re:Invent 2024: AWSがSageMakerでFMのコストと遅延を削減


はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Reduce FM deployment costs and latency with Amazon SageMaker (AIM307)
この動画では、Amazon SageMakerを使用してFoundation Modelのデプロイコストとレイテンシーを削減する方法について解説しています。Sticky Session Routing、Speculative Decoding、Quantizationなどの最適化手法を用いることで、推論レイテンシーを最大50%削減し、コストを大幅に抑制できることをデモを交えて説明しています。また、Capital OneのVP兼Distinguished EngineerのGrant Gillary氏が登壇し、SageMakerを活用して開発期間を8週間から4週間に短縮し、99.95%の可用性SLAを実現した事例を紹介。Foundation Modelの本番環境での実装における具体的な課題と解決策について、詳細な知見を共有しています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Amazon SageMakerを活用したFoundation Modelの効率的なデプロイ

おはようございます。本日は、Amazon SageMakerを使用してFoundation Modelのデプロイコストとレイテンシーを削減する方法についてご説明させていただきます。私はSageMakerのProduct Managementを率いるVenkatesh Krishnanです。本日は、AWSのPrincipal AI/ML Solutions ArchitectであるAmit Aroraも同席しています。また、Capital OneのVP兼Distinguished EngineerであるGrant Gillary氏をお迎えし、Capital OneがSageMakerをモデルホスティングにどのように活用しているかについてお話しいただけることを大変嬉しく思います。
人工知能と機械学習、特にGenerative AIは、ビジネス戦略に革命をもたらしており、お客様はこの技術を活用して、パーソナライズされた没入感のある独自のカスタマーエクスペリエンスを提供することが増えています。それでは、AI/MLの核心である機械学習推論について詳しく見ていきましょう。このセッションでは、機械学習モデルのホスティングにおいて、可能な限り低コストで最適なパフォーマンスを実現し、投資対効果を最大化する方法を探ります。

セッションでは、まずAWSが提供する2つのフルマネージド推論機能であるAmazon BedrockとAmazon SageMakerについて説明します。本日のプレゼンテーションでは、SageMaker推論について詳しく掘り下げていきます。最低限の推論レイテンシー、最高のスループット、そしてビジネス目標に最適なコストを実現するのに役立つSageMaker推論の様々な機能をご紹介します。避けられないトレードオフについて説明し、SageMakerエンドポイントのデプロイメントを効率的に最適化する方法をお示しします。これらの機能の使用方法とその実際の動作を確認できるデモをご覧いただきます。最後に、Capital OneのGrantに登壇いただき、SageMakerでの推論モデルデプロイメントの成功事例をご紹介いただき、Q&Aセッションで締めくくります。
SageMaker推論の特徴とトレードオフの課題

AWSでAIモデルをデプロイする際、お客様は多様なユースケースに対応するため、Amazon BedrockとAmazon SageMakerの両方を活用することが多くあります。この2つのサービスは、モデルへのアクセスとモデルのデプロイメントに関して、それぞれ異なるアプローチを提供し、それぞれに長所と理想的なシナリオがあります。Amazon Bedrockは、サーバーレスデプロイメントが望ましい状況に最適です。Bedrockでは、インスタンスのプロビジョニング、インフラストラクチャの設定、オートスケーリングの設定について心配する必要がなく、すべてサービスによって処理されます。事前学習済みモデルを提供し、Fine-tuningも可能で、カスタマイズのしやすさと使いやすさのバランスが取れています。Bedrockの料金はトークンベースで、オンデマンドとプロビジョンドスループットのオプションがあります。一方、SageMakerは、デプロイメントインフラストラクチャをより詳細に制御する必要がある場合の選択肢です。サーバーベースで、ユーザーがモデル用のマネージドインフラストラクチャを完全に設定できます。また、SageMakerでは独自のモデルを持ち込むことができ、料金はインスタンスベースとなっています。

SageMaker推論についてさらに詳しく見ていきましょう。SageMaker推論は、設定可能なソフトウェアとハードウェアスタックを提供し、お客様に機械学習インフラストラクチャの高い可視性と詳細な制御を提供します。SageMakerで推論用にモデルをデプロイするには、3つの重要なステップがあります。最初のステップは、モデルアーティファクトと推論コードを指定してSageMakerモデルオブジェクトを作成することです。次に、コンピューティングリソースとスケーリングオプションを指定してエンドポイントを設定します。最後に、モデルをエンドポイントにデプロイしてリアルタイム推論に利用できるようにします。CPU、GPU、特殊なアクセラレーターを含む100種類以上のインスタンスタイプにアクセスできるため、モデルのニーズに合わせて正確にコンピューティングリソースを選択できます。カスタムの前処理および後処理ステップを追加することで推論を強化でき、データ変換、結果のフォーマット、またはカスタムビジネスロジックの実装が可能です。デプロイメントを容易にするため、最新のライブラリと推論用ランタイムが事前パッケージ化された、すぐに使用できるコンテナを提供しています。私たちが提供するこれらのベースイメージから始めて、独自のライブラリや独自ソフトウェアを追加してカスタマイズすることができます。複雑なユースケースでは、SageMakerは単一のエンドポイントに複数のモデルをデプロイすることができ、これによりリソースの効率的な利用と管理の簡素化が可能になります。
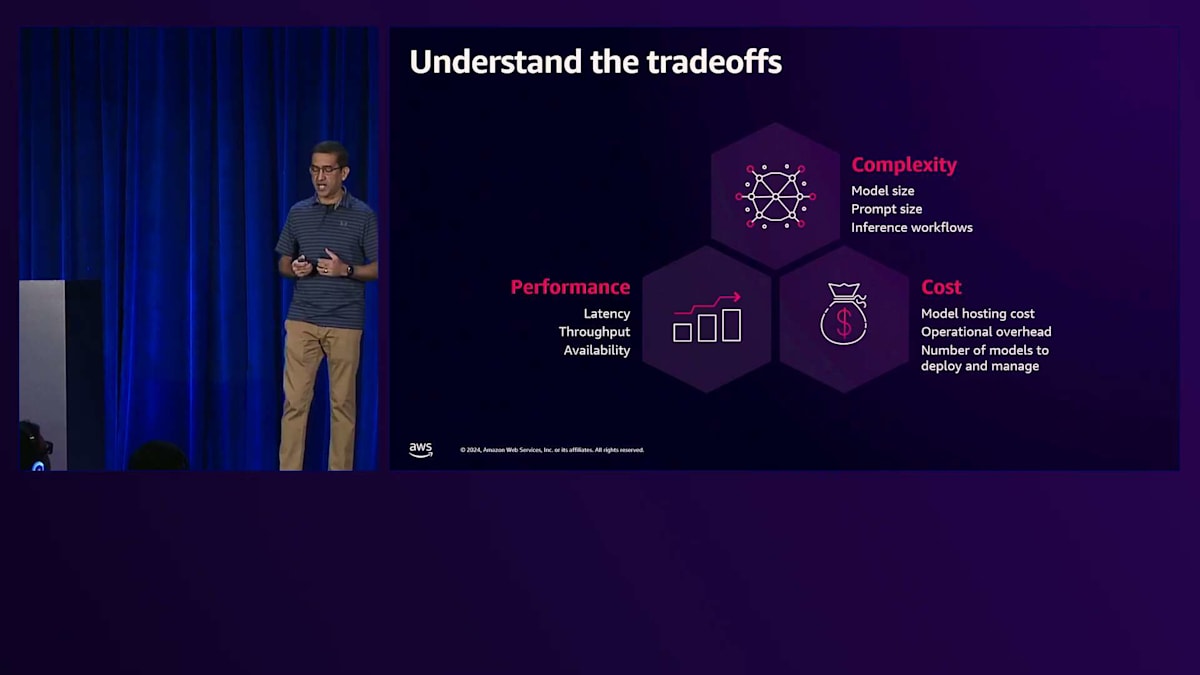
モデルを大規模にデプロイする際には、Generative AIアプリケーションを構築する上で、最高のパフォーマンスを最小のコストで実現するために、3つの要因のバランスを取る必要があります。 この3つの要因とは、複雑性、パフォーマンス、そしてコストです。複雑性は、モデルのサイズや、場合によってはデプロイしたいモデルのアンサンブル、システム、あるいはチェーンとして現れます。コストは重要な考慮事項であり、モデルのホスティングやインフラのコストだけでなく、運用オーバーヘッドのコストも最小限に抑えたいところです。パフォーマンスについては、高度にインタラクティブなアプリケーションを構築している場合、推論のレイテンシーを数ミリ秒まで最小化する必要があります。アプリケーションが何百万人ものエンドユーザーにサービスを提供する場合は、推論の高いスループットを実現する必要があります。
これらの3つの要因 - パフォーマンス、複雑性、コスト - は、しばしばトリレンマを引き起こします。つまり、ビジネス要件を満たすために2つの要因を選択すると、残りの1つの最適化が非常に困難になるということです。例えば、非常に大きなモデルをデプロイし、厳しいレイテンシーやスループットの要件がある場合、高価なGPUインスタンス上でモデルをデプロイする必要があり、コストが急上昇します。あるいは、予算が非常に限られているにもかかわらず、低レイテンシーが要求されるアプリケーションを構築したい場合は、特定のタスク向けに微調整された小規模なモデルをホストするか、モデル蒸留技術の使用を検討する必要があります。Amazon SageMakerで得られる柔軟性により、ビジネス目標を達成するために必要な適切なトレードオフを実現するための多くのレバーが提供されます。
SageMakerによるコスト削減とパフォーマンス最適化の新機能

本日は、これらのトレードオフをより効率的に実現するためにAmazon SageMakerで利用可能なすべての機能について、より深く掘り下げていきましょう。まずは、デプロイメントコストを削減するのに役立つ機能から始めましょう。 Amazon SageMakerは、コスト効率の高いモデルデプロイメントのための強力なソリューションを提供します。この機能により、1つのエンドポイントで複数のFoundation Modelをホストできるため、インスタンスで利用可能なアクセラレーターをより効果的に使用できます。デプロイする各モデルに対してカスタマイズされた数のマシンラーニングアクセラレーターを割り当てることができ、Amazon SageMakerはハードウェアの使用率を常に最大化するようにモデルコンテナをアクセラレーター上に配置します。

トラフィックの増加に応じてモデルのコピー数がスケールアップする際、Amazon SageMakerは新しいインスタンスを追加する前に、既存のインスタンス上の利用可能なアクセラレーターにモデルを自動的に配置します。同様に、スケールダウン時には、Amazon SageMakerは効率的にモデルをビンパッキングし、必要に応じてシームレスに再配置します。 最近、さらにコストを削減するのに役立つ3つの新機能をリリースしました。まず、Auto Scalingを大幅に高速化しました。Amazon SageMakerで標準提供される新しいインフラストラクチャーの革新により、人気のFoundation Modelに対するAuto Scalingのレイテンシーが以前と比べて58%以上低下していることがわかります。スケーリングを高速化することで、Amazon SageMakerは遅いスケーリングに対応するためのオーバープロビジョニングを最小限に抑えることができます。


2つ目は大きなコスト削減要因ですが、トラフィックがない場合にエンドポイントをゼロインスタンスまでスケールダウンできるAuto Scalingポリシーを設定できるようになりました。つまり、トラフィックがない場合にインスタンスの料金を支払う必要がないようにAmazon SageMakerエンドポイントを設定でき、一時停止後にトラフィックが再開された場合、エンドポイントは介入なしに自動的にスケールアップして新しいトラフィックに対応します。 最近リリースした3つ目の機能により、同じエンドポイントで数千のFine-tuningされたモデルバリエーションをホストでき、数千ドルのコストを節約できます。
Parameter-Efficient Fine-Tuning (PEFT)やLoRAなどのFine-tuningテクニックは、パラメータの小さなサブセットのみを学習させることで大規模言語モデルを適応させる効率的な手法として人気を集めています。これらのパラメータはAdapterと呼ばれます。このアプローチにより、ベースモデルから数千もの異なるFine-tuned版を作成することが可能になります。Amazon SageMakerは現在、ベースモデルとすべてのFine-tuned版を同じEndpointの同じインスタンス上でホストできるコスト削減機能を提供しています。この使いやすい機能には、Adapterのライフサイクル管理API、各Adapterの使用状況モニタリング、そしてトラフィックに応じたベースモデルの自動スケーリングが含まれています。
このイノベーションにより、カスタマイズされたAIモデルを大規模にデプロイする際の柔軟性とコスト効率が大幅に向上します。
SageMakerの推論最適化ツールキットとその効果

ここで話題を変えて、SageMaker上でモデルのパフォーマンスを最適化する方法について説明しましょう。SageMakerの機能を使って推論のレイテンシーを削減し、スループットを向上させる方法をご紹介します。エンドツーエンドのレイテンシーを削減するには2つの方法があります:1つ目はEndpointの背後にあるモデルのコピーへのリクエストのルーティングをより効率的にすること、2つ目は推論自体を高速化することです。

SageMakerでリクエストをより効率的にモデルにルーティングするための機能をご紹介します。まず、Load Aware Routingと呼ばれる機能があります。デフォルトでは、SageMaker Endpointはランダムルーティング戦略を使用しており、Endpointにトラフィックが到着すると、SageMakerは背後にあるモデルのコピーにランダムにルーティングします。新しいLoad Aware Routing戦略では、Endpointの設定時にフラグを設定することで、SageMakerは現在トラフィックを処理しているモデルのコピーを追跡し、新しいリクエストを処理可能なコピーにルーティングできるようになります。これにより推論のレイテンシーを20%以上削減できます。
2つ目の機能は、Session Aware Routing(Sticky Routingとも呼ばれます)です。Session Aware Routingを有効にすると、同じセッションからのすべてのリクエストが同じモデルのコピーにルーティングされます。これにより、MLアプリケーションは以前に処理した情報を再利用でき、レイテンシーを削減しユーザー体験を向上させることができます。この機能のデモを後ほどご覧いただきます。

それでは、Machine Learningモデルの実行速度を向上させる方法について見ていきましょう。SageMakerは、Speculative Decoding、Quantization、そしてCompilationといった最先端のテクノロジーを提供する推論最適化ツールキットを用意しています。これらは推論を高速化するものです。スケーラブルで性能テスト済みのSpeculative Decodingのすぐに使える対応、様々なモデルアーキテクチャに対応したQuantization、そして最適化されたモデルのローディングとキャッシングを備えた効率的なCompilationの恩恵を受けることができます。

こちらは、OpenAIのカードデータセットを使用した私たちのベンチマークに基づくパフォーマンスとコストの数値です。平均して、SageMakerで提供している最適化機能をそのまま使用することで、Llama 3モデルのスループットが2倍に向上し、コストを50%削減できることがお分かりいただけると思います。
Amitによる3つのデモンストレーション:Sticky Session Routing、Speculative Decoding、Quantization

それでは、これらの機能が実際にどのように動作するのかを見ていきましょう。同僚のAmit Aroraをお迎えして、これらの機能をデモンストレーションしていただきます。皆様、おはようございます。Amazon SageMakerを使用したFMのデプロイメントコストと推論レイテンシーの削減に関するセッションへようこそ。私はAWSのAI/MLおよびGenerative AIのPrincipal Solutions Architectを務めています。これから20分ほどかけて、先ほどお話しした推論最適化機能のいくつかについてデモをご紹介させていただきます。これから行う3つのデモのコードは、オープンソースのGitHubリポジトリで公開されています。画面に表示されているQRコードがそのリポジトリを指しています。後で活用できる非常に有用なコードサンプルが含まれていますので、ぜひスキャンしていただくことをお勧めします。

それでは、本日最初のデモである、SageMaker Sticky Session Routingについて見ていきましょう。 AIアプリケーションを開発する際、しばしば状態を保持する必要があります。例えば、画像などの大きなマルチメディアアセットや長い多段階の会話がある場合、このデータアセットに対して繰り返し推論を実行したいことがあります。しかし、この大きなデータアセットをGPUメモリに何度もロードする必要があるため、時間がかかってしまいます。リアルタイムワークロードの推論レイテンシーを改善するため、この時間を短縮したいと考えます。これがSticky Session Routingが解決する問題です。この問題には2つの側面があります。まず、このデータアセットが特定のセッションIDに紐付いていることをモデルサーバーに認識させる必要があります。これはTorchServeモデルサービングコンテナを使用して実現します。これを実際に見ていきましょう。次に、SageMakerエンドポイントは、スケールや可用性の理由で複数のインスタンスによってバックアップされている可能性がありますが、SageMakerはセッションが最初に開始されたインスタンスに、その後のリクエストを正確にルーティングすることができます。
これら2つの機能を組み合わせることで、同じデータアセットに対する繰り返しの推論において、大幅に最適化された推論レイテンシーを実現できます。 ここでは録画されたデモをご覧いただきます。私も皆様と同様にライブデモが好きなのですが、re:Inventの初日の月曜日の朝という時間帯で予期せぬ事態を避けるため、このような形式を選択しました。このデモには私が音声解説を付けさせていただきます。画面に私の写真が表示されているように、このコードは実際に私が実行したものです。コードはGitHubで公開されていますので、それでは始めましょう。
ここにあるのはJupyter Notebookです。 私たちは、Large Language and Visual Assistant ModelであるLLaVAモデルでSticky Sessionルーティングを使用します。まず、カスタムDockerコンテナの構築から始めます。PyTorch Serveモデルサーバーから始めて、Hugging Faceからモデルの重みをダウンロードできるようにカスタムコードを追加してカスタムコンテナを構築します。私はすでにこのプロセスを完了していますが、通常5〜7分ほどかかります。画面に表示されているハイライトされたベースイメージは、Amazon ECRで公開されているイメージです。Sticky Sessionルーティングを実装するカスタムコードは、このコードリポジトリの一部として利用可能です。このコードは十分に汎用的で、LLaVA以外のモデルでも変更なしで使用できます。


このコードを使用するためにTorch Model Archiveを使用しますが、このコードはS3バケットにアップロードされています。これはあなたのアカウントのS3バケットでも構いません。 カスタムコンテナと、Sticky Sessionルーティングの実装を提供するこれらのファイルをS3バケットに含めて使用します。構築したカスタムモデルにはモデルのバイナリが含まれています。これでSageMakerエンドポイントにこのモデルをデプロイする準備が整いましたので、SageMaker SDKのModelクラスを使用してデプロイを行います。LLaVAモデルをML P4 24X Largeインスタンスにデプロイします。

ここで特に強調したいのは、このモデルサービング呼び出しの環境変数セクションです。ここに新しいヘッダーがいくつかあります。X-Amazon-SageMaker-Session-IDとセッション開始の表示です。これはSageMakerがTorchServeサーバーに対して、特定の推論リクエストをTorchServeが作成した特定のセッションにリンクしたいということを伝える方法です。SageMakerは、TorchServeモデルコンテナが後続の呼び出しをすでにメモリにロードされているデータアセットにリンクできるように、これらのカスタムヘッダーをすべての後続の呼び出しで渡します。これらの新しいヘッダーを除けば、画面で見たモデルオブジェクトには全く変更はありません。

モデルオブジェクトが作成されたら、コードの変更なしでモデルのデプロイ関数を呼び出します。これは通常のSageMakerでのモデルデプロイ方法と同じです。モデルオブジェクトが作成された後、SageMaker Predictorオブジェクトを作成できます。このPredictorオブジェクトは、作成したモデルエンドポイントで繰り返し推論を実行するために使用されます。 このリポジトリには、APIリクエストをSageMakerが理解できるSDKフォーマットに変換するコードが用意されており、そのすべてのコードがここで利用可能です。

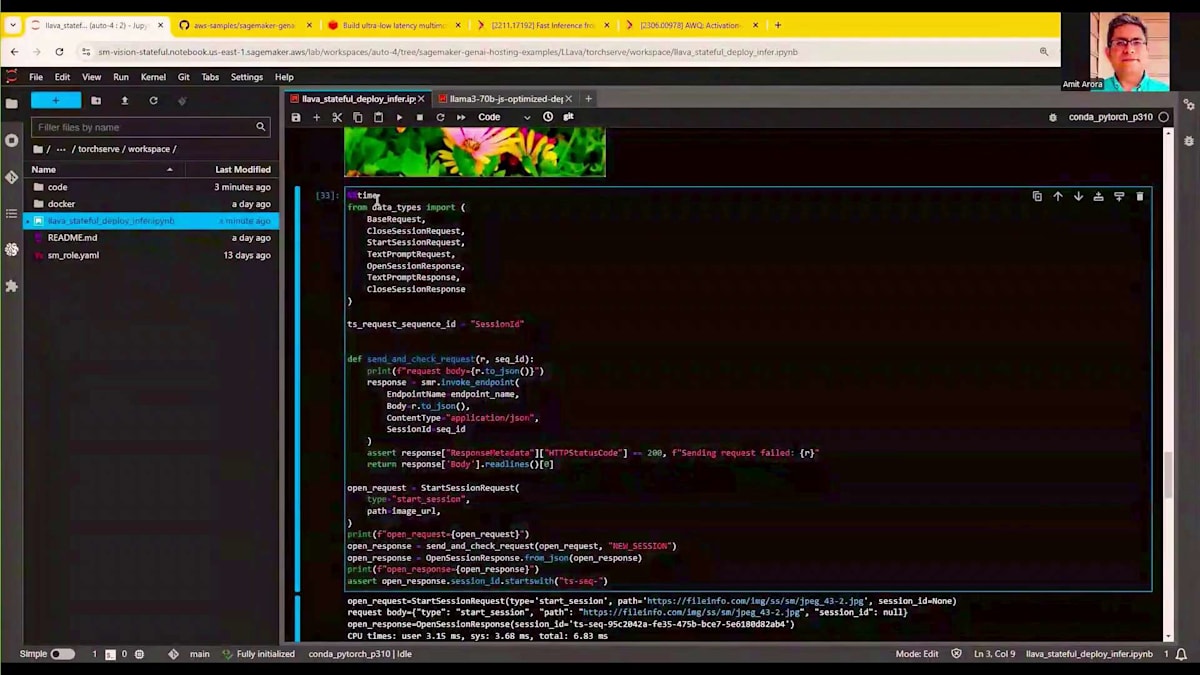
興味深い部分は、画面に表示されているこの画像です。この画像に対して繰り返し推論を実行します。これは公開されている画像で、画像URLはHTTP URLを参照しています。推論を実行したい任意の画像を参照するように変更することができます。 この画像に対して繰り返し推論を実行しますが、最初の推論は時間がかかるものの、データアセットがメモリにロードされているため、後続のリクエストはより高速になることが期待されます。推論を実行するためにSageMakerのInvoke Endpoint関数を使用します。Sticky Sessionを参照する新しいパラメータは、このSession ID変数です。このSession IDは、新しいセッションを作成すると、TorchServeコンテナから提供されます。このハイライトされたコードを見ると、Send and Check Responseを呼び出し、New Sessionという特別な文字列を渡しています。これはTorchServeコンテナに対して、新しいセッションを作成し、このセッションを提供している画像にリンクしたいということを伝えます。このSession IDを参照するTorchServeへの後続の推論リクエストは、すでにメモリにロードされているデータアセットを活用できるようになります。
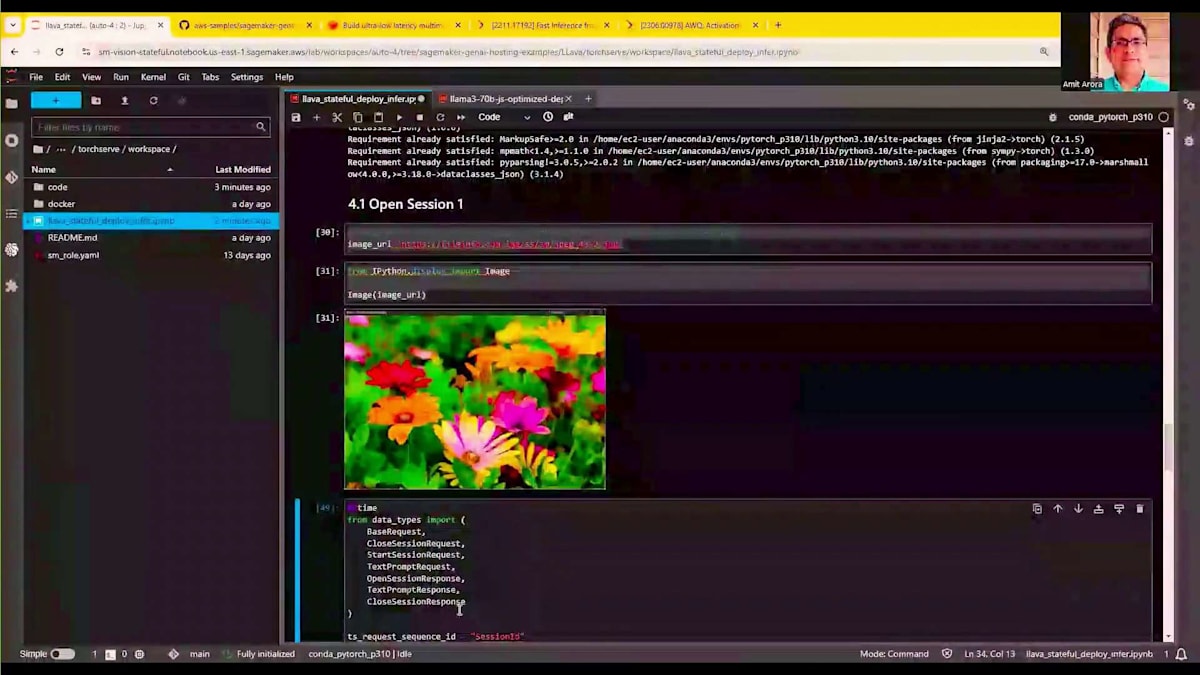

それでは、最初のリクエストを実行する準備が整いました。セッションを作成し、ハイライトされたセッションIDは、TorchServeが提供したセッションIDを示しています。

最初のプロンプトでは、この画像の説明を求め、セッションIDを渡しながら多数のトークンを生成するようリクエストしています。このリクエストを実行すると、画像の説明に約5.39秒かかることがわかります。これは、アップロードした画像に対してLLaVaモデルが推論を実行している時間を表しています。次に実行するリクエストでは、「この画像に草はありますか?もしあれば説明してください」という異なる質問をします。データアセットはすでにGPUメモリにロードされており、画像を再度アップロードする必要なく参照できるため、このリクエストはより高速に実行されるはずです。実際に実行してみると、同じ量のトークンを生成するのにわずか1秒しかかかりませんでした。

別のプロンプトで新しい質問をすることで、このプロセスを続けることができ、今回も1秒で処理が完了します。これは、SageMakerがモデルサーバーと連携して、後続の推論リクエストを既に確立されたセッションIDに紐付けてルーティングできるSticky Session Routingの仕組みを示しています。推論が完了したら、特別なクローズセッションヘッダーを渡してセッションを終了します。これにより、データアセットはGPUメモリから削除され、必要に応じてエンドポイントを削除することができます。

Sticky Session Routingをまとめると、最初の5.39秒から後続の推論では1秒強まで処理時間を短縮できました。これが本日の最初のデモでした。続く2つのデモは、事前最適化(Ahead of Time Optimizations)またはAOTと呼ばれる最適化カテゴリーに属します。先ほど見た最適化が推論時に行われるのに対し、Speculative DecodingとQuantizationというこの2つの手法は、モデルのデプロイ時に事前に最適化を行います。

Speculative Decodingでは、より小さなモデルを使用します。例えば、Llama-3 70Bモデルに対して推論を実行する際、Llama-3 8Bのような大幅に小さなドラフトモデルを使用して、より大きなモデルが生成するであろうトークンを予測生成します。2つ目の手法であるQuantizationでは、モデルの重みを低精度フォーマットで保存します。例えば、Floating Point 16の重みをInt8やInt4フォーマットで保存することで、より小さなインスタンスでモデルを読み込めるようになり、ハードウェアコストを削減できます。

次のデモに移りましょう。この3部構成のデモでは、複数の論文で説明されているSpeculative Decodingという機能をご紹介します。この概念の背景には、大規模な自己回帰型TransformerモdelがK個のトークンを生成する際に、モデル上でK回の処理を直列で実行する必要があるため遅くなるという問題があります。非常に大きなモデルでは、この処理に時間がかかります。私たちの解決策は、より小さなDraftモデルを使用することです。SageMakerは複数のモデルに対して最適化されたDraftモデルを提供しています。今回はLlama-3 70Bでこれをデモンストレーションします。
SageMakerが提供するDraftモデルを使用すると、予想通り推論のレイテンシーが大幅に改善されます。このデモの3番目のパートでは、このDraftモデルをカスタムDraftモデルにすることもできることがわかります。つまり、Hugging Faceから別のモデルをダウンロードしたり、SageMaker上で独自のモデルをファインチューニングしたりして、それをDraftモデルとして使用することで、推論のレイテンシーを削減できるということです。

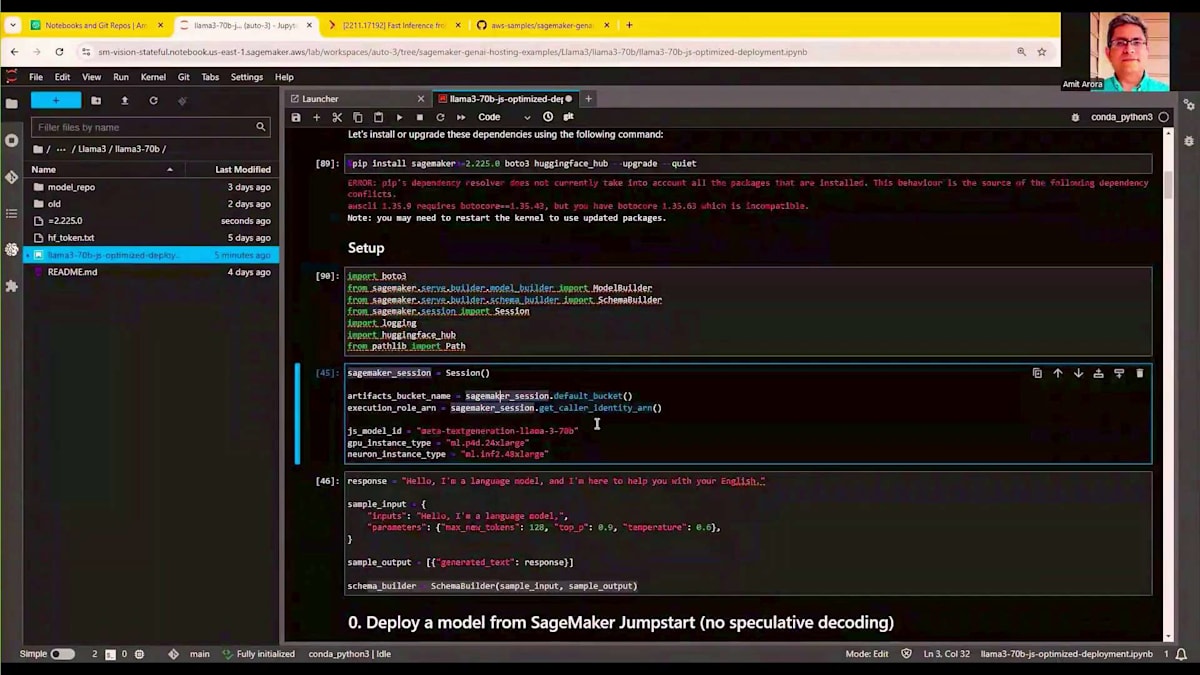
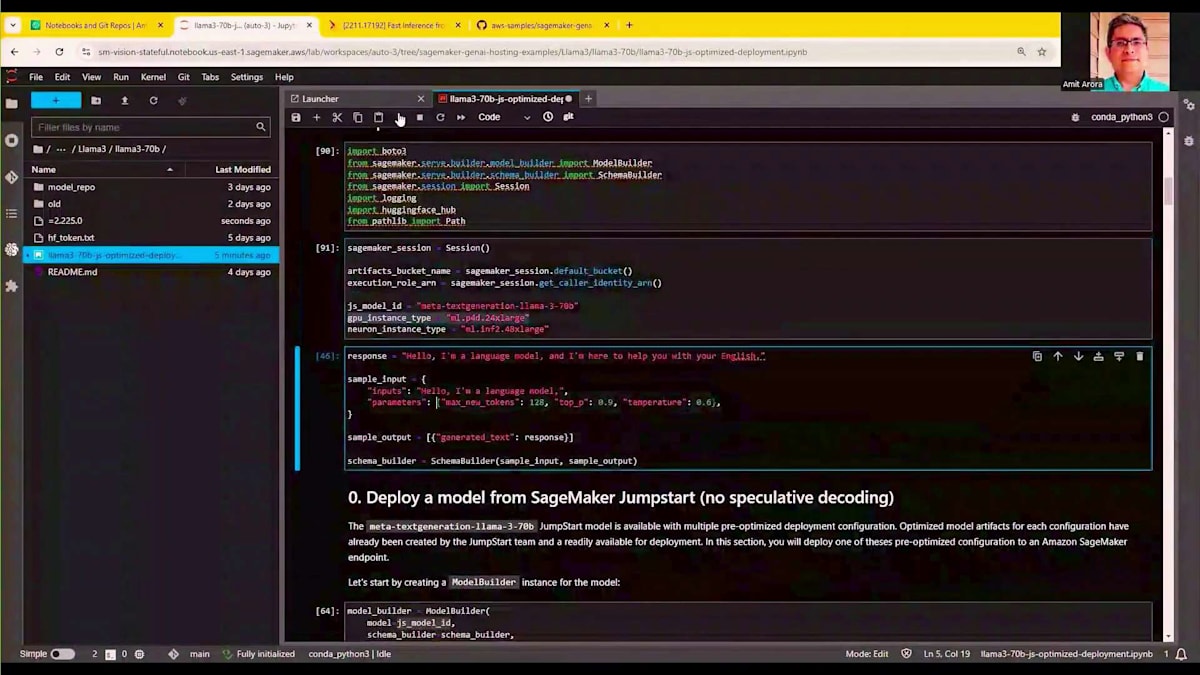
まずは、ライブラリをセットアップし、ベースラインモデルをデプロイするためのSageMakerパッケージをインポートしましょう。SageMakerのセットアップ、SageMaker SDKの更新、そしてパッケージのインポートを行います。LLAMA 370BをP4d.24xlargeインスタンスにデプロイします。ここでハイライトされているモデルIDは、SageMaker JumpStartによって提供されています。SageMaker JumpStartでは、Hugging Faceからダウンロードする代わりに、より高速に読み込めるよう、モデルのバイナリを世界中から読み取り可能なS3バケットに配置しています。


最初のステップは、SageMakerが提供するModel Builderオブジェクトを作成することです。JumpStartのモデルIDを渡し、いくつかのベンチマーク指標を表示できます。補足として、SageMaker上で大規模言語モデルを実行する際には、当然ながら異なるインスタンスタイプでのモデルのパフォーマンスを知りたいと思うでしょう。Model Builder自体の一部としてベンチマークを提供しているので、G5.48xlargeインスタンスでホストした場合のレスポンス時間とスループット、あるいはP4dやP5.48xlargeインスタンスでホストした場合のレスポンス時間とスループットを確認できます。これにより、ワークロードに応じた選択が可能になります。多数の同時ユーザーがいる場合はP5にデプロイし、小規模なワークロードの場合はG5.48xlargeにデプロイしてコストを節約することができます。


さて、デモの興味深い部分に入ります。set_deployment_configを使用してこのモデルをデプロイし、config名としてLMIを指定します。LMIはLarge Model Inferの略で、これは最適化されていないバージョンのモデルをデプロイしていることを意味します。このモデルをデプロイすると、SageMakerはS3内のこれらのモデルバイナリと、使用する推論サーバーを認識します。model_builder.buildを使用してModel Builderオブジェクトを作成し、通常通りSageMakerエンドポイントにこのモデルをデプロイします。

これが完了すると、推論を実行する準備が整います。モデルのバイナリは S3 で利用可能なので、model_builder.build を呼び出し、その後 model_builder.deploy を実行します。LLAMA 370B モデルをデプロイするには約7〜8分かかります。モデルがデプロイされると、サンプル入力に対して予測を実行する準備が整います。サンプル入力では、128トークンを生成し、その時間を記録しました。このモデルのデプロイには約6分33秒かかりましたが、これでサンプル入力に対して推論を実行できます。このセルを実行すると、これらのトークンの生成に約4〜5秒かかることがわかります - 具体的には128トークンの生成に4.5秒かかりました。

これが最適化なしの基本的なパフォーマンスです - SageMaker にデプロイされた LLAMA 370B の場合です。次のステップとして、このエンドポイントを削除し、同じモデルを再度デプロイしますが、今度は Speculative Decoding で最適化して、より良い推論レイテンシーを実現します。以前と同じように、コードを全く変更せずに Model Builder オブジェクトを作成します。 Model Builder に対して、これが私たちの Model ID とスキーマであることを伝え、必要に応じてベンチマークメトリクスを表示します。



それが完了したら、デプロイメント設定を行います。LMI の代わりに、LMI Optimized を指定します。これは、SageMaker が提供する First-party Draft モデルを使用して、Speculative Decoding で最適化されたバージョンのモデルをデプロイしたいことを SageMaker に伝えます。 このパラメータ変更だけでモデルをデプロイします。Speculative Decoding を使用したモデルのデプロイがいかに簡単かを示しています - パラメータの1単語を変更するだけです。 optimized_model.deploy を使用してこの最適化されたモデルをデプロイしますが、これも同様にデプロイに6〜7分かかります。


デプロイメントが完了すると、推論を実行して、より短時間で結果が得られることがわかります。同じ Predictor の predict を全く同じサンプル入力に対して実行すると、今回は4.5秒ではなく2.66秒で出力が得られ、推論レイテンシーが約40〜50%改善されました。 全く同じトークンを生成していますが、はるかに短い時間で実行できています。


時間の都合上、次のデモにスキップしますが、この全く同じコードを使用して、Hugging Face からダウンロードしたカスタムモデルを Draft モデルとして使用できることを言及しておきたいと思います。別の オープンソースモデルを使用したり、独自のモデルをファインチューニングして Draft モデルとして使用したい場合も、先ほど見たコードのパラメータを1つ変更するだけです。私たちが発見したのは、オープンソースの Llama-3 は、Speculative Decoding なしの初期の4.5秒と比較して3.6秒の推論レイテンシーを提供するということです。これは改善を示していますが、2.66 秒を達成できた Amazon SageMaker が提供する Draft モデルほど良くはありません。

まとめますと、最適化前のモデルが4.5秒、Amazon SageMakerが提供するドラフトモデルを使用した投機的デコーディングが2.66秒、そしてデモを完全に実行すると、オープンソースのLlama-3は3.66秒となります。SageMakerのドラフトモデルほどの改善は見られませんが、それでも一定の改善が確認できます。では、次に3番目のデモに移りましょう。これはモデルの量子化に焦点を当てたものです。モデルの量子化については、多くの論文で取り上げられているのでご存知かもしれません。今回はAWQ(Activation-aware Weight Quantization)と呼ばれる量子化手法を使用します。これは、モデルの重みをfloating point 16ではなく、integer 8やinteger 4として保存することで、モデルのサイズを大幅に縮小する手法です。

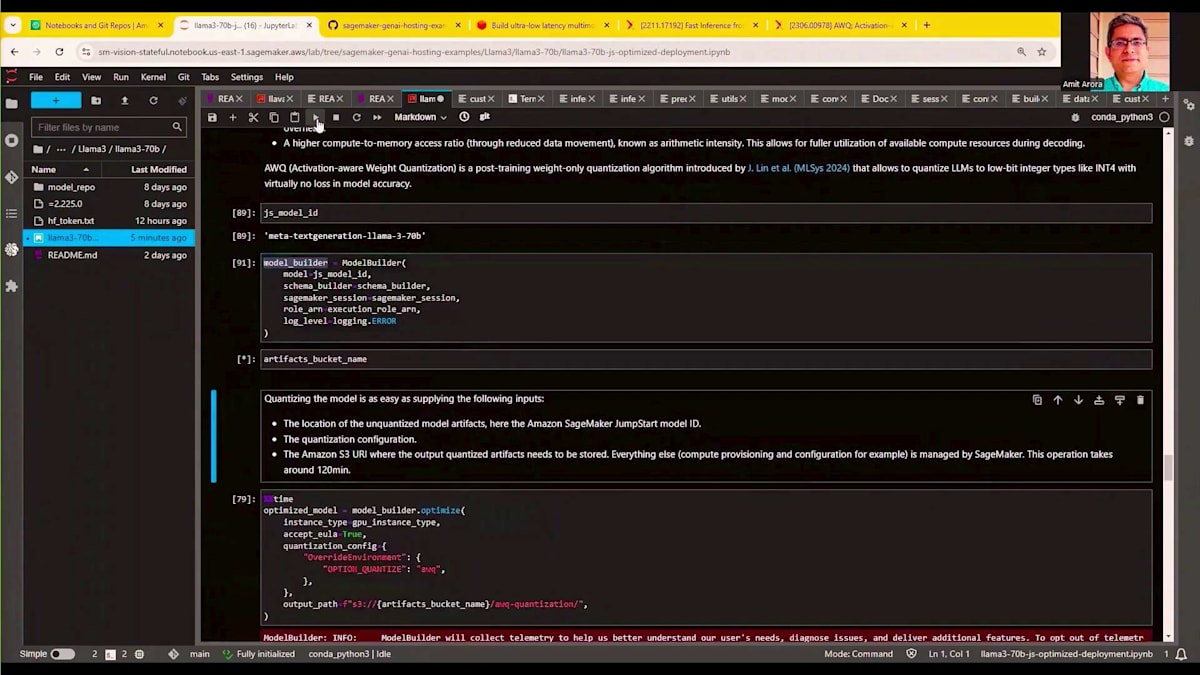

この手法により、より小規模なハードウェアでモデルをデプロイすることが可能になります。前の2つのデモではP4d.24xlargeマシンを使用していましたが、このデモでは量子化されたモデルを使用することで、同じLlama-3 70Bをより小規模なG5.12xlargeマシンにデプロイできることを確認します。このアプローチには4つの利点があります:ハードウェア要件の削減、KVキャッシュのためのスペース増加、そしてデコーディングレイテンシーの改善です。量子化を伴うこのモデルのデプロイプロセスは、これまでと全く同じです。以前と同様にモデルビルダーオブジェクトを作成し、model builder dot optimizeを実行します。このmodel builder dot optimizeでは、Activation-aware Weight Quantizationを指すAWQとして最適化オプションを量子化するという1つのパラメータを指定することができます。

新しいモデルの重みは、指定したS3パスに保存されます。量子化プロセスは多くのモデルの重みを変更するため、約2時間、この場合は1時間54分かかります。元のLlama-3 70Bを量子化したこの新しいモデルは、このS3バケットで利用可能です。以前と同様にモデルをデプロイできますが、今回はG5.12xlargeにデプロイします。比較のために説明すると、G5.12xlargeには4つのNVIDIA A10G GPUが搭載されているのに対し、以前使用していたP4d.24xlargeインスタンスには8つのNVIDIA A100 GPUが搭載されています。これはハードウェア要件の大幅な削減を示しており、量子化バージョンを使用することで、このモデルを大規模にホストする際のコスト効率が大幅に向上することを示しています。
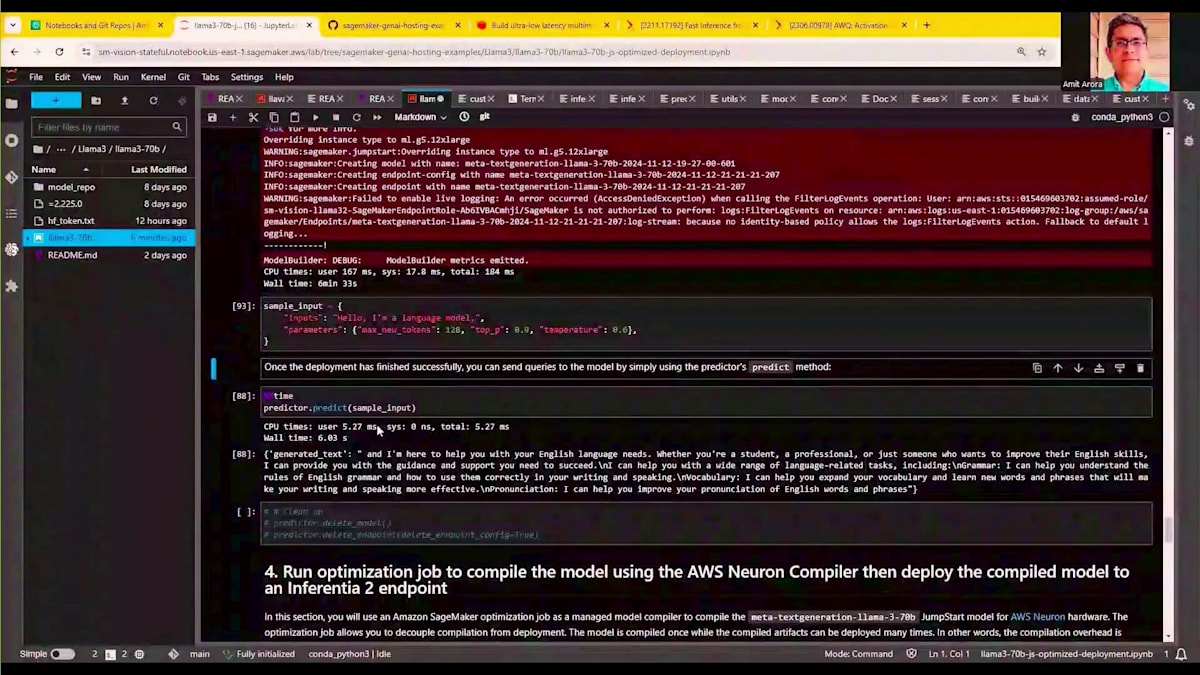
モデルのデプロイが完了すると(約6分かかります)、パフォーマンスベンチマーク用に同じ128トークンを生成するよう、以前と同じサンプル入力を実行します。predictor dot predictを呼び出すと、ほぼ同じ時間でこれらのトークンを生成できます。P4d.24xlargeからG5.12xlargeインスタンスに移行することで得られる潜在的なコスト削減を考えてみてください。これで3番目のデモは終了です。まとめると、私たちは3つのデモを行いました:Sticky Session Routing、投機的デコーディング、そして量子化です。これら3つのデモすべてにおいて、推論レイテンシーの大幅な削減を実証しました。
Capital OneのAI/ML戦略とFoundation Modelへの取り組み
それでは、Capital Oneから尊敬すべきゲストであるVice PresidentでDistinguished EngineerのGrant Gillary氏をお迎えしたいと思います。ありがとうございます。皆さん、聞こえますでしょうか?私はGrant Gillaryです。Capital OneのMLプラットフォームのソフトウェアアーキテクチャを率いています。本日は、SageMaker inferenceを私たちのプラットフォームのバックエンドにどのように統合したかについて、これまでよりも高いレベルでお話ししたいと思います。

本題に入る前に、Capital Oneについてあまりご存知ない方もいらっしゃるかもしれませんので、私たちのAIとMLの取り組みについて背景をお話しさせていただきます。ご存知の通り、私たちはクレジットカード会社であり、銀行でもあります。銀行は必ずしも最先端のテクノロジーを採用していることで知られているわけではありませんが、Capital Oneは例外です。過去20年間の私たちの取り組みを見ていただくと、テクノロジーインフラストラクチャーと人材の両面で大きな変革を遂げてきました。現在では14,000人以上のテクノロジスト組織を社内に構築し、4,000件の特許を取得しています。テクノロジースタックとインフラを再構築し、クラウドを全面的に採用して、サービステクノロジーを活用しながら、クラウドイノベーションの最前線に立ち続けています。
アプリケーションの3分の1以上で、ソフトウェア開発の方法を変革し、API、Microservices、DevOps、自動テストとデプロイメントの早期採用者となりました。AWSインフラストラクチャー上にデータプロダクトに焦点を当てたモダンなデータエコシステムを構築しました。現在は、組織全体でEnterprise Platformへの収束を推進し、多様なユースケースにおける自動化、標準化、スケールを実現しています。これらすべてが、私たちのAIとMLの取り組みの基盤となっています。私たちは、ほぼすべての事業部門でAIとMLのユースケースを本番環境で展開し、1億人の顧客と5万人の従業員に価値を提供しています。

不正検知から、パーソナライズされた顧客体験、開発者支援まで、皆様がご存知かもしれない、あるいはご存知でないかもしれない、さまざまなCapital Oneのプロジェクトや製品の例があります。不正検知について考えると、Venture Xのようなクレジットカード製品では、これが裏で動作しています。私たちが提供しているすべてのモバイルアプリケーションを考えると、それらのパーソナライズされた体験は、お客様の特定のコンテキストに基づいて適切なものとなるよう確保されています。

ここで、私たちのAIとMLの取り組みの次のステージについてお話ししましょう。ここにいる皆様は、Foundation Modelについてご存知だと思います。特に2017年のTransformerベースのモデルから始まり、2022年にはマルチショット学習とChatGPTが登場し、モデル開発の領域を劇的に変化させました。これにより、社内向けと社外向けの両方で、まったく新しいクラスのアプリケーションが可能になりました。私たちは既に多くの製品の中核にAIとMLを組み込んでいましたが、Foundation Modelによってその範囲がさらに拡大し、新しいインフラストラクチャーの構築が必要になりました。
昨年初め、私たちはこの新しいテクノロジーを実現するための取り組みを開始しました。ユースケースの数が増えるにつれて、この文脈における推論は、本番アプリケーションを提供し、すべてのユースケースが本番環境で使用できるようにする上で重要な差別化要因の1つとなります。プラットフォーム中心の組織として、これはプラットフォームを構築することを意味し、適切に管理されながら、多数のユースケースに対して企業全体でスケールできることを確保する必要がありました。

解決策の詳細に入る前に、AIとMLのスタックで起きている変化についてお話ししたいと思います。左側には、MLスタックの比較的シンプルな形を示しています。これは単純化の極みですが、Tree-basedモデルを扱う場合、多くはこのような構成になります。最下層にはCPUインスタンスがあり、その上にステートレスなPython実行環境があり、推論は互いに影響を与えません。その上には比較的小さな、数百メガバイト程度のアーティファクトがあり、最上層には単一の、比較的狭い用途に特化したモデルエンドポイントが配置されています。
右側に移ると、これらの一部は過去10年間で様々な場所で本番環境で使用されてきましたが、Foundation Modelsによってこの新しいスタックへの移行の必要性が高まり、複雑さが大幅に増しています。LLMでは、CUDAライブラリを搭載したマルチGPUインスタンスを使用し、ステートフルな実行環境で動作します。各生成が前後の生成に影響を与えるKVキャッシュを考えると、モデルのアーティファクトは数十ギガバイトにも及びます。そして、モデルエンドポイントは単一テナントの単一エンドポイントか、複数のダウンストリームユーザーが同じモデルエンドポイントにアクセスするマルチテナントのいずれかになります。

これは、私たちが解決すべき2つの重要な課題があることを意味していました。まず、既存の要件に合わせながら、ハードウェアからアプリケーション層まで、Foundation Modelの推論スタックを提供する新しいインフラストラクチャを実現する必要がありました。私たちには、確実に対応しなければならない、明確に定義された本番システムとパイプラインがあります。これは、リスクプロセス、サイバーコントロール、マルチテナント要件への準拠を確保しながら、プラットフォームの可用性、パフォーマンス、スケーリングに対応することを意味していました。
Capital OneのSageMaker Inference統合アーキテクチャと本番環境での活用

私たちが導入したソリューションについてお話しします。解決すべき2つの中核的な問題があったように、2つの主要なコンポーネントがあります。図の左側には、コアプラットフォームがあります。このコアプラットフォームインフラは、すでに多くの非機能要件を満たしていました。右側では、このインフラストラクチャのバックエンドにAmazon SageMaker Inferenceを統合して、Foundation Modelの推論スタックを実現しています。

このアーキテクチャを構築する際、コアプラットフォームについて説明させていただきます。モデルが実際にデプロイされるテナントNamespaceを持つAmazon EKSクラスターのセットがあります。以前のモデルでは、モデルのデプロイとインフラストラクチャの管理を担当する管理APIサービスがその下にあることを示していました。SageMaker Inferenceをこれでフロント化することで、いくつかの利点を得ることができました。同じ内部向けAPI Gatewayを使用できるため、プラットフォームのテナントは大きなインフラの変更なしに同じエンドポイントを使用でき、使い慣れた体験を維持できました。テナントはNamespaceによって分離されているため、プラットフォーム上の複数のテナントに対して大きな変更なしにその分離を維持することができました。
このコアインフラに対して、いくつかの基本的な変更を加える必要がありました。下部にはSageMaker Operatorがあり、これがSageMaker ACKです。SageMaker ACKを統合することで、KubernetesクラスターからSageMakerエンドポイントをデプロイできるようになりました。Tenant Operatorを修正し、各テナントの名前空間内にルーターを配置することで、特定のモデル呼び出しを特定のSageMakerエンドポイントに振り分けられるようにしました。以前は、特定の名前空間内でモデルが実行されていたところです。インフラは既に整備されていたため、異なるリージョンの複数のSageMakerエンドポイントにわたる高可用性を実現するための全体的なアーキテクチャは既に整っていました。
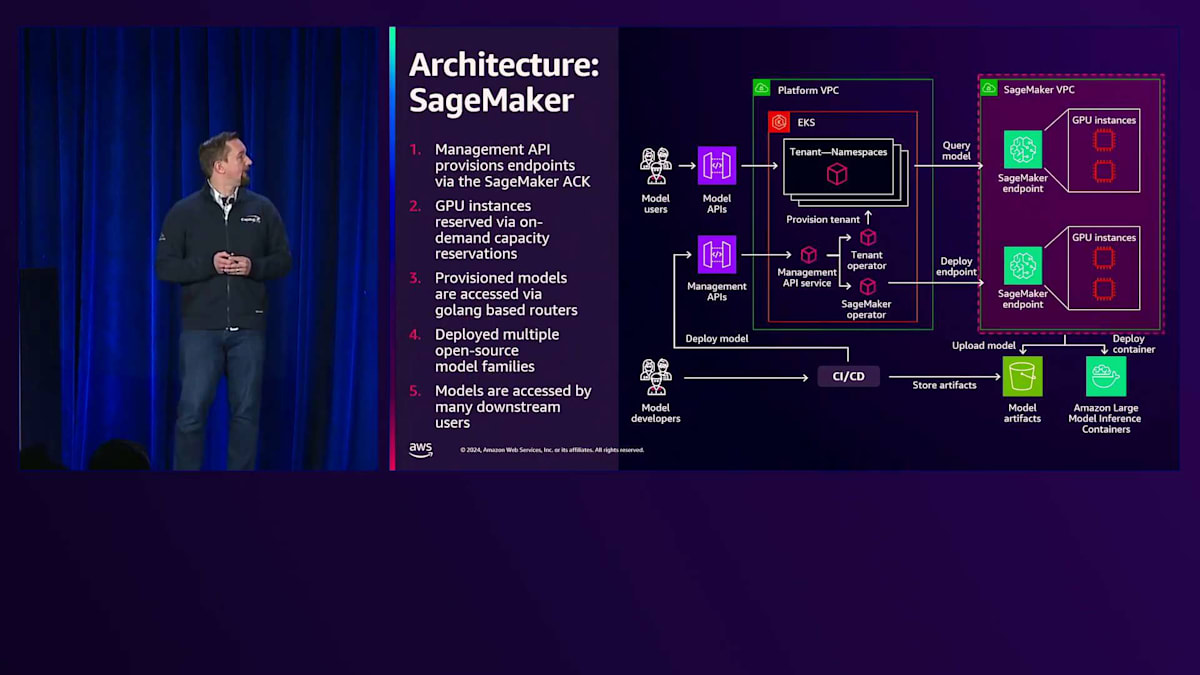
SageMaker側では、管理APIがSageMakerエンドポイントをプロビジョニングしています。これらのSageMakerエンドポイントには、現在オンデマンドキャパシティ予約を通じて確保されているGPUインスタンスがあります。ご存知の通り、供給に制約があるため、これらの制約の中でのリソース管理は、プラットフォームの運用において継続的に取り組んでいる課題です。ユースケースについて話す際、利用可能なインスタンスの分配方法にはある程度の柔軟性があります。これらのモデルはテナントの名前空間にプロビジョニングされ、Golangベースのルーターを介してアクセスされます。現時点で、複数のオープンソースモデルファミリーをデプロイし、モデル開発者とエンドアプリケーションの両方からアクセスされる様々なユースケースで使用しています。

実際にモデルを本番環境に導入する方法について説明させていただきます。外部ベンチマークと自社内部のベンチマークの両方に対してモデルをベンチマークする、詳細なモデルレビューとベンチマーキングプロセスを実施しています。これにより、各モデルがCapital Oneのユースケースに関する品質基準を満たしていることを確認しています。また、エコシステム内のモデル数を必要最小限に抑えることも目指しています。インフラ管理が難しくなり、エンドユーザーが頻繁にバージョンやモデルを変更する必要が生じるため、重複するモデルが多数存在することは避けつつ、ユースケースに対するエンドユーザーの要件をすべて満たすモデルを維持したいと考えています。
モデルが承認されると、S3にハッシュ化して暗号化された状態で保存され、エンドポイントへのアップロードに対してのみアクセスが許可されます。これにより、テスト後のモデルが改ざんされないことが保証されます。AWS Public ECRからAmazonの大規模モデル推論コンテナを取得して使用しています。これは初期段階で大きな助けとなり、独自のイメージを管理する必要がなくなりました。また、対処が必要となる脆弱性へのプラットフォームの露出を減らすことができ、本番環境への移行時間を短縮し、開発者の作業効率を向上させることができました。

このプラットフォームをどのように活用しているのでしょうか?基本的に、プラットフォームの使用パターンには2つの主要なものがあります。
システムは上部の本番環境のユースケースと、下部の開発環境のユースケースに分かれています。本番システムでは、VPC内のアプリケーション層において、さまざまなオーケストレーターやコンピューティングパターンへのアクセスを提供し、各モデルは本番用のModel APIを通じてアクセスされます。一方、下部の開発者向けシステムでは、プロトタイピングや開発作業が可能となっています。両者の基盤となるインフラは分離されており、開発VPC内での開発者の影響範囲を制限し、本番環境にデプロイされたアプリケーションへの影響を防いでいます。
モデルは開発クラスターと本番クラスターの両方に同時にデプロイされるようにしています。これにより、開発環境で行われた作業が本番環境へと明確な道筋を持つことが保証されます。過去の経験から、これが実現されていない場合、特にチームが本番環境でモデルが利用可能であることを前提に計画を立てている場合に、重大な問題が発生する可能性があることがわかっています。そのため、同時デプロイが必要不可欠なのです。また、各クラスターセットには個別のオンボーディングプロセスがあります。開発者に対しては、ガバナンス要件を満たす適切なユースケースを持っていること、Capital One内で適切なレベルでの承認を得ていること、そして適切なインフラが利用可能で処理能力のニーズをサポートできることを確認しています。
本番環境では、従来のソフトウェア開発ライフサイクルに加えて、実際のデプロイ前にモデル評価が実行されます。それぞれの環境のインフラは用途に応じて最適化されています。開発クラスターでは、コスト最適化とスループットのためのバッチ処理に重点を置き、レイテンシーへの要求は低く抑え、より低コストのインスタンスを使用しています。本番環境では、各ユースケースに焦点を当て、ユースケースごとのスループットとレイテンシーのニーズを考慮し、個々のユーザーのコスト制約に基づいてプロビジョニングを行っています。

最後に、開発環境について触れておきたいのは、オープンな環境内でのモデルの使用がプラットフォームの使用基準と大規模言語モデルの使用基準の両方においてCapital Oneの基準を満たしていることを確認するため、ログ記録とセキュリティの推論の確認を行っているということです。このように、私たちは基本的に2つのグループ構成でプラットフォームを構築しました。 バックエンドでのSageMaker統合は、私たちにとって多くのポジティブな影響をもたらしました。オープンソーススタックを使用した自社開発の場合と比較して、開発期間を8週間から4週間に短縮することができました。Deep Learning Containersを使用したコアスタックはすぐに使用可能で、事前にテストされていたため、モデルを実際に導入した際に信頼できるものとなりました。
また、プラットフォームレベルでの脆弱性露出をほぼゼロに抑え、マルチリージョンデプロイメントと組み合わせた99.95%の可用性SLAにより、本番環境でのモデル提供に関する組織全体の高可用性の期待に応えることができました。そして最後に、おそらく私たちの組織にとって最も重要な点として、特に高度に規制された銀行として短期間での提供を確実にするため、既存の推論インフラストラクチャとガバナンスプロセスと統合できたことが挙げられます。これらは既にサイバーセキュリティとリスクの担当パートナーによって評価されていたものです。バックエンドでこれらを統合することで、実際に評価して目的適合性を証明する必要のある項目の数が大幅に減少することがわかっていました。
今後の展望と質疑応答

今後の展開についてですが、現在進行中の最適化が数多くあります。私たちはComponentsの使用を計画しており、すでに評価も行っています。Auto Scalingも同時に導入することで、リソース使用率が100%向上すると見込んでいます。Inference Optimization Toolkitに関しては、Speculative DecodingとQuantizationの両方を検討しています。Speculative Decodingでは、特定のモデルクラスで全体的なレイテンシーが約50%削減されると予想しており、また、Activation Aware Weight Quantizationを用いたQuantizationの評価も進めています。
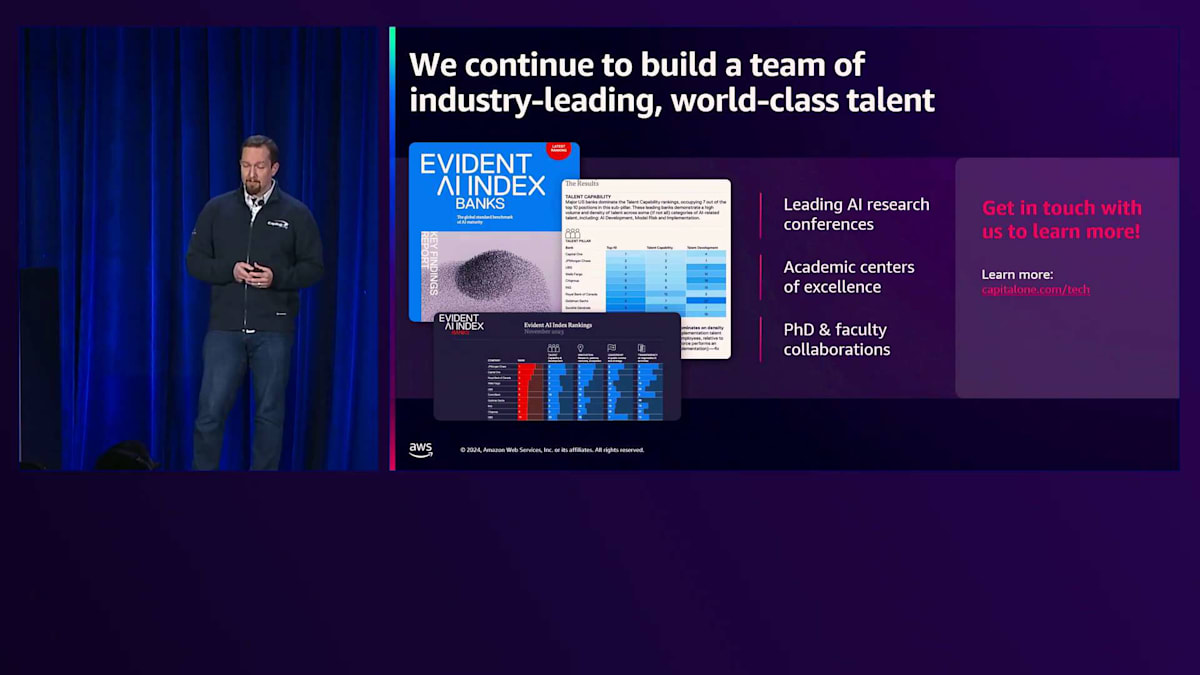
最後に私からの締めくくりとして、冒頭でお話しした Capital Oneの機械学習の取り組みについて触れさせていただきます。私たちは現在も進化を続けており、組織全体で世界クラスの人材を惹きつけ続けています。昨年、独立系調査会社のEvident Insightsが、Capital OneをAI分野でグローバルトップクラスの銀行の一つとして、そしてAI人材においてトップバンクとして評価してくれたことを大変嬉しく思っています。これは、組織のインフラ整備と、様々なAIやMLに関する戦略的目標の達成の両面で、私たちのチームが成し遂げてきた成果の証です。もしご興味がありましたら、capitalone.com/techをご覧ください。

それでは、ありがとうございました。ここからVenkateshに引き継ぎたいと思います。 GrantとAmit、ありがとうございました。また、本日のセッションにご参加いただいた皆様、ありがとうございました。お役に立てたのであれば幸いです。セッション終了後すぐに質疑応答の時間を設けておりますが、その前にモバイルアプリでセッションのアンケートにご協力いただければ幸いです。セッションの内容や発表者に関するフィードバックは、今後のコンテンツ改善に大変役立ちます。それでは質疑応答に移りたいと思います。どんなご質問でもお気軽にどうぞ。また、セッション終了後もしばらく会場に残りますので、直接質問していただくことも可能です。ご清聴ありがとうございました。お時間をいただき、ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion