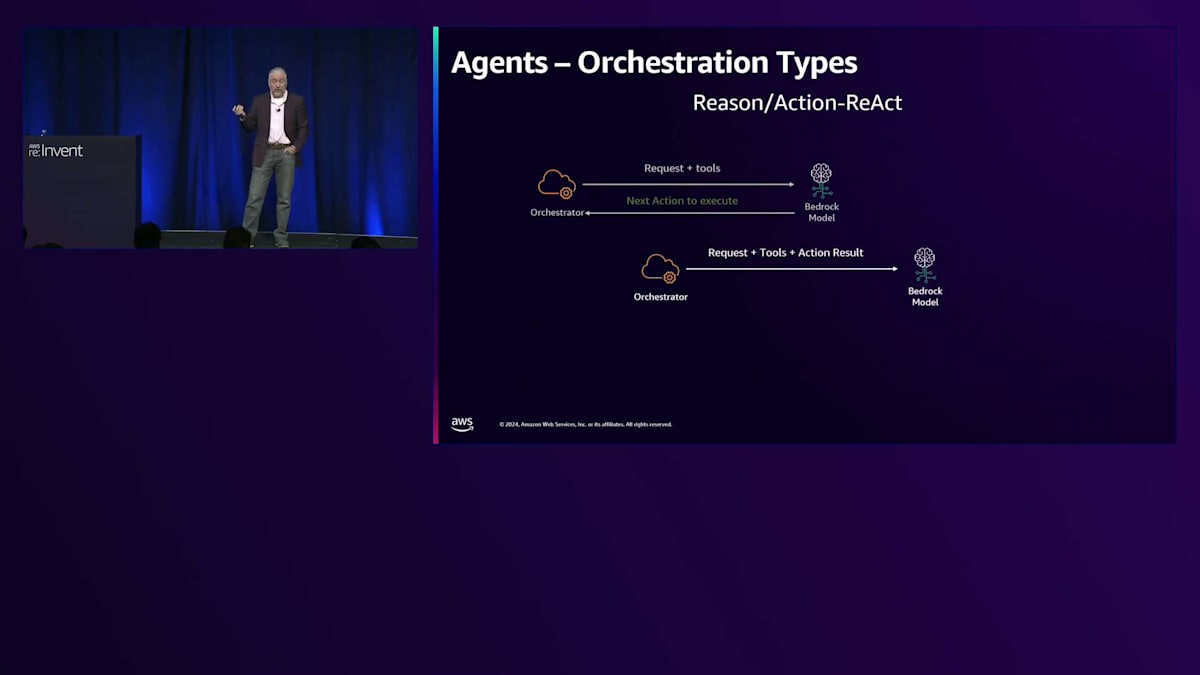
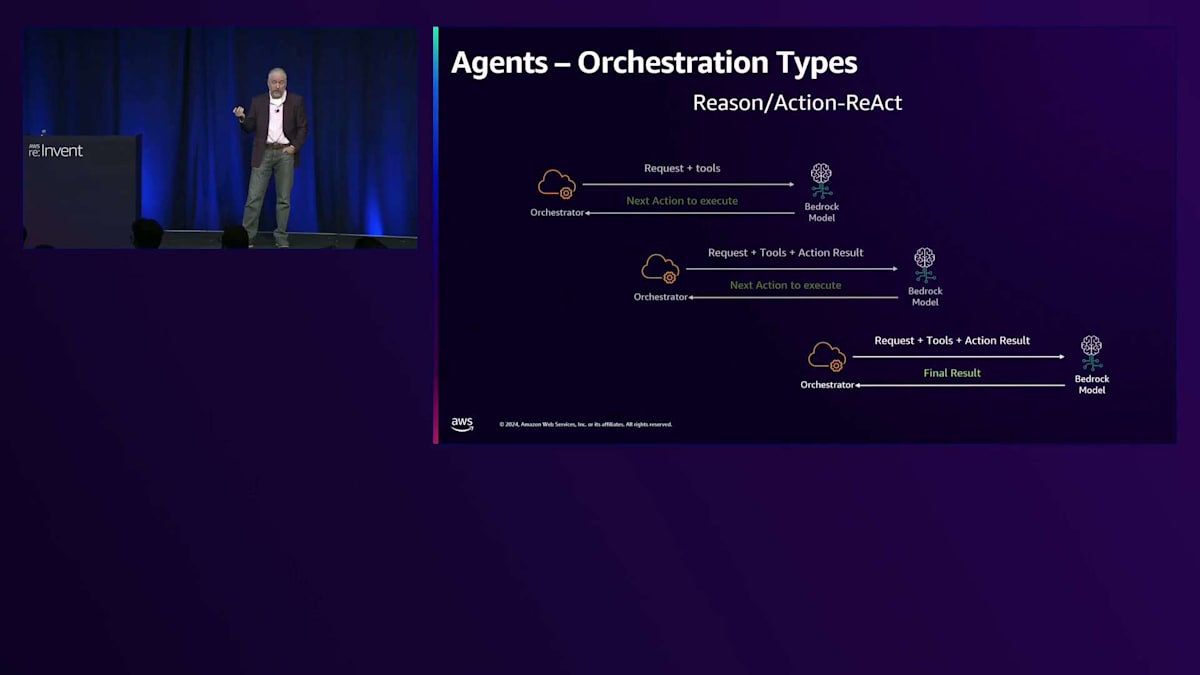
そして、どのアクションを実行すべきかが示され、そのアクションを実行し、リクエスト、元のリクエスト、ツール、そして結果を組み合わせます。最終的な回答が得られるまでこれを繰り返し、得られたら、それをInvoke Agent APIとしてReActで返します。このプロセスがReActアプローチの基本的なワークフローを示しています。
このワークフローに基づき、Reactはオーケストレータースタイルおよびプロンプトスタイルとして、いくつかの利点があります。Reactを見ると、オーケストレーターやプロンプトスタイルという用語に出会いますが、これらはこうしたアプローチを指す呼び方です。主な利点の一つは、各アクションにおいてモデルが次のステップを判断することです。モデルは計画を立てて出力し、そのアクションに基づいて次のアクションを決定し、必要に応じて計画を修正していきます。他のプロンプトスタイルと比べて、精度が高く、堅牢性があり、ツールの使用とも自然に連携します。ほとんどのモデルベンダーは、ReactスタイルのプロンプトやChain of Thoughtスタイルのプロンプトに対応するよう学習を行っています。
このアプローチにはいくつかの欠点もあります。主な懸念は遅延です。2回のツール呼び出しがある場合、3回のモデル呼び出しが必要となり、これらのモデル呼び出しは多くの場合6〜10秒かかります。2〜4回のツール呼び出しがあると、容易に1分近くの遅延が発生します。より長い軌跡や計画では、時間の経過とともに計画を忘れてしまう可能性があり、これは複雑な時間軸に関連します。また、Reactループでは事前に定義された計画に従うことが難しいです。5つのステップを指定しても、Reactはモデルに計画を確立させる設計になっているため、必ずしもそれに従わない場合があります。



ReWoO(Reason Without Observation)のような他のオーケストレーションタイプもあります。 これは、リクエストとツールを送信しますが、次のステップを提供するのではなく、すべてのステップを一度に出力するように指示する、より詳細なプロンプトです。 アクションの完全な計画を提供し、そのアクションのシーケンスを実行します。 オプションとして、結果を送り返すと、自然言語での応答が得られます。
ReWoOの主な利点は遅延の面です。4つのツールを呼び出す必要がある場合、どのツールを使用するかを決定するためのモデル呼び出しを1回で済ませることができます。計画に従うのが非常に得意です。トレードオフとして、モデルの応答からツールの実行をパースするためのコードをより多く書く必要があります。あるツールの出力が別のツールの入力に依存する場合、その依存関係を自分で管理する必要がありますが、Reactではモデルがそれらの依存関係を処理します。ReWoOはより多くのコードが必要で、より脆弱です。Reactでは、コードが少なく、プロンプトが簡潔なため、モデルが改善されるにつれてそのアップグレードの恩恵を受けることができます。ReWoOは新しいモデルのアップグレードに対してより脆弱で、プロンプトエンジニアリングを見直す必要があるかもしれません。

Amazon Bedrock AgentsのデフォルトオーケストレーターはReactですが、ReWoOや他のオーケストレーションタイプを使用することもできます。これは金曜日に発表されたばかりで、Amazon Bedrockカスタムオーケストレーターの使用開始に関するブログ記事があります。今すぐ使用できるReWoOの例があり、デフォルトのReactと比較して、どちらが better に機能するか確認できます。これはカスタマイズ可能で、Lambdaに組み込むことができ、私たちのコードを取得してLambdaに入れ、Agentと一緒に実行できます。プロンプトを再定義したり、好みの方法で実行したりすることも可能です。ブログ記事を読むことをお勧めします。ReactやReWoOのようなplan-and-solveタイプのプロンプトについて深く掘り下げているからです。

それでは、Function callingで見たよりもさらに複雑なAgentの例を見ていきましょう。私たちはAgentでモデルのビジネスドメイン知識を活用したいと考えています。そして、金融企業の新人ソフトウェア開発者という設定はそのままです。同じ日の出来事ですが、問題を解決すると新たな問題が生まれるというのは、すでにお話した通りですよね。

上司に見せたところ、「新入社員なのにこんなに詳しいなんて素晴らしい。もっと難しい課題を任せよう」と言われました。パーセンテージ変化の計算はできましたが、今度はもっと複雑なタスクが来ました:過去30日間のデータに基づいてS&P 500の年間ボラティリティを計算してください、と。


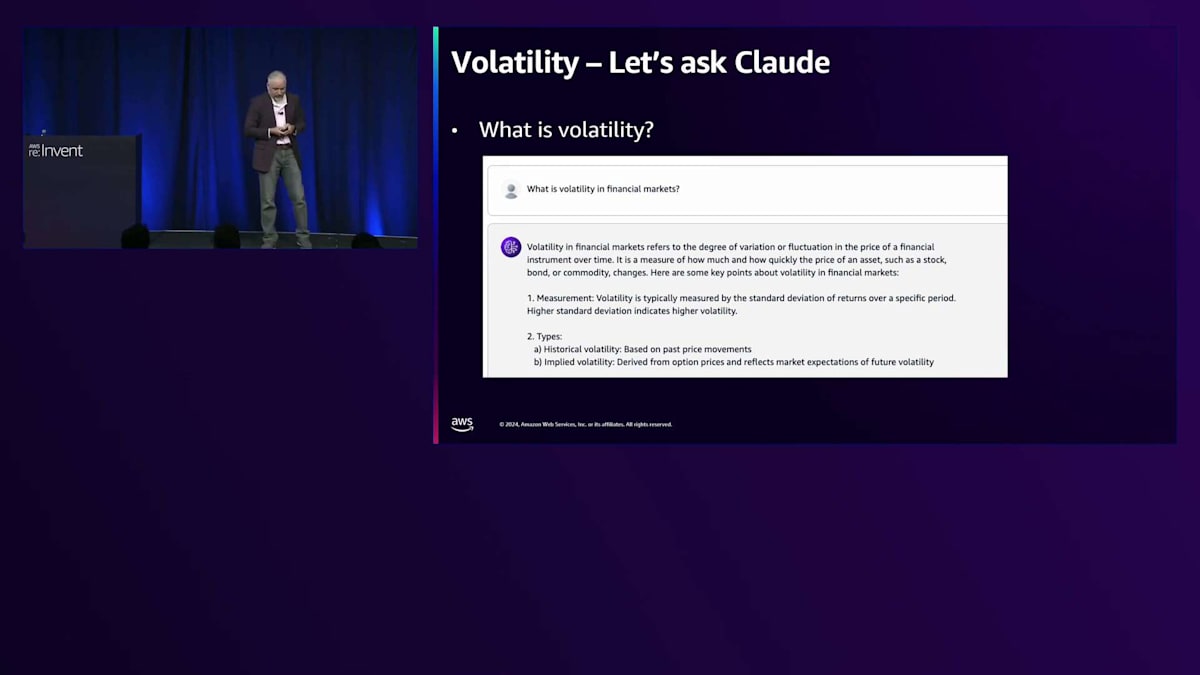
これは複雑そうに聞こえますが、仕事の初日なので上司に印象付けたい。もしかしたら2日目で昇給があるかもしれません。いくつか疑問があります。まず第一に、ボラティリティとは何か?第二に、業界標準の計算方法は何か?第三に、どんなデータが必要か?そこでClaudeに聞いてみることにしました。金融市場におけるボラティリティについて尋ねると、いくつかの回答が返ってきました。重要なポイントを強調させていただきます。最初のポイントは、金融市場におけるボラティリティとは、時間の経過に伴う価格の変動や振れ幅の度合いを指すということです。つまり、ボラティリティが15%だとすると、15%の損益が予想される、あるいは8%上がって7%下がるといった具合です。これは投資アドバイスではありませんが、基本的にボラティリティとはそういうものです。


測定方法は?標準偏差です。学校で習った標準偏差ですね - 標準偏差が大きいほど、ボラティリティも高くなります。正式な定義は平均からの平均距離です。そして3つ目のポイントは、ヒストリカル・ボラティリティです。過去30日間に基づくと言われたので、将来を予測するインプライド・ボラティリティではなく、ヒストリカル・ボラティリティを計算することになります。要件をまとめると:30日分のデータが必要で、パーセンテージ変化を計算する必要があります。過去30日間の日次標準偏差を得るために、この一連のデータの標準偏差を取ります。でも待ってください、年間ボラティリティを求められていますよね。日次ボラティリティが出てくるので、これを1年間で予想される値に変換するにはどうすればいいでしょうか?
そこでAgentを作ることにして、今回は単純な計算ツールではなく、Bedrock Agentでコードインタープリターのチェックボックスにチェックを入れます。Agentを作成する際に、Code interpreterを使うように指示します。Code interpreterはPython REPLのサンドボックス実行環境で、Claudeがコードを生成すると、そのコードを実行して結果を返してくれます。プロンプトエンジニアリングは私たちが行いますので、オンにするだけで環境のサンドボックス化とセッション管理は私たちが行います。実際の市場データを取得できるツールも用意しています。

ここで簡単なUIのデモを作成しました。これを実行すると、質問を入力して、トレースイベントが流れていくのが見えます。トレースイベントとAgentの中間イベントは、どのツールを使用しているか、モデルをいつ呼び出しているか、モデルからいつレスポンスを受け取っているか、そしてコードを生成する時期を教えてくれます。実際に動かして、どのように機能するか見てみましょう。私はCode InterpreterとPrice Toolという2つのツールにアクセスできるBedrock Agentを作成しました。Price Toolは銘柄と日付範囲を指定して株価を照会でき、Code Interpreterは与えられたコードを実行します。モデルがPythonコードを生成すると、Code Interpreterがそれを実行します。ここでは、モデルのビジネスドメインの知識とこれらのツールを組み合わせて、複雑な問題がどのように解決されるかを見てみましょう。画面上では、すべてのトレースが流れていくのが見えました。


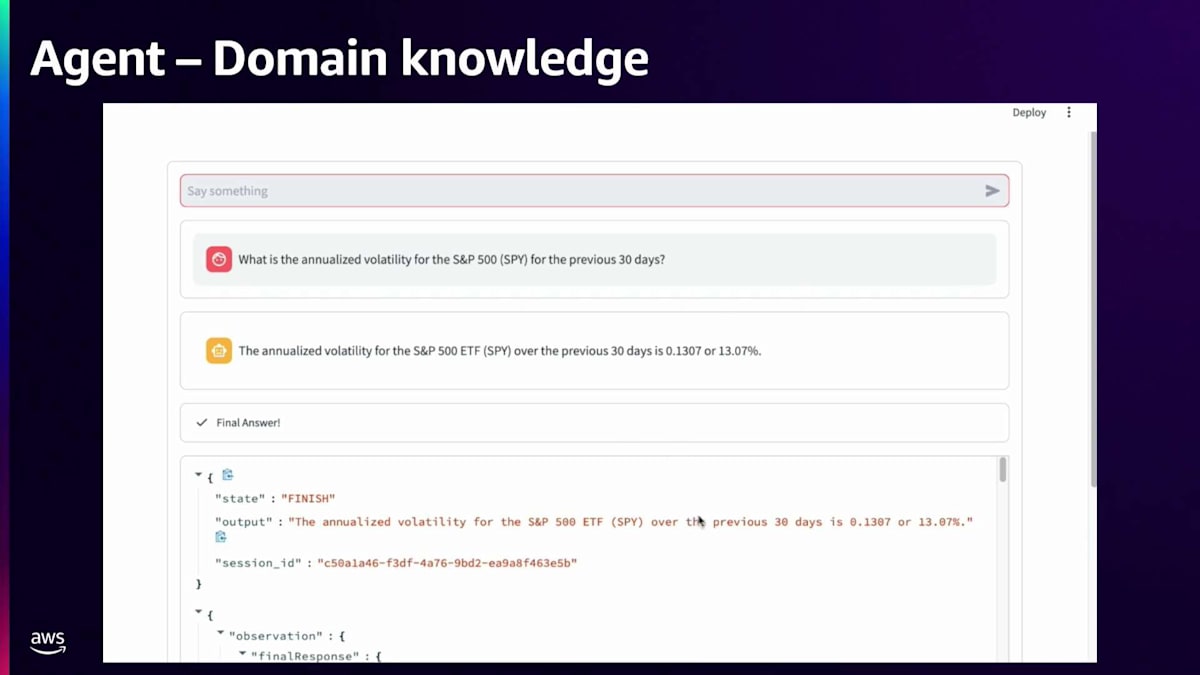
Bedrock Agentsは、実行されているすべての中間ステップを示すトレースイベントを出力します。これらのトレースイベントの中で、データツールやPrice Toolが呼び出されているのを確認できます。また、Code Interpreterが呼び出され、年率換算されたボラティリティが13.07%という答えに至るまでにどのようなコードが生成されたのかも確認できます。データがどのように照会されたのか、下に進んで確認してみましょう。ここでは、Price Toolが銘柄SPY、開始日2024年10月15日、終了日2024年11月14日(今日)というパラメータで呼び出されているのが分かります。このデータを取得した後、どのように活用したのか見てみましょう。

コードに注入されたデータが確認できます。30日間だけだったので、定数として入力することを選択しました。ログリターンを計算するこのコードを生成しました。先ほど関数呼び出しで日々の変化率を決定する際に話したように、終値同士で計算します。そのことを理解した上で、これらのログリターンを取得し、標準偏差を計算して日次のボラティリティを得ています。元の質問が年率換算されたボラティリティを求めるものだったので、そのボラティリティを年間の数値にスケーリングするには時間の平方根を使用する必要があることを理解していました。252は1年の営業日数にほぼ等しいので、252の平方根を取り、標準偏差にそれを掛けてスケーリングし、年率換算されたボラティリティを算出しました。これにより、過去30日間のSPYの年率換算ボラティリティが約13%という最終的な答えが得られました。
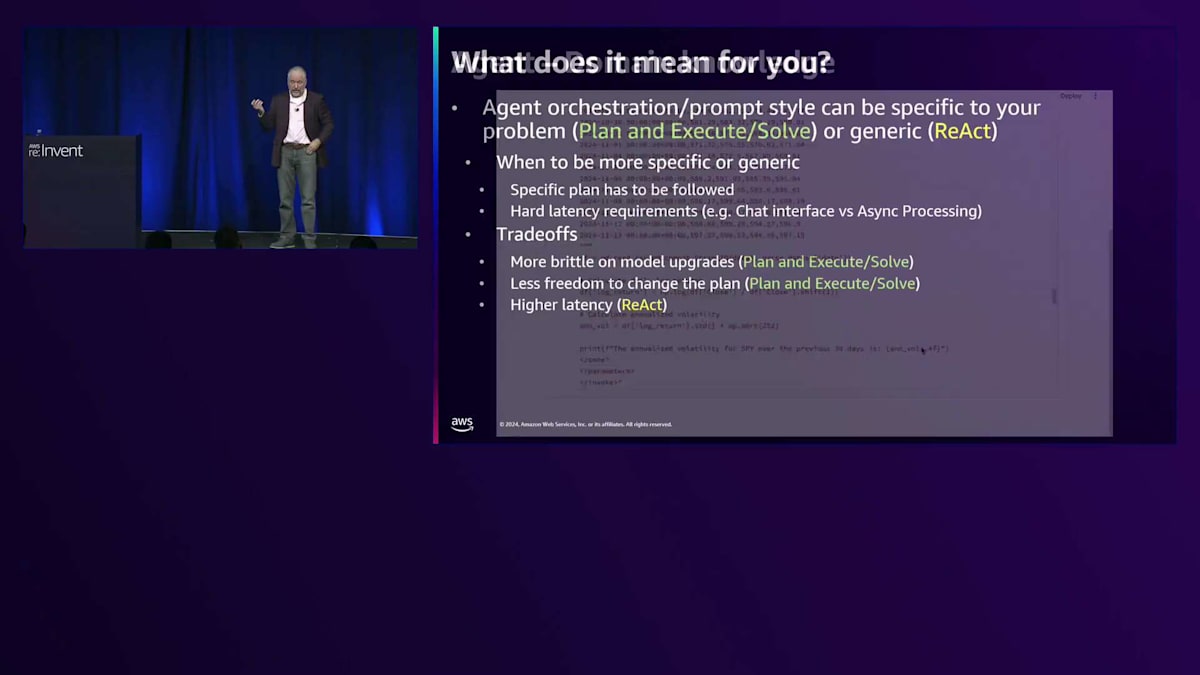
Agentがツールの使用とClaudeがトレーニングプロセスで学習したビジネスドメインの知識を組み合わせる様子が分かりました。興味深いのは、プロンプトエンジニアリングを通じてコンソールで実験を行い、Claudeがあなたのビジネスプロセスや業界標準のプラクティスについてどのような知識を持っているかを探ることができる点です。これらすべては何を意味するのでしょうか?Agentのオーケストレーションとプロンプトスタイルは、Plan Execute and SolveやReWoOのように問題に特化したものにすることも、ReActのように非常に汎用的なものにすることもできます。より特化型と汎用型のどちらを選ぶべきなのでしょうか?具体的な計画に従う必要がある場合や厳しいレイテンシー要件がある場合は、ReWoOのようなPlan Execute and Solveが良い選択かもしれません。非同期処理を行いたい場合や、使用するツールで発生する可能性のある問題に対して回復力を持たせたい場合は、ReActがより良い選択かもしれません。計画を変更する自由度を低くしたい場合は、ReWoOやPlan and Solveが適しています。

もう一つお気づきかもしれませんが、私は計算機やCode Interpreterなど、非常に汎用的なツールを使用していました。これをS3やデータベースにまで拡張することもできます。ツールを非常に汎用的にすべきでしょうか?S3バケットやデータベースへのアクセスをテキストSQLで与えたり、Code Interpreterを提供したりするべきでしょうか?それとも、より具体的にすべきでしょうか?Percentage Change Tool、Volatility Tool、データAPIツールを作成することもできました。どのような場合にどちらを選ぶべきなのでしょうか?汎用的なツールを使用すると、モデルにより多くの自由度を与え、より多くのユースケースに対応できますが、精度が若干低くなる傾向があります。具体的なツールを与えると、Agentが対応できるユースケースは制限されますが、その代わりに精度が若干向上するというトレードオフが見られるかもしれません。


結論として、Function callingは、Claudeのような高度なモデルがサポートする強力な機能で、ツールやビジネスドメインの知識を活用して複雑な問題を解決することができます。標準化された構文を使用することで、AgentはFunction callingの上に構築され、プランニングとオーケストレーションを提供し、より複雑な問題を解決し、Amazon Bedrockの生成AIモデルを使用した作業の自動化を実現します。より詳しい情報については、こちらのブログなどをご覧ください。スライドを見逃された方は、このトークはYouTubeにアップロードされますので、そちらでご確認いただけます。お時間をいただき、ありがとうございました。セッションのアンケートにもぜひご協力ください。私やNicholasとLinkedInでつながりたい方は、お気軽にどうぞ。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion